
情報処理装置
【課題】従来の情報処理装置は、同時発行命令数により並列演算数に制限があった。
【解決手段】本発明の情報処理装置は、命令キャッシュと、データキャッシュと、並列動作可能な複数の演算器を備える第1、第2の演算器群22a、22bと、第1の演算器群22aに対する1以上の演算命令を生成する第1の演算制御回路10と、固定命令レジスタ31の命令コードに基づき第2の演算器群22bに対する1以上の演算命令を生成する第2の演算制御回路30と、を有し、第1の演算器群22aは、第1の演算制御回路10が第1の特定命令コードに基づき生成した演算命令に応じて固定命令レジスタ31に命令コードを設定し、第1の演算制御回路10が第2の特定命令コードに基づき生成した演算命令に応じて第2の演算器群22bに処理データを与え、第2の演算器群22bは、第2の演算制御回路30が生成した演算命令に基づく演算を繰り返し実行する。
【解決手段】本発明の情報処理装置は、命令キャッシュと、データキャッシュと、並列動作可能な複数の演算器を備える第1、第2の演算器群22a、22bと、第1の演算器群22aに対する1以上の演算命令を生成する第1の演算制御回路10と、固定命令レジスタ31の命令コードに基づき第2の演算器群22bに対する1以上の演算命令を生成する第2の演算制御回路30と、を有し、第1の演算器群22aは、第1の演算制御回路10が第1の特定命令コードに基づき生成した演算命令に応じて固定命令レジスタ31に命令コードを設定し、第1の演算制御回路10が第2の特定命令コードに基づき生成した演算命令に応じて第2の演算器群22bに処理データを与え、第2の演算器群22bは、第2の演算制御回路30が生成した演算命令に基づく演算を繰り返し実行する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は情報処理装置に関し、特に複数のプロセッサエレメントを含む情報処理装置に関する。
【背景技術】
【0002】
近年、1度に発行する演算命令に複数の演算命令を含めるVLIW(Very Long Instruction Word)プロセッサが提案されている。VLIWプロセッサで実行される命令コードは、プログラムにおいて並列して実行可能な演算をコンパイラにて抽出される。VLIWプロセッサでは、並列に実行可能な複数の命令コードを取り込んで命令レジスタに格納し、この複数の命令コードを1度にデコードする。そして、VLIWプロセッサでは、このデコード処理により生成された複数の演算命令に基づき複数の演算器を並列して動作させる。
【0003】
例えば、画像処理等の用途では、処理に用いられる計算が有限であり、かつ、繰り返し同じ計算がなされることが多いため、並列して実行可能な演算の抽出が容易である。そのため。このようなVLIWプロセッサは、画像処理等の用途においてより有効に利用される。このVLIWプロセッサの一例が非特許文献1に開示されている。非特許文献1に記載のプロセッサは、複数のプロセッサエレメントを備え、それぞれがVLIWプロセッサとして構成される。このように複数のVLIWプロセッサを備えることで、非特許文献1では、さらに処理能力を向上させることができる。
【先行技術文献】
【非特許文献】
【0004】
【非特許文献1】S.Kyo, et al., "A Low-Cost Mixed-Mode Parallel Processor Architecture for Embedded Systems", Proc. of ACM Int. Conf. on Supercomputing, pp.253-262, June, 2007.
【発明の概要】
【発明が解決しようとする課題】
【0005】
しかしながら、非特許文献1に記載のプロセッサでは、1つのプロセッサエレメントで並列して実行可能な演算命令の数が制限されており、その制限数を超えた演算を他の演算と並列して実行することができない問題がある。つまり、非特許文献1に記載のプロセッサでは、並列して実行可能な演算数に制限があるために、十分に演算の並列性を向上させることができない問題がある。
【課題を解決するための手段】
【0006】
本発明にかかる情報処理装置の一態様は、第1の命令コードが格納される第1のキャッシュと、処理対象のデータが格納される第2のキャッシュと、前記データに対する演算を並列して動作可能な複数の演算器により行う第1、第2の演算器群と、前記第1の命令コードを読み出し、前記第1の命令コードに基づき前記第1の演算器群に対する1以上の演算命令を生成する第1の演算制御回路と、前記第1の演算器群により指定された第2の命令コードを格納する固定命令レジスタを含み、前記第2の命令コードに基づき前記第2の演算器群に対する1以上の演算命令を生成する第2の演算制御回路と、を有し、前記第1の命令コードには少なくとも第1、第2の特定命令コードが含まれ、前記第1の演算器群は、前記第1の演算制御回路が生成する演算命令に前記第1の特定命令コードに基づく第1の演算命令が含まれる場合には前記第1の演算命令に応じて前記固定命令レジスタに前記第2の命令コードを設定し、前記第1の演算制御回路が生成する演算命令に前記第2の特定命令コードに基づく第2の演算命令が含まれる場合には前記第2の演算器群に前記第2の演算器群が処理すべきデータを与え、前記第2の演算器群は、前記第2の演算制御回路が前記第2の命令コードに基づき生成した演算命令に基づく演算を繰り返し実行する。
【0007】
本発明にかかる情報処理装置によれば、第2の演算器群は、第1の演算器群が第1の演算命令に基づき設定した第2の命令コードに基づき1以上の演算を並列して行う。この第1の演算命令は、他の演算命令とともに生成することが可能である。また、第2の演算器群は第2の命令コードが更新されるまで同じ演算を繰り返し実行する。このようなことから、本発明にかかる情報処理装置では、第2の演算器群への演算指示を行うために第1の演算器群の演算能力の全てが用いられることなく、かつ、第1の演算器群での演算と並列して第2の演算器群で演算を行う可能である。つまり、本発明にかかる情報処理装置では、第1の演算器群における並列演算数の制限を超えた演算を並列して実行することができる。
【発明の効果】
【0008】
本発明にかかる情報処理装置では、演算処理についての並列性を向上させることができる。
【図面の簡単な説明】
【0009】
【図1】実施の形態1にかかる情報処理装置のブロック図である。
【図2】実施の形態1にかかる情報処理装置で用いられる第1の特定命令コードのフォーマットを示す図である。
【図3】実施の形態1にかかる情報処理装置で用いられる第2の特定命令コードのフォーマットを示す図である。
【図4】実施の形態1にかかる情報処理装置で用いられる第1、第2の特定命令コードを用いたプログラムの一例である。
【図5】実施の形態1にかかる情報処理装置で用いられる第2の特定命令コードによる演算命令を定義するプログラムの一例である。
【図6】図4、図5で示したプログラムを実行した場合における情報処理装置のサイクル1の動作を示す図である。
【図7】図4、図5で示したプログラムを実行した場合における情報処理装置のサイクル2の動作を示す図である。
【図8】図4、図5で示したプログラムを実行した場合における情報処理装置のサイクル3の動作を示す図である。
【図9】図4、図5で示したプログラムを実行した場合における情報処理装置のサイクル4の動作を示す図である。
【図10】図4、図5で示したプログラムを実行した場合における情報処理装置のサイクル5の動作を示す図である。
【図11】実施の形態1にかかる情報処理装置の主データパスで実行されるプログラムの一例を示した図である。
【図12】実施の形態1にかかる情報処理装置の副データパスで実行されるプログラムの一例を示した図である。
【図13】図11で示したプログラムを実行する場合の情報処理装置の主データパスの処理シーケンスを示すシーケンス図である。
【図14】図12で示したプログラムを実行する場合の情報処理装置の副データパスの処理シーケンスを示すシーケンス図である。
【図15】図11、図12で示したプログラムを実行する場合の情報処理装置の動作を示すシーケンス図である。
【図16】実施の形態2にかかる情報処理装置のブロック図である。
【図17】実施の形態2にかかる情報処理装置がSIMDモードの動作を行う場合に用いられる回路ブロックを示した情報処理装置のブロック図である。
【図18】実施の形態2にかかる情報処理装置がMIMDモードの動作を行う場合に用いられる回路ブロックを示した情報処理装置のブロック図である。
【発明を実施するための形態】
【0010】
実施の形態1
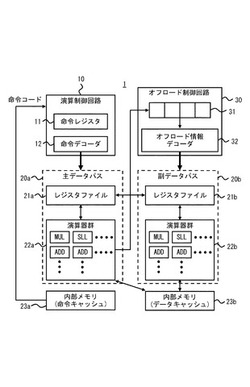
以下、図面を参照して本発明の実施の形態について説明する。実施の形態1にかかる情報処理装置1のブロック図を図1に示す。図1に示すように、情報処理装置1は、第1の演算制御回路(例えば、演算制御回路10)、主データパス20a、副データパス20b、第1のキャッシュ(例えば、内部メモリ23a)、第2のキャッシュ(例えば、内部メモリ23b)、第2の演算制御回路(例えば、オフロード制御回路30)を有する。
【0011】
主データパス20aには、レジスタファイル21aと、第1の演算器群22aが含まれる。また、副データパス20bには、レジスタファイル21bと、第2の演算器群22bが含まれる。主データパス20aでは、第1の演算器群22aがレジスタファイル21aにデータを入出力しながら演算を進める。副データパス20bでは、第2の演算器群22bがレジスタファイル21aにデータを入出力しながら演算を進める。また、レジスタファイル21bには、第1の演算器群22aが第2の演算器群22bが処理するデータをレジスタファイル21bに格納する。第1の演算器群22a及び第2の演算器群22bは、データに対する演算を並列して動作可能な複数の演算器により行う。
【0012】
第1の演算器群22aと第2の演算器群22bには、加算器ADD、乗算器MUL、論理シフト演算ユニットSLL等の複数の演算器を含むものとする。第1の演算器群22a及び第2の演算器群22bは、複数の演算命令を1サイクルで並列して実行できる。このとき、並列して実行する演算は、演算に用いる演算器が重複しないように設定される。つまり、乗算器MULが1つあった場合、1サイクルで2つの乗算を行うことができない。なお、第1の演算器群22a及び第2の演算器群は、同一の演算器の構成を有していることが好ましい。
【0013】
まず、情報処理装置1では、内部メモリ23aに情報処理装置1で利用される演算を指示する第1の命令コードが格納される。つまり、内部メモリ23aは、命令キャッシュとして利用される。また、内部メモリ23bには、情報処理装置1で処理の対象となるデータが格納される。つまり、内部メモリ23bはデータキャッシュとして利用される。
【0014】
演算制御回路10は、内部メモリ23aから第1の命令コードを読み出し、第1の命令コードに基づき第1の演算器群22aに対する1以上の演算命令を生成する。つまり、情報処理装置1は、VLIW型のプロセッサとして動作する。この第1の命令コードには、には少なくとも第1、第2の特定命令コードが含まれる。第1、第2の特定命令コードについての詳細は後述するが、以下の説明では、第1の特定命令コードをオフロード情報設定命令コードと称し、第2の特定命令コードをオフロード処理命令コードと称す。さらに、第1の命令コードには、第1、第2の特定命令コード以外の種々の命令コード(例えば、加算命令コード、論理シフト演算命令コード等)が含まれる。
【0015】
演算制御回路10は、命令レジスタ11、命令デコーダ12を有する。演算制御回路10は、第1の命令コードを読み出して、命令レジスタ11に読み出した第1の命令コードを蓄積する。そして、演算制御回路10は、命令デコーダ12により、第1、第2の特定命令コードと、その他の命令コードと、の中からプログラムに基づき任意に選択した複数の命令コードを1度にデコードする。つまり、命令デコーダ12は、複数の演算命令を1度に生成する。
【0016】
オフロード制御回路30は、第1の演算器群22aにより指定された第2の命令コードを格納する固定命令レジスタ(例えば、オフロードレジスタ31)を含み、第2の命令コードに基づき前記第2の演算器群に対する1以上の演算命令を生成する。オフロード制御回路30は、オフロードレジスタ31に加えてオフロード情報デコーダ32を有する。オフロードレジスタ31には、第2の命令コードとして第2の演算器群22bにおいて並列して動作可能な演算器により実行可能な複数の命令コードが格納される。そして、オフロード情報デコーダ32は、オフロードレジスタ31に格納されている複数の命令コードを1度にデコードすることで、第2の演算器群22bに対して複数の演算命令を同時に生成する。
【0017】
ここで、実施の形態1にかかる情報処理装置1で用いられる第1の特定命令コード(オフロード情報設定命令コード)及び第2の特定命令コード(例えば、オフロード処理命令コード)の詳細について説明する。そこで、まず、オフロード情報設定命令コードの命令フォーマットを図2に示す。図2に示すように、オフロード情報設定命令コードは、プログラムとしては、setofldとの記述で指定される。そして、引数としてオフロード処理指定情報の記述が格納されたデータキャッシュのアドレスaddrが記述される。
【0018】
次いで、オフロード処理命令コードの命令フォーマットを図3に示す。図3に示すように、オフロード処理命令コードは、プログラムとしては、olfdとの記述で指定される。そして、引数として、第1のソースオペランドRA、第2のソースオペランドRB、ディスティネーションオペランドRD、出力遅延サイクル数Latが記述される。なお、第1のソースオペランドRAは、演算対象の第1のデータが格納される主データパス20aのレジスタファイル21aのアドレスである。第2のソースオペランドRBは、演算対象の第2のデータが格納される主データパス20aのレジスタファイル21aのアドレスである。ディスティネーションオペランドRDは、演算結果データを格納する主データパス20aのレジスタファイル21aのアドレスである。出力遅延サイクル数Latは、第1、第2のソースオペランドを与えてからディスティネーションオペランドを得るまでの処理サイクル数である。なお、ソースオペランド及びディスティネーションオペランドの数は指定しない場合も含めて任意に設定できるものとする。また、本実施の形態では、ソースオペランドに対応するデータを副データパス20bのレジスタファイル21bのレジスタr1、r2に格納するものとする。
【0019】
続いて、オフロード情報設定命令コードとオフロード処理命令コードとを含むプログラムの一例を図4に示す。図4に示すように、実施の形態1にかかるオフロード制御回路30及び副データパス20bを利用するためには、オフロード情報設定命令コードとオフロード処理命令コードとを用いてプログラムを記述する必要がある。図4に示す例では、まず、オフロード情報設定命令コード(setofld)が記述される。そして、このオフロード情報設定命令コードにより用いられるオフロー処理指定情報は、.L_OFLD_INFO1に格納されていることがわかる。
【0020】
そして、図4に示す例では、オフロード情報設定命令コードに続いてオフロード処理命令コード(ofld)が4つ記述される。1番目のオフロード処理命令コードは、レジスタr1、r9に格納されたデータをソースオペランドとし、レジスタr5をディスティネーションオペランドとする。また、1番目のオフロード処理命令コードでは、出力遅延サイクル数として3が設定される。その他の3つのオフロード処理命令コードについても1番目のオフロード処理命令コードと同じルールでオペランド及び出力遅延サイクル数が指定される。
【0021】
ここで、オフロード処理指定情報に関する記述について説明する。オフロード処理指定情報のプログラム記述を図5に示す。図5に示す例では、乗算命令コードMUL、論理右シフト演算命令コードSRLI、加算命令コードADD、無演算命令NOPがそれぞれ対応する命令が格納される命令キャッシュのアドレスとして記述されている。また、図5で示す例では、乗算命令コードMULは、副データパス20bのレジスタファイル21bのレジスタr1を第1のソースオペランド、レジスタr3を第2のソースオペランド、レジスタr4をディスティネーションオペランドとする命令コードが格納されるアドレスとして記述されている。論理右シフト演算命令コードSRLIは、副データパス20bのレジスタファイル21bのレジスタr4を第1のソースオペランド、シフト量を2ビット、レジスタr7をディスティネーションオペランドとする命令コードが格納されるアドレスとして記述されている。加算命令コードADDは、副データパス20bのレジスタファイル21bのレジスタr7を第1のソースオペランド、レジスタr2を第2のソースオペランド、レジスタr15をディスティネーションオペランドとする命令コードが格納されるアドレスとして記述されている。
【0022】
実施の形態1にかかる情報処理装置では、演算制御回路10がオフロード情報設定命令コード及びオフロード処理命令コードに基づき演算指示を主データパス20aの第1の演算器群22aに与える。そして、第1の演算器群は、演算制御回路10が生成した演算命令にオフロード情報設定命令コードに基づく第1の演算命令が含まれる場合には第1の演算命令に応じてオフロードレジスタ31に第2の命令コード(例えば、オフロード処理指定情報)を設定する。また、第1の演算器群22aは、演算制御回路10が生成する演算命令にオフロード処理命令コードに基づく第2の演算命令が含まれる場合には第2の演算器群22bが利用するレジスタファイル21bに第2の演算器群22bが処理すべきデータを与える。そして、第2の演算器群22bは、オフロード制御回路30がオフロード処理指定情報に基づき生成した演算命令に基づく演算を繰り返し実行する。
【0023】
そこで、図4、図5で示したプログラムを実行した場合における情報処理装置1の動作を示す図を図6〜図10に示す。なお、図6〜図10では、主データパス20aのレジスタファイル21aと副データパス20bのレジスタファイル21bとの間のデータの授受を用いて情報処理装置1の動作を示した。
【0024】
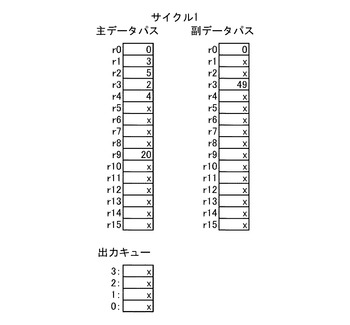
図6は、サイクル1の情報処理装置1の動作を示す図である。図6に示すようにサイクル1では、レジスタファイル21a、21bには何等の操作は行われない。サイクル1では、オフロード情報設定命令コードに基づき第1の演算器群22aが動作する。第1の演算器群22aは、データキャッシュ23bからオフロード処理指定情報を読み出して、オフロード制御回路30のオフロードレジスタ31に格納する。なお、サイクル1において、レジスタファイル21a、21b中のxは不定値を示す。また、サイクル1においてレジスタファイル21bのレジスタr1、r3には予め定数0、49が格納されているものとする。さらに、サイクル1においてレジスタファイル21aには後の計算で用いられるデータが格納されているものとする。
【0025】
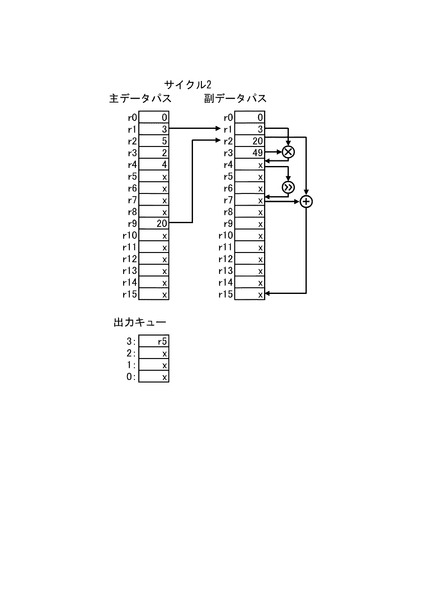
続いて、図7にサイクル2の情報処理装置1の動作を示す。サイクル2では、演算制御回路10が図4の2行目のオフロード処理命令コードに基づき演算命令を生成する。そして、第1の演算器群22aは、演算制御回路10が生成した演算命令に応じて、レジスタファイル21aのレジスタr1、r9に格納されたデータをレジスタファイル21bのレジスタr1、r2に格納する。また、出力キューの3番目にサイクル2で第2の演算器群22bに与えたデータに対する処理結果を格納するレジスタとしてレジスタr5を示す値を格納する。この出力キューに格納された値は、サイクルが進む毎に1つずつ番号の小さい出力キューにずれる。
【0026】
また、サイクル2では、第2の演算器群22bがオフロード制御回路30が生成した演算命令に応じて演算を実行する。しかし、サイクル1でレジスタr1に格納される値は不定値であるため、レジスタr4には、不定値が格納される。また、レジスタr7、r15に格納する値の演算に用いられる値には不定値が含まれるため、レジスタr7、r15に格納される値も不定値となる。
【0027】
続いて、図8にサイクル3の情報処理装置1の動作を示す。サイクル3では、演算制御回路10が図4の3行目のオフロード処理命令コードに基づき演算命令を生成する。そして、第1の演算器群22aは、演算制御回路10が生成した演算命令に応じて、レジスタファイル21aのレジスタr2、r9に格納されたデータをレジスタファイル21bのレジスタr1、r2に格納する。また、出力キューの3番目にサイクル3で第2の演算器群22bに与えたデータに対する処理結果を格納するレジスタとしてレジスタr6を示す値を格納する。このとき、サイクル2で3番目の出力キューに格納されたレジスタr5を示す値は、サイクル3で2番目の出力キューに移動される。
【0028】
また、サイクル3では、第2の演算器群22bがオフロード制御回路30が生成した演算命令に応じて演算を実行する。具体的には、サイクル2でレジスタファイル21bのレジスタr1に格納された値(図7に示す例では2)とレジスタr3の値(図7に示す例では49)との乗算結果がレジスタr4に格納される。しかし、レジスタr7、r15に格納する値の演算に用いられる値には不定値が含まれるため、レジスタr7、r15に格納される値は不定値となる。
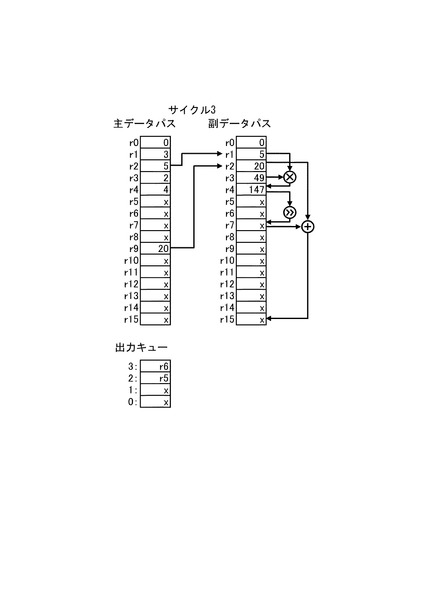
【0029】
続いて、図9にサイクル4の情報処理装置1の動作を示す。サイクル4では、演算制御回路10が図4の4行目のオフロード処理命令コードに基づき演算命令を生成する。そして、第1の演算器群22aは、演算制御回路10が生成した演算命令に応じて、レジスタファイル21aのレジスタr3、r9に格納されたデータをレジスタファイル21bのレジスタr1、r2に格納する。また、出力キューの3番目にサイクル4で第2の演算器群22bに与えたデータに対する処理結果を格納するレジスタとしてレジスタr7を示す値を格納する。このとき、サイクル3で3番目の出力キューに格納されたレジスタr6を示す値は、サイクル4で2番目の出力キューに移動され、サイクル4で2番目の出力キューに格納されたレジスタr5を示す値は1番目の出力キューに移動される。
【0030】
また、サイクル4では、第2の演算器群22bがオフロード制御回路30が生成した演算命令に応じて演算を実行する。具体的には、サイクル3でレジスタファイル21bのレジスタr1に格納された値(図8に示す例では5)とレジスタr3の値(図8に示す例では49)との乗算結果がレジスタr4に格納される。また、サイクル3でレジスタファイル21bのレジスタr4に格納された値を右方向に2ビットシフトした値(r4の値を4で除した値のうち整数成分)がレジスタr7に格納される。しかし、レジスタr15に格納する値の演算に用いられる値には不定値が含まれるため、レジスタr15に格納される値は不定値となる。
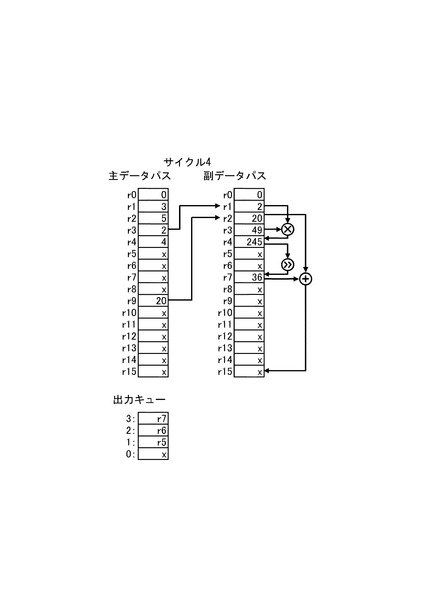
【0031】
続いて、図10にサイクル5の情報処理装置1の動作を示す。サイクル5では、演算制御回路10が図4の5行目のオフロード処理命令コードに基づき演算命令を生成する。そして、第1の演算器群22aは、演算制御回路10が生成した演算命令に応じて、レジスタファイル21aのレジスタr4、r9に格納されたデータをレジスタファイル21bのレジスタr1、r2に格納する。また、出力キューの3番目にサイクル5で第2の演算器群22bに与えたデータに対する処理結果を格納するレジスタとしてレジスタr8を示す値を格納する。このとき、サイクル4で3番目の出力キューに格納されたレジスタr7を示す値は2番目の出力キューに移動され、サイクル4で2番目の出力キューに格納されたレジスタr6を示す値は1番目の出力キューに移動され、サイクル4で1番目の出力キューに格納されたレジスタr5を示す値は0番目の出力キューに移動される。
【0032】
また、サイクル5では、第2の演算器群22bがオフロード制御回路30が生成した演算命令に応じて演算を実行する。具体的には、サイクル4でレジスタファイル21bのレジスタr1に格納された値(図9に示す例では2)とレジスタr3の値(図8に示す例では49)との乗算結果がレジスタr4に格納される。また、サイクル4でレジスタファイル21bのレジスタr4に格納された値を右方向に2ビットシフトした値(r4の値を4で除した値のうち整数成分)がレジスタr7に格納される。また、サイクル4でレジスタファイル21bのレジスタr2、r7に格納された値の加算結果がレジスタr15に格納される。そして、レジスタr15に格納された値は、0番目の出力キューの値に基づきレジスタファイル21aのレジスタr5に格納される。
【0033】
このように、実施の形態1にかかる情報処理装置1では、第1の演算器群22aが1つの命令コード(例えば、オフロード処理命令コード)に基づき生成された演算命令に応じて処理を行うのみで、第2の演算器群22bに対して演算を指示することができる。また、第2の演算器群22bが行う演算は、オフロード情報設定命令コードに基づき設定するのみである。また、この設定処理に必要なサイクル数は1つである。つまり、情報処理装置1では、演算制御回路10がオフロード情報設定命令コード又はオフロード処理命令コードとこの2つの命令コード以外の命令コードとを含めた命令コードに基づき複数の演算命令を第1の演算器群22aに与え、第1の演算器群22aにオフロード情報設定命令コードとオフロード処理命令コード以外の命令コードに基づく他の処理を並列的に実行させることができる。
【0034】
このような並列処理を行う場合における情報処理装置1の動作について具体的な例を挙げて説明する。以下では、処理の一例として、3×3のソベルフィルタの計算を情報処理装置1で行う例について説明する。このソベルフィルタの計算は、画像処理の分野においてエッジ検出を行う場合に用いられる手法の一つであり、異なるデータに対して同じ演算を繰り返し行うという特徴がある。
【0035】
まず、3×3のソベルフィルタの計算を行うプログラムの一例を図11に示す。図11に示すプログラムでは、演算に用いる変数として出力データを示すDOUT[y][x]をlong int型の変数として定義する。また、出力データDOUTは480×640のメモリ領域が指定される。
【0036】
そして、具体的な演算としてx=1を初期値とし、ループ処理が完了する毎にxを1ずつ増加させ、xが479に達するまで処理を繰り返す第1のループ処理が定義される。また、y=1を初期値として、ループ処理が完了する毎にyを1ずつ増加させ、yが639に達するまで処理を繰り返す第2のループ処理が定義される。そして、第2のループ処理では、演算対象画素の値(DOUT[y][x])の計算式が記述される。この計算式において、DINは演算対象画素の値を計算するための入力画素値を示すものであり、DINの後ろにDINの画像中の位置を示す座標が示されている。
【0037】
また、3×3のソベルフィルタの計算では、計算後の出力データを格納するデータキャッシュ中のアドレスDOUT[y][x]を計算する必要がある。そこで、出力データDOUT[y][x]を格納する有効アドレスを計算するプログラムの一例を図12に示す。図12に示す例では、左辺に有効アドレス値addressが示され、右辺に有効アドレス値の計算式が示されている。このプログラム例では、演算対象の画像が格納されている領域の先頭アドレスbaseに対して、y座標値を2560(640×4)倍、x座標値を4倍した値を加算したアドレス(1画素は4バイトで表現されており、画像の1行は640画素あるため)に新たな画素値を格納するように計算がなされる。
【0038】
続いて、図11、図12に示したプログラム例に基づく情報処理装置1の動作について具体的に説明する。以下の説明では、第1の演算器群22aにおいて図11に示すソベルフィルタの計算を行い、第2の演算器群22bにおいて図12に示すアドレス計算を行うものとする。ソベルフィルタの計算に比べて、アドレス計算は必要になる演算器の種類が少ないため、アドレス計算の方がよりオフロード処理に向いているためである。
【0039】
また、演算制御回路10は、最大で4つの演算命令を同時に発行するものとする。また、第1の演算器群22aが少なくとも論理左シフト演算ユニットSLLを2つ、減算器SUBを2つ、加算器ADDを2つ、比較器CMPを1つ、ロードユニットLDを1つ、オフロード設定命令ユニットsetofldを1つ、オフロード処理命令ユニットofldを1つ、ストアユニットSTを1つ、ループ処理を繰り返す分岐命令ユニットBNZを1つ、データ移動命令ユニットMVを1つ、有しているものとする。第2の演算器群22bは、少なくとも乗算MULを1つ、論理左シフト演算ユニットSLLを1つ、加算器ADDを2つ、有しているものとする。また、出力データDOUT[y][x]の値を計算するに当たり、事前に、DIN[y−1][x−1]、DIN[y−1][x+1]、DIN[y][x−1]、DIN[y][x+1]はレジスタファイル21aに格納されているものとする。そして、出力データDOUT[y][x]の値を計算する処理において、新たにDIN[y+1][x−1]、DIN[y+1][x+1]がデータキャッシュから読み出されるものとする。
【0040】
まず、図11に示したプログラムに基づく処理を情報処理装置1が行う場合の演算フローを図13に示す。上述したように、図11に示すプログラムに基づく演算は第1の演算器群22aで行われるものである。
【0041】
図13に示すように、第1の演算器群22aは、サイクル1において、DIN[y+1][x−1]のロードと、DIN[y][x−1]に対する論理左シフト演算と、DIN[y][x+1]の論理左シフト演算と、現在処理対象としているDIN[y][x]の計算結果を格納するデータキャッシュのアドレス値を計算するためのオフロード処理命令コードofldに基づく処理と、を行う。なお、サイクル1におけるオフロード処理命令コードofldに基づく処理は、処理結果を格納する領域DOUTの先頭アドレス値とxの値とyの値とをレジスタファイル21bに格納する。サイクル1で指示されたオフロード処理に応じて得られるアドレス値は、後述するサイクル5のストア処理で利用される。
【0042】
次いで、第1の演算器群22aは、サイクル2において、DIN[y+1][x+1]のロードと、DIN[y−1][x−1]とDIN[y−1][x+1]との減算と、DIN[y][x−1]に対する論理左シフト演算結果とDIN[y][x+1]の論理左シフト演算の結果との減算と、次の処理で利用されるDIN[y+1][x−1]が格納されているデータキャッシュのアドレス値を計算するためのオフロード処理命令コードofldに基づく処理と、を行う。なお、サイクル2におけるオフロード処理命令コードofldに基づく処理は、処理対象の画像領域DINの先頭アドレス値と(x−1)の値とyの値とをレジスタファイル21bに格納する。サイクル2で指示されたオフロード処理に応じて得られるアドレス値は、次の画素に対するソベルフィルタの計算で利用される。
【0043】
次いで、第1の演算器群22aは、サイクル3において、DIN[y+1][x+1]とDIN[y+1][x−1]との減算と、サイクル2で行われた2つの減算の結果に対する加算と、現時点でのyの値と値1との加算と、次の処理で利用されるDIN[y+1][x+1]が格納されているデータキャッシュのアドレス値を計算するためのオフロード処理命令コードofldに基づく処理と、を行う。なお、サイクル3におけるオフロード処理命令コードofldに基づく処理は、処理対象の画像領域DINの先頭アドレス値と(x+1)の値とyの値とをレジスタファイル21bに格納する。サイクル3で指示されたオフロード処理に応じて得られるアドレス値は、次の画素に対するソベルフィルタの計算で利用される。
【0044】
次いで、第1の演算器群22aは、サイクル4において、サイクル3において行われた減算結果とサイクル3において行われたDINに関する加算結果との加算と、yの値と値1との加算結果と、yの上限値(479)との大小比較と、を行う。
【0045】
次いで、第1の演算器群22aは、サイクル5において、第2の演算器群22bから出力データDOUT[y][x]の値のストア処理及びyの値の更新を行う。
【0046】
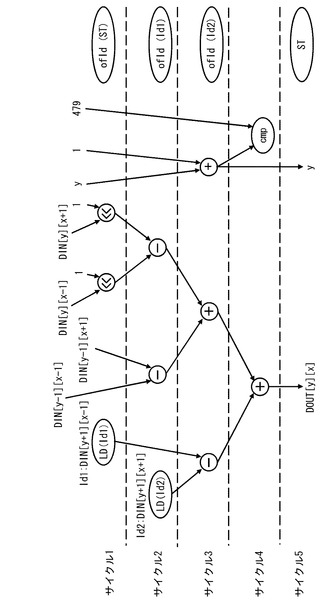
続いて、図12に示したプログラム基づく処理を情報処理装置1が行う場合の演算フローを図14に示す。上述したように、図12に示すプログラムに基づく演算は第2の演算器群22bで行われるものである。
【0047】
図14に示すように、第2の演算器群22bは、サイクル1において、yの値と値2560との乗算と、xの値に対する2ビットの論理左シフト演算(xと4の乗算)と、を行う。次いで、第2の演算器群22bは、サイクル2において、サイクル1で行われた2つの演算の結果の加算を行う。次いで、第2の演算器群22bは、サイクル3において、サイクル2で行われた加算の結果と画像の先頭アドレスbaseとの加算を行う。そして、第2の演算器群22bは、サイクル4において、計算した新たなアドレス値DOUTをレジスタファイル21bの所定のレジスタに格納する。なお、第2の演算器群22bでは、オフロード制御回路30がオフロードレジスタに格納された命令コードに基づき常に4つの演算命令を同時に発行するため、図示しない他の演算も常に行われる。例えば、サイクル1においてもサイクル2の加算処理及びサイクル3の加算処理が行われる。
【0048】
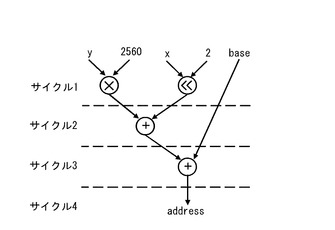
ここで、図11、図12で示したプログラムを実行する場合の情報処理装置の動作を示すシーケンス図を図15に示す。この図15では、図13、図14で示した処理の関係に着目し、各演算器群で実行される命令コードの処理フローを示した。なお、図15では、命令コードを示す符号として命令コードに応じて動作する演算器に付した符号と同じ符号を示した。
【0049】
図15に示す例では、サイクル1で主データパス20aに対してオフロード情報設定命令コードsetofldに基づく演算指示が与えられる。このサイクル1におけるオフロード情報設定命令コードsetofldに基づく演算指示に応じて、サイクル2において副データパス20bの処理で利用される演算が確定する。図15に示す例では、副データパス20bの処理は、1つの乗算器MUL、1つの論理左シフト演算ユニットSLL、及び2つの加算器ADDにより行われる。
【0050】
そして、サイクル10において、主データパス20aにオフロード処理命令コードofldに基づく演算命令が指示される。また、サイクル10では、オフロード処理命令コードofldと共に、ロード命令コードLDに基づく処理と、2つの論理左シフト演算命令コードSLLに基づく処理とが指示される。また、サイクル10では、副データパス20bにサイクル2で設定された命令コードに応じた演算が行われる。つまり、このサイクル10の処理では、図13のサイクル1の処理に相当する処理が行われる。
【0051】
次いで、サイクル11において、主データパス20aにオフロード処理命令コードofldに基づく演算命令が指示される。また、サイクル11では、オフロード処理命令コードofldと共に、ロード命令コードLDに基づく処理と、2つの減算命令コードSUBに基づく処理とが指示される。また、サイクル11では、副データパス20bにサイクル2で設定された命令コードに応じた演算が行われる。このとき、副データパス20bでは、サイクル10で発行されたオフロード処理命令コードに応じて主データパス20a側から与えられた演算データに対して、図14のサイクル1の動作を行う。つまり、このサイクル11の処理では、図13のサイクル2の処理及び図14のサイクル1の処理に相当する処理が行われる。
【0052】
次いで、サイクル12において、主データパス20aにオフロード処理命令コードofldに基づく演算命令が指示される。また、サイクル12では、オフロード処理命令コードofldと共に、減算命令コードSUBに基づく処理と、2つの加算命令コードADDに基づく処理とが指示される。また、サイクル12では、副データパス20bにサイクル2で設定された命令コードに応じた演算が行われる。このとき、副データパス20bでは、サイクル11の副データパス20bの処理結果に対して、図14のサイクル2の動作を行う。つまり、このサイクル12の処理では、図13のサイクル3の処理及び図14のサイクル2の処理に相当する処理が行われる。
【0053】
次いで、サイクル13において、主データパス20aにオフロード処理命令コードofldに基づく演算命令が指示される。また、サイクル13では、オフロード処理命令コードofldと共に、加算命令コードADDに基づく処理と、比較命令コードCMPに基づく処理と、データ移動命令コードMVに基づく処理とが指示される。また、サイクル13では、副データパス20bにサイクル2で設定された命令コードに応じた演算が行われる。このとき、副データパス20bでは、サイクル12の副データパス20bの処理結果に対して、図14のサイクル3の動作を行う。つまり、このサイクル13の処理では、図13のサイクル4の処理及び図14のサイクル3の処理に相当する処理が行われる。
【0054】
第1の演算器群22aが加算器ADDを2つしか有していない場合、第1の演算器群22aの加算器ADDの数の制限によりアドレス計算とデータDOUT[y][x]の計算とを並列して行い、データDOUT[y][x]の計算結果とアドレス計算の結果とを同時に得ることはできない。同時に2つの計算結果を得るためには、最大で3つの加算器を同時に動作させる必要があるためである。また、アドレス計算とデータDOUT[y][x]の計算とを同時に終了するためには最大で5つの演算命令を同時発行しなければならず、演算制御回路10の同時命令発行数が4であった場合にはアドレス計算とデータDOUT[y][x]の計算とを並列して行うことができない。
【0055】
一方、上述したように、実施の形態1にかかる情報処理装置1では、第1の演算器群22aで並列して処理できる演算数に制限がある場合であっても、データDOUT[y][x]の計算結果とアドレス計算の結果とを同時に得ることができる。情報処理装置1では、演算制御回路10がオフロード情報設定命令コードに基づき生成した演算命令に応じて第1の演算器群22aがオフロードレジスタ31に第2の演算器群22bにおける処理に必要な命令コードを設定する。そして、オフロード制御回路30がオフロードレジスタ31に格納された命令コードに基づき演算命令を生成する。第2の演算器群22bは、オフロード制御回路30が生成した演算命令に基づく動作を繰り返し実行する。第2の演算器群22bをこのように動作させることで、情報処理装置1では、演算制御回路10がオフロード処理命令コードに応じて生成した演算命令に基づき第1の演算器群22aが第2の演算器群22b側に第2の演算器群22bが処理すべきデータを渡すのみで、当該データに対する演算を第2の演算器群22bにて行うことができる。つまり、情報処理装置1では、第1の演算器群22aと第2の演算器群22bとが備える演算器群を合わせた並列処理が可能になる。以上のことより、情報処理装置1では、第1の演算器群22aが有する演算器の数の制限を超えた数の演算を並列して行うことができる。さらに、情報処理装置1では、同時に実行可能な演算数を実質的に増加させることができることから、プログラムの処理時間を短縮することができる。
【0056】
また、情報処理装置1では、オフロード情報設定命令コードにより第2の演算器群22bで実行する演算を指定する命令コードを任意に設定できる。そのため、演算制御回路10の同時発行命令数の制限を超えた演算命令をオフロード制御回路30により生成することで、演算制御回路10の同時発行命令数の制限よりも多くの演算を並列して実行する。つまり、情報処理装置1では、実質的に演算制御回路10の同時発行命令数を増加させることができる。一方、従来のプロセッサに関し、主演算器とコプロセッサ等の専用回路とを設け、例えば、浮動小数点演算についてはコプロセッサに実行させる技術がある。しかし、この専用回路は、固定的な演算しか行うことができない。また、専用回路に演算を行わせる場合、演算毎に演算指示と演算データを主演算器が専用回路に与えなければならず主演算器の演算能力を低下させる原因となっていた。つまり、従来のプロセッサにおける主演算器と専用回路との組合せでは、主演算器で同時実行可能な演算命令の数を増やすことはできない。
【0057】
実施の形態2
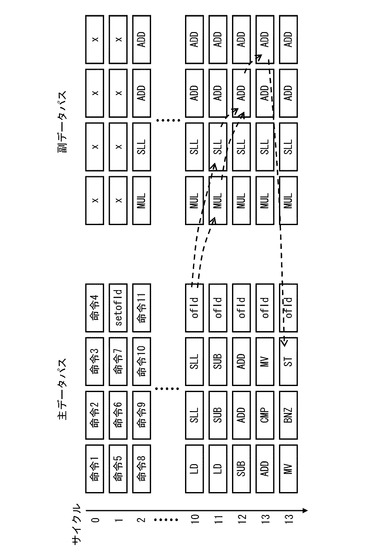
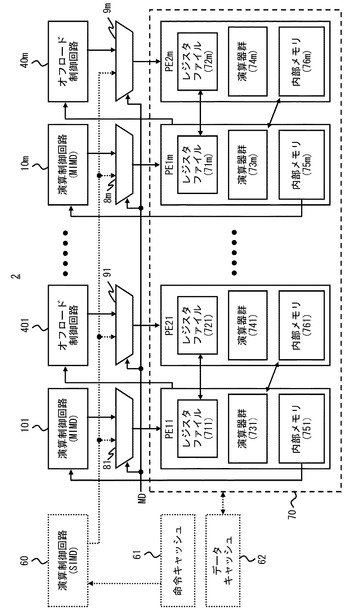
実施の形態2にかかる情報処理装置2のブロック図を図16に示す。図16に示すように、情報処理装置2は、第1の演算制御回路(例えば、演算制御回路101〜10m(mは整数、以下同じ))、第2の演算制御回路(例えば、オフロード制御回路401〜40m)、第3の演算制御回路(例えば、演算制御回路60)、命令キャッシュ61、データキャッシュ62、演算器70、第1の切換回路81〜8m、第2の切換回路91〜9mを有する。
【0058】
さらに、情報処理装置2では、演算器70が第1のプロセッサエレメント(例えば、プロセッサエレメントPE11〜PE1m)と第2のプロセッサエレメント(プロセッサエレメントPE21〜PE2m)とを有する。そして、実施の形態2にかかる情報処理装置2は、動作モードとして第1のモード(例えば、SIMDモード)と第2のモード(例えば、MIMDモード)とを有する。情報処理装置2は、SIMDモードでは、プロセッサエレメントPE11〜PE1m、PE21〜PE2mにおいて異なるデータに対して同じ演算を並列して行う。一方、情報処理装置2は、MINDモードでは、プロセッサエレメントPE11〜PE1mとプロセッサエレメントPE21〜PE2mとを1つの演算器として再構成し、複数の演算器により異なるデータに対する異なる演算を並列して行う。
【0059】
ここで、情報処理装置2の構成についてさらに詳細に説明する。命令キャッシュ61は、SIMDモードにおいて利用される第3の命令コードが格納される。データキャッシュ62は、SIMDモードにおいて処理されるデータが格納される。演算制御回路60は、命令キャッシュ61から第3の命令コードを読み出し、第3の命令コードに基づき演算命令を生成する。
【0060】
第1の切換回路81〜8mは、SIMDモードにおいて演算制御回路60からプロセッサエレメントPE11〜PE1mに演算指示に与え、MIMDモードにおいて演算制御回路101〜10mからプロセッサエレメントPE11〜PE1mに演算指示に与える。第2の切換回路91〜9mは、SIMDモードにおいて演算制御回路60からプロセッサエレメントPE21〜PE2mに演算指示に与え、MIMDモードにおいてオフロード制御回路401〜40mからプロセッサエレメントPE21〜PE2mに演算指示に与える。なお、第1の切換回路81〜8m及び第2の切換回路91〜9mは、図示しない他の回路から与えられるモード切換信号MDに基づき演算指示元の演算制御回路を切り換える。
【0061】
プロセッサエレメントPE11〜PE1mは、レジスタファイル711〜71m、演算器群731〜73m、内部メモリ751〜75mを有する。また、プロセッサエレメントPE21〜PE2mは、レジスタファイル721〜72m、演算器群741〜74m、内部メモリ761〜76mを有する。
【0062】
プロセッサエレメントPE11〜PE1m、PE21〜PE2mは、SIMDモードにおいて、自プロセッサエレメント内の内部メモリに格納されたデータに対して演算を行う。より具体的には、プロセッサエレメントPE11〜PE1m、PE21〜PE2mは、演算器群におけるロード処理により自プロセッサエレメント内のレジスタファイルに内部メモリからデータをロードし、演算器群はレジスタファイル内のデータを用いて演算器群による演算を行う。そして、プロセッサエレメントPE11〜PE1mは、演算結果をレジスタファイルに格納し、演算器群におけるストア処理により自プロセッサエレメント内のレジスタファイルから内部メモリに演算後のデータを格納する。
【0063】
また、プロセッサエレメントPE11〜PE1mは、MIMDモードにおいて、自プロセッサエレメント内の内部メモリを実施の形態1にかかる内部メモリ23a(例えば、命令キャッシュ)として利用する。また、プロセッサエレメントPE11〜PE1mは、MIMDモードにおいて、自プロセッサエレメント内の演算器群を実施の形態1にかかる第1の演算器群22aとして利用する。
【0064】
プロセッサエレメントPE21〜PE2mは、MIMDモードにおいて、自プロセッサエレメント内の内部メモリを実施の形態1にかかる内部メモリ23b(例えば、データキャッシュ)として利用する。また、プロセッサエレメントPE21〜PE2mは、MIMDモードにおいて、自プロセッサエレメント内の演算器群を実施の形態1にかかる第2の演算器群22bとして利用する。
【0065】
なお、プロセッサエレメントPE11〜PE1mの内部メモリ751〜75m及びプロセッサエレメントPE21〜PE2mの内部メモリ761〜76mは、MIMDモードにおいて命令コードが格納される側を命令キャッシュとして利用し、データが格納される側をデータキャッシュとして利用すれば良い。つまり、内部メモリ751〜75m及び内部メモリ761〜76mは、MINDモードにおいて、いずれのキャッシュとして利用するかはアーキテクチャにより任意に設定できる。
【0066】
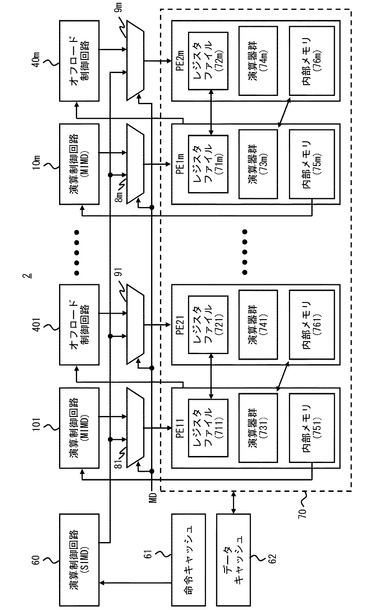
続いて、情報処理装置2をSIMDモードで動作させる場合の動作を示す情報処理装置2のブロック図を図17に示す。図17に示すように、SIMDモードでは、演算制御回路60は、命令キャッシュ61に格納された第3の命令コードに応じて演算命令を生成する。第1の切換回路81〜8m及び第2の切換回路91〜9mは、モード切換信号MDに基づき、演算制御回路60が生成する演算命令をプロセッサエレメントPE11〜PE1m及びプロセッサエレメントPE21〜PE2mに与える。そのため、演算制御回路101〜10m及びオフロード制御回路401〜40mは、実質的に無効化された状態となる。さらに、SIMDモードでは、プロセッサエレメントPE11〜PE1mとプロセッサエレメントPE21〜PE2mとの間のパスが無効化される。
【0067】
そして、プロセッサエレメントPE11〜PE1m、PE21〜PE2mは、演算制御回路60が生成する演算命令に基づき、データキャッシュ62から内部メモリ751〜75m及び内部メモリ761〜76mに処理を担当するデータをロードする。その後、プロセッサエレメントPE11〜PE1m、PE21〜PE2mは、演算制御回路60が生成する演算命令に基づき自プロセッサエレメント内の内部メモリに格納されたデータに対して、同じ演算を行う。つまり、SIMDモードでは、情報処理装置1は、複数のプロセッサエレメントを用いて異なるデータに対する同じ演算を並列して行うことで高速な処理が可能となる。このようなSIMDモードにおける演算は、例えば、1枚の大きな画像のエッジ抽出を行う場合などに有効である。例えば、1枚の大きな画像を短冊状に分割し、分割した複数の領域を複数のプロセッサエレメントで分担して処理することで画像処理を高速に行うことができる。
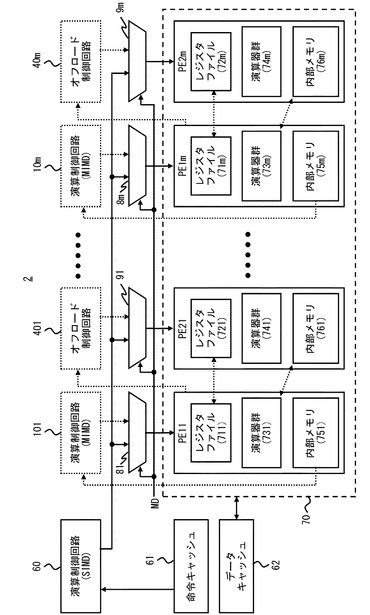
【0068】
続いて、情報処理装置2をMIMDモードで動作させる場合の動作を示す情報処理装置2のブロック図を図18に示す。図18に示すように、MIMDモードでは、演算制御回路101〜10mは、命令キャッシュと利用される内部メモリ751〜75mに格納された第1の命令コードに応じてそれぞれ演算命令を生成する。第1の切換回路81〜8mは、モード切換信号MDに基づき、演算制御回路101〜10mが生成する演算命令をプロセッサエレメントPE11〜PE1mに与える。第2の切換回路91〜9mは、モード切換信号MDに基づき、演算制御回路401〜40mが生成する演算命令をプロセッサエレメントPE21〜PE2mに与える。そのため、演算制御回路60は、実質的に無効化された状態となる。さらに、MIMDモードでは、命令キャッシュ61及びデータキャッシュ62も無効化される。一方、MIMDモードでは、プロセッサエレメントPE11〜PE1mとプロセッサエレメントPE21〜PE2mとの間のパスが有効化される。
【0069】
MIMDモードでは、上記のようにプロセッサ構成を再構成したことにより、プロセッサエレメントPE11、PE21、演算制御回路101、オフロード制御回路401により実施の形態1にかかる情報処理装置1と同じ構成を実現することができる。また、図18に示した例では、情報処理装置2は、実施の形態1にかかる情報処理装置1に相当する回路構成をm個構成することができる。つまり、情報処理装置2は、MIMDモードにおいてm個の独立したプロセッサを構成することができる。このようなMIMDモードにおける構成により演算を行うことで、例えば、1枚の大きな画像中の独立した複数の領域のそれぞれを複数のプロセッサで分担して処理することが可能になる。大きさの異なる複数の領域をSIMDモードの情報処理装置2で処理する場合、各領域を順次処理しなければならない。そのため、SIMDモードの情報処理装置2を用いてこのような画像を処理する場合の処理時間は、複数の領域の大きさの合計値に比例して長くなる。一方、大きさの異なる複数の領域をMIMDモードの情報処理装置2で処理する場合、各領域を複数のプロセッサ(実施の形態1にかかる情報処理装置1)を用いて並列して処理することができる。そのため、MIMDモードの情報処理装置2を用いてこのような画像を処理する場合の処理時間は、最大でも、複数の領域うち最も大きな領域の画像を処理する時間となる。つまり、複数の独立した画像領域を処理する場合はMIMDモードによる処理の方が短時間で処理が完了する。
【0070】
ここで、上記した複数のプロセッサエレメントの構成をSIMDモードとMINDモードとで再構成する技術に関しては非特許文献1に開示されている。しかしながら、非特許文献1に記載のプロセッサでは、MINDモードで複数のプロセッサエレメントにより1つの演算器を構成し、プロセッサ全体としては複数の演算器として互いに並列した処理を行う場合、1つの演算器で利用できる演算器群は複数のプロセッサエレメントに属する複数の演算器群のうちの1つに限られる。つまり、非特許文献1に記載のプロセッサでは、MIMDモードにおいて、1つの演算器に含まれる複数の演算器群のうち1つしか利用できず、処理能力が限られる問題がある。また、非特許文献1に記載のでは、MIMDモードにおいて回路リソースが無駄になる問題がある。
【0071】
しかしながら、実施の形態2にかかる情報処理装置2では、MIMDモードにおいて、オフロード制御回路401〜40mを利用することにより、1つの演算器を構成する複数のプロセッサエレメントに属する全ての演算器群を処理に利用することができる。そのため、実施の形態2にかかる情報処理装置2では、MINDモードにおいて、非特許文献1に記載のプロセッサよりも高い処理能力を実現することができる。また、実施の形態2にかかる情報処理装置2では、回路リソースを有効に利用できるため、処理能力に対する回路面積の効率を高めることができる。
【0072】
なお、本発明は上記実施の形態に限られたものではなく、趣旨を逸脱しない範囲で適宜変更することが可能である。
【符号の説明】
【0073】
1、2 情報処理装置
10、101〜10m 演算制御回路(第1の演算制御回路)
11 命令レジスタ
12 命令デコーダ
20a 主データパス
20b 副データパス
21a、21b、711〜71m、721〜72m レジスタファイル
22a、22b、731〜73m、741〜74m 演算器群
23a、23b、751〜75m、761〜76m 内部メモリ
30、401〜40m オフロード制御回路(第2の演算制御回路)
31 オフロードレジスタ
32 オフロード情報デコーダ
60 演算制御回路(第3の演算制御回路)
61 命令キャッシュ
62 データキャッシュ
70 演算器
81-8m 第1の切換回路
91-9m 第1の切換回路
PE11〜PE1m、PE21〜PE2m プロセッサエレメント
【技術分野】
【0001】
本発明は情報処理装置に関し、特に複数のプロセッサエレメントを含む情報処理装置に関する。
【背景技術】
【0002】
近年、1度に発行する演算命令に複数の演算命令を含めるVLIW(Very Long Instruction Word)プロセッサが提案されている。VLIWプロセッサで実行される命令コードは、プログラムにおいて並列して実行可能な演算をコンパイラにて抽出される。VLIWプロセッサでは、並列に実行可能な複数の命令コードを取り込んで命令レジスタに格納し、この複数の命令コードを1度にデコードする。そして、VLIWプロセッサでは、このデコード処理により生成された複数の演算命令に基づき複数の演算器を並列して動作させる。
【0003】
例えば、画像処理等の用途では、処理に用いられる計算が有限であり、かつ、繰り返し同じ計算がなされることが多いため、並列して実行可能な演算の抽出が容易である。そのため。このようなVLIWプロセッサは、画像処理等の用途においてより有効に利用される。このVLIWプロセッサの一例が非特許文献1に開示されている。非特許文献1に記載のプロセッサは、複数のプロセッサエレメントを備え、それぞれがVLIWプロセッサとして構成される。このように複数のVLIWプロセッサを備えることで、非特許文献1では、さらに処理能力を向上させることができる。
【先行技術文献】
【非特許文献】
【0004】
【非特許文献1】S.Kyo, et al., "A Low-Cost Mixed-Mode Parallel Processor Architecture for Embedded Systems", Proc. of ACM Int. Conf. on Supercomputing, pp.253-262, June, 2007.
【発明の概要】
【発明が解決しようとする課題】
【0005】
しかしながら、非特許文献1に記載のプロセッサでは、1つのプロセッサエレメントで並列して実行可能な演算命令の数が制限されており、その制限数を超えた演算を他の演算と並列して実行することができない問題がある。つまり、非特許文献1に記載のプロセッサでは、並列して実行可能な演算数に制限があるために、十分に演算の並列性を向上させることができない問題がある。
【課題を解決するための手段】
【0006】
本発明にかかる情報処理装置の一態様は、第1の命令コードが格納される第1のキャッシュと、処理対象のデータが格納される第2のキャッシュと、前記データに対する演算を並列して動作可能な複数の演算器により行う第1、第2の演算器群と、前記第1の命令コードを読み出し、前記第1の命令コードに基づき前記第1の演算器群に対する1以上の演算命令を生成する第1の演算制御回路と、前記第1の演算器群により指定された第2の命令コードを格納する固定命令レジスタを含み、前記第2の命令コードに基づき前記第2の演算器群に対する1以上の演算命令を生成する第2の演算制御回路と、を有し、前記第1の命令コードには少なくとも第1、第2の特定命令コードが含まれ、前記第1の演算器群は、前記第1の演算制御回路が生成する演算命令に前記第1の特定命令コードに基づく第1の演算命令が含まれる場合には前記第1の演算命令に応じて前記固定命令レジスタに前記第2の命令コードを設定し、前記第1の演算制御回路が生成する演算命令に前記第2の特定命令コードに基づく第2の演算命令が含まれる場合には前記第2の演算器群に前記第2の演算器群が処理すべきデータを与え、前記第2の演算器群は、前記第2の演算制御回路が前記第2の命令コードに基づき生成した演算命令に基づく演算を繰り返し実行する。
【0007】
本発明にかかる情報処理装置によれば、第2の演算器群は、第1の演算器群が第1の演算命令に基づき設定した第2の命令コードに基づき1以上の演算を並列して行う。この第1の演算命令は、他の演算命令とともに生成することが可能である。また、第2の演算器群は第2の命令コードが更新されるまで同じ演算を繰り返し実行する。このようなことから、本発明にかかる情報処理装置では、第2の演算器群への演算指示を行うために第1の演算器群の演算能力の全てが用いられることなく、かつ、第1の演算器群での演算と並列して第2の演算器群で演算を行う可能である。つまり、本発明にかかる情報処理装置では、第1の演算器群における並列演算数の制限を超えた演算を並列して実行することができる。
【発明の効果】
【0008】
本発明にかかる情報処理装置では、演算処理についての並列性を向上させることができる。
【図面の簡単な説明】
【0009】
【図1】実施の形態1にかかる情報処理装置のブロック図である。
【図2】実施の形態1にかかる情報処理装置で用いられる第1の特定命令コードのフォーマットを示す図である。
【図3】実施の形態1にかかる情報処理装置で用いられる第2の特定命令コードのフォーマットを示す図である。
【図4】実施の形態1にかかる情報処理装置で用いられる第1、第2の特定命令コードを用いたプログラムの一例である。
【図5】実施の形態1にかかる情報処理装置で用いられる第2の特定命令コードによる演算命令を定義するプログラムの一例である。
【図6】図4、図5で示したプログラムを実行した場合における情報処理装置のサイクル1の動作を示す図である。
【図7】図4、図5で示したプログラムを実行した場合における情報処理装置のサイクル2の動作を示す図である。
【図8】図4、図5で示したプログラムを実行した場合における情報処理装置のサイクル3の動作を示す図である。
【図9】図4、図5で示したプログラムを実行した場合における情報処理装置のサイクル4の動作を示す図である。
【図10】図4、図5で示したプログラムを実行した場合における情報処理装置のサイクル5の動作を示す図である。
【図11】実施の形態1にかかる情報処理装置の主データパスで実行されるプログラムの一例を示した図である。
【図12】実施の形態1にかかる情報処理装置の副データパスで実行されるプログラムの一例を示した図である。
【図13】図11で示したプログラムを実行する場合の情報処理装置の主データパスの処理シーケンスを示すシーケンス図である。
【図14】図12で示したプログラムを実行する場合の情報処理装置の副データパスの処理シーケンスを示すシーケンス図である。
【図15】図11、図12で示したプログラムを実行する場合の情報処理装置の動作を示すシーケンス図である。
【図16】実施の形態2にかかる情報処理装置のブロック図である。
【図17】実施の形態2にかかる情報処理装置がSIMDモードの動作を行う場合に用いられる回路ブロックを示した情報処理装置のブロック図である。
【図18】実施の形態2にかかる情報処理装置がMIMDモードの動作を行う場合に用いられる回路ブロックを示した情報処理装置のブロック図である。
【発明を実施するための形態】
【0010】
実施の形態1
以下、図面を参照して本発明の実施の形態について説明する。実施の形態1にかかる情報処理装置1のブロック図を図1に示す。図1に示すように、情報処理装置1は、第1の演算制御回路(例えば、演算制御回路10)、主データパス20a、副データパス20b、第1のキャッシュ(例えば、内部メモリ23a)、第2のキャッシュ(例えば、内部メモリ23b)、第2の演算制御回路(例えば、オフロード制御回路30)を有する。
【0011】
主データパス20aには、レジスタファイル21aと、第1の演算器群22aが含まれる。また、副データパス20bには、レジスタファイル21bと、第2の演算器群22bが含まれる。主データパス20aでは、第1の演算器群22aがレジスタファイル21aにデータを入出力しながら演算を進める。副データパス20bでは、第2の演算器群22bがレジスタファイル21aにデータを入出力しながら演算を進める。また、レジスタファイル21bには、第1の演算器群22aが第2の演算器群22bが処理するデータをレジスタファイル21bに格納する。第1の演算器群22a及び第2の演算器群22bは、データに対する演算を並列して動作可能な複数の演算器により行う。
【0012】
第1の演算器群22aと第2の演算器群22bには、加算器ADD、乗算器MUL、論理シフト演算ユニットSLL等の複数の演算器を含むものとする。第1の演算器群22a及び第2の演算器群22bは、複数の演算命令を1サイクルで並列して実行できる。このとき、並列して実行する演算は、演算に用いる演算器が重複しないように設定される。つまり、乗算器MULが1つあった場合、1サイクルで2つの乗算を行うことができない。なお、第1の演算器群22a及び第2の演算器群は、同一の演算器の構成を有していることが好ましい。
【0013】
まず、情報処理装置1では、内部メモリ23aに情報処理装置1で利用される演算を指示する第1の命令コードが格納される。つまり、内部メモリ23aは、命令キャッシュとして利用される。また、内部メモリ23bには、情報処理装置1で処理の対象となるデータが格納される。つまり、内部メモリ23bはデータキャッシュとして利用される。
【0014】
演算制御回路10は、内部メモリ23aから第1の命令コードを読み出し、第1の命令コードに基づき第1の演算器群22aに対する1以上の演算命令を生成する。つまり、情報処理装置1は、VLIW型のプロセッサとして動作する。この第1の命令コードには、には少なくとも第1、第2の特定命令コードが含まれる。第1、第2の特定命令コードについての詳細は後述するが、以下の説明では、第1の特定命令コードをオフロード情報設定命令コードと称し、第2の特定命令コードをオフロード処理命令コードと称す。さらに、第1の命令コードには、第1、第2の特定命令コード以外の種々の命令コード(例えば、加算命令コード、論理シフト演算命令コード等)が含まれる。
【0015】
演算制御回路10は、命令レジスタ11、命令デコーダ12を有する。演算制御回路10は、第1の命令コードを読み出して、命令レジスタ11に読み出した第1の命令コードを蓄積する。そして、演算制御回路10は、命令デコーダ12により、第1、第2の特定命令コードと、その他の命令コードと、の中からプログラムに基づき任意に選択した複数の命令コードを1度にデコードする。つまり、命令デコーダ12は、複数の演算命令を1度に生成する。
【0016】
オフロード制御回路30は、第1の演算器群22aにより指定された第2の命令コードを格納する固定命令レジスタ(例えば、オフロードレジスタ31)を含み、第2の命令コードに基づき前記第2の演算器群に対する1以上の演算命令を生成する。オフロード制御回路30は、オフロードレジスタ31に加えてオフロード情報デコーダ32を有する。オフロードレジスタ31には、第2の命令コードとして第2の演算器群22bにおいて並列して動作可能な演算器により実行可能な複数の命令コードが格納される。そして、オフロード情報デコーダ32は、オフロードレジスタ31に格納されている複数の命令コードを1度にデコードすることで、第2の演算器群22bに対して複数の演算命令を同時に生成する。
【0017】
ここで、実施の形態1にかかる情報処理装置1で用いられる第1の特定命令コード(オフロード情報設定命令コード)及び第2の特定命令コード(例えば、オフロード処理命令コード)の詳細について説明する。そこで、まず、オフロード情報設定命令コードの命令フォーマットを図2に示す。図2に示すように、オフロード情報設定命令コードは、プログラムとしては、setofldとの記述で指定される。そして、引数としてオフロード処理指定情報の記述が格納されたデータキャッシュのアドレスaddrが記述される。
【0018】
次いで、オフロード処理命令コードの命令フォーマットを図3に示す。図3に示すように、オフロード処理命令コードは、プログラムとしては、olfdとの記述で指定される。そして、引数として、第1のソースオペランドRA、第2のソースオペランドRB、ディスティネーションオペランドRD、出力遅延サイクル数Latが記述される。なお、第1のソースオペランドRAは、演算対象の第1のデータが格納される主データパス20aのレジスタファイル21aのアドレスである。第2のソースオペランドRBは、演算対象の第2のデータが格納される主データパス20aのレジスタファイル21aのアドレスである。ディスティネーションオペランドRDは、演算結果データを格納する主データパス20aのレジスタファイル21aのアドレスである。出力遅延サイクル数Latは、第1、第2のソースオペランドを与えてからディスティネーションオペランドを得るまでの処理サイクル数である。なお、ソースオペランド及びディスティネーションオペランドの数は指定しない場合も含めて任意に設定できるものとする。また、本実施の形態では、ソースオペランドに対応するデータを副データパス20bのレジスタファイル21bのレジスタr1、r2に格納するものとする。
【0019】
続いて、オフロード情報設定命令コードとオフロード処理命令コードとを含むプログラムの一例を図4に示す。図4に示すように、実施の形態1にかかるオフロード制御回路30及び副データパス20bを利用するためには、オフロード情報設定命令コードとオフロード処理命令コードとを用いてプログラムを記述する必要がある。図4に示す例では、まず、オフロード情報設定命令コード(setofld)が記述される。そして、このオフロード情報設定命令コードにより用いられるオフロー処理指定情報は、.L_OFLD_INFO1に格納されていることがわかる。
【0020】
そして、図4に示す例では、オフロード情報設定命令コードに続いてオフロード処理命令コード(ofld)が4つ記述される。1番目のオフロード処理命令コードは、レジスタr1、r9に格納されたデータをソースオペランドとし、レジスタr5をディスティネーションオペランドとする。また、1番目のオフロード処理命令コードでは、出力遅延サイクル数として3が設定される。その他の3つのオフロード処理命令コードについても1番目のオフロード処理命令コードと同じルールでオペランド及び出力遅延サイクル数が指定される。
【0021】
ここで、オフロード処理指定情報に関する記述について説明する。オフロード処理指定情報のプログラム記述を図5に示す。図5に示す例では、乗算命令コードMUL、論理右シフト演算命令コードSRLI、加算命令コードADD、無演算命令NOPがそれぞれ対応する命令が格納される命令キャッシュのアドレスとして記述されている。また、図5で示す例では、乗算命令コードMULは、副データパス20bのレジスタファイル21bのレジスタr1を第1のソースオペランド、レジスタr3を第2のソースオペランド、レジスタr4をディスティネーションオペランドとする命令コードが格納されるアドレスとして記述されている。論理右シフト演算命令コードSRLIは、副データパス20bのレジスタファイル21bのレジスタr4を第1のソースオペランド、シフト量を2ビット、レジスタr7をディスティネーションオペランドとする命令コードが格納されるアドレスとして記述されている。加算命令コードADDは、副データパス20bのレジスタファイル21bのレジスタr7を第1のソースオペランド、レジスタr2を第2のソースオペランド、レジスタr15をディスティネーションオペランドとする命令コードが格納されるアドレスとして記述されている。
【0022】
実施の形態1にかかる情報処理装置では、演算制御回路10がオフロード情報設定命令コード及びオフロード処理命令コードに基づき演算指示を主データパス20aの第1の演算器群22aに与える。そして、第1の演算器群は、演算制御回路10が生成した演算命令にオフロード情報設定命令コードに基づく第1の演算命令が含まれる場合には第1の演算命令に応じてオフロードレジスタ31に第2の命令コード(例えば、オフロード処理指定情報)を設定する。また、第1の演算器群22aは、演算制御回路10が生成する演算命令にオフロード処理命令コードに基づく第2の演算命令が含まれる場合には第2の演算器群22bが利用するレジスタファイル21bに第2の演算器群22bが処理すべきデータを与える。そして、第2の演算器群22bは、オフロード制御回路30がオフロード処理指定情報に基づき生成した演算命令に基づく演算を繰り返し実行する。
【0023】
そこで、図4、図5で示したプログラムを実行した場合における情報処理装置1の動作を示す図を図6〜図10に示す。なお、図6〜図10では、主データパス20aのレジスタファイル21aと副データパス20bのレジスタファイル21bとの間のデータの授受を用いて情報処理装置1の動作を示した。
【0024】
図6は、サイクル1の情報処理装置1の動作を示す図である。図6に示すようにサイクル1では、レジスタファイル21a、21bには何等の操作は行われない。サイクル1では、オフロード情報設定命令コードに基づき第1の演算器群22aが動作する。第1の演算器群22aは、データキャッシュ23bからオフロード処理指定情報を読み出して、オフロード制御回路30のオフロードレジスタ31に格納する。なお、サイクル1において、レジスタファイル21a、21b中のxは不定値を示す。また、サイクル1においてレジスタファイル21bのレジスタr1、r3には予め定数0、49が格納されているものとする。さらに、サイクル1においてレジスタファイル21aには後の計算で用いられるデータが格納されているものとする。
【0025】
続いて、図7にサイクル2の情報処理装置1の動作を示す。サイクル2では、演算制御回路10が図4の2行目のオフロード処理命令コードに基づき演算命令を生成する。そして、第1の演算器群22aは、演算制御回路10が生成した演算命令に応じて、レジスタファイル21aのレジスタr1、r9に格納されたデータをレジスタファイル21bのレジスタr1、r2に格納する。また、出力キューの3番目にサイクル2で第2の演算器群22bに与えたデータに対する処理結果を格納するレジスタとしてレジスタr5を示す値を格納する。この出力キューに格納された値は、サイクルが進む毎に1つずつ番号の小さい出力キューにずれる。
【0026】
また、サイクル2では、第2の演算器群22bがオフロード制御回路30が生成した演算命令に応じて演算を実行する。しかし、サイクル1でレジスタr1に格納される値は不定値であるため、レジスタr4には、不定値が格納される。また、レジスタr7、r15に格納する値の演算に用いられる値には不定値が含まれるため、レジスタr7、r15に格納される値も不定値となる。
【0027】
続いて、図8にサイクル3の情報処理装置1の動作を示す。サイクル3では、演算制御回路10が図4の3行目のオフロード処理命令コードに基づき演算命令を生成する。そして、第1の演算器群22aは、演算制御回路10が生成した演算命令に応じて、レジスタファイル21aのレジスタr2、r9に格納されたデータをレジスタファイル21bのレジスタr1、r2に格納する。また、出力キューの3番目にサイクル3で第2の演算器群22bに与えたデータに対する処理結果を格納するレジスタとしてレジスタr6を示す値を格納する。このとき、サイクル2で3番目の出力キューに格納されたレジスタr5を示す値は、サイクル3で2番目の出力キューに移動される。
【0028】
また、サイクル3では、第2の演算器群22bがオフロード制御回路30が生成した演算命令に応じて演算を実行する。具体的には、サイクル2でレジスタファイル21bのレジスタr1に格納された値(図7に示す例では2)とレジスタr3の値(図7に示す例では49)との乗算結果がレジスタr4に格納される。しかし、レジスタr7、r15に格納する値の演算に用いられる値には不定値が含まれるため、レジスタr7、r15に格納される値は不定値となる。
【0029】
続いて、図9にサイクル4の情報処理装置1の動作を示す。サイクル4では、演算制御回路10が図4の4行目のオフロード処理命令コードに基づき演算命令を生成する。そして、第1の演算器群22aは、演算制御回路10が生成した演算命令に応じて、レジスタファイル21aのレジスタr3、r9に格納されたデータをレジスタファイル21bのレジスタr1、r2に格納する。また、出力キューの3番目にサイクル4で第2の演算器群22bに与えたデータに対する処理結果を格納するレジスタとしてレジスタr7を示す値を格納する。このとき、サイクル3で3番目の出力キューに格納されたレジスタr6を示す値は、サイクル4で2番目の出力キューに移動され、サイクル4で2番目の出力キューに格納されたレジスタr5を示す値は1番目の出力キューに移動される。
【0030】
また、サイクル4では、第2の演算器群22bがオフロード制御回路30が生成した演算命令に応じて演算を実行する。具体的には、サイクル3でレジスタファイル21bのレジスタr1に格納された値(図8に示す例では5)とレジスタr3の値(図8に示す例では49)との乗算結果がレジスタr4に格納される。また、サイクル3でレジスタファイル21bのレジスタr4に格納された値を右方向に2ビットシフトした値(r4の値を4で除した値のうち整数成分)がレジスタr7に格納される。しかし、レジスタr15に格納する値の演算に用いられる値には不定値が含まれるため、レジスタr15に格納される値は不定値となる。
【0031】
続いて、図10にサイクル5の情報処理装置1の動作を示す。サイクル5では、演算制御回路10が図4の5行目のオフロード処理命令コードに基づき演算命令を生成する。そして、第1の演算器群22aは、演算制御回路10が生成した演算命令に応じて、レジスタファイル21aのレジスタr4、r9に格納されたデータをレジスタファイル21bのレジスタr1、r2に格納する。また、出力キューの3番目にサイクル5で第2の演算器群22bに与えたデータに対する処理結果を格納するレジスタとしてレジスタr8を示す値を格納する。このとき、サイクル4で3番目の出力キューに格納されたレジスタr7を示す値は2番目の出力キューに移動され、サイクル4で2番目の出力キューに格納されたレジスタr6を示す値は1番目の出力キューに移動され、サイクル4で1番目の出力キューに格納されたレジスタr5を示す値は0番目の出力キューに移動される。
【0032】
また、サイクル5では、第2の演算器群22bがオフロード制御回路30が生成した演算命令に応じて演算を実行する。具体的には、サイクル4でレジスタファイル21bのレジスタr1に格納された値(図9に示す例では2)とレジスタr3の値(図8に示す例では49)との乗算結果がレジスタr4に格納される。また、サイクル4でレジスタファイル21bのレジスタr4に格納された値を右方向に2ビットシフトした値(r4の値を4で除した値のうち整数成分)がレジスタr7に格納される。また、サイクル4でレジスタファイル21bのレジスタr2、r7に格納された値の加算結果がレジスタr15に格納される。そして、レジスタr15に格納された値は、0番目の出力キューの値に基づきレジスタファイル21aのレジスタr5に格納される。
【0033】
このように、実施の形態1にかかる情報処理装置1では、第1の演算器群22aが1つの命令コード(例えば、オフロード処理命令コード)に基づき生成された演算命令に応じて処理を行うのみで、第2の演算器群22bに対して演算を指示することができる。また、第2の演算器群22bが行う演算は、オフロード情報設定命令コードに基づき設定するのみである。また、この設定処理に必要なサイクル数は1つである。つまり、情報処理装置1では、演算制御回路10がオフロード情報設定命令コード又はオフロード処理命令コードとこの2つの命令コード以外の命令コードとを含めた命令コードに基づき複数の演算命令を第1の演算器群22aに与え、第1の演算器群22aにオフロード情報設定命令コードとオフロード処理命令コード以外の命令コードに基づく他の処理を並列的に実行させることができる。
【0034】
このような並列処理を行う場合における情報処理装置1の動作について具体的な例を挙げて説明する。以下では、処理の一例として、3×3のソベルフィルタの計算を情報処理装置1で行う例について説明する。このソベルフィルタの計算は、画像処理の分野においてエッジ検出を行う場合に用いられる手法の一つであり、異なるデータに対して同じ演算を繰り返し行うという特徴がある。
【0035】
まず、3×3のソベルフィルタの計算を行うプログラムの一例を図11に示す。図11に示すプログラムでは、演算に用いる変数として出力データを示すDOUT[y][x]をlong int型の変数として定義する。また、出力データDOUTは480×640のメモリ領域が指定される。
【0036】
そして、具体的な演算としてx=1を初期値とし、ループ処理が完了する毎にxを1ずつ増加させ、xが479に達するまで処理を繰り返す第1のループ処理が定義される。また、y=1を初期値として、ループ処理が完了する毎にyを1ずつ増加させ、yが639に達するまで処理を繰り返す第2のループ処理が定義される。そして、第2のループ処理では、演算対象画素の値(DOUT[y][x])の計算式が記述される。この計算式において、DINは演算対象画素の値を計算するための入力画素値を示すものであり、DINの後ろにDINの画像中の位置を示す座標が示されている。
【0037】
また、3×3のソベルフィルタの計算では、計算後の出力データを格納するデータキャッシュ中のアドレスDOUT[y][x]を計算する必要がある。そこで、出力データDOUT[y][x]を格納する有効アドレスを計算するプログラムの一例を図12に示す。図12に示す例では、左辺に有効アドレス値addressが示され、右辺に有効アドレス値の計算式が示されている。このプログラム例では、演算対象の画像が格納されている領域の先頭アドレスbaseに対して、y座標値を2560(640×4)倍、x座標値を4倍した値を加算したアドレス(1画素は4バイトで表現されており、画像の1行は640画素あるため)に新たな画素値を格納するように計算がなされる。
【0038】
続いて、図11、図12に示したプログラム例に基づく情報処理装置1の動作について具体的に説明する。以下の説明では、第1の演算器群22aにおいて図11に示すソベルフィルタの計算を行い、第2の演算器群22bにおいて図12に示すアドレス計算を行うものとする。ソベルフィルタの計算に比べて、アドレス計算は必要になる演算器の種類が少ないため、アドレス計算の方がよりオフロード処理に向いているためである。
【0039】
また、演算制御回路10は、最大で4つの演算命令を同時に発行するものとする。また、第1の演算器群22aが少なくとも論理左シフト演算ユニットSLLを2つ、減算器SUBを2つ、加算器ADDを2つ、比較器CMPを1つ、ロードユニットLDを1つ、オフロード設定命令ユニットsetofldを1つ、オフロード処理命令ユニットofldを1つ、ストアユニットSTを1つ、ループ処理を繰り返す分岐命令ユニットBNZを1つ、データ移動命令ユニットMVを1つ、有しているものとする。第2の演算器群22bは、少なくとも乗算MULを1つ、論理左シフト演算ユニットSLLを1つ、加算器ADDを2つ、有しているものとする。また、出力データDOUT[y][x]の値を計算するに当たり、事前に、DIN[y−1][x−1]、DIN[y−1][x+1]、DIN[y][x−1]、DIN[y][x+1]はレジスタファイル21aに格納されているものとする。そして、出力データDOUT[y][x]の値を計算する処理において、新たにDIN[y+1][x−1]、DIN[y+1][x+1]がデータキャッシュから読み出されるものとする。
【0040】
まず、図11に示したプログラムに基づく処理を情報処理装置1が行う場合の演算フローを図13に示す。上述したように、図11に示すプログラムに基づく演算は第1の演算器群22aで行われるものである。
【0041】
図13に示すように、第1の演算器群22aは、サイクル1において、DIN[y+1][x−1]のロードと、DIN[y][x−1]に対する論理左シフト演算と、DIN[y][x+1]の論理左シフト演算と、現在処理対象としているDIN[y][x]の計算結果を格納するデータキャッシュのアドレス値を計算するためのオフロード処理命令コードofldに基づく処理と、を行う。なお、サイクル1におけるオフロード処理命令コードofldに基づく処理は、処理結果を格納する領域DOUTの先頭アドレス値とxの値とyの値とをレジスタファイル21bに格納する。サイクル1で指示されたオフロード処理に応じて得られるアドレス値は、後述するサイクル5のストア処理で利用される。
【0042】
次いで、第1の演算器群22aは、サイクル2において、DIN[y+1][x+1]のロードと、DIN[y−1][x−1]とDIN[y−1][x+1]との減算と、DIN[y][x−1]に対する論理左シフト演算結果とDIN[y][x+1]の論理左シフト演算の結果との減算と、次の処理で利用されるDIN[y+1][x−1]が格納されているデータキャッシュのアドレス値を計算するためのオフロード処理命令コードofldに基づく処理と、を行う。なお、サイクル2におけるオフロード処理命令コードofldに基づく処理は、処理対象の画像領域DINの先頭アドレス値と(x−1)の値とyの値とをレジスタファイル21bに格納する。サイクル2で指示されたオフロード処理に応じて得られるアドレス値は、次の画素に対するソベルフィルタの計算で利用される。
【0043】
次いで、第1の演算器群22aは、サイクル3において、DIN[y+1][x+1]とDIN[y+1][x−1]との減算と、サイクル2で行われた2つの減算の結果に対する加算と、現時点でのyの値と値1との加算と、次の処理で利用されるDIN[y+1][x+1]が格納されているデータキャッシュのアドレス値を計算するためのオフロード処理命令コードofldに基づく処理と、を行う。なお、サイクル3におけるオフロード処理命令コードofldに基づく処理は、処理対象の画像領域DINの先頭アドレス値と(x+1)の値とyの値とをレジスタファイル21bに格納する。サイクル3で指示されたオフロード処理に応じて得られるアドレス値は、次の画素に対するソベルフィルタの計算で利用される。
【0044】
次いで、第1の演算器群22aは、サイクル4において、サイクル3において行われた減算結果とサイクル3において行われたDINに関する加算結果との加算と、yの値と値1との加算結果と、yの上限値(479)との大小比較と、を行う。
【0045】
次いで、第1の演算器群22aは、サイクル5において、第2の演算器群22bから出力データDOUT[y][x]の値のストア処理及びyの値の更新を行う。
【0046】
続いて、図12に示したプログラム基づく処理を情報処理装置1が行う場合の演算フローを図14に示す。上述したように、図12に示すプログラムに基づく演算は第2の演算器群22bで行われるものである。
【0047】
図14に示すように、第2の演算器群22bは、サイクル1において、yの値と値2560との乗算と、xの値に対する2ビットの論理左シフト演算(xと4の乗算)と、を行う。次いで、第2の演算器群22bは、サイクル2において、サイクル1で行われた2つの演算の結果の加算を行う。次いで、第2の演算器群22bは、サイクル3において、サイクル2で行われた加算の結果と画像の先頭アドレスbaseとの加算を行う。そして、第2の演算器群22bは、サイクル4において、計算した新たなアドレス値DOUTをレジスタファイル21bの所定のレジスタに格納する。なお、第2の演算器群22bでは、オフロード制御回路30がオフロードレジスタに格納された命令コードに基づき常に4つの演算命令を同時に発行するため、図示しない他の演算も常に行われる。例えば、サイクル1においてもサイクル2の加算処理及びサイクル3の加算処理が行われる。
【0048】
ここで、図11、図12で示したプログラムを実行する場合の情報処理装置の動作を示すシーケンス図を図15に示す。この図15では、図13、図14で示した処理の関係に着目し、各演算器群で実行される命令コードの処理フローを示した。なお、図15では、命令コードを示す符号として命令コードに応じて動作する演算器に付した符号と同じ符号を示した。
【0049】
図15に示す例では、サイクル1で主データパス20aに対してオフロード情報設定命令コードsetofldに基づく演算指示が与えられる。このサイクル1におけるオフロード情報設定命令コードsetofldに基づく演算指示に応じて、サイクル2において副データパス20bの処理で利用される演算が確定する。図15に示す例では、副データパス20bの処理は、1つの乗算器MUL、1つの論理左シフト演算ユニットSLL、及び2つの加算器ADDにより行われる。
【0050】
そして、サイクル10において、主データパス20aにオフロード処理命令コードofldに基づく演算命令が指示される。また、サイクル10では、オフロード処理命令コードofldと共に、ロード命令コードLDに基づく処理と、2つの論理左シフト演算命令コードSLLに基づく処理とが指示される。また、サイクル10では、副データパス20bにサイクル2で設定された命令コードに応じた演算が行われる。つまり、このサイクル10の処理では、図13のサイクル1の処理に相当する処理が行われる。
【0051】
次いで、サイクル11において、主データパス20aにオフロード処理命令コードofldに基づく演算命令が指示される。また、サイクル11では、オフロード処理命令コードofldと共に、ロード命令コードLDに基づく処理と、2つの減算命令コードSUBに基づく処理とが指示される。また、サイクル11では、副データパス20bにサイクル2で設定された命令コードに応じた演算が行われる。このとき、副データパス20bでは、サイクル10で発行されたオフロード処理命令コードに応じて主データパス20a側から与えられた演算データに対して、図14のサイクル1の動作を行う。つまり、このサイクル11の処理では、図13のサイクル2の処理及び図14のサイクル1の処理に相当する処理が行われる。
【0052】
次いで、サイクル12において、主データパス20aにオフロード処理命令コードofldに基づく演算命令が指示される。また、サイクル12では、オフロード処理命令コードofldと共に、減算命令コードSUBに基づく処理と、2つの加算命令コードADDに基づく処理とが指示される。また、サイクル12では、副データパス20bにサイクル2で設定された命令コードに応じた演算が行われる。このとき、副データパス20bでは、サイクル11の副データパス20bの処理結果に対して、図14のサイクル2の動作を行う。つまり、このサイクル12の処理では、図13のサイクル3の処理及び図14のサイクル2の処理に相当する処理が行われる。
【0053】
次いで、サイクル13において、主データパス20aにオフロード処理命令コードofldに基づく演算命令が指示される。また、サイクル13では、オフロード処理命令コードofldと共に、加算命令コードADDに基づく処理と、比較命令コードCMPに基づく処理と、データ移動命令コードMVに基づく処理とが指示される。また、サイクル13では、副データパス20bにサイクル2で設定された命令コードに応じた演算が行われる。このとき、副データパス20bでは、サイクル12の副データパス20bの処理結果に対して、図14のサイクル3の動作を行う。つまり、このサイクル13の処理では、図13のサイクル4の処理及び図14のサイクル3の処理に相当する処理が行われる。
【0054】
第1の演算器群22aが加算器ADDを2つしか有していない場合、第1の演算器群22aの加算器ADDの数の制限によりアドレス計算とデータDOUT[y][x]の計算とを並列して行い、データDOUT[y][x]の計算結果とアドレス計算の結果とを同時に得ることはできない。同時に2つの計算結果を得るためには、最大で3つの加算器を同時に動作させる必要があるためである。また、アドレス計算とデータDOUT[y][x]の計算とを同時に終了するためには最大で5つの演算命令を同時発行しなければならず、演算制御回路10の同時命令発行数が4であった場合にはアドレス計算とデータDOUT[y][x]の計算とを並列して行うことができない。
【0055】
一方、上述したように、実施の形態1にかかる情報処理装置1では、第1の演算器群22aで並列して処理できる演算数に制限がある場合であっても、データDOUT[y][x]の計算結果とアドレス計算の結果とを同時に得ることができる。情報処理装置1では、演算制御回路10がオフロード情報設定命令コードに基づき生成した演算命令に応じて第1の演算器群22aがオフロードレジスタ31に第2の演算器群22bにおける処理に必要な命令コードを設定する。そして、オフロード制御回路30がオフロードレジスタ31に格納された命令コードに基づき演算命令を生成する。第2の演算器群22bは、オフロード制御回路30が生成した演算命令に基づく動作を繰り返し実行する。第2の演算器群22bをこのように動作させることで、情報処理装置1では、演算制御回路10がオフロード処理命令コードに応じて生成した演算命令に基づき第1の演算器群22aが第2の演算器群22b側に第2の演算器群22bが処理すべきデータを渡すのみで、当該データに対する演算を第2の演算器群22bにて行うことができる。つまり、情報処理装置1では、第1の演算器群22aと第2の演算器群22bとが備える演算器群を合わせた並列処理が可能になる。以上のことより、情報処理装置1では、第1の演算器群22aが有する演算器の数の制限を超えた数の演算を並列して行うことができる。さらに、情報処理装置1では、同時に実行可能な演算数を実質的に増加させることができることから、プログラムの処理時間を短縮することができる。
【0056】
また、情報処理装置1では、オフロード情報設定命令コードにより第2の演算器群22bで実行する演算を指定する命令コードを任意に設定できる。そのため、演算制御回路10の同時発行命令数の制限を超えた演算命令をオフロード制御回路30により生成することで、演算制御回路10の同時発行命令数の制限よりも多くの演算を並列して実行する。つまり、情報処理装置1では、実質的に演算制御回路10の同時発行命令数を増加させることができる。一方、従来のプロセッサに関し、主演算器とコプロセッサ等の専用回路とを設け、例えば、浮動小数点演算についてはコプロセッサに実行させる技術がある。しかし、この専用回路は、固定的な演算しか行うことができない。また、専用回路に演算を行わせる場合、演算毎に演算指示と演算データを主演算器が専用回路に与えなければならず主演算器の演算能力を低下させる原因となっていた。つまり、従来のプロセッサにおける主演算器と専用回路との組合せでは、主演算器で同時実行可能な演算命令の数を増やすことはできない。
【0057】
実施の形態2
実施の形態2にかかる情報処理装置2のブロック図を図16に示す。図16に示すように、情報処理装置2は、第1の演算制御回路(例えば、演算制御回路101〜10m(mは整数、以下同じ))、第2の演算制御回路(例えば、オフロード制御回路401〜40m)、第3の演算制御回路(例えば、演算制御回路60)、命令キャッシュ61、データキャッシュ62、演算器70、第1の切換回路81〜8m、第2の切換回路91〜9mを有する。
【0058】
さらに、情報処理装置2では、演算器70が第1のプロセッサエレメント(例えば、プロセッサエレメントPE11〜PE1m)と第2のプロセッサエレメント(プロセッサエレメントPE21〜PE2m)とを有する。そして、実施の形態2にかかる情報処理装置2は、動作モードとして第1のモード(例えば、SIMDモード)と第2のモード(例えば、MIMDモード)とを有する。情報処理装置2は、SIMDモードでは、プロセッサエレメントPE11〜PE1m、PE21〜PE2mにおいて異なるデータに対して同じ演算を並列して行う。一方、情報処理装置2は、MINDモードでは、プロセッサエレメントPE11〜PE1mとプロセッサエレメントPE21〜PE2mとを1つの演算器として再構成し、複数の演算器により異なるデータに対する異なる演算を並列して行う。
【0059】
ここで、情報処理装置2の構成についてさらに詳細に説明する。命令キャッシュ61は、SIMDモードにおいて利用される第3の命令コードが格納される。データキャッシュ62は、SIMDモードにおいて処理されるデータが格納される。演算制御回路60は、命令キャッシュ61から第3の命令コードを読み出し、第3の命令コードに基づき演算命令を生成する。
【0060】
第1の切換回路81〜8mは、SIMDモードにおいて演算制御回路60からプロセッサエレメントPE11〜PE1mに演算指示に与え、MIMDモードにおいて演算制御回路101〜10mからプロセッサエレメントPE11〜PE1mに演算指示に与える。第2の切換回路91〜9mは、SIMDモードにおいて演算制御回路60からプロセッサエレメントPE21〜PE2mに演算指示に与え、MIMDモードにおいてオフロード制御回路401〜40mからプロセッサエレメントPE21〜PE2mに演算指示に与える。なお、第1の切換回路81〜8m及び第2の切換回路91〜9mは、図示しない他の回路から与えられるモード切換信号MDに基づき演算指示元の演算制御回路を切り換える。
【0061】
プロセッサエレメントPE11〜PE1mは、レジスタファイル711〜71m、演算器群731〜73m、内部メモリ751〜75mを有する。また、プロセッサエレメントPE21〜PE2mは、レジスタファイル721〜72m、演算器群741〜74m、内部メモリ761〜76mを有する。
【0062】
プロセッサエレメントPE11〜PE1m、PE21〜PE2mは、SIMDモードにおいて、自プロセッサエレメント内の内部メモリに格納されたデータに対して演算を行う。より具体的には、プロセッサエレメントPE11〜PE1m、PE21〜PE2mは、演算器群におけるロード処理により自プロセッサエレメント内のレジスタファイルに内部メモリからデータをロードし、演算器群はレジスタファイル内のデータを用いて演算器群による演算を行う。そして、プロセッサエレメントPE11〜PE1mは、演算結果をレジスタファイルに格納し、演算器群におけるストア処理により自プロセッサエレメント内のレジスタファイルから内部メモリに演算後のデータを格納する。
【0063】
また、プロセッサエレメントPE11〜PE1mは、MIMDモードにおいて、自プロセッサエレメント内の内部メモリを実施の形態1にかかる内部メモリ23a(例えば、命令キャッシュ)として利用する。また、プロセッサエレメントPE11〜PE1mは、MIMDモードにおいて、自プロセッサエレメント内の演算器群を実施の形態1にかかる第1の演算器群22aとして利用する。
【0064】
プロセッサエレメントPE21〜PE2mは、MIMDモードにおいて、自プロセッサエレメント内の内部メモリを実施の形態1にかかる内部メモリ23b(例えば、データキャッシュ)として利用する。また、プロセッサエレメントPE21〜PE2mは、MIMDモードにおいて、自プロセッサエレメント内の演算器群を実施の形態1にかかる第2の演算器群22bとして利用する。
【0065】
なお、プロセッサエレメントPE11〜PE1mの内部メモリ751〜75m及びプロセッサエレメントPE21〜PE2mの内部メモリ761〜76mは、MIMDモードにおいて命令コードが格納される側を命令キャッシュとして利用し、データが格納される側をデータキャッシュとして利用すれば良い。つまり、内部メモリ751〜75m及び内部メモリ761〜76mは、MINDモードにおいて、いずれのキャッシュとして利用するかはアーキテクチャにより任意に設定できる。
【0066】
続いて、情報処理装置2をSIMDモードで動作させる場合の動作を示す情報処理装置2のブロック図を図17に示す。図17に示すように、SIMDモードでは、演算制御回路60は、命令キャッシュ61に格納された第3の命令コードに応じて演算命令を生成する。第1の切換回路81〜8m及び第2の切換回路91〜9mは、モード切換信号MDに基づき、演算制御回路60が生成する演算命令をプロセッサエレメントPE11〜PE1m及びプロセッサエレメントPE21〜PE2mに与える。そのため、演算制御回路101〜10m及びオフロード制御回路401〜40mは、実質的に無効化された状態となる。さらに、SIMDモードでは、プロセッサエレメントPE11〜PE1mとプロセッサエレメントPE21〜PE2mとの間のパスが無効化される。
【0067】
そして、プロセッサエレメントPE11〜PE1m、PE21〜PE2mは、演算制御回路60が生成する演算命令に基づき、データキャッシュ62から内部メモリ751〜75m及び内部メモリ761〜76mに処理を担当するデータをロードする。その後、プロセッサエレメントPE11〜PE1m、PE21〜PE2mは、演算制御回路60が生成する演算命令に基づき自プロセッサエレメント内の内部メモリに格納されたデータに対して、同じ演算を行う。つまり、SIMDモードでは、情報処理装置1は、複数のプロセッサエレメントを用いて異なるデータに対する同じ演算を並列して行うことで高速な処理が可能となる。このようなSIMDモードにおける演算は、例えば、1枚の大きな画像のエッジ抽出を行う場合などに有効である。例えば、1枚の大きな画像を短冊状に分割し、分割した複数の領域を複数のプロセッサエレメントで分担して処理することで画像処理を高速に行うことができる。
【0068】
続いて、情報処理装置2をMIMDモードで動作させる場合の動作を示す情報処理装置2のブロック図を図18に示す。図18に示すように、MIMDモードでは、演算制御回路101〜10mは、命令キャッシュと利用される内部メモリ751〜75mに格納された第1の命令コードに応じてそれぞれ演算命令を生成する。第1の切換回路81〜8mは、モード切換信号MDに基づき、演算制御回路101〜10mが生成する演算命令をプロセッサエレメントPE11〜PE1mに与える。第2の切換回路91〜9mは、モード切換信号MDに基づき、演算制御回路401〜40mが生成する演算命令をプロセッサエレメントPE21〜PE2mに与える。そのため、演算制御回路60は、実質的に無効化された状態となる。さらに、MIMDモードでは、命令キャッシュ61及びデータキャッシュ62も無効化される。一方、MIMDモードでは、プロセッサエレメントPE11〜PE1mとプロセッサエレメントPE21〜PE2mとの間のパスが有効化される。
【0069】
MIMDモードでは、上記のようにプロセッサ構成を再構成したことにより、プロセッサエレメントPE11、PE21、演算制御回路101、オフロード制御回路401により実施の形態1にかかる情報処理装置1と同じ構成を実現することができる。また、図18に示した例では、情報処理装置2は、実施の形態1にかかる情報処理装置1に相当する回路構成をm個構成することができる。つまり、情報処理装置2は、MIMDモードにおいてm個の独立したプロセッサを構成することができる。このようなMIMDモードにおける構成により演算を行うことで、例えば、1枚の大きな画像中の独立した複数の領域のそれぞれを複数のプロセッサで分担して処理することが可能になる。大きさの異なる複数の領域をSIMDモードの情報処理装置2で処理する場合、各領域を順次処理しなければならない。そのため、SIMDモードの情報処理装置2を用いてこのような画像を処理する場合の処理時間は、複数の領域の大きさの合計値に比例して長くなる。一方、大きさの異なる複数の領域をMIMDモードの情報処理装置2で処理する場合、各領域を複数のプロセッサ(実施の形態1にかかる情報処理装置1)を用いて並列して処理することができる。そのため、MIMDモードの情報処理装置2を用いてこのような画像を処理する場合の処理時間は、最大でも、複数の領域うち最も大きな領域の画像を処理する時間となる。つまり、複数の独立した画像領域を処理する場合はMIMDモードによる処理の方が短時間で処理が完了する。
【0070】
ここで、上記した複数のプロセッサエレメントの構成をSIMDモードとMINDモードとで再構成する技術に関しては非特許文献1に開示されている。しかしながら、非特許文献1に記載のプロセッサでは、MINDモードで複数のプロセッサエレメントにより1つの演算器を構成し、プロセッサ全体としては複数の演算器として互いに並列した処理を行う場合、1つの演算器で利用できる演算器群は複数のプロセッサエレメントに属する複数の演算器群のうちの1つに限られる。つまり、非特許文献1に記載のプロセッサでは、MIMDモードにおいて、1つの演算器に含まれる複数の演算器群のうち1つしか利用できず、処理能力が限られる問題がある。また、非特許文献1に記載のでは、MIMDモードにおいて回路リソースが無駄になる問題がある。
【0071】
しかしながら、実施の形態2にかかる情報処理装置2では、MIMDモードにおいて、オフロード制御回路401〜40mを利用することにより、1つの演算器を構成する複数のプロセッサエレメントに属する全ての演算器群を処理に利用することができる。そのため、実施の形態2にかかる情報処理装置2では、MINDモードにおいて、非特許文献1に記載のプロセッサよりも高い処理能力を実現することができる。また、実施の形態2にかかる情報処理装置2では、回路リソースを有効に利用できるため、処理能力に対する回路面積の効率を高めることができる。
【0072】
なお、本発明は上記実施の形態に限られたものではなく、趣旨を逸脱しない範囲で適宜変更することが可能である。
【符号の説明】
【0073】
1、2 情報処理装置
10、101〜10m 演算制御回路(第1の演算制御回路)
11 命令レジスタ
12 命令デコーダ
20a 主データパス
20b 副データパス
21a、21b、711〜71m、721〜72m レジスタファイル
22a、22b、731〜73m、741〜74m 演算器群
23a、23b、751〜75m、761〜76m 内部メモリ
30、401〜40m オフロード制御回路(第2の演算制御回路)
31 オフロードレジスタ
32 オフロード情報デコーダ
60 演算制御回路(第3の演算制御回路)
61 命令キャッシュ
62 データキャッシュ
70 演算器
81-8m 第1の切換回路
91-9m 第1の切換回路
PE11〜PE1m、PE21〜PE2m プロセッサエレメント
【特許請求の範囲】
【請求項1】
第1の命令コードが格納される第1のキャッシュと、
処理対象のデータが格納される第2のキャッシュと、
前記データに対する演算を並列して動作可能な複数の演算器により行う第1、第2の演算器群と、
前記第1の命令コードを読み出し、前記第1の命令コードに基づき前記第1の演算器群に対する1以上の演算命令を生成する第1の演算制御回路と、
前記第1の演算器群により指定された第2の命令コードを格納する固定命令レジスタを含み、前記第2の命令コードに基づき前記第2の演算器群に対する1以上の演算命令を生成する第2の演算制御回路と、を有し、
前記第1の命令コードには少なくとも第1、第2の特定命令コードが含まれ、
前記第1の演算器群は、前記第1の演算制御回路が生成する演算命令に前記第1の特定命令コードに基づく第1の演算命令が含まれる場合には前記第1の演算命令に応じて前記固定命令レジスタに前記第2の命令コードを設定し、前記第1の演算制御回路が生成する演算命令に前記第2の特定命令コードに基づく第2の演算命令が含まれる場合には前記第2の演算器群に前記第2の演算器群が処理すべきデータを与え、
前記第2の演算器群は、前記第2の演算制御回路が前記第2の命令コードに基づき生成した演算命令に基づく演算を繰り返し実行する情報処理装置。
【請求項2】
前記第1の命令コードは、前記第1の演算器群において並列して動作可能な演算器により実行可能な複数の命令コードを含む請求項1に記載の情報処理装置。
【請求項3】
前記固定命令レジスタには、前記第2の演算器群において並列して動作可能な演算器により実行可能な複数の命令コードが格納される請求項1又は2に記載の情報処理装置。
【請求項4】
前記第1の演算器群は、前記第1の演算制御回路が前記第1、第2の特定命令コード以外の命令コードに基づき演算を指示した場合には前記第1の演算器群内の演算器により前記データに対する演算を行う請求項1乃至3のいずれか1項に記載の情報処理装置。
【請求項5】
第1のモードにおいて利用される第3の命令コードが格納される命令キャッシュと、
前記第1のモードにおいて処理されるデータが格納されるデータキャッシュと、
前記第3の命令コードに基づき演算命令を生成する第3の演算制御回路と、
第2のモードにおいて前記第1、第2のキャッシュの一方として用いられる第1の内部メモリと、前記第1の演算器群と、を備える第1のプロセッサエレメントと、
前記第2のモードにおいて前記第1、第2のキャッシュの他方として用いられる第2の内部メモリと、前記第2の演算器群とを備える第2のプロセッサエレメントと、
前記第1のモードにおいて前記第3の演算制御回路から前記第1のプロセッサエレメントに演算指示に与え、第2のモードにおいて前記第1の演算制御回路から前記第1のプロセッサエレメントに演算指示に与える第1の切換回路と、
前記第1のモードにおいて前記第3の演算制御回路から前記第2のプロセッサエレメントに演算指示に与え、第2のモードにおいて前記第2の演算制御回路から前記第2のプロセッサエレメントに演算指示に与える第2の切換回路と、
を有する請求項1乃至4のいずれか1項に記載の情報処理装置。
【請求項6】
前記第1の内部メモリには、前記第1のモードにおいて前記第1の演算器群で処理されるデータが格納され、前記第2のモードにおいて前記第1の命令コードと処理対象データとの一方が格納され、
前記第2の内部メモリには、前記第1のモードにおいて前記第2の演算器群で処理されるデータが格納され、前記第2のモードにおいて前記第1の命令コードと前記処理対象データとの他方が格納され、
前記第1、第2の演算器群は、前記第1のモードにおいて前記データキャッシュから与えられたデータに対して前記第3の演算制御回路の演算指示に基づく演算を行い、前記第2のモードにおいて前記第1、第2の内部メモリのうち処理対象の前記データが格納された内部メモリに対して前記データの読み出し及び書き込みを行う請求項5に記載の情報処理装置。
【請求項7】
前記第1の演算器と、前記第2の演算器は、前記複数の演算器の構成が同一である請求項1乃至6のいずれか1項に記載の情報処理装置。
【請求項1】
第1の命令コードが格納される第1のキャッシュと、
処理対象のデータが格納される第2のキャッシュと、
前記データに対する演算を並列して動作可能な複数の演算器により行う第1、第2の演算器群と、
前記第1の命令コードを読み出し、前記第1の命令コードに基づき前記第1の演算器群に対する1以上の演算命令を生成する第1の演算制御回路と、
前記第1の演算器群により指定された第2の命令コードを格納する固定命令レジスタを含み、前記第2の命令コードに基づき前記第2の演算器群に対する1以上の演算命令を生成する第2の演算制御回路と、を有し、
前記第1の命令コードには少なくとも第1、第2の特定命令コードが含まれ、
前記第1の演算器群は、前記第1の演算制御回路が生成する演算命令に前記第1の特定命令コードに基づく第1の演算命令が含まれる場合には前記第1の演算命令に応じて前記固定命令レジスタに前記第2の命令コードを設定し、前記第1の演算制御回路が生成する演算命令に前記第2の特定命令コードに基づく第2の演算命令が含まれる場合には前記第2の演算器群に前記第2の演算器群が処理すべきデータを与え、
前記第2の演算器群は、前記第2の演算制御回路が前記第2の命令コードに基づき生成した演算命令に基づく演算を繰り返し実行する情報処理装置。
【請求項2】
前記第1の命令コードは、前記第1の演算器群において並列して動作可能な演算器により実行可能な複数の命令コードを含む請求項1に記載の情報処理装置。
【請求項3】
前記固定命令レジスタには、前記第2の演算器群において並列して動作可能な演算器により実行可能な複数の命令コードが格納される請求項1又は2に記載の情報処理装置。
【請求項4】
前記第1の演算器群は、前記第1の演算制御回路が前記第1、第2の特定命令コード以外の命令コードに基づき演算を指示した場合には前記第1の演算器群内の演算器により前記データに対する演算を行う請求項1乃至3のいずれか1項に記載の情報処理装置。
【請求項5】
第1のモードにおいて利用される第3の命令コードが格納される命令キャッシュと、
前記第1のモードにおいて処理されるデータが格納されるデータキャッシュと、
前記第3の命令コードに基づき演算命令を生成する第3の演算制御回路と、
第2のモードにおいて前記第1、第2のキャッシュの一方として用いられる第1の内部メモリと、前記第1の演算器群と、を備える第1のプロセッサエレメントと、
前記第2のモードにおいて前記第1、第2のキャッシュの他方として用いられる第2の内部メモリと、前記第2の演算器群とを備える第2のプロセッサエレメントと、
前記第1のモードにおいて前記第3の演算制御回路から前記第1のプロセッサエレメントに演算指示に与え、第2のモードにおいて前記第1の演算制御回路から前記第1のプロセッサエレメントに演算指示に与える第1の切換回路と、
前記第1のモードにおいて前記第3の演算制御回路から前記第2のプロセッサエレメントに演算指示に与え、第2のモードにおいて前記第2の演算制御回路から前記第2のプロセッサエレメントに演算指示に与える第2の切換回路と、
を有する請求項1乃至4のいずれか1項に記載の情報処理装置。
【請求項6】
前記第1の内部メモリには、前記第1のモードにおいて前記第1の演算器群で処理されるデータが格納され、前記第2のモードにおいて前記第1の命令コードと処理対象データとの一方が格納され、
前記第2の内部メモリには、前記第1のモードにおいて前記第2の演算器群で処理されるデータが格納され、前記第2のモードにおいて前記第1の命令コードと前記処理対象データとの他方が格納され、
前記第1、第2の演算器群は、前記第1のモードにおいて前記データキャッシュから与えられたデータに対して前記第3の演算制御回路の演算指示に基づく演算を行い、前記第2のモードにおいて前記第1、第2の内部メモリのうち処理対象の前記データが格納された内部メモリに対して前記データの読み出し及び書き込みを行う請求項5に記載の情報処理装置。
【請求項7】
前記第1の演算器と、前記第2の演算器は、前記複数の演算器の構成が同一である請求項1乃至6のいずれか1項に記載の情報処理装置。
【図1】


【図2】

【図3】

【図4】

【図5】

【図6】
【図7】
【図8】
【図9】
【図10】
【図11】

【図12】

【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【公開番号】特開2012−252374(P2012−252374A)
【公開日】平成24年12月20日(2012.12.20)
【国際特許分類】
【出願番号】特願2011−122095(P2011−122095)
【出願日】平成23年5月31日(2011.5.31)
【出願人】(302062931)ルネサスエレクトロニクス株式会社 (8,021)
【Fターム(参考)】
【公開日】平成24年12月20日(2012.12.20)
【国際特許分類】
【出願日】平成23年5月31日(2011.5.31)
【出願人】(302062931)ルネサスエレクトロニクス株式会社 (8,021)
【Fターム(参考)】
[ Back to top ]