
情報処理方法及び装置
【課題】データ群に含まれるデータのうち、データ間の条件を満たさないと判定されるデータの量を抑制するようにする。
【解決手段】本方法は、第1のデータ群に含まれるN(Nは自然数)個以上のデータとの間で所定の関係を持つ、複数のデータを格納部に格納する処理と、第1のデータ群と異なる第2のデータ群に含まれるあるデータが、第2のデータ群に含まれるN個以上のデータとの間で所定の関係を持たない場合に、あるデータが、格納部に格納された複数のデータに含まれるN個以上のデータと所定の関係を持つか否かの判定を行う処理と、判定により、所定の関係を持つと判定した場合に、あるデータを格納部に格納する処理とを含む。
【解決手段】本方法は、第1のデータ群に含まれるN(Nは自然数)個以上のデータとの間で所定の関係を持つ、複数のデータを格納部に格納する処理と、第1のデータ群と異なる第2のデータ群に含まれるあるデータが、第2のデータ群に含まれるN個以上のデータとの間で所定の関係を持たない場合に、あるデータが、格納部に格納された複数のデータに含まれるN個以上のデータと所定の関係を持つか否かの判定を行う処理と、判定により、所定の関係を持つと判定した場合に、あるデータを格納部に格納する処理とを含む。
【発明の詳細な説明】
【技術分野】
【0001】
本技術は、データの秘匿化技術に関する。
【背景技術】
【0002】
例えば、収集した個人情報を、個人を特定できないようにするために匿名化情報に加工する技術が存在している。
【0003】
一般的に個人情報を匿名化情報にデータ加工しても、他の情報と照合して個人を識別できる(「容易照合性」と呼ぶ)場合は個人情報に該当する。しかしながら、「容易照合性」があるか否かの客観的な基準がなく、安全に匿名化情報を利用できるかの判断が難しい。この「容易照合性」には以下に示すような観点がある。
(1)他の情報と容易に照合できる環境にあるか否か。
(2)他の情報と照合した結果、個人を識別できるか否か。
【0004】
(1)については、データ管理(参照権限、参照範囲、情報漏洩対策)も含めた対策を行って容易照合性が否定されることになるので、ソフトウェアだけで判断はできない。一方、(2)は個人識別可能性とも呼ばれるが、識別リスクのあるレコードを削るといった加工を行うことで、より安全な匿名化情報を生成できる。これにより、他の情報と容易に照合できる場合や、個人を識別する情報が他で漏えいした場合においても、個人を特定することができないため、安全に匿名化情報を利用させることができる。
【0005】
匿名化情報に加工する技術には、例えば、個人情報と照合することで個人の特定につながる情報を判断して除き、匿名化情報に加工する技術がある。
【0006】
また、匿名化情報自身におけるレコードの重複から個人識別可能性を検証してデータ加工する技術も存在している。これは、匿名化情報におけるレコードの重複数がN件以上であれば、個人情報と照合した結果がN件以上となるため匿名化情報から個人は識別できないという法則を利用している。
【0007】
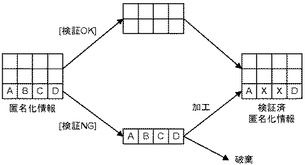
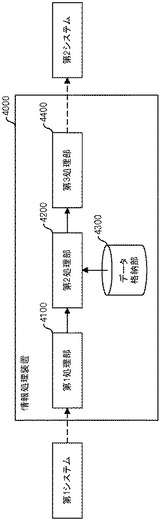
具体的には、図1に示すような処理が実施される。図1の左側に示す匿名化情報は3レコードを含んでおり、上の2行は同一であって2件以上の場合には個人識別可能性がないことが確認されるため[検証OK]として検証済の匿名化情報に加えられる。一方、ABCDというレコードについては1行しかないので、個人識別可能性があり[検証NG]と判定される。そうすると、例えばABCDの一部の属性値B及びCをXに変換してしまい、AXXDというレコードを検証済みの匿名化情報に加える。一方、ABCDというレコード自体については破棄してしまう。このような処理方法は、1つのデータベースにおいて既に蓄積済みのレコードを処理する場合には有効である。
【0008】
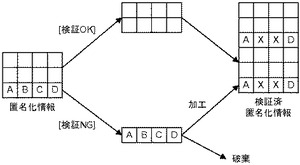
しかしながら、様々な業務システムから適宜収集されるデータを匿名化して、匿名化したデータを活用する他のシステムに出力するような場合には問題がある。具体的には、図1の左側に示すような3レコードがまず収集されて、この3レコードについて上で述べたような処理を実施すると、図1の右側に示すようなデータが他のシステムに出力される。その後、図2の左側に示すような3レコードが新たに収集されて上で述べたような処理を新たな3レコードに実施すると、上2行は同一であって個人識別可能性がないということが確認され検証OKとして検証済みの匿名化情報に加えられる。しかしながら、ABCDというレコードについては1行しかないので、個人識別可能性があり[検証NG]と判定される。そうすると、一部の属性値B及びCをXに変換してしまい、AXXDというレコードを検証済みの匿名化情報に加えることになる。そして、ABCDというレコード自体については破棄してしまう。このように、ABCDというレコードは2度出現しているが、収集タイミングが異なっているので、検証済みの匿名化情報には「AXXD」というレコードが2度登録されてしまう。これでは、ABCDという情報は失われてしまい、他のシステムにおける統計処理などに支障を来すようになる。
【先行技術文献】
【特許文献】
【0009】
【特許文献1】特開2007−287102号公報
【特許文献2】特開2009−181207号公報
【発明の概要】
【発明が解決しようとする課題】
【0010】
本発明の目的は、一側面によれば、データ群に含まれるデータのうち、データ間の条件を満たさないと判定されるデータの量を抑制することである。
【課題を解決するための手段】
【0011】
本情報処理方法は、(A)第1のデータ群に含まれるN(Nは自然数)個以上のデータとの間で所定の関係を持つ、複数のデータを格納部に格納する処理と、(B)第1のデータ群と異なる第2のデータ群に含まれるあるデータが、第2のデータ群に含まれるN個以上のデータとの間で所定の関係を持たない場合に、あるデータが、格納部に格納された複数のデータに含まれるN個以上のデータと所定の関係を持つか否かの判定を行う処理と、(C)判定により、所定の関係を持つと判定した場合に、あるデータを格納部に格納する処理とを含む。
【発明の効果】
【0012】
一側面によれば、データ群に含まれるデータのうち、データ間の条件を満たさないと判定されるデータの量を抑制できる。
【図面の簡単な説明】
【0013】
【図1】図1は、従来技術を説明するための図である。
【図2】図2は、従来技術を説明するための図である。
【図3】図3は、第1の実施の形態の処理の概要を示す図である。
【図4】図4は、第1の実施の形態に係るシステムの概要を示す図である。
【図5】図5は、第1の実施の形態に係る情報処理装置の機能ブロック図である。
【図6】図6は、第1の実施の形態における情報処理装置の処理フローを示す図である。
【図7】図7は、収集されるデータの一例を示す図である。
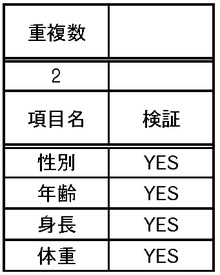
【図8】図8は、第1の実施の形態における定義データの一例を示す図である。
【図9】図9は、変換データの一例を示す図である。
【図10】図10は、第1検証処理の処理フローを示す図である。
【図11】図11は、第1検証処理における検証結果を説明するための図である。
【図12】図12は、第1検証処理における検証成功レコード群の一例を示す図である。
【図13】図13は、第1検証処理における検証失敗レコード群の一例を示す図である。
【図14】図14は、第2検証処理の処理フローを示す図である。
【図15】図15は、初回の処理で検証成功データ格納部に格納されるデータの一例を示す図である。
【図16】図16は、ターゲットシステムにおけるデータ加工の一例を示す図である。
【図17】図17は、次に収集され且つ変換されたデータの一例を示す図である。
【図18】図18は、2回目の第1検証処理における検証結果を説明するための図である。
【図19】図19は、2回目の第1検証処理における検証成功レコード群の一例を示す図である。
【図20】図20は、2回目の第1検証処理において検証失敗レコード群の一例を示す図である。
【図21】図21は、2回目の第2検証処理終了後における検証成功データ格納部に格納されるデータの一例を示す図である。
【図22】図22は、第2の実施の形態の処理の概要を示す図である。
【図23】図23は、第2の実施の形態における情報処理装置の処理フローを示す図である。
【図24】図24は、第2の実施の形態における定義データの一例を示す図である。
【図25】図25は、第3検証処理の処理フローを示す図である。
【図26】図26は、第3検証処理で検証成功と判断されたレコードの一例を示す図である。
【図27】図27は、第3検証処理で検証失敗と判断されたレコードの一例を示す図である。
【図28】図28は、第4検証処理の処理フローを示す図である。
【図29】図29は、第4検証処理の処理フローを示す図である。
【図30】図30は、検証失敗レコードの秘匿化について説明するための図である。
【図31】図31は、データ配布処理の処理フローを示す図である。
【図32】図32は、配布データの一例を示す図である。
【図33】図33は、2回目の第3検証処理によって復元データとして特定されたレコードの一例を示す図である。
【図34】図34は、2回目の第3検証処理によって検証成功レコードとして特定されたレコードの一例を示す図である。
【図35】図35は、2回目の第3検証処理によって検証失敗レコードとして特定されたレコードの一例を示す図である。
【図36】図36は、2回目の配布データの一例を示す図である。
【図37】図37は、ターゲットシステムにおいて蓄積されるデータの一例を示す図である。
【図38】図38は、コンピュータの機能ブロック図である。
【図39】図39は、本実施の形態に係る情報処理装置の機能ブロック図である。
【発明を実施するための形態】
【0014】
[実施の形態1]
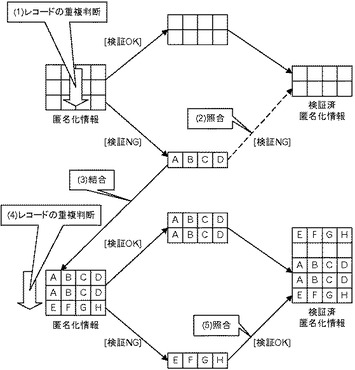
図3を用いて第1の実施の形態における処理の概要を説明する。本実施の形態において処理を実施する情報処理装置は、1又は複数の業務システム(ソースシステムとも呼ぶ。)からデータを収集して匿名化し、以下で述べる処理を実施した上で、匿名化情報を活用する他のシステム(ターゲットシステムとも呼ぶ。)に配布する処理を実施する。例えば、図3の上段左側に示すように3レコード収集した場合、この3レコードの中でレコードの重複を判断する(ステップ(1))。なお、3レコードは、既に匿名化のためのデータ変換処理(例えば該当する値域についてのデータに変換したり、仮名文字化したり、レコードの一部の属性を破棄したりする)を実施した後のデータである。
【0015】
ステップ(1)で例えば2レコード以上重複すると判断された場合、個人識別可能性がないので検証OKとして検証済みの匿名化情報に加えられる。図3の例では上2レコードが検証済みの匿名化情報に加えられる。一方、ABCDという属性値を含む下1レコードは、他のレコードと重複しておらず、個人識別可能性があるので検証NGと判断される。但し、このABCDを含むレコードについては、既に検証済みの匿名化情報と照合して、一致するレコードが、既に検証済みの匿名化情報に含まれているかを確認する(ステップ(2))。この例では、重複するレコードが存在していないので、ステップ(2)でもABCDを含むレコードは検証NGと判断される。本実施の形態では、ABCDを含むレコードを破棄することなく、次に収集されたレコードについての重複レコードが存在するか否かを判断する際に用いるため保持しておく。なお、検証済みの匿名化情報についてはターゲットシステムに配布する。
【0016】
次にソースシステムから2レコードが収集されると、保持しておいたレコードを結合させ(ステップ(3))、合計3レコードについてレコードの重複を判断する(ステップ(4))。例えば、ソースシステムから、ABCDを含むレコードと、EFGHを含むレコードとを収集した場合には、保持しておいた、ABCDを含むレコードと併せて重複を判断する。この場合、ABCDを含むレコードについては個人識別可能性がないので、検証済みの匿名化情報に追加される。一方、EFGHを含むレコードについては、3レコードには重複はないので、個人識別可能性ありで検証NGと判断される。そして、EFGHを含むレコードについては、既に検証済みの匿名化情報と照合して、一致するレコードが、既に検証済みの匿名化情報に含まれているかを確認する(ステップ(5))。図3の例では、既にEFGHを含むレコードが、検証済みの匿名化情報に含まれているので、今回収集され且つEFGHを含むレコードについても検証OKとして、検証済みの匿名化情報に追加される。このように今回検証された3レコードは、ターゲットシステムに配布される。
【0017】
このような処理を実施することで、より多くのレコードがターゲットシステムにおいて有効に活用できるようになる。さらに、収集されたレコードについては収集毎に上で述べたような処理を実施するので、ターゲットシステムでは即時性を損なうことなく最新のデータについて統計処理などの処理を実施することができる。
【0018】
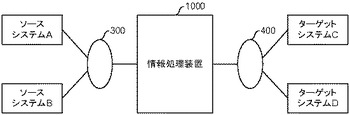
次に、本実施の形態に係るシステムの概要を図4及び図5を用いて説明する。図4に示すように、本実施の形態に係る主要な処理を実施する情報処理装置1000は、ネットワーク300を介してソースシステムA及びBと接続されており、ネットワーク400を介してターゲットシステムC及びDと接続されている。ソースシステム及びターゲットシステムの数は1つの場合もある。ソースシステムA及びBは、例えば自身のデータベースに格納すべきデータ等を、ネットワーク300を介して情報処理装置1000に送信する。
【0019】
ターゲットシステムC及びDも、例えば自身のデータベースに、ネットワーク400を介して情報処理装置1000から受信したデータを蓄積し、データ受信とは非同期に、他の装置などからの要求に対する処理を実施する。
【0020】
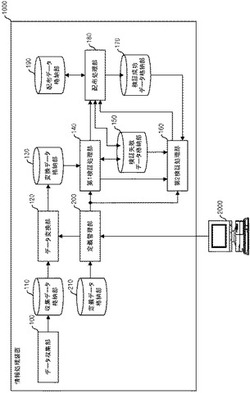
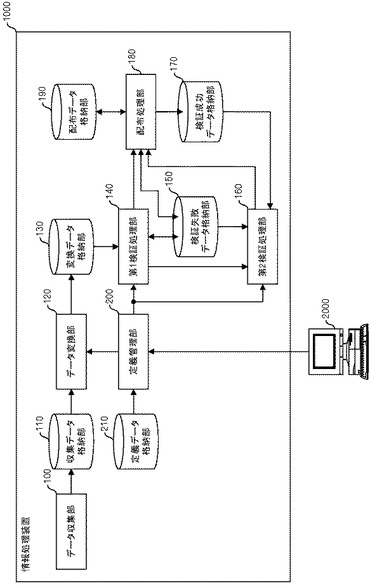
図5に情報処理装置1000の機能ブロック図を示す。情報処理装置1000は、データ収集部100と、収集データ格納部110と、データ変換部120と、変換データ格納部130と、第1検証処理部140と、検証失敗データ格納部150と、第2検証処理部160と、検証成功データ格納部170と、ネットワーク400を介してターゲットシステムに匿名化されたデータを配布する配布処理部180と、配布データ格納部190と、定義管理部200と、定義データ格納部210とを有する。
【0021】
データ収集部100は、ネットワーク400を介してターゲットシステムA及びBからデータを受信して収集データ格納部110に格納する。データ変換部120は、定義データ格納部210に格納されているデータに従ってデータ変換処理を実施し、処理結果を変換データ格納部130に格納する。第1検証処理部140は、変換データ格納部130と検証失敗データ格納部150に格納されているデータに対して、定義データ格納部210に格納されているデータに従って検証処理を実施する。そして、第1検証処理部140は、検証成功したレコードについては配布処理部180に出力し、検証失敗したレコードについては検証失敗データ格納部150に格納する。
【0022】
第2検証処理部160は、検証失敗データ格納部150に格納されているデータについて、検証成功データ格納部170に格納されているデータに対して定義データ格納部210に格納されているデータに従って検証処理を実施する。そして、第2検証処理部160は、検証成功したレコードについては配布処理部180に出力し、検証失敗したレコードについては検証失敗データ格納部150に格納する。配布処理部180は、第1検証処理部140及び第2検証処理部160から受信したデータを配布データ格納部190に格納すると共に、受信したデータで検証成功データ格納部170を更新する。そして、配布処理部180は、配布データ格納部190に格納されているデータをネットワーク400を介してターゲットシステムC及びDに送信する。
【0023】
定義管理部200は、管理者端末2000からの指示に従って、データ変換処理及び検証処理についての定義データを定義データ格納部210に格納する。また、定義管理部200は、データ変換部120、第1検証処理部140及び第2検証処理部160等に、定義データ格納部210に格納されているデータを設定する。
【0024】
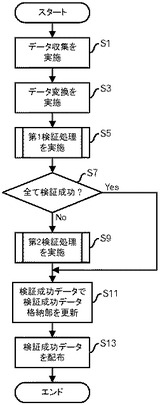
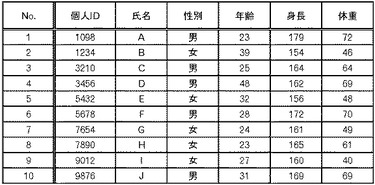
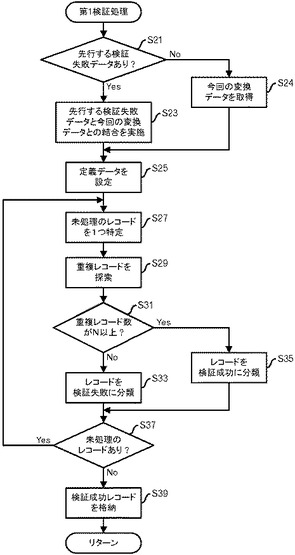
次に、図6乃至図21を用いて情報処理装置1000の処理について説明する。まず、データ収集部100は、ソースシステムA又はBからデータ収集を行い、収集されたデータを、収集データ格納部110に格納する(図6:ステップS1)。例えば、図7に示すようなデータを収集して、収集データ格納部110に格納する。図7の例では、各レコードには、個人識別子(ID)と、氏名と、性別と、年齢と、身長と、体重とが含まれる。なお、番号(No.)は、この後の処理の説明においてレコードを識別しやすくするために、便宜上付加したもので、実際には含まれない。
【0025】
次に、データ変換部120は、定義データ格納部210に格納されているデータに従って、所定のデータ変換を実施し、処理結果を変換データ格納部130に格納する(ステップS3)。本実施の形態では定義データ格納部210に格納されているデータについては定義管理部200がデータ変換部120に設定を行うものとする。また、定義データ格納部210に格納されている定義データの一例を図8に示す。図8の例では、匿名化の判定基準である重複数と、各項目について検証の対象か否かを示すデータとが含まれる。図8の例では、「性別」「年齢」「身長」「体重」が項目として列挙されており、それ以外の項目のデータについては、匿名化のために破棄されるものとする。具体的には「個人ID」及び「氏名」についてはデータ変換部120が破棄する。本実施の形態では、検証の対象として指示されている項目については、曖昧化の一例として、予め定められた値域のいずれに属するかという判定を行って、その値域を特定するためのデータに置換するものとする。例えば、身長が「179」である「A」の場合、170−179の値域に属するということで、当該値域の識別データに置換される。年齢及び体重についても同様に置換される。そうすると、図7のデータは、図9に示すデータに変換されることになる。図9の例では、「個人ID」及び「氏名」の項目が破棄され、性別の項目はそのまま残っているが、「年齢」「身長」「体重」については上で述べたような所属する値域への置換が行われている。
【0026】
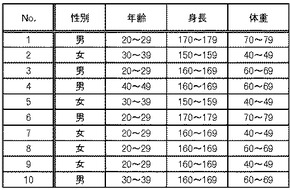
そして、第1検証処理部140は、変換データ格納部130に格納されているデータに対して、定義データ格納部210に格納されている定義データに従って第1検証処理を実施する(ステップS5)。第1検証処理については、図10乃至図13を用いて説明する。
【0027】
第1検証処理において、まず、第1検証処理部140は、先行する検証失敗データが検証失敗データ格納部150に格納されているか確認する(図10:ステップS21)。先行する検証失敗データが存在しない場合には、第1検証処理部140は、変換データ格納部130から今回の変換データを読み出す(ステップS24)。そして、ステップS25に移行する。一方、先行する検証失敗データが存在する場合には、第1検証処理部140は、先行する検証失敗データと、変換データ格納部130に格納されている今回の変換データとの結合を実施する(ステップS23)。
【0028】
そして、第1検証処理部140は、定義データ格納部210に格納されている定義データを設定する(ステップS25)。具体的には、検証の対象となる項目を特定する。図8の例であれば、「性別」「年齢」「身長」「体重」が検証の対象となる。以下、一致するレコード又は同一性を有するレコードとは、検証対象の項目の値が同じであるレコードを言うものとする。
【0029】
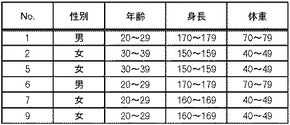
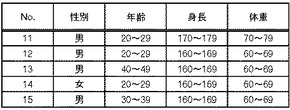
そして、第1検証処理部140は、処理対象のデータ(ステップS24で読み出したデータ又はステップS23で結合したデータ)において未処理のレコードを1つ特定する(ステップS27)。その後、第1検証処理部140は、処理対象のデータにおいて、特定したレコードと一致するレコードを探索する(ステップS29)。図8に示した定義データによれば、2以上の同一レコードがあれば、検証成功となる。先行する検証失敗データが存在せず、図9に示したデータについてステップS29を実施すると、図11に示すような結果が得られる。図11では、番号1と番号6のレコードが一致しており、番号7と番号9のレコードが一致しており、番号2と番号5のレコードが一致していることが分かる。また、番号3、番号10、番号4及び番号8のレコードについては、一致するレコードが存在しない。
【0030】
そして、第1検証処理部140は、特定されたレコードについて、重複レコード数がN(図8の定義データの例では「2」。一般的には2以上の設定された整数。)以上であるか判断する(ステップS31)。重複レコード数がN以上であれば、第1検証処理部140は、特定されたレコードを検証成功に分類する(ステップS35)。例えば、メインメモリなどの記憶装置における検証成功リストに、特定されたレコード及び検出された同一レコードを登録する。そして、ステップS37に移行する。
【0031】
一方、重複レコード数がN未満であれば、第1検証処理部140は、特定されたレコードを検証失敗に分類する(ステップS33)。本実施の形態では、特定されたレコードを、検証失敗データ格納部150に格納する。
【0032】
そして、第1検証処理部140は、処理対象のデータにおいて未処理のレコードが存在しているか判断する(ステップS37)。未処理のレコードが存在する場合にはステップS27に戻る。一方、未処理のレコードが存在しない場合には、第1検証処理部140は、検証成功レコードを配布処理部180に出力し、配布処理部180は、受信した検証成功レコードを配布データ格納部190に格納する(ステップS39)。その後、呼び出し元の処理に戻る。
【0033】
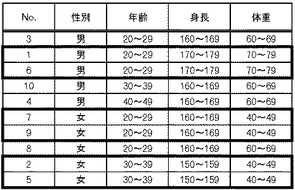
このようにすれば、処理対象のデータは、重複レコード数N以上で検証成功と判断されたレコード群と、重複レコード数N未満で検証失敗と判断されたレコード群とに分類される。例えば、図11で説明したように、検証成功レコード群は図12に示すようなレコード群であり、配布データ格納部190に格納される。一方、検証失敗レコード群は図13に示すようなレコード群であり、検証失敗データ格納部150に一旦格納される。
【0034】
図6の処理の説明に戻って、第1検証処理部140は、処理対象のデータにおける全てのレコードが検証成功であったか判断する(ステップS7)。全てのレコードが検証成功であれば、ステップS11に移行する。一方、検証失敗レコードが存在する場合には、第2検証処理部160に対して処理を指示して、第2検証処理部160は、第2検証処理を実施する(ステップS9)。第2検証処理については、図14を用いて説明する。
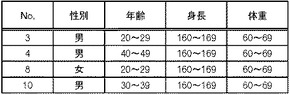
【0035】
第2検証処理において、まず、第2検証処理部160は、定義データ格納部210に格納されている定義データを設定する(図14:ステップS40)。具体的には、検証の対象となる項目を特定する。図8の例であれば、「性別」「年齢」「身長」「体重」が検証の対象となる。その後、第2検証処理部160は、検証失敗データ格納部150に格納されている検証失敗データに含まれる未処理のレコードを1つ特定する(ステップS41)。そして、第2検証処理部160は、検証成功データ格納部170に格納されているデータにおいて、特定されたレコードと一致するレコードを探索する(ステップS43)。なお、上の例では検証成功データ格納部170には何も格納されていないものとする。そうすると、図13に示すようなレコード群については重複レコード数は0となる。
【0036】
そして、第2検証処理部160は、特定されたレコードについて、重複レコード数がN以上であるか判断する(ステップS45)。検証成功データ格納部170に格納されているデータについて探索して重複レコード数がN以上であれば、特定の個人を特定できないので検証成功と判断しても良い。これによって検証成功と判断されるレコードの数が増加してターゲットシステムに配布されるレコード数が増加するため、統計処理への影響を抑えつつ、匿名化を確実に実施できるようになる。
【0037】
従って、第2検証処理部160は、特定されたレコードを検証成功に分類する(ステップS47)。例えば、メインメモリなどの記憶装置における検証成功リストに登録する。そしてステップS51に移行する。
【0038】
一方、重複レコード数がN未満であれば、第2検証処理部160は、特定されたレコードを検証失敗に分類する(ステップS49)。例えば、メインメモリなどの記憶装置における検証失敗リストに登録する。その後、第2検証処理部160は、検証失敗データにおいて未処理のレコードが存在しているか判断する(ステップS51)。未処理のレコードが存在している場合にはステップS41に戻る。一方、未処理のレコードが存在していない場合には、第2検証処理部160は、検証失敗レコードで検証失敗データ格納部150に格納されているデータを更新する(ステップS53)。さらに、第2検証処理部160は、検証成功レコードを配布処理部180に出力し、配布処理部180は、受信した検証成功レコードを配布データ格納部190に格納する(ステップS55)。その後、呼び出し元の処理に戻る。
【0039】
上で述べた例では、検証成功データ格納部170には何も格納されていないので、検証失敗データ格納部150に格納されているデータは、図13に示されたものと同じである。また、配布データ格納部190に格納されるデータについても、図12に示されたものと同じになる。
【0040】
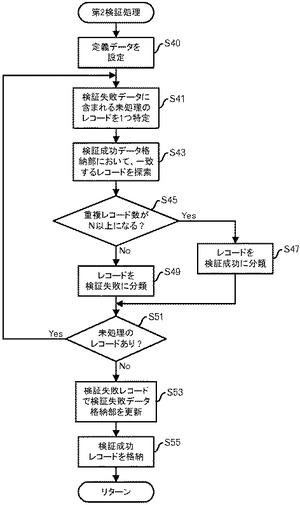
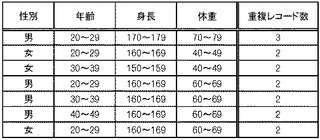
図6の処理の説明に戻って、配布処理部180は、第1検証処理部140及び第2検証処理部160から受信し配布データ格納部190に格納されているデータによって、検証成功データ格納部170を更新する(ステップS11)。本実施の形態では、検証成功データ格納部170については、例えば図15のようなデータを格納する。すなわち、同一のレコードについては1レコードのみを残し、重複レコード数を登録する。既に検証成功データ格納部170に同一のレコードが含まれている場合には、重複レコード数を増分する。
【0041】
さらに、配布処理部180は、配布データ格納部190に格納されている検証成功データをターゲットシステムC及びDに配布する(ステップS13)。具体的には、ネットワーク400を介して検証成功データを送信する。
【0042】
このような処理を実施すれば、より多くのレコードが、匿名性が確保されていると検証されて、ターゲットシステムに配布され、ターゲットシステムにおいて適切な処理を行うことができる。
【0043】
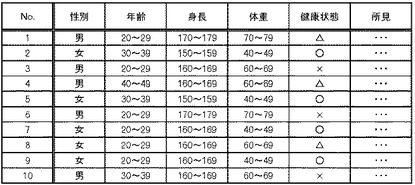
なお、ターゲットシステムC及びDでは、例えば様々な観点に基づく統計処理を行ったり、さらに図16に示すように、健康状態のデータ及び所見のデータを追加して加工した後に統計処理を実施したりする場合もある。
【0044】
なお、次のタイミングで収集されたデータに対してデータ変換処理を実施して、図17のようなデータが得られた場合について説明する。上でも述べたように、図17における番号は説明のためにのみ追加されている。
【0045】
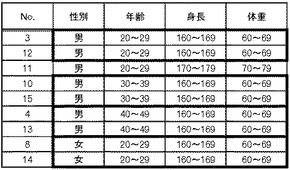
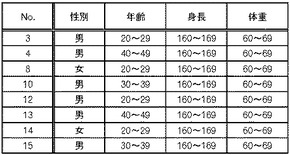
このような場合、第1検証処理においては、図13に示した前回の検証失敗レコードと今回のレコードとを結合して、それらのレコードについて同一のレコードを探索する。そうすると図18に示すように、番号3と番号12のレコードが一致し、番号10と番号15のレコードが一致し、番号4と番号13のレコードが一致し、番号8と番号14のレコードが一致している。従って、図19に示すようなデータが、検証成功レコードとして特定され、配布データ格納部190に格納される。さらに、図20に示すように、番号11のレコードのみが検証失敗レコードとして特定され、検証失敗データ格納部150に一旦格納される。
【0046】
その後、第2検証処理において、図20に示した検証失敗レコードについては、図15に示し且つ検証成功データ格納部170に格納されているデータとの照合を行う。そうすると、図15における最初のレコードと一致していることが分かるので、図20に示した検証失敗レコードについても配布データ格納部190に格納される。さらに、図15に示した検証成功データ格納部170に格納されているデータは、図21に示すように更新される。すなわち、新たなレコードを追加すると共に、同一のレコードが検出されれば重複レコード数が増分される。このような処理を繰り返すことになる。
【0047】
[実施の形態2]
本実施の形態に係る処理の概要を図22を用いて説明する。
【0048】
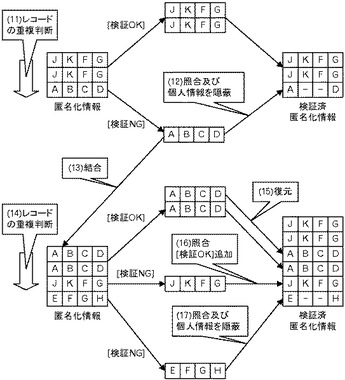
本実施の形態において処理を実施する情報処理装置は、1又は複数のソースシステムからデータを収集して匿名化し、以下で述べる処理を実施した上で、匿名化情報を活用するターゲットシステムに配布する処理を実施する。例えば、図22の上段左側に示すように3レコード収集した場合、この3レコードの中でレコードの重複を判断する(ステップ(11))。なお、3レコードは、既に匿名化のためのデータ変換処理(例えば該当する値域についてのデータに変換したり、仮名文字化したり、レコードの一部の属性を破棄したりする)を実施した後のデータである。
【0049】
ステップ(11)で例えば2レコード以上一致すると判断された場合、個人識別可能性がないので検証OKとして検証済みの匿名化情報に加えられる。図22の例では上2レコードは、JKFGで一致しているため、検証済みの匿名化情報に加えられる。一方、ABCDという属性値を含む下1レコードは、他のレコードと一致しておらず、個人識別可能性があるので検証NGと判断される。但し、このABCDを含むレコードについては、既に検証済みの匿名化情報と照合して、一致するレコードが、既に検証済みの匿名化情報に含まれているかを確認する。この例では、重複するレコードが存在していないので、本照合においても、ABCDを含むレコードは検証NGと判断される。但し、本実施の形態では、ABCDを含むレコードの一部を秘匿化して、検証OKのレコードと共にターゲットシステムに配布される(ステップ(12))。このように一部隠蔽されているが、全てのレコードがターゲットシステムに配布される。また、ABCDを含むレコードについては、別途保持しておく。
【0050】
次にソースシステムから3レコードが収集されると、保持しておいたレコードを結合させ(ステップ(13))、合計4レコードについてレコードの重複を判断する(ステップ(14))。例えば、ソースシステムから、ABCDを含む2レコードと、EFGHを含むレコードとを収集した場合には、前回検証NGと判断され且つABCDを含むレコードと併せて重複を判断すると、ABCDを含むレコードについては個人識別可能性がないので、1つのレコードについては検証済みの匿名化情報に追加される。もう1つについては、ステップ(12)で一部隠蔽されているので、検証済みの匿名化情報においてABCDを含むレコードを復元させる(ステップ(15))。
【0051】
また、JKFGを含むレコードについては、合計4レコードについてレコードの一致を判断すると、他のレコードと一致しておらず、個人識別可能性があるので検証NGと判断される。但し、このJKFGを含むレコードについては、既に検証済みの匿名化情報と照合して、一致するレコードが、既に検証済みの匿名化情報に含まれているかを確認する。図22の例では、既にJKFGを含むレコードが、検証済みの匿名化情報に含まれているので、今回収集され且つJKFGを含むレコードについても検証OKとして、検証済みの匿名化情報に追加される(ステップ(16))。
【0052】
一方、EFGHを含むレコードについては、合計4レコードには一致するレコードはないので、個人識別可能性ありで検証NGと判断される。そして、EFGHを含むレコードについては、既に検証済みの匿名化情報と照合して、一致するレコードが、既に検証済みの匿名化情報に含まれているかを確認する。図22の例では、一致するレコードが存在していないので、本照合においても、EFGHを含むレコードは検証NGと判断される。そして、EFGHを含むレコードの一部を秘匿化して、検証OKのレコードと共にターゲットシステムに配布する(ステップ(17))。
【0053】
このように、個人識別可能性がなくなったレコードについては復元させることができる。また、今回収集されたレコードは、一部隠蔽されている場合もあるが、全てターゲットシステムに配布される。
【0054】
このような処理を実施することで、より多くのレコードがターゲットシステムにおいて有効に活用できるようになる。さらに、収集されたレコードについては収集毎に上で述べたような処理を実施するので、ターゲットシステムでは即時性を損なうことなく最新のデータについて統計処理などの処理を実施することができる。
【0055】
本実施の形態でも、第1の実施の形態におけるシステム全体構成(図4)は同じであり、情報処理装置1000の構成(図5)も同じである。但し、一部の構成要素の動作が異なっている。従って、本実施の形態に係る処理を図23乃至図37を用いて説明する。
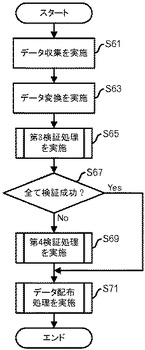
【0056】
まず、データ収集部100は、ソースシステムA又はBからデータ収集を行い、収集されたデータを、収集データ格納部110に格納する(図23:ステップS61)。例えば、図7に示すようなデータを収集して、収集データ格納部110に格納する。
【0057】
次に、データ変換部120は、定義データ格納部210に格納されているデータに従って、所定のデータ変換を実施し、処理結果を変換データ格納部130に格納する(ステップS63)。本実施の形態では定義データ格納部210に格納されているデータについては定義管理部200がデータ変換部120に設定を行うものとする。また、定義データ格納部210に格納されている定義データの一例を図24に示す。図24の例では、匿名化の判定基準である重複数と、各項目について検証の対象か否かを示すデータと、各項目について隠蔽の対象か否かを示すデータとが含まれる。図24の例では、「性別」「年齢」「身長」「体重」が項目として列挙されており、それ以外の項目のデータについては、匿名化のために破棄されるものとする。具体的には「個人ID」及び「氏名」についてはデータ変換部120が破棄する。本実施の形態では、検証の対象として指示されている項目については、曖昧化の一例として、予め定められた値域のいずれに属するかという判定を行って、その値域を特定するためのデータに置換するものとする。そうすると、図7のデータは、図9に示すデータに変換されることになる。これは第1の実施の形態と同じである。
【0058】
そして、第1検証処理部140は、変換データ格納部130に格納されているデータに対して、定義データ格納部210に格納されている定義データに従って第3検証処理を実施する(ステップS65)。第3検証処理については、図25乃至図27を用いて説明する。
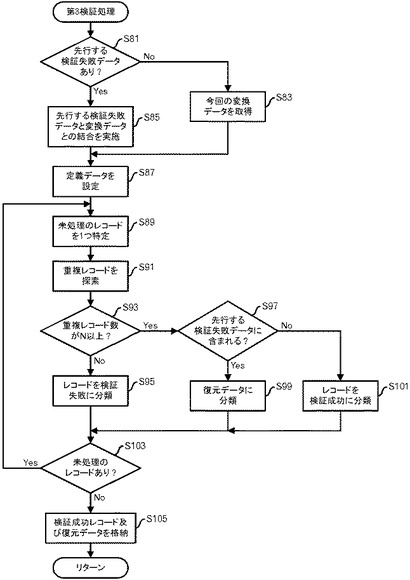
【0059】
第3検証処理において、まず、第1検証処理部140は、先行する検証失敗データが検証失敗データ格納部150に格納されているか確認する(ステップS81)。先行する検証失敗データが存在しない場合には、第1検証処理部140は、変換データ格納部130から今回の変換データを読み出す(ステップS83)。そして、ステップS87に移行する。一方、先行する検証失敗データが存在する場合には、第1検証処理部140は、先行する検証失敗データと、変換データ格納部130に格納されている今回の変換データとの結合を実施する(ステップS85)。
【0060】
そして、第1検証処理部140は、定義データ格納部210に格納されている定義データを設定する(ステップS87)。具体的には、検証の対象となる項目を特定する。図24の例であれば、「性別」「年齢」「身長」「体重」が検証の対象となる。
【0061】
そして、第1検証処理部140は、処理対象のデータ(ステップS83で読み出したデータ又はステップS85で結合されたデータ)において未処理のレコードを1つ特定する(ステップS89)。その後、第1検証処理部140は、処理対象のデータにおいて、特定したレコードと一致するレコードを探索する(ステップS91)。図24に示した定義データによれば、2以上の同一レコードがあれば、検証成功となる。先行する検証失敗データが存在せず、図9に示したデータについてステップS91を実施すると、図11に示すような結果が得られる。ここまでは、第1の実施の形態と同様である。
【0062】
そして、第1検証処理部140は、特定されたレコードについて、重複レコード数がN(図8の定義データの例では「2」。一般的には2以上の設定された整数。)以上であるか判断する(ステップS93)。重複レコード数がN以上であれば、第1検証処理部140は、特定されたレコードが、先行する検証失敗データに含まれるか判断する(ステップS97)。特定されたレコードが、先行する検証失敗データに含まれる場合には、第1検証処理部140は、特定されたレコードを、復元データに分類する(ステップS99)。具体的には、特定されたレコードを、例えばメインメモリなどの記憶装置における、復元データリストに登録する。一方、特定されたレコードが、先行する検証失敗データに含まれない場合には、第1検証処理部140は、特定されたレコードを、検証成功に分類する(ステップS101)。例えば、メインメモリなどの記憶装置における検証成功リストに、特定されたレコード及び検出された同一レコードを登録する。そして、ステップS103に移行する。
【0063】
一方、重複レコード数がN未満であれば、第1検証処理部140は、特定されたレコードを検証失敗に分類する(ステップS95)。本実施の形態では、特定されたレコードを、検証失敗データ格納部150に格納する。
【0064】
そして、第1検証処理部140は、処理対象のデータについて未処理のレコードが存在しているか判断する(ステップS103)。未処理のレコードが存在する場合にはステップS89に戻る。一方、未処理のレコードが存在しない場合には、第1検証処理部140は、検証成功レコード及び復元データを配布処理部180に出力し、配布処理部180は、受信した検証成功レコード及び復元データを配布データ格納部190に格納する(ステップS105)。その後、呼び出し元の処理に戻る。
【0065】
このようにすれば、重複レコード数N以上で検証成功と判断されたレコード群のうち先行する検証失敗データに含まれるレコードと、重複レコード数N以上で検証成功と判断されたレコード群のうち今回変換されたデータに含まれるレコードと、重複レコード数N未満で検証失敗と判断されたレコード群とに分類が行われる。
【0066】
図11のようなデータの場合、先行する検証失敗データが存在していないので、今回変換されたデータのうち検証成功レコード群は図12に示すようなレコード群であり、本実施の形態ではレコード管理識別子(ID)を付加して、図26に示すようなデータが配布データ格納部190に格納される。一方、検証失敗レコード群は図13に示すようなレコード群であり、本実施の形態ではレコード管理IDを付加して、図27に示すようなデータが検証失敗データ格納部150に一旦格納される。
【0067】
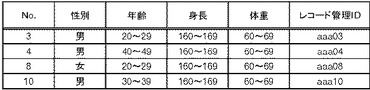
図23の処理の説明に戻って、第1検証処理部140は、処理対象のデータにおける全てのレコードが検証成功であったか判断する(ステップS67)。全てのレコードが検証成功であれば、ステップS71に移行する。一方、検証失敗レコードが存在する場合には、第2検証処理部160に対して処理を指示して、第2検証処理部160は、第4検証処理を実施する(ステップS69)。第4検証処理については、図28乃至図30を用いて説明する。
【0068】
第4検証処理において、まず、第2検証処理部160は、定義データ格納部210に格納されている定義データを設定する(図28:ステップS111)。具体的には、検証の対象となる項目を特定する。図24の例であれば、「性別」「年齢」「身長」「体重」が検証の対象となる。その後、第2検証処理部160は、検証失敗データ格納部150に格納されている検証失敗データに含まれる未処理のレコードを1つ特定する(ステップS113)。そして、第2検証処理部160は、検証成功データ格納部170に格納されているデータにおいて、特定されたレコードと一致するレコードを探索する(ステップS115)。なお、上での例では検証成功データ格納部170には何も格納されていないものとする。そうすると、図27に示すようなレコード群については重複レコード数は0となる。
【0069】
そして、第2検証処理部160は、特定されたレコードについて、重複レコード数がN以上であるか判断する(ステップS117)。検証成功データ格納部170に格納されているデータについて探索して重複レコード数がN以上であれば、特定の個人を特定できないので検証成功と判断しても良い。これによって検証成功と判断されるレコードの数が増加してターゲットシステムに配布されるレコード数が増加するため、統計処理への影響を抑えつつ、匿名性を確保できるようになる。
【0070】
従って、第2検証処理部160は、特定されたレコードを検証成功に分類する(ステップS121)。例えば、メインメモリなどの記憶装置における検証成功リストに登録する。そしてステップS123に移行する。
【0071】
一方、重複レコード数がN未満であれば、第2検証処理部160は、特定されたレコードを検証失敗に分類する(ステップS119)。例えば、メインメモリなどの記憶装置における検証失敗リストに登録する。その後、第2検証処理部160は、検証失敗データにおいて未処理のレコードが存在しているか判断する(ステップS123)。未処理のレコードが存在している場合にはステップS113に戻る。一方、未処理のレコードが存在していない場合には、端子Aを介して図29の処理に移行する。
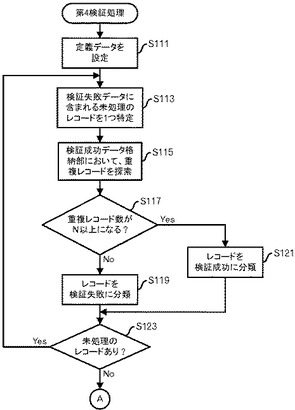
【0072】
図29の処理の説明に移行して、第2検証処理部160は、検証失敗リストにおける検証失敗レコードを、検証失敗データ格納部150に格納されているデータに格納する(ステップS125)。重複レコード数が0であるとすると、図27に示したようなデータが、そのまま検証失敗データ格納部150に格納される。
【0073】
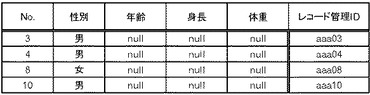
さらに、第2検証処理部160は、先行する検証失敗データに含まれない検証失敗レコード(例えばレコード管理ID等によって1回前の検証失敗データを識別するか又は検証失敗データ格納部150に1回前の検証失敗データを格納しておき識別する)に対して定義データに従って秘匿化処理を実施し、秘匿化処理後のデータを配布処理部180に出力し、配布処理部180は、受信した秘匿化処理後のデータを配布データ格納部190に格納する(ステップS127)。図27に示したようなデータが、先行する検証失敗データに含まれない検証失敗レコードであれば、定義データにおいて秘匿が指示されている項目「年齢」「身長」「体重」の値をnullに設定して図30に示すようなデータを生成する。
【0074】
また、第2検証処理部160は、検証成功レコードを配布処理部180に出力し、配布処理部180は、受信した検証成功レコードを配布データ格納部190に格納する(ステップS129)。その後、呼び出し元の処理に戻る。
【0075】
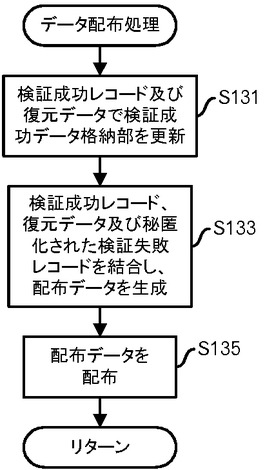
図23の処理の説明に戻って、配布処理部180は、データ配布処理を実施する(ステップS71)。データ配布処理については、図31及び図32を用いて説明する。
【0076】
まず、配布処理部180は、第1検証処理部140及び第2検証処理部160から受信し配布データ格納部190に格納されている検証成功レコード及び復元データによって、検証成功データ格納部170を更新する(図31:ステップS131)。本実施の形態では、検証成功データ格納部170については、例えば図15のようなデータを格納する。すなわち、同一のレコードについては1レコードのみを残し、重複レコード数を登録する。既に検証成功データ格納部170に同一のレコードが含まれている場合には、重複レコード数を増分する。なお、このようなレコードの集約を行ってしまうので、レコード管理IDは認証成功データ格納部170には格納されない。
【0077】
さらに、配布処理部180は、検証成功レコード、復元データ及び秘匿化された検証失敗レコードを結合して配布データを生成する(ステップS133)。そして、配布処理部180は、生成された配布データを、ターゲットシステムC及びDに配布する(ステップS135)。例えば、図32に示すようなデータを、ターゲットシステムC及びDに配布する。上でも述べたように、番号3、番号4、番号8及び番号10のレコードについては秘匿化されているので、「年齢」「身長」「体重」の項目値がnullに設定されている。そして呼び出し元の処理に戻る。
【0078】
このような処理を実施すれば、匿名化が確保されていると検証されたレコードについてはデータ変換後のデータをそのままターゲットシステムに配布し、匿名性が確保されていないレコードについては秘匿化したデータをターゲットシステムに配布する。これにより、ターゲットシステムにおいて適切な処理を行うことができる。
【0079】
なお、次のタイミングで収集されたデータに対してデータ変換処理を実施すると、図17のようなデータが得られた場合について説明する。
【0080】
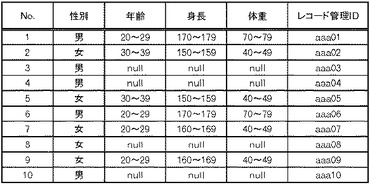
このような場合、第3検証処理においては、図13に示した前回の検証失敗レコードと今回のレコードとを結合して、それらのレコードについて同一のレコードを探索する。そうすると図18に示すように、番号3と番号12のレコードが一致し、番号10と番号15のレコードが一致し、番号4と番号13のレコードが一致し、番号8と番号14のレコードが一致している。
【0081】
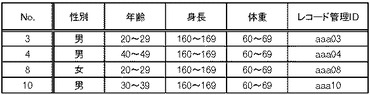
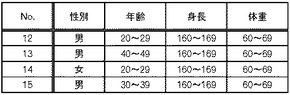
従って、図33に示すように、番号3、番号4、番号8及び番号10のレコードについては、復元データとして特定される。また、図34に示すように、番号12乃至15のレコードについては、検証成功レコードとして特定される。さらに、図35に示すように、番号11のレコードについては、検証失敗レコードとして特定され、検証失敗データ格納部150に一旦格納される。検証成功レコード及び検証失敗レコードについては、第1検証処理部140においてレコード管理IDを付与するようにしても良いし、配布処理部180において付与するようにしてもよい。
【0082】
その後、第4検証処理において、図35に示した検証失敗レコードについては、図15に示し且つ検証成功データ格納部170に格納されているデータとの照合を行う。そうすると、図15における最初のレコードと一致していることが分かるので、図35に示した検証失敗レコードについても配布データ格納部190に格納される。さらに、図15に示した検証成功データ格納部170に格納されているデータは、図21に示すように更新される。すなわち、新たに検証成功とされたレコードについては追加され、同一のレコードが検出されれば重複レコード数が増分される。このような処理を繰り返すことになる。
【0083】
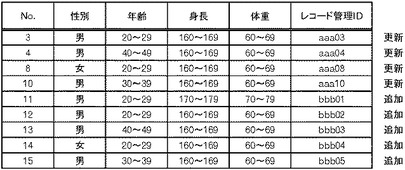
また、配布処理部180は、復元データ、検証成功レコード及び秘匿化された検証失敗レコードを結合して配布データを生成するが、上で述べた例では検証失敗レコードが存在しないので、復元データ及び検証成功レコードによって、図36に示すような配布データが生成される。本実施の形態ではレコード管理IDも配布データに含まれる。ターゲットシステム側では、既に受信したレコードのレコード管理IDと同一のレコード管理IDを含むレコードを受信すると、今回受信した配布データに含まれるレコードで更新を行う。すなわち、元々のレコードのデータを復元することになる。図36の例では、上の4行については既に配布されているレコードを更新するために送信される。一方、新たに検証成功レコードとして特定されたレコードについては、ターゲットシステム側では、同一レコードは存在していないので、ターゲットシステム側のデータベースに追加されることになる。そして、ターゲットシステムC及びDでは、図32に示すようなデータは、図37に示すようなデータに更新される。
【0084】
以上本技術の実施の形態を説明したが、本技術はこれに限定されるものではない。上で述べた機能ブロック図は一例であって、必ずしも実際のプログラムモジュールと一致するわけではない。また、データ構造やデータ保持の態様についても一例であって、上で述べた例は一例に過ぎない。さらに、上では1種類のデータについて処理を行う例を示したが、複数種類のデータを取り扱う場合もある。その場合には、検証成功レコード、検証失敗レコード及び復元データについて識別子を付して区別する。
【0085】
また、処理フローについては、処理結果が変わらない限りにおいてステップの実行順番を入れ替えたり、並列実行する場合もある。
【0086】
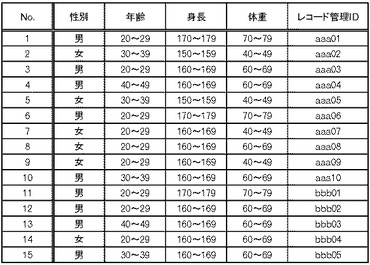
なお、上で述べた情報処理装置1000、ソースシステムA及びB、並びにターゲットシステムC及びDは、1又は複数のコンピュータ装置であって、図38に示すように、メモリ2501とCPU(Central Processing Unit)2503とハードディスク・ドライブ(HDD:Hard Disk Drive)2505と表示装置2509に接続される表示制御部2507とリムーバブル・ディスク2511用のドライブ装置2513と入力装置2515とネットワークに接続するための通信制御部2517とがバス2519で接続されている。オペレーティング・システム(OS:Operating System)及び本実施例における処理を実施するためのアプリケーション・プログラムは、HDD2505に格納されており、CPU2503により実行される際にはHDD2505からメモリ2501に読み出される。CPU2503は、アプリケーション・プログラムの処理内容に応じて表示制御部2507、通信制御部2517、ドライブ装置2513を制御して、所定の動作を行わせる。また、処理途中のデータについては、主としてメモリ2501に格納されるが、HDD2505に格納されるようにしてもよい。本技術の実施例では、上で述べた処理を実施するためのアプリケーション・プログラムはコンピュータ読み取り可能なリムーバブル・ディスク2511に格納されて頒布され、ドライブ装置2513からHDD2505にインストールされる。インターネットなどのネットワーク及び通信制御部2517を経由して、HDD2505にインストールされる場合もある。このようなコンピュータ装置は、上で述べたCPU2503、メモリ2501などのハードウエアとOS及びアプリケーション・プログラムなどのプログラムとが有機的に協働することにより、上で述べたような各種機能を実現する。
【0087】
以上述べた本実施の形態をまとめると、以下のようになる。
【0088】
本実施の形態に係る情報処理方法は、(A)第1のシステムから取得した複数のレコードから、予め定められた同一性の条件を満たすレコードの数が所定数以上となっているレコードである第1のレコードを抽出する第1の処理と、(B)複数のレコードのうち第1のレコード以外のレコードである第2のレコードから、予め定められた同一性の条件を満たすレコードの数が所定数以上となっているレコードとして既に抽出され且つデータ格納部に格納されているレコード群と第2のレコードとの組み合わせで上記予め定められた同一性の条件を満たすレコードの数が所定数以上となっているレコードである第3のレコードを抽出する第2の処理と、(C)第1のレコードと第3のレコードとを、第2のシステムに出力する第3の処理とを含む。
【0089】
このような処理を実施することで、より多くのレコードを第2のシステムに出力することができるようになる。すなわち、匿名性が確保されたより多くのレコードを第2のシステムで活用できるようになる。データ格納部には、予め定められた同一性を有するレコードを集約したデータを保持しておいても良いし、全てのレコードを蓄積するようにしても良い。
【0090】
また、上で述べた複数のレコードが、新たに第1のシステムから取得したレコードと、前回第1のシステムから取得されたが第1の処理及び第2の処理にて抽出されなったレコードとを含むようにしてもよい。このようにすることで、一度検証に失敗した場合でも、後に得たレコード群との関係で匿名性が確保できる可能性もある。
【0091】
さらに、上記情報処理方法は、(D)複数のレコードのうち第1のレコード及び第3のレコード以外のレコードである第4のレコードの少なくとも一部の属性値を秘匿化して第5のレコードを生成する第4の処理と、(E)第5のレコードを第2のシステムに出力する第5の処理と、(F)第1のシステムから新たに取得したレコードと第4のレコードとから、上記予め定められた同一性の条件を満たすレコードの数が所定数以上となっているレコードを抽出する第6の処理と、(G)第6の処理で抽出されたレコードが第4のレコードである場合には、第5のレコードを第4のレコードに復元するためのデータを第2のシステムに出力する第7の処理とをさらに含むようにしてもよい。このようにすることで、匿名性が確保できないレコードについては秘匿化を行った上で第2のシステムに出力することができるようになる。さらに、後に収集されたレコードによって匿名性が確保できれば、秘匿化を行ったレコードについて元のデータを復元するように指示することもできるようになる。
【0092】
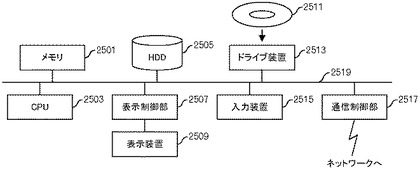
さらに、本実施の形態に係る情報処理装置(図39:4000)は、(A)第1のシステムから取得した複数のレコードから、予め定められた同一性の条件を満たすレコードの数が所定数以上となっているレコードである第1のレコードを抽出する第1処理部(図39:4100)と、(B)複数のレコードのうち第1のレコード以外のレコードである第2のレコードから、上記予め定められた同一性の条件を満たすレコードの数が所定数以上となっているレコードとして既に抽出され且つデータ格納部(図39:4300)に格納されているレコード群と第2のレコードとの組み合わせで上記予め定められた同一性の条件を満たすレコードの数が所定数以上となっているレコードである第3のレコードを抽出する第2処理部(図39:4200)と、(C)第1のレコードと第3のレコードとを、第2のシステムに出力する第3処理部(図39:4400)とを有する。
【0093】
なお、上で述べたような処理をコンピュータに実施させるためのプログラムを作成することができ、当該プログラムは、例えばフレキシブル・ディスク、CD−ROMなどの光ディスク、光磁気ディスク、半導体メモリ(例えばROM)、ハードディスク等のコンピュータ読み取り可能な記憶媒体又は記憶装置に格納される。なお、処理途中のデータについては、RAM等の記憶装置に一時保管される。
【0094】
以上の実施例を含む実施形態に関し、さらに以下の付記を開示する。
【0095】
(付記1)
第1のデータ群に含まれるN(Nは自然数)個以上のデータとの間で所定の関係を持つ、複数のデータを格納部に格納し、
前記第1のデータ群と異なる第2のデータ群に含まれるあるデータが、前記第2のデータ群に含まれるN個以上のデータとの間で前記所定の関係を持たない場合に、前記あるデータが、前記格納部に格納された前記複数のデータに含まれるN個以上のデータと前記所定の関係を持つか否かの判定を行い、
前記判定により、前記所定の関係を持つと判定した場合に、前記あるデータを前記格納部に格納する
ことをコンピュータに実行させるための判定プログラム。
【0096】
(付記2)
前記所定の関係は、一方のデータの所定部分と他方のデータの所定部分とが共通する関係を含むことを特徴とする付記1記載の判定プログラム。
【0097】
(付記3)
前記第2のデータ群が、前記第1のデータ群のうち前記複数のデータ以外のデータを含む
付記1又は2記載の判定プログラム。
【0098】
(付記4)
前記第1のデータ群のうち前記複数のデータ以外のデータの各々の少なくとも一部を秘匿化し、少なくとも一部が秘匿化されたデータを第2の格納部に格納し、
前記第1のデータ群のうち前記複数のデータ以外のデータが、前記第1のデータ群と異なる第3のデータ群に含まれるN個以上のデータとの間で前記所定の関係を持つ場合には、前記第2の格納部において前記少なくとも一部が秘匿化されたデータの秘匿化された部分を元のデータに復元させる
付記1乃至3のいずれか1つ記載の判定プログラム。
【0099】
(付記5)
第1のデータ群に含まれるN(Nは自然数)個以上のデータとの間で所定の関係を持つ、複数のデータを格納部に格納し、
前記第1のデータ群と異なる第2のデータ群に含まれるあるデータが、前記第2のデータ群に含まれるN個以上のデータとの間で前記所定の関係を持たない場合に、前記あるデータが、前記格納部に格納された前記複数のデータに含まれるN個以上のデータと前記所定の関係を持つか否かの判定を行い、
前記判定により、前記所定の関係を持つと判定した場合に、前記あるデータを前記格納部に格納する
ことをコンピュータが実行する情報処理方法。
【0100】
(付記6)
格納部と、
第1のデータ群に含まれるN(Nは自然数)個以上のデータとの間で所定の関係を持つ、複数のデータを前記格納部に格納し、前記第1のデータ群と異なる第2のデータ群に含まれるあるデータが、前記第2のデータ群に含まれるN個以上のデータとの間で前記所定の関係を持たない場合に、前記あるデータが、前記格納部に格納された前記複数のデータに含まれるN個以上のデータと前記所定の関係を持つか否かの判定を行い、前記判定により、前記所定の関係を持つと判定した場合に、前記あるデータを前記格納部に格納する処理部と、
を有する情報処理装置。
【符号の説明】
【0101】
1000 情報処理装置
100 データ収集部
110 収集データ格納部
120 データ変換部
130 変換データ格納部
140 第1検証処理部
150 検証失敗データ格納部
160 第2検証処理部
170 検証成功データ格納部
180 配布処理部
190 配布データ格納部
200 定義管理部
210 定義データ格納部
【技術分野】
【0001】
本技術は、データの秘匿化技術に関する。
【背景技術】
【0002】
例えば、収集した個人情報を、個人を特定できないようにするために匿名化情報に加工する技術が存在している。
【0003】
一般的に個人情報を匿名化情報にデータ加工しても、他の情報と照合して個人を識別できる(「容易照合性」と呼ぶ)場合は個人情報に該当する。しかしながら、「容易照合性」があるか否かの客観的な基準がなく、安全に匿名化情報を利用できるかの判断が難しい。この「容易照合性」には以下に示すような観点がある。
(1)他の情報と容易に照合できる環境にあるか否か。
(2)他の情報と照合した結果、個人を識別できるか否か。
【0004】
(1)については、データ管理(参照権限、参照範囲、情報漏洩対策)も含めた対策を行って容易照合性が否定されることになるので、ソフトウェアだけで判断はできない。一方、(2)は個人識別可能性とも呼ばれるが、識別リスクのあるレコードを削るといった加工を行うことで、より安全な匿名化情報を生成できる。これにより、他の情報と容易に照合できる場合や、個人を識別する情報が他で漏えいした場合においても、個人を特定することができないため、安全に匿名化情報を利用させることができる。
【0005】
匿名化情報に加工する技術には、例えば、個人情報と照合することで個人の特定につながる情報を判断して除き、匿名化情報に加工する技術がある。
【0006】
また、匿名化情報自身におけるレコードの重複から個人識別可能性を検証してデータ加工する技術も存在している。これは、匿名化情報におけるレコードの重複数がN件以上であれば、個人情報と照合した結果がN件以上となるため匿名化情報から個人は識別できないという法則を利用している。
【0007】
具体的には、図1に示すような処理が実施される。図1の左側に示す匿名化情報は3レコードを含んでおり、上の2行は同一であって2件以上の場合には個人識別可能性がないことが確認されるため[検証OK]として検証済の匿名化情報に加えられる。一方、ABCDというレコードについては1行しかないので、個人識別可能性があり[検証NG]と判定される。そうすると、例えばABCDの一部の属性値B及びCをXに変換してしまい、AXXDというレコードを検証済みの匿名化情報に加える。一方、ABCDというレコード自体については破棄してしまう。このような処理方法は、1つのデータベースにおいて既に蓄積済みのレコードを処理する場合には有効である。
【0008】
しかしながら、様々な業務システムから適宜収集されるデータを匿名化して、匿名化したデータを活用する他のシステムに出力するような場合には問題がある。具体的には、図1の左側に示すような3レコードがまず収集されて、この3レコードについて上で述べたような処理を実施すると、図1の右側に示すようなデータが他のシステムに出力される。その後、図2の左側に示すような3レコードが新たに収集されて上で述べたような処理を新たな3レコードに実施すると、上2行は同一であって個人識別可能性がないということが確認され検証OKとして検証済みの匿名化情報に加えられる。しかしながら、ABCDというレコードについては1行しかないので、個人識別可能性があり[検証NG]と判定される。そうすると、一部の属性値B及びCをXに変換してしまい、AXXDというレコードを検証済みの匿名化情報に加えることになる。そして、ABCDというレコード自体については破棄してしまう。このように、ABCDというレコードは2度出現しているが、収集タイミングが異なっているので、検証済みの匿名化情報には「AXXD」というレコードが2度登録されてしまう。これでは、ABCDという情報は失われてしまい、他のシステムにおける統計処理などに支障を来すようになる。
【先行技術文献】
【特許文献】
【0009】
【特許文献1】特開2007−287102号公報
【特許文献2】特開2009−181207号公報
【発明の概要】
【発明が解決しようとする課題】
【0010】
本発明の目的は、一側面によれば、データ群に含まれるデータのうち、データ間の条件を満たさないと判定されるデータの量を抑制することである。
【課題を解決するための手段】
【0011】
本情報処理方法は、(A)第1のデータ群に含まれるN(Nは自然数)個以上のデータとの間で所定の関係を持つ、複数のデータを格納部に格納する処理と、(B)第1のデータ群と異なる第2のデータ群に含まれるあるデータが、第2のデータ群に含まれるN個以上のデータとの間で所定の関係を持たない場合に、あるデータが、格納部に格納された複数のデータに含まれるN個以上のデータと所定の関係を持つか否かの判定を行う処理と、(C)判定により、所定の関係を持つと判定した場合に、あるデータを格納部に格納する処理とを含む。
【発明の効果】
【0012】
一側面によれば、データ群に含まれるデータのうち、データ間の条件を満たさないと判定されるデータの量を抑制できる。
【図面の簡単な説明】
【0013】
【図1】図1は、従来技術を説明するための図である。
【図2】図2は、従来技術を説明するための図である。
【図3】図3は、第1の実施の形態の処理の概要を示す図である。
【図4】図4は、第1の実施の形態に係るシステムの概要を示す図である。
【図5】図5は、第1の実施の形態に係る情報処理装置の機能ブロック図である。
【図6】図6は、第1の実施の形態における情報処理装置の処理フローを示す図である。
【図7】図7は、収集されるデータの一例を示す図である。
【図8】図8は、第1の実施の形態における定義データの一例を示す図である。
【図9】図9は、変換データの一例を示す図である。
【図10】図10は、第1検証処理の処理フローを示す図である。
【図11】図11は、第1検証処理における検証結果を説明するための図である。
【図12】図12は、第1検証処理における検証成功レコード群の一例を示す図である。
【図13】図13は、第1検証処理における検証失敗レコード群の一例を示す図である。
【図14】図14は、第2検証処理の処理フローを示す図である。
【図15】図15は、初回の処理で検証成功データ格納部に格納されるデータの一例を示す図である。
【図16】図16は、ターゲットシステムにおけるデータ加工の一例を示す図である。
【図17】図17は、次に収集され且つ変換されたデータの一例を示す図である。
【図18】図18は、2回目の第1検証処理における検証結果を説明するための図である。
【図19】図19は、2回目の第1検証処理における検証成功レコード群の一例を示す図である。
【図20】図20は、2回目の第1検証処理において検証失敗レコード群の一例を示す図である。
【図21】図21は、2回目の第2検証処理終了後における検証成功データ格納部に格納されるデータの一例を示す図である。
【図22】図22は、第2の実施の形態の処理の概要を示す図である。
【図23】図23は、第2の実施の形態における情報処理装置の処理フローを示す図である。
【図24】図24は、第2の実施の形態における定義データの一例を示す図である。
【図25】図25は、第3検証処理の処理フローを示す図である。
【図26】図26は、第3検証処理で検証成功と判断されたレコードの一例を示す図である。
【図27】図27は、第3検証処理で検証失敗と判断されたレコードの一例を示す図である。
【図28】図28は、第4検証処理の処理フローを示す図である。
【図29】図29は、第4検証処理の処理フローを示す図である。
【図30】図30は、検証失敗レコードの秘匿化について説明するための図である。
【図31】図31は、データ配布処理の処理フローを示す図である。
【図32】図32は、配布データの一例を示す図である。
【図33】図33は、2回目の第3検証処理によって復元データとして特定されたレコードの一例を示す図である。
【図34】図34は、2回目の第3検証処理によって検証成功レコードとして特定されたレコードの一例を示す図である。
【図35】図35は、2回目の第3検証処理によって検証失敗レコードとして特定されたレコードの一例を示す図である。
【図36】図36は、2回目の配布データの一例を示す図である。
【図37】図37は、ターゲットシステムにおいて蓄積されるデータの一例を示す図である。
【図38】図38は、コンピュータの機能ブロック図である。
【図39】図39は、本実施の形態に係る情報処理装置の機能ブロック図である。
【発明を実施するための形態】
【0014】
[実施の形態1]
図3を用いて第1の実施の形態における処理の概要を説明する。本実施の形態において処理を実施する情報処理装置は、1又は複数の業務システム(ソースシステムとも呼ぶ。)からデータを収集して匿名化し、以下で述べる処理を実施した上で、匿名化情報を活用する他のシステム(ターゲットシステムとも呼ぶ。)に配布する処理を実施する。例えば、図3の上段左側に示すように3レコード収集した場合、この3レコードの中でレコードの重複を判断する(ステップ(1))。なお、3レコードは、既に匿名化のためのデータ変換処理(例えば該当する値域についてのデータに変換したり、仮名文字化したり、レコードの一部の属性を破棄したりする)を実施した後のデータである。
【0015】
ステップ(1)で例えば2レコード以上重複すると判断された場合、個人識別可能性がないので検証OKとして検証済みの匿名化情報に加えられる。図3の例では上2レコードが検証済みの匿名化情報に加えられる。一方、ABCDという属性値を含む下1レコードは、他のレコードと重複しておらず、個人識別可能性があるので検証NGと判断される。但し、このABCDを含むレコードについては、既に検証済みの匿名化情報と照合して、一致するレコードが、既に検証済みの匿名化情報に含まれているかを確認する(ステップ(2))。この例では、重複するレコードが存在していないので、ステップ(2)でもABCDを含むレコードは検証NGと判断される。本実施の形態では、ABCDを含むレコードを破棄することなく、次に収集されたレコードについての重複レコードが存在するか否かを判断する際に用いるため保持しておく。なお、検証済みの匿名化情報についてはターゲットシステムに配布する。
【0016】
次にソースシステムから2レコードが収集されると、保持しておいたレコードを結合させ(ステップ(3))、合計3レコードについてレコードの重複を判断する(ステップ(4))。例えば、ソースシステムから、ABCDを含むレコードと、EFGHを含むレコードとを収集した場合には、保持しておいた、ABCDを含むレコードと併せて重複を判断する。この場合、ABCDを含むレコードについては個人識別可能性がないので、検証済みの匿名化情報に追加される。一方、EFGHを含むレコードについては、3レコードには重複はないので、個人識別可能性ありで検証NGと判断される。そして、EFGHを含むレコードについては、既に検証済みの匿名化情報と照合して、一致するレコードが、既に検証済みの匿名化情報に含まれているかを確認する(ステップ(5))。図3の例では、既にEFGHを含むレコードが、検証済みの匿名化情報に含まれているので、今回収集され且つEFGHを含むレコードについても検証OKとして、検証済みの匿名化情報に追加される。このように今回検証された3レコードは、ターゲットシステムに配布される。
【0017】
このような処理を実施することで、より多くのレコードがターゲットシステムにおいて有効に活用できるようになる。さらに、収集されたレコードについては収集毎に上で述べたような処理を実施するので、ターゲットシステムでは即時性を損なうことなく最新のデータについて統計処理などの処理を実施することができる。
【0018】
次に、本実施の形態に係るシステムの概要を図4及び図5を用いて説明する。図4に示すように、本実施の形態に係る主要な処理を実施する情報処理装置1000は、ネットワーク300を介してソースシステムA及びBと接続されており、ネットワーク400を介してターゲットシステムC及びDと接続されている。ソースシステム及びターゲットシステムの数は1つの場合もある。ソースシステムA及びBは、例えば自身のデータベースに格納すべきデータ等を、ネットワーク300を介して情報処理装置1000に送信する。
【0019】
ターゲットシステムC及びDも、例えば自身のデータベースに、ネットワーク400を介して情報処理装置1000から受信したデータを蓄積し、データ受信とは非同期に、他の装置などからの要求に対する処理を実施する。
【0020】
図5に情報処理装置1000の機能ブロック図を示す。情報処理装置1000は、データ収集部100と、収集データ格納部110と、データ変換部120と、変換データ格納部130と、第1検証処理部140と、検証失敗データ格納部150と、第2検証処理部160と、検証成功データ格納部170と、ネットワーク400を介してターゲットシステムに匿名化されたデータを配布する配布処理部180と、配布データ格納部190と、定義管理部200と、定義データ格納部210とを有する。
【0021】
データ収集部100は、ネットワーク400を介してターゲットシステムA及びBからデータを受信して収集データ格納部110に格納する。データ変換部120は、定義データ格納部210に格納されているデータに従ってデータ変換処理を実施し、処理結果を変換データ格納部130に格納する。第1検証処理部140は、変換データ格納部130と検証失敗データ格納部150に格納されているデータに対して、定義データ格納部210に格納されているデータに従って検証処理を実施する。そして、第1検証処理部140は、検証成功したレコードについては配布処理部180に出力し、検証失敗したレコードについては検証失敗データ格納部150に格納する。
【0022】
第2検証処理部160は、検証失敗データ格納部150に格納されているデータについて、検証成功データ格納部170に格納されているデータに対して定義データ格納部210に格納されているデータに従って検証処理を実施する。そして、第2検証処理部160は、検証成功したレコードについては配布処理部180に出力し、検証失敗したレコードについては検証失敗データ格納部150に格納する。配布処理部180は、第1検証処理部140及び第2検証処理部160から受信したデータを配布データ格納部190に格納すると共に、受信したデータで検証成功データ格納部170を更新する。そして、配布処理部180は、配布データ格納部190に格納されているデータをネットワーク400を介してターゲットシステムC及びDに送信する。
【0023】
定義管理部200は、管理者端末2000からの指示に従って、データ変換処理及び検証処理についての定義データを定義データ格納部210に格納する。また、定義管理部200は、データ変換部120、第1検証処理部140及び第2検証処理部160等に、定義データ格納部210に格納されているデータを設定する。
【0024】
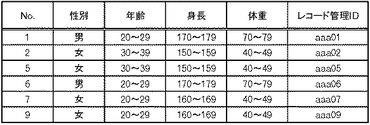
次に、図6乃至図21を用いて情報処理装置1000の処理について説明する。まず、データ収集部100は、ソースシステムA又はBからデータ収集を行い、収集されたデータを、収集データ格納部110に格納する(図6:ステップS1)。例えば、図7に示すようなデータを収集して、収集データ格納部110に格納する。図7の例では、各レコードには、個人識別子(ID)と、氏名と、性別と、年齢と、身長と、体重とが含まれる。なお、番号(No.)は、この後の処理の説明においてレコードを識別しやすくするために、便宜上付加したもので、実際には含まれない。
【0025】
次に、データ変換部120は、定義データ格納部210に格納されているデータに従って、所定のデータ変換を実施し、処理結果を変換データ格納部130に格納する(ステップS3)。本実施の形態では定義データ格納部210に格納されているデータについては定義管理部200がデータ変換部120に設定を行うものとする。また、定義データ格納部210に格納されている定義データの一例を図8に示す。図8の例では、匿名化の判定基準である重複数と、各項目について検証の対象か否かを示すデータとが含まれる。図8の例では、「性別」「年齢」「身長」「体重」が項目として列挙されており、それ以外の項目のデータについては、匿名化のために破棄されるものとする。具体的には「個人ID」及び「氏名」についてはデータ変換部120が破棄する。本実施の形態では、検証の対象として指示されている項目については、曖昧化の一例として、予め定められた値域のいずれに属するかという判定を行って、その値域を特定するためのデータに置換するものとする。例えば、身長が「179」である「A」の場合、170−179の値域に属するということで、当該値域の識別データに置換される。年齢及び体重についても同様に置換される。そうすると、図7のデータは、図9に示すデータに変換されることになる。図9の例では、「個人ID」及び「氏名」の項目が破棄され、性別の項目はそのまま残っているが、「年齢」「身長」「体重」については上で述べたような所属する値域への置換が行われている。
【0026】
そして、第1検証処理部140は、変換データ格納部130に格納されているデータに対して、定義データ格納部210に格納されている定義データに従って第1検証処理を実施する(ステップS5)。第1検証処理については、図10乃至図13を用いて説明する。
【0027】
第1検証処理において、まず、第1検証処理部140は、先行する検証失敗データが検証失敗データ格納部150に格納されているか確認する(図10:ステップS21)。先行する検証失敗データが存在しない場合には、第1検証処理部140は、変換データ格納部130から今回の変換データを読み出す(ステップS24)。そして、ステップS25に移行する。一方、先行する検証失敗データが存在する場合には、第1検証処理部140は、先行する検証失敗データと、変換データ格納部130に格納されている今回の変換データとの結合を実施する(ステップS23)。
【0028】
そして、第1検証処理部140は、定義データ格納部210に格納されている定義データを設定する(ステップS25)。具体的には、検証の対象となる項目を特定する。図8の例であれば、「性別」「年齢」「身長」「体重」が検証の対象となる。以下、一致するレコード又は同一性を有するレコードとは、検証対象の項目の値が同じであるレコードを言うものとする。
【0029】
そして、第1検証処理部140は、処理対象のデータ(ステップS24で読み出したデータ又はステップS23で結合したデータ)において未処理のレコードを1つ特定する(ステップS27)。その後、第1検証処理部140は、処理対象のデータにおいて、特定したレコードと一致するレコードを探索する(ステップS29)。図8に示した定義データによれば、2以上の同一レコードがあれば、検証成功となる。先行する検証失敗データが存在せず、図9に示したデータについてステップS29を実施すると、図11に示すような結果が得られる。図11では、番号1と番号6のレコードが一致しており、番号7と番号9のレコードが一致しており、番号2と番号5のレコードが一致していることが分かる。また、番号3、番号10、番号4及び番号8のレコードについては、一致するレコードが存在しない。
【0030】
そして、第1検証処理部140は、特定されたレコードについて、重複レコード数がN(図8の定義データの例では「2」。一般的には2以上の設定された整数。)以上であるか判断する(ステップS31)。重複レコード数がN以上であれば、第1検証処理部140は、特定されたレコードを検証成功に分類する(ステップS35)。例えば、メインメモリなどの記憶装置における検証成功リストに、特定されたレコード及び検出された同一レコードを登録する。そして、ステップS37に移行する。
【0031】
一方、重複レコード数がN未満であれば、第1検証処理部140は、特定されたレコードを検証失敗に分類する(ステップS33)。本実施の形態では、特定されたレコードを、検証失敗データ格納部150に格納する。
【0032】
そして、第1検証処理部140は、処理対象のデータにおいて未処理のレコードが存在しているか判断する(ステップS37)。未処理のレコードが存在する場合にはステップS27に戻る。一方、未処理のレコードが存在しない場合には、第1検証処理部140は、検証成功レコードを配布処理部180に出力し、配布処理部180は、受信した検証成功レコードを配布データ格納部190に格納する(ステップS39)。その後、呼び出し元の処理に戻る。
【0033】
このようにすれば、処理対象のデータは、重複レコード数N以上で検証成功と判断されたレコード群と、重複レコード数N未満で検証失敗と判断されたレコード群とに分類される。例えば、図11で説明したように、検証成功レコード群は図12に示すようなレコード群であり、配布データ格納部190に格納される。一方、検証失敗レコード群は図13に示すようなレコード群であり、検証失敗データ格納部150に一旦格納される。
【0034】
図6の処理の説明に戻って、第1検証処理部140は、処理対象のデータにおける全てのレコードが検証成功であったか判断する(ステップS7)。全てのレコードが検証成功であれば、ステップS11に移行する。一方、検証失敗レコードが存在する場合には、第2検証処理部160に対して処理を指示して、第2検証処理部160は、第2検証処理を実施する(ステップS9)。第2検証処理については、図14を用いて説明する。
【0035】
第2検証処理において、まず、第2検証処理部160は、定義データ格納部210に格納されている定義データを設定する(図14:ステップS40)。具体的には、検証の対象となる項目を特定する。図8の例であれば、「性別」「年齢」「身長」「体重」が検証の対象となる。その後、第2検証処理部160は、検証失敗データ格納部150に格納されている検証失敗データに含まれる未処理のレコードを1つ特定する(ステップS41)。そして、第2検証処理部160は、検証成功データ格納部170に格納されているデータにおいて、特定されたレコードと一致するレコードを探索する(ステップS43)。なお、上の例では検証成功データ格納部170には何も格納されていないものとする。そうすると、図13に示すようなレコード群については重複レコード数は0となる。
【0036】
そして、第2検証処理部160は、特定されたレコードについて、重複レコード数がN以上であるか判断する(ステップS45)。検証成功データ格納部170に格納されているデータについて探索して重複レコード数がN以上であれば、特定の個人を特定できないので検証成功と判断しても良い。これによって検証成功と判断されるレコードの数が増加してターゲットシステムに配布されるレコード数が増加するため、統計処理への影響を抑えつつ、匿名化を確実に実施できるようになる。
【0037】
従って、第2検証処理部160は、特定されたレコードを検証成功に分類する(ステップS47)。例えば、メインメモリなどの記憶装置における検証成功リストに登録する。そしてステップS51に移行する。
【0038】
一方、重複レコード数がN未満であれば、第2検証処理部160は、特定されたレコードを検証失敗に分類する(ステップS49)。例えば、メインメモリなどの記憶装置における検証失敗リストに登録する。その後、第2検証処理部160は、検証失敗データにおいて未処理のレコードが存在しているか判断する(ステップS51)。未処理のレコードが存在している場合にはステップS41に戻る。一方、未処理のレコードが存在していない場合には、第2検証処理部160は、検証失敗レコードで検証失敗データ格納部150に格納されているデータを更新する(ステップS53)。さらに、第2検証処理部160は、検証成功レコードを配布処理部180に出力し、配布処理部180は、受信した検証成功レコードを配布データ格納部190に格納する(ステップS55)。その後、呼び出し元の処理に戻る。
【0039】
上で述べた例では、検証成功データ格納部170には何も格納されていないので、検証失敗データ格納部150に格納されているデータは、図13に示されたものと同じである。また、配布データ格納部190に格納されるデータについても、図12に示されたものと同じになる。
【0040】
図6の処理の説明に戻って、配布処理部180は、第1検証処理部140及び第2検証処理部160から受信し配布データ格納部190に格納されているデータによって、検証成功データ格納部170を更新する(ステップS11)。本実施の形態では、検証成功データ格納部170については、例えば図15のようなデータを格納する。すなわち、同一のレコードについては1レコードのみを残し、重複レコード数を登録する。既に検証成功データ格納部170に同一のレコードが含まれている場合には、重複レコード数を増分する。
【0041】
さらに、配布処理部180は、配布データ格納部190に格納されている検証成功データをターゲットシステムC及びDに配布する(ステップS13)。具体的には、ネットワーク400を介して検証成功データを送信する。
【0042】
このような処理を実施すれば、より多くのレコードが、匿名性が確保されていると検証されて、ターゲットシステムに配布され、ターゲットシステムにおいて適切な処理を行うことができる。
【0043】
なお、ターゲットシステムC及びDでは、例えば様々な観点に基づく統計処理を行ったり、さらに図16に示すように、健康状態のデータ及び所見のデータを追加して加工した後に統計処理を実施したりする場合もある。
【0044】
なお、次のタイミングで収集されたデータに対してデータ変換処理を実施して、図17のようなデータが得られた場合について説明する。上でも述べたように、図17における番号は説明のためにのみ追加されている。
【0045】
このような場合、第1検証処理においては、図13に示した前回の検証失敗レコードと今回のレコードとを結合して、それらのレコードについて同一のレコードを探索する。そうすると図18に示すように、番号3と番号12のレコードが一致し、番号10と番号15のレコードが一致し、番号4と番号13のレコードが一致し、番号8と番号14のレコードが一致している。従って、図19に示すようなデータが、検証成功レコードとして特定され、配布データ格納部190に格納される。さらに、図20に示すように、番号11のレコードのみが検証失敗レコードとして特定され、検証失敗データ格納部150に一旦格納される。
【0046】
その後、第2検証処理において、図20に示した検証失敗レコードについては、図15に示し且つ検証成功データ格納部170に格納されているデータとの照合を行う。そうすると、図15における最初のレコードと一致していることが分かるので、図20に示した検証失敗レコードについても配布データ格納部190に格納される。さらに、図15に示した検証成功データ格納部170に格納されているデータは、図21に示すように更新される。すなわち、新たなレコードを追加すると共に、同一のレコードが検出されれば重複レコード数が増分される。このような処理を繰り返すことになる。
【0047】
[実施の形態2]
本実施の形態に係る処理の概要を図22を用いて説明する。
【0048】
本実施の形態において処理を実施する情報処理装置は、1又は複数のソースシステムからデータを収集して匿名化し、以下で述べる処理を実施した上で、匿名化情報を活用するターゲットシステムに配布する処理を実施する。例えば、図22の上段左側に示すように3レコード収集した場合、この3レコードの中でレコードの重複を判断する(ステップ(11))。なお、3レコードは、既に匿名化のためのデータ変換処理(例えば該当する値域についてのデータに変換したり、仮名文字化したり、レコードの一部の属性を破棄したりする)を実施した後のデータである。
【0049】
ステップ(11)で例えば2レコード以上一致すると判断された場合、個人識別可能性がないので検証OKとして検証済みの匿名化情報に加えられる。図22の例では上2レコードは、JKFGで一致しているため、検証済みの匿名化情報に加えられる。一方、ABCDという属性値を含む下1レコードは、他のレコードと一致しておらず、個人識別可能性があるので検証NGと判断される。但し、このABCDを含むレコードについては、既に検証済みの匿名化情報と照合して、一致するレコードが、既に検証済みの匿名化情報に含まれているかを確認する。この例では、重複するレコードが存在していないので、本照合においても、ABCDを含むレコードは検証NGと判断される。但し、本実施の形態では、ABCDを含むレコードの一部を秘匿化して、検証OKのレコードと共にターゲットシステムに配布される(ステップ(12))。このように一部隠蔽されているが、全てのレコードがターゲットシステムに配布される。また、ABCDを含むレコードについては、別途保持しておく。
【0050】
次にソースシステムから3レコードが収集されると、保持しておいたレコードを結合させ(ステップ(13))、合計4レコードについてレコードの重複を判断する(ステップ(14))。例えば、ソースシステムから、ABCDを含む2レコードと、EFGHを含むレコードとを収集した場合には、前回検証NGと判断され且つABCDを含むレコードと併せて重複を判断すると、ABCDを含むレコードについては個人識別可能性がないので、1つのレコードについては検証済みの匿名化情報に追加される。もう1つについては、ステップ(12)で一部隠蔽されているので、検証済みの匿名化情報においてABCDを含むレコードを復元させる(ステップ(15))。
【0051】
また、JKFGを含むレコードについては、合計4レコードについてレコードの一致を判断すると、他のレコードと一致しておらず、個人識別可能性があるので検証NGと判断される。但し、このJKFGを含むレコードについては、既に検証済みの匿名化情報と照合して、一致するレコードが、既に検証済みの匿名化情報に含まれているかを確認する。図22の例では、既にJKFGを含むレコードが、検証済みの匿名化情報に含まれているので、今回収集され且つJKFGを含むレコードについても検証OKとして、検証済みの匿名化情報に追加される(ステップ(16))。
【0052】
一方、EFGHを含むレコードについては、合計4レコードには一致するレコードはないので、個人識別可能性ありで検証NGと判断される。そして、EFGHを含むレコードについては、既に検証済みの匿名化情報と照合して、一致するレコードが、既に検証済みの匿名化情報に含まれているかを確認する。図22の例では、一致するレコードが存在していないので、本照合においても、EFGHを含むレコードは検証NGと判断される。そして、EFGHを含むレコードの一部を秘匿化して、検証OKのレコードと共にターゲットシステムに配布する(ステップ(17))。
【0053】
このように、個人識別可能性がなくなったレコードについては復元させることができる。また、今回収集されたレコードは、一部隠蔽されている場合もあるが、全てターゲットシステムに配布される。
【0054】
このような処理を実施することで、より多くのレコードがターゲットシステムにおいて有効に活用できるようになる。さらに、収集されたレコードについては収集毎に上で述べたような処理を実施するので、ターゲットシステムでは即時性を損なうことなく最新のデータについて統計処理などの処理を実施することができる。
【0055】
本実施の形態でも、第1の実施の形態におけるシステム全体構成(図4)は同じであり、情報処理装置1000の構成(図5)も同じである。但し、一部の構成要素の動作が異なっている。従って、本実施の形態に係る処理を図23乃至図37を用いて説明する。
【0056】
まず、データ収集部100は、ソースシステムA又はBからデータ収集を行い、収集されたデータを、収集データ格納部110に格納する(図23:ステップS61)。例えば、図7に示すようなデータを収集して、収集データ格納部110に格納する。
【0057】
次に、データ変換部120は、定義データ格納部210に格納されているデータに従って、所定のデータ変換を実施し、処理結果を変換データ格納部130に格納する(ステップS63)。本実施の形態では定義データ格納部210に格納されているデータについては定義管理部200がデータ変換部120に設定を行うものとする。また、定義データ格納部210に格納されている定義データの一例を図24に示す。図24の例では、匿名化の判定基準である重複数と、各項目について検証の対象か否かを示すデータと、各項目について隠蔽の対象か否かを示すデータとが含まれる。図24の例では、「性別」「年齢」「身長」「体重」が項目として列挙されており、それ以外の項目のデータについては、匿名化のために破棄されるものとする。具体的には「個人ID」及び「氏名」についてはデータ変換部120が破棄する。本実施の形態では、検証の対象として指示されている項目については、曖昧化の一例として、予め定められた値域のいずれに属するかという判定を行って、その値域を特定するためのデータに置換するものとする。そうすると、図7のデータは、図9に示すデータに変換されることになる。これは第1の実施の形態と同じである。
【0058】
そして、第1検証処理部140は、変換データ格納部130に格納されているデータに対して、定義データ格納部210に格納されている定義データに従って第3検証処理を実施する(ステップS65)。第3検証処理については、図25乃至図27を用いて説明する。
【0059】
第3検証処理において、まず、第1検証処理部140は、先行する検証失敗データが検証失敗データ格納部150に格納されているか確認する(ステップS81)。先行する検証失敗データが存在しない場合には、第1検証処理部140は、変換データ格納部130から今回の変換データを読み出す(ステップS83)。そして、ステップS87に移行する。一方、先行する検証失敗データが存在する場合には、第1検証処理部140は、先行する検証失敗データと、変換データ格納部130に格納されている今回の変換データとの結合を実施する(ステップS85)。
【0060】
そして、第1検証処理部140は、定義データ格納部210に格納されている定義データを設定する(ステップS87)。具体的には、検証の対象となる項目を特定する。図24の例であれば、「性別」「年齢」「身長」「体重」が検証の対象となる。
【0061】
そして、第1検証処理部140は、処理対象のデータ(ステップS83で読み出したデータ又はステップS85で結合されたデータ)において未処理のレコードを1つ特定する(ステップS89)。その後、第1検証処理部140は、処理対象のデータにおいて、特定したレコードと一致するレコードを探索する(ステップS91)。図24に示した定義データによれば、2以上の同一レコードがあれば、検証成功となる。先行する検証失敗データが存在せず、図9に示したデータについてステップS91を実施すると、図11に示すような結果が得られる。ここまでは、第1の実施の形態と同様である。
【0062】
そして、第1検証処理部140は、特定されたレコードについて、重複レコード数がN(図8の定義データの例では「2」。一般的には2以上の設定された整数。)以上であるか判断する(ステップS93)。重複レコード数がN以上であれば、第1検証処理部140は、特定されたレコードが、先行する検証失敗データに含まれるか判断する(ステップS97)。特定されたレコードが、先行する検証失敗データに含まれる場合には、第1検証処理部140は、特定されたレコードを、復元データに分類する(ステップS99)。具体的には、特定されたレコードを、例えばメインメモリなどの記憶装置における、復元データリストに登録する。一方、特定されたレコードが、先行する検証失敗データに含まれない場合には、第1検証処理部140は、特定されたレコードを、検証成功に分類する(ステップS101)。例えば、メインメモリなどの記憶装置における検証成功リストに、特定されたレコード及び検出された同一レコードを登録する。そして、ステップS103に移行する。
【0063】
一方、重複レコード数がN未満であれば、第1検証処理部140は、特定されたレコードを検証失敗に分類する(ステップS95)。本実施の形態では、特定されたレコードを、検証失敗データ格納部150に格納する。
【0064】
そして、第1検証処理部140は、処理対象のデータについて未処理のレコードが存在しているか判断する(ステップS103)。未処理のレコードが存在する場合にはステップS89に戻る。一方、未処理のレコードが存在しない場合には、第1検証処理部140は、検証成功レコード及び復元データを配布処理部180に出力し、配布処理部180は、受信した検証成功レコード及び復元データを配布データ格納部190に格納する(ステップS105)。その後、呼び出し元の処理に戻る。
【0065】
このようにすれば、重複レコード数N以上で検証成功と判断されたレコード群のうち先行する検証失敗データに含まれるレコードと、重複レコード数N以上で検証成功と判断されたレコード群のうち今回変換されたデータに含まれるレコードと、重複レコード数N未満で検証失敗と判断されたレコード群とに分類が行われる。
【0066】
図11のようなデータの場合、先行する検証失敗データが存在していないので、今回変換されたデータのうち検証成功レコード群は図12に示すようなレコード群であり、本実施の形態ではレコード管理識別子(ID)を付加して、図26に示すようなデータが配布データ格納部190に格納される。一方、検証失敗レコード群は図13に示すようなレコード群であり、本実施の形態ではレコード管理IDを付加して、図27に示すようなデータが検証失敗データ格納部150に一旦格納される。
【0067】
図23の処理の説明に戻って、第1検証処理部140は、処理対象のデータにおける全てのレコードが検証成功であったか判断する(ステップS67)。全てのレコードが検証成功であれば、ステップS71に移行する。一方、検証失敗レコードが存在する場合には、第2検証処理部160に対して処理を指示して、第2検証処理部160は、第4検証処理を実施する(ステップS69)。第4検証処理については、図28乃至図30を用いて説明する。
【0068】
第4検証処理において、まず、第2検証処理部160は、定義データ格納部210に格納されている定義データを設定する(図28:ステップS111)。具体的には、検証の対象となる項目を特定する。図24の例であれば、「性別」「年齢」「身長」「体重」が検証の対象となる。その後、第2検証処理部160は、検証失敗データ格納部150に格納されている検証失敗データに含まれる未処理のレコードを1つ特定する(ステップS113)。そして、第2検証処理部160は、検証成功データ格納部170に格納されているデータにおいて、特定されたレコードと一致するレコードを探索する(ステップS115)。なお、上での例では検証成功データ格納部170には何も格納されていないものとする。そうすると、図27に示すようなレコード群については重複レコード数は0となる。
【0069】
そして、第2検証処理部160は、特定されたレコードについて、重複レコード数がN以上であるか判断する(ステップS117)。検証成功データ格納部170に格納されているデータについて探索して重複レコード数がN以上であれば、特定の個人を特定できないので検証成功と判断しても良い。これによって検証成功と判断されるレコードの数が増加してターゲットシステムに配布されるレコード数が増加するため、統計処理への影響を抑えつつ、匿名性を確保できるようになる。
【0070】
従って、第2検証処理部160は、特定されたレコードを検証成功に分類する(ステップS121)。例えば、メインメモリなどの記憶装置における検証成功リストに登録する。そしてステップS123に移行する。
【0071】
一方、重複レコード数がN未満であれば、第2検証処理部160は、特定されたレコードを検証失敗に分類する(ステップS119)。例えば、メインメモリなどの記憶装置における検証失敗リストに登録する。その後、第2検証処理部160は、検証失敗データにおいて未処理のレコードが存在しているか判断する(ステップS123)。未処理のレコードが存在している場合にはステップS113に戻る。一方、未処理のレコードが存在していない場合には、端子Aを介して図29の処理に移行する。
【0072】
図29の処理の説明に移行して、第2検証処理部160は、検証失敗リストにおける検証失敗レコードを、検証失敗データ格納部150に格納されているデータに格納する(ステップS125)。重複レコード数が0であるとすると、図27に示したようなデータが、そのまま検証失敗データ格納部150に格納される。
【0073】
さらに、第2検証処理部160は、先行する検証失敗データに含まれない検証失敗レコード(例えばレコード管理ID等によって1回前の検証失敗データを識別するか又は検証失敗データ格納部150に1回前の検証失敗データを格納しておき識別する)に対して定義データに従って秘匿化処理を実施し、秘匿化処理後のデータを配布処理部180に出力し、配布処理部180は、受信した秘匿化処理後のデータを配布データ格納部190に格納する(ステップS127)。図27に示したようなデータが、先行する検証失敗データに含まれない検証失敗レコードであれば、定義データにおいて秘匿が指示されている項目「年齢」「身長」「体重」の値をnullに設定して図30に示すようなデータを生成する。
【0074】
また、第2検証処理部160は、検証成功レコードを配布処理部180に出力し、配布処理部180は、受信した検証成功レコードを配布データ格納部190に格納する(ステップS129)。その後、呼び出し元の処理に戻る。
【0075】
図23の処理の説明に戻って、配布処理部180は、データ配布処理を実施する(ステップS71)。データ配布処理については、図31及び図32を用いて説明する。
【0076】
まず、配布処理部180は、第1検証処理部140及び第2検証処理部160から受信し配布データ格納部190に格納されている検証成功レコード及び復元データによって、検証成功データ格納部170を更新する(図31:ステップS131)。本実施の形態では、検証成功データ格納部170については、例えば図15のようなデータを格納する。すなわち、同一のレコードについては1レコードのみを残し、重複レコード数を登録する。既に検証成功データ格納部170に同一のレコードが含まれている場合には、重複レコード数を増分する。なお、このようなレコードの集約を行ってしまうので、レコード管理IDは認証成功データ格納部170には格納されない。
【0077】
さらに、配布処理部180は、検証成功レコード、復元データ及び秘匿化された検証失敗レコードを結合して配布データを生成する(ステップS133)。そして、配布処理部180は、生成された配布データを、ターゲットシステムC及びDに配布する(ステップS135)。例えば、図32に示すようなデータを、ターゲットシステムC及びDに配布する。上でも述べたように、番号3、番号4、番号8及び番号10のレコードについては秘匿化されているので、「年齢」「身長」「体重」の項目値がnullに設定されている。そして呼び出し元の処理に戻る。
【0078】
このような処理を実施すれば、匿名化が確保されていると検証されたレコードについてはデータ変換後のデータをそのままターゲットシステムに配布し、匿名性が確保されていないレコードについては秘匿化したデータをターゲットシステムに配布する。これにより、ターゲットシステムにおいて適切な処理を行うことができる。
【0079】
なお、次のタイミングで収集されたデータに対してデータ変換処理を実施すると、図17のようなデータが得られた場合について説明する。
【0080】
このような場合、第3検証処理においては、図13に示した前回の検証失敗レコードと今回のレコードとを結合して、それらのレコードについて同一のレコードを探索する。そうすると図18に示すように、番号3と番号12のレコードが一致し、番号10と番号15のレコードが一致し、番号4と番号13のレコードが一致し、番号8と番号14のレコードが一致している。
【0081】
従って、図33に示すように、番号3、番号4、番号8及び番号10のレコードについては、復元データとして特定される。また、図34に示すように、番号12乃至15のレコードについては、検証成功レコードとして特定される。さらに、図35に示すように、番号11のレコードについては、検証失敗レコードとして特定され、検証失敗データ格納部150に一旦格納される。検証成功レコード及び検証失敗レコードについては、第1検証処理部140においてレコード管理IDを付与するようにしても良いし、配布処理部180において付与するようにしてもよい。
【0082】
その後、第4検証処理において、図35に示した検証失敗レコードについては、図15に示し且つ検証成功データ格納部170に格納されているデータとの照合を行う。そうすると、図15における最初のレコードと一致していることが分かるので、図35に示した検証失敗レコードについても配布データ格納部190に格納される。さらに、図15に示した検証成功データ格納部170に格納されているデータは、図21に示すように更新される。すなわち、新たに検証成功とされたレコードについては追加され、同一のレコードが検出されれば重複レコード数が増分される。このような処理を繰り返すことになる。
【0083】
また、配布処理部180は、復元データ、検証成功レコード及び秘匿化された検証失敗レコードを結合して配布データを生成するが、上で述べた例では検証失敗レコードが存在しないので、復元データ及び検証成功レコードによって、図36に示すような配布データが生成される。本実施の形態ではレコード管理IDも配布データに含まれる。ターゲットシステム側では、既に受信したレコードのレコード管理IDと同一のレコード管理IDを含むレコードを受信すると、今回受信した配布データに含まれるレコードで更新を行う。すなわち、元々のレコードのデータを復元することになる。図36の例では、上の4行については既に配布されているレコードを更新するために送信される。一方、新たに検証成功レコードとして特定されたレコードについては、ターゲットシステム側では、同一レコードは存在していないので、ターゲットシステム側のデータベースに追加されることになる。そして、ターゲットシステムC及びDでは、図32に示すようなデータは、図37に示すようなデータに更新される。
【0084】
以上本技術の実施の形態を説明したが、本技術はこれに限定されるものではない。上で述べた機能ブロック図は一例であって、必ずしも実際のプログラムモジュールと一致するわけではない。また、データ構造やデータ保持の態様についても一例であって、上で述べた例は一例に過ぎない。さらに、上では1種類のデータについて処理を行う例を示したが、複数種類のデータを取り扱う場合もある。その場合には、検証成功レコード、検証失敗レコード及び復元データについて識別子を付して区別する。
【0085】
また、処理フローについては、処理結果が変わらない限りにおいてステップの実行順番を入れ替えたり、並列実行する場合もある。
【0086】
なお、上で述べた情報処理装置1000、ソースシステムA及びB、並びにターゲットシステムC及びDは、1又は複数のコンピュータ装置であって、図38に示すように、メモリ2501とCPU(Central Processing Unit)2503とハードディスク・ドライブ(HDD:Hard Disk Drive)2505と表示装置2509に接続される表示制御部2507とリムーバブル・ディスク2511用のドライブ装置2513と入力装置2515とネットワークに接続するための通信制御部2517とがバス2519で接続されている。オペレーティング・システム(OS:Operating System)及び本実施例における処理を実施するためのアプリケーション・プログラムは、HDD2505に格納されており、CPU2503により実行される際にはHDD2505からメモリ2501に読み出される。CPU2503は、アプリケーション・プログラムの処理内容に応じて表示制御部2507、通信制御部2517、ドライブ装置2513を制御して、所定の動作を行わせる。また、処理途中のデータについては、主としてメモリ2501に格納されるが、HDD2505に格納されるようにしてもよい。本技術の実施例では、上で述べた処理を実施するためのアプリケーション・プログラムはコンピュータ読み取り可能なリムーバブル・ディスク2511に格納されて頒布され、ドライブ装置2513からHDD2505にインストールされる。インターネットなどのネットワーク及び通信制御部2517を経由して、HDD2505にインストールされる場合もある。このようなコンピュータ装置は、上で述べたCPU2503、メモリ2501などのハードウエアとOS及びアプリケーション・プログラムなどのプログラムとが有機的に協働することにより、上で述べたような各種機能を実現する。
【0087】
以上述べた本実施の形態をまとめると、以下のようになる。
【0088】
本実施の形態に係る情報処理方法は、(A)第1のシステムから取得した複数のレコードから、予め定められた同一性の条件を満たすレコードの数が所定数以上となっているレコードである第1のレコードを抽出する第1の処理と、(B)複数のレコードのうち第1のレコード以外のレコードである第2のレコードから、予め定められた同一性の条件を満たすレコードの数が所定数以上となっているレコードとして既に抽出され且つデータ格納部に格納されているレコード群と第2のレコードとの組み合わせで上記予め定められた同一性の条件を満たすレコードの数が所定数以上となっているレコードである第3のレコードを抽出する第2の処理と、(C)第1のレコードと第3のレコードとを、第2のシステムに出力する第3の処理とを含む。
【0089】
このような処理を実施することで、より多くのレコードを第2のシステムに出力することができるようになる。すなわち、匿名性が確保されたより多くのレコードを第2のシステムで活用できるようになる。データ格納部には、予め定められた同一性を有するレコードを集約したデータを保持しておいても良いし、全てのレコードを蓄積するようにしても良い。
【0090】
また、上で述べた複数のレコードが、新たに第1のシステムから取得したレコードと、前回第1のシステムから取得されたが第1の処理及び第2の処理にて抽出されなったレコードとを含むようにしてもよい。このようにすることで、一度検証に失敗した場合でも、後に得たレコード群との関係で匿名性が確保できる可能性もある。
【0091】
さらに、上記情報処理方法は、(D)複数のレコードのうち第1のレコード及び第3のレコード以外のレコードである第4のレコードの少なくとも一部の属性値を秘匿化して第5のレコードを生成する第4の処理と、(E)第5のレコードを第2のシステムに出力する第5の処理と、(F)第1のシステムから新たに取得したレコードと第4のレコードとから、上記予め定められた同一性の条件を満たすレコードの数が所定数以上となっているレコードを抽出する第6の処理と、(G)第6の処理で抽出されたレコードが第4のレコードである場合には、第5のレコードを第4のレコードに復元するためのデータを第2のシステムに出力する第7の処理とをさらに含むようにしてもよい。このようにすることで、匿名性が確保できないレコードについては秘匿化を行った上で第2のシステムに出力することができるようになる。さらに、後に収集されたレコードによって匿名性が確保できれば、秘匿化を行ったレコードについて元のデータを復元するように指示することもできるようになる。
【0092】
さらに、本実施の形態に係る情報処理装置(図39:4000)は、(A)第1のシステムから取得した複数のレコードから、予め定められた同一性の条件を満たすレコードの数が所定数以上となっているレコードである第1のレコードを抽出する第1処理部(図39:4100)と、(B)複数のレコードのうち第1のレコード以外のレコードである第2のレコードから、上記予め定められた同一性の条件を満たすレコードの数が所定数以上となっているレコードとして既に抽出され且つデータ格納部(図39:4300)に格納されているレコード群と第2のレコードとの組み合わせで上記予め定められた同一性の条件を満たすレコードの数が所定数以上となっているレコードである第3のレコードを抽出する第2処理部(図39:4200)と、(C)第1のレコードと第3のレコードとを、第2のシステムに出力する第3処理部(図39:4400)とを有する。
【0093】
なお、上で述べたような処理をコンピュータに実施させるためのプログラムを作成することができ、当該プログラムは、例えばフレキシブル・ディスク、CD−ROMなどの光ディスク、光磁気ディスク、半導体メモリ(例えばROM)、ハードディスク等のコンピュータ読み取り可能な記憶媒体又は記憶装置に格納される。なお、処理途中のデータについては、RAM等の記憶装置に一時保管される。
【0094】
以上の実施例を含む実施形態に関し、さらに以下の付記を開示する。
【0095】
(付記1)
第1のデータ群に含まれるN(Nは自然数)個以上のデータとの間で所定の関係を持つ、複数のデータを格納部に格納し、
前記第1のデータ群と異なる第2のデータ群に含まれるあるデータが、前記第2のデータ群に含まれるN個以上のデータとの間で前記所定の関係を持たない場合に、前記あるデータが、前記格納部に格納された前記複数のデータに含まれるN個以上のデータと前記所定の関係を持つか否かの判定を行い、
前記判定により、前記所定の関係を持つと判定した場合に、前記あるデータを前記格納部に格納する
ことをコンピュータに実行させるための判定プログラム。
【0096】
(付記2)
前記所定の関係は、一方のデータの所定部分と他方のデータの所定部分とが共通する関係を含むことを特徴とする付記1記載の判定プログラム。
【0097】
(付記3)
前記第2のデータ群が、前記第1のデータ群のうち前記複数のデータ以外のデータを含む
付記1又は2記載の判定プログラム。
【0098】
(付記4)
前記第1のデータ群のうち前記複数のデータ以外のデータの各々の少なくとも一部を秘匿化し、少なくとも一部が秘匿化されたデータを第2の格納部に格納し、
前記第1のデータ群のうち前記複数のデータ以外のデータが、前記第1のデータ群と異なる第3のデータ群に含まれるN個以上のデータとの間で前記所定の関係を持つ場合には、前記第2の格納部において前記少なくとも一部が秘匿化されたデータの秘匿化された部分を元のデータに復元させる
付記1乃至3のいずれか1つ記載の判定プログラム。
【0099】
(付記5)
第1のデータ群に含まれるN(Nは自然数)個以上のデータとの間で所定の関係を持つ、複数のデータを格納部に格納し、
前記第1のデータ群と異なる第2のデータ群に含まれるあるデータが、前記第2のデータ群に含まれるN個以上のデータとの間で前記所定の関係を持たない場合に、前記あるデータが、前記格納部に格納された前記複数のデータに含まれるN個以上のデータと前記所定の関係を持つか否かの判定を行い、
前記判定により、前記所定の関係を持つと判定した場合に、前記あるデータを前記格納部に格納する
ことをコンピュータが実行する情報処理方法。
【0100】
(付記6)
格納部と、
第1のデータ群に含まれるN(Nは自然数)個以上のデータとの間で所定の関係を持つ、複数のデータを前記格納部に格納し、前記第1のデータ群と異なる第2のデータ群に含まれるあるデータが、前記第2のデータ群に含まれるN個以上のデータとの間で前記所定の関係を持たない場合に、前記あるデータが、前記格納部に格納された前記複数のデータに含まれるN個以上のデータと前記所定の関係を持つか否かの判定を行い、前記判定により、前記所定の関係を持つと判定した場合に、前記あるデータを前記格納部に格納する処理部と、
を有する情報処理装置。
【符号の説明】
【0101】
1000 情報処理装置
100 データ収集部
110 収集データ格納部
120 データ変換部
130 変換データ格納部
140 第1検証処理部
150 検証失敗データ格納部
160 第2検証処理部
170 検証成功データ格納部
180 配布処理部
190 配布データ格納部
200 定義管理部
210 定義データ格納部
【特許請求の範囲】
【請求項1】
第1のデータ群に含まれるN(Nは自然数)個以上のデータとの間で所定の関係を持つ、複数のデータを格納部に格納し、
前記第1のデータ群と異なる第2のデータ群に含まれるあるデータが、前記第2のデータ群に含まれるN個以上のデータとの間で前記所定の関係を持たない場合に、前記あるデータが、前記格納部に格納された前記複数のデータに含まれるN個以上のデータと前記所定の関係を持つか否かの判定を行い、
前記判定により、前記所定の関係を持つと判定した場合に、前記あるデータを前記格納部に格納する
ことをコンピュータに実行させるための判定プログラム。
【請求項2】
前記所定の関係は、一方のデータの所定部分と他方のデータの所定部分とが共通する関係を含むことを特徴とする請求項1記載の判定プログラム。
【請求項3】
前記第2のデータ群が、前記第1のデータ群のうち前記複数のデータ以外のデータを含む
請求項1又は2記載の判定プログラム。
【請求項4】
前記第1のデータ群のうち前記複数のデータ以外のデータの各々の少なくとも一部を秘匿化し、少なくとも一部が秘匿化されたデータを第2の格納部に格納し、
前記第1のデータ群のうち前記複数のデータ以外のデータが、前記第1のデータ群と異なる第3のデータ群に含まれるN個以上のデータとの間で前記所定の関係を持つ場合には、前記第2の格納部において前記少なくとも一部が秘匿化されたデータの秘匿化された部分を元のデータに復元させる
請求項1乃至3のいずれか1つ記載の判定プログラム。
【請求項5】
第1のデータ群に含まれるN(Nは自然数)個以上のデータとの間で所定の関係を持つ、複数のデータを格納部に格納し、
前記第1のデータ群と異なる第2のデータ群に含まれるあるデータが、前記第2のデータ群に含まれるN個以上のデータとの間で前記所定の関係を持たない場合に、前記あるデータが、前記格納部に格納された前記複数のデータに含まれるN個以上のデータと前記所定の関係を持つか否かの判定を行い、
前記判定により、前記所定の関係を持つと判定した場合に、前記あるデータを前記格納部に格納する
ことをコンピュータが実行する情報処理方法。
【請求項6】
格納部と、
第1のデータ群に含まれるN(Nは自然数)個以上のデータとの間で所定の関係を持つ、複数のデータを前記格納部に格納し、前記第1のデータ群と異なる第2のデータ群に含まれるあるデータが、前記第2のデータ群に含まれるN個以上のデータとの間で前記所定の関係を持たない場合に、前記あるデータが、前記格納部に格納された前記複数のデータに含まれるN個以上のデータと前記所定の関係を持つか否かの判定を行い、前記判定により、前記所定の関係を持つと判定した場合に、前記あるデータを前記格納部に格納する処理部と、
を有する情報処理装置。
【請求項1】
第1のデータ群に含まれるN(Nは自然数)個以上のデータとの間で所定の関係を持つ、複数のデータを格納部に格納し、
前記第1のデータ群と異なる第2のデータ群に含まれるあるデータが、前記第2のデータ群に含まれるN個以上のデータとの間で前記所定の関係を持たない場合に、前記あるデータが、前記格納部に格納された前記複数のデータに含まれるN個以上のデータと前記所定の関係を持つか否かの判定を行い、
前記判定により、前記所定の関係を持つと判定した場合に、前記あるデータを前記格納部に格納する
ことをコンピュータに実行させるための判定プログラム。
【請求項2】
前記所定の関係は、一方のデータの所定部分と他方のデータの所定部分とが共通する関係を含むことを特徴とする請求項1記載の判定プログラム。
【請求項3】
前記第2のデータ群が、前記第1のデータ群のうち前記複数のデータ以外のデータを含む
請求項1又は2記載の判定プログラム。
【請求項4】
前記第1のデータ群のうち前記複数のデータ以外のデータの各々の少なくとも一部を秘匿化し、少なくとも一部が秘匿化されたデータを第2の格納部に格納し、
前記第1のデータ群のうち前記複数のデータ以外のデータが、前記第1のデータ群と異なる第3のデータ群に含まれるN個以上のデータとの間で前記所定の関係を持つ場合には、前記第2の格納部において前記少なくとも一部が秘匿化されたデータの秘匿化された部分を元のデータに復元させる
請求項1乃至3のいずれか1つ記載の判定プログラム。
【請求項5】
第1のデータ群に含まれるN(Nは自然数)個以上のデータとの間で所定の関係を持つ、複数のデータを格納部に格納し、
前記第1のデータ群と異なる第2のデータ群に含まれるあるデータが、前記第2のデータ群に含まれるN個以上のデータとの間で前記所定の関係を持たない場合に、前記あるデータが、前記格納部に格納された前記複数のデータに含まれるN個以上のデータと前記所定の関係を持つか否かの判定を行い、
前記判定により、前記所定の関係を持つと判定した場合に、前記あるデータを前記格納部に格納する
ことをコンピュータが実行する情報処理方法。
【請求項6】
格納部と、
第1のデータ群に含まれるN(Nは自然数)個以上のデータとの間で所定の関係を持つ、複数のデータを前記格納部に格納し、前記第1のデータ群と異なる第2のデータ群に含まれるあるデータが、前記第2のデータ群に含まれるN個以上のデータとの間で前記所定の関係を持たない場合に、前記あるデータが、前記格納部に格納された前記複数のデータに含まれるN個以上のデータと前記所定の関係を持つか否かの判定を行い、前記判定により、前記所定の関係を持つと判定した場合に、前記あるデータを前記格納部に格納する処理部と、
を有する情報処理装置。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】

【図16】
【図17】
【図18】
【図19】
【図20】

【図21】
【図22】
【図23】
【図24】

【図25】
【図26】
【図27】
【図28】
【図29】
【図30】
【図31】
【図32】
【図33】
【図34】
【図35】

【図36】
【図37】
【図38】
【図39】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【図23】
【図24】
【図25】
【図26】
【図27】
【図28】
【図29】
【図30】
【図31】
【図32】
【図33】
【図34】
【図35】
【図36】
【図37】
【図38】
【図39】
【公開番号】特開2013−73429(P2013−73429A)
【公開日】平成25年4月22日(2013.4.22)
【国際特許分類】
【出願番号】特願2011−212062(P2011−212062)
【出願日】平成23年9月28日(2011.9.28)
【出願人】(000005223)富士通株式会社 (25,993)
【Fターム(参考)】
【公開日】平成25年4月22日(2013.4.22)
【国際特許分類】
【出願日】平成23年9月28日(2011.9.28)
【出願人】(000005223)富士通株式会社 (25,993)
【Fターム(参考)】
[ Back to top ]