
情報処理装置、情報処理方法、プログラム、データ構造、および媒体
【課題】業務モデルを統一的に表現し、記憶し、処理することで、異なるシステム間においても、情報の一貫性を図る。
【解決手段】識別子と、順序を持つ因子の列として複数の識別子を結合する積演算子と、識別子および因子の列として結合された複数の識別子のいずれかまたは両方から項の組み合わせを構成する和演算子と、によって記述される対象情報を記憶する記憶部と、処理部と、入力部を接続可能なインターフェースと、出力部を接続可能なインターフェースと、を備え、インターフェースに接続された入力部から入力される情報を識別子、因子、項及び項の和である式のいずれか1以上として対象情報に設定し、記憶部に記憶させ、記憶部に記憶されている対象情報を参照し、インターフェースに接続された出力部に出力する。
【解決手段】識別子と、順序を持つ因子の列として複数の識別子を結合する積演算子と、識別子および因子の列として結合された複数の識別子のいずれかまたは両方から項の組み合わせを構成する和演算子と、によって記述される対象情報を記憶する記憶部と、処理部と、入力部を接続可能なインターフェースと、出力部を接続可能なインターフェースと、を備え、インターフェースに接続された入力部から入力される情報を識別子、因子、項及び項の和である式のいずれか1以上として対象情報に設定し、記憶部に記憶させ、記憶部に記憶されている対象情報を参照し、インターフェースに接続された出力部に出力する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、事物をコンピュータで処理可能な所定の表現形式を用いて表現し、コンピュータの記憶装置に記憶し、コンピュータで処理することで、その事物を管理する情報処理技術に関する。
【背景技術】
【0002】
ソフトウエアの開発プロセスは、要求分析、システム設計、実装、テスト、運用、及びメンテナンスの各段階により構成される。そして、ソフトウエア開発の最初のプロセスである、要求分析は特に重要である。なぜなら、最初の要求分析が不十分であると、それ以降のシステム設計、実装段階において、顧客の要求が正しく反映されていないなどの支障をきたすからである。例えばシステムのテスト段階で不具合が発見された場合においても、再度プログラムを修正する必要が生じる。また、大規模な修正が必要な場合には、システム設計を初めからやり直すなどの必要も生じる。しかし、プログラムの修正やシステム設計を最初からやり直しには、時間と労力がかる。その結果、コストが増大するといった問題も生ずる。また、たとえ最初の要求分析が十分であった場合においても、事業活動等様々な変化に対応させるためにはその後のメンテナンスが不可欠であるが、メンテナンスにも時間と労力がかかり、結果としてコストの増大を招くといった問題を生じている。
【0003】
ソフトウエアの開発の一例として、例えばデータベースシステムの開発が例示される。データベースシステムの開発とは、顧客の業務内容をヒアリングして、管理すべきデータ項目を洗い出し、それらの項目を関連付け、利用者が検索しやすいようなビューを設計し、顧客ニーズに合ったデータベースを構築することである。優れたデータベースを構築するためには、概念設計の段階からデータ構造を解析しておく必要がある。データとして管理すべき実体及び属性、実体間の関連を洗い出し、正確に分析することが重要になる。
【0004】
このような観点から開発された既存のデータベースのデータモデルとして、正規化表構造によるリレーショナルモデルや、ノードに属性を持つツリー構造で表現されるオブジェクト指向モデルが知られている。しかし、例えばリレーショナルモデルでは、関係をどのように定義するかは設計者の自由であるため、実装ごとに異なるシステムが生成されることになる。したがって、リレーショナルモデルに基づいて実装された複数のシステムを統合するためには、統合すべき構成要素の組み合わせ数に応じた作業工程が必要となり、システム統合に相当な時間と労力を費やす必要がるといった問題を生じていた。
【0005】
このような事情に鑑み開発されたソフトウエア開発支援装置として、本発明者の一人は、情報を階層化して表現する技術を提案した。この技術では、階層化された情報の各階層においてソフトウエア部品集合による操作が可能に構成されたモジュラ化されたデータ構造が提供される。そして、前記ソフトウエア部品集合が満たすべき仕様を前記階層ごとにインクリメンタルに詳細化することにより、与えられた要求仕様に合致するソフトウエアを前記ソフトウエア部品集合から自動生成する技術を開発した(例えば、特許文献1参照)。
【先行技術文献】
【特許文献】
【0006】
【特許文献1】特開2005−92855号公報
【特許文献2】特開平7−295938号公報
【発明の概要】
【発明が解決しようとする課題】
【0007】
上述したリレーショナルモデルやオブジェクト指向モデルでは、業務のデータモデルをサポートしていなので、個々のシステムでアプリケーションプログラムの開発が必要となる。さらに、一旦アプリケーションプログラムが開発された後であっても、リレーショナルモデルでは、システム開発時に予定されていない属性をデータベースに入力する場合には、新たな属性に対応可能なアプリケーションソフトを開発する必要が生じる。
【0008】
また、オブジェクト指向モデルは、オブジェクトの属性を細分化する有向グラフの一部としてのツリー構造については対応可能である。このツリー構造は、典型的には、有向グラフの根本側、すなわち、ツリー構造の上位には、より抽象化された概念、あるいは、共通化された概念が定義され、グラフの先端側、すなわち、ツリー構造の下位には、それぞれの上位概念を具体化した個別の概念が定義される。しかし、オブジェクト指向モデルは、逆ツリー構造については対応できない。
【0009】
ここで、逆ツリー構造とは、例えば、階層構造の上位には、基本的な概念が定義され、階層構造の下位には、複数の基本概念を組み合わせた概念が定義される。なお、上述したソフトウエア開発支援装置によれば、ソフトウエア開発の効率化を図ることが可能となることが示された。しかし、開発コスト、メンテナンスコストを削減でき、業務モデルを統一的に表現できるデータモデル、およびそのようなデータモデルを利用したさらに効率的なシステム開発技術、情報処理技術が求められていた。
【0010】
本発明は、上記問題に鑑みてなされたものであり、業務モデルを統一的に表現し、記憶し、処理することで、異なるシステム間においても、情報の一貫性を図るとともに新たな業務モデルへの適用、新たな管理対象となる情報項目、種類の追加・変更・削除、あるいは新たな処理機能の追加、変更等が可能なシステム開発技術、および情報処理技術を提供することを課題とする。
【課題を解決するための手段】
【0011】
本発明は前記課題を解決するために、以下の手段を採用した。すなわち、本発明は、識別子と、順序を持つ因子の列として複数の識別子を結合する積演算子と、識別子および因子の列として結合された複数の識別子のいずれかまたは両方から項の組み合わせを構成する和演算子と、によって記述される対象情報を記憶する記憶部と、対象情報を操作する処理部と、情報の入力を受け付ける入力部を接続可能なインターフェースと、情報を出力する出力部を接続可能なインターフェースと、を備える情報処理装置である。そして、本発明では、処理部は、インターフェースに接続された入力部から入力される情報を識別子、因子、項および項の和である式のいずれか1以上として対象情報に設定し、記憶部に記憶させる入力処理部と、記憶部に記憶されている対象情報を参照し、参照した対象情報中の識別子、因子、項および式のいずれか1以上が入力部から入力される情報と所定の関係にあるときに、対象情報を前記インターフェースに接続された出力部に出力する出力処理部と、を有する。
【0012】
本発明によれば、情報処理装置に、入力部が入力されたときに、入力される情報が、識別子、因子、項および式のいずれか1以上として対象情報に設定され、記憶部に記憶される。また、インターフェースに出力部が接続され、記憶手段にて参照した対象情報中の識別子、因子、項および式のいずれか1以上が入力部から入力される情報と所定の関係にあるときに、出力部から、対象情報が出力される。
【0013】
このように、本発明によれば、識別子および各種演算子を組み合わせた表現形式で入力部から入力される対象情報を記述し、記憶し、さらには、参照し、出力部から出力する機能が実現される。
【0014】
本発明は、以上のような処理をコンピュータが実行する方法であってもよい。また、本発明は、コンピュータに以上のような処理を実行させるプログラムであってもよい。また、そのようなプログラムを記録したコンピュータが読み取り可能な記録媒体であってもよい。
【0015】
また、本発明は、上記対象情報を記述するときのデータ構造であってもよい。また、そのようなデータ構造を記録したコンピュータが読み取り可能な記録媒体であってもよい。このようなデータ構造にしたがって対象情報を記憶し、あるいは記録することにより、コンピュータは、識別子および各種演算子を組み合わせた表現形式で入力部から入力される対象情報を記述し、記憶し、さらには、参照し、出力部から出力する機能を実現する。
【発明の効果】
【0016】
本発明に係る情報処理装置によれば、業務モデルを統一的に表現して処理、すなわち事物を所定の表現形式を用いて表現して処理することで、異なるシステム間においても、情報の一貫性を図るとともに新たな業務モデルへの適用、新たな管理対象となる情報項目、種類の追加・変更・削除、あるいは新たな処理機能の追加、変更等が可能なシステム開発技術、および情報処理技術を提供することができる。
【図面の簡単な説明】
【0017】
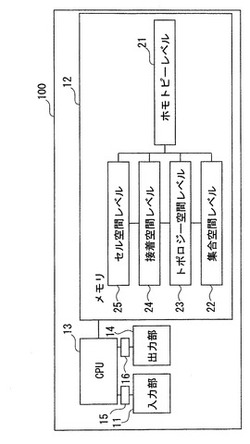
【図1】第1の実施形態に係る情報処理装置の構成を示すブロック図である。
【図2】第1の実施形態に係る情報処理装置のメモリに格納される第一のデータ構造を示す。
【図3】第1の実施形態に係る情報処理装置のメモリに格納される第二のデータ構造を示す。
【図4】第1の実施形態に係る情報処理装置のメモリに格納される第三のデータ構造を示す。
【図5】第1の実施形態に係る情報処理装置におけるプログラム構成を示す図である。
【図6A】横方向展開処理を実行する処理のフローを示す。
【図6B】横方向展開処理を実行中の対象情報の状態の詳細を示す表である。
【図6C】横方向展開処理を実行中の対象情報の状態の詳細を示す表である。
【図7】縦方向展開処理を実行する処理のフローを示す。
【図8A】縦方向展開処理を実行中の対象情報の状態の詳細を示す表である。
【図8B】縦方向展開処理を実行中の対象情報の状態の詳細を示す表である。
【図8C】縦方向展開処理を実行中の対象情報の状態の詳細を示す表である。
【図8D】縦方向展開処理を実行中の対象情報の状態の詳細を示す表である。
【図9】積演算処理を実行する処理のフローを示す。
【図10】積演算処理を実行中の対象情報の状態の詳細を示す表である。
【図11A】商演算処理(サブルーチン1)を実行する処理のフローを示す図である。
【図11B】商演算処理(サブルーチン1)を実行中の対象情報の状態の詳細を示す表(その1)である。
【図11C】商演算処理(サブルーチン1)を実行中の対象情報の状態の詳細を示す表(その2)である。
【図12A】商演算処理(サブルーチン2)を実行する処理のフローを示す図である。
【図12B】商演算処理(サブルーチン2)を実行中の対象情報の状態の詳細を示す表(その1)である。
【図12C】商演算処理(サブルーチン2)を実行中の対象情報の状態の詳細を示す表(その2)である。
【図13】接着演算処理を実行する処理のフローを示す。
【図14】接着演算処理を実行中の対象情報の状態の詳細を示す表である。
【図15】部分集合取得処理を実行する処理のフローを示す。
【図16A】部分集合取得処理を実行中の対象情報の状態の詳細を示す表である。
【図16B】部分集合取得処理を実行中の対象情報の状態の詳細を示す表である。
【図17】ホモトピー保存処理を実行する処理のフローを示す。
【図18】ホモトピー保存式におけるUNDO演算処理のフローを示す。
【図19】ホモトピー保存式におけるREDO演算処理のフローを示す。
【図20】建設業における情報管理、すなわちデータ処理システムが要求される例を示す。
【図21A】本発明の対象情報に相当する社員データ及び伝票データを示す。
【図21B】本発明の対象情報に相当する伝票データを示す。
【図22A】プロジェクトデータを示す。
【図22B】歩掛作成データを示す。
【図23】集合レベル22で表現される対象情報の例を示す。
【図24】トポロジー空間レベル23で表現される対象情報の例を示す。
【図25】接着空間レベル24で表現される対象情報の例を示す。
【図26】セル空間レベル25で表現される対象情報の例を示す。
【図27】本発明の第2の実施形態に係る情報処理装置100の構成である。
【図28A】社員データ管理処理の処理フローを示す図(その1)である。
【図28B】社員データ管理処理の処理フローを示す図(その2)である。
【図29】社員データ入力処理の詳細処理フローを示す図である。
【図30】社員データ検索処理の詳細処理フローを示す図である。
【図31】メモ作成と接着処理の詳細フローを示す図である。
【図32】属性追加処理の詳細処理フローを示す図である。
【発明を実施するための形態】
【0018】
以下、図面を参照して、本発明の実施形態に係る情報処理装置を説明する。
【0019】
《システムの骨子》
本情報処理装置は、情報を集合レベル、トポロジー空間レベル、接着空間レベル、およびセル空間レベルというデータ構造の複雑さの異なるレベルで表現する。データ構造が複雑になればなるほど、表現される情報と情報との間の関連付け、あるいは、情報と情報との拘束が増加する。
【0020】
例えば、集合レベルは、情報が項(以下、要素ともいう)を組み合わせた集合情報として記述される。それぞれの集合情報は、集合IDで識別される。また、トポロジー空間レベルでは、項または集合を組み合わせたトポロジー空間情報として情報が記述される。それぞれのトポロジー空間情報は、トポロジーIDで識別される。
【0021】
すなわち、集合レベルは、単なる項の組み合わせであるのに対し、トポロジー空間レベルは、集合情報の組み合わせを含む点で、より複雑となっている。本実施形態では、この場合に、集合レベルは、トポロジー空間レベルよりも抽象度が高い、ともいう。ただし、トポロジー空間情報は、単一の集合情報をも含む。すなわち、トポロジー空間レベルは、集合レベルの性質をそのまま有している。本実施形態では、この意味で、トポロジー空間レベルは、集合レベルの特性を継承している、という。
【0022】
接着空間レベルは、集合情報またはトポロジー空間情報のいずれか2つ以上(以下、被接着情報)を接着した情報を含む。接着とは、本実施形態にて提案する概念であり、2つ
の被接着情報のそれぞれのデータ構造を維持した上で、被接着情報を互いに結合する機能である。接着においては、2つの被接着情報のそれぞれに含まれる情報で、互い関係付けられる情報が指定される。そして、その関係付けられた情報同士を介して、2つの被接着情報が結合される。接着は、例えば、人の行為である伝票にメモを張り付ける行為をコンピュータ上で実現したものとなる。すなわち、伝票ID、伝票に含まれる項目、および伝票内の位置情報からなるデータ構造と、メモIDおよびメモ内容である文字列情報からなるデータ構造があったときに、伝票上の位置情報と、メモIDとを関連づけ、接着演算を実行することにより、伝票上の指定された位置にメモが添付された状態をコンピュータ上で表現できる。接着された2つの被接着情報は、また、分離することもできる。ただし、接着空間の情報は、それぞれの被接着情報の特性、すなわち、集合レベル、あるいは、トポロジー空間レベルの特性をそのまま有している。そのため、接着空間の情報は、これらのレベルを継承しているという。
【0023】
セル空間レベルとは、属性と値とを含むデータ構造が定義された情報であり、集合情報、トポロジー空間情報、および接着された情報をさらに複雑にしたものと言える。この点で、逆に、集合情報、トポロジー空間情報、および、これらが接着された情報は、セル空間の情報よりも抽象度が高いともいう。ただし、セル空間レベルの集合は、集合レベル、トポロジー空間レベル、および接着空間レベルの特性を有することができ、その意味で、これらのレベルを継承しているという。
【0024】
よってセル空間が定義される(つまり空間に属性,値の意味が付加される)セル空間レベルならば,一般的なトポロジー空間のレベルよりも抽象度が低いと見なされる。
【0025】
本情報処理装置は、抽象度に応じた各レベルの所定の表現形式によって表現される情報が格納される記憶手段と、前記情報を処理する処理手段と、を備える。そして、前記記憶手段には、識別子と、順序を持つ因子の列として複数の識別子を結合する積演算子と、識別子および前記因子の列として結合された複数の識別子のいずれかまたは両方から項の組み合わせを構成する和演算子と、によって記述される対象情報が記憶される。さらに、対象情報は、前記組み合わせ中の項の順序を維持して前記項の組み合わせを関係付けることによって因子または新たな項を構成する順序構成演算子と、前記組み合わせ中の項の順序を維持しないで前記項の組み合わせを関係付けることによって因子または新たな項を構成する集合因子構成演算子と、を含んでもよい。
【0026】
以下、本情報処理装置の記憶手段に記憶され、本情報処理装置で処理される情報を対象情報という。対象情報は、識別子、因子、項(要素)、集合情報、トポロジー空間情報、接着された情報、セル空間の情報を含む。対象情報をオブジェクト情報とも呼ぶ。ただし、本実施形態でのオブジェクト情報は、いわゆるオブジェクト指向データベース、オブジェクト指向言語、オブジェクト指向設計等でいうオブジェクトとは、概念が異なる。そこで、以下では、もっぱらオブジェクト情報という代わりに、対象情報と呼ぶことにする。
【0027】
また、本実施形態では、項の組み合わせから因子を構成する集合因子構成演算子及び順序構成演算子が使用される。集合因子構成演算子は、第一の括弧“()”により表現される。また、順序構成演算子は第二の括弧“{}”により表現される。
【0028】
本発明によれば、対象情報を所定の表現形式のデータとして記憶手段に格納し、これに所定のプログラムに基づいて処理を実行することができる。その結果、異なる対象情報同士の情報の一貫性を図るとともに新たな様々な対象情報のデータベース化及び処理が可能な情報処理装置を提供することが可能となる。また、従来のリレーショナルモデルやオブジェクト指向モデルでは、対応できないデータに対応することができるシステムを開発することができる。
【0029】
記憶手段は、抽象度に応じた各レベルの所定の表現形式によって表現される対象情報を例えばテキストファイルとして格納する。記憶手段は、前記対象情報を十分に格納できる容量を有するものであればよく、ハードディスク等がこれに該当する。対象情報とは、システム開発におけるデータベースを構成する全ての情報を含むものである。例えば既存のデータモデルの正規化表構造を構成するレコードの構成要素や正規化表構造では入力不可能なデータ構造も含む。正規化表構造では入力不可能な情報とは、例えば正規化表構造で表現されるようなデータがある場合に、これに付箋のような前記正規化表構造とは全く関連性のない、すなわち属性の定義のない対象情報を意味する。また、この対象情報は、本情報処理装置の処理を実行することによりその抽象度が変化することを特徴とする。すなわち、あるレベルで入力された対象情報は、本情報処理装置の処理が実行されることによりそのレベルが変化する。そして、そのレベルが変化しても対象情報は、変化前と同一の演算によって、取り扱うことができる。すなわち、対象情報は、抽象レベルが変化しても対象情報の性質には一貫性が保たれるので、同一の演算による操作が可能である。したがって、ある抽象度で格納された対象情報、すなわちデータは本情報処理装置の処理が実行されることにより様々なレベルに変化する。また、上述のように全く関連性のないデータも入力してこれを関連付けることが可能である。したがって、異なる抽象度のレベルにおいて、情報の性質の一貫性が保たれるとともに、新たな様々な事物を示す情報のデータベース化及びデータベース化された情報に対する演算処理が可能となる。
【0030】
前記対象情報は、記号、識別子、第一の括弧及び第二の括弧により表現される因子と、前記因子の積によって表現される項と、前記項の和によって表現される式と、により構成することができる。式を構成する項、および項を構成する因子は、前記対象情報を構成する最小単位である識別子と、前記処理手段において1として処理される単位元εと、前記処理手段において0として処理される零元Φとにより構成することができる。前記第一の括弧は、()により表現することができる。また、前記第二の括弧は{}により表現することができる。このように本発明によれば、対象情報が非常に簡単なデータ構造で表現されている。したがって、高度な技術を有さないユーザであっても容易に理解することが可能となる。
【0031】
前記第一の括弧と前記第二の括弧は演算時の強さが異なる。演算時の強さが異なるとは、前記処理手段の処理を実行する際の展開順序が異なることを意味する。項は、前述した因子の積によって表現され、積は×により表現することができる。本実施形態では、積を構成する因子に、可換律は、成立しない。すなわち、a×bとb×aは、同一とは見なされない。また、式は前記項の和によって表現され、和は+により表現することができる。本実施形態では、和を構成する項に、可換律が、成立する。すなわち、a+bとb+aは、同一とは見なされる。以上より、例えばある対象情報は数1のように表現することができる。
(a+b)×{c+d+e}+f{g+h}×{i+j}・・・(数1)
【0032】
上記数1で表現される対象情報は、第一の項の(a+b)×{c+d+e}と、第二の項のf{g+h}×{i+j}により構成されている。すなわち、数1は第一の項と第二の項との和により構成されている。次に、第一の項と第二の項のそれぞれについてみると、第一の項は、第一の因子の(a+b)と、第二の因子の{c+d+e}とにより構成されている。また、第二の項についてみると、第三の因子のfと、第四の因子の{g+h}と、第五の因子の{i+j}とにより構成されている。なお、上記数1において、“f”の後に、積演算子“×”を明示し、“f×”としてもよい。そして第一の因子から第五の因子のそれぞれについてみると、第一の因子は、第一の括弧と識別子a及びbにより構成されている。また、第二の因子は第二の括弧と識別子c、d及びeにより構成され、第三の因子は識別子fにより構成され、第四の因子は第二の括弧と識別子g及びfにより構成
され、第五の因子は第二の括弧と識別子i及びjにより構成されている。なお、括弧の中は換言すると再帰的に式になっている。例えば、上記のうち(a+b)についてみると、括弧の中は再帰的に式a+bになっている。すなわち、上記式は項としての識別子aと項としての識別子bの和によってなっている。このように、式は、()または{}、およびその両方が複数回入れ子になった構造を含むことができる。
【0033】
対象情報は、上記のように因子、項からなる式で表現される。そしてこのように表現された対象情報は、例えばテキストファイルとして前記記憶手段に格納される。なお、記憶手段への対象情報の格納、換言すると入力はユーザ操作に応答して実行される。この入力時に、グラフィカルユーザインターフェースを用いたユーザインターフェース部を提供してもよい。簡易的には、テキストエディタで、識別子、項、あるいは、項の和を入力するようにしてもよい。情報処理手段は、記憶手段に格納されたその対象情報を処理する。これにより、前記対象情報の抽象度を変化させることが可能となる。
【0034】
本情報処理装置は、前記対象情報を展開する展開手段と、前記対象情報から部分集合を取得する部分集合取得手段と、前記対象情報についてホモトピー保存処理を実行するホモトピー保存処理手段と、異なる対象情報を構成する前記因子間における同値関係の対応に基づき該因子同士を接着して新たな空間である接着空間を作成する接着空間作成手段と、前記対象情報を分割する商空間作成手段と、のうち少なくともいずれか一つを有する。これにより、前記対象情報の抽象度を様々な状態に変化させることが可能となる。
【0035】
展開手段は、前記対象情報を展開する。前記展開手段は、前記対象情報を前記項又は前記因子の単位に分解する分解手段と、前記因子間で集合演算処理をし、集合演算処理後の新たな項を設定する項設定手段と、前記第一の括弧及び第二の括弧で括られた因子を再帰的に展開処理する再帰的展開処理手段と、により構成することができる。そして、例えば上述した数1で表現される対象情報を展開処理すると数2のようになる。
(a+b)×{c+d+e}+f{g+h}×{i+j}
→(a{c+d+e}+b{c+d+e})+{f×g+f×h}×{i+j}
→({a×c+a×d+a×e}+{b×c+b×d+b×e})+{f×g×i+f×h×j}
→a×c+a×d+a×e+b×c+b×d+b×e+f×g×i+f×h×j・・・(数2)
【0036】
すなわち、まず、第一の項を構成する第一の因子と第二の因子が展開する。次に、第一の因子の一番左の識別子であるaと第二の因子を構成する一番左の識別子cが掛け合わせる。次に、d、eの順に掛け合わせて展開する。そして、第一の因子の左から2番目の識別子、換言すると右側の識別子であるbと第二の因子を構成する一番左の識別子cが掛け合わせる。その後、d、eの順に掛け合わせて展開する。一方、第二の項については、まず第二の括弧で括られている第四の因子と同じく第二の括弧で括られている第五の因子を掛け合わせる。なお、第二の括弧は、第一の括弧とは異なり因子の順序ごとに積を作成しその和を出力する展開が行われる。すなわち、まず第四の因子を構成する一番左の識別子gと第五の因子を構成する一番左の識別子iの積を作成する。次に、第四の因子を構成する左から2番目の識別子であるhと第五の因子を構成する左から2番目の識別子であるjの積を作成し、これらの和として出力する。更に第三の因子を構成する識別子fと掛け合わせて展開する。
【0037】
このような展開処理を行うことにより、数1で表現される前記対象情報は、対象情報の最小単位である識別子の積とこれらの和によって表現されることになる。すなわち、展開手段による展開を実行することにより集合で表現することが可能となる。つまりは、展開処理手段を備えることで前記対象情報の抽象度を高くすることが可能となる。
【0038】
部分集合取得手段は、部分集合を取得する。これにより、前記対象情報の中から部分集合を取得することが可能となる。例えば、数3で表現される対象情報について、aについての部分集合を取得すると数4で表現される対象情報となる。
a×c+a×d+a×e+b×c+b×d+b×e+f×g×i+f×h×j・・・(数3)
a(c+d+e)+b×c+b×d+b×e+f×g×i+f×h×j・・・(数4)
【0039】
接着空間作成手段は、異なる対象情報を構成する前記因子間における同値関係の対応に基づき該因子同士を接着する。その結果、新たな空間である接着空間を作成することができる。接着空間作成手段を備えることで、前記対象情報が異なる空間を表現するものであっても、同値関係にある因子を介して関連付け新たな空間を設計することが可能となる。
【0040】
ホモトピー保存処理手段は、前記対象情報についてホモトピー保存処理を実行する。ホモトピー保存処理は、対象情報に対する演算結果とともに、演算前の対象情報、適用された演算、および、演算時に使用されたパラメータを記憶する機能である。これにより、前記処理手段の処理実行前の前記対象情報の状態を取得することが可能となる。そして、例えばホモトピー保存処理手段による処理の実行は数5のように表すことができる。
a(b+c)
↓H
(a×b+a×c)=F(a(b+c)+ε)・・・(数5)
【0041】
数5におけるFは、本情報処理装置100で規定した「展開」という演算をを表す識別子である。また、εは、値“1”を表す記号であり、Fの演算において、値“1”が使用されたことを示している。すなわち、展開処理を実行した後の状態を表す、対象情報(a×b+a×c)は、a(b+c)を展開処理したものであることを意味する。このように、ホモトピー保存処理を実行することによって、前記格納処理手段に格納される対象情報は処理前の状態についても保存されているため、対象情報の過去の状態を取得することが可能となる。
【0042】
本発明に係る情報記憶装置において、前記各レベルは、前記対象情報が最も抽象度が高く表現される集合レベルと、前記集合レベルよりも前記対象情報の抽象度が低く表現され、該対象情報が部分集合によって表現されるトポロジー空間レベルと、前記トポロジー空間レベルよりも前記対象情報の抽象度が低く表現され、該トポロジー空間レベルにおける前記対象情報同士が接着される接着空間レベルと、前記接着空間レベルよりも前記対象情報の抽象度が低く表現され、前記トポロジー空間における前記対象情報が所定の属性をもって表現されるセル空間レベルと、を有するものとしてもよい。
【0043】
ここで、抽象度が高いとは、対象情報同士の関係、あるいは、関連を示す情報が少ないことをいう。
【0044】
例えば、集合レベルは、前記対象情報の抽象度が最も高く表現されるものである。集合レベルにおける対象情報(以下、集合の対象情報ともいう)は対象情報の最小単位である識別子の積を項としてこれらの和からなる式によって表現される。なお、集合レベルには、他の抽象度の低いレベルから展開処理手段の展開処理を実行することにより移行することができる。また、前記記憶手段に格納する際に集合レベルで入力することとしてもよい。
【0045】
トポロジー空間レベルは、前記集合レベルよりも前記対象情報の抽象度が低く表現される。また、対象情報の部分集合を要素として扱うことによって表現される。ただし、部分集合が1つの場合も、トポロジー空間レベルである。例えば前記対象情報が集合レベルで
表現されている場合に、前述した部分集合取得手段の部分集合取得処理を実行する。すると集合レベルで表現されている対象情報は、トポロジー空間レベルに移行されることになる。
【0046】
接着空間レベルは、前記トポロジー空間レベルよりも前記対象情報の抽象度が低く表現される。すなわち、接着空間レベルは、該トポロジー空間レベルにおける前記対象情報同士が同値関係を基準に結合されることで表現されるものである。前記トポロジー空間レベルで表現されている異なる2以上の対象情報に前述した接着手段の接着処理手段を実行することで新たな空間レベル、すなわち接着空間レベルへ移行することが可能となる。
【0047】
セル空間レベルは、トポロジー空間レベルの情報の式表現のうち、特定の式表現に限定して、属性と属性値の関係を定義できるようにしたものである。したがって、当然、セル空間レベルはトポロジー空間レベルの性質、および、機能を有している。この点で、セル空間レベルはトポロジーレベルの1ケースである。
【0048】
このように、セル空間レベルの情報と、トポロジー空間レベルの情報とは、式表現の形式上は、差異がない。すなわち、セル空間レベルの情報は、セル空間IDと属性の定義を示す因子とで括り出された部分集合の式表現と見なせるからである。セル空間レベルの情報は、セル空間IDと属性の定義を示す因子に、セル空間IDという意味、および属性の定義という意味を付加することで、形成される。この意味で、セル空間レベルの情報は、トポロジー空間レベルの情報の特殊ケースである。また、特殊ケースという意味で、セル空間レベルは、トポロジー空間レベルよりも、抽象度が低いとも言える。一方、そのような意味づけを解消すれば、セル空間レベルの情報は、同一の式表現のまま、トポロジー空間レベルの情報となる。
【0049】
さらに、セル空間レベルの情報は、前述した展開手段の展開処理を実行することにより、集合レベルに移行されることもできる。すなわち、すべての括弧を展開すればよい。
【0050】
なお、このセル空間レベルの属性は、通常は、アプリケーションプログラムによって定義されるものである。したがって、本情報処理装置では、セル空間レベルの情報は、アプリケーションプログラムのユーザインターフェースを通じて入力されることを想定している。
【0051】
また、本実施形態では、セル空間レベルは、接着空間レベルの性質、および、機能も有していることとした。したがって、セル空間レベルの複数の対象情報を接着することができる。これは、逆に、セル空間レベルの情報を接着した接着空間レベルの情報は、セル空間レベルの性質、機能を有していると言える。
【0052】
本発明に係る情報記憶装置において、前記各レベルは、前記情報処理手段による処理の実行前の状態を所定の形式によって表現することにより処理前の状態に戻すことが可能なホモトピーレベルを更に有するものとしてもよい。
【0053】
ホモトピーレベルは、前記情報処理手段による処理の実行後の状態が実行前の状態を含んだ状態で所定の表現形式で表現されることで処理前の状態に戻すことが可能な空間である。ホモトピーレベルでは、例えば、式1で示される対象情報が、演算Pによって、式2に変換されたときに、「式2=式1に演算Pを実行」のように記述される。したがって、演算前のレベルには、前述したホモトピー保存処理を実行することにより移行することができる。なお、ホモトピーレベルは、前述した他の空間レベルとは本質的に異なる。すなわち、他の空間レベルは、上述したように対象情報の抽象度によって段階的に表現される空間である。しかし、ホモトピーレベルは他の空間レベルのそれぞれと常に行き来が可能
な空間である。換言すると、ホモトピーレベルは、前述した各空間レベル間の移動を補助する空間であると言える。ホモトピーレベルを前述した各空間レベルと併用することにより、前記対象情報に対する処理前の状態を取得することが可能となるからである。
【0054】
次に、本発明に係る情報処理装置の実施形態について図面に基づいて説明する。
【0055】
《第1実施形態》
(装置構成)
図1は、第1の実施形態に係る情報処理装置100の構成を示すブロック図である。同図に示すように、第1の実施形態に係る情報処理装置100は、対象情報を入力するキーボード、ポインティングデバイス等の入力手段11(本発明の入力部に相当)と、入力された対象情報を格納するメモリ12(本発明の記憶部に相当)と、対象情報を所定のプログラムに基づいて処理するCPU13(本発明の処理部に相当)と、入力された対象情報や処理後の対象情報を出力するディスプレイ等の出力手段14(本発明の出力部に相当)と、CPU13と入力手段11との間を接続するインターフェース15と、CPU13と出力手段14との間を接続するインターフェース16とを備える構成である。
【0056】
インターフェース15は、例えば、USB(Universal Serial Bus)等のシリアルインターフェースである。また、インターフェース16は、例えば、RGB(赤、緑、青)の画像信号および同期クロックの出力インターフェースである。
【0057】
ただし、図1では、省略されているが、情報処理装置100は、大容量のデータを保存する外部記憶装置であるハードディスク、着脱可能な記憶媒体(例えば、CD(Compact disc)、DVD(Digital Versatile Disk)、フラッシュメモリカード等)の駆動装置、ネットワークにアクセスし他の情報処理装置と通信する通信インターフェース等を含んでよい。
【0058】
情報処理装置100は、典型的には、パーソナルコンピュータ、サーバ等のコンピュータである。ただし、情報処理装置100は、そのようなコンピュータに限定されるものではなく、例えば、携帯情報端末、携帯電話、PHS(Personal Handyphone System)、デジタルテレビ、デジタルテレビのチューナあるいはセットトップボックス、ハードディスクを含むテレビジョンの録画装置、車載用の端末等として実現できる。また、メモリ12は、揮発性のDRAM(Dynamic Random Access Memory)、不揮発性のEPROM(Erasable Programmable Read Only Memory)、EEPROM(Electronically Erasable and Programmable Read Only Memory)、フラッシュメモリ等を含む。
【0059】
本情報処理装置の機能は、CPU13がプログラムを実行することで実現される。このプログラムは、メモリ13あるいは不図示の外部記憶装置にインストールされる。プログラムは、通信インターフェースを通じてネットワークから、あるいは、着脱可能な記憶媒体からインストールされる。したがって、このプログラムは、ネットワークあるいは着脱可能な記憶媒体等を通じて流通される。
【0060】
また、メモリ12あるいは不図示の外部記憶装置に格納された対象情報は、CPU13が所定のプログラムを実行することによって各レベルを移行する。なお、各レベルとは、前記対象情報の抽象度が最も高く表現される集合レベル22と、前記集合レベル22よりも前記対象情報の抽象度が低く表現され、該対象情報が部分集合を要素として表現されるトポロジー空間レベル23と、前記トポロジー空間レベルよりも前記対象情報の抽象度が低く表現され、該トポロジー空間レベルにおける前記対象情報同士が接着される接着空間レベル24と、前記トポロジー空間における前記対象情報が所定の属性をもって表現されるセル空間レベル25と、前記情報処理手段による処理の実行前の状態を所定の形式によ
って表現することにより処理前の状態に戻すことが可能なホモトピーレベル21と、を有する。また、本実施形態では、セル空間レベル25は、前記接着空間レベルよりも前記対象情報の抽象度が低いものとして定義する。すなわち、セル空間レベルは、接着空間レベルの情報に、属性と属性値の意味づけを加えたものである、と解することにする。
【0061】
(データ構造)
次に、第1の実施形態に係る情報処理装置100のメモリ12に格納される対象情報の構造、すなわちデータ構造について説明する。なお、本実施形態の情報処理装置100は、以下のデータ構造によって、処理対象のデータを記述し、記憶し、演算処理を行うが、必ずしも、従来のデータ構造である表形式、オブジェクト指向データベースでのオブジェクトの階層構造、あるいは、ポインタでリンクされたデータベースのレコードのデータ構造等と、本実施形態で示すデータ構造との間の相互のデータ変換機能を提供するわけではない。
【0062】
(1)対象情報の構成要素
本情報処理装置は、対象情報を式の形式で表現する。式は、和演算子“+”、積演算子“×”、第1の括弧“(”“)”、および第2の括弧“{”“}”によって記述される。第1の括弧が本発明の集合因子構成演算子に相当する。また、第2の括弧が本発明の順序構成演算子に相当する。このような対象情報の表現形式を式表現とも呼ぶ。
【0063】
式は、1以上の識別子を含む。識別子は、記号または記号列で表現される。本実施形態では、記号として、英数字、および特殊文字(ただし、和演算子“+”、積演算子“×”、第1の括弧“(”“)”、および第2の括弧“{”“}”を除外する)を用いることとする。ただし、記号は、一般的にアルファベットとも呼ばれ、必ずしも、これらの文字には限定されない。
【0064】
本実施形態では、特殊な識別子として、Φおよびεを用いる。Φは、値ゼロ、和演算子において演算結果を変化させない値、または空集合を示す識別子である。本実施形態では、Φを零元と呼ぶ。また、εは、値1、あるいは、積演算子において演算結果を変化させない値である。本実施形態では、εを単位元と呼ぶ。なお、Φを和演算の単位元と呼ぶ場合もあるが、本実施形態では、Φを零元と呼ぶことにする。
【0065】
また、本情報処理装置は、所定の識別子を、演算を表す予約語として使用する。例えば、F(式)は、式を展開する演算であり、G(式+attach(因子1+因子2))は、接着演算を示す予約語(attachは、そのときのパラメータを示す予約語)であり、Hは、ホモトピー保存処理を示す予約語である。これらの予約語については、ユーザは、通常の識別子として使用することができない、という点で制限がある。
【0066】
本実施形態では、以下の規則によって対象情報、すなわち、識別子、因子、項(要素ともいう)、集合情報、ホモトピー情報、接着空間の情報、およびセル空間の情報を記述する式表現が生成される。
(a)識別子、単位元、および零元はいずれも式表現、すなわち、対象情報を記述する表現である。
(b)rとsとがともに、式表現である場合、r+sも式表現である。
(c)rとsとがともに、式表現である場合、r×sも式表現である。この場合、演算の結合の強さは、通常の代数と同様に、r×sの方が、r+sよりも強い。
(d)rが式表現である場合、(r)、{s}も式表現である。
【0067】
(2)式表現の代数的構造
本実施形態において、式表現r、s、t、yは、次の代数の性質を有する。
(a)結合律
r+(s+t)=(r+s)+t;r×(s×t)=(r×s)×t;
(b)可換律
r+s=s+r;
なお、本実施形態の式表現では、積演算子の可換律は成立しない。したがって、積演算子で複数の因子が結合されている場合に、個々の因子位置が情報(あるいは意味)を持つ。すなわち、因子は、いわゆる位置を指定してされた位置パラメータとしての機能を有する。「積演算子の可換律は成立しない」ことは、本発明の積演算子が「順序を持つ因子の列として複数の識別子を結合する」ことに相当する。
(c)積演算の単位元
r×ε=ε×r=r;
(d)積演算、和演算の零元
r×Φ=Φ×r=Φ;r+Φ=r;
(e)分配率
r×(s+t)=r×s+r×t;(r+s)×t=r×t+s×t;
(f)
{r+s}×{t+u}={r×t+s×u};
【0068】
(3)集合情報
集合情報は、項の組み合わせ、あるいは、項の和として、定義される。ここで、それぞれの項は集合ID(本発明の第1の識別因子に相当)となる識別子と値となる識別子の積、すなわち、集合ID×値として定義される。ただし、値は、複数の識別子の積であってもよい。集合の情報の式表現は、典型的には、集合ID×値1+集合ID×値2+・・・である。集合情報の例として、以下のものを挙げることができる。
【0069】
上述のように、本実施形態のデータ構造では、和演算子に可換律が成立することから、集合情報は、順序のない項の組み合わせということができる。一方、項を構成する因子間の位置関係は維持されることになる。
【0070】
このような因子間の位置関係の維持機能は、コンピュータ上で事物、あるいは、概念を表現する場合に、極めて大きな効果を発揮する。すなわち、一般的に、事物、あるいは概念を記述する修飾関係には、可換律が成立しない。例えば、”児玉の机”は、”机の児玉”と意味が異なる。
【0071】
本実施形態の因子と積演算子によれば、このような修飾関係を極めて単純化して、記述することができる。さらに、そのような修飾関係で記述された項を和演算子によって組み合わせることで事物の集合、あるいは、概念の集合を記述し、極めて単純な形式のデータベースを構築できる。
【0072】
さらにまた、管理対象の事物あるいは概念を項の集合として管理する場合に、項における因子の位置関係に意味を付与することもできる。また、項を構成する因子は、それぞれ、いわゆる位置パラメータとしての意義を有するということもできる。
【0073】
例えば、集合情報が、果物×任意形状×任意色×バナナ+果物×任意形状×任意色×りんご+果物×細長×黄色×バナナ+果物×丸×赤×リンゴという集合情報を考える。この場合、項の第1因子は、集合IDである果物であり、第2因子は形状示し、第3因子は色を示し、第4因子は名称を示す。このように、それぞれの因子の位置に意味上の制限を加えて使用することで、属性と属性値との関係を集合レベルでも処理できることを示している。本情報処理装置では、集合情報は、このような順序が維持された因子によって事物の属性を自在に定義することができ、そのような項の組み合わせによって、事物の集合をコ
ンピュータ上に表現する。
(例)
A×a1+A×a2+A×a3、b1×B+b2×B×B、果物×リンゴ+果物×バナナ+果物×ミカン、野菜×キャベツ+野菜×キュウリ+野菜×ゴボウ、社員×A+社員×B+社員×C
すなわち、集合情報は、集合IDで識別される集合に所属する項の組み合わせを記述し、メモリ12に記憶される。この場合、社員Cが退職し、社員Dと社員Eが入社した場合には、社員×A+社員×B+社員×Cのようにメモリ12に格納される。
【0074】
(4)トポロジー空間情報
トポロジー空間情報は、トポロジーID(本発明の第2の識別因子に相当)となる識別子と部分集合の和との積によって以下のように記述される。すなわち、トポロジーID×(部分集合の和)である。ここで、部分集合は、部分集合を識別する部分集合IDと、その部分集合に含まれる項の和との積で表現される。すなわち、部分集合ID×(項の和)である。ただし、項には、さらに項の和を第1の括弧“()”または第2の括弧”{}”で組み合わせたもの、およびそれらの積が含まれてもよい。
(例)トポロジー空間情報の例は、
T×(ABC×(ab1+ac2+bc3)+A×(ab1+ac2)+B×(ab1+bc3)+C(ac2+bc3))、
果物×(全種×(リンゴ+バナナ+ミカン)+赤×リンゴ+黄×(バナナ+ミカン))、果物×(全種×(リンゴ+バナナ+ミカン)+丸×(リンゴ+ミカン)+細長×バナナ)、
野菜×(全種×(大根+キュウリ+ゴボウ)+太×大根+細×(キュウリ+ゴボウ))、会社×(社員×(社員1+社員2+社員3+社員4)+営業×(社員1+社員2)+経理×(社員3+社員4))、等である(この例で、読点“、”は、式の構成要素ではなく、例の区切りである)。この場合に、最後の例について、例えば、総務が新設され、社員5が採用され、総務に配属された場合には、会社×(社員×(社員1+社員2+社員3+社員4+社員5)+営業×(社員1+社員2)+経理×(社員3+社員4)+総務×社員5)のように記述し、メモリ12に格納できる。
【0075】
(5)接着空間情報
接着空間情報は、トポロジー空間情報に含まれる2つの部分集合X(本発明の第1の被接着情報に相当)と部分集合Y(本発明の第2の被接着情報に相当)に対して、それぞれの部分に含まれる部分集合を関係付けることで構成される。本実施形態では、この関係付けによって発生する関係を同値関係という。
【0076】
今、トポロジー空間情報T(トポロジーIDは、Tid)およびトポロジー空間情報U(トポロジーIDは、Yid)が、トポロジー空間情報Tid×(Tに属する部分集合の和)+トポロジー空間情報Uid×(Uに属する部分集合の和)としてメモリ12に記憶されているとする。
【0077】
さらに、Tに属する部分集合の和=部分集合T0+部分集合T−T0と2つの部分集合に分離できるとする。その場合、本情報処理装置では、トポロジー空間情報Tとトポロジー空間情報Uとを関連づけるトポロジー空間情報Tの因子p(本発明の第1の同値因子に相当)と、トポロジー空間情報Uの因子q(本発明の第2の同値因子に相当)が指定される。そして、トポロジー空間情報Tが、因子pを含む部分集合T0(本発明の第1の関連項に相当)と、因子pを含まない部分集合T−T0に分離される。ここで、T−T0は、集合Tから集合T0を削除した差集合である。また、トポロジー空間情報Uが、因子qを含む部分集合U0(本発明の第2の関連項に相当)と、因子qを含まない部分集合U−U0に分離される。ここで、U−U0は、集合Uから集合U0を削除した差集合である。
【0078】
この場合に、上記2つのトポロジー空間情報TとUの和は、トポロジー空間情報Tid×(部分集合T0)+トポロジー空間情報Tid×(部分集合T−T0)+トポロジー空間情報Uid×(部分集合U0)+トポロジー空間情報Uid×(部分集合U−U0)と表現される。このように、集合から特定の因子pを含む部分集合を取り出した場合に、これを商と呼ぶ。また、その商を除く部分集合を剰余という。
【0079】
さらに、部分集合T0=T0id×(T0の項の和)、部分集合U0=U0id×(U0の項の和)と記述されているとする。この場合に、部分集合T0と部分集合U0とを関係付けることによって、以下の接着空間情報を構成できる。すなわち、この場合の接着空間情報は、{部分集合T0におけるpの左因子+部分集合U0におけるqの左因子}{p+q}{部分集合T0におけるpの右因子+部分集合U0におけるqの右因子}+トポロジー
空間情報Tid×(部分集合T−T0)+トポロジー空間情報Uid×(部分集合U−U0)、である。ここで、部分集合T0におけるpの左因子および部分集合T0におけるpの右因子が、ともに、本発明の第1の被接着因子に相当する。また、部分集合U0におけるqの左因子および部分集合U0におけるqの右因子が、ともに、本発明の第2の被接着因子に相当する。
【0080】
なお、ここでは、トポロジー空間レベルの情報を接着する場合を説明したが、トポロジー空間レベルの情報に、属性と属性値が定義されて構成されるセル空間レベルの情報、および、項の組み合わせである集合レベルの集合情報に対しても、接着空間情報が定義できる。また、トポロジー空間、セル空間、集合空間のうち、一のレベルの情報と、他のレベルの情報とについて接着空間情報を定義できる。
(例)
今、以下のような果物のトポロジー空間情報と、野菜のトポロジー空間情報の和、すなわち、果物×(全種×(リンゴ+バナナ+ミカン)+丸×(リンゴ+ミカン)+細長×バナナ)+野菜×(全種×(大根+キュウリ+ゴボウ)+太×大根+細×(キュウリ+ゴボウ))がメモリ12に記憶されているとする。
【0081】
ここで、果物のトポロジー空間情報の因子である細長と、野菜のトポロジー空間情報の部分集合である因子細との関連づけが指定され、同値関係にあるとする。この場合に、2つのトポロジー空間情報は、それぞれ次のように商と剰余とに分離される。すなわち、それぞれの集合情報が商と剰余に分離されたトポロジー空間情報は、
果物×細長×バナナ
+果物×(全種×(リンゴ+バナナ+ミカン)+丸×(リンゴ+ミカン))
+野菜×細×(キュウリ+ゴボウ)
+野菜×(全種×(大根+キュウリ+ゴボウ)+太×大根)
となる。
【0082】
そして、同値関係が指定された細長と、野菜のトポロジー空間情報の部分集合である細とによって、接着空間情報が
{果物+野菜}×{細長+細}{バナナ+(キュウリ+ゴボウ)}
+果物×(全種×(リンゴ+バナナ+ミカン)+丸×(リンゴ+ミカン))
+野菜×(全種×(大根+キュウリ+ゴボウ)+太×大根)、のように構成される。
【0083】
このようにして、接着空間情報は、2つのトポロジー空間情報の構造を維持した状態で、関係付けが指定された同値関係にある因子を基に結合されている。接着空間情報より、”細”と”細長”に同値関係が認められれば,右の因子”バナナ”と”(キュウリ+ゴボウ)”を{バナナ+(キュウリ+ゴボウ)}として関連づけて出力できる。
【0084】
また、 伝票ID1枚目(A{ε+B+C{C1+C2}+D+E{E1+E2}}(a{ε+b+c{c1+c2}+d+e{e1+e2}}+位置(右上+右下)))
+伝票ID2枚目(A{ε+B+C{C1+C2}+D+E{E1+E2}}(a{ε+b+c{c1+c2}+d+e{e1+e2}}))
+MEMO(1(あいう)+2(ABC))
+・・・という伝票の束、およびメモMEMOを記述する情報がメモリ12に格納されていた場合を考える。ここで、MEMOを1枚目の伝票の右上に、位置を指定して張り付ける例を示す。
【0085】
この例で,MEMOの1を1枚目の伝票の右上に張り付けるには,まず、MEMO情報の因子”1”,伝票1枚目の情報の因子”右上”でそれぞれ商空間が作成される。
伝票ID1枚目(A{ε+B+C{C1+C2}+D+E{E1+E2}}(a{ε+b+c{c1+c2}+d+e{e1+e2}}+位置(右下)))+伝票ID1枚目×位置(右上)
+伝票ID2枚目(A{ε+B+C{C1+C2}+D+E{E1+E2}}(a{ε+b+c{c1+c2}+d+e{e1+e2}}))
+MEMO(2(ABC))+MEMO(1(あいう))
+・・・
【0086】
ここで,”1”と”右上”の関係付けを指定し接着すると、接着情報は、
{伝票ID1枚目×位置+MEMO}{右上+1}{ε+(あいう)}+剰余の部分集合を含む情報、として構成される。このように、接着情報は、相互に構造上の共通性がない2つの対象情報について、それぞれの接着前の構造を維持した状態で、2つの対象情報結合し、メモリ12に格納することができる。
【0087】
(6)セル空間情報
セル空間情報は、事物の属性とその属性に対応する属性値とを有する情報である。属性は、キー属性とその他の属性とに分かれる。キー属性は属性値によって情報が識別できる属性であり、データベースの検索においてキーとして使用できる値に対応する。セル空間情報で、属性値(またはその並び)は、インスタンスと呼ばれ、従来のデータベースのレコードに相当する。それぞれのインスタンスは、インスタンスIDと呼ぶ識別情報を有する。また、キー属性、あるいは、その他の属性が複数個ある場合には、キー属性、あるいは、その他の属性は、第2の括弧“{”と“}”とによって順序が維持された因子の形式で記述される。すなわち、いわゆるベクトル形式にて属性とその対応する属性値が記述される。
【0088】
セル空間情報は、セル空間ID(本発明のセル空間識別子に相当)と、キー属性の因子と、単位元およびキー属性以外の属性を有する因子と、インスタンスの集合を有する因子とを含む。セル空間情報は、
セル空間ID×(キー属性×{ε+(その他の属性の和)}
×((インスタンスID×{ε+(値の和)})の和))
で構成される。
【0089】
このキー属性の因子と単位元およびキー属性以外の属性を含む属性を有する因子とが、本発明の属性因子に相当する。また、{ε+(その他の属性の和)}の中のいずれかの属性が複数の識別子の積からなる場合に、そのような識別子の積からなる属性が、本発明の属性の順序列に相当する。また、そのような属性が、第2の括弧“{}”で括られた因子である場合に、その第2の括弧で括られた属性が、本発明の属性の順序因子に相当する。
【0090】
また、そのような属性に対応して、インスタンスの{ε+(値の和)}中の値が、識別
子の積からなるときに、その値が、本発明の値列に相当する。また、値が、第2の括弧“{}”で括られた因子である場合に、その第2の括弧で括られた値が、本発明の値の順序因子に相当する。
(例)
セル空間情報の例は、
果物id×(名前{ε+形+色}(リンゴ{ε+丸+赤}+ミカン{ε+丸+黄}+バナナ{ε+細長+黄}))
+野菜id×(名前{ε+形状+色}(大根{ε+太+白}+キュウリ{ε+細+緑}+ゴボウ{ε+細+茶}))
で示すことができる。この例では、従来のリレーショナルモデルで、果物テーブル、野菜テーブルとして記述されていた情報が、式表現で記述される。なお、この例は、2つのセル空間情報(果物と野菜)を含むことから、統合セル空間情報とも呼ばれる。
【0091】
この統合セル空間情報の処理例を示す。まず、果物のインスタンスのうち、属性“形”が“細長”の値を持つインスタンスとの部分集合(商という)と、その他のインスタンスの部分集合(剰余という)とを作成する。また、まず、野菜のインスタンスのうち、属性“形状”が“細”の値を持つインスタンス(商という)と、その他のインスタンス(剰余という)とに分離する。この場合、結合セル空間情報は、
果物id×バナナ×形×細長
+野菜id×形状×(キュウリ+ゴボウ)細
+果物id×(名前{ε+形+色}(リンゴ{ε+丸+赤}+ミカン{ε+丸+黄}+バナナ{ε+黄}))
+野菜id×(名前{ε+形状+色}(大根{ε+太+白}+キュウリ{ε+緑}+ゴボウ{ε+茶}))
となる。次に、果物のうちの属性“形”が値“細長”を有する部分集合と、野菜のうちの属性“形状”が値“細”を有する部分集合との関係付けを指定し、同値関係を設定する。そして、この同値関係によって接着空間情報を作成すると、
{果物id×形×バナナ+野菜id×形状×(キュウリ+ゴボウ)}{細長+細}{ε+ε}
+果物id×(名前{ε+形+色}(リンゴ{ε+丸+赤}+ミカン{ε+丸+黄}+バナナ{ε+黄}))
+野菜id×(名前{ε+形状+色}(大根{ε+太+白}+キュウリ{ε+緑}+ゴボウ{ε+茶}))
となる。
【0092】
(記述例)
以下、従来のデータ構造である表およびツリー構造が、本実施形態のデータ構造でどのように記述できるかを示す。
【0093】
図3は、第1の実施形態に係る情報処理装置100のメモリ12に格納されるセル空間情報の第一のデータ構造例を示す。同図に示すように、第1の実施形態に係る情報処理装置100では、従来正規化表構造として表形式で表現される対象情報は、表現形式1の状態でメモリ12に格納することができる。表現形式1で、Aは、キー属性(例えば社員番号等)、B,C,D,E等は、その他の属性(例えば、氏名、性別、入社年、所属部署等)である。
【0094】
図2は、第1の実施形態に係る情報処理装置100のメモリ12に格納されるセル空間情報の第二のデータ構造例を示す。同図に示すように、第1の実施形態に係る情報処理装置100では、従来ツリー構造として表現される対象情報は、表現形式2又は3でメモリ12に格納することができる。そして、同図に示すように有向グラフの一部としてのツリ
ー構造について対応可能である。表現形式2で、aは、例えば、動物、bはほ乳類、cは魚類、dは人、eは鯨、fはマグロ、gは鯉等である。この場合、b(ほ乳類)およびc(魚類)は、a(動物)の属性、例えば、食する、呼吸する等を継承する。b(ほ乳類)およびc(魚類)の共通の属性は、a(動物)に定義される。
【0095】
したがって、本実施形態の式表現によって、フレーム等の知識ベース、あるいは、オブジェクト指向データベース等を記述し、メモリ12に格納できる。情報処理装置100は、これらに対応する事物に関する情報の入力を入力部11から受け付け、対応する情報を生成し、メモリ12に格納し、メモリから読み出し、出力部14に出力できる。
【0096】
また、逆ツリー構造で表現される対象情報についても、表現形式3のようにメモリ12に格納することができる。逆ツリー情報は、基本的な情報からより複雑な情報を構成する場合に適用できる。表現形式3では、例えば、aはCPUであり、bはインターフェースであり、cは外部記憶装置の駆動部であり、dはCPUボードであり、eは外部記憶装置であり、fはパーソナルコンピュータである。
【0097】
このように逆ツリー構造は、製品の設計書、事業の工程管理図等、基本情報からより複雑な情報を組み上げて管理することができる。したがって、本実施形態の式表現によって、製品の設計情報、事業の工程等を記述し、メモリ12に格納できる。情報処理装置100は、これらに対応する事物に関する情報の入力を入力部11から受け付け、対応する情報を生成し、メモリ12に格納し、メモリから読み出し、出力部14に出力できる。
【0098】
図4は、第1の実施形態に係る情報処理装置100のメモリ12に格納される第三のデータ構造例を示す。同図に示すように、第1の実施形態に係る情報処理装置100では、非正規化表構造と属性のない対象情報についても表現形式4の状態でメモリ12に格納することができる。ここで、非正規化表構造と属性のない対象情報とは、図4に示すように伝票を示す対象情報と、その対象情報に追加される付箋メモに相当する対象情報とが例示できる。接着処理を実行し、接着空間を作成することで、コンピュータ上で伝票に付箋メモの内容を添付することと同等の処理が実現される。
【0099】
なお、伝票の種類ごとにテーブルに格納する場合には、リレーショナルモデルによって従来のデータベースで情報を管理できる。しかしながら、伝票の種類数が変動する場合、既存の伝票の構成が変更された場合には、リレーショナルモデルでは、対応できない。
【0100】
ここで、本発明に係る所定の表現形式、すなわちデータ構造についてより詳細に上記表現形式4に基づいて説明する。ID又はid(identification)は、格納される対象情報を識別するものである。そしてこの対象情報は、識別子A〜E2,a〜e2と、演算時の結合強さが異なる第一の括弧()及び第二の括弧{}と、これらにより表現される因子{C1+C2},{E1+E2}等と、これら因子の積によって表現される項E{E1+E2}等と、前記項の和によって表現される式と、により構成される。なお、本実施形態では、項を要素ともいう。また、すでに述べたように、単位元εは、所定の処理を実行した場合に1として処理される記号である。上記以外の特別な記号として、所定の処理を実行した場合に0として処理される零元Φが存在する。このような状態でメモリ12に格納された対象情報は、CPU13が所定のプログラムを実行することによって、入力装置11から入力された伝票データにしたがって、生成され、メモリ12に格納され、部分集合に分離され、他の部分集合と接着され、あるいは、検索されることになる。
【0101】
図4の例では、インスタンスとして、伝票ID1で示される1枚目の伝票、伝票ID2で示される2枚目の伝票、およびMEMOで示されるメモが例示されている。また、この場合に、1枚目の伝票と2枚目以降の伝票で、項目の構成が異なっても構わない。本情報
処理装置100は、対象情報を構成する識別子、あるいは項に、個々に属性を付与できるので、異なる属性の並びを有する異なる識別子、あるいは項を自在に記憶し、検索し、変更できる。また、{}内に、+識別子の形式で追加するとともに、属性に対応する値を追加すれば、データベースとして運用中においても、自在に属性と属性値とを追加、変更、削除できる。したがって、本実施形態のデータ構造によれば、情報処理装置100が取り扱うデータを柔軟に変更でき、厳密、正確なファイル設計の必要性が軽減される。
【0102】
(基本演算手順)
図5に、本情報処理装置におけるプログラム構成を示す。本情報処理装置100は、例えば、データを格納し、検索し、変更し、表示するデータベースシステム等、様々事物を管理するシステムに適用できる。その場合、個々の管理対象に応じた機能は、アプリケーションプログラムAPとして提供される。すなわち、アプリケーションプログラムは、入力部11から入力されたデータをメモリ12あるいは外部記憶装置に格納し、これらに格納されたデータにアクセスし、検索し、出力部14に表示する。
【0103】
一方、アプリケーションプログラムがメモリ12あるいは、外部記憶装置に格納するデータの生成、格納、検索等の機能は、上述の式表現を処理する共通関数ライブライリが提供する。共通関数ライブラリは、アプリケーションインターフェースを備えており、アプリケーションプログラムへのこれらの機能、あるいは、サービスを提供する。以下、本情報処理装置100で典型的な共通関数の例を説明する。これらの共通関数は、プリミティブ関数、あるいは、基本演算とも呼ばれる。
【0104】
アプリケーションプログラムからそれぞれの共通関数が呼び出されたときに、本発明の処理手段に相当するCPU13が以下の処理を実行する。
【0105】
(1)積結合演算
積結合演算では、CPU13は、識別子と識別子とを積演算子によって接続する。積結合演算を実行するCPU13が本発明の積演算部に相当する。この場合、識別子自体が式表現であり、識別子が接続された結果も式表現となる。積結合演算のアプリケーションインターフェースは、例えば、戻り値=connect(因子1、因子2、演算結果);のように定
義できる。本実施形態では、式表現が文字列で記述されるので、“因子1”、“因子2”、および“演算結果”は、いずれも文字列である。因子1、および因子2として、識別子、複数の識別子を積結合演算で結合した式表現、第1の括弧“()”で囲まれた式表現、第2の括弧“{}”で囲まれた式表現、ε、およびΦを指定できる。積結合演算では、演算結果には、因子1×因子2が返される。すなわち、因子1と因子2との結合は、記号“×”(以下、積記号)で記述される。すなわち、積結合演算は、因子1と因子2との積演算による演算式を形成する。
【0106】
一方、図9で説明する積演算では、因子1と因子2との積を実行する。因子1と因子2に、第1の括弧“()”および第2の括弧“{}”のいずれもが含まれていない場合には、積結合演算と積演算の結果は、同一である。因子1と因子2に、第1の括弧“()”および第2の括弧“{}”のいずれかが含まれている場合には、積演算の結果は、それの括弧内の項と、括弧外の因子との演算となる。
【0107】
また、戻り値は、処理が正常終了したか否かを示す情報である。ただし、本実施形態では、戻り値の設定処理についての説明は、省略する。
【0108】
(2)和演算
和演算では、CPU13は、識別子および因子の列として接続された複数の識別子のいずれかまたは両方から項の組み合わせを構成する。和演算を実行するCPU13が本発明
の和演算部に相当する。この場合、識別子あるいは因子が式表現であるので、項の組み合わせも式表現となる。和演算のアプリケーションインターフェースは、例えば、戻り値=add(項1、項2、演算結果);のように定義できる。演算結果には、項1+項2が返される。すなわち、項1と項2との和は、記号“+”(以下、和記号)で記述される。
【0109】
(3)項抽出処理、因子抽出処理
項抽出演算では、CPU13は、和記号“+”で組み合わせられた複数の項から、いずれかの項を取り出す。本実施形態では、複数の項のうち、先頭の項を取り出す。項抽出処理のアプリケーションインターフェースは、例えば、戻り値=getterm(式表現、演算結果);のように定義できる。項抽出処理を実行するCPU13が本発明の項抽出部に相当する。
【0110】
同様に、因子抽出演算では、CPU13は、積記号“×”で組み合わせられた複数の因子の並びから、いずれかの因子を取り出す。本実施形態では、複数の因子のうち、先頭の因子を取り出す。因子抽出処理のアプリケーションインターフェースは、戻り値=getfactor(式表現、演算結果);のように定義できる。因子抽出処理を実行するCPU13が本発明の因子抽出部に相当する。
【0111】
(4)集合構成処理
集合構成処理では、CPU13は、和記号“+”で組み合わせられた複数の項を第1の括弧“()”で括る処理を実行する。集合構成処理のアプリケーションインターフェースは、例えば、戻り値=putin1(式表現、演算結果);のように定義できる。演算結果には、(式表現)が返される。集合構成処理を実行するCPU13が本発明の集合因子構成部に相当する。
【0112】
(5)集合展開処理
集合展開処理では、CPU13は、第1の括弧“()”で括られた式表現から、第1の括弧“()”を取り除く処理を実行する。集合展開処理のアプリケーションインターフェースは、例えば、戻り値=putoff1(式表現、演算結果);のように定義できる。集合展開処理を実行するCPU13が本発明の集合因子展開部に相当する。
【0113】
(6)順序構成処理
順序構成処理では、CPU13は、和記号“+”で組み合わせられた複数の項を第2の括弧“{}”で括る処理を実行する。集合構成処理のアプリケーションインターフェースは、例えば、戻り値=putin2(式表現、演算結果);のように定義できる。順序構成処理を実行するCPU13が本発明の順序生成部に相当する。
【0114】
(7)順序展開
順序展開処理では、CPU13は、第2の括弧“{}”で括られた式表現から、第2の括弧“{}”を取り除く処理を実行する。集合展開処理のアプリケーションインターフェースは、例えば、戻り値=putoff2(式表現、演算結果);のように定義できる。順序展開処理を実行するCPU13が本発明の順序展開部に相当する。
【0115】
(8)共通因子括りだし処理
共通因子括りだし処理では、CPU13は、第1の括弧“{}”または第2の括弧“()”が付加された項の組み合わせに含まれる項から共通の因子を抽出する。共通因子括りだし処理のアプリケーションインターフェースは、例えば、戻り値=and(式表現、演算結果);のように定義できる。ここで、式表現には、複数の項が和記号で組み合わせられた式である。共通因子括りだし処理を実行するCPU13が本発明の括り出し部に相当する。
【0116】
(9)横方向展開処理
横方向展開処理は、横方向展開処理とは第一又は第二の括弧を一回外す、すなわち展開する処理である。横方向展開処理のアプリケーションインターフェースは、例えば、戻り値=expand1(展開前の式表現、展開後の式表現);のように定義できる。
【0117】
図6Aは、横方向展開処理を実行する処理のフローを示す。具体的には、ステップS101では、対象情報(“展開前の式表現”)が入力される。すなわち、メモリ12に対象情報が例えばユーザにより入力される。そして、CPU13は、入力された式表現を展開前の式表現に指定して、共通関数expand1が実行される。
【0118】
以下、対象情報として数6に示すデータを用いた場合について説明する。なお、項の数及び因子の数は、左から順に第一、第二のように割り当てられるものとし、2重、3重の括弧で括られている場合には、最も外側の括弧を第一として扱うものとする。
cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))+s(p(p1+p2)+q(q1+q2))・・・(数6)
【0119】
ステップS102では、入力された対象情報を横方向展開処理した項をΦに設定、すなわち初期化する。なお、各展開処理の詳細については後述する。ステップS103では、対象情報を構成する式の長さが0であるかを判断する。すなわち、対象情報が存在するか否かを判断する。式の長さが0であると判断した場合には、ステップS114へ進み横方向展開処理を終了する。一方、式の長さが0であると判断しなかった場合には、次のステップへ進む。
【0120】
ステップS104では、数6で表現される対象情報から第一項を取得する。すなわち、数7に示すデータを取得する。ステップS105では、取得した数7で表現される対象情報をメモリ12に保存する。なお、ここでいう保存とは変数に保存すること、すなわちメモリ12に所定の領域を確保して記録することを意味する。また、以下の処理において取得するステップと削除するステップの間に行われる処理で言う保存は、上記同様メモリ12に所定の領域を確保して記録することを意味することとする。
cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))・・・(数7)
【0121】
ステップS106では、数6の式表現から数7を削除する。これにより、数8により表現されるデータがメモリ12に存在することになる。
s(p(p1+p2)+q(q1+q2))・・・(数8)
【0122】
ステップS107では、横方向展開処理後の因子をεに設定する。次にステップS108では、項の長さが0であるかを判断する。すなわち、対象情報を構成する項が存在するか否かを判断する。項の長さが0であると判断した場合には、ステップS113へ進み横方向展開処理を終了する。一方、式の長さが0であると判断しなかった場合には、次のステップへ進む。
【0123】
ステップS109では、第一項から第一因子であるcellを取得する。ステップ110では、取得した第一因子cellをメモリ12に保存する。次にステップ111では、第一因子cellを第一項より削除する。
【0124】
ステップS112では、展開後の因子に対し取得した因子を積演算し、その結果を展開後の因子とする。すなわち、ステップS107で設定した展開後の因子εにステップS109で取得した第一因子cellを積演算する。積演算の展開処理については後述する。
その後、第一項の項の長さが0であると判断されるまでステップS108からステップS112の処理を繰り返す。
【0125】
ステップS113では、ステップS108で項の長さが0であると判断した場合に、展開後の項に対し展開後の因子の和演算を行い、その結果を展開後の項と設定する。その後、式の長さが0であると判断されるまでステップS103からステップS113の処理を繰り返す。以上のステップを実行することにより、展開後の対象情報は数9により表現される。この式表現が“展開後の式表現”として、アプリケーションプログラムに返されることになる。なお、横方向展開処理を実行中の対象情報の状態の詳細は図6B、図6Cに示す。
cell×id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2})+s×p(p1+p2)+s×q(q1+q2)・・・(数9)
このように、数6の最も外側の“(”と“)”とがはずされた式表現となっている。他の例としては、例えば、a(b+c(d+e))+f(g+h)という式表現を横方向展開した場合には、a×b+ a×c(d+e)+f×g+f×h になる。
【0126】
(10)縦方向展開処理
次に、縦方向展開処理について説明する。縦方向展開処理は、各項をそれぞれ全展開していく処理である。例えば、上記a(b+c(d+e))+f(g+h)について,縦方向展開するとa×b+a×c×d+a×c×e+f×g+f×h になる。一方、横方向展開で式を全展開するには,各項に括弧が無くなるまで各項を展開するという指定が必要となる。縦方向展開処理のアプリケーションインターフェースは、例えば、戻り値=expand2(展開前の式表現、展開後の式表現);のように定義できる。
【0127】
図7は、縦方向展開処理を実行する処理のフローを示す。図7では、図6と同一の処理を実行するステップは、同一の符号で示している。ステップS101では、対象情報(“展開前の式表現”)を入力する。例えば、ユーザインターフェース等を通じて、展開前の式表現が入力される。そして、メモリ12に格納される対象情報がアプリケーションプログラムから共通関数expand2に入力される。以下、対象情報として数10に示すデータを用いた場合について説明する。
cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))+s(p(p1+p2)+q(q1+q2))・・・(数10)
【0128】
ステップS102では、入力された対象情報を展開処理したときに得られる対象情報(項)をΦに設定する。ステップS103では、対象情報を構成する式の長さが0であるかを判断する。すなわち、対象情報が存在するか否かを判断する。式の長さが0であると判断した場合には、ステップS114へ進み縦方向展開処理を終了する。一方、式の長さが0であると判断しなかった場合には、次のステップへ進む。ステップS104では、数10から第一項を取得する。すなわち、数11に示すデータを取得する。ステップS105では、取得した数11で表現される対象情報をメモリ12に保存する。
cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))・・・(数11)
【0129】
ステップS106では、数10から数11を削除する。これにより、メモリ12には、数12により表現されるデータが存在することになる。
s(p(p1+p2)+q(q1+q2))・・・(数12)
【0130】
ステップS107では、第一項を展開したときに得られる、展開後の因子をεに設定する。次にステップS108では、項の長さが0であるかを判断する。すなわち、対象情報を構成する項が存在するか否かを判断する。項の長さが0であると判断した場合には、ス
テップS113へ進み縦方向展開処理を終了する。一方、式の長さが0であると判断しなかった場合には、次のステップへ進む。
【0131】
ステップS109では、第一項から第一因子であるcellを取得する。ステップ110では、取得した第一因子cellをメモリ12に所定の領域を確保して保存する。次にステップ111では、第一因子cellを第一項より削除する。
【0132】
ステップS112aでは、因子が第一の括弧又は第二の括弧で括られているとき、括弧内の式について縦方向展開処理を実行し(すなわち、再帰呼び出しを実行する)、結果を取得した因子とする。次にステップS112bでは、展開後の因子に対し取得した因子を積演算し、その結果を展開後の因子とする。積演算の展開処理については後述する。その後、第一項の項の長さが0であると判断されるまでステップS108からステップS112の処理を繰り返す。
【0133】
ステップS113では、ステップS108で項の長さが0であると判断した場合に、展開後の項に対し展開後の因子の和演算を行い、その結果を展開後の項と設定する。その後、式の長さが0であると判断されるまで再帰的にステップS103からステップS113の処理を繰り返す。以上のステップを実行することにより、展開後の対象情報は数13により表現される。そして、この式表現が“展開後の式表現”として、アプリケーションプログラムに引き渡される。なお、上記ステップを実行中の対象情報の状態の詳細は図8Aから図8Dに示す。
cell×id×1+cell×id×A×1×a1+cell×id×B×1×b1+cell×id×C×1×c1+cell×id×2+cell×id×A×2×a2+cell×id×B×2×b2+cell×id×C×2×c2+s×p×p1+s×p×p2+s×q×q1+s×q×q2・・・(数13)
【0134】
(11)積演算処理
次に積演算処理について説明する。積演算処理は、2つの式表現を入力し、それぞれの式表現を因子とする新たな式表現を生成する処理である。積演算処理のアプリケーションインターフェースは、例えば、戻り値=product(因子1、因子2、積演算後の式);のよ
うに定義できる。積演算処理を実行するCPU13が本発明の共通因子展開部に相当する。
【0135】
図9は、積演算処理を実行する処理のフローを示す。まずステップS201では、第一の因子(“因子1”)及び第二の因子(“因子2“)がアプリケーションプログラムから関数productに入力される。その結果、それぞれの因子がメモリ12の対応する領域に新
たに記憶される。
【0136】
ステップS202では、どちらかの因子がεであるかを判断する。どちらかの因子がεであると判断された場合には他方の因子がデータを構成することになり(ステップS203)、積演算処理を終了する。一方、どちらかの因子がεであると判断されなかった場合には次のステップへ進む。
【0137】
ステップS204では、どちらかの因子がΦであるかを判断する。どちらかの因子がΦであると判断された場合には演算後のデータはΦとなり(ステップS205)、積演算処理を終了する。一方、どちらかの因子がΦであると判断されなかった場合には次のステップへ進む。
【0138】
ステップS206では、両方の因子が第一の括弧により括られているかを判断する。両方の因子が第一の括弧により括られていると判断した場合には、互いの全項の全組み合わ
せでそれぞれ掛けた項の和として処理し(ステップS207)、次のステップへ進む。一方、両方の因子が第一の括弧により括られていると判断しなかった場合には、次のステップへ進む。
【0139】
ステップS208では、一方の因子が第一の括弧により括られているかを判断する。一方の因子が第一の括弧により括られていると判断し場合には、第一の括弧で括られている項に他方の因子をそれぞれ掛けた項の和として処理し(ステップS209)、次のステップへ進む。一方、一方の因子が第一の括弧により括られていると判断しなかった場合には、次のステップへ進む。
【0140】
ステップS210では、両方の因子が第二の括弧により括られているかを判断する。両方の因子が第二の括弧により括られていると判断した場合には、それぞれの第二の括弧内の同じ順序の項をそれぞれ掛けた項の和として処理し(ステップS211)、次のステップへ進む。このとき、第二の括弧は、そのまま維持されるので、演算の前後で第二の括弧内の項の順序はそのまま維持されている。一方、両方の因子が第二の括弧により括られていると判断しなかった場合には、次のステップへ進む。
【0141】
ステップS212では、一方の因子が第二の括弧により括られているかを判断する。一方の因子が第二の括弧により括られていると判断し場合には、第二の括弧で括られている全ての項に他方の因子をそれぞれ掛けた項の和として処理し(ステップS213)、その後積演算処理を終了する。一方、他方の因子が第二の括弧により括られていると判断しなかった場合には、互いの因子を掛けた項を作成し(ステップS214)、その後積演算処理を終了する。その結果、“積演算後の式表現“がアプリケーションプログラムに引き渡される。なお、図10に上記積演算処理の例とともに実際の処理を示す。
【0142】
(12)商演算処理
次に商演算処理について説明する。商演算処理は、対象情報を記述する集合から、指定された因子(識別子を含む)を含む式表現(項、あるいは要素)と、そのような因子を含まない式表現とに分離する処理である。商演算処理のアプリケーションインターフェースは、例えば、戻り値=divide(商演算される式表現、商演算する因子、商の式表現、剰余
の式表現);のように定義できる。本実施形態で、商演算は、“商演算する因子”を含む
式表現を取り出す処理となる。そのため、商演算する因子のことを、同値関係を指定する因子ともいう。商演算する因子は、本発明の演算用因子に相当する。
【0143】
図11Aは、商演算処理(サブルーチン1)を実行する処理のフローを示す。サブルーチン1を実行するCPU13が本発明の商演算部に相当する。なお、図12Aは、商演算のうち、剰余を求める処理(サブルーチン2)である。サブルーチン1は、商演算される式表現である式1、商演算する因子を入力され、商の式表現である式2を出力する。
【0144】
まずステップ301では、商演算処理が実行される前の所定の表現形式によって表現される式1(“商演算される式表現”)、及び商演算する因子(これを同値関係示す因子ともいう)pが入力される。以下、数14により表現される対象情報が入力された場合について説明する。また、1を商演算する因子(同値関係を示す因子p)と設定する。
cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))・・・(数14)
【0145】
次に、ステップS302では、CPU13は、演算後の商(商項ともいう、ここでは、項2で表す)を初期化する。このとき、項2の値は、Φ(空、または0)である。
【0146】
次に、ステップS303では、CPU13は、式1の長さが0であるか否かを判定する
。式1の長さが0である場合、CPU13は、サブルーチン1の処理を終了する。
【0147】
一方、ステップS303の判定において、式1の長さが0でなかった場合、CPU13は、ステップ304に処理を進める。そして、CPU13は、式1から始めの項(以下、項1という)を取得する。ここで、項1は、数14の全体である。さらに、ステップS305において、CPU13は、式1から項1を削除する。
【0148】
次に、ステップS306において、CPU13は、項1が因子p(ここでは、“1”)を含んでいるか否かを判定する。ここで、因子pを含んでいるとは、項1の因子としては、あるいは、項1の第1の括弧で括られた因子内の項のいずれかに、因子pを含むことを言う。すなわち、項1の式表現中に因子pが含まれるか否かを判定する。項1が因子pを含んでいない場合、CPU13は、項1を空とし、処理をS303に戻す。
【0149】
一方、ステップS306の判定において、項1が因子pを含んでいる場合、CPU13は、処理をS308に進める。そして、CPU13は、項3を初期化し、空とする。ここで、項3は、始めの項である項1の商演算結果を格納する変数(メモリ12の領域)である。ここでは、数14の構成から、項1に因子p(=1)が含まれていると判定される。
【0150】
そして、ステップS309において、CPU13は、項1の長さが0であるか否かを判定する(S309)。項1の長さが0でない場合、ステップS310において、CPU13は、項1から始めの因子(以下、因子1という)を取得する。数14の構成から、因子“cell”が取得される。そして、ステップS311において、CPU13は、項1から因子1を削除する。
【0151】
次に、ステップS312において、CPU13は、因子1に商演算する因子pが含まれ、かつ、因子1が第1の括弧“(”と“)”とによって形成された因子であるとき、その括弧内の式を式1に設定し、サブルーチン1を再帰呼び出しする。そして、その再帰呼び出しによる処理結果を因子1とする。この処理によって、商演算される式中で、項に“()”による因子を含む場合は、その項は、()内の式が商演算されることになる。数14の構成の場合、“cell”が因子1の場合には、S312は、実行されない。また、cellの次の因子(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))が、因子1の場合には、S312により、再起呼び出しが実行されることになる。その結果、式表現中に因子p(この例では、1)を含む因子が抽出されることになる。
【0152】
さらに、ステップS313によって、CPU13は、項3に対し因子1を積演算し、結果を項3とする。この処理によって、因子1に商演算される因子pが含まれる場合、そのまま項3に積演算されることになる。また、因子1が()の形式の因子の場合に、()内から因子pを含む項が取り出されることになる。そして、CPU13は、処理をS309に戻す。
【0153】
ステップS309の判定で、項1の長さが0となった場合、CPU13は、処理をステップS314に進める。そして、CPU13は、項2(商項)に対して、得られている項3を和演算する。さらに、ステップS315の処理で、CPU13は、項2を商演算後の式である式2に設定する。その後、CPU13は、処理をS302に戻す。
【0154】
そして、S302の判定で、式1の長さが0になると、CPU13は、サブルーチン1の処理を終了する。このような処理により、式2に、以下の数15Aの式表現が出力され、アプリケーションプログラムに引き渡される。
【0155】
cell×id{ε+A+B+C}×1{ε+a1+b1+c1}・・・(数15A)
図11Bおよび図11Cに、数14の式表現に対して、サブルーチン1が実行された場合の式1、項1、項2、項3、因子1、および式2の変化を示す。図11Bおよび図11Cの第1行目は、各列の要素、すなわち、図11A中の該当する処理を示す番号、式1、項1、項、項3、因子1、および式2を示している。第2行以下の各行は、一連の処理ステップであり、図11B上から下へ、さらに、図11Cの上から下へ実行される。
【0156】
そして、まず、ステップS301で、共通関数へのパラメータを介して、式1である数14が入力され、メモリ12に保持される。
【0157】
項1、因子1および項3に着目すると、これらのうち、“cell”および、id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2})が順次サブルーチン1で処理されることが分かる。
【0158】
さらに、id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2})が因子1としてS312で処理されるときに、再起呼び出しが発生する。そして、同様に、“id”、{ε+A+B+C}、および(1{ε+a1+b1+c1}+2{ε+a2+b2+c2})がサブルーチン1の再起呼び出し1で処理される。
【0159】
さらに、(1{ε+a1+b1+c1}+2{ε+a2+b2+c2})が、S312で処理されるときに、再起呼び出し2が発生する。そして、同様に、1{ε+a1+b1+c1}については、商演算する因子“1“が含まれているので、S306で、YESの判定がなされる。そして、S313によって、1と{ε+a1+b1+c1}とが項3に積演算される。
【0160】
一方、2{ε+a2+b2+c2}については、商演算する因子“1”が含まれていないので、S306で、NOの判定がなされる。その結果、これらの因子は、S307において、Φに設定され、削除される。その結果、再起呼び出し2で商演算の結果、式2として出力されるのは、1{ε+a1+b1+c1}となる。
【0161】
さらに、再起呼び出し1では、S313の処理で、項3に積演算されていたid{ε+A+B+C}と再起呼び出し2での商演算の結果である1{ε+a1+b1+c1}とが、積演算され、id{ε+A+B+C}(1{ε+a1+b1+c1})が、式2として出力される。
【0162】
さらに、そして、再起呼び出し1の前に、項3に積演算されていたcellと、再起呼び出し1による商演算の結果が積演算され、数15Aが式2として、最終的に出力されることになる。
【0163】
次に、図12Aにより、剰余を求める処理(サブルーチン2)を説明する。サブルーチン1を実行するCPU13が本発明の剰余演算部に相当する。サブルーチン2は、商演算される式である式1、商演算する因子pを入力され、剰余の式3を出力する。
【0164】
まずステップ321では、商演算処理が実行される前の所定の表現形式によって表現される式1(“商演算される式”)、及び商演算する因子(同値関係示す因子p)が入力される。以下、図11Aの場合と同様、数14により表現される対象情報が入力された場合について説明する。また、1を商演算する因子(同値関係p)と設定する。
【0165】
次に、ステップS322では、CPU13は、演算後の式(ここでは、式3と呼ぶ)を初期化する。このとき、式3の値は、Φ(空、または0)になる。
【0166】
次に、ステップS323では、CPU13は、式1の長さが0であるか否かを判定する。式1の長さが0である場合、CPU13は、サブルーチン1の処理を終了する。
【0167】
一方、ステップS323の判定において、式1の長さが0でなかった場合、CPU13は、ステップ324に処理を進める。そして、CPU13は、式1から始めの項(以下、項1という)を取得する。さらに、ステップS325において、CPU13は、式1から項1を削除する。
【0168】
次に、ステップS326において、CPU13は、演算後の項(以下、項4と呼ぶ)を初期化する。このとき、項4の値は、Φ(空、または0)になる。
【0169】
次に、ステップS327において、CPU13は、項1の長さが0であるか否かを判定する。そして、項1の長さが0でない場合、CPU13は、ステップS328に処理を進める。そして、ステップS328において、CPU1は、項1から始めの因子(因子1)を取得する。さらに、ステップS329において、CPU13は、項1から因子1を削除する。
【0170】
次に、ステップS329において、CPU13は、因子1が因子pと等しいか否かを判定する。そして因子1が因子pと等しい場合、ステップS331において、CPU13は、因子1をΦ(空、または0)にする。
【0171】
次に、ステップS332において、CPU13は、因子1が第1の括弧“(”と“)”とによって形成された因子であるとき、その括弧内の式を式1に設定し、サブルーチン2を再帰呼び出しする。そして、その再帰呼び出しによる処理結果を因子1とする。この処理によって、商演算される式中で、“()”による因子を含む場合は、その因子は、()がはずされ、内の式から剰余(すなわち、因子pを含まない項)が抽出されることになる。
【0172】
さらに、ステップS333によって、CPU13は、項4に対し因子1を積演算し、結果を項4とする。この処理によって、因子1が商演算される因子pと異なる場合に、そのまま項3に積演算されることになる。また、因子1が()の形式の因子の場合に、()内から因子pを含まない項が取り出されることになる。そして、CPU13は、処理をS327に戻す。
【0173】
ステップS327の判定で、項1の長さが0となった場合、CPU13は、処理をステップS334に進める。そして、CPU13は、式3(剰余項)に対して、得られている項4を和演算する。その後、CPU13は、処理をS323に戻す。
【0174】
そして、S323の判定で、式1の長さが0になると、CPU13は、サブルーチン2の処理を終了する。このような処理により、式3に、以下の数15Bの式表現が剰余として出力され、アプリケーションプログラムに引き渡される。
cell(id{ε+A+B+C}(Φ+2{ε+a2+b2+c2}))・・(数15B)
【0175】
図12Bおよび図12Cに、数14の式表現に対して、サブルーチン2が実行された場合の式1、項1、項4、因子1、および式3の変化を示す。図12Bおよび図12Cの第1行目は、各列の要素、すなわち、図12A中の該当する処理を示す番号、式1、項1、項、項4、因子1、および式3を示している。第2行以下の各行は、一連の処理ステップであり、図12Bの表の上から下へ、さらに、図12Cの表の上から下へ実行される。
【0176】
そして、まず、ステップS321で、共通関数へのパラメータを介して、式1である数14が入力され、メモリ12に保持される。
【0177】
項1、因子1および項4に着目すると、これらのうち、“cell”および、id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2})が順次サブルーチン2で処理されることが分かる。
【0178】
さらに、id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2})が因子1としてS332で処理されるときに、再起呼び出しが発生する。そして、同様に、“id”、{ε+A+B+C}、および(1{ε+a1+b1+c1}+2{ε+a2+b2+c2})がサブルーチン1の再起呼び出し1で処理される。
【0179】
さらに、(1{ε+a1+b1+c1}+2{ε+a2+b2+c2})が、S332で処理されるときに、再起呼び出し2が発生する。そして、1{ε+a1+b1+c1}については、商演算する因子“1”が含まれているので、S330で、YESの判定がなされる。そして、S331によって、因子1にΦに設定され、因子1を含む項1全体がΦとなり、削除される。
【0180】
一方、2{ε+a2+b2+c2}については、商演算する因子“1”が含まれていないので、S330で、それぞれの因子1について、NOの判定がなされる。その結果、これらの因子は、S333において、項4に積演算される。その結果、再起呼び出し2の剰余演算の結果、式3として出力されるのは、2{Φ+a1+b1+c1}となる。
【0181】
さらに、再起呼び出し1では、S333の処理で、項4に積演算されていたid{ε+A+B+C}と再起呼び出し2での商演算の結果である2{Φ+a1+b1+c1}とが、積演算され、id{ε+A+B+C}(2{Φ+a1+b1+c1})が、式3として出力される。
【0182】
さらに、そして、再起呼び出し1の前に、項4に積演算されていたcellと、再起呼び出し1による商演算の結果が積演算され、数15Bが式3として、最終的に出力されることになる。
【0183】
(13)接着演算処理
接着とは、本実施形態にて提案する概念であり、2つの被接着情報のそれぞれのデータ構造を維持した上で、それぞれ被接着情報を結合する機能である。接着においては、2つの被接着情報のそれぞれに含まれる情報で、互い関係付けられる情報(これを同値関係を指定された因子という)が指定される。そして、その関係付けられた因子(同値関係を有する因子)同士を介して、2つの被接着情報が結合される。
【0184】
接着演算処理のアプリケーションインターフェースは、例えば、戻り値=attach(接着
する式1、因子1、接着する式2,因子2、接着演算後の式);のように定義できる。こ
こで、因子1と、因子2とは、接着演算する式1の項と、式2の項とを関係付ける指定である。この指定によって、式1で因子1を含む項と、式2で因子2を含む項とが以下のような手順で結びつけられる。
【0185】
図13は、接着演算処理を実行する処理のフローを示す。ステップS401では、接着する所定の表現形式によって表現される対象情報を入力する。以下の説明では、数16及び数17によって表現される対象情報を接着処理する場合について説明する。すなわち、数16が被接着式1であり、数17が被接着式2である。また、ここでは、数16の因子
“2”と、数17の因子“q”との同値関係が指定されているとする。
cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))・・・(数16)
s(p(p1+p2)+q(q1+q2))・・・(数17)
【0186】
ステップS402では、数16及び17の因子1、因子2による上述した商演算処理(サブルーチン1およびサブルーチン2)を実行して、得られた商と剰余とを和演算処理する。このサブルーチン1を実行し、商を取得するCPU13が、本発明の関連項抽出部に相当する。また、このサブルーチン2を実行し、剰余を取得するCPU13が、本発明の非関連項抽出部に相当する。その結果、“式1から得られた剰余+式1から得られた商+式2から得られた剰余+式2から得られた商”という形式の式が形成される。これを商演算後の式という。このうち、式1からの商を項1とし、式2から得られた商を項2とする。項1は、因子“2”を含む項である。また、項2は、因子“q”を含む項である。このように、同値関係を指定された因子1、因子2を含む項を、同値要素を表す項という。すなわち、式1に対して、因子“2”で商演算した商が項1であり、同値要素を表す項である。また、式2に対して、因子“q”で商演算した商が項2であり、これも同値要素を表す項である。
【0187】
次にステップS403では、因子1および因子2を含む項1、2を取得し商演算後の式から削除する。さらに、因子1を含む項1、および因子2を含む項2をそれぞれ左因子と右因子とに分ける。ここで、左因子とは、ある項の因子pに着目した場合に、pの左に位置する因子又は因子の積をpの左因子という。また、右因子とは、ある項の因子pに着目した場合に、pの右に位置する因子又は因子の積をpの右因子という。例えば、項(a×b+c)×p×d×eについてみると、pの左因子は(a×b+c)であり、pの右因子はd×eとなる。
【0188】
次に、ステップS404では、項1における因子1の左因子をl1,右因子をr1,項2における因子2の左因子をl2,右因子をr2とし,接着空間の式として{l1+l2}{因子1+因子2}{r1+r2}を作成する。次に、ステップS405では、商演算処理後の剰余を示す対象情報、接着演算処理後の対象情報を和演算処理し,接着演算処理後の対象情報とし、処理を終了する。その結果、“接着演算後の式”に演算結果が設定され、アプリケーションプログラムに引き渡される。なお、接着演算処理を実行中の対象情報の状態の詳細は図14に示す。
【0189】
図14に、接着演算処理を実行中の対象情報の状態の詳細を示す。この例では、まず、S401にて接着する式1、式2が入力される。また、因子1として“2”、因子2として、“q”が指定されている。
【0190】
次に、S402にて商演算が実行される。その結果、式1は、cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+Φ))という剰余と、cell(id{ε+A+B+C}(Φ+2{ε+a2+b2+c2}))という商に分離される。また、式2は、s(p(p1+p2)+Φ)という剰余と、s×q(q1+q2)という商に分離されている。図14のS402の行では、これらの剰余と商が和演算された形式で示されている。
【0191】
そして、ここで、式1の同値因子、すなわち、因子“2”を含む項は、cell×id{ε+A+B+C}(Φ+2{ε+a2+b2+c2})であり、同値要素を表す項1という。また、式2の同値因子、すなわち、因子“q”を含む項は、s×q(q1+q2)であり、同値要素を表す項2という。これらから、左因子l1は、cell×id{ε+A+B+C}、左因子l2は、s、右因子r1は、{ε+a2+b2+c2}、右因子r
2は、(q1+q2)である。したがって、接着された結果である接着空間の式は、
{cell×id{ε+A+B+C}+s}{2+q}{(ε+a2+b2+c2)+(q1+q2)}
となる。
【0192】
さらに、これらの剰余の式cell(id{ε+A+B+C}(1{ε+a2+b2+c2}+Φ))とs(p(p1+p2)+Φ)とを和演算することで、接着演算後の式となる。
【0193】
(14)部分集合取得処理
部分集合取得処理は、集合から、指定された因子(以下、指定因子という)を有する項を含む式(部分集合)と、指定因子を有しない項の式(部分集合)に分離する処理である。この処理を実行するCPU13が、本発明の部分集合形成部に相当する。ただし、本実施形態では、指定因子(今pとする)を有する項が複数個存在する場合には、{左因子1+左因子2+・・・}p{左因子1が含まれていた項の右因子+左因子2が含まれていた項の右因子+・・・}+因子pを含まない部分集合の和のように、指定された因子pで括り出す。このように、部分集合取得処理の括り出しでは、括り出し前の各項において、指定因子pの左側に結合する因子(左因子と呼ぶ)と、指因子pの右側に結合する因子(右因子と呼ぶ)とをそれぞれ、第2の{}内に和演算する。そして、左因子の和は、第2の{}によって括られ、その順序を維持して、指定された因子の左側に結合される。
【0194】
また、右因子の和は、第2の{}によって括られ、その順序を維持して、指定された因子の右側に結合される。さらに、同一の左因子に対して、異なる右因子を有する項が複数存在する場合、それらの右因子は、第1の括弧“()”で括り出される。この場合、左因子は、集合情報の識別情報として機能する。例えば、
a1×b×c1+a1×b×c2+a2×b×c1+a2×b×c2+a3×b×c3+a×u×vという式表現に対して、因子bを指定因子として部分集合取得演算を実行すると、
{a1+a2+a3}b{(c1+c2)+(c1+c2)+c3}+a×u×v
となる。この場合、右因子の列は、それぞれ、集合IDがa1の集合の部分集合b(c1+c2)、集合IDがa2の集合の部分集合b(c1+c2)、集合IDがa3の集合の部分集合b×c3を表している。
【0195】
さらに、部分集合取得処理の対象となる項に、第1の括弧“()”または第2の括弧“{}”が含まれている場合には、これらの括弧内の式表現に対して、再起的に部分集合取得処理が実行される。したがって、第1の括弧“()”または第2の括弧“{}”で括られた個々の括弧内で、部分集合取得処理が実行される。
【0196】
部分集合取得処理のアプリケーションインターフェースは、例えば、部分集合取得後の式表現は、戻り値=separate(部分集合取得前の式表現、指定因子);のように定義できる。対象の式,因子を指定すると,括った後の式(戻り値)になります。
【0197】
次に部分集合取得処理について説明する。図15は、部分集合取得処理を実行する処理のフローを示す。ステップS501では、演算前の所定の表現形式で表現される対象情報と、部分集合を指定するための指定因子pを入力する。以下、対象情報として数18に示すデータを用いて、指定因子“p”で部分集合を取得する場合について説明する。
s×p(p1+p2)+t×p(p3+p4)+id(s×p(p1+p2)+t×p(p3+p4))・・・(数18)
【0198】
ステップS502では、部分集合を取得するための因子以外(ここでは、「その他の式
」「左因子式」および「右因子式」)をΦと設定する。ステップS503では「処理後の項」をεに設定する。ステップS504では、対象情報を構成する式の長さが0であるかを判断する。すなわち、対象情報が存在するか否かを判断する。式の長さが0であると判断した場合には、ステップS517へ進む。一方、式の長さが0であると判断しなかった場合には、ステップS505へ進む。
【0199】
ステップS505では、数18から第一項を取得し保存する。次にステップS506では、数18から第一項を削除する。次にステップS507では、取得した項に因子pが含まれるか判断する。取得した項に因子pが含まれると判断した場合にはステップS515へ進む。一方、取得した項に因子pが含まれると判断しなかった場合には、ステップS508へ進む。
【0200】
ステップS508では、項の長さが0であるか否かを判断する。項の長さが0であると判断した場合にはステップS514へ進む。一方、項の長さが0であると判断しなかった場合には、項から第一因子を取得し、これを保存し(ステップS509)、次に項から第一因子を削除する(ステップS510)。
【0201】
次にステップS511では、第一因子が第一の括弧又は第二の括弧で括られているか判断する。因子が第一の括弧又は第二の括弧で括られていると判断した場合には、第一の括弧又は第二の括弧で括られている式に対して、本部分集合取得処理を実行する(ステップS512)。すなわち、再起呼び出しを実行する。一方、第一の括弧又は第二の括弧で括られていると判断しなかった場合には、第一因子を取得した因子とし(S520)、ステップS513へ進む。ステップS513では、処理後の項に取得した因子によって積演算処理を実行し、その結果を処理後の項とし、ステップS508の処理を再度実行する。
【0202】
ステップS508において、項の長さが0であると判断した場合には、その他の式に処理後の項を和演算処理し、その結果をその他の式とする(ステップS514)。ステップS514の処理を実行後、再度ステップS503の処理を実行する。次にステップS504において式の長さが0であると判断した場合には、部分集合の項として{左因子式}p{右因子式}を作成し(ステップS517)、その他の式に部分集合項を和演算し,演算後の式とし(ステップS518)、処理を終了する。以上の処理を実行することにより、数18により表現される対象情報は、数19により表現される対象情報となる。なお、部分集合取得処理を実行中の対象情報の状態の詳細は図16A、図16Bに示す。
id({s+t}p{(p1+p2)+(p3+p4)})+{s+t}p{(p1+p2)+(p3+p4)}・・・(数19)
【0203】
図16Aおよび図16Bに、数18の式表現に対して、部分集合取得処理が実行された場合の「演算前の式」、「部分集合取得のための因子」、「左因子式」、「右因子式」、「左因子」、「右因子」「その他の式」、「取得した項」、「取得した因子」、「処理後の項」、「部分集合項」および「演算後の式」の変化を示す。図16Aの各行と、図16Bの各行は、図15の処理での同一の処理を示している。すなわち、図16Aおよび図16Bを横に接続して、部分集合取得処理の状態変化が表されることになる。
【0204】
図16Aおよび図16Bの第1行目は、各列の要素、すなわち、図15中の該当する処理を示す番号、「その他の式」、「取得した項」、「取得した因子」、「処理後の項」、「部分集合項」および「演算後の式」を示している。第2行以下の各行は、一連の処理ステップであり、図16Aおよび図16Bの表の上から下へ実行される。
【0205】
ここでは、数18の式表現を処理対象とする。部分集合取得処理を実行する共通関数separateに対して、まず、部分集合取得前の式表現である数18が与えられる。この式表現はメモリ12に格納される。また、指定因子はpであるとする。
【0206】
まず、S505、S505の処理で、式から第一項s×p(p1+p2)が取得される。s×p(p1+p2)に指定因子pが含まれているので、S515およびS516が実行され、左因子sおよび右因子(p1+p2)がそれぞれ左因子式および右因子式に和演算される。
【0207】
次に、S505、S506の処理で、式から第二項t×p(p3+p4)が取得される。t×p(p3+p4)に指定因子pが含まれているので、S515およびS516が実行され、左因子tおよび右因子(p3+p4)がそれぞれ左因子式および右因子式に和演算される。
【0208】
さらに、S505、S506の処理で、式から第三項id(s×p(p1+p2)+t×p(p3+p4))が取得される。そして、S509において、第一因子としてidが取得される。項idは、S513にて、処理後の項に積演算される。さらに、S509において、第一項として、次の項(s×p(p1+p2)+t×p(p3+p4))が取得される。これは、S511の判定で、第1の括弧を含むとされるので、S512が実行される。
【0209】
そして、式表現s×p(p1+p2)+t×p(p3+p4)に対して、部分集合取得処理が再起呼び出しで実行される。図16Aおよび図16Bでは、再起呼び出し中の状態は、省略されているので、本文にて説明する。この場合も、s×p(p1+p2)から、左因子s、右因子(p1+p2)が取得される。また、t×p(p3+p4)から、左因子t、右因子(p3+p4)が取得される。これらの左因子および右因子は、S516において、それぞれ左因子式、および右因子式に和演算される。そして、式表現s×p(p1+p2)+t×p(p3+p4)の末尾まで処理が進み、S504で、残りの式の長さが0であると判定される。すると、CPU13は、部分集合の項として、{s+t}p{(p1+p2)+(p3+4)}を作成する。そして、CPU13は、部分集合の項を演算後の式として、再起呼び出しを終了する。
【0210】
再起呼び出しを終了すると、演算後の式を取得するので、これを取得した因子とする。この場合、取得した因子は、({s+t}p{(p1+p2)+(p3+4)})である。そして、CPU13は、S513にて、再起呼び出し前に計算しておいた処理後の項(“id”が積演算されている)に、取得した因子を積演算する。その結果、S513において、処理後の項は、id({s+t}p{(p1+p2)+(p3+4)})となる。CPU13は、S514にて、処理後の項をその他の式として和演算する。
【0211】
そして、S504にて、残りの式の長さが0であると判定されると、CPU13は、再起呼び出し前に作成していた左因子式s+tおよび右因子式(p1+p2)+P3+p4)から、部分集合の項{s+t}p{(p1+p2)+P3+p4)}を作成する。そして、CPU13は、S518にて、その他の式に部分集合の項を和演算する。これによって、演算後の式id({s+t}p{(p1+p2)+(p3+4)})+{s+t}p{(p1+p2)+P3+p4)}が作成されることになる。
【0212】
(15)ホモトピー保存処理
次にホモトピー保存処理について説明する。ホモトピー保存処理は、式1に対して、パラメータを表す項pを用いて演算Gを実行し、式2が得られたとき、
(演算後の式2)=G(演算前の式1+演算時のパラメータを表す項p)
のように、演算実行前後の関係を保持する機能である。この場合、演算実行前の式1、すなわち、初期状態は、式ΦにパラメータΦ項を適用して、式1が得られたと仮定し、演算
前の式を
式1=F(Φ+Φ)
のようにおく。ここで、演算実行前の式をホモトピー保存式1と呼ぶことにする。
【0213】
図17は、ホモトピー保存処理を実行する処理のフローを示す。ここで、式1は、数20の左辺の式である。また、attachによって接着演算が指定され、因子2と因子qとの同値関係が指定されている場合を説明する。
【0214】
まず、ステップS601では、演算実行前の式、すなわち、ホモトピー保存式1と、演算Gと、パラメータ因子pが入力される(S601)。
ここでは、例として、以下の数20によって、式1を仮定する。また、演算Gとして、接着演算を実行する例を示す。また、そのときの、パラメータ因子として、attach(2+q)を指定する。すなわち、因子2と因子qとの同値関係が指定されて、接着演算が実行された場合を例に、ホモトピー保存処理を説明する。
(cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))+s(p(p1+p2)+q(q1+q2)))=F(Φ+Φ)・・・(数20)
【0215】
ステップS602では、数20により表現される式から演算G前の式、すなわち数20の左辺を取得する。これを数21とする。
cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))+s(p(p1+p2)+q(q1+q2))・・・(数21)
【0216】
ステップS603では、演算Gによる演算処理を行い演算G後の式とする。この場合、数22により表現される式が得られる。ここでは、演算Gの例として、接着演算を実行する。また、接着演算の同値関係を指定するパラメータを“2”および“q”とする。すなわち、因子“2”で商演算された商と、因子“q”で商演算された商とを接着する。そのときのホモトピー保存式の例を説明する。
cell(id{ε+A+B+C}(1{ε+a2+b2+c2}+Φ))+s(p(p1+p2)+Φ)+{cell×id{ε+A+B+C}+ε}{2+q}{{ε+a2+b2+c2}+(q1+q2)}・・・(数22)
【0217】
ステップS604では、演算G後のホモトピー保存式2として、(演算G後の式)=G(ホモトピー保存式1+演算時のパラメータp)を作成する。ここで、パラメータpは、“attach(2+q)”である。以上の処理を実行することにより数21により表現された式は、数23により表現される式となる。
(cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+Φ))+s(p(p1+p2)+Φ)+{cell×id{ε+A+B+C}+ε}{2+q}{{ε+a2+b2+c2}+(q1+q2)})
=G((cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))+s(p(p1+p2)+q(q1+q2)))
=G(F(Φ+Φ)+attach(2+q)))・・・(数23)
【0218】
この式は、F(Φ+Φ)で示される式(すなわち、数21)に、attach(2+q)というパラメータで演算G、すなわち、接着演算が実行されて、数23の左辺(最上段の式)が得られたことを示している。
【0219】
(16)UNDO演算処理
次にホモトピー保存式におけるUNDO演算処理について説明する。図18は、ホモトピー保存式におけるUNDO演算処理のフローを示す。ステップS701では、ホモトピ
ー保存式(演算G後の式)=F(演算G前の式+演算時のパラメータを表す式p)の入力をする。以下、対象情報として数24に示すデータを用いた場合について説明する。
(cell(id{ε+A+B+C}(1{ε+a2+b2+c2}+Φ))+s(p(p1+p2)+Φ)+{cell×id{ε+A+B+C}+ε}{2+q}{{ε+a2+b2+c2}+(q1+q2)})
=G((cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))+s(p(p1+p2)+q(q1+q2)))
=F(Φ+Φ)+attach(2+q))・・・(数24)
【0220】
上述のように、ホモトピー保存式は、演算G前の式F(Φ+Φ)に演算(この例では、接着演算G、演算時のパラメータはattach(2+q))を実行することで、数24の最上段(最初の“=”の左辺)の式表現が得られたことを記録している。なお、数24において、中段の式(最初の“=”の右辺)と、最下段の式(2つ目の“=”の右辺)とは、表現形式が異なるだけで実質的に同一の式である。最下段の式は、F(Φ+Φ)を用いて表現を簡略化している。そして、それら中段の式と簡略された式を“=”で結んだ式が、G()という演算の中に挿入されている。
【0221】
UNDO演算処理では、この記録を基に、演算前の式を得る。すなわち、CPU13は、演算の種類と、演算時のパラメータとを基にして、演算前の状態に式を戻す。
【0222】
次にステップS702では、UNDO後の式(演算G前の式)=G-1((演算G後の式)=G(演算G前の式+p))の作成を実行する。この場合、すでに、数24の中段の式と下段の式で、演算の種類G、演算実行前の式、演算時のパラメータattach(2+q)が記録されている。したがって、演算前の式は、直ちに、取り出すことができる。以上の処理を実行することにより数24により表現された対象情報は、数25により表現される対象情報となる。
((cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))+s(p(p1+p2)+q(q1+q2)))=F(Φ+Φ))
=G-1((cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+Φ))+s(p(p1+p2)+Φ)+{cell×id{ε+A+B+C}+ε}{2+q}{{ε+a2+b2+c2}+(q1+q2)})
=G((cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))+s(p(p1+p2)+q(q1+q2)))
=F(Φ+Φ)+attach(2+q))
)・・・(数25)
【0223】
この式は、数24で与えられホモトピー保存式の両辺に、演算G前に戻す演算G-1を実行することによって、演算G前の式(初期状態F(Φ+Φ)が得られたことを示している。これによって、演算G前の式である(cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))+s(p(p1+p2)+q(q1+q2)))=F(ε+ε)が、演算G後の式であるcell(id{ε+A+B+C}(1{ε+a1+b1+c1}+Φ))+s(p(p1+p2)+Φ)+{cell×id{ε+A+B+C}+ε}{2+q}{{ε+a2+b2+c2}+(q1+q2)}から得られることが示される。
【0224】
さらに、この演算G後の式であるcell(id{ε+A+B+C}(1{ε+a1+b1+c1}+Φ))+s(p(p1+p2)+Φ)+{cell×id{ε+A+B+C}+ε}{2+q}{{ε+a2+b2+c2}+(q1+q2)})は、演算G前の式であるcell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+
a2+b2+c2}))+s(p(p1+p2)+q(q1+q2))から得られたことが記録されている。
【0225】
すなわち、演算G前の式(F(Φ+Φ))に演算G、パラメータattach(2+q)を適用することで、演算G後の式が得られ、かつ、その演算G後の式に演算G-1を適用することで、演算G前の式に戻されたことが記録される。
【0226】
このように、UNDO演算処理は、演算後の式から、演算前の式が得られたことを記録するので、次に示すREDO演算処理を実行することで、直ちに、演算後の式を得ることができる。
【0227】
(17)REDO演算処理
次にホモトピー保存式におけるREDO演算処理について説明する。図19は、ホモトピー保存式におけるREDO演算処理のフローを示す。ステップS801では、ホモトピー保存式におけるUNDO後の式(演算G前の式)=G-1((演算G後の式)=G(演算G前の式+p))の入力をする。以下、対象情報として数26に示すデータを用いた場合について説明する。
((cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))+s(p(p1+p2)+q(q1+q2)))=F(ε+ε))
=G-1((cell(id{ε+A+B+C}(1{ε+a2+b2+c2}+Φ))+s(p(p1+p2)+Φ)+{cell×id{ε+A+B+C}+ε}{2+q}{{ε+a2+b2+c2}+(q1+q2)})=G((cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))+s(p(p1+p2)+q(q1+q2)))=F(Φ+Φ)+attach(2+q))
)・・・(数26)
【0228】
上述のように、数26は、演算G前の式(F(Φ+Φ))に接着演算Gおよびパラメータattach(2+q)が適用され、演算G後の結果が得られ、さらに、演算G後の式から演算G前の式に戻されたことが記録されている。
【0229】
次にステップS802では、UNDO後の式から,UNDO演算前の式、すなわち(演算G後の式)=G(演算G前の式+演算時のパラメータp)を取得し、REDO演算後の式とする。以上の処理を実行することにより数26により表現された対象情報は、数27により表現される対象情報となる。
(cell(id{ε+A+B+C}(1{ε+a2+b2+c2}+Φ))+s(p(p1+p2)+Φ)+{cell×id{ε+A+B+C}+ε}{2+q}{{ε+a2+b2+c2}+(q1+q2)})=G((cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))+s(p(p1+p2)+q(q1+q2)))=F(ε+ε)+attach(2+q))・・・(数27)
【0230】
このように、ホモトピー保存処理によって、演算後の結果とともに、演算G前の式(F(Φ+Φ))と、適用される演算の種類Gと、使用されるパラメータattach(2+q)を記録する。これによって、UBDO演算処理で演算前の結果を得ることができる。さらに、UNDO演算処理で、演算後の式から、演算前の式が得られたことを記録することで、REDO演算処理を実行し、直ちに、演算G後の式を得ることができる。このように、ホモトピー保存処理、UNDO演算処理、およびREDO演算処理は、メモリ12の容量を犠牲にして、演算前後の関係を保持する一方、演算を戻す処理と再実行する処理とを簡易に実現する。
【0231】
(適用例)
次にデータ処理システムを開発する際に、本発明に係る情報処理装置を使用する例について説明する。
【0232】
本発明に係る情報処理装置は、様々なデータ処理システムに適用可能である。図20は、建設業における情報管理、すなわちデータ処理システムが要求される例を示す。同図に示すように、例えば建設業における管理として、プロジェクト管理と現場管理が例示できる。プロジェクト管理の主は、財務管理であり、財務管理は予算作成管理、購買管理、資機材管理によって成り立っている。そして、これらの管理は、データベースに格納された情報を管理することによって行われる。また、現場管理においては、工程管理が主であるが工程管理においては作業手帳の情報も管理できることが重要である。そして本発明に係る情報処理システムは、これらあらゆる情報管理、すなわちデータ処理システムに適用できる。以下、具体的に説明する。なお、本実行形態においては建設業における例としたがこれに限定されるわけではない。様々な分野において適用可能である。
【0233】
図21A及び図21Bは、本発明の対象情報に相当する社員データ及び伝票データを示す。図21Aに示す社員データ(マスタデータ)は、正規化表構造で表現されるデータである。これを本発明に係る所定の表現形式によって表現すると、数28により表現される。そして、このデータはメモリ12に格納される。なお、上記社員データはキーボード等の入力部11から入力する。入力された社員データは、ディスプレイ等の出力部14にて確認できる。
社員(社員コード{ε+氏名+年齢+職種+所属}(K100{ε+社員A+30+土木+情報システム}+K101{ε+社員B+49+事務+土木}+K102{ε+社員C+24+建築+建築}))・・・(数28)
【0234】
情報処理装置100は、このようにして、社員データをメモリ12に保持し、データベースとして管理する。この場合、データ入力のためのユーザインターフェース、データ出力のためのユーザインターフェースに限定はない。すなわち、情報処理装置100は、式表現で対象情報を記述し、メモリ12に保持し、上述の演算処理を実行する共通関数によって、演算機能をアプリケーションプログラムに提供する。したがって、アプリケーションプログラムの構成そのものにも限定はない。
【0235】
例えば、社員情報の入力は、社員コード、氏名、年齢、職種、所属部署等の入力フィールドを備えた、画面プログラムで行っても良い。そして、画面プログラムは、入力された情報から、上記式表現(例えば、インスタンスK101{ε+社員B+49+事務+土木})を生成すればよい。ただし、セル空間情報、トポロジー空間情報、集合情報の末尾に、インスタンスを挿入する共通関数を提供してもよい。例えば、戻り値=insert(セル空間ID、インスタンス)というアプリケーションインターフェースを提供してもよい。
【0236】
また、例えば、社員情報の入力は、テキストエディタを用いて、数28の式表現に、インスタンスを直接挿入するようにしても構わない。インスタンスが挿入された後は、上記各種演算によって、共通関数が、アプリケーションプログラムに処理機能を提供する。
【0237】
したがって、情報処理装置100によれば、従来のようなリレーショナルモデルによってテーブルを構成することなく、式表現をメモリ12に保持することによって、社員データのような表形式のデータを管理できる。例えば、有る社員A(社員コードK120)に関するデータを抽出し、表示するには、セル空間IDとして、“社員”を指定し、因子“社員コード×K120”によって同値関係を指定し、部分集合取得処理を実行すればよい。
【0238】
さらに、情報処理装置100のように、式表現で対象情報を表した場合、属性の追加、削除、変更は自在である。式表現を変更すればよいからである。従来の表形式のリレーショナルモデルでは、属性の追加、削除は、データベース自体の再構築が要求される。例えば、社員情報のレコードが、社員コード、氏名、年齢、職種、所属部署のフィールドからなっており、すでに、データベースが運用されている場合に、このレコードに、さらに、性別、入社年、役職を追加することは困難である。しかしながら、情報処理装置100では、属性の追加、削除は、式表現の変更であり、変更のための工数が極めて少なくなる。
【0239】
さらに、情報処理装置100のように、式表現で対象情報を表した場合、異なる形式のセル空間情報、異なる種類のトポロジー空間情報、異なる種類の集合情報を自在に定義できる。したがって、リレーショナルモデルのように、社員データが、特定の表で定義されたレコードの形式で固定されることもない。例えば、社員データを示すセル空間情報として、一般社員の部分集合、管理職の部分集合、非正規社員の部分集合、嘱託社員の部分集合等を自在に定義できる。
【0240】
また、情報処理装置100のように、式表現で対象情報を表した場合に、1つの属性に複数の値を設定できる。さらに、第1の括弧および第2の括弧を用いて、1つの属性に対して、複数階層に渡るデータを定義することも容易である。例えば、社員(コード{ε+氏名+年齢+職種{{国別、公用語}、職種コード}+所属{事業所{国別、事業所コード}、部門、課}}のように複数階層に渡る属性を設定できる。また、1つの属性に対する値として、第1の括弧、第2の括弧を用いて複数個の値を持つ属性値を設定できる。
【0241】
図21Bに示す伝票データは、非正規化表構造で表現されるものである。また、同図に示すように伝票データと属性のまったくない付箋メモが添付されている。従来、このような対象情報をデータベースに入力は、新たなアプリケーションの開発を必要とするなど非常に困難とされていた。しかし、これを本発明に係る所定の表現形式によって表現すると、数29により表現される。そして、このデータはメモリ12に格納され情報管理を行うことができる。なお、midは付箋のidを表し、ptは伝票中の付箋を添付する位置を表す。
伝票ID(伝票コード{プロジェクト名称+期間{開始+終了}+金額+担当者{連絡先+コード}}(a{b+c{c1+c2}+d+e{e1+e2}}))+{伝票ID+ε}{pt+mid}{ε+メモ}・・・(数29)
【0242】
図22A及び図22Bは、プロジェクトデータ及び歩掛作成データを示す。図22Aに示すプロジェクトデータは、有向グラフのツリー構造で表現されるデータである。すなわち、実行予算データは、発注データ1と発注データ2により構成され、更に発注データ1は検収データ1と検収データ2により構成される。また、発注データ2は、検収データ3と検収データ4により構成される。このようなプロジェクトデータは、本発明に係る所定の表現形式によって表現すると、数30により表現される。そして、このデータはメモリ12に格納され情報管理を行うことができる。
【0243】
実行予算(発注データ1(検収データ1+検収データ2)+発注データ2(検収データ3+検収データ4))・・・(数30)
【0244】
図22Bに示す歩掛作成データは、逆ツリー構造で表現されるデータである。同図に示すように土砂掘削には、バックホーの運転とダンプトラックの運転を必要とする。また、バックホーの運転には燃料である軽油と運転手が必要となる。また、ダンプトラックの運転には、軽油及び運転手が必要となり、更に雑費が関係してくる。なお、このような逆ツリー構造で表現される対象情報は、従来データ管理が難しいとされていたものである。しかし、これを本発明に係る所定の表現形式によって表現すると、数31により表現される
。そして、このデータはメモリ12に格納され情報管理を行うことができる。
((軽油+運転手)バックホー運転+(経由+運転手+雑費)ダンプトラック運転)土砂掘削・・・(数31)
【0245】
図22Bで、下側のグラフは、経由および運転手が1つに集約されている。一方、上側のグラフの経由および運転手がバックホー運転と、ダンプトラック運転とで分離している。従来のデータベースでは、このようなことが表現できない。リレーショナルデータベース等で工夫してデータベース設計したとしても、アプリケーションプログラムが煩雑になる。また故に変更時にはメンテが大変になる。これが既存の技術の問題点,表現力の問題で,既存のモデルでは表現できないが故に工夫した設計アプリ開発が必要になりコスト増、また開発業者の品質に差が出る。またデータベース,アプリケーションプログラム設計等技術者が別れ,技術の分離により工期の遅れがあって当然になっている。さらに要求仕様が曖昧だったり開発途中で変更されたりすると手戻りが増え大幅なコスト増になるケースが頻発している。一方、本実施形態の技術では統一的により多くのことが表現可能なので、データベース設計、アプリケーション設計・開発の負担が従来よりも軽減される。つまり、情報処理装置100で処理したい情報を式として入力すれば、本実施形態で説明した演算によって、処理し、検索し、出力できる。本実施形態の技術ではビジュアルに式で各空間を設計して、各関数を使用すると変形されてその場で必要な出力結果が出て確認できる。したがって、仕様の曖昧さがなくなり、アプリケーション開発が極めて少ない故にメンテナンスも容易である。例えば、図22B上側のレコード構成で、バックホー運転を構成する運転手のデータベースに、新たな運転手の情報を追加しても、ダンプトラック側には、反映されない。
【0246】
しかし、本実施形態の情報処理装置100では、図22B上側のグラフおよび下側のグラフは、ともに数31で表される。数31でも、一見、バックホー運転と、ダンプトラック運転とで、運転手のデータベースが分離しているように見える。しかしながら、本実施形態で示したトポロジー空間情報は、部分集合を識別するIDによって、個々の項を分類する。したがって、バックホーというデータを構成する運転手データの部分集合も、ダンプトラック運転を構成する運転手データの部分集合も、ともに同一の部分集合IDを付与した場合には、同一の部分集合として管理される。
【0247】
したがって、運転手データの部分集合が、例えば、社員×運転手×(運転手1+運転手2+・・・+運転手N)のように構成されているとする。この場合に、数31は、以下の数32ように、記述される。
((軽油+社員×運転手×(運転手1+運転手2+・・・+運転手N))バックホー運転+(経由+社員×運転手×(運転手1+運転手2+・・・+運転手N)+雑費)ダンプトラック運転)土砂掘削・・・(数31)
【0248】
この場合に、一旦、社員×運転手×(運転手1+運転手2+・・・+運転手N)によって部分集合取得処理を実行すると、以下のようになる。
({ε+ε}社員×運転手×(運転手1+運転手2+・・・+運転手N){バックホー運転+ダンプトラック運転}+軽油×バックホー運転+(軽油+雑費)×ダンプトラック運転)×土砂掘削・・・(数33)
【0249】
このように、運転手に関するデータが一元化されるので、運転手Mを追加したとしても、バックホー運転と、ダンプトラック運転の両方の運転手を変更できる。
なお、バックホー運転と、ダンプトラック運転とで、運転手データベースを個別に管理したい場合は、それぞれの部分集合IDを異なるものとすればよい。
({ε+ε}社員×({ダンプ運転手×(運転手1+運転手2+・・・+運転手N)+トラック運転手×(運転手1+運転手2+・・・+運転手N)}{バックホー運転+ダンプ
トラック運転})+軽油×バックホー運転+(軽油+雑費)×ダンプトラック運転)×土砂掘削・・・(数33)
【0250】
以上例示的に説明した各種データ、すなわち対象情報は新たな情報の入力や上述した所定の処理を実行することにより様々な状態に変化可能である。すなわち、メモリ12に格納された対象情報をシステム管理する上で最も管理し易い状態、換言すると抽象レベルに移行することができる。次に、本発明に係る抽象度に応じた各レベルについて適用例とともに説明する。
【0251】
図23は、集合レベル22で表現される対象情報の例を示す。集合レベル22では、対象情報の抽象度が高く表現される。集合レベル22は、Σ集合ID×項又はΣ項×集合IDにより表現することができる。社員1、社員2、社員3からなる社員情報と、机、およびPCからなる備品情報が存在する場合について考える。この場合社員が集合IDに相当し、社員1、社員2、社員3がそれぞれ項に相当する。また、備品情報については、備品が集合IDに相当し、机及びPCが項に相当する。したがって、これらの対象情報を集合レベルで表現すると数32のように表現できる。
社員×社員1+社員×社員2+社員×社員3+机×備品+PC×備品・・・(数32)
【0252】
図24は、トポロジー空間レベル23で表現される対象情報の例を示す。トポロジー空間レベル23は、トポロジー空間ID×(Σ部分集合)により表現することができる。ただし、数32に対して、集合IDである社員、あるいは、備品を括りだした式も、トポロジー空間レベル23で表現される対象情報である。以下、数32Aに示す。
社員×(社員1+社員2+社員3)+(机+PC)×備品・・・(数32A)
【0253】
トポロジー空間レベル23では、前記集合レベル22よりも前記対象情報の抽象度が低く表現される。また、該対象情報が部分集合を項として表現される。上述した社員情報及び備品情報に新たに会社情報が追加され、社員情報及び備品情報は会社情報に属している。また、例えば、机のデータが、机1、机2からなり、PCのデータがPC1およびPC2からなり、備品データは、机とPCからなり、会社管理するデータベースが、社員データと、備品データとを有する場合に、会社管理するデータベースは、次のような構成となる。この場合には、備品情報は机1、机2、机3からなる机情報と、PC1、PC2、PC3からなるPC情報により構成される。このように、前述した集合レベル22よりも抽象度がより低く表現されている。そしてこれらの対象情報をトポロジー空間レベル23で表現すると数33のように表現できる。
会社ID(社員(社員1+社員2+社員3)+備品(机(机1+机2)+PC(PC1+PC2)))・・・(数33)
【0254】
ここでは、会社を管理するデータベースは、会社IDによって識別される。“社員”で識別されるデータの部分集合は、社員1、社員2のような個々のデータを有している。ここで、社員1は、例えば、社員1のID×(氏名+所属+職務)等である。また、備品といるIDで識別されるデータの部分集合は、さらに、机というIDで識別される部分集合と、PCというIDで識別される部分集合のデータとが、存在することを示している。机で識別されるデータの部分集合には、机1、机2等の個々のデータが記録される。机1は、例えば、机1のID×(取得原価+時価+設置場所+メーカ)等である。PCで識別されるデータの部分集合も同様である。このように、情報処理装置100によれば、式表現でにて、識別子を×、+、()、{}によって組み合わせることで、管理対象を表現し、コンピュータ上のメモリ12に記憶し、管理することができる。
【0255】
図25は、接着空間レベル24で表現される対象情報の例を示す。トポロジー空間X,Yがそれぞれ部分集合X0,Y0に含まれる因子x,yによって同値関係を指定して接着
すると接着空間は、{トポロジー空間XID×xの左因子+トポロジー空間YID×yの左因子}×{x+y}×{xの右因子+yの右因子}+トポロジー空間XID×(部分集合X−X0)+トポロジー空間YID×(部分集合Y−Y0)となる。接着空間レベル24では、前記トポロジー空間レベル23よりも前記対象情報の抽象度が低く表現される。また、前記トポロジー空間レベル23における前記対象情報同士が接着されて表現される。図25に示すように、上述した会社情報に新たにトポロジー空間レベル23で表現される情報機器情報が追加されている。そして、情報機器情報は、ノート及びデスクトップからなるPC情報とM1及びM2からなるモバイル情報により構成されている。
【0256】
会社情報と情報機器情報をみるとPC情報が共通していることがわかる。このような場合において、上述した所定の処理を実行することにより会社情報及び情報機器情報を展開する。すなわち、まず、商演算処理を実行して対象情報を分割し、その後分解した各情報の中からPC情報を抽出し、接着処理を実行することにより接着空間を形成する。すなわち、トポロジー空間レベル23で表現されていた会社情報及び情報機器情報を接着空間レベル24へ移行されたことになる。これにより、今まで別々の情報として管理されていた情報を関連付けることができる。なお、商演算処理及び接着処理を実行するに当たり、ホモトピー保存処理を実行することで、処理の保存することが可能となる。その結果、前記処理手段の処理実行前の前記対象情報の状態を取得することが可能となる。また、これらは上述した基本となる所定の処理を実行することによって実現できる。しがたって、新たにアプリケーションプログラムを設計する必要もない。
【0257】
図26は、セル空間レベル25で表現される対象情報の例を示す。セル空間レベル25は、セル空間ID×(キー属性×{ε+Σその他属性を表す部分集合}(ΣインスタンスID×{ε+Σ値を表す部分集合}))により表現できる。また、セル空間レベル25は、前記トポロジー空間レベル23よりも前記対象情報の抽象度が低く表現され、前記トポロジー空間における前記対象情報が所定の属性をもって表現される。図26に示すように、社員情報はキー属性すなわち社員コードを持つ社員名、所属、年齢により構成される。また、これら社員名や所属に関する情報は社員ごとに識別情報である社員コードを付与されて区分けされている。そしてこれらの対象情報をセル空間レベル25で表現すると数34のように表現できる。
社員×(社員コード×{ε+社員名+所属+年齢}×(K10×{ε+社員A+土木+30歳}+K11×{ε+社員B+建築+29歳}))・・・(数34)
【0258】
セル空間レベル25で表現される対象情報について新たな属性が追加された場合、従来はこの新たな情報に対応するために全体のデータベース設計,アプリケーションプログラムを組みなおすことが必要とされていた。これは、従来の情報処理では、情報処理の対象となるデータが、表、対象指向データベースでの対象の階層構造、そのような対象間の継承、データ間の関係を示すポインタによるリンク等で記述されるからである。しかし、第1の実行形態に係る情報処理装置によれば、データが、文字列を因子とする1以上の因子の積和形式の多項式で記述されるため、新たな情報の追加を自由に行うことができる。
【0259】
さらに、本情報処理装置は、社員コード×{ε+社員名+所属+年齢}に対して、新たに、性別、役職を追加することもできる。この場合には、既存のデータに対して、性別、役職の初期値としてΦを用いて、社員コード×{ε+社員名+所属+年齢+性別+役職}(101{阿部太郎+営業+23+Φ+Φ}+・途中略・+198{阿部太郎+総務+25+Φ+Φ}+199{山本三郎+設計+20+Φ+Φ})のように表現すればよい。そして、その後、各社員の役職の変更を行えばよい。ただし、属性追加時に、属性値(実際の性別、役職等)を入力してもよい。 また、例えば、
社員コード×{ε+社員名+所属+年齢}(101{阿部太郎+営業+23}+・途中略・+198{阿部太郎+総務+25})からなる社員データベースへの社員データ199{山本三郎+設計+20}の追加後の結果は、社員コード×{ε+社員名+所属+年齢}(101{阿部太郎+営業+23}+・途中略・+198{阿部太郎+総務+25}
というデータが登録されてあり、属性を追加したオブジェクトである 社員コード×{ε+社員名+所属+年齢+性別+役職}(199{山本三郎+設計+20+男+部長}}
を追加したいとき、
社員コード×{ε+社員名+所属+年齢}(101{阿部太郎+営業+23}+・途中略・+198{阿部太郎+総務+25})からなる社員データベースへの社員データ199{山本三郎+設計+20}の追加後の結果は、社員コード×{ε+社員名+所属+年齢}(101{阿部太郎+営業+23}+・途中略・+198{阿部太郎+総務+25})+社員コード×{ε+社員名+所属+年齢+性別+役職}(199{山本三郎+設計+20+男+部長}}
と単純にオブジェクトを追加すればよい。つまり、本情報処理装置100では、管理する対象、記述する概念毎に属性を決めることができる。これは,属性を含めたスキーマ設計が必要ないことを意味する。既存の技術では,データベースのスキーマを変更するにはメンテナンス上の手間が非常に大きくなる。 さらに、作成した式は,上述した所定の処理、すなわち、文字列の横方向展開、縦方向展開、積演算処理、商演算処理、接着演算処理、部分集合取得処理、ホモトピー保存処理、ホモトピー保存式におけるUNDO処理、およびホモトピー保存式におけるREDO処理によって、式を変形することで即座に期待する出力結果を得ることができる。従来の技術ならアプリケーションプログラムの開発が必要とされるところである。
【0260】
さらにまた、情報をプレーンテキストとして保存した場合には、情報の処理、取り扱いに拘束がない反面、情報に対して一貫性のある演算処理を構築することが困難となる。情報処理は、例えば、文字列の検索、挿入、削除、書き換え等に限定される。
【0261】
しかし、本実施形態のように、情報を式表現、識別子、因子、項(要素)、集合情報、トポロジー空間情報、セル空間情報、接着空間情報のように、複雑さをレベル分けし、それぞれのレベルで、式表現を限定することにより、縦方向展開、横方向展開、和、積、商、剰余、部分集合取得、接着等の演算を定義することが可能となる。したがって、メモリに保持した情報をこれらの演算を実行する共通関数で取り扱うことが可能となる。従って、式表現による柔軟性を確保するとともに、式表現の規則によって拘束された形式で事物あるいは概念を記述し、メモリ12に保持し、処理し、表示できる。
【0262】
《第2実施形態》
以下、図27から図32を参照して、本発明の第2実施形態を説明する。上記第1実施形態では、式表現を用いて記述したコンピュータ上の対象情報のデータ構造と、そのような対象情報を取り扱う基本的な演算の種類と、コンピュータ上での演算の処理例を説明した。また、そのようなデータ構造と演算によって、処理されるデータ例を説明した。本実施形態では、第1実施形態で説明したデータ構造および演算によって構成されるアプリケーションプログラムの例を説明する。
【0263】
図27は、本実施形態に係る情報処理装置100の構成である。情報処理装置100のハードウェアの構成は、第1実施形態と同一である。ただし、図27では、CPU13で実行されるプログラムが、ユーザインターフェース部101、情報管理部102、および共通関関数ライブラリ103に分けて示されている。
【0264】
これらのうち、共通関数ライブラリは、第1実施形態で説明した共通関数群をライブラリ化し、アプリケーションプログラムから呼び出し可能としたものである。共通関数群には、和演算、積演算、縦方向展開処理、横方向展開補処理、商演算(剰余取得も含む)、部分集合取得、ホモトピー保存、UNDO、REDU、インスタンス挿入、インスタンス
削除、インスタンス変更等を含む。
【0265】
情報管理部は、入力部11からの操作にしたがってインスタンス等のデータを生成し、メモリ102にデータを格納し、検索し、変更し、削除し、出力部14に出力するアプリケーションプログラムである。本実施形態では、このアプリケーションプログラムの処理を具体的に説明する。
【0266】
ユーザインターフェース部101は、入力部11でのユーザ操作の検出、検出されたユーザ操作の情報管理部102への報告、情報管理部102からの指示に基づくデータの出力部14への出力等を実行する。ユーザインターフェース部101は、例えば、グラフィカルユーザインターフェースを提供する関数群、コントロール等を組み合わせて実現される。本実施形態において、ユーザインターフェース部101は、従来のアプリケーションプログラムのユーザインターフェースと同様である。
【0267】
図28Aおよび図28Bに、社員データ管理処理の処理フローを示す。社員データ管理処理は、データ管理部102の機能の1つである。この処理では、CPU113は、通常、不図示の社員データ管理ウィンドウを出力部14に表示して、ユーザ操作を待つ(S1、S2)。
【0268】
そして、ユーザ操作が検出されると、CPU13は、その操作の種類を判定する。例えば、CPU13は、操作が、新規データの入力要求であるか、否かを判定する(S3)。新規データの入力要求は、新規データの入力を要求するメニューの選択、ウィンドウ上のボタンの押下等によって検知される。
【0269】
操作が、新規データの入力要求である場合、CPU13は、社員データ入力処理を実行する(S4)。その後、CPU13は、制御をS1に戻し、再び、ユーザ操作待ちになる。
【0270】
操作が新規データの入力要求でない場合、CPU13は、操作がデータ検索要求であるか否かを判定する(S5)。
【0271】
操作が、データ検索要求である場合、CPU13は、社員データ検索処理を実行する(S6)。その後、CPU13は、制御をS1に戻し、再び、ユーザ操作待ちになる。
【0272】
操作がデータ検索要求でない場合、CPU13は、操作がデータ削除要求であるか否かを判定する(S7)。
【0273】
操作が、データ削除要求である場合、CPU13は、社員データ削除処理を実行する(S8)。その後、CPU13は、制御をS1に戻し、再び、ユーザ操作待ちになる。
【0274】
操作がデータ削除要求でない場合、CPU13は、操作がデータ変更要求であるか否かを判定する(S9)。
【0275】
操作が、データ変更要求である場合、CPU13は、社員データ変更処理を実行する(SA)。その後、CPU13は、制御をS1に戻し、再び、ユーザ操作待ちになる。
【0276】
操作がデータ変更要求でない場合、CPU13は、操作がメモ接着要求であるか否かを判定する(SB)。
【0277】
操作が、メモ接着要求である場合、CPU13は、メモ作成と接着処理を実行する(S
C)。その後、CPU13は、制御をS1に戻し、再び、ユーザ操作待ちになる。
【0278】
操作がメモ接着要求でない場合、CPU13は、操作がメモ切り離し要求であるか否かを判定する(SD)。
【0279】
操作が、メモ切り離し要求である場合、CPU13は、メモ切り離し処理を実行する(SE)。その後、CPU13は、制御をS1に戻し、再び、ユーザ操作待ちになる。
【0280】
操作がメモ切り離し要求でない場合、CPU13は、操作が集合接着要求であるか否かを判定する(SF)。
【0281】
操作が、集合接着要求である場合、CPU13は、集合接着処理を実行する(SG)。その後、CPU13は、制御をS1に戻し、再び、ユーザ操作待ちになる。
【0282】
操作が集合接着要求でない場合、CPU13は、操作が集合切り離し要求であるか否かを判定する(SH)。
【0283】
操作が、集合切り離し要求である場合、CPU13は、集合切り離し処理を実行する(SI)。その後、CPU13は、制御をS1に戻し、再び、ユーザ操作待ちになる。
【0284】
操作が集合切り離し要求でない場合、CPU13は、操作が属性追加要求であるか否かを判定する(SJ)。
【0285】
操作が、属性追加要求である場合、CPU13は、属性追加処理を実行する(SK)。その後、CPU13は、制御をS1に戻し、再び、ユーザ操作待ちになる。
【0286】
操作が属性追加要求でない場合、CPU13は、操作が属性値構成変更要求であるか否かを判定する(SL)。
【0287】
操作が、属性値構成変更要求である場合、CPU13は、属性値構成変更処理を実行する(SM)。その後、CPU13は、制御をS1に戻し、再び、ユーザ操作待ちになる。
【0288】
図29に、社員データ入力処理(図28AのS4)の詳細処理フローを示す。この処理を実行するCPU13が本発明の入力処理部に相当する。この処理では、CPU13は、出力部14に、社員データ入力画面を表示する(S41)。社員データ入力画面の画面データ自体は、メモリ12または不図示の外部記憶装置(ハードディスク等)の画面IDとともに画面データファイルに格納されている。CPU13は、入力インターフェース部101を通じて、この社員データ入力画面を表示する。なお、本実施形態における他の画面表示処理も同様である。
【0289】
次に、ユーザが、社員データ入力画面に対して社員データ(例えば、社員コード、氏名、年齢、職種、所属)を入力する。すると、CPU13は、入力インターフェース部101を通じて、入力された社員データを取り込む(S42)。
【0290】
次に、CPU13は、入力された社員データに対するインスタンス、例えば、社員コード×{ε+氏名+年齢+職種+所属}に対する101×{ε+山田太郎+26歳+設計+公共事業部}を生成する。そして、インスタンス挿入関数を用いて、社員セル空間情報のインスタンスとして、入力された社員データを挿入する(S43)。この社員データは、メモリ12または不図示の外部記憶装置に保持される。なお、社員データのインスタンスを生成する本アプリケーション専用の関数genins(集合ID、コード、氏名、年齢、職種
、所属)を提供してもよい。関数geninsは、社員コード、氏名、年齢、職種、所属のそれ
ぞれの値から、社員セル空間情報のインスタンスを生成し、集合IDで指定される集合に、生成したインスタンスを挿入し、メモリ12または外部記憶装置に保存する。
【0291】
図30に、社員データ検索処理(図28AのS6)の詳細処理フローを示す。この処理を実行するCPU13が本発明の出力処理部に相当する。この処理では、CPU13は、出力部14に、検索画面を表示する(S61)。
【0292】
次に、ユーザが、検索画面に対して検索するセル空間情報(例えば、社員データ)、属性値p(例えば、社員コードに対する値101)を入力する。すると、CPU13は、入力インターフェース部101を通じて、入力された検索する属性値を取り込む(S62)。この例では、ユニークな検索キーとして、属性×属性値が使用される。すなわち、社員コード×101がCPU13(情報管理部102)に引き渡される。
【0293】
次に、CPU13は、検索キーである社員コード×101を識別子に分解する。この場合には、“社員コード”と、“101”という識別子が得られる。これ検索する識別子という。
【0294】
次に、CPU13は、第1の検索する識別子(例えば、“社員コード”)を用いて、セル空間情報(集合IDが社員データであるセル空間情報)に対して、商演算を実行する(S64)。
【0295】
次に、CPU13は、すべての検索する識別子(“社員コード”と、“101”)で、商演算を実行したか否かを判定する。まだ、商演算を実行してしたいない識別子(例えば、“101”)がある場合、制御をS64に戻し、その識別子にて商演算を実行する。これは、いわゆる絞り込み検索に相当する。
【0296】
そして、CPU13は、ユーザインターフェース部101を通じて出力部14の検索画面に、得られた部分集合、すなわち、コード×101のインスタンスを表示する(S66)。
【0297】
このように、検索対象の情報に対して、検索する識別子によって繰り返し商演算を実行することにより、ほしいデータを検索することができる。
(例)
今、社員データベースとして、以下のものを考え得る。
社員×(社員コード×{ε+氏名+年齢+職種コード+所属名}×(
+101{ε+鈴木一郎+23+100+総務}
+102{ε+鈴木一郎+23+100+総務}
+103{ε+鈴木一郎+23+101+総務}
)
+備品コード×{ε+分類+数量+社員コード}×(
+B50{ε+机 +1+101}
+B51{ε+PC+2+102}))
この場合、まず因子”社員コード”を同値因子として商演算すると商項は、
社員×(社員コード×{ε+氏名+年齢+職種コード+所属名}×(
+101{ε+鈴木一郎+23+100+総務}
+102{ε+鈴木一郎+23+100+総務}
+103{ε+鈴木一郎+23+101+総務}))
さらにこの項に,因子”101”を同値因子として商演算すると商項は、
社員×(社員コード×{ε+氏名+年齢+職種コード+所属名}×(101{ε+鈴木一
郎+23+100+総務})となる。このようにして,全体のデータから、”社員コードが101”についての情報を取得することができる。 図31に、メモ作成と接着処理(図28BのSC)の詳細フローを示す。この処理では、CPU13は、出力部14に、メモ画面を表示する(SC1)。
【0298】
次に、ユーザが、メモ画面に対して、メモIDおよびメモ内容(テキスト情報)を入力する。すると、CPU13は、入力インターフェース部101を通じて、添付する集合、添付先、メモ内容を取り込む(SC2)。
【0299】
次に、CPU13は、取り込んだメモIDおよびメモ内容からメモのインスタンスであるメモID×{ε+テキスト情報}を生成する。そして、CPU13は、インスタンス挿入関数を用いて、メモセル空間情報に、メモのインスタンスを挿入し、メモリ12または不図示の外部記憶装置に保存する(SC3)。なお、入力されたメモIDの代わりに、情報管理部102がユニークなメモID生成するようにしてもよい。すなわち、現在のメモ集合から、すべてのメモIDを読み出し、メモIDをソーティングし、最後尾のメモIDに1を加えた値をメモIDとすればよい。
【0300】
次に、CPU13は、メモを添付する接着箇所、すなわち、セル空間情報(例えば、集合IDが社員データ)、および添付先(例えば、コードに対する値101のインスタンスの指定)を受け付ける(SC4)。
【0301】
そして、CPU13は、指定されたセル空間情報中の指定されたインスタンスであるコード101のインスタンスと、作成したメモIDのメモとの接着演算を実行する(SC5)。これによって、コード101の社員データに、メモが添付されたことになる。
【0302】
図32に、属性追加処理(図28BのSK)の詳細処理フローを示す。この処理では、CPU13は、出力部14に、属性追加設定画面を表示する(SK1)。
【0303】
次に、ユーザが、属性追加設定画面に対して、属性を追加するセル空間ID、属性追加位置、および追加属性を入力する。すると、すると、CPU13は、入力インターフェース部101を通じて、追加するセル空間ID、属性追加位置、および追加属性を取り込む(SK2)。
【0304】
次に、指定されたセル空間IDのセル空間情報に、属性を示す文字列を和演算で追加する(SK3)。
【0305】
次に、既存のインスタンスに対して、追加された属性に対する属性値Φを設定する(SK4)。
【0306】
なお、以上の説明では、社員データ削除処理(図28AのS8)、社員データ変更処理(同図のSA)、メモ切り離し処理(同図のSE)、集合接着(同図のSG)、接着集合切り離し処理(同図のSI)、属性値構成変更処理(同図のSM)については、省略した。しかし、これらの処理は、図29−32の処理とほぼ同様の手順で構成できる。
【0307】
例えば、まず、社員データ削除処理については、S6の社員データ検索処理を実行し、検索された結果をメモリ12から削除すればよい。その場合に、共通関数として、戻り値=delete(セル空間ID、インスタンス);を用意してもよい。
【0308】
また、社員データ変更処理については、S6の社員データ検索処理を実行し、検索された結果をメモリ12から変更すればよい。その場合に、共通関数として、戻り値=replac
e(セル空間ID、変更前のインスタンス、変更後のインスタンス);を用意してもよい。
【0309】
また、メモ切り離し処理(図28AのSE)については、以下の手順である。
(1)同値関係を指定する因子1と、因子2の指定を受け付ける。
(2){因子1×因子2}を含む式表現をメモリ12にて検索する。
(3){(左因子1の和)、(左因子2の和}}×{因子1+因子2}×{(右因子1の
和)+(右因子2の和)}の関係から、左因子1×因子1×右因子1の和+左因子
2×因子2×右因子2の和という式表現を構成する。
(4)得られた式表現をメモリ12に格納する。
【0310】
また、集合接着演算は、以下の手順で構成できる。
(1)接着する2つの集合情報の集合ID(例えば、集合ID1、集合ID2)と、同値
関係を指定する因子1、因子2を受け付ける。
(2)集合ID1の集合情報に商演算を実行し、因子1を含む商(同値要素1)と、剰余
に分ける。
(3)集合ID2の集合情報に商演算を実行し、因子1を含む商(同値要素2)と、剰余
に分ける。
(4)同値要素1の左因子l1、右因子r1,同値要素2の左因子l2、右因子r2を求
め、以下の商空間の式を求める。{l1+l2}{因子1+因子2}{r1+r2
}
(5)商空間の式に、集合ID1の集合情報の剰余の式と、集合ID2の集合情報の剰余の式とを和演算する。
【0311】
以上説明した本実行形態に係る情報処理装置によれば対象を所定の表現形式を用いて表現して処理することで、異なる対象同士の情報の一貫性を図るとともに新たな様々な対象情報のデータベース化及び処理が可能となる。また、所定の処理を実行することにより情報の管理に適したレベルに移行することができる。また、新たな情報を追加した場合やレベルを変化せせる場合も予め本発明に係る情報処理装置が有するプログラムに基づいて実行することができる。すなわち、プログラムの再構築を行う必要もない。
【0312】
以上、本発明の好適な実行形態を説明したが、本発明に係る情報処理装置は、これらに限らず、可能な限りこれらの組み合わせを含むことができる。
【符号の説明】
【0313】
11・・・入力部
12・・・メモリ
13・・・CPU
14・・・出力部
21・・・ホモトピーレベル
22・・・集合レベル
23・・・トポロジー空間レベル
24・・・接着空間レベル
25・・・セル空間レベル
【技術分野】
【0001】
本発明は、事物をコンピュータで処理可能な所定の表現形式を用いて表現し、コンピュータの記憶装置に記憶し、コンピュータで処理することで、その事物を管理する情報処理技術に関する。
【背景技術】
【0002】
ソフトウエアの開発プロセスは、要求分析、システム設計、実装、テスト、運用、及びメンテナンスの各段階により構成される。そして、ソフトウエア開発の最初のプロセスである、要求分析は特に重要である。なぜなら、最初の要求分析が不十分であると、それ以降のシステム設計、実装段階において、顧客の要求が正しく反映されていないなどの支障をきたすからである。例えばシステムのテスト段階で不具合が発見された場合においても、再度プログラムを修正する必要が生じる。また、大規模な修正が必要な場合には、システム設計を初めからやり直すなどの必要も生じる。しかし、プログラムの修正やシステム設計を最初からやり直しには、時間と労力がかる。その結果、コストが増大するといった問題も生ずる。また、たとえ最初の要求分析が十分であった場合においても、事業活動等様々な変化に対応させるためにはその後のメンテナンスが不可欠であるが、メンテナンスにも時間と労力がかかり、結果としてコストの増大を招くといった問題を生じている。
【0003】
ソフトウエアの開発の一例として、例えばデータベースシステムの開発が例示される。データベースシステムの開発とは、顧客の業務内容をヒアリングして、管理すべきデータ項目を洗い出し、それらの項目を関連付け、利用者が検索しやすいようなビューを設計し、顧客ニーズに合ったデータベースを構築することである。優れたデータベースを構築するためには、概念設計の段階からデータ構造を解析しておく必要がある。データとして管理すべき実体及び属性、実体間の関連を洗い出し、正確に分析することが重要になる。
【0004】
このような観点から開発された既存のデータベースのデータモデルとして、正規化表構造によるリレーショナルモデルや、ノードに属性を持つツリー構造で表現されるオブジェクト指向モデルが知られている。しかし、例えばリレーショナルモデルでは、関係をどのように定義するかは設計者の自由であるため、実装ごとに異なるシステムが生成されることになる。したがって、リレーショナルモデルに基づいて実装された複数のシステムを統合するためには、統合すべき構成要素の組み合わせ数に応じた作業工程が必要となり、システム統合に相当な時間と労力を費やす必要がるといった問題を生じていた。
【0005】
このような事情に鑑み開発されたソフトウエア開発支援装置として、本発明者の一人は、情報を階層化して表現する技術を提案した。この技術では、階層化された情報の各階層においてソフトウエア部品集合による操作が可能に構成されたモジュラ化されたデータ構造が提供される。そして、前記ソフトウエア部品集合が満たすべき仕様を前記階層ごとにインクリメンタルに詳細化することにより、与えられた要求仕様に合致するソフトウエアを前記ソフトウエア部品集合から自動生成する技術を開発した(例えば、特許文献1参照)。
【先行技術文献】
【特許文献】
【0006】
【特許文献1】特開2005−92855号公報
【特許文献2】特開平7−295938号公報
【発明の概要】
【発明が解決しようとする課題】
【0007】
上述したリレーショナルモデルやオブジェクト指向モデルでは、業務のデータモデルをサポートしていなので、個々のシステムでアプリケーションプログラムの開発が必要となる。さらに、一旦アプリケーションプログラムが開発された後であっても、リレーショナルモデルでは、システム開発時に予定されていない属性をデータベースに入力する場合には、新たな属性に対応可能なアプリケーションソフトを開発する必要が生じる。
【0008】
また、オブジェクト指向モデルは、オブジェクトの属性を細分化する有向グラフの一部としてのツリー構造については対応可能である。このツリー構造は、典型的には、有向グラフの根本側、すなわち、ツリー構造の上位には、より抽象化された概念、あるいは、共通化された概念が定義され、グラフの先端側、すなわち、ツリー構造の下位には、それぞれの上位概念を具体化した個別の概念が定義される。しかし、オブジェクト指向モデルは、逆ツリー構造については対応できない。
【0009】
ここで、逆ツリー構造とは、例えば、階層構造の上位には、基本的な概念が定義され、階層構造の下位には、複数の基本概念を組み合わせた概念が定義される。なお、上述したソフトウエア開発支援装置によれば、ソフトウエア開発の効率化を図ることが可能となることが示された。しかし、開発コスト、メンテナンスコストを削減でき、業務モデルを統一的に表現できるデータモデル、およびそのようなデータモデルを利用したさらに効率的なシステム開発技術、情報処理技術が求められていた。
【0010】
本発明は、上記問題に鑑みてなされたものであり、業務モデルを統一的に表現し、記憶し、処理することで、異なるシステム間においても、情報の一貫性を図るとともに新たな業務モデルへの適用、新たな管理対象となる情報項目、種類の追加・変更・削除、あるいは新たな処理機能の追加、変更等が可能なシステム開発技術、および情報処理技術を提供することを課題とする。
【課題を解決するための手段】
【0011】
本発明は前記課題を解決するために、以下の手段を採用した。すなわち、本発明は、識別子と、順序を持つ因子の列として複数の識別子を結合する積演算子と、識別子および因子の列として結合された複数の識別子のいずれかまたは両方から項の組み合わせを構成する和演算子と、によって記述される対象情報を記憶する記憶部と、対象情報を操作する処理部と、情報の入力を受け付ける入力部を接続可能なインターフェースと、情報を出力する出力部を接続可能なインターフェースと、を備える情報処理装置である。そして、本発明では、処理部は、インターフェースに接続された入力部から入力される情報を識別子、因子、項および項の和である式のいずれか1以上として対象情報に設定し、記憶部に記憶させる入力処理部と、記憶部に記憶されている対象情報を参照し、参照した対象情報中の識別子、因子、項および式のいずれか1以上が入力部から入力される情報と所定の関係にあるときに、対象情報を前記インターフェースに接続された出力部に出力する出力処理部と、を有する。
【0012】
本発明によれば、情報処理装置に、入力部が入力されたときに、入力される情報が、識別子、因子、項および式のいずれか1以上として対象情報に設定され、記憶部に記憶される。また、インターフェースに出力部が接続され、記憶手段にて参照した対象情報中の識別子、因子、項および式のいずれか1以上が入力部から入力される情報と所定の関係にあるときに、出力部から、対象情報が出力される。
【0013】
このように、本発明によれば、識別子および各種演算子を組み合わせた表現形式で入力部から入力される対象情報を記述し、記憶し、さらには、参照し、出力部から出力する機能が実現される。
【0014】
本発明は、以上のような処理をコンピュータが実行する方法であってもよい。また、本発明は、コンピュータに以上のような処理を実行させるプログラムであってもよい。また、そのようなプログラムを記録したコンピュータが読み取り可能な記録媒体であってもよい。
【0015】
また、本発明は、上記対象情報を記述するときのデータ構造であってもよい。また、そのようなデータ構造を記録したコンピュータが読み取り可能な記録媒体であってもよい。このようなデータ構造にしたがって対象情報を記憶し、あるいは記録することにより、コンピュータは、識別子および各種演算子を組み合わせた表現形式で入力部から入力される対象情報を記述し、記憶し、さらには、参照し、出力部から出力する機能を実現する。
【発明の効果】
【0016】
本発明に係る情報処理装置によれば、業務モデルを統一的に表現して処理、すなわち事物を所定の表現形式を用いて表現して処理することで、異なるシステム間においても、情報の一貫性を図るとともに新たな業務モデルへの適用、新たな管理対象となる情報項目、種類の追加・変更・削除、あるいは新たな処理機能の追加、変更等が可能なシステム開発技術、および情報処理技術を提供することができる。
【図面の簡単な説明】
【0017】
【図1】第1の実施形態に係る情報処理装置の構成を示すブロック図である。
【図2】第1の実施形態に係る情報処理装置のメモリに格納される第一のデータ構造を示す。
【図3】第1の実施形態に係る情報処理装置のメモリに格納される第二のデータ構造を示す。
【図4】第1の実施形態に係る情報処理装置のメモリに格納される第三のデータ構造を示す。
【図5】第1の実施形態に係る情報処理装置におけるプログラム構成を示す図である。
【図6A】横方向展開処理を実行する処理のフローを示す。
【図6B】横方向展開処理を実行中の対象情報の状態の詳細を示す表である。
【図6C】横方向展開処理を実行中の対象情報の状態の詳細を示す表である。
【図7】縦方向展開処理を実行する処理のフローを示す。
【図8A】縦方向展開処理を実行中の対象情報の状態の詳細を示す表である。
【図8B】縦方向展開処理を実行中の対象情報の状態の詳細を示す表である。
【図8C】縦方向展開処理を実行中の対象情報の状態の詳細を示す表である。
【図8D】縦方向展開処理を実行中の対象情報の状態の詳細を示す表である。
【図9】積演算処理を実行する処理のフローを示す。
【図10】積演算処理を実行中の対象情報の状態の詳細を示す表である。
【図11A】商演算処理(サブルーチン1)を実行する処理のフローを示す図である。
【図11B】商演算処理(サブルーチン1)を実行中の対象情報の状態の詳細を示す表(その1)である。
【図11C】商演算処理(サブルーチン1)を実行中の対象情報の状態の詳細を示す表(その2)である。
【図12A】商演算処理(サブルーチン2)を実行する処理のフローを示す図である。
【図12B】商演算処理(サブルーチン2)を実行中の対象情報の状態の詳細を示す表(その1)である。
【図12C】商演算処理(サブルーチン2)を実行中の対象情報の状態の詳細を示す表(その2)である。
【図13】接着演算処理を実行する処理のフローを示す。
【図14】接着演算処理を実行中の対象情報の状態の詳細を示す表である。
【図15】部分集合取得処理を実行する処理のフローを示す。
【図16A】部分集合取得処理を実行中の対象情報の状態の詳細を示す表である。
【図16B】部分集合取得処理を実行中の対象情報の状態の詳細を示す表である。
【図17】ホモトピー保存処理を実行する処理のフローを示す。
【図18】ホモトピー保存式におけるUNDO演算処理のフローを示す。
【図19】ホモトピー保存式におけるREDO演算処理のフローを示す。
【図20】建設業における情報管理、すなわちデータ処理システムが要求される例を示す。
【図21A】本発明の対象情報に相当する社員データ及び伝票データを示す。
【図21B】本発明の対象情報に相当する伝票データを示す。
【図22A】プロジェクトデータを示す。
【図22B】歩掛作成データを示す。
【図23】集合レベル22で表現される対象情報の例を示す。
【図24】トポロジー空間レベル23で表現される対象情報の例を示す。
【図25】接着空間レベル24で表現される対象情報の例を示す。
【図26】セル空間レベル25で表現される対象情報の例を示す。
【図27】本発明の第2の実施形態に係る情報処理装置100の構成である。
【図28A】社員データ管理処理の処理フローを示す図(その1)である。
【図28B】社員データ管理処理の処理フローを示す図(その2)である。
【図29】社員データ入力処理の詳細処理フローを示す図である。
【図30】社員データ検索処理の詳細処理フローを示す図である。
【図31】メモ作成と接着処理の詳細フローを示す図である。
【図32】属性追加処理の詳細処理フローを示す図である。
【発明を実施するための形態】
【0018】
以下、図面を参照して、本発明の実施形態に係る情報処理装置を説明する。
【0019】
《システムの骨子》
本情報処理装置は、情報を集合レベル、トポロジー空間レベル、接着空間レベル、およびセル空間レベルというデータ構造の複雑さの異なるレベルで表現する。データ構造が複雑になればなるほど、表現される情報と情報との間の関連付け、あるいは、情報と情報との拘束が増加する。
【0020】
例えば、集合レベルは、情報が項(以下、要素ともいう)を組み合わせた集合情報として記述される。それぞれの集合情報は、集合IDで識別される。また、トポロジー空間レベルでは、項または集合を組み合わせたトポロジー空間情報として情報が記述される。それぞれのトポロジー空間情報は、トポロジーIDで識別される。
【0021】
すなわち、集合レベルは、単なる項の組み合わせであるのに対し、トポロジー空間レベルは、集合情報の組み合わせを含む点で、より複雑となっている。本実施形態では、この場合に、集合レベルは、トポロジー空間レベルよりも抽象度が高い、ともいう。ただし、トポロジー空間情報は、単一の集合情報をも含む。すなわち、トポロジー空間レベルは、集合レベルの性質をそのまま有している。本実施形態では、この意味で、トポロジー空間レベルは、集合レベルの特性を継承している、という。
【0022】
接着空間レベルは、集合情報またはトポロジー空間情報のいずれか2つ以上(以下、被接着情報)を接着した情報を含む。接着とは、本実施形態にて提案する概念であり、2つ
の被接着情報のそれぞれのデータ構造を維持した上で、被接着情報を互いに結合する機能である。接着においては、2つの被接着情報のそれぞれに含まれる情報で、互い関係付けられる情報が指定される。そして、その関係付けられた情報同士を介して、2つの被接着情報が結合される。接着は、例えば、人の行為である伝票にメモを張り付ける行為をコンピュータ上で実現したものとなる。すなわち、伝票ID、伝票に含まれる項目、および伝票内の位置情報からなるデータ構造と、メモIDおよびメモ内容である文字列情報からなるデータ構造があったときに、伝票上の位置情報と、メモIDとを関連づけ、接着演算を実行することにより、伝票上の指定された位置にメモが添付された状態をコンピュータ上で表現できる。接着された2つの被接着情報は、また、分離することもできる。ただし、接着空間の情報は、それぞれの被接着情報の特性、すなわち、集合レベル、あるいは、トポロジー空間レベルの特性をそのまま有している。そのため、接着空間の情報は、これらのレベルを継承しているという。
【0023】
セル空間レベルとは、属性と値とを含むデータ構造が定義された情報であり、集合情報、トポロジー空間情報、および接着された情報をさらに複雑にしたものと言える。この点で、逆に、集合情報、トポロジー空間情報、および、これらが接着された情報は、セル空間の情報よりも抽象度が高いともいう。ただし、セル空間レベルの集合は、集合レベル、トポロジー空間レベル、および接着空間レベルの特性を有することができ、その意味で、これらのレベルを継承しているという。
【0024】
よってセル空間が定義される(つまり空間に属性,値の意味が付加される)セル空間レベルならば,一般的なトポロジー空間のレベルよりも抽象度が低いと見なされる。
【0025】
本情報処理装置は、抽象度に応じた各レベルの所定の表現形式によって表現される情報が格納される記憶手段と、前記情報を処理する処理手段と、を備える。そして、前記記憶手段には、識別子と、順序を持つ因子の列として複数の識別子を結合する積演算子と、識別子および前記因子の列として結合された複数の識別子のいずれかまたは両方から項の組み合わせを構成する和演算子と、によって記述される対象情報が記憶される。さらに、対象情報は、前記組み合わせ中の項の順序を維持して前記項の組み合わせを関係付けることによって因子または新たな項を構成する順序構成演算子と、前記組み合わせ中の項の順序を維持しないで前記項の組み合わせを関係付けることによって因子または新たな項を構成する集合因子構成演算子と、を含んでもよい。
【0026】
以下、本情報処理装置の記憶手段に記憶され、本情報処理装置で処理される情報を対象情報という。対象情報は、識別子、因子、項(要素)、集合情報、トポロジー空間情報、接着された情報、セル空間の情報を含む。対象情報をオブジェクト情報とも呼ぶ。ただし、本実施形態でのオブジェクト情報は、いわゆるオブジェクト指向データベース、オブジェクト指向言語、オブジェクト指向設計等でいうオブジェクトとは、概念が異なる。そこで、以下では、もっぱらオブジェクト情報という代わりに、対象情報と呼ぶことにする。
【0027】
また、本実施形態では、項の組み合わせから因子を構成する集合因子構成演算子及び順序構成演算子が使用される。集合因子構成演算子は、第一の括弧“()”により表現される。また、順序構成演算子は第二の括弧“{}”により表現される。
【0028】
本発明によれば、対象情報を所定の表現形式のデータとして記憶手段に格納し、これに所定のプログラムに基づいて処理を実行することができる。その結果、異なる対象情報同士の情報の一貫性を図るとともに新たな様々な対象情報のデータベース化及び処理が可能な情報処理装置を提供することが可能となる。また、従来のリレーショナルモデルやオブジェクト指向モデルでは、対応できないデータに対応することができるシステムを開発することができる。
【0029】
記憶手段は、抽象度に応じた各レベルの所定の表現形式によって表現される対象情報を例えばテキストファイルとして格納する。記憶手段は、前記対象情報を十分に格納できる容量を有するものであればよく、ハードディスク等がこれに該当する。対象情報とは、システム開発におけるデータベースを構成する全ての情報を含むものである。例えば既存のデータモデルの正規化表構造を構成するレコードの構成要素や正規化表構造では入力不可能なデータ構造も含む。正規化表構造では入力不可能な情報とは、例えば正規化表構造で表現されるようなデータがある場合に、これに付箋のような前記正規化表構造とは全く関連性のない、すなわち属性の定義のない対象情報を意味する。また、この対象情報は、本情報処理装置の処理を実行することによりその抽象度が変化することを特徴とする。すなわち、あるレベルで入力された対象情報は、本情報処理装置の処理が実行されることによりそのレベルが変化する。そして、そのレベルが変化しても対象情報は、変化前と同一の演算によって、取り扱うことができる。すなわち、対象情報は、抽象レベルが変化しても対象情報の性質には一貫性が保たれるので、同一の演算による操作が可能である。したがって、ある抽象度で格納された対象情報、すなわちデータは本情報処理装置の処理が実行されることにより様々なレベルに変化する。また、上述のように全く関連性のないデータも入力してこれを関連付けることが可能である。したがって、異なる抽象度のレベルにおいて、情報の性質の一貫性が保たれるとともに、新たな様々な事物を示す情報のデータベース化及びデータベース化された情報に対する演算処理が可能となる。
【0030】
前記対象情報は、記号、識別子、第一の括弧及び第二の括弧により表現される因子と、前記因子の積によって表現される項と、前記項の和によって表現される式と、により構成することができる。式を構成する項、および項を構成する因子は、前記対象情報を構成する最小単位である識別子と、前記処理手段において1として処理される単位元εと、前記処理手段において0として処理される零元Φとにより構成することができる。前記第一の括弧は、()により表現することができる。また、前記第二の括弧は{}により表現することができる。このように本発明によれば、対象情報が非常に簡単なデータ構造で表現されている。したがって、高度な技術を有さないユーザであっても容易に理解することが可能となる。
【0031】
前記第一の括弧と前記第二の括弧は演算時の強さが異なる。演算時の強さが異なるとは、前記処理手段の処理を実行する際の展開順序が異なることを意味する。項は、前述した因子の積によって表現され、積は×により表現することができる。本実施形態では、積を構成する因子に、可換律は、成立しない。すなわち、a×bとb×aは、同一とは見なされない。また、式は前記項の和によって表現され、和は+により表現することができる。本実施形態では、和を構成する項に、可換律が、成立する。すなわち、a+bとb+aは、同一とは見なされる。以上より、例えばある対象情報は数1のように表現することができる。
(a+b)×{c+d+e}+f{g+h}×{i+j}・・・(数1)
【0032】
上記数1で表現される対象情報は、第一の項の(a+b)×{c+d+e}と、第二の項のf{g+h}×{i+j}により構成されている。すなわち、数1は第一の項と第二の項との和により構成されている。次に、第一の項と第二の項のそれぞれについてみると、第一の項は、第一の因子の(a+b)と、第二の因子の{c+d+e}とにより構成されている。また、第二の項についてみると、第三の因子のfと、第四の因子の{g+h}と、第五の因子の{i+j}とにより構成されている。なお、上記数1において、“f”の後に、積演算子“×”を明示し、“f×”としてもよい。そして第一の因子から第五の因子のそれぞれについてみると、第一の因子は、第一の括弧と識別子a及びbにより構成されている。また、第二の因子は第二の括弧と識別子c、d及びeにより構成され、第三の因子は識別子fにより構成され、第四の因子は第二の括弧と識別子g及びfにより構成
され、第五の因子は第二の括弧と識別子i及びjにより構成されている。なお、括弧の中は換言すると再帰的に式になっている。例えば、上記のうち(a+b)についてみると、括弧の中は再帰的に式a+bになっている。すなわち、上記式は項としての識別子aと項としての識別子bの和によってなっている。このように、式は、()または{}、およびその両方が複数回入れ子になった構造を含むことができる。
【0033】
対象情報は、上記のように因子、項からなる式で表現される。そしてこのように表現された対象情報は、例えばテキストファイルとして前記記憶手段に格納される。なお、記憶手段への対象情報の格納、換言すると入力はユーザ操作に応答して実行される。この入力時に、グラフィカルユーザインターフェースを用いたユーザインターフェース部を提供してもよい。簡易的には、テキストエディタで、識別子、項、あるいは、項の和を入力するようにしてもよい。情報処理手段は、記憶手段に格納されたその対象情報を処理する。これにより、前記対象情報の抽象度を変化させることが可能となる。
【0034】
本情報処理装置は、前記対象情報を展開する展開手段と、前記対象情報から部分集合を取得する部分集合取得手段と、前記対象情報についてホモトピー保存処理を実行するホモトピー保存処理手段と、異なる対象情報を構成する前記因子間における同値関係の対応に基づき該因子同士を接着して新たな空間である接着空間を作成する接着空間作成手段と、前記対象情報を分割する商空間作成手段と、のうち少なくともいずれか一つを有する。これにより、前記対象情報の抽象度を様々な状態に変化させることが可能となる。
【0035】
展開手段は、前記対象情報を展開する。前記展開手段は、前記対象情報を前記項又は前記因子の単位に分解する分解手段と、前記因子間で集合演算処理をし、集合演算処理後の新たな項を設定する項設定手段と、前記第一の括弧及び第二の括弧で括られた因子を再帰的に展開処理する再帰的展開処理手段と、により構成することができる。そして、例えば上述した数1で表現される対象情報を展開処理すると数2のようになる。
(a+b)×{c+d+e}+f{g+h}×{i+j}
→(a{c+d+e}+b{c+d+e})+{f×g+f×h}×{i+j}
→({a×c+a×d+a×e}+{b×c+b×d+b×e})+{f×g×i+f×h×j}
→a×c+a×d+a×e+b×c+b×d+b×e+f×g×i+f×h×j・・・(数2)
【0036】
すなわち、まず、第一の項を構成する第一の因子と第二の因子が展開する。次に、第一の因子の一番左の識別子であるaと第二の因子を構成する一番左の識別子cが掛け合わせる。次に、d、eの順に掛け合わせて展開する。そして、第一の因子の左から2番目の識別子、換言すると右側の識別子であるbと第二の因子を構成する一番左の識別子cが掛け合わせる。その後、d、eの順に掛け合わせて展開する。一方、第二の項については、まず第二の括弧で括られている第四の因子と同じく第二の括弧で括られている第五の因子を掛け合わせる。なお、第二の括弧は、第一の括弧とは異なり因子の順序ごとに積を作成しその和を出力する展開が行われる。すなわち、まず第四の因子を構成する一番左の識別子gと第五の因子を構成する一番左の識別子iの積を作成する。次に、第四の因子を構成する左から2番目の識別子であるhと第五の因子を構成する左から2番目の識別子であるjの積を作成し、これらの和として出力する。更に第三の因子を構成する識別子fと掛け合わせて展開する。
【0037】
このような展開処理を行うことにより、数1で表現される前記対象情報は、対象情報の最小単位である識別子の積とこれらの和によって表現されることになる。すなわち、展開手段による展開を実行することにより集合で表現することが可能となる。つまりは、展開処理手段を備えることで前記対象情報の抽象度を高くすることが可能となる。
【0038】
部分集合取得手段は、部分集合を取得する。これにより、前記対象情報の中から部分集合を取得することが可能となる。例えば、数3で表現される対象情報について、aについての部分集合を取得すると数4で表現される対象情報となる。
a×c+a×d+a×e+b×c+b×d+b×e+f×g×i+f×h×j・・・(数3)
a(c+d+e)+b×c+b×d+b×e+f×g×i+f×h×j・・・(数4)
【0039】
接着空間作成手段は、異なる対象情報を構成する前記因子間における同値関係の対応に基づき該因子同士を接着する。その結果、新たな空間である接着空間を作成することができる。接着空間作成手段を備えることで、前記対象情報が異なる空間を表現するものであっても、同値関係にある因子を介して関連付け新たな空間を設計することが可能となる。
【0040】
ホモトピー保存処理手段は、前記対象情報についてホモトピー保存処理を実行する。ホモトピー保存処理は、対象情報に対する演算結果とともに、演算前の対象情報、適用された演算、および、演算時に使用されたパラメータを記憶する機能である。これにより、前記処理手段の処理実行前の前記対象情報の状態を取得することが可能となる。そして、例えばホモトピー保存処理手段による処理の実行は数5のように表すことができる。
a(b+c)
↓H
(a×b+a×c)=F(a(b+c)+ε)・・・(数5)
【0041】
数5におけるFは、本情報処理装置100で規定した「展開」という演算をを表す識別子である。また、εは、値“1”を表す記号であり、Fの演算において、値“1”が使用されたことを示している。すなわち、展開処理を実行した後の状態を表す、対象情報(a×b+a×c)は、a(b+c)を展開処理したものであることを意味する。このように、ホモトピー保存処理を実行することによって、前記格納処理手段に格納される対象情報は処理前の状態についても保存されているため、対象情報の過去の状態を取得することが可能となる。
【0042】
本発明に係る情報記憶装置において、前記各レベルは、前記対象情報が最も抽象度が高く表現される集合レベルと、前記集合レベルよりも前記対象情報の抽象度が低く表現され、該対象情報が部分集合によって表現されるトポロジー空間レベルと、前記トポロジー空間レベルよりも前記対象情報の抽象度が低く表現され、該トポロジー空間レベルにおける前記対象情報同士が接着される接着空間レベルと、前記接着空間レベルよりも前記対象情報の抽象度が低く表現され、前記トポロジー空間における前記対象情報が所定の属性をもって表現されるセル空間レベルと、を有するものとしてもよい。
【0043】
ここで、抽象度が高いとは、対象情報同士の関係、あるいは、関連を示す情報が少ないことをいう。
【0044】
例えば、集合レベルは、前記対象情報の抽象度が最も高く表現されるものである。集合レベルにおける対象情報(以下、集合の対象情報ともいう)は対象情報の最小単位である識別子の積を項としてこれらの和からなる式によって表現される。なお、集合レベルには、他の抽象度の低いレベルから展開処理手段の展開処理を実行することにより移行することができる。また、前記記憶手段に格納する際に集合レベルで入力することとしてもよい。
【0045】
トポロジー空間レベルは、前記集合レベルよりも前記対象情報の抽象度が低く表現される。また、対象情報の部分集合を要素として扱うことによって表現される。ただし、部分集合が1つの場合も、トポロジー空間レベルである。例えば前記対象情報が集合レベルで
表現されている場合に、前述した部分集合取得手段の部分集合取得処理を実行する。すると集合レベルで表現されている対象情報は、トポロジー空間レベルに移行されることになる。
【0046】
接着空間レベルは、前記トポロジー空間レベルよりも前記対象情報の抽象度が低く表現される。すなわち、接着空間レベルは、該トポロジー空間レベルにおける前記対象情報同士が同値関係を基準に結合されることで表現されるものである。前記トポロジー空間レベルで表現されている異なる2以上の対象情報に前述した接着手段の接着処理手段を実行することで新たな空間レベル、すなわち接着空間レベルへ移行することが可能となる。
【0047】
セル空間レベルは、トポロジー空間レベルの情報の式表現のうち、特定の式表現に限定して、属性と属性値の関係を定義できるようにしたものである。したがって、当然、セル空間レベルはトポロジー空間レベルの性質、および、機能を有している。この点で、セル空間レベルはトポロジーレベルの1ケースである。
【0048】
このように、セル空間レベルの情報と、トポロジー空間レベルの情報とは、式表現の形式上は、差異がない。すなわち、セル空間レベルの情報は、セル空間IDと属性の定義を示す因子とで括り出された部分集合の式表現と見なせるからである。セル空間レベルの情報は、セル空間IDと属性の定義を示す因子に、セル空間IDという意味、および属性の定義という意味を付加することで、形成される。この意味で、セル空間レベルの情報は、トポロジー空間レベルの情報の特殊ケースである。また、特殊ケースという意味で、セル空間レベルは、トポロジー空間レベルよりも、抽象度が低いとも言える。一方、そのような意味づけを解消すれば、セル空間レベルの情報は、同一の式表現のまま、トポロジー空間レベルの情報となる。
【0049】
さらに、セル空間レベルの情報は、前述した展開手段の展開処理を実行することにより、集合レベルに移行されることもできる。すなわち、すべての括弧を展開すればよい。
【0050】
なお、このセル空間レベルの属性は、通常は、アプリケーションプログラムによって定義されるものである。したがって、本情報処理装置では、セル空間レベルの情報は、アプリケーションプログラムのユーザインターフェースを通じて入力されることを想定している。
【0051】
また、本実施形態では、セル空間レベルは、接着空間レベルの性質、および、機能も有していることとした。したがって、セル空間レベルの複数の対象情報を接着することができる。これは、逆に、セル空間レベルの情報を接着した接着空間レベルの情報は、セル空間レベルの性質、機能を有していると言える。
【0052】
本発明に係る情報記憶装置において、前記各レベルは、前記情報処理手段による処理の実行前の状態を所定の形式によって表現することにより処理前の状態に戻すことが可能なホモトピーレベルを更に有するものとしてもよい。
【0053】
ホモトピーレベルは、前記情報処理手段による処理の実行後の状態が実行前の状態を含んだ状態で所定の表現形式で表現されることで処理前の状態に戻すことが可能な空間である。ホモトピーレベルでは、例えば、式1で示される対象情報が、演算Pによって、式2に変換されたときに、「式2=式1に演算Pを実行」のように記述される。したがって、演算前のレベルには、前述したホモトピー保存処理を実行することにより移行することができる。なお、ホモトピーレベルは、前述した他の空間レベルとは本質的に異なる。すなわち、他の空間レベルは、上述したように対象情報の抽象度によって段階的に表現される空間である。しかし、ホモトピーレベルは他の空間レベルのそれぞれと常に行き来が可能
な空間である。換言すると、ホモトピーレベルは、前述した各空間レベル間の移動を補助する空間であると言える。ホモトピーレベルを前述した各空間レベルと併用することにより、前記対象情報に対する処理前の状態を取得することが可能となるからである。
【0054】
次に、本発明に係る情報処理装置の実施形態について図面に基づいて説明する。
【0055】
《第1実施形態》
(装置構成)
図1は、第1の実施形態に係る情報処理装置100の構成を示すブロック図である。同図に示すように、第1の実施形態に係る情報処理装置100は、対象情報を入力するキーボード、ポインティングデバイス等の入力手段11(本発明の入力部に相当)と、入力された対象情報を格納するメモリ12(本発明の記憶部に相当)と、対象情報を所定のプログラムに基づいて処理するCPU13(本発明の処理部に相当)と、入力された対象情報や処理後の対象情報を出力するディスプレイ等の出力手段14(本発明の出力部に相当)と、CPU13と入力手段11との間を接続するインターフェース15と、CPU13と出力手段14との間を接続するインターフェース16とを備える構成である。
【0056】
インターフェース15は、例えば、USB(Universal Serial Bus)等のシリアルインターフェースである。また、インターフェース16は、例えば、RGB(赤、緑、青)の画像信号および同期クロックの出力インターフェースである。
【0057】
ただし、図1では、省略されているが、情報処理装置100は、大容量のデータを保存する外部記憶装置であるハードディスク、着脱可能な記憶媒体(例えば、CD(Compact disc)、DVD(Digital Versatile Disk)、フラッシュメモリカード等)の駆動装置、ネットワークにアクセスし他の情報処理装置と通信する通信インターフェース等を含んでよい。
【0058】
情報処理装置100は、典型的には、パーソナルコンピュータ、サーバ等のコンピュータである。ただし、情報処理装置100は、そのようなコンピュータに限定されるものではなく、例えば、携帯情報端末、携帯電話、PHS(Personal Handyphone System)、デジタルテレビ、デジタルテレビのチューナあるいはセットトップボックス、ハードディスクを含むテレビジョンの録画装置、車載用の端末等として実現できる。また、メモリ12は、揮発性のDRAM(Dynamic Random Access Memory)、不揮発性のEPROM(Erasable Programmable Read Only Memory)、EEPROM(Electronically Erasable and Programmable Read Only Memory)、フラッシュメモリ等を含む。
【0059】
本情報処理装置の機能は、CPU13がプログラムを実行することで実現される。このプログラムは、メモリ13あるいは不図示の外部記憶装置にインストールされる。プログラムは、通信インターフェースを通じてネットワークから、あるいは、着脱可能な記憶媒体からインストールされる。したがって、このプログラムは、ネットワークあるいは着脱可能な記憶媒体等を通じて流通される。
【0060】
また、メモリ12あるいは不図示の外部記憶装置に格納された対象情報は、CPU13が所定のプログラムを実行することによって各レベルを移行する。なお、各レベルとは、前記対象情報の抽象度が最も高く表現される集合レベル22と、前記集合レベル22よりも前記対象情報の抽象度が低く表現され、該対象情報が部分集合を要素として表現されるトポロジー空間レベル23と、前記トポロジー空間レベルよりも前記対象情報の抽象度が低く表現され、該トポロジー空間レベルにおける前記対象情報同士が接着される接着空間レベル24と、前記トポロジー空間における前記対象情報が所定の属性をもって表現されるセル空間レベル25と、前記情報処理手段による処理の実行前の状態を所定の形式によ
って表現することにより処理前の状態に戻すことが可能なホモトピーレベル21と、を有する。また、本実施形態では、セル空間レベル25は、前記接着空間レベルよりも前記対象情報の抽象度が低いものとして定義する。すなわち、セル空間レベルは、接着空間レベルの情報に、属性と属性値の意味づけを加えたものである、と解することにする。
【0061】
(データ構造)
次に、第1の実施形態に係る情報処理装置100のメモリ12に格納される対象情報の構造、すなわちデータ構造について説明する。なお、本実施形態の情報処理装置100は、以下のデータ構造によって、処理対象のデータを記述し、記憶し、演算処理を行うが、必ずしも、従来のデータ構造である表形式、オブジェクト指向データベースでのオブジェクトの階層構造、あるいは、ポインタでリンクされたデータベースのレコードのデータ構造等と、本実施形態で示すデータ構造との間の相互のデータ変換機能を提供するわけではない。
【0062】
(1)対象情報の構成要素
本情報処理装置は、対象情報を式の形式で表現する。式は、和演算子“+”、積演算子“×”、第1の括弧“(”“)”、および第2の括弧“{”“}”によって記述される。第1の括弧が本発明の集合因子構成演算子に相当する。また、第2の括弧が本発明の順序構成演算子に相当する。このような対象情報の表現形式を式表現とも呼ぶ。
【0063】
式は、1以上の識別子を含む。識別子は、記号または記号列で表現される。本実施形態では、記号として、英数字、および特殊文字(ただし、和演算子“+”、積演算子“×”、第1の括弧“(”“)”、および第2の括弧“{”“}”を除外する)を用いることとする。ただし、記号は、一般的にアルファベットとも呼ばれ、必ずしも、これらの文字には限定されない。
【0064】
本実施形態では、特殊な識別子として、Φおよびεを用いる。Φは、値ゼロ、和演算子において演算結果を変化させない値、または空集合を示す識別子である。本実施形態では、Φを零元と呼ぶ。また、εは、値1、あるいは、積演算子において演算結果を変化させない値である。本実施形態では、εを単位元と呼ぶ。なお、Φを和演算の単位元と呼ぶ場合もあるが、本実施形態では、Φを零元と呼ぶことにする。
【0065】
また、本情報処理装置は、所定の識別子を、演算を表す予約語として使用する。例えば、F(式)は、式を展開する演算であり、G(式+attach(因子1+因子2))は、接着演算を示す予約語(attachは、そのときのパラメータを示す予約語)であり、Hは、ホモトピー保存処理を示す予約語である。これらの予約語については、ユーザは、通常の識別子として使用することができない、という点で制限がある。
【0066】
本実施形態では、以下の規則によって対象情報、すなわち、識別子、因子、項(要素ともいう)、集合情報、ホモトピー情報、接着空間の情報、およびセル空間の情報を記述する式表現が生成される。
(a)識別子、単位元、および零元はいずれも式表現、すなわち、対象情報を記述する表現である。
(b)rとsとがともに、式表現である場合、r+sも式表現である。
(c)rとsとがともに、式表現である場合、r×sも式表現である。この場合、演算の結合の強さは、通常の代数と同様に、r×sの方が、r+sよりも強い。
(d)rが式表現である場合、(r)、{s}も式表現である。
【0067】
(2)式表現の代数的構造
本実施形態において、式表現r、s、t、yは、次の代数の性質を有する。
(a)結合律
r+(s+t)=(r+s)+t;r×(s×t)=(r×s)×t;
(b)可換律
r+s=s+r;
なお、本実施形態の式表現では、積演算子の可換律は成立しない。したがって、積演算子で複数の因子が結合されている場合に、個々の因子位置が情報(あるいは意味)を持つ。すなわち、因子は、いわゆる位置を指定してされた位置パラメータとしての機能を有する。「積演算子の可換律は成立しない」ことは、本発明の積演算子が「順序を持つ因子の列として複数の識別子を結合する」ことに相当する。
(c)積演算の単位元
r×ε=ε×r=r;
(d)積演算、和演算の零元
r×Φ=Φ×r=Φ;r+Φ=r;
(e)分配率
r×(s+t)=r×s+r×t;(r+s)×t=r×t+s×t;
(f)
{r+s}×{t+u}={r×t+s×u};
【0068】
(3)集合情報
集合情報は、項の組み合わせ、あるいは、項の和として、定義される。ここで、それぞれの項は集合ID(本発明の第1の識別因子に相当)となる識別子と値となる識別子の積、すなわち、集合ID×値として定義される。ただし、値は、複数の識別子の積であってもよい。集合の情報の式表現は、典型的には、集合ID×値1+集合ID×値2+・・・である。集合情報の例として、以下のものを挙げることができる。
【0069】
上述のように、本実施形態のデータ構造では、和演算子に可換律が成立することから、集合情報は、順序のない項の組み合わせということができる。一方、項を構成する因子間の位置関係は維持されることになる。
【0070】
このような因子間の位置関係の維持機能は、コンピュータ上で事物、あるいは、概念を表現する場合に、極めて大きな効果を発揮する。すなわち、一般的に、事物、あるいは概念を記述する修飾関係には、可換律が成立しない。例えば、”児玉の机”は、”机の児玉”と意味が異なる。
【0071】
本実施形態の因子と積演算子によれば、このような修飾関係を極めて単純化して、記述することができる。さらに、そのような修飾関係で記述された項を和演算子によって組み合わせることで事物の集合、あるいは、概念の集合を記述し、極めて単純な形式のデータベースを構築できる。
【0072】
さらにまた、管理対象の事物あるいは概念を項の集合として管理する場合に、項における因子の位置関係に意味を付与することもできる。また、項を構成する因子は、それぞれ、いわゆる位置パラメータとしての意義を有するということもできる。
【0073】
例えば、集合情報が、果物×任意形状×任意色×バナナ+果物×任意形状×任意色×りんご+果物×細長×黄色×バナナ+果物×丸×赤×リンゴという集合情報を考える。この場合、項の第1因子は、集合IDである果物であり、第2因子は形状示し、第3因子は色を示し、第4因子は名称を示す。このように、それぞれの因子の位置に意味上の制限を加えて使用することで、属性と属性値との関係を集合レベルでも処理できることを示している。本情報処理装置では、集合情報は、このような順序が維持された因子によって事物の属性を自在に定義することができ、そのような項の組み合わせによって、事物の集合をコ
ンピュータ上に表現する。
(例)
A×a1+A×a2+A×a3、b1×B+b2×B×B、果物×リンゴ+果物×バナナ+果物×ミカン、野菜×キャベツ+野菜×キュウリ+野菜×ゴボウ、社員×A+社員×B+社員×C
すなわち、集合情報は、集合IDで識別される集合に所属する項の組み合わせを記述し、メモリ12に記憶される。この場合、社員Cが退職し、社員Dと社員Eが入社した場合には、社員×A+社員×B+社員×Cのようにメモリ12に格納される。
【0074】
(4)トポロジー空間情報
トポロジー空間情報は、トポロジーID(本発明の第2の識別因子に相当)となる識別子と部分集合の和との積によって以下のように記述される。すなわち、トポロジーID×(部分集合の和)である。ここで、部分集合は、部分集合を識別する部分集合IDと、その部分集合に含まれる項の和との積で表現される。すなわち、部分集合ID×(項の和)である。ただし、項には、さらに項の和を第1の括弧“()”または第2の括弧”{}”で組み合わせたもの、およびそれらの積が含まれてもよい。
(例)トポロジー空間情報の例は、
T×(ABC×(ab1+ac2+bc3)+A×(ab1+ac2)+B×(ab1+bc3)+C(ac2+bc3))、
果物×(全種×(リンゴ+バナナ+ミカン)+赤×リンゴ+黄×(バナナ+ミカン))、果物×(全種×(リンゴ+バナナ+ミカン)+丸×(リンゴ+ミカン)+細長×バナナ)、
野菜×(全種×(大根+キュウリ+ゴボウ)+太×大根+細×(キュウリ+ゴボウ))、会社×(社員×(社員1+社員2+社員3+社員4)+営業×(社員1+社員2)+経理×(社員3+社員4))、等である(この例で、読点“、”は、式の構成要素ではなく、例の区切りである)。この場合に、最後の例について、例えば、総務が新設され、社員5が採用され、総務に配属された場合には、会社×(社員×(社員1+社員2+社員3+社員4+社員5)+営業×(社員1+社員2)+経理×(社員3+社員4)+総務×社員5)のように記述し、メモリ12に格納できる。
【0075】
(5)接着空間情報
接着空間情報は、トポロジー空間情報に含まれる2つの部分集合X(本発明の第1の被接着情報に相当)と部分集合Y(本発明の第2の被接着情報に相当)に対して、それぞれの部分に含まれる部分集合を関係付けることで構成される。本実施形態では、この関係付けによって発生する関係を同値関係という。
【0076】
今、トポロジー空間情報T(トポロジーIDは、Tid)およびトポロジー空間情報U(トポロジーIDは、Yid)が、トポロジー空間情報Tid×(Tに属する部分集合の和)+トポロジー空間情報Uid×(Uに属する部分集合の和)としてメモリ12に記憶されているとする。
【0077】
さらに、Tに属する部分集合の和=部分集合T0+部分集合T−T0と2つの部分集合に分離できるとする。その場合、本情報処理装置では、トポロジー空間情報Tとトポロジー空間情報Uとを関連づけるトポロジー空間情報Tの因子p(本発明の第1の同値因子に相当)と、トポロジー空間情報Uの因子q(本発明の第2の同値因子に相当)が指定される。そして、トポロジー空間情報Tが、因子pを含む部分集合T0(本発明の第1の関連項に相当)と、因子pを含まない部分集合T−T0に分離される。ここで、T−T0は、集合Tから集合T0を削除した差集合である。また、トポロジー空間情報Uが、因子qを含む部分集合U0(本発明の第2の関連項に相当)と、因子qを含まない部分集合U−U0に分離される。ここで、U−U0は、集合Uから集合U0を削除した差集合である。
【0078】
この場合に、上記2つのトポロジー空間情報TとUの和は、トポロジー空間情報Tid×(部分集合T0)+トポロジー空間情報Tid×(部分集合T−T0)+トポロジー空間情報Uid×(部分集合U0)+トポロジー空間情報Uid×(部分集合U−U0)と表現される。このように、集合から特定の因子pを含む部分集合を取り出した場合に、これを商と呼ぶ。また、その商を除く部分集合を剰余という。
【0079】
さらに、部分集合T0=T0id×(T0の項の和)、部分集合U0=U0id×(U0の項の和)と記述されているとする。この場合に、部分集合T0と部分集合U0とを関係付けることによって、以下の接着空間情報を構成できる。すなわち、この場合の接着空間情報は、{部分集合T0におけるpの左因子+部分集合U0におけるqの左因子}{p+q}{部分集合T0におけるpの右因子+部分集合U0におけるqの右因子}+トポロジー
空間情報Tid×(部分集合T−T0)+トポロジー空間情報Uid×(部分集合U−U0)、である。ここで、部分集合T0におけるpの左因子および部分集合T0におけるpの右因子が、ともに、本発明の第1の被接着因子に相当する。また、部分集合U0におけるqの左因子および部分集合U0におけるqの右因子が、ともに、本発明の第2の被接着因子に相当する。
【0080】
なお、ここでは、トポロジー空間レベルの情報を接着する場合を説明したが、トポロジー空間レベルの情報に、属性と属性値が定義されて構成されるセル空間レベルの情報、および、項の組み合わせである集合レベルの集合情報に対しても、接着空間情報が定義できる。また、トポロジー空間、セル空間、集合空間のうち、一のレベルの情報と、他のレベルの情報とについて接着空間情報を定義できる。
(例)
今、以下のような果物のトポロジー空間情報と、野菜のトポロジー空間情報の和、すなわち、果物×(全種×(リンゴ+バナナ+ミカン)+丸×(リンゴ+ミカン)+細長×バナナ)+野菜×(全種×(大根+キュウリ+ゴボウ)+太×大根+細×(キュウリ+ゴボウ))がメモリ12に記憶されているとする。
【0081】
ここで、果物のトポロジー空間情報の因子である細長と、野菜のトポロジー空間情報の部分集合である因子細との関連づけが指定され、同値関係にあるとする。この場合に、2つのトポロジー空間情報は、それぞれ次のように商と剰余とに分離される。すなわち、それぞれの集合情報が商と剰余に分離されたトポロジー空間情報は、
果物×細長×バナナ
+果物×(全種×(リンゴ+バナナ+ミカン)+丸×(リンゴ+ミカン))
+野菜×細×(キュウリ+ゴボウ)
+野菜×(全種×(大根+キュウリ+ゴボウ)+太×大根)
となる。
【0082】
そして、同値関係が指定された細長と、野菜のトポロジー空間情報の部分集合である細とによって、接着空間情報が
{果物+野菜}×{細長+細}{バナナ+(キュウリ+ゴボウ)}
+果物×(全種×(リンゴ+バナナ+ミカン)+丸×(リンゴ+ミカン))
+野菜×(全種×(大根+キュウリ+ゴボウ)+太×大根)、のように構成される。
【0083】
このようにして、接着空間情報は、2つのトポロジー空間情報の構造を維持した状態で、関係付けが指定された同値関係にある因子を基に結合されている。接着空間情報より、”細”と”細長”に同値関係が認められれば,右の因子”バナナ”と”(キュウリ+ゴボウ)”を{バナナ+(キュウリ+ゴボウ)}として関連づけて出力できる。
【0084】
また、 伝票ID1枚目(A{ε+B+C{C1+C2}+D+E{E1+E2}}(a{ε+b+c{c1+c2}+d+e{e1+e2}}+位置(右上+右下)))
+伝票ID2枚目(A{ε+B+C{C1+C2}+D+E{E1+E2}}(a{ε+b+c{c1+c2}+d+e{e1+e2}}))
+MEMO(1(あいう)+2(ABC))
+・・・という伝票の束、およびメモMEMOを記述する情報がメモリ12に格納されていた場合を考える。ここで、MEMOを1枚目の伝票の右上に、位置を指定して張り付ける例を示す。
【0085】
この例で,MEMOの1を1枚目の伝票の右上に張り付けるには,まず、MEMO情報の因子”1”,伝票1枚目の情報の因子”右上”でそれぞれ商空間が作成される。
伝票ID1枚目(A{ε+B+C{C1+C2}+D+E{E1+E2}}(a{ε+b+c{c1+c2}+d+e{e1+e2}}+位置(右下)))+伝票ID1枚目×位置(右上)
+伝票ID2枚目(A{ε+B+C{C1+C2}+D+E{E1+E2}}(a{ε+b+c{c1+c2}+d+e{e1+e2}}))
+MEMO(2(ABC))+MEMO(1(あいう))
+・・・
【0086】
ここで,”1”と”右上”の関係付けを指定し接着すると、接着情報は、
{伝票ID1枚目×位置+MEMO}{右上+1}{ε+(あいう)}+剰余の部分集合を含む情報、として構成される。このように、接着情報は、相互に構造上の共通性がない2つの対象情報について、それぞれの接着前の構造を維持した状態で、2つの対象情報結合し、メモリ12に格納することができる。
【0087】
(6)セル空間情報
セル空間情報は、事物の属性とその属性に対応する属性値とを有する情報である。属性は、キー属性とその他の属性とに分かれる。キー属性は属性値によって情報が識別できる属性であり、データベースの検索においてキーとして使用できる値に対応する。セル空間情報で、属性値(またはその並び)は、インスタンスと呼ばれ、従来のデータベースのレコードに相当する。それぞれのインスタンスは、インスタンスIDと呼ぶ識別情報を有する。また、キー属性、あるいは、その他の属性が複数個ある場合には、キー属性、あるいは、その他の属性は、第2の括弧“{”と“}”とによって順序が維持された因子の形式で記述される。すなわち、いわゆるベクトル形式にて属性とその対応する属性値が記述される。
【0088】
セル空間情報は、セル空間ID(本発明のセル空間識別子に相当)と、キー属性の因子と、単位元およびキー属性以外の属性を有する因子と、インスタンスの集合を有する因子とを含む。セル空間情報は、
セル空間ID×(キー属性×{ε+(その他の属性の和)}
×((インスタンスID×{ε+(値の和)})の和))
で構成される。
【0089】
このキー属性の因子と単位元およびキー属性以外の属性を含む属性を有する因子とが、本発明の属性因子に相当する。また、{ε+(その他の属性の和)}の中のいずれかの属性が複数の識別子の積からなる場合に、そのような識別子の積からなる属性が、本発明の属性の順序列に相当する。また、そのような属性が、第2の括弧“{}”で括られた因子である場合に、その第2の括弧で括られた属性が、本発明の属性の順序因子に相当する。
【0090】
また、そのような属性に対応して、インスタンスの{ε+(値の和)}中の値が、識別
子の積からなるときに、その値が、本発明の値列に相当する。また、値が、第2の括弧“{}”で括られた因子である場合に、その第2の括弧で括られた値が、本発明の値の順序因子に相当する。
(例)
セル空間情報の例は、
果物id×(名前{ε+形+色}(リンゴ{ε+丸+赤}+ミカン{ε+丸+黄}+バナナ{ε+細長+黄}))
+野菜id×(名前{ε+形状+色}(大根{ε+太+白}+キュウリ{ε+細+緑}+ゴボウ{ε+細+茶}))
で示すことができる。この例では、従来のリレーショナルモデルで、果物テーブル、野菜テーブルとして記述されていた情報が、式表現で記述される。なお、この例は、2つのセル空間情報(果物と野菜)を含むことから、統合セル空間情報とも呼ばれる。
【0091】
この統合セル空間情報の処理例を示す。まず、果物のインスタンスのうち、属性“形”が“細長”の値を持つインスタンスとの部分集合(商という)と、その他のインスタンスの部分集合(剰余という)とを作成する。また、まず、野菜のインスタンスのうち、属性“形状”が“細”の値を持つインスタンス(商という)と、その他のインスタンス(剰余という)とに分離する。この場合、結合セル空間情報は、
果物id×バナナ×形×細長
+野菜id×形状×(キュウリ+ゴボウ)細
+果物id×(名前{ε+形+色}(リンゴ{ε+丸+赤}+ミカン{ε+丸+黄}+バナナ{ε+黄}))
+野菜id×(名前{ε+形状+色}(大根{ε+太+白}+キュウリ{ε+緑}+ゴボウ{ε+茶}))
となる。次に、果物のうちの属性“形”が値“細長”を有する部分集合と、野菜のうちの属性“形状”が値“細”を有する部分集合との関係付けを指定し、同値関係を設定する。そして、この同値関係によって接着空間情報を作成すると、
{果物id×形×バナナ+野菜id×形状×(キュウリ+ゴボウ)}{細長+細}{ε+ε}
+果物id×(名前{ε+形+色}(リンゴ{ε+丸+赤}+ミカン{ε+丸+黄}+バナナ{ε+黄}))
+野菜id×(名前{ε+形状+色}(大根{ε+太+白}+キュウリ{ε+緑}+ゴボウ{ε+茶}))
となる。
【0092】
(記述例)
以下、従来のデータ構造である表およびツリー構造が、本実施形態のデータ構造でどのように記述できるかを示す。
【0093】
図3は、第1の実施形態に係る情報処理装置100のメモリ12に格納されるセル空間情報の第一のデータ構造例を示す。同図に示すように、第1の実施形態に係る情報処理装置100では、従来正規化表構造として表形式で表現される対象情報は、表現形式1の状態でメモリ12に格納することができる。表現形式1で、Aは、キー属性(例えば社員番号等)、B,C,D,E等は、その他の属性(例えば、氏名、性別、入社年、所属部署等)である。
【0094】
図2は、第1の実施形態に係る情報処理装置100のメモリ12に格納されるセル空間情報の第二のデータ構造例を示す。同図に示すように、第1の実施形態に係る情報処理装置100では、従来ツリー構造として表現される対象情報は、表現形式2又は3でメモリ12に格納することができる。そして、同図に示すように有向グラフの一部としてのツリ
ー構造について対応可能である。表現形式2で、aは、例えば、動物、bはほ乳類、cは魚類、dは人、eは鯨、fはマグロ、gは鯉等である。この場合、b(ほ乳類)およびc(魚類)は、a(動物)の属性、例えば、食する、呼吸する等を継承する。b(ほ乳類)およびc(魚類)の共通の属性は、a(動物)に定義される。
【0095】
したがって、本実施形態の式表現によって、フレーム等の知識ベース、あるいは、オブジェクト指向データベース等を記述し、メモリ12に格納できる。情報処理装置100は、これらに対応する事物に関する情報の入力を入力部11から受け付け、対応する情報を生成し、メモリ12に格納し、メモリから読み出し、出力部14に出力できる。
【0096】
また、逆ツリー構造で表現される対象情報についても、表現形式3のようにメモリ12に格納することができる。逆ツリー情報は、基本的な情報からより複雑な情報を構成する場合に適用できる。表現形式3では、例えば、aはCPUであり、bはインターフェースであり、cは外部記憶装置の駆動部であり、dはCPUボードであり、eは外部記憶装置であり、fはパーソナルコンピュータである。
【0097】
このように逆ツリー構造は、製品の設計書、事業の工程管理図等、基本情報からより複雑な情報を組み上げて管理することができる。したがって、本実施形態の式表現によって、製品の設計情報、事業の工程等を記述し、メモリ12に格納できる。情報処理装置100は、これらに対応する事物に関する情報の入力を入力部11から受け付け、対応する情報を生成し、メモリ12に格納し、メモリから読み出し、出力部14に出力できる。
【0098】
図4は、第1の実施形態に係る情報処理装置100のメモリ12に格納される第三のデータ構造例を示す。同図に示すように、第1の実施形態に係る情報処理装置100では、非正規化表構造と属性のない対象情報についても表現形式4の状態でメモリ12に格納することができる。ここで、非正規化表構造と属性のない対象情報とは、図4に示すように伝票を示す対象情報と、その対象情報に追加される付箋メモに相当する対象情報とが例示できる。接着処理を実行し、接着空間を作成することで、コンピュータ上で伝票に付箋メモの内容を添付することと同等の処理が実現される。
【0099】
なお、伝票の種類ごとにテーブルに格納する場合には、リレーショナルモデルによって従来のデータベースで情報を管理できる。しかしながら、伝票の種類数が変動する場合、既存の伝票の構成が変更された場合には、リレーショナルモデルでは、対応できない。
【0100】
ここで、本発明に係る所定の表現形式、すなわちデータ構造についてより詳細に上記表現形式4に基づいて説明する。ID又はid(identification)は、格納される対象情報を識別するものである。そしてこの対象情報は、識別子A〜E2,a〜e2と、演算時の結合強さが異なる第一の括弧()及び第二の括弧{}と、これらにより表現される因子{C1+C2},{E1+E2}等と、これら因子の積によって表現される項E{E1+E2}等と、前記項の和によって表現される式と、により構成される。なお、本実施形態では、項を要素ともいう。また、すでに述べたように、単位元εは、所定の処理を実行した場合に1として処理される記号である。上記以外の特別な記号として、所定の処理を実行した場合に0として処理される零元Φが存在する。このような状態でメモリ12に格納された対象情報は、CPU13が所定のプログラムを実行することによって、入力装置11から入力された伝票データにしたがって、生成され、メモリ12に格納され、部分集合に分離され、他の部分集合と接着され、あるいは、検索されることになる。
【0101】
図4の例では、インスタンスとして、伝票ID1で示される1枚目の伝票、伝票ID2で示される2枚目の伝票、およびMEMOで示されるメモが例示されている。また、この場合に、1枚目の伝票と2枚目以降の伝票で、項目の構成が異なっても構わない。本情報
処理装置100は、対象情報を構成する識別子、あるいは項に、個々に属性を付与できるので、異なる属性の並びを有する異なる識別子、あるいは項を自在に記憶し、検索し、変更できる。また、{}内に、+識別子の形式で追加するとともに、属性に対応する値を追加すれば、データベースとして運用中においても、自在に属性と属性値とを追加、変更、削除できる。したがって、本実施形態のデータ構造によれば、情報処理装置100が取り扱うデータを柔軟に変更でき、厳密、正確なファイル設計の必要性が軽減される。
【0102】
(基本演算手順)
図5に、本情報処理装置におけるプログラム構成を示す。本情報処理装置100は、例えば、データを格納し、検索し、変更し、表示するデータベースシステム等、様々事物を管理するシステムに適用できる。その場合、個々の管理対象に応じた機能は、アプリケーションプログラムAPとして提供される。すなわち、アプリケーションプログラムは、入力部11から入力されたデータをメモリ12あるいは外部記憶装置に格納し、これらに格納されたデータにアクセスし、検索し、出力部14に表示する。
【0103】
一方、アプリケーションプログラムがメモリ12あるいは、外部記憶装置に格納するデータの生成、格納、検索等の機能は、上述の式表現を処理する共通関数ライブライリが提供する。共通関数ライブラリは、アプリケーションインターフェースを備えており、アプリケーションプログラムへのこれらの機能、あるいは、サービスを提供する。以下、本情報処理装置100で典型的な共通関数の例を説明する。これらの共通関数は、プリミティブ関数、あるいは、基本演算とも呼ばれる。
【0104】
アプリケーションプログラムからそれぞれの共通関数が呼び出されたときに、本発明の処理手段に相当するCPU13が以下の処理を実行する。
【0105】
(1)積結合演算
積結合演算では、CPU13は、識別子と識別子とを積演算子によって接続する。積結合演算を実行するCPU13が本発明の積演算部に相当する。この場合、識別子自体が式表現であり、識別子が接続された結果も式表現となる。積結合演算のアプリケーションインターフェースは、例えば、戻り値=connect(因子1、因子2、演算結果);のように定
義できる。本実施形態では、式表現が文字列で記述されるので、“因子1”、“因子2”、および“演算結果”は、いずれも文字列である。因子1、および因子2として、識別子、複数の識別子を積結合演算で結合した式表現、第1の括弧“()”で囲まれた式表現、第2の括弧“{}”で囲まれた式表現、ε、およびΦを指定できる。積結合演算では、演算結果には、因子1×因子2が返される。すなわち、因子1と因子2との結合は、記号“×”(以下、積記号)で記述される。すなわち、積結合演算は、因子1と因子2との積演算による演算式を形成する。
【0106】
一方、図9で説明する積演算では、因子1と因子2との積を実行する。因子1と因子2に、第1の括弧“()”および第2の括弧“{}”のいずれもが含まれていない場合には、積結合演算と積演算の結果は、同一である。因子1と因子2に、第1の括弧“()”および第2の括弧“{}”のいずれかが含まれている場合には、積演算の結果は、それの括弧内の項と、括弧外の因子との演算となる。
【0107】
また、戻り値は、処理が正常終了したか否かを示す情報である。ただし、本実施形態では、戻り値の設定処理についての説明は、省略する。
【0108】
(2)和演算
和演算では、CPU13は、識別子および因子の列として接続された複数の識別子のいずれかまたは両方から項の組み合わせを構成する。和演算を実行するCPU13が本発明
の和演算部に相当する。この場合、識別子あるいは因子が式表現であるので、項の組み合わせも式表現となる。和演算のアプリケーションインターフェースは、例えば、戻り値=add(項1、項2、演算結果);のように定義できる。演算結果には、項1+項2が返される。すなわち、項1と項2との和は、記号“+”(以下、和記号)で記述される。
【0109】
(3)項抽出処理、因子抽出処理
項抽出演算では、CPU13は、和記号“+”で組み合わせられた複数の項から、いずれかの項を取り出す。本実施形態では、複数の項のうち、先頭の項を取り出す。項抽出処理のアプリケーションインターフェースは、例えば、戻り値=getterm(式表現、演算結果);のように定義できる。項抽出処理を実行するCPU13が本発明の項抽出部に相当する。
【0110】
同様に、因子抽出演算では、CPU13は、積記号“×”で組み合わせられた複数の因子の並びから、いずれかの因子を取り出す。本実施形態では、複数の因子のうち、先頭の因子を取り出す。因子抽出処理のアプリケーションインターフェースは、戻り値=getfactor(式表現、演算結果);のように定義できる。因子抽出処理を実行するCPU13が本発明の因子抽出部に相当する。
【0111】
(4)集合構成処理
集合構成処理では、CPU13は、和記号“+”で組み合わせられた複数の項を第1の括弧“()”で括る処理を実行する。集合構成処理のアプリケーションインターフェースは、例えば、戻り値=putin1(式表現、演算結果);のように定義できる。演算結果には、(式表現)が返される。集合構成処理を実行するCPU13が本発明の集合因子構成部に相当する。
【0112】
(5)集合展開処理
集合展開処理では、CPU13は、第1の括弧“()”で括られた式表現から、第1の括弧“()”を取り除く処理を実行する。集合展開処理のアプリケーションインターフェースは、例えば、戻り値=putoff1(式表現、演算結果);のように定義できる。集合展開処理を実行するCPU13が本発明の集合因子展開部に相当する。
【0113】
(6)順序構成処理
順序構成処理では、CPU13は、和記号“+”で組み合わせられた複数の項を第2の括弧“{}”で括る処理を実行する。集合構成処理のアプリケーションインターフェースは、例えば、戻り値=putin2(式表現、演算結果);のように定義できる。順序構成処理を実行するCPU13が本発明の順序生成部に相当する。
【0114】
(7)順序展開
順序展開処理では、CPU13は、第2の括弧“{}”で括られた式表現から、第2の括弧“{}”を取り除く処理を実行する。集合展開処理のアプリケーションインターフェースは、例えば、戻り値=putoff2(式表現、演算結果);のように定義できる。順序展開処理を実行するCPU13が本発明の順序展開部に相当する。
【0115】
(8)共通因子括りだし処理
共通因子括りだし処理では、CPU13は、第1の括弧“{}”または第2の括弧“()”が付加された項の組み合わせに含まれる項から共通の因子を抽出する。共通因子括りだし処理のアプリケーションインターフェースは、例えば、戻り値=and(式表現、演算結果);のように定義できる。ここで、式表現には、複数の項が和記号で組み合わせられた式である。共通因子括りだし処理を実行するCPU13が本発明の括り出し部に相当する。
【0116】
(9)横方向展開処理
横方向展開処理は、横方向展開処理とは第一又は第二の括弧を一回外す、すなわち展開する処理である。横方向展開処理のアプリケーションインターフェースは、例えば、戻り値=expand1(展開前の式表現、展開後の式表現);のように定義できる。
【0117】
図6Aは、横方向展開処理を実行する処理のフローを示す。具体的には、ステップS101では、対象情報(“展開前の式表現”)が入力される。すなわち、メモリ12に対象情報が例えばユーザにより入力される。そして、CPU13は、入力された式表現を展開前の式表現に指定して、共通関数expand1が実行される。
【0118】
以下、対象情報として数6に示すデータを用いた場合について説明する。なお、項の数及び因子の数は、左から順に第一、第二のように割り当てられるものとし、2重、3重の括弧で括られている場合には、最も外側の括弧を第一として扱うものとする。
cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))+s(p(p1+p2)+q(q1+q2))・・・(数6)
【0119】
ステップS102では、入力された対象情報を横方向展開処理した項をΦに設定、すなわち初期化する。なお、各展開処理の詳細については後述する。ステップS103では、対象情報を構成する式の長さが0であるかを判断する。すなわち、対象情報が存在するか否かを判断する。式の長さが0であると判断した場合には、ステップS114へ進み横方向展開処理を終了する。一方、式の長さが0であると判断しなかった場合には、次のステップへ進む。
【0120】
ステップS104では、数6で表現される対象情報から第一項を取得する。すなわち、数7に示すデータを取得する。ステップS105では、取得した数7で表現される対象情報をメモリ12に保存する。なお、ここでいう保存とは変数に保存すること、すなわちメモリ12に所定の領域を確保して記録することを意味する。また、以下の処理において取得するステップと削除するステップの間に行われる処理で言う保存は、上記同様メモリ12に所定の領域を確保して記録することを意味することとする。
cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))・・・(数7)
【0121】
ステップS106では、数6の式表現から数7を削除する。これにより、数8により表現されるデータがメモリ12に存在することになる。
s(p(p1+p2)+q(q1+q2))・・・(数8)
【0122】
ステップS107では、横方向展開処理後の因子をεに設定する。次にステップS108では、項の長さが0であるかを判断する。すなわち、対象情報を構成する項が存在するか否かを判断する。項の長さが0であると判断した場合には、ステップS113へ進み横方向展開処理を終了する。一方、式の長さが0であると判断しなかった場合には、次のステップへ進む。
【0123】
ステップS109では、第一項から第一因子であるcellを取得する。ステップ110では、取得した第一因子cellをメモリ12に保存する。次にステップ111では、第一因子cellを第一項より削除する。
【0124】
ステップS112では、展開後の因子に対し取得した因子を積演算し、その結果を展開後の因子とする。すなわち、ステップS107で設定した展開後の因子εにステップS109で取得した第一因子cellを積演算する。積演算の展開処理については後述する。
その後、第一項の項の長さが0であると判断されるまでステップS108からステップS112の処理を繰り返す。
【0125】
ステップS113では、ステップS108で項の長さが0であると判断した場合に、展開後の項に対し展開後の因子の和演算を行い、その結果を展開後の項と設定する。その後、式の長さが0であると判断されるまでステップS103からステップS113の処理を繰り返す。以上のステップを実行することにより、展開後の対象情報は数9により表現される。この式表現が“展開後の式表現”として、アプリケーションプログラムに返されることになる。なお、横方向展開処理を実行中の対象情報の状態の詳細は図6B、図6Cに示す。
cell×id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2})+s×p(p1+p2)+s×q(q1+q2)・・・(数9)
このように、数6の最も外側の“(”と“)”とがはずされた式表現となっている。他の例としては、例えば、a(b+c(d+e))+f(g+h)という式表現を横方向展開した場合には、a×b+ a×c(d+e)+f×g+f×h になる。
【0126】
(10)縦方向展開処理
次に、縦方向展開処理について説明する。縦方向展開処理は、各項をそれぞれ全展開していく処理である。例えば、上記a(b+c(d+e))+f(g+h)について,縦方向展開するとa×b+a×c×d+a×c×e+f×g+f×h になる。一方、横方向展開で式を全展開するには,各項に括弧が無くなるまで各項を展開するという指定が必要となる。縦方向展開処理のアプリケーションインターフェースは、例えば、戻り値=expand2(展開前の式表現、展開後の式表現);のように定義できる。
【0127】
図7は、縦方向展開処理を実行する処理のフローを示す。図7では、図6と同一の処理を実行するステップは、同一の符号で示している。ステップS101では、対象情報(“展開前の式表現”)を入力する。例えば、ユーザインターフェース等を通じて、展開前の式表現が入力される。そして、メモリ12に格納される対象情報がアプリケーションプログラムから共通関数expand2に入力される。以下、対象情報として数10に示すデータを用いた場合について説明する。
cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))+s(p(p1+p2)+q(q1+q2))・・・(数10)
【0128】
ステップS102では、入力された対象情報を展開処理したときに得られる対象情報(項)をΦに設定する。ステップS103では、対象情報を構成する式の長さが0であるかを判断する。すなわち、対象情報が存在するか否かを判断する。式の長さが0であると判断した場合には、ステップS114へ進み縦方向展開処理を終了する。一方、式の長さが0であると判断しなかった場合には、次のステップへ進む。ステップS104では、数10から第一項を取得する。すなわち、数11に示すデータを取得する。ステップS105では、取得した数11で表現される対象情報をメモリ12に保存する。
cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))・・・(数11)
【0129】
ステップS106では、数10から数11を削除する。これにより、メモリ12には、数12により表現されるデータが存在することになる。
s(p(p1+p2)+q(q1+q2))・・・(数12)
【0130】
ステップS107では、第一項を展開したときに得られる、展開後の因子をεに設定する。次にステップS108では、項の長さが0であるかを判断する。すなわち、対象情報を構成する項が存在するか否かを判断する。項の長さが0であると判断した場合には、ス
テップS113へ進み縦方向展開処理を終了する。一方、式の長さが0であると判断しなかった場合には、次のステップへ進む。
【0131】
ステップS109では、第一項から第一因子であるcellを取得する。ステップ110では、取得した第一因子cellをメモリ12に所定の領域を確保して保存する。次にステップ111では、第一因子cellを第一項より削除する。
【0132】
ステップS112aでは、因子が第一の括弧又は第二の括弧で括られているとき、括弧内の式について縦方向展開処理を実行し(すなわち、再帰呼び出しを実行する)、結果を取得した因子とする。次にステップS112bでは、展開後の因子に対し取得した因子を積演算し、その結果を展開後の因子とする。積演算の展開処理については後述する。その後、第一項の項の長さが0であると判断されるまでステップS108からステップS112の処理を繰り返す。
【0133】
ステップS113では、ステップS108で項の長さが0であると判断した場合に、展開後の項に対し展開後の因子の和演算を行い、その結果を展開後の項と設定する。その後、式の長さが0であると判断されるまで再帰的にステップS103からステップS113の処理を繰り返す。以上のステップを実行することにより、展開後の対象情報は数13により表現される。そして、この式表現が“展開後の式表現”として、アプリケーションプログラムに引き渡される。なお、上記ステップを実行中の対象情報の状態の詳細は図8Aから図8Dに示す。
cell×id×1+cell×id×A×1×a1+cell×id×B×1×b1+cell×id×C×1×c1+cell×id×2+cell×id×A×2×a2+cell×id×B×2×b2+cell×id×C×2×c2+s×p×p1+s×p×p2+s×q×q1+s×q×q2・・・(数13)
【0134】
(11)積演算処理
次に積演算処理について説明する。積演算処理は、2つの式表現を入力し、それぞれの式表現を因子とする新たな式表現を生成する処理である。積演算処理のアプリケーションインターフェースは、例えば、戻り値=product(因子1、因子2、積演算後の式);のよ
うに定義できる。積演算処理を実行するCPU13が本発明の共通因子展開部に相当する。
【0135】
図9は、積演算処理を実行する処理のフローを示す。まずステップS201では、第一の因子(“因子1”)及び第二の因子(“因子2“)がアプリケーションプログラムから関数productに入力される。その結果、それぞれの因子がメモリ12の対応する領域に新
たに記憶される。
【0136】
ステップS202では、どちらかの因子がεであるかを判断する。どちらかの因子がεであると判断された場合には他方の因子がデータを構成することになり(ステップS203)、積演算処理を終了する。一方、どちらかの因子がεであると判断されなかった場合には次のステップへ進む。
【0137】
ステップS204では、どちらかの因子がΦであるかを判断する。どちらかの因子がΦであると判断された場合には演算後のデータはΦとなり(ステップS205)、積演算処理を終了する。一方、どちらかの因子がΦであると判断されなかった場合には次のステップへ進む。
【0138】
ステップS206では、両方の因子が第一の括弧により括られているかを判断する。両方の因子が第一の括弧により括られていると判断した場合には、互いの全項の全組み合わ
せでそれぞれ掛けた項の和として処理し(ステップS207)、次のステップへ進む。一方、両方の因子が第一の括弧により括られていると判断しなかった場合には、次のステップへ進む。
【0139】
ステップS208では、一方の因子が第一の括弧により括られているかを判断する。一方の因子が第一の括弧により括られていると判断し場合には、第一の括弧で括られている項に他方の因子をそれぞれ掛けた項の和として処理し(ステップS209)、次のステップへ進む。一方、一方の因子が第一の括弧により括られていると判断しなかった場合には、次のステップへ進む。
【0140】
ステップS210では、両方の因子が第二の括弧により括られているかを判断する。両方の因子が第二の括弧により括られていると判断した場合には、それぞれの第二の括弧内の同じ順序の項をそれぞれ掛けた項の和として処理し(ステップS211)、次のステップへ進む。このとき、第二の括弧は、そのまま維持されるので、演算の前後で第二の括弧内の項の順序はそのまま維持されている。一方、両方の因子が第二の括弧により括られていると判断しなかった場合には、次のステップへ進む。
【0141】
ステップS212では、一方の因子が第二の括弧により括られているかを判断する。一方の因子が第二の括弧により括られていると判断し場合には、第二の括弧で括られている全ての項に他方の因子をそれぞれ掛けた項の和として処理し(ステップS213)、その後積演算処理を終了する。一方、他方の因子が第二の括弧により括られていると判断しなかった場合には、互いの因子を掛けた項を作成し(ステップS214)、その後積演算処理を終了する。その結果、“積演算後の式表現“がアプリケーションプログラムに引き渡される。なお、図10に上記積演算処理の例とともに実際の処理を示す。
【0142】
(12)商演算処理
次に商演算処理について説明する。商演算処理は、対象情報を記述する集合から、指定された因子(識別子を含む)を含む式表現(項、あるいは要素)と、そのような因子を含まない式表現とに分離する処理である。商演算処理のアプリケーションインターフェースは、例えば、戻り値=divide(商演算される式表現、商演算する因子、商の式表現、剰余
の式表現);のように定義できる。本実施形態で、商演算は、“商演算する因子”を含む
式表現を取り出す処理となる。そのため、商演算する因子のことを、同値関係を指定する因子ともいう。商演算する因子は、本発明の演算用因子に相当する。
【0143】
図11Aは、商演算処理(サブルーチン1)を実行する処理のフローを示す。サブルーチン1を実行するCPU13が本発明の商演算部に相当する。なお、図12Aは、商演算のうち、剰余を求める処理(サブルーチン2)である。サブルーチン1は、商演算される式表現である式1、商演算する因子を入力され、商の式表現である式2を出力する。
【0144】
まずステップ301では、商演算処理が実行される前の所定の表現形式によって表現される式1(“商演算される式表現”)、及び商演算する因子(これを同値関係示す因子ともいう)pが入力される。以下、数14により表現される対象情報が入力された場合について説明する。また、1を商演算する因子(同値関係を示す因子p)と設定する。
cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))・・・(数14)
【0145】
次に、ステップS302では、CPU13は、演算後の商(商項ともいう、ここでは、項2で表す)を初期化する。このとき、項2の値は、Φ(空、または0)である。
【0146】
次に、ステップS303では、CPU13は、式1の長さが0であるか否かを判定する
。式1の長さが0である場合、CPU13は、サブルーチン1の処理を終了する。
【0147】
一方、ステップS303の判定において、式1の長さが0でなかった場合、CPU13は、ステップ304に処理を進める。そして、CPU13は、式1から始めの項(以下、項1という)を取得する。ここで、項1は、数14の全体である。さらに、ステップS305において、CPU13は、式1から項1を削除する。
【0148】
次に、ステップS306において、CPU13は、項1が因子p(ここでは、“1”)を含んでいるか否かを判定する。ここで、因子pを含んでいるとは、項1の因子としては、あるいは、項1の第1の括弧で括られた因子内の項のいずれかに、因子pを含むことを言う。すなわち、項1の式表現中に因子pが含まれるか否かを判定する。項1が因子pを含んでいない場合、CPU13は、項1を空とし、処理をS303に戻す。
【0149】
一方、ステップS306の判定において、項1が因子pを含んでいる場合、CPU13は、処理をS308に進める。そして、CPU13は、項3を初期化し、空とする。ここで、項3は、始めの項である項1の商演算結果を格納する変数(メモリ12の領域)である。ここでは、数14の構成から、項1に因子p(=1)が含まれていると判定される。
【0150】
そして、ステップS309において、CPU13は、項1の長さが0であるか否かを判定する(S309)。項1の長さが0でない場合、ステップS310において、CPU13は、項1から始めの因子(以下、因子1という)を取得する。数14の構成から、因子“cell”が取得される。そして、ステップS311において、CPU13は、項1から因子1を削除する。
【0151】
次に、ステップS312において、CPU13は、因子1に商演算する因子pが含まれ、かつ、因子1が第1の括弧“(”と“)”とによって形成された因子であるとき、その括弧内の式を式1に設定し、サブルーチン1を再帰呼び出しする。そして、その再帰呼び出しによる処理結果を因子1とする。この処理によって、商演算される式中で、項に“()”による因子を含む場合は、その項は、()内の式が商演算されることになる。数14の構成の場合、“cell”が因子1の場合には、S312は、実行されない。また、cellの次の因子(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))が、因子1の場合には、S312により、再起呼び出しが実行されることになる。その結果、式表現中に因子p(この例では、1)を含む因子が抽出されることになる。
【0152】
さらに、ステップS313によって、CPU13は、項3に対し因子1を積演算し、結果を項3とする。この処理によって、因子1に商演算される因子pが含まれる場合、そのまま項3に積演算されることになる。また、因子1が()の形式の因子の場合に、()内から因子pを含む項が取り出されることになる。そして、CPU13は、処理をS309に戻す。
【0153】
ステップS309の判定で、項1の長さが0となった場合、CPU13は、処理をステップS314に進める。そして、CPU13は、項2(商項)に対して、得られている項3を和演算する。さらに、ステップS315の処理で、CPU13は、項2を商演算後の式である式2に設定する。その後、CPU13は、処理をS302に戻す。
【0154】
そして、S302の判定で、式1の長さが0になると、CPU13は、サブルーチン1の処理を終了する。このような処理により、式2に、以下の数15Aの式表現が出力され、アプリケーションプログラムに引き渡される。
【0155】
cell×id{ε+A+B+C}×1{ε+a1+b1+c1}・・・(数15A)
図11Bおよび図11Cに、数14の式表現に対して、サブルーチン1が実行された場合の式1、項1、項2、項3、因子1、および式2の変化を示す。図11Bおよび図11Cの第1行目は、各列の要素、すなわち、図11A中の該当する処理を示す番号、式1、項1、項、項3、因子1、および式2を示している。第2行以下の各行は、一連の処理ステップであり、図11B上から下へ、さらに、図11Cの上から下へ実行される。
【0156】
そして、まず、ステップS301で、共通関数へのパラメータを介して、式1である数14が入力され、メモリ12に保持される。
【0157】
項1、因子1および項3に着目すると、これらのうち、“cell”および、id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2})が順次サブルーチン1で処理されることが分かる。
【0158】
さらに、id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2})が因子1としてS312で処理されるときに、再起呼び出しが発生する。そして、同様に、“id”、{ε+A+B+C}、および(1{ε+a1+b1+c1}+2{ε+a2+b2+c2})がサブルーチン1の再起呼び出し1で処理される。
【0159】
さらに、(1{ε+a1+b1+c1}+2{ε+a2+b2+c2})が、S312で処理されるときに、再起呼び出し2が発生する。そして、同様に、1{ε+a1+b1+c1}については、商演算する因子“1“が含まれているので、S306で、YESの判定がなされる。そして、S313によって、1と{ε+a1+b1+c1}とが項3に積演算される。
【0160】
一方、2{ε+a2+b2+c2}については、商演算する因子“1”が含まれていないので、S306で、NOの判定がなされる。その結果、これらの因子は、S307において、Φに設定され、削除される。その結果、再起呼び出し2で商演算の結果、式2として出力されるのは、1{ε+a1+b1+c1}となる。
【0161】
さらに、再起呼び出し1では、S313の処理で、項3に積演算されていたid{ε+A+B+C}と再起呼び出し2での商演算の結果である1{ε+a1+b1+c1}とが、積演算され、id{ε+A+B+C}(1{ε+a1+b1+c1})が、式2として出力される。
【0162】
さらに、そして、再起呼び出し1の前に、項3に積演算されていたcellと、再起呼び出し1による商演算の結果が積演算され、数15Aが式2として、最終的に出力されることになる。
【0163】
次に、図12Aにより、剰余を求める処理(サブルーチン2)を説明する。サブルーチン1を実行するCPU13が本発明の剰余演算部に相当する。サブルーチン2は、商演算される式である式1、商演算する因子pを入力され、剰余の式3を出力する。
【0164】
まずステップ321では、商演算処理が実行される前の所定の表現形式によって表現される式1(“商演算される式”)、及び商演算する因子(同値関係示す因子p)が入力される。以下、図11Aの場合と同様、数14により表現される対象情報が入力された場合について説明する。また、1を商演算する因子(同値関係p)と設定する。
【0165】
次に、ステップS322では、CPU13は、演算後の式(ここでは、式3と呼ぶ)を初期化する。このとき、式3の値は、Φ(空、または0)になる。
【0166】
次に、ステップS323では、CPU13は、式1の長さが0であるか否かを判定する。式1の長さが0である場合、CPU13は、サブルーチン1の処理を終了する。
【0167】
一方、ステップS323の判定において、式1の長さが0でなかった場合、CPU13は、ステップ324に処理を進める。そして、CPU13は、式1から始めの項(以下、項1という)を取得する。さらに、ステップS325において、CPU13は、式1から項1を削除する。
【0168】
次に、ステップS326において、CPU13は、演算後の項(以下、項4と呼ぶ)を初期化する。このとき、項4の値は、Φ(空、または0)になる。
【0169】
次に、ステップS327において、CPU13は、項1の長さが0であるか否かを判定する。そして、項1の長さが0でない場合、CPU13は、ステップS328に処理を進める。そして、ステップS328において、CPU1は、項1から始めの因子(因子1)を取得する。さらに、ステップS329において、CPU13は、項1から因子1を削除する。
【0170】
次に、ステップS329において、CPU13は、因子1が因子pと等しいか否かを判定する。そして因子1が因子pと等しい場合、ステップS331において、CPU13は、因子1をΦ(空、または0)にする。
【0171】
次に、ステップS332において、CPU13は、因子1が第1の括弧“(”と“)”とによって形成された因子であるとき、その括弧内の式を式1に設定し、サブルーチン2を再帰呼び出しする。そして、その再帰呼び出しによる処理結果を因子1とする。この処理によって、商演算される式中で、“()”による因子を含む場合は、その因子は、()がはずされ、内の式から剰余(すなわち、因子pを含まない項)が抽出されることになる。
【0172】
さらに、ステップS333によって、CPU13は、項4に対し因子1を積演算し、結果を項4とする。この処理によって、因子1が商演算される因子pと異なる場合に、そのまま項3に積演算されることになる。また、因子1が()の形式の因子の場合に、()内から因子pを含まない項が取り出されることになる。そして、CPU13は、処理をS327に戻す。
【0173】
ステップS327の判定で、項1の長さが0となった場合、CPU13は、処理をステップS334に進める。そして、CPU13は、式3(剰余項)に対して、得られている項4を和演算する。その後、CPU13は、処理をS323に戻す。
【0174】
そして、S323の判定で、式1の長さが0になると、CPU13は、サブルーチン2の処理を終了する。このような処理により、式3に、以下の数15Bの式表現が剰余として出力され、アプリケーションプログラムに引き渡される。
cell(id{ε+A+B+C}(Φ+2{ε+a2+b2+c2}))・・(数15B)
【0175】
図12Bおよび図12Cに、数14の式表現に対して、サブルーチン2が実行された場合の式1、項1、項4、因子1、および式3の変化を示す。図12Bおよび図12Cの第1行目は、各列の要素、すなわち、図12A中の該当する処理を示す番号、式1、項1、項、項4、因子1、および式3を示している。第2行以下の各行は、一連の処理ステップであり、図12Bの表の上から下へ、さらに、図12Cの表の上から下へ実行される。
【0176】
そして、まず、ステップS321で、共通関数へのパラメータを介して、式1である数14が入力され、メモリ12に保持される。
【0177】
項1、因子1および項4に着目すると、これらのうち、“cell”および、id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2})が順次サブルーチン2で処理されることが分かる。
【0178】
さらに、id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2})が因子1としてS332で処理されるときに、再起呼び出しが発生する。そして、同様に、“id”、{ε+A+B+C}、および(1{ε+a1+b1+c1}+2{ε+a2+b2+c2})がサブルーチン1の再起呼び出し1で処理される。
【0179】
さらに、(1{ε+a1+b1+c1}+2{ε+a2+b2+c2})が、S332で処理されるときに、再起呼び出し2が発生する。そして、1{ε+a1+b1+c1}については、商演算する因子“1”が含まれているので、S330で、YESの判定がなされる。そして、S331によって、因子1にΦに設定され、因子1を含む項1全体がΦとなり、削除される。
【0180】
一方、2{ε+a2+b2+c2}については、商演算する因子“1”が含まれていないので、S330で、それぞれの因子1について、NOの判定がなされる。その結果、これらの因子は、S333において、項4に積演算される。その結果、再起呼び出し2の剰余演算の結果、式3として出力されるのは、2{Φ+a1+b1+c1}となる。
【0181】
さらに、再起呼び出し1では、S333の処理で、項4に積演算されていたid{ε+A+B+C}と再起呼び出し2での商演算の結果である2{Φ+a1+b1+c1}とが、積演算され、id{ε+A+B+C}(2{Φ+a1+b1+c1})が、式3として出力される。
【0182】
さらに、そして、再起呼び出し1の前に、項4に積演算されていたcellと、再起呼び出し1による商演算の結果が積演算され、数15Bが式3として、最終的に出力されることになる。
【0183】
(13)接着演算処理
接着とは、本実施形態にて提案する概念であり、2つの被接着情報のそれぞれのデータ構造を維持した上で、それぞれ被接着情報を結合する機能である。接着においては、2つの被接着情報のそれぞれに含まれる情報で、互い関係付けられる情報(これを同値関係を指定された因子という)が指定される。そして、その関係付けられた因子(同値関係を有する因子)同士を介して、2つの被接着情報が結合される。
【0184】
接着演算処理のアプリケーションインターフェースは、例えば、戻り値=attach(接着
する式1、因子1、接着する式2,因子2、接着演算後の式);のように定義できる。こ
こで、因子1と、因子2とは、接着演算する式1の項と、式2の項とを関係付ける指定である。この指定によって、式1で因子1を含む項と、式2で因子2を含む項とが以下のような手順で結びつけられる。
【0185】
図13は、接着演算処理を実行する処理のフローを示す。ステップS401では、接着する所定の表現形式によって表現される対象情報を入力する。以下の説明では、数16及び数17によって表現される対象情報を接着処理する場合について説明する。すなわち、数16が被接着式1であり、数17が被接着式2である。また、ここでは、数16の因子
“2”と、数17の因子“q”との同値関係が指定されているとする。
cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))・・・(数16)
s(p(p1+p2)+q(q1+q2))・・・(数17)
【0186】
ステップS402では、数16及び17の因子1、因子2による上述した商演算処理(サブルーチン1およびサブルーチン2)を実行して、得られた商と剰余とを和演算処理する。このサブルーチン1を実行し、商を取得するCPU13が、本発明の関連項抽出部に相当する。また、このサブルーチン2を実行し、剰余を取得するCPU13が、本発明の非関連項抽出部に相当する。その結果、“式1から得られた剰余+式1から得られた商+式2から得られた剰余+式2から得られた商”という形式の式が形成される。これを商演算後の式という。このうち、式1からの商を項1とし、式2から得られた商を項2とする。項1は、因子“2”を含む項である。また、項2は、因子“q”を含む項である。このように、同値関係を指定された因子1、因子2を含む項を、同値要素を表す項という。すなわち、式1に対して、因子“2”で商演算した商が項1であり、同値要素を表す項である。また、式2に対して、因子“q”で商演算した商が項2であり、これも同値要素を表す項である。
【0187】
次にステップS403では、因子1および因子2を含む項1、2を取得し商演算後の式から削除する。さらに、因子1を含む項1、および因子2を含む項2をそれぞれ左因子と右因子とに分ける。ここで、左因子とは、ある項の因子pに着目した場合に、pの左に位置する因子又は因子の積をpの左因子という。また、右因子とは、ある項の因子pに着目した場合に、pの右に位置する因子又は因子の積をpの右因子という。例えば、項(a×b+c)×p×d×eについてみると、pの左因子は(a×b+c)であり、pの右因子はd×eとなる。
【0188】
次に、ステップS404では、項1における因子1の左因子をl1,右因子をr1,項2における因子2の左因子をl2,右因子をr2とし,接着空間の式として{l1+l2}{因子1+因子2}{r1+r2}を作成する。次に、ステップS405では、商演算処理後の剰余を示す対象情報、接着演算処理後の対象情報を和演算処理し,接着演算処理後の対象情報とし、処理を終了する。その結果、“接着演算後の式”に演算結果が設定され、アプリケーションプログラムに引き渡される。なお、接着演算処理を実行中の対象情報の状態の詳細は図14に示す。
【0189】
図14に、接着演算処理を実行中の対象情報の状態の詳細を示す。この例では、まず、S401にて接着する式1、式2が入力される。また、因子1として“2”、因子2として、“q”が指定されている。
【0190】
次に、S402にて商演算が実行される。その結果、式1は、cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+Φ))という剰余と、cell(id{ε+A+B+C}(Φ+2{ε+a2+b2+c2}))という商に分離される。また、式2は、s(p(p1+p2)+Φ)という剰余と、s×q(q1+q2)という商に分離されている。図14のS402の行では、これらの剰余と商が和演算された形式で示されている。
【0191】
そして、ここで、式1の同値因子、すなわち、因子“2”を含む項は、cell×id{ε+A+B+C}(Φ+2{ε+a2+b2+c2})であり、同値要素を表す項1という。また、式2の同値因子、すなわち、因子“q”を含む項は、s×q(q1+q2)であり、同値要素を表す項2という。これらから、左因子l1は、cell×id{ε+A+B+C}、左因子l2は、s、右因子r1は、{ε+a2+b2+c2}、右因子r
2は、(q1+q2)である。したがって、接着された結果である接着空間の式は、
{cell×id{ε+A+B+C}+s}{2+q}{(ε+a2+b2+c2)+(q1+q2)}
となる。
【0192】
さらに、これらの剰余の式cell(id{ε+A+B+C}(1{ε+a2+b2+c2}+Φ))とs(p(p1+p2)+Φ)とを和演算することで、接着演算後の式となる。
【0193】
(14)部分集合取得処理
部分集合取得処理は、集合から、指定された因子(以下、指定因子という)を有する項を含む式(部分集合)と、指定因子を有しない項の式(部分集合)に分離する処理である。この処理を実行するCPU13が、本発明の部分集合形成部に相当する。ただし、本実施形態では、指定因子(今pとする)を有する項が複数個存在する場合には、{左因子1+左因子2+・・・}p{左因子1が含まれていた項の右因子+左因子2が含まれていた項の右因子+・・・}+因子pを含まない部分集合の和のように、指定された因子pで括り出す。このように、部分集合取得処理の括り出しでは、括り出し前の各項において、指定因子pの左側に結合する因子(左因子と呼ぶ)と、指因子pの右側に結合する因子(右因子と呼ぶ)とをそれぞれ、第2の{}内に和演算する。そして、左因子の和は、第2の{}によって括られ、その順序を維持して、指定された因子の左側に結合される。
【0194】
また、右因子の和は、第2の{}によって括られ、その順序を維持して、指定された因子の右側に結合される。さらに、同一の左因子に対して、異なる右因子を有する項が複数存在する場合、それらの右因子は、第1の括弧“()”で括り出される。この場合、左因子は、集合情報の識別情報として機能する。例えば、
a1×b×c1+a1×b×c2+a2×b×c1+a2×b×c2+a3×b×c3+a×u×vという式表現に対して、因子bを指定因子として部分集合取得演算を実行すると、
{a1+a2+a3}b{(c1+c2)+(c1+c2)+c3}+a×u×v
となる。この場合、右因子の列は、それぞれ、集合IDがa1の集合の部分集合b(c1+c2)、集合IDがa2の集合の部分集合b(c1+c2)、集合IDがa3の集合の部分集合b×c3を表している。
【0195】
さらに、部分集合取得処理の対象となる項に、第1の括弧“()”または第2の括弧“{}”が含まれている場合には、これらの括弧内の式表現に対して、再起的に部分集合取得処理が実行される。したがって、第1の括弧“()”または第2の括弧“{}”で括られた個々の括弧内で、部分集合取得処理が実行される。
【0196】
部分集合取得処理のアプリケーションインターフェースは、例えば、部分集合取得後の式表現は、戻り値=separate(部分集合取得前の式表現、指定因子);のように定義できる。対象の式,因子を指定すると,括った後の式(戻り値)になります。
【0197】
次に部分集合取得処理について説明する。図15は、部分集合取得処理を実行する処理のフローを示す。ステップS501では、演算前の所定の表現形式で表現される対象情報と、部分集合を指定するための指定因子pを入力する。以下、対象情報として数18に示すデータを用いて、指定因子“p”で部分集合を取得する場合について説明する。
s×p(p1+p2)+t×p(p3+p4)+id(s×p(p1+p2)+t×p(p3+p4))・・・(数18)
【0198】
ステップS502では、部分集合を取得するための因子以外(ここでは、「その他の式
」「左因子式」および「右因子式」)をΦと設定する。ステップS503では「処理後の項」をεに設定する。ステップS504では、対象情報を構成する式の長さが0であるかを判断する。すなわち、対象情報が存在するか否かを判断する。式の長さが0であると判断した場合には、ステップS517へ進む。一方、式の長さが0であると判断しなかった場合には、ステップS505へ進む。
【0199】
ステップS505では、数18から第一項を取得し保存する。次にステップS506では、数18から第一項を削除する。次にステップS507では、取得した項に因子pが含まれるか判断する。取得した項に因子pが含まれると判断した場合にはステップS515へ進む。一方、取得した項に因子pが含まれると判断しなかった場合には、ステップS508へ進む。
【0200】
ステップS508では、項の長さが0であるか否かを判断する。項の長さが0であると判断した場合にはステップS514へ進む。一方、項の長さが0であると判断しなかった場合には、項から第一因子を取得し、これを保存し(ステップS509)、次に項から第一因子を削除する(ステップS510)。
【0201】
次にステップS511では、第一因子が第一の括弧又は第二の括弧で括られているか判断する。因子が第一の括弧又は第二の括弧で括られていると判断した場合には、第一の括弧又は第二の括弧で括られている式に対して、本部分集合取得処理を実行する(ステップS512)。すなわち、再起呼び出しを実行する。一方、第一の括弧又は第二の括弧で括られていると判断しなかった場合には、第一因子を取得した因子とし(S520)、ステップS513へ進む。ステップS513では、処理後の項に取得した因子によって積演算処理を実行し、その結果を処理後の項とし、ステップS508の処理を再度実行する。
【0202】
ステップS508において、項の長さが0であると判断した場合には、その他の式に処理後の項を和演算処理し、その結果をその他の式とする(ステップS514)。ステップS514の処理を実行後、再度ステップS503の処理を実行する。次にステップS504において式の長さが0であると判断した場合には、部分集合の項として{左因子式}p{右因子式}を作成し(ステップS517)、その他の式に部分集合項を和演算し,演算後の式とし(ステップS518)、処理を終了する。以上の処理を実行することにより、数18により表現される対象情報は、数19により表現される対象情報となる。なお、部分集合取得処理を実行中の対象情報の状態の詳細は図16A、図16Bに示す。
id({s+t}p{(p1+p2)+(p3+p4)})+{s+t}p{(p1+p2)+(p3+p4)}・・・(数19)
【0203】
図16Aおよび図16Bに、数18の式表現に対して、部分集合取得処理が実行された場合の「演算前の式」、「部分集合取得のための因子」、「左因子式」、「右因子式」、「左因子」、「右因子」「その他の式」、「取得した項」、「取得した因子」、「処理後の項」、「部分集合項」および「演算後の式」の変化を示す。図16Aの各行と、図16Bの各行は、図15の処理での同一の処理を示している。すなわち、図16Aおよび図16Bを横に接続して、部分集合取得処理の状態変化が表されることになる。
【0204】
図16Aおよび図16Bの第1行目は、各列の要素、すなわち、図15中の該当する処理を示す番号、「その他の式」、「取得した項」、「取得した因子」、「処理後の項」、「部分集合項」および「演算後の式」を示している。第2行以下の各行は、一連の処理ステップであり、図16Aおよび図16Bの表の上から下へ実行される。
【0205】
ここでは、数18の式表現を処理対象とする。部分集合取得処理を実行する共通関数separateに対して、まず、部分集合取得前の式表現である数18が与えられる。この式表現はメモリ12に格納される。また、指定因子はpであるとする。
【0206】
まず、S505、S505の処理で、式から第一項s×p(p1+p2)が取得される。s×p(p1+p2)に指定因子pが含まれているので、S515およびS516が実行され、左因子sおよび右因子(p1+p2)がそれぞれ左因子式および右因子式に和演算される。
【0207】
次に、S505、S506の処理で、式から第二項t×p(p3+p4)が取得される。t×p(p3+p4)に指定因子pが含まれているので、S515およびS516が実行され、左因子tおよび右因子(p3+p4)がそれぞれ左因子式および右因子式に和演算される。
【0208】
さらに、S505、S506の処理で、式から第三項id(s×p(p1+p2)+t×p(p3+p4))が取得される。そして、S509において、第一因子としてidが取得される。項idは、S513にて、処理後の項に積演算される。さらに、S509において、第一項として、次の項(s×p(p1+p2)+t×p(p3+p4))が取得される。これは、S511の判定で、第1の括弧を含むとされるので、S512が実行される。
【0209】
そして、式表現s×p(p1+p2)+t×p(p3+p4)に対して、部分集合取得処理が再起呼び出しで実行される。図16Aおよび図16Bでは、再起呼び出し中の状態は、省略されているので、本文にて説明する。この場合も、s×p(p1+p2)から、左因子s、右因子(p1+p2)が取得される。また、t×p(p3+p4)から、左因子t、右因子(p3+p4)が取得される。これらの左因子および右因子は、S516において、それぞれ左因子式、および右因子式に和演算される。そして、式表現s×p(p1+p2)+t×p(p3+p4)の末尾まで処理が進み、S504で、残りの式の長さが0であると判定される。すると、CPU13は、部分集合の項として、{s+t}p{(p1+p2)+(p3+4)}を作成する。そして、CPU13は、部分集合の項を演算後の式として、再起呼び出しを終了する。
【0210】
再起呼び出しを終了すると、演算後の式を取得するので、これを取得した因子とする。この場合、取得した因子は、({s+t}p{(p1+p2)+(p3+4)})である。そして、CPU13は、S513にて、再起呼び出し前に計算しておいた処理後の項(“id”が積演算されている)に、取得した因子を積演算する。その結果、S513において、処理後の項は、id({s+t}p{(p1+p2)+(p3+4)})となる。CPU13は、S514にて、処理後の項をその他の式として和演算する。
【0211】
そして、S504にて、残りの式の長さが0であると判定されると、CPU13は、再起呼び出し前に作成していた左因子式s+tおよび右因子式(p1+p2)+P3+p4)から、部分集合の項{s+t}p{(p1+p2)+P3+p4)}を作成する。そして、CPU13は、S518にて、その他の式に部分集合の項を和演算する。これによって、演算後の式id({s+t}p{(p1+p2)+(p3+4)})+{s+t}p{(p1+p2)+P3+p4)}が作成されることになる。
【0212】
(15)ホモトピー保存処理
次にホモトピー保存処理について説明する。ホモトピー保存処理は、式1に対して、パラメータを表す項pを用いて演算Gを実行し、式2が得られたとき、
(演算後の式2)=G(演算前の式1+演算時のパラメータを表す項p)
のように、演算実行前後の関係を保持する機能である。この場合、演算実行前の式1、すなわち、初期状態は、式ΦにパラメータΦ項を適用して、式1が得られたと仮定し、演算
前の式を
式1=F(Φ+Φ)
のようにおく。ここで、演算実行前の式をホモトピー保存式1と呼ぶことにする。
【0213】
図17は、ホモトピー保存処理を実行する処理のフローを示す。ここで、式1は、数20の左辺の式である。また、attachによって接着演算が指定され、因子2と因子qとの同値関係が指定されている場合を説明する。
【0214】
まず、ステップS601では、演算実行前の式、すなわち、ホモトピー保存式1と、演算Gと、パラメータ因子pが入力される(S601)。
ここでは、例として、以下の数20によって、式1を仮定する。また、演算Gとして、接着演算を実行する例を示す。また、そのときの、パラメータ因子として、attach(2+q)を指定する。すなわち、因子2と因子qとの同値関係が指定されて、接着演算が実行された場合を例に、ホモトピー保存処理を説明する。
(cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))+s(p(p1+p2)+q(q1+q2)))=F(Φ+Φ)・・・(数20)
【0215】
ステップS602では、数20により表現される式から演算G前の式、すなわち数20の左辺を取得する。これを数21とする。
cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))+s(p(p1+p2)+q(q1+q2))・・・(数21)
【0216】
ステップS603では、演算Gによる演算処理を行い演算G後の式とする。この場合、数22により表現される式が得られる。ここでは、演算Gの例として、接着演算を実行する。また、接着演算の同値関係を指定するパラメータを“2”および“q”とする。すなわち、因子“2”で商演算された商と、因子“q”で商演算された商とを接着する。そのときのホモトピー保存式の例を説明する。
cell(id{ε+A+B+C}(1{ε+a2+b2+c2}+Φ))+s(p(p1+p2)+Φ)+{cell×id{ε+A+B+C}+ε}{2+q}{{ε+a2+b2+c2}+(q1+q2)}・・・(数22)
【0217】
ステップS604では、演算G後のホモトピー保存式2として、(演算G後の式)=G(ホモトピー保存式1+演算時のパラメータp)を作成する。ここで、パラメータpは、“attach(2+q)”である。以上の処理を実行することにより数21により表現された式は、数23により表現される式となる。
(cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+Φ))+s(p(p1+p2)+Φ)+{cell×id{ε+A+B+C}+ε}{2+q}{{ε+a2+b2+c2}+(q1+q2)})
=G((cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))+s(p(p1+p2)+q(q1+q2)))
=G(F(Φ+Φ)+attach(2+q)))・・・(数23)
【0218】
この式は、F(Φ+Φ)で示される式(すなわち、数21)に、attach(2+q)というパラメータで演算G、すなわち、接着演算が実行されて、数23の左辺(最上段の式)が得られたことを示している。
【0219】
(16)UNDO演算処理
次にホモトピー保存式におけるUNDO演算処理について説明する。図18は、ホモトピー保存式におけるUNDO演算処理のフローを示す。ステップS701では、ホモトピ
ー保存式(演算G後の式)=F(演算G前の式+演算時のパラメータを表す式p)の入力をする。以下、対象情報として数24に示すデータを用いた場合について説明する。
(cell(id{ε+A+B+C}(1{ε+a2+b2+c2}+Φ))+s(p(p1+p2)+Φ)+{cell×id{ε+A+B+C}+ε}{2+q}{{ε+a2+b2+c2}+(q1+q2)})
=G((cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))+s(p(p1+p2)+q(q1+q2)))
=F(Φ+Φ)+attach(2+q))・・・(数24)
【0220】
上述のように、ホモトピー保存式は、演算G前の式F(Φ+Φ)に演算(この例では、接着演算G、演算時のパラメータはattach(2+q))を実行することで、数24の最上段(最初の“=”の左辺)の式表現が得られたことを記録している。なお、数24において、中段の式(最初の“=”の右辺)と、最下段の式(2つ目の“=”の右辺)とは、表現形式が異なるだけで実質的に同一の式である。最下段の式は、F(Φ+Φ)を用いて表現を簡略化している。そして、それら中段の式と簡略された式を“=”で結んだ式が、G()という演算の中に挿入されている。
【0221】
UNDO演算処理では、この記録を基に、演算前の式を得る。すなわち、CPU13は、演算の種類と、演算時のパラメータとを基にして、演算前の状態に式を戻す。
【0222】
次にステップS702では、UNDO後の式(演算G前の式)=G-1((演算G後の式)=G(演算G前の式+p))の作成を実行する。この場合、すでに、数24の中段の式と下段の式で、演算の種類G、演算実行前の式、演算時のパラメータattach(2+q)が記録されている。したがって、演算前の式は、直ちに、取り出すことができる。以上の処理を実行することにより数24により表現された対象情報は、数25により表現される対象情報となる。
((cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))+s(p(p1+p2)+q(q1+q2)))=F(Φ+Φ))
=G-1((cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+Φ))+s(p(p1+p2)+Φ)+{cell×id{ε+A+B+C}+ε}{2+q}{{ε+a2+b2+c2}+(q1+q2)})
=G((cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))+s(p(p1+p2)+q(q1+q2)))
=F(Φ+Φ)+attach(2+q))
)・・・(数25)
【0223】
この式は、数24で与えられホモトピー保存式の両辺に、演算G前に戻す演算G-1を実行することによって、演算G前の式(初期状態F(Φ+Φ)が得られたことを示している。これによって、演算G前の式である(cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))+s(p(p1+p2)+q(q1+q2)))=F(ε+ε)が、演算G後の式であるcell(id{ε+A+B+C}(1{ε+a1+b1+c1}+Φ))+s(p(p1+p2)+Φ)+{cell×id{ε+A+B+C}+ε}{2+q}{{ε+a2+b2+c2}+(q1+q2)}から得られることが示される。
【0224】
さらに、この演算G後の式であるcell(id{ε+A+B+C}(1{ε+a1+b1+c1}+Φ))+s(p(p1+p2)+Φ)+{cell×id{ε+A+B+C}+ε}{2+q}{{ε+a2+b2+c2}+(q1+q2)})は、演算G前の式であるcell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+
a2+b2+c2}))+s(p(p1+p2)+q(q1+q2))から得られたことが記録されている。
【0225】
すなわち、演算G前の式(F(Φ+Φ))に演算G、パラメータattach(2+q)を適用することで、演算G後の式が得られ、かつ、その演算G後の式に演算G-1を適用することで、演算G前の式に戻されたことが記録される。
【0226】
このように、UNDO演算処理は、演算後の式から、演算前の式が得られたことを記録するので、次に示すREDO演算処理を実行することで、直ちに、演算後の式を得ることができる。
【0227】
(17)REDO演算処理
次にホモトピー保存式におけるREDO演算処理について説明する。図19は、ホモトピー保存式におけるREDO演算処理のフローを示す。ステップS801では、ホモトピー保存式におけるUNDO後の式(演算G前の式)=G-1((演算G後の式)=G(演算G前の式+p))の入力をする。以下、対象情報として数26に示すデータを用いた場合について説明する。
((cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))+s(p(p1+p2)+q(q1+q2)))=F(ε+ε))
=G-1((cell(id{ε+A+B+C}(1{ε+a2+b2+c2}+Φ))+s(p(p1+p2)+Φ)+{cell×id{ε+A+B+C}+ε}{2+q}{{ε+a2+b2+c2}+(q1+q2)})=G((cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))+s(p(p1+p2)+q(q1+q2)))=F(Φ+Φ)+attach(2+q))
)・・・(数26)
【0228】
上述のように、数26は、演算G前の式(F(Φ+Φ))に接着演算Gおよびパラメータattach(2+q)が適用され、演算G後の結果が得られ、さらに、演算G後の式から演算G前の式に戻されたことが記録されている。
【0229】
次にステップS802では、UNDO後の式から,UNDO演算前の式、すなわち(演算G後の式)=G(演算G前の式+演算時のパラメータp)を取得し、REDO演算後の式とする。以上の処理を実行することにより数26により表現された対象情報は、数27により表現される対象情報となる。
(cell(id{ε+A+B+C}(1{ε+a2+b2+c2}+Φ))+s(p(p1+p2)+Φ)+{cell×id{ε+A+B+C}+ε}{2+q}{{ε+a2+b2+c2}+(q1+q2)})=G((cell(id{ε+A+B+C}(1{ε+a1+b1+c1}+2{ε+a2+b2+c2}))+s(p(p1+p2)+q(q1+q2)))=F(ε+ε)+attach(2+q))・・・(数27)
【0230】
このように、ホモトピー保存処理によって、演算後の結果とともに、演算G前の式(F(Φ+Φ))と、適用される演算の種類Gと、使用されるパラメータattach(2+q)を記録する。これによって、UBDO演算処理で演算前の結果を得ることができる。さらに、UNDO演算処理で、演算後の式から、演算前の式が得られたことを記録することで、REDO演算処理を実行し、直ちに、演算G後の式を得ることができる。このように、ホモトピー保存処理、UNDO演算処理、およびREDO演算処理は、メモリ12の容量を犠牲にして、演算前後の関係を保持する一方、演算を戻す処理と再実行する処理とを簡易に実現する。
【0231】
(適用例)
次にデータ処理システムを開発する際に、本発明に係る情報処理装置を使用する例について説明する。
【0232】
本発明に係る情報処理装置は、様々なデータ処理システムに適用可能である。図20は、建設業における情報管理、すなわちデータ処理システムが要求される例を示す。同図に示すように、例えば建設業における管理として、プロジェクト管理と現場管理が例示できる。プロジェクト管理の主は、財務管理であり、財務管理は予算作成管理、購買管理、資機材管理によって成り立っている。そして、これらの管理は、データベースに格納された情報を管理することによって行われる。また、現場管理においては、工程管理が主であるが工程管理においては作業手帳の情報も管理できることが重要である。そして本発明に係る情報処理システムは、これらあらゆる情報管理、すなわちデータ処理システムに適用できる。以下、具体的に説明する。なお、本実行形態においては建設業における例としたがこれに限定されるわけではない。様々な分野において適用可能である。
【0233】
図21A及び図21Bは、本発明の対象情報に相当する社員データ及び伝票データを示す。図21Aに示す社員データ(マスタデータ)は、正規化表構造で表現されるデータである。これを本発明に係る所定の表現形式によって表現すると、数28により表現される。そして、このデータはメモリ12に格納される。なお、上記社員データはキーボード等の入力部11から入力する。入力された社員データは、ディスプレイ等の出力部14にて確認できる。
社員(社員コード{ε+氏名+年齢+職種+所属}(K100{ε+社員A+30+土木+情報システム}+K101{ε+社員B+49+事務+土木}+K102{ε+社員C+24+建築+建築}))・・・(数28)
【0234】
情報処理装置100は、このようにして、社員データをメモリ12に保持し、データベースとして管理する。この場合、データ入力のためのユーザインターフェース、データ出力のためのユーザインターフェースに限定はない。すなわち、情報処理装置100は、式表現で対象情報を記述し、メモリ12に保持し、上述の演算処理を実行する共通関数によって、演算機能をアプリケーションプログラムに提供する。したがって、アプリケーションプログラムの構成そのものにも限定はない。
【0235】
例えば、社員情報の入力は、社員コード、氏名、年齢、職種、所属部署等の入力フィールドを備えた、画面プログラムで行っても良い。そして、画面プログラムは、入力された情報から、上記式表現(例えば、インスタンスK101{ε+社員B+49+事務+土木})を生成すればよい。ただし、セル空間情報、トポロジー空間情報、集合情報の末尾に、インスタンスを挿入する共通関数を提供してもよい。例えば、戻り値=insert(セル空間ID、インスタンス)というアプリケーションインターフェースを提供してもよい。
【0236】
また、例えば、社員情報の入力は、テキストエディタを用いて、数28の式表現に、インスタンスを直接挿入するようにしても構わない。インスタンスが挿入された後は、上記各種演算によって、共通関数が、アプリケーションプログラムに処理機能を提供する。
【0237】
したがって、情報処理装置100によれば、従来のようなリレーショナルモデルによってテーブルを構成することなく、式表現をメモリ12に保持することによって、社員データのような表形式のデータを管理できる。例えば、有る社員A(社員コードK120)に関するデータを抽出し、表示するには、セル空間IDとして、“社員”を指定し、因子“社員コード×K120”によって同値関係を指定し、部分集合取得処理を実行すればよい。
【0238】
さらに、情報処理装置100のように、式表現で対象情報を表した場合、属性の追加、削除、変更は自在である。式表現を変更すればよいからである。従来の表形式のリレーショナルモデルでは、属性の追加、削除は、データベース自体の再構築が要求される。例えば、社員情報のレコードが、社員コード、氏名、年齢、職種、所属部署のフィールドからなっており、すでに、データベースが運用されている場合に、このレコードに、さらに、性別、入社年、役職を追加することは困難である。しかしながら、情報処理装置100では、属性の追加、削除は、式表現の変更であり、変更のための工数が極めて少なくなる。
【0239】
さらに、情報処理装置100のように、式表現で対象情報を表した場合、異なる形式のセル空間情報、異なる種類のトポロジー空間情報、異なる種類の集合情報を自在に定義できる。したがって、リレーショナルモデルのように、社員データが、特定の表で定義されたレコードの形式で固定されることもない。例えば、社員データを示すセル空間情報として、一般社員の部分集合、管理職の部分集合、非正規社員の部分集合、嘱託社員の部分集合等を自在に定義できる。
【0240】
また、情報処理装置100のように、式表現で対象情報を表した場合に、1つの属性に複数の値を設定できる。さらに、第1の括弧および第2の括弧を用いて、1つの属性に対して、複数階層に渡るデータを定義することも容易である。例えば、社員(コード{ε+氏名+年齢+職種{{国別、公用語}、職種コード}+所属{事業所{国別、事業所コード}、部門、課}}のように複数階層に渡る属性を設定できる。また、1つの属性に対する値として、第1の括弧、第2の括弧を用いて複数個の値を持つ属性値を設定できる。
【0241】
図21Bに示す伝票データは、非正規化表構造で表現されるものである。また、同図に示すように伝票データと属性のまったくない付箋メモが添付されている。従来、このような対象情報をデータベースに入力は、新たなアプリケーションの開発を必要とするなど非常に困難とされていた。しかし、これを本発明に係る所定の表現形式によって表現すると、数29により表現される。そして、このデータはメモリ12に格納され情報管理を行うことができる。なお、midは付箋のidを表し、ptは伝票中の付箋を添付する位置を表す。
伝票ID(伝票コード{プロジェクト名称+期間{開始+終了}+金額+担当者{連絡先+コード}}(a{b+c{c1+c2}+d+e{e1+e2}}))+{伝票ID+ε}{pt+mid}{ε+メモ}・・・(数29)
【0242】
図22A及び図22Bは、プロジェクトデータ及び歩掛作成データを示す。図22Aに示すプロジェクトデータは、有向グラフのツリー構造で表現されるデータである。すなわち、実行予算データは、発注データ1と発注データ2により構成され、更に発注データ1は検収データ1と検収データ2により構成される。また、発注データ2は、検収データ3と検収データ4により構成される。このようなプロジェクトデータは、本発明に係る所定の表現形式によって表現すると、数30により表現される。そして、このデータはメモリ12に格納され情報管理を行うことができる。
【0243】
実行予算(発注データ1(検収データ1+検収データ2)+発注データ2(検収データ3+検収データ4))・・・(数30)
【0244】
図22Bに示す歩掛作成データは、逆ツリー構造で表現されるデータである。同図に示すように土砂掘削には、バックホーの運転とダンプトラックの運転を必要とする。また、バックホーの運転には燃料である軽油と運転手が必要となる。また、ダンプトラックの運転には、軽油及び運転手が必要となり、更に雑費が関係してくる。なお、このような逆ツリー構造で表現される対象情報は、従来データ管理が難しいとされていたものである。しかし、これを本発明に係る所定の表現形式によって表現すると、数31により表現される
。そして、このデータはメモリ12に格納され情報管理を行うことができる。
((軽油+運転手)バックホー運転+(経由+運転手+雑費)ダンプトラック運転)土砂掘削・・・(数31)
【0245】
図22Bで、下側のグラフは、経由および運転手が1つに集約されている。一方、上側のグラフの経由および運転手がバックホー運転と、ダンプトラック運転とで分離している。従来のデータベースでは、このようなことが表現できない。リレーショナルデータベース等で工夫してデータベース設計したとしても、アプリケーションプログラムが煩雑になる。また故に変更時にはメンテが大変になる。これが既存の技術の問題点,表現力の問題で,既存のモデルでは表現できないが故に工夫した設計アプリ開発が必要になりコスト増、また開発業者の品質に差が出る。またデータベース,アプリケーションプログラム設計等技術者が別れ,技術の分離により工期の遅れがあって当然になっている。さらに要求仕様が曖昧だったり開発途中で変更されたりすると手戻りが増え大幅なコスト増になるケースが頻発している。一方、本実施形態の技術では統一的により多くのことが表現可能なので、データベース設計、アプリケーション設計・開発の負担が従来よりも軽減される。つまり、情報処理装置100で処理したい情報を式として入力すれば、本実施形態で説明した演算によって、処理し、検索し、出力できる。本実施形態の技術ではビジュアルに式で各空間を設計して、各関数を使用すると変形されてその場で必要な出力結果が出て確認できる。したがって、仕様の曖昧さがなくなり、アプリケーション開発が極めて少ない故にメンテナンスも容易である。例えば、図22B上側のレコード構成で、バックホー運転を構成する運転手のデータベースに、新たな運転手の情報を追加しても、ダンプトラック側には、反映されない。
【0246】
しかし、本実施形態の情報処理装置100では、図22B上側のグラフおよび下側のグラフは、ともに数31で表される。数31でも、一見、バックホー運転と、ダンプトラック運転とで、運転手のデータベースが分離しているように見える。しかしながら、本実施形態で示したトポロジー空間情報は、部分集合を識別するIDによって、個々の項を分類する。したがって、バックホーというデータを構成する運転手データの部分集合も、ダンプトラック運転を構成する運転手データの部分集合も、ともに同一の部分集合IDを付与した場合には、同一の部分集合として管理される。
【0247】
したがって、運転手データの部分集合が、例えば、社員×運転手×(運転手1+運転手2+・・・+運転手N)のように構成されているとする。この場合に、数31は、以下の数32ように、記述される。
((軽油+社員×運転手×(運転手1+運転手2+・・・+運転手N))バックホー運転+(経由+社員×運転手×(運転手1+運転手2+・・・+運転手N)+雑費)ダンプトラック運転)土砂掘削・・・(数31)
【0248】
この場合に、一旦、社員×運転手×(運転手1+運転手2+・・・+運転手N)によって部分集合取得処理を実行すると、以下のようになる。
({ε+ε}社員×運転手×(運転手1+運転手2+・・・+運転手N){バックホー運転+ダンプトラック運転}+軽油×バックホー運転+(軽油+雑費)×ダンプトラック運転)×土砂掘削・・・(数33)
【0249】
このように、運転手に関するデータが一元化されるので、運転手Mを追加したとしても、バックホー運転と、ダンプトラック運転の両方の運転手を変更できる。
なお、バックホー運転と、ダンプトラック運転とで、運転手データベースを個別に管理したい場合は、それぞれの部分集合IDを異なるものとすればよい。
({ε+ε}社員×({ダンプ運転手×(運転手1+運転手2+・・・+運転手N)+トラック運転手×(運転手1+運転手2+・・・+運転手N)}{バックホー運転+ダンプ
トラック運転})+軽油×バックホー運転+(軽油+雑費)×ダンプトラック運転)×土砂掘削・・・(数33)
【0250】
以上例示的に説明した各種データ、すなわち対象情報は新たな情報の入力や上述した所定の処理を実行することにより様々な状態に変化可能である。すなわち、メモリ12に格納された対象情報をシステム管理する上で最も管理し易い状態、換言すると抽象レベルに移行することができる。次に、本発明に係る抽象度に応じた各レベルについて適用例とともに説明する。
【0251】
図23は、集合レベル22で表現される対象情報の例を示す。集合レベル22では、対象情報の抽象度が高く表現される。集合レベル22は、Σ集合ID×項又はΣ項×集合IDにより表現することができる。社員1、社員2、社員3からなる社員情報と、机、およびPCからなる備品情報が存在する場合について考える。この場合社員が集合IDに相当し、社員1、社員2、社員3がそれぞれ項に相当する。また、備品情報については、備品が集合IDに相当し、机及びPCが項に相当する。したがって、これらの対象情報を集合レベルで表現すると数32のように表現できる。
社員×社員1+社員×社員2+社員×社員3+机×備品+PC×備品・・・(数32)
【0252】
図24は、トポロジー空間レベル23で表現される対象情報の例を示す。トポロジー空間レベル23は、トポロジー空間ID×(Σ部分集合)により表現することができる。ただし、数32に対して、集合IDである社員、あるいは、備品を括りだした式も、トポロジー空間レベル23で表現される対象情報である。以下、数32Aに示す。
社員×(社員1+社員2+社員3)+(机+PC)×備品・・・(数32A)
【0253】
トポロジー空間レベル23では、前記集合レベル22よりも前記対象情報の抽象度が低く表現される。また、該対象情報が部分集合を項として表現される。上述した社員情報及び備品情報に新たに会社情報が追加され、社員情報及び備品情報は会社情報に属している。また、例えば、机のデータが、机1、机2からなり、PCのデータがPC1およびPC2からなり、備品データは、机とPCからなり、会社管理するデータベースが、社員データと、備品データとを有する場合に、会社管理するデータベースは、次のような構成となる。この場合には、備品情報は机1、机2、机3からなる机情報と、PC1、PC2、PC3からなるPC情報により構成される。このように、前述した集合レベル22よりも抽象度がより低く表現されている。そしてこれらの対象情報をトポロジー空間レベル23で表現すると数33のように表現できる。
会社ID(社員(社員1+社員2+社員3)+備品(机(机1+机2)+PC(PC1+PC2)))・・・(数33)
【0254】
ここでは、会社を管理するデータベースは、会社IDによって識別される。“社員”で識別されるデータの部分集合は、社員1、社員2のような個々のデータを有している。ここで、社員1は、例えば、社員1のID×(氏名+所属+職務)等である。また、備品といるIDで識別されるデータの部分集合は、さらに、机というIDで識別される部分集合と、PCというIDで識別される部分集合のデータとが、存在することを示している。机で識別されるデータの部分集合には、机1、机2等の個々のデータが記録される。机1は、例えば、机1のID×(取得原価+時価+設置場所+メーカ)等である。PCで識別されるデータの部分集合も同様である。このように、情報処理装置100によれば、式表現でにて、識別子を×、+、()、{}によって組み合わせることで、管理対象を表現し、コンピュータ上のメモリ12に記憶し、管理することができる。
【0255】
図25は、接着空間レベル24で表現される対象情報の例を示す。トポロジー空間X,Yがそれぞれ部分集合X0,Y0に含まれる因子x,yによって同値関係を指定して接着
すると接着空間は、{トポロジー空間XID×xの左因子+トポロジー空間YID×yの左因子}×{x+y}×{xの右因子+yの右因子}+トポロジー空間XID×(部分集合X−X0)+トポロジー空間YID×(部分集合Y−Y0)となる。接着空間レベル24では、前記トポロジー空間レベル23よりも前記対象情報の抽象度が低く表現される。また、前記トポロジー空間レベル23における前記対象情報同士が接着されて表現される。図25に示すように、上述した会社情報に新たにトポロジー空間レベル23で表現される情報機器情報が追加されている。そして、情報機器情報は、ノート及びデスクトップからなるPC情報とM1及びM2からなるモバイル情報により構成されている。
【0256】
会社情報と情報機器情報をみるとPC情報が共通していることがわかる。このような場合において、上述した所定の処理を実行することにより会社情報及び情報機器情報を展開する。すなわち、まず、商演算処理を実行して対象情報を分割し、その後分解した各情報の中からPC情報を抽出し、接着処理を実行することにより接着空間を形成する。すなわち、トポロジー空間レベル23で表現されていた会社情報及び情報機器情報を接着空間レベル24へ移行されたことになる。これにより、今まで別々の情報として管理されていた情報を関連付けることができる。なお、商演算処理及び接着処理を実行するに当たり、ホモトピー保存処理を実行することで、処理の保存することが可能となる。その結果、前記処理手段の処理実行前の前記対象情報の状態を取得することが可能となる。また、これらは上述した基本となる所定の処理を実行することによって実現できる。しがたって、新たにアプリケーションプログラムを設計する必要もない。
【0257】
図26は、セル空間レベル25で表現される対象情報の例を示す。セル空間レベル25は、セル空間ID×(キー属性×{ε+Σその他属性を表す部分集合}(ΣインスタンスID×{ε+Σ値を表す部分集合}))により表現できる。また、セル空間レベル25は、前記トポロジー空間レベル23よりも前記対象情報の抽象度が低く表現され、前記トポロジー空間における前記対象情報が所定の属性をもって表現される。図26に示すように、社員情報はキー属性すなわち社員コードを持つ社員名、所属、年齢により構成される。また、これら社員名や所属に関する情報は社員ごとに識別情報である社員コードを付与されて区分けされている。そしてこれらの対象情報をセル空間レベル25で表現すると数34のように表現できる。
社員×(社員コード×{ε+社員名+所属+年齢}×(K10×{ε+社員A+土木+30歳}+K11×{ε+社員B+建築+29歳}))・・・(数34)
【0258】
セル空間レベル25で表現される対象情報について新たな属性が追加された場合、従来はこの新たな情報に対応するために全体のデータベース設計,アプリケーションプログラムを組みなおすことが必要とされていた。これは、従来の情報処理では、情報処理の対象となるデータが、表、対象指向データベースでの対象の階層構造、そのような対象間の継承、データ間の関係を示すポインタによるリンク等で記述されるからである。しかし、第1の実行形態に係る情報処理装置によれば、データが、文字列を因子とする1以上の因子の積和形式の多項式で記述されるため、新たな情報の追加を自由に行うことができる。
【0259】
さらに、本情報処理装置は、社員コード×{ε+社員名+所属+年齢}に対して、新たに、性別、役職を追加することもできる。この場合には、既存のデータに対して、性別、役職の初期値としてΦを用いて、社員コード×{ε+社員名+所属+年齢+性別+役職}(101{阿部太郎+営業+23+Φ+Φ}+・途中略・+198{阿部太郎+総務+25+Φ+Φ}+199{山本三郎+設計+20+Φ+Φ})のように表現すればよい。そして、その後、各社員の役職の変更を行えばよい。ただし、属性追加時に、属性値(実際の性別、役職等)を入力してもよい。 また、例えば、
社員コード×{ε+社員名+所属+年齢}(101{阿部太郎+営業+23}+・途中略・+198{阿部太郎+総務+25})からなる社員データベースへの社員データ199{山本三郎+設計+20}の追加後の結果は、社員コード×{ε+社員名+所属+年齢}(101{阿部太郎+営業+23}+・途中略・+198{阿部太郎+総務+25}
というデータが登録されてあり、属性を追加したオブジェクトである 社員コード×{ε+社員名+所属+年齢+性別+役職}(199{山本三郎+設計+20+男+部長}}
を追加したいとき、
社員コード×{ε+社員名+所属+年齢}(101{阿部太郎+営業+23}+・途中略・+198{阿部太郎+総務+25})からなる社員データベースへの社員データ199{山本三郎+設計+20}の追加後の結果は、社員コード×{ε+社員名+所属+年齢}(101{阿部太郎+営業+23}+・途中略・+198{阿部太郎+総務+25})+社員コード×{ε+社員名+所属+年齢+性別+役職}(199{山本三郎+設計+20+男+部長}}
と単純にオブジェクトを追加すればよい。つまり、本情報処理装置100では、管理する対象、記述する概念毎に属性を決めることができる。これは,属性を含めたスキーマ設計が必要ないことを意味する。既存の技術では,データベースのスキーマを変更するにはメンテナンス上の手間が非常に大きくなる。 さらに、作成した式は,上述した所定の処理、すなわち、文字列の横方向展開、縦方向展開、積演算処理、商演算処理、接着演算処理、部分集合取得処理、ホモトピー保存処理、ホモトピー保存式におけるUNDO処理、およびホモトピー保存式におけるREDO処理によって、式を変形することで即座に期待する出力結果を得ることができる。従来の技術ならアプリケーションプログラムの開発が必要とされるところである。
【0260】
さらにまた、情報をプレーンテキストとして保存した場合には、情報の処理、取り扱いに拘束がない反面、情報に対して一貫性のある演算処理を構築することが困難となる。情報処理は、例えば、文字列の検索、挿入、削除、書き換え等に限定される。
【0261】
しかし、本実施形態のように、情報を式表現、識別子、因子、項(要素)、集合情報、トポロジー空間情報、セル空間情報、接着空間情報のように、複雑さをレベル分けし、それぞれのレベルで、式表現を限定することにより、縦方向展開、横方向展開、和、積、商、剰余、部分集合取得、接着等の演算を定義することが可能となる。したがって、メモリに保持した情報をこれらの演算を実行する共通関数で取り扱うことが可能となる。従って、式表現による柔軟性を確保するとともに、式表現の規則によって拘束された形式で事物あるいは概念を記述し、メモリ12に保持し、処理し、表示できる。
【0262】
《第2実施形態》
以下、図27から図32を参照して、本発明の第2実施形態を説明する。上記第1実施形態では、式表現を用いて記述したコンピュータ上の対象情報のデータ構造と、そのような対象情報を取り扱う基本的な演算の種類と、コンピュータ上での演算の処理例を説明した。また、そのようなデータ構造と演算によって、処理されるデータ例を説明した。本実施形態では、第1実施形態で説明したデータ構造および演算によって構成されるアプリケーションプログラムの例を説明する。
【0263】
図27は、本実施形態に係る情報処理装置100の構成である。情報処理装置100のハードウェアの構成は、第1実施形態と同一である。ただし、図27では、CPU13で実行されるプログラムが、ユーザインターフェース部101、情報管理部102、および共通関関数ライブラリ103に分けて示されている。
【0264】
これらのうち、共通関数ライブラリは、第1実施形態で説明した共通関数群をライブラリ化し、アプリケーションプログラムから呼び出し可能としたものである。共通関数群には、和演算、積演算、縦方向展開処理、横方向展開補処理、商演算(剰余取得も含む)、部分集合取得、ホモトピー保存、UNDO、REDU、インスタンス挿入、インスタンス
削除、インスタンス変更等を含む。
【0265】
情報管理部は、入力部11からの操作にしたがってインスタンス等のデータを生成し、メモリ102にデータを格納し、検索し、変更し、削除し、出力部14に出力するアプリケーションプログラムである。本実施形態では、このアプリケーションプログラムの処理を具体的に説明する。
【0266】
ユーザインターフェース部101は、入力部11でのユーザ操作の検出、検出されたユーザ操作の情報管理部102への報告、情報管理部102からの指示に基づくデータの出力部14への出力等を実行する。ユーザインターフェース部101は、例えば、グラフィカルユーザインターフェースを提供する関数群、コントロール等を組み合わせて実現される。本実施形態において、ユーザインターフェース部101は、従来のアプリケーションプログラムのユーザインターフェースと同様である。
【0267】
図28Aおよび図28Bに、社員データ管理処理の処理フローを示す。社員データ管理処理は、データ管理部102の機能の1つである。この処理では、CPU113は、通常、不図示の社員データ管理ウィンドウを出力部14に表示して、ユーザ操作を待つ(S1、S2)。
【0268】
そして、ユーザ操作が検出されると、CPU13は、その操作の種類を判定する。例えば、CPU13は、操作が、新規データの入力要求であるか、否かを判定する(S3)。新規データの入力要求は、新規データの入力を要求するメニューの選択、ウィンドウ上のボタンの押下等によって検知される。
【0269】
操作が、新規データの入力要求である場合、CPU13は、社員データ入力処理を実行する(S4)。その後、CPU13は、制御をS1に戻し、再び、ユーザ操作待ちになる。
【0270】
操作が新規データの入力要求でない場合、CPU13は、操作がデータ検索要求であるか否かを判定する(S5)。
【0271】
操作が、データ検索要求である場合、CPU13は、社員データ検索処理を実行する(S6)。その後、CPU13は、制御をS1に戻し、再び、ユーザ操作待ちになる。
【0272】
操作がデータ検索要求でない場合、CPU13は、操作がデータ削除要求であるか否かを判定する(S7)。
【0273】
操作が、データ削除要求である場合、CPU13は、社員データ削除処理を実行する(S8)。その後、CPU13は、制御をS1に戻し、再び、ユーザ操作待ちになる。
【0274】
操作がデータ削除要求でない場合、CPU13は、操作がデータ変更要求であるか否かを判定する(S9)。
【0275】
操作が、データ変更要求である場合、CPU13は、社員データ変更処理を実行する(SA)。その後、CPU13は、制御をS1に戻し、再び、ユーザ操作待ちになる。
【0276】
操作がデータ変更要求でない場合、CPU13は、操作がメモ接着要求であるか否かを判定する(SB)。
【0277】
操作が、メモ接着要求である場合、CPU13は、メモ作成と接着処理を実行する(S
C)。その後、CPU13は、制御をS1に戻し、再び、ユーザ操作待ちになる。
【0278】
操作がメモ接着要求でない場合、CPU13は、操作がメモ切り離し要求であるか否かを判定する(SD)。
【0279】
操作が、メモ切り離し要求である場合、CPU13は、メモ切り離し処理を実行する(SE)。その後、CPU13は、制御をS1に戻し、再び、ユーザ操作待ちになる。
【0280】
操作がメモ切り離し要求でない場合、CPU13は、操作が集合接着要求であるか否かを判定する(SF)。
【0281】
操作が、集合接着要求である場合、CPU13は、集合接着処理を実行する(SG)。その後、CPU13は、制御をS1に戻し、再び、ユーザ操作待ちになる。
【0282】
操作が集合接着要求でない場合、CPU13は、操作が集合切り離し要求であるか否かを判定する(SH)。
【0283】
操作が、集合切り離し要求である場合、CPU13は、集合切り離し処理を実行する(SI)。その後、CPU13は、制御をS1に戻し、再び、ユーザ操作待ちになる。
【0284】
操作が集合切り離し要求でない場合、CPU13は、操作が属性追加要求であるか否かを判定する(SJ)。
【0285】
操作が、属性追加要求である場合、CPU13は、属性追加処理を実行する(SK)。その後、CPU13は、制御をS1に戻し、再び、ユーザ操作待ちになる。
【0286】
操作が属性追加要求でない場合、CPU13は、操作が属性値構成変更要求であるか否かを判定する(SL)。
【0287】
操作が、属性値構成変更要求である場合、CPU13は、属性値構成変更処理を実行する(SM)。その後、CPU13は、制御をS1に戻し、再び、ユーザ操作待ちになる。
【0288】
図29に、社員データ入力処理(図28AのS4)の詳細処理フローを示す。この処理を実行するCPU13が本発明の入力処理部に相当する。この処理では、CPU13は、出力部14に、社員データ入力画面を表示する(S41)。社員データ入力画面の画面データ自体は、メモリ12または不図示の外部記憶装置(ハードディスク等)の画面IDとともに画面データファイルに格納されている。CPU13は、入力インターフェース部101を通じて、この社員データ入力画面を表示する。なお、本実施形態における他の画面表示処理も同様である。
【0289】
次に、ユーザが、社員データ入力画面に対して社員データ(例えば、社員コード、氏名、年齢、職種、所属)を入力する。すると、CPU13は、入力インターフェース部101を通じて、入力された社員データを取り込む(S42)。
【0290】
次に、CPU13は、入力された社員データに対するインスタンス、例えば、社員コード×{ε+氏名+年齢+職種+所属}に対する101×{ε+山田太郎+26歳+設計+公共事業部}を生成する。そして、インスタンス挿入関数を用いて、社員セル空間情報のインスタンスとして、入力された社員データを挿入する(S43)。この社員データは、メモリ12または不図示の外部記憶装置に保持される。なお、社員データのインスタンスを生成する本アプリケーション専用の関数genins(集合ID、コード、氏名、年齢、職種
、所属)を提供してもよい。関数geninsは、社員コード、氏名、年齢、職種、所属のそれ
ぞれの値から、社員セル空間情報のインスタンスを生成し、集合IDで指定される集合に、生成したインスタンスを挿入し、メモリ12または外部記憶装置に保存する。
【0291】
図30に、社員データ検索処理(図28AのS6)の詳細処理フローを示す。この処理を実行するCPU13が本発明の出力処理部に相当する。この処理では、CPU13は、出力部14に、検索画面を表示する(S61)。
【0292】
次に、ユーザが、検索画面に対して検索するセル空間情報(例えば、社員データ)、属性値p(例えば、社員コードに対する値101)を入力する。すると、CPU13は、入力インターフェース部101を通じて、入力された検索する属性値を取り込む(S62)。この例では、ユニークな検索キーとして、属性×属性値が使用される。すなわち、社員コード×101がCPU13(情報管理部102)に引き渡される。
【0293】
次に、CPU13は、検索キーである社員コード×101を識別子に分解する。この場合には、“社員コード”と、“101”という識別子が得られる。これ検索する識別子という。
【0294】
次に、CPU13は、第1の検索する識別子(例えば、“社員コード”)を用いて、セル空間情報(集合IDが社員データであるセル空間情報)に対して、商演算を実行する(S64)。
【0295】
次に、CPU13は、すべての検索する識別子(“社員コード”と、“101”)で、商演算を実行したか否かを判定する。まだ、商演算を実行してしたいない識別子(例えば、“101”)がある場合、制御をS64に戻し、その識別子にて商演算を実行する。これは、いわゆる絞り込み検索に相当する。
【0296】
そして、CPU13は、ユーザインターフェース部101を通じて出力部14の検索画面に、得られた部分集合、すなわち、コード×101のインスタンスを表示する(S66)。
【0297】
このように、検索対象の情報に対して、検索する識別子によって繰り返し商演算を実行することにより、ほしいデータを検索することができる。
(例)
今、社員データベースとして、以下のものを考え得る。
社員×(社員コード×{ε+氏名+年齢+職種コード+所属名}×(
+101{ε+鈴木一郎+23+100+総務}
+102{ε+鈴木一郎+23+100+総務}
+103{ε+鈴木一郎+23+101+総務}
)
+備品コード×{ε+分類+数量+社員コード}×(
+B50{ε+机 +1+101}
+B51{ε+PC+2+102}))
この場合、まず因子”社員コード”を同値因子として商演算すると商項は、
社員×(社員コード×{ε+氏名+年齢+職種コード+所属名}×(
+101{ε+鈴木一郎+23+100+総務}
+102{ε+鈴木一郎+23+100+総務}
+103{ε+鈴木一郎+23+101+総務}))
さらにこの項に,因子”101”を同値因子として商演算すると商項は、
社員×(社員コード×{ε+氏名+年齢+職種コード+所属名}×(101{ε+鈴木一
郎+23+100+総務})となる。このようにして,全体のデータから、”社員コードが101”についての情報を取得することができる。 図31に、メモ作成と接着処理(図28BのSC)の詳細フローを示す。この処理では、CPU13は、出力部14に、メモ画面を表示する(SC1)。
【0298】
次に、ユーザが、メモ画面に対して、メモIDおよびメモ内容(テキスト情報)を入力する。すると、CPU13は、入力インターフェース部101を通じて、添付する集合、添付先、メモ内容を取り込む(SC2)。
【0299】
次に、CPU13は、取り込んだメモIDおよびメモ内容からメモのインスタンスであるメモID×{ε+テキスト情報}を生成する。そして、CPU13は、インスタンス挿入関数を用いて、メモセル空間情報に、メモのインスタンスを挿入し、メモリ12または不図示の外部記憶装置に保存する(SC3)。なお、入力されたメモIDの代わりに、情報管理部102がユニークなメモID生成するようにしてもよい。すなわち、現在のメモ集合から、すべてのメモIDを読み出し、メモIDをソーティングし、最後尾のメモIDに1を加えた値をメモIDとすればよい。
【0300】
次に、CPU13は、メモを添付する接着箇所、すなわち、セル空間情報(例えば、集合IDが社員データ)、および添付先(例えば、コードに対する値101のインスタンスの指定)を受け付ける(SC4)。
【0301】
そして、CPU13は、指定されたセル空間情報中の指定されたインスタンスであるコード101のインスタンスと、作成したメモIDのメモとの接着演算を実行する(SC5)。これによって、コード101の社員データに、メモが添付されたことになる。
【0302】
図32に、属性追加処理(図28BのSK)の詳細処理フローを示す。この処理では、CPU13は、出力部14に、属性追加設定画面を表示する(SK1)。
【0303】
次に、ユーザが、属性追加設定画面に対して、属性を追加するセル空間ID、属性追加位置、および追加属性を入力する。すると、すると、CPU13は、入力インターフェース部101を通じて、追加するセル空間ID、属性追加位置、および追加属性を取り込む(SK2)。
【0304】
次に、指定されたセル空間IDのセル空間情報に、属性を示す文字列を和演算で追加する(SK3)。
【0305】
次に、既存のインスタンスに対して、追加された属性に対する属性値Φを設定する(SK4)。
【0306】
なお、以上の説明では、社員データ削除処理(図28AのS8)、社員データ変更処理(同図のSA)、メモ切り離し処理(同図のSE)、集合接着(同図のSG)、接着集合切り離し処理(同図のSI)、属性値構成変更処理(同図のSM)については、省略した。しかし、これらの処理は、図29−32の処理とほぼ同様の手順で構成できる。
【0307】
例えば、まず、社員データ削除処理については、S6の社員データ検索処理を実行し、検索された結果をメモリ12から削除すればよい。その場合に、共通関数として、戻り値=delete(セル空間ID、インスタンス);を用意してもよい。
【0308】
また、社員データ変更処理については、S6の社員データ検索処理を実行し、検索された結果をメモリ12から変更すればよい。その場合に、共通関数として、戻り値=replac
e(セル空間ID、変更前のインスタンス、変更後のインスタンス);を用意してもよい。
【0309】
また、メモ切り離し処理(図28AのSE)については、以下の手順である。
(1)同値関係を指定する因子1と、因子2の指定を受け付ける。
(2){因子1×因子2}を含む式表現をメモリ12にて検索する。
(3){(左因子1の和)、(左因子2の和}}×{因子1+因子2}×{(右因子1の
和)+(右因子2の和)}の関係から、左因子1×因子1×右因子1の和+左因子
2×因子2×右因子2の和という式表現を構成する。
(4)得られた式表現をメモリ12に格納する。
【0310】
また、集合接着演算は、以下の手順で構成できる。
(1)接着する2つの集合情報の集合ID(例えば、集合ID1、集合ID2)と、同値
関係を指定する因子1、因子2を受け付ける。
(2)集合ID1の集合情報に商演算を実行し、因子1を含む商(同値要素1)と、剰余
に分ける。
(3)集合ID2の集合情報に商演算を実行し、因子1を含む商(同値要素2)と、剰余
に分ける。
(4)同値要素1の左因子l1、右因子r1,同値要素2の左因子l2、右因子r2を求
め、以下の商空間の式を求める。{l1+l2}{因子1+因子2}{r1+r2
}
(5)商空間の式に、集合ID1の集合情報の剰余の式と、集合ID2の集合情報の剰余の式とを和演算する。
【0311】
以上説明した本実行形態に係る情報処理装置によれば対象を所定の表現形式を用いて表現して処理することで、異なる対象同士の情報の一貫性を図るとともに新たな様々な対象情報のデータベース化及び処理が可能となる。また、所定の処理を実行することにより情報の管理に適したレベルに移行することができる。また、新たな情報を追加した場合やレベルを変化せせる場合も予め本発明に係る情報処理装置が有するプログラムに基づいて実行することができる。すなわち、プログラムの再構築を行う必要もない。
【0312】
以上、本発明の好適な実行形態を説明したが、本発明に係る情報処理装置は、これらに限らず、可能な限りこれらの組み合わせを含むことができる。
【符号の説明】
【0313】
11・・・入力部
12・・・メモリ
13・・・CPU
14・・・出力部
21・・・ホモトピーレベル
22・・・集合レベル
23・・・トポロジー空間レベル
24・・・接着空間レベル
25・・・セル空間レベル
【特許請求の範囲】
【請求項1】
識別子と、順序を持つ因子の列として複数の識別子を結合する積演算子と、識別子および因子の列として結合された複数の識別子のいずれかまたは両方から項の組み合わせを構成する和演算子と、によって記述される対象情報を記憶する記憶部と、
前記対象情報を操作する処理部と、
情報の入力を受け付ける入力部を接続可能なインターフェースと、
情報を出力する出力部を接続可能なインターフェースと、を備え、
前記処理部は、
前記インターフェースに接続された入力部から入力される情報を前記識別子、因子、項および項の組み合わせを含む式のいずれか1以上として前記対象情報に設定し、前記記憶部に記憶させる入力処理部と、
前記記憶部に記憶されている対象情報を参照し、参照した対象情報中の識別子、因子、項および式のいずれか1以上が前記入力部から入力される情報と所定の関係にあるときに、前記対象情報を前記インターフェースに接続された出力部に出力する出力処理部と、を有する情報処理装置。
【請求項2】
前記対象情報は、前記組み合わせ中の項の順序を維持して前記項の組み合わせを関係付けることによって因子または新たな項を構成する順序構成演算子と、前記組み合わせ中の項の順序を維持しないで前記項の組み合わせを関係付けることによって因子または新たな項を構成する集合因子構成演算子とをさらに含み、
前記処理部は、前記積演算子によって、複数の識別子を複数結合する積演算部と、
前記積演算子によって結合された複数の識別子からいずれかの識別子を抽出する因子抽出部と、
前記識別子、または積演算子によって結合された識別子をさらに前記和演算子によって組み合わせて、項の組み合わせを構成する和演算部と、
前記項の組み合わせに含まれるいずれかの項を抽出する項抽出部と、
前記項の組み合わせに順序構成演算子を付加することによって因子または項を構成する順序生成部と、
前記項の組み合わせに順序構成演算子を付加された因子または項から前記順序構成演算子を除去する順序展開部と、
前記項の組み合わせに集合因子構成演算子を付加することによって因子または項を構成する集合因子構成部と、
前記項の組み合わせに集合因子構成演算子を付加された因子または項から前記集合因子構成演算子を除去する集合因子展開部と、
前記対象情報を構成する一の因子が項の組み合わせと前記順序構成演算子とによって構成されているとき、または前記一の因子が項の組み合わせと前記集合因子構成演算子とによって構成されているときに、前記一の因子と同一の項に含まれる、前記一の因子と積演算子で結合されている共通因子を前記項の組み合わせ中のそれぞれの項に付加して前記積演算子によって結合することによって、前記共通因子を展開する共通因子展開部と、をさらに有する請求項1に記載の情報処理装置。
【請求項3】
前記因子または前記項には、前記和演算子による演算に対して単位元となる記号、前記積演算子による演算に対して単位元となる記号、および前記積演算子に対して、演算結果が、識別子が存在しないことを示す零値となる、零元の少なくとも1つを含めることができる請求項1または2に記載の情報処理装置。
【請求項4】
前記処理部は、項の組み合わせを、第1の因子を含む第1の項と前記第1の因子を含まない第2の項とに分類し、第1の因子を含む第1の項が複数存在したときに、第1の項の組み合わせから前記第1の因子を共通因子として抽出する部分集合形成部をさらに有する
請求項1から3のいずれかに記載の情報処理装置。
【請求項5】
前記部分集合形成部は、前記共通因子を含む項から、積演算子によって共通因子の左側に結合される左因子と、積演算子によって共通因子の右側に結合される右因子とを抽出するとともに、前記左因子または右因子がない項に対しては、左因子または右因子に代えて単位元を抽出する因子抽出部と、
前記第1の項として複数の項が分類されたときに、前記因子抽出部から抽出された複数の左因子から、和演算子と順序構成演算子とによって複数の左因子を含む左値因子を構成し、前記因子抽出部から抽出された複数の右因子から、和演算子と順序構成演算子とによって複数の右因子を含む右値因子を構成し、前記左値因子、共通因子、および右値因子列を積演算子で結合する左右因子括り出し部と、を有する請求項4に記載の情報処理装置。
【請求項6】
いずれかの項を構成する因子中に、前記集合因子構成演算子が付加された項の組み合わせである集合因子が含まれるときに、前記処理部は、前記集合因子中の項に対して、前記部分集合形成部による部分集合の形成を実行する請求項4または5に記載の情報処理装置。
【請求項7】
前記処理部は、
項または複数の項の組み合わせに対して、前記項に適用される演算用因子の指定を受け、前記項を構成する因子中に前記演算用因子を含むときにその項を選択する第1の選択演算を実行し、項を構成する因子中に前記演算用因子が含まれておらず、かつ、前記集合因子構成演算子によって関係付けられた項の組み合わせである集合因子を含むときに、前記集合因子中の項に対して前記第1の選択演算を実行し、前記集合因子中のいずれかの項が選択できたときに、前記集合因子中の選択された項と前記項を構成する因子中の前記集合因子以外の因子とを前記積演算子によって結合し、前記演算用因子が含まれる項を抽出する商演算部と、
項または複数の項の組み合わせに対して、前記項を構成する因子中に前記演算用因子を含まないときにその項を構成する因子を選択する第2の選択演算を実行するとともに選択された因子を保持し、前記保持された因子に前記集合因子構成演算子によって関係付けられた項の組み合わせである集合因子を含むときに、前記集合因子中の項に対して前記第2の選択演算を実行し、前記集合因子中のいずれかの項が選択できたときに、前記集合因子中の選択された項と前記保持されている因子のうちの前記集合因子以外の因子とを前記積演算子によって結合し、前記演算用因子が含まれない項を抽出する剰余演算部と、をさらに有する請求項1から6のいずれかに記載の情報処理装置。
【請求項8】
前記対象情報は、項または和演算子で構成された複数の項によって集合情報を構成し、前記項または複数の項は、集合情報を識別する情報である第1の識別因子と、前記集合情報に含まれる値である因子とを含む、請求項1から7のいずれかに記載の情報処理装置。
【請求項9】
前記対象情報は、集合情報から前記共通因子が括り出された部分集合と他の部分集合に分類され、前記部分集合を少なくとも1つ含むトポロジー空間情報を構成し、
前記トポロジー空間情報は、そのトポロジー空間情報を識別する情報である第2の識別因子と、前記部分集合がなす因子または部分集合の組み合わせに集合因子構成演算子を付加した因子とが、積演算子によって結合されている、請求項8に記載の情報処理装置。
【請求項10】
前記対象情報は、属性と属性値との対応関係を含むセル空間情報を構成する請求項1から9のいずれかに記載の情報処理装置。
【請求項11】
前記セル空間情報は、
セル空間情報を他のセル空間情報と識別するセル空間識別因子と、
属性を指定する識別子、属性を指定する複数の識別子を積演算子によって結合した属性列、および、前記属性を指定する識別子および属性列のいずれかまたは双方の組み合わせを順序構成演算子で構成した属性の順序因子のいずれかである属性因子と、
前記属性因子に対応する値を指定する識別子、値を指定する複数の識別子を積演算子によって結合した値列、および、前記属性の順序因子に対応する値を指定する項の組み合わせを順序構成演算子によって構成した値の順序因子のいずれかを1以上含む単一の項またはそのような項の組み合わせを含む値因子と、を積演算子で結合して構成される請求項10に記載の情報処理装置。
【請求項12】
前記処理部は、前記項、前記集合情報、前記トポロジー空間情報、および前記セル空間情報の少なくとも1つを被接着情報とし、被接着情報を2以上結合した接着空間情報を構成する接着処理部を有し、
前記接着空間情報は、第1の被接着情報と第2の被接着情報を含み、
第1の被接着情報は、被接着情報同士を関連づける情報である第1の同値因子と、第1の値因子と積演算子で結合される第1の被接着因子とを含み、
第2の被接着情報は、被接着情報同士を関連づける情報である第2の同値因子と、第2の値因子と積演算子で結合される第2の被接着因子とを含み、
前記接着処理部は、第1の同値因子と第2の同値因子との関連付けの指定を受ける指定部と、
前記第1の同値因子と第2の同値因子との関連付けとともに、第1の被接着情被接着因子と第2の被接着因子との関連づけを前記記憶部に記憶させる接着部と、を有する請求項1から11のいずれかに記載の情報処理装置。
【請求項13】
前記接着処理部は、前記第1の同値因子を前記演算用因子として、前記第1の被接着情報を商演算部で演算することによって、前記第1の同値因子を含む第1の関連項を抽出し、前記第2の同値因子を前記演算用因子として、前記第2の被接着情報を商演算部で演算することによって、前記第2の同値因子を含む第2の関連項を抽出する関連項抽出部と、
前記第1の同値因子を前記演算用因子として、前記第1の被接着情報を剰余演算部で演算することによって、前記第1の同値因子を含ない非関連項を抽出し、前記第2の同値因子を前記演算用因子として、前記第2の被接着情報を剰余演算部で演算することによって、前記第2の同値因子を含ない非関連項を抽出する非関連項抽出部と、
前記第1の関連項から第1の同値因子を括り出すとともに、前記第2の関連項から第2の同値因子を括り出し、さらに、括り出された第1の同値因子と第2の同値因子と順序構成演算子によって関連づける関連づけ部とを有する請求項12に記載の情報処理装置。
【請求項14】
前記接着空間情報は、前記項、前記集合情報、前記トポロジー空間情報、前記セル空間情報、および他の接着空間情報の少なくとも1つとさらに、接着される請求項12または13に記載の情報処理装置。
【請求項15】
識別子と、順序を持つ因子の列として複数の識別子を結合する積演算子と、識別子および因子の列として結合された複数の識別子のいずれかまたは両方から項の組み合わせを構成する和演算子と、によって記述される対象情報を記憶する記憶部と、
情報の入力を受け付ける入力部を接続可能なインターフェースと、
情報を出力する出力部を接続可能なインターフェースと、を備えるコンピュータが、
前記インターフェースに接続された入力部から入力される情報を前記識別子、因子、項および項の組み合わせを含む式のいずれか1以上として前記対象情報に設定し、前記記憶部に記憶させる入力処理ステップと、
前記記憶部に記憶されている対象情報を参照し、参照した対象情報中の識別子、因子、項および式のいずれか1以上が前記入力部から入力される情報と所定の関係にあるときに、前記対象情報を前記インターフェースに接続された出力部に出力する出力処理ステッ
プと、を実行する情報処理方法。
【請求項16】
識別子と、順序を持つ因子の列として複数の識別子を結合する積演算子と、識別子および因子の列として結合された複数の識別子のいずれかまたは両方から項の組み合わせを構成する和演算子と、によって記述される対象情報を記憶する記憶部と、
情報の入力を受け付ける入力部を接続可能なインターフェースと、
情報を出力する出力部を接続可能なインターフェースと、を備えるコンピュータに、前記対象情報を操作させるプログラムであり、
前記インターフェースに接続された入力部から入力される情報を前記識別子、因子、項および項の組み合わせを含む式のいずれか1以上として前記対象情報に設定し、前記記憶部に記憶させる入力処理ステップと、
前記記憶部に記憶されている対象情報を参照し、参照した対象情報中の識別子、因子、項および式のいずれか1以上が前記入力部から入力される情報と所定の関係にあるときに、前記対象情報を前記インターフェースに接続された出力部に出力する出力処理ステップと、を有するプログラム。
【請求項17】
前記対象情報は、前記組み合わせ中の項の順序を維持して前記項の組み合わせを関係付けることによって因子または新たな項を構成する順序構成演算子と、前記組み合わせ中の項の順序を維持しないで前記項の組み合わせを関係付けることによって因子または新たな項を構成する集合因子構成演算子とをさらに含み、
前記積演算子によって、識別子を複数結合する積演算ステップと、
前記積演算子によって結合された複数の識別子からいずれかの識別子を抽出する因子抽出ステップと、
前記識別子、または積演算子によって結合された識別子をさらに前記和演算子によってさらに組み合わせて、項の組み合わせを構成する和演算ステップと、
前記項の組み合わせに含まれるいずれかの項を抽出する項抽出ステップと、
前記項の組み合わせに順序構成演算子を付加することによって因子または項を構成する順序生成ステップと、
前記項の組み合わせに順序構成演算子を付加された因子または項から前記順序構成演算子を除去する順序展開ステップと、
前記項の組み合わせに集合因子構成演算子を付加することによって因子または項を構成する集合構成ステップと、
前記項の組み合わせに集合因子構成演算子を付加された因子または項から前記集合因子構成演算子を除去する集合展開ステップと、
前記対象情報を構成する一の因子が項の組み合わせと前記順序構成演算子とによって構成されているとき、または前記一の因子が項の組み合わせと前記集合因子構成演算子とによって構成されているときに、前記一の因子と同一の項に含まれる、前記一の因子と積演算子で結合されている共通因子を前記項の組み合わせ中のそれぞれの項に付加して前記積演算子によって結合することによって、前記共通因子を展開する因子展開ステップと、をさらに有する請求項16に記載のプログラム。
【請求項18】
前記因子または前記項には、前記和演算子による演算に対して単位元となる記号、前記積演算子による演算に対して単位元となる記号、および前記積演算子に対して、演算結果が、識別子が存在しないことを示す零値となる、零元の少なくとも1つを含めることができる請求項16または17に記載のプログラム。
【請求項19】
項の組み合わせを、第1の因子を含む第1の項と前記第1の因子を含まない第2の項とに分類し、第1の因子を含む第1の項が複数存在したときに、第1の項の組み合わせから前記第1の因子を共通因子として抽出する部分集合形成ステップをさらに有する請求項16から18のいずれかに記載のプログラム。
【請求項20】
前記部分集合形成ステップは、前記共通因子を含む項から、積演算子によって共通因子の左側に結合される左因子と、積演算子によって共通因子の右側に結合される右因子とを抽出するとともに、前記左因子または右因子がない項に対しては、左因子または右因子に代えて単位元を抽出する因子抽出ステップと、
前記第1の項として複数の項が分類されたときに、前記因子抽出ステップにて抽出された複数の左因子から、和演算子と順序構成演算子とによって複数の左因子を含む左値因子を構成し、前記因子抽出ステップにて抽出された複数の右因子から、和演算子と順序構成演算子とによって複数の右因子を含む右値因子を構成し、前記左値因子、共通因子、および右値因子列を積演算子で結合する左右因子括り出しステップと、を有する請求項19に記載のプログラム。
【請求項21】
部分集合形成ステップは、いずれかの項を構成する因子中に、前記集合因子構成演算子が付加された項の組み合わせである集合因子が含まれるときに、前記集合因子中の項に対して、部分集合の形成を実行するステップをさらに有する請求項19または20に記載のプログラム。
【請求項22】
項または複数の項の組み合わせに対して、前記項に適用される演算用因子の指定を受け、前記項を構成する因子中に前記演算用因子を含むときにその項を選択する第1の選択演算を実行し、項を構成する因子中に前記演算用因子が含まれておらず、かつ、前記集合因子構成演算子によって関係付けられた項の組み合わせである集合因子を含むときに、前記集合因子中の項に対して前記第1の選択演算を実行し、前記集合因子中のいずれかの項が選択できたときに、前記集合因子中の選択された項と前記項を構成する因子中の前記集合因子以外の因子とを前記積演算子によって結合し、前記演算用因子が含まれる項を抽出する商演算ステップと、
項または複数の項の組み合わせに対して、前記項を構成する因子中に前記演算用因子を含まないときにその項を構成する因子を選択する第2の選択演算を実行するとともに選択された因子を保持し、前記保持された因子に前記集合因子構成演算子によって関係付けられた項の組み合わせである集合因子を含むときに、前記集合因子中の項に対して前記第2の選択演算を実行し、前記集合因子中のいずれかの項が選択できたときに、前記集合因子中の選択された項と前記保持されている因子のうちの前記集合因子以外の因子とを前記積演算子によって結合し、前記演算用因子が含まれない項を抽出する剰余演算ステップと、をさらに有する請求項16から21のいずれかに記載のプログラム。
【請求項23】
前記対象情報は、項または和演算子で構成された複数の項によって集合情報を構成し、前記項または複数の項は、集合情報を識別する情報である第1の識別因子と、前記集合情報に含まれる値である因子とを含む、請求項16から22のいずれかに記載のプログラム。
【請求項24】
前記対象情報は、集合情報から前記共通因子が括り出された部分集合と他の部分集合に分類され、前記部分集合を少なくとも1つ含むトポロジー空間情報を構成し、
前記トポロジー空間情報は、そのトポロジー空間情報を識別する情報である第2の識別因子と、前記部分集合がなす因子または部分集合の組み合わせに集合因子構成演算子を付加した因子とが、積演算子によって結合されている、請求項23に記載のプログラム。
【請求項25】
前記対象情報は、属性と属性値との対応関係を含むセル空間情報を構成する請求項16から24のいずれかに記載のプログラム。
【請求項26】
前記セル空間情報は、
セル空間情報を他のセル空間情報と識別するセル空間識別因子と、
属性を指定する識別子、属性を指定する複数の識別子を積演算子によって結合した属性列、および、前記属性を指定する識別子および属性列のいずれかまたは双方の組み合わせを順序構成演算子で構成した属性の順序因子のいずれかである属性因子と、
前記属性因子に対応する値を指定する識別子、値を指定する複数の識別子を積演算子によって結合した値列、および、前記属性の順序因子に対応する値を指定する項の組み合わせを順序構成演算子によって構成した値の順序因子のいずれかである値因子と、を積演算子で結合して構成される請求項25に記載のプログラム。
【請求項27】
前記項、前記集合情報、前記トポロジー空間情報、および前記セル空間情報の少なくとも1つを被接着情報とし、被接着情報を2以上結合した接着空間情報を構成する接着処理ステップをさらに有し、
前記接着空間情報は、第1の被接着情報と第2の被接着情報を含み、
第1の被接着情報は、被接着情報同士を関連づける情報である第1の同値因子と、第1の値因子と積演算子で結合される第1の被接着因子とを含み、
第2の被接着情報は、被接着情報同士を関連づける情報である第2の同値因子と、第2の値因子と積演算子で結合される第2の被接着因子とを含み、
前記接着処理ステップは、第1の同値因子と第2の同値因子との関連付けの指定を受けるステップと、
前記第1の同値因子と第2の同値因子との関連付けとともに、第1の被接着情被接着因子と第2の被接着因子との関連づけを記憶するステップと、を有する請求項16から26のいずれかに記載のプログラム。
【請求項28】
前記接着処理ステップは、前記第1の同値因子を前記演算用因子として、前記第1の被接着情報を商演算部で演算することによって、前記第1の同値因子を含む第1の関連項を抽出し、前記第2の同値因子を前記演算用因子として、前記第2の被接着情報を商演算部で演算することによって、前記第2の同値因子を含む第2の関連項を抽出する関連項抽出ステップと、
前記第1の同値因子を前記演算用因子として、前記第1の被接着情報を剰余演算部で演算することによって、前記第1の同値因子を含ない非関連項を抽出し、前記第2の同値因子を前記演算用因子として、前記第2の被接着情報を剰余演算部で演算することによって、前記第1の同値因子を含ない非関連項を抽出する非関連項抽出ステップと、
前記第1の関連項から第1の同値因子を括り出すとともに、前記第2の関連項から第2の同値因子を括り出し、さらに、括り出された第1の同値因子と第2の同値因子と順序構成演算子によって関連づける関連づけステップとを有する請求項27に記載のプログラム。
【請求項29】
前記接着空間情報は、前記項、前記集合情報、前記トポロジー空間情報、前記セル空間情報、および他の接着空間情報の少なくとも1つとさらに、接着される請求項28に記載のプログラム。
【請求項30】
識別子と、順序を持つ因子の列として複数の識別子を結合する積演算子と、識別子および因子の列として結合された複数の識別子のいずれかまたは両方から項の組み合わせを構成する和演算子と、によって記述されるデータ構造であり、
前記データ構造で記述される対象情報を記憶する記憶部と、
前記対象情報を操作する処理部と、
情報の入力を受け付ける入力部を接続可能なインターフェースと、
情報を出力する出力部を接続可能なインターフェースと、を備えるコンピュータが、
前記インターフェースに接続された入力部から入力される情報を前記識別子、因子、項および項の組み合わせを含む式のいずれか1以上として前記対象情報に設定し、前記記憶部に記憶させる入力処理ステップと、
前記記憶部に記憶されている対象情報を参照し、参照した対象情報中の識別子、因子、項および式のいずれか1以上が前記入力部から入力される情報と所定の関係にあるときに、前記対象情報を前記インターフェースに接続された出力部に出力する出力処理ステップと、を実行し、前記記憶部に構成されるデータ構造。
【請求項1】
識別子と、順序を持つ因子の列として複数の識別子を結合する積演算子と、識別子および因子の列として結合された複数の識別子のいずれかまたは両方から項の組み合わせを構成する和演算子と、によって記述される対象情報を記憶する記憶部と、
前記対象情報を操作する処理部と、
情報の入力を受け付ける入力部を接続可能なインターフェースと、
情報を出力する出力部を接続可能なインターフェースと、を備え、
前記処理部は、
前記インターフェースに接続された入力部から入力される情報を前記識別子、因子、項および項の組み合わせを含む式のいずれか1以上として前記対象情報に設定し、前記記憶部に記憶させる入力処理部と、
前記記憶部に記憶されている対象情報を参照し、参照した対象情報中の識別子、因子、項および式のいずれか1以上が前記入力部から入力される情報と所定の関係にあるときに、前記対象情報を前記インターフェースに接続された出力部に出力する出力処理部と、を有する情報処理装置。
【請求項2】
前記対象情報は、前記組み合わせ中の項の順序を維持して前記項の組み合わせを関係付けることによって因子または新たな項を構成する順序構成演算子と、前記組み合わせ中の項の順序を維持しないで前記項の組み合わせを関係付けることによって因子または新たな項を構成する集合因子構成演算子とをさらに含み、
前記処理部は、前記積演算子によって、複数の識別子を複数結合する積演算部と、
前記積演算子によって結合された複数の識別子からいずれかの識別子を抽出する因子抽出部と、
前記識別子、または積演算子によって結合された識別子をさらに前記和演算子によって組み合わせて、項の組み合わせを構成する和演算部と、
前記項の組み合わせに含まれるいずれかの項を抽出する項抽出部と、
前記項の組み合わせに順序構成演算子を付加することによって因子または項を構成する順序生成部と、
前記項の組み合わせに順序構成演算子を付加された因子または項から前記順序構成演算子を除去する順序展開部と、
前記項の組み合わせに集合因子構成演算子を付加することによって因子または項を構成する集合因子構成部と、
前記項の組み合わせに集合因子構成演算子を付加された因子または項から前記集合因子構成演算子を除去する集合因子展開部と、
前記対象情報を構成する一の因子が項の組み合わせと前記順序構成演算子とによって構成されているとき、または前記一の因子が項の組み合わせと前記集合因子構成演算子とによって構成されているときに、前記一の因子と同一の項に含まれる、前記一の因子と積演算子で結合されている共通因子を前記項の組み合わせ中のそれぞれの項に付加して前記積演算子によって結合することによって、前記共通因子を展開する共通因子展開部と、をさらに有する請求項1に記載の情報処理装置。
【請求項3】
前記因子または前記項には、前記和演算子による演算に対して単位元となる記号、前記積演算子による演算に対して単位元となる記号、および前記積演算子に対して、演算結果が、識別子が存在しないことを示す零値となる、零元の少なくとも1つを含めることができる請求項1または2に記載の情報処理装置。
【請求項4】
前記処理部は、項の組み合わせを、第1の因子を含む第1の項と前記第1の因子を含まない第2の項とに分類し、第1の因子を含む第1の項が複数存在したときに、第1の項の組み合わせから前記第1の因子を共通因子として抽出する部分集合形成部をさらに有する
請求項1から3のいずれかに記載の情報処理装置。
【請求項5】
前記部分集合形成部は、前記共通因子を含む項から、積演算子によって共通因子の左側に結合される左因子と、積演算子によって共通因子の右側に結合される右因子とを抽出するとともに、前記左因子または右因子がない項に対しては、左因子または右因子に代えて単位元を抽出する因子抽出部と、
前記第1の項として複数の項が分類されたときに、前記因子抽出部から抽出された複数の左因子から、和演算子と順序構成演算子とによって複数の左因子を含む左値因子を構成し、前記因子抽出部から抽出された複数の右因子から、和演算子と順序構成演算子とによって複数の右因子を含む右値因子を構成し、前記左値因子、共通因子、および右値因子列を積演算子で結合する左右因子括り出し部と、を有する請求項4に記載の情報処理装置。
【請求項6】
いずれかの項を構成する因子中に、前記集合因子構成演算子が付加された項の組み合わせである集合因子が含まれるときに、前記処理部は、前記集合因子中の項に対して、前記部分集合形成部による部分集合の形成を実行する請求項4または5に記載の情報処理装置。
【請求項7】
前記処理部は、
項または複数の項の組み合わせに対して、前記項に適用される演算用因子の指定を受け、前記項を構成する因子中に前記演算用因子を含むときにその項を選択する第1の選択演算を実行し、項を構成する因子中に前記演算用因子が含まれておらず、かつ、前記集合因子構成演算子によって関係付けられた項の組み合わせである集合因子を含むときに、前記集合因子中の項に対して前記第1の選択演算を実行し、前記集合因子中のいずれかの項が選択できたときに、前記集合因子中の選択された項と前記項を構成する因子中の前記集合因子以外の因子とを前記積演算子によって結合し、前記演算用因子が含まれる項を抽出する商演算部と、
項または複数の項の組み合わせに対して、前記項を構成する因子中に前記演算用因子を含まないときにその項を構成する因子を選択する第2の選択演算を実行するとともに選択された因子を保持し、前記保持された因子に前記集合因子構成演算子によって関係付けられた項の組み合わせである集合因子を含むときに、前記集合因子中の項に対して前記第2の選択演算を実行し、前記集合因子中のいずれかの項が選択できたときに、前記集合因子中の選択された項と前記保持されている因子のうちの前記集合因子以外の因子とを前記積演算子によって結合し、前記演算用因子が含まれない項を抽出する剰余演算部と、をさらに有する請求項1から6のいずれかに記載の情報処理装置。
【請求項8】
前記対象情報は、項または和演算子で構成された複数の項によって集合情報を構成し、前記項または複数の項は、集合情報を識別する情報である第1の識別因子と、前記集合情報に含まれる値である因子とを含む、請求項1から7のいずれかに記載の情報処理装置。
【請求項9】
前記対象情報は、集合情報から前記共通因子が括り出された部分集合と他の部分集合に分類され、前記部分集合を少なくとも1つ含むトポロジー空間情報を構成し、
前記トポロジー空間情報は、そのトポロジー空間情報を識別する情報である第2の識別因子と、前記部分集合がなす因子または部分集合の組み合わせに集合因子構成演算子を付加した因子とが、積演算子によって結合されている、請求項8に記載の情報処理装置。
【請求項10】
前記対象情報は、属性と属性値との対応関係を含むセル空間情報を構成する請求項1から9のいずれかに記載の情報処理装置。
【請求項11】
前記セル空間情報は、
セル空間情報を他のセル空間情報と識別するセル空間識別因子と、
属性を指定する識別子、属性を指定する複数の識別子を積演算子によって結合した属性列、および、前記属性を指定する識別子および属性列のいずれかまたは双方の組み合わせを順序構成演算子で構成した属性の順序因子のいずれかである属性因子と、
前記属性因子に対応する値を指定する識別子、値を指定する複数の識別子を積演算子によって結合した値列、および、前記属性の順序因子に対応する値を指定する項の組み合わせを順序構成演算子によって構成した値の順序因子のいずれかを1以上含む単一の項またはそのような項の組み合わせを含む値因子と、を積演算子で結合して構成される請求項10に記載の情報処理装置。
【請求項12】
前記処理部は、前記項、前記集合情報、前記トポロジー空間情報、および前記セル空間情報の少なくとも1つを被接着情報とし、被接着情報を2以上結合した接着空間情報を構成する接着処理部を有し、
前記接着空間情報は、第1の被接着情報と第2の被接着情報を含み、
第1の被接着情報は、被接着情報同士を関連づける情報である第1の同値因子と、第1の値因子と積演算子で結合される第1の被接着因子とを含み、
第2の被接着情報は、被接着情報同士を関連づける情報である第2の同値因子と、第2の値因子と積演算子で結合される第2の被接着因子とを含み、
前記接着処理部は、第1の同値因子と第2の同値因子との関連付けの指定を受ける指定部と、
前記第1の同値因子と第2の同値因子との関連付けとともに、第1の被接着情被接着因子と第2の被接着因子との関連づけを前記記憶部に記憶させる接着部と、を有する請求項1から11のいずれかに記載の情報処理装置。
【請求項13】
前記接着処理部は、前記第1の同値因子を前記演算用因子として、前記第1の被接着情報を商演算部で演算することによって、前記第1の同値因子を含む第1の関連項を抽出し、前記第2の同値因子を前記演算用因子として、前記第2の被接着情報を商演算部で演算することによって、前記第2の同値因子を含む第2の関連項を抽出する関連項抽出部と、
前記第1の同値因子を前記演算用因子として、前記第1の被接着情報を剰余演算部で演算することによって、前記第1の同値因子を含ない非関連項を抽出し、前記第2の同値因子を前記演算用因子として、前記第2の被接着情報を剰余演算部で演算することによって、前記第2の同値因子を含ない非関連項を抽出する非関連項抽出部と、
前記第1の関連項から第1の同値因子を括り出すとともに、前記第2の関連項から第2の同値因子を括り出し、さらに、括り出された第1の同値因子と第2の同値因子と順序構成演算子によって関連づける関連づけ部とを有する請求項12に記載の情報処理装置。
【請求項14】
前記接着空間情報は、前記項、前記集合情報、前記トポロジー空間情報、前記セル空間情報、および他の接着空間情報の少なくとも1つとさらに、接着される請求項12または13に記載の情報処理装置。
【請求項15】
識別子と、順序を持つ因子の列として複数の識別子を結合する積演算子と、識別子および因子の列として結合された複数の識別子のいずれかまたは両方から項の組み合わせを構成する和演算子と、によって記述される対象情報を記憶する記憶部と、
情報の入力を受け付ける入力部を接続可能なインターフェースと、
情報を出力する出力部を接続可能なインターフェースと、を備えるコンピュータが、
前記インターフェースに接続された入力部から入力される情報を前記識別子、因子、項および項の組み合わせを含む式のいずれか1以上として前記対象情報に設定し、前記記憶部に記憶させる入力処理ステップと、
前記記憶部に記憶されている対象情報を参照し、参照した対象情報中の識別子、因子、項および式のいずれか1以上が前記入力部から入力される情報と所定の関係にあるときに、前記対象情報を前記インターフェースに接続された出力部に出力する出力処理ステッ
プと、を実行する情報処理方法。
【請求項16】
識別子と、順序を持つ因子の列として複数の識別子を結合する積演算子と、識別子および因子の列として結合された複数の識別子のいずれかまたは両方から項の組み合わせを構成する和演算子と、によって記述される対象情報を記憶する記憶部と、
情報の入力を受け付ける入力部を接続可能なインターフェースと、
情報を出力する出力部を接続可能なインターフェースと、を備えるコンピュータに、前記対象情報を操作させるプログラムであり、
前記インターフェースに接続された入力部から入力される情報を前記識別子、因子、項および項の組み合わせを含む式のいずれか1以上として前記対象情報に設定し、前記記憶部に記憶させる入力処理ステップと、
前記記憶部に記憶されている対象情報を参照し、参照した対象情報中の識別子、因子、項および式のいずれか1以上が前記入力部から入力される情報と所定の関係にあるときに、前記対象情報を前記インターフェースに接続された出力部に出力する出力処理ステップと、を有するプログラム。
【請求項17】
前記対象情報は、前記組み合わせ中の項の順序を維持して前記項の組み合わせを関係付けることによって因子または新たな項を構成する順序構成演算子と、前記組み合わせ中の項の順序を維持しないで前記項の組み合わせを関係付けることによって因子または新たな項を構成する集合因子構成演算子とをさらに含み、
前記積演算子によって、識別子を複数結合する積演算ステップと、
前記積演算子によって結合された複数の識別子からいずれかの識別子を抽出する因子抽出ステップと、
前記識別子、または積演算子によって結合された識別子をさらに前記和演算子によってさらに組み合わせて、項の組み合わせを構成する和演算ステップと、
前記項の組み合わせに含まれるいずれかの項を抽出する項抽出ステップと、
前記項の組み合わせに順序構成演算子を付加することによって因子または項を構成する順序生成ステップと、
前記項の組み合わせに順序構成演算子を付加された因子または項から前記順序構成演算子を除去する順序展開ステップと、
前記項の組み合わせに集合因子構成演算子を付加することによって因子または項を構成する集合構成ステップと、
前記項の組み合わせに集合因子構成演算子を付加された因子または項から前記集合因子構成演算子を除去する集合展開ステップと、
前記対象情報を構成する一の因子が項の組み合わせと前記順序構成演算子とによって構成されているとき、または前記一の因子が項の組み合わせと前記集合因子構成演算子とによって構成されているときに、前記一の因子と同一の項に含まれる、前記一の因子と積演算子で結合されている共通因子を前記項の組み合わせ中のそれぞれの項に付加して前記積演算子によって結合することによって、前記共通因子を展開する因子展開ステップと、をさらに有する請求項16に記載のプログラム。
【請求項18】
前記因子または前記項には、前記和演算子による演算に対して単位元となる記号、前記積演算子による演算に対して単位元となる記号、および前記積演算子に対して、演算結果が、識別子が存在しないことを示す零値となる、零元の少なくとも1つを含めることができる請求項16または17に記載のプログラム。
【請求項19】
項の組み合わせを、第1の因子を含む第1の項と前記第1の因子を含まない第2の項とに分類し、第1の因子を含む第1の項が複数存在したときに、第1の項の組み合わせから前記第1の因子を共通因子として抽出する部分集合形成ステップをさらに有する請求項16から18のいずれかに記載のプログラム。
【請求項20】
前記部分集合形成ステップは、前記共通因子を含む項から、積演算子によって共通因子の左側に結合される左因子と、積演算子によって共通因子の右側に結合される右因子とを抽出するとともに、前記左因子または右因子がない項に対しては、左因子または右因子に代えて単位元を抽出する因子抽出ステップと、
前記第1の項として複数の項が分類されたときに、前記因子抽出ステップにて抽出された複数の左因子から、和演算子と順序構成演算子とによって複数の左因子を含む左値因子を構成し、前記因子抽出ステップにて抽出された複数の右因子から、和演算子と順序構成演算子とによって複数の右因子を含む右値因子を構成し、前記左値因子、共通因子、および右値因子列を積演算子で結合する左右因子括り出しステップと、を有する請求項19に記載のプログラム。
【請求項21】
部分集合形成ステップは、いずれかの項を構成する因子中に、前記集合因子構成演算子が付加された項の組み合わせである集合因子が含まれるときに、前記集合因子中の項に対して、部分集合の形成を実行するステップをさらに有する請求項19または20に記載のプログラム。
【請求項22】
項または複数の項の組み合わせに対して、前記項に適用される演算用因子の指定を受け、前記項を構成する因子中に前記演算用因子を含むときにその項を選択する第1の選択演算を実行し、項を構成する因子中に前記演算用因子が含まれておらず、かつ、前記集合因子構成演算子によって関係付けられた項の組み合わせである集合因子を含むときに、前記集合因子中の項に対して前記第1の選択演算を実行し、前記集合因子中のいずれかの項が選択できたときに、前記集合因子中の選択された項と前記項を構成する因子中の前記集合因子以外の因子とを前記積演算子によって結合し、前記演算用因子が含まれる項を抽出する商演算ステップと、
項または複数の項の組み合わせに対して、前記項を構成する因子中に前記演算用因子を含まないときにその項を構成する因子を選択する第2の選択演算を実行するとともに選択された因子を保持し、前記保持された因子に前記集合因子構成演算子によって関係付けられた項の組み合わせである集合因子を含むときに、前記集合因子中の項に対して前記第2の選択演算を実行し、前記集合因子中のいずれかの項が選択できたときに、前記集合因子中の選択された項と前記保持されている因子のうちの前記集合因子以外の因子とを前記積演算子によって結合し、前記演算用因子が含まれない項を抽出する剰余演算ステップと、をさらに有する請求項16から21のいずれかに記載のプログラム。
【請求項23】
前記対象情報は、項または和演算子で構成された複数の項によって集合情報を構成し、前記項または複数の項は、集合情報を識別する情報である第1の識別因子と、前記集合情報に含まれる値である因子とを含む、請求項16から22のいずれかに記載のプログラム。
【請求項24】
前記対象情報は、集合情報から前記共通因子が括り出された部分集合と他の部分集合に分類され、前記部分集合を少なくとも1つ含むトポロジー空間情報を構成し、
前記トポロジー空間情報は、そのトポロジー空間情報を識別する情報である第2の識別因子と、前記部分集合がなす因子または部分集合の組み合わせに集合因子構成演算子を付加した因子とが、積演算子によって結合されている、請求項23に記載のプログラム。
【請求項25】
前記対象情報は、属性と属性値との対応関係を含むセル空間情報を構成する請求項16から24のいずれかに記載のプログラム。
【請求項26】
前記セル空間情報は、
セル空間情報を他のセル空間情報と識別するセル空間識別因子と、
属性を指定する識別子、属性を指定する複数の識別子を積演算子によって結合した属性列、および、前記属性を指定する識別子および属性列のいずれかまたは双方の組み合わせを順序構成演算子で構成した属性の順序因子のいずれかである属性因子と、
前記属性因子に対応する値を指定する識別子、値を指定する複数の識別子を積演算子によって結合した値列、および、前記属性の順序因子に対応する値を指定する項の組み合わせを順序構成演算子によって構成した値の順序因子のいずれかである値因子と、を積演算子で結合して構成される請求項25に記載のプログラム。
【請求項27】
前記項、前記集合情報、前記トポロジー空間情報、および前記セル空間情報の少なくとも1つを被接着情報とし、被接着情報を2以上結合した接着空間情報を構成する接着処理ステップをさらに有し、
前記接着空間情報は、第1の被接着情報と第2の被接着情報を含み、
第1の被接着情報は、被接着情報同士を関連づける情報である第1の同値因子と、第1の値因子と積演算子で結合される第1の被接着因子とを含み、
第2の被接着情報は、被接着情報同士を関連づける情報である第2の同値因子と、第2の値因子と積演算子で結合される第2の被接着因子とを含み、
前記接着処理ステップは、第1の同値因子と第2の同値因子との関連付けの指定を受けるステップと、
前記第1の同値因子と第2の同値因子との関連付けとともに、第1の被接着情被接着因子と第2の被接着因子との関連づけを記憶するステップと、を有する請求項16から26のいずれかに記載のプログラム。
【請求項28】
前記接着処理ステップは、前記第1の同値因子を前記演算用因子として、前記第1の被接着情報を商演算部で演算することによって、前記第1の同値因子を含む第1の関連項を抽出し、前記第2の同値因子を前記演算用因子として、前記第2の被接着情報を商演算部で演算することによって、前記第2の同値因子を含む第2の関連項を抽出する関連項抽出ステップと、
前記第1の同値因子を前記演算用因子として、前記第1の被接着情報を剰余演算部で演算することによって、前記第1の同値因子を含ない非関連項を抽出し、前記第2の同値因子を前記演算用因子として、前記第2の被接着情報を剰余演算部で演算することによって、前記第1の同値因子を含ない非関連項を抽出する非関連項抽出ステップと、
前記第1の関連項から第1の同値因子を括り出すとともに、前記第2の関連項から第2の同値因子を括り出し、さらに、括り出された第1の同値因子と第2の同値因子と順序構成演算子によって関連づける関連づけステップとを有する請求項27に記載のプログラム。
【請求項29】
前記接着空間情報は、前記項、前記集合情報、前記トポロジー空間情報、前記セル空間情報、および他の接着空間情報の少なくとも1つとさらに、接着される請求項28に記載のプログラム。
【請求項30】
識別子と、順序を持つ因子の列として複数の識別子を結合する積演算子と、識別子および因子の列として結合された複数の識別子のいずれかまたは両方から項の組み合わせを構成する和演算子と、によって記述されるデータ構造であり、
前記データ構造で記述される対象情報を記憶する記憶部と、
前記対象情報を操作する処理部と、
情報の入力を受け付ける入力部を接続可能なインターフェースと、
情報を出力する出力部を接続可能なインターフェースと、を備えるコンピュータが、
前記インターフェースに接続された入力部から入力される情報を前記識別子、因子、項および項の組み合わせを含む式のいずれか1以上として前記対象情報に設定し、前記記憶部に記憶させる入力処理ステップと、
前記記憶部に記憶されている対象情報を参照し、参照した対象情報中の識別子、因子、項および式のいずれか1以上が前記入力部から入力される情報と所定の関係にあるときに、前記対象情報を前記インターフェースに接続された出力部に出力する出力処理ステップと、を実行し、前記記憶部に構成されるデータ構造。
【図1】


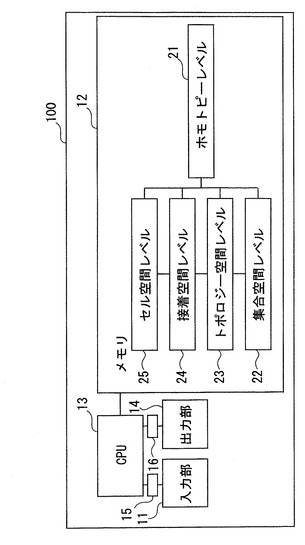
【図2】
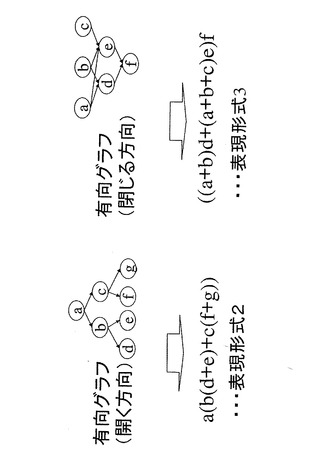
【図3】
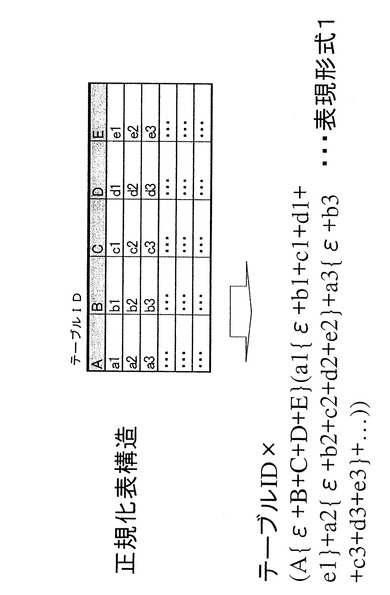
【図4】
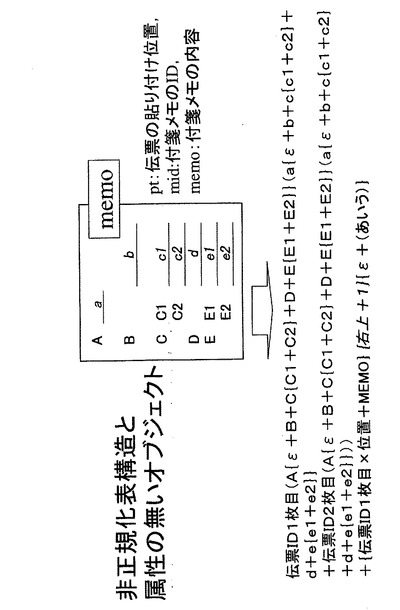
【図5】
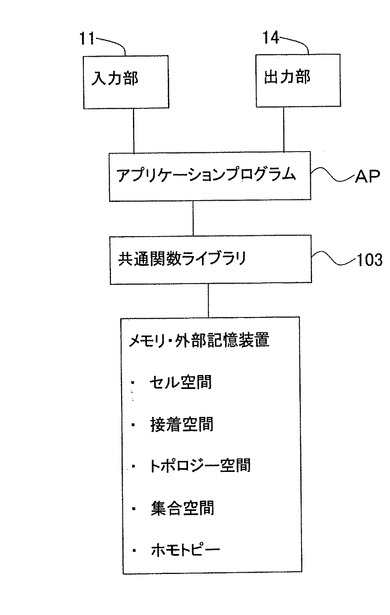
【図6A】
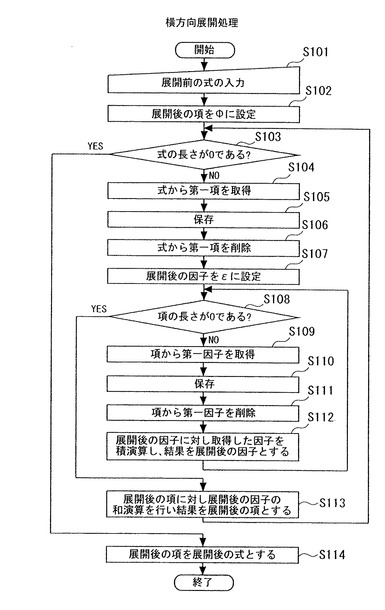
【図6B】
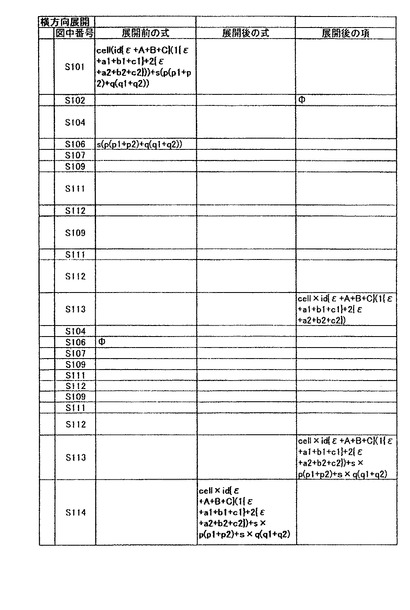
【図6C】
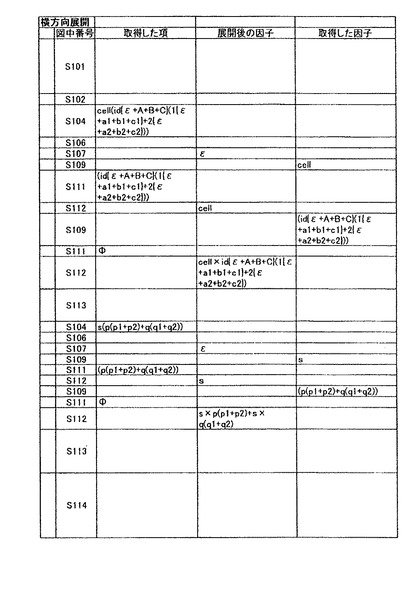
【図7】
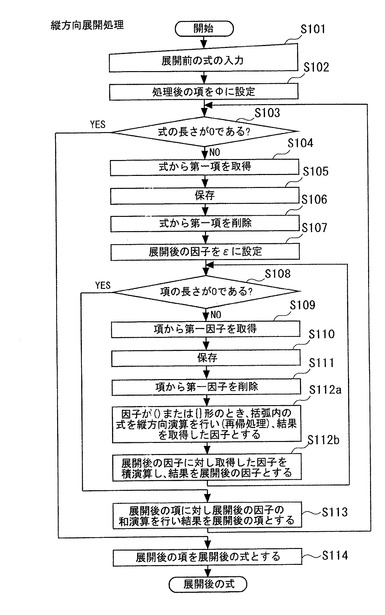
【図8A】
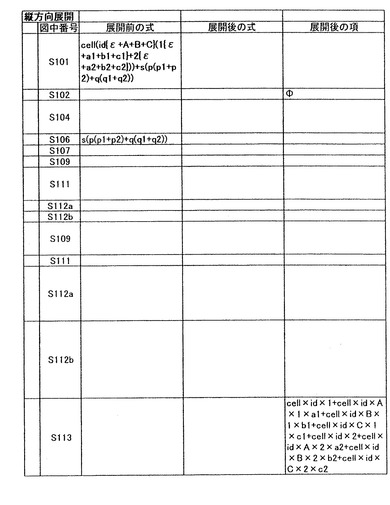
【図8B】

【図8C】
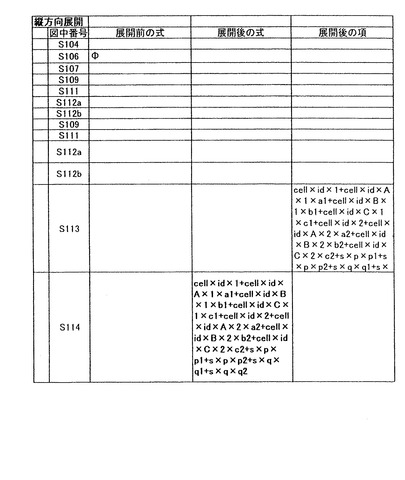
【図8D】
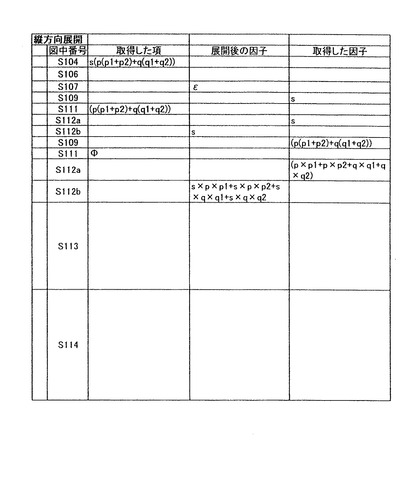
【図9】
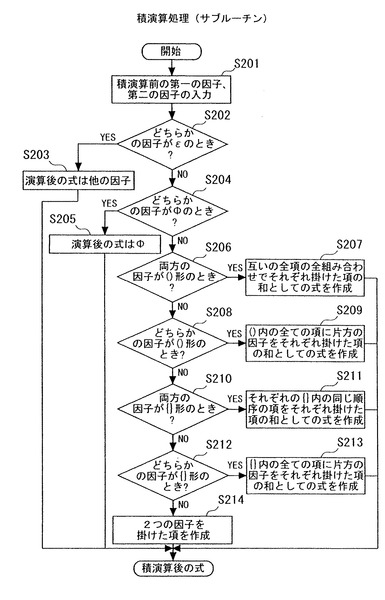
【図10】
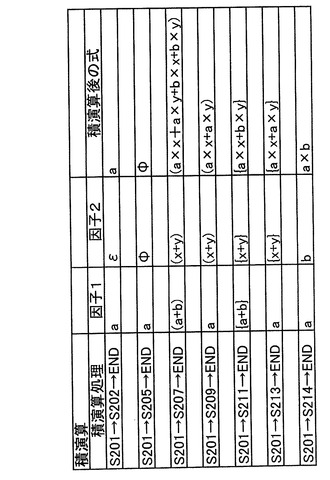
【図11A】
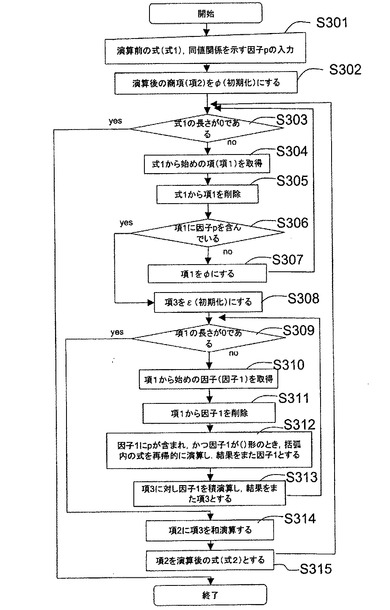
【図11B】

【図11C】

【図12A】
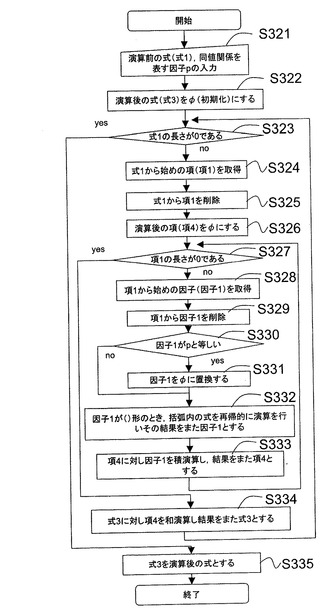
【図12B】
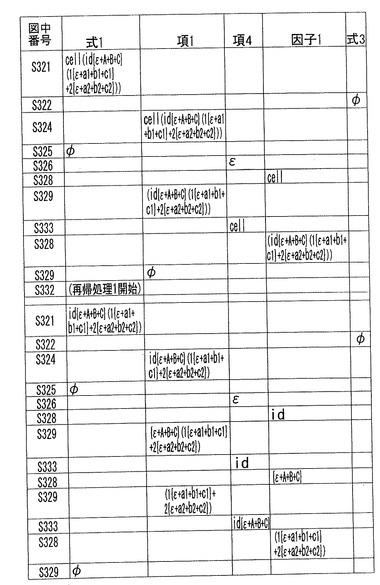
【図12C】

【図13】
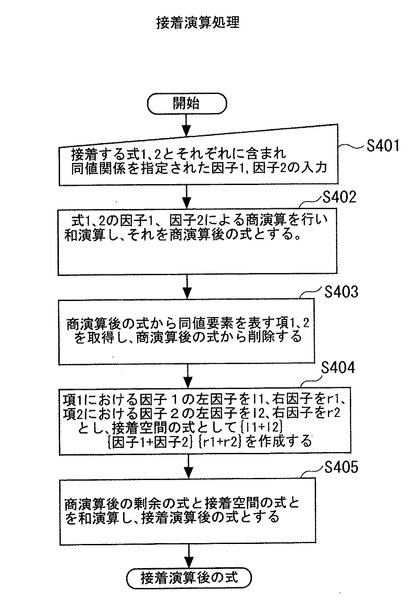
【図14】
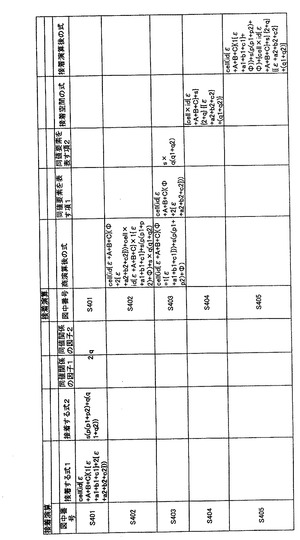
【図15】
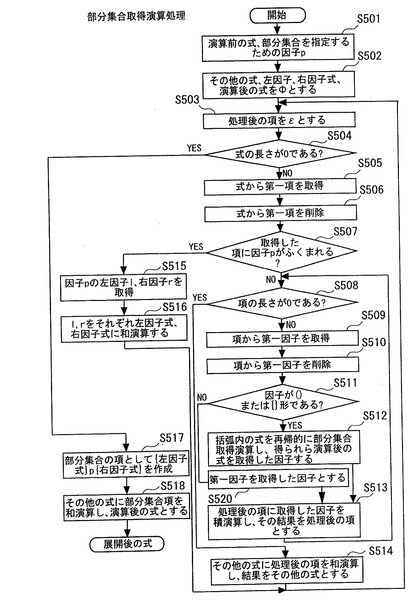
【図16A】
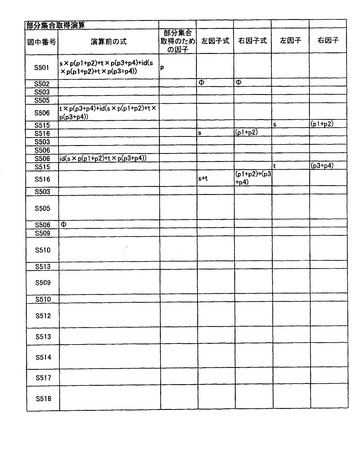
【図16B】
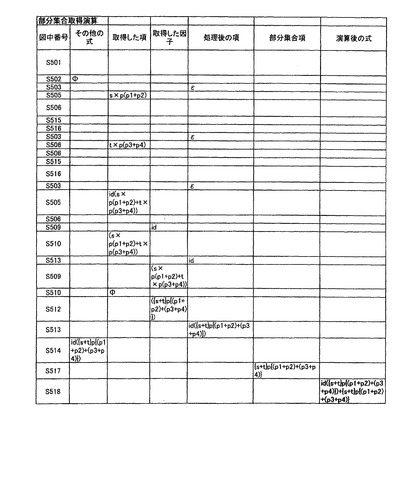
【図17】
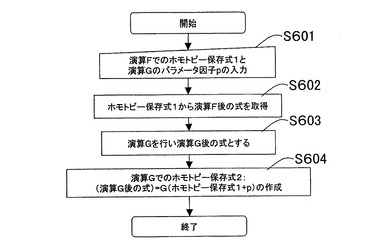
【図18】
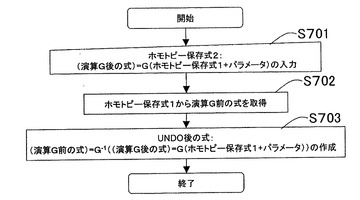
【図19】
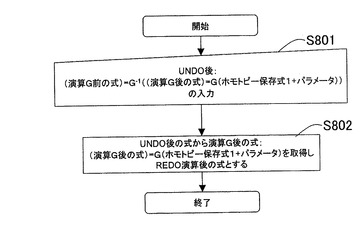
【図20】
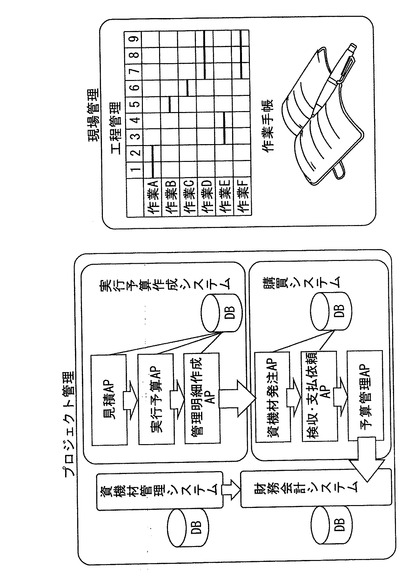
【図21A】
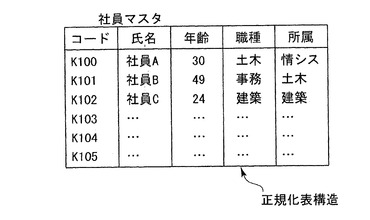
【図21B】
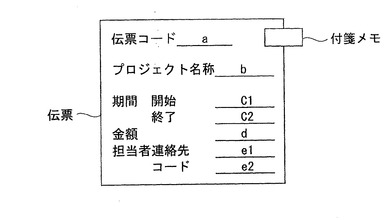
【図22A】
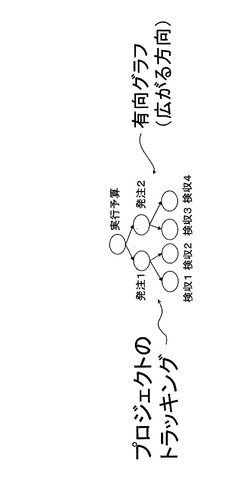
【図22B】
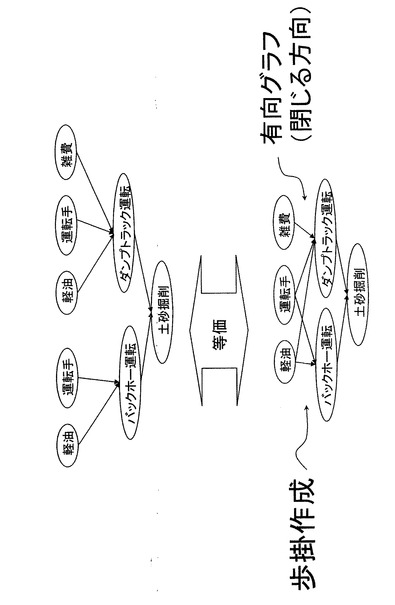
【図23】
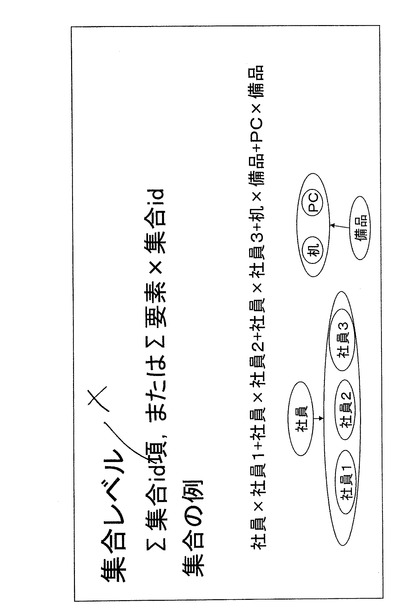
【図24】
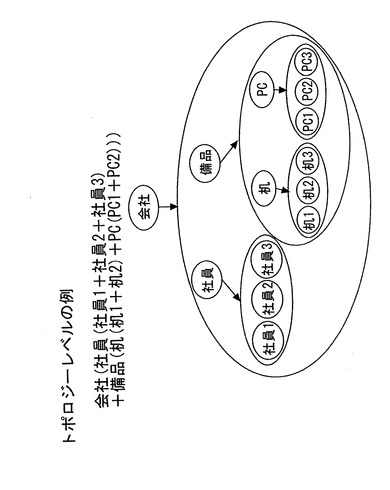
【図25】
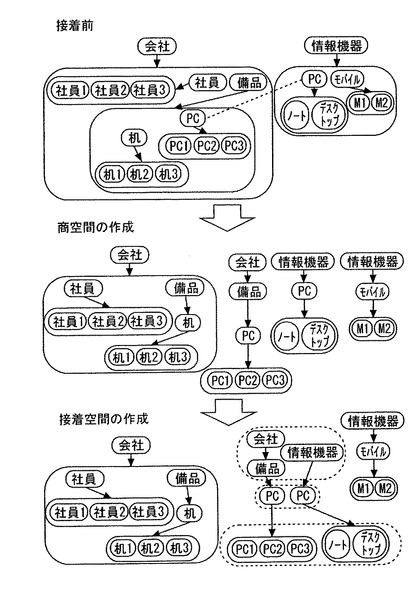
【図26】
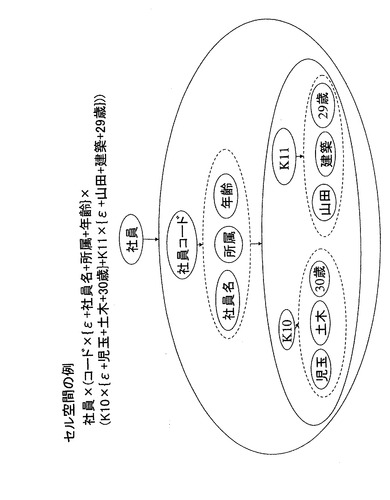
【図27】
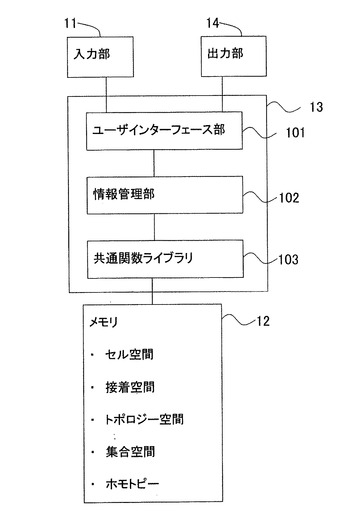
【図28A】
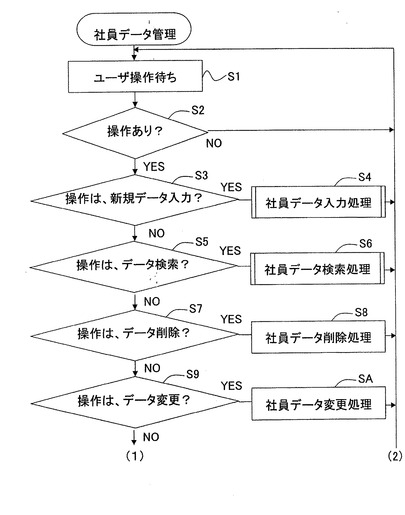
【図28B】
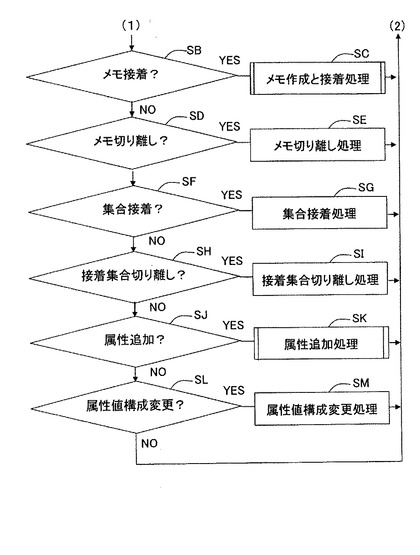
【図29】
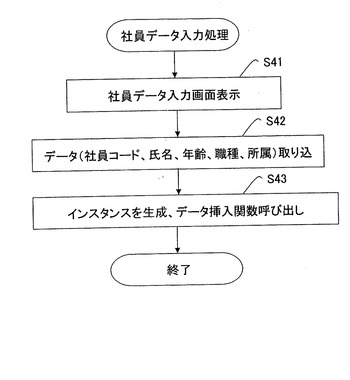
【図30】
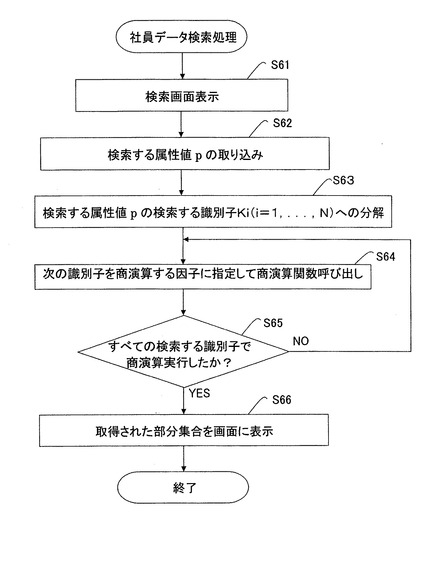
【図31】
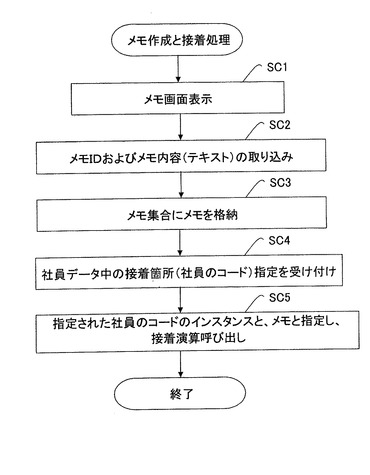
【図32】
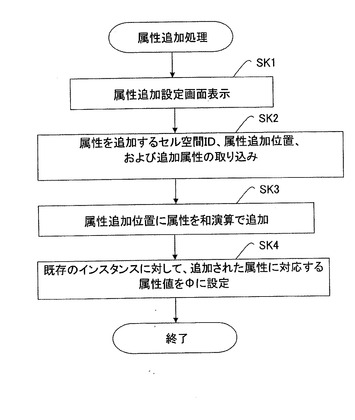
【図2】
【図3】
【図4】
【図5】
【図6A】
【図6B】
【図6C】
【図7】
【図8A】
【図8B】
【図8C】
【図8D】
【図9】
【図10】
【図11A】
【図11B】
【図11C】
【図12A】
【図12B】
【図12C】
【図13】
【図14】
【図15】
【図16A】
【図16B】
【図17】
【図18】
【図19】
【図20】
【図21A】
【図21B】
【図22A】
【図22B】
【図23】
【図24】
【図25】
【図26】
【図27】
【図28A】
【図28B】
【図29】
【図30】
【図31】
【図32】
【公開番号】特開2009−134748(P2009−134748A)
【公開日】平成21年6月18日(2009.6.18)
【国際特許分類】
【出願番号】特願2009−27815(P2009−27815)
【出願日】平成21年2月9日(2009.2.9)
【分割の表示】特願2007−556939(P2007−556939)の分割
【原出願日】平成19年2月2日(2007.2.2)
【公序良俗違反の表示】
(特許庁注:以下のものは登録商標)
1.EEPROM
【出願人】(000201478)前田建設工業株式会社 (358)
【出願人】(506040870)
【出願人】(506314564)
【Fターム(参考)】
【公開日】平成21年6月18日(2009.6.18)
【国際特許分類】
【出願日】平成21年2月9日(2009.2.9)
【分割の表示】特願2007−556939(P2007−556939)の分割
【原出願日】平成19年2月2日(2007.2.2)
【公序良俗違反の表示】
(特許庁注:以下のものは登録商標)
1.EEPROM
【出願人】(000201478)前田建設工業株式会社 (358)
【出願人】(506040870)
【出願人】(506314564)
【Fターム(参考)】
[ Back to top ]