
抄録作成支援システム、プログラム、抄録作成支援方法及び特許文献検索システム並びにその検索方法
【課題】第1言語の特許文献から効率的、適切な第2言語の抄録を作成する。
【解決手段】一定の分類ごとに要部抽出の規則を規定する抽出規則辞書2と、電子化された原文特許明細書の章節構造を解析する文書構造解析部11と、この解析された文書構造解析結果の分類に従って抽出規則辞書を選択し、この辞書の規則に基づいて文書構造解析結果から要部を選定する要部選定部12と、文書構造解析結果を母国語に翻訳処理する機械翻訳部13と、前記要部選定部で選定される各要部ごとに、翻訳された母国語翻訳結果から母国語の抄録候補を抽出する抄録候補抽出部14と、この抽出される母国語抄録候補及びこの母国語抄録候補に対応する原文要部のうち、母国語の抄録候補を表示し、又は母国語の抄録候補と原文要部とを対応付けて表示し、母国語の抄録候補の修正処理を含んで母国語抄録を作成する抄録編集表示制御部15とを設けた抄録作成支援システムである。
【解決手段】一定の分類ごとに要部抽出の規則を規定する抽出規則辞書2と、電子化された原文特許明細書の章節構造を解析する文書構造解析部11と、この解析された文書構造解析結果の分類に従って抽出規則辞書を選択し、この辞書の規則に基づいて文書構造解析結果から要部を選定する要部選定部12と、文書構造解析結果を母国語に翻訳処理する機械翻訳部13と、前記要部選定部で選定される各要部ごとに、翻訳された母国語翻訳結果から母国語の抄録候補を抽出する抄録候補抽出部14と、この抽出される母国語抄録候補及びこの母国語抄録候補に対応する原文要部のうち、母国語の抄録候補を表示し、又は母国語の抄録候補と原文要部とを対応付けて表示し、母国語の抄録候補の修正処理を含んで母国語抄録を作成する抄録編集表示制御部15とを設けた抄録作成支援システムである。
【発明の詳細な説明】
【0001】
【発明の属する技術分野】
本発明は、外国語特許文献等から母国語の抄録を作成する際に利用される抄録作成支援システム、プログラム、抄録作成支援方法及び特許文献検索システム並びに特許文献検索方法に関する。
【0002】
【従来の技術】
従来から日本国以外の国においてどのような特許が出願されているかの情報をサービスすることを目的とし、外国語(例えば英語)で記載された特許文献(請求の範囲を含む明細書、図面等)全文を参照し、母国語(例えば日本語)などの和文抄録を作成することが日常的に行われている。この作成された和文抄録は、検索システムのデータベースに蓄積され、エンドユーザへの閲覧や検索に提供されている。
【0003】
ところで、英語特許文献から和文抄録を作成する場合、現状では、抄録作成者が和文抄録の作成対象となっている英語特許文献の全文を読み、その特許文献から主要部分(以下、要部という)が何であるかを把握し、当該要部を母国語に翻訳する作業が行われている。作成すべき和文抄録は、技術分野、要旨、実施例などの中から予め定められた日本語の長さ(例えば合計文字数600文字〜800文字程度)の範囲で記載し作成している。
【0004】
このような抄録作成作業は、すべて抄録作成者による人手の作業に頼っているので、抄録作成にかかる手間が非常に大きい。また、抄録作成作業工程において、抄録を作成する前段階では、抄録作成者が英語特許文献全文にわたって内容を把握する必要がある。その結果、抄録作成者は、英語特許文献全文を読みきる必要があるが、この読解のために多大な作業コストがかかり、また抄録作成作業の効率が非常に悪いことから、その作業効率の改善が求められていた。
【0005】
そこで、抄録作成作業の効率化を図るために、近年、幾つかの抄録作成支援システムが提案されている。
【0006】
その1つの抄録作成支援システムは、文章を要約するための文章要約システムであって、技術論文などの章節構造を抽出し、章節ごとに抄録としてそのまま利用するか(例えば要旨の部分)、要約処理を行うか、或いは要約処理をせずに無視するか(例えば文献)といった処理の切り分けを行うものである(特許文献1参照)。
【0007】
他の1つの抄録作成支援システムは、文書情報を検索するための文書情報検索装置及び文書検索結果表示方法であって、検索結果を提示する際に、原文から抄録生成を自動的に行い、この生成された抄録をユーザに提示する。そして、抄録と原文との対応関係を取り出し、抄録表示と原文表示との連動や原文表示中の抄録部分を強調表示する構成である(特許文献2参照)。
【0008】
【特許文献1】
特許第2766261号公報
【0009】
【特許文献2】
特許第2957875号公報
【0010】
【発明が解決しようとする課題】
従って、以上のような抄録作成支援システムでは、技術論文などを対象とするものであり、しかも抄録作成のための重要文抽出の処理方法としては、文書中における単語の使用頻度等の統計情報に基づいた方法(例えば使用頻度の高い単語が重要であり、重要語を含む文は重要であるという選定基準)、接続詞や文末の表現に基づいて重要文を選定する方法(例えば、「要するに」という副詞を用いている文は重要であるという選定基準)などが開示されている。
【0011】
しかしながら、これらの重要文抽出の処理方法は、技術論文などを対象にしたものであり、かつ、一律の選定基準に従って重要文を選定する方法であるが、これをそのまま特許文献に適用しても、特許文献的な観点から要部であると判断できる質のよい重要文を抽出することができない問題がある。
【0012】
また、前述する抄録作成支援システムは、単一の言語に関する抄録の作成が目的であり、例えば英語特許文献から和文抄録を作成するための支援機能をもっていないので、英語特許文献から和文抄録が作成できないという問題がある。
【0013】
しかも、理想的には、自動的に抄録が作成されることが好ましいが、品質の良い抄録を作成するためには、最終的には抄録作成者等の人手によるチェックが必要となる。このため、抄録作成を自動的に行うのではなく、抄録作成を支援するというシステムの提供が必要となる。
【0014】
さらに、以上のような抄録作成支援システムでは、「要旨」「発明の属する技術分野」「実施例」などの章節構造に従って、例えば「要旨」については要部として抽出する。しかしながら、要部となるべき単語やフレーズ等の抽出規則辞書に関し、予め国際特許分類(以下、IPC分類と呼ぶ)の区分ごとに準備し、抄録作成対象とする特許文献のIPC分類や「発明の属する技術分野」「実施例」などの章節構造等に従って抽出規則辞書を切り替える等の内容が記載されておらず、その点からも上記システムのままでは利用することが難しい。また、抄録と機械翻訳との連携についても何ら記載されていない。
【0015】
さらに、抄録作成者が作成する文章は和文抄録であるので、要部抽出とともに日本語に翻訳する作業も必要になってくる。従来、人手により翻訳する場合、仕事量との関係から同じ技術分野の特許文献であっても、別の分野の抄録作成者が担当することも多く、人手による翻訳に限れば、専門用語の翻訳に対して一貫性を保持することが非常に難しい状況にある。
【0016】
そこで、英語特許文献から日本語に翻訳支援するための機械翻訳システムの利用が考えられる。機械翻訳システムについては、すでに幾つかのパッケージソフトウエアが市販されており、例えばIPC分類に基づいて機械翻訳するための専門用語辞書を準備し、機械翻訳時にどのIPC分類に関する特許文献であるかを判定し、特許文献のIPC分類に従って専門用語辞書を選択的に切替え使用することにより、適切な翻訳を行うシステムも提案されている(特開2003−16063号公報)。しかし、このシステムは、機械翻訳を意図するものであり、抄録作成については記載されていない。
【0017】
よって、以上の説明から、外国語特許明細書(ここでいう、外国語特許明細書とは、請求の範囲を含み、さらに公開公報、公告公報、登録特許公報を問わず、特許関連文献(実用新案等を含む)の他、請求の範囲を含んだ明細書を指す意味である。従って、各国によって呼び名が異なるが、公に提供された電子化された特許出願書類といえる)を対象とし、従来の抄録作成システムで抄録を作成し、この作成された英文抄録を英日翻訳システムで日本語に翻訳することが考えられる。
【0018】
しかしながら、抄録作成者が質の良い和文抄録を作成するためには、単に日本語に翻訳された結果を読むだけでは不十分であり、対応する英語の原文やその文章の前後の文章の文脈も参照する必要がある。従って、従来の抄録作成支援システムと機械翻訳システムとを組み合わせただけでは、異なる言語の抄録作成作業を一連の作業手順として進めることができないので、英語特許文献から和文抄録を作成するための支援機能を十分に果たすことができない。
【0019】
何れにせよ、技術分野に応じた特許文献の特徴や特許抄録は、技術的な動向を把握し、またその他の実務的な面からも非常に重要な書類であり、外国語特許文献から適切な母国語の抄録を作成する支援システムの実現が待たれているのが実状であると言える。
【0020】
本発明は上記事情にかんがみてなされたもので、電子化された第1言語の特許出願書類から効率的、かつ適切な第2言語の抄録を作成する抄録作成支援システム、プログラム及び抄録作成支援方法を提供することを目的とする。
【0021】
また、本発明の他の目的は、電子化された第1言語の特許出願書類から所要とする第1言語の特許出願書類を検索し、この検索された第1言語の特許出願書類から前記第1言語の検索要部及び第2言語の検索候補(検索要部)を作成し、効率的な検索作業を実現する特許文献検索システム、プログラム及び特許文献検索方法を提供することを目的とする。
【0022】
【課題を解決するための手段】
(1) 上記課題を解決するために、本発明に係る抄録作成支援システムは、一定の分類ごとに少なくとも所要とする第1言語の章節の表題及びこの各表題の章節に記載される説明文中に含まれる第1言語の単語,フレーズ等のキーフレーズを規定する抽出規則辞書と、電子化された第1言語の特許出願書類に記載される文章の章節構造を解析する文書構造解析手段と、この文書構造解析手段で解析された文書構造解析結果に記載されている分類に従って所要の前記抽出規則辞書を選択し、当該抽出規則辞書に規定される表題及びキーフレーズに基づいて前記文書構造解析結果から要部を選定する要部選定手段と、文書構造解析手段で解析された文書構造解析結果を第2言語に翻訳処理する機械翻訳手段と、要部選定手段で選定される各要部ごとに機械翻訳手段で翻訳された第2言語の翻訳結果から第2言語の抄録候補を抽出する抄録候補抽出手段と、この抄録候補抽出手段で抽出される第2言語の抄録候補及びこの第2言語の抄録候補に対応する第1言語の要部のうち、少なくとも第2言語の抄録候補又は第2言語の抄録候補と第1言語の要部とを対応付けて表示し、当該第2言語の抄録候補の修正処理を含んで第2言語の抄録を作成する抄録編集表示制御手段とを設けた構成である。
【0023】
この発明は以上のような構成とすることにより、第1言語の特許出願書類に記載される文章の章節構造から分野別に従って第1言語の要部と第1言語の文書構造解析結果より翻訳処理された第2言語の翻訳結果とから第2言語の抄録候補を取り出し、この第2言語の抄録候補を修正を含めて第2言語の抄録を作成するので、抄録作成者が第1言語の特許出願書類を読解することなく、自動的に第2言語の抄録候補を抽出し、抄録作成者による修正確認を含めて短時間に第2言語の抄録を作成することが可能であり、効率的に抄録を作成でき、かつ、適切な抄録を作成することが可能である。
【0024】
なお、上記抄録の作成は、プログラムに記録されるプログラムや抄録作成方法によっても実現可能であり、これによりシステムと同様な作用効果を奏することができる。
【0025】
(2) また、本発明に係る特許文献検索システムは、電子化された複数の第1言語の特許出願書類を記憶する記憶手段と、検索条件のもとに前記記憶手段から少なくとも1つの第1言語の特許出願書類を検索する文書検索手段と、一定の分類ごとに少なくとも所要とする第1言語の章節の表題及びこの各表題の章節に記載される説明文中に含まれる第1言語の単語,フレーズ等のキーフレーズを規定する抽出規則辞書と、文書検索手段により検索された前記電子化された第1言語の特許出願書類に記載される文章の章節構造を解析する文書構造解析手段と、この文書構造解析手段で解析された文書構造解析結果に記載されている分類に従って所要の抽出規則辞書を選択し、当該抽出規則辞書に規定される表題及びキーフレーズに基づいて文書構造解析結果から検索対象となる要部を選定する要部選定手段と、文書構造解析手段で解析された文書構造解析結果を第2言語に翻訳処理する機械翻訳手段と、要部選定手段で選定される各検索対象要部ごとに機械翻訳手段で翻訳された第2言語の翻訳結果から第2言語の検索候補を抽出する検索候補抽出手段と、この検索候補抽出手段で抽出される第2言語の検索候補及びこの第2言語の検索候補に対応する前記第1言語の検索要部のうち、少なくとも前記第1言語の検索要部又は前記第1言語の検索要部と前記第2言語の検索候補とを対応付けて表示し、或いは前記第1言語の検索要部及び前記第2言語の検索候補と前記第1言語の文書構造解析結果及び前記第2言語の翻訳結果とを選択的に表示する検索結果表示制御手段とを設けた構成である。
【0026】
この発明は以上のような構成とすることにより、第1言語の多数の電子化された第1言語の特許出願書類の中から検索条件に従って少なくとも1つの第1言語の特許出願書類を検索し、この検索された第1言語の特許出願書類に対し、前記(1)に記載する構成を取り込んで、少なくとも第1言語の検索要部と第2言語の検索候補とを取り出して表示できるので、効率的な検索作業を実現することが可能である。
【0027】
なお、上記検索要部や検索候補の取り出しは、プログラムに記録されるプログラムや特許文献検索方法によっても実現可能であり、これによりシステムと同様な作用効果を奏することができる。
【0028】
【発明の実施の形態】
以下、本発明の実施の形態について図面を参照して説明する。
【0029】
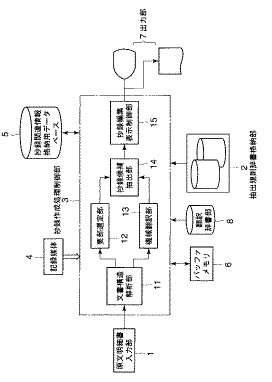
図1は本発明に係る抄録作成支援システムの一実施の形態を説明する構成図である。
【0030】
この抄録作成支援システムは、電子化された外国語特許文献などの第1言語の特許出願書類を入力する原文明細書入力部1と、IPC分類の一定区分ごとに所定の要素をもつ抽出規則で構成された複数の抽出規則辞書を格納する抽出規則辞書格納部2と、前記原文明細書入力部1から入力される外国語特許文献などから母国語などの第2言語の抄録を作成処理する抄録作成処理制御部3と、この抄録作成処理制御部3がCPUで構成されている場合、抄録作成の一連の処理を実行させるためのプログラムを格納する記録媒体4と、この抄録作成処理制御部3で作成される母国語の抄録その他この抄録に関連する情報を保存する抄録関連情報格納用データベース5と、抄録作成の処理途中において必要な情報を一時格納するバッフアメモリ6と、作成された母国語の抄録その他必要な情報を出力する出力部7とにより構成されている。8は翻訳処理時に使用する翻訳処理上の知識を格納する翻訳辞書部である。
【0031】
なお、前述する第1言語の特許出願書類とは、公に提供された刊行物としての性格を有する公開公報、公告公報、登録特許公報及び実用新案に関係する公報を含む全てのテキスト情報を指す。また、特許出願書類の中の明細書とは、厳密な意味で請求の範囲や要約とは別書類の場合も考えられるが、頒布される特許文献では明細書と請求の範囲や要約は所定の順序で一体に印刷されるものであるので、請求の範囲や要約を含めて指すものとする。以下、第1言語の特許出願書類は、説明の便宜上、外国語特許明細書又は英語特許明細書と総称する。
【0032】
原文明細書入力部1は、一般にキーボード、マウスなどが用いられ、キーボードによる各種の制御指示を入力、マウスによる外国語特許明細書中の特定領域の指定により選択される当該外国語特許明細書の入力の他、外国語特許明細書を読み取るOCR(Optical character Rerder)による読み取り情報の入力、フロッピーディスク、磁気テープ、磁気ディスクなどに保存される電子化された外国語特許明細書の入力など、異なる種々の入力形態による外国語特許明細書の入力を含むものである。
【0033】
前記抽出規則辞書格納部2は、一定の区分毎(例えば電気、機械、化学、物理その他の分野などをさらに細分化した区分毎),例えばIPC分類の少なくとも上位分類毎の各抽出規則辞書が設けられ、各抽出規則辞書には所定の抽出規則が規定されている。この各抽出規則辞書の規則の一例としては例えば抄録項目、フィールド、キーフレーズの3つの要素から構成され、具体的な一例としては後記する図5に示す通りである。
【0034】
前記抄録作成処理制御部3は、機能的には、原文明細書入力部1から入力される外国語特許明細書の項目(文書構造)を解析し、各項目ごとに認識可能な一定の形式に基づくタグ付けした文書構造の明細書を作成する文書構造解析手段としての文書構造解析部11と、この構造解析部11で文書構造を解析された文書構造解析結果の中から抽出規則辞書に定められる規則に従って要部を抽出する要部選定手段としての要部選定部12と、文書構造解析部11から出力される文書構造解析結果に対し、翻訳辞書部8に規定する規則・知識を用いて、母国語に翻訳する翻訳処理手段としての機械翻訳部13と、要部選定部12の要部抽出結果である各要部ごとに、機械翻訳部13で翻訳された外国語特許明細書全文の母国語語翻訳結果の全文の中から母国語の抄録候補を抽出する抄録候補抽出手段としての抄録候補抽出部14と、この抄録候補抽出部14から抽出される母国語の抄録候補と要部選定部12で抽出された外国語要部(原文要部)とを対応付けて表示し、又は前記外国語の文書構造解析結果全文及び前記機械翻訳部13で翻訳処理された母国語の翻訳結果とを対応付けて表示し、当該母国語の抄録候補の抄録作成者による修正処理を含んで母国語の抄録を作成する抄録編集表示制御部15とが設けられている。
【0035】
前記出力部7は、機械翻訳部13の出力である翻訳結果を出力したり、入力部1から入力される外国語特許明細書を表示したり、或いは作成された母国語抄録を表示したり、外国語特許明細書全文と翻訳済み明細書全文その他所要とする種々の形式で表示する機能を有するものであって、通常,各種ディスプレイなどの表示手段が用いられるが、その他、例えばプリンタなどの印字手段、或いはフロッピーディスク、磁気テープ、磁気ディスクへの書き込み登録手段、さらには他のメディアに対して送信する送信手段その他ユーザの所望する各種の出力形態が挙げられる。
【0036】
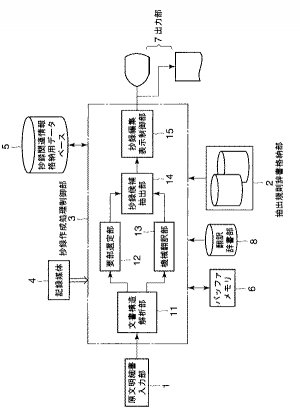
次に、以上のような抄録作成支援システムの動作及び本発明に係るプログラム、抄録作成支援方法について図2を参照しながら説明する。
【0037】
先ず、原文明細書入力部1から電子化された外国語特許明細書,例えば英語特許明細書が入力されると(S1)、抄録作成処理制御部3は、記録媒体4に格納されるプログラムに従って一連の処理を実行する。なお、この抄録作成処理制御部3は、例えば論理回路等で構成されるハード構成によって処理することも可能であるが、ここではプログラムに従って一連の処理を実行するものとする。
【0038】
一般に、英語特許明細書は、図3にその一部を示すように、要旨(Abstract)、請求項(Claims)、発明の分野(FIELD OF THE INVENTION)、発明の背景(BACKGROUND OF THE INVENTION)などの明細書の項目(文書構造)の他、ここでは図示されていないが、発明者やIPC分類コード等が記載されている。
【0039】
そこで、抄録作成処理制御部3は、原文明細書入力部1から入力される電子化された英語特許明細書を受け取ると、例えばバッフアメモリ6に一時格納した後、文書構造解析部11にて英語特許明細書の文書構造解析処理を行う(S2:文書構造解析機能、文書構造解析ステップに相当する)。この文書構造解析処理部11は、特許明細書のフォーマットがXML形式であることを前提とした場合、予め定められる英語特許明細書の各項目(文書構造)を解析し、この項目ごとにXMLタグ情報に基づいてタグ付けした文書構造に置き換え、文書構造解析結果としてバッフアメモリ6又はデータベース5に格納する(S3)。
【0040】
図4は文書構造解析部11により構造解析された文書構造解析結果の一部を示す図である。ここでは、Abstract、Claims、FIELD OF THE INVENTIONといった各項目に従った文書構造がXML形式で表現されている。この文書構造解析結果に示されているように、タグ<field header=”XXXX”>から当該タグに対応する</field>までの範囲が「XXXX」の表題に対応する部分となる。なお、ここでは、特許明細書のフォーマットがXML形式であることを前提とした例であるが、他の形式による場合には英語特許明細書の各項目(文書構造)を解析し、この項目ごとに他の形式に従った文書構造に置き換えることは言うまでもない。
【0041】
以上のようにして文書構造解析結果を得た後、要部選定部12は、抽出規則辞書格納部2に格納される各抽出規則辞書の規則に従い、文書構造解析結果の中から順次要部を抽出する(S4:要部選定機能、要部選定ステップに相当する)。
【0042】
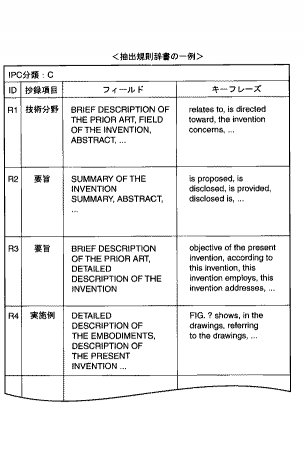
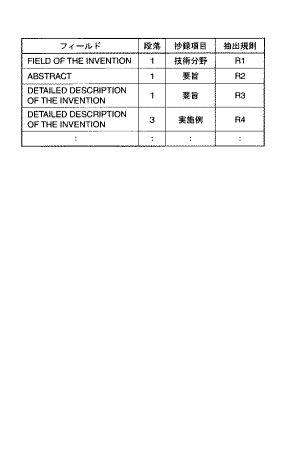
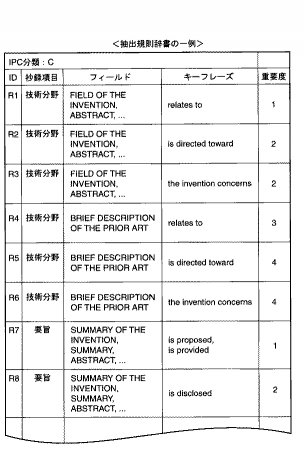
この抽出規則辞書は、クラス(上位分類)からサブグループ(下位分類)まで細分化して展開されているIPC分類に基づく一定の技術区分(例えば、日本の公報発行区分に近い30程度の技術区分や本発明を応用する分野の必要に応じた技術区分)ごとに設けられ、各抽出規則辞書内の規則の形式は、図5に示すように抄録項目、フィールド、キーフレーズの3つの要素から構成されている。抄録項目は、要部として出力する内容を日本語で記載されており、ここでは、技術分野、要旨、実施例(実施の形態を含む)という3つの項目が例示されている。フィールドは文書構造における各章節の表題を示している。キーフレーズは、フィールドで設定されている各章節を検索し、当該キーフレーズに定義されている単語やフレーズが表題の中味を説明する文中に含まれていれば、それを要部として抽出することを意味する。
【0043】
例えば抄録作成対象である英語特許明細書の文書構造において、「BREIF DESCRIPTION OF THE PRIOR ART」「FIELD OF THE INVENTION」「ABSTRACT」などの表題に対応する段落の文中に、辞書の規則で定める技術分野に対応するキーフレーズとなる「relates to」「is directed toward」「the invention concerns」などの単語やフレーズが含まれていれば、その段落が「技術分野」という抄録項目に相当する要部の候補であることを意味する。また、「SUMMARY OF THE INVENTION」「SUMMARY」「ABSTRACT」という表題に対応する段落の文中に、辞書の規則で定める要旨に対応するキーフレーズとなる「is proposed」「is disclosed」「is provided」「disclosed is」などの単語、フレーズが含まれていれば、その段落が「要旨」という抄録項目に相当する要部の候補であることを意味する。なお、各抄録項目にはそれぞれ複数の条件の登録が可能であるので、例えば「要旨」に対応する規則には2つの抽出規則R2、R3に分けて登録されている。4番目の抽出規則であるR4に対応するキーフレーズには「Fig.?」が記載されているが、この「?」は任意の数字に照合することを意味している。つまり、キーフレーズの「Fig.?」は例えば「Fig.1」「Fig.2」等の何れとも照合可能であることを意味する。
【0044】
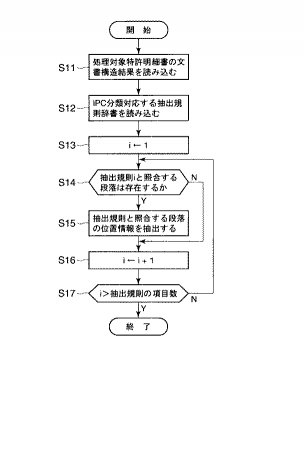
そこで、要部選定部12は、以上のような抽出規則辞書内の規則を用いて、図6に示す要部選定処理を実行する。具体的には、バッフアメモリ6又はデータベース5から図4に示す英語特許明細書の文書構造解析結果を読み込む(S11)。一般に、特許明細書にはIPC分類が記載されているので、図4に示す文書構造解析結果にもタグ情報によりIPCが認識可能になっている。つまり、図4の例では、「<ipc>」と「</ipc>」とで囲まれている範囲がIPC分類が記されている部分であり、詳しくは「C08F 002/00」と記載されている。この分類情報を用いることによって、クラス(上位分類)からサブグループ(下位分類)まで細分化して展開されているIPC分類に基づく技術区分に応じた抽出規則辞書を判断することができる。
【0045】
要部選定部12は、文書構造解析結果からIPC分類を取り出すと、抽出規則辞書格納部2から該当するIPC分類に対応する抽出規則辞書を読み込んだ後(S12)、次のステップS13に移行し、抽出規則辞書の最初に参照すべき抽出規則(ID=R1)として、変数iに1を設定する。そして、変数i=1の抽出規則に基づき、当該規則のフィールド及びキーフレーズと照合する段落が抄録作成対象の英語特許明細書(文書構造解析結果)に存在するか否かを判断する(S14)。ここで、照合する段落が存在していれば、この照合する段落の位置情報(特定情報)を抽出し(図2のS5、図6のS15)、バッフアメモリ6又はデータベース5に記憶する。
【0046】
この段落の位置情報を抽出した後、或いはステップS14において照合する段落が存在しない場合、次のステップS16に移行し、抽出規則辞書に規定する次に処理すべき抽出規則(ID=R2)として、変数iに+1をインクリメントした後、該当変数に相当する抽出規則の項目数全部が終了したか否かを判断し(S17)、未だ抽出規則の項目が残っている場合にはステップS14に戻り、変数iの抽出規則のフィールド及びキーフレーズと照合する段落が抄録作成対象の特許明細書(文書構造解析結果)に存在するか否かを判断し、全ての抽出規則について繰り返し実行する。
【0047】
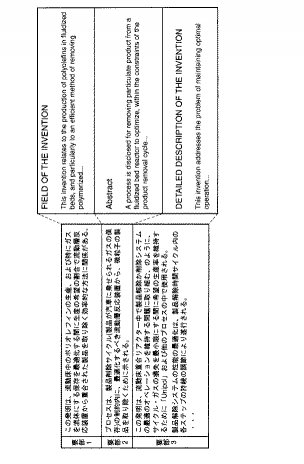
図7は、本発明の主旨を説明するために、要部の抽出部分を模式的に示した図である。例えば図5に示す抽出規則辞書の2番目の抽出規則(ID=R2)では、フィールドの中に「ABSTRACT」、キーフレーズの中に「is disclosed」が記載されている。従って、この2番目の抽出規則が「Abstract」である表題に関係する図示点線枠で囲む説明文21の中に含まれる「is disclosed」(下線引きで示している)と照合するので、この「Abstract」の説明文21又はその文中の段落位置(特定情報)を「要旨」として抽出することになる。また、図5に示す抽出規則辞書の1番目の抽出規則(ID=R1)では、フィールドの中に「FIELD OF THE INVENTION」、キーフレーズの中に「relates to」が記載されている。従って、この1番目の抽出規則が「FIELD OF THE INVENTION」の点線枠で囲む図7の説明文22の中に含まれる「relates to」(下線引きで示している)と照合するので、この「FIELD OF THE INVENTION」の説明文22又はその文中の段落位置(特定情報)を「技術分野」として抽出する。さらに、図5に示す抽出規則辞書の3番目の抽出規則(ID=R3)では、フィールドの中に「DATAILED DESCRIPTION OF THE INVENTION」、キーフレーズの中に「this invention addresses」が記載されている。従って、この3番目の抽出規則が「DATAILED DESCRIPTION OF THE INVENTION」の点線枠で囲む説明文23の中に含まれる「this invention addresses」(下線引きで示している)と照合するので、この「DATAILED DESCRIPTION OF THE INVENTION」の説明文23又はその文中の段落位置(特定情報)を「要旨」として抽出することになる。
【0048】
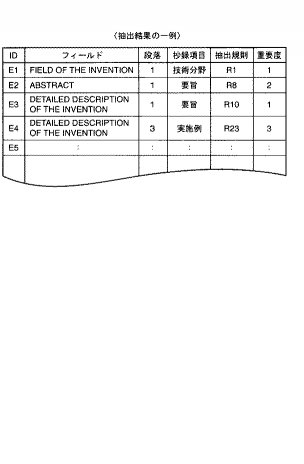
図8は要部選定部12による抽出結果の表現形式の一例を表す図である。
【0049】
図7は図4の文書構造解析結果と対応づけながら抽出される要部について要部特定情報21,22,23を付けて表したが、図8はより具体的に特許明細書中のフィールド、文中の段落位置などのポインタで対応付けて抽出することができる。因みに、図8は、フィールド、段落(段落位置,特定情報)、抄録項目、要部抽出に使用された抽出規則の組み合わせにより構成されている。具体的には、図8の1行目の情報は、「FIELD OF THE INVENTION」という章節であって、1段落目が抽出規則R1に照合したことを示しており、抽出規則R1は、抄録項目の「技術分野」に対応する規則であることを表している。また、3行目の情報は、「DATAILED DESCRIPTION OF THE INVENTION」という章節であって、1段落目が抽出規則R3に照合したことを示しており、この抽出規則R3は、抄録項目の「要旨」に対応する規則であることを表している。
【0050】
以上のようにして要部選定部12が英語文書構造解析結果から例えば図8に示すような要部を抽出した後、或いは要部選定部12による要部選定処理と同時並行的に処理する機械翻訳部13が翻訳辞書部8の翻訳処理上の知識を用いて、英語特許文献の文書構造解析結果を翻訳処理し(S6)、母国語である例えば日本語の翻訳結果を得るものである(S7)。これらステップS6,S7は翻訳処理機能、翻訳処理ステップに相当する。
【0051】
図9は図4に示す英語の文書構造解析結果に対し、XMLタグ以外の他の文書を日本語に翻訳処理した翻訳結果を示す図である。なお、XMLタグを除いて翻訳処理した理由は、翻訳結果についても元の英語の文書構造解析結果を保持しておく必要があるので、XMLタグについては翻訳処理を行わないこととする。なお、英日機械翻訳については、既に幾つかのパッケージソフトが市販されており、それらのパッケージソフトで実現されている翻訳処理技術を利用すればよい。これにより、図9のような翻訳結果を容易に取得することが可能である。
【0052】
引き続き、抄録候補抽出部14は、要部選定部12で抽出された要部抽出結果(図8参照)と機械翻訳部13によって取得された機械翻訳結果(図9参照)とを比較しながら、母国語である例えば日本語の抄録候補を抽出する(S8:抄録候補抽出機能、抄録候補抽出ステップに相当する)。
【0053】
この抄録候補抽出部14では、具体的には、図8の1行目の「FIELD OF THE INVENTION」の1段落目に関する抄録候補を抽出することになる。図9に示す事例では、<field header=”FIELD OF THE INVENTION”>において、「[0001]」で始まる段落が抄録候補に相当する。また、図8の2行目の「ABSTRACT」の1段落目に関する抄録候補を抽出することになる。図9に示す事例からは、<field header=”ABSTRACT”>において、「プロセス」で始まる段落が抄録候補に相当する。以下、同様に図8に示す要部抽出結果の各行の情報に従い、機械翻訳結果から抄録候補を順次取り出し、データベース5の所定エリアに記憶する。図10は、その抄録候補の抽出結果を示す図である。
【0054】
ところで、以上説明した実施の形態では、行数や段落数が変化しないことを前提とし、機械翻訳処理した例について述べたが、機械翻訳処理の中には一文を複数文に分けて訳出する処理を行う場合もある。このような場合、図8に示すように段落や文単位の対応では、対応関係がずれてしまう可能性が生ずる。しかし、文書構造解析部11では、英語特許明細書側の全ての文や段落に対して、ユニークな番号をもつXMLタグを割り振りして処理しているので、その文書構造解析結果に基づいて、XMLタグの情報を保持したままで機械翻訳を行えば問題はなくなる。
【0055】
従って、この抄録作成支援システムでは、以上のようにして抄録候補を抽出した段階では、抄録関連情報格納用データベース5には英語特許明細書全文(図3参照)、英語文書構造解析結果(図4)、日本語機械翻訳結果(図9参照)、日本語抄録候補抽出結果(図10R>0参照)等が格納されているので、抄録編集表示制御部15は、入力部1からの選択操作のもとに、抄録関連情報格納用データベース5から所要の情報を選択的に取り出し、所要のフォーマットに従って出力部7に表示する(S9)。
【0056】
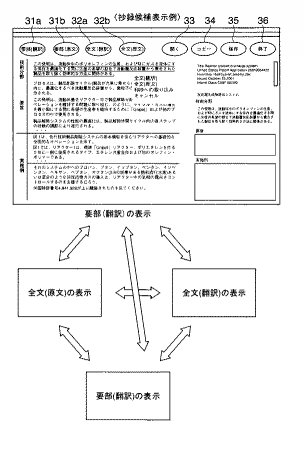
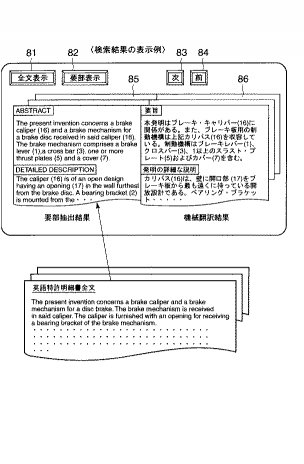
図11は抄録作成者による所要の操作のもとに出力部7に表示された日本語・英語の要部表示(上段)又は日本語・英語の全文表示(下段)の画面表示例を示す図である。
【0057】
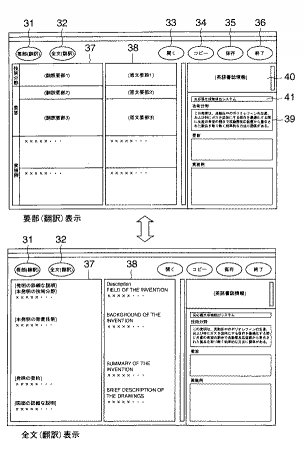
先ず、抄録作成者は、初期画面を取り出すと、この初期画面には要部ボタン31、全文ボタン32、開くボタン33、コピーボタン34、保存ボタン35、終了ボタン36その他の所要とするボタン(図示せず)の他、図11の上段左側の表示エリア37には日本語の翻訳要部(抄録候補)が順次表示される。一方、この翻訳要部の表示に連動して図11の上段右側の表示エリア38に翻訳要部と対応関係をとりながら英語の原文要部が順次表示される。なお、図面のスペースの関係から翻訳要部及び原文要部のそれぞれの文字が記載できないので、図12に一部の翻訳要部及び原文要部を記載してある。なお、各表示エリア37,38は、入力部1を構成するマウスなどのポインティングデバイスによって1つの段落を選択可能になっている。
【0058】
すなわち、表示エリア37と表示エリア38は連動しており、表示エリア37のある段落が選択されると、表示エリア38には原文特許明細書に対応する個所の英文の要部が連動して選択表示される。39は抄録作成エリアであって、抄録作成者が表示エリア37,38の翻訳要部、原文要部を確認しながら最適な抄録であると判断したとき、当該翻訳要部をコピーし、必要に応じて文字削除や挿入等の修正処理を施して和文抄録とするエリアである。つまり、抄録作成者は抄録作成エリア39の内容を適宜編集処理して和文抄録を作成する。また、抄録作成者が参考とするために、表示エリア40には発明者、出願年月日、IPCなどの書誌情報が表示され、表示エリア41には特許された発明の名称の翻訳結果が表示される。
【0059】
さらに、全文ボタン32を操作した時には、図11の下段に示すように翻訳全文と原文全文とが連動して表示される。その後、要部ボタン31を操作すると、同図の上段に示す日本語・英語の要部が表示される。
【0060】
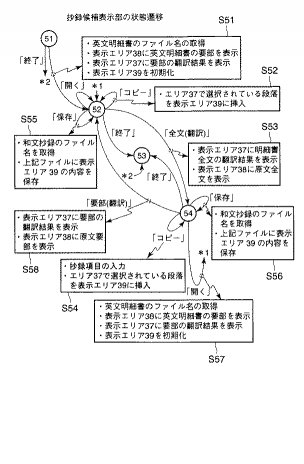
図13は抄録作成者又はユーザ(以下、抄録作成者と総称する)が実際に利用する場合の状態遷移図並びに抄録編集表示制御部15の状態遷移に伴う処理を説明する図である。
【0061】
同図において、状態51はシステムの立ち上げ時の初期状態、状態52は抄録作成者が抄録処理画面の開操作により表示エリア37に翻訳結果の要部が表示されている状態、状態53はシステムの終了を意味する終了状態、状態54は抄録作成者による全文表示の操作により表示エリア37に明細書全文の翻訳結果が表示されている状態を意味する。
【0062】
さらに、具体的に状態遷移について説明すると、抄録作成者が状態51にて開くボタン33を操作すると、英語特許明細書のファイル名を当該抄録作成者に問い合わせて取得することにより、英語特許明細書から抽出された要部の翻訳結果、つまり翻訳要部をデータベース5の所要エリアから取り出し、表示エリア37に表示し、これに連動して表示エリア38には翻訳要部に対応する原文要部を表示し、さらに表示エリア39を初期化した後、状態52に遷移する。
【0063】
この状態52において、表示エリア37に表示されている段落を選択してコピーボタン34を操作すると、当該段落が表示エリア39に挿入される。状態52は、要部(翻訳)の状態であって、抄録項目(図11,図12参照)である「技術分野」「要旨」「実施例」が段落毎に設定されている状態にあるので、その抄録項目に従って表示エリア39にコピーによって順次挿入する(S52)。
【0064】
また、状態54では、全文ボタン37の操作により、表示エリア37に翻訳された全文(全文翻訳)が表示され、これに連動して表示エリア38に原文全文が表示される(S53)。この状態54は、抄録項目が決定されていないので、抄録作成者からの入力を要求する等の処理を経て抄録項目を設定した後、表示エリア37に表示されている段落を必要に応じてコピー操作により表示エリア39にコピーする(S54)。また、状態52或いは状態54において、保存ボタン35を操作すると、抄録作成者による保存先の和文抄録のファイル名の入力に基づき、当該ファイル名のもとにデータベース5に表示エリア39の内容が保存される(S55、S56)。なお、状態54において開くボタン33を操作すれば、ステップS51と同様の処理を実行し(S57)、また要部ボタン31を操作すれば、ステップS52と同様の処理を実行する(S58)。そして、各状態において、終了ボタン36を操作すれば、抄録作成及び所要とする情報の取り出し表示処理が終了する。
【0065】
従って、以上のような実施の形態によれば、外国語特許明細書の項目(文書構造)を解析し、一定の形式に基づくタグ付けした文書構造解析結果を取得した後、この文書構造解析結果に基づいて、要部選定部12が予め定める抽出規則辞書の規則に従って要部を抽出し、また機械翻訳部13では、文書構造解析結果の内容を通常の翻訳処理のもとに例えば母国語に翻訳する。しかる後、抄録候補抽出部14が要部抽出結果である各要部ごとに翻訳された日本語全文の翻訳結果の中から抄録候補を取り出した後、翻訳要部と原文要部を対応付けて表示し、翻訳要部をコピーし、原文要部を参照し、必要に応じて英語特許明細書の文書構造解析結果全部及び翻訳された翻訳結果全文を参照しながら、文字削除、挿入により和文抄録を作成するので、和文抄録を効率的に作成でき、かつ人手による和文抄録作業を適切に支援することができる。
【0066】
なお、要部表示は、図11、図12に示すような形態に限るものではない。例えば図14に示すように、要部ボタン31を翻訳要部ボタン31aと原文要部ボタン31bに分け、また全文ボタン32についても翻訳全文ボタン32aと原文全文ボタン32bとに分け、これらボタンを個別に選択操作することにより、4つの表示形態に選択して表示する構成であってもよい。要するに、英語特許明細書から選択した要部の英文やその翻訳結果、オリジナルの英語特許明細書、その翻訳した全文明細書などを自在に順次表示することが可能である。
【0067】
次に、図15は本発明に係る抄録作成支援システムの他の実施の形態を説明する図である。
【0068】
この実施の形態は、抽出規則辞書格納部2に格納される各抽出規則辞書の規則に予め重要度を設定し、抽出された段落の重要度に基づいて抄録候補の表示量ないし表示数を制御する例である。
【0069】
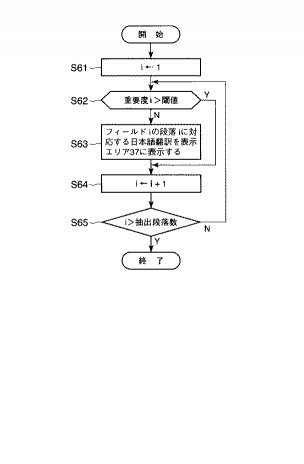
本発明に係る抄録作成支援システムでは、図15に示す抽出規則辞書に予め重要度を設定しておけば、要部選定部12によって要部を選定すると、図8に示す要部抽出結果にさらに重要度が付加された図16に示す要部抽出結果が得られる。つまり、要部抽出結果には、抽出される各段落毎に、抽出の時に用いられた抽出規則の重要度情報が付加されている。その結果、図示されていないが、図10に示す抄録候補の翻訳結果にも各要部ごとに重要度の情報が付加される。なお、予め「1」は重要度が最も高く、数値が大きくなるに従って重要度が低くなるように取り決められているものとする。
【0070】
その結果、抄録編集表示制御部15では、図17に示すごとく重要度を考慮しつつ抄録候補の抽出処理を実行する。すなわち、抄録編集表示制御部15は、先ず最初に変数iに1番目の抽出規則(ID=R1)である1を設定した後(S61)、この抽出規則(ID=R1)に対応する重要度が予め定める閾値よりも大きいか、つまり閾値よりも重要度が高いか否かを判断し(S62)、重要度が高いと判断された場合には、当該フィールドの段落に対応する日本語の翻訳要部を表示エリア37に表示する(S63)。この翻訳要部を表示した後又はステップS62において閾値よりも重要度が低いと判断された場合、ステップS64に移行し、変数iに+1を加えた後、この変数iの番目の抽出規則(ID=Ri)が未だ残っているか否かを判断し(S65)、未だ残っている場合にはステップS62に戻り、同様の処理を実行する。全ての抽出段落数について重要度を調べて要部翻訳を表示したとき、重要度に関する処理は終了する。
【0071】
従って、以上のような実施の形態によれば、抄録作成段階で予め定める閾値よりも重要度の高い翻訳要部だけを表示エリア37に表示して和文抄録を作成することができ、また少ない表示量を用いて効率的に和文抄録を作成できる。
【0072】
なお、重要度の閾値は、抄録作成者が随時変更でき、抄録作成者の所要とする和文抄録を容易に作成できる。
【0073】
図18は本発明に係る抄録作成支援システムのさらに他の実施の形態を説明する図である。
【0074】
この実施の形態は、図4に示す文書構造解析結果に記載される明細書から抄録候補として「代表図の説明」を抽出する例である。
【0075】
本発明に係る抄録作成支援システムでは、抽出規則辞書に規定する規則の中のキーフレーズにフレーズの照合だけでなく、特殊記号を追加することにより、抽出規則辞書の表現形式を拡張し、「代表図の説明」を要部として抽出するものである。
【0076】
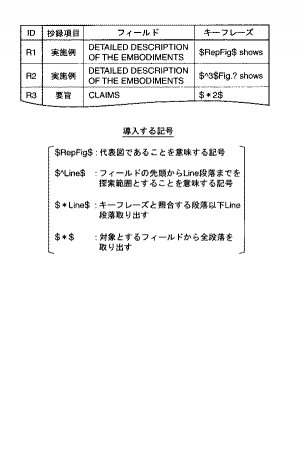
このキーフレーズに導入する記号のうち、「$RepFig$」は代表図であることを意味する記号であり、「$^Line$」は指定されたフィールドの先頭からLine段落までをキーフレーズの探索範囲であることを意味する記号である。「$*Line$」は照合する段落以下のLine段落を取り出すことを意味する。「$*$」は、例えば「SUMMARY」フィールドに関しては全ての段落を要部として取り出すことを意味する。
【0077】
このシステムは、抽出規則辞書部に図18に示すような抽出規則を記載することにより、要部抽出部12では、1番目の抽出規則(ID=R1)に関し、例えば代表図がFig.1であれば、フィールドに規定する「FIELD OF THE INVENTION」に対応する文書構造解析結果の中に「Fig.1 shows」というキーフレーズが存在するかを探索することを意味する。また、2番目の抽出規則(ID=R2)に関し、フィールドに規定する「DATAILED DESCRIPTION OF THE INVENTION」に対応する文書構造解析結果の中の3段落目までを探索範囲とし、「Fig.? shows」(「?」は任意の数字)というキーフレーズが存在しているかを探索することを意味する。さらに、3番目の抽出規則(ID=R3)に関し、フィールドに規定する「CLAIMS」に対応する文書構造解析結果の中の2段落(他のキーフレーズの指定がないため)を抽出することを意味する。
【0078】
因みに、米国公開特許明細書のXML形式の定義である“−//USPTO//DTD PAP V1.6 2002−01−01//EN”におけるpap−v16−2002−01−01.Dtdによれば、<representative・figure>と</representative・figure>とで囲まれた数字が代表図を示している。このような形式で記載された特許明細書を入力した場合、代表図が何であるかを特許明細書中から容易に取り出すことができる。
【0079】
従って、要部選定部12の図6に示すステップS14では、以上のような定義情報を用いて、抽出規則辞書中の「$RepFig$」という記号の具体的な文字列に置き換えた後、通常のキーフレーズに従って探索するように処理すればよい。すなわち、例えば抄録作成対象とする特許明細書の代表図が「Fig.1」であれば、「$RepFig$」は「Fig.1」に置換できるので、抽出規則R1のキーフレーズは「Fig.1 shows」となる。よって、フィールドに規定する「DATAILED DESCRIPTION OF THE INVENTION」に対応する文書構造解析結果の中から「Fig.1 shows」というキーフレーズを探索することになる。
【0080】
また、要部選定部12のキーフレーズの探索のステップS14(図6)において、抽出規則に記載されているキーフレーズに、特殊記号「$RepFig$」が含まれていれば、キーフレーズの探索範囲をLine段落まで限定したり、特殊記号「$*Line$」が含まれていれば、キーフレーズに照合する段落以下のLine段落を要部として抽出したり、キーフレーズに特殊記号「$*$」が含まれていれば、処理対象のフィールドの全段落を要部として選択する等の処理を行うことになる。
【0081】
従って、このような実施の形態によれば、特許明細書の中から代表図の説明を抄録候補として容易に抽出することができる。
【0082】
なお、以上のような特殊記号を新たに定義し、それに合せて要部選定部12を構成すれば、代表図の説明以外にも要部とする内容を容易に抽出することが可能である。
【0083】
図19は本発明に係る抄録作成支援システムのさらに他の実施の形態を説明する図である。
【0084】
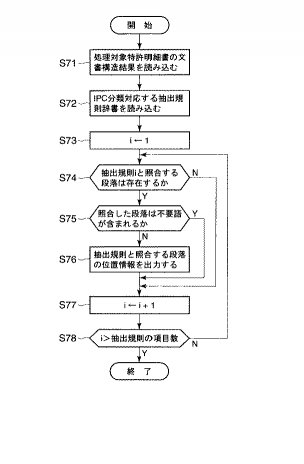
この実施の形態は、抽出規則辞書格納部2の中に新たに不要語辞書を設け、抽出規則辞書の条件に照合する段落であっても、不要語に照合する段落に限り、抽出しない構成とする例である。
【0085】
図19は不要語辞書の一例を示す図であって、例えば1番目と2番目の規則F1,F2の不要語は、第2の実施例を説明する際に用いられるフレーズであり、要部として選択する上で適切でない場合がある。また、3番目と4番目の規則F3,F4の不要語は、従属形式請求項となっている場合に用いられるフレーズであり、これも要部として選択すべきでない場合が多い為である。
【0086】
図20は抽出規則辞書格納部2に抽出規則辞書の他に不要語辞書を加えた場合の要部選定部12の一連の処理例を示すフローチャートである。
【0087】
この要部選定部12において、図6との処理の違いは、ステップS74にて抽出規則iと照合する段落が存在するか否かを判断し、段落有りと判断されとき、不要語辞書の規則に基づいて照合した段落の中に不要語が存在するか否かを判断し(S75)、不要語が含まれている場合には要部として抽出しない処理としたものである。従って、その他のステップS71〜S74は図6のステップS11〜S14に相当し、またステップS76〜S78は図6のステップS15〜S17に相当するので、詳細な処理は図6の説明に譲る。
【0088】
従って、以上のような実施の形態によれば、不要語辞書の規則に定める不要語が機械文翻訳結果の要部に相当する段落に存在する場合、要部として適切でないと判断し、その段落については要部として抽出しないので、より精度の高い和文抄録を作成できる。
【0089】
なお、図19に示す不要語辞書では、IPC分類毎に不要語辞書を用意する場合を想定しているが、例えば抽出規則辞書内の各抄録項目や各抽出規則に対して、不要語を設定するような構成であってもよい。
【0090】
また、前述する各実施の形態では、要部選択並びに抄録候補生成において段落を処理単位とするものであったが、これらは他の言語単位(文や節、フレーズ、単語等)を処理単位として構成することもできる。
【0091】
さらに、本実施の形態では、抄録作成対象とする例えば英語特許明細書に記載されたIPC分類に従って抽出規則辞書を選択的に利用する形態をとったが、例えば機械翻訳に関し、専門分野に応じた専門用語辞書を選択的に利用するようにすれば、翻訳精度の向上が期待され、さらにIPC分類に従って機械翻訳で利用する辞書を選択するように変形することも可能である。
【0092】
さらに、近年、機械翻訳システムでは、翻訳メモリの機能が実現されている(例えばThe 翻訳プロフェッショナルV8.0)。この翻訳メモリとは、ある英文について過去に精度の高い日本語訳を作成した場合、当該英文と類似する英文については、同じ日本語訳を再利用した方が質の良い翻訳を行える可能性が高いという事実に基づき、過去の英文−日本語訳の組合せを記憶しておき、新しい英文を翻訳する際に過去の類似文を検索し、類似文が存在する場合に当該類似文に対応する日本文訳をユーザに提示する機能である。
【0093】
そこで、本発明に係る抄録作成支援システムにおいても、例えば要部選定部12で抽出された要部に関する翻訳結果を抄録作成者に提示し、その翻訳結果を参考にしつつ最終的に和文抄録を作成する構成でもよい。この場合、要部選定部12で抽出された英文要部と修正結果の和文抄録とを記憶しておけば、機械翻訳部13における翻訳メモリ機能を利用することが可能となる。つまり、本発明システムとしては、要部選定部12で抽出された英文要部と抄録作成者による編集終了後の和文抄録とを対として記憶する記憶手段と、翻訳メモリ機能とをさらに設けた機械翻訳部13とすれば、翻訳メモリ機能を有効に活用しながら和文抄録を作成できる。この際、IPC分類に対応させて英文要部−和文抄録を記憶する構成とすれば、抄録作成対象の英語特許明細書のIPC分類に従って探索する英文要部−和文抄録の過去事例を効率的に選択利用することが可能である。
【0094】
また、以上の実施の形態では、日本語を母国語とする抄録作成者が和文抄録する例について述べたが、例えば英語から中国語、英語からドイツ語、日本語から英語など,他の言語対に対しても同様に適用可能である。従って、この場合には、抽出規則辞書における抽出規則や機械翻訳を適用する言語についても、他の言語対に合せて組み込むようにすれば、他の言語対の対応する抄録作成支援システムを実現できることは言うまでもない。
【0095】
また、上記実施の形態では、日本語の抄録候補と原文の要部とを対応付けて表示したが、抄録候補抽出部14で抽出される日本語の抄録候補だけを表示することも可能である。
【0096】
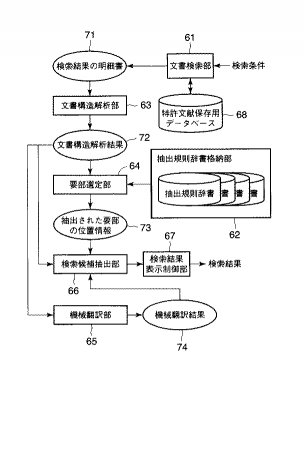
次に、図21は本発明に係る要部作成機能付き検索システムの一実施の形態を説明する機能構成図である。
【0097】
この検索システムは、文書検索部61、図1の抽出規則辞書格納部2と同様の機能をもつ抽出規則辞書格納部62、図1の文書構造解析部11と同様の機能をもつ文書構造解析部63、図1の要部選定部12と同様の機能をもつ要部選定部64、図1の機械翻訳部13と同様の機能をもつ機械翻訳部65、検索候補抽出66、検索結果表示制御部67により構成され、その他種々の構成要素例えば特許文献保存用データベース68、翻訳辞書(図示せず)、一連の検索処理用プログラムを記録する記録媒体等が設けられている。なお、同図において図1と同一機能をもつ構成要素2、63〜65等は、図1,図2で既に詳しく説明しているので、ここでは省略する。
【0098】
先ず、特許文献保存用データベース68には、多数の外国語特許明細書,例えば英語特許明細書が電子化されて蓄積される。
【0099】
この状態において、文書検索部61は、図示しない検索入力部から例えば技術分野やIPC分類等の検索条件のもとに検索指示が入力されると、記録媒体から検索処理用プログラムに従って一連の処理を実行する。すなわち、文書検索部61は、検索条件が入力されると、データベース68から検索条件に適合した複数の英語特許明細書を検索する(71)。なお、この文書検索部61としては、従来公知の種々の文書検索技術が用いられる。
【0100】
文書検索部61で複数の英語特許明細書が検索されると、一時バッフアメモリなどに格納した後、例えば検索された順番に検索結果である特許明細書を文書構造解析部63に送出し、特許明細書の文書構造を解析する。なお、特許明細書の文書構造解析については図1,図2で既に説明した通りである。その結果、図4に示すような文書構造解析結果を取り出すことができる(72)。
【0101】
このようにして取り出された文書構造解析結果は、要部選定部64及び機械翻訳部65に送られる。この要部選定部64は、図6に示す処理の流れに従って文書構造解析結果の中から抽出規則辞書格納部62に格納される抽出規則辞書(図5参照)に定める規則に従って要部を抽出する(73)。この要部抽出結果は図7又は図8に示す通りである。一方、機械翻訳部65では、文書構造解析結果に対し、翻訳辞書部8に規定する規則・知識を用いて、母国語に翻訳し、図9に示すような機械翻訳結果を取得する(74)。なお、これら要部選定部64及び機械翻訳部65は、図1及び図2に関連する説明の中で詳しく説明されているので、ここでは省略する。
【0102】
引き続き、検索候補抽出部66は、要部選定部64の抽出結果である各要部ごとに機械翻訳部65で翻訳された外国語特許明細書全文の日本語翻訳結果の中から翻訳された検索要部を取り出し、例えば検索結果保存用データベース(図示せず)に格納する。この検索結果保存用データベースには、検索した原文である全文英語特許明細書、機械翻訳部65で機械翻訳された全文翻訳された母国語特許明細書、要部選定部64で抽出された原文要部、検索要部生成部66で生成された翻訳要部が格納されている。
【0103】
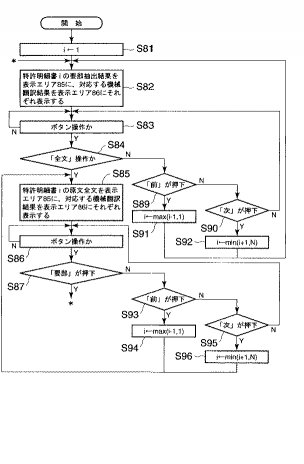
そこで、検索結果表示制御部67では、図22に示す処理手順に従って図1の7に相当する出力部に表示する。図23は画面表示例を示す図である。なお、初期画面には全文表示ボタン81、要部表示ボタン82、次選択ボタン83、前選択ボタン84が形成されている。
【0104】
検索結果表示制御部67は、要部ボタン82が操作されると、検索された英語特許明細書が複数存在する場合には画面奥行き方向に表示エリア85、86が重なりをもって表示される。この状態において、変数iとして1がセットされると、検索結果保存用データベースから検索されたある1つの英語特許明細書iから抽出された原文要部(要部抽出結果)を取り出し、当該原文要部を項分けして表示エリア85に表示する。そして、この原文要部に連動し、各原文要部に対応する翻訳要部を表示エリア86に表示する(S82)。
【0105】
しかる後、何れかのボタンが操作されたかを判断し(S83)、ボタン操作がない場合には繰り返し判断する。このステップS83において、ボタン操作有りと判断された場合には、全文表示ボタン81が操作されたか否かを判断し(S84)、全文ボタン81が操作されたと判断した場合には、該当特許明細書iの原文全文を表示エリア85に表示し、それに伴って原文全文に対応する機械翻訳結果である全文翻訳を表示エリア86に表示する(S85)。そして、次に何れかのボタンが操作されたかを判断し(S86)、ここで、要部表示ボタン82が操作されたと判断された場合(S87)にはステップS82に戻って同様に英語特許明細書iから抽出された原文要部及び翻訳要部を表示する。
【0106】
ところで、ステップS84において、ボタン操作が行われたが、全文表示ボタン81の操作でないと判断された場合、前選択ボタン84の操作か、次選択ボタン83の操作かを判断する(S89、S90)。ここで、前選択ボタン84が操作されたと判断された場合、変数iに1(下限数)の範囲でi−1をセットし(S91)、ステップS82に移行し、1つ前の英語特許明細書iから抽出された原文要部及び翻訳要部を表示エリア85,86にそれぞれ表示する。一方、次選択ボタン83が操作されたと判断された場合、変数iにN(上限数)の範囲でi+1をセットし(S92)、ステップS82に移行し、次の英語特許明細書iから抽出された原文要部及び翻訳要部を表示エリア85,86にそれぞれ表示する。
【0107】
なお、ステップS87において、ボタン操作が要部表示ボタン82の操作でなく、前選択ボタン84が操作された場合(S93)には変数iにi−1をセットし(S94)、ステップS85に移行し、原文全文及び翻訳全文を表示エリア85,86にそれぞれ表示する。また、次選択ボタン83が操作された場合(S95)には変数iにi+1をセットし(S96)、ステップS85に移行し、原文全文及び翻訳全文を表示エリア85,86にそれぞれ表示する。
【0108】
従って、以上のような実施の形態によれば、多数の外国語特許明細書の中から検索条件のもとに少なくとも1つ以上の外国語特許明細書を検索し、この検索された外国語特許明細書について、全文翻訳された母国語特許明細書、原文要部、翻訳要部を取り出し、表示画面に選択的に外国語特許明細書−全文翻訳された母国語特許明細書、原文要部−翻訳要部の如く対の関係で表示するので、検索者は容易に所要とする技術内容を把握でき、ひいては検索効率を大幅に高めることができる。
【0109】
なお、図23では、要部を項目別に表示したが、項目別でなく、要部選定部64で抽出された段落の出現順に表示する構成であってもよい。
【0110】
また、図23には図示されていないが、全文表示の場合、既に要部選定部64で要部が抽出されているので、当該全文中の要部相当部分を例えば異なる色などで強調表示すれば、全文中でどの個所が重要であるかが一目瞭然に認識でき、さらに検索効率を高めることができる。
【0111】
なお、本願発明は、上記実施の形態に限定されるものでなく、その要旨を逸脱しない範囲で種々変形して実施できる。
【0112】
また、各実施の形態は可能な限り組み合わせて実施することが可能であり、その場合には組み合わせによる効果が得られる。さらに、上記各実施の形態には種々の上位,下位段階の発明が含まれており、開示された複数の構成要素の適宜な組み合わせにより種々の発明が抽出され得るものである。例えば問題点を解決するための手段に記載される全構成要件から幾つかの構成要件が省略されうることで発明が抽出された場合には、その抽出された発明を実施する場合には省略部分が周知慣用技術で適宜補われるものである。
【0113】
【発明の効果】
以上説明したように本発明によれば、第1言語の特許文献から効率的、適切な第2言語の抄録を作成できる抄録作成支援システム、プログラム及び抄録作成支援方法を提供できる。
【0114】
また、本発明は、検索された第1言語の特許明細書に対応する全文翻訳の第2言語の特許明細書、原文要部、翻訳要部を作成し、選択的に表示することにより、迅速に技術内容を把握でき、ひいては検索効率を大幅に向上させる特許文献検索システム、プログラム及び特許文献検索方法を提供できる。
【図面の簡単な説明】
【図1】本発明に係る抄録作成支援システムの一実施の形態を示す構成図。
【図2】図1に示す抄録作成支援システムの一連の処理の流れを説明する図。
【図3】抄録作成対象となる例えば英語特許明細書の一例を示す図。
【図4】図1に示す文書構造解析部で解析された英語特許明細書の文書構造解析結果を示す図。
【図5】抽出規則辞書格納部に格納される抽出規則辞書内の規則を説明する図。
【図6】図1に示す要部選定部の具体的な処理の流れを説明するフローチャート。
【図7】要部選定部で抽出された原文要部抽出結果のイメージ図。
【図8】要部選定部で抽出された要部抽出結果の一表現例を示す図。
【図9】図3に示す抄録作成対象となる例えば英語特許明細書の機械翻訳結果を示す図。
【図10】図1に示す抄録候補生成部で取り出した和文の抄録候補の一例を説明する図。
【図11】抄録候補の表示例であって、特に抽出された翻訳要部及び原文要部の表示例、この翻訳要部から和文抄録を編集処理する例及び翻訳全文及び原文全文の表示例を説明する図。
【図12】翻訳要部と原文要部を対応付けて表示する例を示す図。
【図13】図1に示す抄録編集表示制御部による状態遷移とその状態遷移に伴う処理を説明する図。
【図14】別の抄録候補の表示例を示す図。
【図15】本発明に係る抄録作成支援システムの他の実施の形態を説明するための抽出規則辞書の一例を示す図。
【図16】要部選定部において図15に示す抽出規則辞書を用いて抽出した要部抽出結果の一例を示す図。
【図17】要部選定部における一連の処理の流れを説明するフローチャート。
【図18】本発明に係る抄録作成支援システムのさらに他の実施の形態を説明するための抽出規則の一例を示す図。
【図19】本発明に係る抄録作成支援システムのさらに他の実施の形態を説明するための不要語辞書の一例を示す図。
【図20】要部選定部において抽出規則辞書及び不要語辞書を用いて要部を抽出するための処理の一例を示すフローチャート。
【図21】本発明に係る検索システムの一実施の形態を説明する機能構成図。
【図22】図21における検索結果表示制御部の一連の処理を説明するフローチャート。
【図23】検索結果の表示例を示す図。
【符号の説明】
1…原文明細書入力部、2…抽出規則辞書格納部、3…抄録作成処理制御部、4…記録媒体、5…抄録関連情報格納用データベース、7…出力部、8…翻訳辞書部、11…文書構造解析部、12…要部選定部、13…機械翻訳部、14…抄録候補抽出部、15…抄録編集表示制御部、61…文書検索部、62…抽出規則辞書格納部、64…要部選定部、65…機械翻訳部、66…検索候補抽出部、67…検索結果表示制御部。
【0001】
【発明の属する技術分野】
本発明は、外国語特許文献等から母国語の抄録を作成する際に利用される抄録作成支援システム、プログラム、抄録作成支援方法及び特許文献検索システム並びに特許文献検索方法に関する。
【0002】
【従来の技術】
従来から日本国以外の国においてどのような特許が出願されているかの情報をサービスすることを目的とし、外国語(例えば英語)で記載された特許文献(請求の範囲を含む明細書、図面等)全文を参照し、母国語(例えば日本語)などの和文抄録を作成することが日常的に行われている。この作成された和文抄録は、検索システムのデータベースに蓄積され、エンドユーザへの閲覧や検索に提供されている。
【0003】
ところで、英語特許文献から和文抄録を作成する場合、現状では、抄録作成者が和文抄録の作成対象となっている英語特許文献の全文を読み、その特許文献から主要部分(以下、要部という)が何であるかを把握し、当該要部を母国語に翻訳する作業が行われている。作成すべき和文抄録は、技術分野、要旨、実施例などの中から予め定められた日本語の長さ(例えば合計文字数600文字〜800文字程度)の範囲で記載し作成している。
【0004】
このような抄録作成作業は、すべて抄録作成者による人手の作業に頼っているので、抄録作成にかかる手間が非常に大きい。また、抄録作成作業工程において、抄録を作成する前段階では、抄録作成者が英語特許文献全文にわたって内容を把握する必要がある。その結果、抄録作成者は、英語特許文献全文を読みきる必要があるが、この読解のために多大な作業コストがかかり、また抄録作成作業の効率が非常に悪いことから、その作業効率の改善が求められていた。
【0005】
そこで、抄録作成作業の効率化を図るために、近年、幾つかの抄録作成支援システムが提案されている。
【0006】
その1つの抄録作成支援システムは、文章を要約するための文章要約システムであって、技術論文などの章節構造を抽出し、章節ごとに抄録としてそのまま利用するか(例えば要旨の部分)、要約処理を行うか、或いは要約処理をせずに無視するか(例えば文献)といった処理の切り分けを行うものである(特許文献1参照)。
【0007】
他の1つの抄録作成支援システムは、文書情報を検索するための文書情報検索装置及び文書検索結果表示方法であって、検索結果を提示する際に、原文から抄録生成を自動的に行い、この生成された抄録をユーザに提示する。そして、抄録と原文との対応関係を取り出し、抄録表示と原文表示との連動や原文表示中の抄録部分を強調表示する構成である(特許文献2参照)。
【0008】
【特許文献1】
特許第2766261号公報
【0009】
【特許文献2】
特許第2957875号公報
【0010】
【発明が解決しようとする課題】
従って、以上のような抄録作成支援システムでは、技術論文などを対象とするものであり、しかも抄録作成のための重要文抽出の処理方法としては、文書中における単語の使用頻度等の統計情報に基づいた方法(例えば使用頻度の高い単語が重要であり、重要語を含む文は重要であるという選定基準)、接続詞や文末の表現に基づいて重要文を選定する方法(例えば、「要するに」という副詞を用いている文は重要であるという選定基準)などが開示されている。
【0011】
しかしながら、これらの重要文抽出の処理方法は、技術論文などを対象にしたものであり、かつ、一律の選定基準に従って重要文を選定する方法であるが、これをそのまま特許文献に適用しても、特許文献的な観点から要部であると判断できる質のよい重要文を抽出することができない問題がある。
【0012】
また、前述する抄録作成支援システムは、単一の言語に関する抄録の作成が目的であり、例えば英語特許文献から和文抄録を作成するための支援機能をもっていないので、英語特許文献から和文抄録が作成できないという問題がある。
【0013】
しかも、理想的には、自動的に抄録が作成されることが好ましいが、品質の良い抄録を作成するためには、最終的には抄録作成者等の人手によるチェックが必要となる。このため、抄録作成を自動的に行うのではなく、抄録作成を支援するというシステムの提供が必要となる。
【0014】
さらに、以上のような抄録作成支援システムでは、「要旨」「発明の属する技術分野」「実施例」などの章節構造に従って、例えば「要旨」については要部として抽出する。しかしながら、要部となるべき単語やフレーズ等の抽出規則辞書に関し、予め国際特許分類(以下、IPC分類と呼ぶ)の区分ごとに準備し、抄録作成対象とする特許文献のIPC分類や「発明の属する技術分野」「実施例」などの章節構造等に従って抽出規則辞書を切り替える等の内容が記載されておらず、その点からも上記システムのままでは利用することが難しい。また、抄録と機械翻訳との連携についても何ら記載されていない。
【0015】
さらに、抄録作成者が作成する文章は和文抄録であるので、要部抽出とともに日本語に翻訳する作業も必要になってくる。従来、人手により翻訳する場合、仕事量との関係から同じ技術分野の特許文献であっても、別の分野の抄録作成者が担当することも多く、人手による翻訳に限れば、専門用語の翻訳に対して一貫性を保持することが非常に難しい状況にある。
【0016】
そこで、英語特許文献から日本語に翻訳支援するための機械翻訳システムの利用が考えられる。機械翻訳システムについては、すでに幾つかのパッケージソフトウエアが市販されており、例えばIPC分類に基づいて機械翻訳するための専門用語辞書を準備し、機械翻訳時にどのIPC分類に関する特許文献であるかを判定し、特許文献のIPC分類に従って専門用語辞書を選択的に切替え使用することにより、適切な翻訳を行うシステムも提案されている(特開2003−16063号公報)。しかし、このシステムは、機械翻訳を意図するものであり、抄録作成については記載されていない。
【0017】
よって、以上の説明から、外国語特許明細書(ここでいう、外国語特許明細書とは、請求の範囲を含み、さらに公開公報、公告公報、登録特許公報を問わず、特許関連文献(実用新案等を含む)の他、請求の範囲を含んだ明細書を指す意味である。従って、各国によって呼び名が異なるが、公に提供された電子化された特許出願書類といえる)を対象とし、従来の抄録作成システムで抄録を作成し、この作成された英文抄録を英日翻訳システムで日本語に翻訳することが考えられる。
【0018】
しかしながら、抄録作成者が質の良い和文抄録を作成するためには、単に日本語に翻訳された結果を読むだけでは不十分であり、対応する英語の原文やその文章の前後の文章の文脈も参照する必要がある。従って、従来の抄録作成支援システムと機械翻訳システムとを組み合わせただけでは、異なる言語の抄録作成作業を一連の作業手順として進めることができないので、英語特許文献から和文抄録を作成するための支援機能を十分に果たすことができない。
【0019】
何れにせよ、技術分野に応じた特許文献の特徴や特許抄録は、技術的な動向を把握し、またその他の実務的な面からも非常に重要な書類であり、外国語特許文献から適切な母国語の抄録を作成する支援システムの実現が待たれているのが実状であると言える。
【0020】
本発明は上記事情にかんがみてなされたもので、電子化された第1言語の特許出願書類から効率的、かつ適切な第2言語の抄録を作成する抄録作成支援システム、プログラム及び抄録作成支援方法を提供することを目的とする。
【0021】
また、本発明の他の目的は、電子化された第1言語の特許出願書類から所要とする第1言語の特許出願書類を検索し、この検索された第1言語の特許出願書類から前記第1言語の検索要部及び第2言語の検索候補(検索要部)を作成し、効率的な検索作業を実現する特許文献検索システム、プログラム及び特許文献検索方法を提供することを目的とする。
【0022】
【課題を解決するための手段】
(1) 上記課題を解決するために、本発明に係る抄録作成支援システムは、一定の分類ごとに少なくとも所要とする第1言語の章節の表題及びこの各表題の章節に記載される説明文中に含まれる第1言語の単語,フレーズ等のキーフレーズを規定する抽出規則辞書と、電子化された第1言語の特許出願書類に記載される文章の章節構造を解析する文書構造解析手段と、この文書構造解析手段で解析された文書構造解析結果に記載されている分類に従って所要の前記抽出規則辞書を選択し、当該抽出規則辞書に規定される表題及びキーフレーズに基づいて前記文書構造解析結果から要部を選定する要部選定手段と、文書構造解析手段で解析された文書構造解析結果を第2言語に翻訳処理する機械翻訳手段と、要部選定手段で選定される各要部ごとに機械翻訳手段で翻訳された第2言語の翻訳結果から第2言語の抄録候補を抽出する抄録候補抽出手段と、この抄録候補抽出手段で抽出される第2言語の抄録候補及びこの第2言語の抄録候補に対応する第1言語の要部のうち、少なくとも第2言語の抄録候補又は第2言語の抄録候補と第1言語の要部とを対応付けて表示し、当該第2言語の抄録候補の修正処理を含んで第2言語の抄録を作成する抄録編集表示制御手段とを設けた構成である。
【0023】
この発明は以上のような構成とすることにより、第1言語の特許出願書類に記載される文章の章節構造から分野別に従って第1言語の要部と第1言語の文書構造解析結果より翻訳処理された第2言語の翻訳結果とから第2言語の抄録候補を取り出し、この第2言語の抄録候補を修正を含めて第2言語の抄録を作成するので、抄録作成者が第1言語の特許出願書類を読解することなく、自動的に第2言語の抄録候補を抽出し、抄録作成者による修正確認を含めて短時間に第2言語の抄録を作成することが可能であり、効率的に抄録を作成でき、かつ、適切な抄録を作成することが可能である。
【0024】
なお、上記抄録の作成は、プログラムに記録されるプログラムや抄録作成方法によっても実現可能であり、これによりシステムと同様な作用効果を奏することができる。
【0025】
(2) また、本発明に係る特許文献検索システムは、電子化された複数の第1言語の特許出願書類を記憶する記憶手段と、検索条件のもとに前記記憶手段から少なくとも1つの第1言語の特許出願書類を検索する文書検索手段と、一定の分類ごとに少なくとも所要とする第1言語の章節の表題及びこの各表題の章節に記載される説明文中に含まれる第1言語の単語,フレーズ等のキーフレーズを規定する抽出規則辞書と、文書検索手段により検索された前記電子化された第1言語の特許出願書類に記載される文章の章節構造を解析する文書構造解析手段と、この文書構造解析手段で解析された文書構造解析結果に記載されている分類に従って所要の抽出規則辞書を選択し、当該抽出規則辞書に規定される表題及びキーフレーズに基づいて文書構造解析結果から検索対象となる要部を選定する要部選定手段と、文書構造解析手段で解析された文書構造解析結果を第2言語に翻訳処理する機械翻訳手段と、要部選定手段で選定される各検索対象要部ごとに機械翻訳手段で翻訳された第2言語の翻訳結果から第2言語の検索候補を抽出する検索候補抽出手段と、この検索候補抽出手段で抽出される第2言語の検索候補及びこの第2言語の検索候補に対応する前記第1言語の検索要部のうち、少なくとも前記第1言語の検索要部又は前記第1言語の検索要部と前記第2言語の検索候補とを対応付けて表示し、或いは前記第1言語の検索要部及び前記第2言語の検索候補と前記第1言語の文書構造解析結果及び前記第2言語の翻訳結果とを選択的に表示する検索結果表示制御手段とを設けた構成である。
【0026】
この発明は以上のような構成とすることにより、第1言語の多数の電子化された第1言語の特許出願書類の中から検索条件に従って少なくとも1つの第1言語の特許出願書類を検索し、この検索された第1言語の特許出願書類に対し、前記(1)に記載する構成を取り込んで、少なくとも第1言語の検索要部と第2言語の検索候補とを取り出して表示できるので、効率的な検索作業を実現することが可能である。
【0027】
なお、上記検索要部や検索候補の取り出しは、プログラムに記録されるプログラムや特許文献検索方法によっても実現可能であり、これによりシステムと同様な作用効果を奏することができる。
【0028】
【発明の実施の形態】
以下、本発明の実施の形態について図面を参照して説明する。
【0029】
図1は本発明に係る抄録作成支援システムの一実施の形態を説明する構成図である。
【0030】
この抄録作成支援システムは、電子化された外国語特許文献などの第1言語の特許出願書類を入力する原文明細書入力部1と、IPC分類の一定区分ごとに所定の要素をもつ抽出規則で構成された複数の抽出規則辞書を格納する抽出規則辞書格納部2と、前記原文明細書入力部1から入力される外国語特許文献などから母国語などの第2言語の抄録を作成処理する抄録作成処理制御部3と、この抄録作成処理制御部3がCPUで構成されている場合、抄録作成の一連の処理を実行させるためのプログラムを格納する記録媒体4と、この抄録作成処理制御部3で作成される母国語の抄録その他この抄録に関連する情報を保存する抄録関連情報格納用データベース5と、抄録作成の処理途中において必要な情報を一時格納するバッフアメモリ6と、作成された母国語の抄録その他必要な情報を出力する出力部7とにより構成されている。8は翻訳処理時に使用する翻訳処理上の知識を格納する翻訳辞書部である。
【0031】
なお、前述する第1言語の特許出願書類とは、公に提供された刊行物としての性格を有する公開公報、公告公報、登録特許公報及び実用新案に関係する公報を含む全てのテキスト情報を指す。また、特許出願書類の中の明細書とは、厳密な意味で請求の範囲や要約とは別書類の場合も考えられるが、頒布される特許文献では明細書と請求の範囲や要約は所定の順序で一体に印刷されるものであるので、請求の範囲や要約を含めて指すものとする。以下、第1言語の特許出願書類は、説明の便宜上、外国語特許明細書又は英語特許明細書と総称する。
【0032】
原文明細書入力部1は、一般にキーボード、マウスなどが用いられ、キーボードによる各種の制御指示を入力、マウスによる外国語特許明細書中の特定領域の指定により選択される当該外国語特許明細書の入力の他、外国語特許明細書を読み取るOCR(Optical character Rerder)による読み取り情報の入力、フロッピーディスク、磁気テープ、磁気ディスクなどに保存される電子化された外国語特許明細書の入力など、異なる種々の入力形態による外国語特許明細書の入力を含むものである。
【0033】
前記抽出規則辞書格納部2は、一定の区分毎(例えば電気、機械、化学、物理その他の分野などをさらに細分化した区分毎),例えばIPC分類の少なくとも上位分類毎の各抽出規則辞書が設けられ、各抽出規則辞書には所定の抽出規則が規定されている。この各抽出規則辞書の規則の一例としては例えば抄録項目、フィールド、キーフレーズの3つの要素から構成され、具体的な一例としては後記する図5に示す通りである。
【0034】
前記抄録作成処理制御部3は、機能的には、原文明細書入力部1から入力される外国語特許明細書の項目(文書構造)を解析し、各項目ごとに認識可能な一定の形式に基づくタグ付けした文書構造の明細書を作成する文書構造解析手段としての文書構造解析部11と、この構造解析部11で文書構造を解析された文書構造解析結果の中から抽出規則辞書に定められる規則に従って要部を抽出する要部選定手段としての要部選定部12と、文書構造解析部11から出力される文書構造解析結果に対し、翻訳辞書部8に規定する規則・知識を用いて、母国語に翻訳する翻訳処理手段としての機械翻訳部13と、要部選定部12の要部抽出結果である各要部ごとに、機械翻訳部13で翻訳された外国語特許明細書全文の母国語語翻訳結果の全文の中から母国語の抄録候補を抽出する抄録候補抽出手段としての抄録候補抽出部14と、この抄録候補抽出部14から抽出される母国語の抄録候補と要部選定部12で抽出された外国語要部(原文要部)とを対応付けて表示し、又は前記外国語の文書構造解析結果全文及び前記機械翻訳部13で翻訳処理された母国語の翻訳結果とを対応付けて表示し、当該母国語の抄録候補の抄録作成者による修正処理を含んで母国語の抄録を作成する抄録編集表示制御部15とが設けられている。
【0035】
前記出力部7は、機械翻訳部13の出力である翻訳結果を出力したり、入力部1から入力される外国語特許明細書を表示したり、或いは作成された母国語抄録を表示したり、外国語特許明細書全文と翻訳済み明細書全文その他所要とする種々の形式で表示する機能を有するものであって、通常,各種ディスプレイなどの表示手段が用いられるが、その他、例えばプリンタなどの印字手段、或いはフロッピーディスク、磁気テープ、磁気ディスクへの書き込み登録手段、さらには他のメディアに対して送信する送信手段その他ユーザの所望する各種の出力形態が挙げられる。
【0036】
次に、以上のような抄録作成支援システムの動作及び本発明に係るプログラム、抄録作成支援方法について図2を参照しながら説明する。
【0037】
先ず、原文明細書入力部1から電子化された外国語特許明細書,例えば英語特許明細書が入力されると(S1)、抄録作成処理制御部3は、記録媒体4に格納されるプログラムに従って一連の処理を実行する。なお、この抄録作成処理制御部3は、例えば論理回路等で構成されるハード構成によって処理することも可能であるが、ここではプログラムに従って一連の処理を実行するものとする。
【0038】
一般に、英語特許明細書は、図3にその一部を示すように、要旨(Abstract)、請求項(Claims)、発明の分野(FIELD OF THE INVENTION)、発明の背景(BACKGROUND OF THE INVENTION)などの明細書の項目(文書構造)の他、ここでは図示されていないが、発明者やIPC分類コード等が記載されている。
【0039】
そこで、抄録作成処理制御部3は、原文明細書入力部1から入力される電子化された英語特許明細書を受け取ると、例えばバッフアメモリ6に一時格納した後、文書構造解析部11にて英語特許明細書の文書構造解析処理を行う(S2:文書構造解析機能、文書構造解析ステップに相当する)。この文書構造解析処理部11は、特許明細書のフォーマットがXML形式であることを前提とした場合、予め定められる英語特許明細書の各項目(文書構造)を解析し、この項目ごとにXMLタグ情報に基づいてタグ付けした文書構造に置き換え、文書構造解析結果としてバッフアメモリ6又はデータベース5に格納する(S3)。
【0040】
図4は文書構造解析部11により構造解析された文書構造解析結果の一部を示す図である。ここでは、Abstract、Claims、FIELD OF THE INVENTIONといった各項目に従った文書構造がXML形式で表現されている。この文書構造解析結果に示されているように、タグ<field header=”XXXX”>から当該タグに対応する</field>までの範囲が「XXXX」の表題に対応する部分となる。なお、ここでは、特許明細書のフォーマットがXML形式であることを前提とした例であるが、他の形式による場合には英語特許明細書の各項目(文書構造)を解析し、この項目ごとに他の形式に従った文書構造に置き換えることは言うまでもない。
【0041】
以上のようにして文書構造解析結果を得た後、要部選定部12は、抽出規則辞書格納部2に格納される各抽出規則辞書の規則に従い、文書構造解析結果の中から順次要部を抽出する(S4:要部選定機能、要部選定ステップに相当する)。
【0042】
この抽出規則辞書は、クラス(上位分類)からサブグループ(下位分類)まで細分化して展開されているIPC分類に基づく一定の技術区分(例えば、日本の公報発行区分に近い30程度の技術区分や本発明を応用する分野の必要に応じた技術区分)ごとに設けられ、各抽出規則辞書内の規則の形式は、図5に示すように抄録項目、フィールド、キーフレーズの3つの要素から構成されている。抄録項目は、要部として出力する内容を日本語で記載されており、ここでは、技術分野、要旨、実施例(実施の形態を含む)という3つの項目が例示されている。フィールドは文書構造における各章節の表題を示している。キーフレーズは、フィールドで設定されている各章節を検索し、当該キーフレーズに定義されている単語やフレーズが表題の中味を説明する文中に含まれていれば、それを要部として抽出することを意味する。
【0043】
例えば抄録作成対象である英語特許明細書の文書構造において、「BREIF DESCRIPTION OF THE PRIOR ART」「FIELD OF THE INVENTION」「ABSTRACT」などの表題に対応する段落の文中に、辞書の規則で定める技術分野に対応するキーフレーズとなる「relates to」「is directed toward」「the invention concerns」などの単語やフレーズが含まれていれば、その段落が「技術分野」という抄録項目に相当する要部の候補であることを意味する。また、「SUMMARY OF THE INVENTION」「SUMMARY」「ABSTRACT」という表題に対応する段落の文中に、辞書の規則で定める要旨に対応するキーフレーズとなる「is proposed」「is disclosed」「is provided」「disclosed is」などの単語、フレーズが含まれていれば、その段落が「要旨」という抄録項目に相当する要部の候補であることを意味する。なお、各抄録項目にはそれぞれ複数の条件の登録が可能であるので、例えば「要旨」に対応する規則には2つの抽出規則R2、R3に分けて登録されている。4番目の抽出規則であるR4に対応するキーフレーズには「Fig.?」が記載されているが、この「?」は任意の数字に照合することを意味している。つまり、キーフレーズの「Fig.?」は例えば「Fig.1」「Fig.2」等の何れとも照合可能であることを意味する。
【0044】
そこで、要部選定部12は、以上のような抽出規則辞書内の規則を用いて、図6に示す要部選定処理を実行する。具体的には、バッフアメモリ6又はデータベース5から図4に示す英語特許明細書の文書構造解析結果を読み込む(S11)。一般に、特許明細書にはIPC分類が記載されているので、図4に示す文書構造解析結果にもタグ情報によりIPCが認識可能になっている。つまり、図4の例では、「<ipc>」と「</ipc>」とで囲まれている範囲がIPC分類が記されている部分であり、詳しくは「C08F 002/00」と記載されている。この分類情報を用いることによって、クラス(上位分類)からサブグループ(下位分類)まで細分化して展開されているIPC分類に基づく技術区分に応じた抽出規則辞書を判断することができる。
【0045】
要部選定部12は、文書構造解析結果からIPC分類を取り出すと、抽出規則辞書格納部2から該当するIPC分類に対応する抽出規則辞書を読み込んだ後(S12)、次のステップS13に移行し、抽出規則辞書の最初に参照すべき抽出規則(ID=R1)として、変数iに1を設定する。そして、変数i=1の抽出規則に基づき、当該規則のフィールド及びキーフレーズと照合する段落が抄録作成対象の英語特許明細書(文書構造解析結果)に存在するか否かを判断する(S14)。ここで、照合する段落が存在していれば、この照合する段落の位置情報(特定情報)を抽出し(図2のS5、図6のS15)、バッフアメモリ6又はデータベース5に記憶する。
【0046】
この段落の位置情報を抽出した後、或いはステップS14において照合する段落が存在しない場合、次のステップS16に移行し、抽出規則辞書に規定する次に処理すべき抽出規則(ID=R2)として、変数iに+1をインクリメントした後、該当変数に相当する抽出規則の項目数全部が終了したか否かを判断し(S17)、未だ抽出規則の項目が残っている場合にはステップS14に戻り、変数iの抽出規則のフィールド及びキーフレーズと照合する段落が抄録作成対象の特許明細書(文書構造解析結果)に存在するか否かを判断し、全ての抽出規則について繰り返し実行する。
【0047】
図7は、本発明の主旨を説明するために、要部の抽出部分を模式的に示した図である。例えば図5に示す抽出規則辞書の2番目の抽出規則(ID=R2)では、フィールドの中に「ABSTRACT」、キーフレーズの中に「is disclosed」が記載されている。従って、この2番目の抽出規則が「Abstract」である表題に関係する図示点線枠で囲む説明文21の中に含まれる「is disclosed」(下線引きで示している)と照合するので、この「Abstract」の説明文21又はその文中の段落位置(特定情報)を「要旨」として抽出することになる。また、図5に示す抽出規則辞書の1番目の抽出規則(ID=R1)では、フィールドの中に「FIELD OF THE INVENTION」、キーフレーズの中に「relates to」が記載されている。従って、この1番目の抽出規則が「FIELD OF THE INVENTION」の点線枠で囲む図7の説明文22の中に含まれる「relates to」(下線引きで示している)と照合するので、この「FIELD OF THE INVENTION」の説明文22又はその文中の段落位置(特定情報)を「技術分野」として抽出する。さらに、図5に示す抽出規則辞書の3番目の抽出規則(ID=R3)では、フィールドの中に「DATAILED DESCRIPTION OF THE INVENTION」、キーフレーズの中に「this invention addresses」が記載されている。従って、この3番目の抽出規則が「DATAILED DESCRIPTION OF THE INVENTION」の点線枠で囲む説明文23の中に含まれる「this invention addresses」(下線引きで示している)と照合するので、この「DATAILED DESCRIPTION OF THE INVENTION」の説明文23又はその文中の段落位置(特定情報)を「要旨」として抽出することになる。
【0048】
図8は要部選定部12による抽出結果の表現形式の一例を表す図である。
【0049】
図7は図4の文書構造解析結果と対応づけながら抽出される要部について要部特定情報21,22,23を付けて表したが、図8はより具体的に特許明細書中のフィールド、文中の段落位置などのポインタで対応付けて抽出することができる。因みに、図8は、フィールド、段落(段落位置,特定情報)、抄録項目、要部抽出に使用された抽出規則の組み合わせにより構成されている。具体的には、図8の1行目の情報は、「FIELD OF THE INVENTION」という章節であって、1段落目が抽出規則R1に照合したことを示しており、抽出規則R1は、抄録項目の「技術分野」に対応する規則であることを表している。また、3行目の情報は、「DATAILED DESCRIPTION OF THE INVENTION」という章節であって、1段落目が抽出規則R3に照合したことを示しており、この抽出規則R3は、抄録項目の「要旨」に対応する規則であることを表している。
【0050】
以上のようにして要部選定部12が英語文書構造解析結果から例えば図8に示すような要部を抽出した後、或いは要部選定部12による要部選定処理と同時並行的に処理する機械翻訳部13が翻訳辞書部8の翻訳処理上の知識を用いて、英語特許文献の文書構造解析結果を翻訳処理し(S6)、母国語である例えば日本語の翻訳結果を得るものである(S7)。これらステップS6,S7は翻訳処理機能、翻訳処理ステップに相当する。
【0051】
図9は図4に示す英語の文書構造解析結果に対し、XMLタグ以外の他の文書を日本語に翻訳処理した翻訳結果を示す図である。なお、XMLタグを除いて翻訳処理した理由は、翻訳結果についても元の英語の文書構造解析結果を保持しておく必要があるので、XMLタグについては翻訳処理を行わないこととする。なお、英日機械翻訳については、既に幾つかのパッケージソフトが市販されており、それらのパッケージソフトで実現されている翻訳処理技術を利用すればよい。これにより、図9のような翻訳結果を容易に取得することが可能である。
【0052】
引き続き、抄録候補抽出部14は、要部選定部12で抽出された要部抽出結果(図8参照)と機械翻訳部13によって取得された機械翻訳結果(図9参照)とを比較しながら、母国語である例えば日本語の抄録候補を抽出する(S8:抄録候補抽出機能、抄録候補抽出ステップに相当する)。
【0053】
この抄録候補抽出部14では、具体的には、図8の1行目の「FIELD OF THE INVENTION」の1段落目に関する抄録候補を抽出することになる。図9に示す事例では、<field header=”FIELD OF THE INVENTION”>において、「[0001]」で始まる段落が抄録候補に相当する。また、図8の2行目の「ABSTRACT」の1段落目に関する抄録候補を抽出することになる。図9に示す事例からは、<field header=”ABSTRACT”>において、「プロセス」で始まる段落が抄録候補に相当する。以下、同様に図8に示す要部抽出結果の各行の情報に従い、機械翻訳結果から抄録候補を順次取り出し、データベース5の所定エリアに記憶する。図10は、その抄録候補の抽出結果を示す図である。
【0054】
ところで、以上説明した実施の形態では、行数や段落数が変化しないことを前提とし、機械翻訳処理した例について述べたが、機械翻訳処理の中には一文を複数文に分けて訳出する処理を行う場合もある。このような場合、図8に示すように段落や文単位の対応では、対応関係がずれてしまう可能性が生ずる。しかし、文書構造解析部11では、英語特許明細書側の全ての文や段落に対して、ユニークな番号をもつXMLタグを割り振りして処理しているので、その文書構造解析結果に基づいて、XMLタグの情報を保持したままで機械翻訳を行えば問題はなくなる。
【0055】
従って、この抄録作成支援システムでは、以上のようにして抄録候補を抽出した段階では、抄録関連情報格納用データベース5には英語特許明細書全文(図3参照)、英語文書構造解析結果(図4)、日本語機械翻訳結果(図9参照)、日本語抄録候補抽出結果(図10R>0参照)等が格納されているので、抄録編集表示制御部15は、入力部1からの選択操作のもとに、抄録関連情報格納用データベース5から所要の情報を選択的に取り出し、所要のフォーマットに従って出力部7に表示する(S9)。
【0056】
図11は抄録作成者による所要の操作のもとに出力部7に表示された日本語・英語の要部表示(上段)又は日本語・英語の全文表示(下段)の画面表示例を示す図である。
【0057】
先ず、抄録作成者は、初期画面を取り出すと、この初期画面には要部ボタン31、全文ボタン32、開くボタン33、コピーボタン34、保存ボタン35、終了ボタン36その他の所要とするボタン(図示せず)の他、図11の上段左側の表示エリア37には日本語の翻訳要部(抄録候補)が順次表示される。一方、この翻訳要部の表示に連動して図11の上段右側の表示エリア38に翻訳要部と対応関係をとりながら英語の原文要部が順次表示される。なお、図面のスペースの関係から翻訳要部及び原文要部のそれぞれの文字が記載できないので、図12に一部の翻訳要部及び原文要部を記載してある。なお、各表示エリア37,38は、入力部1を構成するマウスなどのポインティングデバイスによって1つの段落を選択可能になっている。
【0058】
すなわち、表示エリア37と表示エリア38は連動しており、表示エリア37のある段落が選択されると、表示エリア38には原文特許明細書に対応する個所の英文の要部が連動して選択表示される。39は抄録作成エリアであって、抄録作成者が表示エリア37,38の翻訳要部、原文要部を確認しながら最適な抄録であると判断したとき、当該翻訳要部をコピーし、必要に応じて文字削除や挿入等の修正処理を施して和文抄録とするエリアである。つまり、抄録作成者は抄録作成エリア39の内容を適宜編集処理して和文抄録を作成する。また、抄録作成者が参考とするために、表示エリア40には発明者、出願年月日、IPCなどの書誌情報が表示され、表示エリア41には特許された発明の名称の翻訳結果が表示される。
【0059】
さらに、全文ボタン32を操作した時には、図11の下段に示すように翻訳全文と原文全文とが連動して表示される。その後、要部ボタン31を操作すると、同図の上段に示す日本語・英語の要部が表示される。
【0060】
図13は抄録作成者又はユーザ(以下、抄録作成者と総称する)が実際に利用する場合の状態遷移図並びに抄録編集表示制御部15の状態遷移に伴う処理を説明する図である。
【0061】
同図において、状態51はシステムの立ち上げ時の初期状態、状態52は抄録作成者が抄録処理画面の開操作により表示エリア37に翻訳結果の要部が表示されている状態、状態53はシステムの終了を意味する終了状態、状態54は抄録作成者による全文表示の操作により表示エリア37に明細書全文の翻訳結果が表示されている状態を意味する。
【0062】
さらに、具体的に状態遷移について説明すると、抄録作成者が状態51にて開くボタン33を操作すると、英語特許明細書のファイル名を当該抄録作成者に問い合わせて取得することにより、英語特許明細書から抽出された要部の翻訳結果、つまり翻訳要部をデータベース5の所要エリアから取り出し、表示エリア37に表示し、これに連動して表示エリア38には翻訳要部に対応する原文要部を表示し、さらに表示エリア39を初期化した後、状態52に遷移する。
【0063】
この状態52において、表示エリア37に表示されている段落を選択してコピーボタン34を操作すると、当該段落が表示エリア39に挿入される。状態52は、要部(翻訳)の状態であって、抄録項目(図11,図12参照)である「技術分野」「要旨」「実施例」が段落毎に設定されている状態にあるので、その抄録項目に従って表示エリア39にコピーによって順次挿入する(S52)。
【0064】
また、状態54では、全文ボタン37の操作により、表示エリア37に翻訳された全文(全文翻訳)が表示され、これに連動して表示エリア38に原文全文が表示される(S53)。この状態54は、抄録項目が決定されていないので、抄録作成者からの入力を要求する等の処理を経て抄録項目を設定した後、表示エリア37に表示されている段落を必要に応じてコピー操作により表示エリア39にコピーする(S54)。また、状態52或いは状態54において、保存ボタン35を操作すると、抄録作成者による保存先の和文抄録のファイル名の入力に基づき、当該ファイル名のもとにデータベース5に表示エリア39の内容が保存される(S55、S56)。なお、状態54において開くボタン33を操作すれば、ステップS51と同様の処理を実行し(S57)、また要部ボタン31を操作すれば、ステップS52と同様の処理を実行する(S58)。そして、各状態において、終了ボタン36を操作すれば、抄録作成及び所要とする情報の取り出し表示処理が終了する。
【0065】
従って、以上のような実施の形態によれば、外国語特許明細書の項目(文書構造)を解析し、一定の形式に基づくタグ付けした文書構造解析結果を取得した後、この文書構造解析結果に基づいて、要部選定部12が予め定める抽出規則辞書の規則に従って要部を抽出し、また機械翻訳部13では、文書構造解析結果の内容を通常の翻訳処理のもとに例えば母国語に翻訳する。しかる後、抄録候補抽出部14が要部抽出結果である各要部ごとに翻訳された日本語全文の翻訳結果の中から抄録候補を取り出した後、翻訳要部と原文要部を対応付けて表示し、翻訳要部をコピーし、原文要部を参照し、必要に応じて英語特許明細書の文書構造解析結果全部及び翻訳された翻訳結果全文を参照しながら、文字削除、挿入により和文抄録を作成するので、和文抄録を効率的に作成でき、かつ人手による和文抄録作業を適切に支援することができる。
【0066】
なお、要部表示は、図11、図12に示すような形態に限るものではない。例えば図14に示すように、要部ボタン31を翻訳要部ボタン31aと原文要部ボタン31bに分け、また全文ボタン32についても翻訳全文ボタン32aと原文全文ボタン32bとに分け、これらボタンを個別に選択操作することにより、4つの表示形態に選択して表示する構成であってもよい。要するに、英語特許明細書から選択した要部の英文やその翻訳結果、オリジナルの英語特許明細書、その翻訳した全文明細書などを自在に順次表示することが可能である。
【0067】
次に、図15は本発明に係る抄録作成支援システムの他の実施の形態を説明する図である。
【0068】
この実施の形態は、抽出規則辞書格納部2に格納される各抽出規則辞書の規則に予め重要度を設定し、抽出された段落の重要度に基づいて抄録候補の表示量ないし表示数を制御する例である。
【0069】
本発明に係る抄録作成支援システムでは、図15に示す抽出規則辞書に予め重要度を設定しておけば、要部選定部12によって要部を選定すると、図8に示す要部抽出結果にさらに重要度が付加された図16に示す要部抽出結果が得られる。つまり、要部抽出結果には、抽出される各段落毎に、抽出の時に用いられた抽出規則の重要度情報が付加されている。その結果、図示されていないが、図10に示す抄録候補の翻訳結果にも各要部ごとに重要度の情報が付加される。なお、予め「1」は重要度が最も高く、数値が大きくなるに従って重要度が低くなるように取り決められているものとする。
【0070】
その結果、抄録編集表示制御部15では、図17に示すごとく重要度を考慮しつつ抄録候補の抽出処理を実行する。すなわち、抄録編集表示制御部15は、先ず最初に変数iに1番目の抽出規則(ID=R1)である1を設定した後(S61)、この抽出規則(ID=R1)に対応する重要度が予め定める閾値よりも大きいか、つまり閾値よりも重要度が高いか否かを判断し(S62)、重要度が高いと判断された場合には、当該フィールドの段落に対応する日本語の翻訳要部を表示エリア37に表示する(S63)。この翻訳要部を表示した後又はステップS62において閾値よりも重要度が低いと判断された場合、ステップS64に移行し、変数iに+1を加えた後、この変数iの番目の抽出規則(ID=Ri)が未だ残っているか否かを判断し(S65)、未だ残っている場合にはステップS62に戻り、同様の処理を実行する。全ての抽出段落数について重要度を調べて要部翻訳を表示したとき、重要度に関する処理は終了する。
【0071】
従って、以上のような実施の形態によれば、抄録作成段階で予め定める閾値よりも重要度の高い翻訳要部だけを表示エリア37に表示して和文抄録を作成することができ、また少ない表示量を用いて効率的に和文抄録を作成できる。
【0072】
なお、重要度の閾値は、抄録作成者が随時変更でき、抄録作成者の所要とする和文抄録を容易に作成できる。
【0073】
図18は本発明に係る抄録作成支援システムのさらに他の実施の形態を説明する図である。
【0074】
この実施の形態は、図4に示す文書構造解析結果に記載される明細書から抄録候補として「代表図の説明」を抽出する例である。
【0075】
本発明に係る抄録作成支援システムでは、抽出規則辞書に規定する規則の中のキーフレーズにフレーズの照合だけでなく、特殊記号を追加することにより、抽出規則辞書の表現形式を拡張し、「代表図の説明」を要部として抽出するものである。
【0076】
このキーフレーズに導入する記号のうち、「$RepFig$」は代表図であることを意味する記号であり、「$^Line$」は指定されたフィールドの先頭からLine段落までをキーフレーズの探索範囲であることを意味する記号である。「$*Line$」は照合する段落以下のLine段落を取り出すことを意味する。「$*$」は、例えば「SUMMARY」フィールドに関しては全ての段落を要部として取り出すことを意味する。
【0077】
このシステムは、抽出規則辞書部に図18に示すような抽出規則を記載することにより、要部抽出部12では、1番目の抽出規則(ID=R1)に関し、例えば代表図がFig.1であれば、フィールドに規定する「FIELD OF THE INVENTION」に対応する文書構造解析結果の中に「Fig.1 shows」というキーフレーズが存在するかを探索することを意味する。また、2番目の抽出規則(ID=R2)に関し、フィールドに規定する「DATAILED DESCRIPTION OF THE INVENTION」に対応する文書構造解析結果の中の3段落目までを探索範囲とし、「Fig.? shows」(「?」は任意の数字)というキーフレーズが存在しているかを探索することを意味する。さらに、3番目の抽出規則(ID=R3)に関し、フィールドに規定する「CLAIMS」に対応する文書構造解析結果の中の2段落(他のキーフレーズの指定がないため)を抽出することを意味する。
【0078】
因みに、米国公開特許明細書のXML形式の定義である“−//USPTO//DTD PAP V1.6 2002−01−01//EN”におけるpap−v16−2002−01−01.Dtdによれば、<representative・figure>と</representative・figure>とで囲まれた数字が代表図を示している。このような形式で記載された特許明細書を入力した場合、代表図が何であるかを特許明細書中から容易に取り出すことができる。
【0079】
従って、要部選定部12の図6に示すステップS14では、以上のような定義情報を用いて、抽出規則辞書中の「$RepFig$」という記号の具体的な文字列に置き換えた後、通常のキーフレーズに従って探索するように処理すればよい。すなわち、例えば抄録作成対象とする特許明細書の代表図が「Fig.1」であれば、「$RepFig$」は「Fig.1」に置換できるので、抽出規則R1のキーフレーズは「Fig.1 shows」となる。よって、フィールドに規定する「DATAILED DESCRIPTION OF THE INVENTION」に対応する文書構造解析結果の中から「Fig.1 shows」というキーフレーズを探索することになる。
【0080】
また、要部選定部12のキーフレーズの探索のステップS14(図6)において、抽出規則に記載されているキーフレーズに、特殊記号「$RepFig$」が含まれていれば、キーフレーズの探索範囲をLine段落まで限定したり、特殊記号「$*Line$」が含まれていれば、キーフレーズに照合する段落以下のLine段落を要部として抽出したり、キーフレーズに特殊記号「$*$」が含まれていれば、処理対象のフィールドの全段落を要部として選択する等の処理を行うことになる。
【0081】
従って、このような実施の形態によれば、特許明細書の中から代表図の説明を抄録候補として容易に抽出することができる。
【0082】
なお、以上のような特殊記号を新たに定義し、それに合せて要部選定部12を構成すれば、代表図の説明以外にも要部とする内容を容易に抽出することが可能である。
【0083】
図19は本発明に係る抄録作成支援システムのさらに他の実施の形態を説明する図である。
【0084】
この実施の形態は、抽出規則辞書格納部2の中に新たに不要語辞書を設け、抽出規則辞書の条件に照合する段落であっても、不要語に照合する段落に限り、抽出しない構成とする例である。
【0085】
図19は不要語辞書の一例を示す図であって、例えば1番目と2番目の規則F1,F2の不要語は、第2の実施例を説明する際に用いられるフレーズであり、要部として選択する上で適切でない場合がある。また、3番目と4番目の規則F3,F4の不要語は、従属形式請求項となっている場合に用いられるフレーズであり、これも要部として選択すべきでない場合が多い為である。
【0086】
図20は抽出規則辞書格納部2に抽出規則辞書の他に不要語辞書を加えた場合の要部選定部12の一連の処理例を示すフローチャートである。
【0087】
この要部選定部12において、図6との処理の違いは、ステップS74にて抽出規則iと照合する段落が存在するか否かを判断し、段落有りと判断されとき、不要語辞書の規則に基づいて照合した段落の中に不要語が存在するか否かを判断し(S75)、不要語が含まれている場合には要部として抽出しない処理としたものである。従って、その他のステップS71〜S74は図6のステップS11〜S14に相当し、またステップS76〜S78は図6のステップS15〜S17に相当するので、詳細な処理は図6の説明に譲る。
【0088】
従って、以上のような実施の形態によれば、不要語辞書の規則に定める不要語が機械文翻訳結果の要部に相当する段落に存在する場合、要部として適切でないと判断し、その段落については要部として抽出しないので、より精度の高い和文抄録を作成できる。
【0089】
なお、図19に示す不要語辞書では、IPC分類毎に不要語辞書を用意する場合を想定しているが、例えば抽出規則辞書内の各抄録項目や各抽出規則に対して、不要語を設定するような構成であってもよい。
【0090】
また、前述する各実施の形態では、要部選択並びに抄録候補生成において段落を処理単位とするものであったが、これらは他の言語単位(文や節、フレーズ、単語等)を処理単位として構成することもできる。
【0091】
さらに、本実施の形態では、抄録作成対象とする例えば英語特許明細書に記載されたIPC分類に従って抽出規則辞書を選択的に利用する形態をとったが、例えば機械翻訳に関し、専門分野に応じた専門用語辞書を選択的に利用するようにすれば、翻訳精度の向上が期待され、さらにIPC分類に従って機械翻訳で利用する辞書を選択するように変形することも可能である。
【0092】
さらに、近年、機械翻訳システムでは、翻訳メモリの機能が実現されている(例えばThe 翻訳プロフェッショナルV8.0)。この翻訳メモリとは、ある英文について過去に精度の高い日本語訳を作成した場合、当該英文と類似する英文については、同じ日本語訳を再利用した方が質の良い翻訳を行える可能性が高いという事実に基づき、過去の英文−日本語訳の組合せを記憶しておき、新しい英文を翻訳する際に過去の類似文を検索し、類似文が存在する場合に当該類似文に対応する日本文訳をユーザに提示する機能である。
【0093】
そこで、本発明に係る抄録作成支援システムにおいても、例えば要部選定部12で抽出された要部に関する翻訳結果を抄録作成者に提示し、その翻訳結果を参考にしつつ最終的に和文抄録を作成する構成でもよい。この場合、要部選定部12で抽出された英文要部と修正結果の和文抄録とを記憶しておけば、機械翻訳部13における翻訳メモリ機能を利用することが可能となる。つまり、本発明システムとしては、要部選定部12で抽出された英文要部と抄録作成者による編集終了後の和文抄録とを対として記憶する記憶手段と、翻訳メモリ機能とをさらに設けた機械翻訳部13とすれば、翻訳メモリ機能を有効に活用しながら和文抄録を作成できる。この際、IPC分類に対応させて英文要部−和文抄録を記憶する構成とすれば、抄録作成対象の英語特許明細書のIPC分類に従って探索する英文要部−和文抄録の過去事例を効率的に選択利用することが可能である。
【0094】
また、以上の実施の形態では、日本語を母国語とする抄録作成者が和文抄録する例について述べたが、例えば英語から中国語、英語からドイツ語、日本語から英語など,他の言語対に対しても同様に適用可能である。従って、この場合には、抽出規則辞書における抽出規則や機械翻訳を適用する言語についても、他の言語対に合せて組み込むようにすれば、他の言語対の対応する抄録作成支援システムを実現できることは言うまでもない。
【0095】
また、上記実施の形態では、日本語の抄録候補と原文の要部とを対応付けて表示したが、抄録候補抽出部14で抽出される日本語の抄録候補だけを表示することも可能である。
【0096】
次に、図21は本発明に係る要部作成機能付き検索システムの一実施の形態を説明する機能構成図である。
【0097】
この検索システムは、文書検索部61、図1の抽出規則辞書格納部2と同様の機能をもつ抽出規則辞書格納部62、図1の文書構造解析部11と同様の機能をもつ文書構造解析部63、図1の要部選定部12と同様の機能をもつ要部選定部64、図1の機械翻訳部13と同様の機能をもつ機械翻訳部65、検索候補抽出66、検索結果表示制御部67により構成され、その他種々の構成要素例えば特許文献保存用データベース68、翻訳辞書(図示せず)、一連の検索処理用プログラムを記録する記録媒体等が設けられている。なお、同図において図1と同一機能をもつ構成要素2、63〜65等は、図1,図2で既に詳しく説明しているので、ここでは省略する。
【0098】
先ず、特許文献保存用データベース68には、多数の外国語特許明細書,例えば英語特許明細書が電子化されて蓄積される。
【0099】
この状態において、文書検索部61は、図示しない検索入力部から例えば技術分野やIPC分類等の検索条件のもとに検索指示が入力されると、記録媒体から検索処理用プログラムに従って一連の処理を実行する。すなわち、文書検索部61は、検索条件が入力されると、データベース68から検索条件に適合した複数の英語特許明細書を検索する(71)。なお、この文書検索部61としては、従来公知の種々の文書検索技術が用いられる。
【0100】
文書検索部61で複数の英語特許明細書が検索されると、一時バッフアメモリなどに格納した後、例えば検索された順番に検索結果である特許明細書を文書構造解析部63に送出し、特許明細書の文書構造を解析する。なお、特許明細書の文書構造解析については図1,図2で既に説明した通りである。その結果、図4に示すような文書構造解析結果を取り出すことができる(72)。
【0101】
このようにして取り出された文書構造解析結果は、要部選定部64及び機械翻訳部65に送られる。この要部選定部64は、図6に示す処理の流れに従って文書構造解析結果の中から抽出規則辞書格納部62に格納される抽出規則辞書(図5参照)に定める規則に従って要部を抽出する(73)。この要部抽出結果は図7又は図8に示す通りである。一方、機械翻訳部65では、文書構造解析結果に対し、翻訳辞書部8に規定する規則・知識を用いて、母国語に翻訳し、図9に示すような機械翻訳結果を取得する(74)。なお、これら要部選定部64及び機械翻訳部65は、図1及び図2に関連する説明の中で詳しく説明されているので、ここでは省略する。
【0102】
引き続き、検索候補抽出部66は、要部選定部64の抽出結果である各要部ごとに機械翻訳部65で翻訳された外国語特許明細書全文の日本語翻訳結果の中から翻訳された検索要部を取り出し、例えば検索結果保存用データベース(図示せず)に格納する。この検索結果保存用データベースには、検索した原文である全文英語特許明細書、機械翻訳部65で機械翻訳された全文翻訳された母国語特許明細書、要部選定部64で抽出された原文要部、検索要部生成部66で生成された翻訳要部が格納されている。
【0103】
そこで、検索結果表示制御部67では、図22に示す処理手順に従って図1の7に相当する出力部に表示する。図23は画面表示例を示す図である。なお、初期画面には全文表示ボタン81、要部表示ボタン82、次選択ボタン83、前選択ボタン84が形成されている。
【0104】
検索結果表示制御部67は、要部ボタン82が操作されると、検索された英語特許明細書が複数存在する場合には画面奥行き方向に表示エリア85、86が重なりをもって表示される。この状態において、変数iとして1がセットされると、検索結果保存用データベースから検索されたある1つの英語特許明細書iから抽出された原文要部(要部抽出結果)を取り出し、当該原文要部を項分けして表示エリア85に表示する。そして、この原文要部に連動し、各原文要部に対応する翻訳要部を表示エリア86に表示する(S82)。
【0105】
しかる後、何れかのボタンが操作されたかを判断し(S83)、ボタン操作がない場合には繰り返し判断する。このステップS83において、ボタン操作有りと判断された場合には、全文表示ボタン81が操作されたか否かを判断し(S84)、全文ボタン81が操作されたと判断した場合には、該当特許明細書iの原文全文を表示エリア85に表示し、それに伴って原文全文に対応する機械翻訳結果である全文翻訳を表示エリア86に表示する(S85)。そして、次に何れかのボタンが操作されたかを判断し(S86)、ここで、要部表示ボタン82が操作されたと判断された場合(S87)にはステップS82に戻って同様に英語特許明細書iから抽出された原文要部及び翻訳要部を表示する。
【0106】
ところで、ステップS84において、ボタン操作が行われたが、全文表示ボタン81の操作でないと判断された場合、前選択ボタン84の操作か、次選択ボタン83の操作かを判断する(S89、S90)。ここで、前選択ボタン84が操作されたと判断された場合、変数iに1(下限数)の範囲でi−1をセットし(S91)、ステップS82に移行し、1つ前の英語特許明細書iから抽出された原文要部及び翻訳要部を表示エリア85,86にそれぞれ表示する。一方、次選択ボタン83が操作されたと判断された場合、変数iにN(上限数)の範囲でi+1をセットし(S92)、ステップS82に移行し、次の英語特許明細書iから抽出された原文要部及び翻訳要部を表示エリア85,86にそれぞれ表示する。
【0107】
なお、ステップS87において、ボタン操作が要部表示ボタン82の操作でなく、前選択ボタン84が操作された場合(S93)には変数iにi−1をセットし(S94)、ステップS85に移行し、原文全文及び翻訳全文を表示エリア85,86にそれぞれ表示する。また、次選択ボタン83が操作された場合(S95)には変数iにi+1をセットし(S96)、ステップS85に移行し、原文全文及び翻訳全文を表示エリア85,86にそれぞれ表示する。
【0108】
従って、以上のような実施の形態によれば、多数の外国語特許明細書の中から検索条件のもとに少なくとも1つ以上の外国語特許明細書を検索し、この検索された外国語特許明細書について、全文翻訳された母国語特許明細書、原文要部、翻訳要部を取り出し、表示画面に選択的に外国語特許明細書−全文翻訳された母国語特許明細書、原文要部−翻訳要部の如く対の関係で表示するので、検索者は容易に所要とする技術内容を把握でき、ひいては検索効率を大幅に高めることができる。
【0109】
なお、図23では、要部を項目別に表示したが、項目別でなく、要部選定部64で抽出された段落の出現順に表示する構成であってもよい。
【0110】
また、図23には図示されていないが、全文表示の場合、既に要部選定部64で要部が抽出されているので、当該全文中の要部相当部分を例えば異なる色などで強調表示すれば、全文中でどの個所が重要であるかが一目瞭然に認識でき、さらに検索効率を高めることができる。
【0111】
なお、本願発明は、上記実施の形態に限定されるものでなく、その要旨を逸脱しない範囲で種々変形して実施できる。
【0112】
また、各実施の形態は可能な限り組み合わせて実施することが可能であり、その場合には組み合わせによる効果が得られる。さらに、上記各実施の形態には種々の上位,下位段階の発明が含まれており、開示された複数の構成要素の適宜な組み合わせにより種々の発明が抽出され得るものである。例えば問題点を解決するための手段に記載される全構成要件から幾つかの構成要件が省略されうることで発明が抽出された場合には、その抽出された発明を実施する場合には省略部分が周知慣用技術で適宜補われるものである。
【0113】
【発明の効果】
以上説明したように本発明によれば、第1言語の特許文献から効率的、適切な第2言語の抄録を作成できる抄録作成支援システム、プログラム及び抄録作成支援方法を提供できる。
【0114】
また、本発明は、検索された第1言語の特許明細書に対応する全文翻訳の第2言語の特許明細書、原文要部、翻訳要部を作成し、選択的に表示することにより、迅速に技術内容を把握でき、ひいては検索効率を大幅に向上させる特許文献検索システム、プログラム及び特許文献検索方法を提供できる。
【図面の簡単な説明】
【図1】本発明に係る抄録作成支援システムの一実施の形態を示す構成図。
【図2】図1に示す抄録作成支援システムの一連の処理の流れを説明する図。
【図3】抄録作成対象となる例えば英語特許明細書の一例を示す図。
【図4】図1に示す文書構造解析部で解析された英語特許明細書の文書構造解析結果を示す図。
【図5】抽出規則辞書格納部に格納される抽出規則辞書内の規則を説明する図。
【図6】図1に示す要部選定部の具体的な処理の流れを説明するフローチャート。
【図7】要部選定部で抽出された原文要部抽出結果のイメージ図。
【図8】要部選定部で抽出された要部抽出結果の一表現例を示す図。
【図9】図3に示す抄録作成対象となる例えば英語特許明細書の機械翻訳結果を示す図。
【図10】図1に示す抄録候補生成部で取り出した和文の抄録候補の一例を説明する図。
【図11】抄録候補の表示例であって、特に抽出された翻訳要部及び原文要部の表示例、この翻訳要部から和文抄録を編集処理する例及び翻訳全文及び原文全文の表示例を説明する図。
【図12】翻訳要部と原文要部を対応付けて表示する例を示す図。
【図13】図1に示す抄録編集表示制御部による状態遷移とその状態遷移に伴う処理を説明する図。
【図14】別の抄録候補の表示例を示す図。
【図15】本発明に係る抄録作成支援システムの他の実施の形態を説明するための抽出規則辞書の一例を示す図。
【図16】要部選定部において図15に示す抽出規則辞書を用いて抽出した要部抽出結果の一例を示す図。
【図17】要部選定部における一連の処理の流れを説明するフローチャート。
【図18】本発明に係る抄録作成支援システムのさらに他の実施の形態を説明するための抽出規則の一例を示す図。
【図19】本発明に係る抄録作成支援システムのさらに他の実施の形態を説明するための不要語辞書の一例を示す図。
【図20】要部選定部において抽出規則辞書及び不要語辞書を用いて要部を抽出するための処理の一例を示すフローチャート。
【図21】本発明に係る検索システムの一実施の形態を説明する機能構成図。
【図22】図21における検索結果表示制御部の一連の処理を説明するフローチャート。
【図23】検索結果の表示例を示す図。
【符号の説明】
1…原文明細書入力部、2…抽出規則辞書格納部、3…抄録作成処理制御部、4…記録媒体、5…抄録関連情報格納用データベース、7…出力部、8…翻訳辞書部、11…文書構造解析部、12…要部選定部、13…機械翻訳部、14…抄録候補抽出部、15…抄録編集表示制御部、61…文書検索部、62…抽出規則辞書格納部、64…要部選定部、65…機械翻訳部、66…検索候補抽出部、67…検索結果表示制御部。
【特許請求の範囲】
【請求項1】
一定の分類ごとに少なくとも所要とする第1言語の章節の表題及びこの各表題の章節に記載される説明文中に含まれる第1言語の単語,フレーズ等のキーフレーズを規定する抽出規則辞書と、
電子化された第1言語の特許出願書類に記載される文章の章節構造を解析する文書構造解析手段と、
この文書構造解析手段で解析された文書構造解析結果に記載されている分類に従って所要の前記抽出規則辞書を選択し、当該抽出規則辞書に規定される表題及びキーフレーズに基づいて前記文書構造解析結果から要部を選定する要部選定手段と、
前記文書構造解析手段で解析された文書構造解析結果を第2言語に翻訳処理する機械翻訳手段と、
前記要部選定手段で選定される各要部ごとに前記機械翻訳手段で翻訳された第2言語の翻訳結果から第2言語の抄録候補を抽出する抄録候補抽出手段と、
この抄録候補抽出手段で抽出される第2言語の抄録候補及のみ表示し、又は当該第2言語の抄録候補と前記第1言語の要部とを対応付けて表示し、当該第2言語の抄録候補の修正処理を含んで第2言語の抄録を作成する抄録編集表示制御手段とを備えたことを特徴とする抄録作成支援システム。
【請求項2】
前記要部選定手段は、前記抽出規則辞書の抽出規則に抄録作成時に項分け記載する第2言語の抄録項目が規定されており、前記抽出規則に照合する要部を特定し、当該要部を特定する情報を出力する際、この要部特定情報に対し、当該要部に対応する前記第2言語の抄録項目を付加し出力する手段をさらに設けたことを特徴とする請求項1に記載の抄録作成支援システム。
【請求項3】
前記抄録編集表示制御手段は、前記抄録候補抽出手段で抽出される第2言語の抄録候補及び前記第1言語の要部と、前記第1言語の文書構造解析結果全文及び前記機械翻訳手段で翻訳処理された第2言語の翻訳結果全文とをそれぞれ選択的に対応付けて表示し、当該第2言語の抄録候補の修正処理を含んで第2言語の抄録を作成する手段をさらに設けたことを特徴とする請求項1に記載の抄録作成支援システム。
【請求項4】
前記抽出規則辞書の抽出規則に新たに重要度情報が規定されており、
前記要部選定手段は、前記抽出規則に照合する要部を特定し、当該要部を特定する情報を出力する際、この要部特定情報に対し、前記重要度情報を付加して出力し、
前記抄録候補抽出手段は、前記要部選定手段から出力される前記重要度情報と予め定める重要度を意味する閾値とを比較し、この閾値よりも高い前記重要度情報が付加されている要部のみ、前記機械翻訳手段で翻訳された第2言語の翻訳結果から第2言語の抄録候補を抽出する手段をさらに設けたことを特徴とする請求項1又は請求項2に記載の抄録作成支援システム。
【請求項5】
前記抽出規則辞書に代表図に関係する符号を含む記号をもつキーフレーズが追加されており、
前記要部選定手段は、前記文書構造解析手段で解析された文書構造解析結果に記載されている分類に従って所要の前記抽出規則辞書を選択し、当該抽出規則辞書に規定される表題及びキーフレーズに基づいて前記文書構造解析結果から代表図を説明する個所を選定することを特徴とする請求項1に記載の抄録作成支援システム。
【請求項6】
前記抽出規則辞書以外に不要語辞書が設けられており、
前記要部選定手段は、前記文書構造解析手段で解析された文書構造解析結果に記載されている分類に従って所要の前記抽出規則辞書を選択し、当該抽出規則辞書に規定される表題及びキーフレーズに基づいて前記文書構造解析結果から要部を選定し、かつ、この選定された要部の中に前記不要語辞書に記載する不要語が存在する場合、前記選定された要部を排除する手段をさらに設けた請求項1ないし請求項5の何れか一項に記載の抄録作成支援システム。
【請求項7】
一定の分類ごとに少なくとも所要とする第1言語の章節の表題及びこの各表題の章節に記載される説明文中に含まれる第1言語の単語,フレーズ等のキーフレーズをもつ抽出規則が記憶され、電子化された第1言語の特許出願書類から第2言語の抄録を作成するコンピュータに、
電子化された第1言語の特許出願書類に記載される文章の章節構造を解析する文書構造解析機能と、
この解析された文書構造解析結果に記載されている分類に従って所要の前記抽出規則辞書を選択し、当該抽出規則辞書に規定される表題及びキーフレーズに基づいて前記文書構造解析結果から要部を選定する要部選定機能と、
前記文書構造解析機能で解析された文書構造解析結果を第2言語に翻訳処理する機械翻訳機能と、
前記要部選定機能により選定される各要部ごとに前記機械翻訳機能で翻訳された第2言語翻訳結果から第2言語の抄録候補を抽出する抄録候補抽出機能と、
この機能によって抽出される第2言語の抄録候補のみを表示し、又は当該第2言語の抄録候補と前記第1言語の要部とを対応付けて表示し、当該第2言語の抄録候補の修正処理を含んで第2言語の抄録を作成する機能とを実現させることを特徴とするプログラム。
【請求項8】
一定の分類ごとに少なくとも所要とする第1言語の章節の表題及びこの各表題の章節に記載される説明文中に含まれる第1言語の単語,フレーズ等のキーフレーズの抽出規則が記憶され、電子化された第1言語の特許出願書類から第2言語の抄録を作成する抄録作成支援方法であって、
電子化された第1言語の特許出願書類に記載される文章の章節構造を解析する文書構造解析ステップと、
この解析された文書構造解析結果に記載されている分類に従って所要の前記抽出規則辞書を選択し、当該抽出規則辞書に規定される表題及びキーフレーズに基づいて前記文書構造解析結果から要部を選定する要部選定ステップと、
前記文書構造解析ステップで解析された文書構造解析結果を第2言語に翻訳処理する機械翻訳処理ステップと、
前記要部選定ステップにより選定される各要部ごとに前記翻訳された第2言語翻訳結果から第2言語の抄録候補を抽出する抄録候補抽出ステップと、
この抽出された第2言語の抄録候補のみを表示し、又は当該第2言語の抄録候補と前記第1言語の要部とを対応付けて表示し、当該第2言語の抄録候補の修正処理を含んで第2言語の抄録を作成するステップとを有することを特徴とする抄録作成支援方法。
【請求項9】
電子化された複数の第1言語の特許出願書類を記憶する記憶手段と、
検索条件のもとに前記記憶手段から少なくとも1つの第1言語の特許出願書類を検索する文書検索手段と、
一定の分類ごとに少なくとも所要とする第1言語の章節の表題及びこの各表題の章節に記載される説明文中に含まれる第1言語の単語,フレーズ等のキーフレーズを規定する抽出規則辞書と、
前記文書検索手段により検索された前記電子化された第1言語の特許出願書類に記載される文章の章節構造を解析する文書構造解析手段と、
この文書構造解析手段で解析された文書構造解析結果に記載されている分類に従って所要の前記抽出規則辞書を選択し、当該抽出規則辞書に規定される表題及びキーフレーズに基づいて前記文書構造解析結果から検索対象となる要部を選定する要部選定手段と、
前記文書構造解析手段で解析された文書構造解析結果を第2言語に翻訳処理する機械翻訳手段と、
前記要部選定手段で選定される各検索対象要部ごとに前記機械翻訳手段で翻訳された第2言語の翻訳結果から第2言語の検索候補を抽出する検索候補抽出手段と、
この検索候補抽出手段で第2言語の検索候補を抽出した後、前記第1言語の検索要部の表示又は当該第1言語の検索要部と前記第2言語の検索候補との対応付け表示もしくは前記第1言語の文書構造解析結果及び前記第2言語の翻訳結果との対応付け表示を行う検索結果表示制御手段とを特徴とする特許文献検索システム。
【請求項10】
前記抽出規則辞書の抽出規則に新たに重要度情報が規定されており、
前記要部選定手段は、前記抽出規則に照合する要部を特定し、当該要部を特定する情報を出力する際、この要部特定情報に対し、前記重要度情報を付加して出力し、
前記検索候補抽出手段は、前記要部選定手段から出力される前記重要度情報と予め定める重要度を意味する閾値とを比較し、この閾値によって検索する量を制御することを特徴とする請求項9に記載の特許文献検索システム。
【請求項11】
電子化された複数の第1言語の特許出願書類及び一定の分類ごとに所要の第1言語の章節の表題及びこの各表題の章節に記載される説明文中に含まれる第1言語の単語,フレーズ等のキーフレーズを規定する抽出規則辞書が記憶され、前記第1言語の特許出願書類から少なくとも第2言語の検索候補を取り出すためのコンピュータに、
検索条件のもとに前記記憶される中から少なくとも1つの第1言語の特許出願書類を検索する文書検索機能と、
この機能により検索された前記電子化された第1言語の特許出願書類に記載される文章の章節構造を解析する文書構造解析機能と、
この機能により解析された文書構造解析結果に記載されている分類に従って所要の前記抽出規則辞書を選択し、当該抽出規則辞書に規定される表題及びキーフレーズに基づいて前記文書構造解析結果から検索対象となる要部を選定する要部選定機能と、
前記文書構造解析機能で解析された文書構造解析結果を第2言語に翻訳処理する機械翻訳機能と、
前記要部選定機能で選定される各検索対象要部ごとに前記機械翻訳機能で翻訳された第2言語の翻訳結果から第2言語の検索候補を抽出する検索候補抽出機能と、
この検索候補抽出機能で抽出される第2言語の検索候補を表示し、又は第2言語の検索候補と前記第1言語の検索要部とを対応付けて表示する検索結果表示制御機能とを実現させることを特徴とするプログラム。
【請求項12】
電子化された複数の第1言語の特許出願書類及び一定の分類ごとに所要の第1言語の章節の表題及びこの各表題の章節に記載される説明文中に含まれる第1言語の単語,フレーズ等のキーフレーズを規定する抽出規則辞書が記憶され、前記第1言語の特許出願書類から少なくとも第2言語の検索候補を取り出す検索方法であって、
検索条件のもとに前記記憶される中から少なくとも1つの第1言語の特許出願書類を検索する文書検索ステップと、
このステップにより検索された前記電子化された第1言語の特許出願書類に記載される文章の章節構造を解析する文書構造解析ステップと、
このステップにより解析された文書構造解析結果に記載されている分類に従って所要の前記抽出規則辞書を選択し、当該抽出規則辞書に規定される表題及びキーフレーズに基づいて前記文書構造解析結果から検索対象となる要部を選定する要部選定ステップと、
前記文書構造解析ステップで解析された文書構造解析結果を第2言語に翻訳処理する機械翻訳処理ステップと、
前記要部選定ステップで選定される各検索対象要部ごとに前記機械翻訳機能で翻訳された第2言語の翻訳結果から第2言語の検索候補を抽出する検索候補抽出ステップと、
この検索候補抽出ステップで抽出される第2言語の検索候補を表示し、又は当該第2言語の検索候補と前記第1言語の検索要部とを対応付けて表示するステップとを有することを特徴とする特許文献検索方法。
【請求項1】
一定の分類ごとに少なくとも所要とする第1言語の章節の表題及びこの各表題の章節に記載される説明文中に含まれる第1言語の単語,フレーズ等のキーフレーズを規定する抽出規則辞書と、
電子化された第1言語の特許出願書類に記載される文章の章節構造を解析する文書構造解析手段と、
この文書構造解析手段で解析された文書構造解析結果に記載されている分類に従って所要の前記抽出規則辞書を選択し、当該抽出規則辞書に規定される表題及びキーフレーズに基づいて前記文書構造解析結果から要部を選定する要部選定手段と、
前記文書構造解析手段で解析された文書構造解析結果を第2言語に翻訳処理する機械翻訳手段と、
前記要部選定手段で選定される各要部ごとに前記機械翻訳手段で翻訳された第2言語の翻訳結果から第2言語の抄録候補を抽出する抄録候補抽出手段と、
この抄録候補抽出手段で抽出される第2言語の抄録候補及のみ表示し、又は当該第2言語の抄録候補と前記第1言語の要部とを対応付けて表示し、当該第2言語の抄録候補の修正処理を含んで第2言語の抄録を作成する抄録編集表示制御手段とを備えたことを特徴とする抄録作成支援システム。
【請求項2】
前記要部選定手段は、前記抽出規則辞書の抽出規則に抄録作成時に項分け記載する第2言語の抄録項目が規定されており、前記抽出規則に照合する要部を特定し、当該要部を特定する情報を出力する際、この要部特定情報に対し、当該要部に対応する前記第2言語の抄録項目を付加し出力する手段をさらに設けたことを特徴とする請求項1に記載の抄録作成支援システム。
【請求項3】
前記抄録編集表示制御手段は、前記抄録候補抽出手段で抽出される第2言語の抄録候補及び前記第1言語の要部と、前記第1言語の文書構造解析結果全文及び前記機械翻訳手段で翻訳処理された第2言語の翻訳結果全文とをそれぞれ選択的に対応付けて表示し、当該第2言語の抄録候補の修正処理を含んで第2言語の抄録を作成する手段をさらに設けたことを特徴とする請求項1に記載の抄録作成支援システム。
【請求項4】
前記抽出規則辞書の抽出規則に新たに重要度情報が規定されており、
前記要部選定手段は、前記抽出規則に照合する要部を特定し、当該要部を特定する情報を出力する際、この要部特定情報に対し、前記重要度情報を付加して出力し、
前記抄録候補抽出手段は、前記要部選定手段から出力される前記重要度情報と予め定める重要度を意味する閾値とを比較し、この閾値よりも高い前記重要度情報が付加されている要部のみ、前記機械翻訳手段で翻訳された第2言語の翻訳結果から第2言語の抄録候補を抽出する手段をさらに設けたことを特徴とする請求項1又は請求項2に記載の抄録作成支援システム。
【請求項5】
前記抽出規則辞書に代表図に関係する符号を含む記号をもつキーフレーズが追加されており、
前記要部選定手段は、前記文書構造解析手段で解析された文書構造解析結果に記載されている分類に従って所要の前記抽出規則辞書を選択し、当該抽出規則辞書に規定される表題及びキーフレーズに基づいて前記文書構造解析結果から代表図を説明する個所を選定することを特徴とする請求項1に記載の抄録作成支援システム。
【請求項6】
前記抽出規則辞書以外に不要語辞書が設けられており、
前記要部選定手段は、前記文書構造解析手段で解析された文書構造解析結果に記載されている分類に従って所要の前記抽出規則辞書を選択し、当該抽出規則辞書に規定される表題及びキーフレーズに基づいて前記文書構造解析結果から要部を選定し、かつ、この選定された要部の中に前記不要語辞書に記載する不要語が存在する場合、前記選定された要部を排除する手段をさらに設けた請求項1ないし請求項5の何れか一項に記載の抄録作成支援システム。
【請求項7】
一定の分類ごとに少なくとも所要とする第1言語の章節の表題及びこの各表題の章節に記載される説明文中に含まれる第1言語の単語,フレーズ等のキーフレーズをもつ抽出規則が記憶され、電子化された第1言語の特許出願書類から第2言語の抄録を作成するコンピュータに、
電子化された第1言語の特許出願書類に記載される文章の章節構造を解析する文書構造解析機能と、
この解析された文書構造解析結果に記載されている分類に従って所要の前記抽出規則辞書を選択し、当該抽出規則辞書に規定される表題及びキーフレーズに基づいて前記文書構造解析結果から要部を選定する要部選定機能と、
前記文書構造解析機能で解析された文書構造解析結果を第2言語に翻訳処理する機械翻訳機能と、
前記要部選定機能により選定される各要部ごとに前記機械翻訳機能で翻訳された第2言語翻訳結果から第2言語の抄録候補を抽出する抄録候補抽出機能と、
この機能によって抽出される第2言語の抄録候補のみを表示し、又は当該第2言語の抄録候補と前記第1言語の要部とを対応付けて表示し、当該第2言語の抄録候補の修正処理を含んで第2言語の抄録を作成する機能とを実現させることを特徴とするプログラム。
【請求項8】
一定の分類ごとに少なくとも所要とする第1言語の章節の表題及びこの各表題の章節に記載される説明文中に含まれる第1言語の単語,フレーズ等のキーフレーズの抽出規則が記憶され、電子化された第1言語の特許出願書類から第2言語の抄録を作成する抄録作成支援方法であって、
電子化された第1言語の特許出願書類に記載される文章の章節構造を解析する文書構造解析ステップと、
この解析された文書構造解析結果に記載されている分類に従って所要の前記抽出規則辞書を選択し、当該抽出規則辞書に規定される表題及びキーフレーズに基づいて前記文書構造解析結果から要部を選定する要部選定ステップと、
前記文書構造解析ステップで解析された文書構造解析結果を第2言語に翻訳処理する機械翻訳処理ステップと、
前記要部選定ステップにより選定される各要部ごとに前記翻訳された第2言語翻訳結果から第2言語の抄録候補を抽出する抄録候補抽出ステップと、
この抽出された第2言語の抄録候補のみを表示し、又は当該第2言語の抄録候補と前記第1言語の要部とを対応付けて表示し、当該第2言語の抄録候補の修正処理を含んで第2言語の抄録を作成するステップとを有することを特徴とする抄録作成支援方法。
【請求項9】
電子化された複数の第1言語の特許出願書類を記憶する記憶手段と、
検索条件のもとに前記記憶手段から少なくとも1つの第1言語の特許出願書類を検索する文書検索手段と、
一定の分類ごとに少なくとも所要とする第1言語の章節の表題及びこの各表題の章節に記載される説明文中に含まれる第1言語の単語,フレーズ等のキーフレーズを規定する抽出規則辞書と、
前記文書検索手段により検索された前記電子化された第1言語の特許出願書類に記載される文章の章節構造を解析する文書構造解析手段と、
この文書構造解析手段で解析された文書構造解析結果に記載されている分類に従って所要の前記抽出規則辞書を選択し、当該抽出規則辞書に規定される表題及びキーフレーズに基づいて前記文書構造解析結果から検索対象となる要部を選定する要部選定手段と、
前記文書構造解析手段で解析された文書構造解析結果を第2言語に翻訳処理する機械翻訳手段と、
前記要部選定手段で選定される各検索対象要部ごとに前記機械翻訳手段で翻訳された第2言語の翻訳結果から第2言語の検索候補を抽出する検索候補抽出手段と、
この検索候補抽出手段で第2言語の検索候補を抽出した後、前記第1言語の検索要部の表示又は当該第1言語の検索要部と前記第2言語の検索候補との対応付け表示もしくは前記第1言語の文書構造解析結果及び前記第2言語の翻訳結果との対応付け表示を行う検索結果表示制御手段とを特徴とする特許文献検索システム。
【請求項10】
前記抽出規則辞書の抽出規則に新たに重要度情報が規定されており、
前記要部選定手段は、前記抽出規則に照合する要部を特定し、当該要部を特定する情報を出力する際、この要部特定情報に対し、前記重要度情報を付加して出力し、
前記検索候補抽出手段は、前記要部選定手段から出力される前記重要度情報と予め定める重要度を意味する閾値とを比較し、この閾値によって検索する量を制御することを特徴とする請求項9に記載の特許文献検索システム。
【請求項11】
電子化された複数の第1言語の特許出願書類及び一定の分類ごとに所要の第1言語の章節の表題及びこの各表題の章節に記載される説明文中に含まれる第1言語の単語,フレーズ等のキーフレーズを規定する抽出規則辞書が記憶され、前記第1言語の特許出願書類から少なくとも第2言語の検索候補を取り出すためのコンピュータに、
検索条件のもとに前記記憶される中から少なくとも1つの第1言語の特許出願書類を検索する文書検索機能と、
この機能により検索された前記電子化された第1言語の特許出願書類に記載される文章の章節構造を解析する文書構造解析機能と、
この機能により解析された文書構造解析結果に記載されている分類に従って所要の前記抽出規則辞書を選択し、当該抽出規則辞書に規定される表題及びキーフレーズに基づいて前記文書構造解析結果から検索対象となる要部を選定する要部選定機能と、
前記文書構造解析機能で解析された文書構造解析結果を第2言語に翻訳処理する機械翻訳機能と、
前記要部選定機能で選定される各検索対象要部ごとに前記機械翻訳機能で翻訳された第2言語の翻訳結果から第2言語の検索候補を抽出する検索候補抽出機能と、
この検索候補抽出機能で抽出される第2言語の検索候補を表示し、又は第2言語の検索候補と前記第1言語の検索要部とを対応付けて表示する検索結果表示制御機能とを実現させることを特徴とするプログラム。
【請求項12】
電子化された複数の第1言語の特許出願書類及び一定の分類ごとに所要の第1言語の章節の表題及びこの各表題の章節に記載される説明文中に含まれる第1言語の単語,フレーズ等のキーフレーズを規定する抽出規則辞書が記憶され、前記第1言語の特許出願書類から少なくとも第2言語の検索候補を取り出す検索方法であって、
検索条件のもとに前記記憶される中から少なくとも1つの第1言語の特許出願書類を検索する文書検索ステップと、
このステップにより検索された前記電子化された第1言語の特許出願書類に記載される文章の章節構造を解析する文書構造解析ステップと、
このステップにより解析された文書構造解析結果に記載されている分類に従って所要の前記抽出規則辞書を選択し、当該抽出規則辞書に規定される表題及びキーフレーズに基づいて前記文書構造解析結果から検索対象となる要部を選定する要部選定ステップと、
前記文書構造解析ステップで解析された文書構造解析結果を第2言語に翻訳処理する機械翻訳処理ステップと、
前記要部選定ステップで選定される各検索対象要部ごとに前記機械翻訳機能で翻訳された第2言語の翻訳結果から第2言語の検索候補を抽出する検索候補抽出ステップと、
この検索候補抽出ステップで抽出される第2言語の検索候補を表示し、又は当該第2言語の検索候補と前記第1言語の検索要部とを対応付けて表示するステップとを有することを特徴とする特許文献検索方法。
【図1】


【図2】
【図3】

【図4】

【図5】
【図6】
【図7】

【図8】
【図9】

【図10】

【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】

【図20】
【図21】
【図22】
【図23】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【図23】
【公開番号】特開2005−31813(P2005−31813A)
【公開日】平成17年2月3日(2005.2.3)
【国際特許分類】
【出願番号】特願2003−193867(P2003−193867)
【出願日】平成15年7月8日(2003.7.8)
【公序良俗違反の表示】
(特許庁注:以下のものは登録商標)
フロッピー
【出願人】(393016631)財団法人日本特許情報機構 (1)
【出願人】(301063496)東芝ソリューション株式会社 (1,478)
【Fターム(参考)】
【公開日】平成17年2月3日(2005.2.3)
【国際特許分類】
【出願日】平成15年7月8日(2003.7.8)
【公序良俗違反の表示】
(特許庁注:以下のものは登録商標)
フロッピー
【出願人】(393016631)財団法人日本特許情報機構 (1)
【出願人】(301063496)東芝ソリューション株式会社 (1,478)
【Fターム(参考)】
[ Back to top ]