
対話装置、対話方法及び対話プログラム
【課題】ユーザとより自然な対話を行うこと。
【解決手段】対話装置は、ユーザの音声を認識する音声認識手段を備え、音声認識手段により認識された音声情報に基づいて、ユーザと対話を行う。また、対話装置は、音声認識手段により認識された音声情報に基づいて、自立語を抽出する自立語抽出手段と、自立語に対応付けられた演出内容を複数記憶する第1記憶手段と、第1記憶手段に記憶された複数の演出内容の中から、自立語抽出手段により抽出された自立語に基づいて、実行する演出内容を決定する演出決定手段と、ユーザとの対話中に、演出決定手段により決定された演出内容を実行する演出実行手段と、を備える。
【解決手段】対話装置は、ユーザの音声を認識する音声認識手段を備え、音声認識手段により認識された音声情報に基づいて、ユーザと対話を行う。また、対話装置は、音声認識手段により認識された音声情報に基づいて、自立語を抽出する自立語抽出手段と、自立語に対応付けられた演出内容を複数記憶する第1記憶手段と、第1記憶手段に記憶された複数の演出内容の中から、自立語抽出手段により抽出された自立語に基づいて、実行する演出内容を決定する演出決定手段と、ユーザとの対話中に、演出決定手段により決定された演出内容を実行する演出実行手段と、を備える。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、ユーザとより自然な対話を行うことができる対話装置、対話方法及び対話プログラムに関するものである。
【背景技術】
【0002】
近年、人間同士が日常的に行う対話と同様に、ユーザとの間で対話を行うことができる対話装置の開発が行われている。例えば、ユーザの音声を認識して対話を行う対話処理装置が知られている(特許文献1参照)。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特許第4062591号
【発明の概要】
【発明が解決しようとする課題】
【0004】
しかしながら、上記特許文献1に示す対話処理装置においては、音声認識の精度向上を目的として情報伝達とは直接関係無い音の発生を抑制しているため、自然な対話を行うことが困難となる問題が生じている。
【0005】
本発明は、このような問題点を解決するためになされたものであり、ユーザとより自然な対話を行うことができる対話装置、対話方法及び対話プログラムを提供することを主たる目的とする。
【課題を解決するための手段】
【0006】
上記目的を達成するための本発明の一態様は、ユーザの音声を認識する音声認識手段を備え、該音声認識手段により認識された音声情報に基づいてユーザと対話を行う対話装置であって、前記音声認識手段により認識された音声情報に基づいて、自立語を抽出する自立語抽出手段と、自立語に対応付けられた演出内容を複数記憶する第1記憶手段と、前記第1記憶手段に記憶された複数の演出内容の中から、前記自立語抽出手段により抽出された自立語に基づいて、実行する演出内容を決定する演出決定手段と、前記ユーザとの対話中に、前記演出決定手段により決定された演出内容を実行する演出実行手段と、を備える、ことを特徴とする対話装置である。
この一態様において、演出内容に対するユーザの嗜好情報が複数記憶された第2記憶手段を更に備え、前記演出決定手段は、前記第1記憶手段に記憶された複数の演出内容の中から、前記第2記憶手段に記憶されたユーザの嗜好情報と、前記自立語抽出手段により抽出された自立語と、に基づいて、実行する演出内容を決定してもよい。
この一態様において、前記演出決定手段は、前記自立語抽出手段により抽出された各自立語に対応する演出内容とユーザとの適合度合いを示す適合度を、予め設定されたモデルデータを用いて算出し、該算出した適合度を前記ユーザの嗜好情報に基づいて加減算し、該加減算した適合度が閾値を超えた前記演出内容を決定してもよい。
この一態様において、前記演出決定手段は、前記第1記憶手段に記憶された複数の演出内容の中から、前記自立語抽出手段により抽出された自立語に対応する演出内容が抽出できなかったとき、該自立語に関連する関連語に対応する演出内容を再検索して、前記実行する演出内容を決定してもよい。
この一態様において、前記演出実行手段は、音楽を再生する音楽再生装置、照明を行う照明装置、ロボット動作を制御するロボット制御装置、空気を調整する空調装置、臭いを発生する臭い発生装置、表示を行う表示装置、及び、ユーザに対して振動を与える振動装置、のうち少なくとも1の前記装置を制御することで、前記演出内容を実行してもよい。
この一態様において、前記演出実行手段により実行された演出内容を記憶する第3記憶手段を更に備え、前記演出決定手段は、前記第3記憶手段に記憶された演出内容の情報に基づいて、前記自立語抽出手段により抽出された自立語と実行する演出内容との関係を学習し、該学習結果に基づいて、前記演出内容を決定してもよい。
この一態様において、前記音声認識手段により音声認識されたテキスト情報を記憶する第4記憶手段を更に備えていてもよい。
他方、上記目的を達成するための本発明の一態様は、ユーザの音声を認識し、該認識された音声情報に基づいてユーザと対話を行う対話方法であって、前記認識された音声情報に基づいて、自立語を抽出するステップと、予め記憶された自立語に夫々対応付けられた複数の演出内容の中から、前記自立語抽出手段により抽出された自立語に基づいて、実行する演出内容を決定するステップと、前記ユーザとの対話中に、前記決定された演出内容を実行するステップと、を含む、ことを特徴とする対話方法であってもよい。
この一態様において、前記記憶された複数の演出内容の中から、前記抽出された自立語に対応する演出内容が抽出できなかったとき、該自立語に関連する関連語に対応する演出内容を再検索して、前記実行する演出内容を決定してもよい。
また、上記目的を達成するための本発明の一態様は、ユーザの音声を認識し、該認識された音声情報に基づいてユーザと対話を行う対話プログラムであって、前記認識された音声情報に基づいて、自立語を抽出する処理と、予め記憶された自立語に夫々対応付けられた複数の演出内容の中から、前記自立語抽出手段により抽出された自立語に基づいて、実行する演出内容を決定する処理と、前記ユーザとの対話中に、前記決定された演出内容を実行する処理と、をコンピュータに実行させる、ことを特徴とする対話プログラムであってもよい。
【発明の効果】
【0007】
本発明によれば、ユーザとより自然な対話を行うことができる対話装置、対話方法及び対話プログラムを提供することができる。
【図面の簡単な説明】
【0008】
【図1】本発明の一実施の形態に係る対話装置の概略的なシステム構成を示すブロック図である。
【図2】本発明の一実施の形態に係る対話装置の概略的なハードウェア構成の一例を示すブロック図である。
【図3】本発明の一実施の形態に係る対話装置による対話処理フローの一例を示すフローチャートである。
【発明を実施するための形態】
【0009】
以下、図面を参照して本発明の実施の形態について説明する。本発明の一実施の形態に係る対話装置1は、ユーザとの対話の音声情報などを解析して、ユーザとの対話中に、その対話に相応しい演出を自動的に実行するものである。これにより、ユーザとの対話がより自然になり、例えば、その対話を長続きさせることができる。
【0010】
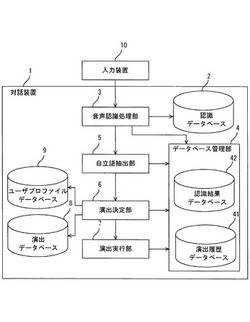
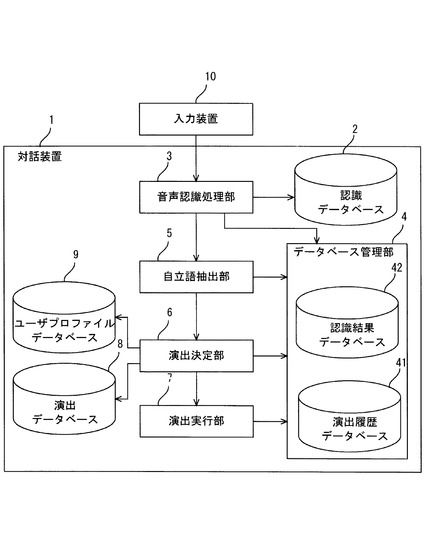
図1は、本実施の形態に係る対話装置の概略的なシステム構成を示すブロック図である。本実施の形態に係る対話装置1は、認識データベース2と、音声認識処理部3と、データベース管理部4と、自立語抽出部5と、演出決定部6と、演出実行部7と、演出データベース8と、ユーザプロファイルデータベース9と、を備えている。
【0011】
認識データベース2は、例えば、音声認識を行うための音響モデル及び言語モデル(N−gramモデル)を予め記憶している。
【0012】
音声認識処理部3は、音声認識手段の一具体例であり、入力装置10などを介して入力された音声情報(音声信号)に対して、音声認識処理を行う。音声認識処理部3は、例えば、入力された音声信号から特徴量を抽出し、抽出した特徴量と、認識データベース2などに予め記憶された音響モデル及び言語モデル(N−gramモデル)と、に基づいて類似度を算出し、算出した類似度に基づいて音声情報のテキスト情報を生成する。音声認識処理部3は、生成したテキスト情報を後述の認識結果データベース2に対して出力する。
【0013】
入力装置10は、ユーザの音声情報、テキスト情報などを入力する機能を有しており、マイク等の音声入力装置、マウスなどのポインティングデバイス、キーボードなどの数値入力デバイス、などから構成されている。なお、対話装置1は、例えば、ユーザの音声情報やテキスト情報を、インターネット、無線LAN(Local Area Network)、WAN(Wide Area Network)などの通信網26を介して、遠隔的に取得してもよい。
【0014】
データベース管理部4は、実行した演出内容を記憶する演出履歴データベース(第3記憶手段の一具体例)41と、音声認識処理部3により認識されたテキスト情報を記憶する認識結果データベース(第4記憶手段の一具体例)42と、を有しており、各データベース41、42の更新を行い、そのタイムスタンプなどを管理する。
【0015】
自立語抽出部5は、自立語抽出手段の一具体例であり、認識結果データベース42に記憶されたテキスト情報に基づいて、形態素解析などを行い、テキスト情報の文字列中に含まれる自立語を抽出する。なお、自立語抽出部5は、認識結果データベース42を介さずに、音声認識処理部3から出力されるテキスト情報に基づいて、直接的に自立語を抽出してもよい。
【0016】
演出決定部6は、演出決定手段の一具体例であり、演出データベース8に記憶された演出内容の中から、ユーザプロファイルデータベース9に記憶されたユーザ嗜好情報と、自立語抽出部5により抽出された自立語と、に基づいて、実行する演出内容を決定する。
【0017】
演出データベース8は、第1記憶手段の一具体例であり、例えば、演出内容(音楽(歌詞、楽譜、歌手、作曲家、作詞家、ジャンル)、効果音、照明、臭い、温度、湿度、振動、ロボット動作、自立語と関連する関連語、自立語と関連する感情、などの演出情報が、関連する自立語と対応付けされて予め記憶している。なお、上記演出内容は一例であり、これに限らず、ユーザの対話をより自然にする演出であれば任意の演出内容が適用可能である。
【0018】
演出決定部6は、検索した演出内容に基づいて、ユーザプロファイルデータベース9のユーザ嗜好情報を検索し、その演出内容に対するユーザ嗜好情報を検索する。
【0019】
ユーザプロファイルデータベース9は、第2記憶手段の一具体例であり、ユーザ嗜好情報(ユーザが各演出内容を好きか嫌いかに関する情報)を各演出内容に夫々対応付けて記憶している。
【0020】
なお、ユーザプロファイルデータベース9、上記した演出データベース8、認識データベース2、演出履歴データベース41、及び認識結果データベース42、は、夫々独立した記憶装置に実現されていてもよく、全てのデータベース2、8、9、41、42を単一の記憶装置あるいは、各データベース2、8、9、41、42を任意に組合わせて夫々同一の記憶装置に実現されてもよい。また、ユーザプロファイルデータベース9、上記した演出データベース8、認識データベース2、演出履歴データベース41、及び認識結果データベース42は、例えば、後述のRAM23、ROM24、補助記憶装置21を用いて構成することができる。
【0021】
ここで、演出決定部6による演出内容の決定方法の一例について、詳細に説明する。
まず、演出決定部6は、検索した演出内容とユーザとの適合度合いを示す適合度(関連度)を、演出データベースに予め記憶されたモデルデータを用いて算出する。なお、モデルデータには、例えば、各演出内容に対するユーザとの適合度合いがアンケートなどの統計的データに基づいて数値化され、適合度として夫々設定されている。
【0022】
演出決定部6は、ユーザプロファイルデータベース9のユーザ嗜好情報に基づいて、検索した演出内容に対して、ユーザがその演出内容を好んでいるユーザ嗜好情報が対応付けられている場合、上記算出した演出内容の適合度を増加させる(例えば、所定値を加算する)。一方、演出決定部6は、検索した演出に対して、ユーザがその演出内容を嫌っている嗜好情報が対応付けられている場合、上記算出した演出内容の適合度を減少させる(例えば、所定値を減算する)。なお、演出決定部6は、検索した演出内容に対して、ユーザがその演出内容を好んでも嫌ってもいないユーザ嗜好情報が対応付けられている場合、その演出内容の適合度を変化させない。
【0023】
演出決定部6は、各自立語に対する演出内容に対して上記適合度の加減算を繰り返す。そして、演出決定部6は、上記のように算出した各演出内容の適合度が閾値を超えているか否かを判断する。演出決定部6は、算出した各演出内容の適合度が閾値を超えていると判断したとき、その演出内容を決定する。
【0024】
なお、上記演出内容の決定方法は、一例であり、これに限らず、自立語に関連した演出内容であり、ユーザの嗜好情報が反映されたものであれば、任意の方法を用いて、演出内容を決定できる。このように、ユーザ嗜好情報を用いて適合度を算出し、ユーザ嗜好情報を反映した演出内容を決定することにより、よりユーザとの対話に適した演出内容を選択でき、より自然な対話が可能となる。
【0025】
また、演出決定部6は、実演履歴データベース41の情報に基づいて、自立語抽出部5により抽出された自立語と実行する演出内容との関係を周知の学習アルゴリズム(ニューラルネットワーク、遺伝的学習アルゴリズム、機械学習アルゴリズムなど)を用いて学習し、その学習結果に基づいて、演出内容を決定してもよい。
【0026】
演出実行部7は、演出実行手段の一具体例であり、ユーザとの対話中において、演出決定部6により決定された演出内容を実行する。例えば、演出内容が音楽の場合、演出実行部7は、音楽再生装置11(図2)を制御して、その音楽を再生する。ユーザとの対話内容に相応しい音楽を再生することで、その対話をより円滑に進行することができる。また、演出内容が照明の場合は、演出実行部7は、照明装置12を制御して、その対話に相応しい、照明の点灯、消灯、点滅、照度調整、照明色の変化などを行う。演出内容がロボットの所定動作(踊り動作、頷き動作、手振り動作など)の場合、ロボット制御装置13を制御して、ロボットにその対話に相応しい所定動作をさせる。演出内容が臭いの発生の場合は、演出実行部7は、臭い発生装置14を制御して、その対話に相応しいユーザの好む臭いを発生させる。演出内容が表示の場合は、演出実行部7は、表示装置15を制御して、その対話に相応しい画像や文字などを表示させる。演出内容が振動の場合は、演出実行部7は振動装置16を制御して、その対話に相応しい振動をユーザに対して与える。演出内容が温度や湿度の場合、演出実行部7は、空調装置17を制御してその対話に相応しい温度や湿度に上昇或いは下降させる。演出内容が風の場合は、演出実行部7は、空調装置17を制御して、その対話に相応し風をユーザに対して当てる。上述したように、ユーザの対話に適合した演出を行うことで、より対話を自然かつスムーズに進行させることができる。
【0027】
なお、上記演出内容の実行は、一例であり、これに限らず、ユーザの五感にうったえ対話をより自然に行う任意の演出内容を実行することができる。また、演出決定部6により複数の演出内容が決定された場合、演出実行部7は、演出決定部6により早く決定された順で演出内容を実行してもよい。さらに、演出実行部7は、演出決定部6により決定された演出内容のうち、適合度の高いものから順に演出内容を実行させてもよく、任意の実行方法が適用可能である。またさらに、演出実行部7は、複数の演出内容を任意に組み合わせて同時に実行させるようにしてもよい。
【0028】
演出実行部7は、実行した演出内容を演出履歴データベース41に記憶させ、演出履歴データベース41の情報を更新させる。
【0029】
ここで、演出決定部6は、自立語抽出部5により抽出された自立語に対応する演出内容が検索できない場合、あるいは、抽出した自立語を更に拡張したい場合に、その自立語に関連する関連語を用いて、演出内容を決定してもよい。
【0030】
この場合、演出決定部6は、自立語抽出部5により抽出された自立語と演出データベース8の関連語の情報と、に基づいて、その自立語に関連する関連語を検索し、演出データベース8の演出内容の中から、検索した関連語に対応する演出内容を検索してもよい。
【0031】
次に、以下のテキスト情報の一具体例を用いて上記対話演出処理を説明する。
例えば、音声認識処理部3により認識されたテキスト情報が以下の場合を想定する。
「S:日焼けしてますね。何処に行ったの? H:先日、ハワイに行ってきたんだよ。 S:ハワイですか、それはいいなあ。何処を見て回ったの? H:ワイキキビーチに行ったんだ。」
【0032】
演出決定部6は、上記テキスト情報の中から自立語「ハワイ」を抽出する。演出決定部6は、抽出した自立語「ハワイ」に対応する演出内容を演出データベース8から抽出する。なお、演出決定部6は、抽出した自立語「ハワイ」に基づいて、その自立語と関連度の高いものから順に演出内容を抽出してもよい。この場合、演出データベース8には、各自立語に対応付けられた演出内容などの情報と共にその自立語と演出内容などの情報との関連度が記憶されている。
【0033】
例えば、演出決定部6は、抽出した自立語「ハワイ」に基づいて、演出データベース8から演出内容「ハワイアン」及び「演歌」を抽出する。さらに、演出決定部6は、ユーザプロファイルデータベース9のユーザ嗜好情報に基づいて、ユーザが「演歌」を好まないというユーザ嗜好情報を得ることができる。
【0034】
演出決定部6は、ユーザプロファイルデータベース9のユーザ嗜好情報に基づいて、演出内容「ハワイアン」の適合度を増加させ、演出内容「演歌」の適合度を減少させる。そして、演出決定部は、演出内容「ハワイアン」の適合度が閾値を超えた場合に、その演出内容「ハワイアン」の実行を決定する。この場合、演出実行部7は、例えば、音楽再生装置11を制御して、ウクレレが主体のハワイアンの音楽を再生する。このような演出を行うことで、ユーザはハワイ旅行などの思い出が回想され、当該対話装置1との対話がより自然に進むこととなる。
【0035】
なお、対話装置1は、通常のユーザと対話を行う機能(音声認識処理によりユーザの音声を認識し、認識された音声情報に基づいて、所定の言語を出力する機能)を有している。通常の対話を行う機能については周知の技術であるため、詳細な説明は省略する。
【0036】
さらに、本実施の形態に係る対話装置1は、上記対話を行いつつ、演出決定部6により決定された演出内容を実行させる。例えば、音声認識処理部3は、対話装置1とユーザとの対話中において、ユーザ及び対話装置1が発した音声を音声認識し、テキスト情報を生成する。自立語抽出部5は、音声認識処理部3により認識されたテキスト情報の中から自立語を抽出する。演出決定部6は、自立語抽出部5により抽出された自立語と、演出データベース8に記憶された演出情報と、ユーザプロファイルデータベース9に記憶されたユーザ嗜好情報と、に基づいて、演出内容を決定する。演出実行部7は、演出決定部6により決定された演出内容を実行させる。このように、ユーザと対話装置1が対話を行いつつも、その対話内容に適した演出内容が実行されることとなる。
【0037】
図2は、本実施の形態に係る対話装置の概略的なハードウェア構成の一例を示すブロック図である。
【0038】
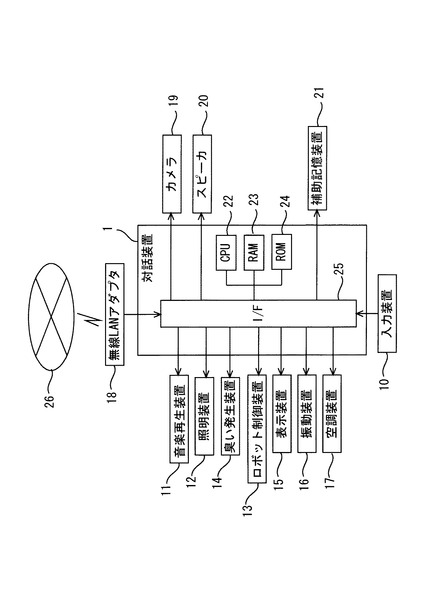
対話装置1は、例えば、制御処理、演算処理等を行うCPU(Central Processing Unit)22、CPU22によって実行される制御プログラム、演算プログラム等が記憶されたROM(Read Only Memory)23、処理データ等を記憶するRAM24、周辺機器との間で信号の入力を行うインターフェイス部25、等からなるマイクロコンピュータを中心にして、ハードウェア構成されている。これらCPU22、ROM23、RAM24及びインターフェイス部(I/F)25は、バス26などを介して相互に接続されている。
【0039】
インターフェイス部25には、例えば、入力装置10、音楽再生装置11、照明装置12、ロボット制御装置13、臭い発生装置14、表示装置15、振動装置16、空調装置17、無線LANアダプタ18、カメラ19、スピーカ20、補助記憶装置21、などが夫々接続されている。なお、上記ハードウェア構成は一例であり、任意のハードウェア構成が適用可能である。
【0040】
次に、本実施の形態に係る対話装置1による対話方法について、詳細に説明する。図3は、本実施の形態に係る対話装置による対話処理フローの一例を示すフローチャートである。なお、図3に示す対話処理は、例えば、所定時間毎に繰り返し実行される。
【0041】
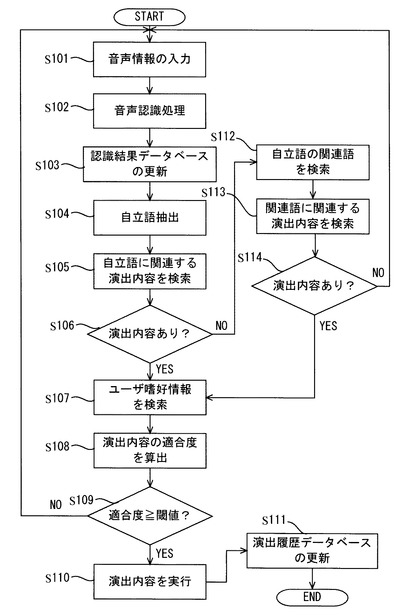
入力装置10から音声認識処理部3に音声情報が入力される(ステップS101)。音声認識処理部3は、入力された音声情報に対して音声認識処理を行ない(ステップS102)、テキスト情報を生成し、生成したテキスト情報を認識結果データベース42に対して出力する。
【0042】
データベース管理部4は、音声認識処理部3から出力されたテキスト情報に基づいて、認識結果データベース42の情報を更新する(ステップS103)。
【0043】
自立語抽出部5は、認識結果データベース42に記憶されたテキスト情報に基づいて、形態素解析などを行い、テキスト情報の文字列中に含まれる自立語を抽出する(ステップS104)。
【0044】
演出決定部6は、演出データベース8に記憶された演出内容の中から、自立語抽出部5により抽出された自立語に対応する演出内容を検索する(ステップS105)。
【0045】
演出決定部6は、演出データベース8に記憶された演出内容の中から、自立語抽出部5により抽出された自立語に対応する演出内容を検索できたとき(ステップS106のYES)、検索した演出内容に基づいて、ユーザプロファイルデータベース9のユーザ嗜好情報を検索し、その演出に対するユーザ嗜好情報を検索する(ステップS107)。
【0046】
演出決定部6は、検索した演出内容の適合度を、予め設定されたモデルデータに基づいて算出する(ステップS108)。さらに、演出決定部6は、ユーザプロファイルデータベース9のユーザ嗜好情報に基づいて、各自立語に関する演出内容に対して上記適合度の加減算を行う。
【0047】
演出決定部6は、上記のように算出した各演出内容の適合度が閾値を超えているか否かを判断する(ステップS109)。
【0048】
演出決定部6は、演出内容の適合度が閾値を超えていると判断したとき(ステップS109のYES)、その演出内容を実行すると決定し、演出実行部7は演出決定部6により決定された演出内容を実行する(ステップS110)。一方、演出決定部6は、演出内容の適合度が閾値を超えていないと判断したとき(ステップS109のNO)、上記(ステップS101)の処理に戻る。
【0049】
演出実行部7は、実行した演出内容を演出履歴データベース41に出力し、データベース管理部4は、演出実行部7から出力された演出内容に基づいて、演出履歴データベース41の情報を更新し(ステップS111)、本処理を終了する。
【0050】
なお、演出決定部6は、演出データベース8に記憶された演出内容の中から、自立語抽出部5により抽出された自立語に対応する演出内容を検索できなかったとき(ステップS106のNO)、演出データベース8からその自立語に関連する関連語を検索する(ステップS112)。さらに、演出決定部6は、演出データベース8の演出内容の中から、関連語に対応する演出内容を検索する(ステップS113)。
【0051】
演出決定部6は、演出データベース8に記憶された演出内容の中から、関連語に対応する演出内容を検索できたとき(ステップS114のYES)、上記(ステップS107)の処理に移行する。一方、演出決定部6は、演出データベース8に記憶された演出内容の中から、関連語に対応する演出内容を検索できないとき(ステップS114のNO)、上記(ステップS101)の処理に移行する。
【0052】
以上、本実施の形態に係る対話装置1において、演出決定部6は、演出データベース8に記憶された演出内容の中から、ユーザプロファイルデータデータベース9に記憶されたユーザ嗜好情報と、自立語抽出部5により抽出された自立語と、に基づいて、実行する演出内容を決定する。そして、演出実行部7は、ユーザとの対話中において、演出決定部6により決定された演出内容を実行する。これにより、ユーザと対話装置1が対話を行いつつ、その対話内容に適した演出内容が実行されることとなる。したがって、ユーザはより自然な対話を行うことができる。
【0053】
なお、本発明は上記実施の形態に限られたものではなく、趣旨を逸脱しない範囲で適宜変更することが可能である。
また、上述の実施の形態では、本発明をハードウェアの構成として説明したが、本発明は、これに限定されるものではない。本発明は、例えば、図3に示す処理を、CPU22にコンピュータプログラムを実行させることにより実現することも可能である。
【0054】
プログラムは、様々なタイプの非一時的なコンピュータ可読媒体(non-transitory computer readable medium)を用いて格納され、コンピュータに供給することができる。非一時的なコンピュータ可読媒体は、様々なタイプの実体のある記録媒体(tangible storage medium)を含む。非一時的なコンピュータ可読媒体の例は、磁気記録媒体(例えばフレキシブルディスク、磁気テープ、ハードディスクドライブ)、光磁気記録媒体(例えば光磁気ディスク)、CD−ROM(Read Only Memory)、CD−R、CD−R/W、半導体メモリ(例えば、マスクROM、PROM(Programmable ROM)、EPROM(Erasable PROM)、フラッシュROM、RAM(random access memory))を含む。
【0055】
また、プログラムは、様々なタイプの一時的なコンピュータ可読媒体(transitory computer readable medium)によってコンピュータに供給されてもよい。一時的なコンピュータ可読媒体の例は、電気信号、光信号、及び電磁波を含む。一時的なコンピュータ可読媒体は、電線及び光ファイバ等の有線通信路、又は無線通信路を介して、プログラムをコンピュータに供給できる。
【産業上の利用可能性】
【0056】
本発明は、例えば、ユーザとより自然な対話を行うことができるエンターテイメントロボットなどに搭載された対話装置に利用可能である。
【符号の説明】
【0057】
1 対話装置
2 認識データベース
3 音声認識処理部
4 データベース管理部
5 自立語抽出部
6 演出決定部
7 演出実行部
8 演出データベース
9 ユーザプロファイルデータベース
10 入力装置
41 演出履歴データベース
42 認識結果データベース
【技術分野】
【0001】
本発明は、ユーザとより自然な対話を行うことができる対話装置、対話方法及び対話プログラムに関するものである。
【背景技術】
【0002】
近年、人間同士が日常的に行う対話と同様に、ユーザとの間で対話を行うことができる対話装置の開発が行われている。例えば、ユーザの音声を認識して対話を行う対話処理装置が知られている(特許文献1参照)。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特許第4062591号
【発明の概要】
【発明が解決しようとする課題】
【0004】
しかしながら、上記特許文献1に示す対話処理装置においては、音声認識の精度向上を目的として情報伝達とは直接関係無い音の発生を抑制しているため、自然な対話を行うことが困難となる問題が生じている。
【0005】
本発明は、このような問題点を解決するためになされたものであり、ユーザとより自然な対話を行うことができる対話装置、対話方法及び対話プログラムを提供することを主たる目的とする。
【課題を解決するための手段】
【0006】
上記目的を達成するための本発明の一態様は、ユーザの音声を認識する音声認識手段を備え、該音声認識手段により認識された音声情報に基づいてユーザと対話を行う対話装置であって、前記音声認識手段により認識された音声情報に基づいて、自立語を抽出する自立語抽出手段と、自立語に対応付けられた演出内容を複数記憶する第1記憶手段と、前記第1記憶手段に記憶された複数の演出内容の中から、前記自立語抽出手段により抽出された自立語に基づいて、実行する演出内容を決定する演出決定手段と、前記ユーザとの対話中に、前記演出決定手段により決定された演出内容を実行する演出実行手段と、を備える、ことを特徴とする対話装置である。
この一態様において、演出内容に対するユーザの嗜好情報が複数記憶された第2記憶手段を更に備え、前記演出決定手段は、前記第1記憶手段に記憶された複数の演出内容の中から、前記第2記憶手段に記憶されたユーザの嗜好情報と、前記自立語抽出手段により抽出された自立語と、に基づいて、実行する演出内容を決定してもよい。
この一態様において、前記演出決定手段は、前記自立語抽出手段により抽出された各自立語に対応する演出内容とユーザとの適合度合いを示す適合度を、予め設定されたモデルデータを用いて算出し、該算出した適合度を前記ユーザの嗜好情報に基づいて加減算し、該加減算した適合度が閾値を超えた前記演出内容を決定してもよい。
この一態様において、前記演出決定手段は、前記第1記憶手段に記憶された複数の演出内容の中から、前記自立語抽出手段により抽出された自立語に対応する演出内容が抽出できなかったとき、該自立語に関連する関連語に対応する演出内容を再検索して、前記実行する演出内容を決定してもよい。
この一態様において、前記演出実行手段は、音楽を再生する音楽再生装置、照明を行う照明装置、ロボット動作を制御するロボット制御装置、空気を調整する空調装置、臭いを発生する臭い発生装置、表示を行う表示装置、及び、ユーザに対して振動を与える振動装置、のうち少なくとも1の前記装置を制御することで、前記演出内容を実行してもよい。
この一態様において、前記演出実行手段により実行された演出内容を記憶する第3記憶手段を更に備え、前記演出決定手段は、前記第3記憶手段に記憶された演出内容の情報に基づいて、前記自立語抽出手段により抽出された自立語と実行する演出内容との関係を学習し、該学習結果に基づいて、前記演出内容を決定してもよい。
この一態様において、前記音声認識手段により音声認識されたテキスト情報を記憶する第4記憶手段を更に備えていてもよい。
他方、上記目的を達成するための本発明の一態様は、ユーザの音声を認識し、該認識された音声情報に基づいてユーザと対話を行う対話方法であって、前記認識された音声情報に基づいて、自立語を抽出するステップと、予め記憶された自立語に夫々対応付けられた複数の演出内容の中から、前記自立語抽出手段により抽出された自立語に基づいて、実行する演出内容を決定するステップと、前記ユーザとの対話中に、前記決定された演出内容を実行するステップと、を含む、ことを特徴とする対話方法であってもよい。
この一態様において、前記記憶された複数の演出内容の中から、前記抽出された自立語に対応する演出内容が抽出できなかったとき、該自立語に関連する関連語に対応する演出内容を再検索して、前記実行する演出内容を決定してもよい。
また、上記目的を達成するための本発明の一態様は、ユーザの音声を認識し、該認識された音声情報に基づいてユーザと対話を行う対話プログラムであって、前記認識された音声情報に基づいて、自立語を抽出する処理と、予め記憶された自立語に夫々対応付けられた複数の演出内容の中から、前記自立語抽出手段により抽出された自立語に基づいて、実行する演出内容を決定する処理と、前記ユーザとの対話中に、前記決定された演出内容を実行する処理と、をコンピュータに実行させる、ことを特徴とする対話プログラムであってもよい。
【発明の効果】
【0007】
本発明によれば、ユーザとより自然な対話を行うことができる対話装置、対話方法及び対話プログラムを提供することができる。
【図面の簡単な説明】
【0008】
【図1】本発明の一実施の形態に係る対話装置の概略的なシステム構成を示すブロック図である。
【図2】本発明の一実施の形態に係る対話装置の概略的なハードウェア構成の一例を示すブロック図である。
【図3】本発明の一実施の形態に係る対話装置による対話処理フローの一例を示すフローチャートである。
【発明を実施するための形態】
【0009】
以下、図面を参照して本発明の実施の形態について説明する。本発明の一実施の形態に係る対話装置1は、ユーザとの対話の音声情報などを解析して、ユーザとの対話中に、その対話に相応しい演出を自動的に実行するものである。これにより、ユーザとの対話がより自然になり、例えば、その対話を長続きさせることができる。
【0010】
図1は、本実施の形態に係る対話装置の概略的なシステム構成を示すブロック図である。本実施の形態に係る対話装置1は、認識データベース2と、音声認識処理部3と、データベース管理部4と、自立語抽出部5と、演出決定部6と、演出実行部7と、演出データベース8と、ユーザプロファイルデータベース9と、を備えている。
【0011】
認識データベース2は、例えば、音声認識を行うための音響モデル及び言語モデル(N−gramモデル)を予め記憶している。
【0012】
音声認識処理部3は、音声認識手段の一具体例であり、入力装置10などを介して入力された音声情報(音声信号)に対して、音声認識処理を行う。音声認識処理部3は、例えば、入力された音声信号から特徴量を抽出し、抽出した特徴量と、認識データベース2などに予め記憶された音響モデル及び言語モデル(N−gramモデル)と、に基づいて類似度を算出し、算出した類似度に基づいて音声情報のテキスト情報を生成する。音声認識処理部3は、生成したテキスト情報を後述の認識結果データベース2に対して出力する。
【0013】
入力装置10は、ユーザの音声情報、テキスト情報などを入力する機能を有しており、マイク等の音声入力装置、マウスなどのポインティングデバイス、キーボードなどの数値入力デバイス、などから構成されている。なお、対話装置1は、例えば、ユーザの音声情報やテキスト情報を、インターネット、無線LAN(Local Area Network)、WAN(Wide Area Network)などの通信網26を介して、遠隔的に取得してもよい。
【0014】
データベース管理部4は、実行した演出内容を記憶する演出履歴データベース(第3記憶手段の一具体例)41と、音声認識処理部3により認識されたテキスト情報を記憶する認識結果データベース(第4記憶手段の一具体例)42と、を有しており、各データベース41、42の更新を行い、そのタイムスタンプなどを管理する。
【0015】
自立語抽出部5は、自立語抽出手段の一具体例であり、認識結果データベース42に記憶されたテキスト情報に基づいて、形態素解析などを行い、テキスト情報の文字列中に含まれる自立語を抽出する。なお、自立語抽出部5は、認識結果データベース42を介さずに、音声認識処理部3から出力されるテキスト情報に基づいて、直接的に自立語を抽出してもよい。
【0016】
演出決定部6は、演出決定手段の一具体例であり、演出データベース8に記憶された演出内容の中から、ユーザプロファイルデータベース9に記憶されたユーザ嗜好情報と、自立語抽出部5により抽出された自立語と、に基づいて、実行する演出内容を決定する。
【0017】
演出データベース8は、第1記憶手段の一具体例であり、例えば、演出内容(音楽(歌詞、楽譜、歌手、作曲家、作詞家、ジャンル)、効果音、照明、臭い、温度、湿度、振動、ロボット動作、自立語と関連する関連語、自立語と関連する感情、などの演出情報が、関連する自立語と対応付けされて予め記憶している。なお、上記演出内容は一例であり、これに限らず、ユーザの対話をより自然にする演出であれば任意の演出内容が適用可能である。
【0018】
演出決定部6は、検索した演出内容に基づいて、ユーザプロファイルデータベース9のユーザ嗜好情報を検索し、その演出内容に対するユーザ嗜好情報を検索する。
【0019】
ユーザプロファイルデータベース9は、第2記憶手段の一具体例であり、ユーザ嗜好情報(ユーザが各演出内容を好きか嫌いかに関する情報)を各演出内容に夫々対応付けて記憶している。
【0020】
なお、ユーザプロファイルデータベース9、上記した演出データベース8、認識データベース2、演出履歴データベース41、及び認識結果データベース42、は、夫々独立した記憶装置に実現されていてもよく、全てのデータベース2、8、9、41、42を単一の記憶装置あるいは、各データベース2、8、9、41、42を任意に組合わせて夫々同一の記憶装置に実現されてもよい。また、ユーザプロファイルデータベース9、上記した演出データベース8、認識データベース2、演出履歴データベース41、及び認識結果データベース42は、例えば、後述のRAM23、ROM24、補助記憶装置21を用いて構成することができる。
【0021】
ここで、演出決定部6による演出内容の決定方法の一例について、詳細に説明する。
まず、演出決定部6は、検索した演出内容とユーザとの適合度合いを示す適合度(関連度)を、演出データベースに予め記憶されたモデルデータを用いて算出する。なお、モデルデータには、例えば、各演出内容に対するユーザとの適合度合いがアンケートなどの統計的データに基づいて数値化され、適合度として夫々設定されている。
【0022】
演出決定部6は、ユーザプロファイルデータベース9のユーザ嗜好情報に基づいて、検索した演出内容に対して、ユーザがその演出内容を好んでいるユーザ嗜好情報が対応付けられている場合、上記算出した演出内容の適合度を増加させる(例えば、所定値を加算する)。一方、演出決定部6は、検索した演出に対して、ユーザがその演出内容を嫌っている嗜好情報が対応付けられている場合、上記算出した演出内容の適合度を減少させる(例えば、所定値を減算する)。なお、演出決定部6は、検索した演出内容に対して、ユーザがその演出内容を好んでも嫌ってもいないユーザ嗜好情報が対応付けられている場合、その演出内容の適合度を変化させない。
【0023】
演出決定部6は、各自立語に対する演出内容に対して上記適合度の加減算を繰り返す。そして、演出決定部6は、上記のように算出した各演出内容の適合度が閾値を超えているか否かを判断する。演出決定部6は、算出した各演出内容の適合度が閾値を超えていると判断したとき、その演出内容を決定する。
【0024】
なお、上記演出内容の決定方法は、一例であり、これに限らず、自立語に関連した演出内容であり、ユーザの嗜好情報が反映されたものであれば、任意の方法を用いて、演出内容を決定できる。このように、ユーザ嗜好情報を用いて適合度を算出し、ユーザ嗜好情報を反映した演出内容を決定することにより、よりユーザとの対話に適した演出内容を選択でき、より自然な対話が可能となる。
【0025】
また、演出決定部6は、実演履歴データベース41の情報に基づいて、自立語抽出部5により抽出された自立語と実行する演出内容との関係を周知の学習アルゴリズム(ニューラルネットワーク、遺伝的学習アルゴリズム、機械学習アルゴリズムなど)を用いて学習し、その学習結果に基づいて、演出内容を決定してもよい。
【0026】
演出実行部7は、演出実行手段の一具体例であり、ユーザとの対話中において、演出決定部6により決定された演出内容を実行する。例えば、演出内容が音楽の場合、演出実行部7は、音楽再生装置11(図2)を制御して、その音楽を再生する。ユーザとの対話内容に相応しい音楽を再生することで、その対話をより円滑に進行することができる。また、演出内容が照明の場合は、演出実行部7は、照明装置12を制御して、その対話に相応しい、照明の点灯、消灯、点滅、照度調整、照明色の変化などを行う。演出内容がロボットの所定動作(踊り動作、頷き動作、手振り動作など)の場合、ロボット制御装置13を制御して、ロボットにその対話に相応しい所定動作をさせる。演出内容が臭いの発生の場合は、演出実行部7は、臭い発生装置14を制御して、その対話に相応しいユーザの好む臭いを発生させる。演出内容が表示の場合は、演出実行部7は、表示装置15を制御して、その対話に相応しい画像や文字などを表示させる。演出内容が振動の場合は、演出実行部7は振動装置16を制御して、その対話に相応しい振動をユーザに対して与える。演出内容が温度や湿度の場合、演出実行部7は、空調装置17を制御してその対話に相応しい温度や湿度に上昇或いは下降させる。演出内容が風の場合は、演出実行部7は、空調装置17を制御して、その対話に相応し風をユーザに対して当てる。上述したように、ユーザの対話に適合した演出を行うことで、より対話を自然かつスムーズに進行させることができる。
【0027】
なお、上記演出内容の実行は、一例であり、これに限らず、ユーザの五感にうったえ対話をより自然に行う任意の演出内容を実行することができる。また、演出決定部6により複数の演出内容が決定された場合、演出実行部7は、演出決定部6により早く決定された順で演出内容を実行してもよい。さらに、演出実行部7は、演出決定部6により決定された演出内容のうち、適合度の高いものから順に演出内容を実行させてもよく、任意の実行方法が適用可能である。またさらに、演出実行部7は、複数の演出内容を任意に組み合わせて同時に実行させるようにしてもよい。
【0028】
演出実行部7は、実行した演出内容を演出履歴データベース41に記憶させ、演出履歴データベース41の情報を更新させる。
【0029】
ここで、演出決定部6は、自立語抽出部5により抽出された自立語に対応する演出内容が検索できない場合、あるいは、抽出した自立語を更に拡張したい場合に、その自立語に関連する関連語を用いて、演出内容を決定してもよい。
【0030】
この場合、演出決定部6は、自立語抽出部5により抽出された自立語と演出データベース8の関連語の情報と、に基づいて、その自立語に関連する関連語を検索し、演出データベース8の演出内容の中から、検索した関連語に対応する演出内容を検索してもよい。
【0031】
次に、以下のテキスト情報の一具体例を用いて上記対話演出処理を説明する。
例えば、音声認識処理部3により認識されたテキスト情報が以下の場合を想定する。
「S:日焼けしてますね。何処に行ったの? H:先日、ハワイに行ってきたんだよ。 S:ハワイですか、それはいいなあ。何処を見て回ったの? H:ワイキキビーチに行ったんだ。」
【0032】
演出決定部6は、上記テキスト情報の中から自立語「ハワイ」を抽出する。演出決定部6は、抽出した自立語「ハワイ」に対応する演出内容を演出データベース8から抽出する。なお、演出決定部6は、抽出した自立語「ハワイ」に基づいて、その自立語と関連度の高いものから順に演出内容を抽出してもよい。この場合、演出データベース8には、各自立語に対応付けられた演出内容などの情報と共にその自立語と演出内容などの情報との関連度が記憶されている。
【0033】
例えば、演出決定部6は、抽出した自立語「ハワイ」に基づいて、演出データベース8から演出内容「ハワイアン」及び「演歌」を抽出する。さらに、演出決定部6は、ユーザプロファイルデータベース9のユーザ嗜好情報に基づいて、ユーザが「演歌」を好まないというユーザ嗜好情報を得ることができる。
【0034】
演出決定部6は、ユーザプロファイルデータベース9のユーザ嗜好情報に基づいて、演出内容「ハワイアン」の適合度を増加させ、演出内容「演歌」の適合度を減少させる。そして、演出決定部は、演出内容「ハワイアン」の適合度が閾値を超えた場合に、その演出内容「ハワイアン」の実行を決定する。この場合、演出実行部7は、例えば、音楽再生装置11を制御して、ウクレレが主体のハワイアンの音楽を再生する。このような演出を行うことで、ユーザはハワイ旅行などの思い出が回想され、当該対話装置1との対話がより自然に進むこととなる。
【0035】
なお、対話装置1は、通常のユーザと対話を行う機能(音声認識処理によりユーザの音声を認識し、認識された音声情報に基づいて、所定の言語を出力する機能)を有している。通常の対話を行う機能については周知の技術であるため、詳細な説明は省略する。
【0036】
さらに、本実施の形態に係る対話装置1は、上記対話を行いつつ、演出決定部6により決定された演出内容を実行させる。例えば、音声認識処理部3は、対話装置1とユーザとの対話中において、ユーザ及び対話装置1が発した音声を音声認識し、テキスト情報を生成する。自立語抽出部5は、音声認識処理部3により認識されたテキスト情報の中から自立語を抽出する。演出決定部6は、自立語抽出部5により抽出された自立語と、演出データベース8に記憶された演出情報と、ユーザプロファイルデータベース9に記憶されたユーザ嗜好情報と、に基づいて、演出内容を決定する。演出実行部7は、演出決定部6により決定された演出内容を実行させる。このように、ユーザと対話装置1が対話を行いつつも、その対話内容に適した演出内容が実行されることとなる。
【0037】
図2は、本実施の形態に係る対話装置の概略的なハードウェア構成の一例を示すブロック図である。
【0038】
対話装置1は、例えば、制御処理、演算処理等を行うCPU(Central Processing Unit)22、CPU22によって実行される制御プログラム、演算プログラム等が記憶されたROM(Read Only Memory)23、処理データ等を記憶するRAM24、周辺機器との間で信号の入力を行うインターフェイス部25、等からなるマイクロコンピュータを中心にして、ハードウェア構成されている。これらCPU22、ROM23、RAM24及びインターフェイス部(I/F)25は、バス26などを介して相互に接続されている。
【0039】
インターフェイス部25には、例えば、入力装置10、音楽再生装置11、照明装置12、ロボット制御装置13、臭い発生装置14、表示装置15、振動装置16、空調装置17、無線LANアダプタ18、カメラ19、スピーカ20、補助記憶装置21、などが夫々接続されている。なお、上記ハードウェア構成は一例であり、任意のハードウェア構成が適用可能である。
【0040】
次に、本実施の形態に係る対話装置1による対話方法について、詳細に説明する。図3は、本実施の形態に係る対話装置による対話処理フローの一例を示すフローチャートである。なお、図3に示す対話処理は、例えば、所定時間毎に繰り返し実行される。
【0041】
入力装置10から音声認識処理部3に音声情報が入力される(ステップS101)。音声認識処理部3は、入力された音声情報に対して音声認識処理を行ない(ステップS102)、テキスト情報を生成し、生成したテキスト情報を認識結果データベース42に対して出力する。
【0042】
データベース管理部4は、音声認識処理部3から出力されたテキスト情報に基づいて、認識結果データベース42の情報を更新する(ステップS103)。
【0043】
自立語抽出部5は、認識結果データベース42に記憶されたテキスト情報に基づいて、形態素解析などを行い、テキスト情報の文字列中に含まれる自立語を抽出する(ステップS104)。
【0044】
演出決定部6は、演出データベース8に記憶された演出内容の中から、自立語抽出部5により抽出された自立語に対応する演出内容を検索する(ステップS105)。
【0045】
演出決定部6は、演出データベース8に記憶された演出内容の中から、自立語抽出部5により抽出された自立語に対応する演出内容を検索できたとき(ステップS106のYES)、検索した演出内容に基づいて、ユーザプロファイルデータベース9のユーザ嗜好情報を検索し、その演出に対するユーザ嗜好情報を検索する(ステップS107)。
【0046】
演出決定部6は、検索した演出内容の適合度を、予め設定されたモデルデータに基づいて算出する(ステップS108)。さらに、演出決定部6は、ユーザプロファイルデータベース9のユーザ嗜好情報に基づいて、各自立語に関する演出内容に対して上記適合度の加減算を行う。
【0047】
演出決定部6は、上記のように算出した各演出内容の適合度が閾値を超えているか否かを判断する(ステップS109)。
【0048】
演出決定部6は、演出内容の適合度が閾値を超えていると判断したとき(ステップS109のYES)、その演出内容を実行すると決定し、演出実行部7は演出決定部6により決定された演出内容を実行する(ステップS110)。一方、演出決定部6は、演出内容の適合度が閾値を超えていないと判断したとき(ステップS109のNO)、上記(ステップS101)の処理に戻る。
【0049】
演出実行部7は、実行した演出内容を演出履歴データベース41に出力し、データベース管理部4は、演出実行部7から出力された演出内容に基づいて、演出履歴データベース41の情報を更新し(ステップS111)、本処理を終了する。
【0050】
なお、演出決定部6は、演出データベース8に記憶された演出内容の中から、自立語抽出部5により抽出された自立語に対応する演出内容を検索できなかったとき(ステップS106のNO)、演出データベース8からその自立語に関連する関連語を検索する(ステップS112)。さらに、演出決定部6は、演出データベース8の演出内容の中から、関連語に対応する演出内容を検索する(ステップS113)。
【0051】
演出決定部6は、演出データベース8に記憶された演出内容の中から、関連語に対応する演出内容を検索できたとき(ステップS114のYES)、上記(ステップS107)の処理に移行する。一方、演出決定部6は、演出データベース8に記憶された演出内容の中から、関連語に対応する演出内容を検索できないとき(ステップS114のNO)、上記(ステップS101)の処理に移行する。
【0052】
以上、本実施の形態に係る対話装置1において、演出決定部6は、演出データベース8に記憶された演出内容の中から、ユーザプロファイルデータデータベース9に記憶されたユーザ嗜好情報と、自立語抽出部5により抽出された自立語と、に基づいて、実行する演出内容を決定する。そして、演出実行部7は、ユーザとの対話中において、演出決定部6により決定された演出内容を実行する。これにより、ユーザと対話装置1が対話を行いつつ、その対話内容に適した演出内容が実行されることとなる。したがって、ユーザはより自然な対話を行うことができる。
【0053】
なお、本発明は上記実施の形態に限られたものではなく、趣旨を逸脱しない範囲で適宜変更することが可能である。
また、上述の実施の形態では、本発明をハードウェアの構成として説明したが、本発明は、これに限定されるものではない。本発明は、例えば、図3に示す処理を、CPU22にコンピュータプログラムを実行させることにより実現することも可能である。
【0054】
プログラムは、様々なタイプの非一時的なコンピュータ可読媒体(non-transitory computer readable medium)を用いて格納され、コンピュータに供給することができる。非一時的なコンピュータ可読媒体は、様々なタイプの実体のある記録媒体(tangible storage medium)を含む。非一時的なコンピュータ可読媒体の例は、磁気記録媒体(例えばフレキシブルディスク、磁気テープ、ハードディスクドライブ)、光磁気記録媒体(例えば光磁気ディスク)、CD−ROM(Read Only Memory)、CD−R、CD−R/W、半導体メモリ(例えば、マスクROM、PROM(Programmable ROM)、EPROM(Erasable PROM)、フラッシュROM、RAM(random access memory))を含む。
【0055】
また、プログラムは、様々なタイプの一時的なコンピュータ可読媒体(transitory computer readable medium)によってコンピュータに供給されてもよい。一時的なコンピュータ可読媒体の例は、電気信号、光信号、及び電磁波を含む。一時的なコンピュータ可読媒体は、電線及び光ファイバ等の有線通信路、又は無線通信路を介して、プログラムをコンピュータに供給できる。
【産業上の利用可能性】
【0056】
本発明は、例えば、ユーザとより自然な対話を行うことができるエンターテイメントロボットなどに搭載された対話装置に利用可能である。
【符号の説明】
【0057】
1 対話装置
2 認識データベース
3 音声認識処理部
4 データベース管理部
5 自立語抽出部
6 演出決定部
7 演出実行部
8 演出データベース
9 ユーザプロファイルデータベース
10 入力装置
41 演出履歴データベース
42 認識結果データベース
【特許請求の範囲】
【請求項1】
ユーザの音声を認識する音声認識手段を備え、該音声認識手段により認識された音声情報に基づいてユーザと対話を行う対話装置であって、
前記音声認識手段により認識された音声情報に基づいて、自立語を抽出する自立語抽出手段と、
自立語に対応付けられた演出内容を複数記憶する第1記憶手段と、
前記第1記憶手段に記憶された複数の演出内容の中から、前記自立語抽出手段により抽出された自立語に基づいて、実行する演出内容を決定する演出決定手段と、
前記ユーザとの対話中に、前記演出決定手段により決定された演出内容を実行する演出実行手段と、
を備える、ことを特徴とする対話装置。
【請求項2】
請求項1記載の対話装置であって、
演出内容に対するユーザの嗜好情報が複数記憶された第2記憶手段を更に備え、
前記演出決定手段は、前記第1記憶手段に記憶された複数の演出内容の中から、前記第2記憶手段に記憶されたユーザの嗜好情報と、前記自立語抽出手段により抽出された自立語と、に基づいて、実行する演出内容を決定する、
ことを特徴とする対話装置。
【請求項3】
請求項1又は2記載の対話装置であって、
前記演出決定手段は、
前記自立語抽出手段により抽出された各自立語に対応する演出内容とユーザとの適合度合いを示す適合度を、予め設定されたモデルデータを用いて算出し、該算出した適合度を前記ユーザの嗜好情報に基づいて加減算し、該加減算した適合度が閾値を超えた前記演出内容を決定する、
ことを特徴とする対話装置。
【請求項4】
請求項1乃至3のうちいずれか1項記載の対話装置であって、
前記演出決定手段は、前記第1記憶手段に記憶された複数の演出内容の中から、前記自立語抽出手段により抽出された自立語に対応する演出内容が抽出できなかったとき、該自立語に関連する関連語に対応する演出内容を再検索して、前記実行する演出内容を決定する、
ことを特徴とする対話装置。
【請求項5】
請求項1乃至4のうちいずれか1項記載の対話装置であって、
前記演出実行手段は、
音楽を再生する音楽再生装置、照明を行う照明装置、ロボット動作を制御するロボット制御装置、空気を調整する空調装置、臭いを発生する臭い発生装置、表示を行う表示装置、及び、ユーザに対して振動を与える振動装置、のうち少なくとも1の前記装置を制御することで、前記演出内容を実行する、ことを特徴とする対話装置。
【請求項6】
請求項1乃至5のうちいずれか1項記載の対話装置であって、
前記演出実行手段により実行された演出内容を記憶する第3記憶手段を更に備え、
前記演出決定手段は、前記第3記憶手段に記憶された演出内容の情報に基づいて、前記自立語抽出手段により抽出された自立語と実行する演出内容との関係を学習し、該学習結果に基づいて、前記演出内容を決定する、ことを特徴とする対話装置。
【請求項7】
請求項1乃至6のうちいずれか1項記載の対話装置であって、
前記音声認識手段により音声認識されたテキスト情報を記憶する第4記憶手段を更に備える、ことを特徴とする対話装置。
【請求項8】
ユーザの音声を認識し、該認識された音声情報に基づいてユーザと対話を行う対話方法であって、
前記認識された音声情報に基づいて、自立語を抽出するステップと、
予め記憶された自立語に夫々対応付けられた複数の演出内容の中から、前記自立語抽出手段により抽出された自立語に基づいて、実行する演出内容を決定するステップと、
前記ユーザとの対話中に、前記決定された演出内容を実行するステップと、
を含む、ことを特徴とする対話方法。
【請求項9】
請求項8記載の対話方法であって、
前記記憶された複数の演出内容の中から、前記抽出された自立語に対応する演出内容が抽出できなかったとき、該自立語に関連する関連語に対応する演出内容を再検索して、前記実行する演出内容を決定する、
ことを特徴とする対話方法。
【請求項10】
ユーザの音声を認識し、該認識された音声情報に基づいてユーザと対話を行う対話プログラムであって、
前記認識された音声情報に基づいて、自立語を抽出する処理と、
予め記憶された自立語に夫々対応付けられた複数の演出内容の中から、前記自立語抽出手段により抽出された自立語に基づいて、実行する演出内容を決定する処理と、
前記ユーザとの対話中に、前記決定された演出内容を実行する処理と、
をコンピュータに実行させる、ことを特徴とする対話プログラム。
【請求項1】
ユーザの音声を認識する音声認識手段を備え、該音声認識手段により認識された音声情報に基づいてユーザと対話を行う対話装置であって、
前記音声認識手段により認識された音声情報に基づいて、自立語を抽出する自立語抽出手段と、
自立語に対応付けられた演出内容を複数記憶する第1記憶手段と、
前記第1記憶手段に記憶された複数の演出内容の中から、前記自立語抽出手段により抽出された自立語に基づいて、実行する演出内容を決定する演出決定手段と、
前記ユーザとの対話中に、前記演出決定手段により決定された演出内容を実行する演出実行手段と、
を備える、ことを特徴とする対話装置。
【請求項2】
請求項1記載の対話装置であって、
演出内容に対するユーザの嗜好情報が複数記憶された第2記憶手段を更に備え、
前記演出決定手段は、前記第1記憶手段に記憶された複数の演出内容の中から、前記第2記憶手段に記憶されたユーザの嗜好情報と、前記自立語抽出手段により抽出された自立語と、に基づいて、実行する演出内容を決定する、
ことを特徴とする対話装置。
【請求項3】
請求項1又は2記載の対話装置であって、
前記演出決定手段は、
前記自立語抽出手段により抽出された各自立語に対応する演出内容とユーザとの適合度合いを示す適合度を、予め設定されたモデルデータを用いて算出し、該算出した適合度を前記ユーザの嗜好情報に基づいて加減算し、該加減算した適合度が閾値を超えた前記演出内容を決定する、
ことを特徴とする対話装置。
【請求項4】
請求項1乃至3のうちいずれか1項記載の対話装置であって、
前記演出決定手段は、前記第1記憶手段に記憶された複数の演出内容の中から、前記自立語抽出手段により抽出された自立語に対応する演出内容が抽出できなかったとき、該自立語に関連する関連語に対応する演出内容を再検索して、前記実行する演出内容を決定する、
ことを特徴とする対話装置。
【請求項5】
請求項1乃至4のうちいずれか1項記載の対話装置であって、
前記演出実行手段は、
音楽を再生する音楽再生装置、照明を行う照明装置、ロボット動作を制御するロボット制御装置、空気を調整する空調装置、臭いを発生する臭い発生装置、表示を行う表示装置、及び、ユーザに対して振動を与える振動装置、のうち少なくとも1の前記装置を制御することで、前記演出内容を実行する、ことを特徴とする対話装置。
【請求項6】
請求項1乃至5のうちいずれか1項記載の対話装置であって、
前記演出実行手段により実行された演出内容を記憶する第3記憶手段を更に備え、
前記演出決定手段は、前記第3記憶手段に記憶された演出内容の情報に基づいて、前記自立語抽出手段により抽出された自立語と実行する演出内容との関係を学習し、該学習結果に基づいて、前記演出内容を決定する、ことを特徴とする対話装置。
【請求項7】
請求項1乃至6のうちいずれか1項記載の対話装置であって、
前記音声認識手段により音声認識されたテキスト情報を記憶する第4記憶手段を更に備える、ことを特徴とする対話装置。
【請求項8】
ユーザの音声を認識し、該認識された音声情報に基づいてユーザと対話を行う対話方法であって、
前記認識された音声情報に基づいて、自立語を抽出するステップと、
予め記憶された自立語に夫々対応付けられた複数の演出内容の中から、前記自立語抽出手段により抽出された自立語に基づいて、実行する演出内容を決定するステップと、
前記ユーザとの対話中に、前記決定された演出内容を実行するステップと、
を含む、ことを特徴とする対話方法。
【請求項9】
請求項8記載の対話方法であって、
前記記憶された複数の演出内容の中から、前記抽出された自立語に対応する演出内容が抽出できなかったとき、該自立語に関連する関連語に対応する演出内容を再検索して、前記実行する演出内容を決定する、
ことを特徴とする対話方法。
【請求項10】
ユーザの音声を認識し、該認識された音声情報に基づいてユーザと対話を行う対話プログラムであって、
前記認識された音声情報に基づいて、自立語を抽出する処理と、
予め記憶された自立語に夫々対応付けられた複数の演出内容の中から、前記自立語抽出手段により抽出された自立語に基づいて、実行する演出内容を決定する処理と、
前記ユーザとの対話中に、前記決定された演出内容を実行する処理と、
をコンピュータに実行させる、ことを特徴とする対話プログラム。
【図1】


【図2】
【図3】
【図2】
【図3】
【公開番号】特開2013−113966(P2013−113966A)
【公開日】平成25年6月10日(2013.6.10)
【国際特許分類】
【出願番号】特願2011−258738(P2011−258738)
【出願日】平成23年11月28日(2011.11.28)
【出願人】(000003207)トヨタ自動車株式会社 (59,920)
【Fターム(参考)】
【公開日】平成25年6月10日(2013.6.10)
【国際特許分類】
【出願日】平成23年11月28日(2011.11.28)
【出願人】(000003207)トヨタ自動車株式会社 (59,920)
【Fターム(参考)】
[ Back to top ]