
応答戦略獲得装置、リアクション選択装置、コンピュータプログラム、及びロボット
【課題】アクションからリアクションが生成される関係を確率モデルとして捉えて、この確率モデルを同定することで、ロボットが自律的に応答戦略を獲得できるようにする。
【解決手段】イニシエーター1が行ったイニシアティブアクションaiに対するリアクションbjを観測することで、イニシアティブアクションaiに対するリアクター2のリアクションbjの出力の仕方を示す応答戦略Z(bj,ai)を獲得する応答戦略獲得装置13であって、複数の種類のイニシアティブアクションaiそれぞれをリアクションbjの発生原因とした場合の当該リアクションの発生時刻sにおけるリアクション発生確率Wai,sを取得し、これらのリアクション発生確率Wai,sに基づいて、当該リアクションbjの選択確率Z(bj,ai)を算出する選択確率推定部22を備えている。
【解決手段】イニシエーター1が行ったイニシアティブアクションaiに対するリアクションbjを観測することで、イニシアティブアクションaiに対するリアクター2のリアクションbjの出力の仕方を示す応答戦略Z(bj,ai)を獲得する応答戦略獲得装置13であって、複数の種類のイニシアティブアクションaiそれぞれをリアクションbjの発生原因とした場合の当該リアクションの発生時刻sにおけるリアクション発生確率Wai,sを取得し、これらのリアクション発生確率Wai,sに基づいて、当該リアクションbjの選択確率Z(bj,ai)を算出する選択確率推定部22を備えている。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、応答戦略獲得装置、リアクション選択装置、コンピュータプログラム、及びロボットに関するものである。
【背景技術】
【0002】
Tmaselloは、子供がことば(記号)を覚える社会的能力の一部を説明するために役割反転模倣(Role Reversal imitation)という言葉を用いている(非特許文献1参照)。
役割反転模倣とは,共同行為を達成するにあたり対象への役割を反転し模倣することである。例えば、二者間のインタラクションであっても、バイバイに対してバイバイを返す事は、この二つで初めて一つの共同行為が達成されたと捉える事できる。
【0003】
このような共同行為を学習する際にお互いの役割を反転する事で、学習者はその行為の社会的な利用方法を学んでいく事が出来ると考えられる。
【0004】
栗山らは、乳児の親子間のやりとりに注目して、やりとり規則を適応的に獲得する手法を研究した(非特許文献2,3参照)。ロボットのメッセージ性のある行動に対しては、随伴性のある行動が現れるはずなので直後の行動が予想しやすくなるという仮定を置き、移動エントロピーを用いてやりとり規則を予想した。栗山らは、明示的なやりとり規則の教示なしに養育者とのインタラクションからメッセージ性のある行動を発見し、やりとり規則を一定程度獲得できることを示した。
【先行技術文献】
【非特許文献】
【0005】
【非特許文献1】マイケル・トマセロ,心とことばの起源を探る,勁草書房,2006
【非特許文献2】T. Kuriyama and Y. Kuniyoshi. Acquisition of Human-Robot Interaction Rules via Imitation and Response Observation. In Proceedings of the 10th international conference on Simulation of Adaptive Behavior: From Animals to Animats, pp.467-476.Springer, 2008.
【非特許文献3】栗山貴国,國吉康夫,模倣からの伝達行動の抽出に基づくやりとり規則の適応的獲得,pp.1252−1253,2007.
【発明の概要】
【発明が解決しようとする課題】
【0006】
しかし、栗山らのモデルでは自分の文脈と直後の養育者の文脈を観察する事によってロボットの行動を決定しているため、養育者の直近の行動に対するやりとり規則しか獲得する事ができない。現実のインタラクションは実時間的であり、他者のどの行動が自らの何秒前の行動に対するリアクションであるかは不明確である。
【0007】
また,与えられた単位行動の内のどの行動がインタラクション上有意義であるかを明示的に知る事は出来ない。
そこで、本発明は、これらの問題に対応するために役割反転模倣の考え方に基づきながら、アクションからリアクションが生成される関係を確率モデルとして捉えて、この確率モデルを同定することで、ロボットが自律的に応答戦略を獲得できるようにすることを目的とする。
また、本発明の他の目的は、インタラクションにおいて、どのアクションがどのアクションに対するリアクションであったか、また、アクションがイニシアティブアクションであるか否かといった役割推定を行うことを可能とすることにある。役割推定を行うことで、リアクションに対してさらにリアクションするということを防止し、イニシアティブアクションに対してのみリアクションする、ということが可能となる。
【課題を解決するための手段】
【0008】
本発明は、イニシエーターが行ったイニシアティブアクションに対するリアクターのリアクションを観測することで、イニシアティブアクションに対するリアクションの出力の仕方を示す応答戦略を獲得する応答戦略獲得装置であって、あるイニシアティブアクションを原因とする何らかのリアクションが、ある時刻において発生する確率を示すリアクション発生確率を、時間とリアクション発生確率との関係を規定したリアクション発生確率密度関数に基づいて算出する発生確率算出部と、あるイニシアティブアクションに対して何らかのリアクションが発生することが決定した場合における、当該イニシアティブアクションに依存して特定の種類のリアクションがリアクターによって選択される選択確率を推定することで、イニシアティブアクションに対するリアクションの出力の仕方を示す応答戦略を獲得する選択確率推定部と、を備え、前記選択確率推定部は、複数の種類のイニシアティブアクションそれぞれをリアクションの発生原因とした場合の当該リアクションの発生時刻におけるリアクション発生確率を、当該複数の種類のイニシアティブアクションそれぞれの発生時刻及び当該リアクションの発生時刻に基づき、前記発生確率算出部を介して取得し、これらのリアクション発生確率に基づいて、当該リアクションの前記選択確率を、当該複数の種類のイニシアティブアクションそれぞれについて算出するよう構成されていることを特徴とする応答戦略獲得装置である。
また,リアクション発生確率密度関数とリアクション選択確率を用いる事で役割推定、すなわち、アクションがイニシアティブアクションであるか、リアクションであるかを判定でき、これにより、事前にどちらがイニシエーターであり、どちらがリアクターであるかが分からなくてもロボットが学習することが可能となる。
【0009】
前記リアクション発生確率密度関数は、イニシアティブアクション発生後から時間経過に伴ってリアクション発生確率が減衰するよう規定されたものを用いることができる。ここで、上記「イニシアティブアクション発生後から時間経過に伴ってリアクション発生確率が減衰する」とは、イニシアティブアクション発生直後から直ちにリアクション発生確率が減衰する場合に限らず、イニシアティブアクション発生から所定の時間(例えば、コンマ数秒後;自然なインタラクションにおいてアクション間に生じる時間差に相当する時間)経過後にピークがきて、その後、減衰するものであってもよい。
【0010】
前記リアクション発生確率密度関数を変化させて、発生したイニシアティブアクションとリアクションとの間の相互情報量が最大となるリアクション発生確率密度関数を探索する探索部を更に備え、前記発生確率算出部は、前記相互情報量が最大となるリアクション発生確率密度関数に基づいて、リアクション発生確率を算出することができる。
【0011】
複数の種類のイニシアティブアクション及び/又はリアクションの重要度を推定する重要度推定部を更に備え、前記重要度推定部は、発生したイニシアティブアクションとリアクションとの間の第1相互情報量と、発生した複数の種類のイニシアティブアクション及び/又はリアクションのうち一部のアクションが存在しないものと仮定した場合のイニシアティブアクションとリアクションとの間の第2相互情報量と、の差に基づいて、存在しないものと仮定した前記一部のアクションの重要度を算出することができる。
【0012】
発生したイニシアティブアクション及び/又はリアクションのうち、応答戦略獲得の対象となる重要アクションを抽出する重要アクション抽出部を更に備え、前記重要アクション抽出部は、発生したイニシアティブアクション及び/又はリアクションそれぞれについて算出された前記重要度に基づいて、重要アクションを抽出することができる。
【0013】
前記選択確率算出部は、EM(Expectation-Maximization)アルゴリズムに基づいて、前記選択確率を算出することができる。
【0014】
発生したアクションがイニシアティブアクションであるかリアクションであるかを推定する役割推定部を更に備え、前記役割推定部は、発生したアクションをリアクションと仮定して、リアクションであると仮定した当該アクションの前記選択確率を推定し、推定した前記選択確率に基づいて、当該アクションの原因となったイニシアティブアクションを推定し、推定したイニシアティブアクションが「何もしないアクション」である場合には、当該アクションはイニシアティブアクションであると推定し、その他の場合には、当該アクションはリアクションであると推定することができる。この場合、インタラクションにおける一方側と他方側の役割を推定でき、応答戦略獲得装置をインタラクション解析装置として機能させることができる。
【0015】
他の観点からみた本発明は、観測されたイニシアティブアクションに対するリアクションの選択を行うリアクション選択装置であって、前記応答戦略獲得装置によって応答戦略として獲得した前記選択確率を用いて、観測されたイニシアティブアクションに対するリアクションの選択を行うことを特徴とするリアクション選択装置である。
【0016】
他の観点からみた本発明は、コンピュータを、前記応答戦略獲得装置として機能させるためのコンピュータプログラムである。
【0017】
他の観点からみた本発明は、コンピュータを、前記リアクション選択装置として機能させるためのコンピュータプログラムである。
【0018】
他の観点からみた本発明は、前記応答戦略獲得装置及び前記リアクション選択装置(22)を備え、前記リアクション選択装置によって選択されたリアクションを生成するリアクション生成部を備えていることを特徴とするロボットである。
【発明の効果】
【0019】
本発明によれば、ロボットが自律的に応答戦略を獲得することができる。
【図面の簡単な説明】
【0020】
【図1】役割反転模倣の概念図である。
【図2】第1実施形態に係るロボットの内部構成を示すブロック図である。
【図3】図3(a)はイニシアティブアクションからリアクションが確率的に発生する発生確率モデルの概要図であり、図3(b)はリアクション発生確率密度関数の他の例である。
【図4】学習後のリアクション選択確率の棒グラフである。
【図5】τによる相互情報量の推移を示すグラフである。
【図6】最適τに基づいて推定されたリアクション選択確率の棒グラフである。
【図7】相互情報量によって推定された重要度を示す棒グラフである。
【図8】第2実施形態に係るロボットのブロック図である。
【図9】学習後のリアクション選択確率の棒グラフである。
【図10】λ、τによる相互情報量の変化を示す図である。
【発明を実施するための形態】
【0021】
以下、本発明の好ましい実施形態について添付図面を参照しながら説明する。
【0022】
[1.役割反転模倣の概念と定義]
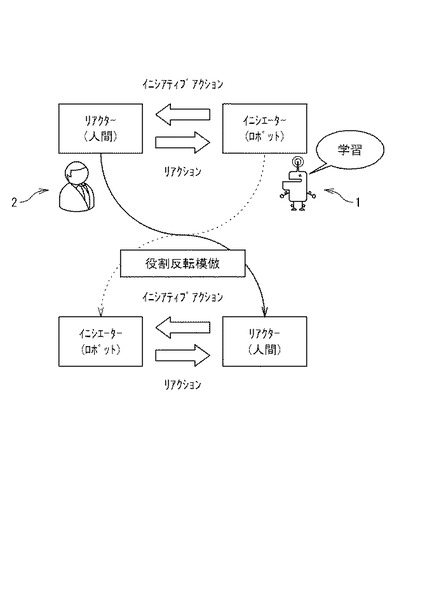
本実施形態に係る自律型ロボット1は、人間2との自然なインタラクションを通じて、人間の応答戦略を獲得する。
前記ロボット1は、人間の動作自体を模倣するのではなく、人間2が行っている動作(アクション)に対して自身がどのような動作を返せば良いか、つまり応答戦略を模倣により獲得する。ただし、ロボット1は、時間については連続的な時間で行動するが、動作については既に幾つかの動作単位(例えば、「お手」、「お手受け」、「バイバイ」、「プルプル」など)を持っており、状況に合わせてそれらを選択し表出しているものとする。
【0023】
図1に示すように、一つの共同行為として見たインタラクションは、自発的な動作とそれに対する応答としての動作により成り立っている。ここでは、前者を「イニシアティブアクション」と呼び、後者を「リアクション」と呼ぶ。イニシアティブアクションとリアクションを包含していう場合、単に「アクション」という。
また、イニシアティブアクション側を「イニシエーター」、リアクションを行う側を「リアクター」と呼ぶ。
一つの共同行為を実現するためには、二者がこれらの役割を担い適切な動作を出力する必要がある。ここででは、イニシエーターとリアクターの役割を反転する事を「役割反転」とし、ロボット自らのイニシアティブアクションに対する人間のリアクションの仕方を人間の「応答戦略」と呼ぶ。
そして、この二つの役割を模倣し、それらを反転する事により適切な行動生成(リアクション選択)を行えるようになる過程を「役割反転模倣」と呼ぶ。
【0024】
このような学習は.明示的にどのアクションがどのアクションに対するリアクションなのか、といったような関係づけが明示的になされている系では比較的簡単に達成しうる。しかし、人間とロボットのインタラクションが連続時間で行われ.かつ役割が明示的に与えられないような場合の学習は決して自明ではない。以下の実施形態では、イニシアティブアクションに対するリアクションの発生を確率的な生成モデルに基づいてモデル化する事で、ロボットの学習フェーズと行動フェーズを分離することなく、人間との実時間相互作用から応答戦略獲得を行う学習則を構築する。
【0025】
[2.第1実施形態]
[2.1 ロボットの構成]
ロボット1は、動作(アクション)を生成可能なロボット本体に、カメラなどの撮像部4及び制御部5などを搭載して構成されている(図2参照)。
ロボット本体は、例えば、人間型、動物型などの形状に構成され、モータなどのアクチュエータ(アクション生成部3)によって実際の人間・動物の動作に類似した動作を行うことができる。
【0026】
撮像部4は、インタラクションにおける相手方(人間2)を撮像した画像を取得するためのものである。撮像部4によって取得した画像は、制御部5に与えられ、画像処理が行われる。人間の動作を獲得するための装置は、撮像部4に限られるものではなく、人間の動作を取得できるものであれば、機械式モーションキャプチャやジャイロセンサーなど他の入力装置であっても構わない。
【0027】
制御部5は、CPU及び記憶装置などを有するコンピュータによって構成されており、撮像部4によって取得した画像の画像処理及びロボット本体の制御などのロボットに必要とされる情報処理を行う。制御部(コンピュータ)5は、以下に説明する応答戦略獲得及び行動戦略などの機能を、当該コンピュータに実行させるためのコンピュータプログラムを有している。なお、画像処理は、制御部5とは別の画像処理プロセッサで行い、処理結果を制御部5が取得するようにしてもよいが、本実施形態では制御部5が行うものとする。
【0028】
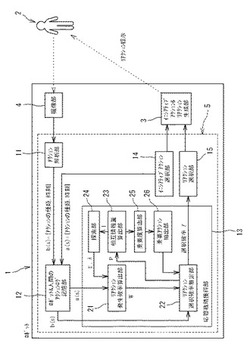
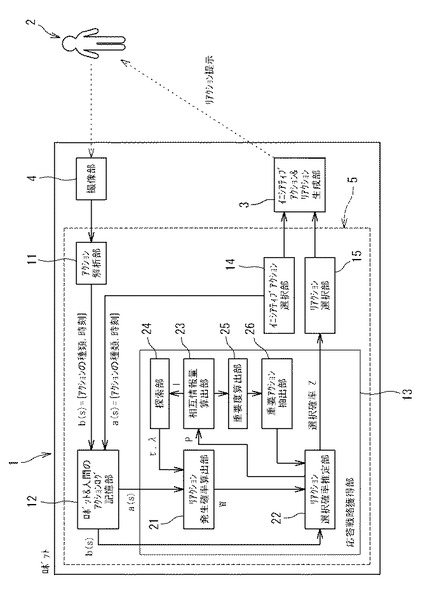
図2に示すように、制御部5は、アクション解析部11、ロボット&人間のアクションログ記憶部12、応答戦略獲得部(応答戦略獲得装置)13、イニシアティブアクション選択部14、リアクション選択部(リアクション選択装置)15としての機能を有している。これらの機能は、コンピュータプログラムによって実現される。
【0029】
アクション解析部11は、撮像部4によって取得した画像から、人間2が行っているアクションの種類を、画像処理によって解析し、特定する。なお、本実施形態において、対象となるアクションの種類は、予め定められたもの(例えば、「お手」、「お手受け」、「バイバイ」、「プルプル」の4種類)であるが、ロボット1が自律的に新たなアクションを抽出し獲得してもよい。また、ロボットの設計者やユーザが新たに加えても構わない。
【0030】
アクション解析部11は、人間2が行っているアクションの種類を特定すると、特定したアクションの種類及びそのアクションの発生時刻を示すアクション情報を出力する。アクション解析部11が出力したアクション情報は、アクションログ記憶部12に、ログ情報として逐次蓄積される。
【0031】
制御部5は、ロボット1自身の自発的な行動であるイニシアティブアクションを発生させるためのイニシアティブアクション選択部14を備えている。イニシアティブアクション選択部14は、予め設定された複数種類のアクションの中からイニシアティブアクションとして出力するアクションを適宜選択する。イニシアティブアクション選択部14によって選択された種類のアクションは、アクション生成部3によってロボット1の実際のアクションとして生成され、人間2に提示される。
【0032】
また、イニシアティブアクション選択部14は、選択したイニシアティブアクションの種類及びそのイニシアティブアクションの発生時刻を示すアクション情報を出力する。イニシアティブアクション選択部14が出力したアクション情報は、アクションログ記憶部12に、ログ情報として逐次蓄積される。
【0033】
この結果、アクションログ記憶部12には、ロボット1及び人間2が過去に行ったアクションの種類及びその発生時刻が記憶されることになる。
第1実施形態では、応答戦略獲得の学習時は、ロボット1をイニシエーターとし、人間2をリアクターとするため、前記アクションログ記憶部12には、イニシエーターとしてのロボット1が行ったイニシアルアクションのログ情報と、リアクターとしての人間2が行ったリアクションのログ情報とが、ロボット1と人間2とのインタラクションの結果を示すログ情報として蓄積されることになる。
【0034】
前記応答戦略獲得部13は、アクションログ記憶部12に記憶されたインタラクションのログ情報に基づいて、人間2の応答戦略を獲得するための処理を行う。応答戦略獲得部13によって獲得した応答戦略は、リアクション選択部15において用いられる。リアクション選択部15は、人間2が行ったイニシアティブアクションに対するロボット1の適切なリアクションを、人間2の応答戦略の役割反転を行うことで選択する。
【0035】
応答戦略獲得部13は、リアクション発生確率を算出するリアクション発生確率算出部21、リアクション発生確率からリアクション選択確率を推定するリアクション選択確率推定部22、イニシアティブアクションとリアクションの相互情報量を算出する相互情報量算出部23、最適なリアクション発生確率密度関数を探索する探索部24、アクションログ記憶部12に記憶されているアクションの重要度を算出する重要度算出部25、アクション記憶部12に記憶されているアクションのうち、重要なアクションを抽出する重要アクション抽出部26を備えている。
以下、これらの機能について説明する。
【0036】
[2.2 リアクション発生確率]
まず、ロボット1の取り得る単位動作(単位アクション)の集合をA={a1,a2,・・・,am}とし、人間2の取り得る単位動作の集合をB={b1,b2,・・・,bm}とする。本実施形態においては、4つの単位動作(m=4)を想定し、具体的には、例えば、A={a1:「お手」,a2:「お手受け」,a3:「バイバイ」,a4:「プルプル」}、B={b1:「お手」,b2:「お手受け」,b3:「バイバイ」,b4:「プルプル」}である。
【0037】
ここで、人間2の単位動作とロボット1の単位動作は身体的な対応関係を表す関数cが存在し、c(ai)=biを通して、一対一対応の関係が存在するものとする。また、ここでは、リアクションはイニシアティブアクションを原因として、時間遅れを伴い確率的に発生すると仮定する。
【0038】
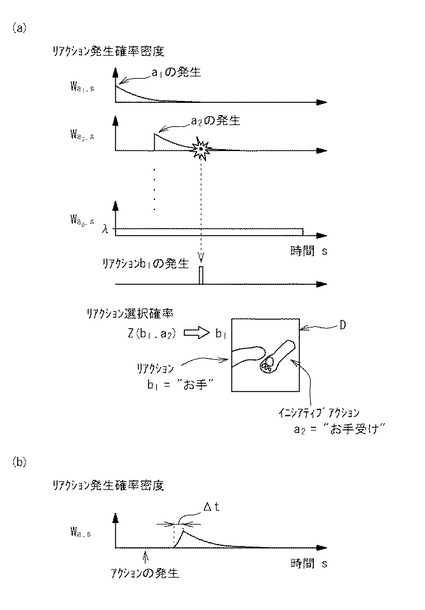
時刻t0においてアクションaiが生じた際に、その後の時刻tにおいてそのアクションaiをイニシアティブアクションとした何らかのリアクション(種類は問わない)が発生する確率密度Waiを次のように定義する。
【数1】

これをリアクション発生確率密度と呼ぶこととする。このリアクション発生確率密度は、イニシアティブアクションの発生時刻から時間経過に従って発生確率が指数的に減衰する関数となっている。なお、τは時定数であり、この時定数の最適化については後述する。
【0039】
リアクション発生確率算出部21では、リアクション発生確率を、1stepをΔt[s]として、以下のように逐次的に更新することで計算する。ここで、sは連続時間をサンプリングしたときの離散時間ステップを指す。
【数2】
【0040】
図3(a)は、上記式に基づいて算出される各イニシアティブアクションai(i:1〜m及びφ)を原因とする何らかのリアクションの発生確率Wai,sの例を示している。例えば、イニシアティブa1についてのリアクション発生確率Wa1,sは、イニシアティブa1が発生した時点では、(Δt/τ)の値をとり、その後、時間経過とともに減衰する。
【0041】
通常のイニシアティブアクションai(i:1〜m)を原因とする何らかのリアクションの発生確率Wai,sは、上記のように、イニシアティブアクション発生から時間経過とともに減衰する特性を有するが、「何もしないアクション」aφについてのリアクション発生確率Wa1,sは、時間経過にかかわらず一定値(=λ)をとる。
ここで、「何もしないアクション」aφbφは、ヌルアクションとよび、イニシアティブアクションは、ヌルアクションを原因として発生するものとする。つまり、イニシアティブアクションは毎ステップにおいて、λの確率で発生するものとする。
【0042】
なお、リアクション発生確率密度関数は、図3(a)のものに限られるわけではない。例えば、図3(b)に示すようにイニシアティブアクション発生から所定時間Δt経過してから、リアクション発生確率がピークをとり、その後、減衰するものであってもよい。Δtは、インタラクションにおいてイニシアティブアクションとリアクションとの間に通常生じる時間差に相当する程度の時間に設定するのが好ましく、具体的には、コンマ数秒程度とすることができる。
【0043】
リアクション発生確率算出部21は、アクションログ記憶部12から、ロボット1が発生させたイニシアティブアクションai(i:1〜m)の種類とその発生時刻の情報を取得し、図3のように、各イニシアティブアクションai(i:1〜m及びφ)を原因とする何らかのリアクションの発生確率Wai,sを、複数種類のイニシアティブアクションai(i:1〜m及びφ)それぞれについて求めて、出力する。
【0044】
[2.3 リアクション選択確率の推定(応答戦略の獲得)]
本実施形態においては、リアクションの発生が決定した後に、その原因となったイニシアティブアクションの種類に依存して実際に出力されるリアクションの種類が選択されると仮定する。
イニシアティブアクションaiに対してリアクションbjが出力される確率Z(bj,ai)をリアクション選択確率と呼ぶ。ロボット1のリアクション選択確率推定部22は、このリアクション選択確率を、図1に示すように、ロボット1のイニシアティブアクションに対する人間2のリアクションを観測することによって、応答戦略として学習する。
【0045】
一定時間のロボット1と人間2のインタラクションを通して、ロボット1のアクションログ情報AO=(a(s)|a(s)∈A,s∈Sa)および人間2のアクションログ情報BO=(b(s)|b(s)∈B,s∈Sb)が得られ、これらのログ情報が、アクションログ記憶部12に記憶されているものとする。ここで、Sa,Sbは、それぞれ、ロボット1と人間2がアクションを起こした時刻の集合である。
【0046】
本実施形態においては、ロボット1のアクションをイニシアティブアクション、人間2のアクションをリアクションと仮定する。すると、人間(リアクター)2の各時刻のアクションbjが、ロボット(イニシエーター)1のどのイニシアティブアクションaiを原因としているかを潜在変数として、人間2のリアクション出力についての不完全データの対数尤度Lは以下のようになる。なお、b(s)は、時刻sにおいて人間2が選択したアクションである。
【数3】
【0047】
上記式を増加させるために、Z(b,a)の、更新則を下記のように定める。
【数4】
となる。
【0048】
上式より、最尤のリアクション選択確率Z(bj,ai)の推定値(応答戦略)は、人間2のリアクションが発生する毎に、
【数5】
を求めて、その値を、それまでのリアクション選択確率Z(bj,ai)に足して、逐次的に更新することで求めることができる。
【0049】
なお、上記式の値は、リアクション選択確率推定部22が、そのリアクション発生時刻における、ロボット1の全ての種類のアクションai(i:1〜m及びφ)についてのリアクション発生確率Wai,sを、リアクション発生確率算出部21の出力から取得し、取得した出力に基づいて、上記式に従い演算することで得られる。
また、そのリアクション発生時刻における各アクションai(i:1〜m及びφ)についてのリアクション発生確率Wai,sは、アクションログ記憶部12から取得したリアクション発生時刻におけるリアクション発生確率密度関数の値を調べることで求めることができる。
【0050】
リアクション選択確率推定部22は、あるリアクションが発生すると、リアクション選択確率Z(bj,ai)の推定値(応答戦略)として、ロボット1の全ての種類のアクションai(i:1〜m及びφ)それぞれについて更新する。
すなわち、例えば、人間2のリアクションb1が発生すると、Z(b1,a1),Z(b1,a2),Z(b1,a2),Z(b1,a4),Z(b1,aφ)の全ての値が更新される。
【0051】
本実施形態では、制御部5にカウント行列Mの記憶部(図示省略)を用意し、人間からのリアクションbjが時刻sにおいて発生する毎に、全てのai∈A+{φ}に対して、
【数6】
と足していく。このカウント行列Mは、時間遅れを伴うイニシアティブアクションaとリアクションbの同時生起頻度であり、リアクション選択確率推定部22では、これに基づいて応答戦略(リアクション選択確率)Z(b,a)の推定値Z^、及び、アクションaiとリアクションbjの同時確率P(bj,ai)を求める。
【数7】
【0052】
[2.4 役割反転による行動(リアクション)選択]
リアクション選択確率推定部22によって獲得された応答戦略(最尤のリアクション選択確率の推定値)は、リアクション選択部15に出力される。
【0053】
役割反転により、人間2がイニシエーター、ロボット1がリアクターとなった場合、ロボット1のリアクション選択部15は、獲得された応答戦略(リアクション選択確率の推定値)Z^(bi,ai)と、身体動作の対応関係を表す関数cを用いて、人間2のイニシアティブアクションbjに対する、ロボット1のリアクションaiの種類を、以下の確率P(ai|bj)で選択する。
【数8】
【0054】
つまり、リアクション選択部15は、上記式によって求めた確率が最も大きくなるリアクションを生成すべきアクションとして決定したり、上記式によって求めた確率でリアクションを確率的に決定したりすることができる。
【0055】
リアクション選択部15が、最終的に時間ステップsにおいて、アクションaiを選択する確率は、
【数9】
となる。ここで、Wbj,sは、Wai,sと同様に、変化する人間の動作を原因としたリアクション発生確率密度である。
[2.5 時定数τの探索]
応答戦略には、W内部の時定数τが関わるが、τについては、以下で定義するインタラクションの相互情報量(イニシアティブアクションとリアクションの相互情報量)を最大化するτを探索し決定する。
【数10】
具体的には、探索部24がτを所定の範囲で変化させて、変化させたτでの確率P(b,a)(式8参照)や確率P(a)P(b)(式10参照)を求め、これらの確率から相互情報量算出部23が、上記式に従い相互情報量I(B,A)を算出し、相互情報量が最大となるτを決定する。
【0056】
このような時定数τの探索は、与えられたインタラクション履歴(アクションログ)AO,BOが高い随伴性で生じていると解釈するためには、リアクションが、イニシアティブアクションに対して、どのくらいの遅れで生じるとするべきかを同定することと等価である。
なお、Wに関わるパラメータとしては、λもあり、これもτと同様に、相互情報量を最大化するように探索することができる。
【0057】
[2.6 インタラクション実験]
上記第1実施形態に係るロボットおける制御部5の部分を実現する学習プログラムを、計算機上に実装し、シミュレーション実験を行った。その内容は、以下の通りである。
【0058】
[2.6.1 実験条件]
実験では、計算機上の画面に2つの犬の手を表し、これをユーザ(人間)とロボット(計算機の学習プログラム)が動かすことで相互作用を行う空間を設計した(図3の画面D参照)。図3の画面Dにおいて、左側手前がユーザの操作する手であり、右側奥がロボットの操作する手である。
【0059】
ユーザはキーボードを押すことで予め設定された単位動作を出力することが出来る。アクションには、a1=「お手」,a2=「お手受け」,a3=「バイバイ」,a4=「プルプル」と名付けた四つの単位動作を設定した。本実験では、ユーザが操作する側の手も、ロボットが操作する側の手も同じであるので、biはaiと同様に、b1=「お手」,b2=「お手受け」,b3=「バイバイ」,b4=「プルプル」と与えた。つまり、関数cは、bi=c(ai)である。
【0060】
計算機のキーボードの1キーから4キーまでがそれぞれa1〜a4に対応付けられており、ユーザがキーを押すと、遅滞なく選択された行動が開始され、ロボットは時間遅れも認識誤り無く瞬時にその行動(種類と発生時刻)を認識できるものとする。フレームレートは10[Hz]とし、また、ロボットのカウント行列Mは、全要素の値を1×10-5で初期化した。
【0061】
実験者は、ロボットに対し、
1.「お手受け」に対して、「お手」をさせる行動
2.「バイバイ」に対して、「バイバイ」を返す行動
を学習することを求めた。被験者は、ロボットが「お手受け」をだしたときに、「お手」をし、ロボットが「バイバイ」をしたときに、「バイバイ」を返し、また、他の時には無規則に行動を表出した。
【0062】
そのようなインタラクション系列に基づき.ロボットはカウント行列Mを更新することで時定数τリアクション選択確率(応答戦略)Z(bj,ai)を獲得する。また、Wに関わるパラメータはオフラインで同定するので、初期値としては、τ=0.3、λ=0.01に設定した。
【0063】
また、本実験では、応答戦略のパラメータ推定に焦点を当てる為、ロボットの行動出力については、式10の生成モデルを直接用いることはせず、簡単の為、ロボットには、τ[s]に一回リアクション出力を行わせ、そのリアクション選択は、獲得したリアクション選択確率に基づくという手法をとった。
【0064】
[2.6.2 実験結果]
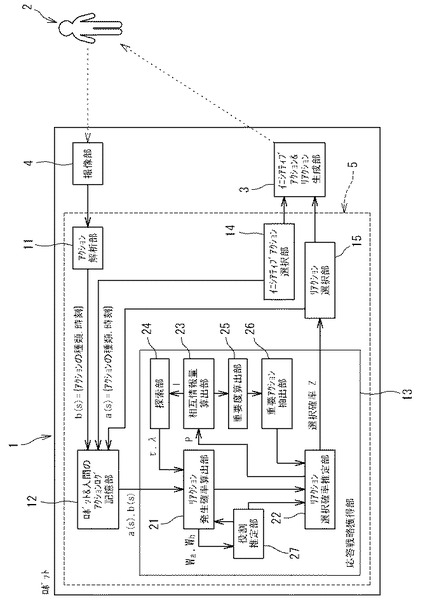
インタラクションは約260秒行われ、その間ユーザは基本的に実験条件に示したような応答を示すよう心がけた。リアクション選択確率Z(bj,ai)の推定自体は、カウント行列Mに、徐々に値を足して行くことで単調的に同定される(式(6)参照)ため、過程は省略するが、最終的に得られたカウント行列Mをイニシアティブアクション毎に正規化することで得られるリアクション選択確率Z^を図4に示した。
【0065】
図4において「NULL」とあるのは、ヌルアクションを指す。図4より、イニシアティブアクションとしてのa2=「お手受け」の後にb1=「お手」が出る確率、a3=「バイバイ」の後にb3=「バイバイ」が出る確率が高くなっていることがわかる。
【0066】
このインタラクションで獲得したカウント行列Mの値を表1に示す。
【表1】
【0067】
カウント行列Mの値は同時確率分布に比例するが、アクション「プルプル」は、発生頻度自体が小さく、被験者に指定した二つの組み合わせの発生頻度が特に大きいことがわかる。
【0068】
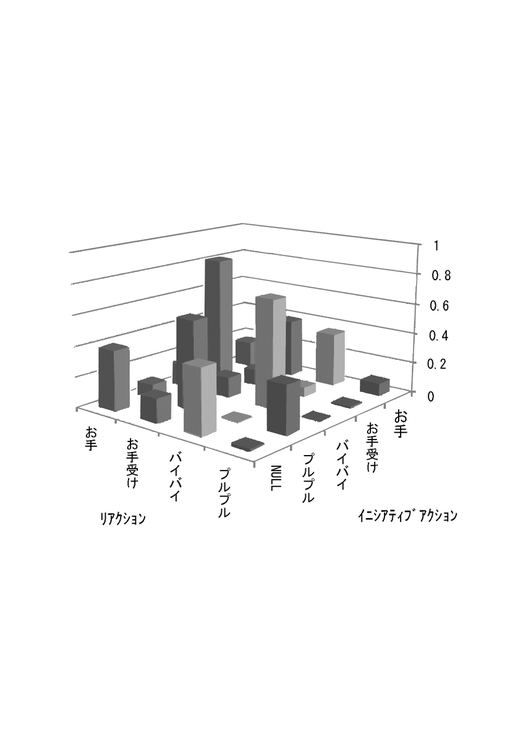
また、このインタラクションの履歴を用いて、リアクション発生確率密度関数の時定数τの推定を行った。τを0.1[s]から10.0[s]までの間で、0.05[s]刻みで変動させ、その結果として計算される時間遅れを考慮したリアクションとイニシアティブアクションの同時確率分布から、リアクション・イニシアティブアクション間の相互情報量を求めた。その結果を図5に示す。
【0069】
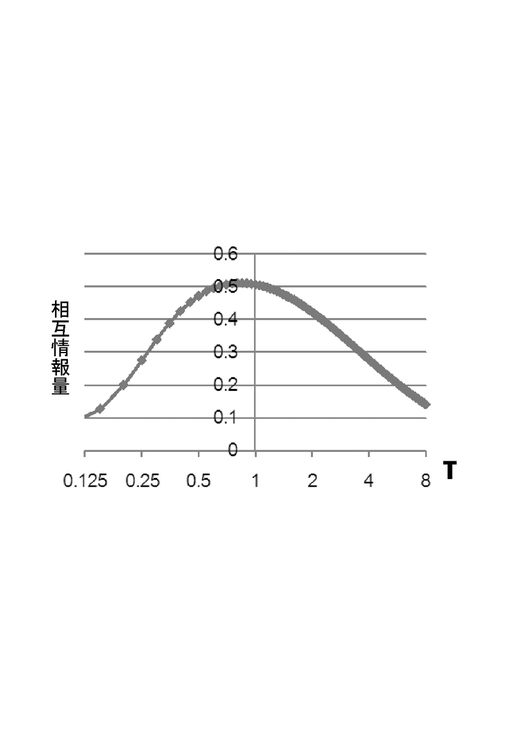
図5では、横軸にτを対数軸でとり、縦軸に相互情報量をとっている。探索の結果、τ=0.75のとき、相互情報量が0.512となり最大となった。この相互情報量はリアクションがアクションに対して担っている情報量である。つまり、相互情報量を最大にするτを探索することは、ロボットがユーザのリアクションを最大限自らの行動に対する因果的な応答であると捉えようとすることを意味する。この最適τに基づいて、同様のインタラクション履歴から学習したリアクション選択確率Z^を図6に示す。
【0070】
図6では、時定数を初期値のτとしていた図4よりも、イニシアティブアクションとリアクションの関係の曖昧性が薄れ、関係性がより顕著になっていることがわかる。
【0071】
[2.6.3 アクションの重要度推定と重要アクションの抽出]
上記の説明においては、予め単位動作が与えられていることを前提としたが、自然な相互作用から様々な動作を獲得するロボットを生み出そうとすると、単位動作自体をロボット自身に獲得させる必要がある。この場合、インタラクション上、価値のない動作系列も単位動作として抽出される可能性がある。
【0072】
先のインタラクション実験では、a4=b4=「プルプル」が、そのようなインタラクション上無意味な動作(重要度が低いアクション)といえる。
一方、先のインタラクション実験での、a2=「お手受け」、b1=「お手」、a3=b3=「バイバイ」などは、インタラクション上重要なアクションである。なお、同じ「お手」、「お手受け」であっても、リアクションとしての「お手受け」やイニシアティブアクションとしての「お手」は重要でない点に留意すべきである。
【0073】
インタラクション上動作とは、他社の行動を適切に制約づける動作(アクション)である。他者に無視され他者の行動に影響を与えない動作はインタラクション上重要でないと考えられる。よって、重要な動作(アクション)のみで形成されたインタラクションには高い情報的結合の存在が期待される。
そこで、重要度算出部25は、アクションログ記憶部12に記憶されているイニシアティブアクション及び/又はリアクションのうち、あるイニシアティブアクション・リアクションが最初から無かった(アクションログ記憶部12に記憶されていない)と考えた場合の同時確率分布を計算し、その前後での相互情報量の変化によって、各アクションの重要度を算出する。
【0074】
アクションログ記憶部12に記憶されているイニシアティブアクション・リアクションのうちあるアクションを記憶部12から削除した場合、もし削除したイニシアティブアクション・リアクションが二者間のインタラクションに重要であるなら、相互情報量は大きく減少し、重要でないならほぼ減少しない、もしくは増加するはずである。
【0075】
あるイニシアティブアクションaiが最初から無かったと仮定するため、重要度算出部25は、一旦生成したカウント行列Mから、列aiを除いた新たな部分行列M’を生成する。この部分行列M’から生成される同時確率によって、相互情報量を計算する。リアクションbjについても同様に行う。
【0076】
元々(削除前)の相互情報量(第1相互情報量)をI(B;A)、アクションaiを削ったインタラクションに基づく相互情報量(第2相互情報量)をI’(B;A−{ai})で表す。リアクションについても同様である。
各イニシアティブアクションの重要度をΔaction(ai)、各リアクションの重要度をΔreaction(bi)、同時確率分布をP(b,a)とすると、重要度算出部25は、それぞれの重要度を下記式により算出する。
【数11】
これらの重要度の値が大きいほど、イニシアティブアクションもしくはリアクションとしてインタラクション上重要であることを示す。
【0077】
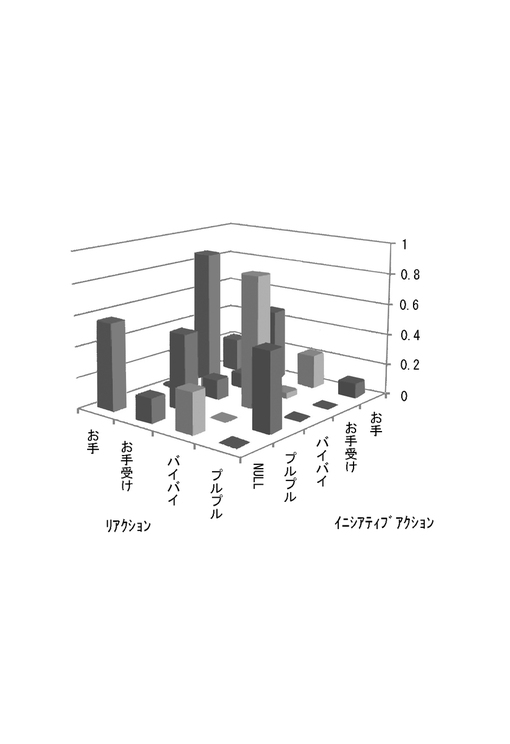
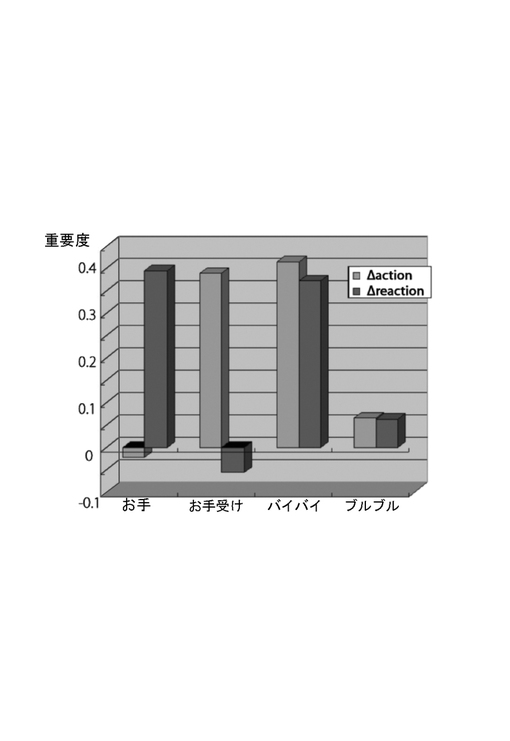
前記インタラクション実験の条件の下で、相互情報量を用いてイニシアティブアクション・リアクションの重要度推定を行った結果を図7に示す。
図7より、イニシアティブアクションとして重要なものは、a2=「お手受け」,a3=「バイバイ」であり、逆に重要でないものはa1=「お手」であることがわかる。
また、リアクションとして重要なものは、b1=「お手」,b3=「バイバイ」であり、学習重要でないのは、b2=「お手受け」であることがわかる。相互情報量を求める事9によって、重要度の推定が正しく行われていることがわかる。
【0078】
重要アクション抽出部26は、例えば、所定の閾値よりも重要度の値が大きいアクションを重要アクションとして抽出する。そして、リアクション選択確率推定部では、非重要アクションを除外し、重要アクションだけが発生したものとしてリアクション選択確率(応答戦略)を獲得し直すことで、より適切な推定が行える。
【0079】
[3.第2実施形態]
第1実施形態における応答戦略の学習則は、発見的手法に基づいているが、第2実施形態では、EMアルゴリズムにより、役割反転模倣を達成する。また、第2実施形態では、潜在変数としての「役割」(イニシエーターであるかリアクターであるかということ)を明示的に推定することで、ロボット1の学習フェーズと行動フェーズを分離することなく、人間2との実時間相互作用から応答戦略獲得を行う学習則を構築する。
【0080】
なお、第2実施形態では、イニシアティブアクションを「IA」、リアクションを「RA」と略記することがある。
【0081】
[3.1 ロボットの構成]
図8は、第2実施形態に係るロボット1の構成を示している。この第2実施形態では、リアクション選択確率推定部22の機能が第1実施形態と異なっているほか、役割推定部27が追加されている。第2実施形態において特に説明しない点は、第1実施形態のものと同様である。
【0082】
[3.2 リアクション発生確率]
第2実施形態では、リアクション発生確率(時刻sにおいてイニシアティブアクションaiを原因とした何らかのリアクションが発生する確率)の関数を次のように定義する。
【数12】
上記確率Waに基づいて、イニシアルアクションから何らかのリアクションが発生するものとする。上記Waを求める為には、各時刻のアクションaiが、イニシアティブアクションであるか否かを知る必要がある。
なお、第2実施形態では、集合A,Bにヌルアクションaφ,bφを追加した集合を、A’,B’とする。
【0083】
第2実施形態では、ロボット2がイニシエーターであるという仮定をとらないため、ロボット2のアクションaiが、イニシアティブアクションであるか否かは、一般に、観測することができない潜在変数となる。あるアクションがイニシアティブアクションであるかリアクションであるかは、役割推定部27によって推定される。この役割推定部27については後述する。
【0084】
[3.3 EMアルゴリズムに基づくリアクション選択確率の推定(応答戦略の獲得)]
リアクション出力確率Waに従い、リアクションの発生が決定した後に、原因となったイニシアティブアクションに依存し出力される具体的なリアクションの種類が確率的に選択される。
第2実施形態では、イニシアティブアクションaiに対してリアクションbjが出力される確率であるリアクション選択確率Z(bj,ai)を、人間2のリアクションの観測に基づき、EM(Expectation-Maximization)アルゴリズムに従って学習する。
【0085】
第2実施形態においても、一定時間のロボット1と人間2のインタラクションを通して、ロボット1のアクションログ情報AO=(a(s)|a(s)∈A,s∈Sa)および人間2のアクションログ情報BO=(b(s)|b(s)∈B,s∈Sb)が得られ、これらのログ情報が、アクションログ記憶部12に記憶される。
【0086】
ロボット1が人間2の応答戦略を学習すると対数尤度Lは、以下の様になる。
【数13】
これを最大化する事でロボット1は、未知パラメータである人間2のリアクション選択確率を推定し、それを反転することで人間2の応答戦略を学習することができる。
【0087】
このとき、BOのうちのどのアクションが、AOのどのアクションを原因として起きたかが分からないという部分観測性が問題となる。このような潜在変数を持つ尤度最大化問題は、EMアルゴリズムを用いる事で解くことが出来る。これは第1実施形態において用いた学習則よりもより理論的であり、正確なものである。ただし一定期間のインタラクションデータを記録してからのバッチ更新となる。
【0088】
EMアルゴリズムとは、E(Expectation)ステップと、M(Maximization)ステップとを反復することで、解を更新する手法である。Eステップでは、完全データの対数尤度関数Lの事後確率による期待値(Q関数)を計算し、Mステップでは、Q関数の未知パラメータZに関する最大化を行う。
【0089】
ここでは、Q関数を以下のように定義する。
【数14】
【0090】
ここで、Z(t)は、t反復での未知パラメータ推定値、Pb(ai|b(s),s)を時刻sでb(s)が生じた際にその原因がaiである確率とする(Eステップに相当)。これより、更新式は下記の通りとなる。
【0091】
【数15】
【0092】
ここで、Sbjは、Sbのうち、出力アクションがbjであるものの集合である。M(t+1)は、IA−RA関係の頻度の数え上げに相当し、J(t+1)は同時確率分布の推定値に相当する。
第2実施形態のリアクション選択確率推定部22では、上記のEMアルゴリズムに基づいて、リアクション選択確率の算出を行う。
【0093】
[3.4 役割推定とリアクション出力確率(発生確率)の推定]
リアクション選択確率の推定は、リアクション発生確率Waが決定すれば、上記のようにEMアルゴリズムで漸近的に推定出来るが、どのアクションがイニシアティブアクションであるかはターンテイクが動的に生じるインタラクション中では明確ではなく、結果的にリアクション出力確率(発生確率)Waも確定的には決定できない。
【0094】
よって、EMアルゴリズムのEステップにおいて、同時に、どのアクションがイニシアティブアクションであるかを推定する必要がある。前記Pbの逆に、ロボット1のsステップ目のアクションa(s)が人間2の動作biへのリアクションである確率をPa(bi|a(s),s)とする。
このとき、Pa(bi|a(s),s)は以下のようになる。
【数16】
【0095】
これらを用い、第2実施形態のリアクション発生確率算出部21では、
【数17】
として、各時刻sのリアクション出力確率(発生確率)を逐次的に推定する。この推定値は、リアクション選択確率推定部22で行われるEMアルゴリズムの更新に利用される。
【0096】
[3.5 役割反転による行動(リアクション)選択]
前述の役割推定部27では、ロボット1又は人間2が発生させる各アクションについて、リアクション発生確率算出部21にて算出される前述のPa(bi|a(s),s)、Pb(ai|b(s),s)を参照することとで、それぞれのアクションが、イニシアティブアクションなのかリアクションなのかを推定する。
【0097】
つまり、役割推定部27では、人間2があるアクションb(s)を行った場合、argmaxiPb(ai|b(s),s)[Pb(ai|b(s),s)が最大となるアクションの種類i]がφであれば、当該アクションb(s)はイニシアティブアクションと推定する。また、φ以外であれば、当該アクションb(s)はリアクションであると推定する。
同様に、ロボット1があるアクションa(s)を行った場合、argmaxiPa(bi|a(s),s)がφであれば、当該アクションa(s)はイニシアティブアクションと推定し、それ以外であればリアクションと推定する。
【0098】
この役割推定部27によって、ロボット1と人間2の役割(イニシエータかリアクターか)が仮定されていなくても、発生したアクションがイニシアティブアクションかリアクションかを推定することができる。したがって、ロボット2のアクションに対する人間2のリアクション発生確率Waを算出することが可能であり、この結果、リアクション選択確率も推定することができる。
【0099】
[3.6 役割反転による行動(リアクション)選択]
第2実施形態においても、リアクション選択確率推定部22によって獲得された応答戦略は、リアクション選択部15に出力される。
【0100】
ロボット1のリアクション選択部15は、獲得された応答戦略Z^(bi,ai)と、身体動作の対応関係を表す関数cを用いて、人間2のアクションbjがイニシアティブアクションであった場合、そのアクションbjに対する、ロボット1のリアクションaiの種類を、以下の確率P(ai|bj)で選択する。
【数18】
【0101】
リアクション選択部15が、最終的に時間ステップsにおいて、アクションaiを選択する確率は、
【数19】
となる。
【0102】
[3.7 インタラクション実験]
上記第2実施形態に係るロボットおける制御部11の部分を実現する学習プログラムを、計算機上に実装し、シミュレーション実験を行った。その内容は、以下の通りである。
【0103】
[3.7.1 実験条件]
実験条件は、[2.6.1 実験条件]に示す条件とほぼ同じである。ただし、ロボット1がリアクションを出力する頻度は、約2[s]とした。また、τ=0.2,λ=0.001とした。
【0104】
[3.7.2 実験結果]
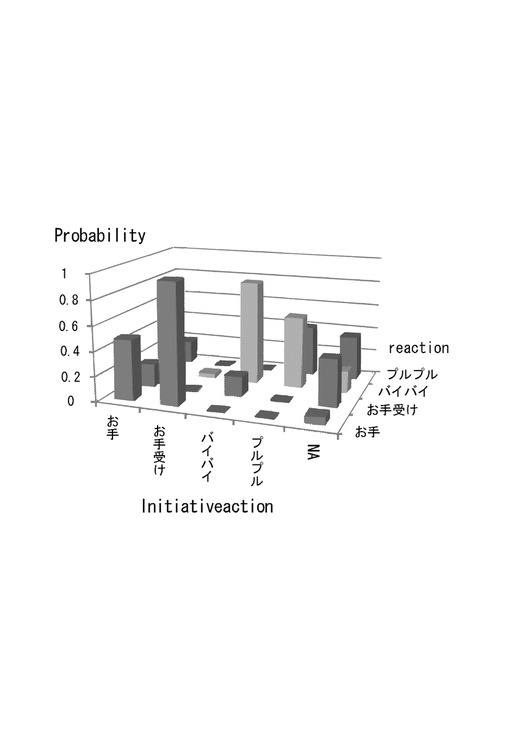
インタラクションは、約300秒行われ、その間、ユーザは基本的に実験条件に応じた応答を示すよう心がけた。この実験で、EMアルゴリズムは5回繰り返した。得られたリアクション選択確率Z(bj,ai)を図9に示す。図9より、特に、「お手受け」、「バイバイ」に対し、それぞれ「お手」と「バイバイ」を返す応答戦略が適切に獲得されていることがわかる。
【0105】
また、λ、τの値を相互情報量を最大化させるように探索した。相互情報量は、下記のように同時確率分布J(b,a)から計算される。
【数20】
【0106】
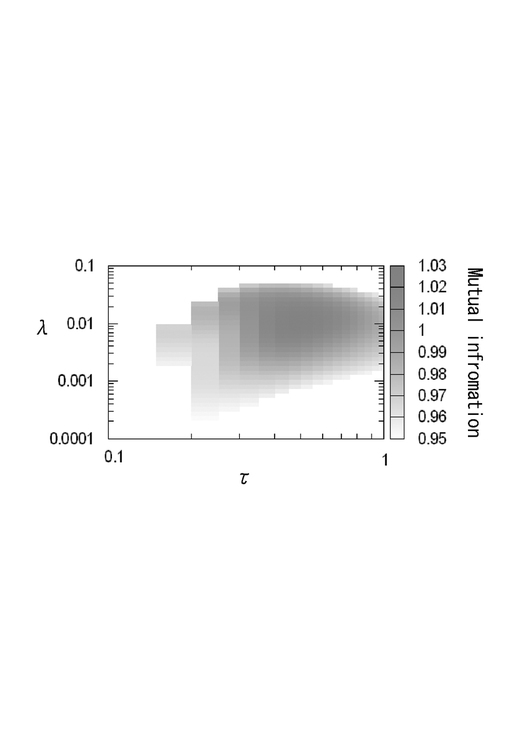
図10に示すように、相互情報量は、λ=0.01、τ=0.5周辺で最大化された。
【0107】
また、役割推定も十分な精度で行われていた。役割推定の典型的な結果の一部を表2に示す。
【表2】
【0108】
上記表2には、全ステップのうち、(1)613〜630ステップと、(2)1326〜1331ステップの推定結果を示している。何も動作が生じなかった時間帯については表示を省略している。
(1)613〜630ステップでは、はじめ、ユーザが「お手受け」を出した後に、ロボットが「お手」をした際に、ユーザの「お手受け」がイニシアティブアクション、ロボットの「お手」がリアクションと推定されている。
【0109】
その後、0.6秒後に、ロボットが「バイバイ」を出しているが、これはユーザの「お手受け」に対するリアクションとは解釈されずに、イニシアティブアクションと推定されている。その後のユーザの「バイバイ」は、ロボットの「バイバイ」に対するリアクションと推定されている。
これにより、実時間的にターンテイクが行われ、かつそれの役割の交代がロボットに正しく認識されていることがわかる。
【0110】
(2)ではロボットが「お手受け」をした後に続けて「お手」を出しているが、その直後0.2秒後にユーザから出された「お手」は、その時点でロボットが出している「お手」ではなく、その直前に出した「お手受け」に対するものであると、ロボットが解釈できていることを示している。
【0111】
[4.付記]
なお、上記において開示した事項は、例示であって、本発明を限定するものではなく、様々な変形が可能である。
【符号の説明】
【0112】
1 ロボット
2 人間
3 アクション生成部
4 撮像部
5 制御部
11 アクション懐石部
12 アクションログ記憶部
13 応答戦略獲得部(応答戦略獲得装置)
14 リアクション選択部(リアクション選択装置)
21 リアクション発生確率算出部
22 役割推定部
23 相互情報量算出部
24 探索部
25 重要度算出部
26 重要アクション抽出部
27 役割推定部
【技術分野】
【0001】
本発明は、応答戦略獲得装置、リアクション選択装置、コンピュータプログラム、及びロボットに関するものである。
【背景技術】
【0002】
Tmaselloは、子供がことば(記号)を覚える社会的能力の一部を説明するために役割反転模倣(Role Reversal imitation)という言葉を用いている(非特許文献1参照)。
役割反転模倣とは,共同行為を達成するにあたり対象への役割を反転し模倣することである。例えば、二者間のインタラクションであっても、バイバイに対してバイバイを返す事は、この二つで初めて一つの共同行為が達成されたと捉える事できる。
【0003】
このような共同行為を学習する際にお互いの役割を反転する事で、学習者はその行為の社会的な利用方法を学んでいく事が出来ると考えられる。
【0004】
栗山らは、乳児の親子間のやりとりに注目して、やりとり規則を適応的に獲得する手法を研究した(非特許文献2,3参照)。ロボットのメッセージ性のある行動に対しては、随伴性のある行動が現れるはずなので直後の行動が予想しやすくなるという仮定を置き、移動エントロピーを用いてやりとり規則を予想した。栗山らは、明示的なやりとり規則の教示なしに養育者とのインタラクションからメッセージ性のある行動を発見し、やりとり規則を一定程度獲得できることを示した。
【先行技術文献】
【非特許文献】
【0005】
【非特許文献1】マイケル・トマセロ,心とことばの起源を探る,勁草書房,2006
【非特許文献2】T. Kuriyama and Y. Kuniyoshi. Acquisition of Human-Robot Interaction Rules via Imitation and Response Observation. In Proceedings of the 10th international conference on Simulation of Adaptive Behavior: From Animals to Animats, pp.467-476.Springer, 2008.
【非特許文献3】栗山貴国,國吉康夫,模倣からの伝達行動の抽出に基づくやりとり規則の適応的獲得,pp.1252−1253,2007.
【発明の概要】
【発明が解決しようとする課題】
【0006】
しかし、栗山らのモデルでは自分の文脈と直後の養育者の文脈を観察する事によってロボットの行動を決定しているため、養育者の直近の行動に対するやりとり規則しか獲得する事ができない。現実のインタラクションは実時間的であり、他者のどの行動が自らの何秒前の行動に対するリアクションであるかは不明確である。
【0007】
また,与えられた単位行動の内のどの行動がインタラクション上有意義であるかを明示的に知る事は出来ない。
そこで、本発明は、これらの問題に対応するために役割反転模倣の考え方に基づきながら、アクションからリアクションが生成される関係を確率モデルとして捉えて、この確率モデルを同定することで、ロボットが自律的に応答戦略を獲得できるようにすることを目的とする。
また、本発明の他の目的は、インタラクションにおいて、どのアクションがどのアクションに対するリアクションであったか、また、アクションがイニシアティブアクションであるか否かといった役割推定を行うことを可能とすることにある。役割推定を行うことで、リアクションに対してさらにリアクションするということを防止し、イニシアティブアクションに対してのみリアクションする、ということが可能となる。
【課題を解決するための手段】
【0008】
本発明は、イニシエーターが行ったイニシアティブアクションに対するリアクターのリアクションを観測することで、イニシアティブアクションに対するリアクションの出力の仕方を示す応答戦略を獲得する応答戦略獲得装置であって、あるイニシアティブアクションを原因とする何らかのリアクションが、ある時刻において発生する確率を示すリアクション発生確率を、時間とリアクション発生確率との関係を規定したリアクション発生確率密度関数に基づいて算出する発生確率算出部と、あるイニシアティブアクションに対して何らかのリアクションが発生することが決定した場合における、当該イニシアティブアクションに依存して特定の種類のリアクションがリアクターによって選択される選択確率を推定することで、イニシアティブアクションに対するリアクションの出力の仕方を示す応答戦略を獲得する選択確率推定部と、を備え、前記選択確率推定部は、複数の種類のイニシアティブアクションそれぞれをリアクションの発生原因とした場合の当該リアクションの発生時刻におけるリアクション発生確率を、当該複数の種類のイニシアティブアクションそれぞれの発生時刻及び当該リアクションの発生時刻に基づき、前記発生確率算出部を介して取得し、これらのリアクション発生確率に基づいて、当該リアクションの前記選択確率を、当該複数の種類のイニシアティブアクションそれぞれについて算出するよう構成されていることを特徴とする応答戦略獲得装置である。
また,リアクション発生確率密度関数とリアクション選択確率を用いる事で役割推定、すなわち、アクションがイニシアティブアクションであるか、リアクションであるかを判定でき、これにより、事前にどちらがイニシエーターであり、どちらがリアクターであるかが分からなくてもロボットが学習することが可能となる。
【0009】
前記リアクション発生確率密度関数は、イニシアティブアクション発生後から時間経過に伴ってリアクション発生確率が減衰するよう規定されたものを用いることができる。ここで、上記「イニシアティブアクション発生後から時間経過に伴ってリアクション発生確率が減衰する」とは、イニシアティブアクション発生直後から直ちにリアクション発生確率が減衰する場合に限らず、イニシアティブアクション発生から所定の時間(例えば、コンマ数秒後;自然なインタラクションにおいてアクション間に生じる時間差に相当する時間)経過後にピークがきて、その後、減衰するものであってもよい。
【0010】
前記リアクション発生確率密度関数を変化させて、発生したイニシアティブアクションとリアクションとの間の相互情報量が最大となるリアクション発生確率密度関数を探索する探索部を更に備え、前記発生確率算出部は、前記相互情報量が最大となるリアクション発生確率密度関数に基づいて、リアクション発生確率を算出することができる。
【0011】
複数の種類のイニシアティブアクション及び/又はリアクションの重要度を推定する重要度推定部を更に備え、前記重要度推定部は、発生したイニシアティブアクションとリアクションとの間の第1相互情報量と、発生した複数の種類のイニシアティブアクション及び/又はリアクションのうち一部のアクションが存在しないものと仮定した場合のイニシアティブアクションとリアクションとの間の第2相互情報量と、の差に基づいて、存在しないものと仮定した前記一部のアクションの重要度を算出することができる。
【0012】
発生したイニシアティブアクション及び/又はリアクションのうち、応答戦略獲得の対象となる重要アクションを抽出する重要アクション抽出部を更に備え、前記重要アクション抽出部は、発生したイニシアティブアクション及び/又はリアクションそれぞれについて算出された前記重要度に基づいて、重要アクションを抽出することができる。
【0013】
前記選択確率算出部は、EM(Expectation-Maximization)アルゴリズムに基づいて、前記選択確率を算出することができる。
【0014】
発生したアクションがイニシアティブアクションであるかリアクションであるかを推定する役割推定部を更に備え、前記役割推定部は、発生したアクションをリアクションと仮定して、リアクションであると仮定した当該アクションの前記選択確率を推定し、推定した前記選択確率に基づいて、当該アクションの原因となったイニシアティブアクションを推定し、推定したイニシアティブアクションが「何もしないアクション」である場合には、当該アクションはイニシアティブアクションであると推定し、その他の場合には、当該アクションはリアクションであると推定することができる。この場合、インタラクションにおける一方側と他方側の役割を推定でき、応答戦略獲得装置をインタラクション解析装置として機能させることができる。
【0015】
他の観点からみた本発明は、観測されたイニシアティブアクションに対するリアクションの選択を行うリアクション選択装置であって、前記応答戦略獲得装置によって応答戦略として獲得した前記選択確率を用いて、観測されたイニシアティブアクションに対するリアクションの選択を行うことを特徴とするリアクション選択装置である。
【0016】
他の観点からみた本発明は、コンピュータを、前記応答戦略獲得装置として機能させるためのコンピュータプログラムである。
【0017】
他の観点からみた本発明は、コンピュータを、前記リアクション選択装置として機能させるためのコンピュータプログラムである。
【0018】
他の観点からみた本発明は、前記応答戦略獲得装置及び前記リアクション選択装置(22)を備え、前記リアクション選択装置によって選択されたリアクションを生成するリアクション生成部を備えていることを特徴とするロボットである。
【発明の効果】
【0019】
本発明によれば、ロボットが自律的に応答戦略を獲得することができる。
【図面の簡単な説明】
【0020】
【図1】役割反転模倣の概念図である。
【図2】第1実施形態に係るロボットの内部構成を示すブロック図である。
【図3】図3(a)はイニシアティブアクションからリアクションが確率的に発生する発生確率モデルの概要図であり、図3(b)はリアクション発生確率密度関数の他の例である。
【図4】学習後のリアクション選択確率の棒グラフである。
【図5】τによる相互情報量の推移を示すグラフである。
【図6】最適τに基づいて推定されたリアクション選択確率の棒グラフである。
【図7】相互情報量によって推定された重要度を示す棒グラフである。
【図8】第2実施形態に係るロボットのブロック図である。
【図9】学習後のリアクション選択確率の棒グラフである。
【図10】λ、τによる相互情報量の変化を示す図である。
【発明を実施するための形態】
【0021】
以下、本発明の好ましい実施形態について添付図面を参照しながら説明する。
【0022】
[1.役割反転模倣の概念と定義]
本実施形態に係る自律型ロボット1は、人間2との自然なインタラクションを通じて、人間の応答戦略を獲得する。
前記ロボット1は、人間の動作自体を模倣するのではなく、人間2が行っている動作(アクション)に対して自身がどのような動作を返せば良いか、つまり応答戦略を模倣により獲得する。ただし、ロボット1は、時間については連続的な時間で行動するが、動作については既に幾つかの動作単位(例えば、「お手」、「お手受け」、「バイバイ」、「プルプル」など)を持っており、状況に合わせてそれらを選択し表出しているものとする。
【0023】
図1に示すように、一つの共同行為として見たインタラクションは、自発的な動作とそれに対する応答としての動作により成り立っている。ここでは、前者を「イニシアティブアクション」と呼び、後者を「リアクション」と呼ぶ。イニシアティブアクションとリアクションを包含していう場合、単に「アクション」という。
また、イニシアティブアクション側を「イニシエーター」、リアクションを行う側を「リアクター」と呼ぶ。
一つの共同行為を実現するためには、二者がこれらの役割を担い適切な動作を出力する必要がある。ここででは、イニシエーターとリアクターの役割を反転する事を「役割反転」とし、ロボット自らのイニシアティブアクションに対する人間のリアクションの仕方を人間の「応答戦略」と呼ぶ。
そして、この二つの役割を模倣し、それらを反転する事により適切な行動生成(リアクション選択)を行えるようになる過程を「役割反転模倣」と呼ぶ。
【0024】
このような学習は.明示的にどのアクションがどのアクションに対するリアクションなのか、といったような関係づけが明示的になされている系では比較的簡単に達成しうる。しかし、人間とロボットのインタラクションが連続時間で行われ.かつ役割が明示的に与えられないような場合の学習は決して自明ではない。以下の実施形態では、イニシアティブアクションに対するリアクションの発生を確率的な生成モデルに基づいてモデル化する事で、ロボットの学習フェーズと行動フェーズを分離することなく、人間との実時間相互作用から応答戦略獲得を行う学習則を構築する。
【0025】
[2.第1実施形態]
[2.1 ロボットの構成]
ロボット1は、動作(アクション)を生成可能なロボット本体に、カメラなどの撮像部4及び制御部5などを搭載して構成されている(図2参照)。
ロボット本体は、例えば、人間型、動物型などの形状に構成され、モータなどのアクチュエータ(アクション生成部3)によって実際の人間・動物の動作に類似した動作を行うことができる。
【0026】
撮像部4は、インタラクションにおける相手方(人間2)を撮像した画像を取得するためのものである。撮像部4によって取得した画像は、制御部5に与えられ、画像処理が行われる。人間の動作を獲得するための装置は、撮像部4に限られるものではなく、人間の動作を取得できるものであれば、機械式モーションキャプチャやジャイロセンサーなど他の入力装置であっても構わない。
【0027】
制御部5は、CPU及び記憶装置などを有するコンピュータによって構成されており、撮像部4によって取得した画像の画像処理及びロボット本体の制御などのロボットに必要とされる情報処理を行う。制御部(コンピュータ)5は、以下に説明する応答戦略獲得及び行動戦略などの機能を、当該コンピュータに実行させるためのコンピュータプログラムを有している。なお、画像処理は、制御部5とは別の画像処理プロセッサで行い、処理結果を制御部5が取得するようにしてもよいが、本実施形態では制御部5が行うものとする。
【0028】
図2に示すように、制御部5は、アクション解析部11、ロボット&人間のアクションログ記憶部12、応答戦略獲得部(応答戦略獲得装置)13、イニシアティブアクション選択部14、リアクション選択部(リアクション選択装置)15としての機能を有している。これらの機能は、コンピュータプログラムによって実現される。
【0029】
アクション解析部11は、撮像部4によって取得した画像から、人間2が行っているアクションの種類を、画像処理によって解析し、特定する。なお、本実施形態において、対象となるアクションの種類は、予め定められたもの(例えば、「お手」、「お手受け」、「バイバイ」、「プルプル」の4種類)であるが、ロボット1が自律的に新たなアクションを抽出し獲得してもよい。また、ロボットの設計者やユーザが新たに加えても構わない。
【0030】
アクション解析部11は、人間2が行っているアクションの種類を特定すると、特定したアクションの種類及びそのアクションの発生時刻を示すアクション情報を出力する。アクション解析部11が出力したアクション情報は、アクションログ記憶部12に、ログ情報として逐次蓄積される。
【0031】
制御部5は、ロボット1自身の自発的な行動であるイニシアティブアクションを発生させるためのイニシアティブアクション選択部14を備えている。イニシアティブアクション選択部14は、予め設定された複数種類のアクションの中からイニシアティブアクションとして出力するアクションを適宜選択する。イニシアティブアクション選択部14によって選択された種類のアクションは、アクション生成部3によってロボット1の実際のアクションとして生成され、人間2に提示される。
【0032】
また、イニシアティブアクション選択部14は、選択したイニシアティブアクションの種類及びそのイニシアティブアクションの発生時刻を示すアクション情報を出力する。イニシアティブアクション選択部14が出力したアクション情報は、アクションログ記憶部12に、ログ情報として逐次蓄積される。
【0033】
この結果、アクションログ記憶部12には、ロボット1及び人間2が過去に行ったアクションの種類及びその発生時刻が記憶されることになる。
第1実施形態では、応答戦略獲得の学習時は、ロボット1をイニシエーターとし、人間2をリアクターとするため、前記アクションログ記憶部12には、イニシエーターとしてのロボット1が行ったイニシアルアクションのログ情報と、リアクターとしての人間2が行ったリアクションのログ情報とが、ロボット1と人間2とのインタラクションの結果を示すログ情報として蓄積されることになる。
【0034】
前記応答戦略獲得部13は、アクションログ記憶部12に記憶されたインタラクションのログ情報に基づいて、人間2の応答戦略を獲得するための処理を行う。応答戦略獲得部13によって獲得した応答戦略は、リアクション選択部15において用いられる。リアクション選択部15は、人間2が行ったイニシアティブアクションに対するロボット1の適切なリアクションを、人間2の応答戦略の役割反転を行うことで選択する。
【0035】
応答戦略獲得部13は、リアクション発生確率を算出するリアクション発生確率算出部21、リアクション発生確率からリアクション選択確率を推定するリアクション選択確率推定部22、イニシアティブアクションとリアクションの相互情報量を算出する相互情報量算出部23、最適なリアクション発生確率密度関数を探索する探索部24、アクションログ記憶部12に記憶されているアクションの重要度を算出する重要度算出部25、アクション記憶部12に記憶されているアクションのうち、重要なアクションを抽出する重要アクション抽出部26を備えている。
以下、これらの機能について説明する。
【0036】
[2.2 リアクション発生確率]
まず、ロボット1の取り得る単位動作(単位アクション)の集合をA={a1,a2,・・・,am}とし、人間2の取り得る単位動作の集合をB={b1,b2,・・・,bm}とする。本実施形態においては、4つの単位動作(m=4)を想定し、具体的には、例えば、A={a1:「お手」,a2:「お手受け」,a3:「バイバイ」,a4:「プルプル」}、B={b1:「お手」,b2:「お手受け」,b3:「バイバイ」,b4:「プルプル」}である。
【0037】
ここで、人間2の単位動作とロボット1の単位動作は身体的な対応関係を表す関数cが存在し、c(ai)=biを通して、一対一対応の関係が存在するものとする。また、ここでは、リアクションはイニシアティブアクションを原因として、時間遅れを伴い確率的に発生すると仮定する。
【0038】
時刻t0においてアクションaiが生じた際に、その後の時刻tにおいてそのアクションaiをイニシアティブアクションとした何らかのリアクション(種類は問わない)が発生する確率密度Waiを次のように定義する。
【数1】
これをリアクション発生確率密度と呼ぶこととする。このリアクション発生確率密度は、イニシアティブアクションの発生時刻から時間経過に従って発生確率が指数的に減衰する関数となっている。なお、τは時定数であり、この時定数の最適化については後述する。
【0039】
リアクション発生確率算出部21では、リアクション発生確率を、1stepをΔt[s]として、以下のように逐次的に更新することで計算する。ここで、sは連続時間をサンプリングしたときの離散時間ステップを指す。
【数2】
【0040】
図3(a)は、上記式に基づいて算出される各イニシアティブアクションai(i:1〜m及びφ)を原因とする何らかのリアクションの発生確率Wai,sの例を示している。例えば、イニシアティブa1についてのリアクション発生確率Wa1,sは、イニシアティブa1が発生した時点では、(Δt/τ)の値をとり、その後、時間経過とともに減衰する。
【0041】
通常のイニシアティブアクションai(i:1〜m)を原因とする何らかのリアクションの発生確率Wai,sは、上記のように、イニシアティブアクション発生から時間経過とともに減衰する特性を有するが、「何もしないアクション」aφについてのリアクション発生確率Wa1,sは、時間経過にかかわらず一定値(=λ)をとる。
ここで、「何もしないアクション」aφbφは、ヌルアクションとよび、イニシアティブアクションは、ヌルアクションを原因として発生するものとする。つまり、イニシアティブアクションは毎ステップにおいて、λの確率で発生するものとする。
【0042】
なお、リアクション発生確率密度関数は、図3(a)のものに限られるわけではない。例えば、図3(b)に示すようにイニシアティブアクション発生から所定時間Δt経過してから、リアクション発生確率がピークをとり、その後、減衰するものであってもよい。Δtは、インタラクションにおいてイニシアティブアクションとリアクションとの間に通常生じる時間差に相当する程度の時間に設定するのが好ましく、具体的には、コンマ数秒程度とすることができる。
【0043】
リアクション発生確率算出部21は、アクションログ記憶部12から、ロボット1が発生させたイニシアティブアクションai(i:1〜m)の種類とその発生時刻の情報を取得し、図3のように、各イニシアティブアクションai(i:1〜m及びφ)を原因とする何らかのリアクションの発生確率Wai,sを、複数種類のイニシアティブアクションai(i:1〜m及びφ)それぞれについて求めて、出力する。
【0044】
[2.3 リアクション選択確率の推定(応答戦略の獲得)]
本実施形態においては、リアクションの発生が決定した後に、その原因となったイニシアティブアクションの種類に依存して実際に出力されるリアクションの種類が選択されると仮定する。
イニシアティブアクションaiに対してリアクションbjが出力される確率Z(bj,ai)をリアクション選択確率と呼ぶ。ロボット1のリアクション選択確率推定部22は、このリアクション選択確率を、図1に示すように、ロボット1のイニシアティブアクションに対する人間2のリアクションを観測することによって、応答戦略として学習する。
【0045】
一定時間のロボット1と人間2のインタラクションを通して、ロボット1のアクションログ情報AO=(a(s)|a(s)∈A,s∈Sa)および人間2のアクションログ情報BO=(b(s)|b(s)∈B,s∈Sb)が得られ、これらのログ情報が、アクションログ記憶部12に記憶されているものとする。ここで、Sa,Sbは、それぞれ、ロボット1と人間2がアクションを起こした時刻の集合である。
【0046】
本実施形態においては、ロボット1のアクションをイニシアティブアクション、人間2のアクションをリアクションと仮定する。すると、人間(リアクター)2の各時刻のアクションbjが、ロボット(イニシエーター)1のどのイニシアティブアクションaiを原因としているかを潜在変数として、人間2のリアクション出力についての不完全データの対数尤度Lは以下のようになる。なお、b(s)は、時刻sにおいて人間2が選択したアクションである。
【数3】
【0047】
上記式を増加させるために、Z(b,a)の、更新則を下記のように定める。
【数4】
となる。
【0048】
上式より、最尤のリアクション選択確率Z(bj,ai)の推定値(応答戦略)は、人間2のリアクションが発生する毎に、
【数5】
を求めて、その値を、それまでのリアクション選択確率Z(bj,ai)に足して、逐次的に更新することで求めることができる。
【0049】
なお、上記式の値は、リアクション選択確率推定部22が、そのリアクション発生時刻における、ロボット1の全ての種類のアクションai(i:1〜m及びφ)についてのリアクション発生確率Wai,sを、リアクション発生確率算出部21の出力から取得し、取得した出力に基づいて、上記式に従い演算することで得られる。
また、そのリアクション発生時刻における各アクションai(i:1〜m及びφ)についてのリアクション発生確率Wai,sは、アクションログ記憶部12から取得したリアクション発生時刻におけるリアクション発生確率密度関数の値を調べることで求めることができる。
【0050】
リアクション選択確率推定部22は、あるリアクションが発生すると、リアクション選択確率Z(bj,ai)の推定値(応答戦略)として、ロボット1の全ての種類のアクションai(i:1〜m及びφ)それぞれについて更新する。
すなわち、例えば、人間2のリアクションb1が発生すると、Z(b1,a1),Z(b1,a2),Z(b1,a2),Z(b1,a4),Z(b1,aφ)の全ての値が更新される。
【0051】
本実施形態では、制御部5にカウント行列Mの記憶部(図示省略)を用意し、人間からのリアクションbjが時刻sにおいて発生する毎に、全てのai∈A+{φ}に対して、
【数6】
と足していく。このカウント行列Mは、時間遅れを伴うイニシアティブアクションaとリアクションbの同時生起頻度であり、リアクション選択確率推定部22では、これに基づいて応答戦略(リアクション選択確率)Z(b,a)の推定値Z^、及び、アクションaiとリアクションbjの同時確率P(bj,ai)を求める。
【数7】
【0052】
[2.4 役割反転による行動(リアクション)選択]
リアクション選択確率推定部22によって獲得された応答戦略(最尤のリアクション選択確率の推定値)は、リアクション選択部15に出力される。
【0053】
役割反転により、人間2がイニシエーター、ロボット1がリアクターとなった場合、ロボット1のリアクション選択部15は、獲得された応答戦略(リアクション選択確率の推定値)Z^(bi,ai)と、身体動作の対応関係を表す関数cを用いて、人間2のイニシアティブアクションbjに対する、ロボット1のリアクションaiの種類を、以下の確率P(ai|bj)で選択する。
【数8】
【0054】
つまり、リアクション選択部15は、上記式によって求めた確率が最も大きくなるリアクションを生成すべきアクションとして決定したり、上記式によって求めた確率でリアクションを確率的に決定したりすることができる。
【0055】
リアクション選択部15が、最終的に時間ステップsにおいて、アクションaiを選択する確率は、
【数9】
となる。ここで、Wbj,sは、Wai,sと同様に、変化する人間の動作を原因としたリアクション発生確率密度である。
[2.5 時定数τの探索]
応答戦略には、W内部の時定数τが関わるが、τについては、以下で定義するインタラクションの相互情報量(イニシアティブアクションとリアクションの相互情報量)を最大化するτを探索し決定する。
【数10】
具体的には、探索部24がτを所定の範囲で変化させて、変化させたτでの確率P(b,a)(式8参照)や確率P(a)P(b)(式10参照)を求め、これらの確率から相互情報量算出部23が、上記式に従い相互情報量I(B,A)を算出し、相互情報量が最大となるτを決定する。
【0056】
このような時定数τの探索は、与えられたインタラクション履歴(アクションログ)AO,BOが高い随伴性で生じていると解釈するためには、リアクションが、イニシアティブアクションに対して、どのくらいの遅れで生じるとするべきかを同定することと等価である。
なお、Wに関わるパラメータとしては、λもあり、これもτと同様に、相互情報量を最大化するように探索することができる。
【0057】
[2.6 インタラクション実験]
上記第1実施形態に係るロボットおける制御部5の部分を実現する学習プログラムを、計算機上に実装し、シミュレーション実験を行った。その内容は、以下の通りである。
【0058】
[2.6.1 実験条件]
実験では、計算機上の画面に2つの犬の手を表し、これをユーザ(人間)とロボット(計算機の学習プログラム)が動かすことで相互作用を行う空間を設計した(図3の画面D参照)。図3の画面Dにおいて、左側手前がユーザの操作する手であり、右側奥がロボットの操作する手である。
【0059】
ユーザはキーボードを押すことで予め設定された単位動作を出力することが出来る。アクションには、a1=「お手」,a2=「お手受け」,a3=「バイバイ」,a4=「プルプル」と名付けた四つの単位動作を設定した。本実験では、ユーザが操作する側の手も、ロボットが操作する側の手も同じであるので、biはaiと同様に、b1=「お手」,b2=「お手受け」,b3=「バイバイ」,b4=「プルプル」と与えた。つまり、関数cは、bi=c(ai)である。
【0060】
計算機のキーボードの1キーから4キーまでがそれぞれa1〜a4に対応付けられており、ユーザがキーを押すと、遅滞なく選択された行動が開始され、ロボットは時間遅れも認識誤り無く瞬時にその行動(種類と発生時刻)を認識できるものとする。フレームレートは10[Hz]とし、また、ロボットのカウント行列Mは、全要素の値を1×10-5で初期化した。
【0061】
実験者は、ロボットに対し、
1.「お手受け」に対して、「お手」をさせる行動
2.「バイバイ」に対して、「バイバイ」を返す行動
を学習することを求めた。被験者は、ロボットが「お手受け」をだしたときに、「お手」をし、ロボットが「バイバイ」をしたときに、「バイバイ」を返し、また、他の時には無規則に行動を表出した。
【0062】
そのようなインタラクション系列に基づき.ロボットはカウント行列Mを更新することで時定数τリアクション選択確率(応答戦略)Z(bj,ai)を獲得する。また、Wに関わるパラメータはオフラインで同定するので、初期値としては、τ=0.3、λ=0.01に設定した。
【0063】
また、本実験では、応答戦略のパラメータ推定に焦点を当てる為、ロボットの行動出力については、式10の生成モデルを直接用いることはせず、簡単の為、ロボットには、τ[s]に一回リアクション出力を行わせ、そのリアクション選択は、獲得したリアクション選択確率に基づくという手法をとった。
【0064】
[2.6.2 実験結果]
インタラクションは約260秒行われ、その間ユーザは基本的に実験条件に示したような応答を示すよう心がけた。リアクション選択確率Z(bj,ai)の推定自体は、カウント行列Mに、徐々に値を足して行くことで単調的に同定される(式(6)参照)ため、過程は省略するが、最終的に得られたカウント行列Mをイニシアティブアクション毎に正規化することで得られるリアクション選択確率Z^を図4に示した。
【0065】
図4において「NULL」とあるのは、ヌルアクションを指す。図4より、イニシアティブアクションとしてのa2=「お手受け」の後にb1=「お手」が出る確率、a3=「バイバイ」の後にb3=「バイバイ」が出る確率が高くなっていることがわかる。
【0066】
このインタラクションで獲得したカウント行列Mの値を表1に示す。
【表1】
【0067】
カウント行列Mの値は同時確率分布に比例するが、アクション「プルプル」は、発生頻度自体が小さく、被験者に指定した二つの組み合わせの発生頻度が特に大きいことがわかる。
【0068】
また、このインタラクションの履歴を用いて、リアクション発生確率密度関数の時定数τの推定を行った。τを0.1[s]から10.0[s]までの間で、0.05[s]刻みで変動させ、その結果として計算される時間遅れを考慮したリアクションとイニシアティブアクションの同時確率分布から、リアクション・イニシアティブアクション間の相互情報量を求めた。その結果を図5に示す。
【0069】
図5では、横軸にτを対数軸でとり、縦軸に相互情報量をとっている。探索の結果、τ=0.75のとき、相互情報量が0.512となり最大となった。この相互情報量はリアクションがアクションに対して担っている情報量である。つまり、相互情報量を最大にするτを探索することは、ロボットがユーザのリアクションを最大限自らの行動に対する因果的な応答であると捉えようとすることを意味する。この最適τに基づいて、同様のインタラクション履歴から学習したリアクション選択確率Z^を図6に示す。
【0070】
図6では、時定数を初期値のτとしていた図4よりも、イニシアティブアクションとリアクションの関係の曖昧性が薄れ、関係性がより顕著になっていることがわかる。
【0071】
[2.6.3 アクションの重要度推定と重要アクションの抽出]
上記の説明においては、予め単位動作が与えられていることを前提としたが、自然な相互作用から様々な動作を獲得するロボットを生み出そうとすると、単位動作自体をロボット自身に獲得させる必要がある。この場合、インタラクション上、価値のない動作系列も単位動作として抽出される可能性がある。
【0072】
先のインタラクション実験では、a4=b4=「プルプル」が、そのようなインタラクション上無意味な動作(重要度が低いアクション)といえる。
一方、先のインタラクション実験での、a2=「お手受け」、b1=「お手」、a3=b3=「バイバイ」などは、インタラクション上重要なアクションである。なお、同じ「お手」、「お手受け」であっても、リアクションとしての「お手受け」やイニシアティブアクションとしての「お手」は重要でない点に留意すべきである。
【0073】
インタラクション上動作とは、他社の行動を適切に制約づける動作(アクション)である。他者に無視され他者の行動に影響を与えない動作はインタラクション上重要でないと考えられる。よって、重要な動作(アクション)のみで形成されたインタラクションには高い情報的結合の存在が期待される。
そこで、重要度算出部25は、アクションログ記憶部12に記憶されているイニシアティブアクション及び/又はリアクションのうち、あるイニシアティブアクション・リアクションが最初から無かった(アクションログ記憶部12に記憶されていない)と考えた場合の同時確率分布を計算し、その前後での相互情報量の変化によって、各アクションの重要度を算出する。
【0074】
アクションログ記憶部12に記憶されているイニシアティブアクション・リアクションのうちあるアクションを記憶部12から削除した場合、もし削除したイニシアティブアクション・リアクションが二者間のインタラクションに重要であるなら、相互情報量は大きく減少し、重要でないならほぼ減少しない、もしくは増加するはずである。
【0075】
あるイニシアティブアクションaiが最初から無かったと仮定するため、重要度算出部25は、一旦生成したカウント行列Mから、列aiを除いた新たな部分行列M’を生成する。この部分行列M’から生成される同時確率によって、相互情報量を計算する。リアクションbjについても同様に行う。
【0076】
元々(削除前)の相互情報量(第1相互情報量)をI(B;A)、アクションaiを削ったインタラクションに基づく相互情報量(第2相互情報量)をI’(B;A−{ai})で表す。リアクションについても同様である。
各イニシアティブアクションの重要度をΔaction(ai)、各リアクションの重要度をΔreaction(bi)、同時確率分布をP(b,a)とすると、重要度算出部25は、それぞれの重要度を下記式により算出する。
【数11】
これらの重要度の値が大きいほど、イニシアティブアクションもしくはリアクションとしてインタラクション上重要であることを示す。
【0077】
前記インタラクション実験の条件の下で、相互情報量を用いてイニシアティブアクション・リアクションの重要度推定を行った結果を図7に示す。
図7より、イニシアティブアクションとして重要なものは、a2=「お手受け」,a3=「バイバイ」であり、逆に重要でないものはa1=「お手」であることがわかる。
また、リアクションとして重要なものは、b1=「お手」,b3=「バイバイ」であり、学習重要でないのは、b2=「お手受け」であることがわかる。相互情報量を求める事9によって、重要度の推定が正しく行われていることがわかる。
【0078】
重要アクション抽出部26は、例えば、所定の閾値よりも重要度の値が大きいアクションを重要アクションとして抽出する。そして、リアクション選択確率推定部では、非重要アクションを除外し、重要アクションだけが発生したものとしてリアクション選択確率(応答戦略)を獲得し直すことで、より適切な推定が行える。
【0079】
[3.第2実施形態]
第1実施形態における応答戦略の学習則は、発見的手法に基づいているが、第2実施形態では、EMアルゴリズムにより、役割反転模倣を達成する。また、第2実施形態では、潜在変数としての「役割」(イニシエーターであるかリアクターであるかということ)を明示的に推定することで、ロボット1の学習フェーズと行動フェーズを分離することなく、人間2との実時間相互作用から応答戦略獲得を行う学習則を構築する。
【0080】
なお、第2実施形態では、イニシアティブアクションを「IA」、リアクションを「RA」と略記することがある。
【0081】
[3.1 ロボットの構成]
図8は、第2実施形態に係るロボット1の構成を示している。この第2実施形態では、リアクション選択確率推定部22の機能が第1実施形態と異なっているほか、役割推定部27が追加されている。第2実施形態において特に説明しない点は、第1実施形態のものと同様である。
【0082】
[3.2 リアクション発生確率]
第2実施形態では、リアクション発生確率(時刻sにおいてイニシアティブアクションaiを原因とした何らかのリアクションが発生する確率)の関数を次のように定義する。
【数12】
上記確率Waに基づいて、イニシアルアクションから何らかのリアクションが発生するものとする。上記Waを求める為には、各時刻のアクションaiが、イニシアティブアクションであるか否かを知る必要がある。
なお、第2実施形態では、集合A,Bにヌルアクションaφ,bφを追加した集合を、A’,B’とする。
【0083】
第2実施形態では、ロボット2がイニシエーターであるという仮定をとらないため、ロボット2のアクションaiが、イニシアティブアクションであるか否かは、一般に、観測することができない潜在変数となる。あるアクションがイニシアティブアクションであるかリアクションであるかは、役割推定部27によって推定される。この役割推定部27については後述する。
【0084】
[3.3 EMアルゴリズムに基づくリアクション選択確率の推定(応答戦略の獲得)]
リアクション出力確率Waに従い、リアクションの発生が決定した後に、原因となったイニシアティブアクションに依存し出力される具体的なリアクションの種類が確率的に選択される。
第2実施形態では、イニシアティブアクションaiに対してリアクションbjが出力される確率であるリアクション選択確率Z(bj,ai)を、人間2のリアクションの観測に基づき、EM(Expectation-Maximization)アルゴリズムに従って学習する。
【0085】
第2実施形態においても、一定時間のロボット1と人間2のインタラクションを通して、ロボット1のアクションログ情報AO=(a(s)|a(s)∈A,s∈Sa)および人間2のアクションログ情報BO=(b(s)|b(s)∈B,s∈Sb)が得られ、これらのログ情報が、アクションログ記憶部12に記憶される。
【0086】
ロボット1が人間2の応答戦略を学習すると対数尤度Lは、以下の様になる。
【数13】
これを最大化する事でロボット1は、未知パラメータである人間2のリアクション選択確率を推定し、それを反転することで人間2の応答戦略を学習することができる。
【0087】
このとき、BOのうちのどのアクションが、AOのどのアクションを原因として起きたかが分からないという部分観測性が問題となる。このような潜在変数を持つ尤度最大化問題は、EMアルゴリズムを用いる事で解くことが出来る。これは第1実施形態において用いた学習則よりもより理論的であり、正確なものである。ただし一定期間のインタラクションデータを記録してからのバッチ更新となる。
【0088】
EMアルゴリズムとは、E(Expectation)ステップと、M(Maximization)ステップとを反復することで、解を更新する手法である。Eステップでは、完全データの対数尤度関数Lの事後確率による期待値(Q関数)を計算し、Mステップでは、Q関数の未知パラメータZに関する最大化を行う。
【0089】
ここでは、Q関数を以下のように定義する。
【数14】
【0090】
ここで、Z(t)は、t反復での未知パラメータ推定値、Pb(ai|b(s),s)を時刻sでb(s)が生じた際にその原因がaiである確率とする(Eステップに相当)。これより、更新式は下記の通りとなる。
【0091】
【数15】
【0092】
ここで、Sbjは、Sbのうち、出力アクションがbjであるものの集合である。M(t+1)は、IA−RA関係の頻度の数え上げに相当し、J(t+1)は同時確率分布の推定値に相当する。
第2実施形態のリアクション選択確率推定部22では、上記のEMアルゴリズムに基づいて、リアクション選択確率の算出を行う。
【0093】
[3.4 役割推定とリアクション出力確率(発生確率)の推定]
リアクション選択確率の推定は、リアクション発生確率Waが決定すれば、上記のようにEMアルゴリズムで漸近的に推定出来るが、どのアクションがイニシアティブアクションであるかはターンテイクが動的に生じるインタラクション中では明確ではなく、結果的にリアクション出力確率(発生確率)Waも確定的には決定できない。
【0094】
よって、EMアルゴリズムのEステップにおいて、同時に、どのアクションがイニシアティブアクションであるかを推定する必要がある。前記Pbの逆に、ロボット1のsステップ目のアクションa(s)が人間2の動作biへのリアクションである確率をPa(bi|a(s),s)とする。
このとき、Pa(bi|a(s),s)は以下のようになる。
【数16】
【0095】
これらを用い、第2実施形態のリアクション発生確率算出部21では、
【数17】
として、各時刻sのリアクション出力確率(発生確率)を逐次的に推定する。この推定値は、リアクション選択確率推定部22で行われるEMアルゴリズムの更新に利用される。
【0096】
[3.5 役割反転による行動(リアクション)選択]
前述の役割推定部27では、ロボット1又は人間2が発生させる各アクションについて、リアクション発生確率算出部21にて算出される前述のPa(bi|a(s),s)、Pb(ai|b(s),s)を参照することとで、それぞれのアクションが、イニシアティブアクションなのかリアクションなのかを推定する。
【0097】
つまり、役割推定部27では、人間2があるアクションb(s)を行った場合、argmaxiPb(ai|b(s),s)[Pb(ai|b(s),s)が最大となるアクションの種類i]がφであれば、当該アクションb(s)はイニシアティブアクションと推定する。また、φ以外であれば、当該アクションb(s)はリアクションであると推定する。
同様に、ロボット1があるアクションa(s)を行った場合、argmaxiPa(bi|a(s),s)がφであれば、当該アクションa(s)はイニシアティブアクションと推定し、それ以外であればリアクションと推定する。
【0098】
この役割推定部27によって、ロボット1と人間2の役割(イニシエータかリアクターか)が仮定されていなくても、発生したアクションがイニシアティブアクションかリアクションかを推定することができる。したがって、ロボット2のアクションに対する人間2のリアクション発生確率Waを算出することが可能であり、この結果、リアクション選択確率も推定することができる。
【0099】
[3.6 役割反転による行動(リアクション)選択]
第2実施形態においても、リアクション選択確率推定部22によって獲得された応答戦略は、リアクション選択部15に出力される。
【0100】
ロボット1のリアクション選択部15は、獲得された応答戦略Z^(bi,ai)と、身体動作の対応関係を表す関数cを用いて、人間2のアクションbjがイニシアティブアクションであった場合、そのアクションbjに対する、ロボット1のリアクションaiの種類を、以下の確率P(ai|bj)で選択する。
【数18】
【0101】
リアクション選択部15が、最終的に時間ステップsにおいて、アクションaiを選択する確率は、
【数19】
となる。
【0102】
[3.7 インタラクション実験]
上記第2実施形態に係るロボットおける制御部11の部分を実現する学習プログラムを、計算機上に実装し、シミュレーション実験を行った。その内容は、以下の通りである。
【0103】
[3.7.1 実験条件]
実験条件は、[2.6.1 実験条件]に示す条件とほぼ同じである。ただし、ロボット1がリアクションを出力する頻度は、約2[s]とした。また、τ=0.2,λ=0.001とした。
【0104】
[3.7.2 実験結果]
インタラクションは、約300秒行われ、その間、ユーザは基本的に実験条件に応じた応答を示すよう心がけた。この実験で、EMアルゴリズムは5回繰り返した。得られたリアクション選択確率Z(bj,ai)を図9に示す。図9より、特に、「お手受け」、「バイバイ」に対し、それぞれ「お手」と「バイバイ」を返す応答戦略が適切に獲得されていることがわかる。
【0105】
また、λ、τの値を相互情報量を最大化させるように探索した。相互情報量は、下記のように同時確率分布J(b,a)から計算される。
【数20】
【0106】
図10に示すように、相互情報量は、λ=0.01、τ=0.5周辺で最大化された。
【0107】
また、役割推定も十分な精度で行われていた。役割推定の典型的な結果の一部を表2に示す。
【表2】
【0108】
上記表2には、全ステップのうち、(1)613〜630ステップと、(2)1326〜1331ステップの推定結果を示している。何も動作が生じなかった時間帯については表示を省略している。
(1)613〜630ステップでは、はじめ、ユーザが「お手受け」を出した後に、ロボットが「お手」をした際に、ユーザの「お手受け」がイニシアティブアクション、ロボットの「お手」がリアクションと推定されている。
【0109】
その後、0.6秒後に、ロボットが「バイバイ」を出しているが、これはユーザの「お手受け」に対するリアクションとは解釈されずに、イニシアティブアクションと推定されている。その後のユーザの「バイバイ」は、ロボットの「バイバイ」に対するリアクションと推定されている。
これにより、実時間的にターンテイクが行われ、かつそれの役割の交代がロボットに正しく認識されていることがわかる。
【0110】
(2)ではロボットが「お手受け」をした後に続けて「お手」を出しているが、その直後0.2秒後にユーザから出された「お手」は、その時点でロボットが出している「お手」ではなく、その直前に出した「お手受け」に対するものであると、ロボットが解釈できていることを示している。
【0111】
[4.付記]
なお、上記において開示した事項は、例示であって、本発明を限定するものではなく、様々な変形が可能である。
【符号の説明】
【0112】
1 ロボット
2 人間
3 アクション生成部
4 撮像部
5 制御部
11 アクション懐石部
12 アクションログ記憶部
13 応答戦略獲得部(応答戦略獲得装置)
14 リアクション選択部(リアクション選択装置)
21 リアクション発生確率算出部
22 役割推定部
23 相互情報量算出部
24 探索部
25 重要度算出部
26 重要アクション抽出部
27 役割推定部
【特許請求の範囲】
【請求項1】
イニシエーター(1)が行ったイニシアティブアクション(ai)に対するリアクター(2)のリアクション(bj)を観測することで、イニシアティブアクション(ai)に対するリアクション(bj)の出力の仕方を示す応答戦略(Z(bj,ai))を獲得する応答戦略獲得装置(13)であって、
あるイニシアティブアクション(ai)を原因とする何らかのリアクションが、ある時刻(s)において発生する確率を示すリアクション発生確率(Wai,s)を、時間とリアクション発生確率との関係を規定したリアクション発生確率密度関数に基づいて算出する発生確率算出部(21)と、
あるイニシアティブアクション(ai)に対して何らかのリアクションが発生することが決定した場合における、当該イニシアティブアクション(ai)に依存して特定の種類のリアクション(bj)がリアクター(2)によって選択される選択確率(Z(bj,ai))を推定することで、イニシアティブアクション(ai)に対するリアクション(bj)の出力の仕方を示す応答戦略を獲得する選択確率推定部(22)と、
を備え、
前記選択確率推定部(22)は、複数の種類のイニシアティブアクション(ai)それぞれをリアクション(bj)の発生原因とした場合の当該リアクションの発生時刻(s)におけるリアクション発生確率(Wai,s)を、当該複数の種類のイニシアティブアクション(ai)それぞれの発生時刻(s)及び当該リアクション(bj)の発生時刻(s)に基づき、前記発生確率算出部(21)を介して取得し、これらのリアクション発生確率(Wai,s)に基づいて、当該リアクション(bj)の前記選択確率(Z(bj,ai))を、当該複数の種類のイニシアティブアクション(ai)それぞれについて算出するよう構成されている
ことを特徴とする応答戦略獲得装置。
【請求項2】
前記リアクション発生確率密度関数は、イニシアティブアクション発生後から時間経過に伴ってリアクション発生確率が減衰するよう規定されたものである
請求項1記載の応答戦略獲得装置。
【請求項3】
前記リアクション発生確率密度関数を変化させて、発生したイニシアティブアクション(A)とリアクション(B)との間の相互情報量(I(B;A))が最大となるリアクション発生確率密度関数を探索する探索部(24)を更に備え、
前記発生確率算出部(21)は、前記相互情報量が最大となるリアクション発生確率密度関数に基づいて、リアクション発生確率を算出する
請求項1又は2記載の応答戦略獲得装置。
【請求項4】
複数の種類のイニシアティブアクション(ai)及び/又はリアクション(bj)の重要度を推定する重要度推定部(25)を更に備え、
前記重要度推定部(25)は、
発生したイニシアティブアクション(ai)とリアクション(bj)との間の第1相互情報量(I(B;A))と、発生した複数の種類のイニシアティブアクション及び/又はリアクションのうち一部のアクション(ai,bj)が存在しないものと仮定した場合のイニシアティブアクションとリアクションとの間の第2相互情報量(I’(B;A−{ai}),I’(B−{bj};A))と、の差に基づいて、存在しないものと仮定した前記一部のアクション(ai,bj)の重要度(Δaction,Δreaction)を算出する
請求項1〜3のいずれか1項に記載の応答戦略獲得装置。
【請求項5】
発生したイニシアティブアクション及び/又はリアクションのうち、応答戦略獲得の対象となる重要アクションを抽出する重要アクション抽出部(26)を更に備え、
前記重要アクション抽出部(26)は、発生したイニシアティブアクション及び/又はリアクションそれぞれについて算出された前記重要度(Δaction,Δreaction)に基づいて、重要アクションを抽出する
請求項4記載の応答戦略獲得装置。
【請求項6】
前記選択確率算出部(22)は、EM(Expectation-Maximization)アルゴリズムに基づいて、前記選択確率を算出する
請求項1〜5のいずれか1項に記載の応答戦略獲得装置。
【請求項7】
発生したアクションがイニシアティブアクションであるかリアクションであるかを推定する役割推定部(27)を更に備え、
前記役割推定部(27)は、
発生したアクションをリアクションと仮定して、リアクションであると仮定した当該アクションの前記選択確率を推定し、
推定した前記選択確率に基づいて、当該アクションの原因となったイニシアティブアクションを推定し、
推定したイニシアティブアクションが「何もしないアクション」である場合には、当該アクションはイニシアティブアクションであると推定し、その他の場合には、当該アクションはリアクションであると推定する
請求項1〜6のいずれか1項に記載の応答戦略獲得装置。
【請求項8】
観測されたイニシアティブアクションに対するリアクションの選択を行うリアクション選択装置(15)であって、
請求項1〜7のいずれか1項に記載の応答戦略獲得装置(22)によって応答戦略として獲得した前記選択確率(Z(bj,ai))を用いて、観測されたイニシアティブアクションに対するリアクションの選択を行うことを特徴とするリアクション選択装置。
【請求項9】
コンピュータを、請求項1〜7のいずれか1項に記載の応答戦略獲得装置として機能させるためのコンピュータプログラム。
【請求項10】
コンピュータを、請求項8記載のリアクション選択装置として機能させるためのコンピュータプログラム。
【請求項11】
請求項1〜7のいずれか1項に記載の応答戦略獲得装置(13)及び請求項8記載のリアクション選択装置(22)を備え、前記リアクション選択装置によって選択されたリアクションを生成するリアクション生成部(3)を備えていることを特徴とするロボット。
【請求項1】
イニシエーター(1)が行ったイニシアティブアクション(ai)に対するリアクター(2)のリアクション(bj)を観測することで、イニシアティブアクション(ai)に対するリアクション(bj)の出力の仕方を示す応答戦略(Z(bj,ai))を獲得する応答戦略獲得装置(13)であって、
あるイニシアティブアクション(ai)を原因とする何らかのリアクションが、ある時刻(s)において発生する確率を示すリアクション発生確率(Wai,s)を、時間とリアクション発生確率との関係を規定したリアクション発生確率密度関数に基づいて算出する発生確率算出部(21)と、
あるイニシアティブアクション(ai)に対して何らかのリアクションが発生することが決定した場合における、当該イニシアティブアクション(ai)に依存して特定の種類のリアクション(bj)がリアクター(2)によって選択される選択確率(Z(bj,ai))を推定することで、イニシアティブアクション(ai)に対するリアクション(bj)の出力の仕方を示す応答戦略を獲得する選択確率推定部(22)と、
を備え、
前記選択確率推定部(22)は、複数の種類のイニシアティブアクション(ai)それぞれをリアクション(bj)の発生原因とした場合の当該リアクションの発生時刻(s)におけるリアクション発生確率(Wai,s)を、当該複数の種類のイニシアティブアクション(ai)それぞれの発生時刻(s)及び当該リアクション(bj)の発生時刻(s)に基づき、前記発生確率算出部(21)を介して取得し、これらのリアクション発生確率(Wai,s)に基づいて、当該リアクション(bj)の前記選択確率(Z(bj,ai))を、当該複数の種類のイニシアティブアクション(ai)それぞれについて算出するよう構成されている
ことを特徴とする応答戦略獲得装置。
【請求項2】
前記リアクション発生確率密度関数は、イニシアティブアクション発生後から時間経過に伴ってリアクション発生確率が減衰するよう規定されたものである
請求項1記載の応答戦略獲得装置。
【請求項3】
前記リアクション発生確率密度関数を変化させて、発生したイニシアティブアクション(A)とリアクション(B)との間の相互情報量(I(B;A))が最大となるリアクション発生確率密度関数を探索する探索部(24)を更に備え、
前記発生確率算出部(21)は、前記相互情報量が最大となるリアクション発生確率密度関数に基づいて、リアクション発生確率を算出する
請求項1又は2記載の応答戦略獲得装置。
【請求項4】
複数の種類のイニシアティブアクション(ai)及び/又はリアクション(bj)の重要度を推定する重要度推定部(25)を更に備え、
前記重要度推定部(25)は、
発生したイニシアティブアクション(ai)とリアクション(bj)との間の第1相互情報量(I(B;A))と、発生した複数の種類のイニシアティブアクション及び/又はリアクションのうち一部のアクション(ai,bj)が存在しないものと仮定した場合のイニシアティブアクションとリアクションとの間の第2相互情報量(I’(B;A−{ai}),I’(B−{bj};A))と、の差に基づいて、存在しないものと仮定した前記一部のアクション(ai,bj)の重要度(Δaction,Δreaction)を算出する
請求項1〜3のいずれか1項に記載の応答戦略獲得装置。
【請求項5】
発生したイニシアティブアクション及び/又はリアクションのうち、応答戦略獲得の対象となる重要アクションを抽出する重要アクション抽出部(26)を更に備え、
前記重要アクション抽出部(26)は、発生したイニシアティブアクション及び/又はリアクションそれぞれについて算出された前記重要度(Δaction,Δreaction)に基づいて、重要アクションを抽出する
請求項4記載の応答戦略獲得装置。
【請求項6】
前記選択確率算出部(22)は、EM(Expectation-Maximization)アルゴリズムに基づいて、前記選択確率を算出する
請求項1〜5のいずれか1項に記載の応答戦略獲得装置。
【請求項7】
発生したアクションがイニシアティブアクションであるかリアクションであるかを推定する役割推定部(27)を更に備え、
前記役割推定部(27)は、
発生したアクションをリアクションと仮定して、リアクションであると仮定した当該アクションの前記選択確率を推定し、
推定した前記選択確率に基づいて、当該アクションの原因となったイニシアティブアクションを推定し、
推定したイニシアティブアクションが「何もしないアクション」である場合には、当該アクションはイニシアティブアクションであると推定し、その他の場合には、当該アクションはリアクションであると推定する
請求項1〜6のいずれか1項に記載の応答戦略獲得装置。
【請求項8】
観測されたイニシアティブアクションに対するリアクションの選択を行うリアクション選択装置(15)であって、
請求項1〜7のいずれか1項に記載の応答戦略獲得装置(22)によって応答戦略として獲得した前記選択確率(Z(bj,ai))を用いて、観測されたイニシアティブアクションに対するリアクションの選択を行うことを特徴とするリアクション選択装置。
【請求項9】
コンピュータを、請求項1〜7のいずれか1項に記載の応答戦略獲得装置として機能させるためのコンピュータプログラム。
【請求項10】
コンピュータを、請求項8記載のリアクション選択装置として機能させるためのコンピュータプログラム。
【請求項11】
請求項1〜7のいずれか1項に記載の応答戦略獲得装置(13)及び請求項8記載のリアクション選択装置(22)を備え、前記リアクション選択装置によって選択されたリアクションを生成するリアクション生成部(3)を備えていることを特徴とするロボット。
【図1】

【図2】
【図3】
【図8】
【図4】
【図5】
【図6】
【図7】
【図9】
【図10】
【図2】
【図3】
【図8】
【図4】
【図5】
【図6】
【図7】
【図9】
【図10】
【公開番号】特開2011−34447(P2011−34447A)
【公開日】平成23年2月17日(2011.2.17)
【国際特許分類】
【出願番号】特願2009−181828(P2009−181828)
【出願日】平成21年8月4日(2009.8.4)
【新規性喪失の例外の表示】特許法第30条第1項適用申請有り 平成21年2月23日 立命館大学主催の「2008年度卒業研究論文発表会」において文書をもって発表
【出願人】(593006630)学校法人立命館 (359)
【出願人】(301022471)独立行政法人情報通信研究機構 (1,071)
【Fターム(参考)】
【公開日】平成23年2月17日(2011.2.17)
【国際特許分類】
【出願日】平成21年8月4日(2009.8.4)
【新規性喪失の例外の表示】特許法第30条第1項適用申請有り 平成21年2月23日 立命館大学主催の「2008年度卒業研究論文発表会」において文書をもって発表
【出願人】(593006630)学校法人立命館 (359)
【出願人】(301022471)独立行政法人情報通信研究機構 (1,071)
【Fターム(参考)】
[ Back to top ]