
情報絞り込み検出機能を備えたメモリ、その使用方法、このメモリを含む装置。
【課題】
パターン認識など情報検出の最大の課題は検索時間でありメモリの逐次比較処理が不要な非ノイマン型情報検出メモリを実現する。
【解決方法】
メモリアドレスごとに情報を記憶しその情報を読み出し可能なメモリで、このメモリは、外部から与えられる第1のデータは記憶されたメモリのデータを比較するためのデータ、第2のデータはアドレス同士を比較するためのデータ、の双方の入力データの入力手段と、この入力手段から与えられた上記双方の入力データにより記憶された情報のデータと、そのアドレスと、の双方を二重並列に合否判定し、その双方の合否判定結果をさらに並列に論理演算する手段と、上記論理演算に合格するこのメモリの上記アドレスを出力する手段と、を具備することを特徴とする情報絞り込み検出機能を備えたメモリであるのでインテリジェンスな情報検索はもとより人工知能等に広く利用可能である。
パターン認識など情報検出の最大の課題は検索時間でありメモリの逐次比較処理が不要な非ノイマン型情報検出メモリを実現する。
【解決方法】
メモリアドレスごとに情報を記憶しその情報を読み出し可能なメモリで、このメモリは、外部から与えられる第1のデータは記憶されたメモリのデータを比較するためのデータ、第2のデータはアドレス同士を比較するためのデータ、の双方の入力データの入力手段と、この入力手段から与えられた上記双方の入力データにより記憶された情報のデータと、そのアドレスと、の双方を二重並列に合否判定し、その双方の合否判定結果をさらに並列に論理演算する手段と、上記論理演算に合格するこのメモリの上記アドレスを出力する手段と、を具備することを特徴とする情報絞り込み検出機能を備えたメモリであるのでインテリジェンスな情報検索はもとより人工知能等に広く利用可能である。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は情報絞り込み検出機能を備えたメモリ、その使用方法、このメモリを使用した装置、人工知能に関する。
【背景技術】
【0002】
情報がデータ化され手軽に利用することが可能な時代において、この莫大な情報データの中から適切な情報を検出し利用するには様々な課題が残されている。
とりわけ画像認識、音声認識、OCR文字認識、全文検索、指紋等の生体認証などに代表される情報検出に共通し基礎となる技術は、情報の中から一致や類似する情報(パターン)を検出もしくは解析するパターン認識技術であり、社会インフラ設備、産業用設備、工場設備からデジタルカメラや家電商品、さらには最新のロボットや人工知能等あらゆる分野に利用されており高度な情報処理に不可欠な存在である。
【0003】
しかしながらパターン認識を一例とする情報検出の技術上の最大の課題は、情報の比較の際の比較組合せ回数(検索回数)であり、通常対象となる情報に最適なアルゴリズムを見出し組合せ比較回数(検索回数)の削減をするなり、対象とする情報の内容によってはスパコンなど高速な演算処理マシーンを利用して答えを見つけ出すなり、場合によっては検出の精度を犠牲にする必要もあった。
【0004】
本発明は以上のようなパターン認識や情報検出技術の永年の課題である情報検出の精度を保証し比較組合せ回数(検索回数、検索時間)を極限まで低減させる事の可能なメモリの実現とその利用方法であり、同一出願人、同一発明者の平成22年2月18日出願、特願2010−33376、情報処理装置の情報の共通管理方法、情報の検出方法、データおよびアドレスの相対関係一括並列比較連想メモリ、情報を共通管理する機能を有する情報処理装置、そのソフトウエアプログラム、におけるデータおよびアドレスの相対関係一括並列比較連想メモリ、に関連する全項目を本出願に対し優先権主張するものである。
【0005】
同じく平成22年3月4日出願の特願2010−47215、情報絞り込み検出機能を備えた半導体集積回路、その使用法、この半導体集積回路を使用した装置、は上記特願2010−33376を、独立した発明とし、情報絞り込み検出機能を備えた半導体集積回路、と発明の名称の表現を変更し、本発明の最大の特徴である二重並列の合否判定結果の論理演算の考え方を明らかにしたものである、また検出する情報の範囲を二次元の画像のみならず一次元から多次元までの情報に拡大したものであり、この出願全体を本出願に対し優先権を主張するものである。
【0006】
本出願は、情報絞り込み検出機能を備えたメモリ、とより発明の名称の表現を明確にするとともに、以上2つの先願を統合し、上記特願2010−47215に主として、情報絞り込み回路数を削減するための手段、二重並列論理演算の多重化手段、さらには人工知能への応用などを一例とするこのメモリの使用方法を追加し、説明不足を補い、一部の表現方法を変更したものである。
【0007】
先に説明のようにパターン認識やパターンマッチングを一例とする情報検出の技術は極めて幅が広く、その検索時間の短縮に係る発明は膨大な数であるが、本発明のように検出時間を短縮するために、ノイマン型コンピュータの宿命である個別メモリの逐次処理を本質的に回避するための手法やそのメモリの例は見当たらない。
参考までであるが特開平7−114577、データ検索装置、データ圧縮装置及び方法、は隣り合った情報同士の比較により情報を繰返し検索するための手法が示されているが、本出願の発明は隣り合った情報同士の比較のみならず、全メモリの情報を対象にデータの内容とそのアドレスの位置関係を二重並列に比較するものである。
【先行技術文献】
【特許文献】
【0008】
【特許文献1】特開平7−114577
【発明の概要】
【発明が解決しようとする課題】
【0009】
本発明が解決しようとする課題は、
一次元から多次元でアドレス配列された情報もしくは配列可能な情報を対象にして、検出される情報(未知の情報)と、検出の基準になる情報(既知の情報)と、の互いの情報の複数のアドレスの、そのデータと、そのアドレスと、の双方の関係が条件に合格することをもって、未知の情報の内から既知の情報と同一情報もしくは類似情報と判定するようなパターン認識や知識処理などの情報検出において、検出の精度を保証し、データの比較回数を極限まで削減し、メモリ自身が上記情報の検出を可能する非ノイマン型の情報検出メモリの実現とその使用方法を確立することである。
【課題を解決するための手段】
【0010】
以上のような課題を解決するために、
請求項1では
メモリアドレスごとに情報を記憶しその情報を読み出し可能なメモリであって
このメモリは、
外部から与えられる第1のデータは記憶されたこのメモリのデータを比較するためのデータ、第2のデータはこのメモリのアドレスを比較するためのデータ、の双方の入力データの入力手段と、
(1)第1のデータでメモリに記憶されたデータを並列に比較し合否判定する手段と
(2)第2のデータでメモリのアドレスを並列に比較し合否判定する手段と
(3)以上(1)、(2)双方の合否判定結果をさらに並列に論理演算するデータとアドレスの二重並列論理演算手段と
を具備することを特徴とする。
請求項2では
前記(1)の合否判定手段ならびに前記(3)の二重並列論理演算手段を、その演算結果が前記(1)の合否判定と前記(2)の合否判定との論理積(AND)と等価となる、等価二重並列論理積(AND)演算手段で構成したことを特徴とする。
請求項3では
前記メモリは、
毎次の前記等価二重並列論理積(AND)演算手段の結果をメモリアドレスごとに計測するカウンタ手段と、
初回の前記比較は、前記第1のデータによって、メモリを並列に合否判定して合格したメモリアドレスの上記カウンタを1にカウントアップしこれを1次突破アドレスとする手段と、
以降の比較は、上記第1のデータによって、メモリを並列に合否判定して合格したメモリアドレスと、上記1次突破アドレスと、の双方のアドレスの位置関係を、前記第2のデータによって、前記等価二重並列論理積(AND)演算手段で演算し、この演算を突破した上記1次突破アドレスのカウンタをカウントアップしてN(2以上の整数)次突破アドレスとする手段と、
このN次突破アドレスのアドレスを出力する手段と、
を具備することを特徴とする。
請求項4では
前記等価二重並列論理積(AND)演算手段は前記第2のデータであるアドレスを比較するためのデータにもとづくアドレスのスワップ(交換)手段によって繰返し実施することを特徴とする。
請求項5では
前記第2のデータであるアドレスを比較するためのデータは、前記1次突破アドレスを基準とし、
(1)比較対象のアドレスが相対アドレスに一致するか否かの比較データ
(2)比較対象のアドレスが比較する範囲の内外に存在するか否かの比較データ
以上(1)(2)のいずれかもしくは双方であることを特徴とする。
請求項6では
前記メモリは
(1)音声情報を一例とする一次元情報として記憶されたもしくは記憶可能な情報
(2)画像情報を一例とする二次元情報として記憶されたもしくは記憶可能な情報
(3)立体情報を一例とする三次元情報として記憶されたもしくは記憶可能な情報
(4)時空間情報を一例とする多次元情報として記憶されたもしくは記憶可能な情報
(5)クラスタリング情報を一例とする情報をアドレスのグループ別に記憶されたもしくは記憶可能な情報
以上(1)から(5)の少なくとも1つの情報の検出を対象とするメモリ構成であることを特徴とする。
請求項7では
前記第1のデータである記憶されたメモリのデータを比較するためのデータは
(1)メモリデータの一致
(2)メモリデータの大小
(3)メモリbit個別のDon‘t Careを含む比較
以上(1)から(3)の少なくとも1つであることを特徴とする。
請求項8では
前記第1のデータ、第2のデータは
(1)データバス
(2)専用入力
以上(1)(2)のいずれかもしくは双方により入力されることを特徴とする。
請求項9では
前記N次突破アドレスのアドレスを出力する手段は
(1)データバス
(2)専用出力
以上(1)(2)のいずれかもしくは双方により出力されることを特徴とする。
請求項10では
前記カウンタ手段に1次突破アドレスを記憶する手段を付加することにより、カウンタ手段の回路数量を確率的に出現する1次突破アドレスの数量に見合う回路数量に削減したことを特徴とする。
請求項11では
前記アドレスのスワップ(交換)手段にプロセッサを用いることを特徴とする。
請求項12では
前記二重並列論理演算をメモリのバンク毎に切り替え実施することを特徴とする。
請求項13では
複数の前記第1のデータならびに第2のデータの入力手段と、
複数の前記二重並列論理演算手段と、を具備することを特徴とする。
請求項14では
前記メモリはCPUを一例とする他の目的の半導体に組込まれ使用されることを特徴とする。
請求項15では
検出される情報(未知の情報)と、検出の基準になる情報(既知の情報)と、の互いの情報の複数のアドレスの、そのデータと、そのアドレスと、の双方が必要回数の比較条件に合格することをもって、未知の情報の内から既知の情報と同一もしくは類似の情報を検出することをもって、情報とその情報の位置を検出することを目的として
既知の情報を前記第1のデータと第2のデータとすることにより、請求項1記載のメモリに記憶された未知の情報を比較し、未知の情報の内から既知の情報と同一もしくは類似する情報とそのアドレスを、前記N次突破アドレスを読み出すことにより検出することを特徴とする。
請求項16では
前記検出の基準になる情報(既知の情報)の内から、統計確率にもとづき前記同一情報もしくは類似情報を判定するに必要十分な複数個数のサンプルを抽出し、これを前記第1のデータと、第2のデータと、として比較条件とすることにより、同一情報もしくは類似情報を判定するために必要な前記比較回数を上記サンプル数以内とすることを特徴とする。
請求項17では
前記サンプルを抽出する際、隣接するサンプル間のデータの相互のデータの差の絶対値を求め、これを集計することにより得られるサンプル特徴量を基準値以上として情報検出をすることを特徴とする。
請求項18では
請求項3記載のアドレスの位置関係は
(1)前記一次元情報として配列記憶されたアドレス配列上の位置関係
(2)前記二次元情報として配列記憶されたアドレス配列上の位置関係
(3)前記三次元情報として配列記憶されたアドレス配列上の位置関係
(4)前記多次元情報として配列記憶されたアドレス配列上の位置関係
以上(1)から(4)の少なくとも1つの位置関係であり、このアドレスの位置関係を用いてパターン認識をすることを特徴とする。
請求項19では
前記1次突破アドレスとなる最初の比較サンプルを複数種類のサンプルとする、もしくは一定の範囲を持させ検出を行うことを特徴とする。
請求項20では
前記情報絞り込み検出機能を備えたメモリをアクセスしデータの読み出し書込みが可能なCPUを併用することを特徴とする。
請求項21では
前記情報絞り込み検出機能を備えたメモリに知識情報を記憶させ知識処理をすることを特徴とする。
請求項22では
前記情報絞り込み検出機能を備えたメモリを使用したことを特徴とする装置。
請求項23では
前記情報絞り込み検出機能を備えたメモリを使用したことを特徴とする人工知能。
としている。
【発明の効果】
【0011】
インテリジェンスな知識をもったメモリとして利用することが可能で、あらゆる情報の同一性ならびに類似性を確実でかつ高速に検出もしくは解析することのみならず、情報予測の分野や高度な知識処理にも幅広く利用可能で、本格的な非ノイマン型情報処理による新しい情報処理の流れが期待できる。
【図面の簡単な説明】
【0012】
【図1】図1はサンプリングポイントの例である(実施例1)
【図2】図2はサンプリングポイントによる情報検出実施例である(実施例2)
【図3】図3はサンプリングポイントの評価方法例である(実施例3)
【図4】図4はデータおよびアドレスの二重並列論理演算の概念例である
【図5】図5は情報絞り込み検出機能を備えたメモリ例である(実施例4)
【図6】図6はアドレススワップ手段Aの例である(実施例5)
【図7】図7はアドレススワップのイメージAである
【図8】図8はアドレススワップのイメージBである
【図9】図9はアドレススワップのイメージCである
【図10】図10は変形画像の検出の概念である(実施例6)
【図11】図11はアドレススワップ手段Bの例である(実施例7)
【図12】図12はアドレススワップ手段Cの例である(実施例8)
【図13】図13は情報絞り込み検出回路の削減例である(実施例9)
【図14】図14は多重化したデータとアドレスの二重並列論理演算の概念例である
【図15】図15はアドレス一次元配列の情報検出例である(実施例10)
【図16】図16はアドレス三次元配列の情報検出例である(実施例11)
【図17】図17は本発明のメモリを用いた高度な知識処理の例である(実施例12)
【発明を実施するための形態】
【0013】
先ず本発明の情報検出の概念を、二次元情報である画像を例にして説明する。
【0014】
通常検出対象の画像(未知の情報2)と、検出の基準の画像(既知の情報1)と、で画像の同一性を検出する場合、検出の基準となる画像(既知の情報1)から採取される何らかの画像情報をもとに、未知の検出対象の画像を総当たり方式で検索するのが基本になり、その精度を求める場合には画像の座標毎であることが必要となる。
【0015】
検索に掛る時間の一例としてパーソナルコンピュータやデジタルテレビジョン信号によるテレビ画面の特定ピクセルを対象として、表示されている画像上から特定データを探し出す場合、200万ピクセル程度がその対象となる。
一旦この全画面のビットマップデータをグラフィックメモリから検索用メモリにデータ展開し、仮に展開したデータの全範囲を、CPUが1ピクセル当たり平均50n秒で、特定のデータを探し出すなど単純な検索をさせる場合、初回の全グラフィック範囲(全画面範囲)の検索は200万×50n秒=100m秒となり、通常、2回目以降は検索対象が絞られるため検索時間は短くなるものの目的の画像を特定するのに数百m秒程度は必要になる、従がって1画面上で大量な画像を検索する必要がある場合は如何に高速な処理を行っても検索時間を無視することが出来なくなる。
【0016】
さらに以上の説明は完全に同一画像の場合であるが、仮に画像のサイズの変更や回転がある場合には、座標変換の演算を繰返し実施する必要があるので処理時間は以上の数百倍から数千倍、さらに必要になる場合もあり、このような検索は実現困難である。
以上はメモリのアドレス毎のCPU逐次検索を必要とするノイマン型コンピュータによる情報検出の宿命である。
【0017】
以上のような検索時間の技術的背景から現在の検索の主流は画像の特徴を抽出した特徴データのクラスタリングによる画像同士の類似性を対象とする検索となっており、最近のデジタルカメラの顔認識やスマイル認識を始め音声認識などに幅広く利用されている。
しかしながら検出の精度や検索の時間、検出出来る情報など検索の能力はこれらの特徴抽出の手法やクラスタリングの手法次第で大きく左右される。
また画像の検索の利用分野においては、誤認率が致命的である場合も多く類似性よりも同一性を求める画像の検索のニーズも少なくない。
【0018】
以上のように、画像検索の確実性を追求し、さらに時間短縮と云う、テーマは互いに矛盾し相容れないものであるが、先ずは画像検索における確実な同一画像の検出について説明する。
【0019】
以上の説明のように本発明は確実性を求めて、原則的に1座標(アドレス)を対象として情報の検出を行うものであり、以下にこれを実現する上で切り離すことの出来ない情報の種類とその分解能について説明する。
【0020】
画像の情報は様々な種類が存在するが、ここでは大きく2種の画像情報データを例に説明する。
【0021】
その第1は、表示されている画像のフレームバッファ(グラフィックメモリ)からのデータを画像情報とする場合で通常、カラーの場合R、G、B、16bitから32bitのデータ深度で情報を持っている。
このR、G、B、色信号をそのまま利用することも可能であるが、効果的な画像の検出の一例として、通常パソコンや映像装置のフレームバッファの200万ピクセル程度を対象にして、R、G、B、各4bit(16通りの組合せ3組)を採取して1つのピクセルデータとすることにより、どの様な色彩の画像であっても精度よく画像を検出することが出来る。
この場合、この色の組合せは12bit、4096通りの組合せであり、画面上の色がばらついている場合、1つの色が画面上に存在する確率は200万/4096≒488ピクセル(アドレス)である。
【0022】
その第2は、一例としてJPEG(Joint Photographic Experts Group)やMPEG(Moving Picture Experts Group)その他多くの圧縮された画像データの1ブロック(一例として8×8ピクセル)を1座標とし、そのブロックの輝度や色差信号のDTC(離散コサイン変換)のDC(直流)成分データをその座標のそのデータとしてそのまま利用することやその他の情報、例えばベクトル情報を利用することも可能である。
このDCTの場合はブロック単位であるのでピクセルに比較して大幅(一例として1/64)に座標の数(アドレス)を減らすことが出来る。
【0023】
云うまでもなくどちらの場合でも分解能が高いに越したことはないが、メモリ容量が大きくなるので、以上のような量子化データ15のLSB側から必要なbit数を選び画像情報データとすればよい。
以降以上説明のピクセルを対象とし、200万ピクセル(アドレス)で12bit、4096通りのR、G、B、の組合せデータによる画像データを画像情報とし、これを検出する場合の例で説明する。
【実施例1】
【0024】
図1(サンプリングポイントの例)は検出基準になる画像(既知の情報1)のサンプリングポイント13を示したものである。
検出基準画像Aは比較的サイズの小さい画像を対象とし、検出の基準になる画像(既知の情報1)の領域上に座標y0、x0を中心として、上下左右等間隔に合計25個の座標をサンプリングポイント13として自動配列した場合であり、この場合XY軸ともに各33ピクセル11、合計1089ピクセル11を対象としたものである。
検出基準の画像のサイズを大きくすることも全く問題ない。
【0025】
図に示す1から25の数字は比較順序14を示すもので、本例では中心から遠いサンプリングポイント13から近いサンプリングポイント13を対角順に検出するよう設定されているが、配列や比較順序14はこれに限るものではない、これについての詳細は後述する。
【0026】
検出基準画像Bは以上説明の等間隔に配列することなく、検出基準の画像に対応させて1から22までのサンプリングポイント13を手動で設定した場合の例である、このように手動でサンプリングポイント13を設定し検出する方法は人間の特徴認識能力の高さを利用するものであり、特徴的なポイントや特徴的な範囲を指定して他のピクセルとの差別化をするのに有効である。
【0027】
このように画像検出の確実性を求めるために1座標を検出の単位とする検出方法であることによって1座標毎にサンプルポイント設定が出来るのも、一定領域をまとめて特徴サンプルとすることの多い他の検索、検出方式では実現できない本方式の特徴の1つでもある。
【実施例2】
【0028】
図2(サンプリングポイントによる情報検出実施例)は先に説明の図1の検出基準画像Aを検出の基準の画像として、画像の検出を実施した場合の説明である。
検出の基準になる画像(既知の情報1)と、検出の対象になる画像(未知の情報2)を同一画像上に表現しているが、実際には別の画像の場合が殆どであるが、説明の関係上同一画面で表現している。
図に示すグループAは1次比較では一致したが2次比較でNGとなった場合である、グループBは11次比較でNG、グループCは22次比較でNG、グループDは全部のサンプリングポイント13が一致した場合である、これらの検出は先に説明の座標のデータ12、をアドレス毎に読取り相互に比較すればよい。
この図ではグループAからグループEは位置的に完全に分離された画像領域で説明されているが画像の場合、通常同一データである座標が隣接もしくは集中し、分解能が低い程その傾向は顕著であるが互いの相対位置関係を正しく比較すれば問題ない。
【0029】
この場合、確率上グループDの領域は基準となる画面と同一画像であると判断することも十分可能であるが、サンプリングポイント13に加えて互いの画像の全てのピクセル同士の一致を念押し確認することにより、類似の画像を排除し完全に同じ画像であることを保証することが可能となる、この方法は対象となる画像のサイズが比較的小さい場合の検出に最適である。
【0030】
以上のような検証方法を活用することにより、グループEのようなサンプリングポイント13が部分的に集中して不一致となるような場合には、この一致する画像の部分を一部の画像に変化が加えられた変形画像と判断することも出来る、またグループCのような場合は類似画像と判断することも出来る、これらについては後述する。
【0031】
以上のように先ずどこかサンプリングポイント13の1座標を基準として、以降の座標のデータとの相対位置の判定を行い相対位置に矛盾のない座標を候補座標として残す方法はパターン認識など情報検索の常套手段であり、これらの組合せ的な検索を効率的に実施し、画像(情報)を超高速で検出する方法とディバイスが本発明の趣旨であり、この詳細に関しては後述する。
【0032】
以上の説明の画像の検出方法で特に重要な事は、サンプリングポイント13の選択方法で、1つは一定の画像データの範囲と、もう1つは画像データの変化の度合いである。
例えば変化のない黒画像部分や白画像部分や変化の少ない画像、もしくは例えば文字情報のみの画像など特徴の少ない画像を指定した場合などでは、当該画像の検出が困難になる。
【0033】
以下に画像の検出の有効性、信頼性に深い関係があるサンプリングポイント13についての考え方を示す。
画像上の1座標を基準にすると、この座標に隣接する座標は基準座標と同一もしくは近似する量子化データ15となる確率、つまり相関性が高くなり、座標が離れることにより相関性は低くなる、従がって図1のサンプルのように、毎回遠いサンプリングポイント13から順次確認する方がダメ出しが速く効率的な検出となる確率が高い。
【0034】
従がって完全に分散化された複数のサンプリングポイント全体による同一座標群の存在確率は、これらのサンプリングポイント13のデータのbit数に、サンプリングポイント13の数が積算された指数になる。
【0035】
例えば、先に説明の1座標がR、G、B、各4bit構成の場合、組合せ数は2の12乗(4K通り)であるが、サンプリングポイント13が10個所であれば2の120乗の組合せ数、実動作上、無限大に相当する確率組合せとなり、特徴の少ない単調な画像同士でなければこれらの全てのサンプリングポイント13が全て一致すれば同一画像と判断して良い。
【0036】
しかしながら、限られた狭い範囲の画像を対象とする場合や、文字などの白黒画像も対象となるので、以上のように完全に分散化されたサンプリングポイント13を採ることは出来ない。
【0037】
従がって以下に説明するサンプリングポイント13の識別能力評価を行い、アラームを挙げるなり、画像領域を拡大するなり、サンプリングポイント13を追加するなど適切な対策を採ればよい。
【実施例3】
【0038】
図3(サンプリングポイントの評価方法例)は図1の検出基準画像Aの場合のこのサンプリングポイント13の識別能力を評価する例であり、座標1を検出基準座標として最後は座標25までの合計25個のサンプリングポイント13に対し隣接する4つのサンプリングポイント13を1組とするAからPまでの合計16組の隣接サンプリングポイント群を現したものである。
【0039】
一例としてA群には2、10、14、18の4つのサンプリングポイント13が含まれ、B群には10、6、18、22の4つのサンプリングポイント13が含まれ、以下同様である。
この時、A群からP群のそれぞれの4つのサンプリングポイント13は、それぞれの群の中で輝度情報や色情報のいずれにおいても座標のデータ12に違いがある事が特徴の大きさ、つまりサンプル特徴量の大きさにつながるので、この4サンプルから2つを採る組合せの6つの組合せ、2−10、2−14、2−18、10−14、10−18、14−18により、そのデータの差分量の絶対値を求めこの6つの組合せの合計と全体(16群)の集計を採ることにより、当該群の特徴量の基準値とすることが出来る。
本例のようにR、G、B、の複合されたデータの場合、各独立して評価すればよい。
また同一サンプル数の場合の識別能力の把握の場合には、A群からP群のそれぞれの特徴量を合計し16群で除した平均特徴量が特徴量の大きさの尺度(基準値)として利用することが出来る。
【0040】
云うまでもなくこのサンプルの特徴量が少なければサンプリングポイント13としての識別能力に影響が出るため、検出の基準画像を指定しその画像領域を決定する際、基準値以上の値となるよう、必要によりサンプリングポイント13の数を増やすことや画像の領域を増やすなど調整すればよい、当然反対の場合も可能であり、このサンプリングポイント13の評価方法は画像の検出の検索処理数(時間)を理に適った合理的な検索処理数(時間)とする上で重要である。
以上は手動でサンプリングポイント13を決める際にももちろん有効である。
本例は二次元情報を対象に識別能力を評価した一例であるが一次元から多次元まで隣接するサンプルとそのデータの差分を採ることによる考え方で特徴量を判定することが出来る。
さらに対象となる情報の種類によって、その情報の特徴からサンプルの基準を独自に定め判定すればさらに確実な情報の検出が可能になる。
【0041】
これまで本発明を実現するにあって不可欠となる確実性を追求した情報の検出について二次元情報の画像を対象に説明してきたがこの考え方の基本的な内容は他の次元の情報に対しても共通である。
【0042】
ここで本発明を実現するためのメモリに記憶する情報の配列について説明する。
一次元配列の情報はメモリアドレス上に連続的に記憶された情報であり、二次元
の情報は図1の1からnまでのアドレス3のようにそれぞれの次元の最大座標数を配列基本条件としテーブル変換され一次元のメモリアドレス配列として連続して記憶された情報、もしくは記憶可能な情報であり、メモリのデータサイズならびにメモリ容量はそれぞれの目的にあったメモリ構成である。
三次元、さらには多次元の情報をメモリアドレス上に記憶する場合も同様に、これらの情報はそれぞれの次元の最大座標数を配列基本条件としテーブル変換された上記同様の情報であり、メモリ構成も同様である。
【0043】
従がってこの情報は、それぞれの次元に対応する座標データが与えられれば、配列基本条件である各次元の最大座標数をもとに与えられた座標データに対応するアドレスが特定可能であり、座標の相対位置や座標の範囲も同様に特定可能である。
もちろん、高次元の情報でも対象とするアドレスが直接分かる場合は直接そのアドレスや相対アドレスで指定することが出来る。
以上は確認のため、念のため記載したものであり、このアドレス配列方法は通常行われている一般的な情報の配列方法で、この一般的なメモリに対する情報の配列方法が本発明を実現する上での基本情報配列であるので極めて利用し易い。
【0044】
以降これまでの考え方にもとづく、本発明の情報絞り込み検出機能を備えたメモリ21を連想メモリに適応した場合について説明する。
【0045】
連想メモリはキャッシュメモリや通信データ処理など、情報処理装置の中で特に重要で高速処理を必要とするメモリに利用されている。
また画像データなどに対しては特にクラスタリング手法による類似画像を検出するための最短距離検索(類似度距離検索)を目的とした検索ディバイスとして盛んに研究されている。
【0046】
以降連想メモリの概要を説明する。
高速なデータ処理に利用されている連想メモリは、通常のメモリ機能の他に外部から比較するデータを全メモリ同時(並列)に与え、その合格するメモリのアドレスを読み出すことが可能な情報の検索に大変都合のよいディバイスである。
この並列処理53のイメージの一例を上げれば、大勢の人が集まる会場に座席(アドレス)を用意し座って貰い、この人達が好きな色のカード(データ)を自由に選ぶことが出来るようにした場合、例えば赤のカード(データ)を持つ人を調べる場合、通常のメモリの場合は全ての人を座席順等、逐次比較で調べる必要があるのに対し、連想メモリの場合は、例えば赤のカードの人は一斉に手を挙げて貰い(並列比較)、その座席(アドレス)を確認(出力処理)するだけでよいので極めて高速な判定が出来る。
このように連想メモリは大量な情報を並列に比較し、その中から必要とするデータのみを探し出す場合に好都合のデバィスである。
【0047】
様々なメリットを持つ連想メモリであるが構成上の弱点の1つとして、データバスとアドレスバスによるデータの読み書きをするメモリデバィスの場合、外部から与えられた比較データ(この場合赤色)に対し同時にその合格判定が可能であっても、合格するアドレスが複数の場合には一遍にそのアドレスを出力することが出来ない。
【0048】
これを解決するには、出力にプライオリティ機能を持たせ、合格するメモリに対し順次合格するメモリのアドレスを出力すればよいが、十分に絞り込みされたアドレス数となっていないと読み出しにも時間が必要である。
通常の場合このアドレスを読み出し、読み出されたアドレスに対し次の比較条件が与えられ、以降はこの条件を元に逐次処理による絞り込みが行われる。
先の例の200万ピクセル(アドレス)で12bit、4096通りの組合せデータの場合には平均488個のアドレスを対象として、以降の条件比較を繰り返す必要があり、通常その大半は対象外(残らない)のピクセルであり無駄な処理である、3次以降も同様である。
【0049】
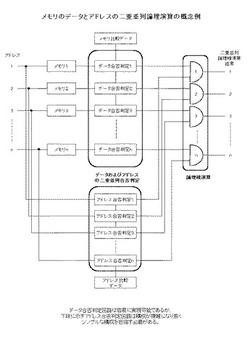
従がって本発明の情報絞り込み検出機能を備えたメモリ21はこのような逐次処理を完全に排除するために、さらに赤のカードで手を挙げた人同士で、その座席の関係(アドレスの関係)が一致する人(例えば隣同士や前後左右で赤のカードを持つ人)以外は一斉に手を降ろして貰う機能、つまりデータとそのアドレスの関係、つまり毎次、全メモリ(座席の人)を対象に比較条件(カードの色と、座席の相対関係)与えることによって、記憶されたデータの合格(カードの色)と、そのアドレスの位置(座席の相対関係)の合格と、の双方の並列合否判定結果による論理積(AND)演算55に合格するアドレス(隣同士や前後左右で赤のカードを持つ座席の人)を絞り込み検出しこれを出力する機能を持った二重並列合否判定54の出来るメモリ、さらに様々な二重並列論理演算60が可能なメモリを実現させることにある。
【0050】
図4(データおよびアドレスの二重並列論理演算の概念)は以上説明のメモリのデータとそのアドレスの二重並列合否判定結果の論理積(AND)演算の概念である。
それぞれのアドレスのデータの内容の比較と、それぞれのアドレスの比較をそれぞれ並列(二重並列)に合否判定54し、その合否判定結果に基づき情報の絞り込みを行うための論理積(AND)演算55がさらに並列に行われるものである。
この演算結果はどのような形態で利用されても構わない。
【0051】
以上のように1回の絞り込みでも極めて大きな絞り込み効果が得られるが、さらにこれらの二重並列論理演算60が連続繰返し実施出来れば理想の情報絞り込み検出が可能になる。
【0052】
以上の考えを実現する上で図4の下段のアドレス比較のアドレス合否判定回路は概念として表現することは容易であるが、通常の考え方では、どの様にアドレスを比較するのか、どのアドレスと比較するのかが定まらないので実際にこの概念を論理回路化することは容易ではない。
【0053】
例えばこれまで説明の初回に比較し生き残ったアドレス、これを1次突破アドレス56としてこれを基準にして各アドレスと比較をする方法が考えられるが、この方法においても、先に説明の通り1次突破アドレス56が仮に488アドレスあれば、全てのアドレスとこの488アドレスの組合せによる、組合せ並列アドレス比較回路を構成しなければならないので極めて大掛かりな構成になる。
【0054】
小規模なメモリアドレス数であれば以上の構成でアドレス比較を実現することも可能であるが、本実施例では大規模なメモリであっても図4の論理構成を出来るだけシンプルな回路構成で実現するために、1次突破アドレス56を毎回(毎次)の比較のための基準原点のアドレスと定義することにより、以降毎回比較するアドレス(座標)は、このそれぞれの1次突破アドレス56と相対アドレス(座標)が毎回の比較とも相対的に同一な位置(アドレス)であることに着目しこの論理回路の最適解を求めている。
【0055】
具体的には先に説明の図1に示すそれぞれのサンプリングポイントに対し1次突破アドレス56を基準原点座標とし、比較するアドレスに一定の相対的なバイアスもしくは範囲を設定し、それぞれの1次突破アドレス56の相手先のアドレスのデータがこれに合格しているのかどうかを確認して、合格していればこれを突破アドレスとする構成とすればよい。
【0056】
さらにそれぞれのアドレスに突破の回数を記録するカウンタを設け、基準原点である1次突破アドレス56に突破回数が累積されカウントアップ出来るようにすることによって、1次突破アドレス56の内で最多突破回数(N回)のメモリのアドレスをN次突破アドレス57と判定することにより連続絞り込みの論理回路が可能となり、極めてシンプルな論理回路構成であっても当初の目的を全て満たす構成となり、情報処理永年の課題の1つを克服するディバイスを実現することが出来る。
【0057】
後述するが図4の二重並列論理演算60は論理積(AND)演算55のみに限定されるものでなく、またこの演算結果の利用の仕方も自由である。
【実施例4】
【0058】
図5(情報絞り込み検出機能を備えたメモリ例)は以上の内容に関連する本発明のメモリ21の機能概要を連想メモリをベースに示したものであり、データ処理のタイミング等細部は省略され、本発明に関係するところの概念のみを説明するものである。
【0059】
この情報絞り込み検出機能を備えたメモリ21(以降本発明のメモリとも記載する)には、アドレスバス22、データバス23が接続されていて、外部とデータを授受可能な構成になっている。
従がってメモリ1からnのメモリ32はアドレスバス22のアドレスデコーダ31によりアドレスが選択されデータバス23からデータの書込み、読み出しが可能である。
【0060】
入力データ25は本発明のメモリ21に情報検出のためのデータを与えるもので、第1のデータであるメモリ比較データ26は外部からメモリのデータ比較のためのデータであり、この入力データとメモリ1からnまでのメモリ32とデータの合否の比較をデータ比較回路33により判定し合格の場合その結果をアドレススワップ前合格出力41として出力する。
第2の入力データ25であるアドレス比較データ27ならびにアドレススワップ回路34については後述する。
【0061】
突破回数カウンタ35はアドレススワップ後合格出力42によりデータ比較回路33の合格回数を突破回数として記憶加算するカウンタであり、この突破回数カウンタ35は、情報同士の比較回数をカウントする比較回数カウンタ29の比較回数信号43との一致出力機能を有しその出力がORゲート36と、インヒビットゲート37に接続されており若いアドレスから順次カスケード44接続される信号により、突破回数がN回の突破回数カウンタ35の中で一番若いアドレスのカウンタが優先され1アドレスのみ出力をする出力優先(プライオリティ)処理がなされている。
【0062】
突破アドレス出力処理回路38は優先出力のアドレスを出力バス24に乗せる処理と、出力処理の完了したアドレスの突破回数カウンタ35をクリアーする処理をすることにより、以降他にN回突破の突破回数カウンタ35があればそのアドレスを次の優先出力とし、順次N次突破のアドレスを、出力バス24によって外部に送り出すことが可能な構成となっている。
本例の専用バス出力の専用出力形態は一例であり、データバス23に直接出力結果を乗せることも可能である。
従がって、この構成によれば、突破回数が一番多い(N回)突破回数カウンタ35のアドレス(座標)がWinner(N回突破アドレス57)でありその若いアドレス順にそのアドレスを出力する構成である。
【実施例5】
【0063】
図6(アドレススワップ回路Aの例)は極めてシンプルな論理回路構成で本発明を実現するための手段であるアドレススワップ回路34の基本概念を示すものである。
アドレススワップ回路34はデータ比較回路33と突破回数カウンタ35の中間に設けられており、このアドレススワップ回路34は毎サンプル比較時、目的の1次突破アドレス56に突破の出力を二重並列論理積演算結果として累積加算するために設けられ、本例の場合、先の説明の入力データ25の第2のデータであるアドレス比較データ27の、相対アドレス比較データ51によって、アドレススワップ前合格出力41、図6のi、j、kをXY軸座標データに変換し、変換した合格出力を相対アドレス分シフトして、アドレススワップ後合格出力42として該当するアドレスの突破回数カウンタ35(1次突破アドレス56)に合格出力を突破出力として入力出来るように構成されている。
つまりアドレススワップ後合格出力42は1次突破アドレス56のアドレスの相対アドレス条件に合格した場合、突破出力として1次突破アドレス56に入力される。
もちろん座標データではなく相対アドレス比較データ51を直接相対アドレスで指定し相対アドレス分シフトすることも可能である。
【0064】
以上説明の第1、第2のデータの入力はデータバス23から与えることも専用入力から与えることも自由である。
この構成の本発明のメモリ21に先に説明の画像のピクセルデータ、またはこれに相当する情報データをメモリに記憶し、この未知の情報2から画像を検出する場合の例を説明する。
【0065】
先に説明の図5のメモリ1からnまでのメモリ32には画像のピクセルデータがそれぞれの座標に対応したアドレスに書込みされており、比較回数カウンタ29ならびに全ての突破回数カウンタ35は全てクリアーされて0となっていて、以降比較回数カウンタ29は比較の都度にカウントアップされて行く。
先ず1次比較としてサンプル1のピクセルデータをメモリ比較データ26に入力データ25として与え、全メモリの合格判定を並列に行いデータ比較回路33のアドレススワップ前合格出力41を1次合格出力として出力し、この1次合格出力はアドレススワップすることなく、アドレススワップ後合格出力42としてそのまま突破回数カウンタ35の入力に加え突破したアドレスのカウンタの値を1にする、これが1次突破アドレス56である、以上の通り1次比較に第2のデータは不要である。
先に説明のように平均的な1次突破アドレス56の出現個数は488である(図6のi、j、k)この出現個数はイメージのための数字であり多くても少なくても問題ない、以下同様である。
図2の場合この時、突破回数カウンタ35の値が1となっているメモリアドレスはグループAの1、グループBの1、グループCの1、グループDの1、グループEの1の5個所の座標がWinnerの候補(1次突破アドレス56)であり、これがこれからの説明のポイントとなるアドレス(座標)である。
【0066】
次に2次比較としてサンプル2のピクセルデータをメモリ比較データ26に指定することによりまた別なアドレスが新しく2次合格出力として平均し488個選ばれる。
さらにサンプル1とサンプル2のアドレスの差分を、アドレス比較データ27の相対アドレス比較データ51として指定することにより、新たに選択された488個のアドレスの中で、先に説明の1次突破アドレス56との相対関係が合格するもの、つまりグループの関係が成立するアドレスを、図6に示すアドレススワップ回路34でこの差分に相当するアドレス(座標)をシフト変換し、シフト変換した相対位置の突破回数カウンタ35(1次突破アドレス56)にアドレススワップ後合格出力42を突破出力として加算入力する。
【0067】
つまり、本来は図2のグループAからEの2の座標(アドレス)の突破回数カウンタ35がカウントアップされるところ、サンプル1の判定で生き残った候補座標の突破回数カウンタ35(1次突破アドレス56)に、継続してカウントアップが出来るように相対アドレスのバイアスをかけて2次突破出力として、1次突破アドレス56に突破入力を与えている。
【0068】
先に説明の図2の場合この時、突破回数カウンタ35の値が2になっている1次突破アドレス56はグループBの1、グループCの1、グループDの1、グループEの1の4個所が候補として維持される座標であり、グループAの1はカウントアップ出来ず候補から脱落する。
以上の内容は対象とするメモリのアドレス位置(2次サンプルに相当するアドレス位置)が1次突破アドレス56を基準にして目的の位置(相対アドレス比較データ51)に存在するか否かを判定し、2次のデータ比較による合格アドレスと並列に論理積(AND)演算55しその結果を1次突破アドレス56の突破回数カウンタ35に突破出力として入力したのと等価である。
【0069】
順次同様にメモリ32のデータ比較と、1次比較のサンプル1を基準とする他のサンプルとの相対アドレスと、を一対の入力データ25として読み込み、それぞれのアドレスグループ内で突破するメモリを1次突破アドレス56に集約してカウントアップすることにより、1次突破アドレス56(Winner候補)の絞り込みを連続して行う事が出来る。
【0070】
従がって図2において最後のサンプル25(Nが25)まで突破する1次突破アドレス56はグループDの1の座標(25次Winner)のみでありこの座標(アドレス)の突破回数カウンタ35の値は25になっており、この突破回数カウンタ35は比較回数カウンタ29の比較回数信号43と一致しその出力が以降のORゲート36ならびにインヒビットゲート37に入力される。
【0071】
図7(アドレススワップのイメージA)はこれまで説明のデータの合格と、アドレスの相対関係、の双方の合格、つまり二重並列論理積演算による突破の内容をイメージとして説明するものである。
図に示すように、画面の座標には最初の1次比較により1次突破アドレス56がAからFまで計6個示されている。
このアドレススワップは全アドレスを対象として相対的に行われるものであるが、1次突破アドレス56は、あたかも比較の対象になるそれぞれのアドレスグループ内で次に比較される2次比較の相対座標位置を望遠鏡で覗きこみ、2次合格アドレスの合格出力(本図では黒丸印)があればこれを突破出力として奪い取る、まさにスワップのイメージである。
3次比較も同様に比較される相対座標位置を望遠鏡で覗き込み、3次合格アドレスの合格出力(本図では黒三角印)を突破出力として奪い取る、以降も同様のスワップのイメージである。
本例の場合、Eのカウンタは2に更新され、さらにBのカウンタは3に更新される。
【0072】
図8(アドレススワップのイメージB)は以上の図7に示されるA、B、2つの1次突破アドレス56の座標上のイメージをアドレス上のイメージとして説明するものである。
図8に示すように、1次突破アドレス56は、サンプル2からサンプル25までのデータ比較回路を望遠鏡で覗き込み、覗き込んだデータ比較回路に合格があればこれを突破出力として奪い取るイメージである。
云うまでもなく望遠鏡の切替えはアドレスの相対位置関係を比較するためのデータである相対アドレス比較データ51により毎回設定される。
【0073】
実際には1次突破アドレス56のアドレスと相対関係のない2次、3次、N次比較による合格出力も相対的にシフトされたアドレスにカウントアップされるがサンプルが適正で意図的なものでなければ毎回散発的であり合格出力が特定アドレスに集中することはない。
これはサンプルとなる画像(情報)と未知の画像(情報)の特定部分が同一であると云う特別な関係(パターン)が成立しないからである。
1次突破アドレス56は常にカウントの優位性を保ち(最初に1)、さらに1次突破アドレス56の相対アドレスに関連付けされたサンプルのアドレスのグループを代表し合格出力を突破出力として集める権利を持つ支配者のイメージである。
【0074】
図9(アドレススワップのイメージC)は実際の二次元配列アドレスにおけるアドレススワップの例を示すものである。
表A、Bはアドレススワップ前のアドレス(座標)1から100までを示すものであり、24、50、67、72の4つのアドレス(座標)が1次突破アドレス56となっている。
表Aは2次比較アドレスを相対アドレスが−22のアドレスをデータ比較アドレスとする場合であり、この時72のアドレスは相手先の座標が対象外である。
表Bは3次比較アドレスを相対アドレスが+31のアドレスをデータ比較アドレスとする場合であり、この時50および72のアドレスは相手先の座標が対象外である。
表Cは表Aを−22アドレスシフトしたものであり、24、50、67の1次突破アドレス56は正常にそれぞれの相手先のデータの合否結果を得ることが出来、合格結果があればそれぞれ突破出力としてカウントアップ(スワップカウント)することが出来る。
表Dは表Bを+31アドレスシフトしたものであり、24、67の1次突破アドレス56は正常にそれぞれの相手先のデータの合否結果を得ることが出来、合格結果があればそれぞれ突破出力としてカウントアップ(スワップカウント)することが出来る。
以上が所定回数繰り返され比較対象の相手先のアドレスの座標位置が正常な1次突破アドレス56が最終まで生き残ることが出来る。
【0075】
以上様々な例にもとづき説明してきたがこれまでの内容は、アドレススワップ(交換)することにより、1次突破アドレス56を基準にして、以降毎回比較されるサンプリングポイント13と同一のデータ(データの合格)が存在し、さらに目的の位置(相対アドレス比較データ51)に存在するか否か、の双方を連続的に二重並列に合否判定54を行いさらに並列に論理積(AND)演算55し、その結果を1次突破アドレス56の突破回数カウンタ35に毎回出力するのと等価であり、アドレススワップ回路34は図4の下段の並列アドレス合否判定と並列論理積演算が一体化され、一人二役をこなす極めて効率的な論理回路、つまり等価二重並列論理積(AND)演算61手段である。
最終結果はこの比較回数であるN次突破アドレス57を突破アドレス出力処理回路38および出力バス24で読み出しすれば、N次突破アドレス57を含む情報のグループのアドレスを特定つまりパターン認識をしたことになる。
比較回数カウンタ29をプリセッタブルカウンタとして比較回数信号43を指定することにより任意のカウント値のカウンタ(N次突破アドレス57)のアドレスやその途中経過も読み出すことが可能になる。
【0076】
アドレススワップ回路34の一例は図6に示すようにアドレス変換用のレジスタを用意し、データ比較回路33よりのアドレススワップ前合格出力41を、相対アドレス比較データ51の座標データにより相対的に移し替え、アドレススワップ後合格出力42とする、このレジスタ操作は全てのアドレスの相対シフトであるので、加減算演算によるデータシフト手段、もしくは一番シンプルなのはアドレス分のデータ長のシフトレジスタによっても容易に実現可能である。
【0077】
以上のレジスタを用いるアドレススワップ方法は説明のための一例であり、アドレスデコーダを直接利用してスワップ(交換)するなど他の方法で実施しても構わない。
同様にアドレススワップ回路34ならびに突破回数カウンタ35は本発明の情報の絞り込み検出を実現する上で不可欠な手段であるがこの構成に限定されるものではなく他の方法でアドレス毎に個別に実施することも可能である。
【0078】
データとそのアドレスの相対関係を一括して合否判定するこの方法は、図4に示す全メモリ32のデータ比較条件の合格と、全アドレス比較条件の合格と、の双方を二重並列に合否判定54を行い、これをさらに並列に論理積演算55したものと等価であるので、原理的に個別アドレスを対象としたノイマン型情報処理のアドレス逐次処理を不要とするものである。
【0079】
従がってこれまで説明の200万ピクセルの未知の画像を、分解能12bit、データのグループ数を4096グループとする場合、未知の画像の中から同一画像の検出するに必要なデータの比較回数は通常2から3回で収斂し、最大でもサンプル数(本例では25回)のデータ比較回数で目的の画像を確実に見つけることが可能である。
【0080】
さらにこの方式は図7で示すように1次突破アドレス56を基準原点とした入力データによる全座標パターンマッチングの繰返し(毎回全メモリを対象として比較)であるので、部分的に一部の画像が欠落しているような場合の近似の画像(以降近似画像)の検出も実施出来る。
【0081】
たとえば、図2の場合、25回の比較完了後、グループAの1の座標のカウンタは1、グループBの座標のカウンタは10、グループCの1の座標のカウンタの値は21、グループDの1の座標の値は25、グループEの1の座標の値は22になっている。
つまりカウンタ値の高い座標のアドレスは部分画像が欠落した画像や近似の画像の可能性が高い、この場合1次突破アドレス56以外であってもよい。
カウンタ値が一定値以上(例えば20回)となる座標を読み出ししておき、所定(この場合25回)の比較完了後、必要により周辺の座標を詳しく判定すればよい。
従がってこの方式は同一画像を高速で検出することのみなならず一定の定義もとづく近似画像にも有効である。
【0082】
またこのアドレスワップ(交換)の考え方をさらに発展させることにより、画像が拡大縮小もしくは回転、以降変形画像と呼ぶ、の画像も最少の検出回数で検出することも可能になる。
【実施例6】
【0083】
図10(変形画像の検出の概念)は比較する画像が拡大縮小もしくは回転、場合によってはデータに変化が加わった変形画像を前提として検出する場合に効果的な方法を説明する。
【0084】
図10には、1次サンプルの比較が合格した未知の画像の1次突破アドレス56の上に、既知の画像のサンプリングポイント13を重ねたものである。
本例では座標1の基準原点を中心にして未知の画像のサイズが、XY軸ともに2倍(画面としては4倍)に拡大される可能性があるとした場合を示している。
もし探し出す変形画像がこの中に存在する場合、変形画像に対応するサンプルの2から25の全ての座標は、図に示す円の内部に存在するはずである、従がって円を包含する座標範囲をこの座標1の画像検出範囲とすればよい。
【0085】
従がって、これまでのアドレス(座標)シフト変換の概念を拡大し、座標1の基準原点より指定する座標範囲にサンプルと同一のデータ値を持つ座標が存在するかどうか、この場合個数は関係なく単純にあるのか無いのか、を判定し、指定するサンプル数(本例では25個)のサンプルに相当する座標がこの範囲にあることを判定することにより変形画像を検出することが可能になる。
【0086】
この場合もサンプルの特徴量を判定してサンプルの数と識別能力を一定基準とし対象の範囲を一定の範囲内とすることによりその確実性は高いものになる。
【0087】
この場合も毎時目的の1次突破アドレス56にデータとアドレス双方の合格(突破)の出力を集中させて記憶加算する手段、本例では1の座標の突破回数カウンタ35に判定の結果を累積させる方法が出来れば、このような変形画像に対しても、サンプル数を最大とする最少データ比較回数で画像の検出が可能になる。
【実施例7】
【0088】
図11(アドレススワップ手段Bの例)は以上の考え方を実現させるために図6で説明のアドレス変換を1対1のアドレスシフト変換からアドレスの範囲として捉え、これを外部からアドレス比較データ27に、アドレス範囲比較データ52として入力することにより、このアドレスの範囲で合格のあったi、j、kのアドレススワップ前合格出力41を、比較条件に該当するアドレス範囲として取り込み、この場合もそれぞれのアドレスグループ内の1次突破アドレス56の突破回数カウンタ35にアドレススワップ後合格出力42を入力する構成としたものである。
先に図7で説明の望遠鏡をパラボラ型の天体望遠鏡に変えて1次突破アドレス56に突破出力を奪い取るイメージである。
【0089】
例えばこれまで説明の図1に示す1000ピクセル程度を画像範囲とする画像の1座標を基準とする場合、その1座標を中心としてXY軸7000ピクセル強の座標範囲を比較範囲の座標とすれば2倍まで拡大された回転を伴う変形画像においてもサンプル数を最大とする最少データ比較回数で画像の検出が可能になる。
【0090】
座標変換や画像が縮小された場合の画像などでは、サンプル座標に対応する座標が欠落する場合もあるので適切にサンプル合格回数の基準を設ければよい。
この方法は図6で説明の相対座標の完全一致方法に比較すれば確実性は落ちるがサンプルの識別能力やその数を適切にすることにより極めて高速な画像の検出が可能になる。
【0091】
さらにメモリ32のデータ比較回路33をデータ一致の合否の比較から、輝度や色のレベルの範囲を持った大小比較として合否の判定を行えば、変形画像のみでなく、その定義の仕方にもよるが類似の画像の検出も可能となる。
このような場合には大小もしくは一致による合否判定以外、メモリbit個別のDon‘t Careによる比較が可能な3値メモリを利用し合否判定をするとさらに効果的である。
【0092】
通常、画像のサイズの変化や回転が加わった画像の検出は座標変換など極めて多大な検索の処理回数を必要とするがこの方式によればサンプル数分の比較をするだけで目的の変形画像(近似画像を含む)を検出することが可能となる。
多くの場合以上のように変形画像や類似画像の中心位置や重心位置などが検出出来れば良い場合が殆どであるが、もし画像の拡大縮小や回転角度を検出する必要がある場合にも何回かのデータ比較を追加することにより対応可能である。
【0093】
以上のような必要がある場合、一旦画像が存在する範囲を検出した後に、図10に示すように、2、4、3、5の4個の対角の座標が何処に存在するのかを、分割検出範囲Aの4分割、分割検出範囲Bの16分割のように分割し範囲を限定し検出すればよい、4分割の場合で16回、16分割で64回合計して最大でも80回のデータ比較を行えば凡その画像の変形の様子を掴む事が出来る。
通常このような変形の度合いが推定出来ない変形画像を検出する場合には、考えられる画像の変形情況を推測して多数の座標変換を行いパターンマッチングを採る必要があり、このような変形画像の検出に比べれば比較することが出来ない程高速なパターンマッチングが可能である。
分割する範囲を細分化すればより正確な検出も可能である。
以上は一例であるがこのように最小限のデータ比較の回数を追加することにより複雑な画像の検出も可能である。
【0094】
本例では画像が拡大縮小さらには回転される可能性があることを前提に全サンプリングポイントを対象にして大きな範囲を範囲設定した場合の例で説明を行ったが、それぞれのサンプリングポイントに対して個別に一定の範囲を指定して検出をすることも出来る、この方法はデータとそのアドレス(位置)の不確かさを補完する上でも、同一もしくは類似するデータが連続して存在する場合に重要な意味を持ち、サンプリングポイント13の位置やそのデータを元に類似画像の定義を行えば、同一画像、近似画像、変形画像、類似画像まで幅広く検出が可能となる。
【0095】
この本発明のメモリ21はこれまで説明の座標シフト方式(アドレスが比較する相対アドレスと一致)と座標範囲方式(アドレスが比較する座標の範囲内に存在)の2つの検出方法以外、例えば比較する座標の範囲外、等にもアドレススワップの応用が可能であり、いずれもアドレススワップ回路34のアドレス比較データ27のデータ設定のみで実現出来るのでこれらを一体にした構成とすることが可能であり、これらの画像検出方法を組合せすることにより、より様々な画像の検出を可能にする。
本例では説明を簡素化するためR、G、Bの色データをまとめて1つのアドレスのデータとする方法で説明したがR、G、Bのそれぞれのアドレスを独立させて比較する方法も容易に実現可能である。
【0096】
この本発明のメモリ21は並列にメモリデータを比較可能な基本構造のメモリ、例えば連想メモリ等に、アドレスのスワップ(交換)を行うための手段と、合格回数を記憶するカウンタと、一般的なプライオリティエンコーダで構成可能な極めてシンプルな構造であるので大容量化もし易い。
【0097】
また本発明のメモリ21は云うまでもなくデータとそのデータのアドレスの相互関係に基づく組合せ問題の探索(比較)回数を根本的に解決し、適正に選択されたサンプルであればサンプル数を上限とする最少のデータ比較回数を保証するディバイスであり、クラスタリングした類似特徴の座標相関による画像の検出や、その他の様々な情報の検出に応用することが可能である。
【0098】
これまでの説明では、情報を繰返し絞り込みする場合で説明しているが、絞り込みを1次比較、2次比較だけとする単発の情報検出も可能であることは云うまでもない。
【0099】
以上のように自らが情報検出可能なインテリジェンスな知識をもった本発明のメモリ21を用いることが出来れば、情報検索時CPUやGPUは入力データを与えその結果を読取るだけなのでその負担を大幅に軽減出来る。
極めて高速な情報検出が可能なのでメモリのサイズが不足する場合には、情報を分割して情報検出を実行してもよい。
【0100】
この本発明のメモリ21の毎回のデータ比較処理時間が、控え目にみた処理時間で仮に毎回平均1μ秒であっても、どの様なサイズの画像を対象としても数μ秒から長くても数百μ秒以内で目的とする情報を確実に検出することが可能になるので、動画像を対象とした1コマ(フレーム)上の情報を検出することも、検出したい既知の情報1が連続して大量にある場合にでも広く応用が可能となる。
云うまでもないが本発明のメモリ21のメモリ32をアクセスして逐次処理する通常のCPUとのコラボレーション(併用)によりさらに高度な情報検出が可能となる。
【0101】
以上画像情報を中心に本発明の概要を説明してきたが、この情報検出の方法と本発明のメモリ21は、一次元情報(音声等)や多次元空間として配列された情報の検出にも有効である。
【実施例8】
【0102】
図12(アドレススワップ手段Cの例)は図6の二次元情報を、X、Y、Zの3軸に拡大し、三次元空間に配列された情報の同一配列や類似配列を検出可能にする例であり、N次元空間とすることも可能である、情報検出の具体例は後述する。
【0103】
これまでの説明の情報絞り込み検出機能を備えたメモリ21は、全てのメモリを対象に突破回数をカウント可能にし、その突破の回数で同一情報ならびに類似情報を連続して検出するものであったが、メモリ数が大規模な場合や回路構成をさらに簡素化する目的で突破回数カウンタ35、ORゲート36、インヒビットゲート37の回路数を削減することが出来る。
【実施例9】
【0104】
図13(情報絞り込み検出回路の削減例)は図4、図5に示す本発明のメモリ21の基本構想をもとに回路数を削減したもので、これまでの説明のように利用される突破回数カウンタ35以降の回路の数は、通常の場合1次比較で出現する1次突破アドレス56の数(これまでの説明では200万アドレスで分解能4096通り、平均488アドレス)であることに着目しこれに見合う数量、例えば突破回数カウンタ35以降の回路数をメモリ32のアドレスの数量の、例えば1000分の1や2000分の1に削減、図ではAからXまでの出力に削減したものである。
【0105】
この場合カウンタは、図7で説明のそれぞれのアドレスグループの1突破アドレス56を記憶しこのアドレスを読み出しが可能な構成のグループ別突破カウンタ58とし、このカウンタ58別に1次突破アドレス56を読み出し出来る構成とすればよい。
このような構成とする場合にはアドレススワップ回路34に簡単なアドレス演算プロセッサを搭載するなどしてアドレススワップを行ってもよい、このように演算プロセッサを利用してアドレススワップ(交換)の自由度を高めることによりさらに様々な手法の情報の絞り込みも期待できる。
【0106】
仮に1次突破アドレス56の数が多くオーバフローする場合にはアラームを挙げて1次比較のサンプルを変更するなどすればよい。
【0107】
また回路数を削減する方法として、二重並列論理演算60をメモリのバンク毎に切り替えて実施するなどの回路構成も可能である。
【0108】
全てのメモリを対象に合格回数をカウント可能な方式は1次突破アドレス56の出現数の制限がなく理想であるが、このように情報絞り込み機能の回路構成を簡素化した、情報絞り込み検出機能を備えたメモリ21であっても、これまでの説明の情報検出の方法で目的の情報を確実に検出することが可能である。
【0109】
以上のような構成とすることによりこの本発明のメモリ21のメモリのアドレス数やそのbit数、つまりメモリ容量に関しての自由度を増すことが出来る、また前述のごとく3値メモリとすることも可能である。
【0110】
図14(多重化したデータとアドレスの二重並列論理演算の概念例)は、図4で説明の二重並列論理演算を多重化した例である。
図に示す通り、本発明のメモリ21はメモリのデータを比較するための比較データとアドレスを比較するためのデータを2組と、二重並列合否判定回路を2組と、二重並列論理積演算回路を2組、をそれぞれ持っており論理積演算結果をさらに並列に論理和(OR)演算59し出力をする構成になっている。
【0111】
このような構成も図5に示すメモリ21の回路構成を応用することでも可能である。
このような構成にすることにより、2つのパターンを同時に検出することが出来る。
本例は多重化の一例であり、2組以外多数の組合せとすることも、演算を論理積(AND)や論理和(OR)以外、排他論理やその他任意の論理演算とすることが出来る。
検出する情報の種類や目的に応じてこのように多重化し、様々な論理演算の二重並列論理演算60を使用することにより、より高度な情報の検出が可能になる。
【0112】
これまでの説明の図4、図14等を総合して本発明のメモリ21の構成をまとめると、
メモリアドレスごとに情報を記憶しその情報を読み出し可能なメモリであって
このメモリは、
外部から与えられる第1のデータは記憶されたこのメモリのデータを比較するためのデータ、第2のデータはこのメモリのアドレスを比較するためのデータ、の双方の入力データの入力手段と、
(1)第1のデータでメモリに記憶されたデータを並列に比較し合否判定する手段と
(2)第2のデータでメモリのアドレスを並列に比較し合否判定する手段と
(3)以上(1)、(2)双方の合否判定結果をさらに並列に論理演算するデータとアドレスの二重並列論理演算60手段と
を具備することを特徴とする情報絞り込み検出機能を備えたメモリである。
【0113】
さらこのメモリの情報の絞り込みをシンプルな回路構成とするための一例として、
前記(1)の合否判定手段ならびに前記(3)の二重並列論理演算手段60を、その演算結果が前記(1)の合否判定と前記(2)の合否判定との論理積(AND)と等価となる、等価二重並列論理積(AND)演算61手段で構成したことを特徴とする請求項1の情報絞り込み検出機能を備えたメモリである。
【0114】
さらに図5、図13等に示すようにこのメモリを連続繰返し二重並列論理演算60するために
毎次の前記等価二重並列論理積(AND)演算61手段の結果をメモリアドレスごとに計測するカウンタ35手段と、
初回の前記比較は、前記第1のデータによって、メモリを並列に合否判定して合格したメモリアドレスの上記カウンタを1にカウントアップしこれを1次突破アドレス56とする手段と、
以降の比較は、上記第1のデータによって、メモリを並列に合否判定して合格したメモリアドレスと、上記1次突破アドレスと、の双方のアドレスの位置関係を、前記第2のデータによって、前記等価二重並列論理積(AND)演算61手段で演算し、この演算を突破した上記1次突破アドレスのカウンタをカウントアップしてN(2以上の整数)次突破アドレスとする手段と、
このN次突破アドレスのアドレスを出力する手段と、
を具備することを特徴とするメモリである。
【0115】
さらに前記等価二重並列論理積(AND)演算61手段は前記第2のデータであるアドレスを比較するためのデータにもとづくアドレスのスワップ(交換)手段によって繰返し実施することを特徴とするメモリである。
【0116】
さらに前記第2のデータであるアドレスを比較するためのデータは、前記1次突破アドレスを基準とし、
(1)比較対象のアドレスが相対アドレスに一致するか否かの比較データ
(2)比較対象のアドレスが比較する範囲の内外に存在するか否かの比較データ
以上(1)(2)のいずれかもしくは双方であることを特徴とするメモリである。
【0117】
さらにこのメモリは、絞り込みのための回路の削減や二重並列論理演算60を多重化することも、論理演算を論理積や論理和のみならず様々な論理演算のデータとアドレスの二重並列論理演算60をすることが可能なメモリである。
【0118】
以上で本発明のメモリ21のそのものの説明を終えて、以下に一次元、多次元空間の情報検出の例を説明する。
【実施例10】
【0119】
図15(アドレス一次元配列の情報検出例)は、例えば横軸を時間軸としてアドレスに対応させ景気動向や株価、気温などのデータを縦軸に表示したものであり、サンプルとして与えられた既知の情報のデータを基に未知の情報である、過去の膨大なデータベースの中から情報検出を行ったものである、このような情報検出は、メモリアドレスを時間軸に関連付けるように配列記憶されたデータにより極めて簡単に行うことが出来る。
【0120】
時間軸を対象とした情報検出のもう一例として音声の場合には圧縮前のサンプリング時間とこの時間に対応した音声データや圧縮音声データのAAU(オーデオ復号単位)毎の音声データをもとにして情報検出が可能である。
3値データの比較が可能な本発明のメモリ21の一例として人の声などのスペクトラムの帯域をクラス化してクラス別にデータ化して、1時刻、1アドレス分のデータとすれば極めて簡単に時系列配列が作成出来る。
これを元にテンプレート音源などと類似パターン認識すればよく極めて高速な音声認識が可能となり、様々な音声認識の分野に利用することが可能である。
【0121】
またこのような一次元配列情報の検出は多大な情報処理を必要とするDNA配列、ゲノムの4つの塩基配列の組合せ解析を高速に実施する上で極めて有効である。
同様に文字列の配列による解析も同様である。
【実施例11】
【0122】
図16(アドレス三次元配列の情報検出例)は三次元空間に配列された情報を検出する場合の例を示したものである。
図に示すように三次元空間に配列される特定のパターンをこれまで説明の内容と同様な方法で検出したイメージである。
【0123】
云うまでもなく三次元空間は我々が存在する実空間を表現出来るので、三次元空間の位置とそのデータが定量化出来る全ての三次元情報に適応可能である、さらに時間軸を加えた時空間情報など多次元情報に展開することも可能である。
【0124】
このような三次元空間の情報検出は原子や分子レベルから宇宙空間のあらゆる配置関係の解析に利用可能である。
【0125】
特に高速な検出が可能であるのでリアルタイム処理が必要なロボットを対象として、例えば動きの速い物体などを対象として多数のテンプレート画面と比較を行うような立体パターン認識、立体物体認識や物体移動追跡など用途は無限である。
【0126】
いずれの場合もメモリアドレスと、X、Y、Z、3軸を対応付けするようデータをアドレス配列記憶することにより容易に実現可能であり、同一情報はもとより画像の検出で説明の近似情報や類似情報の検出も可能であることは云うまでもない。
【0127】
以上の説明は一次元から多次元までの空間を対象として既にアドレス配置された情報もしくはアドレス配列可能な情報のパターン認識を行ったものであるが、一例としてアドレスをクラスタリングされた情報グループに分類するなどしてこれを情報検出するなどアドレスとデータの配列を工夫することにより、これまでのアルゴリズムを駆使した情報検出を併用することも可能である。
【0128】
以上が一次元から多次元までの情報を検出する場合の概要であるが、本発明のメモリ21の特徴をまとめると次の通りである。
【0129】
本発明のメモリ21を使用した情報の検出は1アドレスとそのデータを検出の単位とし、入力データの設定方法により、特に厳密で正確な同一情報の検出から近似情報、変形情報、類似情報など幅広い情報を高速で確実に検出することが出来る。
【0130】
情報検出のためのサンプリング数もサンプリングポイントの選び方も統計的手法で評価可能でサンプリングを自動化することも可能であるのでサンプリング数の無駄も省け、検出時間を理に適った合理的な時間とすることが出来る、また1アドレス(座標)毎にサンプルポイント設定が出来るのも特徴の1つである。
【0131】
未知の情報上に対象となる情報がない場合の検出打ち切りが極めて速いことも特筆できる。
【0132】
この検出方法は一定の条件を満たせば互いの情報の大きさ(サイズ)に制約がないのであらゆる情報に適応可能であり、本発明のメモリ21のメモリのサイズに合わせて情報を分割処理することも可能である。
【0133】
一次元情報から多次元情報、その他の情報が混在し記憶されたメモリからでも目的とするパターンの認識をすることも可能である。
【0134】
また本方式は、未知の情報を適切にアドレス配置し本発明のメモリ21に記憶させれば、サンプルポイント以外、他のパターン認識で行われるような情報の加工、特徴抽出やクラス化などのデータの前処理が必要ないことも大きな特徴である。
【0135】
さらに本方式はアルゴリズムの開発など情報検出の実施前の時間が不要となるのも大きな特徴であり検出方法(比較条件の設定)も極めてシンプルな構成である。
従がってシステム試験時のカット&トライ的な調整も不要で、設定通りの検出方法で期待する情報を確実に検出してくれる、従がって特段情報検出の専門家でなくても本方式を利用して様々な情報検出のアプリケーションに広く利用することが出来る。
【0136】
これまでの説明では既知の情報1があることを前提としてこれからサンプルを採取して情報を検出することを中心に説明してきたが、人の判断や推測に基づき入力データ25を設定し情報解析することも重要である。
【0137】
このような場合、最初の入力データ25である、1次比較データは検出の結果を左右するので、複数の比較データとするか、入力データに範囲を持させ検出を行い、この1次比較の結果により徐々に範囲を限定する方法で解析を行えばよい。
このような解析は天文、気象、物理、化学、経済などのあらゆる分野の情報予測などデータ解析の時間とその労力を大幅に軽減するものである。
【0138】
この本発明の情報絞り込み機能を備えたメモリ21は、ノイマン型コンピュータの宿命であるメモリの逐次処理を排除し、メモリ自身がインテリジェンスな知識を備えて情報検出を行うものであり、これまでのメモリの常識を大きく打ち破るものである。
従がって従来から研究され利用されている画像認識、音声認識、OCR文字認識、全文検索、指紋認証、虹彩認証、ロボットの人工知能のパターン認識に利用されるのみでなく、天候、景気、株価、分子構造、DNA、ゲノム、文字配列、などの解析はもとより、新たな情報の発見(情報予測)や、社会インフラから産業用設備、工業用設備、家庭用装置はもとより、これまで対象とされることのなかった未知の分野の情報検出にも幅広く利用することが可能である。
【実施例12】
【0139】
この本発明の情報絞り込み機能を備えたメモリ21は、様々な情報の検出を必要とする人工知能のエンジンとして知識処理に利用することも可能である。
例えば本発明のメモリ21を人の脳の大脳や小脳、さらには右脳や左脳などに当てはめ並列さらには階層状に複数配列して、それぞれにテンプレートとして、物体の認識の情報、人物認識の情報、文字の認識の情報、音声認識の情報、味覚の情報、触覚の情報、など様々な種類の情報を記憶させておき、リアルタイムで与えられた周囲の画像や音声さらには様々なセンサの情報と比較することにより、人の認識能力と同様に様々な情報を同時に識別し、その情報の中で最適な行動を選択し実行するような極めて高度な知識処理に利用することも可能であり、利用の仕方は無限である。
図17(本発明のメモリを用いた高度な知識処理の例)は以上説明の知識情報を本発明のメモリ21に記憶し知識処理を行う実施例であり、最適な行動の結果をもとにメモリ21を更新することによって学習効果も容易に実現可能である。
【産業上の利用可能性】
【0140】
本発明のメモリ21はこれまで従来型のメモリの概念を超越し、用途は極めて広範囲であり、情報処理の新しい流れを築くものである。
【0141】
本発明のメモリ21は、連想メモリ以外、ASIC(Application
Specific Integrated Circuit)やFPGA(Field Programmable Gate Array)によって一般的なRAMやROM構成のメモリとしても実現可能であり、セルベースCPUに組込むことも、CCDセンサに直接組込むことも、本発明のメモリ21を独自専用構造のメモリ構成とすることも、新しいタイプの半導体で構成することも、他の機能を付与することも自由である。
【0142】
将来においては以上のような半導体によるメモリ以外に、現在研究途上の光素子や磁気素子、ジョセフソン素子など新しい素子による本発明のメモリも期待が持てる。
【符号の説明】
【0143】
1.既知の情報
2.未知の情報
3.アドレス
4.アドレスのデータ
11.ピクセル
12.座標のデータ
13.サンプリングポイント
14.比較順序
15.量子化データ
21.情報絞り込み検出機能を備えたメモリ
22.アドレスバス
23.データバス
24.出力バス
25.入力データ
26.メモリ比較データ
27.アドレス比較データ
28.リセット信号
29.比較回数カウンタ
31.アドレスデコーダ
32.メモリ
33.データ比較回路
34.アドレススワップ回路
35.突破回数カウンタ
36.ORゲート
37.インヒビットゲート
38.突破アドレス出力処理回路
41.アドレススワップ前合格出力
42.アドレススワップ後合格出力
43.比較回数信号
44.カスケード接続
51.相対アドレス比較データ
52.アドレス範囲比較データ
53.並列処理
54.二重並列合否判定
55.論理積(AND)演算
56.1次突破アドレス
57.N次突破アドレス
58.グループ別突破カウンタ
59.論理和(OR)演算
60.二重並列論理演算
61.等価二重並列論理積(AND)演算
【技術分野】
【0001】
本発明は情報絞り込み検出機能を備えたメモリ、その使用方法、このメモリを使用した装置、人工知能に関する。
【背景技術】
【0002】
情報がデータ化され手軽に利用することが可能な時代において、この莫大な情報データの中から適切な情報を検出し利用するには様々な課題が残されている。
とりわけ画像認識、音声認識、OCR文字認識、全文検索、指紋等の生体認証などに代表される情報検出に共通し基礎となる技術は、情報の中から一致や類似する情報(パターン)を検出もしくは解析するパターン認識技術であり、社会インフラ設備、産業用設備、工場設備からデジタルカメラや家電商品、さらには最新のロボットや人工知能等あらゆる分野に利用されており高度な情報処理に不可欠な存在である。
【0003】
しかしながらパターン認識を一例とする情報検出の技術上の最大の課題は、情報の比較の際の比較組合せ回数(検索回数)であり、通常対象となる情報に最適なアルゴリズムを見出し組合せ比較回数(検索回数)の削減をするなり、対象とする情報の内容によってはスパコンなど高速な演算処理マシーンを利用して答えを見つけ出すなり、場合によっては検出の精度を犠牲にする必要もあった。
【0004】
本発明は以上のようなパターン認識や情報検出技術の永年の課題である情報検出の精度を保証し比較組合せ回数(検索回数、検索時間)を極限まで低減させる事の可能なメモリの実現とその利用方法であり、同一出願人、同一発明者の平成22年2月18日出願、特願2010−33376、情報処理装置の情報の共通管理方法、情報の検出方法、データおよびアドレスの相対関係一括並列比較連想メモリ、情報を共通管理する機能を有する情報処理装置、そのソフトウエアプログラム、におけるデータおよびアドレスの相対関係一括並列比較連想メモリ、に関連する全項目を本出願に対し優先権主張するものである。
【0005】
同じく平成22年3月4日出願の特願2010−47215、情報絞り込み検出機能を備えた半導体集積回路、その使用法、この半導体集積回路を使用した装置、は上記特願2010−33376を、独立した発明とし、情報絞り込み検出機能を備えた半導体集積回路、と発明の名称の表現を変更し、本発明の最大の特徴である二重並列の合否判定結果の論理演算の考え方を明らかにしたものである、また検出する情報の範囲を二次元の画像のみならず一次元から多次元までの情報に拡大したものであり、この出願全体を本出願に対し優先権を主張するものである。
【0006】
本出願は、情報絞り込み検出機能を備えたメモリ、とより発明の名称の表現を明確にするとともに、以上2つの先願を統合し、上記特願2010−47215に主として、情報絞り込み回路数を削減するための手段、二重並列論理演算の多重化手段、さらには人工知能への応用などを一例とするこのメモリの使用方法を追加し、説明不足を補い、一部の表現方法を変更したものである。
【0007】
先に説明のようにパターン認識やパターンマッチングを一例とする情報検出の技術は極めて幅が広く、その検索時間の短縮に係る発明は膨大な数であるが、本発明のように検出時間を短縮するために、ノイマン型コンピュータの宿命である個別メモリの逐次処理を本質的に回避するための手法やそのメモリの例は見当たらない。
参考までであるが特開平7−114577、データ検索装置、データ圧縮装置及び方法、は隣り合った情報同士の比較により情報を繰返し検索するための手法が示されているが、本出願の発明は隣り合った情報同士の比較のみならず、全メモリの情報を対象にデータの内容とそのアドレスの位置関係を二重並列に比較するものである。
【先行技術文献】
【特許文献】
【0008】
【特許文献1】特開平7−114577
【発明の概要】
【発明が解決しようとする課題】
【0009】
本発明が解決しようとする課題は、
一次元から多次元でアドレス配列された情報もしくは配列可能な情報を対象にして、検出される情報(未知の情報)と、検出の基準になる情報(既知の情報)と、の互いの情報の複数のアドレスの、そのデータと、そのアドレスと、の双方の関係が条件に合格することをもって、未知の情報の内から既知の情報と同一情報もしくは類似情報と判定するようなパターン認識や知識処理などの情報検出において、検出の精度を保証し、データの比較回数を極限まで削減し、メモリ自身が上記情報の検出を可能する非ノイマン型の情報検出メモリの実現とその使用方法を確立することである。
【課題を解決するための手段】
【0010】
以上のような課題を解決するために、
請求項1では
メモリアドレスごとに情報を記憶しその情報を読み出し可能なメモリであって
このメモリは、
外部から与えられる第1のデータは記憶されたこのメモリのデータを比較するためのデータ、第2のデータはこのメモリのアドレスを比較するためのデータ、の双方の入力データの入力手段と、
(1)第1のデータでメモリに記憶されたデータを並列に比較し合否判定する手段と
(2)第2のデータでメモリのアドレスを並列に比較し合否判定する手段と
(3)以上(1)、(2)双方の合否判定結果をさらに並列に論理演算するデータとアドレスの二重並列論理演算手段と
を具備することを特徴とする。
請求項2では
前記(1)の合否判定手段ならびに前記(3)の二重並列論理演算手段を、その演算結果が前記(1)の合否判定と前記(2)の合否判定との論理積(AND)と等価となる、等価二重並列論理積(AND)演算手段で構成したことを特徴とする。
請求項3では
前記メモリは、
毎次の前記等価二重並列論理積(AND)演算手段の結果をメモリアドレスごとに計測するカウンタ手段と、
初回の前記比較は、前記第1のデータによって、メモリを並列に合否判定して合格したメモリアドレスの上記カウンタを1にカウントアップしこれを1次突破アドレスとする手段と、
以降の比較は、上記第1のデータによって、メモリを並列に合否判定して合格したメモリアドレスと、上記1次突破アドレスと、の双方のアドレスの位置関係を、前記第2のデータによって、前記等価二重並列論理積(AND)演算手段で演算し、この演算を突破した上記1次突破アドレスのカウンタをカウントアップしてN(2以上の整数)次突破アドレスとする手段と、
このN次突破アドレスのアドレスを出力する手段と、
を具備することを特徴とする。
請求項4では
前記等価二重並列論理積(AND)演算手段は前記第2のデータであるアドレスを比較するためのデータにもとづくアドレスのスワップ(交換)手段によって繰返し実施することを特徴とする。
請求項5では
前記第2のデータであるアドレスを比較するためのデータは、前記1次突破アドレスを基準とし、
(1)比較対象のアドレスが相対アドレスに一致するか否かの比較データ
(2)比較対象のアドレスが比較する範囲の内外に存在するか否かの比較データ
以上(1)(2)のいずれかもしくは双方であることを特徴とする。
請求項6では
前記メモリは
(1)音声情報を一例とする一次元情報として記憶されたもしくは記憶可能な情報
(2)画像情報を一例とする二次元情報として記憶されたもしくは記憶可能な情報
(3)立体情報を一例とする三次元情報として記憶されたもしくは記憶可能な情報
(4)時空間情報を一例とする多次元情報として記憶されたもしくは記憶可能な情報
(5)クラスタリング情報を一例とする情報をアドレスのグループ別に記憶されたもしくは記憶可能な情報
以上(1)から(5)の少なくとも1つの情報の検出を対象とするメモリ構成であることを特徴とする。
請求項7では
前記第1のデータである記憶されたメモリのデータを比較するためのデータは
(1)メモリデータの一致
(2)メモリデータの大小
(3)メモリbit個別のDon‘t Careを含む比較
以上(1)から(3)の少なくとも1つであることを特徴とする。
請求項8では
前記第1のデータ、第2のデータは
(1)データバス
(2)専用入力
以上(1)(2)のいずれかもしくは双方により入力されることを特徴とする。
請求項9では
前記N次突破アドレスのアドレスを出力する手段は
(1)データバス
(2)専用出力
以上(1)(2)のいずれかもしくは双方により出力されることを特徴とする。
請求項10では
前記カウンタ手段に1次突破アドレスを記憶する手段を付加することにより、カウンタ手段の回路数量を確率的に出現する1次突破アドレスの数量に見合う回路数量に削減したことを特徴とする。
請求項11では
前記アドレスのスワップ(交換)手段にプロセッサを用いることを特徴とする。
請求項12では
前記二重並列論理演算をメモリのバンク毎に切り替え実施することを特徴とする。
請求項13では
複数の前記第1のデータならびに第2のデータの入力手段と、
複数の前記二重並列論理演算手段と、を具備することを特徴とする。
請求項14では
前記メモリはCPUを一例とする他の目的の半導体に組込まれ使用されることを特徴とする。
請求項15では
検出される情報(未知の情報)と、検出の基準になる情報(既知の情報)と、の互いの情報の複数のアドレスの、そのデータと、そのアドレスと、の双方が必要回数の比較条件に合格することをもって、未知の情報の内から既知の情報と同一もしくは類似の情報を検出することをもって、情報とその情報の位置を検出することを目的として
既知の情報を前記第1のデータと第2のデータとすることにより、請求項1記載のメモリに記憶された未知の情報を比較し、未知の情報の内から既知の情報と同一もしくは類似する情報とそのアドレスを、前記N次突破アドレスを読み出すことにより検出することを特徴とする。
請求項16では
前記検出の基準になる情報(既知の情報)の内から、統計確率にもとづき前記同一情報もしくは類似情報を判定するに必要十分な複数個数のサンプルを抽出し、これを前記第1のデータと、第2のデータと、として比較条件とすることにより、同一情報もしくは類似情報を判定するために必要な前記比較回数を上記サンプル数以内とすることを特徴とする。
請求項17では
前記サンプルを抽出する際、隣接するサンプル間のデータの相互のデータの差の絶対値を求め、これを集計することにより得られるサンプル特徴量を基準値以上として情報検出をすることを特徴とする。
請求項18では
請求項3記載のアドレスの位置関係は
(1)前記一次元情報として配列記憶されたアドレス配列上の位置関係
(2)前記二次元情報として配列記憶されたアドレス配列上の位置関係
(3)前記三次元情報として配列記憶されたアドレス配列上の位置関係
(4)前記多次元情報として配列記憶されたアドレス配列上の位置関係
以上(1)から(4)の少なくとも1つの位置関係であり、このアドレスの位置関係を用いてパターン認識をすることを特徴とする。
請求項19では
前記1次突破アドレスとなる最初の比較サンプルを複数種類のサンプルとする、もしくは一定の範囲を持させ検出を行うことを特徴とする。
請求項20では
前記情報絞り込み検出機能を備えたメモリをアクセスしデータの読み出し書込みが可能なCPUを併用することを特徴とする。
請求項21では
前記情報絞り込み検出機能を備えたメモリに知識情報を記憶させ知識処理をすることを特徴とする。
請求項22では
前記情報絞り込み検出機能を備えたメモリを使用したことを特徴とする装置。
請求項23では
前記情報絞り込み検出機能を備えたメモリを使用したことを特徴とする人工知能。
としている。
【発明の効果】
【0011】
インテリジェンスな知識をもったメモリとして利用することが可能で、あらゆる情報の同一性ならびに類似性を確実でかつ高速に検出もしくは解析することのみならず、情報予測の分野や高度な知識処理にも幅広く利用可能で、本格的な非ノイマン型情報処理による新しい情報処理の流れが期待できる。
【図面の簡単な説明】
【0012】
【図1】図1はサンプリングポイントの例である(実施例1)
【図2】図2はサンプリングポイントによる情報検出実施例である(実施例2)
【図3】図3はサンプリングポイントの評価方法例である(実施例3)
【図4】図4はデータおよびアドレスの二重並列論理演算の概念例である
【図5】図5は情報絞り込み検出機能を備えたメモリ例である(実施例4)
【図6】図6はアドレススワップ手段Aの例である(実施例5)
【図7】図7はアドレススワップのイメージAである
【図8】図8はアドレススワップのイメージBである
【図9】図9はアドレススワップのイメージCである
【図10】図10は変形画像の検出の概念である(実施例6)
【図11】図11はアドレススワップ手段Bの例である(実施例7)
【図12】図12はアドレススワップ手段Cの例である(実施例8)
【図13】図13は情報絞り込み検出回路の削減例である(実施例9)
【図14】図14は多重化したデータとアドレスの二重並列論理演算の概念例である
【図15】図15はアドレス一次元配列の情報検出例である(実施例10)
【図16】図16はアドレス三次元配列の情報検出例である(実施例11)
【図17】図17は本発明のメモリを用いた高度な知識処理の例である(実施例12)
【発明を実施するための形態】
【0013】
先ず本発明の情報検出の概念を、二次元情報である画像を例にして説明する。
【0014】
通常検出対象の画像(未知の情報2)と、検出の基準の画像(既知の情報1)と、で画像の同一性を検出する場合、検出の基準となる画像(既知の情報1)から採取される何らかの画像情報をもとに、未知の検出対象の画像を総当たり方式で検索するのが基本になり、その精度を求める場合には画像の座標毎であることが必要となる。
【0015】
検索に掛る時間の一例としてパーソナルコンピュータやデジタルテレビジョン信号によるテレビ画面の特定ピクセルを対象として、表示されている画像上から特定データを探し出す場合、200万ピクセル程度がその対象となる。
一旦この全画面のビットマップデータをグラフィックメモリから検索用メモリにデータ展開し、仮に展開したデータの全範囲を、CPUが1ピクセル当たり平均50n秒で、特定のデータを探し出すなど単純な検索をさせる場合、初回の全グラフィック範囲(全画面範囲)の検索は200万×50n秒=100m秒となり、通常、2回目以降は検索対象が絞られるため検索時間は短くなるものの目的の画像を特定するのに数百m秒程度は必要になる、従がって1画面上で大量な画像を検索する必要がある場合は如何に高速な処理を行っても検索時間を無視することが出来なくなる。
【0016】
さらに以上の説明は完全に同一画像の場合であるが、仮に画像のサイズの変更や回転がある場合には、座標変換の演算を繰返し実施する必要があるので処理時間は以上の数百倍から数千倍、さらに必要になる場合もあり、このような検索は実現困難である。
以上はメモリのアドレス毎のCPU逐次検索を必要とするノイマン型コンピュータによる情報検出の宿命である。
【0017】
以上のような検索時間の技術的背景から現在の検索の主流は画像の特徴を抽出した特徴データのクラスタリングによる画像同士の類似性を対象とする検索となっており、最近のデジタルカメラの顔認識やスマイル認識を始め音声認識などに幅広く利用されている。
しかしながら検出の精度や検索の時間、検出出来る情報など検索の能力はこれらの特徴抽出の手法やクラスタリングの手法次第で大きく左右される。
また画像の検索の利用分野においては、誤認率が致命的である場合も多く類似性よりも同一性を求める画像の検索のニーズも少なくない。
【0018】
以上のように、画像検索の確実性を追求し、さらに時間短縮と云う、テーマは互いに矛盾し相容れないものであるが、先ずは画像検索における確実な同一画像の検出について説明する。
【0019】
以上の説明のように本発明は確実性を求めて、原則的に1座標(アドレス)を対象として情報の検出を行うものであり、以下にこれを実現する上で切り離すことの出来ない情報の種類とその分解能について説明する。
【0020】
画像の情報は様々な種類が存在するが、ここでは大きく2種の画像情報データを例に説明する。
【0021】
その第1は、表示されている画像のフレームバッファ(グラフィックメモリ)からのデータを画像情報とする場合で通常、カラーの場合R、G、B、16bitから32bitのデータ深度で情報を持っている。
このR、G、B、色信号をそのまま利用することも可能であるが、効果的な画像の検出の一例として、通常パソコンや映像装置のフレームバッファの200万ピクセル程度を対象にして、R、G、B、各4bit(16通りの組合せ3組)を採取して1つのピクセルデータとすることにより、どの様な色彩の画像であっても精度よく画像を検出することが出来る。
この場合、この色の組合せは12bit、4096通りの組合せであり、画面上の色がばらついている場合、1つの色が画面上に存在する確率は200万/4096≒488ピクセル(アドレス)である。
【0022】
その第2は、一例としてJPEG(Joint Photographic Experts Group)やMPEG(Moving Picture Experts Group)その他多くの圧縮された画像データの1ブロック(一例として8×8ピクセル)を1座標とし、そのブロックの輝度や色差信号のDTC(離散コサイン変換)のDC(直流)成分データをその座標のそのデータとしてそのまま利用することやその他の情報、例えばベクトル情報を利用することも可能である。
このDCTの場合はブロック単位であるのでピクセルに比較して大幅(一例として1/64)に座標の数(アドレス)を減らすことが出来る。
【0023】
云うまでもなくどちらの場合でも分解能が高いに越したことはないが、メモリ容量が大きくなるので、以上のような量子化データ15のLSB側から必要なbit数を選び画像情報データとすればよい。
以降以上説明のピクセルを対象とし、200万ピクセル(アドレス)で12bit、4096通りのR、G、B、の組合せデータによる画像データを画像情報とし、これを検出する場合の例で説明する。
【実施例1】
【0024】
図1(サンプリングポイントの例)は検出基準になる画像(既知の情報1)のサンプリングポイント13を示したものである。
検出基準画像Aは比較的サイズの小さい画像を対象とし、検出の基準になる画像(既知の情報1)の領域上に座標y0、x0を中心として、上下左右等間隔に合計25個の座標をサンプリングポイント13として自動配列した場合であり、この場合XY軸ともに各33ピクセル11、合計1089ピクセル11を対象としたものである。
検出基準の画像のサイズを大きくすることも全く問題ない。
【0025】
図に示す1から25の数字は比較順序14を示すもので、本例では中心から遠いサンプリングポイント13から近いサンプリングポイント13を対角順に検出するよう設定されているが、配列や比較順序14はこれに限るものではない、これについての詳細は後述する。
【0026】
検出基準画像Bは以上説明の等間隔に配列することなく、検出基準の画像に対応させて1から22までのサンプリングポイント13を手動で設定した場合の例である、このように手動でサンプリングポイント13を設定し検出する方法は人間の特徴認識能力の高さを利用するものであり、特徴的なポイントや特徴的な範囲を指定して他のピクセルとの差別化をするのに有効である。
【0027】
このように画像検出の確実性を求めるために1座標を検出の単位とする検出方法であることによって1座標毎にサンプルポイント設定が出来るのも、一定領域をまとめて特徴サンプルとすることの多い他の検索、検出方式では実現できない本方式の特徴の1つでもある。
【実施例2】
【0028】
図2(サンプリングポイントによる情報検出実施例)は先に説明の図1の検出基準画像Aを検出の基準の画像として、画像の検出を実施した場合の説明である。
検出の基準になる画像(既知の情報1)と、検出の対象になる画像(未知の情報2)を同一画像上に表現しているが、実際には別の画像の場合が殆どであるが、説明の関係上同一画面で表現している。
図に示すグループAは1次比較では一致したが2次比較でNGとなった場合である、グループBは11次比較でNG、グループCは22次比較でNG、グループDは全部のサンプリングポイント13が一致した場合である、これらの検出は先に説明の座標のデータ12、をアドレス毎に読取り相互に比較すればよい。
この図ではグループAからグループEは位置的に完全に分離された画像領域で説明されているが画像の場合、通常同一データである座標が隣接もしくは集中し、分解能が低い程その傾向は顕著であるが互いの相対位置関係を正しく比較すれば問題ない。
【0029】
この場合、確率上グループDの領域は基準となる画面と同一画像であると判断することも十分可能であるが、サンプリングポイント13に加えて互いの画像の全てのピクセル同士の一致を念押し確認することにより、類似の画像を排除し完全に同じ画像であることを保証することが可能となる、この方法は対象となる画像のサイズが比較的小さい場合の検出に最適である。
【0030】
以上のような検証方法を活用することにより、グループEのようなサンプリングポイント13が部分的に集中して不一致となるような場合には、この一致する画像の部分を一部の画像に変化が加えられた変形画像と判断することも出来る、またグループCのような場合は類似画像と判断することも出来る、これらについては後述する。
【0031】
以上のように先ずどこかサンプリングポイント13の1座標を基準として、以降の座標のデータとの相対位置の判定を行い相対位置に矛盾のない座標を候補座標として残す方法はパターン認識など情報検索の常套手段であり、これらの組合せ的な検索を効率的に実施し、画像(情報)を超高速で検出する方法とディバイスが本発明の趣旨であり、この詳細に関しては後述する。
【0032】
以上の説明の画像の検出方法で特に重要な事は、サンプリングポイント13の選択方法で、1つは一定の画像データの範囲と、もう1つは画像データの変化の度合いである。
例えば変化のない黒画像部分や白画像部分や変化の少ない画像、もしくは例えば文字情報のみの画像など特徴の少ない画像を指定した場合などでは、当該画像の検出が困難になる。
【0033】
以下に画像の検出の有効性、信頼性に深い関係があるサンプリングポイント13についての考え方を示す。
画像上の1座標を基準にすると、この座標に隣接する座標は基準座標と同一もしくは近似する量子化データ15となる確率、つまり相関性が高くなり、座標が離れることにより相関性は低くなる、従がって図1のサンプルのように、毎回遠いサンプリングポイント13から順次確認する方がダメ出しが速く効率的な検出となる確率が高い。
【0034】
従がって完全に分散化された複数のサンプリングポイント全体による同一座標群の存在確率は、これらのサンプリングポイント13のデータのbit数に、サンプリングポイント13の数が積算された指数になる。
【0035】
例えば、先に説明の1座標がR、G、B、各4bit構成の場合、組合せ数は2の12乗(4K通り)であるが、サンプリングポイント13が10個所であれば2の120乗の組合せ数、実動作上、無限大に相当する確率組合せとなり、特徴の少ない単調な画像同士でなければこれらの全てのサンプリングポイント13が全て一致すれば同一画像と判断して良い。
【0036】
しかしながら、限られた狭い範囲の画像を対象とする場合や、文字などの白黒画像も対象となるので、以上のように完全に分散化されたサンプリングポイント13を採ることは出来ない。
【0037】
従がって以下に説明するサンプリングポイント13の識別能力評価を行い、アラームを挙げるなり、画像領域を拡大するなり、サンプリングポイント13を追加するなど適切な対策を採ればよい。
【実施例3】
【0038】
図3(サンプリングポイントの評価方法例)は図1の検出基準画像Aの場合のこのサンプリングポイント13の識別能力を評価する例であり、座標1を検出基準座標として最後は座標25までの合計25個のサンプリングポイント13に対し隣接する4つのサンプリングポイント13を1組とするAからPまでの合計16組の隣接サンプリングポイント群を現したものである。
【0039】
一例としてA群には2、10、14、18の4つのサンプリングポイント13が含まれ、B群には10、6、18、22の4つのサンプリングポイント13が含まれ、以下同様である。
この時、A群からP群のそれぞれの4つのサンプリングポイント13は、それぞれの群の中で輝度情報や色情報のいずれにおいても座標のデータ12に違いがある事が特徴の大きさ、つまりサンプル特徴量の大きさにつながるので、この4サンプルから2つを採る組合せの6つの組合せ、2−10、2−14、2−18、10−14、10−18、14−18により、そのデータの差分量の絶対値を求めこの6つの組合せの合計と全体(16群)の集計を採ることにより、当該群の特徴量の基準値とすることが出来る。
本例のようにR、G、B、の複合されたデータの場合、各独立して評価すればよい。
また同一サンプル数の場合の識別能力の把握の場合には、A群からP群のそれぞれの特徴量を合計し16群で除した平均特徴量が特徴量の大きさの尺度(基準値)として利用することが出来る。
【0040】
云うまでもなくこのサンプルの特徴量が少なければサンプリングポイント13としての識別能力に影響が出るため、検出の基準画像を指定しその画像領域を決定する際、基準値以上の値となるよう、必要によりサンプリングポイント13の数を増やすことや画像の領域を増やすなど調整すればよい、当然反対の場合も可能であり、このサンプリングポイント13の評価方法は画像の検出の検索処理数(時間)を理に適った合理的な検索処理数(時間)とする上で重要である。
以上は手動でサンプリングポイント13を決める際にももちろん有効である。
本例は二次元情報を対象に識別能力を評価した一例であるが一次元から多次元まで隣接するサンプルとそのデータの差分を採ることによる考え方で特徴量を判定することが出来る。
さらに対象となる情報の種類によって、その情報の特徴からサンプルの基準を独自に定め判定すればさらに確実な情報の検出が可能になる。
【0041】
これまで本発明を実現するにあって不可欠となる確実性を追求した情報の検出について二次元情報の画像を対象に説明してきたがこの考え方の基本的な内容は他の次元の情報に対しても共通である。
【0042】
ここで本発明を実現するためのメモリに記憶する情報の配列について説明する。
一次元配列の情報はメモリアドレス上に連続的に記憶された情報であり、二次元
の情報は図1の1からnまでのアドレス3のようにそれぞれの次元の最大座標数を配列基本条件としテーブル変換され一次元のメモリアドレス配列として連続して記憶された情報、もしくは記憶可能な情報であり、メモリのデータサイズならびにメモリ容量はそれぞれの目的にあったメモリ構成である。
三次元、さらには多次元の情報をメモリアドレス上に記憶する場合も同様に、これらの情報はそれぞれの次元の最大座標数を配列基本条件としテーブル変換された上記同様の情報であり、メモリ構成も同様である。
【0043】
従がってこの情報は、それぞれの次元に対応する座標データが与えられれば、配列基本条件である各次元の最大座標数をもとに与えられた座標データに対応するアドレスが特定可能であり、座標の相対位置や座標の範囲も同様に特定可能である。
もちろん、高次元の情報でも対象とするアドレスが直接分かる場合は直接そのアドレスや相対アドレスで指定することが出来る。
以上は確認のため、念のため記載したものであり、このアドレス配列方法は通常行われている一般的な情報の配列方法で、この一般的なメモリに対する情報の配列方法が本発明を実現する上での基本情報配列であるので極めて利用し易い。
【0044】
以降これまでの考え方にもとづく、本発明の情報絞り込み検出機能を備えたメモリ21を連想メモリに適応した場合について説明する。
【0045】
連想メモリはキャッシュメモリや通信データ処理など、情報処理装置の中で特に重要で高速処理を必要とするメモリに利用されている。
また画像データなどに対しては特にクラスタリング手法による類似画像を検出するための最短距離検索(類似度距離検索)を目的とした検索ディバイスとして盛んに研究されている。
【0046】
以降連想メモリの概要を説明する。
高速なデータ処理に利用されている連想メモリは、通常のメモリ機能の他に外部から比較するデータを全メモリ同時(並列)に与え、その合格するメモリのアドレスを読み出すことが可能な情報の検索に大変都合のよいディバイスである。
この並列処理53のイメージの一例を上げれば、大勢の人が集まる会場に座席(アドレス)を用意し座って貰い、この人達が好きな色のカード(データ)を自由に選ぶことが出来るようにした場合、例えば赤のカード(データ)を持つ人を調べる場合、通常のメモリの場合は全ての人を座席順等、逐次比較で調べる必要があるのに対し、連想メモリの場合は、例えば赤のカードの人は一斉に手を挙げて貰い(並列比較)、その座席(アドレス)を確認(出力処理)するだけでよいので極めて高速な判定が出来る。
このように連想メモリは大量な情報を並列に比較し、その中から必要とするデータのみを探し出す場合に好都合のデバィスである。
【0047】
様々なメリットを持つ連想メモリであるが構成上の弱点の1つとして、データバスとアドレスバスによるデータの読み書きをするメモリデバィスの場合、外部から与えられた比較データ(この場合赤色)に対し同時にその合格判定が可能であっても、合格するアドレスが複数の場合には一遍にそのアドレスを出力することが出来ない。
【0048】
これを解決するには、出力にプライオリティ機能を持たせ、合格するメモリに対し順次合格するメモリのアドレスを出力すればよいが、十分に絞り込みされたアドレス数となっていないと読み出しにも時間が必要である。
通常の場合このアドレスを読み出し、読み出されたアドレスに対し次の比較条件が与えられ、以降はこの条件を元に逐次処理による絞り込みが行われる。
先の例の200万ピクセル(アドレス)で12bit、4096通りの組合せデータの場合には平均488個のアドレスを対象として、以降の条件比較を繰り返す必要があり、通常その大半は対象外(残らない)のピクセルであり無駄な処理である、3次以降も同様である。
【0049】
従がって本発明の情報絞り込み検出機能を備えたメモリ21はこのような逐次処理を完全に排除するために、さらに赤のカードで手を挙げた人同士で、その座席の関係(アドレスの関係)が一致する人(例えば隣同士や前後左右で赤のカードを持つ人)以外は一斉に手を降ろして貰う機能、つまりデータとそのアドレスの関係、つまり毎次、全メモリ(座席の人)を対象に比較条件(カードの色と、座席の相対関係)与えることによって、記憶されたデータの合格(カードの色)と、そのアドレスの位置(座席の相対関係)の合格と、の双方の並列合否判定結果による論理積(AND)演算55に合格するアドレス(隣同士や前後左右で赤のカードを持つ座席の人)を絞り込み検出しこれを出力する機能を持った二重並列合否判定54の出来るメモリ、さらに様々な二重並列論理演算60が可能なメモリを実現させることにある。
【0050】
図4(データおよびアドレスの二重並列論理演算の概念)は以上説明のメモリのデータとそのアドレスの二重並列合否判定結果の論理積(AND)演算の概念である。
それぞれのアドレスのデータの内容の比較と、それぞれのアドレスの比較をそれぞれ並列(二重並列)に合否判定54し、その合否判定結果に基づき情報の絞り込みを行うための論理積(AND)演算55がさらに並列に行われるものである。
この演算結果はどのような形態で利用されても構わない。
【0051】
以上のように1回の絞り込みでも極めて大きな絞り込み効果が得られるが、さらにこれらの二重並列論理演算60が連続繰返し実施出来れば理想の情報絞り込み検出が可能になる。
【0052】
以上の考えを実現する上で図4の下段のアドレス比較のアドレス合否判定回路は概念として表現することは容易であるが、通常の考え方では、どの様にアドレスを比較するのか、どのアドレスと比較するのかが定まらないので実際にこの概念を論理回路化することは容易ではない。
【0053】
例えばこれまで説明の初回に比較し生き残ったアドレス、これを1次突破アドレス56としてこれを基準にして各アドレスと比較をする方法が考えられるが、この方法においても、先に説明の通り1次突破アドレス56が仮に488アドレスあれば、全てのアドレスとこの488アドレスの組合せによる、組合せ並列アドレス比較回路を構成しなければならないので極めて大掛かりな構成になる。
【0054】
小規模なメモリアドレス数であれば以上の構成でアドレス比較を実現することも可能であるが、本実施例では大規模なメモリであっても図4の論理構成を出来るだけシンプルな回路構成で実現するために、1次突破アドレス56を毎回(毎次)の比較のための基準原点のアドレスと定義することにより、以降毎回比較するアドレス(座標)は、このそれぞれの1次突破アドレス56と相対アドレス(座標)が毎回の比較とも相対的に同一な位置(アドレス)であることに着目しこの論理回路の最適解を求めている。
【0055】
具体的には先に説明の図1に示すそれぞれのサンプリングポイントに対し1次突破アドレス56を基準原点座標とし、比較するアドレスに一定の相対的なバイアスもしくは範囲を設定し、それぞれの1次突破アドレス56の相手先のアドレスのデータがこれに合格しているのかどうかを確認して、合格していればこれを突破アドレスとする構成とすればよい。
【0056】
さらにそれぞれのアドレスに突破の回数を記録するカウンタを設け、基準原点である1次突破アドレス56に突破回数が累積されカウントアップ出来るようにすることによって、1次突破アドレス56の内で最多突破回数(N回)のメモリのアドレスをN次突破アドレス57と判定することにより連続絞り込みの論理回路が可能となり、極めてシンプルな論理回路構成であっても当初の目的を全て満たす構成となり、情報処理永年の課題の1つを克服するディバイスを実現することが出来る。
【0057】
後述するが図4の二重並列論理演算60は論理積(AND)演算55のみに限定されるものでなく、またこの演算結果の利用の仕方も自由である。
【実施例4】
【0058】
図5(情報絞り込み検出機能を備えたメモリ例)は以上の内容に関連する本発明のメモリ21の機能概要を連想メモリをベースに示したものであり、データ処理のタイミング等細部は省略され、本発明に関係するところの概念のみを説明するものである。
【0059】
この情報絞り込み検出機能を備えたメモリ21(以降本発明のメモリとも記載する)には、アドレスバス22、データバス23が接続されていて、外部とデータを授受可能な構成になっている。
従がってメモリ1からnのメモリ32はアドレスバス22のアドレスデコーダ31によりアドレスが選択されデータバス23からデータの書込み、読み出しが可能である。
【0060】
入力データ25は本発明のメモリ21に情報検出のためのデータを与えるもので、第1のデータであるメモリ比較データ26は外部からメモリのデータ比較のためのデータであり、この入力データとメモリ1からnまでのメモリ32とデータの合否の比較をデータ比較回路33により判定し合格の場合その結果をアドレススワップ前合格出力41として出力する。
第2の入力データ25であるアドレス比較データ27ならびにアドレススワップ回路34については後述する。
【0061】
突破回数カウンタ35はアドレススワップ後合格出力42によりデータ比較回路33の合格回数を突破回数として記憶加算するカウンタであり、この突破回数カウンタ35は、情報同士の比較回数をカウントする比較回数カウンタ29の比較回数信号43との一致出力機能を有しその出力がORゲート36と、インヒビットゲート37に接続されており若いアドレスから順次カスケード44接続される信号により、突破回数がN回の突破回数カウンタ35の中で一番若いアドレスのカウンタが優先され1アドレスのみ出力をする出力優先(プライオリティ)処理がなされている。
【0062】
突破アドレス出力処理回路38は優先出力のアドレスを出力バス24に乗せる処理と、出力処理の完了したアドレスの突破回数カウンタ35をクリアーする処理をすることにより、以降他にN回突破の突破回数カウンタ35があればそのアドレスを次の優先出力とし、順次N次突破のアドレスを、出力バス24によって外部に送り出すことが可能な構成となっている。
本例の専用バス出力の専用出力形態は一例であり、データバス23に直接出力結果を乗せることも可能である。
従がって、この構成によれば、突破回数が一番多い(N回)突破回数カウンタ35のアドレス(座標)がWinner(N回突破アドレス57)でありその若いアドレス順にそのアドレスを出力する構成である。
【実施例5】
【0063】
図6(アドレススワップ回路Aの例)は極めてシンプルな論理回路構成で本発明を実現するための手段であるアドレススワップ回路34の基本概念を示すものである。
アドレススワップ回路34はデータ比較回路33と突破回数カウンタ35の中間に設けられており、このアドレススワップ回路34は毎サンプル比較時、目的の1次突破アドレス56に突破の出力を二重並列論理積演算結果として累積加算するために設けられ、本例の場合、先の説明の入力データ25の第2のデータであるアドレス比較データ27の、相対アドレス比較データ51によって、アドレススワップ前合格出力41、図6のi、j、kをXY軸座標データに変換し、変換した合格出力を相対アドレス分シフトして、アドレススワップ後合格出力42として該当するアドレスの突破回数カウンタ35(1次突破アドレス56)に合格出力を突破出力として入力出来るように構成されている。
つまりアドレススワップ後合格出力42は1次突破アドレス56のアドレスの相対アドレス条件に合格した場合、突破出力として1次突破アドレス56に入力される。
もちろん座標データではなく相対アドレス比較データ51を直接相対アドレスで指定し相対アドレス分シフトすることも可能である。
【0064】
以上説明の第1、第2のデータの入力はデータバス23から与えることも専用入力から与えることも自由である。
この構成の本発明のメモリ21に先に説明の画像のピクセルデータ、またはこれに相当する情報データをメモリに記憶し、この未知の情報2から画像を検出する場合の例を説明する。
【0065】
先に説明の図5のメモリ1からnまでのメモリ32には画像のピクセルデータがそれぞれの座標に対応したアドレスに書込みされており、比較回数カウンタ29ならびに全ての突破回数カウンタ35は全てクリアーされて0となっていて、以降比較回数カウンタ29は比較の都度にカウントアップされて行く。
先ず1次比較としてサンプル1のピクセルデータをメモリ比較データ26に入力データ25として与え、全メモリの合格判定を並列に行いデータ比較回路33のアドレススワップ前合格出力41を1次合格出力として出力し、この1次合格出力はアドレススワップすることなく、アドレススワップ後合格出力42としてそのまま突破回数カウンタ35の入力に加え突破したアドレスのカウンタの値を1にする、これが1次突破アドレス56である、以上の通り1次比較に第2のデータは不要である。
先に説明のように平均的な1次突破アドレス56の出現個数は488である(図6のi、j、k)この出現個数はイメージのための数字であり多くても少なくても問題ない、以下同様である。
図2の場合この時、突破回数カウンタ35の値が1となっているメモリアドレスはグループAの1、グループBの1、グループCの1、グループDの1、グループEの1の5個所の座標がWinnerの候補(1次突破アドレス56)であり、これがこれからの説明のポイントとなるアドレス(座標)である。
【0066】
次に2次比較としてサンプル2のピクセルデータをメモリ比較データ26に指定することによりまた別なアドレスが新しく2次合格出力として平均し488個選ばれる。
さらにサンプル1とサンプル2のアドレスの差分を、アドレス比較データ27の相対アドレス比較データ51として指定することにより、新たに選択された488個のアドレスの中で、先に説明の1次突破アドレス56との相対関係が合格するもの、つまりグループの関係が成立するアドレスを、図6に示すアドレススワップ回路34でこの差分に相当するアドレス(座標)をシフト変換し、シフト変換した相対位置の突破回数カウンタ35(1次突破アドレス56)にアドレススワップ後合格出力42を突破出力として加算入力する。
【0067】
つまり、本来は図2のグループAからEの2の座標(アドレス)の突破回数カウンタ35がカウントアップされるところ、サンプル1の判定で生き残った候補座標の突破回数カウンタ35(1次突破アドレス56)に、継続してカウントアップが出来るように相対アドレスのバイアスをかけて2次突破出力として、1次突破アドレス56に突破入力を与えている。
【0068】
先に説明の図2の場合この時、突破回数カウンタ35の値が2になっている1次突破アドレス56はグループBの1、グループCの1、グループDの1、グループEの1の4個所が候補として維持される座標であり、グループAの1はカウントアップ出来ず候補から脱落する。
以上の内容は対象とするメモリのアドレス位置(2次サンプルに相当するアドレス位置)が1次突破アドレス56を基準にして目的の位置(相対アドレス比較データ51)に存在するか否かを判定し、2次のデータ比較による合格アドレスと並列に論理積(AND)演算55しその結果を1次突破アドレス56の突破回数カウンタ35に突破出力として入力したのと等価である。
【0069】
順次同様にメモリ32のデータ比較と、1次比較のサンプル1を基準とする他のサンプルとの相対アドレスと、を一対の入力データ25として読み込み、それぞれのアドレスグループ内で突破するメモリを1次突破アドレス56に集約してカウントアップすることにより、1次突破アドレス56(Winner候補)の絞り込みを連続して行う事が出来る。
【0070】
従がって図2において最後のサンプル25(Nが25)まで突破する1次突破アドレス56はグループDの1の座標(25次Winner)のみでありこの座標(アドレス)の突破回数カウンタ35の値は25になっており、この突破回数カウンタ35は比較回数カウンタ29の比較回数信号43と一致しその出力が以降のORゲート36ならびにインヒビットゲート37に入力される。
【0071】
図7(アドレススワップのイメージA)はこれまで説明のデータの合格と、アドレスの相対関係、の双方の合格、つまり二重並列論理積演算による突破の内容をイメージとして説明するものである。
図に示すように、画面の座標には最初の1次比較により1次突破アドレス56がAからFまで計6個示されている。
このアドレススワップは全アドレスを対象として相対的に行われるものであるが、1次突破アドレス56は、あたかも比較の対象になるそれぞれのアドレスグループ内で次に比較される2次比較の相対座標位置を望遠鏡で覗きこみ、2次合格アドレスの合格出力(本図では黒丸印)があればこれを突破出力として奪い取る、まさにスワップのイメージである。
3次比較も同様に比較される相対座標位置を望遠鏡で覗き込み、3次合格アドレスの合格出力(本図では黒三角印)を突破出力として奪い取る、以降も同様のスワップのイメージである。
本例の場合、Eのカウンタは2に更新され、さらにBのカウンタは3に更新される。
【0072】
図8(アドレススワップのイメージB)は以上の図7に示されるA、B、2つの1次突破アドレス56の座標上のイメージをアドレス上のイメージとして説明するものである。
図8に示すように、1次突破アドレス56は、サンプル2からサンプル25までのデータ比較回路を望遠鏡で覗き込み、覗き込んだデータ比較回路に合格があればこれを突破出力として奪い取るイメージである。
云うまでもなく望遠鏡の切替えはアドレスの相対位置関係を比較するためのデータである相対アドレス比較データ51により毎回設定される。
【0073】
実際には1次突破アドレス56のアドレスと相対関係のない2次、3次、N次比較による合格出力も相対的にシフトされたアドレスにカウントアップされるがサンプルが適正で意図的なものでなければ毎回散発的であり合格出力が特定アドレスに集中することはない。
これはサンプルとなる画像(情報)と未知の画像(情報)の特定部分が同一であると云う特別な関係(パターン)が成立しないからである。
1次突破アドレス56は常にカウントの優位性を保ち(最初に1)、さらに1次突破アドレス56の相対アドレスに関連付けされたサンプルのアドレスのグループを代表し合格出力を突破出力として集める権利を持つ支配者のイメージである。
【0074】
図9(アドレススワップのイメージC)は実際の二次元配列アドレスにおけるアドレススワップの例を示すものである。
表A、Bはアドレススワップ前のアドレス(座標)1から100までを示すものであり、24、50、67、72の4つのアドレス(座標)が1次突破アドレス56となっている。
表Aは2次比較アドレスを相対アドレスが−22のアドレスをデータ比較アドレスとする場合であり、この時72のアドレスは相手先の座標が対象外である。
表Bは3次比較アドレスを相対アドレスが+31のアドレスをデータ比較アドレスとする場合であり、この時50および72のアドレスは相手先の座標が対象外である。
表Cは表Aを−22アドレスシフトしたものであり、24、50、67の1次突破アドレス56は正常にそれぞれの相手先のデータの合否結果を得ることが出来、合格結果があればそれぞれ突破出力としてカウントアップ(スワップカウント)することが出来る。
表Dは表Bを+31アドレスシフトしたものであり、24、67の1次突破アドレス56は正常にそれぞれの相手先のデータの合否結果を得ることが出来、合格結果があればそれぞれ突破出力としてカウントアップ(スワップカウント)することが出来る。
以上が所定回数繰り返され比較対象の相手先のアドレスの座標位置が正常な1次突破アドレス56が最終まで生き残ることが出来る。
【0075】
以上様々な例にもとづき説明してきたがこれまでの内容は、アドレススワップ(交換)することにより、1次突破アドレス56を基準にして、以降毎回比較されるサンプリングポイント13と同一のデータ(データの合格)が存在し、さらに目的の位置(相対アドレス比較データ51)に存在するか否か、の双方を連続的に二重並列に合否判定54を行いさらに並列に論理積(AND)演算55し、その結果を1次突破アドレス56の突破回数カウンタ35に毎回出力するのと等価であり、アドレススワップ回路34は図4の下段の並列アドレス合否判定と並列論理積演算が一体化され、一人二役をこなす極めて効率的な論理回路、つまり等価二重並列論理積(AND)演算61手段である。
最終結果はこの比較回数であるN次突破アドレス57を突破アドレス出力処理回路38および出力バス24で読み出しすれば、N次突破アドレス57を含む情報のグループのアドレスを特定つまりパターン認識をしたことになる。
比較回数カウンタ29をプリセッタブルカウンタとして比較回数信号43を指定することにより任意のカウント値のカウンタ(N次突破アドレス57)のアドレスやその途中経過も読み出すことが可能になる。
【0076】
アドレススワップ回路34の一例は図6に示すようにアドレス変換用のレジスタを用意し、データ比較回路33よりのアドレススワップ前合格出力41を、相対アドレス比較データ51の座標データにより相対的に移し替え、アドレススワップ後合格出力42とする、このレジスタ操作は全てのアドレスの相対シフトであるので、加減算演算によるデータシフト手段、もしくは一番シンプルなのはアドレス分のデータ長のシフトレジスタによっても容易に実現可能である。
【0077】
以上のレジスタを用いるアドレススワップ方法は説明のための一例であり、アドレスデコーダを直接利用してスワップ(交換)するなど他の方法で実施しても構わない。
同様にアドレススワップ回路34ならびに突破回数カウンタ35は本発明の情報の絞り込み検出を実現する上で不可欠な手段であるがこの構成に限定されるものではなく他の方法でアドレス毎に個別に実施することも可能である。
【0078】
データとそのアドレスの相対関係を一括して合否判定するこの方法は、図4に示す全メモリ32のデータ比較条件の合格と、全アドレス比較条件の合格と、の双方を二重並列に合否判定54を行い、これをさらに並列に論理積演算55したものと等価であるので、原理的に個別アドレスを対象としたノイマン型情報処理のアドレス逐次処理を不要とするものである。
【0079】
従がってこれまで説明の200万ピクセルの未知の画像を、分解能12bit、データのグループ数を4096グループとする場合、未知の画像の中から同一画像の検出するに必要なデータの比較回数は通常2から3回で収斂し、最大でもサンプル数(本例では25回)のデータ比較回数で目的の画像を確実に見つけることが可能である。
【0080】
さらにこの方式は図7で示すように1次突破アドレス56を基準原点とした入力データによる全座標パターンマッチングの繰返し(毎回全メモリを対象として比較)であるので、部分的に一部の画像が欠落しているような場合の近似の画像(以降近似画像)の検出も実施出来る。
【0081】
たとえば、図2の場合、25回の比較完了後、グループAの1の座標のカウンタは1、グループBの座標のカウンタは10、グループCの1の座標のカウンタの値は21、グループDの1の座標の値は25、グループEの1の座標の値は22になっている。
つまりカウンタ値の高い座標のアドレスは部分画像が欠落した画像や近似の画像の可能性が高い、この場合1次突破アドレス56以外であってもよい。
カウンタ値が一定値以上(例えば20回)となる座標を読み出ししておき、所定(この場合25回)の比較完了後、必要により周辺の座標を詳しく判定すればよい。
従がってこの方式は同一画像を高速で検出することのみなならず一定の定義もとづく近似画像にも有効である。
【0082】
またこのアドレスワップ(交換)の考え方をさらに発展させることにより、画像が拡大縮小もしくは回転、以降変形画像と呼ぶ、の画像も最少の検出回数で検出することも可能になる。
【実施例6】
【0083】
図10(変形画像の検出の概念)は比較する画像が拡大縮小もしくは回転、場合によってはデータに変化が加わった変形画像を前提として検出する場合に効果的な方法を説明する。
【0084】
図10には、1次サンプルの比較が合格した未知の画像の1次突破アドレス56の上に、既知の画像のサンプリングポイント13を重ねたものである。
本例では座標1の基準原点を中心にして未知の画像のサイズが、XY軸ともに2倍(画面としては4倍)に拡大される可能性があるとした場合を示している。
もし探し出す変形画像がこの中に存在する場合、変形画像に対応するサンプルの2から25の全ての座標は、図に示す円の内部に存在するはずである、従がって円を包含する座標範囲をこの座標1の画像検出範囲とすればよい。
【0085】
従がって、これまでのアドレス(座標)シフト変換の概念を拡大し、座標1の基準原点より指定する座標範囲にサンプルと同一のデータ値を持つ座標が存在するかどうか、この場合個数は関係なく単純にあるのか無いのか、を判定し、指定するサンプル数(本例では25個)のサンプルに相当する座標がこの範囲にあることを判定することにより変形画像を検出することが可能になる。
【0086】
この場合もサンプルの特徴量を判定してサンプルの数と識別能力を一定基準とし対象の範囲を一定の範囲内とすることによりその確実性は高いものになる。
【0087】
この場合も毎時目的の1次突破アドレス56にデータとアドレス双方の合格(突破)の出力を集中させて記憶加算する手段、本例では1の座標の突破回数カウンタ35に判定の結果を累積させる方法が出来れば、このような変形画像に対しても、サンプル数を最大とする最少データ比較回数で画像の検出が可能になる。
【実施例7】
【0088】
図11(アドレススワップ手段Bの例)は以上の考え方を実現させるために図6で説明のアドレス変換を1対1のアドレスシフト変換からアドレスの範囲として捉え、これを外部からアドレス比較データ27に、アドレス範囲比較データ52として入力することにより、このアドレスの範囲で合格のあったi、j、kのアドレススワップ前合格出力41を、比較条件に該当するアドレス範囲として取り込み、この場合もそれぞれのアドレスグループ内の1次突破アドレス56の突破回数カウンタ35にアドレススワップ後合格出力42を入力する構成としたものである。
先に図7で説明の望遠鏡をパラボラ型の天体望遠鏡に変えて1次突破アドレス56に突破出力を奪い取るイメージである。
【0089】
例えばこれまで説明の図1に示す1000ピクセル程度を画像範囲とする画像の1座標を基準とする場合、その1座標を中心としてXY軸7000ピクセル強の座標範囲を比較範囲の座標とすれば2倍まで拡大された回転を伴う変形画像においてもサンプル数を最大とする最少データ比較回数で画像の検出が可能になる。
【0090】
座標変換や画像が縮小された場合の画像などでは、サンプル座標に対応する座標が欠落する場合もあるので適切にサンプル合格回数の基準を設ければよい。
この方法は図6で説明の相対座標の完全一致方法に比較すれば確実性は落ちるがサンプルの識別能力やその数を適切にすることにより極めて高速な画像の検出が可能になる。
【0091】
さらにメモリ32のデータ比較回路33をデータ一致の合否の比較から、輝度や色のレベルの範囲を持った大小比較として合否の判定を行えば、変形画像のみでなく、その定義の仕方にもよるが類似の画像の検出も可能となる。
このような場合には大小もしくは一致による合否判定以外、メモリbit個別のDon‘t Careによる比較が可能な3値メモリを利用し合否判定をするとさらに効果的である。
【0092】
通常、画像のサイズの変化や回転が加わった画像の検出は座標変換など極めて多大な検索の処理回数を必要とするがこの方式によればサンプル数分の比較をするだけで目的の変形画像(近似画像を含む)を検出することが可能となる。
多くの場合以上のように変形画像や類似画像の中心位置や重心位置などが検出出来れば良い場合が殆どであるが、もし画像の拡大縮小や回転角度を検出する必要がある場合にも何回かのデータ比較を追加することにより対応可能である。
【0093】
以上のような必要がある場合、一旦画像が存在する範囲を検出した後に、図10に示すように、2、4、3、5の4個の対角の座標が何処に存在するのかを、分割検出範囲Aの4分割、分割検出範囲Bの16分割のように分割し範囲を限定し検出すればよい、4分割の場合で16回、16分割で64回合計して最大でも80回のデータ比較を行えば凡その画像の変形の様子を掴む事が出来る。
通常このような変形の度合いが推定出来ない変形画像を検出する場合には、考えられる画像の変形情況を推測して多数の座標変換を行いパターンマッチングを採る必要があり、このような変形画像の検出に比べれば比較することが出来ない程高速なパターンマッチングが可能である。
分割する範囲を細分化すればより正確な検出も可能である。
以上は一例であるがこのように最小限のデータ比較の回数を追加することにより複雑な画像の検出も可能である。
【0094】
本例では画像が拡大縮小さらには回転される可能性があることを前提に全サンプリングポイントを対象にして大きな範囲を範囲設定した場合の例で説明を行ったが、それぞれのサンプリングポイントに対して個別に一定の範囲を指定して検出をすることも出来る、この方法はデータとそのアドレス(位置)の不確かさを補完する上でも、同一もしくは類似するデータが連続して存在する場合に重要な意味を持ち、サンプリングポイント13の位置やそのデータを元に類似画像の定義を行えば、同一画像、近似画像、変形画像、類似画像まで幅広く検出が可能となる。
【0095】
この本発明のメモリ21はこれまで説明の座標シフト方式(アドレスが比較する相対アドレスと一致)と座標範囲方式(アドレスが比較する座標の範囲内に存在)の2つの検出方法以外、例えば比較する座標の範囲外、等にもアドレススワップの応用が可能であり、いずれもアドレススワップ回路34のアドレス比較データ27のデータ設定のみで実現出来るのでこれらを一体にした構成とすることが可能であり、これらの画像検出方法を組合せすることにより、より様々な画像の検出を可能にする。
本例では説明を簡素化するためR、G、Bの色データをまとめて1つのアドレスのデータとする方法で説明したがR、G、Bのそれぞれのアドレスを独立させて比較する方法も容易に実現可能である。
【0096】
この本発明のメモリ21は並列にメモリデータを比較可能な基本構造のメモリ、例えば連想メモリ等に、アドレスのスワップ(交換)を行うための手段と、合格回数を記憶するカウンタと、一般的なプライオリティエンコーダで構成可能な極めてシンプルな構造であるので大容量化もし易い。
【0097】
また本発明のメモリ21は云うまでもなくデータとそのデータのアドレスの相互関係に基づく組合せ問題の探索(比較)回数を根本的に解決し、適正に選択されたサンプルであればサンプル数を上限とする最少のデータ比較回数を保証するディバイスであり、クラスタリングした類似特徴の座標相関による画像の検出や、その他の様々な情報の検出に応用することが可能である。
【0098】
これまでの説明では、情報を繰返し絞り込みする場合で説明しているが、絞り込みを1次比較、2次比較だけとする単発の情報検出も可能であることは云うまでもない。
【0099】
以上のように自らが情報検出可能なインテリジェンスな知識をもった本発明のメモリ21を用いることが出来れば、情報検索時CPUやGPUは入力データを与えその結果を読取るだけなのでその負担を大幅に軽減出来る。
極めて高速な情報検出が可能なのでメモリのサイズが不足する場合には、情報を分割して情報検出を実行してもよい。
【0100】
この本発明のメモリ21の毎回のデータ比較処理時間が、控え目にみた処理時間で仮に毎回平均1μ秒であっても、どの様なサイズの画像を対象としても数μ秒から長くても数百μ秒以内で目的とする情報を確実に検出することが可能になるので、動画像を対象とした1コマ(フレーム)上の情報を検出することも、検出したい既知の情報1が連続して大量にある場合にでも広く応用が可能となる。
云うまでもないが本発明のメモリ21のメモリ32をアクセスして逐次処理する通常のCPUとのコラボレーション(併用)によりさらに高度な情報検出が可能となる。
【0101】
以上画像情報を中心に本発明の概要を説明してきたが、この情報検出の方法と本発明のメモリ21は、一次元情報(音声等)や多次元空間として配列された情報の検出にも有効である。
【実施例8】
【0102】
図12(アドレススワップ手段Cの例)は図6の二次元情報を、X、Y、Zの3軸に拡大し、三次元空間に配列された情報の同一配列や類似配列を検出可能にする例であり、N次元空間とすることも可能である、情報検出の具体例は後述する。
【0103】
これまでの説明の情報絞り込み検出機能を備えたメモリ21は、全てのメモリを対象に突破回数をカウント可能にし、その突破の回数で同一情報ならびに類似情報を連続して検出するものであったが、メモリ数が大規模な場合や回路構成をさらに簡素化する目的で突破回数カウンタ35、ORゲート36、インヒビットゲート37の回路数を削減することが出来る。
【実施例9】
【0104】
図13(情報絞り込み検出回路の削減例)は図4、図5に示す本発明のメモリ21の基本構想をもとに回路数を削減したもので、これまでの説明のように利用される突破回数カウンタ35以降の回路の数は、通常の場合1次比較で出現する1次突破アドレス56の数(これまでの説明では200万アドレスで分解能4096通り、平均488アドレス)であることに着目しこれに見合う数量、例えば突破回数カウンタ35以降の回路数をメモリ32のアドレスの数量の、例えば1000分の1や2000分の1に削減、図ではAからXまでの出力に削減したものである。
【0105】
この場合カウンタは、図7で説明のそれぞれのアドレスグループの1突破アドレス56を記憶しこのアドレスを読み出しが可能な構成のグループ別突破カウンタ58とし、このカウンタ58別に1次突破アドレス56を読み出し出来る構成とすればよい。
このような構成とする場合にはアドレススワップ回路34に簡単なアドレス演算プロセッサを搭載するなどしてアドレススワップを行ってもよい、このように演算プロセッサを利用してアドレススワップ(交換)の自由度を高めることによりさらに様々な手法の情報の絞り込みも期待できる。
【0106】
仮に1次突破アドレス56の数が多くオーバフローする場合にはアラームを挙げて1次比較のサンプルを変更するなどすればよい。
【0107】
また回路数を削減する方法として、二重並列論理演算60をメモリのバンク毎に切り替えて実施するなどの回路構成も可能である。
【0108】
全てのメモリを対象に合格回数をカウント可能な方式は1次突破アドレス56の出現数の制限がなく理想であるが、このように情報絞り込み機能の回路構成を簡素化した、情報絞り込み検出機能を備えたメモリ21であっても、これまでの説明の情報検出の方法で目的の情報を確実に検出することが可能である。
【0109】
以上のような構成とすることによりこの本発明のメモリ21のメモリのアドレス数やそのbit数、つまりメモリ容量に関しての自由度を増すことが出来る、また前述のごとく3値メモリとすることも可能である。
【0110】
図14(多重化したデータとアドレスの二重並列論理演算の概念例)は、図4で説明の二重並列論理演算を多重化した例である。
図に示す通り、本発明のメモリ21はメモリのデータを比較するための比較データとアドレスを比較するためのデータを2組と、二重並列合否判定回路を2組と、二重並列論理積演算回路を2組、をそれぞれ持っており論理積演算結果をさらに並列に論理和(OR)演算59し出力をする構成になっている。
【0111】
このような構成も図5に示すメモリ21の回路構成を応用することでも可能である。
このような構成にすることにより、2つのパターンを同時に検出することが出来る。
本例は多重化の一例であり、2組以外多数の組合せとすることも、演算を論理積(AND)や論理和(OR)以外、排他論理やその他任意の論理演算とすることが出来る。
検出する情報の種類や目的に応じてこのように多重化し、様々な論理演算の二重並列論理演算60を使用することにより、より高度な情報の検出が可能になる。
【0112】
これまでの説明の図4、図14等を総合して本発明のメモリ21の構成をまとめると、
メモリアドレスごとに情報を記憶しその情報を読み出し可能なメモリであって
このメモリは、
外部から与えられる第1のデータは記憶されたこのメモリのデータを比較するためのデータ、第2のデータはこのメモリのアドレスを比較するためのデータ、の双方の入力データの入力手段と、
(1)第1のデータでメモリに記憶されたデータを並列に比較し合否判定する手段と
(2)第2のデータでメモリのアドレスを並列に比較し合否判定する手段と
(3)以上(1)、(2)双方の合否判定結果をさらに並列に論理演算するデータとアドレスの二重並列論理演算60手段と
を具備することを特徴とする情報絞り込み検出機能を備えたメモリである。
【0113】
さらこのメモリの情報の絞り込みをシンプルな回路構成とするための一例として、
前記(1)の合否判定手段ならびに前記(3)の二重並列論理演算手段60を、その演算結果が前記(1)の合否判定と前記(2)の合否判定との論理積(AND)と等価となる、等価二重並列論理積(AND)演算61手段で構成したことを特徴とする請求項1の情報絞り込み検出機能を備えたメモリである。
【0114】
さらに図5、図13等に示すようにこのメモリを連続繰返し二重並列論理演算60するために
毎次の前記等価二重並列論理積(AND)演算61手段の結果をメモリアドレスごとに計測するカウンタ35手段と、
初回の前記比較は、前記第1のデータによって、メモリを並列に合否判定して合格したメモリアドレスの上記カウンタを1にカウントアップしこれを1次突破アドレス56とする手段と、
以降の比較は、上記第1のデータによって、メモリを並列に合否判定して合格したメモリアドレスと、上記1次突破アドレスと、の双方のアドレスの位置関係を、前記第2のデータによって、前記等価二重並列論理積(AND)演算61手段で演算し、この演算を突破した上記1次突破アドレスのカウンタをカウントアップしてN(2以上の整数)次突破アドレスとする手段と、
このN次突破アドレスのアドレスを出力する手段と、
を具備することを特徴とするメモリである。
【0115】
さらに前記等価二重並列論理積(AND)演算61手段は前記第2のデータであるアドレスを比較するためのデータにもとづくアドレスのスワップ(交換)手段によって繰返し実施することを特徴とするメモリである。
【0116】
さらに前記第2のデータであるアドレスを比較するためのデータは、前記1次突破アドレスを基準とし、
(1)比較対象のアドレスが相対アドレスに一致するか否かの比較データ
(2)比較対象のアドレスが比較する範囲の内外に存在するか否かの比較データ
以上(1)(2)のいずれかもしくは双方であることを特徴とするメモリである。
【0117】
さらにこのメモリは、絞り込みのための回路の削減や二重並列論理演算60を多重化することも、論理演算を論理積や論理和のみならず様々な論理演算のデータとアドレスの二重並列論理演算60をすることが可能なメモリである。
【0118】
以上で本発明のメモリ21のそのものの説明を終えて、以下に一次元、多次元空間の情報検出の例を説明する。
【実施例10】
【0119】
図15(アドレス一次元配列の情報検出例)は、例えば横軸を時間軸としてアドレスに対応させ景気動向や株価、気温などのデータを縦軸に表示したものであり、サンプルとして与えられた既知の情報のデータを基に未知の情報である、過去の膨大なデータベースの中から情報検出を行ったものである、このような情報検出は、メモリアドレスを時間軸に関連付けるように配列記憶されたデータにより極めて簡単に行うことが出来る。
【0120】
時間軸を対象とした情報検出のもう一例として音声の場合には圧縮前のサンプリング時間とこの時間に対応した音声データや圧縮音声データのAAU(オーデオ復号単位)毎の音声データをもとにして情報検出が可能である。
3値データの比較が可能な本発明のメモリ21の一例として人の声などのスペクトラムの帯域をクラス化してクラス別にデータ化して、1時刻、1アドレス分のデータとすれば極めて簡単に時系列配列が作成出来る。
これを元にテンプレート音源などと類似パターン認識すればよく極めて高速な音声認識が可能となり、様々な音声認識の分野に利用することが可能である。
【0121】
またこのような一次元配列情報の検出は多大な情報処理を必要とするDNA配列、ゲノムの4つの塩基配列の組合せ解析を高速に実施する上で極めて有効である。
同様に文字列の配列による解析も同様である。
【実施例11】
【0122】
図16(アドレス三次元配列の情報検出例)は三次元空間に配列された情報を検出する場合の例を示したものである。
図に示すように三次元空間に配列される特定のパターンをこれまで説明の内容と同様な方法で検出したイメージである。
【0123】
云うまでもなく三次元空間は我々が存在する実空間を表現出来るので、三次元空間の位置とそのデータが定量化出来る全ての三次元情報に適応可能である、さらに時間軸を加えた時空間情報など多次元情報に展開することも可能である。
【0124】
このような三次元空間の情報検出は原子や分子レベルから宇宙空間のあらゆる配置関係の解析に利用可能である。
【0125】
特に高速な検出が可能であるのでリアルタイム処理が必要なロボットを対象として、例えば動きの速い物体などを対象として多数のテンプレート画面と比較を行うような立体パターン認識、立体物体認識や物体移動追跡など用途は無限である。
【0126】
いずれの場合もメモリアドレスと、X、Y、Z、3軸を対応付けするようデータをアドレス配列記憶することにより容易に実現可能であり、同一情報はもとより画像の検出で説明の近似情報や類似情報の検出も可能であることは云うまでもない。
【0127】
以上の説明は一次元から多次元までの空間を対象として既にアドレス配置された情報もしくはアドレス配列可能な情報のパターン認識を行ったものであるが、一例としてアドレスをクラスタリングされた情報グループに分類するなどしてこれを情報検出するなどアドレスとデータの配列を工夫することにより、これまでのアルゴリズムを駆使した情報検出を併用することも可能である。
【0128】
以上が一次元から多次元までの情報を検出する場合の概要であるが、本発明のメモリ21の特徴をまとめると次の通りである。
【0129】
本発明のメモリ21を使用した情報の検出は1アドレスとそのデータを検出の単位とし、入力データの設定方法により、特に厳密で正確な同一情報の検出から近似情報、変形情報、類似情報など幅広い情報を高速で確実に検出することが出来る。
【0130】
情報検出のためのサンプリング数もサンプリングポイントの選び方も統計的手法で評価可能でサンプリングを自動化することも可能であるのでサンプリング数の無駄も省け、検出時間を理に適った合理的な時間とすることが出来る、また1アドレス(座標)毎にサンプルポイント設定が出来るのも特徴の1つである。
【0131】
未知の情報上に対象となる情報がない場合の検出打ち切りが極めて速いことも特筆できる。
【0132】
この検出方法は一定の条件を満たせば互いの情報の大きさ(サイズ)に制約がないのであらゆる情報に適応可能であり、本発明のメモリ21のメモリのサイズに合わせて情報を分割処理することも可能である。
【0133】
一次元情報から多次元情報、その他の情報が混在し記憶されたメモリからでも目的とするパターンの認識をすることも可能である。
【0134】
また本方式は、未知の情報を適切にアドレス配置し本発明のメモリ21に記憶させれば、サンプルポイント以外、他のパターン認識で行われるような情報の加工、特徴抽出やクラス化などのデータの前処理が必要ないことも大きな特徴である。
【0135】
さらに本方式はアルゴリズムの開発など情報検出の実施前の時間が不要となるのも大きな特徴であり検出方法(比較条件の設定)も極めてシンプルな構成である。
従がってシステム試験時のカット&トライ的な調整も不要で、設定通りの検出方法で期待する情報を確実に検出してくれる、従がって特段情報検出の専門家でなくても本方式を利用して様々な情報検出のアプリケーションに広く利用することが出来る。
【0136】
これまでの説明では既知の情報1があることを前提としてこれからサンプルを採取して情報を検出することを中心に説明してきたが、人の判断や推測に基づき入力データ25を設定し情報解析することも重要である。
【0137】
このような場合、最初の入力データ25である、1次比較データは検出の結果を左右するので、複数の比較データとするか、入力データに範囲を持させ検出を行い、この1次比較の結果により徐々に範囲を限定する方法で解析を行えばよい。
このような解析は天文、気象、物理、化学、経済などのあらゆる分野の情報予測などデータ解析の時間とその労力を大幅に軽減するものである。
【0138】
この本発明の情報絞り込み機能を備えたメモリ21は、ノイマン型コンピュータの宿命であるメモリの逐次処理を排除し、メモリ自身がインテリジェンスな知識を備えて情報検出を行うものであり、これまでのメモリの常識を大きく打ち破るものである。
従がって従来から研究され利用されている画像認識、音声認識、OCR文字認識、全文検索、指紋認証、虹彩認証、ロボットの人工知能のパターン認識に利用されるのみでなく、天候、景気、株価、分子構造、DNA、ゲノム、文字配列、などの解析はもとより、新たな情報の発見(情報予測)や、社会インフラから産業用設備、工業用設備、家庭用装置はもとより、これまで対象とされることのなかった未知の分野の情報検出にも幅広く利用することが可能である。
【実施例12】
【0139】
この本発明の情報絞り込み機能を備えたメモリ21は、様々な情報の検出を必要とする人工知能のエンジンとして知識処理に利用することも可能である。
例えば本発明のメモリ21を人の脳の大脳や小脳、さらには右脳や左脳などに当てはめ並列さらには階層状に複数配列して、それぞれにテンプレートとして、物体の認識の情報、人物認識の情報、文字の認識の情報、音声認識の情報、味覚の情報、触覚の情報、など様々な種類の情報を記憶させておき、リアルタイムで与えられた周囲の画像や音声さらには様々なセンサの情報と比較することにより、人の認識能力と同様に様々な情報を同時に識別し、その情報の中で最適な行動を選択し実行するような極めて高度な知識処理に利用することも可能であり、利用の仕方は無限である。
図17(本発明のメモリを用いた高度な知識処理の例)は以上説明の知識情報を本発明のメモリ21に記憶し知識処理を行う実施例であり、最適な行動の結果をもとにメモリ21を更新することによって学習効果も容易に実現可能である。
【産業上の利用可能性】
【0140】
本発明のメモリ21はこれまで従来型のメモリの概念を超越し、用途は極めて広範囲であり、情報処理の新しい流れを築くものである。
【0141】
本発明のメモリ21は、連想メモリ以外、ASIC(Application
Specific Integrated Circuit)やFPGA(Field Programmable Gate Array)によって一般的なRAMやROM構成のメモリとしても実現可能であり、セルベースCPUに組込むことも、CCDセンサに直接組込むことも、本発明のメモリ21を独自専用構造のメモリ構成とすることも、新しいタイプの半導体で構成することも、他の機能を付与することも自由である。
【0142】
将来においては以上のような半導体によるメモリ以外に、現在研究途上の光素子や磁気素子、ジョセフソン素子など新しい素子による本発明のメモリも期待が持てる。
【符号の説明】
【0143】
1.既知の情報
2.未知の情報
3.アドレス
4.アドレスのデータ
11.ピクセル
12.座標のデータ
13.サンプリングポイント
14.比較順序
15.量子化データ
21.情報絞り込み検出機能を備えたメモリ
22.アドレスバス
23.データバス
24.出力バス
25.入力データ
26.メモリ比較データ
27.アドレス比較データ
28.リセット信号
29.比較回数カウンタ
31.アドレスデコーダ
32.メモリ
33.データ比較回路
34.アドレススワップ回路
35.突破回数カウンタ
36.ORゲート
37.インヒビットゲート
38.突破アドレス出力処理回路
41.アドレススワップ前合格出力
42.アドレススワップ後合格出力
43.比較回数信号
44.カスケード接続
51.相対アドレス比較データ
52.アドレス範囲比較データ
53.並列処理
54.二重並列合否判定
55.論理積(AND)演算
56.1次突破アドレス
57.N次突破アドレス
58.グループ別突破カウンタ
59.論理和(OR)演算
60.二重並列論理演算
61.等価二重並列論理積(AND)演算
【特許請求の範囲】
【請求項1】
メモリアドレスごとに情報を記憶しその情報を読み出し可能なメモリであって
このメモリは、
外部から与えられる第1のデータは記憶されたこのメモリのデータを比較するためのデータ、第2のデータはこのメモリのアドレスを比較するためのデータ、の双方の入力データの入力手段と、
(1)第1のデータでメモリに記憶されたデータを並列に比較し合否判定する手段と
(2)第2のデータでメモリのアドレスを並列に比較し合否判定する手段と
(3)以上(1)、(2)双方の合否判定結果をさらに並列に論理演算するデータとアドレスの二重並列論理演算手段と
を具備することを特徴とする情報絞り込み検出機能を備えたメモリ。
【請求項2】
前記(1)の合否判定手段ならびに前記(3)の二重並列論理演算手段を、その演算結果が前記(1)の合否判定と前記(2)の合否判定との論理積(AND)と等価となる、等価二重並列論理積(AND)演算手段で構成したことを特徴とする請求項1の情報絞り込み検出機能を備えたメモリ。
【請求項3】
前記メモリは、
毎次の前記等価二重並列論理積(AND)演算手段の結果をメモリアドレスごとに計測するカウンタ手段と、
初回の前記比較は、前記第1のデータによって、メモリを並列に合否判定して合格したメモリアドレスの上記カウンタを1にカウントアップしこれを1次突破アドレスとする手段と、
以降の比較は、上記第1のデータによって、メモリを並列に合否判定して合格したメモリアドレスと、上記1次突破アドレスと、の双方のアドレスの位置関係を、前記第2のデータによって、前記等価二重並列論理積(AND)演算手段で演算し、この演算を突破した上記1次突破アドレスのカウンタをカウントアップしてN(2以上の整数)次突破アドレスとする手段と、
このN次突破アドレスのアドレスを出力する手段と、
を具備することを特徴とする請求項2記載の情報絞り込み検出機能を備えたメモリ。
【請求項4】
前記等価二重並列論理積(AND)演算手段は前記第2のデータであるアドレスを比較するためのデータにもとづくアドレスのスワップ(交換)手段によって繰返し実施することを特徴とする請求項3記載の情報絞り込み検出機能を備えたメモリ。
【請求項5】
前記第2のデータであるアドレスを比較するためのデータは、前記1次突破アドレスを基準とし、
(1)比較対象のアドレスが相対アドレスに一致するか否かの比較データ
(2)比較対象のアドレスが比較する範囲の内外に存在するか否かの比較データ
以上(1)(2)のいずれかもしくは双方であることを特徴とする請求項3記載の情報絞り込み検出機能を備えたメモリ。
【請求項6】
前記メモリは
(1)音声情報を一例とする一次元情報として記憶されたもしくは記憶可能な情報
(2)画像情報を一例とする二次元情報として記憶されたもしくは記憶可能な情報
(3)立体情報を一例とする三次元情報として記憶されたもしくは記憶可能な情報
(4)時空間情報を一例とする多次元情報として記憶されたもしくは記憶可能な情報
(5)クラスタリング情報を一例とする情報をアドレスのグループ別に記憶されたもしくは記憶可能な情報
以上(1)から(5)の少なくとも1つの情報の検出を対象とするメモリ構成であることを特徴とする請求項3記載の情報絞り込み検出機能を備えたメモリ。
【請求項7】
前記第1のデータである記憶されたメモリのデータを比較するためのデータは
(1)メモリデータの一致
(2)メモリデータの大小
(3)メモリbit個別のDon‘t Careを含む比較
以上(1)から(3)の少なくとも1つであることを特徴とする請求項3記載の情報絞り込み検出機能を備えたメモリ。
【請求項8】
前記第1のデータ、第2のデータは
(1)データバス
(2)専用入力
以上(1)(2)のいずれかもしくは双方により入力されることを特徴とする請求項3記載の情報絞り込み検出機能を備えたメモリ。
【請求項9】
前記N次突破アドレスのアドレスを出力する手段は
(1)データバス
(2)専用出力
以上(1)(2)のいずれかもしくは双方により出力されることを特徴とする請求項3記載の情報絞り込み検出機能を備えたメモリ。
【請求項10】
前記カウンタ手段に1次突破アドレスを記憶する手段を付加することにより、カウンタ手段の回路数量を確率的に出現する1次突破アドレスの数量に見合う回路数量に削減したことを特徴とする請求項3記載の情報絞り込み検出機能を備えたメモリ。
【請求項11】
前記アドレスのスワップ(交換)手段にプロセッサを用いることを特徴とする請求項3記載の情報絞り込み検出機能を備えたメモリ。
【請求項12】
前記二重並列論理演算をメモリのバンク毎に切り替え実施することを特徴とする請求項1記載の情報絞り込み検出機能を備えたメモリ。
【請求項13】
複数の前記第1のデータならびに第2のデータの入力手段と、
複数の前記二重並列論理演算手段と、を具備することを特徴とする請求項1記載の情報絞り込み検出機能を備えたメモリ。
【請求項14】
前記メモリはCPUを一例とする他の目的の半導体に組込まれ使用されることを特徴とする請求項1記載の情報絞り込み検出機能を備えたメモリ。
【請求項15】
検出される情報(未知の情報)と、検出の基準になる情報(既知の情報)と、の互いの情報の複数のアドレスの、そのデータと、そのアドレスと、の双方が必要回数の比較条件に合格することをもって、未知の情報の内から既知の情報と同一もしくは類似の情報を検出することをもって、情報とその情報の位置を検出することを目的として
既知の情報を前記第1のデータと第2のデータとすることにより、請求項1記載のメモリに記憶された未知の情報を比較し、未知の情報の内から既知の情報と同一もしくは類似する情報とそのアドレスを、前記N次突破アドレスを読み出すことにより検出することを特徴とする情報絞り込み検出機能を備えたメモリの使用方法。
【請求項16】
前記検出の基準になる情報(既知の情報)の内から、統計確率にもとづき前記同一情報もしくは類似情報を判定するに必要十分な複数個数のサンプルを抽出し、これを前記第1のデータと、第2のデータと、として比較条件とすることにより、同一情報もしくは類似情報を判定するために必要な前記比較回数を上記サンプル数以内とすることを特徴とする請求項15記載の情報絞り込み検出機能を備えたメモリの使用方法。
【請求項17】
前記サンプルを抽出する際、隣接するサンプル間のデータの相互のデータの差の絶対値を求め、これを集計することにより得られるサンプル特徴量を基準値以上として情報検出をすることを特徴とする請求項15記載の情報絞り込み検出機能を備えたメモリの使用方法。
【請求項18】
請求項3記載のアドレスの位置関係は
(1)前記一次元情報として配列記憶されたアドレス配列上の位置関係
(2)前記二次元情報として配列記憶されたアドレス配列上の位置関係
(3)前記三次元情報として配列記憶されたアドレス配列上の位置関係
(4)前記多次元情報として配列記憶されたアドレス配列上の位置関係
以上(1)から(4)の少なくとも1つの位置関係であり、このアドレスの位置関係を用いてパターン認識をすることを特徴とする請求項15記載の情報絞り込み検出機能を備えたメモリの使用方法。
【請求項19】
前記1次突破アドレスとなる最初の比較サンプルを複数種類のサンプルとする、もしくは一定の範囲を持させ検出を行うことを特徴とする請求項15記載の情報絞り込み検出機能を備えたメモリの使用方法。
【請求項20】
前記情報絞り込み検出機能を備えたメモリをアクセスしデータの読み出し書込みが可能なCPUを併用することを特徴とする情報絞り込み検出機能を備えたメモリの使用方法。
【請求項21】
前記情報絞り込み検出機能を備えたメモリに知識情報を記憶させ知識処理をすることを特徴とする情報絞り込み検出機能を備えたメモリの使用方法。
【請求項22】
前記情報絞り込み検出機能を備えたメモリを使用したことを特徴とする装置。
【請求項23】
前記情報絞り込み検出機能を備えたメモリを使用したことを特徴とする人工知能。
【請求項1】
メモリアドレスごとに情報を記憶しその情報を読み出し可能なメモリであって
このメモリは、
外部から与えられる第1のデータは記憶されたこのメモリのデータを比較するためのデータ、第2のデータはこのメモリのアドレスを比較するためのデータ、の双方の入力データの入力手段と、
(1)第1のデータでメモリに記憶されたデータを並列に比較し合否判定する手段と
(2)第2のデータでメモリのアドレスを並列に比較し合否判定する手段と
(3)以上(1)、(2)双方の合否判定結果をさらに並列に論理演算するデータとアドレスの二重並列論理演算手段と
を具備することを特徴とする情報絞り込み検出機能を備えたメモリ。
【請求項2】
前記(1)の合否判定手段ならびに前記(3)の二重並列論理演算手段を、その演算結果が前記(1)の合否判定と前記(2)の合否判定との論理積(AND)と等価となる、等価二重並列論理積(AND)演算手段で構成したことを特徴とする請求項1の情報絞り込み検出機能を備えたメモリ。
【請求項3】
前記メモリは、
毎次の前記等価二重並列論理積(AND)演算手段の結果をメモリアドレスごとに計測するカウンタ手段と、
初回の前記比較は、前記第1のデータによって、メモリを並列に合否判定して合格したメモリアドレスの上記カウンタを1にカウントアップしこれを1次突破アドレスとする手段と、
以降の比較は、上記第1のデータによって、メモリを並列に合否判定して合格したメモリアドレスと、上記1次突破アドレスと、の双方のアドレスの位置関係を、前記第2のデータによって、前記等価二重並列論理積(AND)演算手段で演算し、この演算を突破した上記1次突破アドレスのカウンタをカウントアップしてN(2以上の整数)次突破アドレスとする手段と、
このN次突破アドレスのアドレスを出力する手段と、
を具備することを特徴とする請求項2記載の情報絞り込み検出機能を備えたメモリ。
【請求項4】
前記等価二重並列論理積(AND)演算手段は前記第2のデータであるアドレスを比較するためのデータにもとづくアドレスのスワップ(交換)手段によって繰返し実施することを特徴とする請求項3記載の情報絞り込み検出機能を備えたメモリ。
【請求項5】
前記第2のデータであるアドレスを比較するためのデータは、前記1次突破アドレスを基準とし、
(1)比較対象のアドレスが相対アドレスに一致するか否かの比較データ
(2)比較対象のアドレスが比較する範囲の内外に存在するか否かの比較データ
以上(1)(2)のいずれかもしくは双方であることを特徴とする請求項3記載の情報絞り込み検出機能を備えたメモリ。
【請求項6】
前記メモリは
(1)音声情報を一例とする一次元情報として記憶されたもしくは記憶可能な情報
(2)画像情報を一例とする二次元情報として記憶されたもしくは記憶可能な情報
(3)立体情報を一例とする三次元情報として記憶されたもしくは記憶可能な情報
(4)時空間情報を一例とする多次元情報として記憶されたもしくは記憶可能な情報
(5)クラスタリング情報を一例とする情報をアドレスのグループ別に記憶されたもしくは記憶可能な情報
以上(1)から(5)の少なくとも1つの情報の検出を対象とするメモリ構成であることを特徴とする請求項3記載の情報絞り込み検出機能を備えたメモリ。
【請求項7】
前記第1のデータである記憶されたメモリのデータを比較するためのデータは
(1)メモリデータの一致
(2)メモリデータの大小
(3)メモリbit個別のDon‘t Careを含む比較
以上(1)から(3)の少なくとも1つであることを特徴とする請求項3記載の情報絞り込み検出機能を備えたメモリ。
【請求項8】
前記第1のデータ、第2のデータは
(1)データバス
(2)専用入力
以上(1)(2)のいずれかもしくは双方により入力されることを特徴とする請求項3記載の情報絞り込み検出機能を備えたメモリ。
【請求項9】
前記N次突破アドレスのアドレスを出力する手段は
(1)データバス
(2)専用出力
以上(1)(2)のいずれかもしくは双方により出力されることを特徴とする請求項3記載の情報絞り込み検出機能を備えたメモリ。
【請求項10】
前記カウンタ手段に1次突破アドレスを記憶する手段を付加することにより、カウンタ手段の回路数量を確率的に出現する1次突破アドレスの数量に見合う回路数量に削減したことを特徴とする請求項3記載の情報絞り込み検出機能を備えたメモリ。
【請求項11】
前記アドレスのスワップ(交換)手段にプロセッサを用いることを特徴とする請求項3記載の情報絞り込み検出機能を備えたメモリ。
【請求項12】
前記二重並列論理演算をメモリのバンク毎に切り替え実施することを特徴とする請求項1記載の情報絞り込み検出機能を備えたメモリ。
【請求項13】
複数の前記第1のデータならびに第2のデータの入力手段と、
複数の前記二重並列論理演算手段と、を具備することを特徴とする請求項1記載の情報絞り込み検出機能を備えたメモリ。
【請求項14】
前記メモリはCPUを一例とする他の目的の半導体に組込まれ使用されることを特徴とする請求項1記載の情報絞り込み検出機能を備えたメモリ。
【請求項15】
検出される情報(未知の情報)と、検出の基準になる情報(既知の情報)と、の互いの情報の複数のアドレスの、そのデータと、そのアドレスと、の双方が必要回数の比較条件に合格することをもって、未知の情報の内から既知の情報と同一もしくは類似の情報を検出することをもって、情報とその情報の位置を検出することを目的として
既知の情報を前記第1のデータと第2のデータとすることにより、請求項1記載のメモリに記憶された未知の情報を比較し、未知の情報の内から既知の情報と同一もしくは類似する情報とそのアドレスを、前記N次突破アドレスを読み出すことにより検出することを特徴とする情報絞り込み検出機能を備えたメモリの使用方法。
【請求項16】
前記検出の基準になる情報(既知の情報)の内から、統計確率にもとづき前記同一情報もしくは類似情報を判定するに必要十分な複数個数のサンプルを抽出し、これを前記第1のデータと、第2のデータと、として比較条件とすることにより、同一情報もしくは類似情報を判定するために必要な前記比較回数を上記サンプル数以内とすることを特徴とする請求項15記載の情報絞り込み検出機能を備えたメモリの使用方法。
【請求項17】
前記サンプルを抽出する際、隣接するサンプル間のデータの相互のデータの差の絶対値を求め、これを集計することにより得られるサンプル特徴量を基準値以上として情報検出をすることを特徴とする請求項15記載の情報絞り込み検出機能を備えたメモリの使用方法。
【請求項18】
請求項3記載のアドレスの位置関係は
(1)前記一次元情報として配列記憶されたアドレス配列上の位置関係
(2)前記二次元情報として配列記憶されたアドレス配列上の位置関係
(3)前記三次元情報として配列記憶されたアドレス配列上の位置関係
(4)前記多次元情報として配列記憶されたアドレス配列上の位置関係
以上(1)から(4)の少なくとも1つの位置関係であり、このアドレスの位置関係を用いてパターン認識をすることを特徴とする請求項15記載の情報絞り込み検出機能を備えたメモリの使用方法。
【請求項19】
前記1次突破アドレスとなる最初の比較サンプルを複数種類のサンプルとする、もしくは一定の範囲を持させ検出を行うことを特徴とする請求項15記載の情報絞り込み検出機能を備えたメモリの使用方法。
【請求項20】
前記情報絞り込み検出機能を備えたメモリをアクセスしデータの読み出し書込みが可能なCPUを併用することを特徴とする情報絞り込み検出機能を備えたメモリの使用方法。
【請求項21】
前記情報絞り込み検出機能を備えたメモリに知識情報を記憶させ知識処理をすることを特徴とする情報絞り込み検出機能を備えたメモリの使用方法。
【請求項22】
前記情報絞り込み検出機能を備えたメモリを使用したことを特徴とする装置。
【請求項23】
前記情報絞り込み検出機能を備えたメモリを使用したことを特徴とする人工知能。
【図1】


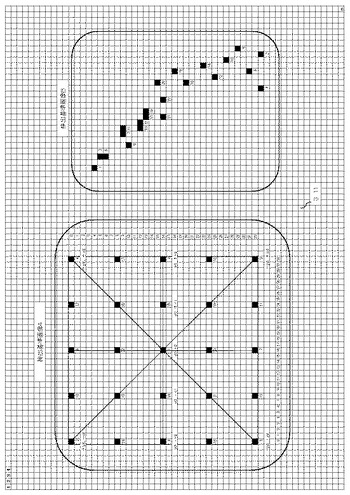
【図2】
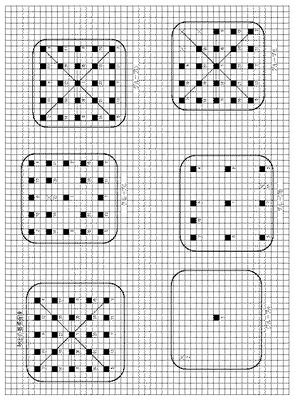
【図3】

【図4】
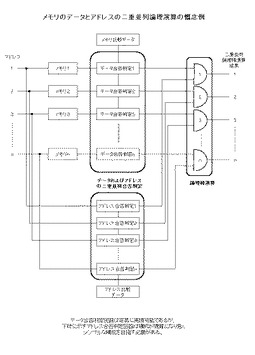
【図5】
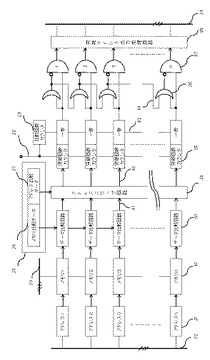
【図6】
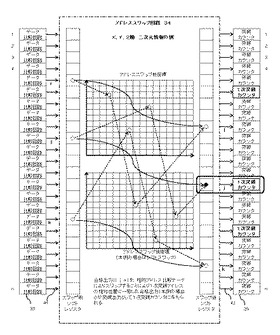
【図7】
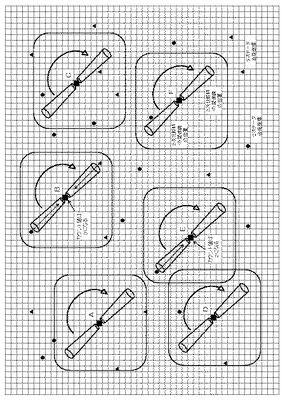
【図8】
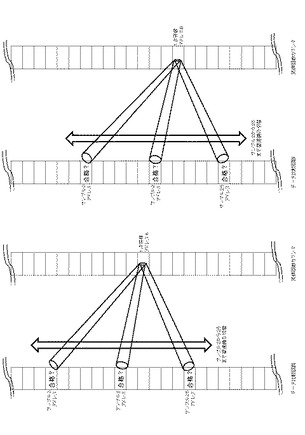
【図9】
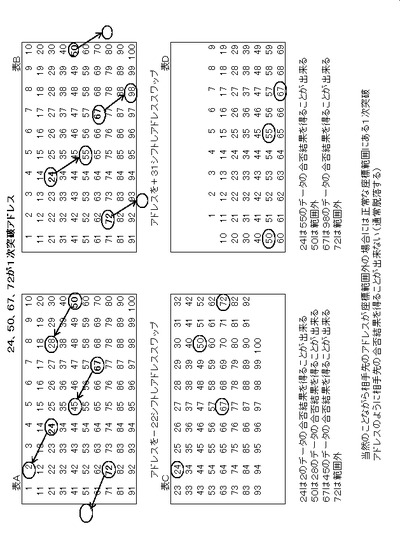
【図10】
【図11】
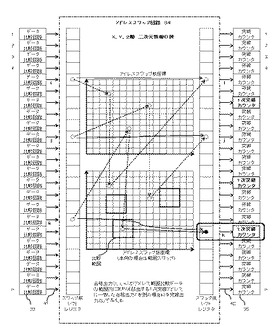
【図12】
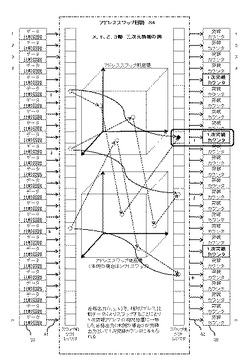
【図13】
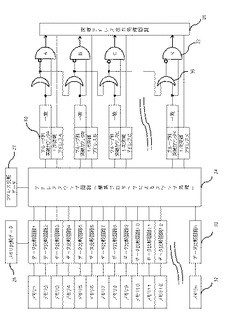
【図14】
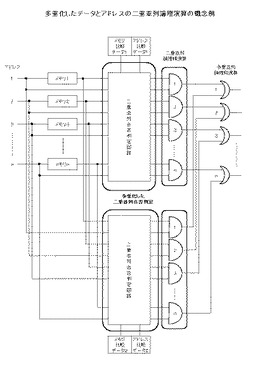
【図15】

【図16】
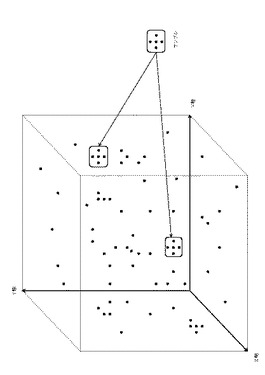
【図17】
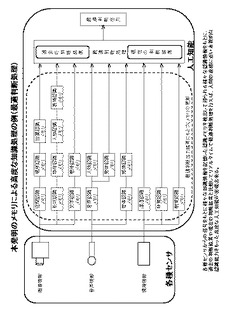
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【公開番号】特開2012−252368(P2012−252368A)
【公開日】平成24年12月20日(2012.12.20)
【国際特許分類】
【出願番号】特願2010−65597(P2010−65597)
【出願日】平成22年3月23日(2010.3.23)
【特許番号】特許第4588114号(P4588114)
【特許公報発行日】平成22年11月24日(2010.11.24)
【出願人】(508220504)
【Fターム(参考)】
【公開日】平成24年12月20日(2012.12.20)
【国際特許分類】
【出願日】平成22年3月23日(2010.3.23)
【特許番号】特許第4588114号(P4588114)
【特許公報発行日】平成22年11月24日(2010.11.24)
【出願人】(508220504)
【Fターム(参考)】
[ Back to top ]