
多重範囲スキャンでのNソートクエリを最適に処理する方法及び装置
【課題】本発明は、多重範囲スキャンでのNソートクエリを最適に処理するための方法及び装置に関する。
【解決手段】本発明によるクエリ処理方法は、クエリ処理装置で実行される各段階が、クエリに含まれた抽出レコード数に基づいてバッファを割り当てる段階と、前記クエリに含まれた第1リストのうち第1属性に係わる第1データを抽出して前記バッファに記憶する段階と、前記クエリに含まれた第1リストのうち抽出されていない第1属性に係わる第2データを抽出する段階と、前記バッファに記憶されたデータ及び前記第2データを比較することにより、前記クエリを満たすように前記バッファを更新する段階と、を含み、前記クエリは、第1属性及び第2属性に基づいてソートされた一つ以上のレコードに対する多重範囲スキャンでのNソートクエリである。
【解決手段】本発明によるクエリ処理方法は、クエリ処理装置で実行される各段階が、クエリに含まれた抽出レコード数に基づいてバッファを割り当てる段階と、前記クエリに含まれた第1リストのうち第1属性に係わる第1データを抽出して前記バッファに記憶する段階と、前記クエリに含まれた第1リストのうち抽出されていない第1属性に係わる第2データを抽出する段階と、前記バッファに記憶されたデータ及び前記第2データを比較することにより、前記クエリを満たすように前記バッファを更新する段階と、を含み、前記クエリは、第1属性及び第2属性に基づいてソートされた一つ以上のレコードに対する多重範囲スキャンでのNソートクエリである。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、多重範囲スキャンでのNソート(N sort)クエリを最小の時間と最小のメモリ空間で、最適に処理するための方法及び装置に関する。より詳細には、データベース管理システム(Database Management System、以下「DBMS」という)に含まれるインデックス(index)を用いて、範囲スキャン(range scan)機能を提供する全てのデータ管理システムに適用可能である多重範囲スキャンでのNソートクエリを最適に処理する方法及び装置に関する。
【背景技術】
【0002】
インターネットの発達に伴い、インターネットを利用する様々なSNS(Social Networking Service)が脚光を浴びている。SNSは、オンライン上で知人との人間関係を深め、不特定の人と新しい人間関係を築くことができるようにするサービスを通称するものである。SNSとしては、韓国ではSKコミュニケーションズのサイワールド(Cyworld)、米国ではフェイスブック(Facebook)など、それぞれの特性による様々な種類の開発及びサービスが提供されている。
【0003】
SNSの一分野として、マイクロブログ(Microblog)も最近多くのユーザにより使用されている。マイクロブログとは、一、二文の短いメッセージを利用して多数の人とコミュニケーションができるブログの一種であり、ミニブログ(miniblog)とも呼ばれている。マイクロブログの特徴は、短いテキストを用いて、ユーザが互いに情報を発信し、発信した情報がリアルタイムでアップデートされるという特性を有している。また、マイクロブログでは、写真や動画などをアップロードすることもできる。即ち、ブログとメッセンジャを結合したような形態であり、ユーザはまるでチャットをしているような感じを受ける。また、個人の細かい日常の出来事や普段考えていること、感じたこと、感情、情報などを短いテキストで作成して交流するため、書くことや読むことに対する負担なく、簡単に使用できるという長所がある。、このため、マイクロブログは、多くの人気を集めている。マイクロブログの代表的な例としては、ツイッタ(twitter)、及び韓国ではミートゥデイ(me2day)などが挙げられる。
【0004】
SNS、特にマイクロブログの場合、多くのユーザが交わす情報がほぼリアルタイムで更新される。そして、ユーザ本人やユーザと関係がある他のユーザ(以下、「友達」という、少なくとも数人〜数千または数万人以上)が交わす情報から、最新情報の一部のみを抽出してユーザ本人または友達に表示する方式のクエリが非常に頻繁に使用されている。例えば、友達が作成した文章のうち最近作成した所定個数(例えば、N(Nは自然数)個)の文章、またはある特定時点以後に作成されたN個の文章のみを抽出するクエリが頻繁に使用されている。このようなクエリの処理は、各友達に対して特定時点以後にその友達が作成した文章を範囲スキャンするだけでなく、全ての友達に対して繰り返して実行する多重範囲スキャン(multi−range scan)の形態で実行しなければならない。そのため、このような多重範囲スキャンによりアクセスする友達の文章のうち最新またはある特定時点以後のN個の文章のみをソート順に抽出(以下、このような抽出に用いられるクエリを「Nソートクエリ」という)するための作業が必要である。しかし、従来のデータベース管理システム(Database Management System、以下「DBMS」という)を含むデータ管理システムは、SNSなどで主に使用されている多重範囲スキャンでのNソートクエリに対する最適化処理を考慮していない状態である。一例として、既存のDBMSでは、多重範囲スキャンによりアクセスされる友達の全ての文章を中間結果として抽出した後、抽出した文章を生成時間の逆順にソートしなければならない。このため、その処理速度が非常に遅く、中間結果を記憶するために非常に大きい記憶空間が必要となるという問題点があった。これにより、既存のDBMSの機能のみでは、SNSなどで頻繁に実行されるクエリを効率的に処理するには足りない面が多かった。
【0005】
このような従来のクエリ処理方式は、ユーザ毎に作成した文章の数が多くなるほど、また友達の数が多くなるほど、DBMSがスキャンしなければならない全体レコードの数が幾何級数的に増加する。そのため、ソートのために必要な中間レコードセットを格納するための多くのメモリ空間が必要であり、その多くのレコードをソートするための作業実行に対する負担のため、クエリ処理にかかる時間及び空間の無駄が非常に多かった。
【0006】
従って、SNSなどで頻繁に使用される多重範囲スキャンでのNソートクエリを受信した場合、スキャン対象となる友達の文章の数を最小化しながらも、限定された大きさの記憶空間のみを使用して該当クエリ処理を実行することができる方式、即ち、時間及び空間的なコストの面で最適なクエリ処理方式に対する要求が高まっている。
【0007】
さらに、このようなクエリ処理方式は、既存のDBMSだけでなく、DBMSの前段で範囲スキャン機能を提供する高速のデータリポジトリ、即ち、メモリでのみデータを記憶管理して、そのデータのコレクション(collection)に対するインデックスを用いて範囲スキャンを提供する高速のデータリポジトリにおいても、その必要性が高まっている。例えば、最近多く開発されているNoSQLデータベース、即ち、SQLインタフェースを用いたクエリ処理機能を提供するDBMSでなく、新しいインタフェースを提供し、処理性能またはシステム拡張性に重点を置いているデータベースタイプにこのような高速のデータリポジトリが含まれている。
【先行技術文献】
【特許文献】
【0008】
【特許文献1】韓国公開特許第2000―0047630号公報
【発明の概要】
【発明が解決しようとする課題】
【0009】
本発明の目的は、上述した従来技術の問題点を解決することにある。
【0010】
本発明の目的は、多重範囲スキャンでのNソートクエリを受信した場合、スキャン対象となるレコードの数を最小化にしながら、スキャン中にソートされた結果を直ちに得るようにすることで、クエリ処理にかかる時間を最小化しながらも少ないメモリ空間のみを使用するようにすることである。
【0011】
本発明の他の目的は、クエリ処理技術をDBMSまたは高速のデータリポジトリを用いて、SNSなど多重範囲スキャンでのNソートクエリを多く使用する環境で用いることで、SNSなどのサービスを行う時のクエリ処理性能を極大化することにある。本発明のさらに他の目的は、開発者が従来のDBMSで効果的なクエリ処理のために、DBMS毎に多重範囲スキャンでのNソートクエリがどのように処理されるか内部的な処理方式を把握し、それに応じてDBMS毎に最適化するためにクエリを修正する必要がなく、従来のクエリをそのまま使用しても最適の方式でNソートクエリが処理されるため、SNSなどの設計及び開発などにおいてその便宜性及び開発速度の向上を図ることができるようにすることにある。
【課題を解決するための手段】
【0012】
上記のような本発明の目的を果たし、後述する本発明の特有の効果を果たすための本発明の特徴的な構成は下記のとおりである。
【0013】
本発明の一実施形態によるクエリ処理方法は、クエリに含まれた抽出レコード数に基づいてバッファを割り当て、前記クエリに含まれた第1リストのうち第1属性に係わる第1データを抽出して前記バッファに記憶し、前記クエリに含まれた前記第1リストのうち抽出されていない前記第1属性に係わる第2データを抽出し、前記バッファに記憶された前記第1データ及び前記第2データを比較することにより、前記クエリを満たすように前記バッファを更新し、前記クエリは、前記第1属性及び前記第2属性に基づいて前記ソートされた一つ以上の前記レコードに対する多重範囲スキャンでのNソートクエリであることを特徴とする。
【0014】
本発明の他の態様によるクエリ処理装置は、クエリに含まれた抽出レコード数に基づいてバッファを割り当てるバッファ割り当て部と、前記クエリに含まれた第1リストのうち第1属性に係わる第1データを抽出して前記バッファに記憶し、前記クエリに含まれた第1リストのうち抽出されていない第1属性に係わる第2データを抽出し、前記バッファに記憶されたデータ及び前記第2データを比較することにより、前記クエリを満たすように前記バッファを更新するスキャン部と、を含み、前記クエリは、第1属性及び第2属性に基づいてソートされた一つ以上のレコードに対する多重範囲スキャンでのNソートクエリであることを特徴とする。
【0015】
この他にも、本発明を実現するための上記の方法を行うコンピュータプログラムを記録するコンピュータ読み取り可能な記録媒体がさらに提供される。
【発明の効果】
【0016】
本発明によると、多重範囲スキャンでのNソートクエリを受信した場合、スキャン対象となるレコードの数を最小化にしながら、スキャン中にソートされた結果を直ちに得るようにすることで、クエリ処理にかかる時間を最小化しながらも少ないメモリ空間のみを使用することができる。
【0017】
また、本発明によると、クエリ処理技術をDBMSまたは高速のデータリポジトリに具現し、SNSなど多重範囲スキャンでのNソートクエリを多く使用する環境で使用することで、SNSなどのサービスを行う時のクエリ処理性能を極大化することができる。
【0018】
また、本発明によると、開発者が従来のDBMSで効果的なクエリ処理のために、DBMS毎に多重範囲スキャンでのNソートクエリがどのように処理されるか内部的な処理方式を把握し、それに応じてDBMS毎に最適化するためにクエリを修正する必要がなく、従来のクエリをそのまま使用しても最適の方式でNソートクエリが処理されるため、SNSなどの設計及び開発などにおいてその便宜性及び開発速度の向上を図ることができる。
【図面の簡単な説明】
【0019】
【図1】本発明の一実施形態によるDBMSが多重範囲スキャンでのNソートクエリ処理時において、インデックスを用いてスキャンする範囲を示す図面である。
【図2】本発明の第1実施形態及び第2実施形態による多重範囲スキャンでのNソートクエリを処理するクエリ処理装置を示す構成図である。
【図3】本発明の第1実施形態によるスキャン部で実行される多重範囲スキャンでのNソートクエリの処理方法を示すフローチャートである。
【図4】本発明の第2実施形態によるスキャン部で実行される多重範囲スキャンでのNソートクエリの処理方法を示すフローチャートである。
【図5】本発明の第2実施形態によるスキャン部で実行される多重範囲スキャンでのNソートクエリの処理方法を示すフローチャートである。
【図6】本発明の第1実施形態による多重範囲スキャンでのNソートクエリの処理方法のうちローバッファを更新する工程を示す図面である。
【図7a】本発明の第2実施形態による多重範囲スキャンでのNソートクエリの処理方法のうちスキャンバッファ及びローバッファの形態とスキャンバッファ及びローバッファの更新工程を示す図面である。
【図7b】本発明の第2実施形態による多重範囲スキャンでのNソートクエリの処理方法のうちスキャンバッファ及びローバッファの形態とスキャンバッファ及びローバッファの更新工程を示す図面である。
【図7c】本発明の第2実施形態による多重範囲スキャンでのNソートクエリの処理方法のうちスキャンバッファ及びローバッファの形態とスキャンバッファ及びローバッファの更新工程を示す図面である。
【図7d】本発明の第2実施形態による多重範囲スキャンでのNソートクエリの処理方法のうちスキャンバッファ及びローバッファの形態とスキャンバッファ及びローバッファの更新工程を示す図面である。
【発明を実施するための形態】
【0020】
以下、本発明の好適な実施形態を、図面を参照して詳細に説明する。以下の実施形態は、当業者が本発明を十分に実施することができるように詳細に説明される。本発明の多様な実施形態は、互いに異なり、必要などに応じて相互に組み合わせることができることを理解すべきである。例えば、ここに記載されている特定形状、構造及び特徴は、一実施形態に関連して本発明の思想及び範囲を外れずに他の実施形態に用いることができる。また、それぞれの開示された実施形態の構成要素の位置または配置は、本発明の思想及び範囲を外れずに変更可能であることを理解すべきである。従って、後述する詳細な説明は限定的な意味で扱うものでなく、本発明の範囲は、適切に説明されるならば、その特許請求の範囲が主張するものと均等な全ての範囲と共に、添付した特許請求の範囲によってのみ限定される。図面において、同一の参照符号は、様々な側面にわたって同一または類似の機能を示す。
【0021】
以下、本発明が属する技術分野において通常の知識を有する者が本発明を容易に実施できるように、本発明の好適な実施形態について添付図面を参照して詳細に説明する。
【0022】
[クエリ処理時のスキャン範囲]
図1は、本発明の一実施形態によるDBMSが、多重範囲スキャンでのNソートクエリの処理時に、インデックス(index)を用いてスキャンする範囲を示す図面である。
【0023】
多重範囲スキャンでのNソートクエリを利用するサービスまたはシステムにおいて、ユーザが作成する文章の記憶と検索対象となるデータベースは様々な方式で実現できる。また、一般的に、文章を作成したユーザのID、作成した時間情報を示すタイムスタンプ(Time Stamp)、作成された文章の内容、及び付加的な情報に対する属性をさらに有してもよい。以下、説明の便宜上、DBMSとSQL(Structured Query Language)を基に説明する。DBMSでユーザのIDをuserid、タイムスタンプをts、作成された文章の内容をcontentsと命名したテーブルを以下の表1のように示す。表1に示したテーブルの名称をpostsと仮定する。
【0024】
【表1】

【0025】
一方、上記表1のようなpostsテーブルで、あるユーザの友達全体を対象として最近作成され、または、特定時点から最も近い時期に作成された文章から特定個数の文章のみを抽出するための多重範囲スキャンでのNソートクエリは多様な方式で実現されてもよく、一般的に以下の例示的なSQL文のように実現することができる。
【0026】
SELECT ts、 userid
FROM posts
WHERE userid IN(friends_list)AND ts<sysdate()
ORDER BY ts DESC
LIMIT N;
(ここで、friends_listは所定ユーザの友達のユーザIDリストのみを含み、所定ユーザを含んで友達のユーザIDリストを含む。これは、該当クエリを実行する特定サービスまたはシステムでどのようなユーザの文章を集めるかによって変わる。また、Nは抽出する文章の個数を意味する。)
【0027】
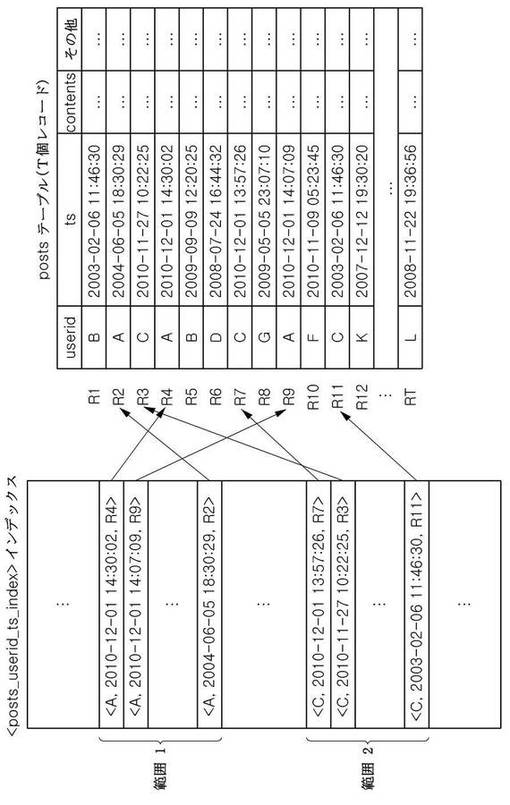
このSQL文を効率的に処理するためには、表1に示すpostsテーブルに対してユーザIDの順に、その内部でタイムスタンプの逆順にレコードを速く検索するためのインデックスが必要である。このため、一般的にuseridに対して昇順、tsに対して降順のキー(key)を有するインデックスを生成し、このようなインデックスを説明の便宜上「posts_userid_ts_index」と仮定する。
【0028】
インデックスは、テーブルの各レコードに対応する一つのキーを保持する。ここで、その一つのキーは、キー値とそのキー値を有するレコードの識別子で構成される。例えば、図1に示す範囲1の一番目のキーは、キー値としてA及び2010−12−01 14:30:02を有し、さらに、このキー値を有するレコードの識別子として、R4を有する。または、メモリに全てのデータを記憶するメインメモリデータベース(Main−Memory DBMS:MMDBMS)の場合、キー値を有するレコードが常にメモリに記憶されているため、キーのレコード識別子を介して、そのキー値を直接アクセスすることできる。従って、MMDBMSでインデックスのキーは、一般的にレコード識別子のみを有する。よって、図1に示したインデックスでのキーは、キー値とレコード識別子を全て有する一般的なディスクDBMSを仮定して表現したものであり、インデックスでのキー構成が図1に限定されず、データリポジトリの具現特性によってインデックスでのキー構成が変わることは自明である。上述した表1のようにレコードが任意の順に記憶されており、図1の右側に示したpostsテーブルに対して上記のSQL文を効率的に実行するためには、図1の左側に示したようにpostsテーブルに係る「posts_userid_ts_index」インデックスが備えられることが前提とされる。この「posts_userid_ts_index」インデックスを基に、本発明の実施形態によってSQL文のような多重範囲スキャンでのNソートクエリを実行するための具体的な順序については、図6−図7dを参照して以下でより詳細に説明する。
【0029】
[多重範囲スキャンでのNソートクエリを処理するクエリ処理装置]
図2は、本発明の一実施形態による多重範囲スキャンでのNソートクエリを処理するクエリ処理装置を示す構成図である。
【0030】
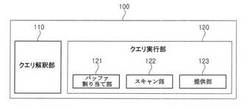
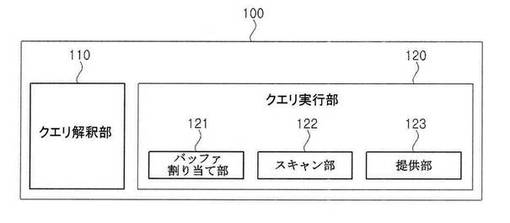
図2を参照すると、本発明の一実施形態によるクエリ処理装置100は、クエリ解釈部110とクエリ実行部120とに大別される。クエリ実行部120は、バッファ割り当て部121と、スキャン部122と、提供部123と、を含む。
【0031】
本発明の一実施形態によるクエリ解釈部110は、特定形式によるクエリを受信し、受信されたクエリが多重範囲スキャンでのNソートクエリであるか否かを判断する。クエリ解釈部110に特定形式によるクエリを伝送する伝送装置とは、クエリ処理装置100との通信を介してクエリ処理装置100にアクセスしてデータを要求することができる装置または構成要素を全て含む広義の概念である。クエリ処理装置100に対するクエリ伝送は、伝送装置とクエリ処理装置100との間の認証などの手順を経て、伝送装置がクエリ処理装置100にクエリを介して特定データを要求することができる正当な権限があるか否かを予め確認した後に行ってもよい。この場合、認証手順は公知のDBMSアクセス(access)時に使用される認証手順を利用することができる。クエリ解釈部110が受信した特定形式によるクエリは、公知のSQLによるSQL構文であってもよい。クエリ解釈部110はパージング(parsing)機能を利用して、受信されたクエリが多重範囲スキャンでのNソートクエリであるか否かを判断することができる。
【0032】
本発明の一実施形態によるクエリ解釈部110は、単に多重範囲スキャンでのNソートクエリであるか否かを判断するだけでなく、受信したクエリを具体的に解釈し、抽出されるべきのレコードの数、スキャン対象となるユーザID及びソートの基準となるタイムスタンプ値などに関する情報をさらに解釈して抽出する機能をさらに備えていてもよい。
【0033】
本発明の一実施形態によるクエリ実行部120は、クエリ解釈部110により解釈された情報に基づいてクエリを実行する。クエリ実行部120は、様々な構成要素を有してもよい。なお、多重範囲スキャンでのNソートクエリに対する効率的な処理方式に焦点を当てその説明を容易にするために、バッファ割り当て部121、スキャン部122、提供部123を有してもよい。まず、本発明の一実施形態によるバッファ割り当て部121は、クエリ解釈部110により、受信されたクエリが多重範囲スキャンでのNソートクエリであると判断された場合、メモリ上にスキャンのための一時的な記憶空間であるバッファを割り当てる。割り当てられるバッファの大きさは、クエリ解釈部110により解釈された情報のうち抽出されるべきのレコードの個数に対応する。例えば、抽出されるべきのレコードの個数がN個であると、バッファ割り当て部121は、後述するスキャン部122のスキャン方式に応じて、N個のソートができるローバッファ(row buffer)、またはN個のスキャンバッファ(scan buffer)とローバッファ(row buffer)を割り当てる。ここで、ローバッファとは、インデックススキャンにより抽出されるレコードのキー値と識別子を記憶したり、またはレコードの識別子のみを記憶したりすることができるメモリ領域を意味する。また、スキャンバッファとは、多数のユーザに対するインデックススキャンのうち最新のレコードをスキャンしているインデックススキャンの識別子情報を記憶することができるメモリ領域を意味する。次に、本発明の一実施形態によるスキャン部122は、バッファ割り当て部121により割り当てられた、限定された数のバッファを利用して、最小限のインデックススキャンによりクエリ解釈部110により解釈された多重範囲スキャンで最上位のNソートクエリを行う。本発明の好ましい実施形態によるスキャン部122の具体的なクエリ実行順序については後述する。
【0034】
最後に、本発明の一実施形態による提供部123は、スキャン部122の動作により実行されたクエリに対する結果として、バッファ割り当て部121により割り当てられたローバッファに記憶された特定個数のレコードをクエリに対する結果としてクエリを要請した特定個体に伝送する。
【0035】
図2に示すクエリ解釈部110、クエリ実行部120のバッファ割り当て部121、スキャン部122及び提供部123は、物理的に単一の装置内に構成されてもよく、一部またはそれぞれが物理的に異なる装置に構成されてもよく、また、同様の機能を有する物理的に複数存在する装置が並列的に存在してもよい。このように、本発明の実施形態は、各構成部が設けられた機械またはデータベースの物理的な数及び位置に限定されず、多様な方式に設計変更されることということは、本発明が属する技術分野において通常の知識を有する者において自明のことである。
【0036】
図2の各構成要素は、本発明を説明するために必要な必須構成要素に限定して開示及び説明され、各構成要素は本発明で説明されていない公知の他の機能を実行したり、または図2に示していない、公知の他の機能を実行したりするための別の構成要素がクエリ処理装置100内に追加され得るということは、本発明が属する技術分野において通常の知識を有する者において自明のことである。
【0037】
[第1実施形態]
[多重範囲スキャンでNソートクエリの処理]
次に、図3、図4及び図5を参照して、本発明の好ましい実施形態により、スキャン部122で実行される多重範囲スキャンでのNソートクエリの処理方法について詳細に説明する。
【0038】
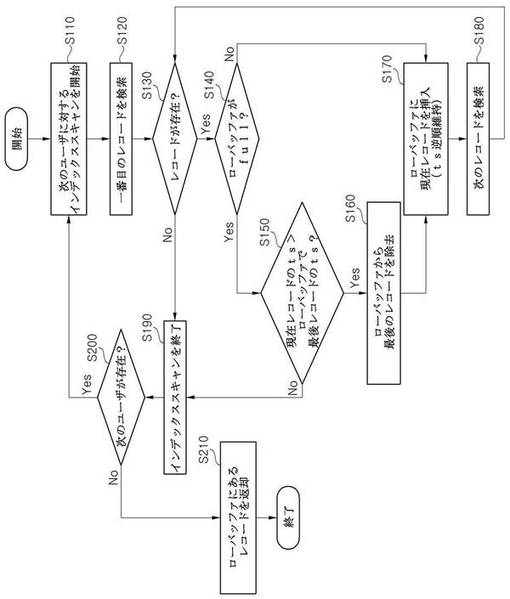
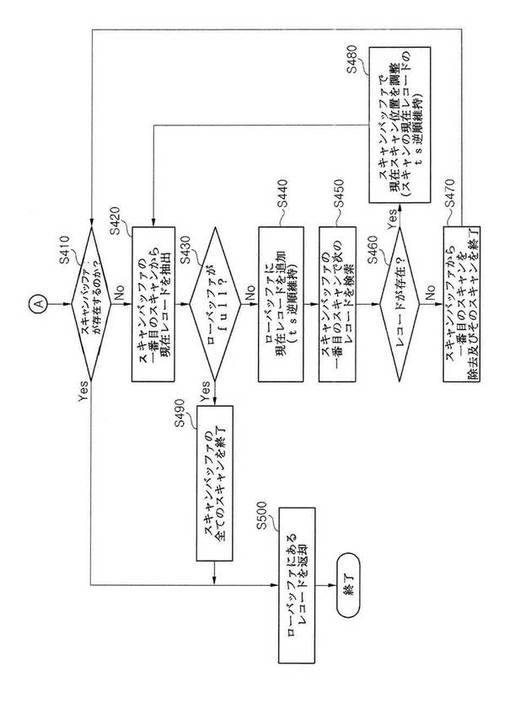
まず、本発明の第1実施形態によると、バッファ割り当て部121は抽出されるべきのレコードの数(以下、「N」という)だけのローバッファを割り当てていることを仮定する。図3に示した本発明の第1実施形態によると、クエリ処理装置100のスキャン部122は、上記表1で仮定した「posts_userid_ts_index」インデックスを基に各ユーザに対して、最新または特定時点以後の文章のみを検索するためのインデックススキャンを始める(ステップS110)。インデックススキャンは、インデックスを、たとえばルート(root)ノードから最下位ノードであるリーフ(leaf)ノードまで探索しながら、検索条件を満たす一番目のレコードを検索する(ステップS120)。検索条件を満たす一番目のレコードが見つけられなかった場合は(S130)、現在ユーザが特定時点以後に作成された文章が存在しないということを意味するため、現在のインデックススキャンを終了する(S190)。検索条件を満たす一番目のレコードが存在する場合は(S130)、スキャン部122は、ローバッファに現在のレコード情報を記憶するための作業を以下のように実行する。即ち、まず、N大きさのローバッファがフル(full)状態であるかを確認する(S140)。ローバッファがフル状態でない場合は(S140)、レコード情報を記憶する空間がローバッファに残っている状態であることを意味するため、現在検索したレコードのタイムスタンプ値とローバッファに記憶されたレコードのタイムスタンプ値とを比較して、タイムスタンプの逆順が維持されるように、ローバッファに挿入すべき位置を探してその位置に現在レコード情報を記録する(S170)。このような方式により、ローバッファ内に記憶されたレコード情報は、常にそのタイムスタンプの逆順にソートされている。ローバッファがフル状態である場合は(S140)、現在検索したレコードのタイムスタンプ値とローバッファに記憶された最後のレコード、即ち、タイムスタンプの逆順にソートされたローバッファで最も小さいタイムスタンプ値を有するレコードのタイムスタンプ値とを比較して、現在検索したレコードをローバッファに挿入できるかを確認する(S150)。現在のレコードのタイムスタンプ値がローバッファにある最後のレコードのタイムスタンプ値より小さいかまたは同一である場合は(S150)、現在のユーザが作成した文章が、既に他のユーザが作成した、即ち、ローバッファ内に記憶されたレコード情報に対応するN個の文章より古い文章ということが明らかであるため、現在ユーザに対して検索したレコードをローバッファに挿入する必要がなく、現在ユーザの次のレコードを検索する必要もなくなる。従って、現在ユーザの文章をスキャンする作業を中止する(S190)。現在のレコードのタイムスタンプ値がローバッファにある最後のレコードのタイムスタンプ値より大きい場合は(S150)、最後のレコードをローバッファから除去した後(S160)、ローバッファに現在のレコードを挿入する(S170)。この場合にも、ローバッファに記録されたレコードは、タイムスタンプの逆順へのソートが維持されるように、現在のレコードの適切な挿入位置を探して挿入する(S170)。本発明の第1実施形態によるローバッファへのレコードの挿入によるローバッファの更新を示した図6を参照すると、スキャン部122が、既にN個のレコードが記憶されているローバッファ内にユーザCが作成したレコードが抽出され挿入されようとしている。挿入されようとする、ユーザCが作成したレコードのタイムスタンプは「2010−12−01 13:57:26」であり、ローバッファに記憶された最後のレコードのタイムスタンプである「2010−11−29 23:48:01」より最新のものである。また、2番目に位置するタイムスタンプが「2010−12−01 14:07:09」であるレコードよりは最新ではないが、3番目に位置するタイムスタンプが「2010−12−01 13:46:52」であるレコードよりは最新のものであるため、その間に位置するべきである。従って、スキャン部122は、ローバッファの最後の位置にあるレコード(識別子がR44であるレコード)を除去し、ローバッファの3番目の位置に現在レコードを記憶する。従って、元のローバッファで3番目の位置からN−1番目の位置まで記憶されていたレコードは、ユーザCが作成したレコードの挿入により一つずつ後側に移動して記憶される。従って、挿入後のローバッファに記憶された最後のレコードは、従来のN−1番目の位置に記憶されたレコードと同一の、識別子としてR62を有するレコードであることが分かる。
【0039】
また、図3をさらに参照すると、ローバッファに現在検索したレコードを挿入した場合には、現在のインデックススキャンにより次のレコードを検索し(S180)、次のレコードの存在有無に応じて(S130)上述の処理工程を繰り返す。
【0040】
現在のユーザに対するインデックススキャンで検索するレコードがそれ以上ない場合や(S130)、検索したレコードのタイムスタンプがローバッファに記録されたレコードの最小タイムスタンプ値より小さいかまたは同一である場合(S150)、現在のユーザに対するスキャンをそれ以上行う必要がないため、上述のように現在のユーザに対するインデックススキャンを終了する(S190)。
【0041】
現在のユーザに対するスキャンを終了すると、次のユーザがあるかを確認する(S200)。次のユーザがある場合(S200)、そのユーザに対するインデックススキャンを始め(S110)、上述の処理工程を繰り返す。次のユーザがない場合(S200)、ローバッファにあるレコードが最終のクエリ結果となるため(S210)、全体処理工程を終了する。ここで、ユーザとは、Nソート結果を得るクエリを利用するサービスまたはシステムの設計または開発特性によって、所定ユーザ本人を含むかまたは含まない所定ユーザの友達を意味する。
【0042】
図3に示した本発明の第1実施形態の順序を実行して完了した場合、バッファ割り当て部121により割り当てられたN個のローバッファに記憶されたN個のレコードは、クエリ解釈部110により解釈された多重範囲スキャンでのNソートクエリの実行結果として、所定ユーザの友達(所定ユーザが含まれてもよく、含まれなくてもよい)が作成した全ての文章を対象として最新または特定時点以後に作成されたN個の文章を格納していることが分かる。
【0043】
[第2実施形態]
図4及び図5は本発明の第2実施形態によるスキャン部122が多重範囲スキャンでのNソートクエリを実行する順序を示したフローチャートである。
【0044】
まず、DBMSまたは他のデータリポジトリからインデックススキャンにより特定範囲のレコードを検索する場合の技術的な順序を詳細に説明する。インデックスアクセス時にスキャン対象となるテーブルとインデックスをアクセスするための情報を取り込み、インデックススキャン情報を格納するための構造体に格納しておく。そして、その情報に基づいてそのインデックスをアクセスする。例えば、インデックスのルート(root)ノード識別子などがこれに該当する。また、インデックスを用いて検索するキーの範囲及び範囲内の各キーまたはレコードに対して適用するフィルタリング情報などを保管し、これを用いて検索範囲にあるキーまたはレコードをスキャンする際に検索条件に合致するレコードを探す。その他にも、インデックスで現在アクセスしているキーの位置情報とそのキーを有するレコードの識別子を維持する。このような情報は、初めは空値(NULL)などとして設定され、一番目のレコードとともに次のレコードを探す度に現在のキーと現在のレコード情報に更新される。インデックススキャンによりスキャン範囲を外れると、スキャン情報が格納されている構造体を破棄するなどのインデックススキャンの終了作業を行う。
【0045】
次に、本発明の第2実施形態におけるスキャンバッファは、各インデックススキャンが現在指し示しているレコードのタイムスタンプを基準に、最新のタイムスタンプを有するレコードを指し示すインデックススキャンの識別子情報を記憶するバッファである。インデックススキャンの識別子としては、インデックススキャン情報を有している構造体のアドレス(address)としてもよく、インデックススキャン情報を有している構造体が配列(array)形態に構成される場合、その配列での位置値になってもよい。または、DBMSでなく他のデータリポジトリでは、テーブルの概念がなく実際のレコードのデータがインデックスのキー内に全て含まれてもよく、スキャンの現在のキー位置情報のみを有してスキャンを行ってもよい。例えば、スキャンを開始する際に、現在のキーの位置情報はルートノードに設定された後、一番目のキーまたは次のキーを探す度に現在のキーの位置情報は実際のキーの位置情報に設定されてもよい。この場合、キーの位置情報の大きさが大きくないため、このようなキーの位置情報そのものをスキャンバッファに記録することもできる。従って、スキャンバッファに記録される情報は、インデックススキャン機能を提供する該当データリポジトリの実際の内部方式によって変わることは当業者において自明のことである。
【0046】
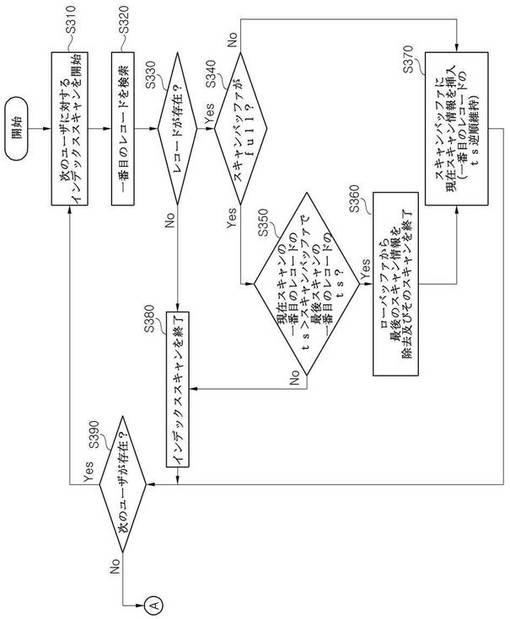
本発明の第2実施形態によると、バッファ割り当て部121は抽出されるべきレコードの個数(以下、「N」個という)だけのスキャンバッファ及びローバッファを割り当てていることを仮定する。図4を参照して、上述の特定レコード抽出の順序及び仮定事項を参照して本発明の第2実施形態を説明する。クエリ処理装置100のスキャン部122は、上述の「posts_userid_ts_index」インデックスを利用して、各ユーザに対して最新または特定時点以後の文章のみを検索するためのインデックススキャンを開始する(S310)。インデックススキャンは、該当インデックスを探索して検索条件を満たす一番目のレコードを検索する(S320)。検索条件を満たす一番目のレコードが存在しない場合(S330)、現在のユーザが特定時点以後に作成された文章が存在しないということを意味するため、現在のインデックススキャンを終了する(S380)。検索条件を満たす一番目のレコードが存在する場合(S330)、スキャンバッファに現在のインデックススキャン情報を記憶するための処理を実行する。このために、まず、N大きさのスキャンバッファがフル状態であるかを確認する(S340)。スキャンバッファがフル状態でない場合(S340)、インデックススキャン情報を記憶する空間がスキャンバッファに残っている状態であることを意味するため、現在インデックススキャンが指し示すレコードのタイムスタンプ値とスキャンバッファに記録されたインデックススキャンが指し示すレコードのタイムスタンプ値とを比較して、タイムスタンプの逆順にソートされるように、スキャンバッファに挿入する位置を探して該当位置に現在のインデックススキャン情報を記録する(S370)。このような方式により、スキャンバッファ内に記憶されたインデックススキャン情報は、それぞれのインデックススキャンが指し示すレコードのタイムスタンプが逆順にソートされている。スキャンバッファがフル状態である場合(S340)、現在インデックススキャンが指し示すレコードのタイムスタンプ値と、それぞれのインデックススキャンが指し示すレコードのタイムスタンプの逆順にソートされたスキャンバッファに記憶された最後のインデックススキャンが指し示すレコードのタイムスタンプ値と、を比較することにより、現在のインデックススキャンをスキャンバッファに挿入できるかを確認する(S350)。現在のインデックススキャンが指し示すレコードのタイムスタンプ値がスキャンバッファに記録された最後のインデックススキャンが指し示すレコードのタイムスタンプ値より小さいかまたは同一である場合(S350)、これは、現在インデックススキャンの検索対象となるユーザが作成した文章より最新の文章を作成したユーザに対するインデックススキャンが既にスキャンバッファにN個登録されている状態であることを意味するため、現在ユーザに対するインデックススキャンをそれ以上行う必要がなくなる。従って、現在ユーザに対するインデックススキャン作業を中止する(S380)。現在インデックススキャンが指し示すレコードのタイムスタンプ値がスキャンバッファに記録された最後のインデックススキャンが指し示すレコードのタイムスタンプ値より大きい場合(S350)、スキャン部122は、それぞれのインデックススキャンが指し示すレコードのタイムスタンプの逆順にソートされたスキャンバッファで最も古いタイムスタンプを有したレコードを指し示すインデックススキャンである最後のインデックススキャン情報をスキャンバッファから除去し、そのスキャンを終了させた後(S360)、現在のインデックススキャンの情報をスキャンバッファに挿入する(S370)。この場合にも、スキャンバッファでインデックススキャンが指し示すレコードのタイムスタンプの逆順にそのインデックススキャンの記憶順序が維持されなければならないため、現在のインデックススキャンの適切な挿入位置を探して挿入する。現在ユーザに対するインデックススキャンで検索する一番目のレコードがない場合(S330)や、現在インデックススキャンが検索した一番目のレコードのタイムスタンプがスキャンバッファに記録された最後のインデックススキャンが指し示すレコードの最小タイムスタンプ値より小さいか同一である場合(S350)は、現在ユーザに対するスキャンをそれ以上行う必要がないため、上述のように現在ユーザに対するインデックススキャンを終了した後(S380)、次のユーザが存在するかを確認する段階(S390)に進む。また、現在のインデックススキャンをスキャンバッファに登録した場合にも(S370)、そのインデックススキャンを終了していない状態で次のユーザが存在するかを確認する段階(S390)に進む。次のユーザが存在する場合(S390)、そのユーザに対するインデックススキャンを始めて(S310)、上述の処理工程を繰り返す。次のユーザが存在しない場合は(S390)、スキャンバッファには最新または特定時点以後に作成されたN個のレコードを抽出するに適したインデックススキャンが登録された状態であることを意味する。
【0047】
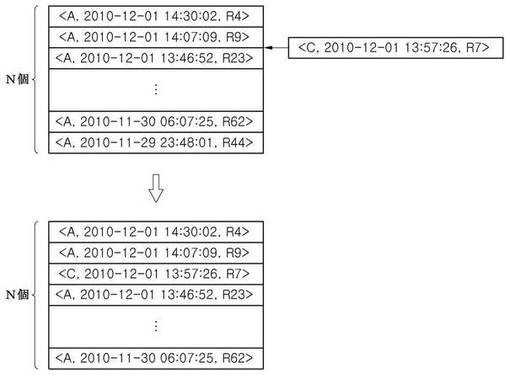
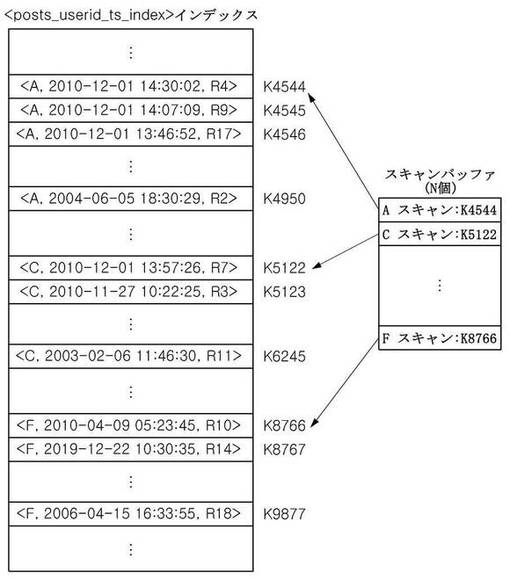
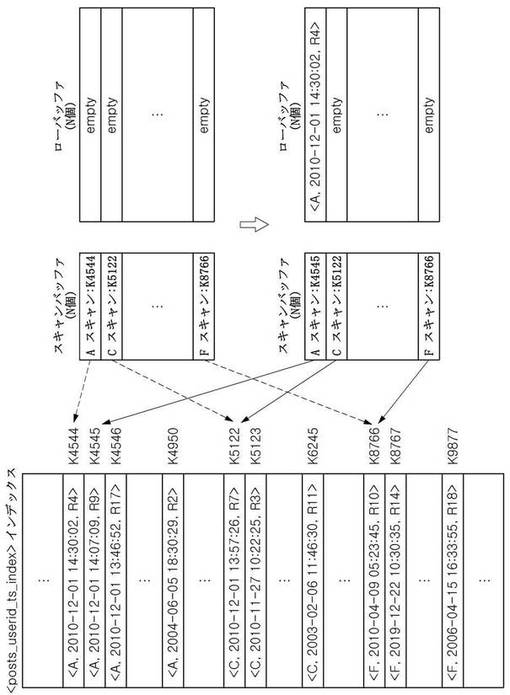
このような段階を経て得られるスキャンバッファの一例は図7aに図示されている。右側のスキャンバッファに記憶されたユーザAに対するインデックススキャンは、左側の「posts_userid_ts_index」インデックスにおいてユーザAによるレコードのうち最もタイムスタンプが最新であるレコードを指し示しており、ユーザCとFに対するインデックススキャンもそれぞれユーザCとFによるレコードのうち最もタイムスタンプが最新であるレコードを指し示している。また、各インデックススキャンが指し示すレコードのタイムスタンプの逆順にこれらインデックススキャンの位置が順序化されている。
【0048】
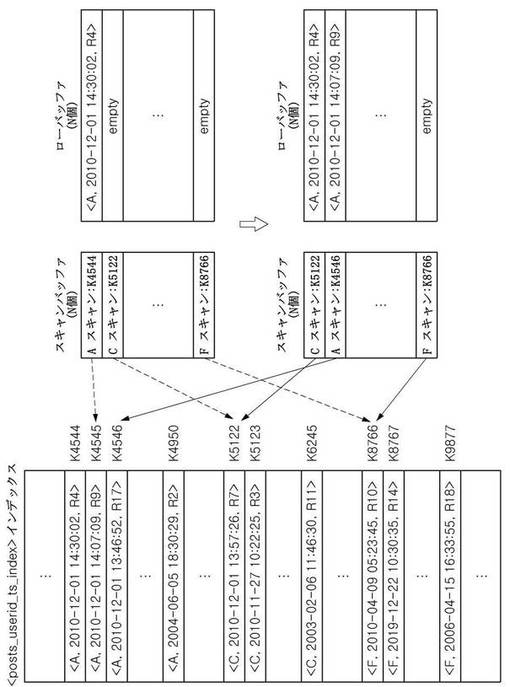
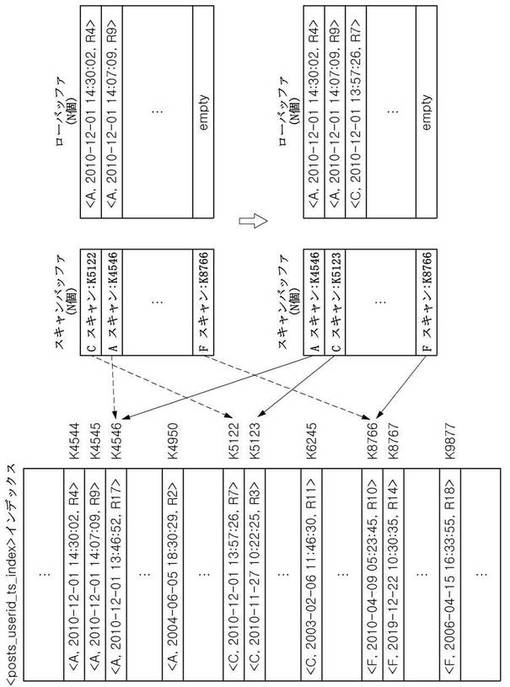
次に、指し示すレコードのタイムスタンプの逆順にソートされた、スキャンバッファに格納されたインデックススキャンを基に、最新または特定時点以後に作成されたN個の文章のみを抽出するための順序を、図5を参照して詳細に説明する。スキャン部122は、まずスキャンバッファに記録されたインデックススキャンが存在するかを確認する(S410)。インデックススキャンが存在する場合(S410)、スキャンバッファに存在する一番目のインデックススキャンが指し示すレコード、即ち、最新のタイムスタンプを有するレコードを抽出した後(S420)、そのレコードをローバッファに記録する処理を実行する。ここで、スキャンバッファに記憶されたインデックススキャンはそれらがそれぞれ指し示しているレコードのタイムスタンプの逆順、即ち最新の順にソートされているため、段階S420で抽出されるレコードはスキャンバッファの先頭にあるインデックススキャンが指し示すレコードに該当する。この作業は、ローバッファがフル状態であるかを先に確認してから実行する(S430)。ローバッファがフル状態でないと(S430)、ローバッファに空いている先頭の空間にそのレコードを挿入する(S440)。その後、現在のインデックススキャンで次のレコードを検索し(S450)、次のレコードが存在するかを確認する(S460)。次のレコードが存在しない場合(S460)、現在のインデックススキャンをスキャンバッファから除去し、そのインデックススキャンを終了する(S470)。その後、スキャンバッファにインデックススキャンが残っているかを確認する段階(S410)に進む。次のレコードが存在する場合(S460)、現在インデックススキャンが指し示すレコードが次のレコードに変更されたため、そのレコードのタイムスタンプ値を基準にスキャンバッファで現在のインデックススキャンの位置を再調整する(S480)。この場合にも同様に、レコードのタイムスタンプの逆順にソートされたインデックススキャンの順序が維持されるように、適切な位置にインデックススキャン情報を挿入することによりスキャンバッファで位置を再調整する。インデックススキャンの位置を再調整する場合、スキャンバッファにインデックススキャンが残っているということが保障され、また、スキャンバッファに記憶されたインデックススキャンもそれぞれが指し示すレコードのタイムスタンプの逆順にソートされた順序が維持されるため、スキャンバッファで先頭にある、即ち最もタイムスタンプが最新のレコードを指し示すインデックススキャンから現在のレコードを抽出する段階(S420)に進み、上述の順序を繰り返す。
【0049】
このような実行順序に従ってスキャンバッファで一番目のインデックススキャンが指し示すレコードを抽出する工程を繰り返すと、抽出するレコードの順序もタイムスタンプが最新である順序になる。従って、このようなレコードをローバッファに挿入する場合、ローバッファに挿入する位置を探すために別のバイナリサーチまたは他の方法による再調整などが必要でなく、単にローバッファの先頭から空いている空間順にレコードを追加(append)してローバッファを満たしていくとローバッファ内のレコードの順序は、タイムスタンプの逆順にソートされた順序が維持される。
【0050】
一方、スキャン部122がスキャンバッファにある一番目のインデックススキャンが指し示すレコードを抽出してローバッファに記憶しようとする際に、ローバッファが既にフル状態である場合(S430)、これは、既に最新順序のN個のレコードを全て探した状態であることを意味する。従って、それ以上のスキャンを行う必要がないため、スキャンバッファにある全てのインデックススキャンを終了させる(S490)。また、ローバッファにあるN個のレコードが最終結果となるため(S500)、全体処理工程を終了する。
【0051】
上記の順序を実行する工程中に、スキャンバッファにインデックススキャンが存在しない場合があり得る(S410)。この場合は、既にローバッファに0個以上のレコードが存在している状態であり、ローバッファにあるそのレコードが最終結果となるため、スキャン部122は全体処理工程を終了する。参考に、ローバッファにあるレコードの数が0であると、これはクエリの検索条件を満たすレコードがないということを意味する。即ち、多数のユーザが作成した文章のうち特定時点以後に作成された文章がないということを意味し、この結果が正常な実行結果となるのである。
【0052】
本発明の第2実施形態によるスキャンバッファからレコードを抽出してローバッファに挿入または追加する一部実行工程を示すと、図7b、図7c、図7dのとおりである。図7bを参照して、最新レコードを指し示すインデックススキャンがスキャンバッファに登録されており、ローバッファは空いている状態で始める。スキャン部122は、まず一番目のインデックススキャンであるAスキャンでキーの位置情報であるK4544を介して現在のキーまたは現在のレコードをアクセスしてそのレコードをローバッファの先頭に挿入する。また、Aスキャンの次のキーであるK4545に移動して、該当キーが指し示すレコードのタイムスタンプを基準にスキャンバッファでAスキャンの位置を再調整する。キーの位置情報であるK4545が指し示すレコードのタイムスタンプ値は「2010−12−01 14:07:09」であり、スキャンバッファにある二番目のスキャンであるCスキャンの現在キーの位置情報であるK5122が指し示すレコードのタイムスタンプ「2010−12−01 13:57:26」より最新のものであるため、Aスキャンに対してスキャンバッファで一番目の位置をそのまま維持する。次に、二番目のレコードを探すために図7cを参照すると、上記と同様に、スキャン部122は、スキャンバッファにある一番目のインデックススキャンであるAスキャンがK4545を介して現在指し示すキーをアクセスし、そのキーのレコードをローバッファで空いている先頭、即ち二番目の位置に挿入する。次に、Aスキャンの次のキーであるK4546に移動して、そのキーが指し示すそのレコードのタイムスタンプを基準にスキャンバッファでAスキャンの位置を再調整する。この場合、Aスキャンの現在レコードのタイムスタンプ(「2010−12−01 13:46:52」)がCスキャンの現在レコードのタイムスタンプ(「2010−12−01 13:57:26」)より最新でないため、スキャンバッファでCスキャンが先頭に、またAスキャンが二番目の位置に位置するようにスキャンバッファの位置を再調整する。図7dを参照して次のレコードを抽出する工程を説明すると、スキャン部122は、スキャンバッファで一番目のインデックススキャンであるCスキャンの現在レコードを抽出してローバッファに挿入し、Cスキャンの次のキーであるK5123に移動して、スキャンバッファで位置を調整する。この場合にも、CスキャンのキーK5123が指し示すレコードのタイムスタンプ(「2010−11−27 10:22:25」)がAスキャンのキーK4546が指し示すレコードのタイムスタンプ(「2010−12−01 13:46:52」)より最新でないため、それぞれのキーが指し示すレコードのタイムスタンプの逆順にソートされるように、スキャンバッファ内に記憶されたインデックススキャンの位置が再調整される。このような工程をN回実行することにより、ローバッファにはタイムスタンプが最新である順にN個レコードが記憶される。
【0053】
上述の本発明の第1実施形態及び第2実施形態は、以下の点で実行段階の共通点を有していることを確認することができる。
【0054】
まず、クエリ実行部のバッファ割り当て部は、クエリに含まれた抽出レコード数(例えば、N個)に基づいてバッファを割り当てる。第1実施形態の場合はN個のローバッファが、第2実施形態の場合はN個のスキャンバッファ及びローバッファが割り当てられる。次に、ユーザのID順及びタイムスタンプの逆順にインデックスされてソートされた一つ以上のレコードに対する多重範囲スキャンでのNソートクエリとしてクエリ解釈部により解釈されたクエリに基づいて、クエリ実行部のスキャン部は一つのユーザIDに対するレコードを抽出し、第1実施形態の場合はローバッファに、第2実施形態の場合はスキャンバッファに記憶する。その後、上記で抽出されなかったユーザIDに対するレコードを抽出した後バッファに記憶された、上記で抽出されたレコードとタイムスタンプを比較してクエリの内容である多重範囲スキャンでのNソートクエリを満たすために、そのタイムスタンプの逆順を維持するように、第1実施形態の場合はローバッファを、第2実施形態の場合はスキャンバッファを更新する。
【0055】
上述のような本発明の実行段階の共通点に、上記で各図面などを参照して詳細に説明した第1実施形態及び第2実施形態の特有の追加的な実行段階を有機的に組み合わせ、本発明の第1実施形態及び第2実施形態を施すことができる。
【0056】
[従来技術と本発明の実施形態との時間コストの比較]
本発明の第1実施形態及び第2実施形態により、多重範囲スキャンで最上位のNソートクエリを実行する場合、従来技術に比べ得られる速度上の効果を、以下で計算する時間コストにより確認する。
【0057】
まず、各実行方式の時間コストを計算するために、以下のような変数を仮定する。
N:検索しようとするレコードの個数
Us:特定ユーザの友達の数
Kt:該当インデックスで全体キーの数(該当テーブルで全体レコードの数と同一)
Ku:該当インデックスでユーザ毎の平均キーの数(該当テーブルでユーザ毎の平均レコードの数と同一)
Ks:本発明の第1実施形態において、ユーザ毎のインデックスを用いてスキャンするようになる平均キーの数
【0058】
各インデックススキャンでは検索条件を満たす一番目のレコードを探す「get_first_row」演算が1回実行され、次のレコードを探す「get_next_row」演算が検索条件に合致する全てのレコードが探されるまで繰り返して実行される。全体キーの個数がKtであるインデックスにおいて「get_first_row」演算は、一般的にバイナリサーチ(binary search)法によりKt個のキーのうち検索条件を満たす一番目のキーを探してレコードをアクセスするため、log2(Kt)のコストが消費され、「get_next_row」演算は現在キーから次のキーを直ちに探してレコードをアクセスすることができるため、1のコストが消費されるといえる。
【0059】
get_first_row:log2(Kt)
get_next_row:1
【0060】
従来技術による実行方式では、友達ユーザのそれぞれに対してインデックススキャンが行われなければならないためUs回のインデックススキャンが行われ、各インデックススキャン時にKu個のレコードを抽出して中間レコードセットに記憶する。結局、1回のlog2(Kt)コストとKu回の1コストを有したインデックススキャンがUs回実行される。また、記憶された中間レコードセットをタイムスタンプが最新である順にソートする作業は、全体レコードの数が(Us×Ku)である中間レコードセットに対して実行するため、このようなソートコストは(Us×Ku)×log2(Us×Ku)であるといえる。従って、従来技術による実行方式により発生する実行時間コストを数式で表すると、以下の数式1のとおりである。
【0061】
(数式1)
時間コスト(従来技術)=スキャンコスト+ソートコスト
=(Us×(log2(Kt)+Ku))+((Us×Ku)×log2(Us×Ku))
=Us×(log2(Kt)+Ku+Ku×log2(Us×Ku))
=Us×(log2(Kt)+Ku×(1+log2(Us×Ku)))
【0062】
一方、本発明の第1実施形態による実行方式も、友達ユーザのそれぞれに対してインデックススキャンが行われなければならないためUs回のインデックススキャンが実行されることは同じであるが、各インデックススキャン時にKs個のレコードのみを抽出し、抽出されたレコードをN個のローバッファにソートされた順に格納する。即ち、(log2(Kt)+Ks)のスキャンコストを有しながら、抽出したKs個のレコードを、N大きさのローバッファでタイムスタンプの逆順上の挿入位置をバイナリサーチで探して挿入するために、(Ks×log2(N))のコストを有するインデックススキャンがUs回実行される。従って、本発明の第1実施形態による実行方式により発生する実行時間コストを数式で表すると、以下の数式2のとおりである。
【0063】
(数式2)
時間コスト(第1実施形態)=Us×(log2(Kt)+Ks+Ks×log2(N))
=Us×(log2(Kt)+Ks×(1+log2(N)))
【0064】
また、本発明の第2実施形態による実行方式の場合、Us回のインデックススキャンを実行しながら、「get_first_row」演算で探した一番目のレコードのタイムスタンプを基準に比較して、最新のレコードを指し示しているインデックススキャン情報N個を記憶するスキャンバッファに挿入するための作業を実行する。従って、Us回のインデックススキャンそれぞれに対して一番目のレコードを探すためのlog2(Kt)のコストとスキャンバッファに格納するためのlog2(N)のコストが消費されるため、全体コストは(Us×(log2(Kt)+log2(N))となる。その後、スキャンバッファに記憶されたN個のインデックススキャンを利用してソート−併合(sort−merge)方式で最新のレコードを抽出しながら、最終的にN個のローバッファに最新の順にレコードを格納するようになる。これを詳細に説明すると、スキャンバッファにある一番目のインデックススキャンから現在レコードを抽出してローバッファに格納するコストは1が消費され、そのインデックススキャンの次のレコードを得るための「get_next_row」実行コストも1が消費され、またそのインデックススキャンの新しい現在レコードのタイムスタンプを基準にスキャンバッファでそのインデックススキャンを再位置させるためにlog2(N)のコストが消費される。また、このような作業が最大N回実行されるため、全体コストは(N×(log2(N)+2))が消費されるようになる。従って、本発明の第2実施形態による実行方式によって発生する実行時間コストを数式で表すると、以下の数式3のとおりである。
【0065】
(数式3)
時間コスト(第2実施形態)=スキャンしながらスキャン情報をスキャンバッファに格納するコスト+ローバッファに最終レコードを格納するコスト
=(Us×(log2(Kt)+log2(N)))+(N×(log2(N)+2))
【0066】
上記で仮定した各変数に以下のような値を代入して、数式1、2、3により計算された実行時間コストの具体的な値は、以下の表2に示す。
【0067】
N:20
Us:100,000
Kt:100,000,000
Ku:1,000
Ks:5
【0068】
【表2】
【0069】
前記表2に計算されたように、本発明の第1実施形態によると従来技術に比べ約500倍の速度性能の向上が、第2実施形態によると従来技術に比べ約900倍の速度性能の向上がなされることが分かる。
【0070】
また、クエリ実行時に使用される空間コストの面では、従来技術の場合は、Us×Ku個のレコードを中間レコードセットとして抽出してソートするためのバッファが必要である。これだけのバッファを割り当てることができる空間がメモリ内に存在しない場合、メモリでなくディスクを利用してバッファを割り当てなければならないため、メモリとディスクのアクセス(access)速度差による速度上の損失が発生する。これに反して、本発明の第1実施形態の場合はN個のローバッファが割り当てられ、第2実施形態の場合はN個のスキャンバッファ及びN個のローバッファのみが割り当てられればよいため、その空間コストは従来技術に比べ無視できるほど小さいと言える。
【0071】
ここでのコストの計算は、一つのインデックスに全てのユーザのキーが存在する一般的なDBMSでの状況を仮定したものである。インデックス機能を提供する他のデータリポジトリの場合は、ユーザ毎に小さい大きさのインデックスを別に作って使用する場合もある。この場合は、各インデックスが有するキーの数がKtでなくKuとなり、この場合のインデックス探索コストはlog2(Kt)でなくlog2(Ku)となる。
【0072】
本発明による実施形態は、多様なコンピュータ手段によって実行可能なプログラム命令の形態により実現され、コンピュータ読み取り可能な媒体に記録することができる。この場合、コンピュータ読み取り可能な媒体は、プログラム命令、データファイル、データ構造などを単独に、または組み合わせて含むことができる。このような媒体に記録されるプログラム命令は、本発明のために特別に設計及び構成されたものであってもよく、コンピュータソフトウェア分野の当業者に公知されて使用可能なものであってもよい。コンピュータ読み取り可能な記録媒体の例としては、ハードディスク、フロッピー(登録商標)ディスク及び磁気テープなどの磁気媒体(Magnetic Media)、CD−ROM、DVDなどの光記録媒体(Optical Media)、フロプティカルディスク(Floptical Disk)などの磁気−光媒体(Magneto−Optical Media)、及びROM、RAM、フラッシュメモリなどの、プログラム命令を記憶及び実行するように特別に構成されたハードウェア装置が含まれる。プログラム命令の例としては、コンパイラーによって作られるもののような機械語コードだけでなく、インタープリターなどを用いてコンピュータによって実行されることができる高級言語コードを含む。前記ハードウェア装置は、本発明の動作を行うために一つ以上のソフトウェアモジュールとして作動するように構成されることができ、その逆も同様である。
【0073】
以上のように本発明では、具体的な構成要素などのような特定事項と限定された実施形態及び図面によって説明されたが、これは本発明の全般的な理解をより容易にするために提供されたものに過ぎず、本発明は上記の実施形態に限定されるものではなく、本発明が属する分野において通常の知識を有する者であれば、このような記載から多様な修正及び変形が可能である。
【0074】
従って、本発明の思想は、説明された実施形態に限って決まってはならず、添付する特許請求範囲だけでなく、この特許請求範囲と均等または等価的変形がある全てのものなどは本発明の思想の範囲に属するといえる。
【技術分野】
【0001】
本発明は、多重範囲スキャンでのNソート(N sort)クエリを最小の時間と最小のメモリ空間で、最適に処理するための方法及び装置に関する。より詳細には、データベース管理システム(Database Management System、以下「DBMS」という)に含まれるインデックス(index)を用いて、範囲スキャン(range scan)機能を提供する全てのデータ管理システムに適用可能である多重範囲スキャンでのNソートクエリを最適に処理する方法及び装置に関する。
【背景技術】
【0002】
インターネットの発達に伴い、インターネットを利用する様々なSNS(Social Networking Service)が脚光を浴びている。SNSは、オンライン上で知人との人間関係を深め、不特定の人と新しい人間関係を築くことができるようにするサービスを通称するものである。SNSとしては、韓国ではSKコミュニケーションズのサイワールド(Cyworld)、米国ではフェイスブック(Facebook)など、それぞれの特性による様々な種類の開発及びサービスが提供されている。
【0003】
SNSの一分野として、マイクロブログ(Microblog)も最近多くのユーザにより使用されている。マイクロブログとは、一、二文の短いメッセージを利用して多数の人とコミュニケーションができるブログの一種であり、ミニブログ(miniblog)とも呼ばれている。マイクロブログの特徴は、短いテキストを用いて、ユーザが互いに情報を発信し、発信した情報がリアルタイムでアップデートされるという特性を有している。また、マイクロブログでは、写真や動画などをアップロードすることもできる。即ち、ブログとメッセンジャを結合したような形態であり、ユーザはまるでチャットをしているような感じを受ける。また、個人の細かい日常の出来事や普段考えていること、感じたこと、感情、情報などを短いテキストで作成して交流するため、書くことや読むことに対する負担なく、簡単に使用できるという長所がある。、このため、マイクロブログは、多くの人気を集めている。マイクロブログの代表的な例としては、ツイッタ(twitter)、及び韓国ではミートゥデイ(me2day)などが挙げられる。
【0004】
SNS、特にマイクロブログの場合、多くのユーザが交わす情報がほぼリアルタイムで更新される。そして、ユーザ本人やユーザと関係がある他のユーザ(以下、「友達」という、少なくとも数人〜数千または数万人以上)が交わす情報から、最新情報の一部のみを抽出してユーザ本人または友達に表示する方式のクエリが非常に頻繁に使用されている。例えば、友達が作成した文章のうち最近作成した所定個数(例えば、N(Nは自然数)個)の文章、またはある特定時点以後に作成されたN個の文章のみを抽出するクエリが頻繁に使用されている。このようなクエリの処理は、各友達に対して特定時点以後にその友達が作成した文章を範囲スキャンするだけでなく、全ての友達に対して繰り返して実行する多重範囲スキャン(multi−range scan)の形態で実行しなければならない。そのため、このような多重範囲スキャンによりアクセスする友達の文章のうち最新またはある特定時点以後のN個の文章のみをソート順に抽出(以下、このような抽出に用いられるクエリを「Nソートクエリ」という)するための作業が必要である。しかし、従来のデータベース管理システム(Database Management System、以下「DBMS」という)を含むデータ管理システムは、SNSなどで主に使用されている多重範囲スキャンでのNソートクエリに対する最適化処理を考慮していない状態である。一例として、既存のDBMSでは、多重範囲スキャンによりアクセスされる友達の全ての文章を中間結果として抽出した後、抽出した文章を生成時間の逆順にソートしなければならない。このため、その処理速度が非常に遅く、中間結果を記憶するために非常に大きい記憶空間が必要となるという問題点があった。これにより、既存のDBMSの機能のみでは、SNSなどで頻繁に実行されるクエリを効率的に処理するには足りない面が多かった。
【0005】
このような従来のクエリ処理方式は、ユーザ毎に作成した文章の数が多くなるほど、また友達の数が多くなるほど、DBMSがスキャンしなければならない全体レコードの数が幾何級数的に増加する。そのため、ソートのために必要な中間レコードセットを格納するための多くのメモリ空間が必要であり、その多くのレコードをソートするための作業実行に対する負担のため、クエリ処理にかかる時間及び空間の無駄が非常に多かった。
【0006】
従って、SNSなどで頻繁に使用される多重範囲スキャンでのNソートクエリを受信した場合、スキャン対象となる友達の文章の数を最小化しながらも、限定された大きさの記憶空間のみを使用して該当クエリ処理を実行することができる方式、即ち、時間及び空間的なコストの面で最適なクエリ処理方式に対する要求が高まっている。
【0007】
さらに、このようなクエリ処理方式は、既存のDBMSだけでなく、DBMSの前段で範囲スキャン機能を提供する高速のデータリポジトリ、即ち、メモリでのみデータを記憶管理して、そのデータのコレクション(collection)に対するインデックスを用いて範囲スキャンを提供する高速のデータリポジトリにおいても、その必要性が高まっている。例えば、最近多く開発されているNoSQLデータベース、即ち、SQLインタフェースを用いたクエリ処理機能を提供するDBMSでなく、新しいインタフェースを提供し、処理性能またはシステム拡張性に重点を置いているデータベースタイプにこのような高速のデータリポジトリが含まれている。
【先行技術文献】
【特許文献】
【0008】
【特許文献1】韓国公開特許第2000―0047630号公報
【発明の概要】
【発明が解決しようとする課題】
【0009】
本発明の目的は、上述した従来技術の問題点を解決することにある。
【0010】
本発明の目的は、多重範囲スキャンでのNソートクエリを受信した場合、スキャン対象となるレコードの数を最小化にしながら、スキャン中にソートされた結果を直ちに得るようにすることで、クエリ処理にかかる時間を最小化しながらも少ないメモリ空間のみを使用するようにすることである。
【0011】
本発明の他の目的は、クエリ処理技術をDBMSまたは高速のデータリポジトリを用いて、SNSなど多重範囲スキャンでのNソートクエリを多く使用する環境で用いることで、SNSなどのサービスを行う時のクエリ処理性能を極大化することにある。本発明のさらに他の目的は、開発者が従来のDBMSで効果的なクエリ処理のために、DBMS毎に多重範囲スキャンでのNソートクエリがどのように処理されるか内部的な処理方式を把握し、それに応じてDBMS毎に最適化するためにクエリを修正する必要がなく、従来のクエリをそのまま使用しても最適の方式でNソートクエリが処理されるため、SNSなどの設計及び開発などにおいてその便宜性及び開発速度の向上を図ることができるようにすることにある。
【課題を解決するための手段】
【0012】
上記のような本発明の目的を果たし、後述する本発明の特有の効果を果たすための本発明の特徴的な構成は下記のとおりである。
【0013】
本発明の一実施形態によるクエリ処理方法は、クエリに含まれた抽出レコード数に基づいてバッファを割り当て、前記クエリに含まれた第1リストのうち第1属性に係わる第1データを抽出して前記バッファに記憶し、前記クエリに含まれた前記第1リストのうち抽出されていない前記第1属性に係わる第2データを抽出し、前記バッファに記憶された前記第1データ及び前記第2データを比較することにより、前記クエリを満たすように前記バッファを更新し、前記クエリは、前記第1属性及び前記第2属性に基づいて前記ソートされた一つ以上の前記レコードに対する多重範囲スキャンでのNソートクエリであることを特徴とする。
【0014】
本発明の他の態様によるクエリ処理装置は、クエリに含まれた抽出レコード数に基づいてバッファを割り当てるバッファ割り当て部と、前記クエリに含まれた第1リストのうち第1属性に係わる第1データを抽出して前記バッファに記憶し、前記クエリに含まれた第1リストのうち抽出されていない第1属性に係わる第2データを抽出し、前記バッファに記憶されたデータ及び前記第2データを比較することにより、前記クエリを満たすように前記バッファを更新するスキャン部と、を含み、前記クエリは、第1属性及び第2属性に基づいてソートされた一つ以上のレコードに対する多重範囲スキャンでのNソートクエリであることを特徴とする。
【0015】
この他にも、本発明を実現するための上記の方法を行うコンピュータプログラムを記録するコンピュータ読み取り可能な記録媒体がさらに提供される。
【発明の効果】
【0016】
本発明によると、多重範囲スキャンでのNソートクエリを受信した場合、スキャン対象となるレコードの数を最小化にしながら、スキャン中にソートされた結果を直ちに得るようにすることで、クエリ処理にかかる時間を最小化しながらも少ないメモリ空間のみを使用することができる。
【0017】
また、本発明によると、クエリ処理技術をDBMSまたは高速のデータリポジトリに具現し、SNSなど多重範囲スキャンでのNソートクエリを多く使用する環境で使用することで、SNSなどのサービスを行う時のクエリ処理性能を極大化することができる。
【0018】
また、本発明によると、開発者が従来のDBMSで効果的なクエリ処理のために、DBMS毎に多重範囲スキャンでのNソートクエリがどのように処理されるか内部的な処理方式を把握し、それに応じてDBMS毎に最適化するためにクエリを修正する必要がなく、従来のクエリをそのまま使用しても最適の方式でNソートクエリが処理されるため、SNSなどの設計及び開発などにおいてその便宜性及び開発速度の向上を図ることができる。
【図面の簡単な説明】
【0019】
【図1】本発明の一実施形態によるDBMSが多重範囲スキャンでのNソートクエリ処理時において、インデックスを用いてスキャンする範囲を示す図面である。
【図2】本発明の第1実施形態及び第2実施形態による多重範囲スキャンでのNソートクエリを処理するクエリ処理装置を示す構成図である。
【図3】本発明の第1実施形態によるスキャン部で実行される多重範囲スキャンでのNソートクエリの処理方法を示すフローチャートである。
【図4】本発明の第2実施形態によるスキャン部で実行される多重範囲スキャンでのNソートクエリの処理方法を示すフローチャートである。
【図5】本発明の第2実施形態によるスキャン部で実行される多重範囲スキャンでのNソートクエリの処理方法を示すフローチャートである。
【図6】本発明の第1実施形態による多重範囲スキャンでのNソートクエリの処理方法のうちローバッファを更新する工程を示す図面である。
【図7a】本発明の第2実施形態による多重範囲スキャンでのNソートクエリの処理方法のうちスキャンバッファ及びローバッファの形態とスキャンバッファ及びローバッファの更新工程を示す図面である。
【図7b】本発明の第2実施形態による多重範囲スキャンでのNソートクエリの処理方法のうちスキャンバッファ及びローバッファの形態とスキャンバッファ及びローバッファの更新工程を示す図面である。
【図7c】本発明の第2実施形態による多重範囲スキャンでのNソートクエリの処理方法のうちスキャンバッファ及びローバッファの形態とスキャンバッファ及びローバッファの更新工程を示す図面である。
【図7d】本発明の第2実施形態による多重範囲スキャンでのNソートクエリの処理方法のうちスキャンバッファ及びローバッファの形態とスキャンバッファ及びローバッファの更新工程を示す図面である。
【発明を実施するための形態】
【0020】
以下、本発明の好適な実施形態を、図面を参照して詳細に説明する。以下の実施形態は、当業者が本発明を十分に実施することができるように詳細に説明される。本発明の多様な実施形態は、互いに異なり、必要などに応じて相互に組み合わせることができることを理解すべきである。例えば、ここに記載されている特定形状、構造及び特徴は、一実施形態に関連して本発明の思想及び範囲を外れずに他の実施形態に用いることができる。また、それぞれの開示された実施形態の構成要素の位置または配置は、本発明の思想及び範囲を外れずに変更可能であることを理解すべきである。従って、後述する詳細な説明は限定的な意味で扱うものでなく、本発明の範囲は、適切に説明されるならば、その特許請求の範囲が主張するものと均等な全ての範囲と共に、添付した特許請求の範囲によってのみ限定される。図面において、同一の参照符号は、様々な側面にわたって同一または類似の機能を示す。
【0021】
以下、本発明が属する技術分野において通常の知識を有する者が本発明を容易に実施できるように、本発明の好適な実施形態について添付図面を参照して詳細に説明する。
【0022】
[クエリ処理時のスキャン範囲]
図1は、本発明の一実施形態によるDBMSが、多重範囲スキャンでのNソートクエリの処理時に、インデックス(index)を用いてスキャンする範囲を示す図面である。
【0023】
多重範囲スキャンでのNソートクエリを利用するサービスまたはシステムにおいて、ユーザが作成する文章の記憶と検索対象となるデータベースは様々な方式で実現できる。また、一般的に、文章を作成したユーザのID、作成した時間情報を示すタイムスタンプ(Time Stamp)、作成された文章の内容、及び付加的な情報に対する属性をさらに有してもよい。以下、説明の便宜上、DBMSとSQL(Structured Query Language)を基に説明する。DBMSでユーザのIDをuserid、タイムスタンプをts、作成された文章の内容をcontentsと命名したテーブルを以下の表1のように示す。表1に示したテーブルの名称をpostsと仮定する。
【0024】
【表1】
【0025】
一方、上記表1のようなpostsテーブルで、あるユーザの友達全体を対象として最近作成され、または、特定時点から最も近い時期に作成された文章から特定個数の文章のみを抽出するための多重範囲スキャンでのNソートクエリは多様な方式で実現されてもよく、一般的に以下の例示的なSQL文のように実現することができる。
【0026】
SELECT ts、 userid
FROM posts
WHERE userid IN(friends_list)AND ts<sysdate()
ORDER BY ts DESC
LIMIT N;
(ここで、friends_listは所定ユーザの友達のユーザIDリストのみを含み、所定ユーザを含んで友達のユーザIDリストを含む。これは、該当クエリを実行する特定サービスまたはシステムでどのようなユーザの文章を集めるかによって変わる。また、Nは抽出する文章の個数を意味する。)
【0027】
このSQL文を効率的に処理するためには、表1に示すpostsテーブルに対してユーザIDの順に、その内部でタイムスタンプの逆順にレコードを速く検索するためのインデックスが必要である。このため、一般的にuseridに対して昇順、tsに対して降順のキー(key)を有するインデックスを生成し、このようなインデックスを説明の便宜上「posts_userid_ts_index」と仮定する。
【0028】
インデックスは、テーブルの各レコードに対応する一つのキーを保持する。ここで、その一つのキーは、キー値とそのキー値を有するレコードの識別子で構成される。例えば、図1に示す範囲1の一番目のキーは、キー値としてA及び2010−12−01 14:30:02を有し、さらに、このキー値を有するレコードの識別子として、R4を有する。または、メモリに全てのデータを記憶するメインメモリデータベース(Main−Memory DBMS:MMDBMS)の場合、キー値を有するレコードが常にメモリに記憶されているため、キーのレコード識別子を介して、そのキー値を直接アクセスすることできる。従って、MMDBMSでインデックスのキーは、一般的にレコード識別子のみを有する。よって、図1に示したインデックスでのキーは、キー値とレコード識別子を全て有する一般的なディスクDBMSを仮定して表現したものであり、インデックスでのキー構成が図1に限定されず、データリポジトリの具現特性によってインデックスでのキー構成が変わることは自明である。上述した表1のようにレコードが任意の順に記憶されており、図1の右側に示したpostsテーブルに対して上記のSQL文を効率的に実行するためには、図1の左側に示したようにpostsテーブルに係る「posts_userid_ts_index」インデックスが備えられることが前提とされる。この「posts_userid_ts_index」インデックスを基に、本発明の実施形態によってSQL文のような多重範囲スキャンでのNソートクエリを実行するための具体的な順序については、図6−図7dを参照して以下でより詳細に説明する。
【0029】
[多重範囲スキャンでのNソートクエリを処理するクエリ処理装置]
図2は、本発明の一実施形態による多重範囲スキャンでのNソートクエリを処理するクエリ処理装置を示す構成図である。
【0030】
図2を参照すると、本発明の一実施形態によるクエリ処理装置100は、クエリ解釈部110とクエリ実行部120とに大別される。クエリ実行部120は、バッファ割り当て部121と、スキャン部122と、提供部123と、を含む。
【0031】
本発明の一実施形態によるクエリ解釈部110は、特定形式によるクエリを受信し、受信されたクエリが多重範囲スキャンでのNソートクエリであるか否かを判断する。クエリ解釈部110に特定形式によるクエリを伝送する伝送装置とは、クエリ処理装置100との通信を介してクエリ処理装置100にアクセスしてデータを要求することができる装置または構成要素を全て含む広義の概念である。クエリ処理装置100に対するクエリ伝送は、伝送装置とクエリ処理装置100との間の認証などの手順を経て、伝送装置がクエリ処理装置100にクエリを介して特定データを要求することができる正当な権限があるか否かを予め確認した後に行ってもよい。この場合、認証手順は公知のDBMSアクセス(access)時に使用される認証手順を利用することができる。クエリ解釈部110が受信した特定形式によるクエリは、公知のSQLによるSQL構文であってもよい。クエリ解釈部110はパージング(parsing)機能を利用して、受信されたクエリが多重範囲スキャンでのNソートクエリであるか否かを判断することができる。
【0032】
本発明の一実施形態によるクエリ解釈部110は、単に多重範囲スキャンでのNソートクエリであるか否かを判断するだけでなく、受信したクエリを具体的に解釈し、抽出されるべきのレコードの数、スキャン対象となるユーザID及びソートの基準となるタイムスタンプ値などに関する情報をさらに解釈して抽出する機能をさらに備えていてもよい。
【0033】
本発明の一実施形態によるクエリ実行部120は、クエリ解釈部110により解釈された情報に基づいてクエリを実行する。クエリ実行部120は、様々な構成要素を有してもよい。なお、多重範囲スキャンでのNソートクエリに対する効率的な処理方式に焦点を当てその説明を容易にするために、バッファ割り当て部121、スキャン部122、提供部123を有してもよい。まず、本発明の一実施形態によるバッファ割り当て部121は、クエリ解釈部110により、受信されたクエリが多重範囲スキャンでのNソートクエリであると判断された場合、メモリ上にスキャンのための一時的な記憶空間であるバッファを割り当てる。割り当てられるバッファの大きさは、クエリ解釈部110により解釈された情報のうち抽出されるべきのレコードの個数に対応する。例えば、抽出されるべきのレコードの個数がN個であると、バッファ割り当て部121は、後述するスキャン部122のスキャン方式に応じて、N個のソートができるローバッファ(row buffer)、またはN個のスキャンバッファ(scan buffer)とローバッファ(row buffer)を割り当てる。ここで、ローバッファとは、インデックススキャンにより抽出されるレコードのキー値と識別子を記憶したり、またはレコードの識別子のみを記憶したりすることができるメモリ領域を意味する。また、スキャンバッファとは、多数のユーザに対するインデックススキャンのうち最新のレコードをスキャンしているインデックススキャンの識別子情報を記憶することができるメモリ領域を意味する。次に、本発明の一実施形態によるスキャン部122は、バッファ割り当て部121により割り当てられた、限定された数のバッファを利用して、最小限のインデックススキャンによりクエリ解釈部110により解釈された多重範囲スキャンで最上位のNソートクエリを行う。本発明の好ましい実施形態によるスキャン部122の具体的なクエリ実行順序については後述する。
【0034】
最後に、本発明の一実施形態による提供部123は、スキャン部122の動作により実行されたクエリに対する結果として、バッファ割り当て部121により割り当てられたローバッファに記憶された特定個数のレコードをクエリに対する結果としてクエリを要請した特定個体に伝送する。
【0035】
図2に示すクエリ解釈部110、クエリ実行部120のバッファ割り当て部121、スキャン部122及び提供部123は、物理的に単一の装置内に構成されてもよく、一部またはそれぞれが物理的に異なる装置に構成されてもよく、また、同様の機能を有する物理的に複数存在する装置が並列的に存在してもよい。このように、本発明の実施形態は、各構成部が設けられた機械またはデータベースの物理的な数及び位置に限定されず、多様な方式に設計変更されることということは、本発明が属する技術分野において通常の知識を有する者において自明のことである。
【0036】
図2の各構成要素は、本発明を説明するために必要な必須構成要素に限定して開示及び説明され、各構成要素は本発明で説明されていない公知の他の機能を実行したり、または図2に示していない、公知の他の機能を実行したりするための別の構成要素がクエリ処理装置100内に追加され得るということは、本発明が属する技術分野において通常の知識を有する者において自明のことである。
【0037】
[第1実施形態]
[多重範囲スキャンでNソートクエリの処理]
次に、図3、図4及び図5を参照して、本発明の好ましい実施形態により、スキャン部122で実行される多重範囲スキャンでのNソートクエリの処理方法について詳細に説明する。
【0038】
まず、本発明の第1実施形態によると、バッファ割り当て部121は抽出されるべきのレコードの数(以下、「N」という)だけのローバッファを割り当てていることを仮定する。図3に示した本発明の第1実施形態によると、クエリ処理装置100のスキャン部122は、上記表1で仮定した「posts_userid_ts_index」インデックスを基に各ユーザに対して、最新または特定時点以後の文章のみを検索するためのインデックススキャンを始める(ステップS110)。インデックススキャンは、インデックスを、たとえばルート(root)ノードから最下位ノードであるリーフ(leaf)ノードまで探索しながら、検索条件を満たす一番目のレコードを検索する(ステップS120)。検索条件を満たす一番目のレコードが見つけられなかった場合は(S130)、現在ユーザが特定時点以後に作成された文章が存在しないということを意味するため、現在のインデックススキャンを終了する(S190)。検索条件を満たす一番目のレコードが存在する場合は(S130)、スキャン部122は、ローバッファに現在のレコード情報を記憶するための作業を以下のように実行する。即ち、まず、N大きさのローバッファがフル(full)状態であるかを確認する(S140)。ローバッファがフル状態でない場合は(S140)、レコード情報を記憶する空間がローバッファに残っている状態であることを意味するため、現在検索したレコードのタイムスタンプ値とローバッファに記憶されたレコードのタイムスタンプ値とを比較して、タイムスタンプの逆順が維持されるように、ローバッファに挿入すべき位置を探してその位置に現在レコード情報を記録する(S170)。このような方式により、ローバッファ内に記憶されたレコード情報は、常にそのタイムスタンプの逆順にソートされている。ローバッファがフル状態である場合は(S140)、現在検索したレコードのタイムスタンプ値とローバッファに記憶された最後のレコード、即ち、タイムスタンプの逆順にソートされたローバッファで最も小さいタイムスタンプ値を有するレコードのタイムスタンプ値とを比較して、現在検索したレコードをローバッファに挿入できるかを確認する(S150)。現在のレコードのタイムスタンプ値がローバッファにある最後のレコードのタイムスタンプ値より小さいかまたは同一である場合は(S150)、現在のユーザが作成した文章が、既に他のユーザが作成した、即ち、ローバッファ内に記憶されたレコード情報に対応するN個の文章より古い文章ということが明らかであるため、現在ユーザに対して検索したレコードをローバッファに挿入する必要がなく、現在ユーザの次のレコードを検索する必要もなくなる。従って、現在ユーザの文章をスキャンする作業を中止する(S190)。現在のレコードのタイムスタンプ値がローバッファにある最後のレコードのタイムスタンプ値より大きい場合は(S150)、最後のレコードをローバッファから除去した後(S160)、ローバッファに現在のレコードを挿入する(S170)。この場合にも、ローバッファに記録されたレコードは、タイムスタンプの逆順へのソートが維持されるように、現在のレコードの適切な挿入位置を探して挿入する(S170)。本発明の第1実施形態によるローバッファへのレコードの挿入によるローバッファの更新を示した図6を参照すると、スキャン部122が、既にN個のレコードが記憶されているローバッファ内にユーザCが作成したレコードが抽出され挿入されようとしている。挿入されようとする、ユーザCが作成したレコードのタイムスタンプは「2010−12−01 13:57:26」であり、ローバッファに記憶された最後のレコードのタイムスタンプである「2010−11−29 23:48:01」より最新のものである。また、2番目に位置するタイムスタンプが「2010−12−01 14:07:09」であるレコードよりは最新ではないが、3番目に位置するタイムスタンプが「2010−12−01 13:46:52」であるレコードよりは最新のものであるため、その間に位置するべきである。従って、スキャン部122は、ローバッファの最後の位置にあるレコード(識別子がR44であるレコード)を除去し、ローバッファの3番目の位置に現在レコードを記憶する。従って、元のローバッファで3番目の位置からN−1番目の位置まで記憶されていたレコードは、ユーザCが作成したレコードの挿入により一つずつ後側に移動して記憶される。従って、挿入後のローバッファに記憶された最後のレコードは、従来のN−1番目の位置に記憶されたレコードと同一の、識別子としてR62を有するレコードであることが分かる。
【0039】
また、図3をさらに参照すると、ローバッファに現在検索したレコードを挿入した場合には、現在のインデックススキャンにより次のレコードを検索し(S180)、次のレコードの存在有無に応じて(S130)上述の処理工程を繰り返す。
【0040】
現在のユーザに対するインデックススキャンで検索するレコードがそれ以上ない場合や(S130)、検索したレコードのタイムスタンプがローバッファに記録されたレコードの最小タイムスタンプ値より小さいかまたは同一である場合(S150)、現在のユーザに対するスキャンをそれ以上行う必要がないため、上述のように現在のユーザに対するインデックススキャンを終了する(S190)。
【0041】
現在のユーザに対するスキャンを終了すると、次のユーザがあるかを確認する(S200)。次のユーザがある場合(S200)、そのユーザに対するインデックススキャンを始め(S110)、上述の処理工程を繰り返す。次のユーザがない場合(S200)、ローバッファにあるレコードが最終のクエリ結果となるため(S210)、全体処理工程を終了する。ここで、ユーザとは、Nソート結果を得るクエリを利用するサービスまたはシステムの設計または開発特性によって、所定ユーザ本人を含むかまたは含まない所定ユーザの友達を意味する。
【0042】
図3に示した本発明の第1実施形態の順序を実行して完了した場合、バッファ割り当て部121により割り当てられたN個のローバッファに記憶されたN個のレコードは、クエリ解釈部110により解釈された多重範囲スキャンでのNソートクエリの実行結果として、所定ユーザの友達(所定ユーザが含まれてもよく、含まれなくてもよい)が作成した全ての文章を対象として最新または特定時点以後に作成されたN個の文章を格納していることが分かる。
【0043】
[第2実施形態]
図4及び図5は本発明の第2実施形態によるスキャン部122が多重範囲スキャンでのNソートクエリを実行する順序を示したフローチャートである。
【0044】
まず、DBMSまたは他のデータリポジトリからインデックススキャンにより特定範囲のレコードを検索する場合の技術的な順序を詳細に説明する。インデックスアクセス時にスキャン対象となるテーブルとインデックスをアクセスするための情報を取り込み、インデックススキャン情報を格納するための構造体に格納しておく。そして、その情報に基づいてそのインデックスをアクセスする。例えば、インデックスのルート(root)ノード識別子などがこれに該当する。また、インデックスを用いて検索するキーの範囲及び範囲内の各キーまたはレコードに対して適用するフィルタリング情報などを保管し、これを用いて検索範囲にあるキーまたはレコードをスキャンする際に検索条件に合致するレコードを探す。その他にも、インデックスで現在アクセスしているキーの位置情報とそのキーを有するレコードの識別子を維持する。このような情報は、初めは空値(NULL)などとして設定され、一番目のレコードとともに次のレコードを探す度に現在のキーと現在のレコード情報に更新される。インデックススキャンによりスキャン範囲を外れると、スキャン情報が格納されている構造体を破棄するなどのインデックススキャンの終了作業を行う。
【0045】
次に、本発明の第2実施形態におけるスキャンバッファは、各インデックススキャンが現在指し示しているレコードのタイムスタンプを基準に、最新のタイムスタンプを有するレコードを指し示すインデックススキャンの識別子情報を記憶するバッファである。インデックススキャンの識別子としては、インデックススキャン情報を有している構造体のアドレス(address)としてもよく、インデックススキャン情報を有している構造体が配列(array)形態に構成される場合、その配列での位置値になってもよい。または、DBMSでなく他のデータリポジトリでは、テーブルの概念がなく実際のレコードのデータがインデックスのキー内に全て含まれてもよく、スキャンの現在のキー位置情報のみを有してスキャンを行ってもよい。例えば、スキャンを開始する際に、現在のキーの位置情報はルートノードに設定された後、一番目のキーまたは次のキーを探す度に現在のキーの位置情報は実際のキーの位置情報に設定されてもよい。この場合、キーの位置情報の大きさが大きくないため、このようなキーの位置情報そのものをスキャンバッファに記録することもできる。従って、スキャンバッファに記録される情報は、インデックススキャン機能を提供する該当データリポジトリの実際の内部方式によって変わることは当業者において自明のことである。
【0046】
本発明の第2実施形態によると、バッファ割り当て部121は抽出されるべきレコードの個数(以下、「N」個という)だけのスキャンバッファ及びローバッファを割り当てていることを仮定する。図4を参照して、上述の特定レコード抽出の順序及び仮定事項を参照して本発明の第2実施形態を説明する。クエリ処理装置100のスキャン部122は、上述の「posts_userid_ts_index」インデックスを利用して、各ユーザに対して最新または特定時点以後の文章のみを検索するためのインデックススキャンを開始する(S310)。インデックススキャンは、該当インデックスを探索して検索条件を満たす一番目のレコードを検索する(S320)。検索条件を満たす一番目のレコードが存在しない場合(S330)、現在のユーザが特定時点以後に作成された文章が存在しないということを意味するため、現在のインデックススキャンを終了する(S380)。検索条件を満たす一番目のレコードが存在する場合(S330)、スキャンバッファに現在のインデックススキャン情報を記憶するための処理を実行する。このために、まず、N大きさのスキャンバッファがフル状態であるかを確認する(S340)。スキャンバッファがフル状態でない場合(S340)、インデックススキャン情報を記憶する空間がスキャンバッファに残っている状態であることを意味するため、現在インデックススキャンが指し示すレコードのタイムスタンプ値とスキャンバッファに記録されたインデックススキャンが指し示すレコードのタイムスタンプ値とを比較して、タイムスタンプの逆順にソートされるように、スキャンバッファに挿入する位置を探して該当位置に現在のインデックススキャン情報を記録する(S370)。このような方式により、スキャンバッファ内に記憶されたインデックススキャン情報は、それぞれのインデックススキャンが指し示すレコードのタイムスタンプが逆順にソートされている。スキャンバッファがフル状態である場合(S340)、現在インデックススキャンが指し示すレコードのタイムスタンプ値と、それぞれのインデックススキャンが指し示すレコードのタイムスタンプの逆順にソートされたスキャンバッファに記憶された最後のインデックススキャンが指し示すレコードのタイムスタンプ値と、を比較することにより、現在のインデックススキャンをスキャンバッファに挿入できるかを確認する(S350)。現在のインデックススキャンが指し示すレコードのタイムスタンプ値がスキャンバッファに記録された最後のインデックススキャンが指し示すレコードのタイムスタンプ値より小さいかまたは同一である場合(S350)、これは、現在インデックススキャンの検索対象となるユーザが作成した文章より最新の文章を作成したユーザに対するインデックススキャンが既にスキャンバッファにN個登録されている状態であることを意味するため、現在ユーザに対するインデックススキャンをそれ以上行う必要がなくなる。従って、現在ユーザに対するインデックススキャン作業を中止する(S380)。現在インデックススキャンが指し示すレコードのタイムスタンプ値がスキャンバッファに記録された最後のインデックススキャンが指し示すレコードのタイムスタンプ値より大きい場合(S350)、スキャン部122は、それぞれのインデックススキャンが指し示すレコードのタイムスタンプの逆順にソートされたスキャンバッファで最も古いタイムスタンプを有したレコードを指し示すインデックススキャンである最後のインデックススキャン情報をスキャンバッファから除去し、そのスキャンを終了させた後(S360)、現在のインデックススキャンの情報をスキャンバッファに挿入する(S370)。この場合にも、スキャンバッファでインデックススキャンが指し示すレコードのタイムスタンプの逆順にそのインデックススキャンの記憶順序が維持されなければならないため、現在のインデックススキャンの適切な挿入位置を探して挿入する。現在ユーザに対するインデックススキャンで検索する一番目のレコードがない場合(S330)や、現在インデックススキャンが検索した一番目のレコードのタイムスタンプがスキャンバッファに記録された最後のインデックススキャンが指し示すレコードの最小タイムスタンプ値より小さいか同一である場合(S350)は、現在ユーザに対するスキャンをそれ以上行う必要がないため、上述のように現在ユーザに対するインデックススキャンを終了した後(S380)、次のユーザが存在するかを確認する段階(S390)に進む。また、現在のインデックススキャンをスキャンバッファに登録した場合にも(S370)、そのインデックススキャンを終了していない状態で次のユーザが存在するかを確認する段階(S390)に進む。次のユーザが存在する場合(S390)、そのユーザに対するインデックススキャンを始めて(S310)、上述の処理工程を繰り返す。次のユーザが存在しない場合は(S390)、スキャンバッファには最新または特定時点以後に作成されたN個のレコードを抽出するに適したインデックススキャンが登録された状態であることを意味する。
【0047】
このような段階を経て得られるスキャンバッファの一例は図7aに図示されている。右側のスキャンバッファに記憶されたユーザAに対するインデックススキャンは、左側の「posts_userid_ts_index」インデックスにおいてユーザAによるレコードのうち最もタイムスタンプが最新であるレコードを指し示しており、ユーザCとFに対するインデックススキャンもそれぞれユーザCとFによるレコードのうち最もタイムスタンプが最新であるレコードを指し示している。また、各インデックススキャンが指し示すレコードのタイムスタンプの逆順にこれらインデックススキャンの位置が順序化されている。
【0048】
次に、指し示すレコードのタイムスタンプの逆順にソートされた、スキャンバッファに格納されたインデックススキャンを基に、最新または特定時点以後に作成されたN個の文章のみを抽出するための順序を、図5を参照して詳細に説明する。スキャン部122は、まずスキャンバッファに記録されたインデックススキャンが存在するかを確認する(S410)。インデックススキャンが存在する場合(S410)、スキャンバッファに存在する一番目のインデックススキャンが指し示すレコード、即ち、最新のタイムスタンプを有するレコードを抽出した後(S420)、そのレコードをローバッファに記録する処理を実行する。ここで、スキャンバッファに記憶されたインデックススキャンはそれらがそれぞれ指し示しているレコードのタイムスタンプの逆順、即ち最新の順にソートされているため、段階S420で抽出されるレコードはスキャンバッファの先頭にあるインデックススキャンが指し示すレコードに該当する。この作業は、ローバッファがフル状態であるかを先に確認してから実行する(S430)。ローバッファがフル状態でないと(S430)、ローバッファに空いている先頭の空間にそのレコードを挿入する(S440)。その後、現在のインデックススキャンで次のレコードを検索し(S450)、次のレコードが存在するかを確認する(S460)。次のレコードが存在しない場合(S460)、現在のインデックススキャンをスキャンバッファから除去し、そのインデックススキャンを終了する(S470)。その後、スキャンバッファにインデックススキャンが残っているかを確認する段階(S410)に進む。次のレコードが存在する場合(S460)、現在インデックススキャンが指し示すレコードが次のレコードに変更されたため、そのレコードのタイムスタンプ値を基準にスキャンバッファで現在のインデックススキャンの位置を再調整する(S480)。この場合にも同様に、レコードのタイムスタンプの逆順にソートされたインデックススキャンの順序が維持されるように、適切な位置にインデックススキャン情報を挿入することによりスキャンバッファで位置を再調整する。インデックススキャンの位置を再調整する場合、スキャンバッファにインデックススキャンが残っているということが保障され、また、スキャンバッファに記憶されたインデックススキャンもそれぞれが指し示すレコードのタイムスタンプの逆順にソートされた順序が維持されるため、スキャンバッファで先頭にある、即ち最もタイムスタンプが最新のレコードを指し示すインデックススキャンから現在のレコードを抽出する段階(S420)に進み、上述の順序を繰り返す。
【0049】
このような実行順序に従ってスキャンバッファで一番目のインデックススキャンが指し示すレコードを抽出する工程を繰り返すと、抽出するレコードの順序もタイムスタンプが最新である順序になる。従って、このようなレコードをローバッファに挿入する場合、ローバッファに挿入する位置を探すために別のバイナリサーチまたは他の方法による再調整などが必要でなく、単にローバッファの先頭から空いている空間順にレコードを追加(append)してローバッファを満たしていくとローバッファ内のレコードの順序は、タイムスタンプの逆順にソートされた順序が維持される。
【0050】
一方、スキャン部122がスキャンバッファにある一番目のインデックススキャンが指し示すレコードを抽出してローバッファに記憶しようとする際に、ローバッファが既にフル状態である場合(S430)、これは、既に最新順序のN個のレコードを全て探した状態であることを意味する。従って、それ以上のスキャンを行う必要がないため、スキャンバッファにある全てのインデックススキャンを終了させる(S490)。また、ローバッファにあるN個のレコードが最終結果となるため(S500)、全体処理工程を終了する。
【0051】
上記の順序を実行する工程中に、スキャンバッファにインデックススキャンが存在しない場合があり得る(S410)。この場合は、既にローバッファに0個以上のレコードが存在している状態であり、ローバッファにあるそのレコードが最終結果となるため、スキャン部122は全体処理工程を終了する。参考に、ローバッファにあるレコードの数が0であると、これはクエリの検索条件を満たすレコードがないということを意味する。即ち、多数のユーザが作成した文章のうち特定時点以後に作成された文章がないということを意味し、この結果が正常な実行結果となるのである。
【0052】
本発明の第2実施形態によるスキャンバッファからレコードを抽出してローバッファに挿入または追加する一部実行工程を示すと、図7b、図7c、図7dのとおりである。図7bを参照して、最新レコードを指し示すインデックススキャンがスキャンバッファに登録されており、ローバッファは空いている状態で始める。スキャン部122は、まず一番目のインデックススキャンであるAスキャンでキーの位置情報であるK4544を介して現在のキーまたは現在のレコードをアクセスしてそのレコードをローバッファの先頭に挿入する。また、Aスキャンの次のキーであるK4545に移動して、該当キーが指し示すレコードのタイムスタンプを基準にスキャンバッファでAスキャンの位置を再調整する。キーの位置情報であるK4545が指し示すレコードのタイムスタンプ値は「2010−12−01 14:07:09」であり、スキャンバッファにある二番目のスキャンであるCスキャンの現在キーの位置情報であるK5122が指し示すレコードのタイムスタンプ「2010−12−01 13:57:26」より最新のものであるため、Aスキャンに対してスキャンバッファで一番目の位置をそのまま維持する。次に、二番目のレコードを探すために図7cを参照すると、上記と同様に、スキャン部122は、スキャンバッファにある一番目のインデックススキャンであるAスキャンがK4545を介して現在指し示すキーをアクセスし、そのキーのレコードをローバッファで空いている先頭、即ち二番目の位置に挿入する。次に、Aスキャンの次のキーであるK4546に移動して、そのキーが指し示すそのレコードのタイムスタンプを基準にスキャンバッファでAスキャンの位置を再調整する。この場合、Aスキャンの現在レコードのタイムスタンプ(「2010−12−01 13:46:52」)がCスキャンの現在レコードのタイムスタンプ(「2010−12−01 13:57:26」)より最新でないため、スキャンバッファでCスキャンが先頭に、またAスキャンが二番目の位置に位置するようにスキャンバッファの位置を再調整する。図7dを参照して次のレコードを抽出する工程を説明すると、スキャン部122は、スキャンバッファで一番目のインデックススキャンであるCスキャンの現在レコードを抽出してローバッファに挿入し、Cスキャンの次のキーであるK5123に移動して、スキャンバッファで位置を調整する。この場合にも、CスキャンのキーK5123が指し示すレコードのタイムスタンプ(「2010−11−27 10:22:25」)がAスキャンのキーK4546が指し示すレコードのタイムスタンプ(「2010−12−01 13:46:52」)より最新でないため、それぞれのキーが指し示すレコードのタイムスタンプの逆順にソートされるように、スキャンバッファ内に記憶されたインデックススキャンの位置が再調整される。このような工程をN回実行することにより、ローバッファにはタイムスタンプが最新である順にN個レコードが記憶される。
【0053】
上述の本発明の第1実施形態及び第2実施形態は、以下の点で実行段階の共通点を有していることを確認することができる。
【0054】
まず、クエリ実行部のバッファ割り当て部は、クエリに含まれた抽出レコード数(例えば、N個)に基づいてバッファを割り当てる。第1実施形態の場合はN個のローバッファが、第2実施形態の場合はN個のスキャンバッファ及びローバッファが割り当てられる。次に、ユーザのID順及びタイムスタンプの逆順にインデックスされてソートされた一つ以上のレコードに対する多重範囲スキャンでのNソートクエリとしてクエリ解釈部により解釈されたクエリに基づいて、クエリ実行部のスキャン部は一つのユーザIDに対するレコードを抽出し、第1実施形態の場合はローバッファに、第2実施形態の場合はスキャンバッファに記憶する。その後、上記で抽出されなかったユーザIDに対するレコードを抽出した後バッファに記憶された、上記で抽出されたレコードとタイムスタンプを比較してクエリの内容である多重範囲スキャンでのNソートクエリを満たすために、そのタイムスタンプの逆順を維持するように、第1実施形態の場合はローバッファを、第2実施形態の場合はスキャンバッファを更新する。
【0055】
上述のような本発明の実行段階の共通点に、上記で各図面などを参照して詳細に説明した第1実施形態及び第2実施形態の特有の追加的な実行段階を有機的に組み合わせ、本発明の第1実施形態及び第2実施形態を施すことができる。
【0056】
[従来技術と本発明の実施形態との時間コストの比較]
本発明の第1実施形態及び第2実施形態により、多重範囲スキャンで最上位のNソートクエリを実行する場合、従来技術に比べ得られる速度上の効果を、以下で計算する時間コストにより確認する。
【0057】
まず、各実行方式の時間コストを計算するために、以下のような変数を仮定する。
N:検索しようとするレコードの個数
Us:特定ユーザの友達の数
Kt:該当インデックスで全体キーの数(該当テーブルで全体レコードの数と同一)
Ku:該当インデックスでユーザ毎の平均キーの数(該当テーブルでユーザ毎の平均レコードの数と同一)
Ks:本発明の第1実施形態において、ユーザ毎のインデックスを用いてスキャンするようになる平均キーの数
【0058】
各インデックススキャンでは検索条件を満たす一番目のレコードを探す「get_first_row」演算が1回実行され、次のレコードを探す「get_next_row」演算が検索条件に合致する全てのレコードが探されるまで繰り返して実行される。全体キーの個数がKtであるインデックスにおいて「get_first_row」演算は、一般的にバイナリサーチ(binary search)法によりKt個のキーのうち検索条件を満たす一番目のキーを探してレコードをアクセスするため、log2(Kt)のコストが消費され、「get_next_row」演算は現在キーから次のキーを直ちに探してレコードをアクセスすることができるため、1のコストが消費されるといえる。
【0059】
get_first_row:log2(Kt)
get_next_row:1
【0060】
従来技術による実行方式では、友達ユーザのそれぞれに対してインデックススキャンが行われなければならないためUs回のインデックススキャンが行われ、各インデックススキャン時にKu個のレコードを抽出して中間レコードセットに記憶する。結局、1回のlog2(Kt)コストとKu回の1コストを有したインデックススキャンがUs回実行される。また、記憶された中間レコードセットをタイムスタンプが最新である順にソートする作業は、全体レコードの数が(Us×Ku)である中間レコードセットに対して実行するため、このようなソートコストは(Us×Ku)×log2(Us×Ku)であるといえる。従って、従来技術による実行方式により発生する実行時間コストを数式で表すると、以下の数式1のとおりである。
【0061】
(数式1)
時間コスト(従来技術)=スキャンコスト+ソートコスト
=(Us×(log2(Kt)+Ku))+((Us×Ku)×log2(Us×Ku))
=Us×(log2(Kt)+Ku+Ku×log2(Us×Ku))
=Us×(log2(Kt)+Ku×(1+log2(Us×Ku)))
【0062】
一方、本発明の第1実施形態による実行方式も、友達ユーザのそれぞれに対してインデックススキャンが行われなければならないためUs回のインデックススキャンが実行されることは同じであるが、各インデックススキャン時にKs個のレコードのみを抽出し、抽出されたレコードをN個のローバッファにソートされた順に格納する。即ち、(log2(Kt)+Ks)のスキャンコストを有しながら、抽出したKs個のレコードを、N大きさのローバッファでタイムスタンプの逆順上の挿入位置をバイナリサーチで探して挿入するために、(Ks×log2(N))のコストを有するインデックススキャンがUs回実行される。従って、本発明の第1実施形態による実行方式により発生する実行時間コストを数式で表すると、以下の数式2のとおりである。
【0063】
(数式2)
時間コスト(第1実施形態)=Us×(log2(Kt)+Ks+Ks×log2(N))
=Us×(log2(Kt)+Ks×(1+log2(N)))
【0064】
また、本発明の第2実施形態による実行方式の場合、Us回のインデックススキャンを実行しながら、「get_first_row」演算で探した一番目のレコードのタイムスタンプを基準に比較して、最新のレコードを指し示しているインデックススキャン情報N個を記憶するスキャンバッファに挿入するための作業を実行する。従って、Us回のインデックススキャンそれぞれに対して一番目のレコードを探すためのlog2(Kt)のコストとスキャンバッファに格納するためのlog2(N)のコストが消費されるため、全体コストは(Us×(log2(Kt)+log2(N))となる。その後、スキャンバッファに記憶されたN個のインデックススキャンを利用してソート−併合(sort−merge)方式で最新のレコードを抽出しながら、最終的にN個のローバッファに最新の順にレコードを格納するようになる。これを詳細に説明すると、スキャンバッファにある一番目のインデックススキャンから現在レコードを抽出してローバッファに格納するコストは1が消費され、そのインデックススキャンの次のレコードを得るための「get_next_row」実行コストも1が消費され、またそのインデックススキャンの新しい現在レコードのタイムスタンプを基準にスキャンバッファでそのインデックススキャンを再位置させるためにlog2(N)のコストが消費される。また、このような作業が最大N回実行されるため、全体コストは(N×(log2(N)+2))が消費されるようになる。従って、本発明の第2実施形態による実行方式によって発生する実行時間コストを数式で表すると、以下の数式3のとおりである。
【0065】
(数式3)
時間コスト(第2実施形態)=スキャンしながらスキャン情報をスキャンバッファに格納するコスト+ローバッファに最終レコードを格納するコスト
=(Us×(log2(Kt)+log2(N)))+(N×(log2(N)+2))
【0066】
上記で仮定した各変数に以下のような値を代入して、数式1、2、3により計算された実行時間コストの具体的な値は、以下の表2に示す。
【0067】
N:20
Us:100,000
Kt:100,000,000
Ku:1,000
Ks:5
【0068】
【表2】
【0069】
前記表2に計算されたように、本発明の第1実施形態によると従来技術に比べ約500倍の速度性能の向上が、第2実施形態によると従来技術に比べ約900倍の速度性能の向上がなされることが分かる。
【0070】
また、クエリ実行時に使用される空間コストの面では、従来技術の場合は、Us×Ku個のレコードを中間レコードセットとして抽出してソートするためのバッファが必要である。これだけのバッファを割り当てることができる空間がメモリ内に存在しない場合、メモリでなくディスクを利用してバッファを割り当てなければならないため、メモリとディスクのアクセス(access)速度差による速度上の損失が発生する。これに反して、本発明の第1実施形態の場合はN個のローバッファが割り当てられ、第2実施形態の場合はN個のスキャンバッファ及びN個のローバッファのみが割り当てられればよいため、その空間コストは従来技術に比べ無視できるほど小さいと言える。
【0071】
ここでのコストの計算は、一つのインデックスに全てのユーザのキーが存在する一般的なDBMSでの状況を仮定したものである。インデックス機能を提供する他のデータリポジトリの場合は、ユーザ毎に小さい大きさのインデックスを別に作って使用する場合もある。この場合は、各インデックスが有するキーの数がKtでなくKuとなり、この場合のインデックス探索コストはlog2(Kt)でなくlog2(Ku)となる。
【0072】
本発明による実施形態は、多様なコンピュータ手段によって実行可能なプログラム命令の形態により実現され、コンピュータ読み取り可能な媒体に記録することができる。この場合、コンピュータ読み取り可能な媒体は、プログラム命令、データファイル、データ構造などを単独に、または組み合わせて含むことができる。このような媒体に記録されるプログラム命令は、本発明のために特別に設計及び構成されたものであってもよく、コンピュータソフトウェア分野の当業者に公知されて使用可能なものであってもよい。コンピュータ読み取り可能な記録媒体の例としては、ハードディスク、フロッピー(登録商標)ディスク及び磁気テープなどの磁気媒体(Magnetic Media)、CD−ROM、DVDなどの光記録媒体(Optical Media)、フロプティカルディスク(Floptical Disk)などの磁気−光媒体(Magneto−Optical Media)、及びROM、RAM、フラッシュメモリなどの、プログラム命令を記憶及び実行するように特別に構成されたハードウェア装置が含まれる。プログラム命令の例としては、コンパイラーによって作られるもののような機械語コードだけでなく、インタープリターなどを用いてコンピュータによって実行されることができる高級言語コードを含む。前記ハードウェア装置は、本発明の動作を行うために一つ以上のソフトウェアモジュールとして作動するように構成されることができ、その逆も同様である。
【0073】
以上のように本発明では、具体的な構成要素などのような特定事項と限定された実施形態及び図面によって説明されたが、これは本発明の全般的な理解をより容易にするために提供されたものに過ぎず、本発明は上記の実施形態に限定されるものではなく、本発明が属する分野において通常の知識を有する者であれば、このような記載から多様な修正及び変形が可能である。
【0074】
従って、本発明の思想は、説明された実施形態に限って決まってはならず、添付する特許請求範囲だけでなく、この特許請求範囲と均等または等価的変形がある全てのものなどは本発明の思想の範囲に属するといえる。
【特許請求の範囲】
【請求項1】
クエリに含まれた抽出レコード数に基づいてバッファを割り当て、
前記クエリに含まれた第1リストのうち第1属性に係わる第1データを抽出して前記バッファに記憶し、
前記クエリに含まれた前記第1リストのうち抽出されていない前記第1属性に係わる第2データを抽出し、
前記バッファに記憶された前記第1データ及び前記第2データを比較することにより、前記クエリを満たすように前記バッファを更新し、
前記クエリは、前記第1属性及び前記第2属性に基づいて前記ソートされた一つ以上の前記レコードに対する多重範囲スキャンでのNソートクエリであることを特徴とするクエリ処理方法。
【請求項2】
前記バッファに記憶することは、
前記第1属性が同一の前記レコードを前記抽出レコード数及び前記第1属性に係わる全ての前記レコードの個数のうち小さい数だけ抽出し、
抽出された前記レコードを前記第1データとして前記バッファに記憶すること特徴とする請求項1に記載のクエリ処理方法。
【請求項3】
前記第2データは、抽出された前記第1データが有する前記第1属性とは異なる前記第1属性を有するレコードであることを特徴とする請求項1または2に記載のクエリ処理方法。
【請求項4】
前記バッファを更新することは、
前記第2データを前記バッファに記憶されたデータと比較して第1条件を満たすかを確認し、
前記第2データが前記第1条件を満たす場合、前記第2データが前記バッファに記憶するように前記バッファを更新して、前記更新されたバッファは、前記クエリを満たすことを特徴とする請求項1乃至3の何れか一つに記載のクエリ処理方法。
【請求項5】
前記第1条件は、前記第2データの前記第2属性が前記バッファに記憶されたデータの第2属性のうち少なくとも何れか一つに先立つ条件であることを特徴とする請求項4に記載のクエリ処理方法。
【請求項6】
前記第2データを前記バッファに記憶するように前記バッファを更新することは、
前記バッファがフル状態である場合、前記バッファに記憶された前記第2データのうち前記第2属性が最も古いレコードを前記バッファから削除し、
前記第2データを含んで前記バッファ内に記憶されたデータが、前記第2属性が最新である順にソートされるように、前記第2データを前記バッファの第1位置に挿入すること特徴とする請求項5に記載のクエリ処理方法。
【請求項7】
前記第2データが前記バッファに記憶されたデータと比較して前記第1条件を満たすか、または前記第2データが存在するまで、前記第1属性が同一の前記第2データを順次的に一つずつ抽出して前記バッファを更新することを繰り返すことを特徴とする請求項4から6の何れか一つに記載のクエリ処理方法。
【請求項8】
前記クエリに含まれた第1リストに残っている全ての前記第1属性に対して、前記第2データを抽出すること及びバッファを更新することを繰り返すことを特徴とする請求項7に記載のクエリ処理方法。
【請求項9】
前記バッファを割り当てることは、前記抽出レコード数に基づいて前記第2バッファをさらに割り当てて、前記バッファは、前記レコードを指し示すスキャン情報を記憶するスキャンバッファであり、前記第2バッファは、前記レコードを記憶するローバッファであることを特徴とする請求項1乃至8の何れか一つに記載のクエリ処理方法。
【請求項10】
前記バッファを更新することは、
前記第2データであるスキャン情報が指し示すレコードと、前記バッファに記憶されたデータであるスキャン情報が指し示すレコードとを比較して第2条件を満たすかを確認し、
前記第2条件を満たす場合、前記第2データが前記バッファに記憶されるように前記バッファを更新し、前記更新されたバッファは前記クエリを満たすことを特徴とする請求項9に記載のクエリ処理方法。
【請求項11】
前記第2条件は、前記第2データであるスキャン情報が指し示すレコードの前記第2属性が前記バッファに記憶されたデータであるスキャン情報が指し示すレコードの前記第2属性のうち少なくとも何れか一つに先立つ条件であることを特徴とする請求項10に記載のクエリ処理方法。
【請求項12】
前記第2データが前記バッファに記憶されるように前記バッファを更新することは、前記バッファがフル状態である場合、前記バッファに記憶されたデータであるスキャン情報が指し示すレコードのうち第2属性が最も古いレコードを指し示すスキャン情報を前記バッファから削除し、
前記第2データを含んで前記バッファ内に記憶されたデータが指し示すレコードの第2属性が最新である順にソートされるように、前記第2データを前記バッファの第2位置に挿入することを特徴とする請求項11に記載のクエリ処理方法。
【請求項13】
前記第1データは、前記第1属性を有する最初のレコードを指し示すスキャン情報であることを特徴とする請求項9から12の何れか一つに記載のクエリ処理方法。
【請求項14】
前記クエリに含まれた第1リストに残っている全ての第1属性に対して、前記第2データを抽出すること及びバッファを更新することを繰り返すことを特徴とする請求項12または13に記載のクエリ処理方法。
【請求項15】
前記第2データを抽出すること及びバッファを更新することを繰り返して完了した後、前記スキャン部により、前記バッファのソートされたスキャン情報のうち一番目のスキャン情報が指し示すレコードを前記第2バッファの空いている位置のうち先頭に記憶し、
前記スキャン部により、前記スキャン情報を、前記スキャン情報が指し示すレコードが有する第1属性と同一で前記第2属性が最新である順にソートされたレコードのうち次のレコードを指し示すように移動し、
前記スキャン部により、移動された前記スキャン情報を含んで前記バッファに記憶されたデータであるスキャン情報が指し示すレコードの第2属性が最新である順に前記バッファをソートすることを特徴とする請求項14に記載のクエリ処理方法。
【請求項16】
前記第2データを抽出すること及びバッファを更新することを繰り返して完了した後に行う前記記憶は、移動すること及びソートすることが、前記第2バッファがフル状態になるまで繰り返されることを特徴とする請求項15に記載のクエリ処理方法。
【請求項17】
前記クエリが、前記第1属性及び前記第2属性に基づいてソートされた一つ以上のレコードに対する多重範囲スキャンでのNソートクエリであるか否かを判断することをさらに含み、前記判断結果がNソートクエリである場合にのみ、前記バッファを割り当てること、前記バッファを記憶すること、前記第2データを抽出すること及び前記バッファを更新することが実行されることを特徴とする請求項1から16の何れか一つに記載のクエリ処理方法。
【請求項18】
前記第1属性はユーザIDであり、前記第2属性はタイムスタンプであることを特徴とする請求項1から17の何れか一つに記載のクエリ処理方法。
【請求項19】
請求項1から18の何れか一つに記載の方法の各段階をコンピュータ上で行うためのプログラムを記録したコンピュータ読み取り可能な記録媒体。
【請求項20】
クエリに含まれた抽出レコード数に基づいてバッファを割り当てるバッファ割り当て部と、
前記クエリに含まれた第1リストのうち第1属性に係わる第1データを抽出して前記バッファに記憶し、前記クエリに含まれた第1リストのうち抽出されていない第1属性に係わる第2データを抽出し、前記バッファに記憶されたデータ及び前記第2データを比較することにより、前記クエリを満たすように前記バッファを更新するスキャン部と、を含み、
前記クエリは、第1属性及び第2属性に基づいてソートされた一つ以上のレコードに対する多重範囲スキャンでのNソートクエリであることを特徴とするクエリ処理装置。
【請求項1】
クエリに含まれた抽出レコード数に基づいてバッファを割り当て、
前記クエリに含まれた第1リストのうち第1属性に係わる第1データを抽出して前記バッファに記憶し、
前記クエリに含まれた前記第1リストのうち抽出されていない前記第1属性に係わる第2データを抽出し、
前記バッファに記憶された前記第1データ及び前記第2データを比較することにより、前記クエリを満たすように前記バッファを更新し、
前記クエリは、前記第1属性及び前記第2属性に基づいて前記ソートされた一つ以上の前記レコードに対する多重範囲スキャンでのNソートクエリであることを特徴とするクエリ処理方法。
【請求項2】
前記バッファに記憶することは、
前記第1属性が同一の前記レコードを前記抽出レコード数及び前記第1属性に係わる全ての前記レコードの個数のうち小さい数だけ抽出し、
抽出された前記レコードを前記第1データとして前記バッファに記憶すること特徴とする請求項1に記載のクエリ処理方法。
【請求項3】
前記第2データは、抽出された前記第1データが有する前記第1属性とは異なる前記第1属性を有するレコードであることを特徴とする請求項1または2に記載のクエリ処理方法。
【請求項4】
前記バッファを更新することは、
前記第2データを前記バッファに記憶されたデータと比較して第1条件を満たすかを確認し、
前記第2データが前記第1条件を満たす場合、前記第2データが前記バッファに記憶するように前記バッファを更新して、前記更新されたバッファは、前記クエリを満たすことを特徴とする請求項1乃至3の何れか一つに記載のクエリ処理方法。
【請求項5】
前記第1条件は、前記第2データの前記第2属性が前記バッファに記憶されたデータの第2属性のうち少なくとも何れか一つに先立つ条件であることを特徴とする請求項4に記載のクエリ処理方法。
【請求項6】
前記第2データを前記バッファに記憶するように前記バッファを更新することは、
前記バッファがフル状態である場合、前記バッファに記憶された前記第2データのうち前記第2属性が最も古いレコードを前記バッファから削除し、
前記第2データを含んで前記バッファ内に記憶されたデータが、前記第2属性が最新である順にソートされるように、前記第2データを前記バッファの第1位置に挿入すること特徴とする請求項5に記載のクエリ処理方法。
【請求項7】
前記第2データが前記バッファに記憶されたデータと比較して前記第1条件を満たすか、または前記第2データが存在するまで、前記第1属性が同一の前記第2データを順次的に一つずつ抽出して前記バッファを更新することを繰り返すことを特徴とする請求項4から6の何れか一つに記載のクエリ処理方法。
【請求項8】
前記クエリに含まれた第1リストに残っている全ての前記第1属性に対して、前記第2データを抽出すること及びバッファを更新することを繰り返すことを特徴とする請求項7に記載のクエリ処理方法。
【請求項9】
前記バッファを割り当てることは、前記抽出レコード数に基づいて前記第2バッファをさらに割り当てて、前記バッファは、前記レコードを指し示すスキャン情報を記憶するスキャンバッファであり、前記第2バッファは、前記レコードを記憶するローバッファであることを特徴とする請求項1乃至8の何れか一つに記載のクエリ処理方法。
【請求項10】
前記バッファを更新することは、
前記第2データであるスキャン情報が指し示すレコードと、前記バッファに記憶されたデータであるスキャン情報が指し示すレコードとを比較して第2条件を満たすかを確認し、
前記第2条件を満たす場合、前記第2データが前記バッファに記憶されるように前記バッファを更新し、前記更新されたバッファは前記クエリを満たすことを特徴とする請求項9に記載のクエリ処理方法。
【請求項11】
前記第2条件は、前記第2データであるスキャン情報が指し示すレコードの前記第2属性が前記バッファに記憶されたデータであるスキャン情報が指し示すレコードの前記第2属性のうち少なくとも何れか一つに先立つ条件であることを特徴とする請求項10に記載のクエリ処理方法。
【請求項12】
前記第2データが前記バッファに記憶されるように前記バッファを更新することは、前記バッファがフル状態である場合、前記バッファに記憶されたデータであるスキャン情報が指し示すレコードのうち第2属性が最も古いレコードを指し示すスキャン情報を前記バッファから削除し、
前記第2データを含んで前記バッファ内に記憶されたデータが指し示すレコードの第2属性が最新である順にソートされるように、前記第2データを前記バッファの第2位置に挿入することを特徴とする請求項11に記載のクエリ処理方法。
【請求項13】
前記第1データは、前記第1属性を有する最初のレコードを指し示すスキャン情報であることを特徴とする請求項9から12の何れか一つに記載のクエリ処理方法。
【請求項14】
前記クエリに含まれた第1リストに残っている全ての第1属性に対して、前記第2データを抽出すること及びバッファを更新することを繰り返すことを特徴とする請求項12または13に記載のクエリ処理方法。
【請求項15】
前記第2データを抽出すること及びバッファを更新することを繰り返して完了した後、前記スキャン部により、前記バッファのソートされたスキャン情報のうち一番目のスキャン情報が指し示すレコードを前記第2バッファの空いている位置のうち先頭に記憶し、
前記スキャン部により、前記スキャン情報を、前記スキャン情報が指し示すレコードが有する第1属性と同一で前記第2属性が最新である順にソートされたレコードのうち次のレコードを指し示すように移動し、
前記スキャン部により、移動された前記スキャン情報を含んで前記バッファに記憶されたデータであるスキャン情報が指し示すレコードの第2属性が最新である順に前記バッファをソートすることを特徴とする請求項14に記載のクエリ処理方法。
【請求項16】
前記第2データを抽出すること及びバッファを更新することを繰り返して完了した後に行う前記記憶は、移動すること及びソートすることが、前記第2バッファがフル状態になるまで繰り返されることを特徴とする請求項15に記載のクエリ処理方法。
【請求項17】
前記クエリが、前記第1属性及び前記第2属性に基づいてソートされた一つ以上のレコードに対する多重範囲スキャンでのNソートクエリであるか否かを判断することをさらに含み、前記判断結果がNソートクエリである場合にのみ、前記バッファを割り当てること、前記バッファを記憶すること、前記第2データを抽出すること及び前記バッファを更新することが実行されることを特徴とする請求項1から16の何れか一つに記載のクエリ処理方法。
【請求項18】
前記第1属性はユーザIDであり、前記第2属性はタイムスタンプであることを特徴とする請求項1から17の何れか一つに記載のクエリ処理方法。
【請求項19】
請求項1から18の何れか一つに記載の方法の各段階をコンピュータ上で行うためのプログラムを記録したコンピュータ読み取り可能な記録媒体。
【請求項20】
クエリに含まれた抽出レコード数に基づいてバッファを割り当てるバッファ割り当て部と、
前記クエリに含まれた第1リストのうち第1属性に係わる第1データを抽出して前記バッファに記憶し、前記クエリに含まれた第1リストのうち抽出されていない第1属性に係わる第2データを抽出し、前記バッファに記憶されたデータ及び前記第2データを比較することにより、前記クエリを満たすように前記バッファを更新するスキャン部と、を含み、
前記クエリは、第1属性及び第2属性に基づいてソートされた一つ以上のレコードに対する多重範囲スキャンでのNソートクエリであることを特徴とするクエリ処理装置。
【図1】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7a】
【図7b】
【図7c】
【図7d】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7a】
【図7b】
【図7c】
【図7d】
【公開番号】特開2012−256318(P2012−256318A)
【公開日】平成24年12月27日(2012.12.27)
【国際特許分類】
【出願番号】特願2012−92668(P2012−92668)
【出願日】平成24年4月16日(2012.4.16)
【公序良俗違反の表示】
(特許庁注:以下のものは登録商標)
1.FACEBOOK
2.TWITTER
【出願人】(505205812)エヌエイチエヌ コーポレーション (408)
【公開日】平成24年12月27日(2012.12.27)
【国際特許分類】
【出願日】平成24年4月16日(2012.4.16)
【公序良俗違反の表示】
(特許庁注:以下のものは登録商標)
1.FACEBOOK
2.TWITTER
【出願人】(505205812)エヌエイチエヌ コーポレーション (408)
[ Back to top ]