
名寄せ処理プログラム、名寄せ処理方法、および名寄せ処理装置
【課題】作業者による関与を削減し、名寄せ処理効率の向上を図ること。
【解決手段】指定部301は、データ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する。特定部302は、第1のデータと名寄せしあう第3のデータを特定する。この場合、決定部303は、第2のデータと第3のデータを、名寄せしあうデータの組み合わせに決定する。また、決定部303は、第2のデータを含むグループのデータと、第3のデータを含むグループのデータを名寄せ元/先データとする組み合わせのデータどうしを、名寄せしあうデータの組み合わせに決定する。
【解決手段】指定部301は、データ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する。特定部302は、第1のデータと名寄せしあう第3のデータを特定する。この場合、決定部303は、第2のデータと第3のデータを、名寄せしあうデータの組み合わせに決定する。また、決定部303は、第2のデータを含むグループのデータと、第3のデータを含むグループのデータを名寄せ元/先データとする組み合わせのデータどうしを、名寄せしあうデータの組み合わせに決定する。
【発明の詳細な説明】
【技術分野】
【0001】
この発明は、名寄せ処理プログラム、名寄せ処理方法、および名寄せ処理装置に関する。
【背景技術】
【0002】
従来、金融機関において複数口座を所有する預金者の同一性を確認する名寄せが公知である。広義に解釈して、名寄せは、企業合併などにより企業内データを統合する場合や、重複する顧客情報などを統合または削除する場合に、データベースに蓄積されたデータ群の中から統合または削除可能なデータを特定することも含まれる。
【0003】
従来の名寄せでは、まず、たとえばデータベースから名寄せをおこなうデータを取得し、このデータに対して、表記の統一、表記ゆれの補正、文字列の分離および分割などをおこなう(標準化,クレンジング)。具体的には、たとえば半角と全角や、(株)と株式会社などの表記を統一したり、キョーやキョウなどの表記ゆれを統一したり、企業の名称から株式会社などを分離する作業をおこなう。
【0004】
その後、予め設定された抽出条件に基づいて、標準化されたデータから、名寄せする候補となるデータを抽出する。たとえば、名寄せされるデータ(以下、名寄せ元データとする)の照合先となるデータ(以下、名寄せ先データとする)を抽出する。そして、名寄せ元データと名寄せ先データとのたとえば類似度合いを示す度数などを算出し、名寄せ元データと名寄せ先データとを比較する。
【0005】
名寄せ元データと名寄せ先データとの比較結果に基づいて、名寄せ元データを名寄せ先データと名寄せしあうことができるか否かを判定し、この判定結果を名寄せ結果とする。名寄せ結果は、たとえば市販のデータ統合装置などに入力される。そして、データ統合装置の記憶領域に記憶された名寄せ処理のプログラムなどによって、名寄せ結果に基づいた名寄せがおこなわれる。名寄せのための同一視の判定方法として、たとえば、下記特許文献1,2がある。
【先行技術文献】
【特許文献】
【0006】
【特許文献1】特開2006−018340号公報
【特許文献2】特許第3721315号公報
【発明の概要】
【発明が解決しようとする課題】
【0007】
しかしながら、従来の名寄せでは、作業者が、コンピュータによって作成された名寄せ結果に目を通し、名寄せ元データと名寄せ先データが名寄せしあう組み合わせのデータであるか否かを判定している。作業者が確認する必要のあるデータ件数は、数百万件程度と膨大な件数となるため、作業者がすべての比較結果に目を通すことは現実的には難しい。
【0008】
また、作業者のミスにより誤った判定がおこなわれた場合、名寄せ結果データに矛盾が生じてしまう。したがって、作業者が確認すべきデータ件数を、現実的なデータ件数にまで絞る必要がある。
【0009】
また、作業者の確認するデータ件数が膨大であるため、現状では、コンピュータによって機械的に、名寄せしあう組み合わせのデータであるか否かを比較した結果を、そのまま名寄せ結果データとして用いらざるを得ない。この場合、名寄せできない組み合わせのデータを名寄せ結果に含めないために、比較条件を厳しくする必要がある。
【0010】
また、従来の名寄せでは、名寄せしあう複数のデータごとにグループに分けることは可能であるが、複数のデータに対して1つの名寄せ先データを決定することは難しい。
【0011】
本開示技術は、上述した従来技術による問題点を解消するため、作業者による名寄せ作業の工数を軽減することができる名寄せ処理プログラム、名寄せ処理方法、および名寄せ処理装置を提供することを目的とする。
【課題を解決するための手段】
【0012】
上述した課題を解決し、目的を達成するため、本名寄せ処理プログラム、名寄せ処理方法、および名寄せ処理装置では、一例として、データ群の中から、名寄せしあう第1のデータおよび第2のデータを指定し、かつ第1のデータと名寄せしあう第3のデータを特定した場合、第2のデータと第3のデータを、名寄せしあうデータの組み合わせに決定する。
【0013】
本開示技術によれば、作業者による名寄せ作業の工数を軽減し、かつ名寄せ結果に矛盾が生じることを防止することができる。
【発明の効果】
【0014】
本名寄せ処理プログラム、名寄せ処理方法、および名寄せ処理装置によれば、作業者による名寄せ作業の工数を軽減することができるという効果を奏する。
【図面の簡単な説明】
【0015】
【図1】実施の形態1にかかる名寄せ処理装置のハードウェア構成を示すブロック図である。
【図2】実施の形態1にかかるデータ運用の一例を示す説明図である。
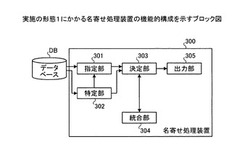
【図3】実施の形態1にかかる名寄せ処理装置の機能的構成を示すブロック図である。
【図4】実施の形態1にかかる名寄せ処理の一例を示す説明図である。
【図5】実施の形態1にかかる名寄せ処理前の名寄せ候補レコードの一例を示す説明図である。
【図6】実施の形態1にかかる名寄せ処理中の名寄せ候補レコードの一例を示す説明図である。
【図7】実施の形態1にかかる名寄せ処理中の名寄せ候補レコードの一例を示す説明図である。
【図8】実施の形態1にかかる名寄せ処理中の名寄せ候補レコードの一例を示す説明図である。
【図9】実施の形態1にかかる名寄せ処理中の名寄せ候補レコードの一例を示す説明図である。
【図10】実施の形態1にかかる名寄せ処理中の名寄せ候補レコードの一例を示す説明図である。
【図11】実施の形態1にかかる名寄せ処理中の名寄せ候補レコードの一例を示す説明図である。
【図12】実施の形態1にかかる名寄せ元/先データを示す説明図である。
【図13】実施の形態1にかかるグループの統合される過程の一例を順に示す説明図である。
【図14】実施の形態1にかかるグループの統合される過程の一例を順に示す説明図である。
【図15】実施の形態1にかかるグループの統合される過程の一例を順に示す説明図である。
【図16】実施の形態1にかかるグループの統合される過程の一例を順に示す説明図である。
【図17】実施の形態1にかかるグループの統合される過程の一例を順に示す説明図である。
【図18】実施の形態1にかかるグループの統合される過程の一例を順に示す説明図である。
【図19】実施の形態1にかかるグループの統合される過程の一例を順に示す説明図である。
【図20】実施の形態1にかかる名寄せ処理中の名寄せ候補レコードの別の一例を示す説明図である。
【図21−1】実施の形態1にかかる名寄せ処理手順の一例を示すフローチャートである。
【図21−2】実施の形態1にかかる名寄せ処理手順の一例を示すフローチャートである。
【図22−1】実施の形態1にかかる名寄せ処理手順の別の一例を示すフローチャートである。
【図22−2】実施の形態1にかかる名寄せ処理手順の別の一例を示すフローチャートである。
【図23】実施の形態1にかかるグループ統合処理手順の一例を示すフローチャートである。
【図24】実施の形態2にかかる名寄せ処理装置の機能的構成を示すブロック図である。
【図25】実施の形態2にかかる名寄せ処理の一例を示す説明図である。
【図26】実施の形態2にかかる名寄せ相手レコードの一例を示す説明図である。
【図27】実施の形態2にかかる名寄せ処理による決定結果の一例を示す説明図である。
【図28】実施の形態2にかかる名寄せ処理手順の一例を示すフローチャートである。
【図29】実施の形態2にかかる評価値算出処理手順の一例を示すフローチャートである。
【発明を実施するための形態】
【0016】
以下に添付図面を参照して、この発明にかかる名寄せ処理プログラム、名寄せ処理方法、および名寄せ処理装置の好適な実施の形態を詳細に説明する。
【0017】
・実施の形態1
(名寄せ処理装置のハードウェア構成)
図1は、実施の形態1にかかる名寄せ処理装置のハードウェア構成を示すブロック図である。図1において、名寄せ処理装置は、CPU(Central Processing Unit)101と、ROM(Read‐Only Memory)102と、RAM(Random Access Memory)103と、磁気ディスクドライブ104と、磁気ディスク105と、光ディスクドライブ106と、光ディスク107と、ディスプレイ108と、I/F(Interface)109と、キーボード110と、マウス111と、スキャナ112と、プリンタ113と、を備えている。また、各構成部はバス100によってそれぞれ接続されている。
【0018】
ここで、CPU101は、名寄せ処理装置の全体の制御を司る。ROM102は、ブートプログラムなどのプログラムを記憶している。RAM103は、CPU101のワークエリアとして使用される。磁気ディスクドライブ104は、CPU101の制御にしたがって磁気ディスク105に対するデータのリード/ライトを制御する。磁気ディスク105は、磁気ディスクドライブ104の制御で書き込まれたデータを記憶する。
【0019】
光ディスクドライブ106は、CPU101の制御にしたがって光ディスク107に対するデータのリード/ライトを制御する。光ディスク107は、光ディスクドライブ106の制御で書き込まれたデータを記憶したり、光ディスク107に記憶されたデータをコンピュータに読み取らせたりする。
【0020】
ディスプレイ108は、カーソル、アイコンあるいはツールボックスをはじめ、文書、画像、機能情報などのデータを表示する。このディスプレイ108は、たとえば、CRT、TFT液晶ディスプレイ、プラズマディスプレイなどを採用することができる。
【0021】
インターフェース(以下、「I/F」と略する。)109は、通信回線を通じてLAN(Local Area Network)、WAN(Wide Area Network)、インターネットなどのネットワーク114に接続され、このネットワーク114を介して他の装置に接続される。そして、I/F109は、ネットワーク114と内部のインターフェースを司り、外部装置からのデータの入出力を制御する。I/F109には、たとえばモデムやLANアダプタなどを採用することができる。
【0022】
キーボード110は、文字、数字、各種指示などの入力のためのキーを備え、データの入力をおこなう。また、タッチパネル式の入力パッドやテンキーなどであってもよい。マウス111は、カーソルの移動や範囲選択、あるいはウィンドウの移動やサイズの変更などをおこなう。ポインティングデバイスとして同様に機能を備えるものであれば、トラックボールやジョイスティックなどであってもよい。
【0023】
スキャナ112は、画像を光学的に読み取り、名寄せ処理装置内に画像データを取り込む。なお、スキャナ112は、OCR(Optical Character Reader)機能を持たせてもよい。また、プリンタ113は、画像データや文書データを印刷する。プリンタ113には、たとえば、レーザプリンタやインクジェットプリンタを採用することができる。
【0024】
(データ運用方法)
つぎに、データベースから取得したデータを名寄せするときのデータ運用方法について、図2を参照して説明する。図2は、実施の形態1にかかるデータ運用方法の一例を示す説明図である。まず、名寄せ処理装置200は、データベース211にアクセスし、たとえば、データベース211に記憶された整理対象のデータ群(以下、整理対象データ群とする)201の中からデータを取り出し、名寄せ候補となるデータを抽出する。
【0025】
具体的には、たとえば、名寄せ処理装置200は、整理対象データ群201の中から、名寄せされるデータ(名寄せ元データ)と、名寄せ元データの照合先となるデータ(名寄せ先データ)を抽出する。抽出されたデータは、たとえばレコード(以下、名寄せ候補レコードとする)単位で記憶され、1テーブルにまとまられたデータ(以下、名寄せ候補データとする)202として出力される。
【0026】
整理対象データ群201は、たとえば重複や類似したデータを含むデータ群であってもよいし、実際には重複や類似したデータは含まれないが、所定の名寄せ条件に基づいて名寄せさせるデータを含むデータ群であってもよい。また、整理対象データ群の中のデータは、標準化やクレンジングがおこなわれていてもよい。
【0027】
ここで、データとは、たとえばロゴマークなどの静止画データ、単語や文章などの文字列データ、音声データなど、コンピュータで処理可能な二進数で記号化することができるデータである。具体的には、データとは、文字列データを一例として説明すると、会社名,氏名,住所,商品名,国名,地名などである。
【0028】
また、名寄せとは、整理対象データ群の中の1つ以上の整理対象データを、1つの整理対象データに関連付けることである。たとえば、「株式会社○○」,「株式会社 ○○」,「(株)○○」,「株○○」が同一の会社名である場合、これら会社名をあらわす文字列を、たとえば「株式会社○○」に関連付けることである。また、「東京」,「とうきょう」,「トウキョウ(全角文字列)」,「トウキョウ(半角文字列)」「Tokyo」が同一の地名である場合、これら地名をあらわす文字列を、たとえば「東京」に関連付けることである。
【0029】
また、名寄せは、たとえば文字列の類似度数に基づいて、コンピュータによって処理されてもよいし、文字列が類似しているか否かによらず、作業者の入力によって処理されてもよい。
【0030】
名寄せ候補レコードは、たとえば名寄せ元データの識別記号(以下、名寄せ元IDとする)と、名寄せ先データの識別記号(名寄せ先IDとする)から構成される。また、名寄せ候補レコードには、名寄せ元データと名寄せ先データの比較結果が記憶されていてもよい。また、名寄せ元データを照合する名寄せ先データが抽出されない場合、この名寄せ元データに対応する名寄せ候補レコードは作成されなくてもよい。
【0031】
比較結果とは、名寄せ元データと名寄せ先データを比較するための情報であり、名寄せ元データと名寄せ先データが類似している度合いを示す度数(以下、類似度数とする)であってもよいし、名寄せ元データと名寄せ先データが相違している度合いを示す度数(以下、相違度数とする)であってもよい。
【0032】
また、整理対象データ群201のうち、名寄せ元データとして抽出されたデータは、グループに登録されていてもよい。具体的には、たとえば、1つのグループ(以下、名寄せ元グループとする)には、1つの名寄せ元データが登録される。
【0033】
グループとしてデータを扱うことで、異なるグループが統合されたときに、名寄せしあう組み合わせのデータのみを確実に同一グループに含めることができる。これにより、決定結果に矛盾が生じることを防止することができる。
【0034】
ついで、名寄せ処理装置200は、複数の名寄せ候補レコードに記憶された情報に基づいて、名寄せ元データと名寄せ先データが名寄せしあう組み合わせか否かを決定する。名寄せしあう組み合わせか否かを決定する詳細な方法の説明は、後述する。
【0035】
名寄せ処理装置200により決定された結果は、たとえば決定結果データ203に書き込まれる。決定結果データ203は、たとえば、名寄せ候補データ202に決定結果が書き込まれたデータである。名寄せ候補データ202および決定結果データ203は、たとえばデータベース211などに記憶されてもよい。
【0036】
名寄せ元データの照合先は、名寄せ元データ自身であってもよい。つまり、名寄せ元データおよび名寄せ先データは、ともに整理対象データ群201の中から指定されてもよい。また、名寄せ元データの照合先は、たとえば整理対象データ群201のマスターデータであってもよい。つまり、名寄せ元データおよび名寄せ先データは、異なるデータ群の中からそれぞれ指定されてもよい。
【0037】
ついで、名寄せ処理装置200は、決定結果データ203に基づいて、一般的なデータ統合装置212の入力形式に対応した名寄せ結果データ204を作成する。具体的には、たとえば、名寄せ処理装置200は、1つ以上の名寄せ元データに対して1つの名寄せ先データが関連付けられたレコードを、名寄せ結果データ204として出力する。
【0038】
名寄せ結果データ204は、データ統合装置212に入力される。データ統合装置212は、名寄せ結果データ204に基づいて、整理対象データ群201の中の各データを名寄せする。名寄せ処理後の整理対象データ群201は、たとえばデータベース211に記憶される。名寄せ処理装置200は、データ統合装置212の機能を有していてもよい。
【0039】
(名寄せ処理装置の機能的構成)
つぎに、実施の形態1にかかる名寄せ処理装置の機能的構成について説明する。図3は、実施の形態1にかかる名寄せ処理装置の機能的構成を示すブロック図である。名寄せ処理装置300は、指定部301と、特定部302と、決定部303と、統合部304と、出力部305と、を含む構成である。この制御部となる機能(指定部301〜出力部305)は、具体的には、たとえば、図1に示したROM102、RAM103、磁気ディスク105、光ディスク107などの記憶装置に記憶されたプログラムをCPU101に実行させることにより、または、I/F109により、その機能を実現する。
【0040】
指定部301は、データ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する機能を有する。具体的には、たとえば、指定部301は、データベースDBに記憶された整理対象データ群の中から、名寄せ元データ(または名寄せ先データ)と名寄せしあう可能性のあるデータの組み合わせを指定する。
【0041】
特定部302は、データ群の中から、指定部301によって指定された第1のデータと名寄せしあう第3のデータを特定する機能を有する。また、特定部302は、データ群の中から、指定部301によって指定された第1のデータと名寄せできない第3のデータを特定する機能を有する。
【0042】
具体的には、たとえば、特定部302は、データベースDBに記憶された整理対象データ群の中から、名寄せ先データ(または名寄せ元データ)と、指定部301によって指定された第1のデータとが名寄せしあうデータの組み合わせであるか、または名寄せできないデータの組み合わせであるかを特定する。
【0043】
決定部303は、指定部301によって指定された第2のデータと特定部302によって特定された第3のデータを、名寄せしあうデータの組み合わせに決定する機能を有する。具体的には、たとえば、決定部303は、名寄せ元データと名寄せ先データを名寄せしあうデータの組み合わせに決定する(以下、第1の決定方法とする)。
【0044】
決定部303により決定された決定結果は、たとえば名寄せ候補レコードの決定結果に記憶される。なお、決定されたデータは、RAM103、磁気ディスク105、光ディスク107などの記憶領域に記憶される。図4は、実施の形態1にかかる名寄せ処理の一例を示す説明図である。
【0045】
具体的には、たとえば、名寄せ元データおよび名寄せ先データ以外のデータの名寄せ元/先ID=1、名寄せ元ID=2、名寄せ先ID=3としたときに、名寄せ候補レコード(名寄せ元ID,名寄せ先ID)=名寄せ候補レコード(2,3)の決定結果が○(マル)または×(バツ)になる一例について、図4を参照して説明する。
【0046】
ここで、決定結果○は、2つのデータが名寄せしあうデータの組み合わせであることを意味し、決定結果×は、2つのデータが名寄せできないデータの組み合わせであることを意味する。まず、名寄せ候補レコード(2,3)の決定結果が○になる一例について説明する。
【0047】
指定部301は、たとえば名寄せ元ID=2の名寄せ候補レコードの中から、名寄せ元データと名寄せしあう第1のデータX1を指定する。具体的には、指定部301は、決定結果が○である名寄せ候補レコード(2,1)を第1のデータX1として指定する。また、指定部301は、名寄せ候補レコード(1,2)の決定結果が○であることにより、指定するデータを第1のデータX1としてもよい。つまり、第1のデータX1と第2のデータX2は、名寄せしあうデータの組み合わせであり、第1のデータX1と第2のデータX2の決定結果a12は○である(図4−(a)参照)。
【0048】
さらに、特定部302は、たとえば名寄せ先ID=3の名寄せ候補レコードの中から、名寄せ先データと第1のデータX1が名寄せしあうデータの組み合わせであることを特定する。具体的には、特定部302は、名寄せ候補レコード(1,3)の決定結果が○であることを特定する。また、特定部302は、名寄せ候補レコード(3,1)の決定結果が○であることを特定してもよい。つまり、第1のデータX1と第3のデータX3は、名寄せしあうデータの組み合わせであり、第1のデータX1と第3のデータX3の決定結果a13は○である(図4−(b)参照)。
【0049】
決定結果a12=○であり、かつ決定結果a13=○であることにより、決定部303は、第2のデータX2と第3のデータX3の決定結果a23を○に決定する(図4−(c)参照)。具体的には、決定部303は、名寄せ候補レコード(2,3)の決定結果を○にする。つまり、第2,3のデータにそれぞれ共通する第1のデータX1の決定結果a12,a13が○であることにより、第2のデータX2と第3のデータX3の決定結果a23は一意に○に決定される。
【0050】
つぎに、名寄せ候補レコード(2,3)の決定結果が×になる場合について説明する。指定部301は、たとえば名寄せ元ID=2の名寄せ候補レコードの中から、名寄せ元データと名寄せしあう第1のデータX1を指定する。つまり、第1のデータX1と第2のデータX2の決定結果a12は○である(図4−(d)参照)。
【0051】
さらに、特定部302は、たとえば名寄せ元ID=3の名寄せ候補レコードの中から、名寄せ先データと第1のデータX1が名寄せできないデータの組み合わせであることを特定する。つまり、第1のデータX1と第3のデータX3は、名寄せできないデータの組み合わせであり、第1のデータX1と第3のデータX3の決定結果a13は×である(図4−(e)参照)。
【0052】
決定結果a12=○であり、かつ決定結果a13=×であることにより、決定部303は、第2のデータX2と第3のデータX3の決定結果a23を×に決定する(図4−(f)参照)。つまり、決定結果a12,a13のいずれかが×であることにより、第2のデータX2と第3のデータX3の決定結果a23は一意に×に決定される。
【0053】
また、名寄せ候補レコード(2,3)と名寄せ候補レコード(3,2)の決定結果は、同じ結果となる。このため、決定部303は、たとえば名寄せ候補レコード(2,3),・・・,名寄せ候補レコード(3,2)の順で決定結果が決定される場合、名寄せ候補レコード(3,2)の決定結果を、名寄せ候補レコード(2,3)の決定結果を決定したときに決定してもよいし、順次名寄せ候補レコードを読み込んでいき、名寄せ候補レコード(3,2)を読み込んだときに決定してもよい。
【0054】
指定部301および特定部302が参照する名寄せ候補レコードの決定結果は、所定の名寄せ条件に基づいて予め決定された決定結果であってもよいし、決定部303による決定処理中に決定された決定結果であってもよい。
【0055】
決定結果を予め設定する場合、名寄せ処理前に、作業者がたとえば可視化された名寄せ候補レコードを確認し、名寄せ候補レコードの決定結果に○や×を書き込んでもよい。図5は、実施の形態1にかかる名寄せ処理前の名寄せ候補レコードの一例を示す説明図である。
【0056】
図5において、名寄せ候補レコードは、名寄せ元IDおよび名寄せ先IDから構成される。名寄せ候補レコード(名寄せ元ID,名寄せ先ID)には、たとえば類似度数、作業者により書き込まれた決定結果(初期条件に中黒の星印★の書き込まれたレコード)、および名寄せ元グループなど名寄せ処理に用いる主要なデータがそれぞれ書き込まれている。図5では、名寄せ候補レコードの主要な部分のみを示す(以下、図6〜11,20においても同様)。
【0057】
具体的には、たとえば、名寄せ候補レコード(1,2)は、次のデータを記憶する。名寄せ元ID=1である。名寄せ先ID=2である。名寄せ元/先ID=1,2のデータの組み合わせを比較した類似度数=50である。名寄せ元/先ID=1,2のデータの組み合わせは、作業者により、名寄せしあうデータの組み合わせに決定されている。つまり、名寄せ候補レコード(1,2)の決定結果には、名寄せ処理前に予め決定結果○が書き込まれている。名寄せ元ID=1のデータは、グループG1に登録されている。
【0058】
なお、名寄せ候補レコードの初期条件(★)または閾値(☆)は、名寄せ候補レコードの構成要素ではない。名寄せ候補レコードの決定結果が、第1の決定方法に基づいた決定結果ではないことを明確にするものである。
【0059】
つまり、初期条件または閾値=星印★の場合、作業者により決定結果が書き込まれている。初期条件または閾値=星印☆の場合、比較結果の閾値に基づいて決定結果が書き込まれている。また、初期条件または閾値=NULLの場合、名寄せ候補レコードの決定結果は、第1の決定方法に基づいて名寄せされている(以下、図6〜11,20においても同様)。
【0060】
また、図5では、名寄せ処理に用いる主要なデータのすべてを1テーブルに記憶させているが、これに限らず、名寄せ処理に用いる主要なデータをそれぞれ異なるテーブルに記憶させてもよい。たとえば、名寄せ元グループを、図5に示す名寄せ候補レコードには書き込まず、図5に示すテーブルとは異なるテーブルに書き込んでもよい。図12は、実施の形態1にかかる名寄せ元/先データを示す説明図である。
【0061】
たとえば、図12に示すように、名寄せ元/先IDごとに名寄せ元/先データが記憶されたテーブルに、名寄せ元/先IDごとに名寄せ元グループを書き込んでもよいし、図12に示すテーブルとは異なるテーブルに、名寄せ元/先IDごとに名寄せ元グループのみを書き込んでもよい。
【0062】
つまり、名寄せ処理に用いる主要なデータは、名寄せ処理装置200が記録および参照することができればよく、1テーブルに記憶されていてもよいし、名寄せ処理に用いる主要なデータごとに異なるテーブルに記憶されていてもよい。ここでは、各データの書き込まれる順序を明確にするために、名寄せ処理に用いる主要なデータを1テーブルに記憶した場合を例に説明する。
【0063】
決定部303は、名寄せ元データと名寄せ先データの比較結果に基づいて、名寄せ元データと名寄せ先データを名寄せしあうデータの組み合わせに決定してもよい(以下、第2の決定方法とする)。
【0064】
具体的には、たとえば、類似度数の閾値の上限値を90とし、下限値を30とした場合、決定部303は、名寄せ候補レコードの類似度数が90以上である場合に、この名寄せ候補レコードの決定結果を○に決定する。また、決定部303は、名寄せ候補レコードの類似度数が30以下である場合に、この名寄せ候補レコードの決定結果を×に決定する。図6〜図11は、実施の形態1にかかる名寄せ処理中の名寄せ候補レコードの一例を示す説明図である。
【0065】
図6において、たとえば、名寄せ候補レコード(1,6)の類似度数は、100である。このため、決定部303は、名寄せ候補レコード(1,6)の決定結果を○に決定する(中抜きの星印☆の書き込まれたレコード)。
【0066】
また、決定部303は、名寄せ元データと名寄せ先データが同一グループに含まれる場合に、名寄せ元データと名寄せ先データを名寄せしあうデータの組み合わせに決定してもよい(以下、第3の決定方法とする)。
【0067】
具体的には、たとえば、決定部303は、名寄せ候補レコード(6,1)の決定結果を決定する場合、名寄せ元ID=1,6の名寄せ元グループがともにグループG1であることにより、名寄せ候補レコード(6,1)の決定結果を○に決定する(図11参照)。
【0068】
統合部304は、決定部303により、名寄せ元データと名寄せ先データを名寄せしあう組み合わせに決定した場合、名寄せ元データを含むグループと名寄せ先データを含むグループを統合する機能を有する。具体的には、たとえば、図6において、統合部304は、決定部303により名寄せ候補レコード(1,6)の決定結果が○に決定された場合、名寄せ元ID=6の名寄せ元グループをグループG6からグループG1に変更する。なお、統合された結果は、RAM103、磁気ディスク105、光ディスク107などの記憶領域に記憶される。
【0069】
たとえば、図4−cにおいて、第1,2のデータが同一グループであるとする。この場合、決定部303により、第2のデータX2と第3のデータX3が名寄せしあう組み合わせのデータに決定されると、統合部304は、第1のデータX1を含むグループに、第3のデータX3を含むグループを統合する。
【0070】
さらに、決定部303が、第1のデータX1と、図示省略する第4のデータを名寄せしあう組み合わせに決定した場合、統合部304は、第1のデータX1を含むグループにさらに、第4のデータを含むグループを統合する。つまり、第1〜第4のデータは、同一グループとなる。
【0071】
一方、図4−fでは、決定部303により、第2のデータX2と第3のデータX3が名寄せできない組み合わせのデータに決定されている。このため、図示省略する第4のデータが第3のデータX3と同一グループである場合、決定部303は、第1のデータX1と第4のデータを名寄せできないデータの組み合わせに決定する。
【0072】
つまり、異なるグループ間のデータの組み合わせの中に、1つでも名寄せできないデータの組み合わせがある場合、この異なるグループ間のデータの組み合わせは、決定部303により、名寄せできないデータの組み合わせに決定される。
【0073】
つぎに、決定部303により決定結果が作成されるまでの処理過程の一例を、図5〜図11を参照して説明する。図5に示す名寄せ候補レコードには、名寄せ処理前に、作業者により書き込まれた決定結果のみが示されている(中黒の星印★のレコード)。ここで、決定部303は、名寄せ候補データ中の名寄せ候補レコードを先頭レコードから順に読み込むこととする。
【0074】
まず、決定部303は、名寄せ候補レコード(1,6)を取得する。ついで、決定部303は、名寄せ元ID=1,6の名寄せ候補レコードの名寄せ元グループが同一グループであるか否かを判断する(第3の決定方法)。具体的には、決定部303は、名寄せ元ID=1のデータのグループG1と名寄せ元ID=6のデータのグループG6が異なるため、続けて第1の決定方法をおこなう。
【0075】
第1の決定方法では、指定部301は、名寄せ元/先ID=1の名寄せ候補レコードの中から、名寄せ元ID=1のデータと名寄せしあうデータ(または名寄せできないデータ)を指定する。具体的には、指定部301は、名寄せ元ID=1のデータと名寄せしあうデータとして、名寄せ候補レコード(1,2),(1,3),(1,4)を指定する。
【0076】
そして、特定部302は、指定部301によって指定された名寄せ元/先ID=2,3,4のデータと名寄せしあう名寄せ元ID=6のデータ(または名寄せできない名寄せ元ID=6のデータ)を特定する。具体的には、特定部302は、名寄せ候補レコード(2,6),(3,6),(4,6),(6,2),(6,3),(6,4)の中で、決定結果が○となる名寄せ候補レコードを特定する。
【0077】
しかし、特定部302は、上記名寄せ候補レコードの中から、名寄せ先ID=6のデータと名寄せしあうデータを特定することができない。このため、決定部303は、続けて第2の決定方法をおこなう。
【0078】
第2の決定方法では、決定部303は、名寄せ候補レコード(1,6)の類似度数に基づいて、名寄せをおこなう。名寄せ候補レコード(1,6)の類似度数は、類似度数の閾値の上限値90以上であるため、決定部303は、名寄せ候補レコード(1,6)の決定結果に○を書き込む(図6参照)。図6〜11,20の名寄せ候補レコードにおいて、名寄せ処理または統合処理により、書き換えられた部分を二重線で囲む。
【0079】
決定部303によって名寄せ候補レコード(1,6)の決定結果に○が書き込まれるとともに、統合部304は、名寄せ元ID=6と同じグループG6が書き込まれているすべての名寄せ候補レコードの名寄せ元グループをグループG6からグループG1に変更する。なお、図6〜12,20においては、名寄せ元グループの変更された経緯を矢印で示す。具体的には、名寄せ候補レコード(1,6)では、グループG1がグループG6に変更されているため、G1→G6となる。
【0080】
以下、決定部303は、すべての名寄せ候補レコードに対して、上述した名寄せ候補レコード(1,6)に対する名寄せ処理と同様の手順で名寄せ処理をおこなうが、以下、詳細な説明は省略する。
【0081】
ついで、決定部303は、すでに決定結果の書き込まれている名寄せ候補レコード(1,2),(1,3), (1,4)を飛ばし、名寄せ候補レコード(1,7)に対する名寄せ処理をおこなう。しかし、この段階では、決定部303は、第1〜第3の決定方法に基づいて、名寄せ候補レコード(1,7)の決定結果を得ることができない。
【0082】
このため、決定部303は、名寄せ候補レコード(1,7)の決定結果には何も書き込まず、続けて次の名寄せ候補レコード(1,5)の名寄せ処理をおこなう。そして、決定部303は、第2の決定方法に基づいて、名寄せ候補レコード(1,5)の決定結果に×を書き込む(図7参照)。以下、統合部304によるグループ統合処理の伴わない名寄せ処理については、説明を省略する。
【0083】
決定部303は、第1の決定方法に基づいて、名寄せ候補レコード(2,1),(2,3),(2,4),(3,7)の決定結果にこの順に○を書き込む。そして、統合部304は、名寄せ候補レコード(2,1)の決定結果に○が書き込まれるとともに、名寄せ元ID=2と同じグループG3が書き込まれているすべての名寄せ元グループをグループG2からグループG1に変更する(図7参照)。
【0084】
また、統合部304は、名寄せ候補レコード(2,3)の決定結果に○が書き込まれるとともに、名寄せ元ID=3と同じグループG3が書き込まれているすべての名寄せ元グループをグループG3からグループG1に変更する(図8参照)。
【0085】
また、統合部304は、名寄せ候補レコード(2,4)の決定結果に○が書き込まれるとともに、名寄せ元ID=4と同じグループG3が書き込まれているすべての名寄せ元グループをグループG4からグループG1に変更する(図9参照)。
【0086】
また、統合部304は、名寄せ候補レコード(3,7)の決定結果に○が書き込まれるとともに、名寄せ元ID=7と同じグループG3が書き込まれているすべての名寄せ元グループをグループG7からグループG1に変更する(図10参照)。以下、決定部303および統合部304は、同様の処理を繰り返す。これにより、ほぼすべての名寄せ候補レコードの決定結果に○または×が書き込まれ、決定結果データが完成する(図11参照)。
【0087】
これにより、図12に示すように、名寄せ処理前のグループG2,G3、G4,G6,G7は、グループG1に変更される。つまり、上述した統合部304によるグループ統合処理により、グループG2,G3、G4,G6,G7は消滅する。
【0088】
ここでは、統合部304により、グループG2〜G7が順にグループG1に変更されているが、名寄せ候補レコードの読み込まれる順番により、名寄せ元グループの変更される順番は変わる。たとえば、グループG7がグループG3に変更された後、グループG3がグループG1に変更され、名寄せ処理が終了した場合、名寄せ処理前のグループG7は、名寄せ処理が終了した時点でグループG1に変更されている。つまり、名寄せ元ID=7の名寄せ候補レコードの名寄せ元グループは、G7→G3→G1と変更される(不図示)。
【0089】
名寄せ処理がすべて終了し、決定結果データが完成した後に、図示省略した他の名寄せ候補レコードの名寄せ元グループを手作業により書き換えてもよい。具体的には、たとえば、作業者は、名寄せ候補レコードの名寄せ元グループをグループG11からグループG1に書き換える。
【0090】
これにより、名寄せ処理前のグループG11,G12は、グループG1に変更され、グループG11,G12は消滅する。つまり、決定部303による名寄せ処理後においても、グループを統合することができる。図13〜図19は、実施の形態1にかかるグループの統合される過程の一例を順に示す説明図である。上述した図5〜図12に示すようにグループを統合した状態を、図13〜図19を参照して説明する。
【0091】
図13において、名寄せ元データX1〜X31は、それぞれ異なるグループG1〜G31に登録される。図13に示す状態は、名寄せ候補レコードの名寄せ先グループに、グループG1〜G31が書き込まれた状態である(図5参照)。ここで、名寄せ元データX1〜X31は、図5における名寄せ元ID=1〜31のデータに該当する(以下、図14〜図19においても同様)。なお、図5では、名寄せ元ID=8〜31は図示省略している。
【0092】
図14において、まず、統合部304により、グループG6は、グループG1に統合されて消滅する。決定部303により、名寄せ候補レコード(1,6)の決定結果が○に決定されたことによるものである(図6参照)。これにより、名寄せ元データX6は、グループG1に登録される。
【0093】
ついで、図15〜図18において、統合部304により、グループG2,G3,G4,G7は、この順でグループG1に順次統合されて消滅する。決定部303により、名寄せ候補レコード(2,1),(2,3),(2,4),(3,7)の決定結果が順次○に決定されたことによるものである(図7〜10参照)。これにより、名寄せ元データX2,X3,X4,X7は、グループG1に順次登録される。
【0094】
また、図19において、グループG11が、グループG1に統合されて消滅する。作業者により、名寄せ元ID=11のデータの名寄せ元グループが、グループG11からグループG1に変更されたことによるものである(図12参照)。これにより、名寄せ元データX11,X12は、グループG1に登録される。
【0095】
次に、決定結果データが作成されるまでの処理過程の別の一例を、図20を参照して説明する。図20は、実施の形態1にかかる名寄せ処理中の名寄せ候補レコードの別の一例を示す説明図である。まず、決定部303は、図5に示す名寄せ処理と同様に、名寄せ候補レコード(1,6)を取得する。
【0096】
ついで、図20において、決定部303は、図6に示す名寄せ処理と同様に、第2の決定方法に基づいて、名寄せ候補レコード(1,6)の決定結果を○に決定する。そして、統合部304は、図6に示すグループ統合処理と同様に、名寄せ元ID=6のすべての名寄せ候補レコードの名寄せ元グループをグループG6からグループG1に変更する。
【0097】
ついで、指定部301は、決定部303により決定結果を○に決定された名寄せ候補レコード(1,6)を指定する。そして、特定部302は、指定部301によって指定された名寄せ元/先ID=1,6のデータと名寄せしあう名寄せ候補レコード(1,2),(1,3), (1,4)を特定する。
【0098】
これにより、決定部303は、指定部301により指定された名寄せ元/先ID=1,6と、特定部302により特定された名寄せ元/先ID=2,3,4のデータの、すべての組み合わせのデータを、名寄せしあうデータの組み合わせに決定する。
【0099】
具体的には、決定部303は、名寄せ候補レコード(2,1), (2,3),(2,4),(2,6),(3,1),(3,2),(3,4),(3,6), (4,1),(4,2),(4,3),(4,6), (6,1),(6,2),(6,3),(6,4)の決定結果を○に決定する。
【0100】
つまり、指定部301は、グループG1内の、名寄せしあうデータの組み合わせを順に指定する。そして、特定部302は、指定部301がデータを指定する都度、指定部301により指定されたデータと名寄せしあうデータを特定する。これにより、決定部303は、グループG1内のすべての組み合わせのデータを、名寄せ候補レコード(1,6)の決定結果を○に決定すると同時に名寄せしあうデータの組み合わせに決定する。
【0101】
その後、統合部304により、グループ統合処理がおこなわれ、グループG2,G3,G4,G6は同時にグループG1に統合される。このように、ある名寄せ候補レコードの決定結果が決定することで決定結果が確定する名寄せ候補レコードの決定結果を、ある名寄せ候補レコードの決定結果と同時に決定してもよい。
【0102】
出力部305は、決定部303により決定された名寄せ結果を出力する機能を有する。具体的には、たとえば、出力部305は、決定結果データに基づいて、一般的なデータ統合装置212の入力形式に対応した名寄せ結果データを作成する。出力形式としては、たとえば、ディスプレイ108への表示、プリンタ113への印刷出力、I/F109による外部装置への送信がある。また、RAM103、磁気ディスク105、光ディスク107などの記憶領域に記憶することとしてもよい。
【0103】
実施の形態1によれば、作業者による名寄せ作業の工数を軽減することができる。これにより、作業者のミスにより、誤った名寄せ結果が作成されることを回避することができる。また、名寄せしあう組み合わせのデータ、および名寄せすることができない組み合わせのデータを正確に特定することができる。これにより、名寄せ結果に矛盾が生じることを防止することができる。
【0104】
(名寄せ処理手順)
つぎに、実施の形態1にかかる名寄せ処理手順の一例について説明する。図21−1,21−2は、実施の形態1にかかる名寄せ処理手順の一例を示すフローチャートである。図21−1において、まず、名寄せ処理装置により、名寄せ元の整理対象データ(名寄せ元データ)および名寄せ先の整理対象データ(名寄せ先データ)を抽出し、名寄せ元データを1グループ1データでグループに登録する(ステップS2101)。ついで、決定部303により、名寄せ元データ数nを取得する(ステップS2102)。そして、初期値をI=1とし、変数i=名寄せ元データ(I)のIDとする(ステップS2103)。
【0105】
ついで、決定部303により、名寄せ元ID=iの名寄せ候補レコードのレコード数mを取得する(ステップS2104)。名寄せ元ID=iの名寄せ候補レコードがある場合(ステップS2105:Yes)、決定部303により、初期値をJ=1とし、変数j=名寄せ先データ(I,J)のIDとする(ステップS2106)。
【0106】
ついで、決定部303により、名寄せ候補レコード(i,j)を取得する(ステップS2107)。そして、決定部303により、名寄せ候補レコード(i,j)の決定結果=NULLであるか否かを判定する(ステップS2108)。つまり、決定部303は、名寄せ候補レコード(i,j)の決定結果が決定済みであるか否かを判定する。
【0107】
名寄せ候補レコード(i,j)の決定結果=NULLである場合(ステップS2108:Yes)、決定部303により、ID=iの名寄せ元データの登録されたグループG(i)を取得する(ステップS2109)。つまり、名寄せ元データ(I)の登録されたグループを取得する。また、決定部303により、ID=jの名寄せ元データの登録されたグループG(j)を取得する(ステップS2110)。つまり、名寄せ先データ(I,J)のIDと同じIDの名寄せ元データの登録されたグループを取得する。
【0108】
グループG(i)=グループG(j)である場合(ステップS2111:Yes)、決定部303により、名寄せ候補レコード(i,j)の決定結果に○を書き込む(ステップS2112)。ついで、Jをインクリメントして(ステップS2113)、J>mでない場合(ステップS2114:No)、ステップS2107に移行し、決定部303により、名寄せ候補レコード(i,j)を取得する。
【0109】
一方、グループG(i)=グループG(j)でない場合(ステップS2111:No)、指定部301および特定部302により、グループG(i)の整理対象データとグループG(j)の整理対象データを名寄せ元/先データとする組み合わせの、名寄せ候補レコードの決定結果を○に決定したことがあるか否かを判定する(ステップS2117)。
【0110】
つまり、ステップS2117において、指定部301および特定部302は、グループG(i)の整理対象データのIDとグループG(j)の整理対象データのIDを名寄せ元/先IDとする名寄せ候補レコードに、決定結果○の名寄せ候補レコードが少なくとも1レコードあるか否か判定する。
【0111】
決定結果○の名寄せ候補レコードがある場合(ステップS2117:Yes)、統合部304により、グループ統合処理をおこない(ステップS2118)、決定部303により、名寄せ候補レコード(i,j)の決定結果に○を書き込む(ステップS2112)。
【0112】
一方、決定結果○の名寄せ候補レコードがない場合(ステップS2117:No)、指定部301および特定部302により、グループG(i)の整理対象データとグループG(j)の整理対象データを名寄せ元/先データとする組み合わせの、名寄せ候補レコードの決定結果を×に決定したことがあるか否かを判定する(ステップS2119)。
【0113】
つまり、ステップS2119において、指定部301および特定部302は、グループG(i)の整理対象データのIDとグループG(j)の整理対象データのIDを名寄せ元/先IDとする名寄せ候補レコードに、決定結果×の名寄せ候補レコードが少なくとも1レコードあるか否か判定する。
【0114】
決定結果×の名寄せ候補レコードがない場合(ステップS2119:No)、決定部303により、名寄せ候補レコード(i,j)の類似度数が閾値の上限値以上であるか否かを判定する(ステップS2120)。
【0115】
一方、決定結果×の名寄せ候補レコードがある場合(ステップS2119:Yes)、決定部303により、名寄せ候補レコード(i,j)の決定結果に×を書き込む(ステップS2122)。
【0116】
ステップS2120において、名寄せ候補レコード(i,j)の類似度数が閾値の上限値以上である場合(ステップS2120:Yes)、統合部304によりグループ統合処理をおこない(ステップS2118)、決定部303により名寄せ候補レコード(i,j)の決定結果に○を書き込む(ステップS2112)。
【0117】
一方、名寄せ候補レコード(i,j)の類似度数が閾値の上限値以上でない場合(ステップS2120:No)、決定部303により、名寄せ候補レコード(i,j)の類似度数が閾値の下限値以下であるか否かを判定する(ステップS2121)。
【0118】
名寄せ候補レコード(i,j)の類似度数が閾値の下限値以下である場合(ステップS2121:Yes)、決定部303により、名寄せ候補レコード(i,j)の決定結果に×を書き込む(ステップS2122)。
【0119】
一方、名寄せ候補レコード(i,j)の類似度数が閾値の下限値以下でない場合(ステップS2121:No)、Jをインクリメントし(ステップS2113)、J>mでない場合(ステップS2114:No)、ステップS2107に移行し、決定部303により、名寄せ候補レコード(i,j)を取得する。
【0120】
ステップS2108において、名寄せ候補レコード(i,j)の決定結果=NULLでない場合(ステップS2108:No)、ステップS2109〜ステップS2122の処理はおこなわずに、ステップS2113に移行する。
【0121】
また、ステップS2105において、名寄せ元ID=iの名寄せ候補レコードがない場合においても同様に(ステップS2105:No)、ステップS2113に移行する。
【0122】
また、ステップS2114において、J>mである場合(ステップS2114:Yes)、Iをインクリメントし(ステップS2115)、I>nでない場合(ステップS2116:No)、ステップS2104に移行し、決定部303により、名寄せ元ID=iの名寄せ候補レコードのレコード数mを取得する。
【0123】
一方、ステップS2116において、I>nである場合(ステップS2116:Yes)、名寄せ処理装置は一連の処理を終了する。
【0124】
つぎに、実施の形態1にかかる名寄せ処理手順の別の一例について説明する。図22−1,22−2は、実施の形態1にかかる名寄せ処理手順の別の一例を示すフローチャートである。図22−1において、まず、名寄せ処理装置により、名寄せ元データを1グループ1データでグループに登録する(ステップS2201)。ついで、名寄せ元の整理対象データ数nを取得する(ステップS2202)。そして、初期値をI=1とし、変数i=名寄せ元データ(I)のIDとする(ステップS2203)。
【0125】
ついで、決定部303により、名寄せ元ID=iの名寄せ候補レコードのレコード数mを取得する(ステップS2204)。名寄せ元ID=iの名寄せ候補レコードがある場合(ステップS2205:Yes)、決定部303により、初期値をJ=1とし、変数j=名寄せ先データ(I,J)のIDとする(ステップS2206)。
【0126】
ついで、決定部303により、名寄せ候補レコード(i,j)を取得する(ステップS2207)。そして、決定部303により、名寄せ候補レコード(i,j)の決定結果=NULLであるか否かを判定する(ステップS2208)。つまり、決定部303は、名寄せ候補レコード(i,j)の決定結果が決定済みであるか否かを判定する。
【0127】
名寄せ候補レコード(i,j)の決定結果=NULLである場合(ステップS2208:Yes)、決定部303により、ID=iの名寄せ元データの登録されたグループG(i)を取得する(ステップS2209)。つまり、名寄せ元データ(I)の登録されたグループを取得する。また、決定部303により、ID=jの名寄せ元データの登録されたグループG(j)を取得する(ステップS2210)。つまり、名寄せ先データ(I,J)のIDと同じIDの名寄せ元データの登録されたグループを取得する。
【0128】
グループG(i)=グループG(j)である場合(ステップS2211:Yes)、決定部303により、グループG(i)の整理対象データを名寄せ元/先データとする組み合わせの、すべての名寄せ候補レコードの決定結果に○を書き込む(ステップS2212)。つまり、決定部303により、グループG(i)内の整理対象データの全組み合わせは、名寄せしあうデータの組み合わせに決定される。
【0129】
ついで、Jをインクリメントして(ステップS2213)、J>mでない場合(ステップS2214:No)、ステップS2207に移行し、決定部303により、名寄せ候補レコード(i,j)を取得する。
【0130】
一方、グループG(i)=グループG(j)でない場合(ステップS2211:No)、指定部301および特定部302により、グループG(i)の整理対象データとグループG(j)の整理対象データを1組の名寄せ元/先データとする組み合わせの、名寄せ候補レコードの決定結果を○に決定したことがあるか否かを判定する(ステップS2217)。
【0131】
ステップS2217において、決定結果○の名寄せ候補レコードがある場合(ステップS2217:Yes)、統合部304により、グループ統合処理をおこない(ステップS2218)、決定部303により、グループG(i)の整理対象データとグループG(j)の整理対象データを1組の名寄せ元/先データとする組み合わせの、すべての名寄せ候補レコードの決定結果に○を書き込む(ステップS2219)。つまり、ステップS2219において、グループG(i)の整理対象データのIDとグループG(j)の整理対象データのIDを名寄せ元/先IDとするすべての名寄せ候補レコードの決定結果が○になる。
【0132】
一方、ステップS2217において、決定結果○の名寄せ候補レコードがない場合(ステップS2217:No)、指定部301および特定部302により、グループG(i)の整理対象データとグループG(j)の整理対象データを1組の名寄せ元/先データとする組み合わせの、名寄せ候補の決定結果を×に決定したことがあるか否かを判定する(ステップS2220)。
【0133】
ステップS2220において、決定結果×の名寄せ候補レコードがない場合(ステップS2220:No)、決定部303により、名寄せ候補レコード(i,j)の類似度数が閾値の上限値以上であるか否かを判定する(ステップS2221)。
【0134】
一方、ステップS2220において、決定結果×の名寄せ候補レコードがある場合(ステップS2220:Yes)、決定部303により、グループG(i)の整理対象データとグループG(j)の整理対象データを1組の名寄せ元/先データとする組み合わせの、すべての名寄せ候補の決定結果に×を書き込む(ステップS2222)。つまり、グループG(i)の整理対象データのIDとグループG(j)の整理対象データのIDを名寄せ元/先IDとするすべての名寄せ候補レコードの決定結果が×になる。
【0135】
ステップS2221において、名寄せ候補レコード(i,j)の類似度数が閾値の上限値以上である場合(ステップS2221:Yes)、統合部304によりグループ統合処理をおこない(ステップS2218)、決定部303により、グループG(i)の整理対象データとグループG(j)の整理対象データを1組の名寄せ元/先データとする組み合わせの、すべての名寄せ候補レコードの決定結果に○を書き込む(ステップS2219)。
【0136】
一方、名寄せ候補レコード(i,j)の類似度数が閾値の上限値以上でない場合(ステップS2221:No)、決定部303により、名寄せ候補レコード(i,j)の類似度数が閾値の下限値以下であるか否かを判定する(ステップS2223)。
【0137】
名寄せ候補レコード(i,j)の類似度数が閾値の下限値以下である場合(ステップS2223:Yes)、決定部303により、グループG(i)の整理対象データとグループG(j)の整理対象データを1組の名寄せ元/先データとする組み合わせの、すべての名寄せ候補レコードの決定結果に×を書き込む(ステップS2222)。
【0138】
一方、名寄せ候補レコード(i,j)の類似度数が閾値の下限値以下でない場合(ステップS2223:No)、Jをインクリメントし(ステップS2213)、J>mでない場合(ステップS2214:No)、ステップS2207に移行し、決定部303により、名寄せ候補レコード(i,j)を取得する。
【0139】
ステップS2208において、名寄せ候補レコード(i,j)の決定結果=NULLでない場合(ステップS2208:No)、ステップS2209〜ステップS2223の処理はおこなわずに、ステップS2213に移行する。
【0140】
また、ステップS2205において、名寄せ元ID=iの名寄せ候補レコードがない場合においても同様に(ステップS2205:No)、ステップS2213に移行する。
【0141】
また、ステップS2214において、J>mである場合(ステップS2214:Yes)、Iをインクリメントし(ステップS2215)、I>nでない場合(ステップS2216:No)、ステップS2204に移行し、決定部303により、名寄せ元ID=iの名寄せ候補レコードのレコード数mを取得する。
【0142】
一方、ステップS2216において、I>nである場合(ステップS2216:Yes)、名寄せ処理装置は一連の処理を終了する。
【0143】
(グループ統合処理手順)
つぎに、実施の形態1にかかるグループ統合処理手順の一例について説明する。図23は、実施の形態1にかかるグループ統合処理手順の一例を示すフローチャートである。図23において、まず、統合部304により、グループG(j)の名寄せ候補レコードを取得する(ステップS2301)。
【0144】
ついで、統合部304により、グループG(j)の名寄せ候補レコード数lを取得し、初期値をk=1とする(ステップS2302,S2303)。ついで、統合部304により、グループG(j)の名寄せ候補レコードのグループをグループG(i)に書き換える(ステップS2304)。
【0145】
kをインクリメントし(ステップS2305)、k>lでない場合(ステップS2306:No)、ステップS2304に移行する。k>lである場合(ステップS2306:Yes)、統合部304は一連の処理を終了する。
【0146】
・実施の形態2
(名寄せ処理装置の機能的構成)
つぎに、実施の形態2にかかる名寄せ処理装置の機能的構成について説明する。図24は、実施の形態2にかかる名寄せ処理装置の機能的構成を示すブロック図である。名寄せ処理装置400は、指定部401と、算出部402と、決定部403と、出力部305と、を含む構成である。名寄せ処理装置400のハードウェア構成は、実施の形態1と同様である。
【0147】
名寄せ処理装置400は、データベースDBにアクセスし、整理対象データ群201の中から、名寄せされるデータ(名寄せ元データ)と、名寄せしあう組み合わせに決定したデータ(名寄せ先データ)を抽出する。抽出されたデータは、たとえばレコード(以下、名寄せ相手レコードとする)単位で記憶される。
【0148】
名寄せ処理装置400は、たとえば、予め設定された抽出条件に基づいて、名寄せ相手レコードを作成してもよいし、実施の形態1に示す名寄せ処理により出力された名寄せ結果によって名寄せ相手レコードを作成してもよい。名寄せ相手レコードは、たとえば名寄せ元データの識別記号(名寄せ元ID)と、名寄せ先データの識別番号(名寄せ先ID)から構成される。
【0149】
名寄せ元データは、たとえば名寄せ元データ間の関連度に基づいて、グループに登録されている。具体的には、1グループに複数の名寄せ元データが登録されている。ここで、関連度とは、たとえば類似度数や相違度数など、整理対象データ間の似ている度合いを点数化したものである。
【0150】
図25において、第1〜第9の名寄せ元データX41〜X49は、たとえば類似度数に基づいてそれぞれ異なるグループG41,G42に登録される。具体的には、たとえば、第1〜第6の名寄せ元データX41〜X46は、グループG41に登録されている。第7〜第9の名寄せ元データX47〜X49は、グループG42に登録されている。
【0151】
名寄せ元データと他の名寄せ元データとの間の関連度が算出されている場合、名寄せ元データと他の名寄せ元データは、それぞれ関連度に基づく関係(以下、関係線とする)で結ばれている。具体的には、たとえば、図25において、第1の名寄せ元データと第2の名寄せ元データは、関係線a12で結ばれている。
【0152】
指定部401は、データ群の中から対象データを順次指定する機能を有する。具体的には、たとえば、指定部401は、1つのグループに登録された名寄せ元データ群の中から名寄せ元データを順次指定する。なお、指定結果は、RAM103、磁気ディスク105、光ディスク107などの記憶領域に記憶される。
【0153】
算出部402は、指定部401によって対象データが指定される都度、対象データとデータ群内の他のデータとの関連度に基づいて、対象データごとにデータ群内での評価値を算出する機能を有する。具体的には、たとえば、算出部402は、指定部401によって名寄せ元データが指定される都度、グループ内の他の名寄せ元データとの関連度に基づいて、名寄せ元データごとにグループ内での評価値を算出する。
【0154】
算出部402は、たとえば名寄せ相手レコードに記憶された名寄せ元データ間の関連度に基づいて、名寄せ元データのグループ内での評価値を算出する。算出部402は、複数の方法で評価値を算出してもよい。算出した評価値は、たとえば名寄せ元IDごとに1レコードに記憶される。なお、算出結果は、RAM103、磁気ディスク105、光ディスク107などの記憶領域に記憶される。図26は、実施の形態2にかかる名寄せ相手レコードの一例を示す説明図である。
【0155】
図26において、名寄せ相手レコードは、名寄せ元IDおよび名寄せ先IDから構成される。名寄せ相手レコード(名寄せ元ID,名寄せ先ID)には、たとえば名寄せ元グループがそれぞれ記憶されていてもよい。
【0156】
具体的には、たとえば、名寄せ相手レコード(1,2)は、次のデータを記憶する。名寄せ元ID=1である。名寄せ先ID=2である。第1の名寄せ元データX41と第2の名寄せ元デーダX42間の関連度(比較結果)=65である。図26では、関連度として類似度数を示しているが、これに限らず、名寄せ元データと名寄せ先データを比較するための情報であればよく、他の方法で算出された関連度であってもよい。
【0157】
算出部402は、たとえば図26に示すような名寄せ相手レコードから、名寄せ元データの関連度を取得する。図27は、実施の形態2にかかる名寄せ処理による決定結果の一例を示す説明図である。
【0158】
図27において、決定結果レコードは、たとえば名寄せ元IDから構成される。決定結果レコード(名寄せ元ID)には、たとえば名寄せ元グループ、算出部402により算出される評価値、および決定部403により決定される決定結果がそれぞれ記憶されている。
【0159】
また、算出部402は、対象データと関連度を有する他のデータの数に基づいて、対象データごとにデータ群内での評価値を算出する。具体的には、たとえば、算出部402は、評価値として、名寄せ元データから他のデータに伸びる関係線の本数を算出する(以下、第1の評価値とする)。
【0160】
図27において、グループG41の第1の名寄せ元データX41は、第2の名寄せ元データX42〜第4の名寄せ元データX44および第6の名寄せ元データX46と、それぞれ関係線a12,a13,a14,a16で結ばれている。このため、算出部402は、第1の名寄せ元データX41の第1の評価値=4と算出する。
【0161】
また、算出部402は、対象データと関連度を有する他のデータの関連度の総和に基づいて、対象データごとにデータ群内での評価値を算出する。具体的には、たとえば、算出部402は、評価値として、名寄せ元データ間の関連度の総和を算出する(以下、第2の評価値とする)。
【0162】
図27において、グループG41の第1の名寄せ元データX41は、第2の名寄せ元データX42〜第4の名寄せ元データX44および第6の名寄せ元データX46との間に類似度数が設定されている。このため、算出部402は、第1の名寄せ元データX41の第2の評価値=65+77+65+70=277と算出する。
【0163】
また、算出部402は、対象データと関連度を有する他のデータの数と当該他のデータの関連度の総和に基づいて、対象データごとにデータ群内での評価値を算出する。具体的には、たとえば、算出部402は、評価値として、名寄せ元データ間の関連度の総和の平均値を算出する(以下、第3の評価値とする)。
【0164】
図27において、算出部402は、第1の名寄せ元データX41の第3の評価値=第1の評価値/第2の評価値=69.3と算出する。
【0165】
また、算出部402は、対象データと関連度を有する他のデータの関連度の中の最大関連度に基づいて、対象データごとにデータ群内での評価値を算出する。具体的には、たとえば、算出部402は、評価値として、対象の名寄せ元データと、他のデータ間の関連度のうち最大値を選択する(以下、第4の評価値とする)。
【0166】
たとえば関連度がデータ間の類似度数である場合、第4の評価値が高い値であるほど、対象の名寄せ元データがグループ内の他のデータと名寄せしあう可能性が高いことを示す。また、たとえば関連度がデータ間の相違度数である場合、第4の評価値が高い値であるほど、対象の名寄せ元データがグループ内の他のデータと名寄せできない可能性が高いことを示す。
【0167】
図27において、第1の名寄せ元データX41と、第2の名寄せ元データX42〜第4の名寄せ元データX44および第6の名寄せ元データX46間の関連度は、それぞれ65,77,65および70である。このため、算出部402は、第1の名寄せ元データX41の第4の評価値=77と算出する。
【0168】
また、算出部402は、対象データと関連度を有する他のデータの関連度の中の最小関連度に基づいて、対象データごとにデータ群内での評価値を算出する。具体的には、たとえば、算出部402は、評価値として、名寄せ元データと他のデータ間の関連度のうち最小値を選択する(以下、第5の評価値とする)。
【0169】
たとえば関連度がデータ間の類似度数である場合、第5の評価値が低い値であるほど、対象の名寄せ元データがグループ内の他のデータと名寄せできない可能性が高いことを示す。また、たとえば関連度がデータ間の相違度数である場合、第5の評価値が低い値であるほど、対象の名寄せ元データがグループ内の他のデータと名寄せしあう可能性が高いことを示す。
【0170】
たとえば、関連度がデータ間の類似度数である場合に、算出部402は、第5の評価値を次のように算出する。図26において、第1の名寄せ元データX41と、第2の名寄せ元データX42〜第4の名寄せ元データX44および第6の名寄せ元データX46間の関連度は、それぞれ65,77,65および70である。このため、算出部402は、第1の名寄せ元データX41の第5の評価値=65と算出する。
【0171】
また、算出部402は、第1〜第5の評価値を2つ以上組み合わせて、評価値を算出してもよい(以下、第6の評価値とする)。具体的には、たとえば、算出部402は、第1の評価値に第2の評価値を組み合わせることができない場合は、第1の評価値と第3の評価値を組み合わせるなど、評価値の算出方法に合わせて種々変更可能である。
【0172】
第6の評価値の算出方法は、理論上、5C2+5C3+5C4+5C5=26種類である。このため、評価値の計算方法の総数は、理論上、第1〜第5の評価値の5種類+第6の評価値の26種類=31種類となる。評価値の算出方法は一例であり、上述した算出方法に限らず、種々の方法で算出可能である。また、評価値の数は一例であり、評価値をさらに増やしてもよいし、減らしてもよい。
【0173】
決定部403は、算出部402によって算出された評価値に基づいて、データ群の中から代表的な名寄せ元データを決定する機能を有する。具体的には、たとえば、決定部403は、算出部402によって算出された評価値に基づいて、グループ内の名寄せ元データ群の中から、他の名寄せ元データのすべてと名寄せしあう代表的な名寄せ元データ(以下、代表的な名寄せ元データとする)を決定する。なお、決定結果は、RAM103、磁気ディスク105、光ディスク107などの記憶領域に記憶される。
【0174】
また、決定部403は、関連度がデータ間の類似度数である場合、評価値が最大となる対象データを、代表的な名寄せ元データに決定する。具体的には、たとえば、決定部403は、名寄せ元データ間の関連度が類似度数である場合、名寄せ元データ間の関連度が最大となる名寄せ元データを、代表的な名寄せ元データに決定する。
【0175】
また、決定部403は、第1〜第6の決定結果をさらに組み合わせて、グループ内の名寄せ元データ群の中から代表的な名寄せ元データを決定してもよい。
【0176】
図27において、第1〜第6の決定結果○は、たとえば最も評価値の高いことを意味し、決定結果×は最も評価値の低いことを意味する。たとえば第2の評価値を用いてグループG1内の代表的な名寄せ元データを決定する場合、第3の名寄せ元データX43の第2の評価値=293が最大であるため、決定部403は、代表的な名寄せ元データを第3の名寄せ元データX43に決定する。
【0177】
また、決定部403は、評価値が最小となる対象データを、決定部403は、評価値が最小となる対象データを、代表的な名寄せ元データと名寄せできないデータ候補に決定する。代表的な名寄せ元データと名寄せできないデータ候補とは、代表的な名寄せ元データと名寄せできない可能性の高いデータの候補である。さらに、決定部403は、評価値が所定値以下となる対象データを、代表的な名寄せ元データと名寄せできないデータ候補に決定してもよい。
【0178】
具体的には、たとえば、決定部403は、各名寄せ元データ間の関連度が類似度数である場合、名寄せ元データ間の関連度が最小または所定値以下となる名寄せ元データを、決定部403により決定した代表的な名寄せ元データに名寄せできないデータ候補に決定する。作業者により確認の必要なデータを評価値の低いデータに絞ることで、名寄せの効率が向上する。
【0179】
また、決定部403は、関連度がデータ間の相違度である場合、評価値が最小となる対象データを、代表的な名寄せ元データに決定する。具体的には、たとえば、決定部403は、名寄せ元データ間の関連度が相違度数である場合、名寄せ元データ間の関連度が最小となる名寄せ元データを、代表的な名寄せ元データに決定する。
【0180】
また、決定部403は、関連度がデータ間の相違度である場合、評価値が最大となる対象データを、代表的な名寄せ元データと名寄せできないデータ候補に決定する。さらに、決定部403は、関連度がデータ間の相違度である場合、評価値が所定値以上となる対象データを、代表的な名寄せ元データと名寄せできないデータ候補に決定してもよい。作業者により確認の必要なデータを評価値の高いデータに絞ることで、名寄せの効率が向上する。
【0181】
本実施の形態2によれば、名寄せ結果のデータ件数を、作業者が確認することができる現実的な件数にまで減らすことができる。このため、あいまいな名寄せ条件に基づいて名寄せ処理がおこなわれたとしても、作業者が、名寄せしあう可能性の高い結果または怪しい名寄せ結果に絞って確認することができるため、名寄せ処理の効率が向上する。
【0182】
また、名寄せしあうデータ群の中のデータごとに評価値を算出するため、評価値の大小によりデータごとに、名寄せしあうデータ群に含めてもよいデータであるか否かを確認することができる。つまり、名寄せしあうデータ群の中の各データが、このデータ群に含まれてよいデータであるか、または含まれてはいけないデータであるかを視覚化できる。このため、作業者は、従来の名寄せ処理では名寄せ結果として露出しなかった予想外の名寄せ結果を、評価値を確認することにより確認することができる。
【0183】
また、作業者は、確認したい名寄せ結果を、評価値により絞り込むことができる。たとえば、関連度が類似度数である場合に、名寄せしあうデータ候補を確認したい場合には、作業者は評価値の高いデータに絞り込んでデータを確認することができる。また、名寄せできないデータ候補を確認したい場合には、作業者は評価値の低いデータに絞り込んでデータを確認することができる。
【0184】
(名寄せ処理手順)
つぎに、実施の形態2にかかる名寄せ処理手順の一例について説明する。図28は、実施の形態2にかかる名寄せ処理手順の一例を示すフローチャートである。図28において、まず、名寄せ処理装置により、複数の名寄せ元データをグループに登録する(ステップS2801)。ついで、指定部401により、グループ数Nを取得し、初期値をi=1とする(ステップS2802,S2803)。
【0185】
ついで、指定部401により、グループG(i)内の名寄せ元データ数nを取得し、初期値j=1とする(ステップS2804,S2805)。ついで、算出部402により、名寄せ元ID(j)のすべての名寄せ相手レコードを取得する(ステップS2806)。
【0186】
ついで、算出部402により、評価値算出処理をおこなう(ステップS2807)。そして、jをインクリメントし(ステップS2808)、j>nでない場合(ステップS2809:No)、ステップS2806に移行し、算出部402により、名寄せ元ID(j)のすべての名寄せ相手レコードを取得する。
【0187】
ステップS2809において、j>nである場合(ステップS2809:Yes)、決定部403により、評価値の計算方法の個数jとし、初期値j=1とする(ステップS2810)。ついで、決定部403により、第jの評価値が最も高い名寄せ元データの第jの決定結果に○を書き込む(ステップS2811)。
【0188】
さらに、決定部403により、第jの評価値が最も低い名寄せ元データの第jの決定結果に×を書き込む(ステップS2812)。そして、jをインクリメントし(ステップS2813)、j>評価値の数(たとえば図27においては、評価値の数=6)でない場合(ステップS2814:No)、ステップS2811に移行する。
【0189】
ステップS2814において、j>評価値の数となるまで(ステップS2814:Yes)、ステップS2811〜S2813を繰り返し、決定部403により、評価値の計算方法ごとの決定結果を、名寄せ元データの決定結果に書き込む(図27参照)。ここでは、評価値の計算方法を6種類としたが、さらに評価値の計算方法を増やしてもよいし、減らしてもよい。
【0190】
ステップS2814において、j>評価値の数である場合(ステップS2814:Yes)、iをインクリメントし(ステップS2815)、i>nでない場合(ステップS2816:No)、ステップS2804に移行し、グループG(i)内の名寄せ元データ数nを取得し、初期値j=1とする(ステップS2804,S2805)。
【0191】
ステップS2816において、i>nである場合(ステップS2816:Yes)、名寄せ処理装置は一連の処理を終了する。一連の名寄せ処理が終了した後、たとえば決定結果に○の最も多い名寄せ元データを、代表的な名寄せ元データとしてもよい。
【0192】
(評価値算出処理手順)
つぎに、実施の形態2にかかる評価値算出処理手順の一例について説明する。図29は、実施の形態2にかかる評価値算出処理手順の一例を示すフローチャートである。算出部402により、名寄せ元ID(j)の名寄せ相手レコード数mを取得する(ステップS2901)。そして、算出部402により、名寄せ元ID(j)の名寄せ相手レコードの第1の評価値に、名寄せ元ID(j)の名寄せ相手レコード数を書き込む(ステップS2902)。
【0193】
ステップS2902では、算出部402により、名寄せ元ID(j)の名寄せ相手レコードの第1の評価値に、名寄せ元ID(j)の名寄せ元データの関係線の数が書き込まれる(図26では図示省略)。ここでは、評価値を名寄せ相手レコードに書き込んでいるが、上述したように、評価値および決定結果を、新たに作成した構成の異なる他のレコードに書き込んでもよい(図27参照)。
【0194】
算出部402により、名寄せ元ID(j)の名寄せ相手レコードの類似度数の総和Tを算出する(ステップS2903)。そして、算出部402により、名寄せ元ID(j)の名寄せ相手レコードの第2の評価値に、類似度数の総和Tを書き込む(ステップS2904)。
【0195】
算出部402により、名寄せ元ID(j)の名寄せ相手レコードの類似度数の平均値T/mを算出する(ステップS2905)。そして、算出部402により、名寄せ元ID(j)の名寄せ相手レコードの第3の評価値に、類似度数の平均値T/mを書き込む(ステップS2906)。
【0196】
算出部402により、名寄せ元ID(j)の名寄せ相手レコードの類似度数のうち、最も高い類似度数Fmaxを取得する(ステップS2907)。そして、算出部402により、名寄せ元ID(j)の名寄せ相手レコードの第4の評価値に、類似度数Fmaxを書き込む(ステップS2908)。
【0197】
算出部402により、名寄せ元ID(j)の名寄せ相手レコードの類似度数のうち、最も低い類似度数Fminを取得する(ステップS2909)。そして、算出部402により、名寄せ元ID(j)の名寄せ相手レコードの第5の評価値に、類似度数Fminを書き込む(ステップS2910)。
【0198】
算出部402により、第1〜第5の評価値の少なくとも2つ以上を組み合わせて、第6の評価値を算出する(ステップS2911)。そして、算出部402により、名寄せ元ID(j)の名寄せ相手レコードの第6の評価値に、算出した第6の評価値を書き込む(ステップS2912)。これにより、算出部402は一連の処理を終了する。
【0199】
図29に示す評価値算出処理では、第1〜第6の評価値のすべてを順番に算出しているが、この算出処理は一例であり、種々変更可能である。たとえば、算出部402により、すべての評価値を算出してもよいし、すべての評価値のうち少なくとも1つ以上の評価値を算出してもよい。具体的には、算出部402により、第1〜第6の評価値のすべてを算出してもよいし、例えば第1の評価値のみを算出してもよい。
【0200】
また、算出部402により、複数の評価値を組み合わせて評価値を算出する場合、算出部402により、複数の評価値を組み合わせて算出された1つの評価値のみを、名寄せ相手レコードに書き込んでもよい。具体的には、算出部402により、第1〜第5の評価値は名寄せ相手レコードに書き込まず、第6の評価値のみを名寄せ相手レコードに書き込んでもよい。
【0201】
実施の形態2にかかる名寄せ処理は、図26に示す名寄せ相手レコードに対して適用する場合に限らず、複数のデータを含むグループが作成される場合に適用することができる。たとえば、実施の形態1において、統合部により統合されたグループに対して適用してもよい。
【0202】
以上説明したように、名寄せ処理プログラム、名寄せ処理方法、および名寄せ処理装置によれば、名寄せしあう(または名寄せできない)データの組み合わせを効率よく特定することにより、作業者の関与する作業を減らすことができ、名寄せ結果の精度を向上するができる。
【0203】
また、データ群の中のデータごとにデータ群内での評価値を算出することにより、作業者の確認する名寄せ結果の件数を減らし、かつ名寄せ結果の効率を向上することができる。
【0204】
なお、本実施の形態で説明した名寄せ処理法は、予め用意されたプログラムをパーソナル・コンピュータやワークステーション等のコンピュータで実行することにより実現することができる。本名寄せ処理プログラムは、ハードディスク、フレキシブルディスク、CD−ROM、MO、DVD等のコンピュータで読み取り可能な記録媒体に記録され、コンピュータによって記録媒体から読み出されることによって実行される。また本名寄せ処理プログラムは、インターネット等のネットワークを介して配布してもよい。
【0205】
上述した実施の形態に関し、さらに以下の付記を開示する。
【0206】
(付記1)データ群を記憶するデータベースにアクセス可能なコンピュータに、
前記データ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する指定工程と、
前記データ群の中から、前記指定工程によって指定された第1のデータと名寄せしあう第3のデータを特定する特定工程と、
前記指定工程によって指定された第2のデータと前記特定工程によって特定された第3のデータを、名寄せしあうデータの組み合わせに決定する決定工程と、
前記決定工程によって決定された決定結果を出力する出力工程と、
を実行させることを特徴とする名寄せ処理プログラム。
【0207】
(付記2)前記特定工程は、
前記データ群の中から、前記指定工程によって指定された第1のデータと名寄せしあう第4のデータを特定し、
決定工程は、
前記第2のデータと前記特定工程によって特定された第4のデータとを、名寄せしあうデータの組み合わせに決定するとともに、前記第3のデータと前記第4のデータを、名寄せしあうデータの組み合わせに決定することを特徴とする付記1に記載の名寄せ処理プログラム。
【0208】
(付記3)前記特定工程は、
前記データ群の中から、前記指定工程によって指定された第1のデータと名寄せできない第4のデータを特定し、
決定工程は、
前記第2のデータと前記特定工程によって特定された第4のデータとを、名寄せできないデータの組み合わせに決定するとともに、前記第3のデータと前記第4のデータを、名寄せできないデータの組み合わせに決定することを特徴とする付記1に記載の名寄せ処理プログラム。
【0209】
(付記4)名寄せしあうデータ群を記憶するデータベースにアクセス可能なコンピュータに、
前記データ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する指定工程と、
前記データ群の中から、前記指定工程によって指定された第1のデータと名寄せできない第3のデータを特定する特定工程と、
前記指定工程によって指定された第2のデータと前記特定工程によって特定された第3のデータを、名寄せできないデータの組み合わせに決定する決定工程と、
前記決定工程によって決定された決定結果を出力する出力工程と、
を実行させることを特徴とする名寄せ処理プログラム。
【0210】
(付記5)データ間の関連性を示す関連度を有するデータ群を記憶するデータベースにアクセス可能なコンピュータに、
前記データ群の中から対象データを順次指定する指定工程と、
前記指定工程によって対象データが指定される都度、前記対象データと前記データ群内の他のデータとの関連度に基づいて、前記対象データごとに前記データ群内での評価値を算出する算出工程と、
前記算出工程によって算出された評価値に基づいて、前記データ群の中から前記他のデータのすべてと名寄せしあう代表的なデータを決定する決定工程と、
前記決定工程によって決定された決定結果を出力する出力工程と、
を実行させることを特徴とする名寄せ処理プログラム。
【0211】
(付記6)前記算出工程は、
前記対象データと関連度を有する前記他のデータの数に基づいて、前記対象データごとに前記データ群内での評価値を算出することを特徴とする付記5に記載の名寄せ処理プログラム。
【0212】
(付記7)前記対象データと関連度を有する前記他のデータの関連度の総和に基づいて、前記対象データごとに前記データ群内での評価値を算出することを特徴とする付記5に記載の名寄せ処理プログラム。
【0213】
(付記8)前記対象データと関連度を有する前記他のデータの数と当該他のデータの関連度の総和に基づいて、前記対象データごとに前記データ群内での評価値を算出することを特徴とする付記5に記載の名寄せ処理プログラム。
【0214】
(付記9)前記関連度が前記データ間の類似度である場合、前記対象データと関連度を有する前記他のデータの関連度の中の最大関連度に基づいて、前記対象データごとに前記データ群内での評価値を算出することを特徴とする付記5に記載の名寄せ処理プログラム。
【0215】
(付記10)前記関連度が前記データ間の相違度である場合、前記対象データと関連度を有する前記他のデータの関連度の中の最小関連度に基づいて、前記対象データごとに前記データ群内での評価値を算出することを特徴とする付記5に記載の名寄せ処理プログラム。
【0216】
(付記11)前記決定工程は、
前記関連度が前記データ間の類似度である場合、前記評価値が最大となる対象データを、前記代表的なデータに決定することを特徴とする付記5〜9のいずれか一つに記載の名寄せ処理プログラム。
【0217】
(付記12)前記決定工程は、
前記評価値が最小となる対象データを、前記代表的なデータと名寄せできないデータ候補に決定することを特徴とする付記11に記載の名寄せ処理プログラム。
【0218】
(付記13)前記決定工程は、
前記評価値が所定値以下となる対象データを、前記代表的なデータと名寄せできないデータ候補に決定することを特徴とする付記12に記載の名寄せ処理プログラム。
【0219】
(付記14)前記決定工程は、
前記関連度が前記データ間の相違度である場合、前記評価値が最小となる対象データを、前記代表的なデータに決定することを特徴とする付記5〜8、10のいずれか一つに記載の名寄せ処理プログラム。
【0220】
(付記15)前記決定工程は、
前記評価値が最大となる対象データを、前記代表的なデータと名寄せできないデータ候補に決定することを特徴とする付記14に記載の名寄せ処理プログラム。
【0221】
(付記16)前記決定工程は、
前記評価値が所定値以上となる対象データを、前記代表的なデータと名寄せできないデータ候補に決定することを特徴とする付記15に記載の名寄せ処理プログラム。
【0222】
(付記17)データ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する指定工程と、
前記データ群の中から、前記指定工程によって指定された第1のデータと名寄せしあう第3のデータを特定する特定工程と、
前記指定工程によって指定された第2のデータと前記特定工程によって特定された第3のデータを、名寄せしあうデータの組み合わせに決定する決定工程と、
前記決定工程によって決定された決定結果を出力する出力工程と、
を含むことを特徴とする名寄せ処理方法。
【0223】
(付記18)名寄せしあうデータ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する指定工程と、
前記データ群の中から、前記指定工程によって指定された第1のデータと名寄せできない第3のデータを特定する特定工程と、
前記指定工程によって指定された第2のデータと前記特定工程によって特定された第3のデータを、名寄せできないデータの組み合わせに決定する決定工程と、
前記決定工程によって決定された決定結果を出力する出力工程と、
を含むことを特徴とする名寄せ処理方法。
【0224】
(付記19)データ間の関連性を示す関連度を有するデータ群の中から対象データを順次指定する指定工程と、
前記指定工程によって対象データが指定される都度、前記対象データと前記データ群内の他のデータとの関連度に基づいて、前記対象データごとに前記データ群内での評価値を算出する算出工程と、
前記算出工程によって算出された評価値に基づいて、前記データ群の中から前記他のデータのすべてと名寄せしあう代表的なデータを決定する決定工程と、
前記決定工程によって決定された決定結果を出力する出力工程と、
を含むことを特徴とする名寄せ処理方法。
【0225】
(付記20)データ群を記憶するデータベースにアクセス可能な名寄せ処理装置であって、
前記データ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する指定手段と、
前記データ群の中から、前記指定手段によって指定された第1のデータと名寄せしあう第3のデータを特定する特定手段と、
前記指定手段によって指定された第2のデータと前記特定手段によって特定された第3のデータを、名寄せしあうデータの組み合わせに決定する決定手段と、
前記決定手段によって決定された決定結果を出力する出力手段と、
を備えることを特徴とする名寄せ処理装置。
【0226】
(付記21)名寄せしあうデータ群を記憶するデータベースにアクセス可能な名寄せ処理装置であって、
前記データ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する指定手段と、
前記データ群の中から、前記指定手段によって指定された第1のデータと名寄せできない第3のデータを特定する特定手段と、
前記指定手段によって指定された第2のデータと前記特定手段によって特定された第3のデータを、名寄せできないデータの組み合わせに決定する決定手段と、
前記決定手段によって決定された決定結果を出力する出力手段と、
を備えることを特徴とする名寄せ処理装置。
【0227】
(付記22)データ間の関連性を示す関連度を有するデータ群を記憶するデータベースにアクセス可能な名寄せ処理装置であって、
前記データ群の中から対象データを順次指定する指定手段と、
前記指定手段によって対象データが指定される都度、前記対象データと前記データ群内の他のデータとの関連度に基づいて、前記対象データごとに前記データ群内での評価値を算出する算出手段と、
前記算出手段によって算出された評価値に基づいて、前記データ群の中から前記他のデータのすべてと名寄せしあう代表的なデータを決定する決定手段と、
前記決定手段によって決定された決定結果を出力する出力手段と、
を備えることを特徴とする名寄せ処理装置。
【符号の説明】
【0228】
300 名寄せ処理装置
301 指定部
302 特定部
303 決定部
304 統合部
305 出力部
【技術分野】
【0001】
この発明は、名寄せ処理プログラム、名寄せ処理方法、および名寄せ処理装置に関する。
【背景技術】
【0002】
従来、金融機関において複数口座を所有する預金者の同一性を確認する名寄せが公知である。広義に解釈して、名寄せは、企業合併などにより企業内データを統合する場合や、重複する顧客情報などを統合または削除する場合に、データベースに蓄積されたデータ群の中から統合または削除可能なデータを特定することも含まれる。
【0003】
従来の名寄せでは、まず、たとえばデータベースから名寄せをおこなうデータを取得し、このデータに対して、表記の統一、表記ゆれの補正、文字列の分離および分割などをおこなう(標準化,クレンジング)。具体的には、たとえば半角と全角や、(株)と株式会社などの表記を統一したり、キョーやキョウなどの表記ゆれを統一したり、企業の名称から株式会社などを分離する作業をおこなう。
【0004】
その後、予め設定された抽出条件に基づいて、標準化されたデータから、名寄せする候補となるデータを抽出する。たとえば、名寄せされるデータ(以下、名寄せ元データとする)の照合先となるデータ(以下、名寄せ先データとする)を抽出する。そして、名寄せ元データと名寄せ先データとのたとえば類似度合いを示す度数などを算出し、名寄せ元データと名寄せ先データとを比較する。
【0005】
名寄せ元データと名寄せ先データとの比較結果に基づいて、名寄せ元データを名寄せ先データと名寄せしあうことができるか否かを判定し、この判定結果を名寄せ結果とする。名寄せ結果は、たとえば市販のデータ統合装置などに入力される。そして、データ統合装置の記憶領域に記憶された名寄せ処理のプログラムなどによって、名寄せ結果に基づいた名寄せがおこなわれる。名寄せのための同一視の判定方法として、たとえば、下記特許文献1,2がある。
【先行技術文献】
【特許文献】
【0006】
【特許文献1】特開2006−018340号公報
【特許文献2】特許第3721315号公報
【発明の概要】
【発明が解決しようとする課題】
【0007】
しかしながら、従来の名寄せでは、作業者が、コンピュータによって作成された名寄せ結果に目を通し、名寄せ元データと名寄せ先データが名寄せしあう組み合わせのデータであるか否かを判定している。作業者が確認する必要のあるデータ件数は、数百万件程度と膨大な件数となるため、作業者がすべての比較結果に目を通すことは現実的には難しい。
【0008】
また、作業者のミスにより誤った判定がおこなわれた場合、名寄せ結果データに矛盾が生じてしまう。したがって、作業者が確認すべきデータ件数を、現実的なデータ件数にまで絞る必要がある。
【0009】
また、作業者の確認するデータ件数が膨大であるため、現状では、コンピュータによって機械的に、名寄せしあう組み合わせのデータであるか否かを比較した結果を、そのまま名寄せ結果データとして用いらざるを得ない。この場合、名寄せできない組み合わせのデータを名寄せ結果に含めないために、比較条件を厳しくする必要がある。
【0010】
また、従来の名寄せでは、名寄せしあう複数のデータごとにグループに分けることは可能であるが、複数のデータに対して1つの名寄せ先データを決定することは難しい。
【0011】
本開示技術は、上述した従来技術による問題点を解消するため、作業者による名寄せ作業の工数を軽減することができる名寄せ処理プログラム、名寄せ処理方法、および名寄せ処理装置を提供することを目的とする。
【課題を解決するための手段】
【0012】
上述した課題を解決し、目的を達成するため、本名寄せ処理プログラム、名寄せ処理方法、および名寄せ処理装置では、一例として、データ群の中から、名寄せしあう第1のデータおよび第2のデータを指定し、かつ第1のデータと名寄せしあう第3のデータを特定した場合、第2のデータと第3のデータを、名寄せしあうデータの組み合わせに決定する。
【0013】
本開示技術によれば、作業者による名寄せ作業の工数を軽減し、かつ名寄せ結果に矛盾が生じることを防止することができる。
【発明の効果】
【0014】
本名寄せ処理プログラム、名寄せ処理方法、および名寄せ処理装置によれば、作業者による名寄せ作業の工数を軽減することができるという効果を奏する。
【図面の簡単な説明】
【0015】
【図1】実施の形態1にかかる名寄せ処理装置のハードウェア構成を示すブロック図である。
【図2】実施の形態1にかかるデータ運用の一例を示す説明図である。
【図3】実施の形態1にかかる名寄せ処理装置の機能的構成を示すブロック図である。
【図4】実施の形態1にかかる名寄せ処理の一例を示す説明図である。
【図5】実施の形態1にかかる名寄せ処理前の名寄せ候補レコードの一例を示す説明図である。
【図6】実施の形態1にかかる名寄せ処理中の名寄せ候補レコードの一例を示す説明図である。
【図7】実施の形態1にかかる名寄せ処理中の名寄せ候補レコードの一例を示す説明図である。
【図8】実施の形態1にかかる名寄せ処理中の名寄せ候補レコードの一例を示す説明図である。
【図9】実施の形態1にかかる名寄せ処理中の名寄せ候補レコードの一例を示す説明図である。
【図10】実施の形態1にかかる名寄せ処理中の名寄せ候補レコードの一例を示す説明図である。
【図11】実施の形態1にかかる名寄せ処理中の名寄せ候補レコードの一例を示す説明図である。
【図12】実施の形態1にかかる名寄せ元/先データを示す説明図である。
【図13】実施の形態1にかかるグループの統合される過程の一例を順に示す説明図である。
【図14】実施の形態1にかかるグループの統合される過程の一例を順に示す説明図である。
【図15】実施の形態1にかかるグループの統合される過程の一例を順に示す説明図である。
【図16】実施の形態1にかかるグループの統合される過程の一例を順に示す説明図である。
【図17】実施の形態1にかかるグループの統合される過程の一例を順に示す説明図である。
【図18】実施の形態1にかかるグループの統合される過程の一例を順に示す説明図である。
【図19】実施の形態1にかかるグループの統合される過程の一例を順に示す説明図である。
【図20】実施の形態1にかかる名寄せ処理中の名寄せ候補レコードの別の一例を示す説明図である。
【図21−1】実施の形態1にかかる名寄せ処理手順の一例を示すフローチャートである。
【図21−2】実施の形態1にかかる名寄せ処理手順の一例を示すフローチャートである。
【図22−1】実施の形態1にかかる名寄せ処理手順の別の一例を示すフローチャートである。
【図22−2】実施の形態1にかかる名寄せ処理手順の別の一例を示すフローチャートである。
【図23】実施の形態1にかかるグループ統合処理手順の一例を示すフローチャートである。
【図24】実施の形態2にかかる名寄せ処理装置の機能的構成を示すブロック図である。
【図25】実施の形態2にかかる名寄せ処理の一例を示す説明図である。
【図26】実施の形態2にかかる名寄せ相手レコードの一例を示す説明図である。
【図27】実施の形態2にかかる名寄せ処理による決定結果の一例を示す説明図である。
【図28】実施の形態2にかかる名寄せ処理手順の一例を示すフローチャートである。
【図29】実施の形態2にかかる評価値算出処理手順の一例を示すフローチャートである。
【発明を実施するための形態】
【0016】
以下に添付図面を参照して、この発明にかかる名寄せ処理プログラム、名寄せ処理方法、および名寄せ処理装置の好適な実施の形態を詳細に説明する。
【0017】
・実施の形態1
(名寄せ処理装置のハードウェア構成)
図1は、実施の形態1にかかる名寄せ処理装置のハードウェア構成を示すブロック図である。図1において、名寄せ処理装置は、CPU(Central Processing Unit)101と、ROM(Read‐Only Memory)102と、RAM(Random Access Memory)103と、磁気ディスクドライブ104と、磁気ディスク105と、光ディスクドライブ106と、光ディスク107と、ディスプレイ108と、I/F(Interface)109と、キーボード110と、マウス111と、スキャナ112と、プリンタ113と、を備えている。また、各構成部はバス100によってそれぞれ接続されている。
【0018】
ここで、CPU101は、名寄せ処理装置の全体の制御を司る。ROM102は、ブートプログラムなどのプログラムを記憶している。RAM103は、CPU101のワークエリアとして使用される。磁気ディスクドライブ104は、CPU101の制御にしたがって磁気ディスク105に対するデータのリード/ライトを制御する。磁気ディスク105は、磁気ディスクドライブ104の制御で書き込まれたデータを記憶する。
【0019】
光ディスクドライブ106は、CPU101の制御にしたがって光ディスク107に対するデータのリード/ライトを制御する。光ディスク107は、光ディスクドライブ106の制御で書き込まれたデータを記憶したり、光ディスク107に記憶されたデータをコンピュータに読み取らせたりする。
【0020】
ディスプレイ108は、カーソル、アイコンあるいはツールボックスをはじめ、文書、画像、機能情報などのデータを表示する。このディスプレイ108は、たとえば、CRT、TFT液晶ディスプレイ、プラズマディスプレイなどを採用することができる。
【0021】
インターフェース(以下、「I/F」と略する。)109は、通信回線を通じてLAN(Local Area Network)、WAN(Wide Area Network)、インターネットなどのネットワーク114に接続され、このネットワーク114を介して他の装置に接続される。そして、I/F109は、ネットワーク114と内部のインターフェースを司り、外部装置からのデータの入出力を制御する。I/F109には、たとえばモデムやLANアダプタなどを採用することができる。
【0022】
キーボード110は、文字、数字、各種指示などの入力のためのキーを備え、データの入力をおこなう。また、タッチパネル式の入力パッドやテンキーなどであってもよい。マウス111は、カーソルの移動や範囲選択、あるいはウィンドウの移動やサイズの変更などをおこなう。ポインティングデバイスとして同様に機能を備えるものであれば、トラックボールやジョイスティックなどであってもよい。
【0023】
スキャナ112は、画像を光学的に読み取り、名寄せ処理装置内に画像データを取り込む。なお、スキャナ112は、OCR(Optical Character Reader)機能を持たせてもよい。また、プリンタ113は、画像データや文書データを印刷する。プリンタ113には、たとえば、レーザプリンタやインクジェットプリンタを採用することができる。
【0024】
(データ運用方法)
つぎに、データベースから取得したデータを名寄せするときのデータ運用方法について、図2を参照して説明する。図2は、実施の形態1にかかるデータ運用方法の一例を示す説明図である。まず、名寄せ処理装置200は、データベース211にアクセスし、たとえば、データベース211に記憶された整理対象のデータ群(以下、整理対象データ群とする)201の中からデータを取り出し、名寄せ候補となるデータを抽出する。
【0025】
具体的には、たとえば、名寄せ処理装置200は、整理対象データ群201の中から、名寄せされるデータ(名寄せ元データ)と、名寄せ元データの照合先となるデータ(名寄せ先データ)を抽出する。抽出されたデータは、たとえばレコード(以下、名寄せ候補レコードとする)単位で記憶され、1テーブルにまとまられたデータ(以下、名寄せ候補データとする)202として出力される。
【0026】
整理対象データ群201は、たとえば重複や類似したデータを含むデータ群であってもよいし、実際には重複や類似したデータは含まれないが、所定の名寄せ条件に基づいて名寄せさせるデータを含むデータ群であってもよい。また、整理対象データ群の中のデータは、標準化やクレンジングがおこなわれていてもよい。
【0027】
ここで、データとは、たとえばロゴマークなどの静止画データ、単語や文章などの文字列データ、音声データなど、コンピュータで処理可能な二進数で記号化することができるデータである。具体的には、データとは、文字列データを一例として説明すると、会社名,氏名,住所,商品名,国名,地名などである。
【0028】
また、名寄せとは、整理対象データ群の中の1つ以上の整理対象データを、1つの整理対象データに関連付けることである。たとえば、「株式会社○○」,「株式会社 ○○」,「(株)○○」,「株○○」が同一の会社名である場合、これら会社名をあらわす文字列を、たとえば「株式会社○○」に関連付けることである。また、「東京」,「とうきょう」,「トウキョウ(全角文字列)」,「トウキョウ(半角文字列)」「Tokyo」が同一の地名である場合、これら地名をあらわす文字列を、たとえば「東京」に関連付けることである。
【0029】
また、名寄せは、たとえば文字列の類似度数に基づいて、コンピュータによって処理されてもよいし、文字列が類似しているか否かによらず、作業者の入力によって処理されてもよい。
【0030】
名寄せ候補レコードは、たとえば名寄せ元データの識別記号(以下、名寄せ元IDとする)と、名寄せ先データの識別記号(名寄せ先IDとする)から構成される。また、名寄せ候補レコードには、名寄せ元データと名寄せ先データの比較結果が記憶されていてもよい。また、名寄せ元データを照合する名寄せ先データが抽出されない場合、この名寄せ元データに対応する名寄せ候補レコードは作成されなくてもよい。
【0031】
比較結果とは、名寄せ元データと名寄せ先データを比較するための情報であり、名寄せ元データと名寄せ先データが類似している度合いを示す度数(以下、類似度数とする)であってもよいし、名寄せ元データと名寄せ先データが相違している度合いを示す度数(以下、相違度数とする)であってもよい。
【0032】
また、整理対象データ群201のうち、名寄せ元データとして抽出されたデータは、グループに登録されていてもよい。具体的には、たとえば、1つのグループ(以下、名寄せ元グループとする)には、1つの名寄せ元データが登録される。
【0033】
グループとしてデータを扱うことで、異なるグループが統合されたときに、名寄せしあう組み合わせのデータのみを確実に同一グループに含めることができる。これにより、決定結果に矛盾が生じることを防止することができる。
【0034】
ついで、名寄せ処理装置200は、複数の名寄せ候補レコードに記憶された情報に基づいて、名寄せ元データと名寄せ先データが名寄せしあう組み合わせか否かを決定する。名寄せしあう組み合わせか否かを決定する詳細な方法の説明は、後述する。
【0035】
名寄せ処理装置200により決定された結果は、たとえば決定結果データ203に書き込まれる。決定結果データ203は、たとえば、名寄せ候補データ202に決定結果が書き込まれたデータである。名寄せ候補データ202および決定結果データ203は、たとえばデータベース211などに記憶されてもよい。
【0036】
名寄せ元データの照合先は、名寄せ元データ自身であってもよい。つまり、名寄せ元データおよび名寄せ先データは、ともに整理対象データ群201の中から指定されてもよい。また、名寄せ元データの照合先は、たとえば整理対象データ群201のマスターデータであってもよい。つまり、名寄せ元データおよび名寄せ先データは、異なるデータ群の中からそれぞれ指定されてもよい。
【0037】
ついで、名寄せ処理装置200は、決定結果データ203に基づいて、一般的なデータ統合装置212の入力形式に対応した名寄せ結果データ204を作成する。具体的には、たとえば、名寄せ処理装置200は、1つ以上の名寄せ元データに対して1つの名寄せ先データが関連付けられたレコードを、名寄せ結果データ204として出力する。
【0038】
名寄せ結果データ204は、データ統合装置212に入力される。データ統合装置212は、名寄せ結果データ204に基づいて、整理対象データ群201の中の各データを名寄せする。名寄せ処理後の整理対象データ群201は、たとえばデータベース211に記憶される。名寄せ処理装置200は、データ統合装置212の機能を有していてもよい。
【0039】
(名寄せ処理装置の機能的構成)
つぎに、実施の形態1にかかる名寄せ処理装置の機能的構成について説明する。図3は、実施の形態1にかかる名寄せ処理装置の機能的構成を示すブロック図である。名寄せ処理装置300は、指定部301と、特定部302と、決定部303と、統合部304と、出力部305と、を含む構成である。この制御部となる機能(指定部301〜出力部305)は、具体的には、たとえば、図1に示したROM102、RAM103、磁気ディスク105、光ディスク107などの記憶装置に記憶されたプログラムをCPU101に実行させることにより、または、I/F109により、その機能を実現する。
【0040】
指定部301は、データ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する機能を有する。具体的には、たとえば、指定部301は、データベースDBに記憶された整理対象データ群の中から、名寄せ元データ(または名寄せ先データ)と名寄せしあう可能性のあるデータの組み合わせを指定する。
【0041】
特定部302は、データ群の中から、指定部301によって指定された第1のデータと名寄せしあう第3のデータを特定する機能を有する。また、特定部302は、データ群の中から、指定部301によって指定された第1のデータと名寄せできない第3のデータを特定する機能を有する。
【0042】
具体的には、たとえば、特定部302は、データベースDBに記憶された整理対象データ群の中から、名寄せ先データ(または名寄せ元データ)と、指定部301によって指定された第1のデータとが名寄せしあうデータの組み合わせであるか、または名寄せできないデータの組み合わせであるかを特定する。
【0043】
決定部303は、指定部301によって指定された第2のデータと特定部302によって特定された第3のデータを、名寄せしあうデータの組み合わせに決定する機能を有する。具体的には、たとえば、決定部303は、名寄せ元データと名寄せ先データを名寄せしあうデータの組み合わせに決定する(以下、第1の決定方法とする)。
【0044】
決定部303により決定された決定結果は、たとえば名寄せ候補レコードの決定結果に記憶される。なお、決定されたデータは、RAM103、磁気ディスク105、光ディスク107などの記憶領域に記憶される。図4は、実施の形態1にかかる名寄せ処理の一例を示す説明図である。
【0045】
具体的には、たとえば、名寄せ元データおよび名寄せ先データ以外のデータの名寄せ元/先ID=1、名寄せ元ID=2、名寄せ先ID=3としたときに、名寄せ候補レコード(名寄せ元ID,名寄せ先ID)=名寄せ候補レコード(2,3)の決定結果が○(マル)または×(バツ)になる一例について、図4を参照して説明する。
【0046】
ここで、決定結果○は、2つのデータが名寄せしあうデータの組み合わせであることを意味し、決定結果×は、2つのデータが名寄せできないデータの組み合わせであることを意味する。まず、名寄せ候補レコード(2,3)の決定結果が○になる一例について説明する。
【0047】
指定部301は、たとえば名寄せ元ID=2の名寄せ候補レコードの中から、名寄せ元データと名寄せしあう第1のデータX1を指定する。具体的には、指定部301は、決定結果が○である名寄せ候補レコード(2,1)を第1のデータX1として指定する。また、指定部301は、名寄せ候補レコード(1,2)の決定結果が○であることにより、指定するデータを第1のデータX1としてもよい。つまり、第1のデータX1と第2のデータX2は、名寄せしあうデータの組み合わせであり、第1のデータX1と第2のデータX2の決定結果a12は○である(図4−(a)参照)。
【0048】
さらに、特定部302は、たとえば名寄せ先ID=3の名寄せ候補レコードの中から、名寄せ先データと第1のデータX1が名寄せしあうデータの組み合わせであることを特定する。具体的には、特定部302は、名寄せ候補レコード(1,3)の決定結果が○であることを特定する。また、特定部302は、名寄せ候補レコード(3,1)の決定結果が○であることを特定してもよい。つまり、第1のデータX1と第3のデータX3は、名寄せしあうデータの組み合わせであり、第1のデータX1と第3のデータX3の決定結果a13は○である(図4−(b)参照)。
【0049】
決定結果a12=○であり、かつ決定結果a13=○であることにより、決定部303は、第2のデータX2と第3のデータX3の決定結果a23を○に決定する(図4−(c)参照)。具体的には、決定部303は、名寄せ候補レコード(2,3)の決定結果を○にする。つまり、第2,3のデータにそれぞれ共通する第1のデータX1の決定結果a12,a13が○であることにより、第2のデータX2と第3のデータX3の決定結果a23は一意に○に決定される。
【0050】
つぎに、名寄せ候補レコード(2,3)の決定結果が×になる場合について説明する。指定部301は、たとえば名寄せ元ID=2の名寄せ候補レコードの中から、名寄せ元データと名寄せしあう第1のデータX1を指定する。つまり、第1のデータX1と第2のデータX2の決定結果a12は○である(図4−(d)参照)。
【0051】
さらに、特定部302は、たとえば名寄せ元ID=3の名寄せ候補レコードの中から、名寄せ先データと第1のデータX1が名寄せできないデータの組み合わせであることを特定する。つまり、第1のデータX1と第3のデータX3は、名寄せできないデータの組み合わせであり、第1のデータX1と第3のデータX3の決定結果a13は×である(図4−(e)参照)。
【0052】
決定結果a12=○であり、かつ決定結果a13=×であることにより、決定部303は、第2のデータX2と第3のデータX3の決定結果a23を×に決定する(図4−(f)参照)。つまり、決定結果a12,a13のいずれかが×であることにより、第2のデータX2と第3のデータX3の決定結果a23は一意に×に決定される。
【0053】
また、名寄せ候補レコード(2,3)と名寄せ候補レコード(3,2)の決定結果は、同じ結果となる。このため、決定部303は、たとえば名寄せ候補レコード(2,3),・・・,名寄せ候補レコード(3,2)の順で決定結果が決定される場合、名寄せ候補レコード(3,2)の決定結果を、名寄せ候補レコード(2,3)の決定結果を決定したときに決定してもよいし、順次名寄せ候補レコードを読み込んでいき、名寄せ候補レコード(3,2)を読み込んだときに決定してもよい。
【0054】
指定部301および特定部302が参照する名寄せ候補レコードの決定結果は、所定の名寄せ条件に基づいて予め決定された決定結果であってもよいし、決定部303による決定処理中に決定された決定結果であってもよい。
【0055】
決定結果を予め設定する場合、名寄せ処理前に、作業者がたとえば可視化された名寄せ候補レコードを確認し、名寄せ候補レコードの決定結果に○や×を書き込んでもよい。図5は、実施の形態1にかかる名寄せ処理前の名寄せ候補レコードの一例を示す説明図である。
【0056】
図5において、名寄せ候補レコードは、名寄せ元IDおよび名寄せ先IDから構成される。名寄せ候補レコード(名寄せ元ID,名寄せ先ID)には、たとえば類似度数、作業者により書き込まれた決定結果(初期条件に中黒の星印★の書き込まれたレコード)、および名寄せ元グループなど名寄せ処理に用いる主要なデータがそれぞれ書き込まれている。図5では、名寄せ候補レコードの主要な部分のみを示す(以下、図6〜11,20においても同様)。
【0057】
具体的には、たとえば、名寄せ候補レコード(1,2)は、次のデータを記憶する。名寄せ元ID=1である。名寄せ先ID=2である。名寄せ元/先ID=1,2のデータの組み合わせを比較した類似度数=50である。名寄せ元/先ID=1,2のデータの組み合わせは、作業者により、名寄せしあうデータの組み合わせに決定されている。つまり、名寄せ候補レコード(1,2)の決定結果には、名寄せ処理前に予め決定結果○が書き込まれている。名寄せ元ID=1のデータは、グループG1に登録されている。
【0058】
なお、名寄せ候補レコードの初期条件(★)または閾値(☆)は、名寄せ候補レコードの構成要素ではない。名寄せ候補レコードの決定結果が、第1の決定方法に基づいた決定結果ではないことを明確にするものである。
【0059】
つまり、初期条件または閾値=星印★の場合、作業者により決定結果が書き込まれている。初期条件または閾値=星印☆の場合、比較結果の閾値に基づいて決定結果が書き込まれている。また、初期条件または閾値=NULLの場合、名寄せ候補レコードの決定結果は、第1の決定方法に基づいて名寄せされている(以下、図6〜11,20においても同様)。
【0060】
また、図5では、名寄せ処理に用いる主要なデータのすべてを1テーブルに記憶させているが、これに限らず、名寄せ処理に用いる主要なデータをそれぞれ異なるテーブルに記憶させてもよい。たとえば、名寄せ元グループを、図5に示す名寄せ候補レコードには書き込まず、図5に示すテーブルとは異なるテーブルに書き込んでもよい。図12は、実施の形態1にかかる名寄せ元/先データを示す説明図である。
【0061】
たとえば、図12に示すように、名寄せ元/先IDごとに名寄せ元/先データが記憶されたテーブルに、名寄せ元/先IDごとに名寄せ元グループを書き込んでもよいし、図12に示すテーブルとは異なるテーブルに、名寄せ元/先IDごとに名寄せ元グループのみを書き込んでもよい。
【0062】
つまり、名寄せ処理に用いる主要なデータは、名寄せ処理装置200が記録および参照することができればよく、1テーブルに記憶されていてもよいし、名寄せ処理に用いる主要なデータごとに異なるテーブルに記憶されていてもよい。ここでは、各データの書き込まれる順序を明確にするために、名寄せ処理に用いる主要なデータを1テーブルに記憶した場合を例に説明する。
【0063】
決定部303は、名寄せ元データと名寄せ先データの比較結果に基づいて、名寄せ元データと名寄せ先データを名寄せしあうデータの組み合わせに決定してもよい(以下、第2の決定方法とする)。
【0064】
具体的には、たとえば、類似度数の閾値の上限値を90とし、下限値を30とした場合、決定部303は、名寄せ候補レコードの類似度数が90以上である場合に、この名寄せ候補レコードの決定結果を○に決定する。また、決定部303は、名寄せ候補レコードの類似度数が30以下である場合に、この名寄せ候補レコードの決定結果を×に決定する。図6〜図11は、実施の形態1にかかる名寄せ処理中の名寄せ候補レコードの一例を示す説明図である。
【0065】
図6において、たとえば、名寄せ候補レコード(1,6)の類似度数は、100である。このため、決定部303は、名寄せ候補レコード(1,6)の決定結果を○に決定する(中抜きの星印☆の書き込まれたレコード)。
【0066】
また、決定部303は、名寄せ元データと名寄せ先データが同一グループに含まれる場合に、名寄せ元データと名寄せ先データを名寄せしあうデータの組み合わせに決定してもよい(以下、第3の決定方法とする)。
【0067】
具体的には、たとえば、決定部303は、名寄せ候補レコード(6,1)の決定結果を決定する場合、名寄せ元ID=1,6の名寄せ元グループがともにグループG1であることにより、名寄せ候補レコード(6,1)の決定結果を○に決定する(図11参照)。
【0068】
統合部304は、決定部303により、名寄せ元データと名寄せ先データを名寄せしあう組み合わせに決定した場合、名寄せ元データを含むグループと名寄せ先データを含むグループを統合する機能を有する。具体的には、たとえば、図6において、統合部304は、決定部303により名寄せ候補レコード(1,6)の決定結果が○に決定された場合、名寄せ元ID=6の名寄せ元グループをグループG6からグループG1に変更する。なお、統合された結果は、RAM103、磁気ディスク105、光ディスク107などの記憶領域に記憶される。
【0069】
たとえば、図4−cにおいて、第1,2のデータが同一グループであるとする。この場合、決定部303により、第2のデータX2と第3のデータX3が名寄せしあう組み合わせのデータに決定されると、統合部304は、第1のデータX1を含むグループに、第3のデータX3を含むグループを統合する。
【0070】
さらに、決定部303が、第1のデータX1と、図示省略する第4のデータを名寄せしあう組み合わせに決定した場合、統合部304は、第1のデータX1を含むグループにさらに、第4のデータを含むグループを統合する。つまり、第1〜第4のデータは、同一グループとなる。
【0071】
一方、図4−fでは、決定部303により、第2のデータX2と第3のデータX3が名寄せできない組み合わせのデータに決定されている。このため、図示省略する第4のデータが第3のデータX3と同一グループである場合、決定部303は、第1のデータX1と第4のデータを名寄せできないデータの組み合わせに決定する。
【0072】
つまり、異なるグループ間のデータの組み合わせの中に、1つでも名寄せできないデータの組み合わせがある場合、この異なるグループ間のデータの組み合わせは、決定部303により、名寄せできないデータの組み合わせに決定される。
【0073】
つぎに、決定部303により決定結果が作成されるまでの処理過程の一例を、図5〜図11を参照して説明する。図5に示す名寄せ候補レコードには、名寄せ処理前に、作業者により書き込まれた決定結果のみが示されている(中黒の星印★のレコード)。ここで、決定部303は、名寄せ候補データ中の名寄せ候補レコードを先頭レコードから順に読み込むこととする。
【0074】
まず、決定部303は、名寄せ候補レコード(1,6)を取得する。ついで、決定部303は、名寄せ元ID=1,6の名寄せ候補レコードの名寄せ元グループが同一グループであるか否かを判断する(第3の決定方法)。具体的には、決定部303は、名寄せ元ID=1のデータのグループG1と名寄せ元ID=6のデータのグループG6が異なるため、続けて第1の決定方法をおこなう。
【0075】
第1の決定方法では、指定部301は、名寄せ元/先ID=1の名寄せ候補レコードの中から、名寄せ元ID=1のデータと名寄せしあうデータ(または名寄せできないデータ)を指定する。具体的には、指定部301は、名寄せ元ID=1のデータと名寄せしあうデータとして、名寄せ候補レコード(1,2),(1,3),(1,4)を指定する。
【0076】
そして、特定部302は、指定部301によって指定された名寄せ元/先ID=2,3,4のデータと名寄せしあう名寄せ元ID=6のデータ(または名寄せできない名寄せ元ID=6のデータ)を特定する。具体的には、特定部302は、名寄せ候補レコード(2,6),(3,6),(4,6),(6,2),(6,3),(6,4)の中で、決定結果が○となる名寄せ候補レコードを特定する。
【0077】
しかし、特定部302は、上記名寄せ候補レコードの中から、名寄せ先ID=6のデータと名寄せしあうデータを特定することができない。このため、決定部303は、続けて第2の決定方法をおこなう。
【0078】
第2の決定方法では、決定部303は、名寄せ候補レコード(1,6)の類似度数に基づいて、名寄せをおこなう。名寄せ候補レコード(1,6)の類似度数は、類似度数の閾値の上限値90以上であるため、決定部303は、名寄せ候補レコード(1,6)の決定結果に○を書き込む(図6参照)。図6〜11,20の名寄せ候補レコードにおいて、名寄せ処理または統合処理により、書き換えられた部分を二重線で囲む。
【0079】
決定部303によって名寄せ候補レコード(1,6)の決定結果に○が書き込まれるとともに、統合部304は、名寄せ元ID=6と同じグループG6が書き込まれているすべての名寄せ候補レコードの名寄せ元グループをグループG6からグループG1に変更する。なお、図6〜12,20においては、名寄せ元グループの変更された経緯を矢印で示す。具体的には、名寄せ候補レコード(1,6)では、グループG1がグループG6に変更されているため、G1→G6となる。
【0080】
以下、決定部303は、すべての名寄せ候補レコードに対して、上述した名寄せ候補レコード(1,6)に対する名寄せ処理と同様の手順で名寄せ処理をおこなうが、以下、詳細な説明は省略する。
【0081】
ついで、決定部303は、すでに決定結果の書き込まれている名寄せ候補レコード(1,2),(1,3), (1,4)を飛ばし、名寄せ候補レコード(1,7)に対する名寄せ処理をおこなう。しかし、この段階では、決定部303は、第1〜第3の決定方法に基づいて、名寄せ候補レコード(1,7)の決定結果を得ることができない。
【0082】
このため、決定部303は、名寄せ候補レコード(1,7)の決定結果には何も書き込まず、続けて次の名寄せ候補レコード(1,5)の名寄せ処理をおこなう。そして、決定部303は、第2の決定方法に基づいて、名寄せ候補レコード(1,5)の決定結果に×を書き込む(図7参照)。以下、統合部304によるグループ統合処理の伴わない名寄せ処理については、説明を省略する。
【0083】
決定部303は、第1の決定方法に基づいて、名寄せ候補レコード(2,1),(2,3),(2,4),(3,7)の決定結果にこの順に○を書き込む。そして、統合部304は、名寄せ候補レコード(2,1)の決定結果に○が書き込まれるとともに、名寄せ元ID=2と同じグループG3が書き込まれているすべての名寄せ元グループをグループG2からグループG1に変更する(図7参照)。
【0084】
また、統合部304は、名寄せ候補レコード(2,3)の決定結果に○が書き込まれるとともに、名寄せ元ID=3と同じグループG3が書き込まれているすべての名寄せ元グループをグループG3からグループG1に変更する(図8参照)。
【0085】
また、統合部304は、名寄せ候補レコード(2,4)の決定結果に○が書き込まれるとともに、名寄せ元ID=4と同じグループG3が書き込まれているすべての名寄せ元グループをグループG4からグループG1に変更する(図9参照)。
【0086】
また、統合部304は、名寄せ候補レコード(3,7)の決定結果に○が書き込まれるとともに、名寄せ元ID=7と同じグループG3が書き込まれているすべての名寄せ元グループをグループG7からグループG1に変更する(図10参照)。以下、決定部303および統合部304は、同様の処理を繰り返す。これにより、ほぼすべての名寄せ候補レコードの決定結果に○または×が書き込まれ、決定結果データが完成する(図11参照)。
【0087】
これにより、図12に示すように、名寄せ処理前のグループG2,G3、G4,G6,G7は、グループG1に変更される。つまり、上述した統合部304によるグループ統合処理により、グループG2,G3、G4,G6,G7は消滅する。
【0088】
ここでは、統合部304により、グループG2〜G7が順にグループG1に変更されているが、名寄せ候補レコードの読み込まれる順番により、名寄せ元グループの変更される順番は変わる。たとえば、グループG7がグループG3に変更された後、グループG3がグループG1に変更され、名寄せ処理が終了した場合、名寄せ処理前のグループG7は、名寄せ処理が終了した時点でグループG1に変更されている。つまり、名寄せ元ID=7の名寄せ候補レコードの名寄せ元グループは、G7→G3→G1と変更される(不図示)。
【0089】
名寄せ処理がすべて終了し、決定結果データが完成した後に、図示省略した他の名寄せ候補レコードの名寄せ元グループを手作業により書き換えてもよい。具体的には、たとえば、作業者は、名寄せ候補レコードの名寄せ元グループをグループG11からグループG1に書き換える。
【0090】
これにより、名寄せ処理前のグループG11,G12は、グループG1に変更され、グループG11,G12は消滅する。つまり、決定部303による名寄せ処理後においても、グループを統合することができる。図13〜図19は、実施の形態1にかかるグループの統合される過程の一例を順に示す説明図である。上述した図5〜図12に示すようにグループを統合した状態を、図13〜図19を参照して説明する。
【0091】
図13において、名寄せ元データX1〜X31は、それぞれ異なるグループG1〜G31に登録される。図13に示す状態は、名寄せ候補レコードの名寄せ先グループに、グループG1〜G31が書き込まれた状態である(図5参照)。ここで、名寄せ元データX1〜X31は、図5における名寄せ元ID=1〜31のデータに該当する(以下、図14〜図19においても同様)。なお、図5では、名寄せ元ID=8〜31は図示省略している。
【0092】
図14において、まず、統合部304により、グループG6は、グループG1に統合されて消滅する。決定部303により、名寄せ候補レコード(1,6)の決定結果が○に決定されたことによるものである(図6参照)。これにより、名寄せ元データX6は、グループG1に登録される。
【0093】
ついで、図15〜図18において、統合部304により、グループG2,G3,G4,G7は、この順でグループG1に順次統合されて消滅する。決定部303により、名寄せ候補レコード(2,1),(2,3),(2,4),(3,7)の決定結果が順次○に決定されたことによるものである(図7〜10参照)。これにより、名寄せ元データX2,X3,X4,X7は、グループG1に順次登録される。
【0094】
また、図19において、グループG11が、グループG1に統合されて消滅する。作業者により、名寄せ元ID=11のデータの名寄せ元グループが、グループG11からグループG1に変更されたことによるものである(図12参照)。これにより、名寄せ元データX11,X12は、グループG1に登録される。
【0095】
次に、決定結果データが作成されるまでの処理過程の別の一例を、図20を参照して説明する。図20は、実施の形態1にかかる名寄せ処理中の名寄せ候補レコードの別の一例を示す説明図である。まず、決定部303は、図5に示す名寄せ処理と同様に、名寄せ候補レコード(1,6)を取得する。
【0096】
ついで、図20において、決定部303は、図6に示す名寄せ処理と同様に、第2の決定方法に基づいて、名寄せ候補レコード(1,6)の決定結果を○に決定する。そして、統合部304は、図6に示すグループ統合処理と同様に、名寄せ元ID=6のすべての名寄せ候補レコードの名寄せ元グループをグループG6からグループG1に変更する。
【0097】
ついで、指定部301は、決定部303により決定結果を○に決定された名寄せ候補レコード(1,6)を指定する。そして、特定部302は、指定部301によって指定された名寄せ元/先ID=1,6のデータと名寄せしあう名寄せ候補レコード(1,2),(1,3), (1,4)を特定する。
【0098】
これにより、決定部303は、指定部301により指定された名寄せ元/先ID=1,6と、特定部302により特定された名寄せ元/先ID=2,3,4のデータの、すべての組み合わせのデータを、名寄せしあうデータの組み合わせに決定する。
【0099】
具体的には、決定部303は、名寄せ候補レコード(2,1), (2,3),(2,4),(2,6),(3,1),(3,2),(3,4),(3,6), (4,1),(4,2),(4,3),(4,6), (6,1),(6,2),(6,3),(6,4)の決定結果を○に決定する。
【0100】
つまり、指定部301は、グループG1内の、名寄せしあうデータの組み合わせを順に指定する。そして、特定部302は、指定部301がデータを指定する都度、指定部301により指定されたデータと名寄せしあうデータを特定する。これにより、決定部303は、グループG1内のすべての組み合わせのデータを、名寄せ候補レコード(1,6)の決定結果を○に決定すると同時に名寄せしあうデータの組み合わせに決定する。
【0101】
その後、統合部304により、グループ統合処理がおこなわれ、グループG2,G3,G4,G6は同時にグループG1に統合される。このように、ある名寄せ候補レコードの決定結果が決定することで決定結果が確定する名寄せ候補レコードの決定結果を、ある名寄せ候補レコードの決定結果と同時に決定してもよい。
【0102】
出力部305は、決定部303により決定された名寄せ結果を出力する機能を有する。具体的には、たとえば、出力部305は、決定結果データに基づいて、一般的なデータ統合装置212の入力形式に対応した名寄せ結果データを作成する。出力形式としては、たとえば、ディスプレイ108への表示、プリンタ113への印刷出力、I/F109による外部装置への送信がある。また、RAM103、磁気ディスク105、光ディスク107などの記憶領域に記憶することとしてもよい。
【0103】
実施の形態1によれば、作業者による名寄せ作業の工数を軽減することができる。これにより、作業者のミスにより、誤った名寄せ結果が作成されることを回避することができる。また、名寄せしあう組み合わせのデータ、および名寄せすることができない組み合わせのデータを正確に特定することができる。これにより、名寄せ結果に矛盾が生じることを防止することができる。
【0104】
(名寄せ処理手順)
つぎに、実施の形態1にかかる名寄せ処理手順の一例について説明する。図21−1,21−2は、実施の形態1にかかる名寄せ処理手順の一例を示すフローチャートである。図21−1において、まず、名寄せ処理装置により、名寄せ元の整理対象データ(名寄せ元データ)および名寄せ先の整理対象データ(名寄せ先データ)を抽出し、名寄せ元データを1グループ1データでグループに登録する(ステップS2101)。ついで、決定部303により、名寄せ元データ数nを取得する(ステップS2102)。そして、初期値をI=1とし、変数i=名寄せ元データ(I)のIDとする(ステップS2103)。
【0105】
ついで、決定部303により、名寄せ元ID=iの名寄せ候補レコードのレコード数mを取得する(ステップS2104)。名寄せ元ID=iの名寄せ候補レコードがある場合(ステップS2105:Yes)、決定部303により、初期値をJ=1とし、変数j=名寄せ先データ(I,J)のIDとする(ステップS2106)。
【0106】
ついで、決定部303により、名寄せ候補レコード(i,j)を取得する(ステップS2107)。そして、決定部303により、名寄せ候補レコード(i,j)の決定結果=NULLであるか否かを判定する(ステップS2108)。つまり、決定部303は、名寄せ候補レコード(i,j)の決定結果が決定済みであるか否かを判定する。
【0107】
名寄せ候補レコード(i,j)の決定結果=NULLである場合(ステップS2108:Yes)、決定部303により、ID=iの名寄せ元データの登録されたグループG(i)を取得する(ステップS2109)。つまり、名寄せ元データ(I)の登録されたグループを取得する。また、決定部303により、ID=jの名寄せ元データの登録されたグループG(j)を取得する(ステップS2110)。つまり、名寄せ先データ(I,J)のIDと同じIDの名寄せ元データの登録されたグループを取得する。
【0108】
グループG(i)=グループG(j)である場合(ステップS2111:Yes)、決定部303により、名寄せ候補レコード(i,j)の決定結果に○を書き込む(ステップS2112)。ついで、Jをインクリメントして(ステップS2113)、J>mでない場合(ステップS2114:No)、ステップS2107に移行し、決定部303により、名寄せ候補レコード(i,j)を取得する。
【0109】
一方、グループG(i)=グループG(j)でない場合(ステップS2111:No)、指定部301および特定部302により、グループG(i)の整理対象データとグループG(j)の整理対象データを名寄せ元/先データとする組み合わせの、名寄せ候補レコードの決定結果を○に決定したことがあるか否かを判定する(ステップS2117)。
【0110】
つまり、ステップS2117において、指定部301および特定部302は、グループG(i)の整理対象データのIDとグループG(j)の整理対象データのIDを名寄せ元/先IDとする名寄せ候補レコードに、決定結果○の名寄せ候補レコードが少なくとも1レコードあるか否か判定する。
【0111】
決定結果○の名寄せ候補レコードがある場合(ステップS2117:Yes)、統合部304により、グループ統合処理をおこない(ステップS2118)、決定部303により、名寄せ候補レコード(i,j)の決定結果に○を書き込む(ステップS2112)。
【0112】
一方、決定結果○の名寄せ候補レコードがない場合(ステップS2117:No)、指定部301および特定部302により、グループG(i)の整理対象データとグループG(j)の整理対象データを名寄せ元/先データとする組み合わせの、名寄せ候補レコードの決定結果を×に決定したことがあるか否かを判定する(ステップS2119)。
【0113】
つまり、ステップS2119において、指定部301および特定部302は、グループG(i)の整理対象データのIDとグループG(j)の整理対象データのIDを名寄せ元/先IDとする名寄せ候補レコードに、決定結果×の名寄せ候補レコードが少なくとも1レコードあるか否か判定する。
【0114】
決定結果×の名寄せ候補レコードがない場合(ステップS2119:No)、決定部303により、名寄せ候補レコード(i,j)の類似度数が閾値の上限値以上であるか否かを判定する(ステップS2120)。
【0115】
一方、決定結果×の名寄せ候補レコードがある場合(ステップS2119:Yes)、決定部303により、名寄せ候補レコード(i,j)の決定結果に×を書き込む(ステップS2122)。
【0116】
ステップS2120において、名寄せ候補レコード(i,j)の類似度数が閾値の上限値以上である場合(ステップS2120:Yes)、統合部304によりグループ統合処理をおこない(ステップS2118)、決定部303により名寄せ候補レコード(i,j)の決定結果に○を書き込む(ステップS2112)。
【0117】
一方、名寄せ候補レコード(i,j)の類似度数が閾値の上限値以上でない場合(ステップS2120:No)、決定部303により、名寄せ候補レコード(i,j)の類似度数が閾値の下限値以下であるか否かを判定する(ステップS2121)。
【0118】
名寄せ候補レコード(i,j)の類似度数が閾値の下限値以下である場合(ステップS2121:Yes)、決定部303により、名寄せ候補レコード(i,j)の決定結果に×を書き込む(ステップS2122)。
【0119】
一方、名寄せ候補レコード(i,j)の類似度数が閾値の下限値以下でない場合(ステップS2121:No)、Jをインクリメントし(ステップS2113)、J>mでない場合(ステップS2114:No)、ステップS2107に移行し、決定部303により、名寄せ候補レコード(i,j)を取得する。
【0120】
ステップS2108において、名寄せ候補レコード(i,j)の決定結果=NULLでない場合(ステップS2108:No)、ステップS2109〜ステップS2122の処理はおこなわずに、ステップS2113に移行する。
【0121】
また、ステップS2105において、名寄せ元ID=iの名寄せ候補レコードがない場合においても同様に(ステップS2105:No)、ステップS2113に移行する。
【0122】
また、ステップS2114において、J>mである場合(ステップS2114:Yes)、Iをインクリメントし(ステップS2115)、I>nでない場合(ステップS2116:No)、ステップS2104に移行し、決定部303により、名寄せ元ID=iの名寄せ候補レコードのレコード数mを取得する。
【0123】
一方、ステップS2116において、I>nである場合(ステップS2116:Yes)、名寄せ処理装置は一連の処理を終了する。
【0124】
つぎに、実施の形態1にかかる名寄せ処理手順の別の一例について説明する。図22−1,22−2は、実施の形態1にかかる名寄せ処理手順の別の一例を示すフローチャートである。図22−1において、まず、名寄せ処理装置により、名寄せ元データを1グループ1データでグループに登録する(ステップS2201)。ついで、名寄せ元の整理対象データ数nを取得する(ステップS2202)。そして、初期値をI=1とし、変数i=名寄せ元データ(I)のIDとする(ステップS2203)。
【0125】
ついで、決定部303により、名寄せ元ID=iの名寄せ候補レコードのレコード数mを取得する(ステップS2204)。名寄せ元ID=iの名寄せ候補レコードがある場合(ステップS2205:Yes)、決定部303により、初期値をJ=1とし、変数j=名寄せ先データ(I,J)のIDとする(ステップS2206)。
【0126】
ついで、決定部303により、名寄せ候補レコード(i,j)を取得する(ステップS2207)。そして、決定部303により、名寄せ候補レコード(i,j)の決定結果=NULLであるか否かを判定する(ステップS2208)。つまり、決定部303は、名寄せ候補レコード(i,j)の決定結果が決定済みであるか否かを判定する。
【0127】
名寄せ候補レコード(i,j)の決定結果=NULLである場合(ステップS2208:Yes)、決定部303により、ID=iの名寄せ元データの登録されたグループG(i)を取得する(ステップS2209)。つまり、名寄せ元データ(I)の登録されたグループを取得する。また、決定部303により、ID=jの名寄せ元データの登録されたグループG(j)を取得する(ステップS2210)。つまり、名寄せ先データ(I,J)のIDと同じIDの名寄せ元データの登録されたグループを取得する。
【0128】
グループG(i)=グループG(j)である場合(ステップS2211:Yes)、決定部303により、グループG(i)の整理対象データを名寄せ元/先データとする組み合わせの、すべての名寄せ候補レコードの決定結果に○を書き込む(ステップS2212)。つまり、決定部303により、グループG(i)内の整理対象データの全組み合わせは、名寄せしあうデータの組み合わせに決定される。
【0129】
ついで、Jをインクリメントして(ステップS2213)、J>mでない場合(ステップS2214:No)、ステップS2207に移行し、決定部303により、名寄せ候補レコード(i,j)を取得する。
【0130】
一方、グループG(i)=グループG(j)でない場合(ステップS2211:No)、指定部301および特定部302により、グループG(i)の整理対象データとグループG(j)の整理対象データを1組の名寄せ元/先データとする組み合わせの、名寄せ候補レコードの決定結果を○に決定したことがあるか否かを判定する(ステップS2217)。
【0131】
ステップS2217において、決定結果○の名寄せ候補レコードがある場合(ステップS2217:Yes)、統合部304により、グループ統合処理をおこない(ステップS2218)、決定部303により、グループG(i)の整理対象データとグループG(j)の整理対象データを1組の名寄せ元/先データとする組み合わせの、すべての名寄せ候補レコードの決定結果に○を書き込む(ステップS2219)。つまり、ステップS2219において、グループG(i)の整理対象データのIDとグループG(j)の整理対象データのIDを名寄せ元/先IDとするすべての名寄せ候補レコードの決定結果が○になる。
【0132】
一方、ステップS2217において、決定結果○の名寄せ候補レコードがない場合(ステップS2217:No)、指定部301および特定部302により、グループG(i)の整理対象データとグループG(j)の整理対象データを1組の名寄せ元/先データとする組み合わせの、名寄せ候補の決定結果を×に決定したことがあるか否かを判定する(ステップS2220)。
【0133】
ステップS2220において、決定結果×の名寄せ候補レコードがない場合(ステップS2220:No)、決定部303により、名寄せ候補レコード(i,j)の類似度数が閾値の上限値以上であるか否かを判定する(ステップS2221)。
【0134】
一方、ステップS2220において、決定結果×の名寄せ候補レコードがある場合(ステップS2220:Yes)、決定部303により、グループG(i)の整理対象データとグループG(j)の整理対象データを1組の名寄せ元/先データとする組み合わせの、すべての名寄せ候補の決定結果に×を書き込む(ステップS2222)。つまり、グループG(i)の整理対象データのIDとグループG(j)の整理対象データのIDを名寄せ元/先IDとするすべての名寄せ候補レコードの決定結果が×になる。
【0135】
ステップS2221において、名寄せ候補レコード(i,j)の類似度数が閾値の上限値以上である場合(ステップS2221:Yes)、統合部304によりグループ統合処理をおこない(ステップS2218)、決定部303により、グループG(i)の整理対象データとグループG(j)の整理対象データを1組の名寄せ元/先データとする組み合わせの、すべての名寄せ候補レコードの決定結果に○を書き込む(ステップS2219)。
【0136】
一方、名寄せ候補レコード(i,j)の類似度数が閾値の上限値以上でない場合(ステップS2221:No)、決定部303により、名寄せ候補レコード(i,j)の類似度数が閾値の下限値以下であるか否かを判定する(ステップS2223)。
【0137】
名寄せ候補レコード(i,j)の類似度数が閾値の下限値以下である場合(ステップS2223:Yes)、決定部303により、グループG(i)の整理対象データとグループG(j)の整理対象データを1組の名寄せ元/先データとする組み合わせの、すべての名寄せ候補レコードの決定結果に×を書き込む(ステップS2222)。
【0138】
一方、名寄せ候補レコード(i,j)の類似度数が閾値の下限値以下でない場合(ステップS2223:No)、Jをインクリメントし(ステップS2213)、J>mでない場合(ステップS2214:No)、ステップS2207に移行し、決定部303により、名寄せ候補レコード(i,j)を取得する。
【0139】
ステップS2208において、名寄せ候補レコード(i,j)の決定結果=NULLでない場合(ステップS2208:No)、ステップS2209〜ステップS2223の処理はおこなわずに、ステップS2213に移行する。
【0140】
また、ステップS2205において、名寄せ元ID=iの名寄せ候補レコードがない場合においても同様に(ステップS2205:No)、ステップS2213に移行する。
【0141】
また、ステップS2214において、J>mである場合(ステップS2214:Yes)、Iをインクリメントし(ステップS2215)、I>nでない場合(ステップS2216:No)、ステップS2204に移行し、決定部303により、名寄せ元ID=iの名寄せ候補レコードのレコード数mを取得する。
【0142】
一方、ステップS2216において、I>nである場合(ステップS2216:Yes)、名寄せ処理装置は一連の処理を終了する。
【0143】
(グループ統合処理手順)
つぎに、実施の形態1にかかるグループ統合処理手順の一例について説明する。図23は、実施の形態1にかかるグループ統合処理手順の一例を示すフローチャートである。図23において、まず、統合部304により、グループG(j)の名寄せ候補レコードを取得する(ステップS2301)。
【0144】
ついで、統合部304により、グループG(j)の名寄せ候補レコード数lを取得し、初期値をk=1とする(ステップS2302,S2303)。ついで、統合部304により、グループG(j)の名寄せ候補レコードのグループをグループG(i)に書き換える(ステップS2304)。
【0145】
kをインクリメントし(ステップS2305)、k>lでない場合(ステップS2306:No)、ステップS2304に移行する。k>lである場合(ステップS2306:Yes)、統合部304は一連の処理を終了する。
【0146】
・実施の形態2
(名寄せ処理装置の機能的構成)
つぎに、実施の形態2にかかる名寄せ処理装置の機能的構成について説明する。図24は、実施の形態2にかかる名寄せ処理装置の機能的構成を示すブロック図である。名寄せ処理装置400は、指定部401と、算出部402と、決定部403と、出力部305と、を含む構成である。名寄せ処理装置400のハードウェア構成は、実施の形態1と同様である。
【0147】
名寄せ処理装置400は、データベースDBにアクセスし、整理対象データ群201の中から、名寄せされるデータ(名寄せ元データ)と、名寄せしあう組み合わせに決定したデータ(名寄せ先データ)を抽出する。抽出されたデータは、たとえばレコード(以下、名寄せ相手レコードとする)単位で記憶される。
【0148】
名寄せ処理装置400は、たとえば、予め設定された抽出条件に基づいて、名寄せ相手レコードを作成してもよいし、実施の形態1に示す名寄せ処理により出力された名寄せ結果によって名寄せ相手レコードを作成してもよい。名寄せ相手レコードは、たとえば名寄せ元データの識別記号(名寄せ元ID)と、名寄せ先データの識別番号(名寄せ先ID)から構成される。
【0149】
名寄せ元データは、たとえば名寄せ元データ間の関連度に基づいて、グループに登録されている。具体的には、1グループに複数の名寄せ元データが登録されている。ここで、関連度とは、たとえば類似度数や相違度数など、整理対象データ間の似ている度合いを点数化したものである。
【0150】
図25において、第1〜第9の名寄せ元データX41〜X49は、たとえば類似度数に基づいてそれぞれ異なるグループG41,G42に登録される。具体的には、たとえば、第1〜第6の名寄せ元データX41〜X46は、グループG41に登録されている。第7〜第9の名寄せ元データX47〜X49は、グループG42に登録されている。
【0151】
名寄せ元データと他の名寄せ元データとの間の関連度が算出されている場合、名寄せ元データと他の名寄せ元データは、それぞれ関連度に基づく関係(以下、関係線とする)で結ばれている。具体的には、たとえば、図25において、第1の名寄せ元データと第2の名寄せ元データは、関係線a12で結ばれている。
【0152】
指定部401は、データ群の中から対象データを順次指定する機能を有する。具体的には、たとえば、指定部401は、1つのグループに登録された名寄せ元データ群の中から名寄せ元データを順次指定する。なお、指定結果は、RAM103、磁気ディスク105、光ディスク107などの記憶領域に記憶される。
【0153】
算出部402は、指定部401によって対象データが指定される都度、対象データとデータ群内の他のデータとの関連度に基づいて、対象データごとにデータ群内での評価値を算出する機能を有する。具体的には、たとえば、算出部402は、指定部401によって名寄せ元データが指定される都度、グループ内の他の名寄せ元データとの関連度に基づいて、名寄せ元データごとにグループ内での評価値を算出する。
【0154】
算出部402は、たとえば名寄せ相手レコードに記憶された名寄せ元データ間の関連度に基づいて、名寄せ元データのグループ内での評価値を算出する。算出部402は、複数の方法で評価値を算出してもよい。算出した評価値は、たとえば名寄せ元IDごとに1レコードに記憶される。なお、算出結果は、RAM103、磁気ディスク105、光ディスク107などの記憶領域に記憶される。図26は、実施の形態2にかかる名寄せ相手レコードの一例を示す説明図である。
【0155】
図26において、名寄せ相手レコードは、名寄せ元IDおよび名寄せ先IDから構成される。名寄せ相手レコード(名寄せ元ID,名寄せ先ID)には、たとえば名寄せ元グループがそれぞれ記憶されていてもよい。
【0156】
具体的には、たとえば、名寄せ相手レコード(1,2)は、次のデータを記憶する。名寄せ元ID=1である。名寄せ先ID=2である。第1の名寄せ元データX41と第2の名寄せ元デーダX42間の関連度(比較結果)=65である。図26では、関連度として類似度数を示しているが、これに限らず、名寄せ元データと名寄せ先データを比較するための情報であればよく、他の方法で算出された関連度であってもよい。
【0157】
算出部402は、たとえば図26に示すような名寄せ相手レコードから、名寄せ元データの関連度を取得する。図27は、実施の形態2にかかる名寄せ処理による決定結果の一例を示す説明図である。
【0158】
図27において、決定結果レコードは、たとえば名寄せ元IDから構成される。決定結果レコード(名寄せ元ID)には、たとえば名寄せ元グループ、算出部402により算出される評価値、および決定部403により決定される決定結果がそれぞれ記憶されている。
【0159】
また、算出部402は、対象データと関連度を有する他のデータの数に基づいて、対象データごとにデータ群内での評価値を算出する。具体的には、たとえば、算出部402は、評価値として、名寄せ元データから他のデータに伸びる関係線の本数を算出する(以下、第1の評価値とする)。
【0160】
図27において、グループG41の第1の名寄せ元データX41は、第2の名寄せ元データX42〜第4の名寄せ元データX44および第6の名寄せ元データX46と、それぞれ関係線a12,a13,a14,a16で結ばれている。このため、算出部402は、第1の名寄せ元データX41の第1の評価値=4と算出する。
【0161】
また、算出部402は、対象データと関連度を有する他のデータの関連度の総和に基づいて、対象データごとにデータ群内での評価値を算出する。具体的には、たとえば、算出部402は、評価値として、名寄せ元データ間の関連度の総和を算出する(以下、第2の評価値とする)。
【0162】
図27において、グループG41の第1の名寄せ元データX41は、第2の名寄せ元データX42〜第4の名寄せ元データX44および第6の名寄せ元データX46との間に類似度数が設定されている。このため、算出部402は、第1の名寄せ元データX41の第2の評価値=65+77+65+70=277と算出する。
【0163】
また、算出部402は、対象データと関連度を有する他のデータの数と当該他のデータの関連度の総和に基づいて、対象データごとにデータ群内での評価値を算出する。具体的には、たとえば、算出部402は、評価値として、名寄せ元データ間の関連度の総和の平均値を算出する(以下、第3の評価値とする)。
【0164】
図27において、算出部402は、第1の名寄せ元データX41の第3の評価値=第1の評価値/第2の評価値=69.3と算出する。
【0165】
また、算出部402は、対象データと関連度を有する他のデータの関連度の中の最大関連度に基づいて、対象データごとにデータ群内での評価値を算出する。具体的には、たとえば、算出部402は、評価値として、対象の名寄せ元データと、他のデータ間の関連度のうち最大値を選択する(以下、第4の評価値とする)。
【0166】
たとえば関連度がデータ間の類似度数である場合、第4の評価値が高い値であるほど、対象の名寄せ元データがグループ内の他のデータと名寄せしあう可能性が高いことを示す。また、たとえば関連度がデータ間の相違度数である場合、第4の評価値が高い値であるほど、対象の名寄せ元データがグループ内の他のデータと名寄せできない可能性が高いことを示す。
【0167】
図27において、第1の名寄せ元データX41と、第2の名寄せ元データX42〜第4の名寄せ元データX44および第6の名寄せ元データX46間の関連度は、それぞれ65,77,65および70である。このため、算出部402は、第1の名寄せ元データX41の第4の評価値=77と算出する。
【0168】
また、算出部402は、対象データと関連度を有する他のデータの関連度の中の最小関連度に基づいて、対象データごとにデータ群内での評価値を算出する。具体的には、たとえば、算出部402は、評価値として、名寄せ元データと他のデータ間の関連度のうち最小値を選択する(以下、第5の評価値とする)。
【0169】
たとえば関連度がデータ間の類似度数である場合、第5の評価値が低い値であるほど、対象の名寄せ元データがグループ内の他のデータと名寄せできない可能性が高いことを示す。また、たとえば関連度がデータ間の相違度数である場合、第5の評価値が低い値であるほど、対象の名寄せ元データがグループ内の他のデータと名寄せしあう可能性が高いことを示す。
【0170】
たとえば、関連度がデータ間の類似度数である場合に、算出部402は、第5の評価値を次のように算出する。図26において、第1の名寄せ元データX41と、第2の名寄せ元データX42〜第4の名寄せ元データX44および第6の名寄せ元データX46間の関連度は、それぞれ65,77,65および70である。このため、算出部402は、第1の名寄せ元データX41の第5の評価値=65と算出する。
【0171】
また、算出部402は、第1〜第5の評価値を2つ以上組み合わせて、評価値を算出してもよい(以下、第6の評価値とする)。具体的には、たとえば、算出部402は、第1の評価値に第2の評価値を組み合わせることができない場合は、第1の評価値と第3の評価値を組み合わせるなど、評価値の算出方法に合わせて種々変更可能である。
【0172】
第6の評価値の算出方法は、理論上、5C2+5C3+5C4+5C5=26種類である。このため、評価値の計算方法の総数は、理論上、第1〜第5の評価値の5種類+第6の評価値の26種類=31種類となる。評価値の算出方法は一例であり、上述した算出方法に限らず、種々の方法で算出可能である。また、評価値の数は一例であり、評価値をさらに増やしてもよいし、減らしてもよい。
【0173】
決定部403は、算出部402によって算出された評価値に基づいて、データ群の中から代表的な名寄せ元データを決定する機能を有する。具体的には、たとえば、決定部403は、算出部402によって算出された評価値に基づいて、グループ内の名寄せ元データ群の中から、他の名寄せ元データのすべてと名寄せしあう代表的な名寄せ元データ(以下、代表的な名寄せ元データとする)を決定する。なお、決定結果は、RAM103、磁気ディスク105、光ディスク107などの記憶領域に記憶される。
【0174】
また、決定部403は、関連度がデータ間の類似度数である場合、評価値が最大となる対象データを、代表的な名寄せ元データに決定する。具体的には、たとえば、決定部403は、名寄せ元データ間の関連度が類似度数である場合、名寄せ元データ間の関連度が最大となる名寄せ元データを、代表的な名寄せ元データに決定する。
【0175】
また、決定部403は、第1〜第6の決定結果をさらに組み合わせて、グループ内の名寄せ元データ群の中から代表的な名寄せ元データを決定してもよい。
【0176】
図27において、第1〜第6の決定結果○は、たとえば最も評価値の高いことを意味し、決定結果×は最も評価値の低いことを意味する。たとえば第2の評価値を用いてグループG1内の代表的な名寄せ元データを決定する場合、第3の名寄せ元データX43の第2の評価値=293が最大であるため、決定部403は、代表的な名寄せ元データを第3の名寄せ元データX43に決定する。
【0177】
また、決定部403は、評価値が最小となる対象データを、決定部403は、評価値が最小となる対象データを、代表的な名寄せ元データと名寄せできないデータ候補に決定する。代表的な名寄せ元データと名寄せできないデータ候補とは、代表的な名寄せ元データと名寄せできない可能性の高いデータの候補である。さらに、決定部403は、評価値が所定値以下となる対象データを、代表的な名寄せ元データと名寄せできないデータ候補に決定してもよい。
【0178】
具体的には、たとえば、決定部403は、各名寄せ元データ間の関連度が類似度数である場合、名寄せ元データ間の関連度が最小または所定値以下となる名寄せ元データを、決定部403により決定した代表的な名寄せ元データに名寄せできないデータ候補に決定する。作業者により確認の必要なデータを評価値の低いデータに絞ることで、名寄せの効率が向上する。
【0179】
また、決定部403は、関連度がデータ間の相違度である場合、評価値が最小となる対象データを、代表的な名寄せ元データに決定する。具体的には、たとえば、決定部403は、名寄せ元データ間の関連度が相違度数である場合、名寄せ元データ間の関連度が最小となる名寄せ元データを、代表的な名寄せ元データに決定する。
【0180】
また、決定部403は、関連度がデータ間の相違度である場合、評価値が最大となる対象データを、代表的な名寄せ元データと名寄せできないデータ候補に決定する。さらに、決定部403は、関連度がデータ間の相違度である場合、評価値が所定値以上となる対象データを、代表的な名寄せ元データと名寄せできないデータ候補に決定してもよい。作業者により確認の必要なデータを評価値の高いデータに絞ることで、名寄せの効率が向上する。
【0181】
本実施の形態2によれば、名寄せ結果のデータ件数を、作業者が確認することができる現実的な件数にまで減らすことができる。このため、あいまいな名寄せ条件に基づいて名寄せ処理がおこなわれたとしても、作業者が、名寄せしあう可能性の高い結果または怪しい名寄せ結果に絞って確認することができるため、名寄せ処理の効率が向上する。
【0182】
また、名寄せしあうデータ群の中のデータごとに評価値を算出するため、評価値の大小によりデータごとに、名寄せしあうデータ群に含めてもよいデータであるか否かを確認することができる。つまり、名寄せしあうデータ群の中の各データが、このデータ群に含まれてよいデータであるか、または含まれてはいけないデータであるかを視覚化できる。このため、作業者は、従来の名寄せ処理では名寄せ結果として露出しなかった予想外の名寄せ結果を、評価値を確認することにより確認することができる。
【0183】
また、作業者は、確認したい名寄せ結果を、評価値により絞り込むことができる。たとえば、関連度が類似度数である場合に、名寄せしあうデータ候補を確認したい場合には、作業者は評価値の高いデータに絞り込んでデータを確認することができる。また、名寄せできないデータ候補を確認したい場合には、作業者は評価値の低いデータに絞り込んでデータを確認することができる。
【0184】
(名寄せ処理手順)
つぎに、実施の形態2にかかる名寄せ処理手順の一例について説明する。図28は、実施の形態2にかかる名寄せ処理手順の一例を示すフローチャートである。図28において、まず、名寄せ処理装置により、複数の名寄せ元データをグループに登録する(ステップS2801)。ついで、指定部401により、グループ数Nを取得し、初期値をi=1とする(ステップS2802,S2803)。
【0185】
ついで、指定部401により、グループG(i)内の名寄せ元データ数nを取得し、初期値j=1とする(ステップS2804,S2805)。ついで、算出部402により、名寄せ元ID(j)のすべての名寄せ相手レコードを取得する(ステップS2806)。
【0186】
ついで、算出部402により、評価値算出処理をおこなう(ステップS2807)。そして、jをインクリメントし(ステップS2808)、j>nでない場合(ステップS2809:No)、ステップS2806に移行し、算出部402により、名寄せ元ID(j)のすべての名寄せ相手レコードを取得する。
【0187】
ステップS2809において、j>nである場合(ステップS2809:Yes)、決定部403により、評価値の計算方法の個数jとし、初期値j=1とする(ステップS2810)。ついで、決定部403により、第jの評価値が最も高い名寄せ元データの第jの決定結果に○を書き込む(ステップS2811)。
【0188】
さらに、決定部403により、第jの評価値が最も低い名寄せ元データの第jの決定結果に×を書き込む(ステップS2812)。そして、jをインクリメントし(ステップS2813)、j>評価値の数(たとえば図27においては、評価値の数=6)でない場合(ステップS2814:No)、ステップS2811に移行する。
【0189】
ステップS2814において、j>評価値の数となるまで(ステップS2814:Yes)、ステップS2811〜S2813を繰り返し、決定部403により、評価値の計算方法ごとの決定結果を、名寄せ元データの決定結果に書き込む(図27参照)。ここでは、評価値の計算方法を6種類としたが、さらに評価値の計算方法を増やしてもよいし、減らしてもよい。
【0190】
ステップS2814において、j>評価値の数である場合(ステップS2814:Yes)、iをインクリメントし(ステップS2815)、i>nでない場合(ステップS2816:No)、ステップS2804に移行し、グループG(i)内の名寄せ元データ数nを取得し、初期値j=1とする(ステップS2804,S2805)。
【0191】
ステップS2816において、i>nである場合(ステップS2816:Yes)、名寄せ処理装置は一連の処理を終了する。一連の名寄せ処理が終了した後、たとえば決定結果に○の最も多い名寄せ元データを、代表的な名寄せ元データとしてもよい。
【0192】
(評価値算出処理手順)
つぎに、実施の形態2にかかる評価値算出処理手順の一例について説明する。図29は、実施の形態2にかかる評価値算出処理手順の一例を示すフローチャートである。算出部402により、名寄せ元ID(j)の名寄せ相手レコード数mを取得する(ステップS2901)。そして、算出部402により、名寄せ元ID(j)の名寄せ相手レコードの第1の評価値に、名寄せ元ID(j)の名寄せ相手レコード数を書き込む(ステップS2902)。
【0193】
ステップS2902では、算出部402により、名寄せ元ID(j)の名寄せ相手レコードの第1の評価値に、名寄せ元ID(j)の名寄せ元データの関係線の数が書き込まれる(図26では図示省略)。ここでは、評価値を名寄せ相手レコードに書き込んでいるが、上述したように、評価値および決定結果を、新たに作成した構成の異なる他のレコードに書き込んでもよい(図27参照)。
【0194】
算出部402により、名寄せ元ID(j)の名寄せ相手レコードの類似度数の総和Tを算出する(ステップS2903)。そして、算出部402により、名寄せ元ID(j)の名寄せ相手レコードの第2の評価値に、類似度数の総和Tを書き込む(ステップS2904)。
【0195】
算出部402により、名寄せ元ID(j)の名寄せ相手レコードの類似度数の平均値T/mを算出する(ステップS2905)。そして、算出部402により、名寄せ元ID(j)の名寄せ相手レコードの第3の評価値に、類似度数の平均値T/mを書き込む(ステップS2906)。
【0196】
算出部402により、名寄せ元ID(j)の名寄せ相手レコードの類似度数のうち、最も高い類似度数Fmaxを取得する(ステップS2907)。そして、算出部402により、名寄せ元ID(j)の名寄せ相手レコードの第4の評価値に、類似度数Fmaxを書き込む(ステップS2908)。
【0197】
算出部402により、名寄せ元ID(j)の名寄せ相手レコードの類似度数のうち、最も低い類似度数Fminを取得する(ステップS2909)。そして、算出部402により、名寄せ元ID(j)の名寄せ相手レコードの第5の評価値に、類似度数Fminを書き込む(ステップS2910)。
【0198】
算出部402により、第1〜第5の評価値の少なくとも2つ以上を組み合わせて、第6の評価値を算出する(ステップS2911)。そして、算出部402により、名寄せ元ID(j)の名寄せ相手レコードの第6の評価値に、算出した第6の評価値を書き込む(ステップS2912)。これにより、算出部402は一連の処理を終了する。
【0199】
図29に示す評価値算出処理では、第1〜第6の評価値のすべてを順番に算出しているが、この算出処理は一例であり、種々変更可能である。たとえば、算出部402により、すべての評価値を算出してもよいし、すべての評価値のうち少なくとも1つ以上の評価値を算出してもよい。具体的には、算出部402により、第1〜第6の評価値のすべてを算出してもよいし、例えば第1の評価値のみを算出してもよい。
【0200】
また、算出部402により、複数の評価値を組み合わせて評価値を算出する場合、算出部402により、複数の評価値を組み合わせて算出された1つの評価値のみを、名寄せ相手レコードに書き込んでもよい。具体的には、算出部402により、第1〜第5の評価値は名寄せ相手レコードに書き込まず、第6の評価値のみを名寄せ相手レコードに書き込んでもよい。
【0201】
実施の形態2にかかる名寄せ処理は、図26に示す名寄せ相手レコードに対して適用する場合に限らず、複数のデータを含むグループが作成される場合に適用することができる。たとえば、実施の形態1において、統合部により統合されたグループに対して適用してもよい。
【0202】
以上説明したように、名寄せ処理プログラム、名寄せ処理方法、および名寄せ処理装置によれば、名寄せしあう(または名寄せできない)データの組み合わせを効率よく特定することにより、作業者の関与する作業を減らすことができ、名寄せ結果の精度を向上するができる。
【0203】
また、データ群の中のデータごとにデータ群内での評価値を算出することにより、作業者の確認する名寄せ結果の件数を減らし、かつ名寄せ結果の効率を向上することができる。
【0204】
なお、本実施の形態で説明した名寄せ処理法は、予め用意されたプログラムをパーソナル・コンピュータやワークステーション等のコンピュータで実行することにより実現することができる。本名寄せ処理プログラムは、ハードディスク、フレキシブルディスク、CD−ROM、MO、DVD等のコンピュータで読み取り可能な記録媒体に記録され、コンピュータによって記録媒体から読み出されることによって実行される。また本名寄せ処理プログラムは、インターネット等のネットワークを介して配布してもよい。
【0205】
上述した実施の形態に関し、さらに以下の付記を開示する。
【0206】
(付記1)データ群を記憶するデータベースにアクセス可能なコンピュータに、
前記データ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する指定工程と、
前記データ群の中から、前記指定工程によって指定された第1のデータと名寄せしあう第3のデータを特定する特定工程と、
前記指定工程によって指定された第2のデータと前記特定工程によって特定された第3のデータを、名寄せしあうデータの組み合わせに決定する決定工程と、
前記決定工程によって決定された決定結果を出力する出力工程と、
を実行させることを特徴とする名寄せ処理プログラム。
【0207】
(付記2)前記特定工程は、
前記データ群の中から、前記指定工程によって指定された第1のデータと名寄せしあう第4のデータを特定し、
決定工程は、
前記第2のデータと前記特定工程によって特定された第4のデータとを、名寄せしあうデータの組み合わせに決定するとともに、前記第3のデータと前記第4のデータを、名寄せしあうデータの組み合わせに決定することを特徴とする付記1に記載の名寄せ処理プログラム。
【0208】
(付記3)前記特定工程は、
前記データ群の中から、前記指定工程によって指定された第1のデータと名寄せできない第4のデータを特定し、
決定工程は、
前記第2のデータと前記特定工程によって特定された第4のデータとを、名寄せできないデータの組み合わせに決定するとともに、前記第3のデータと前記第4のデータを、名寄せできないデータの組み合わせに決定することを特徴とする付記1に記載の名寄せ処理プログラム。
【0209】
(付記4)名寄せしあうデータ群を記憶するデータベースにアクセス可能なコンピュータに、
前記データ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する指定工程と、
前記データ群の中から、前記指定工程によって指定された第1のデータと名寄せできない第3のデータを特定する特定工程と、
前記指定工程によって指定された第2のデータと前記特定工程によって特定された第3のデータを、名寄せできないデータの組み合わせに決定する決定工程と、
前記決定工程によって決定された決定結果を出力する出力工程と、
を実行させることを特徴とする名寄せ処理プログラム。
【0210】
(付記5)データ間の関連性を示す関連度を有するデータ群を記憶するデータベースにアクセス可能なコンピュータに、
前記データ群の中から対象データを順次指定する指定工程と、
前記指定工程によって対象データが指定される都度、前記対象データと前記データ群内の他のデータとの関連度に基づいて、前記対象データごとに前記データ群内での評価値を算出する算出工程と、
前記算出工程によって算出された評価値に基づいて、前記データ群の中から前記他のデータのすべてと名寄せしあう代表的なデータを決定する決定工程と、
前記決定工程によって決定された決定結果を出力する出力工程と、
を実行させることを特徴とする名寄せ処理プログラム。
【0211】
(付記6)前記算出工程は、
前記対象データと関連度を有する前記他のデータの数に基づいて、前記対象データごとに前記データ群内での評価値を算出することを特徴とする付記5に記載の名寄せ処理プログラム。
【0212】
(付記7)前記対象データと関連度を有する前記他のデータの関連度の総和に基づいて、前記対象データごとに前記データ群内での評価値を算出することを特徴とする付記5に記載の名寄せ処理プログラム。
【0213】
(付記8)前記対象データと関連度を有する前記他のデータの数と当該他のデータの関連度の総和に基づいて、前記対象データごとに前記データ群内での評価値を算出することを特徴とする付記5に記載の名寄せ処理プログラム。
【0214】
(付記9)前記関連度が前記データ間の類似度である場合、前記対象データと関連度を有する前記他のデータの関連度の中の最大関連度に基づいて、前記対象データごとに前記データ群内での評価値を算出することを特徴とする付記5に記載の名寄せ処理プログラム。
【0215】
(付記10)前記関連度が前記データ間の相違度である場合、前記対象データと関連度を有する前記他のデータの関連度の中の最小関連度に基づいて、前記対象データごとに前記データ群内での評価値を算出することを特徴とする付記5に記載の名寄せ処理プログラム。
【0216】
(付記11)前記決定工程は、
前記関連度が前記データ間の類似度である場合、前記評価値が最大となる対象データを、前記代表的なデータに決定することを特徴とする付記5〜9のいずれか一つに記載の名寄せ処理プログラム。
【0217】
(付記12)前記決定工程は、
前記評価値が最小となる対象データを、前記代表的なデータと名寄せできないデータ候補に決定することを特徴とする付記11に記載の名寄せ処理プログラム。
【0218】
(付記13)前記決定工程は、
前記評価値が所定値以下となる対象データを、前記代表的なデータと名寄せできないデータ候補に決定することを特徴とする付記12に記載の名寄せ処理プログラム。
【0219】
(付記14)前記決定工程は、
前記関連度が前記データ間の相違度である場合、前記評価値が最小となる対象データを、前記代表的なデータに決定することを特徴とする付記5〜8、10のいずれか一つに記載の名寄せ処理プログラム。
【0220】
(付記15)前記決定工程は、
前記評価値が最大となる対象データを、前記代表的なデータと名寄せできないデータ候補に決定することを特徴とする付記14に記載の名寄せ処理プログラム。
【0221】
(付記16)前記決定工程は、
前記評価値が所定値以上となる対象データを、前記代表的なデータと名寄せできないデータ候補に決定することを特徴とする付記15に記載の名寄せ処理プログラム。
【0222】
(付記17)データ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する指定工程と、
前記データ群の中から、前記指定工程によって指定された第1のデータと名寄せしあう第3のデータを特定する特定工程と、
前記指定工程によって指定された第2のデータと前記特定工程によって特定された第3のデータを、名寄せしあうデータの組み合わせに決定する決定工程と、
前記決定工程によって決定された決定結果を出力する出力工程と、
を含むことを特徴とする名寄せ処理方法。
【0223】
(付記18)名寄せしあうデータ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する指定工程と、
前記データ群の中から、前記指定工程によって指定された第1のデータと名寄せできない第3のデータを特定する特定工程と、
前記指定工程によって指定された第2のデータと前記特定工程によって特定された第3のデータを、名寄せできないデータの組み合わせに決定する決定工程と、
前記決定工程によって決定された決定結果を出力する出力工程と、
を含むことを特徴とする名寄せ処理方法。
【0224】
(付記19)データ間の関連性を示す関連度を有するデータ群の中から対象データを順次指定する指定工程と、
前記指定工程によって対象データが指定される都度、前記対象データと前記データ群内の他のデータとの関連度に基づいて、前記対象データごとに前記データ群内での評価値を算出する算出工程と、
前記算出工程によって算出された評価値に基づいて、前記データ群の中から前記他のデータのすべてと名寄せしあう代表的なデータを決定する決定工程と、
前記決定工程によって決定された決定結果を出力する出力工程と、
を含むことを特徴とする名寄せ処理方法。
【0225】
(付記20)データ群を記憶するデータベースにアクセス可能な名寄せ処理装置であって、
前記データ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する指定手段と、
前記データ群の中から、前記指定手段によって指定された第1のデータと名寄せしあう第3のデータを特定する特定手段と、
前記指定手段によって指定された第2のデータと前記特定手段によって特定された第3のデータを、名寄せしあうデータの組み合わせに決定する決定手段と、
前記決定手段によって決定された決定結果を出力する出力手段と、
を備えることを特徴とする名寄せ処理装置。
【0226】
(付記21)名寄せしあうデータ群を記憶するデータベースにアクセス可能な名寄せ処理装置であって、
前記データ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する指定手段と、
前記データ群の中から、前記指定手段によって指定された第1のデータと名寄せできない第3のデータを特定する特定手段と、
前記指定手段によって指定された第2のデータと前記特定手段によって特定された第3のデータを、名寄せできないデータの組み合わせに決定する決定手段と、
前記決定手段によって決定された決定結果を出力する出力手段と、
を備えることを特徴とする名寄せ処理装置。
【0227】
(付記22)データ間の関連性を示す関連度を有するデータ群を記憶するデータベースにアクセス可能な名寄せ処理装置であって、
前記データ群の中から対象データを順次指定する指定手段と、
前記指定手段によって対象データが指定される都度、前記対象データと前記データ群内の他のデータとの関連度に基づいて、前記対象データごとに前記データ群内での評価値を算出する算出手段と、
前記算出手段によって算出された評価値に基づいて、前記データ群の中から前記他のデータのすべてと名寄せしあう代表的なデータを決定する決定手段と、
前記決定手段によって決定された決定結果を出力する出力手段と、
を備えることを特徴とする名寄せ処理装置。
【符号の説明】
【0228】
300 名寄せ処理装置
301 指定部
302 特定部
303 決定部
304 統合部
305 出力部
【特許請求の範囲】
【請求項1】
データ群を記憶するデータベースにアクセス可能なコンピュータに、
前記データ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する指定工程と、
前記データ群の中から、前記指定工程によって指定された第1のデータと名寄せしあう第3のデータを特定する特定工程と、
前記指定工程によって指定された第2のデータと前記特定工程によって特定された第3のデータを、名寄せしあうデータの組み合わせに決定する決定工程と、
前記決定工程によって決定された決定結果を出力する出力工程と、
を実行させることを特徴とする名寄せ処理プログラム。
【請求項2】
名寄せしあうデータ群を記憶するデータベースにアクセス可能なコンピュータに、
前記データ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する指定工程と、
前記データ群の中から、前記指定工程によって指定された第1のデータと名寄せできない第3のデータを特定する特定工程と、
前記指定工程によって指定された第2のデータと前記特定工程によって特定された第3のデータを、名寄せできないデータの組み合わせに決定する決定工程と、
前記決定工程によって決定された決定結果を出力する出力工程と、
を実行させることを特徴とする名寄せ処理プログラム。
【請求項3】
データ間の関連性を示す関連度を有するデータ群を記憶するデータベースにアクセス可能なコンピュータに、
前記データ群の中から対象データを順次指定する指定工程と、
前記指定工程によって対象データが指定される都度、前記対象データと前記データ群内の他のデータとの関連度に基づいて、前記対象データごとに前記データ群内での評価値を算出する算出工程と、
前記算出工程によって算出された評価値に基づいて、前記データ群の中から前記他のデータのすべてと名寄せしあう代表的なデータを決定する決定工程と、
前記決定工程によって決定された決定結果を出力する出力工程と、
を実行させることを特徴とする名寄せ処理プログラム。
【請求項4】
データ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する指定工程と、
前記データ群の中から、前記指定工程によって指定された第1のデータと名寄せしあう第3のデータを特定する特定工程と、
前記指定工程によって指定された第2のデータと前記特定工程によって特定された第3のデータを、名寄せしあうデータの組み合わせに決定する決定工程と、
前記決定工程によって決定された決定結果を出力する出力工程と、
を含むことを特徴とする名寄せ処理方法。
【請求項5】
名寄せしあうデータ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する指定工程と、
前記データ群の中から、前記指定工程によって指定された第1のデータと名寄せできない第3のデータを特定する特定工程と、
前記指定工程によって指定された第2のデータと前記特定工程によって特定された第3のデータを、名寄せできないデータの組み合わせに決定する決定工程と、
前記決定工程によって決定された決定結果を出力する出力工程と、
を含むことを特徴とする名寄せ処理方法。
【請求項6】
データ間の関連性を示す関連度を有するデータ群の中から対象データを順次指定する指定工程と、
前記指定工程によって対象データが指定される都度、前記対象データと前記データ群内の他のデータとの関連度に基づいて、前記対象データごとに前記データ群内での評価値を算出する算出工程と、
前記算出工程によって算出された評価値に基づいて、前記データ群の中から前記他のデータのすべてと名寄せしあう代表的なデータを決定する決定工程と、
前記決定工程によって決定された決定結果を出力する出力工程と、
を含むことを特徴とする名寄せ処理方法。
【請求項7】
データ群を記憶するデータベースにアクセス可能な名寄せ処理装置であって、
前記データ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する指定手段と、
前記データ群の中から、前記指定手段によって指定された第1のデータと名寄せしあう第3のデータを特定する特定手段と、
前記指定手段によって指定された第2のデータと前記特定手段によって特定された第3のデータを、名寄せしあうデータの組み合わせに決定する決定手段と、
前記決定手段によって決定された決定結果を出力する出力手段と、
を備えることを特徴とする名寄せ処理装置。
【請求項8】
データ間の関連性を示す関連度を有するデータ群を記憶するデータベースにアクセス可能な名寄せ処理装置であって、
前記データ群の中から対象データを順次指定する指定手段と、
前記指定手段によって対象データが指定される都度、前記対象データと前記データ群内の他のデータとの関連度に基づいて、前記対象データごとに前記データ群内での評価値を算出する算出手段と、
前記算出手段によって算出された評価値に基づいて、前記データ群の中から前記他のデータのすべてと名寄せしあう代表的なデータを決定する決定手段と、
前記決定手段によって決定された決定結果を出力する出力手段と、
を備えることを特徴とする名寄せ処理装置。
【請求項1】
データ群を記憶するデータベースにアクセス可能なコンピュータに、
前記データ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する指定工程と、
前記データ群の中から、前記指定工程によって指定された第1のデータと名寄せしあう第3のデータを特定する特定工程と、
前記指定工程によって指定された第2のデータと前記特定工程によって特定された第3のデータを、名寄せしあうデータの組み合わせに決定する決定工程と、
前記決定工程によって決定された決定結果を出力する出力工程と、
を実行させることを特徴とする名寄せ処理プログラム。
【請求項2】
名寄せしあうデータ群を記憶するデータベースにアクセス可能なコンピュータに、
前記データ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する指定工程と、
前記データ群の中から、前記指定工程によって指定された第1のデータと名寄せできない第3のデータを特定する特定工程と、
前記指定工程によって指定された第2のデータと前記特定工程によって特定された第3のデータを、名寄せできないデータの組み合わせに決定する決定工程と、
前記決定工程によって決定された決定結果を出力する出力工程と、
を実行させることを特徴とする名寄せ処理プログラム。
【請求項3】
データ間の関連性を示す関連度を有するデータ群を記憶するデータベースにアクセス可能なコンピュータに、
前記データ群の中から対象データを順次指定する指定工程と、
前記指定工程によって対象データが指定される都度、前記対象データと前記データ群内の他のデータとの関連度に基づいて、前記対象データごとに前記データ群内での評価値を算出する算出工程と、
前記算出工程によって算出された評価値に基づいて、前記データ群の中から前記他のデータのすべてと名寄せしあう代表的なデータを決定する決定工程と、
前記決定工程によって決定された決定結果を出力する出力工程と、
を実行させることを特徴とする名寄せ処理プログラム。
【請求項4】
データ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する指定工程と、
前記データ群の中から、前記指定工程によって指定された第1のデータと名寄せしあう第3のデータを特定する特定工程と、
前記指定工程によって指定された第2のデータと前記特定工程によって特定された第3のデータを、名寄せしあうデータの組み合わせに決定する決定工程と、
前記決定工程によって決定された決定結果を出力する出力工程と、
を含むことを特徴とする名寄せ処理方法。
【請求項5】
名寄せしあうデータ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する指定工程と、
前記データ群の中から、前記指定工程によって指定された第1のデータと名寄せできない第3のデータを特定する特定工程と、
前記指定工程によって指定された第2のデータと前記特定工程によって特定された第3のデータを、名寄せできないデータの組み合わせに決定する決定工程と、
前記決定工程によって決定された決定結果を出力する出力工程と、
を含むことを特徴とする名寄せ処理方法。
【請求項6】
データ間の関連性を示す関連度を有するデータ群の中から対象データを順次指定する指定工程と、
前記指定工程によって対象データが指定される都度、前記対象データと前記データ群内の他のデータとの関連度に基づいて、前記対象データごとに前記データ群内での評価値を算出する算出工程と、
前記算出工程によって算出された評価値に基づいて、前記データ群の中から前記他のデータのすべてと名寄せしあう代表的なデータを決定する決定工程と、
前記決定工程によって決定された決定結果を出力する出力工程と、
を含むことを特徴とする名寄せ処理方法。
【請求項7】
データ群を記憶するデータベースにアクセス可能な名寄せ処理装置であって、
前記データ群の中から、名寄せしあう第1のデータおよび第2のデータを指定する指定手段と、
前記データ群の中から、前記指定手段によって指定された第1のデータと名寄せしあう第3のデータを特定する特定手段と、
前記指定手段によって指定された第2のデータと前記特定手段によって特定された第3のデータを、名寄せしあうデータの組み合わせに決定する決定手段と、
前記決定手段によって決定された決定結果を出力する出力手段と、
を備えることを特徴とする名寄せ処理装置。
【請求項8】
データ間の関連性を示す関連度を有するデータ群を記憶するデータベースにアクセス可能な名寄せ処理装置であって、
前記データ群の中から対象データを順次指定する指定手段と、
前記指定手段によって対象データが指定される都度、前記対象データと前記データ群内の他のデータとの関連度に基づいて、前記対象データごとに前記データ群内での評価値を算出する算出手段と、
前記算出手段によって算出された評価値に基づいて、前記データ群の中から前記他のデータのすべてと名寄せしあう代表的なデータを決定する決定手段と、
前記決定手段によって決定された決定結果を出力する出力手段と、
を備えることを特徴とする名寄せ処理装置。
【図1】


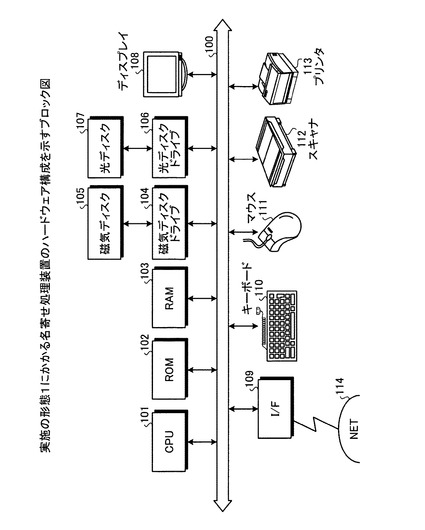
【図2】
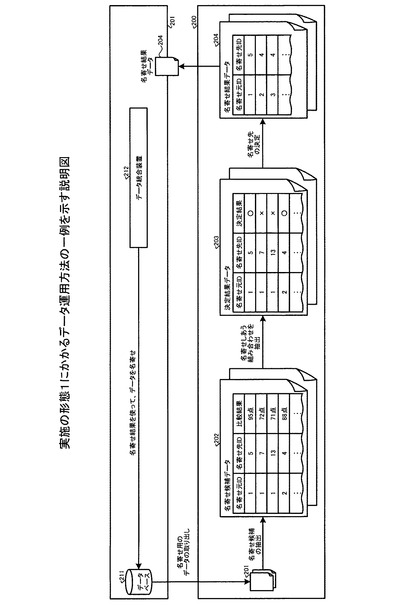
【図3】
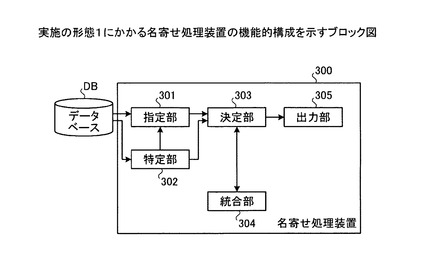
【図4】
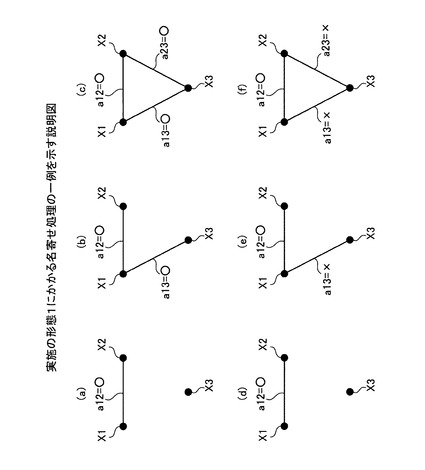
【図5】

【図6】
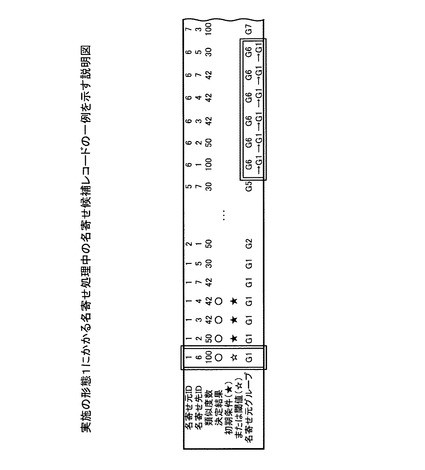
【図7】
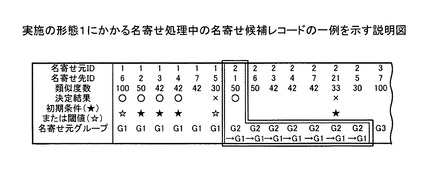
【図8】
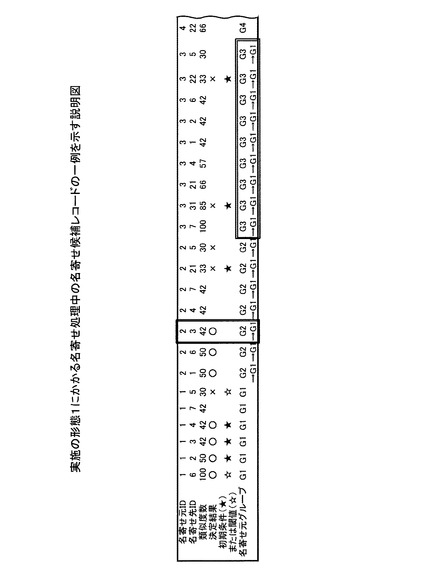
【図9】
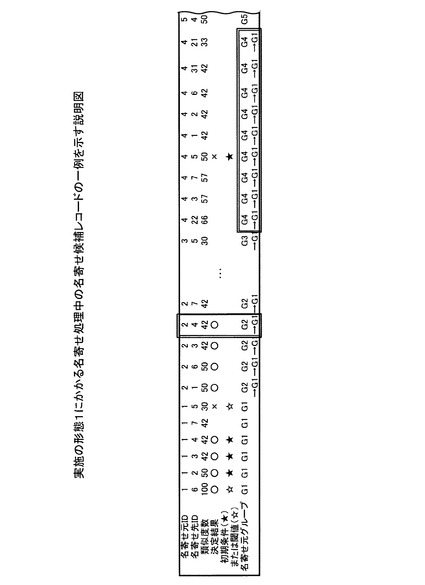
【図10】
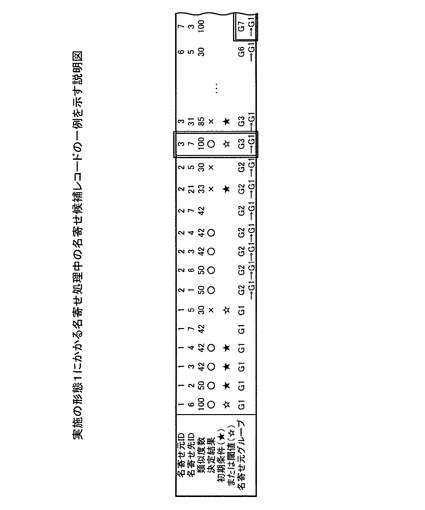
【図11】

【図12】

【図13】
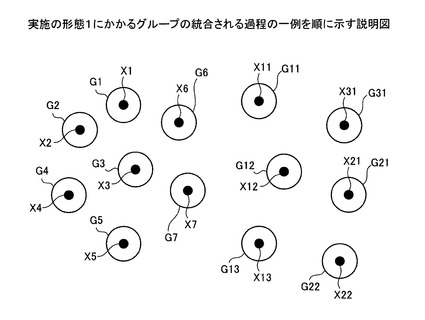
【図14】
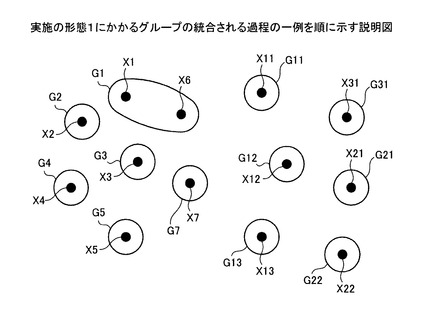
【図15】
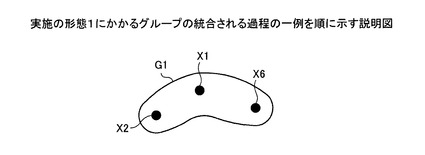
【図16】
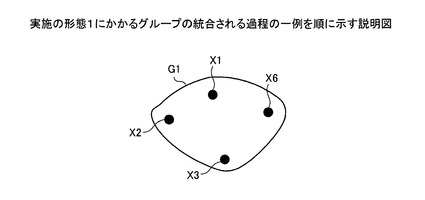
【図17】
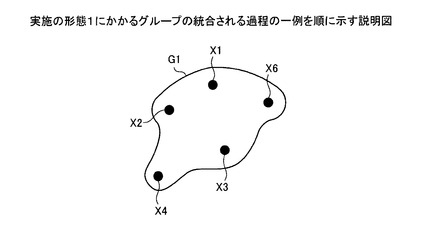
【図18】
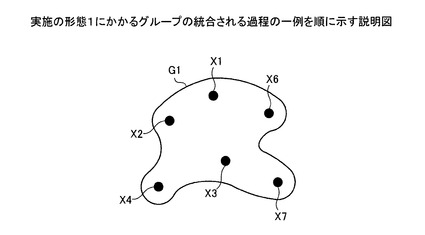
【図19】
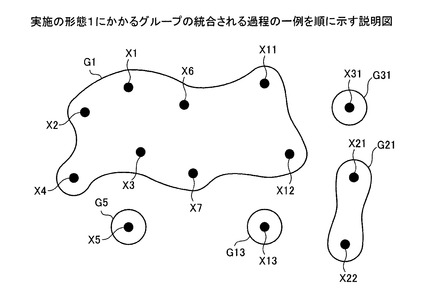
【図20】
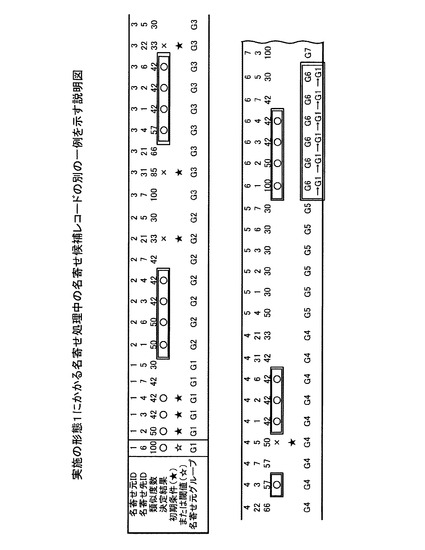
【図21−1】
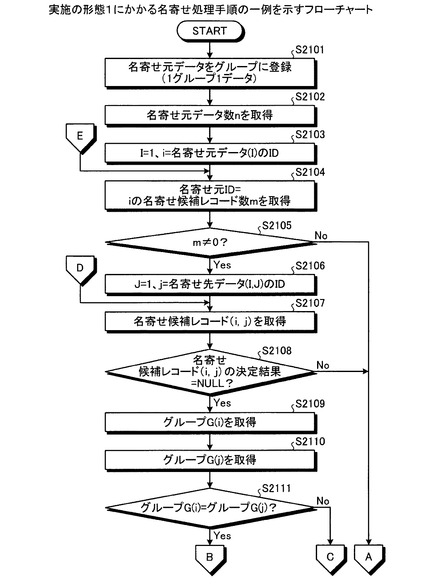
【図21−2】
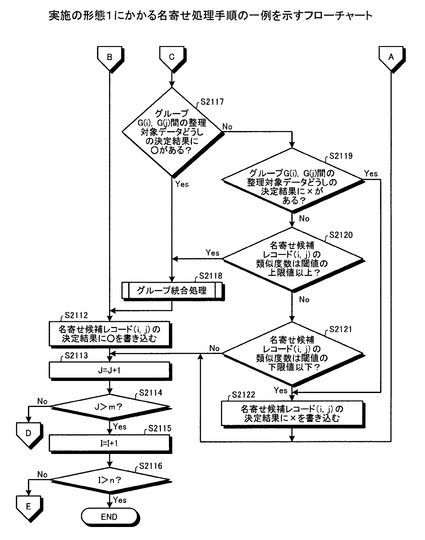
【図22−1】
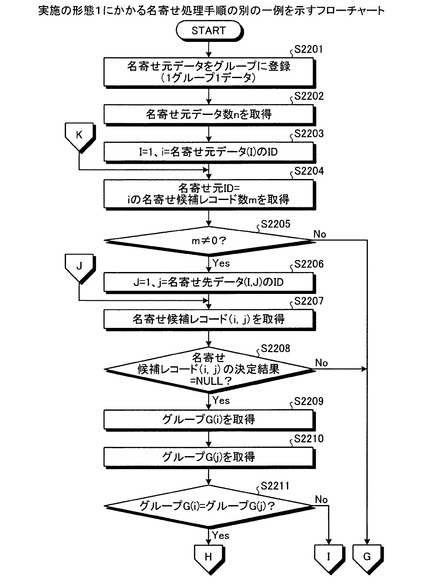
【図22−2】
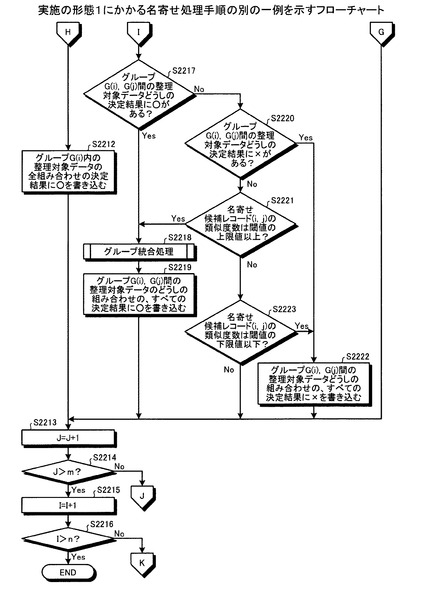
【図23】
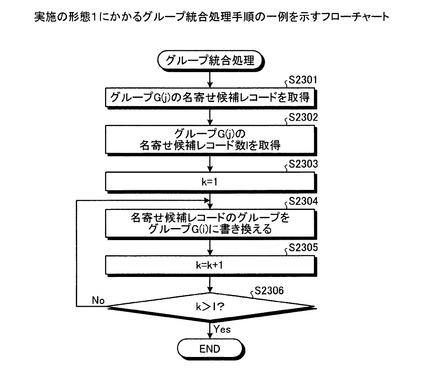
【図24】
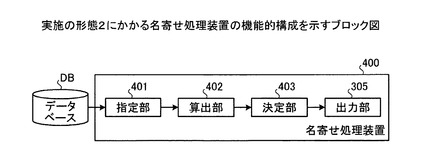
【図25】
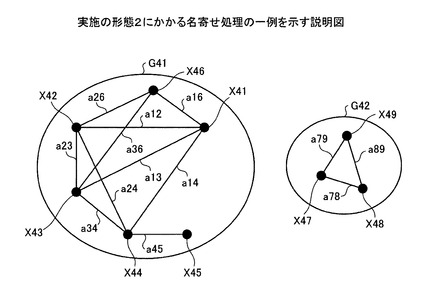
【図26】

【図27】
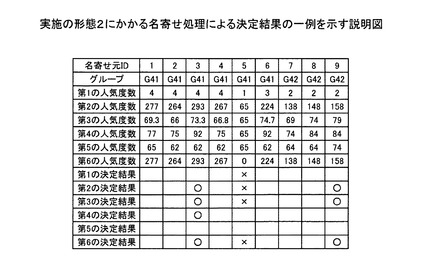
【図28】
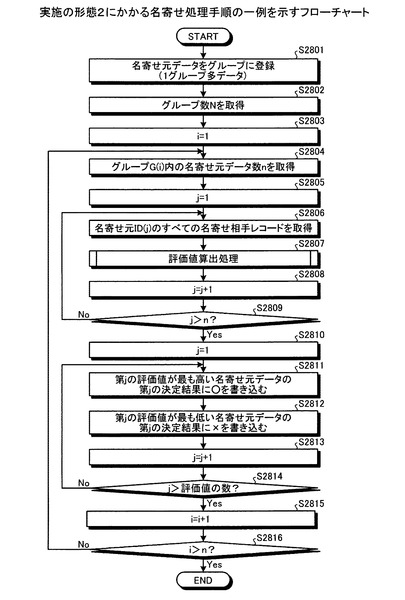
【図29】
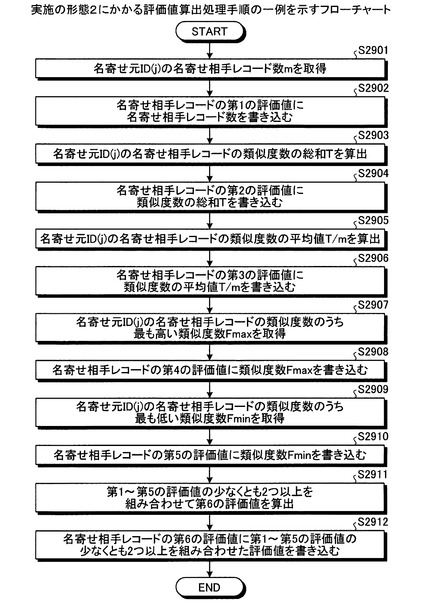
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21−1】
【図21−2】
【図22−1】
【図22−2】
【図23】
【図24】
【図25】
【図26】
【図27】
【図28】
【図29】
【公開番号】特開2011−253232(P2011−253232A)
【公開日】平成23年12月15日(2011.12.15)
【国際特許分類】
【出願番号】特願2010−124867(P2010−124867)
【出願日】平成22年5月31日(2010.5.31)
【出願人】(000005223)富士通株式会社 (25,993)
【Fターム(参考)】
【公開日】平成23年12月15日(2011.12.15)
【国際特許分類】
【出願日】平成22年5月31日(2010.5.31)
【出願人】(000005223)富士通株式会社 (25,993)
【Fターム(参考)】
[ Back to top ]