
帳票処理装置、該装置実行のためのプログラム、及び、帳票書式作成プログラム
【課題】同じ帳票種にも関わらず,帳票ごとに文字枠やフィールド枠の位置や大きさが異なったり,枠の配置関係が異なる帳票に対して,帳票ごとの書式情報を作成せずに枠の座標を検出する。
【解決手段】帳票を部分領域に分割し,領域ごとに複数の部分書式情報を作成する。帳票認識時には,部分領域ごとに入力画像と部分書式との照合処理を行ない,最適な部分書式を選択する。各部分領域における最適な部分書式を合成することにより帳票全体の書式情報を生成する。このように動的に生成された書式情報から枠の座標を抽出する。
【効果】準定型帳票を,部分書式情報を利用することにより精度良く認識することができる。さらに,従来に比べて書式情報の作成工数を削減し書式情報の容量を削減できる。
【解決手段】帳票を部分領域に分割し,領域ごとに複数の部分書式情報を作成する。帳票認識時には,部分領域ごとに入力画像と部分書式との照合処理を行ない,最適な部分書式を選択する。各部分領域における最適な部分書式を合成することにより帳票全体の書式情報を生成する。このように動的に生成された書式情報から枠の座標を抽出する。
【効果】準定型帳票を,部分書式情報を利用することにより精度良く認識することができる。さらに,従来に比べて書式情報の作成工数を削減し書式情報の容量を削減できる。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は,光学式文字読取装置(OCR)や帳票処理装置に関する。特に,帳票上に記入された文字の位置を定義する帳票書式情報作成装置及び該装置を実行するプログラムと,その書式情報を用いて帳票を認識する帳票処理装置及び該装置を実行するためのプログラムに関する。
【背景技術】
【0002】
まず,本発明で用いる語句である,帳票の「書式情報」を以下のように定義する。書式情報とは,帳票上の文字の読取りや位置検出のために,文字やチェックマークなどが記載される枠や領域を定義している情報である。書式情報には,座標情報だけでなく,その領域の読取項目名や文字の種類などの属性を含んでもよい。以下に示す従来技術には,1帳票種に対して1つの書式情報を保持しているという共通点がある。
第1の従来技術として,「フォーマットジェネレータ」がある(例えば、非特許文献1参照)。ここで利用されている書式情報は,帳票種ごとに文字枠やフィールド枠の位置を厳密に指定されている。既存のOCRには,フォーマットジェネレータと同様の書式情報を採用している機種が多い。
【0003】
第2の従来技術として,帳票上の表の構造をあらかじめ定義しておき,入力帳票画像に対して表を照合することにより,枠の位置を自動的に検出する方式ある(例えば、特許文献1参照)。この技術では,定型帳票に対して部分的な歪みや帳票の裁断誤差等に起因する枠の位置の違いを検出できる点や,カスレやノイズに頑健な表照合ができるという効果がある。
【0004】
第3の従来技術として,帳票上の枠同士の配置関係を帳票書式情報とする方式がある(例えば、非特許文献2)。この技術では,あらかじめ帳票全面に対して枠同士の配置関係をモデルとして記述しておく。入力帳票画像とモデルとを照合することにより,枠の位置だけでなく大きさも異なる帳票でも枠の位置を検出できるという効果がある。
【特許文献1】特開平7-282193号公報
【非特許文献1】「日立OCRソリューションImaging OCR Products」カタログ、株式会社日立製作所、2002年1月版、P5〜6
【非特許文献2】駱琴, 渡辺豊英, 杉江昇,「多種帳票文書の構造認識」電子情報通信学会論文誌, 1993年,Vol.J76-D-II,No.10,pp.2165-2176
【発明の開示】
【発明が解決しようとする課題】
【0005】
まず,帳票処理装置が取扱う帳票の種類について定義する。本発明では,OCR専用帳票以外の帳票を書式の観点から「定型帳票」,「準定型帳票」,「非定型帳票」の3つに分類して定義する。定型帳票とは,同じ種類の帳票であれば罫線や文字などの位置が固定である帳票である。準定型帳票とは源泉徴収票やレセプト(診療報酬明細書)などのように,同じ種類の帳票でも1枚ごとに罫線や枠の位置などが微妙に異なる帳票である。本発明では,罫線や枠の位置の違いが帳票サイズの20%以内であれば準定型帳票と呼ぶことにする。非定型帳票とは,領収書などのように,同じ種類の帳票でも書式も記載内容も異なる帳票であって、上記準定型帳票を除くものとする。
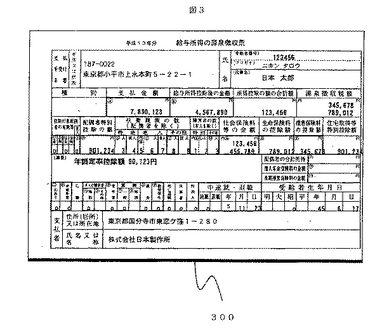
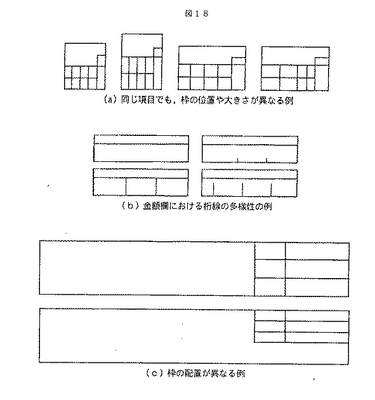
本発明では,準定型帳票を認識することを課題とする。準定型帳票の課題について,図3に示す「源泉徴収票」を例に説明する。源泉徴収票は,枠の配置がほぼ決まっているものの,帳票ごとに枠の位置が微妙に異なっている。これは,記載項目の配置の順序などのおおまかな書式は決まっているものの,枠の大きさなどの厳密な書式は発行元の企業(事業主)が独自に決めているためである。図18に書式の違いの具体例を示す。図18(a)は,同じ項目でも枠の大きさが異なる例である。図18(b)は,主に金額欄において桁線の有無や長さが異なる例である。図18(c)は枠の配置自体が異なる例である。このような書式の違いの他に,帳票認識共通の課題として,画質の問題がある。帳票の印字品質や状態は様々なので,画像入力時の画質は一定でなく,かすれやノイズが発生する場合がある。かすれやノイズが発生すると,帳票画像から罫線や枠の位置を判断する際に,誤った対応付けをする確率が高くなる。
【0006】
このような特徴を持つ準定型帳票は,前述の従来技術では認識することが困難である。
第1の従来例では,枠や文字の位置が同じであることを前提としているため,準定型帳票の認識は困難である。認識対象となる帳票の書式情報を全て登録することにより,原理的には準定型帳票の認識は可能である。しかし,以下の3つの理由により現実的には認識が非常に困難である。第1の理由は,作成すべき帳票の書式情報の数が膨大となるため,書式情報作成のコストが多くなることである。
第2の理由は,全ての帳票を事前に収集して書式情報を作成することが困難なことである。源泉徴収票の例では,国内の全ての事業者が発行する源泉徴収票を収集しなければならない。その上,同じ事業者でも年度ごとに書式を変える可能性もあるため,全てを収集することは不可能である。第3の理由は,仮に上記の2つの問題を解決できたとしても,微妙な書式の違いを判別して適切な書式情報を自動的に選択する技術を実現することは非常に困難であるためである。
【0007】
第2の従来例では,文字枠やフィールド枠の位置の違いは対応できるものの,枠の大きさが異なる準定型帳票の認識は不可能である。
第3の従来例では,文字枠やフィールド枠の位置の違いや大きさの違いには対応できるものの,帳票の一部の領域の枠の配置だけが異なる場合でも,帳票全面分の帳票書式情報を新たに作成しなければならない。このため,帳票ごとに微妙な枠の配置が異なる準定型帳票を認識するには帳票書式情報の数が膨大になるという問題がある。また,この方式で用いているモデルは矩形以外の枠を記述できないため,モデルとして記述できない帳票が多く存在するという問題がある。さらに,この方式は枠の配置情報に基づいた照合をしているため,かすれやノイズがあるために枠を正しく抽出できない帳票画像には不向きであるという問題がある。
【0008】
本発明は,このような課題を解決するためになされたものである。同じ帳票種でも枠の位置や大きさが異なり,部分的な枠の配置が異なる準定型帳票に対して,少ない帳票書式情報で高精度に書式を照合する帳票処理装置を提供する。さらに,低品質な帳票画像に対しても頑健に書式を照合する帳票処理装置を提供する。
【課題を解決するための手段】
【0009】
上記課題を解決するために本願において開示する代表的な発明の概要は以下の通りである。記憶手段に帳票画像を構成する複数の領域毎に該帳票の書式情報を記憶する帳票処理装置であって、取得した帳票画像を構成する複数の部分領域の各々の書式と上記記憶される書式情報と照合を行い、照合の結果に基づいて、決定された上記複数の書式情報を結合して上記帳票画像の書式を決定する帳票処理装置。
又、帳票画像を表示し、該帳票画像に記載されるレイアウトを解析して格子点情報を抽出して記録手段に記録し,
入力手段を介して指定された帳票画像中の部分領域の格子点情報を上記記憶手段から読み出し、入力される属性情報と上記格子点情報とを対応づけて上記記憶手段に記録する処理を各領域について繰り返す帳票書式作成方法を実行するためのプログラム。
【発明の効果】
【0010】
以上説明したように,本発明によれば,同じ帳票種にも関わらず帳票ごとに枠の位置や大きさが異なったり,枠の配置が異なるという準定型帳票を,部分書式情報を利用することにより精度良く認識することができる。さらに,従来に比べて書式情報の作成工数を削減できるという効果がある。さらに,書式情報の容量を削減できるという効果がある。
【発明を実施するための最良の形態】
【0011】
以下,図に示す実施例により本発明をさらに詳細に説明する。なお,これにより本発明が限定されるものではない。
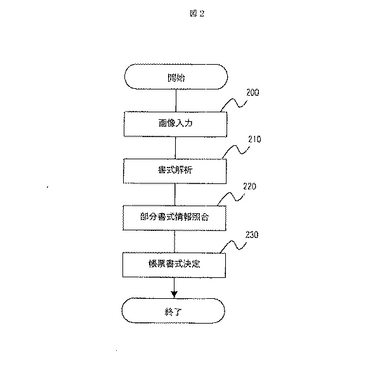
図1は,本発明の一実施例である帳票処理装置のハードウェア構成の一例である。図1において,10はコマンドやコードデータなどを入力するための入力装置,20は処理対象の帳票画像を入力するための画像入力装置,30は書式解析や書式照合などを行なう帳票認識装置,40は部分書式情報を格納するデータベース,50は認識結果を表示する表示装置である。なお,20の画像入力装置の代わりに60の画像データベースから帳票画像を入力してもよい。
【0012】
具体的な処理の内容を説明する前に,本発明の基本方針と効果について説明する。
本発明では,前述の課題を解決するために,帳票を部分領域に分割し,その部分領域ごとに帳票書式情報を作成する。本発明では,これを部分書式情報と呼ぶことにする。同じ領域内で異なる書式があれば,その数だけ部分書式情報を作成する。
帳票処理の際には,部分領域ごとに帳票画像と部分書式情報を照合して,最適な部分書式情報を動的に選択し,その結果を合成することにより帳票全面の書式情報を得ることができる。この部分書式情報を用いた帳票処理の詳細については図2を用いて後述する。
この帳票処理により,以下に示すように準定型帳票の課題を解決することができる。
まず,照合において枠の位置や大きさの違いを吸収する方式を採用することにより,準定型帳票の課題の図18(a)を解決できる。次に,照合において不要な線分と枠の罫線を区別する方式を採用することにより,図18(b)の課題を解決できる。さらに,このような照合方式を採用して罫線のかすれやノイズ線分を本来の罫線と区別することにより,低品質画像に対しても高精度な処理が可能である。
【0013】
図18(c)の課題については,同一領域での部分書式情報を複数定義することにより解決できる。照合の際に,同じ部分領域に対して複数の部分書式情報を照合し,照合類似度が最も高い部分書式情報を選択することにより,枠の配置が異なる場合でも適切な部分書式情報を得ることができる。
部分領域ごとの書式情報が決定すれば,書式情報に記録された情報を利用して,帳票画像から文字枠やフィールド枠の位置を検出することができる。このように,部分書式情報を利用した書式照合を採用することにより,準定型帳票を認識する帳票処理装置を実現することができる。
【0014】
従来手法では新規の書式の帳票が現れるたびに,帳票全面分の書式情報を作成しなければならなかったのに対し,本発明では,既存の部分書式情報に該当しない領域のみ,書式情報を追加すればよいため,書式情報作成のコストを大幅に削減できる。
部分書式情報を作成する手段は以下の通りである。まず,帳票画像を入力し,罫線抽出などの書式解析をすることにより,帳票書式を記述するための特徴量を生成する。次に,ユーザにより部分書式情報を生成したい部分領域が選択される。
選択された部分領域内について,かすれやノイズに起因する特徴量の誤りがユーザにより修正される。最後に,部分領域内の特徴量に基づいて個々の枠領域を特定し,それぞれの枠領域の属性がユーザにより指定されることにより,部分書式情報が生成できる。この部分書式情報作成処理の詳細については図16を用いて後述する。
【0015】
以下,処理の詳細について図を用いて説明する。
図2は,本発明の帳票処理装置による帳票処理の概略を示すフロー図である。ステップ200では,画像入力装置20もしくは画像データベース60より帳票画像を入力する。ステップ210では,帳票画像のレイアウトを解析しステップ220で利用する特徴量を抽出する。この特徴量については図7と図8を用いて後述する。ステップ220では,帳票画像の部分領域ごとに,部分書式情報データベース40に記憶された部分書式情報を照合し,照合類似度が最大となる部分書式情報を選択する。この部分書式情報については図5を,照合処理については図6を用いて後述する。ステップ230では,部分領域ごとに決定された部分書式情報から帳票全体の書式情報を決定する。
帳票処理の詳細について説明する前に,本発明で用いる部分領域と部分書式情報の具体例について,図3から図5を用いて説明する。
【0016】
図3は,処理対象の準定型帳票の一例である源泉徴収票を示す。図4の太線で示した領域400から440は,図3の源泉徴収票に対して設定した部分領域示す。部分領域は帳票種ごとに任意に設定される部分領域の設定基準の例を以下に示す。第1の基準は,領域400のように,項目名が記載された枠とデータが記載される枠をひとまとまりを1つの部分領域とする。以降,これらの2つの枠を項目名枠とデータ枠と呼ぶことにする。なお,1つの領域内に複数の項目名枠とデータ枠の組を含んでもよい。第2の基準は,領域410から440のように,表全体を横もしくは縦に分割する長い罫線で領域を分割するものである。なお,領域410から440には,領域内にも表を分割する罫線が存在するが,項目名枠とデータ枠を同じ領域にするという第1の基準を優先して領域を設定している。部分書式情報は,この部分領域ごとに生成される。
【0017】
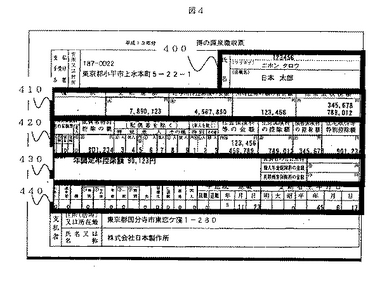
図5は,部分書式情報データベース40に記憶された部分書式情報の構造を示す。部分書式情報は,帳票種,部分領域,部分書式の3階層から構成される木構造である。図5の例では,帳票種としてAやBなどが記憶されている。帳票種Aでは,部分領域A1,A2などに分割されている。部分領域A1では,枠の配置の違いに基づき,A1a,A1bなどの部分書式を記憶している。なお,各階層の要素数は必要に応じて1個でも良い。
【0018】
部分書式情報を利用する効果は以下の通りである。帳票を認識する際に,部分書式を動的に合成して帳票全面の書式を作成れば,少ない部分書式でレイアウトの異なる多数の帳票の書式情報を合成することができる。源泉徴収票の例では,5つの部分領域においてそれぞれ3個ずつの部分書式が存在すると仮定すると,15(3×5)個の部分書式から243(3の5乗)種類の帳票全面の書式情報を合成することができる。
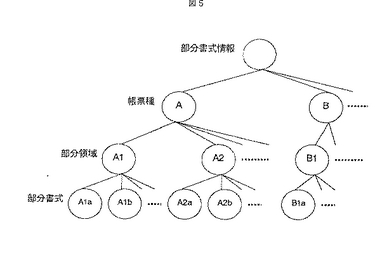
次に,図6を用いて,図2のステップ220の部分書式照合処理の詳細について説明する。ステップ600では,処理対象とする帳票種の数だけステップ610から650の処理を繰り返す。例えば,入力帳票が源泉徴収票と確定申告票の2種類であれば,2回繰り返す。ステップ610では,部分領域の数だけステップ620から640の処理を繰り返す。図4に示す源泉徴収票の例では5つの部分領域に分けられているので,5回繰り返す。ステップ620では,各部分領域内で定義された部分書式の数だけステップ630の処理を繰り返す。ステップ630では,入力画像と部分書式との照合を行ない,照合類似度を求める。照合処理の詳細については図11から16を用いて後述する。ステップ640では,各領域において最適な部分書式を選択する。選択方法の一例としては,ステップ630で求められた部分書式の中から,照合類似度が最も高い部分書式選択する方式が挙げられる。ステップ650では,帳票種ごとに帳票全面での最適な書式情報を決定する。この処理の一例としては,ステップ640で求められた最適な部分書式を合成する方式が挙げられる。ステップ660では,入力画像の帳票種を決定する。この処理の一例としては,ステップ650で求められた帳票全面の書式に対して,帳票種ごとに類似度を計算し,最もその類似度が高い帳票種を選択する方式が挙げられる。これらの一連の処理により,帳票種と書式情報を決定できる。
【0019】
なお,帳票種が1種類だけの場合や,他の処理やユーザの指定により帳票種があらかじめ決定されている場合には,ステップ600とステップ660の処理を省略することができる。同様に,帳票全面を一つの領域とする場合や部分領域が一つの場合は,ステップ610と650の処理を省略することができる。
【0020】
以下,部分書式情報の照合方法について詳細に説明する。まず,図7と図8を用いて照合に利用する特徴量について説明し,図9と図10を用いて照合対象である部分書式情報に記憶されているデータの内容について説明し,図11から図16を用いて具体的な照合処理のアルゴリズムについて説明する。なお,ここでは照合方式の一実施例を挙げるが,部分書式照合は他の手段を用いて実現してもよい。
【0021】
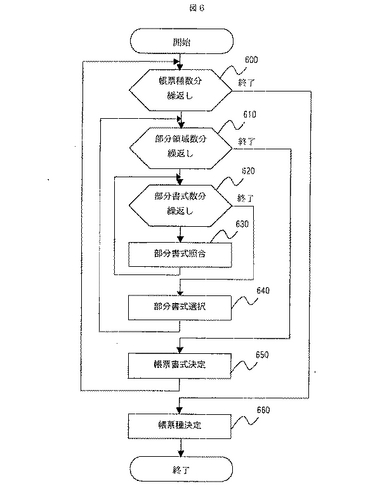
図7は,部分書式照合に用いる特徴量の例である。本発明では,この特徴量を「格子点情報」と呼ぶことにする。格子点情報の生成方法については,特開平11-053466号公報に開示されている。格子点情報は,格子点と呼ぶ点の配置情報である。この格子点とは傾き補正後の全ての実線と点線の端点から仮想的に水平垂直に引いた補助線の交点と定義する。各格子点では,傾き補正前後の座標値や罫線の交差形状などが記録されている。
【0022】
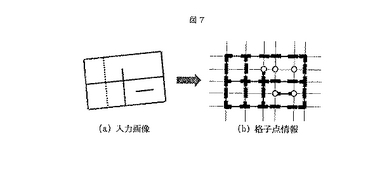
図8は,各格子点における罫線の交差形状に応じて付加する符号(交点符号)の例である。交点符号0は、罫線がないことを表す。交点符号1から4は、罫線の端点を表す。交点符号5と6は、罫線の一部分であることを表す。交点符号7から10は、2本の罫線がL字型に交差した交点を表す。交点符号11から14は、2本の罫線がT字型に交差した交点を表す。交点符号15は、2本の罫線が十字型に交差した交点を表す。
図7に示すように,帳票の枠構造は格子点情報を用いて記述することができる。
直交する罫線の交点座標は,該当する格子点の座標値から獲得することができる。平行する2本の縦罫線間の距離は,罫線が存在する格子点の列間の距離から算出できる。帳票上の矩形枠は,枠の四隅に相当する格子点の組合せにより表現することができる。
なお,格子点情報を作成するための実線の抽出方式の例としては特開平11-232382号公報に,点線の抽出方式の例としては特開平09-319824号公報に開示されている。
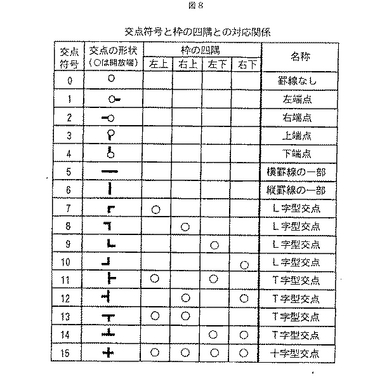
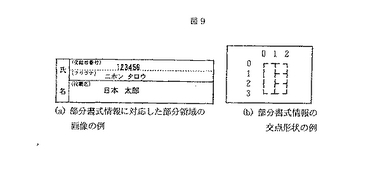
図9は,部分書式情報に対応する帳票の部分領域の画像と,その格子点情報の例である。図10は,この格子点情報に基づいて生成された部分書式情報のデータの例である。
図10の部分書式情報のデータの例として,まず,帳票種番号が記憶されている。次に,部分領域番号が記憶されている。次に,水平垂直方向の格子点の数が記憶されている。図9の例では,格子点情報は4行3列に配置されているため,水平方向が3,垂直方向が4となる。次に,帳票上の任意の位置を原点とした水平垂直方向の格子点の座標値が記録されている。この値を利用することにより,平行な罫線間の距離,すなわち枠の幅や高さを求めることができる。次に,各格子点での交点符号が記憶されている。この交点符号は図8に示す通りである。例えば,図9の格子点情報において,0行2列の格子点の交点符号は8となる。次に,この部分領域内の枠数が記憶されている。図9の例では,4つの枠が存在しているため,4となる。最後に,各枠の四隅の格子点の位置と読取項目が記憶されている。i行j列の格子点を(i,j)と記載することにすると,図9の「フリガナ」欄の枠の四隅は,左上から反時計回りに(1,1),(1,2),(2,2),(2,1)となる。この他に,罫線や領域の色情報,格子点での罫線に対する実線と点線の区別などの情報を付加してもよい。
【0023】
なお,図10において,処理対象の帳票種が1種類のみである場合は,帳票種番号はなくてもよい。また,枠数については,領域内の全ての枠数ではなく,読取対象の枠数だけでもよい。この場合は,「枠の頂点位置/枠属性」も読取対象分のみ指定する。さらに,枠の形状については矩形だけでなく,L字型のような多角形でもよい。この場合も,枠領域の頂点の格子点を順番に記憶しておけばよい。さらに,この例では枠内の領域のみを読取領域と指定していしているが,枠外でもよい。枠外の場合には,領域の境界上の格子点を頂点位置として指定する。
次に,部分書式照合処理のアルゴリズムについて説明する。
本実施例では,照合処理の一例として音声認識などに利用されている動的計画法(Dynamic Programing)を用いたDPマッチングによる照合方式を説明する。動的計画法の原理については,T.コルメン,C.ライザーソン,R.リベスト共著,、「アルゴリズムイントロダクション」第2巻,P5〜29、近代科学社,1995年出版をはじめ,さまざまな文献において解説されている。
照合アルゴリズムにDPマッチングを採用する理由は次の2つである。第1は,照合対象の特徴量間の距離の大小に依存しない照合ができるため,図18(a)に示すような罫線間距離の大小,すなわち枠の大きさの違いに対応できるからである。第2は,特徴量の数の増減の影響を受けにくい照合ができるため,図18(b)や低品質画像に起因する罫線の本数の増減に対応できるからである。
なお,通常DPマッチングは1次元のデータに対して適用される。部分書式情報は2次元の情報であるため,本実施例では横方向と縦方向に分けて処理を行なう。具体的には,格子点情報を横方向にDPマッチングを行い,ここで得られた結果を縦方向に検証するという方式をとる。なお,2次元のDPマッチングの手法も提案されているので,この方式を適用することも可能である。
【0024】
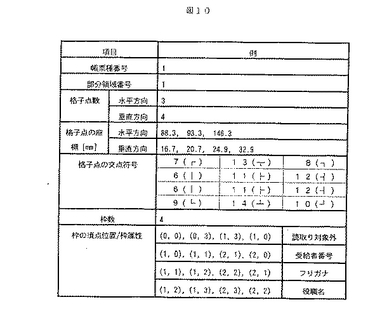
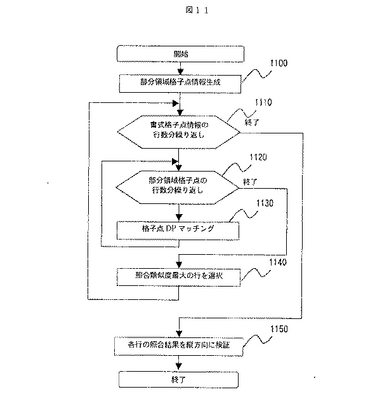
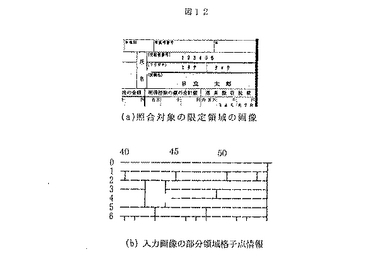
図11は,DPマッチングを用いた部分書式照合処理のフロー図である。ステップ1100では,部分領域ごとに照合対象の領域を設定し,ステップ210によって生成された帳票全面の格子点情報から領域内の格子点情報のみを抽出する。この処理を図9と図12利用して具体的に説明する。まず,図9の部分書式情報に対する入力画像の領域を図12(a)と設定する。この領域は,図9の部分書式情報の領域の位置を基準に,位置ズレを考慮して拡張した領域である。帳票全面の格子点情報から,図12(a)の領域に相当する領域の格子点情報を抽出した結果が図12(b)である。この例では,0から6行目までと40から54列目までの領域内の格子点情報が抽出されている。以下,この入力画像における部分領域の格子点情報を部分領域格子点情報,部分書式情報における格子点情報を書式格子点情報と記す。
ステップ1110では,書式格子点情報の各行ごとにステップ1120から1140の処理を繰り返す。図9(b)の例では,0から3行目まで繰り返す。
ステップ1120では,部分領域格子点情報の各行ごとにステップ1130の処理を繰り返す。図12(b)の例では,0から6行目まで繰り返す。
ステップ1130では,書式格子点情報と部分領域格子点情報の行同士をDPマッチングし,格子点の列同士の対応関係とその際の照合スコアを求める。この処理において,照合類似度があらかじめ設定された基準以下であれば,照合失敗としてリジェクトにすることができる。このDPマッチングによる照合処理の詳細については,図13と図14を用いて後述する。
ステップ1140では,ステップ1130にて求められた照合結果の中から,照合スコアが最大となる部分領域格子点情報の行を選択する。図9と図12の例では,書式情報格子点の0行目に対して,部分領域格子点情報の0から6行目までの行を照合した結果,照合類似度が最大になる行として2行目が選択される。書式格子点情報の1行目以下についても同様である。
ステップ1150では,ステップ1140にて求められた最適な部分領域格子点情報の行の照合結果に基づいて,列ごとに照合の正当性を検証する。この処理の詳細については後述する。
なお,1140で照合類似度が基準を超える行がない場合や,1150で列方向の正当性が検証できない場合は,領域単位での照合失敗としてリジェクトにすることができる。
【0025】
以下,ステップ1130のDPマッチングについて図13と図14を用いて説明する。図13は,図9の書式情報格子点の1行目の交点符号と図12の部分領域格子点情報の3行目の交点符号に対するDPマッチングの照合マトリクスである。この照合マトリクス上にDPマッチングの結果であるDPネットワークを構築できる。DPネットワークの各ノードでは,右斜め下方向,右方向,下方向の3種類の遷移のみが許されている。このネットワークにおいて,右斜め下方向の遷移は,入力画像中の格子点と書式情報中の格子点が対応付けられたことを意味する(対応)。右方向の遷移は,入力画像中に照合対象の格子点がなかったことを意味する(欠損)。逆に,下方向の遷移は,書式情報に含まれていない格子点が入力画像中に存在することを意味する(挿入)。
次に、照合スコアの計算方法から,DPネットワーク内での最適な照合経路の求め方を説明する。照合マトリクス内のノードのスコアは,左列から右列に向かって順々に計算していく。最初に照合マトリクスの最左列を0に初期化する。その他のノードのスコアは,左から,上から,左上からの3通りの遷移のうち、遷移元のスコアとその遷移のスコアとの和が最大になる遷移を選択し,そのスコアをノードのスコアとする。
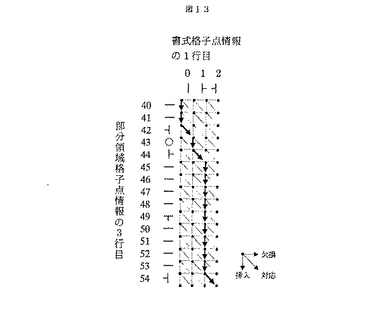
ノードのスコア計算について,図14を用いて具体的に説明する。ノード1430のスコアを求めるには,ノード1400から,1410から,1420からの3通りの遷移のスコアを比較する。ここで,ノード内の値をノードのスコア,遷移の線上の値を遷移のスコアとすると,1400からの遷移のスコアが8で最大となる。この結果,1430への遷移は1400からとなり,1430のスコアは8に決定する。なお,遷移のスコア計算の詳細については後述する。
このようにして全てのノードのスコアを計算する。最右列のうち最もスコアの高いノード選択し,このノードを終端とする経路を最適な照合結果を示す経路とする。図13では,太線で示した経路が最適な経路である。この最適経路の終端ノードのスコアをDPマッチングの照合類似度とする。
【0026】
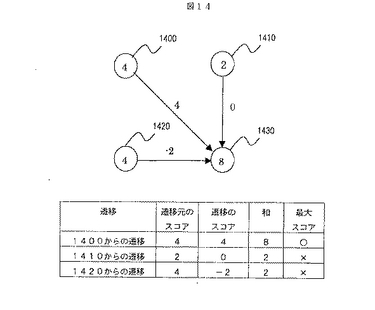
各ノード上での遷移のスコアの計算の一例を説明する。まず,対応を意味する右下方向への遷移について説明する。図15は交点符号15と交点符号13の格子点を照合する場合のスコア計算の例である。この遷移では,照合対象の格子点の交点符号の一致度が高いほど高いスコアになるように定義する。ここでは,格子点を中心として4方向の罫線の有無の一致度から不一致度を引いた値と定義する。図15の例では,4方向のうち3方向の罫線の存在が一致し,下方向のみ罫線の存在が一致しない。したがって,照合の遷移のスコアを(3α-β)と計算することができる。ここで,αとβは定数である。
【0027】
次に,挿入を意味する下方向の遷移について説明する。挿入については,罫線があるべき箇所に挿入する場合とない箇所に挿入する場合に分けて計算する。図13の書式情報格子点において,0列目と1列目の間に格子点を挿入する場合には,横罫線は存在しているべきである。したがって,このような状況では,格子点符号5(横罫線の一部)と入力画像の格子点符号との間で,上記の対応と同様のスコア計算を行なう。一方,1列目と2列目の間に格子点を挿入する場合は,罫線は存在してはいけない。したがって,このような状況では,格子点符号0(罫線なし)と入力画像の格子点符号との間で,上記の対応と同様のスコア計算を行なう。
最後に,欠損を意味する右方向の遷移について説明する。この遷移は照合対象の格子点が存在しないことを意味するので,照合スコアはペナルティとして(-γ)と定義する。ここでγは定数である。
【0028】
なお,これらのスコア計算は一例である。各係数の可変化や,格子点間隔等の別の評価基準の導入など,スコア計算を変更してもよい。格子点間隔を評価基準に入れる場合には,罫線間隔や交点間隔の一致度を評価できるため,照合精度の向上につながる。これは,枠サイズの変動が少なく同位置の変動が多い帳票を対象とする場合に,より大きな効果が得られる。
【0029】
図13の太い矢印は,このようなスコア計算により求められた最適な照合結果である。この例では,書式格子点情報の0,1,2列目の格子点が,部分領域格子点情報の42,44,54列目の格子点に対応したという結果が得られる。なお,部分領域格子点情報の42列目については左方向に不要な罫線が存在している。しかし,この格子点は書式情報格子点の左端に対応付けられているため,境界条件として左方向の罫線の存在は無視している。この処理は,上下左右端で実行される。
【0030】
以上,格子点情報を用いたDPマッチングについて説明した。しかし,照合方式はこの例に限定されない。照合の精度は劣るものの,単純に罫線や枠の座標値の比較などによる照合を行なってもよい。
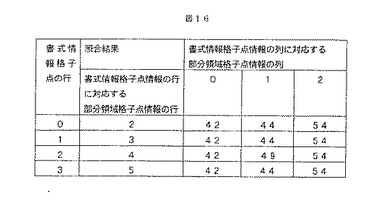
次に,列方向の検証について図16の例を用いて説明する。図16は,ステップ1140で得られた書式情報格子点の各行における照合結果である。書式格子点情報の0行目は部分領域格子点情報の2行目に対応している。書式情報格子点の0,1,2列は,部分領域格子点情報の42,44,54列に対応している。ここで,書式格子点情報の0列目と2列目は,全ての行で同じ結果が出ているため,42,54列が対応していると判定する。しかし,1列目は,0,1,3行目での照合結果は44であるのに対し,2行目の照合結果49となっており矛盾が生じている。このような矛盾に対応する一例としては多数決が挙げられる。この場合には44が3つ,49が1つであるため44が選択される。その他の対応策としては,44の結果を出した行の照合スコアの和と,49の結果を出した照合スコアの和を比較するということも挙げられる。
【0031】
このようにして,部分領域内において書式格子点情報の行と列が決定することができる。
書式情報格子点の行と列が決定すれば,図10の枠の頂点位置・枠属性を利用して入力画像上での枠座標を得ることができる。フリガナ欄を例にすると,入力画像の格子点情報の中で,部分書式情報に登録された枠の四隅に対応する格子点は左上から反時計回りに(44,3),(44,4),(54,4),(54,3)である。この格子点における入力画像上の座標を検出することにより,フリガナ欄の四隅座標を得ることができる。
なお,部分書式ごとの照合類似度は,各行で計算された照合スコアの和などで定義することができる。同じ部分領域内に部分書式が複数ある場合には,照合類似度が最大となる部分書式を選択する。
帳票種ごとの照合類似度は,部分領域ごとに計算された部分書式の照合類似度の和などで定義することができる。処理対象の帳票の種類が複数である場合には,帳票種の照合類似度が最大となる帳票を選択する。
【0032】
次に,本発明の帳票処理装置を利用した文字読取装置について説明する。図2における帳票処理によって得られた読取領域の座標を利用して,入力画像から文字もしくは文字列の画像を切り出す。切り出された画像から文字を検出して文字識別することにより,帳票上の文字を識別することができる。なお,この処理は,図2の帳票処理に利用するCPU(30)にて行なってもよい。したがって,図2の帳票処理装置と,これを利用した文字読取装置は同じ構成で実現できる。
【0033】
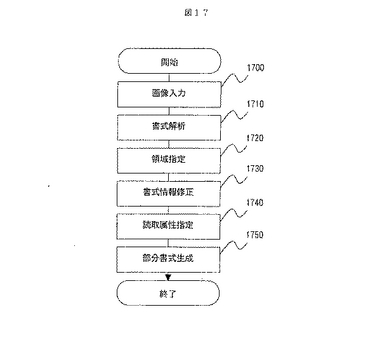
次に,本発明で用いる部分書式情報の作成方法について説明する。
図17は,部分書式情報作成のフロー図である。ステップ1700では,画像入力装置20もしくは画像データベース60より帳票画像を入力する。ステップ1710では,帳票画像に対して罫線抽出等のレイアウト解析を実行し,格子点情報を生成する。ステップ1720では,入力装置10により入力される部分書式作成対象の領域指定に基づき,1710で作成された格子点情報から,指定領域内の格子点情報を抽出する。この格子点情報の抽出結果を表示装置50で表示する。この段階での格子点情報は,画像上のかすれやノイズなどに起因する誤りを含んでいる可能性がある。このため,ステップ1730では,入力装置10により指定された誤りの修正内容に基づき,1720にて得られた格子点情報を修正する。格子点の修正結果は表示装置50に表示される。この修正作業は,ユーザが誤りがないと判断するまで繰り返される。抽出された格子点情報は記録手段に記録される。ステップ1740では,1730にて修正された格子点情報に対して,部分領域の識別情報,読取項目の位置や項目名などの属性情報を,入力装置10により入力する。ステップ1750では,1740までの情報を適当な装置に保持される変換ルールを用いて所定のデータフォーマットに変換して部分書式情報を生成する。なお,図17のフローにおいて,部分書式情報として帳票全面を対象とする場合には,ステップ1720を省略することが可能である。また,1710にて得られた格子点情報に誤りがなければ,ステップ1730を省略することが可能である。また,帳票画像の品質が低いために1710にて得られた格子点情報に誤りが多ければ,帳票画像を替えて1700から再試行することも可能である。さらに,1710の書式解析を行なわずに,全ての情報を入力装置10により入力することも可能である。
【0034】
次に,既存の部分書式情報で対応できない帳票に対して,部分書式情報を追加作成する方法について説明する。
まず,追加作成したい帳票画像を入力し,既存の部分書式情報を用いて認識をする。既存の部分書式情報で対応できる部分領域については,照合により特定できた部分領域を表示する。この表示方法の例としては,帳票画像上に照合できた部分領域を色分けして表示することが挙げられる。この表示の結果,色分けされていない領域が既存の部分書式情報で対応できなかった領域と判断できる。この領域を自動的に検出,もしくは入力装置10から指定することにより,追加する部分書式情報の領域を特定できる。以降は,図17のステップ1730以降の処理をすることにより,部分書式情報の追加をすることができる。
【図面の簡単な説明】
【0035】
【図1】本発明の一実施例の関わる帳票処理装置の概略構成を示すブロック図。
【図2】本実施例における帳票処理のフローを示す図。
【図3】本実施例における処理対象の一例を示す図。
【図4】図3の帳票に対する領域分割を示す図。
【図5】本実施例における部分書式情報の構成を示す図。
【図6】図2の帳票処理のうち,部分書式情報照合のフローを示す図。
【図7】本実施例における部分書式照合で特徴量として用いる格子点情報を説明する図。
【図8】格子点情報の交点形状を示す図。
【図9】本実施例における部分書式情報を説明する図。
【図10】本実施例における部分書式情報の内部データの一例を示す図。
【図11】図6の部分書式照合のうち,部分書式照合のフローを示す図。
【図12】本実施例における,入力画像から部分領域の照合対象の格子点の生成を説明する図。
【図13】本実施例における格子点同士のDPマッチングを示す図。
【図14】図13のDPマッチングにおける,ノード間の遷移とスコアの計算を説明する図。
【図15】図13のDPマッチングにおける照合スコア計算を説明する図。
【図16】図11におけるステップ1150を説明する図。
【図17】本実施例における部分書式情報作成のフローを示す図。
【図18】本実施例における処理対象である準定型帳票の課題を示す図。
【技術分野】
【0001】
本発明は,光学式文字読取装置(OCR)や帳票処理装置に関する。特に,帳票上に記入された文字の位置を定義する帳票書式情報作成装置及び該装置を実行するプログラムと,その書式情報を用いて帳票を認識する帳票処理装置及び該装置を実行するためのプログラムに関する。
【背景技術】
【0002】
まず,本発明で用いる語句である,帳票の「書式情報」を以下のように定義する。書式情報とは,帳票上の文字の読取りや位置検出のために,文字やチェックマークなどが記載される枠や領域を定義している情報である。書式情報には,座標情報だけでなく,その領域の読取項目名や文字の種類などの属性を含んでもよい。以下に示す従来技術には,1帳票種に対して1つの書式情報を保持しているという共通点がある。
第1の従来技術として,「フォーマットジェネレータ」がある(例えば、非特許文献1参照)。ここで利用されている書式情報は,帳票種ごとに文字枠やフィールド枠の位置を厳密に指定されている。既存のOCRには,フォーマットジェネレータと同様の書式情報を採用している機種が多い。
【0003】
第2の従来技術として,帳票上の表の構造をあらかじめ定義しておき,入力帳票画像に対して表を照合することにより,枠の位置を自動的に検出する方式ある(例えば、特許文献1参照)。この技術では,定型帳票に対して部分的な歪みや帳票の裁断誤差等に起因する枠の位置の違いを検出できる点や,カスレやノイズに頑健な表照合ができるという効果がある。
【0004】
第3の従来技術として,帳票上の枠同士の配置関係を帳票書式情報とする方式がある(例えば、非特許文献2)。この技術では,あらかじめ帳票全面に対して枠同士の配置関係をモデルとして記述しておく。入力帳票画像とモデルとを照合することにより,枠の位置だけでなく大きさも異なる帳票でも枠の位置を検出できるという効果がある。
【特許文献1】特開平7-282193号公報
【非特許文献1】「日立OCRソリューションImaging OCR Products」カタログ、株式会社日立製作所、2002年1月版、P5〜6
【非特許文献2】駱琴, 渡辺豊英, 杉江昇,「多種帳票文書の構造認識」電子情報通信学会論文誌, 1993年,Vol.J76-D-II,No.10,pp.2165-2176
【発明の開示】
【発明が解決しようとする課題】
【0005】
まず,帳票処理装置が取扱う帳票の種類について定義する。本発明では,OCR専用帳票以外の帳票を書式の観点から「定型帳票」,「準定型帳票」,「非定型帳票」の3つに分類して定義する。定型帳票とは,同じ種類の帳票であれば罫線や文字などの位置が固定である帳票である。準定型帳票とは源泉徴収票やレセプト(診療報酬明細書)などのように,同じ種類の帳票でも1枚ごとに罫線や枠の位置などが微妙に異なる帳票である。本発明では,罫線や枠の位置の違いが帳票サイズの20%以内であれば準定型帳票と呼ぶことにする。非定型帳票とは,領収書などのように,同じ種類の帳票でも書式も記載内容も異なる帳票であって、上記準定型帳票を除くものとする。
本発明では,準定型帳票を認識することを課題とする。準定型帳票の課題について,図3に示す「源泉徴収票」を例に説明する。源泉徴収票は,枠の配置がほぼ決まっているものの,帳票ごとに枠の位置が微妙に異なっている。これは,記載項目の配置の順序などのおおまかな書式は決まっているものの,枠の大きさなどの厳密な書式は発行元の企業(事業主)が独自に決めているためである。図18に書式の違いの具体例を示す。図18(a)は,同じ項目でも枠の大きさが異なる例である。図18(b)は,主に金額欄において桁線の有無や長さが異なる例である。図18(c)は枠の配置自体が異なる例である。このような書式の違いの他に,帳票認識共通の課題として,画質の問題がある。帳票の印字品質や状態は様々なので,画像入力時の画質は一定でなく,かすれやノイズが発生する場合がある。かすれやノイズが発生すると,帳票画像から罫線や枠の位置を判断する際に,誤った対応付けをする確率が高くなる。
【0006】
このような特徴を持つ準定型帳票は,前述の従来技術では認識することが困難である。
第1の従来例では,枠や文字の位置が同じであることを前提としているため,準定型帳票の認識は困難である。認識対象となる帳票の書式情報を全て登録することにより,原理的には準定型帳票の認識は可能である。しかし,以下の3つの理由により現実的には認識が非常に困難である。第1の理由は,作成すべき帳票の書式情報の数が膨大となるため,書式情報作成のコストが多くなることである。
第2の理由は,全ての帳票を事前に収集して書式情報を作成することが困難なことである。源泉徴収票の例では,国内の全ての事業者が発行する源泉徴収票を収集しなければならない。その上,同じ事業者でも年度ごとに書式を変える可能性もあるため,全てを収集することは不可能である。第3の理由は,仮に上記の2つの問題を解決できたとしても,微妙な書式の違いを判別して適切な書式情報を自動的に選択する技術を実現することは非常に困難であるためである。
【0007】
第2の従来例では,文字枠やフィールド枠の位置の違いは対応できるものの,枠の大きさが異なる準定型帳票の認識は不可能である。
第3の従来例では,文字枠やフィールド枠の位置の違いや大きさの違いには対応できるものの,帳票の一部の領域の枠の配置だけが異なる場合でも,帳票全面分の帳票書式情報を新たに作成しなければならない。このため,帳票ごとに微妙な枠の配置が異なる準定型帳票を認識するには帳票書式情報の数が膨大になるという問題がある。また,この方式で用いているモデルは矩形以外の枠を記述できないため,モデルとして記述できない帳票が多く存在するという問題がある。さらに,この方式は枠の配置情報に基づいた照合をしているため,かすれやノイズがあるために枠を正しく抽出できない帳票画像には不向きであるという問題がある。
【0008】
本発明は,このような課題を解決するためになされたものである。同じ帳票種でも枠の位置や大きさが異なり,部分的な枠の配置が異なる準定型帳票に対して,少ない帳票書式情報で高精度に書式を照合する帳票処理装置を提供する。さらに,低品質な帳票画像に対しても頑健に書式を照合する帳票処理装置を提供する。
【課題を解決するための手段】
【0009】
上記課題を解決するために本願において開示する代表的な発明の概要は以下の通りである。記憶手段に帳票画像を構成する複数の領域毎に該帳票の書式情報を記憶する帳票処理装置であって、取得した帳票画像を構成する複数の部分領域の各々の書式と上記記憶される書式情報と照合を行い、照合の結果に基づいて、決定された上記複数の書式情報を結合して上記帳票画像の書式を決定する帳票処理装置。
又、帳票画像を表示し、該帳票画像に記載されるレイアウトを解析して格子点情報を抽出して記録手段に記録し,
入力手段を介して指定された帳票画像中の部分領域の格子点情報を上記記憶手段から読み出し、入力される属性情報と上記格子点情報とを対応づけて上記記憶手段に記録する処理を各領域について繰り返す帳票書式作成方法を実行するためのプログラム。
【発明の効果】
【0010】
以上説明したように,本発明によれば,同じ帳票種にも関わらず帳票ごとに枠の位置や大きさが異なったり,枠の配置が異なるという準定型帳票を,部分書式情報を利用することにより精度良く認識することができる。さらに,従来に比べて書式情報の作成工数を削減できるという効果がある。さらに,書式情報の容量を削減できるという効果がある。
【発明を実施するための最良の形態】
【0011】
以下,図に示す実施例により本発明をさらに詳細に説明する。なお,これにより本発明が限定されるものではない。
図1は,本発明の一実施例である帳票処理装置のハードウェア構成の一例である。図1において,10はコマンドやコードデータなどを入力するための入力装置,20は処理対象の帳票画像を入力するための画像入力装置,30は書式解析や書式照合などを行なう帳票認識装置,40は部分書式情報を格納するデータベース,50は認識結果を表示する表示装置である。なお,20の画像入力装置の代わりに60の画像データベースから帳票画像を入力してもよい。
【0012】
具体的な処理の内容を説明する前に,本発明の基本方針と効果について説明する。
本発明では,前述の課題を解決するために,帳票を部分領域に分割し,その部分領域ごとに帳票書式情報を作成する。本発明では,これを部分書式情報と呼ぶことにする。同じ領域内で異なる書式があれば,その数だけ部分書式情報を作成する。
帳票処理の際には,部分領域ごとに帳票画像と部分書式情報を照合して,最適な部分書式情報を動的に選択し,その結果を合成することにより帳票全面の書式情報を得ることができる。この部分書式情報を用いた帳票処理の詳細については図2を用いて後述する。
この帳票処理により,以下に示すように準定型帳票の課題を解決することができる。
まず,照合において枠の位置や大きさの違いを吸収する方式を採用することにより,準定型帳票の課題の図18(a)を解決できる。次に,照合において不要な線分と枠の罫線を区別する方式を採用することにより,図18(b)の課題を解決できる。さらに,このような照合方式を採用して罫線のかすれやノイズ線分を本来の罫線と区別することにより,低品質画像に対しても高精度な処理が可能である。
【0013】
図18(c)の課題については,同一領域での部分書式情報を複数定義することにより解決できる。照合の際に,同じ部分領域に対して複数の部分書式情報を照合し,照合類似度が最も高い部分書式情報を選択することにより,枠の配置が異なる場合でも適切な部分書式情報を得ることができる。
部分領域ごとの書式情報が決定すれば,書式情報に記録された情報を利用して,帳票画像から文字枠やフィールド枠の位置を検出することができる。このように,部分書式情報を利用した書式照合を採用することにより,準定型帳票を認識する帳票処理装置を実現することができる。
【0014】
従来手法では新規の書式の帳票が現れるたびに,帳票全面分の書式情報を作成しなければならなかったのに対し,本発明では,既存の部分書式情報に該当しない領域のみ,書式情報を追加すればよいため,書式情報作成のコストを大幅に削減できる。
部分書式情報を作成する手段は以下の通りである。まず,帳票画像を入力し,罫線抽出などの書式解析をすることにより,帳票書式を記述するための特徴量を生成する。次に,ユーザにより部分書式情報を生成したい部分領域が選択される。
選択された部分領域内について,かすれやノイズに起因する特徴量の誤りがユーザにより修正される。最後に,部分領域内の特徴量に基づいて個々の枠領域を特定し,それぞれの枠領域の属性がユーザにより指定されることにより,部分書式情報が生成できる。この部分書式情報作成処理の詳細については図16を用いて後述する。
【0015】
以下,処理の詳細について図を用いて説明する。
図2は,本発明の帳票処理装置による帳票処理の概略を示すフロー図である。ステップ200では,画像入力装置20もしくは画像データベース60より帳票画像を入力する。ステップ210では,帳票画像のレイアウトを解析しステップ220で利用する特徴量を抽出する。この特徴量については図7と図8を用いて後述する。ステップ220では,帳票画像の部分領域ごとに,部分書式情報データベース40に記憶された部分書式情報を照合し,照合類似度が最大となる部分書式情報を選択する。この部分書式情報については図5を,照合処理については図6を用いて後述する。ステップ230では,部分領域ごとに決定された部分書式情報から帳票全体の書式情報を決定する。
帳票処理の詳細について説明する前に,本発明で用いる部分領域と部分書式情報の具体例について,図3から図5を用いて説明する。
【0016】
図3は,処理対象の準定型帳票の一例である源泉徴収票を示す。図4の太線で示した領域400から440は,図3の源泉徴収票に対して設定した部分領域示す。部分領域は帳票種ごとに任意に設定される部分領域の設定基準の例を以下に示す。第1の基準は,領域400のように,項目名が記載された枠とデータが記載される枠をひとまとまりを1つの部分領域とする。以降,これらの2つの枠を項目名枠とデータ枠と呼ぶことにする。なお,1つの領域内に複数の項目名枠とデータ枠の組を含んでもよい。第2の基準は,領域410から440のように,表全体を横もしくは縦に分割する長い罫線で領域を分割するものである。なお,領域410から440には,領域内にも表を分割する罫線が存在するが,項目名枠とデータ枠を同じ領域にするという第1の基準を優先して領域を設定している。部分書式情報は,この部分領域ごとに生成される。
【0017】
図5は,部分書式情報データベース40に記憶された部分書式情報の構造を示す。部分書式情報は,帳票種,部分領域,部分書式の3階層から構成される木構造である。図5の例では,帳票種としてAやBなどが記憶されている。帳票種Aでは,部分領域A1,A2などに分割されている。部分領域A1では,枠の配置の違いに基づき,A1a,A1bなどの部分書式を記憶している。なお,各階層の要素数は必要に応じて1個でも良い。
【0018】
部分書式情報を利用する効果は以下の通りである。帳票を認識する際に,部分書式を動的に合成して帳票全面の書式を作成れば,少ない部分書式でレイアウトの異なる多数の帳票の書式情報を合成することができる。源泉徴収票の例では,5つの部分領域においてそれぞれ3個ずつの部分書式が存在すると仮定すると,15(3×5)個の部分書式から243(3の5乗)種類の帳票全面の書式情報を合成することができる。
次に,図6を用いて,図2のステップ220の部分書式照合処理の詳細について説明する。ステップ600では,処理対象とする帳票種の数だけステップ610から650の処理を繰り返す。例えば,入力帳票が源泉徴収票と確定申告票の2種類であれば,2回繰り返す。ステップ610では,部分領域の数だけステップ620から640の処理を繰り返す。図4に示す源泉徴収票の例では5つの部分領域に分けられているので,5回繰り返す。ステップ620では,各部分領域内で定義された部分書式の数だけステップ630の処理を繰り返す。ステップ630では,入力画像と部分書式との照合を行ない,照合類似度を求める。照合処理の詳細については図11から16を用いて後述する。ステップ640では,各領域において最適な部分書式を選択する。選択方法の一例としては,ステップ630で求められた部分書式の中から,照合類似度が最も高い部分書式選択する方式が挙げられる。ステップ650では,帳票種ごとに帳票全面での最適な書式情報を決定する。この処理の一例としては,ステップ640で求められた最適な部分書式を合成する方式が挙げられる。ステップ660では,入力画像の帳票種を決定する。この処理の一例としては,ステップ650で求められた帳票全面の書式に対して,帳票種ごとに類似度を計算し,最もその類似度が高い帳票種を選択する方式が挙げられる。これらの一連の処理により,帳票種と書式情報を決定できる。
【0019】
なお,帳票種が1種類だけの場合や,他の処理やユーザの指定により帳票種があらかじめ決定されている場合には,ステップ600とステップ660の処理を省略することができる。同様に,帳票全面を一つの領域とする場合や部分領域が一つの場合は,ステップ610と650の処理を省略することができる。
【0020】
以下,部分書式情報の照合方法について詳細に説明する。まず,図7と図8を用いて照合に利用する特徴量について説明し,図9と図10を用いて照合対象である部分書式情報に記憶されているデータの内容について説明し,図11から図16を用いて具体的な照合処理のアルゴリズムについて説明する。なお,ここでは照合方式の一実施例を挙げるが,部分書式照合は他の手段を用いて実現してもよい。
【0021】
図7は,部分書式照合に用いる特徴量の例である。本発明では,この特徴量を「格子点情報」と呼ぶことにする。格子点情報の生成方法については,特開平11-053466号公報に開示されている。格子点情報は,格子点と呼ぶ点の配置情報である。この格子点とは傾き補正後の全ての実線と点線の端点から仮想的に水平垂直に引いた補助線の交点と定義する。各格子点では,傾き補正前後の座標値や罫線の交差形状などが記録されている。
【0022】
図8は,各格子点における罫線の交差形状に応じて付加する符号(交点符号)の例である。交点符号0は、罫線がないことを表す。交点符号1から4は、罫線の端点を表す。交点符号5と6は、罫線の一部分であることを表す。交点符号7から10は、2本の罫線がL字型に交差した交点を表す。交点符号11から14は、2本の罫線がT字型に交差した交点を表す。交点符号15は、2本の罫線が十字型に交差した交点を表す。
図7に示すように,帳票の枠構造は格子点情報を用いて記述することができる。
直交する罫線の交点座標は,該当する格子点の座標値から獲得することができる。平行する2本の縦罫線間の距離は,罫線が存在する格子点の列間の距離から算出できる。帳票上の矩形枠は,枠の四隅に相当する格子点の組合せにより表現することができる。
なお,格子点情報を作成するための実線の抽出方式の例としては特開平11-232382号公報に,点線の抽出方式の例としては特開平09-319824号公報に開示されている。
図9は,部分書式情報に対応する帳票の部分領域の画像と,その格子点情報の例である。図10は,この格子点情報に基づいて生成された部分書式情報のデータの例である。
図10の部分書式情報のデータの例として,まず,帳票種番号が記憶されている。次に,部分領域番号が記憶されている。次に,水平垂直方向の格子点の数が記憶されている。図9の例では,格子点情報は4行3列に配置されているため,水平方向が3,垂直方向が4となる。次に,帳票上の任意の位置を原点とした水平垂直方向の格子点の座標値が記録されている。この値を利用することにより,平行な罫線間の距離,すなわち枠の幅や高さを求めることができる。次に,各格子点での交点符号が記憶されている。この交点符号は図8に示す通りである。例えば,図9の格子点情報において,0行2列の格子点の交点符号は8となる。次に,この部分領域内の枠数が記憶されている。図9の例では,4つの枠が存在しているため,4となる。最後に,各枠の四隅の格子点の位置と読取項目が記憶されている。i行j列の格子点を(i,j)と記載することにすると,図9の「フリガナ」欄の枠の四隅は,左上から反時計回りに(1,1),(1,2),(2,2),(2,1)となる。この他に,罫線や領域の色情報,格子点での罫線に対する実線と点線の区別などの情報を付加してもよい。
【0023】
なお,図10において,処理対象の帳票種が1種類のみである場合は,帳票種番号はなくてもよい。また,枠数については,領域内の全ての枠数ではなく,読取対象の枠数だけでもよい。この場合は,「枠の頂点位置/枠属性」も読取対象分のみ指定する。さらに,枠の形状については矩形だけでなく,L字型のような多角形でもよい。この場合も,枠領域の頂点の格子点を順番に記憶しておけばよい。さらに,この例では枠内の領域のみを読取領域と指定していしているが,枠外でもよい。枠外の場合には,領域の境界上の格子点を頂点位置として指定する。
次に,部分書式照合処理のアルゴリズムについて説明する。
本実施例では,照合処理の一例として音声認識などに利用されている動的計画法(Dynamic Programing)を用いたDPマッチングによる照合方式を説明する。動的計画法の原理については,T.コルメン,C.ライザーソン,R.リベスト共著,、「アルゴリズムイントロダクション」第2巻,P5〜29、近代科学社,1995年出版をはじめ,さまざまな文献において解説されている。
照合アルゴリズムにDPマッチングを採用する理由は次の2つである。第1は,照合対象の特徴量間の距離の大小に依存しない照合ができるため,図18(a)に示すような罫線間距離の大小,すなわち枠の大きさの違いに対応できるからである。第2は,特徴量の数の増減の影響を受けにくい照合ができるため,図18(b)や低品質画像に起因する罫線の本数の増減に対応できるからである。
なお,通常DPマッチングは1次元のデータに対して適用される。部分書式情報は2次元の情報であるため,本実施例では横方向と縦方向に分けて処理を行なう。具体的には,格子点情報を横方向にDPマッチングを行い,ここで得られた結果を縦方向に検証するという方式をとる。なお,2次元のDPマッチングの手法も提案されているので,この方式を適用することも可能である。
【0024】
図11は,DPマッチングを用いた部分書式照合処理のフロー図である。ステップ1100では,部分領域ごとに照合対象の領域を設定し,ステップ210によって生成された帳票全面の格子点情報から領域内の格子点情報のみを抽出する。この処理を図9と図12利用して具体的に説明する。まず,図9の部分書式情報に対する入力画像の領域を図12(a)と設定する。この領域は,図9の部分書式情報の領域の位置を基準に,位置ズレを考慮して拡張した領域である。帳票全面の格子点情報から,図12(a)の領域に相当する領域の格子点情報を抽出した結果が図12(b)である。この例では,0から6行目までと40から54列目までの領域内の格子点情報が抽出されている。以下,この入力画像における部分領域の格子点情報を部分領域格子点情報,部分書式情報における格子点情報を書式格子点情報と記す。
ステップ1110では,書式格子点情報の各行ごとにステップ1120から1140の処理を繰り返す。図9(b)の例では,0から3行目まで繰り返す。
ステップ1120では,部分領域格子点情報の各行ごとにステップ1130の処理を繰り返す。図12(b)の例では,0から6行目まで繰り返す。
ステップ1130では,書式格子点情報と部分領域格子点情報の行同士をDPマッチングし,格子点の列同士の対応関係とその際の照合スコアを求める。この処理において,照合類似度があらかじめ設定された基準以下であれば,照合失敗としてリジェクトにすることができる。このDPマッチングによる照合処理の詳細については,図13と図14を用いて後述する。
ステップ1140では,ステップ1130にて求められた照合結果の中から,照合スコアが最大となる部分領域格子点情報の行を選択する。図9と図12の例では,書式情報格子点の0行目に対して,部分領域格子点情報の0から6行目までの行を照合した結果,照合類似度が最大になる行として2行目が選択される。書式格子点情報の1行目以下についても同様である。
ステップ1150では,ステップ1140にて求められた最適な部分領域格子点情報の行の照合結果に基づいて,列ごとに照合の正当性を検証する。この処理の詳細については後述する。
なお,1140で照合類似度が基準を超える行がない場合や,1150で列方向の正当性が検証できない場合は,領域単位での照合失敗としてリジェクトにすることができる。
【0025】
以下,ステップ1130のDPマッチングについて図13と図14を用いて説明する。図13は,図9の書式情報格子点の1行目の交点符号と図12の部分領域格子点情報の3行目の交点符号に対するDPマッチングの照合マトリクスである。この照合マトリクス上にDPマッチングの結果であるDPネットワークを構築できる。DPネットワークの各ノードでは,右斜め下方向,右方向,下方向の3種類の遷移のみが許されている。このネットワークにおいて,右斜め下方向の遷移は,入力画像中の格子点と書式情報中の格子点が対応付けられたことを意味する(対応)。右方向の遷移は,入力画像中に照合対象の格子点がなかったことを意味する(欠損)。逆に,下方向の遷移は,書式情報に含まれていない格子点が入力画像中に存在することを意味する(挿入)。
次に、照合スコアの計算方法から,DPネットワーク内での最適な照合経路の求め方を説明する。照合マトリクス内のノードのスコアは,左列から右列に向かって順々に計算していく。最初に照合マトリクスの最左列を0に初期化する。その他のノードのスコアは,左から,上から,左上からの3通りの遷移のうち、遷移元のスコアとその遷移のスコアとの和が最大になる遷移を選択し,そのスコアをノードのスコアとする。
ノードのスコア計算について,図14を用いて具体的に説明する。ノード1430のスコアを求めるには,ノード1400から,1410から,1420からの3通りの遷移のスコアを比較する。ここで,ノード内の値をノードのスコア,遷移の線上の値を遷移のスコアとすると,1400からの遷移のスコアが8で最大となる。この結果,1430への遷移は1400からとなり,1430のスコアは8に決定する。なお,遷移のスコア計算の詳細については後述する。
このようにして全てのノードのスコアを計算する。最右列のうち最もスコアの高いノード選択し,このノードを終端とする経路を最適な照合結果を示す経路とする。図13では,太線で示した経路が最適な経路である。この最適経路の終端ノードのスコアをDPマッチングの照合類似度とする。
【0026】
各ノード上での遷移のスコアの計算の一例を説明する。まず,対応を意味する右下方向への遷移について説明する。図15は交点符号15と交点符号13の格子点を照合する場合のスコア計算の例である。この遷移では,照合対象の格子点の交点符号の一致度が高いほど高いスコアになるように定義する。ここでは,格子点を中心として4方向の罫線の有無の一致度から不一致度を引いた値と定義する。図15の例では,4方向のうち3方向の罫線の存在が一致し,下方向のみ罫線の存在が一致しない。したがって,照合の遷移のスコアを(3α-β)と計算することができる。ここで,αとβは定数である。
【0027】
次に,挿入を意味する下方向の遷移について説明する。挿入については,罫線があるべき箇所に挿入する場合とない箇所に挿入する場合に分けて計算する。図13の書式情報格子点において,0列目と1列目の間に格子点を挿入する場合には,横罫線は存在しているべきである。したがって,このような状況では,格子点符号5(横罫線の一部)と入力画像の格子点符号との間で,上記の対応と同様のスコア計算を行なう。一方,1列目と2列目の間に格子点を挿入する場合は,罫線は存在してはいけない。したがって,このような状況では,格子点符号0(罫線なし)と入力画像の格子点符号との間で,上記の対応と同様のスコア計算を行なう。
最後に,欠損を意味する右方向の遷移について説明する。この遷移は照合対象の格子点が存在しないことを意味するので,照合スコアはペナルティとして(-γ)と定義する。ここでγは定数である。
【0028】
なお,これらのスコア計算は一例である。各係数の可変化や,格子点間隔等の別の評価基準の導入など,スコア計算を変更してもよい。格子点間隔を評価基準に入れる場合には,罫線間隔や交点間隔の一致度を評価できるため,照合精度の向上につながる。これは,枠サイズの変動が少なく同位置の変動が多い帳票を対象とする場合に,より大きな効果が得られる。
【0029】
図13の太い矢印は,このようなスコア計算により求められた最適な照合結果である。この例では,書式格子点情報の0,1,2列目の格子点が,部分領域格子点情報の42,44,54列目の格子点に対応したという結果が得られる。なお,部分領域格子点情報の42列目については左方向に不要な罫線が存在している。しかし,この格子点は書式情報格子点の左端に対応付けられているため,境界条件として左方向の罫線の存在は無視している。この処理は,上下左右端で実行される。
【0030】
以上,格子点情報を用いたDPマッチングについて説明した。しかし,照合方式はこの例に限定されない。照合の精度は劣るものの,単純に罫線や枠の座標値の比較などによる照合を行なってもよい。
次に,列方向の検証について図16の例を用いて説明する。図16は,ステップ1140で得られた書式情報格子点の各行における照合結果である。書式格子点情報の0行目は部分領域格子点情報の2行目に対応している。書式情報格子点の0,1,2列は,部分領域格子点情報の42,44,54列に対応している。ここで,書式格子点情報の0列目と2列目は,全ての行で同じ結果が出ているため,42,54列が対応していると判定する。しかし,1列目は,0,1,3行目での照合結果は44であるのに対し,2行目の照合結果49となっており矛盾が生じている。このような矛盾に対応する一例としては多数決が挙げられる。この場合には44が3つ,49が1つであるため44が選択される。その他の対応策としては,44の結果を出した行の照合スコアの和と,49の結果を出した照合スコアの和を比較するということも挙げられる。
【0031】
このようにして,部分領域内において書式格子点情報の行と列が決定することができる。
書式情報格子点の行と列が決定すれば,図10の枠の頂点位置・枠属性を利用して入力画像上での枠座標を得ることができる。フリガナ欄を例にすると,入力画像の格子点情報の中で,部分書式情報に登録された枠の四隅に対応する格子点は左上から反時計回りに(44,3),(44,4),(54,4),(54,3)である。この格子点における入力画像上の座標を検出することにより,フリガナ欄の四隅座標を得ることができる。
なお,部分書式ごとの照合類似度は,各行で計算された照合スコアの和などで定義することができる。同じ部分領域内に部分書式が複数ある場合には,照合類似度が最大となる部分書式を選択する。
帳票種ごとの照合類似度は,部分領域ごとに計算された部分書式の照合類似度の和などで定義することができる。処理対象の帳票の種類が複数である場合には,帳票種の照合類似度が最大となる帳票を選択する。
【0032】
次に,本発明の帳票処理装置を利用した文字読取装置について説明する。図2における帳票処理によって得られた読取領域の座標を利用して,入力画像から文字もしくは文字列の画像を切り出す。切り出された画像から文字を検出して文字識別することにより,帳票上の文字を識別することができる。なお,この処理は,図2の帳票処理に利用するCPU(30)にて行なってもよい。したがって,図2の帳票処理装置と,これを利用した文字読取装置は同じ構成で実現できる。
【0033】
次に,本発明で用いる部分書式情報の作成方法について説明する。
図17は,部分書式情報作成のフロー図である。ステップ1700では,画像入力装置20もしくは画像データベース60より帳票画像を入力する。ステップ1710では,帳票画像に対して罫線抽出等のレイアウト解析を実行し,格子点情報を生成する。ステップ1720では,入力装置10により入力される部分書式作成対象の領域指定に基づき,1710で作成された格子点情報から,指定領域内の格子点情報を抽出する。この格子点情報の抽出結果を表示装置50で表示する。この段階での格子点情報は,画像上のかすれやノイズなどに起因する誤りを含んでいる可能性がある。このため,ステップ1730では,入力装置10により指定された誤りの修正内容に基づき,1720にて得られた格子点情報を修正する。格子点の修正結果は表示装置50に表示される。この修正作業は,ユーザが誤りがないと判断するまで繰り返される。抽出された格子点情報は記録手段に記録される。ステップ1740では,1730にて修正された格子点情報に対して,部分領域の識別情報,読取項目の位置や項目名などの属性情報を,入力装置10により入力する。ステップ1750では,1740までの情報を適当な装置に保持される変換ルールを用いて所定のデータフォーマットに変換して部分書式情報を生成する。なお,図17のフローにおいて,部分書式情報として帳票全面を対象とする場合には,ステップ1720を省略することが可能である。また,1710にて得られた格子点情報に誤りがなければ,ステップ1730を省略することが可能である。また,帳票画像の品質が低いために1710にて得られた格子点情報に誤りが多ければ,帳票画像を替えて1700から再試行することも可能である。さらに,1710の書式解析を行なわずに,全ての情報を入力装置10により入力することも可能である。
【0034】
次に,既存の部分書式情報で対応できない帳票に対して,部分書式情報を追加作成する方法について説明する。
まず,追加作成したい帳票画像を入力し,既存の部分書式情報を用いて認識をする。既存の部分書式情報で対応できる部分領域については,照合により特定できた部分領域を表示する。この表示方法の例としては,帳票画像上に照合できた部分領域を色分けして表示することが挙げられる。この表示の結果,色分けされていない領域が既存の部分書式情報で対応できなかった領域と判断できる。この領域を自動的に検出,もしくは入力装置10から指定することにより,追加する部分書式情報の領域を特定できる。以降は,図17のステップ1730以降の処理をすることにより,部分書式情報の追加をすることができる。
【図面の簡単な説明】
【0035】
【図1】本発明の一実施例の関わる帳票処理装置の概略構成を示すブロック図。
【図2】本実施例における帳票処理のフローを示す図。
【図3】本実施例における処理対象の一例を示す図。
【図4】図3の帳票に対する領域分割を示す図。
【図5】本実施例における部分書式情報の構成を示す図。
【図6】図2の帳票処理のうち,部分書式情報照合のフローを示す図。
【図7】本実施例における部分書式照合で特徴量として用いる格子点情報を説明する図。
【図8】格子点情報の交点形状を示す図。
【図9】本実施例における部分書式情報を説明する図。
【図10】本実施例における部分書式情報の内部データの一例を示す図。
【図11】図6の部分書式照合のうち,部分書式照合のフローを示す図。
【図12】本実施例における,入力画像から部分領域の照合対象の格子点の生成を説明する図。
【図13】本実施例における格子点同士のDPマッチングを示す図。
【図14】図13のDPマッチングにおける,ノード間の遷移とスコアの計算を説明する図。
【図15】図13のDPマッチングにおける照合スコア計算を説明する図。
【図16】図11におけるステップ1150を説明する図。
【図17】本実施例における部分書式情報作成のフローを示す図。
【図18】本実施例における処理対象である準定型帳票の課題を示す図。
【特許請求の範囲】
【請求項1】
帳票画像を構成する複数の領域毎に、それぞれの領域について照合に必要な情報および該領域内の読取項目を特定する項目情報を含む、該帳票の書式情報を記憶する記憶する記憶手段と、
帳票画像を取得する入力手段と、
上記記憶手段から上記書式情報を読み出し、上記取得した帳票画像を構成する複数の部分領域のそれぞれを前記書式情報のいずれかと照合して該当する書式情報を判定する書式情報判定手段と、
前記複数の部分領域毎に、前記該当すると判定された書式情報に含まれる項目情報を参照して該部分領域内において認識する文字の位置を決定する文字位置決定手段とを有することを特徴とする帳票処理装置。
【請求項2】
請求項1記載の帳票処理装置であって、前記決定された位置の文字を認識して項目読取結果とする項目読取手段を有することを特徴とする帳票処理装置。
【請求項3】
請求項1記載の帳票処理装置であって、前記項目情報は、該領域内における読取項目とその記載位置を特定する情報を対応付けたものであることを特徴とする帳票処理装置。
【請求項4】
請求項1記載の帳票処理装置であって、前記記憶手段には、帳票画像を構成する複数の部分領域のうちの少なくとも一部の複数の部分領域について、該部分領域と対応付けて複数種類の書式情報が記憶され、また、複数の帳票種類について、該帳票種類に対応する前記部分領域の書式情報の組み合わせである帳票種類情報が記憶され、
前記書式情報判定手段は、前記取得した帳票画像の部分領域が、該部分領域に対応する書式情報のいずれに該当するかを判定し、前記取得した帳票画像の各部分領域が該当すると判定された書式情報の組み合わせを用いて前記帳票種類情報を参照し、前記取得した帳票画像の帳票種類を判定することを特徴とする帳票処理装置。
【請求項5】
帳票画像を構成する複数の領域毎に、それぞれの領域について照合に必要な情報および該領域内の読取項目を特定する項目情報を含む、該帳票の書式情報を記憶する記憶する記憶手段と、帳票画像を取得する入力手段と、帳票処理部とを有する帳票処理装置における帳票処理方法であって、
上記記憶手段から上記書式情報を読み出し、上記取得した帳票画像を構成する複数の部分領域のそれぞれを前記書式情報のいずれかと照合して該当する書式情報を判定する第1のステップと、
前記複数の部分領域毎に、前記該当すると判定された書式情報に含まれる項目情報を参照して該部分領域内において認識する文字の位置を決定する第2のステップと、
を有することを特徴とする帳票処理方法。
【請求項6】
請求項5記載の帳票処理方法であって、前記決定された位置の文字を認識して項目読取結果とする第3のステップを有することを特徴とする帳票処理方法。
【請求項7】
請求項5記載の帳票処理方法であって、前記項目情報は、該領域内における読取項目とその記載位置を特定する情報を対応付けたものであることを特徴とする帳票処理方法。
【請求項8】
請求項5記載の帳票処理方法であって、前記記憶手段には、帳票画像を構成する複数の部分領域のうちの少なくとも一部の複数の部分領域について、該部分領域と対応付けて複数種類の書式情報が記憶され、また、複数の帳票種類について、該帳票種類に対応する前記部分領域の書式情報の組み合わせである帳票種類情報が記憶され、
前記第1のステップは、前記取得した帳票画像の部分領域が、該部分領域に対応する書式情報のいずれに該当するかを判定し、前記取得した帳票画像の各部分領域が該当すると判定された書式情報の組み合わせを用いて前記帳票種類情報を参照し、前記取得した帳票画像の帳票種類を判定することを特徴とする帳票処理方法。
【請求項1】
帳票画像を構成する複数の領域毎に、それぞれの領域について照合に必要な情報および該領域内の読取項目を特定する項目情報を含む、該帳票の書式情報を記憶する記憶する記憶手段と、
帳票画像を取得する入力手段と、
上記記憶手段から上記書式情報を読み出し、上記取得した帳票画像を構成する複数の部分領域のそれぞれを前記書式情報のいずれかと照合して該当する書式情報を判定する書式情報判定手段と、
前記複数の部分領域毎に、前記該当すると判定された書式情報に含まれる項目情報を参照して該部分領域内において認識する文字の位置を決定する文字位置決定手段とを有することを特徴とする帳票処理装置。
【請求項2】
請求項1記載の帳票処理装置であって、前記決定された位置の文字を認識して項目読取結果とする項目読取手段を有することを特徴とする帳票処理装置。
【請求項3】
請求項1記載の帳票処理装置であって、前記項目情報は、該領域内における読取項目とその記載位置を特定する情報を対応付けたものであることを特徴とする帳票処理装置。
【請求項4】
請求項1記載の帳票処理装置であって、前記記憶手段には、帳票画像を構成する複数の部分領域のうちの少なくとも一部の複数の部分領域について、該部分領域と対応付けて複数種類の書式情報が記憶され、また、複数の帳票種類について、該帳票種類に対応する前記部分領域の書式情報の組み合わせである帳票種類情報が記憶され、
前記書式情報判定手段は、前記取得した帳票画像の部分領域が、該部分領域に対応する書式情報のいずれに該当するかを判定し、前記取得した帳票画像の各部分領域が該当すると判定された書式情報の組み合わせを用いて前記帳票種類情報を参照し、前記取得した帳票画像の帳票種類を判定することを特徴とする帳票処理装置。
【請求項5】
帳票画像を構成する複数の領域毎に、それぞれの領域について照合に必要な情報および該領域内の読取項目を特定する項目情報を含む、該帳票の書式情報を記憶する記憶する記憶手段と、帳票画像を取得する入力手段と、帳票処理部とを有する帳票処理装置における帳票処理方法であって、
上記記憶手段から上記書式情報を読み出し、上記取得した帳票画像を構成する複数の部分領域のそれぞれを前記書式情報のいずれかと照合して該当する書式情報を判定する第1のステップと、
前記複数の部分領域毎に、前記該当すると判定された書式情報に含まれる項目情報を参照して該部分領域内において認識する文字の位置を決定する第2のステップと、
を有することを特徴とする帳票処理方法。
【請求項6】
請求項5記載の帳票処理方法であって、前記決定された位置の文字を認識して項目読取結果とする第3のステップを有することを特徴とする帳票処理方法。
【請求項7】
請求項5記載の帳票処理方法であって、前記項目情報は、該領域内における読取項目とその記載位置を特定する情報を対応付けたものであることを特徴とする帳票処理方法。
【請求項8】
請求項5記載の帳票処理方法であって、前記記憶手段には、帳票画像を構成する複数の部分領域のうちの少なくとも一部の複数の部分領域について、該部分領域と対応付けて複数種類の書式情報が記憶され、また、複数の帳票種類について、該帳票種類に対応する前記部分領域の書式情報の組み合わせである帳票種類情報が記憶され、
前記第1のステップは、前記取得した帳票画像の部分領域が、該部分領域に対応する書式情報のいずれに該当するかを判定し、前記取得した帳票画像の各部分領域が該当すると判定された書式情報の組み合わせを用いて前記帳票種類情報を参照し、前記取得した帳票画像の帳票種類を判定することを特徴とする帳票処理方法。
【図1】


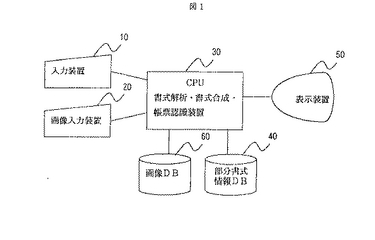
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【公開番号】特開2006−244526(P2006−244526A)
【公開日】平成18年9月14日(2006.9.14)
【国際特許分類】
【出願番号】特願2006−154163(P2006−154163)
【出願日】平成18年6月2日(2006.6.2)
【分割の表示】特願2002−305283(P2002−305283)の分割
【原出願日】平成14年10月21日(2002.10.21)
【出願人】(504373093)日立オムロンターミナルソリューションズ株式会社 (1,225)
【Fターム(参考)】
【公開日】平成18年9月14日(2006.9.14)
【国際特許分類】
【出願日】平成18年6月2日(2006.6.2)
【分割の表示】特願2002−305283(P2002−305283)の分割
【原出願日】平成14年10月21日(2002.10.21)
【出願人】(504373093)日立オムロンターミナルソリューションズ株式会社 (1,225)
【Fターム(参考)】
[ Back to top ]