
情報処理装置及び情報処理装置のデータキャッシング方法並びにマルチプロセッサシステム
【課題】メモリ装置を共有する複数プロセッサからなるシステムで、プリフェッチ命令によるキャッシュ機構の効果が、メモリ装置への競合アクセスに起因して無効となることを、簡単な回路構成で防止すること。
【解決手段】通常必要とするキャッシュ22以外に、メモリ装置から返却されたリプライデータを一定期間保持するためのプリキャッシュ23をキャッシュ22の前段に設け、Snoop命令は、既成の情報処理装置と同じく、キャッシュ22に対してのみ実行可能とし、プリキャッシュ23は該命令の実行対象外とする。キャッシュのエントリフルによるSwap-out処理も、キャッシュ22からのみ実行されるものとする。プロセッサ2のCore21から発行される命令に対しては、プリキャッシュ23もキャッシュ22の一部としてリード及びライトを可能とする。プリキャッシュ23内に保存したデータは、一定期間保持した後、キャッシュ22に移動させる。
【解決手段】通常必要とするキャッシュ22以外に、メモリ装置から返却されたリプライデータを一定期間保持するためのプリキャッシュ23をキャッシュ22の前段に設け、Snoop命令は、既成の情報処理装置と同じく、キャッシュ22に対してのみ実行可能とし、プリキャッシュ23は該命令の実行対象外とする。キャッシュのエントリフルによるSwap-out処理も、キャッシュ22からのみ実行されるものとする。プロセッサ2のCore21から発行される命令に対しては、プリキャッシュ23もキャッシュ22の一部としてリード及びライトを可能とする。プリキャッシュ23内に保存したデータは、一定期間保持した後、キャッシュ22に移動させる。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は情報処理装置及び情報処理装置のデータキャッシング方法並びにマルチプロセッサシステムに係り、特に、メモリ装置が共有される場合に、プリフェッチ命令による性能向上機能を維持させる情報処理装置及び情報処理装置のデータキャッシング方法並びにマルチプロセッサシステムに関する。
【背景技術】
【0002】
通常、情報処理装置(以下、「プロセッサ」と称する)においては、メモリ装置(主記憶装置)のアクセス速度を高めるために、前記メモリ装置以外の装置として、CPUに高速の記憶装置を備えたキャッシュ機構(以下、単に「キャッシュ」と略称することもある)を設置し、データのキャッシングを行っている。
このようなデータのキャッシングを行うキャッシュ機構にあっては、高速の記憶装置上でのヒット率を高めて、アクセス速度を向上させることが意図されるが、その他に、前記メモリ装置間のデータの一貫性(coherence)が配慮され、前記メモリ装置でデータの不一致が生じたり、前記メモリ装置への不要な格納処理や更新処理がなされないように工夫される。
また、このようなデータのキャッシングを行うキャッシュ機構を備えた複数のCPUが、メモリ装置を(主記憶装置)共有する構成となっている場合もある。
【0003】
複数のCPUが主記憶装置を共有する構成の場合、例えば、2つの異なるCPUと、該主記憶装置との3者間で、前述のデータの一貫性がとれなくなることがある。
例えば、キャッシュと主記憶装置との間がバスで接続されている場合、主記憶装置にデータを書き込む際には、該書き込みの要求は該バスに接続された全構成要素にブロードキャスト(発信)され、各CPUのキャッシュは、該ブロードキャストされた要求をsnoop(監視)命令で監視し、書き込みデータのアドレス(一意名)が自分のキャッシュに有るものと同一である場合には、当該キャッシュ上のデータが乗っているラインを無効化する(無効化する理由は、該アドレスが示す当該キャッシュ上のデータは、一般に、前記書き込みデータとは異なるものとなるから)。
これにより、次回のアクセス時(より具体的には読み出し時)には当該キャッシュではミス・ヒットとなるので、主記憶装置の方から最新のデータを取得することができることになり、結果としてキャッシュの一貫性を維持することができることになる。ちなみに、このような機能を有するキャッシュを「snoop cache」と称している。
【0004】
他方、プロセッサは、自装置が使用する予定のあるデータをプリフェッチ命令により、先行してプロセッサ内のキャッシュに読み出しておく処理を行っている。しかしながら、このプリフェッチ機能は、例えば前述のsnoop(監視)命令の実行により、その期待された効果が無効となる場合があり、この点の解決が課題となっている。
このプリフェッチ命令が出されるタイミングは、全体的な処理の流れから見て、本来ならば読み取り命令が出されても良い正当なタイミングであるが、もしもプロセッサ内のキャッシュに、該当するデータが存在しない場合には、主記憶装置から、該データを読み出すことになるので、アクセス時間が多大に掛かるため、このプリフェッチ命令を先行して発行することにより、まずは、先付け処理として、プロセッサ内のキャッシュに該データを読み出しておくものである。このプリフェッチ命令を発行した時点から以降、該データが本当に必要になるまでの間、または該データが読み出されるまでの間は、該プロセッサは、他のタスクを実行することができる。
なお、このプリフェッチ命令は、リード命令の結果が直ぐに欲しい場合に、該リード命令に先行して発行しておくことも有効な使用法である。
【0005】
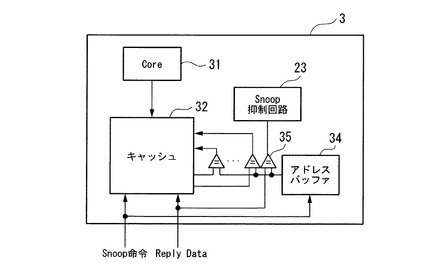
プリフェッチ処理機能を有してデータのキャッシングを行う既成のプロセッサとしては、例えば図3に示すようなものがある。
以下、周知の技術として、プリフェッチしたデータを一定期間キャッシュ内に保持して性能改善を図る方法を説明する。
図3は、プリフェッチしたデータを一定期間キャッシュ内に保持して性能改善を図る周知の方法が適用されるプロセッサの内部構成を示す構成図である。
同図に示すプロセッサ3は、リードやライト等の命令を発行するCore(演算処理装置)31と、プロセッサから発行したリード命令によりメモリ装置から読み出して持ってきたデータを保持するキャッシュ32と、アドレスバッファ34とSnoop命令のアドレスとが一致したことによりキャッシュにSnoop命令の実行抑止指示を出すSnoop抑止回路33と、リプライデータ(以下、「Reply Data」と書くこともある)の返却時に返却されたデータのアドレスを一定期間保持するアドレスバッファ34と、アドレスバッファ内のアドレスとSnoop命令やSwap-out対象のキャッシュ内データのアドレスとを比較するコンパレータ35と、を備える。
【0006】
但し、図3に示すプロセッサ3の構成は当業者にとってよく知られており、これ以外に他の機能に対応した構成要素も存在するが、本発明とは直接関係しない構成要素であるので、ここでは省略している。
以下、図1及び図3を参照して、既成のプロセッサであるプロセッサ3の動作を説明する。
まず、メモリ装置13からReply Data(c2)(図1参照)を受信すると、プロセッサ3は、キャッシュ32にデータを登録すると共に、Reply Data(c2)のデータのアドレスをアドレスバッファ34に登録する。アドレスバッファ34内にはキャッシュ内に対象データを保持しておきたい時間だけ登録しておく。アドレスバッファ34内にアドレスが登録されている間に、メモリ装置13からのSnoop命令(以下、単に「Snoop」と略称する)(c4)を受信すると、キャッシュ32でSnoop(c4)を実行する前に、コンパレータ35によりアドレスバッファ34内のアドレスとSnoop(c4)のアドレスとを比較する。
【0007】
この比較の結果、アドレスバッファ34内に一致するアドレスが登録されていると、Snoop抑止回路33に報告され、Snoop 抑止回路33は、キャッシュ32におけるSnoop (c4)の実行を抑止する。この場合のSnoop(c4)の抑止処理は、メモリ装置13に一度リトライ指示を返却して、メモリ装置13からSnoop(c4)を再発行したり、プロセッサ3内において保持したりと、システムによって一貫性維持のための処理形態が異なるため、ここでは詳細には説明しない。
また、Swap-out処理においても、吐き出す対象のエントリにおいて、コンパレータ35によりアドレスバッファ34内のアドレスとSwap-out対象のエントリ内の全データのアドレスとを比較して、該比較した結果をキャッシュ32に戻すことで、アドレスバッファ34内のアドレスと一致したデータについてはSwap-out対象外としてSwap-outするデータを決定する処理が行われる。この場合、キャッシュ32の構成がNウェイセットアソシアティブである場合は、コンパレータ35の比較回路もN個必要となる。
【0008】
これらの対策により、アドレスバッファ34内にアドレスが格納されている間は、キャッシュ32から対象データは吐き出されないことになるため、Core31からプリフェッチにより先読みを行った(例えばコンペア&スワップ命令)が実行されれば、確実にキャッシュヒットすることになるので、プリフェッチ(c1)で先行して読み出した効果により、処理が速くなり、よって性能改善となる。その後、アドレスバッファ34からアドレスが削除されると、Snoop(c4)に対する抑止処理が解除され、実行されることになったり、Swap-out可能となることでメモリ装置13に書き戻されたりすることになる。
【0009】
本発明の分野に関する公知技術としては、例えば、特許文献1には、キャッシュユニットをSnoopする技術が開示されている。
また、例えば、特許文献2には、「スヌープ・キャッシュ」なる用語が見られ、特許文献1と同様の技術が開示されている。
また、例えば、特許文献3には、メモリのプリフェッチ性能を改善する技術が開示されている。
さらに、例えば、特許文献4には、複数のキャッシュを使用する技術が開示されている。
【先行技術文献】
【特許文献】
【0010】
【特許文献1】特開2006−216075号公報
【特許文献2】特開平3−189845号公報
【特許文献3】特開平11−328018号公報
【特許文献4】特許第3286258号公報
【発明の概要】
【発明が解決しようとする課題】
【0011】
ところで、上記背景技術で述べた従来の情報処理装置及び情報処理装置のデータキャッシング方法にあっては、プリフェッチしたデータを一定期間キャッシュ内に保持して性能改善を図る方法が適用される構成の場合、先行リードしたデータを使用する前にキャッシュから吐き出されてしまわないように、保持しておきたいデータのアドレスを比較回路付きバッファ内に保持しておき、このバッファ内のデータアドレスとキャッシュ内のデータアドレスとが一致する場合はキャッシュからの吐き出しの対象外としている。このため、キャッシュにおけるSnoop動作やSwap-out動作に抑止機能が追加となったり、アドレスを保持するバッファに比較回路が多数必要になったりと、キャッシュ及びその周りの論理及び動作が複雑化するという問題点があった。
【0012】
以上の問題点をさらに具体的に纏めると、
第1の問題点は、比較回路付きのアドレスバッファを設けるなど、複雑な回路の追加が必要となってしまうことである。
第2の課題は、キャッシュに対して、Snoop命令のデータアドレスがアドレスバッファ(前述の比較回路付きバッファ)内のアドレスと一致した場合に、該Snoop命令の実行を抑止する機能が必要になるなど、複雑な論理回路の追加や、回路の変更が必要となってしまうことである。
第3の課題は、キャッシュに対して、Swap-outするエントリ内のデータに対して、そのアドレスが、アドレスバッファ内のアドレスと一致したデータについては該Swap-outの対象外とする機能を必要とするなど、複雑な論理回路の追加や、回路の変更が必要となってしまうことである。
【0013】
なお、本発明は、
(a) 通常のキャッシュ機構に加えて、該キャッシュ機構の前段にプリキャッシュ機構を設けること、
(b) 外部のメモリ装置に格納されている指定データを、プリキャッシュ機構に取り入れさせる効果を有する周知のプリフェッチ命令を使用すること、
(c) メモリ装置から受け付けるSnoop命令については、通常のキャッシュ機構に対してのみ実行可能とし、プリキャッシュ機構については実行対象外とすること、
(d) 外部のメモリ装置から返却されたリプライデータをプリキャッシュ機構に一定期間保持した後、プリキャッシュ機構からキャッシュ機構にデータを移動すること、
を骨子としている。
しかしながら、前述の特許文献1〜4には、前記の(a)項記載の技術と同様の技術は開示されているが、前記の(b)項、(c)項、及び(d)項記載の技術は開示されていない。
【0014】
本発明は、上記従来の問題点に鑑みてなされたものであって、メモリ装置を共有する複数プロセッサからなるシステムで、プリフェッチ命令によるキャッシュ機構の効果が、メモリ装置の競合アクセスに起因して無効となることを、簡単な回路構成で防止することができる情報処理装置のキャッシュ機構及び情報処理装置のデータキャッシング方法並びにマルチプロセッサシステムを提供することを目的としている。
【課題を解決するための手段】
【0015】
上記課題を解決するために、本発明に係る情報処理装置は、他の情報処理装置と共有される主記憶装置の動作速度を改善するためのデータキャッシュ機構として、前記主記憶装置から返却されるリプライデータを保持するキャッシュ機構と、前記キャッシュ機構の前段で前記主記憶装置から返却されるリプライデータを保持するプリキャッシュ機構とを備え、さらに、前記主記憶装置から返却された前記リプライデータを、前記プリキャッシュ機構に、所定の一定期間だけ保持する手段と、演算処理装置から発行される命令に対しては、前記プリキャッシュ機構も、前記キャッシュ機構の一部として、リード及びライトを可能にする手段と、前記主記憶装置から受け付けるSnoop(監視)命令については、前記キャッシュ機構のみを対象として実行し、前記プリキャッシュ機構に対しては、該Snoop命令の実行対象外とする手段と、を備えたことを特徴とする。
【0016】
また、本発明に係る情報処理装置のデータキャッシング方法は、主記憶装置を他の情報処理装置と共有する情報処理装置のデータキャッシュ機構を制御するための情報処理装置のデータキャッシング方法であって、他の情報処理装置と共有される前記主記憶装置の動作速度を改善するためのデータキャッシュ機構の一部として、前記主記憶装置から返却されるリプライデータを保持するキャッシュ機構と、前記キャッシュ機構の前段で前記主記憶装置から返却されるリプライデータを保持するプリキャッシュ機構と、を設けると共に、前記主記憶装置から返却される前記リプライデータを、前記プリキャッシュ機構に、所定の一定期間だけ保持するステップと、演算処理装置から発行される命令に対しては、前記プリキャッシュ機構も、前記キャッシュ機構の一部として、リード及びライトを可能にするステップと、前記主記憶装置から受け付けるSnoop(監視)命令については、前記キャッシュ機構に対してのみ実行可能とし、前記プリキャッシュ機構については該Snoop命令の実行対象外とするステップと、を有することを特徴とする。
【0017】
また、本発明に係るマルチプロセッサとして、前記の情報処理装置を構成要素に含むマルチプロセッサシステムを提供するものである。
【発明の効果】
【0018】
以上説明したように、本発明の情報処理装置によれば、主記憶装置を共有する複数プロセッサからなるシステム等で、プリフェッチ命令の場合のキャッシュ機構の効果が、該主記憶装置の競合アクセスに起因して無効となることを、通常のキャッシュ機構に加えて、通常のキャッシュ機構と同様にリプライデータを保持するためのプリキャッシュ機構を追加しただけという、極めて簡単な構成でもって防止することができる効果が有る。
【図面の簡単な説明】
【0019】
【図1】本発明の実施形態に係る情報処理装置を含むマルチプロセッサシステムの全体構成を示す構成図である。
【図2】本発明の実施形態に係る情報処理装置の主要な構成を示す構成図である。
【図3】プリフェッチしたデータを一定期間キャッシュ内に保持して性能改善を図る周知の方法が適用されるプロセッサの内部構成を示す構成図である。
【発明を実施するための形態】
【0020】
本発明の情報処理装置及び情報処理装置のデータキャッシング方法は、プリフェッチ命令による本来の性能向上効果が低下することを防止するものであり、複数プロセッサからなるシステムの競合動作において、プロセッサが使用する予定のあるデータをプリフェッチ命令により、先行してプロセッサ内のキャッシュに読み出しておくための動作に対して、プロセッサが先行リードしたデータを使用する前にキャッシュから吐き出されてしまうことによる性能低下問題を、キャッシュの前段にプリキャッシュを追加することだけで、容易に解決するものである。
【0021】
このため、プロセッサ内に、通常必要とするキャッシュ以外に、メモリ装置(主記憶装置)から返却されたリプライデータを一定期間保持するためのプリキャッシュを新たに設け、プリキャッシュ内に一定期間保持した後、プリキャッシュからキャッシュにデータを移動する。
メモリ装置から受け付けるSnoop命令は、既成の情報処理装置と同じく、キャッシュに対してのみ実行可能として、プリキャッシュはSnoop命令実行の対象外とする。また、キャッシュのエントリフルによるSwap-out処理も、キャッシュからのみ実行されるものとして、プリキャッシュからはSwap-out処理を実行できないようにする。
また、プロセッサ内のCore部から発行される命令に対しては、プリキャッシュもキャッシュの一部としてリード及びライトを可能とする。これにより、プリキャッシュにおいて一定期間リプライデータを保持していることで、既成の情報処理装置による吐き出し抑止の方法と同様に、保持しておきたいデータは、Core部(演算処理装置)から見ると、キャッシュ内に一定期間は保持されていることになり、本来の性能向上効果が発揮される効果が得られる。
【0022】
以下、本発明の情報処理装置及び情報処理装置のデータキャッシング方法並びにマルチプロセッサシステムの実施形態について、図面を参照して詳細に説明する。
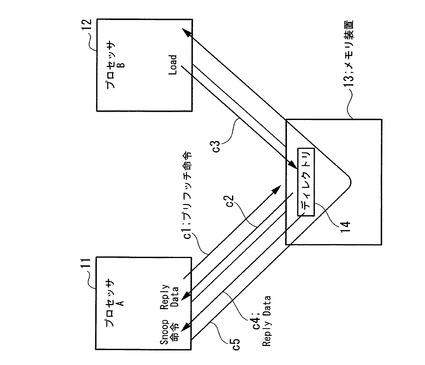
図1は、本発明の実施形態に係る情報処理装置を含むマルチプロセッサシステムの全体構成を示す構成図である。
同図において、本実施形態の情報処理装置は、プロセッサA(11)と、プロセッサB(12)である。プロセッサA(11)と、プロセッサB(12)は、メモリ装置13(主記憶装置)を共有する。
即ち、図1に示す情報処理システムは、マルチプロセッサシステムであり、プロセッサA(11)と、プロセッサB(12)と、メモリ装置13と、を備える。
プロセッサA(11)とメモリ装置13との間、及びプロセッサB(12)とメモリ装置13との間はインタフェースで接続される。メモリ装置13内には、複数のプロセッサ間のデータの一貫性(coherence)を制御するディレクトリ14が実装され、メモリ装置13上のデータをプロセッサがリードすると、ディレクトリ14内にデータを持っていったプロセッサのID(識別名)等の情報を設定する。
【0023】
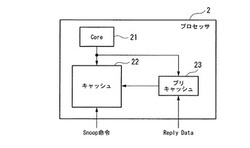
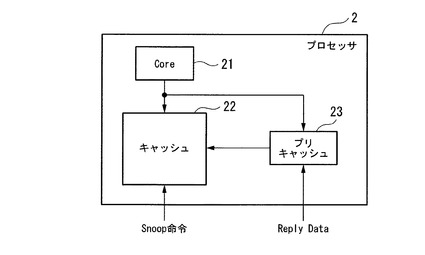
図2は、本発明の実施形態に係る情報処理装置の主要な構成を示す構成図である。
図2において、本発明の実施形態に係る情報処理装置はプロセッサ2であり、図1に示すプロセッサA(11)、及びプロセッサB(12)の主要な構成も、図2に示すプロセッサ2の構成と同じである。
図2に示すプロセッサ2は、リードやライト等の命令を発行するCore21(演算処理装置)と、プロセッサから発行したリード命令により、メモリ装置13(図1参照)から読み出して持ってきたデータを保持するキャッシュ22と、キャッシュ22の前段に置かれ、本発明の特徴的な処理として、メモリ装置13から読み出したリプライデータを一定期間保持するプリキャッシュ23と、を備えて構成される。
【0024】
図2に示す回路配線により、Core21(演算処理装置)から発行される命令に対しては、キャッシュ22、及びプリキャッシュ23の両方に対してリード及びライト可能とする。また、メモリ装置13(図1)から受け付けるSnoop命令に対しては、キャッシュ22に対してのみ実行可能として、プリキャッシュ23には実行不可とする。
また、Core21から発行される命令として、メモリ装置13に格納されているデータをプリキャッシュ23に取り入れさせる効果を有する命令、即ち周知のプリフェッチ命令を含める。
【0025】
図1に示すメモリ装置13の詳細機能、及び図2に示すプロセッサ2の他の機能については、当業者にとってよく知られており、また本発明とは直接関係しないので、その詳細な構成の記載及び説明は省略する。
また、本実施形態では、図1に示すメモリ装置13に接続されるプロセッサの台数をプロセッサA(11)とプロセッサB(12)との、計2台としているが、一般に、本発明では、メモリ装置13を共有するマルチプロセッサシステムとして配備可能なプロセッサの台数は任意の複数であってもよい。
【0026】
以下、図1を参照しながら、本実施形態に係る情報処理装置(ここでは、図2に示すプロセッサ2)のキャッシユ機構の動作を説明する。
まず、図1に示す情報処理システムの構成要素である情報処理装置(ここでは、図2に示すプロセッサ2)において、今、仮に、プリキャッシュ23が設置されておらず、また、Reply Data(c2)も、プリキャッシュ22に取り入れられる構成となっている場合に生じる問題点について総括的に述べる。
一般に、情報処理装置が前記構成のプロセッサA(11)であり、かつCore21からの命令処理において、該命令が完了しないと次の命令に進まないような処理が含まれている場合、このような命令の実行時間は該情報処理装置の性能に大きく影響する。
【0027】
このような命令の1例として、例えば、コンペア&スワップ命令がある。このコンペア&スワップ命令は、比較結果により、その後の処理が変わるため、命令サイクル内の処理の完了を待ち合わせる必要がある。この命令の動作手順としては、まずデータのリードを行い、読み出したデータを期待値と比較して、両者の一致がとれた場合は、このデータに対し、スワップ処理としてライトを行い、一致しなかった場合には何も実行しない。
【0028】
このようなコンペア&スワップ命令を一連の処理サイクルの中で実行する場合、前記の構成のプロセッサ内のキャッシュ22にデータが格納されていると、処理を速く完了させることが可能となる。このため、コンペア&スワップ命令の実行に先行してプリフェッチ命令(c1)を発行することで、メモリ装置13内の対象データを、Reply Data(c2)として、前記のプロセッサA(11)内のキャッシュ22に返却して保持させる。この時、プリフェッチ命令(c1)がアクセスするアドレスと同一のアドレスに対して、プロセッサB(12)から、Load命令(c3)が発行され、メモリ装置13で競合が発生するが、ここでは、プロセッサA(11)からのプリフェッチ命令(c1)が先に処理されたとする。
【0029】
メモリ装置13においてはプリフェッチ命令(c1)を処理したことにより、Reply Data(c2)を返却すると共に、ディレクトリ14に対して、プロセッサA(11)が対象データを持っていったことを、プロセッサA(11)の識別名と対応させて記録する。
メモリ装置13においては、競合したプロセッサB(12)からのLoad命令(c3)を続いて処理するが、ディレクトリ14にプロセッサA(11)が対象データを持っていったことが記録されているため、メモリ装置13からプロセッサA(11)に対してReply Data(c2)を追いかけるように、Snoop命令(c4)が発行される。
【0030】
他方、プロセッサA(11)においては、Reply Data(c2)を受信すると、キャッシュ22に登録し、Core21からのコンペア&スワップ命令の実行を待つ。しかしながら、もしもコンペア&スワップ命令を実行する前に、Reply Data(c2)を追いかけてきたSnoop命令(c4)を受け付けて処理してしまうと、プロセッサA(11)のキャッシュ22から対象データが読み出されてしまう結果となり、Snoop命令(c4)に対するReply Data(c5)により、メモリ装置13経由でプロセッサB(12)に対象データが持っていかれる結果となる。
【0031】
また、同様の問題点として、前記構成のプロセッサA(11)のキャッシュ22にあっては、エントリ(図示は省略)がフルになると、データの一部をSwap-outすることがあり、この時、前記と同様の処理対象データがSwap-out対象として選ばれると、キャッシュから吐き出されてメモリ装置13に書き戻されてしまう。
これらの各ケースにおいて、キャッシュ22からデータを吐き出した後にCore21からのコンペア&スワップ命令が発行されると、キャッシュには既にプリフェッチ命令(c1)による対象データが無いため、再度リードを発行して、メモリ装置13またはプロセッサB(12)から対象データを読み出す必要が発生してしまい、プリフェッチ命令(c1)による先行リードの効果が無効になってしまう。
【0032】
次に、上記の各問題点を解決するための本実施形態の性能改善手段について述べる。
本実施形態では、上記の各問題点を解決する性能改善手段として、図2に示すとおり、キャッシュ22に加えて、キャッシュ22と並べて配置されたキャッシュ23を設けると共に、Reply Data(c2)は、最初にキャッシュ23の方に取り入れる構成とする。
このような構成において、プリフェッチ命令(c1)により先行して読み出した対象データを有効活用するために、プロセッサA(11)のキャッシュ23においては、Reply Data(c2)を受け付けてキャッシュに登録した時点から一定期間は、該キャッシュ23から対象データを吐き出さないように抑止を行う。これにより、Core21から発行されるコンペア&スワップ命令などの命令に対してキャッシュヒットさせることができるため、速度の速い処理が可能となり、プリフェッチ命令の効果が有効に維持される。
【0033】
本実施形態は、上記の性能改善手段を基本機能とし、Reply Data(c2)を受け付けてキャッシュ23に登録した時点からの一定期間内はキャッシュ23からの吐き出しを抑止する機能を簡単な構成で実現している。
以下、図1,2を参照しながら、本実施形態に係る情報処理装置の動作を、上記の性能改善手段を中心にして説明する。
ここでは、キャッシュ22(図2)において、図1に示すSnoop 命令(c4)、及びSwap-out命令によるキャッシュ22からの吐き出しを、Reply Data(c2)が返却された後の一定期間抑止する動作について説明する。
【0034】
対象データが、Reply Data(c2)としてメモリ装置13からプロセッサA(11)に返却されると、プロセッサA(11)内ではキャッシュ22ではなく、図2の回路配線に示すように、プリキャッシュ23の方に該対象データを登録する。プリキャッシュ23に登録された該対象データは、Core21からの命令に対してはキャッシュ22と同様にリードやライトが可能であるため、アクセス速度の観点からは、プリキャッシュ23に格納された時点で、Core21に対しては対象データを自プロセッサのキャッシュ22に持ってきたことと等価になる。よって、プリキャッシュ23内に対象データが存在する間であっても、Core21からの後続のコンペア&スワップ命令は速く処理することが可能となる。
【0035】
また、プリキャッシュ23は、図2の回路配線に示すように、メモリ装置13からのSnoop命令(c4)(図1)による命令処理の対象外の構成要素となるように構成しているため、プリキャッシュ23内に対象データが存在する間にSnoop命令(c4)を受信した場合には、キャッシュ22においてはReply Data(c2)はメモリ装置13から未返却(即ち、未だプリキャッシュ23から受け取っていない)の状態と判断され、Snoop処理は実行されない。
この場合の、Reply Data(c2)未返却時のSnoop命令(c4)の処理は、メモリ装置13に一度リトライ指示を返却してメモリ装置13からSnoop 命令(c4)を再発行したり、プロセッサA(11)内においてReply Data(c2)が返却されるまでの間はSnoop命令(c4)を保持したりと、システムによって一貫性(coherence)を維持するための処理形態が異なるため、ここでは詳細な説明を省略する。
【0036】
また、プリキャッシュ23の構成を、最初のリプライデータ分のエントリに加えて、一定期間内にさらに返却されるデータの個数に対応可能なエントリを備える構成とするならば、Swap-out処理は不要となる。例えば、2Tが経過する毎に1回の割合で、Reply Data(c2)が返却されるとして、プリキャッシュ23内で32Tが経過するまでの期間は保持する必要があるとする場合は、プリキャッシュは、最初のリプライデータ分のエントリに加えて、最低でも16エントリを用意すればよい。
【0037】
このように構成することにより、プリキャッシュ23内に格納されている対象データについては、Snoop命令(c4)による吐き出しも起こらず、エントリフルによるSwap-outの吐き出しも起こらないことになるため、この間にCore21からのコンペア&スワップ命令が実行されれば、確実にキャッシュヒットすることになるので、プリフェッチ命令(c1)で先行して対象データを読み出していた効果により、処理速度が速くなり、速度性能の改善効果が得られる。その後は、プリキャッシュ23においては、各エントリのタイマにより、データを格納してから一定期間経過後に、該データをキャッシュ22に移動させるように構成する。これにより、キャッシュ22への格納後にSnoop 命令(c4)による処理を実行させたり、図示しないSwap-out命令によりメモリ装置13に書き戻させたりすることができる(即ち、データの一貫性(coherence)維持の処理等がなされる)。
【0038】
本実施形態に係る情報処理装置及び情報処理装置のデータキャッシング方法並びにマルチプロセッサシステムによれば、プロセッサにプリキャッシュ23を追加しただけという簡単な構成変更により、プリフェッチ命令によるアクセス速度の改善効果を最大限に活かす性能改善方法をサポートできる効果がある。
また、キャッシュ22においては、プリキャッシュ23からReply Dataを受け取るようにすること以外の機能変更は不要であり、よって、複雑な論理回路の追加や、回路変更無しで、プリフェッチ命令によるアクセス速度の改善効果を最大限に活かした性能改善方法をサポートできる効果がある。
【産業上の利用可能性】
【0039】
本発明は、主記憶装置が他の情報処理装置と共有される構成の情報処理装置の構築に適用可能であり、特に、そのデータキャッシング機構の構築に好適である。
【符号の説明】
【0040】
11 プロセッサA
12 プロセッサB
13 メモリ装置(主記憶装置)
14 ディレクトリ
21 Core(演算処理装置)
22 キャッシュ(キャッシュ機構)
23 プリキャッシュ
c1 プリフェッチ命令
c2,c5 Reply Data
c3 Load命令
c4 Snoop命令
【技術分野】
【0001】
本発明は情報処理装置及び情報処理装置のデータキャッシング方法並びにマルチプロセッサシステムに係り、特に、メモリ装置が共有される場合に、プリフェッチ命令による性能向上機能を維持させる情報処理装置及び情報処理装置のデータキャッシング方法並びにマルチプロセッサシステムに関する。
【背景技術】
【0002】
通常、情報処理装置(以下、「プロセッサ」と称する)においては、メモリ装置(主記憶装置)のアクセス速度を高めるために、前記メモリ装置以外の装置として、CPUに高速の記憶装置を備えたキャッシュ機構(以下、単に「キャッシュ」と略称することもある)を設置し、データのキャッシングを行っている。
このようなデータのキャッシングを行うキャッシュ機構にあっては、高速の記憶装置上でのヒット率を高めて、アクセス速度を向上させることが意図されるが、その他に、前記メモリ装置間のデータの一貫性(coherence)が配慮され、前記メモリ装置でデータの不一致が生じたり、前記メモリ装置への不要な格納処理や更新処理がなされないように工夫される。
また、このようなデータのキャッシングを行うキャッシュ機構を備えた複数のCPUが、メモリ装置を(主記憶装置)共有する構成となっている場合もある。
【0003】
複数のCPUが主記憶装置を共有する構成の場合、例えば、2つの異なるCPUと、該主記憶装置との3者間で、前述のデータの一貫性がとれなくなることがある。
例えば、キャッシュと主記憶装置との間がバスで接続されている場合、主記憶装置にデータを書き込む際には、該書き込みの要求は該バスに接続された全構成要素にブロードキャスト(発信)され、各CPUのキャッシュは、該ブロードキャストされた要求をsnoop(監視)命令で監視し、書き込みデータのアドレス(一意名)が自分のキャッシュに有るものと同一である場合には、当該キャッシュ上のデータが乗っているラインを無効化する(無効化する理由は、該アドレスが示す当該キャッシュ上のデータは、一般に、前記書き込みデータとは異なるものとなるから)。
これにより、次回のアクセス時(より具体的には読み出し時)には当該キャッシュではミス・ヒットとなるので、主記憶装置の方から最新のデータを取得することができることになり、結果としてキャッシュの一貫性を維持することができることになる。ちなみに、このような機能を有するキャッシュを「snoop cache」と称している。
【0004】
他方、プロセッサは、自装置が使用する予定のあるデータをプリフェッチ命令により、先行してプロセッサ内のキャッシュに読み出しておく処理を行っている。しかしながら、このプリフェッチ機能は、例えば前述のsnoop(監視)命令の実行により、その期待された効果が無効となる場合があり、この点の解決が課題となっている。
このプリフェッチ命令が出されるタイミングは、全体的な処理の流れから見て、本来ならば読み取り命令が出されても良い正当なタイミングであるが、もしもプロセッサ内のキャッシュに、該当するデータが存在しない場合には、主記憶装置から、該データを読み出すことになるので、アクセス時間が多大に掛かるため、このプリフェッチ命令を先行して発行することにより、まずは、先付け処理として、プロセッサ内のキャッシュに該データを読み出しておくものである。このプリフェッチ命令を発行した時点から以降、該データが本当に必要になるまでの間、または該データが読み出されるまでの間は、該プロセッサは、他のタスクを実行することができる。
なお、このプリフェッチ命令は、リード命令の結果が直ぐに欲しい場合に、該リード命令に先行して発行しておくことも有効な使用法である。
【0005】
プリフェッチ処理機能を有してデータのキャッシングを行う既成のプロセッサとしては、例えば図3に示すようなものがある。
以下、周知の技術として、プリフェッチしたデータを一定期間キャッシュ内に保持して性能改善を図る方法を説明する。
図3は、プリフェッチしたデータを一定期間キャッシュ内に保持して性能改善を図る周知の方法が適用されるプロセッサの内部構成を示す構成図である。
同図に示すプロセッサ3は、リードやライト等の命令を発行するCore(演算処理装置)31と、プロセッサから発行したリード命令によりメモリ装置から読み出して持ってきたデータを保持するキャッシュ32と、アドレスバッファ34とSnoop命令のアドレスとが一致したことによりキャッシュにSnoop命令の実行抑止指示を出すSnoop抑止回路33と、リプライデータ(以下、「Reply Data」と書くこともある)の返却時に返却されたデータのアドレスを一定期間保持するアドレスバッファ34と、アドレスバッファ内のアドレスとSnoop命令やSwap-out対象のキャッシュ内データのアドレスとを比較するコンパレータ35と、を備える。
【0006】
但し、図3に示すプロセッサ3の構成は当業者にとってよく知られており、これ以外に他の機能に対応した構成要素も存在するが、本発明とは直接関係しない構成要素であるので、ここでは省略している。
以下、図1及び図3を参照して、既成のプロセッサであるプロセッサ3の動作を説明する。
まず、メモリ装置13からReply Data(c2)(図1参照)を受信すると、プロセッサ3は、キャッシュ32にデータを登録すると共に、Reply Data(c2)のデータのアドレスをアドレスバッファ34に登録する。アドレスバッファ34内にはキャッシュ内に対象データを保持しておきたい時間だけ登録しておく。アドレスバッファ34内にアドレスが登録されている間に、メモリ装置13からのSnoop命令(以下、単に「Snoop」と略称する)(c4)を受信すると、キャッシュ32でSnoop(c4)を実行する前に、コンパレータ35によりアドレスバッファ34内のアドレスとSnoop(c4)のアドレスとを比較する。
【0007】
この比較の結果、アドレスバッファ34内に一致するアドレスが登録されていると、Snoop抑止回路33に報告され、Snoop 抑止回路33は、キャッシュ32におけるSnoop (c4)の実行を抑止する。この場合のSnoop(c4)の抑止処理は、メモリ装置13に一度リトライ指示を返却して、メモリ装置13からSnoop(c4)を再発行したり、プロセッサ3内において保持したりと、システムによって一貫性維持のための処理形態が異なるため、ここでは詳細には説明しない。
また、Swap-out処理においても、吐き出す対象のエントリにおいて、コンパレータ35によりアドレスバッファ34内のアドレスとSwap-out対象のエントリ内の全データのアドレスとを比較して、該比較した結果をキャッシュ32に戻すことで、アドレスバッファ34内のアドレスと一致したデータについてはSwap-out対象外としてSwap-outするデータを決定する処理が行われる。この場合、キャッシュ32の構成がNウェイセットアソシアティブである場合は、コンパレータ35の比較回路もN個必要となる。
【0008】
これらの対策により、アドレスバッファ34内にアドレスが格納されている間は、キャッシュ32から対象データは吐き出されないことになるため、Core31からプリフェッチにより先読みを行った(例えばコンペア&スワップ命令)が実行されれば、確実にキャッシュヒットすることになるので、プリフェッチ(c1)で先行して読み出した効果により、処理が速くなり、よって性能改善となる。その後、アドレスバッファ34からアドレスが削除されると、Snoop(c4)に対する抑止処理が解除され、実行されることになったり、Swap-out可能となることでメモリ装置13に書き戻されたりすることになる。
【0009】
本発明の分野に関する公知技術としては、例えば、特許文献1には、キャッシュユニットをSnoopする技術が開示されている。
また、例えば、特許文献2には、「スヌープ・キャッシュ」なる用語が見られ、特許文献1と同様の技術が開示されている。
また、例えば、特許文献3には、メモリのプリフェッチ性能を改善する技術が開示されている。
さらに、例えば、特許文献4には、複数のキャッシュを使用する技術が開示されている。
【先行技術文献】
【特許文献】
【0010】
【特許文献1】特開2006−216075号公報
【特許文献2】特開平3−189845号公報
【特許文献3】特開平11−328018号公報
【特許文献4】特許第3286258号公報
【発明の概要】
【発明が解決しようとする課題】
【0011】
ところで、上記背景技術で述べた従来の情報処理装置及び情報処理装置のデータキャッシング方法にあっては、プリフェッチしたデータを一定期間キャッシュ内に保持して性能改善を図る方法が適用される構成の場合、先行リードしたデータを使用する前にキャッシュから吐き出されてしまわないように、保持しておきたいデータのアドレスを比較回路付きバッファ内に保持しておき、このバッファ内のデータアドレスとキャッシュ内のデータアドレスとが一致する場合はキャッシュからの吐き出しの対象外としている。このため、キャッシュにおけるSnoop動作やSwap-out動作に抑止機能が追加となったり、アドレスを保持するバッファに比較回路が多数必要になったりと、キャッシュ及びその周りの論理及び動作が複雑化するという問題点があった。
【0012】
以上の問題点をさらに具体的に纏めると、
第1の問題点は、比較回路付きのアドレスバッファを設けるなど、複雑な回路の追加が必要となってしまうことである。
第2の課題は、キャッシュに対して、Snoop命令のデータアドレスがアドレスバッファ(前述の比較回路付きバッファ)内のアドレスと一致した場合に、該Snoop命令の実行を抑止する機能が必要になるなど、複雑な論理回路の追加や、回路の変更が必要となってしまうことである。
第3の課題は、キャッシュに対して、Swap-outするエントリ内のデータに対して、そのアドレスが、アドレスバッファ内のアドレスと一致したデータについては該Swap-outの対象外とする機能を必要とするなど、複雑な論理回路の追加や、回路の変更が必要となってしまうことである。
【0013】
なお、本発明は、
(a) 通常のキャッシュ機構に加えて、該キャッシュ機構の前段にプリキャッシュ機構を設けること、
(b) 外部のメモリ装置に格納されている指定データを、プリキャッシュ機構に取り入れさせる効果を有する周知のプリフェッチ命令を使用すること、
(c) メモリ装置から受け付けるSnoop命令については、通常のキャッシュ機構に対してのみ実行可能とし、プリキャッシュ機構については実行対象外とすること、
(d) 外部のメモリ装置から返却されたリプライデータをプリキャッシュ機構に一定期間保持した後、プリキャッシュ機構からキャッシュ機構にデータを移動すること、
を骨子としている。
しかしながら、前述の特許文献1〜4には、前記の(a)項記載の技術と同様の技術は開示されているが、前記の(b)項、(c)項、及び(d)項記載の技術は開示されていない。
【0014】
本発明は、上記従来の問題点に鑑みてなされたものであって、メモリ装置を共有する複数プロセッサからなるシステムで、プリフェッチ命令によるキャッシュ機構の効果が、メモリ装置の競合アクセスに起因して無効となることを、簡単な回路構成で防止することができる情報処理装置のキャッシュ機構及び情報処理装置のデータキャッシング方法並びにマルチプロセッサシステムを提供することを目的としている。
【課題を解決するための手段】
【0015】
上記課題を解決するために、本発明に係る情報処理装置は、他の情報処理装置と共有される主記憶装置の動作速度を改善するためのデータキャッシュ機構として、前記主記憶装置から返却されるリプライデータを保持するキャッシュ機構と、前記キャッシュ機構の前段で前記主記憶装置から返却されるリプライデータを保持するプリキャッシュ機構とを備え、さらに、前記主記憶装置から返却された前記リプライデータを、前記プリキャッシュ機構に、所定の一定期間だけ保持する手段と、演算処理装置から発行される命令に対しては、前記プリキャッシュ機構も、前記キャッシュ機構の一部として、リード及びライトを可能にする手段と、前記主記憶装置から受け付けるSnoop(監視)命令については、前記キャッシュ機構のみを対象として実行し、前記プリキャッシュ機構に対しては、該Snoop命令の実行対象外とする手段と、を備えたことを特徴とする。
【0016】
また、本発明に係る情報処理装置のデータキャッシング方法は、主記憶装置を他の情報処理装置と共有する情報処理装置のデータキャッシュ機構を制御するための情報処理装置のデータキャッシング方法であって、他の情報処理装置と共有される前記主記憶装置の動作速度を改善するためのデータキャッシュ機構の一部として、前記主記憶装置から返却されるリプライデータを保持するキャッシュ機構と、前記キャッシュ機構の前段で前記主記憶装置から返却されるリプライデータを保持するプリキャッシュ機構と、を設けると共に、前記主記憶装置から返却される前記リプライデータを、前記プリキャッシュ機構に、所定の一定期間だけ保持するステップと、演算処理装置から発行される命令に対しては、前記プリキャッシュ機構も、前記キャッシュ機構の一部として、リード及びライトを可能にするステップと、前記主記憶装置から受け付けるSnoop(監視)命令については、前記キャッシュ機構に対してのみ実行可能とし、前記プリキャッシュ機構については該Snoop命令の実行対象外とするステップと、を有することを特徴とする。
【0017】
また、本発明に係るマルチプロセッサとして、前記の情報処理装置を構成要素に含むマルチプロセッサシステムを提供するものである。
【発明の効果】
【0018】
以上説明したように、本発明の情報処理装置によれば、主記憶装置を共有する複数プロセッサからなるシステム等で、プリフェッチ命令の場合のキャッシュ機構の効果が、該主記憶装置の競合アクセスに起因して無効となることを、通常のキャッシュ機構に加えて、通常のキャッシュ機構と同様にリプライデータを保持するためのプリキャッシュ機構を追加しただけという、極めて簡単な構成でもって防止することができる効果が有る。
【図面の簡単な説明】
【0019】
【図1】本発明の実施形態に係る情報処理装置を含むマルチプロセッサシステムの全体構成を示す構成図である。
【図2】本発明の実施形態に係る情報処理装置の主要な構成を示す構成図である。
【図3】プリフェッチしたデータを一定期間キャッシュ内に保持して性能改善を図る周知の方法が適用されるプロセッサの内部構成を示す構成図である。
【発明を実施するための形態】
【0020】
本発明の情報処理装置及び情報処理装置のデータキャッシング方法は、プリフェッチ命令による本来の性能向上効果が低下することを防止するものであり、複数プロセッサからなるシステムの競合動作において、プロセッサが使用する予定のあるデータをプリフェッチ命令により、先行してプロセッサ内のキャッシュに読み出しておくための動作に対して、プロセッサが先行リードしたデータを使用する前にキャッシュから吐き出されてしまうことによる性能低下問題を、キャッシュの前段にプリキャッシュを追加することだけで、容易に解決するものである。
【0021】
このため、プロセッサ内に、通常必要とするキャッシュ以外に、メモリ装置(主記憶装置)から返却されたリプライデータを一定期間保持するためのプリキャッシュを新たに設け、プリキャッシュ内に一定期間保持した後、プリキャッシュからキャッシュにデータを移動する。
メモリ装置から受け付けるSnoop命令は、既成の情報処理装置と同じく、キャッシュに対してのみ実行可能として、プリキャッシュはSnoop命令実行の対象外とする。また、キャッシュのエントリフルによるSwap-out処理も、キャッシュからのみ実行されるものとして、プリキャッシュからはSwap-out処理を実行できないようにする。
また、プロセッサ内のCore部から発行される命令に対しては、プリキャッシュもキャッシュの一部としてリード及びライトを可能とする。これにより、プリキャッシュにおいて一定期間リプライデータを保持していることで、既成の情報処理装置による吐き出し抑止の方法と同様に、保持しておきたいデータは、Core部(演算処理装置)から見ると、キャッシュ内に一定期間は保持されていることになり、本来の性能向上効果が発揮される効果が得られる。
【0022】
以下、本発明の情報処理装置及び情報処理装置のデータキャッシング方法並びにマルチプロセッサシステムの実施形態について、図面を参照して詳細に説明する。
図1は、本発明の実施形態に係る情報処理装置を含むマルチプロセッサシステムの全体構成を示す構成図である。
同図において、本実施形態の情報処理装置は、プロセッサA(11)と、プロセッサB(12)である。プロセッサA(11)と、プロセッサB(12)は、メモリ装置13(主記憶装置)を共有する。
即ち、図1に示す情報処理システムは、マルチプロセッサシステムであり、プロセッサA(11)と、プロセッサB(12)と、メモリ装置13と、を備える。
プロセッサA(11)とメモリ装置13との間、及びプロセッサB(12)とメモリ装置13との間はインタフェースで接続される。メモリ装置13内には、複数のプロセッサ間のデータの一貫性(coherence)を制御するディレクトリ14が実装され、メモリ装置13上のデータをプロセッサがリードすると、ディレクトリ14内にデータを持っていったプロセッサのID(識別名)等の情報を設定する。
【0023】
図2は、本発明の実施形態に係る情報処理装置の主要な構成を示す構成図である。
図2において、本発明の実施形態に係る情報処理装置はプロセッサ2であり、図1に示すプロセッサA(11)、及びプロセッサB(12)の主要な構成も、図2に示すプロセッサ2の構成と同じである。
図2に示すプロセッサ2は、リードやライト等の命令を発行するCore21(演算処理装置)と、プロセッサから発行したリード命令により、メモリ装置13(図1参照)から読み出して持ってきたデータを保持するキャッシュ22と、キャッシュ22の前段に置かれ、本発明の特徴的な処理として、メモリ装置13から読み出したリプライデータを一定期間保持するプリキャッシュ23と、を備えて構成される。
【0024】
図2に示す回路配線により、Core21(演算処理装置)から発行される命令に対しては、キャッシュ22、及びプリキャッシュ23の両方に対してリード及びライト可能とする。また、メモリ装置13(図1)から受け付けるSnoop命令に対しては、キャッシュ22に対してのみ実行可能として、プリキャッシュ23には実行不可とする。
また、Core21から発行される命令として、メモリ装置13に格納されているデータをプリキャッシュ23に取り入れさせる効果を有する命令、即ち周知のプリフェッチ命令を含める。
【0025】
図1に示すメモリ装置13の詳細機能、及び図2に示すプロセッサ2の他の機能については、当業者にとってよく知られており、また本発明とは直接関係しないので、その詳細な構成の記載及び説明は省略する。
また、本実施形態では、図1に示すメモリ装置13に接続されるプロセッサの台数をプロセッサA(11)とプロセッサB(12)との、計2台としているが、一般に、本発明では、メモリ装置13を共有するマルチプロセッサシステムとして配備可能なプロセッサの台数は任意の複数であってもよい。
【0026】
以下、図1を参照しながら、本実施形態に係る情報処理装置(ここでは、図2に示すプロセッサ2)のキャッシユ機構の動作を説明する。
まず、図1に示す情報処理システムの構成要素である情報処理装置(ここでは、図2に示すプロセッサ2)において、今、仮に、プリキャッシュ23が設置されておらず、また、Reply Data(c2)も、プリキャッシュ22に取り入れられる構成となっている場合に生じる問題点について総括的に述べる。
一般に、情報処理装置が前記構成のプロセッサA(11)であり、かつCore21からの命令処理において、該命令が完了しないと次の命令に進まないような処理が含まれている場合、このような命令の実行時間は該情報処理装置の性能に大きく影響する。
【0027】
このような命令の1例として、例えば、コンペア&スワップ命令がある。このコンペア&スワップ命令は、比較結果により、その後の処理が変わるため、命令サイクル内の処理の完了を待ち合わせる必要がある。この命令の動作手順としては、まずデータのリードを行い、読み出したデータを期待値と比較して、両者の一致がとれた場合は、このデータに対し、スワップ処理としてライトを行い、一致しなかった場合には何も実行しない。
【0028】
このようなコンペア&スワップ命令を一連の処理サイクルの中で実行する場合、前記の構成のプロセッサ内のキャッシュ22にデータが格納されていると、処理を速く完了させることが可能となる。このため、コンペア&スワップ命令の実行に先行してプリフェッチ命令(c1)を発行することで、メモリ装置13内の対象データを、Reply Data(c2)として、前記のプロセッサA(11)内のキャッシュ22に返却して保持させる。この時、プリフェッチ命令(c1)がアクセスするアドレスと同一のアドレスに対して、プロセッサB(12)から、Load命令(c3)が発行され、メモリ装置13で競合が発生するが、ここでは、プロセッサA(11)からのプリフェッチ命令(c1)が先に処理されたとする。
【0029】
メモリ装置13においてはプリフェッチ命令(c1)を処理したことにより、Reply Data(c2)を返却すると共に、ディレクトリ14に対して、プロセッサA(11)が対象データを持っていったことを、プロセッサA(11)の識別名と対応させて記録する。
メモリ装置13においては、競合したプロセッサB(12)からのLoad命令(c3)を続いて処理するが、ディレクトリ14にプロセッサA(11)が対象データを持っていったことが記録されているため、メモリ装置13からプロセッサA(11)に対してReply Data(c2)を追いかけるように、Snoop命令(c4)が発行される。
【0030】
他方、プロセッサA(11)においては、Reply Data(c2)を受信すると、キャッシュ22に登録し、Core21からのコンペア&スワップ命令の実行を待つ。しかしながら、もしもコンペア&スワップ命令を実行する前に、Reply Data(c2)を追いかけてきたSnoop命令(c4)を受け付けて処理してしまうと、プロセッサA(11)のキャッシュ22から対象データが読み出されてしまう結果となり、Snoop命令(c4)に対するReply Data(c5)により、メモリ装置13経由でプロセッサB(12)に対象データが持っていかれる結果となる。
【0031】
また、同様の問題点として、前記構成のプロセッサA(11)のキャッシュ22にあっては、エントリ(図示は省略)がフルになると、データの一部をSwap-outすることがあり、この時、前記と同様の処理対象データがSwap-out対象として選ばれると、キャッシュから吐き出されてメモリ装置13に書き戻されてしまう。
これらの各ケースにおいて、キャッシュ22からデータを吐き出した後にCore21からのコンペア&スワップ命令が発行されると、キャッシュには既にプリフェッチ命令(c1)による対象データが無いため、再度リードを発行して、メモリ装置13またはプロセッサB(12)から対象データを読み出す必要が発生してしまい、プリフェッチ命令(c1)による先行リードの効果が無効になってしまう。
【0032】
次に、上記の各問題点を解決するための本実施形態の性能改善手段について述べる。
本実施形態では、上記の各問題点を解決する性能改善手段として、図2に示すとおり、キャッシュ22に加えて、キャッシュ22と並べて配置されたキャッシュ23を設けると共に、Reply Data(c2)は、最初にキャッシュ23の方に取り入れる構成とする。
このような構成において、プリフェッチ命令(c1)により先行して読み出した対象データを有効活用するために、プロセッサA(11)のキャッシュ23においては、Reply Data(c2)を受け付けてキャッシュに登録した時点から一定期間は、該キャッシュ23から対象データを吐き出さないように抑止を行う。これにより、Core21から発行されるコンペア&スワップ命令などの命令に対してキャッシュヒットさせることができるため、速度の速い処理が可能となり、プリフェッチ命令の効果が有効に維持される。
【0033】
本実施形態は、上記の性能改善手段を基本機能とし、Reply Data(c2)を受け付けてキャッシュ23に登録した時点からの一定期間内はキャッシュ23からの吐き出しを抑止する機能を簡単な構成で実現している。
以下、図1,2を参照しながら、本実施形態に係る情報処理装置の動作を、上記の性能改善手段を中心にして説明する。
ここでは、キャッシュ22(図2)において、図1に示すSnoop 命令(c4)、及びSwap-out命令によるキャッシュ22からの吐き出しを、Reply Data(c2)が返却された後の一定期間抑止する動作について説明する。
【0034】
対象データが、Reply Data(c2)としてメモリ装置13からプロセッサA(11)に返却されると、プロセッサA(11)内ではキャッシュ22ではなく、図2の回路配線に示すように、プリキャッシュ23の方に該対象データを登録する。プリキャッシュ23に登録された該対象データは、Core21からの命令に対してはキャッシュ22と同様にリードやライトが可能であるため、アクセス速度の観点からは、プリキャッシュ23に格納された時点で、Core21に対しては対象データを自プロセッサのキャッシュ22に持ってきたことと等価になる。よって、プリキャッシュ23内に対象データが存在する間であっても、Core21からの後続のコンペア&スワップ命令は速く処理することが可能となる。
【0035】
また、プリキャッシュ23は、図2の回路配線に示すように、メモリ装置13からのSnoop命令(c4)(図1)による命令処理の対象外の構成要素となるように構成しているため、プリキャッシュ23内に対象データが存在する間にSnoop命令(c4)を受信した場合には、キャッシュ22においてはReply Data(c2)はメモリ装置13から未返却(即ち、未だプリキャッシュ23から受け取っていない)の状態と判断され、Snoop処理は実行されない。
この場合の、Reply Data(c2)未返却時のSnoop命令(c4)の処理は、メモリ装置13に一度リトライ指示を返却してメモリ装置13からSnoop 命令(c4)を再発行したり、プロセッサA(11)内においてReply Data(c2)が返却されるまでの間はSnoop命令(c4)を保持したりと、システムによって一貫性(coherence)を維持するための処理形態が異なるため、ここでは詳細な説明を省略する。
【0036】
また、プリキャッシュ23の構成を、最初のリプライデータ分のエントリに加えて、一定期間内にさらに返却されるデータの個数に対応可能なエントリを備える構成とするならば、Swap-out処理は不要となる。例えば、2Tが経過する毎に1回の割合で、Reply Data(c2)が返却されるとして、プリキャッシュ23内で32Tが経過するまでの期間は保持する必要があるとする場合は、プリキャッシュは、最初のリプライデータ分のエントリに加えて、最低でも16エントリを用意すればよい。
【0037】
このように構成することにより、プリキャッシュ23内に格納されている対象データについては、Snoop命令(c4)による吐き出しも起こらず、エントリフルによるSwap-outの吐き出しも起こらないことになるため、この間にCore21からのコンペア&スワップ命令が実行されれば、確実にキャッシュヒットすることになるので、プリフェッチ命令(c1)で先行して対象データを読み出していた効果により、処理速度が速くなり、速度性能の改善効果が得られる。その後は、プリキャッシュ23においては、各エントリのタイマにより、データを格納してから一定期間経過後に、該データをキャッシュ22に移動させるように構成する。これにより、キャッシュ22への格納後にSnoop 命令(c4)による処理を実行させたり、図示しないSwap-out命令によりメモリ装置13に書き戻させたりすることができる(即ち、データの一貫性(coherence)維持の処理等がなされる)。
【0038】
本実施形態に係る情報処理装置及び情報処理装置のデータキャッシング方法並びにマルチプロセッサシステムによれば、プロセッサにプリキャッシュ23を追加しただけという簡単な構成変更により、プリフェッチ命令によるアクセス速度の改善効果を最大限に活かす性能改善方法をサポートできる効果がある。
また、キャッシュ22においては、プリキャッシュ23からReply Dataを受け取るようにすること以外の機能変更は不要であり、よって、複雑な論理回路の追加や、回路変更無しで、プリフェッチ命令によるアクセス速度の改善効果を最大限に活かした性能改善方法をサポートできる効果がある。
【産業上の利用可能性】
【0039】
本発明は、主記憶装置が他の情報処理装置と共有される構成の情報処理装置の構築に適用可能であり、特に、そのデータキャッシング機構の構築に好適である。
【符号の説明】
【0040】
11 プロセッサA
12 プロセッサB
13 メモリ装置(主記憶装置)
14 ディレクトリ
21 Core(演算処理装置)
22 キャッシュ(キャッシュ機構)
23 プリキャッシュ
c1 プリフェッチ命令
c2,c5 Reply Data
c3 Load命令
c4 Snoop命令
【特許請求の範囲】
【請求項1】
他の情報処理装置と共有される主記憶装置の動作速度を改善するためのデータキャッシュ機構として、
前記主記憶装置から返却されるリプライデータを保持するキャッシュ機構と、
前記キャッシュ機構の前段で前記主記憶装置から返却されるリプライデータを保持するプリキャッシュ機構とを備え、さらに、
前記主記憶装置から返却された前記リプライデータを、前記プリキャッシュ機構に、所定の一定期間だけ保持する手段と、
演算処理装置から発行される命令に対しては、前記プリキャッシュ機構も、前記キャッシュ機構の一部として、リード及びライトを可能にする手段と、
前記主記憶装置から受け付けるSnoop (監視)命令については、前記キャッシュ機構のみを対象として実行し、前記プリキャッシュ機構に対しては、該Snoop 命令の実行対象外とする手段と、
を備えたことを特徴とする情報処理装置。
【請求項2】
前記プリキャッシュ機構に保持されたデータは、前記所定の一定時間の経過後に、前記キャッシュ機構に移動されることを特徴とする請求項1記載の情報処理装置。
【請求項3】
前記主記憶装置は、他の情報処理装置と共有されている記憶装置であることを特徴とする請求項1又は2に記載の情報処理装置。
【請求項4】
前記プリキャッシュ機構は、前記リプライデータ分のエントリに加えて、前記所定の一定時間内にさらに前記主記憶装置から返却されるリプライデータを保持できるエントリを備えていることを特徴とする請求項1乃至3のいずれか1項に記載の情報処理装置。
【請求項5】
主記憶装置を他の情報処理装置と共有する構成の情報処理装置の、データキャッシュ機構を制御するための情報処理装置のデータキャッシング方法であって、
他の情報処理装置と共有される前記主記憶装置の動作速度を改善するためのデータキャッシュ機構の一部として、
前記主記憶装置から返却されるリプライデータを保持するキャッシュ機構と、
前記キャッシュ機構の前段で前記主記憶装置から返却されるリプライデータを保持するプリキャッシュ機構と、を設けると共に、
前記主記憶装置から返却される前記リプライデータを、前記プリキャッシュ機構に、所定の一定期間だけ保持するステップと、
演算処理装置から発行される命令に対しては、前記プリキャッシュ機構も、前記キャッシュ機構の一部として、リード及びライトを可能にするステップと、
前記主記憶装置から受け付けるSnoop (監視)命令については、前記キャッシュ機構に対してのみ実行可能とし、前記プリキャッシュ機構については該Snoop 命令の実行対象外とするステップと、
を有することを特徴とする情報処理装置のデータキャッシング方法。
【請求項6】
請求項1乃至4に記載の情報処理装置を構成要素に含むマルチプロセッサシステム。
【請求項1】
他の情報処理装置と共有される主記憶装置の動作速度を改善するためのデータキャッシュ機構として、
前記主記憶装置から返却されるリプライデータを保持するキャッシュ機構と、
前記キャッシュ機構の前段で前記主記憶装置から返却されるリプライデータを保持するプリキャッシュ機構とを備え、さらに、
前記主記憶装置から返却された前記リプライデータを、前記プリキャッシュ機構に、所定の一定期間だけ保持する手段と、
演算処理装置から発行される命令に対しては、前記プリキャッシュ機構も、前記キャッシュ機構の一部として、リード及びライトを可能にする手段と、
前記主記憶装置から受け付けるSnoop (監視)命令については、前記キャッシュ機構のみを対象として実行し、前記プリキャッシュ機構に対しては、該Snoop 命令の実行対象外とする手段と、
を備えたことを特徴とする情報処理装置。
【請求項2】
前記プリキャッシュ機構に保持されたデータは、前記所定の一定時間の経過後に、前記キャッシュ機構に移動されることを特徴とする請求項1記載の情報処理装置。
【請求項3】
前記主記憶装置は、他の情報処理装置と共有されている記憶装置であることを特徴とする請求項1又は2に記載の情報処理装置。
【請求項4】
前記プリキャッシュ機構は、前記リプライデータ分のエントリに加えて、前記所定の一定時間内にさらに前記主記憶装置から返却されるリプライデータを保持できるエントリを備えていることを特徴とする請求項1乃至3のいずれか1項に記載の情報処理装置。
【請求項5】
主記憶装置を他の情報処理装置と共有する構成の情報処理装置の、データキャッシュ機構を制御するための情報処理装置のデータキャッシング方法であって、
他の情報処理装置と共有される前記主記憶装置の動作速度を改善するためのデータキャッシュ機構の一部として、
前記主記憶装置から返却されるリプライデータを保持するキャッシュ機構と、
前記キャッシュ機構の前段で前記主記憶装置から返却されるリプライデータを保持するプリキャッシュ機構と、を設けると共に、
前記主記憶装置から返却される前記リプライデータを、前記プリキャッシュ機構に、所定の一定期間だけ保持するステップと、
演算処理装置から発行される命令に対しては、前記プリキャッシュ機構も、前記キャッシュ機構の一部として、リード及びライトを可能にするステップと、
前記主記憶装置から受け付けるSnoop (監視)命令については、前記キャッシュ機構に対してのみ実行可能とし、前記プリキャッシュ機構については該Snoop 命令の実行対象外とするステップと、
を有することを特徴とする情報処理装置のデータキャッシング方法。
【請求項6】
請求項1乃至4に記載の情報処理装置を構成要素に含むマルチプロセッサシステム。
【図1】


【図2】
【図3】
【図2】
【図3】
【公開番号】特開2011−76345(P2011−76345A)
【公開日】平成23年4月14日(2011.4.14)
【国際特許分類】
【出願番号】特願2009−226802(P2009−226802)
【出願日】平成21年9月30日(2009.9.30)
【出願人】(000168285)エヌイーシーコンピュータテクノ株式会社 (572)
【Fターム(参考)】
【公開日】平成23年4月14日(2011.4.14)
【国際特許分類】
【出願日】平成21年9月30日(2009.9.30)
【出願人】(000168285)エヌイーシーコンピュータテクノ株式会社 (572)
【Fターム(参考)】
[ Back to top ]