
情報処理装置、情報処理方法、及びプログラム
【課題】報酬推定機を効率的に自動構築できるようにすること。
【解決手段】エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成し、エージェントがとりうる行動のうち、報酬推定機を用いて推定される報酬値が高く、かつ、行動履歴データに含まれない行動を優先的に選択し、選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を行動履歴データに追加し、行動履歴データに状態データ、行動データ、及び報酬値が追加された場合に報酬推定機を再生成する、情報処理装置が提供される。
【解決手段】エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成し、エージェントがとりうる行動のうち、報酬推定機を用いて推定される報酬値が高く、かつ、行動履歴データに含まれない行動を優先的に選択し、選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を行動履歴データに追加し、行動履歴データに状態データ、行動データ、及び報酬値が追加された場合に報酬推定機を再生成する、情報処理装置が提供される。
【発明の詳細な説明】
【技術分野】
【0001】
本技術は、情報処理装置、情報処理方法、及びプログラムに関する。
【背景技術】
【0002】
近年、定量的に特徴を決定づけることが難しい任意のデータ群から、そのデータ群の特徴量を機械的に抽出する手法に注目が集まっている。例えば、任意の音楽データを入力とし、その音楽データが属する音楽のジャンルを機械的に抽出するアルゴリズムを自動構築する手法が知られている。ジャズ、クラシック、ポップス等、音楽のジャンルは、楽器の種類や演奏形態に応じて定量的に決まるものではない。そのため、これまでは任意の音楽データが与えられたときに、その音楽データから機械的に音楽のジャンルを抽出することは一般的に難しいと考えられていた。
【0003】
しかし、実際には、音楽データに含まれる音程の組み合わせ、音程の組み合わせ方、楽器の種類の組み合わせ、メロディーラインやベースラインの構造等、様々な情報の組み合わせの中に、音楽のジャンルを分ける特徴が潜在的に含まれている。そのため、この特徴を抽出するアルゴリズム(以下、特徴量抽出機)を機械学習により自動構築できないか、という観点から特徴量抽出機の研究が行われた。その研究成果の一つとして、例えば、下記の特許文献1に記載された遺伝アルゴリズムに基づく特徴量抽出機の自動構築方法を挙げることができる。遺伝アルゴリズムとは、生物の進化過程に倣い、機械学習の過程で、選択、交差、突然変異の要素を考慮したものを言う。
【0004】
同文献に記載の特徴量抽出機自動構築アルゴリズムを利用することにより、任意の音楽データから、その音楽データが属する音楽のジャンルを抽出する特徴量抽出機を自動構築することができるようになる。また、同文献に記載の特徴量抽出機自動構築アルゴリズムは、非常に汎用性が高く、音楽データに限らず、任意のデータ群から、そのデータ群の特徴量を抽出する特徴量抽出機を自動構築することができる。そのため、同文献に記載の特徴量抽出機自動構築アルゴリズムは、音楽データや映像データのような人工的なデータの特徴量解析、自然界に存在する様々な観測量の特徴量解析への応用が期待されている。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開2009−48266号公報
【発明の概要】
【発明が解決しようとする課題】
【0006】
ところで、本件発明者は、同文献に記載の技術に対して更なる工夫を施すことで、エージェントを賢く行動させるアルゴリズムを自動構築する技術に発展させられないか検討を行ってきた。その検討の中で、本件発明者は、ある状態におかれたエージェントがとりうる行動の中で選択すべき行動を決定するための思考ルーチンを自動構築する技術に注目した。本技術は、このような技術に関するものであり、エージェントがとるべき行動を選択する際に決め手となる情報を出力する推定機を効率よく自動構築することが可能な、新規かつ改良された情報処理装置、情報処理方法、及びプログラムを提供することを意図している。
【課題を解決するための手段】
【0007】
本技術のある観点によれば、エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成部と、エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、前記行動履歴データに含まれない行動を優先的に選択する行動選択部と、前記行動選択部による選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加する行動履歴追加部と、を備え、前記報酬推定機生成部は、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成する、情報処理装置が提供される。
【0008】
また、本技術の別の観点によれば、エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成部と、エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、当該報酬値の推定誤差が大きい行動を優先的に選択する行動選択部と、前記行動選択部による選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加する行動履歴追加部と、を備え、前記報酬推定機生成部は、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成する、情報処理装置が提供される。
【0009】
また、本技術の別の観点によれば、エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成するステップと、エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、前記行動履歴データに含まれない行動を優先的に選択するステップと、選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加するステップと、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成するステップと、を含む、情報処理方法が提供される。
【0010】
また、本技術の別の観点によれば、エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成するステップと、エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、当該報酬値の推定誤差が大きい行動を優先的に選択するステップと、選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加するステップと、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成するステップと、を含む、情報処理方法が提供される。
【0011】
また、本技術の別の観点によれば、エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成機能と、エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、前記行動履歴データに含まれない行動を優先的に選択する行動選択機能と、前記行動選択機能による選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加する行動履歴追加機能と、をコンピュータに実現させるためのプログラムであり、前記報酬推定機生成機能は、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成する、プログラムが提供される。
【0012】
また、本技術の別の観点によれば、エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成機能と、エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、当該報酬値の推定誤差が大きい行動を優先的に選択する行動選択機能と、前記行動選択機能による選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加する行動履歴追加機能と、をコンピュータに実現させるためのプログラムであり、前記報酬推定機生成機能は、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成する、プログラムが提供される。
【0013】
また、本技術の別の観点によれば、上記のプログラムが記録された、コンピュータにより読み取り可能な記録媒体が提供される。
【発明の効果】
【0014】
以上説明したように本技術によれば、エージェントがとるべき行動を選択する際に決め手となる情報を出力する推定機を効率よく自動構築することが可能になる。
【図面の簡単な説明】
【0015】
【図1】推定機の自動構築方法について説明するための説明図である。
【図2】推定機の自動構築方法について説明するための説明図である。
【図3】推定機の自動構築方法について説明するための説明図である。
【図4】推定機の自動構築方法について説明するための説明図である。
【図5】推定機の自動構築方法について説明するための説明図である。
【図6】推定機の自動構築方法について説明するための説明図である。
【図7】推定機の自動構築方法について説明するための説明図である。
【図8】推定機の自動構築方法について説明するための説明図である。
【図9】推定機の自動構築方法について説明するための説明図である。
【図10】推定機の自動構築方法について説明するための説明図である。
【図11】推定機の自動構築方法について説明するための説明図である。
【図12】推定機の自動構築方法について説明するための説明図である。
【図13】オンライン学習に基づく推定機の自動構築方法について説明するための説明図である。
【図14】データセットの統合方法について説明するための説明図である。
【図15】データセットの統合方法について説明するための説明図である。
【図16】データセットの統合方法について説明するための説明図である。
【図17】データセットの統合方法について説明するための説明図である。
【図18】データセットの統合方法について説明するための説明図である。
【図19】データセットの統合方法について説明するための説明図である。
【図20】データセットの統合方法について説明するための説明図である。
【図21】データセットの統合方法について説明するための説明図である。
【図22】データセットの統合方法について説明するための説明図である。
【図23】データセットの統合方法について説明するための説明図である。
【図24】データセットの統合方法について説明するための説明図である。
【図25】データセットの統合方法について説明するための説明図である。
【図26】データセットの統合方法について説明するための説明図である。
【図27】データセットの統合方法について説明するための説明図である。
【図28】データセットの統合方法について説明するための説明図である。
【図29】データセットの統合方法について説明するための説明図である。
【図30】データセットの統合方法について説明するための説明図である。
【図31】データセットの統合方法について説明するための説明図である。
【図32】データセットの統合方法について説明するための説明図である。
【図33】データセットの統合方法について説明するための説明図である。
【図34】思考ルーチンの構成について説明するための説明図である。
【図35】思考ルーチンの構成について説明するための説明図である。
【図36】思考ルーチンの構成について説明するための説明図である。
【図37】思考ルーチンの構成について説明するための説明図である。
【図38】思考ルーチンの構築方法について説明するための説明図である。
【図39】情報処理装置10の機能構成例について説明するための説明図である。
【図40】情報処理装置10の機能構成例について説明するための説明図である。
【図41】効率的な報酬推定機の構築方法について説明するための説明図である。
【図42】効率的な報酬推定機の構築方法について説明するための説明図である。
【図43】アクションスコア推定機を用いた思考ルーチンの構成について説明するための説明図である。
【図44】アクションスコア推定機を用いた思考ルーチンの構成について説明するための説明図である。
【図45】予測機を用いた報酬の推定方法について説明するための説明図である。
【図46】予測機を用いた報酬の推定方法について説明するための説明図である。
【図47】予測機を用いた報酬の推定方法について説明するための説明図である。
【図48】「三目並べ」への応用について説明するための説明図である。
【図49】「三目並べ」への応用について説明するための説明図である。
【図50】「三目並べ」への応用について説明するための説明図である。
【図51】「三目並べ」への応用について説明するための説明図である。
【図52】「三目並べ」への応用について説明するための説明図である。
【図53】「三目並べ」への応用について説明するための説明図である。
【図54】「三目並べ」への応用について説明するための説明図である。
【図55】「対戦ゲーム」への応用について説明するための説明図である。
【図56】「対戦ゲーム」への応用について説明するための説明図である。
【図57】「対戦ゲーム」への応用について説明するための説明図である。
【図58】「対戦ゲーム」への応用について説明するための説明図である。
【図59】「対戦ゲーム」への応用について説明するための説明図である。
【図60】「対戦ゲーム」への応用について説明するための説明図である。
【図61】「対戦ゲーム」への応用について説明するための説明図である。
【図62】「対戦ゲーム」への応用について説明するための説明図である。
【図63】「五目並べ」への応用について説明するための説明図である。
【図64】「五目並べ」への応用について説明するための説明図である。
【図65】「ポーカー」への応用について説明するための説明図である。
【図66】「ポーカー」への応用について説明するための説明図である。
【図67】「ポーカー」への応用について説明するための説明図である。
【図68】「ロールプレイングゲーム」への応用について説明するための説明図である。
【図69】「ロールプレイングゲーム」への応用について説明するための説明図である。
【図70】「ロールプレイングゲーム」への応用について説明するための説明図である。
【図71】「ロールプレイングゲーム」への応用について説明するための説明図である。
【図72】「ロールプレイングゲーム」への応用について説明するための説明図である。
【図73】「ロールプレイングゲーム」への応用について説明するための説明図である。
【図74】「ロールプレイングゲーム」への応用について説明するための説明図である。
【図75】「ロールプレイングゲーム」への応用について説明するための説明図である。
【図76】「ロールプレイングゲーム」への応用について説明するための説明図である。
【図77】「ロールプレイングゲーム」への応用について説明するための説明図である。
【図78】「ロールプレイングゲーム」への応用について説明するための説明図である。
【図79】「ロールプレイングゲーム」への応用について説明するための説明図である。
【図80】情報処理装置の機能を実現することが可能なハードウェア構成例について説明するための説明図である。
【発明を実施するための形態】
【0016】
以下に添付図面を参照しながら、本技術に係る好適な実施の形態について詳細に説明する。なお、本明細書及び図面において、実質的に同一の機能構成を有する構成要素については、同一の符号を付することにより重複説明を省略する。
【0017】
[説明の流れについて]
ここで、以下に記載する説明の流れについて簡単に述べる。
【0018】
まず、本実施形態に係る基盤技術について説明する。具体的には、まず、図1〜図12を参照しながら、推定機の自動構築方法について説明する。次いで、図13を参照しながら、オンライン学習に基づく推定機の自動構築方法について説明する。
【0019】
次いで、図14〜図16を参照しながら、データセットの統合方法について説明する。次いで、図17〜図23を参照しながら、効率的なデータセットのサンプリング方法について説明する。次いで、図24〜図27を参照しながら、効率的な重み付け方法について説明する。次いで、図28を参照しながら、効率的なデータセットのサンプリング方法及び重み付け方法を組み合わせる方法について説明する。次いで、図29〜図33を参照しながら、その他のデータセットのサンプリング方法及び重み付け方法について説明する。
【0020】
次いで、図34〜図38を参照しながら、思考ルーチンの構成及び思考ルーチンの構築方法について説明する。次いで、図39及び図40を参照しながら、本実施形態に係る情報処理装置10の機能構成について説明する。次いで、図41及び図42を参照しながら、効率的な報酬推定機の構築方法について説明する。次いで、図43及び図44を参照しながら、アクションスコア推定機を用いた思考ルーチンの構成について説明する。次いで、図45〜図47を参照しながら、予測機を用いた報酬の推定方法について説明する。
【0021】
次いで、図48〜図54を参照しながら、本実施形態に係る技術を「三目並べ」へ応用する方法について説明する。次いで、図55〜図62を参照しながら、本実施形態に係る技術を「対戦ゲーム」へ応用する方法について説明する。次いで、図63及び図64を参照しながら、本実施形態に係る技術を「五目並べ」へ応用する方法について説明する。次いで、図65〜図67を参照しながら、本実施形態に係る技術を「ポーカー」へ応用する方法について説明する。次いで、図68〜図79を参照しながら、本実施形態に係る技術を「ロールプレイングゲーム」へ応用する方法について説明する。
【0022】
次いで、図80を参照しながら、本実施形態に係る情報処理装置10の機能を実現することが可能なハードウェア構成例について説明する。最後に、同実施形態の技術的思想について纏め、当該技術的思想から得られる作用効果について簡単に説明する。
【0023】
(説明項目)
1:基盤技術
1−1:推定機の自動構築方法
1−1−1:推定機の構成
1−1−2:構築処理の流れ
1−2:オンライン学習について
1−3:学習用データの統合方法
1−3−1:特徴量空間における学習用データの分布と推定機の精度
1−3−2:データ統合時にサンプリングする構成
1−3−3:データ統合時に重み付けする構成
1−3−4:データ統合時にサンプリング及び重み付けする構成
1−4:効率的なサンプリング/重み付け方法
1−4−1:サンプリング方法
1−4−2:重み付け方法
1−4−3:組み合わせ方法
1−5:サンプリング処理及び重み付け処理に関する変形例
1−5−1:変形例1(距離に基づく処理)
1−5−2:変形例2(クラスタリングに基づく処理)
1−5−3:変形例3(密度推定手法に基づく処理)
2:実施形態
2−1:思考ルーチンの自動構築方法
2−1−1:思考ルーチンとは
2−1−2:思考ルーチンの構成
2−1−3:報酬推定機の構築方法
2−2:情報処理装置10の構成
2−3:効率的な推定報酬機の構築方法
2−4:(変形例1)アクションスコア推定機を用いる思考ルーチン
2−5:(変形例2)予測機を用いた報酬の推定
2−5−1:予測機の構築方法
2−5−2:報酬の推定方法
2−6:(変形例3)複数エージェントの同時学習
3:応用例
3−1:「三目並べ」への応用
3−2:「対戦ゲーム」への応用
3−3:「五目並べ」への応用
3−4:「ポーカー」への応用
3−5:「ロールプレイングゲーム」への応用
4:ハードウェア構成例
5:まとめ
【0024】
<1:基盤技術>
後述する実施形態は、推定機の自動構築方法に関する。また、同実施形態は、推定機の構築に用いる学習用データを追加できるようにする仕組み(以下、オンライン学習)に関する。そこで、同実施形態に係る技術について詳細に説明するに先立ち、推定機の自動構築方法及びオンライン学習方法(以下、基盤技術)について説明する。なお、以下では遺伝アルゴリズムに基づく推定機の自動構築方法を例に挙げて説明を進めるが、同実施形態に係る技術の適用範囲はこれに限定されない。
【0025】
[1−1:推定機の自動構築方法]
推定機の自動構築方法について説明する。
【0026】
(1−1−1:推定機の構成)
はじめに、図1〜図3を参照しながら、推定機の構成について説明する。図1は、推定機を利用するシステムのシステム構成例を示した説明図である。また、図2は、推定機の構築に利用する学習用データの構成例を示した説明図である。そして、図3は、推定機の構造及び構築方法の概要を示した説明図である。
【0027】
まず、図1を参照する。図1に示すように、推定機の構築及び推定値の算出は、例えば、情報処理装置10により実行される。情報処理装置10は、学習用データ(X1,t1),…,(XN,tN)を利用して推定機を構築する。また、情報処理装置10は、構築した推定機を利用して入力データXから推定値yを算出する。この推定値yは、入力データXの認識に利用される。例えば、推定値yが所定の閾値Thより大きい場合に認識結果YESが得られ、推定値yが所定の閾値Thより小さい場合に認識結果NOが得られる。
【0028】
図2を参照しながら、より具体的に推定機の構成について考えてみよう。図2に例示した学習用データの集合は、“海”の画像を認識する画像認識機の構築に利用されるものである。この場合、情報処理装置10により構築される推定機は、入力された画像の“海らしさ”を表す推定値yを出力するものとなる。図2に示すように、学習用データは、データXkと目的変数tkとのペア(但し、k=1〜N)により構成される。データXkは、k番目の画像データ(画像#k)である。また、目的変数tkは、画像#kが“海”の画像である場合に1、画像#kが“海”の画像でない場合に0となる変数である。
【0029】
図2の例では、画像#1が“海”の画像であり、画像#2が“海”の画像であり、…、画像#Nが“海”の画像でない。この場合、t1=1、t2=1、…、tN=0となる。この学習用データが入力されると、情報処理装置10は、入力された学習用データに基づく機械学習により、入力された画像の“海らしさ”を表す推定値yを出力する推定機を構築する。この推定値yは、入力された画像の“海らしさ”が高いほど1に近づき、“海らしさ”が低いほど0に近づく値である。
【0030】
また、新たに入力データX(画像X)が入力されると、情報処理装置10は、学習用データの集合を利用して構築された推定機に画像Xを入力し、画像Xの“海らしさ”を表す推定値yを算出する。この推定値yを利用すると、画像Xが“海”の画像であるか否かを認識することが可能になる。例えば、推定値y≧所定の閾値Thの場合、入力された画像Xが“海”の画像であると認識される。一方、推定値y<所定の閾値Thの場合、入力された画像Xが“海”の画像でないと認識される。
【0031】
本実施形態は、上記のような推定機を自動構築する技術に関する。なお、ここでは画像認識機の構築に利用される推定機について説明したが、本実施形態に係る技術は、様々な推定機の自動構築方法に適用することができる。例えば、言語解析機の構築に適用することもできるし、楽曲のメロディーラインやコード進行などを解析する音楽解析機の構築にも適用することができる。さらに、蝶の動きや雲の流れなどの自然現象を再現したり、自然の振る舞いを予測したりする動き予測機の構築などにも適用することができる。
【0032】
例えば、特開2009−48266号公報、特願2010−159598号明細書、特願2010−159597号明細書、特願2009−277083号明細書、特願2009−277084号明細書などに記載のアルゴリズムに適用することができる。また、AdaBoostなどのアンサンブル学習手法や、SVMやSVRなどのカーネルを用いた学習手法などにも適用できる。AdaBoostなどのアンサンブル学習手法に適用する場合、弱学習機(Weak Learner)が後述する基底関数φに対応する。また、SVMやSVRなどの学習手法に適用する場合、カーネルが後述する基底関数φに対応する。なお、SVMはSupport Vector Machine、SVRはSupport Vector Regression、RVMはRelevance Vector Machineの略である。
【0033】
ここで、図3を参照しながら、推定機の構造について説明する。図3に示すように、推定機は、基底関数リスト(φ1,…,φM)及び推定関数fにより構成される。基底関数リスト(φ1,…,φM)は、M個の基底関数φk(k=1〜M)を含む。また、基底関数φkは、入力データXの入力に応じて特徴量zkを出力する関数である。さらに、推定関数fは、M個の特徴量zk(k=1〜M)を要素として含む特徴量ベクトルZ=(z1,…,zM)の入力に応じて推定値yを出力する関数である。基底関数φkは、予め用意された1又は複数の処理関数を組み合わせて生成される。
【0034】
処理関数としては、例えば、三角関数、指数関数、四則演算、デジタルフィルタ、微分演算、中央値フィルタ、正規化演算、ホワイトノイズの付加処理、画像処理フィルタなどが利用可能である。例えば、入力データXが画像の場合、ホワイトノイズの付加処理AddWhiteNoise()、中央値フィルタMedian()、ぼかし処理Blur()を組み合わせた基底関数φj(X)=AddWhiteNoise(Median(Blur(X)))などが利用される。この基底関数φjは、入力データXに対し、ぼかし処理、中央値フィルタ処理、及びホワイトノイズの付加処理を順次施すことを意味する。
【0035】
(1−1−2:構築処理の流れ)
さて、基底関数φk(k=1〜M)の構成、基底関数リストの構成、推定関数fの構成は、学習用データに基づく機械学習により決定される。以下、この機械学習による推定機の構築処理について、より詳細に説明する。
【0036】
(全体構成)
まず、図4を参照しながら、全体的な処理の流れについて説明する。図4は、全体的な処理の流れについて説明するための説明図である。なお、以下で説明する処理は、情報処理装置10により実行される。
【0037】
図4に示すように、まず、情報処理装置10に学習用データが入力される(S101)。なお、学習用データとしては、データXと目的変数tの組が入力される。学習用データが入力されると、情報処理装置10は、処理関数を組み合わせて基底関数を生成する(S102)。次いで、情報処理装置10は、基底関数にデータXを入力して特徴量ベクトルZを算出する(S103)。次いで、情報処理装置10は、基底関数の評価及び推定関数の生成を行う(S104)。
【0038】
次いで、情報処理装置10は、所定の終了条件を満たしたか否かを判定する(S105)。所定の終了条件を満たした場合、情報処理装置10は、処理をステップS106に進める。一方、所定の終了条件を満たしていない場合、情報処理装置10は、処理をステップS102に戻し、ステップS102〜S104の処理を繰り返し実行する。処理をステップS106に進めた場合、情報処理装置10は、推定関数を出力する(S106)。上記の通り、ステップS102〜S104の処理は、繰り返し実行される。そこで、以下の説明においては、第τ回目の繰り返し処理においてステップS102で生成される基底関数を第τ世代の基底関数と呼ぶことにする。
【0039】
(基底関数の生成(S102))
ここで、図5〜図10を参照しながら、ステップS102の処理(基底関数の生成)について、より詳細に説明する。
【0040】
まず、図5を参照する。図5に示すように、情報処理装置10は、現在の世代が2世代目以降であるか否かを判定する(S111)。つまり、情報処理装置10は、現在実行しようとしているステップS102の処理が第2回目以降の繰り返し処理であるか否かを判定する。2世代目以降である場合、情報処理装置10は、処理をステップS113に進める。一方、2世代目以降でない場合(第1世代である場合)、情報処理装置10は、処理をステップS112に進める。処理をステップS112に進めた場合、情報処理装置10は、基底関数をランダムに生成する(S112)。一方、処理をステップS113に進めた場合、情報処理装置10は、基底関数を進化的に生成する(S113)。そして、情報処理装置10は、ステップS112又はS113の処理が完了すると、ステップS102の処理を終了する。
【0041】
(S112:基底関数をランダムに生成)
次に、図6及び図7を参照しながら、ステップS112の処理について、より詳細に説明する。ステップS112の処理は、第1世代の基底関数を生成する処理に関する。
【0042】
まず、図6を参照する。図6に示すように、情報処理装置10は、基底関数のインデックスm(m=0〜M−1)に関する処理ループを開始する(S121)。次いで、情報処理装置10は、基底関数φm(x)をランダムに生成する(S122)。次いで、情報処理装置10は、基底関数のインデックスmがM−1に達したか否かを判定し、基底関数のインデックスmがM−1に達していない場合、情報処理装置10は、基底関数のインデックスmをインクリメントしてステップS121に処理を戻す(S124)。一方、基底関数のインデックスmがm=M−1の場合、情報処理装置10は、処理ループを終了する(S124)。ステップS124で処理ループを終了すると、情報処理装置10は、ステップS112の処理を完了する。
【0043】
(ステップS122の詳細)
次に、図7を参照しながら、ステップS122の処理について、より詳細に説明する。
【0044】
ステップS122の処理を開始すると、図7に示すように、情報処理装置10は、基底関数のプロトタイプをランダムに決定する(S131)。プロトタイプとしては、既に例示した処理関数の他、線形項、ガウシアンカーネル、シグモイドカーネルなどの処理関数が利用可能である。次いで、情報処理装置10は、決定したプロトタイプのパラメータをランダムに決定し、基底関数を生成する(S132)。
【0045】
(S113:基底関数を進化的に生成)
次に、図8〜図10を参照しながら、ステップS113の処理について、より詳細に説明する。ステップS113の処理は、第τ世代(τ≧2)の基底関数を生成する処理に関する。従って、ステップS113を実行する際には、第τ−1世代の基底関数φm,τ−1(m=1〜M)及び当該基底関数φm,τ−1の評価値vm,τ−1が得られている。
【0046】
まず、図8を参照する。図8に示すように、情報処理装置10は、基底関数の数Mを更新する(S141)。つまり、情報処理装置10は、第τ世代の基底関数の数Mτを決定する。次いで、情報処理装置10は、第τ−1世代の基底関数φm,τ−1(m=1〜M)に対する評価値vτ−1={v1,τ−1,…,vM,τ−1}に基づき、第τ−1世代の基底関数の中からe個の有用な基底関数を選択して第τ世代の基底関数φ1,τ、…、φe,τに設定する(S142)。
【0047】
次いで、情報処理装置10は、残り(Mτ−e)個の基底関数φe+1,τ、…、φMτ,τを生成する方法を交差、突然変異、ランダム生成の中からランダムに選択する(S143)。交差を選択した場合、情報処理装置10は、処理をステップS144に進める。また、突然変異を選択した場合、情報処理装置10は、処理をステップS145に進める。そして、ランダム生成を選択した場合、情報処理装置10は、処理をステップS146に進める。
【0048】
処理をステップS144に進めた場合、情報処理装置10は、ステップS142で選択された基底関数φ1,τ、…、φe,τの中から選択された基底関数を交差させて新たな基底関数φm’,τ(m’≧e+1)を生成する(S144)。また、処理をステップS145に進めた場合、情報処理装置10は、ステップS142で選択された基底関数φ1,τ、…、φe,τの中から選択された基底関数を突然変異させて新たな基底関数φm’,τ(m’≧e+1)を生成する(S145)。一方、処理をステップS146に進めた場合、情報処理装置10は、ランダムに新たな基底関数φm’,τ(m’≧e+1)を生成する(S146)。
【0049】
ステップS144、S145、S146のいずれかの処理を終えると、情報処理装置10は、処理をステップS147に進める。処理をステップS147に進めると、情報処理装置10は、第τ世代の基底関数がM個(M=Mτ)に達したか否かを判定する(S147)。第τ世代の基底関数がM個に達していない場合、情報処理装置10は、処理を再びステップS143に戻す。一方、第τ世代の基底関数がM個に達した場合、情報処理装置10は、ステップS113の処理を終了する。
【0050】
(S144の詳細:交差)
次に、図9を参照しながら、ステップS144の処理について、より詳細に説明する。
【0051】
ステップS144の処理を開始すると、図9に示すように、情報処理装置10は、ステップS142で選択された基底関数φ1,τ、…、φe,τの中から同じプロトタイプを持つ基底関数をランダムに2つ選択する(S151)。次いで、情報処理装置10は、選択した2つの基底関数が持つパラメータを交差させて新たな基底関数を生成する(S152)。
【0052】
(S145の詳細:突然変異)
次に、図10を参照しながら、ステップS145の処理について、より詳細に説明する。
【0053】
ステップS145の処理を開始すると、図10に示すように、情報処理装置10は、ステップS142で選択された基底関数φ1,τ、…、φe,τの中から基底関数をランダムに1つ選択する(S161)。次いで、情報処理装置10は、選択した基底関数が持つパラメータの一部をランダムに変更して新たな基底関数を生成する(S162)。
【0054】
(S146の詳細:ランダム生成)
次に、図7を参照しながら、ステップS146の処理について、より詳細に説明する。
【0055】
ステップS122の処理を開始すると、図7に示すように、情報処理装置10は、基底関数のプロトタイプをランダムに決定する(S131)。プロトタイプとしては、既に例示した処理関数の他、線形項、ガウシアンカーネル、シグモイドカーネルなどの処理関数が利用可能である。次いで、情報処理装置10は、決定したプロトタイプのパラメータをランダムに決定し、基底関数を生成する(S132)。
【0056】
以上、ステップS102の処理(基底関数の生成)について、より詳細に説明した。
【0057】
(基底関数の計算(S103))
次に、図11を参照しながら、ステップS103の処理(基底関数の計算)について、より詳細に説明する。
【0058】
図11に示すように、情報処理装置10は、学習用データに含まれるi番目のデータX(i)のインデックスiに関する処理ループを開始する(S171)。例えば、学習用データとしてN個のデータの組{X(1),…,X(N)}が入力された場合には、i=1〜Nに関して処理ループが実行される。次いで、情報処理装置10は、基底関数φmのインデックスmに関する処理ループを開始する(S172)。例えば、M個の基底関数を生成した場合には、m=1〜Mに関して処理ループが実行される。
【0059】
次いで、情報処理装置10は、特徴量zmi=φm(x(i))を計算する(S173)。次いで、情報処理装置10は、処理をステップS174に進め、基底関数のインデックスmに関する処理ループを続ける。そして、情報処理装置10は、基底関数のインデックスmに関する処理ループが終了すると、処理をステップS175に進め、インデックスiに関する処理ループを続ける。インデックスiに関する処理ループが終了した場合、情報処理装置10は、ステップS103の処理を終了する。
【0060】
以上、ステップS103の処理(基底関数の計算)について、より詳細に説明した。
【0061】
(基底関数の評価・推定関数の生成(S104))
次に、図12を参照しながら、ステップS104の処理(基底関数の評価・推定関数の生成)について、より詳細に説明する。
【0062】
図12に示すように、情報処理装置10は、AIC基準の増減法に基づく回帰/判別学習により推定関数のパラメータw={w0,…,wM}を算出する(S181)。つまり、情報処理装置10は、特徴量zmi=φm,τ(x(i))と目的変数t(i)の組(i=1〜N)が推定関数fによりフィッティングされるように、回帰/判別学習によりベクトルw={w0,…,wM}を求める。但し、推定関数f(x)は、f(x)=Σwmφm,τ(x)+w0であるとする。次いで、情報処理装置10は、パラメータwが0となる基底関数の評価値vを0に設定し、それ以外の基底関数の評価値vを1に設定する(S182)。つまり、評価値vが1の基底関数は有用な基底関数である。
【0063】
以上、ステップS104の処理(基底関数の評価・推定関数の生成)について、より詳細に説明した。
【0064】
推定機の構築に係る処理の流れは上記の通りである。このように、ステップS102〜S104の処理が繰り返し実行され、基底関数が進化的手法により逐次更新されることにより推定精度の高い推定関数が得られる。つまり、上記の方法を適用することで、高性能な推定機を自動構築することができる。
【0065】
[1−2:オンライン学習について]
さて、上記のように、機械学習により推定機を自動構築するアルゴリズムの場合、学習用データの数が多いほど、構築される推定機の性能が高くなる。そのため、可能な限り多くの学習用データを利用して推定機を構築するのが好ましい。また、後述する実施形態に係る技術においては、学習用データを追加する仕組みが利用される。そこで、学習用データを追加できるようにする新たな仕組み(以下、オンライン学習)について紹介する。
【0066】
オンライン学習に係る推定機の構築は、図13に示すような処理の流れに沿って行われる。図13に示すように、まず、学習用データの集合が情報処理装置10に入力される(Step 1)。次いで、情報処理装置10は、入力された学習用データの集合を利用し、既に説明した推定機の自動構築方法により推定機を構築する(Step 2)。
【0067】
次いで、情報処理装置10は、随時又は所定のタイミングで追加の学習用データを取得する(Step 3)。次いで、情報処理装置10は、(Step 1)で入力された学習用データの集合に、(Step 3)で取得した学習用データを統合する(Step 4)。このとき、情報処理装置10は、学習用データのサンプリング処理や重み付け処理を実行し、統合後の学習用データの集合を生成する。そして、情報処理装置10は、統合後の学習用データの集合を利用し、再び推定機を構築する(Step 2)。このとき、情報処理装置10は、既に説明した推定機の自動構築方法により推定機を構築する。
【0068】
また、(Step 2)〜(Step 4)の処理は繰り返し実行される。そして、学習用データは、処理が繰り返される度に更新される。例えば、繰り返しの度に学習用データが追加されるようにすれば、推定機の構築処理に利用される学習用データの数が増加するため、推定機の性能が向上する。なお、(Step 4)で実行される学習用データの統合処理においては、情報処理装置10のリソースをより有効に利用すべく、より有用な学習用データが推定機の構築に利用されるように統合の仕方を工夫する。以下、この工夫について紹介する。
【0069】
[1−3:学習用データの統合方法]
学習用データの統合方法について、より詳細に説明する。
【0070】
(1−3−1:特徴量空間における学習用データの分布と推定機の精度)
まず、図14を参照しながら、特徴量空間における学習用データの分布と推定機の精度との関係について考察する。図14は、特徴量空間における学習用データの分布例を示した説明図である。
【0071】
1つの特徴量ベクトルは、1つの学習用データを構成するデータを基底関数リストに含まれる各基底関数に入力することで得られる。つまり、1つの学習用データには1つの特徴量ベクトル(特徴量座標)が対応する。そのため、特徴量座標の分布を特徴量空間における学習用データの分布と呼ぶことにする。特徴量空間における学習用データの分布は、例えば、図14のようになる。なお、表現の都合上、図14の例では2次元の特徴量空間を考えているが、特徴量空間の次元数はこれに限定されない。
【0072】
さて、図14に例示した特徴量座標の分布を参照すると、第4象限に疎な領域が存在していることに気づくであろう。既に説明した通り、推定関数は、全ての学習用データについて特徴量ベクトルと目的変数との関係がうまく表現されるように回帰/判別学習により生成される。そのため、特徴量座標の密度が疎な領域について、推定関数は、特徴量ベクトルと目的変数との関係をうまく表現できていない可能性が高い。従って、認識処理の対象となる入力データに対応する特徴量座標が上記の疎な領域に位置する場合、高精度の認識結果を期待することは難しい。
【0073】
図15に示すように、学習データセットの数が多くなると疎な領域が生じにくくなり、どの領域に対応する入力データが入力されても高い精度で認識結果を出力することが可能な推定機を構築できるようになると期待される。また、学習データセットの数が比較的少なくても、特徴量座標が特徴量空間において満遍なく分布していれば、高い精度で認識結果を出力することが可能な推定機を構築できるものと期待される。そこで、本件発明者は、学習用データを統合する際に特徴量座標の分布を考慮し、統合後の学習用データの集合に対応する特徴量座標の分布が所定の分布(例えば、一様分布やガウス分布など)となるように調整する仕組みを考案した。
【0074】
(1−3−2:データ統合時にサンプリングする構成)
まず、図16を参照しながら、学習用データをサンプリングする方法について説明する。図16は、学習用データをサンプリングする方法について説明するための説明図である。
【0075】
既に説明したように、オンライン学習を適用する場合、逐次的に学習用データを追加できるため、多量の学習用データを用いて推定機を構築することが可能になる。しかし、情報処理装置10のメモリリソースが限られている場合、学習用データの統合時に、推定機の構築に利用する学習用データの数を絞り込む必要がある。このとき、ランダムに学習用データを間引くのではなく、特徴量座標の分布を考慮して学習用データを間引くことで、推定機の精度を低下させることなく、学習用データの数を絞り込むことができる。例えば、図16に示すように、密な領域に含まれる特徴量座標を多く間引き、疎な領域に含まれる特徴量座標を極力残すようにする。
【0076】
このような方法で学習用データを間引くことにより、統合後の学習用データの集合に対応する特徴量座標の密度が均一になる。つまり、学習用データの数は少なくなったが、特徴量空間の全体に満遍なく特徴量座標が分布しているため、推定関数の生成時に実行する回帰/判別学習の際に特徴量空間の全体が考慮されることになる。その結果、情報処理装置10のメモリリソースが限られていても、高い精度で正しい認識結果を推定することが可能な推定機を構築することが可能になる。
【0077】
(1−3−3:データ統合時に重み付けする構成)
次に、学習用データに重みを設定する方法について説明する。
【0078】
情報処理装置10のメモリリソースが限られている場合、学習用データの統合時に学習用データを間引く方法は有効である。一方、メモリリソースに余裕がある場合、学習用データを間引く代わりに、学習用データに重みを設定することで推定機の性能を向上させることが可能になる。例えば、疎な領域に特徴量座標が含まれる学習用データには大きな重みを設定し、密な領域に特徴量座標が含まれる学習用データには小さな重みを設定する。そして、推定関数の生成時に実行する回帰/判別学習の際に各学習用データに設定された重みを考慮するようにする。
【0079】
(1−3−4:データ統合時にサンプリング及び重み付けする構成)
また、学習用データをサンプリングする方法と、学習用データに重みを設定する方法とを組み合わせてもよい。例えば、特徴量座標の分布が所定の分布となるように学習用データを間引いた後、間引き後の学習用データの集合に属する学習用データに対し、特徴量座標の密度に応じた重みを設定する。このように、間引き処理と重み付け処理とを組み合わせることにより、メモリリソースが限られていても、より高精度の推定機を構築することが可能になる。
【0080】
[1−4:効率的なサンプリング/重み付け方法]
次に、学習用データの効率的なサンプリング/重み付け方法について説明する。
【0081】
(1−4−1:サンプリング方法)
まず、図17を参照しながら、学習用データの効率的なサンプリング方法について説明する。図17は、学習用データの効率的なサンプリング方法について説明するための説明図である。
【0082】
図17に示すように、情報処理装置10は、全ての学習用データについて特徴量ベクトル(特徴量座標)を算出する(S201)。次いで、情報処理装置10は、算出した特徴量座標を正規化する(S202)。例えば、情報処理装置10は、図18に示すように、各特徴量について、分散が1、平均が0となるように値を正規化する。
【0083】
次いで、情報処理装置10は、ランダムにハッシュ関数gを生成する(S203)。例えば、情報処理装置10は、下記の式(1)に示すような5ビットの値を出力するハッシュ関数gを複数生成する。このとき、情報処理装置10は、Q個のハッシュ関数gq(q=1〜Q)を生成する。但し、関数hj(j=1〜5)は、下記の式(2)により定義される。また、d及びThresholdは、乱数により決定される。
【0084】
但し、特徴量座標の分布を一様分布に近づける場合、Thresholdの決定に用いる乱数として一様乱数を用いる。また、特徴量座標の分布をガウス分布に近づける場合、Thresholdの決定に用いる乱数としてガウス乱数を用いる。他の分布についても同様である。また、dの決定は、zdの算出に用いた基底関数の寄与率に応じた偏りのある乱数を用いて行われる。例えば、zdの算出に用いた基底関数の寄与率が大きいほど、dの発生する確率が高くなる乱数が用いられる。
【0085】
【数1】

【0086】
ハッシュ関数gq(q=1〜Q)を生成すると、情報処理装置10は、各学習用データに対応する特徴量ベクトルZをハッシュ関数gqに入力し、ハッシュ値を算出する。そして、情報処理装置10は、算出したハッシュ値に基づいて学習用データをバケットに割り当てる(S204)。但し、ここで言うバケットとは、ハッシュ値として取り得る値が対応付けられた領域を意味する。
【0087】
例えば、ハッシュ値が5ビット、Q=256の場合について考えてみよう。この場合、バケットの構成は図19のようになる。図19に示すように、ハッシュ値が5ビットであるから、1つのハッシュ関数gqに対し、32個のバケット(以下、バケットセット)が設けられる。また、Q=256であるから、256組のバケットセットが設けられる。この例に沿って、学習用データをバケットに割り当てる方法について説明する。
【0088】
ある学習用データに対応する特徴量ベクトルZが与えられると、256個のハッシュ関数g1〜g256を用いて256個のハッシュ値が算出される。例えば、g1(Z)=2(10進数表示)であった場合、情報処理装置10は、その学習用データをg1に対応するバケットセットの中で2に対応するバケットに割り当てる。同様に、gq(Z)(q=2〜256)を算出し、各値に対応するバケットに学習用データを割り当てる。図19の例では、2種類の学習用データを白丸と黒丸とで表現し、各バケットとの対応関係を模式的に表現している。
【0089】
このようにして各学習用データをバケットに割り当てると、情報処理装置10は、所定の順序でバケットから学習用データを1つ選択する(S205)。例えば、情報処理装置10は、図20に示すように、左上(ハッシュ関数のインデックスqが小さく、バケットに割り当てられた値が小さい側)から順にバケットを走査し、バケットに割り当てられた学習用データを1つ選択する。
【0090】
バケットから学習用データを選択するルールは、図21に示した通りである。第1に、情報処理装置10は、空のバケットをスキップする。第2に、情報処理装置10は、1つの学習用データを選択した場合、同じ学習用データを他の全てのバケットから除く。第3に、情報処理装置10は、1つのバケットに複数の学習用データが割り当てられている場合にはランダムに1つの学習用データを選択する。なお、選択された学習用データの情報は、情報処理装置10により保持される。
【0091】
1つの学習用データを選択した後、情報処理装置10は、所定数の学習用データを選択し終えたか否かを判定する(S206)。所定数の学習用データを選択し終えた場合、情報処理装置10は、選択した所定数の学習用データを統合後の学習用データの集合として出力し、学習用データの統合に係る一連の処理を終了する。一方、所定数の学習用データを選択し終えていない場合、情報処理装置10は、処理をステップS205に進める。
【0092】
以上、学習用データの効率的なサンプリング方法について説明した。なお、特徴量空間と上記のバケットとの対応関係は図22に示したイメージ図のようになる。また、上記の方法により学習用データのサンプリングを行った結果は、例えば、図23(一様分布の例)のようになる。図23を参照すると、疎な領域に含まれる特徴量座標は残り、密な領域に含まれる特徴量座標が間引かれていることが分かる。なお、上記のバケットを利用しない場合、学習用データのサンプリングに要する演算負荷は格段に大きくなる点に注意されたい。
【0093】
(1−4−2:重み付け方法)
次に、図24を参照しながら、学習用データの効率的な重み付け方法について説明する。図24は、学習用データの効率的な重み付け方法について説明するための説明図である。
【0094】
図24に示すように、情報処理装置10は、全ての学習用データについて特徴量ベクトル(特徴量座標)を算出する(S211)。次いで、情報処理装置10は、算出した特徴量座標を正規化する(S212)。例えば、情報処理装置10は、図24に示すように、各特徴量について、分散が1、平均が0となるように値を正規化する。
【0095】
次いで、情報処理装置10は、ランダムにハッシュ関数gを生成する(S213)。例えば、情報処理装置10は、上記の式(1)に示すような5ビットの値を出力するハッシュ関数gを複数生成する。このとき、情報処理装置10は、Q個のハッシュ関数gq(q=1〜Q)を生成する。但し、関数hj(j=1〜5)は、上記の式(2)により定義される。また、d及びThresholdは、乱数により決定される。
【0096】
但し、特徴量座標の分布を一様分布に近づける場合、Thresholdの決定に用いる乱数として一様乱数を用いる。また、特徴量座標の分布をガウス分布に近づける場合、Thresholdの決定に用いる乱数としてガウス乱数を用いる。他の分布についても同様である。また、dの決定は、zdの算出に用いた基底関数の寄与率に応じた偏りのある乱数を用いて行われる。例えば、zdの算出に用いた基底関数の寄与率が大きいほど、dの発生する確率が高くなる乱数が用いられる。
【0097】
ハッシュ関数gq(q=1〜Q)を生成すると、情報処理装置10は、各学習用データに対応する特徴量ベクトルZをハッシュ関数gqに入力し、ハッシュ値を算出する。そして、情報処理装置10は、算出したハッシュ値に基づいて学習用データをバケットに割り当てる(S214)。次いで、情報処理装置10は、各学習用データについて密度を算出する(S215)。例えば、図25に示すように、学習データセットがバケットに割り当てられているものとしよう。また、白丸で表現された学習用データに注目する。
【0098】
この場合、情報処理装置10は、まず、各ハッシュ関数に対応するバケットセットについて、白丸を含むバケットに割り当てられている学習用データの数をカウントする。例えば、ハッシュ関数g1に対応するバケットセットを参照すると、白丸を含むバケットに割り当てられている学習用データの数は1である。同様に、ハッシュ関数g2に対応するバケットセットを参照すると、白丸を含むバケットに割り当てられている学習用データの数は2である。情報処理装置10は、ハッシュ関数g1〜g256に対応するバケットセットについて、白丸を含むバケットに割り当てられている学習用データの数をカウントする。
【0099】
そして、情報処理装置10は、カウントした数の平均値を算出し、算出した平均値を白丸に対応する学習用データの密度とみなす。同様にして、情報処理装置10は、全ての学習用データの密度を算出する。なお、各学習用データの密度は図26のB図のように表現される。但し、色が濃い部分の密度が高く、色が薄い部分の密度が低い。
【0100】
さて、全ての学習用データについて密度を算出し終えると、情報処理装置10は、処理をステップS217に進める(S216)。ステップS217に処理を進めた場合、情報処理装置10は、算出した密度から各学習用データに設定する重みを算出する(S217)。例えば、情報処理装置10は、密度の逆数を重みに設定する。なお、各学習用データに設定される重みの分布は図27のB図のように表現される。但し、色が濃い部分の重みが大きく、色が薄い部分の重みが小さい。図27を参照すると、密な領域の重みが小さく、疎な領域の重みが大きくなっていることが分かるであろう。
【0101】
上記のようにして各学習用データに設定する重みを算出し終えると、情報処理装置10は、重み付けに係る一連の処理を終了する。以上、学習用データの効率的な重み付け方法について説明した。なお、上記のバケットを利用しない場合、学習用データの重み付けに要する演算負荷は格段に大きくなる点に注意されたい。
【0102】
(1−4−3:組み合わせ方法)
次に、図28を参照しながら、上記の効率的なサンプリング方法と効率的な重み付け方法とを組み合わせる方法について説明する。図28は、上記の効率的なサンプリング方法と効率的な重み付け方法とを組み合わせる方法について説明するための説明図である。
【0103】
図28に示すように、情報処理装置10は、まず、学習用データのサンプリング処理を実行する(S221)。このサンプリング処理は、図17に示した処理の流れに沿って実行される。そして、所定数の学習用データが得られると、情報処理装置10は、得られた学習用データを対象に重み付け処理を実行する(S222)。この重み付け処理は、図24に示した処理の流れに沿って実行される。なお、サンプリング処理の際に算出した特徴量ベクトルやハッシュ関数を流用してもよい。サンプリング処理及び重み付け処理を実行し終えると、情報処理装置10は、一連の処理を終了する。
【0104】
以上、学習用データの効率的なサンプリング/重み付け方法について説明した。
【0105】
[1−5:サンプリング処理及び重み付け処理に関する変形例]
次に、サンプリング処理及び重み付け処理に関する変形例を紹介する。
【0106】
(1−5−1:変形例1(距離に基づく処理))
まず、図29を参照しながら、特徴量座標間の距離に基づく学習用データのサンプリング方法について説明する。図29は、特徴量座標間の距離に基づく学習用データのサンプリング方法について説明するための説明図である。
【0107】
図29に示すように、情報処理装置10は、まず、ランダムに1つの特徴量座標を選択する(S231)。次いで、情報処理装置10は、インデックスjを1に初期化する(S232)。次いで、情報処理装置10は、未だ選択されてないJ個の特徴量座標の中からj番目の特徴量座標を対象座標に設定する(S233)。次いで、情報処理装置10は、既に選択された全ての特徴量座標と対象座標との距離Dを算出する(S234)。次いで、情報処理装置10は、算出した距離Dの最小値Dminを抽出する(S235)。
【0108】
次いで、情報処理装置10は、j=Jであるか否かを判定する(S236)。j=Jである場合、情報処理装置10は、処理をステップS237に進める。一方、j≠Jである場合、情報処理装置10は、処理をステップS233に進める。処理をステップS237に進めた場合、情報処理装置10は、最小値Dminが最大となる対象座標(特徴量座標)を選択する(S237)。次いで、情報処理装置10は、ステップS231及びS237において選択された特徴量座標の数が所定数に達したか否かを判定する(S238)。
【0109】
ステップS231及びS237において選択された特徴量座標の数が所定数に達した場合、情報処理装置10は、選択された特徴量座標に対応する学習用データを統合後の学習用データの集合として出力し、一連の処理を終了する。一方、ステップS231及びS237において選択された特徴量座標の数が所定数に達していない場合、情報処理装置10は、処理をステップS232に進める。
【0110】
以上、特徴量座標間の距離に基づく学習用データのサンプリング方法について説明した。
【0111】
(1−5−2:変形例2(クラスタリングに基づく処理))
次に、クラスタリングに基づく学習用データのサンプリング/重み付け方法について説明する。なお、以下ではサンプリング方法及び重み付け方法についてそれぞれ別々に説明するが、これらの方法を組み合わせてもよい。
【0112】
(データセットの選択)
まず、図30を参照しながら、クラスタリングに基づく学習用データのサンプリング方法について説明する。図30は、クラスタリングに基づく学習用データのサンプリング方法について説明するための説明図である。
【0113】
図30に示すように、まず、情報処理装置10は、特徴量ベクトルを所定数のクラスタに分類する(S241)。クラスタリング手法としては、例えば、k−means法や階層的クラスタリングなどの手法が利用可能である。次いで、情報処理装置10は、各クラスタから順に1つずつ特徴量ベクトルを選択する(S242)。そして、情報処理装置10は、選択した特徴量ベクトルに対応する学習用データを統合後の学習用データの集合として出力し、一連の処理を終了する。
【0114】
(重みの設定)
次に、図31を参照しながら、クラスタリングに基づく学習用データの重み付け方法について説明する。図31は、クラスタリングに基づく学習用データの重み付け方法について説明するための説明図である。
【0115】
図31に示すように、まず、情報処理装置10は、特徴量ベクトルを所定数のクラスタに分類する(S251)。クラスタリング手法としては、例えば、k−means法や階層的クラスタリングなどの手法が利用可能である。次いで、情報処理装置10は、各クラスタの要素数をカウントし、要素数の逆数を算出する(S252)。そして、情報処理装置10は、算出した要素数の逆数を重みとして出力し、一連の処理を終了する。
【0116】
以上、クラスタリングに基づく学習用データのサンプリング/重み付け方法について説明した。
【0117】
(1−5−3:変形例3(密度推定手法に基づく処理))
次に、密度推定手法に基づく学習用データのサンプリング/重み付け方法について説明する。なお、以下ではサンプリング方法及び重み付け方法についてそれぞれ別々に説明するが、これらの方法を組み合わせてもよい。
【0118】
(データセットの選択)
まず、図32を参照しながら、密度推定手法に基づく学習用データのサンプリング方法について説明する。図32は、密度推定手法に基づく学習用データのサンプリング方法について説明するための説明図である。
【0119】
図32に示すように、まず、情報処理装置10は、特徴量座標の密度をモデル化する(S261)。密度のモデル化には、例えば、GMM(Gaussian Mixture Model)などの密度推定手法が利用される。次いで、情報処理装置10は、構築したモデルに基づいて各特徴量座標の密度を算出する(S262)。次いで、情報処理装置10は、未だ選択されていない特徴量座標の中から、密度の逆数に比例する確率でランダムに特徴量座標を選択する(S263)。
【0120】
次いで、情報処理装置10は、所定数の特徴量座標を選択したか否かを判定する(S264)。所定数の特徴量座標を選択していない場合、情報処理装置10は、処理をステップS263に進める。一方、所定数の特徴量座標を選択した場合、情報処理装置10は、選択した特徴量座標に対応する学習用データを統合後の学習用データの集合として出力し、一連の処理を終了する。
【0121】
(重みの設定)
次に、図33を参照しながら、密度推定手法に基づく学習用データの重み付け方法について説明する。図33は、密度推定手法に基づく学習用データの重み付け方法について説明するための説明図である。
【0122】
図33に示すように、まず、情報処理装置10は、特徴量座標の密度をモデル化する(S271)。密度のモデル化には、例えば、GMMなどの密度推定手法が利用される。次いで、情報処理装置10は、構築したモデルに基づいて各特徴量座標の密度を算出する(S272)。そして、情報処理装置10は、算出した密度の逆数を重みに設定し、一連の処理を終了する。
【0123】
以上、密度推定手法に基づく学習用データのサンプリング/重み付け方法について説明した。
【0124】
以上、後述する実施形態において利用可能な基盤技術について説明した。但し、後述する実施形態に係る技術は、ここで説明した基盤技術の全てを利用しなくてもよいし、当該基盤技術を変形して利用したり、或いは、他の機械学習アルゴリズムを組み合わせて利用したりしてもよい点に注意されたい。
【0125】
<2:実施形態>
以下、本技術の一実施形態について説明する。
【0126】
[2−1:思考ルーチンの自動構築方法]
本実施形態は、ロボットのようなエージェントの思考ルーチンや様々なゲームに登場するNPC(Non−Player Character)の思考ルーチンを自動構築する技術に関する。例えば、本実施形態は、ある状態SにおかれたNPCが次にとる行動aを決定する思考ルーチンを自動構築する技術に関する。本稿においては、状態Sの入力に応じて行動aを出力するプログラムを思考ルーチンと呼ぶことにする。また、以下では、NPCの行動aを決定する思考ルーチンを例に挙げて説明を進めることにする。もちろん、ロボットなどの行動を決定する思考ルーチンも同様に自動構築することが可能である。
【0127】
(2−1−1:思考ルーチンとは)
上記の通り、本稿に言う思考ルーチンは、図34に示すように、状態Sの入力に応じて行動aを出力するプログラムである。なお、状態Sとは、ある瞬間に、行動aを決定すべきNPCがおかれた環境を意味する。例えば、図34に示すように、2つのNPC(NPC#1及び#2)が対戦する対戦ゲームについて考えてみよう。この対戦ゲームは、NPC#1及び#2がそれぞれヒットポイントを有しており、ダメージを受けるとヒットポイントが減少していく仕組みになっているものとする。この例において、ある瞬間における状態Sは、NPC#1及び#2のヒットポイント及び位置関係になる。
【0128】
この状態Sが入力されると、思考ルーチンは、NPC#1がNPC#2にダメージを与え、最終的にNPC#2のヒットポイントを0にできることが期待されるNPC#1の行動aを決定する。例えば、NPC#1のヒットポイントが十分に残っており、NPC#2のヒットポイントが僅かである場合、思考ルーチンは、NPC#1が多少のダメージを受けることを許容してNPC#2に素早くダメージを与える行動aを決定するかもしれない。また、NPC#1のヒットポイントが残り僅かであり、NPC#2のヒットポイントが十分に残っている場合、思考ルーチンは、NPC#1がダメージを受けないようにしつつ、NPC#2にダメージを与える行動aを決定するだろう。
【0129】
これまで、NPCの行動を決定する思考ルーチンは、熟練した技術者により長い時間をかけて設計されていた。もちろん、NPCの行動をランダムに決定する思考ルーチンも存在するであろう。しかし、賢いNPCの行動を実現することが可能な思考ルーチンを構築するには、ユーザ操作の分析や環境に応じた最適な行動の研究が欠かせなかった。さらに、こうした分析や研究の結果を踏まえて、環境に応じたNPCの最適な行動を決定するための条件設計を行う必要があった。そのため、思考ルーチンの構築には長い時間と大きな労力とが必要であった。こうした事情を踏まえ、本件発明者は、このような思考ルーチンを人手に依らずに自動構築する技術を開発した。
【0130】
(2−1−2:思考ルーチンの構成)
図35に示すように、本実施形態に係る思考ルーチンは、行動履歴データに基づく思考ルーチンの自動構築技術により生成される。この行動履歴データは、状態S、行動a、報酬rにより構成される。例えば、状態S=S1において、NPC#1が行動a=“右へ移動”をとった場合にNPC#2からダメージを受けてヒットポイントが0になったとしよう。この場合、行動履歴データは、状態S=S1、行動a=“右へ移動”、報酬r=“0”となる。このような構成を有する行動履歴データを予め蓄積しておき、この行動履歴データを学習データとする機械学習により思考ルーチンを自動構築することができる。
【0131】
本実施形態に係る思考ルーチンは、図36に示すような構成を有する。図36に示すように、この思考ルーチンは、状態Sの入力に応じてNPCがとりうる行動aをリストアップし、各行動aについてNPCが得るであろう報酬rの推定値(以下、推定報酬y)を算出する。そして、思考ルーチンは、推定報酬yが最も高い行動aを選択する。なお、推定報酬yは、報酬推定機を利用して算出される。この推定報酬機は、状態S及び行動aの入力に応じて推定報酬yを出力するアルゴリズムである。また、この報酬推定機は、行動履歴データを学習データとする機械学習により自動構築される。例えば、先に紹介した推定機の自動構築方法を応用することにより、報酬推定機を自動構築することができる。
【0132】
報酬推定機は、図37に示すように、基底関数リスト(φ1,…,φM)及び推定関数fにより構成される。基底関数リスト(φ1,…,φM)は、M個の基底関数φk(k=1〜M)を含む。また、基底関数φkは、入力データX(状態S及び行動a)の入力に応じて特徴量zkを出力する関数である。さらに、推定関数fは、M個の特徴量zk(k=1〜M)を要素として含む特徴量ベクトルZ=(z1,…,zM)の入力に応じて推定報酬yを出力する関数である。基底関数φkは、予め用意された1又は複数の処理関数を組み合わせて生成される。処理関数としては、例えば、三角関数、指数関数、四則演算、デジタルフィルタ、微分演算、中央値フィルタ、正規化演算などが利用可能である。
【0133】
また、本実施形態に係る思考ルーチンの自動構築技術は、自動構築された思考ルーチンを利用してNPCを行動させ、その行動の結果として得られた行動履歴データを追加した行動履歴データを利用して思考ルーチンを更新する。但し、行動履歴データの追加には、先に紹介したオンライン学習に係る技術を利用することができる。
【0134】
(2−1−3:報酬推定機の構築方法)
例えば、オンライン学習に係る技術を利用した報酬推定機の構築及び更新は、図38に示すような処理の流れに沿って行われる。なお、これらの処理は、情報処理装置10により実行されるものとする。図38に示すように、まず、行動履歴データが情報処理装置10に入力される(Step 1)。
【0135】
(Step 1)において、情報処理装置10は、予め設計された簡易な思考ルーチンを用いて行動aを決定しながらNPCを環境中で振る舞わせ、行動履歴データ(S,a,r)を得る。この簡易な思考ルーチンは、強化学習の分野においてInnate(赤ちゃんが行う本能的な動きに相当)と呼ばれる。このInnateは、NPCが取り得るアクションの中からランダムに行動を選択するものであってもよい。この場合、Innateの設計も不要になる。情報処理装置10は、所定数の行動履歴データが得られるまでInnateに基づくNPCの行動を繰り返し実行する。次いで、情報処理装置10は、入力された行動履歴データを利用し、既に説明した推定機の自動構築方法と同様にして報酬推定機を構築する(Step 2)。
【0136】
次いで、情報処理装置10は、随時又は所定のタイミングで追加の行動履歴データを取得する(Step 3)。次いで、情報処理装置10は、(Step 1)で入力された行動履歴データと、(Step 3)で取得した行動履歴データとを統合する(Step 4)。このとき、情報処理装置10は、行動履歴データのサンプリング処理や重み付け処理を実行し、統合後の行動履歴データを生成する。そして、情報処理装置10は、統合後の行動履歴データを利用し、再び報酬推定機を構築する(Step 2)。また、(Step 2)〜(Step 4)の処理は繰り返し実行される。そして、行動履歴データは、処理が繰り返される度に更新される。
【0137】
以上、思考ルーチンの自動構築方法について簡単に説明した。ここではNPCの行動を決定する思考ルーチンの自動構築方法について述べたが、行動履歴データの構成を変えることで様々な種類の思考ルーチンを同じように自動構築することができる。つまり、本実施形態の技術を適用することにより、統一的な仕組みで様々な思考ルーチンを構築できるようになる。また、自動的に思考ルーチンが構築されるため、思考ルーチンの構築に人が時間を費やさずに済み、労力が大幅に軽減される。
【0138】
[2−2:情報処理装置10の構成]
ここで、図39及び図40を参照しながら、本実施形態に係る情報処理装置10の機能構成について説明する。図39は、本実施形態に係る情報処理装置10の全体的な機能構成を示した説明図である。一方、図40は、本実施形態に係る情報処理装置10を構成する報酬推定機構築部12の詳細な機能構成を示した説明図である。
【0139】
(全体的な機能構成)
まず、図39を参照しながら、全体的な機能構成について説明する。図39に示すように、情報処理装置10は、主に、行動履歴データ取得部11と、報酬推定機構築部12と、入力データ取得部13と、行動選択部14とにより構成される。
【0140】
思考ルーチンの構築処理が開始されると、行動履歴データ取得部11は、報酬推定機の構築に利用する行動履歴データを取得する。例えば、行動履歴データ取得部11は、簡易な思考ルーチン(Innate)に基づいて繰り返しNPCを行動させ、所定数の行動履歴データを取得する。但し、行動履歴データ取得部11は、記憶装置(非図示)に予め格納された行動履歴データを読み出したり、或いは、行動履歴データを提供するシステムなどからネットワークを介して行動履歴データを取得したりしてもよい。
【0141】
行動履歴データ取得部11により取得された行動履歴データは、報酬推定機構築部12に入力される。行動履歴データが入力されると、報酬推定機構築部12は、入力された行動履歴データに基づく機械学習により報酬推定機を構築する。例えば、報酬推定機構築部12は、既に説明した遺伝アルゴリズムに基づく推定機の自動構築方法を利用して報酬推定機を構築する。また、行動履歴データ取得部11から追加の行動履歴データが入力された場合、報酬推定機構築部12は、行動履歴データを統合し、統合後の行動履歴データを利用して報酬推定機を構築する。
【0142】
報酬推定機構築部12により構築された報酬推定機は、行動選択部14に入力される。この報酬推定機は、任意の入力データ(状態S)に対して最適な行動を選択するために利用される。入力データ取得部13により入力データ(状態S)が取得されると、取得された入力データは、行動選択部14に入力される。入力データが入力されると、行動選択部14は、入力された入力データが示す状態S及び状態SにおいてNPCがとりうる行動aを報酬推定機に入力し、報酬推定機から出力される推定報酬yに基づいて行動aを選択する。例えば、図36に示すように、行動選択部14は、推定報酬yが最も高くなる行動aを選択する。
【0143】
以上、情報処理装置10の全体的な機能構成について説明した。
【0144】
(報酬推定機構築部12の機能構成)
次に、図40を参照しながら、報酬推定機構築部12の機能構成について詳細に説明する。図40に示すように、報酬推定機構築部12は、基底関数リスト生成部121と、特徴量計算部122と、推定関数生成部123と、行動履歴データ統合部124とにより構成される。
【0145】
思考ルーチンの構築処理が開始されると、まず、基底関数リスト生成部121は、基底関数リストを生成する。そして、基底関数リスト生成部121により生成された基底関数リストは、特徴量計算部122に入力される。また、特徴量計算部122には、行動履歴データが入力される。基底関数リスト及び行動履歴データが入力されると、特徴量計算部122は、入力された行動履歴データを基底関数リストに含まれる各基底関数に入力して特徴量を算出する。特徴量計算部122により算出された特徴量の組(特徴量ベクトル)は、推定関数生成部123に入力される。
【0146】
特徴量ベクトルが入力されると、推定関数生成部123は、入力された特徴量ベクトル及び行動履歴データを構成する報酬値rに基づいて回帰/判別学習により推定関数を生成する。なお、遺伝アルゴリズムに基づく推定機の構築方法を適用する場合、推定関数生成部123は、生成した推定関数に対する各基底関数の寄与率(評価値)を算出し、その寄与率に基づいて終了条件を満たすか否かを判定する。終了条件を満たす場合、推定関数生成部123は、基底関数リスト及び推定関数を含む報酬推定機を出力する。
【0147】
一方、終了条件を満たさない場合、推定関数生成部123は、生成した推定関数に対する各基底関数の寄与率を基底関数リスト生成部121に通知する。この通知を受けた基底関数リスト生成部121は、遺伝アルゴリズムにより各基底関数の寄与率に基づいて基底関数リストを更新する。基底関数リストを更新した場合、基底関数リスト生成部121は、更新後の基底関数リストを特徴量計算部122に入力する。更新後の基底関数リストが入力された場合、特徴量計算部122は、更新後の基底関数リストを用いて特徴量ベクトルを算出する。そして、特徴量計算部122により算出された特徴量ベクトルは、推定関数生成部123に入力される。
【0148】
上記のように、遺伝アルゴリズムに基づく推定機の構築方法を適用する場合、終了条件が満たされるまで、推定関数生成部123による推定関数の生成処理、基底関数リスト生成部121による基底関数リストの更新処理、及び特徴量計算部122による特徴量ベクトルの算出処理が繰り返し実行される。そして、終了条件が満たされた場合、推定関数生成部123から報酬推定機が出力される。
【0149】
また、追加の行動履歴データが入力されると、入力された追加の行動履歴データは、特徴量計算部122及び行動履歴データ統合部124に入力される。追加の行動履歴データが入力されると、特徴量計算部122は、追加の行動履歴データを基底関数リストに含まれる各基底関数に入力して特徴量を生成する。そして、追加の行動履歴データに対応する特徴量ベクトル及び既存の行動履歴データに対応する特徴量ベクトルは、行動履歴データ統合部124に入力される。なお、行動履歴データ統合部124には、既存の行動履歴データも入力されているものとする。
【0150】
行動履歴データ統合部124は、先に紹介したデータセットの統合方法を応用して既存の行動履歴データと追加の行動履歴データとを統合する。例えば、行動履歴データ統合部124は、特徴量空間において特徴量ベクトルにより示される座標(特徴量座標)の分布が所定の分布となるように行動履歴データを間引いたり、行動履歴データに重みを設定したりする。行動履歴データを間引いた場合、間引き後の行動履歴データが統合後の行動履歴データとして利用される。一方、行動履歴データに重みを設定した場合、推定関数生成部123による回帰/判別学習の際に各行動履歴データに設定された重みが考慮される。
【0151】
行動履歴データが統合されると、統合後の行動履歴データを用いて報酬推定機の自動構築処理が実行される。具体的には、行動履歴データ統合部124から推定関数生成部123に統合後の行動履歴データと、統合後の行動履歴データに対応する特徴量ベクトルとが入力され、推定関数生成部123により推定関数が生成される。また、遺伝アルゴリズムに基づく推定機の構築方法を適用する場合、統合後の行動履歴データを利用して推定関数の生成、寄与率の算出、基底関数リストの更新などの処理が実行される。
【0152】
以上、報酬推定機構築部12の詳細な機能構成について説明した。
【0153】
以上、本実施形態に係る情報処理装置10の構成について説明した。上記の構成を適用することにより、任意の状態SからNPCがとるべき次の行動aを決定する思考ルーチンを自動構築することができる。また、この思考ルーチンを利用して賢くNPCを行動させることが可能になる。なお、利用する行動履歴データを変えることで、ロボットなどのエージェントについても同様に賢く行動させることが可能になる。
【0154】
[2−3:効率的な推定報酬機の構築方法]
これまで、先に紹介した推定機の自動構築方法に基づく思考ルーチンの自動構築方法について説明してきた。確かに、この方法を適用すると、思考ルーチンを自動構築することが可能になる。しかし、賢く行動するNPCの思考ルーチンを自動構築するには、ある程度長い時間をかけて学習処理を繰り返し実行する必要がある。そこで、本件発明者は、より効率良く高性能な推定報酬機を構築する方法を考案した。
【0155】
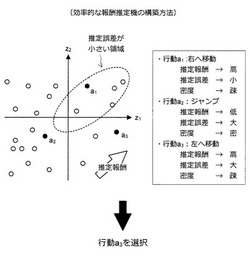
以下、図41及び図42を参照しながら、効率的な推定報酬機の構築方法について説明する。この方法は、より学習効率の高い行動履歴データを取得する方法に関する。より学習効率の高い行動履歴データとは、より推定報酬が高く、より推定誤差が大きく、かつ、特徴量空間における密度が疎な領域にある特徴量座標に対応するデータである。そこで、図42に示す3つのスコアを導入する。1つ目は、推定報酬が高いほど大きな値となる報酬スコアである。2つ目は、特徴量空間における密度が疎であるほど大きな値となる未知スコアである。3つ目は、推定誤差が大きいほど大きな値となる誤差スコアである。
【0156】
例えば、図41に示した行動a1、a2、a3に注目しよう。仮に、鎖線で囲まれた領域は、推定誤差の小さい領域であるとする。また、図の右上方向に向かうにつれて推定報酬が高くなっているとする。この場合、行動a1は、報酬スコアが比較的高く、未知スコアが比較的高く、誤差スコアが比較的低い行動であると言える。また、行動a2は、報酬スコアが比較的低く、未知スコアが比較的低く、誤差スコアが比較的高い行動であると言える。そして、行動a3は、報酬スコアが比較的高く、未知スコアが比較的高く、誤差スコアが比較的高い行動であると言える。
【0157】
より報酬スコアの高い行動を優先的に選択することにより、高い報酬を実現するために必要な行動履歴データを収集することができる。また、より未知スコアが高いか、より誤差スコアが高い行動を優先的に選択することにより、その行動を選択した結果が不定であるような行動履歴データを収集することができる。例えば、図41の例では、行動a3を選択することにより、より高い報酬を得られることが期待され、かつ、その行動を選択した結果が不定であるような行動履歴データを収集できると考えられる。図38に示した処理のうち、(Step 1)及び/又は(Step 3)において上記の方法による行動履歴データの取得を行うことで、(Step 2)における報酬推定機の構築をより効率的に実現することが可能になる。
【0158】
以上、効率的な推定報酬機の構築方法について説明した。
【0159】
[2−4:(変形例1)アクションスコア推定機を用いる思考ルーチン]
さて、これまでは報酬推定機を用いて報酬を推定し、推定した報酬に基づいて行動を選択する思考ルーチンについて考えてきた。ここでは、図44に示すように、アクションスコア推定機を用いてアクションスコアを推定し、推定したアクションスコアに基づいて行動を選択する思考ルーチンについて考えてみたい。ここで言うアクションスコアとは、とりうる各行動に対応付けられたスコアであり、対応する行動をとることで好ましい結果が得られる確率の高さを表す。
【0160】
アクションスコアを利用する場合、行動履歴データは、図43に示すような形で与えられる。まず、情報処理装置10は、これまで説明してきた行動履歴データと同様にして状態S、行動a、報酬rの組を収集する。その後、情報処理装置10は、報酬rに基づいてアクションスコアを算出する。
【0161】
例えば、状態S=S1において行動a=“R(右へ移動)”をとった場合に報酬r=“0”が得られたものとしよう。この場合、行動a=“R”に対応するアクションスコアは“0”となり、それ以外の行動(“L”“N”“J”)に対応するアクションスコアは“1”となる。その結果、状態S=S1及び行動a=“R”に対応するアクションスコア(R,L,N,J)=(0,1,1,1)が得られる。
【0162】
また、状態S=S2において行動a=“L(左へ移動)”をとった場合に報酬r=“1”が得られたものとしよう。この場合、行動a=“L”に対応するアクションスコアは“1”となり、それ以外の行動(“R”“N”“J”)に対応するアクションスコアは“0”となる。その結果、状態S=S2及び行動a=“L”に対応するアクションスコア(R,L,N,J)=(0,1,0,0)が得られる。
【0163】
上記のようにして得られた状態S、行動a、アクションスコアの組を行動履歴データとして利用すると、機械学習により、状態Sの入力に応じてアクションスコアの推定値を算出するアクションスコア推定機が得られる。例えば、遺伝アルゴリズムに基づく推定機の自動構築方法を適用すれば、高性能なアクションスコア推定機を自動構築することができる。また、行動履歴データを収集する際に、効率的な報酬推定機の構築方法と同様の方法を用いれば、効率的にアクションスコア推定機を自動構築することができる。
【0164】
アクションスコア推定機を用いる場合、思考ルーチンの構成は図44のようになる。つまり、状態Sを思考ルーチンに入力すると、思考ルーチンは、アクションスコア推定機に状態Sを入力し、アクションスコアの推定値を算出する。そして、思考ルーチンは、アクションスコアの推定値が最も高い行動を選択する。例えば、図44に示すように、アクションスコアの推定値が(R,L,J,N)=(0.6,0.3,0.4,0.2)であった場合、思考ルーチンは、推定値“0.6”に対応する行動“R”を選択する。
【0165】
以上、アクションスコア推定機を用いる思考ルーチンについて説明した。
【0166】
[2−5:(変形例2)予測機を用いた報酬の推定]
次に、予測機を用いた報酬の推定方法について説明する。なお、ここで言う予測機とは、ある時刻t1における状態S(t1)及び状態S(t1)においてNPCがとった行動a(t1)を入力した場合に、次の時刻t2における状態S(t2)を出力するアルゴリズムのことを意味する。
【0167】
(2−5−1:予測機の構築方法)
上記の予測機は、図45に示すような方法で構築される。図45に示すように、時刻毎に取得された行動履歴データが学習データとして利用される。例えば、時刻t2において状態S2にあるNPCが何もしなかった場合に好ましい結果が得られた場合、行動履歴データは、時刻t=t2、状態S=S2、行動a=“何もせず”、報酬r=“1”となる。なお、予測機の自動構築方法については、特願2009−277084号明細書に詳しく記載されている。同明細書には、ある時点までの観測値から将来の時点における観測値を予測する予測機を機械学習により自動構築する方法が記載されている。
【0168】
(2−5−2:報酬の推定方法)
上記の予測機を利用すると、図46に示すように、将来得るであろう報酬を推定することが可能になる。例えば、時刻tにおいて状態S(t)にあるNPCが行動a(t)をとった場合に時刻t+1において実現される状態S(t+1)を予測し、その状態S(t+1)においてNPCがとりうる行動毎に推定報酬yを算出することができるようになる。そのため、時刻t+1において推定される報酬に基づいて時刻tにおいてNPCがとるべき行動を選択することができるようになる。また、図47に示すように、予測機を繰り返し用いて数ステップ先の状態S(t+q)から推定される推定報酬yを算出することもできる。この場合、各時刻においてNPCがとりうる行動の組み合わせを考慮し、最終的に最も高い推定報酬が得られる行動の組み合わせを選択することができるようになる。
【0169】
以上、予測機を用いた報酬の推定方法について説明した。
【0170】
[2−6:(変形例3)複数エージェントの同時学習]
さて、これまでは1つのNPCに注目して最適な行動を選択する思考ルーチンの構築方法について考えてきた。しかし、2つ以上のNPCがとる行動を同時に考慮して思考ルーチンを構築することも可能である。2つのNPCが同じ環境中で行動する場合、両NPCがとる行動は状態Sに反映される。そのため、この方法を適用すると、他のNPCが最も高い推定報酬を見込める行動を選択して行動する環境中において、自身のNPCが最も高い推定報酬を見込める行動を選択するような思考ルーチンを自動構築することができる。例えば、MinMax法などを用いることにより、このような思考ルーチンの自動構築が実現される。以上、複数エージェントの同時学習について説明した。
【0171】
以上、本技術の一実施形態について説明した。
【0172】
<3:応用例>
次に、本実施形態の技術を具体的に応用する方法について紹介する。
【0173】
[3−1:「三目並べ」への応用]
まず、図48〜図54を参照しながら、本実施形態に係る技術を「三目並べ」へ応用する方法について説明する。図48に示すように、「三目並べ」の主なルールは、(1)交互に手を打つ、(2)先に3つのマークが1列に並んだ方が勝ち、の2点である。また、「三目並べ」において、状態Sは盤面であり、行動aは各プレーヤが打つ手である。
【0174】
「三目並べ」は、互いに最適な手を打つと必ず引き分けになることが知られている。このような完全情報ゲームに用いられる思考ルーチンの多くは、静的評価関数と先読みアルゴリズムとにより構成されている。この静的評価関数は、ある局面の有利/不利を数値化する関数である。例えば、図49に示すような局面が与えられた場合、静的評価関数は、その局面の有利/不利を表す数値y(“○不利”:−1、“どちらでもない”:0、“○有利”:+1など)を出力する。本実施形態の場合、この静的評価関数の機能は、報酬推定機により実現される。
【0175】
また、先読みアルゴリズムは、先の手を読み、将来の静的評価関数の出力値がより高くなるような手を選択するアルゴリズムである。例えば、先読みアルゴリズムは、MinMax法などを利用して実現される。例えば、図50に示すように、先読みアルゴリズムは、自分の手番で手を打った後に、相手の手番で相手が打つ可能性のある手を想定し、想定した各手に対して自分が打てる手を想定して、自分が最も有利になる手を選択する。
【0176】
ところで、上記のような静的評価関数は、これまで人手により設計されていた。例えば、将棋のAIとして有名なボナンザでさえ、静的評価関数で考慮する局面の特徴などの設計事項は人手により設計されていた。また、ゲームの種類が変わると、特徴量の設計も変更する必要がある。そのため、これまでは試行錯誤を繰り返しながら静的評価関数をゲーム毎に人手で設計する必要があった。しかし、本実施形態に係る技術を適用すると、人手による設計作業を省いて思考ルーチンを自動構築することが可能になる。
【0177】
「三目並べ」の場合、図51に示すように、状態S及び行動aを3×3のマトリックスで表現する。但し、状態Sは、自分の手番となた時点の盤面を表す。また、自分の手番で打った手を反映した盤面を(S,a)と表現する。さらに、自分の手を“1”、相手の手を“−1”、空白を“0”と表現する。つまり、盤面及び手を数値で表現する。このようにして盤面及び手が数値で表現できると、本実施形態に係る報酬推定機の自動構築方法を用いて思考ルーチンを自動構築することが可能になる。
【0178】
例えば、情報処理装置10は、まず、ランダムな場所に自分の手と相手の手とを打つInnateを利用して行動履歴データを生成する。上記の通り、(S,a)は、3×3マトリックスにより表現される。また、情報処理装置10は、図52に示すように、勝ちに至るまでに打った全ての手に対応する(S,a)に報酬“1”を与える。一方、情報処理装置10は、図53に示すように、負けに至るまでに打った全ての手に対応する(S,a)に報酬“−1”を与える。このようにして行動履歴データを蓄積すると、情報処理装置10は、蓄積した行動履歴データを利用して報酬推定機を構築する。
【0179】
実際に手を選択する場合、情報処理装置10は、図54に示すように、報酬推定機を利用して現在の状態Sから推定報酬yを算出し、推定報酬yが最大となる手を選択する。図54の例では、最大の推定報酬に対応する手(C)が選択される。なお、図54の例では1手先の報酬を評価して手の選択を行っているが、対戦相手についても同じように推定報酬を算出し、MinMax法などを用いて数手先読みした結果を用いて現在の手を選択するように構成してもよい。
【0180】
また、学習により得られた報酬推定機を用いて常に最適な行動を選択するように構成すると、NPCによる手の選択が毎回同じになってしまうことがある。そこで、推定報酬を算出する工程に何らかのランダムネスを加えてもよい。例えば、報酬推定機により算出した推定報酬に僅かだけ乱数を加える方法が考えられる。また、遺伝アルゴリズムに基づく機械学習により報酬推定機を算出している場合、学習世代毎に算出される報酬推定機を保持しておき、利用する報酬推定機をランダムに切り替えるように構成してもよい。
【0181】
以上、「三目並べ」への応用について説明した。
【0182】
[3−2:「対戦ゲーム」への応用]
次に、図55〜図62を参照しながら、本実施形態に係る技術を「対戦ゲーム」へと応用する方法について説明する。ここで考える「対戦ゲーム」の主なルールは、図55に示すように、(1)2人対戦ゲームであること、(2)各プレーヤの行動は「左移動」「右移動」「左右移動なし」「ジャンプ」「ジャンプなし」の組み合わせであること、(3)相手のプレーヤを踏んだらY軸方向の加速度差に応じて相手にダメージを与えられること、の3点である。また、ヒットポイントが0になったプレーヤが負けである。なお、「対戦ゲーム」への応用には、先に説明したアクションスコア推定機を用いる思考ルーチンの構築方法が用いられる。
【0183】
この場合、状態Sとしては、自分の絶対座標、相手の絶対座標、時刻が利用される。そのため、状態Sは、図56に示すように3次元マトリックスにより表現される。また、ここでは、3次元マトリックスで表現される状態Sの入力に応じて5つの要素(N,L,R,J,NJ)を持つアクションスコアを推定するアクションスコア推定機の自動構築方法について考える。但し、要素Nは、行動a=“左右移動なし”に対応するアクションスコアである。また、要素Lは、行動a=“左移動”に対応するアクションスコアである。要素Rは、行動a=“右移動”に対応するアクションスコアである。要素Jは、行動a=“ジャンプ”に対応するアクションスコアである。要素NJは、行動a=“ジャンプなし”に対応するアクションスコアである。
【0184】
行動履歴データを収集するためのInnateとしては、例えば、完全にランダムにプレーヤの行動を選択するものが用いられる。例えば、このInnateは、N(左右移動なし)、L(左移動)、R(右移動)の中から1つの行動をランダムに選び、選んだ行動に組み合わせる行動をJ(ジャンプ)又はNJ(ジャンプなし)からランダムに1つ選ぶ。また、情報処理装置10は、図57に示すように、自分が相手にダメージを与えた時点で、前回自分又は相手がダメージを受けた時点から現時点までの行動履歴データの報酬を1に設定する。一方、自分が相手からダメージを受けた場合、情報処理装置10は、図57に示すように、前回自分又は相手がダメージを受けた時点から現時点までの行動履歴データの報酬を0に設定する。
【0185】
なお、報酬が1に設定された行動履歴データについて、情報処理装置10は、実際に行った行動のアクションスコアを1、行わなかった行動のアクションスコアを0に設定する。一方、報酬が0に設定された行動履歴データについて、情報処理装置10は、実際に行った行動のアクションスコアを0に設定し、行わなかった行動のアクションスコアを0に設定する。このような処理を繰り返すことにより、状態Sとアクションスコアとで構成される図57に示すような行動履歴データが得られる。
【0186】
行動履歴データが得られると、情報処理装置10は、図58に示した処理の流れに沿って思考ルーチンを構築する。図58に示すように、行動履歴データを取得すると(S301)、情報処理装置10は、取得した行動履歴データを利用した機械学習により思考ルーチンを構築する(S302)。次いで、情報処理装置10は、必要に応じて追加の行動履歴データを取得する(S303)。次いで、情報処理装置10は、追加した行動履歴データと元の行動履歴データとを統合する(S304)。次いで、情報処理装置10は、終了条件を満たしたか否かを判定する(S305)。
【0187】
例えば、ユーザによる終了操作が与えられた場合や、ランダムに行動するプレーヤに対する勝率が所定の閾値を越えた場合などに、情報処理装置10は、終了条件を満たしたと判定する。終了条件を満たしていない場合、情報処理装置10は、処理をステップS302に進める。一方、終了条件を満たした場合、情報処理装置10は、思考ルーチンの構築に係る一連の処理を終了する。
【0188】
このようにして自動構築された思考ルーチンを用いてプレーヤを行動させた結果、ランダムに行動するプレーヤに対する勝率について、図59に示すような結果が得られた。図59に示すように、15世代(図58のステップS302〜S304の繰り返し回数が15)で思考ルーチンを利用して行動するプレーヤの勝率が100%近くに達した。なお、行動の選択は、最もアクションスコアの高い行動を選択する方法で行われている。但し、この例では、行動を選択する際に、各アクションスコアに僅かの乱数を加えてから行動を選択するようにしている。
【0189】
また、先に説明した複数エージェントの同時学習を適用し、2人のプレーヤの行動を同時に学習して思考ルーチンを構築してみた。複数エージェントの同時学習を適用すると、ランダムでない動きをするプレーヤに対して勝とうとする思考ルーチンが自動構築されるため、より賢くプレーヤを行動させる思考ルーチンが構築される。なお、互いに思考ルーチンを用いて行動する2人のプレーヤを対戦させた結果を図60に示した。図60に示すように、学習世代によりプレーヤ1が大きく勝ち越す場合もあるが、プレーヤ2が大きく勝ち越す場合もある。
【0190】
また、ある学習世代において実験的に1000試合のゲームを行った結果、図61に示すように、プレーヤ1が大きく勝ち越す結果(対戦勝率)が得られた。但し、ランダムに行動するプレーヤを相手にした場合(ランダム相手)、プレーヤ1もプレーヤ2も相手に対して9割以上の高い勝率を得た。つまり、思考ルーチンを利用して行動するプレーヤは、十分に賢く行動しているのである。このように、複数エージェントの同時学習を適用すると、相手に勝とうとして思考ルーチンを強化しているうちに、ランダムに行動する相手に対しても高い確率で勝てる汎用的なアルゴリズムが得られる。
【0191】
ところで、これまでは状態Sとして、自分の座標、相手の座標、時刻を表現した3次元マトリクスを用いていたが、この3次元マトリクスに代えてゲーム画面の画像情報をそのまま用いる方法も考えられる。例えば、状態Sとして、図62に示すようなゲーム画面の輝度画像を用いることができる。つまり、状態Sは、行動を決定するために有用な情報が含まれてさえいれば何でもよいのである。この考えに基づくと、本実施形態に係る技術が様々なゲームやタスクに関する思考ルーチンの自動構築方法に応用できることが容易に想像できるであろう。
【0192】
以上、「対戦ゲーム」への応用について説明した。
【0193】
[3−3:「五目並べ」への応用]
次に、図63及び図64を参照しながら、本実施形態に係る技術を「五目並べ」へと応用する方法について説明する。「五目並べ」の主なルールは、(1)交互に手を打つ、(2)縦横斜めに先に5つの石を並べた方が勝ち、の2点である。また、「五目並べ」において、状態Sは盤面であり、行動aは各プレーヤが打つ手である。
【0194】
「五目並べ」への応用方法は、基本的に「三目並べ」への応用方法と同じである。つまり、状態S及び行動aは、図63に示すように、2次元マトリクスで表現される。また、最初に用いる行動履歴データは、完全にランダムに石を配置するInnateを用いて取得される。そして、最終的に勝ちに至った全ての(S,a)に報酬1が設定され、負けに至った全ての(S,a)に報酬0が設定される。情報処理装置10は、この行動履歴データを用いて思考ルーチンを構築する。また、情報処理装置10は、思考ルーチンを用いて対局し、その結果を統合した行動履歴データを用いて思考ルーチンを構築する。これらの処理を繰り返すことにより、賢い行動を選択する思考ルーチンが構築される。
【0195】
また、行動を選択する際、情報処理装置10は、「三目並べ」の場合と同様に全ての行動の可能性について(石を置ける全ての点について石を置いたとして)推定報酬を求め、最も推定報酬の高くなる点に石を置く。もちろん、情報処理装置10は、数手先を読んで石を置く位置を選択するように構成されていてもよい。なお、「五目並べ」は、「三目並べ」に比べて盤面の組み合わせ数が膨大である。そのため、ランダムに石を置くプレーヤは、見当違いの手を打ちがちであるために非常に弱い。
【0196】
従って、ランダムに石を置くプレーヤを相手に学習を行っても非常に弱い相手に勝つための思考ルーチンができあがるだけで、賢い思考ルーチンはなかなか得られない。そこで、対戦ゲームと同様に、複数エージェントの同時学習を適用し、自分と相手とを同じ環境で学習させる手法を用いる方が好ましい。このような構成にすることで、比較的高性能な思考ルーチンを自動構築することが可能になる。互いに思考ルーチンを用いて行動するプレーヤによる対局結果を図64に示した。
【0197】
以上、「五目並べ」への応用について説明した。
【0198】
[3−4:「ポーカー」への応用]
次に、図65〜図67を参照しながら、本実施形態に係る技術を「ポーカー」へと応用する方法について説明する。「ポーカー」の主なルールは、図65に示すように、(1)5枚のカードを配る、(2)捨てるカードを選択する、(3)役の強い方が勝ち、の3点である。ここでは、カードが配られたときに、捨てるカードを決める思考ルーチンの構築方法について考える。
【0199】
図66に示すように、状態S及び行動aは、記号列で表現される。例えば、ハートのエースを“HA”、クラブの2を“C2”、ダイヤのKを“DK”などと表現する。図66の場合、状態Sは、記号列“SJCJC0D9D7”で表現される。また、ダイヤの9及びダイヤの7を捨てた場合、行動aは、記号列“D9D7”で表現される。また、ゲームに勝った場合には報酬“1”が与えられ、負けた場合には報酬“0”が与えられる。このような表現を用いると、例えば、図67に示すような行動履歴データが得られる。
【0200】
最初に行動履歴データを取得するInnateとしては、例えば、完全にランダムに5枚のカードそれぞれを捨てるかどうか決定するものを利用する。また、情報処理装置10は、勝った行動履歴データには報酬“1”を設定し、負けた行動履歴データには報酬“0”を設定する。そして、情報処理装置10は、蓄積された行動履歴データを用いて思考ルーチンを構築する。このとき、行動を選択した結果、どのような役が揃ったか、相手の役がどのようなものだったかなどの情報は利用されない。つまり、純粋に勝ち負けだけを考慮して思考ルーチンが構築される。但し、自分が強い役を揃えるのに有利なカードの切り方を選択した行動履歴データほど報酬が1になる確率は高くなる傾向にある。
【0201】
さて、行動を選択する際、配られた5枚のカードそれぞれについて、カードを切る、カードを切らない、の選択肢が与えられる。そのため、行動の組み合わせは、2の5乗=32通り存在する。従って、思考ルーチンは、報酬推定機を利用し、32通りの(S,a)について推定報酬を算出し、最も推定報酬の高い行動を選択する。
【0202】
以上、「ポーカー」への応用について説明した。
【0203】
[3−5:「ロールプレイングゲーム」への応用]
次に、図68〜図79を参照しながら、本実施形態に係る技術を「ロールプレイングゲーム」へと応用する方法について説明する。ここでは、「ロールプレイングゲーム」の戦闘シーンにおいてプレーヤに代わってキャラクタを賢く自動操作する思考ルーチンの自動構築方法について考える。なお、ここで考える「ロールプレイングゲーム」のルールは、図68に示した通りである。また、図68に示すように、状態Sはプレーヤに提供される情報であり、行動aはキャラクタを操作するコマンドである。
【0204】
戦闘シーンの環境は、図69に示した通りである。まず、戦闘に勝つと生存者で経験値が山分けされる。さらに、経験値が貯まるとレベルアップする。また、レベルアップすると、キャラクタの職業に応じてステータスの値がアップしたり、魔法を覚えたりする。また、戦闘に5回連続で勝つと敵のレベルが1つアップすると共に、キャラクタのヒットポイントが回復する。また、敵のレベルが31に達するとゲームをクリアしたことになる。
【0205】
なお、戦闘シーンにおいて、キャラクタが持つステータスの1つである“素早さ”の値に応じて各キャラクタが行動をおこせるタイミングが決まる。また、キャラクタがとれる行動は、“攻撃”及び“魔法(魔法を覚えている場合)”である。魔法の種類としては、Heal、Fire、Iceがある。Healは、味方のヒットポイント(HP)を回復する魔法である。Fireは、火を用いて敵を攻撃する魔法である。Iceは、氷を用いて敵を攻撃する魔法である。また、魔法をかけるターゲットは、単体又は全体のいずれかを選択可能である。但し、全体を選択した場合には魔法の効果が半減する。また、使える魔法の種類やレベルは、キャラクタのレベルに応じて変わる。さらに、同じ魔法でもレベルの高い魔法ほどマジックポイント(MP)を多く消費するが、効果は高い。
【0206】
キャラクタの職業及び職業毎のステータスは、図70に示した通りである。ステータス上昇率は、キャラクタのレベルが1つアップする度にステータスがアップする割合を示している。また、魔法を覚えるLvは、記載された値のレベルに達した場合にキャラクタが魔法を覚えるレベルを示している。但し、空欄に対応する魔法は覚えられない。また、0と記載されている箇所は、最初から魔法を覚えていることを示している。なお、味方のパーティは、上側4種類の職業を持つキャラクタにより構成される。一方、敵のパーティは、下側4種類の職業を持つキャラクタから選択されたキャラクタにより構成される。
【0207】
状態Sとして利用される味方側の情報は、図71に示した通りである。例えば、生存する味方のレベル、職業、HP、最大HP、MP、最大MP、攻撃力、防御力、素早さなどが状態Sとして利用される。なお、職業の欄は、当てはまる職業の欄に1、それ以外の欄に0が記入される。また、その他の欄には現状の値が記入される。一方、状態Sとして利用される敵側の情報は、図72に示した通りである。例えば、生存する敵のレベル、職業、累積ダメージなどが状態Sとして利用される。なお、累積ダメージは、それまでに与えたダメージの合計値を示している。
【0208】
また、行動aとして利用される味方側の情報は、図73に示した通りである。例えば、行動者の欄には、これから行動を行うキャラクタの場合に1、それ以外の場合に0が記入される。また、行動対象の欄には、行動の対象となるキャラクタの場合に1、それ以外の場合に0が記入される。例えば、回復魔法を受けるキャラクタに対応する行動対象の欄には1が記入される。また、アクションの種類の欄には、行う行動の欄に1、行わない行動の欄に0が記入される。一方、行動aとして利用される敵側の情報は、図74に示した通りである。図74に示すように、敵側の情報としては行動対象の情報が利用される。
【0209】
さて、これまで説明してきた応用例と同様、情報処理装置10は、まず、行動履歴データを取得する。このとき、情報処理装置10は、行動の種類毎に選択確率に重みを付けた上で、ランダムに行動を選択するInnateを用いて行動履歴データを取得する。例えば、情報処理装置10は、魔法よりも攻撃を選択する確率を高く設定したInnateを用いてキャラクタを行動させる。また、図75に示すように、情報処理装置10は、味方がやられた場合には報酬“−5”を行動履歴データに設定し、敵を倒した場合には報酬“1”を行動履歴データに設定する。その結果、図76のA図に示すような行動履歴データが得られる。但し、味方や敵がやられる過程の評価も考慮するため、情報処理装置10は、図76のB図に示すように、直線的に報酬の値をDecayさせる。
【0210】
情報処理装置10は、上記のようにして取得された行動履歴データを用いて思考ルーチンを構築する。このとき、情報処理装置10は、時刻tにおける状態S及び行動aから時刻t+1における状態S’を推定する予測機を構築する。また、情報処理装置10は、時刻t+1における状態S’から推定報酬を算出する報酬推定機を構築する。そして、情報処理装置10は、図77に示すように、現在の状態Sにおいてキャラクタがとりうる行動毎に、予測機を用いて次の状態S’を予測する。さらに、情報処理装置10は、予測した状態S’を報酬推定機に入力して推定報酬yを算出する。推定報酬yを算出した情報処理装置10は、推定報酬yが最大となる行動aを選択する。
【0211】
図77の例では、行動a=“敵全体にFire”に対応する推定報酬yが最大となっている。そのため、この例においては、最適な行動として、行動a=“敵全体にFire”が選択される。但し、思考ルーチンは、図78に示すように、推定報酬が高く、推定誤差が大きく、特徴量空間における密度が疎な特徴量座標に対応する行動を選択するように構成されていてもよい。つまり、先に説明した効率的な推定報酬機の構築方法で紹介した報酬スコア、未知スコア、誤差スコアに基づいて思考ルーチンが構築されていてもよい。
【0212】
なお、報酬スコアは、とりうる全ての行動について報酬推定機を用いて推定報酬を求め、推定報酬の低い方から順に1、2、3、…と、推定報酬が高くなるほど大きくなるようにスコアを与えることで得られる。また、未知スコアは、図25などに示した方法を用いて、全ての行動について特徴量座標の周辺密度を求め、密度が高い方から順に1、2、3、…と、密度が低くなるほど大きくなるようにスコアを与えることで得られる。
【0213】
また、誤差スコアを求める場合、情報処理装置10は、まず、既存の行動履歴データの全てについて、推定報酬yの値を実際の報酬rと比較し、その誤差を求める。次いで、情報処理装置10は、平均値よりも誤差の大きい行動履歴データに対応する特徴量座標を特徴量空間にプロットする。次いで、情報処理装置10は、プロットした特徴量座標の密度分布を求める。最後に、情報処理装置10は、全ての行動履歴データに対応する特徴量座標について密度を求め、密度が低い方から順に1、2、3、…と、密度が高くなるほど大きくなるようにスコアを与える。
【0214】
例えば、報酬スコアをs1、未知スコアをs2、誤差スコアをs3と表記した場合、情報処理装置10は、行動を選択する際に、s1*w1+s2*w2+s3*w3(但し、w1〜w3は所定の重み)の値を算出し、この値が最も大きくなる行動を選択する。このようにして行動を選択することにより、報酬が高く、推定誤差が大きく、特徴量空間における特徴量座標の密度が疎な行動を選択することが可能になる。
【0215】
ここで、図79を参照しながら、効率的な推定報酬機の構築方法を適用した場合の効果について述べる。図79のグラフは、最も高い推定報酬が得られる行動を選択した場合(最適戦略)と、効率的な推定報酬機の構築方法を適用した場合(探索行動)とでシナリオクリアまでの1ステップ当たりの平均Rewardを比較したグラフである。図79のグラフから明らかなように、3つのスコアを利用して構築された思考ルーチン(探索行動)の方が安定して高い報酬が得られている。この評価結果から、効率的な推定報酬機の構築方法を適用することで、演算負荷を軽減できるばかりか、より高性能な思考ルーチンを構築できることが分かった。
【0216】
なお、「ロールプレイングゲーム」に応用すべく自動構築された思考ルーチンは、以下のような戦略を自身で身に付けていることも分かった。
(A)集中攻撃:
集中攻撃することで敵の数を素早く減らす。
(B)HP減少したら回復:
HPが減少した味方のHPを回復して味方が倒されにくくする。
(C)単体攻撃、全体攻撃の使い分け:
敵の数がある程度多い時は全体攻撃魔法を使う。現在集中攻撃中の敵が残りわずかなダメージで倒せそうなときは、全体攻撃魔法を用いて集中攻撃中の敵を倒しながら、他の敵にもダメージを与える。
(D)魔法の無駄打ちはしない:
HPの減っていない味方に対して回復魔法を使わない。魔法の効かない敵に対して魔法を使わない。
【0217】
以上、「ロールプレイングゲーム」への応用について説明した。
【0218】
以上説明したように、本実施形態に係る技術を適用すると、人手による調整を介さずに様々な思考ルーチンを自動構築することが可能になる。
【0219】
<4:ハードウェア構成例>
上記の情報処理装置10が有する各構成要素の機能は、例えば、図80に示すハードウェア構成を用いて実現することが可能である。つまり、当該各構成要素の機能は、コンピュータプログラムを用いて図80に示すハードウェアを制御することにより実現される。なお、このハードウェアの形態は任意であり、例えば、パーソナルコンピュータ、携帯電話、PHS、PDA等の携帯情報端末、ゲーム機、又は種々の情報家電がこれに含まれる。但し、上記のPHSは、Personal Handy−phone Systemの略である。また、上記のPDAは、Personal Digital Assistantの略である。
【0220】
図80に示すように、このハードウェアは、主に、CPU902と、ROM904と、RAM906と、ホストバス908と、ブリッジ910と、を有する。さらに、このハードウェアは、外部バス912と、インターフェース914と、入力部916と、出力部918と、記憶部920と、ドライブ922と、接続ポート924と、通信部926と、を有する。但し、上記のCPUは、Central Processing Unitの略である。また、上記のROMは、Read Only Memoryの略である。そして、上記のRAMは、Random Access Memoryの略である。
【0221】
CPU902は、例えば、演算処理装置又は制御装置として機能し、ROM904、RAM906、記憶部920、又はリムーバブル記録媒体928に記録された各種プログラムに基づいて各構成要素の動作全般又はその一部を制御する。ROM904は、CPU902に読み込まれるプログラムや演算に用いるデータ等を格納する手段である。RAM906には、例えば、CPU902に読み込まれるプログラムや、そのプログラムを実行する際に適宜変化する各種パラメータ等が一時的又は永続的に格納される。
【0222】
これらの構成要素は、例えば、高速なデータ伝送が可能なホストバス908を介して相互に接続される。一方、ホストバス908は、例えば、ブリッジ910を介して比較的データ伝送速度が低速な外部バス912に接続される。また、入力部916としては、例えば、マウス、キーボード、タッチパネル、ボタン、スイッチ、及びレバー等が用いられる。さらに、入力部916としては、赤外線やその他の電波を利用して制御信号を送信することが可能なリモートコントローラ(以下、リモコン)が用いられることもある。
【0223】
出力部918としては、例えば、CRT、LCD、PDP、又はELD等のディスプレイ装置、スピーカ、ヘッドホン等のオーディオ出力装置、プリンタ、携帯電話、又はファクシミリ等、取得した情報を利用者に対して視覚的又は聴覚的に通知することが可能な装置である。但し、上記のCRTは、Cathode Ray Tubeの略である。また、上記のLCDは、Liquid Crystal Displayの略である。そして、上記のPDPは、Plasma DisplayPanelの略である。さらに、上記のELDは、Electro−Luminescence Displayの略である。
【0224】
記憶部920は、各種のデータを格納するための装置である。記憶部920としては、例えば、ハードディスクドライブ(HDD)等の磁気記憶デバイス、半導体記憶デバイス、光記憶デバイス、又は光磁気記憶デバイス等が用いられる。但し、上記のHDDは、Hard Disk Driveの略である。
【0225】
ドライブ922は、例えば、磁気ディスク、光ディスク、光磁気ディスク、又は半導体メモリ等のリムーバブル記録媒体928に記録された情報を読み出し、又はリムーバブル記録媒体928に情報を書き込む装置である。リムーバブル記録媒体928は、例えば、DVDメディア、Blu−rayメディア、HD DVDメディア、各種の半導体記憶メディア等である。もちろん、リムーバブル記録媒体928は、例えば、非接触型ICチップを搭載したICカード、又は電子機器等であってもよい。但し、上記のICは、Integrated Circuitの略である。
【0226】
接続ポート924は、例えば、USBポート、IEEE1394ポート、SCSI、RS−232Cポート、又は光オーディオ端子等のような外部接続機器930を接続するためのポートである。外部接続機器930は、例えば、プリンタ、携帯音楽プレーヤ、デジタルカメラ、デジタルビデオカメラ、又はICレコーダ等である。但し、上記のUSBは、Universal Serial Busの略である。また、上記のSCSIは、Small Computer System Interfaceの略である。
【0227】
通信部926は、ネットワーク932に接続するための通信デバイスであり、例えば、有線又は無線LAN、Bluetooth(登録商標)、又はWUSB用の通信カード、光通信用のルータ、ADSL用のルータ、又は各種通信用のモデム等である。また、通信部926に接続されるネットワーク932は、有線又は無線により接続されたネットワークにより構成され、例えば、インターネット、家庭内LAN、赤外線通信、可視光通信、放送、又は衛星通信等である。但し、上記のLANは、Local Area Networkの略である。また、上記のWUSBは、Wireless USBの略である。そして、上記のADSLは、Asymmetric Digital Subscriber Lineの略である。
【0228】
以上、ハードウェア構成例について説明した。
【0229】
<5:まとめ>
最後に、本実施形態の技術的思想について簡単に纏める。以下に記載する技術的思想は、例えば、PC、携帯電話、携帯ゲーム機、携帯情報端末、情報家電、カーナビゲーションシステム等、種々の情報処理装置に対して適用することができる。
【0230】
上記の情報処理装置の機能構成は以下のように表現することができる。例えば、下記(1)に記載の情報処理装置は、行動履歴データを用いて報酬推定機を自動構築することができる。この報酬推定機を利用すると、エージェントがおかれた状態に応じて、その状態でエージェントがとりうる行動毎に、行動を行ったエージェントが得る報酬を推定することができる。そのため、高い報酬を得ると推定される行動をエージェントがとるように制御することで、賢く行動するエージェントの動きを実現することが可能になる。言い換えると、下記(1)に記載の情報処理装置は、賢く行動するエージェントの動きを実現することが可能な思考ルーチンを自動構築することができる。とりわけ、下記(1)に記載の情報処理装置は、報酬値が高く、かつ、行動履歴データに含まれない行動を優先的に選択するようにしているため、効率よく思考ルーチンを自動構築することができる。
【0231】
(1)
エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成部と、
エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、前記行動履歴データに含まれない行動を優先的に選択する行動選択部と、
前記行動選択部による選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加する行動履歴追加部と、
を備え、
前記報酬推定機生成部は、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成する、
情報処理装置。
【0232】
(2)
前記行動選択部は、前記報酬推定機を用いて推定される報酬値が高く、当該報酬値の推定誤差が大きく、かつ、前記行動履歴データに含まれない行動を優先的に選択する、
上記(1)に記載の情報処理装置。
【0233】
(3)
前記報酬推定機生成部は、
複数の処理関数を組み合わせて複数の基底関数を生成する基底関数生成部と、
前記行動履歴データに含まれる状態データ及び行動データを前記複数の基底関数に入力して特徴量ベクトルを算出する特徴量ベクトル算出部と、
前記特徴量ベクトルから前記行動履歴データに含まれる報酬値を推定する推定関数を回帰/判別学習により算出する推定関数算出部と、
を含み、
前記報酬推定機は、前記複数の基底関数と前記推定関数とにより構成される、
上記(1)又は(2)に記載の情報処理装置。
【0234】
(4)
前記状態データ、前記行動データ、及び前記報酬値の組が前記行動履歴データに追加された場合、前記特徴量ベクトル算出部は、前記行動履歴データに含まれる全ての状態データ及び行動データについて特徴量ベクトルを算出し、
前記情報処理装置は、特徴領空間において前記特徴量ベクトルにより示される座標点の分布が所定の分布に近づくように前記行動履歴データに含まれる前記状態データ、前記行動データ、及び前記報酬値の組を間引く分布調整部をさらに備える、
上記(3)に記載の情報処理装置。
【0235】
(5)
前記状態データ、前記行動データ、及び前記報酬値の組が前記行動履歴データに追加された場合、前記特徴量ベクトル算出部は、前記行動履歴データに含まれる全ての状態データ及び行動データについて特徴量ベクトルを算出し、
前記情報処理装置は、特徴領空間において前記特徴量ベクトルにより示される座標点の分布が所定の分布に近づくように前記行動履歴データに含まれる前記状態データ、前記行動データ、及び前記報酬値の組のそれぞれに重みを設定する分布調整部をさらに備える、
上記(3)に記載の情報処理装置。
【0236】
(6)
前記分布調整部は、間引き後に残った前記状態データ、前記行動データ、及び前記報酬値の組について、特徴領空間において前記特徴量ベクトルにより示される座標点の分布が所定の分布に近づくように前記行動履歴データに含まれる前記状態データ、前記行動データ、及び前記報酬値の組のそれぞれに重みを設定する、
上記(4)に記載の情報処理装置。
【0237】
(7)
前記基底関数生成部は、遺伝的アルゴリズムに基づいて前記基底関数を更新し、
前記特徴量ベクトル算出部は、前記基底関数が更新された場合に、更新後の前記基底関数に前記状態データ及び前記行動データを入力して特徴量ベクトルを算出し、
前記推定関数算出部は、前記更新後の基底関数を用いて算出された特徴量ベクトルの入力に応じて前記報酬値を推定する推定関数を算出する、
上記(3)〜(6)のいずれか1項に記載の情報処理装置。
【0238】
(8)
エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成部と、
エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、当該報酬値の推定誤差が大きい行動を優先的に選択する行動選択部と、
前記行動選択部による選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加する行動履歴追加部と、
を備え、
前記報酬推定機生成部は、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成する、
情報処理装置。
【0239】
(9)
エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成するステップと、
エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、前記行動履歴データに含まれない行動を優先的に選択するステップと、
選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加するステップと、
前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成するステップと、
を含む、
情報処理方法。
【0240】
(10)
エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成するステップと、
エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、当該報酬値の推定誤差が大きい行動を優先的に選択するステップと、
選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加するステップと、
前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成するステップと、
を含む、
情報処理方法。
【0241】
(11)
エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成機能と、
エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、前記行動履歴データに含まれない行動を優先的に選択する行動選択機能と、
前記行動選択機能による選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加する行動履歴追加機能と、
をコンピュータに実現させるためのプログラムであり、
前記報酬推定機生成機能は、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成する、
プログラム。
【0242】
(12)
エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成機能と、
エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、当該報酬値の推定誤差が大きい行動を優先的に選択する行動選択機能と、
前記行動選択機能による選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加する行動履歴追加機能と、
をコンピュータに実現させるためのプログラムであり、
前記報酬推定機生成機能は、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成する、
プログラム。
【0243】
(備考)
上記の報酬推定機構築部12は、報酬推定機生成部の一例である。上記の行動履歴データ取得部11は、行動履歴追加部の一例である。上記の基底関数リスト生成部121は、基底関数生成部の一例である。上記の特徴量計算部122は、特徴量ベクトル算出部の一例である。上記の推定関数生成部123は、推定関数算出部の一例である。上記の行動履歴データ統合部124は、分布調整部の一例である。
【0244】
以上、添付図面を参照しながら本技術に係る好適な実施形態について説明したが、本技術はここで開示した構成例に限定されないことは言うまでもない。当業者であれば、特許請求の範囲に記載された範疇内において、各種の変更例又は修正例に想到し得ることは明らかであり、それらについても当然に本技術の技術的範囲に属するものと了解される。
【符号の説明】
【0245】
10 情報処理装置
11 行動履歴データ取得部
12 報酬推定機構築部
121 基底関数リスト生成部
122 特徴量計算部
123 推定関数生成部
124 行動履歴データ統合部
13 入力データ取得部
14 行動選択部
【技術分野】
【0001】
本技術は、情報処理装置、情報処理方法、及びプログラムに関する。
【背景技術】
【0002】
近年、定量的に特徴を決定づけることが難しい任意のデータ群から、そのデータ群の特徴量を機械的に抽出する手法に注目が集まっている。例えば、任意の音楽データを入力とし、その音楽データが属する音楽のジャンルを機械的に抽出するアルゴリズムを自動構築する手法が知られている。ジャズ、クラシック、ポップス等、音楽のジャンルは、楽器の種類や演奏形態に応じて定量的に決まるものではない。そのため、これまでは任意の音楽データが与えられたときに、その音楽データから機械的に音楽のジャンルを抽出することは一般的に難しいと考えられていた。
【0003】
しかし、実際には、音楽データに含まれる音程の組み合わせ、音程の組み合わせ方、楽器の種類の組み合わせ、メロディーラインやベースラインの構造等、様々な情報の組み合わせの中に、音楽のジャンルを分ける特徴が潜在的に含まれている。そのため、この特徴を抽出するアルゴリズム(以下、特徴量抽出機)を機械学習により自動構築できないか、という観点から特徴量抽出機の研究が行われた。その研究成果の一つとして、例えば、下記の特許文献1に記載された遺伝アルゴリズムに基づく特徴量抽出機の自動構築方法を挙げることができる。遺伝アルゴリズムとは、生物の進化過程に倣い、機械学習の過程で、選択、交差、突然変異の要素を考慮したものを言う。
【0004】
同文献に記載の特徴量抽出機自動構築アルゴリズムを利用することにより、任意の音楽データから、その音楽データが属する音楽のジャンルを抽出する特徴量抽出機を自動構築することができるようになる。また、同文献に記載の特徴量抽出機自動構築アルゴリズムは、非常に汎用性が高く、音楽データに限らず、任意のデータ群から、そのデータ群の特徴量を抽出する特徴量抽出機を自動構築することができる。そのため、同文献に記載の特徴量抽出機自動構築アルゴリズムは、音楽データや映像データのような人工的なデータの特徴量解析、自然界に存在する様々な観測量の特徴量解析への応用が期待されている。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開2009−48266号公報
【発明の概要】
【発明が解決しようとする課題】
【0006】
ところで、本件発明者は、同文献に記載の技術に対して更なる工夫を施すことで、エージェントを賢く行動させるアルゴリズムを自動構築する技術に発展させられないか検討を行ってきた。その検討の中で、本件発明者は、ある状態におかれたエージェントがとりうる行動の中で選択すべき行動を決定するための思考ルーチンを自動構築する技術に注目した。本技術は、このような技術に関するものであり、エージェントがとるべき行動を選択する際に決め手となる情報を出力する推定機を効率よく自動構築することが可能な、新規かつ改良された情報処理装置、情報処理方法、及びプログラムを提供することを意図している。
【課題を解決するための手段】
【0007】
本技術のある観点によれば、エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成部と、エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、前記行動履歴データに含まれない行動を優先的に選択する行動選択部と、前記行動選択部による選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加する行動履歴追加部と、を備え、前記報酬推定機生成部は、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成する、情報処理装置が提供される。
【0008】
また、本技術の別の観点によれば、エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成部と、エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、当該報酬値の推定誤差が大きい行動を優先的に選択する行動選択部と、前記行動選択部による選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加する行動履歴追加部と、を備え、前記報酬推定機生成部は、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成する、情報処理装置が提供される。
【0009】
また、本技術の別の観点によれば、エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成するステップと、エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、前記行動履歴データに含まれない行動を優先的に選択するステップと、選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加するステップと、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成するステップと、を含む、情報処理方法が提供される。
【0010】
また、本技術の別の観点によれば、エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成するステップと、エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、当該報酬値の推定誤差が大きい行動を優先的に選択するステップと、選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加するステップと、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成するステップと、を含む、情報処理方法が提供される。
【0011】
また、本技術の別の観点によれば、エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成機能と、エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、前記行動履歴データに含まれない行動を優先的に選択する行動選択機能と、前記行動選択機能による選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加する行動履歴追加機能と、をコンピュータに実現させるためのプログラムであり、前記報酬推定機生成機能は、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成する、プログラムが提供される。
【0012】
また、本技術の別の観点によれば、エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成機能と、エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、当該報酬値の推定誤差が大きい行動を優先的に選択する行動選択機能と、前記行動選択機能による選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加する行動履歴追加機能と、をコンピュータに実現させるためのプログラムであり、前記報酬推定機生成機能は、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成する、プログラムが提供される。
【0013】
また、本技術の別の観点によれば、上記のプログラムが記録された、コンピュータにより読み取り可能な記録媒体が提供される。
【発明の効果】
【0014】
以上説明したように本技術によれば、エージェントがとるべき行動を選択する際に決め手となる情報を出力する推定機を効率よく自動構築することが可能になる。
【図面の簡単な説明】
【0015】
【図1】推定機の自動構築方法について説明するための説明図である。
【図2】推定機の自動構築方法について説明するための説明図である。
【図3】推定機の自動構築方法について説明するための説明図である。
【図4】推定機の自動構築方法について説明するための説明図である。
【図5】推定機の自動構築方法について説明するための説明図である。
【図6】推定機の自動構築方法について説明するための説明図である。
【図7】推定機の自動構築方法について説明するための説明図である。
【図8】推定機の自動構築方法について説明するための説明図である。
【図9】推定機の自動構築方法について説明するための説明図である。
【図10】推定機の自動構築方法について説明するための説明図である。
【図11】推定機の自動構築方法について説明するための説明図である。
【図12】推定機の自動構築方法について説明するための説明図である。
【図13】オンライン学習に基づく推定機の自動構築方法について説明するための説明図である。
【図14】データセットの統合方法について説明するための説明図である。
【図15】データセットの統合方法について説明するための説明図である。
【図16】データセットの統合方法について説明するための説明図である。
【図17】データセットの統合方法について説明するための説明図である。
【図18】データセットの統合方法について説明するための説明図である。
【図19】データセットの統合方法について説明するための説明図である。
【図20】データセットの統合方法について説明するための説明図である。
【図21】データセットの統合方法について説明するための説明図である。
【図22】データセットの統合方法について説明するための説明図である。
【図23】データセットの統合方法について説明するための説明図である。
【図24】データセットの統合方法について説明するための説明図である。
【図25】データセットの統合方法について説明するための説明図である。
【図26】データセットの統合方法について説明するための説明図である。
【図27】データセットの統合方法について説明するための説明図である。
【図28】データセットの統合方法について説明するための説明図である。
【図29】データセットの統合方法について説明するための説明図である。
【図30】データセットの統合方法について説明するための説明図である。
【図31】データセットの統合方法について説明するための説明図である。
【図32】データセットの統合方法について説明するための説明図である。
【図33】データセットの統合方法について説明するための説明図である。
【図34】思考ルーチンの構成について説明するための説明図である。
【図35】思考ルーチンの構成について説明するための説明図である。
【図36】思考ルーチンの構成について説明するための説明図である。
【図37】思考ルーチンの構成について説明するための説明図である。
【図38】思考ルーチンの構築方法について説明するための説明図である。
【図39】情報処理装置10の機能構成例について説明するための説明図である。
【図40】情報処理装置10の機能構成例について説明するための説明図である。
【図41】効率的な報酬推定機の構築方法について説明するための説明図である。
【図42】効率的な報酬推定機の構築方法について説明するための説明図である。
【図43】アクションスコア推定機を用いた思考ルーチンの構成について説明するための説明図である。
【図44】アクションスコア推定機を用いた思考ルーチンの構成について説明するための説明図である。
【図45】予測機を用いた報酬の推定方法について説明するための説明図である。
【図46】予測機を用いた報酬の推定方法について説明するための説明図である。
【図47】予測機を用いた報酬の推定方法について説明するための説明図である。
【図48】「三目並べ」への応用について説明するための説明図である。
【図49】「三目並べ」への応用について説明するための説明図である。
【図50】「三目並べ」への応用について説明するための説明図である。
【図51】「三目並べ」への応用について説明するための説明図である。
【図52】「三目並べ」への応用について説明するための説明図である。
【図53】「三目並べ」への応用について説明するための説明図である。
【図54】「三目並べ」への応用について説明するための説明図である。
【図55】「対戦ゲーム」への応用について説明するための説明図である。
【図56】「対戦ゲーム」への応用について説明するための説明図である。
【図57】「対戦ゲーム」への応用について説明するための説明図である。
【図58】「対戦ゲーム」への応用について説明するための説明図である。
【図59】「対戦ゲーム」への応用について説明するための説明図である。
【図60】「対戦ゲーム」への応用について説明するための説明図である。
【図61】「対戦ゲーム」への応用について説明するための説明図である。
【図62】「対戦ゲーム」への応用について説明するための説明図である。
【図63】「五目並べ」への応用について説明するための説明図である。
【図64】「五目並べ」への応用について説明するための説明図である。
【図65】「ポーカー」への応用について説明するための説明図である。
【図66】「ポーカー」への応用について説明するための説明図である。
【図67】「ポーカー」への応用について説明するための説明図である。
【図68】「ロールプレイングゲーム」への応用について説明するための説明図である。
【図69】「ロールプレイングゲーム」への応用について説明するための説明図である。
【図70】「ロールプレイングゲーム」への応用について説明するための説明図である。
【図71】「ロールプレイングゲーム」への応用について説明するための説明図である。
【図72】「ロールプレイングゲーム」への応用について説明するための説明図である。
【図73】「ロールプレイングゲーム」への応用について説明するための説明図である。
【図74】「ロールプレイングゲーム」への応用について説明するための説明図である。
【図75】「ロールプレイングゲーム」への応用について説明するための説明図である。
【図76】「ロールプレイングゲーム」への応用について説明するための説明図である。
【図77】「ロールプレイングゲーム」への応用について説明するための説明図である。
【図78】「ロールプレイングゲーム」への応用について説明するための説明図である。
【図79】「ロールプレイングゲーム」への応用について説明するための説明図である。
【図80】情報処理装置の機能を実現することが可能なハードウェア構成例について説明するための説明図である。
【発明を実施するための形態】
【0016】
以下に添付図面を参照しながら、本技術に係る好適な実施の形態について詳細に説明する。なお、本明細書及び図面において、実質的に同一の機能構成を有する構成要素については、同一の符号を付することにより重複説明を省略する。
【0017】
[説明の流れについて]
ここで、以下に記載する説明の流れについて簡単に述べる。
【0018】
まず、本実施形態に係る基盤技術について説明する。具体的には、まず、図1〜図12を参照しながら、推定機の自動構築方法について説明する。次いで、図13を参照しながら、オンライン学習に基づく推定機の自動構築方法について説明する。
【0019】
次いで、図14〜図16を参照しながら、データセットの統合方法について説明する。次いで、図17〜図23を参照しながら、効率的なデータセットのサンプリング方法について説明する。次いで、図24〜図27を参照しながら、効率的な重み付け方法について説明する。次いで、図28を参照しながら、効率的なデータセットのサンプリング方法及び重み付け方法を組み合わせる方法について説明する。次いで、図29〜図33を参照しながら、その他のデータセットのサンプリング方法及び重み付け方法について説明する。
【0020】
次いで、図34〜図38を参照しながら、思考ルーチンの構成及び思考ルーチンの構築方法について説明する。次いで、図39及び図40を参照しながら、本実施形態に係る情報処理装置10の機能構成について説明する。次いで、図41及び図42を参照しながら、効率的な報酬推定機の構築方法について説明する。次いで、図43及び図44を参照しながら、アクションスコア推定機を用いた思考ルーチンの構成について説明する。次いで、図45〜図47を参照しながら、予測機を用いた報酬の推定方法について説明する。
【0021】
次いで、図48〜図54を参照しながら、本実施形態に係る技術を「三目並べ」へ応用する方法について説明する。次いで、図55〜図62を参照しながら、本実施形態に係る技術を「対戦ゲーム」へ応用する方法について説明する。次いで、図63及び図64を参照しながら、本実施形態に係る技術を「五目並べ」へ応用する方法について説明する。次いで、図65〜図67を参照しながら、本実施形態に係る技術を「ポーカー」へ応用する方法について説明する。次いで、図68〜図79を参照しながら、本実施形態に係る技術を「ロールプレイングゲーム」へ応用する方法について説明する。
【0022】
次いで、図80を参照しながら、本実施形態に係る情報処理装置10の機能を実現することが可能なハードウェア構成例について説明する。最後に、同実施形態の技術的思想について纏め、当該技術的思想から得られる作用効果について簡単に説明する。
【0023】
(説明項目)
1:基盤技術
1−1:推定機の自動構築方法
1−1−1:推定機の構成
1−1−2:構築処理の流れ
1−2:オンライン学習について
1−3:学習用データの統合方法
1−3−1:特徴量空間における学習用データの分布と推定機の精度
1−3−2:データ統合時にサンプリングする構成
1−3−3:データ統合時に重み付けする構成
1−3−4:データ統合時にサンプリング及び重み付けする構成
1−4:効率的なサンプリング/重み付け方法
1−4−1:サンプリング方法
1−4−2:重み付け方法
1−4−3:組み合わせ方法
1−5:サンプリング処理及び重み付け処理に関する変形例
1−5−1:変形例1(距離に基づく処理)
1−5−2:変形例2(クラスタリングに基づく処理)
1−5−3:変形例3(密度推定手法に基づく処理)
2:実施形態
2−1:思考ルーチンの自動構築方法
2−1−1:思考ルーチンとは
2−1−2:思考ルーチンの構成
2−1−3:報酬推定機の構築方法
2−2:情報処理装置10の構成
2−3:効率的な推定報酬機の構築方法
2−4:(変形例1)アクションスコア推定機を用いる思考ルーチン
2−5:(変形例2)予測機を用いた報酬の推定
2−5−1:予測機の構築方法
2−5−2:報酬の推定方法
2−6:(変形例3)複数エージェントの同時学習
3:応用例
3−1:「三目並べ」への応用
3−2:「対戦ゲーム」への応用
3−3:「五目並べ」への応用
3−4:「ポーカー」への応用
3−5:「ロールプレイングゲーム」への応用
4:ハードウェア構成例
5:まとめ
【0024】
<1:基盤技術>
後述する実施形態は、推定機の自動構築方法に関する。また、同実施形態は、推定機の構築に用いる学習用データを追加できるようにする仕組み(以下、オンライン学習)に関する。そこで、同実施形態に係る技術について詳細に説明するに先立ち、推定機の自動構築方法及びオンライン学習方法(以下、基盤技術)について説明する。なお、以下では遺伝アルゴリズムに基づく推定機の自動構築方法を例に挙げて説明を進めるが、同実施形態に係る技術の適用範囲はこれに限定されない。
【0025】
[1−1:推定機の自動構築方法]
推定機の自動構築方法について説明する。
【0026】
(1−1−1:推定機の構成)
はじめに、図1〜図3を参照しながら、推定機の構成について説明する。図1は、推定機を利用するシステムのシステム構成例を示した説明図である。また、図2は、推定機の構築に利用する学習用データの構成例を示した説明図である。そして、図3は、推定機の構造及び構築方法の概要を示した説明図である。
【0027】
まず、図1を参照する。図1に示すように、推定機の構築及び推定値の算出は、例えば、情報処理装置10により実行される。情報処理装置10は、学習用データ(X1,t1),…,(XN,tN)を利用して推定機を構築する。また、情報処理装置10は、構築した推定機を利用して入力データXから推定値yを算出する。この推定値yは、入力データXの認識に利用される。例えば、推定値yが所定の閾値Thより大きい場合に認識結果YESが得られ、推定値yが所定の閾値Thより小さい場合に認識結果NOが得られる。
【0028】
図2を参照しながら、より具体的に推定機の構成について考えてみよう。図2に例示した学習用データの集合は、“海”の画像を認識する画像認識機の構築に利用されるものである。この場合、情報処理装置10により構築される推定機は、入力された画像の“海らしさ”を表す推定値yを出力するものとなる。図2に示すように、学習用データは、データXkと目的変数tkとのペア(但し、k=1〜N)により構成される。データXkは、k番目の画像データ(画像#k)である。また、目的変数tkは、画像#kが“海”の画像である場合に1、画像#kが“海”の画像でない場合に0となる変数である。
【0029】
図2の例では、画像#1が“海”の画像であり、画像#2が“海”の画像であり、…、画像#Nが“海”の画像でない。この場合、t1=1、t2=1、…、tN=0となる。この学習用データが入力されると、情報処理装置10は、入力された学習用データに基づく機械学習により、入力された画像の“海らしさ”を表す推定値yを出力する推定機を構築する。この推定値yは、入力された画像の“海らしさ”が高いほど1に近づき、“海らしさ”が低いほど0に近づく値である。
【0030】
また、新たに入力データX(画像X)が入力されると、情報処理装置10は、学習用データの集合を利用して構築された推定機に画像Xを入力し、画像Xの“海らしさ”を表す推定値yを算出する。この推定値yを利用すると、画像Xが“海”の画像であるか否かを認識することが可能になる。例えば、推定値y≧所定の閾値Thの場合、入力された画像Xが“海”の画像であると認識される。一方、推定値y<所定の閾値Thの場合、入力された画像Xが“海”の画像でないと認識される。
【0031】
本実施形態は、上記のような推定機を自動構築する技術に関する。なお、ここでは画像認識機の構築に利用される推定機について説明したが、本実施形態に係る技術は、様々な推定機の自動構築方法に適用することができる。例えば、言語解析機の構築に適用することもできるし、楽曲のメロディーラインやコード進行などを解析する音楽解析機の構築にも適用することができる。さらに、蝶の動きや雲の流れなどの自然現象を再現したり、自然の振る舞いを予測したりする動き予測機の構築などにも適用することができる。
【0032】
例えば、特開2009−48266号公報、特願2010−159598号明細書、特願2010−159597号明細書、特願2009−277083号明細書、特願2009−277084号明細書などに記載のアルゴリズムに適用することができる。また、AdaBoostなどのアンサンブル学習手法や、SVMやSVRなどのカーネルを用いた学習手法などにも適用できる。AdaBoostなどのアンサンブル学習手法に適用する場合、弱学習機(Weak Learner)が後述する基底関数φに対応する。また、SVMやSVRなどの学習手法に適用する場合、カーネルが後述する基底関数φに対応する。なお、SVMはSupport Vector Machine、SVRはSupport Vector Regression、RVMはRelevance Vector Machineの略である。
【0033】
ここで、図3を参照しながら、推定機の構造について説明する。図3に示すように、推定機は、基底関数リスト(φ1,…,φM)及び推定関数fにより構成される。基底関数リスト(φ1,…,φM)は、M個の基底関数φk(k=1〜M)を含む。また、基底関数φkは、入力データXの入力に応じて特徴量zkを出力する関数である。さらに、推定関数fは、M個の特徴量zk(k=1〜M)を要素として含む特徴量ベクトルZ=(z1,…,zM)の入力に応じて推定値yを出力する関数である。基底関数φkは、予め用意された1又は複数の処理関数を組み合わせて生成される。
【0034】
処理関数としては、例えば、三角関数、指数関数、四則演算、デジタルフィルタ、微分演算、中央値フィルタ、正規化演算、ホワイトノイズの付加処理、画像処理フィルタなどが利用可能である。例えば、入力データXが画像の場合、ホワイトノイズの付加処理AddWhiteNoise()、中央値フィルタMedian()、ぼかし処理Blur()を組み合わせた基底関数φj(X)=AddWhiteNoise(Median(Blur(X)))などが利用される。この基底関数φjは、入力データXに対し、ぼかし処理、中央値フィルタ処理、及びホワイトノイズの付加処理を順次施すことを意味する。
【0035】
(1−1−2:構築処理の流れ)
さて、基底関数φk(k=1〜M)の構成、基底関数リストの構成、推定関数fの構成は、学習用データに基づく機械学習により決定される。以下、この機械学習による推定機の構築処理について、より詳細に説明する。
【0036】
(全体構成)
まず、図4を参照しながら、全体的な処理の流れについて説明する。図4は、全体的な処理の流れについて説明するための説明図である。なお、以下で説明する処理は、情報処理装置10により実行される。
【0037】
図4に示すように、まず、情報処理装置10に学習用データが入力される(S101)。なお、学習用データとしては、データXと目的変数tの組が入力される。学習用データが入力されると、情報処理装置10は、処理関数を組み合わせて基底関数を生成する(S102)。次いで、情報処理装置10は、基底関数にデータXを入力して特徴量ベクトルZを算出する(S103)。次いで、情報処理装置10は、基底関数の評価及び推定関数の生成を行う(S104)。
【0038】
次いで、情報処理装置10は、所定の終了条件を満たしたか否かを判定する(S105)。所定の終了条件を満たした場合、情報処理装置10は、処理をステップS106に進める。一方、所定の終了条件を満たしていない場合、情報処理装置10は、処理をステップS102に戻し、ステップS102〜S104の処理を繰り返し実行する。処理をステップS106に進めた場合、情報処理装置10は、推定関数を出力する(S106)。上記の通り、ステップS102〜S104の処理は、繰り返し実行される。そこで、以下の説明においては、第τ回目の繰り返し処理においてステップS102で生成される基底関数を第τ世代の基底関数と呼ぶことにする。
【0039】
(基底関数の生成(S102))
ここで、図5〜図10を参照しながら、ステップS102の処理(基底関数の生成)について、より詳細に説明する。
【0040】
まず、図5を参照する。図5に示すように、情報処理装置10は、現在の世代が2世代目以降であるか否かを判定する(S111)。つまり、情報処理装置10は、現在実行しようとしているステップS102の処理が第2回目以降の繰り返し処理であるか否かを判定する。2世代目以降である場合、情報処理装置10は、処理をステップS113に進める。一方、2世代目以降でない場合(第1世代である場合)、情報処理装置10は、処理をステップS112に進める。処理をステップS112に進めた場合、情報処理装置10は、基底関数をランダムに生成する(S112)。一方、処理をステップS113に進めた場合、情報処理装置10は、基底関数を進化的に生成する(S113)。そして、情報処理装置10は、ステップS112又はS113の処理が完了すると、ステップS102の処理を終了する。
【0041】
(S112:基底関数をランダムに生成)
次に、図6及び図7を参照しながら、ステップS112の処理について、より詳細に説明する。ステップS112の処理は、第1世代の基底関数を生成する処理に関する。
【0042】
まず、図6を参照する。図6に示すように、情報処理装置10は、基底関数のインデックスm(m=0〜M−1)に関する処理ループを開始する(S121)。次いで、情報処理装置10は、基底関数φm(x)をランダムに生成する(S122)。次いで、情報処理装置10は、基底関数のインデックスmがM−1に達したか否かを判定し、基底関数のインデックスmがM−1に達していない場合、情報処理装置10は、基底関数のインデックスmをインクリメントしてステップS121に処理を戻す(S124)。一方、基底関数のインデックスmがm=M−1の場合、情報処理装置10は、処理ループを終了する(S124)。ステップS124で処理ループを終了すると、情報処理装置10は、ステップS112の処理を完了する。
【0043】
(ステップS122の詳細)
次に、図7を参照しながら、ステップS122の処理について、より詳細に説明する。
【0044】
ステップS122の処理を開始すると、図7に示すように、情報処理装置10は、基底関数のプロトタイプをランダムに決定する(S131)。プロトタイプとしては、既に例示した処理関数の他、線形項、ガウシアンカーネル、シグモイドカーネルなどの処理関数が利用可能である。次いで、情報処理装置10は、決定したプロトタイプのパラメータをランダムに決定し、基底関数を生成する(S132)。
【0045】
(S113:基底関数を進化的に生成)
次に、図8〜図10を参照しながら、ステップS113の処理について、より詳細に説明する。ステップS113の処理は、第τ世代(τ≧2)の基底関数を生成する処理に関する。従って、ステップS113を実行する際には、第τ−1世代の基底関数φm,τ−1(m=1〜M)及び当該基底関数φm,τ−1の評価値vm,τ−1が得られている。
【0046】
まず、図8を参照する。図8に示すように、情報処理装置10は、基底関数の数Mを更新する(S141)。つまり、情報処理装置10は、第τ世代の基底関数の数Mτを決定する。次いで、情報処理装置10は、第τ−1世代の基底関数φm,τ−1(m=1〜M)に対する評価値vτ−1={v1,τ−1,…,vM,τ−1}に基づき、第τ−1世代の基底関数の中からe個の有用な基底関数を選択して第τ世代の基底関数φ1,τ、…、φe,τに設定する(S142)。
【0047】
次いで、情報処理装置10は、残り(Mτ−e)個の基底関数φe+1,τ、…、φMτ,τを生成する方法を交差、突然変異、ランダム生成の中からランダムに選択する(S143)。交差を選択した場合、情報処理装置10は、処理をステップS144に進める。また、突然変異を選択した場合、情報処理装置10は、処理をステップS145に進める。そして、ランダム生成を選択した場合、情報処理装置10は、処理をステップS146に進める。
【0048】
処理をステップS144に進めた場合、情報処理装置10は、ステップS142で選択された基底関数φ1,τ、…、φe,τの中から選択された基底関数を交差させて新たな基底関数φm’,τ(m’≧e+1)を生成する(S144)。また、処理をステップS145に進めた場合、情報処理装置10は、ステップS142で選択された基底関数φ1,τ、…、φe,τの中から選択された基底関数を突然変異させて新たな基底関数φm’,τ(m’≧e+1)を生成する(S145)。一方、処理をステップS146に進めた場合、情報処理装置10は、ランダムに新たな基底関数φm’,τ(m’≧e+1)を生成する(S146)。
【0049】
ステップS144、S145、S146のいずれかの処理を終えると、情報処理装置10は、処理をステップS147に進める。処理をステップS147に進めると、情報処理装置10は、第τ世代の基底関数がM個(M=Mτ)に達したか否かを判定する(S147)。第τ世代の基底関数がM個に達していない場合、情報処理装置10は、処理を再びステップS143に戻す。一方、第τ世代の基底関数がM個に達した場合、情報処理装置10は、ステップS113の処理を終了する。
【0050】
(S144の詳細:交差)
次に、図9を参照しながら、ステップS144の処理について、より詳細に説明する。
【0051】
ステップS144の処理を開始すると、図9に示すように、情報処理装置10は、ステップS142で選択された基底関数φ1,τ、…、φe,τの中から同じプロトタイプを持つ基底関数をランダムに2つ選択する(S151)。次いで、情報処理装置10は、選択した2つの基底関数が持つパラメータを交差させて新たな基底関数を生成する(S152)。
【0052】
(S145の詳細:突然変異)
次に、図10を参照しながら、ステップS145の処理について、より詳細に説明する。
【0053】
ステップS145の処理を開始すると、図10に示すように、情報処理装置10は、ステップS142で選択された基底関数φ1,τ、…、φe,τの中から基底関数をランダムに1つ選択する(S161)。次いで、情報処理装置10は、選択した基底関数が持つパラメータの一部をランダムに変更して新たな基底関数を生成する(S162)。
【0054】
(S146の詳細:ランダム生成)
次に、図7を参照しながら、ステップS146の処理について、より詳細に説明する。
【0055】
ステップS122の処理を開始すると、図7に示すように、情報処理装置10は、基底関数のプロトタイプをランダムに決定する(S131)。プロトタイプとしては、既に例示した処理関数の他、線形項、ガウシアンカーネル、シグモイドカーネルなどの処理関数が利用可能である。次いで、情報処理装置10は、決定したプロトタイプのパラメータをランダムに決定し、基底関数を生成する(S132)。
【0056】
以上、ステップS102の処理(基底関数の生成)について、より詳細に説明した。
【0057】
(基底関数の計算(S103))
次に、図11を参照しながら、ステップS103の処理(基底関数の計算)について、より詳細に説明する。
【0058】
図11に示すように、情報処理装置10は、学習用データに含まれるi番目のデータX(i)のインデックスiに関する処理ループを開始する(S171)。例えば、学習用データとしてN個のデータの組{X(1),…,X(N)}が入力された場合には、i=1〜Nに関して処理ループが実行される。次いで、情報処理装置10は、基底関数φmのインデックスmに関する処理ループを開始する(S172)。例えば、M個の基底関数を生成した場合には、m=1〜Mに関して処理ループが実行される。
【0059】
次いで、情報処理装置10は、特徴量zmi=φm(x(i))を計算する(S173)。次いで、情報処理装置10は、処理をステップS174に進め、基底関数のインデックスmに関する処理ループを続ける。そして、情報処理装置10は、基底関数のインデックスmに関する処理ループが終了すると、処理をステップS175に進め、インデックスiに関する処理ループを続ける。インデックスiに関する処理ループが終了した場合、情報処理装置10は、ステップS103の処理を終了する。
【0060】
以上、ステップS103の処理(基底関数の計算)について、より詳細に説明した。
【0061】
(基底関数の評価・推定関数の生成(S104))
次に、図12を参照しながら、ステップS104の処理(基底関数の評価・推定関数の生成)について、より詳細に説明する。
【0062】
図12に示すように、情報処理装置10は、AIC基準の増減法に基づく回帰/判別学習により推定関数のパラメータw={w0,…,wM}を算出する(S181)。つまり、情報処理装置10は、特徴量zmi=φm,τ(x(i))と目的変数t(i)の組(i=1〜N)が推定関数fによりフィッティングされるように、回帰/判別学習によりベクトルw={w0,…,wM}を求める。但し、推定関数f(x)は、f(x)=Σwmφm,τ(x)+w0であるとする。次いで、情報処理装置10は、パラメータwが0となる基底関数の評価値vを0に設定し、それ以外の基底関数の評価値vを1に設定する(S182)。つまり、評価値vが1の基底関数は有用な基底関数である。
【0063】
以上、ステップS104の処理(基底関数の評価・推定関数の生成)について、より詳細に説明した。
【0064】
推定機の構築に係る処理の流れは上記の通りである。このように、ステップS102〜S104の処理が繰り返し実行され、基底関数が進化的手法により逐次更新されることにより推定精度の高い推定関数が得られる。つまり、上記の方法を適用することで、高性能な推定機を自動構築することができる。
【0065】
[1−2:オンライン学習について]
さて、上記のように、機械学習により推定機を自動構築するアルゴリズムの場合、学習用データの数が多いほど、構築される推定機の性能が高くなる。そのため、可能な限り多くの学習用データを利用して推定機を構築するのが好ましい。また、後述する実施形態に係る技術においては、学習用データを追加する仕組みが利用される。そこで、学習用データを追加できるようにする新たな仕組み(以下、オンライン学習)について紹介する。
【0066】
オンライン学習に係る推定機の構築は、図13に示すような処理の流れに沿って行われる。図13に示すように、まず、学習用データの集合が情報処理装置10に入力される(Step 1)。次いで、情報処理装置10は、入力された学習用データの集合を利用し、既に説明した推定機の自動構築方法により推定機を構築する(Step 2)。
【0067】
次いで、情報処理装置10は、随時又は所定のタイミングで追加の学習用データを取得する(Step 3)。次いで、情報処理装置10は、(Step 1)で入力された学習用データの集合に、(Step 3)で取得した学習用データを統合する(Step 4)。このとき、情報処理装置10は、学習用データのサンプリング処理や重み付け処理を実行し、統合後の学習用データの集合を生成する。そして、情報処理装置10は、統合後の学習用データの集合を利用し、再び推定機を構築する(Step 2)。このとき、情報処理装置10は、既に説明した推定機の自動構築方法により推定機を構築する。
【0068】
また、(Step 2)〜(Step 4)の処理は繰り返し実行される。そして、学習用データは、処理が繰り返される度に更新される。例えば、繰り返しの度に学習用データが追加されるようにすれば、推定機の構築処理に利用される学習用データの数が増加するため、推定機の性能が向上する。なお、(Step 4)で実行される学習用データの統合処理においては、情報処理装置10のリソースをより有効に利用すべく、より有用な学習用データが推定機の構築に利用されるように統合の仕方を工夫する。以下、この工夫について紹介する。
【0069】
[1−3:学習用データの統合方法]
学習用データの統合方法について、より詳細に説明する。
【0070】
(1−3−1:特徴量空間における学習用データの分布と推定機の精度)
まず、図14を参照しながら、特徴量空間における学習用データの分布と推定機の精度との関係について考察する。図14は、特徴量空間における学習用データの分布例を示した説明図である。
【0071】
1つの特徴量ベクトルは、1つの学習用データを構成するデータを基底関数リストに含まれる各基底関数に入力することで得られる。つまり、1つの学習用データには1つの特徴量ベクトル(特徴量座標)が対応する。そのため、特徴量座標の分布を特徴量空間における学習用データの分布と呼ぶことにする。特徴量空間における学習用データの分布は、例えば、図14のようになる。なお、表現の都合上、図14の例では2次元の特徴量空間を考えているが、特徴量空間の次元数はこれに限定されない。
【0072】
さて、図14に例示した特徴量座標の分布を参照すると、第4象限に疎な領域が存在していることに気づくであろう。既に説明した通り、推定関数は、全ての学習用データについて特徴量ベクトルと目的変数との関係がうまく表現されるように回帰/判別学習により生成される。そのため、特徴量座標の密度が疎な領域について、推定関数は、特徴量ベクトルと目的変数との関係をうまく表現できていない可能性が高い。従って、認識処理の対象となる入力データに対応する特徴量座標が上記の疎な領域に位置する場合、高精度の認識結果を期待することは難しい。
【0073】
図15に示すように、学習データセットの数が多くなると疎な領域が生じにくくなり、どの領域に対応する入力データが入力されても高い精度で認識結果を出力することが可能な推定機を構築できるようになると期待される。また、学習データセットの数が比較的少なくても、特徴量座標が特徴量空間において満遍なく分布していれば、高い精度で認識結果を出力することが可能な推定機を構築できるものと期待される。そこで、本件発明者は、学習用データを統合する際に特徴量座標の分布を考慮し、統合後の学習用データの集合に対応する特徴量座標の分布が所定の分布(例えば、一様分布やガウス分布など)となるように調整する仕組みを考案した。
【0074】
(1−3−2:データ統合時にサンプリングする構成)
まず、図16を参照しながら、学習用データをサンプリングする方法について説明する。図16は、学習用データをサンプリングする方法について説明するための説明図である。
【0075】
既に説明したように、オンライン学習を適用する場合、逐次的に学習用データを追加できるため、多量の学習用データを用いて推定機を構築することが可能になる。しかし、情報処理装置10のメモリリソースが限られている場合、学習用データの統合時に、推定機の構築に利用する学習用データの数を絞り込む必要がある。このとき、ランダムに学習用データを間引くのではなく、特徴量座標の分布を考慮して学習用データを間引くことで、推定機の精度を低下させることなく、学習用データの数を絞り込むことができる。例えば、図16に示すように、密な領域に含まれる特徴量座標を多く間引き、疎な領域に含まれる特徴量座標を極力残すようにする。
【0076】
このような方法で学習用データを間引くことにより、統合後の学習用データの集合に対応する特徴量座標の密度が均一になる。つまり、学習用データの数は少なくなったが、特徴量空間の全体に満遍なく特徴量座標が分布しているため、推定関数の生成時に実行する回帰/判別学習の際に特徴量空間の全体が考慮されることになる。その結果、情報処理装置10のメモリリソースが限られていても、高い精度で正しい認識結果を推定することが可能な推定機を構築することが可能になる。
【0077】
(1−3−3:データ統合時に重み付けする構成)
次に、学習用データに重みを設定する方法について説明する。
【0078】
情報処理装置10のメモリリソースが限られている場合、学習用データの統合時に学習用データを間引く方法は有効である。一方、メモリリソースに余裕がある場合、学習用データを間引く代わりに、学習用データに重みを設定することで推定機の性能を向上させることが可能になる。例えば、疎な領域に特徴量座標が含まれる学習用データには大きな重みを設定し、密な領域に特徴量座標が含まれる学習用データには小さな重みを設定する。そして、推定関数の生成時に実行する回帰/判別学習の際に各学習用データに設定された重みを考慮するようにする。
【0079】
(1−3−4:データ統合時にサンプリング及び重み付けする構成)
また、学習用データをサンプリングする方法と、学習用データに重みを設定する方法とを組み合わせてもよい。例えば、特徴量座標の分布が所定の分布となるように学習用データを間引いた後、間引き後の学習用データの集合に属する学習用データに対し、特徴量座標の密度に応じた重みを設定する。このように、間引き処理と重み付け処理とを組み合わせることにより、メモリリソースが限られていても、より高精度の推定機を構築することが可能になる。
【0080】
[1−4:効率的なサンプリング/重み付け方法]
次に、学習用データの効率的なサンプリング/重み付け方法について説明する。
【0081】
(1−4−1:サンプリング方法)
まず、図17を参照しながら、学習用データの効率的なサンプリング方法について説明する。図17は、学習用データの効率的なサンプリング方法について説明するための説明図である。
【0082】
図17に示すように、情報処理装置10は、全ての学習用データについて特徴量ベクトル(特徴量座標)を算出する(S201)。次いで、情報処理装置10は、算出した特徴量座標を正規化する(S202)。例えば、情報処理装置10は、図18に示すように、各特徴量について、分散が1、平均が0となるように値を正規化する。
【0083】
次いで、情報処理装置10は、ランダムにハッシュ関数gを生成する(S203)。例えば、情報処理装置10は、下記の式(1)に示すような5ビットの値を出力するハッシュ関数gを複数生成する。このとき、情報処理装置10は、Q個のハッシュ関数gq(q=1〜Q)を生成する。但し、関数hj(j=1〜5)は、下記の式(2)により定義される。また、d及びThresholdは、乱数により決定される。
【0084】
但し、特徴量座標の分布を一様分布に近づける場合、Thresholdの決定に用いる乱数として一様乱数を用いる。また、特徴量座標の分布をガウス分布に近づける場合、Thresholdの決定に用いる乱数としてガウス乱数を用いる。他の分布についても同様である。また、dの決定は、zdの算出に用いた基底関数の寄与率に応じた偏りのある乱数を用いて行われる。例えば、zdの算出に用いた基底関数の寄与率が大きいほど、dの発生する確率が高くなる乱数が用いられる。
【0085】
【数1】
【0086】
ハッシュ関数gq(q=1〜Q)を生成すると、情報処理装置10は、各学習用データに対応する特徴量ベクトルZをハッシュ関数gqに入力し、ハッシュ値を算出する。そして、情報処理装置10は、算出したハッシュ値に基づいて学習用データをバケットに割り当てる(S204)。但し、ここで言うバケットとは、ハッシュ値として取り得る値が対応付けられた領域を意味する。
【0087】
例えば、ハッシュ値が5ビット、Q=256の場合について考えてみよう。この場合、バケットの構成は図19のようになる。図19に示すように、ハッシュ値が5ビットであるから、1つのハッシュ関数gqに対し、32個のバケット(以下、バケットセット)が設けられる。また、Q=256であるから、256組のバケットセットが設けられる。この例に沿って、学習用データをバケットに割り当てる方法について説明する。
【0088】
ある学習用データに対応する特徴量ベクトルZが与えられると、256個のハッシュ関数g1〜g256を用いて256個のハッシュ値が算出される。例えば、g1(Z)=2(10進数表示)であった場合、情報処理装置10は、その学習用データをg1に対応するバケットセットの中で2に対応するバケットに割り当てる。同様に、gq(Z)(q=2〜256)を算出し、各値に対応するバケットに学習用データを割り当てる。図19の例では、2種類の学習用データを白丸と黒丸とで表現し、各バケットとの対応関係を模式的に表現している。
【0089】
このようにして各学習用データをバケットに割り当てると、情報処理装置10は、所定の順序でバケットから学習用データを1つ選択する(S205)。例えば、情報処理装置10は、図20に示すように、左上(ハッシュ関数のインデックスqが小さく、バケットに割り当てられた値が小さい側)から順にバケットを走査し、バケットに割り当てられた学習用データを1つ選択する。
【0090】
バケットから学習用データを選択するルールは、図21に示した通りである。第1に、情報処理装置10は、空のバケットをスキップする。第2に、情報処理装置10は、1つの学習用データを選択した場合、同じ学習用データを他の全てのバケットから除く。第3に、情報処理装置10は、1つのバケットに複数の学習用データが割り当てられている場合にはランダムに1つの学習用データを選択する。なお、選択された学習用データの情報は、情報処理装置10により保持される。
【0091】
1つの学習用データを選択した後、情報処理装置10は、所定数の学習用データを選択し終えたか否かを判定する(S206)。所定数の学習用データを選択し終えた場合、情報処理装置10は、選択した所定数の学習用データを統合後の学習用データの集合として出力し、学習用データの統合に係る一連の処理を終了する。一方、所定数の学習用データを選択し終えていない場合、情報処理装置10は、処理をステップS205に進める。
【0092】
以上、学習用データの効率的なサンプリング方法について説明した。なお、特徴量空間と上記のバケットとの対応関係は図22に示したイメージ図のようになる。また、上記の方法により学習用データのサンプリングを行った結果は、例えば、図23(一様分布の例)のようになる。図23を参照すると、疎な領域に含まれる特徴量座標は残り、密な領域に含まれる特徴量座標が間引かれていることが分かる。なお、上記のバケットを利用しない場合、学習用データのサンプリングに要する演算負荷は格段に大きくなる点に注意されたい。
【0093】
(1−4−2:重み付け方法)
次に、図24を参照しながら、学習用データの効率的な重み付け方法について説明する。図24は、学習用データの効率的な重み付け方法について説明するための説明図である。
【0094】
図24に示すように、情報処理装置10は、全ての学習用データについて特徴量ベクトル(特徴量座標)を算出する(S211)。次いで、情報処理装置10は、算出した特徴量座標を正規化する(S212)。例えば、情報処理装置10は、図24に示すように、各特徴量について、分散が1、平均が0となるように値を正規化する。
【0095】
次いで、情報処理装置10は、ランダムにハッシュ関数gを生成する(S213)。例えば、情報処理装置10は、上記の式(1)に示すような5ビットの値を出力するハッシュ関数gを複数生成する。このとき、情報処理装置10は、Q個のハッシュ関数gq(q=1〜Q)を生成する。但し、関数hj(j=1〜5)は、上記の式(2)により定義される。また、d及びThresholdは、乱数により決定される。
【0096】
但し、特徴量座標の分布を一様分布に近づける場合、Thresholdの決定に用いる乱数として一様乱数を用いる。また、特徴量座標の分布をガウス分布に近づける場合、Thresholdの決定に用いる乱数としてガウス乱数を用いる。他の分布についても同様である。また、dの決定は、zdの算出に用いた基底関数の寄与率に応じた偏りのある乱数を用いて行われる。例えば、zdの算出に用いた基底関数の寄与率が大きいほど、dの発生する確率が高くなる乱数が用いられる。
【0097】
ハッシュ関数gq(q=1〜Q)を生成すると、情報処理装置10は、各学習用データに対応する特徴量ベクトルZをハッシュ関数gqに入力し、ハッシュ値を算出する。そして、情報処理装置10は、算出したハッシュ値に基づいて学習用データをバケットに割り当てる(S214)。次いで、情報処理装置10は、各学習用データについて密度を算出する(S215)。例えば、図25に示すように、学習データセットがバケットに割り当てられているものとしよう。また、白丸で表現された学習用データに注目する。
【0098】
この場合、情報処理装置10は、まず、各ハッシュ関数に対応するバケットセットについて、白丸を含むバケットに割り当てられている学習用データの数をカウントする。例えば、ハッシュ関数g1に対応するバケットセットを参照すると、白丸を含むバケットに割り当てられている学習用データの数は1である。同様に、ハッシュ関数g2に対応するバケットセットを参照すると、白丸を含むバケットに割り当てられている学習用データの数は2である。情報処理装置10は、ハッシュ関数g1〜g256に対応するバケットセットについて、白丸を含むバケットに割り当てられている学習用データの数をカウントする。
【0099】
そして、情報処理装置10は、カウントした数の平均値を算出し、算出した平均値を白丸に対応する学習用データの密度とみなす。同様にして、情報処理装置10は、全ての学習用データの密度を算出する。なお、各学習用データの密度は図26のB図のように表現される。但し、色が濃い部分の密度が高く、色が薄い部分の密度が低い。
【0100】
さて、全ての学習用データについて密度を算出し終えると、情報処理装置10は、処理をステップS217に進める(S216)。ステップS217に処理を進めた場合、情報処理装置10は、算出した密度から各学習用データに設定する重みを算出する(S217)。例えば、情報処理装置10は、密度の逆数を重みに設定する。なお、各学習用データに設定される重みの分布は図27のB図のように表現される。但し、色が濃い部分の重みが大きく、色が薄い部分の重みが小さい。図27を参照すると、密な領域の重みが小さく、疎な領域の重みが大きくなっていることが分かるであろう。
【0101】
上記のようにして各学習用データに設定する重みを算出し終えると、情報処理装置10は、重み付けに係る一連の処理を終了する。以上、学習用データの効率的な重み付け方法について説明した。なお、上記のバケットを利用しない場合、学習用データの重み付けに要する演算負荷は格段に大きくなる点に注意されたい。
【0102】
(1−4−3:組み合わせ方法)
次に、図28を参照しながら、上記の効率的なサンプリング方法と効率的な重み付け方法とを組み合わせる方法について説明する。図28は、上記の効率的なサンプリング方法と効率的な重み付け方法とを組み合わせる方法について説明するための説明図である。
【0103】
図28に示すように、情報処理装置10は、まず、学習用データのサンプリング処理を実行する(S221)。このサンプリング処理は、図17に示した処理の流れに沿って実行される。そして、所定数の学習用データが得られると、情報処理装置10は、得られた学習用データを対象に重み付け処理を実行する(S222)。この重み付け処理は、図24に示した処理の流れに沿って実行される。なお、サンプリング処理の際に算出した特徴量ベクトルやハッシュ関数を流用してもよい。サンプリング処理及び重み付け処理を実行し終えると、情報処理装置10は、一連の処理を終了する。
【0104】
以上、学習用データの効率的なサンプリング/重み付け方法について説明した。
【0105】
[1−5:サンプリング処理及び重み付け処理に関する変形例]
次に、サンプリング処理及び重み付け処理に関する変形例を紹介する。
【0106】
(1−5−1:変形例1(距離に基づく処理))
まず、図29を参照しながら、特徴量座標間の距離に基づく学習用データのサンプリング方法について説明する。図29は、特徴量座標間の距離に基づく学習用データのサンプリング方法について説明するための説明図である。
【0107】
図29に示すように、情報処理装置10は、まず、ランダムに1つの特徴量座標を選択する(S231)。次いで、情報処理装置10は、インデックスjを1に初期化する(S232)。次いで、情報処理装置10は、未だ選択されてないJ個の特徴量座標の中からj番目の特徴量座標を対象座標に設定する(S233)。次いで、情報処理装置10は、既に選択された全ての特徴量座標と対象座標との距離Dを算出する(S234)。次いで、情報処理装置10は、算出した距離Dの最小値Dminを抽出する(S235)。
【0108】
次いで、情報処理装置10は、j=Jであるか否かを判定する(S236)。j=Jである場合、情報処理装置10は、処理をステップS237に進める。一方、j≠Jである場合、情報処理装置10は、処理をステップS233に進める。処理をステップS237に進めた場合、情報処理装置10は、最小値Dminが最大となる対象座標(特徴量座標)を選択する(S237)。次いで、情報処理装置10は、ステップS231及びS237において選択された特徴量座標の数が所定数に達したか否かを判定する(S238)。
【0109】
ステップS231及びS237において選択された特徴量座標の数が所定数に達した場合、情報処理装置10は、選択された特徴量座標に対応する学習用データを統合後の学習用データの集合として出力し、一連の処理を終了する。一方、ステップS231及びS237において選択された特徴量座標の数が所定数に達していない場合、情報処理装置10は、処理をステップS232に進める。
【0110】
以上、特徴量座標間の距離に基づく学習用データのサンプリング方法について説明した。
【0111】
(1−5−2:変形例2(クラスタリングに基づく処理))
次に、クラスタリングに基づく学習用データのサンプリング/重み付け方法について説明する。なお、以下ではサンプリング方法及び重み付け方法についてそれぞれ別々に説明するが、これらの方法を組み合わせてもよい。
【0112】
(データセットの選択)
まず、図30を参照しながら、クラスタリングに基づく学習用データのサンプリング方法について説明する。図30は、クラスタリングに基づく学習用データのサンプリング方法について説明するための説明図である。
【0113】
図30に示すように、まず、情報処理装置10は、特徴量ベクトルを所定数のクラスタに分類する(S241)。クラスタリング手法としては、例えば、k−means法や階層的クラスタリングなどの手法が利用可能である。次いで、情報処理装置10は、各クラスタから順に1つずつ特徴量ベクトルを選択する(S242)。そして、情報処理装置10は、選択した特徴量ベクトルに対応する学習用データを統合後の学習用データの集合として出力し、一連の処理を終了する。
【0114】
(重みの設定)
次に、図31を参照しながら、クラスタリングに基づく学習用データの重み付け方法について説明する。図31は、クラスタリングに基づく学習用データの重み付け方法について説明するための説明図である。
【0115】
図31に示すように、まず、情報処理装置10は、特徴量ベクトルを所定数のクラスタに分類する(S251)。クラスタリング手法としては、例えば、k−means法や階層的クラスタリングなどの手法が利用可能である。次いで、情報処理装置10は、各クラスタの要素数をカウントし、要素数の逆数を算出する(S252)。そして、情報処理装置10は、算出した要素数の逆数を重みとして出力し、一連の処理を終了する。
【0116】
以上、クラスタリングに基づく学習用データのサンプリング/重み付け方法について説明した。
【0117】
(1−5−3:変形例3(密度推定手法に基づく処理))
次に、密度推定手法に基づく学習用データのサンプリング/重み付け方法について説明する。なお、以下ではサンプリング方法及び重み付け方法についてそれぞれ別々に説明するが、これらの方法を組み合わせてもよい。
【0118】
(データセットの選択)
まず、図32を参照しながら、密度推定手法に基づく学習用データのサンプリング方法について説明する。図32は、密度推定手法に基づく学習用データのサンプリング方法について説明するための説明図である。
【0119】
図32に示すように、まず、情報処理装置10は、特徴量座標の密度をモデル化する(S261)。密度のモデル化には、例えば、GMM(Gaussian Mixture Model)などの密度推定手法が利用される。次いで、情報処理装置10は、構築したモデルに基づいて各特徴量座標の密度を算出する(S262)。次いで、情報処理装置10は、未だ選択されていない特徴量座標の中から、密度の逆数に比例する確率でランダムに特徴量座標を選択する(S263)。
【0120】
次いで、情報処理装置10は、所定数の特徴量座標を選択したか否かを判定する(S264)。所定数の特徴量座標を選択していない場合、情報処理装置10は、処理をステップS263に進める。一方、所定数の特徴量座標を選択した場合、情報処理装置10は、選択した特徴量座標に対応する学習用データを統合後の学習用データの集合として出力し、一連の処理を終了する。
【0121】
(重みの設定)
次に、図33を参照しながら、密度推定手法に基づく学習用データの重み付け方法について説明する。図33は、密度推定手法に基づく学習用データの重み付け方法について説明するための説明図である。
【0122】
図33に示すように、まず、情報処理装置10は、特徴量座標の密度をモデル化する(S271)。密度のモデル化には、例えば、GMMなどの密度推定手法が利用される。次いで、情報処理装置10は、構築したモデルに基づいて各特徴量座標の密度を算出する(S272)。そして、情報処理装置10は、算出した密度の逆数を重みに設定し、一連の処理を終了する。
【0123】
以上、密度推定手法に基づく学習用データのサンプリング/重み付け方法について説明した。
【0124】
以上、後述する実施形態において利用可能な基盤技術について説明した。但し、後述する実施形態に係る技術は、ここで説明した基盤技術の全てを利用しなくてもよいし、当該基盤技術を変形して利用したり、或いは、他の機械学習アルゴリズムを組み合わせて利用したりしてもよい点に注意されたい。
【0125】
<2:実施形態>
以下、本技術の一実施形態について説明する。
【0126】
[2−1:思考ルーチンの自動構築方法]
本実施形態は、ロボットのようなエージェントの思考ルーチンや様々なゲームに登場するNPC(Non−Player Character)の思考ルーチンを自動構築する技術に関する。例えば、本実施形態は、ある状態SにおかれたNPCが次にとる行動aを決定する思考ルーチンを自動構築する技術に関する。本稿においては、状態Sの入力に応じて行動aを出力するプログラムを思考ルーチンと呼ぶことにする。また、以下では、NPCの行動aを決定する思考ルーチンを例に挙げて説明を進めることにする。もちろん、ロボットなどの行動を決定する思考ルーチンも同様に自動構築することが可能である。
【0127】
(2−1−1:思考ルーチンとは)
上記の通り、本稿に言う思考ルーチンは、図34に示すように、状態Sの入力に応じて行動aを出力するプログラムである。なお、状態Sとは、ある瞬間に、行動aを決定すべきNPCがおかれた環境を意味する。例えば、図34に示すように、2つのNPC(NPC#1及び#2)が対戦する対戦ゲームについて考えてみよう。この対戦ゲームは、NPC#1及び#2がそれぞれヒットポイントを有しており、ダメージを受けるとヒットポイントが減少していく仕組みになっているものとする。この例において、ある瞬間における状態Sは、NPC#1及び#2のヒットポイント及び位置関係になる。
【0128】
この状態Sが入力されると、思考ルーチンは、NPC#1がNPC#2にダメージを与え、最終的にNPC#2のヒットポイントを0にできることが期待されるNPC#1の行動aを決定する。例えば、NPC#1のヒットポイントが十分に残っており、NPC#2のヒットポイントが僅かである場合、思考ルーチンは、NPC#1が多少のダメージを受けることを許容してNPC#2に素早くダメージを与える行動aを決定するかもしれない。また、NPC#1のヒットポイントが残り僅かであり、NPC#2のヒットポイントが十分に残っている場合、思考ルーチンは、NPC#1がダメージを受けないようにしつつ、NPC#2にダメージを与える行動aを決定するだろう。
【0129】
これまで、NPCの行動を決定する思考ルーチンは、熟練した技術者により長い時間をかけて設計されていた。もちろん、NPCの行動をランダムに決定する思考ルーチンも存在するであろう。しかし、賢いNPCの行動を実現することが可能な思考ルーチンを構築するには、ユーザ操作の分析や環境に応じた最適な行動の研究が欠かせなかった。さらに、こうした分析や研究の結果を踏まえて、環境に応じたNPCの最適な行動を決定するための条件設計を行う必要があった。そのため、思考ルーチンの構築には長い時間と大きな労力とが必要であった。こうした事情を踏まえ、本件発明者は、このような思考ルーチンを人手に依らずに自動構築する技術を開発した。
【0130】
(2−1−2:思考ルーチンの構成)
図35に示すように、本実施形態に係る思考ルーチンは、行動履歴データに基づく思考ルーチンの自動構築技術により生成される。この行動履歴データは、状態S、行動a、報酬rにより構成される。例えば、状態S=S1において、NPC#1が行動a=“右へ移動”をとった場合にNPC#2からダメージを受けてヒットポイントが0になったとしよう。この場合、行動履歴データは、状態S=S1、行動a=“右へ移動”、報酬r=“0”となる。このような構成を有する行動履歴データを予め蓄積しておき、この行動履歴データを学習データとする機械学習により思考ルーチンを自動構築することができる。
【0131】
本実施形態に係る思考ルーチンは、図36に示すような構成を有する。図36に示すように、この思考ルーチンは、状態Sの入力に応じてNPCがとりうる行動aをリストアップし、各行動aについてNPCが得るであろう報酬rの推定値(以下、推定報酬y)を算出する。そして、思考ルーチンは、推定報酬yが最も高い行動aを選択する。なお、推定報酬yは、報酬推定機を利用して算出される。この推定報酬機は、状態S及び行動aの入力に応じて推定報酬yを出力するアルゴリズムである。また、この報酬推定機は、行動履歴データを学習データとする機械学習により自動構築される。例えば、先に紹介した推定機の自動構築方法を応用することにより、報酬推定機を自動構築することができる。
【0132】
報酬推定機は、図37に示すように、基底関数リスト(φ1,…,φM)及び推定関数fにより構成される。基底関数リスト(φ1,…,φM)は、M個の基底関数φk(k=1〜M)を含む。また、基底関数φkは、入力データX(状態S及び行動a)の入力に応じて特徴量zkを出力する関数である。さらに、推定関数fは、M個の特徴量zk(k=1〜M)を要素として含む特徴量ベクトルZ=(z1,…,zM)の入力に応じて推定報酬yを出力する関数である。基底関数φkは、予め用意された1又は複数の処理関数を組み合わせて生成される。処理関数としては、例えば、三角関数、指数関数、四則演算、デジタルフィルタ、微分演算、中央値フィルタ、正規化演算などが利用可能である。
【0133】
また、本実施形態に係る思考ルーチンの自動構築技術は、自動構築された思考ルーチンを利用してNPCを行動させ、その行動の結果として得られた行動履歴データを追加した行動履歴データを利用して思考ルーチンを更新する。但し、行動履歴データの追加には、先に紹介したオンライン学習に係る技術を利用することができる。
【0134】
(2−1−3:報酬推定機の構築方法)
例えば、オンライン学習に係る技術を利用した報酬推定機の構築及び更新は、図38に示すような処理の流れに沿って行われる。なお、これらの処理は、情報処理装置10により実行されるものとする。図38に示すように、まず、行動履歴データが情報処理装置10に入力される(Step 1)。
【0135】
(Step 1)において、情報処理装置10は、予め設計された簡易な思考ルーチンを用いて行動aを決定しながらNPCを環境中で振る舞わせ、行動履歴データ(S,a,r)を得る。この簡易な思考ルーチンは、強化学習の分野においてInnate(赤ちゃんが行う本能的な動きに相当)と呼ばれる。このInnateは、NPCが取り得るアクションの中からランダムに行動を選択するものであってもよい。この場合、Innateの設計も不要になる。情報処理装置10は、所定数の行動履歴データが得られるまでInnateに基づくNPCの行動を繰り返し実行する。次いで、情報処理装置10は、入力された行動履歴データを利用し、既に説明した推定機の自動構築方法と同様にして報酬推定機を構築する(Step 2)。
【0136】
次いで、情報処理装置10は、随時又は所定のタイミングで追加の行動履歴データを取得する(Step 3)。次いで、情報処理装置10は、(Step 1)で入力された行動履歴データと、(Step 3)で取得した行動履歴データとを統合する(Step 4)。このとき、情報処理装置10は、行動履歴データのサンプリング処理や重み付け処理を実行し、統合後の行動履歴データを生成する。そして、情報処理装置10は、統合後の行動履歴データを利用し、再び報酬推定機を構築する(Step 2)。また、(Step 2)〜(Step 4)の処理は繰り返し実行される。そして、行動履歴データは、処理が繰り返される度に更新される。
【0137】
以上、思考ルーチンの自動構築方法について簡単に説明した。ここではNPCの行動を決定する思考ルーチンの自動構築方法について述べたが、行動履歴データの構成を変えることで様々な種類の思考ルーチンを同じように自動構築することができる。つまり、本実施形態の技術を適用することにより、統一的な仕組みで様々な思考ルーチンを構築できるようになる。また、自動的に思考ルーチンが構築されるため、思考ルーチンの構築に人が時間を費やさずに済み、労力が大幅に軽減される。
【0138】
[2−2:情報処理装置10の構成]
ここで、図39及び図40を参照しながら、本実施形態に係る情報処理装置10の機能構成について説明する。図39は、本実施形態に係る情報処理装置10の全体的な機能構成を示した説明図である。一方、図40は、本実施形態に係る情報処理装置10を構成する報酬推定機構築部12の詳細な機能構成を示した説明図である。
【0139】
(全体的な機能構成)
まず、図39を参照しながら、全体的な機能構成について説明する。図39に示すように、情報処理装置10は、主に、行動履歴データ取得部11と、報酬推定機構築部12と、入力データ取得部13と、行動選択部14とにより構成される。
【0140】
思考ルーチンの構築処理が開始されると、行動履歴データ取得部11は、報酬推定機の構築に利用する行動履歴データを取得する。例えば、行動履歴データ取得部11は、簡易な思考ルーチン(Innate)に基づいて繰り返しNPCを行動させ、所定数の行動履歴データを取得する。但し、行動履歴データ取得部11は、記憶装置(非図示)に予め格納された行動履歴データを読み出したり、或いは、行動履歴データを提供するシステムなどからネットワークを介して行動履歴データを取得したりしてもよい。
【0141】
行動履歴データ取得部11により取得された行動履歴データは、報酬推定機構築部12に入力される。行動履歴データが入力されると、報酬推定機構築部12は、入力された行動履歴データに基づく機械学習により報酬推定機を構築する。例えば、報酬推定機構築部12は、既に説明した遺伝アルゴリズムに基づく推定機の自動構築方法を利用して報酬推定機を構築する。また、行動履歴データ取得部11から追加の行動履歴データが入力された場合、報酬推定機構築部12は、行動履歴データを統合し、統合後の行動履歴データを利用して報酬推定機を構築する。
【0142】
報酬推定機構築部12により構築された報酬推定機は、行動選択部14に入力される。この報酬推定機は、任意の入力データ(状態S)に対して最適な行動を選択するために利用される。入力データ取得部13により入力データ(状態S)が取得されると、取得された入力データは、行動選択部14に入力される。入力データが入力されると、行動選択部14は、入力された入力データが示す状態S及び状態SにおいてNPCがとりうる行動aを報酬推定機に入力し、報酬推定機から出力される推定報酬yに基づいて行動aを選択する。例えば、図36に示すように、行動選択部14は、推定報酬yが最も高くなる行動aを選択する。
【0143】
以上、情報処理装置10の全体的な機能構成について説明した。
【0144】
(報酬推定機構築部12の機能構成)
次に、図40を参照しながら、報酬推定機構築部12の機能構成について詳細に説明する。図40に示すように、報酬推定機構築部12は、基底関数リスト生成部121と、特徴量計算部122と、推定関数生成部123と、行動履歴データ統合部124とにより構成される。
【0145】
思考ルーチンの構築処理が開始されると、まず、基底関数リスト生成部121は、基底関数リストを生成する。そして、基底関数リスト生成部121により生成された基底関数リストは、特徴量計算部122に入力される。また、特徴量計算部122には、行動履歴データが入力される。基底関数リスト及び行動履歴データが入力されると、特徴量計算部122は、入力された行動履歴データを基底関数リストに含まれる各基底関数に入力して特徴量を算出する。特徴量計算部122により算出された特徴量の組(特徴量ベクトル)は、推定関数生成部123に入力される。
【0146】
特徴量ベクトルが入力されると、推定関数生成部123は、入力された特徴量ベクトル及び行動履歴データを構成する報酬値rに基づいて回帰/判別学習により推定関数を生成する。なお、遺伝アルゴリズムに基づく推定機の構築方法を適用する場合、推定関数生成部123は、生成した推定関数に対する各基底関数の寄与率(評価値)を算出し、その寄与率に基づいて終了条件を満たすか否かを判定する。終了条件を満たす場合、推定関数生成部123は、基底関数リスト及び推定関数を含む報酬推定機を出力する。
【0147】
一方、終了条件を満たさない場合、推定関数生成部123は、生成した推定関数に対する各基底関数の寄与率を基底関数リスト生成部121に通知する。この通知を受けた基底関数リスト生成部121は、遺伝アルゴリズムにより各基底関数の寄与率に基づいて基底関数リストを更新する。基底関数リストを更新した場合、基底関数リスト生成部121は、更新後の基底関数リストを特徴量計算部122に入力する。更新後の基底関数リストが入力された場合、特徴量計算部122は、更新後の基底関数リストを用いて特徴量ベクトルを算出する。そして、特徴量計算部122により算出された特徴量ベクトルは、推定関数生成部123に入力される。
【0148】
上記のように、遺伝アルゴリズムに基づく推定機の構築方法を適用する場合、終了条件が満たされるまで、推定関数生成部123による推定関数の生成処理、基底関数リスト生成部121による基底関数リストの更新処理、及び特徴量計算部122による特徴量ベクトルの算出処理が繰り返し実行される。そして、終了条件が満たされた場合、推定関数生成部123から報酬推定機が出力される。
【0149】
また、追加の行動履歴データが入力されると、入力された追加の行動履歴データは、特徴量計算部122及び行動履歴データ統合部124に入力される。追加の行動履歴データが入力されると、特徴量計算部122は、追加の行動履歴データを基底関数リストに含まれる各基底関数に入力して特徴量を生成する。そして、追加の行動履歴データに対応する特徴量ベクトル及び既存の行動履歴データに対応する特徴量ベクトルは、行動履歴データ統合部124に入力される。なお、行動履歴データ統合部124には、既存の行動履歴データも入力されているものとする。
【0150】
行動履歴データ統合部124は、先に紹介したデータセットの統合方法を応用して既存の行動履歴データと追加の行動履歴データとを統合する。例えば、行動履歴データ統合部124は、特徴量空間において特徴量ベクトルにより示される座標(特徴量座標)の分布が所定の分布となるように行動履歴データを間引いたり、行動履歴データに重みを設定したりする。行動履歴データを間引いた場合、間引き後の行動履歴データが統合後の行動履歴データとして利用される。一方、行動履歴データに重みを設定した場合、推定関数生成部123による回帰/判別学習の際に各行動履歴データに設定された重みが考慮される。
【0151】
行動履歴データが統合されると、統合後の行動履歴データを用いて報酬推定機の自動構築処理が実行される。具体的には、行動履歴データ統合部124から推定関数生成部123に統合後の行動履歴データと、統合後の行動履歴データに対応する特徴量ベクトルとが入力され、推定関数生成部123により推定関数が生成される。また、遺伝アルゴリズムに基づく推定機の構築方法を適用する場合、統合後の行動履歴データを利用して推定関数の生成、寄与率の算出、基底関数リストの更新などの処理が実行される。
【0152】
以上、報酬推定機構築部12の詳細な機能構成について説明した。
【0153】
以上、本実施形態に係る情報処理装置10の構成について説明した。上記の構成を適用することにより、任意の状態SからNPCがとるべき次の行動aを決定する思考ルーチンを自動構築することができる。また、この思考ルーチンを利用して賢くNPCを行動させることが可能になる。なお、利用する行動履歴データを変えることで、ロボットなどのエージェントについても同様に賢く行動させることが可能になる。
【0154】
[2−3:効率的な推定報酬機の構築方法]
これまで、先に紹介した推定機の自動構築方法に基づく思考ルーチンの自動構築方法について説明してきた。確かに、この方法を適用すると、思考ルーチンを自動構築することが可能になる。しかし、賢く行動するNPCの思考ルーチンを自動構築するには、ある程度長い時間をかけて学習処理を繰り返し実行する必要がある。そこで、本件発明者は、より効率良く高性能な推定報酬機を構築する方法を考案した。
【0155】
以下、図41及び図42を参照しながら、効率的な推定報酬機の構築方法について説明する。この方法は、より学習効率の高い行動履歴データを取得する方法に関する。より学習効率の高い行動履歴データとは、より推定報酬が高く、より推定誤差が大きく、かつ、特徴量空間における密度が疎な領域にある特徴量座標に対応するデータである。そこで、図42に示す3つのスコアを導入する。1つ目は、推定報酬が高いほど大きな値となる報酬スコアである。2つ目は、特徴量空間における密度が疎であるほど大きな値となる未知スコアである。3つ目は、推定誤差が大きいほど大きな値となる誤差スコアである。
【0156】
例えば、図41に示した行動a1、a2、a3に注目しよう。仮に、鎖線で囲まれた領域は、推定誤差の小さい領域であるとする。また、図の右上方向に向かうにつれて推定報酬が高くなっているとする。この場合、行動a1は、報酬スコアが比較的高く、未知スコアが比較的高く、誤差スコアが比較的低い行動であると言える。また、行動a2は、報酬スコアが比較的低く、未知スコアが比較的低く、誤差スコアが比較的高い行動であると言える。そして、行動a3は、報酬スコアが比較的高く、未知スコアが比較的高く、誤差スコアが比較的高い行動であると言える。
【0157】
より報酬スコアの高い行動を優先的に選択することにより、高い報酬を実現するために必要な行動履歴データを収集することができる。また、より未知スコアが高いか、より誤差スコアが高い行動を優先的に選択することにより、その行動を選択した結果が不定であるような行動履歴データを収集することができる。例えば、図41の例では、行動a3を選択することにより、より高い報酬を得られることが期待され、かつ、その行動を選択した結果が不定であるような行動履歴データを収集できると考えられる。図38に示した処理のうち、(Step 1)及び/又は(Step 3)において上記の方法による行動履歴データの取得を行うことで、(Step 2)における報酬推定機の構築をより効率的に実現することが可能になる。
【0158】
以上、効率的な推定報酬機の構築方法について説明した。
【0159】
[2−4:(変形例1)アクションスコア推定機を用いる思考ルーチン]
さて、これまでは報酬推定機を用いて報酬を推定し、推定した報酬に基づいて行動を選択する思考ルーチンについて考えてきた。ここでは、図44に示すように、アクションスコア推定機を用いてアクションスコアを推定し、推定したアクションスコアに基づいて行動を選択する思考ルーチンについて考えてみたい。ここで言うアクションスコアとは、とりうる各行動に対応付けられたスコアであり、対応する行動をとることで好ましい結果が得られる確率の高さを表す。
【0160】
アクションスコアを利用する場合、行動履歴データは、図43に示すような形で与えられる。まず、情報処理装置10は、これまで説明してきた行動履歴データと同様にして状態S、行動a、報酬rの組を収集する。その後、情報処理装置10は、報酬rに基づいてアクションスコアを算出する。
【0161】
例えば、状態S=S1において行動a=“R(右へ移動)”をとった場合に報酬r=“0”が得られたものとしよう。この場合、行動a=“R”に対応するアクションスコアは“0”となり、それ以外の行動(“L”“N”“J”)に対応するアクションスコアは“1”となる。その結果、状態S=S1及び行動a=“R”に対応するアクションスコア(R,L,N,J)=(0,1,1,1)が得られる。
【0162】
また、状態S=S2において行動a=“L(左へ移動)”をとった場合に報酬r=“1”が得られたものとしよう。この場合、行動a=“L”に対応するアクションスコアは“1”となり、それ以外の行動(“R”“N”“J”)に対応するアクションスコアは“0”となる。その結果、状態S=S2及び行動a=“L”に対応するアクションスコア(R,L,N,J)=(0,1,0,0)が得られる。
【0163】
上記のようにして得られた状態S、行動a、アクションスコアの組を行動履歴データとして利用すると、機械学習により、状態Sの入力に応じてアクションスコアの推定値を算出するアクションスコア推定機が得られる。例えば、遺伝アルゴリズムに基づく推定機の自動構築方法を適用すれば、高性能なアクションスコア推定機を自動構築することができる。また、行動履歴データを収集する際に、効率的な報酬推定機の構築方法と同様の方法を用いれば、効率的にアクションスコア推定機を自動構築することができる。
【0164】
アクションスコア推定機を用いる場合、思考ルーチンの構成は図44のようになる。つまり、状態Sを思考ルーチンに入力すると、思考ルーチンは、アクションスコア推定機に状態Sを入力し、アクションスコアの推定値を算出する。そして、思考ルーチンは、アクションスコアの推定値が最も高い行動を選択する。例えば、図44に示すように、アクションスコアの推定値が(R,L,J,N)=(0.6,0.3,0.4,0.2)であった場合、思考ルーチンは、推定値“0.6”に対応する行動“R”を選択する。
【0165】
以上、アクションスコア推定機を用いる思考ルーチンについて説明した。
【0166】
[2−5:(変形例2)予測機を用いた報酬の推定]
次に、予測機を用いた報酬の推定方法について説明する。なお、ここで言う予測機とは、ある時刻t1における状態S(t1)及び状態S(t1)においてNPCがとった行動a(t1)を入力した場合に、次の時刻t2における状態S(t2)を出力するアルゴリズムのことを意味する。
【0167】
(2−5−1:予測機の構築方法)
上記の予測機は、図45に示すような方法で構築される。図45に示すように、時刻毎に取得された行動履歴データが学習データとして利用される。例えば、時刻t2において状態S2にあるNPCが何もしなかった場合に好ましい結果が得られた場合、行動履歴データは、時刻t=t2、状態S=S2、行動a=“何もせず”、報酬r=“1”となる。なお、予測機の自動構築方法については、特願2009−277084号明細書に詳しく記載されている。同明細書には、ある時点までの観測値から将来の時点における観測値を予測する予測機を機械学習により自動構築する方法が記載されている。
【0168】
(2−5−2:報酬の推定方法)
上記の予測機を利用すると、図46に示すように、将来得るであろう報酬を推定することが可能になる。例えば、時刻tにおいて状態S(t)にあるNPCが行動a(t)をとった場合に時刻t+1において実現される状態S(t+1)を予測し、その状態S(t+1)においてNPCがとりうる行動毎に推定報酬yを算出することができるようになる。そのため、時刻t+1において推定される報酬に基づいて時刻tにおいてNPCがとるべき行動を選択することができるようになる。また、図47に示すように、予測機を繰り返し用いて数ステップ先の状態S(t+q)から推定される推定報酬yを算出することもできる。この場合、各時刻においてNPCがとりうる行動の組み合わせを考慮し、最終的に最も高い推定報酬が得られる行動の組み合わせを選択することができるようになる。
【0169】
以上、予測機を用いた報酬の推定方法について説明した。
【0170】
[2−6:(変形例3)複数エージェントの同時学習]
さて、これまでは1つのNPCに注目して最適な行動を選択する思考ルーチンの構築方法について考えてきた。しかし、2つ以上のNPCがとる行動を同時に考慮して思考ルーチンを構築することも可能である。2つのNPCが同じ環境中で行動する場合、両NPCがとる行動は状態Sに反映される。そのため、この方法を適用すると、他のNPCが最も高い推定報酬を見込める行動を選択して行動する環境中において、自身のNPCが最も高い推定報酬を見込める行動を選択するような思考ルーチンを自動構築することができる。例えば、MinMax法などを用いることにより、このような思考ルーチンの自動構築が実現される。以上、複数エージェントの同時学習について説明した。
【0171】
以上、本技術の一実施形態について説明した。
【0172】
<3:応用例>
次に、本実施形態の技術を具体的に応用する方法について紹介する。
【0173】
[3−1:「三目並べ」への応用]
まず、図48〜図54を参照しながら、本実施形態に係る技術を「三目並べ」へ応用する方法について説明する。図48に示すように、「三目並べ」の主なルールは、(1)交互に手を打つ、(2)先に3つのマークが1列に並んだ方が勝ち、の2点である。また、「三目並べ」において、状態Sは盤面であり、行動aは各プレーヤが打つ手である。
【0174】
「三目並べ」は、互いに最適な手を打つと必ず引き分けになることが知られている。このような完全情報ゲームに用いられる思考ルーチンの多くは、静的評価関数と先読みアルゴリズムとにより構成されている。この静的評価関数は、ある局面の有利/不利を数値化する関数である。例えば、図49に示すような局面が与えられた場合、静的評価関数は、その局面の有利/不利を表す数値y(“○不利”:−1、“どちらでもない”:0、“○有利”:+1など)を出力する。本実施形態の場合、この静的評価関数の機能は、報酬推定機により実現される。
【0175】
また、先読みアルゴリズムは、先の手を読み、将来の静的評価関数の出力値がより高くなるような手を選択するアルゴリズムである。例えば、先読みアルゴリズムは、MinMax法などを利用して実現される。例えば、図50に示すように、先読みアルゴリズムは、自分の手番で手を打った後に、相手の手番で相手が打つ可能性のある手を想定し、想定した各手に対して自分が打てる手を想定して、自分が最も有利になる手を選択する。
【0176】
ところで、上記のような静的評価関数は、これまで人手により設計されていた。例えば、将棋のAIとして有名なボナンザでさえ、静的評価関数で考慮する局面の特徴などの設計事項は人手により設計されていた。また、ゲームの種類が変わると、特徴量の設計も変更する必要がある。そのため、これまでは試行錯誤を繰り返しながら静的評価関数をゲーム毎に人手で設計する必要があった。しかし、本実施形態に係る技術を適用すると、人手による設計作業を省いて思考ルーチンを自動構築することが可能になる。
【0177】
「三目並べ」の場合、図51に示すように、状態S及び行動aを3×3のマトリックスで表現する。但し、状態Sは、自分の手番となた時点の盤面を表す。また、自分の手番で打った手を反映した盤面を(S,a)と表現する。さらに、自分の手を“1”、相手の手を“−1”、空白を“0”と表現する。つまり、盤面及び手を数値で表現する。このようにして盤面及び手が数値で表現できると、本実施形態に係る報酬推定機の自動構築方法を用いて思考ルーチンを自動構築することが可能になる。
【0178】
例えば、情報処理装置10は、まず、ランダムな場所に自分の手と相手の手とを打つInnateを利用して行動履歴データを生成する。上記の通り、(S,a)は、3×3マトリックスにより表現される。また、情報処理装置10は、図52に示すように、勝ちに至るまでに打った全ての手に対応する(S,a)に報酬“1”を与える。一方、情報処理装置10は、図53に示すように、負けに至るまでに打った全ての手に対応する(S,a)に報酬“−1”を与える。このようにして行動履歴データを蓄積すると、情報処理装置10は、蓄積した行動履歴データを利用して報酬推定機を構築する。
【0179】
実際に手を選択する場合、情報処理装置10は、図54に示すように、報酬推定機を利用して現在の状態Sから推定報酬yを算出し、推定報酬yが最大となる手を選択する。図54の例では、最大の推定報酬に対応する手(C)が選択される。なお、図54の例では1手先の報酬を評価して手の選択を行っているが、対戦相手についても同じように推定報酬を算出し、MinMax法などを用いて数手先読みした結果を用いて現在の手を選択するように構成してもよい。
【0180】
また、学習により得られた報酬推定機を用いて常に最適な行動を選択するように構成すると、NPCによる手の選択が毎回同じになってしまうことがある。そこで、推定報酬を算出する工程に何らかのランダムネスを加えてもよい。例えば、報酬推定機により算出した推定報酬に僅かだけ乱数を加える方法が考えられる。また、遺伝アルゴリズムに基づく機械学習により報酬推定機を算出している場合、学習世代毎に算出される報酬推定機を保持しておき、利用する報酬推定機をランダムに切り替えるように構成してもよい。
【0181】
以上、「三目並べ」への応用について説明した。
【0182】
[3−2:「対戦ゲーム」への応用]
次に、図55〜図62を参照しながら、本実施形態に係る技術を「対戦ゲーム」へと応用する方法について説明する。ここで考える「対戦ゲーム」の主なルールは、図55に示すように、(1)2人対戦ゲームであること、(2)各プレーヤの行動は「左移動」「右移動」「左右移動なし」「ジャンプ」「ジャンプなし」の組み合わせであること、(3)相手のプレーヤを踏んだらY軸方向の加速度差に応じて相手にダメージを与えられること、の3点である。また、ヒットポイントが0になったプレーヤが負けである。なお、「対戦ゲーム」への応用には、先に説明したアクションスコア推定機を用いる思考ルーチンの構築方法が用いられる。
【0183】
この場合、状態Sとしては、自分の絶対座標、相手の絶対座標、時刻が利用される。そのため、状態Sは、図56に示すように3次元マトリックスにより表現される。また、ここでは、3次元マトリックスで表現される状態Sの入力に応じて5つの要素(N,L,R,J,NJ)を持つアクションスコアを推定するアクションスコア推定機の自動構築方法について考える。但し、要素Nは、行動a=“左右移動なし”に対応するアクションスコアである。また、要素Lは、行動a=“左移動”に対応するアクションスコアである。要素Rは、行動a=“右移動”に対応するアクションスコアである。要素Jは、行動a=“ジャンプ”に対応するアクションスコアである。要素NJは、行動a=“ジャンプなし”に対応するアクションスコアである。
【0184】
行動履歴データを収集するためのInnateとしては、例えば、完全にランダムにプレーヤの行動を選択するものが用いられる。例えば、このInnateは、N(左右移動なし)、L(左移動)、R(右移動)の中から1つの行動をランダムに選び、選んだ行動に組み合わせる行動をJ(ジャンプ)又はNJ(ジャンプなし)からランダムに1つ選ぶ。また、情報処理装置10は、図57に示すように、自分が相手にダメージを与えた時点で、前回自分又は相手がダメージを受けた時点から現時点までの行動履歴データの報酬を1に設定する。一方、自分が相手からダメージを受けた場合、情報処理装置10は、図57に示すように、前回自分又は相手がダメージを受けた時点から現時点までの行動履歴データの報酬を0に設定する。
【0185】
なお、報酬が1に設定された行動履歴データについて、情報処理装置10は、実際に行った行動のアクションスコアを1、行わなかった行動のアクションスコアを0に設定する。一方、報酬が0に設定された行動履歴データについて、情報処理装置10は、実際に行った行動のアクションスコアを0に設定し、行わなかった行動のアクションスコアを0に設定する。このような処理を繰り返すことにより、状態Sとアクションスコアとで構成される図57に示すような行動履歴データが得られる。
【0186】
行動履歴データが得られると、情報処理装置10は、図58に示した処理の流れに沿って思考ルーチンを構築する。図58に示すように、行動履歴データを取得すると(S301)、情報処理装置10は、取得した行動履歴データを利用した機械学習により思考ルーチンを構築する(S302)。次いで、情報処理装置10は、必要に応じて追加の行動履歴データを取得する(S303)。次いで、情報処理装置10は、追加した行動履歴データと元の行動履歴データとを統合する(S304)。次いで、情報処理装置10は、終了条件を満たしたか否かを判定する(S305)。
【0187】
例えば、ユーザによる終了操作が与えられた場合や、ランダムに行動するプレーヤに対する勝率が所定の閾値を越えた場合などに、情報処理装置10は、終了条件を満たしたと判定する。終了条件を満たしていない場合、情報処理装置10は、処理をステップS302に進める。一方、終了条件を満たした場合、情報処理装置10は、思考ルーチンの構築に係る一連の処理を終了する。
【0188】
このようにして自動構築された思考ルーチンを用いてプレーヤを行動させた結果、ランダムに行動するプレーヤに対する勝率について、図59に示すような結果が得られた。図59に示すように、15世代(図58のステップS302〜S304の繰り返し回数が15)で思考ルーチンを利用して行動するプレーヤの勝率が100%近くに達した。なお、行動の選択は、最もアクションスコアの高い行動を選択する方法で行われている。但し、この例では、行動を選択する際に、各アクションスコアに僅かの乱数を加えてから行動を選択するようにしている。
【0189】
また、先に説明した複数エージェントの同時学習を適用し、2人のプレーヤの行動を同時に学習して思考ルーチンを構築してみた。複数エージェントの同時学習を適用すると、ランダムでない動きをするプレーヤに対して勝とうとする思考ルーチンが自動構築されるため、より賢くプレーヤを行動させる思考ルーチンが構築される。なお、互いに思考ルーチンを用いて行動する2人のプレーヤを対戦させた結果を図60に示した。図60に示すように、学習世代によりプレーヤ1が大きく勝ち越す場合もあるが、プレーヤ2が大きく勝ち越す場合もある。
【0190】
また、ある学習世代において実験的に1000試合のゲームを行った結果、図61に示すように、プレーヤ1が大きく勝ち越す結果(対戦勝率)が得られた。但し、ランダムに行動するプレーヤを相手にした場合(ランダム相手)、プレーヤ1もプレーヤ2も相手に対して9割以上の高い勝率を得た。つまり、思考ルーチンを利用して行動するプレーヤは、十分に賢く行動しているのである。このように、複数エージェントの同時学習を適用すると、相手に勝とうとして思考ルーチンを強化しているうちに、ランダムに行動する相手に対しても高い確率で勝てる汎用的なアルゴリズムが得られる。
【0191】
ところで、これまでは状態Sとして、自分の座標、相手の座標、時刻を表現した3次元マトリクスを用いていたが、この3次元マトリクスに代えてゲーム画面の画像情報をそのまま用いる方法も考えられる。例えば、状態Sとして、図62に示すようなゲーム画面の輝度画像を用いることができる。つまり、状態Sは、行動を決定するために有用な情報が含まれてさえいれば何でもよいのである。この考えに基づくと、本実施形態に係る技術が様々なゲームやタスクに関する思考ルーチンの自動構築方法に応用できることが容易に想像できるであろう。
【0192】
以上、「対戦ゲーム」への応用について説明した。
【0193】
[3−3:「五目並べ」への応用]
次に、図63及び図64を参照しながら、本実施形態に係る技術を「五目並べ」へと応用する方法について説明する。「五目並べ」の主なルールは、(1)交互に手を打つ、(2)縦横斜めに先に5つの石を並べた方が勝ち、の2点である。また、「五目並べ」において、状態Sは盤面であり、行動aは各プレーヤが打つ手である。
【0194】
「五目並べ」への応用方法は、基本的に「三目並べ」への応用方法と同じである。つまり、状態S及び行動aは、図63に示すように、2次元マトリクスで表現される。また、最初に用いる行動履歴データは、完全にランダムに石を配置するInnateを用いて取得される。そして、最終的に勝ちに至った全ての(S,a)に報酬1が設定され、負けに至った全ての(S,a)に報酬0が設定される。情報処理装置10は、この行動履歴データを用いて思考ルーチンを構築する。また、情報処理装置10は、思考ルーチンを用いて対局し、その結果を統合した行動履歴データを用いて思考ルーチンを構築する。これらの処理を繰り返すことにより、賢い行動を選択する思考ルーチンが構築される。
【0195】
また、行動を選択する際、情報処理装置10は、「三目並べ」の場合と同様に全ての行動の可能性について(石を置ける全ての点について石を置いたとして)推定報酬を求め、最も推定報酬の高くなる点に石を置く。もちろん、情報処理装置10は、数手先を読んで石を置く位置を選択するように構成されていてもよい。なお、「五目並べ」は、「三目並べ」に比べて盤面の組み合わせ数が膨大である。そのため、ランダムに石を置くプレーヤは、見当違いの手を打ちがちであるために非常に弱い。
【0196】
従って、ランダムに石を置くプレーヤを相手に学習を行っても非常に弱い相手に勝つための思考ルーチンができあがるだけで、賢い思考ルーチンはなかなか得られない。そこで、対戦ゲームと同様に、複数エージェントの同時学習を適用し、自分と相手とを同じ環境で学習させる手法を用いる方が好ましい。このような構成にすることで、比較的高性能な思考ルーチンを自動構築することが可能になる。互いに思考ルーチンを用いて行動するプレーヤによる対局結果を図64に示した。
【0197】
以上、「五目並べ」への応用について説明した。
【0198】
[3−4:「ポーカー」への応用]
次に、図65〜図67を参照しながら、本実施形態に係る技術を「ポーカー」へと応用する方法について説明する。「ポーカー」の主なルールは、図65に示すように、(1)5枚のカードを配る、(2)捨てるカードを選択する、(3)役の強い方が勝ち、の3点である。ここでは、カードが配られたときに、捨てるカードを決める思考ルーチンの構築方法について考える。
【0199】
図66に示すように、状態S及び行動aは、記号列で表現される。例えば、ハートのエースを“HA”、クラブの2を“C2”、ダイヤのKを“DK”などと表現する。図66の場合、状態Sは、記号列“SJCJC0D9D7”で表現される。また、ダイヤの9及びダイヤの7を捨てた場合、行動aは、記号列“D9D7”で表現される。また、ゲームに勝った場合には報酬“1”が与えられ、負けた場合には報酬“0”が与えられる。このような表現を用いると、例えば、図67に示すような行動履歴データが得られる。
【0200】
最初に行動履歴データを取得するInnateとしては、例えば、完全にランダムに5枚のカードそれぞれを捨てるかどうか決定するものを利用する。また、情報処理装置10は、勝った行動履歴データには報酬“1”を設定し、負けた行動履歴データには報酬“0”を設定する。そして、情報処理装置10は、蓄積された行動履歴データを用いて思考ルーチンを構築する。このとき、行動を選択した結果、どのような役が揃ったか、相手の役がどのようなものだったかなどの情報は利用されない。つまり、純粋に勝ち負けだけを考慮して思考ルーチンが構築される。但し、自分が強い役を揃えるのに有利なカードの切り方を選択した行動履歴データほど報酬が1になる確率は高くなる傾向にある。
【0201】
さて、行動を選択する際、配られた5枚のカードそれぞれについて、カードを切る、カードを切らない、の選択肢が与えられる。そのため、行動の組み合わせは、2の5乗=32通り存在する。従って、思考ルーチンは、報酬推定機を利用し、32通りの(S,a)について推定報酬を算出し、最も推定報酬の高い行動を選択する。
【0202】
以上、「ポーカー」への応用について説明した。
【0203】
[3−5:「ロールプレイングゲーム」への応用]
次に、図68〜図79を参照しながら、本実施形態に係る技術を「ロールプレイングゲーム」へと応用する方法について説明する。ここでは、「ロールプレイングゲーム」の戦闘シーンにおいてプレーヤに代わってキャラクタを賢く自動操作する思考ルーチンの自動構築方法について考える。なお、ここで考える「ロールプレイングゲーム」のルールは、図68に示した通りである。また、図68に示すように、状態Sはプレーヤに提供される情報であり、行動aはキャラクタを操作するコマンドである。
【0204】
戦闘シーンの環境は、図69に示した通りである。まず、戦闘に勝つと生存者で経験値が山分けされる。さらに、経験値が貯まるとレベルアップする。また、レベルアップすると、キャラクタの職業に応じてステータスの値がアップしたり、魔法を覚えたりする。また、戦闘に5回連続で勝つと敵のレベルが1つアップすると共に、キャラクタのヒットポイントが回復する。また、敵のレベルが31に達するとゲームをクリアしたことになる。
【0205】
なお、戦闘シーンにおいて、キャラクタが持つステータスの1つである“素早さ”の値に応じて各キャラクタが行動をおこせるタイミングが決まる。また、キャラクタがとれる行動は、“攻撃”及び“魔法(魔法を覚えている場合)”である。魔法の種類としては、Heal、Fire、Iceがある。Healは、味方のヒットポイント(HP)を回復する魔法である。Fireは、火を用いて敵を攻撃する魔法である。Iceは、氷を用いて敵を攻撃する魔法である。また、魔法をかけるターゲットは、単体又は全体のいずれかを選択可能である。但し、全体を選択した場合には魔法の効果が半減する。また、使える魔法の種類やレベルは、キャラクタのレベルに応じて変わる。さらに、同じ魔法でもレベルの高い魔法ほどマジックポイント(MP)を多く消費するが、効果は高い。
【0206】
キャラクタの職業及び職業毎のステータスは、図70に示した通りである。ステータス上昇率は、キャラクタのレベルが1つアップする度にステータスがアップする割合を示している。また、魔法を覚えるLvは、記載された値のレベルに達した場合にキャラクタが魔法を覚えるレベルを示している。但し、空欄に対応する魔法は覚えられない。また、0と記載されている箇所は、最初から魔法を覚えていることを示している。なお、味方のパーティは、上側4種類の職業を持つキャラクタにより構成される。一方、敵のパーティは、下側4種類の職業を持つキャラクタから選択されたキャラクタにより構成される。
【0207】
状態Sとして利用される味方側の情報は、図71に示した通りである。例えば、生存する味方のレベル、職業、HP、最大HP、MP、最大MP、攻撃力、防御力、素早さなどが状態Sとして利用される。なお、職業の欄は、当てはまる職業の欄に1、それ以外の欄に0が記入される。また、その他の欄には現状の値が記入される。一方、状態Sとして利用される敵側の情報は、図72に示した通りである。例えば、生存する敵のレベル、職業、累積ダメージなどが状態Sとして利用される。なお、累積ダメージは、それまでに与えたダメージの合計値を示している。
【0208】
また、行動aとして利用される味方側の情報は、図73に示した通りである。例えば、行動者の欄には、これから行動を行うキャラクタの場合に1、それ以外の場合に0が記入される。また、行動対象の欄には、行動の対象となるキャラクタの場合に1、それ以外の場合に0が記入される。例えば、回復魔法を受けるキャラクタに対応する行動対象の欄には1が記入される。また、アクションの種類の欄には、行う行動の欄に1、行わない行動の欄に0が記入される。一方、行動aとして利用される敵側の情報は、図74に示した通りである。図74に示すように、敵側の情報としては行動対象の情報が利用される。
【0209】
さて、これまで説明してきた応用例と同様、情報処理装置10は、まず、行動履歴データを取得する。このとき、情報処理装置10は、行動の種類毎に選択確率に重みを付けた上で、ランダムに行動を選択するInnateを用いて行動履歴データを取得する。例えば、情報処理装置10は、魔法よりも攻撃を選択する確率を高く設定したInnateを用いてキャラクタを行動させる。また、図75に示すように、情報処理装置10は、味方がやられた場合には報酬“−5”を行動履歴データに設定し、敵を倒した場合には報酬“1”を行動履歴データに設定する。その結果、図76のA図に示すような行動履歴データが得られる。但し、味方や敵がやられる過程の評価も考慮するため、情報処理装置10は、図76のB図に示すように、直線的に報酬の値をDecayさせる。
【0210】
情報処理装置10は、上記のようにして取得された行動履歴データを用いて思考ルーチンを構築する。このとき、情報処理装置10は、時刻tにおける状態S及び行動aから時刻t+1における状態S’を推定する予測機を構築する。また、情報処理装置10は、時刻t+1における状態S’から推定報酬を算出する報酬推定機を構築する。そして、情報処理装置10は、図77に示すように、現在の状態Sにおいてキャラクタがとりうる行動毎に、予測機を用いて次の状態S’を予測する。さらに、情報処理装置10は、予測した状態S’を報酬推定機に入力して推定報酬yを算出する。推定報酬yを算出した情報処理装置10は、推定報酬yが最大となる行動aを選択する。
【0211】
図77の例では、行動a=“敵全体にFire”に対応する推定報酬yが最大となっている。そのため、この例においては、最適な行動として、行動a=“敵全体にFire”が選択される。但し、思考ルーチンは、図78に示すように、推定報酬が高く、推定誤差が大きく、特徴量空間における密度が疎な特徴量座標に対応する行動を選択するように構成されていてもよい。つまり、先に説明した効率的な推定報酬機の構築方法で紹介した報酬スコア、未知スコア、誤差スコアに基づいて思考ルーチンが構築されていてもよい。
【0212】
なお、報酬スコアは、とりうる全ての行動について報酬推定機を用いて推定報酬を求め、推定報酬の低い方から順に1、2、3、…と、推定報酬が高くなるほど大きくなるようにスコアを与えることで得られる。また、未知スコアは、図25などに示した方法を用いて、全ての行動について特徴量座標の周辺密度を求め、密度が高い方から順に1、2、3、…と、密度が低くなるほど大きくなるようにスコアを与えることで得られる。
【0213】
また、誤差スコアを求める場合、情報処理装置10は、まず、既存の行動履歴データの全てについて、推定報酬yの値を実際の報酬rと比較し、その誤差を求める。次いで、情報処理装置10は、平均値よりも誤差の大きい行動履歴データに対応する特徴量座標を特徴量空間にプロットする。次いで、情報処理装置10は、プロットした特徴量座標の密度分布を求める。最後に、情報処理装置10は、全ての行動履歴データに対応する特徴量座標について密度を求め、密度が低い方から順に1、2、3、…と、密度が高くなるほど大きくなるようにスコアを与える。
【0214】
例えば、報酬スコアをs1、未知スコアをs2、誤差スコアをs3と表記した場合、情報処理装置10は、行動を選択する際に、s1*w1+s2*w2+s3*w3(但し、w1〜w3は所定の重み)の値を算出し、この値が最も大きくなる行動を選択する。このようにして行動を選択することにより、報酬が高く、推定誤差が大きく、特徴量空間における特徴量座標の密度が疎な行動を選択することが可能になる。
【0215】
ここで、図79を参照しながら、効率的な推定報酬機の構築方法を適用した場合の効果について述べる。図79のグラフは、最も高い推定報酬が得られる行動を選択した場合(最適戦略)と、効率的な推定報酬機の構築方法を適用した場合(探索行動)とでシナリオクリアまでの1ステップ当たりの平均Rewardを比較したグラフである。図79のグラフから明らかなように、3つのスコアを利用して構築された思考ルーチン(探索行動)の方が安定して高い報酬が得られている。この評価結果から、効率的な推定報酬機の構築方法を適用することで、演算負荷を軽減できるばかりか、より高性能な思考ルーチンを構築できることが分かった。
【0216】
なお、「ロールプレイングゲーム」に応用すべく自動構築された思考ルーチンは、以下のような戦略を自身で身に付けていることも分かった。
(A)集中攻撃:
集中攻撃することで敵の数を素早く減らす。
(B)HP減少したら回復:
HPが減少した味方のHPを回復して味方が倒されにくくする。
(C)単体攻撃、全体攻撃の使い分け:
敵の数がある程度多い時は全体攻撃魔法を使う。現在集中攻撃中の敵が残りわずかなダメージで倒せそうなときは、全体攻撃魔法を用いて集中攻撃中の敵を倒しながら、他の敵にもダメージを与える。
(D)魔法の無駄打ちはしない:
HPの減っていない味方に対して回復魔法を使わない。魔法の効かない敵に対して魔法を使わない。
【0217】
以上、「ロールプレイングゲーム」への応用について説明した。
【0218】
以上説明したように、本実施形態に係る技術を適用すると、人手による調整を介さずに様々な思考ルーチンを自動構築することが可能になる。
【0219】
<4:ハードウェア構成例>
上記の情報処理装置10が有する各構成要素の機能は、例えば、図80に示すハードウェア構成を用いて実現することが可能である。つまり、当該各構成要素の機能は、コンピュータプログラムを用いて図80に示すハードウェアを制御することにより実現される。なお、このハードウェアの形態は任意であり、例えば、パーソナルコンピュータ、携帯電話、PHS、PDA等の携帯情報端末、ゲーム機、又は種々の情報家電がこれに含まれる。但し、上記のPHSは、Personal Handy−phone Systemの略である。また、上記のPDAは、Personal Digital Assistantの略である。
【0220】
図80に示すように、このハードウェアは、主に、CPU902と、ROM904と、RAM906と、ホストバス908と、ブリッジ910と、を有する。さらに、このハードウェアは、外部バス912と、インターフェース914と、入力部916と、出力部918と、記憶部920と、ドライブ922と、接続ポート924と、通信部926と、を有する。但し、上記のCPUは、Central Processing Unitの略である。また、上記のROMは、Read Only Memoryの略である。そして、上記のRAMは、Random Access Memoryの略である。
【0221】
CPU902は、例えば、演算処理装置又は制御装置として機能し、ROM904、RAM906、記憶部920、又はリムーバブル記録媒体928に記録された各種プログラムに基づいて各構成要素の動作全般又はその一部を制御する。ROM904は、CPU902に読み込まれるプログラムや演算に用いるデータ等を格納する手段である。RAM906には、例えば、CPU902に読み込まれるプログラムや、そのプログラムを実行する際に適宜変化する各種パラメータ等が一時的又は永続的に格納される。
【0222】
これらの構成要素は、例えば、高速なデータ伝送が可能なホストバス908を介して相互に接続される。一方、ホストバス908は、例えば、ブリッジ910を介して比較的データ伝送速度が低速な外部バス912に接続される。また、入力部916としては、例えば、マウス、キーボード、タッチパネル、ボタン、スイッチ、及びレバー等が用いられる。さらに、入力部916としては、赤外線やその他の電波を利用して制御信号を送信することが可能なリモートコントローラ(以下、リモコン)が用いられることもある。
【0223】
出力部918としては、例えば、CRT、LCD、PDP、又はELD等のディスプレイ装置、スピーカ、ヘッドホン等のオーディオ出力装置、プリンタ、携帯電話、又はファクシミリ等、取得した情報を利用者に対して視覚的又は聴覚的に通知することが可能な装置である。但し、上記のCRTは、Cathode Ray Tubeの略である。また、上記のLCDは、Liquid Crystal Displayの略である。そして、上記のPDPは、Plasma DisplayPanelの略である。さらに、上記のELDは、Electro−Luminescence Displayの略である。
【0224】
記憶部920は、各種のデータを格納するための装置である。記憶部920としては、例えば、ハードディスクドライブ(HDD)等の磁気記憶デバイス、半導体記憶デバイス、光記憶デバイス、又は光磁気記憶デバイス等が用いられる。但し、上記のHDDは、Hard Disk Driveの略である。
【0225】
ドライブ922は、例えば、磁気ディスク、光ディスク、光磁気ディスク、又は半導体メモリ等のリムーバブル記録媒体928に記録された情報を読み出し、又はリムーバブル記録媒体928に情報を書き込む装置である。リムーバブル記録媒体928は、例えば、DVDメディア、Blu−rayメディア、HD DVDメディア、各種の半導体記憶メディア等である。もちろん、リムーバブル記録媒体928は、例えば、非接触型ICチップを搭載したICカード、又は電子機器等であってもよい。但し、上記のICは、Integrated Circuitの略である。
【0226】
接続ポート924は、例えば、USBポート、IEEE1394ポート、SCSI、RS−232Cポート、又は光オーディオ端子等のような外部接続機器930を接続するためのポートである。外部接続機器930は、例えば、プリンタ、携帯音楽プレーヤ、デジタルカメラ、デジタルビデオカメラ、又はICレコーダ等である。但し、上記のUSBは、Universal Serial Busの略である。また、上記のSCSIは、Small Computer System Interfaceの略である。
【0227】
通信部926は、ネットワーク932に接続するための通信デバイスであり、例えば、有線又は無線LAN、Bluetooth(登録商標)、又はWUSB用の通信カード、光通信用のルータ、ADSL用のルータ、又は各種通信用のモデム等である。また、通信部926に接続されるネットワーク932は、有線又は無線により接続されたネットワークにより構成され、例えば、インターネット、家庭内LAN、赤外線通信、可視光通信、放送、又は衛星通信等である。但し、上記のLANは、Local Area Networkの略である。また、上記のWUSBは、Wireless USBの略である。そして、上記のADSLは、Asymmetric Digital Subscriber Lineの略である。
【0228】
以上、ハードウェア構成例について説明した。
【0229】
<5:まとめ>
最後に、本実施形態の技術的思想について簡単に纏める。以下に記載する技術的思想は、例えば、PC、携帯電話、携帯ゲーム機、携帯情報端末、情報家電、カーナビゲーションシステム等、種々の情報処理装置に対して適用することができる。
【0230】
上記の情報処理装置の機能構成は以下のように表現することができる。例えば、下記(1)に記載の情報処理装置は、行動履歴データを用いて報酬推定機を自動構築することができる。この報酬推定機を利用すると、エージェントがおかれた状態に応じて、その状態でエージェントがとりうる行動毎に、行動を行ったエージェントが得る報酬を推定することができる。そのため、高い報酬を得ると推定される行動をエージェントがとるように制御することで、賢く行動するエージェントの動きを実現することが可能になる。言い換えると、下記(1)に記載の情報処理装置は、賢く行動するエージェントの動きを実現することが可能な思考ルーチンを自動構築することができる。とりわけ、下記(1)に記載の情報処理装置は、報酬値が高く、かつ、行動履歴データに含まれない行動を優先的に選択するようにしているため、効率よく思考ルーチンを自動構築することができる。
【0231】
(1)
エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成部と、
エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、前記行動履歴データに含まれない行動を優先的に選択する行動選択部と、
前記行動選択部による選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加する行動履歴追加部と、
を備え、
前記報酬推定機生成部は、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成する、
情報処理装置。
【0232】
(2)
前記行動選択部は、前記報酬推定機を用いて推定される報酬値が高く、当該報酬値の推定誤差が大きく、かつ、前記行動履歴データに含まれない行動を優先的に選択する、
上記(1)に記載の情報処理装置。
【0233】
(3)
前記報酬推定機生成部は、
複数の処理関数を組み合わせて複数の基底関数を生成する基底関数生成部と、
前記行動履歴データに含まれる状態データ及び行動データを前記複数の基底関数に入力して特徴量ベクトルを算出する特徴量ベクトル算出部と、
前記特徴量ベクトルから前記行動履歴データに含まれる報酬値を推定する推定関数を回帰/判別学習により算出する推定関数算出部と、
を含み、
前記報酬推定機は、前記複数の基底関数と前記推定関数とにより構成される、
上記(1)又は(2)に記載の情報処理装置。
【0234】
(4)
前記状態データ、前記行動データ、及び前記報酬値の組が前記行動履歴データに追加された場合、前記特徴量ベクトル算出部は、前記行動履歴データに含まれる全ての状態データ及び行動データについて特徴量ベクトルを算出し、
前記情報処理装置は、特徴領空間において前記特徴量ベクトルにより示される座標点の分布が所定の分布に近づくように前記行動履歴データに含まれる前記状態データ、前記行動データ、及び前記報酬値の組を間引く分布調整部をさらに備える、
上記(3)に記載の情報処理装置。
【0235】
(5)
前記状態データ、前記行動データ、及び前記報酬値の組が前記行動履歴データに追加された場合、前記特徴量ベクトル算出部は、前記行動履歴データに含まれる全ての状態データ及び行動データについて特徴量ベクトルを算出し、
前記情報処理装置は、特徴領空間において前記特徴量ベクトルにより示される座標点の分布が所定の分布に近づくように前記行動履歴データに含まれる前記状態データ、前記行動データ、及び前記報酬値の組のそれぞれに重みを設定する分布調整部をさらに備える、
上記(3)に記載の情報処理装置。
【0236】
(6)
前記分布調整部は、間引き後に残った前記状態データ、前記行動データ、及び前記報酬値の組について、特徴領空間において前記特徴量ベクトルにより示される座標点の分布が所定の分布に近づくように前記行動履歴データに含まれる前記状態データ、前記行動データ、及び前記報酬値の組のそれぞれに重みを設定する、
上記(4)に記載の情報処理装置。
【0237】
(7)
前記基底関数生成部は、遺伝的アルゴリズムに基づいて前記基底関数を更新し、
前記特徴量ベクトル算出部は、前記基底関数が更新された場合に、更新後の前記基底関数に前記状態データ及び前記行動データを入力して特徴量ベクトルを算出し、
前記推定関数算出部は、前記更新後の基底関数を用いて算出された特徴量ベクトルの入力に応じて前記報酬値を推定する推定関数を算出する、
上記(3)〜(6)のいずれか1項に記載の情報処理装置。
【0238】
(8)
エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成部と、
エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、当該報酬値の推定誤差が大きい行動を優先的に選択する行動選択部と、
前記行動選択部による選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加する行動履歴追加部と、
を備え、
前記報酬推定機生成部は、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成する、
情報処理装置。
【0239】
(9)
エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成するステップと、
エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、前記行動履歴データに含まれない行動を優先的に選択するステップと、
選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加するステップと、
前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成するステップと、
を含む、
情報処理方法。
【0240】
(10)
エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成するステップと、
エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、当該報酬値の推定誤差が大きい行動を優先的に選択するステップと、
選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加するステップと、
前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成するステップと、
を含む、
情報処理方法。
【0241】
(11)
エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成機能と、
エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、前記行動履歴データに含まれない行動を優先的に選択する行動選択機能と、
前記行動選択機能による選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加する行動履歴追加機能と、
をコンピュータに実現させるためのプログラムであり、
前記報酬推定機生成機能は、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成する、
プログラム。
【0242】
(12)
エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成機能と、
エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、当該報酬値の推定誤差が大きい行動を優先的に選択する行動選択機能と、
前記行動選択機能による選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加する行動履歴追加機能と、
をコンピュータに実現させるためのプログラムであり、
前記報酬推定機生成機能は、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成する、
プログラム。
【0243】
(備考)
上記の報酬推定機構築部12は、報酬推定機生成部の一例である。上記の行動履歴データ取得部11は、行動履歴追加部の一例である。上記の基底関数リスト生成部121は、基底関数生成部の一例である。上記の特徴量計算部122は、特徴量ベクトル算出部の一例である。上記の推定関数生成部123は、推定関数算出部の一例である。上記の行動履歴データ統合部124は、分布調整部の一例である。
【0244】
以上、添付図面を参照しながら本技術に係る好適な実施形態について説明したが、本技術はここで開示した構成例に限定されないことは言うまでもない。当業者であれば、特許請求の範囲に記載された範疇内において、各種の変更例又は修正例に想到し得ることは明らかであり、それらについても当然に本技術の技術的範囲に属するものと了解される。
【符号の説明】
【0245】
10 情報処理装置
11 行動履歴データ取得部
12 報酬推定機構築部
121 基底関数リスト生成部
122 特徴量計算部
123 推定関数生成部
124 行動履歴データ統合部
13 入力データ取得部
14 行動選択部
【特許請求の範囲】
【請求項1】
エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成部と、
エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、前記行動履歴データに含まれない行動を優先的に選択する行動選択部と、
前記行動選択部による選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加する行動履歴追加部と、
を備え、
前記報酬推定機生成部は、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成する、
情報処理装置。
【請求項2】
前記行動選択部は、前記報酬推定機を用いて推定される報酬値が高く、当該報酬値の推定誤差が大きく、かつ、前記行動履歴データに含まれない行動を優先的に選択する、
請求項1に記載の情報処理装置。
【請求項3】
前記報酬推定機生成部は、
複数の処理関数を組み合わせて複数の基底関数を生成する基底関数生成部と、
前記行動履歴データに含まれる状態データ及び行動データを前記複数の基底関数に入力して特徴量ベクトルを算出する特徴量ベクトル算出部と、
前記特徴量ベクトルから前記行動履歴データに含まれる報酬値を推定する推定関数を回帰/判別学習により算出する推定関数算出部と、
を含み、
前記報酬推定機は、前記複数の基底関数と前記推定関数とにより構成される、
請求項1に記載の情報処理装置。
【請求項4】
前記状態データ、前記行動データ、及び前記報酬値の組が前記行動履歴データに追加された場合、前記特徴量ベクトル算出部は、前記行動履歴データに含まれる全ての状態データ及び行動データについて特徴量ベクトルを算出し、
前記情報処理装置は、特徴領空間において前記特徴量ベクトルにより示される座標点の分布が所定の分布に近づくように前記行動履歴データに含まれる前記状態データ、前記行動データ、及び前記報酬値の組を間引く分布調整部をさらに備える、
請求項3に記載の情報処理装置。
【請求項5】
前記状態データ、前記行動データ、及び前記報酬値の組が前記行動履歴データに追加された場合、前記特徴量ベクトル算出部は、前記行動履歴データに含まれる全ての状態データ及び行動データについて特徴量ベクトルを算出し、
前記情報処理装置は、特徴領空間において前記特徴量ベクトルにより示される座標点の分布が所定の分布に近づくように前記行動履歴データに含まれる前記状態データ、前記行動データ、及び前記報酬値の組のそれぞれに重みを設定する分布調整部をさらに備える、
請求項3に記載の情報処理装置。
【請求項6】
前記分布調整部は、間引き後に残った前記状態データ、前記行動データ、及び前記報酬値の組について、特徴領空間において前記特徴量ベクトルにより示される座標点の分布が所定の分布に近づくように前記行動履歴データに含まれる前記状態データ、前記行動データ、及び前記報酬値の組のそれぞれに重みを設定する、
請求項4に記載の情報処理装置。
【請求項7】
前記基底関数生成部は、遺伝的アルゴリズムに基づいて前記基底関数を更新し、
前記特徴量ベクトル算出部は、前記基底関数が更新された場合に、更新後の前記基底関数に前記状態データ及び前記行動データを入力して特徴量ベクトルを算出し、
前記推定関数算出部は、前記更新後の基底関数を用いて算出された特徴量ベクトルの入力に応じて前記報酬値を推定する推定関数を算出する、
請求項3に記載の情報処理装置。
【請求項8】
エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成部と、
エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、当該報酬値の推定誤差が大きい行動を優先的に選択する行動選択部と、
前記行動選択部による選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加する行動履歴追加部と、
を備え、
前記報酬推定機生成部は、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成する、
情報処理装置。
【請求項9】
エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成するステップと、
エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、前記行動履歴データに含まれない行動を優先的に選択するステップと、
選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加するステップと、
前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成するステップと、
を含む、
情報処理方法。
【請求項10】
エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成するステップと、
エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、当該報酬値の推定誤差が大きい行動を優先的に選択するステップと、
選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加するステップと、
前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成するステップと、
を含む、
情報処理方法。
【請求項11】
エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成機能と、
エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、前記行動履歴データに含まれない行動を優先的に選択する行動選択機能と、
前記行動選択機能による選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加する行動履歴追加機能と、
をコンピュータに実現させるためのプログラムであり、
前記報酬推定機生成機能は、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成する、
プログラム。
【請求項12】
エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成機能と、
エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、当該報酬値の推定誤差が大きい行動を優先的に選択する行動選択機能と、
前記行動選択機能による選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加する行動履歴追加機能と、
をコンピュータに実現させるためのプログラムであり、
前記報酬推定機生成機能は、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成する、
プログラム。
【請求項1】
エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成部と、
エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、前記行動履歴データに含まれない行動を優先的に選択する行動選択部と、
前記行動選択部による選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加する行動履歴追加部と、
を備え、
前記報酬推定機生成部は、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成する、
情報処理装置。
【請求項2】
前記行動選択部は、前記報酬推定機を用いて推定される報酬値が高く、当該報酬値の推定誤差が大きく、かつ、前記行動履歴データに含まれない行動を優先的に選択する、
請求項1に記載の情報処理装置。
【請求項3】
前記報酬推定機生成部は、
複数の処理関数を組み合わせて複数の基底関数を生成する基底関数生成部と、
前記行動履歴データに含まれる状態データ及び行動データを前記複数の基底関数に入力して特徴量ベクトルを算出する特徴量ベクトル算出部と、
前記特徴量ベクトルから前記行動履歴データに含まれる報酬値を推定する推定関数を回帰/判別学習により算出する推定関数算出部と、
を含み、
前記報酬推定機は、前記複数の基底関数と前記推定関数とにより構成される、
請求項1に記載の情報処理装置。
【請求項4】
前記状態データ、前記行動データ、及び前記報酬値の組が前記行動履歴データに追加された場合、前記特徴量ベクトル算出部は、前記行動履歴データに含まれる全ての状態データ及び行動データについて特徴量ベクトルを算出し、
前記情報処理装置は、特徴領空間において前記特徴量ベクトルにより示される座標点の分布が所定の分布に近づくように前記行動履歴データに含まれる前記状態データ、前記行動データ、及び前記報酬値の組を間引く分布調整部をさらに備える、
請求項3に記載の情報処理装置。
【請求項5】
前記状態データ、前記行動データ、及び前記報酬値の組が前記行動履歴データに追加された場合、前記特徴量ベクトル算出部は、前記行動履歴データに含まれる全ての状態データ及び行動データについて特徴量ベクトルを算出し、
前記情報処理装置は、特徴領空間において前記特徴量ベクトルにより示される座標点の分布が所定の分布に近づくように前記行動履歴データに含まれる前記状態データ、前記行動データ、及び前記報酬値の組のそれぞれに重みを設定する分布調整部をさらに備える、
請求項3に記載の情報処理装置。
【請求項6】
前記分布調整部は、間引き後に残った前記状態データ、前記行動データ、及び前記報酬値の組について、特徴領空間において前記特徴量ベクトルにより示される座標点の分布が所定の分布に近づくように前記行動履歴データに含まれる前記状態データ、前記行動データ、及び前記報酬値の組のそれぞれに重みを設定する、
請求項4に記載の情報処理装置。
【請求項7】
前記基底関数生成部は、遺伝的アルゴリズムに基づいて前記基底関数を更新し、
前記特徴量ベクトル算出部は、前記基底関数が更新された場合に、更新後の前記基底関数に前記状態データ及び前記行動データを入力して特徴量ベクトルを算出し、
前記推定関数算出部は、前記更新後の基底関数を用いて算出された特徴量ベクトルの入力に応じて前記報酬値を推定する推定関数を算出する、
請求項3に記載の情報処理装置。
【請求項8】
エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成部と、
エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、当該報酬値の推定誤差が大きい行動を優先的に選択する行動選択部と、
前記行動選択部による選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加する行動履歴追加部と、
を備え、
前記報酬推定機生成部は、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成する、
情報処理装置。
【請求項9】
エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成するステップと、
エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、前記行動履歴データに含まれない行動を優先的に選択するステップと、
選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加するステップと、
前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成するステップと、
を含む、
情報処理方法。
【請求項10】
エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成するステップと、
エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、当該報酬値の推定誤差が大きい行動を優先的に選択するステップと、
選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加するステップと、
前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成するステップと、
を含む、
情報処理方法。
【請求項11】
エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成機能と、
エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、前記行動履歴データに含まれない行動を優先的に選択する行動選択機能と、
前記行動選択機能による選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加する行動履歴追加機能と、
をコンピュータに実現させるためのプログラムであり、
前記報酬推定機生成機能は、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成する、
プログラム。
【請求項12】
エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成機能と、
エージェントがとりうる行動のうち、前記報酬推定機を用いて推定される報酬値が高く、かつ、当該報酬値の推定誤差が大きい行動を優先的に選択する行動選択機能と、
前記行動選択機能による選択結果に従ってエージェントを行動させ、当該行動の過程で得られる状態データ及び行動データ、及び当該行動の結果として得られる報酬値を対応付けて前記行動履歴データに追加する行動履歴追加機能と、
をコンピュータに実現させるためのプログラムであり、
前記報酬推定機生成機能は、前記行動履歴データに状態データ、行動データ、及び報酬値の組が追加された場合に前記報酬推定機を再生成する、
プログラム。
【図1】

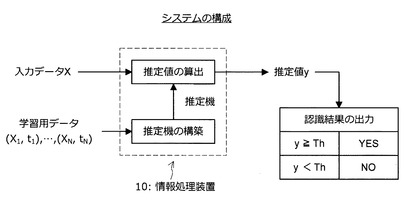
【図2】
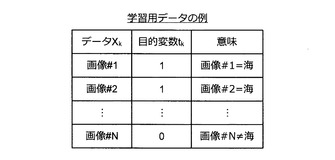
【図3】
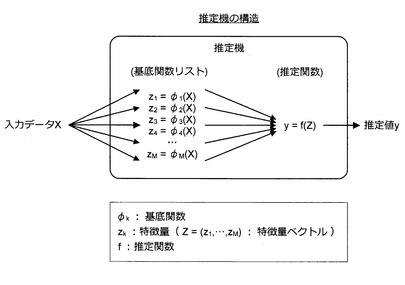
【図4】
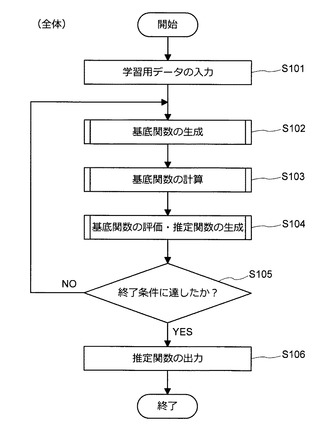
【図5】
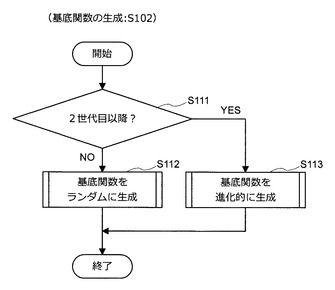
【図6】

【図7】

【図8】
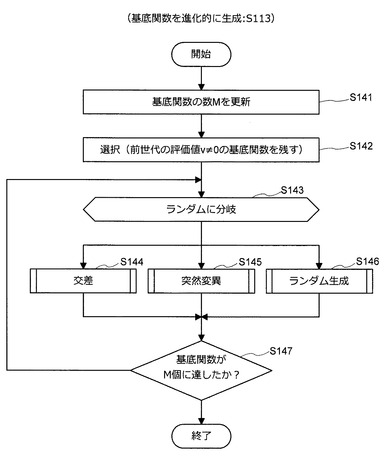
【図9】
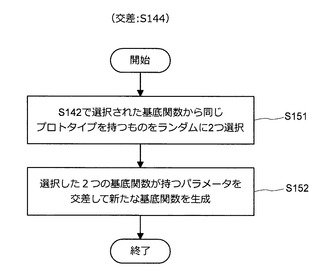
【図10】
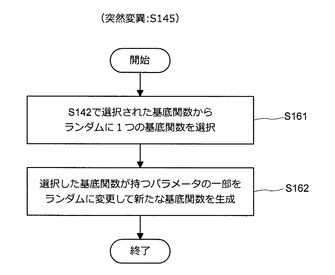
【図11】
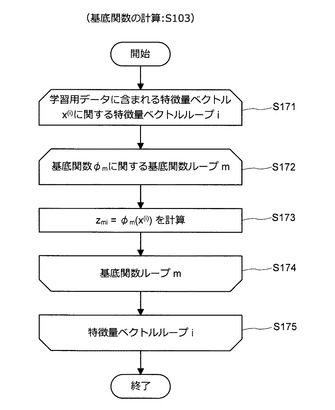
【図12】
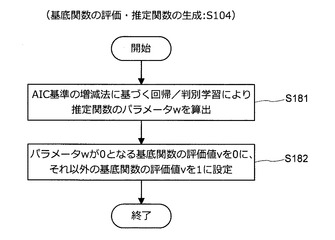
【図13】
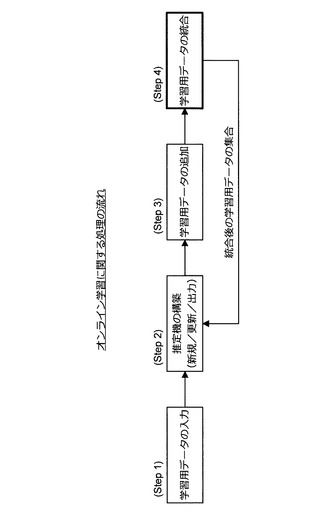
【図14】

【図15】
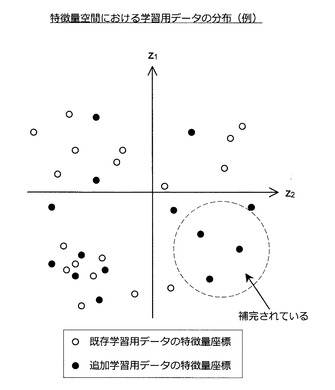
【図16】
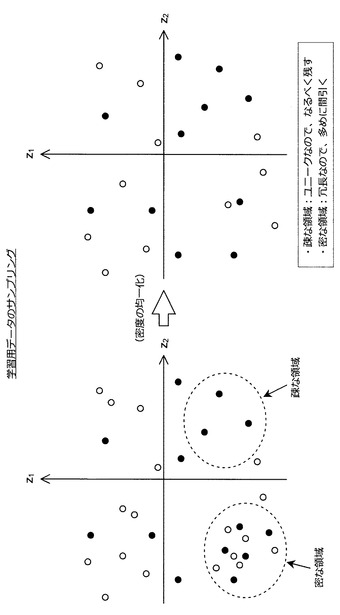
【図17】

【図18】
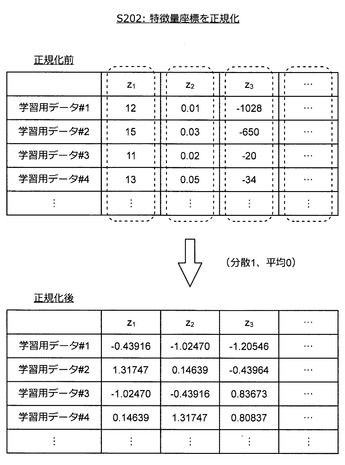
【図19】
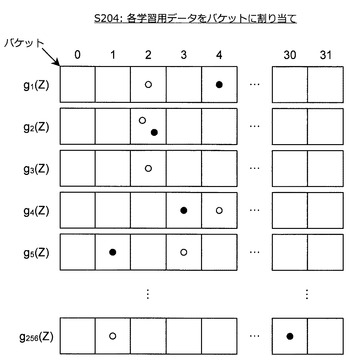
【図20】
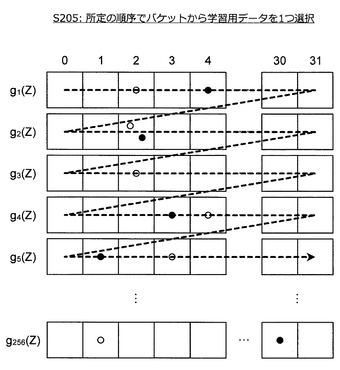
【図21】

【図22】
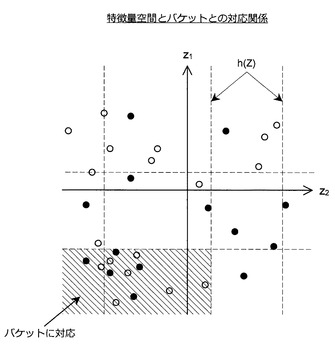
【図23】

【図24】
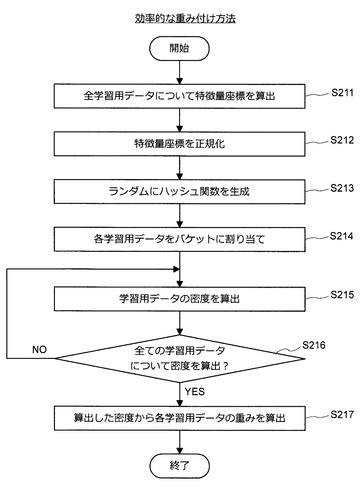
【図25】

【図26】
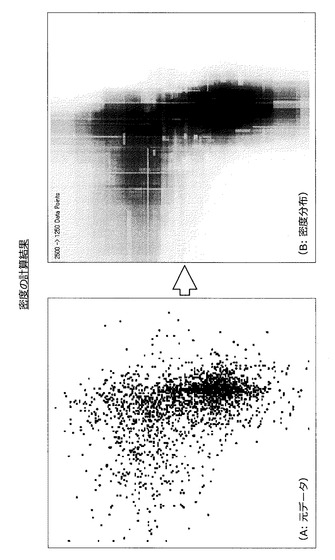
【図27】
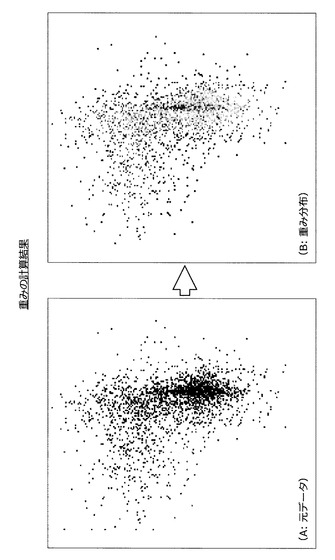
【図28】
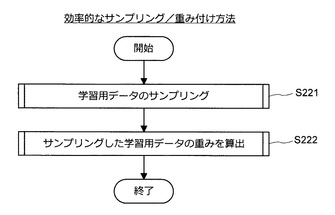
【図29】
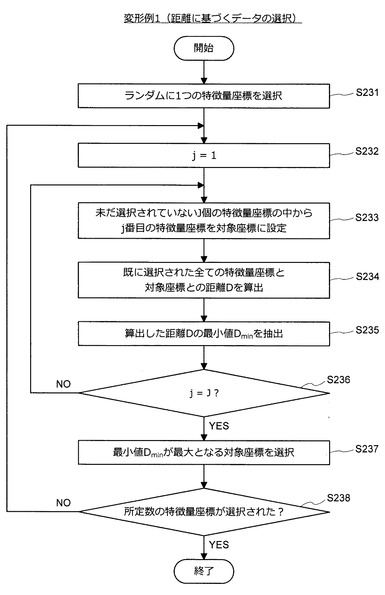
【図30】
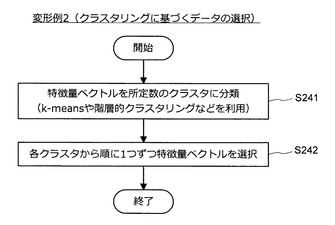
【図31】
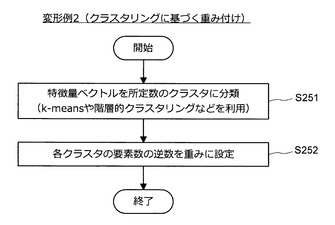
【図32】
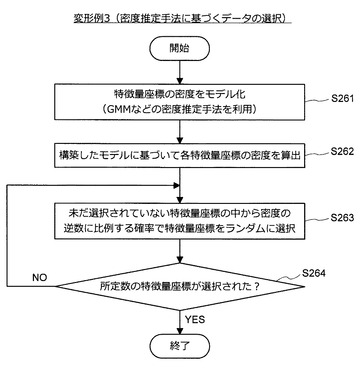
【図33】
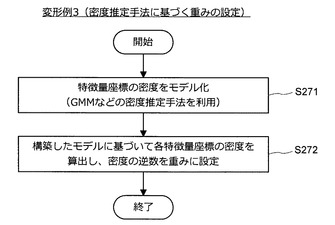
【図34】
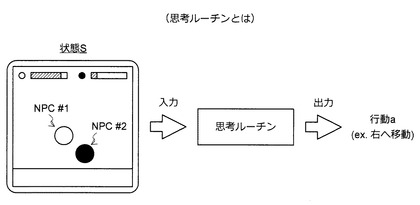
【図35】

【図36】
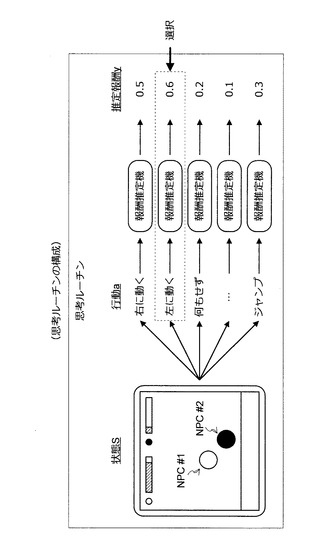
【図37】
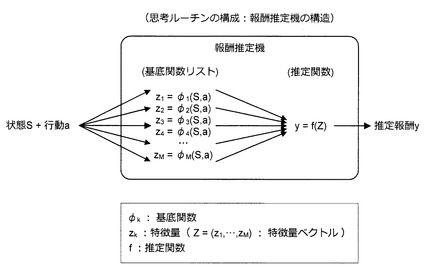
【図38】
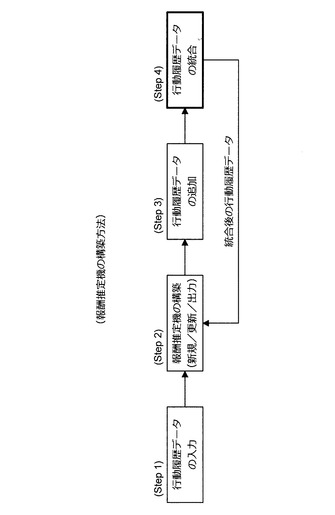
【図39】
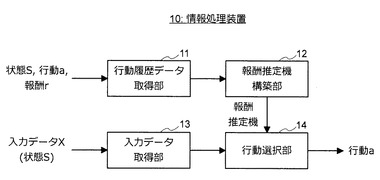
【図40】
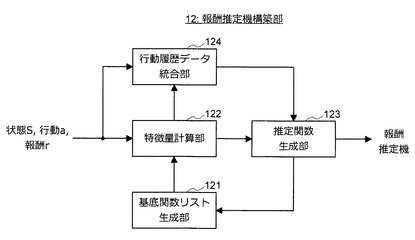
【図41】
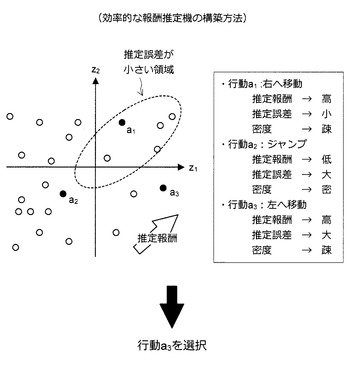
【図42】

【図43】
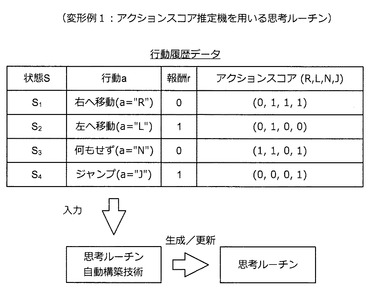
【図44】
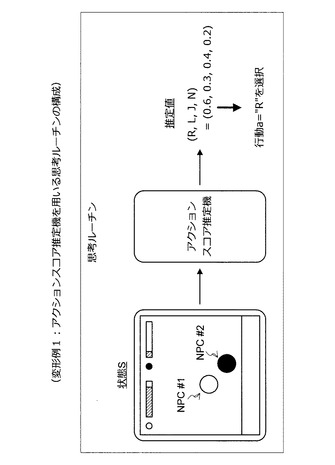
【図45】

【図46】
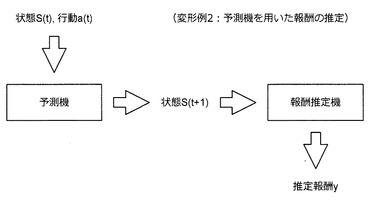
【図47】

【図48】
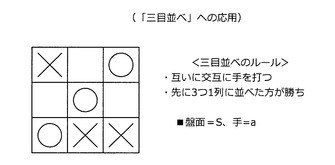
【図49】
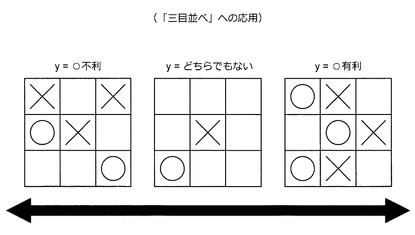
【図50】
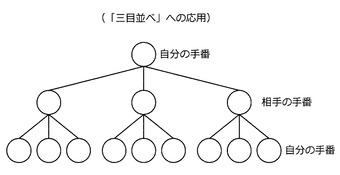
【図51】
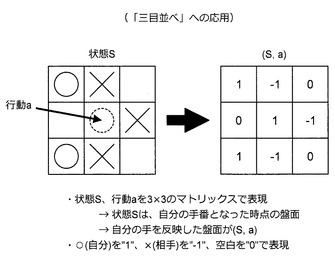
【図52】
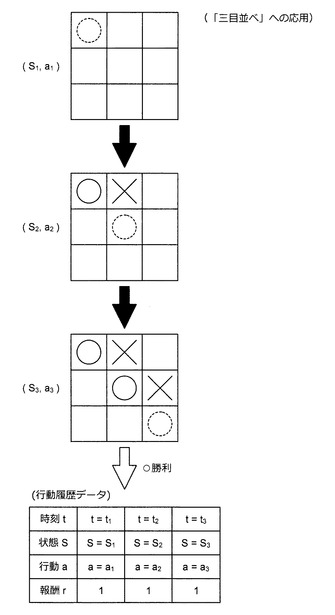
【図53】
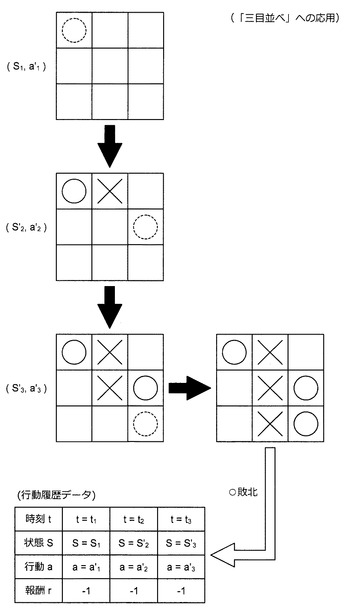
【図54】
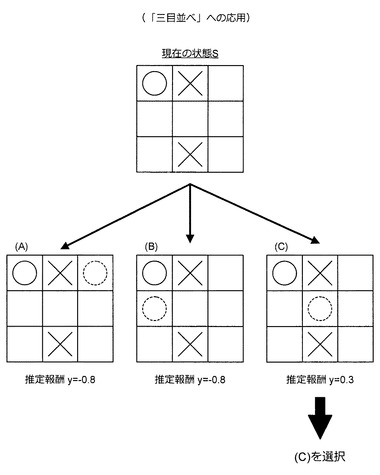
【図55】
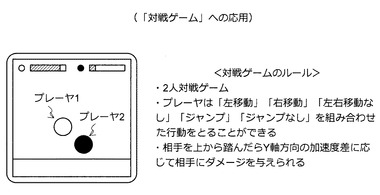
【図56】
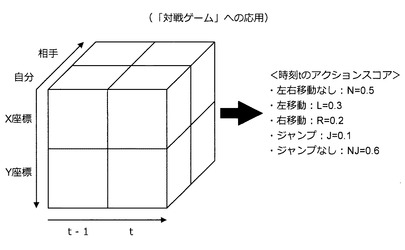
【図57】
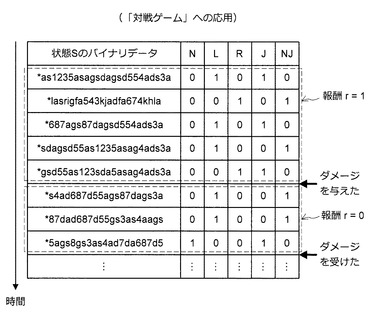
【図58】
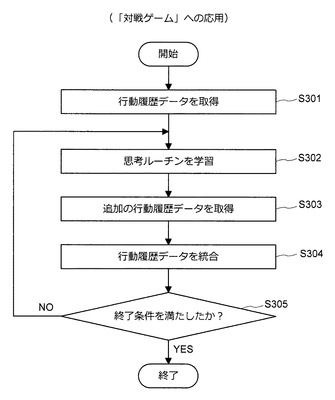
【図59】
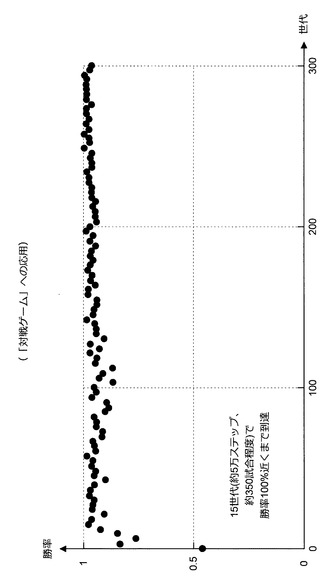
【図60】
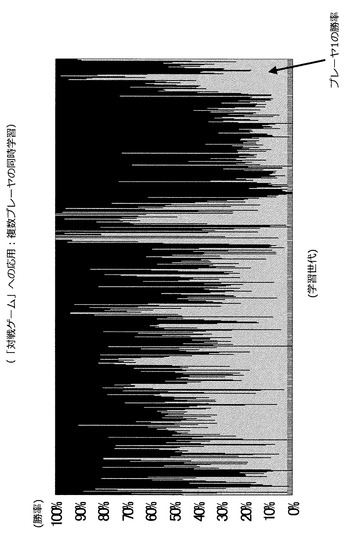
【図61】
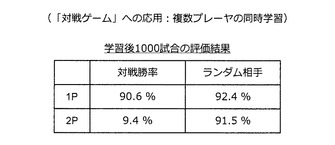
【図62】
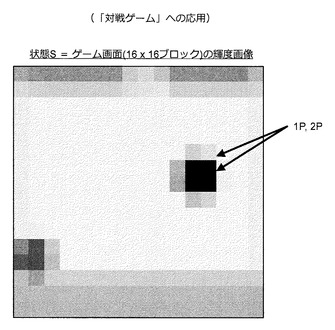
【図63】
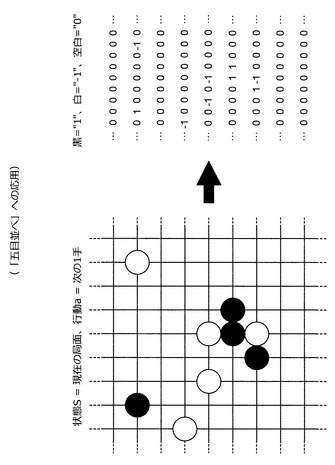
【図64】

【図65】
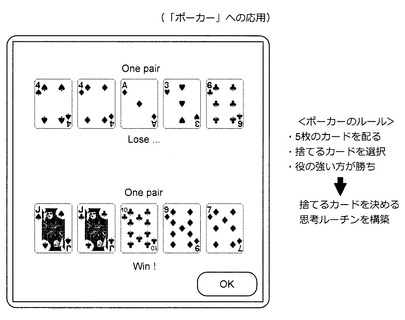
【図66】
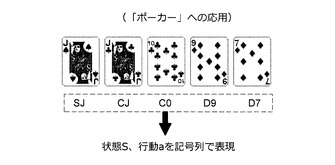
【図67】
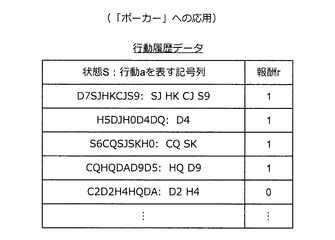
【図68】

【図69】
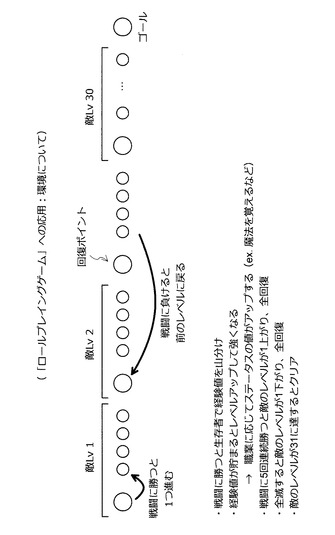
【図70】
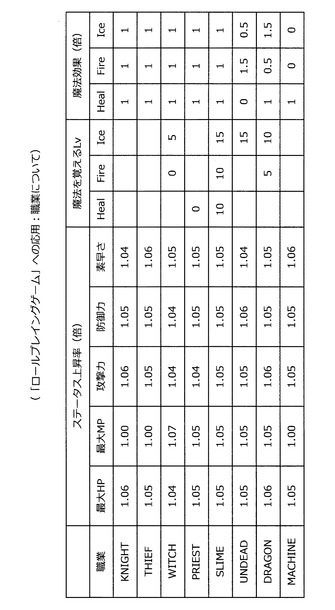
【図71】
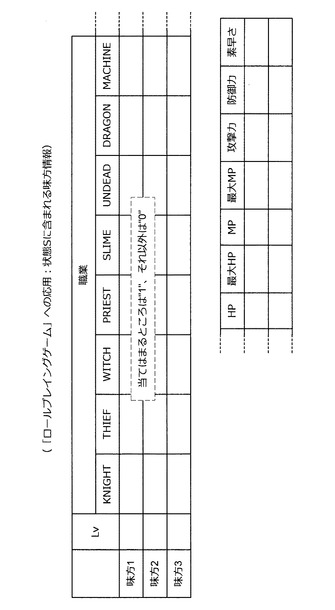
【図72】
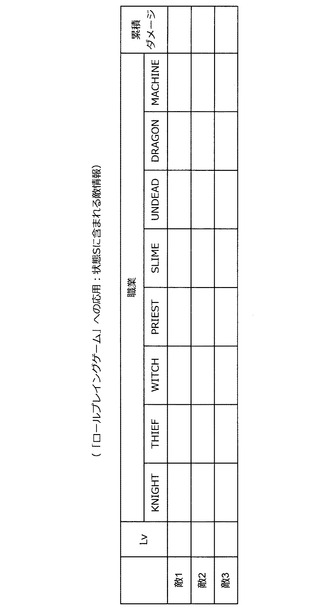
【図73】
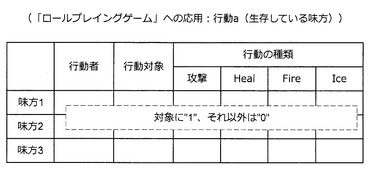
【図74】
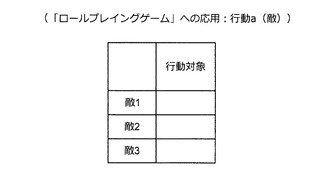
【図75】
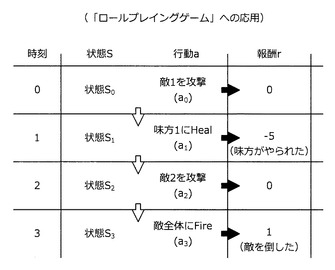
【図76】
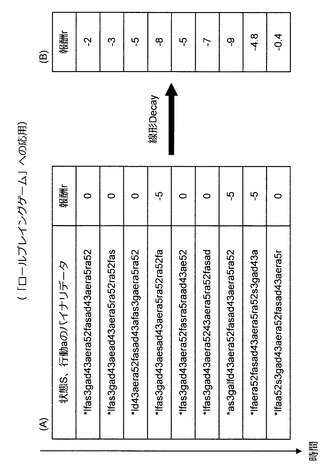
【図77】
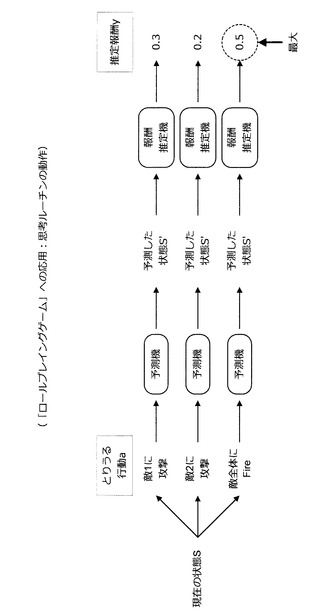
【図78】
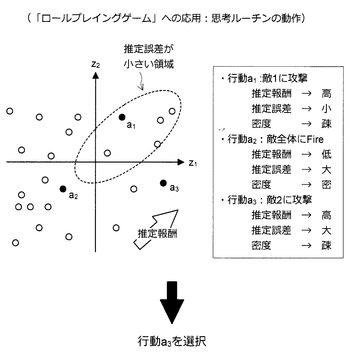
【図79】
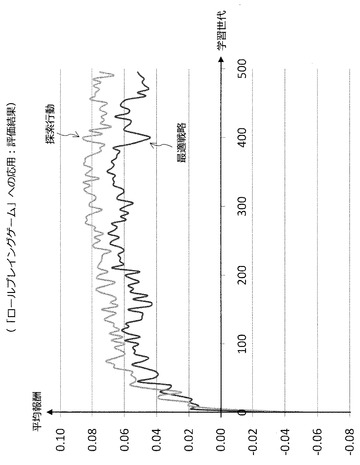
【図80】
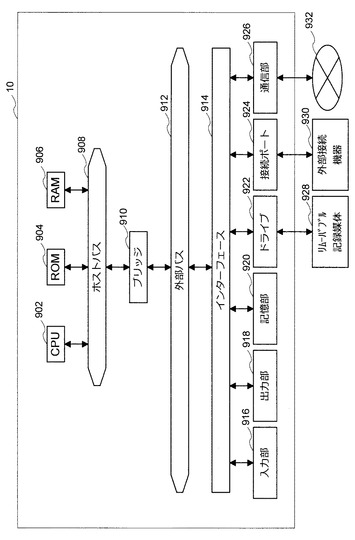
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【図23】
【図24】
【図25】
【図26】
【図27】
【図28】
【図29】
【図30】
【図31】
【図32】
【図33】
【図34】
【図35】
【図36】
【図37】
【図38】
【図39】
【図40】
【図41】
【図42】
【図43】
【図44】
【図45】
【図46】
【図47】
【図48】
【図49】
【図50】
【図51】
【図52】
【図53】
【図54】
【図55】
【図56】
【図57】
【図58】
【図59】
【図60】
【図61】
【図62】
【図63】
【図64】
【図65】
【図66】
【図67】
【図68】
【図69】
【図70】
【図71】
【図72】
【図73】
【図74】
【図75】
【図76】
【図77】
【図78】
【図79】
【図80】
【公開番号】特開2013−81683(P2013−81683A)
【公開日】平成25年5月9日(2013.5.9)
【国際特許分類】
【出願番号】特願2011−224639(P2011−224639)
【出願日】平成23年10月12日(2011.10.12)
【出願人】(000002185)ソニー株式会社 (34,172)
【Fターム(参考)】
【公開日】平成25年5月9日(2013.5.9)
【国際特許分類】
【出願日】平成23年10月12日(2011.10.12)
【出願人】(000002185)ソニー株式会社 (34,172)
【Fターム(参考)】
[ Back to top ]