
懐く挙動を示す玩具
ユーザーに懐く挙動を示す玩具、およびそのような挙動をシュミレートする方法が提供される。玩具は、ユーザーからの対話的入力を受ける入力センサ(18)と、ユーザーとコミュニケートする出力装置(24)と、プロセッサ(12)と、機械語命令を格納したメモリ(16)と、を備える。機械語命令により、プロセッサ(12)は、対話的入力を受け取り、受け取った入力信号を処理し、制御信号を出力装置に送る。プロセッサ(12)は、受け取った入力信号をポジティブまたはネガティブに分類し、当該分類に従ってメモリ(16)に記憶・蓄積された入力信号を調整する。制御信号は、蓄積された入力に依存している。

【発明の詳細な説明】
【技術分野】
【0001】
本発明は、対話(あるいは交流、interaction)型玩具に関する。より詳細には、人間に懐く挙動を示す人形に関する。この懐く挙動(bonding behaviour)は、親と子の間で自然に行われる動作を模したものを意味する。本発明は、1人または複数の人間に対して、玩具が懐く挙動をシミュレートする方法も対象としている。
【背景技術】
【0002】
玩具、特に人形は、世界の人々に何百年もの間、所有されてきた。子供たちは、人形で遊び、対人関係を学び、時に安心感を覚える。子供(特に幼い子供)は、しばしば、人形との間に強い結付きを形成する。それは、子供の成長の一部を担う。多くの理由から、人形は大人にも所有される。審美的な特質または情緒的愛着から、コレクターのアイテムとなることもある。
【0003】
過去何年間に及ぶ技術的進歩により、人形は進化し、ますます洗練され、実際、生きているかのようになった。本件発明者は、人の限られた挙動をシミュレートできる人形の存在を知っている。例えば、泣く、眠る、話すである。さらには、食べる、あるいは排泄するといった身体機能をシミュレートできる人形も知っている。さらに、本件発明者は、マイクロホン、音響トランスデューサ、動作アクチュエータ、その他の電子機器が、人形に組み入れられていることも知っている。
【0004】
例えば、米国特許出願番号US2007/0128979(対話型の先端技術の人形)に開示された人形は、人間のような顔の表情を有し、人が話す特定の言葉を認識する。さらには、予め決められた質問および回答のシナリオに基づいて、生きた人間と特定の会話を続けることができる。
人形が話し言葉を認識するのは、当該人形に組み入れられたプロセッサで制御される会話−音声認識技術に基づいており、それは、人形が特定の人の音声を識別できるよう訓練されることを可能としており、その人に対する特定の役割(母親など)を担う。
人形は、顔の内部に動作アクチュエータを備えている。これにより、話し言葉と同時に(あるいは独立して)、目、口および頬が、予め決められた顔の表情を作り出し、これにより、ヒトの感情をシミュレートする。
限られた会話を行う能力は、この分野で広く知られている基本的な、音声−会話認識技術に基づいている。各シナリオにおいて、人形は、予め記録された質問をし、特定の回答を待つ。人形は、予期された回答を受けると、にこやかに応答する。回答が予期されたものでない場合、人形の応答は、やや不機嫌となる。
しかしながら、出願明細書には、人形が長期的に渡る学習能力を有するとの説明はない。そうではなく、人形の挙動は、主として現在のユーザーによる入力および内蔵時計に応答するステートマシン(state machine)で統治されているようだ。
【発明の概要】
【発明が解決しようとする課題】
【0005】
本発明は、対話型玩具を提供することを目的とする。より詳細には、人間に懐く挙動をシュミレートできる人形を提供することを目的としており、それは、上に概説した先行技術に対する改善である。
【課題を解決するための手段および発明の効果】
【0006】
本発明により提供される玩具は、本体を備えており、当該本体は、ヒトユーザーからの入力を受け取る、少なくとも1つの入力センサと、当該玩具が上記ユーザーと相互交流するための、少なくとも1つの出力装置と、入力センサおよび出力装置と交信するプロセッサと、プロセッサと交信するメモリと、を備える。
当該玩具は、以下のことを特徴とする。すなわち、プロセッサは、受け取った各入力を、ポジティブであるかネガティブであるかに分類し、当該分類に従って、メモリに記憶された蓄積された入力を調整し、蓄積された入力に依存する制御信号を、出力装置に送る、ようプログラムされており、それにより、ある期間に渡る一連の支配的なポジティブな入力に応答して、懐く挙動を強くするとともに、ある期間に渡る一連の支配的なネガティブな入力に応答して、懐く挙動を減じることを特徴としている。
【0007】
本発明の特徴は、さらに次の特徴を有する。
上記ヒトユーザーから受け取る入力は、音、動作、画像のうちの1または2以上に対応する、玩具とヒトとの相互交流に対応している。
上記プロセッサは、叫びに関連する音、および物理的虐待に関連する動作を、ネガティブな入力として分類する。
本発明の玩具は、少なくとも2つの入力センサを含み、第1のセンサは、音声およびその振幅を検出するマイクロフォンであり、第2のセンサは、玩具の動作および加速度を検出する加速度計である。
上記蓄積された入力は、少なくともある程度、玩具の好みのユーザーの音声を表している。
上記プロセッサは、マイクロフォンで受け取った音声入力と、蓄積された入力との類似度合いを決定するようプログラムされている。
上記蓄積された入力は、受け取った入力がポジティブであると分類されるときは、ユーザーをより強く表すように成るように調整され、上記類似度合いが低いとき、または、受け取った入力がネガティブであると分類されるときは、好みのユーザーを表す度合いが小さくなるか、または変化しない。
上記プロセッサは、予め決めた最大音声振幅に対して、それよりも大きい振幅の音声入力をネガティブな入力として分類し、それよりも小さい振幅の音声入力をポジティブな入力として分類するようにプログラムされている。
上記プロセッサは、予め決めた最大加速度閾値に対して、それよりも大きい加速度の動作入力をネガティブな入力として分類し、それよりも小さい加速度の動作入力をポジティブな入力として分類するようにプログラムされている。
上記プロセッサは、状況に応じて、受け取った入力のポジティブな度合い、またはネガティブな度合いを決定し、ポジティブまたはネガティブな度合いに比例して、蓄積された入力を調整するようにプログラムされている。
【0008】
本発明のさらなる特徴は、次の通りである。
玩具は、上記プロセッサと交信する計時手段を備えていて、プロセッサは、予め決めた時間長に対して、それよりも長く入力が無かったとき、それをネガティブな入力として分類し、それに応じて、好みのユーザーを表す度合いが低くなるよう蓄積された入力を調整するようにプログラムされている。
上記出力装置は、音響トランスデューサおよび動作アクチュエータの一方または両方を備えており、プロセッサは、受け取った音声入力の類似度合いが高い場合には、より頻繁に、および(または)よりクオリティの高い制御信号を、出力装置に送るようにプログラムされている。また、プロセッサは、受け取った音声入力の類似度合いが低い場合には、より低い頻度で、および(または)よりクオリティの低い制御信号を、出力装置に送るようにプログラムされている。
【0009】
本発明のさらなる特徴は、次の通りである。
上記蓄積された入力は、一般的なバックグランド話者に関連する音声から抽出された特徴の集合を含んでおり、当該特徴のそれぞれは、関連する多様な重み付けを有しており、重み付けられた特徴の集合は、好みのユーザーの音声を表している。
上記蓄積された入力が好みのユーザーの音声をより強く、またはより弱く表すこととなるように、上記特徴に関連する多様な重み付けが調整される。
上記蓄積された入力が現在の好みのユーザーの音声を表す程度が小さくなると、当該蓄積された入力が、少なくとも1人の別のユーザーの音声をより強く表すように成るよう調整され、蓄積された入力が、当該別のユーザーの音声を、現在の好みのユーザーのそれよりも強く表すように成った時、当該別のユーザーが新しい好みのユーザーになる。
【0010】
本発明により、次の方法が提供される。
すなわち、本発明の方法は、玩具がヒトに懐く挙動をシュミレートする方法であって、好みのユーザーを表す蓄積された入力を、当該玩具に関連するメモリに記憶するステップと、当該玩具に組み込まれた少なくとも1つの入力センサにより、ユーザーからの入力を受け取るステップと、受け取った入力を、ポジティブであるか、ネガティブであるかに分類するステップと、ポジティブな入力に応じて好みのユーザーをより強く表すように成るように、また、ネガティブな入力に応じて好みのユーザーをより弱く表すように成るように、蓄積された入力を調整するステップと、入力に応答して、蓄積された入力に依存する制御信号を、当該玩具の出力装置へ発するステップと、を含む。
【0011】
本発明の方法は次の点に特徴を有する。
すなわち、予め決めた振幅よりも大きな振幅の音声入力を受け取ったとき、当該入力をネガティブであると分類するステップと、予め決めた範囲の加速度を超える加速度の動作入力を受け取ったとき、当該入力をネガティブであると分類するステップと、予め決めた時間長よりも長い時間入力がなかったとき、それをネガティブな入力であると分類するステップと、を含む。
または、本発明の方法は、好みのユーザーの音声入力に対する受け取った音声入力の類似度合いを決定し、当該類似度合いに比例した制御信号を、玩具の出力装置へ発するステップを含む。
【図面の簡単な説明】
【0012】
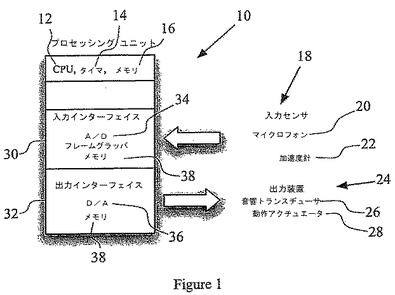
【図1】本発明の第1実施形態において、人間に懐く挙動を示す玩具人形の内部コンポーネントを示す概略図。
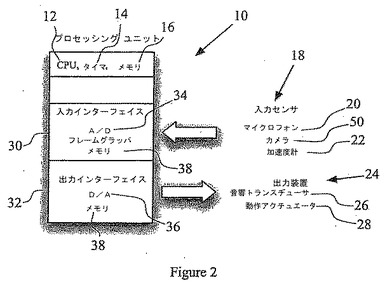
【図2】図1の玩具人形の別実施形態を示す概略図。
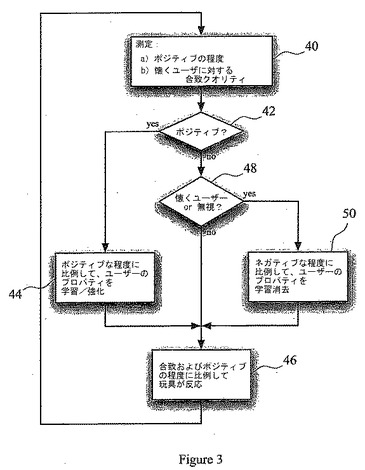
【図3】本発明による玩具人形のマクロな挙動を示す流れ図。
【発明を実施するための形態】
【0013】
図1は、本発明の第1実施形態に関して、玩具人形(図示せず)の内部機能コンポーネント(10)を示している。人形は図示しない本体を備えているが、この人形本体は、あらゆる外観を為すことが可能である。例えば、乳幼児、よちよち歩きの幼児、動物、あるいは玩具キャラクター等である。
コンポーネント(10)は、人形内部の都合の良い位置に配置される。例えば、本体の胸腔内に配置すれば、本体によってコンポーネント(10)が保護される。玩具本体上の都合の良い位置を利用して、コンポーネントの中で定期的に交換あるいはメンテナンスが必要となる部分(例えば、電源またはバッテリーパック)へのアクセスを確保する。
【0014】
コンポーネント(10)は、必要な挙動をサポートするため、CPU(12)、記憶ユニット(16)、入力センサ(18)、出力装置(24)を含む。
CPUすなわちデジタル中央処理装置(12)は、計時手段(14)を含んでおり、この実施形態ではデジタル・タイマーである。記憶ユニット(16)は、不揮発性のメモリモジュールである。入力センサ(18)は、入力を検出するもので、この実施形態では、マイクロホン(20)および加速度計(22)である。出力装置(24)は、ユーザーとコミュニケーションをとる。
この実施形態において、出力装置は、玩具の腕(図示せず)に接続された音響トランスデューサ(26)および動作アクチュエータ(28)を含んでいる。玩具の動作を制御するために、動作アクチュエータ(28)は、玩具のいずれのアームに接続してもよい。CPU(12)は、入力インターフェース(30)および出力インタフェース(32)を介して、それぞれ、入力センサ(18)および出力装置(26)に接続されている。
入力インターフェース(30)は、アナログ−デジタル(A/D)コンバータ(34)を含んでいて、出力インタフェース(32)は、デジタル−アナログ(D/A)コンバータ(36)を含んでいる。ソフトウェア(図示せず)の形態で与えられる機械語命令(machine instruction)は、メモリ(16)あるいは増設メモリモジュール(38)に記憶されていて、入力インターフェース(30)および出力インターフェース(32)、並びに関連するA/DおよびD/Aコンバータを駆動する。また、機械語命令は、CPUに対して、入力センサを介して入力を受け取らせて、受け取った入力を処理させて、制御信号を出力装置へ送らせる、命令を含んでいる。
【0015】
玩具の挙動を統制する追加的なソフトウェアも、蓄積された入力変数と共にメモリ(16)に記憶されている。入力変数は、デジタル・モデル(図示せず)の形態であって、ユーザーの声および(または)挙動から抽出されたキャラクターまたはプロパティの修正から構成され、そこには、現時点での好みのユーザー、並びに好みのユーザーのキャラクターを、一般の他のユーザーと、どのようにして区別するかの基準が含まれる。
蓄積された入力は、可変な程度で、現時点での好みのユーザーを表していて、不揮発性メモリモジュール(16)に記憶される。
ソフトウェアは、さらに、音声およびスピーチ認識機能性、他の特徴抽出ソフトウェアを含んでいる。特徴抽出ソフトウェアは、プロセッサが受け取った入力を解析することを可能にし、また、それが現時点での好みのユーザーのデジタル・モデルに対応する程度を同プロセッサが決定することを可能にする。このようにして、受け取った音声入力の、蓄積された入力として表わされた好みのユーザーに対する、類似性の程度を作り出す。
【0016】
さらに、メモリ(16)は、次のようなソフトウェアを格納している。そのソフトウェアは、入力センサ(18)によって検出された入力をCPUが分析することを可能にし、その入力を本来的にポジティブであるかネガティブであるのかをCPUが分類することを可能し、受け取った入力に対して、ポジティブな程度またはネガティブな程度をCPUが割り当てることを可能にする。
仮に、入力を介して受け取ったカレント・ユーザーとの交流がポジティブであると考えられる場合、その入力は、当該カレント・ユーザーのプロパティを更に学習するために提供される。また、蓄積された入力は、更なるプロパティとしてアップデートされる。
カレント・ユーザーの更なるプロパティを、蓄積された入力に追加することにより、当該入力がポジティブに分類される限り、蓄積された入力がカレント・ユーザーをより強く表すこととなり、従って、当該カレント・ユーザーにますますより強く懐くようになる。カレント・ユーザーが好みのユーザーに近似する場合、蓄積された入力は、ますます強く好みのユーザーを表すようになり、当該カレント・ユーザーに対してより強く懐くようになる。
しかし、カレント・ユーザーが好みのユーザーを表さない場合には、玩具は好みのユーザーに懐くことが少なくなり、カレント・ユーザーにより強く懐くようになる。従って、カレント・ユーザーは、玩具とのポジティブな交流を続けることで、好みのユーザーとなることが可能である。
【0017】
玩具との交流がネガティブであると考えられる場合、カレント・ユーザーが、蓄積された入力に含まれた好みのユーザーを表すプロパティと合致する程度において、学習消去プロセス(unlearning process)が、蓄積された入力を徐々に戻す、あるいは劣化させて、当該蓄積された入力は、好みのユーザーを表さなくなり、他のまたは一般的なバックグラウンド・ユーザーをより強く表すようになる。
【0018】
学習または学習消去の程度は、ケースに応じて、ユーザーからの交流がポジティブまたはネガティブであると分類される程度に比例する。機械語命令(ソフトウェア)は、検出した運動入力の加速度と、受け取った音声入力の振幅との閾値を含んでいる。
閾値を超える振幅の音声を受け取った場合、その声は、ネガティブな入力として分類され、叫び声またはノイズに相当するものとなる。同様に、閾値を超える加速度の動作は、ネガティブな入力として分類され、身体的虐待、投げ、あるいは落下に相当するものとなる。
また、ソフトウェアにより、CPU(12)が、サウンド入力のピッチ・パターンにおける標準的な偏差を、歌っているものとして特定することが可能となり、およびCPU(12)が、予め定めた最大閾値と最小閾値の間における標準的な加速を、揺さぶりとして特定することが可能となること、が予見できる。それらは、ポジティブな入力であると解釈される。
【0019】
ユーザーからの交流がポジティブであると考えられ、そして、カレント・ユーザーの特徴が、好みのユーザーのそれと近似している限り、換言すると、カレント・ユーザーの音声と好みのユーザーの音声(蓄積された入力で表わされる)とが近似する度合いが強い場合、頻度および(または)クオリティという点において、玩具からのポジティブな応答が増える。このポジティブな応答は、CPU(12)によって出力装置(26)に送られる命令によって形成される。
反対に、カレント・ユーザーの特徴が好みのユーザーのそれと一致しない場合、頻度および(または)クオリティという点において、玩具からのポジティブな応答は減少する。このポジティブな応答は、CPUによって出力装置(26)に送られる命令によって形成される。
【0020】
センサ(18)によって検出されたスピーチおよび動作等の入力に加えて、ソフトウェアにより、CPU(12)は、タイマー(14)をモニタリングして、所定時間よりも長く玩具との交流が無いことを特定する。これは、玩具を無視していることであり、ネガティブな入力として分類され、蓄積された入力に対してそのような影響を及ぼす。これは、好みのユーザーを学習消去することに繋がる。
【0021】
玩具のマクロな挙動は、図3の流れ図を参照してより単に説明できる。図3において、入力センサ(18)のうちの1つによって入力が検出されたとき(ステップ40)、CPU(12)は当該入力をポジティブかネガティブに分類し、ケースによって、ポジティブまたはネガティブの程度を測定する。さらにCPU(12)は、音声入力に関連する音声と、好みのユーザーのそれとの類似性の程度を決定する。図において、このステップは、「懐くユーザーに対する合致クオリティ」として示されている。
入力がポジティブに分類された場合(これはステップ42として示されている)、CPU(12)は、カレント・ユーザーのプロパティを学習するまたは強化するように命じられる。これは、蓄積された入力を、受け取った入力のポジティブな程度に比例して、好みのユーザーをより強く表すことで実現される(ステップ44)。その後、ステップ(46)において、CPU(12)は、出力装置(18)に指示を送る。この指示は、好みのユーザーに対するカレント・ユーザーの類似性の程度、および入力のポジティブな程度に比例している。
【0022】
ステップ(42)で入力がネガティブであるとされた場合、ステップ(48)において、CPU(12)は、カレント・ユーザーが現在の好みのユーザーでもあるのか、あるいは、入力が無視すべきものかどうかを決定する。カレント・ユーザーが現在の好みのユーザーではなく、入力が無視すべきものでもない場合には、ステップ(46)において、CPU(12)は、好みのユーザーに対するカレント・ユーザーの類似性の程度、および入力のネガティブな程度に比例する命令を、再度、出力装置(18)に送る。
しかしながら、ステップ(48)において、カレント・ユーザーが現在の好みのユーザーであると認定されるか、入力が無視すべきものであると認定されれば、CPU(12)は、入力のネガティブな程度に比例して、カレント・ユーザーのプロパティを学習消去(unlearn)するように命じられる(ステップ50)。この後、CPU(12)は、好みのユーザーに対するカレント・ユーザーの類似性の程度、および入力のネガティブな程度に比例して、出力装置(18)に指示を送る(ステップ46)。
【0023】
ステップ(46)で出力装置へ送られた命令を完了すると、CPU(12)は、次の入力の受取り、またはタイマーが交流無しを表示するのを待つ。
【0024】
本発明の別の実施形態を図2に示している。図2では、図1の実施形態と同じ特徴については、同じ数字で示している。図2の実施形態においても、デジタル中央処理装置(CPU)(12)が含まれる。この実施形態は、デジタル・タイマー(14)、不揮発性メモリ・モジュールとして与えられた記憶ユニット(16)、入力を検出する入力センサ(18)、マイクロホン(20)、および加速度計(22)を含んでいる。
この実施形態は、追加的に、デジタル映像記録装置(50)を含んでいる。それは、この実施形態においては、デジタルカメラである。この実施形態は、さらに、ユーザーとのコミュニケーションを図るための出力装置(24)を含んでいる。ここでも出力装置は、音響トランスデューサ(26)および動作アクチュエータ(28)を含んでいて、それらは、玩具の肢体(図示せず)に接続されている。
CPU(12)は、入力インターフェース(30)および出力インタフェース(32)を介して、それぞれ、入力センサ(18)および出力装置(26)に接続されている。入力インターフェース(30)は、アナログ・デジタル(A/D)コンバータ(34)を含んでいる。出力インタフェース(32)は、デジタル・アナログ(D/A)コンバータ(36)を含んでいる。ソフトウェア(図示せず)として与えられた機械語命令は、メモリ(16)または追加のメモリモジュール(38)に格納されていて、入力インターフェース(30)および出力インターフェース(32)、並びに関連するA/DコンバータおよびD/Aコンバータを駆動する。
【0025】
本発明のこの実施形態において、デジタルカメラ(50)を使用して、ユーザーの画像を周期的に捕らえてもよい。それは、例えば、ユーザーからの交流が検出されたときである。この画像を音声記録と組み合わせて、あるいは別々に用いて、好みのユーザーの顔を認識してもよい。デジタル画像を、メモリ(16)に格納された好みのユーザーの画像と比較するために使用できる、複雑な画像認識ソフトウェアは入手可能である。
上述したように、そして音声認識に関して更に以下に説明するように、画像認識ソフトウェアを使用して、カメラ(50)で撮影した好みのユーザーの画像と、後段階で撮影されるカレント・ユーザーの画像との類似性の程度を決定することができる。CPU(12)によって出力装置(24)に送られた制御信号もまた、カレント・ユーザーの画像と好みのユーザーの画像との類似性の程度に依存する。
【0026】
以上の説明は、玩具の動作全体を概観したものである。次に、ソフトウェアによって採用され、CPU(12)によって実施されるアルゴリズムについて、その詳細な分析を説明する。
アルゴリズム(それは、ソフトウェアまたはハードウェアで実行されるもので、メモリ(16)内に存在するものではない)は、CPU(12)上で実行され、カレント・ユーザーとの交流を評価し、それに基づいて好みのユーザーについての内部表現(蓄積された入力)を変更し、ユーザーとの交流の性質を決定する。
【0027】
ユーザーからの入力(この場合は、スピーチ)は、検出時にサンプリングされ、デジタルの形式でCPUが利用可能となる。この信号は、その後、デジタルで処理されて、関連する情報内容を決定する。様々な代替が可能であるが、この実施形態では、信号は、互いに50%オーバーラップする連続した30ミリセカンドのフレームへと細分される。
各フレームは、ウィンドウ生成機能(windowing function)によって形成され、そのパワーレベルおよびメル周波数ケプストラム係数(MFCCs)が決定される(RASTA PLP等、他の様々な分解も使用可能である)。これは、その与えられた時刻におけるピッチ周波数で増大される。
これらの情報すべてが、そのフレームに関連するスピーチ情報を要約する特徴ベクトルx(n)内に組み合わせられる。インデックスnは、このベクトルが決定された特定のフレーム番号を示している。情報を利用可能とした状態で、信号は、サイレントとスピーチのセグメントに分割できる。そのための実行(implementation)が幾つか知られている。
【0028】
同様に、加速度計から得られた入力は、玩具の動作を要約する他の特徴ベクトルy(n)内に集めることができる。
【0029】
x(n)から、信号出力(振幅)およびピッチ周波数の両方は、時間の関数として知られている。声の大きさは、この信号出力から直接決定される。音の大きさが予め定めた最小閾値と最大閾値の間にある場合、交流はポジティブであると考えられる。予め定めた時間長に音声が全く存在しない場合、それは無視、したがってネガティブと考えられる。一方、最大閾値を超える大きな声が存在する場合、それは叫び声、従ってこれもネガティブと考えられる。
【0030】
これらの態様を組み合わせて、所定時間長におけるクオリティメジャー(quality measure)とすることができる。これは、0を中立として、次のように表すことができる。
【0031】
話者の同一性を決定するために、統計モデルを使用して、ターゲットとなる話者と、一般的なバックグランドの話者との両方を記述する。ここでいう記述とは、話者の特徴をモデル化し、これを用いて、未知のスピーチサンプルと特定の話者との間におけるマッチィングを決定するという、特定の実行を意味するが、それを行う他の技術を排除するものではない。
この特許において、その正確な技術または実行は重要ではなく、一般的な話者認識および機械学習(パターン認識)という広い分野から利用可能な幾つかの候補が存在する。ここで説明したものの代わりとして、サポート・ベクター・マシン(SVM)あるいは他のポピュラーなパターン分類アプローチを使用することも可能である。
【0032】
一般的なバックグランドの話者は、ガウスの混合物モデル(GMM)を用いて表わされるもので、ここでは、ユニバーサル・バックグランド・モデル(UBM)と呼ぶ。その最も単純化した形態において、そのような混合物は、単一のガウス密度へと崩壊(collapse)し、その結果、コンピュータ上の要求を大きくに減じる。代表的に、UBMは、多数の話者のスピーチから集合的に訓練される。
【0033】
その後、このUBMは、MAP適合(Maximum a Posteriori adaptation)、MLLR(Maximum-Likelihood Linear Regression)、またはMLED(Maximum-Likelihood Eigendecomposition)等のプロセスを介して、ターゲットとなる特定の話者(この実施形態では、好みのユーザー)のスピーチに適合される。
訓練されたUBMパラメータは、安定した初期モデル評価を形成する。その後、初期モデル評価は、幾つかの方法で再度重み付けが行われ、好みのユーザーの特徴にさらによく似せる。このようにして、好みの話者モデルが作られる。以下に、このアプローチについて、さらに詳しく説明する。
【0034】
利用可能なUBMおよびターゲットの話者モデルを持つことで、好みのユーザーのモデルに対して未知のスピーチ・セグメントがどの程度マッチしているかについての近似性(closeness)を評価することができる。このことは、バックグランド話者のモデル(UBM)および好みのユーザーのモデル(蓄積された入力によって表わされている)の両方に対する当該スピーチ・セグメントの対数スコアを評価することで行われる。
これらのスコア間における差異は、LLRスコア(log-likelihood-ratio score)にほぼ等しく、好みのユーザーが与えられたスピーチにどれくらい良く一致しているのか、に直接変換される。
数学的には、n番目のフレームのLLRスコア、s(n)は、次式で表される。
上式において、fは、ガウスまたはGMM確率密度関数のいずれかを示す。下付文字T、Uは、それぞれ、ターゲット話者およびUBM話者を示す。
【0035】
シングルフレームに基づく決定は、不安定である。代表的には、その前にN個のフレームが集められる。Nは、10〜30秒の時間期間に対応して選択される。そのような各セグメントのスコアは、次式で与えられる。
大きなスコアは、そのスピーチが好みのユーザーにより発せられた可能性が大きい(類似性が高い)ことを示している。ゼロ値は、そのスピーチが一般的なバックグランド話者と区別できない(類似性が低い)ことを示している。ここでも、幾つかの代替案がある。
テスト標準化(TNORM)は、注目すべき別例であって、これは、単一のUBMを多くのバックグランド話者モデルで置き換える
【0036】
多次元のガウス密度は、意味/中心ベクトルmおよび共分散マトリクスCからなる。ガウス中心ベクトルのMAPアダプテーションは、既存の先の中心ベクトルおよび新しく観察されたターゲット特徴ベクトルの重み付けされた組合せを具体的に導き、そのとき共分散マトリクスCは変化せず、一定である。
ここでは、この考えを用いて、計算上効率的な方法によりシステムが、最近の話者の特徴を学習し、これと同時に以前の話者の特徴を徐々に学習消去していくことを可能にしている。
【0037】
単一のターゲットとなるガウス中心のアダプテーションが最初に記述され、その後、GMMに埋め込まれたガウス中心のアダプテーションにまで拡張される。玩具を最初に使用する前に、ターゲット中心は、UBMからクローニングされる。従ってこの段階では、好みのユーザーは、一般的なバックグランド話者と区別できない。
したがって、
Tはターゲットを、UはUBMを、nの値はアダプテーションタイムステップ(adaptation time step)を示している。なお、ターゲット中心は時間nの関数であるが、UBM中心は一定である。ここでターゲット特徴ベクトルは、ユーザーのスピーチから導き出されるもので、x(n)で表される。
ターゲット中心は、回帰法を用いて適合される。
ここで、λは小さな正の定数で、n=0、1、2・・・である。この差分方程式は、デジタルのローパスフィルタを表しており、そのDCゲインは1である。λの値が小さいほど、既存の中心値に対して大きな強調が置かれることとなり、新しく観察された特徴ベクトルに置かれる強調は小さくなる。
従ってλは、システムが過去の中心として有しているメモリの長さを有効に制御する。このメモリの有効長は、このフィルターのインパルス応答が、もとのインパルス高さの約10%に戻すのに要する時間に注目することで決定できる。
【0038】
このことを、次の表に要約して示す。
表1:異なるλの値に対するメモリの有効長。ミニッツ(minute)の長さは、15ミリ秒のタイムステップに基づく。
【0039】
従って、λ=10−5の場合、前の話者を学習消去し、新しい好みの話者に懐くには、約1時間の支持されるスピーチが必要である。このような学習率は、λを以下のように設定することで、対話(あるいは交流)の質により調整できる。
【0040】
より精巧なシステムは、ガウスの混合物モデル(GMM)を用いる。これは、上に説明したような単一のガウス密度の代わりに、K個のガウス要素モデルから成る。可能性のある特徴ベクトルx(n)が与えられた場合、i番目のガウス要素はfi(x(n))で与えられ、GMMからの可能性のある結果は、次のような加重和となるであろう。
wiは混合の重み付けで、i=1、2、…、Kである。
このようなモデルをアップデートするとき、ターゲットの特徴ベクトルx(n)は、様々なガウス要素と比例関係にあるだろう。全体として、1つのガウス要素だけと関係するのではない。これらの比例定数は、リスポンサビリティ(responsibilities)として知られており、次のように決定することができる。
【0041】
GMMのアダプテーションは、特徴ベクトルを比例して用いることで、対応して行われて、ガウス要素の各々をアップデートする。これにより、もとのアップデートされた漸化式は、次のように変更される。
このアダプテーションの方法を用いて、既存のユーザーに懐くことを、そのユーザーが交流を続ける限り、継続することができる。しかしながら、別のユーザーが玩具と交流を持ち始めれば、もとのユーザーの記憶は徐々に衰えて新しいユーザーのそれと置き換わっていくだろう。それは、まさに所望の挙動である。
【0042】
現在の好みのユーザーが玩具との交流を怠っている場合、我々は、彼(彼女)が玩具の記憶から消えて行くこと、別の言葉で表現すれば、玩具が彼(彼女)の声の特徴を学習消去すること、を望んでいる。このことは、周期的に下記余分の特徴ベクトルを適合プロセスに挿入することで達成される。
この余分の特徴ベクトルは、UBM中心から出てくるものである。それらの対応するリスポンサビリティ定数は、次式で表される。
【0043】
これは、好みのユーザーの特徴から離れるように、そして、一般的なバックグランド話者に近づくように、ターゲットモデルを移動させる。しかしながら、これらのベクトルの影響は、真のターゲット話者の入力ベクトルのそれよりも、はるかに小さく宣告されるべきである。
従って、それらは、大体20回のタイムフレーム(またはそれ以上)の後に挿入されるべきであり、この学習消去プロセスは、学習プロセスのほぼ20倍遅くなる。これは、2つの目的に役立つ。
第1に、ターゲットモデルは、UBMに向かって絶えず安定させられ、非本質的な外部ノイズに対して、ある種の頑固さを提供する。第2に、ユーザーが長期間の玩具を無視した場合、玩具は徐々にそのユーザーを“忘れる”。
【0044】
好みのユーザーが“虐待的”な挙動を示した場合、我々は、即座にそのユーザーを玩具のメモリから追い出したい。好みのユーザーは、高い識別スコアs(X)によって認識される。虐待の存在は、交流クオリティQの大きく否定的な値によって示される。それらが混在する場合には、次式で表される非常に増大させた値を用いて、直ちにこの手順の適用することで、上述の学習消去プロセスを加速させる。
【0045】
これは、素早くUBMに戻るようターゲットモデルを移動させるだろう。しかし、その場合でも、スピーチが好ましい話者から実際に発生したかも知れないという不確実性を依然として考慮に入れている。
【0046】
交流が、a)ポジティブであって、かつ、b)好みのユーザーに対するマッチ度合いが強い、と認められる限りにおいて、玩具からのポジティブな交流は、頻度およびクオリティの両面において増大する。これらは、玩具からの会話応答、可能な顔の表情のコントロール、肢体を使った動作で表現される。
【0047】
ここでの説明は、叫び声に対して静かで滑らかな音声を、あるいは、投げるまたは落ちるに対してソフトに締め付ける動作を、検出する特定の態様に関連している。しかし、そのようにする他の態様、および考えられる他のタイプのジェスチャが除外されるものではない。詳細な技術または態様は、本件特許においてクリティカルではない。
【0048】
さらに、ここでは説明していないが、好みの個人の顔を、その一般的な表情に基づいて識別する同様のプロセスを工夫することが可能である。それに対する1つのアプローチは、固有の顔表情の第1要素によって提供される一般的な顔に対して、好みの顔がそこからどの位逸れているのかを測定することである。
【0049】
以上の説明は単なる例示であって、多数の修正、応用、および他の態様が可能である。例えば、図示した要素に対して、置換、追加、修正が可能である。また、ここで説明した方法に対して、置換、配置変更、工程の追加をすることが可能である。さらに、デジタル的なものとして説明したすべての要素は、玩具のハードウェアに対して適切な変更が行われる場合には、アナログ回路によって同等に実施することができる。従って、以上の説明は、発明を限定するものではない。
【技術分野】
【0001】
本発明は、対話(あるいは交流、interaction)型玩具に関する。より詳細には、人間に懐く挙動を示す人形に関する。この懐く挙動(bonding behaviour)は、親と子の間で自然に行われる動作を模したものを意味する。本発明は、1人または複数の人間に対して、玩具が懐く挙動をシミュレートする方法も対象としている。
【背景技術】
【0002】
玩具、特に人形は、世界の人々に何百年もの間、所有されてきた。子供たちは、人形で遊び、対人関係を学び、時に安心感を覚える。子供(特に幼い子供)は、しばしば、人形との間に強い結付きを形成する。それは、子供の成長の一部を担う。多くの理由から、人形は大人にも所有される。審美的な特質または情緒的愛着から、コレクターのアイテムとなることもある。
【0003】
過去何年間に及ぶ技術的進歩により、人形は進化し、ますます洗練され、実際、生きているかのようになった。本件発明者は、人の限られた挙動をシミュレートできる人形の存在を知っている。例えば、泣く、眠る、話すである。さらには、食べる、あるいは排泄するといった身体機能をシミュレートできる人形も知っている。さらに、本件発明者は、マイクロホン、音響トランスデューサ、動作アクチュエータ、その他の電子機器が、人形に組み入れられていることも知っている。
【0004】
例えば、米国特許出願番号US2007/0128979(対話型の先端技術の人形)に開示された人形は、人間のような顔の表情を有し、人が話す特定の言葉を認識する。さらには、予め決められた質問および回答のシナリオに基づいて、生きた人間と特定の会話を続けることができる。
人形が話し言葉を認識するのは、当該人形に組み入れられたプロセッサで制御される会話−音声認識技術に基づいており、それは、人形が特定の人の音声を識別できるよう訓練されることを可能としており、その人に対する特定の役割(母親など)を担う。
人形は、顔の内部に動作アクチュエータを備えている。これにより、話し言葉と同時に(あるいは独立して)、目、口および頬が、予め決められた顔の表情を作り出し、これにより、ヒトの感情をシミュレートする。
限られた会話を行う能力は、この分野で広く知られている基本的な、音声−会話認識技術に基づいている。各シナリオにおいて、人形は、予め記録された質問をし、特定の回答を待つ。人形は、予期された回答を受けると、にこやかに応答する。回答が予期されたものでない場合、人形の応答は、やや不機嫌となる。
しかしながら、出願明細書には、人形が長期的に渡る学習能力を有するとの説明はない。そうではなく、人形の挙動は、主として現在のユーザーによる入力および内蔵時計に応答するステートマシン(state machine)で統治されているようだ。
【発明の概要】
【発明が解決しようとする課題】
【0005】
本発明は、対話型玩具を提供することを目的とする。より詳細には、人間に懐く挙動をシュミレートできる人形を提供することを目的としており、それは、上に概説した先行技術に対する改善である。
【課題を解決するための手段および発明の効果】
【0006】
本発明により提供される玩具は、本体を備えており、当該本体は、ヒトユーザーからの入力を受け取る、少なくとも1つの入力センサと、当該玩具が上記ユーザーと相互交流するための、少なくとも1つの出力装置と、入力センサおよび出力装置と交信するプロセッサと、プロセッサと交信するメモリと、を備える。
当該玩具は、以下のことを特徴とする。すなわち、プロセッサは、受け取った各入力を、ポジティブであるかネガティブであるかに分類し、当該分類に従って、メモリに記憶された蓄積された入力を調整し、蓄積された入力に依存する制御信号を、出力装置に送る、ようプログラムされており、それにより、ある期間に渡る一連の支配的なポジティブな入力に応答して、懐く挙動を強くするとともに、ある期間に渡る一連の支配的なネガティブな入力に応答して、懐く挙動を減じることを特徴としている。
【0007】
本発明の特徴は、さらに次の特徴を有する。
上記ヒトユーザーから受け取る入力は、音、動作、画像のうちの1または2以上に対応する、玩具とヒトとの相互交流に対応している。
上記プロセッサは、叫びに関連する音、および物理的虐待に関連する動作を、ネガティブな入力として分類する。
本発明の玩具は、少なくとも2つの入力センサを含み、第1のセンサは、音声およびその振幅を検出するマイクロフォンであり、第2のセンサは、玩具の動作および加速度を検出する加速度計である。
上記蓄積された入力は、少なくともある程度、玩具の好みのユーザーの音声を表している。
上記プロセッサは、マイクロフォンで受け取った音声入力と、蓄積された入力との類似度合いを決定するようプログラムされている。
上記蓄積された入力は、受け取った入力がポジティブであると分類されるときは、ユーザーをより強く表すように成るように調整され、上記類似度合いが低いとき、または、受け取った入力がネガティブであると分類されるときは、好みのユーザーを表す度合いが小さくなるか、または変化しない。
上記プロセッサは、予め決めた最大音声振幅に対して、それよりも大きい振幅の音声入力をネガティブな入力として分類し、それよりも小さい振幅の音声入力をポジティブな入力として分類するようにプログラムされている。
上記プロセッサは、予め決めた最大加速度閾値に対して、それよりも大きい加速度の動作入力をネガティブな入力として分類し、それよりも小さい加速度の動作入力をポジティブな入力として分類するようにプログラムされている。
上記プロセッサは、状況に応じて、受け取った入力のポジティブな度合い、またはネガティブな度合いを決定し、ポジティブまたはネガティブな度合いに比例して、蓄積された入力を調整するようにプログラムされている。
【0008】
本発明のさらなる特徴は、次の通りである。
玩具は、上記プロセッサと交信する計時手段を備えていて、プロセッサは、予め決めた時間長に対して、それよりも長く入力が無かったとき、それをネガティブな入力として分類し、それに応じて、好みのユーザーを表す度合いが低くなるよう蓄積された入力を調整するようにプログラムされている。
上記出力装置は、音響トランスデューサおよび動作アクチュエータの一方または両方を備えており、プロセッサは、受け取った音声入力の類似度合いが高い場合には、より頻繁に、および(または)よりクオリティの高い制御信号を、出力装置に送るようにプログラムされている。また、プロセッサは、受け取った音声入力の類似度合いが低い場合には、より低い頻度で、および(または)よりクオリティの低い制御信号を、出力装置に送るようにプログラムされている。
【0009】
本発明のさらなる特徴は、次の通りである。
上記蓄積された入力は、一般的なバックグランド話者に関連する音声から抽出された特徴の集合を含んでおり、当該特徴のそれぞれは、関連する多様な重み付けを有しており、重み付けられた特徴の集合は、好みのユーザーの音声を表している。
上記蓄積された入力が好みのユーザーの音声をより強く、またはより弱く表すこととなるように、上記特徴に関連する多様な重み付けが調整される。
上記蓄積された入力が現在の好みのユーザーの音声を表す程度が小さくなると、当該蓄積された入力が、少なくとも1人の別のユーザーの音声をより強く表すように成るよう調整され、蓄積された入力が、当該別のユーザーの音声を、現在の好みのユーザーのそれよりも強く表すように成った時、当該別のユーザーが新しい好みのユーザーになる。
【0010】
本発明により、次の方法が提供される。
すなわち、本発明の方法は、玩具がヒトに懐く挙動をシュミレートする方法であって、好みのユーザーを表す蓄積された入力を、当該玩具に関連するメモリに記憶するステップと、当該玩具に組み込まれた少なくとも1つの入力センサにより、ユーザーからの入力を受け取るステップと、受け取った入力を、ポジティブであるか、ネガティブであるかに分類するステップと、ポジティブな入力に応じて好みのユーザーをより強く表すように成るように、また、ネガティブな入力に応じて好みのユーザーをより弱く表すように成るように、蓄積された入力を調整するステップと、入力に応答して、蓄積された入力に依存する制御信号を、当該玩具の出力装置へ発するステップと、を含む。
【0011】
本発明の方法は次の点に特徴を有する。
すなわち、予め決めた振幅よりも大きな振幅の音声入力を受け取ったとき、当該入力をネガティブであると分類するステップと、予め決めた範囲の加速度を超える加速度の動作入力を受け取ったとき、当該入力をネガティブであると分類するステップと、予め決めた時間長よりも長い時間入力がなかったとき、それをネガティブな入力であると分類するステップと、を含む。
または、本発明の方法は、好みのユーザーの音声入力に対する受け取った音声入力の類似度合いを決定し、当該類似度合いに比例した制御信号を、玩具の出力装置へ発するステップを含む。
【図面の簡単な説明】
【0012】
【図1】本発明の第1実施形態において、人間に懐く挙動を示す玩具人形の内部コンポーネントを示す概略図。
【図2】図1の玩具人形の別実施形態を示す概略図。
【図3】本発明による玩具人形のマクロな挙動を示す流れ図。
【発明を実施するための形態】
【0013】
図1は、本発明の第1実施形態に関して、玩具人形(図示せず)の内部機能コンポーネント(10)を示している。人形は図示しない本体を備えているが、この人形本体は、あらゆる外観を為すことが可能である。例えば、乳幼児、よちよち歩きの幼児、動物、あるいは玩具キャラクター等である。
コンポーネント(10)は、人形内部の都合の良い位置に配置される。例えば、本体の胸腔内に配置すれば、本体によってコンポーネント(10)が保護される。玩具本体上の都合の良い位置を利用して、コンポーネントの中で定期的に交換あるいはメンテナンスが必要となる部分(例えば、電源またはバッテリーパック)へのアクセスを確保する。
【0014】
コンポーネント(10)は、必要な挙動をサポートするため、CPU(12)、記憶ユニット(16)、入力センサ(18)、出力装置(24)を含む。
CPUすなわちデジタル中央処理装置(12)は、計時手段(14)を含んでおり、この実施形態ではデジタル・タイマーである。記憶ユニット(16)は、不揮発性のメモリモジュールである。入力センサ(18)は、入力を検出するもので、この実施形態では、マイクロホン(20)および加速度計(22)である。出力装置(24)は、ユーザーとコミュニケーションをとる。
この実施形態において、出力装置は、玩具の腕(図示せず)に接続された音響トランスデューサ(26)および動作アクチュエータ(28)を含んでいる。玩具の動作を制御するために、動作アクチュエータ(28)は、玩具のいずれのアームに接続してもよい。CPU(12)は、入力インターフェース(30)および出力インタフェース(32)を介して、それぞれ、入力センサ(18)および出力装置(26)に接続されている。
入力インターフェース(30)は、アナログ−デジタル(A/D)コンバータ(34)を含んでいて、出力インタフェース(32)は、デジタル−アナログ(D/A)コンバータ(36)を含んでいる。ソフトウェア(図示せず)の形態で与えられる機械語命令(machine instruction)は、メモリ(16)あるいは増設メモリモジュール(38)に記憶されていて、入力インターフェース(30)および出力インターフェース(32)、並びに関連するA/DおよびD/Aコンバータを駆動する。また、機械語命令は、CPUに対して、入力センサを介して入力を受け取らせて、受け取った入力を処理させて、制御信号を出力装置へ送らせる、命令を含んでいる。
【0015】
玩具の挙動を統制する追加的なソフトウェアも、蓄積された入力変数と共にメモリ(16)に記憶されている。入力変数は、デジタル・モデル(図示せず)の形態であって、ユーザーの声および(または)挙動から抽出されたキャラクターまたはプロパティの修正から構成され、そこには、現時点での好みのユーザー、並びに好みのユーザーのキャラクターを、一般の他のユーザーと、どのようにして区別するかの基準が含まれる。
蓄積された入力は、可変な程度で、現時点での好みのユーザーを表していて、不揮発性メモリモジュール(16)に記憶される。
ソフトウェアは、さらに、音声およびスピーチ認識機能性、他の特徴抽出ソフトウェアを含んでいる。特徴抽出ソフトウェアは、プロセッサが受け取った入力を解析することを可能にし、また、それが現時点での好みのユーザーのデジタル・モデルに対応する程度を同プロセッサが決定することを可能にする。このようにして、受け取った音声入力の、蓄積された入力として表わされた好みのユーザーに対する、類似性の程度を作り出す。
【0016】
さらに、メモリ(16)は、次のようなソフトウェアを格納している。そのソフトウェアは、入力センサ(18)によって検出された入力をCPUが分析することを可能にし、その入力を本来的にポジティブであるかネガティブであるのかをCPUが分類することを可能し、受け取った入力に対して、ポジティブな程度またはネガティブな程度をCPUが割り当てることを可能にする。
仮に、入力を介して受け取ったカレント・ユーザーとの交流がポジティブであると考えられる場合、その入力は、当該カレント・ユーザーのプロパティを更に学習するために提供される。また、蓄積された入力は、更なるプロパティとしてアップデートされる。
カレント・ユーザーの更なるプロパティを、蓄積された入力に追加することにより、当該入力がポジティブに分類される限り、蓄積された入力がカレント・ユーザーをより強く表すこととなり、従って、当該カレント・ユーザーにますますより強く懐くようになる。カレント・ユーザーが好みのユーザーに近似する場合、蓄積された入力は、ますます強く好みのユーザーを表すようになり、当該カレント・ユーザーに対してより強く懐くようになる。
しかし、カレント・ユーザーが好みのユーザーを表さない場合には、玩具は好みのユーザーに懐くことが少なくなり、カレント・ユーザーにより強く懐くようになる。従って、カレント・ユーザーは、玩具とのポジティブな交流を続けることで、好みのユーザーとなることが可能である。
【0017】
玩具との交流がネガティブであると考えられる場合、カレント・ユーザーが、蓄積された入力に含まれた好みのユーザーを表すプロパティと合致する程度において、学習消去プロセス(unlearning process)が、蓄積された入力を徐々に戻す、あるいは劣化させて、当該蓄積された入力は、好みのユーザーを表さなくなり、他のまたは一般的なバックグラウンド・ユーザーをより強く表すようになる。
【0018】
学習または学習消去の程度は、ケースに応じて、ユーザーからの交流がポジティブまたはネガティブであると分類される程度に比例する。機械語命令(ソフトウェア)は、検出した運動入力の加速度と、受け取った音声入力の振幅との閾値を含んでいる。
閾値を超える振幅の音声を受け取った場合、その声は、ネガティブな入力として分類され、叫び声またはノイズに相当するものとなる。同様に、閾値を超える加速度の動作は、ネガティブな入力として分類され、身体的虐待、投げ、あるいは落下に相当するものとなる。
また、ソフトウェアにより、CPU(12)が、サウンド入力のピッチ・パターンにおける標準的な偏差を、歌っているものとして特定することが可能となり、およびCPU(12)が、予め定めた最大閾値と最小閾値の間における標準的な加速を、揺さぶりとして特定することが可能となること、が予見できる。それらは、ポジティブな入力であると解釈される。
【0019】
ユーザーからの交流がポジティブであると考えられ、そして、カレント・ユーザーの特徴が、好みのユーザーのそれと近似している限り、換言すると、カレント・ユーザーの音声と好みのユーザーの音声(蓄積された入力で表わされる)とが近似する度合いが強い場合、頻度および(または)クオリティという点において、玩具からのポジティブな応答が増える。このポジティブな応答は、CPU(12)によって出力装置(26)に送られる命令によって形成される。
反対に、カレント・ユーザーの特徴が好みのユーザーのそれと一致しない場合、頻度および(または)クオリティという点において、玩具からのポジティブな応答は減少する。このポジティブな応答は、CPUによって出力装置(26)に送られる命令によって形成される。
【0020】
センサ(18)によって検出されたスピーチおよび動作等の入力に加えて、ソフトウェアにより、CPU(12)は、タイマー(14)をモニタリングして、所定時間よりも長く玩具との交流が無いことを特定する。これは、玩具を無視していることであり、ネガティブな入力として分類され、蓄積された入力に対してそのような影響を及ぼす。これは、好みのユーザーを学習消去することに繋がる。
【0021】
玩具のマクロな挙動は、図3の流れ図を参照してより単に説明できる。図3において、入力センサ(18)のうちの1つによって入力が検出されたとき(ステップ40)、CPU(12)は当該入力をポジティブかネガティブに分類し、ケースによって、ポジティブまたはネガティブの程度を測定する。さらにCPU(12)は、音声入力に関連する音声と、好みのユーザーのそれとの類似性の程度を決定する。図において、このステップは、「懐くユーザーに対する合致クオリティ」として示されている。
入力がポジティブに分類された場合(これはステップ42として示されている)、CPU(12)は、カレント・ユーザーのプロパティを学習するまたは強化するように命じられる。これは、蓄積された入力を、受け取った入力のポジティブな程度に比例して、好みのユーザーをより強く表すことで実現される(ステップ44)。その後、ステップ(46)において、CPU(12)は、出力装置(18)に指示を送る。この指示は、好みのユーザーに対するカレント・ユーザーの類似性の程度、および入力のポジティブな程度に比例している。
【0022】
ステップ(42)で入力がネガティブであるとされた場合、ステップ(48)において、CPU(12)は、カレント・ユーザーが現在の好みのユーザーでもあるのか、あるいは、入力が無視すべきものかどうかを決定する。カレント・ユーザーが現在の好みのユーザーではなく、入力が無視すべきものでもない場合には、ステップ(46)において、CPU(12)は、好みのユーザーに対するカレント・ユーザーの類似性の程度、および入力のネガティブな程度に比例する命令を、再度、出力装置(18)に送る。
しかしながら、ステップ(48)において、カレント・ユーザーが現在の好みのユーザーであると認定されるか、入力が無視すべきものであると認定されれば、CPU(12)は、入力のネガティブな程度に比例して、カレント・ユーザーのプロパティを学習消去(unlearn)するように命じられる(ステップ50)。この後、CPU(12)は、好みのユーザーに対するカレント・ユーザーの類似性の程度、および入力のネガティブな程度に比例して、出力装置(18)に指示を送る(ステップ46)。
【0023】
ステップ(46)で出力装置へ送られた命令を完了すると、CPU(12)は、次の入力の受取り、またはタイマーが交流無しを表示するのを待つ。
【0024】
本発明の別の実施形態を図2に示している。図2では、図1の実施形態と同じ特徴については、同じ数字で示している。図2の実施形態においても、デジタル中央処理装置(CPU)(12)が含まれる。この実施形態は、デジタル・タイマー(14)、不揮発性メモリ・モジュールとして与えられた記憶ユニット(16)、入力を検出する入力センサ(18)、マイクロホン(20)、および加速度計(22)を含んでいる。
この実施形態は、追加的に、デジタル映像記録装置(50)を含んでいる。それは、この実施形態においては、デジタルカメラである。この実施形態は、さらに、ユーザーとのコミュニケーションを図るための出力装置(24)を含んでいる。ここでも出力装置は、音響トランスデューサ(26)および動作アクチュエータ(28)を含んでいて、それらは、玩具の肢体(図示せず)に接続されている。
CPU(12)は、入力インターフェース(30)および出力インタフェース(32)を介して、それぞれ、入力センサ(18)および出力装置(26)に接続されている。入力インターフェース(30)は、アナログ・デジタル(A/D)コンバータ(34)を含んでいる。出力インタフェース(32)は、デジタル・アナログ(D/A)コンバータ(36)を含んでいる。ソフトウェア(図示せず)として与えられた機械語命令は、メモリ(16)または追加のメモリモジュール(38)に格納されていて、入力インターフェース(30)および出力インターフェース(32)、並びに関連するA/DコンバータおよびD/Aコンバータを駆動する。
【0025】
本発明のこの実施形態において、デジタルカメラ(50)を使用して、ユーザーの画像を周期的に捕らえてもよい。それは、例えば、ユーザーからの交流が検出されたときである。この画像を音声記録と組み合わせて、あるいは別々に用いて、好みのユーザーの顔を認識してもよい。デジタル画像を、メモリ(16)に格納された好みのユーザーの画像と比較するために使用できる、複雑な画像認識ソフトウェアは入手可能である。
上述したように、そして音声認識に関して更に以下に説明するように、画像認識ソフトウェアを使用して、カメラ(50)で撮影した好みのユーザーの画像と、後段階で撮影されるカレント・ユーザーの画像との類似性の程度を決定することができる。CPU(12)によって出力装置(24)に送られた制御信号もまた、カレント・ユーザーの画像と好みのユーザーの画像との類似性の程度に依存する。
【0026】
以上の説明は、玩具の動作全体を概観したものである。次に、ソフトウェアによって採用され、CPU(12)によって実施されるアルゴリズムについて、その詳細な分析を説明する。
アルゴリズム(それは、ソフトウェアまたはハードウェアで実行されるもので、メモリ(16)内に存在するものではない)は、CPU(12)上で実行され、カレント・ユーザーとの交流を評価し、それに基づいて好みのユーザーについての内部表現(蓄積された入力)を変更し、ユーザーとの交流の性質を決定する。
【0027】
ユーザーからの入力(この場合は、スピーチ)は、検出時にサンプリングされ、デジタルの形式でCPUが利用可能となる。この信号は、その後、デジタルで処理されて、関連する情報内容を決定する。様々な代替が可能であるが、この実施形態では、信号は、互いに50%オーバーラップする連続した30ミリセカンドのフレームへと細分される。
各フレームは、ウィンドウ生成機能(windowing function)によって形成され、そのパワーレベルおよびメル周波数ケプストラム係数(MFCCs)が決定される(RASTA PLP等、他の様々な分解も使用可能である)。これは、その与えられた時刻におけるピッチ周波数で増大される。
これらの情報すべてが、そのフレームに関連するスピーチ情報を要約する特徴ベクトルx(n)内に組み合わせられる。インデックスnは、このベクトルが決定された特定のフレーム番号を示している。情報を利用可能とした状態で、信号は、サイレントとスピーチのセグメントに分割できる。そのための実行(implementation)が幾つか知られている。
【0028】
同様に、加速度計から得られた入力は、玩具の動作を要約する他の特徴ベクトルy(n)内に集めることができる。
【0029】
x(n)から、信号出力(振幅)およびピッチ周波数の両方は、時間の関数として知られている。声の大きさは、この信号出力から直接決定される。音の大きさが予め定めた最小閾値と最大閾値の間にある場合、交流はポジティブであると考えられる。予め定めた時間長に音声が全く存在しない場合、それは無視、したがってネガティブと考えられる。一方、最大閾値を超える大きな声が存在する場合、それは叫び声、従ってこれもネガティブと考えられる。
【0030】
これらの態様を組み合わせて、所定時間長におけるクオリティメジャー(quality measure)とすることができる。これは、0を中立として、次のように表すことができる。
【0031】
話者の同一性を決定するために、統計モデルを使用して、ターゲットとなる話者と、一般的なバックグランドの話者との両方を記述する。ここでいう記述とは、話者の特徴をモデル化し、これを用いて、未知のスピーチサンプルと特定の話者との間におけるマッチィングを決定するという、特定の実行を意味するが、それを行う他の技術を排除するものではない。
この特許において、その正確な技術または実行は重要ではなく、一般的な話者認識および機械学習(パターン認識)という広い分野から利用可能な幾つかの候補が存在する。ここで説明したものの代わりとして、サポート・ベクター・マシン(SVM)あるいは他のポピュラーなパターン分類アプローチを使用することも可能である。
【0032】
一般的なバックグランドの話者は、ガウスの混合物モデル(GMM)を用いて表わされるもので、ここでは、ユニバーサル・バックグランド・モデル(UBM)と呼ぶ。その最も単純化した形態において、そのような混合物は、単一のガウス密度へと崩壊(collapse)し、その結果、コンピュータ上の要求を大きくに減じる。代表的に、UBMは、多数の話者のスピーチから集合的に訓練される。
【0033】
その後、このUBMは、MAP適合(Maximum a Posteriori adaptation)、MLLR(Maximum-Likelihood Linear Regression)、またはMLED(Maximum-Likelihood Eigendecomposition)等のプロセスを介して、ターゲットとなる特定の話者(この実施形態では、好みのユーザー)のスピーチに適合される。
訓練されたUBMパラメータは、安定した初期モデル評価を形成する。その後、初期モデル評価は、幾つかの方法で再度重み付けが行われ、好みのユーザーの特徴にさらによく似せる。このようにして、好みの話者モデルが作られる。以下に、このアプローチについて、さらに詳しく説明する。
【0034】
利用可能なUBMおよびターゲットの話者モデルを持つことで、好みのユーザーのモデルに対して未知のスピーチ・セグメントがどの程度マッチしているかについての近似性(closeness)を評価することができる。このことは、バックグランド話者のモデル(UBM)および好みのユーザーのモデル(蓄積された入力によって表わされている)の両方に対する当該スピーチ・セグメントの対数スコアを評価することで行われる。
これらのスコア間における差異は、LLRスコア(log-likelihood-ratio score)にほぼ等しく、好みのユーザーが与えられたスピーチにどれくらい良く一致しているのか、に直接変換される。
数学的には、n番目のフレームのLLRスコア、s(n)は、次式で表される。
上式において、fは、ガウスまたはGMM確率密度関数のいずれかを示す。下付文字T、Uは、それぞれ、ターゲット話者およびUBM話者を示す。
【0035】
シングルフレームに基づく決定は、不安定である。代表的には、その前にN個のフレームが集められる。Nは、10〜30秒の時間期間に対応して選択される。そのような各セグメントのスコアは、次式で与えられる。
大きなスコアは、そのスピーチが好みのユーザーにより発せられた可能性が大きい(類似性が高い)ことを示している。ゼロ値は、そのスピーチが一般的なバックグランド話者と区別できない(類似性が低い)ことを示している。ここでも、幾つかの代替案がある。
テスト標準化(TNORM)は、注目すべき別例であって、これは、単一のUBMを多くのバックグランド話者モデルで置き換える
【0036】
多次元のガウス密度は、意味/中心ベクトルmおよび共分散マトリクスCからなる。ガウス中心ベクトルのMAPアダプテーションは、既存の先の中心ベクトルおよび新しく観察されたターゲット特徴ベクトルの重み付けされた組合せを具体的に導き、そのとき共分散マトリクスCは変化せず、一定である。
ここでは、この考えを用いて、計算上効率的な方法によりシステムが、最近の話者の特徴を学習し、これと同時に以前の話者の特徴を徐々に学習消去していくことを可能にしている。
【0037】
単一のターゲットとなるガウス中心のアダプテーションが最初に記述され、その後、GMMに埋め込まれたガウス中心のアダプテーションにまで拡張される。玩具を最初に使用する前に、ターゲット中心は、UBMからクローニングされる。従ってこの段階では、好みのユーザーは、一般的なバックグランド話者と区別できない。
したがって、
Tはターゲットを、UはUBMを、nの値はアダプテーションタイムステップ(adaptation time step)を示している。なお、ターゲット中心は時間nの関数であるが、UBM中心は一定である。ここでターゲット特徴ベクトルは、ユーザーのスピーチから導き出されるもので、x(n)で表される。
ターゲット中心は、回帰法を用いて適合される。
ここで、λは小さな正の定数で、n=0、1、2・・・である。この差分方程式は、デジタルのローパスフィルタを表しており、そのDCゲインは1である。λの値が小さいほど、既存の中心値に対して大きな強調が置かれることとなり、新しく観察された特徴ベクトルに置かれる強調は小さくなる。
従ってλは、システムが過去の中心として有しているメモリの長さを有効に制御する。このメモリの有効長は、このフィルターのインパルス応答が、もとのインパルス高さの約10%に戻すのに要する時間に注目することで決定できる。
【0038】
このことを、次の表に要約して示す。
表1:異なるλの値に対するメモリの有効長。ミニッツ(minute)の長さは、15ミリ秒のタイムステップに基づく。
【0039】
従って、λ=10−5の場合、前の話者を学習消去し、新しい好みの話者に懐くには、約1時間の支持されるスピーチが必要である。このような学習率は、λを以下のように設定することで、対話(あるいは交流)の質により調整できる。
【0040】
より精巧なシステムは、ガウスの混合物モデル(GMM)を用いる。これは、上に説明したような単一のガウス密度の代わりに、K個のガウス要素モデルから成る。可能性のある特徴ベクトルx(n)が与えられた場合、i番目のガウス要素はfi(x(n))で与えられ、GMMからの可能性のある結果は、次のような加重和となるであろう。
wiは混合の重み付けで、i=1、2、…、Kである。
このようなモデルをアップデートするとき、ターゲットの特徴ベクトルx(n)は、様々なガウス要素と比例関係にあるだろう。全体として、1つのガウス要素だけと関係するのではない。これらの比例定数は、リスポンサビリティ(responsibilities)として知られており、次のように決定することができる。
【0041】
GMMのアダプテーションは、特徴ベクトルを比例して用いることで、対応して行われて、ガウス要素の各々をアップデートする。これにより、もとのアップデートされた漸化式は、次のように変更される。
このアダプテーションの方法を用いて、既存のユーザーに懐くことを、そのユーザーが交流を続ける限り、継続することができる。しかしながら、別のユーザーが玩具と交流を持ち始めれば、もとのユーザーの記憶は徐々に衰えて新しいユーザーのそれと置き換わっていくだろう。それは、まさに所望の挙動である。
【0042】
現在の好みのユーザーが玩具との交流を怠っている場合、我々は、彼(彼女)が玩具の記憶から消えて行くこと、別の言葉で表現すれば、玩具が彼(彼女)の声の特徴を学習消去すること、を望んでいる。このことは、周期的に下記余分の特徴ベクトルを適合プロセスに挿入することで達成される。
この余分の特徴ベクトルは、UBM中心から出てくるものである。それらの対応するリスポンサビリティ定数は、次式で表される。
【0043】
これは、好みのユーザーの特徴から離れるように、そして、一般的なバックグランド話者に近づくように、ターゲットモデルを移動させる。しかしながら、これらのベクトルの影響は、真のターゲット話者の入力ベクトルのそれよりも、はるかに小さく宣告されるべきである。
従って、それらは、大体20回のタイムフレーム(またはそれ以上)の後に挿入されるべきであり、この学習消去プロセスは、学習プロセスのほぼ20倍遅くなる。これは、2つの目的に役立つ。
第1に、ターゲットモデルは、UBMに向かって絶えず安定させられ、非本質的な外部ノイズに対して、ある種の頑固さを提供する。第2に、ユーザーが長期間の玩具を無視した場合、玩具は徐々にそのユーザーを“忘れる”。
【0044】
好みのユーザーが“虐待的”な挙動を示した場合、我々は、即座にそのユーザーを玩具のメモリから追い出したい。好みのユーザーは、高い識別スコアs(X)によって認識される。虐待の存在は、交流クオリティQの大きく否定的な値によって示される。それらが混在する場合には、次式で表される非常に増大させた値を用いて、直ちにこの手順の適用することで、上述の学習消去プロセスを加速させる。
【0045】
これは、素早くUBMに戻るようターゲットモデルを移動させるだろう。しかし、その場合でも、スピーチが好ましい話者から実際に発生したかも知れないという不確実性を依然として考慮に入れている。
【0046】
交流が、a)ポジティブであって、かつ、b)好みのユーザーに対するマッチ度合いが強い、と認められる限りにおいて、玩具からのポジティブな交流は、頻度およびクオリティの両面において増大する。これらは、玩具からの会話応答、可能な顔の表情のコントロール、肢体を使った動作で表現される。
【0047】
ここでの説明は、叫び声に対して静かで滑らかな音声を、あるいは、投げるまたは落ちるに対してソフトに締め付ける動作を、検出する特定の態様に関連している。しかし、そのようにする他の態様、および考えられる他のタイプのジェスチャが除外されるものではない。詳細な技術または態様は、本件特許においてクリティカルではない。
【0048】
さらに、ここでは説明していないが、好みの個人の顔を、その一般的な表情に基づいて識別する同様のプロセスを工夫することが可能である。それに対する1つのアプローチは、固有の顔表情の第1要素によって提供される一般的な顔に対して、好みの顔がそこからどの位逸れているのかを測定することである。
【0049】
以上の説明は単なる例示であって、多数の修正、応用、および他の態様が可能である。例えば、図示した要素に対して、置換、追加、修正が可能である。また、ここで説明した方法に対して、置換、配置変更、工程の追加をすることが可能である。さらに、デジタル的なものとして説明したすべての要素は、玩具のハードウェアに対して適切な変更が行われる場合には、アナログ回路によって同等に実施することができる。従って、以上の説明は、発明を限定するものではない。
【特許請求の範囲】
【請求項1】
本体を備えた玩具であって、本体は、
ヒトユーザーからの入力を受け取る、少なくとも1つの入力センサ(18)と、
当該玩具が上記ユーザーと相互交流するための、少なくとも1つの出力装置(24)と、
入力センサ(18)および出力装置(24)と交信するプロセッサ(12)と、
プロセッサ(12)と交信するメモリ(16)と、を備えており、
以下のことを特徴とする、すなわち、
プロセッサ(12)は、
受け取った各入力を、ポジティブであるかネガティブであるかに分類し、
当該分類に従って、メモリ(16)に記憶された蓄積された入力を調整し、
蓄積された入力に依存する制御信号を、出力装置(24)に送る、ようプログラムされており、
それにより、ある期間に渡る一連の支配的なポジティブな入力に応答して、懐く挙動を強くするとともに、ある期間に渡る一連の支配的なネガティブな入力に応答して、懐く挙動を減じることを特徴とする、玩具。
【請求項2】
上記ヒトユーザーから受け取る入力は、音、動作、画像のうちの1または2以上に対応する、玩具とヒトとの相互交流に対応している、請求項1記載の玩具。
【請求項3】
上記プロセッサ(12)は、叫びに関連する音、および物理的虐待に関連する動作を、ネガティブな入力として分類する、請求項2記載の玩具。
【請求項4】
少なくとも2つの入力センサ(18)を含み、
第1のセンサは、音声およびその振幅を検出するマイクロフォン(20)であり、
第2のセンサは、玩具の動作および加速度を検出する加速度計(22)である、請求項1〜3のいずれか1つに記載の玩具。
【請求項5】
上記蓄積された入力は、少なくともある程度、玩具の好みのユーザーの音声を表している、請求項1〜4のいずれか1つに記載の玩具。
【請求項6】
上記プロセッサ(12)は、マイクロフォン(20)で受け取った音声入力と、蓄積された入力との類似度合いを決定するようプログラムされている、請求項4または5記載の玩具。
【請求項7】
上記蓄積された入力は、受け取った入力がポジティブであると分類されるときは、ユーザーをより強く表すように成るように調整され、
上記類似度合いが低いとき、または、受け取った入力がネガティブであると分類されるときは、好みのユーザーを表す度合いが小さくなるか、または変化しない、請求項6記載の玩具。
【請求項8】
上記プロセッサ(12)は、予め決めた最大音声振幅に対して、それよりも大きい振幅の音声入力をネガティブな入力として分類し、それよりも小さい振幅の音声入力をポジティブな入力として分類するようにプログラムされている、請求項1〜7のいずれか1つに記載の玩具。
【請求項9】
上記プロセッサ(12)は、予め決めた最大加速度閾値に対して、それよりも大きい加速度の動作入力をネガティブな入力として分類し、それよりも小さい加速度の動作入力をポジティブな入力として分類するようにプログラムされている、請求項1〜8のいずれか1つに記載の玩具。
【請求項10】
上記プロセッサ(12)は、状況に応じて、受け取った入力のポジティブな度合い、またはネガティブな度合いを決定し、
ポジティブまたはネガティブな度合いに比例して、蓄積された入力を調整するようにプログラムされている、請求項1〜9のいずれか1つに記載の玩具。
【請求項11】
上記プロセッサ(12)と交信する計時手段(14)を備えていて、
プロセッサ(12)は、予め決めた時間長に対して、それよりも長く入力が無かったとき、それをネガティブな入力として分類し、
それに応じて、好みのユーザーを表す度合いが低くなるよう蓄積された入力を調整するようにプログラムされている、請求項1〜10のいずれか1つに記載の玩具。
【請求項12】
上記出力装置(24)は、音響トランスデューサ(26)および動作アクチュエータ(28)の一方または両方を備えており、
プロセッサ(12)は、受け取った音声入力の類似度合いが高い場合には、より頻繁に、および(または)よりクオリティの高い制御信号を、出力装置(24)に送るようにプログラムされており、
プロセッサ(12)は、受け取った音声入力の類似度合いが低い場合には、より低い頻度で、および(または)よりクオリティの低い制御信号を、出力装置(24)に送るようにプログラムされている、請求項1〜11のいずれか1つに記載の玩具。
【請求項13】
上記蓄積された入力は、一般的なバックグランド話者に関連する音声から抽出された特徴の集合を含んでおり、
当該特徴のそれぞれは、関連する多様な重み付けを有しており、重み付けられた特徴の集合は、好みのユーザーの音声を表している、請求項1〜12のいずれか1つに記載の玩具。
【請求項14】
上記蓄積された入力が好みのユーザーの音声をより強く、またはより弱く表すこととなるように、上記特徴に関連する多様な重み付けが調整される、請求項13記載の玩具。
【請求項15】
上記蓄積された入力が現在の好みのユーザーの音声を表す程度が小さくなると、当該蓄積された入力が、少なくとも1人の別のユーザーの音声をより強く表すように成るよう調整され、
蓄積された入力が、当該別のユーザーの音声を、現在の好みのユーザーのそれよりも強く表すように成った時、当該別のユーザーが新しい好みのユーザーになる、請求項13または14記載の玩具。
【請求項16】
玩具がヒトに懐く挙動をシュミレートする方法であって、
好みのユーザーを表す蓄積された入力を、当該玩具に関連するメモリ(16)に記憶するステップと、
当該玩具に組み込まれた少なくとも1つの入力センサ(18)により、ユーザーからの入力を受け取るステップと、
受け取った入力を、ポジティブであるか、ネガティブであるかに分類するステップと、
ポジティブな入力に応じて好みのユーザーをより強く表すように成るように、また、ネガティブな入力に応じて好みのユーザーをより弱く表すように成るように、蓄積された入力を調整するステップと、
入力に応答して、蓄積された入力に依存する制御信号を、当該玩具の出力装置(26)へ発するステップと、を含む方法。
【請求項17】
予め決めた振幅よりも大きな振幅の音声入力を受け取ったとき、当該入力をネガティブであると分類するステップと、
予め決めた範囲の加速度以外の加速度の動作入力を受け取ったとき、当該入力をネガティブであると分類するステップと、
予め決めた時間長よりも長い時間入力がなかったとき、それをネガティブな入力であると分類するステップと、を含む請求項16記載の方法。
【請求項18】
好みのユーザーの音声入力に対する受け取った音声入力の類似度合いを決定し、当該類似度合いに比例した制御信号を、玩具の出力装置へ発するステップを含む、請求項16または17記載の方法。
【請求項1】
本体を備えた玩具であって、本体は、
ヒトユーザーからの入力を受け取る、少なくとも1つの入力センサ(18)と、
当該玩具が上記ユーザーと相互交流するための、少なくとも1つの出力装置(24)と、
入力センサ(18)および出力装置(24)と交信するプロセッサ(12)と、
プロセッサ(12)と交信するメモリ(16)と、を備えており、
以下のことを特徴とする、すなわち、
プロセッサ(12)は、
受け取った各入力を、ポジティブであるかネガティブであるかに分類し、
当該分類に従って、メモリ(16)に記憶された蓄積された入力を調整し、
蓄積された入力に依存する制御信号を、出力装置(24)に送る、ようプログラムされており、
それにより、ある期間に渡る一連の支配的なポジティブな入力に応答して、懐く挙動を強くするとともに、ある期間に渡る一連の支配的なネガティブな入力に応答して、懐く挙動を減じることを特徴とする、玩具。
【請求項2】
上記ヒトユーザーから受け取る入力は、音、動作、画像のうちの1または2以上に対応する、玩具とヒトとの相互交流に対応している、請求項1記載の玩具。
【請求項3】
上記プロセッサ(12)は、叫びに関連する音、および物理的虐待に関連する動作を、ネガティブな入力として分類する、請求項2記載の玩具。
【請求項4】
少なくとも2つの入力センサ(18)を含み、
第1のセンサは、音声およびその振幅を検出するマイクロフォン(20)であり、
第2のセンサは、玩具の動作および加速度を検出する加速度計(22)である、請求項1〜3のいずれか1つに記載の玩具。
【請求項5】
上記蓄積された入力は、少なくともある程度、玩具の好みのユーザーの音声を表している、請求項1〜4のいずれか1つに記載の玩具。
【請求項6】
上記プロセッサ(12)は、マイクロフォン(20)で受け取った音声入力と、蓄積された入力との類似度合いを決定するようプログラムされている、請求項4または5記載の玩具。
【請求項7】
上記蓄積された入力は、受け取った入力がポジティブであると分類されるときは、ユーザーをより強く表すように成るように調整され、
上記類似度合いが低いとき、または、受け取った入力がネガティブであると分類されるときは、好みのユーザーを表す度合いが小さくなるか、または変化しない、請求項6記載の玩具。
【請求項8】
上記プロセッサ(12)は、予め決めた最大音声振幅に対して、それよりも大きい振幅の音声入力をネガティブな入力として分類し、それよりも小さい振幅の音声入力をポジティブな入力として分類するようにプログラムされている、請求項1〜7のいずれか1つに記載の玩具。
【請求項9】
上記プロセッサ(12)は、予め決めた最大加速度閾値に対して、それよりも大きい加速度の動作入力をネガティブな入力として分類し、それよりも小さい加速度の動作入力をポジティブな入力として分類するようにプログラムされている、請求項1〜8のいずれか1つに記載の玩具。
【請求項10】
上記プロセッサ(12)は、状況に応じて、受け取った入力のポジティブな度合い、またはネガティブな度合いを決定し、
ポジティブまたはネガティブな度合いに比例して、蓄積された入力を調整するようにプログラムされている、請求項1〜9のいずれか1つに記載の玩具。
【請求項11】
上記プロセッサ(12)と交信する計時手段(14)を備えていて、
プロセッサ(12)は、予め決めた時間長に対して、それよりも長く入力が無かったとき、それをネガティブな入力として分類し、
それに応じて、好みのユーザーを表す度合いが低くなるよう蓄積された入力を調整するようにプログラムされている、請求項1〜10のいずれか1つに記載の玩具。
【請求項12】
上記出力装置(24)は、音響トランスデューサ(26)および動作アクチュエータ(28)の一方または両方を備えており、
プロセッサ(12)は、受け取った音声入力の類似度合いが高い場合には、より頻繁に、および(または)よりクオリティの高い制御信号を、出力装置(24)に送るようにプログラムされており、
プロセッサ(12)は、受け取った音声入力の類似度合いが低い場合には、より低い頻度で、および(または)よりクオリティの低い制御信号を、出力装置(24)に送るようにプログラムされている、請求項1〜11のいずれか1つに記載の玩具。
【請求項13】
上記蓄積された入力は、一般的なバックグランド話者に関連する音声から抽出された特徴の集合を含んでおり、
当該特徴のそれぞれは、関連する多様な重み付けを有しており、重み付けられた特徴の集合は、好みのユーザーの音声を表している、請求項1〜12のいずれか1つに記載の玩具。
【請求項14】
上記蓄積された入力が好みのユーザーの音声をより強く、またはより弱く表すこととなるように、上記特徴に関連する多様な重み付けが調整される、請求項13記載の玩具。
【請求項15】
上記蓄積された入力が現在の好みのユーザーの音声を表す程度が小さくなると、当該蓄積された入力が、少なくとも1人の別のユーザーの音声をより強く表すように成るよう調整され、
蓄積された入力が、当該別のユーザーの音声を、現在の好みのユーザーのそれよりも強く表すように成った時、当該別のユーザーが新しい好みのユーザーになる、請求項13または14記載の玩具。
【請求項16】
玩具がヒトに懐く挙動をシュミレートする方法であって、
好みのユーザーを表す蓄積された入力を、当該玩具に関連するメモリ(16)に記憶するステップと、
当該玩具に組み込まれた少なくとも1つの入力センサ(18)により、ユーザーからの入力を受け取るステップと、
受け取った入力を、ポジティブであるか、ネガティブであるかに分類するステップと、
ポジティブな入力に応じて好みのユーザーをより強く表すように成るように、また、ネガティブな入力に応じて好みのユーザーをより弱く表すように成るように、蓄積された入力を調整するステップと、
入力に応答して、蓄積された入力に依存する制御信号を、当該玩具の出力装置(26)へ発するステップと、を含む方法。
【請求項17】
予め決めた振幅よりも大きな振幅の音声入力を受け取ったとき、当該入力をネガティブであると分類するステップと、
予め決めた範囲の加速度以外の加速度の動作入力を受け取ったとき、当該入力をネガティブであると分類するステップと、
予め決めた時間長よりも長い時間入力がなかったとき、それをネガティブな入力であると分類するステップと、を含む請求項16記載の方法。
【請求項18】
好みのユーザーの音声入力に対する受け取った音声入力の類似度合いを決定し、当該類似度合いに比例した制御信号を、玩具の出力装置へ発するステップを含む、請求項16または17記載の方法。
【図1】

【図2】
【図3】
【図2】
【図3】
【公表番号】特表2012−519501(P2012−519501A)
【公表日】平成24年8月30日(2012.8.30)
【国際特許分類】
【出願番号】特願2011−538069(P2011−538069)
【出願日】平成21年11月27日(2009.11.27)
【国際出願番号】PCT/IB2009/007585
【国際公開番号】WO2010/061286
【国際公開日】平成22年6月3日(2010.6.3)
【出願人】(510337919)ステレンボッシュ ユニバーシティ (4)
【氏名又は名称原語表記】STELLENBOSCH UNIVERSITY
【Fターム(参考)】
【公表日】平成24年8月30日(2012.8.30)
【国際特許分類】
【出願日】平成21年11月27日(2009.11.27)
【国際出願番号】PCT/IB2009/007585
【国際公開番号】WO2010/061286
【国際公開日】平成22年6月3日(2010.6.3)
【出願人】(510337919)ステレンボッシュ ユニバーシティ (4)
【氏名又は名称原語表記】STELLENBOSCH UNIVERSITY
【Fターム(参考)】
[ Back to top ]