
学習装置、クラス識別装置、学習方法、およびプログラム
【課題】時間とともに複雑な変化をともなうデータストリームの特徴を入力ベクトルの属性で表現することは困難である。
【解決手段】
履歴数入力部26は過去履歴の参照範囲を履歴数として入力する。教師ストリーム構造データ作成部28は属するクラスが既知である履歴数個のデータをひとつの教師ストリーム構造データとしてまとめる。教師ストリームカーネル作成部30は教師ストリーム構造データに基づいて教師ストリームカーネルを作成する。機械学習部32は教師ストリームカーネルの出力値を機械学習することにより、任意のストリーム構造データの属するクラスを識別するための識別器を生成する。
【解決手段】
履歴数入力部26は過去履歴の参照範囲を履歴数として入力する。教師ストリーム構造データ作成部28は属するクラスが既知である履歴数個のデータをひとつの教師ストリーム構造データとしてまとめる。教師ストリームカーネル作成部30は教師ストリーム構造データに基づいて教師ストリームカーネルを作成する。機械学習部32は教師ストリームカーネルの出力値を機械学習することにより、任意のストリーム構造データの属するクラスを識別するための識別器を生成する。
【発明の詳細な説明】
【技術分野】
【0001】
この発明は学習装置、クラス識別装置、学習方法、およびプログラムに関する。
【背景技術】
【0002】
近年、金融や流通分野の取引記録、ネットワーク監視システムの通信記録等のデータストリームが新しいタイプの大規模データとして注目を集めている。このようなデータストリームの識別は、一般的に教師付き学習が用いられる。従来の教師付き学習は、オンラインで到着するデータを特徴ベクトルで表し、それを事前に作成した識別器に入力することで、あらかじめ定義されたカテゴリへ識別することが行われている。
【0003】
大規模に蓄積されたデータストリームを解析し、その結果を有効に活用する研究は、データマインイング1)、情報検索、統計的学習分野2)等において長年活発に行われてきた。カーネル法3),4)は、データの非線形構造をとらえる強力な手法として注目されており、分類5)や識別6)等に適用され、高い精度を得ている。特に識別において、線形識別器であるSVMにカーネルトリックを適用し、非線形識別関数を構成することで非線形識別を可能にした非線形SVMは、最も識別性能に優れたモデルのひとつである(特許文献1参照)。
【先行技術文献】
【特許文献】
【0004】
【特許文献1】特開2006−153582号公報
【発明の概要】
【発明が解決しようとする課題】
【0005】
しかし、データストリームを対象にした場合の識別精度は、静的データを対象にした場合と比べると識別精度が劣るという欠点がある。時間とともに複雑な変化をともなうデータストリームの特徴を入力ベクトルの属性で表現することは困難であり、無理に特徴を出そうと入力ベクトルの属性数を増やせば、次元の呪いによって識別器の汎化性能が失われるという欠点もある。
【0006】
本発明はこうした状況に鑑みてなされたものであり、その目的は、汎化性を持って精度良くデータを識別することができる情報処理装置を提供することにある。
【課題を解決するための手段】
【0007】
本発明のある態様は学習装置に関する。この装置は、過去履歴の参照範囲を履歴数として入力する履歴数入力部と、属するクラスが既知である履歴数個のデータをひとつの教師ストリーム構造データとしてまとめる教師ストリーム構造データ作成部と、教師ストリーム構造データに基づいて教師ストリームカーネルを作成する教師ストリームカーネル作成部と、教師ストリームカーネルの出力値を機械学習することにより、任意のストリーム構造データの属するクラスを識別するための識別器を生成する機械学習部とを含む。
【0008】
本発明の別の態様はクラス識別装置に関する。この装置は、オンラインで受け取ったデータと当該データの過去履歴とから識別用ストリーム構造データを構築するストリーム構造データ構築部と、前記識別用ストリーム構造データと、教師ストリームカーネルの値を機械学習することにより得られた識別器とを用いて識別用ストリームカーネルを作成する識別用ストリームカーネル作成部と、識別用ストリームカーネルの出力値に基づいて当該データの属するクラスを識別する識別部とを含む。
【0009】
本発明のさらに別の態様は学習方法に関する。この方法は、過去履歴の参照範囲を履歴数として入力するステップと、属するクラスが既知である履歴数個のデータをひとつの教師ストリーム構造データとしてまとめるステップと、教師ストリーム構造データに基づいて教師ストリームカーネルを作成するステップと、教師ストリームカーネルの出力値を機械学習することにより、任意のストリーム構造データの属するクラスを識別するための識別器を生成するステップとをプロセッサに実行させる。
【0010】
本発明のさらに別の態様は、ストリーム構造データを識別する識別器を生成するためのプログラムに関する。このプログラムは、過去履歴の参照範囲を履歴数として入力する機能と、属するクラスが既知である履歴数個のデータをひとつの教師ストリーム構造データとしてまとめる機能と、教師ストリーム構造データに基づいて教師ストリームカーネルを作成する機能と、教師ストリームカーネルの出力値を機械学習することにより、任意のストリーム構造データの属するクラスを識別するための識別器を生成する機能とをコンピュータに実現させる。
【0011】
なお、以上の構成要素の任意の組合せ、本発明の表現を方法、装置、サーバ、システム、コンピュータプログラム、記録媒体などの間で変換したものもまた、本発明の態様として有効である。
【発明の効果】
【0012】
本発明によれば、汎化性を持って精度良くデータを識別する技術を提供することができる。
【図面の簡単な説明】
【0013】
【図1】実施の形態に係る識別プロセスを表す図である。
【図2】カーネル法による線形分離の様子を例示する図である。
【図3】ストリーム構造データの構成図である。
【図4】振舞い属性を考慮した識別を表す図である。
【図5】ストリーム構造データの作成を表す図である。
【図6】CAP曲線による性能比較を表す図である。
【図7】CAP曲線の見方を説明する図である。
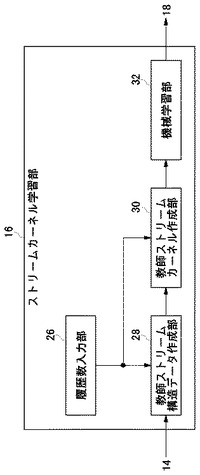
【図8】実施の形態に係る情報処理装置の全体構成を表す図である。
【図9】ストリームカーネル学習部の構成図である。
【図10】教師ストリームカーネル作成部の構成図である。
【図11】ストリームカーネルを作成する処理の流れを表す図である。
【図12】ストリーム構造データ識別部の構成図である。
【発明を実施するための形態】
【0014】
以下本発明を好適な実施の形態をもとに説明する。まず、実施の形態の基礎となる理論を前提技術として述べ、その後、具体的な実施の形態を説明する。
【0015】
[前提技術]
[1] はじめに
実施の形態は、大規模データストリームのための履歴情報を用いたカーネル法の拡張に関するものである。実施の形態の基礎技術は、カーネル法を拡張してデータストリームを構造データと見なして識別することである。
【0016】
近年、金融や流通分野の取引記録や、ネットワーク監視システムの通信記録等のデータストリームが新しいタイプの大規模データとして注目を集めている。データストリームには、日々刻々と生成され、時間とともに複雑な変化をともなう性質があり、この蓄積されたデータをいかに分析し活用するかが重要な課題となっている。そこで、データマイニングや機械学習がその有力な手法となる。
【0017】
データマイニングや機械学習は、大量のデータから知識やルールを発見するための分析手法であり、本実施の形態ではこのデータストリームを識別することに焦点を当てる。これはクレジットカードの不正利用識別、POSトランザクションからの優良顧客識別、ネットワークログからの不正侵入識別等、その応用は多岐にわたる。しかし、時間とともに複雑な変化をともなうデータストリームの識別は困難であり、識別性能を向上させることは重要な課題である。
【0018】
このようなデータストリームの識別は、一般的に教師付き学習が用いられる。従来の教師付き学習は、オンラインで到着するデータを特徴ベクトルxで表し、それを事前に作成した識別器y=f(x)に入力することで、あらかじめ定義されたカテゴリへ識別する。ここで識別精度を上げるために重要なことは、対象データ世界の特徴を抽出することである。従来の識別手法を用いれば、複雑なストリームの特徴をベクトル形式で表現しなければならない。識別で十分な精度が得られないのは、ベクトルの属性値に識別のための特徴が出ていないからである。特徴を出そうと属性の数を増やせば、次元の呪いによって識別器の汎化性能が失われ、また、その特徴抽出には深い領域知識が必要である。
【0019】
一方、線形識別器であるサポートベクタマシン(SVM)は、カーネル法によって非線形識別を行うことができる非線形SVMへと拡張された。詳細は後述するが、カーネル法は元のデータ空間を高次元空間へ埋め込み、この空間で線形識別を実行する。その計算はカーネル関数と呼ばれる高次元空間上の内積を表す関数で行われ、実際には高次元へ写像することなく、高次元空間上での動作を可能にする。この仕組みはカーネルトリックと呼ばれ、カーネルトリックを用いて非線形識別関数を構成することで非線形識別を可能にするSVMを非線形SVMという。そしてこの非線形SVMは、最も識別性能に優れたモデルのひとつである。
【0020】
また、このカーネル法は近年、構造を持つデータを入力にすることができるように拡張され、これまでに木、配列、グラフ等の構造データに対するカーネル関数が提案されている。このような構造データを用いると、ベクトル形式では失われていたデータの特徴を識別に用いることができ、ベクトル形式で識別するよりも高い精度が得られている。
【0021】
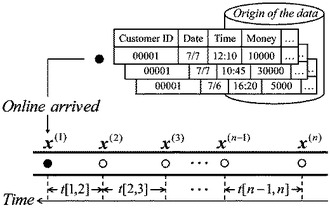
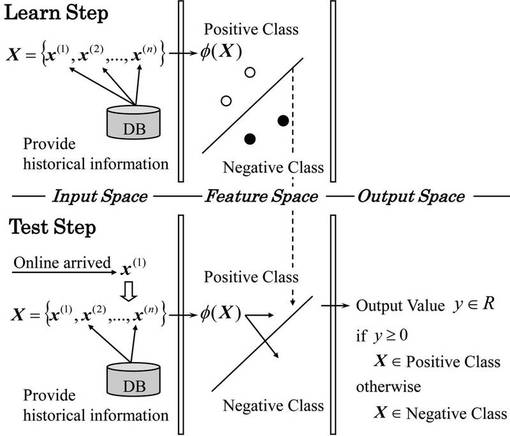
そこで、本実施の形態では、カーネル法を拡張して、データストリームを構造データと見なして識別する手法を提案する。図1は実施の形態に係る識別プロセスを表す図である。例えば、クレジットカードデータの場合、この構造データは、オンラインで到着するデータ(特徴ベクトルx)だけでなく、あるユーザの過去n回までの履歴情報をまとめた、ひとつのストリーム構造を持つデータX={x(1),x(2),・・・,x(n)}である。また、このストリーム構造データに適用できるカーネル関数は、新しいデータであるほど識別の影響が大きく、古いデータほど識別の影響が小さくなるようにデータを扱い、履歴情報から得られるデータストリームの時間的な変化を特徴にする。
【0022】
まとめると、本実施の形態は既存の手法・研究と比較して、以下の技術的特徴を有する。
・オンラインで到着するデータのみを入力として分析に用いるのではなく、過去n回までの履歴をまとめたものを、ひとつのストリーム構造を持つデータとして扱い、これを入力するカーネル関数(以下、「ストリームカーネル」という。)を構築する。
・従来のベクトルを入力とした場合、すなわちオンラインで到着したデータのみを用いて、過去の履歴を用いない場合のカーネルの計算量に対して、このストリームカーネルの計算量はO(n)である。
・大規模な実際のクレジットカードデータを用いた識別実験を行い、既存の手法よりも優れた精度であることを示す。
【0023】
本実施の形態では二値の識別に関して述べるが、この制約は重要ではない。なぜなら、どのような二値識別器でも、多重クラスの問題へ拡張できるからである。たとえば代表的なone−versus−restは、C1,・・・,Ckのk個のクラスへの識別問題においてあるクラスCiと、それ以外のクラス∪j≠iCjとを識別する二値識別器をk個構築する。クラスラベルが未知のデータに対する予測は、k個の識別器が一貫した出力をした場合、そのクラスへ割り当て、そうでない場合は候補の中からランダムにあるいは識別器の出力の中から最もあてはまりが良いクラスへ割り当てられる。
【0024】
[2] 関連研究
大規模に蓄積されたデータストリームを解析し、その結果を有効に活用する研究は、データマイニング1)、情報検索、統計的学習分野2)等において長年活発に行われてきた。カーネル法3),4)は、データの非線形構造をとらえる強力な手法として注目されており、分類(clustering)5)や識別(classification)6)等に適用され、高い精度を得ている。
【0025】
特に識別において、線形識別器であるSVMにカーネルトリックを適用し、非線形識別関数を構成することで非線形識別を可能にした非線形SVM3)は、最も識別性能に優れたモデルのひとつである。このことは、本実施の形態について行った実際の大規模なクレジットカードデータを不正利用と正常利用に識別する実験でも示されており、本実施の形態における識別器に非線形SVMを選択した動機である。
【0026】
しかし、データストリームを対象にした場合(ネットワーク侵入識別、優良顧客識別8)等)の識別精度は、静的なデータを対象にした場合(画像認識、テキスト識別等9))と比べると劣り、先行研究では複雑な個人情報ストリームの識別が困難であることを示している。ここで使われている多くの識別アルゴリズム(K−最近傍法、決定木、ベイジアン識別器、ニューラルネットワーク、SVM、ロジステック回帰)の入力はベクトル形式であり、過去には識別精度を向上させるために識別に有効なベクトルの属性が考えられてきた8)。しかし、時間とともに複雑な変化をともなうデータストリームの特徴をすべてベクトルの属性で表現することは困難であり、無理に特徴を出そうとベクトルの属性数を増やせば、次元の呪いによって識別器の汎化性能は失われる。
【0027】
本実施の形態では、従来識別器に用いてきたデータだけではなく、過去の履歴データに注目する。そして、遡って得られるデータ群をひとつのストリーム構造データとして定義し、このストリーム構造データを入力して識別を行う新しい手法を提案する。
【0028】
まず初めに直面する課題は、どのようにして構造データを入力として扱うかということであるが、上述したカーネル法は近年、配列やグラフ等の構造データを入力にして扱えるように拡張され12),13)、テキスト識別等で高い識別精度を得ている11),14)。しかし、これらは単に構造データの共通部分構造を数え上げるものであり、次の理由でデータストリームに適用することができない:共通部分の数え上げは、部分構造が一致している数をカウントしたものである。たとえば、文字列を配列として扱う文字カーネルにおいて、ふたつの文字列“cat”と“cart”には、“c,a,t,ca,at,ct,cat”という7つの共通部分文字列がある。このようにデータ要素がすべてカテゴリデータであれば、部分構造が一致している数をカウントできる。しかし、データストリームの属性は基本的にカテゴリ属性だけで構成されているわけではなく、連続値の属性も含む。したがって、共通部分の構造の数え上げという概念を持ち込むことができない。また、従来手法はデータストリームの時間的に変化する性質を考慮していない。
【0029】
これらの課題から、本実施の形態では構造データを扱う基礎理論である畳み込みカーネルを用いて、データストリームに適用できるカーネル法を提案する。提案手法は、新しいデータほど識別の影響を大きく、古いデータほど識別の影響を小さくするようにデータを扱い、識別を行う。これによりストリームの時間的な変化を特徴にすることができる。また、上述した配列・グラフ等の構造データに対するカーネル法が高い精度を得ていることは、本実施の形態におけるデータストリームに適用できるカーネル法を提案することで精度を向上させる根拠となる。
【0030】
[3] カーネル法と非線形サポートベクタマシン
[3.1] カーネル法
カーネル法は、データの非線形構造をとらえる強力な手法であり、ふたつの本質的な要素からなる。
(1) データを高次元特徴空間に埋め込む。
(2) 高次元特徴空間で、線形識別アルゴリズムを適用する。
【0031】
線形識別アルゴリズムは多く研究されているが、真の識別境界が非線形である場合、十分な性能が実現できない。そこで、カーネル法は元のデータ空間をいったん線形識別アルゴリズムを適用できる高次元空間へ写像し、この空間で線形識別アルゴリズムを適用する。しかし、カーネル法はデータを高次元特徴空間では明確に示さず、カーネル関数と呼ばれる半正定値関数K:χ×χ→Rを用いて、高次元特徴空間での動作を可能にする。
K(x,z)=〈φ(x),φ(z)〉 (1)
図2はこのようなカーネル法による線形分離の様子を例示する図である。
【0032】
Mercerの定理を満たす半正定値関数Kをカーネル関数と呼び、これはφによって写像された高次元特徴空間上での内積を意味する。このように実際に高次元特徴空間へ写像する計算を避け、入力空間でのカーネル関数を用いて高次元特徴空間上での内積を計算する仕掛けをカーネルトリックと呼ぶ。また、カーネル関数には次のようなものが知られている。
・多項式カーネル
K(xi,xj)=(xiTxj+c)d (2)
・ガウスカーネル
K(xi,xj)=exp(−‖xi−xj‖2/σ2) (3)
・シグモイドカーネル
K(xi,xj)=tanh(axiTxj−b) (4)
【0033】
線形識別器であるSVMは、上述したカーネルトリックを用いて非線形識別を行うことができる識別器へと拡張された。SVMによる識別は、異なるクラスのデータ間の距離(マージン)を最大にする超平面を考える。このときの目的関数と識別関数は、特徴ベクトルの内積のみに依存した形で記述される。たとえば識別関数は、クラスレベル変数t、サポートベクタの集合S、Langrange乗数αi*>0、最適な閾値h*を用いて次式で書ける。
【数1】

【0034】
この線形識別関数は、カーネルトリックを適用することにより以下の形に書き変えることができる。
【数2】
【0035】
ここで、元の空間よりも高次元に写像するカーネル関数Kを選択すれば、高次元空間上で線形SVMを実行したことになり、これは元の空間で非線形識別を実行したことと等価である。このように、カーネルトリックによって非線形識別関数を構成することで、非線形識別を可能にしたSVMを、非線形SVMという。
【0036】
また、これらカーネル関数はふたつの入力の類似度を定めていると考えることができる。すなわち、適当に類似度Rを定義した関数Kを、カーネル関数として使うことができる。したがって、上述したカーネル関数のふたつの入力xi,xjがベクトルでなく、DNA配列やテキスト等の配列、XMLやHTMLで記述された構文解析木のような木構造、あるいは化合物の分子構造のようなグラフで表現される場合にも、カーネル法を適用することができる。本実施例はストリーム構造を持ったデータ間のカーネル関数であり、これら構造を持ったデータ間のカーネルを定義するための基礎理論である畳み込みカーネルについて、以下述べる。
【0037】
[3.2] 畳み込みカーネル
本節では、カーネル関数の入力がベクトルでなく、配列やグラフ等の構造を持ったデータに対するカーネル関数を構築するための基礎理論である畳み込みカーネルについて述べる。畳み込みカーネル15)は、構造を持つデータ間のカーネル関数はその構造の部分構造どうしのカーネル関数によって再帰的に計算されるという考えに基づいている。
【0038】
xはある構造を持つデータ、S(x)はxに含まれる部分構造の集合、sxをその部分構造とする。これはzについても同様である。Ksを部分構造間のカーネル関数とすると、畳み込みカーネルは以下で表現される。
【数3】
【0039】
また、畳み込みカーネルは部分構造sに対する重みf(s|x)を用いて次のように記述することができる。
【数4】
【0040】
この部分構造のカーネル関数Ksは、更に分けられた部分構造による畳み込みカーネルにより、再帰的に表現される。つまり、構造を持ったデータxとzは、ここから取り出される部分構造sx∈S(x)とsz∈S(z)のカーネル関数の値をすべて足し合わせることで全体のカーネル関数が定義される。本実施例では、ストリーム構造を持つデータX={x(1),x(2),・・・,x(n)}間のカーネル関数を提案する。このカーネル関数がストリームカーネルであるが、このストリームカーネルも畳み込みカーネルを基礎理論としている。
【0041】
[4] ストリームカーネル
[4.1] ストリーム構造データの定義
データストリームに対する従来の識別手法は、オンラインで到着したデータをベクトルx=(x1,x2,・・・,xd)で表現し、これを入力に用いる。これに対し、本実施例における識別手法は、次の特徴を持った構造データを入力に用いる。
(1) オンラインで到着したx(1)だけでなく、過去の履歴n個のデータを持つ。
(2) n個の前後のデータ間に、n−1個の時間間隔を持つ。
本実施例ではこれをストリーム構造データと定義し、次のように表現する。
X={x(1),x(2),・・・,x(n)} (10)
【0042】
なお、x(1)が新しいデータ、x(n)が古いデータとし、括弧内の上付き添え字を履歴番号と呼ぶ。時間間隔とは、データが到着した時間の間隔であり、例えばx(1)とx(2)との時間間隔はt[1,2]と表す。図3はストリーム構造データの構成図である。
【0043】
ここで、時間間隔を計算に用いる上で注意すべきことがある。時間間隔は、後述するように、古い情報ほど識別の影響を小さくする重みを計算するときに用いられるが、このとき、遡った期間全体を1に正規化する。つまり、たとえばn=4とし、過去の履歴4件を遡る場合、得られる時間間隔は、t[1,2]、t[2,3]、t[3,4]であり、その合計をt[1,2]+t[2,3]+t[3,4]=1となるように値を変換する。これは単に、各時間間隔についての、遡った期間全体に対する比を考えるだけである。たとえばクレジットカードデータを考えると、クレジットカードを1週間に1度の間隔で使う人もいれば、1カ月に1度の間隔で使う人もいる。時間間隔を正規化することで、各人それぞれの利用の間隔を同じ尺度でとらえることができる。
【0044】
[4.2] 部分構造間のカーネル
本実施例におけるストリームカーネルは前述した畳み込みカーネルが基本理論となっている。したがって、まず前述したストリーム構造データX={x(1),x(2),・・・,x(n)}の部分構造sを定義する。例として、遡る履歴の数をn=3としたX={x(1),x(2),x(3)}の場合について考える。Xの部分構造全体の集合をS(X)とすると、順序関係を考慮して、S(X)は以下の6つの部分構造へ分割される。このとき、遡る履歴の数nに対して、得られる部分構造の数はn(n+1)/2である。
S(X)={s1,s2,s3,s4,s5,s6}
={{x(1)},{x(2)},{x(3)},{x(1),x(2)},{x(2),x(3)},{x(1),x(2),x(3)}}
【0045】
次に、分割された部分構造のカーネルの組合せを考える。ここで、異なる履歴番号で観測されたデータが独立であるとする。すなわち、K(x(i),z(j))=0,i≠jとし、部分構造間のカーネルを、部分構造に含まれるデータのカーネルの積で表現する。すると、部分構造のデータ数が同じで,かつ履歴番号が同じであるときのみ、その部分構造どうしのカーネルKsは計算され、次式で表される。
【数5】
【数6】
【0046】
なお、K(x(i),z(i))は前述した半正定値カーネルである。これにより、考えるべきカーネルの組合せはn(n+1)/2通りとなる。
【0047】
[4.3] 部分構造の重み
次に、畳み込みカーネルにおける部分構造の重みf(s|X)を定義する。このf(s|X)は前述した部分構造のカーネルが、全体の類似度にどれほどの影響力を持つかを表す。これを考えるうえで、理解が単純になるよう再度クレジットカードデータの例を用いる。
【0048】
オンラインで到着した顧客AのデータをxA(1)とすると、この利用xA(1)が正常利用か、不正利用かを識別するために、顧客Aの利用履歴を過去n回遡ったストリーム構造データXA={xA(1),xA(2),・・・,xA(n)}を得る。xA(1)が新しいデータ、xA(n)が古いデータとすると、xA(1)とxA(n)とを同じ重みで扱うと正確な識別を行うことができない。なぜなら、知りたいのは到着したデータxA(1)が不正利用か、正常利用かということである。古いデータがいくら正常利用らしくても、到着したデータが明らかに不正利用らしければ、到着したデータの方を優先すべきである。したがって、新しいデータを含む部分構造であるほど重み(影響度)を大きく、古いデータを含む部分構造であるほど重みを小さくする。この重みf(s|X)は、前述した時間間隔tと、新たに導入するパラメータλ∈(0,1)とを用いた単調減少関数λtによって定義される。
【0049】
ここで、部分構造に含まれるそれぞれのデータに対して具体的に重みを与える。すなわちn番目の履歴データに対して、重みを
【数7】
と定義する。例として、sx={x(2),x(3),x(4)}とsz={z(2),z(3),z(4)}の重みf(sx|X)とf(sz|Z)とを求める。部分構造sxに含まれるデータそれぞれの重みを表1に示す。
【表1】
なお、txは、ストリーム構造データXが持つ時間間隔であるとし、記述の簡略化のため、
【数8】
とする。このxをすべてzで置き換えれば、同様に部分構造szに含まれるデータそれぞれの重みを表す。簡略化せずに重みを詳細に記述すれば、f(sx|X)とf(sz|Z)はそれぞれ次式で表される。
【数9】
【数10】
【0050】
したがって、このときの部分構造の重みを含めたカーネルは式(11)を用いて、
【数11】
となる。
【0051】
[4.4] ストリームカーネル計算アルゴリズム
Kn(X,Z)と、XとZとがともに過去n件のストリーム構造データからなるときのストリームカーネルとする。また、過去n件からなるXに、さらにもう1件遡って得られるx(n+1)が、Xに付与されることをXx(n+1)と表現する。もちろんこれはZについても同様であるが、以降はZにも同じ作業を与えたとして、その記述は省略する。
【0052】
ここで具体的に、例としてn=1の場合から考える。このとき、XはX={x(1)}であり、S(X)={s1}={x(1)}である。したがって、単純にK1(X,Z)は次で表される。
K1(X,Z)=K(x(1),z(1)) (15)
【0053】
次に、X={x(1)}にx(2)が付与され、Xx(2)={x(1),x(2)}となったときのK2(Xx(2),Zz(2))を考える。Xx(2)={x(1),x(2)}により、前述と同様の手法で、Xx(2)は3つの部分構造に分割できる。
S(Xx(2))={s1,s2,s3}
={{x(1)},{x(2)},{x(1),x(2)}}
【0054】
式(9)、(11)、(14)により、K2(Xx(2),Zz(2))は次式で記述できる。なお、数式の簡略化のため、tx[i,i+1]+tz[i,i+1]=T[i,i+1]とする。
K2(Xx(2),Zz(2))=K(x(1),z(1))+λT[1,2]K(x(2),z(2))+λT[1,2]K(x(1),z(1))K(x(2),z(2)) (16)
【0055】
ここで、式(15)と式(16)とを比較し、x(2)が付与されることで増加するカーネルの量を計算する。この量をJ2とすると、J2は次のようにJ1を用いた形で書くことができる。
J2=K2(Xx(2),Zz(2))−K1(X,Z)
=λT[1,2]K(x(2),z(2))+λT[1,2]K(x(1),z(1))K(x(2),z(2))
=λT[1,2]K(x(2),z(2)){1+K(x(1),z(1))}
=λT[1,2]K(x(2),z(2)){1+J1} (17)
【0056】
同様に、X={x(1),x(2)}にx(3)を付与した場合を展開しても、x(2)が付与されることで増加するカーネルの量J3もまた、J2を用いた形で書くことができる。したがって、遡るデータがひとつ増えることで、全体のカーネルに加えられる部分構造のデータのカーネルの量をJnとすると、ストリームカーネルは以下のように一般化した形で、再帰的に表現することができる。
Kn(Xx(n),Zz(m))=Knー1(X,Z)+Jn (18)
【数12】
ただし、K0(X,Z)=1、J1=K(x(1),z(1))である。
【0057】
動的計画法を用いることにより、この計算量は遡るデータ数nに対してO(n)で済む。また、XとZのデータ数が異なる場合、このままでは、データ数が少ない部分集合のカーネルのみを考えてしまう。たとえば、X={x(1),x(2),x(3)},Z={z(1),z(2)}とすると、x(3)はカーネルの計算にまったく用いられない。そこで、以下の式で正規化を行い、これをストリームカーネルの最終出力値とする。
【数13】
【0058】
さらに、このストリームカーネルが半正定値性を満たすことを述べる。いくつかの半正定値性を満たすカーネル関数は、これを足し合わせたり、掛け合わせたり、また定数倍したりしたものもまた、半正定値性を満たすカーネル関数となることが知られている。ストリームカーネルは、半正定値性を満たすカーネル関数を基本として用い、部分構造どうしのカーネルの計算ではこのカーネルを掛け合わせ、部分構造の重みはカーネルを定数倍し、畳み込みで表現された構造全体のカーネルはこれらを足し合わせたものである。したがって,ストリームカーネルは半正定値性を満たす。
【0059】
[5] 実験評価
本実施例では、実際のデータストリームであるクレジットカードデータ(実験データの詳細は後述する。)に対して、ガウスカーネルを用いた通常のSVMと、本実施例のストリームカーネルSVM(以下、「SKSVM」という。)を適用し,正常利用と不正利用に識別した。また、その性能を以下の点から比較した:
(a) 学習・検証にかかる時間
(b) 識別の精度(正答率)
(c) モデルの性能(CAP曲線)
【0060】
[5.1] 実験準備
実験は2GHzのCPUと、3GBのメモリを持つハードウェア環境を使用した。本実施例に係るSKSVMは、OSSであるsvm−light16)(C言語)上で実装を行った。
【0061】
実験で使用したカーネル関数は、ガウスカーネルK(xi,xj)=exp(−‖xi−xj‖2/σ2)である。ガウスカーネルは、パラメータσの設定によってはシグモイドカーネルようにも動作し、また、先行研究で行った実験結果により、ガウスカーネルが識別に最も有効に動作すると判断した。ガウスカーネルのパラメータσは、事前に‖xi−xj‖2の統計を取り、これらが適切にK(xi,xj)∈(0,1)を得るような範囲を確定し、SVMの正則化パラメータCとともに試行錯誤的に決定した。
【0062】
ストリームカーネルのパラメータλは、一番最近のデータのカーネル関数の値が、ストリームカーネル全体の影響の7割程度を占めるように設定した。これは、過去の情報の重みを大きくしすぎてしまうと、一番重要な最近のデータの特徴が埋もれてしまうためである。また、顧客の遡る履歴数nは、n=5に設定した。これら実験で用いたパラメータを表2に示す。
【表2】
【0063】
本実施例ではモデルの性能をCAP曲線によって評価するため、新たにスコア値という考えを導入している。スコア値とは、値が高いものほど不正利用であるらしく、逆に値が低いものほど正常利用であるらしいという指標である。具体的には、SVMの出力yに対して、スコア値scoreは以下の式で1〜1000の値で出力される。
【数14】
【0064】
[5.2] 実験データ
本実験で用いたデータセットは、実際のクレジットカードデータである。クレジットカードデータは、約2年分のデータが用意されており、そのデータ量は約1TBに及ぶ。クレジットカードデータの属性は、大きく次の2つのグループに分類される。
(a) オーソリデータ属性: 利用時の状況を記述した属性
(b) 振舞いデータ属性: 顧客の行動パターンを記述した属性
【0065】
属性(a)は、単にクレジットカードの取引データ(以下、「オーソリデータ」という。)の属性である。たとえばこの属性には、顧客ID、生年月日、利用時間、利用金額、購入商品コード等があり、計84属性からなる。しかし、これらの属性には識別に有効な(不正利用と正常利用で、はっきり値が異なるような)属性は少ない。したがって、この属性だけを用いて識別アルゴリズムを適用しても高い精度は得られない。そこで、識別の特徴として貢献するような以下の属性(b)を、人工的に作成する。
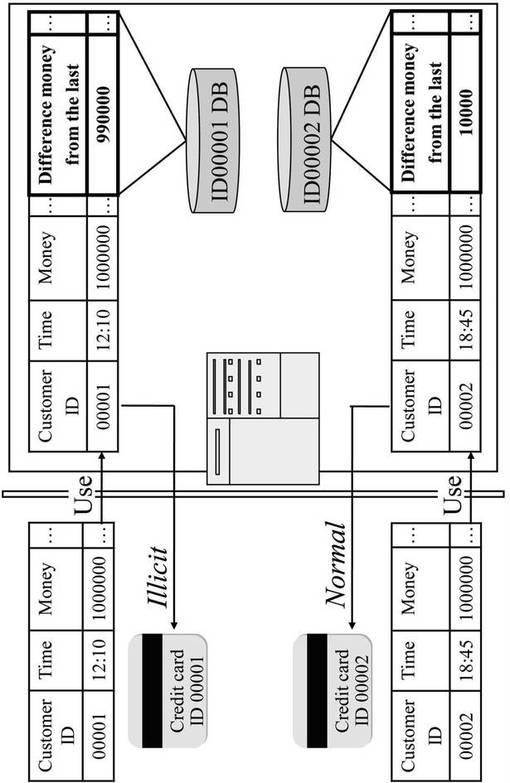
【0066】
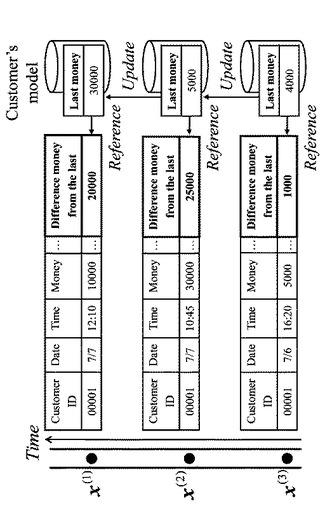
属性(b)は過去の履歴情報から作成した顧客モデル(過去の利用金額の平均や分散、過去の利用時間帯の頻度等)との乖離値であり、顧客の行動パターンを記述した属性である。たとえばある人が高額な買い物をしたとする。その人が前回も同程度の額の買い物をしていたならば、その利用は本人、すなわち正常利用らしいが、逆に前回低額な買い物をしていたならば、第三者利用、すなわち不正利用である可能性があると判断することができる。図4は振舞い属性を考慮した識別を表す図である。
【0067】
このように顧客モデルに基づいてその顧客の行動パターンの時間的変化に注目することは、クレジットカードの領域だけでなく、ネットワーク侵入や個人認証等、他の多くの領域・データにあてはまり、有用である。この属性(b)には「前回利用時間との差」、「前回利用金額との差」、「過去6カ月の曜日ごとの利用回数との比較」等があり、計40属性からなる。本実験で用いたクレジットカードデータセットは属性(a)と属性(b)とから55属性を分析に用いた。データセットの詳細を表3に示す。
【表3】
【0068】
SKSVMとSVMの学習・検証データの違いは、利用時点から過去n回の履歴があるか、ないかである。SKSVMの学習・検証データは、図5で示すように、上述した顧客モデルを更新しながら属性(b)を作成して、ストリームデータ構造を作成する。本実験では、n=5とし過去5回の履歴を遡ってストリーム構造データを作成し、識別を行う。
【0069】
クレジットカードデータを、ストリーム構造データとして扱ううえでの注意すべき点として、顧客のマスタ情報を繰り返し用いることがあげられる。たとえば、顧客の「性別」等属性を分析に用いるとする。すると、過去2件目、3件目にも同じ性別の属性が、繰り返し入ることになる。一見これはデータの冗長性から無駄のように見えるが、これらは全て必要である。なぜなら、冗長性のある「性別」という属性を1件目だけに用いて、それ以降の過去2件目、3件目には用いない場合を考える。そしてもし、その「性別」という属性が、不正利用につながる重要な属性であるとすれば、部分集合間のカーネルを考える際、不十分な情報で過去の履歴を処理してしまい、全体として、特徴が薄れてしまうためである。
【0070】
[5.3] 実験結果と考察
[5.3.1] 学習と検証の時間
通常のSVMと、SKSVMの学習時間・検証時間の比較を表4で示す。表4における数字の単位は秒である。実験の結果、学習時間・検証時間ともに、本実施例の手法は通常のSVMと比べて約10倍の時間がかかった。SKSVMのカーネルの計算量は、通常のSVMのカーネルの計算量に比べ、理論上では遡る履歴の数nに対してO(n)で増加するものの、実際のデータでは欠損値の場合の処理、時間間隔データの変換等の事前計算処理が必要であるため、表4に示した結果はこれらオーバーヘッドを含んだものである。
【表4】
【0071】
次に、通常のSVMと、SKSVMのモデルの大きさであるサポートベクタ(SV)の数の比較を表5で示す。これは式(7)において検証の際に計算を繰り返す数を表している。したがって、SVの数が少なければ、より少ない計算量で検証を行うことができることを示し、また、スパースな解が得られていることになる。表5で示すように、SKSVMの方がよりスパースな解を得ていることが分かる。
【表5】
【0072】
[5.3.2] 識別の精度(正答率)
識別の精度を評価する指標には、一般に適合率(precision)と再現率(recall)が用いられる。しかし、本実験で用いた実際のクレジットカードデータは、不正利用の数が正常利用の数に比べて約0.02%と極端に少なく、また、識別能力の弱い識別器を用いるとすべてを正常利用であると判断してしまうほど、正常利用と不正利用との識別は困難である。したがって、適合率と再現率はともに数%という値しか取ることができず、実際のクレジットカードデータを不正利用と正常利用に識別するというこの領域においては、これらの指標は適当ではない。
【0073】
本実施例にかかるSKSVMによる識別精度の向上を明確にするため、本実験の識別精度は正答率で評価する。正答率は、識別を行った全件(720,920件)に対し、その識別結果が正しかった件数の割合である。表6と表7で示すように、SVMの正答率が99.82%であったのに対し、SKSVMの正答率は99.89%であり、0.07%向上している。
【0074】
割合からはそれほどの向上は見られないが、これは大きな変化である。表6において、SVMが不正利用であると判断した件数は、1110件である。しかし、そのうち1080件は実際には正常利用であり、これは間違った識別である。一方、表7において、SKSVMが不正利用であると判断した件数は586件である。これはSVMと比べると約半分のヒット件数であるにもかかわらず、実際に不正利用であった件数は変わらない(30件と28件)。検証データとして用いたデータセットは不正利用の数が少ないため、この変化は割合として大きく現れないが、実際にはSKSVMは不正利用データを発見するときのノイズを半分に減らしていることが分かる。
【表6】
【表7】
【0075】
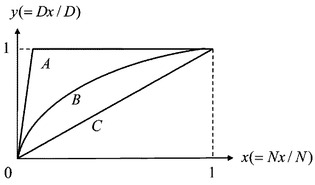
[5.3.3] CAP曲線による比較
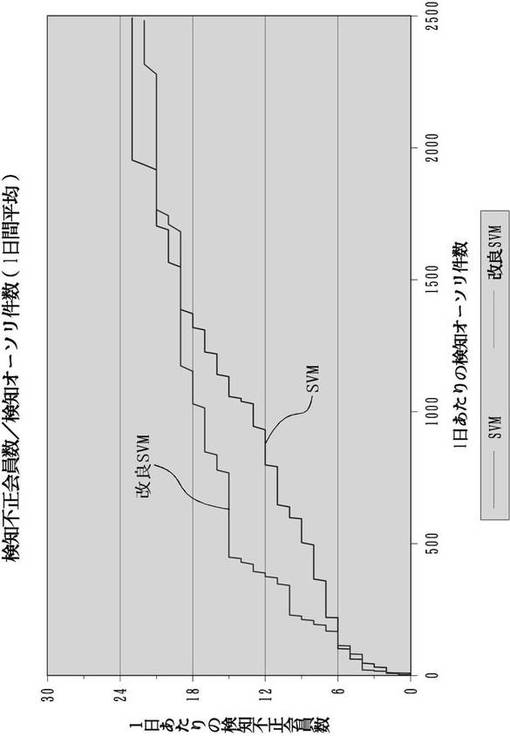
CAP(Cumulative Accuracy Profiles)曲線は、予測モデルの性能を評価するのに用いられ、実際のクレジットカード業界でも使用されている。横軸は、不正利用である確率(スコア値)が高いと識別器が判断したクレジットカードデータを順に並べた数であり、縦軸は、その中で実際に不正利用であった顧客の人数である。図6は、通常のSVMと、SKSVMのCAP曲線による比較を示している。また、図7はCAP曲線の見方を説明する図である。もし得られた曲線が、図7で示すCに近いならば、スコア値はランダムにつけられたものと等価であり、モデルにまったく説明力がないことを示す。対称的に、得られた曲線がAに近いならば、実際に不正利用であるクレジットカードデータに対して高いスコア値をつけられていることになり、モデルの性能が高いことを示す。実際にはAとCとの間の、Bのような曲線を取る。
【0076】
図6から、SKSVMは不正らしい上位500件を監視すれば、15人の不正利用者を検知できていることを示している。これに対し、SVMは同様に不正らしい上位500件を監視しても、約半数の8人の不正利用者しか検知できていない。さらに、SKSVMが不正らしい上位500件を監視するだけで検知できる15人の不正利用者を、SVMが検知しようとすれば、不正らしい上位1,000件(SKSVMの場合の倍)もの監視をしなければならないと言うことも示している。
【0077】
[6] 参考文献
1) McCarthy, J.: PHENOMENAL DATA MINING: FROM DATA TO PHENOMENA, ACM SIGKDD Explorations, Vol.1, No.2, pp.24-29, (2000).
2) Martin, H.C.L., Zhang, N. and Anil, K.J.: Nonlinear Manifold Learning For Data Stream, Proc. SIAM International Conference for Data Mining, pp.33-44 (2004).
3) Scholkopf, B. and Smola, A.J.: Learning with Kernels, MIT Press (2002)
4) Shawe-Taylor, J. and Cristianini, N.: Kernel Methods for Pattern Analysis, Cambridge University Press (2004).
5) Jain, A., Zhang, Z. and Chang, E.Y.: Adaptive non-linear clustering in data streams, CIKM '06: Proc. 15th ACM International Conference on Information and Knowledge Management, New York, NY, USA, pp.122-131, ACM (2006).
6) Milenova, B.L., Yarmus, J.S. and Campos, M.M.: SVM in Oracle Database 10g: Removing the Barriers to Widespread Adoption of Support Vector Machines, VLDB '05: Proc. 31st International Conference on Very Large Data Bases, VLDB Endowment, pp.1152-1163 (2005).
7) 都築 学、小西 修、新美礼彦:カーネル法による現象データマイニング、電子情報通信学会第18回データ工学ワークショップ(2006).
8) 鈴木秀男、水野 誠、住田 潮、佐治 明:CRMのための優良顧客識別手法の特性評価と財務効果、Department of Social Systems and Management Discussion Paper Series, No.1123 (2005).
9) Hoi, S.C.H., Jin, R. and Lyu, M.R.: Large-scale text categorization by batch mode active learning, WWW '06: Proc. 15th International Conference on World Wide Web, pp.633-642, ACM (2006).
10) Komarek, P. and Moore, A.: Making Logistic Regression A Core Data Mining Tool: A Practical Investigation of Accuracy, Speed, and Simplicity, Technical report, Robotics Institute, Carnegie Mellon University, Pittsburgh, PA (2005).
11) Joachims, T.: Text categorization with support vector machines: Learning with many relevant features, Proc. European Conference on Machine Learning (ECML'98), pp.137-142 (1998).
12) 鹿島久嗣:カーネル法による構造データマイニング、情報処理、Vol.46, No.1, pp.27-33 (2005).
13) 津田宏治:カーネル設計の技術、情報論的学習理論ワークショップ(IBIS2002), pp.1-10 (2002).
14) Lodhi, H., Saunders, C., Shawe-Taylor, J., Cristianini, N. and Watkins, C.: Text classification using string kernels, Journal of Machine Learning Research, Vol.2, pp.419-444 (2002).
15) Haussler, D.: Convolution Kernels on Discrete Structures, Technical report, UC Santa Cruz (1999).
16) Joachims, T.: SVM-Light Support Vector Machine. http://svmlight.joachims.org/
【0078】
[具体例]
実施の形態
図8は、実施の形態に係る情報処理装置100の全体構成を表す図である。これらの構成は、ハードウェア的には、任意のコンピュータのCPU、メモリ、その他のLSIで実現でき、ソフトウェア的にはメモリにロードされたプログラムなどによって実現されるが、ここではそれらの連携によって実現される機能ブロックを描いている。したがって、これらの機能ブロックがハードウェアのみ、ソフトウェアのみ、またはそれらの組合せによっていろいろな形で実現できることは、当業者には理解されるところである。
【0079】
情報処理装置100は、学習部10と識別部12とを含む。学習部10はさらに、教師データ格納部14、ストリームカーネル学習部16、識別器格納部18を含む。また、識別部12はさらに、ストリーム構造データ識別部20、ストリームデータ格納部22、出力部24を含む。
【0080】
本実施の形態に係る情報処理装置は、あらかじめ機械学習手法であるストリームカーネルSVMによって識別器を作成しておき、その識別器に基づいてオンラインで到着するデータの属するクラスを判別するという構造を持つ。そこで、まずストリームカーネルSVMによる学習過程について説明する。
【0081】
教師データ格納部14は機械学習に用いるためのデータを格納する部分である。教師データとは、そのデータの属するクラスが既知であるデータの集合のことである。たとえば、クレジットカードの取引データについて、その取引が正常利用であるのか不正利用であるのかの二値に分類する問題を考える。このとき、教師データとは、その取引が正常利用か不正利用であるかが既知であるデータの集合である。
【0082】
ストリームカーネル学習部16は、教師データ格納部14から受け取った教師データに基づいてストリーム構造データを構築し、ストリームカーネルSVMを用いて機械学習により識別器を作成する部分である。これは主に前提技術[4]に記載の技術に基づいて作成したストリームカーネルを使って前提技術[3]に記載の非線形SVMにより学習する。
【0083】
識別器格納部18はストリームカーネル学習部16が出力した学習結果である識別器を格納する部分である。
【0084】
ストリーム構造データ識別部20は、過去の履歴データと、ストリームデータ格納部22から受け取るオンラインで到着したデータとからストリーム構造データを構築し、識別器格納部18から受け取った識別器に基づいて、当該オンラインで到着したデータのクラスを識別する部分である。これは主に前提技術[4]に記載の技術に基づくものである。出力部24はストリーム構造データ識別部20が識別した結果を図示しないモニタ等の出力ディバイスやストレージ等に出力する。
【0085】
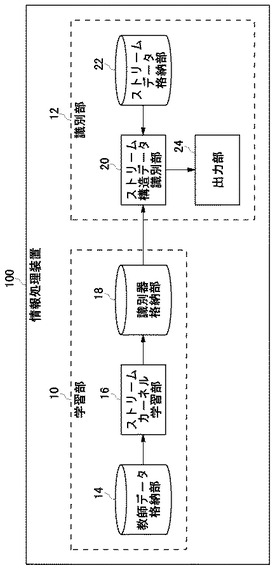
図9はストリームカーネル学習部16の構成図である。ストリームカーネル学習部16は履歴数入力部26、教師ストリーム構造データ作成部28、教師ストリームカーネル作成部30、機械学習部32を含む。
【0086】
履歴数入力部26はストリーム構造データを作成するに際し、過去何回までの履歴をまとめるかについての情報を入力する部分である。ユーザが任意の回数を自由に入力できるようにしても良いし、例えば5回のように固定されていても良い。教師ストリーム構造データ作成部28は、履歴数入力部26から参照すべき過去の履歴回数を受け取り、ストリーム構造データを作成する部分である。ストリーム構造データは前提技術[4.1]に記載の構造のデータであるが、ここではさらに、おのおののデータが正常利用であるか不正利用であるかの情報をも付与された教師データとして作成される。
【0087】
教師ストリームカーネル作成部30は、教師ストリーム構造データ作成部28から教師ストリーム構造データを受け取り、SVMの学習に供すべき教師ストリームカーネルを作成する部分である。詳細は後述するが、これは前提技術[4.2]、[4.3]、[4.4]に記載のアルゴリズムに基づく。
【0088】
機械学習部32は、教師ストリームカーネル作成部30が作成した教師ストリームカーネルを用いてSVMの学習を行う部分である。SVMは前提技術[3.1]に記載の非線形識別アルゴリズムに基づく。
【0089】
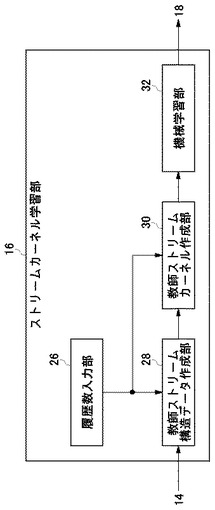
図10は教師ストリームカーネル作成部30の構成図である。教師ストリームカーネル作成部30は時間間隔正規化部34、ストリームカーネル作成部36、カーネル正規化部38を含む。
【0090】
時間間隔正規化部34は、教師ストリーム構造データ作成部28から受け取ったストリーム構造データに含まれる履歴の発生日時を参照して、各履歴間の時間間隔を正規化する部分である。これは前提技術[4.1]に記載のアルゴリズムに基づくものであり、その目的はデータによって異なる履歴の発生間隔を正規化して、それぞれの履歴の発生間隔を同じ尺度でとらえることである。
【0091】
ストリームカーネル作成部36は、教師ストリーム構造データ作成部28から受け取った教師ストリーム構造データと時間間隔正規化部34から受け取った正規化された時間間隔とを受け取って、ストリームカーネルを計算する部分である。これは前提技術[4.4]に記載のアルゴリズムに基づくものである。式(18)、式(19)で表されるように、ストリームカーネルは漸化式を用いて表現できるため、動的計画法を適用することでストリームカーネル生成の計算量を抑制することができる。
【0092】
カーネル正規化部38は、ストリームカーネル作成部36が作成したカーネルを正規化する部分である。これは、ストリームカーネルの計算に用いるストリーム構造データXとZとの履歴数が異なる場合には、履歴数の少ない部分集合のカーネルのみとなるため、前提技術[4.4]の式(20)を用いて是正するものである。
【0093】
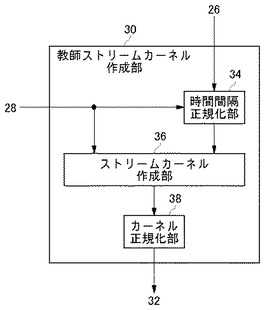
図11はストリームカーネルを作成する処理の流れを表す。ステップS10およびステップS12は前提技術[4.4]に記載の漸化式(18)、(19)を計算するための初期値を設定する。具体的には、まずK0(X,Z)の値を1に設定し(S10)、J1の値をK(x(1),z(1))に設定する(S12)。ここで、K(x(1),z(1))としては、たとえば前提技術[3.1]における式(3)に示すガウスカーネルを用いる。次に、ループ変数iを1に初期化する(S14)。
【0094】
ステップS16はループの終了を判断するステップである。具体的には、ループ変数iの値が遡る履歴回数n以下の場合にはステップS18に進む(S16Y)。そうでない場合にはループを終了し、ステップS24に進む(S16N)。
【0095】
ステップS18からステップS22は、前提技術[4.4]に記載の漸化式(18)、(19)を用いて、順次更新することによりストリームカーネルを生成するステップである。まず式(18)に基づき、Ki(Xx(i),Zz(i))をJiとKi−1(X,Z)との和により求める(S18)。例えばi=1の場合にはK1(Xx(1),Zz(1))=K0(X,Z)+J1となるが、右辺はそれぞれ前述のステップS10およびS12において定められている。結局、K1(Xx(1),Zz(1))=K(x(1),z(1))となる。
【0096】
次に、式(19)に基づき、Ji+1をJi、K(x(i+1),z(i+1))および前提技術[4.3]のアルゴリズムに基づいて求めた重みを用いて求める(S20)。例えばi=1の場合にはJ2=(1+J1)K(x(2),z(2))λT[1,2]となる。ここで、J1はステップS12において定められており、K(x(2),z(2))は例えば前提技術[3.1]における式(3)のガウスカーネルを用いれば計算できる。またλT[1,2]は前提技術[4.3]のアルゴリズムに基づき、時間間隔正規化部34であらかじめ計算しておいたデータを用いればよい。
【0097】
ステップS18およびステップS20によりKi(Xx(i),Zz(i))およびJi+1が更新できたので、ループ変数iをi+1に更新し、ステップS16に戻る(S22)。ループ変数iがn以下の間、以上のループを回すことにより、ストリームカーネルKn(X,Z)を漸化式を用いて順に更新することができる。こうして得られたストリームカーネルKn(X,Z)を出力し(S24)、終了する。
【0098】
以上ストリーム構造データをSVMで扱うためのストリームカーネルの作成方法について説明した。ストリームカーネルを用いることにより、あるひとつのストリーム構造データから対応するひとつのストリームカーネルの出力値を得ることができる。この出力値を用いれば従来のSVMによる機械学習を行うことができる。このように、ストリームカーネルの出力値を用いて従来のSVMによる機械学習を行うことがストリームカーネルSVMである。
【0099】
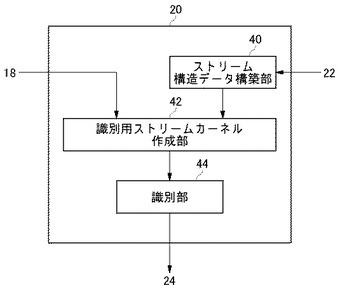
次に、ストリームカーネルSVMの学習結果である識別器を用いて、オンラインで到着するデータがどのクラスに属するかを識別する方法について説明する。
【0100】
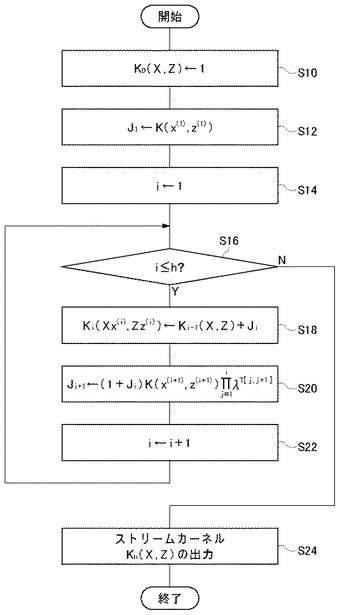
図12はストリーム構造データ識別部20の構成図である。ストリーム構造データ識別部20はストリーム構造データ構築部40、識別用ストリームカーネル作成部42、識別部44を含む。
【0101】
ストリーム構造データ構築部40は、ストリームデータ格納部22からオンラインで到着したデータを受け取り、当該データを含め過去n回までの履歴データを基にストリーム構造データを構築する部分である。これにより、オンラインで到着するデータのみならず、過去n回までの履歴を入力として識別することが可能となる。これは主に前提技術[4.1]〜[4.3]に記載のアルゴリズムに基づく。
【0102】
識別用ストリームカーネル作成部42は、識別器格納部18から識別器と、ストリーム構造データ構築部40で構築されたオンラインで到着したデータを含むストリーム構造データとを受け取り、識別用のストリームカーネルを作成する部分である。識別器には複数のストリーム構造データがサポートベクタとして含まれている。これらのサポートベクタを例えば前提技術[4.1]〜[4.4]に記載のアルゴリズムのZとし、ストリーム構造データ構築部40で構築されたストリーム構造データをXとすれば、識別用のストリームカーネルを構築することができる。
【0103】
識別部44は、識別用ストリームカーネル作成部42で作成された識別用のストリームカーネルに基づき、オンラインで到着したデータの属するクラスを識別する部分である。具体的には、前提技術[3.1]に記載の式(7)におけるK(xi,x)を前記ストリームカーネルに置換し、その出力値の正負によってふたつのクラスに識別すればよい。
【0104】
以上、本発明を実施の形態をもとに説明した。これらの実施の形態は例示であり、それらの各構成要素や各処理プロセスの組合せにいろいろな変形例が可能なこと、またそうした変形例も本発明の範囲にあることは当業者に理解されるところである。
【符号の説明】
【0105】
10 学習部、 12 識別部、 14 教師データ格納部、 16 ストリームカーネル学習部、 18 識別器格納部、 20 ストリーム構造データ識別部、 22 ストリームデータ格納部、 24 出力部、 26 履歴数入力部、 28 教師ストリーム構造データ作成部、 30 教師ストリームカーネル作成部、 32 機械学習部、 34 時間間隔正規化部、 36 ストリームカーネル作成部、 38 カーネル正規化部、 40 ストリーム構造データ構築部、 42 識別用ストリームカーネル作成部、 44 識別部、 100 情報処理装置。
【技術分野】
【0001】
この発明は学習装置、クラス識別装置、学習方法、およびプログラムに関する。
【背景技術】
【0002】
近年、金融や流通分野の取引記録、ネットワーク監視システムの通信記録等のデータストリームが新しいタイプの大規模データとして注目を集めている。このようなデータストリームの識別は、一般的に教師付き学習が用いられる。従来の教師付き学習は、オンラインで到着するデータを特徴ベクトルで表し、それを事前に作成した識別器に入力することで、あらかじめ定義されたカテゴリへ識別することが行われている。
【0003】
大規模に蓄積されたデータストリームを解析し、その結果を有効に活用する研究は、データマインイング1)、情報検索、統計的学習分野2)等において長年活発に行われてきた。カーネル法3),4)は、データの非線形構造をとらえる強力な手法として注目されており、分類5)や識別6)等に適用され、高い精度を得ている。特に識別において、線形識別器であるSVMにカーネルトリックを適用し、非線形識別関数を構成することで非線形識別を可能にした非線形SVMは、最も識別性能に優れたモデルのひとつである(特許文献1参照)。
【先行技術文献】
【特許文献】
【0004】
【特許文献1】特開2006−153582号公報
【発明の概要】
【発明が解決しようとする課題】
【0005】
しかし、データストリームを対象にした場合の識別精度は、静的データを対象にした場合と比べると識別精度が劣るという欠点がある。時間とともに複雑な変化をともなうデータストリームの特徴を入力ベクトルの属性で表現することは困難であり、無理に特徴を出そうと入力ベクトルの属性数を増やせば、次元の呪いによって識別器の汎化性能が失われるという欠点もある。
【0006】
本発明はこうした状況に鑑みてなされたものであり、その目的は、汎化性を持って精度良くデータを識別することができる情報処理装置を提供することにある。
【課題を解決するための手段】
【0007】
本発明のある態様は学習装置に関する。この装置は、過去履歴の参照範囲を履歴数として入力する履歴数入力部と、属するクラスが既知である履歴数個のデータをひとつの教師ストリーム構造データとしてまとめる教師ストリーム構造データ作成部と、教師ストリーム構造データに基づいて教師ストリームカーネルを作成する教師ストリームカーネル作成部と、教師ストリームカーネルの出力値を機械学習することにより、任意のストリーム構造データの属するクラスを識別するための識別器を生成する機械学習部とを含む。
【0008】
本発明の別の態様はクラス識別装置に関する。この装置は、オンラインで受け取ったデータと当該データの過去履歴とから識別用ストリーム構造データを構築するストリーム構造データ構築部と、前記識別用ストリーム構造データと、教師ストリームカーネルの値を機械学習することにより得られた識別器とを用いて識別用ストリームカーネルを作成する識別用ストリームカーネル作成部と、識別用ストリームカーネルの出力値に基づいて当該データの属するクラスを識別する識別部とを含む。
【0009】
本発明のさらに別の態様は学習方法に関する。この方法は、過去履歴の参照範囲を履歴数として入力するステップと、属するクラスが既知である履歴数個のデータをひとつの教師ストリーム構造データとしてまとめるステップと、教師ストリーム構造データに基づいて教師ストリームカーネルを作成するステップと、教師ストリームカーネルの出力値を機械学習することにより、任意のストリーム構造データの属するクラスを識別するための識別器を生成するステップとをプロセッサに実行させる。
【0010】
本発明のさらに別の態様は、ストリーム構造データを識別する識別器を生成するためのプログラムに関する。このプログラムは、過去履歴の参照範囲を履歴数として入力する機能と、属するクラスが既知である履歴数個のデータをひとつの教師ストリーム構造データとしてまとめる機能と、教師ストリーム構造データに基づいて教師ストリームカーネルを作成する機能と、教師ストリームカーネルの出力値を機械学習することにより、任意のストリーム構造データの属するクラスを識別するための識別器を生成する機能とをコンピュータに実現させる。
【0011】
なお、以上の構成要素の任意の組合せ、本発明の表現を方法、装置、サーバ、システム、コンピュータプログラム、記録媒体などの間で変換したものもまた、本発明の態様として有効である。
【発明の効果】
【0012】
本発明によれば、汎化性を持って精度良くデータを識別する技術を提供することができる。
【図面の簡単な説明】
【0013】
【図1】実施の形態に係る識別プロセスを表す図である。
【図2】カーネル法による線形分離の様子を例示する図である。
【図3】ストリーム構造データの構成図である。
【図4】振舞い属性を考慮した識別を表す図である。
【図5】ストリーム構造データの作成を表す図である。
【図6】CAP曲線による性能比較を表す図である。
【図7】CAP曲線の見方を説明する図である。
【図8】実施の形態に係る情報処理装置の全体構成を表す図である。
【図9】ストリームカーネル学習部の構成図である。
【図10】教師ストリームカーネル作成部の構成図である。
【図11】ストリームカーネルを作成する処理の流れを表す図である。
【図12】ストリーム構造データ識別部の構成図である。
【発明を実施するための形態】
【0014】
以下本発明を好適な実施の形態をもとに説明する。まず、実施の形態の基礎となる理論を前提技術として述べ、その後、具体的な実施の形態を説明する。
【0015】
[前提技術]
[1] はじめに
実施の形態は、大規模データストリームのための履歴情報を用いたカーネル法の拡張に関するものである。実施の形態の基礎技術は、カーネル法を拡張してデータストリームを構造データと見なして識別することである。
【0016】
近年、金融や流通分野の取引記録や、ネットワーク監視システムの通信記録等のデータストリームが新しいタイプの大規模データとして注目を集めている。データストリームには、日々刻々と生成され、時間とともに複雑な変化をともなう性質があり、この蓄積されたデータをいかに分析し活用するかが重要な課題となっている。そこで、データマイニングや機械学習がその有力な手法となる。
【0017】
データマイニングや機械学習は、大量のデータから知識やルールを発見するための分析手法であり、本実施の形態ではこのデータストリームを識別することに焦点を当てる。これはクレジットカードの不正利用識別、POSトランザクションからの優良顧客識別、ネットワークログからの不正侵入識別等、その応用は多岐にわたる。しかし、時間とともに複雑な変化をともなうデータストリームの識別は困難であり、識別性能を向上させることは重要な課題である。
【0018】
このようなデータストリームの識別は、一般的に教師付き学習が用いられる。従来の教師付き学習は、オンラインで到着するデータを特徴ベクトルxで表し、それを事前に作成した識別器y=f(x)に入力することで、あらかじめ定義されたカテゴリへ識別する。ここで識別精度を上げるために重要なことは、対象データ世界の特徴を抽出することである。従来の識別手法を用いれば、複雑なストリームの特徴をベクトル形式で表現しなければならない。識別で十分な精度が得られないのは、ベクトルの属性値に識別のための特徴が出ていないからである。特徴を出そうと属性の数を増やせば、次元の呪いによって識別器の汎化性能が失われ、また、その特徴抽出には深い領域知識が必要である。
【0019】
一方、線形識別器であるサポートベクタマシン(SVM)は、カーネル法によって非線形識別を行うことができる非線形SVMへと拡張された。詳細は後述するが、カーネル法は元のデータ空間を高次元空間へ埋め込み、この空間で線形識別を実行する。その計算はカーネル関数と呼ばれる高次元空間上の内積を表す関数で行われ、実際には高次元へ写像することなく、高次元空間上での動作を可能にする。この仕組みはカーネルトリックと呼ばれ、カーネルトリックを用いて非線形識別関数を構成することで非線形識別を可能にするSVMを非線形SVMという。そしてこの非線形SVMは、最も識別性能に優れたモデルのひとつである。
【0020】
また、このカーネル法は近年、構造を持つデータを入力にすることができるように拡張され、これまでに木、配列、グラフ等の構造データに対するカーネル関数が提案されている。このような構造データを用いると、ベクトル形式では失われていたデータの特徴を識別に用いることができ、ベクトル形式で識別するよりも高い精度が得られている。
【0021】
そこで、本実施の形態では、カーネル法を拡張して、データストリームを構造データと見なして識別する手法を提案する。図1は実施の形態に係る識別プロセスを表す図である。例えば、クレジットカードデータの場合、この構造データは、オンラインで到着するデータ(特徴ベクトルx)だけでなく、あるユーザの過去n回までの履歴情報をまとめた、ひとつのストリーム構造を持つデータX={x(1),x(2),・・・,x(n)}である。また、このストリーム構造データに適用できるカーネル関数は、新しいデータであるほど識別の影響が大きく、古いデータほど識別の影響が小さくなるようにデータを扱い、履歴情報から得られるデータストリームの時間的な変化を特徴にする。
【0022】
まとめると、本実施の形態は既存の手法・研究と比較して、以下の技術的特徴を有する。
・オンラインで到着するデータのみを入力として分析に用いるのではなく、過去n回までの履歴をまとめたものを、ひとつのストリーム構造を持つデータとして扱い、これを入力するカーネル関数(以下、「ストリームカーネル」という。)を構築する。
・従来のベクトルを入力とした場合、すなわちオンラインで到着したデータのみを用いて、過去の履歴を用いない場合のカーネルの計算量に対して、このストリームカーネルの計算量はO(n)である。
・大規模な実際のクレジットカードデータを用いた識別実験を行い、既存の手法よりも優れた精度であることを示す。
【0023】
本実施の形態では二値の識別に関して述べるが、この制約は重要ではない。なぜなら、どのような二値識別器でも、多重クラスの問題へ拡張できるからである。たとえば代表的なone−versus−restは、C1,・・・,Ckのk個のクラスへの識別問題においてあるクラスCiと、それ以外のクラス∪j≠iCjとを識別する二値識別器をk個構築する。クラスラベルが未知のデータに対する予測は、k個の識別器が一貫した出力をした場合、そのクラスへ割り当て、そうでない場合は候補の中からランダムにあるいは識別器の出力の中から最もあてはまりが良いクラスへ割り当てられる。
【0024】
[2] 関連研究
大規模に蓄積されたデータストリームを解析し、その結果を有効に活用する研究は、データマイニング1)、情報検索、統計的学習分野2)等において長年活発に行われてきた。カーネル法3),4)は、データの非線形構造をとらえる強力な手法として注目されており、分類(clustering)5)や識別(classification)6)等に適用され、高い精度を得ている。
【0025】
特に識別において、線形識別器であるSVMにカーネルトリックを適用し、非線形識別関数を構成することで非線形識別を可能にした非線形SVM3)は、最も識別性能に優れたモデルのひとつである。このことは、本実施の形態について行った実際の大規模なクレジットカードデータを不正利用と正常利用に識別する実験でも示されており、本実施の形態における識別器に非線形SVMを選択した動機である。
【0026】
しかし、データストリームを対象にした場合(ネットワーク侵入識別、優良顧客識別8)等)の識別精度は、静的なデータを対象にした場合(画像認識、テキスト識別等9))と比べると劣り、先行研究では複雑な個人情報ストリームの識別が困難であることを示している。ここで使われている多くの識別アルゴリズム(K−最近傍法、決定木、ベイジアン識別器、ニューラルネットワーク、SVM、ロジステック回帰)の入力はベクトル形式であり、過去には識別精度を向上させるために識別に有効なベクトルの属性が考えられてきた8)。しかし、時間とともに複雑な変化をともなうデータストリームの特徴をすべてベクトルの属性で表現することは困難であり、無理に特徴を出そうとベクトルの属性数を増やせば、次元の呪いによって識別器の汎化性能は失われる。
【0027】
本実施の形態では、従来識別器に用いてきたデータだけではなく、過去の履歴データに注目する。そして、遡って得られるデータ群をひとつのストリーム構造データとして定義し、このストリーム構造データを入力して識別を行う新しい手法を提案する。
【0028】
まず初めに直面する課題は、どのようにして構造データを入力として扱うかということであるが、上述したカーネル法は近年、配列やグラフ等の構造データを入力にして扱えるように拡張され12),13)、テキスト識別等で高い識別精度を得ている11),14)。しかし、これらは単に構造データの共通部分構造を数え上げるものであり、次の理由でデータストリームに適用することができない:共通部分の数え上げは、部分構造が一致している数をカウントしたものである。たとえば、文字列を配列として扱う文字カーネルにおいて、ふたつの文字列“cat”と“cart”には、“c,a,t,ca,at,ct,cat”という7つの共通部分文字列がある。このようにデータ要素がすべてカテゴリデータであれば、部分構造が一致している数をカウントできる。しかし、データストリームの属性は基本的にカテゴリ属性だけで構成されているわけではなく、連続値の属性も含む。したがって、共通部分の構造の数え上げという概念を持ち込むことができない。また、従来手法はデータストリームの時間的に変化する性質を考慮していない。
【0029】
これらの課題から、本実施の形態では構造データを扱う基礎理論である畳み込みカーネルを用いて、データストリームに適用できるカーネル法を提案する。提案手法は、新しいデータほど識別の影響を大きく、古いデータほど識別の影響を小さくするようにデータを扱い、識別を行う。これによりストリームの時間的な変化を特徴にすることができる。また、上述した配列・グラフ等の構造データに対するカーネル法が高い精度を得ていることは、本実施の形態におけるデータストリームに適用できるカーネル法を提案することで精度を向上させる根拠となる。
【0030】
[3] カーネル法と非線形サポートベクタマシン
[3.1] カーネル法
カーネル法は、データの非線形構造をとらえる強力な手法であり、ふたつの本質的な要素からなる。
(1) データを高次元特徴空間に埋め込む。
(2) 高次元特徴空間で、線形識別アルゴリズムを適用する。
【0031】
線形識別アルゴリズムは多く研究されているが、真の識別境界が非線形である場合、十分な性能が実現できない。そこで、カーネル法は元のデータ空間をいったん線形識別アルゴリズムを適用できる高次元空間へ写像し、この空間で線形識別アルゴリズムを適用する。しかし、カーネル法はデータを高次元特徴空間では明確に示さず、カーネル関数と呼ばれる半正定値関数K:χ×χ→Rを用いて、高次元特徴空間での動作を可能にする。
K(x,z)=〈φ(x),φ(z)〉 (1)
図2はこのようなカーネル法による線形分離の様子を例示する図である。
【0032】
Mercerの定理を満たす半正定値関数Kをカーネル関数と呼び、これはφによって写像された高次元特徴空間上での内積を意味する。このように実際に高次元特徴空間へ写像する計算を避け、入力空間でのカーネル関数を用いて高次元特徴空間上での内積を計算する仕掛けをカーネルトリックと呼ぶ。また、カーネル関数には次のようなものが知られている。
・多項式カーネル
K(xi,xj)=(xiTxj+c)d (2)
・ガウスカーネル
K(xi,xj)=exp(−‖xi−xj‖2/σ2) (3)
・シグモイドカーネル
K(xi,xj)=tanh(axiTxj−b) (4)
【0033】
線形識別器であるSVMは、上述したカーネルトリックを用いて非線形識別を行うことができる識別器へと拡張された。SVMによる識別は、異なるクラスのデータ間の距離(マージン)を最大にする超平面を考える。このときの目的関数と識別関数は、特徴ベクトルの内積のみに依存した形で記述される。たとえば識別関数は、クラスレベル変数t、サポートベクタの集合S、Langrange乗数αi*>0、最適な閾値h*を用いて次式で書ける。
【数1】
【0034】
この線形識別関数は、カーネルトリックを適用することにより以下の形に書き変えることができる。
【数2】
【0035】
ここで、元の空間よりも高次元に写像するカーネル関数Kを選択すれば、高次元空間上で線形SVMを実行したことになり、これは元の空間で非線形識別を実行したことと等価である。このように、カーネルトリックによって非線形識別関数を構成することで、非線形識別を可能にしたSVMを、非線形SVMという。
【0036】
また、これらカーネル関数はふたつの入力の類似度を定めていると考えることができる。すなわち、適当に類似度Rを定義した関数Kを、カーネル関数として使うことができる。したがって、上述したカーネル関数のふたつの入力xi,xjがベクトルでなく、DNA配列やテキスト等の配列、XMLやHTMLで記述された構文解析木のような木構造、あるいは化合物の分子構造のようなグラフで表現される場合にも、カーネル法を適用することができる。本実施例はストリーム構造を持ったデータ間のカーネル関数であり、これら構造を持ったデータ間のカーネルを定義するための基礎理論である畳み込みカーネルについて、以下述べる。
【0037】
[3.2] 畳み込みカーネル
本節では、カーネル関数の入力がベクトルでなく、配列やグラフ等の構造を持ったデータに対するカーネル関数を構築するための基礎理論である畳み込みカーネルについて述べる。畳み込みカーネル15)は、構造を持つデータ間のカーネル関数はその構造の部分構造どうしのカーネル関数によって再帰的に計算されるという考えに基づいている。
【0038】
xはある構造を持つデータ、S(x)はxに含まれる部分構造の集合、sxをその部分構造とする。これはzについても同様である。Ksを部分構造間のカーネル関数とすると、畳み込みカーネルは以下で表現される。
【数3】
【0039】
また、畳み込みカーネルは部分構造sに対する重みf(s|x)を用いて次のように記述することができる。
【数4】
【0040】
この部分構造のカーネル関数Ksは、更に分けられた部分構造による畳み込みカーネルにより、再帰的に表現される。つまり、構造を持ったデータxとzは、ここから取り出される部分構造sx∈S(x)とsz∈S(z)のカーネル関数の値をすべて足し合わせることで全体のカーネル関数が定義される。本実施例では、ストリーム構造を持つデータX={x(1),x(2),・・・,x(n)}間のカーネル関数を提案する。このカーネル関数がストリームカーネルであるが、このストリームカーネルも畳み込みカーネルを基礎理論としている。
【0041】
[4] ストリームカーネル
[4.1] ストリーム構造データの定義
データストリームに対する従来の識別手法は、オンラインで到着したデータをベクトルx=(x1,x2,・・・,xd)で表現し、これを入力に用いる。これに対し、本実施例における識別手法は、次の特徴を持った構造データを入力に用いる。
(1) オンラインで到着したx(1)だけでなく、過去の履歴n個のデータを持つ。
(2) n個の前後のデータ間に、n−1個の時間間隔を持つ。
本実施例ではこれをストリーム構造データと定義し、次のように表現する。
X={x(1),x(2),・・・,x(n)} (10)
【0042】
なお、x(1)が新しいデータ、x(n)が古いデータとし、括弧内の上付き添え字を履歴番号と呼ぶ。時間間隔とは、データが到着した時間の間隔であり、例えばx(1)とx(2)との時間間隔はt[1,2]と表す。図3はストリーム構造データの構成図である。
【0043】
ここで、時間間隔を計算に用いる上で注意すべきことがある。時間間隔は、後述するように、古い情報ほど識別の影響を小さくする重みを計算するときに用いられるが、このとき、遡った期間全体を1に正規化する。つまり、たとえばn=4とし、過去の履歴4件を遡る場合、得られる時間間隔は、t[1,2]、t[2,3]、t[3,4]であり、その合計をt[1,2]+t[2,3]+t[3,4]=1となるように値を変換する。これは単に、各時間間隔についての、遡った期間全体に対する比を考えるだけである。たとえばクレジットカードデータを考えると、クレジットカードを1週間に1度の間隔で使う人もいれば、1カ月に1度の間隔で使う人もいる。時間間隔を正規化することで、各人それぞれの利用の間隔を同じ尺度でとらえることができる。
【0044】
[4.2] 部分構造間のカーネル
本実施例におけるストリームカーネルは前述した畳み込みカーネルが基本理論となっている。したがって、まず前述したストリーム構造データX={x(1),x(2),・・・,x(n)}の部分構造sを定義する。例として、遡る履歴の数をn=3としたX={x(1),x(2),x(3)}の場合について考える。Xの部分構造全体の集合をS(X)とすると、順序関係を考慮して、S(X)は以下の6つの部分構造へ分割される。このとき、遡る履歴の数nに対して、得られる部分構造の数はn(n+1)/2である。
S(X)={s1,s2,s3,s4,s5,s6}
={{x(1)},{x(2)},{x(3)},{x(1),x(2)},{x(2),x(3)},{x(1),x(2),x(3)}}
【0045】
次に、分割された部分構造のカーネルの組合せを考える。ここで、異なる履歴番号で観測されたデータが独立であるとする。すなわち、K(x(i),z(j))=0,i≠jとし、部分構造間のカーネルを、部分構造に含まれるデータのカーネルの積で表現する。すると、部分構造のデータ数が同じで,かつ履歴番号が同じであるときのみ、その部分構造どうしのカーネルKsは計算され、次式で表される。
【数5】
【数6】
【0046】
なお、K(x(i),z(i))は前述した半正定値カーネルである。これにより、考えるべきカーネルの組合せはn(n+1)/2通りとなる。
【0047】
[4.3] 部分構造の重み
次に、畳み込みカーネルにおける部分構造の重みf(s|X)を定義する。このf(s|X)は前述した部分構造のカーネルが、全体の類似度にどれほどの影響力を持つかを表す。これを考えるうえで、理解が単純になるよう再度クレジットカードデータの例を用いる。
【0048】
オンラインで到着した顧客AのデータをxA(1)とすると、この利用xA(1)が正常利用か、不正利用かを識別するために、顧客Aの利用履歴を過去n回遡ったストリーム構造データXA={xA(1),xA(2),・・・,xA(n)}を得る。xA(1)が新しいデータ、xA(n)が古いデータとすると、xA(1)とxA(n)とを同じ重みで扱うと正確な識別を行うことができない。なぜなら、知りたいのは到着したデータxA(1)が不正利用か、正常利用かということである。古いデータがいくら正常利用らしくても、到着したデータが明らかに不正利用らしければ、到着したデータの方を優先すべきである。したがって、新しいデータを含む部分構造であるほど重み(影響度)を大きく、古いデータを含む部分構造であるほど重みを小さくする。この重みf(s|X)は、前述した時間間隔tと、新たに導入するパラメータλ∈(0,1)とを用いた単調減少関数λtによって定義される。
【0049】
ここで、部分構造に含まれるそれぞれのデータに対して具体的に重みを与える。すなわちn番目の履歴データに対して、重みを
【数7】
と定義する。例として、sx={x(2),x(3),x(4)}とsz={z(2),z(3),z(4)}の重みf(sx|X)とf(sz|Z)とを求める。部分構造sxに含まれるデータそれぞれの重みを表1に示す。
【表1】
なお、txは、ストリーム構造データXが持つ時間間隔であるとし、記述の簡略化のため、
【数8】
とする。このxをすべてzで置き換えれば、同様に部分構造szに含まれるデータそれぞれの重みを表す。簡略化せずに重みを詳細に記述すれば、f(sx|X)とf(sz|Z)はそれぞれ次式で表される。
【数9】
【数10】
【0050】
したがって、このときの部分構造の重みを含めたカーネルは式(11)を用いて、
【数11】
となる。
【0051】
[4.4] ストリームカーネル計算アルゴリズム
Kn(X,Z)と、XとZとがともに過去n件のストリーム構造データからなるときのストリームカーネルとする。また、過去n件からなるXに、さらにもう1件遡って得られるx(n+1)が、Xに付与されることをXx(n+1)と表現する。もちろんこれはZについても同様であるが、以降はZにも同じ作業を与えたとして、その記述は省略する。
【0052】
ここで具体的に、例としてn=1の場合から考える。このとき、XはX={x(1)}であり、S(X)={s1}={x(1)}である。したがって、単純にK1(X,Z)は次で表される。
K1(X,Z)=K(x(1),z(1)) (15)
【0053】
次に、X={x(1)}にx(2)が付与され、Xx(2)={x(1),x(2)}となったときのK2(Xx(2),Zz(2))を考える。Xx(2)={x(1),x(2)}により、前述と同様の手法で、Xx(2)は3つの部分構造に分割できる。
S(Xx(2))={s1,s2,s3}
={{x(1)},{x(2)},{x(1),x(2)}}
【0054】
式(9)、(11)、(14)により、K2(Xx(2),Zz(2))は次式で記述できる。なお、数式の簡略化のため、tx[i,i+1]+tz[i,i+1]=T[i,i+1]とする。
K2(Xx(2),Zz(2))=K(x(1),z(1))+λT[1,2]K(x(2),z(2))+λT[1,2]K(x(1),z(1))K(x(2),z(2)) (16)
【0055】
ここで、式(15)と式(16)とを比較し、x(2)が付与されることで増加するカーネルの量を計算する。この量をJ2とすると、J2は次のようにJ1を用いた形で書くことができる。
J2=K2(Xx(2),Zz(2))−K1(X,Z)
=λT[1,2]K(x(2),z(2))+λT[1,2]K(x(1),z(1))K(x(2),z(2))
=λT[1,2]K(x(2),z(2)){1+K(x(1),z(1))}
=λT[1,2]K(x(2),z(2)){1+J1} (17)
【0056】
同様に、X={x(1),x(2)}にx(3)を付与した場合を展開しても、x(2)が付与されることで増加するカーネルの量J3もまた、J2を用いた形で書くことができる。したがって、遡るデータがひとつ増えることで、全体のカーネルに加えられる部分構造のデータのカーネルの量をJnとすると、ストリームカーネルは以下のように一般化した形で、再帰的に表現することができる。
Kn(Xx(n),Zz(m))=Knー1(X,Z)+Jn (18)
【数12】
ただし、K0(X,Z)=1、J1=K(x(1),z(1))である。
【0057】
動的計画法を用いることにより、この計算量は遡るデータ数nに対してO(n)で済む。また、XとZのデータ数が異なる場合、このままでは、データ数が少ない部分集合のカーネルのみを考えてしまう。たとえば、X={x(1),x(2),x(3)},Z={z(1),z(2)}とすると、x(3)はカーネルの計算にまったく用いられない。そこで、以下の式で正規化を行い、これをストリームカーネルの最終出力値とする。
【数13】
【0058】
さらに、このストリームカーネルが半正定値性を満たすことを述べる。いくつかの半正定値性を満たすカーネル関数は、これを足し合わせたり、掛け合わせたり、また定数倍したりしたものもまた、半正定値性を満たすカーネル関数となることが知られている。ストリームカーネルは、半正定値性を満たすカーネル関数を基本として用い、部分構造どうしのカーネルの計算ではこのカーネルを掛け合わせ、部分構造の重みはカーネルを定数倍し、畳み込みで表現された構造全体のカーネルはこれらを足し合わせたものである。したがって,ストリームカーネルは半正定値性を満たす。
【0059】
[5] 実験評価
本実施例では、実際のデータストリームであるクレジットカードデータ(実験データの詳細は後述する。)に対して、ガウスカーネルを用いた通常のSVMと、本実施例のストリームカーネルSVM(以下、「SKSVM」という。)を適用し,正常利用と不正利用に識別した。また、その性能を以下の点から比較した:
(a) 学習・検証にかかる時間
(b) 識別の精度(正答率)
(c) モデルの性能(CAP曲線)
【0060】
[5.1] 実験準備
実験は2GHzのCPUと、3GBのメモリを持つハードウェア環境を使用した。本実施例に係るSKSVMは、OSSであるsvm−light16)(C言語)上で実装を行った。
【0061】
実験で使用したカーネル関数は、ガウスカーネルK(xi,xj)=exp(−‖xi−xj‖2/σ2)である。ガウスカーネルは、パラメータσの設定によってはシグモイドカーネルようにも動作し、また、先行研究で行った実験結果により、ガウスカーネルが識別に最も有効に動作すると判断した。ガウスカーネルのパラメータσは、事前に‖xi−xj‖2の統計を取り、これらが適切にK(xi,xj)∈(0,1)を得るような範囲を確定し、SVMの正則化パラメータCとともに試行錯誤的に決定した。
【0062】
ストリームカーネルのパラメータλは、一番最近のデータのカーネル関数の値が、ストリームカーネル全体の影響の7割程度を占めるように設定した。これは、過去の情報の重みを大きくしすぎてしまうと、一番重要な最近のデータの特徴が埋もれてしまうためである。また、顧客の遡る履歴数nは、n=5に設定した。これら実験で用いたパラメータを表2に示す。
【表2】
【0063】
本実施例ではモデルの性能をCAP曲線によって評価するため、新たにスコア値という考えを導入している。スコア値とは、値が高いものほど不正利用であるらしく、逆に値が低いものほど正常利用であるらしいという指標である。具体的には、SVMの出力yに対して、スコア値scoreは以下の式で1〜1000の値で出力される。
【数14】
【0064】
[5.2] 実験データ
本実験で用いたデータセットは、実際のクレジットカードデータである。クレジットカードデータは、約2年分のデータが用意されており、そのデータ量は約1TBに及ぶ。クレジットカードデータの属性は、大きく次の2つのグループに分類される。
(a) オーソリデータ属性: 利用時の状況を記述した属性
(b) 振舞いデータ属性: 顧客の行動パターンを記述した属性
【0065】
属性(a)は、単にクレジットカードの取引データ(以下、「オーソリデータ」という。)の属性である。たとえばこの属性には、顧客ID、生年月日、利用時間、利用金額、購入商品コード等があり、計84属性からなる。しかし、これらの属性には識別に有効な(不正利用と正常利用で、はっきり値が異なるような)属性は少ない。したがって、この属性だけを用いて識別アルゴリズムを適用しても高い精度は得られない。そこで、識別の特徴として貢献するような以下の属性(b)を、人工的に作成する。
【0066】
属性(b)は過去の履歴情報から作成した顧客モデル(過去の利用金額の平均や分散、過去の利用時間帯の頻度等)との乖離値であり、顧客の行動パターンを記述した属性である。たとえばある人が高額な買い物をしたとする。その人が前回も同程度の額の買い物をしていたならば、その利用は本人、すなわち正常利用らしいが、逆に前回低額な買い物をしていたならば、第三者利用、すなわち不正利用である可能性があると判断することができる。図4は振舞い属性を考慮した識別を表す図である。
【0067】
このように顧客モデルに基づいてその顧客の行動パターンの時間的変化に注目することは、クレジットカードの領域だけでなく、ネットワーク侵入や個人認証等、他の多くの領域・データにあてはまり、有用である。この属性(b)には「前回利用時間との差」、「前回利用金額との差」、「過去6カ月の曜日ごとの利用回数との比較」等があり、計40属性からなる。本実験で用いたクレジットカードデータセットは属性(a)と属性(b)とから55属性を分析に用いた。データセットの詳細を表3に示す。
【表3】
【0068】
SKSVMとSVMの学習・検証データの違いは、利用時点から過去n回の履歴があるか、ないかである。SKSVMの学習・検証データは、図5で示すように、上述した顧客モデルを更新しながら属性(b)を作成して、ストリームデータ構造を作成する。本実験では、n=5とし過去5回の履歴を遡ってストリーム構造データを作成し、識別を行う。
【0069】
クレジットカードデータを、ストリーム構造データとして扱ううえでの注意すべき点として、顧客のマスタ情報を繰り返し用いることがあげられる。たとえば、顧客の「性別」等属性を分析に用いるとする。すると、過去2件目、3件目にも同じ性別の属性が、繰り返し入ることになる。一見これはデータの冗長性から無駄のように見えるが、これらは全て必要である。なぜなら、冗長性のある「性別」という属性を1件目だけに用いて、それ以降の過去2件目、3件目には用いない場合を考える。そしてもし、その「性別」という属性が、不正利用につながる重要な属性であるとすれば、部分集合間のカーネルを考える際、不十分な情報で過去の履歴を処理してしまい、全体として、特徴が薄れてしまうためである。
【0070】
[5.3] 実験結果と考察
[5.3.1] 学習と検証の時間
通常のSVMと、SKSVMの学習時間・検証時間の比較を表4で示す。表4における数字の単位は秒である。実験の結果、学習時間・検証時間ともに、本実施例の手法は通常のSVMと比べて約10倍の時間がかかった。SKSVMのカーネルの計算量は、通常のSVMのカーネルの計算量に比べ、理論上では遡る履歴の数nに対してO(n)で増加するものの、実際のデータでは欠損値の場合の処理、時間間隔データの変換等の事前計算処理が必要であるため、表4に示した結果はこれらオーバーヘッドを含んだものである。
【表4】
【0071】
次に、通常のSVMと、SKSVMのモデルの大きさであるサポートベクタ(SV)の数の比較を表5で示す。これは式(7)において検証の際に計算を繰り返す数を表している。したがって、SVの数が少なければ、より少ない計算量で検証を行うことができることを示し、また、スパースな解が得られていることになる。表5で示すように、SKSVMの方がよりスパースな解を得ていることが分かる。
【表5】
【0072】
[5.3.2] 識別の精度(正答率)
識別の精度を評価する指標には、一般に適合率(precision)と再現率(recall)が用いられる。しかし、本実験で用いた実際のクレジットカードデータは、不正利用の数が正常利用の数に比べて約0.02%と極端に少なく、また、識別能力の弱い識別器を用いるとすべてを正常利用であると判断してしまうほど、正常利用と不正利用との識別は困難である。したがって、適合率と再現率はともに数%という値しか取ることができず、実際のクレジットカードデータを不正利用と正常利用に識別するというこの領域においては、これらの指標は適当ではない。
【0073】
本実施例にかかるSKSVMによる識別精度の向上を明確にするため、本実験の識別精度は正答率で評価する。正答率は、識別を行った全件(720,920件)に対し、その識別結果が正しかった件数の割合である。表6と表7で示すように、SVMの正答率が99.82%であったのに対し、SKSVMの正答率は99.89%であり、0.07%向上している。
【0074】
割合からはそれほどの向上は見られないが、これは大きな変化である。表6において、SVMが不正利用であると判断した件数は、1110件である。しかし、そのうち1080件は実際には正常利用であり、これは間違った識別である。一方、表7において、SKSVMが不正利用であると判断した件数は586件である。これはSVMと比べると約半分のヒット件数であるにもかかわらず、実際に不正利用であった件数は変わらない(30件と28件)。検証データとして用いたデータセットは不正利用の数が少ないため、この変化は割合として大きく現れないが、実際にはSKSVMは不正利用データを発見するときのノイズを半分に減らしていることが分かる。
【表6】
【表7】
【0075】
[5.3.3] CAP曲線による比較
CAP(Cumulative Accuracy Profiles)曲線は、予測モデルの性能を評価するのに用いられ、実際のクレジットカード業界でも使用されている。横軸は、不正利用である確率(スコア値)が高いと識別器が判断したクレジットカードデータを順に並べた数であり、縦軸は、その中で実際に不正利用であった顧客の人数である。図6は、通常のSVMと、SKSVMのCAP曲線による比較を示している。また、図7はCAP曲線の見方を説明する図である。もし得られた曲線が、図7で示すCに近いならば、スコア値はランダムにつけられたものと等価であり、モデルにまったく説明力がないことを示す。対称的に、得られた曲線がAに近いならば、実際に不正利用であるクレジットカードデータに対して高いスコア値をつけられていることになり、モデルの性能が高いことを示す。実際にはAとCとの間の、Bのような曲線を取る。
【0076】
図6から、SKSVMは不正らしい上位500件を監視すれば、15人の不正利用者を検知できていることを示している。これに対し、SVMは同様に不正らしい上位500件を監視しても、約半数の8人の不正利用者しか検知できていない。さらに、SKSVMが不正らしい上位500件を監視するだけで検知できる15人の不正利用者を、SVMが検知しようとすれば、不正らしい上位1,000件(SKSVMの場合の倍)もの監視をしなければならないと言うことも示している。
【0077】
[6] 参考文献
1) McCarthy, J.: PHENOMENAL DATA MINING: FROM DATA TO PHENOMENA, ACM SIGKDD Explorations, Vol.1, No.2, pp.24-29, (2000).
2) Martin, H.C.L., Zhang, N. and Anil, K.J.: Nonlinear Manifold Learning For Data Stream, Proc. SIAM International Conference for Data Mining, pp.33-44 (2004).
3) Scholkopf, B. and Smola, A.J.: Learning with Kernels, MIT Press (2002)
4) Shawe-Taylor, J. and Cristianini, N.: Kernel Methods for Pattern Analysis, Cambridge University Press (2004).
5) Jain, A., Zhang, Z. and Chang, E.Y.: Adaptive non-linear clustering in data streams, CIKM '06: Proc. 15th ACM International Conference on Information and Knowledge Management, New York, NY, USA, pp.122-131, ACM (2006).
6) Milenova, B.L., Yarmus, J.S. and Campos, M.M.: SVM in Oracle Database 10g: Removing the Barriers to Widespread Adoption of Support Vector Machines, VLDB '05: Proc. 31st International Conference on Very Large Data Bases, VLDB Endowment, pp.1152-1163 (2005).
7) 都築 学、小西 修、新美礼彦:カーネル法による現象データマイニング、電子情報通信学会第18回データ工学ワークショップ(2006).
8) 鈴木秀男、水野 誠、住田 潮、佐治 明:CRMのための優良顧客識別手法の特性評価と財務効果、Department of Social Systems and Management Discussion Paper Series, No.1123 (2005).
9) Hoi, S.C.H., Jin, R. and Lyu, M.R.: Large-scale text categorization by batch mode active learning, WWW '06: Proc. 15th International Conference on World Wide Web, pp.633-642, ACM (2006).
10) Komarek, P. and Moore, A.: Making Logistic Regression A Core Data Mining Tool: A Practical Investigation of Accuracy, Speed, and Simplicity, Technical report, Robotics Institute, Carnegie Mellon University, Pittsburgh, PA (2005).
11) Joachims, T.: Text categorization with support vector machines: Learning with many relevant features, Proc. European Conference on Machine Learning (ECML'98), pp.137-142 (1998).
12) 鹿島久嗣:カーネル法による構造データマイニング、情報処理、Vol.46, No.1, pp.27-33 (2005).
13) 津田宏治:カーネル設計の技術、情報論的学習理論ワークショップ(IBIS2002), pp.1-10 (2002).
14) Lodhi, H., Saunders, C., Shawe-Taylor, J., Cristianini, N. and Watkins, C.: Text classification using string kernels, Journal of Machine Learning Research, Vol.2, pp.419-444 (2002).
15) Haussler, D.: Convolution Kernels on Discrete Structures, Technical report, UC Santa Cruz (1999).
16) Joachims, T.: SVM-Light Support Vector Machine. http://svmlight.joachims.org/
【0078】
[具体例]
実施の形態
図8は、実施の形態に係る情報処理装置100の全体構成を表す図である。これらの構成は、ハードウェア的には、任意のコンピュータのCPU、メモリ、その他のLSIで実現でき、ソフトウェア的にはメモリにロードされたプログラムなどによって実現されるが、ここではそれらの連携によって実現される機能ブロックを描いている。したがって、これらの機能ブロックがハードウェアのみ、ソフトウェアのみ、またはそれらの組合せによっていろいろな形で実現できることは、当業者には理解されるところである。
【0079】
情報処理装置100は、学習部10と識別部12とを含む。学習部10はさらに、教師データ格納部14、ストリームカーネル学習部16、識別器格納部18を含む。また、識別部12はさらに、ストリーム構造データ識別部20、ストリームデータ格納部22、出力部24を含む。
【0080】
本実施の形態に係る情報処理装置は、あらかじめ機械学習手法であるストリームカーネルSVMによって識別器を作成しておき、その識別器に基づいてオンラインで到着するデータの属するクラスを判別するという構造を持つ。そこで、まずストリームカーネルSVMによる学習過程について説明する。
【0081】
教師データ格納部14は機械学習に用いるためのデータを格納する部分である。教師データとは、そのデータの属するクラスが既知であるデータの集合のことである。たとえば、クレジットカードの取引データについて、その取引が正常利用であるのか不正利用であるのかの二値に分類する問題を考える。このとき、教師データとは、その取引が正常利用か不正利用であるかが既知であるデータの集合である。
【0082】
ストリームカーネル学習部16は、教師データ格納部14から受け取った教師データに基づいてストリーム構造データを構築し、ストリームカーネルSVMを用いて機械学習により識別器を作成する部分である。これは主に前提技術[4]に記載の技術に基づいて作成したストリームカーネルを使って前提技術[3]に記載の非線形SVMにより学習する。
【0083】
識別器格納部18はストリームカーネル学習部16が出力した学習結果である識別器を格納する部分である。
【0084】
ストリーム構造データ識別部20は、過去の履歴データと、ストリームデータ格納部22から受け取るオンラインで到着したデータとからストリーム構造データを構築し、識別器格納部18から受け取った識別器に基づいて、当該オンラインで到着したデータのクラスを識別する部分である。これは主に前提技術[4]に記載の技術に基づくものである。出力部24はストリーム構造データ識別部20が識別した結果を図示しないモニタ等の出力ディバイスやストレージ等に出力する。
【0085】
図9はストリームカーネル学習部16の構成図である。ストリームカーネル学習部16は履歴数入力部26、教師ストリーム構造データ作成部28、教師ストリームカーネル作成部30、機械学習部32を含む。
【0086】
履歴数入力部26はストリーム構造データを作成するに際し、過去何回までの履歴をまとめるかについての情報を入力する部分である。ユーザが任意の回数を自由に入力できるようにしても良いし、例えば5回のように固定されていても良い。教師ストリーム構造データ作成部28は、履歴数入力部26から参照すべき過去の履歴回数を受け取り、ストリーム構造データを作成する部分である。ストリーム構造データは前提技術[4.1]に記載の構造のデータであるが、ここではさらに、おのおののデータが正常利用であるか不正利用であるかの情報をも付与された教師データとして作成される。
【0087】
教師ストリームカーネル作成部30は、教師ストリーム構造データ作成部28から教師ストリーム構造データを受け取り、SVMの学習に供すべき教師ストリームカーネルを作成する部分である。詳細は後述するが、これは前提技術[4.2]、[4.3]、[4.4]に記載のアルゴリズムに基づく。
【0088】
機械学習部32は、教師ストリームカーネル作成部30が作成した教師ストリームカーネルを用いてSVMの学習を行う部分である。SVMは前提技術[3.1]に記載の非線形識別アルゴリズムに基づく。
【0089】
図10は教師ストリームカーネル作成部30の構成図である。教師ストリームカーネル作成部30は時間間隔正規化部34、ストリームカーネル作成部36、カーネル正規化部38を含む。
【0090】
時間間隔正規化部34は、教師ストリーム構造データ作成部28から受け取ったストリーム構造データに含まれる履歴の発生日時を参照して、各履歴間の時間間隔を正規化する部分である。これは前提技術[4.1]に記載のアルゴリズムに基づくものであり、その目的はデータによって異なる履歴の発生間隔を正規化して、それぞれの履歴の発生間隔を同じ尺度でとらえることである。
【0091】
ストリームカーネル作成部36は、教師ストリーム構造データ作成部28から受け取った教師ストリーム構造データと時間間隔正規化部34から受け取った正規化された時間間隔とを受け取って、ストリームカーネルを計算する部分である。これは前提技術[4.4]に記載のアルゴリズムに基づくものである。式(18)、式(19)で表されるように、ストリームカーネルは漸化式を用いて表現できるため、動的計画法を適用することでストリームカーネル生成の計算量を抑制することができる。
【0092】
カーネル正規化部38は、ストリームカーネル作成部36が作成したカーネルを正規化する部分である。これは、ストリームカーネルの計算に用いるストリーム構造データXとZとの履歴数が異なる場合には、履歴数の少ない部分集合のカーネルのみとなるため、前提技術[4.4]の式(20)を用いて是正するものである。
【0093】
図11はストリームカーネルを作成する処理の流れを表す。ステップS10およびステップS12は前提技術[4.4]に記載の漸化式(18)、(19)を計算するための初期値を設定する。具体的には、まずK0(X,Z)の値を1に設定し(S10)、J1の値をK(x(1),z(1))に設定する(S12)。ここで、K(x(1),z(1))としては、たとえば前提技術[3.1]における式(3)に示すガウスカーネルを用いる。次に、ループ変数iを1に初期化する(S14)。
【0094】
ステップS16はループの終了を判断するステップである。具体的には、ループ変数iの値が遡る履歴回数n以下の場合にはステップS18に進む(S16Y)。そうでない場合にはループを終了し、ステップS24に進む(S16N)。
【0095】
ステップS18からステップS22は、前提技術[4.4]に記載の漸化式(18)、(19)を用いて、順次更新することによりストリームカーネルを生成するステップである。まず式(18)に基づき、Ki(Xx(i),Zz(i))をJiとKi−1(X,Z)との和により求める(S18)。例えばi=1の場合にはK1(Xx(1),Zz(1))=K0(X,Z)+J1となるが、右辺はそれぞれ前述のステップS10およびS12において定められている。結局、K1(Xx(1),Zz(1))=K(x(1),z(1))となる。
【0096】
次に、式(19)に基づき、Ji+1をJi、K(x(i+1),z(i+1))および前提技術[4.3]のアルゴリズムに基づいて求めた重みを用いて求める(S20)。例えばi=1の場合にはJ2=(1+J1)K(x(2),z(2))λT[1,2]となる。ここで、J1はステップS12において定められており、K(x(2),z(2))は例えば前提技術[3.1]における式(3)のガウスカーネルを用いれば計算できる。またλT[1,2]は前提技術[4.3]のアルゴリズムに基づき、時間間隔正規化部34であらかじめ計算しておいたデータを用いればよい。
【0097】
ステップS18およびステップS20によりKi(Xx(i),Zz(i))およびJi+1が更新できたので、ループ変数iをi+1に更新し、ステップS16に戻る(S22)。ループ変数iがn以下の間、以上のループを回すことにより、ストリームカーネルKn(X,Z)を漸化式を用いて順に更新することができる。こうして得られたストリームカーネルKn(X,Z)を出力し(S24)、終了する。
【0098】
以上ストリーム構造データをSVMで扱うためのストリームカーネルの作成方法について説明した。ストリームカーネルを用いることにより、あるひとつのストリーム構造データから対応するひとつのストリームカーネルの出力値を得ることができる。この出力値を用いれば従来のSVMによる機械学習を行うことができる。このように、ストリームカーネルの出力値を用いて従来のSVMによる機械学習を行うことがストリームカーネルSVMである。
【0099】
次に、ストリームカーネルSVMの学習結果である識別器を用いて、オンラインで到着するデータがどのクラスに属するかを識別する方法について説明する。
【0100】
図12はストリーム構造データ識別部20の構成図である。ストリーム構造データ識別部20はストリーム構造データ構築部40、識別用ストリームカーネル作成部42、識別部44を含む。
【0101】
ストリーム構造データ構築部40は、ストリームデータ格納部22からオンラインで到着したデータを受け取り、当該データを含め過去n回までの履歴データを基にストリーム構造データを構築する部分である。これにより、オンラインで到着するデータのみならず、過去n回までの履歴を入力として識別することが可能となる。これは主に前提技術[4.1]〜[4.3]に記載のアルゴリズムに基づく。
【0102】
識別用ストリームカーネル作成部42は、識別器格納部18から識別器と、ストリーム構造データ構築部40で構築されたオンラインで到着したデータを含むストリーム構造データとを受け取り、識別用のストリームカーネルを作成する部分である。識別器には複数のストリーム構造データがサポートベクタとして含まれている。これらのサポートベクタを例えば前提技術[4.1]〜[4.4]に記載のアルゴリズムのZとし、ストリーム構造データ構築部40で構築されたストリーム構造データをXとすれば、識別用のストリームカーネルを構築することができる。
【0103】
識別部44は、識別用ストリームカーネル作成部42で作成された識別用のストリームカーネルに基づき、オンラインで到着したデータの属するクラスを識別する部分である。具体的には、前提技術[3.1]に記載の式(7)におけるK(xi,x)を前記ストリームカーネルに置換し、その出力値の正負によってふたつのクラスに識別すればよい。
【0104】
以上、本発明を実施の形態をもとに説明した。これらの実施の形態は例示であり、それらの各構成要素や各処理プロセスの組合せにいろいろな変形例が可能なこと、またそうした変形例も本発明の範囲にあることは当業者に理解されるところである。
【符号の説明】
【0105】
10 学習部、 12 識別部、 14 教師データ格納部、 16 ストリームカーネル学習部、 18 識別器格納部、 20 ストリーム構造データ識別部、 22 ストリームデータ格納部、 24 出力部、 26 履歴数入力部、 28 教師ストリーム構造データ作成部、 30 教師ストリームカーネル作成部、 32 機械学習部、 34 時間間隔正規化部、 36 ストリームカーネル作成部、 38 カーネル正規化部、 40 ストリーム構造データ構築部、 42 識別用ストリームカーネル作成部、 44 識別部、 100 情報処理装置。
【特許請求の範囲】
【請求項1】
過去履歴の参照範囲を履歴数として入力する履歴数入力部と、
属するクラスが既知である履歴数個のデータをひとつの教師ストリーム構造データとしてまとめる教師ストリーム構造データ作成部と、
教師ストリーム構造データに基づいて教師ストリームカーネルを作成する教師ストリームカーネル作成部と、
教師ストリームカーネルの出力値を機械学習することにより、任意のストリーム構造データの属するクラスを識別するための識別器を生成する機械学習部とを含むことを特徴とする学習装置。
【請求項2】
前記教師ストリームカーネル作成部は、前記履歴数個のデータのうち最新のデータと最古のデータとの時間間隔に基づいて前記履歴数個のデータ間の時間間隔を正規化する時間間隔正規化部を含むことを特徴とする請求項1に記載の学習装置。
【請求項3】
前記教師ストリームカーネル作成部は、前記正規化された時間間隔に基づいて、前記教師ストリーム構造データの各部分構造が持つストリームカーネルに対する寄与率を定めることを特徴とする請求項2に記載の学習装置。
【請求項4】
前記教師ストリームカーネル作成部は、前記教師ストリーム構造データの各部分構造のカーネル関数と前記寄与率との積の総和をストリームカーネルとして出力することを特徴とする請求項3記載の学習装置。
【請求項5】
前記教師ストリームカーネル作成部は、前記履歴数個のうち古いデータほど前記寄与率を小さく設定することを特徴とする請求項3または4に記載の学習装置。
【請求項6】
前記機械学習部は、前記履歴数個のデータ間で時間の経過とともに変化しうる情報を識別のための特徴ベクトルとして学習することを特徴とする請求項1から5のいずれかに記載の学習装置。
【請求項7】
オンラインで受け取ったデータと当該データの過去履歴とから識別用ストリーム構造データを構築するストリーム構造データ構築部と、
前記識別用ストリーム構造データと、教師ストリームカーネルの値を機械学習することにより得られた識別器とを用いて識別用ストリームカーネルを作成する識別用ストリームカーネル作成部と、
識別用ストリームカーネルの出力値に基づいて当該データの属するクラスを識別する識別部とを含むことを特徴とするクラス識別装置。
【請求項8】
過去履歴の参照範囲を履歴数として入力するステップと、
属するクラスが既知である履歴数個のデータをひとつの教師ストリーム構造データとしてまとめるステップと、
教師ストリーム構造データに基づいて教師ストリームカーネルを作成するステップと、
教師ストリームカーネルの出力値を機械学習することにより、任意のストリーム構造データの属するクラスを識別するための識別器を生成するステップとをプロセッサに実行させることを特徴とする学習方法。
【請求項9】
過去履歴の参照範囲を履歴数として入力する機能と、
属するクラスが既知である履歴数個のデータをひとつの教師ストリーム構造データとしてまとめる機能と、
教師ストリーム構造データに基づいて教師ストリームカーネルを作成する機能と、
教師ストリームカーネルの出力値を機械学習することにより、任意のストリーム構造データの属するクラスを識別するための識別器を生成する機能とをコンピュータに実現させることを特徴とするプログラム。
【請求項1】
過去履歴の参照範囲を履歴数として入力する履歴数入力部と、
属するクラスが既知である履歴数個のデータをひとつの教師ストリーム構造データとしてまとめる教師ストリーム構造データ作成部と、
教師ストリーム構造データに基づいて教師ストリームカーネルを作成する教師ストリームカーネル作成部と、
教師ストリームカーネルの出力値を機械学習することにより、任意のストリーム構造データの属するクラスを識別するための識別器を生成する機械学習部とを含むことを特徴とする学習装置。
【請求項2】
前記教師ストリームカーネル作成部は、前記履歴数個のデータのうち最新のデータと最古のデータとの時間間隔に基づいて前記履歴数個のデータ間の時間間隔を正規化する時間間隔正規化部を含むことを特徴とする請求項1に記載の学習装置。
【請求項3】
前記教師ストリームカーネル作成部は、前記正規化された時間間隔に基づいて、前記教師ストリーム構造データの各部分構造が持つストリームカーネルに対する寄与率を定めることを特徴とする請求項2に記載の学習装置。
【請求項4】
前記教師ストリームカーネル作成部は、前記教師ストリーム構造データの各部分構造のカーネル関数と前記寄与率との積の総和をストリームカーネルとして出力することを特徴とする請求項3記載の学習装置。
【請求項5】
前記教師ストリームカーネル作成部は、前記履歴数個のうち古いデータほど前記寄与率を小さく設定することを特徴とする請求項3または4に記載の学習装置。
【請求項6】
前記機械学習部は、前記履歴数個のデータ間で時間の経過とともに変化しうる情報を識別のための特徴ベクトルとして学習することを特徴とする請求項1から5のいずれかに記載の学習装置。
【請求項7】
オンラインで受け取ったデータと当該データの過去履歴とから識別用ストリーム構造データを構築するストリーム構造データ構築部と、
前記識別用ストリーム構造データと、教師ストリームカーネルの値を機械学習することにより得られた識別器とを用いて識別用ストリームカーネルを作成する識別用ストリームカーネル作成部と、
識別用ストリームカーネルの出力値に基づいて当該データの属するクラスを識別する識別部とを含むことを特徴とするクラス識別装置。
【請求項8】
過去履歴の参照範囲を履歴数として入力するステップと、
属するクラスが既知である履歴数個のデータをひとつの教師ストリーム構造データとしてまとめるステップと、
教師ストリーム構造データに基づいて教師ストリームカーネルを作成するステップと、
教師ストリームカーネルの出力値を機械学習することにより、任意のストリーム構造データの属するクラスを識別するための識別器を生成するステップとをプロセッサに実行させることを特徴とする学習方法。
【請求項9】
過去履歴の参照範囲を履歴数として入力する機能と、
属するクラスが既知である履歴数個のデータをひとつの教師ストリーム構造データとしてまとめる機能と、
教師ストリーム構造データに基づいて教師ストリームカーネルを作成する機能と、
教師ストリームカーネルの出力値を機械学習することにより、任意のストリーム構造データの属するクラスを識別するための識別器を生成する機能とをコンピュータに実現させることを特徴とするプログラム。
【図3】

【図5】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図1】
【図2】
【図4】
【図6】
【図5】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図1】
【図2】
【図4】
【図6】
【公開番号】特開2010−282440(P2010−282440A)
【公開日】平成22年12月16日(2010.12.16)
【国際特許分類】
【出願番号】特願2009−135501(P2009−135501)
【出願日】平成21年6月4日(2009.6.4)
【新規性喪失の例外の表示】特許法第30条第1項適用申請有り 平成20年12月26日 http://fw8.bookpark.ne.jp/cm/ipsj/particulars.asp?content_id=IPSJ−TOD0103006−PDFに発表
【出願人】(508236240)公立大学法人公立はこだて未来大学 (16)
【出願人】(397067853)株式会社インテリジェントウェイブ (20)
【公開日】平成22年12月16日(2010.12.16)
【国際特許分類】
【出願日】平成21年6月4日(2009.6.4)
【新規性喪失の例外の表示】特許法第30条第1項適用申請有り 平成20年12月26日 http://fw8.bookpark.ne.jp/cm/ipsj/particulars.asp?content_id=IPSJ−TOD0103006−PDFに発表
【出願人】(508236240)公立大学法人公立はこだて未来大学 (16)
【出願人】(397067853)株式会社インテリジェントウェイブ (20)
[ Back to top ]