
情報処理装置、および情報処理方法、並びにプログラム
【課題】不確実で非同期な入力情報に基づく情報解析により、ユーザ位置や識別情報、発話者情報などを生成する構成を実現する。
【解決手段】画像情報や音声情報に基づいてユーザの推定位置および推定識別データを含むイベント情報を入力し、入力イベント情報に基づいて、各ユーザの位置およびユーザ識別情報を含むターゲット情報と、イベント発生源の確率値を示すシグナル情報を生成する情報統合処理部を有し、情報統合処理部は、発話源確率算出部を有し、発話源確率算出部は、各ターゲットの発話源確率を示す指標値としての発話源スコアを、イベント検出部から入力する複数の異なる情報に対して発話状況に応じた重みを乗算して算出する処理を行う。
【解決手段】画像情報や音声情報に基づいてユーザの推定位置および推定識別データを含むイベント情報を入力し、入力イベント情報に基づいて、各ユーザの位置およびユーザ識別情報を含むターゲット情報と、イベント発生源の確率値を示すシグナル情報を生成する情報統合処理部を有し、情報統合処理部は、発話源確率算出部を有し、発話源確率算出部は、各ターゲットの発話源確率を示す指標値としての発話源スコアを、イベント検出部から入力する複数の異なる情報に対して発話状況に応じた重みを乗算して算出する処理を行う。
【発明の詳細な説明】
【技術分野】
【0001】
本開示は、情報処理装置、および情報処理方法、並びにプログラムに関する。さらに詳細には、外界からの入力情報、例えば画像、音声などの情報を入力し、入力情報に基づく外界環境の解析、具体的には言葉を発している人物の位置や誰であるか等の解析処理を実行する情報処理装置、および情報処理方法、並びにプログラムに関する。
【0002】
さらに、複数の人物が同時発話を行った場合に、発声したユーザの識別を行い、それぞれの発話を解析する情報処理装置、および情報処理方法、並びにプログラムに関する。
【背景技術】
【0003】
人とPCやロボットなどの情報処理装置との相互間の処理、例えばコミュニケーションやインタラクティブ処理を行うシステムはマン−マシン・インタラクション・システムと呼ばれる。このマン−マシン・インタラクション・システムにおいて、PCやロボット等の情報処理装置は、人のアクション例えば人の動作や言葉を認識するために画像情報や音声情報を入力して入力情報に基づく解析を行う。
【0004】
人が情報を伝達する場合、言葉のみならずしぐさ、視線、表情など様々なチャネルを情報伝達チャネルとして利用する。このようなすべてのチャネルの解析をマシンにおいて行うことができれば、人とマシンとのコミュニケーションも人と人とのコミュニケーションと同レベルに到達することができる。このような複数のチャネル(モダリティ、モーダルとも呼ばれる)からの入力情報の解析を行うインタフェースは、マルチモーダルインタフェースと呼ばれ、近年、開発、研究が盛んに行われている。
【0005】
例えばカメラによって撮影された画像情報、マイクによって取得された音声情報を入力して解析を行う場合、より詳細な解析を行うためには、様々なポイントに設置した複数のカメラおよび複数のマイクから多くの情報を入力することが有効である。
【0006】
具体的なシステムとしては、例えば以下のようなシステムが想定される。情報処理装置(テレビ)が、カメラおよびマイクを介して、テレビの前のユーザ(父、母、姉、弟)の画像および音声を入力し、それぞれのユーザの位置やどのユーザが発した言葉であるか等を解析し、テレビが解析情報に応じた処理、例えば会話を行ったユーザに対するカメラのズームアップや、会話を行ったユーザに対する的確な応答を行うなどのシステムが実現可能となる。
【0007】
従来のマン−マシン・インタラクション・システムを開示した従来技術として、例えば特許文献1(特開2009−31951号公報)や、特許文献2(特開2009−140366号公報)がある。これらの従来技術では、複数チャネル(モーダル)からの情報を確率的に統合して、複数のユーザがそれぞれどこにいて、それらは誰で、誰がシグナルを発したのか、すなわち発話行ったのかを決定するという処理を行っている。
【0008】
例えば誰がシグナルを発したのかを決定する際に、複数のユーザに対応する仮想的なターゲット(tID=1〜m)を設定し、カメラによって撮影される画像データや、マイクを介して得られる音声情報の解析結果から各ターゲットが発話源である確率を算出している。
【0009】
具体的には、例えば以下のような処理を行っている。
(a)マイクを介して得られる音声イベントの音源方向情報、話者識別情報から得られるユーザ位置情報と、ユーザ識別情報のみから得られるターゲットtIDの発話源確率P(tID)と、
(b)カメラを介して得られる画像に基づく顔認識処理によって取得される顔属性スコア[S(tID)]の面積であるSΔt(tID)、
これらの(a),(b)を算出し、さらに予め設定した配分重み係数としてのαを用いて重みαを考慮した加算または乗算によって、各ターゲット(tID=1〜m)の発話者確率Ps(tID)またはPp(tID)を算出する。
なお、この処理の詳細は、例えば上記の特許文献2(特開2009−140366号公報)に記載されている。
【0010】
上記の従来技術における発話者確率の算出処理においては、上記のように重み係数αを事前に調整しておくことが必要となる。このような重み係数の事前調整は煩わしいばかりでなく、重み係数が適切な数値に調整されていないと、発話者確率の算出結果の妥当性そのものにも大きく影響を与えるという問題がある。
【先行技術文献】
【特許文献】
【0011】
【特許文献1】特開2009−31951号公報
【特許文献2】特開2009−140366号公報
【発明の概要】
【発明が解決しようとする課題】
【0012】
本開示は、例えば上述の問題点に鑑みてなされたものであり、複数のチャネル(モダリティ、モーダル)からの入力情報の解析、具体的には、例えば周囲にいる人物の位置などの特定処理を行うシステムにおいて、画像、音声情報などの様々な入力情報に含まれる不確実な情報に対する確率的な処理を行ってより精度の高いと推定される情報に統合する処理を行うことによりロバスト性を向上させ、精度の高い解析を行う情報処理装置、および情報処理方法、並びにプログラムを提供することを目的とする。
【0013】
また、本開示の一実施例では、複数の人物が同時発話を行った場合に、発声したユーザの識別を行い、それぞれの発話を解析する情報処理装置、および情報処理方法、並びにプログラムを提供することを目的とする。
【課題を解決するための手段】
【0014】
本開示の第1の側面は、
実空間の観測情報を入力する複数の情報入力部と、
前記情報入力部から入力する情報の解析により、前記実空間に存在するユーザの推定位置情報および推定識別情報を含むイベント情報を生成するイベント検出部と、
前記イベント情報を入力し、入力イベント情報に基づいて、各ユーザの位置およびユーザ識別情報を含むターゲット情報と、
前記イベント発生源の確率値を示すシグナル情報を生成する情報統合処理部を有し、
前記情報統合処理部は、発話源確率算出部を有し、
前記発話源確率算出部は、各ターゲットの発話源確率を示す指標値としての発話源スコアを、イベント検出部から入力する複数の異なる情報に対して発話状況に応じた重みを乗算して算出する処理を行う情報処理装置にある。
【0015】
さらに、本開示の情報処理装置の一実施態様において、前記発話源確率算出部は、前記イベント検出部を構成する音声イベント検出部からの入力情報として、発話イベントに対応する、
(a)ユーザ位置情報(音源方向情報)、
(b)ユーザ識別情報(話者識別情報)、
を入力し、
さらに、前記イベント検出部を構成する画像イベント検出部からの入力情報に基づいて生成されるターゲット情報として、
(a)ユーザ位置情報(顔位置情報)、
(b)ユーザ識別情報(顔識別情報)、
(c)口唇動作情報、
これらの情報を入力し、少なくともこれらの情報のいずれかを適用して、入力情報に基づく発話源スコアを算出する処理を行う。
【0016】
さらに、本開示の情報処理装置の一実施態様において、前記発話源確率算出部は、音源方向情報Dと、話者識別情報Sと、口唇動作情報Lを適用して、発話源スコアPを、以下の算出式、
P=Dα・Sβ・Lγ
ただし、
α:音源方向情報の重み係数、
β:話者識別情報の重み係数、
γ:口唇動作情報の重み係数、
α+β+γ=1
上記発話源スコアPの算出式に従って発話源スコアを算出する処理を行う。
【0017】
さらに、本開示の情報処理装置の一実施態様において、前記発話源確率算出部は、前記各重み係数:α、β、γを発話状況に応じて調整する処理を行う。
【0018】
さらに、本開示の情報処理装置の一実施態様において、前記発話源確率算出部は、以下の2つの条件、
(条件1)1つのターゲットのみによる単独発話か、あるいは2つのターゲットによる同時発話か、
(条件2)2つのターゲットの位置が近いか、あるいは2つのターゲットの位置が遠いか、
上記2つの条件に応じて、前記各重み係数:α、β、γを調整する処理を行う。
【0019】
さらに、本開示の情報処理装置の一実施態様において、前記発話源確率算出部は、発話可能性のあるターゲットが2である状況において、2つのターゲットが同時発声する場合、口唇動作情報の重みγを小さくするように前記各重み係数:α、β、γを調整する処理を行う。
【0020】
さらに、本開示の情報処理装置の一実施態様において、前記発話源確率算出部は、発話可能性のあるターゲットが2である状況において、2つのターゲットの位置が近く、1ターゲットのみが単独発声する場合、音源方向情報の重みαを小さくするように前記各重み係数:α、β、γを調整する処理を行う。
【0021】
さらに、本開示の情報処理装置の一実施態様において、前記発話源確率算出部は、発話可能性のあるターゲットが2である状況において、2つのターゲットの位置が近く、2つのターゲットが同時に発声する場合、口唇動作情報の重みγと音源方向情報の重みαを小さくするように前記各重み係数:α、β、γを調整する処理を行う。
【0022】
さらに、本開示の第2の側面は、
情報処理装置において、情報解析処理を実行する情報処理方法であり、
複数の情報入力部が、実空間における観測情報を入力する情報入力ステップと、
イベント検出部が、前記情報入力部から入力する情報の解析により、前記実空間に存在するユーザの推定位置情報および推定識別情報を含むイベント情報を生成するイベント検出ステップと、
情報統合処理部が、前記イベント情報を入力し、入力イベント情報に基づいて、各ユーザの位置およびユーザ識別情報を含むターゲット情報と、
前記イベント発生源の確率値を示すシグナル情報を生成する情報統合処理ステップを有し、
前記情報統合処理ステップは、
各ターゲットの発話源確率を示す指標値としての発話源スコアを、イベント検出ステップにおいて入力する複数の異なる情報に対して発話状況に応じた重みを乗算して算出する処理を行う情報処理方法にある。
【0023】
さらに、本開示の第3の側面は、
情報処理装置において、情報解析処理を実行させるプログラムであり、
複数の情報入力部に、実空間における観測情報を入力させる情報入力ステップと、
イベント検出部に、前記情報入力部から入力する情報の解析により、前記実空間に存在するユーザの推定位置情報および推定識別情報を含むイベント情報を生成させるイベント検出ステップと、
情報統合処理部に、前記イベント情報を入力し、入力イベント情報に基づいて、各ユーザの位置およびユーザ識別情報を含むターゲット情報と、
前記イベント発生源の確率値を示すシグナル情報を生成させる情報統合処理ステップを実行させ、
前記情報統合処理ステップにおいては、
各ターゲットの発話源確率を示す指標値としての発話源スコアを、イベント検出ステップにおいて入力する複数の異なる情報に対して発話状況に応じた重みを乗算して算出する処理を行わせるプログラムにある。
【0024】
なお、本開示のプログラムは、例えば、様々なプログラム・コードを実行可能な情報処理装置やコンピュータ・システムに対して、コンピュータ可読な形式で提供する記憶媒体、通信媒体によって提供可能なプログラムである。このようなプログラムをコンピュータ可読な形式で提供することにより、情報処理装置やコンピュータ・システム上でプログラムに応じた処理が実現される。
【0025】
本開示のさらに他の目的、特徴や利点は、後述する実施例や添付する図面に基づくより詳細な説明によって明らかになるであろう。なお、本明細書においてシステムとは、複数の装置の論理的集合構成であり、各構成の装置が同一筐体内にあるものには限らない。
【発明の効果】
【0026】
本開示の一実施例の構成によれば、不確実で非同期な入力情報に基づく情報解析により、ユーザ位置や識別情報、発話者情報などを生成する構成が実現される。
具体的には、画像情報や音声情報に基づいてユーザの推定位置および推定識別データを含むイベント情報を入力し、入力イベント情報に基づいて、各ユーザの位置およびユーザ識別情報を含むターゲット情報と、イベント発生源の確率値を示すシグナル情報を生成する情報統合処理部を有し、情報統合処理部は、発話源確率算出部を有し、発話源確率算出部は、各ターゲットの発話源確率を示す指標値としての発話源スコアを、イベント検出部から入力する複数の異なる情報に対して発話状況に応じた重みを乗算して算出する処理を行う。
これらの処理によって、例えば2つのターゲット(2人)が同時に発話した状況においても、どちらが発話したかを高精度に推定することが可能となる。
【図面の簡単な説明】
【0027】
【図1】本開示に係る情報処理装置の実行する処理の概要について説明する図である。
【図2】本開示の一実施例の情報処理装置の構成および処理について説明する図である。
【図3】音声イベント検出部122および画像イベント検出部112が生成し情報統合処理部131に入力する情報の例について説明する図である。
【図4】パーティクル・フィルタ(Particle Filter)を適用した基本的な処理例について説明する図である。
【図5】本処理例で設定するパーティクルの構成について説明する図である。
【図6】各パーティクルに含まれるターゲット各々が有するターゲットデータの構成について説明する図である。
【図7】ターゲット情報の構成および生成処理について説明する図である。
【図8】ターゲット情報の構成および生成処理について説明する図である。
【図9】ターゲット情報の構成および生成処理について説明する図である。
【図10】情報統合処理部131の実行する処理シーケンスを説明するフローチャートを示す図である。
【図11】パーティクル重み[WpID]の算出処理の詳細について説明する図である。
【図12】発話者特定処理について説明する図である。
【図13】発話源確率算出部の実行する処理シーケンスの一例について説明するフローチャートを示す図である。
【図14】発話源確率算出部の実行する発話源スコアの算出処理について説明する図である。
【図15】発話源確率算出部の実行する発話源スコアの算出処理シーケンスを説明するフローチャートを示す図である。
【図16】発話源確率算出部の実行する発話源スコアの算出処理における重み係数の決定要素となる発話状況の例について説明する図である。
【図17】発話源確率算出部の実行する発話源スコアの算出処理における重み係数の決定処理例について説明する図である。
【図18】発話源確率算出部の実行する発話源スコアの算出処理における重み係数の決定処理例について説明する図である。
【発明を実施するための形態】
【0028】
以下、図面を参照しながら本開示の実施形態に係る情報処理装置、および情報処理方法、並びにプログラムの詳細について説明する。なお、説明は以下の項目に従って行う。
1.本開示の情報処理装置の実行する処理の概要について
2,本開示の情報処理装置の構成と処理の詳細について
3.本開示の情報処理装置の実行する処理シーケンスについて
4.発話源確率算出部の実行する処理の詳細について
5.発話源スコアの算出処理について
6.本開示の構成のまとめ
【0029】
[1.本開示の情報処理装置の実行する処理の概要について]
ます、本開示の情報処理装置の実行する処理の概要について説明する。
本開示は、例えば、入力イベント情報の内、ユーザの発話に対応する音声イベント情報に関しては、発話源確率の算出において識別器を用い、背景技術の欄において説明した重み係数の事前調整を行う必要のない構成を実現するものである。
具体的には、各ターゲットが発話源らしいかどうかを識別する識別器や、2つのターゲット情報のみを対象として、どちらがより発話源らしいか判定する識別器を用いる。識別器への入力情報は、音声イベント情報に含まれる音源方向情報や話者識別情報や、イベント情報の内、画像イベント情報に含まれる口唇動作情報や、ターゲット情報に含まれるターゲット位置やターゲット総数を用いる。発話源確率の算出において識別器を用いることによって、背景技術の欄において説明した重み係数の事前調整が必要なくなり、且つより適切な発話源確率の算出が可能となる。
【0030】
まず、図1を参照して本開示に係る情報処理装置の実行する処理の概要について説明する。本開示の情報処理装置100は、実空間における観測情報を入力するセンサ、ここでは一例としてカメラ21と、複数のマイク31〜34から画像情報、音声情報を入力し、これらの入力情報に基づいて環境の解析を行う。具体的には、複数のユーザ1,11〜2,12の位置の解析、およびその位置にいるユーザの識別を行う。
【0031】
図に示す例において、例えばユーザ1,11〜ユーザ2,12が家族である姉、弟であるとき、情報処理装置100は、カメラ21と、複数のマイク31〜34から入力する画像情報、音声情報の解析を行い、2人のユーザ1〜2の存在する位置、各位置にいるユーザが姉、弟のいずれであるかを識別する。識別処理結果は様々な処理に利用される。例えば、例えば会話を行ったユーザに対するカメラのズームアップや、会話を行ったユーザに対してテレビから応答を行うなどの処理に利用される。
【0032】
なお、本開示に係る情報処理装置100の主要な処理は、複数の情報入力部(カメラ21,マイク31〜34)からの入力情報に基づいて、ユーザの位置識別およびユーザの特定処理としてのユーザ識別処理を行うことである。この識別結果の利用処理については特に限定するものではない。カメラ21と、複数のマイク31〜34から入力する画像情報、音声情報には様々な不確実な情報が含まれる。本開示の情報処理装置100では、これらの入力情報に含まれる不確実な情報に対する確率的な処理を行って、精度の高いと推定される情報に統合する処理を行う。この推定処理によりロバスト性を向上させ、精度の高い解析を行う。
【0033】
[2,本開示の情報処理装置の構成と処理の詳細について]
図2に情報処理装置100の構成例を示す。情報処理装置100は、入力デバイスとして画像入力部(カメラ)111、複数の音声入力部(マイク)121a〜dを有する。画像入力部(カメラ)111から画像情報を入力し、音声入力部(マイク)121から音声情報を入力し、これらの入力情報に基づいて解析を行う。複数の音声入力部(マイク)121a〜dの各々は、図1に示すように様々な位置に配置されている。
【0034】
複数のマイク121a〜dから入力された音声情報は、音声イベント検出部122を介して情報統合処理部131に入力される。音声イベント検出部122は、複数の異なるポジションに配置された複数の音声入力部(マイク)121a〜dから入力する音声情報を解析し統合する。具体的には、音声入力部(マイク)121a〜dから入力する音声情報に基づいて、発生した音の位置およびどのユーザの発生させた音であるかのユーザ識別情報を生成して情報統合処理部131に入力する。
【0035】
なお、情報処理装置100の実行する具体的な処理は、例えば図1に示すように複数のユーザが存在する環境で、ユーザA〜Bがどの位置にいて、会話を行ったユーザがどのユーザであるかを識別すること、すなわち、ユーザ位置およびユーザ識別を行うことであり、さらに声を発した人物(発話者)などのイベント発生源を特定する処理である。
【0036】
音声イベント検出部122は、複数の異なるポジションに配置された複数の音声入力部(マイク)121a〜dから入力する音声情報を解析し、音声の発生源の位置情報を確率分布データとして生成する。具体的には、音源方向に関する期待値と分散データN(me,σe)を生成する。また、予め登録されたユーザの声の特徴情報との比較処理に基づいてユーザ識別情報を生成する。この識別情報も確率的な推定値として生成する。音声イベント検出部122には、予め検証すべき複数のユーザの声についての特徴情報が登録されており、入力音声と登録音声との比較処理を実行して、どのユーザの声である確率が高いかを判定する処理を行い、全登録ユーザに対する事後確率、あるいはスコアを算出する。
【0037】
このように、音声イベント検出部122は、複数の異なるポジションに配置された複数の音声入力部(マイク)121a〜dから入力する音声情報を解析し、音声の発生源の位置情報を確率分布データと、確率的な推定値からなるユーザ識別情報とによって構成される[統合音声イベント情報]を生成して情報統合処理部131に入力する。
【0038】
一方、画像入力部(カメラ)111から入力された画像情報は、画像イベント検出部112を介して情報統合処理部131に入力される。画像イベント検出部112は、画像入力部(カメラ)111から入力する画像情報を解析し、画像に含まれる人物の顔を抽出し、顔の位置情報を確率分布データとして生成する。具体的には、顔の位置や方向に関する期待値と分散データN(me,σe)を生成する。
【0039】
また、画像イベント検出部112は、予め登録されたユーザの顔の特徴情報との比較処理に基づいて顔を識別してユーザ識別情報を生成する。この識別情報も確率的な推定値として生成する。画像イベント検出部112には、予め検証すべき複数のユーザの顔についての特徴情報が登録されており、入力画像から抽出した顔領域の画像の特徴情報と登録された顔画像の特徴情報との比較処理を実行して、どのユーザの顔である確率が高いかを判定する処理を行い、全登録ユーザに対する事後確率、あるいはスコアを算出する。
【0040】
さらに、画像イベント検出部112は、画像入力部(カメラ)111から入力された画像に含まれる顔に対応する属性スコア、例えば口領域の動きに基づいて生成される顔属性スコアを算出する。
【0041】
顔属性スコアは、例えば、
(a)画像に含まれる顔の口領域の動きに対応するスコア、
(b)画像に含まれる顔が笑顔か否かに応じて設定するスコア、
(c)画像に含まれる顔が男であるか女であるかに応じて設定するスコア、
(d)画像に含まれる顔が大人であるか子供であるかに応じて設定するスコア、
このような様々な顔属性スコアを算出する設定が可能である。
以下に説明する実施例では、
(a)画像に含まれる顔の口領域の動きに対応するスコアを顔属性スコアとして算出して利用する例について説明する。すなわち、顔の口領域の動きに対応するスコアを顔属性スコアとして算出し、この顔属性スコアに基づいて発話者の特定を行なう。
【0042】
画像イベント検出部112は、画像入力部(カメラ)111から入力された画像に含まれる顔領域から口領域を識別して、口領域の動き検出を行い、口領域の動き検出結果に対応したスコア、例えば口の動きがあると判定された場合に高いスコアとするスコアを算出する。
【0043】
なお、口領域の動き検出処理は、例えばVSD(Visual Speech Detection)を適用した処理として実行する。本発明の出願人と同一の出願に係る特開2005−157679に開示の方法を適用することができる。具体的には、例えば、画像入力部(カメラ)111からの入力画像から検出された顔画像から唇の左右端点を検出し、N番目のフレームとN+1番目のフレームにおいて唇の左右端点をそれぞれそろえてから輝度の差分を算出し、この差分値を閾値処理することで、口の動きを検出することができる。
【0044】
なお、音声イベント検出部122や画像イベント検出部112において実行する音声識別や、顔検出、顔識別処理は従来から知られる技術を適用する。例えば顔検出、顔識別処理としては以下の文献に開示された技術の適用が可能である。
佐部 浩太郎,日台 健一,"ピクセル差分特徴を用いた実時間任意姿勢顔検出器の学習",第10回画像センシングシンポジウム講演論文集,pp.547−552,2004
特開2004−302644(P2004−302644A)[発明の名称:顔識別装置、顔識別方法、記録媒体、及びロボット装置]
【0045】
情報統合処理部131は、音声イベント検出部122や画像イベント検出部112からの入力情報に基づいて、複数のユーザが、それぞれどこにいて、それらは誰で、誰が音声等のシグナルを発したのかを確率的に推定する処理を実行する。
【0046】
具体的には、情報統合処理部131は音声イベント検出部122や画像イベント検出部112からの入力情報に基づいて、
(a)複数のユーザが、それぞれどこにいて、それらは誰であるかの推定情報としての[ターゲット情報]
(b)例えば発話したユーザなどのイベント発生源を[シグナル情報]、
これらの各情報を処理決定部132に出力する。
なお、シグナル情報には、以下の2つのシグナル情報が含まれる。
(b1)音声イベントに基づくシグナル情報
(b2)画像イベントに基づくシグナル情報
【0047】
情報統合処理部131のターゲット情報更新部141は、画像イベント検出部112において検出された画像イベント情報を入力して、例えばパーティクル・フィルタを用いたターゲット更新処理を実行して、画像イベントに基づくターゲット情報とシグナル情報を生成して処理決定部132に出力する。なお、更新結果としてのターゲット情報は発話源確率算出部142にも出力される。
【0048】
情報統合処理部131の発話源確率算出部142は、音声イベント検出部122において検出された音声イベント情報を入力して、識別モデル(識別器)を用いて各ターゲットが入力音声イベントの発話源である確率を算出する。発話源確率算出部142は、この算出値に基づいて、音声イベントに基づくシグナル情報を生成して処理決定部132に出力する。
これらの処理については後段で詳細に説明する。
【0049】
情報統合処理部131の生成したターゲット情報、シグナル情報を含む識別処理結果を受領した処理決定部132は、識別処理結果を利用した処理を実行する、例えば、例えば会話を行ったユーザに対するカメラのズームアップや、会話を行ったユーザに対してテレビから応答を行うなどの処理を行う。
【0050】
上述したように、音声イベント検出部122は、音声の発生源の位置情報の確率分布データ、具体的には、音源方向に関する期待値と分散データN(me,σe)を生成する。また、予め登録されたユーザの声の特徴情報との比較処理に基づいてユーザ識別情報を生成して情報統合処理部131に入力する。
【0051】
また、画像イベント検出部112は、画像に含まれる人物の顔を抽出し、顔の位置情報を確率分布データとして生成する。具体的には、顔の位置や方向に関する期待値と分散データN(me,σe)を生成する。また、予め登録されたユーザの顔の特徴情報との比較処理に基づいてユーザ識別情報を生成して情報統合処理部131に入力する。さらに、画像入力部(カメラ)111から入力された画像中の顔領域から顔属性情報としての顔属性スコア、例えば口領域の動き検出を行い、口領域の動き検出結果に対応したスコア、具体的には口の動きが大きいと判定された場合に高いスコアとする顔属性スコアを算出して情報統合処理部131に入力する。
【0052】
図3を参照して、音声イベント検出部122および画像イベント検出部112が生成し情報統合処理部131に入力する情報の例について説明する。
【0053】
本開示の構成では、画像イベント検出部112は、
(Va)顔の位置や方向に関する期待値と分散データN(me,σe)、
(Vb)顔画像の特徴情報に基づくユーザ識別情報、
(Vc)検出された顔の属性に対応するスコア、例えば口領域の動きに基づいて生成される顔属性スコア、
これらのデータを生成して情報統合処理部131に入力し、
音声イベント検出部122が、
(Aa)音源方向に関する期待値と分散データN(me,σe)、
(Ab)声の特徴情報に基づくユーザ識別情報、
これらのデータを情報統合処理部131に入力する。
【0054】
図3(A)は図1を参照して説明したと同様のカメラやマイクが備えられた実環境の例を示し、複数のユーザ1〜k,201〜20kが存在する。この環境で、あるユーザが何らかの発話を行ったとすると、マイクで音声が入力される。また、カメラは連続的に画像を撮影している。
【0055】
音声イベント検出部122および画像イベント検出部112が生成して、情報統合処理部131に入力する情報は、
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報または話者識別情報)
(c)顔属性情報(顔属性スコア)
これら3種類に大別できる。
【0056】
すなわち、
(a)ユーザ位置情報は、
画像イベント検出部112の生成する
(Va)顔の位置や方向に関する期待値と分散データN(me,σe)と、
音声イベント検出部122の生成する
(Aa)音源方向に関する期待値と分散データN(me,σe)、
これらの統合データである。
【0057】
また、
(b)ユーザ識別情報(顔識別情報または話者識別情報)は、
画像イベント検出部112の生成する
(Vb)顔画像の特徴情報に基づくユーザ識別情報と、
音声イベント検出部122の生成する
(Ab)声の特徴情報に基づくユーザ識別情報、
これらの統合データである。
【0058】
(c)顔属性情報(顔属性スコア)は、
画像イベント検出部112の生成する
(Vc)検出された顔の属性に対応するスコア、例えば口領域の動きに基づいて生成される顔属性スコア、
に対応する。
【0059】
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報または話者識別情報)
(c)顔属性情報(顔属性スコア)、
これらの3つの情報は、イベントの発生毎に生成される。音声イベント検出部122は、音声入力部(マイク)121a〜dから音声情報が入力された場合に、その音声情報に基づいて上記の(a)ユーザ位置情報、(b)ユーザ識別情報を生成して情報統合処理部131に入力する。画像イベント検出部112は、例えば予め定めた一定のフレーム間隔で、画像入力部(カメラ)111から入力された画像情報に基づいて(a)ユーザ位置情報、(b)ユーザ識別情報、(c)顔属性情報(顔属性スコア)を生成して情報統合処理部131に入力する。なお、本例では、画像入力部(カメラ)111は1台のカメラを設定した例を示しており、1つのカメラに複数のユーザの画像が撮影される設定であり、この場合、1つの画像に含まれる複数の顔の各々について(a)ユーザ位置情報、(b)ユーザ識別情報を生成して情報統合処理部131に入力する。
【0060】
音声イベント検出部122が音声入力部(マイク)121a〜dから入力する音声情報に基づいて、
(a)ユーザ位置情報
(b)ユーザ識別情報(話者識別情報)
これらの情報を生成する処理について説明する。
【0061】
[音声イベント検出部122による(a)ユーザ位置情報の生成処理]
音声イベント検出部122は、音声入力部(マイク)121a〜dから入力された音声情報に基づいて解析された声を発したユーザ、すなわち[話者]の位置の推定情報を生成する。すなわち、話者が存在すると推定される位置を、期待値(平均)[me]と分散情報[σe]からなるガウス分布(正規分布)データN(me,σe)として生成する。
【0062】
[音声イベント検出部122による(b)ユーザ識別情報(話者識別情報)の生成処理]
音声イベント検出部122は、音声入力部(マイク)121a〜dから入力された音声情報に基づいて話者が誰であるかを、入力音声と予め登録されたユーザ1〜kの声の特徴情報との比較処理により推定する。具体的には話者が各ユーザ1〜kである確率を算出する。この算出値を(b)ユーザ識別情報(話者識別情報)とする。例えば入力音声の特徴と最も近い登録された音声特徴を有するユーザに最も高いスコアを配分し、最も異なる特徴を持つユーザに最低のスコア(例えば0)を配分する処理によって各ユーザである確率を設定したデータを生成して、これを(b)ユーザ識別情報(話者識別情報)とする。
【0063】
次に、画像イベント検出部112が画像入力部(カメラ)111から入力する画像情報に基づいて、
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報)
(c)顔属性情報(顔属性スコア)
これらの情報を生成する処理について説明する。
【0064】
[画像イベント検出部112による(a)ユーザ位置情報の生成処理]
画像イベント検出部112は、画像入力部(カメラ)111から入力された画像情報に含まれる顔の各々について顔の位置の推定情報を生成する。すなわち、画像から検出された顔が存在すると推定される位置を、期待値(平均)[me]と分散情報[σe]からなるガウス分布(正規分布)データN(me,σe)として生成する。
【0065】
[画像イベント検出部112による(b)ユーザ識別情報(顔識別情報)の生成処理]
画像イベント検出部112は、画像入力部(カメラ)111から入力された画像情報に基づいて、画像情報に含まれる顔を検出し、各顔が誰であるかを、入力画像情報と予め登録されたユーザ1〜kの顔の特徴情報との比較処理により推定する。具体的には抽出された各顔が各ユーザ1〜kである確率を算出する。この算出値を(b)ユーザ識別情報(顔識別情報)とする。例えば入力画像に含まれる顔の特徴と最も近い登録された顔の特徴を有するユーザに最も高いスコアを配分し、最も異なる特徴を持つユーザに最低のスコア(例えば0)を配分する処理によって各ユーザである確率を設定したデータを生成して、これを(b)ユーザ識別情報(顔識別情報)とする。
【0066】
[画像イベント検出部112による(c)顔属性情報(顔属性スコア)の生成処理]
画像イベント検出部112は、画像入力部(カメラ)111から入力された画像情報に基づいて、画像情報に含まれる顔領域を検出し、検出された各顔の属性、具体的には先に説明したように顔の口領域の動き、笑顔か否か、男であるか女であるか、大人であるかこどもであるかなどの属性スコアを算出することが可能であるが、本処理例では、画像に含まれる顔の口領域の動きに対応するスコアを顔属性スコアとして算出して利用する例について説明する。
【0067】
顔の口領域の動きに対応するスコアを算出する処理として、前述したように画像イベント検出部112は、例えば、画像入力部(カメラ)111からの入力画像から検出された顔画像から唇の左右端点を検出し、N番目のフレームとN+1番目のフレームにおいて唇の左右端点をそれぞれそろえてから輝度の差分を算出し、この差分値を閾値処理する。この処理により、口の動きを検出し、口の動きが大きいほど高いスコアとする顔属性スコアを設定する。
【0068】
なお、カメラの撮影画像から複数の顔が検出された場合、画像イベント検出部112は、各検出顔に応じてそれぞれ個別のイベントとして、各顔対応のイベント情報を生成する。すなわち、以下の情報を含むイベント情報を生成して情報統合処理部131に入力する。
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報)
(c)顔属性情報(顔属性スコア)
これらの情報を生成して、情報統合処理部131に入力する。
【0069】
本例では、画像入力部111として1台のカメラを利用した例を説明するが、複数のカメラの撮影画像を利用してもよく、その場合は、画像イベント検出部112は、各カメラの撮影画像の各々に含まれる各顔について、
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報)
(c)顔属性情報(顔属性スコア)
これらの情報を生成して、情報統合処理部131に入力する。
【0070】
次に、情報統合処理部131の実行する処理について説明する。情報統合処理部131は、上述したように、音声イベント検出部122および画像イベント検出部112から、図3(B)に示す3つの情報、すなわち、
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報または話者識別情報)
(c)顔属性情報(顔属性スコア)
これらの情報を逐次入力する。なお、これらの各情報の入力タイミングは様々な設定が可能であるが、例えば、音声イベント検出部122は新たな音声が入力された場合に上記(a),(b)の各情報を音声イベント情報として生成して入力し、画像イベント検出部112は、一定のフレーム周期単位で、上記(a),(b),(c)の各情報を音声イベント情報として生成して入力するといった設定が可能である。
【0071】
情報統合処理部131の実行する処理について、図4以下を参照して説明する。
先に説明したように、情報統合処理部131は、ターゲット情報更新部141、発話源確率算出部142を有し、それぞれ以下の処理を実行する。
【0072】
ターゲット情報更新部141は、画像イベント検出部112において検出された画像イベント情報を入力して、例えばパーティクル・フィルタを用いたターゲット更新処理を実行して、画像イベントに基づくターゲット情報とシグナル情報を生成して処理決定部132に出力する。なお、更新結果としてのターゲット情報は発話源確率算出部142にも出力される。
【0073】
発話源確率算出部142は、音声イベント検出部122において検出された音声イベント情報を入力して、識別モデル(識別器)を用いて各ターゲットが入力音声イベントの発話源である確率を算出する。発話源確率算出部142は、この算出値に基づいて、音声イベントに基づくシグナル情報を生成して処理決定部132に出力する。
【0074】
まず、ターゲット情報更新部141の実行する処理について説明する。
情報統合処理部131のターゲット情報更新部141は、ユーザの位置および識別情報についての仮説(Hypothesis)の確率分布データを設定し、その仮説を入力情報に基づいて更新することで、より確からしい仮説のみを残す処理を行う。この処理手法として、パーティクル・フィルタ(Particle Filter)を適用した処理を実行する。
【0075】
パーティクル・フィルタ(Particle Filter)を適用した処理は、様々な仮説に対応するパーティクルを多数設定して行なわれる。本例では、ユーザの位置と誰であるかの仮説に対応するパーティクルを多数設定し、画像イベント検出部112から、図3(B)に示す3つの情報、すなわち、
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報または話者識別情報)
(c)顔属性情報(顔属性スコア)
これらの入力情報に基づいて、より確からしいパーティクルの重み(ウェイト)を高めていくという処理を行う。
【0076】
パーティクル・フィルタ(Particle Filter)を適用した基本的な処理例について図4を参照して説明する。例えば、図4に示す例は、あるユーザに対応する存在位置をパーティクル・フィルタにより推定する処理例を示している。図4に示す例は、ある直線上の1次元領域におけるユーザ301の存在する位置を推定する処理である。
【0077】
初期的な仮説(H)は、図4(a)に示すように均一なパーティクル分布データとなる。次に、画像データ302が取得され、取得画像に基づくユーザ301の存在確率分布データが図4(b)のデータとして取得される。この取得画像に基づく確率分布データに基づいて、図4(a)のパーティクル分布データが更新され、図4(c)の更新された仮説確率分布データが得られる。このような処理を、入力情報に基づいて繰り返し実行して、ユーザのより確からしい位置情報を得る。
【0078】
なお、パーティクル・フィルタを用いた処理の詳細については、例えば[D. Schulz, D. Fox, and J. Hightower. People Tracking with Anonymous and ID−sensors Using Rao−Blackwellised Particle Filters.Proc. of the International Joint Conference on Artificial Intelligence (IJCAI−03)]に記載されている。
【0079】
図4に示す処理例は、ユーザの存在位置のみについて、入力情報を画像データのみとした処理例として説明しており、パーティクルの各々は、ユーザ301の存在位置のみの情報を有している。
【0080】
情報統合処理部131のターゲット情報更新部141は、画像イベント検出部112から、図3(B)に示す情報、すなわち、
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報または話者識別情報)
(c)顔属性情報(顔属性スコア)
これらの情報を取得して、複数のユーザの位置と複数のユーザがそれぞれ誰であるかを判別する処理を行うことになる。従って、パーティクル・フィルタ(Particle Filter)を適用した処理では、情報統合処理部131が、ユーザの位置と誰であるかの仮説に対応するパーティクルを多数設定して、画像イベント検出部112から、図3(B)に示す2つの情報に基づいて、パーティクル更新を行うことになる。
【0081】
情報統合処理部131が、音声イベント検出部122および画像イベント検出部112から、図3(B)に示す3つの情報、すなわち、
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報または話者識別情報)
(c)顔属性情報(顔属性スコア)
これらを入力して実行するパーティクル更新処理例について図5を参照して説明する。
【0082】
なお、以下に説明するパーティクル更新処理は、情報統合処理部131のターゲット情報更新部141において画像イベント情報のみを用いて実行する処理例として説明する。
【0083】
パーティクルの構成について説明する。情報統合処理部131のターゲット情報更新部141は、予め設定した数=mのパーティクルを有する。図5に示すパーティクル1〜mである。各パーティクルには識別子としてのパーティクルID(PID=1〜m)が設定されている。
【0084】
各パーティクルに、仮想的なオブジェクトに対応する複数のターゲットtID=1,2,・・・nを設定する。本例では、例えば実空間に存在すると推定される人数以上の仮想のユーザに対応する複数(n個)のターゲットを各パーティクルに設定する。m個のパーティクルの各々はターゲット単位でデータをターゲット数分保持する。図5に示す例では、1つのパーティクルにn個(n=2)のターゲットが含まれる。
【0085】
情報統合処理部131のターゲット情報更新部141は、画像イベント検出部112から、図3(B)に示すイベント情報、すなわち、
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報または話者識別情報)
(c)顔属性情報(顔属性スコア[SeID])
これらのイベント情報を入力してm個のパーティクル(PID=1〜m)の更新処理を行う。
【0086】
図5に示す情報統合処理部131に設定される各パーティクル1〜mに含まれるターゲット1〜nの各々は、入力するイベント情報の各々(eID=1〜k)に予め対応付けられており、その対応に従って、入力イベントに対応する選択されたターゲットの更新が実行される。具体的には、例えば画像イベント検出部112において検出された顔画像を個別のイベントとして、この顔画像イベント各々にターゲットを対応付けて処理を行なう。
【0087】
具体的な更新処理について説明する。例えば、画像イベント検出部112は、予め定めた一定のフレーム間隔で、画像入力部(カメラ)111から入力された画像情報に基づいて(a)ユーザ位置情報、(b)ユーザ識別情報、(c)顔属性情報(顔属性スコア)を生成して情報統合処理部131に入力する。
【0088】
このとき、図5に示す画像フレーム350がイベントの検出対象フレームである場合、画像フレームに含まれる顔画像の数に応じたイベントが検出される。すなわち、図5に示す第1顔画像351に対応するイベント1(eID=1)と、第2顔画像352に対応するイベント2(eID=2)である。
【0089】
画像イベント検出部112は、これらの各イベントの各々(eID=1,2,・・・)について、
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報または話者識別情報)
(c)顔属性情報(顔属性スコア)
これらを生成して情報統合処理部131に入力する。すなわち、図5に示すイベント対応情報361,362である。
【0090】
情報統合処理部131のターゲット情報更新部141に設定されたパーティクル1〜mの各々に含まれるターゲット1〜nの各々は、イベント(eID=1〜k)の各々に予め対応付けられており、それぞれのパーティクルに含まれるどのターゲットを更新するかを予め設定した構成としている。なお、イベント(eID=1〜k)各々に対するターゲット(tID)の対応付けは、重複しない設定とする。すなわち、各パーティクルで重複がないように取得イベント分のイベント発生源仮説を生成する。
図5に示す例では、
(1)パーティクル1(pID=1)は、
[イベントID=1(eID=1)]の対応ターゲット=[ターゲットID=1(tID=1)]、
[イベントID=2(eID=2)]の対応ターゲット=[ターゲットID=2(tID=2)]、
(2)パーティクル2(pID=2)は、
[イベントID=1(eID=1)]の対応ターゲット=[ターゲットID=1(tID=1)]、
[イベントID=2(eID=2)]の対応ターゲット=[ターゲットID=2(tID=2)]、
:
(m)パーティクルm(pID=m)は、
[イベントID=1(eID=1)]の対応ターゲット=[ターゲットID=2(tID=2)]、
[イベントID=2(eID=2)]の対応ターゲット=[ターゲットID=1(tID=1)]、
【0091】
このように、情報統合処理部131のターゲット情報更新部141に設定されたパーティクル1〜mの各々に含まれるターゲット1〜nの各々は、イベント(eID=1〜k)の各々に予め対応付けられており、各イベントIDに応じて各パーティクルに含まれるどのターゲットを更新するかが決定された構成を持つ。例えば、図5に示す[イベントID=1(eID=1)]のイベント対応情報361によって、パーティクル1(pID=1)では、ターゲットID=1(tID=1)のデータのみが選択的に更新される。
【0092】
同様に、図5に示す[イベントID=1(eID=1)]のイベント対応情報361によって、パーティクル2(pID=2)も、ターゲットID=1(tID=1)のデータのみが選択的に更新される。また、図5に示す[イベントID=1(eID=1)]のイベント対応情報361によって、パーティクルm(pID=m)では、ターゲットID=2(tID=2)のデータのみが選択的に更新される。
【0093】
図5に示すイベント発生源仮設データ371,372が、各パーティクルに設定されたイベント発生源仮設データであり、これらが各パーティクルに設定されており、この情報に従ってイベントIDに対応する更新ターゲットが決定される。
【0094】
各パーティクルに含まれる各ターゲットデータについて図6を参照して説明する。図6は、図5に示すパーティクル1(pID=1)に含まれる1つのターゲット(ターゲットID:tID=n)375のターゲットデータの構成である。ターゲット375のターゲットデータは、図6に示すように、以下のデータ、すなわち、
(a)各ターゲット各々に対応する存在位置の確率分布[ガウス分布:N(m1n,σ1n)]、
(b)各ターゲットが誰であるかを示すユーザ確信度情報(uID)
uID1n1=0.0
uID1n2=0.1
:
uID1nk=0.5
これらのデータによって構成される。
【0095】
なお、(a)に示すガウス分布:N(m1n,σ1n)における[m1n,σ1n]の(1n)は、パーティクルID:pID=1におけるターゲットID:tID=nに対応する存在確率分布としてのガウス分布であることを意味する。
また、(b)に示すユーザ確信度情報(uID)における、[uID1n1]に含まれる(1n1)は、パーティクルID:pID=1におけるターゲットID:tID=nの、ユーザ=ユーザ1である確率を意味する。すなわちターゲットID=nのデータは、
ユーザ1である確率が0.0、
ユーザ2である確率が0.1、
:
ユーザkである確率が0.5、
であることを意味している。
【0096】
図5に戻り、情報統合処理部131のターゲット情報更新部141の設定するパーティクルについての説明を続ける。図5に示すように、情報統合処理部131のターゲット情報更新部141は、予め決定した数=mのパーティクル(PID=1〜m)を設定し、各パーティクルは、実空間に存在すると推定されるターゲット(tID=1〜n)各々について、
(a)各ターゲット各々に対応する存在位置の確率分布[ガウス分布:N(m,σ)]、
(b)各ターゲットが誰であるかを示すユーザ確信度情報(uID)
これらのターゲットデータを有する。
【0097】
情報統合処理部131のターゲット情報更新部141は、音声イベント検出部122および画像イベント検出部112から、図3(B)に示すイベント情報、すなわち、
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報または話者識別情報)
(c)顔属性情報(顔属性スコア[SeID])
これらのイベント情報(eID=1,2・・・)を入力し、各パーティクルにおいて予め設定されたイベント対応のターゲットの更新を実行する。
【0098】
なお、更新対象は各ターゲットデータに含まれる以下のデータ、すなわち、
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報または話者識別情報)
これらのデータである。
【0099】
(c)顔属性情報(顔属性スコア[SeID])は、イベント発生源を示す[シグナル情報]として最終的に利用される。ある程度の数のイベントが入力されると、各パーティクルの重み(ウェイト)も更新され、実空間の情報に最も近いデータを持つパーティクルの重みが大きくなり、実空間の情報に適合しないデータを持つパーティクルの重みが小さくなっていく。このようにパーティクルの重みに偏りが発生し収束した段階で、顔属性情報(顔属性スコア)に基づくシグナル情報、すなわち、イベント発生源を示す[シグナル情報]が算出される。
【0100】
ある特定のターゲットx(tID=x)が、あるイベント(eID=y)の発生源である確率を、
PeID=x(tID=y)
として示す。例えば、図5に示すようにm個のパーティクル(pID=1〜m)が設定され、各パーティクルに2つのターゲット(tID=1,2)が設定されている場合、
第1ターゲット(tID=1)が第1イベント(eID=1)の発生源である確率は、
PeID=1(tID=1)
第2ターゲット(tID=2)が第1イベント(eID=1)の発生源である確率は、
PeID=1(tID=2)
である。
また、
第1ターゲット(tID=1)が第2イベント(eID=2)の発生源である確率は、
PeID=2(tID=1)
第2ターゲット(tID=2)が第2イベント(eID=2)の発生源である確率は、
PeID=2(tID=2)
である。
【0101】
イベント発生源を示す[シグナル情報]は、あるイベント(eID=y)の発生源が特定のターゲットx(tID=x)である確率、
PeID=x(tID=y)
であり、これは、情報統合処理部131のターゲット情報更新部141に設定されたパーティクル数:mと、各イベントに対するターゲットの割り当て数との比に相当し、図5に示す例では、
PeID=1(tID=1)=[第1イベント(eID=1)にtID=1を割り当てたパーティクル数)/(m)]
PeID=1(tID=2)=[第1イベント(eID=1)にtID=2を割り当てたパーティクル数)/(m)]
PeID=2(tID=1)=[第2イベント(eID=2)にtID=1を割り当てたパーティクル数)/(m)]
PeID=2(tID=2)=[第2イベント(eID=2)にtID=2を割り当てたパーティクル数)/(m)]
このような対応関係となる。
このデータがイベント発生源を示す[シグナル情報]として最終的に利用される。
【0102】
さらに、あるイベント(eID=y)の発生源が特定のターゲットx(tID=x)である確率、
PeID=x(tID=y)
このデータは、ターゲット情報に含まれる顔属性情報の算出にも適用される。すなわち、
顔属性情報StID=1〜nの算出の際に利用される。顔属性情報StID=xは、ターゲットID=xのターゲットの最終的な顔属性の期待値、すなわち、発話者である可能性を示す値に相当する。
【0103】
情報統合処理部131のターゲット情報更新部141は、画像イベント検出部112から、イベント情報(eID=1,2・・・)を入力し、各パーティクルにおいて予め設定されたイベント対応のターゲットの更新を実行して、
(a)複数のユーザが、それぞれどこにいるかを示す位置推定情報と、誰であるかの推定情報(uID推定情報)、さらに、顔属性情報(StID)の期待値、例えば口を動かして話しをしていることを示す顔属性期待値を含む[ターゲット情報]、
(b)例えば話をしたユーザなどのイベント発生源を示す[シグナル情報(画像イベント対応シグナル情報)]、
これらを生成して処理決定部132に出力する。
【0104】
[ターゲット情報]は、図7の右端のターゲット情報380に示すように、各パーティクル(PID=1〜m)に含まれる各ターゲット(tID=1〜n)対応データの重み付き総和データとして生成される。図7には、情報統合処理部131の有するm個のパーティクル(pID=1〜m)と、これらのm個のパーティクル(pID=1〜m)から生成されるターゲット情報380を示している。各パーティクルの重みについては後述する。
【0105】
ターゲット情報380は、情報統合処理部131が予め設定した仮想的なユーザに対応するターゲット(tID=1〜n)の
(a)存在位置
(b)誰であるか(uID1〜uIDkのいずれであるか)
(c)顔属性の期待値(本処理例では発話者である期待値(確率))
これらを示す情報である。
【0106】
各ターゲットの(c)顔属性の期待値(本処理例では発話者である期待値(確率))は、前述したようにイベント発生源を示す[シグナル情報]に相当する確率、
PeID=x(tID=y)
と、各イベントに対応する顔属性スコアSeID=iに基づいて算出される。iはイベントIDである。
例えばターゲットID=1の顔属性の期待値:StID=1は、以下の式で算出される。
StID=1=ΣeIDPeID=i(tID=1)×SeID=i
一般化して示すと、
ターゲットの顔属性の期待値:StIDは、以下の式で算出される。
StID=ΣeIDPeID=i(tID)×SeID
・・・(式1)
として示される。
【0107】
例えば、図5に示すように、システム内部にターゲットが2つ存在する場合、画像1フレーム内の画像イベント検出部112から、顔画像イベント2つ(eID=1,2)が情報統合処理部131に入力された際の各ターゲット(tID=1,2)顔属性の期待値計算例を図8に示す。
【0108】
図8に示す右端のデータは、図7に示すターゲット情報380に相当するターゲット情報390であり、各パーティクル(PID=1〜m)に含まれる各ターゲット(tID=1〜n)対応データの重み付き総和データとして生成される情報に相当する。
【0109】
このターゲット情報390における各ターゲットの顔属性は、前述したようにイベント発生源を示す[シグナル情報]に相当する確率[PeID=x(tID=y)]と、各イベントに対応する顔属性スコア[SeID=i]に基づいて算出される。iはイベントIDである。
ターゲットID=1の顔属性の期待値:StID=1は、
StID=1=ΣeIDPeID=i(tID=1)×SeID=i
ターゲットID=2の顔属性の期待値:StID=2は、
StID=2=ΣeIDPeID=i(tID=2)×SeID=i
このように示される。
これら各ターゲットの顔属性の期待値:StIDの全ターゲットの総和は[1]になる。本処理例では、各ターゲットについて1〜0の顔属性の期待値:StIDが設定され、期待値が高いターゲットは発話者である確率が高いと判定される。
【0110】
なお、顔画像イベントeIDに(顔属性スコア[SeID])が存在しない場合(例えば、顔検出できても口が手で覆われていて口の動き検出ができない場合)は顔属性スコア[SeID]に事前知識の値[Sprior]等を用いる。事前知識の値としては、各ターゲット毎に直前に取得した値が存在する場合はその値を用いたり、事前にオフラインで所得した顔画像イベントから顔属性の平均値計算しておきその値を用いたりする構成が可能である。
【0111】
ターゲット数と画像1フレーム内の顔画像イベントは常に同数とは限らない。ターゲット数が顔画像イベント数よりも多いときには、前述したイベント発生源を示す[シグナル情報]に相当する確率[PeID(tID)]の総和が[1]にならないため、前述した各ターゲットの顔属性の期待値算出式、すなわち、
StID=ΣeIDPeID=i(tID)×SeID
・・・(式1)
上記式の各ターゲットについての期待値総和も[1]にならず、精度の高い期待値が計算できない。
【0112】
図9に示すように、画像フレーム350に前の処理レームには存在していた第3イベント対応の第3顔画像395が検出されなくなった場合には、上記式(式1)の各ターゲットについての期待値総和も[1]にならず、精度の高い期待値が計算できない。このような場合、各ターゲットの顔属性の期待値算出式を変更する。すなわち、各ターゲットの顔属性の期待値[StID]の総和を[1]にするために、補数[1−ΣeIDPeID(tID)]と事前知識の値[Sprior]を用いて顔イベント属性の期待値StIDを次式(式2)で計算する。
StID=ΣeIDPeID(tID)×SeID+(1−ΣeIDPeID(tID))×Sprior
・・・(式2)
【0113】
図9は、システム内部にイベント対応のターゲットが3つ設定されているが、画像1フレーム内の顔画像イベントとして2つのみが画像イベント検出部112から、情報統合処理部131に入力された際の顔属性の期待値計算例を示している。
【0114】
ターゲットID=1の顔属性の期待値:StID=1は、
StID=1=ΣeIDPeID=i(tID=1)×SeID=i+(1−ΣeIDPeID(tID=1)×Sprior
ターゲットID=2の顔属性の期待値:StID=2は、
StID=2=ΣeIDPeID=i(tID=2)×SeID=i+(1−ΣeIDPeID(tID=2)×Sprior
ターゲットID=3の顔属性の期待値:StID=3は、
StID=3=ΣeIDPeID=i(tID=3)×SeID=i+(1−ΣeIDPeID(tID=3)×Sprior
このように計算される。
【0115】
なお、逆に、ターゲット数が顔画像イベント数よりも少ないときは、イベント数と同数になるようにターゲットを生成して前述の(式1)を適用して各ターゲットの顔属性の期待値[StID=1]を算出する。
【0116】
なお、顔属性は、本処理例では、口の動きに対応するスコアに基づく顔属性期待値、すなわち各ターゲットが発話者である期待値を示すデータとして説明しているが、前述したように、顔属性スコアは、笑顔や年齢などのスコアとして算出することが可能であり、この場合の顔属性期待値は、そのスコアに対応する属性に対応するデータとして算出されることになる。
【0117】
ターゲット情報は、パーティクルの更新に伴い、順次更新されることになり、例えばユーザ1〜kが実環境内で移動しない場合、ユーザ1〜kの各々が、n個のターゲット(tID=1〜n)から選択されたk個にそれぞれ対応するデータとして収束することになる。
【0118】
例えば、図7に示すターゲット情報380中の最上段のターゲット1(tID=1)のデータ中に含まれるユーザ確信度情報(uID)は、ユーザ2(uID12=0.7)について最も高い確率を有している。従って、このターゲット1(tID=1)のデータは、ユーザ2に対応するものであると推定されることになる。なお、ユーザ確信度情報(uID)を示すデータ[uID12=0.7]中の(uID12)内の(12)は、ターゲットID=1のユーザ=2のユーザ確信度情報(uID)に対応する確率であることを示している。
【0119】
このターゲット情報380中の最上段のターゲット1(tID=1)のデータは、ユーザ2である確率が最も高く、このユーザ2は、その存在位置が、ターゲット情報380中の最上段のターゲット1(tID=1)のデータに含まれる存在確率分布データに示す範囲にいると推定されることなる。
【0120】
このように、ターゲット情報380は、初期的に仮想的なオブジェクト(仮想ユーザ)として設定した各ターゲット(tID=1〜n)の各々について、
(a)存在位置
(b)誰であるか(uID1〜uIDkのいずれであるか)
(c)顔属性期待値(本処理例では発話者である期待値(確率))
の各情報を示す。従って、各ターゲット(tID=1〜n)のk個のターゲット情報の各々は、ユーザが移動しない場合は、ユーザ1〜kに対応するように収束する。
【0121】
先に説明したように、情報統合処理部131は、入力情報に基づくパーティクルの更新処理を実行して、
(a)複数のユーザが、それぞれどこにいて、それらは誰であるかの推定情報としての[ターゲット情報]、
(b)例えば話をしたユーザなどのイベント発生源を示す[シグナル情報]、
これらを生成して処理決定部132に出力する。
【0122】
このように、情報統合処理部131のターゲット情報更新部141は、仮想的なユーザに対応する複数のターゲットデータを設定した複数のパーティクルを適用したパーティクルフィルタリング処理を実行して実空間に存在するユーザの位置情報を含む解析情報を生成する。すなわち、パーティクルに設定するターゲットデータの各々をイベント検出部から入力するイベント各々に対応付けて設定し、入力イベント識別子に応じて各パーティクルから選択されるイベント対応ターゲットデータの更新を行う。
【0123】
また、ターゲット情報更新部141は、各パーティクルに設定したイベント発生源仮説ターゲットと、イベント検出部から入力するイベント情報との尤度を算出し、該尤度の大小に応じた値をパーティクル重みとして各パーティクルに設定し、パーティクル重みの大きいパーティクルを優先的に再選択するリサンプリング処理を実行して、パーティクルの更新処理を行う。この処理については後述する。さらに、各パーティクルに設定したターゲットについて、経過時間を考慮した更新処理を実行する。また、パーティクルの各々に設定したイベント発生源仮説ターゲットの数に応じて、イベント発生源の確率値としてのシグナル情報の生成を行う。
【0124】
一方、情報統合処理部131の発話源確率算出部142は、音声イベント検出部122において検出された音声イベント情報を入力して、識別モデル(識別器)を用いて各ターゲットが入力音声イベントの発話源である確率を算出する。発話源確率算出部142は、この算出値に基づいて、音声イベントに基づくシグナル情報を生成して処理決定部132に出力する。
発話源確率算出部142の実行する処理の詳細については後段で説明する。
【0125】
[3.本開示の情報処理装置の実行する処理シーケンスについて]
次に、図10に示すフローチャートを参照して情報統合処理部131の実行する処理シーケンスについて説明する。
情報統合処理部131は、音声イベント検出部122および画像イベント検出部112から、図3(B)に示すイベント情報、すなわち、ユーザ位置情報と、ユーザ識別情報(顔識別情報または話者識別情報)、これらのイベント情報を入力して、
(a)複数のユーザが、それぞれどこにいて、それらは誰であるかの推定情報としての[ターゲット情報]、
(b)例えば話をしたユーザなどのイベント発生源を示す[シグナル情報]、
これらの情報を生成して処理決定部132に出力する。この処理シーケンスについて、図10に示すフローチャートを参照して説明する。
【0126】
まず、ステップS101において、情報統合処理部131は、音声イベント検出部122および画像イベント検出部112から、
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報または話者識別情報)
(c)顔属性情報(顔属性スコア)
これらのイベント情報を入力する。
【0127】
イベント情報の取得に成功した場合は、ステップS102に進み、イベント情報の取得に失敗した場合は、ステップS121に進む。ステップS121の処理については後段で説明する。
【0128】
イベント情報の取得に成功した場合は、情報統合処理部131は、ステップS102において、音声イベントが入力されたか否かを判定する。入力イベントが音声イベントである場合は、ステップS111に進み、画像イベントである場合は、ステップS103に進む。
【0129】
入力イベントが音声イベントである場合は、ステップS111において、各ターゲットが入力音声イベントの発話源である確率を、識別モデル(識別器)を用いて算出する。算出結果を音声イベントに基づくシグナル情報として処理決定部132(図2参照)に出力する。このステップS111の処理の詳細については後段で説明する。
【0130】
入力イベントが画像イベントである場合は、ステップS103以下において、入力情報に基づくパーティクル更新処理を行うことになるが、パーティクル更新処理の前に、まずステップS103において、各パーティクルに対する新たなターゲットの設定が必要であるか否かを判定する。本開示の構成では、先に、図5を参照して説明したように、情報統合処理部131に設定される各パーティクル1〜mに含まれるターゲット1〜nの各々は、入力するイベント情報の各々(eID=1〜k)に予め対応付けられており、その対応に従って、入力イベントに対応する選択されたターゲットの更新が実行する構成としている。
【0131】
従って、例えば画像イベント検出部112から入力するイベント数が、ターゲット数より多い場合には、新たなターゲットの設定を行なうことが必要となる。具体的には、例えば図5に示す画像フレーム350にこれまで存在しなかった顔が出現した場合などである。このような場合は、ステップS104に進み、各パーティクルに新たなターゲットを設定する。このターゲットはこの新たなイベントに対応して更新されるターゲットとして設定される。
【0132】
次に、ステップS105において、情報統合処理部131に設定されたパーティクル1〜mのm個のパーティクル(pID=1〜m)の各々にイベントの発生源の仮説を設定する。イベント発生源とは、例えば、音声イベントであれば、話をしたユーザがイベント発生源であり、画像イベントであれば、抽出した顔を持つユーザがイベント発生源である。
【0133】
本開示の仮説設定処理は、先に図5等を参照して説明したように、各パーティクル1〜mに含まれるターゲット1〜nの各々に、入力するイベント情報の各々(eID=1〜k)を対応付けて設定する。
【0134】
すなわち、先に図5を参照して説明したように、パーティクル1〜mの各々に含まれるターゲット1〜nの各々は、イベント(eID=1〜k)の各々に対応付けて、それぞれのパーティクルに含まれるどのターゲットを更新するかが予め設定される。このように各パーティクルで、重複がないように取得イベント分のイベント発生源仮説を生成する。なお、初期的には例えば各イベントが均等に配分されるような設定としてよい。パーティクルの数:mは、ターゲットの数:nより大きく設定されるので、複数のパーティクルが同一のイベントID−ターゲットIDの対応をもつパーティクルとして設定される。例えば、ターゲットの数:nが10とした場合、パーティクル数:m=100〜1000程度に設定した処理などが行われる。
【0135】
ステップS105における仮説設定の後、ステップS106に進む。ステップS106では、各パーティクル対応の重み、すなわちパーティクル重み[WpID]の算出を行う。このパーティクル重み[WpID]は初期的には各パーティクルに均一な値が設定されるが、イベント入力に応じて更新される。
【0136】
図11を参照して、パーティクル重み[WpID]の算出処理の詳細について説明する。パーティクル重み[WpID]は、イベント発生源の仮説ターゲットを生成した各パーティクルの仮説の正しさの指標に相当する。パーティクル重み[WpID]は、m個のパーティクル(pID=1〜m)の各々において設定された複数のターゲット各々に対応付けられたイベント発生源の入力イベントとの類似度であるイベント−ターゲット間尤度として算出される。
【0137】
図11には、情報統合処理部131が、音声イベント検出部122および画像イベント検出部112から入力する1つのイベント(eID=1)に対応するイベント情報401と、情報統合処理部131が保持する1つのパーティクル421を示している。パーティクル421のターゲット(tID=2)は、イベント(eID=1)に対応付けられているターゲットである。
【0138】
図11下段には、イベント−ターゲット間尤度の算出処理例を示している。パーティクル重み[WpID]は、各パーティクルにおいて算出されるイベント−ターゲットとの類似度指標としてのイベント−ターゲット間尤度の総和に対応する値として算出される。
【0139】
図11の下段に示す尤度算出処理は、
(a)ユーザ位置情報についてのイベントと、ターゲットデータとの類似度データとしてのガウス分布間尤度[DL]、
(b)ユーザ識別情報(顔識別情報または話者識別情報)についてのイベントと、ターゲットデータとの類似度データとしてのユーザ確信度情報(uID)間尤度[UL]
これらを個別に算出する例を示している。
【0140】
(a)ユーザ位置情報についてのイベントと、仮説ターゲットとの類似度データとしてのガウス分布間尤度[DL]の算出処理は以下の処理となる。
入力イベント情報中の、ユーザ位置情報に対応するガウス分布をN(me,σe)、
パーティクルから選択された仮説ターゲットのユーザ位置情報に対応するガウス分布をN(mt,σt)、
として、ガウス分布間尤度[DL]を、以下の式によって算出する。
DL=N(mt,σt+σe)x|me
上記式は、中心mtで分散σt+σeのガウス分布においてx=meの位置の値を算出する式である。
【0141】
(b)ユーザ識別情報(顔識別情報または話者識別情報)についてのイベントと、仮説ターゲットとの類似度データとしてのユーザ確信度情報(uID)間尤度[UL]の算出処理は以下の処理となる。
入力イベント情報中の、ユーザ確信度情報(uID)の各ユーザ1〜kの確信度の値(スコア)をPe[i]とする。なお、iはユーザ識別子1〜kに対応する変数である。
パーティクルから選択された仮説ターゲットのユーザ確信度情報(uID)の各ユーザ1〜kの確信度の値(スコア)をPt[i]として、ユーザ確信度情報(uID)間尤度[UL]は、以下の式によって算出する。
UL=ΣPe[i]×Pt[i]
上記式は、2つのデータのユーザ確信度情報(uID)に含まれる各対応ユーザの確信度の値(スコア)の積の総和を求める式であり、この値をユーザ確信度情報(uID)間尤度[UL]とする。
【0142】
パーティクル重み[WpID]は、上記の2つの尤度、すなわち、
ガウス分布間尤度[DL]と、
ユーザ確信度情報(uID)間尤度[UL]
これら2つの尤度を利用し、重みα(α=0〜1)を用いて下式によって算出する。
パーティクル重み[WpID]=ΣnULα×DL1−α
nは、パーティクルに含まれるイベント対応ターゲットの数である。
上記式により、パーティクル重み[WpID]を算出する。
ただし、α=0〜1とする。
このパーティクル重み[WpID]は、各パーティクルについて各々算出する。
【0143】
なお、パーティクル重み[WpID]の算出に適用する重み[α]は、予め固定された値としてもよいし、入力イベントに応じて値を変更する設定としてもよい。例えば入力イベントが画像である場合において、顔検出に成功し位置情報は取得できたが顔識別に失敗した場合などは、α=0の設定として、ユーザ確信度情報(uID)間尤度:UL=1としてガウス分布間尤度[DL]のみに依存してパーティクル重み[WpID]を算出する構成としてもよい。また、入力イベントが音声である場合において、話者識別に成功し話者情報破取得できたが、位置情報の取得に失敗した場合などは、α=0の設定として、ガウス分布間尤度[DL]=1として、ユーザ確信度情報(uID)間尤度[UL]のみに依存してパーティクル重み[WpID]を算出する構成としてもよい。
【0144】
図10のフローにおけるステップS106の各パーティクル対応の重み[WpID]の算出は、このように図11を参照して説明した処理として実行される。次に、ステップS107において、ステップS106で設定した各パーティクルのパーティクル重み[WpID]に基づくパーティクルのリサンプリング処理を実行する。
【0145】
このパーティクルリサンプリング処理は、m個のパーティクルから、パーティクル重み[WpID]に応じてパーティクルを取捨選択する処理として実行される。具体的には、例えば、パーティクル数:m=5のとき、
パーティクル1:パーティクル重み[WpID]=0.40
パーティクル2:パーティクル重み[WpID]=0.10
パーティクル3:パーティクル重み[WpID]=0.25
パーティクル4:パーティクル重み[WpID]=0.05
パーティクル5:パーティクル重み[WpID]=0.20
これらのパーティクル重みが各々設定されていた場合、
パーティクル1は、40%の確率でリサンプリングされ、パーティクル2は10%の確率でリサンプリングされる。なお、実際にはm=100〜1000といった多数であり、リサンプリングされた結果は、パーティクルの重みに応じた配分比率のパーティクルによって構成されることになる。
【0146】
この処理によって、パーティクル重み[WpID]の大きなパーティクルがより多く残存することになる。なお、リサンプリング後もパーティクルの総数[m]は変更されない。また、リサンプリング後は、各パーティクルの重み[WpID]はリセットされ、新たなイベントの入力に応じてステップS101から処理が繰り返される。
【0147】
ステップS108では、各パーティクルに含まれるターゲットデータ(ユーザ位置およびユーザ確信度)の更新処理を実行する。各ターゲットは、先に図7等を参照して説明したように、
(a)ユーザ位置:各ターゲット各々に対応する存在位置の確率分布[ガウス分布:N(mt,σt)]、
(b)ユーザ確信度:各ターゲットが誰であるかを示すユーザ確信度情報(uID)として各ユーザ1〜kである確立値(スコア):Pt[i](i=1〜k)、すなわち、
uIDt1=Pt[1]
uIDt2=Pt[2]
:
uIDtk=Pt[k]
さらに、
(c)顔属性の期待値(本処理例では発話者である期待値(確率))
これらのデータによって構成される。
【0148】
(c)顔属性の期待値(本処理例では発話者である期待値(確率))は、前述したようにイベント発生源を示す[シグナル情報]に相当する確率、
PeID=x(tID=y)
と、各イベントに対応する顔属性スコアSeID=iに基づいて算出される。iはイベントIDである。
例えばターゲットID=1の顔属性の期待値:StID=1は、以下の式で算出される。
StID=1=ΣeIDPeID=i(tID=1)×SeID=i
一般化して示すと、
ターゲットの顔属性の期待値:StIDは、以下の式で算出される。
StID=ΣeIDPeID=i(tID)×SeID
・・・(式1)
として示される。
【0149】
なお、ターゲット数が顔画像イベント数よりも多いときには、各ターゲットの顔属性の期待値[StID]の総和を[1]にするために、補数[1−ΣeIDPeID(tID)]と事前知識の値[Sprior]を用いて顔イベント属性の期待値[StID]は、を次式(式2)で計算される。
StID=ΣeIDPeID(tID)×SeID+(1−ΣeIDPeID(tID))×Sprior
・・・(式2)
【0150】
ステップS108におけるターゲットデータの更新は、(a)ユーザ位置、(b)ユーザ確信度、(c)顔属性の期待値(本処理例では発話者である期待値(確率))の各々について実行する。まず、(a)ユーザ位置の更新処理について説明する。
【0151】
ユーザ位置の更新は、
(a1)全パーティクルの全ターゲットを対象とする更新処理、
(a2)各パーティクルに設定されたイベント発生源仮説ターゲットを対象とした更新処理、
これらの2段階の更新処理として実行する。
【0152】
(a1)全パーティクルの全ターゲットを対象とする更新処理は、イベント発生源仮説ターゲットとして選択されたターゲットおよびその他のターゲットのすべてを対象として実行する。この処理は、時間経過に伴うユーザ位置の分散が拡大するという仮定に基づいて実行され、前回の更新処理からの経過時間とイベントの位置情報によってカルマン・フィルタ(Kalman Filter)を用い更新される。
【0153】
以下、位置情報が1次元の場合の更新処理例について説明する。まず、前回の更新処理時間からの経過時間[dt]とし、全ターゲットについての、dt後のユーザ位置の予測分布を計算する。すなわち、ユーザ位置の分布情報としてのガウス分布:N(mt,σt)の期待値(平均):[mt]、分散[σt]について、以下の更新を行う。
mt=mt+xc×dt
σt2=σt2+σc2×dt
なお、
mt:予測期待値(predicted state)
σt2:予測共分散(predicted estimate covariance)
xc:移動情報(control model)
σc2:ノイズ(process noise)
である。
なお、ユーザが移動しない条件の下で処理する場合は、xc=0として更新処理を行うことができる。
上記の算出処理により、全ターゲットに含まれるユーザ位置情報としてのガウス分布:N(mt,σt)を更新する。
【0154】
(a2)各パーティクルに設定されたイベント発生源仮説ターゲットを対象とした更新処理、
次に、各パーティクルに設定されたイベント発生源仮説ターゲットを対象とした更新処理について説明する。
ステップS104において設定したイベントの発生源の仮説に従って選択されたターゲットを更新する。先に図5を参照して説明したように、パーティクル1〜mの各々に含まれるターゲット1〜nの各々は、イベント(eID=1〜k)の各々に対応付けられたターゲットとして設定されている。
【0155】
すなわち、イベントID(eID)に応じてそれぞれのパーティクルに含まれるどのターゲットを更新するかが予め設定されており、その設定に従って各入力イベントに対応付けられたターゲットのみを更新する。例えば、図5に示す[イベントID=1(eID=1)]のイベント対応情報361によって、パーティクル1(pID=1)では、ターゲットID=1(tID=1)のデータのみが選択的に更新される。
【0156】
このイベントの発生源の仮説に従った更新処理では、このようにイベントに対応付けられたターゲットの更新を行なう。音声イベント検出部122や画像イベント検出部112から入力するイベント情報に含まれるユーザ位置を示すガウス分布:N(me,σe)などを用いた更新処理を実行する。
例えば、
K:カルマンゲイン(Kalman Gain)
me:入力イベント情報:N(me,σe)に含まれる観測値(Observed state)
σe2:入力イベント情報:N(me,σe)に含まれる観測値(Observed covariance)
として、以下の更新処理を行う。
K=σt2/(σt2+σe2)
mt=mt+K(xc−mt)
σt2=(1−K)σt2
【0157】
次に、ターゲットデータの更新処理として実行する(b)ユーザ確信度の更新処理について説明する。ターゲットデータには上記のユーザ位置情報の他に、各ターゲットが誰であるかを示すユーザ確信度情報(uID)として各ユーザ1〜kである確率値(スコア):Pt[i](i=1〜k)が含まれている。ステップS108では、このユーザ確信度情報(uID)についても更新処理を行う。
【0158】
各パーティクルに含まれるターゲットのユーザ確信度情報(uID):Pt[i](i=1〜k)についての更新は、登録ユーザ全員分の事後確率と、音声イベント検出部122や画像イベント検出部112から入力するイベント情報に含まれるユーザ確信度情報(uID):Pe[i](i=1〜k)によって、予め設定した0〜1の範囲の値を持つ更新率[β]を適用して更新する。
【0159】
ターゲットのユーザ確信度情報(uID):Pt[i](i=1〜k)についての更新は、以下の式によって実行する。
Pt[i]=(1−β)×Pt[i]+β*Pe[i]
ただし、
i=1〜k
β:0〜1
である。なお、更新率[β]は、0〜1の範囲の値であり予め設定する。
【0160】
ステップS108では、この更新されたターゲットデータに含まれる以下のデータ、すなわち、
(a)ユーザ位置:各ターゲット各々に対応する存在位置の確率分布[ガウス分布:N(mt,σt)]、
(b)ユーザ確信度:各ターゲットが誰であるかを示すユーザ確信度情報(uID)として各ユーザ1〜kである確立値(スコア):Pt[i](i=1〜k)、すなわち、
uIDt1=Pt[1]
uIDt2=Pt[2]
:
uIDtk=Pt[k]
(c)顔属性の期待値(本処理例では発話者である期待値(確率))
これらのデータによって構成される。
これらのデータと、各パーティクル重み[WpID]とに基づいて、ターゲット情報を生成して、処理決定部132に出力する。
【0161】
なお、ターゲット情報は、各パーティクル(PID=1〜m)に含まれる各ターゲット(tID=1〜n)対応データの重み付き総和データとして生成される。図7の右端のターゲット情報380に示すデータである。ターゲット情報は、各ターゲット(tID=1〜n)各々の
(a)ユーザ位置情報、
(b)ユーザ確信度情報、
(c)顔属性の期待値(本処理例では発話者である期待値(確率))
これらの情報を含む情報として生成される。
【0162】
例えば、ターゲット(tID=1)に対応するターゲット情報中の、ユーザ位置情報は、
【0163】
【数1】

【0164】
上記式で表される。上記式において、Wiは、パーティクル重み[WpID]を示している。
【0165】
また、ターゲット(tID=1)に対応するターゲット情報中の、ユーザ確信度情報は、
【0166】
【数2】
【0167】
上記式で表される。上記式において、Wiは、パーティクル重み[WpID]を示している。
【0168】
また、ターゲット(tID=1)に対応するターゲット情報中の、顔属性の期待値(本処理例では発話者である期待値(確率))は、
StID=1=ΣeIDPeID=i(tID=1)×SeID=i
上記式、または、
StID=1=ΣeIDPeID=i(tID=1)×SeID=i+(1−ΣeIDPeID(tID=1)×Sprior
で表される。
【0169】
情報統合処理部131は、これらのターゲット情報をn個の各ターゲット(tID=1〜n)各々について算出し、算出したターゲット情報を処理決定部132に出力する。
【0170】
次に、図8に示すフローのステップS109の処理について説明する。情報統合処理部131は、ステップS109において、n個のターゲット(tID=1〜n)の各々がイベントの発生源である確率を算出し、これをシグナル情報として処理決定部132に出力する。
【0171】
先に説明したように、イベント発生源を示す[シグナル情報]は、音声イベントについては、誰が話をしたか、すなわち[発話者]を示すデータであり、画像イベントについては、画像に含まれる顔が誰であるかおよび[発話者]を示すデータである。
【0172】
情報統合処理部131は、各パーティクルに設定されたイベント発生源の仮説ターゲットの数に基づいて、各ターゲットがイベント発生源である確率を算出する。すなわち、ターゲット(tID=1〜n)の各々がイベント発生源である確率を[P(tID=i)とする。ただしi=1〜nである。例えば、あるイベント(eID=y)の発生源が特定のターゲットx(tID=x)である確率は、先に説明したように、
PeID=x(tID=y)
として示され、これは、情報統合処理部131に設定されたパーティクル数:mと、各イベントに対するターゲットの割り当て数との比に相当する。例えば、図5に示す例では、
PeID=1(tID=1)=[第1イベント(eID=1)にtID=1を割り当てたパーティクル数)/(m)]
PeID=1(tID=2)=[第1イベント(eID=1)にtID=2を割り当てたパーティクル数)/(m)]
PeID=2(tID=1)=[第2イベント(eID=2)にtID=1を割り当てたパーティクル数)/(m)]
PeID=2(tID=2)=[第2イベント(eID=2)にtID=2を割り当てたパーティクル数)/(m)]
このような対応関係となる。
このデータがイベント発生源を示す[シグナル情報]として、処理決定部132に出力される。
【0173】
ステップS109の処理が終了したら、ステップS101に戻り、音声イベント検出部122および画像イベント検出部112からのイベント情報の入力の待機状態に移行する。
【0174】
以上が、図10に示すフローのステップS101〜S109の説明である。ステップS101において、情報統合処理部131が、音声イベント検出部122および画像イベント検出部112から、図3(B)に示すイベント情報を取得できなかった場合も、ステップS121において、各パーティクルに含まれるターゲットの構成データの更新が実行される。この更新は、時間経過に伴うユーザ位置の変化を考慮した処理である。
【0175】
このターゲット更新処理は、先のステップS108の説明における(a1)全パーティクルの全ターゲットを対象とする更新処理と同様の処理であり、時間経過に伴うユーザ位置の分散が拡大するという仮定に基づいて実行され、前回の更新処理からの経過時間とイベントの位置情報によってカルマン・フィルタ(Kalman Filter)を用い更新される。
【0176】
位置情報が1次元の場合の更新処理例について説明する。まず、前回の更新処理時間からの経過時間[dt]とし、全ターゲットについての、dt後のユーザ位置の予測分布を計算する。すなわち、ユーザ位置の分布情報としてのガウス分布:N(mt,σt)の期待値(平均):[mt]、分散[σt]について、以下の更新を行う。
mt=mt+xc×dt
σt2=σt2+σc2×dt
なお、
mt:予測期待値(predicted state)
σt2:予測共分散(predicted estimate covariance)
xc:移動情報(control model)
σc2:ノイズ(process noise)
である。
なお、ユーザが移動しない条件の下で処理する場合は、xc=0として更新処理を行うことができる。
上記の算出処理により、全ターゲットに含まれるユーザ位置情報としてのガウス分布:N(mt,σt)を更新する。
【0177】
なお、各パーティクルのターゲットに含まれるユーザ確信度情報(uID)については、イベントの登録ユーザ全員分の事後確率、もしくはイベント情報からスコア[Pe]が取得できない限りは更新しない。
【0178】
ステップS121の処理が終了したら、ステップS122において、ターゲットの削除要否を判定し必要であればステップS123においてターゲットを削除する。ターゲット削除は、例えば、ターゲットに含まれるユーザ位置情報にピークが検出されない場合など、特定のユーザ位置が得られていないようなデータを削除する処理として実行される。このようなターゲットがない場合は削除処理は不要であるステップS122〜S123の処理後にステップS101に戻り、音声イベント検出部122および画像イベント検出部112からのイベント情報の入力の待機状態に移行する。
【0179】
以上、図10を参照して情報統合処理部131の実行する処理について説明した。情報統合処理部131は、図10に示すフローに従った処理を音声イベント検出部122および画像イベント検出部112からのイベント情報の入力ごとに繰り返し実行する。この繰り返し処理により、より信頼度の高いターゲットを仮説ターゲットとして設定したパーティクルの重みが大きくなり、パーティクル重みに基づくリサンプリング処理により、より重みの大きいパーティクルが残存することになる。結果として音声イベント検出部122および画像イベント検出部112から入力するイベント情報に類似する信頼度の高いデータが残存することになり、最終的に信頼度の高い以下の各情報、すなわち、
(a)複数のユーザが、それぞれどこにいて、それらは誰であるかの推定情報としての[ターゲット情報]、
(b)例えば話をしたユーザなどのイベント発生源を示す[シグナル情報]
これらが生成されて処理決定部132に出力される。
なお、シグナル情報には、以下の2つのシグナル情報が含まれる。
(b1)ステップS111の処理によって生成する音声イベントに基づくシグナル情報
(b2)ステップS103〜S109の処理によって生成する画像イベントに基づくシグナル情報
【0180】
[4.発話源確率算出部において実行する処理の詳細について]
次に、図10に示すフローチャートのステップS111の処理、すなわち、音声イベントに基づくシグナル情報の生成処理の詳細について説明する。
【0181】
先に説明したように、図2に示す情報統合処理部131は、ターゲット情報更新部141と、発話源確率算出部142を有する。
ターゲット情報更新部141において画像イベント情報毎に更新されたターゲット情報は発話源確率算出部142にも出力される。
発話源確率算出部142は、音声イベント検出部122から入力する音声イベント情報と、ターゲット情報更新部141において画像イベント情報毎に更新されたターゲット情報を適用して音声イベントに基づくシグナル情報を生成する。すなわち、各ターゲットがどの程度、当該音声イベント情報の発話源らしいかを表す発話源確率としてのシグナル情報である。
【0182】
発話源確率算出部142では、音声イベント情報が入力された場合には、ターゲット情報更新部141から入力するターゲット情報を用いて、各ターゲットがどの程度、当該音声イベント情報の発話源らしいかを表す発話源確率を算出する。
【0183】
図12に、発話源確率算出部142に入力される、
(A)音声イベント情報、
(B)ターゲット情報、
これ等の入力情報の例を示す。
(A)音声イベント情報は、音声イベント検出部122から入力する音声イベント情報である。
(B)ターゲット情報は、ターゲット情報更新部141において画像イベント情報毎に更新されたターゲット情報である。
【0184】
発話源確率の算出には、図12(A)に示す音声イベント情報に含まれる音源方向情報(位置情報)や話者識別情報や、画像イベント情報に含まれる口唇動作情報や、ターゲット情報に含まれるターゲット位置やターゲット総数といった情報が利用される。
【0185】
なお、元々は画像イベント情報に含まれている口唇動作情報は、ターゲット情報に含まれる顔属性情報の一つとして、ターゲット情報更新部141から発話源確率算出部142に供給される。
また、本処理例における口唇動作情報とは、視覚的音声検出(Visual Speech Detection)技術を適用して求められた口唇状態スコアから生成される。なお、視覚的音声検出技術(Visual Speech Detection)については、例えば、[Visual lip activity detection and speaker detection using mouth region intensities/IEEE Transactions on Circuits and Systems for Video Technology, Volume 19, Issue 1 (January 2009), Pages: 133-137(参考URL: http://poseidon.csd.auth.gr/papers/PUBLISHED/JOURNAL/pdf/Siatras09a)]、[Facilitating Speech Detection in Style!: The Effect of Visual Speaking Style on the Detection of Speech in Noise Auditory-Visual Speech Processing 2005(参考URL:http://www.isca-speech.org/archive/avsp05/av05_023.html)]等に記載されており、これらの技術を適用可能である。
【0186】
口唇動作情報の生成方法の概要は次の通りである。
入力された音声イベント情報が、ある時間間隔Δtに対応するとして、
Δt=(t_end〜t_begin)
この時間間隔Δtに含まれる複数の口唇状態スコアを順に並べて時系列データとする。この時系列データが成す領域の面積を口唇動作情報とする。
図12(B)ターゲット情報の最下段に示す[時間/口唇状態スコア]のグラフが口唇動作情報に相当する。
なお、ここでの口唇動作情報は、全ターゲットの口唇動作情報の和をもって正規化される。
【0187】
なお、口唇動作情報の生成処理については、例えば特開2009−223761号公報や、特許第4462339号公報に記載があり、これらの公報に記載の処理を適用可能である。
また、音源方向情報の生成処理としては特2010−20294号公報、話者識別情報については、特開2004−286805号公報に記載があり、これらの既存の処理を適用することも可能である。
【0188】
発話源確率算出部142は、図12に示すように、
音声イベント検出部122から入力する音声イベント情報として発話に対応する音声イベントに応じた、
(a)ユーザ位置情報(音源方向情報)
(b)ユーザ識別情報(話者識別情報)
を取得する。
さらに、ターゲット情報更新部141において画像イベント情報毎に更新されたターゲット情報として、
(a)ユーザ位置情報
(b)ユーザ識別情報
(c)口唇動作情報
これらの情報を取得する。
さらに、ターゲット情報に含まれるターゲット位置やターゲット総数といった情報も入力する。
発話源確率算出部142は、これらの情報に基づいて、各ターゲットが発話源である確率(シグナル情報)を生成して処理決定部132に出力する。
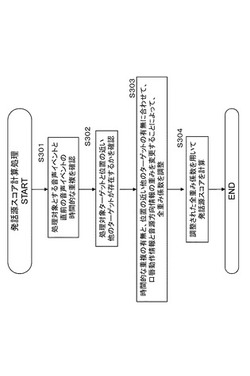
【0189】
発話源確率算出部142の実行する各ターゲット毎の発話源確率の算出方法のシーケンスの一例について、図13に示すフローチャートを参照して説明する。
図13のフローチャートに示す処理例は、ターゲットを個別に選択して、選択ターゲットに関する情報を利用して、そのターゲットが発話源であるかどうかを示す発話源確率(発話源スコア)判定する処理である。
【0190】
まず、ステップS201において、全ターゲットから処理対象とするターゲットを1つ選択する。
次にステップS202において、発話源確率算出部142の保持する識別器を用いて、選択したターゲットが発話源であるかどうかの確率値としての発話源スコアを求める。
【0191】
識別器は、音声イベント検出部122から入力する、
(a)ユーザ位置情報(音源方向情報)
(b)ユーザ識別情報(話者識別情報)
ターゲット情報更新部141から入力する、
(a)ユーザ位置情報
(b)ユーザ識別情報
(c)口唇動作情報
(d)ターゲット位置やターゲット総数
これらの入力情報に基づいて、各ターゲット毎の発話源確率を算出する識別器である。
【0192】
なお、識別器への入力情報は、上記のすべての情報としてもよいが、これらの入力情報の内そのいくつかだけを入力して利用してもよい。
識別器は、ステップS202において、選択したターゲットが発話源であるかどうかの確率値としての発話源スコアを算出する。
なお、ステップS202において実行する発話源スコアの算出処理の詳細については、図14以下を参照して後段で詳細に説明する。
【0193】
ステップS203において、他の未処理ターゲットがあるか否かを判定し、未処理ターゲットが存在する場合は、未処理ターゲットについてステップS201以下の処理を実行する。
【0194】
ステップS203において、他の未処理ターゲットがないと判定した場合は、ステップS204に進む。
ステップS204では、各ターゲット毎に求められた発話源スコアを、全体ターゲットの発話源スコアの和をもって正規化処理を実行し、各ターゲットに対する発話源確率としての発話源スコアを決定する。
この発話源スコアの最も高いターゲットが発話源であると推定されることになる。
【0195】
[5.発話源スコアの算出処理について]
次に、図13に示すフローチャートにおけるステップS202の発話源スコアの算出処理の詳細について説明する。
この発話源スコアは、図2に示す発話源確率算出部142において算出される。すなわち、選択したターゲットが発話源であるかどうかの確率値としての発話源スコアを算出する。
前述のように、発話源確率算出部142は、例えば、
音声イベント検出部122から、
(a)ユーザ位置情報(音源方向情報)
(b)ユーザ識別情報(話者識別情報)
ターゲット情報更新部141から、
(a)ユーザ位置情報
(b)ユーザ識別情報
(c)口唇動作情報
(d)ターゲット位置やターゲット総数
これらの情報を入力して、各ターゲット毎の発話源確率を求めるための発話源スコアを算出する。
【0196】
なお、発話源確率算出部142は、上記のすべての情報を用いてスコア算出を行う構成としてもよいが、その一部を用いてスコア算出を実行する構成としてもよい。
図14以下を参照して、
音源方向情報:D、
話者識別情報:S、
口唇動作情報:L、
これらの3情報を適用した発話源スコア:Pの算出処理例について説明する。
【0197】
上記3つの情報D,S,Lを用いた発話源スコアPの算出式は、たとえば図14に示すように、以下の式によって定義できる。
P=Dα・Sβ・Lγ
なお、
D:音源方向情報、
S:話者識別情報、
L:口唇動作情報、
α:音源方向情報の重み係数、
β:話者識別情報の重み係数、
γ:口唇動作情報の重み係数、
α+β+γ=1
である。
【0198】
上記の発話源算出式:P=Dα・Sβ・Lγを適用して、選択したターゲットが発話源であるかどうかの確率値としての発話源スコアを算出する。
【0199】
上記の発話源算出式:P=Dα・Sβ・Lγを適用した発話源スコア算出処理を行う場合、
入力情報として、
D:音源方向情報、
S:話者識別情報、
L:口唇動作情報、
これらの3情報が取得されていることが条件である。
【0200】
さらに、
α:音源方向情報の重み係数、
β:話者識別情報の重み係数、
γ:口唇動作情報の重み係数、
これらの係数を決定する処理が必要となる。
【0201】
上記の発話源算出式:P=Dα・Sβ・Lγを適用した発話源スコア算出処理を行うための係数決定処理を伴う発話源スコア算出処理のシーケンスについて、図15に示すフローチャートを参照して説明する。
【0202】
なお、音声イベント検出部122から入力する音声イベントに含まれる1つの音声認識結果には以下の情報が付随しているものとする。
(1)音声区間情報(その音声の開始時間と終了時間)
(2)音源方向情報
(3)話者識別情報
発話源確率算出部142は、発話源スコアを算出する処理対象となる音声イベントと直前の音声イベントとの時間的な重複の有無と、当該ターゲットと位置の近い他のターゲットの有無に合わせて、口唇動作情報と音源方向情報の重みを変更することによって全重み係数を調整し、その調整された全重み係数を用いて発話源スコアを計算する。
【0203】
発話源確率算出部142は、上記の発話源スコア算出式:P=Dα・Sβ・Lγを適用した発話源スコア算出処理に適用する係数(α、β、γ)の決定処理のために、
発話の時間的な重複の有無、
位置の近い他のターゲットの有無、
これらの情報を画像イベント検出部112、音声イベント検出部122からの入力情報に基づいて取得し、これらの情報を適用して、発話源スコア算出処理に適用する係数(α、β、γ)の決定処理を行う。
【0204】
図15に示すフローの各ステップの処理について説明する。
まず、ステップS301において、発話源スコア算出処理の処理対象とする音声イベントと直前の音声イベントの時間的な重複を確認する。
【0205】
なお、この時間的な重複の有無に関する判断は、時間的に少しだけずれた後続する音声イベントのみで判断可能である。これは、先行する音声イベントが検知された時点(=先行する音声イベントの終了時間が決定された瞬間)では、時間的に重複するその他の音声イベントが存在するかどうかを完全には決定できないためである。
【0206】
次に、ステップS302において、処理対象ターゲットと位置の近い他のターゲットが存在するかを確認する。この処理は、例えば、ターゲット情報更新部141から入力するユーザ位置情報を用いて実行可能である。
【0207】
次に、ステップS303において、ステップS301で判定した時間的な重複の有無と、ステップS302で判定した位置の近い他のターゲットの有無に応じて、
α:音源方向情報の重み係数、
γ:口唇動作情報の重み係数、
これらの重み係数を変更して、全重み係数を調整する。
なお、重み係数の調整に際しては、
α+β+γ=1
この制約条件を満たすように調整を行う。
【0208】
最後に、ステップS304において、発話源確率算出部142は、
入力情報としての、
D:音源方向情報、
S:話者識別情報、
L:口唇動作情報、
これらを適用し、さらに、ステップS303において決定した各重み係数、すなわち、
α:音源方向情報の重み係数、
β:話者識別情報の重み係数、
γ:口唇動作情報の重み係数、
ただし、α+β+γ=1
これらを適用して、発話源スコア算出式、
P=Dα・Sβ・Lγ
を適用して、ターゲットの発話源スコアを算出する。
【0209】
図16以下を参照して、具体的に状況に応じた発話源スコア算出処理の具体例について説明する。
図15のフローを参照して説明したように、発話源スコアの算出処理においては、音声が発せられる状況に応じて、どの入力情報を重視するかを適応的に変更する。
【0210】
発話を行う可能性のある人物が2名であるとき、音声が発せられる状況の例としては、例えば図16(a)〜(d)に示すように以下の状況が想定される。
(a)2名の位置が遠く、1名のみが発声する場合
(b)2名の位置が遠く、2名が同時に発声する場合
(c)2名の位置が近く、1名のみが発声する場合
(d)2名の位置が近く、2名が同時に発声する場合
【0211】
図17は、音声が発せられる状況と、上述した発話源スコア算出式:P=Dα・Sβ・Lγを適用した発話源スコア算出処理に適用する係数(α、β、γ)の調整方法の関係と、数値例を示している。
【0212】
発話源確率算出部142は、各入力情報の重み係数をそれぞれどのような値に設定するかを、音声が発せられた状況に応じて、動的に調整する。
重み係数を調整する状況は、以下の2つの条件の組み合わせから成る。
(条件1)ユーザ1名(1つのターゲット)のみによる単独発話か、あるいはユーザ2名(2つのターゲット)による同時発話か、
(条件2)ユーザ2名(2つのターゲット)の位置が近いか、あるいはユーザ2名(2つのターゲット)の位置が遠いか、
【0213】
なお、上記(条件2)のユーザ2名の位置が近いか遠いかに関しては、音源方向の差、すなわち音源方向を示す角度に基づいて、予め設定した所定のしきい値を適用して遠近を判断する。
例えば、ユーザ2名の位置に対応した音源方向の差の絶対値が10°以下の場合を「ユーザ2名の位置が近い」と判定する。
なお、源方向の差の絶対値が10°以下とは、マイクの位置から3メートル離れた位置において、ユーザ2名の間の距離が約53センチメートル以内であることに対応する。
このように、「音源方向が近い」ということを、「ユーザの間の距離が近い」あるいは「ユーザ間の位置が近い」と言い換えることとする。
【0214】
以下、図16に示す(a)〜(d)の各発話状況に応じた重み係数、すなわち、
α:音源方向情報の重み係数、
β:話者識別情報の重み係数、
γ:口唇動作情報の重み係数、
ただし、α+β+γ=1
これらの重み係数(α、β、γ)の調整方法の具体例について説明する。
【0215】
図16(a)ユーザ2名の位置が遠く、1名のみが単独発声する場合
この場合は、全ての重み係数(α、β、γ)の調整は行わず、予め設定した既定値を利用する。
すなわち、発話源確率算出部142は、発話可能性のあるターゲットが2である状況において、1つのターゲットのみが単独発声する場合、全ての重み係数(α、β、γ)の調整は行わず、予め設定した既定値を利用する。
【0216】
図16(b)ユーザ2名の位置が遠く、その2名が同時発声する場合、
この場合は、口唇動作情報の重み(γ)を小さくするように調整を行う。
すなわち、発話源確率算出部142は、発話可能性のあるターゲットが2である状況において、2つのターゲットが同時発声する場合、口唇動作情報の重みγを小さくするように前記各重み係数:α、β、γを調整する処理を行う。
【0217】
図16(c)ユーザ2名の位置が近く、1名のみが単独発声する場合
この場合は、音源方向情報の重み(α)を小さくするように調整を行う。
すなわち、発話源確率算出部142は、発話可能性のあるターゲットが2である状況において、2つのターゲットの位置が近く、1ターゲットのみが単独発声する場合、音源方向情報の重みαを小さくするように前記各重み係数:α、β、γを調整する処理を行う。
【0218】
図16(d)ユーザ2名の位置が近く、その2名が同時発声する場合
この場合は、口唇動作情報の重み(γ)と音源方向情報の重み(α)を小さくするように調整を行う。
すなわち、発話源確率算出部142は、発話可能性のあるターゲットが2である状況において、2つのターゲットの位置が近く、2のターゲットが同時に発声する場合、口唇動作情報の重みγと音源方向情報の重みαを小さくするように前記各重み係数:α、β、γを調整する処理を行う。
【0219】
なお、いずれの処理に際しても、
α+β+γ=1
の制約を満たすように調整する。
これらの重み係数(α、β、γ)の調整例をまとめた図を図17に示す。
【0220】
なお、音声が発せられたそれぞれの状況において、所望の重み係数をどの程度大きくするか、あるいは各重み係数をどのように設定するかに関しては、評価データを用いた事前の検討作業によって決められたものを用いてよい。
【0221】
図18は、具体的な重み係数(α、β、γ)の調整例として、以下の2つの例を示す図である。
(A)全重み係数の数値例(既定値が全て等しい場合(既定値:α=β=γ))
(B)全重み係数の数値例(既定値が異なる場合(既定値:α≠β≠γ))
【0222】
(A)の場合は、既定値:α=β=γ=0.333である。
(B)の場合は、既定値:α≠β≠γであり、各既定値は、
α=0.500
β=0.200
γ=0.300
としている。
【0223】
なお、(A),(B)いずれの場合も、所望の重み係数を小さくする場合には、その重み係数の既定値から1/2となるように調整している。
また、小さくする重み係数が一つのみ場合には、その他の2つの重み係数はその比率を既定値の場合と同じにするようにして調整している。
【0224】
図18(A)において口唇動作情報の重み係数(γ)を1/2(0.333から0.167)にする場合には、その他の2つの重み係数は既定値では同じ数値(0.333と0.333)となっているので、調整後にも同じ比率となるように2つの重み係数共に0.417としている。
【0225】
また、図18(B)において口唇動作情報の重み係数(γ)を1/2(0.300から0.150)にする場合には、その他の2つの重み係数は既定値では0.500と0.200となっているので、調整後にも同じ比率となるように2つの重み係数を0.607と0.243としている。
【0226】
図15のフローチャートにおけるステップS303においては、例えば、このように、
α:音源方向情報の重み係数、
β:話者識別情報の重み係数、
γ:口唇動作情報の重み係数、
これらの重み係数を調整する。
その後、この調整した重み係数を適用して、前述の発話源スコア算出式、
P=Dα・Sβ・Lγ
を適用して、ターゲットの発話源スコアを算出する。
上記式に従って、各ターゲットについての発話源スコアを算出し、そのスコア比較により、最も高いスコアを持つターゲットを発話源であると判定することができる。
【0227】
本開示の情報処理装置では、上述したように、音源方向情報、話者識別情報、口唇動作情報、これらの全てを考慮し、さらに発話状況に応じて、これらの情報の適用重みを変更して発話源スコアを算出して、算出したスコアに応じて発話源確率を算出する構成とした。
この処理によって、例えば、複数の発話者が同時に発話したような状況であってもスコア算出とスコア比較によって、発話者の特定を高精度に行うことが可能となる。
すなわち、より現実的な様々な状況においても、発話者を正しく推定することが可能となる。
【0228】
[6.本開示の構成のまとめ]
以上、特定の実施例を参照しながら、実施例について詳解してきた。しかしながら、本開示の要旨を逸脱しない範囲で当業者が実施例の修正や代用を成し得ることは自明である。すなわち、例示という形態で本発明を開示してきたのであり、限定的に解釈されるべきではない。本開示の要旨を判断するためには、特許請求の範囲の欄を参酌すべきである。
【0229】
なお、本明細書において開示した技術は、以下のような構成をとることができる。
(1) 実空間の観測情報を入力する複数の情報入力部と、
前記情報入力部から入力する情報の解析により、前記実空間に存在するユーザの推定位置情報および推定識別情報を含むイベント情報を生成するイベント検出部と、
前記イベント情報を入力し、入力イベント情報に基づいて、各ユーザの位置およびユーザ識別情報を含むターゲット情報と、
前記イベント発生源の確率値を示すシグナル情報を生成する情報統合処理部を有し、
前記情報統合処理部は、発話源確率算出部を有し、
前記発話源確率算出部は、各ターゲットの発話源確率を示す指標値としての発話源スコアを、イベント検出部から入力する複数の異なる情報に対して発話状況に応じた重みを乗算して算出する処理を行う情報処理装置。
【0230】
(2)前記発話源確率算出部は、前記イベント検出部を構成する音声イベント検出部からの入力情報として、発話イベントに対応する、
(a)ユーザ位置情報(音源方向情報)、
(b)ユーザ識別情報(話者識別情報)、
を入力し、
さらに、前記イベント検出部を構成する画像イベント検出部からの入力情報に基づいて生成されるターゲット情報として、
(a)ユーザ位置情報(顔位置情報)、
(b)ユーザ識別情報(顔識別情報)、
(c)口唇動作情報、
これらの情報を入力し、少なくともこれらの情報のいずれかを適用して、入力情報に基づく発話源スコアを算出する処理を行う請求項1に記載の情報処理装置。
【0231】
(3)前記発話源確率算出部は、音源方向情報Dと、話者識別情報Sと、口唇動作情報Lを適用して、発話源スコアPを、以下の算出式、
P=Dα・Sβ・Lγ
ただし、
α:音源方向情報の重み係数、
β:話者識別情報の重み係数、
γ:口唇動作情報の重み係数、
α+β+γ=1
上記発話源スコアPの算出式に従って発話源スコアを算出する処理を行う前記(1)または(2)に記載の情報処理装置。
【0232】
(4)前記発話源確率算出部は、前記各重み係数:α、β、γを発話状況に応じて調整する処理を行う前記(3)に記載の情報処理装置。
(5)前記発話源確率算出部は、以下の2つの条件、(条件1)1つのターゲットのみによる単独発話か、あるいは2つのターゲットによる同時発話か、
(条件2)2つのターゲットの位置が近いか、あるいは2つのターゲットの位置が遠いか、
上記2つの条件に応じて、前記各重み係数:α、β、γを調整する処理を行う前記(3)または(4)に記載の情報処理装置。
【0233】
(6)前記発話源確率算出部は、発話可能性のあるターゲットが2である状況において、2つのターゲットが同時発声する場合、口唇動作情報の重みγを小さくするように前記各重み係数:α、β、γを調整する処理を行う前記(3)〜(5)いずれかに記載の情報処理装置。
(7)前記発話源確率算出部は、発話可能性のあるターゲットが2である状況において、2つのターゲットの位置が近く、1ターゲットのみが単独発声する場合、音源方向情報の重みαを小さくするように前記各重み係数:α、β、γを調整する処理を行う前記(3)〜(5)いずれかに記載の情報処理装置。
(8)前記発話源確率算出部は、発話可能性のあるターゲットが2である状況において、2つのターゲットの位置が近く、2つのターゲットが同時に発声する場合、口唇動作情報の重みγと音源方向情報の重みαを小さくするように前記各重み係数:α、β、γを調整する処理を行う前記(3)〜(5)いずれかに記載の情報処理装置。
【0234】
さらに、上記した装置等において実行する処理の方法や、処理を実行させるプログラムも本開示の構成に含まれる。
【0235】
また、明細書中において説明した一連の処理はハードウェア、またはソフトウェア、あるいは両者の複合構成によって実行することが可能である。ソフトウェアによる処理を実行する場合は、処理シーケンスを記録したプログラムを、専用のハードウェアに組み込まれたコンピュータ内のメモリにインストールして実行させるか、あるいは、各種処理が実行可能な汎用コンピュータにプログラムをインストールして実行させることが可能である。例えば、プログラムは記録媒体に予め記録しておくことができる。記録媒体からコンピュータにインストールする他、LAN(Local Area Network)、インターネットといったネットワークを介してプログラムを受信し、内蔵するハードディスク等の記録媒体にインストールすることができる。
【0236】
なお、明細書に記載された各種の処理は、記載に従って時系列に実行されるのみならず、処理を実行する装置の処理能力あるいは必要に応じて並列的にあるいは個別に実行されてもよい。また、本明細書においてシステムとは、複数の装置の論理的集合構成であり、各構成の装置が同一筐体内にあるものには限らない。
【産業上の利用可能性】
【0237】
以上、説明したように、本開示の一実施例の構成によれば、不確実で非同期な入力情報に基づく情報解析により、ユーザ位置や識別情報、発話者情報などを生成する構成が実現される。
具体的には、画像情報や音声情報に基づいてユーザの推定位置および推定識別データを含むイベント情報を入力し、入力イベント情報に基づいて、各ユーザの位置およびユーザ識別情報を含むターゲット情報と、イベント発生源の確率値を示すシグナル情報を生成する情報統合処理部を有し、情報統合処理部は、発話源確率算出部を有し、発話源確率算出部は、各ターゲットの発話源確率を示す指標値としての発話源スコアを、イベント検出部から入力する複数の異なる情報に対して発話状況に応じた重みを乗算して算出する処理を行う。
これらの処理によって、例えば2つのターゲット(2人)が同時に発話した状況においても、どちらが発話したかを高精度に推定することが可能となる。
【符号の説明】
【0238】
11〜12 ユーザ
21 カメラ
31〜34 マイク
100 情報処理装置
111 画像入力部
112 画像イベント検出部
121 音声入力部
122 音声イベント検出部
131 情報統合処理部
132 処理決定部
141 ターゲット情報更新部
142 発話源確率算出部
201〜20k ユーザ
301 ユーザ
302 画像データ
350 画像フレーム
351 第1顔画像
352 第2顔画像
361,362 イベント情報
371,372 イベント発生源仮設データ
375 ターゲットデータ
380 ターゲット情報
390 ターゲット情報
395 第3顔画像
401 イベント情報
421 パーティクル
【技術分野】
【0001】
本開示は、情報処理装置、および情報処理方法、並びにプログラムに関する。さらに詳細には、外界からの入力情報、例えば画像、音声などの情報を入力し、入力情報に基づく外界環境の解析、具体的には言葉を発している人物の位置や誰であるか等の解析処理を実行する情報処理装置、および情報処理方法、並びにプログラムに関する。
【0002】
さらに、複数の人物が同時発話を行った場合に、発声したユーザの識別を行い、それぞれの発話を解析する情報処理装置、および情報処理方法、並びにプログラムに関する。
【背景技術】
【0003】
人とPCやロボットなどの情報処理装置との相互間の処理、例えばコミュニケーションやインタラクティブ処理を行うシステムはマン−マシン・インタラクション・システムと呼ばれる。このマン−マシン・インタラクション・システムにおいて、PCやロボット等の情報処理装置は、人のアクション例えば人の動作や言葉を認識するために画像情報や音声情報を入力して入力情報に基づく解析を行う。
【0004】
人が情報を伝達する場合、言葉のみならずしぐさ、視線、表情など様々なチャネルを情報伝達チャネルとして利用する。このようなすべてのチャネルの解析をマシンにおいて行うことができれば、人とマシンとのコミュニケーションも人と人とのコミュニケーションと同レベルに到達することができる。このような複数のチャネル(モダリティ、モーダルとも呼ばれる)からの入力情報の解析を行うインタフェースは、マルチモーダルインタフェースと呼ばれ、近年、開発、研究が盛んに行われている。
【0005】
例えばカメラによって撮影された画像情報、マイクによって取得された音声情報を入力して解析を行う場合、より詳細な解析を行うためには、様々なポイントに設置した複数のカメラおよび複数のマイクから多くの情報を入力することが有効である。
【0006】
具体的なシステムとしては、例えば以下のようなシステムが想定される。情報処理装置(テレビ)が、カメラおよびマイクを介して、テレビの前のユーザ(父、母、姉、弟)の画像および音声を入力し、それぞれのユーザの位置やどのユーザが発した言葉であるか等を解析し、テレビが解析情報に応じた処理、例えば会話を行ったユーザに対するカメラのズームアップや、会話を行ったユーザに対する的確な応答を行うなどのシステムが実現可能となる。
【0007】
従来のマン−マシン・インタラクション・システムを開示した従来技術として、例えば特許文献1(特開2009−31951号公報)や、特許文献2(特開2009−140366号公報)がある。これらの従来技術では、複数チャネル(モーダル)からの情報を確率的に統合して、複数のユーザがそれぞれどこにいて、それらは誰で、誰がシグナルを発したのか、すなわち発話行ったのかを決定するという処理を行っている。
【0008】
例えば誰がシグナルを発したのかを決定する際に、複数のユーザに対応する仮想的なターゲット(tID=1〜m)を設定し、カメラによって撮影される画像データや、マイクを介して得られる音声情報の解析結果から各ターゲットが発話源である確率を算出している。
【0009】
具体的には、例えば以下のような処理を行っている。
(a)マイクを介して得られる音声イベントの音源方向情報、話者識別情報から得られるユーザ位置情報と、ユーザ識別情報のみから得られるターゲットtIDの発話源確率P(tID)と、
(b)カメラを介して得られる画像に基づく顔認識処理によって取得される顔属性スコア[S(tID)]の面積であるSΔt(tID)、
これらの(a),(b)を算出し、さらに予め設定した配分重み係数としてのαを用いて重みαを考慮した加算または乗算によって、各ターゲット(tID=1〜m)の発話者確率Ps(tID)またはPp(tID)を算出する。
なお、この処理の詳細は、例えば上記の特許文献2(特開2009−140366号公報)に記載されている。
【0010】
上記の従来技術における発話者確率の算出処理においては、上記のように重み係数αを事前に調整しておくことが必要となる。このような重み係数の事前調整は煩わしいばかりでなく、重み係数が適切な数値に調整されていないと、発話者確率の算出結果の妥当性そのものにも大きく影響を与えるという問題がある。
【先行技術文献】
【特許文献】
【0011】
【特許文献1】特開2009−31951号公報
【特許文献2】特開2009−140366号公報
【発明の概要】
【発明が解決しようとする課題】
【0012】
本開示は、例えば上述の問題点に鑑みてなされたものであり、複数のチャネル(モダリティ、モーダル)からの入力情報の解析、具体的には、例えば周囲にいる人物の位置などの特定処理を行うシステムにおいて、画像、音声情報などの様々な入力情報に含まれる不確実な情報に対する確率的な処理を行ってより精度の高いと推定される情報に統合する処理を行うことによりロバスト性を向上させ、精度の高い解析を行う情報処理装置、および情報処理方法、並びにプログラムを提供することを目的とする。
【0013】
また、本開示の一実施例では、複数の人物が同時発話を行った場合に、発声したユーザの識別を行い、それぞれの発話を解析する情報処理装置、および情報処理方法、並びにプログラムを提供することを目的とする。
【課題を解決するための手段】
【0014】
本開示の第1の側面は、
実空間の観測情報を入力する複数の情報入力部と、
前記情報入力部から入力する情報の解析により、前記実空間に存在するユーザの推定位置情報および推定識別情報を含むイベント情報を生成するイベント検出部と、
前記イベント情報を入力し、入力イベント情報に基づいて、各ユーザの位置およびユーザ識別情報を含むターゲット情報と、
前記イベント発生源の確率値を示すシグナル情報を生成する情報統合処理部を有し、
前記情報統合処理部は、発話源確率算出部を有し、
前記発話源確率算出部は、各ターゲットの発話源確率を示す指標値としての発話源スコアを、イベント検出部から入力する複数の異なる情報に対して発話状況に応じた重みを乗算して算出する処理を行う情報処理装置にある。
【0015】
さらに、本開示の情報処理装置の一実施態様において、前記発話源確率算出部は、前記イベント検出部を構成する音声イベント検出部からの入力情報として、発話イベントに対応する、
(a)ユーザ位置情報(音源方向情報)、
(b)ユーザ識別情報(話者識別情報)、
を入力し、
さらに、前記イベント検出部を構成する画像イベント検出部からの入力情報に基づいて生成されるターゲット情報として、
(a)ユーザ位置情報(顔位置情報)、
(b)ユーザ識別情報(顔識別情報)、
(c)口唇動作情報、
これらの情報を入力し、少なくともこれらの情報のいずれかを適用して、入力情報に基づく発話源スコアを算出する処理を行う。
【0016】
さらに、本開示の情報処理装置の一実施態様において、前記発話源確率算出部は、音源方向情報Dと、話者識別情報Sと、口唇動作情報Lを適用して、発話源スコアPを、以下の算出式、
P=Dα・Sβ・Lγ
ただし、
α:音源方向情報の重み係数、
β:話者識別情報の重み係数、
γ:口唇動作情報の重み係数、
α+β+γ=1
上記発話源スコアPの算出式に従って発話源スコアを算出する処理を行う。
【0017】
さらに、本開示の情報処理装置の一実施態様において、前記発話源確率算出部は、前記各重み係数:α、β、γを発話状況に応じて調整する処理を行う。
【0018】
さらに、本開示の情報処理装置の一実施態様において、前記発話源確率算出部は、以下の2つの条件、
(条件1)1つのターゲットのみによる単独発話か、あるいは2つのターゲットによる同時発話か、
(条件2)2つのターゲットの位置が近いか、あるいは2つのターゲットの位置が遠いか、
上記2つの条件に応じて、前記各重み係数:α、β、γを調整する処理を行う。
【0019】
さらに、本開示の情報処理装置の一実施態様において、前記発話源確率算出部は、発話可能性のあるターゲットが2である状況において、2つのターゲットが同時発声する場合、口唇動作情報の重みγを小さくするように前記各重み係数:α、β、γを調整する処理を行う。
【0020】
さらに、本開示の情報処理装置の一実施態様において、前記発話源確率算出部は、発話可能性のあるターゲットが2である状況において、2つのターゲットの位置が近く、1ターゲットのみが単独発声する場合、音源方向情報の重みαを小さくするように前記各重み係数:α、β、γを調整する処理を行う。
【0021】
さらに、本開示の情報処理装置の一実施態様において、前記発話源確率算出部は、発話可能性のあるターゲットが2である状況において、2つのターゲットの位置が近く、2つのターゲットが同時に発声する場合、口唇動作情報の重みγと音源方向情報の重みαを小さくするように前記各重み係数:α、β、γを調整する処理を行う。
【0022】
さらに、本開示の第2の側面は、
情報処理装置において、情報解析処理を実行する情報処理方法であり、
複数の情報入力部が、実空間における観測情報を入力する情報入力ステップと、
イベント検出部が、前記情報入力部から入力する情報の解析により、前記実空間に存在するユーザの推定位置情報および推定識別情報を含むイベント情報を生成するイベント検出ステップと、
情報統合処理部が、前記イベント情報を入力し、入力イベント情報に基づいて、各ユーザの位置およびユーザ識別情報を含むターゲット情報と、
前記イベント発生源の確率値を示すシグナル情報を生成する情報統合処理ステップを有し、
前記情報統合処理ステップは、
各ターゲットの発話源確率を示す指標値としての発話源スコアを、イベント検出ステップにおいて入力する複数の異なる情報に対して発話状況に応じた重みを乗算して算出する処理を行う情報処理方法にある。
【0023】
さらに、本開示の第3の側面は、
情報処理装置において、情報解析処理を実行させるプログラムであり、
複数の情報入力部に、実空間における観測情報を入力させる情報入力ステップと、
イベント検出部に、前記情報入力部から入力する情報の解析により、前記実空間に存在するユーザの推定位置情報および推定識別情報を含むイベント情報を生成させるイベント検出ステップと、
情報統合処理部に、前記イベント情報を入力し、入力イベント情報に基づいて、各ユーザの位置およびユーザ識別情報を含むターゲット情報と、
前記イベント発生源の確率値を示すシグナル情報を生成させる情報統合処理ステップを実行させ、
前記情報統合処理ステップにおいては、
各ターゲットの発話源確率を示す指標値としての発話源スコアを、イベント検出ステップにおいて入力する複数の異なる情報に対して発話状況に応じた重みを乗算して算出する処理を行わせるプログラムにある。
【0024】
なお、本開示のプログラムは、例えば、様々なプログラム・コードを実行可能な情報処理装置やコンピュータ・システムに対して、コンピュータ可読な形式で提供する記憶媒体、通信媒体によって提供可能なプログラムである。このようなプログラムをコンピュータ可読な形式で提供することにより、情報処理装置やコンピュータ・システム上でプログラムに応じた処理が実現される。
【0025】
本開示のさらに他の目的、特徴や利点は、後述する実施例や添付する図面に基づくより詳細な説明によって明らかになるであろう。なお、本明細書においてシステムとは、複数の装置の論理的集合構成であり、各構成の装置が同一筐体内にあるものには限らない。
【発明の効果】
【0026】
本開示の一実施例の構成によれば、不確実で非同期な入力情報に基づく情報解析により、ユーザ位置や識別情報、発話者情報などを生成する構成が実現される。
具体的には、画像情報や音声情報に基づいてユーザの推定位置および推定識別データを含むイベント情報を入力し、入力イベント情報に基づいて、各ユーザの位置およびユーザ識別情報を含むターゲット情報と、イベント発生源の確率値を示すシグナル情報を生成する情報統合処理部を有し、情報統合処理部は、発話源確率算出部を有し、発話源確率算出部は、各ターゲットの発話源確率を示す指標値としての発話源スコアを、イベント検出部から入力する複数の異なる情報に対して発話状況に応じた重みを乗算して算出する処理を行う。
これらの処理によって、例えば2つのターゲット(2人)が同時に発話した状況においても、どちらが発話したかを高精度に推定することが可能となる。
【図面の簡単な説明】
【0027】
【図1】本開示に係る情報処理装置の実行する処理の概要について説明する図である。
【図2】本開示の一実施例の情報処理装置の構成および処理について説明する図である。
【図3】音声イベント検出部122および画像イベント検出部112が生成し情報統合処理部131に入力する情報の例について説明する図である。
【図4】パーティクル・フィルタ(Particle Filter)を適用した基本的な処理例について説明する図である。
【図5】本処理例で設定するパーティクルの構成について説明する図である。
【図6】各パーティクルに含まれるターゲット各々が有するターゲットデータの構成について説明する図である。
【図7】ターゲット情報の構成および生成処理について説明する図である。
【図8】ターゲット情報の構成および生成処理について説明する図である。
【図9】ターゲット情報の構成および生成処理について説明する図である。
【図10】情報統合処理部131の実行する処理シーケンスを説明するフローチャートを示す図である。
【図11】パーティクル重み[WpID]の算出処理の詳細について説明する図である。
【図12】発話者特定処理について説明する図である。
【図13】発話源確率算出部の実行する処理シーケンスの一例について説明するフローチャートを示す図である。
【図14】発話源確率算出部の実行する発話源スコアの算出処理について説明する図である。
【図15】発話源確率算出部の実行する発話源スコアの算出処理シーケンスを説明するフローチャートを示す図である。
【図16】発話源確率算出部の実行する発話源スコアの算出処理における重み係数の決定要素となる発話状況の例について説明する図である。
【図17】発話源確率算出部の実行する発話源スコアの算出処理における重み係数の決定処理例について説明する図である。
【図18】発話源確率算出部の実行する発話源スコアの算出処理における重み係数の決定処理例について説明する図である。
【発明を実施するための形態】
【0028】
以下、図面を参照しながら本開示の実施形態に係る情報処理装置、および情報処理方法、並びにプログラムの詳細について説明する。なお、説明は以下の項目に従って行う。
1.本開示の情報処理装置の実行する処理の概要について
2,本開示の情報処理装置の構成と処理の詳細について
3.本開示の情報処理装置の実行する処理シーケンスについて
4.発話源確率算出部の実行する処理の詳細について
5.発話源スコアの算出処理について
6.本開示の構成のまとめ
【0029】
[1.本開示の情報処理装置の実行する処理の概要について]
ます、本開示の情報処理装置の実行する処理の概要について説明する。
本開示は、例えば、入力イベント情報の内、ユーザの発話に対応する音声イベント情報に関しては、発話源確率の算出において識別器を用い、背景技術の欄において説明した重み係数の事前調整を行う必要のない構成を実現するものである。
具体的には、各ターゲットが発話源らしいかどうかを識別する識別器や、2つのターゲット情報のみを対象として、どちらがより発話源らしいか判定する識別器を用いる。識別器への入力情報は、音声イベント情報に含まれる音源方向情報や話者識別情報や、イベント情報の内、画像イベント情報に含まれる口唇動作情報や、ターゲット情報に含まれるターゲット位置やターゲット総数を用いる。発話源確率の算出において識別器を用いることによって、背景技術の欄において説明した重み係数の事前調整が必要なくなり、且つより適切な発話源確率の算出が可能となる。
【0030】
まず、図1を参照して本開示に係る情報処理装置の実行する処理の概要について説明する。本開示の情報処理装置100は、実空間における観測情報を入力するセンサ、ここでは一例としてカメラ21と、複数のマイク31〜34から画像情報、音声情報を入力し、これらの入力情報に基づいて環境の解析を行う。具体的には、複数のユーザ1,11〜2,12の位置の解析、およびその位置にいるユーザの識別を行う。
【0031】
図に示す例において、例えばユーザ1,11〜ユーザ2,12が家族である姉、弟であるとき、情報処理装置100は、カメラ21と、複数のマイク31〜34から入力する画像情報、音声情報の解析を行い、2人のユーザ1〜2の存在する位置、各位置にいるユーザが姉、弟のいずれであるかを識別する。識別処理結果は様々な処理に利用される。例えば、例えば会話を行ったユーザに対するカメラのズームアップや、会話を行ったユーザに対してテレビから応答を行うなどの処理に利用される。
【0032】
なお、本開示に係る情報処理装置100の主要な処理は、複数の情報入力部(カメラ21,マイク31〜34)からの入力情報に基づいて、ユーザの位置識別およびユーザの特定処理としてのユーザ識別処理を行うことである。この識別結果の利用処理については特に限定するものではない。カメラ21と、複数のマイク31〜34から入力する画像情報、音声情報には様々な不確実な情報が含まれる。本開示の情報処理装置100では、これらの入力情報に含まれる不確実な情報に対する確率的な処理を行って、精度の高いと推定される情報に統合する処理を行う。この推定処理によりロバスト性を向上させ、精度の高い解析を行う。
【0033】
[2,本開示の情報処理装置の構成と処理の詳細について]
図2に情報処理装置100の構成例を示す。情報処理装置100は、入力デバイスとして画像入力部(カメラ)111、複数の音声入力部(マイク)121a〜dを有する。画像入力部(カメラ)111から画像情報を入力し、音声入力部(マイク)121から音声情報を入力し、これらの入力情報に基づいて解析を行う。複数の音声入力部(マイク)121a〜dの各々は、図1に示すように様々な位置に配置されている。
【0034】
複数のマイク121a〜dから入力された音声情報は、音声イベント検出部122を介して情報統合処理部131に入力される。音声イベント検出部122は、複数の異なるポジションに配置された複数の音声入力部(マイク)121a〜dから入力する音声情報を解析し統合する。具体的には、音声入力部(マイク)121a〜dから入力する音声情報に基づいて、発生した音の位置およびどのユーザの発生させた音であるかのユーザ識別情報を生成して情報統合処理部131に入力する。
【0035】
なお、情報処理装置100の実行する具体的な処理は、例えば図1に示すように複数のユーザが存在する環境で、ユーザA〜Bがどの位置にいて、会話を行ったユーザがどのユーザであるかを識別すること、すなわち、ユーザ位置およびユーザ識別を行うことであり、さらに声を発した人物(発話者)などのイベント発生源を特定する処理である。
【0036】
音声イベント検出部122は、複数の異なるポジションに配置された複数の音声入力部(マイク)121a〜dから入力する音声情報を解析し、音声の発生源の位置情報を確率分布データとして生成する。具体的には、音源方向に関する期待値と分散データN(me,σe)を生成する。また、予め登録されたユーザの声の特徴情報との比較処理に基づいてユーザ識別情報を生成する。この識別情報も確率的な推定値として生成する。音声イベント検出部122には、予め検証すべき複数のユーザの声についての特徴情報が登録されており、入力音声と登録音声との比較処理を実行して、どのユーザの声である確率が高いかを判定する処理を行い、全登録ユーザに対する事後確率、あるいはスコアを算出する。
【0037】
このように、音声イベント検出部122は、複数の異なるポジションに配置された複数の音声入力部(マイク)121a〜dから入力する音声情報を解析し、音声の発生源の位置情報を確率分布データと、確率的な推定値からなるユーザ識別情報とによって構成される[統合音声イベント情報]を生成して情報統合処理部131に入力する。
【0038】
一方、画像入力部(カメラ)111から入力された画像情報は、画像イベント検出部112を介して情報統合処理部131に入力される。画像イベント検出部112は、画像入力部(カメラ)111から入力する画像情報を解析し、画像に含まれる人物の顔を抽出し、顔の位置情報を確率分布データとして生成する。具体的には、顔の位置や方向に関する期待値と分散データN(me,σe)を生成する。
【0039】
また、画像イベント検出部112は、予め登録されたユーザの顔の特徴情報との比較処理に基づいて顔を識別してユーザ識別情報を生成する。この識別情報も確率的な推定値として生成する。画像イベント検出部112には、予め検証すべき複数のユーザの顔についての特徴情報が登録されており、入力画像から抽出した顔領域の画像の特徴情報と登録された顔画像の特徴情報との比較処理を実行して、どのユーザの顔である確率が高いかを判定する処理を行い、全登録ユーザに対する事後確率、あるいはスコアを算出する。
【0040】
さらに、画像イベント検出部112は、画像入力部(カメラ)111から入力された画像に含まれる顔に対応する属性スコア、例えば口領域の動きに基づいて生成される顔属性スコアを算出する。
【0041】
顔属性スコアは、例えば、
(a)画像に含まれる顔の口領域の動きに対応するスコア、
(b)画像に含まれる顔が笑顔か否かに応じて設定するスコア、
(c)画像に含まれる顔が男であるか女であるかに応じて設定するスコア、
(d)画像に含まれる顔が大人であるか子供であるかに応じて設定するスコア、
このような様々な顔属性スコアを算出する設定が可能である。
以下に説明する実施例では、
(a)画像に含まれる顔の口領域の動きに対応するスコアを顔属性スコアとして算出して利用する例について説明する。すなわち、顔の口領域の動きに対応するスコアを顔属性スコアとして算出し、この顔属性スコアに基づいて発話者の特定を行なう。
【0042】
画像イベント検出部112は、画像入力部(カメラ)111から入力された画像に含まれる顔領域から口領域を識別して、口領域の動き検出を行い、口領域の動き検出結果に対応したスコア、例えば口の動きがあると判定された場合に高いスコアとするスコアを算出する。
【0043】
なお、口領域の動き検出処理は、例えばVSD(Visual Speech Detection)を適用した処理として実行する。本発明の出願人と同一の出願に係る特開2005−157679に開示の方法を適用することができる。具体的には、例えば、画像入力部(カメラ)111からの入力画像から検出された顔画像から唇の左右端点を検出し、N番目のフレームとN+1番目のフレームにおいて唇の左右端点をそれぞれそろえてから輝度の差分を算出し、この差分値を閾値処理することで、口の動きを検出することができる。
【0044】
なお、音声イベント検出部122や画像イベント検出部112において実行する音声識別や、顔検出、顔識別処理は従来から知られる技術を適用する。例えば顔検出、顔識別処理としては以下の文献に開示された技術の適用が可能である。
佐部 浩太郎,日台 健一,"ピクセル差分特徴を用いた実時間任意姿勢顔検出器の学習",第10回画像センシングシンポジウム講演論文集,pp.547−552,2004
特開2004−302644(P2004−302644A)[発明の名称:顔識別装置、顔識別方法、記録媒体、及びロボット装置]
【0045】
情報統合処理部131は、音声イベント検出部122や画像イベント検出部112からの入力情報に基づいて、複数のユーザが、それぞれどこにいて、それらは誰で、誰が音声等のシグナルを発したのかを確率的に推定する処理を実行する。
【0046】
具体的には、情報統合処理部131は音声イベント検出部122や画像イベント検出部112からの入力情報に基づいて、
(a)複数のユーザが、それぞれどこにいて、それらは誰であるかの推定情報としての[ターゲット情報]
(b)例えば発話したユーザなどのイベント発生源を[シグナル情報]、
これらの各情報を処理決定部132に出力する。
なお、シグナル情報には、以下の2つのシグナル情報が含まれる。
(b1)音声イベントに基づくシグナル情報
(b2)画像イベントに基づくシグナル情報
【0047】
情報統合処理部131のターゲット情報更新部141は、画像イベント検出部112において検出された画像イベント情報を入力して、例えばパーティクル・フィルタを用いたターゲット更新処理を実行して、画像イベントに基づくターゲット情報とシグナル情報を生成して処理決定部132に出力する。なお、更新結果としてのターゲット情報は発話源確率算出部142にも出力される。
【0048】
情報統合処理部131の発話源確率算出部142は、音声イベント検出部122において検出された音声イベント情報を入力して、識別モデル(識別器)を用いて各ターゲットが入力音声イベントの発話源である確率を算出する。発話源確率算出部142は、この算出値に基づいて、音声イベントに基づくシグナル情報を生成して処理決定部132に出力する。
これらの処理については後段で詳細に説明する。
【0049】
情報統合処理部131の生成したターゲット情報、シグナル情報を含む識別処理結果を受領した処理決定部132は、識別処理結果を利用した処理を実行する、例えば、例えば会話を行ったユーザに対するカメラのズームアップや、会話を行ったユーザに対してテレビから応答を行うなどの処理を行う。
【0050】
上述したように、音声イベント検出部122は、音声の発生源の位置情報の確率分布データ、具体的には、音源方向に関する期待値と分散データN(me,σe)を生成する。また、予め登録されたユーザの声の特徴情報との比較処理に基づいてユーザ識別情報を生成して情報統合処理部131に入力する。
【0051】
また、画像イベント検出部112は、画像に含まれる人物の顔を抽出し、顔の位置情報を確率分布データとして生成する。具体的には、顔の位置や方向に関する期待値と分散データN(me,σe)を生成する。また、予め登録されたユーザの顔の特徴情報との比較処理に基づいてユーザ識別情報を生成して情報統合処理部131に入力する。さらに、画像入力部(カメラ)111から入力された画像中の顔領域から顔属性情報としての顔属性スコア、例えば口領域の動き検出を行い、口領域の動き検出結果に対応したスコア、具体的には口の動きが大きいと判定された場合に高いスコアとする顔属性スコアを算出して情報統合処理部131に入力する。
【0052】
図3を参照して、音声イベント検出部122および画像イベント検出部112が生成し情報統合処理部131に入力する情報の例について説明する。
【0053】
本開示の構成では、画像イベント検出部112は、
(Va)顔の位置や方向に関する期待値と分散データN(me,σe)、
(Vb)顔画像の特徴情報に基づくユーザ識別情報、
(Vc)検出された顔の属性に対応するスコア、例えば口領域の動きに基づいて生成される顔属性スコア、
これらのデータを生成して情報統合処理部131に入力し、
音声イベント検出部122が、
(Aa)音源方向に関する期待値と分散データN(me,σe)、
(Ab)声の特徴情報に基づくユーザ識別情報、
これらのデータを情報統合処理部131に入力する。
【0054】
図3(A)は図1を参照して説明したと同様のカメラやマイクが備えられた実環境の例を示し、複数のユーザ1〜k,201〜20kが存在する。この環境で、あるユーザが何らかの発話を行ったとすると、マイクで音声が入力される。また、カメラは連続的に画像を撮影している。
【0055】
音声イベント検出部122および画像イベント検出部112が生成して、情報統合処理部131に入力する情報は、
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報または話者識別情報)
(c)顔属性情報(顔属性スコア)
これら3種類に大別できる。
【0056】
すなわち、
(a)ユーザ位置情報は、
画像イベント検出部112の生成する
(Va)顔の位置や方向に関する期待値と分散データN(me,σe)と、
音声イベント検出部122の生成する
(Aa)音源方向に関する期待値と分散データN(me,σe)、
これらの統合データである。
【0057】
また、
(b)ユーザ識別情報(顔識別情報または話者識別情報)は、
画像イベント検出部112の生成する
(Vb)顔画像の特徴情報に基づくユーザ識別情報と、
音声イベント検出部122の生成する
(Ab)声の特徴情報に基づくユーザ識別情報、
これらの統合データである。
【0058】
(c)顔属性情報(顔属性スコア)は、
画像イベント検出部112の生成する
(Vc)検出された顔の属性に対応するスコア、例えば口領域の動きに基づいて生成される顔属性スコア、
に対応する。
【0059】
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報または話者識別情報)
(c)顔属性情報(顔属性スコア)、
これらの3つの情報は、イベントの発生毎に生成される。音声イベント検出部122は、音声入力部(マイク)121a〜dから音声情報が入力された場合に、その音声情報に基づいて上記の(a)ユーザ位置情報、(b)ユーザ識別情報を生成して情報統合処理部131に入力する。画像イベント検出部112は、例えば予め定めた一定のフレーム間隔で、画像入力部(カメラ)111から入力された画像情報に基づいて(a)ユーザ位置情報、(b)ユーザ識別情報、(c)顔属性情報(顔属性スコア)を生成して情報統合処理部131に入力する。なお、本例では、画像入力部(カメラ)111は1台のカメラを設定した例を示しており、1つのカメラに複数のユーザの画像が撮影される設定であり、この場合、1つの画像に含まれる複数の顔の各々について(a)ユーザ位置情報、(b)ユーザ識別情報を生成して情報統合処理部131に入力する。
【0060】
音声イベント検出部122が音声入力部(マイク)121a〜dから入力する音声情報に基づいて、
(a)ユーザ位置情報
(b)ユーザ識別情報(話者識別情報)
これらの情報を生成する処理について説明する。
【0061】
[音声イベント検出部122による(a)ユーザ位置情報の生成処理]
音声イベント検出部122は、音声入力部(マイク)121a〜dから入力された音声情報に基づいて解析された声を発したユーザ、すなわち[話者]の位置の推定情報を生成する。すなわち、話者が存在すると推定される位置を、期待値(平均)[me]と分散情報[σe]からなるガウス分布(正規分布)データN(me,σe)として生成する。
【0062】
[音声イベント検出部122による(b)ユーザ識別情報(話者識別情報)の生成処理]
音声イベント検出部122は、音声入力部(マイク)121a〜dから入力された音声情報に基づいて話者が誰であるかを、入力音声と予め登録されたユーザ1〜kの声の特徴情報との比較処理により推定する。具体的には話者が各ユーザ1〜kである確率を算出する。この算出値を(b)ユーザ識別情報(話者識別情報)とする。例えば入力音声の特徴と最も近い登録された音声特徴を有するユーザに最も高いスコアを配分し、最も異なる特徴を持つユーザに最低のスコア(例えば0)を配分する処理によって各ユーザである確率を設定したデータを生成して、これを(b)ユーザ識別情報(話者識別情報)とする。
【0063】
次に、画像イベント検出部112が画像入力部(カメラ)111から入力する画像情報に基づいて、
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報)
(c)顔属性情報(顔属性スコア)
これらの情報を生成する処理について説明する。
【0064】
[画像イベント検出部112による(a)ユーザ位置情報の生成処理]
画像イベント検出部112は、画像入力部(カメラ)111から入力された画像情報に含まれる顔の各々について顔の位置の推定情報を生成する。すなわち、画像から検出された顔が存在すると推定される位置を、期待値(平均)[me]と分散情報[σe]からなるガウス分布(正規分布)データN(me,σe)として生成する。
【0065】
[画像イベント検出部112による(b)ユーザ識別情報(顔識別情報)の生成処理]
画像イベント検出部112は、画像入力部(カメラ)111から入力された画像情報に基づいて、画像情報に含まれる顔を検出し、各顔が誰であるかを、入力画像情報と予め登録されたユーザ1〜kの顔の特徴情報との比較処理により推定する。具体的には抽出された各顔が各ユーザ1〜kである確率を算出する。この算出値を(b)ユーザ識別情報(顔識別情報)とする。例えば入力画像に含まれる顔の特徴と最も近い登録された顔の特徴を有するユーザに最も高いスコアを配分し、最も異なる特徴を持つユーザに最低のスコア(例えば0)を配分する処理によって各ユーザである確率を設定したデータを生成して、これを(b)ユーザ識別情報(顔識別情報)とする。
【0066】
[画像イベント検出部112による(c)顔属性情報(顔属性スコア)の生成処理]
画像イベント検出部112は、画像入力部(カメラ)111から入力された画像情報に基づいて、画像情報に含まれる顔領域を検出し、検出された各顔の属性、具体的には先に説明したように顔の口領域の動き、笑顔か否か、男であるか女であるか、大人であるかこどもであるかなどの属性スコアを算出することが可能であるが、本処理例では、画像に含まれる顔の口領域の動きに対応するスコアを顔属性スコアとして算出して利用する例について説明する。
【0067】
顔の口領域の動きに対応するスコアを算出する処理として、前述したように画像イベント検出部112は、例えば、画像入力部(カメラ)111からの入力画像から検出された顔画像から唇の左右端点を検出し、N番目のフレームとN+1番目のフレームにおいて唇の左右端点をそれぞれそろえてから輝度の差分を算出し、この差分値を閾値処理する。この処理により、口の動きを検出し、口の動きが大きいほど高いスコアとする顔属性スコアを設定する。
【0068】
なお、カメラの撮影画像から複数の顔が検出された場合、画像イベント検出部112は、各検出顔に応じてそれぞれ個別のイベントとして、各顔対応のイベント情報を生成する。すなわち、以下の情報を含むイベント情報を生成して情報統合処理部131に入力する。
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報)
(c)顔属性情報(顔属性スコア)
これらの情報を生成して、情報統合処理部131に入力する。
【0069】
本例では、画像入力部111として1台のカメラを利用した例を説明するが、複数のカメラの撮影画像を利用してもよく、その場合は、画像イベント検出部112は、各カメラの撮影画像の各々に含まれる各顔について、
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報)
(c)顔属性情報(顔属性スコア)
これらの情報を生成して、情報統合処理部131に入力する。
【0070】
次に、情報統合処理部131の実行する処理について説明する。情報統合処理部131は、上述したように、音声イベント検出部122および画像イベント検出部112から、図3(B)に示す3つの情報、すなわち、
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報または話者識別情報)
(c)顔属性情報(顔属性スコア)
これらの情報を逐次入力する。なお、これらの各情報の入力タイミングは様々な設定が可能であるが、例えば、音声イベント検出部122は新たな音声が入力された場合に上記(a),(b)の各情報を音声イベント情報として生成して入力し、画像イベント検出部112は、一定のフレーム周期単位で、上記(a),(b),(c)の各情報を音声イベント情報として生成して入力するといった設定が可能である。
【0071】
情報統合処理部131の実行する処理について、図4以下を参照して説明する。
先に説明したように、情報統合処理部131は、ターゲット情報更新部141、発話源確率算出部142を有し、それぞれ以下の処理を実行する。
【0072】
ターゲット情報更新部141は、画像イベント検出部112において検出された画像イベント情報を入力して、例えばパーティクル・フィルタを用いたターゲット更新処理を実行して、画像イベントに基づくターゲット情報とシグナル情報を生成して処理決定部132に出力する。なお、更新結果としてのターゲット情報は発話源確率算出部142にも出力される。
【0073】
発話源確率算出部142は、音声イベント検出部122において検出された音声イベント情報を入力して、識別モデル(識別器)を用いて各ターゲットが入力音声イベントの発話源である確率を算出する。発話源確率算出部142は、この算出値に基づいて、音声イベントに基づくシグナル情報を生成して処理決定部132に出力する。
【0074】
まず、ターゲット情報更新部141の実行する処理について説明する。
情報統合処理部131のターゲット情報更新部141は、ユーザの位置および識別情報についての仮説(Hypothesis)の確率分布データを設定し、その仮説を入力情報に基づいて更新することで、より確からしい仮説のみを残す処理を行う。この処理手法として、パーティクル・フィルタ(Particle Filter)を適用した処理を実行する。
【0075】
パーティクル・フィルタ(Particle Filter)を適用した処理は、様々な仮説に対応するパーティクルを多数設定して行なわれる。本例では、ユーザの位置と誰であるかの仮説に対応するパーティクルを多数設定し、画像イベント検出部112から、図3(B)に示す3つの情報、すなわち、
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報または話者識別情報)
(c)顔属性情報(顔属性スコア)
これらの入力情報に基づいて、より確からしいパーティクルの重み(ウェイト)を高めていくという処理を行う。
【0076】
パーティクル・フィルタ(Particle Filter)を適用した基本的な処理例について図4を参照して説明する。例えば、図4に示す例は、あるユーザに対応する存在位置をパーティクル・フィルタにより推定する処理例を示している。図4に示す例は、ある直線上の1次元領域におけるユーザ301の存在する位置を推定する処理である。
【0077】
初期的な仮説(H)は、図4(a)に示すように均一なパーティクル分布データとなる。次に、画像データ302が取得され、取得画像に基づくユーザ301の存在確率分布データが図4(b)のデータとして取得される。この取得画像に基づく確率分布データに基づいて、図4(a)のパーティクル分布データが更新され、図4(c)の更新された仮説確率分布データが得られる。このような処理を、入力情報に基づいて繰り返し実行して、ユーザのより確からしい位置情報を得る。
【0078】
なお、パーティクル・フィルタを用いた処理の詳細については、例えば[D. Schulz, D. Fox, and J. Hightower. People Tracking with Anonymous and ID−sensors Using Rao−Blackwellised Particle Filters.Proc. of the International Joint Conference on Artificial Intelligence (IJCAI−03)]に記載されている。
【0079】
図4に示す処理例は、ユーザの存在位置のみについて、入力情報を画像データのみとした処理例として説明しており、パーティクルの各々は、ユーザ301の存在位置のみの情報を有している。
【0080】
情報統合処理部131のターゲット情報更新部141は、画像イベント検出部112から、図3(B)に示す情報、すなわち、
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報または話者識別情報)
(c)顔属性情報(顔属性スコア)
これらの情報を取得して、複数のユーザの位置と複数のユーザがそれぞれ誰であるかを判別する処理を行うことになる。従って、パーティクル・フィルタ(Particle Filter)を適用した処理では、情報統合処理部131が、ユーザの位置と誰であるかの仮説に対応するパーティクルを多数設定して、画像イベント検出部112から、図3(B)に示す2つの情報に基づいて、パーティクル更新を行うことになる。
【0081】
情報統合処理部131が、音声イベント検出部122および画像イベント検出部112から、図3(B)に示す3つの情報、すなわち、
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報または話者識別情報)
(c)顔属性情報(顔属性スコア)
これらを入力して実行するパーティクル更新処理例について図5を参照して説明する。
【0082】
なお、以下に説明するパーティクル更新処理は、情報統合処理部131のターゲット情報更新部141において画像イベント情報のみを用いて実行する処理例として説明する。
【0083】
パーティクルの構成について説明する。情報統合処理部131のターゲット情報更新部141は、予め設定した数=mのパーティクルを有する。図5に示すパーティクル1〜mである。各パーティクルには識別子としてのパーティクルID(PID=1〜m)が設定されている。
【0084】
各パーティクルに、仮想的なオブジェクトに対応する複数のターゲットtID=1,2,・・・nを設定する。本例では、例えば実空間に存在すると推定される人数以上の仮想のユーザに対応する複数(n個)のターゲットを各パーティクルに設定する。m個のパーティクルの各々はターゲット単位でデータをターゲット数分保持する。図5に示す例では、1つのパーティクルにn個(n=2)のターゲットが含まれる。
【0085】
情報統合処理部131のターゲット情報更新部141は、画像イベント検出部112から、図3(B)に示すイベント情報、すなわち、
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報または話者識別情報)
(c)顔属性情報(顔属性スコア[SeID])
これらのイベント情報を入力してm個のパーティクル(PID=1〜m)の更新処理を行う。
【0086】
図5に示す情報統合処理部131に設定される各パーティクル1〜mに含まれるターゲット1〜nの各々は、入力するイベント情報の各々(eID=1〜k)に予め対応付けられており、その対応に従って、入力イベントに対応する選択されたターゲットの更新が実行される。具体的には、例えば画像イベント検出部112において検出された顔画像を個別のイベントとして、この顔画像イベント各々にターゲットを対応付けて処理を行なう。
【0087】
具体的な更新処理について説明する。例えば、画像イベント検出部112は、予め定めた一定のフレーム間隔で、画像入力部(カメラ)111から入力された画像情報に基づいて(a)ユーザ位置情報、(b)ユーザ識別情報、(c)顔属性情報(顔属性スコア)を生成して情報統合処理部131に入力する。
【0088】
このとき、図5に示す画像フレーム350がイベントの検出対象フレームである場合、画像フレームに含まれる顔画像の数に応じたイベントが検出される。すなわち、図5に示す第1顔画像351に対応するイベント1(eID=1)と、第2顔画像352に対応するイベント2(eID=2)である。
【0089】
画像イベント検出部112は、これらの各イベントの各々(eID=1,2,・・・)について、
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報または話者識別情報)
(c)顔属性情報(顔属性スコア)
これらを生成して情報統合処理部131に入力する。すなわち、図5に示すイベント対応情報361,362である。
【0090】
情報統合処理部131のターゲット情報更新部141に設定されたパーティクル1〜mの各々に含まれるターゲット1〜nの各々は、イベント(eID=1〜k)の各々に予め対応付けられており、それぞれのパーティクルに含まれるどのターゲットを更新するかを予め設定した構成としている。なお、イベント(eID=1〜k)各々に対するターゲット(tID)の対応付けは、重複しない設定とする。すなわち、各パーティクルで重複がないように取得イベント分のイベント発生源仮説を生成する。
図5に示す例では、
(1)パーティクル1(pID=1)は、
[イベントID=1(eID=1)]の対応ターゲット=[ターゲットID=1(tID=1)]、
[イベントID=2(eID=2)]の対応ターゲット=[ターゲットID=2(tID=2)]、
(2)パーティクル2(pID=2)は、
[イベントID=1(eID=1)]の対応ターゲット=[ターゲットID=1(tID=1)]、
[イベントID=2(eID=2)]の対応ターゲット=[ターゲットID=2(tID=2)]、
:
(m)パーティクルm(pID=m)は、
[イベントID=1(eID=1)]の対応ターゲット=[ターゲットID=2(tID=2)]、
[イベントID=2(eID=2)]の対応ターゲット=[ターゲットID=1(tID=1)]、
【0091】
このように、情報統合処理部131のターゲット情報更新部141に設定されたパーティクル1〜mの各々に含まれるターゲット1〜nの各々は、イベント(eID=1〜k)の各々に予め対応付けられており、各イベントIDに応じて各パーティクルに含まれるどのターゲットを更新するかが決定された構成を持つ。例えば、図5に示す[イベントID=1(eID=1)]のイベント対応情報361によって、パーティクル1(pID=1)では、ターゲットID=1(tID=1)のデータのみが選択的に更新される。
【0092】
同様に、図5に示す[イベントID=1(eID=1)]のイベント対応情報361によって、パーティクル2(pID=2)も、ターゲットID=1(tID=1)のデータのみが選択的に更新される。また、図5に示す[イベントID=1(eID=1)]のイベント対応情報361によって、パーティクルm(pID=m)では、ターゲットID=2(tID=2)のデータのみが選択的に更新される。
【0093】
図5に示すイベント発生源仮設データ371,372が、各パーティクルに設定されたイベント発生源仮設データであり、これらが各パーティクルに設定されており、この情報に従ってイベントIDに対応する更新ターゲットが決定される。
【0094】
各パーティクルに含まれる各ターゲットデータについて図6を参照して説明する。図6は、図5に示すパーティクル1(pID=1)に含まれる1つのターゲット(ターゲットID:tID=n)375のターゲットデータの構成である。ターゲット375のターゲットデータは、図6に示すように、以下のデータ、すなわち、
(a)各ターゲット各々に対応する存在位置の確率分布[ガウス分布:N(m1n,σ1n)]、
(b)各ターゲットが誰であるかを示すユーザ確信度情報(uID)
uID1n1=0.0
uID1n2=0.1
:
uID1nk=0.5
これらのデータによって構成される。
【0095】
なお、(a)に示すガウス分布:N(m1n,σ1n)における[m1n,σ1n]の(1n)は、パーティクルID:pID=1におけるターゲットID:tID=nに対応する存在確率分布としてのガウス分布であることを意味する。
また、(b)に示すユーザ確信度情報(uID)における、[uID1n1]に含まれる(1n1)は、パーティクルID:pID=1におけるターゲットID:tID=nの、ユーザ=ユーザ1である確率を意味する。すなわちターゲットID=nのデータは、
ユーザ1である確率が0.0、
ユーザ2である確率が0.1、
:
ユーザkである確率が0.5、
であることを意味している。
【0096】
図5に戻り、情報統合処理部131のターゲット情報更新部141の設定するパーティクルについての説明を続ける。図5に示すように、情報統合処理部131のターゲット情報更新部141は、予め決定した数=mのパーティクル(PID=1〜m)を設定し、各パーティクルは、実空間に存在すると推定されるターゲット(tID=1〜n)各々について、
(a)各ターゲット各々に対応する存在位置の確率分布[ガウス分布:N(m,σ)]、
(b)各ターゲットが誰であるかを示すユーザ確信度情報(uID)
これらのターゲットデータを有する。
【0097】
情報統合処理部131のターゲット情報更新部141は、音声イベント検出部122および画像イベント検出部112から、図3(B)に示すイベント情報、すなわち、
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報または話者識別情報)
(c)顔属性情報(顔属性スコア[SeID])
これらのイベント情報(eID=1,2・・・)を入力し、各パーティクルにおいて予め設定されたイベント対応のターゲットの更新を実行する。
【0098】
なお、更新対象は各ターゲットデータに含まれる以下のデータ、すなわち、
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報または話者識別情報)
これらのデータである。
【0099】
(c)顔属性情報(顔属性スコア[SeID])は、イベント発生源を示す[シグナル情報]として最終的に利用される。ある程度の数のイベントが入力されると、各パーティクルの重み(ウェイト)も更新され、実空間の情報に最も近いデータを持つパーティクルの重みが大きくなり、実空間の情報に適合しないデータを持つパーティクルの重みが小さくなっていく。このようにパーティクルの重みに偏りが発生し収束した段階で、顔属性情報(顔属性スコア)に基づくシグナル情報、すなわち、イベント発生源を示す[シグナル情報]が算出される。
【0100】
ある特定のターゲットx(tID=x)が、あるイベント(eID=y)の発生源である確率を、
PeID=x(tID=y)
として示す。例えば、図5に示すようにm個のパーティクル(pID=1〜m)が設定され、各パーティクルに2つのターゲット(tID=1,2)が設定されている場合、
第1ターゲット(tID=1)が第1イベント(eID=1)の発生源である確率は、
PeID=1(tID=1)
第2ターゲット(tID=2)が第1イベント(eID=1)の発生源である確率は、
PeID=1(tID=2)
である。
また、
第1ターゲット(tID=1)が第2イベント(eID=2)の発生源である確率は、
PeID=2(tID=1)
第2ターゲット(tID=2)が第2イベント(eID=2)の発生源である確率は、
PeID=2(tID=2)
である。
【0101】
イベント発生源を示す[シグナル情報]は、あるイベント(eID=y)の発生源が特定のターゲットx(tID=x)である確率、
PeID=x(tID=y)
であり、これは、情報統合処理部131のターゲット情報更新部141に設定されたパーティクル数:mと、各イベントに対するターゲットの割り当て数との比に相当し、図5に示す例では、
PeID=1(tID=1)=[第1イベント(eID=1)にtID=1を割り当てたパーティクル数)/(m)]
PeID=1(tID=2)=[第1イベント(eID=1)にtID=2を割り当てたパーティクル数)/(m)]
PeID=2(tID=1)=[第2イベント(eID=2)にtID=1を割り当てたパーティクル数)/(m)]
PeID=2(tID=2)=[第2イベント(eID=2)にtID=2を割り当てたパーティクル数)/(m)]
このような対応関係となる。
このデータがイベント発生源を示す[シグナル情報]として最終的に利用される。
【0102】
さらに、あるイベント(eID=y)の発生源が特定のターゲットx(tID=x)である確率、
PeID=x(tID=y)
このデータは、ターゲット情報に含まれる顔属性情報の算出にも適用される。すなわち、
顔属性情報StID=1〜nの算出の際に利用される。顔属性情報StID=xは、ターゲットID=xのターゲットの最終的な顔属性の期待値、すなわち、発話者である可能性を示す値に相当する。
【0103】
情報統合処理部131のターゲット情報更新部141は、画像イベント検出部112から、イベント情報(eID=1,2・・・)を入力し、各パーティクルにおいて予め設定されたイベント対応のターゲットの更新を実行して、
(a)複数のユーザが、それぞれどこにいるかを示す位置推定情報と、誰であるかの推定情報(uID推定情報)、さらに、顔属性情報(StID)の期待値、例えば口を動かして話しをしていることを示す顔属性期待値を含む[ターゲット情報]、
(b)例えば話をしたユーザなどのイベント発生源を示す[シグナル情報(画像イベント対応シグナル情報)]、
これらを生成して処理決定部132に出力する。
【0104】
[ターゲット情報]は、図7の右端のターゲット情報380に示すように、各パーティクル(PID=1〜m)に含まれる各ターゲット(tID=1〜n)対応データの重み付き総和データとして生成される。図7には、情報統合処理部131の有するm個のパーティクル(pID=1〜m)と、これらのm個のパーティクル(pID=1〜m)から生成されるターゲット情報380を示している。各パーティクルの重みについては後述する。
【0105】
ターゲット情報380は、情報統合処理部131が予め設定した仮想的なユーザに対応するターゲット(tID=1〜n)の
(a)存在位置
(b)誰であるか(uID1〜uIDkのいずれであるか)
(c)顔属性の期待値(本処理例では発話者である期待値(確率))
これらを示す情報である。
【0106】
各ターゲットの(c)顔属性の期待値(本処理例では発話者である期待値(確率))は、前述したようにイベント発生源を示す[シグナル情報]に相当する確率、
PeID=x(tID=y)
と、各イベントに対応する顔属性スコアSeID=iに基づいて算出される。iはイベントIDである。
例えばターゲットID=1の顔属性の期待値:StID=1は、以下の式で算出される。
StID=1=ΣeIDPeID=i(tID=1)×SeID=i
一般化して示すと、
ターゲットの顔属性の期待値:StIDは、以下の式で算出される。
StID=ΣeIDPeID=i(tID)×SeID
・・・(式1)
として示される。
【0107】
例えば、図5に示すように、システム内部にターゲットが2つ存在する場合、画像1フレーム内の画像イベント検出部112から、顔画像イベント2つ(eID=1,2)が情報統合処理部131に入力された際の各ターゲット(tID=1,2)顔属性の期待値計算例を図8に示す。
【0108】
図8に示す右端のデータは、図7に示すターゲット情報380に相当するターゲット情報390であり、各パーティクル(PID=1〜m)に含まれる各ターゲット(tID=1〜n)対応データの重み付き総和データとして生成される情報に相当する。
【0109】
このターゲット情報390における各ターゲットの顔属性は、前述したようにイベント発生源を示す[シグナル情報]に相当する確率[PeID=x(tID=y)]と、各イベントに対応する顔属性スコア[SeID=i]に基づいて算出される。iはイベントIDである。
ターゲットID=1の顔属性の期待値:StID=1は、
StID=1=ΣeIDPeID=i(tID=1)×SeID=i
ターゲットID=2の顔属性の期待値:StID=2は、
StID=2=ΣeIDPeID=i(tID=2)×SeID=i
このように示される。
これら各ターゲットの顔属性の期待値:StIDの全ターゲットの総和は[1]になる。本処理例では、各ターゲットについて1〜0の顔属性の期待値:StIDが設定され、期待値が高いターゲットは発話者である確率が高いと判定される。
【0110】
なお、顔画像イベントeIDに(顔属性スコア[SeID])が存在しない場合(例えば、顔検出できても口が手で覆われていて口の動き検出ができない場合)は顔属性スコア[SeID]に事前知識の値[Sprior]等を用いる。事前知識の値としては、各ターゲット毎に直前に取得した値が存在する場合はその値を用いたり、事前にオフラインで所得した顔画像イベントから顔属性の平均値計算しておきその値を用いたりする構成が可能である。
【0111】
ターゲット数と画像1フレーム内の顔画像イベントは常に同数とは限らない。ターゲット数が顔画像イベント数よりも多いときには、前述したイベント発生源を示す[シグナル情報]に相当する確率[PeID(tID)]の総和が[1]にならないため、前述した各ターゲットの顔属性の期待値算出式、すなわち、
StID=ΣeIDPeID=i(tID)×SeID
・・・(式1)
上記式の各ターゲットについての期待値総和も[1]にならず、精度の高い期待値が計算できない。
【0112】
図9に示すように、画像フレーム350に前の処理レームには存在していた第3イベント対応の第3顔画像395が検出されなくなった場合には、上記式(式1)の各ターゲットについての期待値総和も[1]にならず、精度の高い期待値が計算できない。このような場合、各ターゲットの顔属性の期待値算出式を変更する。すなわち、各ターゲットの顔属性の期待値[StID]の総和を[1]にするために、補数[1−ΣeIDPeID(tID)]と事前知識の値[Sprior]を用いて顔イベント属性の期待値StIDを次式(式2)で計算する。
StID=ΣeIDPeID(tID)×SeID+(1−ΣeIDPeID(tID))×Sprior
・・・(式2)
【0113】
図9は、システム内部にイベント対応のターゲットが3つ設定されているが、画像1フレーム内の顔画像イベントとして2つのみが画像イベント検出部112から、情報統合処理部131に入力された際の顔属性の期待値計算例を示している。
【0114】
ターゲットID=1の顔属性の期待値:StID=1は、
StID=1=ΣeIDPeID=i(tID=1)×SeID=i+(1−ΣeIDPeID(tID=1)×Sprior
ターゲットID=2の顔属性の期待値:StID=2は、
StID=2=ΣeIDPeID=i(tID=2)×SeID=i+(1−ΣeIDPeID(tID=2)×Sprior
ターゲットID=3の顔属性の期待値:StID=3は、
StID=3=ΣeIDPeID=i(tID=3)×SeID=i+(1−ΣeIDPeID(tID=3)×Sprior
このように計算される。
【0115】
なお、逆に、ターゲット数が顔画像イベント数よりも少ないときは、イベント数と同数になるようにターゲットを生成して前述の(式1)を適用して各ターゲットの顔属性の期待値[StID=1]を算出する。
【0116】
なお、顔属性は、本処理例では、口の動きに対応するスコアに基づく顔属性期待値、すなわち各ターゲットが発話者である期待値を示すデータとして説明しているが、前述したように、顔属性スコアは、笑顔や年齢などのスコアとして算出することが可能であり、この場合の顔属性期待値は、そのスコアに対応する属性に対応するデータとして算出されることになる。
【0117】
ターゲット情報は、パーティクルの更新に伴い、順次更新されることになり、例えばユーザ1〜kが実環境内で移動しない場合、ユーザ1〜kの各々が、n個のターゲット(tID=1〜n)から選択されたk個にそれぞれ対応するデータとして収束することになる。
【0118】
例えば、図7に示すターゲット情報380中の最上段のターゲット1(tID=1)のデータ中に含まれるユーザ確信度情報(uID)は、ユーザ2(uID12=0.7)について最も高い確率を有している。従って、このターゲット1(tID=1)のデータは、ユーザ2に対応するものであると推定されることになる。なお、ユーザ確信度情報(uID)を示すデータ[uID12=0.7]中の(uID12)内の(12)は、ターゲットID=1のユーザ=2のユーザ確信度情報(uID)に対応する確率であることを示している。
【0119】
このターゲット情報380中の最上段のターゲット1(tID=1)のデータは、ユーザ2である確率が最も高く、このユーザ2は、その存在位置が、ターゲット情報380中の最上段のターゲット1(tID=1)のデータに含まれる存在確率分布データに示す範囲にいると推定されることなる。
【0120】
このように、ターゲット情報380は、初期的に仮想的なオブジェクト(仮想ユーザ)として設定した各ターゲット(tID=1〜n)の各々について、
(a)存在位置
(b)誰であるか(uID1〜uIDkのいずれであるか)
(c)顔属性期待値(本処理例では発話者である期待値(確率))
の各情報を示す。従って、各ターゲット(tID=1〜n)のk個のターゲット情報の各々は、ユーザが移動しない場合は、ユーザ1〜kに対応するように収束する。
【0121】
先に説明したように、情報統合処理部131は、入力情報に基づくパーティクルの更新処理を実行して、
(a)複数のユーザが、それぞれどこにいて、それらは誰であるかの推定情報としての[ターゲット情報]、
(b)例えば話をしたユーザなどのイベント発生源を示す[シグナル情報]、
これらを生成して処理決定部132に出力する。
【0122】
このように、情報統合処理部131のターゲット情報更新部141は、仮想的なユーザに対応する複数のターゲットデータを設定した複数のパーティクルを適用したパーティクルフィルタリング処理を実行して実空間に存在するユーザの位置情報を含む解析情報を生成する。すなわち、パーティクルに設定するターゲットデータの各々をイベント検出部から入力するイベント各々に対応付けて設定し、入力イベント識別子に応じて各パーティクルから選択されるイベント対応ターゲットデータの更新を行う。
【0123】
また、ターゲット情報更新部141は、各パーティクルに設定したイベント発生源仮説ターゲットと、イベント検出部から入力するイベント情報との尤度を算出し、該尤度の大小に応じた値をパーティクル重みとして各パーティクルに設定し、パーティクル重みの大きいパーティクルを優先的に再選択するリサンプリング処理を実行して、パーティクルの更新処理を行う。この処理については後述する。さらに、各パーティクルに設定したターゲットについて、経過時間を考慮した更新処理を実行する。また、パーティクルの各々に設定したイベント発生源仮説ターゲットの数に応じて、イベント発生源の確率値としてのシグナル情報の生成を行う。
【0124】
一方、情報統合処理部131の発話源確率算出部142は、音声イベント検出部122において検出された音声イベント情報を入力して、識別モデル(識別器)を用いて各ターゲットが入力音声イベントの発話源である確率を算出する。発話源確率算出部142は、この算出値に基づいて、音声イベントに基づくシグナル情報を生成して処理決定部132に出力する。
発話源確率算出部142の実行する処理の詳細については後段で説明する。
【0125】
[3.本開示の情報処理装置の実行する処理シーケンスについて]
次に、図10に示すフローチャートを参照して情報統合処理部131の実行する処理シーケンスについて説明する。
情報統合処理部131は、音声イベント検出部122および画像イベント検出部112から、図3(B)に示すイベント情報、すなわち、ユーザ位置情報と、ユーザ識別情報(顔識別情報または話者識別情報)、これらのイベント情報を入力して、
(a)複数のユーザが、それぞれどこにいて、それらは誰であるかの推定情報としての[ターゲット情報]、
(b)例えば話をしたユーザなどのイベント発生源を示す[シグナル情報]、
これらの情報を生成して処理決定部132に出力する。この処理シーケンスについて、図10に示すフローチャートを参照して説明する。
【0126】
まず、ステップS101において、情報統合処理部131は、音声イベント検出部122および画像イベント検出部112から、
(a)ユーザ位置情報
(b)ユーザ識別情報(顔識別情報または話者識別情報)
(c)顔属性情報(顔属性スコア)
これらのイベント情報を入力する。
【0127】
イベント情報の取得に成功した場合は、ステップS102に進み、イベント情報の取得に失敗した場合は、ステップS121に進む。ステップS121の処理については後段で説明する。
【0128】
イベント情報の取得に成功した場合は、情報統合処理部131は、ステップS102において、音声イベントが入力されたか否かを判定する。入力イベントが音声イベントである場合は、ステップS111に進み、画像イベントである場合は、ステップS103に進む。
【0129】
入力イベントが音声イベントである場合は、ステップS111において、各ターゲットが入力音声イベントの発話源である確率を、識別モデル(識別器)を用いて算出する。算出結果を音声イベントに基づくシグナル情報として処理決定部132(図2参照)に出力する。このステップS111の処理の詳細については後段で説明する。
【0130】
入力イベントが画像イベントである場合は、ステップS103以下において、入力情報に基づくパーティクル更新処理を行うことになるが、パーティクル更新処理の前に、まずステップS103において、各パーティクルに対する新たなターゲットの設定が必要であるか否かを判定する。本開示の構成では、先に、図5を参照して説明したように、情報統合処理部131に設定される各パーティクル1〜mに含まれるターゲット1〜nの各々は、入力するイベント情報の各々(eID=1〜k)に予め対応付けられており、その対応に従って、入力イベントに対応する選択されたターゲットの更新が実行する構成としている。
【0131】
従って、例えば画像イベント検出部112から入力するイベント数が、ターゲット数より多い場合には、新たなターゲットの設定を行なうことが必要となる。具体的には、例えば図5に示す画像フレーム350にこれまで存在しなかった顔が出現した場合などである。このような場合は、ステップS104に進み、各パーティクルに新たなターゲットを設定する。このターゲットはこの新たなイベントに対応して更新されるターゲットとして設定される。
【0132】
次に、ステップS105において、情報統合処理部131に設定されたパーティクル1〜mのm個のパーティクル(pID=1〜m)の各々にイベントの発生源の仮説を設定する。イベント発生源とは、例えば、音声イベントであれば、話をしたユーザがイベント発生源であり、画像イベントであれば、抽出した顔を持つユーザがイベント発生源である。
【0133】
本開示の仮説設定処理は、先に図5等を参照して説明したように、各パーティクル1〜mに含まれるターゲット1〜nの各々に、入力するイベント情報の各々(eID=1〜k)を対応付けて設定する。
【0134】
すなわち、先に図5を参照して説明したように、パーティクル1〜mの各々に含まれるターゲット1〜nの各々は、イベント(eID=1〜k)の各々に対応付けて、それぞれのパーティクルに含まれるどのターゲットを更新するかが予め設定される。このように各パーティクルで、重複がないように取得イベント分のイベント発生源仮説を生成する。なお、初期的には例えば各イベントが均等に配分されるような設定としてよい。パーティクルの数:mは、ターゲットの数:nより大きく設定されるので、複数のパーティクルが同一のイベントID−ターゲットIDの対応をもつパーティクルとして設定される。例えば、ターゲットの数:nが10とした場合、パーティクル数:m=100〜1000程度に設定した処理などが行われる。
【0135】
ステップS105における仮説設定の後、ステップS106に進む。ステップS106では、各パーティクル対応の重み、すなわちパーティクル重み[WpID]の算出を行う。このパーティクル重み[WpID]は初期的には各パーティクルに均一な値が設定されるが、イベント入力に応じて更新される。
【0136】
図11を参照して、パーティクル重み[WpID]の算出処理の詳細について説明する。パーティクル重み[WpID]は、イベント発生源の仮説ターゲットを生成した各パーティクルの仮説の正しさの指標に相当する。パーティクル重み[WpID]は、m個のパーティクル(pID=1〜m)の各々において設定された複数のターゲット各々に対応付けられたイベント発生源の入力イベントとの類似度であるイベント−ターゲット間尤度として算出される。
【0137】
図11には、情報統合処理部131が、音声イベント検出部122および画像イベント検出部112から入力する1つのイベント(eID=1)に対応するイベント情報401と、情報統合処理部131が保持する1つのパーティクル421を示している。パーティクル421のターゲット(tID=2)は、イベント(eID=1)に対応付けられているターゲットである。
【0138】
図11下段には、イベント−ターゲット間尤度の算出処理例を示している。パーティクル重み[WpID]は、各パーティクルにおいて算出されるイベント−ターゲットとの類似度指標としてのイベント−ターゲット間尤度の総和に対応する値として算出される。
【0139】
図11の下段に示す尤度算出処理は、
(a)ユーザ位置情報についてのイベントと、ターゲットデータとの類似度データとしてのガウス分布間尤度[DL]、
(b)ユーザ識別情報(顔識別情報または話者識別情報)についてのイベントと、ターゲットデータとの類似度データとしてのユーザ確信度情報(uID)間尤度[UL]
これらを個別に算出する例を示している。
【0140】
(a)ユーザ位置情報についてのイベントと、仮説ターゲットとの類似度データとしてのガウス分布間尤度[DL]の算出処理は以下の処理となる。
入力イベント情報中の、ユーザ位置情報に対応するガウス分布をN(me,σe)、
パーティクルから選択された仮説ターゲットのユーザ位置情報に対応するガウス分布をN(mt,σt)、
として、ガウス分布間尤度[DL]を、以下の式によって算出する。
DL=N(mt,σt+σe)x|me
上記式は、中心mtで分散σt+σeのガウス分布においてx=meの位置の値を算出する式である。
【0141】
(b)ユーザ識別情報(顔識別情報または話者識別情報)についてのイベントと、仮説ターゲットとの類似度データとしてのユーザ確信度情報(uID)間尤度[UL]の算出処理は以下の処理となる。
入力イベント情報中の、ユーザ確信度情報(uID)の各ユーザ1〜kの確信度の値(スコア)をPe[i]とする。なお、iはユーザ識別子1〜kに対応する変数である。
パーティクルから選択された仮説ターゲットのユーザ確信度情報(uID)の各ユーザ1〜kの確信度の値(スコア)をPt[i]として、ユーザ確信度情報(uID)間尤度[UL]は、以下の式によって算出する。
UL=ΣPe[i]×Pt[i]
上記式は、2つのデータのユーザ確信度情報(uID)に含まれる各対応ユーザの確信度の値(スコア)の積の総和を求める式であり、この値をユーザ確信度情報(uID)間尤度[UL]とする。
【0142】
パーティクル重み[WpID]は、上記の2つの尤度、すなわち、
ガウス分布間尤度[DL]と、
ユーザ確信度情報(uID)間尤度[UL]
これら2つの尤度を利用し、重みα(α=0〜1)を用いて下式によって算出する。
パーティクル重み[WpID]=ΣnULα×DL1−α
nは、パーティクルに含まれるイベント対応ターゲットの数である。
上記式により、パーティクル重み[WpID]を算出する。
ただし、α=0〜1とする。
このパーティクル重み[WpID]は、各パーティクルについて各々算出する。
【0143】
なお、パーティクル重み[WpID]の算出に適用する重み[α]は、予め固定された値としてもよいし、入力イベントに応じて値を変更する設定としてもよい。例えば入力イベントが画像である場合において、顔検出に成功し位置情報は取得できたが顔識別に失敗した場合などは、α=0の設定として、ユーザ確信度情報(uID)間尤度:UL=1としてガウス分布間尤度[DL]のみに依存してパーティクル重み[WpID]を算出する構成としてもよい。また、入力イベントが音声である場合において、話者識別に成功し話者情報破取得できたが、位置情報の取得に失敗した場合などは、α=0の設定として、ガウス分布間尤度[DL]=1として、ユーザ確信度情報(uID)間尤度[UL]のみに依存してパーティクル重み[WpID]を算出する構成としてもよい。
【0144】
図10のフローにおけるステップS106の各パーティクル対応の重み[WpID]の算出は、このように図11を参照して説明した処理として実行される。次に、ステップS107において、ステップS106で設定した各パーティクルのパーティクル重み[WpID]に基づくパーティクルのリサンプリング処理を実行する。
【0145】
このパーティクルリサンプリング処理は、m個のパーティクルから、パーティクル重み[WpID]に応じてパーティクルを取捨選択する処理として実行される。具体的には、例えば、パーティクル数:m=5のとき、
パーティクル1:パーティクル重み[WpID]=0.40
パーティクル2:パーティクル重み[WpID]=0.10
パーティクル3:パーティクル重み[WpID]=0.25
パーティクル4:パーティクル重み[WpID]=0.05
パーティクル5:パーティクル重み[WpID]=0.20
これらのパーティクル重みが各々設定されていた場合、
パーティクル1は、40%の確率でリサンプリングされ、パーティクル2は10%の確率でリサンプリングされる。なお、実際にはm=100〜1000といった多数であり、リサンプリングされた結果は、パーティクルの重みに応じた配分比率のパーティクルによって構成されることになる。
【0146】
この処理によって、パーティクル重み[WpID]の大きなパーティクルがより多く残存することになる。なお、リサンプリング後もパーティクルの総数[m]は変更されない。また、リサンプリング後は、各パーティクルの重み[WpID]はリセットされ、新たなイベントの入力に応じてステップS101から処理が繰り返される。
【0147】
ステップS108では、各パーティクルに含まれるターゲットデータ(ユーザ位置およびユーザ確信度)の更新処理を実行する。各ターゲットは、先に図7等を参照して説明したように、
(a)ユーザ位置:各ターゲット各々に対応する存在位置の確率分布[ガウス分布:N(mt,σt)]、
(b)ユーザ確信度:各ターゲットが誰であるかを示すユーザ確信度情報(uID)として各ユーザ1〜kである確立値(スコア):Pt[i](i=1〜k)、すなわち、
uIDt1=Pt[1]
uIDt2=Pt[2]
:
uIDtk=Pt[k]
さらに、
(c)顔属性の期待値(本処理例では発話者である期待値(確率))
これらのデータによって構成される。
【0148】
(c)顔属性の期待値(本処理例では発話者である期待値(確率))は、前述したようにイベント発生源を示す[シグナル情報]に相当する確率、
PeID=x(tID=y)
と、各イベントに対応する顔属性スコアSeID=iに基づいて算出される。iはイベントIDである。
例えばターゲットID=1の顔属性の期待値:StID=1は、以下の式で算出される。
StID=1=ΣeIDPeID=i(tID=1)×SeID=i
一般化して示すと、
ターゲットの顔属性の期待値:StIDは、以下の式で算出される。
StID=ΣeIDPeID=i(tID)×SeID
・・・(式1)
として示される。
【0149】
なお、ターゲット数が顔画像イベント数よりも多いときには、各ターゲットの顔属性の期待値[StID]の総和を[1]にするために、補数[1−ΣeIDPeID(tID)]と事前知識の値[Sprior]を用いて顔イベント属性の期待値[StID]は、を次式(式2)で計算される。
StID=ΣeIDPeID(tID)×SeID+(1−ΣeIDPeID(tID))×Sprior
・・・(式2)
【0150】
ステップS108におけるターゲットデータの更新は、(a)ユーザ位置、(b)ユーザ確信度、(c)顔属性の期待値(本処理例では発話者である期待値(確率))の各々について実行する。まず、(a)ユーザ位置の更新処理について説明する。
【0151】
ユーザ位置の更新は、
(a1)全パーティクルの全ターゲットを対象とする更新処理、
(a2)各パーティクルに設定されたイベント発生源仮説ターゲットを対象とした更新処理、
これらの2段階の更新処理として実行する。
【0152】
(a1)全パーティクルの全ターゲットを対象とする更新処理は、イベント発生源仮説ターゲットとして選択されたターゲットおよびその他のターゲットのすべてを対象として実行する。この処理は、時間経過に伴うユーザ位置の分散が拡大するという仮定に基づいて実行され、前回の更新処理からの経過時間とイベントの位置情報によってカルマン・フィルタ(Kalman Filter)を用い更新される。
【0153】
以下、位置情報が1次元の場合の更新処理例について説明する。まず、前回の更新処理時間からの経過時間[dt]とし、全ターゲットについての、dt後のユーザ位置の予測分布を計算する。すなわち、ユーザ位置の分布情報としてのガウス分布:N(mt,σt)の期待値(平均):[mt]、分散[σt]について、以下の更新を行う。
mt=mt+xc×dt
σt2=σt2+σc2×dt
なお、
mt:予測期待値(predicted state)
σt2:予測共分散(predicted estimate covariance)
xc:移動情報(control model)
σc2:ノイズ(process noise)
である。
なお、ユーザが移動しない条件の下で処理する場合は、xc=0として更新処理を行うことができる。
上記の算出処理により、全ターゲットに含まれるユーザ位置情報としてのガウス分布:N(mt,σt)を更新する。
【0154】
(a2)各パーティクルに設定されたイベント発生源仮説ターゲットを対象とした更新処理、
次に、各パーティクルに設定されたイベント発生源仮説ターゲットを対象とした更新処理について説明する。
ステップS104において設定したイベントの発生源の仮説に従って選択されたターゲットを更新する。先に図5を参照して説明したように、パーティクル1〜mの各々に含まれるターゲット1〜nの各々は、イベント(eID=1〜k)の各々に対応付けられたターゲットとして設定されている。
【0155】
すなわち、イベントID(eID)に応じてそれぞれのパーティクルに含まれるどのターゲットを更新するかが予め設定されており、その設定に従って各入力イベントに対応付けられたターゲットのみを更新する。例えば、図5に示す[イベントID=1(eID=1)]のイベント対応情報361によって、パーティクル1(pID=1)では、ターゲットID=1(tID=1)のデータのみが選択的に更新される。
【0156】
このイベントの発生源の仮説に従った更新処理では、このようにイベントに対応付けられたターゲットの更新を行なう。音声イベント検出部122や画像イベント検出部112から入力するイベント情報に含まれるユーザ位置を示すガウス分布:N(me,σe)などを用いた更新処理を実行する。
例えば、
K:カルマンゲイン(Kalman Gain)
me:入力イベント情報:N(me,σe)に含まれる観測値(Observed state)
σe2:入力イベント情報:N(me,σe)に含まれる観測値(Observed covariance)
として、以下の更新処理を行う。
K=σt2/(σt2+σe2)
mt=mt+K(xc−mt)
σt2=(1−K)σt2
【0157】
次に、ターゲットデータの更新処理として実行する(b)ユーザ確信度の更新処理について説明する。ターゲットデータには上記のユーザ位置情報の他に、各ターゲットが誰であるかを示すユーザ確信度情報(uID)として各ユーザ1〜kである確率値(スコア):Pt[i](i=1〜k)が含まれている。ステップS108では、このユーザ確信度情報(uID)についても更新処理を行う。
【0158】
各パーティクルに含まれるターゲットのユーザ確信度情報(uID):Pt[i](i=1〜k)についての更新は、登録ユーザ全員分の事後確率と、音声イベント検出部122や画像イベント検出部112から入力するイベント情報に含まれるユーザ確信度情報(uID):Pe[i](i=1〜k)によって、予め設定した0〜1の範囲の値を持つ更新率[β]を適用して更新する。
【0159】
ターゲットのユーザ確信度情報(uID):Pt[i](i=1〜k)についての更新は、以下の式によって実行する。
Pt[i]=(1−β)×Pt[i]+β*Pe[i]
ただし、
i=1〜k
β:0〜1
である。なお、更新率[β]は、0〜1の範囲の値であり予め設定する。
【0160】
ステップS108では、この更新されたターゲットデータに含まれる以下のデータ、すなわち、
(a)ユーザ位置:各ターゲット各々に対応する存在位置の確率分布[ガウス分布:N(mt,σt)]、
(b)ユーザ確信度:各ターゲットが誰であるかを示すユーザ確信度情報(uID)として各ユーザ1〜kである確立値(スコア):Pt[i](i=1〜k)、すなわち、
uIDt1=Pt[1]
uIDt2=Pt[2]
:
uIDtk=Pt[k]
(c)顔属性の期待値(本処理例では発話者である期待値(確率))
これらのデータによって構成される。
これらのデータと、各パーティクル重み[WpID]とに基づいて、ターゲット情報を生成して、処理決定部132に出力する。
【0161】
なお、ターゲット情報は、各パーティクル(PID=1〜m)に含まれる各ターゲット(tID=1〜n)対応データの重み付き総和データとして生成される。図7の右端のターゲット情報380に示すデータである。ターゲット情報は、各ターゲット(tID=1〜n)各々の
(a)ユーザ位置情報、
(b)ユーザ確信度情報、
(c)顔属性の期待値(本処理例では発話者である期待値(確率))
これらの情報を含む情報として生成される。
【0162】
例えば、ターゲット(tID=1)に対応するターゲット情報中の、ユーザ位置情報は、
【0163】
【数1】
【0164】
上記式で表される。上記式において、Wiは、パーティクル重み[WpID]を示している。
【0165】
また、ターゲット(tID=1)に対応するターゲット情報中の、ユーザ確信度情報は、
【0166】
【数2】
【0167】
上記式で表される。上記式において、Wiは、パーティクル重み[WpID]を示している。
【0168】
また、ターゲット(tID=1)に対応するターゲット情報中の、顔属性の期待値(本処理例では発話者である期待値(確率))は、
StID=1=ΣeIDPeID=i(tID=1)×SeID=i
上記式、または、
StID=1=ΣeIDPeID=i(tID=1)×SeID=i+(1−ΣeIDPeID(tID=1)×Sprior
で表される。
【0169】
情報統合処理部131は、これらのターゲット情報をn個の各ターゲット(tID=1〜n)各々について算出し、算出したターゲット情報を処理決定部132に出力する。
【0170】
次に、図8に示すフローのステップS109の処理について説明する。情報統合処理部131は、ステップS109において、n個のターゲット(tID=1〜n)の各々がイベントの発生源である確率を算出し、これをシグナル情報として処理決定部132に出力する。
【0171】
先に説明したように、イベント発生源を示す[シグナル情報]は、音声イベントについては、誰が話をしたか、すなわち[発話者]を示すデータであり、画像イベントについては、画像に含まれる顔が誰であるかおよび[発話者]を示すデータである。
【0172】
情報統合処理部131は、各パーティクルに設定されたイベント発生源の仮説ターゲットの数に基づいて、各ターゲットがイベント発生源である確率を算出する。すなわち、ターゲット(tID=1〜n)の各々がイベント発生源である確率を[P(tID=i)とする。ただしi=1〜nである。例えば、あるイベント(eID=y)の発生源が特定のターゲットx(tID=x)である確率は、先に説明したように、
PeID=x(tID=y)
として示され、これは、情報統合処理部131に設定されたパーティクル数:mと、各イベントに対するターゲットの割り当て数との比に相当する。例えば、図5に示す例では、
PeID=1(tID=1)=[第1イベント(eID=1)にtID=1を割り当てたパーティクル数)/(m)]
PeID=1(tID=2)=[第1イベント(eID=1)にtID=2を割り当てたパーティクル数)/(m)]
PeID=2(tID=1)=[第2イベント(eID=2)にtID=1を割り当てたパーティクル数)/(m)]
PeID=2(tID=2)=[第2イベント(eID=2)にtID=2を割り当てたパーティクル数)/(m)]
このような対応関係となる。
このデータがイベント発生源を示す[シグナル情報]として、処理決定部132に出力される。
【0173】
ステップS109の処理が終了したら、ステップS101に戻り、音声イベント検出部122および画像イベント検出部112からのイベント情報の入力の待機状態に移行する。
【0174】
以上が、図10に示すフローのステップS101〜S109の説明である。ステップS101において、情報統合処理部131が、音声イベント検出部122および画像イベント検出部112から、図3(B)に示すイベント情報を取得できなかった場合も、ステップS121において、各パーティクルに含まれるターゲットの構成データの更新が実行される。この更新は、時間経過に伴うユーザ位置の変化を考慮した処理である。
【0175】
このターゲット更新処理は、先のステップS108の説明における(a1)全パーティクルの全ターゲットを対象とする更新処理と同様の処理であり、時間経過に伴うユーザ位置の分散が拡大するという仮定に基づいて実行され、前回の更新処理からの経過時間とイベントの位置情報によってカルマン・フィルタ(Kalman Filter)を用い更新される。
【0176】
位置情報が1次元の場合の更新処理例について説明する。まず、前回の更新処理時間からの経過時間[dt]とし、全ターゲットについての、dt後のユーザ位置の予測分布を計算する。すなわち、ユーザ位置の分布情報としてのガウス分布:N(mt,σt)の期待値(平均):[mt]、分散[σt]について、以下の更新を行う。
mt=mt+xc×dt
σt2=σt2+σc2×dt
なお、
mt:予測期待値(predicted state)
σt2:予測共分散(predicted estimate covariance)
xc:移動情報(control model)
σc2:ノイズ(process noise)
である。
なお、ユーザが移動しない条件の下で処理する場合は、xc=0として更新処理を行うことができる。
上記の算出処理により、全ターゲットに含まれるユーザ位置情報としてのガウス分布:N(mt,σt)を更新する。
【0177】
なお、各パーティクルのターゲットに含まれるユーザ確信度情報(uID)については、イベントの登録ユーザ全員分の事後確率、もしくはイベント情報からスコア[Pe]が取得できない限りは更新しない。
【0178】
ステップS121の処理が終了したら、ステップS122において、ターゲットの削除要否を判定し必要であればステップS123においてターゲットを削除する。ターゲット削除は、例えば、ターゲットに含まれるユーザ位置情報にピークが検出されない場合など、特定のユーザ位置が得られていないようなデータを削除する処理として実行される。このようなターゲットがない場合は削除処理は不要であるステップS122〜S123の処理後にステップS101に戻り、音声イベント検出部122および画像イベント検出部112からのイベント情報の入力の待機状態に移行する。
【0179】
以上、図10を参照して情報統合処理部131の実行する処理について説明した。情報統合処理部131は、図10に示すフローに従った処理を音声イベント検出部122および画像イベント検出部112からのイベント情報の入力ごとに繰り返し実行する。この繰り返し処理により、より信頼度の高いターゲットを仮説ターゲットとして設定したパーティクルの重みが大きくなり、パーティクル重みに基づくリサンプリング処理により、より重みの大きいパーティクルが残存することになる。結果として音声イベント検出部122および画像イベント検出部112から入力するイベント情報に類似する信頼度の高いデータが残存することになり、最終的に信頼度の高い以下の各情報、すなわち、
(a)複数のユーザが、それぞれどこにいて、それらは誰であるかの推定情報としての[ターゲット情報]、
(b)例えば話をしたユーザなどのイベント発生源を示す[シグナル情報]
これらが生成されて処理決定部132に出力される。
なお、シグナル情報には、以下の2つのシグナル情報が含まれる。
(b1)ステップS111の処理によって生成する音声イベントに基づくシグナル情報
(b2)ステップS103〜S109の処理によって生成する画像イベントに基づくシグナル情報
【0180】
[4.発話源確率算出部において実行する処理の詳細について]
次に、図10に示すフローチャートのステップS111の処理、すなわち、音声イベントに基づくシグナル情報の生成処理の詳細について説明する。
【0181】
先に説明したように、図2に示す情報統合処理部131は、ターゲット情報更新部141と、発話源確率算出部142を有する。
ターゲット情報更新部141において画像イベント情報毎に更新されたターゲット情報は発話源確率算出部142にも出力される。
発話源確率算出部142は、音声イベント検出部122から入力する音声イベント情報と、ターゲット情報更新部141において画像イベント情報毎に更新されたターゲット情報を適用して音声イベントに基づくシグナル情報を生成する。すなわち、各ターゲットがどの程度、当該音声イベント情報の発話源らしいかを表す発話源確率としてのシグナル情報である。
【0182】
発話源確率算出部142では、音声イベント情報が入力された場合には、ターゲット情報更新部141から入力するターゲット情報を用いて、各ターゲットがどの程度、当該音声イベント情報の発話源らしいかを表す発話源確率を算出する。
【0183】
図12に、発話源確率算出部142に入力される、
(A)音声イベント情報、
(B)ターゲット情報、
これ等の入力情報の例を示す。
(A)音声イベント情報は、音声イベント検出部122から入力する音声イベント情報である。
(B)ターゲット情報は、ターゲット情報更新部141において画像イベント情報毎に更新されたターゲット情報である。
【0184】
発話源確率の算出には、図12(A)に示す音声イベント情報に含まれる音源方向情報(位置情報)や話者識別情報や、画像イベント情報に含まれる口唇動作情報や、ターゲット情報に含まれるターゲット位置やターゲット総数といった情報が利用される。
【0185】
なお、元々は画像イベント情報に含まれている口唇動作情報は、ターゲット情報に含まれる顔属性情報の一つとして、ターゲット情報更新部141から発話源確率算出部142に供給される。
また、本処理例における口唇動作情報とは、視覚的音声検出(Visual Speech Detection)技術を適用して求められた口唇状態スコアから生成される。なお、視覚的音声検出技術(Visual Speech Detection)については、例えば、[Visual lip activity detection and speaker detection using mouth region intensities/IEEE Transactions on Circuits and Systems for Video Technology, Volume 19, Issue 1 (January 2009), Pages: 133-137(参考URL: http://poseidon.csd.auth.gr/papers/PUBLISHED/JOURNAL/pdf/Siatras09a)]、[Facilitating Speech Detection in Style!: The Effect of Visual Speaking Style on the Detection of Speech in Noise Auditory-Visual Speech Processing 2005(参考URL:http://www.isca-speech.org/archive/avsp05/av05_023.html)]等に記載されており、これらの技術を適用可能である。
【0186】
口唇動作情報の生成方法の概要は次の通りである。
入力された音声イベント情報が、ある時間間隔Δtに対応するとして、
Δt=(t_end〜t_begin)
この時間間隔Δtに含まれる複数の口唇状態スコアを順に並べて時系列データとする。この時系列データが成す領域の面積を口唇動作情報とする。
図12(B)ターゲット情報の最下段に示す[時間/口唇状態スコア]のグラフが口唇動作情報に相当する。
なお、ここでの口唇動作情報は、全ターゲットの口唇動作情報の和をもって正規化される。
【0187】
なお、口唇動作情報の生成処理については、例えば特開2009−223761号公報や、特許第4462339号公報に記載があり、これらの公報に記載の処理を適用可能である。
また、音源方向情報の生成処理としては特2010−20294号公報、話者識別情報については、特開2004−286805号公報に記載があり、これらの既存の処理を適用することも可能である。
【0188】
発話源確率算出部142は、図12に示すように、
音声イベント検出部122から入力する音声イベント情報として発話に対応する音声イベントに応じた、
(a)ユーザ位置情報(音源方向情報)
(b)ユーザ識別情報(話者識別情報)
を取得する。
さらに、ターゲット情報更新部141において画像イベント情報毎に更新されたターゲット情報として、
(a)ユーザ位置情報
(b)ユーザ識別情報
(c)口唇動作情報
これらの情報を取得する。
さらに、ターゲット情報に含まれるターゲット位置やターゲット総数といった情報も入力する。
発話源確率算出部142は、これらの情報に基づいて、各ターゲットが発話源である確率(シグナル情報)を生成して処理決定部132に出力する。
【0189】
発話源確率算出部142の実行する各ターゲット毎の発話源確率の算出方法のシーケンスの一例について、図13に示すフローチャートを参照して説明する。
図13のフローチャートに示す処理例は、ターゲットを個別に選択して、選択ターゲットに関する情報を利用して、そのターゲットが発話源であるかどうかを示す発話源確率(発話源スコア)判定する処理である。
【0190】
まず、ステップS201において、全ターゲットから処理対象とするターゲットを1つ選択する。
次にステップS202において、発話源確率算出部142の保持する識別器を用いて、選択したターゲットが発話源であるかどうかの確率値としての発話源スコアを求める。
【0191】
識別器は、音声イベント検出部122から入力する、
(a)ユーザ位置情報(音源方向情報)
(b)ユーザ識別情報(話者識別情報)
ターゲット情報更新部141から入力する、
(a)ユーザ位置情報
(b)ユーザ識別情報
(c)口唇動作情報
(d)ターゲット位置やターゲット総数
これらの入力情報に基づいて、各ターゲット毎の発話源確率を算出する識別器である。
【0192】
なお、識別器への入力情報は、上記のすべての情報としてもよいが、これらの入力情報の内そのいくつかだけを入力して利用してもよい。
識別器は、ステップS202において、選択したターゲットが発話源であるかどうかの確率値としての発話源スコアを算出する。
なお、ステップS202において実行する発話源スコアの算出処理の詳細については、図14以下を参照して後段で詳細に説明する。
【0193】
ステップS203において、他の未処理ターゲットがあるか否かを判定し、未処理ターゲットが存在する場合は、未処理ターゲットについてステップS201以下の処理を実行する。
【0194】
ステップS203において、他の未処理ターゲットがないと判定した場合は、ステップS204に進む。
ステップS204では、各ターゲット毎に求められた発話源スコアを、全体ターゲットの発話源スコアの和をもって正規化処理を実行し、各ターゲットに対する発話源確率としての発話源スコアを決定する。
この発話源スコアの最も高いターゲットが発話源であると推定されることになる。
【0195】
[5.発話源スコアの算出処理について]
次に、図13に示すフローチャートにおけるステップS202の発話源スコアの算出処理の詳細について説明する。
この発話源スコアは、図2に示す発話源確率算出部142において算出される。すなわち、選択したターゲットが発話源であるかどうかの確率値としての発話源スコアを算出する。
前述のように、発話源確率算出部142は、例えば、
音声イベント検出部122から、
(a)ユーザ位置情報(音源方向情報)
(b)ユーザ識別情報(話者識別情報)
ターゲット情報更新部141から、
(a)ユーザ位置情報
(b)ユーザ識別情報
(c)口唇動作情報
(d)ターゲット位置やターゲット総数
これらの情報を入力して、各ターゲット毎の発話源確率を求めるための発話源スコアを算出する。
【0196】
なお、発話源確率算出部142は、上記のすべての情報を用いてスコア算出を行う構成としてもよいが、その一部を用いてスコア算出を実行する構成としてもよい。
図14以下を参照して、
音源方向情報:D、
話者識別情報:S、
口唇動作情報:L、
これらの3情報を適用した発話源スコア:Pの算出処理例について説明する。
【0197】
上記3つの情報D,S,Lを用いた発話源スコアPの算出式は、たとえば図14に示すように、以下の式によって定義できる。
P=Dα・Sβ・Lγ
なお、
D:音源方向情報、
S:話者識別情報、
L:口唇動作情報、
α:音源方向情報の重み係数、
β:話者識別情報の重み係数、
γ:口唇動作情報の重み係数、
α+β+γ=1
である。
【0198】
上記の発話源算出式:P=Dα・Sβ・Lγを適用して、選択したターゲットが発話源であるかどうかの確率値としての発話源スコアを算出する。
【0199】
上記の発話源算出式:P=Dα・Sβ・Lγを適用した発話源スコア算出処理を行う場合、
入力情報として、
D:音源方向情報、
S:話者識別情報、
L:口唇動作情報、
これらの3情報が取得されていることが条件である。
【0200】
さらに、
α:音源方向情報の重み係数、
β:話者識別情報の重み係数、
γ:口唇動作情報の重み係数、
これらの係数を決定する処理が必要となる。
【0201】
上記の発話源算出式:P=Dα・Sβ・Lγを適用した発話源スコア算出処理を行うための係数決定処理を伴う発話源スコア算出処理のシーケンスについて、図15に示すフローチャートを参照して説明する。
【0202】
なお、音声イベント検出部122から入力する音声イベントに含まれる1つの音声認識結果には以下の情報が付随しているものとする。
(1)音声区間情報(その音声の開始時間と終了時間)
(2)音源方向情報
(3)話者識別情報
発話源確率算出部142は、発話源スコアを算出する処理対象となる音声イベントと直前の音声イベントとの時間的な重複の有無と、当該ターゲットと位置の近い他のターゲットの有無に合わせて、口唇動作情報と音源方向情報の重みを変更することによって全重み係数を調整し、その調整された全重み係数を用いて発話源スコアを計算する。
【0203】
発話源確率算出部142は、上記の発話源スコア算出式:P=Dα・Sβ・Lγを適用した発話源スコア算出処理に適用する係数(α、β、γ)の決定処理のために、
発話の時間的な重複の有無、
位置の近い他のターゲットの有無、
これらの情報を画像イベント検出部112、音声イベント検出部122からの入力情報に基づいて取得し、これらの情報を適用して、発話源スコア算出処理に適用する係数(α、β、γ)の決定処理を行う。
【0204】
図15に示すフローの各ステップの処理について説明する。
まず、ステップS301において、発話源スコア算出処理の処理対象とする音声イベントと直前の音声イベントの時間的な重複を確認する。
【0205】
なお、この時間的な重複の有無に関する判断は、時間的に少しだけずれた後続する音声イベントのみで判断可能である。これは、先行する音声イベントが検知された時点(=先行する音声イベントの終了時間が決定された瞬間)では、時間的に重複するその他の音声イベントが存在するかどうかを完全には決定できないためである。
【0206】
次に、ステップS302において、処理対象ターゲットと位置の近い他のターゲットが存在するかを確認する。この処理は、例えば、ターゲット情報更新部141から入力するユーザ位置情報を用いて実行可能である。
【0207】
次に、ステップS303において、ステップS301で判定した時間的な重複の有無と、ステップS302で判定した位置の近い他のターゲットの有無に応じて、
α:音源方向情報の重み係数、
γ:口唇動作情報の重み係数、
これらの重み係数を変更して、全重み係数を調整する。
なお、重み係数の調整に際しては、
α+β+γ=1
この制約条件を満たすように調整を行う。
【0208】
最後に、ステップS304において、発話源確率算出部142は、
入力情報としての、
D:音源方向情報、
S:話者識別情報、
L:口唇動作情報、
これらを適用し、さらに、ステップS303において決定した各重み係数、すなわち、
α:音源方向情報の重み係数、
β:話者識別情報の重み係数、
γ:口唇動作情報の重み係数、
ただし、α+β+γ=1
これらを適用して、発話源スコア算出式、
P=Dα・Sβ・Lγ
を適用して、ターゲットの発話源スコアを算出する。
【0209】
図16以下を参照して、具体的に状況に応じた発話源スコア算出処理の具体例について説明する。
図15のフローを参照して説明したように、発話源スコアの算出処理においては、音声が発せられる状況に応じて、どの入力情報を重視するかを適応的に変更する。
【0210】
発話を行う可能性のある人物が2名であるとき、音声が発せられる状況の例としては、例えば図16(a)〜(d)に示すように以下の状況が想定される。
(a)2名の位置が遠く、1名のみが発声する場合
(b)2名の位置が遠く、2名が同時に発声する場合
(c)2名の位置が近く、1名のみが発声する場合
(d)2名の位置が近く、2名が同時に発声する場合
【0211】
図17は、音声が発せられる状況と、上述した発話源スコア算出式:P=Dα・Sβ・Lγを適用した発話源スコア算出処理に適用する係数(α、β、γ)の調整方法の関係と、数値例を示している。
【0212】
発話源確率算出部142は、各入力情報の重み係数をそれぞれどのような値に設定するかを、音声が発せられた状況に応じて、動的に調整する。
重み係数を調整する状況は、以下の2つの条件の組み合わせから成る。
(条件1)ユーザ1名(1つのターゲット)のみによる単独発話か、あるいはユーザ2名(2つのターゲット)による同時発話か、
(条件2)ユーザ2名(2つのターゲット)の位置が近いか、あるいはユーザ2名(2つのターゲット)の位置が遠いか、
【0213】
なお、上記(条件2)のユーザ2名の位置が近いか遠いかに関しては、音源方向の差、すなわち音源方向を示す角度に基づいて、予め設定した所定のしきい値を適用して遠近を判断する。
例えば、ユーザ2名の位置に対応した音源方向の差の絶対値が10°以下の場合を「ユーザ2名の位置が近い」と判定する。
なお、源方向の差の絶対値が10°以下とは、マイクの位置から3メートル離れた位置において、ユーザ2名の間の距離が約53センチメートル以内であることに対応する。
このように、「音源方向が近い」ということを、「ユーザの間の距離が近い」あるいは「ユーザ間の位置が近い」と言い換えることとする。
【0214】
以下、図16に示す(a)〜(d)の各発話状況に応じた重み係数、すなわち、
α:音源方向情報の重み係数、
β:話者識別情報の重み係数、
γ:口唇動作情報の重み係数、
ただし、α+β+γ=1
これらの重み係数(α、β、γ)の調整方法の具体例について説明する。
【0215】
図16(a)ユーザ2名の位置が遠く、1名のみが単独発声する場合
この場合は、全ての重み係数(α、β、γ)の調整は行わず、予め設定した既定値を利用する。
すなわち、発話源確率算出部142は、発話可能性のあるターゲットが2である状況において、1つのターゲットのみが単独発声する場合、全ての重み係数(α、β、γ)の調整は行わず、予め設定した既定値を利用する。
【0216】
図16(b)ユーザ2名の位置が遠く、その2名が同時発声する場合、
この場合は、口唇動作情報の重み(γ)を小さくするように調整を行う。
すなわち、発話源確率算出部142は、発話可能性のあるターゲットが2である状況において、2つのターゲットが同時発声する場合、口唇動作情報の重みγを小さくするように前記各重み係数:α、β、γを調整する処理を行う。
【0217】
図16(c)ユーザ2名の位置が近く、1名のみが単独発声する場合
この場合は、音源方向情報の重み(α)を小さくするように調整を行う。
すなわち、発話源確率算出部142は、発話可能性のあるターゲットが2である状況において、2つのターゲットの位置が近く、1ターゲットのみが単独発声する場合、音源方向情報の重みαを小さくするように前記各重み係数:α、β、γを調整する処理を行う。
【0218】
図16(d)ユーザ2名の位置が近く、その2名が同時発声する場合
この場合は、口唇動作情報の重み(γ)と音源方向情報の重み(α)を小さくするように調整を行う。
すなわち、発話源確率算出部142は、発話可能性のあるターゲットが2である状況において、2つのターゲットの位置が近く、2のターゲットが同時に発声する場合、口唇動作情報の重みγと音源方向情報の重みαを小さくするように前記各重み係数:α、β、γを調整する処理を行う。
【0219】
なお、いずれの処理に際しても、
α+β+γ=1
の制約を満たすように調整する。
これらの重み係数(α、β、γ)の調整例をまとめた図を図17に示す。
【0220】
なお、音声が発せられたそれぞれの状況において、所望の重み係数をどの程度大きくするか、あるいは各重み係数をどのように設定するかに関しては、評価データを用いた事前の検討作業によって決められたものを用いてよい。
【0221】
図18は、具体的な重み係数(α、β、γ)の調整例として、以下の2つの例を示す図である。
(A)全重み係数の数値例(既定値が全て等しい場合(既定値:α=β=γ))
(B)全重み係数の数値例(既定値が異なる場合(既定値:α≠β≠γ))
【0222】
(A)の場合は、既定値:α=β=γ=0.333である。
(B)の場合は、既定値:α≠β≠γであり、各既定値は、
α=0.500
β=0.200
γ=0.300
としている。
【0223】
なお、(A),(B)いずれの場合も、所望の重み係数を小さくする場合には、その重み係数の既定値から1/2となるように調整している。
また、小さくする重み係数が一つのみ場合には、その他の2つの重み係数はその比率を既定値の場合と同じにするようにして調整している。
【0224】
図18(A)において口唇動作情報の重み係数(γ)を1/2(0.333から0.167)にする場合には、その他の2つの重み係数は既定値では同じ数値(0.333と0.333)となっているので、調整後にも同じ比率となるように2つの重み係数共に0.417としている。
【0225】
また、図18(B)において口唇動作情報の重み係数(γ)を1/2(0.300から0.150)にする場合には、その他の2つの重み係数は既定値では0.500と0.200となっているので、調整後にも同じ比率となるように2つの重み係数を0.607と0.243としている。
【0226】
図15のフローチャートにおけるステップS303においては、例えば、このように、
α:音源方向情報の重み係数、
β:話者識別情報の重み係数、
γ:口唇動作情報の重み係数、
これらの重み係数を調整する。
その後、この調整した重み係数を適用して、前述の発話源スコア算出式、
P=Dα・Sβ・Lγ
を適用して、ターゲットの発話源スコアを算出する。
上記式に従って、各ターゲットについての発話源スコアを算出し、そのスコア比較により、最も高いスコアを持つターゲットを発話源であると判定することができる。
【0227】
本開示の情報処理装置では、上述したように、音源方向情報、話者識別情報、口唇動作情報、これらの全てを考慮し、さらに発話状況に応じて、これらの情報の適用重みを変更して発話源スコアを算出して、算出したスコアに応じて発話源確率を算出する構成とした。
この処理によって、例えば、複数の発話者が同時に発話したような状況であってもスコア算出とスコア比較によって、発話者の特定を高精度に行うことが可能となる。
すなわち、より現実的な様々な状況においても、発話者を正しく推定することが可能となる。
【0228】
[6.本開示の構成のまとめ]
以上、特定の実施例を参照しながら、実施例について詳解してきた。しかしながら、本開示の要旨を逸脱しない範囲で当業者が実施例の修正や代用を成し得ることは自明である。すなわち、例示という形態で本発明を開示してきたのであり、限定的に解釈されるべきではない。本開示の要旨を判断するためには、特許請求の範囲の欄を参酌すべきである。
【0229】
なお、本明細書において開示した技術は、以下のような構成をとることができる。
(1) 実空間の観測情報を入力する複数の情報入力部と、
前記情報入力部から入力する情報の解析により、前記実空間に存在するユーザの推定位置情報および推定識別情報を含むイベント情報を生成するイベント検出部と、
前記イベント情報を入力し、入力イベント情報に基づいて、各ユーザの位置およびユーザ識別情報を含むターゲット情報と、
前記イベント発生源の確率値を示すシグナル情報を生成する情報統合処理部を有し、
前記情報統合処理部は、発話源確率算出部を有し、
前記発話源確率算出部は、各ターゲットの発話源確率を示す指標値としての発話源スコアを、イベント検出部から入力する複数の異なる情報に対して発話状況に応じた重みを乗算して算出する処理を行う情報処理装置。
【0230】
(2)前記発話源確率算出部は、前記イベント検出部を構成する音声イベント検出部からの入力情報として、発話イベントに対応する、
(a)ユーザ位置情報(音源方向情報)、
(b)ユーザ識別情報(話者識別情報)、
を入力し、
さらに、前記イベント検出部を構成する画像イベント検出部からの入力情報に基づいて生成されるターゲット情報として、
(a)ユーザ位置情報(顔位置情報)、
(b)ユーザ識別情報(顔識別情報)、
(c)口唇動作情報、
これらの情報を入力し、少なくともこれらの情報のいずれかを適用して、入力情報に基づく発話源スコアを算出する処理を行う請求項1に記載の情報処理装置。
【0231】
(3)前記発話源確率算出部は、音源方向情報Dと、話者識別情報Sと、口唇動作情報Lを適用して、発話源スコアPを、以下の算出式、
P=Dα・Sβ・Lγ
ただし、
α:音源方向情報の重み係数、
β:話者識別情報の重み係数、
γ:口唇動作情報の重み係数、
α+β+γ=1
上記発話源スコアPの算出式に従って発話源スコアを算出する処理を行う前記(1)または(2)に記載の情報処理装置。
【0232】
(4)前記発話源確率算出部は、前記各重み係数:α、β、γを発話状況に応じて調整する処理を行う前記(3)に記載の情報処理装置。
(5)前記発話源確率算出部は、以下の2つの条件、(条件1)1つのターゲットのみによる単独発話か、あるいは2つのターゲットによる同時発話か、
(条件2)2つのターゲットの位置が近いか、あるいは2つのターゲットの位置が遠いか、
上記2つの条件に応じて、前記各重み係数:α、β、γを調整する処理を行う前記(3)または(4)に記載の情報処理装置。
【0233】
(6)前記発話源確率算出部は、発話可能性のあるターゲットが2である状況において、2つのターゲットが同時発声する場合、口唇動作情報の重みγを小さくするように前記各重み係数:α、β、γを調整する処理を行う前記(3)〜(5)いずれかに記載の情報処理装置。
(7)前記発話源確率算出部は、発話可能性のあるターゲットが2である状況において、2つのターゲットの位置が近く、1ターゲットのみが単独発声する場合、音源方向情報の重みαを小さくするように前記各重み係数:α、β、γを調整する処理を行う前記(3)〜(5)いずれかに記載の情報処理装置。
(8)前記発話源確率算出部は、発話可能性のあるターゲットが2である状況において、2つのターゲットの位置が近く、2つのターゲットが同時に発声する場合、口唇動作情報の重みγと音源方向情報の重みαを小さくするように前記各重み係数:α、β、γを調整する処理を行う前記(3)〜(5)いずれかに記載の情報処理装置。
【0234】
さらに、上記した装置等において実行する処理の方法や、処理を実行させるプログラムも本開示の構成に含まれる。
【0235】
また、明細書中において説明した一連の処理はハードウェア、またはソフトウェア、あるいは両者の複合構成によって実行することが可能である。ソフトウェアによる処理を実行する場合は、処理シーケンスを記録したプログラムを、専用のハードウェアに組み込まれたコンピュータ内のメモリにインストールして実行させるか、あるいは、各種処理が実行可能な汎用コンピュータにプログラムをインストールして実行させることが可能である。例えば、プログラムは記録媒体に予め記録しておくことができる。記録媒体からコンピュータにインストールする他、LAN(Local Area Network)、インターネットといったネットワークを介してプログラムを受信し、内蔵するハードディスク等の記録媒体にインストールすることができる。
【0236】
なお、明細書に記載された各種の処理は、記載に従って時系列に実行されるのみならず、処理を実行する装置の処理能力あるいは必要に応じて並列的にあるいは個別に実行されてもよい。また、本明細書においてシステムとは、複数の装置の論理的集合構成であり、各構成の装置が同一筐体内にあるものには限らない。
【産業上の利用可能性】
【0237】
以上、説明したように、本開示の一実施例の構成によれば、不確実で非同期な入力情報に基づく情報解析により、ユーザ位置や識別情報、発話者情報などを生成する構成が実現される。
具体的には、画像情報や音声情報に基づいてユーザの推定位置および推定識別データを含むイベント情報を入力し、入力イベント情報に基づいて、各ユーザの位置およびユーザ識別情報を含むターゲット情報と、イベント発生源の確率値を示すシグナル情報を生成する情報統合処理部を有し、情報統合処理部は、発話源確率算出部を有し、発話源確率算出部は、各ターゲットの発話源確率を示す指標値としての発話源スコアを、イベント検出部から入力する複数の異なる情報に対して発話状況に応じた重みを乗算して算出する処理を行う。
これらの処理によって、例えば2つのターゲット(2人)が同時に発話した状況においても、どちらが発話したかを高精度に推定することが可能となる。
【符号の説明】
【0238】
11〜12 ユーザ
21 カメラ
31〜34 マイク
100 情報処理装置
111 画像入力部
112 画像イベント検出部
121 音声入力部
122 音声イベント検出部
131 情報統合処理部
132 処理決定部
141 ターゲット情報更新部
142 発話源確率算出部
201〜20k ユーザ
301 ユーザ
302 画像データ
350 画像フレーム
351 第1顔画像
352 第2顔画像
361,362 イベント情報
371,372 イベント発生源仮設データ
375 ターゲットデータ
380 ターゲット情報
390 ターゲット情報
395 第3顔画像
401 イベント情報
421 パーティクル
【特許請求の範囲】
【請求項1】
実空間の観測情報を入力する複数の情報入力部と、
前記情報入力部から入力する情報の解析により、前記実空間に存在するユーザの推定位置情報および推定識別情報を含むイベント情報を生成するイベント検出部と、
前記イベント情報を入力し、入力イベント情報に基づいて、各ユーザの位置およびユーザ識別情報を含むターゲット情報と、
前記イベント発生源の確率値を示すシグナル情報を生成する情報統合処理部を有し、
前記情報統合処理部は、発話源確率算出部を有し、
前記発話源確率算出部は、各ターゲットの発話源確率を示す指標値としての発話源スコアを、イベント検出部から入力する複数の異なる情報に対して発話状況に応じた重みを乗算して算出する処理を行う情報処理装置。
【請求項2】
前記発話源確率算出部は、
前記イベント検出部を構成する音声イベント検出部からの入力情報として、発話イベントに対応する、
(a)ユーザ位置情報(音源方向情報)、
(b)ユーザ識別情報(話者識別情報)、
を入力し、
さらに、前記イベント検出部を構成する画像イベント検出部からの入力情報に基づいて生成されるターゲット情報として、
(a)ユーザ位置情報(顔位置情報)、
(b)ユーザ識別情報(顔識別情報)、
(c)口唇動作情報、
これらの情報を入力し、少なくともこれらの情報のいずれかを適用して、入力情報に基づく発話源スコアを算出する処理を行う請求項1に記載の情報処理装置。
【請求項3】
前記発話源確率算出部は、
音源方向情報Dと、話者識別情報Sと、口唇動作情報Lを適用して、
発話源スコアPを、以下の算出式、
P=Dα・Sβ・Lγ
ただし、
α:音源方向情報の重み係数、
β:話者識別情報の重み係数、
γ:口唇動作情報の重み係数、
α+β+γ=1
上記発話源スコアPの算出式に従って発話源スコアを算出する処理を行う請求項1に記載の情報処理装置。
【請求項4】
前記発話源確率算出部は、
前記各重み係数:α、β、γを発話状況に応じて調整する処理を行う請求項3に記載の情報処理装置。
【請求項5】
前記発話源確率算出部は、以下の2つの条件、
(条件1)1つのターゲットのみによる単独発話か、あるいは2つのターゲットによる同時発話か、
(条件2)2つのターゲットの位置が近いか、あるいは2つのターゲットの位置が遠いか、
上記2つの条件に応じて、前記各重み係数:α、β、γを調整する処理を行う請求項3に記載の情報処理装置。
【請求項6】
前記発話源確率算出部は、
発話可能性のあるターゲットが2である状況において、2つのターゲットが同時発声する場合、口唇動作情報の重みγを小さくするように前記各重み係数:α、β、γを調整する処理を行う請求項3に記載の情報処理装置。
【請求項7】
前記発話源確率算出部は、
発話可能性のあるターゲットが2である状況において、2つのターゲットの位置が近く、1ターゲットのみが単独発声する場合、音源方向情報の重みαを小さくするように前記各重み係数:α、β、γを調整する処理を行う請求項3に記載の情報処理装置。
【請求項8】
前記発話源確率算出部は、
発話可能性のあるターゲットが2である状況において、2つのターゲットの位置が近く、2つのターゲットが同時に発声する場合、口唇動作情報の重みγと音源方向情報の重みαを小さくするように前記各重み係数:α、β、γを調整する処理を行う請求項3に記載の情報処理装置。
【請求項9】
情報処理装置において、情報解析処理を実行する情報処理方法であり、
複数の情報入力部が、実空間における観測情報を入力する情報入力ステップと、
イベント検出部が、前記情報入力部から入力する情報の解析により、前記実空間に存在するユーザの推定位置情報および推定識別情報を含むイベント情報を生成するイベント検出ステップと、
情報統合処理部が、前記イベント情報を入力し、入力イベント情報に基づいて、各ユーザの位置およびユーザ識別情報を含むターゲット情報と、
前記イベント発生源の確率値を示すシグナル情報を生成する情報統合処理ステップを有し、
前記情報統合処理ステップは、
各ターゲットの発話源確率を示す指標値としての発話源スコアを、イベント検出ステップにおいて入力する複数の異なる情報に対して発話状況に応じた重みを乗算して算出する処理を行う情報処理方法。
【請求項10】
情報処理装置において、情報解析処理を実行させるプログラムであり、
複数の情報入力部に、実空間における観測情報を入力させる情報入力ステップと、
イベント検出部に、前記情報入力部から入力する情報の解析により、前記実空間に存在するユーザの推定位置情報および推定識別情報を含むイベント情報を生成させるイベント検出ステップと、
情報統合処理部に、前記イベント情報を入力し、入力イベント情報に基づいて、各ユーザの位置およびユーザ識別情報を含むターゲット情報と、
前記イベント発生源の確率値を示すシグナル情報を生成させる情報統合処理ステップを実行させ、
前記情報統合処理ステップにおいては、
各ターゲットの発話源確率を示す指標値としての発話源スコアを、イベント検出ステップにおいて入力する複数の異なる情報に対して発話状況に応じた重みを乗算して算出する処理を行わせるプログラム。
【請求項1】
実空間の観測情報を入力する複数の情報入力部と、
前記情報入力部から入力する情報の解析により、前記実空間に存在するユーザの推定位置情報および推定識別情報を含むイベント情報を生成するイベント検出部と、
前記イベント情報を入力し、入力イベント情報に基づいて、各ユーザの位置およびユーザ識別情報を含むターゲット情報と、
前記イベント発生源の確率値を示すシグナル情報を生成する情報統合処理部を有し、
前記情報統合処理部は、発話源確率算出部を有し、
前記発話源確率算出部は、各ターゲットの発話源確率を示す指標値としての発話源スコアを、イベント検出部から入力する複数の異なる情報に対して発話状況に応じた重みを乗算して算出する処理を行う情報処理装置。
【請求項2】
前記発話源確率算出部は、
前記イベント検出部を構成する音声イベント検出部からの入力情報として、発話イベントに対応する、
(a)ユーザ位置情報(音源方向情報)、
(b)ユーザ識別情報(話者識別情報)、
を入力し、
さらに、前記イベント検出部を構成する画像イベント検出部からの入力情報に基づいて生成されるターゲット情報として、
(a)ユーザ位置情報(顔位置情報)、
(b)ユーザ識別情報(顔識別情報)、
(c)口唇動作情報、
これらの情報を入力し、少なくともこれらの情報のいずれかを適用して、入力情報に基づく発話源スコアを算出する処理を行う請求項1に記載の情報処理装置。
【請求項3】
前記発話源確率算出部は、
音源方向情報Dと、話者識別情報Sと、口唇動作情報Lを適用して、
発話源スコアPを、以下の算出式、
P=Dα・Sβ・Lγ
ただし、
α:音源方向情報の重み係数、
β:話者識別情報の重み係数、
γ:口唇動作情報の重み係数、
α+β+γ=1
上記発話源スコアPの算出式に従って発話源スコアを算出する処理を行う請求項1に記載の情報処理装置。
【請求項4】
前記発話源確率算出部は、
前記各重み係数:α、β、γを発話状況に応じて調整する処理を行う請求項3に記載の情報処理装置。
【請求項5】
前記発話源確率算出部は、以下の2つの条件、
(条件1)1つのターゲットのみによる単独発話か、あるいは2つのターゲットによる同時発話か、
(条件2)2つのターゲットの位置が近いか、あるいは2つのターゲットの位置が遠いか、
上記2つの条件に応じて、前記各重み係数:α、β、γを調整する処理を行う請求項3に記載の情報処理装置。
【請求項6】
前記発話源確率算出部は、
発話可能性のあるターゲットが2である状況において、2つのターゲットが同時発声する場合、口唇動作情報の重みγを小さくするように前記各重み係数:α、β、γを調整する処理を行う請求項3に記載の情報処理装置。
【請求項7】
前記発話源確率算出部は、
発話可能性のあるターゲットが2である状況において、2つのターゲットの位置が近く、1ターゲットのみが単独発声する場合、音源方向情報の重みαを小さくするように前記各重み係数:α、β、γを調整する処理を行う請求項3に記載の情報処理装置。
【請求項8】
前記発話源確率算出部は、
発話可能性のあるターゲットが2である状況において、2つのターゲットの位置が近く、2つのターゲットが同時に発声する場合、口唇動作情報の重みγと音源方向情報の重みαを小さくするように前記各重み係数:α、β、γを調整する処理を行う請求項3に記載の情報処理装置。
【請求項9】
情報処理装置において、情報解析処理を実行する情報処理方法であり、
複数の情報入力部が、実空間における観測情報を入力する情報入力ステップと、
イベント検出部が、前記情報入力部から入力する情報の解析により、前記実空間に存在するユーザの推定位置情報および推定識別情報を含むイベント情報を生成するイベント検出ステップと、
情報統合処理部が、前記イベント情報を入力し、入力イベント情報に基づいて、各ユーザの位置およびユーザ識別情報を含むターゲット情報と、
前記イベント発生源の確率値を示すシグナル情報を生成する情報統合処理ステップを有し、
前記情報統合処理ステップは、
各ターゲットの発話源確率を示す指標値としての発話源スコアを、イベント検出ステップにおいて入力する複数の異なる情報に対して発話状況に応じた重みを乗算して算出する処理を行う情報処理方法。
【請求項10】
情報処理装置において、情報解析処理を実行させるプログラムであり、
複数の情報入力部に、実空間における観測情報を入力させる情報入力ステップと、
イベント検出部に、前記情報入力部から入力する情報の解析により、前記実空間に存在するユーザの推定位置情報および推定識別情報を含むイベント情報を生成させるイベント検出ステップと、
情報統合処理部に、前記イベント情報を入力し、入力イベント情報に基づいて、各ユーザの位置およびユーザ識別情報を含むターゲット情報と、
前記イベント発生源の確率値を示すシグナル情報を生成させる情報統合処理ステップを実行させ、
前記情報統合処理ステップにおいては、
各ターゲットの発話源確率を示す指標値としての発話源スコアを、イベント検出ステップにおいて入力する複数の異なる情報に対して発話状況に応じた重みを乗算して算出する処理を行わせるプログラム。
【図3】

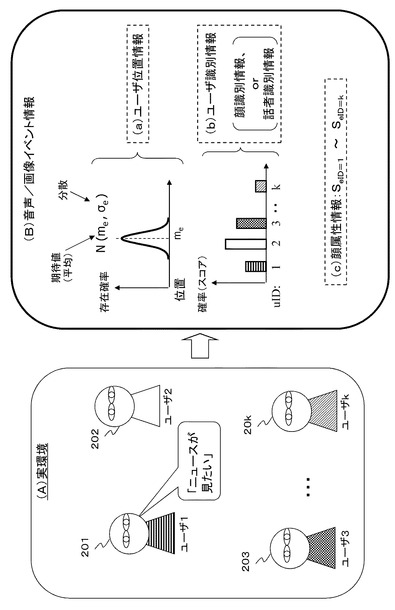
【図5】
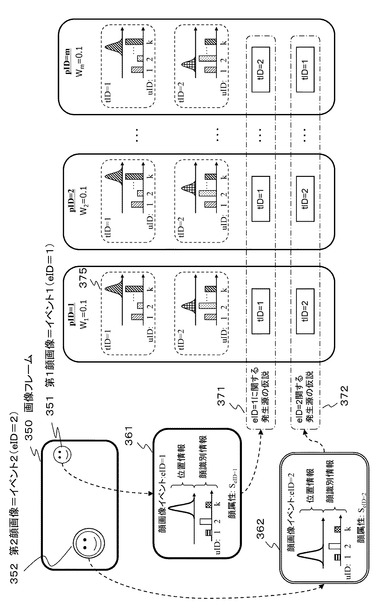
【図6】
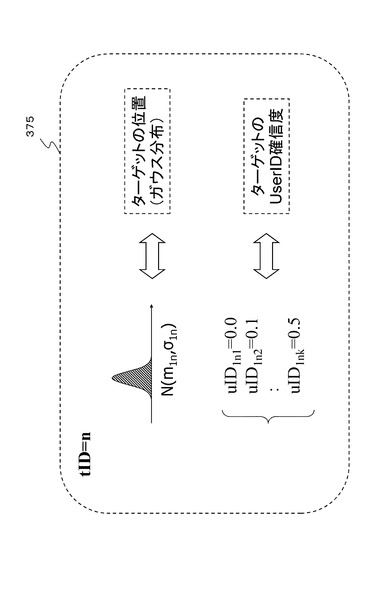
【図7】
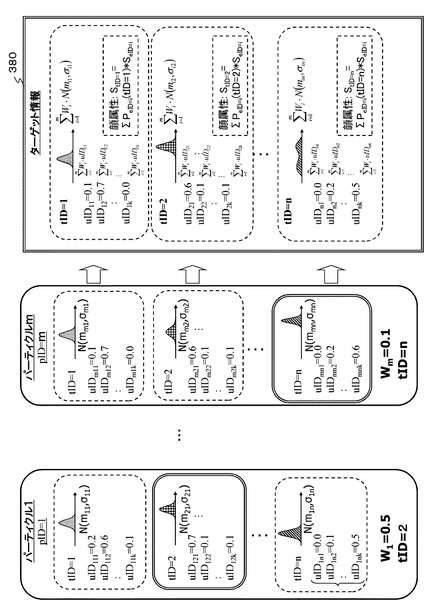
【図8】
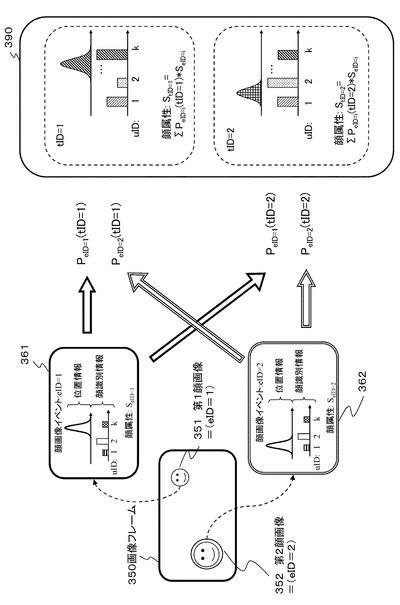
【図9】
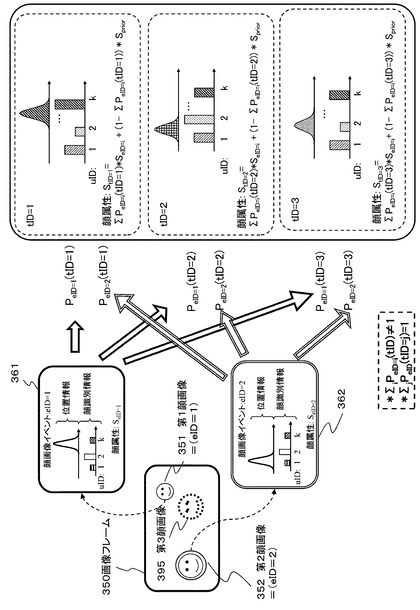
【図10】
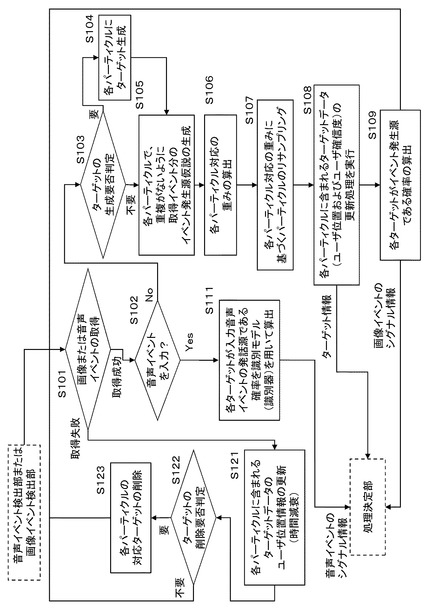
【図11】
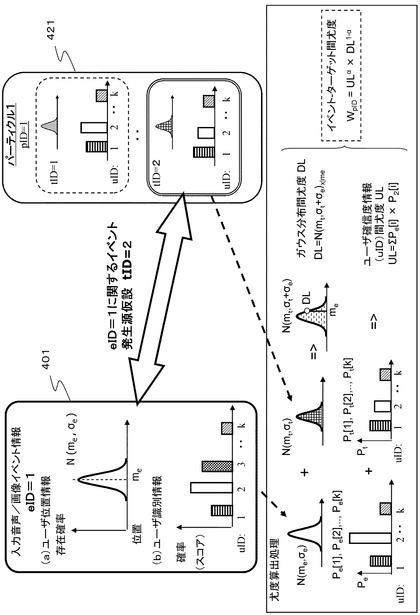
【図13】
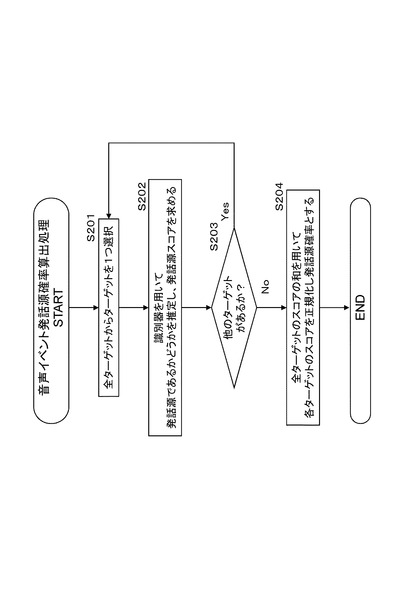
【図14】

【図15】
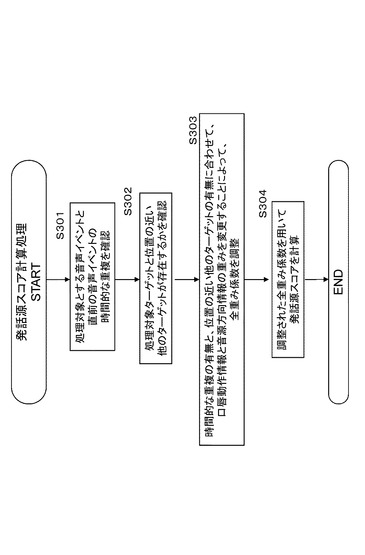
【図16】
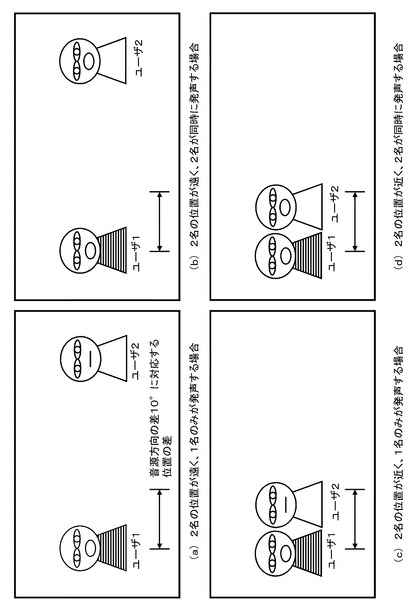
【図17】
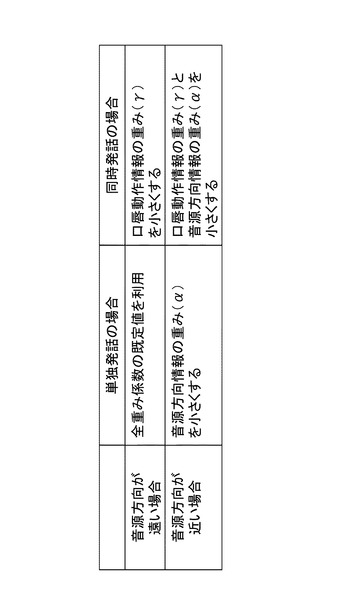
【図18】
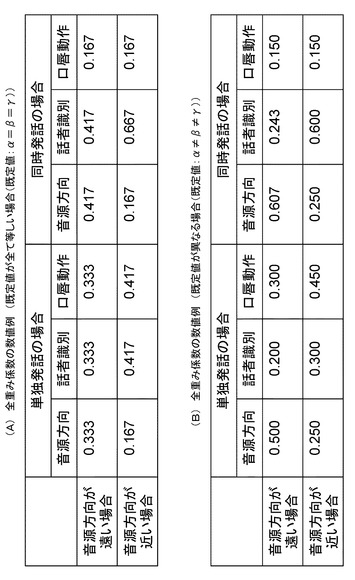
【図1】
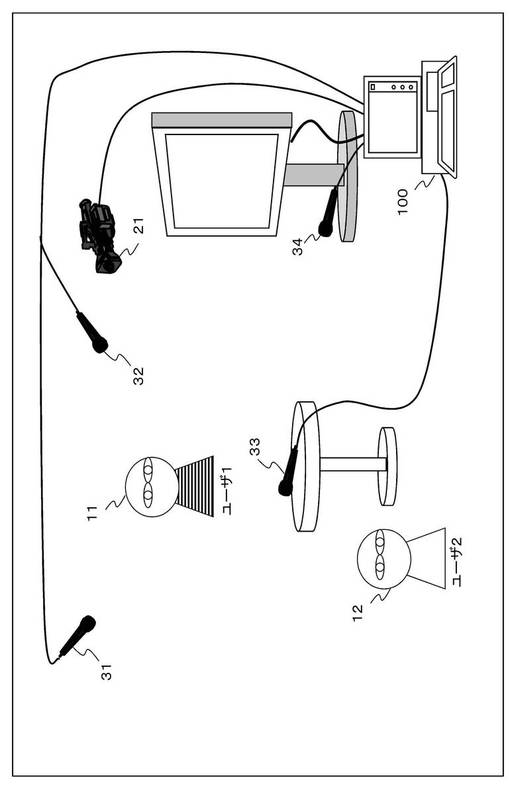
【図2】
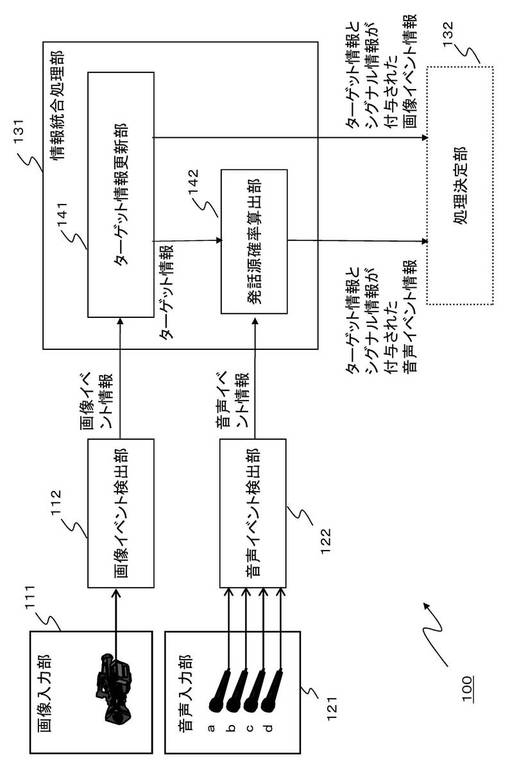
【図4】
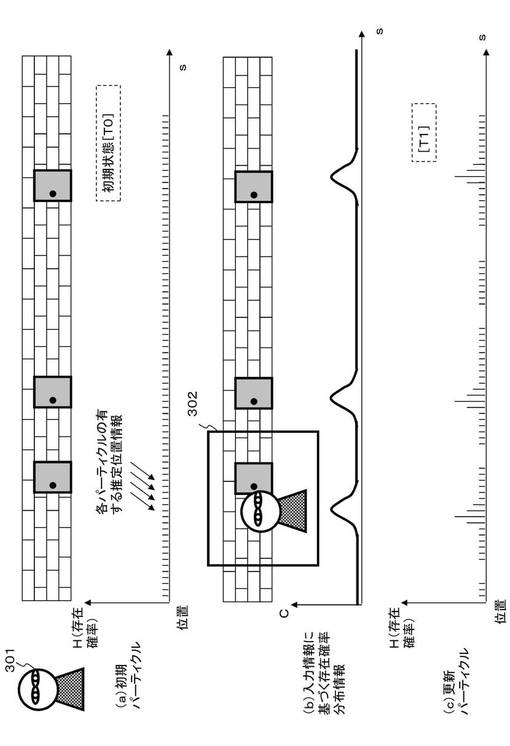
【図12】
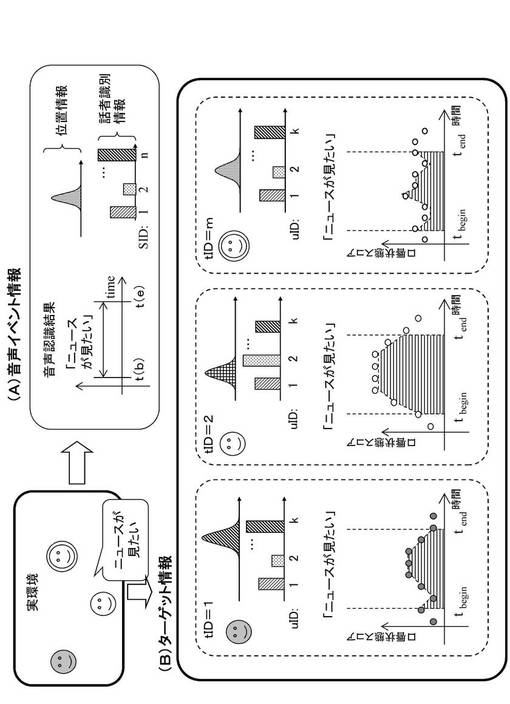
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図1】
【図2】
【図4】
【図12】
【公開番号】特開2013−104938(P2013−104938A)
【公開日】平成25年5月30日(2013.5.30)
【国際特許分類】
【出願番号】特願2011−247130(P2011−247130)
【出願日】平成23年11月11日(2011.11.11)
【出願人】(000002185)ソニー株式会社 (34,172)
【Fターム(参考)】
【公開日】平成25年5月30日(2013.5.30)
【国際特許分類】
【出願日】平成23年11月11日(2011.11.11)
【出願人】(000002185)ソニー株式会社 (34,172)
【Fターム(参考)】
[ Back to top ]