
哺乳動物由来の検体の癌化度を評価する方法
【課題】癌を早期に発見するための診断方法や治療方法等の評価に適する、遺伝子異常の検出に基づいた哺乳動物由来の検体の癌化度評価方法を提供すること。
【解決手段】哺乳動物由来の検体の癌化度を評価する方法であって、
(1)哺乳動物由来の検体に含まれる(a)〜(al)から選ばれる少なくとも1つを有するDNAのメチル化頻度又はそれに相関関係がある指標値を測定する第一工程、及び
(2)測定された前記メチル化頻度又はそれに相関関係がある指標値と、対照とを比較することにより得られる差異に基づき前記検体の癌化度を判定する第二工程
を有することを特徴とする評価方法等に関する。
【解決手段】哺乳動物由来の検体の癌化度を評価する方法であって、
(1)哺乳動物由来の検体に含まれる(a)〜(al)から選ばれる少なくとも1つを有するDNAのメチル化頻度又はそれに相関関係がある指標値を測定する第一工程、及び
(2)測定された前記メチル化頻度又はそれに相関関係がある指標値と、対照とを比較することにより得られる差異に基づき前記検体の癌化度を判定する第二工程
を有することを特徴とする評価方法等に関する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、哺乳動物由来の検体の癌化度を評価する方法等に関する。
【背景技術】
【0002】
癌が遺伝子異常を原因とする疾病であること等が次第に明らかになりつつあるが、癌患者の死亡率は未だ高く、現在利用可能な診断方法や治療方法等の評価が必ずしも十分に満足できるものではないことを示している。その1つの原因として癌組織の種類に基づく多様性、マーカーとなる遺伝子等の低い正確性や低い検出感度等が考えられる。
【先行技術文献】
【非特許文献】
【0003】
【非特許文献1】「遺伝子の病気としてのがん」(ISBN4-89553-447-2 C3047)、黒木登志夫・垣添忠生編集、株式会社メジカルビュー社発行(1994年5月10日)
【発明の概要】
【発明が解決しようとする課題】
【0004】
そこで、癌を早期に発見するための診断方法や治療方法等の評価に適する、遺伝子異常の検出に基づいた哺乳動物由来の検体の癌化度評価方法の開発が切望されている。
【課題を解決するための手段】
【0005】
本発明者らは、かかる状況の下、鋭意検討した結果、癌組織検体あるいは、がん患者由来の血液、血清、血漿、体液、体分泌地物、糞尿等の生体試料に存在するDNAおいて配列番号1−19で示されるDNA領域に含まれるCpG配列のシトシン塩基が、不死化正常細胞株及び正常組織検体あるいは健常者由来の血液、血清、血漿、体液、体分泌地物、糞尿等の生体試料に存在するDNAと比較して有意に高い頻度でメチル化されていることを見出し、本発明に至った。
即ち、本発明は、
1. 哺乳動物由来の検体の癌化度を評価する方法であって、
(1)哺乳動物由来の検体に含まれる下記の塩基配列から選ばれる少なくとも1つを有するDNAのメチル化頻度又はそれに相関関係がある指標値を測定する第一工程、及び
(2)測定された前記メチル化頻度又はそれに相関関係がある指標値と、対照とを比較することにより得られる差異に基づき前記検体の癌化度を判定する第二工程
を有することを特徴とする評価方法。
(a)配列番号1で示された塩基配列又は配列番号1で示された塩基配列と80%以上の相同性を有する塩基配列
(b)配列番号1と相補的な塩基配列又は配列番号1と相補的な塩基配列と80%以上の相同性を有する塩基配列
(c)配列番号2で示された塩基配列又は配列番号2で示された塩基配列と80%以上の相同性を有する塩基配列
(d)配列番号2と相補的な塩基配列又は配列番号2と相補的な塩基配列と80%以上の相同性を有する塩基配列
(e)配列番号3で示された塩基配列又は配列番号3で示された塩基配列と80%以上の相同性を有する塩基配列
(f)配列番号3と相補的な塩基配列又は配列番号3と相補的な塩基配列と80%以上の相同性を有する塩基配列
(g)配列番号4で示された塩基配列又は配列番号4で示された塩基配列と80%以上の相同性を有する塩基配列
(h)配列番号4と相補的な塩基配列又は配列番号4と相補的な塩基配列と80%以上の相同性を有する塩基配列
(i)配列番号5で示された塩基配列又は配列番号5で示された塩基配列と80%以上の相同性を有する塩基配列
(j)配列番号5と相補的な塩基配列又は配列番号5と相補的な塩基配列と80%以上の相同性を有する塩基配列
(k)配列番号6で示された塩基配列又は配列番号6で示された塩基配列と80%以上の相同性を有する塩基配列
(l)配列番号6と相補的な塩基配列又は配列番号6と相補的な塩基配列と80%以上の相同性を有する塩基配列
(m)配列番号7で示された塩基配列又は配列番号7で示された塩基配列と80%以上の相同性を有する塩基配列
(n)配列番号7と相補的な塩基配列又は配列番号7と相補的な塩基配列と80%以上の相同性を有する塩基配列
(o)配列番号8で示された塩基配列又は配列番号8で示された塩基配列と80%以上の相同性を有する塩基配列
(p)配列番号8と相補的な塩基配列又は配列番号8と相補的な塩基配列と80%以上の相同性を有する塩基配列
(q)配列番号9で示された塩基配列又は配列番号9で示された塩基配列と80%以上の相同性を有する塩基配列
(r)配列番号9と相補的な塩基配列又は配列番号9と相補的な塩基配列と80%以上の相同性を有する塩基配列
(s)配列番号10で示された塩基配列又は配列番号10で示された塩基配列と80%以上の相同性を有する塩基配列
(t)配列番号10と相補的な塩基配列又は配列番号10と相補的な塩基配列と80%以上の相同性を有する塩基配列
(u)配列番号11で示された塩基配列又は配列番号11で示された塩基配列と80%以上の相同性を有する塩基配列
(v)配列番号11と相補的な塩基配列又は配列番号11と相補的な塩基配列と80%以上の相同性を有する塩基配列
(w)配列番号12で示された塩基配列又は配列番号12で示された塩基配列と80%以上の相同性を有する塩基配列
(x)配列番号12と相補的な塩基配列又は配列番号12と相補的な塩基配列と80%以上の相同性を有する塩基配列
(y)配列番号13で示された塩基配列又は配列番号13で示された塩基配列と80%以上の相同性を有する塩基配列
(z)配列番号13と相補的な塩基配列又は配列番号13と相補的な塩基配列と80%以上の相同性を有する塩基配列
(aa)配列番号14で示された塩基配列又は配列番号14で示された塩基配列と80%以上の相同性を有する塩基配列
(ab)配列番号14と相補的な塩基配列又は配列番号14と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ac)配列番号15で示された塩基配列又は配列番号15で示された塩基配列と80%以上の相同性を有する塩基配列
(ad)配列番号15と相補的な塩基配列又は配列番号15と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ae)配列番号16で示された塩基配列又は配列番号16で示された塩基配列と80%以上の相同性を有する塩基配列
(af)配列番号16と相補的な塩基配列又は配列番号16と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ag)配列番号17で示された塩基配列又は配列番号17で示された塩基配列と80%以上の相同性を有する塩基配列
(ah)配列番号17と相補的な塩基配列又は配列番号17と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ai)配列番号18で示された塩基配列又は配列番号18で示された塩基配列と80%以上の相同性を有する塩基配列
(aj)配列番号18と相補的な塩基配列又は配列番号18と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ak)配列番号19で示された塩基配列又は配列番号19で示された塩基配列と80%以上の相同性を有する塩基配列
(al)配列番号19と相補的な塩基配列又は配列番号19と相補的な塩基配列と80%以上の相同性を有する塩基配列
2. 哺乳動物由来の検体が細胞であることを特徴とする前記1記載の評価方法。
3. 哺乳動物由来の検体が組織であることを特徴とする前記1記載の評価方法。
4. 哺乳動物由来の検体が生体試料であることを特徴とする前記1記載の評価方法。
5. 哺乳動物由来の検体の癌化度を評価する方法であって、
(1)哺乳動物由来の検体に含まれる下記の塩基配列から選ばれる少なくとも1つを有するDNAのメチル化頻度又はそれに相関関係がある指標値を測定する第一工程、及び
(2)測定された前記メチル化頻度と、対照とを比較することにより得られる差異に基づき前記検体の癌化度を判定する第二工程
を有することを特徴とする評価方法。
(a)配列番号1で示された塩基配列又は配列番号1で示された塩基配列と80%以上の相同性を有する塩基配列
(b)配列番号1と相補的な塩基配列又は配列番号1と相補的な塩基配列と80%以上の相同性を有する塩基配列
(c)配列番号2で示された塩基配列又は配列番号2で示された塩基配列と80%以上の相同性を有する塩基配列
(d)配列番号2と相補的な塩基配列又は配列番号2と相補的な塩基配列と80%以上の相同性を有する塩基配列
(e)配列番号3で示された塩基配列又は配列番号3で示された塩基配列と80%以上の相同性を有する塩基配列
(f)配列番号3と相補的な塩基配列又は配列番号3と相補的な塩基配列と80%以上の相同性を有する塩基配列
(g)配列番号4で示された塩基配列又は配列番号4で示された塩基配列と80%以上の相同性を有する塩基配列
(h)配列番号4と相補的な塩基配列又は配列番号4と相補的な塩基配列と80%以上の相同性を有する塩基配列
(i)配列番号5で示された塩基配列又は配列番号5で示された塩基配列と80%以上の相同性を有する塩基配列
(j)配列番号5と相補的な塩基配列又は配列番号5と相補的な塩基配列と80%以上の相同性を有する塩基配列
(k)配列番号6で示された塩基配列又は配列番号6で示された塩基配列と80%以上の相同性を有する塩基配列
(l)配列番号6と相補的な塩基配列又は配列番号6と相補的な塩基配列と80%以上の相同性を有する塩基配列
(m)配列番号7で示された塩基配列又は配列番号7で示された塩基配列と80%以上の相同性を有する塩基配列
(n)配列番号7と相補的な塩基配列又は配列番号7と相補的な塩基配列と80%以上の相同性を有する塩基配列
(o)配列番号8で示された塩基配列又は配列番号8で示された塩基配列と80%以上の相同性を有する塩基配列
(p)配列番号8と相補的な塩基配列又は配列番号8と相補的な塩基配列と80%以上の相同性を有する塩基配列
(q)配列番号9で示された塩基配列又は配列番号9で示された塩基配列と80%以上の相同性を有する塩基配列
(r)配列番号9と相補的な塩基配列又は配列番号9と相補的な塩基配列と80%以上の相同性を有する塩基配列
(s)配列番号10で示された塩基配列又は配列番号10で示された塩基配列と80%以上の相同性を有する塩基配列
(t)配列番号10と相補的な塩基配列又は配列番号10と相補的な塩基配列と80%以上の相同性を有する塩基配列
(u)配列番号11で示された塩基配列又は配列番号11で示された塩基配列と80%以上の相同性を有する塩基配列
(v)配列番号11と相補的な塩基配列又は配列番号11と相補的な塩基配列と80%以上の相同性を有する塩基配列
(w)配列番号12で示された塩基配列又は配列番号12で示された塩基配列と80%以上の相同性を有する塩基配列
(x)配列番号12と相補的な塩基配列又は配列番号12と相補的な塩基配列と80%以上の相同性を有する塩基配列
(y)配列番号13で示された塩基配列又は配列番号13で示された塩基配列と80%以上の相同性を有する塩基配列
(z)配列番号13と相補的な塩基配列又は配列番号13と相補的な塩基配列と80%以上の相同性を有する塩基配列
(aa)配列番号14で示された塩基配列又は配列番号14で示された塩基配列と80%以上の相同性を有する塩基配列
(ab)配列番号14と相補的な塩基配列又は配列番号14と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ac)配列番号15で示された塩基配列又は配列番号15で示された塩基配列と80%以上の相同性を有する塩基配列
(ad)配列番号15と相補的な塩基配列又は配列番号15と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ae)配列番号16で示された塩基配列又は配列番号16で示された塩基配列と80%以上の相同性を有する塩基配列
(af)配列番号16と相補的な塩基配列又は配列番号16と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ag)配列番号17で示された塩基配列又は配列番号17で示された塩基配列と80%以上の相同性を有する塩基配列
(ah)配列番号17と相補的な塩基配列又は配列番号17と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ai)配列番号18で示された塩基配列又は配列番号18で示された塩基配列と80%以上の相同性を有する塩基配列
(aj)配列番号18と相補的な塩基配列又は配列番号18と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ak)配列番号19で示された塩基配列又は配列番号19で示された塩基配列と80%以上の相同性を有する塩基配列
(al)配列番号19と相補的な塩基配列又は配列番号19と相補的な塩基配列と80%以上の相同性を有する塩基配列
6. 哺乳動物由来の検体が細胞であって、且つ、当該検体の癌化度が哺乳動物由来の細胞の悪性度であることを特徴とする前記1又は5記載の評価方法。
7. 哺乳動物由来の検体が組織であって、且つ、当該検体の癌化度が哺乳動物由来の組織における癌細胞の存在量であることを特徴とする前記1又は5記載の評価方法。
8. 哺乳動物由来の検体が哺乳動物から採取した生体試料であって、且つ、当該検体の癌化度が当該生体試料を採取した当該哺乳動物のいずれかの体組織における癌細胞の存在量であることを特徴とする前記1又は5記載の評価方法。
9. 組織が大腸組織であることを特徴とする前記7に記載の評価方法。
10. 組織が肺組織であることを特徴とする前記7に記載の評価方法。
11. 組織が乳腺組織であることを特徴とする前記7に記載の評価方法。
12. 生体試料が血液、血清、血漿、体液、体分泌地物、糞尿、のいずれかであることを特徴とする前記8記載の評価方法。
13. 前記DNAのメチル化頻度が、前記DNAの塩基配列内に存在する一つ以上の5'-CG-3'で示される塩基配列中のシトシンのメチル化頻度であることを特徴とする前記1〜12のいずれか記載の評価方法。
14. 哺乳動物由来の検体の癌化度を評価する方法であって、
(1)哺乳動物由来の検体に含まれる下記の塩基配列から選ばれる少なくとも1つを有するDNAのメチル化頻度に相関関係がある指標値を測定する第一工程、及び
(2)測定された前記メチル化頻度又はそれに相関関係がある指標値と、対照とを比較することにより得られる差異に基づき前記検体の癌化度を判定する第二工程
を有することを特徴と評価方法。
(a)配列番号1で示された塩基配列又は配列番号1で示された塩基配列と80%以上の相同性を有する塩基配列
(b)配列番号1と相補的な塩基配列又は配列番号1と相補的な塩基配列と80%以上の相同性を有する塩基配列
(c)配列番号2で示された塩基配列又は配列番号2で示された塩基配列と80%以上の相同性を有する塩基配列
(d)配列番号2と相補的な塩基配列又は配列番号2と相補的な塩基配列と80%以上の相同性を有する塩基配列
(e)配列番号3で示された塩基配列又は配列番号3で示された塩基配列と80%以上の相同性を有する塩基配列
(f)配列番号3と相補的な塩基配列又は配列番号3と相補的な塩基配列と80%以上の相同性を有する塩基配列
(g)配列番号4で示された塩基配列又は配列番号4で示された塩基配列と80%以上の相同性を有する塩基配列
(h)配列番号4と相補的な塩基配列又は配列番号4と相補的な塩基配列と80%以上の相同性を有する塩基配列
(i)配列番号5で示された塩基配列又は配列番号5で示された塩基配列と80%以上の相同性を有する塩基配列
(j)配列番号5と相補的な塩基配列又は配列番号5と相補的な塩基配列と80%以上の相同性を有する塩基配列
(k)配列番号6で示された塩基配列又は配列番号6で示された塩基配列と80%以上の相同性を有する塩基配列
(l)配列番号6と相補的な塩基配列又は配列番号6と相補的な塩基配列と80%以上の相同性を有する塩基配列
(m)配列番号7で示された塩基配列又は配列番号7で示された塩基配列と80%以上の相同性を有する塩基配列
(n)配列番号7と相補的な塩基配列又は配列番号7と相補的な塩基配列と80%以上の相同性を有する塩基配列
(o)配列番号8で示された塩基配列又は配列番号8で示された塩基配列と80%以上の相同性を有する塩基配列
(p)配列番号8と相補的な塩基配列又は配列番号8と相補的な塩基配列と80%以上の相同性を有する塩基配列
(q)配列番号9で示された塩基配列又は配列番号9で示された塩基配列と80%以上の相同性を有する塩基配列
(r)配列番号9と相補的な塩基配列又は配列番号9と相補的な塩基配列と80%以上の相同性を有する塩基配列
(s)配列番号10で示された塩基配列又は配列番号10で示された塩基配列と80%以上の相同性を有する塩基配列
(t)配列番号10と相補的な塩基配列又は配列番号10と相補的な塩基配列と80%以上の相同性を有する塩基配列
(u)配列番号11で示された塩基配列又は配列番号11で示された塩基配列と80%以上の相同性を有する塩基配列
(v)配列番号11と相補的な塩基配列又は配列番号11と相補的な塩基配列と80%以上の相同性を有する塩基配列
(w)配列番号12で示された塩基配列又は配列番号12で示された塩基配列と80%以上の相同性を有する塩基配列
(x)配列番号12と相補的な塩基配列又は配列番号12と相補的な塩基配列と80%以上の相同性を有する塩基配列
(y)配列番号13で示された塩基配列又は配列番号13で示された塩基配列と80%以上の相同性を有する塩基配列
(z)配列番号13と相補的な塩基配列又は配列番号13と相補的な塩基配列と80%以上の相同性を有する塩基配列
(aa)配列番号14で示された塩基配列又は配列番号14で示された塩基配列と80%以上の相同性を有する塩基配列
(ab)配列番号14と相補的な塩基配列又は配列番号14と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ac)配列番号15で示された塩基配列又は配列番号15で示された塩基配列と80%以上の相同性を有する塩基配列
(ad)配列番号15と相補的な塩基配列又は配列番号15と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ae)配列番号16で示された塩基配列又は配列番号16で示された塩基配列と80%以上の相同性を有する塩基配列
(af)配列番号16と相補的な塩基配列又は配列番号16と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ag)配列番号17で示された塩基配列又は配列番号17で示された塩基配列と80%以上の相同性を有する塩基配列
(ah)配列番号17と相補的な塩基配列又は配列番号17と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ai)配列番号18で示された塩基配列又は配列番号18で示された塩基配列と80%以上の相同性を有する塩基配列
(aj)配列番号18と相補的な塩基配列又は配列番号18と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ak)配列番号19で示された塩基配列又は配列番号19で示された塩基配列と80%以上の相同性を有する塩基配列
(al)配列番号19と相補的な塩基配列又は配列番号19と相補的な塩基配列と80%以上の相同性を有する塩基配列
15. 相関関係がある指標値が、当該塩基配列から選ばれる少なくとも1つのDNAの下流に存在する遺伝子のいずれかの発現産物の量であることを特徴とする前記14記載の評価方法。
16. 遺伝子の発現産物の量が、遺伝子の転写産物の量であることを特徴とする前記15記載の評価方法。
17. 癌マーカーとしての、下記の塩基配列から選ばれる少なくとも1つを有するメチル化DNAの使用
(a)配列番号1で示された塩基配列又は配列番号1で示された塩基配列と80%以上の相同性を有する塩基配列
(b)配列番号1と相補的な塩基配列又は配列番号1と相補的な塩基配列と80%以上の相同性を有する塩基配列
(c)配列番号2で示された塩基配列又は配列番号2で示された塩基配列と80%以上の相同性を有する塩基配列
(d)配列番号2と相補的な塩基配列又は配列番号2と相補的な塩基配列と80%以上の相同性を有する塩基配列
(e)配列番号3で示された塩基配列又は配列番号3で示された塩基配列と80%以上の相同性を有する塩基配列
(f)配列番号3と相補的な塩基配列又は配列番号3と相補的な塩基配列と80%以上の相同性を有する塩基配列
(g)配列番号4で示された塩基配列又は配列番号4で示された塩基配列と80%以上の相同性を有する塩基配列
(h)配列番号4と相補的な塩基配列又は配列番号4と相補的な塩基配列と80%以上の相同性を有する塩基配列
(i)配列番号5で示された塩基配列又は配列番号5で示された塩基配列と80%以上の相同性を有する塩基配列
(j)配列番号5と相補的な塩基配列又は配列番号5と相補的な塩基配列と80%以上の相同性を有する塩基配列
(k)配列番号6で示された塩基配列又は配列番号6で示された塩基配列と80%以上の相同性を有する塩基配列
(l)配列番号6と相補的な塩基配列又は配列番号6と相補的な塩基配列と80%以上の相同性を有する塩基配列
(m)配列番号7で示された塩基配列又は配列番号7で示された塩基配列と80%以上の相同性を有する塩基配列
(n)配列番号7と相補的な塩基配列又は配列番号7と相補的な塩基配列と80%以上の相同性を有する塩基配列
(o)配列番号8で示された塩基配列又は配列番号8で示された塩基配列と80%以上の相同性を有する塩基配列
(p)配列番号8と相補的な塩基配列又は配列番号8と相補的な塩基配列と80%以上の相同性を有する塩基配列
(q)配列番号9で示された塩基配列又は配列番号9で示された塩基配列と80%以上の相同性を有する塩基配列
(r)配列番号9と相補的な塩基配列又は配列番号9と相補的な塩基配列と80%以上の相同性を有する塩基配列
(s)配列番号10で示された塩基配列又は配列番号10で示された塩基配列と80%以上の相同性を有する塩基配列
(t)配列番号10と相補的な塩基配列又は配列番号10と相補的な塩基配列と80%以上の相同性を有する塩基配列
(u)配列番号11で示された塩基配列又は配列番号11で示された塩基配列と80%以上の相同性を有する塩基配列
(v)配列番号11と相補的な塩基配列又は配列番号11と相補的な塩基配列と80%以上の相同性を有する塩基配列
(w)配列番号12で示された塩基配列又は配列番号12で示された塩基配列と80%以上の相同性を有する塩基配列
(x)配列番号12と相補的な塩基配列又は配列番号12と相補的な塩基配列と80%以上の相同性を有する塩基配列
(y)配列番号13で示された塩基配列又は配列番号13で示された塩基配列と80%以上の相同性を有する塩基配列
(z)配列番号13と相補的な塩基配列又は配列番号13と相補的な塩基配列と80%以上の相同性を有する塩基配列
(aa)配列番号14で示された塩基配列又は配列番号14で示された塩基配列と80%以上の相同性を有する塩基配列
(ab)配列番号14と相補的な塩基配列又は配列番号14と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ac)配列番号15で示された塩基配列又は配列番号15で示された塩基配列と80%以上の相同性を有する塩基配列
(ad)配列番号15と相補的な塩基配列又は配列番号15と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ae)配列番号16で示された塩基配列又は配列番号16で示された塩基配列と80%以上の相同性を有する塩基配列
(af)配列番号16と相補的な塩基配列又は配列番号16と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ag)配列番号17で示された塩基配列又は配列番号17で示された塩基配列と80%以上の相同性を有する塩基配列
(ah)配列番号17と相補的な塩基配列又は配列番号17と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ai)配列番号18で示された塩基配列又は配列番号18で示された塩基配列と80%以上の相同性を有する塩基配列
(aj)配列番号18と相補的な塩基配列又は配列番号18と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ak)配列番号19で示された塩基配列又は配列番号19で示された塩基配列と80%以上の相同性を有する塩基配列
(al)配列番号19と相補的な塩基配列又は配列番号19と相補的な塩基配列と80%以上の相同性を有する塩基配列
【発明の効果】
【0006】
本発明により、哺乳動物由来の検体の癌化度を評価する方法等が提供可能となる。
【図面の簡単な説明】
【0007】
【図1】図1は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号1で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget02_3_CpGまたは図下のバーのTarget02_3は、配列番号1で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号1におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号1で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0008】
【図2】図2は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号2で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget03_9_CpGまたは図下のバーのTarget03_9は、配列番号2で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号2におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号2で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0009】
【図3】図3は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号3で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget04_19_CpGまたは図下のバーのTarget04_19は、配列番号3で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号3におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号3で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0010】
【図4】図4は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号6で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget09_15_CpGまたは図下のバーのTarget09_15は、配列番号6で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号6におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号6で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0011】
【図5】図5は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号7で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget10_9_CpGまたは図下のバーのTarget10_9は、配列番号7で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号7におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号7で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0012】
【図6】図6は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号8で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget11_3_CpGまたは図下のバーのTarget11_3は、配列番号8で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号8におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号8で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【図7】図7は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号9で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget12_3_CpGまたは図下のバーのTarget12_3は、配列番号9で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号9におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号9で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0013】
【図8】図8は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号10で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget15_4_CpGまたは図下のバーのTarget15_4は、配列番号10で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号10におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号10で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0014】
【図9】図9は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号11で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget18_1_CpGまたは図下のバーのTarget18_1は、配列番号11で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号11におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号11で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0015】
【図10】図10は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号12で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget19_2_CpGまたは図下のバーのTarget19_2は、配列番号12で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号12におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号12で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0016】
【図11】図11は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号13で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget21_13_CpGまたは図下のバーのTarget21_13は、配列番号13で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号13におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号13で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0017】
【図12】図12は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号14で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget23_11_CpGまたは図下のバーのTarget23_11は、配列番号14で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号14におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号14で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0018】
【図13】図13は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号16で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget40_18_CpGまたは図下のバーのTarget40_18は、配列番号16で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号16におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号16で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0019】
【図14】図14は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号17および配列番号18で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget41_10_CpGまたは図下のバーのTarget41_10は、配列番号17で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号17におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号17で示される塩基配列におけるメチル化されうるシトシンの位置を示す。Target41_17は、配列番号18で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号18におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号18で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0020】
【図15】図15は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号19で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget44_9_CpGまたは図下のバーのTarget44_9は、配列番号19で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号19におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号19で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0021】
【図16】図16は、ヒト肺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)について配列番号1で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget02_3_CpGまたは図下のバーのTarget02_3は、配列番号1で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号1におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号1で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)におけるCGのメチル化割合はヒト肺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0022】
【図17】図17は、ヒト肺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)について配列番号3で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget04_19_CpGまたは図下のバーのTarget04_19は、配列番号3で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号3におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号3で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)におけるCGのメチル化割合はヒト肺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【図18】図18は、ヒト肺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)について配列番号4で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget06_21_CpGまたは図下のバーのTarget06_21は、配列番号4で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号4におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号4で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)におけるCGのメチル化割合はヒト肺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0023】
【図19】図19は、ヒト肺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)について配列番号6で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget09_15_CpGまたは図下のバーのTarget09_15は、配列番号6で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号6におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号6で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)におけるCGのメチル化割合はヒト肺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0024】
【図20】図20は、ヒト肺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)について配列番号8で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget11_3_CpGまたは図下のバーのTarget11_3は、配列番号8で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号8におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号8で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)におけるCGのメチル化割合はヒト肺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0025】
【図21】図21は、ヒト肺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)について配列番号10で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget15_4_CpGまたは図下のバーのTarget15_4は、配列番号10で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号10におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号10で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)におけるCGのメチル化割合はヒト肺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0026】
【図22】図22は、ヒト肺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)について配列番号11で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget18_1_CpGまたは図下のバーのTarget18_1は、配列番号11で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号11におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号11で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)におけるCGのメチル化割合はヒト肺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【図23】図23は、ヒト肺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)について配列番号12で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget19_2_CpGまたは図下のバーのTarget19_2は、配列番号12で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号12におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号12で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)におけるCGのメチル化割合はヒト肺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0027】
【図24】図24は、ヒト肺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)について配列番号13で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget21_13_CpGまたは図下のバーのTarget21_13は、配列番号13で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号13におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号13で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)におけるCGのメチル化割合はヒト肺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0028】
【図25】図25は、ヒト肺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)について配列番号15で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget33_9_CpGまたは図下のバーのTarget39_9は、配列番号15で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号15におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号15で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)におけるCGのメチル化割合はヒト肺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0029】
【図26】図26は、ヒト肺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)について配列番号16で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget40_18_CpGまたは図下のバーのTarget40_18は、配列番号16で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号16におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号16で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)におけるCGのメチル化割合はヒト肺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【図27】図27は、ヒト肺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)について配列番号19で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget44_9_CpGまたは図下のバーのTarget44_9は、配列番号19で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号19におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号19で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)におけるCGのメチル化割合はヒト肺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0030】
【図28】図28は、ヒト大腸健常組織ゲノムDNAサンプル(N01およびN02)およびヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号1で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget02_3_CpGまたは図下のバーのTarget02_3は、配列番号1で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号1におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号1で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト大腸健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0031】
【図29】図29は、ヒト大腸健常組織ゲノムDNAサンプル(N01およびN02)およびヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号3で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget04_19_CpGまたは図下のバーのTarget04_19は、配列番号3で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号3におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号3で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト大腸健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0032】
【図30】図30は、ヒト大腸健常組織ゲノムDNAサンプル(N01およびN02)およびヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号5で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget08_6_CpGまたは図下のバーのTarget08_6は、配列番号5で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号5におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号5で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト大腸健常組織ゲノムDNA(N01およびN02)に比して高かった。
【図31】図31は、ヒト大腸健常組織ゲノムDNAサンプル(N01およびN02)およびヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号6で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget09_15_CpGまたは図下のバーのTarget09_15は、配列番号6で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号6におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号6で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト大腸健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0033】
【図32】図32は、ヒト大腸健常組織ゲノムDNAサンプル(N01およびN02)およびヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号7で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget10_9_CpGまたは図下のバーのTarget10_9は、配列番号7で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号7におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号7で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト大腸健常組織ゲノムDNA(N01およびN02)に比して高かった。
【図33】図33は、ヒト大腸健常組織ゲノムDNAサンプル(N01およびN02)およびヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号9で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget12_3_CpGまたは図下のバーのTarget12_3は、配列番号9で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号9におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号9で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト大腸健常組織ゲノムDNA(N01およびN02)に比して高かった。
【図34】図34は、ヒト大腸健常組織ゲノムDNAサンプル(N01およびN02)およびヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号10で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget15_4_CpGまたは図下のバーのTarget15_4は、配列番号10で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号10におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号10で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト大腸健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0034】
【図35】図35は、ヒト大腸健常組織ゲノムDNAサンプル(N01およびN02)およびヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号11で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget18_1_CpGまたは図下のバーのTarget18_1は、配列番号11で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号11におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号11で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト大腸健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0035】
【図36】図36は、ヒト大腸健常組織ゲノムDNAサンプル(N01およびN02)およびヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号12で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget19_2_CpGまたは図下のバーのTarget19_2は、配列番号12で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号12におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号12で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト大腸健常組織ゲノムDNA(N01およびN02)に比して高かった。
【図37】図37は、ヒト大腸健常組織ゲノムDNAサンプル(N01およびN02)およびヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号13で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget21_13_CpGまたは図下のバーのTarget21_13は、配列番号13で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号13におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号13で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト大腸健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0036】
【図38】図38は、ヒト大腸健常組織ゲノムDNAサンプル(N01およびN02)およびヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号14で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget23_11_CpGまたは図下のバーのTarget23_11は、配列番号14で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号14におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号14で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト大腸健常組織ゲノムDNA(N01およびN02)に比して高かった。
【図39】図39は、ヒト大腸健常組織ゲノムDNAサンプル(N01およびN02)およびヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号15で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget33_9_CpGまたは図下のバーのTarget33_9は、配列番号15で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号15におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号15で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト大腸健常組織ゲノムDNA(N01およびN02)に比して高かった。
【発明を実施するための形態】
【0037】
以下に本発明を詳細に説明する。
本発明は、癌マーカー(例えば、大腸癌マーカー、乳癌マーカー、肺癌マーカー等)としての、メチル化されたDNAの使用等に関連する発明である。
【0038】
本発明における「癌」は、例えば、肺癌(非小細胞肺癌、小細胞肺癌)、食道癌、胃癌、十二指腸癌、大腸癌、直腸癌、肝癌(肝細胞癌、胆管細胞癌)、胆嚢癌、胆管癌、膵癌、結腸癌、肛門癌、乳癌、子宮頸癌、子宮体癌、子宮癌、卵巣癌、外陰癌、膣癌、前立腺癌、腎臓癌、尿管癌、膀胱癌、前立腺癌、陰茎癌、精巣(睾丸)癌、上顎癌、舌癌、(上、中、下)咽頭癌、喉頭癌、急性骨髄性白血病、慢性骨髄性白血病、急性リンパ性白血病 、慢性リンパ性白血病、悪性リンパ腫、骨髄異形成症候群、甲状腺癌、脳腫瘍、骨肉腫、皮膚癌(基底細胞癌、有棘細胞癌)等の、哺乳動物の臓器で発症する固形癌と、哺乳動物の血液で発症する非固形癌のいずれの癌も含む。
尚、本発明において、癌を発症した被験者を「癌患者」と記載し、癌を発症していない被験者を「非癌患者」と記載し、ヒトの組織の非癌部位又は癌を発症していない被験者から採取した組織を「正常組織」と記載し、癌を発症していない被験者から採取した血液を「正常血液」と記載することもある。
【0039】
本発明における「癌マーカー」としては、例えば、哺乳動物において癌が発生している組織及びその癌化度を間接的に把握しうる指標を挙げることができる。具体的には例えば、大腸癌マーカーとしては、大腸の癌の有無及び大腸癌の癌化度、癌の良性若しくは悪性等と記載される癌の性質等を間接的に把握できる生体物質からなる指標を挙げることができる。
【0040】
本発明においてマーカーDNAとして用いられるDNAとしては、下記の塩基配列から選ばれる少なくとも1つを有するのDNA(以下、本発明DNAという場合がある)を挙げることができる。
(a)配列番号1(Genbank Accession No. NT_022171.15, 12175690-12176178)で示された塩基配列又は配列番号1で示された塩基配列と80%以上の相同性を有する塩基配列
(b)配列番号1と相補的な塩基配列又は配列番号1と相補的な塩基配列と80%以上の相同性を有する塩基配列
(c)配列番号2(Genbank Accession No. NT_005403.17, 75486912-75487393, Homo sapiens )で示された塩基配列又は配列番号2で示された塩基配列と80%以上の相同性を有する塩基配列
(d)配列番号2と相補的な塩基配列又は配列番号2と相補的な塩基配列と80%以上の相同性を有する塩基配列
(e)配列番号3(Genbank Accession No. NT_005612.16, 53571894-53571566, Homo sapiens )で示された塩基配列又は配列番号3で示された塩基配列と80%以上の相同性を有する塩基配列
(f)配列番号3と相補的な塩基配列又は配列番号3と相補的な塩基配列と80%以上の相同性を有する塩基配列
(g)配列番号4(Genbank Accession No. NT_006576.16, 14316619-14316186, Homo sapiens )で示された塩基配列又は配列番号4で示された塩基配列と80%以上の相同性を有する塩基配列
(h)配列番号4と相補的な塩基配列又は配列番号4と相補的な塩基配列と80%以上の相同性を有する塩基配列
(i)配列番号5(Genbank Accession No. NT_029289.11, 10354292-10354661, Homo sapiens )で示された塩基配列又は配列番号5で示された塩基配列と80%以上の相同性を有する塩基配列
(j)配列番号5と相補的な塩基配列又は配列番号5と相補的な塩基配列と80%以上の相同性を有する塩基配列
(k)配列番号6(Genbank Accession No. NT_007592.15, 26661779-26661515, Homo sapiens )で示された塩基配列又は配列番号6で示された塩基配列と80%以上の相同性を有する塩基配列
(l)配列番号6と相補的な塩基配列又は配列番号6と相補的な塩基配列と80%以上の相同性を有する塩基配列
(m)配列番号7(Genbank Accession No. NT_113891.2, 256579-256958, Homo sapiens )で示された塩基配列又は配列番号7で示された塩基配列と80%以上の相同性を有する塩基配列
(n)配列番号7と相補的な塩基配列又は配列番号7と相補的な塩基配列と80%以上の相同性を有する塩基配列
(o)配列番号8(Genbank Accession No. NT_007592.15, 42159778-42160229, Homo sapiens )で示された塩基配列又は配列番号8で示された塩基配列と80%以上の相同性を有する塩基配列
(p)配列番号8と相補的な塩基配列又は配列番号8と相補的な塩基配列と80%以上の相同性を有する塩基配列
(q)配列番号9(Genbank Accession No. NT_007592.15, 55383171-55383670, Homo sapiens )で示された塩基配列又は配列番号9で示された塩基配列と80%以上の相同性を有する塩基配列
(r)配列番号9と相補的な塩基配列又は配列番号9と相補的な塩基配列と80%以上の相同性を示す塩基配列
(s)配列番号10(Genbank Accession No. NT_030059.13, 30491593-30491957, Homo sapiens )で示された塩基配列又は配列番号10で示された塩基配列と80%以上の相同性を有する塩基配列
(t)配列番号10と相補的な塩基配列又は配列番号10と相補的な塩基配列と80%以上の相同性を有する塩基配列
(u)配列番号11(Genbank Accession No. NT_033899.8, 28297833-28298273, Homo sapiens )で示された塩基配列又は配列番号11で示された塩基配列と80%以上の相同性を有する塩基配列
(v)配列番号11と相補的な塩基配列又は配列番号11と相補的な塩基配列と80%以上の相同性を有する塩基配列
(w)配列番号12(Genbank Accession No. NT_033899.8, 28298052-28298521, Homo sapiens )で示された塩基配列又は配列番号12で示された塩基配列と80%以上の相同性を有する塩基配列
(x)配列番号12と相補的な塩基配列又は配列番号12と相補的な塩基配列と80%以上の相同性を有する塩基配列
(y)配列番号13(Genbank Accession No. NT_011362.10, 24774687-24774253, Homo sapiens )で示された塩基配列又は配列番号13で示された塩基配列と80%以上の相同性を有する塩基配列
(z)配列番号13と相補的な塩基配列又は配列番号13と相補的な塩基配列と80%以上の相同性を有する塩基配列
(aa)配列番号14(Genbank Accession No. NT_011519.10, 2547951-2548291, Homo sapiens )で示された塩基配列又は配列番号14で示された塩基配列と80%以上の相同性を有する塩基配列
(ab)配列番号14と相補的な塩基配列又は配列番号14と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ac)配列番号15(Genbank Accession No. NT_004350.19, 1161852-1162153, Homo sapiens )で示された塩基配列又は配列番号15で示された塩基配列と80%以上の相同性を有する塩基配列
(ad)配列番号15と相補的な塩基配列又は配列番号15と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ae)配列番号16(Genbank Accession No. NT_016354.19, 5428867-5428472, Homo sapiens )で示された塩基配列又は配列番号16で示された塩基配列と80%以上の相同性を有する塩基配列
(af)配列番号16と相補的な塩基配列又は配列番号16と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ag)配列番号17(Genbank Accession No. NT_006576.16, 17509792-17510071, Homo sapiens )で示された塩基配列又は配列番号17で示された塩基配列と80%以上の相同性を有する塩基配列
(ah)配列番号17と相補的な塩基配列又は配列番号17と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ai)配列番号18(Genbank Accession No. NT_006576.16, 17509828-17509379, Homo sapiens )で示された塩基配列又は配列番号18で示された塩基配列と80%以上の相同性を有する塩基配列
(aj)配列番号18と相補的な塩基配列又は配列番号18と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ak)配列番号19(Genbank Accession No. NT_167187.1, 9763431, 9763927, Homo sapiens )で示された塩基配列又は配列番号19で示された塩基配列と80%以上の相同性を有する塩基配列
(al)配列番号19と相補的な塩基配列又は配列番号19と相補的な塩基配列と80%以上の相同性を有する塩基配列
【0041】
配列番号1〜19で示される塩基配列は、NCBI(National Center for Biotechnology Information)に登録されている塩基配列であり、これらは、NCBIのWEBペ−ジ(URL;http://www.ncbi.nlm.nih.gov)から、登録番号(Accession No)をもとに、データベースを検索することによって入手することができる。
【0042】
本発明DNAにおける、上記(a)〜(al)の塩基配列と80%以上の相同性を有する塩基配列としては、好ましくは90%以上、より好ましくは95%以上の配列相同性を有する塩基配列があげられる。また、上記塩基配列に、生物の種差、個体差若しくは器官、組織間の差異等により天然に生じる変異による塩基の欠失、置換若しくは付加が生じた塩基配列を有するDNAも含まれる。
【0043】
また、本発明DNAにおける、上記(a)〜(al)の塩基配列と相補的な塩基配列と80%以上の相同性を有する塩基配列としては、好ましくは、90%以上、より好ましくは95%以上の配列相同性を有する塩基配列があげられる。また、上記塩基配列に、生物の種差、個体差若しくは器官、組織間の差異等により天然に生じる変異による塩基の欠失、置換若しくは付加が生じた塩基配列を有するDNAも含まれる。
ここで、「相補的な塩基配列」とは、もとの塩基配列と塩基対を形成しうるような塩基配列をいい、「塩基対」とは、核酸の塩基のうち、アデニン(A)とチミン(T)、グアニン(G)とシトシン(C)が水素結合により対合したものをいう。
【0044】
哺乳動物では、遺伝子(ゲノムDNA)を構成する4種類の塩基のうち、シトシンのみがメチル化されるという現象がある。哺乳動物由来のゲノム上の塩基配列、例えば、配列番号1(Genbank Accession No. NT_022171.15, 12175690-12176178, Homo sapiens)で示される塩基配列を有するDNAでは、当該DNAのゲノムDNAの一部のシトシンがメチル化されている。そして、DNAのメチル化修飾は、5'-CG-3'で示される塩基配列(Cはシトシンを表し、Gはグアニンを表す。以下、当該塩基配列をCpGと記すこともある。)中のシトシンに限られる。シトシンにおいてメチル化される部位は、その5位である。細胞分裂に先立つDNA複製に際して、複製直後は鋳型鎖のCpG中のシトシンのみがメチル化された状態となるが、メチル基転移酵素の働きにより即座に新生鎖のCpG中のシトシンもメチル化される。従って、DNAのメチル化の状態は、DNA複製後も、新しい2組のDNAにそのまま引き継がれることになる。
【0045】
本発明評価方法の第一工程において「メチル化頻度」とは、例えば、調査対象となるCpG中のシトシンのメチル化の有無を複数のハプロイドについて調べたときの、当該シトシンがメチル化されているハプロイドの割合で表される。
また本発明評価方法の第一工程において「(メチル化頻度)に相関関係がある指標値」とは、例えば、配列番号1(Genbank Accession No. NT_022171.15, 12175690-12176178, Homo sapiens)で示される塩基配列を有するDNAの下流の遺伝子の発現産物の量(より具体的には、当該遺伝子の転写産物の量)等をあげることができる。このような発現産物の量の場合には、上記メチル化頻度が高くなればそれに伴い減少するような負の相関関係が存在する。
【0046】
本発明評価方法の第一工程における哺乳動物由来の検体としては、生体試料をそのまま検体として用いてもよく、また、かかる生体試料から分離、分画、固定化等の種々の操作により調製された生体試料を検体として用いてもよい。このような検体としては、例えば、(a)哺乳動物由来の血液、体液、糞尿、体分泌物、細胞溶解液又は組織溶解液、(b)哺乳動物由来の血液、体液、糞尿、体分泌物、細胞溶解液及び組織溶解液からなる群より選ばれる一から抽出されたDNA、(c)哺乳動物由来の組織、細胞、組織溶解液及び細胞溶解液からなる群より選ばれる一から抽出されたRNAを鋳型として作製されたDNA等を挙げることができる。尚、前記組織とは、血液、リンパ節等を含む広義の意味であり、前記体液とは血漿、血清、リンパ液等を意味し、前記体分泌物とは尿や乳汁等を意味する。
癌が大腸癌である場合、被験動物から採取された大腸組織等をあげることができる。また、癌が乳癌である場合、被験動物から採取された乳房組織等をあげることができる。癌が肺癌である場合、被験動物から採取された肺組織等をあげることができる。哺乳動物由来の検体が血液、体液又は体分泌物等である場合には、定期健康診断や簡便な検査等で採取したものを利用することができる。
【0047】
本発明における「哺乳動物」としては、哺乳動物に属する動物の全てを挙げることができる。哺乳動物に属する動物とは、動物界 脊索動物門 脊椎動物亜門 哺乳綱(Mammalia)に分類される動物の総称である。より具体的には例えば、ヒト、サル、マーモセット、モルモット、ラット、マウス、ウシ、ヒツジ、イヌ、ネコ等を挙げることができる。
【0048】
本発明における「体液」としては、例えば、血漿や間質液のような、固体を構成する細胞間に存在する液体(多くの場合、固体の恒常性の維持機能を果たす)を挙げることができる。具体的には例えば、リンパ液、組織液(組織間液、細胞間液、間質液)、体腔液、漿膜腔液、胸水、腹水、心嚢液、脳脊髄液(髄液)、関節液(滑液)、眼房水(房水)、脳脊髄液、子宮内浸出液等を挙げることができる。
【0049】
本発明における「体分泌液」としては、例えば、外分泌腺からの分泌液を挙げることができる。具体的には例えば、唾液、胃液、胆汁、腸液、汗、涙、鼻水、精液、膣液、羊水、乳汁等挙げることができる。
【0050】
本発明における「細胞溶解液」としては、例えば、細胞培養用の10cmプレート等で培養した細胞(即ち、細胞株、初代培養細胞、血球細胞等)を破壊することにより得られる細胞内液を含む溶解液を挙げることができる。
ここで、細胞膜を破壊する方法としては、例えば、超音波による方法、界面活性剤を用いる方法、アルカリ溶液を用いる方法等を挙げることができる。尚、細胞を溶解するためには、様々な市販キット等を利用してもよい。
具体的には例えば、10cmプレートでコンフルエントになるまで細胞を培養した後、培養液を捨てて、0.6mLのRIPAバッファー(1× TBS, 1% nonidet P-40, 0.5% sodium deo×ysholate, 0.1% SDS, 0.004% sodium azide)を10cmプレートに加える。4℃で15分間プレートをゆっくり揺り動かしてから、10cmプレート上の接着細胞を、スクレーパー等を用いて剥がし、プレート上の溶解液をマイクロチューブに移す。溶解液の1/10容量の10mg/mL PMSFを添加してから、氷上で30〜60分間放置する。4℃で10分間、10,000×gで遠心することにより、上清を細胞溶解液として取得すればよい。
【0051】
本発明における「組織溶解液」としては、例えば、哺乳動物等の動物から採取した組織中の細胞を破壊することにより得られる細胞内液を含む溶解液を挙げることができる。
具体的には例えば、哺乳動物から取得した組織の重量を測定した後、カミソリ等を用いて組織を小片に裁断する。凍結組織をスライスする場合には、更に小さい小片にする必要がある。裁断後、氷冷RIPAバッファー(プロテアーゼインヒビター、フォスファターゼインヒビター等を添加してもよく、例えば、RIPAバッファーの1/10容量の10mg/mL PMSFを添加しても良い)を組織1gあたり3mLの比率で添加し、4℃でホモジナイズする。ホモジナイズには、ソニケーターや加圧型細胞破砕装置を用いる。ホモジナイズの作業では、溶液を常に4℃に維持し、発熱を抑えるようにする。ホモジナイズ液を、マイクロチューブに移して、4℃で10分間、10,000×gで遠心することにより、上清を組織溶解液として取得する。
【0052】
本発明評価方法の第一工程において、哺乳動物由来の検体に含まれる本発明DNAのメチル化頻度又はそれに相関関係がある指標値を測定する方法は、例えば、以下のように行えばよい。
【0053】
第一の方法として、哺乳動物由来の検体から、例えば、市販のDNA抽出用キット等を用いてDNAを抽出する。
因みに、血液を検体として用いる場合には、血液から通常の方法に準じて血漿又は血清を調製し、調製された血漿又は血清を検体としてその中に含まれる遊離DNA(大腸癌細胞等の癌細胞由来のDNAが含まれる)を分析すると、血球由来のDNAを避けて大腸癌細胞等の癌細胞由来のDNAを解析することができ、大腸癌細胞等の癌細胞、それを含む組織等を検出する感度を向上させることができる。
次いで、抽出されたDNAを、非メチル化シトシンを修飾する試薬と接触させた後、本発明DNAのプロモーター領域、非翻訳領域又は翻訳領域(コーディング領域)の塩基配列中に存在する一つ以上のCpGで示される塩基配列中のシトシンを含むDNAを、解析対象とするシトシンのメチル化の有無を識別可能なプライマーを用いてポリメラーゼチェイン反応(以下、PCRと記す。)で増幅し、得られる増幅産物の量を調べる。
【0054】
非メチル化シトシンを修飾する試薬(即ち、メチル化シトシンを修飾せずに非メチル化シトシンを選択的に修飾する試薬)としては、シトシンと5-メチルシトシンとの化学的性質の違いを利用することにより非メチル化シトシンを修飾する試薬であればよく、例えば、亜硫酸水素ナトリウム等の重亜硫酸塩(bisulfite)等を用いることができる。因みに、原理的には、メチル化シトシンのみを特異的に修飾する試薬を用いても良い。
【0055】
非メチル化シトシンを修飾する試薬に抽出されたゲノムDNA試料を可能な限り均一に接触させるには、ゲノムDNAの変性を行う必要がある。例えば、まず当該DNAをアルカリ溶液(pH9〜14)で変性した後、亜硫酸水素ナトリウム等の重亜硫酸塩(bisulfite)(溶液中の濃度:例えば、終濃度3M)等で約10〜16時間(一晩)程度、55℃で処理する。反応を促進するため、95℃での変性と、50℃での反応を10-20回繰り返すことも出来る。この場合、メチル化されていないシトシンはウラシルに変換され、一方、メチル化されているシトシンはウラシルに変換されず、シトシンのままである(Furuichiら、Biochem. Biophys. Res. Commun. 41:1185〜1191、1970)。
【0056】
亜硫酸水素ナトリウム等の重亜硫酸塩での処理に次いで、塩基配列中に存在する一つ以上のCpGで示される塩基配列中のシトシンを含むDNAを、解析対象とするシトシンのメチル化の有無を識別可能なプライマーを用いてPCR法で増幅し、得られる増幅産物の量を調べればよい。
重亜硫酸塩等で処理されたDNAを鋳型とし、且つ、メチル化されたシトシンが含まれる場合の塩基配列[メチル化される位置のシトシン(CpG中のシトシン)はシトシンのままであり、メチル化されていないシトシン(CpGに含まれないシトシン)はウラシルとなった塩基配列]とかかる塩基配列に対して相補的な塩基配列からそれぞれ選ばれる一対のメチル化特異的プライマーを用いるPCR(以下、メチル化特異的PCRとも記すこともある。)と、重亜硫酸塩等で処理されたDNAを鋳型とし、且つ、シトシンがメチル化されていない場合の塩基配列(全てのシトシンがウラシルとなった塩基配列)とかかる塩基配列に対して相補的な塩基配列からそれぞれ選ばれる一対の非メチル化特異的プライマーを用いるPCR(以下、非メチル化特異的PCRとも記すこともある。)とを行う。
【0057】
上記PCRにおいて、メチル化特異的プライマーを用いるPCRの場合(前者)には、解析対象とするシトシンがメチル化されているDNAが増幅され、一方、非メチル化特異的プライマーを用いるPCRの場合(後者)には、解析対象とするシトシンがメチル化されていないDNAが増幅される。これらの増幅産物の量を比較することにより、対象となるシトシンのメチル化の有無を調べる。このようにしてメチル化頻度を測定することができる。
【0058】
ここで、メチル化特異的プライマーは、メチル化を受けていないシトシンがウラシルに変換され、且つ、メチル化を受けているシトシンはウラシルに変換されないことを考慮して、メチル化を受けているシトシンを含む塩基配列に特異的なPCRプライマー(メチル化特異的プライマー)を設計し、また、メチル化を受けていないシトシンを含む塩基配列に特異的なPCRプライマー(非メチル化特異的プライマー)を設計する。重亜硫酸塩処理により化学的に変換され相補的ではなくなったDNA鎖を基に設計することから、元来二本鎖であったDNAのそれぞれの鎖を基に、それぞれからメチル化特異的プライマーと非メチル化特異的プライマーとを作製することもできる。かかるプライマーは、メチル、非メチルの特異性を高めるために、プライマーの3'末端近傍にCpG中のシトシンを含むように設計することが好ましい。また、解析を容易にするために、プライマーの一方を標識してもよい。
【0059】
メチル化特異的PCRにおける反応液としては、例えば、鋳型とするDNAを50ngと、10pmol/μlの各プライマー溶液を各1μlと、2.5mM dNTPを4μlと、10×緩衝液(100mM Tris-HCl pH8.3、500mM KCl、20mM MgCl2)を2.5μlと、耐熱性DNAポリメラーゼ 5U/μlを0.2μlとを混合し、これに滅菌超純水を加えて液量を25μlとした反応液をあげることができる。反応条件としては、例えば、前記のような反応液を、95℃にて10分間保温した後、95℃にて30秒間次いで55〜65℃にて30秒間さらに72℃にて30秒間を1サイクルとする保温を30〜40サイクル行う条件があげられる。
かかるPCRを行った後、得られた増幅産物の量を比較する。例えば、メチル化特異的プライマーを用いたPCRと非メチル化特異的プライマーを用いたPCRで得られた各々の増幅産物の量を比較することができる分析方法(変性ポリアクリルアミドゲル電気泳動やアガロースゲル電気泳動)である場合には、電気泳動後のゲルをDNA染色して増幅産物のバンドを検出し、検出されたバンドの濃度を比較する。ここでDNA染色の代わりに予め標識されたプライマーを使用してその標識を指標としてバンドの濃度を比較することもできる。また、定量を必要とする場合には、PCR反応産物をリアルタイムでモニタリングしカイネティックス分析を行うことにより、例えば、遺伝子量に関して2倍程度のほんの僅かな差異をも検出できる高精度の定量が可能なPCR法であるリアルタイムPCRを用いて、それぞれの産物の量を比較することもできる。リアルタイムPCRを行う方法としては、例えば鋳型依存性核酸ポリメラーゼプローブ等のプローブを用いる方法又はサイバーグリーン等のインターカレーターを用いる方法等が挙げられる。リアルタイムPCR法のための装置及びキットは既に市販されている。
【0060】
第二の方法として、亜硫酸水素ナトリウム等の重亜硫酸塩での処理に次いで、蛍光に基づくリアルタイムPCR(米国特許第6,331,393号;Eadsら、Nucleic Acids Res. 28:E32、2000)(以下、メチライト法という場合がある)を利用すすることもできる。メチライト法では、5'末端に蛍光レポーター色素を有し、かつ、3'末端に消光色素を有する位置特異的PCRプライマーを用い、蛍光に基づくリアルタイム定量的PCRによりメチル化DNAを増幅する。PCR反応の間に蛍光レポーター色素が、酵素によって放出されるため、PCR産物の量に比例し蛍光強度が増加する。従ってメチル化の程度に比例する蛍光を、自動ヌクレオチドシーケンサー装置において連続的に検出することができる。
【0061】
第三の方法として、亜硫酸水素ナトリウム等の重亜硫酸塩での処理に次いで、シークエンシングすることもできる。
一般的には、ゲノムDNA試料の変性と亜硫酸水素塩による処理に続いて、プライマー伸張によってdsDNAを取得し、さらに、PCR技術によって増幅する(Clarkら、Nucl. Acids Res. 22:2990〜2997、1994)方法である。次に、当該PCR産物を標準的なDNAシークエンシング法によって配列を決定しシトシン(亜硫酸水素塩による処理前のメチルシトシンに相当する)を検出する。シークエンス法としては、ジデオキシ法だけでなく、パイロシークエンス法(SOLiDシステム)等の方法であっても、塩基配列を決定する方法であれば何でもよい。
または前記PCR産物をプラスミドベクターにクローニングした後、個々のクローンをシークエンシングすることができるが、単一のDNA分子のメチル化マップを提供することも可能である。シークエンスによりメチルシトシンを決定するための幾つかの変法(Radlinska&Skowronek、Acta Microbiol. Pol. 47:327〜334、1998)が知られている。
【0062】
具体的に、dsDNAをPCR法により増幅して塩基配列を決定するために、PCRにおける反応液としては、例えば、鋳型とする重亜硫酸ナトリウム処理したDNA溶液をDNAが20ng又は80ng相当含まれる総液量50μLの反応液を調製し、これを用いればよい。具体的には、鋳型とする重亜硫酸ナトリウム処理したDNA溶液と、5μMに調製された各オリゴヌクレオチドプライマー溶液とを夫々総液量の3/5と、GeneAmpR dNTP Mi×(2 mM each)を総液量の1/10と、10×緩衝液(100 mM Tris-HCl pH 8.3、500 mM KCl、15 mM MgCl2、0.01% Gelatin)5μLを総液量の1/10と、25 mM MgCl2溶液を総液量の1/50と、耐熱性DNAポリメラーゼ(AmpliTaq Gold、5 U/μL、ABI社製)を0.25μLと、滅菌超純水とを混合することにより、総液量50μLの反応液を調製すればよい。当該反応液を、95℃にて10分間保温した後、95℃にて30秒間次いで55℃にて30秒間更に72℃にて45秒間を1サイクルとする保温を40サイクル行う条件でPCRすればよい。
【0063】
PCRを行った後、1.5%アガロースゲル電気泳動により増幅を確認した後、得られたDNA断片についてクローニングを行えばよい。
【0064】
クローニングにはTOPO TA CloningR Kit For Sequencing(インビトロジェン社)を使用すればよい。Salt Solutionを0.4μLと、TOPO vectorを0.4μLと、前記のPCR増幅産物を1.6μLとを氷上で混合し、これを室温で5分間静置した。ライゲーション反応液を2μLとコンピテントセルを50μLとを混合し、氷中に30分間静置する。静置後、42℃で30秒間インキュベートし、氷中に保存すればよい。反応液にSOC培地を250μL加え振盪培養(37℃、225rpm、1時間)する。X-gal溶液(10mg/mL DMF)を100μLを塗布したLBプレート(アンピシリン終濃度50μg/mL)に、培養液を塗布し、培養(37℃、18時間)すればよい。
【0065】
培養液を塗布し、培養したLBプレート上に得られる大腸菌コロニーのうち、白色のコロニーを、爪楊枝でピックアップし、2mLのLB培地(アンピシリン終濃度50μg/mL)でさらに培養(37℃、15時間)し、得られた大腸菌からプラスミド抽出装置(PI-50、KURABO)を用いてプラスミドを抽出すれば、プラスミド溶液を取得できる。
【0066】
当該プラスミド溶液を2μLと、BigDyeRTerminator v3.1 Cycle Sequencing RR-100(ABI社)を1μLと、BigDyeRTerminator v1.1/v3.1 Sequencing Buffer(5×)(ABI社)を2μLと、シークエンス反応のために設計されたオリゴヌクレオチドプライマー(M13R)の3.2μM溶液を1μLと、滅菌超純水を4μLとを混合する。当該反応液を、96℃にて1分間保温した後、96℃にて10秒間次いで50℃にて5秒間更に60℃にて4分間を1サイクルとする保温を25サイクル行う条件でシークエンス反応をおこなえばよい。
【0067】
PCRにおける反応液としては、例えば、鋳型とするDNAを25ngと、20pmol/μlの各プライマー溶液を各1μlと、2mM dNTPを3μlと、10×緩衝液(100mM Tris-HCl pH 8.3、500mM KCl、15mM MgCl2)を2.5μlと、耐熱性DNAポリメラーゼ 5U/μlを0.2μlとを混合し、これに滅菌超純水を加えて液量を25μlとした反応液をあげることができる。反応条件としては、例えば、前記のような反応液を、95℃にて10分間保温した後、95℃にて30秒間次いで53℃にて30秒間さらに72℃にて30秒間を1サイクルとする保温を30〜40サイクル行う条件があげられる。
かかるPCRを行った後、得られた増幅産物の塩基配列を比較し当該比較からメチル化頻度を測定する。
即ち、当該増幅産物の塩基配列を直接的に解析することにより、解析対象とするシトシンに相当する位置の塩基がシトシンであるかチミン(ウラシル)であるかを判定する。得られた増幅産物における塩基を示すピークのチャートにおいて、解析対象とするシトシンに相当する位置に検出されたシトシンを示すピークの面積とチミン(ウラシル)を示すピークの面積とを比較することにより、解析対象となるシトシンのメチル化の頻度を測定することができる。また、塩基配列を直接的に解析する方法として、PCRで得られた増幅産物を一旦大腸菌等を宿主としてクローニングして得られた複数のクローンから、それぞれクローニングされたDNAを調製し、当該DNAの塩基配列を解析してもよい。解析される試料のうちの解析対象とするシトシンに相当する位置に検出された塩基がシトシンである試料の割合を求めることにより、解析対象となるシトシンのメチル化の頻度を測定することもできる。
【0068】
第四の方法として、目的とするDNAの塩基配列中に存在する一つ以上のCpGで示される塩基配列中のシトシンを含むDNAと、解析対象とするシトシンのメチル化の有無を識別可能なプローブとをハイブリダイゼーションさせ、前記DNAと当該プローブとの結合の有無を調べることもできる。
【0069】
具体的には、検体から抽出したゲノムDNAを、非メチル化シトシンを修飾する試薬を作用させてから、シトシンのメチル化の有無を識別可能なプローブをハイブリダイゼーションさせる方法が挙げられる。当該ハイブリダイゼーションに用いられるプローブは、解析対象とするシトシンを含む塩基配列を基にして、メチル化を受けていないシトシンがウラシルに変換され、且つ、メチル化を受けているシトシンはウラシルに変換されないことを考慮して設計するとよい。即ち、メチル化されたシトシンが含まれる場合の塩基配列[メチル化される位置のシトシン(CpG中のシトシン)はシトシンのままであり、メチル化されていないシトシン(CpGに含まれないシトシン)はウラシルとなった塩基配列]又はかかる塩基配列に対して相補的な塩基配列を有するメチル化特異的プローブと、シトシンがメチル化されていない場合の塩基配列(全てのシトシンがウラシルとなった塩基配列)又はかかる塩基配列に対して相補的な塩基配列を有する非メチル化特異的プローブを設計する。尚、このようなプローブは、DNAとプローブとの結合の有無についての解析を容易にするために標識してから用いてもよい。またプローブを通常の方法に準じて担体上に固定して用いてもよいが、この場合には、哺乳動物由来の検体から抽出されたDNAを予め標識しておくとよい。
【0070】
非メチル化シトシンを修飾する試薬としては、例えば、亜硫酸水素ナトリウム等の重亜硫酸塩(bisulfite)等を用いることができる。因みに、原理的には、メチル化シトシンのみを特異的に修飾する試薬を用いてもよい。
【0071】
非メチル化シトシンを修飾する試薬に抽出されたDNAを接触させるには、例えば、まず当該DNAをアルカリ溶液(pH9〜14)で変性した後、亜硫酸水素ナトリウム等の重亜硫酸塩(bisulfite)(溶液中の濃度:例えば、終濃度3M)等で約10〜16時間(一晩)程度、55℃で処理する。反応を促進するため、95℃での変性と、50℃での反応を10-20回繰り返すことも出来る。この場合、メチル化されていないシトシンはウラシルに変換され、一方、メチル化されているシトシンはウラシルに変換されず、シトシンのままである。
必要に応じて、重亜硫酸塩等で処理されたDNAを鋳型として第二の方法と同様にPCRを行うことにより当該DNAを予め増幅させておいてもよい。
次いで、重亜硫酸塩等で処理されたDNA又は前記PCRで予め増幅されたDNAと、解析対象とするシトシンのメチル化の有無を識別可能なプローブとのハイブリダイゼーションを行う。メチル化特異的プローブと結合するDNAの量と、非メチル化特異的プローブと結合するDNAの量とを比較することにより、解析対象となるシトシンのメチル化の頻度を測定することができる。
【0072】
ハイブリダイゼーションは、例えば、Sambrook J., Frisch E. F., Maniatis T.著、モレキュラークローニング第2版(Molecular Cloning 2nd edition)、コールド スプリング ハーバー ラボラトリー発行(Cold Spring Harbor Laboratory press)等に記載される通常の方法に準じて行うことができる。ハイブリダイゼーションは、通常ストリンジェントな条件下に行われる。ここで「ストリンジェントな条件下」とは、例えば、6×SSC(1.5M NaCl、0.15M クエン酸三ナトリウムを含む溶液を10×SSCとする)を含む溶液中で45℃にてハイブリッドを形成させた後、2×SSCで50℃にて洗浄するような条件(Molecular Biology, John Wiley & Sons, N. Y. (1989), 6.3.1-6.3.6)等を挙げることができる。洗浄ステップにおける塩濃度は、例えば、2×SSCで50℃の条件(低ストリンジェンシーな条件)から0.2×SSCで50℃までの条件(高ストリンジェンシーな条件)から選択することができる。洗浄ステップにおける温度は、例えば、室温(低ストリンジェンシーな条件)から65℃(高ストリンジェンシーな条件)から選択することができる。また、塩濃度と温度との両方を変えることもできる。
かかるハイブリダイゼーションを行った後、メチル化特異的プローブと結合したDNAの量と、非メチル化特異的プローブと結合したDNAの量とを比較することにより、解析対象となるシトシン(即ち、プローブの設計の基となった塩基配列に含まれるCpG中のシトシン)のメチル化の頻度を測定することができる。
【0073】
第五の方法として、目的とするDNAの塩基配列中の、解析対象とするシトシンのメチル化の有無を識別可能な制限酵素に作用させた後、当該制限酵素による消化の有無を調べる方法をあげることもできる。
【0074】
当該方法で用いられる「シトシンのメチル化の有無を識別可能な制限酵素」(以下、メチル化感受性制限酵素と記すこともある。)とは、メチル化されたシトシンを含む認識配列を消化せず、メチル化されていないシトシンを含む認識配列を消化することのできる制限酵素を意味する。即ち、メチル化感受性制限酵素が本来認識することができる「認識配列」に含まれるシトシンがメチル化されているDNAの場合、メチル化感受性制限酵素を作用させても当該DNAは切断されず、一方、メチル化感受性制限酵素が本来認識することができる「認識配列」に含まれるシトシンがメチル化されていないDNAの場合、メチル化感受性制限酵素を作用させれば当該DNAは切断される。このようなメチル化感受性酵素の具体的な例としては、例えば、HpaII、BstUI、NarI、SacII等をあげることができる(例えば、Nucleic Acid Research, 9、2509-2515参照)。
【0075】
当該制限酵素による消化の有無を調べる方法としては、例えば、前記DNAを鋳型とし、解析対象とするシトシンを認識配列に含み、当該認識配列以外には前記制限酵素の認識配列を含まないDNAを増幅可能なプライマー対を用いてPCRを行い、DNAの増幅(増幅産物)の有無を調べる方法をあげることができる。解析対象とするシトシンがメチル化されている場合には、増幅産物が得られる。一方、解析対象とするシトシンがメチル化されていない場合には、増幅産物が得られない。このようにして、増幅されたDNAの量を比較することにより、解析対象となるシトシンのメチル化の頻度を測定することができる。即ち、哺乳動物由来検体中に含まれるゲノムDNAがメチル化されていれば、前記メチル化感受性制限酵素がメチル化状態であるDNAを切断しないという特性を利用することにより、前記哺乳動物由来検体中に含まれるゲノムDNAにおける前記メチル化感受性制限酵素の認識部位の中に存在している少なくとも1つ以上のCpG対におけるシトシンがメチル化されていたか否かを区別することができる。言い換えれば、前記メチル化感受性制限酵素で消化処理することにより、仮に哺乳動物由来検体中に含まれるゲノムDNAにおける前記メチル化感受性制限酵素の認識部位の中に存在している少なくとも1つ以上のCpG対におけるシトシンがメチル化されていないのであれば、該メチル化感受性制限酵素により切断される。また、仮に哺乳動物由来検体中に含まれるゲノムDNAにおける前記メチル化感受性制限酵素の認識部位の中に存在している全てのCpG対におけるシトシンがメチル化されていたのであれば、該メチル化感受性制限酵素により切断されない。従って、消化処理を実施した後、後述のように、前記目的とするDNA領域を増幅可能な一対のプライマーを用いたPCRを実施することにより、哺乳動物由来検体中に含まれるゲノムDNAにおける前記制限酵素の認識部位の中に存在している少なくとも1つ以上のCpG対におけるシトシンがメチル化されていないのであれば、PCRによる増幅産物は得られず、一方、哺乳動物由来検体中に含まれるゲノムDNAにおける前記メチル化感受性制限酵素の認識部位の中に存在している全てのCpG対におけるシトシンがメチル化されていたのであれば、PCRによる増幅産物が得られることになる。
定量を必要とする場合には、PCR反応産物をリアルタイムでモニタリングしカイネティックス分析を行うことにより、例えば、遺伝子量に関して2倍程度のほんのわずかな差異をも検出できる高精度の定量が可能なPCR法であるリアルタイムPCRを用いて、それぞれの産物の量を比較することもできる。リアルタイムPCRを行う方法としては、例えば鋳型依存性核酸ポリメラーゼプローブ等のプローブを用いる方法又はサイバーグリーン等のインターカレーターを用いる方法等が挙げられる。リアルタイムPCR法のための装置及びキットは既に市販されている。
【0076】
また、当該制限酵素による消化の有無を調べる他の方法としては、例えば、解析対象とするシトシンを認識配列に含むメチル化感受性制限酵素を作用させたDNAに対して、Arginine vasopressin receptor 1A遺伝子に由来し、且つ、当該制限酵素の認識配列を含まないDNAをプローブとしたサザンハイブリダイゼーションを行い、ハイブリダイズしたDNAの長さを調べる方法をあげることもできる。解析対象とするシトシンがメチル化されている場合には、当該シトシンがメチル化されていない場合よりも長いDNAが検出される。検出された長いDNAの量と短いDNAの量とを比較することにより、解析対象となるシトシンのメチル化の頻度を測定することができる。
【0077】
以上のような各種方法を用いて、哺乳動物由来の検体に含まれる本発明DNAのメチル化頻度を測定する。測定されたメチル化頻度と、例えば、大腸癌細胞、肺癌細胞、乳癌細胞等の癌細胞を持たないと診断され得る健常な哺乳動物由来の検体に含まれる目的とするDNAのメチル化頻度(対照)とを比較して、当該比較により得られる差異に基づき前記検体の癌化度を判定する。仮に、哺乳動物由来の検体に含まれる本発明DNAのメチル化頻度が対照と比較して高ければ(本発明DNAが対照と比較の上で高メチル化状態であれば)、当該検体の癌化度が対照と比較の上で高いと判定することができる。
ここで「癌化度」とは、一般に当該分野において使用される意味と同様であって、具体的には、例えば、哺乳動物由来の検体が細胞である場合には当該細胞の悪性度を意味し、また、例えば、哺乳動物由来の検体が組織である場合には当該組織における癌細胞の存在量等を意味している。
【0078】
第六の方法として、目的とするDNAに含まれるシトシンのメチル化割合を、SEQUENOM社のMassARRAYシステムを用いて定量的にメチル化シトシンを測定することもできる。
【0079】
具体的には、検体から抽出したゲノムDNAに、非メチル化シトシンを修飾する試薬を作用させてから、目的とするDNA領域をPCR法により増幅する。次に、増幅したDNA領域をRNAポリメラーゼによりRNAへ転写する。さらに、得られた転写産物をRNaseで処理し、MASSによる質量分析を行う。
本方法は、非メチル化シトシンを修飾する試薬を作用させることにより、分子量が変化することに基づいて、検体中のDNAに含まれるメチルシトシンを定量する方法である。
【0080】
より具体的には、SEQUENOMアプリケーションノートに示されるMassARRAYシステムを用いた定量的DNAメチル化解析用EpiTYPERの概論に従った以下の手法を用いてもよい。
【0081】
メチル化解析用に以下のプライマーシステムを設計する。In vitro転写に適した産物を得るため、T7プロモータを付加したリバースプライマー。サイクリング失敗を防ぐために8bpインサートを挿入する。また、PCRのバランスをとるために10merタグを付加したフォワードプライマーとする。
Bisulfite処理:
サンプルゲノムDNAのBisulfite変換処理にはZymo Research社のEZ-96DNA Methylation KitまたはEZ DNA Methylation Kitを使用する。このプロトコルの初回インキュベーション後、以下のとおりサイクル反応をおこなう。
45サイクル:
95℃30分
50℃15分
(1)ステップ1:増幅
385-マイクロタイターフォーマットを用いて総容量5 μL中1 μLのDNAを増幅する(1反応あたり最終濃度2 ng/μLとするために10 ng/μL以上のDNAを1.00 μL以上使用する)。各反応液を2種類の切断反応(T切断反応とC切断反応)に分ける。プレートを密封し、以下のとおりサイクル反応をおこなう。
・94℃15分
・45サイクル
94℃20秒
56℃30秒
72℃1分
・72℃3分
(2)ステップ2:脱リン酸化
各PCR反応液5 μLにエビ由来アルカリフォスファターゼ(SAP)酵素2 μLを添加し、PCRに組み込まれなかったdNTPを脱リン酸化する。プレートを37℃で20分インキュベートし次いで85℃で5分インキュベートする。
(3)ステップ3:In vitro転写とRNase切断
各切断反応(TおよびC)用に転写/RNaseAカクテルを調製する。標準セットアップでは1プレートあたり、1つの転写/RNaseAカクテルを調製する。サイクル反応をおこなっていない新しいマイクロタイタープレートに、転写/RNaseAカクテル5 μLとPCR/SAPサンプル2 μLを添加する。プレートを1分間遠心し、次にプレートを37℃で3時間インキュベートする。
(4)ステップ4:サンプルコンディショニング
384穴プレートの各サンプルにddH2O 20 μLを加える。レジンプレートを用いて各穴にClean Resinを6 mg加える。10分間攪拌し、3,200xgで5分間スピンダウンする。
(5)ステップ5:サンプルの移動
10〜15 nLのEpiTYPER反応産物を384穴SpectroCHIPに分注する。
ステップ6:サンプル解析
MassARRAYシステムを用いて2種類の切断反応のスペクトルを得る。
(6)ステップ6:解析ソフトウェア
結果をEpiTYPERソフトウェアにより解析し、目的とするDNAのメチル化割合を測定する。
【0082】
本発明DNAは、以下のメチル化DNA含量測定方法により、メチル化されたDNAの含量を測定することができる。
【0083】
メチル化DNA含量測定方法は、哺乳動物由来の検体中に含まれる目的とするDNA領域の塩基配列が有する目的とするDNA領域におけるメチル化されたDNAの含量を測定する方法であって、
(1)哺乳動物由来の検体中に含まれるゲノムDNA由来のDNA試料をメチル化感受性制限酵素による消化処理を行う第一工程、
(2)第一工程で得られた消化処理が行われたDNA試料からメチル化された一本鎖DNAを取得し、該一本鎖DNAと、固定化メチル化DNA抗体とを結合させて一本鎖DNAを選択する第二工程、及び、
(3)下記の各本工程の前工程として第二工程で選択された一本鎖DNAを、固定化メチル化DNA抗体から分離して一本鎖状態であるDNA(正鎖)にする工程(第一前工程)と、
第一前工程で一本鎖状態にされたゲノム由来のDNA(正鎖)を、一本鎖状態であるDNA(正鎖)が有する塩基配列の部分塩基配列(正鎖)であって、且つ、前記の目的とするDNA領域の塩基配列(正鎖)の3’末端よりさらに3’末端側に位置する部分塩基配列(正鎖)、に対して相補性である塩基配列(負鎖)を有する伸長プライマー(フォーワード用プライマー)を伸長プライマーとして、該伸長プライマーを1回伸長させることにより、目的とするDNA領域を含む一本鎖DNA(正鎖)を二本鎖DNAに伸長形成させる工程(第二前工程)と、
第二前工程で伸長形成された二本鎖DNAを、目的とするDNA領域を含む一本鎖DNA(正鎖)と目的とするDNA領域を含む一本鎖DNA(負鎖)に一旦分離する工程(第三前工程)を有し、且つ、本工程として
(a)生成した目的とするDNA領域を含む一本鎖DNA(正鎖)を鋳型として、前記フォワード用プライマーを伸長プライマーとして、該伸長プライマーを一回伸長させることにより、前記の目的とするDNA領域を含む一本鎖DNAを二本鎖DNAとして伸長形成させる第A工程(本工程)と、
(b)生成した目的とするDNA領域を含む一本鎖DNA(負鎖)を鋳型として、前記の目的とするDNA領域を含む一本鎖DNA(負鎖)が有する塩基配列の部分塩基配列(負鎖)であって、且つ、前記の目的とするDNA領域の塩基配列(正鎖)に対して相補性である塩基配列(負鎖)の3’末端よりさらに3’末端側に位置する部分塩基配列(負鎖)、に対して相補性である塩基配列(正鎖)を有する伸長プライマー(リバース用プライマー)を伸長プライマーとして、該伸長プライマーを1回伸長させることにより、前記の目的とするDNA領域を含む一本鎖DNAを二本鎖DNAとして伸長形成させる第B工程(本工程)とを有し、
さらに第三工程の各本工程を、前記各本工程で得られた伸長形成された二本鎖DNAを一本鎖状態に一旦分離した後、繰り返すことにより、前記の目的とするDNA領域におけるメチル化されたDNAを検出可能な量になるまで増幅し、増幅されたDNAの量を定量する第三工程、を有することを特徴とする。
【0084】
本発明メチル化DNA含量測定方法における「相補性である」とは、塩基同士の水素結合による塩基対合により二本鎖DNAを形成することを意味する。例えば、DNAを構成する二本鎖の各々一本鎖DNAを構成する塩基が、プリンとピリミジンとの塩基対合により二本鎖を形成することであり、具体的には例えば、複数の連続した、チミンとシトシンとの間の水素結合による塩基結合、又は、グアニンとアデニンとの間の水素結合による塩基結合により、二本鎖DNAを形成することを意味する。相補性によって結合することを「相補的な結合」と記載することもある。「相補的な結合」は、「相補的に塩基対合しうる」又は「相補性により結合」と記載することもある。また、相補的に結合しうる塩基配列を互いに「相補性を有する」「相補性によって結合(相補的な(塩基対合による)結合)」と記載することもある。尚、本発明メチル化DNA含量測定方法においては、人工的に作成されるオリゴヌクレオチドに含まれるイノシンがシトシン、アデニン若しくはチミンと水素結合で結合することも、「相補性である」に含まれる。
【0085】
本発明メチル化DNA含量測定方法における「目的とするDNA領域を含む一本鎖DNA(負鎖)」とは、目的とするDNA領域を含む一本鎖DNAとの結合体(二本鎖)を形成するために必要な塩基配列、即ち、目的とするDNA領域の塩基配列の一部に相補的な塩基配列を含む塩基配列であることを意味し、「相補的塩基配列」あるいは「相補配列」と記載することもある。また、相補的塩基配列は、「相補的」と表現することもある。
【0086】
本発明メチル化DNA含量測定方法における「メチル化されたDNA」、「メチル化DNA」とは、DNAの塩基配列中の5’−CG−3’で示される塩基配列(以下、当該塩基配列を「CpG」と記すこともある。)中のシトシンの5位がメチル化されたDNAを意味する。
【0087】
本発明メチル化DNA含量測定方法におけるの第一工程において「メチル化頻度」とは、本発明評価方法でのものと同じ意味であり、例えば、調査対象となるCpG中のシトシンのメチル化の有無を複数のハプロイドについて調べたときの、当該シトシンがメチル化されているハプロイドの割合で表される。
【0088】
また本発明評価方法の第一工程において「(メチル化頻度)に相関関係がある指標値」とは、本発明評価方法でのものと同じ意味であり、例えば、本発明DNAの発現産物の量(より具体的には、当該本発明DNAの転写産物の量や、当該本発明DNAの翻訳産物の量)等をあげることができる。このような発現産物の量の場合には、上記メチル化頻度が高くなればそれに伴い減少するような負の相関関係が存在する。
【0089】
本発明メチル化DNA含量測定方法における「固定化メチル化DNA抗体」としては、例えば、メチルシトシン抗体等を挙げることができる。当該固定化メチル化DNA抗体は、支持体に固定化され得るものであればよく、「支持体に固定化され得るもの」とは、固定化メチル化DNA抗体を支持体へ直接的又は間接的に固定できることを意味する。このように固定化されるためには、固定化メチル化DNA抗体を通常の遺伝子工学的な操作方法又は市販のキット・装置等に従って、支持体に固定すればよい(固相への結合)。具体的には、固定化メチル化DNA抗体をビオチン化して得られたビオチン化固定化メチル化DNA抗体をストレプトアビジンで被覆した支持体(例えば、ストレプトアビジンで被覆したPCRチューブ、ストレプトアビジンで被覆した磁気ビーズ等)に固定する方法を挙げることができる。
また固定化メチル化DNA抗体を、アミノ基、チオール基、アルデヒド基等の活性官能基を有する分子を共有結合させた後、シランカップリング剤等で表面を活性化させたガラス、多糖類誘導体、シリカゲル、合成樹脂等から作製された支持体に共有結合させる方法もある。尚、共有結合には、例えば、トリグリセライドを5個直列に連結してなるようなスペーサー、クロスリンカー等により共有結合させる方法も挙げられる。
更に、固定化メチル化DNA抗体を直接支持体に固定化してもよく、また固定化メチル化DNA抗体に対する抗体(二次抗体)を支持体に固定化し、当該二次抗体にメチル化抗体を結合させることで支持体に固定してもよい。
尚、一本鎖DNAと固定化メチル化DNA抗体との結合前の段階で、固定化メチル化DNA抗体と支持体との結合により固定化されるものであってもよく、また一本鎖DNAと固定化メチル化DNA抗体との結合後の段階で、固定化メチル化DNA抗体と支持体との結合により固定化されるものであってもよい。
【0090】
本発明メチル化DNA含量測定方法で用いられる「メチル化感受性制限酵素」(具体的には、シトシンのメチル化の有無を識別可能な制限酵素)とは、本発明評価方法でのものと同じ意味であり、メチル化されたシトシンを含む認識配列を消化せず、メチル化されていないシトシンを含む認識配列を消化することのできる制限酵素を意味する。即ち、メチル化感受性制限酵素が本来認識することができる「認識配列」に含まれるシトシンがメチル化されているDNAの場合、メチル化感受性制限酵素を作用させても当該DNAは切断されず、一方、メチル化感受性制限酵素が本来認識することができる「認識配列」に含まれるシトシンがメチル化されていないDNAの場合、メチル化感受性制限酵素を作用させれば当該DNAは切断される。このようなメチル化感受性酵素の具体的な例としては、例えば、HpaII、BstUI、NarI、SacII等をあげることができる(例えば、Nucleic Acid Research, 9、2509-2515参照)。
【0091】
本発明メチル化DNA含量測定方法における「メチル化感受性制限酵素」としては、例えば、本発明DNAの塩基配列を目的とするDNA領域の中に認識切断部位を有する制限酵素又はHhaI等を挙げることができる。
【0092】
本発明メチル化DNA含量測定方法の応用として、当該方法における第一工程におけるメチル化感受性制限酵素による消化処理を行わずに第二工程を行う方法もありうる。
【0093】
本発明メチル化DNA含量測定方法の第二工程は、第一工程で得られた消化処理が行われたDNA試料に含まれるメチル化された二本鎖DNAをメチル化された一本鎖DNAに分離する第A工程(即ち、第二工程における第A工程)と、当該第A工程で得られたメチル化一本鎖DNAと固定化メチル化DNA抗体と結合させる第B工程(即ち、第二工程における第B工程)とから構成されてもよい。
【0094】
本発明メチル化DNA含量測定方法の第二工程において、第一工程で得られた消化処理が行われたDNA試料に含まれるメチル化された二本鎖DNAをメチル化された一本鎖DNAに分離するには、二本鎖DNAを一本鎖DNAにするための一般的な操作を行えばよい。具体的には例えば、哺乳動物由来検体中に含まれるゲノムDNA由来のDNA試料を適当量の超純水に溶解し、95℃で10分間加熱し、氷中で急冷すればよい。
【0095】
本発明メチル化DNA含量測定方法の第二工程において、上記のようにして分離されたメチル化一本鎖DNAと固定化メチル化DNA抗体と結合させることによって一本鎖DNAを選択するには、上記の「固定化メチル化DNA抗体」に係る説明で述べたように、具体的には例えば、固定化メチル化DNA抗体として「ビオチン標識されたビオチン化メチルシトシン抗体」を使用して以下のように実施すればよい。
(a)ビオチン化メチルシトシン抗体を適当量(例えば、0.1μg/50μL)アビジン被覆PCRチューブに添加し、その後、これを室温で約1時間静置することにより、ビオチン化メチルシトシン抗体とストレプトアビジンとの固定化を促す。PCRチューブ内から残溶液の除去及び洗浄後、洗浄バッファー[例えば、0.05% Tween20含有リン酸バッファー(1mM KH2PO4、3mM Na2HPO・7H2O、154mM NaCl pH7.4)]を100μL/チューブの割合で添加する。PCRチューブ内から溶液の除去及び洗浄後(当該洗浄操作を数回繰り返した後)、支持体に固定化されたビオチン化メチルシトシン抗体をPCRチューブ内に残す。
(b)哺乳動物由来検体中に含まれるゲノムDNA由来の二本鎖DNAとバッファー(例えば、33mM Tris-Acetate pH 7.9、66mM KOAc、10mM Mg(OAc)2、0.5mM Dithothreitol)とを混合し、得られた混合物を95℃で数分間加熱する。加熱後、前記混合物を約0〜4℃の温度まで速やかに冷却し、その温度で数分間保温することにより、一本鎖DNAを形成させる。得られた混合物を室温に戻す。
(c)形成された前記一本鎖DNAを、ビオチン化メチルシトシン抗体が固定化されたアビジン被覆PCRチューブに添加し、得られた混合物を室温で約1時間静置することにより、ビオチン化メチルシトシン抗体と前記一本鎖DNAのうちメチル化された一本鎖DNAとの結合を促す(結合体の形成)(この段階で、少なくともメチル化されてないDNA領域を含む一本鎖DNAは結合体を形成しない。)。その後、PCRチューブ内から残溶液を除去し、洗浄を行う。PCRチューブ内に洗浄バッファー[例えば、0.05% Tween20含有リン酸バッファー(1mM KH2PO4、3mM Na2HPO・7H2O、154mM NaCl pH7.4)]を100μL/チューブの割合で添加した後、PCRチューブ内から溶液を取り除く。当該洗浄操作を数回繰り返すことにより、洗浄された結合体をPCRチューブ内に残す(結合体の選択)。
上記(b)において使用されるバッファーとしては、生物試料由来のゲノムDNA由来の二本鎖DNAを一本鎖DNAへ分離するために適したものであればよく、前記バッファーに限ったわけではない。
上記(a)及び上記(c)における洗浄操作では、溶液中に浮遊している固定化されていない固定化メチル化DNA抗体、固定化メチル化DNA抗体に結合しなかった溶液中に浮遊しているメチル化されていない一本鎖DNA、又は、後述の制限酵素で消化された溶液中に浮遊しているDNA等を反応溶液から取り除くために重要な操作である。尚、洗浄バッファーは、上記の遊離の固定化メチル化DNA抗体、溶液中に浮遊している一本鎖DNA等の除去に適したものであればよく、前記洗浄バッファーに限らず、DELFIAバッファー(PerkinElmer社製、Tris-HCl pH 7.8 with Tween 80)、TEバッファー等でもよい。
【0096】
他に第二工程における第A工程において、メチル化された一本鎖DNAを分離する際の好ましい態様としては、例えば、カウンターオリゴヌクレオチドを添加すること等を挙げることができる。カウンターオリゴヌクレオチドとしては、例えば、目的とするDNA領域と同じ塩基配列を短いオリゴヌクレオチドに分割したものを挙げることができる。通常10〜100塩基、より好ましくは、20〜50塩基の長さに設計したものを好ましく挙げることができる。尚、カウンターオリゴヌクレオチドは、フォーワード用プライマー又はリバース用プライマーが目的とするDNA領域と相補的に結合する塩基配列上には設計しない。カウンターオリゴヌクレオチドは、ゲノムDNAに比し、大過剰で添加され、目的とするDNA領域を一本鎖(正鎖)にした後、固定化メチル化DNA抗体と結合させる際に、目的とするDNA領域の相補鎖(負鎖)と目的とするDNA領域を一本鎖(正鎖)が相補性により再結合することを妨げるために添加する。目的とするDNA領域にメチル化DNA抗体を結合させて、DNAのメチル化頻度又はそれに相関関係のある指標値を測定する際に、目的領域が一本鎖である方がメチル化DNA抗体に結合しやすいからである。尚、カンウターオリゴヌクレオチドは、目的とするDNA領域に比べて、少なくとも10倍、通常は100倍以上の量が添加されることが好ましい。
【0097】
ここで、「(メチル化された一本鎖DNAを分離する際に)カウンターオリゴヌクレオチドを添加する」とは、具体的には、哺乳動物由来検体中に含まれるゲノムDNA由来のDNA試料から、メチル化された一本鎖DNAを選択するために、哺乳動物由来検体中に含まれるゲノムDNA由来のDNA試料をカウンターオリゴヌクレオチドと混合して、目的とするDNA領域の相補鎖とカウンターオリゴヌクレオチドとの二本鎖を形成させればよい。例えば、前記DNA試料と、前記カウンターオリゴヌクレオチドとの混合物に、緩衝液(330mM Tris-Acetate pH7.9、660mM KOAc、100mM MgOAc2、5mM Dithiothreitol)5μLと、100mMのMgCl2溶液5μLと、1mg/mLのBSA溶液5μLを添加し、さらに当該混合物に滅菌超純水を加えて液量を50μLとし、混合して、95℃で10分間加熱し、70℃まで速やかに冷却し、その温度で10分間保温し、次いで、50℃まで冷却し10分間保温し、さらに37℃で10分間保温した後室温に戻せばよい。
【0098】
本発明メチル化DNA含量測定方法の第三工程は、以下の各工程を含む
(1)前工程((i)第一前工程、(ii)第二前工程、(iii)第三前工程)
(2)本工程((i)第A工程、(ii)第B工程)
(3)繰り返し工程((i)増幅工程、(ii)定量工程)
【0099】
(1)第三工程における前工程
(i)第三工程における前工程での第一前工程
・第二工程で選択された一本鎖DNAを、固定化メチル化DNA抗体から分離して遊離の一本鎖状態のDNAにする工程
・具体的には例えば、第二工程で選択された一本鎖DNAに、アニーリングバッファーを添加することにより、混合物を得る。次いで、得られた混合物を95℃で数分間加熱することにより、一本鎖状態であるDNA(正鎖)を得る。
(ii)第三工程における前工程での第二前工程
・第一前工程で遊離の一本鎖状態にされたゲノム由来のDNA(正鎖)と、一本鎖状態であるDNA(正鎖)が有する塩基配列の部分塩基配列(正鎖)であって、且つ、前記の目的とするDNA領域の塩基配列(正鎖)の3’末端より更に3’ 末端側に位置する部分塩基配列(正鎖)、に対して相補性である塩基配列(負鎖)を有する伸長プライマー(フォーワード用プライマー)を伸長プライマーとして、該伸長プライマーを1回伸長させることにより、遊離の一本鎖状態であるDNA(正鎖)を二本鎖DNAに伸長形成させる工程
・具体的には例えば、第一前工程で得られた一本鎖状態のDNA(正鎖)とフォワードプライマーとを、滅菌超純水を17.85μL、最適な緩衝液(例えば、100mM Tris-HCl pH 8.3、500mM KCl、15mM MgCl2)を3μL、2mM dNTPを3μL、5Nベタインを6μL加え、次いで得られた混合物にAmpliTaq(DNAポリメラーゼの1種:5U/μL)を0.15μL加えて液量を30μLとした溶液中で混合する。得られた混合物を37℃で約2時間インキュベーションすることにより、目的とするDNA領域を含む一本鎖DNA(正鎖)を二本鎖DNAに伸長形成させる。
(iii)第三工程における前工程での第三前工程
・第二前工程で伸長形成された二本鎖DNAを、目的とするDNA領域を含む一本鎖DNA(正鎖)と目的とするDNA領域に対して相補性である塩基配列を含む一本鎖DNA(負鎖)に一旦分離する工程
・具体的には例えば、第二前工程で伸長形成された二本鎖DNAに、アニーリングバッファーを添加することにより混合物を得て、得られた混合物を95℃で数分間加熱することにより、目的とするDNA領域を含む一本鎖DNAに一旦分離する。
【0100】
(2)第三工程における本工程
(i)第三工程における本工程での第A工程
・生成した目的とするDNA領域を含む一本鎖DNA(正鎖)を鋳型として、前記フォーワード用プライマーを伸長プライマーとして、該伸長プライマーを一回伸長させることにより、前記の目的とするDNA領域を含む一本鎖DNAを二本鎖DNAとして伸長形成させる第A工程
・後述の説明や前述の本発明の第二前工程における伸長反応での操作方法等に準じて実施すればよいが、具体的には例えば、
(a)生成した目的とするDNA領域を含む一本鎖DNA(正鎖)に、前記のフォーワード用プライマーをアニーリングさせるために、例えば、前記のフォーワード用プライマーのTm値の約0〜20℃低い温度まで速やかに冷却し、その温度で数分間保温する。
(b)その後、室温に戻す。
(c)上記(c)でアニーリングさせた前記の一本鎖状態であるDNAを鋳型として、前記のフォーワード用プライマーを伸長プライマーとして、該プライマーを1回伸長させることにより、前記の目的とするDNA領域に対して相補性である塩基配列を含む一本鎖DNAを二本鎖DNAとして伸長形成させる。
(ii)第三工程における本工程での第B工程
・生成した目的とするDNA領域に対して相補性である塩基配列を含む一本鎖DNA(負鎖)を鋳型として、前記の目的とするDNA領域に対して相補性である塩基配列を含む一本鎖DNA(負鎖)が有する塩基配列の部分塩基配列(負鎖)であって、且つ、前記の目的とするDNA領域の塩基配列(正鎖)に対して相補性である塩基配列(負鎖)の3’ 末端より更に3’ 末端側に位置する部分塩基配列(負鎖)、に対して相補性である塩基配列(正鎖)を有する伸長プライマー(リバース用プライマー)を伸長プライマーとして、該伸長プライマーを1回伸長させることにより、前記の目的とするDNA領域を含む一本鎖DNAを二本鎖DNAとして伸長形成させる第B工程
・後述の説明や前述の本発明の第二前工程における伸長反応での操作方法等に準じて実施すればよいが、具体的には例えば、上記(i)の第三工程における本工程での第A工程と同様な操作方法等に準じて実施すればよい。
【0101】
(3)第三工程における繰り返し工程
(i)第三工程における繰り返し工程での増幅工程
・第三工程の各本工程を、前記各本工程で得られた伸長形成された二本鎖DNAを一本鎖状態に一旦分離した後、繰り返すことにより、前記の目的とするDNA領域におけるメチル化されたDNAを検出可能な量になるまで増幅する工程
・具体的には例えば、上記(2)の第三工程における本工程での第A工程及び第B工程と同様な操作方法等に準じて実施すればよい。
(ii)第三工程における繰り返し工程での定量工程
・第三工程の繰り返し工程における増幅工程により増幅されたDNAの量を定量する工程
【0102】
尚、本発明メチル化DNA含量測定方法の第三工程は、前工程における第一前工程から開始して本工程及び繰り返し工程に至るまでの反応を、一つのPCR反応として実施することもできる。また、前工程における第一前工程から第三前工程まで、各々、独立した反応として実施し、次いで本工程のみをPCR反応として実施することもできる。
【0103】
本発明メチル化DNA含量測定方法において、選択された一本鎖DNAに含まれる目的とするDNA領域(即ち、目的領域)を増幅する方法としては、例えば、PCRを用いることができる。目的領域を増幅する際に、予め蛍光等で標識されたプライマーを使用してその標識を指標とすれば、電気泳動等の煩わしい操作を実施せずに増幅産物の有無を評価できる。PCR反応液としては、例えば、本発明の第二工程で得たDNAに、50μMのプライマーの溶液を0.15μlと、2mM dNTPを2.5μlと、10×緩衝液(100mM Tris-HCl pH 8.3、500mM KCl、20mM MgCl2、0.01% Gelatin)を2.5μlと、AmpliTaq Gold(耐熱性DNAポリメラーゼの一種:5U/μl)を0.2μlとを混合し、これに滅菌超純水を加えて液量を25μlとした反応液を挙げることができる。
目的とするDNA領域(即ち、目的領域)は、GCリッチな塩基配列が多いため、時に、ベタイン、DMSO等を適量加えて反応を実施してもよい。反応条件としては、例えば、前記のような反応液を、95℃にて10分間保温した後、95℃にて30秒間、次いで55〜65℃にて30秒間、更に72℃にて30秒間、を1サイクルとする保温を30〜40サイクル行う条件を挙げることができる。かかるPCRを行った後、得られた増幅産物を検出する。例えば、予め標識されたプライマーを使用した場合には、上述と同様な洗浄・精製操作を実施した後、蛍光標識体の量の測定によりPCR反応での増幅産物の量を測定することができる。また、標識されていない通常のプライマーを用いたPCRを実施した場合には、金コロイド粒子、蛍光等で標識したプローブ等をアニーリングさせた後、目的領域に結合した当該プローブの量を測定すればよい。また、増幅産物の量をより精度よく測定するには、例えば、リアルタイムPCR法を用いればよい。ここで「リアルタイムPCR法」とは、PCRをリアルタイムでモニターし、得られたモニター結果をカイネティックス分析する方法であり、例えば、遺伝子の量に関して2倍程度のほんの僅かな差異をも検出できる高精度の定量PCR法として知られる方法をいう。当該リアルタイムPCR法としては、例えば、鋳型依存性核酸ポリメラーゼプローブ等のプローブを用いる方法、サイバーグリーン等のインターカレーターを用いる方法等を挙げることができる。リアルタイムPCR法のための装置及びキットは市販されるものを利用してもよい。以上の如く、検出については特に限定されることはなく、これまでに周知のあらゆる方法による検出が可能である。これら方法では、反応容器を移し換えることなく検出までの操作が可能となる。
【0104】
更に、本発明評価方法において「メチル化頻度又はそれに相関関係がある指標値を測定する」際の実施態様の一例としては、例えば、以下に示される方法1〜7等も挙げることができる。
【0105】
[方法1]
・第一工程、第二工程、第三工程、第四工程(前工程、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程)、繰り返し工程((i)増幅工程、(ii)定量工程)
・哺乳動物由来検体中に含まれる本発明DNAの塩基配列を目的とするDNA領域として、目的とするDNA領域におけるメチル化されたDNAの含量を測定する方法であって、
(1)哺乳動物由来検体中に含まれるゲノムDNA由来のDNA試料をメチル化感受性制限酵素による消化処理を行う第一工程、
(2)第一工程で得られた消化処理が行われたDNA試料から目的とするDNA領域を含む一本鎖DNA(正鎖)を取得し、該一本鎖DNA(正鎖)と、該一本鎖DNAの3’末端の一部(但し、前記の目的とするDNA領域を含まない。)に対して相補性のある塩基配列を有する一本鎖固定化オリゴヌクレオチドとを結合させることにより、前記一本鎖DNAを選択する第二工程、
(3)第二工程で選択された一本鎖DNAを鋳型として、前記一本鎖固定化オリゴヌクレオチドをプライマーとして、該プライマーを1回伸長させることにより、前記一本鎖DNAを二本鎖DNAとして伸長形成させる第三工程、及び、
(4)下記の各本工程の前工程として、第三工程で得られた伸長形成された二本鎖DNAを一本鎖状態に一旦分離する工程(前工程)を有し、且つ、本工程として
(a)生成した一本鎖状態であるDNA(正鎖)と前記一本鎖固定化オリゴヌクレオチド(負鎖)とを結合させることにより、前記一本鎖状態であるDNAを選択する第A1工程と、
第A1工程で選択された一本鎖状態であるDNAを鋳型として、前記一本鎖固定化オリゴヌクレオチドをプライマーとして、該プライマーを1回伸長させることにより、前記一本鎖状態であるDNAを二本鎖DNAとして伸長形成させる第A2工程と、を有する第A工程(本工程)と、
(b)生成した一本鎖状態であるDNA(負鎖)を鋳型として、前記一本鎖状態であるDNA(負鎖)が有する塩基配列の部分塩基配列(負鎖)であって、且つ、前記目的とするDNA領域の塩基配列(正鎖)に対して相補性のある塩基配列(負鎖)の3’末端より更に3’末端側に位置する部分塩基配列(負鎖)に対して相補性のある塩基配列(正鎖)を有するプライマー(リバース用プライマー)を伸長プライマーとして、該伸長プライマーを1回伸長させることにより、前記一本鎖状態であるDNAを二本鎖DNAとして伸長形成させる第B工程(本工程)とを有し、
更に前記各本工程で得られた伸長形成された二本鎖DNAを一本鎖状態に一旦分離した後、繰り返すことにより、前記目的とするDNA領域におけるメチル化されたDNAを検出可能な量になるまで増幅し、増幅されたDNAの量を定量する第四工程、
を有することを特徴とする方法。
【0106】
[方法2]
・第一工程、第二工程、第三工程、第四工程(前工程、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程)、繰り返し工程((i)増幅工程、(ii)定量工程)
・第二工程において目的とするDNA領域を含む一本鎖DNA(正鎖)と、該一本鎖DNAの3’末端の一部(但し、前記目的とするDNA領域を含まない。)に対して相補性のある塩基配列を有する一本鎖固定化オリゴヌクレオチドとを結合させる際に、二価陽イオンを含有する反応系中で結合させる前記方法1に記載される方法。
【0107】
[方法3]
・第一工程、第二工程、第三工程、第四工程(前工程、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程)、繰り返し工程((i)増幅工程、(ii)定量工程)
・二価陽イオンがマグネシウムイオンである前記方法2に記載される方法。
【0108】
[方法4]
・第一工程、第二工程、第三工程、第四工程(前工程(追加前工程を含む)、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程、(iii)第C工程((iii1)第C1工程、(iii2)第C2工程))、繰り返し工程((i)増幅工程、(ii)定量工程)
・第四工程の前工程の前操作段階において、前記目的とするDNA領域を含む一本鎖DNA(正鎖)の3’末端の一部(但し、前記目的とするDNA領域を含まない。)に対して相補性のある塩基配列を有し且つ遊離状態である一本鎖オリゴヌクレオチド(負鎖)を反応系内に添加する工程(追加前工程)を追加的に有し、且つ、第四工程の各本工程として、下記の1つの工程を更に追加的に有する方法。
(c)(i)生成した一本鎖状態であるDNA(正鎖)と、前記追加前工程で反応系内に添加された一本鎖オリゴヌクレオチド(負鎖)とを結合させることにより、前記一本鎖状態であるDNAを選択する第C1工程と、
(ii)第C1工程で選択された一本鎖状態であるDNAを鋳型として、前記一本鎖オリゴヌクレオチド(負鎖)をプライマーとして、該プライマーを1回伸長させることにより、前記一本鎖状態であるDNAを二本鎖DNAとして伸長形成させる第C2工程とを有する第C工程(本工程)
【0109】
[方法5]
・第一工程、第二工程、第三工程、第四工程(前工程(追加前工程、追加再前工程を含む)、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程、(iii)第C工程)、繰り返し工程((i)増幅工程、(ii)定量工程))
・第四工程の前工程の後操作段階において、前記目的とするDNA領域を含む一本鎖DNA(正鎖)の3’末端の一部(但し、前記目的とするDNA領域を含まない。)に対して相補性のある塩基配列を有し且つ遊離状態である一本鎖オリゴヌクレオチド(負鎖)を反応系内に添加する工程(追加前工程)を追加的に有し、且つ、
第三工程及び前記追加前工程を経て得られた未消化物である伸長形成された二本鎖DNA(前記メチル化感受性制限酵素の認識部位にアンメチル状態のCpG対を含まない伸長形成された二本鎖DNA)を一本鎖状態に一旦分離する工程(追加再前工程)を有し、且つ、
第四工程の各本工程として、下記の1つの工程を更に追加的に有する方法。
(c)(i)生成した一本鎖状態であるDNA(正鎖)と、前記追加前工程で反応系内に添加された一本鎖オリゴヌクレオチド(負鎖)とを結合させることにより、前記一本鎖状態であるDNAを選択する第C1工程と、
(ii)第C1工程で選択された一本鎖状態であるDNAを鋳型として、前記一本鎖オリゴヌクレオチド(負鎖)をプライマーとして、該プライマーを1回伸長させることにより、前記一本鎖状態であるDNAを二本鎖DNAとして伸長形成させる第C2工程とを有する第C工程(本工程)
【0110】
[方法6]
・前記方法1〜5のいずれか一に記載された方法の工程として、下記の2つの工程を更に追加的に有するメチル化割合の測定方法。
(5)前記方法1〜5のいずれか一に記載の方法の第一工程を行うことなく、発明1〜5のいずれか一に記載の方法における第二工程から第四工程を行うことにより、前記目的とするDNA領域のDNA(メチル化されたDNA及びメチルされていないDNAの総量)を検出可能な量になるまで増幅し、増幅されたDNAの量を定量する第五工程、及び、
(6)前記方法1〜5のいずれか一に記載の第四工程により定量されたDNAの量と、第五工程により定量されたDNAの量とを比較することにより得られる差異に基づき前記目的とするDNA領域におけるメチル化されたDNAの割合を算出する第六工程
【0111】
[方法7]
・前記1〜6の方法に記載された第一工程におけるメチル化感受性制限酵素による消化処理を行わずに第二工程を行う方法。
【0112】
・前記方法1〜7に記載された第二工程において、第一工程で得られた消化処理が行われたDNA試料から目的とするDNA領域を含む一本鎖DNA(正鎖)を取得し、該一本鎖DNA(正鎖)と、該一本鎖DNAの3’末端の一部(但し、前記目的とするDNA領域を含まない。)に対して相補性である塩基配列を有する一本鎖固定化オリゴヌクレオチドとを結合させることにより、前記一本鎖DNAを選択する。
【0113】
前記方法1〜7に記載される「一本鎖固定化オリゴヌクレオチド」とは、目的とするDNA領域を含む一本鎖DNA(正鎖)の3’末端の一部(但し、前記目的とするDNA領域を含まない。)に対して相補性である塩基配列を有する一本鎖固定化オリゴヌクレオチド(以下、本固定化オリゴヌクレオチドと記すこともある。)である。
本固定化オリゴヌクレオチドは、哺乳動物由来検体中に含まれるゲノムDNA由来のDNA試料から、目的とするDNA領域を含む一本鎖DNA(正鎖)を選択するために用いられる。本固定化オリゴヌクレオチドは、5〜50塩基長であることが好ましい。
本固定化オリゴヌクレオチドの5’末端側は、担体と固定化され得るものであり、一方その3’末端側は、後述する第三工程及び第A2工程により5’末端から3’末端に向かって進行する一回伸長反応が可能なようにフリーな状態であってもよい。
または、本固定化オリゴヌクレオチドは、5’或いは3’末端が担体と固定化されてもよい。
【0114】
前記方法1〜7に記載される「担体と固定化され得るもの」とは、前記目的とするDNA領域を含む一本鎖DNA(正鎖)を選択する際に本固定化オリゴヌクレオチドが担体に固定化されていればよく、(1)該一本鎖DNA(正鎖)と本固定化オリゴヌクレオチドとの結合前の段階で、本固定化オリゴヌクレオチドと担体との結合により固定化されるものであってもよく、また(2)該一本鎖DNA(正鎖)と本固定化オリゴヌクレオチドとの結合後の段階で、本固定化オリゴヌクレオチドと担体との結合により固定化されるものであってもよい。
このような構造を得るには、目的とするDNA領域を含む一本鎖DNA(正鎖)の3’末端の一部(但し、前記目的とするDNA領域を含まない。)に対して相補性である塩基配列を有するオリゴヌクレオチド(以下、本オリゴヌクレオチドと記すこともある。)の5’末端を通常の遺伝子工学的な操作方法又は市販のキット・装置等に従い、担体に固定すればよい(固相への結合)。具体的には例えば、本オリゴヌクレオチドの5’末端をビオチン化した後、得られたビオチン化オリゴヌクレオチドをストレプトアビジンで被覆した支持体(例えば、ストレプトアビジンで被覆したPCRチューブ、ストレプトアビジンで被覆した磁気ビーズ等)に固定する方法を挙げることができる。
また、本オリゴヌクレオチドの5’末端側に、アミノ基、アルデヒド基、チオール基等の活性官能基を有する分子を共有結合させた後、これを表面がシランカップリング剤等で活性化させたガラス、シリカ若しくは耐熱性プラスチック製の支持体に、例えば、トリグリセリドを5個直列に連結したもの等のスペーサー、クロスリンカー等を介して共有結合させる方法も挙げられる。またさらに、ガラス若しくはシリコン製の支持体の上で直接、本オリゴヌクレオチドの5’末端側から化学合成させる方法も挙げられる。
【0115】
前記方法1〜7に記載される第二工程は、具体的には例えば、本固定化オリゴヌクレオチドがビオチン化オリゴヌクレオチドの場合には、
(a)まず、哺乳動物由来検体中に含まれるゲノムDNA由来のDNA試料に、アニーリングバッファー及びビオチン化オリゴヌクレオチド(該一本鎖DNA(正鎖)と本固定化オリゴヌクレオチドとの結合後の段階で、本固定化オリゴヌクレオチドと担体との結合により固定化されるものであるために、現段階では遊離状態にあるもの)を添加することにより、混合物を得る。次いで、得られた混合物を、哺乳動物由来検体中に含まれるゲノムDNA由来のDNA試料に存在する目的とするDNA領域を含む二本鎖DNAを一本鎖にするために、95℃で数分間加熱する。その後、ビオチン化オリゴヌクレオチドとの二本鎖を形成させるために、ビオチン化オリゴヌクレオチドのTm値の約10〜20℃低い温度まで速やかに冷却し、その温度で数分間保温する。
(b)その後、室温に戻す。
(c)ストレプトアビジンで被覆した支持体に、上記(b)で得られた混合物を添加し、さらに、これを37℃で数分間保温することにより、ビオチン化オリゴヌクレオチドをストレプトアビジンで被覆した支持体に固定する。
因みに、前述の如く、上記(a)〜(c)では、前記目的とするDNA領域を含む一本鎖DNA(正鎖)と、ビオチン化オリゴヌクレオチドとの結合を、ビオチン化オリゴヌクレオチドとストレプトアビジンで被覆した支持体との固定よりも前段階で実施しているが、この順番は、どちらが先でも構わない。即ち、例えば、ストレプトアビジンで被覆した支持体に固定化されたビオチン化オリゴヌクレオチドに、哺乳動物由来検体中に含まれるゲノムDNA由来のDNA試料を添加することにより混合物を得て、得られた混合物を哺乳動物由来検体中に含まれるゲノムDNA由来のDNA試料に存在する目的とするDNA領域を含む二本鎖DNAを一本鎖にするために、95℃で数分間加熱し、その後ビオチン化オリゴヌクレオチドとの二本鎖を形成させるために、ビオチン化オリゴヌクレオチドのTm値の約10〜20℃低い温度まで速やかに冷却し、その温度で数分間保温してもよい。
(d)このようにしてビオチン化オリゴヌクレオチドをストレプトアビジンで被覆した支持体に固定した後、残溶液の除去及び洗浄(DNA精製)を行う。
より具体的には例えば、ストレプトアビジンで被覆したPCRチューブを使用する場合には、まず溶液をピペッティング又はデカンテーションにより取り除いた後、これに哺乳動物由来検体の容量と略等量のTEバッファーを添加し、その後該TEバッファーをピペッティング又はデカンテーションにより取り除けばよい。またストレプトアビジンで被覆した磁気ビーズを使用する場合には、磁石によりビーズを固定した後、まず溶液をピペッティング又はデカンテーションにより取り除いた後、哺乳動物由来検体の容量と略等量のTEバッファーを添加し、その後該TEバッファーをピペッティング又はデカンテーションにより取り除けばよい。
次いで、このような操作を数回実施することにより、残溶液の除去及び洗浄(DNA精製)を行う。
当該操作は、固定化されていないDNA、又は、後述の制限酵素で消化された溶液中に浮遊しているDNA、を反応溶液から取り除くため、重要である。これら操作が不十分であれば、反応溶液中に浮遊しているDNAが鋳型となり、増幅反応で予期せぬ増幅産物が得られることとなる。支持体と哺乳動物由来検体中DNAとの非特異的結合を避けるためには、目的領域とはまったく異なる塩基配列を有するDNA(例えば、ヒトの哺乳動物由来検体の場合は、ラットDNA等)を大量に哺乳動物由来検体に添加し、上記の操作を実施すればよい。
【0116】
前記方法1〜7に記載される第二工程における好ましい態様としては、目的とするDNA領域を含む一本鎖DNA(正鎖)と、該一本鎖DNAの3’末端の一部(但し、前記目的とするDNA領域を含まない。)に対して相補性である塩基配列を有する一本鎖固定化オリゴヌクレオチドとを結合させる際に、二価陽イオンを含有する反応系中で結合させることを挙げることができる。より好ましくは、二価陽イオンがマグネシウムイオンであることが挙げられる。ここで「二価陽イオンを含有する反応系」とは、前記一本鎖DNA(正鎖)と前記一本鎖固定化オリゴヌクレオチドとを結合させるために用いられるアニーリングバッファー中に二価陽イオンを含有するような反応系を意味し、具体的には例えば、マグネシウムイオンを構成要素とする塩(例えば、Mg(OAc)2、MgCl2等)を1mM〜600mMの濃度で含まれることがよい。
【0117】
前記方法1〜7に記載される第三工程において、第二工程で選択された一本鎖DNAを鋳型として、前記一本鎖固定化オリゴヌクレオチドをプライマーとして、該プライマーを1回伸長させることにより、前記一本鎖DNAを二本鎖DNAとして伸長形成させる。この場合、該一本鎖DNAを鋳型として、前記一本鎖固定化オリゴヌクレオチドをプライマーとして、該プライマーを1回伸長させるためには、DNAポリメラーゼを用いて伸長反応を実施すればよい。
【0118】
前記方法1〜7に記載される第三工程は、具体的には例えば、本固定化オリゴヌクレオチドがビオチン化オリゴヌクレオチドの場合には、以下のように実施すればよい。
前記第二工程で選択された前記目的とするDNA領域を含む一本鎖DNAに、滅菌超純水を17.85μL、最適な10×緩衝液(100mM Tris-HCl pH 8.3、500mM KCl、15mM MgCl2)を3μL、2mM dNTPを3μL、5N ベタインを6μL加え、次いで該混合物にAmpliTaq(DNAポリメラーゼの1種:5U/μL)を0.15μL加えて液量を30μLとし、37℃で2時間インキュベーションする。その後、インキュベーションされた溶液をピペッティング又はデカンテーションにより取り除いた後、これに哺乳動物由来検体の容量と略等量のTEバッファーを添加し、該TEバッファーをピペッティング又はデカンテーションにより取り除けばよい。
より具体的には例えば、ストレプトアビジンで被覆したPCRチューブを使用する場合には、まず溶液をピペッティング又はデカンテーションにより取り除いた後、これに哺乳動物由来検体の容量と略等量のTEバッファーを添加し、その後該TEバッファーをピペッティング又はデカンテーションにより取り除けばよい。またストレプトアビジンで被覆した磁気ビーズを使用する場合には、磁石によりビーズを固定した後、まず溶液をピペッティング又はデカンテーションにより取り除いた後、哺乳動物由来検体の容量と略等量のTEバッファーを添加し、その後該TEバッファーをピペッティング又はデカンテーションにより取り除けばよい。次いで、このような操作を数回実施することにより、残溶液の除去及び洗浄(DNA精製)を行う。
【0119】
また、前記方法1〜7に記載される第三工程は、前記第二工程で選択された一本鎖DNAを固定化オリゴヌクレオチドから分離して一本鎖状態に一旦分離する工程を有し、生成した一本鎖状態であるDNA(正鎖)を鋳型として、前記目的とするDNA領域の塩基配列(正鎖)の3’末端より更に3’末端側に位置する部分塩基配列(正鎖)に対して相補性のある塩基配列(負鎖)を有するフォーワード用プライマーを伸長プライマーとして、該プライマーを1回伸長させることにより、前記の一本鎖DNAを二本鎖DNAとして伸長形成させる工程であってもよい。
この場合の方法としては、具体的に例えば、二本鎖DNAを一本鎖にするために、95℃で数分間加熱すればよい。さらに、フォーワード用プライマーを添加した後、フォーワード用プライマーのTm値の約10〜20℃低い温度まで速やかに冷却し、その温度で数分間保温し、前記の生成した一本鎖状態であるDNA(正鎖)とフォーワード用プライマーとの二本鎖を形成させる。生成した二本鎖DNAの溶液に、最適な10×緩衝液(100mM Tris-HCl pH 8.3、500mM KCl、15mM MgCl2)を3μL、2mM dNTPを3μL、5N ベタインを6μL加え、次いで当該混合物にAmpliTaq(DNAポリメラーゼの1種:5U/μL)を0.15μL加え、滅菌超純水を加えて液量を30μLとし、37℃で2時間インキュベーションする。
尚、第三工程は、第四工程と独立に実施しても良いし、第四工程で実施されるPCR反応と連続して実施しても構わない。
【0120】
前記方法1〜7に記載される第四工程において、下記の各本工程の前工程として、第三工程で得られた伸長形成された二本鎖DNA(前記メチル化感受性制限酵素の認識部位にアンメチル状態のCpG対を含まない伸長形成された二本鎖DNA)を一本鎖状態に一旦分離する工程(前工程)を有し、且つ、本工程として
(a)生成した一本鎖状態であるDNA(正鎖)と前記一本鎖固定化オリゴヌクレオチド(負鎖)とを結合させることにより、前記一本鎖状態であるDNAを選択する第A1工程と、第A1工程で選択された一本鎖状態であるDNAを鋳型として、前記一本鎖固定化オリゴヌクレオチドをプライマーとして、該プライマーを1回伸長させることにより、前記一本鎖状態であるDNAを二本鎖DNAとして伸長形成させる第A2工程とを有する第A工程(本工程)と、
(b)生成した一本鎖状態であるDNA(負鎖)を鋳型として、前記一本鎖状態であるDNA(負鎖)が有する塩基配列の部分塩基配列(負鎖)であって、且つ、前記目的とするDNA領域の塩基配列(正鎖)に対して相補性である塩基配列(負鎖)の3’末端よりさらに3’末端側に位置する部分塩基配列(負鎖)、に対して相補性である塩基配列(正鎖)を有する伸長プライマー(リバース用プライマー)を伸長プライマーとして、該伸長プライマーを1回伸長させることにより、前記一本鎖状態であるDNAを二本鎖DNAとして伸長形成させる第B工程(本工程)とを有し、
さらに第四工程の各本工程を、前記各本工程で得られた伸長形成された二本鎖DNAを一本鎖状態に一旦分離した後、繰り返すことにより、前記目的とするDNA領域におけるメチル化されたDNAを検出可能な量になるまで増幅し、増幅されたDNAの量を定量する。
【0121】
前記方法1〜7に記載される第四工程では、まず、下記の各本工程の前工程として、第三工程で得られた未消化物である伸長形成された二本鎖DNA(前記メチル化感受性制限酵素の認識部位にアンメチル状態のCpG対を含まない伸長形成された二本鎖DNA)を一本鎖状態に一旦分離する。具体的には例えば、第三工程で得られた未消化物である伸長形成された二本鎖DNA(前記メチル化感受性制限酵素の認識部位にアンメチル状態のCpG対を含まない伸長形成された二本鎖DNA)に、アニーリングバッファーを添加することにより、混合物を得る。次いで、得られた混合物を95℃で数分間加熱する。
その後、本工程として、
(i)生成した一本鎖状態であるDNA(正鎖)を、前記一本鎖固定化オリゴヌクレオチド(負鎖)にアニーリングさせるために、前記一本鎖固定化オリゴヌクレオチド(負鎖)のTm値の約10〜20℃低い温度まで速やかに冷却し、その温度で数分間保温する。
(ii)その後、室温に戻す。(第A工程における第A1工程)
(iii)上記(i)で選択された一本鎖状態であるDNAを鋳型として、前記一本鎖固定化オリゴヌクレオチドをプライマーとして、該プライマーを1回伸長させることにより、前記一本鎖状態であるDNAを二本鎖DNAとして伸長形成させる(即ち、第A工程における第A2工程)。具体的には例えば、後述の説明や前述の方法1〜7に記載の第二工程における伸長反応での操作方法等に準じて実施すればよい。
(iv)生成した一本鎖状態であるDNA(負鎖)を鋳型として、前記一本鎖状態であるDNA(負鎖)が有する塩基配列の部分塩基配列(負鎖)であって、且つ、前記目的とするDNA領域の塩基配列(正鎖)に対して相補性である塩基配列(負鎖)の3’末端よりさらに3’末端側に位置する部分塩基配列(負鎖)、に対して相補性である塩基配列(正鎖)を有する伸長プライマー(リバース用プライマー))を伸長プライマー(リバース用プライマー)として、該伸長プライマーを1回伸長させることにより、前記一本鎖状態であるDNAを二本鎖DNAとして伸長形成させる(即ち、第B工程)。具体的には例えば、上記(iii)と同様に、後述の説明や前述の方法1〜7に記載の第二工程における伸長反応での操作方法等に準じて実施すればよい。
(v)さらに第四工程の各本工程を、前記各本工程で得られた伸長形成された二本鎖DNAを一本鎖状態に一旦分離した後、繰り返すこと(例えば、第A工程及び第B工程)により、前記目的とするDNA領域におけるメチル化されたDNAを検出可能な量になるまで増幅し、増幅されたDNAの量を定量する。具体的には例えば、上記と同様に、後述の説明や前述の方法1〜7に記載される第四工程における前工程、第A工程及び第B工程での操作方法等に準じて実施すればよい。
【0122】
前記方法1〜7に記載されるメチル化感受性制限酵素による消化処理の後に目的とするDNA領域(即ち、目的領域)を増幅する方法としては、例えば、PCRを用いることができる。目的領域を増幅する際に、片側のプライマーとして固定化オリゴヌクレオチドを用いることができるので、もう一方のプライマーのみ添加してPCRを行うことにより、増幅産物が得られ、その増幅産物も固定化されることとなる。この際、予め蛍光等で標識されたプライマーを使用してその標識を指標とすれば、電気泳動等の煩わしい操作を実施せずに増幅産物の有無を評価できる。PCR反応液としては、例えば、前記方法1〜7に記載の第三工程で得たDNAに、50μMのプライマーの溶液を0.15μlと、2mM dNTPを2.5μlと、10×緩衝液(100mM Tris-HCl pH 8.3、500mM KCl、20mM MgCl2、0.01% Gelatin)を2.5μlと、AmpliTaq Gold (耐熱性DNAポリメラーゼの一種: 5U/μl)を0.2μlとを混合し、これに滅菌超純水を加えて液量を25μlとした反応液を挙げることができる。
目的とするDNA領域(即ち、目的領域)は、GCリッチな塩基配列が多いため、時に、ベタイン、DMSO等を適量加えて反応を実施してもよい。反応条件としては、例えば、前記ように反応液を、95℃にて10分間保温した後、95℃にて30秒間次いで55〜65℃にて30秒間さらに72℃にて30秒間を1サイクルとする保温を30〜40サイクル行う条件があげられる。かかるPCRを行った後、得られた増幅産物を検出する。例えば、予め標識されたプライマーを使用した場合には、先と同様の洗浄・精製操作を実施後、固定化された蛍光標識体の量を測定することができる。また、標識されていない通常のプライマーを用いたPCRを実施した場合は、金コロイド粒子、蛍光等で標識したプローブ等をアニーリングさせ、目的領域に結合した該プローブの量を測定することにより検出することができる。また、増幅産物の量をより精度よく求めるには、例えば、リアルタイムPCR法を用いればよい。リアルタイムPCR法とは、PCRをリアルタイムでモニターし、得られたモニター結果をカイネティックス分析する方法であり、例えば、遺伝子量に関して2倍程度のほんのわずかな差異をも検出できる高精度の定量PCR法として知られる方法である。該リアルタイムPCR法には、例えば、鋳型依存性核酸ポリメラーゼプローブ等のプローブを用いる方法、サイバーグリーン等のインターカレーターを用いる方法等を挙げることができる。リアルタイムPCR法のための装置及びキットは市販されるものを利用してもよい。以上の如く、検出については特に限定されることはなく、これまでに周知のあらゆる方法による検出が可能である。これら方法では、反応容器を移し換えることなく検出までの操作が可能となる。
【0123】
更に、前記方法1〜7に記載される固定化オリゴヌクレオチドと同じ塩基配列のビオチン化オリゴヌクレオチドを片側のプライマー、又は、固定化オリゴヌクレオチドより、3’端側に新しいビオチン化オリゴヌクレオチドを設計しそれを片側のプライマーとし、その相補側プライマーを用いて、目的領域を増幅することもできる。この場合、得られた増幅産物は、ストレプトアビジンで被覆した支持体があれば固定化されるので、例えば、ストレプトアビジンコートPCRチューブでPCRを実施した場合には、チューブ内に固定されるため、上記の通り、標識されたプライマーを用いれば、増幅産物の検出が容易である。また、先の固定化オリゴヌクレオチドが共有結合等による固定化の場合であれば、PCRで得られた増幅産物を含む溶液をストレプトアビジン被覆支持体が存在する容器に移し、増幅産物を固定化することが可能である。検出については、上述の通り実施すればよい。目的領域を増幅する相補側のプライマーは、メチル化感受性制限酵素の認識部位を1つ以上有する目的領域を増幅でき、且つ、その認識部位を含まないプライマーでなければいけない。この理由は、以下の通りである。選択及び1回伸長反応で得られた二本鎖DNAの固定化オリゴヌクレオチド側のDNA鎖(新生鎖)の一番3’端側のメチル化感受性制限酵素の認識部位のみがメチル化されていない場合には、その部分だけがメチル化感受性制限酵素で消化されることになる。消化後、前述のように洗浄操作を行っても、新生鎖で言う3’端の一部だけを失った二本鎖DNAが固定化されたままの状態で存在する。相補側のプライマーが、この一番3’端側のメチル化感受性制限酵素の認識部位を含んでいた場合には、該プライマーの3’端側の数塩基が、新生鎖の3’端の数塩基とアニーリングし、その結果、目的領域がPCRにより増幅する可能性があるからである。
【0124】
前記方法1〜7に記載される方法は、第四工程の前工程の前操作段階又は後操作段階において、前記目的とするDNA領域を含む一本鎖DNA(正鎖)の3’末端の一部(但し、前記目的とするDNA領域を含まない。)に対して相補性である塩基配列を有し且つ遊離状態である一本鎖オリゴヌクレオチド(負鎖)を反応系内に添加する工程(追加前工程)を追加的に有するような変法を含む。
即ち、
【0125】
(変法1)
前記方法1〜7に記載される方法の第四工程の前工程の前操作段階において、
前記目的とするDNA領域を含む一本鎖DNA(正鎖)の3’末端の一部(但し、前記目的とするDNA領域を含まない。)に対して相補性である塩基配列を有し且つ遊離状態である一本鎖オリゴヌクレオチド(負鎖)を反応系内に添加する工程(追加前工程)を追加的に有し、且つ、
前記方法1〜7に記載の方法の第四工程の各本工程として、下記の1つの工程をさらに追加的に有することを特徴とする方法。
(c)(i)生成した一本鎖状態であるDNA(正鎖)と、上記の追加前工程で反応系内に添加された一本鎖オリゴヌクレオチド(負鎖)とを結合させることにより、前記一本鎖状態であるDNAを選択する第C1工程と、
(ii)第C1工程で選択された一本鎖状態であるDNAを鋳型として、前記一本鎖オリゴヌクレオチド(負鎖)をプライマーとして、該プライマーを1回伸長させることにより、前記一本鎖状態であるDNAを二本鎖DNAとして伸長形成させる第C2工程とを有する第C工程(本工程)
【0126】
(変法2)
前記方法1〜7に記載される方法の第四工程の前工程の後操作段階において、
前記目的とするDNA領域を含む一本鎖DNA(正鎖)の3’末端の一部(但し、前記目的とするDNA領域を含まない。)に対して相補性である塩基配列を有し且つ遊離状態である一本鎖オリゴヌクレオチド(負鎖)を反応系内に添加する工程(追加前工程)を追加的に有し、且つ、第三工程及び上記の追加前工程を経て得られた未消化物である伸長形成された二本鎖DNA(前記メチル化感受性制限酵素の認識部位にアンメチル状態のCpG対を含まない伸長形成された二本鎖DNA)を一本鎖状態に一旦分離する工程(追加再前工程)を有し、且つ、
前記方法1〜7に記載の方法の第四工程の各本工程として、下記の1つの工程をさらに追加的に有することを特徴とする方法(以下、方法1〜7に記載のメチル化割合測定方法と記すこともある。)
(c)(i)生成した一本鎖状態であるDNA(正鎖)と、上記の追加前工程で反応系内に添加された一本鎖オリゴヌクレオチド(負鎖)とを結合させることにより、前記一本鎖状態であるDNAを選択する第C1工程と、
(ii)第C1工程で選択された一本鎖状態であるDNAを鋳型として、前記一本鎖オリゴヌクレオチド(負鎖)をプライマーとして、該プライマーを1回伸長させることにより、前記一本鎖状態であるDNAを二本鎖DNAとして伸長形成させる第C2工程とを有する第C工程(本工程)
【0127】
前記方法1〜7に記載される方法において、当該変法では、外部から「前記目的とするDNA領域を含む一本鎖DNA(正鎖)の3’末端の一部(但し、前記目的とするDNA領域を含まない。)に対して相補性である塩基配列を有し且つ遊離状態である一本鎖オリゴヌクレオチド(負鎖)」を反応系内に添加すること等により、第四工程における前述の目的とするDNA領域の増幅効率を容易に向上させることが可能となる。なお、追加前工程で反応系内に添加される一本鎖オリゴヌクレオチド(負鎖)は、一本鎖DNAの3’末端の一部(但し、前記目的とするDNA領域を含まない。)に対して相補性である塩基配列であって、5’末端が、前記一本鎖固定化オリゴヌクレオチドと同じである塩基配列を有する遊離状態である一本鎖オリゴヌクレオチドであれば、前記一本鎖固定化オリゴヌクレオチドと同じ塩基配列であっても、又は、短い塩基配列であっても、或いは、長い配列であっても良い。ただし、前記一本鎖固定化オリゴヌクレオチドよりも長い配列の場合には、前記リバース用プライマー(正鎖)を伸長プライマーとし、該一本鎖オリゴヌクレオチド(負鎖)を鋳型として、伸長プライマーを伸長させる反応に利用できない遊離状態である一本鎖オリゴヌクレオチドでなければならない。
【0128】
前記方法1〜7に記載される方法において、目的領域を増幅する際に、片側のプライマーとして固定化オリゴヌクレオチドを用いて、もう一方のプライマーのみ添加してPCRを行う例を前記したが、目的産物の検出のために他の方法(例えば、PCRで得られた各々の増幅産物の量を比較することができる分析方法)を実施するのであれば、上記の如く、目的領域を増幅する際に、固定化オリゴヌクレオチドを一方(片側)のプライマーとして使用せず、一対のプライマーを添加してPCRを実施してもよい。かかるPCRを行った後、得られた増幅産物の量を求める。
【0129】
前記方法1〜7に記載される方法において、第四工程は繰り返し工程を有するが、例えば、第A1工程における「生成した一本鎖状態であるDNA(正鎖)」とは、第1回目の第四工程の操作及び第2回目以降の第四工程の繰り返し操作の両操作において「生成した『遊離の』一本鎖状態であるDNA(正鎖)」を意味することになる。
また、第B工程における「生成した一本鎖状態であるDNA(負鎖)」とは、第1回目の第四工程の操作及び第2回目以降の第四工程の繰り返し操作の両操作において「生成した『固定の』一本鎖状態であるDNA(正鎖)」を意味する。但し、第四工程がさらに追加的にC工程を有する場合には、第1回目の第四工程の操作において「生成した『固定の』一本鎖状態であるDNA(正鎖)」を意味し、一方、第2回目以降の第四工程の繰り返し操作において「生成した『固定の』一本鎖状態であるDNA(正鎖)」と「生成した『遊離の』一本鎖状態であるDNA(正鎖)」との両者を意味することになる。
【0130】
また、前記方法1〜7に記載される方法において、第四工程の各本工程で得られた「伸長形成された二本鎖DNA」とは、第A工程の場合には、第1回目の第四工程の操作において「前記メチル化感受性制限酵素の認識部位に、アンメチル状態のCpG対を含まない伸長形成された二本鎖DNA」を意味し、一方、第2回目以降の第四工程の繰り返し操作において「前記メチル化感受性制限酵素の認識部位に、アンメチル状態のCpG対を含まない伸長形成された二本鎖DNA」と「前記メチル化感受性制限酵素の認識部位に、アンメチル状態のCpG対を含む伸長形成された二本鎖DNA」との両者を意味することになる。第B工程の場合には、第1回目の第四工程の操作及び第2回目以降の第四工程の繰り返し操作の両操作において「前記メチル化感受性制限酵素の認識部位では全てがアンメチル状態のCpG対である伸長形成された二本鎖DNA」を意味することになる。
尚、第四工程がさらに追加的にC工程を有する場合にも同様である。
【0131】
また、前記方法1〜7に記載される方法において、第四工程がさらに追加的にC工程を有する場合において、第C1工程における「生成した一本鎖状態であるDNA(正鎖)」とは、第1回目の第四工程の操作及び第2回目以降の第四工程の繰り返し操作の両操作において「生成した『遊離の』一本鎖状態であるDNA(正鎖)」を意味することになる。
【0132】
また前記方法1〜7に記載される方法における工程として、下記の2つの工程をさらに追加的に有することを特徴とするメチル化割合の測定方法(即ち、前記方法1〜7に記載のメチル化割合測定方法)を含んでもよい。
(5)前記方法1〜7に記載される方法の(前記変法を含む)、第一工程及び第二工程を行った後、前記方法1〜7に記載される方法(前記変法を含む)の第三工程を行うことなく、前記方法1〜7に記載(前記変法を含む)される第四工程を行うことにより、前記目的とするDNA領域のDNA(メチル化されたDNA及びメチルされていないDNAの総量)を検出可能な量になるまで増幅し、増幅されたDNAの量を定量する第五工程、及び、
(6)前記方法1〜7に記載される方法(前記変法を含む)の第四工程により定量されたDNAの量と、第五工程により定量されたDNAの量とを比較することにより得られる差異に基づき前記目的とするDNA領域におけるメチル化されたDNAの割合を算出する第六工程。
【0133】
このような本発明又は本発明メチル化割合測定方法において、本発明DNAの塩基配列を目的とするDNA領域として、目的とするDNA領域のメチル化されたDNA量の測定、メチル化割合の測定を行うための各種方法で使用し得る制限酵素、プライマー又はプローブは、検出用キットの試薬として有用である。本発明は、これら制限酵素、プライマー又はプローブ等を試薬として含有する検出用キットや、これらプライマー又はプローブ等が担体上に固定化されてなる検出用チップも提供しており、本発明又は本発明メチル化割合測定方法の権利範囲は、当該方法の実質的な原理を利用してなる検出用キットや検出用チップのような形態での使用ももちろん含むものである。
【0134】
また更に、本発明評価方法において「メチル化頻度又はそれに相関関係がある指標値を測定する」際の他実施態様の一例としては、例えば、以下に示される方法1〜8等を挙げることができる。
【0135】
[方法1]
・第一工程、第二工程、第三工程(第一前工程、第二前工程((i)第二(A)前工程、(ii)第二(B)前工程))、第三前工程、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程)、繰り返し工程((i)増幅工程、(ii)定量工程))
・生物由来検体中に含まれるゲノムDNAが有する目的とするDNA領域におけるメチル化されたDNAの含量を測定する方法であって、
(1)生物由来検体中に含まれるゲノムDNA由来のDNA試料から、目的とするDNA領域を含む一本鎖DNA(正鎖)と、当該一本鎖DNAの目的とするDNA領域に対して相補性である塩基配列を有する一本鎖固定化オリゴヌクレオチドとを結合させることにより、前記の一本鎖DNAを選択し、選択された一本鎖DNAと前記の一本鎖固定化オリゴヌクレオチドとが結合してなる二本鎖DNAを結合形成させる第一工程、
(2)第一工程で結合形成させた二本鎖DNAを少なくとも1種類以上のメチル化感受性制限酵素で消化処理した後、生成した遊離の消化物(前記のメチル化感受性制限酵素の認識部位に少なくとも1つ以上のアンメチル状態のCpG対を含む二本鎖DNA)を除去する第二工程、及び、
(3)下記の各本工程の前工程として、第二工程で得られた未消化物である結合形成された二本鎖DNA(前記のメチル化感受性制限酵素の認識部位にアンメチル状態のCpG対を含まない結合形成された二本鎖DNA)を一本鎖状態に一旦分離する工程(第一前工程)と、
生成した遊離の一本鎖状態であるDNA(正鎖)と、前記の一本鎖固定化オリゴヌクレオチドとを結合させることにより、前記の生成した遊離の一本鎖状態であるDNAを選択し、選択された一本鎖DNAと前記の一本鎖固定化オリゴヌクレオチドとが結合してなる二本鎖DNAを結合形成させる工程(第二(A)前工程)と、
当該工程(第二(A)前工程)で結合形成された二本鎖DNAを、前記の選択された一本鎖DNAを鋳型として、前記の一本鎖固定化オリゴヌクレオチドをプライマーとして、当該プライマーを1回伸長させることにより、前記の選択された一本鎖DNAを伸長形成された二本鎖DNAとする工程(第二(B)前工程)と
を有する工程(第二前工程)と、
第二前工程で伸長形成された二本鎖DNA(前記のメチル化感受性制限酵素の認識部位にアンメチル状態のCpG対を含まない伸長形成された二本鎖DNA)を、一本鎖状態であるDNA(正鎖)と一本鎖状態であるDNA(負鎖)に一旦分離する工程(第三前工程)とを有し、且つ、本工程として
(a)生成した一本鎖状態であるDNA(正鎖)と、前記の一本鎖固定化オリゴヌクレオチド(負鎖)とを結合させることにより、前記の一本鎖状態であるDNAを選択する第A1工程と、第A1工程で選択された一本鎖状態であるDNAを鋳型として、前記の一本鎖固定化オリゴヌクレオチドをプライマーとして、当該プライマーを1回伸長させることにより、前記の一本鎖状態であるDNAを二本鎖DNAとして伸長形成させる第A2工程とを有する第A工程(本工程)と、
(b)生成した一本鎖状態であるDNA(負鎖)を鋳型として、前記の一本鎖状態であるDNA(負鎖)が有する塩基配列の部分塩基配列(負鎖)であって、且つ、前記の目的とするDNA領域の塩基配列(正鎖)に対して相補性である塩基配列(負鎖)の3’末端よりさらに3’末端側に位置する部分塩基配列(負鎖)、に対して相補性である塩基配列(正鎖)を有し、且つ、前記の一本鎖固定化オリゴヌクレオチドを鋳型とする伸長反応に利用できない伸長プライマー(リバース用プライマー)を伸長プライマーとして、当該伸長プライマーを1回伸長させることにより、前記の一本鎖状態であるDNAを伸長形成された二本鎖DNAとする第B工程(本工程)とを有し、
さらに第三工程の各本工程を、前記各本工程で得られた伸長形成された二本鎖DNAを一本鎖状態に一旦分離した後、繰り返すことにより、前記の目的とするDNA領域におけるメチル化されたDNAを検出可能な量になるまで増幅し、増幅されたDNAの量を定量する第三工程、
を有することを特徴とする方法。
【0136】
[方法2]
・第一工程、第二工程、第三工程(第一前工程、第二前工程((i)第二(A)前工程、(ii)第二(B)前工程))、第三前工程、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程)、繰り返し工程((i)増幅工程、(ii)定量工程))
・第一工程において、目的とするDNA領域を含む一本鎖DNA(正鎖)と、当該一本鎖DNAの目的とするDNA領域に対して相補性である塩基配列を有する一本鎖固定化オリゴヌクレオチドとを結合させる際に、二価陽イオンを含有する反応系中で結合させることを特徴とする前記方法1に記載される方法。
【0137】
[方法3]
・第一工程、第二工程、第三工程(第一前工程、第二前工程((i)第二(A)前工程、(ii)第二(B)前工程))、第三前工程、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程)、繰り返し工程((i)増幅工程、(ii)定量工程))
・二価陽イオンがマグネシウムイオンであることを特徴とする前記方法2に記載される方法。
【0138】
[方法4]
・第一工程、第二工程、第三工程(第一前工程(追加前工程を含む)、第二前工程((i)第二(A)前工程、(ii)第二(B)前工程))、第三前工程、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程、(iii)第C工程((iii1)第C1工程、(iii2)第C2工程))、繰り返し工程((i)増幅工程、(ii)定量工程))
・前記方法1〜3のいずれかの前記方法に記載される第三工程の第一前工程の前操作段階において、
前記の目的とするDNA領域を含む一本鎖DNA(正鎖)の3’末端の一部に対して相補性である塩基配列を有し且つ遊離状態である一本鎖オリゴヌクレオチド(負鎖)を反応系内に添加する工程(追加前工程)を追加的に有し、且つ、
前記方法1〜3のいずれかの前記方法に記載の第三工程の各本工程として、下記の1つの工程をさらに追加的に有することを特徴とする方法。
(c)(i)生成した一本鎖状態であるDNA(正鎖)と、上記の追加前工程で反応系内に添加された一本鎖オリゴヌクレオチド(負鎖)とを結合させることにより、前記の一本鎖状態であるDNAを選択する第C1工程と、
(ii)第C1工程で選択された一本鎖状態であるDNAを鋳型として、前記の一本鎖オリゴヌクレオチド(負鎖)をプライマーとして、当該プライマーを1回伸長させることにより、前記の一本鎖状態であるDNAを伸長形成された二本鎖DNAとする第C2工程と
を有する第C工程(本工程);
【0139】
[方法5]
・第一工程、第二工程、第三工程(第一前工程(追加前工程及び追加再前工程を含む)、第二前工程((i)第二(A)前工程、(ii)第二(B)前工程))、第三前工程、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程、(iii)第C工程((iii1)第C1工程、(iii2)第C2工程))、繰り返し工程((i)増幅工程、(ii)定量工程))
・前記方法1〜3のいずれかの前記方法に記載される第三工程の第一前工程の後操作段階において、
前記の目的とするDNA領域を含む一本鎖DNA(正鎖)の3’末端の一部に対して相補性である塩基配列を有し且つ遊離状態である一本鎖オリゴヌクレオチド(負鎖)を反応系内に添加する工程(追加前工程)を追加的に有し、且つ、第二工程及び上記の追加前工程を経て得られた未消化物である二本鎖DNA(前記のメチル化感受性制限酵素の認識部位にアンメチル状態のCpG対を含まない伸長形成された二本鎖DNA)を一本鎖状態に一旦分離する工程(追加再前工程)を有し、且つ、
前記方法1〜3のいずれかの前記方法に記載の第三工程の各本工程として、下記の1つの工程をさらに追加的に有することを特徴とする方法(以下、本発明メチル化割合測定方法と記すこともある。)
(c)(i)生成した一本鎖状態であるDNA(正鎖)と、上記の追加前工程で反応系内に添加された一本鎖オリゴヌクレオチド(負鎖)とを結合させることにより、前記の一本鎖状態であるDNAを選択する第C1工程と、
(ii)第C1工程で選択された一本鎖状態であるDNAを鋳型として、前記の一本鎖オリゴヌクレオチド(負鎖)をプライマーとして、当該プライマーを1回伸長させることにより、前記の一本鎖状態であるDNAを伸長形成された二本鎖DNAとする第C2工程と
を有する第C工程(本工程)
【0140】
[方法6]
・第一工程、第二工程、第三工程(第一前工程(追加前工程を含む)、第二前工程((i)第二(A)前工程、(ii)第二(B)前工程))、第三前工程、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程、(iii)第C工程((iii1)第C1工程、(iii2)第C2工程))、繰り返し工程((i)増幅工程、(ii)定量工程))
・前記方法1〜3のいずれかの前記方法に記載される第三工程の第三前工程の前操作段階において、
前記の目的とするDNA領域を含む一本鎖DNA(正鎖)の3’末端の一部に対して相補性である塩基配列を有し且つ遊離状態である一本鎖オリゴヌクレオチド(負鎖)を反応系内に添加する工程(追加前工程)を追加的に有し、且つ、
前記方法1〜3のいずれかの前記方法記載の第三工程の各本工程として、下記の1つの工程をさらに追加的に有することを特徴とする方法。
(c)(i)生成した一本鎖状態であるDNA(正鎖)と、上記の追加前工程で反応系内に添加された一本鎖オリゴヌクレオチド(負鎖)とを結合させることにより、前記の一本鎖状態であるDNAを選択する第C1工程と、
(ii)第C1工程で選択された一本鎖状態であるDNAを鋳型として、前記の一本鎖オリゴヌクレオチド(負鎖)をプライマーとして、当該プライマーを1回伸長させることにより、前記の一本鎖状態であるDNAを伸長形成された二本鎖DNAとする第C2工程と
を有する第C工程(本工程);
【0141】
[方法7]
・第一工程、第二工程、第三工程(第一前工程(追加前工程及び追加再前工程を含む)、第二前工程((i)第二(A)前工程、(ii)第二(B)前工程))、第三前工程、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程、(iii)第C工程((iii1)第C1工程、(iii2)第C2工程))、繰り返し工程((i)増幅工程、(ii)定量工程))
・前記方法1〜3のいずれかの前記方法に記載される第三工程の第三前工程の後操作段階において、
前記の目的とするDNA領域を含む一本鎖DNA(正鎖)の3’末端の一部に対して相補性である塩基配列を有し且つ遊離状態である一本鎖オリゴヌクレオチド(負鎖)を反応系内に添加する工程(追加前工程)を追加的に有し、且つ、第二工程及び上記の追加前工程を経て得られた未消化物である二本鎖DNA(前記のメチル化感受性制限酵素の認識部位にアンメチル状態のCpG対を含まない伸長形成された二本鎖DNA)を一本鎖状態に一旦分離する工程(追加再前工程)を有し、且つ、
前記方法1〜3のいずれかの前記方法に記載の第三工程の各本工程として、下記の1つの工程をさらに追加的に有することを特徴とする方法。
(c)(i)生成した一本鎖状態であるDNA(正鎖)と、上記の追加前工程で反応系内に添加された一本鎖オリゴヌクレオチド(負鎖)とを結合させることにより、前記の一本鎖状態であるDNAを選択する第C1工程と、
(ii)第C1工程で選択された一本鎖状態であるDNAを鋳型として、前記の一本鎖オリゴヌクレオチド(負鎖)をプライマーとして、当該プライマーを1回伸長させることにより、前記の一本鎖状態であるDNAを伸長形成された二本鎖DNAとする第C2工程と
を有する第C工程(本工程)
【0142】
[方法8]
・第一工程、第三工程(第一前工程、第二前工程((i)第二(A)前工程、(ii)第二(B)前工程))、第三前工程、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程)、第四工程((i)増幅工程、(ii)定量工程)、第五工程)
・前記方法1〜7のいずれかの前記方法に記載される方法の工程として、下記の2つの工程をさらに追加的に有することを特徴とするメチル化割合の測定方法。
(4)前記方法1〜7のいずれかの前記方法に記載される方法の第一工程を行った後、前記方法1〜7のいずれかの前記方法に記載される方法の第二工程を行うことなく、前記方法1〜7のいずれかの方法記載の方法における第三工程を行うことにより、前記の目的とするDNA領域のDNA(メチル化されたDNA及びメチルされていないDNAの総量)を検出可能な量になるまで増幅し、増幅されたDNAの量を定量する第四工程、及び、
(5)前記方法1〜7のいずれかの前記方法に記載の第三工程により定量されたDNAの量と、第四工程により定量されたDNAの量とを比較することにより得られる差異に基づき前記の目的とするDNA領域におけるメチル化されたDNAの割合を算出する第五工程、を有することを特徴とする方法。
【0143】
本発明評価方法の第一工程において、哺乳動物由来の検体に含まれる本発明DNAのメチル化頻度に相関関係がある指標値を測定する方法としては、例えば、本発明DNAの下流に存在する遺伝子の転写産物であるmRNAの量を測定する方法をあげることができる。当該測定には、例えば、リアルタイムPCR法、ノザンブロット法〔Molecular Cloning,Cold Spring Harbor Laboratory(1989)〕、in situ RT−PCR法〔Nucleic Acids Res.,21,3159−3166(1993)〕、in situハイブリダイゼーション法、NASBA法〔Nucleic acid sequence−based amplification,nature,350,91−92(1991)〕等の公知な方法を用いればよい。
哺乳動物由来の検体に含まれる本発明DNAの下流に存在する遺伝子の転写産物であるmRNAを含む試料は、通常の方法に準じて当該検体から抽出、精製等により調製すればよい。
調製された試料中に含まれるmRNAの量を測定するためにノザンブロット法が用いられる場合には、検出用プローブは本発明DNAの下流に存在する遺伝子又はその一部(本発明DNAの下流に存在する遺伝子の制限酵素切断、本発明DNAの下流に存在する遺伝子の塩基配列に従い化学合成した約100bp〜約1000bp程度のオリゴヌクレオチド等)を含むものであればよく、前記試料中に含まれるmRNAとのハイブリダイゼーションにおいて用いられる検出条件下に検出可能な特異性を与えるものであれば特に制限はない。
また調製された試料中に含まれるmRNAの量を測定するためにリアルタイムPCR法が用いられる場合には、使用されるプライマーは、本発明DNAの下流に存在する遺伝子のみを特異的に増幅できるものであればよく、その増幅する領域や塩基長等には特に制限はない。リアルタイム-PCR法による転写産物の量を測定することもできる。定量を必要とする場合には、PCR反応産物をリアルタイムでモニタリングしカイネティックス分析を行うことにより、例えば、遺伝子量に関して2倍程度のほんのわずかな差異をも検出できる高精度の定量が可能なPCR法であるリアルタイムPCRを用いて、それぞれの産物の量を比較することもできる。リアルタイムPCRを行う方法としては、例えば、鋳型依存性核酸ポリメラーゼプローブ等のプローブを用いる方法又はサイバーグリーン等のインターカレーターを用いる方法等が挙げられる。リアルタイムPCR法のための装置及びキットは既に市販されている。
【0144】
また本発明評価方法の第一工程において、哺乳動物由来の検体に含まれる本発明DNAのメチル化頻度に相関関係がある指標値を測定する他の方法としては、例えば、本発明DNAの下流に存在する遺伝子の翻訳産物であるタンパク質の量を測定する方法をあげることができる。当該測定には、例えば、当該タンパク質に対する特異的抗体(モノクロナル抗体、ポリクロナル抗体)を用いた、細胞工学ハンドブック、羊土社、207(1992)等に記載されるイムノブロット法、免疫沈降による分離法、間接競合阻害法(ELISA 法)等の公知な方法を用いればよい。
因みに、タンパク質に対する特異的抗体は、当該タンパク質を免疫抗原として用いる通常の免疫学的な方法に準じて製造することができる。
【0145】
以上のような各種方法を用いて、哺乳動物由来の検体に含まれる目的とするDNAのメチル化頻度に相関関係がある指標値を測定する。測定されたメチル化頻度に相関関係がある指標値と、例えば、大腸癌細胞等の癌細胞を持たないと診断され得る健常な哺乳動物由来の検体に含まれる目的とするDNAのメチル化頻度に相関関係がある指標値(対照)とを比較して、当該比較により得られる差異に基づき前記検体の癌化度を判定する。仮に、哺乳動物由来の検体に含まれる目的とするDNAのメチル化頻度に正の相関関係がある指標値が対照と比較して高ければ又は負の相関関係がある指標値が対照と比較して低ければ(目的とするDNAが対照と比較の上で高メチル化状態であれば)、当該検体の癌化度が対照と比較の上で高いと判定することができる。
【0146】
本発明評価方法における、目的とするDNAのメチル化頻度又はそれに相関関係がある指標値を測定するための各種方法で使用し得るプライマー、プローブ又は特異的抗体は、大腸癌細胞等の癌細胞の検出用キットの試薬として有用である。本発明は、これらプライマー、プローブ又は特異的抗体等を試薬として含有する大腸癌細胞等の癌細胞の検出用キットや、これらプライマー、プローブ又は特異的抗体等が担体上に固定化されてなる大腸癌細胞等の癌細胞の検出用チップも提供しており、本発明評価方法の権利範囲は、当該方法の実質的な原理を利用してなる前記のような検出用キットや検出用チップのような形態での使用ももちろん含むものである。
【実施例】
【0147】
以下に実施例により本発明を詳細に説明するが、本発明はこれらに限定されるものではない。
【0148】
実施例1
(シトシンのメチル化割合の測定)
Biochain社より下表に示されるヒト組織由来ゲノムDNA入手し、MassARRAYシステムを用いたMassARRAY解析を実施した。詳細はSEQUENOMアプリケーションノートに示される定量的DNAメチル化解析用EpiTYPERの概論に従った手法にしたがって、配列番号1-19に示される塩基配列からなるオリゴヌクレオチドであるアンプリコン1−19に含まれるシトシンのメチル化割合を測定した。
【0149】
ヒト組織由来ゲノムDNA:

【0150】
アンプリコン1−19を以下に示す。
【0151】
アンプリコン1:TACTAGGAGGAGAGACCTGGAAGGCAATCACAAAAAGTCTCATTTAAATTCCTGGAAAGCACAGCTTCTCCAAACACAGCTATTCAGCTCTTTGGAAGGCAGCACTTGCGGGAGCCATTGAGTTTAACTTCACTCAGTCCCCCAACACAGAACCGGCAAATCCGAATGAGATGGACGTCACACTCCCTACTCAAAAGAATGCATCAAATATCCACTCCGTAACACCGCGGAAAGTAAACCCAAAAGCGGAGTTTGCCGCCTGCCAACTACATAAGAATTAACACTCGGGTATTTAGGATTCTAAAGATCCCTACTACCCCAAACATTATAGCCACAGAGAACCAGAAATGAACAGAACACACTTTAACCTTTAAGAAGTGCAGTTTTGTACGGGGGTTGGCTGAAGAAAGACAAAAATCTTCACTCCCTTCCAGAGCCAAAAGAGCCAAAATAAAAGATCACCTTTACTGAGCCACAGGGGCACAACTG(配列番号1)
【0152】
アンプリコン2:TGTTATGCACAAGGCCAAGTGGCTTTGCTCATTCCCAAAACAGGCCAGCCAGCTCGTGGCGATTAGTGAGATAATGAGCTTGCATGTCCCTGGCACAGGATCTGTGCCCGACAATGCTTTCCTTTCTTTAGCGTAGGCAATGTGTGTACTGAATTTCAGTGATTTCATTTGGTACTACTGTATGTGCTTGCTCCATATTTTTAATCCAACCAGTTCTGAGCGACTTTATGAGAACACACATTTTAACATAAATGCATTTGGATTTATTGTTCTTAAGTAGAAAGCTGAGTAGTTTCTATATAAGGGAAATCTAAAGCCTATAGGATAGAAATTATCTGTTCAGCAAAGTCTTACTTGAAGATTAAGAACAGGGACTTTTTTGCGGGGGGACGGGAGGGATGGAGTCTCCCTCTGTCACCCAGGCTGGAGTTCAGTGGCATGATCTCAGCTCACTACAACCTCTGCCTCCTGGGTTCAAGTGA(配列番号2)
【0153】
アンプリコン3:TGATGGCTCACTCAGGGGGCCCTATAGAAACGCCCCCAAGGATTCAACCACCTGGGAGGCTCTTTACTTCTGGTATTTCTCCTAAGGATGAAACTTGCAATTCAAACACTCTCGTTGCCGATTCTCTCCTCCCGCACCGCTCTTACCTCCACTCCCACATTCCCCTCCCAGCAAGGTTAGCGCACTGGAAGCAATGTGAAGGGGCTGTGGGGAAGGTGAGGCCCGAGTTTCAGGCTACTTTTGTCTGATTCAGACTCTTTCAGAATGACCAGCAAGTTCAACCTGTACCGCAGAGCCAGGACTCACTGGGGAGAAATGACTTTTGCATC(配列番号3)
【0154】
アンプリコン4:GTGTGGTGTGGGCTCATTCCTCAGTACACCAGTGCCCTCTAATGGACAAAACAACAGTCCCAAGGTCACGGTTGTTCCAAAGTGGACCGTGCACACTTGAAACAGCTACCATCGCTCAGCACCTAAGTCAAATGTCAGAAGGCAGAAAGCTGTTCAGAATGTTTAGCTTAACTCCCTGTTTGTAATGAAAAGGAAACCAAGGTCCTAATTGCAAGACTGAACGTGATGGTGGCATGATTACGGTCATTTGACCAGCAATCATCTCGCCATCTGAGCACCTGCTGTGGAAGCAGCCCCTGACCTAAGGCTGTGTGTGCAGTGAGCCATCCATCCTCACAGTGAGCCAGGGGTAGGGCGATCCCTATCCTCTTACAGATGAAGACACAGGCAGGGCCCTCTGTGACTTTATGGGAAAGCCTGAGTGTGCACTAGAA(配列番号4)
【0155】
アンプリコン5:AGGTGTCCCAGGGCAGTGTCAGGGATCCTGGCTTTCTCCATCCTGTTGCCCTGCCTACCAGGCAGAGCTGCCTTGGTCCCTGGAAACTGGGCTTCTTACTGGTTGGCTGGGTCTGGCCCAGCCTTGGAGCTCAGTTCTGAGCACTGGACCCCATCTTCTTCTCTGGACTGGAAGATCCACTCCCGCCAGACCTGGTGACCTCCTGTGGGGTCGCCTTACTCCAAGCCCTGACCAGGTACCTACTTGGCTAAGGCTTGGAGCCCGGCTGTGAAGGGCTGAGAATCACCAAGGTTGAGCTCTGCAAGCCTGAACCCGGATGCTTCCGCACAGAAAGGGCCTTGGATGCTGGGTTGAGATCTTTTGCCTTAAA(配列番号5)
【0156】
アンプリコン6:AAATACTCACTTCTGGGAAACATGGGCGAATTCAGTGGGAATCGTGCTAGAAGTTACGAGCAGAGGAGCCTGGGTGGGGACTTATACTGGCCTTGACGGCCCGTGGAAAGGAACTGGCGGCAATTCCTTCCGTTTTCCGTCAATTTCTTCACGGGTCGCTCAGAAGCTACGGAAGCAAAGTAGAAAGGAGTGATAGGGACAGGCCACAGTACCGGCGGACGGTGATGGCGTTGCGTTTAAAAGGGTGGTCACTGAAACCCTTTGT(配列番号6)
【0157】
アンプリコン7:GGACAGACCAGTTGAGCTCTTTGGGTATGCACGTAATGTCGCATTTTTATTTTCAGTTCAGGAAATGCTGATATTGGAGCTTCTGAGGGAGCTGCAGTGATTTCCCGATTTCCTGCGCGCCTGTGTGGAAAGTTAGAAGCGGAATCTACCGGCAGCTTTGAGACTAAGCATGACGGTGGAAACAGCTAATTTTATTAGCTTTTGTCTGAAATGCAAAAGATGAGAAAGAAAATTCCCGTTTGTTTGCTCCACATACTTCTCTTAGAAGCCTATGGAAAGCCAACTTTCCCCCTGAAGAAACTCCTCCTGGCATTTGCAAAGAGCTCCTTTACTCCTCTTGTCCAGCTCTTCTCTCAAAAGGACTCTGCAGAGCTGGACAG(配列番号7)
【0158】
アンプリコン8:AACCACACATGGGTGGGAAGGTGCTGAGAGCAACAGAGGGCTGGACTGTGCATCGTGGTGGGGGTTGAGCGCCAGAAGCCACTGCAACAGCACTTTCCTCTGTGGATCCTGTACAGGGTTCATGTGGCCTTGGCAAGCAGCCATTAGATCTGGGCAAGTTGCCCACCACGTCGGCCCTTCCCCCATAGCACATCTCTCCTGGGTCCCAGCACTGGTCACTTTTTCCTTTTCTTAATGAACGGCTTGGAGTGGGTGGGAAAGGGAAGATAATGAGTAAAGTAAGGAAGTGATTTTCGTAGGCCTGTGTCTTTGTCTTTCTCCCCAAACTTACAGCCTCCCGCCCTGACATGGACAGGCTCAGGCAGGCCTGGGAGACCTGAACTCCCTCTCCAGATAACTGGGAGCCTGGAGAGCAAATTCGGGGCTGGGACTCAGGATGGTGACACTGGCCA(配列番号8)
【0159】
アンプリコン9:TGCCCTTTCAGGAACAATGTGGGAATAAATTTTAGTCTGAAATTGCTGTTATTTACACTTTCTTTCAAGTTTGTTGAAGCACAAATACATTTGGGATAATTAATGTTCTGATGGATTATTTCATCCTACTATGTCTTCTTAACCTTCTACCGGTTTCATTCCTTTTTCTGCCTCACATTGTGACAAATTTGTAGTCTTTGTTACACAGTACAAGGAGCACTGAGAATAAGGGCGGTATCCTTGAAGGAATACCTATGAATACAAATTGTATTACGTAATGCATCCCTTTCCAGGAAAACACAGAGAAGGAATTCTTTTCTTTAGGCGACCAGCAAATGGTCACAGGCAGGGATTTTGCAGGGTCTGATCTGTAGAGGCGGGTCGATACATTCACCGAAGAGAGATAACGGGAAACCGTTTAAGGGGTGCGGCCTAACACGACAGAACTGCTGCGGGAAGGGTCCTGGGGTGAGGAGGTGACATAAAGGGAGGAGGGCACC(配列番号9)
【0160】
アンプリコン10:AATACAGCCTGGAGACAAATGGTGGGGAGGGTTTCCCCTAAATTTGGACATCTCCAGATTAAGACCTCCGCCGAATCCGTGAGGCTTTCCCTCTCCAAGGAGCTCCTAAGAGAATTTCCCAGTAAAATCGCCTCAACTGCGGTAAATAGGCTGTTCCCCGCGCCAGCATTTGAGAAGAGCTGGTCCCCAGAGTGTAAAGGAGTTAGGATGTTGGCAGGAGGAAGGATGTGTCGCCGGATGAGGAAAAGAAAGGTGGGTGTCTGCGGTGCAGTCCTTGGTCTTTCTGGCAAGTGAGGCGCTCTCCCCCTAAATGTCTCAGAGGGAGACAAATCAGCGGACTACCTTGCTTCCTTTGATGACTTGGA(配列番号10)
【0161】
アンプリコン11:CTCAGACCCAGGGGCTGGGCCCCCAGCCCCCAGTCCCGATCCCAGCTGGGTCGAGCCATGCTGCGCTACCTGCTGAAAACGCTGCTGCAGATGAACTTGTTCGCGGACTCTCTGGCCGGGGACATCTCCAACTCCAGCGAGCTGCTCTTGGGCTTCAACTCCTCGCTGGCGGCGCTCAACCACACCCTGCTGCCTCCCGGCGATCCCTCTCTCAACGGTGAGACCCTGCCTCTTGGGGATATGGGATCCTGGGATGGGGATGAGGTGAGAGGGCGGCGTGGAAGGGAAGGAGAAGCGCTCCTGTCCCGAGGTCCGGGATTGAGTGGCGCCTCCCAGCGCCTCCCTGGGTCGTGGGGTCTAAGGGATAATTTGGAGCTTCGAGCACATGAGTGGGGGTACCCGCGGGAGGTCGAGGGCTTGGGAGAAGATGGCTACTGAGTC(配列番号11)
【0162】
アンプリコン12:GAGACCCTGCCTCTTGGGGATATGGGATCCTGGGATGGGGATGAGGTGAGAGGGCGGCGTGGAAGGGAAGGAGAAGCGCTCCTGTCCCGAGGTCCGGGATTGAGTGGCGCCTCCCAGCGCCTCCCTGGGTCGTGGGGTCTAAGGGATAATTTGGAGCTTCGAGCACATGAGTGGGGGTACCCGCGGGAGGTCGAGGGCTTGGGAGAAGATGGCTACTGAGTCTTTTTACACCTCCTTCCCTTCCCCTACAACGCCCACCCCAGGTGAGAAGAACCGTTGCTGGTAACGGGCAGGGAAGTCCGAGCTAAGAAAGGCCCGGGCCCAGCGCAGGGAGGGCAGAGGAGGGGGCACAGTCTCCCGCCGGCCTCGGCCAAGCCAGGTCACTCGGTGACCCACCCAGGCAGCTGGTCTTCGGAACCCCGAAGTTTCCCAAGAACTCACTTAGGACCAGAGGAAGCCAAAATGCTGGA(配列番号12)
【0163】
アンプリコン13:TGGCCAGATCTTGGTGCCCTTGCTCAGACTCCTCTGCGGGTGCCGCTGAGGCTGCTCCCTGGGTACCTTTGCGGAACAGGATAAATGTTTGATTTGTTTCTCCCAGGTAGAGAAGCTTCTCTCCCAAGAGAGCCCCGGGCTTCCACACTCTTCAGAGATCGGGCAGGTGGCCGCGGAGGGCGGGGGCAGAGCCGGGGGTCAGATCTCGCCTGCAGGTTCCACTGTTCGTGTGCCAGGCACCGCTGGCACTGCCGCTGCCTCGGAGTAGGCAGCAAGCCCTTCTCCGGTACTTAGAGAAAAGTTGCGGAGGAGGGGAGGAAAAGGAATTTGGCAACTGCGCTGAGCTCCTGTAGGAAAGCGCTTGGGAGCCAGTTCTCCCTTCCCGGGCTCATGTCCTTTCAGAGAATTGCAAATAGCTGGGGAAAGACAGACTTT(配列番号13)
【0164】
アンプリコン14:AGACTGTCCAAAGATGGTTCTGTGGGCGGGCCGAGTCTTCTGCTGAATAACTCACCCAGGTGTGCAGCCAACATCTGTGCCTTCAGACAGCAGGCCGAGGGGAGTTACCGCCGCACGGGGCCTTATCTTTCTAATTACAAACACATGTGCTAACCTTGGGCACTCTGCCAACACGCAAAGCCTGCAAAGGGCCACTCTGTAATACCTAAGTGATTGTCCATCTGGCAAAGCATCTTGGGAATATTTTCATCCTTCTCGTCATCCTCCTGGAGGACTGGAGACATATTCCAGATCACAACCTTCCCAGAATCCTGCCCTGGAACAAAGGAGCAGAAATGGCT(配列番号14)
【0165】
アンプリコン15:GGGCAGCAGTAACCAGGACACCAGGGTCCGACCACGGCCTCCACACACCTGTGCCCGTGGAAGACGCGGGCGCCGGGGTAGGCAGCATCCACGTGCTCCACAGCTGCCGGTGCTGGGCAGGCTGGAGACTCACGGGAGAGGCAGGAGGAGAATCAGCGTGTTGAGTCCCTCGCTGTGTTAGTGTGAAAAATTCTCATTACAGTTGCAAATAAAAGGGATCACGATCACTAGCCCCGGAAACCCTCATCTCCCGGACCATCAGGATCGCACTGAACAGAATGGTCCCCTAATGGTCCCTGAGG(配列番号15)
【0166】
アンプリコン16:TTCTGGAGTAAAGAGGGATTACTCTCCCATTATCTTTCTCTAATTCTTTCATTTCTCTCCCTTGTCTGACTTCCTAACATTGATTGAGGCTTCCACTGCTTTGTCCTCATTGTTAGAGACGTCGTTAGACATCATTCTTAGACAATGCGACCTTCCCTCTTGAATTCCACTTGCATGTCTCTGAGAGCTTATATGAATTTTCCGCTTTGACCCCCTGTTGTCACTACATTATCTGTGTTTAGCGGGACTTAGCCATTTTCCTCATGTATGTCTTTCAAATTGTAGTTATATAACTTTTCTCTCAGTCATTTGCTCTATCCCTCACCAGATGTATCTAAACTGAGGCCCACTAGACTTAAGCACACCATTGTGGTTCCCACAGCTCAGTGAGCAGGG(配列番号16)
【0167】
アンプリコン17:GGTTTGAAGGACACAGAGAGAGCCTACTGACACTTCACTTTCGCTACACGTGGTGATTTTTCCAGTGCTTCCGGAGACACTGAAATTTAGTTCCAAACATTGCCTTAGAGGATTCTTCATTTTATTCATTCTACCGATGATCCACTCAGAAAATCAAACCTGAGTACGGAGACATTGGAGAAGTCGTTAAAGTATTGGACCAAGTCGGTTCGTCACGAGTGACAAAGTTATTCCACACTCTACTTGTACATACTCTGCTTTGCCTTCATGATGGCAAAGA(配列番号17)
【0168】
アンプリコン18:TGAAGTGTCAGTAGGCTCTCTCTGTGTCCTTCAAACCGCCCATATGGTCGTTACAAACGGCGGCTTGAGGAAAGGTGGTTTTGGAATCGGTTTCTCTCTGGTCTTACATGATGCATCTATACTATACTGCATTATAATACAGGAAAGGGTCACTTGCTGACATAAAGCACAGCAGGCAGGAATAGAAGAGTCAACTTAGGGGAAAAAAAGAAAGTGCTTTGTGATTTCAATTTGGTGTCTGCAGTTTGGAAAACGGTTGATCAGTTTAACTGTTTTCGTGGTGACTCACAAAAATACATATGAGCGTTGAAATTCTGCAGAAGAACAACAATCGGGGAAACATTTCTGCAAGCTCCAATTACTGGAACCCAGACATAAGCCTACAAGCTAAGACAGAGCTACACCAGGCTTCAGCAGGAAACCATACAGATCTCCTGGGAAGGGCTTCCC(配列番号18)
【0169】
アンプリコン19:TGTTCTTGTTGGCCACTGTTGCCTCTCTAAATAGGATGCCATCTCACCAGGCAGAGTTCCCTGGGCTCACGGCCCCGTTGTTCCCGTTGTCCCTCCTCAGTCGTCCAAAATAGGCCGTAAGGGCGACACCCCAGACCAGGGTAGGTGGACAAATGCCCTTCCTGTCCTTGCTTCTCCCGCAGCCCAGCGGGAAGAGCAAAGACTGCGTGTTCACGGAGATCGTGCTGGAGAACAACTATACGGCCTTCCAGAACGCCCGGCACGAGGGCTGGTTCATGGCCTTCACGCGGCAGGGGCGGCCCCGCCAGGCTTCCCGCAGCCGCCAGAACCAGCGCGAGGCCCACTTCATCAAGCGCCTCTACCAAGGCCAGCTGCCCTTCCCCAACCACGCCGAGAAGCAGAAGCAGTTCGAGTTTGTGGGCTCCGCCCCCACCCGCCGGACCAAGCGCACACGGCGGCCCCAGCCCCTCACGTAGTCTGGGAGGCAGGGGGCAGCA(配列番号19)
【0170】
上記の19アンプリコンで示される塩基配列をBisulfite処理して得られるDNAを増幅させるために設計された19プライマーセットを以下に示す。
アンプリコン1に対するプライマーセットは、プライマーF1とプライマーR1である。
アンプリコン2に対するプライマーセットは、プライマーF2とプライマーR2である。
アンプリコン3に対するプライマーセットは、プライマーF3とプライマーR3である。
アンプリコン4に対するプライマーセットは、プライマーF4とプライマーR4である。
アンプリコン5に対するプライマーセットは、プライマーF5とプライマーR5である。
アンプリコン6に対するプライマーセットは、プライマーF6とプライマーR6である。
アンプリコン7に対するプライマーセットは、プライマーF7とプライマーR7である。
アンプリコン8に対するプライマーセットは、プライマーF8とプライマーR8である。
アンプリコン9に対するプライマーセットは、プライマーF9とプライマーR9である。
アンプリコン10に対するプライマーセットは、プライマーF10とプライマーR10である。
アンプリコン11に対するプライマーセットは、プライマーF11とプライマーR11である。
アンプリコン12に対するプライマーセットは、プライマーF12とプライマーR12である。
アンプリコン13に対するプライマーセットは、プライマーF13とプライマーR13である。
アンプリコン14に対するプライマーセットは、プライマーF14とプライマーR14である。
アンプリコン15に対するプライマーセットは、プライマーF15とプライマーR15である。
アンプリコン16に対するプライマーセットは、プライマーF16とプライマーR16である。
アンプリコン17に対するプライマーセットは、プライマーF17とプライマーR17である。
アンプリコン18に対するプライマーセットは、プライマーF18とプライマーR18である。
アンプリコン19に対するプライマーセットは、プライマーF19とプライマーR19である。
【0171】
プライマーF1:AGGAAGAGAGTATTAGGAGGAGAGATTTGGAAGGT(配列番号20)
プライマーR1:CAGTAATACGACTCACTATAGGGAGAAGGCTCAATTATACCCCTATAACTCAATAAAAA(配列番号21)
【0172】
プライマーF2:AGGAAGAGAGTGTTATGTATAAGGTTAAGTGGTTTTG(配列番号22)
プライマーR2:CAGTAATACGACTCACTATAGGGAGAAGGCTTCACTTAAACCCAAAAAACAAAAAT(配列番号23)
【0173】
プライマーF3:AGGAAGAGAGTGATGGTTTATTTAGGGGGTTTTAT(配列番号24)
プライマーR3:CAGTAATACGACTCACTATAGGGAGAAGGCTAATACAAAAATCATTTCTCCCCAAT(配列番号25)
【0174】
プライマーF4:AGGAAGAGAGGTGTGGTGTGGGTTTATTTTTTAGT(配列番号26)
プライマーR4:CAGTAATACGACTCACTATAGGGAGAAGGCTTTCTAATACACACTCAAACTTTCCCA(配列番号27)
【0175】
プライマーF5:AGGAAGAGAGAGGTGTTTTAGGGTAGTGTTAGGGA(配列番号28)
プライマーR5:CAGTAATACGACTCACTATAGGGAGAAGGCTTTTAAAACAAAAAATCTCAACCCAA(配列番号29)
【0176】
プライマーF6:AGGAAGAGAGAAATATTTATTTTTGGGAAATATGGG(配列番号30)
プライマーR6:CAGTAATACGACTCACTATAGGGAGAAGGCTACAAAAAATTTCAATAACCACCCTT(配列番号31)
【0177】
プライマーF7:AGGAAGAGAGGGATAGATTAGTTGAGTTTTTTGGG(配列番号32)
プライマーR7:CAGTAATACGACTCACTATAGGGAGAAGGCTCTATCCAACTCTACAAAATCCTTTTA(配列番号33)
【0178】
プライマーF8:AGGAAGAGAGAATTATATATGGGTGGGAAGGTGTT(配列番号34)
プライマーR8:CAGTAATACGACTCACTATAGGGAGAAGGCTTAACCAATATCACCATCCTAAATCC(配列番号35)
【0179】
プライマーF9:AGGAAGAGAGTGTTTTTTTAGGAATAATGTGGGAA(配列番号36)
プライマーR9:CAGTAATACGACTCACTATAGGGAGAAGGCTAATACCCTCCTCCCTTTATATCACC(配列番号37)
【0180】
プライマーF10:AGGAAGAGAGAATATAGTTTGGAGATAAATGGTGGG(配列番号38)
プライマーR10:CAGTAATACGACTCACTATAGGGAGAAGGCTTCCAAATCATCAAAAAAAACAAAAT(配列番号39)
【0181】
プライマーF11:AGGAAGAGAGTTTAGATTTAGGGGTTGGGTTTTTA(配列番号40)
プライマーR11:CAGTAATACGACTCACTATAGGGAGAAGGCTAACTCAATAACCATCTTCTCCCAAA(配列番号41)
【0182】
プライマーF12:AGGAAGAGAGGAGATTTTGTTTTTTGGGGATATG(配列番号42)
プライマーR12:CAGTAATACGACTCACTATAGGGAGAAGGCTTCCAACATTTTAACTTCCTCTAATCC(配列番号43)
【0183】
プライマーF13:AGGAAGAGAGTGGTTAGATTTTGGTGTTTTTGTTT(配列番号44)
プライマーR13:CAGTAATACGACTCACTATAGGGAGAAGGCTAAAATCTATCTTTCCCCAACTATTTACA(配列番号45)
【0184】
プライマーF14:AGGAAGAGAGAGATTGTTTAAAGATGGTTTTGTGG(配列番号46)
プライマーR14:CAGTAATACGACTCACTATAGGGAGAAGGCTAACCATTTCTACTCCTTTATTCCAAA(配列番号47)
【0185】
プライマーF15:AGGAAGAGAGGGGTAGTAGTAATTAGGATATTAGGGTT(配列番号48)
プライマーR15:CAGTAATACGACTCACTATAGGGAGAAGGCTCCTCAAAAACCATTAAAAAACCATT(配列番号49)
【0186】
プライマーF16:AGGAAGAGAGTTTTGGAGTAAAGAGGGATTATTTTT(配列番号50)
プライマーR16:CAGTAATACGACTCACTATAGGGAGAAGGCTCCCTACTCACTAAACTATAAAAACCACA(配列番号51)
【0187】
プライマーF17:AGGAAGAGAGGGTTTGAAGGATATAGAGAGAGTTTATTG(配列番号52)
プライマーR17:CAGTAATACGACTCACTATAGGGAGAAGGCTTCTTTACCATCATAAAAACAAAACAAA(配列番号53)
【0188】
プライマーF18:AGGAAGAGAGTGAAGTGTTAGTAGGTTTTTTTTGTGTT(配列番号54)
プライマーR18:CAGTAATACGACTCACTATAGGGAGAAGGCTAAAAAACCCTTCCCAAAAAATCTAT(配列番号55)
【0189】
プライマーF19:AGGAAGAGAGTGTTTTTGTTGGTTATTGTTGTTTTT(配列番号56)
プライマーR19:CAGTAATACGACTCACTATAGGGAGAAGGCTTACTACCCCCTACCTCCCAAACTAC(配列番号57)
【0190】
以下にSEQUENOMアプリケーションノートに示されるMassARRAYシステムを用いた定量的DNAメチル化解析用EpiTYPERの概要を示す。
【0191】
プライマー設計:
メチル化解析用に以下のプライマーシステムを設計する。In vitro転写に適した産物を得るため、T7プロモータを付加したリバースプライマー。サイクリング失敗を防ぐために8bpインサートを挿入する。また、PCRのバランスをとるために10merタグを付加したフォワードプライマーとする。
【0192】
Bisulfite処理:
サンプルゲノムDNAのBisulfite変換処理にはZymo Research社のEZ-96DNA Methylation KitまたはEZ DNA Methylation Kitを使用する。このプロトコルの初回インキュベーション後、以下のとおりサイクル反応をおこなう。
45サイクル:
95℃30分
50℃15分
【0193】
(1)ステップ1:増幅
385-マイクロタイターフォーマットを用いて総容量5 μL中1 μLのDNAを増幅する(1反応あたり最終濃度2 ng/μLとするために10 ng/μL以上のDNAを1.00 μL以上使用する)。各反応液を2種類の切断反応(T切断反応とC切断反応)に分ける。プレートを密封し、以下のとおりサイクル反応をおこなう。
・94℃15分
・45サイクル
94℃20秒
56℃30秒
72℃1分
・72℃3分
(2)ステップ2:脱リン酸化
各PCR反応液5 μLにエビ由来アルカリフォスファターゼ(SAP)酵素2 μLを添加し、PCRに組み込まれなかったdNTPを脱リン酸化する。プレートを37℃で20分インキュベートし次いで85℃で5分インキュベートする。
(3)ステップ3:In vitro転写とRNase切断
各切断反応(TおよびC)用に転写/RNaseAカクテルを調製する。標準セットアップでは1プレートあたり、1つの転写/RNaseAカクテルを調製する。サイクル反応をおこなっていない新しいマイクロタイタープレートに、転写/RNaseAカクテル5 μLとPCR/SAPサンプル2 μLを添加する。プレートを1分間遠心し、次にプレートを37℃で3時間インキュベートする。
(4)ステップ4:サンプルコンディショニング
384穴プレートの各サンプルにddH2O 20 μLを加える。レジンプレートを用いて各穴にClean Resinを6 mg加える。10分間攪拌し、3,200xgで5分間スピンダウンする。
(5)ステップ5:サンプルの移動
10〜15 nLのEpiTYPER反応産物を384穴SpectroCHIPに分注する。
(6)ステップ6:サンプル解析
MassARRAYシステムを用いて2種類の切断反応のスペクトルを得る。
(7)ステップ7:解析ソフトウェア
結果をEpiTYPERソフトウェアにより解析する。
【0194】
上記の解析により得られたメチル化DNA割合の結果をグラフ化し、図1〜22に示した。ヒト大腸がん組織ゲノムDNAのメチル化割合はヒト大腸健常組織ゲノムDNAのメチル化割合に比して高いことが示された。ヒト乳がん組織ゲノムDNAのメチル化割合はヒト乳腺健常組織ゲノムDNAのメチル化割合に比して高いことが示された。ヒト肺がん組織ゲノムDNAのメチル化割合はヒト肺健常組織ゲノムDNAのメチル化割合に比して高いことが示された。
【0195】
以上より、(1)ヒト大腸組織ゲノムDNAのメチル化割合を測定することにより、大腸がんか否か、(2)ヒト乳腺組織ゲノムDNAのメチル化割合を測定することにより、乳がんか否か、あるいは(3)ヒト肺組織ゲノムDNAのメチル化割合を測定することにより、肺がんか否かを診断できることが確認された。
【産業上の利用可能性】
【0196】
本発明により、生物由来検体中に含まれるゲノムDNAが有する目的とするDNA領域におけるメチル化されたDNAの含量を測定し、大腸がんか否か、乳がんか否か、肺がんか否かを診断する方法等を提供することが可能となる。
また、同様に、本発明に記載の配列番号1から配列番号19までの塩基配列を利用することにより、簡便に癌を検出することを可能にし、極めて初期の段階での癌の検出や、癌の再発のモニタリング、癌リスク検出、癌の進行度予測などに適したキットの提供を可能にする。加えて、本願発明の方法およびキットは、内視鏡検査等の他の検査方法との併用に有用であり、より精密な検査結果を得ることを可能にするものである。
【配列表フリーテキスト】
【0197】
配列番号1
目的とするDNA領域からなるオリゴヌクレオチド
配列番号2
目的とするDNA領域からなるオリゴヌクレオチド
配列番号3
目的とするDNA領域からなるオリゴヌクレオチド
配列番号4
目的とするDNA領域からなるオリゴヌクレオチド
配列番号5
目的とするDNA領域からなるオリゴヌクレオチド
配列番号6
目的とするDNA領域からなるオリゴヌクレオチド
配列番号7
目的とするDNA領域からなるオリゴヌクレオチド
配列番号8
目的とするDNA領域からなるオリゴヌクレオチド
配列番号9
目的とするDNA領域からなるオリゴヌクレオチド
配列番号10
目的とするDNA領域からなるオリゴヌクレオチド
配列番号11
目的とするDNA領域からなるオリゴヌクレオチド
配列番号12
目的とするDNA領域からなるオリゴヌクレオチド
配列番号13
目的とするDNA領域からなるオリゴヌクレオチド
配列番号14
目的とするDNA領域からなるオリゴヌクレオチド
配列番号15
目的とするDNA領域からなるオリゴヌクレオチド
配列番号16
目的とするDNA領域からなるオリゴヌクレオチド
配列番号17
目的とするDNA領域からなるオリゴヌクレオチド
配列番号18
目的とするDNA領域からなるオリゴヌクレオチド
配列番号19
目的とするDNA領域からなるオリゴヌクレオチド
配列番号20
実験のために設計されたオリゴヌクレオチドプライマー
配列番号21
実験のために設計されたオリゴヌクレオチドプライマー
配列番号22
実験のために設計されたオリゴヌクレオチドプライマー
配列番号23
実験のために設計されたオリゴヌクレオチドプライマー
配列番号24
実験のために設計されたオリゴヌクレオチドプライマー
配列番号25
実験のために設計されたオリゴヌクレオチドプライマー
配列番号26
実験のために設計されたオリゴヌクレオチドプライマー
配列番号27
実験のために設計されたオリゴヌクレオチドプライマー
配列番号28
実験のために設計されたオリゴヌクレオチドプライマー
配列番号29
実験のために設計されたオリゴヌクレオチドプライマー
配列番号30
実験のために設計されたオリゴヌクレオチドプライマー
配列番号31
実験のために設計されたオリゴヌクレオチドプライマー
配列番号32
実験のために設計されたオリゴヌクレオチドプライマー
配列番号33
実験のために設計されたオリゴヌクレオチドプライマー
配列番号34
実験のために設計されたオリゴヌクレオチドプライマー
配列番号35
実験のために設計されたオリゴヌクレオチドプライマー
配列番号36
実験のために設計されたオリゴヌクレオチドプライマー
配列番号37
実験のために設計されたオリゴヌクレオチドプライマー
配列番号38
実験のために設計されたオリゴヌクレオチドプライマー
配列番号39
実験のために設計されたオリゴヌクレオチドプライマー
配列番号40
実験のために設計されたオリゴヌクレオチドプライマー
配列番号41
実験のために設計されたオリゴヌクレオチドプライマー
配列番号42
実験のために設計されたオリゴヌクレオチドプライマー
配列番号43
実験のために設計されたオリゴヌクレオチドプライマー
配列番号44
実験のために設計されたオリゴヌクレオチドプライマー
配列番号45
実験のために設計されたオリゴヌクレオチドプライマー
配列番号46
実験のために設計されたオリゴヌクレオチドプライマー
配列番号47
実験のために設計されたオリゴヌクレオチドプライマー
配列番号48
実験のために設計されたオリゴヌクレオチドプライマー
配列番号49
実験のために設計されたオリゴヌクレオチドプライマー
配列番号50
実験のために設計されたオリゴヌクレオチドプライマー
配列番号51
実験のために設計されたオリゴヌクレオチドプライマー
配列番号52
実験のために設計されたオリゴヌクレオチドプライマー
配列番号53
実験のために設計されたオリゴヌクレオチドプライマー
配列番号54
実験のために設計されたオリゴヌクレオチドプライマー
配列番号55
実験のために設計されたオリゴヌクレオチドプライマー
配列番号56
実験のために設計されたオリゴヌクレオチドプライマー
配列番号57
実験のために設計されたオリゴヌクレオチドプライマー
【技術分野】
【0001】
本発明は、哺乳動物由来の検体の癌化度を評価する方法等に関する。
【背景技術】
【0002】
癌が遺伝子異常を原因とする疾病であること等が次第に明らかになりつつあるが、癌患者の死亡率は未だ高く、現在利用可能な診断方法や治療方法等の評価が必ずしも十分に満足できるものではないことを示している。その1つの原因として癌組織の種類に基づく多様性、マーカーとなる遺伝子等の低い正確性や低い検出感度等が考えられる。
【先行技術文献】
【非特許文献】
【0003】
【非特許文献1】「遺伝子の病気としてのがん」(ISBN4-89553-447-2 C3047)、黒木登志夫・垣添忠生編集、株式会社メジカルビュー社発行(1994年5月10日)
【発明の概要】
【発明が解決しようとする課題】
【0004】
そこで、癌を早期に発見するための診断方法や治療方法等の評価に適する、遺伝子異常の検出に基づいた哺乳動物由来の検体の癌化度評価方法の開発が切望されている。
【課題を解決するための手段】
【0005】
本発明者らは、かかる状況の下、鋭意検討した結果、癌組織検体あるいは、がん患者由来の血液、血清、血漿、体液、体分泌地物、糞尿等の生体試料に存在するDNAおいて配列番号1−19で示されるDNA領域に含まれるCpG配列のシトシン塩基が、不死化正常細胞株及び正常組織検体あるいは健常者由来の血液、血清、血漿、体液、体分泌地物、糞尿等の生体試料に存在するDNAと比較して有意に高い頻度でメチル化されていることを見出し、本発明に至った。
即ち、本発明は、
1. 哺乳動物由来の検体の癌化度を評価する方法であって、
(1)哺乳動物由来の検体に含まれる下記の塩基配列から選ばれる少なくとも1つを有するDNAのメチル化頻度又はそれに相関関係がある指標値を測定する第一工程、及び
(2)測定された前記メチル化頻度又はそれに相関関係がある指標値と、対照とを比較することにより得られる差異に基づき前記検体の癌化度を判定する第二工程
を有することを特徴とする評価方法。
(a)配列番号1で示された塩基配列又は配列番号1で示された塩基配列と80%以上の相同性を有する塩基配列
(b)配列番号1と相補的な塩基配列又は配列番号1と相補的な塩基配列と80%以上の相同性を有する塩基配列
(c)配列番号2で示された塩基配列又は配列番号2で示された塩基配列と80%以上の相同性を有する塩基配列
(d)配列番号2と相補的な塩基配列又は配列番号2と相補的な塩基配列と80%以上の相同性を有する塩基配列
(e)配列番号3で示された塩基配列又は配列番号3で示された塩基配列と80%以上の相同性を有する塩基配列
(f)配列番号3と相補的な塩基配列又は配列番号3と相補的な塩基配列と80%以上の相同性を有する塩基配列
(g)配列番号4で示された塩基配列又は配列番号4で示された塩基配列と80%以上の相同性を有する塩基配列
(h)配列番号4と相補的な塩基配列又は配列番号4と相補的な塩基配列と80%以上の相同性を有する塩基配列
(i)配列番号5で示された塩基配列又は配列番号5で示された塩基配列と80%以上の相同性を有する塩基配列
(j)配列番号5と相補的な塩基配列又は配列番号5と相補的な塩基配列と80%以上の相同性を有する塩基配列
(k)配列番号6で示された塩基配列又は配列番号6で示された塩基配列と80%以上の相同性を有する塩基配列
(l)配列番号6と相補的な塩基配列又は配列番号6と相補的な塩基配列と80%以上の相同性を有する塩基配列
(m)配列番号7で示された塩基配列又は配列番号7で示された塩基配列と80%以上の相同性を有する塩基配列
(n)配列番号7と相補的な塩基配列又は配列番号7と相補的な塩基配列と80%以上の相同性を有する塩基配列
(o)配列番号8で示された塩基配列又は配列番号8で示された塩基配列と80%以上の相同性を有する塩基配列
(p)配列番号8と相補的な塩基配列又は配列番号8と相補的な塩基配列と80%以上の相同性を有する塩基配列
(q)配列番号9で示された塩基配列又は配列番号9で示された塩基配列と80%以上の相同性を有する塩基配列
(r)配列番号9と相補的な塩基配列又は配列番号9と相補的な塩基配列と80%以上の相同性を有する塩基配列
(s)配列番号10で示された塩基配列又は配列番号10で示された塩基配列と80%以上の相同性を有する塩基配列
(t)配列番号10と相補的な塩基配列又は配列番号10と相補的な塩基配列と80%以上の相同性を有する塩基配列
(u)配列番号11で示された塩基配列又は配列番号11で示された塩基配列と80%以上の相同性を有する塩基配列
(v)配列番号11と相補的な塩基配列又は配列番号11と相補的な塩基配列と80%以上の相同性を有する塩基配列
(w)配列番号12で示された塩基配列又は配列番号12で示された塩基配列と80%以上の相同性を有する塩基配列
(x)配列番号12と相補的な塩基配列又は配列番号12と相補的な塩基配列と80%以上の相同性を有する塩基配列
(y)配列番号13で示された塩基配列又は配列番号13で示された塩基配列と80%以上の相同性を有する塩基配列
(z)配列番号13と相補的な塩基配列又は配列番号13と相補的な塩基配列と80%以上の相同性を有する塩基配列
(aa)配列番号14で示された塩基配列又は配列番号14で示された塩基配列と80%以上の相同性を有する塩基配列
(ab)配列番号14と相補的な塩基配列又は配列番号14と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ac)配列番号15で示された塩基配列又は配列番号15で示された塩基配列と80%以上の相同性を有する塩基配列
(ad)配列番号15と相補的な塩基配列又は配列番号15と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ae)配列番号16で示された塩基配列又は配列番号16で示された塩基配列と80%以上の相同性を有する塩基配列
(af)配列番号16と相補的な塩基配列又は配列番号16と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ag)配列番号17で示された塩基配列又は配列番号17で示された塩基配列と80%以上の相同性を有する塩基配列
(ah)配列番号17と相補的な塩基配列又は配列番号17と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ai)配列番号18で示された塩基配列又は配列番号18で示された塩基配列と80%以上の相同性を有する塩基配列
(aj)配列番号18と相補的な塩基配列又は配列番号18と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ak)配列番号19で示された塩基配列又は配列番号19で示された塩基配列と80%以上の相同性を有する塩基配列
(al)配列番号19と相補的な塩基配列又は配列番号19と相補的な塩基配列と80%以上の相同性を有する塩基配列
2. 哺乳動物由来の検体が細胞であることを特徴とする前記1記載の評価方法。
3. 哺乳動物由来の検体が組織であることを特徴とする前記1記載の評価方法。
4. 哺乳動物由来の検体が生体試料であることを特徴とする前記1記載の評価方法。
5. 哺乳動物由来の検体の癌化度を評価する方法であって、
(1)哺乳動物由来の検体に含まれる下記の塩基配列から選ばれる少なくとも1つを有するDNAのメチル化頻度又はそれに相関関係がある指標値を測定する第一工程、及び
(2)測定された前記メチル化頻度と、対照とを比較することにより得られる差異に基づき前記検体の癌化度を判定する第二工程
を有することを特徴とする評価方法。
(a)配列番号1で示された塩基配列又は配列番号1で示された塩基配列と80%以上の相同性を有する塩基配列
(b)配列番号1と相補的な塩基配列又は配列番号1と相補的な塩基配列と80%以上の相同性を有する塩基配列
(c)配列番号2で示された塩基配列又は配列番号2で示された塩基配列と80%以上の相同性を有する塩基配列
(d)配列番号2と相補的な塩基配列又は配列番号2と相補的な塩基配列と80%以上の相同性を有する塩基配列
(e)配列番号3で示された塩基配列又は配列番号3で示された塩基配列と80%以上の相同性を有する塩基配列
(f)配列番号3と相補的な塩基配列又は配列番号3と相補的な塩基配列と80%以上の相同性を有する塩基配列
(g)配列番号4で示された塩基配列又は配列番号4で示された塩基配列と80%以上の相同性を有する塩基配列
(h)配列番号4と相補的な塩基配列又は配列番号4と相補的な塩基配列と80%以上の相同性を有する塩基配列
(i)配列番号5で示された塩基配列又は配列番号5で示された塩基配列と80%以上の相同性を有する塩基配列
(j)配列番号5と相補的な塩基配列又は配列番号5と相補的な塩基配列と80%以上の相同性を有する塩基配列
(k)配列番号6で示された塩基配列又は配列番号6で示された塩基配列と80%以上の相同性を有する塩基配列
(l)配列番号6と相補的な塩基配列又は配列番号6と相補的な塩基配列と80%以上の相同性を有する塩基配列
(m)配列番号7で示された塩基配列又は配列番号7で示された塩基配列と80%以上の相同性を有する塩基配列
(n)配列番号7と相補的な塩基配列又は配列番号7と相補的な塩基配列と80%以上の相同性を有する塩基配列
(o)配列番号8で示された塩基配列又は配列番号8で示された塩基配列と80%以上の相同性を有する塩基配列
(p)配列番号8と相補的な塩基配列又は配列番号8と相補的な塩基配列と80%以上の相同性を有する塩基配列
(q)配列番号9で示された塩基配列又は配列番号9で示された塩基配列と80%以上の相同性を有する塩基配列
(r)配列番号9と相補的な塩基配列又は配列番号9と相補的な塩基配列と80%以上の相同性を有する塩基配列
(s)配列番号10で示された塩基配列又は配列番号10で示された塩基配列と80%以上の相同性を有する塩基配列
(t)配列番号10と相補的な塩基配列又は配列番号10と相補的な塩基配列と80%以上の相同性を有する塩基配列
(u)配列番号11で示された塩基配列又は配列番号11で示された塩基配列と80%以上の相同性を有する塩基配列
(v)配列番号11と相補的な塩基配列又は配列番号11と相補的な塩基配列と80%以上の相同性を有する塩基配列
(w)配列番号12で示された塩基配列又は配列番号12で示された塩基配列と80%以上の相同性を有する塩基配列
(x)配列番号12と相補的な塩基配列又は配列番号12と相補的な塩基配列と80%以上の相同性を有する塩基配列
(y)配列番号13で示された塩基配列又は配列番号13で示された塩基配列と80%以上の相同性を有する塩基配列
(z)配列番号13と相補的な塩基配列又は配列番号13と相補的な塩基配列と80%以上の相同性を有する塩基配列
(aa)配列番号14で示された塩基配列又は配列番号14で示された塩基配列と80%以上の相同性を有する塩基配列
(ab)配列番号14と相補的な塩基配列又は配列番号14と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ac)配列番号15で示された塩基配列又は配列番号15で示された塩基配列と80%以上の相同性を有する塩基配列
(ad)配列番号15と相補的な塩基配列又は配列番号15と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ae)配列番号16で示された塩基配列又は配列番号16で示された塩基配列と80%以上の相同性を有する塩基配列
(af)配列番号16と相補的な塩基配列又は配列番号16と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ag)配列番号17で示された塩基配列又は配列番号17で示された塩基配列と80%以上の相同性を有する塩基配列
(ah)配列番号17と相補的な塩基配列又は配列番号17と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ai)配列番号18で示された塩基配列又は配列番号18で示された塩基配列と80%以上の相同性を有する塩基配列
(aj)配列番号18と相補的な塩基配列又は配列番号18と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ak)配列番号19で示された塩基配列又は配列番号19で示された塩基配列と80%以上の相同性を有する塩基配列
(al)配列番号19と相補的な塩基配列又は配列番号19と相補的な塩基配列と80%以上の相同性を有する塩基配列
6. 哺乳動物由来の検体が細胞であって、且つ、当該検体の癌化度が哺乳動物由来の細胞の悪性度であることを特徴とする前記1又は5記載の評価方法。
7. 哺乳動物由来の検体が組織であって、且つ、当該検体の癌化度が哺乳動物由来の組織における癌細胞の存在量であることを特徴とする前記1又は5記載の評価方法。
8. 哺乳動物由来の検体が哺乳動物から採取した生体試料であって、且つ、当該検体の癌化度が当該生体試料を採取した当該哺乳動物のいずれかの体組織における癌細胞の存在量であることを特徴とする前記1又は5記載の評価方法。
9. 組織が大腸組織であることを特徴とする前記7に記載の評価方法。
10. 組織が肺組織であることを特徴とする前記7に記載の評価方法。
11. 組織が乳腺組織であることを特徴とする前記7に記載の評価方法。
12. 生体試料が血液、血清、血漿、体液、体分泌地物、糞尿、のいずれかであることを特徴とする前記8記載の評価方法。
13. 前記DNAのメチル化頻度が、前記DNAの塩基配列内に存在する一つ以上の5'-CG-3'で示される塩基配列中のシトシンのメチル化頻度であることを特徴とする前記1〜12のいずれか記載の評価方法。
14. 哺乳動物由来の検体の癌化度を評価する方法であって、
(1)哺乳動物由来の検体に含まれる下記の塩基配列から選ばれる少なくとも1つを有するDNAのメチル化頻度に相関関係がある指標値を測定する第一工程、及び
(2)測定された前記メチル化頻度又はそれに相関関係がある指標値と、対照とを比較することにより得られる差異に基づき前記検体の癌化度を判定する第二工程
を有することを特徴と評価方法。
(a)配列番号1で示された塩基配列又は配列番号1で示された塩基配列と80%以上の相同性を有する塩基配列
(b)配列番号1と相補的な塩基配列又は配列番号1と相補的な塩基配列と80%以上の相同性を有する塩基配列
(c)配列番号2で示された塩基配列又は配列番号2で示された塩基配列と80%以上の相同性を有する塩基配列
(d)配列番号2と相補的な塩基配列又は配列番号2と相補的な塩基配列と80%以上の相同性を有する塩基配列
(e)配列番号3で示された塩基配列又は配列番号3で示された塩基配列と80%以上の相同性を有する塩基配列
(f)配列番号3と相補的な塩基配列又は配列番号3と相補的な塩基配列と80%以上の相同性を有する塩基配列
(g)配列番号4で示された塩基配列又は配列番号4で示された塩基配列と80%以上の相同性を有する塩基配列
(h)配列番号4と相補的な塩基配列又は配列番号4と相補的な塩基配列と80%以上の相同性を有する塩基配列
(i)配列番号5で示された塩基配列又は配列番号5で示された塩基配列と80%以上の相同性を有する塩基配列
(j)配列番号5と相補的な塩基配列又は配列番号5と相補的な塩基配列と80%以上の相同性を有する塩基配列
(k)配列番号6で示された塩基配列又は配列番号6で示された塩基配列と80%以上の相同性を有する塩基配列
(l)配列番号6と相補的な塩基配列又は配列番号6と相補的な塩基配列と80%以上の相同性を有する塩基配列
(m)配列番号7で示された塩基配列又は配列番号7で示された塩基配列と80%以上の相同性を有する塩基配列
(n)配列番号7と相補的な塩基配列又は配列番号7と相補的な塩基配列と80%以上の相同性を有する塩基配列
(o)配列番号8で示された塩基配列又は配列番号8で示された塩基配列と80%以上の相同性を有する塩基配列
(p)配列番号8と相補的な塩基配列又は配列番号8と相補的な塩基配列と80%以上の相同性を有する塩基配列
(q)配列番号9で示された塩基配列又は配列番号9で示された塩基配列と80%以上の相同性を有する塩基配列
(r)配列番号9と相補的な塩基配列又は配列番号9と相補的な塩基配列と80%以上の相同性を有する塩基配列
(s)配列番号10で示された塩基配列又は配列番号10で示された塩基配列と80%以上の相同性を有する塩基配列
(t)配列番号10と相補的な塩基配列又は配列番号10と相補的な塩基配列と80%以上の相同性を有する塩基配列
(u)配列番号11で示された塩基配列又は配列番号11で示された塩基配列と80%以上の相同性を有する塩基配列
(v)配列番号11と相補的な塩基配列又は配列番号11と相補的な塩基配列と80%以上の相同性を有する塩基配列
(w)配列番号12で示された塩基配列又は配列番号12で示された塩基配列と80%以上の相同性を有する塩基配列
(x)配列番号12と相補的な塩基配列又は配列番号12と相補的な塩基配列と80%以上の相同性を有する塩基配列
(y)配列番号13で示された塩基配列又は配列番号13で示された塩基配列と80%以上の相同性を有する塩基配列
(z)配列番号13と相補的な塩基配列又は配列番号13と相補的な塩基配列と80%以上の相同性を有する塩基配列
(aa)配列番号14で示された塩基配列又は配列番号14で示された塩基配列と80%以上の相同性を有する塩基配列
(ab)配列番号14と相補的な塩基配列又は配列番号14と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ac)配列番号15で示された塩基配列又は配列番号15で示された塩基配列と80%以上の相同性を有する塩基配列
(ad)配列番号15と相補的な塩基配列又は配列番号15と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ae)配列番号16で示された塩基配列又は配列番号16で示された塩基配列と80%以上の相同性を有する塩基配列
(af)配列番号16と相補的な塩基配列又は配列番号16と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ag)配列番号17で示された塩基配列又は配列番号17で示された塩基配列と80%以上の相同性を有する塩基配列
(ah)配列番号17と相補的な塩基配列又は配列番号17と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ai)配列番号18で示された塩基配列又は配列番号18で示された塩基配列と80%以上の相同性を有する塩基配列
(aj)配列番号18と相補的な塩基配列又は配列番号18と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ak)配列番号19で示された塩基配列又は配列番号19で示された塩基配列と80%以上の相同性を有する塩基配列
(al)配列番号19と相補的な塩基配列又は配列番号19と相補的な塩基配列と80%以上の相同性を有する塩基配列
15. 相関関係がある指標値が、当該塩基配列から選ばれる少なくとも1つのDNAの下流に存在する遺伝子のいずれかの発現産物の量であることを特徴とする前記14記載の評価方法。
16. 遺伝子の発現産物の量が、遺伝子の転写産物の量であることを特徴とする前記15記載の評価方法。
17. 癌マーカーとしての、下記の塩基配列から選ばれる少なくとも1つを有するメチル化DNAの使用
(a)配列番号1で示された塩基配列又は配列番号1で示された塩基配列と80%以上の相同性を有する塩基配列
(b)配列番号1と相補的な塩基配列又は配列番号1と相補的な塩基配列と80%以上の相同性を有する塩基配列
(c)配列番号2で示された塩基配列又は配列番号2で示された塩基配列と80%以上の相同性を有する塩基配列
(d)配列番号2と相補的な塩基配列又は配列番号2と相補的な塩基配列と80%以上の相同性を有する塩基配列
(e)配列番号3で示された塩基配列又は配列番号3で示された塩基配列と80%以上の相同性を有する塩基配列
(f)配列番号3と相補的な塩基配列又は配列番号3と相補的な塩基配列と80%以上の相同性を有する塩基配列
(g)配列番号4で示された塩基配列又は配列番号4で示された塩基配列と80%以上の相同性を有する塩基配列
(h)配列番号4と相補的な塩基配列又は配列番号4と相補的な塩基配列と80%以上の相同性を有する塩基配列
(i)配列番号5で示された塩基配列又は配列番号5で示された塩基配列と80%以上の相同性を有する塩基配列
(j)配列番号5と相補的な塩基配列又は配列番号5と相補的な塩基配列と80%以上の相同性を有する塩基配列
(k)配列番号6で示された塩基配列又は配列番号6で示された塩基配列と80%以上の相同性を有する塩基配列
(l)配列番号6と相補的な塩基配列又は配列番号6と相補的な塩基配列と80%以上の相同性を有する塩基配列
(m)配列番号7で示された塩基配列又は配列番号7で示された塩基配列と80%以上の相同性を有する塩基配列
(n)配列番号7と相補的な塩基配列又は配列番号7と相補的な塩基配列と80%以上の相同性を有する塩基配列
(o)配列番号8で示された塩基配列又は配列番号8で示された塩基配列と80%以上の相同性を有する塩基配列
(p)配列番号8と相補的な塩基配列又は配列番号8と相補的な塩基配列と80%以上の相同性を有する塩基配列
(q)配列番号9で示された塩基配列又は配列番号9で示された塩基配列と80%以上の相同性を有する塩基配列
(r)配列番号9と相補的な塩基配列又は配列番号9と相補的な塩基配列と80%以上の相同性を有する塩基配列
(s)配列番号10で示された塩基配列又は配列番号10で示された塩基配列と80%以上の相同性を有する塩基配列
(t)配列番号10と相補的な塩基配列又は配列番号10と相補的な塩基配列と80%以上の相同性を有する塩基配列
(u)配列番号11で示された塩基配列又は配列番号11で示された塩基配列と80%以上の相同性を有する塩基配列
(v)配列番号11と相補的な塩基配列又は配列番号11と相補的な塩基配列と80%以上の相同性を有する塩基配列
(w)配列番号12で示された塩基配列又は配列番号12で示された塩基配列と80%以上の相同性を有する塩基配列
(x)配列番号12と相補的な塩基配列又は配列番号12と相補的な塩基配列と80%以上の相同性を有する塩基配列
(y)配列番号13で示された塩基配列又は配列番号13で示された塩基配列と80%以上の相同性を有する塩基配列
(z)配列番号13と相補的な塩基配列又は配列番号13と相補的な塩基配列と80%以上の相同性を有する塩基配列
(aa)配列番号14で示された塩基配列又は配列番号14で示された塩基配列と80%以上の相同性を有する塩基配列
(ab)配列番号14と相補的な塩基配列又は配列番号14と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ac)配列番号15で示された塩基配列又は配列番号15で示された塩基配列と80%以上の相同性を有する塩基配列
(ad)配列番号15と相補的な塩基配列又は配列番号15と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ae)配列番号16で示された塩基配列又は配列番号16で示された塩基配列と80%以上の相同性を有する塩基配列
(af)配列番号16と相補的な塩基配列又は配列番号16と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ag)配列番号17で示された塩基配列又は配列番号17で示された塩基配列と80%以上の相同性を有する塩基配列
(ah)配列番号17と相補的な塩基配列又は配列番号17と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ai)配列番号18で示された塩基配列又は配列番号18で示された塩基配列と80%以上の相同性を有する塩基配列
(aj)配列番号18と相補的な塩基配列又は配列番号18と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ak)配列番号19で示された塩基配列又は配列番号19で示された塩基配列と80%以上の相同性を有する塩基配列
(al)配列番号19と相補的な塩基配列又は配列番号19と相補的な塩基配列と80%以上の相同性を有する塩基配列
【発明の効果】
【0006】
本発明により、哺乳動物由来の検体の癌化度を評価する方法等が提供可能となる。
【図面の簡単な説明】
【0007】
【図1】図1は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号1で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget02_3_CpGまたは図下のバーのTarget02_3は、配列番号1で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号1におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号1で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0008】
【図2】図2は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号2で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget03_9_CpGまたは図下のバーのTarget03_9は、配列番号2で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号2におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号2で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0009】
【図3】図3は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号3で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget04_19_CpGまたは図下のバーのTarget04_19は、配列番号3で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号3におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号3で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0010】
【図4】図4は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号6で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget09_15_CpGまたは図下のバーのTarget09_15は、配列番号6で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号6におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号6で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0011】
【図5】図5は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号7で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget10_9_CpGまたは図下のバーのTarget10_9は、配列番号7で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号7におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号7で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0012】
【図6】図6は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号8で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget11_3_CpGまたは図下のバーのTarget11_3は、配列番号8で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号8におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号8で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【図7】図7は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号9で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget12_3_CpGまたは図下のバーのTarget12_3は、配列番号9で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号9におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号9で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0013】
【図8】図8は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号10で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget15_4_CpGまたは図下のバーのTarget15_4は、配列番号10で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号10におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号10で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0014】
【図9】図9は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号11で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget18_1_CpGまたは図下のバーのTarget18_1は、配列番号11で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号11におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号11で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0015】
【図10】図10は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号12で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget19_2_CpGまたは図下のバーのTarget19_2は、配列番号12で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号12におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号12で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0016】
【図11】図11は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号13で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget21_13_CpGまたは図下のバーのTarget21_13は、配列番号13で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号13におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号13で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0017】
【図12】図12は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号14で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget23_11_CpGまたは図下のバーのTarget23_11は、配列番号14で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号14におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号14で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0018】
【図13】図13は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号16で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget40_18_CpGまたは図下のバーのTarget40_18は、配列番号16で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号16におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号16で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0019】
【図14】図14は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号17および配列番号18で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget41_10_CpGまたは図下のバーのTarget41_10は、配列番号17で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号17におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号17で示される塩基配列におけるメチル化されうるシトシンの位置を示す。Target41_17は、配列番号18で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号18におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号18で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0020】
【図15】図15は、ヒト乳腺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号19で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget44_9_CpGまたは図下のバーのTarget44_9は、配列番号19で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号19におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号19で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト乳がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト乳腺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0021】
【図16】図16は、ヒト肺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)について配列番号1で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget02_3_CpGまたは図下のバーのTarget02_3は、配列番号1で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号1におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号1で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)におけるCGのメチル化割合はヒト肺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0022】
【図17】図17は、ヒト肺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)について配列番号3で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget04_19_CpGまたは図下のバーのTarget04_19は、配列番号3で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号3におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号3で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)におけるCGのメチル化割合はヒト肺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【図18】図18は、ヒト肺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)について配列番号4で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget06_21_CpGまたは図下のバーのTarget06_21は、配列番号4で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号4におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号4で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)におけるCGのメチル化割合はヒト肺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0023】
【図19】図19は、ヒト肺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)について配列番号6で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget09_15_CpGまたは図下のバーのTarget09_15は、配列番号6で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号6におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号6で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)におけるCGのメチル化割合はヒト肺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0024】
【図20】図20は、ヒト肺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)について配列番号8で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget11_3_CpGまたは図下のバーのTarget11_3は、配列番号8で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号8におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号8で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)におけるCGのメチル化割合はヒト肺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0025】
【図21】図21は、ヒト肺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)について配列番号10で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget15_4_CpGまたは図下のバーのTarget15_4は、配列番号10で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号10におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号10で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)におけるCGのメチル化割合はヒト肺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0026】
【図22】図22は、ヒト肺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)について配列番号11で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget18_1_CpGまたは図下のバーのTarget18_1は、配列番号11で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号11におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号11で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)におけるCGのメチル化割合はヒト肺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【図23】図23は、ヒト肺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)について配列番号12で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget19_2_CpGまたは図下のバーのTarget19_2は、配列番号12で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号12におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号12で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)におけるCGのメチル化割合はヒト肺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0027】
【図24】図24は、ヒト肺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)について配列番号13で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget21_13_CpGまたは図下のバーのTarget21_13は、配列番号13で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号13におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号13で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)におけるCGのメチル化割合はヒト肺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0028】
【図25】図25は、ヒト肺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)について配列番号15で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget33_9_CpGまたは図下のバーのTarget39_9は、配列番号15で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号15におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号15で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)におけるCGのメチル化割合はヒト肺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0029】
【図26】図26は、ヒト肺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)について配列番号16で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget40_18_CpGまたは図下のバーのTarget40_18は、配列番号16で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号16におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号16で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)におけるCGのメチル化割合はヒト肺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【図27】図27は、ヒト肺健常組織ゲノムDNAサンプル(N01およびN02)およびヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)について配列番号19で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget44_9_CpGまたは図下のバーのTarget44_9は、配列番号19で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号19におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号19で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト肺がん組織ゲノムDNAサンプル(C01、C02およびC03)におけるCGのメチル化割合はヒト肺健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0030】
【図28】図28は、ヒト大腸健常組織ゲノムDNAサンプル(N01およびN02)およびヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号1で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget02_3_CpGまたは図下のバーのTarget02_3は、配列番号1で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号1におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号1で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト大腸健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0031】
【図29】図29は、ヒト大腸健常組織ゲノムDNAサンプル(N01およびN02)およびヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号3で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget04_19_CpGまたは図下のバーのTarget04_19は、配列番号3で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号3におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号3で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト大腸健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0032】
【図30】図30は、ヒト大腸健常組織ゲノムDNAサンプル(N01およびN02)およびヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号5で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget08_6_CpGまたは図下のバーのTarget08_6は、配列番号5で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号5におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号5で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト大腸健常組織ゲノムDNA(N01およびN02)に比して高かった。
【図31】図31は、ヒト大腸健常組織ゲノムDNAサンプル(N01およびN02)およびヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号6で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget09_15_CpGまたは図下のバーのTarget09_15は、配列番号6で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号6におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号6で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト大腸健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0033】
【図32】図32は、ヒト大腸健常組織ゲノムDNAサンプル(N01およびN02)およびヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号7で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget10_9_CpGまたは図下のバーのTarget10_9は、配列番号7で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号7におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号7で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト大腸健常組織ゲノムDNA(N01およびN02)に比して高かった。
【図33】図33は、ヒト大腸健常組織ゲノムDNAサンプル(N01およびN02)およびヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号9で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget12_3_CpGまたは図下のバーのTarget12_3は、配列番号9で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号9におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号9で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト大腸健常組織ゲノムDNA(N01およびN02)に比して高かった。
【図34】図34は、ヒト大腸健常組織ゲノムDNAサンプル(N01およびN02)およびヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号10で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget15_4_CpGまたは図下のバーのTarget15_4は、配列番号10で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号10におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号10で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト大腸健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0034】
【図35】図35は、ヒト大腸健常組織ゲノムDNAサンプル(N01およびN02)およびヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号11で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget18_1_CpGまたは図下のバーのTarget18_1は、配列番号11で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号11におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号11で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト大腸健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0035】
【図36】図36は、ヒト大腸健常組織ゲノムDNAサンプル(N01およびN02)およびヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号12で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget19_2_CpGまたは図下のバーのTarget19_2は、配列番号12で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号12におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号12で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト大腸健常組織ゲノムDNA(N01およびN02)に比して高かった。
【図37】図37は、ヒト大腸健常組織ゲノムDNAサンプル(N01およびN02)およびヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号13で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget21_13_CpGまたは図下のバーのTarget21_13は、配列番号13で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号13におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号13で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト大腸健常組織ゲノムDNA(N01およびN02)に比して高かった。
【0036】
【図38】図38は、ヒト大腸健常組織ゲノムDNAサンプル(N01およびN02)およびヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号14で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget23_11_CpGまたは図下のバーのTarget23_11は、配列番号14で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号14におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号14で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト大腸健常組織ゲノムDNA(N01およびN02)に比して高かった。
【図39】図39は、ヒト大腸健常組織ゲノムDNAサンプル(N01およびN02)およびヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)について配列番号15で示される塩基配列からなる目的とするDNA領域におけるメチル化DNA割合をMassARRAY解析により測定した結果を示している。図中のTarget33_9_CpGまたは図下のバーのTarget33_9は、配列番号15で示される塩基配列からなるDNAを示し、バーの上側の目盛は配列番号15におけるDNAの塩基番号を意味し、バーの下側の目盛は、配列番号15で示される塩基配列におけるメチル化されうるシトシンの位置を示す。ヒト大腸がん組織ゲノムDNAサンプル(C01、C02、C03およびC04)におけるCGのメチル化割合はヒト大腸健常組織ゲノムDNA(N01およびN02)に比して高かった。
【発明を実施するための形態】
【0037】
以下に本発明を詳細に説明する。
本発明は、癌マーカー(例えば、大腸癌マーカー、乳癌マーカー、肺癌マーカー等)としての、メチル化されたDNAの使用等に関連する発明である。
【0038】
本発明における「癌」は、例えば、肺癌(非小細胞肺癌、小細胞肺癌)、食道癌、胃癌、十二指腸癌、大腸癌、直腸癌、肝癌(肝細胞癌、胆管細胞癌)、胆嚢癌、胆管癌、膵癌、結腸癌、肛門癌、乳癌、子宮頸癌、子宮体癌、子宮癌、卵巣癌、外陰癌、膣癌、前立腺癌、腎臓癌、尿管癌、膀胱癌、前立腺癌、陰茎癌、精巣(睾丸)癌、上顎癌、舌癌、(上、中、下)咽頭癌、喉頭癌、急性骨髄性白血病、慢性骨髄性白血病、急性リンパ性白血病 、慢性リンパ性白血病、悪性リンパ腫、骨髄異形成症候群、甲状腺癌、脳腫瘍、骨肉腫、皮膚癌(基底細胞癌、有棘細胞癌)等の、哺乳動物の臓器で発症する固形癌と、哺乳動物の血液で発症する非固形癌のいずれの癌も含む。
尚、本発明において、癌を発症した被験者を「癌患者」と記載し、癌を発症していない被験者を「非癌患者」と記載し、ヒトの組織の非癌部位又は癌を発症していない被験者から採取した組織を「正常組織」と記載し、癌を発症していない被験者から採取した血液を「正常血液」と記載することもある。
【0039】
本発明における「癌マーカー」としては、例えば、哺乳動物において癌が発生している組織及びその癌化度を間接的に把握しうる指標を挙げることができる。具体的には例えば、大腸癌マーカーとしては、大腸の癌の有無及び大腸癌の癌化度、癌の良性若しくは悪性等と記載される癌の性質等を間接的に把握できる生体物質からなる指標を挙げることができる。
【0040】
本発明においてマーカーDNAとして用いられるDNAとしては、下記の塩基配列から選ばれる少なくとも1つを有するのDNA(以下、本発明DNAという場合がある)を挙げることができる。
(a)配列番号1(Genbank Accession No. NT_022171.15, 12175690-12176178)で示された塩基配列又は配列番号1で示された塩基配列と80%以上の相同性を有する塩基配列
(b)配列番号1と相補的な塩基配列又は配列番号1と相補的な塩基配列と80%以上の相同性を有する塩基配列
(c)配列番号2(Genbank Accession No. NT_005403.17, 75486912-75487393, Homo sapiens )で示された塩基配列又は配列番号2で示された塩基配列と80%以上の相同性を有する塩基配列
(d)配列番号2と相補的な塩基配列又は配列番号2と相補的な塩基配列と80%以上の相同性を有する塩基配列
(e)配列番号3(Genbank Accession No. NT_005612.16, 53571894-53571566, Homo sapiens )で示された塩基配列又は配列番号3で示された塩基配列と80%以上の相同性を有する塩基配列
(f)配列番号3と相補的な塩基配列又は配列番号3と相補的な塩基配列と80%以上の相同性を有する塩基配列
(g)配列番号4(Genbank Accession No. NT_006576.16, 14316619-14316186, Homo sapiens )で示された塩基配列又は配列番号4で示された塩基配列と80%以上の相同性を有する塩基配列
(h)配列番号4と相補的な塩基配列又は配列番号4と相補的な塩基配列と80%以上の相同性を有する塩基配列
(i)配列番号5(Genbank Accession No. NT_029289.11, 10354292-10354661, Homo sapiens )で示された塩基配列又は配列番号5で示された塩基配列と80%以上の相同性を有する塩基配列
(j)配列番号5と相補的な塩基配列又は配列番号5と相補的な塩基配列と80%以上の相同性を有する塩基配列
(k)配列番号6(Genbank Accession No. NT_007592.15, 26661779-26661515, Homo sapiens )で示された塩基配列又は配列番号6で示された塩基配列と80%以上の相同性を有する塩基配列
(l)配列番号6と相補的な塩基配列又は配列番号6と相補的な塩基配列と80%以上の相同性を有する塩基配列
(m)配列番号7(Genbank Accession No. NT_113891.2, 256579-256958, Homo sapiens )で示された塩基配列又は配列番号7で示された塩基配列と80%以上の相同性を有する塩基配列
(n)配列番号7と相補的な塩基配列又は配列番号7と相補的な塩基配列と80%以上の相同性を有する塩基配列
(o)配列番号8(Genbank Accession No. NT_007592.15, 42159778-42160229, Homo sapiens )で示された塩基配列又は配列番号8で示された塩基配列と80%以上の相同性を有する塩基配列
(p)配列番号8と相補的な塩基配列又は配列番号8と相補的な塩基配列と80%以上の相同性を有する塩基配列
(q)配列番号9(Genbank Accession No. NT_007592.15, 55383171-55383670, Homo sapiens )で示された塩基配列又は配列番号9で示された塩基配列と80%以上の相同性を有する塩基配列
(r)配列番号9と相補的な塩基配列又は配列番号9と相補的な塩基配列と80%以上の相同性を示す塩基配列
(s)配列番号10(Genbank Accession No. NT_030059.13, 30491593-30491957, Homo sapiens )で示された塩基配列又は配列番号10で示された塩基配列と80%以上の相同性を有する塩基配列
(t)配列番号10と相補的な塩基配列又は配列番号10と相補的な塩基配列と80%以上の相同性を有する塩基配列
(u)配列番号11(Genbank Accession No. NT_033899.8, 28297833-28298273, Homo sapiens )で示された塩基配列又は配列番号11で示された塩基配列と80%以上の相同性を有する塩基配列
(v)配列番号11と相補的な塩基配列又は配列番号11と相補的な塩基配列と80%以上の相同性を有する塩基配列
(w)配列番号12(Genbank Accession No. NT_033899.8, 28298052-28298521, Homo sapiens )で示された塩基配列又は配列番号12で示された塩基配列と80%以上の相同性を有する塩基配列
(x)配列番号12と相補的な塩基配列又は配列番号12と相補的な塩基配列と80%以上の相同性を有する塩基配列
(y)配列番号13(Genbank Accession No. NT_011362.10, 24774687-24774253, Homo sapiens )で示された塩基配列又は配列番号13で示された塩基配列と80%以上の相同性を有する塩基配列
(z)配列番号13と相補的な塩基配列又は配列番号13と相補的な塩基配列と80%以上の相同性を有する塩基配列
(aa)配列番号14(Genbank Accession No. NT_011519.10, 2547951-2548291, Homo sapiens )で示された塩基配列又は配列番号14で示された塩基配列と80%以上の相同性を有する塩基配列
(ab)配列番号14と相補的な塩基配列又は配列番号14と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ac)配列番号15(Genbank Accession No. NT_004350.19, 1161852-1162153, Homo sapiens )で示された塩基配列又は配列番号15で示された塩基配列と80%以上の相同性を有する塩基配列
(ad)配列番号15と相補的な塩基配列又は配列番号15と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ae)配列番号16(Genbank Accession No. NT_016354.19, 5428867-5428472, Homo sapiens )で示された塩基配列又は配列番号16で示された塩基配列と80%以上の相同性を有する塩基配列
(af)配列番号16と相補的な塩基配列又は配列番号16と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ag)配列番号17(Genbank Accession No. NT_006576.16, 17509792-17510071, Homo sapiens )で示された塩基配列又は配列番号17で示された塩基配列と80%以上の相同性を有する塩基配列
(ah)配列番号17と相補的な塩基配列又は配列番号17と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ai)配列番号18(Genbank Accession No. NT_006576.16, 17509828-17509379, Homo sapiens )で示された塩基配列又は配列番号18で示された塩基配列と80%以上の相同性を有する塩基配列
(aj)配列番号18と相補的な塩基配列又は配列番号18と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ak)配列番号19(Genbank Accession No. NT_167187.1, 9763431, 9763927, Homo sapiens )で示された塩基配列又は配列番号19で示された塩基配列と80%以上の相同性を有する塩基配列
(al)配列番号19と相補的な塩基配列又は配列番号19と相補的な塩基配列と80%以上の相同性を有する塩基配列
【0041】
配列番号1〜19で示される塩基配列は、NCBI(National Center for Biotechnology Information)に登録されている塩基配列であり、これらは、NCBIのWEBペ−ジ(URL;http://www.ncbi.nlm.nih.gov)から、登録番号(Accession No)をもとに、データベースを検索することによって入手することができる。
【0042】
本発明DNAにおける、上記(a)〜(al)の塩基配列と80%以上の相同性を有する塩基配列としては、好ましくは90%以上、より好ましくは95%以上の配列相同性を有する塩基配列があげられる。また、上記塩基配列に、生物の種差、個体差若しくは器官、組織間の差異等により天然に生じる変異による塩基の欠失、置換若しくは付加が生じた塩基配列を有するDNAも含まれる。
【0043】
また、本発明DNAにおける、上記(a)〜(al)の塩基配列と相補的な塩基配列と80%以上の相同性を有する塩基配列としては、好ましくは、90%以上、より好ましくは95%以上の配列相同性を有する塩基配列があげられる。また、上記塩基配列に、生物の種差、個体差若しくは器官、組織間の差異等により天然に生じる変異による塩基の欠失、置換若しくは付加が生じた塩基配列を有するDNAも含まれる。
ここで、「相補的な塩基配列」とは、もとの塩基配列と塩基対を形成しうるような塩基配列をいい、「塩基対」とは、核酸の塩基のうち、アデニン(A)とチミン(T)、グアニン(G)とシトシン(C)が水素結合により対合したものをいう。
【0044】
哺乳動物では、遺伝子(ゲノムDNA)を構成する4種類の塩基のうち、シトシンのみがメチル化されるという現象がある。哺乳動物由来のゲノム上の塩基配列、例えば、配列番号1(Genbank Accession No. NT_022171.15, 12175690-12176178, Homo sapiens)で示される塩基配列を有するDNAでは、当該DNAのゲノムDNAの一部のシトシンがメチル化されている。そして、DNAのメチル化修飾は、5'-CG-3'で示される塩基配列(Cはシトシンを表し、Gはグアニンを表す。以下、当該塩基配列をCpGと記すこともある。)中のシトシンに限られる。シトシンにおいてメチル化される部位は、その5位である。細胞分裂に先立つDNA複製に際して、複製直後は鋳型鎖のCpG中のシトシンのみがメチル化された状態となるが、メチル基転移酵素の働きにより即座に新生鎖のCpG中のシトシンもメチル化される。従って、DNAのメチル化の状態は、DNA複製後も、新しい2組のDNAにそのまま引き継がれることになる。
【0045】
本発明評価方法の第一工程において「メチル化頻度」とは、例えば、調査対象となるCpG中のシトシンのメチル化の有無を複数のハプロイドについて調べたときの、当該シトシンがメチル化されているハプロイドの割合で表される。
また本発明評価方法の第一工程において「(メチル化頻度)に相関関係がある指標値」とは、例えば、配列番号1(Genbank Accession No. NT_022171.15, 12175690-12176178, Homo sapiens)で示される塩基配列を有するDNAの下流の遺伝子の発現産物の量(より具体的には、当該遺伝子の転写産物の量)等をあげることができる。このような発現産物の量の場合には、上記メチル化頻度が高くなればそれに伴い減少するような負の相関関係が存在する。
【0046】
本発明評価方法の第一工程における哺乳動物由来の検体としては、生体試料をそのまま検体として用いてもよく、また、かかる生体試料から分離、分画、固定化等の種々の操作により調製された生体試料を検体として用いてもよい。このような検体としては、例えば、(a)哺乳動物由来の血液、体液、糞尿、体分泌物、細胞溶解液又は組織溶解液、(b)哺乳動物由来の血液、体液、糞尿、体分泌物、細胞溶解液及び組織溶解液からなる群より選ばれる一から抽出されたDNA、(c)哺乳動物由来の組織、細胞、組織溶解液及び細胞溶解液からなる群より選ばれる一から抽出されたRNAを鋳型として作製されたDNA等を挙げることができる。尚、前記組織とは、血液、リンパ節等を含む広義の意味であり、前記体液とは血漿、血清、リンパ液等を意味し、前記体分泌物とは尿や乳汁等を意味する。
癌が大腸癌である場合、被験動物から採取された大腸組織等をあげることができる。また、癌が乳癌である場合、被験動物から採取された乳房組織等をあげることができる。癌が肺癌である場合、被験動物から採取された肺組織等をあげることができる。哺乳動物由来の検体が血液、体液又は体分泌物等である場合には、定期健康診断や簡便な検査等で採取したものを利用することができる。
【0047】
本発明における「哺乳動物」としては、哺乳動物に属する動物の全てを挙げることができる。哺乳動物に属する動物とは、動物界 脊索動物門 脊椎動物亜門 哺乳綱(Mammalia)に分類される動物の総称である。より具体的には例えば、ヒト、サル、マーモセット、モルモット、ラット、マウス、ウシ、ヒツジ、イヌ、ネコ等を挙げることができる。
【0048】
本発明における「体液」としては、例えば、血漿や間質液のような、固体を構成する細胞間に存在する液体(多くの場合、固体の恒常性の維持機能を果たす)を挙げることができる。具体的には例えば、リンパ液、組織液(組織間液、細胞間液、間質液)、体腔液、漿膜腔液、胸水、腹水、心嚢液、脳脊髄液(髄液)、関節液(滑液)、眼房水(房水)、脳脊髄液、子宮内浸出液等を挙げることができる。
【0049】
本発明における「体分泌液」としては、例えば、外分泌腺からの分泌液を挙げることができる。具体的には例えば、唾液、胃液、胆汁、腸液、汗、涙、鼻水、精液、膣液、羊水、乳汁等挙げることができる。
【0050】
本発明における「細胞溶解液」としては、例えば、細胞培養用の10cmプレート等で培養した細胞(即ち、細胞株、初代培養細胞、血球細胞等)を破壊することにより得られる細胞内液を含む溶解液を挙げることができる。
ここで、細胞膜を破壊する方法としては、例えば、超音波による方法、界面活性剤を用いる方法、アルカリ溶液を用いる方法等を挙げることができる。尚、細胞を溶解するためには、様々な市販キット等を利用してもよい。
具体的には例えば、10cmプレートでコンフルエントになるまで細胞を培養した後、培養液を捨てて、0.6mLのRIPAバッファー(1× TBS, 1% nonidet P-40, 0.5% sodium deo×ysholate, 0.1% SDS, 0.004% sodium azide)を10cmプレートに加える。4℃で15分間プレートをゆっくり揺り動かしてから、10cmプレート上の接着細胞を、スクレーパー等を用いて剥がし、プレート上の溶解液をマイクロチューブに移す。溶解液の1/10容量の10mg/mL PMSFを添加してから、氷上で30〜60分間放置する。4℃で10分間、10,000×gで遠心することにより、上清を細胞溶解液として取得すればよい。
【0051】
本発明における「組織溶解液」としては、例えば、哺乳動物等の動物から採取した組織中の細胞を破壊することにより得られる細胞内液を含む溶解液を挙げることができる。
具体的には例えば、哺乳動物から取得した組織の重量を測定した後、カミソリ等を用いて組織を小片に裁断する。凍結組織をスライスする場合には、更に小さい小片にする必要がある。裁断後、氷冷RIPAバッファー(プロテアーゼインヒビター、フォスファターゼインヒビター等を添加してもよく、例えば、RIPAバッファーの1/10容量の10mg/mL PMSFを添加しても良い)を組織1gあたり3mLの比率で添加し、4℃でホモジナイズする。ホモジナイズには、ソニケーターや加圧型細胞破砕装置を用いる。ホモジナイズの作業では、溶液を常に4℃に維持し、発熱を抑えるようにする。ホモジナイズ液を、マイクロチューブに移して、4℃で10分間、10,000×gで遠心することにより、上清を組織溶解液として取得する。
【0052】
本発明評価方法の第一工程において、哺乳動物由来の検体に含まれる本発明DNAのメチル化頻度又はそれに相関関係がある指標値を測定する方法は、例えば、以下のように行えばよい。
【0053】
第一の方法として、哺乳動物由来の検体から、例えば、市販のDNA抽出用キット等を用いてDNAを抽出する。
因みに、血液を検体として用いる場合には、血液から通常の方法に準じて血漿又は血清を調製し、調製された血漿又は血清を検体としてその中に含まれる遊離DNA(大腸癌細胞等の癌細胞由来のDNAが含まれる)を分析すると、血球由来のDNAを避けて大腸癌細胞等の癌細胞由来のDNAを解析することができ、大腸癌細胞等の癌細胞、それを含む組織等を検出する感度を向上させることができる。
次いで、抽出されたDNAを、非メチル化シトシンを修飾する試薬と接触させた後、本発明DNAのプロモーター領域、非翻訳領域又は翻訳領域(コーディング領域)の塩基配列中に存在する一つ以上のCpGで示される塩基配列中のシトシンを含むDNAを、解析対象とするシトシンのメチル化の有無を識別可能なプライマーを用いてポリメラーゼチェイン反応(以下、PCRと記す。)で増幅し、得られる増幅産物の量を調べる。
【0054】
非メチル化シトシンを修飾する試薬(即ち、メチル化シトシンを修飾せずに非メチル化シトシンを選択的に修飾する試薬)としては、シトシンと5-メチルシトシンとの化学的性質の違いを利用することにより非メチル化シトシンを修飾する試薬であればよく、例えば、亜硫酸水素ナトリウム等の重亜硫酸塩(bisulfite)等を用いることができる。因みに、原理的には、メチル化シトシンのみを特異的に修飾する試薬を用いても良い。
【0055】
非メチル化シトシンを修飾する試薬に抽出されたゲノムDNA試料を可能な限り均一に接触させるには、ゲノムDNAの変性を行う必要がある。例えば、まず当該DNAをアルカリ溶液(pH9〜14)で変性した後、亜硫酸水素ナトリウム等の重亜硫酸塩(bisulfite)(溶液中の濃度:例えば、終濃度3M)等で約10〜16時間(一晩)程度、55℃で処理する。反応を促進するため、95℃での変性と、50℃での反応を10-20回繰り返すことも出来る。この場合、メチル化されていないシトシンはウラシルに変換され、一方、メチル化されているシトシンはウラシルに変換されず、シトシンのままである(Furuichiら、Biochem. Biophys. Res. Commun. 41:1185〜1191、1970)。
【0056】
亜硫酸水素ナトリウム等の重亜硫酸塩での処理に次いで、塩基配列中に存在する一つ以上のCpGで示される塩基配列中のシトシンを含むDNAを、解析対象とするシトシンのメチル化の有無を識別可能なプライマーを用いてPCR法で増幅し、得られる増幅産物の量を調べればよい。
重亜硫酸塩等で処理されたDNAを鋳型とし、且つ、メチル化されたシトシンが含まれる場合の塩基配列[メチル化される位置のシトシン(CpG中のシトシン)はシトシンのままであり、メチル化されていないシトシン(CpGに含まれないシトシン)はウラシルとなった塩基配列]とかかる塩基配列に対して相補的な塩基配列からそれぞれ選ばれる一対のメチル化特異的プライマーを用いるPCR(以下、メチル化特異的PCRとも記すこともある。)と、重亜硫酸塩等で処理されたDNAを鋳型とし、且つ、シトシンがメチル化されていない場合の塩基配列(全てのシトシンがウラシルとなった塩基配列)とかかる塩基配列に対して相補的な塩基配列からそれぞれ選ばれる一対の非メチル化特異的プライマーを用いるPCR(以下、非メチル化特異的PCRとも記すこともある。)とを行う。
【0057】
上記PCRにおいて、メチル化特異的プライマーを用いるPCRの場合(前者)には、解析対象とするシトシンがメチル化されているDNAが増幅され、一方、非メチル化特異的プライマーを用いるPCRの場合(後者)には、解析対象とするシトシンがメチル化されていないDNAが増幅される。これらの増幅産物の量を比較することにより、対象となるシトシンのメチル化の有無を調べる。このようにしてメチル化頻度を測定することができる。
【0058】
ここで、メチル化特異的プライマーは、メチル化を受けていないシトシンがウラシルに変換され、且つ、メチル化を受けているシトシンはウラシルに変換されないことを考慮して、メチル化を受けているシトシンを含む塩基配列に特異的なPCRプライマー(メチル化特異的プライマー)を設計し、また、メチル化を受けていないシトシンを含む塩基配列に特異的なPCRプライマー(非メチル化特異的プライマー)を設計する。重亜硫酸塩処理により化学的に変換され相補的ではなくなったDNA鎖を基に設計することから、元来二本鎖であったDNAのそれぞれの鎖を基に、それぞれからメチル化特異的プライマーと非メチル化特異的プライマーとを作製することもできる。かかるプライマーは、メチル、非メチルの特異性を高めるために、プライマーの3'末端近傍にCpG中のシトシンを含むように設計することが好ましい。また、解析を容易にするために、プライマーの一方を標識してもよい。
【0059】
メチル化特異的PCRにおける反応液としては、例えば、鋳型とするDNAを50ngと、10pmol/μlの各プライマー溶液を各1μlと、2.5mM dNTPを4μlと、10×緩衝液(100mM Tris-HCl pH8.3、500mM KCl、20mM MgCl2)を2.5μlと、耐熱性DNAポリメラーゼ 5U/μlを0.2μlとを混合し、これに滅菌超純水を加えて液量を25μlとした反応液をあげることができる。反応条件としては、例えば、前記のような反応液を、95℃にて10分間保温した後、95℃にて30秒間次いで55〜65℃にて30秒間さらに72℃にて30秒間を1サイクルとする保温を30〜40サイクル行う条件があげられる。
かかるPCRを行った後、得られた増幅産物の量を比較する。例えば、メチル化特異的プライマーを用いたPCRと非メチル化特異的プライマーを用いたPCRで得られた各々の増幅産物の量を比較することができる分析方法(変性ポリアクリルアミドゲル電気泳動やアガロースゲル電気泳動)である場合には、電気泳動後のゲルをDNA染色して増幅産物のバンドを検出し、検出されたバンドの濃度を比較する。ここでDNA染色の代わりに予め標識されたプライマーを使用してその標識を指標としてバンドの濃度を比較することもできる。また、定量を必要とする場合には、PCR反応産物をリアルタイムでモニタリングしカイネティックス分析を行うことにより、例えば、遺伝子量に関して2倍程度のほんの僅かな差異をも検出できる高精度の定量が可能なPCR法であるリアルタイムPCRを用いて、それぞれの産物の量を比較することもできる。リアルタイムPCRを行う方法としては、例えば鋳型依存性核酸ポリメラーゼプローブ等のプローブを用いる方法又はサイバーグリーン等のインターカレーターを用いる方法等が挙げられる。リアルタイムPCR法のための装置及びキットは既に市販されている。
【0060】
第二の方法として、亜硫酸水素ナトリウム等の重亜硫酸塩での処理に次いで、蛍光に基づくリアルタイムPCR(米国特許第6,331,393号;Eadsら、Nucleic Acids Res. 28:E32、2000)(以下、メチライト法という場合がある)を利用すすることもできる。メチライト法では、5'末端に蛍光レポーター色素を有し、かつ、3'末端に消光色素を有する位置特異的PCRプライマーを用い、蛍光に基づくリアルタイム定量的PCRによりメチル化DNAを増幅する。PCR反応の間に蛍光レポーター色素が、酵素によって放出されるため、PCR産物の量に比例し蛍光強度が増加する。従ってメチル化の程度に比例する蛍光を、自動ヌクレオチドシーケンサー装置において連続的に検出することができる。
【0061】
第三の方法として、亜硫酸水素ナトリウム等の重亜硫酸塩での処理に次いで、シークエンシングすることもできる。
一般的には、ゲノムDNA試料の変性と亜硫酸水素塩による処理に続いて、プライマー伸張によってdsDNAを取得し、さらに、PCR技術によって増幅する(Clarkら、Nucl. Acids Res. 22:2990〜2997、1994)方法である。次に、当該PCR産物を標準的なDNAシークエンシング法によって配列を決定しシトシン(亜硫酸水素塩による処理前のメチルシトシンに相当する)を検出する。シークエンス法としては、ジデオキシ法だけでなく、パイロシークエンス法(SOLiDシステム)等の方法であっても、塩基配列を決定する方法であれば何でもよい。
または前記PCR産物をプラスミドベクターにクローニングした後、個々のクローンをシークエンシングすることができるが、単一のDNA分子のメチル化マップを提供することも可能である。シークエンスによりメチルシトシンを決定するための幾つかの変法(Radlinska&Skowronek、Acta Microbiol. Pol. 47:327〜334、1998)が知られている。
【0062】
具体的に、dsDNAをPCR法により増幅して塩基配列を決定するために、PCRにおける反応液としては、例えば、鋳型とする重亜硫酸ナトリウム処理したDNA溶液をDNAが20ng又は80ng相当含まれる総液量50μLの反応液を調製し、これを用いればよい。具体的には、鋳型とする重亜硫酸ナトリウム処理したDNA溶液と、5μMに調製された各オリゴヌクレオチドプライマー溶液とを夫々総液量の3/5と、GeneAmpR dNTP Mi×(2 mM each)を総液量の1/10と、10×緩衝液(100 mM Tris-HCl pH 8.3、500 mM KCl、15 mM MgCl2、0.01% Gelatin)5μLを総液量の1/10と、25 mM MgCl2溶液を総液量の1/50と、耐熱性DNAポリメラーゼ(AmpliTaq Gold、5 U/μL、ABI社製)を0.25μLと、滅菌超純水とを混合することにより、総液量50μLの反応液を調製すればよい。当該反応液を、95℃にて10分間保温した後、95℃にて30秒間次いで55℃にて30秒間更に72℃にて45秒間を1サイクルとする保温を40サイクル行う条件でPCRすればよい。
【0063】
PCRを行った後、1.5%アガロースゲル電気泳動により増幅を確認した後、得られたDNA断片についてクローニングを行えばよい。
【0064】
クローニングにはTOPO TA CloningR Kit For Sequencing(インビトロジェン社)を使用すればよい。Salt Solutionを0.4μLと、TOPO vectorを0.4μLと、前記のPCR増幅産物を1.6μLとを氷上で混合し、これを室温で5分間静置した。ライゲーション反応液を2μLとコンピテントセルを50μLとを混合し、氷中に30分間静置する。静置後、42℃で30秒間インキュベートし、氷中に保存すればよい。反応液にSOC培地を250μL加え振盪培養(37℃、225rpm、1時間)する。X-gal溶液(10mg/mL DMF)を100μLを塗布したLBプレート(アンピシリン終濃度50μg/mL)に、培養液を塗布し、培養(37℃、18時間)すればよい。
【0065】
培養液を塗布し、培養したLBプレート上に得られる大腸菌コロニーのうち、白色のコロニーを、爪楊枝でピックアップし、2mLのLB培地(アンピシリン終濃度50μg/mL)でさらに培養(37℃、15時間)し、得られた大腸菌からプラスミド抽出装置(PI-50、KURABO)を用いてプラスミドを抽出すれば、プラスミド溶液を取得できる。
【0066】
当該プラスミド溶液を2μLと、BigDyeRTerminator v3.1 Cycle Sequencing RR-100(ABI社)を1μLと、BigDyeRTerminator v1.1/v3.1 Sequencing Buffer(5×)(ABI社)を2μLと、シークエンス反応のために設計されたオリゴヌクレオチドプライマー(M13R)の3.2μM溶液を1μLと、滅菌超純水を4μLとを混合する。当該反応液を、96℃にて1分間保温した後、96℃にて10秒間次いで50℃にて5秒間更に60℃にて4分間を1サイクルとする保温を25サイクル行う条件でシークエンス反応をおこなえばよい。
【0067】
PCRにおける反応液としては、例えば、鋳型とするDNAを25ngと、20pmol/μlの各プライマー溶液を各1μlと、2mM dNTPを3μlと、10×緩衝液(100mM Tris-HCl pH 8.3、500mM KCl、15mM MgCl2)を2.5μlと、耐熱性DNAポリメラーゼ 5U/μlを0.2μlとを混合し、これに滅菌超純水を加えて液量を25μlとした反応液をあげることができる。反応条件としては、例えば、前記のような反応液を、95℃にて10分間保温した後、95℃にて30秒間次いで53℃にて30秒間さらに72℃にて30秒間を1サイクルとする保温を30〜40サイクル行う条件があげられる。
かかるPCRを行った後、得られた増幅産物の塩基配列を比較し当該比較からメチル化頻度を測定する。
即ち、当該増幅産物の塩基配列を直接的に解析することにより、解析対象とするシトシンに相当する位置の塩基がシトシンであるかチミン(ウラシル)であるかを判定する。得られた増幅産物における塩基を示すピークのチャートにおいて、解析対象とするシトシンに相当する位置に検出されたシトシンを示すピークの面積とチミン(ウラシル)を示すピークの面積とを比較することにより、解析対象となるシトシンのメチル化の頻度を測定することができる。また、塩基配列を直接的に解析する方法として、PCRで得られた増幅産物を一旦大腸菌等を宿主としてクローニングして得られた複数のクローンから、それぞれクローニングされたDNAを調製し、当該DNAの塩基配列を解析してもよい。解析される試料のうちの解析対象とするシトシンに相当する位置に検出された塩基がシトシンである試料の割合を求めることにより、解析対象となるシトシンのメチル化の頻度を測定することもできる。
【0068】
第四の方法として、目的とするDNAの塩基配列中に存在する一つ以上のCpGで示される塩基配列中のシトシンを含むDNAと、解析対象とするシトシンのメチル化の有無を識別可能なプローブとをハイブリダイゼーションさせ、前記DNAと当該プローブとの結合の有無を調べることもできる。
【0069】
具体的には、検体から抽出したゲノムDNAを、非メチル化シトシンを修飾する試薬を作用させてから、シトシンのメチル化の有無を識別可能なプローブをハイブリダイゼーションさせる方法が挙げられる。当該ハイブリダイゼーションに用いられるプローブは、解析対象とするシトシンを含む塩基配列を基にして、メチル化を受けていないシトシンがウラシルに変換され、且つ、メチル化を受けているシトシンはウラシルに変換されないことを考慮して設計するとよい。即ち、メチル化されたシトシンが含まれる場合の塩基配列[メチル化される位置のシトシン(CpG中のシトシン)はシトシンのままであり、メチル化されていないシトシン(CpGに含まれないシトシン)はウラシルとなった塩基配列]又はかかる塩基配列に対して相補的な塩基配列を有するメチル化特異的プローブと、シトシンがメチル化されていない場合の塩基配列(全てのシトシンがウラシルとなった塩基配列)又はかかる塩基配列に対して相補的な塩基配列を有する非メチル化特異的プローブを設計する。尚、このようなプローブは、DNAとプローブとの結合の有無についての解析を容易にするために標識してから用いてもよい。またプローブを通常の方法に準じて担体上に固定して用いてもよいが、この場合には、哺乳動物由来の検体から抽出されたDNAを予め標識しておくとよい。
【0070】
非メチル化シトシンを修飾する試薬としては、例えば、亜硫酸水素ナトリウム等の重亜硫酸塩(bisulfite)等を用いることができる。因みに、原理的には、メチル化シトシンのみを特異的に修飾する試薬を用いてもよい。
【0071】
非メチル化シトシンを修飾する試薬に抽出されたDNAを接触させるには、例えば、まず当該DNAをアルカリ溶液(pH9〜14)で変性した後、亜硫酸水素ナトリウム等の重亜硫酸塩(bisulfite)(溶液中の濃度:例えば、終濃度3M)等で約10〜16時間(一晩)程度、55℃で処理する。反応を促進するため、95℃での変性と、50℃での反応を10-20回繰り返すことも出来る。この場合、メチル化されていないシトシンはウラシルに変換され、一方、メチル化されているシトシンはウラシルに変換されず、シトシンのままである。
必要に応じて、重亜硫酸塩等で処理されたDNAを鋳型として第二の方法と同様にPCRを行うことにより当該DNAを予め増幅させておいてもよい。
次いで、重亜硫酸塩等で処理されたDNA又は前記PCRで予め増幅されたDNAと、解析対象とするシトシンのメチル化の有無を識別可能なプローブとのハイブリダイゼーションを行う。メチル化特異的プローブと結合するDNAの量と、非メチル化特異的プローブと結合するDNAの量とを比較することにより、解析対象となるシトシンのメチル化の頻度を測定することができる。
【0072】
ハイブリダイゼーションは、例えば、Sambrook J., Frisch E. F., Maniatis T.著、モレキュラークローニング第2版(Molecular Cloning 2nd edition)、コールド スプリング ハーバー ラボラトリー発行(Cold Spring Harbor Laboratory press)等に記載される通常の方法に準じて行うことができる。ハイブリダイゼーションは、通常ストリンジェントな条件下に行われる。ここで「ストリンジェントな条件下」とは、例えば、6×SSC(1.5M NaCl、0.15M クエン酸三ナトリウムを含む溶液を10×SSCとする)を含む溶液中で45℃にてハイブリッドを形成させた後、2×SSCで50℃にて洗浄するような条件(Molecular Biology, John Wiley & Sons, N. Y. (1989), 6.3.1-6.3.6)等を挙げることができる。洗浄ステップにおける塩濃度は、例えば、2×SSCで50℃の条件(低ストリンジェンシーな条件)から0.2×SSCで50℃までの条件(高ストリンジェンシーな条件)から選択することができる。洗浄ステップにおける温度は、例えば、室温(低ストリンジェンシーな条件)から65℃(高ストリンジェンシーな条件)から選択することができる。また、塩濃度と温度との両方を変えることもできる。
かかるハイブリダイゼーションを行った後、メチル化特異的プローブと結合したDNAの量と、非メチル化特異的プローブと結合したDNAの量とを比較することにより、解析対象となるシトシン(即ち、プローブの設計の基となった塩基配列に含まれるCpG中のシトシン)のメチル化の頻度を測定することができる。
【0073】
第五の方法として、目的とするDNAの塩基配列中の、解析対象とするシトシンのメチル化の有無を識別可能な制限酵素に作用させた後、当該制限酵素による消化の有無を調べる方法をあげることもできる。
【0074】
当該方法で用いられる「シトシンのメチル化の有無を識別可能な制限酵素」(以下、メチル化感受性制限酵素と記すこともある。)とは、メチル化されたシトシンを含む認識配列を消化せず、メチル化されていないシトシンを含む認識配列を消化することのできる制限酵素を意味する。即ち、メチル化感受性制限酵素が本来認識することができる「認識配列」に含まれるシトシンがメチル化されているDNAの場合、メチル化感受性制限酵素を作用させても当該DNAは切断されず、一方、メチル化感受性制限酵素が本来認識することができる「認識配列」に含まれるシトシンがメチル化されていないDNAの場合、メチル化感受性制限酵素を作用させれば当該DNAは切断される。このようなメチル化感受性酵素の具体的な例としては、例えば、HpaII、BstUI、NarI、SacII等をあげることができる(例えば、Nucleic Acid Research, 9、2509-2515参照)。
【0075】
当該制限酵素による消化の有無を調べる方法としては、例えば、前記DNAを鋳型とし、解析対象とするシトシンを認識配列に含み、当該認識配列以外には前記制限酵素の認識配列を含まないDNAを増幅可能なプライマー対を用いてPCRを行い、DNAの増幅(増幅産物)の有無を調べる方法をあげることができる。解析対象とするシトシンがメチル化されている場合には、増幅産物が得られる。一方、解析対象とするシトシンがメチル化されていない場合には、増幅産物が得られない。このようにして、増幅されたDNAの量を比較することにより、解析対象となるシトシンのメチル化の頻度を測定することができる。即ち、哺乳動物由来検体中に含まれるゲノムDNAがメチル化されていれば、前記メチル化感受性制限酵素がメチル化状態であるDNAを切断しないという特性を利用することにより、前記哺乳動物由来検体中に含まれるゲノムDNAにおける前記メチル化感受性制限酵素の認識部位の中に存在している少なくとも1つ以上のCpG対におけるシトシンがメチル化されていたか否かを区別することができる。言い換えれば、前記メチル化感受性制限酵素で消化処理することにより、仮に哺乳動物由来検体中に含まれるゲノムDNAにおける前記メチル化感受性制限酵素の認識部位の中に存在している少なくとも1つ以上のCpG対におけるシトシンがメチル化されていないのであれば、該メチル化感受性制限酵素により切断される。また、仮に哺乳動物由来検体中に含まれるゲノムDNAにおける前記メチル化感受性制限酵素の認識部位の中に存在している全てのCpG対におけるシトシンがメチル化されていたのであれば、該メチル化感受性制限酵素により切断されない。従って、消化処理を実施した後、後述のように、前記目的とするDNA領域を増幅可能な一対のプライマーを用いたPCRを実施することにより、哺乳動物由来検体中に含まれるゲノムDNAにおける前記制限酵素の認識部位の中に存在している少なくとも1つ以上のCpG対におけるシトシンがメチル化されていないのであれば、PCRによる増幅産物は得られず、一方、哺乳動物由来検体中に含まれるゲノムDNAにおける前記メチル化感受性制限酵素の認識部位の中に存在している全てのCpG対におけるシトシンがメチル化されていたのであれば、PCRによる増幅産物が得られることになる。
定量を必要とする場合には、PCR反応産物をリアルタイムでモニタリングしカイネティックス分析を行うことにより、例えば、遺伝子量に関して2倍程度のほんのわずかな差異をも検出できる高精度の定量が可能なPCR法であるリアルタイムPCRを用いて、それぞれの産物の量を比較することもできる。リアルタイムPCRを行う方法としては、例えば鋳型依存性核酸ポリメラーゼプローブ等のプローブを用いる方法又はサイバーグリーン等のインターカレーターを用いる方法等が挙げられる。リアルタイムPCR法のための装置及びキットは既に市販されている。
【0076】
また、当該制限酵素による消化の有無を調べる他の方法としては、例えば、解析対象とするシトシンを認識配列に含むメチル化感受性制限酵素を作用させたDNAに対して、Arginine vasopressin receptor 1A遺伝子に由来し、且つ、当該制限酵素の認識配列を含まないDNAをプローブとしたサザンハイブリダイゼーションを行い、ハイブリダイズしたDNAの長さを調べる方法をあげることもできる。解析対象とするシトシンがメチル化されている場合には、当該シトシンがメチル化されていない場合よりも長いDNAが検出される。検出された長いDNAの量と短いDNAの量とを比較することにより、解析対象となるシトシンのメチル化の頻度を測定することができる。
【0077】
以上のような各種方法を用いて、哺乳動物由来の検体に含まれる本発明DNAのメチル化頻度を測定する。測定されたメチル化頻度と、例えば、大腸癌細胞、肺癌細胞、乳癌細胞等の癌細胞を持たないと診断され得る健常な哺乳動物由来の検体に含まれる目的とするDNAのメチル化頻度(対照)とを比較して、当該比較により得られる差異に基づき前記検体の癌化度を判定する。仮に、哺乳動物由来の検体に含まれる本発明DNAのメチル化頻度が対照と比較して高ければ(本発明DNAが対照と比較の上で高メチル化状態であれば)、当該検体の癌化度が対照と比較の上で高いと判定することができる。
ここで「癌化度」とは、一般に当該分野において使用される意味と同様であって、具体的には、例えば、哺乳動物由来の検体が細胞である場合には当該細胞の悪性度を意味し、また、例えば、哺乳動物由来の検体が組織である場合には当該組織における癌細胞の存在量等を意味している。
【0078】
第六の方法として、目的とするDNAに含まれるシトシンのメチル化割合を、SEQUENOM社のMassARRAYシステムを用いて定量的にメチル化シトシンを測定することもできる。
【0079】
具体的には、検体から抽出したゲノムDNAに、非メチル化シトシンを修飾する試薬を作用させてから、目的とするDNA領域をPCR法により増幅する。次に、増幅したDNA領域をRNAポリメラーゼによりRNAへ転写する。さらに、得られた転写産物をRNaseで処理し、MASSによる質量分析を行う。
本方法は、非メチル化シトシンを修飾する試薬を作用させることにより、分子量が変化することに基づいて、検体中のDNAに含まれるメチルシトシンを定量する方法である。
【0080】
より具体的には、SEQUENOMアプリケーションノートに示されるMassARRAYシステムを用いた定量的DNAメチル化解析用EpiTYPERの概論に従った以下の手法を用いてもよい。
【0081】
メチル化解析用に以下のプライマーシステムを設計する。In vitro転写に適した産物を得るため、T7プロモータを付加したリバースプライマー。サイクリング失敗を防ぐために8bpインサートを挿入する。また、PCRのバランスをとるために10merタグを付加したフォワードプライマーとする。
Bisulfite処理:
サンプルゲノムDNAのBisulfite変換処理にはZymo Research社のEZ-96DNA Methylation KitまたはEZ DNA Methylation Kitを使用する。このプロトコルの初回インキュベーション後、以下のとおりサイクル反応をおこなう。
45サイクル:
95℃30分
50℃15分
(1)ステップ1:増幅
385-マイクロタイターフォーマットを用いて総容量5 μL中1 μLのDNAを増幅する(1反応あたり最終濃度2 ng/μLとするために10 ng/μL以上のDNAを1.00 μL以上使用する)。各反応液を2種類の切断反応(T切断反応とC切断反応)に分ける。プレートを密封し、以下のとおりサイクル反応をおこなう。
・94℃15分
・45サイクル
94℃20秒
56℃30秒
72℃1分
・72℃3分
(2)ステップ2:脱リン酸化
各PCR反応液5 μLにエビ由来アルカリフォスファターゼ(SAP)酵素2 μLを添加し、PCRに組み込まれなかったdNTPを脱リン酸化する。プレートを37℃で20分インキュベートし次いで85℃で5分インキュベートする。
(3)ステップ3:In vitro転写とRNase切断
各切断反応(TおよびC)用に転写/RNaseAカクテルを調製する。標準セットアップでは1プレートあたり、1つの転写/RNaseAカクテルを調製する。サイクル反応をおこなっていない新しいマイクロタイタープレートに、転写/RNaseAカクテル5 μLとPCR/SAPサンプル2 μLを添加する。プレートを1分間遠心し、次にプレートを37℃で3時間インキュベートする。
(4)ステップ4:サンプルコンディショニング
384穴プレートの各サンプルにddH2O 20 μLを加える。レジンプレートを用いて各穴にClean Resinを6 mg加える。10分間攪拌し、3,200xgで5分間スピンダウンする。
(5)ステップ5:サンプルの移動
10〜15 nLのEpiTYPER反応産物を384穴SpectroCHIPに分注する。
ステップ6:サンプル解析
MassARRAYシステムを用いて2種類の切断反応のスペクトルを得る。
(6)ステップ6:解析ソフトウェア
結果をEpiTYPERソフトウェアにより解析し、目的とするDNAのメチル化割合を測定する。
【0082】
本発明DNAは、以下のメチル化DNA含量測定方法により、メチル化されたDNAの含量を測定することができる。
【0083】
メチル化DNA含量測定方法は、哺乳動物由来の検体中に含まれる目的とするDNA領域の塩基配列が有する目的とするDNA領域におけるメチル化されたDNAの含量を測定する方法であって、
(1)哺乳動物由来の検体中に含まれるゲノムDNA由来のDNA試料をメチル化感受性制限酵素による消化処理を行う第一工程、
(2)第一工程で得られた消化処理が行われたDNA試料からメチル化された一本鎖DNAを取得し、該一本鎖DNAと、固定化メチル化DNA抗体とを結合させて一本鎖DNAを選択する第二工程、及び、
(3)下記の各本工程の前工程として第二工程で選択された一本鎖DNAを、固定化メチル化DNA抗体から分離して一本鎖状態であるDNA(正鎖)にする工程(第一前工程)と、
第一前工程で一本鎖状態にされたゲノム由来のDNA(正鎖)を、一本鎖状態であるDNA(正鎖)が有する塩基配列の部分塩基配列(正鎖)であって、且つ、前記の目的とするDNA領域の塩基配列(正鎖)の3’末端よりさらに3’末端側に位置する部分塩基配列(正鎖)、に対して相補性である塩基配列(負鎖)を有する伸長プライマー(フォーワード用プライマー)を伸長プライマーとして、該伸長プライマーを1回伸長させることにより、目的とするDNA領域を含む一本鎖DNA(正鎖)を二本鎖DNAに伸長形成させる工程(第二前工程)と、
第二前工程で伸長形成された二本鎖DNAを、目的とするDNA領域を含む一本鎖DNA(正鎖)と目的とするDNA領域を含む一本鎖DNA(負鎖)に一旦分離する工程(第三前工程)を有し、且つ、本工程として
(a)生成した目的とするDNA領域を含む一本鎖DNA(正鎖)を鋳型として、前記フォワード用プライマーを伸長プライマーとして、該伸長プライマーを一回伸長させることにより、前記の目的とするDNA領域を含む一本鎖DNAを二本鎖DNAとして伸長形成させる第A工程(本工程)と、
(b)生成した目的とするDNA領域を含む一本鎖DNA(負鎖)を鋳型として、前記の目的とするDNA領域を含む一本鎖DNA(負鎖)が有する塩基配列の部分塩基配列(負鎖)であって、且つ、前記の目的とするDNA領域の塩基配列(正鎖)に対して相補性である塩基配列(負鎖)の3’末端よりさらに3’末端側に位置する部分塩基配列(負鎖)、に対して相補性である塩基配列(正鎖)を有する伸長プライマー(リバース用プライマー)を伸長プライマーとして、該伸長プライマーを1回伸長させることにより、前記の目的とするDNA領域を含む一本鎖DNAを二本鎖DNAとして伸長形成させる第B工程(本工程)とを有し、
さらに第三工程の各本工程を、前記各本工程で得られた伸長形成された二本鎖DNAを一本鎖状態に一旦分離した後、繰り返すことにより、前記の目的とするDNA領域におけるメチル化されたDNAを検出可能な量になるまで増幅し、増幅されたDNAの量を定量する第三工程、を有することを特徴とする。
【0084】
本発明メチル化DNA含量測定方法における「相補性である」とは、塩基同士の水素結合による塩基対合により二本鎖DNAを形成することを意味する。例えば、DNAを構成する二本鎖の各々一本鎖DNAを構成する塩基が、プリンとピリミジンとの塩基対合により二本鎖を形成することであり、具体的には例えば、複数の連続した、チミンとシトシンとの間の水素結合による塩基結合、又は、グアニンとアデニンとの間の水素結合による塩基結合により、二本鎖DNAを形成することを意味する。相補性によって結合することを「相補的な結合」と記載することもある。「相補的な結合」は、「相補的に塩基対合しうる」又は「相補性により結合」と記載することもある。また、相補的に結合しうる塩基配列を互いに「相補性を有する」「相補性によって結合(相補的な(塩基対合による)結合)」と記載することもある。尚、本発明メチル化DNA含量測定方法においては、人工的に作成されるオリゴヌクレオチドに含まれるイノシンがシトシン、アデニン若しくはチミンと水素結合で結合することも、「相補性である」に含まれる。
【0085】
本発明メチル化DNA含量測定方法における「目的とするDNA領域を含む一本鎖DNA(負鎖)」とは、目的とするDNA領域を含む一本鎖DNAとの結合体(二本鎖)を形成するために必要な塩基配列、即ち、目的とするDNA領域の塩基配列の一部に相補的な塩基配列を含む塩基配列であることを意味し、「相補的塩基配列」あるいは「相補配列」と記載することもある。また、相補的塩基配列は、「相補的」と表現することもある。
【0086】
本発明メチル化DNA含量測定方法における「メチル化されたDNA」、「メチル化DNA」とは、DNAの塩基配列中の5’−CG−3’で示される塩基配列(以下、当該塩基配列を「CpG」と記すこともある。)中のシトシンの5位がメチル化されたDNAを意味する。
【0087】
本発明メチル化DNA含量測定方法におけるの第一工程において「メチル化頻度」とは、本発明評価方法でのものと同じ意味であり、例えば、調査対象となるCpG中のシトシンのメチル化の有無を複数のハプロイドについて調べたときの、当該シトシンがメチル化されているハプロイドの割合で表される。
【0088】
また本発明評価方法の第一工程において「(メチル化頻度)に相関関係がある指標値」とは、本発明評価方法でのものと同じ意味であり、例えば、本発明DNAの発現産物の量(より具体的には、当該本発明DNAの転写産物の量や、当該本発明DNAの翻訳産物の量)等をあげることができる。このような発現産物の量の場合には、上記メチル化頻度が高くなればそれに伴い減少するような負の相関関係が存在する。
【0089】
本発明メチル化DNA含量測定方法における「固定化メチル化DNA抗体」としては、例えば、メチルシトシン抗体等を挙げることができる。当該固定化メチル化DNA抗体は、支持体に固定化され得るものであればよく、「支持体に固定化され得るもの」とは、固定化メチル化DNA抗体を支持体へ直接的又は間接的に固定できることを意味する。このように固定化されるためには、固定化メチル化DNA抗体を通常の遺伝子工学的な操作方法又は市販のキット・装置等に従って、支持体に固定すればよい(固相への結合)。具体的には、固定化メチル化DNA抗体をビオチン化して得られたビオチン化固定化メチル化DNA抗体をストレプトアビジンで被覆した支持体(例えば、ストレプトアビジンで被覆したPCRチューブ、ストレプトアビジンで被覆した磁気ビーズ等)に固定する方法を挙げることができる。
また固定化メチル化DNA抗体を、アミノ基、チオール基、アルデヒド基等の活性官能基を有する分子を共有結合させた後、シランカップリング剤等で表面を活性化させたガラス、多糖類誘導体、シリカゲル、合成樹脂等から作製された支持体に共有結合させる方法もある。尚、共有結合には、例えば、トリグリセライドを5個直列に連結してなるようなスペーサー、クロスリンカー等により共有結合させる方法も挙げられる。
更に、固定化メチル化DNA抗体を直接支持体に固定化してもよく、また固定化メチル化DNA抗体に対する抗体(二次抗体)を支持体に固定化し、当該二次抗体にメチル化抗体を結合させることで支持体に固定してもよい。
尚、一本鎖DNAと固定化メチル化DNA抗体との結合前の段階で、固定化メチル化DNA抗体と支持体との結合により固定化されるものであってもよく、また一本鎖DNAと固定化メチル化DNA抗体との結合後の段階で、固定化メチル化DNA抗体と支持体との結合により固定化されるものであってもよい。
【0090】
本発明メチル化DNA含量測定方法で用いられる「メチル化感受性制限酵素」(具体的には、シトシンのメチル化の有無を識別可能な制限酵素)とは、本発明評価方法でのものと同じ意味であり、メチル化されたシトシンを含む認識配列を消化せず、メチル化されていないシトシンを含む認識配列を消化することのできる制限酵素を意味する。即ち、メチル化感受性制限酵素が本来認識することができる「認識配列」に含まれるシトシンがメチル化されているDNAの場合、メチル化感受性制限酵素を作用させても当該DNAは切断されず、一方、メチル化感受性制限酵素が本来認識することができる「認識配列」に含まれるシトシンがメチル化されていないDNAの場合、メチル化感受性制限酵素を作用させれば当該DNAは切断される。このようなメチル化感受性酵素の具体的な例としては、例えば、HpaII、BstUI、NarI、SacII等をあげることができる(例えば、Nucleic Acid Research, 9、2509-2515参照)。
【0091】
本発明メチル化DNA含量測定方法における「メチル化感受性制限酵素」としては、例えば、本発明DNAの塩基配列を目的とするDNA領域の中に認識切断部位を有する制限酵素又はHhaI等を挙げることができる。
【0092】
本発明メチル化DNA含量測定方法の応用として、当該方法における第一工程におけるメチル化感受性制限酵素による消化処理を行わずに第二工程を行う方法もありうる。
【0093】
本発明メチル化DNA含量測定方法の第二工程は、第一工程で得られた消化処理が行われたDNA試料に含まれるメチル化された二本鎖DNAをメチル化された一本鎖DNAに分離する第A工程(即ち、第二工程における第A工程)と、当該第A工程で得られたメチル化一本鎖DNAと固定化メチル化DNA抗体と結合させる第B工程(即ち、第二工程における第B工程)とから構成されてもよい。
【0094】
本発明メチル化DNA含量測定方法の第二工程において、第一工程で得られた消化処理が行われたDNA試料に含まれるメチル化された二本鎖DNAをメチル化された一本鎖DNAに分離するには、二本鎖DNAを一本鎖DNAにするための一般的な操作を行えばよい。具体的には例えば、哺乳動物由来検体中に含まれるゲノムDNA由来のDNA試料を適当量の超純水に溶解し、95℃で10分間加熱し、氷中で急冷すればよい。
【0095】
本発明メチル化DNA含量測定方法の第二工程において、上記のようにして分離されたメチル化一本鎖DNAと固定化メチル化DNA抗体と結合させることによって一本鎖DNAを選択するには、上記の「固定化メチル化DNA抗体」に係る説明で述べたように、具体的には例えば、固定化メチル化DNA抗体として「ビオチン標識されたビオチン化メチルシトシン抗体」を使用して以下のように実施すればよい。
(a)ビオチン化メチルシトシン抗体を適当量(例えば、0.1μg/50μL)アビジン被覆PCRチューブに添加し、その後、これを室温で約1時間静置することにより、ビオチン化メチルシトシン抗体とストレプトアビジンとの固定化を促す。PCRチューブ内から残溶液の除去及び洗浄後、洗浄バッファー[例えば、0.05% Tween20含有リン酸バッファー(1mM KH2PO4、3mM Na2HPO・7H2O、154mM NaCl pH7.4)]を100μL/チューブの割合で添加する。PCRチューブ内から溶液の除去及び洗浄後(当該洗浄操作を数回繰り返した後)、支持体に固定化されたビオチン化メチルシトシン抗体をPCRチューブ内に残す。
(b)哺乳動物由来検体中に含まれるゲノムDNA由来の二本鎖DNAとバッファー(例えば、33mM Tris-Acetate pH 7.9、66mM KOAc、10mM Mg(OAc)2、0.5mM Dithothreitol)とを混合し、得られた混合物を95℃で数分間加熱する。加熱後、前記混合物を約0〜4℃の温度まで速やかに冷却し、その温度で数分間保温することにより、一本鎖DNAを形成させる。得られた混合物を室温に戻す。
(c)形成された前記一本鎖DNAを、ビオチン化メチルシトシン抗体が固定化されたアビジン被覆PCRチューブに添加し、得られた混合物を室温で約1時間静置することにより、ビオチン化メチルシトシン抗体と前記一本鎖DNAのうちメチル化された一本鎖DNAとの結合を促す(結合体の形成)(この段階で、少なくともメチル化されてないDNA領域を含む一本鎖DNAは結合体を形成しない。)。その後、PCRチューブ内から残溶液を除去し、洗浄を行う。PCRチューブ内に洗浄バッファー[例えば、0.05% Tween20含有リン酸バッファー(1mM KH2PO4、3mM Na2HPO・7H2O、154mM NaCl pH7.4)]を100μL/チューブの割合で添加した後、PCRチューブ内から溶液を取り除く。当該洗浄操作を数回繰り返すことにより、洗浄された結合体をPCRチューブ内に残す(結合体の選択)。
上記(b)において使用されるバッファーとしては、生物試料由来のゲノムDNA由来の二本鎖DNAを一本鎖DNAへ分離するために適したものであればよく、前記バッファーに限ったわけではない。
上記(a)及び上記(c)における洗浄操作では、溶液中に浮遊している固定化されていない固定化メチル化DNA抗体、固定化メチル化DNA抗体に結合しなかった溶液中に浮遊しているメチル化されていない一本鎖DNA、又は、後述の制限酵素で消化された溶液中に浮遊しているDNA等を反応溶液から取り除くために重要な操作である。尚、洗浄バッファーは、上記の遊離の固定化メチル化DNA抗体、溶液中に浮遊している一本鎖DNA等の除去に適したものであればよく、前記洗浄バッファーに限らず、DELFIAバッファー(PerkinElmer社製、Tris-HCl pH 7.8 with Tween 80)、TEバッファー等でもよい。
【0096】
他に第二工程における第A工程において、メチル化された一本鎖DNAを分離する際の好ましい態様としては、例えば、カウンターオリゴヌクレオチドを添加すること等を挙げることができる。カウンターオリゴヌクレオチドとしては、例えば、目的とするDNA領域と同じ塩基配列を短いオリゴヌクレオチドに分割したものを挙げることができる。通常10〜100塩基、より好ましくは、20〜50塩基の長さに設計したものを好ましく挙げることができる。尚、カウンターオリゴヌクレオチドは、フォーワード用プライマー又はリバース用プライマーが目的とするDNA領域と相補的に結合する塩基配列上には設計しない。カウンターオリゴヌクレオチドは、ゲノムDNAに比し、大過剰で添加され、目的とするDNA領域を一本鎖(正鎖)にした後、固定化メチル化DNA抗体と結合させる際に、目的とするDNA領域の相補鎖(負鎖)と目的とするDNA領域を一本鎖(正鎖)が相補性により再結合することを妨げるために添加する。目的とするDNA領域にメチル化DNA抗体を結合させて、DNAのメチル化頻度又はそれに相関関係のある指標値を測定する際に、目的領域が一本鎖である方がメチル化DNA抗体に結合しやすいからである。尚、カンウターオリゴヌクレオチドは、目的とするDNA領域に比べて、少なくとも10倍、通常は100倍以上の量が添加されることが好ましい。
【0097】
ここで、「(メチル化された一本鎖DNAを分離する際に)カウンターオリゴヌクレオチドを添加する」とは、具体的には、哺乳動物由来検体中に含まれるゲノムDNA由来のDNA試料から、メチル化された一本鎖DNAを選択するために、哺乳動物由来検体中に含まれるゲノムDNA由来のDNA試料をカウンターオリゴヌクレオチドと混合して、目的とするDNA領域の相補鎖とカウンターオリゴヌクレオチドとの二本鎖を形成させればよい。例えば、前記DNA試料と、前記カウンターオリゴヌクレオチドとの混合物に、緩衝液(330mM Tris-Acetate pH7.9、660mM KOAc、100mM MgOAc2、5mM Dithiothreitol)5μLと、100mMのMgCl2溶液5μLと、1mg/mLのBSA溶液5μLを添加し、さらに当該混合物に滅菌超純水を加えて液量を50μLとし、混合して、95℃で10分間加熱し、70℃まで速やかに冷却し、その温度で10分間保温し、次いで、50℃まで冷却し10分間保温し、さらに37℃で10分間保温した後室温に戻せばよい。
【0098】
本発明メチル化DNA含量測定方法の第三工程は、以下の各工程を含む
(1)前工程((i)第一前工程、(ii)第二前工程、(iii)第三前工程)
(2)本工程((i)第A工程、(ii)第B工程)
(3)繰り返し工程((i)増幅工程、(ii)定量工程)
【0099】
(1)第三工程における前工程
(i)第三工程における前工程での第一前工程
・第二工程で選択された一本鎖DNAを、固定化メチル化DNA抗体から分離して遊離の一本鎖状態のDNAにする工程
・具体的には例えば、第二工程で選択された一本鎖DNAに、アニーリングバッファーを添加することにより、混合物を得る。次いで、得られた混合物を95℃で数分間加熱することにより、一本鎖状態であるDNA(正鎖)を得る。
(ii)第三工程における前工程での第二前工程
・第一前工程で遊離の一本鎖状態にされたゲノム由来のDNA(正鎖)と、一本鎖状態であるDNA(正鎖)が有する塩基配列の部分塩基配列(正鎖)であって、且つ、前記の目的とするDNA領域の塩基配列(正鎖)の3’末端より更に3’ 末端側に位置する部分塩基配列(正鎖)、に対して相補性である塩基配列(負鎖)を有する伸長プライマー(フォーワード用プライマー)を伸長プライマーとして、該伸長プライマーを1回伸長させることにより、遊離の一本鎖状態であるDNA(正鎖)を二本鎖DNAに伸長形成させる工程
・具体的には例えば、第一前工程で得られた一本鎖状態のDNA(正鎖)とフォワードプライマーとを、滅菌超純水を17.85μL、最適な緩衝液(例えば、100mM Tris-HCl pH 8.3、500mM KCl、15mM MgCl2)を3μL、2mM dNTPを3μL、5Nベタインを6μL加え、次いで得られた混合物にAmpliTaq(DNAポリメラーゼの1種:5U/μL)を0.15μL加えて液量を30μLとした溶液中で混合する。得られた混合物を37℃で約2時間インキュベーションすることにより、目的とするDNA領域を含む一本鎖DNA(正鎖)を二本鎖DNAに伸長形成させる。
(iii)第三工程における前工程での第三前工程
・第二前工程で伸長形成された二本鎖DNAを、目的とするDNA領域を含む一本鎖DNA(正鎖)と目的とするDNA領域に対して相補性である塩基配列を含む一本鎖DNA(負鎖)に一旦分離する工程
・具体的には例えば、第二前工程で伸長形成された二本鎖DNAに、アニーリングバッファーを添加することにより混合物を得て、得られた混合物を95℃で数分間加熱することにより、目的とするDNA領域を含む一本鎖DNAに一旦分離する。
【0100】
(2)第三工程における本工程
(i)第三工程における本工程での第A工程
・生成した目的とするDNA領域を含む一本鎖DNA(正鎖)を鋳型として、前記フォーワード用プライマーを伸長プライマーとして、該伸長プライマーを一回伸長させることにより、前記の目的とするDNA領域を含む一本鎖DNAを二本鎖DNAとして伸長形成させる第A工程
・後述の説明や前述の本発明の第二前工程における伸長反応での操作方法等に準じて実施すればよいが、具体的には例えば、
(a)生成した目的とするDNA領域を含む一本鎖DNA(正鎖)に、前記のフォーワード用プライマーをアニーリングさせるために、例えば、前記のフォーワード用プライマーのTm値の約0〜20℃低い温度まで速やかに冷却し、その温度で数分間保温する。
(b)その後、室温に戻す。
(c)上記(c)でアニーリングさせた前記の一本鎖状態であるDNAを鋳型として、前記のフォーワード用プライマーを伸長プライマーとして、該プライマーを1回伸長させることにより、前記の目的とするDNA領域に対して相補性である塩基配列を含む一本鎖DNAを二本鎖DNAとして伸長形成させる。
(ii)第三工程における本工程での第B工程
・生成した目的とするDNA領域に対して相補性である塩基配列を含む一本鎖DNA(負鎖)を鋳型として、前記の目的とするDNA領域に対して相補性である塩基配列を含む一本鎖DNA(負鎖)が有する塩基配列の部分塩基配列(負鎖)であって、且つ、前記の目的とするDNA領域の塩基配列(正鎖)に対して相補性である塩基配列(負鎖)の3’ 末端より更に3’ 末端側に位置する部分塩基配列(負鎖)、に対して相補性である塩基配列(正鎖)を有する伸長プライマー(リバース用プライマー)を伸長プライマーとして、該伸長プライマーを1回伸長させることにより、前記の目的とするDNA領域を含む一本鎖DNAを二本鎖DNAとして伸長形成させる第B工程
・後述の説明や前述の本発明の第二前工程における伸長反応での操作方法等に準じて実施すればよいが、具体的には例えば、上記(i)の第三工程における本工程での第A工程と同様な操作方法等に準じて実施すればよい。
【0101】
(3)第三工程における繰り返し工程
(i)第三工程における繰り返し工程での増幅工程
・第三工程の各本工程を、前記各本工程で得られた伸長形成された二本鎖DNAを一本鎖状態に一旦分離した後、繰り返すことにより、前記の目的とするDNA領域におけるメチル化されたDNAを検出可能な量になるまで増幅する工程
・具体的には例えば、上記(2)の第三工程における本工程での第A工程及び第B工程と同様な操作方法等に準じて実施すればよい。
(ii)第三工程における繰り返し工程での定量工程
・第三工程の繰り返し工程における増幅工程により増幅されたDNAの量を定量する工程
【0102】
尚、本発明メチル化DNA含量測定方法の第三工程は、前工程における第一前工程から開始して本工程及び繰り返し工程に至るまでの反応を、一つのPCR反応として実施することもできる。また、前工程における第一前工程から第三前工程まで、各々、独立した反応として実施し、次いで本工程のみをPCR反応として実施することもできる。
【0103】
本発明メチル化DNA含量測定方法において、選択された一本鎖DNAに含まれる目的とするDNA領域(即ち、目的領域)を増幅する方法としては、例えば、PCRを用いることができる。目的領域を増幅する際に、予め蛍光等で標識されたプライマーを使用してその標識を指標とすれば、電気泳動等の煩わしい操作を実施せずに増幅産物の有無を評価できる。PCR反応液としては、例えば、本発明の第二工程で得たDNAに、50μMのプライマーの溶液を0.15μlと、2mM dNTPを2.5μlと、10×緩衝液(100mM Tris-HCl pH 8.3、500mM KCl、20mM MgCl2、0.01% Gelatin)を2.5μlと、AmpliTaq Gold(耐熱性DNAポリメラーゼの一種:5U/μl)を0.2μlとを混合し、これに滅菌超純水を加えて液量を25μlとした反応液を挙げることができる。
目的とするDNA領域(即ち、目的領域)は、GCリッチな塩基配列が多いため、時に、ベタイン、DMSO等を適量加えて反応を実施してもよい。反応条件としては、例えば、前記のような反応液を、95℃にて10分間保温した後、95℃にて30秒間、次いで55〜65℃にて30秒間、更に72℃にて30秒間、を1サイクルとする保温を30〜40サイクル行う条件を挙げることができる。かかるPCRを行った後、得られた増幅産物を検出する。例えば、予め標識されたプライマーを使用した場合には、上述と同様な洗浄・精製操作を実施した後、蛍光標識体の量の測定によりPCR反応での増幅産物の量を測定することができる。また、標識されていない通常のプライマーを用いたPCRを実施した場合には、金コロイド粒子、蛍光等で標識したプローブ等をアニーリングさせた後、目的領域に結合した当該プローブの量を測定すればよい。また、増幅産物の量をより精度よく測定するには、例えば、リアルタイムPCR法を用いればよい。ここで「リアルタイムPCR法」とは、PCRをリアルタイムでモニターし、得られたモニター結果をカイネティックス分析する方法であり、例えば、遺伝子の量に関して2倍程度のほんの僅かな差異をも検出できる高精度の定量PCR法として知られる方法をいう。当該リアルタイムPCR法としては、例えば、鋳型依存性核酸ポリメラーゼプローブ等のプローブを用いる方法、サイバーグリーン等のインターカレーターを用いる方法等を挙げることができる。リアルタイムPCR法のための装置及びキットは市販されるものを利用してもよい。以上の如く、検出については特に限定されることはなく、これまでに周知のあらゆる方法による検出が可能である。これら方法では、反応容器を移し換えることなく検出までの操作が可能となる。
【0104】
更に、本発明評価方法において「メチル化頻度又はそれに相関関係がある指標値を測定する」際の実施態様の一例としては、例えば、以下に示される方法1〜7等も挙げることができる。
【0105】
[方法1]
・第一工程、第二工程、第三工程、第四工程(前工程、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程)、繰り返し工程((i)増幅工程、(ii)定量工程)
・哺乳動物由来検体中に含まれる本発明DNAの塩基配列を目的とするDNA領域として、目的とするDNA領域におけるメチル化されたDNAの含量を測定する方法であって、
(1)哺乳動物由来検体中に含まれるゲノムDNA由来のDNA試料をメチル化感受性制限酵素による消化処理を行う第一工程、
(2)第一工程で得られた消化処理が行われたDNA試料から目的とするDNA領域を含む一本鎖DNA(正鎖)を取得し、該一本鎖DNA(正鎖)と、該一本鎖DNAの3’末端の一部(但し、前記の目的とするDNA領域を含まない。)に対して相補性のある塩基配列を有する一本鎖固定化オリゴヌクレオチドとを結合させることにより、前記一本鎖DNAを選択する第二工程、
(3)第二工程で選択された一本鎖DNAを鋳型として、前記一本鎖固定化オリゴヌクレオチドをプライマーとして、該プライマーを1回伸長させることにより、前記一本鎖DNAを二本鎖DNAとして伸長形成させる第三工程、及び、
(4)下記の各本工程の前工程として、第三工程で得られた伸長形成された二本鎖DNAを一本鎖状態に一旦分離する工程(前工程)を有し、且つ、本工程として
(a)生成した一本鎖状態であるDNA(正鎖)と前記一本鎖固定化オリゴヌクレオチド(負鎖)とを結合させることにより、前記一本鎖状態であるDNAを選択する第A1工程と、
第A1工程で選択された一本鎖状態であるDNAを鋳型として、前記一本鎖固定化オリゴヌクレオチドをプライマーとして、該プライマーを1回伸長させることにより、前記一本鎖状態であるDNAを二本鎖DNAとして伸長形成させる第A2工程と、を有する第A工程(本工程)と、
(b)生成した一本鎖状態であるDNA(負鎖)を鋳型として、前記一本鎖状態であるDNA(負鎖)が有する塩基配列の部分塩基配列(負鎖)であって、且つ、前記目的とするDNA領域の塩基配列(正鎖)に対して相補性のある塩基配列(負鎖)の3’末端より更に3’末端側に位置する部分塩基配列(負鎖)に対して相補性のある塩基配列(正鎖)を有するプライマー(リバース用プライマー)を伸長プライマーとして、該伸長プライマーを1回伸長させることにより、前記一本鎖状態であるDNAを二本鎖DNAとして伸長形成させる第B工程(本工程)とを有し、
更に前記各本工程で得られた伸長形成された二本鎖DNAを一本鎖状態に一旦分離した後、繰り返すことにより、前記目的とするDNA領域におけるメチル化されたDNAを検出可能な量になるまで増幅し、増幅されたDNAの量を定量する第四工程、
を有することを特徴とする方法。
【0106】
[方法2]
・第一工程、第二工程、第三工程、第四工程(前工程、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程)、繰り返し工程((i)増幅工程、(ii)定量工程)
・第二工程において目的とするDNA領域を含む一本鎖DNA(正鎖)と、該一本鎖DNAの3’末端の一部(但し、前記目的とするDNA領域を含まない。)に対して相補性のある塩基配列を有する一本鎖固定化オリゴヌクレオチドとを結合させる際に、二価陽イオンを含有する反応系中で結合させる前記方法1に記載される方法。
【0107】
[方法3]
・第一工程、第二工程、第三工程、第四工程(前工程、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程)、繰り返し工程((i)増幅工程、(ii)定量工程)
・二価陽イオンがマグネシウムイオンである前記方法2に記載される方法。
【0108】
[方法4]
・第一工程、第二工程、第三工程、第四工程(前工程(追加前工程を含む)、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程、(iii)第C工程((iii1)第C1工程、(iii2)第C2工程))、繰り返し工程((i)増幅工程、(ii)定量工程)
・第四工程の前工程の前操作段階において、前記目的とするDNA領域を含む一本鎖DNA(正鎖)の3’末端の一部(但し、前記目的とするDNA領域を含まない。)に対して相補性のある塩基配列を有し且つ遊離状態である一本鎖オリゴヌクレオチド(負鎖)を反応系内に添加する工程(追加前工程)を追加的に有し、且つ、第四工程の各本工程として、下記の1つの工程を更に追加的に有する方法。
(c)(i)生成した一本鎖状態であるDNA(正鎖)と、前記追加前工程で反応系内に添加された一本鎖オリゴヌクレオチド(負鎖)とを結合させることにより、前記一本鎖状態であるDNAを選択する第C1工程と、
(ii)第C1工程で選択された一本鎖状態であるDNAを鋳型として、前記一本鎖オリゴヌクレオチド(負鎖)をプライマーとして、該プライマーを1回伸長させることにより、前記一本鎖状態であるDNAを二本鎖DNAとして伸長形成させる第C2工程とを有する第C工程(本工程)
【0109】
[方法5]
・第一工程、第二工程、第三工程、第四工程(前工程(追加前工程、追加再前工程を含む)、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程、(iii)第C工程)、繰り返し工程((i)増幅工程、(ii)定量工程))
・第四工程の前工程の後操作段階において、前記目的とするDNA領域を含む一本鎖DNA(正鎖)の3’末端の一部(但し、前記目的とするDNA領域を含まない。)に対して相補性のある塩基配列を有し且つ遊離状態である一本鎖オリゴヌクレオチド(負鎖)を反応系内に添加する工程(追加前工程)を追加的に有し、且つ、
第三工程及び前記追加前工程を経て得られた未消化物である伸長形成された二本鎖DNA(前記メチル化感受性制限酵素の認識部位にアンメチル状態のCpG対を含まない伸長形成された二本鎖DNA)を一本鎖状態に一旦分離する工程(追加再前工程)を有し、且つ、
第四工程の各本工程として、下記の1つの工程を更に追加的に有する方法。
(c)(i)生成した一本鎖状態であるDNA(正鎖)と、前記追加前工程で反応系内に添加された一本鎖オリゴヌクレオチド(負鎖)とを結合させることにより、前記一本鎖状態であるDNAを選択する第C1工程と、
(ii)第C1工程で選択された一本鎖状態であるDNAを鋳型として、前記一本鎖オリゴヌクレオチド(負鎖)をプライマーとして、該プライマーを1回伸長させることにより、前記一本鎖状態であるDNAを二本鎖DNAとして伸長形成させる第C2工程とを有する第C工程(本工程)
【0110】
[方法6]
・前記方法1〜5のいずれか一に記載された方法の工程として、下記の2つの工程を更に追加的に有するメチル化割合の測定方法。
(5)前記方法1〜5のいずれか一に記載の方法の第一工程を行うことなく、発明1〜5のいずれか一に記載の方法における第二工程から第四工程を行うことにより、前記目的とするDNA領域のDNA(メチル化されたDNA及びメチルされていないDNAの総量)を検出可能な量になるまで増幅し、増幅されたDNAの量を定量する第五工程、及び、
(6)前記方法1〜5のいずれか一に記載の第四工程により定量されたDNAの量と、第五工程により定量されたDNAの量とを比較することにより得られる差異に基づき前記目的とするDNA領域におけるメチル化されたDNAの割合を算出する第六工程
【0111】
[方法7]
・前記1〜6の方法に記載された第一工程におけるメチル化感受性制限酵素による消化処理を行わずに第二工程を行う方法。
【0112】
・前記方法1〜7に記載された第二工程において、第一工程で得られた消化処理が行われたDNA試料から目的とするDNA領域を含む一本鎖DNA(正鎖)を取得し、該一本鎖DNA(正鎖)と、該一本鎖DNAの3’末端の一部(但し、前記目的とするDNA領域を含まない。)に対して相補性である塩基配列を有する一本鎖固定化オリゴヌクレオチドとを結合させることにより、前記一本鎖DNAを選択する。
【0113】
前記方法1〜7に記載される「一本鎖固定化オリゴヌクレオチド」とは、目的とするDNA領域を含む一本鎖DNA(正鎖)の3’末端の一部(但し、前記目的とするDNA領域を含まない。)に対して相補性である塩基配列を有する一本鎖固定化オリゴヌクレオチド(以下、本固定化オリゴヌクレオチドと記すこともある。)である。
本固定化オリゴヌクレオチドは、哺乳動物由来検体中に含まれるゲノムDNA由来のDNA試料から、目的とするDNA領域を含む一本鎖DNA(正鎖)を選択するために用いられる。本固定化オリゴヌクレオチドは、5〜50塩基長であることが好ましい。
本固定化オリゴヌクレオチドの5’末端側は、担体と固定化され得るものであり、一方その3’末端側は、後述する第三工程及び第A2工程により5’末端から3’末端に向かって進行する一回伸長反応が可能なようにフリーな状態であってもよい。
または、本固定化オリゴヌクレオチドは、5’或いは3’末端が担体と固定化されてもよい。
【0114】
前記方法1〜7に記載される「担体と固定化され得るもの」とは、前記目的とするDNA領域を含む一本鎖DNA(正鎖)を選択する際に本固定化オリゴヌクレオチドが担体に固定化されていればよく、(1)該一本鎖DNA(正鎖)と本固定化オリゴヌクレオチドとの結合前の段階で、本固定化オリゴヌクレオチドと担体との結合により固定化されるものであってもよく、また(2)該一本鎖DNA(正鎖)と本固定化オリゴヌクレオチドとの結合後の段階で、本固定化オリゴヌクレオチドと担体との結合により固定化されるものであってもよい。
このような構造を得るには、目的とするDNA領域を含む一本鎖DNA(正鎖)の3’末端の一部(但し、前記目的とするDNA領域を含まない。)に対して相補性である塩基配列を有するオリゴヌクレオチド(以下、本オリゴヌクレオチドと記すこともある。)の5’末端を通常の遺伝子工学的な操作方法又は市販のキット・装置等に従い、担体に固定すればよい(固相への結合)。具体的には例えば、本オリゴヌクレオチドの5’末端をビオチン化した後、得られたビオチン化オリゴヌクレオチドをストレプトアビジンで被覆した支持体(例えば、ストレプトアビジンで被覆したPCRチューブ、ストレプトアビジンで被覆した磁気ビーズ等)に固定する方法を挙げることができる。
また、本オリゴヌクレオチドの5’末端側に、アミノ基、アルデヒド基、チオール基等の活性官能基を有する分子を共有結合させた後、これを表面がシランカップリング剤等で活性化させたガラス、シリカ若しくは耐熱性プラスチック製の支持体に、例えば、トリグリセリドを5個直列に連結したもの等のスペーサー、クロスリンカー等を介して共有結合させる方法も挙げられる。またさらに、ガラス若しくはシリコン製の支持体の上で直接、本オリゴヌクレオチドの5’末端側から化学合成させる方法も挙げられる。
【0115】
前記方法1〜7に記載される第二工程は、具体的には例えば、本固定化オリゴヌクレオチドがビオチン化オリゴヌクレオチドの場合には、
(a)まず、哺乳動物由来検体中に含まれるゲノムDNA由来のDNA試料に、アニーリングバッファー及びビオチン化オリゴヌクレオチド(該一本鎖DNA(正鎖)と本固定化オリゴヌクレオチドとの結合後の段階で、本固定化オリゴヌクレオチドと担体との結合により固定化されるものであるために、現段階では遊離状態にあるもの)を添加することにより、混合物を得る。次いで、得られた混合物を、哺乳動物由来検体中に含まれるゲノムDNA由来のDNA試料に存在する目的とするDNA領域を含む二本鎖DNAを一本鎖にするために、95℃で数分間加熱する。その後、ビオチン化オリゴヌクレオチドとの二本鎖を形成させるために、ビオチン化オリゴヌクレオチドのTm値の約10〜20℃低い温度まで速やかに冷却し、その温度で数分間保温する。
(b)その後、室温に戻す。
(c)ストレプトアビジンで被覆した支持体に、上記(b)で得られた混合物を添加し、さらに、これを37℃で数分間保温することにより、ビオチン化オリゴヌクレオチドをストレプトアビジンで被覆した支持体に固定する。
因みに、前述の如く、上記(a)〜(c)では、前記目的とするDNA領域を含む一本鎖DNA(正鎖)と、ビオチン化オリゴヌクレオチドとの結合を、ビオチン化オリゴヌクレオチドとストレプトアビジンで被覆した支持体との固定よりも前段階で実施しているが、この順番は、どちらが先でも構わない。即ち、例えば、ストレプトアビジンで被覆した支持体に固定化されたビオチン化オリゴヌクレオチドに、哺乳動物由来検体中に含まれるゲノムDNA由来のDNA試料を添加することにより混合物を得て、得られた混合物を哺乳動物由来検体中に含まれるゲノムDNA由来のDNA試料に存在する目的とするDNA領域を含む二本鎖DNAを一本鎖にするために、95℃で数分間加熱し、その後ビオチン化オリゴヌクレオチドとの二本鎖を形成させるために、ビオチン化オリゴヌクレオチドのTm値の約10〜20℃低い温度まで速やかに冷却し、その温度で数分間保温してもよい。
(d)このようにしてビオチン化オリゴヌクレオチドをストレプトアビジンで被覆した支持体に固定した後、残溶液の除去及び洗浄(DNA精製)を行う。
より具体的には例えば、ストレプトアビジンで被覆したPCRチューブを使用する場合には、まず溶液をピペッティング又はデカンテーションにより取り除いた後、これに哺乳動物由来検体の容量と略等量のTEバッファーを添加し、その後該TEバッファーをピペッティング又はデカンテーションにより取り除けばよい。またストレプトアビジンで被覆した磁気ビーズを使用する場合には、磁石によりビーズを固定した後、まず溶液をピペッティング又はデカンテーションにより取り除いた後、哺乳動物由来検体の容量と略等量のTEバッファーを添加し、その後該TEバッファーをピペッティング又はデカンテーションにより取り除けばよい。
次いで、このような操作を数回実施することにより、残溶液の除去及び洗浄(DNA精製)を行う。
当該操作は、固定化されていないDNA、又は、後述の制限酵素で消化された溶液中に浮遊しているDNA、を反応溶液から取り除くため、重要である。これら操作が不十分であれば、反応溶液中に浮遊しているDNAが鋳型となり、増幅反応で予期せぬ増幅産物が得られることとなる。支持体と哺乳動物由来検体中DNAとの非特異的結合を避けるためには、目的領域とはまったく異なる塩基配列を有するDNA(例えば、ヒトの哺乳動物由来検体の場合は、ラットDNA等)を大量に哺乳動物由来検体に添加し、上記の操作を実施すればよい。
【0116】
前記方法1〜7に記載される第二工程における好ましい態様としては、目的とするDNA領域を含む一本鎖DNA(正鎖)と、該一本鎖DNAの3’末端の一部(但し、前記目的とするDNA領域を含まない。)に対して相補性である塩基配列を有する一本鎖固定化オリゴヌクレオチドとを結合させる際に、二価陽イオンを含有する反応系中で結合させることを挙げることができる。より好ましくは、二価陽イオンがマグネシウムイオンであることが挙げられる。ここで「二価陽イオンを含有する反応系」とは、前記一本鎖DNA(正鎖)と前記一本鎖固定化オリゴヌクレオチドとを結合させるために用いられるアニーリングバッファー中に二価陽イオンを含有するような反応系を意味し、具体的には例えば、マグネシウムイオンを構成要素とする塩(例えば、Mg(OAc)2、MgCl2等)を1mM〜600mMの濃度で含まれることがよい。
【0117】
前記方法1〜7に記載される第三工程において、第二工程で選択された一本鎖DNAを鋳型として、前記一本鎖固定化オリゴヌクレオチドをプライマーとして、該プライマーを1回伸長させることにより、前記一本鎖DNAを二本鎖DNAとして伸長形成させる。この場合、該一本鎖DNAを鋳型として、前記一本鎖固定化オリゴヌクレオチドをプライマーとして、該プライマーを1回伸長させるためには、DNAポリメラーゼを用いて伸長反応を実施すればよい。
【0118】
前記方法1〜7に記載される第三工程は、具体的には例えば、本固定化オリゴヌクレオチドがビオチン化オリゴヌクレオチドの場合には、以下のように実施すればよい。
前記第二工程で選択された前記目的とするDNA領域を含む一本鎖DNAに、滅菌超純水を17.85μL、最適な10×緩衝液(100mM Tris-HCl pH 8.3、500mM KCl、15mM MgCl2)を3μL、2mM dNTPを3μL、5N ベタインを6μL加え、次いで該混合物にAmpliTaq(DNAポリメラーゼの1種:5U/μL)を0.15μL加えて液量を30μLとし、37℃で2時間インキュベーションする。その後、インキュベーションされた溶液をピペッティング又はデカンテーションにより取り除いた後、これに哺乳動物由来検体の容量と略等量のTEバッファーを添加し、該TEバッファーをピペッティング又はデカンテーションにより取り除けばよい。
より具体的には例えば、ストレプトアビジンで被覆したPCRチューブを使用する場合には、まず溶液をピペッティング又はデカンテーションにより取り除いた後、これに哺乳動物由来検体の容量と略等量のTEバッファーを添加し、その後該TEバッファーをピペッティング又はデカンテーションにより取り除けばよい。またストレプトアビジンで被覆した磁気ビーズを使用する場合には、磁石によりビーズを固定した後、まず溶液をピペッティング又はデカンテーションにより取り除いた後、哺乳動物由来検体の容量と略等量のTEバッファーを添加し、その後該TEバッファーをピペッティング又はデカンテーションにより取り除けばよい。次いで、このような操作を数回実施することにより、残溶液の除去及び洗浄(DNA精製)を行う。
【0119】
また、前記方法1〜7に記載される第三工程は、前記第二工程で選択された一本鎖DNAを固定化オリゴヌクレオチドから分離して一本鎖状態に一旦分離する工程を有し、生成した一本鎖状態であるDNA(正鎖)を鋳型として、前記目的とするDNA領域の塩基配列(正鎖)の3’末端より更に3’末端側に位置する部分塩基配列(正鎖)に対して相補性のある塩基配列(負鎖)を有するフォーワード用プライマーを伸長プライマーとして、該プライマーを1回伸長させることにより、前記の一本鎖DNAを二本鎖DNAとして伸長形成させる工程であってもよい。
この場合の方法としては、具体的に例えば、二本鎖DNAを一本鎖にするために、95℃で数分間加熱すればよい。さらに、フォーワード用プライマーを添加した後、フォーワード用プライマーのTm値の約10〜20℃低い温度まで速やかに冷却し、その温度で数分間保温し、前記の生成した一本鎖状態であるDNA(正鎖)とフォーワード用プライマーとの二本鎖を形成させる。生成した二本鎖DNAの溶液に、最適な10×緩衝液(100mM Tris-HCl pH 8.3、500mM KCl、15mM MgCl2)を3μL、2mM dNTPを3μL、5N ベタインを6μL加え、次いで当該混合物にAmpliTaq(DNAポリメラーゼの1種:5U/μL)を0.15μL加え、滅菌超純水を加えて液量を30μLとし、37℃で2時間インキュベーションする。
尚、第三工程は、第四工程と独立に実施しても良いし、第四工程で実施されるPCR反応と連続して実施しても構わない。
【0120】
前記方法1〜7に記載される第四工程において、下記の各本工程の前工程として、第三工程で得られた伸長形成された二本鎖DNA(前記メチル化感受性制限酵素の認識部位にアンメチル状態のCpG対を含まない伸長形成された二本鎖DNA)を一本鎖状態に一旦分離する工程(前工程)を有し、且つ、本工程として
(a)生成した一本鎖状態であるDNA(正鎖)と前記一本鎖固定化オリゴヌクレオチド(負鎖)とを結合させることにより、前記一本鎖状態であるDNAを選択する第A1工程と、第A1工程で選択された一本鎖状態であるDNAを鋳型として、前記一本鎖固定化オリゴヌクレオチドをプライマーとして、該プライマーを1回伸長させることにより、前記一本鎖状態であるDNAを二本鎖DNAとして伸長形成させる第A2工程とを有する第A工程(本工程)と、
(b)生成した一本鎖状態であるDNA(負鎖)を鋳型として、前記一本鎖状態であるDNA(負鎖)が有する塩基配列の部分塩基配列(負鎖)であって、且つ、前記目的とするDNA領域の塩基配列(正鎖)に対して相補性である塩基配列(負鎖)の3’末端よりさらに3’末端側に位置する部分塩基配列(負鎖)、に対して相補性である塩基配列(正鎖)を有する伸長プライマー(リバース用プライマー)を伸長プライマーとして、該伸長プライマーを1回伸長させることにより、前記一本鎖状態であるDNAを二本鎖DNAとして伸長形成させる第B工程(本工程)とを有し、
さらに第四工程の各本工程を、前記各本工程で得られた伸長形成された二本鎖DNAを一本鎖状態に一旦分離した後、繰り返すことにより、前記目的とするDNA領域におけるメチル化されたDNAを検出可能な量になるまで増幅し、増幅されたDNAの量を定量する。
【0121】
前記方法1〜7に記載される第四工程では、まず、下記の各本工程の前工程として、第三工程で得られた未消化物である伸長形成された二本鎖DNA(前記メチル化感受性制限酵素の認識部位にアンメチル状態のCpG対を含まない伸長形成された二本鎖DNA)を一本鎖状態に一旦分離する。具体的には例えば、第三工程で得られた未消化物である伸長形成された二本鎖DNA(前記メチル化感受性制限酵素の認識部位にアンメチル状態のCpG対を含まない伸長形成された二本鎖DNA)に、アニーリングバッファーを添加することにより、混合物を得る。次いで、得られた混合物を95℃で数分間加熱する。
その後、本工程として、
(i)生成した一本鎖状態であるDNA(正鎖)を、前記一本鎖固定化オリゴヌクレオチド(負鎖)にアニーリングさせるために、前記一本鎖固定化オリゴヌクレオチド(負鎖)のTm値の約10〜20℃低い温度まで速やかに冷却し、その温度で数分間保温する。
(ii)その後、室温に戻す。(第A工程における第A1工程)
(iii)上記(i)で選択された一本鎖状態であるDNAを鋳型として、前記一本鎖固定化オリゴヌクレオチドをプライマーとして、該プライマーを1回伸長させることにより、前記一本鎖状態であるDNAを二本鎖DNAとして伸長形成させる(即ち、第A工程における第A2工程)。具体的には例えば、後述の説明や前述の方法1〜7に記載の第二工程における伸長反応での操作方法等に準じて実施すればよい。
(iv)生成した一本鎖状態であるDNA(負鎖)を鋳型として、前記一本鎖状態であるDNA(負鎖)が有する塩基配列の部分塩基配列(負鎖)であって、且つ、前記目的とするDNA領域の塩基配列(正鎖)に対して相補性である塩基配列(負鎖)の3’末端よりさらに3’末端側に位置する部分塩基配列(負鎖)、に対して相補性である塩基配列(正鎖)を有する伸長プライマー(リバース用プライマー))を伸長プライマー(リバース用プライマー)として、該伸長プライマーを1回伸長させることにより、前記一本鎖状態であるDNAを二本鎖DNAとして伸長形成させる(即ち、第B工程)。具体的には例えば、上記(iii)と同様に、後述の説明や前述の方法1〜7に記載の第二工程における伸長反応での操作方法等に準じて実施すればよい。
(v)さらに第四工程の各本工程を、前記各本工程で得られた伸長形成された二本鎖DNAを一本鎖状態に一旦分離した後、繰り返すこと(例えば、第A工程及び第B工程)により、前記目的とするDNA領域におけるメチル化されたDNAを検出可能な量になるまで増幅し、増幅されたDNAの量を定量する。具体的には例えば、上記と同様に、後述の説明や前述の方法1〜7に記載される第四工程における前工程、第A工程及び第B工程での操作方法等に準じて実施すればよい。
【0122】
前記方法1〜7に記載されるメチル化感受性制限酵素による消化処理の後に目的とするDNA領域(即ち、目的領域)を増幅する方法としては、例えば、PCRを用いることができる。目的領域を増幅する際に、片側のプライマーとして固定化オリゴヌクレオチドを用いることができるので、もう一方のプライマーのみ添加してPCRを行うことにより、増幅産物が得られ、その増幅産物も固定化されることとなる。この際、予め蛍光等で標識されたプライマーを使用してその標識を指標とすれば、電気泳動等の煩わしい操作を実施せずに増幅産物の有無を評価できる。PCR反応液としては、例えば、前記方法1〜7に記載の第三工程で得たDNAに、50μMのプライマーの溶液を0.15μlと、2mM dNTPを2.5μlと、10×緩衝液(100mM Tris-HCl pH 8.3、500mM KCl、20mM MgCl2、0.01% Gelatin)を2.5μlと、AmpliTaq Gold (耐熱性DNAポリメラーゼの一種: 5U/μl)を0.2μlとを混合し、これに滅菌超純水を加えて液量を25μlとした反応液を挙げることができる。
目的とするDNA領域(即ち、目的領域)は、GCリッチな塩基配列が多いため、時に、ベタイン、DMSO等を適量加えて反応を実施してもよい。反応条件としては、例えば、前記ように反応液を、95℃にて10分間保温した後、95℃にて30秒間次いで55〜65℃にて30秒間さらに72℃にて30秒間を1サイクルとする保温を30〜40サイクル行う条件があげられる。かかるPCRを行った後、得られた増幅産物を検出する。例えば、予め標識されたプライマーを使用した場合には、先と同様の洗浄・精製操作を実施後、固定化された蛍光標識体の量を測定することができる。また、標識されていない通常のプライマーを用いたPCRを実施した場合は、金コロイド粒子、蛍光等で標識したプローブ等をアニーリングさせ、目的領域に結合した該プローブの量を測定することにより検出することができる。また、増幅産物の量をより精度よく求めるには、例えば、リアルタイムPCR法を用いればよい。リアルタイムPCR法とは、PCRをリアルタイムでモニターし、得られたモニター結果をカイネティックス分析する方法であり、例えば、遺伝子量に関して2倍程度のほんのわずかな差異をも検出できる高精度の定量PCR法として知られる方法である。該リアルタイムPCR法には、例えば、鋳型依存性核酸ポリメラーゼプローブ等のプローブを用いる方法、サイバーグリーン等のインターカレーターを用いる方法等を挙げることができる。リアルタイムPCR法のための装置及びキットは市販されるものを利用してもよい。以上の如く、検出については特に限定されることはなく、これまでに周知のあらゆる方法による検出が可能である。これら方法では、反応容器を移し換えることなく検出までの操作が可能となる。
【0123】
更に、前記方法1〜7に記載される固定化オリゴヌクレオチドと同じ塩基配列のビオチン化オリゴヌクレオチドを片側のプライマー、又は、固定化オリゴヌクレオチドより、3’端側に新しいビオチン化オリゴヌクレオチドを設計しそれを片側のプライマーとし、その相補側プライマーを用いて、目的領域を増幅することもできる。この場合、得られた増幅産物は、ストレプトアビジンで被覆した支持体があれば固定化されるので、例えば、ストレプトアビジンコートPCRチューブでPCRを実施した場合には、チューブ内に固定されるため、上記の通り、標識されたプライマーを用いれば、増幅産物の検出が容易である。また、先の固定化オリゴヌクレオチドが共有結合等による固定化の場合であれば、PCRで得られた増幅産物を含む溶液をストレプトアビジン被覆支持体が存在する容器に移し、増幅産物を固定化することが可能である。検出については、上述の通り実施すればよい。目的領域を増幅する相補側のプライマーは、メチル化感受性制限酵素の認識部位を1つ以上有する目的領域を増幅でき、且つ、その認識部位を含まないプライマーでなければいけない。この理由は、以下の通りである。選択及び1回伸長反応で得られた二本鎖DNAの固定化オリゴヌクレオチド側のDNA鎖(新生鎖)の一番3’端側のメチル化感受性制限酵素の認識部位のみがメチル化されていない場合には、その部分だけがメチル化感受性制限酵素で消化されることになる。消化後、前述のように洗浄操作を行っても、新生鎖で言う3’端の一部だけを失った二本鎖DNAが固定化されたままの状態で存在する。相補側のプライマーが、この一番3’端側のメチル化感受性制限酵素の認識部位を含んでいた場合には、該プライマーの3’端側の数塩基が、新生鎖の3’端の数塩基とアニーリングし、その結果、目的領域がPCRにより増幅する可能性があるからである。
【0124】
前記方法1〜7に記載される方法は、第四工程の前工程の前操作段階又は後操作段階において、前記目的とするDNA領域を含む一本鎖DNA(正鎖)の3’末端の一部(但し、前記目的とするDNA領域を含まない。)に対して相補性である塩基配列を有し且つ遊離状態である一本鎖オリゴヌクレオチド(負鎖)を反応系内に添加する工程(追加前工程)を追加的に有するような変法を含む。
即ち、
【0125】
(変法1)
前記方法1〜7に記載される方法の第四工程の前工程の前操作段階において、
前記目的とするDNA領域を含む一本鎖DNA(正鎖)の3’末端の一部(但し、前記目的とするDNA領域を含まない。)に対して相補性である塩基配列を有し且つ遊離状態である一本鎖オリゴヌクレオチド(負鎖)を反応系内に添加する工程(追加前工程)を追加的に有し、且つ、
前記方法1〜7に記載の方法の第四工程の各本工程として、下記の1つの工程をさらに追加的に有することを特徴とする方法。
(c)(i)生成した一本鎖状態であるDNA(正鎖)と、上記の追加前工程で反応系内に添加された一本鎖オリゴヌクレオチド(負鎖)とを結合させることにより、前記一本鎖状態であるDNAを選択する第C1工程と、
(ii)第C1工程で選択された一本鎖状態であるDNAを鋳型として、前記一本鎖オリゴヌクレオチド(負鎖)をプライマーとして、該プライマーを1回伸長させることにより、前記一本鎖状態であるDNAを二本鎖DNAとして伸長形成させる第C2工程とを有する第C工程(本工程)
【0126】
(変法2)
前記方法1〜7に記載される方法の第四工程の前工程の後操作段階において、
前記目的とするDNA領域を含む一本鎖DNA(正鎖)の3’末端の一部(但し、前記目的とするDNA領域を含まない。)に対して相補性である塩基配列を有し且つ遊離状態である一本鎖オリゴヌクレオチド(負鎖)を反応系内に添加する工程(追加前工程)を追加的に有し、且つ、第三工程及び上記の追加前工程を経て得られた未消化物である伸長形成された二本鎖DNA(前記メチル化感受性制限酵素の認識部位にアンメチル状態のCpG対を含まない伸長形成された二本鎖DNA)を一本鎖状態に一旦分離する工程(追加再前工程)を有し、且つ、
前記方法1〜7に記載の方法の第四工程の各本工程として、下記の1つの工程をさらに追加的に有することを特徴とする方法(以下、方法1〜7に記載のメチル化割合測定方法と記すこともある。)
(c)(i)生成した一本鎖状態であるDNA(正鎖)と、上記の追加前工程で反応系内に添加された一本鎖オリゴヌクレオチド(負鎖)とを結合させることにより、前記一本鎖状態であるDNAを選択する第C1工程と、
(ii)第C1工程で選択された一本鎖状態であるDNAを鋳型として、前記一本鎖オリゴヌクレオチド(負鎖)をプライマーとして、該プライマーを1回伸長させることにより、前記一本鎖状態であるDNAを二本鎖DNAとして伸長形成させる第C2工程とを有する第C工程(本工程)
【0127】
前記方法1〜7に記載される方法において、当該変法では、外部から「前記目的とするDNA領域を含む一本鎖DNA(正鎖)の3’末端の一部(但し、前記目的とするDNA領域を含まない。)に対して相補性である塩基配列を有し且つ遊離状態である一本鎖オリゴヌクレオチド(負鎖)」を反応系内に添加すること等により、第四工程における前述の目的とするDNA領域の増幅効率を容易に向上させることが可能となる。なお、追加前工程で反応系内に添加される一本鎖オリゴヌクレオチド(負鎖)は、一本鎖DNAの3’末端の一部(但し、前記目的とするDNA領域を含まない。)に対して相補性である塩基配列であって、5’末端が、前記一本鎖固定化オリゴヌクレオチドと同じである塩基配列を有する遊離状態である一本鎖オリゴヌクレオチドであれば、前記一本鎖固定化オリゴヌクレオチドと同じ塩基配列であっても、又は、短い塩基配列であっても、或いは、長い配列であっても良い。ただし、前記一本鎖固定化オリゴヌクレオチドよりも長い配列の場合には、前記リバース用プライマー(正鎖)を伸長プライマーとし、該一本鎖オリゴヌクレオチド(負鎖)を鋳型として、伸長プライマーを伸長させる反応に利用できない遊離状態である一本鎖オリゴヌクレオチドでなければならない。
【0128】
前記方法1〜7に記載される方法において、目的領域を増幅する際に、片側のプライマーとして固定化オリゴヌクレオチドを用いて、もう一方のプライマーのみ添加してPCRを行う例を前記したが、目的産物の検出のために他の方法(例えば、PCRで得られた各々の増幅産物の量を比較することができる分析方法)を実施するのであれば、上記の如く、目的領域を増幅する際に、固定化オリゴヌクレオチドを一方(片側)のプライマーとして使用せず、一対のプライマーを添加してPCRを実施してもよい。かかるPCRを行った後、得られた増幅産物の量を求める。
【0129】
前記方法1〜7に記載される方法において、第四工程は繰り返し工程を有するが、例えば、第A1工程における「生成した一本鎖状態であるDNA(正鎖)」とは、第1回目の第四工程の操作及び第2回目以降の第四工程の繰り返し操作の両操作において「生成した『遊離の』一本鎖状態であるDNA(正鎖)」を意味することになる。
また、第B工程における「生成した一本鎖状態であるDNA(負鎖)」とは、第1回目の第四工程の操作及び第2回目以降の第四工程の繰り返し操作の両操作において「生成した『固定の』一本鎖状態であるDNA(正鎖)」を意味する。但し、第四工程がさらに追加的にC工程を有する場合には、第1回目の第四工程の操作において「生成した『固定の』一本鎖状態であるDNA(正鎖)」を意味し、一方、第2回目以降の第四工程の繰り返し操作において「生成した『固定の』一本鎖状態であるDNA(正鎖)」と「生成した『遊離の』一本鎖状態であるDNA(正鎖)」との両者を意味することになる。
【0130】
また、前記方法1〜7に記載される方法において、第四工程の各本工程で得られた「伸長形成された二本鎖DNA」とは、第A工程の場合には、第1回目の第四工程の操作において「前記メチル化感受性制限酵素の認識部位に、アンメチル状態のCpG対を含まない伸長形成された二本鎖DNA」を意味し、一方、第2回目以降の第四工程の繰り返し操作において「前記メチル化感受性制限酵素の認識部位に、アンメチル状態のCpG対を含まない伸長形成された二本鎖DNA」と「前記メチル化感受性制限酵素の認識部位に、アンメチル状態のCpG対を含む伸長形成された二本鎖DNA」との両者を意味することになる。第B工程の場合には、第1回目の第四工程の操作及び第2回目以降の第四工程の繰り返し操作の両操作において「前記メチル化感受性制限酵素の認識部位では全てがアンメチル状態のCpG対である伸長形成された二本鎖DNA」を意味することになる。
尚、第四工程がさらに追加的にC工程を有する場合にも同様である。
【0131】
また、前記方法1〜7に記載される方法において、第四工程がさらに追加的にC工程を有する場合において、第C1工程における「生成した一本鎖状態であるDNA(正鎖)」とは、第1回目の第四工程の操作及び第2回目以降の第四工程の繰り返し操作の両操作において「生成した『遊離の』一本鎖状態であるDNA(正鎖)」を意味することになる。
【0132】
また前記方法1〜7に記載される方法における工程として、下記の2つの工程をさらに追加的に有することを特徴とするメチル化割合の測定方法(即ち、前記方法1〜7に記載のメチル化割合測定方法)を含んでもよい。
(5)前記方法1〜7に記載される方法の(前記変法を含む)、第一工程及び第二工程を行った後、前記方法1〜7に記載される方法(前記変法を含む)の第三工程を行うことなく、前記方法1〜7に記載(前記変法を含む)される第四工程を行うことにより、前記目的とするDNA領域のDNA(メチル化されたDNA及びメチルされていないDNAの総量)を検出可能な量になるまで増幅し、増幅されたDNAの量を定量する第五工程、及び、
(6)前記方法1〜7に記載される方法(前記変法を含む)の第四工程により定量されたDNAの量と、第五工程により定量されたDNAの量とを比較することにより得られる差異に基づき前記目的とするDNA領域におけるメチル化されたDNAの割合を算出する第六工程。
【0133】
このような本発明又は本発明メチル化割合測定方法において、本発明DNAの塩基配列を目的とするDNA領域として、目的とするDNA領域のメチル化されたDNA量の測定、メチル化割合の測定を行うための各種方法で使用し得る制限酵素、プライマー又はプローブは、検出用キットの試薬として有用である。本発明は、これら制限酵素、プライマー又はプローブ等を試薬として含有する検出用キットや、これらプライマー又はプローブ等が担体上に固定化されてなる検出用チップも提供しており、本発明又は本発明メチル化割合測定方法の権利範囲は、当該方法の実質的な原理を利用してなる検出用キットや検出用チップのような形態での使用ももちろん含むものである。
【0134】
また更に、本発明評価方法において「メチル化頻度又はそれに相関関係がある指標値を測定する」際の他実施態様の一例としては、例えば、以下に示される方法1〜8等を挙げることができる。
【0135】
[方法1]
・第一工程、第二工程、第三工程(第一前工程、第二前工程((i)第二(A)前工程、(ii)第二(B)前工程))、第三前工程、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程)、繰り返し工程((i)増幅工程、(ii)定量工程))
・生物由来検体中に含まれるゲノムDNAが有する目的とするDNA領域におけるメチル化されたDNAの含量を測定する方法であって、
(1)生物由来検体中に含まれるゲノムDNA由来のDNA試料から、目的とするDNA領域を含む一本鎖DNA(正鎖)と、当該一本鎖DNAの目的とするDNA領域に対して相補性である塩基配列を有する一本鎖固定化オリゴヌクレオチドとを結合させることにより、前記の一本鎖DNAを選択し、選択された一本鎖DNAと前記の一本鎖固定化オリゴヌクレオチドとが結合してなる二本鎖DNAを結合形成させる第一工程、
(2)第一工程で結合形成させた二本鎖DNAを少なくとも1種類以上のメチル化感受性制限酵素で消化処理した後、生成した遊離の消化物(前記のメチル化感受性制限酵素の認識部位に少なくとも1つ以上のアンメチル状態のCpG対を含む二本鎖DNA)を除去する第二工程、及び、
(3)下記の各本工程の前工程として、第二工程で得られた未消化物である結合形成された二本鎖DNA(前記のメチル化感受性制限酵素の認識部位にアンメチル状態のCpG対を含まない結合形成された二本鎖DNA)を一本鎖状態に一旦分離する工程(第一前工程)と、
生成した遊離の一本鎖状態であるDNA(正鎖)と、前記の一本鎖固定化オリゴヌクレオチドとを結合させることにより、前記の生成した遊離の一本鎖状態であるDNAを選択し、選択された一本鎖DNAと前記の一本鎖固定化オリゴヌクレオチドとが結合してなる二本鎖DNAを結合形成させる工程(第二(A)前工程)と、
当該工程(第二(A)前工程)で結合形成された二本鎖DNAを、前記の選択された一本鎖DNAを鋳型として、前記の一本鎖固定化オリゴヌクレオチドをプライマーとして、当該プライマーを1回伸長させることにより、前記の選択された一本鎖DNAを伸長形成された二本鎖DNAとする工程(第二(B)前工程)と
を有する工程(第二前工程)と、
第二前工程で伸長形成された二本鎖DNA(前記のメチル化感受性制限酵素の認識部位にアンメチル状態のCpG対を含まない伸長形成された二本鎖DNA)を、一本鎖状態であるDNA(正鎖)と一本鎖状態であるDNA(負鎖)に一旦分離する工程(第三前工程)とを有し、且つ、本工程として
(a)生成した一本鎖状態であるDNA(正鎖)と、前記の一本鎖固定化オリゴヌクレオチド(負鎖)とを結合させることにより、前記の一本鎖状態であるDNAを選択する第A1工程と、第A1工程で選択された一本鎖状態であるDNAを鋳型として、前記の一本鎖固定化オリゴヌクレオチドをプライマーとして、当該プライマーを1回伸長させることにより、前記の一本鎖状態であるDNAを二本鎖DNAとして伸長形成させる第A2工程とを有する第A工程(本工程)と、
(b)生成した一本鎖状態であるDNA(負鎖)を鋳型として、前記の一本鎖状態であるDNA(負鎖)が有する塩基配列の部分塩基配列(負鎖)であって、且つ、前記の目的とするDNA領域の塩基配列(正鎖)に対して相補性である塩基配列(負鎖)の3’末端よりさらに3’末端側に位置する部分塩基配列(負鎖)、に対して相補性である塩基配列(正鎖)を有し、且つ、前記の一本鎖固定化オリゴヌクレオチドを鋳型とする伸長反応に利用できない伸長プライマー(リバース用プライマー)を伸長プライマーとして、当該伸長プライマーを1回伸長させることにより、前記の一本鎖状態であるDNAを伸長形成された二本鎖DNAとする第B工程(本工程)とを有し、
さらに第三工程の各本工程を、前記各本工程で得られた伸長形成された二本鎖DNAを一本鎖状態に一旦分離した後、繰り返すことにより、前記の目的とするDNA領域におけるメチル化されたDNAを検出可能な量になるまで増幅し、増幅されたDNAの量を定量する第三工程、
を有することを特徴とする方法。
【0136】
[方法2]
・第一工程、第二工程、第三工程(第一前工程、第二前工程((i)第二(A)前工程、(ii)第二(B)前工程))、第三前工程、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程)、繰り返し工程((i)増幅工程、(ii)定量工程))
・第一工程において、目的とするDNA領域を含む一本鎖DNA(正鎖)と、当該一本鎖DNAの目的とするDNA領域に対して相補性である塩基配列を有する一本鎖固定化オリゴヌクレオチドとを結合させる際に、二価陽イオンを含有する反応系中で結合させることを特徴とする前記方法1に記載される方法。
【0137】
[方法3]
・第一工程、第二工程、第三工程(第一前工程、第二前工程((i)第二(A)前工程、(ii)第二(B)前工程))、第三前工程、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程)、繰り返し工程((i)増幅工程、(ii)定量工程))
・二価陽イオンがマグネシウムイオンであることを特徴とする前記方法2に記載される方法。
【0138】
[方法4]
・第一工程、第二工程、第三工程(第一前工程(追加前工程を含む)、第二前工程((i)第二(A)前工程、(ii)第二(B)前工程))、第三前工程、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程、(iii)第C工程((iii1)第C1工程、(iii2)第C2工程))、繰り返し工程((i)増幅工程、(ii)定量工程))
・前記方法1〜3のいずれかの前記方法に記載される第三工程の第一前工程の前操作段階において、
前記の目的とするDNA領域を含む一本鎖DNA(正鎖)の3’末端の一部に対して相補性である塩基配列を有し且つ遊離状態である一本鎖オリゴヌクレオチド(負鎖)を反応系内に添加する工程(追加前工程)を追加的に有し、且つ、
前記方法1〜3のいずれかの前記方法に記載の第三工程の各本工程として、下記の1つの工程をさらに追加的に有することを特徴とする方法。
(c)(i)生成した一本鎖状態であるDNA(正鎖)と、上記の追加前工程で反応系内に添加された一本鎖オリゴヌクレオチド(負鎖)とを結合させることにより、前記の一本鎖状態であるDNAを選択する第C1工程と、
(ii)第C1工程で選択された一本鎖状態であるDNAを鋳型として、前記の一本鎖オリゴヌクレオチド(負鎖)をプライマーとして、当該プライマーを1回伸長させることにより、前記の一本鎖状態であるDNAを伸長形成された二本鎖DNAとする第C2工程と
を有する第C工程(本工程);
【0139】
[方法5]
・第一工程、第二工程、第三工程(第一前工程(追加前工程及び追加再前工程を含む)、第二前工程((i)第二(A)前工程、(ii)第二(B)前工程))、第三前工程、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程、(iii)第C工程((iii1)第C1工程、(iii2)第C2工程))、繰り返し工程((i)増幅工程、(ii)定量工程))
・前記方法1〜3のいずれかの前記方法に記載される第三工程の第一前工程の後操作段階において、
前記の目的とするDNA領域を含む一本鎖DNA(正鎖)の3’末端の一部に対して相補性である塩基配列を有し且つ遊離状態である一本鎖オリゴヌクレオチド(負鎖)を反応系内に添加する工程(追加前工程)を追加的に有し、且つ、第二工程及び上記の追加前工程を経て得られた未消化物である二本鎖DNA(前記のメチル化感受性制限酵素の認識部位にアンメチル状態のCpG対を含まない伸長形成された二本鎖DNA)を一本鎖状態に一旦分離する工程(追加再前工程)を有し、且つ、
前記方法1〜3のいずれかの前記方法に記載の第三工程の各本工程として、下記の1つの工程をさらに追加的に有することを特徴とする方法(以下、本発明メチル化割合測定方法と記すこともある。)
(c)(i)生成した一本鎖状態であるDNA(正鎖)と、上記の追加前工程で反応系内に添加された一本鎖オリゴヌクレオチド(負鎖)とを結合させることにより、前記の一本鎖状態であるDNAを選択する第C1工程と、
(ii)第C1工程で選択された一本鎖状態であるDNAを鋳型として、前記の一本鎖オリゴヌクレオチド(負鎖)をプライマーとして、当該プライマーを1回伸長させることにより、前記の一本鎖状態であるDNAを伸長形成された二本鎖DNAとする第C2工程と
を有する第C工程(本工程)
【0140】
[方法6]
・第一工程、第二工程、第三工程(第一前工程(追加前工程を含む)、第二前工程((i)第二(A)前工程、(ii)第二(B)前工程))、第三前工程、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程、(iii)第C工程((iii1)第C1工程、(iii2)第C2工程))、繰り返し工程((i)増幅工程、(ii)定量工程))
・前記方法1〜3のいずれかの前記方法に記載される第三工程の第三前工程の前操作段階において、
前記の目的とするDNA領域を含む一本鎖DNA(正鎖)の3’末端の一部に対して相補性である塩基配列を有し且つ遊離状態である一本鎖オリゴヌクレオチド(負鎖)を反応系内に添加する工程(追加前工程)を追加的に有し、且つ、
前記方法1〜3のいずれかの前記方法記載の第三工程の各本工程として、下記の1つの工程をさらに追加的に有することを特徴とする方法。
(c)(i)生成した一本鎖状態であるDNA(正鎖)と、上記の追加前工程で反応系内に添加された一本鎖オリゴヌクレオチド(負鎖)とを結合させることにより、前記の一本鎖状態であるDNAを選択する第C1工程と、
(ii)第C1工程で選択された一本鎖状態であるDNAを鋳型として、前記の一本鎖オリゴヌクレオチド(負鎖)をプライマーとして、当該プライマーを1回伸長させることにより、前記の一本鎖状態であるDNAを伸長形成された二本鎖DNAとする第C2工程と
を有する第C工程(本工程);
【0141】
[方法7]
・第一工程、第二工程、第三工程(第一前工程(追加前工程及び追加再前工程を含む)、第二前工程((i)第二(A)前工程、(ii)第二(B)前工程))、第三前工程、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程、(iii)第C工程((iii1)第C1工程、(iii2)第C2工程))、繰り返し工程((i)増幅工程、(ii)定量工程))
・前記方法1〜3のいずれかの前記方法に記載される第三工程の第三前工程の後操作段階において、
前記の目的とするDNA領域を含む一本鎖DNA(正鎖)の3’末端の一部に対して相補性である塩基配列を有し且つ遊離状態である一本鎖オリゴヌクレオチド(負鎖)を反応系内に添加する工程(追加前工程)を追加的に有し、且つ、第二工程及び上記の追加前工程を経て得られた未消化物である二本鎖DNA(前記のメチル化感受性制限酵素の認識部位にアンメチル状態のCpG対を含まない伸長形成された二本鎖DNA)を一本鎖状態に一旦分離する工程(追加再前工程)を有し、且つ、
前記方法1〜3のいずれかの前記方法に記載の第三工程の各本工程として、下記の1つの工程をさらに追加的に有することを特徴とする方法。
(c)(i)生成した一本鎖状態であるDNA(正鎖)と、上記の追加前工程で反応系内に添加された一本鎖オリゴヌクレオチド(負鎖)とを結合させることにより、前記の一本鎖状態であるDNAを選択する第C1工程と、
(ii)第C1工程で選択された一本鎖状態であるDNAを鋳型として、前記の一本鎖オリゴヌクレオチド(負鎖)をプライマーとして、当該プライマーを1回伸長させることにより、前記の一本鎖状態であるDNAを伸長形成された二本鎖DNAとする第C2工程と
を有する第C工程(本工程)
【0142】
[方法8]
・第一工程、第三工程(第一前工程、第二前工程((i)第二(A)前工程、(ii)第二(B)前工程))、第三前工程、本工程((i)第A工程((i1)第A1工程、(i2)第A2工程))、(ii)第B工程)、第四工程((i)増幅工程、(ii)定量工程)、第五工程)
・前記方法1〜7のいずれかの前記方法に記載される方法の工程として、下記の2つの工程をさらに追加的に有することを特徴とするメチル化割合の測定方法。
(4)前記方法1〜7のいずれかの前記方法に記載される方法の第一工程を行った後、前記方法1〜7のいずれかの前記方法に記載される方法の第二工程を行うことなく、前記方法1〜7のいずれかの方法記載の方法における第三工程を行うことにより、前記の目的とするDNA領域のDNA(メチル化されたDNA及びメチルされていないDNAの総量)を検出可能な量になるまで増幅し、増幅されたDNAの量を定量する第四工程、及び、
(5)前記方法1〜7のいずれかの前記方法に記載の第三工程により定量されたDNAの量と、第四工程により定量されたDNAの量とを比較することにより得られる差異に基づき前記の目的とするDNA領域におけるメチル化されたDNAの割合を算出する第五工程、を有することを特徴とする方法。
【0143】
本発明評価方法の第一工程において、哺乳動物由来の検体に含まれる本発明DNAのメチル化頻度に相関関係がある指標値を測定する方法としては、例えば、本発明DNAの下流に存在する遺伝子の転写産物であるmRNAの量を測定する方法をあげることができる。当該測定には、例えば、リアルタイムPCR法、ノザンブロット法〔Molecular Cloning,Cold Spring Harbor Laboratory(1989)〕、in situ RT−PCR法〔Nucleic Acids Res.,21,3159−3166(1993)〕、in situハイブリダイゼーション法、NASBA法〔Nucleic acid sequence−based amplification,nature,350,91−92(1991)〕等の公知な方法を用いればよい。
哺乳動物由来の検体に含まれる本発明DNAの下流に存在する遺伝子の転写産物であるmRNAを含む試料は、通常の方法に準じて当該検体から抽出、精製等により調製すればよい。
調製された試料中に含まれるmRNAの量を測定するためにノザンブロット法が用いられる場合には、検出用プローブは本発明DNAの下流に存在する遺伝子又はその一部(本発明DNAの下流に存在する遺伝子の制限酵素切断、本発明DNAの下流に存在する遺伝子の塩基配列に従い化学合成した約100bp〜約1000bp程度のオリゴヌクレオチド等)を含むものであればよく、前記試料中に含まれるmRNAとのハイブリダイゼーションにおいて用いられる検出条件下に検出可能な特異性を与えるものであれば特に制限はない。
また調製された試料中に含まれるmRNAの量を測定するためにリアルタイムPCR法が用いられる場合には、使用されるプライマーは、本発明DNAの下流に存在する遺伝子のみを特異的に増幅できるものであればよく、その増幅する領域や塩基長等には特に制限はない。リアルタイム-PCR法による転写産物の量を測定することもできる。定量を必要とする場合には、PCR反応産物をリアルタイムでモニタリングしカイネティックス分析を行うことにより、例えば、遺伝子量に関して2倍程度のほんのわずかな差異をも検出できる高精度の定量が可能なPCR法であるリアルタイムPCRを用いて、それぞれの産物の量を比較することもできる。リアルタイムPCRを行う方法としては、例えば、鋳型依存性核酸ポリメラーゼプローブ等のプローブを用いる方法又はサイバーグリーン等のインターカレーターを用いる方法等が挙げられる。リアルタイムPCR法のための装置及びキットは既に市販されている。
【0144】
また本発明評価方法の第一工程において、哺乳動物由来の検体に含まれる本発明DNAのメチル化頻度に相関関係がある指標値を測定する他の方法としては、例えば、本発明DNAの下流に存在する遺伝子の翻訳産物であるタンパク質の量を測定する方法をあげることができる。当該測定には、例えば、当該タンパク質に対する特異的抗体(モノクロナル抗体、ポリクロナル抗体)を用いた、細胞工学ハンドブック、羊土社、207(1992)等に記載されるイムノブロット法、免疫沈降による分離法、間接競合阻害法(ELISA 法)等の公知な方法を用いればよい。
因みに、タンパク質に対する特異的抗体は、当該タンパク質を免疫抗原として用いる通常の免疫学的な方法に準じて製造することができる。
【0145】
以上のような各種方法を用いて、哺乳動物由来の検体に含まれる目的とするDNAのメチル化頻度に相関関係がある指標値を測定する。測定されたメチル化頻度に相関関係がある指標値と、例えば、大腸癌細胞等の癌細胞を持たないと診断され得る健常な哺乳動物由来の検体に含まれる目的とするDNAのメチル化頻度に相関関係がある指標値(対照)とを比較して、当該比較により得られる差異に基づき前記検体の癌化度を判定する。仮に、哺乳動物由来の検体に含まれる目的とするDNAのメチル化頻度に正の相関関係がある指標値が対照と比較して高ければ又は負の相関関係がある指標値が対照と比較して低ければ(目的とするDNAが対照と比較の上で高メチル化状態であれば)、当該検体の癌化度が対照と比較の上で高いと判定することができる。
【0146】
本発明評価方法における、目的とするDNAのメチル化頻度又はそれに相関関係がある指標値を測定するための各種方法で使用し得るプライマー、プローブ又は特異的抗体は、大腸癌細胞等の癌細胞の検出用キットの試薬として有用である。本発明は、これらプライマー、プローブ又は特異的抗体等を試薬として含有する大腸癌細胞等の癌細胞の検出用キットや、これらプライマー、プローブ又は特異的抗体等が担体上に固定化されてなる大腸癌細胞等の癌細胞の検出用チップも提供しており、本発明評価方法の権利範囲は、当該方法の実質的な原理を利用してなる前記のような検出用キットや検出用チップのような形態での使用ももちろん含むものである。
【実施例】
【0147】
以下に実施例により本発明を詳細に説明するが、本発明はこれらに限定されるものではない。
【0148】
実施例1
(シトシンのメチル化割合の測定)
Biochain社より下表に示されるヒト組織由来ゲノムDNA入手し、MassARRAYシステムを用いたMassARRAY解析を実施した。詳細はSEQUENOMアプリケーションノートに示される定量的DNAメチル化解析用EpiTYPERの概論に従った手法にしたがって、配列番号1-19に示される塩基配列からなるオリゴヌクレオチドであるアンプリコン1−19に含まれるシトシンのメチル化割合を測定した。
【0149】
ヒト組織由来ゲノムDNA:
【0150】
アンプリコン1−19を以下に示す。
【0151】
アンプリコン1:TACTAGGAGGAGAGACCTGGAAGGCAATCACAAAAAGTCTCATTTAAATTCCTGGAAAGCACAGCTTCTCCAAACACAGCTATTCAGCTCTTTGGAAGGCAGCACTTGCGGGAGCCATTGAGTTTAACTTCACTCAGTCCCCCAACACAGAACCGGCAAATCCGAATGAGATGGACGTCACACTCCCTACTCAAAAGAATGCATCAAATATCCACTCCGTAACACCGCGGAAAGTAAACCCAAAAGCGGAGTTTGCCGCCTGCCAACTACATAAGAATTAACACTCGGGTATTTAGGATTCTAAAGATCCCTACTACCCCAAACATTATAGCCACAGAGAACCAGAAATGAACAGAACACACTTTAACCTTTAAGAAGTGCAGTTTTGTACGGGGGTTGGCTGAAGAAAGACAAAAATCTTCACTCCCTTCCAGAGCCAAAAGAGCCAAAATAAAAGATCACCTTTACTGAGCCACAGGGGCACAACTG(配列番号1)
【0152】
アンプリコン2:TGTTATGCACAAGGCCAAGTGGCTTTGCTCATTCCCAAAACAGGCCAGCCAGCTCGTGGCGATTAGTGAGATAATGAGCTTGCATGTCCCTGGCACAGGATCTGTGCCCGACAATGCTTTCCTTTCTTTAGCGTAGGCAATGTGTGTACTGAATTTCAGTGATTTCATTTGGTACTACTGTATGTGCTTGCTCCATATTTTTAATCCAACCAGTTCTGAGCGACTTTATGAGAACACACATTTTAACATAAATGCATTTGGATTTATTGTTCTTAAGTAGAAAGCTGAGTAGTTTCTATATAAGGGAAATCTAAAGCCTATAGGATAGAAATTATCTGTTCAGCAAAGTCTTACTTGAAGATTAAGAACAGGGACTTTTTTGCGGGGGGACGGGAGGGATGGAGTCTCCCTCTGTCACCCAGGCTGGAGTTCAGTGGCATGATCTCAGCTCACTACAACCTCTGCCTCCTGGGTTCAAGTGA(配列番号2)
【0153】
アンプリコン3:TGATGGCTCACTCAGGGGGCCCTATAGAAACGCCCCCAAGGATTCAACCACCTGGGAGGCTCTTTACTTCTGGTATTTCTCCTAAGGATGAAACTTGCAATTCAAACACTCTCGTTGCCGATTCTCTCCTCCCGCACCGCTCTTACCTCCACTCCCACATTCCCCTCCCAGCAAGGTTAGCGCACTGGAAGCAATGTGAAGGGGCTGTGGGGAAGGTGAGGCCCGAGTTTCAGGCTACTTTTGTCTGATTCAGACTCTTTCAGAATGACCAGCAAGTTCAACCTGTACCGCAGAGCCAGGACTCACTGGGGAGAAATGACTTTTGCATC(配列番号3)
【0154】
アンプリコン4:GTGTGGTGTGGGCTCATTCCTCAGTACACCAGTGCCCTCTAATGGACAAAACAACAGTCCCAAGGTCACGGTTGTTCCAAAGTGGACCGTGCACACTTGAAACAGCTACCATCGCTCAGCACCTAAGTCAAATGTCAGAAGGCAGAAAGCTGTTCAGAATGTTTAGCTTAACTCCCTGTTTGTAATGAAAAGGAAACCAAGGTCCTAATTGCAAGACTGAACGTGATGGTGGCATGATTACGGTCATTTGACCAGCAATCATCTCGCCATCTGAGCACCTGCTGTGGAAGCAGCCCCTGACCTAAGGCTGTGTGTGCAGTGAGCCATCCATCCTCACAGTGAGCCAGGGGTAGGGCGATCCCTATCCTCTTACAGATGAAGACACAGGCAGGGCCCTCTGTGACTTTATGGGAAAGCCTGAGTGTGCACTAGAA(配列番号4)
【0155】
アンプリコン5:AGGTGTCCCAGGGCAGTGTCAGGGATCCTGGCTTTCTCCATCCTGTTGCCCTGCCTACCAGGCAGAGCTGCCTTGGTCCCTGGAAACTGGGCTTCTTACTGGTTGGCTGGGTCTGGCCCAGCCTTGGAGCTCAGTTCTGAGCACTGGACCCCATCTTCTTCTCTGGACTGGAAGATCCACTCCCGCCAGACCTGGTGACCTCCTGTGGGGTCGCCTTACTCCAAGCCCTGACCAGGTACCTACTTGGCTAAGGCTTGGAGCCCGGCTGTGAAGGGCTGAGAATCACCAAGGTTGAGCTCTGCAAGCCTGAACCCGGATGCTTCCGCACAGAAAGGGCCTTGGATGCTGGGTTGAGATCTTTTGCCTTAAA(配列番号5)
【0156】
アンプリコン6:AAATACTCACTTCTGGGAAACATGGGCGAATTCAGTGGGAATCGTGCTAGAAGTTACGAGCAGAGGAGCCTGGGTGGGGACTTATACTGGCCTTGACGGCCCGTGGAAAGGAACTGGCGGCAATTCCTTCCGTTTTCCGTCAATTTCTTCACGGGTCGCTCAGAAGCTACGGAAGCAAAGTAGAAAGGAGTGATAGGGACAGGCCACAGTACCGGCGGACGGTGATGGCGTTGCGTTTAAAAGGGTGGTCACTGAAACCCTTTGT(配列番号6)
【0157】
アンプリコン7:GGACAGACCAGTTGAGCTCTTTGGGTATGCACGTAATGTCGCATTTTTATTTTCAGTTCAGGAAATGCTGATATTGGAGCTTCTGAGGGAGCTGCAGTGATTTCCCGATTTCCTGCGCGCCTGTGTGGAAAGTTAGAAGCGGAATCTACCGGCAGCTTTGAGACTAAGCATGACGGTGGAAACAGCTAATTTTATTAGCTTTTGTCTGAAATGCAAAAGATGAGAAAGAAAATTCCCGTTTGTTTGCTCCACATACTTCTCTTAGAAGCCTATGGAAAGCCAACTTTCCCCCTGAAGAAACTCCTCCTGGCATTTGCAAAGAGCTCCTTTACTCCTCTTGTCCAGCTCTTCTCTCAAAAGGACTCTGCAGAGCTGGACAG(配列番号7)
【0158】
アンプリコン8:AACCACACATGGGTGGGAAGGTGCTGAGAGCAACAGAGGGCTGGACTGTGCATCGTGGTGGGGGTTGAGCGCCAGAAGCCACTGCAACAGCACTTTCCTCTGTGGATCCTGTACAGGGTTCATGTGGCCTTGGCAAGCAGCCATTAGATCTGGGCAAGTTGCCCACCACGTCGGCCCTTCCCCCATAGCACATCTCTCCTGGGTCCCAGCACTGGTCACTTTTTCCTTTTCTTAATGAACGGCTTGGAGTGGGTGGGAAAGGGAAGATAATGAGTAAAGTAAGGAAGTGATTTTCGTAGGCCTGTGTCTTTGTCTTTCTCCCCAAACTTACAGCCTCCCGCCCTGACATGGACAGGCTCAGGCAGGCCTGGGAGACCTGAACTCCCTCTCCAGATAACTGGGAGCCTGGAGAGCAAATTCGGGGCTGGGACTCAGGATGGTGACACTGGCCA(配列番号8)
【0159】
アンプリコン9:TGCCCTTTCAGGAACAATGTGGGAATAAATTTTAGTCTGAAATTGCTGTTATTTACACTTTCTTTCAAGTTTGTTGAAGCACAAATACATTTGGGATAATTAATGTTCTGATGGATTATTTCATCCTACTATGTCTTCTTAACCTTCTACCGGTTTCATTCCTTTTTCTGCCTCACATTGTGACAAATTTGTAGTCTTTGTTACACAGTACAAGGAGCACTGAGAATAAGGGCGGTATCCTTGAAGGAATACCTATGAATACAAATTGTATTACGTAATGCATCCCTTTCCAGGAAAACACAGAGAAGGAATTCTTTTCTTTAGGCGACCAGCAAATGGTCACAGGCAGGGATTTTGCAGGGTCTGATCTGTAGAGGCGGGTCGATACATTCACCGAAGAGAGATAACGGGAAACCGTTTAAGGGGTGCGGCCTAACACGACAGAACTGCTGCGGGAAGGGTCCTGGGGTGAGGAGGTGACATAAAGGGAGGAGGGCACC(配列番号9)
【0160】
アンプリコン10:AATACAGCCTGGAGACAAATGGTGGGGAGGGTTTCCCCTAAATTTGGACATCTCCAGATTAAGACCTCCGCCGAATCCGTGAGGCTTTCCCTCTCCAAGGAGCTCCTAAGAGAATTTCCCAGTAAAATCGCCTCAACTGCGGTAAATAGGCTGTTCCCCGCGCCAGCATTTGAGAAGAGCTGGTCCCCAGAGTGTAAAGGAGTTAGGATGTTGGCAGGAGGAAGGATGTGTCGCCGGATGAGGAAAAGAAAGGTGGGTGTCTGCGGTGCAGTCCTTGGTCTTTCTGGCAAGTGAGGCGCTCTCCCCCTAAATGTCTCAGAGGGAGACAAATCAGCGGACTACCTTGCTTCCTTTGATGACTTGGA(配列番号10)
【0161】
アンプリコン11:CTCAGACCCAGGGGCTGGGCCCCCAGCCCCCAGTCCCGATCCCAGCTGGGTCGAGCCATGCTGCGCTACCTGCTGAAAACGCTGCTGCAGATGAACTTGTTCGCGGACTCTCTGGCCGGGGACATCTCCAACTCCAGCGAGCTGCTCTTGGGCTTCAACTCCTCGCTGGCGGCGCTCAACCACACCCTGCTGCCTCCCGGCGATCCCTCTCTCAACGGTGAGACCCTGCCTCTTGGGGATATGGGATCCTGGGATGGGGATGAGGTGAGAGGGCGGCGTGGAAGGGAAGGAGAAGCGCTCCTGTCCCGAGGTCCGGGATTGAGTGGCGCCTCCCAGCGCCTCCCTGGGTCGTGGGGTCTAAGGGATAATTTGGAGCTTCGAGCACATGAGTGGGGGTACCCGCGGGAGGTCGAGGGCTTGGGAGAAGATGGCTACTGAGTC(配列番号11)
【0162】
アンプリコン12:GAGACCCTGCCTCTTGGGGATATGGGATCCTGGGATGGGGATGAGGTGAGAGGGCGGCGTGGAAGGGAAGGAGAAGCGCTCCTGTCCCGAGGTCCGGGATTGAGTGGCGCCTCCCAGCGCCTCCCTGGGTCGTGGGGTCTAAGGGATAATTTGGAGCTTCGAGCACATGAGTGGGGGTACCCGCGGGAGGTCGAGGGCTTGGGAGAAGATGGCTACTGAGTCTTTTTACACCTCCTTCCCTTCCCCTACAACGCCCACCCCAGGTGAGAAGAACCGTTGCTGGTAACGGGCAGGGAAGTCCGAGCTAAGAAAGGCCCGGGCCCAGCGCAGGGAGGGCAGAGGAGGGGGCACAGTCTCCCGCCGGCCTCGGCCAAGCCAGGTCACTCGGTGACCCACCCAGGCAGCTGGTCTTCGGAACCCCGAAGTTTCCCAAGAACTCACTTAGGACCAGAGGAAGCCAAAATGCTGGA(配列番号12)
【0163】
アンプリコン13:TGGCCAGATCTTGGTGCCCTTGCTCAGACTCCTCTGCGGGTGCCGCTGAGGCTGCTCCCTGGGTACCTTTGCGGAACAGGATAAATGTTTGATTTGTTTCTCCCAGGTAGAGAAGCTTCTCTCCCAAGAGAGCCCCGGGCTTCCACACTCTTCAGAGATCGGGCAGGTGGCCGCGGAGGGCGGGGGCAGAGCCGGGGGTCAGATCTCGCCTGCAGGTTCCACTGTTCGTGTGCCAGGCACCGCTGGCACTGCCGCTGCCTCGGAGTAGGCAGCAAGCCCTTCTCCGGTACTTAGAGAAAAGTTGCGGAGGAGGGGAGGAAAAGGAATTTGGCAACTGCGCTGAGCTCCTGTAGGAAAGCGCTTGGGAGCCAGTTCTCCCTTCCCGGGCTCATGTCCTTTCAGAGAATTGCAAATAGCTGGGGAAAGACAGACTTT(配列番号13)
【0164】
アンプリコン14:AGACTGTCCAAAGATGGTTCTGTGGGCGGGCCGAGTCTTCTGCTGAATAACTCACCCAGGTGTGCAGCCAACATCTGTGCCTTCAGACAGCAGGCCGAGGGGAGTTACCGCCGCACGGGGCCTTATCTTTCTAATTACAAACACATGTGCTAACCTTGGGCACTCTGCCAACACGCAAAGCCTGCAAAGGGCCACTCTGTAATACCTAAGTGATTGTCCATCTGGCAAAGCATCTTGGGAATATTTTCATCCTTCTCGTCATCCTCCTGGAGGACTGGAGACATATTCCAGATCACAACCTTCCCAGAATCCTGCCCTGGAACAAAGGAGCAGAAATGGCT(配列番号14)
【0165】
アンプリコン15:GGGCAGCAGTAACCAGGACACCAGGGTCCGACCACGGCCTCCACACACCTGTGCCCGTGGAAGACGCGGGCGCCGGGGTAGGCAGCATCCACGTGCTCCACAGCTGCCGGTGCTGGGCAGGCTGGAGACTCACGGGAGAGGCAGGAGGAGAATCAGCGTGTTGAGTCCCTCGCTGTGTTAGTGTGAAAAATTCTCATTACAGTTGCAAATAAAAGGGATCACGATCACTAGCCCCGGAAACCCTCATCTCCCGGACCATCAGGATCGCACTGAACAGAATGGTCCCCTAATGGTCCCTGAGG(配列番号15)
【0166】
アンプリコン16:TTCTGGAGTAAAGAGGGATTACTCTCCCATTATCTTTCTCTAATTCTTTCATTTCTCTCCCTTGTCTGACTTCCTAACATTGATTGAGGCTTCCACTGCTTTGTCCTCATTGTTAGAGACGTCGTTAGACATCATTCTTAGACAATGCGACCTTCCCTCTTGAATTCCACTTGCATGTCTCTGAGAGCTTATATGAATTTTCCGCTTTGACCCCCTGTTGTCACTACATTATCTGTGTTTAGCGGGACTTAGCCATTTTCCTCATGTATGTCTTTCAAATTGTAGTTATATAACTTTTCTCTCAGTCATTTGCTCTATCCCTCACCAGATGTATCTAAACTGAGGCCCACTAGACTTAAGCACACCATTGTGGTTCCCACAGCTCAGTGAGCAGGG(配列番号16)
【0167】
アンプリコン17:GGTTTGAAGGACACAGAGAGAGCCTACTGACACTTCACTTTCGCTACACGTGGTGATTTTTCCAGTGCTTCCGGAGACACTGAAATTTAGTTCCAAACATTGCCTTAGAGGATTCTTCATTTTATTCATTCTACCGATGATCCACTCAGAAAATCAAACCTGAGTACGGAGACATTGGAGAAGTCGTTAAAGTATTGGACCAAGTCGGTTCGTCACGAGTGACAAAGTTATTCCACACTCTACTTGTACATACTCTGCTTTGCCTTCATGATGGCAAAGA(配列番号17)
【0168】
アンプリコン18:TGAAGTGTCAGTAGGCTCTCTCTGTGTCCTTCAAACCGCCCATATGGTCGTTACAAACGGCGGCTTGAGGAAAGGTGGTTTTGGAATCGGTTTCTCTCTGGTCTTACATGATGCATCTATACTATACTGCATTATAATACAGGAAAGGGTCACTTGCTGACATAAAGCACAGCAGGCAGGAATAGAAGAGTCAACTTAGGGGAAAAAAAGAAAGTGCTTTGTGATTTCAATTTGGTGTCTGCAGTTTGGAAAACGGTTGATCAGTTTAACTGTTTTCGTGGTGACTCACAAAAATACATATGAGCGTTGAAATTCTGCAGAAGAACAACAATCGGGGAAACATTTCTGCAAGCTCCAATTACTGGAACCCAGACATAAGCCTACAAGCTAAGACAGAGCTACACCAGGCTTCAGCAGGAAACCATACAGATCTCCTGGGAAGGGCTTCCC(配列番号18)
【0169】
アンプリコン19:TGTTCTTGTTGGCCACTGTTGCCTCTCTAAATAGGATGCCATCTCACCAGGCAGAGTTCCCTGGGCTCACGGCCCCGTTGTTCCCGTTGTCCCTCCTCAGTCGTCCAAAATAGGCCGTAAGGGCGACACCCCAGACCAGGGTAGGTGGACAAATGCCCTTCCTGTCCTTGCTTCTCCCGCAGCCCAGCGGGAAGAGCAAAGACTGCGTGTTCACGGAGATCGTGCTGGAGAACAACTATACGGCCTTCCAGAACGCCCGGCACGAGGGCTGGTTCATGGCCTTCACGCGGCAGGGGCGGCCCCGCCAGGCTTCCCGCAGCCGCCAGAACCAGCGCGAGGCCCACTTCATCAAGCGCCTCTACCAAGGCCAGCTGCCCTTCCCCAACCACGCCGAGAAGCAGAAGCAGTTCGAGTTTGTGGGCTCCGCCCCCACCCGCCGGACCAAGCGCACACGGCGGCCCCAGCCCCTCACGTAGTCTGGGAGGCAGGGGGCAGCA(配列番号19)
【0170】
上記の19アンプリコンで示される塩基配列をBisulfite処理して得られるDNAを増幅させるために設計された19プライマーセットを以下に示す。
アンプリコン1に対するプライマーセットは、プライマーF1とプライマーR1である。
アンプリコン2に対するプライマーセットは、プライマーF2とプライマーR2である。
アンプリコン3に対するプライマーセットは、プライマーF3とプライマーR3である。
アンプリコン4に対するプライマーセットは、プライマーF4とプライマーR4である。
アンプリコン5に対するプライマーセットは、プライマーF5とプライマーR5である。
アンプリコン6に対するプライマーセットは、プライマーF6とプライマーR6である。
アンプリコン7に対するプライマーセットは、プライマーF7とプライマーR7である。
アンプリコン8に対するプライマーセットは、プライマーF8とプライマーR8である。
アンプリコン9に対するプライマーセットは、プライマーF9とプライマーR9である。
アンプリコン10に対するプライマーセットは、プライマーF10とプライマーR10である。
アンプリコン11に対するプライマーセットは、プライマーF11とプライマーR11である。
アンプリコン12に対するプライマーセットは、プライマーF12とプライマーR12である。
アンプリコン13に対するプライマーセットは、プライマーF13とプライマーR13である。
アンプリコン14に対するプライマーセットは、プライマーF14とプライマーR14である。
アンプリコン15に対するプライマーセットは、プライマーF15とプライマーR15である。
アンプリコン16に対するプライマーセットは、プライマーF16とプライマーR16である。
アンプリコン17に対するプライマーセットは、プライマーF17とプライマーR17である。
アンプリコン18に対するプライマーセットは、プライマーF18とプライマーR18である。
アンプリコン19に対するプライマーセットは、プライマーF19とプライマーR19である。
【0171】
プライマーF1:AGGAAGAGAGTATTAGGAGGAGAGATTTGGAAGGT(配列番号20)
プライマーR1:CAGTAATACGACTCACTATAGGGAGAAGGCTCAATTATACCCCTATAACTCAATAAAAA(配列番号21)
【0172】
プライマーF2:AGGAAGAGAGTGTTATGTATAAGGTTAAGTGGTTTTG(配列番号22)
プライマーR2:CAGTAATACGACTCACTATAGGGAGAAGGCTTCACTTAAACCCAAAAAACAAAAAT(配列番号23)
【0173】
プライマーF3:AGGAAGAGAGTGATGGTTTATTTAGGGGGTTTTAT(配列番号24)
プライマーR3:CAGTAATACGACTCACTATAGGGAGAAGGCTAATACAAAAATCATTTCTCCCCAAT(配列番号25)
【0174】
プライマーF4:AGGAAGAGAGGTGTGGTGTGGGTTTATTTTTTAGT(配列番号26)
プライマーR4:CAGTAATACGACTCACTATAGGGAGAAGGCTTTCTAATACACACTCAAACTTTCCCA(配列番号27)
【0175】
プライマーF5:AGGAAGAGAGAGGTGTTTTAGGGTAGTGTTAGGGA(配列番号28)
プライマーR5:CAGTAATACGACTCACTATAGGGAGAAGGCTTTTAAAACAAAAAATCTCAACCCAA(配列番号29)
【0176】
プライマーF6:AGGAAGAGAGAAATATTTATTTTTGGGAAATATGGG(配列番号30)
プライマーR6:CAGTAATACGACTCACTATAGGGAGAAGGCTACAAAAAATTTCAATAACCACCCTT(配列番号31)
【0177】
プライマーF7:AGGAAGAGAGGGATAGATTAGTTGAGTTTTTTGGG(配列番号32)
プライマーR7:CAGTAATACGACTCACTATAGGGAGAAGGCTCTATCCAACTCTACAAAATCCTTTTA(配列番号33)
【0178】
プライマーF8:AGGAAGAGAGAATTATATATGGGTGGGAAGGTGTT(配列番号34)
プライマーR8:CAGTAATACGACTCACTATAGGGAGAAGGCTTAACCAATATCACCATCCTAAATCC(配列番号35)
【0179】
プライマーF9:AGGAAGAGAGTGTTTTTTTAGGAATAATGTGGGAA(配列番号36)
プライマーR9:CAGTAATACGACTCACTATAGGGAGAAGGCTAATACCCTCCTCCCTTTATATCACC(配列番号37)
【0180】
プライマーF10:AGGAAGAGAGAATATAGTTTGGAGATAAATGGTGGG(配列番号38)
プライマーR10:CAGTAATACGACTCACTATAGGGAGAAGGCTTCCAAATCATCAAAAAAAACAAAAT(配列番号39)
【0181】
プライマーF11:AGGAAGAGAGTTTAGATTTAGGGGTTGGGTTTTTA(配列番号40)
プライマーR11:CAGTAATACGACTCACTATAGGGAGAAGGCTAACTCAATAACCATCTTCTCCCAAA(配列番号41)
【0182】
プライマーF12:AGGAAGAGAGGAGATTTTGTTTTTTGGGGATATG(配列番号42)
プライマーR12:CAGTAATACGACTCACTATAGGGAGAAGGCTTCCAACATTTTAACTTCCTCTAATCC(配列番号43)
【0183】
プライマーF13:AGGAAGAGAGTGGTTAGATTTTGGTGTTTTTGTTT(配列番号44)
プライマーR13:CAGTAATACGACTCACTATAGGGAGAAGGCTAAAATCTATCTTTCCCCAACTATTTACA(配列番号45)
【0184】
プライマーF14:AGGAAGAGAGAGATTGTTTAAAGATGGTTTTGTGG(配列番号46)
プライマーR14:CAGTAATACGACTCACTATAGGGAGAAGGCTAACCATTTCTACTCCTTTATTCCAAA(配列番号47)
【0185】
プライマーF15:AGGAAGAGAGGGGTAGTAGTAATTAGGATATTAGGGTT(配列番号48)
プライマーR15:CAGTAATACGACTCACTATAGGGAGAAGGCTCCTCAAAAACCATTAAAAAACCATT(配列番号49)
【0186】
プライマーF16:AGGAAGAGAGTTTTGGAGTAAAGAGGGATTATTTTT(配列番号50)
プライマーR16:CAGTAATACGACTCACTATAGGGAGAAGGCTCCCTACTCACTAAACTATAAAAACCACA(配列番号51)
【0187】
プライマーF17:AGGAAGAGAGGGTTTGAAGGATATAGAGAGAGTTTATTG(配列番号52)
プライマーR17:CAGTAATACGACTCACTATAGGGAGAAGGCTTCTTTACCATCATAAAAACAAAACAAA(配列番号53)
【0188】
プライマーF18:AGGAAGAGAGTGAAGTGTTAGTAGGTTTTTTTTGTGTT(配列番号54)
プライマーR18:CAGTAATACGACTCACTATAGGGAGAAGGCTAAAAAACCCTTCCCAAAAAATCTAT(配列番号55)
【0189】
プライマーF19:AGGAAGAGAGTGTTTTTGTTGGTTATTGTTGTTTTT(配列番号56)
プライマーR19:CAGTAATACGACTCACTATAGGGAGAAGGCTTACTACCCCCTACCTCCCAAACTAC(配列番号57)
【0190】
以下にSEQUENOMアプリケーションノートに示されるMassARRAYシステムを用いた定量的DNAメチル化解析用EpiTYPERの概要を示す。
【0191】
プライマー設計:
メチル化解析用に以下のプライマーシステムを設計する。In vitro転写に適した産物を得るため、T7プロモータを付加したリバースプライマー。サイクリング失敗を防ぐために8bpインサートを挿入する。また、PCRのバランスをとるために10merタグを付加したフォワードプライマーとする。
【0192】
Bisulfite処理:
サンプルゲノムDNAのBisulfite変換処理にはZymo Research社のEZ-96DNA Methylation KitまたはEZ DNA Methylation Kitを使用する。このプロトコルの初回インキュベーション後、以下のとおりサイクル反応をおこなう。
45サイクル:
95℃30分
50℃15分
【0193】
(1)ステップ1:増幅
385-マイクロタイターフォーマットを用いて総容量5 μL中1 μLのDNAを増幅する(1反応あたり最終濃度2 ng/μLとするために10 ng/μL以上のDNAを1.00 μL以上使用する)。各反応液を2種類の切断反応(T切断反応とC切断反応)に分ける。プレートを密封し、以下のとおりサイクル反応をおこなう。
・94℃15分
・45サイクル
94℃20秒
56℃30秒
72℃1分
・72℃3分
(2)ステップ2:脱リン酸化
各PCR反応液5 μLにエビ由来アルカリフォスファターゼ(SAP)酵素2 μLを添加し、PCRに組み込まれなかったdNTPを脱リン酸化する。プレートを37℃で20分インキュベートし次いで85℃で5分インキュベートする。
(3)ステップ3:In vitro転写とRNase切断
各切断反応(TおよびC)用に転写/RNaseAカクテルを調製する。標準セットアップでは1プレートあたり、1つの転写/RNaseAカクテルを調製する。サイクル反応をおこなっていない新しいマイクロタイタープレートに、転写/RNaseAカクテル5 μLとPCR/SAPサンプル2 μLを添加する。プレートを1分間遠心し、次にプレートを37℃で3時間インキュベートする。
(4)ステップ4:サンプルコンディショニング
384穴プレートの各サンプルにddH2O 20 μLを加える。レジンプレートを用いて各穴にClean Resinを6 mg加える。10分間攪拌し、3,200xgで5分間スピンダウンする。
(5)ステップ5:サンプルの移動
10〜15 nLのEpiTYPER反応産物を384穴SpectroCHIPに分注する。
(6)ステップ6:サンプル解析
MassARRAYシステムを用いて2種類の切断反応のスペクトルを得る。
(7)ステップ7:解析ソフトウェア
結果をEpiTYPERソフトウェアにより解析する。
【0194】
上記の解析により得られたメチル化DNA割合の結果をグラフ化し、図1〜22に示した。ヒト大腸がん組織ゲノムDNAのメチル化割合はヒト大腸健常組織ゲノムDNAのメチル化割合に比して高いことが示された。ヒト乳がん組織ゲノムDNAのメチル化割合はヒト乳腺健常組織ゲノムDNAのメチル化割合に比して高いことが示された。ヒト肺がん組織ゲノムDNAのメチル化割合はヒト肺健常組織ゲノムDNAのメチル化割合に比して高いことが示された。
【0195】
以上より、(1)ヒト大腸組織ゲノムDNAのメチル化割合を測定することにより、大腸がんか否か、(2)ヒト乳腺組織ゲノムDNAのメチル化割合を測定することにより、乳がんか否か、あるいは(3)ヒト肺組織ゲノムDNAのメチル化割合を測定することにより、肺がんか否かを診断できることが確認された。
【産業上の利用可能性】
【0196】
本発明により、生物由来検体中に含まれるゲノムDNAが有する目的とするDNA領域におけるメチル化されたDNAの含量を測定し、大腸がんか否か、乳がんか否か、肺がんか否かを診断する方法等を提供することが可能となる。
また、同様に、本発明に記載の配列番号1から配列番号19までの塩基配列を利用することにより、簡便に癌を検出することを可能にし、極めて初期の段階での癌の検出や、癌の再発のモニタリング、癌リスク検出、癌の進行度予測などに適したキットの提供を可能にする。加えて、本願発明の方法およびキットは、内視鏡検査等の他の検査方法との併用に有用であり、より精密な検査結果を得ることを可能にするものである。
【配列表フリーテキスト】
【0197】
配列番号1
目的とするDNA領域からなるオリゴヌクレオチド
配列番号2
目的とするDNA領域からなるオリゴヌクレオチド
配列番号3
目的とするDNA領域からなるオリゴヌクレオチド
配列番号4
目的とするDNA領域からなるオリゴヌクレオチド
配列番号5
目的とするDNA領域からなるオリゴヌクレオチド
配列番号6
目的とするDNA領域からなるオリゴヌクレオチド
配列番号7
目的とするDNA領域からなるオリゴヌクレオチド
配列番号8
目的とするDNA領域からなるオリゴヌクレオチド
配列番号9
目的とするDNA領域からなるオリゴヌクレオチド
配列番号10
目的とするDNA領域からなるオリゴヌクレオチド
配列番号11
目的とするDNA領域からなるオリゴヌクレオチド
配列番号12
目的とするDNA領域からなるオリゴヌクレオチド
配列番号13
目的とするDNA領域からなるオリゴヌクレオチド
配列番号14
目的とするDNA領域からなるオリゴヌクレオチド
配列番号15
目的とするDNA領域からなるオリゴヌクレオチド
配列番号16
目的とするDNA領域からなるオリゴヌクレオチド
配列番号17
目的とするDNA領域からなるオリゴヌクレオチド
配列番号18
目的とするDNA領域からなるオリゴヌクレオチド
配列番号19
目的とするDNA領域からなるオリゴヌクレオチド
配列番号20
実験のために設計されたオリゴヌクレオチドプライマー
配列番号21
実験のために設計されたオリゴヌクレオチドプライマー
配列番号22
実験のために設計されたオリゴヌクレオチドプライマー
配列番号23
実験のために設計されたオリゴヌクレオチドプライマー
配列番号24
実験のために設計されたオリゴヌクレオチドプライマー
配列番号25
実験のために設計されたオリゴヌクレオチドプライマー
配列番号26
実験のために設計されたオリゴヌクレオチドプライマー
配列番号27
実験のために設計されたオリゴヌクレオチドプライマー
配列番号28
実験のために設計されたオリゴヌクレオチドプライマー
配列番号29
実験のために設計されたオリゴヌクレオチドプライマー
配列番号30
実験のために設計されたオリゴヌクレオチドプライマー
配列番号31
実験のために設計されたオリゴヌクレオチドプライマー
配列番号32
実験のために設計されたオリゴヌクレオチドプライマー
配列番号33
実験のために設計されたオリゴヌクレオチドプライマー
配列番号34
実験のために設計されたオリゴヌクレオチドプライマー
配列番号35
実験のために設計されたオリゴヌクレオチドプライマー
配列番号36
実験のために設計されたオリゴヌクレオチドプライマー
配列番号37
実験のために設計されたオリゴヌクレオチドプライマー
配列番号38
実験のために設計されたオリゴヌクレオチドプライマー
配列番号39
実験のために設計されたオリゴヌクレオチドプライマー
配列番号40
実験のために設計されたオリゴヌクレオチドプライマー
配列番号41
実験のために設計されたオリゴヌクレオチドプライマー
配列番号42
実験のために設計されたオリゴヌクレオチドプライマー
配列番号43
実験のために設計されたオリゴヌクレオチドプライマー
配列番号44
実験のために設計されたオリゴヌクレオチドプライマー
配列番号45
実験のために設計されたオリゴヌクレオチドプライマー
配列番号46
実験のために設計されたオリゴヌクレオチドプライマー
配列番号47
実験のために設計されたオリゴヌクレオチドプライマー
配列番号48
実験のために設計されたオリゴヌクレオチドプライマー
配列番号49
実験のために設計されたオリゴヌクレオチドプライマー
配列番号50
実験のために設計されたオリゴヌクレオチドプライマー
配列番号51
実験のために設計されたオリゴヌクレオチドプライマー
配列番号52
実験のために設計されたオリゴヌクレオチドプライマー
配列番号53
実験のために設計されたオリゴヌクレオチドプライマー
配列番号54
実験のために設計されたオリゴヌクレオチドプライマー
配列番号55
実験のために設計されたオリゴヌクレオチドプライマー
配列番号56
実験のために設計されたオリゴヌクレオチドプライマー
配列番号57
実験のために設計されたオリゴヌクレオチドプライマー
【特許請求の範囲】
【請求項1】
哺乳動物由来の検体の癌化度を評価する方法であって、
(1)哺乳動物由来の検体に含まれる下記の塩基配列から選ばれる少なくとも1つを有するDNAのメチル化頻度又はそれに相関関係がある指標値を測定する第一工程、及び
(2)測定された前記メチル化頻度又はそれに相関関係がある指標値と、対照とを比較することにより得られる差異に基づき前記検体の癌化度を判定する第二工程
を有することを特徴とする評価方法。
(a)配列番号1で示された塩基配列又は配列番号1で示された塩基配列と80%以上の相同性を有する塩基配列
(b)配列番号1と相補的な塩基配列又は配列番号1と相補的な塩基配列と80%以上の相同性を有する塩基配列
(c)配列番号2で示された塩基配列又は配列番号2で示された塩基配列と80%以上の相同性を有する塩基配列
(d)配列番号2と相補的な塩基配列又は配列番号2と相補的な塩基配列と80%以上の相同性を有する塩基配列
(e)配列番号3で示された塩基配列又は配列番号3で示された塩基配列と80%以上の相同性を有する塩基配列
(f)配列番号3と相補的な塩基配列又は配列番号3と相補的な塩基配列と80%以上の相同性を有する塩基配列
(g)配列番号4で示された塩基配列又は配列番号4で示された塩基配列と80%以上の相同性を有する塩基配列
(h)配列番号4と相補的な塩基配列又は配列番号4と相補的な塩基配列と80%以上の相同性を有する塩基配列
(i)配列番号5で示された塩基配列又は配列番号5で示された塩基配列と80%以上の相同性を有する塩基配列
(j)配列番号5と相補的な塩基配列又は配列番号5と相補的な塩基配列と80%以上の相同性を有する塩基配列
(k)配列番号6で示された塩基配列又は配列番号6で示された塩基配列と80%以上の相同性を有する塩基配列
(l)配列番号6と相補的な塩基配列又は配列番号6と相補的な塩基配列と80%以上の相同性を有する塩基配列
(m)配列番号7で示された塩基配列又は配列番号7で示された塩基配列と80%以上の相同性を有する塩基配列
(n)配列番号7と相補的な塩基配列又は配列番号7と相補的な塩基配列と80%以上の相同性を有する塩基配列
(o)配列番号8で示された塩基配列又は配列番号8で示された塩基配列と80%以上の相同性を有する塩基配列
(p)配列番号8と相補的な塩基配列又は配列番号8と相補的な塩基配列と80%以上の相同性を有する塩基配列
(q)配列番号9で示された塩基配列又は配列番号9で示された塩基配列と80%以上の相同性を有する塩基配列
(r)配列番号9と相補的な塩基配列又は配列番号9と相補的な塩基配列と80%以上の相同性を有する塩基配列
(s)配列番号10で示された塩基配列又は配列番号10で示された塩基配列と80%以上の相同性を有する塩基配列
(t)配列番号10と相補的な塩基配列又は配列番号10と相補的な塩基配列と80%以上の相同性を有する塩基配列
(u)配列番号11で示された塩基配列又は配列番号11で示された塩基配列と80%以上の相同性を有する塩基配列
(v)配列番号11と相補的な塩基配列又は配列番号11と相補的な塩基配列と80%以上の相同性を有する塩基配列
(w)配列番号12で示された塩基配列又は配列番号12で示された塩基配列と80%以上の相同性を有する塩基配列
(x)配列番号12と相補的な塩基配列又は配列番号12と相補的な塩基配列と80%以上の相同性を有する塩基配列
(y)配列番号13で示された塩基配列又は配列番号13で示された塩基配列と80%以上の相同性を有する塩基配列
(z)配列番号13と相補的な塩基配列又は配列番号13と相補的な塩基配列と80%以上の相同性を有する塩基配列
(aa)配列番号14で示された塩基配列又は配列番号14で示された塩基配列と80%以上の相同性を有する塩基配列
(ab)配列番号14と相補的な塩基配列又は配列番号14と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ac)配列番号15で示された塩基配列又は配列番号15で示された塩基配列と80%以上の相同性を有する塩基配列
(ad)配列番号15と相補的な塩基配列又は配列番号15と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ae)配列番号16で示された塩基配列又は配列番号16で示された塩基配列と80%以上の相同性を有する塩基配列
(af)配列番号16と相補的な塩基配列又は配列番号16と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ag)配列番号17で示された塩基配列又は配列番号17で示された塩基配列と80%以上の相同性を有する塩基配列
(ah)配列番号17と相補的な塩基配列又は配列番号17と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ai)配列番号18で示された塩基配列又は配列番号18で示された塩基配列と80%以上の相同性を有する塩基配列
(aj)配列番号18と相補的な塩基配列又は配列番号18と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ak)配列番号19で示された塩基配列又は配列番号19で示された塩基配列と80%以上の相同性を有する塩基配列
(al)配列番号19と相補的な塩基配列又は配列番号19と相補的な塩基配列と80%以上の相同性を有する塩基配列
【請求項2】
哺乳動物由来の検体が細胞であることを特徴とする請求項1記載の評価方法。
【請求項3】
哺乳動物由来の検体が組織であることを特徴とする請求項1記載の評価方法。
【請求項4】
哺乳動物由来の検体が生体試料であることを特徴とする請求項1記載の評価方法。
【請求項5】
哺乳動物由来の検体の癌化度を評価する方法であって、
(1)哺乳動物由来の検体に含まれる下記の塩基配列から選ばれる少なくとも1つを有するDNAのメチル化頻度又はそれに相関関係がある指標値を測定する第一工程、及び
(2)測定された前記メチル化頻度と、対照とを比較することにより得られる差異に基づき前記検体の癌化度を判定する第二工程
を有することを特徴とする評価方法。
(a)配列番号1で示された塩基配列又は配列番号1で示された塩基配列と80%以上の相同性を有する塩基配列
(b)配列番号1と相補的な塩基配列又は配列番号1と相補的な塩基配列と80%以上の相同性を有する塩基配列
(c)配列番号2で示された塩基配列又は配列番号2で示された塩基配列と80%以上の相同性を有する塩基配列
(d)配列番号2と相補的な塩基配列又は配列番号2と相補的な塩基配列と80%以上の相同性を有する塩基配列
(e)配列番号3で示された塩基配列又は配列番号3で示された塩基配列と80%以上の相同性を有する塩基配列
(f)配列番号3と相補的な塩基配列又は配列番号3と相補的な塩基配列と80%以上の相同性を有する塩基配列
(g)配列番号4で示された塩基配列又は配列番号4で示された塩基配列と80%以上の相同性を有する塩基配列
(h)配列番号4と相補的な塩基配列又は配列番号4と相補的な塩基配列と80%以上の相同性を有する塩基配列
(i)配列番号5で示された塩基配列又は配列番号5で示された塩基配列と80%以上の相同性を有する塩基配列
(j)配列番号5と相補的な塩基配列又は配列番号5と相補的な塩基配列と80%以上の相同性を有する塩基配列
(k)配列番号6で示された塩基配列又は配列番号6で示された塩基配列と80%以上の相同性を有する塩基配列
(l)配列番号6と相補的な塩基配列又は配列番号6と相補的な塩基配列と80%以上の相同性を有する塩基配列
(m)配列番号7で示された塩基配列又は配列番号7で示された塩基配列と80%以上の相同性を有する塩基配列
(n)配列番号7と相補的な塩基配列又は配列番号7と相補的な塩基配列と80%以上の相同性を有する塩基配列
(o)配列番号8で示された塩基配列又は配列番号8で示された塩基配列と80%以上の相同性を有する塩基配列
(p)配列番号8と相補的な塩基配列又は配列番号8と相補的な塩基配列と80%以上の相同性を有する塩基配列
(q)配列番号9で示された塩基配列又は配列番号9で示された塩基配列と80%以上の相同性を有する塩基配列
(r)配列番号9と相補的な塩基配列又は配列番号9と相補的な塩基配列と80%以上の相同性を有する塩基配列
(s)配列番号10で示された塩基配列又は配列番号10で示された塩基配列と80%以上の相同性を有する塩基配列
(t)配列番号10と相補的な塩基配列又は配列番号10と相補的な塩基配列と80%以上の相同性を有する塩基配列
(u)配列番号11で示された塩基配列又は配列番号11で示された塩基配列と80%以上の相同性を有する塩基配列
(v)配列番号11と相補的な塩基配列又は配列番号11と相補的な塩基配列と80%以上の相同性を有する塩基配列
(w)配列番号12で示された塩基配列又は配列番号12で示された塩基配列と80%以上の相同性を有する塩基配列
(x)配列番号12と相補的な塩基配列又は配列番号12と相補的な塩基配列と80%以上の相同性を有する塩基配列
(y)配列番号13で示された塩基配列又は配列番号13で示された塩基配列と80%以上の相同性を有する塩基配列
(z)配列番号13と相補的な塩基配列又は配列番号13と相補的な塩基配列と80%以上の相同性を有する塩基配列
(aa)配列番号14で示された塩基配列又は配列番号14で示された塩基配列と80%以上の相同性を有する塩基配列
(ab)配列番号14と相補的な塩基配列又は配列番号14と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ac)配列番号15で示された塩基配列又は配列番号15で示された塩基配列と80%以上の相同性を有する塩基配列
(ad)配列番号15と相補的な塩基配列又は配列番号15と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ae)配列番号16で示された塩基配列又は配列番号16で示された塩基配列と80%以上の相同性を有する塩基配列
(af)配列番号16と相補的な塩基配列又は配列番号16と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ag)配列番号17で示された塩基配列又は配列番号17で示された塩基配列と80%以上の相同性を有する塩基配列
(ah)配列番号17と相補的な塩基配列又は配列番号17と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ai)配列番号18で示された塩基配列又は配列番号18で示された塩基配列と80%以上の相同性を有する塩基配列
(aj)配列番号18と相補的な塩基配列又は配列番号18と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ak)配列番号19で示された塩基配列又は配列番号19で示された塩基配列と80%以上の相同性を有する塩基配列
(al)配列番号19と相補的な塩基配列又は配列番号19と相補的な塩基配列と80%以上の相同性を有する塩基配列
【請求項6】
哺乳動物由来の検体が細胞であって、且つ、当該検体の癌化度が哺乳動物由来の細胞の悪性度であることを特徴とする請求項1又は5記載の評価方法。
【請求項7】
哺乳動物由来の検体が組織であって、且つ、当該検体の癌化度が哺乳動物由来の組織における癌細胞の存在量であることを特徴とする請求項1又は5記載の評価方法。
【請求項8】
哺乳動物由来の検体が哺乳動物から採取した生体試料であって、且つ、当該検体の癌化度が当該生体試料を採取した当該哺乳動物のいずれかの体組織における癌細胞の存在量であることを特徴とする請求項1又は5記載の評価方法。
【請求項9】
組織が大腸組織であることを特徴とする請求項7に記載の評価方法。
【請求項10】
組織が肺組織であることを特徴とする請求項7に記載の評価方法。
【請求項11】
組織が乳腺組織であることを特徴とする請求項7に記載の評価方法。
【請求項12】
生体試料が血液、血清、血漿、体液、体分泌地物、糞尿、のいずれかであることを特徴とする請求項8記載の評価方法。
【請求項13】
前記DNAのメチル化頻度が、前記DNAの塩基配列内に存在する一つ以上の5'-CG-3'で示される塩基配列中のシトシンのメチル化頻度であることを特徴とする請求項1〜12のいずれか記載の評価方法。
【請求項14】
哺乳動物由来の検体の癌化度を評価する方法であって、
(1)哺乳動物由来の検体に含まれる下記の塩基配列から選ばれる少なくとも1つを有するDNAのメチル化頻度に相関関係がある指標値を測定する第一工程、及び
(2)測定された前記メチル化頻度又はそれに相関関係がある指標値と、対照とを比較することにより得られる差異に基づき前記検体の癌化度を判定する第二工程
を有することを特徴と評価方法。
(a)配列番号1で示された塩基配列又は配列番号1で示された塩基配列と80%以上の相同性を有する塩基配列
(b)配列番号1と相補的な塩基配列又は配列番号1と相補的な塩基配列と80%以上の相同性を有する塩基配列
(c)配列番号2で示された塩基配列又は配列番号2で示された塩基配列と80%以上の相同性を有する塩基配列
(d)配列番号2と相補的な塩基配列又は配列番号2と相補的な塩基配列と80%以上の相同性を有する塩基配列
(e)配列番号3で示された塩基配列又は配列番号3で示された塩基配列と80%以上の相同性を有する塩基配列
(f)配列番号3と相補的な塩基配列又は配列番号3と相補的な塩基配列と80%以上の相同性を有する塩基配列
(g)配列番号4で示された塩基配列又は配列番号4で示された塩基配列と80%以上の相同性を有する塩基配列
(h)配列番号4と相補的な塩基配列又は配列番号4と相補的な塩基配列と80%以上の相同性を有する塩基配列
(i)配列番号5で示された塩基配列又は配列番号5で示された塩基配列と80%以上の相同性を有する塩基配列
(j)配列番号5と相補的な塩基配列又は配列番号5と相補的な塩基配列と80%以上の相同性を有する塩基配列
(k)配列番号6で示された塩基配列又は配列番号6で示された塩基配列と80%以上の相同性を有する塩基配列
(l)配列番号6と相補的な塩基配列又は配列番号6と相補的な塩基配列と80%以上の相同性を有する塩基配列
(m)配列番号7で示された塩基配列又は配列番号7で示された塩基配列と80%以上の相同性を有する塩基配列
(n)配列番号7と相補的な塩基配列又は配列番号7と相補的な塩基配列と80%以上の相同性を有する塩基配列
(o)配列番号8で示された塩基配列又は配列番号8で示された塩基配列と80%以上の相同性を有する塩基配列
(p)配列番号8と相補的な塩基配列又は配列番号8と相補的な塩基配列と80%以上の相同性を有する塩基配列
(q)配列番号9で示された塩基配列又は配列番号9で示された塩基配列と80%以上の相同性を有する塩基配列
(r)配列番号9と相補的な塩基配列又は配列番号9と相補的な塩基配列と80%以上の相同性を有する塩基配列
(s)配列番号10で示された塩基配列又は配列番号10で示された塩基配列と80%以上の相同性を有する塩基配列
(t)配列番号10と相補的な塩基配列又は配列番号10と相補的な塩基配列と80%以上の相同性を有する塩基配列
(u)配列番号11で示された塩基配列又は配列番号11で示された塩基配列と80%以上の相同性を有する塩基配列
(v)配列番号11と相補的な塩基配列又は配列番号11と相補的な塩基配列と80%以上の相同性を有する塩基配列
(w)配列番号12で示された塩基配列又は配列番号12で示された塩基配列と80%以上の相同性を有する塩基配列
(x)配列番号12と相補的な塩基配列又は配列番号12と相補的な塩基配列と80%以上の相同性を有する塩基配列
(y)配列番号13で示された塩基配列又は配列番号13で示された塩基配列と80%以上の相同性を有する塩基配列
(z)配列番号13と相補的な塩基配列又は配列番号13と相補的な塩基配列と80%以上の相同性を有する塩基配列
(aa)配列番号14で示された塩基配列又は配列番号14で示された塩基配列と80%以上の相同性を有する塩基配列
(ab)配列番号14と相補的な塩基配列又は配列番号14と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ac)配列番号15で示された塩基配列又は配列番号15で示された塩基配列と80%以上の相同性を有する塩基配列
(ad)配列番号15と相補的な塩基配列又は配列番号15と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ae)配列番号16で示された塩基配列又は配列番号16で示された塩基配列と80%以上の相同性を有する塩基配列
(af)配列番号16と相補的な塩基配列又は配列番号16と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ag)配列番号17で示された塩基配列又は配列番号17で示された塩基配列と80%以上の相同性を有する塩基配列
(ah)配列番号17と相補的な塩基配列又は配列番号17と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ai)配列番号18で示された塩基配列又は配列番号18で示された塩基配列と80%以上の相同性を有する塩基配列
(aj)配列番号18と相補的な塩基配列又は配列番号18と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ak)配列番号19で示された塩基配列又は配列番号19で示された塩基配列と80%以上の相同性を有する塩基配列
(al)配列番号19と相補的な塩基配列又は配列番号19と相補的な塩基配列と80%以上の相同性を有する塩基配列
【請求項15】
相関関係がある指標値が、当該塩基配列から選ばれる少なくとも1つのDNAの下流に存在する遺伝子のいずれかの発現産物の量であることを特徴とする請求項14記載の評価方法。
【請求項16】
遺伝子の発現産物の量が、遺伝子の転写産物の量であることを特徴とする請求項15記載の評価方法。
【請求項17】
癌マーカーとしての、下記の塩基配列から選ばれる少なくとも1つを有するメチル化DNAの使用
(a)配列番号1で示された塩基配列又は配列番号1で示された塩基配列と80%以上の相同性を有する塩基配列
(b)配列番号1と相補的な塩基配列又は配列番号1と相補的な塩基配列と80%以上の相同性を有する塩基配列
(c)配列番号2で示された塩基配列又は配列番号2で示された塩基配列と80%以上の相同性を有する塩基配列
(d)配列番号2と相補的な塩基配列又は配列番号2と相補的な塩基配列と80%以上の相同性を有する塩基配列
(e)配列番号3で示された塩基配列又は配列番号3で示された塩基配列と80%以上の相同性を有する塩基配列
(f)配列番号3と相補的な塩基配列又は配列番号3と相補的な塩基配列と80%以上の相同性を有する塩基配列
(g)配列番号4で示された塩基配列又は配列番号4で示された塩基配列と80%以上の相同性を有する塩基配列
(h)配列番号4と相補的な塩基配列又は配列番号4と相補的な塩基配列と80%以上の相同性を有する塩基配列
(i)配列番号5で示された塩基配列又は配列番号5で示された塩基配列と80%以上の相同性を有する塩基配列
(j)配列番号5と相補的な塩基配列又は配列番号5と相補的な塩基配列と80%以上の相同性を有する塩基配列
(k)配列番号6で示された塩基配列又は配列番号6で示された塩基配列と80%以上の相同性を有する塩基配列
(l)配列番号6と相補的な塩基配列又は配列番号6と相補的な塩基配列と80%以上の相同性を有する塩基配列
(m)配列番号7で示された塩基配列又は配列番号7で示された塩基配列と80%以上の相同性を有する塩基配列
(n)配列番号7と相補的な塩基配列又は配列番号7と相補的な塩基配列と80%以上の相同性を有する塩基配列
(o)配列番号8で示された塩基配列又は配列番号8で示された塩基配列と80%以上の相同性を有する塩基配列
(p)配列番号8と相補的な塩基配列又は配列番号8と相補的な塩基配列と80%以上の相同性を有する塩基配列
(q)配列番号9で示された塩基配列又は配列番号9で示された塩基配列と80%以上の相同性を有する塩基配列
(r)配列番号9と相補的な塩基配列又は配列番号9と相補的な塩基配列と80%以上の相同性を有する塩基配列
(s)配列番号10で示された塩基配列又は配列番号10で示された塩基配列と80%以上の相同性を有する塩基配列
(t)配列番号10と相補的な塩基配列又は配列番号10と相補的な塩基配列と80%以上の相同性を有する塩基配列
(u)配列番号11で示された塩基配列又は配列番号11で示された塩基配列と80%以上の相同性を有する塩基配列
(v)配列番号11と相補的な塩基配列又は配列番号11と相補的な塩基配列と80%以上の相同性を有する塩基配列
(w)配列番号12で示された塩基配列又は配列番号12で示された塩基配列と80%以上の相同性を有する塩基配列
(x)配列番号12と相補的な塩基配列又は配列番号12と相補的な塩基配列と80%以上の相同性を有する塩基配列
(y)配列番号13で示された塩基配列又は配列番号13で示された塩基配列と80%以上の相同性を有する塩基配列
(z)配列番号13と相補的な塩基配列又は配列番号13と相補的な塩基配列と80%以上の相同性を有する塩基配列
(aa)配列番号14で示された塩基配列又は配列番号14で示された塩基配列と80%以上の相同性を有する塩基配列
(ab)配列番号14と相補的な塩基配列又は配列番号14と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ac)配列番号15で示された塩基配列又は配列番号15で示された塩基配列と80%以上の相同性を有する塩基配列
(ad)配列番号15と相補的な塩基配列又は配列番号15と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ae)配列番号16で示された塩基配列又は配列番号16で示された塩基配列と80%以上の相同性を有する塩基配列
(af)配列番号16と相補的な塩基配列又は配列番号16と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ag)配列番号17で示された塩基配列又は配列番号17で示された塩基配列と80%以上の相同性を有する塩基配列
(ah)配列番号17と相補的な塩基配列又は配列番号17と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ai)配列番号18で示された塩基配列又は配列番号18で示された塩基配列と80%以上の相同性を有する塩基配列
(aj)配列番号18と相補的な塩基配列又は配列番号18と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ak)配列番号19で示された塩基配列又は配列番号19で示された塩基配列と80%以上の相同性を有する塩基配列
(al)配列番号19と相補的な塩基配列又は配列番号19と相補的な塩基配列と80%以上の相同性を有する塩基配列
【請求項1】
哺乳動物由来の検体の癌化度を評価する方法であって、
(1)哺乳動物由来の検体に含まれる下記の塩基配列から選ばれる少なくとも1つを有するDNAのメチル化頻度又はそれに相関関係がある指標値を測定する第一工程、及び
(2)測定された前記メチル化頻度又はそれに相関関係がある指標値と、対照とを比較することにより得られる差異に基づき前記検体の癌化度を判定する第二工程
を有することを特徴とする評価方法。
(a)配列番号1で示された塩基配列又は配列番号1で示された塩基配列と80%以上の相同性を有する塩基配列
(b)配列番号1と相補的な塩基配列又は配列番号1と相補的な塩基配列と80%以上の相同性を有する塩基配列
(c)配列番号2で示された塩基配列又は配列番号2で示された塩基配列と80%以上の相同性を有する塩基配列
(d)配列番号2と相補的な塩基配列又は配列番号2と相補的な塩基配列と80%以上の相同性を有する塩基配列
(e)配列番号3で示された塩基配列又は配列番号3で示された塩基配列と80%以上の相同性を有する塩基配列
(f)配列番号3と相補的な塩基配列又は配列番号3と相補的な塩基配列と80%以上の相同性を有する塩基配列
(g)配列番号4で示された塩基配列又は配列番号4で示された塩基配列と80%以上の相同性を有する塩基配列
(h)配列番号4と相補的な塩基配列又は配列番号4と相補的な塩基配列と80%以上の相同性を有する塩基配列
(i)配列番号5で示された塩基配列又は配列番号5で示された塩基配列と80%以上の相同性を有する塩基配列
(j)配列番号5と相補的な塩基配列又は配列番号5と相補的な塩基配列と80%以上の相同性を有する塩基配列
(k)配列番号6で示された塩基配列又は配列番号6で示された塩基配列と80%以上の相同性を有する塩基配列
(l)配列番号6と相補的な塩基配列又は配列番号6と相補的な塩基配列と80%以上の相同性を有する塩基配列
(m)配列番号7で示された塩基配列又は配列番号7で示された塩基配列と80%以上の相同性を有する塩基配列
(n)配列番号7と相補的な塩基配列又は配列番号7と相補的な塩基配列と80%以上の相同性を有する塩基配列
(o)配列番号8で示された塩基配列又は配列番号8で示された塩基配列と80%以上の相同性を有する塩基配列
(p)配列番号8と相補的な塩基配列又は配列番号8と相補的な塩基配列と80%以上の相同性を有する塩基配列
(q)配列番号9で示された塩基配列又は配列番号9で示された塩基配列と80%以上の相同性を有する塩基配列
(r)配列番号9と相補的な塩基配列又は配列番号9と相補的な塩基配列と80%以上の相同性を有する塩基配列
(s)配列番号10で示された塩基配列又は配列番号10で示された塩基配列と80%以上の相同性を有する塩基配列
(t)配列番号10と相補的な塩基配列又は配列番号10と相補的な塩基配列と80%以上の相同性を有する塩基配列
(u)配列番号11で示された塩基配列又は配列番号11で示された塩基配列と80%以上の相同性を有する塩基配列
(v)配列番号11と相補的な塩基配列又は配列番号11と相補的な塩基配列と80%以上の相同性を有する塩基配列
(w)配列番号12で示された塩基配列又は配列番号12で示された塩基配列と80%以上の相同性を有する塩基配列
(x)配列番号12と相補的な塩基配列又は配列番号12と相補的な塩基配列と80%以上の相同性を有する塩基配列
(y)配列番号13で示された塩基配列又は配列番号13で示された塩基配列と80%以上の相同性を有する塩基配列
(z)配列番号13と相補的な塩基配列又は配列番号13と相補的な塩基配列と80%以上の相同性を有する塩基配列
(aa)配列番号14で示された塩基配列又は配列番号14で示された塩基配列と80%以上の相同性を有する塩基配列
(ab)配列番号14と相補的な塩基配列又は配列番号14と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ac)配列番号15で示された塩基配列又は配列番号15で示された塩基配列と80%以上の相同性を有する塩基配列
(ad)配列番号15と相補的な塩基配列又は配列番号15と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ae)配列番号16で示された塩基配列又は配列番号16で示された塩基配列と80%以上の相同性を有する塩基配列
(af)配列番号16と相補的な塩基配列又は配列番号16と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ag)配列番号17で示された塩基配列又は配列番号17で示された塩基配列と80%以上の相同性を有する塩基配列
(ah)配列番号17と相補的な塩基配列又は配列番号17と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ai)配列番号18で示された塩基配列又は配列番号18で示された塩基配列と80%以上の相同性を有する塩基配列
(aj)配列番号18と相補的な塩基配列又は配列番号18と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ak)配列番号19で示された塩基配列又は配列番号19で示された塩基配列と80%以上の相同性を有する塩基配列
(al)配列番号19と相補的な塩基配列又は配列番号19と相補的な塩基配列と80%以上の相同性を有する塩基配列
【請求項2】
哺乳動物由来の検体が細胞であることを特徴とする請求項1記載の評価方法。
【請求項3】
哺乳動物由来の検体が組織であることを特徴とする請求項1記載の評価方法。
【請求項4】
哺乳動物由来の検体が生体試料であることを特徴とする請求項1記載の評価方法。
【請求項5】
哺乳動物由来の検体の癌化度を評価する方法であって、
(1)哺乳動物由来の検体に含まれる下記の塩基配列から選ばれる少なくとも1つを有するDNAのメチル化頻度又はそれに相関関係がある指標値を測定する第一工程、及び
(2)測定された前記メチル化頻度と、対照とを比較することにより得られる差異に基づき前記検体の癌化度を判定する第二工程
を有することを特徴とする評価方法。
(a)配列番号1で示された塩基配列又は配列番号1で示された塩基配列と80%以上の相同性を有する塩基配列
(b)配列番号1と相補的な塩基配列又は配列番号1と相補的な塩基配列と80%以上の相同性を有する塩基配列
(c)配列番号2で示された塩基配列又は配列番号2で示された塩基配列と80%以上の相同性を有する塩基配列
(d)配列番号2と相補的な塩基配列又は配列番号2と相補的な塩基配列と80%以上の相同性を有する塩基配列
(e)配列番号3で示された塩基配列又は配列番号3で示された塩基配列と80%以上の相同性を有する塩基配列
(f)配列番号3と相補的な塩基配列又は配列番号3と相補的な塩基配列と80%以上の相同性を有する塩基配列
(g)配列番号4で示された塩基配列又は配列番号4で示された塩基配列と80%以上の相同性を有する塩基配列
(h)配列番号4と相補的な塩基配列又は配列番号4と相補的な塩基配列と80%以上の相同性を有する塩基配列
(i)配列番号5で示された塩基配列又は配列番号5で示された塩基配列と80%以上の相同性を有する塩基配列
(j)配列番号5と相補的な塩基配列又は配列番号5と相補的な塩基配列と80%以上の相同性を有する塩基配列
(k)配列番号6で示された塩基配列又は配列番号6で示された塩基配列と80%以上の相同性を有する塩基配列
(l)配列番号6と相補的な塩基配列又は配列番号6と相補的な塩基配列と80%以上の相同性を有する塩基配列
(m)配列番号7で示された塩基配列又は配列番号7で示された塩基配列と80%以上の相同性を有する塩基配列
(n)配列番号7と相補的な塩基配列又は配列番号7と相補的な塩基配列と80%以上の相同性を有する塩基配列
(o)配列番号8で示された塩基配列又は配列番号8で示された塩基配列と80%以上の相同性を有する塩基配列
(p)配列番号8と相補的な塩基配列又は配列番号8と相補的な塩基配列と80%以上の相同性を有する塩基配列
(q)配列番号9で示された塩基配列又は配列番号9で示された塩基配列と80%以上の相同性を有する塩基配列
(r)配列番号9と相補的な塩基配列又は配列番号9と相補的な塩基配列と80%以上の相同性を有する塩基配列
(s)配列番号10で示された塩基配列又は配列番号10で示された塩基配列と80%以上の相同性を有する塩基配列
(t)配列番号10と相補的な塩基配列又は配列番号10と相補的な塩基配列と80%以上の相同性を有する塩基配列
(u)配列番号11で示された塩基配列又は配列番号11で示された塩基配列と80%以上の相同性を有する塩基配列
(v)配列番号11と相補的な塩基配列又は配列番号11と相補的な塩基配列と80%以上の相同性を有する塩基配列
(w)配列番号12で示された塩基配列又は配列番号12で示された塩基配列と80%以上の相同性を有する塩基配列
(x)配列番号12と相補的な塩基配列又は配列番号12と相補的な塩基配列と80%以上の相同性を有する塩基配列
(y)配列番号13で示された塩基配列又は配列番号13で示された塩基配列と80%以上の相同性を有する塩基配列
(z)配列番号13と相補的な塩基配列又は配列番号13と相補的な塩基配列と80%以上の相同性を有する塩基配列
(aa)配列番号14で示された塩基配列又は配列番号14で示された塩基配列と80%以上の相同性を有する塩基配列
(ab)配列番号14と相補的な塩基配列又は配列番号14と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ac)配列番号15で示された塩基配列又は配列番号15で示された塩基配列と80%以上の相同性を有する塩基配列
(ad)配列番号15と相補的な塩基配列又は配列番号15と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ae)配列番号16で示された塩基配列又は配列番号16で示された塩基配列と80%以上の相同性を有する塩基配列
(af)配列番号16と相補的な塩基配列又は配列番号16と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ag)配列番号17で示された塩基配列又は配列番号17で示された塩基配列と80%以上の相同性を有する塩基配列
(ah)配列番号17と相補的な塩基配列又は配列番号17と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ai)配列番号18で示された塩基配列又は配列番号18で示された塩基配列と80%以上の相同性を有する塩基配列
(aj)配列番号18と相補的な塩基配列又は配列番号18と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ak)配列番号19で示された塩基配列又は配列番号19で示された塩基配列と80%以上の相同性を有する塩基配列
(al)配列番号19と相補的な塩基配列又は配列番号19と相補的な塩基配列と80%以上の相同性を有する塩基配列
【請求項6】
哺乳動物由来の検体が細胞であって、且つ、当該検体の癌化度が哺乳動物由来の細胞の悪性度であることを特徴とする請求項1又は5記載の評価方法。
【請求項7】
哺乳動物由来の検体が組織であって、且つ、当該検体の癌化度が哺乳動物由来の組織における癌細胞の存在量であることを特徴とする請求項1又は5記載の評価方法。
【請求項8】
哺乳動物由来の検体が哺乳動物から採取した生体試料であって、且つ、当該検体の癌化度が当該生体試料を採取した当該哺乳動物のいずれかの体組織における癌細胞の存在量であることを特徴とする請求項1又は5記載の評価方法。
【請求項9】
組織が大腸組織であることを特徴とする請求項7に記載の評価方法。
【請求項10】
組織が肺組織であることを特徴とする請求項7に記載の評価方法。
【請求項11】
組織が乳腺組織であることを特徴とする請求項7に記載の評価方法。
【請求項12】
生体試料が血液、血清、血漿、体液、体分泌地物、糞尿、のいずれかであることを特徴とする請求項8記載の評価方法。
【請求項13】
前記DNAのメチル化頻度が、前記DNAの塩基配列内に存在する一つ以上の5'-CG-3'で示される塩基配列中のシトシンのメチル化頻度であることを特徴とする請求項1〜12のいずれか記載の評価方法。
【請求項14】
哺乳動物由来の検体の癌化度を評価する方法であって、
(1)哺乳動物由来の検体に含まれる下記の塩基配列から選ばれる少なくとも1つを有するDNAのメチル化頻度に相関関係がある指標値を測定する第一工程、及び
(2)測定された前記メチル化頻度又はそれに相関関係がある指標値と、対照とを比較することにより得られる差異に基づき前記検体の癌化度を判定する第二工程
を有することを特徴と評価方法。
(a)配列番号1で示された塩基配列又は配列番号1で示された塩基配列と80%以上の相同性を有する塩基配列
(b)配列番号1と相補的な塩基配列又は配列番号1と相補的な塩基配列と80%以上の相同性を有する塩基配列
(c)配列番号2で示された塩基配列又は配列番号2で示された塩基配列と80%以上の相同性を有する塩基配列
(d)配列番号2と相補的な塩基配列又は配列番号2と相補的な塩基配列と80%以上の相同性を有する塩基配列
(e)配列番号3で示された塩基配列又は配列番号3で示された塩基配列と80%以上の相同性を有する塩基配列
(f)配列番号3と相補的な塩基配列又は配列番号3と相補的な塩基配列と80%以上の相同性を有する塩基配列
(g)配列番号4で示された塩基配列又は配列番号4で示された塩基配列と80%以上の相同性を有する塩基配列
(h)配列番号4と相補的な塩基配列又は配列番号4と相補的な塩基配列と80%以上の相同性を有する塩基配列
(i)配列番号5で示された塩基配列又は配列番号5で示された塩基配列と80%以上の相同性を有する塩基配列
(j)配列番号5と相補的な塩基配列又は配列番号5と相補的な塩基配列と80%以上の相同性を有する塩基配列
(k)配列番号6で示された塩基配列又は配列番号6で示された塩基配列と80%以上の相同性を有する塩基配列
(l)配列番号6と相補的な塩基配列又は配列番号6と相補的な塩基配列と80%以上の相同性を有する塩基配列
(m)配列番号7で示された塩基配列又は配列番号7で示された塩基配列と80%以上の相同性を有する塩基配列
(n)配列番号7と相補的な塩基配列又は配列番号7と相補的な塩基配列と80%以上の相同性を有する塩基配列
(o)配列番号8で示された塩基配列又は配列番号8で示された塩基配列と80%以上の相同性を有する塩基配列
(p)配列番号8と相補的な塩基配列又は配列番号8と相補的な塩基配列と80%以上の相同性を有する塩基配列
(q)配列番号9で示された塩基配列又は配列番号9で示された塩基配列と80%以上の相同性を有する塩基配列
(r)配列番号9と相補的な塩基配列又は配列番号9と相補的な塩基配列と80%以上の相同性を有する塩基配列
(s)配列番号10で示された塩基配列又は配列番号10で示された塩基配列と80%以上の相同性を有する塩基配列
(t)配列番号10と相補的な塩基配列又は配列番号10と相補的な塩基配列と80%以上の相同性を有する塩基配列
(u)配列番号11で示された塩基配列又は配列番号11で示された塩基配列と80%以上の相同性を有する塩基配列
(v)配列番号11と相補的な塩基配列又は配列番号11と相補的な塩基配列と80%以上の相同性を有する塩基配列
(w)配列番号12で示された塩基配列又は配列番号12で示された塩基配列と80%以上の相同性を有する塩基配列
(x)配列番号12と相補的な塩基配列又は配列番号12と相補的な塩基配列と80%以上の相同性を有する塩基配列
(y)配列番号13で示された塩基配列又は配列番号13で示された塩基配列と80%以上の相同性を有する塩基配列
(z)配列番号13と相補的な塩基配列又は配列番号13と相補的な塩基配列と80%以上の相同性を有する塩基配列
(aa)配列番号14で示された塩基配列又は配列番号14で示された塩基配列と80%以上の相同性を有する塩基配列
(ab)配列番号14と相補的な塩基配列又は配列番号14と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ac)配列番号15で示された塩基配列又は配列番号15で示された塩基配列と80%以上の相同性を有する塩基配列
(ad)配列番号15と相補的な塩基配列又は配列番号15と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ae)配列番号16で示された塩基配列又は配列番号16で示された塩基配列と80%以上の相同性を有する塩基配列
(af)配列番号16と相補的な塩基配列又は配列番号16と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ag)配列番号17で示された塩基配列又は配列番号17で示された塩基配列と80%以上の相同性を有する塩基配列
(ah)配列番号17と相補的な塩基配列又は配列番号17と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ai)配列番号18で示された塩基配列又は配列番号18で示された塩基配列と80%以上の相同性を有する塩基配列
(aj)配列番号18と相補的な塩基配列又は配列番号18と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ak)配列番号19で示された塩基配列又は配列番号19で示された塩基配列と80%以上の相同性を有する塩基配列
(al)配列番号19と相補的な塩基配列又は配列番号19と相補的な塩基配列と80%以上の相同性を有する塩基配列
【請求項15】
相関関係がある指標値が、当該塩基配列から選ばれる少なくとも1つのDNAの下流に存在する遺伝子のいずれかの発現産物の量であることを特徴とする請求項14記載の評価方法。
【請求項16】
遺伝子の発現産物の量が、遺伝子の転写産物の量であることを特徴とする請求項15記載の評価方法。
【請求項17】
癌マーカーとしての、下記の塩基配列から選ばれる少なくとも1つを有するメチル化DNAの使用
(a)配列番号1で示された塩基配列又は配列番号1で示された塩基配列と80%以上の相同性を有する塩基配列
(b)配列番号1と相補的な塩基配列又は配列番号1と相補的な塩基配列と80%以上の相同性を有する塩基配列
(c)配列番号2で示された塩基配列又は配列番号2で示された塩基配列と80%以上の相同性を有する塩基配列
(d)配列番号2と相補的な塩基配列又は配列番号2と相補的な塩基配列と80%以上の相同性を有する塩基配列
(e)配列番号3で示された塩基配列又は配列番号3で示された塩基配列と80%以上の相同性を有する塩基配列
(f)配列番号3と相補的な塩基配列又は配列番号3と相補的な塩基配列と80%以上の相同性を有する塩基配列
(g)配列番号4で示された塩基配列又は配列番号4で示された塩基配列と80%以上の相同性を有する塩基配列
(h)配列番号4と相補的な塩基配列又は配列番号4と相補的な塩基配列と80%以上の相同性を有する塩基配列
(i)配列番号5で示された塩基配列又は配列番号5で示された塩基配列と80%以上の相同性を有する塩基配列
(j)配列番号5と相補的な塩基配列又は配列番号5と相補的な塩基配列と80%以上の相同性を有する塩基配列
(k)配列番号6で示された塩基配列又は配列番号6で示された塩基配列と80%以上の相同性を有する塩基配列
(l)配列番号6と相補的な塩基配列又は配列番号6と相補的な塩基配列と80%以上の相同性を有する塩基配列
(m)配列番号7で示された塩基配列又は配列番号7で示された塩基配列と80%以上の相同性を有する塩基配列
(n)配列番号7と相補的な塩基配列又は配列番号7と相補的な塩基配列と80%以上の相同性を有する塩基配列
(o)配列番号8で示された塩基配列又は配列番号8で示された塩基配列と80%以上の相同性を有する塩基配列
(p)配列番号8と相補的な塩基配列又は配列番号8と相補的な塩基配列と80%以上の相同性を有する塩基配列
(q)配列番号9で示された塩基配列又は配列番号9で示された塩基配列と80%以上の相同性を有する塩基配列
(r)配列番号9と相補的な塩基配列又は配列番号9と相補的な塩基配列と80%以上の相同性を有する塩基配列
(s)配列番号10で示された塩基配列又は配列番号10で示された塩基配列と80%以上の相同性を有する塩基配列
(t)配列番号10と相補的な塩基配列又は配列番号10と相補的な塩基配列と80%以上の相同性を有する塩基配列
(u)配列番号11で示された塩基配列又は配列番号11で示された塩基配列と80%以上の相同性を有する塩基配列
(v)配列番号11と相補的な塩基配列又は配列番号11と相補的な塩基配列と80%以上の相同性を有する塩基配列
(w)配列番号12で示された塩基配列又は配列番号12で示された塩基配列と80%以上の相同性を有する塩基配列
(x)配列番号12と相補的な塩基配列又は配列番号12と相補的な塩基配列と80%以上の相同性を有する塩基配列
(y)配列番号13で示された塩基配列又は配列番号13で示された塩基配列と80%以上の相同性を有する塩基配列
(z)配列番号13と相補的な塩基配列又は配列番号13と相補的な塩基配列と80%以上の相同性を有する塩基配列
(aa)配列番号14で示された塩基配列又は配列番号14で示された塩基配列と80%以上の相同性を有する塩基配列
(ab)配列番号14と相補的な塩基配列又は配列番号14と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ac)配列番号15で示された塩基配列又は配列番号15で示された塩基配列と80%以上の相同性を有する塩基配列
(ad)配列番号15と相補的な塩基配列又は配列番号15と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ae)配列番号16で示された塩基配列又は配列番号16で示された塩基配列と80%以上の相同性を有する塩基配列
(af)配列番号16と相補的な塩基配列又は配列番号16と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ag)配列番号17で示された塩基配列又は配列番号17で示された塩基配列と80%以上の相同性を有する塩基配列
(ah)配列番号17と相補的な塩基配列又は配列番号17と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ai)配列番号18で示された塩基配列又は配列番号18で示された塩基配列と80%以上の相同性を有する塩基配列
(aj)配列番号18と相補的な塩基配列又は配列番号18と相補的な塩基配列と80%以上の相同性を有する塩基配列
(ak)配列番号19で示された塩基配列又は配列番号19で示された塩基配列と80%以上の相同性を有する塩基配列
(al)配列番号19と相補的な塩基配列又は配列番号19と相補的な塩基配列と80%以上の相同性を有する塩基配列
【図1】

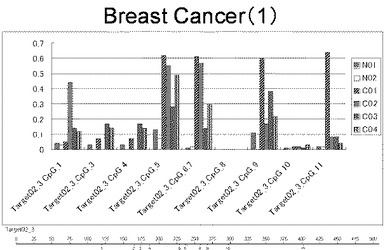
【図2】
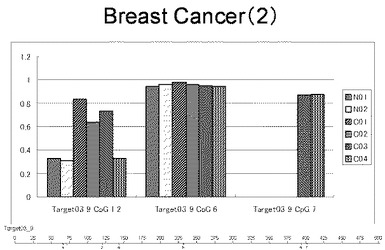
【図3】
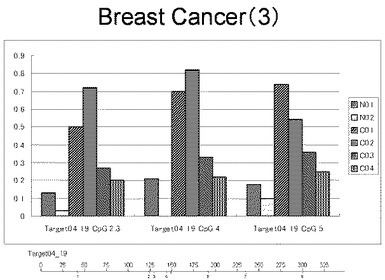
【図4】
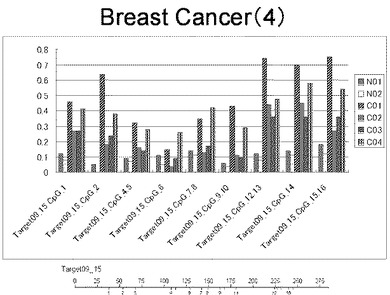
【図5】
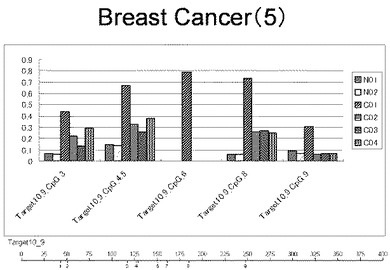
【図6】
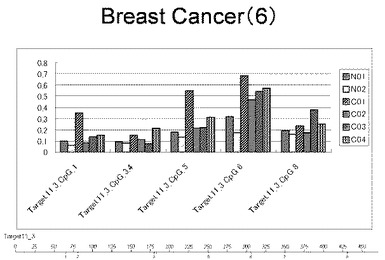
【図7】
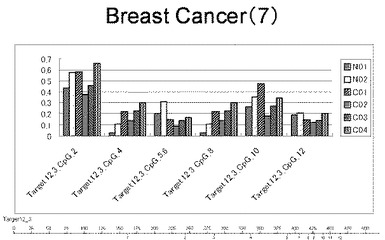
【図8】
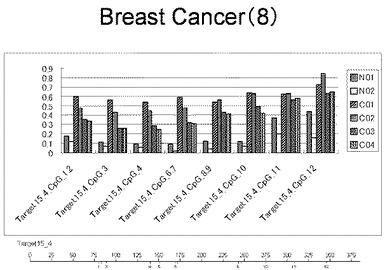
【図9】
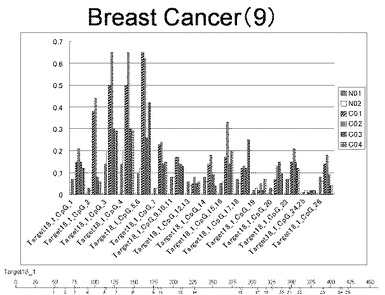
【図10】
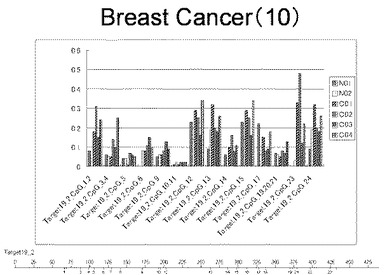
【図11】
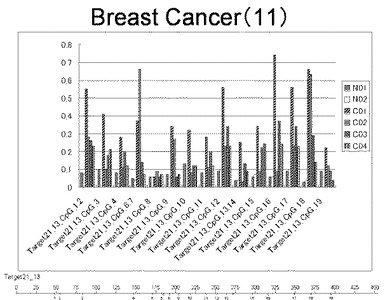
【図12】
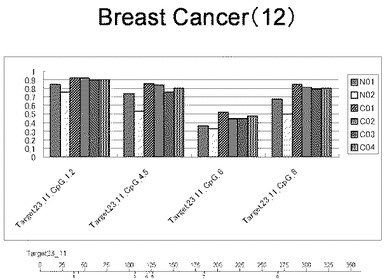
【図13】
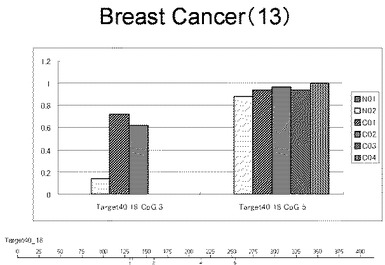
【図14】
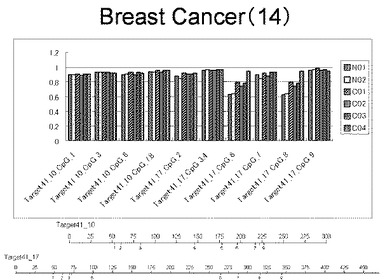
【図15】
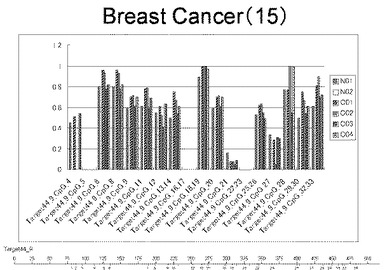
【図16】
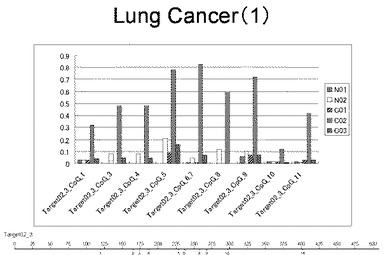
【図17】
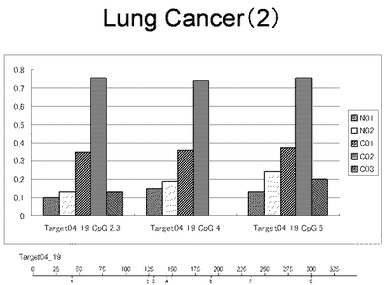
【図18】
【図19】
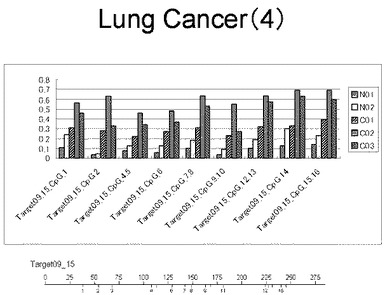
【図20】
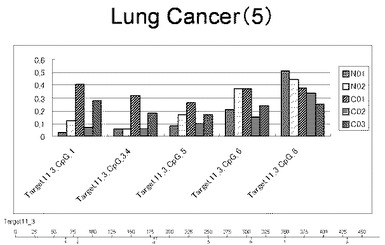
【図21】
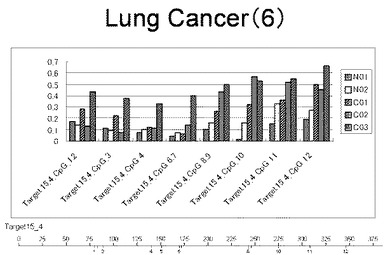
【図22】
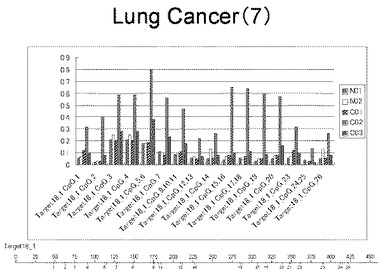
【図23】
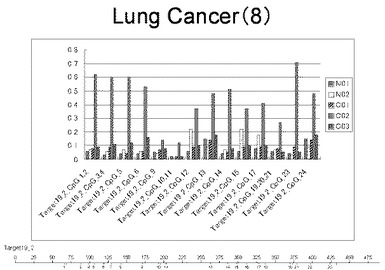
【図24】
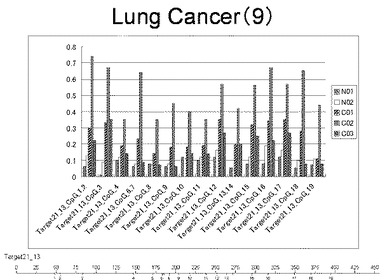
【図25】
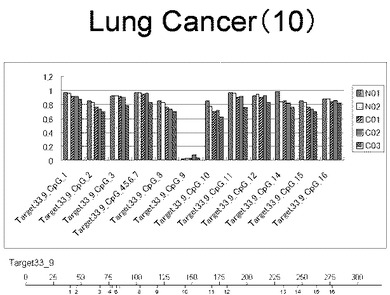
【図26】
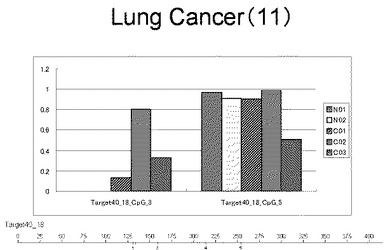
【図27】
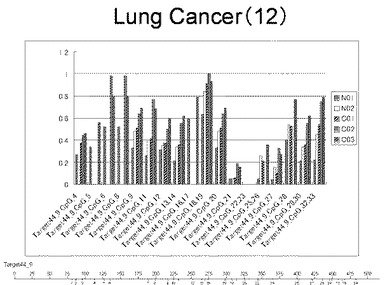
【図28】
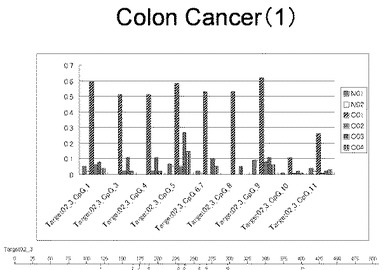
【図29】
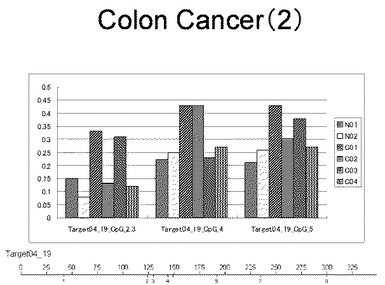
【図30】
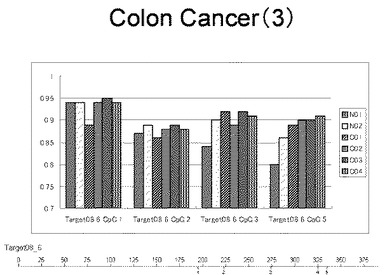
【図31】
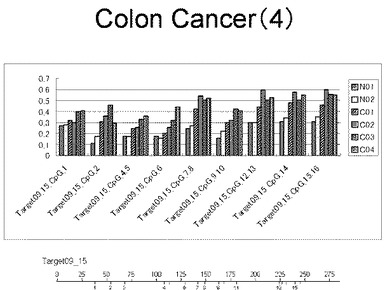
【図32】
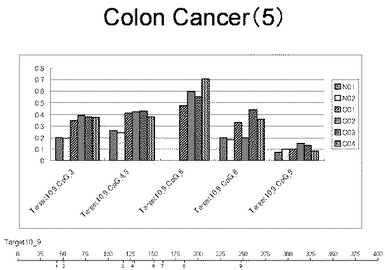
【図33】
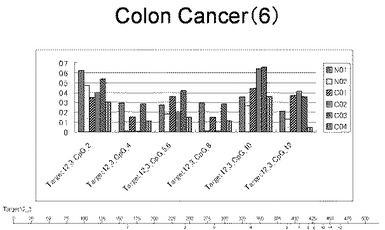
【図34】
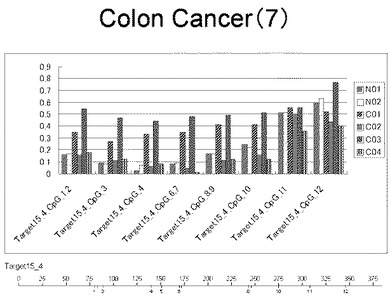
【図35】
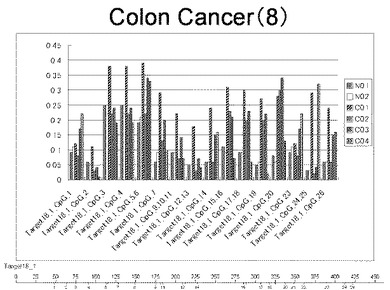
【図36】
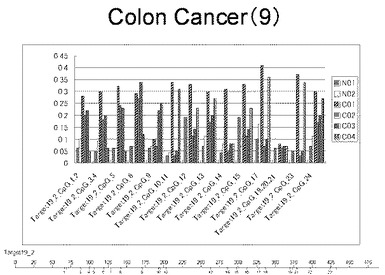
【図37】
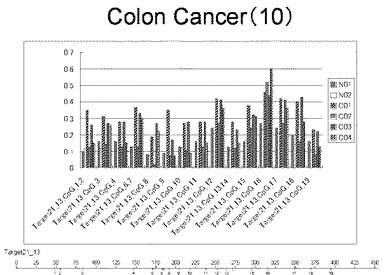
【図38】
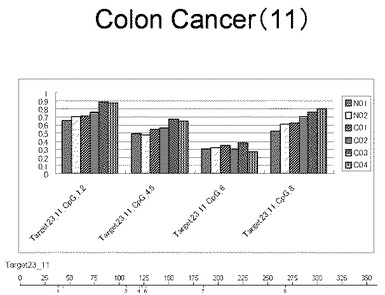
【図39】
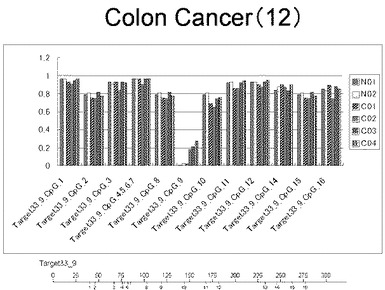
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【図23】
【図24】
【図25】
【図26】
【図27】
【図28】
【図29】
【図30】
【図31】
【図32】
【図33】
【図34】
【図35】
【図36】
【図37】
【図38】
【図39】
【公開番号】特開2013−74837(P2013−74837A)
【公開日】平成25年4月25日(2013.4.25)
【国際特許分類】
【出願番号】特願2011−216496(P2011−216496)
【出願日】平成23年9月30日(2011.9.30)
【出願人】(000002093)住友化学株式会社 (8,981)
【Fターム(参考)】
【公開日】平成25年4月25日(2013.4.25)
【国際特許分類】
【出願日】平成23年9月30日(2011.9.30)
【出願人】(000002093)住友化学株式会社 (8,981)
【Fターム(参考)】
[ Back to top ]