
急上昇ワード抽出装置及び方法
【課題】本発明は、検索クエリの入力件数とは別に、かつ直接的にWebコンテンツにおける急上昇ワードを抽出することができる急上昇ワード抽出装置及び方法を提供すること。
【解決手段】急上昇ワード抽出装置(10)は、インターネット(30)上のWebサイトを所定の周期で巡回し、新規のコンテンツを取得して当該新規のコンテンツのURLに関連付けてこれを記憶すると共に、これまでに取得していた同じURLの既存コンテンツと対比して、新規のコンテンツにおいて新たに追加された、既存コンテンツとの差分である差分コンテンツを抽出し、記憶する。さらに、急上昇ワード抽出装置(10)は、差分コンテンツに含まれるワードの種類毎に当該ワードが含まれる差分コンテンツのURLの数を集計し、当該URLの数が、所定の基準数を超えたワードを急上昇ワードとして抽出する。
【解決手段】急上昇ワード抽出装置(10)は、インターネット(30)上のWebサイトを所定の周期で巡回し、新規のコンテンツを取得して当該新規のコンテンツのURLに関連付けてこれを記憶すると共に、これまでに取得していた同じURLの既存コンテンツと対比して、新規のコンテンツにおいて新たに追加された、既存コンテンツとの差分である差分コンテンツを抽出し、記憶する。さらに、急上昇ワード抽出装置(10)は、差分コンテンツに含まれるワードの種類毎に当該ワードが含まれる差分コンテンツのURLの数を集計し、当該URLの数が、所定の基準数を超えたワードを急上昇ワードとして抽出する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、インターネット上で出現頻度が急上昇しているワードを抽出する急上昇ワード抽出装置及び方法に関する。
【背景技術】
【0002】
インターネット上の情報を検索する検索エンジンでは、クエリの入力を受け付けると、入力されたクエリと一致するキーワードを含むWebサイトを検索し、検索結果として表示する。また、検索エンジンを提供する検索システムは、入力されたクエリを時刻情報と共に蓄積しておき、所定期間に頻繁に使用されたクエリを、そのときに社会で注目されている事柄に関連するキーワードとして特定することができる。そして、所定期間に頻繁に入力されたクエリを使用してWebページを検索をすることで、ユーザは、現在注目されている事項に関する情報を容易に得ることが可能となる(例えば、特許文献1)。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開2005−99964号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
特許文献1には、検索に使用された頻度の高いキーワードと、ユーザにより入力されたカテゴリの情報に基づいて、人気のあるカテゴリやカテゴリに含まれる情報に簡単にアクセスすることができる装置が開示されている。しかし、使用頻度の高い検索キーワードのみでは、実際にインターネット上でどの程度そのキーワードが出現しているかを知ることはできない。
【0005】
ところで、注目度が上昇しているワードについては、インターネット上でそのワードを取り上げるコンテンツも多くなることが予想されるため、インターネット上で、当該ワードを含むコンテンツの出現頻度の上昇率が高いほど、より注目度が上昇しているワードであると予想される。したがって、入力頻度の高いクエリに着目した技術とは別に、インターネット上のコンテンツの出現頻度の上昇率に基づいて注目度が上昇しているワードを抽出する装置が求められている。
【0006】
本発明は、インターネット上で注目度が上昇している急上昇ワードを抽出する急上昇ワード抽出装置及び方法を提供することを目的とする。
【課題を解決するための手段】
【0007】
(1)インターネット上で注目度が上昇している急上昇ワードを抽出する急上昇ワード抽出装置であって、前記インターネット上のWebサイトを所定の周期で巡回して新規のコンテンツを取得するWebクロール手段と、前記Webクロール手段が取得した新規のコンテンツを当該新規のコンテンツのURLに関連付けて記憶する新規コンテンツ記憶手段と、前記Webクロール手段が前回の巡回までに取得した既存のコンテンツを当該既存のコンテンツのURLに関連付けて記憶している既存コンテンツ記憶手段と、前記新規コンテンツ記憶手段が記憶した新規のコンテンツを、前記既存コンテンツ記憶手段が記憶している既存のコンテンツであって、当該新規のコンテンツと同じURLの既存コンテンツと比較して、当該新規のコンテンツにおいて新たに追加された差分コンテンツを抽出する差分コンテンツ抽出手段と、前記差分コンテンツ抽出手段が抽出した差分コンテンツを、当該差分コンテンツのURLに関連付けて記憶する差分コンテンツ記憶手段と、前記差分コンテンツ記憶手段が記憶した差分コンテンツに含まれるワードの種類毎に、当該ワードが含まれる前記差分コンテンツのURLの数を集計し、前記URLの数が所定の基準数を超えたワードを急上昇ワードとして抽出する急上昇ワード抽出手段と、を備える急上昇ワード抽出装置。
【0008】
(1)の急上昇ワード抽出装置は、インターネット上のWebサイトを所定の周期で巡回し、新規のコンテンツを取得して当該新規のコンテンツのURLに関連付けてこれを記憶すると共に、これまでに取得していた同じURLの既存コンテンツと対比して、新規のコンテンツにおいて新たに追加された、既存コンテンツとの差分である差分コンテンツを抽出し、記憶する。さらに、急上昇ワード抽出装置は、差分コンテンツに含まれるワードの種類毎に当該ワードが含まれる差分コンテンツのURLの数を集計し、当該URLの数が、所定の基準数を超えたワードを急上昇ワードとして抽出する。
インターネット上のWebサイトに含まれるコンテンツに使用されたワードの数を単純に数えるのではなく、当該ワードが登場したURLの数を数えることができるため、話題として取り上げた情報源の数を元にして注目度の高いキーワードが何かを判別し、抽出することができる。また、例えば、1つのWebページ内に同一のワードが脈絡無く多数登場するようなものであってもその影響を最小限にして注目度の高いキーワードを抽出することができる。
【0009】
(2)前記Webクロール手段が新規のコンテンツを取得して前記新規コンテンツ記憶手段が新規のコンテンツを記憶する毎に、前記差分コンテンツ抽出手段及び前記差分コンテンツ記憶手段の処理を繰り返す繰り返し手段をさらに備え、前記急上昇ワード抽出手段は、所定期間において取得した複数の差分コンテンツに含まれるワードの種類の中から、前記URLの数が前記所定の基準数を超えた回数が所定の基準回数を超えたものを特定して、前記急上昇ワードとして抽出する(1)に記載の急上昇ワード抽出装置。
【0010】
(2)の急上昇ワード抽出装置は、(1)の急上昇ワード抽出装置に加えて、Webクロール手段が新規のコンテンツを取得して当該新規のコンテンツを記憶する毎に、差分コンテンツを抽出して記憶する処理を繰り返し、所定期間内において差分コンテンツに含まれるワードの種類の中からURLの数が所定の基準数を超えた回数が所定の基準回数を超えたものを急上昇ワードとして抽出する。これにより、所定期間において、複数回にわたって所定の基準数を超えたワードを急上昇ワードとして抽出することができる。このため、例えば所定の基準回数を1より大きいものとした場合、1回だけ所定の基準数を超えたようなワードを除外することができる。
【0011】
(3)前記急上昇ワード抽出手段は、前記URLの数を、前記URLが示すドメイン又は所定のサブドメイン毎に集計し、前記URLの数が所定の基準数を超えたワードを、当該ドメイン又は所定のサブドメイン毎の急上昇ワードとして抽出する(1)又は(2)に記載の急上昇ワード抽出装置。
【0012】
(3)の急上昇ワード抽出装置は、(1)又は(2)の急上昇ワード抽出装置に加えて、差分コンテンツ記憶手段が記憶した差分コンテンツのURLの数を、当該URLが示すドメイン又は所定のサブドメイン毎に集計し、ドメイン又は所定のサブドメイン毎に集計したURLの数が所定の基準数を超えたワードを、当該ドメイン又は所定のサブドメインの急上昇ワードとして抽出する。
これにより、ドメイン又は所定のサブドメイン内のコンテンツにおいて、中心として取り上げられているトピックを示すキーワードを抽出することができるので、急上昇ワード自体をそれぞれのドメイン又はサブドメインを分類するキーとしても使用することが可能となる。
【0013】
(4)インターネット上で注目度が上昇している急上昇ワードを抽出する急上昇ワード抽出方法であって、コンピュータは、記憶手段を備え、コンピュータに、前記インターネット上のWebサイトを所定の周期で巡回して新規のコンテンツを取得するWebクロールステップと、前記Webクロール手段が取得した新規のコンテンツを当該新規のコンテンツのURLに関連付けて前記記憶手段に記憶させる新規コンテンツ記憶ステップと、前記Webクロール手段が前回の巡回までに取得した既存のコンテンツを当該既存のコンテンツのURLに関連付けて前記記憶手段に記憶させる既存コンテンツ記憶ステップと、前記新規コンテンツ記憶ステップで前記記憶手段に記憶させた新規のコンテンツを、前記記憶手段が記憶している既存のコンテンツであって、当該新規のコンテンツと同じURLのコンテンツとを比較して、当該新規のコンテンツにおいて新たに追加された差分コンテンツを抽出する差分コンテンツ抽出ステップと、前記差分コンテンツ抽出ステップにおいて抽出された差分コンテンツを、当該差分コンテンツのURLに関連付けて前記記憶手段に記憶させる差分コンテンツ記憶ステップと、前記差分コンテンツ記憶ステップで記憶手段に記憶させた差分コンテンツに含まれるワードの種類毎に、当該ワードが含まれる前記差分コンテンツのURLの数を集計し、前記URLの数が所定の基準数を超えたワードを急上昇ワードとして抽出する急上昇ワード抽出ステップと、を実行させる急上昇ワード抽出方法。
【0014】
(4)の急上昇ワード抽出方法は、(1)の急上昇ワード抽出装置と同様の効果を奏することができる。
【発明の効果】
【0015】
本発明によれば、インターネット上で注目度が上昇している急上昇ワードを抽出する急上昇ワード抽出装置及び方法を提供することができる。
【図面の簡単な説明】
【0016】
【図1】本発明の一実施形態に係る急上昇ワード抽出装置の機能ブロック示す図である。
【図2】本発明の一実施形態に係る急上昇ワード抽出装置の既存WebコンテンツDBに格納されているテーブルの一例である。
【図3】本発明の一実施形態に係る急上昇ワード抽出装置の差分Webコンテンツ・アーカイブに格納されているテーブルの一例である。
【図4】本発明の一実施形態に係る急上昇ワード抽出装置の急上昇ワードDBに格納されているテーブルの一例である。
【図5】本発明の一実施形態に係る急上昇ワード抽出装置が行う急上昇ワードの抽出を説明するための概念図である。
【図6】本発明の一実施形態に係る急上昇ワード抽出装置が行う処理のフローチャートである。
【図7】本発明の一実施形態に係る急上昇ワード抽出装置が行う処理のフローチャートである。
【図8】本発明の第2実施形態に係る急上昇ワード抽出装置が行う処理のフローチャートである。
【図9】本発明の第3実施形態に係る急上昇ワード抽出装置が行う処理のフローチャートである。
【発明を実施するための形態】
【0017】
以下、本発明の実施形態について図面を参照して説明する。なお、以下に説明する実施形態は、あくまでも一例であって、本発明の技術的範囲はこれに限られるものではない。
【0018】
図1から図4を参照して、本発明の一実施形態に係る急上昇ワード抽出装置10について説明する。
【0019】
図1を参照して、本発明の一実施形態に係る急上昇ワード抽出装置10について説明する。図1は、急上昇ワード抽出装置10の機能ブロックを示す図である。
【0020】
本実施形態は、コンピュータ(急上昇ワード抽出装置10)及びその周辺装置に適用される。本実施形態における各部は、コンピュータ及びその周辺装置が備えるハードウェア並びにこのハードウェアを制御するソフトウェアによって構成される。また、急上昇ワード抽出装置10は、通信ネットワークとしてのインターネット30に接続している各種サーバ(図示せず)に接続し、互いに通信を行う。
【0021】
上記ハードウェアには、制御部としてのCPUの他、記憶部、通信部、表示部及び入力部が含まれる。記憶部としては、例えば、メモリ(RAM、ROM等)、ハードディスクドライブ(HDD)及び光ディスク(CD、DVD等)ドライブが挙げられる。通信部としては、例えば、各種有線及び無線インターフェース装置が挙げられる。表示部としては、例えば、液晶ディスプレイ、プラズマディスプレイ等の各種ディスプレイが挙げられる。入力部としては、例えば、キーボード及びポインティング・デバイス(マウス、トラッキングボール等)が挙げられる。
【0022】
上記ソフトウェアには、上記ハードウェアを制御するコンピュータ・プログラムやデータが含まれる。コンピュータ・プログラムやデータは、記憶部により記憶され、制御部により適宜実行、参照される。また、コンピュータ・プログラムやデータは、通信ネットワークを介して配布することも可能であり、CD−ROM等のコンピュータ可読媒体に記憶して配布することも可能である。
【0023】
以下、急上昇ワード抽出装置10の機能構成について説明する。
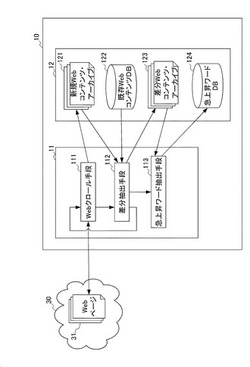
急上昇ワード抽出装置10は、急上昇ワード抽出装置10に係る各機能を統括的に制御する制御部11と、本発明の機能を実行するプログラム(図示省略)等を記憶する記憶部12と、を少なくとも有する。
【0024】
制御部11は、CPU等により構成されており、急上昇ワード抽出装置10の各処理動作の制御や情報の通信制御を行う。この制御部11は、Webクロール手段111と、差分コンテンツ抽出手段112と、急上昇ワード抽出手段113と、を備える。詳細は後述する。
【0025】
記憶部12は、上述の各種プログラムの他に、新規コンテンツ記憶手段としての新規Webコンテンツ・アーカイブ121と、既存コンテンツ記憶手段としての既存Webコンテンツ・データベース(以下、データベースをDBと表記する。)122と、差分コンテンツ記憶手段としての差分Webコンテンツ・アーカイブ123と、急上昇ワードDB124と、を備える。詳細は後述する。
【0026】
制御部11のWebクロール手段111は、インターネット30上に公開されているWebページ31を巡回し、接続したWebページ31のURL(Uniform Resorce Locater)と、当該Webページ31のデータ(コンテンツ)とを取得する。そして、Webクロール手段111は、インターネット30から取得したWebページ31のデータ(コンテンツ)を記憶部12の新規Webコンテンツ・アーカイブ121に記憶させる。
ここで、Webクロール手段111が取得するWebページ31は、所定の内容により構成されるWebページであり、いわゆるニュース等の何らかの情報を提供するサイトのページに限らず、掲示板、ブログやショートブログメッセージを表示するWebページも含む。
【0027】
ここで、新規Webコンテンツ・アーカイブ121には、Webクロール手段111が取得したWebページのデータ(コンテンツ)が当該WebページのURLと共に記憶されている。
【0028】
差分コンテンツ抽出手段112は、新規Webコンテンツ・アーカイブ121と既存WebコンテンツDB122とを参照して、新規Webコンテンツ・アーカイブ121に格納されたWebページのデータ(以下、新規コンテンツという)と、当該Webページと同じURLの既存WebコンテンツDB122に格納されているWebページのデータ(以下、既存コンテンツという)とを対比し、その差分(以下、抽出された差分のデータを差分コンテンツという)を抽出する。そして、差分コンテンツ抽出手段112は、抽出した差分コンテンツを差分Webコンテンツ・アーカイブ123にURLと共に記憶させる。
【0029】
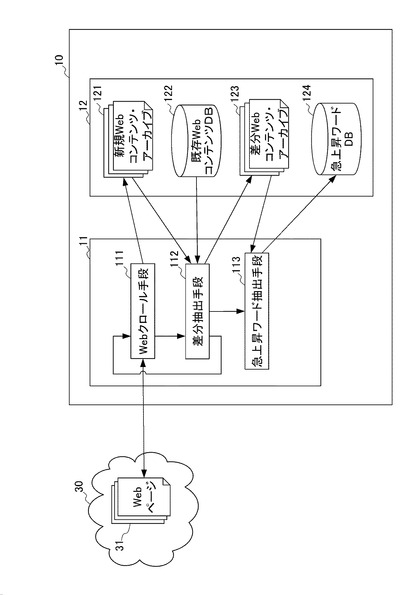
ここで、既存WebコンテンツDB122について説明する。既存WebコンテンツDB122は、既存コンテンツがURLと共に格納されている。例えば、図2に示すテーブル1221のように、URLと既存コンテンツとがそれぞれ互いに関連付けられて記憶される。
【0030】
この既存コンテンツは、Webクロール手段111が取得したWebページのデータが順次格納される。既存WebコンテンツDB122には、Webクロール手段111とは別に異なるクロール手段により取得したデータが格納されていてもよい。
【0031】
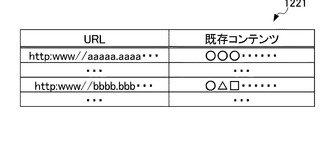
また、差分Webコンテンツ・アーカイブ123は、図3のテーブル1231に示すように、差分コンテンツ抽出手段112により抽出された差分コンテンツをURL及び日時の情報と共に記憶する。このURLは、差分コンテンツが含まれるWebページのURLである。また、日時の情報は、例えば、Webクロール手段111が当該URLのWebページのデータを取得した日時である。
【0032】
急上昇ワード抽出手段113は、差分Webコンテンツ・アーカイブ123を参照し、個々の差分コンテンツに含まれる追加差分ワードを抽出し、その数を集計して、所定の基準数を超えたワードを急上昇ワードDB124に記憶させる。追加差分ワードは、差分コンテンツに含まれるワードの種類単位で抽出したワードをいう。このワードは、本実施形態においては、コンテンツに含まれるひとまとまりの単語をいい、1つのコンテンツにおいて同じワードが重複しないものであり、ワードの種類毎に抽出される。例えば、1つのコンテンツ内で複数回同じワードが登場したとしても、複数回登場したワードの個数を数えるのではなく、一度、1つのコンテンツ内で登場したワードは、そのコンテンツにおいて何回登場しようともそのワードは1つとして数える。以下、この抽出したワードを追加差分ワードという。
【0033】
なお、追加差分ワードの抽出については、例えば、形態素解析によりコンテンツに含まれる文章を形態素ごとに細分化し、これを品詞別に集計して形容詞や名詞等の所定の品詞に関して追加差分ワードとして抽出することができる。その他既存の技術を採用することが可能である。
【0034】
そして急上昇ワード抽出手段113は、抽出した追加差分ワードが含まれる差分コンテンツのURLの数を集計し、集計値が所定の基準数を超えたか否かを判別する。急上昇ワード抽出手段113は、所定の基準数を超えた場合、これを急上昇ワードとして、急上昇ワードDB124に記憶させる。若しくは、所定の品詞についてTF−idf(term frequency−inverse document frequency)法により算出した重要度の高い単語を急上昇ワードして抽出をしてもよい。
【0035】
ここで、図4を参照して急上昇ワードDB124について説明する。図4は、急上昇ワードDB124が記憶するテーブル1241の例である。急上昇ワードDB124は、急上昇ワードと日時の情報を少なくとも記憶する。急上昇ワードの欄には、急上昇ワード抽出手段113が抽出した急上昇ワード、すなわち、追加差分ワードのうち、当該追加差分ワードが含まれる差分コンテンツのURLの数が所定の基準数を超えたものが格納される。また、日時の欄には、Webクロール手段111が当該URLのWebページのデータを取得した日時の情報が格納される。
【0036】
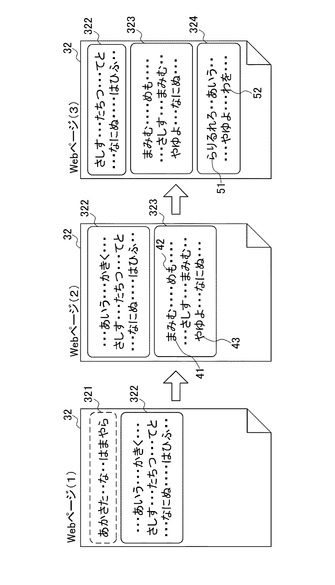
図5を参照して、急上昇ワードの抽出について詳細に説明する。図5は、急上昇ワード抽出装置10が行う急上昇ワードの抽出を説明するための概念図である。
【0037】
まず、所定のWebページ32において、コンテンツ321とコンテンツ322とが存在し、既存WebコンテンツDB122に記憶されているものとする(図5のWebページ(1)参照)。このコンテンツ321及びコンテンツ322が既存コンテンツとなる。
【0038】
次に、Webクロール手段111がWebページ32のURLに再度接続して、Webページ32の新規のコンテンツを取得したとする(図5のWebページ(2)参照)。このWebクロール手段111が新たに取得した新規コンテンツは、当該Webページ32のURLと共に新規Webコンテンツ・アーカイブ121に記憶される。
【0039】
次に差分コンテンツ抽出手段112は、同じURLの新規Webコンテンツ・アーカイブ121に格納された新規コンテンツと、既存WebコンテンツDB122に格納された既存コンテンツとをそれぞれ読み出して対比し、その差分を抽出する。図5によると、既存コンテンツ321が削除され、もう一つの既存コンテンツ322がそのまま残されている。また、新たにコンテンツ323が追加されている。
差分コンテンツ抽出手段112は、この新たに追加されたコンテンツ323を差分コンテンツとして差分Webコンテンツ・アーカイブ123に記憶させる。
【0040】
次に、急上昇ワード抽出手段113は、差分Webコンテンツ・アーカイブ123を参照して、追加差分ワードを抽出する。図5の例でいうと、既存のコンテンツ321,322と新規のコンテンツ323とを対比したとき、新たに登場したワードは、「まみむ」(図5のワード41)、「めも」(図5のワード42)及び「やゆよ」(図5のワード43)である。したがって、差分コンテンツ抽出手段112はこの3つのワードを追加差分ワードとして抽出する。なお、新規のコンテンツ323をみると、「まみむ」が2回登場しているが、これを2つのワードとしてワード数を2として抽出するのではなく、1種類のワードとして抽出する。
【0041】
そして、急上昇ワード抽出手段113は、差分Webコンテンツ・アーカイブを参照し、抽出した追加差分ワードのそれぞれについて、追加差分ワードが含まれる差分コンテンツの数、すなわち、追加差分ワードが含まれる差分コンテンツのURLの数を集計し、その集計値が所定の基準数を超えるか否かを判別する。急上昇ワード抽出手段113は、集計値が基準数を超える場合、集計値が基準数を超えた追加差分ワードを急上昇ワードとして急上昇ワードDB124に記憶させる。
【0042】
その後、さらにWebクロール手段111がWebページ32のURLに再度接続して、Webページ32のデータを新たに取得したとする(図5のWebページ(3)参照)。このWebクロール手段111が新たに取得したWebページ32のデータも新規コンテンツとして当該Webページ32のURLと共に新規Webコンテンツ・アーカイブ121に格納される。
【0043】
次に差分コンテンツ抽出手段112が差分コンテンツを抽出するが、対比する対象は、前回新規コンテンツとして対比したときのWebページ32のコンテンツと、今回新たに取得した新規コンテンツとなる。図5によると、コンテンツ322の一部が削除されており、コンテンツ323がそのまま残され、新たにコンテンツ324が追加されている。
差分コンテンツ抽出手段112は、この新たに追加されたコンテンツ324を差分コンテンツとして差分Webコンテンツ・アーカイブ123に記憶させる。
【0044】
次に、急上昇ワード抽出手段113は、上記と同様に、差分Webコンテンツ・アーカイブ123を参照して、追加差分ワードを抽出する。図5の例でいうと、既存のコンテンツ322,323と新規のコンテンツ324とを対比したとき、新たに登場したワードは、「らりるれろ」(図5のワード51)、「わを」(図5のワード52)である。したがって、差分コンテンツ抽出手段112はこの2つのワードを追加差分ワードとして抽出する。
【0045】
そして、急上昇ワード抽出手段113は、Webページ(2)のときと同様に、抽出した追加差分ワードのそれぞれについて、追加差分ワードが含まれる差分コンテンツのURLの数を集計し、その集計値が所定の基準数を超えるか否かを判別する。急上昇ワード抽出手段113は、集計値が基準数を超える場合、集計値が基準数を超えた追加差分ワードを急上昇ワードとして急上昇ワードDB124に記憶させる。
【0046】
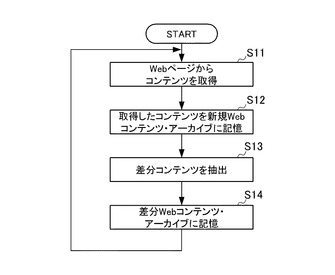
図6及び図7を参照して急上昇ワード抽出装置10が行う処理の流れについて説明する。図6及び図7は、急上昇ワード抽出装置10が行う処理のフローチャートである。
【0047】
図6のステップS11では、急上昇ワード抽出装置10のWebクロール手段111は、インターネット30からWebページのデータ(コンテンツ)を取得する。
【0048】
ステップS12では、急上昇ワード抽出装置10のWebクロール手段111は、ステップS11で取得したコンテンツを新規コンテンツとして新規Webコンテンツ・アーカイブ121に記憶させる。
【0049】
ステップS13では、急上昇ワード抽出装置10の差分コンテンツ抽出手段112は、同じURLの新規Webコンテンツ・アーカイブ121の新規コンテンツと既存WebコンテンツDB122の既存コンテンツとを対比して、差分コンテンツを抽出する。
【0050】
ステップS14では、急上昇ワード抽出装置10の差分コンテンツ抽出手段112は、ステップS13で抽出した差分コンテンツを差分Webコンテンツ・アーカイブ123に記憶させる。そして、急上昇ワード抽出装置10のWebクロール手段111及び差分コンテンツ抽出手段112は、これらの処理を繰り返し行う。
【0051】
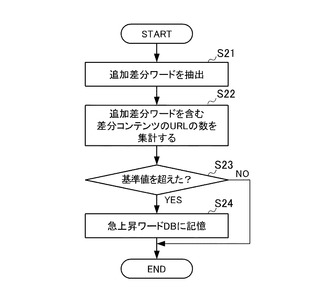
図7のステップS21では、急上昇ワード抽出装置10の急上昇ワード抽出手段113は、差分Webコンテンツ・アーカイブ123から追加差分ワードを抽出する。
【0052】
ステップS22では、急上昇ワード抽出手段113は、同じ追加差分ワードの差分コンテンツのURLの数を集計する。
【0053】
ステップS23では、急上昇ワード抽出手段113は、集計したURL数が基準数を超えたか否かを判別する。急上昇ワード抽出手段113は、当該判別がYESの場合、ステップS24に処理を移し、当該判別がNOの場合は、本フローチャートの処理を終了する。
【0054】
ステップS24では、急上昇ワード抽出手段113は、所定の基準数を超えた追加差分ワードを急上昇ワードとして急上昇ワードDB124に記憶させ、本フローチャートの処理を終了する。
【0055】
図8を参照して第2実施形態について説明する。第2実施形態は、急上昇ワードの抽出方法が第1実施形態と異なる。図8は、第2実施形態における急上昇ワード抽出装置10が行う処理のフローチャートである。なお、以下では、第1実施形態と異なる部分を中心に説明し、特に説明しない部分は第1実施形態と同様である。
【0056】
急上昇ワード抽出装置10の制御部11は、Webクロール手段111が新規のコンテンツを取得して新規Webコンテンツ・アーカイブに当該新規のコンテンツを記憶させる毎に、差分コンテンツ抽出手段112が差分コンテンツを抽出し、差分Webコンテンツ・アーカイブ123に差分コンテンツを記憶させる処理を繰り返す繰り返し手段として機能する。
【0057】
急上昇ワード抽出手段113は、差分Webコンテンツ・アーカイブ123に記憶された差分コンテンツから、追加差分ワードを抽出し、抽出した追加差分ワードのうち、追加差分ワードを含む差分コンテンツのURLの数が所定の基準数を超えたものを第1急上昇ワードとして抽出し、急上昇ワードDB124に記憶させる。さらに、急上昇ワード抽出手段113は、急上昇ワードDB124に記憶させた第1急上昇ワードのうち、所定期間において第1急上昇ワードとして抽出された回数が所定の基準回数を超えたものを第2急上昇ワードとして抽出する。
なお、基準回数は、少なくとも、1より大きい値であることが好ましい。これにより、新規コンテンツに登場した数が基準数より大きくなった回数が複数回以上のものを抽出することができる。このため、所定期間内において、継続して注目されている話題(トピック)を示すキーワードを抽出することが可能となる。
【0058】
図8を参照して急上昇ワード抽出装置10の急上昇ワード抽出手段113で行う処理について説明する。図8の処理は、第1実施形態の図7において、急上昇ワードを抽出し、急上昇ワードDB124に記憶したことを前提に行われる処理である。図7の処理において抽出された急上昇ワードが本実施形態における第1急上昇ワードとなる。
【0059】
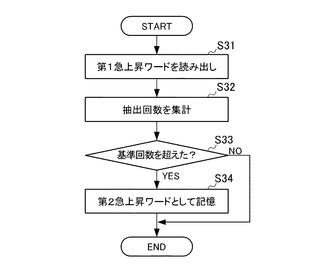
ステップS31では、急上昇ワード抽出装置10の急上昇ワード抽出手段113は、急上昇ワードDB124から、所定期間内に記憶された第1急上昇ワードを読み出す。
【0060】
ステップS32では、急上昇ワード抽出手段113は、第1急上昇ワードが、当該所定期間内に抽出された回数を第1急上昇ワード毎に集計する。
【0061】
ステップS33では、急上昇ワード抽出手段113は、第1急上昇ワードが集計された回数が基準回数を超えたか否かを判別する。急上昇ワード抽出手段113は、当該判別がYESの場合、ステップS34に処理を移し、当該判別がNOの場合は、本フローチャートの処理を終了する。
【0062】
ステップS34では、急上昇ワード抽出手段113は、所定の基準回数を超えた第1急上昇ワードを第2急上昇ワードとして急上昇ワードDB124に記憶させ、本フローチャートの処理を終了する。
【0063】
図9を参照して第3実施形態について説明する。第3実施形態は、急上昇ワードの抽出方法が第1実施形態及び第2実施形態と異なる。図9は、第3実施形態における急上昇ワード抽出装置10が行う処理のフローチャートである。なお、以下では、第1実施形態及び第2実施形態と異なる部分を中心に説明し、特に説明しない部分は第1実施形態及び第2実施形態と同様である。
【0064】
急上昇ワード抽出装置10の急上昇ワード抽出手段113は、差分Webコンテンツ・アーカイブ123が記憶した差分コンテンツのURLの数を、当該URLが示すドメイン又は所定のサブドメイン毎に集計し、ドメイン又は所定のサブドメイン毎に集計したURLの数が所定の基準数を超えたワードを、当該ドメイン又は所定のサブドメインの急上昇ワードとして抽出する。
【0065】
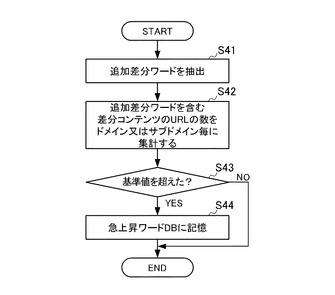
ステップS41では、急上昇ワード抽出装置10の急上昇ワード抽出手段113は、差分Webコンテンツ・アーカイブ123から追加差分ワードを抽出する。
【0066】
ステップS42では、急上昇ワード抽出手段113は、追加差分ワードを含む差分コンテンツのURLの数をドメイン又はサブドメイン毎に集計する。
【0067】
ステップS43では、急上昇ワード抽出手段113は、各ドメイン又は所定のサブドメイン毎に、URLの数が基準値を超えたか否かを判断する。この判別でYESの場合はステップS44に移り、NOの場合は、本フローチャートの処理を終了する。
【0068】
ステップS44では、急上昇ワード抽出手段113は、ステップS43でURLの数が基準値を超えた追加差分ワードを急上昇ワードとして急上昇ワードDB124に記憶させ、本フローチャートの処理を終了する。
【0069】
本実施形態は、上記の構成を備えることにより、ドメイン又は所定のサブドメイン内のコンテンツにおいて、中心として取り上げられているトピックを示すキーワードを抽出することができる。このため、急上昇ワード自体をそれぞれのドメイン又はサブドメインを分類するキーとしても使用することが可能となる。
【0070】
なお、本実施形態において、同一の急上昇ワードと抽出したWebサイトのドメイン又はサブドメインが複数ある場合には、当該サイトの特定の信頼度スコアに基づいて、各ドメイン又はサブドメイン毎に抽出した急上昇ワードを、当該サイトの特定の信頼度スコアに基づいて、いわゆるレコメンドに利用することができる。
【0071】
例えば、急上昇ワード抽出装置10の制御部11は、Webクロール手段111が取得したURLに関し、そのドメイン又はサブドメインの信頼度スコアを算出し、記憶部12に記憶させておくことができる。そして、いわゆるEC(electronic commerce)サイトにおいて、急上昇ワードを抽出したドメイン又はサブドメインの信頼度スコアが所定の値以上である場合に、優先的にレコメンドに表示することができる。ここで、信頼度スコアは、例えば、当該サイトの運営主体の信頼性、ニュース記事等のコンテンツの信頼性、WebページやWebサイト等の安全度を示すスコアであり、任意のものを使用することができる。また、この信頼度スコアは、急上昇ワード抽出装置10以外の装置が算出したデータをインターネット30等のネットワークを通じて取得し使用してもよい。
【0072】
なお、基準値に関しては、ドメイン又はサブドメイン毎に集計する際の基準値と、ドメイン又はサブドメインとは関係なく、全てのURLの数で集計する際の基準値とを別々に設定し、併用してもよい。
【0073】
上記の実施形態によれば、急上昇ワード抽出装置10は、インターネット30で公開されたWebページ31のデータ(コンテンツ)に登場したワードのWebページの数を数えることができるため、話題として取り上げた情報源の数を元にして注目度の高いキーワードが何かを判別し、抽出することができる。また、例えば、1つのWebページ内に脈絡無く同一のワードが繰り返し登場するようなものであってもその影響を最小限にして注目度の高いキーワードを抽出することができる。
【0074】
上述の実施形態によれば、急上昇ワード抽出装置10は、従来のように、検索クエリとして使用されたキーワードの使用回数に基づいて注目度の高いキーワードを抽出するのとは別に、注目度の高いキーワードとしての急上昇ワードを抽出することができる。このため、検索クエリの解析とは別に急上昇ワードを抽出することが可能となる。
【0075】
上述の実施形態によれば、急上昇ワード抽出装置10は、差分コンテンツから追加差分ワードを抽出して、急上昇ワードであるか否かを判別するので、従来のように、個々にWebページを既存のものと対比してキーワードを抽出するよりもハードウェアに与える負担を軽くすることができる。
【0076】
以上、本発明の実施形態について説明したが、本発明は上述した実施形態に限るものではない。また、本発明の実施形態に記載された効果は、本発明から生じる最も好適な効果を列挙したに過ぎず、本発明による効果は、本発明の実施形態に記載されたものに限定されるものではない。
【符号の説明】
【0077】
10 急上昇ワード抽出装置
11 制御部
12 記憶部
30 インターネット
111 Webクロール手段
112 差分コンテンツ抽出手段
113 急上昇ワード抽出手段
121 新規Webコンテンツ・アーカイブ
122 既存WebコンテンツDB
123 差分Webコンテンツ・アーカイブ
124 急上昇ワードDB
【技術分野】
【0001】
本発明は、インターネット上で出現頻度が急上昇しているワードを抽出する急上昇ワード抽出装置及び方法に関する。
【背景技術】
【0002】
インターネット上の情報を検索する検索エンジンでは、クエリの入力を受け付けると、入力されたクエリと一致するキーワードを含むWebサイトを検索し、検索結果として表示する。また、検索エンジンを提供する検索システムは、入力されたクエリを時刻情報と共に蓄積しておき、所定期間に頻繁に使用されたクエリを、そのときに社会で注目されている事柄に関連するキーワードとして特定することができる。そして、所定期間に頻繁に入力されたクエリを使用してWebページを検索をすることで、ユーザは、現在注目されている事項に関する情報を容易に得ることが可能となる(例えば、特許文献1)。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開2005−99964号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
特許文献1には、検索に使用された頻度の高いキーワードと、ユーザにより入力されたカテゴリの情報に基づいて、人気のあるカテゴリやカテゴリに含まれる情報に簡単にアクセスすることができる装置が開示されている。しかし、使用頻度の高い検索キーワードのみでは、実際にインターネット上でどの程度そのキーワードが出現しているかを知ることはできない。
【0005】
ところで、注目度が上昇しているワードについては、インターネット上でそのワードを取り上げるコンテンツも多くなることが予想されるため、インターネット上で、当該ワードを含むコンテンツの出現頻度の上昇率が高いほど、より注目度が上昇しているワードであると予想される。したがって、入力頻度の高いクエリに着目した技術とは別に、インターネット上のコンテンツの出現頻度の上昇率に基づいて注目度が上昇しているワードを抽出する装置が求められている。
【0006】
本発明は、インターネット上で注目度が上昇している急上昇ワードを抽出する急上昇ワード抽出装置及び方法を提供することを目的とする。
【課題を解決するための手段】
【0007】
(1)インターネット上で注目度が上昇している急上昇ワードを抽出する急上昇ワード抽出装置であって、前記インターネット上のWebサイトを所定の周期で巡回して新規のコンテンツを取得するWebクロール手段と、前記Webクロール手段が取得した新規のコンテンツを当該新規のコンテンツのURLに関連付けて記憶する新規コンテンツ記憶手段と、前記Webクロール手段が前回の巡回までに取得した既存のコンテンツを当該既存のコンテンツのURLに関連付けて記憶している既存コンテンツ記憶手段と、前記新規コンテンツ記憶手段が記憶した新規のコンテンツを、前記既存コンテンツ記憶手段が記憶している既存のコンテンツであって、当該新規のコンテンツと同じURLの既存コンテンツと比較して、当該新規のコンテンツにおいて新たに追加された差分コンテンツを抽出する差分コンテンツ抽出手段と、前記差分コンテンツ抽出手段が抽出した差分コンテンツを、当該差分コンテンツのURLに関連付けて記憶する差分コンテンツ記憶手段と、前記差分コンテンツ記憶手段が記憶した差分コンテンツに含まれるワードの種類毎に、当該ワードが含まれる前記差分コンテンツのURLの数を集計し、前記URLの数が所定の基準数を超えたワードを急上昇ワードとして抽出する急上昇ワード抽出手段と、を備える急上昇ワード抽出装置。
【0008】
(1)の急上昇ワード抽出装置は、インターネット上のWebサイトを所定の周期で巡回し、新規のコンテンツを取得して当該新規のコンテンツのURLに関連付けてこれを記憶すると共に、これまでに取得していた同じURLの既存コンテンツと対比して、新規のコンテンツにおいて新たに追加された、既存コンテンツとの差分である差分コンテンツを抽出し、記憶する。さらに、急上昇ワード抽出装置は、差分コンテンツに含まれるワードの種類毎に当該ワードが含まれる差分コンテンツのURLの数を集計し、当該URLの数が、所定の基準数を超えたワードを急上昇ワードとして抽出する。
インターネット上のWebサイトに含まれるコンテンツに使用されたワードの数を単純に数えるのではなく、当該ワードが登場したURLの数を数えることができるため、話題として取り上げた情報源の数を元にして注目度の高いキーワードが何かを判別し、抽出することができる。また、例えば、1つのWebページ内に同一のワードが脈絡無く多数登場するようなものであってもその影響を最小限にして注目度の高いキーワードを抽出することができる。
【0009】
(2)前記Webクロール手段が新規のコンテンツを取得して前記新規コンテンツ記憶手段が新規のコンテンツを記憶する毎に、前記差分コンテンツ抽出手段及び前記差分コンテンツ記憶手段の処理を繰り返す繰り返し手段をさらに備え、前記急上昇ワード抽出手段は、所定期間において取得した複数の差分コンテンツに含まれるワードの種類の中から、前記URLの数が前記所定の基準数を超えた回数が所定の基準回数を超えたものを特定して、前記急上昇ワードとして抽出する(1)に記載の急上昇ワード抽出装置。
【0010】
(2)の急上昇ワード抽出装置は、(1)の急上昇ワード抽出装置に加えて、Webクロール手段が新規のコンテンツを取得して当該新規のコンテンツを記憶する毎に、差分コンテンツを抽出して記憶する処理を繰り返し、所定期間内において差分コンテンツに含まれるワードの種類の中からURLの数が所定の基準数を超えた回数が所定の基準回数を超えたものを急上昇ワードとして抽出する。これにより、所定期間において、複数回にわたって所定の基準数を超えたワードを急上昇ワードとして抽出することができる。このため、例えば所定の基準回数を1より大きいものとした場合、1回だけ所定の基準数を超えたようなワードを除外することができる。
【0011】
(3)前記急上昇ワード抽出手段は、前記URLの数を、前記URLが示すドメイン又は所定のサブドメイン毎に集計し、前記URLの数が所定の基準数を超えたワードを、当該ドメイン又は所定のサブドメイン毎の急上昇ワードとして抽出する(1)又は(2)に記載の急上昇ワード抽出装置。
【0012】
(3)の急上昇ワード抽出装置は、(1)又は(2)の急上昇ワード抽出装置に加えて、差分コンテンツ記憶手段が記憶した差分コンテンツのURLの数を、当該URLが示すドメイン又は所定のサブドメイン毎に集計し、ドメイン又は所定のサブドメイン毎に集計したURLの数が所定の基準数を超えたワードを、当該ドメイン又は所定のサブドメインの急上昇ワードとして抽出する。
これにより、ドメイン又は所定のサブドメイン内のコンテンツにおいて、中心として取り上げられているトピックを示すキーワードを抽出することができるので、急上昇ワード自体をそれぞれのドメイン又はサブドメインを分類するキーとしても使用することが可能となる。
【0013】
(4)インターネット上で注目度が上昇している急上昇ワードを抽出する急上昇ワード抽出方法であって、コンピュータは、記憶手段を備え、コンピュータに、前記インターネット上のWebサイトを所定の周期で巡回して新規のコンテンツを取得するWebクロールステップと、前記Webクロール手段が取得した新規のコンテンツを当該新規のコンテンツのURLに関連付けて前記記憶手段に記憶させる新規コンテンツ記憶ステップと、前記Webクロール手段が前回の巡回までに取得した既存のコンテンツを当該既存のコンテンツのURLに関連付けて前記記憶手段に記憶させる既存コンテンツ記憶ステップと、前記新規コンテンツ記憶ステップで前記記憶手段に記憶させた新規のコンテンツを、前記記憶手段が記憶している既存のコンテンツであって、当該新規のコンテンツと同じURLのコンテンツとを比較して、当該新規のコンテンツにおいて新たに追加された差分コンテンツを抽出する差分コンテンツ抽出ステップと、前記差分コンテンツ抽出ステップにおいて抽出された差分コンテンツを、当該差分コンテンツのURLに関連付けて前記記憶手段に記憶させる差分コンテンツ記憶ステップと、前記差分コンテンツ記憶ステップで記憶手段に記憶させた差分コンテンツに含まれるワードの種類毎に、当該ワードが含まれる前記差分コンテンツのURLの数を集計し、前記URLの数が所定の基準数を超えたワードを急上昇ワードとして抽出する急上昇ワード抽出ステップと、を実行させる急上昇ワード抽出方法。
【0014】
(4)の急上昇ワード抽出方法は、(1)の急上昇ワード抽出装置と同様の効果を奏することができる。
【発明の効果】
【0015】
本発明によれば、インターネット上で注目度が上昇している急上昇ワードを抽出する急上昇ワード抽出装置及び方法を提供することができる。
【図面の簡単な説明】
【0016】
【図1】本発明の一実施形態に係る急上昇ワード抽出装置の機能ブロック示す図である。
【図2】本発明の一実施形態に係る急上昇ワード抽出装置の既存WebコンテンツDBに格納されているテーブルの一例である。
【図3】本発明の一実施形態に係る急上昇ワード抽出装置の差分Webコンテンツ・アーカイブに格納されているテーブルの一例である。
【図4】本発明の一実施形態に係る急上昇ワード抽出装置の急上昇ワードDBに格納されているテーブルの一例である。
【図5】本発明の一実施形態に係る急上昇ワード抽出装置が行う急上昇ワードの抽出を説明するための概念図である。
【図6】本発明の一実施形態に係る急上昇ワード抽出装置が行う処理のフローチャートである。
【図7】本発明の一実施形態に係る急上昇ワード抽出装置が行う処理のフローチャートである。
【図8】本発明の第2実施形態に係る急上昇ワード抽出装置が行う処理のフローチャートである。
【図9】本発明の第3実施形態に係る急上昇ワード抽出装置が行う処理のフローチャートである。
【発明を実施するための形態】
【0017】
以下、本発明の実施形態について図面を参照して説明する。なお、以下に説明する実施形態は、あくまでも一例であって、本発明の技術的範囲はこれに限られるものではない。
【0018】
図1から図4を参照して、本発明の一実施形態に係る急上昇ワード抽出装置10について説明する。
【0019】
図1を参照して、本発明の一実施形態に係る急上昇ワード抽出装置10について説明する。図1は、急上昇ワード抽出装置10の機能ブロックを示す図である。
【0020】
本実施形態は、コンピュータ(急上昇ワード抽出装置10)及びその周辺装置に適用される。本実施形態における各部は、コンピュータ及びその周辺装置が備えるハードウェア並びにこのハードウェアを制御するソフトウェアによって構成される。また、急上昇ワード抽出装置10は、通信ネットワークとしてのインターネット30に接続している各種サーバ(図示せず)に接続し、互いに通信を行う。
【0021】
上記ハードウェアには、制御部としてのCPUの他、記憶部、通信部、表示部及び入力部が含まれる。記憶部としては、例えば、メモリ(RAM、ROM等)、ハードディスクドライブ(HDD)及び光ディスク(CD、DVD等)ドライブが挙げられる。通信部としては、例えば、各種有線及び無線インターフェース装置が挙げられる。表示部としては、例えば、液晶ディスプレイ、プラズマディスプレイ等の各種ディスプレイが挙げられる。入力部としては、例えば、キーボード及びポインティング・デバイス(マウス、トラッキングボール等)が挙げられる。
【0022】
上記ソフトウェアには、上記ハードウェアを制御するコンピュータ・プログラムやデータが含まれる。コンピュータ・プログラムやデータは、記憶部により記憶され、制御部により適宜実行、参照される。また、コンピュータ・プログラムやデータは、通信ネットワークを介して配布することも可能であり、CD−ROM等のコンピュータ可読媒体に記憶して配布することも可能である。
【0023】
以下、急上昇ワード抽出装置10の機能構成について説明する。
急上昇ワード抽出装置10は、急上昇ワード抽出装置10に係る各機能を統括的に制御する制御部11と、本発明の機能を実行するプログラム(図示省略)等を記憶する記憶部12と、を少なくとも有する。
【0024】
制御部11は、CPU等により構成されており、急上昇ワード抽出装置10の各処理動作の制御や情報の通信制御を行う。この制御部11は、Webクロール手段111と、差分コンテンツ抽出手段112と、急上昇ワード抽出手段113と、を備える。詳細は後述する。
【0025】
記憶部12は、上述の各種プログラムの他に、新規コンテンツ記憶手段としての新規Webコンテンツ・アーカイブ121と、既存コンテンツ記憶手段としての既存Webコンテンツ・データベース(以下、データベースをDBと表記する。)122と、差分コンテンツ記憶手段としての差分Webコンテンツ・アーカイブ123と、急上昇ワードDB124と、を備える。詳細は後述する。
【0026】
制御部11のWebクロール手段111は、インターネット30上に公開されているWebページ31を巡回し、接続したWebページ31のURL(Uniform Resorce Locater)と、当該Webページ31のデータ(コンテンツ)とを取得する。そして、Webクロール手段111は、インターネット30から取得したWebページ31のデータ(コンテンツ)を記憶部12の新規Webコンテンツ・アーカイブ121に記憶させる。
ここで、Webクロール手段111が取得するWebページ31は、所定の内容により構成されるWebページであり、いわゆるニュース等の何らかの情報を提供するサイトのページに限らず、掲示板、ブログやショートブログメッセージを表示するWebページも含む。
【0027】
ここで、新規Webコンテンツ・アーカイブ121には、Webクロール手段111が取得したWebページのデータ(コンテンツ)が当該WebページのURLと共に記憶されている。
【0028】
差分コンテンツ抽出手段112は、新規Webコンテンツ・アーカイブ121と既存WebコンテンツDB122とを参照して、新規Webコンテンツ・アーカイブ121に格納されたWebページのデータ(以下、新規コンテンツという)と、当該Webページと同じURLの既存WebコンテンツDB122に格納されているWebページのデータ(以下、既存コンテンツという)とを対比し、その差分(以下、抽出された差分のデータを差分コンテンツという)を抽出する。そして、差分コンテンツ抽出手段112は、抽出した差分コンテンツを差分Webコンテンツ・アーカイブ123にURLと共に記憶させる。
【0029】
ここで、既存WebコンテンツDB122について説明する。既存WebコンテンツDB122は、既存コンテンツがURLと共に格納されている。例えば、図2に示すテーブル1221のように、URLと既存コンテンツとがそれぞれ互いに関連付けられて記憶される。
【0030】
この既存コンテンツは、Webクロール手段111が取得したWebページのデータが順次格納される。既存WebコンテンツDB122には、Webクロール手段111とは別に異なるクロール手段により取得したデータが格納されていてもよい。
【0031】
また、差分Webコンテンツ・アーカイブ123は、図3のテーブル1231に示すように、差分コンテンツ抽出手段112により抽出された差分コンテンツをURL及び日時の情報と共に記憶する。このURLは、差分コンテンツが含まれるWebページのURLである。また、日時の情報は、例えば、Webクロール手段111が当該URLのWebページのデータを取得した日時である。
【0032】
急上昇ワード抽出手段113は、差分Webコンテンツ・アーカイブ123を参照し、個々の差分コンテンツに含まれる追加差分ワードを抽出し、その数を集計して、所定の基準数を超えたワードを急上昇ワードDB124に記憶させる。追加差分ワードは、差分コンテンツに含まれるワードの種類単位で抽出したワードをいう。このワードは、本実施形態においては、コンテンツに含まれるひとまとまりの単語をいい、1つのコンテンツにおいて同じワードが重複しないものであり、ワードの種類毎に抽出される。例えば、1つのコンテンツ内で複数回同じワードが登場したとしても、複数回登場したワードの個数を数えるのではなく、一度、1つのコンテンツ内で登場したワードは、そのコンテンツにおいて何回登場しようともそのワードは1つとして数える。以下、この抽出したワードを追加差分ワードという。
【0033】
なお、追加差分ワードの抽出については、例えば、形態素解析によりコンテンツに含まれる文章を形態素ごとに細分化し、これを品詞別に集計して形容詞や名詞等の所定の品詞に関して追加差分ワードとして抽出することができる。その他既存の技術を採用することが可能である。
【0034】
そして急上昇ワード抽出手段113は、抽出した追加差分ワードが含まれる差分コンテンツのURLの数を集計し、集計値が所定の基準数を超えたか否かを判別する。急上昇ワード抽出手段113は、所定の基準数を超えた場合、これを急上昇ワードとして、急上昇ワードDB124に記憶させる。若しくは、所定の品詞についてTF−idf(term frequency−inverse document frequency)法により算出した重要度の高い単語を急上昇ワードして抽出をしてもよい。
【0035】
ここで、図4を参照して急上昇ワードDB124について説明する。図4は、急上昇ワードDB124が記憶するテーブル1241の例である。急上昇ワードDB124は、急上昇ワードと日時の情報を少なくとも記憶する。急上昇ワードの欄には、急上昇ワード抽出手段113が抽出した急上昇ワード、すなわち、追加差分ワードのうち、当該追加差分ワードが含まれる差分コンテンツのURLの数が所定の基準数を超えたものが格納される。また、日時の欄には、Webクロール手段111が当該URLのWebページのデータを取得した日時の情報が格納される。
【0036】
図5を参照して、急上昇ワードの抽出について詳細に説明する。図5は、急上昇ワード抽出装置10が行う急上昇ワードの抽出を説明するための概念図である。
【0037】
まず、所定のWebページ32において、コンテンツ321とコンテンツ322とが存在し、既存WebコンテンツDB122に記憶されているものとする(図5のWebページ(1)参照)。このコンテンツ321及びコンテンツ322が既存コンテンツとなる。
【0038】
次に、Webクロール手段111がWebページ32のURLに再度接続して、Webページ32の新規のコンテンツを取得したとする(図5のWebページ(2)参照)。このWebクロール手段111が新たに取得した新規コンテンツは、当該Webページ32のURLと共に新規Webコンテンツ・アーカイブ121に記憶される。
【0039】
次に差分コンテンツ抽出手段112は、同じURLの新規Webコンテンツ・アーカイブ121に格納された新規コンテンツと、既存WebコンテンツDB122に格納された既存コンテンツとをそれぞれ読み出して対比し、その差分を抽出する。図5によると、既存コンテンツ321が削除され、もう一つの既存コンテンツ322がそのまま残されている。また、新たにコンテンツ323が追加されている。
差分コンテンツ抽出手段112は、この新たに追加されたコンテンツ323を差分コンテンツとして差分Webコンテンツ・アーカイブ123に記憶させる。
【0040】
次に、急上昇ワード抽出手段113は、差分Webコンテンツ・アーカイブ123を参照して、追加差分ワードを抽出する。図5の例でいうと、既存のコンテンツ321,322と新規のコンテンツ323とを対比したとき、新たに登場したワードは、「まみむ」(図5のワード41)、「めも」(図5のワード42)及び「やゆよ」(図5のワード43)である。したがって、差分コンテンツ抽出手段112はこの3つのワードを追加差分ワードとして抽出する。なお、新規のコンテンツ323をみると、「まみむ」が2回登場しているが、これを2つのワードとしてワード数を2として抽出するのではなく、1種類のワードとして抽出する。
【0041】
そして、急上昇ワード抽出手段113は、差分Webコンテンツ・アーカイブを参照し、抽出した追加差分ワードのそれぞれについて、追加差分ワードが含まれる差分コンテンツの数、すなわち、追加差分ワードが含まれる差分コンテンツのURLの数を集計し、その集計値が所定の基準数を超えるか否かを判別する。急上昇ワード抽出手段113は、集計値が基準数を超える場合、集計値が基準数を超えた追加差分ワードを急上昇ワードとして急上昇ワードDB124に記憶させる。
【0042】
その後、さらにWebクロール手段111がWebページ32のURLに再度接続して、Webページ32のデータを新たに取得したとする(図5のWebページ(3)参照)。このWebクロール手段111が新たに取得したWebページ32のデータも新規コンテンツとして当該Webページ32のURLと共に新規Webコンテンツ・アーカイブ121に格納される。
【0043】
次に差分コンテンツ抽出手段112が差分コンテンツを抽出するが、対比する対象は、前回新規コンテンツとして対比したときのWebページ32のコンテンツと、今回新たに取得した新規コンテンツとなる。図5によると、コンテンツ322の一部が削除されており、コンテンツ323がそのまま残され、新たにコンテンツ324が追加されている。
差分コンテンツ抽出手段112は、この新たに追加されたコンテンツ324を差分コンテンツとして差分Webコンテンツ・アーカイブ123に記憶させる。
【0044】
次に、急上昇ワード抽出手段113は、上記と同様に、差分Webコンテンツ・アーカイブ123を参照して、追加差分ワードを抽出する。図5の例でいうと、既存のコンテンツ322,323と新規のコンテンツ324とを対比したとき、新たに登場したワードは、「らりるれろ」(図5のワード51)、「わを」(図5のワード52)である。したがって、差分コンテンツ抽出手段112はこの2つのワードを追加差分ワードとして抽出する。
【0045】
そして、急上昇ワード抽出手段113は、Webページ(2)のときと同様に、抽出した追加差分ワードのそれぞれについて、追加差分ワードが含まれる差分コンテンツのURLの数を集計し、その集計値が所定の基準数を超えるか否かを判別する。急上昇ワード抽出手段113は、集計値が基準数を超える場合、集計値が基準数を超えた追加差分ワードを急上昇ワードとして急上昇ワードDB124に記憶させる。
【0046】
図6及び図7を参照して急上昇ワード抽出装置10が行う処理の流れについて説明する。図6及び図7は、急上昇ワード抽出装置10が行う処理のフローチャートである。
【0047】
図6のステップS11では、急上昇ワード抽出装置10のWebクロール手段111は、インターネット30からWebページのデータ(コンテンツ)を取得する。
【0048】
ステップS12では、急上昇ワード抽出装置10のWebクロール手段111は、ステップS11で取得したコンテンツを新規コンテンツとして新規Webコンテンツ・アーカイブ121に記憶させる。
【0049】
ステップS13では、急上昇ワード抽出装置10の差分コンテンツ抽出手段112は、同じURLの新規Webコンテンツ・アーカイブ121の新規コンテンツと既存WebコンテンツDB122の既存コンテンツとを対比して、差分コンテンツを抽出する。
【0050】
ステップS14では、急上昇ワード抽出装置10の差分コンテンツ抽出手段112は、ステップS13で抽出した差分コンテンツを差分Webコンテンツ・アーカイブ123に記憶させる。そして、急上昇ワード抽出装置10のWebクロール手段111及び差分コンテンツ抽出手段112は、これらの処理を繰り返し行う。
【0051】
図7のステップS21では、急上昇ワード抽出装置10の急上昇ワード抽出手段113は、差分Webコンテンツ・アーカイブ123から追加差分ワードを抽出する。
【0052】
ステップS22では、急上昇ワード抽出手段113は、同じ追加差分ワードの差分コンテンツのURLの数を集計する。
【0053】
ステップS23では、急上昇ワード抽出手段113は、集計したURL数が基準数を超えたか否かを判別する。急上昇ワード抽出手段113は、当該判別がYESの場合、ステップS24に処理を移し、当該判別がNOの場合は、本フローチャートの処理を終了する。
【0054】
ステップS24では、急上昇ワード抽出手段113は、所定の基準数を超えた追加差分ワードを急上昇ワードとして急上昇ワードDB124に記憶させ、本フローチャートの処理を終了する。
【0055】
図8を参照して第2実施形態について説明する。第2実施形態は、急上昇ワードの抽出方法が第1実施形態と異なる。図8は、第2実施形態における急上昇ワード抽出装置10が行う処理のフローチャートである。なお、以下では、第1実施形態と異なる部分を中心に説明し、特に説明しない部分は第1実施形態と同様である。
【0056】
急上昇ワード抽出装置10の制御部11は、Webクロール手段111が新規のコンテンツを取得して新規Webコンテンツ・アーカイブに当該新規のコンテンツを記憶させる毎に、差分コンテンツ抽出手段112が差分コンテンツを抽出し、差分Webコンテンツ・アーカイブ123に差分コンテンツを記憶させる処理を繰り返す繰り返し手段として機能する。
【0057】
急上昇ワード抽出手段113は、差分Webコンテンツ・アーカイブ123に記憶された差分コンテンツから、追加差分ワードを抽出し、抽出した追加差分ワードのうち、追加差分ワードを含む差分コンテンツのURLの数が所定の基準数を超えたものを第1急上昇ワードとして抽出し、急上昇ワードDB124に記憶させる。さらに、急上昇ワード抽出手段113は、急上昇ワードDB124に記憶させた第1急上昇ワードのうち、所定期間において第1急上昇ワードとして抽出された回数が所定の基準回数を超えたものを第2急上昇ワードとして抽出する。
なお、基準回数は、少なくとも、1より大きい値であることが好ましい。これにより、新規コンテンツに登場した数が基準数より大きくなった回数が複数回以上のものを抽出することができる。このため、所定期間内において、継続して注目されている話題(トピック)を示すキーワードを抽出することが可能となる。
【0058】
図8を参照して急上昇ワード抽出装置10の急上昇ワード抽出手段113で行う処理について説明する。図8の処理は、第1実施形態の図7において、急上昇ワードを抽出し、急上昇ワードDB124に記憶したことを前提に行われる処理である。図7の処理において抽出された急上昇ワードが本実施形態における第1急上昇ワードとなる。
【0059】
ステップS31では、急上昇ワード抽出装置10の急上昇ワード抽出手段113は、急上昇ワードDB124から、所定期間内に記憶された第1急上昇ワードを読み出す。
【0060】
ステップS32では、急上昇ワード抽出手段113は、第1急上昇ワードが、当該所定期間内に抽出された回数を第1急上昇ワード毎に集計する。
【0061】
ステップS33では、急上昇ワード抽出手段113は、第1急上昇ワードが集計された回数が基準回数を超えたか否かを判別する。急上昇ワード抽出手段113は、当該判別がYESの場合、ステップS34に処理を移し、当該判別がNOの場合は、本フローチャートの処理を終了する。
【0062】
ステップS34では、急上昇ワード抽出手段113は、所定の基準回数を超えた第1急上昇ワードを第2急上昇ワードとして急上昇ワードDB124に記憶させ、本フローチャートの処理を終了する。
【0063】
図9を参照して第3実施形態について説明する。第3実施形態は、急上昇ワードの抽出方法が第1実施形態及び第2実施形態と異なる。図9は、第3実施形態における急上昇ワード抽出装置10が行う処理のフローチャートである。なお、以下では、第1実施形態及び第2実施形態と異なる部分を中心に説明し、特に説明しない部分は第1実施形態及び第2実施形態と同様である。
【0064】
急上昇ワード抽出装置10の急上昇ワード抽出手段113は、差分Webコンテンツ・アーカイブ123が記憶した差分コンテンツのURLの数を、当該URLが示すドメイン又は所定のサブドメイン毎に集計し、ドメイン又は所定のサブドメイン毎に集計したURLの数が所定の基準数を超えたワードを、当該ドメイン又は所定のサブドメインの急上昇ワードとして抽出する。
【0065】
ステップS41では、急上昇ワード抽出装置10の急上昇ワード抽出手段113は、差分Webコンテンツ・アーカイブ123から追加差分ワードを抽出する。
【0066】
ステップS42では、急上昇ワード抽出手段113は、追加差分ワードを含む差分コンテンツのURLの数をドメイン又はサブドメイン毎に集計する。
【0067】
ステップS43では、急上昇ワード抽出手段113は、各ドメイン又は所定のサブドメイン毎に、URLの数が基準値を超えたか否かを判断する。この判別でYESの場合はステップS44に移り、NOの場合は、本フローチャートの処理を終了する。
【0068】
ステップS44では、急上昇ワード抽出手段113は、ステップS43でURLの数が基準値を超えた追加差分ワードを急上昇ワードとして急上昇ワードDB124に記憶させ、本フローチャートの処理を終了する。
【0069】
本実施形態は、上記の構成を備えることにより、ドメイン又は所定のサブドメイン内のコンテンツにおいて、中心として取り上げられているトピックを示すキーワードを抽出することができる。このため、急上昇ワード自体をそれぞれのドメイン又はサブドメインを分類するキーとしても使用することが可能となる。
【0070】
なお、本実施形態において、同一の急上昇ワードと抽出したWebサイトのドメイン又はサブドメインが複数ある場合には、当該サイトの特定の信頼度スコアに基づいて、各ドメイン又はサブドメイン毎に抽出した急上昇ワードを、当該サイトの特定の信頼度スコアに基づいて、いわゆるレコメンドに利用することができる。
【0071】
例えば、急上昇ワード抽出装置10の制御部11は、Webクロール手段111が取得したURLに関し、そのドメイン又はサブドメインの信頼度スコアを算出し、記憶部12に記憶させておくことができる。そして、いわゆるEC(electronic commerce)サイトにおいて、急上昇ワードを抽出したドメイン又はサブドメインの信頼度スコアが所定の値以上である場合に、優先的にレコメンドに表示することができる。ここで、信頼度スコアは、例えば、当該サイトの運営主体の信頼性、ニュース記事等のコンテンツの信頼性、WebページやWebサイト等の安全度を示すスコアであり、任意のものを使用することができる。また、この信頼度スコアは、急上昇ワード抽出装置10以外の装置が算出したデータをインターネット30等のネットワークを通じて取得し使用してもよい。
【0072】
なお、基準値に関しては、ドメイン又はサブドメイン毎に集計する際の基準値と、ドメイン又はサブドメインとは関係なく、全てのURLの数で集計する際の基準値とを別々に設定し、併用してもよい。
【0073】
上記の実施形態によれば、急上昇ワード抽出装置10は、インターネット30で公開されたWebページ31のデータ(コンテンツ)に登場したワードのWebページの数を数えることができるため、話題として取り上げた情報源の数を元にして注目度の高いキーワードが何かを判別し、抽出することができる。また、例えば、1つのWebページ内に脈絡無く同一のワードが繰り返し登場するようなものであってもその影響を最小限にして注目度の高いキーワードを抽出することができる。
【0074】
上述の実施形態によれば、急上昇ワード抽出装置10は、従来のように、検索クエリとして使用されたキーワードの使用回数に基づいて注目度の高いキーワードを抽出するのとは別に、注目度の高いキーワードとしての急上昇ワードを抽出することができる。このため、検索クエリの解析とは別に急上昇ワードを抽出することが可能となる。
【0075】
上述の実施形態によれば、急上昇ワード抽出装置10は、差分コンテンツから追加差分ワードを抽出して、急上昇ワードであるか否かを判別するので、従来のように、個々にWebページを既存のものと対比してキーワードを抽出するよりもハードウェアに与える負担を軽くすることができる。
【0076】
以上、本発明の実施形態について説明したが、本発明は上述した実施形態に限るものではない。また、本発明の実施形態に記載された効果は、本発明から生じる最も好適な効果を列挙したに過ぎず、本発明による効果は、本発明の実施形態に記載されたものに限定されるものではない。
【符号の説明】
【0077】
10 急上昇ワード抽出装置
11 制御部
12 記憶部
30 インターネット
111 Webクロール手段
112 差分コンテンツ抽出手段
113 急上昇ワード抽出手段
121 新規Webコンテンツ・アーカイブ
122 既存WebコンテンツDB
123 差分Webコンテンツ・アーカイブ
124 急上昇ワードDB
【特許請求の範囲】
【請求項1】
インターネット上で注目度が上昇している急上昇ワードを抽出する急上昇ワード抽出装置であって、
前記インターネット上のWebサイトを所定の周期で巡回して新規のコンテンツを取得するWebクロール手段と、
前記Webクロール手段が取得した新規のコンテンツを当該新規のコンテンツのURLに関連付けて記憶する新規コンテンツ記憶手段と、
前記Webクロール手段が前回の巡回までに取得した既存のコンテンツを当該既存のコンテンツのURLに関連付けて記憶している既存コンテンツ記憶手段と、
前記新規コンテンツ記憶手段が記憶した新規のコンテンツを、前記既存コンテンツ記憶手段が記憶している既存のコンテンツであって、当該新規のコンテンツと同じURLの既存コンテンツと比較して、当該新規のコンテンツにおいて新たに追加された差分コンテンツを抽出する差分コンテンツ抽出手段と、
前記差分コンテンツ抽出手段が抽出した差分コンテンツを、当該差分コンテンツのURLに関連付けて記憶する差分コンテンツ記憶手段と、
前記差分コンテンツ記憶手段が記憶した差分コンテンツに含まれるワードの種類毎に、当該ワードが含まれる前記差分コンテンツのURLの数を集計し、前記URLの数が所定の基準数を超えたワードを急上昇ワードとして抽出する急上昇ワード抽出手段と、を備える急上昇ワード抽出装置。
【請求項2】
前記Webクロール手段が新規のコンテンツを取得して前記新規コンテンツ記憶手段が新規のコンテンツを記憶する毎に、前記差分コンテンツ抽出手段及び前記差分コンテンツ記憶手段の処理を繰り返す繰り返し手段をさらに備え、
前記急上昇ワード抽出手段は、所定期間において取得した複数の差分コンテンツに含まれるワードの種類の中から、前記URLの数が前記所定の基準数を超えた回数が所定の基準回数を超えたものを特定して、前記急上昇ワードとして抽出する請求項1に記載の急上昇ワード抽出装置。
【請求項3】
前記急上昇ワード抽出手段は、前記URLの数を、前記URLが示すドメイン又は所定のサブドメイン毎に集計し、前記URLの数が所定の基準数を超えたワードを、当該ドメイン又は所定のサブドメイン毎の急上昇ワードとして抽出する請求項1又は2に記載の急上昇ワード抽出装置。
【請求項4】
インターネット上で注目度が上昇している急上昇ワードを抽出する急上昇ワード抽出方法であって、
コンピュータは、記憶手段を備え、
コンピュータに、
前記インターネット上のWebサイトを所定の周期で巡回して新規のコンテンツを取得するWebクロールステップと、
前記Webクロール手段が取得した新規のコンテンツを当該新規のコンテンツのURLに関連付けて前記記憶手段に記憶させる新規コンテンツ記憶ステップと、
前記Webクロール手段が前回の巡回までに取得した既存のコンテンツを当該既存のコンテンツのURLに関連付けて前記記憶手段に記憶させる既存コンテンツ記憶ステップと、
前記新規コンテンツ記憶ステップで前記記憶手段に記憶させた新規のコンテンツを、前記記憶手段が記憶している既存のコンテンツであって、当該新規のコンテンツと同じURLのコンテンツとを比較して、当該新規のコンテンツにおいて新たに追加された差分コンテンツを抽出する差分コンテンツ抽出ステップと、
前記差分コンテンツ抽出ステップにおいて抽出された差分コンテンツを、当該差分コンテンツのURLに関連付けて前記記憶手段に記憶させる差分コンテンツ記憶ステップと、
前記差分コンテンツ記憶ステップで記憶手段に記憶させた差分コンテンツに含まれるワードの種類毎に、当該ワードが含まれる前記差分コンテンツのURLの数を集計し、前記URLの数が所定の基準数を超えたワードを急上昇ワードとして抽出する急上昇ワード抽出ステップと、を実行させる急上昇ワード抽出方法。
【請求項1】
インターネット上で注目度が上昇している急上昇ワードを抽出する急上昇ワード抽出装置であって、
前記インターネット上のWebサイトを所定の周期で巡回して新規のコンテンツを取得するWebクロール手段と、
前記Webクロール手段が取得した新規のコンテンツを当該新規のコンテンツのURLに関連付けて記憶する新規コンテンツ記憶手段と、
前記Webクロール手段が前回の巡回までに取得した既存のコンテンツを当該既存のコンテンツのURLに関連付けて記憶している既存コンテンツ記憶手段と、
前記新規コンテンツ記憶手段が記憶した新規のコンテンツを、前記既存コンテンツ記憶手段が記憶している既存のコンテンツであって、当該新規のコンテンツと同じURLの既存コンテンツと比較して、当該新規のコンテンツにおいて新たに追加された差分コンテンツを抽出する差分コンテンツ抽出手段と、
前記差分コンテンツ抽出手段が抽出した差分コンテンツを、当該差分コンテンツのURLに関連付けて記憶する差分コンテンツ記憶手段と、
前記差分コンテンツ記憶手段が記憶した差分コンテンツに含まれるワードの種類毎に、当該ワードが含まれる前記差分コンテンツのURLの数を集計し、前記URLの数が所定の基準数を超えたワードを急上昇ワードとして抽出する急上昇ワード抽出手段と、を備える急上昇ワード抽出装置。
【請求項2】
前記Webクロール手段が新規のコンテンツを取得して前記新規コンテンツ記憶手段が新規のコンテンツを記憶する毎に、前記差分コンテンツ抽出手段及び前記差分コンテンツ記憶手段の処理を繰り返す繰り返し手段をさらに備え、
前記急上昇ワード抽出手段は、所定期間において取得した複数の差分コンテンツに含まれるワードの種類の中から、前記URLの数が前記所定の基準数を超えた回数が所定の基準回数を超えたものを特定して、前記急上昇ワードとして抽出する請求項1に記載の急上昇ワード抽出装置。
【請求項3】
前記急上昇ワード抽出手段は、前記URLの数を、前記URLが示すドメイン又は所定のサブドメイン毎に集計し、前記URLの数が所定の基準数を超えたワードを、当該ドメイン又は所定のサブドメイン毎の急上昇ワードとして抽出する請求項1又は2に記載の急上昇ワード抽出装置。
【請求項4】
インターネット上で注目度が上昇している急上昇ワードを抽出する急上昇ワード抽出方法であって、
コンピュータは、記憶手段を備え、
コンピュータに、
前記インターネット上のWebサイトを所定の周期で巡回して新規のコンテンツを取得するWebクロールステップと、
前記Webクロール手段が取得した新規のコンテンツを当該新規のコンテンツのURLに関連付けて前記記憶手段に記憶させる新規コンテンツ記憶ステップと、
前記Webクロール手段が前回の巡回までに取得した既存のコンテンツを当該既存のコンテンツのURLに関連付けて前記記憶手段に記憶させる既存コンテンツ記憶ステップと、
前記新規コンテンツ記憶ステップで前記記憶手段に記憶させた新規のコンテンツを、前記記憶手段が記憶している既存のコンテンツであって、当該新規のコンテンツと同じURLのコンテンツとを比較して、当該新規のコンテンツにおいて新たに追加された差分コンテンツを抽出する差分コンテンツ抽出ステップと、
前記差分コンテンツ抽出ステップにおいて抽出された差分コンテンツを、当該差分コンテンツのURLに関連付けて前記記憶手段に記憶させる差分コンテンツ記憶ステップと、
前記差分コンテンツ記憶ステップで記憶手段に記憶させた差分コンテンツに含まれるワードの種類毎に、当該ワードが含まれる前記差分コンテンツのURLの数を集計し、前記URLの数が所定の基準数を超えたワードを急上昇ワードとして抽出する急上昇ワード抽出ステップと、を実行させる急上昇ワード抽出方法。
【図1】


【図2】
【図3】

【図4】

【図5】
【図6】
【図7】
【図8】
【図9】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【公開番号】特開2013−11998(P2013−11998A)
【公開日】平成25年1月17日(2013.1.17)
【国際特許分類】
【出願番号】特願2011−143578(P2011−143578)
【出願日】平成23年6月28日(2011.6.28)
【出願人】(500257300)ヤフー株式会社 (1,128)
【公開日】平成25年1月17日(2013.1.17)
【国際特許分類】
【出願日】平成23年6月28日(2011.6.28)
【出願人】(500257300)ヤフー株式会社 (1,128)
[ Back to top ]