
強化学習装置、制御装置、および強化学習方法

【課題】従来、報酬関数を構成する多数の項の間で発生するトレードオフが、ロボットの運動学習の妨げとなっていた。
【解決手段】制御対象の環境に関する1以上の第一種環境パラメータの値を取得する第一種環境パラメータ取得手段と、1以上の第一種環境パラメータの値を報酬関数に代入し、報酬関数が出力する報酬を最大とするような1以上の制御パラメータの値を算出する制御パラメータ値算出手段と、1以上の制御パラメータの値を制御対象に対して出力する制御パラメータ値出力手段と、仮想外力に関連する1以上の第二種環境パラメータの値を取得する第二種環境パラメータ取得手段と、1以上の第二種環境パラメータを仮想外力関数に代入し、仮想外力を算出する仮想外力算出手段と、仮想外力を制御対象に対して出力する仮想外力出力手段とを具備する強化学習装置により、すばやくかつ安定して、ロボットの運動学習が行える。
【解決手段】制御対象の環境に関する1以上の第一種環境パラメータの値を取得する第一種環境パラメータ取得手段と、1以上の第一種環境パラメータの値を報酬関数に代入し、報酬関数が出力する報酬を最大とするような1以上の制御パラメータの値を算出する制御パラメータ値算出手段と、1以上の制御パラメータの値を制御対象に対して出力する制御パラメータ値出力手段と、仮想外力に関連する1以上の第二種環境パラメータの値を取得する第二種環境パラメータ取得手段と、1以上の第二種環境パラメータを仮想外力関数に代入し、仮想外力を算出する仮想外力算出手段と、仮想外力を制御対象に対して出力する仮想外力出力手段とを具備する強化学習装置により、すばやくかつ安定して、ロボットの運動学習が行える。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、ロボットの運動学習を行う強化学習装置等に関するものである。
【背景技術】
【0002】
強化学習は制御対象や環境のダイナミクスが未知であっても実装可能であり、また課題に応じた報酬関数を設定するだけで自律的に学習を行うため、ロボットの運動学習手法として広く用いられている(例えば、特許文献1参照)。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開2007−66242号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
しかしながら、従来の技術において、複雑な運動軌道のための報酬関数は様々な項の和で表現されることが多く、各項の間で発生するトレードオフが学習の妨げとなる(これをトレードオフ問題という)、という課題があった。例えば、2点間到達運動課題における報酬関数は、一般に、目標地点で与えられる正の報酬と使用したエネルギーに対する負の報酬から構成される。この2つの要素の比率を適切なものに設定しないと、学習結果の速度が非常に速くなったり、遅くなったりと、望ましくない運動軌道となってしまう。さらに到達運動に加え、障害物回避等の要求が加わると、このトレードオフ問題はさらに困難なものとなる。障害物に接触したときの負の報酬が小さすぎると障害物にぶつかってしまい、また大きすぎると開始地点から動かないような学習結果となってしまう。報酬関数が複雑になってしまった場合、要素間のバランス調節を設計者が経験的に行わなければならず、強化学習の利点を損なってしまう。
【課題を解決するための手段】
【0005】
本第一の発明の強化学習装置は、報酬を出力とする報酬関数を格納し得る報酬関数格納手段と、移動する制御対象の環境に関する第一種のパラメータである1以上の第一種環境パラメータの値を取得する第一種環境パラメータ取得手段と、1以上の第一種環境パラメータの値を報酬関数に代入し、報酬関数が出力する報酬を最大とするような1以上の制御パラメータの値を算出する制御パラメータ値算出手段と、1以上の制御パラメータの値を制御対象に対して出力する制御パラメータ値出力手段と、仮想的な外力である仮想外力を出力とする仮想外力関数を格納し得る仮想外力関数格納手段と、仮想外力に関連する第二種のパラメータである1以上の第二種環境パラメータの値を取得する第二種環境パラメータ取得手段と、1以上の第二種環境パラメータを仮想外力関数に代入し、仮想外力を算出する仮想外力算出手段と、仮想外力を制御対象に対して出力する仮想外力出力手段とを具備する強化学習装置である。
【0006】
かかる構成により、障害物の回避に対する要求を仮想外力によって解決するために、単純な報酬関数ですばやく、かつ安定して、ロボットの運動学習が行える。
【0007】
また、本第二の発明の強化学習装置は、第一の発明に対して、強化学習器と、強化学習器とは分離されている仮想外力発生器とを具備する強化学習装置であって、強化学習器は、報酬関数格納手段と、第一種環境パラメータ取得手段と、制御パラメータ値算出手段と、制御パラメータ値出力手段とを具備し、仮想外力発生器は、仮想外力関数格納手段と、第二種環境パラメータ取得手段と、仮想外力算出手段と、仮想外力出力手段とを具備する強化学習装置である。
【0008】
かかる構成により、運動開始位置や目標位置が変更した場合に、再学習を行うのは到達運動に関する部分のみで足り、回避運動に関する学習結果は、障害物の位置や形状が変わらない限り再利用することができる。
【0009】
また、本第三の発明の強化学習装置は、第一または第二の発明に対して、制御パラメータ値出力手段が出力する1以上の制御パラメータの値と、仮想外力出力手段が出力する仮想外力とが加えられて制御対象に与えられる強化学習装置である。
【0010】
かかる構成により、障害物の回避に対する要求を仮想外力によって解決するために、単純な報酬関数ですばやく、かつ安定して、ロボットの運動学習が行える。
【0011】
また、本第四の発明の強化学習装置は、第一から第三いずれかの発明に対して、強化学習装置は、仮想外力近似器をさらに具備し、仮想外力近似器は、第二種環境パラメータとは少なくとも一部に異なる観測可能な第三種のパラメータである2以上の第三種パラメータを有し、第二の仮想外力を出力とする関数近似器を格納し得る関数近似器格納手段と、制御対象を観測し、制御対象の状態に関する情報である1以上の状態情報を取得する状態情報取得手段と、状態情報を関数近似器に代入し、第二の仮想外力を算出する第二仮想外力算出手段と、仮想外力発生器が出力する仮想外力と第二の仮想外力との差異に関する情報である差異情報を算出する差異情報算出手段と、差異情報が最小となるように、関数近似器のパラメータを更新する近似手段とを具備する強化学習装置である。
【0012】
かかる構成により、簡易な構成で制御対象を制御するための準備ができる。
【0013】
また、本第五の発明の強化学習装置は、第四の発明に対して、差異情報が所定の条件を満たすか否かを判断する判断手段と、判断手段が所定の条件を満たすほど、仮想外力発生器が出力する仮想外力と第二の仮想外力との差異が小さいと判断した場合に、制御対象に対して出力する仮想外力を、仮想外力発生器の出力から仮想外力近似器の出力へ切り替える切替手段とをさらに具備する強化学習装置である。
【0014】
かかる構成により、簡易な構成で制御対象を制御することができる。
【0015】
また、本第六の発明の強化学習装置は、第一から第五いずれかの発明に対して、障害物を避けながら一の目標地点に到達する課題である2点間到達運動課題を解決する強化学習装置である。
【0016】
かかる構成により、2点間到達運動課題を解決する制御対象について、単純な報酬関数ですばやく、かつ安定して、ロボットの運動学習が行える。
【0017】
また、本第七の発明の強化学習装置は、第四から第六いずれかの発明に対して、仮想外力の座標系は、制御対象の特定の箇所に対する相対座標である強化学習装置である。
【0018】
かかる構成により、障害物の位置や姿勢が変わった場合でも、仮想外力近似器の学習結果を再利用できる。
【0019】
また、本第八の発明の強化学習装置は、第四から第七いずれかの発明に対して、状態情報取得手段が取得した1以上の状態情報のうち、変化が閾値より大きい1以上の状態情報を取得する選択手段をさらに具備し、第二仮想外力算出手段は、選択手段が取得した1以上の状態情報のみを関数近似器に代入し、第二の仮想外力を算出する強化学習装置である。
【0020】
かかる構成により、関数近似器のパラメータを絞ることができ、学習速度を短縮できる。
【0021】
また、本第九の発明の制御装置は、第四から第八いずれかの発明に対して、仮想外力近似器と、強化学習器とを用いて、移動する制御対象を制御する制御装置である。
【0022】
かかる構成により、簡易な構成で制御対象を制御することができる。
【発明の効果】
【0023】
本発明による強化学習装置によれば、すばやくかつ安定して、ロボットの運動学習が行える。
【図面の簡単な説明】
【0024】
【図1】実施の形態1における強化学習システムが行う動作を説明する概略図
【図2】同強化学習システムのブロック図
【図3】同障害物との距離と仮想外力との関係を示す図
【図4】同強化学習システムの動作について説明するフローチャート
【図5】同強化学習器、仮想外力発生器、および仮想外力近似器と制御対象との概略図
【図6】同強化学習器、仮想外力発生器、および仮想外力近似器と制御対象との概略図
【図7】同実験結果を示す図
【図8】同実験結果を示す図
【図9】実施の形態2における強化学習システムのブロック図
【図10】上記実施の形態におけるコンピュータシステムの概観図
【図11】同コンピュータシステムのブロック図
【発明を実施するための形態】
【0025】
以下、強化学習システム等の実施形態について図面を参照して説明する。なお、実施の形態において同じ符号を付した構成要素は同様の動作を行うので、再度の説明を省略する場合がある。
(実施の形態1)
【0026】
本実施の形態において、仮想的な外力を発生させる機能を有する強化学習装置等について説明する。また、本実施の形態において、強化学習装置を構成する強化学習器と仮想外力発生器とが分離している強化学習装置について説明する。また、本実施の形態において、仮想外力発生器から仮想外力近似器への自動切り替えを行える強化学習装置について説明する。また、本実施の形態において、仮想外力発生器の再利用性を向上できる強化学習装置について説明する。さらに、本実施の形態において、関数近似器のモデル選択を行える強化学習装置について説明する。
【0027】
図1は、本実施の形態における強化学習システムAが行う動作を説明する概略図である。強化学習システムAは、主として、障害物を避けて移動を行う制御対象に対して強化学習を行うシステムである。また、図1に示すように、強化学習システムAは、例えば、制御対象であるロボットアームの手先に仮想的な外力を発生させることで障害物を避けて移動する。強化学習システムAにおいて、例えば、障害物の表面に対し垂直な方向に仮想外力を発生させ、強化学習器の出力に足しこむことで障害物を回避しつつ到達運動を達成する。
【0028】
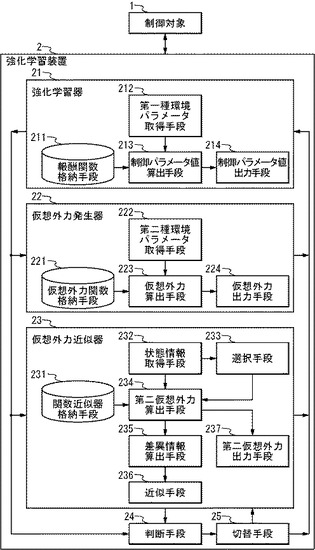
図2は、本実施の形態における強化学習システムAのブロック図である。強化学習システムAは、制御対象1、および強化学習装置2を具備する。また、強化学習装置2は、強化学習器21、仮想外力発生器22、仮想外力近似器23、判断手段24、および切替手段25を具備する。
【0029】
また、強化学習器21は、報酬関数格納手段211、第一種環境パラメータ取得手段212、制御パラメータ値算出手段213、および制御パラメータ値出力手段214を具備する。
【0030】
また、仮想外力発生器22は、仮想外力関数格納手段221、第二種環境パラメータ取得手段222、仮想外力算出手段223、および仮想外力出力手段224を具備する。
【0031】
さらに、仮想外力近似器23は、関数近似器格納手段231、状態情報取得手段232、選択手段233、第二仮想外力算出手段234、差異情報算出手段235、近似手段236、および第二仮想外力出力手段237を具備する。
【0032】
制御対象1は、制御の対象であり、例えば、移動するロボットである。また、制御対象1は、例えば、2点間到達運動を達成するロボットである。
【0033】
強化学習装置2を構成する強化学習器21は、制御対象1や環境のダイナミクスが未知であっても実装可能であり、また課題に応じた報酬関数を設定するだけで自律的に学習を行える装置である。
【0034】
強化学習器21を構成する報酬関数格納手段211は、報酬関数を格納し得る。報酬関数は、報酬を出力とする。また、報酬関数は、通常、2以上の項の和で表現される。例えば、2点間到達運動課題における報酬関数は、一般に、目標点までの距離に応じた正の報酬と、出力の大きさに応じた負の報酬の和から構成される。さらに具体的には、例えば、報酬関数は、目標点までの距離に応じた正の報酬をガウス分布、出力の大きさに応じた負の報酬を2次形式とした関数である。
【0035】
また、報酬関数r(t)は、例えば、以下の数式1である。なお、tは時刻である。
【数1】

【0036】
数式1において、p(t)は手先位置、pgoalは手先の目標位置、σは正の報酬が与えられる範囲を決めるパラメータである。また、u(t)は、時刻tにおける行動である。行動とは、制御対象の運動を決定する情報である。行動uは、例えば、ロボットの各関節に与えられる制御力を並べたベクトルである。さらに、Rは、行列であり、制御力の大きさに対する負の報酬を決めるパラメータであり、一般に正定行列を用いる。Rが大きいと小さな制御力でゆっくりゴールへ、また逆に小さいと大きな制御力で素早くゴールへ向かう運動を学習する。なお、行動uは、後述する1以上の制御パラメータである。また、1以上の制御パラメータは、制御パラメータ値算出手段213により算出される。
【0037】
また、強化学習を行うエージェント(強化学習装置2に該当)は、例えば、状態空間上を試行錯誤によって探索することで、報酬を最大とするような行動則を学習する。ただし、どのような変数を状態空間に取るかは様々な方法がある。ロボットアームの制御では各関節の角度と角速度からなるベクトルを状態空間とすることが一般的である。一方、障害物のある2点間到達運動では、関節の角度と角速度に加えて、手先の位置と速度も状態空間に含めることにより、学習効率が飛躍的に上昇する。これは、報酬関数や仮想外力が手先座標に依存するため、手先座標に関する情報が重要な役割を担っているためであると考えられる。
【0038】
第一種環境パラメータ取得手段212は、制御対象1の環境に関する第一種のパラメータである1以上の第一種環境パラメータの値を取得する。第一種環境パラメータは、例えば、目標地点までの距離、現在地点、ロボットアームの各関節の角度、角速度や、手先の位置と速度などである。第一種環境パラメータは、報酬関数に代入され得る値に対応するパラメータである。第一種環境パラメータ取得手段212は、例えば、高解像度のステレオカメラや距離センサ等、およびCPU等により実現され得る。
【0039】
制御パラメータ値算出手段213は、1以上の第一種環境パラメータを報酬関数に代入し、報酬関数が出力する報酬を最大とするような1以上の制御パラメータの値を算出する。制御パラメータは、制御対象の構造や学習アルゴリズムの種類に依存して決定される。なお、かかる処理は、強化学習である。強化学習のアルゴリズムにはQ学習、SARSA、方策勾配法などがあり、状況に応じて様々なものを実装できる。また、連続時間、連続空間における強化学習では、価値関数や方策の表現に関数近似器を用いる必要があり、これにはNGNet、RBF、ニューラルネット、CMACなど様々なものから選択可能である。強化学習のアルゴリズムは公知技術であるので、詳細な説明は省略する。
【0040】
制御パラメータ値出力手段214は、制御パラメータ値算出手段213が算出した1以上の制御パラメータの値を制御対象1に対して出力する。なお、ここでの出力とは、通常、仮想外力または第二仮想外力と合成されるための出力である。そして、合成された力(通常、ベクトル)が、制御対象1に与えられる。
【0041】
仮想外力発生器22は、仮想的な外力である仮想外力を発生し、制御対象1に対して出力する。仮想外力発生器22は、高解像度のステレオカメラや距離センサ等を用いて障害物の表面を検知し、障害物を避けるような仮想外力fvを手先に発生させる。なお、fvは手先座標系で表される仮想外力であり、最終的に、関節角座標系で表される仮想外力へと変換される。障害物を確実に避けるためには仮想外力fvを大きな値とする必要があるが、大きな力が突然発生することは、安全性や学習の安定性などの面から好ましくない。そこで仮想外力fvを障害物との距離に応じて滑らかに変化させることが好適である。つまり、例えば、図3に示すように、仮想外力発生器22は、障害物からの距離との関係を担保するように、仮想外力を発生させることは好適である。図3において、障害物との距離の3乗に比例して、仮想外力の大きさが変化する場合を示している。点線で表されている変数aが仮想外力の大きさを決定する。dは障害物との距離を表しており、wより近い領域では、変数aは距離dの3乗に比例して大きくなり、wより遠い領域では変数aはゼロとなる。距離wの近傍において変数aの変化は連続的になっていることが望ましい。また、変数aの増加の傾きは、物理系のパラメータから大まかに決定することができる。
【0042】
そして、手先に加わる仮想外力fvは変数aを用いて、数式2のように表される。
【数2】
【0043】
ここでhは、カメラや距離センサ等を用いて計測された、障害物表面に対して垂直な単位ベクトルである。
【0044】
また、仮想外力fvはヤコビ行列J(t)を用いて、手先座標系から関節座標系へと変換される。関節座標系における仮想外力uvは、数式3により算出され得る。
【数3】
【0045】
なお、手先自由度と関節自由度が異なる場合、ヤコビ行列の逆行列は計算できないので、その場合は擬似逆行列などを用いて対処する。手先自由度の方が関節自由度より大きいヤコビ行列の擬似逆行列は(JTJ)−1JT、また手先自由度より関節自由度が大きいヤコビ行列の擬似逆行列はJT(JJT)−1を用いることが先行研究では一般的に行われている。
【0046】
仮想外力発生器22を構成する仮想外力関数格納手段221は、仮想外力を出力とする仮想外力関数を格納し得る。なお、仮想外力関数とは、通常、障害物との距離をパラメータとする関数である。また、通常、仮想外力関数は、障害物との距離をパラメータとする減少関数である。また、例えば、仮想外力関数は、障害物との距離の3乗に比例して、仮想外力の大きさが小さくなる関数である。仮想外力関数は、数式2、数式3、図3により示される情報であることは好適である。
【0047】
第二種環境パラメータ取得手段222は、仮想外力に関連する第二種のパラメータである1以上の第二種環境パラメータの値を取得する。なお、第二種環境パラメータは、例えば、障害物との距離などである。また、第二種環境パラメータ取得手段222は、高解像度のステレオカメラや距離センサ等により実現され得る。
【0048】
仮想外力算出手段223は、仮想外力関数格納手段221の仮想外力関数に、1以上の第二種環境パラメータを代入し、仮想外力を算出する。
【0049】
仮想外力出力手段224は、仮想外力算出手段223が算出した仮想外力を制御対象1に対して出力する。なお、ここでの出力とは、通常、1以上の制御パラメータの値と合成されるための出力である。そして、合成された力(通常、ベクトル)が、制御対象1に与えられる。
【0050】
仮想外力近似器23は、仮想外力発生器22の出力uvを模擬する。仮想外力近似器23はどのような状態でどのような仮想外力が発生しているかを観測し、その近似出力uv^(^はuの真上に存在する)を学習する。そして、強化学習装置2は、近似精度が十分に良くなった後は、仮想外力発生器22の変わりに、仮想外力近似器23を用いることにより、高価な機器が無くても障害物を避けるための仮想外力を発生させられる。また、仮想外力近似器23は、以下の数式4により、近似出力uv^を算出する。なお、近似出力uv^は、第二の仮想外力とも言う。
【数4】
【0051】
数式4において、φは、後述する関数近似器である。また、数式4において、θは各関節の角度から構成されるベクトル、pは手先の位置ベクトル、tは時刻である。
【0052】
関数近似器格納手段231は、第二種環境パラメータとは少なくとも一部に異なる観測可能な第三種のパラメータである2以上の第三種パラメータを有し、第二の仮想外力を出力とする関数近似器を格納し得る。ここで、第三種パラメータは、例えば、関節の角度ベクトル、手先の位置ベクトル、時刻などである。第三種パラメータは、通常、制御対象1から値が得られるパラメータなどである。第三種パラメータは、ステレオカメラや距離センサなどの特別なハードウェアを用いずに観測可能なパラメータであることが好適である。また、第三種パラメータは、後述する状態情報が代入されるパラメータである。また、関数近似器とは、関数である。また、関数近似器は、NGNet、RBF、ニューラルネット、CMACなど様々なものから選択可能である。
【0053】
状態情報取得手段232は、制御対象1を観測し、制御対象1の状態に関する情報である1以上の状態情報を取得する。状態情報とは、関節の角度ベクトル、手先の位置ベクトルなどである。
【0054】
選択手段233は、状態情報取得手段232が取得した1以上の状態情報のうち、変化が閾値より大きい1以上の状態情報を取得する。選択手段233は、通常、障害物を避けるために重要な関節を制御するための情報である1以上の状態情報を取得する。
【0055】
第二仮想外力算出手段234は、状態情報を関数近似器に代入し、第二の仮想外力を算出する。また、第二仮想外力算出手段234は、例えば、数式4により、第二の仮想外力uv^を算出する。なお、第二仮想外力算出手段234は、選択手段233が取得した1以上の状態情報のみを関数近似器に代入し、第二の仮想外力を算出することは好適である。
【0056】
差異情報算出手段235は、仮想外力発生器22が出力する仮想外力と第二の仮想外力との差異に関する情報である差異情報を算出する。差異情報とは、差の絶対値でも良いし、差の絶対値の対数値などでも良い。差異情報算出手段235は、例えば、数式5により、差異情報eを算出する。数式5において、差異情報は、仮想外力と第二の仮想外力との差のノルムの2乗である。
【数5】
【0057】
近似手段236は、差異情報eが最小となるように、関数近似器のパラメータを更新する。さらに具体的には、近似手段236は、差異情報eを関数近似器のパラメータにより偏微分し、その勾配が下降する方向に向かって関数近似器のパラメータを更新する。この更新を繰り返す事により、近似手段236は、差異情報eを最も小さくするような関数近似器のパラメータを獲得できる。
【0058】
第二仮想外力出力手段237は、第二仮想外力算出手段234が算出した第二の仮想外力uv^を、制御対象1に出力する。なお、ここでの出力とは、通常、1以上の制御パラメータの値と合成されるための出力である。そして、合成された力(通常、ベクトル)が、制御対象1に与えられる。
【0059】
判断手段24は、差異情報eが所定の条件を満たすか否かを判断する。また、判断手段24は、差異情報の履歴が、所定の条件を満たすか否かを判断しても良い。所定の条件は、通常、差異情報eが閾値より小さい(閾値以下も含む)ことや、差異情報eが収束してきたこと等である。
【0060】
切替手段25は、判断手段24が所定の条件を満たすほど、仮想外力発生器22が出力する仮想外力と第二の仮想外力との差異が小さいと判断した場合に、制御対象1に対して出力する仮想外力を、仮想外力発生器22の出力から仮想外力近似器23の出力へ切り替える。なお、仮想外力近似器23が仮想外力発生器22の役割を十分模擬できたと、判断手段24が判断した場合には、仮想外力発生器22の出力から仮想外力発生器23の出力へ切り替え、近似手段236は、パラメータの更新を終了する。
【0061】
報酬関数格納手段211、仮想外力関数格納手段221、関数近似器格納手段231は、不揮発性の記録媒体が好適であるが、揮発性の記録媒体でも実現可能である。また、報酬関数格納手段211等に報酬関数等が記憶される過程は問わない。例えば、記録媒体を介して報酬関数等が報酬関数格納手段211等で記憶されるようになってもよく、通信回線等を介して送信された報酬関数等が報酬関数格納手段211等で記憶されるようになってもよく、あるいは、入力デバイスを介して入力された報酬関数等が報酬関数格納手段211等で記憶されるようになってもよい。
【0062】
制御パラメータ値算出手段213、制御パラメータ値出力手段214、第二種環境パラメータ取得手段222、仮想外力算出手段223、仮想外力出力手段224、状態情報取得手段232、選択手段233、第二仮想外力算出手段234、差異情報算出手段235、および近似手段236は、通常、MPUやメモリ等から実現され得る。制御パラメータ値算出手段213等の処理手順は、通常、ソフトウェアで実現され、当該ソフトウェアはROM等の記録媒体に記録されている。但し、ハードウェア(専用回路)で実現しても良い。
【0063】
次に、強化学習システムAの動作について、図4のフローチャートを用いて説明する。
【0064】
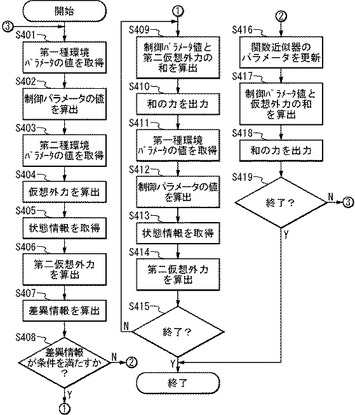
(ステップS401)強化学習器21の第一種環境パラメータ取得手段212は、制御対象1の1以上の第一種環境パラメータの値を取得する。
【0065】
(ステップS402)制御パラメータ値算出手段213は、報酬関数格納手段211から報酬関数を読み出す。そして、制御パラメータ値算出手段213は、当該報酬関数に、ステップS401で取得された1以上の第一種環境パラメータの値を代入し、報酬関数が出力する報酬を最大とするような1以上の制御パラメータの値を算出する。かかる場合のアルゴリズムは、Q学習、SARSA、方策勾配法など、上述したように問わない。
【0066】
(ステップS403)仮想外力発生器22の第二種環境パラメータ取得手段222は、1以上の第二種環境パラメータの値を取得する。
【0067】
(ステップS404)仮想外力算出手段223は、仮想外力関数格納手段221から仮想外力関数を読み出す。そして、仮想外力算出手段223は、当該仮想外力関数に、ステップS403で取得された1以上の第二種環境パラメータの値を代入し、仮想外力を算出する。
【0068】
(ステップS405)仮想外力近似器23を構成する状態情報取得手段232は、制御対象1を観測し、1以上の状態情報を取得する。
【0069】
(ステップS406)第二仮想外力算出手段234は、関数近似器格納手段231から関数近似器を読み出す。次に、第二仮想外力算出手段234は、当該関数近似器に、ステップS405で取得された1以上の状態情報を代入し、第二の仮想外力を算出する。なお、第二仮想外力を算出する前に、状態情報取得手段232が取得した1以上の状態情報のうち、選択手段233が、変化が閾値より大きい1以上の状態情報を選択し、第二仮想外力算出手段234は、当該選択された状態情報のみを利用して、第二仮想外力を算出しても良い。
【0070】
(ステップS407)差異情報算出手段235は、ステップS404で算出された仮想外力とステップS406で算出された第二仮想外力との差異情報を算出する。
【0071】
(ステップS408)判断手段24は、ステップS407で算出された差異情報が所定の条件を満たすほど、小さいか否かを判断する。なお、判断手段24は、時間的に連続する2以上の差異情報(差異情報の履歴)を用いて、所定の条件を満たすか否かを判断しても良い。所定の条件を満たす場合はステップS409に行き、所定の条件を満たさない場合はステップS416に行く。
【0072】
(ステップS409)強化学習装置2は、1以上の制御パラメータの値と第二仮想外力との和を算出する。なお、かかる算出は、強化学習装置2が有する図示しない合成手段によりなされる、と考えても良い。
【0073】
(ステップS410)強化学習装置2は、ステップS409で算出した和の力ベクトルを、制御対象に出力する。なお、かかる出力も、強化学習装置2が有する図示しない合成手段によりなされる、と考えても良い。
【0074】
(ステップS411)第一種環境パラメータ取得手段212は、制御対象1の1以上の第一種環境パラメータの値を取得する。
【0075】
(ステップS412)制御パラメータ値算出手段213は、報酬関数に、ステップS411で取得された1以上の第一種環境パラメータの値を代入し、報酬関数が出力する報酬を最大とするような1以上の制御パラメータの値を算出する。
【0076】
(ステップS413)状態情報取得手段232は、制御対象1を観測し、1以上の状態情報を取得する。
【0077】
(ステップS414)第二仮想外力算出手段234は、関数近似器に、ステップS413で取得された1以上の状態情報を代入し、第二仮想外力を算出する。
【0078】
(ステップS415)強化学習装置2は、処理を終了するか否かを判断する。処理を終了すると判断した場合は処理を終了し、処理を終了しないと判断した場合はステップS409に戻る。なお、目標を達成した場合に、処理を終了する、と判断される。なお、かかる判断は、判断手段24が行っても良い。
【0079】
(ステップS416)近似手段236は、ステップS407で取得した差異情報が最小となるように、関数近似器のパラメータを更新する。
【0080】
(ステップS417)強化学習装置2は、1以上の制御パラメータの値と仮想外力との和を算出する。なお、かかる算出は、強化学習装置2が有する図示しない合成手段によりなされる、と考えても良い。
【0081】
(ステップS418)強化学習装置2は、ステップS417で算出した和の力ベクトルを、制御対象に出力する。なお、かかる出力も、強化学習装置2が有する図示しない合成手段によりなされる、と考えても良い。
【0082】
(ステップS419)強化学習装置2は、処理を終了するか否かを判断する。処理を終了すると判断した場合は処理を終了し、処理を終了しないと判断した場合はステップS409に戻る。なお、目標を達成した場合に、処理を終了する、と判断される。なお、かかる判断は、判断手段24が行っても良い。
【0083】
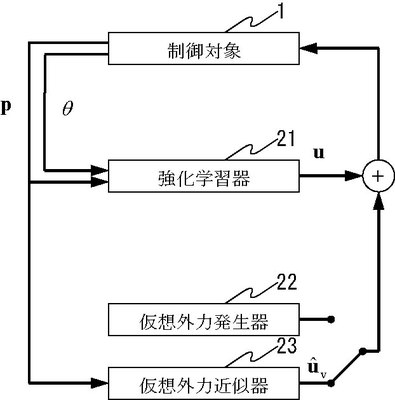
以下、本実施の形態における強化学習システムAの動作の概略について説明する。ここでの動作は、ロボットの手先に、仮想的な外力を発生させることで障害物を避ける2点間到達運動を行う動作である。強化学習システムAにおいて、障害物の表面に対し垂直な方向に仮想外力を発生させ(図1参照)、強化学習器の出力に足しこむことにより、障害物を回避しつつ到達運動を達成する。かかる場合の強化学習システムAを構成する強化学習器21、仮想外力発生器22、および仮想外力近似器23と制御対象1との概略図は図5である。
【0084】
図5において、強化学習器21は、与えられた報酬関数(例えば、数式1)に従い、2点間到達運動を行うための行動u(1以上の制御パラメータに該当)を出力する。行動uは、ロボットの各関節に与えられる制御力を並べたベクトルである。図5において、pは制御対象1の手先位置に関する情報である。また、θは制御対象1の関節の角度のベクトルである。
【0085】
また、仮想外力発生器22は、高解像度のステレオカメラや距離センサ等を用いて障害物を認識し、障害物と手先が反発するような仮想外力uvを算出する。行動uと仮想外力uvの和が各関節に与えられることで、強化学習装置2は、障害物を避けつつ、2点間到達運動を達成できる。
【0086】
また、仮想外力近似器23は、仮想外力発生器22の挙動を模擬するものであり、どのような時間や状態において、どのような仮想外力が出力されているのかを学習する。仮想外力近似器23の学習が十分に収束した後は、仮想外力発生器22の代わりに仮想外力近似器23の出力uv^を強化学習器の行動uに足しこむことで、仮想外力発生器22を用いずに課題を達成できるようになる(図6参照)。
(実験結果)
【0087】
以下、実験結果について説明する。本実験において、制御対象1は、7自由度のロボットアームである。そして、本実験において、7自由度のロボットアームシミュレータを用いて、障害物のある2点間到達運動課題を行った。その結果を図7に示す。なお、図7において、太い実線(70など)は、ロボットアームである。また、図7において、縦軸、横軸の座標は、ロボットアームの位置を示す。
【0088】
エージェント(強化学習装置2)は、ロボットアーム(制御対象1)の手先を初期位置(0.48,−0.16)から目標地点(0.3,0.3)まで障害物を避けながら到達する行動則を学習する。実線71、72は、障害物の表面を表しており、点線73、74よりも実線71、72に近づいたとき、変数aが0より大きくなり仮想外力fvが発生する。発生した手先座標系における仮想外力fvは、図の下部の実線(75、76、77、78等)で表している。
【0089】
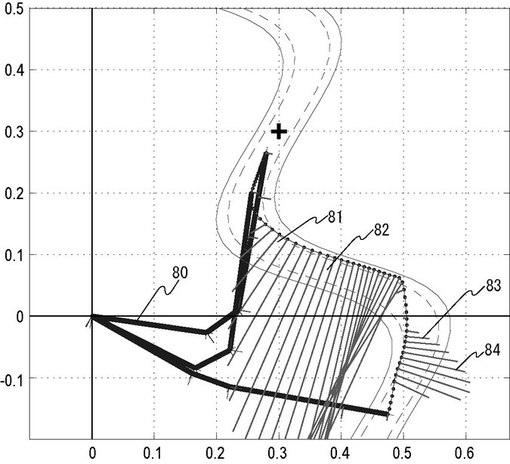
仮想外力近似器23の学習が十分に進んだ後、仮想外力発生器22を使用しない場合の結果を図8に示す。実線(81、82、83、84等)は関節座標系において近似された仮想外力uv^(t)[^はuの真上の存在する]をヤコビ行列J(t)によって手先座標系に変換した結果を示している。なお、図8において表示している、手先座標系における仮想外力の近似出力はアルゴリズムの実行上、必ずしも必要ではない。近似の結果を確認するため、便宜上算出したものである。この結果より、仮想外力発生器22が無くても障害物を避けながら目標地点にたどり着けていることが分かる。なお、図8において、太い実線(80など)は、ロボットアームである。
【0090】
以上、本実施の形態によれば、障害物の回避に対する要求を仮想外力によって解決するために、単純な報酬関数ですばやく、かつ安定して、ロボットの運動学習が行える。
【0091】
また、本実施の形態によれば、強化学習器21と仮想外力発生器22とを分離していることにより、運動開始位置や目標位置が変更した場合に、再学習を行うのは到達運動に関する部分(強化学習装置21)のみで足り、仮想外力近似器23の近似結果は、障害物の位置や形状が変わらない限り再利用することができる。
【0092】
また、本実施の形態によれば、仮想外力近似器23により、簡易な構成で制御対象を制御するための準備ができる。
【0093】
また、本実施の形態によれば、仮想外力発生器22から仮想外力近似器23への自動切り替えを行うことにより、簡易な構成で制御対象を制御することができる。
【0094】
また、本実施の形態によれば、特に、2点間到達運動課題を解決する制御対象1について、単純な報酬関数ですばやく、かつ安定して、ロボットの運動学習が行える。
【0095】
また、本実施の形態によれば、仮想外力の座標系は、制御対象1の特定の箇所に対する相対座標であることにより、障害物の位置や姿勢が変わった場合でも、仮想外力近似器の学習結果を再利用できる。
【0096】
さらに、本実施の形態によれば、選択手段233により、関数近似器のパラメータを絞ることができ、学習速度を短縮できる。さらに具体的には、数式3におけるヤコビ行列の逆行列を調べることにより、手先座標系における仮想外力の近似に各関節がどの程度寄与しているかを知ることが出来る。ヤコビ行列はロボットの設計図等から容易に求めることが出来るものであるため、実験前にヤコビ行列を算出することで関数近似器のパラメータを効率よく配置できる。このようにしてパラメータの個数を絞れば、学習時間を短縮できる。
【0097】
なお、本実施の形態によれば、強化学習装置2で構成された仮想外力近似器23と強化学習器21とを用いて、移動する制御対象を制御する制御装置が構築可能である。かかる制御装置により、簡易な構成で制御対象を制御することができる。
【0098】
また、本実施の形態によれば、強化学習装置2において、仮想外力近似器23、判断手段24、および切替手段25は存在しなくても良い。
【0099】
さらに、本実施の形態によれば、仮想外力近似器23において、選択手段233は存在しなくても良い。
(実施の形態2)
【0100】
本実施の形態において、強化学習器と仮想外力発生器とが分離していない強化学習装置等について説明する。
【0101】
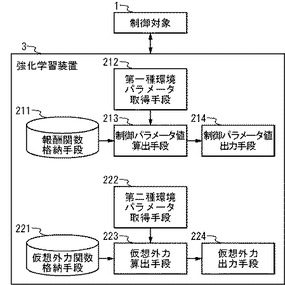
図9は、本実施の形態における強化学習システムBのブロック図である。
強化学習システムBは、制御対象1、強化学習装置3を具備する。強化学習装置3と強化学習装置2との違いは、強化学習器と仮想外力発生器とが分離しているか否かの違いである。強化学習装置3において、強化学習器と仮想外力発生器とが分離していない。
【0102】
強化学習装置3は、報酬関数格納手段211、第一種環境パラメータ取得手段212、制御パラメータ値算出手段213、制御パラメータ値出力手段214、仮想外力関数格納手段221、第二種環境パラメータ取得手段222、仮想外力算出手段223、仮想外力出力手段224を具備する。
【0103】
なお、強化学習装置3と強化学習装置2とは、その動作は同様であるので、強化学習装置3の動作の説明を省略する。
【0104】
以上、本実施の形態によれば、障害物の回避に対する要求を仮想外力によって解決するために、単純な報酬関数ですばやく、かつ安定して、ロボットの運動学習が行える。
【0105】
また、本実施の形態によれば、特に、2点間到達運動課題を解決する制御対象1について、単純な報酬関数ですばやく、かつ安定して、ロボットの運動学習が行える。
【0106】
なお、図10は、本明細書で述べたプログラムを実行して、上述した実施の形態の強化学習装置等を実現するコンピュータの外観を示す。上述の実施の形態は、コンピュータハードウェア及びその上で実行されるコンピュータプログラムで実現され得る。図10は、このコンピュータシステム340の概観図であり、図11は、コンピュータシステム340のブロック図である。
【0107】
図10において、コンピュータシステム340は、FDドライブ、CD−ROMドライブを含むコンピュータ341と、キーボード342と、マウス343と、モニタ344とを含む。
【0108】
図11において、コンピュータ341は、FDドライブ3411、CD−ROMドライブ3412に加えて、MPU3413と、CD−ROMドライブ3412及びFDドライブ3411に接続されたバス3414と、ブートアッププログラム等のプログラムを記憶するためのROM3415とに接続され、アプリケーションプログラムの命令を一時的に記憶するとともに一時記憶空間を提供するためのRAM3416と、アプリケーションプログラム、システムプログラム、及びデータを記憶するためのハードディスク3417とを含む。ここでは、図示しないが、コンピュータ341は、さらに、LANへの接続を提供するネットワークカードを含んでも良い。
【0109】
コンピュータシステム340に、上述した実施の形態の強化学習装置等の機能を実行させるプログラムは、CD−ROM3501、またはFD3502に記憶されて、CD−ROMドライブ3412またはFDドライブ3411に挿入され、さらにハードディスク3417に転送されても良い。これに代えて、プログラムは、図示しないネットワークを介してコンピュータ341に送信され、ハードディスク3417に記憶されても良い。プログラムは実行の際にRAM3416にロードされる。プログラムは、CD−ROM3501、FD3502またはネットワークから直接、ロードされても良い。
【0110】
プログラムは、コンピュータ341に、上述した実施の形態の強化学習装置等の機能を実行させるオペレーティングシステム(OS)、またはサードパーティープログラム等は、必ずしも含まなくても良い。プログラムは、制御された態様で適切な機能(モジュール)を呼び出し、所望の結果が得られるようにする命令の部分のみを含んでいれば良い。コンピュータシステム340がどのように動作するかは周知であり、詳細な説明は省略する。
【0111】
なお、上記プログラムにおいて、情報を送信する送信ステップや、情報を受信する受信ステップなどでは、ハードウェアによって行われる処理、例えば、送信ステップにおけるモデムやインターフェースカードなどで行われる処理(ハードウェアでしか行われない処理)は含まれない。
【0112】
また、上記プログラムを実行するコンピュータは、単数であってもよく、複数であってもよい。すなわち、集中処理を行ってもよく、あるいは分散処理を行ってもよい。
【0113】
また、上記各実施の形態において、各処理(各機能)は、単一の装置(システム)によって集中処理されることによって実現されてもよく、あるいは、複数の装置によって分散処理されることによって実現されてもよい。
本発明は、以上の実施の形態に限定されることなく、種々の変更が可能であり、それらも本発明の範囲内に包含されるものであることは言うまでもない。
【産業上の利用可能性】
【0114】
以上のように、本発明にかかる強化学習システムは、すばやくかつ安定して、ロボットの運動学習が行える、という効果を有し、ロボットの制御システム等として有用である。
【符号の説明】
【0115】
1 制御対象
2、3 強化学習装置
21 強化学習器
22 仮想外力発生器
23 仮想外力近似器
24 判断手段
25 切替手段
211 報酬関数格納手段
212 第一種環境パラメータ取得手段
213 制御パラメータ値算出手段
214 制御パラメータ値出力手段
221 仮想外力関数格納手段
222 第二種環境パラメータ取得手段
223 仮想外力算出手段
224 仮想外力出力手段
231 関数近似器格納手段
232 状態情報取得手段
233 選択手段
234 第二仮想外力算出手段
235 差異情報算出手段
236 近似手段
237 第二仮想外力出力手段
【技術分野】
【0001】
本発明は、ロボットの運動学習を行う強化学習装置等に関するものである。
【背景技術】
【0002】
強化学習は制御対象や環境のダイナミクスが未知であっても実装可能であり、また課題に応じた報酬関数を設定するだけで自律的に学習を行うため、ロボットの運動学習手法として広く用いられている(例えば、特許文献1参照)。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開2007−66242号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
しかしながら、従来の技術において、複雑な運動軌道のための報酬関数は様々な項の和で表現されることが多く、各項の間で発生するトレードオフが学習の妨げとなる(これをトレードオフ問題という)、という課題があった。例えば、2点間到達運動課題における報酬関数は、一般に、目標地点で与えられる正の報酬と使用したエネルギーに対する負の報酬から構成される。この2つの要素の比率を適切なものに設定しないと、学習結果の速度が非常に速くなったり、遅くなったりと、望ましくない運動軌道となってしまう。さらに到達運動に加え、障害物回避等の要求が加わると、このトレードオフ問題はさらに困難なものとなる。障害物に接触したときの負の報酬が小さすぎると障害物にぶつかってしまい、また大きすぎると開始地点から動かないような学習結果となってしまう。報酬関数が複雑になってしまった場合、要素間のバランス調節を設計者が経験的に行わなければならず、強化学習の利点を損なってしまう。
【課題を解決するための手段】
【0005】
本第一の発明の強化学習装置は、報酬を出力とする報酬関数を格納し得る報酬関数格納手段と、移動する制御対象の環境に関する第一種のパラメータである1以上の第一種環境パラメータの値を取得する第一種環境パラメータ取得手段と、1以上の第一種環境パラメータの値を報酬関数に代入し、報酬関数が出力する報酬を最大とするような1以上の制御パラメータの値を算出する制御パラメータ値算出手段と、1以上の制御パラメータの値を制御対象に対して出力する制御パラメータ値出力手段と、仮想的な外力である仮想外力を出力とする仮想外力関数を格納し得る仮想外力関数格納手段と、仮想外力に関連する第二種のパラメータである1以上の第二種環境パラメータの値を取得する第二種環境パラメータ取得手段と、1以上の第二種環境パラメータを仮想外力関数に代入し、仮想外力を算出する仮想外力算出手段と、仮想外力を制御対象に対して出力する仮想外力出力手段とを具備する強化学習装置である。
【0006】
かかる構成により、障害物の回避に対する要求を仮想外力によって解決するために、単純な報酬関数ですばやく、かつ安定して、ロボットの運動学習が行える。
【0007】
また、本第二の発明の強化学習装置は、第一の発明に対して、強化学習器と、強化学習器とは分離されている仮想外力発生器とを具備する強化学習装置であって、強化学習器は、報酬関数格納手段と、第一種環境パラメータ取得手段と、制御パラメータ値算出手段と、制御パラメータ値出力手段とを具備し、仮想外力発生器は、仮想外力関数格納手段と、第二種環境パラメータ取得手段と、仮想外力算出手段と、仮想外力出力手段とを具備する強化学習装置である。
【0008】
かかる構成により、運動開始位置や目標位置が変更した場合に、再学習を行うのは到達運動に関する部分のみで足り、回避運動に関する学習結果は、障害物の位置や形状が変わらない限り再利用することができる。
【0009】
また、本第三の発明の強化学習装置は、第一または第二の発明に対して、制御パラメータ値出力手段が出力する1以上の制御パラメータの値と、仮想外力出力手段が出力する仮想外力とが加えられて制御対象に与えられる強化学習装置である。
【0010】
かかる構成により、障害物の回避に対する要求を仮想外力によって解決するために、単純な報酬関数ですばやく、かつ安定して、ロボットの運動学習が行える。
【0011】
また、本第四の発明の強化学習装置は、第一から第三いずれかの発明に対して、強化学習装置は、仮想外力近似器をさらに具備し、仮想外力近似器は、第二種環境パラメータとは少なくとも一部に異なる観測可能な第三種のパラメータである2以上の第三種パラメータを有し、第二の仮想外力を出力とする関数近似器を格納し得る関数近似器格納手段と、制御対象を観測し、制御対象の状態に関する情報である1以上の状態情報を取得する状態情報取得手段と、状態情報を関数近似器に代入し、第二の仮想外力を算出する第二仮想外力算出手段と、仮想外力発生器が出力する仮想外力と第二の仮想外力との差異に関する情報である差異情報を算出する差異情報算出手段と、差異情報が最小となるように、関数近似器のパラメータを更新する近似手段とを具備する強化学習装置である。
【0012】
かかる構成により、簡易な構成で制御対象を制御するための準備ができる。
【0013】
また、本第五の発明の強化学習装置は、第四の発明に対して、差異情報が所定の条件を満たすか否かを判断する判断手段と、判断手段が所定の条件を満たすほど、仮想外力発生器が出力する仮想外力と第二の仮想外力との差異が小さいと判断した場合に、制御対象に対して出力する仮想外力を、仮想外力発生器の出力から仮想外力近似器の出力へ切り替える切替手段とをさらに具備する強化学習装置である。
【0014】
かかる構成により、簡易な構成で制御対象を制御することができる。
【0015】
また、本第六の発明の強化学習装置は、第一から第五いずれかの発明に対して、障害物を避けながら一の目標地点に到達する課題である2点間到達運動課題を解決する強化学習装置である。
【0016】
かかる構成により、2点間到達運動課題を解決する制御対象について、単純な報酬関数ですばやく、かつ安定して、ロボットの運動学習が行える。
【0017】
また、本第七の発明の強化学習装置は、第四から第六いずれかの発明に対して、仮想外力の座標系は、制御対象の特定の箇所に対する相対座標である強化学習装置である。
【0018】
かかる構成により、障害物の位置や姿勢が変わった場合でも、仮想外力近似器の学習結果を再利用できる。
【0019】
また、本第八の発明の強化学習装置は、第四から第七いずれかの発明に対して、状態情報取得手段が取得した1以上の状態情報のうち、変化が閾値より大きい1以上の状態情報を取得する選択手段をさらに具備し、第二仮想外力算出手段は、選択手段が取得した1以上の状態情報のみを関数近似器に代入し、第二の仮想外力を算出する強化学習装置である。
【0020】
かかる構成により、関数近似器のパラメータを絞ることができ、学習速度を短縮できる。
【0021】
また、本第九の発明の制御装置は、第四から第八いずれかの発明に対して、仮想外力近似器と、強化学習器とを用いて、移動する制御対象を制御する制御装置である。
【0022】
かかる構成により、簡易な構成で制御対象を制御することができる。
【発明の効果】
【0023】
本発明による強化学習装置によれば、すばやくかつ安定して、ロボットの運動学習が行える。
【図面の簡単な説明】
【0024】
【図1】実施の形態1における強化学習システムが行う動作を説明する概略図
【図2】同強化学習システムのブロック図
【図3】同障害物との距離と仮想外力との関係を示す図
【図4】同強化学習システムの動作について説明するフローチャート
【図5】同強化学習器、仮想外力発生器、および仮想外力近似器と制御対象との概略図
【図6】同強化学習器、仮想外力発生器、および仮想外力近似器と制御対象との概略図
【図7】同実験結果を示す図
【図8】同実験結果を示す図
【図9】実施の形態2における強化学習システムのブロック図
【図10】上記実施の形態におけるコンピュータシステムの概観図
【図11】同コンピュータシステムのブロック図
【発明を実施するための形態】
【0025】
以下、強化学習システム等の実施形態について図面を参照して説明する。なお、実施の形態において同じ符号を付した構成要素は同様の動作を行うので、再度の説明を省略する場合がある。
(実施の形態1)
【0026】
本実施の形態において、仮想的な外力を発生させる機能を有する強化学習装置等について説明する。また、本実施の形態において、強化学習装置を構成する強化学習器と仮想外力発生器とが分離している強化学習装置について説明する。また、本実施の形態において、仮想外力発生器から仮想外力近似器への自動切り替えを行える強化学習装置について説明する。また、本実施の形態において、仮想外力発生器の再利用性を向上できる強化学習装置について説明する。さらに、本実施の形態において、関数近似器のモデル選択を行える強化学習装置について説明する。
【0027】
図1は、本実施の形態における強化学習システムAが行う動作を説明する概略図である。強化学習システムAは、主として、障害物を避けて移動を行う制御対象に対して強化学習を行うシステムである。また、図1に示すように、強化学習システムAは、例えば、制御対象であるロボットアームの手先に仮想的な外力を発生させることで障害物を避けて移動する。強化学習システムAにおいて、例えば、障害物の表面に対し垂直な方向に仮想外力を発生させ、強化学習器の出力に足しこむことで障害物を回避しつつ到達運動を達成する。
【0028】
図2は、本実施の形態における強化学習システムAのブロック図である。強化学習システムAは、制御対象1、および強化学習装置2を具備する。また、強化学習装置2は、強化学習器21、仮想外力発生器22、仮想外力近似器23、判断手段24、および切替手段25を具備する。
【0029】
また、強化学習器21は、報酬関数格納手段211、第一種環境パラメータ取得手段212、制御パラメータ値算出手段213、および制御パラメータ値出力手段214を具備する。
【0030】
また、仮想外力発生器22は、仮想外力関数格納手段221、第二種環境パラメータ取得手段222、仮想外力算出手段223、および仮想外力出力手段224を具備する。
【0031】
さらに、仮想外力近似器23は、関数近似器格納手段231、状態情報取得手段232、選択手段233、第二仮想外力算出手段234、差異情報算出手段235、近似手段236、および第二仮想外力出力手段237を具備する。
【0032】
制御対象1は、制御の対象であり、例えば、移動するロボットである。また、制御対象1は、例えば、2点間到達運動を達成するロボットである。
【0033】
強化学習装置2を構成する強化学習器21は、制御対象1や環境のダイナミクスが未知であっても実装可能であり、また課題に応じた報酬関数を設定するだけで自律的に学習を行える装置である。
【0034】
強化学習器21を構成する報酬関数格納手段211は、報酬関数を格納し得る。報酬関数は、報酬を出力とする。また、報酬関数は、通常、2以上の項の和で表現される。例えば、2点間到達運動課題における報酬関数は、一般に、目標点までの距離に応じた正の報酬と、出力の大きさに応じた負の報酬の和から構成される。さらに具体的には、例えば、報酬関数は、目標点までの距離に応じた正の報酬をガウス分布、出力の大きさに応じた負の報酬を2次形式とした関数である。
【0035】
また、報酬関数r(t)は、例えば、以下の数式1である。なお、tは時刻である。
【数1】
【0036】
数式1において、p(t)は手先位置、pgoalは手先の目標位置、σは正の報酬が与えられる範囲を決めるパラメータである。また、u(t)は、時刻tにおける行動である。行動とは、制御対象の運動を決定する情報である。行動uは、例えば、ロボットの各関節に与えられる制御力を並べたベクトルである。さらに、Rは、行列であり、制御力の大きさに対する負の報酬を決めるパラメータであり、一般に正定行列を用いる。Rが大きいと小さな制御力でゆっくりゴールへ、また逆に小さいと大きな制御力で素早くゴールへ向かう運動を学習する。なお、行動uは、後述する1以上の制御パラメータである。また、1以上の制御パラメータは、制御パラメータ値算出手段213により算出される。
【0037】
また、強化学習を行うエージェント(強化学習装置2に該当)は、例えば、状態空間上を試行錯誤によって探索することで、報酬を最大とするような行動則を学習する。ただし、どのような変数を状態空間に取るかは様々な方法がある。ロボットアームの制御では各関節の角度と角速度からなるベクトルを状態空間とすることが一般的である。一方、障害物のある2点間到達運動では、関節の角度と角速度に加えて、手先の位置と速度も状態空間に含めることにより、学習効率が飛躍的に上昇する。これは、報酬関数や仮想外力が手先座標に依存するため、手先座標に関する情報が重要な役割を担っているためであると考えられる。
【0038】
第一種環境パラメータ取得手段212は、制御対象1の環境に関する第一種のパラメータである1以上の第一種環境パラメータの値を取得する。第一種環境パラメータは、例えば、目標地点までの距離、現在地点、ロボットアームの各関節の角度、角速度や、手先の位置と速度などである。第一種環境パラメータは、報酬関数に代入され得る値に対応するパラメータである。第一種環境パラメータ取得手段212は、例えば、高解像度のステレオカメラや距離センサ等、およびCPU等により実現され得る。
【0039】
制御パラメータ値算出手段213は、1以上の第一種環境パラメータを報酬関数に代入し、報酬関数が出力する報酬を最大とするような1以上の制御パラメータの値を算出する。制御パラメータは、制御対象の構造や学習アルゴリズムの種類に依存して決定される。なお、かかる処理は、強化学習である。強化学習のアルゴリズムにはQ学習、SARSA、方策勾配法などがあり、状況に応じて様々なものを実装できる。また、連続時間、連続空間における強化学習では、価値関数や方策の表現に関数近似器を用いる必要があり、これにはNGNet、RBF、ニューラルネット、CMACなど様々なものから選択可能である。強化学習のアルゴリズムは公知技術であるので、詳細な説明は省略する。
【0040】
制御パラメータ値出力手段214は、制御パラメータ値算出手段213が算出した1以上の制御パラメータの値を制御対象1に対して出力する。なお、ここでの出力とは、通常、仮想外力または第二仮想外力と合成されるための出力である。そして、合成された力(通常、ベクトル)が、制御対象1に与えられる。
【0041】
仮想外力発生器22は、仮想的な外力である仮想外力を発生し、制御対象1に対して出力する。仮想外力発生器22は、高解像度のステレオカメラや距離センサ等を用いて障害物の表面を検知し、障害物を避けるような仮想外力fvを手先に発生させる。なお、fvは手先座標系で表される仮想外力であり、最終的に、関節角座標系で表される仮想外力へと変換される。障害物を確実に避けるためには仮想外力fvを大きな値とする必要があるが、大きな力が突然発生することは、安全性や学習の安定性などの面から好ましくない。そこで仮想外力fvを障害物との距離に応じて滑らかに変化させることが好適である。つまり、例えば、図3に示すように、仮想外力発生器22は、障害物からの距離との関係を担保するように、仮想外力を発生させることは好適である。図3において、障害物との距離の3乗に比例して、仮想外力の大きさが変化する場合を示している。点線で表されている変数aが仮想外力の大きさを決定する。dは障害物との距離を表しており、wより近い領域では、変数aは距離dの3乗に比例して大きくなり、wより遠い領域では変数aはゼロとなる。距離wの近傍において変数aの変化は連続的になっていることが望ましい。また、変数aの増加の傾きは、物理系のパラメータから大まかに決定することができる。
【0042】
そして、手先に加わる仮想外力fvは変数aを用いて、数式2のように表される。
【数2】
【0043】
ここでhは、カメラや距離センサ等を用いて計測された、障害物表面に対して垂直な単位ベクトルである。
【0044】
また、仮想外力fvはヤコビ行列J(t)を用いて、手先座標系から関節座標系へと変換される。関節座標系における仮想外力uvは、数式3により算出され得る。
【数3】
【0045】
なお、手先自由度と関節自由度が異なる場合、ヤコビ行列の逆行列は計算できないので、その場合は擬似逆行列などを用いて対処する。手先自由度の方が関節自由度より大きいヤコビ行列の擬似逆行列は(JTJ)−1JT、また手先自由度より関節自由度が大きいヤコビ行列の擬似逆行列はJT(JJT)−1を用いることが先行研究では一般的に行われている。
【0046】
仮想外力発生器22を構成する仮想外力関数格納手段221は、仮想外力を出力とする仮想外力関数を格納し得る。なお、仮想外力関数とは、通常、障害物との距離をパラメータとする関数である。また、通常、仮想外力関数は、障害物との距離をパラメータとする減少関数である。また、例えば、仮想外力関数は、障害物との距離の3乗に比例して、仮想外力の大きさが小さくなる関数である。仮想外力関数は、数式2、数式3、図3により示される情報であることは好適である。
【0047】
第二種環境パラメータ取得手段222は、仮想外力に関連する第二種のパラメータである1以上の第二種環境パラメータの値を取得する。なお、第二種環境パラメータは、例えば、障害物との距離などである。また、第二種環境パラメータ取得手段222は、高解像度のステレオカメラや距離センサ等により実現され得る。
【0048】
仮想外力算出手段223は、仮想外力関数格納手段221の仮想外力関数に、1以上の第二種環境パラメータを代入し、仮想外力を算出する。
【0049】
仮想外力出力手段224は、仮想外力算出手段223が算出した仮想外力を制御対象1に対して出力する。なお、ここでの出力とは、通常、1以上の制御パラメータの値と合成されるための出力である。そして、合成された力(通常、ベクトル)が、制御対象1に与えられる。
【0050】
仮想外力近似器23は、仮想外力発生器22の出力uvを模擬する。仮想外力近似器23はどのような状態でどのような仮想外力が発生しているかを観測し、その近似出力uv^(^はuの真上に存在する)を学習する。そして、強化学習装置2は、近似精度が十分に良くなった後は、仮想外力発生器22の変わりに、仮想外力近似器23を用いることにより、高価な機器が無くても障害物を避けるための仮想外力を発生させられる。また、仮想外力近似器23は、以下の数式4により、近似出力uv^を算出する。なお、近似出力uv^は、第二の仮想外力とも言う。
【数4】
【0051】
数式4において、φは、後述する関数近似器である。また、数式4において、θは各関節の角度から構成されるベクトル、pは手先の位置ベクトル、tは時刻である。
【0052】
関数近似器格納手段231は、第二種環境パラメータとは少なくとも一部に異なる観測可能な第三種のパラメータである2以上の第三種パラメータを有し、第二の仮想外力を出力とする関数近似器を格納し得る。ここで、第三種パラメータは、例えば、関節の角度ベクトル、手先の位置ベクトル、時刻などである。第三種パラメータは、通常、制御対象1から値が得られるパラメータなどである。第三種パラメータは、ステレオカメラや距離センサなどの特別なハードウェアを用いずに観測可能なパラメータであることが好適である。また、第三種パラメータは、後述する状態情報が代入されるパラメータである。また、関数近似器とは、関数である。また、関数近似器は、NGNet、RBF、ニューラルネット、CMACなど様々なものから選択可能である。
【0053】
状態情報取得手段232は、制御対象1を観測し、制御対象1の状態に関する情報である1以上の状態情報を取得する。状態情報とは、関節の角度ベクトル、手先の位置ベクトルなどである。
【0054】
選択手段233は、状態情報取得手段232が取得した1以上の状態情報のうち、変化が閾値より大きい1以上の状態情報を取得する。選択手段233は、通常、障害物を避けるために重要な関節を制御するための情報である1以上の状態情報を取得する。
【0055】
第二仮想外力算出手段234は、状態情報を関数近似器に代入し、第二の仮想外力を算出する。また、第二仮想外力算出手段234は、例えば、数式4により、第二の仮想外力uv^を算出する。なお、第二仮想外力算出手段234は、選択手段233が取得した1以上の状態情報のみを関数近似器に代入し、第二の仮想外力を算出することは好適である。
【0056】
差異情報算出手段235は、仮想外力発生器22が出力する仮想外力と第二の仮想外力との差異に関する情報である差異情報を算出する。差異情報とは、差の絶対値でも良いし、差の絶対値の対数値などでも良い。差異情報算出手段235は、例えば、数式5により、差異情報eを算出する。数式5において、差異情報は、仮想外力と第二の仮想外力との差のノルムの2乗である。
【数5】
【0057】
近似手段236は、差異情報eが最小となるように、関数近似器のパラメータを更新する。さらに具体的には、近似手段236は、差異情報eを関数近似器のパラメータにより偏微分し、その勾配が下降する方向に向かって関数近似器のパラメータを更新する。この更新を繰り返す事により、近似手段236は、差異情報eを最も小さくするような関数近似器のパラメータを獲得できる。
【0058】
第二仮想外力出力手段237は、第二仮想外力算出手段234が算出した第二の仮想外力uv^を、制御対象1に出力する。なお、ここでの出力とは、通常、1以上の制御パラメータの値と合成されるための出力である。そして、合成された力(通常、ベクトル)が、制御対象1に与えられる。
【0059】
判断手段24は、差異情報eが所定の条件を満たすか否かを判断する。また、判断手段24は、差異情報の履歴が、所定の条件を満たすか否かを判断しても良い。所定の条件は、通常、差異情報eが閾値より小さい(閾値以下も含む)ことや、差異情報eが収束してきたこと等である。
【0060】
切替手段25は、判断手段24が所定の条件を満たすほど、仮想外力発生器22が出力する仮想外力と第二の仮想外力との差異が小さいと判断した場合に、制御対象1に対して出力する仮想外力を、仮想外力発生器22の出力から仮想外力近似器23の出力へ切り替える。なお、仮想外力近似器23が仮想外力発生器22の役割を十分模擬できたと、判断手段24が判断した場合には、仮想外力発生器22の出力から仮想外力発生器23の出力へ切り替え、近似手段236は、パラメータの更新を終了する。
【0061】
報酬関数格納手段211、仮想外力関数格納手段221、関数近似器格納手段231は、不揮発性の記録媒体が好適であるが、揮発性の記録媒体でも実現可能である。また、報酬関数格納手段211等に報酬関数等が記憶される過程は問わない。例えば、記録媒体を介して報酬関数等が報酬関数格納手段211等で記憶されるようになってもよく、通信回線等を介して送信された報酬関数等が報酬関数格納手段211等で記憶されるようになってもよく、あるいは、入力デバイスを介して入力された報酬関数等が報酬関数格納手段211等で記憶されるようになってもよい。
【0062】
制御パラメータ値算出手段213、制御パラメータ値出力手段214、第二種環境パラメータ取得手段222、仮想外力算出手段223、仮想外力出力手段224、状態情報取得手段232、選択手段233、第二仮想外力算出手段234、差異情報算出手段235、および近似手段236は、通常、MPUやメモリ等から実現され得る。制御パラメータ値算出手段213等の処理手順は、通常、ソフトウェアで実現され、当該ソフトウェアはROM等の記録媒体に記録されている。但し、ハードウェア(専用回路)で実現しても良い。
【0063】
次に、強化学習システムAの動作について、図4のフローチャートを用いて説明する。
【0064】
(ステップS401)強化学習器21の第一種環境パラメータ取得手段212は、制御対象1の1以上の第一種環境パラメータの値を取得する。
【0065】
(ステップS402)制御パラメータ値算出手段213は、報酬関数格納手段211から報酬関数を読み出す。そして、制御パラメータ値算出手段213は、当該報酬関数に、ステップS401で取得された1以上の第一種環境パラメータの値を代入し、報酬関数が出力する報酬を最大とするような1以上の制御パラメータの値を算出する。かかる場合のアルゴリズムは、Q学習、SARSA、方策勾配法など、上述したように問わない。
【0066】
(ステップS403)仮想外力発生器22の第二種環境パラメータ取得手段222は、1以上の第二種環境パラメータの値を取得する。
【0067】
(ステップS404)仮想外力算出手段223は、仮想外力関数格納手段221から仮想外力関数を読み出す。そして、仮想外力算出手段223は、当該仮想外力関数に、ステップS403で取得された1以上の第二種環境パラメータの値を代入し、仮想外力を算出する。
【0068】
(ステップS405)仮想外力近似器23を構成する状態情報取得手段232は、制御対象1を観測し、1以上の状態情報を取得する。
【0069】
(ステップS406)第二仮想外力算出手段234は、関数近似器格納手段231から関数近似器を読み出す。次に、第二仮想外力算出手段234は、当該関数近似器に、ステップS405で取得された1以上の状態情報を代入し、第二の仮想外力を算出する。なお、第二仮想外力を算出する前に、状態情報取得手段232が取得した1以上の状態情報のうち、選択手段233が、変化が閾値より大きい1以上の状態情報を選択し、第二仮想外力算出手段234は、当該選択された状態情報のみを利用して、第二仮想外力を算出しても良い。
【0070】
(ステップS407)差異情報算出手段235は、ステップS404で算出された仮想外力とステップS406で算出された第二仮想外力との差異情報を算出する。
【0071】
(ステップS408)判断手段24は、ステップS407で算出された差異情報が所定の条件を満たすほど、小さいか否かを判断する。なお、判断手段24は、時間的に連続する2以上の差異情報(差異情報の履歴)を用いて、所定の条件を満たすか否かを判断しても良い。所定の条件を満たす場合はステップS409に行き、所定の条件を満たさない場合はステップS416に行く。
【0072】
(ステップS409)強化学習装置2は、1以上の制御パラメータの値と第二仮想外力との和を算出する。なお、かかる算出は、強化学習装置2が有する図示しない合成手段によりなされる、と考えても良い。
【0073】
(ステップS410)強化学習装置2は、ステップS409で算出した和の力ベクトルを、制御対象に出力する。なお、かかる出力も、強化学習装置2が有する図示しない合成手段によりなされる、と考えても良い。
【0074】
(ステップS411)第一種環境パラメータ取得手段212は、制御対象1の1以上の第一種環境パラメータの値を取得する。
【0075】
(ステップS412)制御パラメータ値算出手段213は、報酬関数に、ステップS411で取得された1以上の第一種環境パラメータの値を代入し、報酬関数が出力する報酬を最大とするような1以上の制御パラメータの値を算出する。
【0076】
(ステップS413)状態情報取得手段232は、制御対象1を観測し、1以上の状態情報を取得する。
【0077】
(ステップS414)第二仮想外力算出手段234は、関数近似器に、ステップS413で取得された1以上の状態情報を代入し、第二仮想外力を算出する。
【0078】
(ステップS415)強化学習装置2は、処理を終了するか否かを判断する。処理を終了すると判断した場合は処理を終了し、処理を終了しないと判断した場合はステップS409に戻る。なお、目標を達成した場合に、処理を終了する、と判断される。なお、かかる判断は、判断手段24が行っても良い。
【0079】
(ステップS416)近似手段236は、ステップS407で取得した差異情報が最小となるように、関数近似器のパラメータを更新する。
【0080】
(ステップS417)強化学習装置2は、1以上の制御パラメータの値と仮想外力との和を算出する。なお、かかる算出は、強化学習装置2が有する図示しない合成手段によりなされる、と考えても良い。
【0081】
(ステップS418)強化学習装置2は、ステップS417で算出した和の力ベクトルを、制御対象に出力する。なお、かかる出力も、強化学習装置2が有する図示しない合成手段によりなされる、と考えても良い。
【0082】
(ステップS419)強化学習装置2は、処理を終了するか否かを判断する。処理を終了すると判断した場合は処理を終了し、処理を終了しないと判断した場合はステップS409に戻る。なお、目標を達成した場合に、処理を終了する、と判断される。なお、かかる判断は、判断手段24が行っても良い。
【0083】
以下、本実施の形態における強化学習システムAの動作の概略について説明する。ここでの動作は、ロボットの手先に、仮想的な外力を発生させることで障害物を避ける2点間到達運動を行う動作である。強化学習システムAにおいて、障害物の表面に対し垂直な方向に仮想外力を発生させ(図1参照)、強化学習器の出力に足しこむことにより、障害物を回避しつつ到達運動を達成する。かかる場合の強化学習システムAを構成する強化学習器21、仮想外力発生器22、および仮想外力近似器23と制御対象1との概略図は図5である。
【0084】
図5において、強化学習器21は、与えられた報酬関数(例えば、数式1)に従い、2点間到達運動を行うための行動u(1以上の制御パラメータに該当)を出力する。行動uは、ロボットの各関節に与えられる制御力を並べたベクトルである。図5において、pは制御対象1の手先位置に関する情報である。また、θは制御対象1の関節の角度のベクトルである。
【0085】
また、仮想外力発生器22は、高解像度のステレオカメラや距離センサ等を用いて障害物を認識し、障害物と手先が反発するような仮想外力uvを算出する。行動uと仮想外力uvの和が各関節に与えられることで、強化学習装置2は、障害物を避けつつ、2点間到達運動を達成できる。
【0086】
また、仮想外力近似器23は、仮想外力発生器22の挙動を模擬するものであり、どのような時間や状態において、どのような仮想外力が出力されているのかを学習する。仮想外力近似器23の学習が十分に収束した後は、仮想外力発生器22の代わりに仮想外力近似器23の出力uv^を強化学習器の行動uに足しこむことで、仮想外力発生器22を用いずに課題を達成できるようになる(図6参照)。
(実験結果)
【0087】
以下、実験結果について説明する。本実験において、制御対象1は、7自由度のロボットアームである。そして、本実験において、7自由度のロボットアームシミュレータを用いて、障害物のある2点間到達運動課題を行った。その結果を図7に示す。なお、図7において、太い実線(70など)は、ロボットアームである。また、図7において、縦軸、横軸の座標は、ロボットアームの位置を示す。
【0088】
エージェント(強化学習装置2)は、ロボットアーム(制御対象1)の手先を初期位置(0.48,−0.16)から目標地点(0.3,0.3)まで障害物を避けながら到達する行動則を学習する。実線71、72は、障害物の表面を表しており、点線73、74よりも実線71、72に近づいたとき、変数aが0より大きくなり仮想外力fvが発生する。発生した手先座標系における仮想外力fvは、図の下部の実線(75、76、77、78等)で表している。
【0089】
仮想外力近似器23の学習が十分に進んだ後、仮想外力発生器22を使用しない場合の結果を図8に示す。実線(81、82、83、84等)は関節座標系において近似された仮想外力uv^(t)[^はuの真上の存在する]をヤコビ行列J(t)によって手先座標系に変換した結果を示している。なお、図8において表示している、手先座標系における仮想外力の近似出力はアルゴリズムの実行上、必ずしも必要ではない。近似の結果を確認するため、便宜上算出したものである。この結果より、仮想外力発生器22が無くても障害物を避けながら目標地点にたどり着けていることが分かる。なお、図8において、太い実線(80など)は、ロボットアームである。
【0090】
以上、本実施の形態によれば、障害物の回避に対する要求を仮想外力によって解決するために、単純な報酬関数ですばやく、かつ安定して、ロボットの運動学習が行える。
【0091】
また、本実施の形態によれば、強化学習器21と仮想外力発生器22とを分離していることにより、運動開始位置や目標位置が変更した場合に、再学習を行うのは到達運動に関する部分(強化学習装置21)のみで足り、仮想外力近似器23の近似結果は、障害物の位置や形状が変わらない限り再利用することができる。
【0092】
また、本実施の形態によれば、仮想外力近似器23により、簡易な構成で制御対象を制御するための準備ができる。
【0093】
また、本実施の形態によれば、仮想外力発生器22から仮想外力近似器23への自動切り替えを行うことにより、簡易な構成で制御対象を制御することができる。
【0094】
また、本実施の形態によれば、特に、2点間到達運動課題を解決する制御対象1について、単純な報酬関数ですばやく、かつ安定して、ロボットの運動学習が行える。
【0095】
また、本実施の形態によれば、仮想外力の座標系は、制御対象1の特定の箇所に対する相対座標であることにより、障害物の位置や姿勢が変わった場合でも、仮想外力近似器の学習結果を再利用できる。
【0096】
さらに、本実施の形態によれば、選択手段233により、関数近似器のパラメータを絞ることができ、学習速度を短縮できる。さらに具体的には、数式3におけるヤコビ行列の逆行列を調べることにより、手先座標系における仮想外力の近似に各関節がどの程度寄与しているかを知ることが出来る。ヤコビ行列はロボットの設計図等から容易に求めることが出来るものであるため、実験前にヤコビ行列を算出することで関数近似器のパラメータを効率よく配置できる。このようにしてパラメータの個数を絞れば、学習時間を短縮できる。
【0097】
なお、本実施の形態によれば、強化学習装置2で構成された仮想外力近似器23と強化学習器21とを用いて、移動する制御対象を制御する制御装置が構築可能である。かかる制御装置により、簡易な構成で制御対象を制御することができる。
【0098】
また、本実施の形態によれば、強化学習装置2において、仮想外力近似器23、判断手段24、および切替手段25は存在しなくても良い。
【0099】
さらに、本実施の形態によれば、仮想外力近似器23において、選択手段233は存在しなくても良い。
(実施の形態2)
【0100】
本実施の形態において、強化学習器と仮想外力発生器とが分離していない強化学習装置等について説明する。
【0101】
図9は、本実施の形態における強化学習システムBのブロック図である。
強化学習システムBは、制御対象1、強化学習装置3を具備する。強化学習装置3と強化学習装置2との違いは、強化学習器と仮想外力発生器とが分離しているか否かの違いである。強化学習装置3において、強化学習器と仮想外力発生器とが分離していない。
【0102】
強化学習装置3は、報酬関数格納手段211、第一種環境パラメータ取得手段212、制御パラメータ値算出手段213、制御パラメータ値出力手段214、仮想外力関数格納手段221、第二種環境パラメータ取得手段222、仮想外力算出手段223、仮想外力出力手段224を具備する。
【0103】
なお、強化学習装置3と強化学習装置2とは、その動作は同様であるので、強化学習装置3の動作の説明を省略する。
【0104】
以上、本実施の形態によれば、障害物の回避に対する要求を仮想外力によって解決するために、単純な報酬関数ですばやく、かつ安定して、ロボットの運動学習が行える。
【0105】
また、本実施の形態によれば、特に、2点間到達運動課題を解決する制御対象1について、単純な報酬関数ですばやく、かつ安定して、ロボットの運動学習が行える。
【0106】
なお、図10は、本明細書で述べたプログラムを実行して、上述した実施の形態の強化学習装置等を実現するコンピュータの外観を示す。上述の実施の形態は、コンピュータハードウェア及びその上で実行されるコンピュータプログラムで実現され得る。図10は、このコンピュータシステム340の概観図であり、図11は、コンピュータシステム340のブロック図である。
【0107】
図10において、コンピュータシステム340は、FDドライブ、CD−ROMドライブを含むコンピュータ341と、キーボード342と、マウス343と、モニタ344とを含む。
【0108】
図11において、コンピュータ341は、FDドライブ3411、CD−ROMドライブ3412に加えて、MPU3413と、CD−ROMドライブ3412及びFDドライブ3411に接続されたバス3414と、ブートアッププログラム等のプログラムを記憶するためのROM3415とに接続され、アプリケーションプログラムの命令を一時的に記憶するとともに一時記憶空間を提供するためのRAM3416と、アプリケーションプログラム、システムプログラム、及びデータを記憶するためのハードディスク3417とを含む。ここでは、図示しないが、コンピュータ341は、さらに、LANへの接続を提供するネットワークカードを含んでも良い。
【0109】
コンピュータシステム340に、上述した実施の形態の強化学習装置等の機能を実行させるプログラムは、CD−ROM3501、またはFD3502に記憶されて、CD−ROMドライブ3412またはFDドライブ3411に挿入され、さらにハードディスク3417に転送されても良い。これに代えて、プログラムは、図示しないネットワークを介してコンピュータ341に送信され、ハードディスク3417に記憶されても良い。プログラムは実行の際にRAM3416にロードされる。プログラムは、CD−ROM3501、FD3502またはネットワークから直接、ロードされても良い。
【0110】
プログラムは、コンピュータ341に、上述した実施の形態の強化学習装置等の機能を実行させるオペレーティングシステム(OS)、またはサードパーティープログラム等は、必ずしも含まなくても良い。プログラムは、制御された態様で適切な機能(モジュール)を呼び出し、所望の結果が得られるようにする命令の部分のみを含んでいれば良い。コンピュータシステム340がどのように動作するかは周知であり、詳細な説明は省略する。
【0111】
なお、上記プログラムにおいて、情報を送信する送信ステップや、情報を受信する受信ステップなどでは、ハードウェアによって行われる処理、例えば、送信ステップにおけるモデムやインターフェースカードなどで行われる処理(ハードウェアでしか行われない処理)は含まれない。
【0112】
また、上記プログラムを実行するコンピュータは、単数であってもよく、複数であってもよい。すなわち、集中処理を行ってもよく、あるいは分散処理を行ってもよい。
【0113】
また、上記各実施の形態において、各処理(各機能)は、単一の装置(システム)によって集中処理されることによって実現されてもよく、あるいは、複数の装置によって分散処理されることによって実現されてもよい。
本発明は、以上の実施の形態に限定されることなく、種々の変更が可能であり、それらも本発明の範囲内に包含されるものであることは言うまでもない。
【産業上の利用可能性】
【0114】
以上のように、本発明にかかる強化学習システムは、すばやくかつ安定して、ロボットの運動学習が行える、という効果を有し、ロボットの制御システム等として有用である。
【符号の説明】
【0115】
1 制御対象
2、3 強化学習装置
21 強化学習器
22 仮想外力発生器
23 仮想外力近似器
24 判断手段
25 切替手段
211 報酬関数格納手段
212 第一種環境パラメータ取得手段
213 制御パラメータ値算出手段
214 制御パラメータ値出力手段
221 仮想外力関数格納手段
222 第二種環境パラメータ取得手段
223 仮想外力算出手段
224 仮想外力出力手段
231 関数近似器格納手段
232 状態情報取得手段
233 選択手段
234 第二仮想外力算出手段
235 差異情報算出手段
236 近似手段
237 第二仮想外力出力手段
【特許請求の範囲】
【請求項1】
報酬を出力とする報酬関数を格納し得る報酬関数格納手段と、
移動する制御対象の環境に関する第一種のパラメータである1以上の第一種環境パラメータの値を取得する第一種環境パラメータ取得手段と、
前記1以上の第一種環境パラメータの値を前記報酬関数に代入し、当該報酬関数が出力する報酬を最大とするような1以上の制御パラメータの値を算出する制御パラメータ値算出手段と、
前記1以上の制御パラメータの値を前記制御対象に対して出力する制御パラメータ値出力手段と、
仮想的な外力である仮想外力を出力とする仮想外力関数を格納し得る仮想外力関数格納手段と、
前記仮想外力に関連する第二種のパラメータである1以上の第二種環境パラメータの値を取得する第二種環境パラメータ取得手段と、
前記1以上の第二種環境パラメータを前記仮想外力関数に代入し、仮想外力を算出する仮想外力算出手段と、
前記仮想外力を前記制御対象に対して出力する仮想外力出力手段とを具備する強化学習装置。
【請求項2】
強化学習器と、当該強化学習器とは分離されている仮想外力発生器とを具備する請求項1記載の強化学習装置であって、
前記強化学習器は、
前記報酬関数格納手段と、前記第一種環境パラメータ取得手段と、前記制御パラメータ値算出手段と、前記制御パラメータ値出力手段とを具備し、
前記仮想外力発生器は、
前記仮想外力関数格納手段と、前記第二種環境パラメータ取得手段と、前記仮想外力算出手段と、前記仮想外力出力手段とを具備する請求項1記載の強化学習装置。
【請求項3】
前記制御パラメータ値出力手段が出力する前記1以上の制御パラメータの値と、前記仮想外力出力手段が出力する前記仮想外力とが加えられて前記制御対象に与えられる請求項1または請求項2記載の強化学習装置。
【請求項4】
前記強化学習装置は、仮想外力近似器をさらに具備し、
前記仮想外力近似器は、
前記第二種環境パラメータとは少なくとも一部に異なる観測可能な第三種のパラメータである2以上の第三種パラメータを有し、第二の仮想外力を出力とする関数近似器を格納し得る関数近似器格納手段と、
前記制御対象を観測し、当該制御対象の状態に関する情報である1以上の状態情報を取得する状態情報取得手段と、
前記状態情報を前記関数近似器に代入し、第二の仮想外力を算出する第二仮想外力算出手段と、
前記仮想外力発生器が出力する仮想外力と前記第二の仮想外力との差異に関する情報である差異情報を算出する差異情報算出手段と、
前記差異情報が最小となるように、前記関数近似器のパラメータを更新する近似手段とを具備する請求項1から請求項3いずれか記載の強化学習装置。
【請求項5】
前記差異情報が所定の条件を満たすか否かを判断する判断手段と、
前記判断手段が前記所定の条件を満たすほど、前記仮想外力発生器が出力する仮想外力と前記第二の仮想外力との差異が小さいと判断した場合に、前記制御対象に対して出力する仮想外力を、前記仮想外力発生器の出力から前記仮想外力近似器の出力へ切り替える切替手段とをさらに具備する請求項4記載の強化学習装置。
【請求項6】
障害物を避けながら一の目標地点に到達する課題である2点間到達運動課題を解決する請求項1から請求項5いずれか記載の強化学習装置。
【請求項7】
前記仮想外力の座標系は、
前記制御対象の特定の箇所に対する相対座標である請求項4から請求項6いずれか記載の強化学習装置。
【請求項8】
前記状態情報取得手段が取得した1以上の状態情報のうち、変化が閾値より大きい1以上の状態情報を取得する選択手段をさらに具備し、
前記第二仮想外力算出手段は、
前記選択手段が取得した1以上の状態情報のみを前記関数近似器に代入し、第二の仮想外力を算出する請求項4から請求項7いずれか記載の強化学習装置。
【請求項9】
請求項4から請求項8いずれか記載の仮想外力近似器と、請求項4から請求項8いずれか記載の強化学習器とを用いて、移動する制御対象を制御する制御装置。
【請求項10】
記憶媒体に、
報酬を出力とする報酬関数と、
仮想的な外力である仮想外力を出力とする仮想外力関数とを格納しており、
第一種環境パラメータ取得手段、制御パラメータ値算出手段、制御パラメータ値出力手段、第二種環境パラメータ取得手段、仮想外力算出手段、および仮想外力出力手段により実現される強化学習方法であって、
前記第一種環境パラメータ取得手段が、移動する制御対象の環境に関する第一種のパラメータである1以上の第一種環境パラメータを取得する第一種環境パラメータ取得ステップと、
前記制御パラメータ値算出手段が、前記1以上の第一種環境パラメータと前記仮想外力とを前記報酬関数に代入し、当該報酬関数が出力する報酬を最大とするような1以上の制御パラメータの値を算出する制御パラメータ値算出ステップと、
前記制御パラメータ値出力手段が、前記1以上の制御パラメータの値を前記制御対象に対して出力する制御パラメータ値出力ステップと、
前記第二種環境パラメータ取得手段が、前記仮想外力に関連する第二種のパラメータである1以上の第二種環境パラメータの値を取得する第二種環境パラメータ取得ステップと、
前記仮想外力算出手段が、前記1以上の第二種環境パラメータを前記仮想外力関数に代入し、仮想外力を算出する仮想外力算出ステップと、
前記仮想外力出力手段が、前記仮想外力を前記制御対象に対して出力する仮想外力出力ステップとを具備する強化学習方法。
【請求項1】
報酬を出力とする報酬関数を格納し得る報酬関数格納手段と、
移動する制御対象の環境に関する第一種のパラメータである1以上の第一種環境パラメータの値を取得する第一種環境パラメータ取得手段と、
前記1以上の第一種環境パラメータの値を前記報酬関数に代入し、当該報酬関数が出力する報酬を最大とするような1以上の制御パラメータの値を算出する制御パラメータ値算出手段と、
前記1以上の制御パラメータの値を前記制御対象に対して出力する制御パラメータ値出力手段と、
仮想的な外力である仮想外力を出力とする仮想外力関数を格納し得る仮想外力関数格納手段と、
前記仮想外力に関連する第二種のパラメータである1以上の第二種環境パラメータの値を取得する第二種環境パラメータ取得手段と、
前記1以上の第二種環境パラメータを前記仮想外力関数に代入し、仮想外力を算出する仮想外力算出手段と、
前記仮想外力を前記制御対象に対して出力する仮想外力出力手段とを具備する強化学習装置。
【請求項2】
強化学習器と、当該強化学習器とは分離されている仮想外力発生器とを具備する請求項1記載の強化学習装置であって、
前記強化学習器は、
前記報酬関数格納手段と、前記第一種環境パラメータ取得手段と、前記制御パラメータ値算出手段と、前記制御パラメータ値出力手段とを具備し、
前記仮想外力発生器は、
前記仮想外力関数格納手段と、前記第二種環境パラメータ取得手段と、前記仮想外力算出手段と、前記仮想外力出力手段とを具備する請求項1記載の強化学習装置。
【請求項3】
前記制御パラメータ値出力手段が出力する前記1以上の制御パラメータの値と、前記仮想外力出力手段が出力する前記仮想外力とが加えられて前記制御対象に与えられる請求項1または請求項2記載の強化学習装置。
【請求項4】
前記強化学習装置は、仮想外力近似器をさらに具備し、
前記仮想外力近似器は、
前記第二種環境パラメータとは少なくとも一部に異なる観測可能な第三種のパラメータである2以上の第三種パラメータを有し、第二の仮想外力を出力とする関数近似器を格納し得る関数近似器格納手段と、
前記制御対象を観測し、当該制御対象の状態に関する情報である1以上の状態情報を取得する状態情報取得手段と、
前記状態情報を前記関数近似器に代入し、第二の仮想外力を算出する第二仮想外力算出手段と、
前記仮想外力発生器が出力する仮想外力と前記第二の仮想外力との差異に関する情報である差異情報を算出する差異情報算出手段と、
前記差異情報が最小となるように、前記関数近似器のパラメータを更新する近似手段とを具備する請求項1から請求項3いずれか記載の強化学習装置。
【請求項5】
前記差異情報が所定の条件を満たすか否かを判断する判断手段と、
前記判断手段が前記所定の条件を満たすほど、前記仮想外力発生器が出力する仮想外力と前記第二の仮想外力との差異が小さいと判断した場合に、前記制御対象に対して出力する仮想外力を、前記仮想外力発生器の出力から前記仮想外力近似器の出力へ切り替える切替手段とをさらに具備する請求項4記載の強化学習装置。
【請求項6】
障害物を避けながら一の目標地点に到達する課題である2点間到達運動課題を解決する請求項1から請求項5いずれか記載の強化学習装置。
【請求項7】
前記仮想外力の座標系は、
前記制御対象の特定の箇所に対する相対座標である請求項4から請求項6いずれか記載の強化学習装置。
【請求項8】
前記状態情報取得手段が取得した1以上の状態情報のうち、変化が閾値より大きい1以上の状態情報を取得する選択手段をさらに具備し、
前記第二仮想外力算出手段は、
前記選択手段が取得した1以上の状態情報のみを前記関数近似器に代入し、第二の仮想外力を算出する請求項4から請求項7いずれか記載の強化学習装置。
【請求項9】
請求項4から請求項8いずれか記載の仮想外力近似器と、請求項4から請求項8いずれか記載の強化学習器とを用いて、移動する制御対象を制御する制御装置。
【請求項10】
記憶媒体に、
報酬を出力とする報酬関数と、
仮想的な外力である仮想外力を出力とする仮想外力関数とを格納しており、
第一種環境パラメータ取得手段、制御パラメータ値算出手段、制御パラメータ値出力手段、第二種環境パラメータ取得手段、仮想外力算出手段、および仮想外力出力手段により実現される強化学習方法であって、
前記第一種環境パラメータ取得手段が、移動する制御対象の環境に関する第一種のパラメータである1以上の第一種環境パラメータを取得する第一種環境パラメータ取得ステップと、
前記制御パラメータ値算出手段が、前記1以上の第一種環境パラメータと前記仮想外力とを前記報酬関数に代入し、当該報酬関数が出力する報酬を最大とするような1以上の制御パラメータの値を算出する制御パラメータ値算出ステップと、
前記制御パラメータ値出力手段が、前記1以上の制御パラメータの値を前記制御対象に対して出力する制御パラメータ値出力ステップと、
前記第二種環境パラメータ取得手段が、前記仮想外力に関連する第二種のパラメータである1以上の第二種環境パラメータの値を取得する第二種環境パラメータ取得ステップと、
前記仮想外力算出手段が、前記1以上の第二種環境パラメータを前記仮想外力関数に代入し、仮想外力を算出する仮想外力算出ステップと、
前記仮想外力出力手段が、前記仮想外力を前記制御対象に対して出力する仮想外力出力ステップとを具備する強化学習方法。
【図2】

【図4】
【図9】
【図10】

【図11】

【図1】

【図3】

【図5】

【図6】
【図7】

【図8】
【図4】
【図9】
【図10】
【図11】
【図1】
【図3】
【図5】
【図6】
【図7】
【図8】
【公開番号】特開2012−208789(P2012−208789A)
【公開日】平成24年10月25日(2012.10.25)
【国際特許分類】
【出願番号】特願2011−74694(P2011−74694)
【出願日】平成23年3月30日(2011.3.30)
【出願人】(393031586)株式会社国際電気通信基礎技術研究所 (905)
【出願人】(000005326)本田技研工業株式会社 (23,863)
【Fターム(参考)】
【公開日】平成24年10月25日(2012.10.25)
【国際特許分類】
【出願日】平成23年3月30日(2011.3.30)
【出願人】(393031586)株式会社国際電気通信基礎技術研究所 (905)
【出願人】(000005326)本田技研工業株式会社 (23,863)
【Fターム(参考)】
[ Back to top ]