
手描き入力方法
【課題】手描き文字の編集を容易にする技術を提供する。
【解決手段】ユーザによって入力される文字の軌跡を一連の座標データとして検出し、前記ステップで検出した一連の座標データを所定条件に基づいて区切り、区切られた各座標データを手描き文字データとし、前記手描き文字データを所定書式情報に基づき表示領域に表示させる。ここで、前記手描き文字データの文字認識を行い、当該手描き文字データの文字コードを特定し、各手描き文字データと文字コードを対応付けて記憶部に記憶させても、連続する前記文字コードを辞書データと比較して、単語又は文節の区切りの情報を求め、前記書式情報に追加しても良い。
【解決手段】ユーザによって入力される文字の軌跡を一連の座標データとして検出し、前記ステップで検出した一連の座標データを所定条件に基づいて区切り、区切られた各座標データを手描き文字データとし、前記手描き文字データを所定書式情報に基づき表示領域に表示させる。ここで、前記手描き文字データの文字認識を行い、当該手描き文字データの文字コードを特定し、各手描き文字データと文字コードを対応付けて記憶部に記憶させても、連続する前記文字コードを辞書データと比較して、単語又は文節の区切りの情報を求め、前記書式情報に追加しても良い。
【発明の詳細な説明】
【技術分野】
【0001】
本件は、手描き文字入力の技術に関する。
【背景技術】
【0002】
紙にペンで文字を手描きする際に、ペンの位置座標を検出器で検出してコンピュータに入力し、このコンピュータが入力された位置座標に基づき、手描きされた文字を表示装置に表示するシステムが知られている(特許文献1)。
また、電子ホワイトボードの手描き入力を行う場合に、入力済の文字に基づいて次の文字候補を示し、この候補から入力する文字を選択することで、手描き入力をより簡易にするシステムも提案されている(特許文献2)。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開2009−86769号公報
【特許文献2】特開2007−265171号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
上述のように手描き入力を行うシステムでは、入力された文字が図形(ベクトルデータ)やイメージとして扱われるので、テキストデータのようには自由に編集出来ないという問題点があった。例えば、手描き文字の字詰めを変更して並べ変えることや、一部の文字を削除し、以降の文字を繰り上げるといった編集を行うことはできない。
このため、入力された手描き文字を文字認識処理によりテキストデータに変換し、編集を可能にするシステムも知られている。
しかし、文字認識を行うシステムでは、手描き入力した際に複数の抽出される変換候補を逐次選択する必要があり、紙にメモをとるようにスムーズに入力を行うことはできなかった。
また、文字認識後は、各文字の文字コードに対応するフォントが表示されるため、手描きで入力したユーザの筆跡を残すことができなかった。
そこで、本発明は、手描き文字の編集を容易に可能とする技術の提供を目的とする。
【課題を解決するための手段】
【0005】
上記の課題を解決するため、本発明の手描き入力方法は、
ユーザによって入力される文字の軌跡を一連の座標データとして検出するステップと、
前記ステップで検出した一連の座標データを所定条件に基づいて区切り、区切られた各座標データを手描き文字データとするステップと、
前記手描き文字データに基づき表示領域に手描き文字を表示させるステップと、
をコンピュータが実行する。
【0006】
また、本発明の手描き入力装置は、
ユーザによって入力される文字の軌跡を一連の座標データとして検出する入力検出部と、
前記入力検出部で検出した一連の座標データを所定条件に基づいて区切り、区切られた各座標データを手描き文字データとする文字区切り認識部と、
前記手描き文字データに基づき表示領域に手描き文字を表示させる表示制御部とを備えた。
【0007】
また、上記課題を解決するため、本発明は上記手描き入力方法をコンピュータに実行させるための手描き入力プログラムであつても良い。更に、この手描き入力プログラムをコンピュータが読み取り可能な記録媒体に記録しても良い。コンピュータに、この記録媒体のプログラムを読み込ませて実行させることにより、その機能を提供させることができる。
【0008】
ここで、コンピュータが読み取り可能な記録媒体とは、データやプログラム等の情報を電気的、磁気的、光学的、機械的、または化学的作用によって蓄積し、コンピュータから読み取ることができる記録媒体をいう。このような記録媒体の内コンピュータから取り外し可能なものとしては、例えばフレキシブルディスク、光磁気ディスク、CD-ROM、CD-R/W、DVD、DAT、8mmテープ、メモリカード等がある。
【0009】
また、コンピュータに固定された記録媒体としてハードディスクやROM(リードオンリーメモリ)等がある。
【発明の効果】
【0010】
本発明は、手描き文字の編集を容易にする技術を提供できる。
【図面の簡単な説明】
【0011】
【図1】手描き文字入力の説明図
【図2】手描き文字入力の説明図
【図3】手描き入力装置の概略構成図
【図4】手描き入力方法の説明図
【図5】手描き文字の修飾処理の説明図
【図6】手描き文字の修飾処理の説明図
【図7】仮名漢字混じりの変換例1の説明図
【図8】仮名漢字混じりの変換例3の説明図
【図9】表計算に適用した例を示す図
【図10】表計算に適用した例を示す図
【図11】書き流しモードの入力処理の説明図
【図12】仮名漢字変換処理の説明図
【図13】変換例を示す図
【発明を実施するための形態】
【0012】
以下、図面を参照して本発明を実施するための最良の形態について説明する。以下の実施の形態の構成は例示であり、本発明は実施の形態の構成に限定されない。
【0013】
〈実施形態1〉
1.手描き文字入力の概要
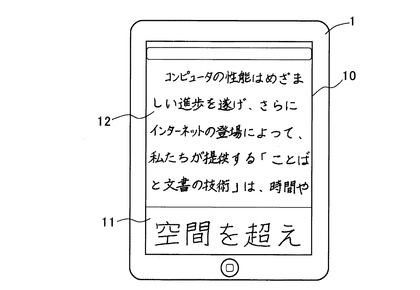
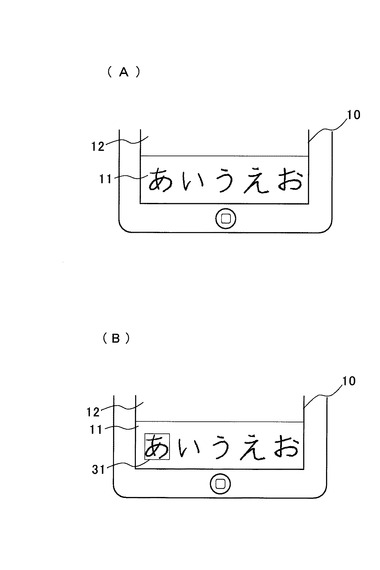
図1において、1は本発明の手描き入力方法を採用したコンピュータ(手描き入力装置)であり、ディスプレイ10の表面にタッチパネルを備え、タッチパネルの手描き入力欄11に対してユーザが手描き入力を行うと、その軌跡を検出して表示欄(表示領域)12に手描き文字列を表示する。この手描き文字列は、従来、そのページ毎にベクトルデータやイメージデータで示していた為、文字単位での編集を行うことができなかった。
【0014】
例えば、表示欄12を狭く変更する場合、そのページを縮小して幅を狭めることになるので、手描き文字も同率で縮小されて読み難くなってしまうことがあった。また、従来の手描き文字列は、行の途中で折り返して字詰めを変えたり、一部の文字を削除して以降の文字を繰り上げるように、文字の並びを変更したりといった編集ができなかった。
【0015】
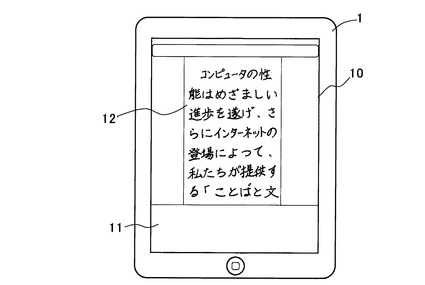
これに対し、本実施形態の手描き入力方法では、一文字毎に文字の区切りを認識し、文字毎のストロークデータ或いはイメージデータで表しているので、図2のように表示欄12の幅を変えて、文字の折り返し位置を変更するような編集を可能にしている。
【0016】
2.手描き入力装置の構成
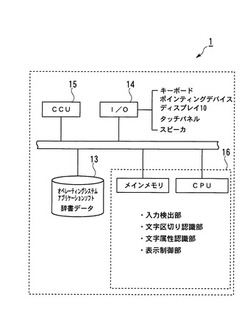
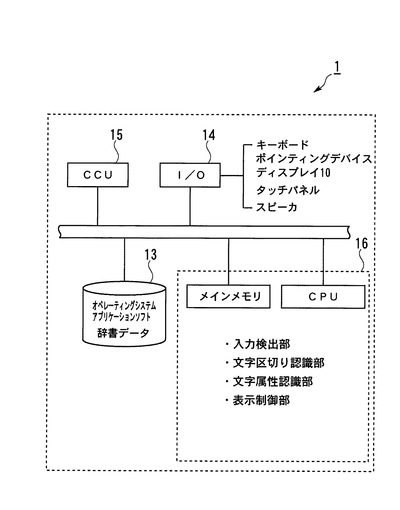
図3は、本実施形態における手描き入力装置1の概略構成図である。図3に示すように、手描き入力装置1は、本体内にCPU(central processing unit)やメインメモリ等
よりなる演算処理部16、演算処理の為のデータやソフトウェアを記憶した記憶部(フラッシュメモリ)13、入出力ポート14、通信制御部(CCU:Communication Control Unit)15等を備えたコンピュータである。
【0017】
該入出力ポート14には、キーボード(操作ボタン等)やポインティングデバイス、記憶媒体(メモリカード等)の読み取り装置、タッチパネル等の入力デバイス、そしてディスプレイ10や記憶媒体の書き込み装置、スピーカ等の出力デバイスが適宜接続される。
CCU15は、ネットワークを介して他のコンピュータと通信を行うものである。
【0018】
記憶部13には、オペレーティングシステム(OS)やアプリケーションソフト(手描き入力プログラム)、辞書データ等がインストールされている。
【0019】
演算処理部16は、前記OSやアプリケーションプログラムを記憶部13から適宜読み出して実行し、入出力ポート14やCCU15から入力された情報、及び記憶部13から読み出した情報を演算処理することにより、入力検出部や、文字区切り認識部、文字整形部、文字属性認識部、表示制御部としても機能する。
【0020】
この入力検出部としては、ユーザによってタッチパッドの入力欄11に入力される文字の軌跡を一連の座標データとして検出する。
【0021】
文字区切り認識部としては、入力検出部で検出した一連の座標データを所定条件に基づいて区切り、区切られた各座標データを手描き文字データとする。
【0022】
文字整形部は、文字区切り認識部で区切られた手描き文字データをストロークデータ等の所定フォーマットに整形する。
【0023】
文字属性認識部としては、前記手描き文字データの書き順や文字の形等の特徴に基づいて対応する文字コードを求める。例えば、手描き文字データの書き順や文字の形等の特徴と文字コードとを対応付けた文字コードデータベースを記憶部13に記憶させておき、ユーザによって入力された手描き文字データの特徴と類似する特徴と対応する文字コードを辞書データベースから抽出する。抽出した文字コードは、当該手描き文字データの属性情報としてメモリ或いは記憶部13に記憶する。
【0024】
表示制御部としては、前記手描き文字データに基づきディスプレイ10の表示領域12に手描き文字を表示させる。
【0025】
3.手描き入力方法
図4は、上記構成の手描き入力装置が、手描き入力プログラムに従って実行する手描き入力方法の説明図である。
先ず、ユーザによってタッチパネルの入力欄11に対して手描き入力が行われると、入力検出部は、この入力された文字の軌跡を一連の座標データとして検出する(ステップS1)。
【0026】
次に文字区切り認識部は、ステップS1で検出した一連の座標データを所定条件に基づいて一文字毎のデータに区切り、区切られた各座標データを手描き文字データとする(ステップS2)。
【0027】
文字属性認識部は、ステップS2で求めた手描き文字データの書き順や文字の形等の特徴に基づき、文字コードデータベースを参照して対応する文字コードを求め、当該手描き文字データの属性情報とする(ステップS3)。なお、この文字コードの候補が複数抽出された場合には、この複数の文字コードを全て或いは所定数を属性情報としても良い。更に文字コードを抽出する際、手描き文字データの特徴の類似度が高い順に優先度を付しても良い。
【0028】
また、文字属性認識部は、前記文字コードを辞書データと比較して、仮名漢字変換を行う(ステップS4)。
【0029】
また、文字属性認識部は、前記文字コードを辞書データと比較する際、単語又は文節の区切りの情報を求めても良い。
【0030】
そして、表示制御部は、前記手描き文字データに基づきディスプレイ10の表示欄12に所定の書式で手描き文字を表示させる(ステップS5)。ここで、所定の書式とは、文字の大きさ、1行の文字数、文字間隔、行間隔、左寄せ、禁則処理などである。所定の書式は、予め設定しておくものでも良いし、入力時に選択するものでも良い。
【0031】
以上のように、本実施形態によれば、手描き文字データを区切り、一文字毎に管理できるので、入力した手描き文字データの編集が容易となる。
【0032】
4.文字区切り処理
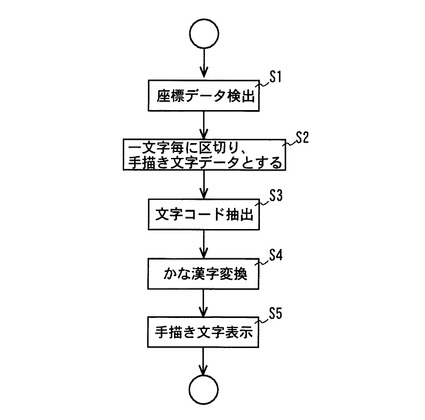
図5は、入力された手描き文字の区切りを判定する処理の説明図である。
先ず、ユーザが入力欄11に対してタッチペンで図5(A)のように文字を手描きすると、タッチパネルは、このタッチペンの接触箇所(ポイント)を検出し、その座標を逐次演算処理部16に入力する。即ち、文字を描いた際の接触ポイントの移動軌跡を次のような一連の座標データとする。
(54 , 58) (56 , 58) (58 , 58) ・・・・(247 , 68)
(249 , 68) (251 , 68) (253 , 68) ・・・(147 , 10)
(54 , 58) (56 , 58) (58 , 58) ・・・・(247 , 68)
(249 , 68) (251 , 68) (253 , 68) ・・・(147 , 10)
(54 , 58) (56 , 58) (58 , 58) ・・・・(247 , 68)
(249 , 68) (251 , 68) (253 , 68) ・・・(147 , 10)
:
:
【0033】
そして、文字区切り認識部は、この座標データに基づき、図5(B)に示すように手描き文字を囲む矩形31を設定する。ここで矩形31の高さは前記座標データが収まる高さとし、矩形31の幅は、幅方向に連続する座標が途切れ、所定以上の距離が空いたことを条件に、ここを文字の区切りと判定し、この区切りまでの座標が収まる幅に設定する。
【0034】
また、矩形31の高さに対する幅の比率が所定値より小さい場合、即ち矩形31の幅が狭い縦長の形状であった場合、1やI、!など、縦長の文字とのパターンマッチングを行
い、一致した場合には文字区切りを確定し、そうでない場合には隣接する矩形内の座標データと合わせて漢字とのパターンマッチングを行い、一致したことを条件に、この合わせた座標データを一文字の漢字として矩形を設定し、区切りを変更する。
【0035】
文字整形部は、上記手描き文字データとしての一連の座標データをストロークデータ等の所定フォーマットに整形する。
例えば、以下のフォーマットで各ストロークの通過点や方向を示す。
(character
(value 文字コード)
(width 矩形幅)
(height 矩形高さ)
(strokes
((1画1点目のx y) (1画2点目のx y) ... (1画n点目のx y))
((2画1点目のx y) (2画2点目のx y) ... (2画n点目のx y))
((3画1点目のx y) (3画2点目のx y) ... (3画n点目のx y))
...))
【0036】
このように、strokesに続く()で綴じられているデータが一つのストロークを示し、
各ストロークを示す()内の各xy座標が各ストロークの通過点を示す。なお、各ストロークの通過点を示すxy座標は、width,heightで定義した各文字の矩形の左上を原点と
した当該矩形内の座標を示す。
【0037】
具体的には、例えば以下のようなデータとする。
(character (value あ) (width 300) (height 300) (strokes ((54 58)(249 68)) ((147 10)(145 201)(182 252)) ((224 103)(149 230)(82 240)(53 204)(86 149)(182 139)(240 172)(248 224)(228 250))))
このxy座標で示される通過点を通るように各ストロークをスプライン曲線で描画することで、文字を表示する。
【0038】
5.修飾処理
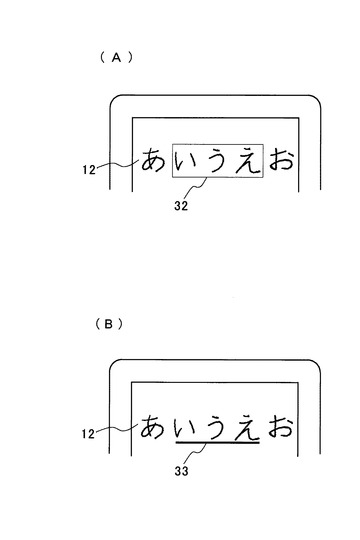
上記のように、本実施形態では、手描き文字を文字単位で区切ったデータとしたため、この各文字の手描き文字データに属性情報を付加することで、文字毎に修飾することができる。図6は手描き文字の修飾処理の説明図である。
【0039】
例えば、図6(A)に示すようにユーザがディスプレイ10に表示されている文字を範囲指定して修飾を指定した場合、この範囲指定32された文字列の前後に当該修飾を示すタグを挿入する。
【0040】
図6(B)では、文字列「あいうえお」のうち、範囲指定した文字「いうえ」にアンダーライン33を付加した場合の表示例を示している。この場合、次のようにアンダーラインを示すタグ(<u>〜</u>)を挿入する。
(character (value あ) (width 300) (height 300) (strokes ((54 58)(249 68)) ((147 10)(145 201)(182 252)) ((224 103)(149 230)(82 240)(53 204)(86 149)(182 139)(240 172)(248 224)(228 250))))
<u>
(character (value い) (width 300) (height 300) (strokes ((56 63)(43 213)(67 259)(94 243)) ((213 66)(231 171)(208 217))))
(character (value う) (width 300) (height 300) (strokes ((102 35)(187 45)) ((73 121)(167 105)(206 139)(198 211)(135 275))))
(character (value え) (width 300) (height 300) (strokes ((140 19)(162 38)) ((62 105)(208 100)(51 263)(128 205)(188 268)(260 252))))
</u>
(character (value お) (width 300) (height 300) (strokes ((64 94)(240 98)) ((148
35)(159 129)(140 199)(105 247)(64 228)(101 161)(192 161)(222 223)(189 257)) ((223 49)(253 89))))
【0041】
なお、アンダーラインに限らず、取り消し線、罫線、網掛け、太字、イタリック体、右寄せ、左寄せ、センターリング、色指定などの修飾も同様に行うことができる。
【0042】
また、図6(B)に示すように複数の文字にアンダーラインを付す場合、各文字だけでなく、文字間についても連続して設けるように表示するのが良い。この文字間についても連続して修飾することは、取り消し線や罫線、網掛けなどについても同じである。
【0043】
6.仮名漢字混じりの単語の変換処理
文字属性認識部は、入力された文字が仮名であった場合、図4のステップS4に示したように、漢字に変換することができる。
【0044】
なお、キーボードを用いた入力では、必ず仮名を入力し、これを漢字に変換する処理であるため、単語の読み仮名と漢字とを対応付けた辞書を参照し、単語の読み仮名をインデックスとして対応する漢字を抽出することで変換を行っている。
【0045】
これに対し、本実施形態では、手書きで文字を入力するため、漢字で入力することができ、漢字と仮名が混在した入力が行われることがある。
【0046】
例えば、「議事録」と入力する場合に「ぎ事録」や「ぎ事ろく」「ぎじ録」と入力されることがある。この場合、読み仮名が単語の一部分しかなく、従来のように単語の読み仮名と漢字を対応させた辞書ではインデックスが一致せず、単語としては検索できないため、効率良く変換を行うことができない。
【0047】
そこで、本実施形態では、仮名漢字混じりの単語が入力された場合に効率良く変換するために以下の処理を採用した。なお、この変換処理を行う場合の変換単位は、入力欄11に入力された手描き文字を所定時間間隔で変換する構成であっても良いし、ユーザが変換ボタン(不図示)を選択する等の操作によって変換指示を受けた際に入力欄11に入力されている手描き文字を変換する構成であっても良い。
【0048】
(6−1)変換例1
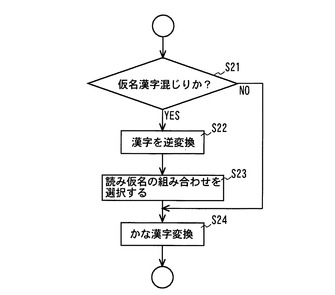
図7は仮名漢字混じりの変換例1の説明図である。
図4のステップS3で求めた文字コードに漢字が含まれているか否かを判定し(ステップS21)、漢字が含まれていれば、漢字読み辞書を参照して逆変換し、当該漢字の読み仮名を求める(ステップS22)。なお、漢字読み辞書は、漢字とその読みとを対応付けた辞書データであり、記憶部13に格納しておく。
【0049】
次にステップS22で求めた漢字の読みのうち、前後の文字との組み合わせが妥当なものを選択する(ステップS23)。
【0050】
例えば入力された文字が「ぎ事ろく」であった場合、ステップS21で漢字「事」が含まれていると判定し、この漢字「事」の読み仮名として「じ」「こと」が抽出され、この組み合わせは、「ぎじ」「ぎこと」「じろく」「ことろく」となる。
【0051】
文字属性認識部は、この読み仮名の組み合わせのうち、仮名漢字変換辞書のインデックスと一致するものを選択する。即ち、単語として意味をなす「ぎじ」を選択する。
【0052】
そして文字属性認識部は、ステップS23で選択した読み仮名を用いて「ぎじろく」を
仮名漢字変換する(ステップS24)。
【0053】
このように本例によれば、仮名漢字混じりの単語が入力されても漢字を仮名に逆変換してから、単語単位で仮名漢字変換を行うので、適切な変換を行うことができる。
【0054】
なお、前記漢字読み辞書は、仮名漢字変換辞書の単漢字変換用のデータを利用しても良い。この単漢字変換用のデータは、単漢字の読み仮名をインデックスとして単漢字を索出するものであるので、本例では、これを逆に利用し、単漢字をインデックスとして読み仮名を索出すれば良い。但し、本例の逆変換を行うためには、「六本木」のように「六」を「ろっ」、「本」を「ぽん」「木」を「ぎ」のように、本来の読み仮名とは違う読み仮名となるものがあるため、このような逆変換用の読み仮名も単漢字変換用のデータに追加して漢字読み辞書として利用しても良い。この場合、単漢字の仮名漢字変換の際には、単漢字変換用のデータを用いて変換を行い、逆変換の際には、単漢字変換用のデータ及び逆変換用の読み仮名を用いて変換を行うように、切り換えても良い。これにより、仮名漢字変換時に逆変換用の読み仮名がノイズとなるのを防止できる。
【0055】
(6−2)変換例2
変換例2としては、先ず仮名漢字混じりの単語を変換するため、仮名漢字混じりの単語と変換後の漢字とを対応付けた仮名漢字混在辞書を予め作成して記憶部13に記憶させておく。
【0056】
例えば「ぎ事ろく」「ぎじ録」「議じろく」「議事ろく」等の仮名漢字混じりの単語と、変換後の漢字「議事録」とを対応付けて仮名漢字混在辞書とする。
【0057】
そして、仮名漢字混じりの単語が入力された場合には、この仮名漢字混在辞書を参照して対応する漢字を抽出する。
【0058】
(6−3)変換例3
本例では、仮名漢字変換用の辞書を仮名漢字混じりの単語の変換に利用できるようにした例を示している。
【0059】
先ず、仮名漢字変換用の辞書の読み仮名に漢字一文字毎の区切り情報を与えた「区切り付き辞書」を予め作成し、記憶部13に記憶させておく。
例えば、次のような辞書を作成する。
読み仮名 変換候補
-------------------------
へん▲かん → 変換
がく▲しゅう → 学習
ろっ▲ぽん▲ぎ → 六本木
-------------------------
【0060】
なお、読み仮名部分のインデックスは、各文字の切れ目を先頭として検索できるようにする。即ち、上記の例では、「かん」、「しゅう」、「ぽんぎ」で検索した場合でも変換、学習、六本木を索出できる。
【0061】
図8は仮名漢字混じりの変換例3の説明図である。
図4のステップS3で求めた文字コードに漢字が含まれているか否かを判定し(ステップS31)、漢字が含まれていれば、区切り付き辞書を参照して当該単語の読み仮名と部分一致する単語を検索する(ステップS32)。
【0062】
次にステップS32で求めた単語と、前記仮名漢字混じりの単語の漢字部分が一致するか否かを判定し(ステップS33)、一致する単語を変換候補として表示し、ユーザに選択を促す(ステップS34)。
【0063】
そして、ユーザに選択された単語を変換後の単語として確定する(ステップS35)。
例えば、"変かんする"と入力された場合、
1-a) 1文字目の漢字をスキップして2文字目以降のひらがな"かんする"を検索対象と
する。
1-b) 辞書の2文字目以降の読みに対して検索をかける。
1-c) よみが一致した場合には、1文字目の漢字が一致するかどうかをチェックし、一
致するものだけを変換候補として表示する。
1-d) ユーザによって選択された単語を変換結果として確定する。
【0064】
2) "へん換する"と入力された場合、
2-a) 通常の仮名漢字変換の流れで"へん"に対応する検索をかける。
2-b) よみが一致した場合には、2文字目の漢字が一致するかどうかをチェックし、一
致するものだけを変換候補として表示する。
2-c) ユーザによって選択された単語を変換結果として確定する。
【0065】
本例によれば、仮名漢字混じりの単語を適切に変換できると共に、仮名漢字変換用の辞書と、仮名漢字混じりの単語を変換する辞書とを兼用でき、構成が簡素化される。
【0066】
なお、上記変換処理は、適宜組み合わせて利用しても良い。例えば変換例2の変換処理を行い、この処理で変換できなかった単語について変換例1或いは変換例3の変換処理を行っても良い。
【0067】
仮名で手描き入力された文字が、上記変換処理によって漢字に変換された場合、文字属性認識部は、変換後の漢字の文字コードを演算処理部16にわたし(入力し)、表示制御部がこの文字コードに応じた文字をディスプレイ10に表示させる。ここで、表示制御部は、この漢字を手描きで再入力するようにメッセージを表示する等してユーザに入力を促し、ユーザがディスプレイ10上の漢字を手描き入力すると、表示制御部は、この漢字の手描き文字データを前記仮名の手描き文字データと代えて表示領域12に表示させる。
【0068】
また、表示制御部は、上記のようにユーザに再入力を促すのではなく、前記文字コードに応じて明朝体やゴシック体等の既存のフォントを用いて当該文字を表示領域12に表示させても良いし、予め手描き文字データを手書き文字辞書として登録しておき、当該文字コードと対応する漢字の手描き文字データを読み出して前記仮名の手描き文字データと代えて表示領域12に表示させても良い。
【0069】
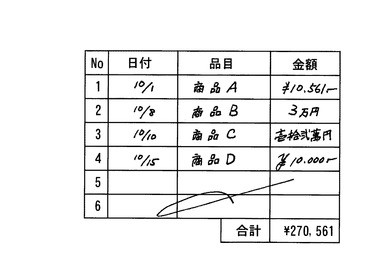
7.表計算ソフトへの適用
図9は、本実施形態の手描き入力を表計算ソフトに適用した例である。
図9に示すように、本例では、各セルの入力を手描きで行う。各セルの表示は、入力された手描き文字で行い、表計算については、属性情報の文字コードに従って行う。即ち、集計するセルの手描き文字データには、数字の文字コードを属性情報として付加しておく。
これにより表の数値を手描き文字とした場合でも表計算を行うことができる。
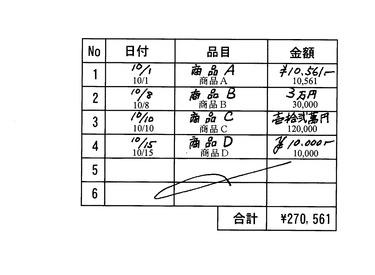
また、手描き入力を表計算ソフトに適用した場合、表示モードを変更することにより、手描き文字と、各文字コードが示す文字とを切り換えて表示しても良い。また、図10の例では、各セルに手描き文字と各文字コードが示す文字とを両方同時に表示させた例を示している。これにより手描き文字と文字コードとの対応をユーザが容易に視認できるよう
にしている。
【0070】
〈実施形態2〉
本実施形態2では、メインメモリや記憶部13等の記憶媒体上に記憶された一連の手描き文字データを一括して仮名漢字変換する処理例を示す。なお、この処理以外の構成は前述の実施形態1と同じであるので、同一の要素には同符号を付すなどして再度の説明を省略している。
【0071】
図11,図12は、本実施形態2の処理例を示すフローチャート、図13は、変換例を示す図である。
先ず、図11に示すように、ユーザによってタッチパネルの入力欄11に対して手描き入力が行われると、入力検出部は、この入力された文字の軌跡を一連の座標データとして検出する(ステップS41)。
【0072】
次に文字区切り認識部は、ステップS1で検出した一連の座標データを所定条件に基づいて一文字毎のデータに区切り、区切られた各座標データを手描き文字データとし(ステップS42)、メインメモリや記憶部13等の記憶媒体に記録させる(ステップS43)。
【0073】
このように、本実施形態2では、手書き入力された文字を逐次変換せずに入力を行い、手書き文字データを記録してゆくことで、入力作業を漢字変換のために中断することなく手描き入力を続ける、即ち書き続けることができる。以下これを書き流しとも称す。
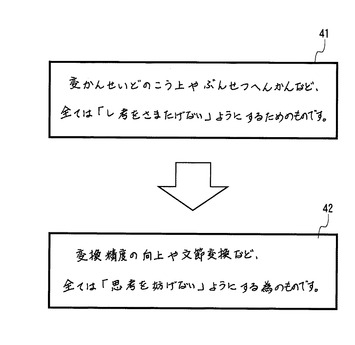
【0074】
図13の入力データ41は、この書き流しモードで手書き入力したデータである。図13に示すように、書き流しモードで入力した場合、漢字も平仮名も入力したまま手書き文字データとして記録される。
【0075】
会議や打ち合わせでメモをとる場合、入力した文字を逐一変換していては、会議や打ち合わせに支障を来すため、書き流しモードで入力するのが望ましい。
【0076】
そして、会議や打ち合わせの後、漢字変換の時間がとれる時に一括して変換すれば良い。図12は、後から変換を行う処理のフローチャートである。
【0077】
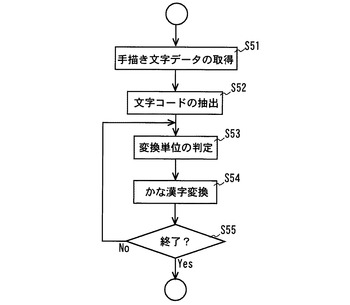
この後から変換をユーザが選択すると、コンピュータ1は、先ず図11の書き流しモードで記録した手描き文字データを記録媒体から取得する(ステップS51)。この手描き文字データの取得とは、例えばメインメモリから手描き文字データをCPUが読み出す処理、またする処理は、メインメモリを介して記憶部13から手描き文字データをCPUが読み出す処理である。
【0078】
次に文字属性認識部は、ステップS51で取得した手描き文字データの書き順や文字の形等の特徴に基づき、文字コードデータベースを参照して対応する文字コードを求め、当該手描き文字データの属性情報とする(ステップS52)。
【0079】
また、文字属性認識部は、手描き文字データを仮名漢字変換するための変換単位に区切り、最先の変換単位となるデータを求める(ステップS53)。例えば、先頭から所定の文字数のデータを抽出して辞書と比較する。また、手描き文字データを括弧や句読点、疑問符等の約物や助詞で区切り、変換単位とする。更に、手描き文字データの文字コードに基づいて形態素解析を行い、文節単位に区切り、各文節を変換単位としても良い。
【0080】
更に、文字属性認識部は、変換単位の手描き文字データを辞書データと比較する等して
仮名漢字変換を行う(ステップS54)。当該ステップS54の仮名漢字変換は、前述の実施形態1におけるステップS4と同じである。即ち、仮名漢字混じりの手描き文字データを漢字変換する。そして、変換単位の判定と仮名漢字変換の処理(ステップS53−S54)を繰り返し、最後の変換単位の仮名漢字変換が完了した場合に処理を終了する(ステップS55)。
【0081】
図12の42は、変換後のデータの例を示す。例えば、前述の変換例1によれば、入力データ41の「変かんせいどの」を変換単位とし、この変換単位に含まれる漢字「変」の読みを辞書から「へん」と求め、「へんかんせいど」を検索対象として仮名漢字変換辞書を検索し、「変換精度」と変換する。ここで「変換精度」が熟語として登録されていなけば、「変換」と「精度」に分けて変換しても良い。また、前述の変換例1に限らず、変換例2や変換例3、或いはこれらの組み合わせによって変換しても良い。
【0082】
このように本実施形態2によれば、書き流しモードで入力した手描き文字データを後から変換することができる。従って、会議や打ち合わせ等において、紙にメモをとるように手描き入力が行え、且つ手描き入力したデータを時間のある時に後から仮名漢字変換して清書するといったことができ、手描き入力の利便性が向上する。
【0083】
〈その他〉
本発明は、上述の図示例にのみ限定されるものではなく、本発明の要旨を逸脱しない範囲内において種々変更を加え得ることは勿論である。
例えば、以下に付記した構成であっても上述の実施形態と同様の効果が得られる。また、これらの構成要素は可能な限り組み合わせることができる。
【0084】
(付記1)
ユーザによって入力された文字の軌跡を一連の座標データとして検出するステップと、
前記ステップで検出した一連の座標データを所定条件に基づいて区切り、区切られた各座標データを手描き文字データとするステップと、
前記手描き文字データに基づき表示領域に手描き文字を表示させるステップと、
をコンピュータが実行する手描き入力方法。
【0085】
(付記2)
前記手描き文字をそれぞれ、所定の書式情報に基づいて前記表示領域に配列させる付記1に記載の手描き入力方法。
【0086】
(付記3)
前記手描き文字データの文字認識を行い、当該手描き文字データの文字コードを特定し、各手描き文字データと文字コードを対応付けて記憶部に記憶させるステップを実行する付記1又は2に記載の手描き入力方法。
【0087】
(付記4)
連続する前記文字コードを辞書データと比較して、単語又は文節の区切りの情報を求め、前記書式情報に追加するステップを実行する付記3に記載の手描き入力方法。
【0088】
(付記5)
文字コードが入力された場合に、前記当該文字コードと対応する手描き文字データを記憶部から読み出して出力するステップを実行する付記4に記載の手描き入力方法。
【0089】
(付記6)
アンダーライン、取り消し線、罫線、網掛け、太字、イタリック体、右寄せ、左寄せ、
センターリングの少なくとも一つの修飾を行うための属性情報を前記手描き文字に付加する付記1乃至5の何れか1項に記載の手描き入力方法。
【0090】
(付記7)
前記表示領域が、表形式の入力欄である付記1乃至6の何れか1項に記載の手描き入力方法。
【0091】
(付記8)
前記手描き文字データに仮名及び漢字が含まれているか否かを判定するステップと、
前記手描き文字データに仮名及び漢字が含まれている場合に、当該仮名と当該漢字を逆変換した仮名との組み合わせを仮名漢字変換辞書を参照して漢字に変換するステップと、を実行する付記1乃至7の何れか1項に記載の手描き入力方法。
【0092】
(付記9)
前記手描き文字データに仮名漢字混じりの単語が含まれているか否かを判定するステップと、
前記手描き文字データに仮名漢字混じりの単語が含まれている場合に、仮名漢字混じりの単語と当該仮名を漢字とした単語とを対応付けた仮名漢字混在辞書を参照して、仮名漢字混じりの単語を対応する漢字の単語に変換するステップを実行する付記1乃至8の何れか1項に記載の手描き入力方法。
【0093】
(付記10)
前記手描き文字データに仮名漢字混じりの単語が含まれているか否かを判定するステップと、
前記手描き文字データに仮名漢字混じりの単語が含まれている場合に、変換結果としての漢字の単語と、当該単語の読み仮名を当該漢字の一文字毎に区切ったインデックスとを対応付けた区切り付き辞書を参照して、仮名漢字混じりの単語を、当該単語の仮名部分と前記インデックスとが一致する単語に変換するステップを実行する付記1乃至9の何れか1項に記載の手描き入力方法。
【0094】
(付記11)
ユーザによって入力された文字の軌跡を一連の座標データとして検出するステップと、
前記ステップで検出した一連の座標データを所定条件に基づいて区切り、区切られた各座標データを手描き文字データとするステップと、
前記手描き文字データに基づき表示領域に手描き文字を表示させるステップと、
をコンピュータに実行させるための手描き入力プログラム。
【0095】
(付記12)
前記手描き文字をそれぞれ、所定の書式情報に基づいて前記表示領域に配列させる付記11に記載の手描き入力プログラム。
【0096】
(付記13)
前記手描き文字データの文字認識を行い、当該手描き文字データの文字コードを特定し、各手描き文字データと文字コードを対応付けて記憶部に記憶させるステップを実行する付記11又は12に記載の手描き入力プログラム。
【0097】
(付記14)
連続する前記文字コードを辞書データと比較して、単語又は文節の区切りの情報を求め、前記書式情報に追加するステップを実行する付記13に記載の手描き入力プログラム。
【0098】
(付記15)
文字コードが入力された場合に、前記当該文字コードと対応する手描き文字データを記憶部から読み出して出力するステップを実行する付記14に記載の手描き入力プログラム。
【0099】
(付記16)
アンダーライン、取り消し線、罫線、網掛け、太字、イタリック体、右寄せ、左寄せ、センターリングの少なくとも一つの修飾を行うための属性情報を前記手描き文字に付加する付記11乃至15の何れか1項に記載の手描き入力プログラム。
【0100】
(付記17)
前記表示領域が、表形式の入力欄である付記11乃至16の何れか1項に記載の手描き入力プログラム。
【0101】
(付記18)
前記手描き文字データに仮名及び漢字が含まれているか否かを判定するステップと、
前記手描き文字データに仮名及び漢字が含まれている場合に、当該仮名と当該漢字を逆変換した仮名との組み合わせを仮名漢字変換辞書を参照して漢字に変換するステップと、を実行する付記11乃至17の何れか1項に記載の手描き入力プログラム。
【0102】
(付記19)
前記手描き文字データに仮名漢字混じりの単語が含まれているか否かを判定するステップと、
前記手描き文字データに仮名漢字混じりの単語が含まれている場合に、仮名漢字混じりの単語と当該仮名を漢字とした単語とを対応付けた仮名漢字混在辞書を参照して、仮名漢字混じりの単語を対応する漢字の単語に変換するステップを実行する付記11乃至18の何れか1項に記載の手描き入力プログラム。
【0103】
(付記20)
前記手描き文字データに仮名漢字混じりの単語が含まれているか否かを判定するステップと、
前記手描き文字データに仮名漢字混じりの単語が含まれている場合に、変換結果としての漢字の単語と、当該単語の読み仮名を当該漢字の一文字毎に区切ったインデックスとを対応付けた区切り付き辞書を参照して、仮名漢字混じりの単語を、当該単語の仮名部分と前記インデックスとが一致する単語に変換するステップを実行する付記11乃至19の何れか1項に記載の手描き入力プログラム。
【0104】
(付記21)
ユーザによって入力された文字の軌跡を一連の座標データとして検出する入力検出部と、
前記入力検出部で検出した一連の座標データを所定条件に基づいて区切り、区切られた各座標データを手描き文字データとする文字区切り認識部と、
前記手描き文字データに基づき表示領域に手描き文字を表示させる表示制御部と、
を備えた手描き入力装置。
【0105】
(付記22)
前記手描き文字をそれぞれ、所定の書式情報に基づいて前記表示領域に配列させる付記21に記載の手描き入力装置。
【0106】
(付記23)
前記手描き文字データの文字認識を行い、当該手描き文字データの文字コードを特定し、各手描き文字データと文字コードを対応付けて記憶部に記憶させる文字属性認識部を備える付記21又は22に記載の手描き入力装置。
【0107】
(付記24)
前記文字属性認識部が、連続する前記文字コードを辞書データと比較して、単語又は文節の区切りの情報を求め、前記書式情報に追加する付記23に記載の手描き入力装置。
【0108】
(付記25)
前記表示制御部が、文字コードが入力された場合に、前記当該文字コードと対応する手描き文字データを記憶部から読み出して出力する付記24に記載の手描き入力装置。
【0109】
(付記26)
前記文字属性認識部が、アンダーライン、取り消し線、罫線、網掛け、太字、イタリック体、右寄せ、左寄せ、センターリングの少なくとも一つの修飾を行うための属性情報を前記手描き文字に付加する付記21乃至25の何れか1項に記載の手描き入力装置。
【0110】
(付記27)
前記表示領域が、表形式の入力欄である付記21乃至26の何れか1項に記載の手描き入力装置。
【0111】
(付記28)
前記文字属性認識部が、
前記手描き文字データに仮名及び漢字が含まれているか否かを判定し、
前記手描き文字データに仮名及び漢字が含まれている場合に、当該仮名と当該漢字を逆変換した仮名との組み合わせを仮名漢字変換辞書を参照して漢字に変換する
付記21乃至27の何れか1項に記載の手描き入力装置。
【0112】
(付記29)
前記文字属性認識部が、
前記手描き文字データに仮名漢字混じりの単語が含まれているか否かを判定し、
前記手描き文字データに仮名漢字混じりの単語が含まれている場合に、仮名漢字混じりの単語と当該仮名を漢字とした単語とを対応付けた仮名漢字混在辞書を参照して、仮名漢字混じりの単語を対応する漢字の単語に変換する
付記21乃至28の何れか1項に記載の手描き入力装置。
【0113】
(付記30)
前記文字属性認識部が、
前記手描き文字データに仮名漢字混じりの単語が含まれているか否かを判定し、
前記手描き文字データに仮名漢字混じりの単語が含まれている場合に、変換結果としての漢字の単語と、当該単語の読み仮名を当該漢字の一文字毎に区切ったインデックスとを対応付けた区切り付き辞書を参照して、仮名漢字混じりの単語を、当該単語の仮名部分と前記インデックスとが一致する単語に変換する
付記21乃至29の何れか1項に記載の手描き入力装置。
【符号の説明】
【0114】
1 手描き入力装置
16 演算処理部
13 記憶部(ハードディスク)
14 入出力ポート
15 通信制御部
【技術分野】
【0001】
本件は、手描き文字入力の技術に関する。
【背景技術】
【0002】
紙にペンで文字を手描きする際に、ペンの位置座標を検出器で検出してコンピュータに入力し、このコンピュータが入力された位置座標に基づき、手描きされた文字を表示装置に表示するシステムが知られている(特許文献1)。
また、電子ホワイトボードの手描き入力を行う場合に、入力済の文字に基づいて次の文字候補を示し、この候補から入力する文字を選択することで、手描き入力をより簡易にするシステムも提案されている(特許文献2)。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開2009−86769号公報
【特許文献2】特開2007−265171号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
上述のように手描き入力を行うシステムでは、入力された文字が図形(ベクトルデータ)やイメージとして扱われるので、テキストデータのようには自由に編集出来ないという問題点があった。例えば、手描き文字の字詰めを変更して並べ変えることや、一部の文字を削除し、以降の文字を繰り上げるといった編集を行うことはできない。
このため、入力された手描き文字を文字認識処理によりテキストデータに変換し、編集を可能にするシステムも知られている。
しかし、文字認識を行うシステムでは、手描き入力した際に複数の抽出される変換候補を逐次選択する必要があり、紙にメモをとるようにスムーズに入力を行うことはできなかった。
また、文字認識後は、各文字の文字コードに対応するフォントが表示されるため、手描きで入力したユーザの筆跡を残すことができなかった。
そこで、本発明は、手描き文字の編集を容易に可能とする技術の提供を目的とする。
【課題を解決するための手段】
【0005】
上記の課題を解決するため、本発明の手描き入力方法は、
ユーザによって入力される文字の軌跡を一連の座標データとして検出するステップと、
前記ステップで検出した一連の座標データを所定条件に基づいて区切り、区切られた各座標データを手描き文字データとするステップと、
前記手描き文字データに基づき表示領域に手描き文字を表示させるステップと、
をコンピュータが実行する。
【0006】
また、本発明の手描き入力装置は、
ユーザによって入力される文字の軌跡を一連の座標データとして検出する入力検出部と、
前記入力検出部で検出した一連の座標データを所定条件に基づいて区切り、区切られた各座標データを手描き文字データとする文字区切り認識部と、
前記手描き文字データに基づき表示領域に手描き文字を表示させる表示制御部とを備えた。
【0007】
また、上記課題を解決するため、本発明は上記手描き入力方法をコンピュータに実行させるための手描き入力プログラムであつても良い。更に、この手描き入力プログラムをコンピュータが読み取り可能な記録媒体に記録しても良い。コンピュータに、この記録媒体のプログラムを読み込ませて実行させることにより、その機能を提供させることができる。
【0008】
ここで、コンピュータが読み取り可能な記録媒体とは、データやプログラム等の情報を電気的、磁気的、光学的、機械的、または化学的作用によって蓄積し、コンピュータから読み取ることができる記録媒体をいう。このような記録媒体の内コンピュータから取り外し可能なものとしては、例えばフレキシブルディスク、光磁気ディスク、CD-ROM、CD-R/W、DVD、DAT、8mmテープ、メモリカード等がある。
【0009】
また、コンピュータに固定された記録媒体としてハードディスクやROM(リードオンリーメモリ)等がある。
【発明の効果】
【0010】
本発明は、手描き文字の編集を容易にする技術を提供できる。
【図面の簡単な説明】
【0011】
【図1】手描き文字入力の説明図
【図2】手描き文字入力の説明図
【図3】手描き入力装置の概略構成図
【図4】手描き入力方法の説明図
【図5】手描き文字の修飾処理の説明図
【図6】手描き文字の修飾処理の説明図
【図7】仮名漢字混じりの変換例1の説明図
【図8】仮名漢字混じりの変換例3の説明図
【図9】表計算に適用した例を示す図
【図10】表計算に適用した例を示す図
【図11】書き流しモードの入力処理の説明図
【図12】仮名漢字変換処理の説明図
【図13】変換例を示す図
【発明を実施するための形態】
【0012】
以下、図面を参照して本発明を実施するための最良の形態について説明する。以下の実施の形態の構成は例示であり、本発明は実施の形態の構成に限定されない。
【0013】
〈実施形態1〉
1.手描き文字入力の概要
図1において、1は本発明の手描き入力方法を採用したコンピュータ(手描き入力装置)であり、ディスプレイ10の表面にタッチパネルを備え、タッチパネルの手描き入力欄11に対してユーザが手描き入力を行うと、その軌跡を検出して表示欄(表示領域)12に手描き文字列を表示する。この手描き文字列は、従来、そのページ毎にベクトルデータやイメージデータで示していた為、文字単位での編集を行うことができなかった。
【0014】
例えば、表示欄12を狭く変更する場合、そのページを縮小して幅を狭めることになるので、手描き文字も同率で縮小されて読み難くなってしまうことがあった。また、従来の手描き文字列は、行の途中で折り返して字詰めを変えたり、一部の文字を削除して以降の文字を繰り上げるように、文字の並びを変更したりといった編集ができなかった。
【0015】
これに対し、本実施形態の手描き入力方法では、一文字毎に文字の区切りを認識し、文字毎のストロークデータ或いはイメージデータで表しているので、図2のように表示欄12の幅を変えて、文字の折り返し位置を変更するような編集を可能にしている。
【0016】
2.手描き入力装置の構成
図3は、本実施形態における手描き入力装置1の概略構成図である。図3に示すように、手描き入力装置1は、本体内にCPU(central processing unit)やメインメモリ等
よりなる演算処理部16、演算処理の為のデータやソフトウェアを記憶した記憶部(フラッシュメモリ)13、入出力ポート14、通信制御部(CCU:Communication Control Unit)15等を備えたコンピュータである。
【0017】
該入出力ポート14には、キーボード(操作ボタン等)やポインティングデバイス、記憶媒体(メモリカード等)の読み取り装置、タッチパネル等の入力デバイス、そしてディスプレイ10や記憶媒体の書き込み装置、スピーカ等の出力デバイスが適宜接続される。
CCU15は、ネットワークを介して他のコンピュータと通信を行うものである。
【0018】
記憶部13には、オペレーティングシステム(OS)やアプリケーションソフト(手描き入力プログラム)、辞書データ等がインストールされている。
【0019】
演算処理部16は、前記OSやアプリケーションプログラムを記憶部13から適宜読み出して実行し、入出力ポート14やCCU15から入力された情報、及び記憶部13から読み出した情報を演算処理することにより、入力検出部や、文字区切り認識部、文字整形部、文字属性認識部、表示制御部としても機能する。
【0020】
この入力検出部としては、ユーザによってタッチパッドの入力欄11に入力される文字の軌跡を一連の座標データとして検出する。
【0021】
文字区切り認識部としては、入力検出部で検出した一連の座標データを所定条件に基づいて区切り、区切られた各座標データを手描き文字データとする。
【0022】
文字整形部は、文字区切り認識部で区切られた手描き文字データをストロークデータ等の所定フォーマットに整形する。
【0023】
文字属性認識部としては、前記手描き文字データの書き順や文字の形等の特徴に基づいて対応する文字コードを求める。例えば、手描き文字データの書き順や文字の形等の特徴と文字コードとを対応付けた文字コードデータベースを記憶部13に記憶させておき、ユーザによって入力された手描き文字データの特徴と類似する特徴と対応する文字コードを辞書データベースから抽出する。抽出した文字コードは、当該手描き文字データの属性情報としてメモリ或いは記憶部13に記憶する。
【0024】
表示制御部としては、前記手描き文字データに基づきディスプレイ10の表示領域12に手描き文字を表示させる。
【0025】
3.手描き入力方法
図4は、上記構成の手描き入力装置が、手描き入力プログラムに従って実行する手描き入力方法の説明図である。
先ず、ユーザによってタッチパネルの入力欄11に対して手描き入力が行われると、入力検出部は、この入力された文字の軌跡を一連の座標データとして検出する(ステップS1)。
【0026】
次に文字区切り認識部は、ステップS1で検出した一連の座標データを所定条件に基づいて一文字毎のデータに区切り、区切られた各座標データを手描き文字データとする(ステップS2)。
【0027】
文字属性認識部は、ステップS2で求めた手描き文字データの書き順や文字の形等の特徴に基づき、文字コードデータベースを参照して対応する文字コードを求め、当該手描き文字データの属性情報とする(ステップS3)。なお、この文字コードの候補が複数抽出された場合には、この複数の文字コードを全て或いは所定数を属性情報としても良い。更に文字コードを抽出する際、手描き文字データの特徴の類似度が高い順に優先度を付しても良い。
【0028】
また、文字属性認識部は、前記文字コードを辞書データと比較して、仮名漢字変換を行う(ステップS4)。
【0029】
また、文字属性認識部は、前記文字コードを辞書データと比較する際、単語又は文節の区切りの情報を求めても良い。
【0030】
そして、表示制御部は、前記手描き文字データに基づきディスプレイ10の表示欄12に所定の書式で手描き文字を表示させる(ステップS5)。ここで、所定の書式とは、文字の大きさ、1行の文字数、文字間隔、行間隔、左寄せ、禁則処理などである。所定の書式は、予め設定しておくものでも良いし、入力時に選択するものでも良い。
【0031】
以上のように、本実施形態によれば、手描き文字データを区切り、一文字毎に管理できるので、入力した手描き文字データの編集が容易となる。
【0032】
4.文字区切り処理
図5は、入力された手描き文字の区切りを判定する処理の説明図である。
先ず、ユーザが入力欄11に対してタッチペンで図5(A)のように文字を手描きすると、タッチパネルは、このタッチペンの接触箇所(ポイント)を検出し、その座標を逐次演算処理部16に入力する。即ち、文字を描いた際の接触ポイントの移動軌跡を次のような一連の座標データとする。
(54 , 58) (56 , 58) (58 , 58) ・・・・(247 , 68)
(249 , 68) (251 , 68) (253 , 68) ・・・(147 , 10)
(54 , 58) (56 , 58) (58 , 58) ・・・・(247 , 68)
(249 , 68) (251 , 68) (253 , 68) ・・・(147 , 10)
(54 , 58) (56 , 58) (58 , 58) ・・・・(247 , 68)
(249 , 68) (251 , 68) (253 , 68) ・・・(147 , 10)
:
:
【0033】
そして、文字区切り認識部は、この座標データに基づき、図5(B)に示すように手描き文字を囲む矩形31を設定する。ここで矩形31の高さは前記座標データが収まる高さとし、矩形31の幅は、幅方向に連続する座標が途切れ、所定以上の距離が空いたことを条件に、ここを文字の区切りと判定し、この区切りまでの座標が収まる幅に設定する。
【0034】
また、矩形31の高さに対する幅の比率が所定値より小さい場合、即ち矩形31の幅が狭い縦長の形状であった場合、1やI、!など、縦長の文字とのパターンマッチングを行
い、一致した場合には文字区切りを確定し、そうでない場合には隣接する矩形内の座標データと合わせて漢字とのパターンマッチングを行い、一致したことを条件に、この合わせた座標データを一文字の漢字として矩形を設定し、区切りを変更する。
【0035】
文字整形部は、上記手描き文字データとしての一連の座標データをストロークデータ等の所定フォーマットに整形する。
例えば、以下のフォーマットで各ストロークの通過点や方向を示す。
(character
(value 文字コード)
(width 矩形幅)
(height 矩形高さ)
(strokes
((1画1点目のx y) (1画2点目のx y) ... (1画n点目のx y))
((2画1点目のx y) (2画2点目のx y) ... (2画n点目のx y))
((3画1点目のx y) (3画2点目のx y) ... (3画n点目のx y))
...))
【0036】
このように、strokesに続く()で綴じられているデータが一つのストロークを示し、
各ストロークを示す()内の各xy座標が各ストロークの通過点を示す。なお、各ストロークの通過点を示すxy座標は、width,heightで定義した各文字の矩形の左上を原点と
した当該矩形内の座標を示す。
【0037】
具体的には、例えば以下のようなデータとする。
(character (value あ) (width 300) (height 300) (strokes ((54 58)(249 68)) ((147 10)(145 201)(182 252)) ((224 103)(149 230)(82 240)(53 204)(86 149)(182 139)(240 172)(248 224)(228 250))))
このxy座標で示される通過点を通るように各ストロークをスプライン曲線で描画することで、文字を表示する。
【0038】
5.修飾処理
上記のように、本実施形態では、手描き文字を文字単位で区切ったデータとしたため、この各文字の手描き文字データに属性情報を付加することで、文字毎に修飾することができる。図6は手描き文字の修飾処理の説明図である。
【0039】
例えば、図6(A)に示すようにユーザがディスプレイ10に表示されている文字を範囲指定して修飾を指定した場合、この範囲指定32された文字列の前後に当該修飾を示すタグを挿入する。
【0040】
図6(B)では、文字列「あいうえお」のうち、範囲指定した文字「いうえ」にアンダーライン33を付加した場合の表示例を示している。この場合、次のようにアンダーラインを示すタグ(<u>〜</u>)を挿入する。
(character (value あ) (width 300) (height 300) (strokes ((54 58)(249 68)) ((147 10)(145 201)(182 252)) ((224 103)(149 230)(82 240)(53 204)(86 149)(182 139)(240 172)(248 224)(228 250))))
<u>
(character (value い) (width 300) (height 300) (strokes ((56 63)(43 213)(67 259)(94 243)) ((213 66)(231 171)(208 217))))
(character (value う) (width 300) (height 300) (strokes ((102 35)(187 45)) ((73 121)(167 105)(206 139)(198 211)(135 275))))
(character (value え) (width 300) (height 300) (strokes ((140 19)(162 38)) ((62 105)(208 100)(51 263)(128 205)(188 268)(260 252))))
</u>
(character (value お) (width 300) (height 300) (strokes ((64 94)(240 98)) ((148
35)(159 129)(140 199)(105 247)(64 228)(101 161)(192 161)(222 223)(189 257)) ((223 49)(253 89))))
【0041】
なお、アンダーラインに限らず、取り消し線、罫線、網掛け、太字、イタリック体、右寄せ、左寄せ、センターリング、色指定などの修飾も同様に行うことができる。
【0042】
また、図6(B)に示すように複数の文字にアンダーラインを付す場合、各文字だけでなく、文字間についても連続して設けるように表示するのが良い。この文字間についても連続して修飾することは、取り消し線や罫線、網掛けなどについても同じである。
【0043】
6.仮名漢字混じりの単語の変換処理
文字属性認識部は、入力された文字が仮名であった場合、図4のステップS4に示したように、漢字に変換することができる。
【0044】
なお、キーボードを用いた入力では、必ず仮名を入力し、これを漢字に変換する処理であるため、単語の読み仮名と漢字とを対応付けた辞書を参照し、単語の読み仮名をインデックスとして対応する漢字を抽出することで変換を行っている。
【0045】
これに対し、本実施形態では、手書きで文字を入力するため、漢字で入力することができ、漢字と仮名が混在した入力が行われることがある。
【0046】
例えば、「議事録」と入力する場合に「ぎ事録」や「ぎ事ろく」「ぎじ録」と入力されることがある。この場合、読み仮名が単語の一部分しかなく、従来のように単語の読み仮名と漢字を対応させた辞書ではインデックスが一致せず、単語としては検索できないため、効率良く変換を行うことができない。
【0047】
そこで、本実施形態では、仮名漢字混じりの単語が入力された場合に効率良く変換するために以下の処理を採用した。なお、この変換処理を行う場合の変換単位は、入力欄11に入力された手描き文字を所定時間間隔で変換する構成であっても良いし、ユーザが変換ボタン(不図示)を選択する等の操作によって変換指示を受けた際に入力欄11に入力されている手描き文字を変換する構成であっても良い。
【0048】
(6−1)変換例1
図7は仮名漢字混じりの変換例1の説明図である。
図4のステップS3で求めた文字コードに漢字が含まれているか否かを判定し(ステップS21)、漢字が含まれていれば、漢字読み辞書を参照して逆変換し、当該漢字の読み仮名を求める(ステップS22)。なお、漢字読み辞書は、漢字とその読みとを対応付けた辞書データであり、記憶部13に格納しておく。
【0049】
次にステップS22で求めた漢字の読みのうち、前後の文字との組み合わせが妥当なものを選択する(ステップS23)。
【0050】
例えば入力された文字が「ぎ事ろく」であった場合、ステップS21で漢字「事」が含まれていると判定し、この漢字「事」の読み仮名として「じ」「こと」が抽出され、この組み合わせは、「ぎじ」「ぎこと」「じろく」「ことろく」となる。
【0051】
文字属性認識部は、この読み仮名の組み合わせのうち、仮名漢字変換辞書のインデックスと一致するものを選択する。即ち、単語として意味をなす「ぎじ」を選択する。
【0052】
そして文字属性認識部は、ステップS23で選択した読み仮名を用いて「ぎじろく」を
仮名漢字変換する(ステップS24)。
【0053】
このように本例によれば、仮名漢字混じりの単語が入力されても漢字を仮名に逆変換してから、単語単位で仮名漢字変換を行うので、適切な変換を行うことができる。
【0054】
なお、前記漢字読み辞書は、仮名漢字変換辞書の単漢字変換用のデータを利用しても良い。この単漢字変換用のデータは、単漢字の読み仮名をインデックスとして単漢字を索出するものであるので、本例では、これを逆に利用し、単漢字をインデックスとして読み仮名を索出すれば良い。但し、本例の逆変換を行うためには、「六本木」のように「六」を「ろっ」、「本」を「ぽん」「木」を「ぎ」のように、本来の読み仮名とは違う読み仮名となるものがあるため、このような逆変換用の読み仮名も単漢字変換用のデータに追加して漢字読み辞書として利用しても良い。この場合、単漢字の仮名漢字変換の際には、単漢字変換用のデータを用いて変換を行い、逆変換の際には、単漢字変換用のデータ及び逆変換用の読み仮名を用いて変換を行うように、切り換えても良い。これにより、仮名漢字変換時に逆変換用の読み仮名がノイズとなるのを防止できる。
【0055】
(6−2)変換例2
変換例2としては、先ず仮名漢字混じりの単語を変換するため、仮名漢字混じりの単語と変換後の漢字とを対応付けた仮名漢字混在辞書を予め作成して記憶部13に記憶させておく。
【0056】
例えば「ぎ事ろく」「ぎじ録」「議じろく」「議事ろく」等の仮名漢字混じりの単語と、変換後の漢字「議事録」とを対応付けて仮名漢字混在辞書とする。
【0057】
そして、仮名漢字混じりの単語が入力された場合には、この仮名漢字混在辞書を参照して対応する漢字を抽出する。
【0058】
(6−3)変換例3
本例では、仮名漢字変換用の辞書を仮名漢字混じりの単語の変換に利用できるようにした例を示している。
【0059】
先ず、仮名漢字変換用の辞書の読み仮名に漢字一文字毎の区切り情報を与えた「区切り付き辞書」を予め作成し、記憶部13に記憶させておく。
例えば、次のような辞書を作成する。
読み仮名 変換候補
-------------------------
へん▲かん → 変換
がく▲しゅう → 学習
ろっ▲ぽん▲ぎ → 六本木
-------------------------
【0060】
なお、読み仮名部分のインデックスは、各文字の切れ目を先頭として検索できるようにする。即ち、上記の例では、「かん」、「しゅう」、「ぽんぎ」で検索した場合でも変換、学習、六本木を索出できる。
【0061】
図8は仮名漢字混じりの変換例3の説明図である。
図4のステップS3で求めた文字コードに漢字が含まれているか否かを判定し(ステップS31)、漢字が含まれていれば、区切り付き辞書を参照して当該単語の読み仮名と部分一致する単語を検索する(ステップS32)。
【0062】
次にステップS32で求めた単語と、前記仮名漢字混じりの単語の漢字部分が一致するか否かを判定し(ステップS33)、一致する単語を変換候補として表示し、ユーザに選択を促す(ステップS34)。
【0063】
そして、ユーザに選択された単語を変換後の単語として確定する(ステップS35)。
例えば、"変かんする"と入力された場合、
1-a) 1文字目の漢字をスキップして2文字目以降のひらがな"かんする"を検索対象と
する。
1-b) 辞書の2文字目以降の読みに対して検索をかける。
1-c) よみが一致した場合には、1文字目の漢字が一致するかどうかをチェックし、一
致するものだけを変換候補として表示する。
1-d) ユーザによって選択された単語を変換結果として確定する。
【0064】
2) "へん換する"と入力された場合、
2-a) 通常の仮名漢字変換の流れで"へん"に対応する検索をかける。
2-b) よみが一致した場合には、2文字目の漢字が一致するかどうかをチェックし、一
致するものだけを変換候補として表示する。
2-c) ユーザによって選択された単語を変換結果として確定する。
【0065】
本例によれば、仮名漢字混じりの単語を適切に変換できると共に、仮名漢字変換用の辞書と、仮名漢字混じりの単語を変換する辞書とを兼用でき、構成が簡素化される。
【0066】
なお、上記変換処理は、適宜組み合わせて利用しても良い。例えば変換例2の変換処理を行い、この処理で変換できなかった単語について変換例1或いは変換例3の変換処理を行っても良い。
【0067】
仮名で手描き入力された文字が、上記変換処理によって漢字に変換された場合、文字属性認識部は、変換後の漢字の文字コードを演算処理部16にわたし(入力し)、表示制御部がこの文字コードに応じた文字をディスプレイ10に表示させる。ここで、表示制御部は、この漢字を手描きで再入力するようにメッセージを表示する等してユーザに入力を促し、ユーザがディスプレイ10上の漢字を手描き入力すると、表示制御部は、この漢字の手描き文字データを前記仮名の手描き文字データと代えて表示領域12に表示させる。
【0068】
また、表示制御部は、上記のようにユーザに再入力を促すのではなく、前記文字コードに応じて明朝体やゴシック体等の既存のフォントを用いて当該文字を表示領域12に表示させても良いし、予め手描き文字データを手書き文字辞書として登録しておき、当該文字コードと対応する漢字の手描き文字データを読み出して前記仮名の手描き文字データと代えて表示領域12に表示させても良い。
【0069】
7.表計算ソフトへの適用
図9は、本実施形態の手描き入力を表計算ソフトに適用した例である。
図9に示すように、本例では、各セルの入力を手描きで行う。各セルの表示は、入力された手描き文字で行い、表計算については、属性情報の文字コードに従って行う。即ち、集計するセルの手描き文字データには、数字の文字コードを属性情報として付加しておく。
これにより表の数値を手描き文字とした場合でも表計算を行うことができる。
また、手描き入力を表計算ソフトに適用した場合、表示モードを変更することにより、手描き文字と、各文字コードが示す文字とを切り換えて表示しても良い。また、図10の例では、各セルに手描き文字と各文字コードが示す文字とを両方同時に表示させた例を示している。これにより手描き文字と文字コードとの対応をユーザが容易に視認できるよう
にしている。
【0070】
〈実施形態2〉
本実施形態2では、メインメモリや記憶部13等の記憶媒体上に記憶された一連の手描き文字データを一括して仮名漢字変換する処理例を示す。なお、この処理以外の構成は前述の実施形態1と同じであるので、同一の要素には同符号を付すなどして再度の説明を省略している。
【0071】
図11,図12は、本実施形態2の処理例を示すフローチャート、図13は、変換例を示す図である。
先ず、図11に示すように、ユーザによってタッチパネルの入力欄11に対して手描き入力が行われると、入力検出部は、この入力された文字の軌跡を一連の座標データとして検出する(ステップS41)。
【0072】
次に文字区切り認識部は、ステップS1で検出した一連の座標データを所定条件に基づいて一文字毎のデータに区切り、区切られた各座標データを手描き文字データとし(ステップS42)、メインメモリや記憶部13等の記憶媒体に記録させる(ステップS43)。
【0073】
このように、本実施形態2では、手書き入力された文字を逐次変換せずに入力を行い、手書き文字データを記録してゆくことで、入力作業を漢字変換のために中断することなく手描き入力を続ける、即ち書き続けることができる。以下これを書き流しとも称す。
【0074】
図13の入力データ41は、この書き流しモードで手書き入力したデータである。図13に示すように、書き流しモードで入力した場合、漢字も平仮名も入力したまま手書き文字データとして記録される。
【0075】
会議や打ち合わせでメモをとる場合、入力した文字を逐一変換していては、会議や打ち合わせに支障を来すため、書き流しモードで入力するのが望ましい。
【0076】
そして、会議や打ち合わせの後、漢字変換の時間がとれる時に一括して変換すれば良い。図12は、後から変換を行う処理のフローチャートである。
【0077】
この後から変換をユーザが選択すると、コンピュータ1は、先ず図11の書き流しモードで記録した手描き文字データを記録媒体から取得する(ステップS51)。この手描き文字データの取得とは、例えばメインメモリから手描き文字データをCPUが読み出す処理、またする処理は、メインメモリを介して記憶部13から手描き文字データをCPUが読み出す処理である。
【0078】
次に文字属性認識部は、ステップS51で取得した手描き文字データの書き順や文字の形等の特徴に基づき、文字コードデータベースを参照して対応する文字コードを求め、当該手描き文字データの属性情報とする(ステップS52)。
【0079】
また、文字属性認識部は、手描き文字データを仮名漢字変換するための変換単位に区切り、最先の変換単位となるデータを求める(ステップS53)。例えば、先頭から所定の文字数のデータを抽出して辞書と比較する。また、手描き文字データを括弧や句読点、疑問符等の約物や助詞で区切り、変換単位とする。更に、手描き文字データの文字コードに基づいて形態素解析を行い、文節単位に区切り、各文節を変換単位としても良い。
【0080】
更に、文字属性認識部は、変換単位の手描き文字データを辞書データと比較する等して
仮名漢字変換を行う(ステップS54)。当該ステップS54の仮名漢字変換は、前述の実施形態1におけるステップS4と同じである。即ち、仮名漢字混じりの手描き文字データを漢字変換する。そして、変換単位の判定と仮名漢字変換の処理(ステップS53−S54)を繰り返し、最後の変換単位の仮名漢字変換が完了した場合に処理を終了する(ステップS55)。
【0081】
図12の42は、変換後のデータの例を示す。例えば、前述の変換例1によれば、入力データ41の「変かんせいどの」を変換単位とし、この変換単位に含まれる漢字「変」の読みを辞書から「へん」と求め、「へんかんせいど」を検索対象として仮名漢字変換辞書を検索し、「変換精度」と変換する。ここで「変換精度」が熟語として登録されていなけば、「変換」と「精度」に分けて変換しても良い。また、前述の変換例1に限らず、変換例2や変換例3、或いはこれらの組み合わせによって変換しても良い。
【0082】
このように本実施形態2によれば、書き流しモードで入力した手描き文字データを後から変換することができる。従って、会議や打ち合わせ等において、紙にメモをとるように手描き入力が行え、且つ手描き入力したデータを時間のある時に後から仮名漢字変換して清書するといったことができ、手描き入力の利便性が向上する。
【0083】
〈その他〉
本発明は、上述の図示例にのみ限定されるものではなく、本発明の要旨を逸脱しない範囲内において種々変更を加え得ることは勿論である。
例えば、以下に付記した構成であっても上述の実施形態と同様の効果が得られる。また、これらの構成要素は可能な限り組み合わせることができる。
【0084】
(付記1)
ユーザによって入力された文字の軌跡を一連の座標データとして検出するステップと、
前記ステップで検出した一連の座標データを所定条件に基づいて区切り、区切られた各座標データを手描き文字データとするステップと、
前記手描き文字データに基づき表示領域に手描き文字を表示させるステップと、
をコンピュータが実行する手描き入力方法。
【0085】
(付記2)
前記手描き文字をそれぞれ、所定の書式情報に基づいて前記表示領域に配列させる付記1に記載の手描き入力方法。
【0086】
(付記3)
前記手描き文字データの文字認識を行い、当該手描き文字データの文字コードを特定し、各手描き文字データと文字コードを対応付けて記憶部に記憶させるステップを実行する付記1又は2に記載の手描き入力方法。
【0087】
(付記4)
連続する前記文字コードを辞書データと比較して、単語又は文節の区切りの情報を求め、前記書式情報に追加するステップを実行する付記3に記載の手描き入力方法。
【0088】
(付記5)
文字コードが入力された場合に、前記当該文字コードと対応する手描き文字データを記憶部から読み出して出力するステップを実行する付記4に記載の手描き入力方法。
【0089】
(付記6)
アンダーライン、取り消し線、罫線、網掛け、太字、イタリック体、右寄せ、左寄せ、
センターリングの少なくとも一つの修飾を行うための属性情報を前記手描き文字に付加する付記1乃至5の何れか1項に記載の手描き入力方法。
【0090】
(付記7)
前記表示領域が、表形式の入力欄である付記1乃至6の何れか1項に記載の手描き入力方法。
【0091】
(付記8)
前記手描き文字データに仮名及び漢字が含まれているか否かを判定するステップと、
前記手描き文字データに仮名及び漢字が含まれている場合に、当該仮名と当該漢字を逆変換した仮名との組み合わせを仮名漢字変換辞書を参照して漢字に変換するステップと、を実行する付記1乃至7の何れか1項に記載の手描き入力方法。
【0092】
(付記9)
前記手描き文字データに仮名漢字混じりの単語が含まれているか否かを判定するステップと、
前記手描き文字データに仮名漢字混じりの単語が含まれている場合に、仮名漢字混じりの単語と当該仮名を漢字とした単語とを対応付けた仮名漢字混在辞書を参照して、仮名漢字混じりの単語を対応する漢字の単語に変換するステップを実行する付記1乃至8の何れか1項に記載の手描き入力方法。
【0093】
(付記10)
前記手描き文字データに仮名漢字混じりの単語が含まれているか否かを判定するステップと、
前記手描き文字データに仮名漢字混じりの単語が含まれている場合に、変換結果としての漢字の単語と、当該単語の読み仮名を当該漢字の一文字毎に区切ったインデックスとを対応付けた区切り付き辞書を参照して、仮名漢字混じりの単語を、当該単語の仮名部分と前記インデックスとが一致する単語に変換するステップを実行する付記1乃至9の何れか1項に記載の手描き入力方法。
【0094】
(付記11)
ユーザによって入力された文字の軌跡を一連の座標データとして検出するステップと、
前記ステップで検出した一連の座標データを所定条件に基づいて区切り、区切られた各座標データを手描き文字データとするステップと、
前記手描き文字データに基づき表示領域に手描き文字を表示させるステップと、
をコンピュータに実行させるための手描き入力プログラム。
【0095】
(付記12)
前記手描き文字をそれぞれ、所定の書式情報に基づいて前記表示領域に配列させる付記11に記載の手描き入力プログラム。
【0096】
(付記13)
前記手描き文字データの文字認識を行い、当該手描き文字データの文字コードを特定し、各手描き文字データと文字コードを対応付けて記憶部に記憶させるステップを実行する付記11又は12に記載の手描き入力プログラム。
【0097】
(付記14)
連続する前記文字コードを辞書データと比較して、単語又は文節の区切りの情報を求め、前記書式情報に追加するステップを実行する付記13に記載の手描き入力プログラム。
【0098】
(付記15)
文字コードが入力された場合に、前記当該文字コードと対応する手描き文字データを記憶部から読み出して出力するステップを実行する付記14に記載の手描き入力プログラム。
【0099】
(付記16)
アンダーライン、取り消し線、罫線、網掛け、太字、イタリック体、右寄せ、左寄せ、センターリングの少なくとも一つの修飾を行うための属性情報を前記手描き文字に付加する付記11乃至15の何れか1項に記載の手描き入力プログラム。
【0100】
(付記17)
前記表示領域が、表形式の入力欄である付記11乃至16の何れか1項に記載の手描き入力プログラム。
【0101】
(付記18)
前記手描き文字データに仮名及び漢字が含まれているか否かを判定するステップと、
前記手描き文字データに仮名及び漢字が含まれている場合に、当該仮名と当該漢字を逆変換した仮名との組み合わせを仮名漢字変換辞書を参照して漢字に変換するステップと、を実行する付記11乃至17の何れか1項に記載の手描き入力プログラム。
【0102】
(付記19)
前記手描き文字データに仮名漢字混じりの単語が含まれているか否かを判定するステップと、
前記手描き文字データに仮名漢字混じりの単語が含まれている場合に、仮名漢字混じりの単語と当該仮名を漢字とした単語とを対応付けた仮名漢字混在辞書を参照して、仮名漢字混じりの単語を対応する漢字の単語に変換するステップを実行する付記11乃至18の何れか1項に記載の手描き入力プログラム。
【0103】
(付記20)
前記手描き文字データに仮名漢字混じりの単語が含まれているか否かを判定するステップと、
前記手描き文字データに仮名漢字混じりの単語が含まれている場合に、変換結果としての漢字の単語と、当該単語の読み仮名を当該漢字の一文字毎に区切ったインデックスとを対応付けた区切り付き辞書を参照して、仮名漢字混じりの単語を、当該単語の仮名部分と前記インデックスとが一致する単語に変換するステップを実行する付記11乃至19の何れか1項に記載の手描き入力プログラム。
【0104】
(付記21)
ユーザによって入力された文字の軌跡を一連の座標データとして検出する入力検出部と、
前記入力検出部で検出した一連の座標データを所定条件に基づいて区切り、区切られた各座標データを手描き文字データとする文字区切り認識部と、
前記手描き文字データに基づき表示領域に手描き文字を表示させる表示制御部と、
を備えた手描き入力装置。
【0105】
(付記22)
前記手描き文字をそれぞれ、所定の書式情報に基づいて前記表示領域に配列させる付記21に記載の手描き入力装置。
【0106】
(付記23)
前記手描き文字データの文字認識を行い、当該手描き文字データの文字コードを特定し、各手描き文字データと文字コードを対応付けて記憶部に記憶させる文字属性認識部を備える付記21又は22に記載の手描き入力装置。
【0107】
(付記24)
前記文字属性認識部が、連続する前記文字コードを辞書データと比較して、単語又は文節の区切りの情報を求め、前記書式情報に追加する付記23に記載の手描き入力装置。
【0108】
(付記25)
前記表示制御部が、文字コードが入力された場合に、前記当該文字コードと対応する手描き文字データを記憶部から読み出して出力する付記24に記載の手描き入力装置。
【0109】
(付記26)
前記文字属性認識部が、アンダーライン、取り消し線、罫線、網掛け、太字、イタリック体、右寄せ、左寄せ、センターリングの少なくとも一つの修飾を行うための属性情報を前記手描き文字に付加する付記21乃至25の何れか1項に記載の手描き入力装置。
【0110】
(付記27)
前記表示領域が、表形式の入力欄である付記21乃至26の何れか1項に記載の手描き入力装置。
【0111】
(付記28)
前記文字属性認識部が、
前記手描き文字データに仮名及び漢字が含まれているか否かを判定し、
前記手描き文字データに仮名及び漢字が含まれている場合に、当該仮名と当該漢字を逆変換した仮名との組み合わせを仮名漢字変換辞書を参照して漢字に変換する
付記21乃至27の何れか1項に記載の手描き入力装置。
【0112】
(付記29)
前記文字属性認識部が、
前記手描き文字データに仮名漢字混じりの単語が含まれているか否かを判定し、
前記手描き文字データに仮名漢字混じりの単語が含まれている場合に、仮名漢字混じりの単語と当該仮名を漢字とした単語とを対応付けた仮名漢字混在辞書を参照して、仮名漢字混じりの単語を対応する漢字の単語に変換する
付記21乃至28の何れか1項に記載の手描き入力装置。
【0113】
(付記30)
前記文字属性認識部が、
前記手描き文字データに仮名漢字混じりの単語が含まれているか否かを判定し、
前記手描き文字データに仮名漢字混じりの単語が含まれている場合に、変換結果としての漢字の単語と、当該単語の読み仮名を当該漢字の一文字毎に区切ったインデックスとを対応付けた区切り付き辞書を参照して、仮名漢字混じりの単語を、当該単語の仮名部分と前記インデックスとが一致する単語に変換する
付記21乃至29の何れか1項に記載の手描き入力装置。
【符号の説明】
【0114】
1 手描き入力装置
16 演算処理部
13 記憶部(ハードディスク)
14 入出力ポート
15 通信制御部
【特許請求の範囲】
【請求項1】
ユーザによって入力された文字の軌跡を一連の座標データとして検出するステップと、
前記ステップで検出した一連の座標データを所定条件に基づいて区切り、区切られた各座標データを手描き文字データとするステップと、
前記手描き文字データに基づき表示領域に手描き文字を表示させるステップと、
をコンピュータが実行する手描き入力方法。
【請求項2】
前記手描き文字をそれぞれ、所定の書式情報に基づいて前記表示領域に配列させる請求項1に記載の手描き入力方法。
【請求項3】
前記手描き文字データの文字認識を行い、当該手描き文字データの文字コードを特定し、各手描き文字データと文字コードを対応付けて記憶部に記憶させるステップを実行する請求項1又は2に記載の手描き入力方法。
【請求項4】
連続する前記文字コードを辞書データと比較して、単語又は文節の区切りの情報を求め、前記書式情報に追加するステップを実行する請求項3に記載の手描き入力方法。
【請求項5】
文字コードが入力された場合に、前記当該文字コードと対応する手描き文字データを記憶部から読み出して出力するステップを実行する請求項4に記載の手描き入力方法。
【請求項6】
アンダーライン、取り消し線、罫線、網掛け、太字、イタリック体、右寄せ、左寄せ、センターリングの少なくとも一つの修飾を行うための属性情報を前記手描き文字に付加する請求項1乃至5の何れか1項に記載の手描き入力方法。
【請求項7】
前記表示領域が、表形式の入力欄である請求項1乃至6の何れか1項に記載の手描き入力方法。
【請求項8】
前記手描き文字データに仮名及び漢字が含まれているか否かを判定するステップと、
前記手描き文字データに仮名及び漢字が含まれている場合に、当該仮名と当該漢字を逆変換した仮名との組み合わせを仮名漢字変換辞書を参照して漢字に変換するステップと、を実行する請求項1乃至7の何れか1項に記載の手描き入力方法。
【請求項9】
前記手描き文字データに仮名漢字混じりの単語が含まれているか否かを判定するステップと、
前記手描き文字データに仮名漢字混じりの単語が含まれている場合に、仮名漢字混じりの単語と当該仮名を漢字とした単語とを対応付けた仮名漢字混在辞書を参照して、仮名漢字混じりの単語を対応する漢字の単語に変換するステップを実行する請求項1乃至8の何れか1項に記載の手描き入力方法。
【請求項10】
前記手描き文字データに仮名漢字混じりの単語が含まれているか否かを判定するステップと、
前記手描き文字データに仮名漢字混じりの単語が含まれている場合に、変換結果としての漢字の単語と、当該単語の読み仮名を当該漢字の一文字毎に区切ったインデックスとを対応付けた区切り付き辞書を参照して、仮名漢字混じりの単語を、当該単語の仮名部分と前記インデックスとが一致する単語に変換するステップを実行する請求項1乃至9の何れか1項に記載の手描き入力方法。
【請求項11】
ユーザによって入力された文字の軌跡を一連の座標データとして検出するステップと、
前記ステップで検出した一連の座標データを所定条件に基づいて区切り、区切られた各
座標データを手描き文字データとするステップと、
前記手描き文字データに基づき表示領域に手描き文字を表示させるステップと、
をコンピュータに実行させるための手描き入力プログラム。
【請求項12】
ユーザによって入力される文字の軌跡を一連の座標データとして検出する入力検出部と、
前記入力検出部で検出した一連の座標データを所定条件に基づいて区切り、区切られた各座標データを手描き文字データとする文字区切り認識部と、
前記手描き文字データに基づき表示領域に手描き文字を表示させる表示制御部と、
を備えた手描き入力装置。
【請求項1】
ユーザによって入力された文字の軌跡を一連の座標データとして検出するステップと、
前記ステップで検出した一連の座標データを所定条件に基づいて区切り、区切られた各座標データを手描き文字データとするステップと、
前記手描き文字データに基づき表示領域に手描き文字を表示させるステップと、
をコンピュータが実行する手描き入力方法。
【請求項2】
前記手描き文字をそれぞれ、所定の書式情報に基づいて前記表示領域に配列させる請求項1に記載の手描き入力方法。
【請求項3】
前記手描き文字データの文字認識を行い、当該手描き文字データの文字コードを特定し、各手描き文字データと文字コードを対応付けて記憶部に記憶させるステップを実行する請求項1又は2に記載の手描き入力方法。
【請求項4】
連続する前記文字コードを辞書データと比較して、単語又は文節の区切りの情報を求め、前記書式情報に追加するステップを実行する請求項3に記載の手描き入力方法。
【請求項5】
文字コードが入力された場合に、前記当該文字コードと対応する手描き文字データを記憶部から読み出して出力するステップを実行する請求項4に記載の手描き入力方法。
【請求項6】
アンダーライン、取り消し線、罫線、網掛け、太字、イタリック体、右寄せ、左寄せ、センターリングの少なくとも一つの修飾を行うための属性情報を前記手描き文字に付加する請求項1乃至5の何れか1項に記載の手描き入力方法。
【請求項7】
前記表示領域が、表形式の入力欄である請求項1乃至6の何れか1項に記載の手描き入力方法。
【請求項8】
前記手描き文字データに仮名及び漢字が含まれているか否かを判定するステップと、
前記手描き文字データに仮名及び漢字が含まれている場合に、当該仮名と当該漢字を逆変換した仮名との組み合わせを仮名漢字変換辞書を参照して漢字に変換するステップと、を実行する請求項1乃至7の何れか1項に記載の手描き入力方法。
【請求項9】
前記手描き文字データに仮名漢字混じりの単語が含まれているか否かを判定するステップと、
前記手描き文字データに仮名漢字混じりの単語が含まれている場合に、仮名漢字混じりの単語と当該仮名を漢字とした単語とを対応付けた仮名漢字混在辞書を参照して、仮名漢字混じりの単語を対応する漢字の単語に変換するステップを実行する請求項1乃至8の何れか1項に記載の手描き入力方法。
【請求項10】
前記手描き文字データに仮名漢字混じりの単語が含まれているか否かを判定するステップと、
前記手描き文字データに仮名漢字混じりの単語が含まれている場合に、変換結果としての漢字の単語と、当該単語の読み仮名を当該漢字の一文字毎に区切ったインデックスとを対応付けた区切り付き辞書を参照して、仮名漢字混じりの単語を、当該単語の仮名部分と前記インデックスとが一致する単語に変換するステップを実行する請求項1乃至9の何れか1項に記載の手描き入力方法。
【請求項11】
ユーザによって入力された文字の軌跡を一連の座標データとして検出するステップと、
前記ステップで検出した一連の座標データを所定条件に基づいて区切り、区切られた各
座標データを手描き文字データとするステップと、
前記手描き文字データに基づき表示領域に手描き文字を表示させるステップと、
をコンピュータに実行させるための手描き入力プログラム。
【請求項12】
ユーザによって入力される文字の軌跡を一連の座標データとして検出する入力検出部と、
前記入力検出部で検出した一連の座標データを所定条件に基づいて区切り、区切られた各座標データを手描き文字データとする文字区切り認識部と、
前記手描き文字データに基づき表示領域に手描き文字を表示させる表示制御部と、
を備えた手描き入力装置。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【公開番号】特開2012−108893(P2012−108893A)
【公開日】平成24年6月7日(2012.6.7)
【国際特許分類】
【出願番号】特願2011−232948(P2011−232948)
【出願日】平成23年10月24日(2011.10.24)
【出願人】(509291127)株式会社MetaMoJi (4)
【Fターム(参考)】
【公開日】平成24年6月7日(2012.6.7)
【国際特許分類】
【出願日】平成23年10月24日(2011.10.24)
【出願人】(509291127)株式会社MetaMoJi (4)
【Fターム(参考)】
[ Back to top ]