
待機状態にあるプロセッサ実行リソースの共有
【課題】待機状態のプロセッサの資源を、他のプロセッサで利用可能とする。
【解決手段】1つのプロセッサは、複数の論理プロセッサおよび命令セットを有する。命令セットは、第1の論理プロセッサによって実行されたとき、第1の論理プロセッサが待機状態に移行するようにスケジュールされたことに応じて、第1の論理プロセッサが、第1のプロセッサに対して予めリザーブされたプロセッサ実行リソースを、複数のプロセッサのうちの第2のプロセッサに対して使用可能にする命令を1つ以上有する。
【解決手段】1つのプロセッサは、複数の論理プロセッサおよび命令セットを有する。命令セットは、第1の論理プロセッサによって実行されたとき、第1の論理プロセッサが待機状態に移行するようにスケジュールされたことに応じて、第1の論理プロセッサが、第1のプロセッサに対して予めリザーブされたプロセッサ実行リソースを、複数のプロセッサのうちの第2のプロセッサに対して使用可能にする命令を1つ以上有する。
【発明の詳細な説明】
【背景技術】
【0001】
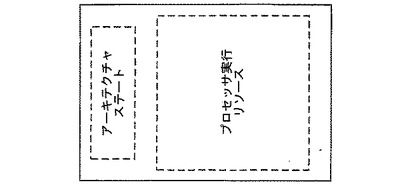
図1aに示されるプロセッサの概念図を参照すると、プロセッサは、例えばレジスタやプログラムカウンタのようなプロセッサのアーキテクチャステートを実装する第1のコンポーネント、および、例えばトランスレーション・ルックアサイド・バッファ(TLB)のようなプロセッサ実行リソースから成る第2のコンポーネントの2つのコンポーネントから構成されていると概念化されうる。
【0002】
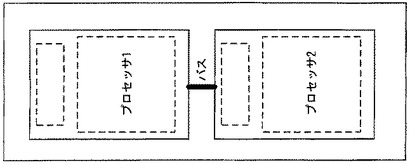
図1bに示されるマルチプロセッシング・プロセッサ・ベースのシステムの一形態では、複数の物理プロセッサは、バスシステムによって相互に接続され、各物理プロセッサは、それぞれ独立したハードウェアのアーキテクチャステートと、独立したハードウェアのプロセッサ実行リソースのセットとを保持する。このようなシステムの各プロセッサがそれぞれ異なるスレッドを実行するようにスケジュールされるスレッド・スケジューリング・シナリオでは、システムのプロセッサの1つがディスクドライブのようなシステム内の遅いデバイスを待つため、または、スレッドを実行するようにスケジュールされていないために待機状態となりうる。この状況では、プロセッサだけでなくその全ての実行リソースも待機状態となり、これらはシステムの他のプロセッサから使用不可能となる。
【0003】
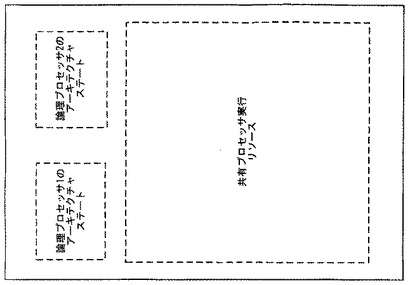
図1cに示されるプロセッサ・ベースのシステムのもう1つの形態では、ハードウェアプロセッサは、複数の論理プロセッサに対してそれぞれ独立したプロセッサ・ハードウェアのアーキテクチャステートを保持するが、複数の論理プロセッサによって共有される1つのプロセッサ・コア・パイプラインと、TLBを含む複数の論理プロセッサによって共有される1つのプロセッサ実行リソースセットとを有してもよい。このようなプロセッサ・アーキテクチャは、数あるプロセッサの中でも特にハイパースレッディングテクノロジを有するIntel Xeon(登録商標)プロセッサによって例証されており、よく知られた従来技術である。
【0004】
このような論理マルチプロセッシング・システムでは、各論理プロセッサが他の全ての論理プロセッサから独立して自身のアーキテクチャステートを保持するため、スレッドスケジューラは、各論理プロセッサ上でそれぞれ異なるスレッドを実行するようにスケジュールしてもよい。オペレーティングシステムのスレッドスケジューラによって論理プロセッサが待機状態とされたとき、または、論理プロセッサが遅いストレージデバイスからのデータを待っているとき、論理プロセッサは、一般的に小規模なループである待機タスクを実行して定期的にインタラプトを確認する、または、自身の実行をサスペンドしてスレッドの実行を再開するような働きをするウェイクアップ信号を待つ。
【0005】
プロセッサ実行リソースが物理的に独立しているマルチプロセッシング・システムに対して、このような論理マルチプロセッシング・システムでは、システムの複数の論理プロセッサのうち1つが待機状態となった場合には、待機状態の論理プロセッサによって使用されていない動的に割り当てられるプロセッサ実行リソースは、ユーザまたはシステムのスレッドを実行している他の論理プロセッサに対して使用可能にされてもよい。
【0006】
しかし、論理マルチプロセッシング・システムのプロセッサ実行リソースは、論理プロセッサに対してリザーブされることがある。この状況は種々の方法によって起こりうる。その方法の一例としては、論理プロセッサは、TLBからトランスレーションレジスタ(TR)のような動的に割り当てられるプロセッサ実行リソースをロックし、結果的にそのリソースを他の論理プロセッサから使用不可能とすることがある。その方法の他の一例としては、TCのようなプロセッサ実行リソースが論理プロセッサに対して静的に割り当てられ、結果として、静的に割り当てられたリソースは、他の論理プロセッサから使用不可能となりうる。これらのリザーブされたリソースは、これらのリソースがリザーブされた論理プロセッサが待機状態になった後も、概して、他の論理プロセッサから使用不可能であり続ける。このように、論理プロセッサによってロックされたTRは、概して、論理プロセッサが待機状態である間も論理プロセッサによってロックされ続け、また、論理プロセッサに対して静的に割り当てられたTCは、論理プロセッサが待機状態である間も論理プロセッサに対して静的に割り当てられ続ける。
【図面の簡単な説明】
【0007】
【図1a】種々のタイプのプロセッサ・アーキテクチャを示す第1の概念図である。
【図1b】種々のタイプのプロセッサ・アーキテクチャを示す第2の概念図である。
【図1c】種々のタイプのプロセッサ・アーキテクチャを示す第3の概念図である。
【図2】本発明の一実施形態における処理を示すフロー図である。
【図3】本発明の一実施形態におけるプロセッサ・ベースのシステムを示す図である。
【発明を実施するための最良の形態】
【0008】
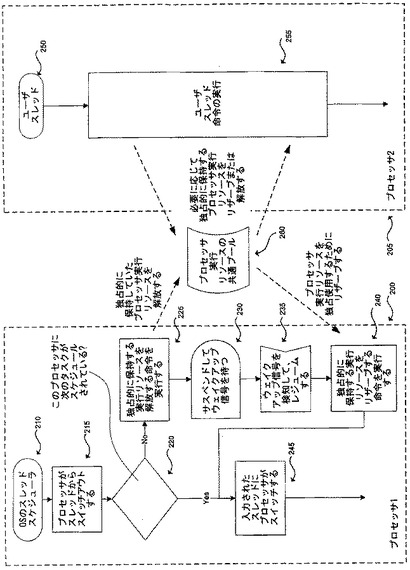
本発明の一実施形態では、処理は、図2のフロー図に示されるように行われる。図2を参照すると、2つの論理プロセッサ、プロセッサ1 200およびプロセッサ2 205は、スレッドスケジューラ210を含む、オペレーティングシステムによってスケジュールされたスレッドを実行する。215において、プロセッサ1は、例えばスレッドの実行終了またはページフォールトのために、実行するスレッドからスイッチアウトされてスレッドスケジューラの実行に戻る。220において、この論理プロセッサに対してスケジュールされたタスクがこれ以上存在しない場合、プロセッサは、225から230の待機シーケンスを実行する。まず、225において、論理プロセッサは、自身が確保する全てのリザーブされたプロセッサ実行リソースの確保を取りやめて、それらを共通プール260に解放する。このように、例えば、プロセッサ1は、トランスレーション・キャッシュ・エントリまたはトランスレーション・キャッシュ・レジスタを、トランスレーション・ルックアサイド・バッファ内にあるレジスタの一般プールに返還する。
【0009】
本発明の他の実施形態では、ステップ225における処理は異なってもよい。本発明のいくつかの実施形態では、解放された独占的に確保されたリソースは、動的に割り当てられるリソースであり、かつ、プロセッサ1によって予めロックされていたリソースであってもよい。このような実施形態では、ステップ225において、論理プロセッサは、リソースをアンロックしてそのリソースを他の論理プロセッサから使用可能にする。別の実施形態では、独占的に確保されたリソースは、プロセッサ1に対して予め静的に割り当てられているリソースであってもよい。このような実施形態では、ステップ225において、静的に割り当てられたリソースは解放され、そのリソースは動的に割り当てられるリソースのプール260に返還される。
【0010】
プロセッサ1は、本実施形態におけるサスペンション状態230のような待機状態に移行したあと、インタラプト235のようなウェイクアップ信号よって、新規スレッドまたはレジュームするスレッドの実行を要求されうる。本発明の他の実施形態では、プロセッサは、230に示されるサスペンション状態ではなく待機タスクループに移行して定期的にインタラプトを確認してもよい。
【0011】
ウェイクアップ信号に続いて、240において、論理プロセッサは、必要に応じてリソースをロック、または、リソースを自身に対して静的に割り当てることによって、独占的にリザーブするリソースを再取得する。そして、論理プロセッサは、245において、入力されたスレッドにスイッチしてそのスレッドの実行を継続する。
【0012】
225において、サスペンション状態または待機状態の前にプロセッサ1によって解放されたリソースは、図示されたユーザスレッド250のようなスレッドを実行する、プロセッサ2 205のような他の論理プロセッサから使用可能となる。その後、これらのリソースは、スレッドの実行中255に、共有プロセッサ実行リソースのプールから論理プロセッサに対して必要に応じて動的に割り当てられてもよい。
【0013】
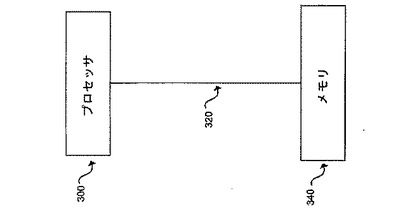
図3は、本発明の一実施形態における、プロセッサ300の一部として論理プロセッサが実装されたプロセッサ・ベースのシステムを示す。論理プロセッサ上で実行されるプログラムは、バスシステム320によってプロセッサと接続されたメモリ340に保存される。メモリは、上述の処理を実質的に実行するスレッドスケジューラを含むファームウェアを保存する非揮発性メモリのセクションを有してもよい。
【0014】
この他多くの実施形態が可能である。例えば、上述の説明はその説明の対象を論理プロセッサに限定しているが、あらゆる共通実行リソースを共有する物理的に独立したマルチプロセッサに対しても、同様の処理が適用可能である。そのような実施形態では、独立したアーキテクチャステートおよびいくつかの実行リソースはハードウェア的に独立するが、その他の実行リソースはハードウェア的に共有され、図2に示される方法と同様の処理を使用して解放されうる、論理マルチプロセッシングおよび物理マルチプロセッシングのハイブリッド版が実装される。上述のスレッドスケジューラは、本発明のいくつかの実施形態では、図3に示される非揮発性メモリ内に存在するファームウェアのコンポーネントの形をとってもよく、その他の実施形態においては、プロセッサからアクセス可能なディスクメディア上に保存されたオペレーティングシステムの一部分の形をとってもよい。プロセッサ実行リソースを解放およびリザーブするために実行される動作は、本発明のいくつかの実施形態では、ハードウェアに直接実装されてプロセッサの命令実行システムを補助してもよく、その他の実施形態では、1つ以上の命令の実行の一部としてプロセッサによって実行される動作であってもよい。本発明のいくつかの実施形態では、共有される実行リソースは、TLBとは無関係の特別な目的を有するレジスタを含んでもよい。本発明の実施形態は、2つのプロセッサに制限されず、3つ以上のプロセッサが実行リソースを共有して、上述の処理に類似する処理を実行してもよい。
【0015】
特許請求の範囲に従った実施形態は、マシンによってアクセスされたときにマシンが特許請求の範囲に従った処理を実行するデータが保存されたマシン読み取り可能な媒体を含む、コンピュータ・プログラム・プロダクトとして提供されてもよい。マシン読み取り可能な媒体は、フロッピーディスク、光ディスク、DVD−ROMディスク、DVD−RAMディスク、DVD−RWディスク、DVD+RWディスク、CD−Rディスク、CD−RWディスク、CD−ROMディスクおよび磁気光ディスク、ROMs、RAMs、EPROMs、EEPROMs、磁気または光カード、フラッシュメモリ、またはその他の電子命令の保存に適したメディア/マシン読み取り可能な媒体を含んでもよく、また、これらに限定されない。更に、本発明の実施形態は、通信リンク(例:モデムまたはネットワーク接続)による搬送波内またはその他の伝播媒体内に埋め込まれたデータ信号によってプログラムがリモートコンピュータから要求側コンピュータに転送されるように、コンピュータ・プログラム・プロダクトとしてダウンロードされてもよい。
【0016】
多くの方法は最も基本的な形式で説明されているが、特許請求の範囲の基本的な領域から逸れることなく、上述の方法に対して手順が追加または削除されることができ、また、上述の説明内容に対して情報が追加または削除されることができる。当業者にとって、更なる修正または適用が可能であることは明白である。特定の実施形態は、本発明を制限するためではなく、本発明を説明するために提供される。本発明の特許請求の範囲は、上述の特定の例によっては決定されず、添付の特許請求の範囲によってのみ決定される。
【背景技術】
【0001】
図1aに示されるプロセッサの概念図を参照すると、プロセッサは、例えばレジスタやプログラムカウンタのようなプロセッサのアーキテクチャステートを実装する第1のコンポーネント、および、例えばトランスレーション・ルックアサイド・バッファ(TLB)のようなプロセッサ実行リソースから成る第2のコンポーネントの2つのコンポーネントから構成されていると概念化されうる。
【0002】
図1bに示されるマルチプロセッシング・プロセッサ・ベースのシステムの一形態では、複数の物理プロセッサは、バスシステムによって相互に接続され、各物理プロセッサは、それぞれ独立したハードウェアのアーキテクチャステートと、独立したハードウェアのプロセッサ実行リソースのセットとを保持する。このようなシステムの各プロセッサがそれぞれ異なるスレッドを実行するようにスケジュールされるスレッド・スケジューリング・シナリオでは、システムのプロセッサの1つがディスクドライブのようなシステム内の遅いデバイスを待つため、または、スレッドを実行するようにスケジュールされていないために待機状態となりうる。この状況では、プロセッサだけでなくその全ての実行リソースも待機状態となり、これらはシステムの他のプロセッサから使用不可能となる。
【0003】
図1cに示されるプロセッサ・ベースのシステムのもう1つの形態では、ハードウェアプロセッサは、複数の論理プロセッサに対してそれぞれ独立したプロセッサ・ハードウェアのアーキテクチャステートを保持するが、複数の論理プロセッサによって共有される1つのプロセッサ・コア・パイプラインと、TLBを含む複数の論理プロセッサによって共有される1つのプロセッサ実行リソースセットとを有してもよい。このようなプロセッサ・アーキテクチャは、数あるプロセッサの中でも特にハイパースレッディングテクノロジを有するIntel Xeon(登録商標)プロセッサによって例証されており、よく知られた従来技術である。
【0004】
このような論理マルチプロセッシング・システムでは、各論理プロセッサが他の全ての論理プロセッサから独立して自身のアーキテクチャステートを保持するため、スレッドスケジューラは、各論理プロセッサ上でそれぞれ異なるスレッドを実行するようにスケジュールしてもよい。オペレーティングシステムのスレッドスケジューラによって論理プロセッサが待機状態とされたとき、または、論理プロセッサが遅いストレージデバイスからのデータを待っているとき、論理プロセッサは、一般的に小規模なループである待機タスクを実行して定期的にインタラプトを確認する、または、自身の実行をサスペンドしてスレッドの実行を再開するような働きをするウェイクアップ信号を待つ。
【0005】
プロセッサ実行リソースが物理的に独立しているマルチプロセッシング・システムに対して、このような論理マルチプロセッシング・システムでは、システムの複数の論理プロセッサのうち1つが待機状態となった場合には、待機状態の論理プロセッサによって使用されていない動的に割り当てられるプロセッサ実行リソースは、ユーザまたはシステムのスレッドを実行している他の論理プロセッサに対して使用可能にされてもよい。
【0006】
しかし、論理マルチプロセッシング・システムのプロセッサ実行リソースは、論理プロセッサに対してリザーブされることがある。この状況は種々の方法によって起こりうる。その方法の一例としては、論理プロセッサは、TLBからトランスレーションレジスタ(TR)のような動的に割り当てられるプロセッサ実行リソースをロックし、結果的にそのリソースを他の論理プロセッサから使用不可能とすることがある。その方法の他の一例としては、TCのようなプロセッサ実行リソースが論理プロセッサに対して静的に割り当てられ、結果として、静的に割り当てられたリソースは、他の論理プロセッサから使用不可能となりうる。これらのリザーブされたリソースは、これらのリソースがリザーブされた論理プロセッサが待機状態になった後も、概して、他の論理プロセッサから使用不可能であり続ける。このように、論理プロセッサによってロックされたTRは、概して、論理プロセッサが待機状態である間も論理プロセッサによってロックされ続け、また、論理プロセッサに対して静的に割り当てられたTCは、論理プロセッサが待機状態である間も論理プロセッサに対して静的に割り当てられ続ける。
【図面の簡単な説明】
【0007】
【図1a】種々のタイプのプロセッサ・アーキテクチャを示す第1の概念図である。
【図1b】種々のタイプのプロセッサ・アーキテクチャを示す第2の概念図である。
【図1c】種々のタイプのプロセッサ・アーキテクチャを示す第3の概念図である。
【図2】本発明の一実施形態における処理を示すフロー図である。
【図3】本発明の一実施形態におけるプロセッサ・ベースのシステムを示す図である。
【発明を実施するための最良の形態】
【0008】
本発明の一実施形態では、処理は、図2のフロー図に示されるように行われる。図2を参照すると、2つの論理プロセッサ、プロセッサ1 200およびプロセッサ2 205は、スレッドスケジューラ210を含む、オペレーティングシステムによってスケジュールされたスレッドを実行する。215において、プロセッサ1は、例えばスレッドの実行終了またはページフォールトのために、実行するスレッドからスイッチアウトされてスレッドスケジューラの実行に戻る。220において、この論理プロセッサに対してスケジュールされたタスクがこれ以上存在しない場合、プロセッサは、225から230の待機シーケンスを実行する。まず、225において、論理プロセッサは、自身が確保する全てのリザーブされたプロセッサ実行リソースの確保を取りやめて、それらを共通プール260に解放する。このように、例えば、プロセッサ1は、トランスレーション・キャッシュ・エントリまたはトランスレーション・キャッシュ・レジスタを、トランスレーション・ルックアサイド・バッファ内にあるレジスタの一般プールに返還する。
【0009】
本発明の他の実施形態では、ステップ225における処理は異なってもよい。本発明のいくつかの実施形態では、解放された独占的に確保されたリソースは、動的に割り当てられるリソースであり、かつ、プロセッサ1によって予めロックされていたリソースであってもよい。このような実施形態では、ステップ225において、論理プロセッサは、リソースをアンロックしてそのリソースを他の論理プロセッサから使用可能にする。別の実施形態では、独占的に確保されたリソースは、プロセッサ1に対して予め静的に割り当てられているリソースであってもよい。このような実施形態では、ステップ225において、静的に割り当てられたリソースは解放され、そのリソースは動的に割り当てられるリソースのプール260に返還される。
【0010】
プロセッサ1は、本実施形態におけるサスペンション状態230のような待機状態に移行したあと、インタラプト235のようなウェイクアップ信号よって、新規スレッドまたはレジュームするスレッドの実行を要求されうる。本発明の他の実施形態では、プロセッサは、230に示されるサスペンション状態ではなく待機タスクループに移行して定期的にインタラプトを確認してもよい。
【0011】
ウェイクアップ信号に続いて、240において、論理プロセッサは、必要に応じてリソースをロック、または、リソースを自身に対して静的に割り当てることによって、独占的にリザーブするリソースを再取得する。そして、論理プロセッサは、245において、入力されたスレッドにスイッチしてそのスレッドの実行を継続する。
【0012】
225において、サスペンション状態または待機状態の前にプロセッサ1によって解放されたリソースは、図示されたユーザスレッド250のようなスレッドを実行する、プロセッサ2 205のような他の論理プロセッサから使用可能となる。その後、これらのリソースは、スレッドの実行中255に、共有プロセッサ実行リソースのプールから論理プロセッサに対して必要に応じて動的に割り当てられてもよい。
【0013】
図3は、本発明の一実施形態における、プロセッサ300の一部として論理プロセッサが実装されたプロセッサ・ベースのシステムを示す。論理プロセッサ上で実行されるプログラムは、バスシステム320によってプロセッサと接続されたメモリ340に保存される。メモリは、上述の処理を実質的に実行するスレッドスケジューラを含むファームウェアを保存する非揮発性メモリのセクションを有してもよい。
【0014】
この他多くの実施形態が可能である。例えば、上述の説明はその説明の対象を論理プロセッサに限定しているが、あらゆる共通実行リソースを共有する物理的に独立したマルチプロセッサに対しても、同様の処理が適用可能である。そのような実施形態では、独立したアーキテクチャステートおよびいくつかの実行リソースはハードウェア的に独立するが、その他の実行リソースはハードウェア的に共有され、図2に示される方法と同様の処理を使用して解放されうる、論理マルチプロセッシングおよび物理マルチプロセッシングのハイブリッド版が実装される。上述のスレッドスケジューラは、本発明のいくつかの実施形態では、図3に示される非揮発性メモリ内に存在するファームウェアのコンポーネントの形をとってもよく、その他の実施形態においては、プロセッサからアクセス可能なディスクメディア上に保存されたオペレーティングシステムの一部分の形をとってもよい。プロセッサ実行リソースを解放およびリザーブするために実行される動作は、本発明のいくつかの実施形態では、ハードウェアに直接実装されてプロセッサの命令実行システムを補助してもよく、その他の実施形態では、1つ以上の命令の実行の一部としてプロセッサによって実行される動作であってもよい。本発明のいくつかの実施形態では、共有される実行リソースは、TLBとは無関係の特別な目的を有するレジスタを含んでもよい。本発明の実施形態は、2つのプロセッサに制限されず、3つ以上のプロセッサが実行リソースを共有して、上述の処理に類似する処理を実行してもよい。
【0015】
特許請求の範囲に従った実施形態は、マシンによってアクセスされたときにマシンが特許請求の範囲に従った処理を実行するデータが保存されたマシン読み取り可能な媒体を含む、コンピュータ・プログラム・プロダクトとして提供されてもよい。マシン読み取り可能な媒体は、フロッピーディスク、光ディスク、DVD−ROMディスク、DVD−RAMディスク、DVD−RWディスク、DVD+RWディスク、CD−Rディスク、CD−RWディスク、CD−ROMディスクおよび磁気光ディスク、ROMs、RAMs、EPROMs、EEPROMs、磁気または光カード、フラッシュメモリ、またはその他の電子命令の保存に適したメディア/マシン読み取り可能な媒体を含んでもよく、また、これらに限定されない。更に、本発明の実施形態は、通信リンク(例:モデムまたはネットワーク接続)による搬送波内またはその他の伝播媒体内に埋め込まれたデータ信号によってプログラムがリモートコンピュータから要求側コンピュータに転送されるように、コンピュータ・プログラム・プロダクトとしてダウンロードされてもよい。
【0016】
多くの方法は最も基本的な形式で説明されているが、特許請求の範囲の基本的な領域から逸れることなく、上述の方法に対して手順が追加または削除されることができ、また、上述の説明内容に対して情報が追加または削除されることができる。当業者にとって、更なる修正または適用が可能であることは明白である。特定の実施形態は、本発明を制限するためではなく、本発明を説明するために提供される。本発明の特許請求の範囲は、上述の特定の例によっては決定されず、添付の特許請求の範囲によってのみ決定される。
【特許請求の範囲】
【請求項1】
複数のプロセッサがプロセッサ実行リソースを共有するプロセッサ・ベースのシステムにおいて、前記複数のプロセッサのうちの第1のプロセッサが待機状態に移行するようにスケジュールされたことに応じて、前記第1のプロセッサに対して予めリザーブされたプロセッサ実行リソースを、前記複数のプロセッサのうちの第2のプロセッサに対して使用可能にするステップを備える方法。
【請求項2】
前記第1のプロセッサがタスクを実行するようにスケジュールされたことに応じて、前記プロセッサ実行リソースを前記第1のプロセッサに対してリザーブするステップを更に備える請求項1に記載の方法。
【請求項3】
前記複数のプロセッサの各プロセッサは、前記プロセッサ・ベースのシステムの論理プロセッサである請求項2に記載の方法。
【請求項4】
前記第1のプロセッサが待機状態に移行するようにスケジュールされるステップは、前記第1のプロセッサが前記第1のプロセッサを待機状態に移行させるように要求するプロセッサ命令を実行するステップを更に備える請求項3に記載の方法。
【請求項5】
前記第1のプロセッサに対して予めリザーブされた前記プロセッサ実行リソースを第2のプロセッサに対して使用可能にするステップは、前記プロセッサ実行リソースを前記第2のプロセッサからアクセス可能なプロセッサ実行リソースの共通プールに解放するステップをさらに備える請求項4に記載の方法。
【請求項6】
前記第1のプロセッサがタスクを実行するようにスケジュールされるステップは、前記第1のプロセッサがウェイクアップ信号を受信するステップを更に備える請求項5に記載の方法。
【請求項7】
前記第1のプロセッサに対して予めリザーブされた前記プロセッサ実行リソースは、前記第1のプロセッサに対して予め静的に割り当てられた前記プロセッサ実行リソースを更に備え、前記プロセッサ実行リソースをプロセッサ実行リソースの共通プールに解放するステップは、前記プロセッサ実行リソースを解放するステップを更に備える請求項6に記載の方法。
【請求項8】
前記第1のプロセッサに対して予めリザーブされた前記プロセッサ実行リソースは、前記第1のプロセッサによって予めロックされた前記プロセッサ実行リソースを更に備え、前記プロセッサ実行リソースをプロセッサ実行リソースの共通プールに解放するステップは、前記第1のプロセッサが前記プロセッサ実行リソースをアンロックするステップを更に備える請求項6に記載の方法。
【請求項9】
プロセッサ実行リソースの前記共通プールは、トランスレーション・ルックアサイド・バッファを備え、前記プロセッサ実行リソースは、前記トランスレーション・ルックアサイド・バッファからのトランスレーション・キャッシュ・エントリである請求項6に記載の方法。
【請求項10】
複数の論理プロセッサと、
第1の論理プロセッサによって実行されたとき、前記第1の論理プロセッサが待機状態に移行するようにスケジュールされたことに応じて、前記第1の論理プロセッサが前記第1のプロセッサに対して予めリザーブされたプロセッサ実行リソースを前記複数のプロセッサのうちの第2のプロセッサに対して使用可能にする命令を1つ以上有する命令セットと
を備えるプロセッサ。
【請求項11】
前記第1の論理プロセッサが待機状態に移行するようにスケジュールされることは、前記第1のプロセッサが、前記第1の論理プロセッサを待機状態に移行させるように要求するプロセッサ命令を実行することを更に備える請求項10に記載のプロセッサ。
【請求項12】
前記第1の論理プロセッサに、前記第1の論理プロセッサに対して予めリザーブされた前記プロセッサ実行リソースを第2の論理プロセッサに対して使用可能にさせることは、前記プロセッサ実行リソースを前記第2の論理プロセッサからアクセス可能なプロセッサ実行リソースの共通プールに解放すること更に備える請求項11に記載のプロセッサ。
【請求項13】
前記第1の論理プロセッサに対して予めリザーブされた前記プロセッサ実行リソースは、前記第1の論理プロセッサに対して予め静的に割り当てられた前記プロセッサ実行リソースを更に備え、前記プロセッサ実行リソースをプロセッサ実行リソースの共通プールに解放することは、前記プロセッサ実行リソースを解放することを更に備える請求項12に記載のプロセッサ。
【請求項14】
前記第1の論理プロセッサに対して予めリザーブされた前記プロセッサ実行リソースは、前記第1の論理プロセッサに対して予め静的に割り当てられた前記プロセッサ実行リソースを更に備え、前記プロセッサ実行リソースをプロセッサ実行リソースの共通プールに解放することは、前記第1のプロセッサが前記プロセッサ実行リソースをアンロックすることを更に備える請求項12に記載のプロセッサ。
【請求項15】
複数の論理プロセッサ、および、第1の論理プロセッサによって実行されたとき、前記第1の論理プロセッサが待機状態に移行するようにスケジュールされたことに応じて、前記第1の論理プロセッサが前記第1のプロセッサに対して予めリザーブされたプロセッサ実行リソースを前記複数のプロセッサのうちの第2のプロセッサに対して使用可能にする命令を1つ以上含む命令セットを有するプロセッサと、
前記第1の論理プロセッサが待機状態に移行するようにスケジュールするファームウェアと、
前記ファームウェアと前記プロセッサとを相互接続するバスと
を備えるシステム。
【請求項16】
前記第1の論理プロセッサが待機状態に移行するようにスケジュールされることは、前記第1のプロセッサが前記第1のプロセッサを待機状態に移行させるように要求するプロセッサ命令を実行することを更に備える請求項15に記載のシステム。
【請求項17】
前記第1の論理プロセッサに、前記第1の論理プロセッサに対して予めリザーブされた前記プロセッサ実行リソースを第2の論理プロセッサに対して使用可能にさせることは、前記プロセッサ実行リソースを前記第2の論理プロセッサからアクセス可能なプロセッサ実行リソースの共通プールに解放することさらに備える請求項16に記載のシステム。
【請求項18】
前記第1の論理プロセッサに対して予めリザーブされた前記プロセッサ実行リソースは、前記第1の論理プロセッサに対して予め静的に割り当てられた前記プロセッサ実行リソースを更に備え、前記プロセッサ実行リソースをプロセッサ実行リソースの共通プールに解放することは、前記プロセッサ実行リソースを解放することを更に備える請求項17に記載のシステム。
【請求項19】
前記第1の論理プロセッサに対して予めリザーブされた前記プロセッサ実行リソースは、前記第1の論理プロセッサに対して予め静的に割り当てられた前記プロセッサ実行リソースを更に備え、前記プロセッサ実行リソースをプロセッサ実行リソースの共通プールに解放することは、前記第1のプロセッサが前記プロセッサ実行リソースをアンロックすることを更に備える請求項17に記載のシステム。
【請求項20】
マシンによってアクセスされたときにマシンにある方法を実行させるデータが保存されたマシンアクセス可能な媒体であって、前記方法は、複数のプロセッサがプロセッサ実行リソースを共有するプロセッサ・ベースのシステムにおいて、前記複数のプロセッサのうちの第1のプロセッサが待機状態に移行するようにスケジュールされたことに応じて、前記第1のプロセッサに対して予めリザーブされたプロセッサ実行リソースを前記複数のプロセッサのうちの第2のプロセッサに対して使用可能にする媒体。
【請求項21】
前記第1のプロセッサがタスクを実行するようにスケジュールされたことに応じて、前記プロセッサ実行リソースを前記第1のプロセッサに対してリザーブすることを更に備える請求項20に記載の媒体。
【請求項22】
前記複数のプロセッサの各プロセッサは、前記プロセッサ・ベースのシステムの論理プロセッサである請求項21に記載の媒体。
【請求項23】
前記第1のプロセッサが待機状態に移行するようにスケジュールされることは、前記第1のプロセッサが前記第1のプロセッサを待機状態に移行させるように要求するプロセッサ命令を実行することを更に備える請求項22に記載の媒体。
【請求項24】
前記第1のプロセッサに対して予めリザーブされた前記プロセッサ実行リソースを第2のプロセッサに対して使用可能にすることは、前記プロセッサ実行リソースを前記第2のプロセッサからアクセス可能なプロセッサ実行リソースの共通プールに解放することをさらに備える請求項23に記載の媒体。
【請求項25】
前記第1のプロセッサがタスクを実行するようにスケジュールされることは、前記第1のプロセッサがウェイクアップ信号を受信することを更に備える請求項24に記載の媒体。
【請求項26】
前記第1のプロセッサに対して予めリザーブされた前記プロセッサ実行リソースは、前記第1のプロセッサに対して予め静的に割り当てられた前記プロセッサ実行リソースを更に備え、前記プロセッサ実行リソースをプロセッサ実行リソースの共通プールに解放することは、前記プロセッサ実行リソースを解放することを更に備える請求項25に記載の媒体。
【請求項27】
前記第1のプロセッサに対して予めリザーブされた前記プロセッサ実行リソースは、前記第1のプロセッサによって予めロックされた前記プロセッサ実行リソースを更に備え、前記プロセッサ実行リソースをプロセッサ実行リソースの共通プールに解放することは、前記第1のプロセッサが前記プロセッサ実行リソースをアンロックすることを更に備える請求項25に記載の媒体。
【請求項28】
プロセッサ実行リソースの前記共通プールは、トランスレーション・ルックアサイド・バッファを備え、前記プロセッサ実行リソースは前記トランスレーション・ルックアサイド・バッファからのトランスレーション・キャッシュ・エントリである請求項25に記載の媒体。
【請求項1】
複数のプロセッサがプロセッサ実行リソースを共有するプロセッサ・ベースのシステムにおいて、前記複数のプロセッサのうちの第1のプロセッサが待機状態に移行するようにスケジュールされたことに応じて、前記第1のプロセッサに対して予めリザーブされたプロセッサ実行リソースを、前記複数のプロセッサのうちの第2のプロセッサに対して使用可能にするステップを備える方法。
【請求項2】
前記第1のプロセッサがタスクを実行するようにスケジュールされたことに応じて、前記プロセッサ実行リソースを前記第1のプロセッサに対してリザーブするステップを更に備える請求項1に記載の方法。
【請求項3】
前記複数のプロセッサの各プロセッサは、前記プロセッサ・ベースのシステムの論理プロセッサである請求項2に記載の方法。
【請求項4】
前記第1のプロセッサが待機状態に移行するようにスケジュールされるステップは、前記第1のプロセッサが前記第1のプロセッサを待機状態に移行させるように要求するプロセッサ命令を実行するステップを更に備える請求項3に記載の方法。
【請求項5】
前記第1のプロセッサに対して予めリザーブされた前記プロセッサ実行リソースを第2のプロセッサに対して使用可能にするステップは、前記プロセッサ実行リソースを前記第2のプロセッサからアクセス可能なプロセッサ実行リソースの共通プールに解放するステップをさらに備える請求項4に記載の方法。
【請求項6】
前記第1のプロセッサがタスクを実行するようにスケジュールされるステップは、前記第1のプロセッサがウェイクアップ信号を受信するステップを更に備える請求項5に記載の方法。
【請求項7】
前記第1のプロセッサに対して予めリザーブされた前記プロセッサ実行リソースは、前記第1のプロセッサに対して予め静的に割り当てられた前記プロセッサ実行リソースを更に備え、前記プロセッサ実行リソースをプロセッサ実行リソースの共通プールに解放するステップは、前記プロセッサ実行リソースを解放するステップを更に備える請求項6に記載の方法。
【請求項8】
前記第1のプロセッサに対して予めリザーブされた前記プロセッサ実行リソースは、前記第1のプロセッサによって予めロックされた前記プロセッサ実行リソースを更に備え、前記プロセッサ実行リソースをプロセッサ実行リソースの共通プールに解放するステップは、前記第1のプロセッサが前記プロセッサ実行リソースをアンロックするステップを更に備える請求項6に記載の方法。
【請求項9】
プロセッサ実行リソースの前記共通プールは、トランスレーション・ルックアサイド・バッファを備え、前記プロセッサ実行リソースは、前記トランスレーション・ルックアサイド・バッファからのトランスレーション・キャッシュ・エントリである請求項6に記載の方法。
【請求項10】
複数の論理プロセッサと、
第1の論理プロセッサによって実行されたとき、前記第1の論理プロセッサが待機状態に移行するようにスケジュールされたことに応じて、前記第1の論理プロセッサが前記第1のプロセッサに対して予めリザーブされたプロセッサ実行リソースを前記複数のプロセッサのうちの第2のプロセッサに対して使用可能にする命令を1つ以上有する命令セットと
を備えるプロセッサ。
【請求項11】
前記第1の論理プロセッサが待機状態に移行するようにスケジュールされることは、前記第1のプロセッサが、前記第1の論理プロセッサを待機状態に移行させるように要求するプロセッサ命令を実行することを更に備える請求項10に記載のプロセッサ。
【請求項12】
前記第1の論理プロセッサに、前記第1の論理プロセッサに対して予めリザーブされた前記プロセッサ実行リソースを第2の論理プロセッサに対して使用可能にさせることは、前記プロセッサ実行リソースを前記第2の論理プロセッサからアクセス可能なプロセッサ実行リソースの共通プールに解放すること更に備える請求項11に記載のプロセッサ。
【請求項13】
前記第1の論理プロセッサに対して予めリザーブされた前記プロセッサ実行リソースは、前記第1の論理プロセッサに対して予め静的に割り当てられた前記プロセッサ実行リソースを更に備え、前記プロセッサ実行リソースをプロセッサ実行リソースの共通プールに解放することは、前記プロセッサ実行リソースを解放することを更に備える請求項12に記載のプロセッサ。
【請求項14】
前記第1の論理プロセッサに対して予めリザーブされた前記プロセッサ実行リソースは、前記第1の論理プロセッサに対して予め静的に割り当てられた前記プロセッサ実行リソースを更に備え、前記プロセッサ実行リソースをプロセッサ実行リソースの共通プールに解放することは、前記第1のプロセッサが前記プロセッサ実行リソースをアンロックすることを更に備える請求項12に記載のプロセッサ。
【請求項15】
複数の論理プロセッサ、および、第1の論理プロセッサによって実行されたとき、前記第1の論理プロセッサが待機状態に移行するようにスケジュールされたことに応じて、前記第1の論理プロセッサが前記第1のプロセッサに対して予めリザーブされたプロセッサ実行リソースを前記複数のプロセッサのうちの第2のプロセッサに対して使用可能にする命令を1つ以上含む命令セットを有するプロセッサと、
前記第1の論理プロセッサが待機状態に移行するようにスケジュールするファームウェアと、
前記ファームウェアと前記プロセッサとを相互接続するバスと
を備えるシステム。
【請求項16】
前記第1の論理プロセッサが待機状態に移行するようにスケジュールされることは、前記第1のプロセッサが前記第1のプロセッサを待機状態に移行させるように要求するプロセッサ命令を実行することを更に備える請求項15に記載のシステム。
【請求項17】
前記第1の論理プロセッサに、前記第1の論理プロセッサに対して予めリザーブされた前記プロセッサ実行リソースを第2の論理プロセッサに対して使用可能にさせることは、前記プロセッサ実行リソースを前記第2の論理プロセッサからアクセス可能なプロセッサ実行リソースの共通プールに解放することさらに備える請求項16に記載のシステム。
【請求項18】
前記第1の論理プロセッサに対して予めリザーブされた前記プロセッサ実行リソースは、前記第1の論理プロセッサに対して予め静的に割り当てられた前記プロセッサ実行リソースを更に備え、前記プロセッサ実行リソースをプロセッサ実行リソースの共通プールに解放することは、前記プロセッサ実行リソースを解放することを更に備える請求項17に記載のシステム。
【請求項19】
前記第1の論理プロセッサに対して予めリザーブされた前記プロセッサ実行リソースは、前記第1の論理プロセッサに対して予め静的に割り当てられた前記プロセッサ実行リソースを更に備え、前記プロセッサ実行リソースをプロセッサ実行リソースの共通プールに解放することは、前記第1のプロセッサが前記プロセッサ実行リソースをアンロックすることを更に備える請求項17に記載のシステム。
【請求項20】
マシンによってアクセスされたときにマシンにある方法を実行させるデータが保存されたマシンアクセス可能な媒体であって、前記方法は、複数のプロセッサがプロセッサ実行リソースを共有するプロセッサ・ベースのシステムにおいて、前記複数のプロセッサのうちの第1のプロセッサが待機状態に移行するようにスケジュールされたことに応じて、前記第1のプロセッサに対して予めリザーブされたプロセッサ実行リソースを前記複数のプロセッサのうちの第2のプロセッサに対して使用可能にする媒体。
【請求項21】
前記第1のプロセッサがタスクを実行するようにスケジュールされたことに応じて、前記プロセッサ実行リソースを前記第1のプロセッサに対してリザーブすることを更に備える請求項20に記載の媒体。
【請求項22】
前記複数のプロセッサの各プロセッサは、前記プロセッサ・ベースのシステムの論理プロセッサである請求項21に記載の媒体。
【請求項23】
前記第1のプロセッサが待機状態に移行するようにスケジュールされることは、前記第1のプロセッサが前記第1のプロセッサを待機状態に移行させるように要求するプロセッサ命令を実行することを更に備える請求項22に記載の媒体。
【請求項24】
前記第1のプロセッサに対して予めリザーブされた前記プロセッサ実行リソースを第2のプロセッサに対して使用可能にすることは、前記プロセッサ実行リソースを前記第2のプロセッサからアクセス可能なプロセッサ実行リソースの共通プールに解放することをさらに備える請求項23に記載の媒体。
【請求項25】
前記第1のプロセッサがタスクを実行するようにスケジュールされることは、前記第1のプロセッサがウェイクアップ信号を受信することを更に備える請求項24に記載の媒体。
【請求項26】
前記第1のプロセッサに対して予めリザーブされた前記プロセッサ実行リソースは、前記第1のプロセッサに対して予め静的に割り当てられた前記プロセッサ実行リソースを更に備え、前記プロセッサ実行リソースをプロセッサ実行リソースの共通プールに解放することは、前記プロセッサ実行リソースを解放することを更に備える請求項25に記載の媒体。
【請求項27】
前記第1のプロセッサに対して予めリザーブされた前記プロセッサ実行リソースは、前記第1のプロセッサによって予めロックされた前記プロセッサ実行リソースを更に備え、前記プロセッサ実行リソースをプロセッサ実行リソースの共通プールに解放することは、前記第1のプロセッサが前記プロセッサ実行リソースをアンロックすることを更に備える請求項25に記載の媒体。
【請求項28】
プロセッサ実行リソースの前記共通プールは、トランスレーション・ルックアサイド・バッファを備え、前記プロセッサ実行リソースは前記トランスレーション・ルックアサイド・バッファからのトランスレーション・キャッシュ・エントリである請求項25に記載の媒体。
【図1a】


【図1b】
【図1c】
【図2】
【図3】
【図1b】
【図1c】
【図2】
【図3】
【公開番号】特開2012−104140(P2012−104140A)
【公開日】平成24年5月31日(2012.5.31)
【国際特許分類】
【外国語出願】
【出願番号】特願2011−288768(P2011−288768)
【出願日】平成23年12月28日(2011.12.28)
【分割の表示】特願2006−552130(P2006−552130)の分割
【原出願日】平成17年1月14日(2005.1.14)
【公序良俗違反の表示】
(特許庁注:以下のものは登録商標)
1.フロッピー
【出願人】(591003943)インテル・コーポレーション (1,101)
【公開日】平成24年5月31日(2012.5.31)
【国際特許分類】
【出願番号】特願2011−288768(P2011−288768)
【出願日】平成23年12月28日(2011.12.28)
【分割の表示】特願2006−552130(P2006−552130)の分割
【原出願日】平成17年1月14日(2005.1.14)
【公序良俗違反の表示】
(特許庁注:以下のものは登録商標)
1.フロッピー
【出願人】(591003943)インテル・コーポレーション (1,101)
[ Back to top ]