
周波数特徴を選択する方法
【課題】計算複雑度が極度に高い処理を、高い分類性能を達成しながら、データ分類にかかる時間を低減できる、サポートベクターマシンを用いたデータ分類方法を提供する。
【解決手段】線形分類器を用いたデータの二項分類に用いられる周波数特徴が、d次元のラベル付けされたトレーニングデータを用いてd次元空間において仮説のセットを求めることによって選択される。仮説ごとにマッピング関数が構築される。マッピング関数がトレーニングデータに適用されて周波数特徴が生成され、周波数のサブセットが反復的に選択される。次に、周波数特徴のサブセットおよびトレーニングデータのラベルを用いて線形関数がトレーニングされる。
【解決手段】線形分類器を用いたデータの二項分類に用いられる周波数特徴が、d次元のラベル付けされたトレーニングデータを用いてd次元空間において仮説のセットを求めることによって選択される。仮説ごとにマッピング関数が構築される。マッピング関数がトレーニングデータに適用されて周波数特徴が生成され、周波数のサブセットが反復的に選択される。次に、周波数特徴のサブセットおよびトレーニングデータのラベルを用いて線形関数がトレーニングされる。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、包括的にはデータを分類することに関し、より詳細には、線形サポートベクターマシンを用いて二項分類の非線形特徴を選択することに関する。
【背景技術】
【0002】
サポートベクターマシン(SVM)は、多くの場合にデータの二項分類に用いられる。SVMは、線形カーネルまたは非線形カーネルとともに機能することができる。SVMは、高次元空間または無限次元空間において、分類、回帰、または他のタスクに用いることができる超平面または超平面のセットを構築する。良好な分離は、最も近いトレーニングデータへの最も大きい距離を有する超平面が存在する場合、該超平面によって達成される。なぜなら、一般に、マージンが大きくなるほど、分類器の汎化誤差が低くなるためである。放射基底関数SVMは、分離超平面を、より高い、場合によっては無限の次元空間にリフティングするので、2つのクラス間の任意の判定境界を近似することができる。
【0003】
しかしながら、SVMは、トレーニングデータ量が非常に多いときに非線形カーネルに対し良好にスケーリングしない。放射基底関数SVM等の非線形SVMをトレーニングすることには数日かかる可能性があり、非線形SVMを用いた未知のデータのテストは、実際の用途に組み込むには極めて低速となる可能性がある。これは、線形カーネルが用いられる場合、特にデータの次元数が小さいときにはあてはまらない。
【0004】
カーネルがガウス放射基底関数を用いる場合、対応する特徴空間は、無限次元のヒルベルト空間である。非線形カーネルの場合、ここではN(サポートベクトル数)個のカーネル評価を用いて、再生カーネルヒルベルト空間(RKHS)における超平面の法線ベクトルに対する未知のデータの射影を求めなくてはならない。これは、無限次元となる可能性があるRKHSへの直接アクセスではなく、カーネル関数によって提供された内積を通じた間接アクセスを有するためである。
【0005】
1つの可能な解決法は、カーネル行列を因数分解し、因子行列の列を、線形カーネルを有する特徴として用いて、非線形カーネルの計算が複雑になるのを回避することである。線形カーネルを用いた未知のデータの分類は、2つのデータクラス間の分離超平面の法線ベクトルを射影しさえすればよいので、高速である。
【0006】
別の解決法は、ランダムでデータ盲目的なフーリエ特徴の空間内のカーネルを、変換データの内積として近似することであり、これらの特徴に対し、線形カーネルをトレーニングすることができる。この手法では、必要なフーリエ特徴数が比較的小さく、すなわち、フーリエ特徴の空間の次元数が低く、かつ線形カーネルを用いたトレーニングが非線形カーネルを用いたトレーニングよりもかなり高速であることが知られている。しかしながら、トレーニングされたSVMは、盲目的であり、事前データを一切用いることができず、分類性能が限られている。
【発明の概要】
【発明が解決しようとする課題】
【0007】
いくつかの用途の場合、分類の計算複雑度が極度に高い。したがって、非線形カーネルのような高い分類性能を達成しながら、データ分類にかかる時間を低減することが望ましい。
【課題を解決するための手段】
【0008】
本発明の実施の形態は、サポートベクターマシンを用いて元の領域の代わりに周波数領域においてデータを分類する方法を提供する。
【0009】
周波数特徴のセットがトレーニングデータから選択される。特徴のセットは、連続したシフト不変のカーネルを表すのに十分である。次に、特徴選択、例えば、LogitBoostプロセスを適用して、特徴のセットのサブセットを反復的に選択し、分類正確度を直接最適化する。
【0010】
本発明では、以下のマッピングを構築する。二項分類タスクの場合、ラベルyiを有するトレーニングデータxi、すなわち{xi,yi}(ここでxi∈Rdおよびyi∈{−1,+1}である)を所与とすると、SVMリフティング関数Φ:Rd→Rmは、入力データ点xを、Φによって規定された周波数特徴空間に、
【数1】

となるようにマッピングする。
【0011】
ここで、周波数特徴は、zω(x)jである。本発明の1つの焦点は、周波数特徴の選択である。二項データ分類タスクのためのSVMのトレーニングフェーズおよび分類フェーズの双方を加速するために、入力データを周波数特徴のデータ駆動型低次元空間にマッピングする。
【0012】
データを{xi,yi}→{z(xi),yi}に変換した後、線形分類器をトレーニングする。この線形分類器は、1つの実施の形態では、低次元周波数特徴空間における線形カーネルを有するSVMである。mは、dよりも大幅に小さいので、トレーニングおよび分類の双方の観点で、SVMの計算複雑度の劇的な低減が得られ、分類性能は、より良好にならないにしても劣っていない。
【0013】
まず、変換データの内積が、仮説特徴を介して、所定の連続したシフト不変カーネルの再生カーネルヒルベルト空間内の内積に概ね等しくなるように、ラベル付けされたトレーニングデータを用いて特徴のセットを生成する。これらの特徴のサブセットを、カーネル関数を近似するのと対照的に、分類正確度を直接ターゲットにする特徴選択プロセスによって選択する。特に、LogitBoostプロセスを特徴選択プロセスとして用い、次に、線形分類器を適用する。線形分類器には、線形カーネルを有するSVMを用いる。
【0014】
役に立たないか、冗長であるか、または無関係の特徴を除去するために、特徴選択を適用する。特徴選択は、正確なモデルを構築するための関連する特徴のサブセットを選択する。データから最も無関係で冗長な特徴を取り除くことによって、特徴選択は、次元の呪いの影響を軽減し、汎化能力を高め、トレーニングプロセスを高速化し、モデル解釈可能性を改善することによってモデルの性能を改善するのに役立つ。特徴選択は、重要な特徴およびそれらの関係も示す。
【0015】
トレーニングプロセスを高速化するために、特徴選択のための元の周波数ベースのサブセットを求める。最適なサブセットを求めることは、組合せ問題であるため非常に困難である。このため、本発明の特徴選択では、反復的な解法に従う。このようにして、有用な特徴のみが線形SVMをトレーニングするために選択される。カーネル関数を内積として近似し、分類の観点から非判別的な特徴を除去することによって、トレーニングおよび分類の双方の観点からカーネルマシンの計算複雑度の大幅な低減が得られる。
【0016】
特徴は、トレーニングデータおよびそれらの対応するラベルを用いて選択される。このため、本方法は、教師あり法である。さらに、本方法は、カーネル関数を近似しない。代わりに、新たなカーネルを内積として構築する。このため、本方法は、カーネル設計として特徴付けられ、このため、本方法の分類正確度は、あらかじめ設定されたカーネル関数によって制限されない。
【0017】
計算負荷を大きく低減するために、周波数空間内への非線形カーネルのデータ駆動型表現が開示されるのは、これが初めてである。
【発明の効果】
【0018】
サポートベクターマシンを用いて二項分布の最適な性能を提供するために、データの周波数特徴を抽出して分類境界を表す。特徴をブースティングして冗長な特徴を除去し、関連する特徴のみを用いる。
【0019】
このようにして、データの非常にコンパクトな表現であるが、依然として2つのクラスを分離する力が十分ある表現が得られる。このため、これによって分類およびカーネルマシンのトレーニングフェーズの測度が改善する。本方法は、結果として大きな速度改善をもたらす。
【図面の簡単な説明】
【0020】
【図1】本発明の実施の形態によって用いられるサポートベクターマシンの概略図である。
【図2】本発明の実施の形態によって用いられる放射カーネル基底関数サポートベクターマシンの概略図である。
【図3】本発明の実施の形態によって用いられるマッピング関数の概略図である。
【図4】本発明の実施の形態による、周波数空間へのマッピングの概略図である。
【図5】本発明の実施の形態による、周波数マッピングおよびデータ分離の概略図である。
【図6】従来のSVMの性能を本発明の実施の形態によるSVMと比較するグラフである。
【図7】データの二項分類に用いられる周波数特徴を選択する方法の流れ図である。
【発明を実施するための形態】
【0021】
サポートベクターマシン(SVM)
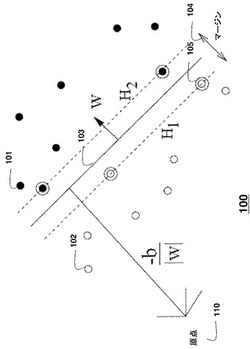
図1は、本発明の実施の形態によって用いられるサポートベクターマシン(SVM)100の基本概念を示している。2つのクラスに分類されることになるデータが、原点110に対し黒丸101および白丸102によって示されている。トレーニングデータから構築された超平面103は、2つのクラスを分離する。超平面は、サポートベクトル105によってサポートされる。超平面H1とH2との間の分離量は、マージン104であり、wは、超平面に垂直なベクトルである。
【0022】
トレーニングデータxiおよび対応するラベルyi(ここで、xi∈Rdおよびyi∈{−1,+1})を所与とすると、トレーニング手順は、判定関数を構築し、該判定関数によって未知データのクラスが決まる。判定関数は、トレーニングデータの構造に依拠して線形境界または非線形境界を規定することができる。最適な分類がデータの線形関数を通じたものである場合、線形カーネルを用い、そうでない場合、非線形カーネルを用いる。
【0023】
トレーニングデータは、全てのiについて
【数2】
となるようなベクトルw∈Rd、転置演算子T、および実数b∈Rが存在する場合、分離可能であり、そうでない場合、データ線形に分離可能でないと判断する。
【0024】
分離可能データの線形SVM
最も単純な事例から始める。分離可能なトレーニングデータ{xi,yi}(ここで、xi∈Rdおよびyi∈{−1,+1})を有し、全てのiについて、yt(wTxt+b)−1≧0となるような少なくとも1つの対(w,b)が存在する。分離可能性を満たす法線ベクトルwを有する任意の超平面を分類器として用いることができる。理論的に、無限数の超平面が存在する。最適な分離超平面を選択する。
【0025】
所与の分離超平面について、超平面に対する正のクラス(負のクラス)の点からの最も短い垂直距離が、s+(s−)とされ、マージンは、s++s−である。
【0026】
分離超平面について、適切に選択されたwおよびbを用いて、いくつかのデータ点について、以下の等式を有することができる。
【0027】
【数3】
【0028】
このとき、
【数4】
である。
【0029】
このように、最適な分離超平面を、マージンを最大にする分離超平面として見つけることができる。分離可能トレーニングデータの線形SVMは、以下の主最適化を解く。
【0030】
【数5】
【0031】
ただし、すべてのiについて
【数6】
である。上記の最適化の制約を満たすデータがサポートベクトル105であり、これを取り除くことによって解が変化する。
【0032】
問題のラグラシアン定式化に切り換えることによって、結果として凸二次計画問題が生じる。この凸二次計画問題によって、ウォルフ双対定式化を利用することにより、上記の主最適化が、以下のように書き換えられることになる(双対形式最適化)。
【0033】
【数7】
【0034】
ただし、
【数8】
である。ここで、αiは、双対定式化におけるラグランジュパラメーターである。
【0035】
双対最適化および主最適化によって同じ一意の解、すなわち、最適分離超平面が得られる。双対最適化問題において、αi>0を有するトレーニングセット内のデータは、サポートベクトルである。1つのサポートベクトルであっても取り除くと解が完全に変わる可能性があり、サポートベクトルでない全てのデータを取り除いても問題に対する解が変わらないので、サポートベクトルは、トレーニングデータセットの最も重要な要素である。サポートベクトルは、分離超平面に最も近いデータであるので、サポートベクトルは、トレーニングデータの小さなサブセットでしかない。N個のサポートベクトルが存在する場合、
【数9】
となる。
【0036】
SVMの最適化問題は、重要な態様を有する。制約は、常に線形であり、かつ凸である。これは、カルシュ−キューン−タッカー(KKT)条件として知られ、w*、b*、a*が最適解となるための必要十分条件である。SVM問題のKKT条件に対する解を求めることは、主双対最適化の数値法を展開する際に中心的な役割を果たす。さらに、双対定式化では、バイアス解b*は、明確に求められないが、KKT条件が成り立たなくてはならないという知識により、バイアスを容易に求めることができる。
【0037】
分離不可能データの線形SVM:ソフトマージンおよびハードマージン
ほとんどの実データについて、データの2つのクラスを完全に分離する超平面は、存在しないため、上記の分離可能性の前提は、緩和される必要がある。まず、分類されるデータが分離不可能なデータである場合、解は、存在しない。このため、次に、これを変更したい。緩和させたいのは、以下である。
【0038】
【数10】
【0039】
これは、誤差が許容されるときに達成することができる。候補超平面の誤った側にあるデータは、データと超平面との間の距離に比例する量だけペナルティを付けられる。この概念を上記の定式化に組み込むために、スラック変数ψを用いる。
【0040】
【数11】
【0041】
このため、誤差が発生するには、対応するψiが1を超えなくてはならない。このとき、Σψiを全ての誤差にわたって規定されたコスト関数として最小化するのが当然である。このとき、SVM問題の主定式化は、以下となる。
【0042】
【数12】
【0043】
ただし、
【数13】
である。ここで、Cは、誤差最小化とマージン最大化との間のトレードオフを表すパラメーターであり、Cが大きくなるとハードマージン分類器が導かれ、結果として過剰適合が生じる可能性があり、Cが小さくなるとソフトマージン分類器が導かれる。
【0044】
それに応じて、双対定式化は以下となる。
【0045】
【数14】
【0046】
ただし、
【数15】
である。
【0047】
このため、唯一の違いは、ここで、αiがCによって上界を設けられていることである。上述したように、KKT条件は、この分離不可能な場合にも容易に適用することができる。
【0048】
カーネルSVMおよび非線形判定境界
データのクラスを分離することができる超平面が存在しない場合、非線形境界が用いられる。線形SVMの双対定式化を考えると、データに対する依存性は、ドット積xi・xjによってのみ生じる。マッピングΦ:Rd→H,x→Φ(x)を介して別のユークリッド空間H(無限次元の可能性がある)にデータをマッピングすることができる。
【0049】
H内の線形SVMをトレーニングする場合、カーネル関数
【数16】
が既知であるとき、情報Φ(xi)・xiを提供しさえすればよい。換言すれば、Φのカーネルを有するとき、関数Φを知る必要はない。H内の線形SVMをトレーニングするために、以下に従って双対式を変更する。
【0050】
【数17】
【0051】
ただし、
【数18】
である。
【0052】
1つの観測は、w∈Hであるため、分類のためにwを明示的に知る必要があるように見える場合がある。しかしながら、関係K(xi,xj)=Φ(xi)Φ(xj)を利用することによって、Hにおけるドット積の観点から判定関数を表すことができ、このため、分類は、以下となる。
【0053】
【数19】
【0054】
分類器を未知のデータに適用するために、NS個のカーネル評価が必要である。これは、用途またはタスクによっては実際的でなく、計算的に過度に複雑になり適用不可能になる可能性がある。これは、以下に起因するSVMの主要な制限のうちの1つである。サポートベクトル数に対し制御がされていない。サポートベクトルは、トレーニングデータから選択されなくてはならない。サポートベクトルが全体空間から選択される場合、サポートベクトルのセットは、はるかに小さくなる。
【0055】
1つの可能な解決法は、同じ形式の展開を減らしてカーネル分類関数を近似する。すなわち、NSは、NZとなり、NZ<<NSである。別の解決法は、サポートベクトルのサブセットのみを用いることである。しかしながら、この解決法の結果、分類性能が著しく低減する。この意味で、サポートベクトルのセットは、最小セットである。
【0056】
最も一般的に用いられているカーネルは、あるgについての、よく知られたガウスカーネルまたは放射基底関数(RBF)
【数20】
である。この特定の例では、Hは、無限次元である。マッピングΦが明確に知られている場合であっても、無限次元オブジェクトをSVM定式化に組み込むことは、非常に困難であろう。しかしながら、これは、RBFカーネルを通じて、トレーニングおよび分類の双方の観点で非常に簡単になる。
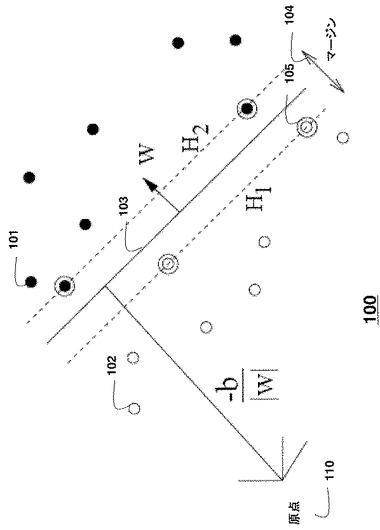
【0057】
図2は、上述したようなマッピング関数Φ(x)203を用いた、第1の空間201から、第2の、無限次元である可能性がある空間202へのSVMのマッピングの全体的な概念を示している。
【0058】
SVMにカーネルを用いるという概念は、入力データ201を、線形分離可能性を予期する非常に高次元の空間202にマッピングする(203)ことである。この場合、線形SVMは、高次元空間内でトレーニングされ、返される超平面は、非線形判定境界に対応する。カーネルを選択することにより、新たな相関構造、すなわち、高次元空間内のドット積が線形分離を可能にするように、非線形カーネルを通じて入力空間の元の相関構造が乱されるので、非線形判定境界が得られる。線形カーネル
【数21】
を用いる場合、線形SVMが得られる。
【0059】
マーセル条件
全ての関数K:Rd×Rd→Rが、K(xi,xj)=Φ(xi)Φ(xj)となるように空間HおよびマッピングΦ(x):Rd→Hに対応するとは限らない。換言すれば、全てのKがカーネルであるとは限らない。関数Kがカーネルであるか否かを判断するために、マーセル条件を用いることができる。ここで、Kは、全ての二乗可積分関数について
【数22】
である場合にのみ、カーネルである。
【0060】
周波数特徴
ターゲット画像領域の検出は、車両ナビゲーションを含む多くの用途において、重要なタスクである。この目的で、走査ウィンドウを入力画像にわたって適用することによって、SVM分類器を用いて、例えば、道路標識を検出することが可能である。道路標識の大きさは、未知であるので、走査は、異なる大きさのウィンドウを用いて、複数のスケールで行われなくてはならない。
【0061】
1つの用途では、10,000個の正の画像からなる第1のセットと、1,000,000個の負の画像からなる第2のセットとを用いて分類器をトレーニングし、NS個〜700個のサポートベクトルを有するカーネル(RBF)SVM分類器を得る。低レベルの特徴として、全ての画像について勾配方向ヒストグラム(HOG)を抽出する。これは
【数23】
を意味する。本発明の実験によれば、良好な正確度(90%)では、高精細画像の分類に約20分かかる。これは、リアルタイムの道路標識検出の場合、計算量が多すぎる。このため、分類時間を低減しなくてはならず、そのためには、カーネルSVMの計算複雑度を低減しなくてはならない。
【0062】
ここで、非線形カーネルマシンのテストを劇的に高速化する新規の方法を説明する。カーネル関数自体を因数分解するが、この因数分解は、好都合にはデータ駆動型であり、バイナリクラスラベルの分布によって求められた比較的低次元の特徴空間にデータをマッピングすることによって、カーネルマシンのトレーニングおよび評価を線形マシンの対応する動作に変換することが可能になる。
【0063】
まず、データ点の2つのクラス間の分離境界を近似するのに十分に豊富な周波数特徴のセット、および暗黙的に課す連続したシフト不変のカーネルを生成する。カーネルトリックによって与えられるリフティングに依存する代わりに、変換された点の対間の内積が、それらのカーネル評価k(x,y)=(φ(x),φ(y))≒z(x)Tz(y)を近似するように、データ駆動型特徴マップz:Rd→Rmを用いて、データを低次元ユークリッド内積空間に明示的にマッピングする。カーネルのリフティングφizが低次元であるのと異なる。このように、zへの周波数マッピングを用いて入力を単に変換することができ、次に線形法を適応して、非線形カーネルを通じて確立された判定境界を近似することができる。
【0064】
1つの実施の形態では、カーネル関数近似をターゲットにするのとは対照的に、トレーニングにおいて、超平面法線に対するロジスティック回帰である既知のLogitBoostプロセスを用いて、分類正確度を直接最適化しながら、このセットから特徴を選択する。仮説のセット、すなわち、ラベル付けされたトレーニングデータから構築される周波数特徴から始める。次に、各仮説についてデータをベクトル上にマッピングする。マッピングデータに対しラベルの加重最小二乗適合を適用し、回帰誤差を計算する。最小回帰誤差を与える仮説を選択する。重みを調整した後、次の仮説を選択する。
【0065】
このようにして、有用な周波数特徴のみを集めて、線形マシンをトレーニングする。特徴が完全にランダムに独立して集められる従来技術と比較して、本発明では、教師あり設定において利用可能なトレーニングデータおよび対応するラベルを利用する。
【0066】
非線形分離境界を周波数変換特徴の内積として近似し、特徴選択により非記述的な特徴を除去することによって、これらのデータ駆動型特徴マップにより、分類器を迅速に評価する極めて高速な方法が得られる。例えば、カーネルトリックを用いて、テスト点xにおいて放射基底関数サポートベクターマシンを評価することは、境界が単純かつスパースでない限り、データセットの多くを計算し保持するのに、O(Nd)個の演算を必要とする。ここで、Nは、トレーニング点の数である。これは、大きなデータセットの場合、多くの場合に受入不可能である。他方で、超平面ωを学習した後、線形マシンは、単にf(x)=ωTz(x)によって評価することができる。これは、O(m(d+1))個の演算およびストレージしか必要としない。ここで、mは、選択された特徴の数である。ほとんどの問題について、m<<d<Nであることに留意されたい。
【0067】
これは、カーネルを近似するのと対照的に、データ駆動型カーネルを当然構築するカーネル設計とみなすこともできる。したがって、本方法の分類正確度は、固定カーネル関数によって上界を設けられない。実際に、計算負荷を大幅に減らすことに加えて、いくつかのデータセットにおいて、より良好な分類結果が得られる。
【0068】
グループに対する調和解析からのボクナーの定理は、正の有限測度のフーリエ変換を特徴付ける。実線Lに対する正の有限ボレル測度μを所与とすると、μのフーリエ変換f(ω)は、連続関数
【数24】
である。
【0069】
関数f(ω)は、正定関数であり、すなわち、カーネルk(x,y)=f(x−y)は、正定値である。ボクナーの定理は、逆も真であることを述べており、すなわち、全ての正定関数f(ω)は、正の有限ボレル測度μのフーリエ変換である。
【0070】
Rdに対する連続カーネルk(x、y)=f(x−y)は、f(x−y)が非負測度のフーリエ変換である場合にのみ正定値である。
【0071】
カーネルk(x,y)が適切にスケーリングされているとき、ボクナーの定理は、そのフーリエ変換f(ω)が適切な確率分布であることを保証する。
【0072】
【数25】
【0073】
ここで、Tは、転置演算子である。
【0074】
換言すれば、
【数26】
は、ωがフーリエ変換fから導き出されたときの、k(x,y)のバイアスされていない推定値である。カーネルは、偶数であり、かつ実数値であり、確率分布f(ω)は、純実数であるので、被積分関数
【数27】
は、cos(ωT(x−y))と置き換えることができる。zω(x)Tzω(y)=cos(ωT(x−y))であるので、
【数28】
を定義することによって、条件E[zω(x)Tzω(y)]=k(x,y)を満たす実数値マッピングが得られる。換言すれば、各ωは、
【数29】
としてデータ点を2つの係数にマッピングする。
【0075】
また、
【数30】
および
【数31】
を定義することによっても、この場合は、単一の係数に対し、条件E[z(x)Tz(y)]=k(x,y)を満たす実数値マッピングが得られることを示すことも可能である。ここで、nは、セットωiの濃度であり、bは、位相パラメーターであり、データに関して設定することもできるし、[0,2π]から一様に導き出すこともできる。適切に導き出されたベースのセット{ωi}について、大数の法則により、z(x)Tz(y)≒k(x,y)である。
【0076】
換言すれば、ガウスカーネルおよび任意のシフト不変の連続カーネルを、周波数特徴の期待値として書くことができる。ここで、ベースは、確率測度に対してランダムであり、確率測度は、カーネルの逆フーリエ変換である。
【0077】
この近似によって、非常に興味深い特性が明らかとなる。これは、ガウスカーネル、および任意のシフト不変の連続カーネルを、周波数特徴の空間内のマッピングされた点の内積として近似することができるということである。これは、カーネルトリックとして知られるものと全く同じである。すなわち、データを非常に高次元の空間にマッピングし、該空間において新たな共分散構造がカーネルを通じて生じる。このため、上記の導出によって、周波数特徴の空間内で線形SVMをトレーニングすることができ、かつ依然としてガウスカーネルの場合と同じ分類正確度を期待することができる。本方法の計算量の低減および高速化は、この結果からもたらされる。
【0078】
上記では、周波数特徴は、任意の偶数で実数値である非線形カーネルを近似することができることを説明した。しかしながら、このプロセスは、クラスラベル情報または点の密度分布を利用しないので、内容および所与のトレーニングデータを考慮に入れない。
【0079】
本発明の目標は、プレフィックスされたカーネルを近似することではなく、分類性能を最適化する周波数特徴を介して、複雑な分離境界の線形表現を見つけることである。ここで、問題は、最終分類性能が最適化されるようなωのセットをどのように選択するかということになる。オブジェクト検出タスクのために、クラスメンバーシップを示すバイナリラベルを有するトレーニングデータセットが、多くの場合に利用可能である。これらの追加の事前データを最大限に利用することが望ましい。
【0080】
これを達成するために、以下のセクションにおいて検討するような、データの負の二項対数尤度を最小にする顕著な周波数特徴を選択する。
【0081】
ブースティングされた特徴選択
反復的にブースティングすることによって、弱い分類器(仮説)を組み合わせて強い分類器にする。このブースティングは、前の仮説によって誤って分類されたインスタンスを優先する。「ブースティング」において、用語「弱い」および「強い」は、当該技術分野においてよく知られたものとして定義される。各ラウンドにおいて、データ点重みの分布が更新される。誤って分類された各データ点の重みが増やされ、正しく分類された各データ点の重みが減らされ、新たな分類器が、これらの例により集中するようにする。
【0082】
二項分類問題の場合、yi∈{−1,1}を有する。全てのn=1,...,Nについて、第1のラウンド
【数32】
におけるデータ点の重みを初期化する。重み付けされたデータ点に関して弱い分類器htを選択する。xがクラス1にある確率は、
【数33】
よって表され、全体の応答は、
【数34】
によって得られる。
【0083】
LogitBoostプロセスは、ニュートン反復を通じて
【数35】
によってデータの負の二項対数尤度を最小にすることによって、回帰関数のセットht(x){t=1,...,L}を学習する。プロセスのコアにおいて、LogitBoostは、トレーニング点xnの加重最小二乗回帰ht(x)を適合し、値λnおよび重みβnに以下のように応答する。
【0084】
【数36】
【0085】
ここで、
【数37】
である。
【0086】
分類器の最終応答は、
【数38】
である。
【0087】
各反復において、仮説のセットSM:{ω1,...,ωM}がテストされる。負の指数損失を最も低減する仮説は、仮説Smのサブセット内に含まれる、現在の弱い分類器としてブースティングされた分類器に結合され、性能レベルが達成されるかまたは計算負荷の上限に達するまで、m個の反復が繰り返される。ここで、mは、変換空間の次元数であり、セットの濃度Sm⊂SMである。
【0088】
重要な問いは、仮説のセットSM、したがってトレーニングデータに適応するSmをどのように求めるかということである。各仮説ωは、周波数特徴
【数39】
に対応し、2つのクラス間の分離超平面に対する法線となることが望ましい。このベクトルの大きさは、空間合成周波数を表す。
【0089】
1つの実施の形態では、仮説のセットSMを得るために、発生モデルに基づく選択方式を適用する。双方のクラス{−1,+1}の局所密度を示す別個の確率分布関数p−およびp+を抽出する。これらの分布のそれぞれからM個の点をサンプリングし、点対{(x−,x+)}{1,...,M}を構築する。各仮説は、
【数40】
となるような対に対応し、合成周波数は、|ω|=π|x+−x−|−1であり、対応する位相シフトは、b=−ωTx+である。換言すれば、
【数41】
かつ
【数42】
となるように、サンプリングされた対の点を補正されたノルムに連結するベクトルとして、ωを割り当てる。
【0090】
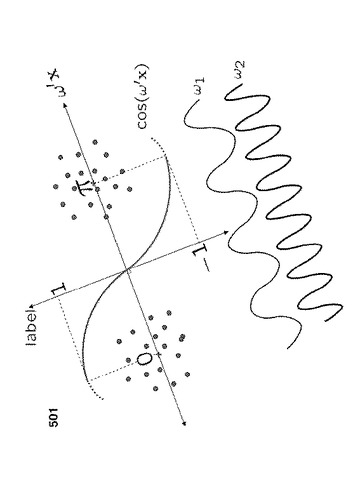
図5に示すように、分離境界501(余弦関数は、無限に多くの符号変化を有するので、複数の分離境界)のうちの1つを、図5に示すような双方の点の中央に配置する。
【0091】
より密に適合するために確率密度関数p−、p+を抽出するときに、点重みを組み込むことによって各反復において加重判別制約を適用することも可能である。
【0092】
LogitBoost特徴選択後、分類の観点でm個の有用な周波数特徴しか有しない。このマッピングは、周波数ベースの性質上、非線形であり、用いる手順は、セットSMからm個の特徴を選択する。したがって、この新たな変換空間において、線形方法をトレーニングすることができ、
【数43】
が、ブースティングされた特徴選択によって返される。
【0093】
周波数マッピングに基づく特徴選択は、冗長で分類に無関係の特徴を除去するのに役立つ。加えて、周波数マッピングに基づく特徴選択は、汎化能力を高め、トレーニングプロセスおよびテスト負荷の双方を高速化する。計算上、上記の変換は、m個のドット積しか必要としない。有用な特徴しか用いないので、セットSMは、最小であり、このため、このプロセスにより高速化が生じる。
【0094】
最適なサブセットを求めることは、性質上、組合せ問題上に射影されるので、NP困難であることに留意すべきである。しかし、貪欲ブースティングによる解決法は、特にM〜Nのときにテストフェーズのスピードに影響を及ぼすことなく、満足な性能を与える。
【0095】
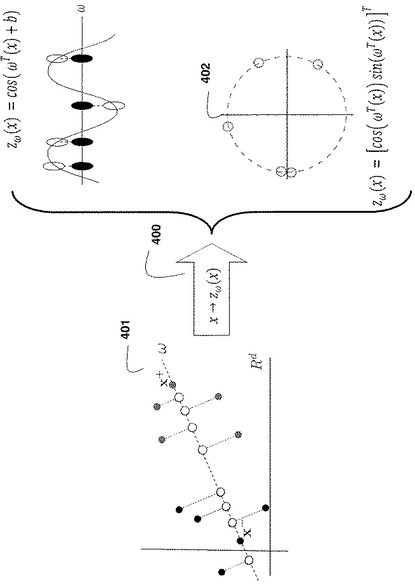
図3は、本発明の実施の形態によって用いられるデータ点401のマッピング関数を示している。
【0096】
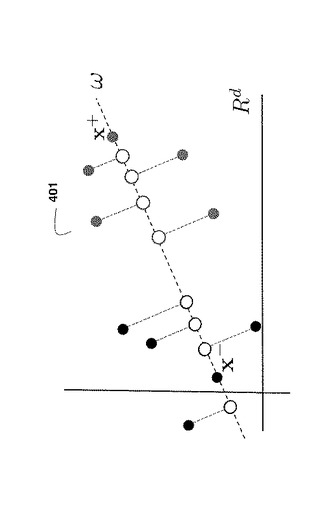
図4に示すように、マッピングx→zω(x)=[cos(ωT(x))sin(ωT(x))]T400は、データ点401を2m’次元空間402にマッピングし、他方で、マッピングx→zω(x)=cos(ωTx+b)は、データをm次元空間にマッピングする。このため、計算的に、第2のマッピングがよりコンパクトである。このマッピングは、2つのパラメーターおよびさらなる自由度を有する。後続のデータ分布についてbが固定の場合、1つの単一周波数特徴であっても良好な分類正確度を得るのに十分である。
【0097】
1つの既知の方法は、ラベルと選択された特徴との間の統計的依存度が最大になるように、貪欲形式で1つずつ特徴を求めることに基づく。しかしながら、依存度最大化を用いることは、選択の測度としての統計的依存性が、ラベルとのデータの非線形関係も考慮するので、本発明の目的に適していない。本発明では、周波数特徴によって非線形特性を既に得ているので、選択後に線形法を適用したいだけである。このため、選択の測度として、線形法である共分散最大化を用いる。
【0098】
別の実施の形態では、ランダム周波数ベースのセットから始める。次に、このセットからの各基底について、まず本発明の一次元の変換データを生成する。次に、変換データにラベルの加重最小二乗適合を適用する。これによって回帰誤差が与えられる。最小の回帰誤差を与える基底を選択する。重みを調整した後、次の基底を選択する。このプロセスは、本発明の分類に用いる特徴のセットを返す。このセットを構築した後、本発明の最終的な非線形変換を規定する。このため、元のデータのこの最終非線形変換により、分類の観点で有用な周波数特徴のみを有する。
【0099】
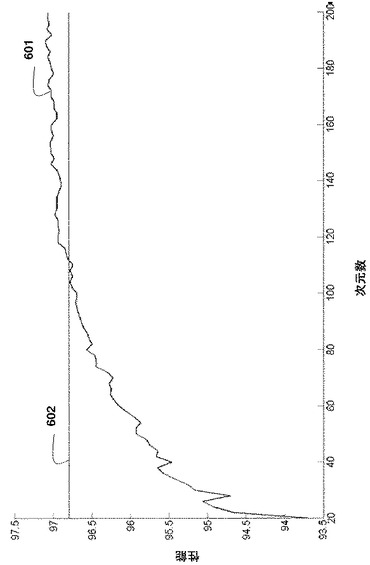
図6は、本方法の性能601を、2次元の分離不可能なデータセットの次元数の関数として、従来のSVM602と比較する。
【0100】
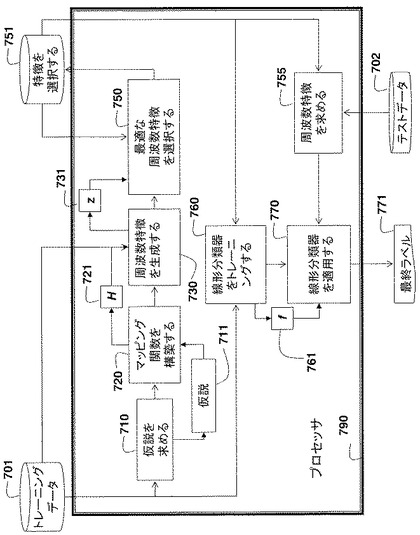
方法
図7は、線形分類器を用いたデータの二項分類に用いられる周波数特徴を選択する本方法の基本ステップを示している。d次元のラベル付けされたトレーニングデータ701を用いて、d次元空間内で仮説のセット711を求める(710)。各仮説についてマッピング関数721を構築する(720)。
【0101】
マッピング関数をトレーニングデータのd次元データ点に適用して、周波数特徴731を生成し(730)、次に、最適な分類性能が得られるm個の周波数特徴のサブセットを反復的に選択する(750)。選択された特徴は、メモリ内に格納することができる。
【0102】
周波数特徴のサブセットおよびトレーニングデータのラベルを用いて、線形分類器f761をトレーニングする(760)。
【0103】
続いて、動作中、テストデータ202の周波数特徴を求めることができ(755)、線形分類器をテストデータの周波数特徴に適用して(770)、テストデータを分類する最終ラベル771を得ることができる。
【0104】
本方法のステップは、当該技術分野において既知のメモリおよび入力/出力インターフェースに接続されたプロセッサにおいて実行することができる。
【技術分野】
【0001】
本発明は、包括的にはデータを分類することに関し、より詳細には、線形サポートベクターマシンを用いて二項分類の非線形特徴を選択することに関する。
【背景技術】
【0002】
サポートベクターマシン(SVM)は、多くの場合にデータの二項分類に用いられる。SVMは、線形カーネルまたは非線形カーネルとともに機能することができる。SVMは、高次元空間または無限次元空間において、分類、回帰、または他のタスクに用いることができる超平面または超平面のセットを構築する。良好な分離は、最も近いトレーニングデータへの最も大きい距離を有する超平面が存在する場合、該超平面によって達成される。なぜなら、一般に、マージンが大きくなるほど、分類器の汎化誤差が低くなるためである。放射基底関数SVMは、分離超平面を、より高い、場合によっては無限の次元空間にリフティングするので、2つのクラス間の任意の判定境界を近似することができる。
【0003】
しかしながら、SVMは、トレーニングデータ量が非常に多いときに非線形カーネルに対し良好にスケーリングしない。放射基底関数SVM等の非線形SVMをトレーニングすることには数日かかる可能性があり、非線形SVMを用いた未知のデータのテストは、実際の用途に組み込むには極めて低速となる可能性がある。これは、線形カーネルが用いられる場合、特にデータの次元数が小さいときにはあてはまらない。
【0004】
カーネルがガウス放射基底関数を用いる場合、対応する特徴空間は、無限次元のヒルベルト空間である。非線形カーネルの場合、ここではN(サポートベクトル数)個のカーネル評価を用いて、再生カーネルヒルベルト空間(RKHS)における超平面の法線ベクトルに対する未知のデータの射影を求めなくてはならない。これは、無限次元となる可能性があるRKHSへの直接アクセスではなく、カーネル関数によって提供された内積を通じた間接アクセスを有するためである。
【0005】
1つの可能な解決法は、カーネル行列を因数分解し、因子行列の列を、線形カーネルを有する特徴として用いて、非線形カーネルの計算が複雑になるのを回避することである。線形カーネルを用いた未知のデータの分類は、2つのデータクラス間の分離超平面の法線ベクトルを射影しさえすればよいので、高速である。
【0006】
別の解決法は、ランダムでデータ盲目的なフーリエ特徴の空間内のカーネルを、変換データの内積として近似することであり、これらの特徴に対し、線形カーネルをトレーニングすることができる。この手法では、必要なフーリエ特徴数が比較的小さく、すなわち、フーリエ特徴の空間の次元数が低く、かつ線形カーネルを用いたトレーニングが非線形カーネルを用いたトレーニングよりもかなり高速であることが知られている。しかしながら、トレーニングされたSVMは、盲目的であり、事前データを一切用いることができず、分類性能が限られている。
【発明の概要】
【発明が解決しようとする課題】
【0007】
いくつかの用途の場合、分類の計算複雑度が極度に高い。したがって、非線形カーネルのような高い分類性能を達成しながら、データ分類にかかる時間を低減することが望ましい。
【課題を解決するための手段】
【0008】
本発明の実施の形態は、サポートベクターマシンを用いて元の領域の代わりに周波数領域においてデータを分類する方法を提供する。
【0009】
周波数特徴のセットがトレーニングデータから選択される。特徴のセットは、連続したシフト不変のカーネルを表すのに十分である。次に、特徴選択、例えば、LogitBoostプロセスを適用して、特徴のセットのサブセットを反復的に選択し、分類正確度を直接最適化する。
【0010】
本発明では、以下のマッピングを構築する。二項分類タスクの場合、ラベルyiを有するトレーニングデータxi、すなわち{xi,yi}(ここでxi∈Rdおよびyi∈{−1,+1}である)を所与とすると、SVMリフティング関数Φ:Rd→Rmは、入力データ点xを、Φによって規定された周波数特徴空間に、
【数1】
となるようにマッピングする。
【0011】
ここで、周波数特徴は、zω(x)jである。本発明の1つの焦点は、周波数特徴の選択である。二項データ分類タスクのためのSVMのトレーニングフェーズおよび分類フェーズの双方を加速するために、入力データを周波数特徴のデータ駆動型低次元空間にマッピングする。
【0012】
データを{xi,yi}→{z(xi),yi}に変換した後、線形分類器をトレーニングする。この線形分類器は、1つの実施の形態では、低次元周波数特徴空間における線形カーネルを有するSVMである。mは、dよりも大幅に小さいので、トレーニングおよび分類の双方の観点で、SVMの計算複雑度の劇的な低減が得られ、分類性能は、より良好にならないにしても劣っていない。
【0013】
まず、変換データの内積が、仮説特徴を介して、所定の連続したシフト不変カーネルの再生カーネルヒルベルト空間内の内積に概ね等しくなるように、ラベル付けされたトレーニングデータを用いて特徴のセットを生成する。これらの特徴のサブセットを、カーネル関数を近似するのと対照的に、分類正確度を直接ターゲットにする特徴選択プロセスによって選択する。特に、LogitBoostプロセスを特徴選択プロセスとして用い、次に、線形分類器を適用する。線形分類器には、線形カーネルを有するSVMを用いる。
【0014】
役に立たないか、冗長であるか、または無関係の特徴を除去するために、特徴選択を適用する。特徴選択は、正確なモデルを構築するための関連する特徴のサブセットを選択する。データから最も無関係で冗長な特徴を取り除くことによって、特徴選択は、次元の呪いの影響を軽減し、汎化能力を高め、トレーニングプロセスを高速化し、モデル解釈可能性を改善することによってモデルの性能を改善するのに役立つ。特徴選択は、重要な特徴およびそれらの関係も示す。
【0015】
トレーニングプロセスを高速化するために、特徴選択のための元の周波数ベースのサブセットを求める。最適なサブセットを求めることは、組合せ問題であるため非常に困難である。このため、本発明の特徴選択では、反復的な解法に従う。このようにして、有用な特徴のみが線形SVMをトレーニングするために選択される。カーネル関数を内積として近似し、分類の観点から非判別的な特徴を除去することによって、トレーニングおよび分類の双方の観点からカーネルマシンの計算複雑度の大幅な低減が得られる。
【0016】
特徴は、トレーニングデータおよびそれらの対応するラベルを用いて選択される。このため、本方法は、教師あり法である。さらに、本方法は、カーネル関数を近似しない。代わりに、新たなカーネルを内積として構築する。このため、本方法は、カーネル設計として特徴付けられ、このため、本方法の分類正確度は、あらかじめ設定されたカーネル関数によって制限されない。
【0017】
計算負荷を大きく低減するために、周波数空間内への非線形カーネルのデータ駆動型表現が開示されるのは、これが初めてである。
【発明の効果】
【0018】
サポートベクターマシンを用いて二項分布の最適な性能を提供するために、データの周波数特徴を抽出して分類境界を表す。特徴をブースティングして冗長な特徴を除去し、関連する特徴のみを用いる。
【0019】
このようにして、データの非常にコンパクトな表現であるが、依然として2つのクラスを分離する力が十分ある表現が得られる。このため、これによって分類およびカーネルマシンのトレーニングフェーズの測度が改善する。本方法は、結果として大きな速度改善をもたらす。
【図面の簡単な説明】
【0020】
【図1】本発明の実施の形態によって用いられるサポートベクターマシンの概略図である。
【図2】本発明の実施の形態によって用いられる放射カーネル基底関数サポートベクターマシンの概略図である。
【図3】本発明の実施の形態によって用いられるマッピング関数の概略図である。
【図4】本発明の実施の形態による、周波数空間へのマッピングの概略図である。
【図5】本発明の実施の形態による、周波数マッピングおよびデータ分離の概略図である。
【図6】従来のSVMの性能を本発明の実施の形態によるSVMと比較するグラフである。
【図7】データの二項分類に用いられる周波数特徴を選択する方法の流れ図である。
【発明を実施するための形態】
【0021】
サポートベクターマシン(SVM)
図1は、本発明の実施の形態によって用いられるサポートベクターマシン(SVM)100の基本概念を示している。2つのクラスに分類されることになるデータが、原点110に対し黒丸101および白丸102によって示されている。トレーニングデータから構築された超平面103は、2つのクラスを分離する。超平面は、サポートベクトル105によってサポートされる。超平面H1とH2との間の分離量は、マージン104であり、wは、超平面に垂直なベクトルである。
【0022】
トレーニングデータxiおよび対応するラベルyi(ここで、xi∈Rdおよびyi∈{−1,+1})を所与とすると、トレーニング手順は、判定関数を構築し、該判定関数によって未知データのクラスが決まる。判定関数は、トレーニングデータの構造に依拠して線形境界または非線形境界を規定することができる。最適な分類がデータの線形関数を通じたものである場合、線形カーネルを用い、そうでない場合、非線形カーネルを用いる。
【0023】
トレーニングデータは、全てのiについて
【数2】
となるようなベクトルw∈Rd、転置演算子T、および実数b∈Rが存在する場合、分離可能であり、そうでない場合、データ線形に分離可能でないと判断する。
【0024】
分離可能データの線形SVM
最も単純な事例から始める。分離可能なトレーニングデータ{xi,yi}(ここで、xi∈Rdおよびyi∈{−1,+1})を有し、全てのiについて、yt(wTxt+b)−1≧0となるような少なくとも1つの対(w,b)が存在する。分離可能性を満たす法線ベクトルwを有する任意の超平面を分類器として用いることができる。理論的に、無限数の超平面が存在する。最適な分離超平面を選択する。
【0025】
所与の分離超平面について、超平面に対する正のクラス(負のクラス)の点からの最も短い垂直距離が、s+(s−)とされ、マージンは、s++s−である。
【0026】
分離超平面について、適切に選択されたwおよびbを用いて、いくつかのデータ点について、以下の等式を有することができる。
【0027】
【数3】
【0028】
このとき、
【数4】
である。
【0029】
このように、最適な分離超平面を、マージンを最大にする分離超平面として見つけることができる。分離可能トレーニングデータの線形SVMは、以下の主最適化を解く。
【0030】
【数5】
【0031】
ただし、すべてのiについて
【数6】
である。上記の最適化の制約を満たすデータがサポートベクトル105であり、これを取り除くことによって解が変化する。
【0032】
問題のラグラシアン定式化に切り換えることによって、結果として凸二次計画問題が生じる。この凸二次計画問題によって、ウォルフ双対定式化を利用することにより、上記の主最適化が、以下のように書き換えられることになる(双対形式最適化)。
【0033】
【数7】
【0034】
ただし、
【数8】
である。ここで、αiは、双対定式化におけるラグランジュパラメーターである。
【0035】
双対最適化および主最適化によって同じ一意の解、すなわち、最適分離超平面が得られる。双対最適化問題において、αi>0を有するトレーニングセット内のデータは、サポートベクトルである。1つのサポートベクトルであっても取り除くと解が完全に変わる可能性があり、サポートベクトルでない全てのデータを取り除いても問題に対する解が変わらないので、サポートベクトルは、トレーニングデータセットの最も重要な要素である。サポートベクトルは、分離超平面に最も近いデータであるので、サポートベクトルは、トレーニングデータの小さなサブセットでしかない。N個のサポートベクトルが存在する場合、
【数9】
となる。
【0036】
SVMの最適化問題は、重要な態様を有する。制約は、常に線形であり、かつ凸である。これは、カルシュ−キューン−タッカー(KKT)条件として知られ、w*、b*、a*が最適解となるための必要十分条件である。SVM問題のKKT条件に対する解を求めることは、主双対最適化の数値法を展開する際に中心的な役割を果たす。さらに、双対定式化では、バイアス解b*は、明確に求められないが、KKT条件が成り立たなくてはならないという知識により、バイアスを容易に求めることができる。
【0037】
分離不可能データの線形SVM:ソフトマージンおよびハードマージン
ほとんどの実データについて、データの2つのクラスを完全に分離する超平面は、存在しないため、上記の分離可能性の前提は、緩和される必要がある。まず、分類されるデータが分離不可能なデータである場合、解は、存在しない。このため、次に、これを変更したい。緩和させたいのは、以下である。
【0038】
【数10】
【0039】
これは、誤差が許容されるときに達成することができる。候補超平面の誤った側にあるデータは、データと超平面との間の距離に比例する量だけペナルティを付けられる。この概念を上記の定式化に組み込むために、スラック変数ψを用いる。
【0040】
【数11】
【0041】
このため、誤差が発生するには、対応するψiが1を超えなくてはならない。このとき、Σψiを全ての誤差にわたって規定されたコスト関数として最小化するのが当然である。このとき、SVM問題の主定式化は、以下となる。
【0042】
【数12】
【0043】
ただし、
【数13】
である。ここで、Cは、誤差最小化とマージン最大化との間のトレードオフを表すパラメーターであり、Cが大きくなるとハードマージン分類器が導かれ、結果として過剰適合が生じる可能性があり、Cが小さくなるとソフトマージン分類器が導かれる。
【0044】
それに応じて、双対定式化は以下となる。
【0045】
【数14】
【0046】
ただし、
【数15】
である。
【0047】
このため、唯一の違いは、ここで、αiがCによって上界を設けられていることである。上述したように、KKT条件は、この分離不可能な場合にも容易に適用することができる。
【0048】
カーネルSVMおよび非線形判定境界
データのクラスを分離することができる超平面が存在しない場合、非線形境界が用いられる。線形SVMの双対定式化を考えると、データに対する依存性は、ドット積xi・xjによってのみ生じる。マッピングΦ:Rd→H,x→Φ(x)を介して別のユークリッド空間H(無限次元の可能性がある)にデータをマッピングすることができる。
【0049】
H内の線形SVMをトレーニングする場合、カーネル関数
【数16】
が既知であるとき、情報Φ(xi)・xiを提供しさえすればよい。換言すれば、Φのカーネルを有するとき、関数Φを知る必要はない。H内の線形SVMをトレーニングするために、以下に従って双対式を変更する。
【0050】
【数17】
【0051】
ただし、
【数18】
である。
【0052】
1つの観測は、w∈Hであるため、分類のためにwを明示的に知る必要があるように見える場合がある。しかしながら、関係K(xi,xj)=Φ(xi)Φ(xj)を利用することによって、Hにおけるドット積の観点から判定関数を表すことができ、このため、分類は、以下となる。
【0053】
【数19】
【0054】
分類器を未知のデータに適用するために、NS個のカーネル評価が必要である。これは、用途またはタスクによっては実際的でなく、計算的に過度に複雑になり適用不可能になる可能性がある。これは、以下に起因するSVMの主要な制限のうちの1つである。サポートベクトル数に対し制御がされていない。サポートベクトルは、トレーニングデータから選択されなくてはならない。サポートベクトルが全体空間から選択される場合、サポートベクトルのセットは、はるかに小さくなる。
【0055】
1つの可能な解決法は、同じ形式の展開を減らしてカーネル分類関数を近似する。すなわち、NSは、NZとなり、NZ<<NSである。別の解決法は、サポートベクトルのサブセットのみを用いることである。しかしながら、この解決法の結果、分類性能が著しく低減する。この意味で、サポートベクトルのセットは、最小セットである。
【0056】
最も一般的に用いられているカーネルは、あるgについての、よく知られたガウスカーネルまたは放射基底関数(RBF)
【数20】
である。この特定の例では、Hは、無限次元である。マッピングΦが明確に知られている場合であっても、無限次元オブジェクトをSVM定式化に組み込むことは、非常に困難であろう。しかしながら、これは、RBFカーネルを通じて、トレーニングおよび分類の双方の観点で非常に簡単になる。
【0057】
図2は、上述したようなマッピング関数Φ(x)203を用いた、第1の空間201から、第2の、無限次元である可能性がある空間202へのSVMのマッピングの全体的な概念を示している。
【0058】
SVMにカーネルを用いるという概念は、入力データ201を、線形分離可能性を予期する非常に高次元の空間202にマッピングする(203)ことである。この場合、線形SVMは、高次元空間内でトレーニングされ、返される超平面は、非線形判定境界に対応する。カーネルを選択することにより、新たな相関構造、すなわち、高次元空間内のドット積が線形分離を可能にするように、非線形カーネルを通じて入力空間の元の相関構造が乱されるので、非線形判定境界が得られる。線形カーネル
【数21】
を用いる場合、線形SVMが得られる。
【0059】
マーセル条件
全ての関数K:Rd×Rd→Rが、K(xi,xj)=Φ(xi)Φ(xj)となるように空間HおよびマッピングΦ(x):Rd→Hに対応するとは限らない。換言すれば、全てのKがカーネルであるとは限らない。関数Kがカーネルであるか否かを判断するために、マーセル条件を用いることができる。ここで、Kは、全ての二乗可積分関数について
【数22】
である場合にのみ、カーネルである。
【0060】
周波数特徴
ターゲット画像領域の検出は、車両ナビゲーションを含む多くの用途において、重要なタスクである。この目的で、走査ウィンドウを入力画像にわたって適用することによって、SVM分類器を用いて、例えば、道路標識を検出することが可能である。道路標識の大きさは、未知であるので、走査は、異なる大きさのウィンドウを用いて、複数のスケールで行われなくてはならない。
【0061】
1つの用途では、10,000個の正の画像からなる第1のセットと、1,000,000個の負の画像からなる第2のセットとを用いて分類器をトレーニングし、NS個〜700個のサポートベクトルを有するカーネル(RBF)SVM分類器を得る。低レベルの特徴として、全ての画像について勾配方向ヒストグラム(HOG)を抽出する。これは
【数23】
を意味する。本発明の実験によれば、良好な正確度(90%)では、高精細画像の分類に約20分かかる。これは、リアルタイムの道路標識検出の場合、計算量が多すぎる。このため、分類時間を低減しなくてはならず、そのためには、カーネルSVMの計算複雑度を低減しなくてはならない。
【0062】
ここで、非線形カーネルマシンのテストを劇的に高速化する新規の方法を説明する。カーネル関数自体を因数分解するが、この因数分解は、好都合にはデータ駆動型であり、バイナリクラスラベルの分布によって求められた比較的低次元の特徴空間にデータをマッピングすることによって、カーネルマシンのトレーニングおよび評価を線形マシンの対応する動作に変換することが可能になる。
【0063】
まず、データ点の2つのクラス間の分離境界を近似するのに十分に豊富な周波数特徴のセット、および暗黙的に課す連続したシフト不変のカーネルを生成する。カーネルトリックによって与えられるリフティングに依存する代わりに、変換された点の対間の内積が、それらのカーネル評価k(x,y)=(φ(x),φ(y))≒z(x)Tz(y)を近似するように、データ駆動型特徴マップz:Rd→Rmを用いて、データを低次元ユークリッド内積空間に明示的にマッピングする。カーネルのリフティングφizが低次元であるのと異なる。このように、zへの周波数マッピングを用いて入力を単に変換することができ、次に線形法を適応して、非線形カーネルを通じて確立された判定境界を近似することができる。
【0064】
1つの実施の形態では、カーネル関数近似をターゲットにするのとは対照的に、トレーニングにおいて、超平面法線に対するロジスティック回帰である既知のLogitBoostプロセスを用いて、分類正確度を直接最適化しながら、このセットから特徴を選択する。仮説のセット、すなわち、ラベル付けされたトレーニングデータから構築される周波数特徴から始める。次に、各仮説についてデータをベクトル上にマッピングする。マッピングデータに対しラベルの加重最小二乗適合を適用し、回帰誤差を計算する。最小回帰誤差を与える仮説を選択する。重みを調整した後、次の仮説を選択する。
【0065】
このようにして、有用な周波数特徴のみを集めて、線形マシンをトレーニングする。特徴が完全にランダムに独立して集められる従来技術と比較して、本発明では、教師あり設定において利用可能なトレーニングデータおよび対応するラベルを利用する。
【0066】
非線形分離境界を周波数変換特徴の内積として近似し、特徴選択により非記述的な特徴を除去することによって、これらのデータ駆動型特徴マップにより、分類器を迅速に評価する極めて高速な方法が得られる。例えば、カーネルトリックを用いて、テスト点xにおいて放射基底関数サポートベクターマシンを評価することは、境界が単純かつスパースでない限り、データセットの多くを計算し保持するのに、O(Nd)個の演算を必要とする。ここで、Nは、トレーニング点の数である。これは、大きなデータセットの場合、多くの場合に受入不可能である。他方で、超平面ωを学習した後、線形マシンは、単にf(x)=ωTz(x)によって評価することができる。これは、O(m(d+1))個の演算およびストレージしか必要としない。ここで、mは、選択された特徴の数である。ほとんどの問題について、m<<d<Nであることに留意されたい。
【0067】
これは、カーネルを近似するのと対照的に、データ駆動型カーネルを当然構築するカーネル設計とみなすこともできる。したがって、本方法の分類正確度は、固定カーネル関数によって上界を設けられない。実際に、計算負荷を大幅に減らすことに加えて、いくつかのデータセットにおいて、より良好な分類結果が得られる。
【0068】
グループに対する調和解析からのボクナーの定理は、正の有限測度のフーリエ変換を特徴付ける。実線Lに対する正の有限ボレル測度μを所与とすると、μのフーリエ変換f(ω)は、連続関数
【数24】
である。
【0069】
関数f(ω)は、正定関数であり、すなわち、カーネルk(x,y)=f(x−y)は、正定値である。ボクナーの定理は、逆も真であることを述べており、すなわち、全ての正定関数f(ω)は、正の有限ボレル測度μのフーリエ変換である。
【0070】
Rdに対する連続カーネルk(x、y)=f(x−y)は、f(x−y)が非負測度のフーリエ変換である場合にのみ正定値である。
【0071】
カーネルk(x,y)が適切にスケーリングされているとき、ボクナーの定理は、そのフーリエ変換f(ω)が適切な確率分布であることを保証する。
【0072】
【数25】
【0073】
ここで、Tは、転置演算子である。
【0074】
換言すれば、
【数26】
は、ωがフーリエ変換fから導き出されたときの、k(x,y)のバイアスされていない推定値である。カーネルは、偶数であり、かつ実数値であり、確率分布f(ω)は、純実数であるので、被積分関数
【数27】
は、cos(ωT(x−y))と置き換えることができる。zω(x)Tzω(y)=cos(ωT(x−y))であるので、
【数28】
を定義することによって、条件E[zω(x)Tzω(y)]=k(x,y)を満たす実数値マッピングが得られる。換言すれば、各ωは、
【数29】
としてデータ点を2つの係数にマッピングする。
【0075】
また、
【数30】
および
【数31】
を定義することによっても、この場合は、単一の係数に対し、条件E[z(x)Tz(y)]=k(x,y)を満たす実数値マッピングが得られることを示すことも可能である。ここで、nは、セットωiの濃度であり、bは、位相パラメーターであり、データに関して設定することもできるし、[0,2π]から一様に導き出すこともできる。適切に導き出されたベースのセット{ωi}について、大数の法則により、z(x)Tz(y)≒k(x,y)である。
【0076】
換言すれば、ガウスカーネルおよび任意のシフト不変の連続カーネルを、周波数特徴の期待値として書くことができる。ここで、ベースは、確率測度に対してランダムであり、確率測度は、カーネルの逆フーリエ変換である。
【0077】
この近似によって、非常に興味深い特性が明らかとなる。これは、ガウスカーネル、および任意のシフト不変の連続カーネルを、周波数特徴の空間内のマッピングされた点の内積として近似することができるということである。これは、カーネルトリックとして知られるものと全く同じである。すなわち、データを非常に高次元の空間にマッピングし、該空間において新たな共分散構造がカーネルを通じて生じる。このため、上記の導出によって、周波数特徴の空間内で線形SVMをトレーニングすることができ、かつ依然としてガウスカーネルの場合と同じ分類正確度を期待することができる。本方法の計算量の低減および高速化は、この結果からもたらされる。
【0078】
上記では、周波数特徴は、任意の偶数で実数値である非線形カーネルを近似することができることを説明した。しかしながら、このプロセスは、クラスラベル情報または点の密度分布を利用しないので、内容および所与のトレーニングデータを考慮に入れない。
【0079】
本発明の目標は、プレフィックスされたカーネルを近似することではなく、分類性能を最適化する周波数特徴を介して、複雑な分離境界の線形表現を見つけることである。ここで、問題は、最終分類性能が最適化されるようなωのセットをどのように選択するかということになる。オブジェクト検出タスクのために、クラスメンバーシップを示すバイナリラベルを有するトレーニングデータセットが、多くの場合に利用可能である。これらの追加の事前データを最大限に利用することが望ましい。
【0080】
これを達成するために、以下のセクションにおいて検討するような、データの負の二項対数尤度を最小にする顕著な周波数特徴を選択する。
【0081】
ブースティングされた特徴選択
反復的にブースティングすることによって、弱い分類器(仮説)を組み合わせて強い分類器にする。このブースティングは、前の仮説によって誤って分類されたインスタンスを優先する。「ブースティング」において、用語「弱い」および「強い」は、当該技術分野においてよく知られたものとして定義される。各ラウンドにおいて、データ点重みの分布が更新される。誤って分類された各データ点の重みが増やされ、正しく分類された各データ点の重みが減らされ、新たな分類器が、これらの例により集中するようにする。
【0082】
二項分類問題の場合、yi∈{−1,1}を有する。全てのn=1,...,Nについて、第1のラウンド
【数32】
におけるデータ点の重みを初期化する。重み付けされたデータ点に関して弱い分類器htを選択する。xがクラス1にある確率は、
【数33】
よって表され、全体の応答は、
【数34】
によって得られる。
【0083】
LogitBoostプロセスは、ニュートン反復を通じて
【数35】
によってデータの負の二項対数尤度を最小にすることによって、回帰関数のセットht(x){t=1,...,L}を学習する。プロセスのコアにおいて、LogitBoostは、トレーニング点xnの加重最小二乗回帰ht(x)を適合し、値λnおよび重みβnに以下のように応答する。
【0084】
【数36】
【0085】
ここで、
【数37】
である。
【0086】
分類器の最終応答は、
【数38】
である。
【0087】
各反復において、仮説のセットSM:{ω1,...,ωM}がテストされる。負の指数損失を最も低減する仮説は、仮説Smのサブセット内に含まれる、現在の弱い分類器としてブースティングされた分類器に結合され、性能レベルが達成されるかまたは計算負荷の上限に達するまで、m個の反復が繰り返される。ここで、mは、変換空間の次元数であり、セットの濃度Sm⊂SMである。
【0088】
重要な問いは、仮説のセットSM、したがってトレーニングデータに適応するSmをどのように求めるかということである。各仮説ωは、周波数特徴
【数39】
に対応し、2つのクラス間の分離超平面に対する法線となることが望ましい。このベクトルの大きさは、空間合成周波数を表す。
【0089】
1つの実施の形態では、仮説のセットSMを得るために、発生モデルに基づく選択方式を適用する。双方のクラス{−1,+1}の局所密度を示す別個の確率分布関数p−およびp+を抽出する。これらの分布のそれぞれからM個の点をサンプリングし、点対{(x−,x+)}{1,...,M}を構築する。各仮説は、
【数40】
となるような対に対応し、合成周波数は、|ω|=π|x+−x−|−1であり、対応する位相シフトは、b=−ωTx+である。換言すれば、
【数41】
かつ
【数42】
となるように、サンプリングされた対の点を補正されたノルムに連結するベクトルとして、ωを割り当てる。
【0090】
図5に示すように、分離境界501(余弦関数は、無限に多くの符号変化を有するので、複数の分離境界)のうちの1つを、図5に示すような双方の点の中央に配置する。
【0091】
より密に適合するために確率密度関数p−、p+を抽出するときに、点重みを組み込むことによって各反復において加重判別制約を適用することも可能である。
【0092】
LogitBoost特徴選択後、分類の観点でm個の有用な周波数特徴しか有しない。このマッピングは、周波数ベースの性質上、非線形であり、用いる手順は、セットSMからm個の特徴を選択する。したがって、この新たな変換空間において、線形方法をトレーニングすることができ、
【数43】
が、ブースティングされた特徴選択によって返される。
【0093】
周波数マッピングに基づく特徴選択は、冗長で分類に無関係の特徴を除去するのに役立つ。加えて、周波数マッピングに基づく特徴選択は、汎化能力を高め、トレーニングプロセスおよびテスト負荷の双方を高速化する。計算上、上記の変換は、m個のドット積しか必要としない。有用な特徴しか用いないので、セットSMは、最小であり、このため、このプロセスにより高速化が生じる。
【0094】
最適なサブセットを求めることは、性質上、組合せ問題上に射影されるので、NP困難であることに留意すべきである。しかし、貪欲ブースティングによる解決法は、特にM〜Nのときにテストフェーズのスピードに影響を及ぼすことなく、満足な性能を与える。
【0095】
図3は、本発明の実施の形態によって用いられるデータ点401のマッピング関数を示している。
【0096】
図4に示すように、マッピングx→zω(x)=[cos(ωT(x))sin(ωT(x))]T400は、データ点401を2m’次元空間402にマッピングし、他方で、マッピングx→zω(x)=cos(ωTx+b)は、データをm次元空間にマッピングする。このため、計算的に、第2のマッピングがよりコンパクトである。このマッピングは、2つのパラメーターおよびさらなる自由度を有する。後続のデータ分布についてbが固定の場合、1つの単一周波数特徴であっても良好な分類正確度を得るのに十分である。
【0097】
1つの既知の方法は、ラベルと選択された特徴との間の統計的依存度が最大になるように、貪欲形式で1つずつ特徴を求めることに基づく。しかしながら、依存度最大化を用いることは、選択の測度としての統計的依存性が、ラベルとのデータの非線形関係も考慮するので、本発明の目的に適していない。本発明では、周波数特徴によって非線形特性を既に得ているので、選択後に線形法を適用したいだけである。このため、選択の測度として、線形法である共分散最大化を用いる。
【0098】
別の実施の形態では、ランダム周波数ベースのセットから始める。次に、このセットからの各基底について、まず本発明の一次元の変換データを生成する。次に、変換データにラベルの加重最小二乗適合を適用する。これによって回帰誤差が与えられる。最小の回帰誤差を与える基底を選択する。重みを調整した後、次の基底を選択する。このプロセスは、本発明の分類に用いる特徴のセットを返す。このセットを構築した後、本発明の最終的な非線形変換を規定する。このため、元のデータのこの最終非線形変換により、分類の観点で有用な周波数特徴のみを有する。
【0099】
図6は、本方法の性能601を、2次元の分離不可能なデータセットの次元数の関数として、従来のSVM602と比較する。
【0100】
方法
図7は、線形分類器を用いたデータの二項分類に用いられる周波数特徴を選択する本方法の基本ステップを示している。d次元のラベル付けされたトレーニングデータ701を用いて、d次元空間内で仮説のセット711を求める(710)。各仮説についてマッピング関数721を構築する(720)。
【0101】
マッピング関数をトレーニングデータのd次元データ点に適用して、周波数特徴731を生成し(730)、次に、最適な分類性能が得られるm個の周波数特徴のサブセットを反復的に選択する(750)。選択された特徴は、メモリ内に格納することができる。
【0102】
周波数特徴のサブセットおよびトレーニングデータのラベルを用いて、線形分類器f761をトレーニングする(760)。
【0103】
続いて、動作中、テストデータ202の周波数特徴を求めることができ(755)、線形分類器をテストデータの周波数特徴に適用して(770)、テストデータを分類する最終ラベル771を得ることができる。
【0104】
本方法のステップは、当該技術分野において既知のメモリおよび入力/出力インターフェースに接続されたプロセッサにおいて実行することができる。
【特許請求の範囲】
【請求項1】
線形分類器を用いたデータの二項分類に用いられる周波数特徴を選択する方法であって、
d次元のラベル付けされたトレーニングデータを用いて、d次元空間において仮説のセットを求めるステップと、
前記仮説ごとにマッピング関数を構築するステップと、
周波数特徴を生成するために、前記マッピング関数を前記トレーニングデータに適用するステップと、
前記周波数特徴のサブセットを反復的に選択するステップと、
前記周波数特徴のサブセットおよび前記トレーニングデータのラベルを用いて前記線形分類器をトレーニングするステップと、
を含み、前記ステップのそれぞれは、プロセッサにおいて実行される
線形分類器を用いたデータの二項分類に用いられる周波数特徴を選択する方法。
【請求項2】
前記トレーニングデータは、正のラベルを有する正のトレーニングデータの第1のサブセットと、負のラベルを有する負のトレーニングデータの第2のサブセットとを含み、基底ベクトルが、前記トレーニングデータの前記第1のサブセットと前記第2のサブセットとの間の分離境界を規定する
請求項1に記載の方法。
【請求項3】
前記各仮説は、前記トレーニングデータのベクトルωである
請求項1に記載の方法。
【請求項4】
前記各仮説は、前記トレーニングデータの2つのクラスを分離する超平面に対し垂直なベクトルである
請求項1に記載の方法。
【請求項5】
各仮説ベクトルの大きさは、空間合成周波数である
請求項1に記載の方法。
【請求項6】
前記トレーニングデータから別個の確率分布関数P+およびP−を抽出するステップであって、P+は、正のラベル付けされたデータの前記確率分布関数であり、P−は、負のトレーニングデータ点のサブセットの前記確率分布関数である、抽出するステップと、
前記分布のそれぞれについてM個のデータ点をサンプリングするステップであって、点対
【数1】
を構築し、ここでx−は前記分布p−からのデータ点であり、ここでx+は前記分布p+からのデータ点である、サンプリングするステップと、
前記仮説ωを、前記点対を連結する前記ベクトルとして割り当てるステップと
をさらに含む請求項4に記載の方法。
【請求項7】
前記確率密度関数p+およびp−を抽出する間、加重判別制約を適用する
請求項6に記載の方法。
【請求項8】
マッピング関数が
【数2】
によって規定され、ここで、Tは、ベクトル転置演算子であり、bは、位相シフトパラメーターである
請求項6に記載の方法。
【請求項9】
Rd→R2からの前記マッピング関数は、
【数3】
によって規定され、ここで、Tは、ベクトル転置演算子である
請求項6に記載の方法。
【請求項10】
前記位相シフトは、b=−ωTx+である
請求項8に記載の方法。
【請求項11】
前記周波数特徴のサブセットをブースティング法によって選択する
請求項1に記載の方法。
【請求項12】
前記選択を、前記線形分類器の所望の性能レベルに達するまで繰り返す
請求項11に記載の方法。
【請求項13】
前記選択を、計算負荷の上限に達するまで反復する
請求項11に記載の方法。
【請求項14】
前記線形分類器は、線形カーネルを有するサポートベクターマシンである
請求項1に記載の方法。
【請求項15】
前記仮説のセットをランダムサンプリングによって選択する
請求項1に記載の方法。
【請求項16】
前記トレーニングデータは、複数のクラスを有する
請求項1に記載の方法。
【請求項17】
テストデータの前記周波数特徴を求めるステップと、
前記テストデータを分類する最終ラベルを得るために、前記周波数特徴に前記線形分類器を適用するステップと
をさらに含む請求項1に記載の方法。
【請求項1】
線形分類器を用いたデータの二項分類に用いられる周波数特徴を選択する方法であって、
d次元のラベル付けされたトレーニングデータを用いて、d次元空間において仮説のセットを求めるステップと、
前記仮説ごとにマッピング関数を構築するステップと、
周波数特徴を生成するために、前記マッピング関数を前記トレーニングデータに適用するステップと、
前記周波数特徴のサブセットを反復的に選択するステップと、
前記周波数特徴のサブセットおよび前記トレーニングデータのラベルを用いて前記線形分類器をトレーニングするステップと、
を含み、前記ステップのそれぞれは、プロセッサにおいて実行される
線形分類器を用いたデータの二項分類に用いられる周波数特徴を選択する方法。
【請求項2】
前記トレーニングデータは、正のラベルを有する正のトレーニングデータの第1のサブセットと、負のラベルを有する負のトレーニングデータの第2のサブセットとを含み、基底ベクトルが、前記トレーニングデータの前記第1のサブセットと前記第2のサブセットとの間の分離境界を規定する
請求項1に記載の方法。
【請求項3】
前記各仮説は、前記トレーニングデータのベクトルωである
請求項1に記載の方法。
【請求項4】
前記各仮説は、前記トレーニングデータの2つのクラスを分離する超平面に対し垂直なベクトルである
請求項1に記載の方法。
【請求項5】
各仮説ベクトルの大きさは、空間合成周波数である
請求項1に記載の方法。
【請求項6】
前記トレーニングデータから別個の確率分布関数P+およびP−を抽出するステップであって、P+は、正のラベル付けされたデータの前記確率分布関数であり、P−は、負のトレーニングデータ点のサブセットの前記確率分布関数である、抽出するステップと、
前記分布のそれぞれについてM個のデータ点をサンプリングするステップであって、点対
【数1】
を構築し、ここでx−は前記分布p−からのデータ点であり、ここでx+は前記分布p+からのデータ点である、サンプリングするステップと、
前記仮説ωを、前記点対を連結する前記ベクトルとして割り当てるステップと
をさらに含む請求項4に記載の方法。
【請求項7】
前記確率密度関数p+およびp−を抽出する間、加重判別制約を適用する
請求項6に記載の方法。
【請求項8】
マッピング関数が
【数2】
によって規定され、ここで、Tは、ベクトル転置演算子であり、bは、位相シフトパラメーターである
請求項6に記載の方法。
【請求項9】
Rd→R2からの前記マッピング関数は、
【数3】
によって規定され、ここで、Tは、ベクトル転置演算子である
請求項6に記載の方法。
【請求項10】
前記位相シフトは、b=−ωTx+である
請求項8に記載の方法。
【請求項11】
前記周波数特徴のサブセットをブースティング法によって選択する
請求項1に記載の方法。
【請求項12】
前記選択を、前記線形分類器の所望の性能レベルに達するまで繰り返す
請求項11に記載の方法。
【請求項13】
前記選択を、計算負荷の上限に達するまで反復する
請求項11に記載の方法。
【請求項14】
前記線形分類器は、線形カーネルを有するサポートベクターマシンである
請求項1に記載の方法。
【請求項15】
前記仮説のセットをランダムサンプリングによって選択する
請求項1に記載の方法。
【請求項16】
前記トレーニングデータは、複数のクラスを有する
請求項1に記載の方法。
【請求項17】
テストデータの前記周波数特徴を求めるステップと、
前記テストデータを分類する最終ラベルを得るために、前記周波数特徴に前記線形分類器を適用するステップと
をさらに含む請求項1に記載の方法。
【図1】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【公開番号】特開2012−216191(P2012−216191A)
【公開日】平成24年11月8日(2012.11.8)
【国際特許分類】
【外国語出願】
【出願番号】特願2012−52831(P2012−52831)
【出願日】平成24年3月9日(2012.3.9)
【出願人】(597067574)ミツビシ・エレクトリック・リサーチ・ラボラトリーズ・インコーポレイテッド (484)
【住所又は居所原語表記】201 BROADWAY, CAMBRIDGE, MASSACHUSETTS 02139, U.S.A.
【公開日】平成24年11月8日(2012.11.8)
【国際特許分類】
【出願番号】特願2012−52831(P2012−52831)
【出願日】平成24年3月9日(2012.3.9)
【出願人】(597067574)ミツビシ・エレクトリック・リサーチ・ラボラトリーズ・インコーポレイテッド (484)
【住所又は居所原語表記】201 BROADWAY, CAMBRIDGE, MASSACHUSETTS 02139, U.S.A.
[ Back to top ]