
属性特定装置、属性特定方法、及びプログラム
【課題】入力された単語の属性を精度良く特定する。
【解決手段】文書数取得部104は、検索エンジン200を用いて、入力された単語と関連属性記憶部110が記憶する関連語とが係り受け関係にある文書の数を関連属性記憶部110が記憶する関連語毎に取得する。属性特定部106は、文書数取得部104が取得した文書数が最も多い関連語に関連付けられた属性を関連属性記憶部110から読み出し、当該属性を前記入力された単語の属性とする。
【解決手段】文書数取得部104は、検索エンジン200を用いて、入力された単語と関連属性記憶部110が記憶する関連語とが係り受け関係にある文書の数を関連属性記憶部110が記憶する関連語毎に取得する。属性特定部106は、文書数取得部104が取得した文書数が最も多い関連語に関連付けられた属性を関連属性記憶部110から読み出し、当該属性を前記入力された単語の属性とする。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、入力された単語の属性を特定する属性特定装置、属性特定方法、及びプログラムに関する。
【背景技術】
【0002】
機械翻訳やデータマイニングなどの自然言語処理を行う際に、単語の属性を用いて処理を行うことがある。単語の属性の例としては、単語のカテゴリ(場所、料理、人名など)を示す情報等が挙げられる。そのため、自然言語処理に用いる、単語と属性とを関連付けた辞書データが求められている。
【0003】
従来、自然言語処理に用いる辞書データを作成する方法として、文書における単語同士の共起頻度によって2つの単語を関連付ける方法が用いられている(例えば、特許文献1、2を参照)。例えば、収集した文書内に「特許」という単語と「出願」という単語の組み合わせが頻出する場合は、「特許」と「出願」とが関連すると判定し、辞書データに登録する。
【先行技術文献】
【特許文献】
【0004】
【特許文献1】特開平8−161343号公報
【特許文献2】特開平11−203311号公報
【発明の概要】
【発明が解決しようとする課題】
【0005】
しかしながら、共起頻度によって単語の関連性を判断する方法を用いる場合、2つの単語同士の関連性は推定できるものの、単語のカテゴリなどの属性を推定することができないため、単語と属性とを関連付けた辞書データの作成が困難であるという問題があった。
【課題を解決するための手段】
【0006】
本発明は上記の課題を解決するためになされたものであり、入力された単語の属性を特定する属性特定装置であって、単語に係り受けする形態素と当該形態素が係り受けする単語の属性とを関連付けて記憶する関連属性記憶部と、所定の文書集合において、入力された単語と前記関連属性記憶部が記憶する形態素とが係り受け関係にある文の数、当該文を含むページのページ数、または当該文を含む文書の数である係り受けヒット数を、前記形態素毎に取得する係り受けヒット数取得部と、前記係り受けヒット数取得部が取得した係り受けヒット数が最も多い形態素に関連付けられた属性を前記関連属性記憶部から読み出し、当該属性を前記入力された単語の属性とする属性特定部とを備えることを特徴とする。
【0007】
また、本発明においては、前記係り受けヒット数取得部は、前記入力された単語と前記形態素とが所定の単語間距離以下で共起する文書の数を、前記係り受けヒット数として取得することが好ましい。
【0008】
また、本発明においては、前記係り受けヒット数取得部は、複数の検索エンジンを用いて、それぞれの検索エンジンから係り受けヒット数を取得し、前記属性特定部は、前記係り受けヒット数取得部が取得した係り受けヒット数が最も多い形態素に関連付けられた属性を前記検索エンジン毎に前記関連属性記憶部から読み出し、前記属性のうち読み出された数が最も多い属性を前記入力された単語の属性とすることが好ましい。
【0009】
また、本発明においては、前記文書集合において前記関連属性記憶部が記憶する形態素の数、当該形態素を含むページのページ数、または当該形態素を含む文書の数である形態素ヒット数を、前記形態素毎に取得する形態素ヒット数取得部と、前記形態素ヒット数取得部が取得した形態素ヒット数が多いほど値が小さくなるように前記形態素の形態素重みを算出する形態素重み算出部とを備え、前記属性特定部は、前記係り受けヒット数取得部が取得した係り受けヒット数に前記形態素重み算出部が算出した形態素重みを乗算した値が最も大きい形態素に関連付けられた属性を、前記関連属性記憶部から読み出し、当該属性を前記入力された単語の属性とすることが好ましい。
【0010】
また、本発明においては、単語と当該単語の属性とを関連付けて記憶する属性記憶部と、所定の文書集合において、前記属性記憶部が記憶する単語と前記関連属性記憶部が記憶する形態素とが係り受け関係にある文の数、当該文を含むページのページ数、または当該文を含む文書の数を前記形態素毎に取得し、当該数に基づいて前記形態素と属性との関連度を算出する関連度算出部とを備え、前記関連属性記憶部は、1つの属性に関連付けて複数の形態素を記憶しており、前記係り受けヒット数取得部は、所定の文書集合において、前記関連属性記憶部が記憶する同じ属性に関連付けられた形態素のうち、前記関連度算出部が算出した関連度が最も高い形態素と前記入力された単語とが係り受け関係にある文のヒット数を取得することが好ましい。
【0011】
また、本発明は、単語に係り受けする形態素と当該形態素が係り受けする単語の属性とを関連付けて記憶する関連属性記憶部を備え、入力された単語の属性を特定する属性特定装置を用いた属性特定方法であって、係り受けヒット数取得部は、所定の文書集合において、入力された単語と前記関連属性記憶部が記憶する形態素とが係り受け関係にある文の数、当該文を含むページのページ数、または当該文を含む文書の数である係り受けヒット数を、前記形態素毎に取得し、属性特定部は、前記係り受けヒット数取得部が取得した係り受けヒット数が最も多い形態素に関連付けられた属性を前記関連属性記憶部から読み出し、当該属性を前記入力された単語の属性とすることを特徴とする。
【0012】
また、本発明は、単語に係り受けする形態素と当該形態素が係り受けする単語の属性とを関連付けて記憶する関連属性記憶部を備えるコンピュータを、所定の文書集合において、入力された単語と前記関連属性記憶部が記憶する形態素とが係り受け関係にある文の数、当該文を含むページのページ数、または当該文を含む文書の数である係り受けヒット数を、前記形態素毎に取得する係り受けヒット数取得部、前記係り受けヒット数取得部が取得した係り受けヒット数が最も多い形態素に関連付けられた属性を前記関連属性記憶部から読み出し、当該属性を前記入力された単語の属性とする属性特定部として機能させるプログラムである。
【発明の効果】
【0013】
本発明によれば、属性特定装置は、入力された単語に係り受けする頻度の高い形態素を特定し、当該形態素が係り受けする単語の属性を入力された単語の属性とする。これにより、入力された単語の属性を精度良く特定することができる。
【図面の簡単な説明】
【0014】
【図1】本発明の一実施形態による属性特定装置の構成を示す概略ブロック図である。
【図2】属性記憶部及び関連属性記憶部が記憶する情報の例を示す図である。
【図3】本実施形態による属性特定装置の属性特定動作を示すフローチャートである。
【図4】本実施形態による属性特定装置の関連度更新動作を示すフローチャートである。
【発明を実施するための形態】
【0015】
以下、図面を参照しながら本発明の実施形態について詳しく説明する。
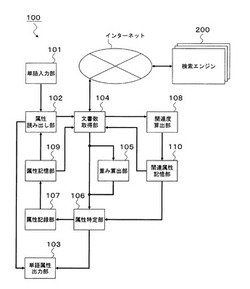
図1は、本発明の一実施形態による属性特定装置100の構成を示す概略ブロック図である。
属性特定装置100は、単語入力部101、属性読み出し部102、単語属性出力部103、文書数取得部104(係り受けヒット数取得部、単語ヒット数取得部、形態素ヒット数取得部)、重み算出部105(検索重み算出部、形態素重み算出部)、属性特定部106、属性記録部107、関連度算出部108、属性記憶部109、関連属性記憶部110を備える。
【0016】
単語入力部101は、利用者による属性の特定対象となる単語の入力を取得する。
属性読み出し部102は、単語入力部101が取得した単語に関連付けられた属性が属性記憶部109に記憶されているか否かを判定する。単語入力部101が取得した単語に関連付けられた属性が属性記憶部109に記憶されている場合、当該属性を単語属性出力部103に出力する。他方、単語入力部101が取得した単語に関連付けられた属性が属性記憶部109に記憶されていない場合、単語入力部101が取得した単語を文書数取得部104に出力する。
単語属性出力部103は、属性読み出し部102が読み出した属性または属性特定部106が特定した属性を出力する。
【0017】
文書数取得部104は、単語入力部101が取得した単語と関連属性記憶部110が記憶する関連語とから検索キーワードを生成し、検索エンジン200から当該検索キーワードを含む文書数を取得する。なお、検索エンジン200とは、インターネット上に存在する文書の中から、入力された検索キーワードを含む文書を検索し、当該文書の一覧及び文書数を出力するソフトウェアである。また、本実施形態において「関連語」とは、ある属性を有する単語に連なって使用され、当該単語に係り受けする頻度が高い形態素を含む語句のことを示す。
重み算出部105は、文書数取得部104が取得した文書数から、検索エンジン200毎の重み及び関連属性記憶部110が記憶する関連語毎の重みを算出する。なお、重みとは、相対的な重要性を表す係数のことである。
【0018】
属性特定部106は、文書数取得部104が取得した文書数及び重み算出部105が算出した重みを用いて、単語入力部101が取得した単語の属性を特定する。
属性記録部107は、単語入力部101が取得した単語と属性特定部106が特定した属性とを関連付けて属性記憶部109に記録する。
関連度算出部108は、文書数取得部104が取得した文書数を用いて関連属性記憶部110が記憶する関連語と属性との関連度を算出する。
【0019】
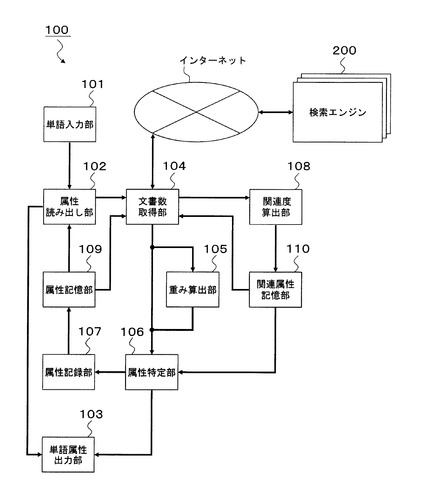
図2は、属性記憶部109及び関連属性記憶部110が記憶する情報の例を示す図である。
属性記憶部109は、図2(A)に示すように、単語と当該単語の属性とを関連付けて記憶する。
関連属性記憶部110は、図2(B)に示すように、単語の属性と関連語と当該単語・属性間の関連度とを、関連付けて記憶する。なお、形態素とは、意味を有する文字列の最小単位のことであり、例えば、活用しない品詞(名詞、助詞など)、活用する品詞(動詞、形容詞など)の語根、接辞(接頭辞、接尾辞など)が挙げられる。また、形態素と関連語の例としては、属性「料理」の単語に係り受けする頻度が高い形態素「食べ(動詞の語根)」を含む関連語として「を食べる」が挙げられる。また、関連語は形態素そのものであっても良く、例えば属性「人名」の単語に係り受けする頻度が高い形態素「さん(接尾辞)」を含む関連語として「さん」を用いることができる。なお、関連語は、単語と結合されることで、形態素と単語とが係り受け関係を有することとなる。
【0020】
次に、本実施形態による属性特定装置100が、入力された単語の属性を特定する際の動作について説明する。
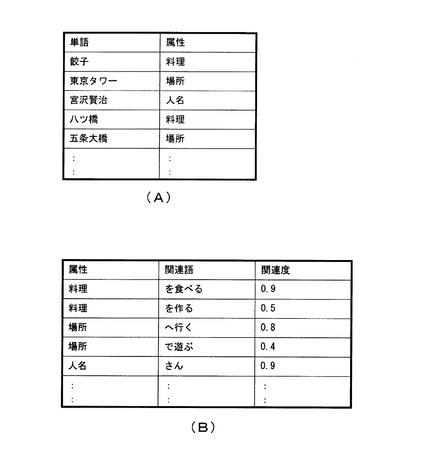
図3は、本実施形態による属性特定装置100の属性特定動作を示すフローチャートである。
まず、利用者がキーボード等の入力装置を介して、属性特定装置100に単語を入力すると、単語入力部101は、利用者が入力した単語を取得する(ステップS1)。なお、単語の取得は、入力装置を介するものに限られず、例えば単語を設定したファイルから1つずつ読み取るようにしても良い。次に、属性読み出し部102は、単語入力部101が取得した単語に関連付けられた属性が属性記憶部109に記憶されているか否かを判定する(ステップS2)。属性読み出し部102は、単語入力部101が取得した単語に関連付けられた属性が属性記憶部109に記憶されていると判定した場合(ステップS2:YES)、属性記憶部109から該当する属性を読み出し、単語属性出力部103に出力する。そして、単語属性出力部103は、属性読み出し部102が出力した属性を、ディスプレイなどの表示装置に出力し(ステップS3)、処理を終了する。
【0021】
他方、属性読み出し部102は、単語入力部101が取得した単語に関連付けられた属性が属性記憶部109に記憶されていないと判定した場合(ステップS2:NO)、取得した単語を文書数取得部104に出力する。次に、文書数取得部104は、関連属性記憶部110から各属性に関連付けられた関連語のうち、関連度が最も高い関連語を属性毎に読み出す(ステップS4)。例えば、図2に示す例では、属性「料理」に関連付けられた関連語が「を食べる」と「を作る」であり、関連度は、それぞれ「0.9」と「0.5」である。そのため、文書数取得部104は、関連度が最も高い関連語「を食べる」を読み出す。以降、属性「場所」、「人名」等についても同様の処理を行う。
【0022】
次に、文書数取得部104は、取得した単語に対して属性特定部106から読み出した関連語をそれぞれ結合して検索キーワードを作成する(ステップS5)。例えば、入力された単語が「スカイツリー」であり、関連属性記憶部110から読み出した関連語が「を食べる」、「へ行く」であった場合、文書数取得部104は、それぞれ「スカイツリーを食べる」、「スカイツリーへ行く」という検索キーワードを作成することとなる。
【0023】
次に、文書数取得部104は、作成した検索キーワードを複数の検索エンジン200に入力し、各検索エンジン200から当該検索キーワードと一致する文字列を含む文書の数を取得する(ステップS6)。つまり、文書数取得部104は、入力された単語と関連語とが単語間距離0で共起する文書の数を、入力された単語と関連属性記憶部110が記憶する関連語に含まれる形態素とが係り受け関係にある文を含む文書書の数として取得する。例えば、ステップS5で作成した検索キーワードが「スカイツリーを食べる」、「スカイツリーへ行く」である場合、それぞれを検索エンジンAで検索すると、「スカイツリーを食べる」を含む文書の数として4、「スカイツリーへ行く」を含む文書の数として11600が得られることとなる。
そして、文書数取得部104は、取得した文書数を、関連語と検索エンジン200との組み合わせに関連付けて属性特定部106に出力する。また、文書数取得部104は、入力された単語を属性特定部106に出力する。
【0024】
また、文書数取得部104は、ステップS4で読み出した関連語それぞれを検索キーワードとして各検索エンジン200に入力し、各検索エンジン200から当該関連語を含む文書の数を取得する(ステップS7)。次に、重み算出部105は、文書数取得部104が取得した、関連語を含む文書の数の逆数を算出し、当該逆数を文書数取得部104が取得した関連語それぞれの重み(関連語重み)とする(ステップS8)。例えば、ステップS4で読み出した関連語が「を食べる」、「へ行く」である場合において、それぞれを検索エンジンAで検索すると、「を食べる」を含む文書の数として21600000、「へ行く」を含む文書の数として32900000が得られることとなる。この場合、重み算出部105は、「を食べる」の関連語重みを、1/21600000とし、「へ行く」の関連語重みを1/32900000とする。
そして、重み算出部105は、算出した関連語重みを、検索キーワードとした関連語と検索エンジン200との組み合わせに関連付けて属性特定部106に出力する。
【0025】
また、文書数取得部104は、ステップS1で取得した単語を検索キーワードとして各検索エンジン200に入力し、各検索エンジン200から当該単語を含む文書の数を取得する(ステップS9)。次に、重み算出部105は、文書数取得部104が取得した、単語を含む文書の数を、当該単語における検索エンジン200の重み(検索重み)とする(ステップS10)。そして、重み算出部105は、算出した検索重みを、検索エンジン200に関連付けて属性特定部106に出力する。
【0026】
次に、属性特定部106は、関連語と検索エンジン200の組み合わせ毎に、文書数取得部104がステップS6で取得した文書数と重み算出部105が算出した関連語重みを乗算した値を算出する(ステップS11)。具体的には、検索キーワードが「スカイツリーへ行く」である場合、属性特定部は、「検索キーワード『スカイツリーへ行く』を含む文書の数」に、「関連語『へ行く』を含む文書の数から算出した関連語重み」を乗算した値を算出する。上述した例を用いると、「スカイツリーを食べる」に対して算出される値は、4/21600000=0.0018×10−6、「スカイツリーへ行く」に対して算出される値は、11600/32900000=3.52×10−6となる。
【0027】
次に、属性特定部106は、検索エンジン200毎に、ステップS11で算出した値が最も大きい関連語に関連付けられた属性を、関連属性記憶部110から読み出す(ステップS12)。上述した例の場合、ステップS11で算出した値のうち「スカイツリーへ行く」に対して算出された値が最も大きいため、属性特定部106は、関連語「へ行く」に関連付けられた属性「場所」を読み出す。
【0028】
次に、属性特定部106は、検索エンジン200毎に読み出された属性のうち、最も多い属性が複数存在するか否かを判定する(ステップS13)。最も多い属性が複数存在する場合とは、例えば5つの検索エンジン200を用いて検索を行った場合において、ステップS12で検索エンジン200毎に読み出された属性の個数が、「料理」2つ、「場所」2つ、「人名」1つであるときなどが挙げられる。
【0029】
属性特定部106は、検索エンジン200毎に読み出された属性のうち、最も多い属性が1つだけ存在すると判定した場合(ステップS13:NO)、当該最も多い属性を、入力された単語の属性とする(ステップS14)。他方、属性特定部106は、検索エンジン200毎に読み出された属性のうち、最も多い属性が複数存在すると判定した場合(ステップS13:YES)、属性毎に、当該属性を読み出す元となった検索エンジンの検索重みの総和を算出する(ステップS15)。次に、属性特定部106は、当該算出した値が最も大きくなる属性を、入力された単語の属性とする(ステップS16)。
【0030】
ここで、ステップS15、ステップS16の動作について具体例を用いて説明する。5つの検索エンジン200−1〜200−5を用いて検索を行ったものとする。
このとき、検索重みが「0.6」である検索エンジン200−1の検索結果から読み出された属性が「料理」であった。また、検索重みが「0.8」である検索エンジン200−2の検索結果から読み出された属性が「場所」であった。また、検索重みが「0.2」である検索エンジン200−3の検索結果から読み出された属性が「料理」であった。また、検索重みが「0.3」である検索エンジン200−4の検索結果から読み出された属性が「人名」であった。また、検索重みが「0.7」である検索エンジン200−5の検索結果から読み出された属性が「場所」であった。
このとき、「料理」の検索重みの総和は、0.6+0.2=0.8であり、「場所」の検索重みの総和は、0.8+0.7=1.5であり、「人名」の検索重みの総和は、0.3である。したがって、属性特定部106は、検索重みの総和が最も大きい属性「場所」を、入力された単語の属性とする。
【0031】
属性特定部106は、ステップS14またはステップS16で入力された単語の属性を特定すると、属性記録部107は、入力された単語と特定した属性とを関連付けて属性記憶部109に記録する(ステップS17)。また、単語属性出力部103は、属性特定部106がステップS16で特定した属性を、ディスプレイなどの表示装置に出力し(ステップS18)、処理を終了する。
【0032】
次に、本実施形態による属性特定装置100が、属性と関連語との関連度を更新する際の動作について説明する。
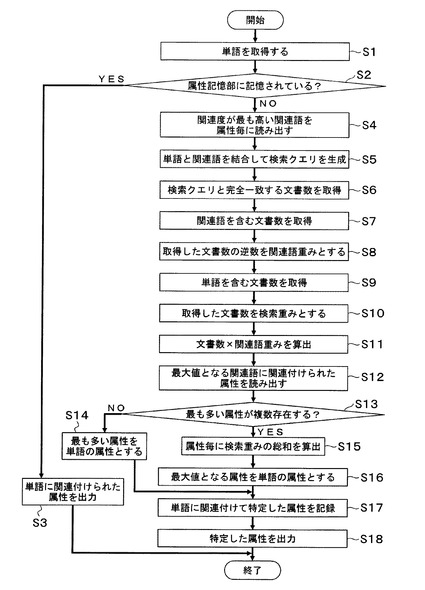
図4は、本実施形態による属性特定装置100の関連度更新動作を示すフローチャートである。
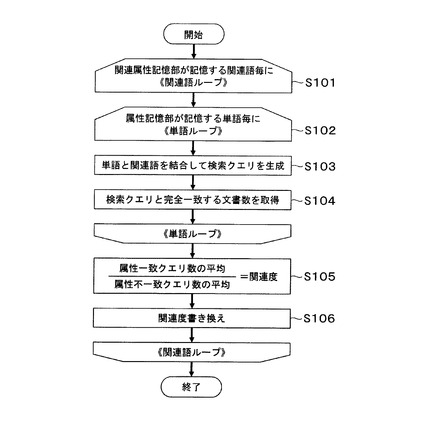
属性特定装置100は、定期的に関連属性記憶部110が記憶する属性と関連語との関連度を更新する。関連度の更新を開始すると、文書数取得部104は、関連属性記憶部110から1つの関連語と当該関連語が連なる単語の属性とを読み出す(ステップS101)。なお、ステップS101からステップS106の処理は、関連属性記憶部110が記憶する関連語毎に繰り返す。次に、文書数取得部104は、属性記憶部109が記憶する単語と当該単語の属性とを読み出す(ステップS102)。なお、ステップS102からステップS104の処理は、属性記憶部109が記憶する単語毎に繰り返す。
【0033】
次に、文書数取得部104は、ステップS101で読み出した関連語とステップS102で読み出した単語とを結合して検索キーワードを作成する(ステップS103)。次に、文書数取得部104は、作成した検索キーワードを複数の検索エンジン200に入力し、各検索エンジン200から当該検索キーワードと完全一致する文字列を含む文書の数を取得する(ステップS104)。そして、文書数取得部104は、取得した文書数を、単語と、当該単語の属性と、関連語と、当該関連語が連なる単語の属性との組み合わせに関連付けて、関連度算出部108に出力する。
【0034】
ステップS102からステップS104の処理を属性記憶部109が記憶する単語毎に実行すると、関連度算出部108は、まず、ある関連語と当該関連語の属性と同じ属性の複数単語の検索キーワードを含む文書数をそれぞれ取得し、当該文書数を単語数・検索エンジン数等で平均化した値Aを算出する。また、関連度算出部108は、ある関連語と当該関連語の属性と異なる属性の複数単語の検索キーワードを含む文書数をそれぞれ取得し、当該文書数を単語数・検索エンジン数等で平均化した値Bを算出する。そして、関連度算出部108は、値Aを値Bで除算した値を、関連語と属性との関連度とする(ステップS105)。
【0035】
ここで、ステップS105の具体例として、ステップS101で関連属性記憶部110から読み出した関連語が「を食べる(属性「料理」の関連語)」であり、検索キーワードとして「餃子を食べる(属性「料理」の単語+属性「料理」の関連語)」、「東京タワーを食べる(属性「場所」の単語+属性「料理」の関連語)」、「宮沢賢治を食べる(属性「人名」の単語+属性「料理」の関連語)」を用いた場合について説明する。
まず、関連度算出部108は、関連語と単語の属性が一致するキーワードを含む文書の数を取得する。本例では、関連度算出部108は、「餃子を食べる」を含む文書の数を取得する。検索エンジン200−1、200−2で検索を行った結果、「餃子を食べる」の文書数がそれぞれ2500000件と1380000件であった場合、これらの平均値である1940000を値Aとする。
また、関連度算出部108は、関連語と単語の属性が一致しないキーワードを含む文書の数を取得する。本例では、関連度算出部108は、「東京タワーを食べる」及び「宮沢賢治を食べる」を含む文書の数を取得する。検索エンジン200−1、200−2で検索を行った結果、「東京タワーを食べる」の文書数がそれぞれ4件と7件であり、「宮沢賢治を食べる」の文書数がそれぞれ7件と5件であった場合、これらの平均値である5.75を値Bとする。
そして値Aである1940000を値Bである5.75で除算した337391を、関連語「を食べる」と属性「料理」の関連度とする。
【0036】
ここで、ステップS105の計算によって関連度を算出する理由を説明する。関連語と属性との関連度が高い場合、属性が一致する単語と当該関連語とで係り受けする数が多くなるため、検索キーワードを含む文書数と関連度との間には正の相関がある。他方、関連語と属性との関連度が高い場合、属性が一致しない単語と当該関連語とで係り受けする数が少なくなるため、検索キーワードを含む文書数と関連度との間には負の相関がある。そのため、単語と関連語との属性が一致する検索キーワードを含む文書数の平均値と、単語と関連語との属性が一致しない検索キーワードを含む文書数の平均値の逆数とを乗算することで、関連語と属性との関連度を算出することができる。
【0037】
関連度算出部108は、ステップS105で関連度を算出すると、関連属性記憶部110が記憶する関連語の関連度を算出した関連度に書き換える(ステップS106)。ステップS101からステップS106の処理を関連属性記憶部110が記憶する関連語毎に実行すると、属性特定装置100は、関連度更新動作を終了する。
【0038】
このように、本実施形態によれば、属性特定装置100は、入力された単語に係り受けする頻度の高い関連語を特定し、当該関連語が連なる単語の属性を入力された単語の属性とする。これにより、属性特定装置100は、入力された単語の属性を精度良く特定することができる。
【0039】
また、本実施形態によれば、文書数取得部104は、検索エンジン200を用いてインターネット上に存在する文書の集合から、入力された単語と関連語とが係り受け関係にある文書数を取得する。これにより、属性特定装置100は、単一文書ソースから共起情報を取得する場合と比較して判定の偏りの発生を少なくすることができる。また、新語などが発生した場合にも、新たに文書ソースを収集しなおす必要がないため、単語と属性の関係の判定を容易に行うことができる。
【0040】
また、本実施形態によれば、文書数取得部104は、複数の検索エンジン200を用いて、それぞれの検索エンジン200から文書数を取得し、属性特定部106は、文書数取得部104が取得した文書数が最も多い関連語に関連付けられた属性を、検索エンジン200毎に関連属性記憶部110から読み出す。そして属性特定部106は、読み出された数が最も多い属性を、入力された単語の属性とする。これにより、属性特定装置100は、検索エンジン200における検索結果の偏りの影響を抑えることができる。
【0041】
また、本実施形態によれば、文書数取得部104は、関連属性記憶部110が記憶する形態素が含まれる文書の数を、関連語毎に取得し、重み算出部105は、文書数取得部104が取得した文書数が多いほど値が小さくなるように関連語重みを算出する。そして、属性特定部106は、文書数取得部104がステップS6で取得した文書数に重み算出部105が算出した関連語重みを乗算した値が最も大きい関連語に関連付けられた属性を、関連属性記憶部110から読み出す。つまり、属性特定部106は、ある関連語が入力された単語に連なる確率に基づいて単語の属性を特定する。これにより、属性特定装置100は、関連語の絶対数に影響されずに単語の属性を特定することができ、また異なる属性の単語に連なることができる関連語の重みを小さくすることができる。
【0042】
また、本実施形態によれば、関連度算出部108は、文書数に基づいて関連語と属性との関連度を算出し、文書数取得部104は、関連属性記憶部110が記憶する同じ属性に関連付けられた形態素のうち、関連度算出部108が算出した関連度が最も高い関連語と入力された単語とを結合した検索キーワードを生成する。これにより、属性特定装置100は、属性との関連度が高い関連語のみを用いて検索を行うことができるために検索数が減少し、属性の判定に要する時間を短くすることができる。
【0043】
以上、図面を参照してこの発明の一実施形態について詳しく説明してきたが、具体的な構成は上述のものに限られることはなく、この発明の要旨を逸脱しない範囲内において様々な設計変更等をすることが可能である。
例えば、本実施形態では、関連属性記憶部110が関連語と当該関連語が連なる単語の属性とを関連付けて記憶し、また文書数取得部104が入力された単語と関連語とを結合した検索キーワードに完全一致する(入力された単語と関連語との単語間距離が0で共起する)文書の数を取得する場合を説明したが、これに限られない。例えば、検索エンジン200が近傍検索(2つの文字列が所定の単語間距離以内で出現する文書を検索する検索方式)に対応している場合は、以下に示す方法を用いて処理を行っても良い。
【0044】
関連属性記憶部110は、関連語の代わりに単語に係り受けする形態素を記憶する。
文書数取得部104は、入力された単語と関連属性記憶部110が記憶する形態素とが所定の単語間距離(例えば、2単語以内や、5文字以内など)以下で共起する文書の数を取得する。これにより、文書数取得部104は、入力された単語と形態素との単語間距離が近い文書の数を取得することができる。入力された単語と形態素との単語間距離が近いということは、入力された単語と形態素とが係り受け関係にある確率が高いことを示す。したがって、上記実施形態と同様に、入力された単語の属性を精度良く特定することができる。また、関連語でなく形態素を用いることで、関連語を用いる上記実施形態と異なり、単語と形態素とを接続する助詞や助動詞が異なる文書も取得することができる。
【0045】
また、例えば、検索エンジン200が係り受け解析を伴う検索(2つの形態素が係り受け関係にある文書を検索する検索方式)に対応している場合は、以下に示す方法を用いて処理を行っても良い。
【0046】
関連属性記憶部110は、関連語の代わりに単語に係り受けする形態素を記憶する。
文書数取得部104は、入力された単語と関連属性記憶部110が記憶する形態素とが係り受け関係にある文書の数を取得する。係り受け関係を指定して検索することができる場合、入力された単語と形態素とが係り受け関係にない文書を取得することがなく、また単語と形態素とを接続する助詞や助動詞が異なる文書も取得することができる。
【0047】
また、本実施形態では、重み算出部105は、関連語を含む文書数の逆数を算出することで関連語重みを算出する場合を説明したが、これに限られず、文書数取得部104が取得した文書数が多いほど値が小さくなるのであれば、他の算出方法を用いても良い。
【0048】
また、本実施形態では、重み算出部105は、入力された単語を含む検索エンジン200毎の文書数を検索重みとする場合を説明したが、これに限られず、文書数取得部104が取得した文書数が多いほど値が大きくなるのであれば、他の算出方法を用いても良い。
【0049】
なお、本実施形態では、関連語(形態素)が単語に係り受けする文を含む文書の数を用いて単語の属性を特定する場合を説明したが、これに限られない。例えば、関連語(形態素)が単語に係り受けする文の数、または当該文を含むページのページ数を用いて単語の属性を特定しても良い。
【0050】
上述の属性特定装置100は内部に、コンピュータシステムを有している。そして、上述した各処理部の動作は、プログラムの形式でコンピュータ読み取り可能な記録媒体に記憶されており、このプログラムをコンピュータが読み出して実行することによって、上記処理が行われる。ここでコンピュータ読み取り可能な記録媒体とは、磁気ディスク、光磁気ディスク、CD−ROM、DVD−ROM、半導体メモリ等をいう。また、このコンピュータプログラムを通信回線によってコンピュータに配信し、この配信を受けたコンピュータが当該プログラムを実行するようにしても良い。
【0051】
また、上記プログラムは、前述した機能の一部を実現するためのものであっても良い。さらに、前述した機能をコンピュータシステムにすでに記録されているプログラムとの組み合わせで実現できるもの、いわゆる差分ファイル(差分プログラム)であっても良い。
【符号の説明】
【0052】
100…属性特定装置 101…単語入力部 102…属性読み出し部 103…単語属性出力部 104…文書数取得部 105…重み算出部 106…属性特定部 107…属性記録部 108…関連度算出部 109…属性記憶部 110…関連属性記憶部 200…検索エンジン
【技術分野】
【0001】
本発明は、入力された単語の属性を特定する属性特定装置、属性特定方法、及びプログラムに関する。
【背景技術】
【0002】
機械翻訳やデータマイニングなどの自然言語処理を行う際に、単語の属性を用いて処理を行うことがある。単語の属性の例としては、単語のカテゴリ(場所、料理、人名など)を示す情報等が挙げられる。そのため、自然言語処理に用いる、単語と属性とを関連付けた辞書データが求められている。
【0003】
従来、自然言語処理に用いる辞書データを作成する方法として、文書における単語同士の共起頻度によって2つの単語を関連付ける方法が用いられている(例えば、特許文献1、2を参照)。例えば、収集した文書内に「特許」という単語と「出願」という単語の組み合わせが頻出する場合は、「特許」と「出願」とが関連すると判定し、辞書データに登録する。
【先行技術文献】
【特許文献】
【0004】
【特許文献1】特開平8−161343号公報
【特許文献2】特開平11−203311号公報
【発明の概要】
【発明が解決しようとする課題】
【0005】
しかしながら、共起頻度によって単語の関連性を判断する方法を用いる場合、2つの単語同士の関連性は推定できるものの、単語のカテゴリなどの属性を推定することができないため、単語と属性とを関連付けた辞書データの作成が困難であるという問題があった。
【課題を解決するための手段】
【0006】
本発明は上記の課題を解決するためになされたものであり、入力された単語の属性を特定する属性特定装置であって、単語に係り受けする形態素と当該形態素が係り受けする単語の属性とを関連付けて記憶する関連属性記憶部と、所定の文書集合において、入力された単語と前記関連属性記憶部が記憶する形態素とが係り受け関係にある文の数、当該文を含むページのページ数、または当該文を含む文書の数である係り受けヒット数を、前記形態素毎に取得する係り受けヒット数取得部と、前記係り受けヒット数取得部が取得した係り受けヒット数が最も多い形態素に関連付けられた属性を前記関連属性記憶部から読み出し、当該属性を前記入力された単語の属性とする属性特定部とを備えることを特徴とする。
【0007】
また、本発明においては、前記係り受けヒット数取得部は、前記入力された単語と前記形態素とが所定の単語間距離以下で共起する文書の数を、前記係り受けヒット数として取得することが好ましい。
【0008】
また、本発明においては、前記係り受けヒット数取得部は、複数の検索エンジンを用いて、それぞれの検索エンジンから係り受けヒット数を取得し、前記属性特定部は、前記係り受けヒット数取得部が取得した係り受けヒット数が最も多い形態素に関連付けられた属性を前記検索エンジン毎に前記関連属性記憶部から読み出し、前記属性のうち読み出された数が最も多い属性を前記入力された単語の属性とすることが好ましい。
【0009】
また、本発明においては、前記文書集合において前記関連属性記憶部が記憶する形態素の数、当該形態素を含むページのページ数、または当該形態素を含む文書の数である形態素ヒット数を、前記形態素毎に取得する形態素ヒット数取得部と、前記形態素ヒット数取得部が取得した形態素ヒット数が多いほど値が小さくなるように前記形態素の形態素重みを算出する形態素重み算出部とを備え、前記属性特定部は、前記係り受けヒット数取得部が取得した係り受けヒット数に前記形態素重み算出部が算出した形態素重みを乗算した値が最も大きい形態素に関連付けられた属性を、前記関連属性記憶部から読み出し、当該属性を前記入力された単語の属性とすることが好ましい。
【0010】
また、本発明においては、単語と当該単語の属性とを関連付けて記憶する属性記憶部と、所定の文書集合において、前記属性記憶部が記憶する単語と前記関連属性記憶部が記憶する形態素とが係り受け関係にある文の数、当該文を含むページのページ数、または当該文を含む文書の数を前記形態素毎に取得し、当該数に基づいて前記形態素と属性との関連度を算出する関連度算出部とを備え、前記関連属性記憶部は、1つの属性に関連付けて複数の形態素を記憶しており、前記係り受けヒット数取得部は、所定の文書集合において、前記関連属性記憶部が記憶する同じ属性に関連付けられた形態素のうち、前記関連度算出部が算出した関連度が最も高い形態素と前記入力された単語とが係り受け関係にある文のヒット数を取得することが好ましい。
【0011】
また、本発明は、単語に係り受けする形態素と当該形態素が係り受けする単語の属性とを関連付けて記憶する関連属性記憶部を備え、入力された単語の属性を特定する属性特定装置を用いた属性特定方法であって、係り受けヒット数取得部は、所定の文書集合において、入力された単語と前記関連属性記憶部が記憶する形態素とが係り受け関係にある文の数、当該文を含むページのページ数、または当該文を含む文書の数である係り受けヒット数を、前記形態素毎に取得し、属性特定部は、前記係り受けヒット数取得部が取得した係り受けヒット数が最も多い形態素に関連付けられた属性を前記関連属性記憶部から読み出し、当該属性を前記入力された単語の属性とすることを特徴とする。
【0012】
また、本発明は、単語に係り受けする形態素と当該形態素が係り受けする単語の属性とを関連付けて記憶する関連属性記憶部を備えるコンピュータを、所定の文書集合において、入力された単語と前記関連属性記憶部が記憶する形態素とが係り受け関係にある文の数、当該文を含むページのページ数、または当該文を含む文書の数である係り受けヒット数を、前記形態素毎に取得する係り受けヒット数取得部、前記係り受けヒット数取得部が取得した係り受けヒット数が最も多い形態素に関連付けられた属性を前記関連属性記憶部から読み出し、当該属性を前記入力された単語の属性とする属性特定部として機能させるプログラムである。
【発明の効果】
【0013】
本発明によれば、属性特定装置は、入力された単語に係り受けする頻度の高い形態素を特定し、当該形態素が係り受けする単語の属性を入力された単語の属性とする。これにより、入力された単語の属性を精度良く特定することができる。
【図面の簡単な説明】
【0014】
【図1】本発明の一実施形態による属性特定装置の構成を示す概略ブロック図である。
【図2】属性記憶部及び関連属性記憶部が記憶する情報の例を示す図である。
【図3】本実施形態による属性特定装置の属性特定動作を示すフローチャートである。
【図4】本実施形態による属性特定装置の関連度更新動作を示すフローチャートである。
【発明を実施するための形態】
【0015】
以下、図面を参照しながら本発明の実施形態について詳しく説明する。
図1は、本発明の一実施形態による属性特定装置100の構成を示す概略ブロック図である。
属性特定装置100は、単語入力部101、属性読み出し部102、単語属性出力部103、文書数取得部104(係り受けヒット数取得部、単語ヒット数取得部、形態素ヒット数取得部)、重み算出部105(検索重み算出部、形態素重み算出部)、属性特定部106、属性記録部107、関連度算出部108、属性記憶部109、関連属性記憶部110を備える。
【0016】
単語入力部101は、利用者による属性の特定対象となる単語の入力を取得する。
属性読み出し部102は、単語入力部101が取得した単語に関連付けられた属性が属性記憶部109に記憶されているか否かを判定する。単語入力部101が取得した単語に関連付けられた属性が属性記憶部109に記憶されている場合、当該属性を単語属性出力部103に出力する。他方、単語入力部101が取得した単語に関連付けられた属性が属性記憶部109に記憶されていない場合、単語入力部101が取得した単語を文書数取得部104に出力する。
単語属性出力部103は、属性読み出し部102が読み出した属性または属性特定部106が特定した属性を出力する。
【0017】
文書数取得部104は、単語入力部101が取得した単語と関連属性記憶部110が記憶する関連語とから検索キーワードを生成し、検索エンジン200から当該検索キーワードを含む文書数を取得する。なお、検索エンジン200とは、インターネット上に存在する文書の中から、入力された検索キーワードを含む文書を検索し、当該文書の一覧及び文書数を出力するソフトウェアである。また、本実施形態において「関連語」とは、ある属性を有する単語に連なって使用され、当該単語に係り受けする頻度が高い形態素を含む語句のことを示す。
重み算出部105は、文書数取得部104が取得した文書数から、検索エンジン200毎の重み及び関連属性記憶部110が記憶する関連語毎の重みを算出する。なお、重みとは、相対的な重要性を表す係数のことである。
【0018】
属性特定部106は、文書数取得部104が取得した文書数及び重み算出部105が算出した重みを用いて、単語入力部101が取得した単語の属性を特定する。
属性記録部107は、単語入力部101が取得した単語と属性特定部106が特定した属性とを関連付けて属性記憶部109に記録する。
関連度算出部108は、文書数取得部104が取得した文書数を用いて関連属性記憶部110が記憶する関連語と属性との関連度を算出する。
【0019】
図2は、属性記憶部109及び関連属性記憶部110が記憶する情報の例を示す図である。
属性記憶部109は、図2(A)に示すように、単語と当該単語の属性とを関連付けて記憶する。
関連属性記憶部110は、図2(B)に示すように、単語の属性と関連語と当該単語・属性間の関連度とを、関連付けて記憶する。なお、形態素とは、意味を有する文字列の最小単位のことであり、例えば、活用しない品詞(名詞、助詞など)、活用する品詞(動詞、形容詞など)の語根、接辞(接頭辞、接尾辞など)が挙げられる。また、形態素と関連語の例としては、属性「料理」の単語に係り受けする頻度が高い形態素「食べ(動詞の語根)」を含む関連語として「を食べる」が挙げられる。また、関連語は形態素そのものであっても良く、例えば属性「人名」の単語に係り受けする頻度が高い形態素「さん(接尾辞)」を含む関連語として「さん」を用いることができる。なお、関連語は、単語と結合されることで、形態素と単語とが係り受け関係を有することとなる。
【0020】
次に、本実施形態による属性特定装置100が、入力された単語の属性を特定する際の動作について説明する。
図3は、本実施形態による属性特定装置100の属性特定動作を示すフローチャートである。
まず、利用者がキーボード等の入力装置を介して、属性特定装置100に単語を入力すると、単語入力部101は、利用者が入力した単語を取得する(ステップS1)。なお、単語の取得は、入力装置を介するものに限られず、例えば単語を設定したファイルから1つずつ読み取るようにしても良い。次に、属性読み出し部102は、単語入力部101が取得した単語に関連付けられた属性が属性記憶部109に記憶されているか否かを判定する(ステップS2)。属性読み出し部102は、単語入力部101が取得した単語に関連付けられた属性が属性記憶部109に記憶されていると判定した場合(ステップS2:YES)、属性記憶部109から該当する属性を読み出し、単語属性出力部103に出力する。そして、単語属性出力部103は、属性読み出し部102が出力した属性を、ディスプレイなどの表示装置に出力し(ステップS3)、処理を終了する。
【0021】
他方、属性読み出し部102は、単語入力部101が取得した単語に関連付けられた属性が属性記憶部109に記憶されていないと判定した場合(ステップS2:NO)、取得した単語を文書数取得部104に出力する。次に、文書数取得部104は、関連属性記憶部110から各属性に関連付けられた関連語のうち、関連度が最も高い関連語を属性毎に読み出す(ステップS4)。例えば、図2に示す例では、属性「料理」に関連付けられた関連語が「を食べる」と「を作る」であり、関連度は、それぞれ「0.9」と「0.5」である。そのため、文書数取得部104は、関連度が最も高い関連語「を食べる」を読み出す。以降、属性「場所」、「人名」等についても同様の処理を行う。
【0022】
次に、文書数取得部104は、取得した単語に対して属性特定部106から読み出した関連語をそれぞれ結合して検索キーワードを作成する(ステップS5)。例えば、入力された単語が「スカイツリー」であり、関連属性記憶部110から読み出した関連語が「を食べる」、「へ行く」であった場合、文書数取得部104は、それぞれ「スカイツリーを食べる」、「スカイツリーへ行く」という検索キーワードを作成することとなる。
【0023】
次に、文書数取得部104は、作成した検索キーワードを複数の検索エンジン200に入力し、各検索エンジン200から当該検索キーワードと一致する文字列を含む文書の数を取得する(ステップS6)。つまり、文書数取得部104は、入力された単語と関連語とが単語間距離0で共起する文書の数を、入力された単語と関連属性記憶部110が記憶する関連語に含まれる形態素とが係り受け関係にある文を含む文書書の数として取得する。例えば、ステップS5で作成した検索キーワードが「スカイツリーを食べる」、「スカイツリーへ行く」である場合、それぞれを検索エンジンAで検索すると、「スカイツリーを食べる」を含む文書の数として4、「スカイツリーへ行く」を含む文書の数として11600が得られることとなる。
そして、文書数取得部104は、取得した文書数を、関連語と検索エンジン200との組み合わせに関連付けて属性特定部106に出力する。また、文書数取得部104は、入力された単語を属性特定部106に出力する。
【0024】
また、文書数取得部104は、ステップS4で読み出した関連語それぞれを検索キーワードとして各検索エンジン200に入力し、各検索エンジン200から当該関連語を含む文書の数を取得する(ステップS7)。次に、重み算出部105は、文書数取得部104が取得した、関連語を含む文書の数の逆数を算出し、当該逆数を文書数取得部104が取得した関連語それぞれの重み(関連語重み)とする(ステップS8)。例えば、ステップS4で読み出した関連語が「を食べる」、「へ行く」である場合において、それぞれを検索エンジンAで検索すると、「を食べる」を含む文書の数として21600000、「へ行く」を含む文書の数として32900000が得られることとなる。この場合、重み算出部105は、「を食べる」の関連語重みを、1/21600000とし、「へ行く」の関連語重みを1/32900000とする。
そして、重み算出部105は、算出した関連語重みを、検索キーワードとした関連語と検索エンジン200との組み合わせに関連付けて属性特定部106に出力する。
【0025】
また、文書数取得部104は、ステップS1で取得した単語を検索キーワードとして各検索エンジン200に入力し、各検索エンジン200から当該単語を含む文書の数を取得する(ステップS9)。次に、重み算出部105は、文書数取得部104が取得した、単語を含む文書の数を、当該単語における検索エンジン200の重み(検索重み)とする(ステップS10)。そして、重み算出部105は、算出した検索重みを、検索エンジン200に関連付けて属性特定部106に出力する。
【0026】
次に、属性特定部106は、関連語と検索エンジン200の組み合わせ毎に、文書数取得部104がステップS6で取得した文書数と重み算出部105が算出した関連語重みを乗算した値を算出する(ステップS11)。具体的には、検索キーワードが「スカイツリーへ行く」である場合、属性特定部は、「検索キーワード『スカイツリーへ行く』を含む文書の数」に、「関連語『へ行く』を含む文書の数から算出した関連語重み」を乗算した値を算出する。上述した例を用いると、「スカイツリーを食べる」に対して算出される値は、4/21600000=0.0018×10−6、「スカイツリーへ行く」に対して算出される値は、11600/32900000=3.52×10−6となる。
【0027】
次に、属性特定部106は、検索エンジン200毎に、ステップS11で算出した値が最も大きい関連語に関連付けられた属性を、関連属性記憶部110から読み出す(ステップS12)。上述した例の場合、ステップS11で算出した値のうち「スカイツリーへ行く」に対して算出された値が最も大きいため、属性特定部106は、関連語「へ行く」に関連付けられた属性「場所」を読み出す。
【0028】
次に、属性特定部106は、検索エンジン200毎に読み出された属性のうち、最も多い属性が複数存在するか否かを判定する(ステップS13)。最も多い属性が複数存在する場合とは、例えば5つの検索エンジン200を用いて検索を行った場合において、ステップS12で検索エンジン200毎に読み出された属性の個数が、「料理」2つ、「場所」2つ、「人名」1つであるときなどが挙げられる。
【0029】
属性特定部106は、検索エンジン200毎に読み出された属性のうち、最も多い属性が1つだけ存在すると判定した場合(ステップS13:NO)、当該最も多い属性を、入力された単語の属性とする(ステップS14)。他方、属性特定部106は、検索エンジン200毎に読み出された属性のうち、最も多い属性が複数存在すると判定した場合(ステップS13:YES)、属性毎に、当該属性を読み出す元となった検索エンジンの検索重みの総和を算出する(ステップS15)。次に、属性特定部106は、当該算出した値が最も大きくなる属性を、入力された単語の属性とする(ステップS16)。
【0030】
ここで、ステップS15、ステップS16の動作について具体例を用いて説明する。5つの検索エンジン200−1〜200−5を用いて検索を行ったものとする。
このとき、検索重みが「0.6」である検索エンジン200−1の検索結果から読み出された属性が「料理」であった。また、検索重みが「0.8」である検索エンジン200−2の検索結果から読み出された属性が「場所」であった。また、検索重みが「0.2」である検索エンジン200−3の検索結果から読み出された属性が「料理」であった。また、検索重みが「0.3」である検索エンジン200−4の検索結果から読み出された属性が「人名」であった。また、検索重みが「0.7」である検索エンジン200−5の検索結果から読み出された属性が「場所」であった。
このとき、「料理」の検索重みの総和は、0.6+0.2=0.8であり、「場所」の検索重みの総和は、0.8+0.7=1.5であり、「人名」の検索重みの総和は、0.3である。したがって、属性特定部106は、検索重みの総和が最も大きい属性「場所」を、入力された単語の属性とする。
【0031】
属性特定部106は、ステップS14またはステップS16で入力された単語の属性を特定すると、属性記録部107は、入力された単語と特定した属性とを関連付けて属性記憶部109に記録する(ステップS17)。また、単語属性出力部103は、属性特定部106がステップS16で特定した属性を、ディスプレイなどの表示装置に出力し(ステップS18)、処理を終了する。
【0032】
次に、本実施形態による属性特定装置100が、属性と関連語との関連度を更新する際の動作について説明する。
図4は、本実施形態による属性特定装置100の関連度更新動作を示すフローチャートである。
属性特定装置100は、定期的に関連属性記憶部110が記憶する属性と関連語との関連度を更新する。関連度の更新を開始すると、文書数取得部104は、関連属性記憶部110から1つの関連語と当該関連語が連なる単語の属性とを読み出す(ステップS101)。なお、ステップS101からステップS106の処理は、関連属性記憶部110が記憶する関連語毎に繰り返す。次に、文書数取得部104は、属性記憶部109が記憶する単語と当該単語の属性とを読み出す(ステップS102)。なお、ステップS102からステップS104の処理は、属性記憶部109が記憶する単語毎に繰り返す。
【0033】
次に、文書数取得部104は、ステップS101で読み出した関連語とステップS102で読み出した単語とを結合して検索キーワードを作成する(ステップS103)。次に、文書数取得部104は、作成した検索キーワードを複数の検索エンジン200に入力し、各検索エンジン200から当該検索キーワードと完全一致する文字列を含む文書の数を取得する(ステップS104)。そして、文書数取得部104は、取得した文書数を、単語と、当該単語の属性と、関連語と、当該関連語が連なる単語の属性との組み合わせに関連付けて、関連度算出部108に出力する。
【0034】
ステップS102からステップS104の処理を属性記憶部109が記憶する単語毎に実行すると、関連度算出部108は、まず、ある関連語と当該関連語の属性と同じ属性の複数単語の検索キーワードを含む文書数をそれぞれ取得し、当該文書数を単語数・検索エンジン数等で平均化した値Aを算出する。また、関連度算出部108は、ある関連語と当該関連語の属性と異なる属性の複数単語の検索キーワードを含む文書数をそれぞれ取得し、当該文書数を単語数・検索エンジン数等で平均化した値Bを算出する。そして、関連度算出部108は、値Aを値Bで除算した値を、関連語と属性との関連度とする(ステップS105)。
【0035】
ここで、ステップS105の具体例として、ステップS101で関連属性記憶部110から読み出した関連語が「を食べる(属性「料理」の関連語)」であり、検索キーワードとして「餃子を食べる(属性「料理」の単語+属性「料理」の関連語)」、「東京タワーを食べる(属性「場所」の単語+属性「料理」の関連語)」、「宮沢賢治を食べる(属性「人名」の単語+属性「料理」の関連語)」を用いた場合について説明する。
まず、関連度算出部108は、関連語と単語の属性が一致するキーワードを含む文書の数を取得する。本例では、関連度算出部108は、「餃子を食べる」を含む文書の数を取得する。検索エンジン200−1、200−2で検索を行った結果、「餃子を食べる」の文書数がそれぞれ2500000件と1380000件であった場合、これらの平均値である1940000を値Aとする。
また、関連度算出部108は、関連語と単語の属性が一致しないキーワードを含む文書の数を取得する。本例では、関連度算出部108は、「東京タワーを食べる」及び「宮沢賢治を食べる」を含む文書の数を取得する。検索エンジン200−1、200−2で検索を行った結果、「東京タワーを食べる」の文書数がそれぞれ4件と7件であり、「宮沢賢治を食べる」の文書数がそれぞれ7件と5件であった場合、これらの平均値である5.75を値Bとする。
そして値Aである1940000を値Bである5.75で除算した337391を、関連語「を食べる」と属性「料理」の関連度とする。
【0036】
ここで、ステップS105の計算によって関連度を算出する理由を説明する。関連語と属性との関連度が高い場合、属性が一致する単語と当該関連語とで係り受けする数が多くなるため、検索キーワードを含む文書数と関連度との間には正の相関がある。他方、関連語と属性との関連度が高い場合、属性が一致しない単語と当該関連語とで係り受けする数が少なくなるため、検索キーワードを含む文書数と関連度との間には負の相関がある。そのため、単語と関連語との属性が一致する検索キーワードを含む文書数の平均値と、単語と関連語との属性が一致しない検索キーワードを含む文書数の平均値の逆数とを乗算することで、関連語と属性との関連度を算出することができる。
【0037】
関連度算出部108は、ステップS105で関連度を算出すると、関連属性記憶部110が記憶する関連語の関連度を算出した関連度に書き換える(ステップS106)。ステップS101からステップS106の処理を関連属性記憶部110が記憶する関連語毎に実行すると、属性特定装置100は、関連度更新動作を終了する。
【0038】
このように、本実施形態によれば、属性特定装置100は、入力された単語に係り受けする頻度の高い関連語を特定し、当該関連語が連なる単語の属性を入力された単語の属性とする。これにより、属性特定装置100は、入力された単語の属性を精度良く特定することができる。
【0039】
また、本実施形態によれば、文書数取得部104は、検索エンジン200を用いてインターネット上に存在する文書の集合から、入力された単語と関連語とが係り受け関係にある文書数を取得する。これにより、属性特定装置100は、単一文書ソースから共起情報を取得する場合と比較して判定の偏りの発生を少なくすることができる。また、新語などが発生した場合にも、新たに文書ソースを収集しなおす必要がないため、単語と属性の関係の判定を容易に行うことができる。
【0040】
また、本実施形態によれば、文書数取得部104は、複数の検索エンジン200を用いて、それぞれの検索エンジン200から文書数を取得し、属性特定部106は、文書数取得部104が取得した文書数が最も多い関連語に関連付けられた属性を、検索エンジン200毎に関連属性記憶部110から読み出す。そして属性特定部106は、読み出された数が最も多い属性を、入力された単語の属性とする。これにより、属性特定装置100は、検索エンジン200における検索結果の偏りの影響を抑えることができる。
【0041】
また、本実施形態によれば、文書数取得部104は、関連属性記憶部110が記憶する形態素が含まれる文書の数を、関連語毎に取得し、重み算出部105は、文書数取得部104が取得した文書数が多いほど値が小さくなるように関連語重みを算出する。そして、属性特定部106は、文書数取得部104がステップS6で取得した文書数に重み算出部105が算出した関連語重みを乗算した値が最も大きい関連語に関連付けられた属性を、関連属性記憶部110から読み出す。つまり、属性特定部106は、ある関連語が入力された単語に連なる確率に基づいて単語の属性を特定する。これにより、属性特定装置100は、関連語の絶対数に影響されずに単語の属性を特定することができ、また異なる属性の単語に連なることができる関連語の重みを小さくすることができる。
【0042】
また、本実施形態によれば、関連度算出部108は、文書数に基づいて関連語と属性との関連度を算出し、文書数取得部104は、関連属性記憶部110が記憶する同じ属性に関連付けられた形態素のうち、関連度算出部108が算出した関連度が最も高い関連語と入力された単語とを結合した検索キーワードを生成する。これにより、属性特定装置100は、属性との関連度が高い関連語のみを用いて検索を行うことができるために検索数が減少し、属性の判定に要する時間を短くすることができる。
【0043】
以上、図面を参照してこの発明の一実施形態について詳しく説明してきたが、具体的な構成は上述のものに限られることはなく、この発明の要旨を逸脱しない範囲内において様々な設計変更等をすることが可能である。
例えば、本実施形態では、関連属性記憶部110が関連語と当該関連語が連なる単語の属性とを関連付けて記憶し、また文書数取得部104が入力された単語と関連語とを結合した検索キーワードに完全一致する(入力された単語と関連語との単語間距離が0で共起する)文書の数を取得する場合を説明したが、これに限られない。例えば、検索エンジン200が近傍検索(2つの文字列が所定の単語間距離以内で出現する文書を検索する検索方式)に対応している場合は、以下に示す方法を用いて処理を行っても良い。
【0044】
関連属性記憶部110は、関連語の代わりに単語に係り受けする形態素を記憶する。
文書数取得部104は、入力された単語と関連属性記憶部110が記憶する形態素とが所定の単語間距離(例えば、2単語以内や、5文字以内など)以下で共起する文書の数を取得する。これにより、文書数取得部104は、入力された単語と形態素との単語間距離が近い文書の数を取得することができる。入力された単語と形態素との単語間距離が近いということは、入力された単語と形態素とが係り受け関係にある確率が高いことを示す。したがって、上記実施形態と同様に、入力された単語の属性を精度良く特定することができる。また、関連語でなく形態素を用いることで、関連語を用いる上記実施形態と異なり、単語と形態素とを接続する助詞や助動詞が異なる文書も取得することができる。
【0045】
また、例えば、検索エンジン200が係り受け解析を伴う検索(2つの形態素が係り受け関係にある文書を検索する検索方式)に対応している場合は、以下に示す方法を用いて処理を行っても良い。
【0046】
関連属性記憶部110は、関連語の代わりに単語に係り受けする形態素を記憶する。
文書数取得部104は、入力された単語と関連属性記憶部110が記憶する形態素とが係り受け関係にある文書の数を取得する。係り受け関係を指定して検索することができる場合、入力された単語と形態素とが係り受け関係にない文書を取得することがなく、また単語と形態素とを接続する助詞や助動詞が異なる文書も取得することができる。
【0047】
また、本実施形態では、重み算出部105は、関連語を含む文書数の逆数を算出することで関連語重みを算出する場合を説明したが、これに限られず、文書数取得部104が取得した文書数が多いほど値が小さくなるのであれば、他の算出方法を用いても良い。
【0048】
また、本実施形態では、重み算出部105は、入力された単語を含む検索エンジン200毎の文書数を検索重みとする場合を説明したが、これに限られず、文書数取得部104が取得した文書数が多いほど値が大きくなるのであれば、他の算出方法を用いても良い。
【0049】
なお、本実施形態では、関連語(形態素)が単語に係り受けする文を含む文書の数を用いて単語の属性を特定する場合を説明したが、これに限られない。例えば、関連語(形態素)が単語に係り受けする文の数、または当該文を含むページのページ数を用いて単語の属性を特定しても良い。
【0050】
上述の属性特定装置100は内部に、コンピュータシステムを有している。そして、上述した各処理部の動作は、プログラムの形式でコンピュータ読み取り可能な記録媒体に記憶されており、このプログラムをコンピュータが読み出して実行することによって、上記処理が行われる。ここでコンピュータ読み取り可能な記録媒体とは、磁気ディスク、光磁気ディスク、CD−ROM、DVD−ROM、半導体メモリ等をいう。また、このコンピュータプログラムを通信回線によってコンピュータに配信し、この配信を受けたコンピュータが当該プログラムを実行するようにしても良い。
【0051】
また、上記プログラムは、前述した機能の一部を実現するためのものであっても良い。さらに、前述した機能をコンピュータシステムにすでに記録されているプログラムとの組み合わせで実現できるもの、いわゆる差分ファイル(差分プログラム)であっても良い。
【符号の説明】
【0052】
100…属性特定装置 101…単語入力部 102…属性読み出し部 103…単語属性出力部 104…文書数取得部 105…重み算出部 106…属性特定部 107…属性記録部 108…関連度算出部 109…属性記憶部 110…関連属性記憶部 200…検索エンジン
【特許請求の範囲】
【請求項1】
入力された単語の属性を特定する属性特定装置であって、
単語に係り受けする形態素と当該形態素が係り受けする単語の属性とを関連付けて記憶する関連属性記憶部と、
所定の文書集合において、入力された単語と前記関連属性記憶部が記憶する形態素とが係り受け関係にある文の数、当該文を含むページのページ数、または当該文を含む文書の数である係り受けヒット数を、前記形態素毎に取得する係り受けヒット数取得部と、
前記係り受けヒット数取得部が取得した係り受けヒット数が最も多い形態素に関連付けられた属性を前記関連属性記憶部から読み出し、当該属性を前記入力された単語の属性とする属性特定部と
を備えることを特徴とする属性特定装置。
【請求項2】
前記係り受けヒット数取得部は、前記入力された単語と前記形態素とが所定の単語間距離以下で共起する文書の数を、前記係り受けヒット数として取得する
ことを特徴とする請求項1に記載の属性特定装置。
【請求項3】
前記係り受けヒット数取得部は、複数の検索エンジンを用いて、それぞれの検索エンジンから係り受けヒット数を取得し、
前記属性特定部は、前記係り受けヒット数取得部が取得した係り受けヒット数が最も多い形態素に関連付けられた属性を前記検索エンジン毎に前記関連属性記憶部から読み出し、前記属性のうち読み出された数が最も多い属性を前記入力された単語の属性とする
ことを特徴とする請求項1または請求項2に記載の属性特定装置。
【請求項4】
前記文書集合において前記関連属性記憶部が記憶する形態素の数、当該形態素を含むページのページ数、または当該形態素を含む文書の数である形態素ヒット数を、前記形態素毎に取得する形態素ヒット数取得部と、
前記形態素ヒット数取得部が取得した形態素ヒット数が多いほど値が小さくなるように前記形態素の形態素重みを算出する形態素重み算出部と
を備え、
前記属性特定部は、前記係り受けヒット数取得部が取得した係り受けヒット数に前記形態素重み算出部が算出した形態素重みを乗算した値が最も大きい形態素に関連付けられた属性を、前記関連属性記憶部から読み出し、当該属性を前記入力された単語の属性とする
ことを特徴とする請求項1から請求項3の何れか1項に記載の属性特定装置。
【請求項5】
単語と当該単語の属性とを関連付けて記憶する属性記憶部と、
所定の文書集合において、前記属性記憶部が記憶する単語と前記関連属性記憶部が記憶する形態素とが係り受け関係にある文の数、当該文を含むページのページ数、または当該文を含む文書の数を前記形態素毎に取得し、当該数に基づいて前記形態素と属性との関連度を算出する関連度算出部とを備え、
前記関連属性記憶部は、1つの属性に関連付けて複数の形態素を記憶しており、
前記係り受けヒット数取得部は、所定の文書集合において、前記関連属性記憶部が記憶する同じ属性に関連付けられた形態素のうち、前記関連度算出部が算出した関連度が最も高い形態素と、前記入力された単語とが係り受け関係にある文のヒット数を取得する
ことを特徴とする請求項1から請求項4の何れか1項に記載の属性特定装置。
【請求項6】
単語に係り受けする形態素と当該形態素が係り受けする単語の属性とを関連付けて記憶する関連属性記憶部を備え、入力された単語の属性を特定する属性特定装置を用いた属性特定方法であって、
係り受けヒット数取得部は、所定の文書集合において、入力された単語と前記関連属性記憶部が記憶する形態素とが係り受け関係にある文の数、当該文を含むページのページ数、または当該文を含む文書の数である係り受けヒット数を、前記形態素毎に取得し、
属性特定部は、前記係り受けヒット数取得部が取得した係り受けヒット数が最も多い形態素に関連付けられた属性を前記関連属性記憶部から読み出し、当該属性を前記入力された単語の属性とする
ことを特徴とする属性特定方法。
【請求項7】
単語に係り受けする形態素と当該形態素が係り受けする単語の属性とを関連付けて記憶する関連属性記憶部を備えるコンピュータを、
所定の文書集合において、入力された単語と前記関連属性記憶部が記憶する形態素とが係り受け関係にある文の数、当該文を含むページのページ数、または当該文を含む文書の数である係り受けヒット数を、前記形態素毎に取得する係り受けヒット数取得部、
前記係り受けヒット数取得部が取得した係り受けヒット数が最も多い形態素に関連付けられた属性を前記関連属性記憶部から読み出し、当該属性を前記入力された単語の属性とする属性特定部
として機能させるプログラム。
【請求項1】
入力された単語の属性を特定する属性特定装置であって、
単語に係り受けする形態素と当該形態素が係り受けする単語の属性とを関連付けて記憶する関連属性記憶部と、
所定の文書集合において、入力された単語と前記関連属性記憶部が記憶する形態素とが係り受け関係にある文の数、当該文を含むページのページ数、または当該文を含む文書の数である係り受けヒット数を、前記形態素毎に取得する係り受けヒット数取得部と、
前記係り受けヒット数取得部が取得した係り受けヒット数が最も多い形態素に関連付けられた属性を前記関連属性記憶部から読み出し、当該属性を前記入力された単語の属性とする属性特定部と
を備えることを特徴とする属性特定装置。
【請求項2】
前記係り受けヒット数取得部は、前記入力された単語と前記形態素とが所定の単語間距離以下で共起する文書の数を、前記係り受けヒット数として取得する
ことを特徴とする請求項1に記載の属性特定装置。
【請求項3】
前記係り受けヒット数取得部は、複数の検索エンジンを用いて、それぞれの検索エンジンから係り受けヒット数を取得し、
前記属性特定部は、前記係り受けヒット数取得部が取得した係り受けヒット数が最も多い形態素に関連付けられた属性を前記検索エンジン毎に前記関連属性記憶部から読み出し、前記属性のうち読み出された数が最も多い属性を前記入力された単語の属性とする
ことを特徴とする請求項1または請求項2に記載の属性特定装置。
【請求項4】
前記文書集合において前記関連属性記憶部が記憶する形態素の数、当該形態素を含むページのページ数、または当該形態素を含む文書の数である形態素ヒット数を、前記形態素毎に取得する形態素ヒット数取得部と、
前記形態素ヒット数取得部が取得した形態素ヒット数が多いほど値が小さくなるように前記形態素の形態素重みを算出する形態素重み算出部と
を備え、
前記属性特定部は、前記係り受けヒット数取得部が取得した係り受けヒット数に前記形態素重み算出部が算出した形態素重みを乗算した値が最も大きい形態素に関連付けられた属性を、前記関連属性記憶部から読み出し、当該属性を前記入力された単語の属性とする
ことを特徴とする請求項1から請求項3の何れか1項に記載の属性特定装置。
【請求項5】
単語と当該単語の属性とを関連付けて記憶する属性記憶部と、
所定の文書集合において、前記属性記憶部が記憶する単語と前記関連属性記憶部が記憶する形態素とが係り受け関係にある文の数、当該文を含むページのページ数、または当該文を含む文書の数を前記形態素毎に取得し、当該数に基づいて前記形態素と属性との関連度を算出する関連度算出部とを備え、
前記関連属性記憶部は、1つの属性に関連付けて複数の形態素を記憶しており、
前記係り受けヒット数取得部は、所定の文書集合において、前記関連属性記憶部が記憶する同じ属性に関連付けられた形態素のうち、前記関連度算出部が算出した関連度が最も高い形態素と、前記入力された単語とが係り受け関係にある文のヒット数を取得する
ことを特徴とする請求項1から請求項4の何れか1項に記載の属性特定装置。
【請求項6】
単語に係り受けする形態素と当該形態素が係り受けする単語の属性とを関連付けて記憶する関連属性記憶部を備え、入力された単語の属性を特定する属性特定装置を用いた属性特定方法であって、
係り受けヒット数取得部は、所定の文書集合において、入力された単語と前記関連属性記憶部が記憶する形態素とが係り受け関係にある文の数、当該文を含むページのページ数、または当該文を含む文書の数である係り受けヒット数を、前記形態素毎に取得し、
属性特定部は、前記係り受けヒット数取得部が取得した係り受けヒット数が最も多い形態素に関連付けられた属性を前記関連属性記憶部から読み出し、当該属性を前記入力された単語の属性とする
ことを特徴とする属性特定方法。
【請求項7】
単語に係り受けする形態素と当該形態素が係り受けする単語の属性とを関連付けて記憶する関連属性記憶部を備えるコンピュータを、
所定の文書集合において、入力された単語と前記関連属性記憶部が記憶する形態素とが係り受け関係にある文の数、当該文を含むページのページ数、または当該文を含む文書の数である係り受けヒット数を、前記形態素毎に取得する係り受けヒット数取得部、
前記係り受けヒット数取得部が取得した係り受けヒット数が最も多い形態素に関連付けられた属性を前記関連属性記憶部から読み出し、当該属性を前記入力された単語の属性とする属性特定部
として機能させるプログラム。
【図1】


【図2】
【図3】
【図4】
【図2】
【図3】
【図4】
【公開番号】特開2012−185744(P2012−185744A)
【公開日】平成24年9月27日(2012.9.27)
【国際特許分類】
【出願番号】特願2011−49561(P2011−49561)
【出願日】平成23年3月7日(2011.3.7)
【出願人】(397065480)エヌ・ティ・ティ・コムウェア株式会社 (187)
【Fターム(参考)】
【公開日】平成24年9月27日(2012.9.27)
【国際特許分類】
【出願日】平成23年3月7日(2011.3.7)
【出願人】(397065480)エヌ・ティ・ティ・コムウェア株式会社 (187)
【Fターム(参考)】
[ Back to top ]