
抑制されたベクトル量子化
本発明は、信号のベクトル量子化のための辞書を生成する方法に関する。上記方法は、信号を表す複数の駆動ベクトルの統計解析を行って、上記複数の駆動ベクトルを表す符号ベクトルの有限集合(CITER)の決定を行う段階10を有する。本発明の方法は、修正された符号ベクトルの2つずつの間の距離が最小となるように、符号ベクトルの有限集合の修正を行う段階3をさらに有することを特徴とする。上記修正された符号ベクトルの集合が辞書を形成する。

【発明の詳細な説明】
【技術分野】
【0001】
本発明は、音声及び映像信号、並びに、より一般的には、マルチメディア信号といった信号に対して、それらの格納又は転送を目的とした符号化及び復号を行うための量子化辞書に関する。
より正確には、本発明は、歪みしきい値の事前知識を含む非構造化統計的ベクトル量子化の問題への解決策を提案する。
【背景技術】
【0002】
信号処理、特に、デジタル信号の処理に対して広く用いられているソリューションが、ベクトル量子化(VQ)である。一般に、ベクトル量子化は、有限集合の中から選択された同一次元のベクトルによって入力ベクトルを表す。この有限集合は、再生アルファベット、辞書、又はインデックスと称され、かつその構成要素は、符号ベクトル、符号語、出力ポイント、又は代表と称される。
【0003】
ベクトル量子化において、信号のn個のサンプルのひとかたまりは、n次元のベクトルとして扱われる。ベクトルは、有限集合の中から、そのベクトルに最も「似ている(resemble)」符号ベクトルを選び出すことによって符号化される。例えば、この構成要素と入力ベクトルとの間の距離が最も小さい辞書構成要素を選択するために、辞書の構成要素のすべてにわたる全数検索が実行される。
【0004】
一般に、ベクトル量子化辞書は、符号化が行われる信号のサンプルの解析に基づいて設計されるとともに、GLA(generalized Lloyd-Max algorithm)又はLBG(for Linde, Buzo and Gray)アルゴリズムといった統計的手法を用いる駆動シーケンス又は学習シーケンスを形成する。このようなタイプのアルゴリズムが、例えば、非特許文献1に記載されている。
【0005】
駆動シーケンス及び初期辞書に基づき、辞書は繰り返し構築される。各繰り返しは、最近傍則に従って駆動シーケンスの量子化範囲を構成するための駆動ベクトルの分類ステップと、セントロイド法と称される規則に従って、以前の符号ベクトルを範囲内のセントロイドで置き換えることによる辞書の改良ステップとを有する。
【0006】
この決定的反復アルゴリズムの極小への収束を回避するために、セントロイド構成のステップ及び/又はクラス構成のステップへランダムなパートを挿入する確率緩和(SKA: Stochastic K-means algorithm)と称される変形手法が提案されている。このような修正が、例えば、非特許文献2に記載されている。
【0007】
この方法で得られる辞書又は統計的ベクトル量子化器は、特殊な構成を有しておらず、それらの調査を、計算及び記録の面で割高とする。その上、従来の統計的ベクトル量子化によって得られたこのような辞書の使用は、しばしば制限を受け、特にリアルタイムで、ベクトル毎に4ないし10ビット程度の低い次元及び/又は低いレートの符号化しか行えない。
【0008】
一般に、統計的ベクトル量子化は、処理される信号の確率分布の形状を利用する。それは、統計的ベクトル量子化の辞書の符号ベクトルの分布に再び見出せる。ベクトル量子化で使用される構造アルゴリズムは、平均歪みの最小化を目的とし、したがって、それらは、高密度の部位に多くの符号ベクトルを配置する傾向にある。符号化される信号の高密度部位でのセントロイドの集中は、必ずしも認識の観点に基づく関連性があるとは限らない。故に、高密度部位の2つの符号ベクトルは、他方に対する一方の代理によって生成された歪みがごくわずかとなる可能性が高い。
【0009】
さらに、低分解能の量子化、すなわち、わずかな符号ベクトルしか備えない場合には、この集中は、符号化される信号の確率分布の低密度部位の損失を引き起こす。このとき、上記部位は悪い状態で表される。すなわち、間違った符号化がなされる。
【0010】
大きさ及び次元の制限から解放するために、統計的ベクトル量子化のいくつかの変形手法が開発されている。特に、辞書の構造の不備を改善し、それによって、計算量を品質の損失に換えることが試みられている。しかしながら、妥協していた計算能力が改善されることによって、ベクトル量子化が効率的に適用可能な分解能の範囲及び/又は次元を増大できるようになった。抑制された(constrained)ベクトル量子化ための多くの手法が、文献に提案されており、具体的には、ツリーベクトル量子化、多段ベクトル量子化、“デカルト積”ベクトル量子化、又は特殊なデカルト積ベクトル量子化である“ゲイン/オリエンテーション”ベクトル量子化がある。
【0011】
非構造化ベクトル量子化として、抑制された方法によって得られる辞書は、互いに接近した非常に大量の符号ベクトル、具体的には、その違いが受信機には感知できない複数の符号ベクトルを常に有する。これは、最適ではない品質をもたらす。
【0012】
また、代数的ベクトル量子化と称される別の取り組みが提案されている。代数的ベクトル量子化は、正規格子(regular lattice)の点又は誤り訂正符号に比べて、高度に構造化された辞書を用いる。正規格子の一例が、立方格子であり、これは、例えば、整数座標の点集合で形成される。
【0013】
これらの辞書の代数的特性により、代数的ベクトル量子化は、容易に実行されるとともに、メモリに格納される必要が無い。これらの辞書の規則的構造の開発によって、対応する符号ベクトルにインデックスを関連付けるための、例えば、計算式による最適かつ高速な検索アルゴリズム及びメカニズムを開発できるようになった。
【0014】
代数的ベクトル量子化のために従来技術で開発された技術は、正規格子又は配列の部分集合である辞書をもたらす。
【0015】
正規格子の主要パラメータのうちの1つは、符号ベクトルが位置した2点間の最小二乗距離である。インデックス付与を容易にするために、一般に、辞書は、超立方体又は超球体のような正規多面体、又はその表面と、格子との交点として選択される。そして、この交点の外側の点が外れ値である。所与の割合、すなわち、決められた数の交点に対する外れ値の制限は、2つの符号ベクトル間の最短距離の増大をもたらす。
【0016】
代数的ベクトル量子化は、実行する計算量が少なく、かつ多くのメモリを必要としないが、一様な分布の信号を符号化するためのみにしか適さない。
【0017】
また、符号ベクトルにインデックスを付与するための演算又は番号を付与するための演算、及び復号のための逆演算は、統計的ベクトル量子化の場合よりも多くの計算を要することに留意しなければならない。統計的ベクトル量子化での演算は、テーブルから読み取るだけで実行される。
【0018】
最後に、代数的量子化と統計的量子化とを組み合わせた、さらに別のベクトル量子化がある。これは、非特許文献3に記載されたファイン−コース(fine-coarse)ベクトル量子化に該当する。この量子化は、2つの量子化を含む。第1の高分解能又は細分解能量子化は、一般に、充分に構造化され、かつ実行が複雑でない。一方、第2の粗分解能量子化は、非構造化統計的ベクトル量子化である。第1段は、事前計算のためのものであり、第2段での検索を高速化する。
【0019】
“ファイン−コース”量子化は、統計的ベクトル量子化に対して上記で示されたものと同様の欠点を有する。実際には、細分解能量子化と粗分解能量子化との間のリンクは、単なる対応テーブルである。それによって、たとえ高分解能ベクトル量子化が符号ベクトル間の最小距離を備えた正規格子の有限集合であっても、この条件は、統計的ベクトル量子化の基本的な技術によって構成される粗分解能ベクトル量子化に課せられない。
【0020】
故に、統計的ベクトル量子化は、点の分布が不適切な辞書をもたらすと考えられる。これらの点のいくつかは、受信機のレベルでは感知できないので、冗長となる。
【0021】
一方、代数的ベクトル量子化は、一様な確率分布を備えた信号に対してのみ適する分布の辞書をもたらすとともに、他の信号に対する符号化品質の低下をもたらす。
【非特許文献1】Gersho A., Gray R. M, "Vector Quantization and Signal Compression", Kluwer Academic Publishers, 1992
【非特許文献2】Kovesi, B.; Saoudi, S.; Boucher, J. M.; Reguly, Z., "A fast robust stochastic algorithm for vector quantizer design for nonstationary channels", IEEE International Conference on Acoustics, Speech, and Signal Processing, Vol. 1, pp. 269-272, 1995
【非特許文献3】Moayeri, N., Neuhoff D. L.; Stark, W. E., "Fine-coarse vector quantization", IEEE Trans. on Information Theory, Vol. 37, Issue 4, pp. 1503-1515, July 1991
【非特許文献4】UIT-T, COM 16, D214(WP 3/16), "High level description of the scalable 8-32 kbit/s algorithm submitted to the Qualification Test by Matsushita, Mindspeed and Siemens," Q.10/16, Study Period 2005-2008, Geneva, 26 July - 5 August 2005 (Source: Siemens)
【発明の開示】
【発明が解決しようとする課題】
【0022】
本発明は、符号化が行われる信号に適し、かつ認識しきい値を考慮に入れた統計的ベクトル量子化による辞書取得の適切な方法を定義する格別な利点を有する。
【課題を解決するための手段】
【0023】
この目的に対して、本発明の要旨は、信号に対するベクトル量子化辞書の生成方法を提供することにあり、本方法は、信号を表す複数の駆動ベクトルの統計解析を行って、上記複数の駆動ベクトルを代表する符号ベクトルの有限集合を決定する段階から成る方式の方法であって、修正された符号ベクトル2つずつの間の距離が最小となるように、上記符号ベクトル有限集合の修正を行う段階をさらに有する。上記複数の修正された符号ベクトルが上記辞書を形成する。
故に、本発明は、複数の駆動ベクトルの統計解析を行う段階により、符号ベクトル間の距離が最小となるため、信号に適した辞書をもたらし、それによって、非常に接近した符号ベクトル同士は認識のレベルでは区別が付かないということを考慮できるようになる。
【0024】
本発明の他の特徴により、統計解析を行う段階は、初期辞書を生成する副段階と、量子化範囲を形成するために、初期辞書に基づいて複数の駆動ベクトルを分類する副段階と、範囲毎のセントロイドを決定する副段階とを有する。上記セントロイドが、上記符号ベクトルとなる。このような実施態様は、統計解析の特殊な実行に対応する。
好ましくは、上記初期辞書を生成する副段階は、上記複数の駆動ベクトルに基づいて実行されるとともに、正規格子の点上で選択された丸めベクトルによる各駆動ベクトルの置換と、それらの出現頻度に応じた丸めベクトルの選択的除去とを含む。
【0025】
本発明の特殊な実施態様において、統計解析を行う段階は、初期辞書の歪みを算出する副段階と、この歪みを許容しきい値と比較する副段階とをさらに有する。上記比較の結果が不一致である場合、上記統計解析を行う段階が繰り返される。このような反復手法によって、より良い品質の初期辞書を得ることができるようになる。
【0026】
変形例において、修正を行う段階は、正規格子の点上で選択された隣接符号ベクトルによって、上記複数の符号ベクトルのそれぞれを置き換えること含む。このような一実施態様によって、符号ベクトル間の最小距離を確保できるようになる。
【0027】
好ましくは、本方法は、上記複数の修正された符号ベクトル中の重複の除去を行う段階をさらに有する。その結果、辞書のサイズが小さくなる。
特殊な実施態様において、重複の除去を行う段階は、複数の修正された符号ベクトルを互いに比較することによって、重複の検索を行う副段階と、重複の削除を行う副段階とを有する。
【0028】
好ましくは、本方法は、辞書の複数の駆動ベクトルの分布を改善するように、複数の修正された符号ベクトルを、少なくとも互いに上記最小距離を有する複数の駆動ベクトルと統合する段階を有する。
特殊な実施態様において、この統合を行う段階は、正規格子の点上で選択された丸めベクトルによって、各駆動ベクトルの置換を行う副段階と、複数の修正された符号ベクトルと複数の丸め駆動ベクトルとを合成する副段階とを有する。故にまた、複数の修正された符号ベクトルと合成された丸め駆動ベクトルの2つずつは、最小距離を有する。
【0029】
別の変形例において、上記統合を行う段階は、それらの出現頻度に従って複数の丸め駆動ベクトルの整列を行うことと、上記複数の丸め駆動ベクトルを複数の修正された符号ベクトルと合成するために、上記複数の丸めベクトルの有限数の選択を行なうこととをさらに含む。
一実施態様において、上記合成を行う副段階は、有限数の丸め駆動ベクトルを上記複数の修正された符号ベクトルに追加することを含む。上記有限数の丸め駆動ベクトルは、上記複数の修正された符号ベクトルとは異なるものである。
【0030】
変形例において、正規格子の点は、上記信号の送信先である受信機の感度レベルに対応した間隔を有する。それによって、実際の認識に対応して、2つの符号ベクトル間の距離を最小化できるようになる。
【0031】
別の実施態様において、本方法は、上記辞書の最適化を行う段階をさらに有する。
例えば、最適化を行う段階は、辞書の歪みを算出する段階と、この歪みを許容しきい値と比較する段階とを有する。上記比較の結果が不一致である場合、上記統計解析を行う段階及び修正を行う段階が繰り返される。
あるいは、最適化を行う段階は、上記複数の修正された符号ベクトルから形成された辞書に基づいて実行される方法の少なくとも1回の繰り返しを含む。
【0032】
本発明の別の目的は、上記の方法を実行する命令コードを具備するコンピュータプログラムと、このコンピュータプログラムを実行するための、例えば、ワークメモリ、プロセッサなどの手段からなるデバイスと、を提供することにある。それによって、本発明の手法に含まれるベクトル量子化辞書を生成する。
また、この発明は、符号化及び復号の方法、並びに本発明に従って得られた辞書を使用するデコーダを対象とする。
【発明を実施するための最良の形態】
【0033】
本発明は、限定を目的としない実施形態として与えられた以下の記載に照らし、かつ添付の図面の参照によって、一層の理解を得られる。
【0034】
これより、図1を参照して、本発明によるベクトル量子化辞書の取得方法を記載する。
記載された実施形態において、この方法は、音声信号などのデジタルオーディオ信号を表す複数の駆動ベクトルに対して実行される。
【0035】
この方法は、最初に、駆動ベクトルの統計解析を行うステップ10を有する。記載された実施形態において、ステップ10は、GLAの適用に相当する。
ステップ10は、C0で示される初期辞書を生成するサブステップ12から開始される。この辞書は、駆動ベクトルの解析に基づいて生成されるか、又は他の既知の手段、例えば、駆動ベクトルの有限数のランダム選択、又は「分割(splitting)」LBGアルゴリズムと称されるアルゴリズムなどによって生成される。この初期辞書C0は、決められたサイズの辞書である。
【0036】
記載された実施形態において、本方法は、次に、現在の変数を初期化するサブステップ14を有する。具体的には、サブステップ14は、反復回数に相当する変数ITERと、歪み値に相当する変数DITERとの初期化を行う。
【0037】
ついで、ステップ10は、分類範囲を形成するために、初期辞書C0に関連する駆動ベクトルの分類を行うサブステップ16と、範囲毎のセントロイドを決定するサブステップ18とを有する。
より正確には、分類を行うサブステップ16において、駆動ベクトル毎に現在の辞書全体が走査される。すなわち、辞書C0が連続的な反復によって修正されて、駆動ベクトルとの二乗誤差を最小化する符号ベクトルが辞書から選択される。
【0038】
サブステップ18は、以下のように表される。クラス又は範囲Vi毎に、新しいセントロイドが算出される。
Viは、Q(xj)=yiとなる駆動ベクトルxjの集合として定義される。ここで、Q()は、量子化関数であり、yiは、辞書の符号ベクトルである。
NiをViのベクトルの数とし、Vi(j,k)をViのj番目のベクトルのk番目の要素とする。
セントロイドyiのk番目の要素が、以下の式で示される。
【0039】
【数1】
【0040】
サブステップ20において、現在の辞書に対する歪み値が算出される。
このサブステップ20では、駆動ベクトルは、上記のステップによって与えられた現在の辞書を用いて量子化される。駆動ベクトルとそれらの量子化バージョンとの間の二乗誤差は、歪み寸法を形成する。
【0041】
そして、サブステップ16、18、及び20は、最大反復回数ITERMAXに達するまで、又は歪みが許容しきい値より小さくなるまで、繰り返し実行される。この検査は、サブステップ22で実行される。
【0042】
上記で示されたように、実施例において、このステップ10、具体的には、サブステップ16、18、20、及び22の繰り返しは、GLAの適用に相当する。
よって、ステップ10の終端で、本方法は、駆動ベクトルの反復統計解析によって形成された辞書CITERを生成する。
【0043】
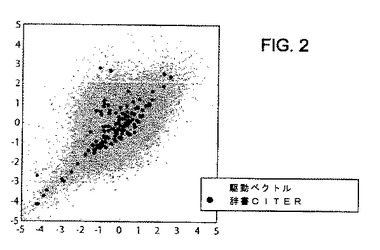
辞書CITERの2つの次元での表示が図2に示されている。ここで、符号ベクトルは、点の集まりによって表される。この表示において、灰色の点は、駆動ベクトル又は信号ベクトルに対応し、黒い点は、辞書のベクトルに対応する。辞書CITERのベクトルの歪みが駆動ベクトルの密度に従い、かつ多数のベクトルが互いに近接していることが見て取れる。
【0044】
ついで、本方法は、符号ベクトル2つずつの間の距離を最小化するために、辞書CITERの修正を行うステップ30を有する。
この修正ステップ30は、符号ベクトルのそれぞれを、デカルトグリッドのような正規格子の点上で選択された隣接ベクトルで置き換えることを含む。これらの修正されたベクトルは、丸め(rounded)ベクトルとも称される。記載された実施形態において、選択された隣接ベクトルは、符号ベクトルに最も近い正規格子上に位置するベクトルである。実施の形態及びベクトルのタイプに応じて、ベクトル間の距離以外の基準が、符号ベクトルの隣接ベクトルを決定するために使用されてよい。
【0045】
よって、ステップ30は、ステップ10で得られた辞書CITERを正規格子上で丸めることによって得られる新しい辞書C’を提供する。
正規格子上の符号語の丸めは、pを格子の間隔と置き、以下のように実行される。
【0046】
【数2】
【0047】
ここで、i=1...Mであり、k=1...nであり、かつ[.]は最も近い値の整数に丸めることを示す。
【0048】
ついで、本方法は、辞書C’を形成する修正された符号ベクトルから重複の除去を行うステップ32を有する。
ステップ32は、重複の検索を行うサブステップと、続いて、重複の抑制を行うサブステップとを有する。重複の検索を行うサブステップは、符号ベクトルのそれぞれを辞書中の他のベクトルと比較することによって、辞書C’全体で実行される。
このステップ32の終端では、辞書C’は、辞書CITERよりも少ない符号ベクトルを含むこととなる。
【0049】
ついで、本方法は、辞書のサイズが縮小されたならば、辞書を完成させるために、修正された辞書を丸められた駆動ベクトルと統合するステップ34を有する。
このステップ34は、各駆動ベクトルを、正規格子の点上で選択された隣接ベクトルで置き換えるサブステップ36から開始される。上記隣接ベクトルは、丸め駆動ベクトルと称される。好ましくは、ステップ30と同一の格子が使用される。ついで、丸め駆動ベクトルは、出現頻度の高いものから順に整列される。好ましくは、上記整列は、重複の除去が行われた後に行われる。
【0050】
ついで、本方法は、修正された符号ベクトルの辞書C’を丸め駆動ベクトルと合成するサブステップ38を有する。このサブステップの過程では、辞書C’は、当該辞書には存在しない丸め駆動ベクトルを追加することによって完成する。好ましくは、上記追加は、丸めベクトルの出現頻度の高い順に行われる。
よって、辞書C”は、辞書の符号ベクトルを形成するセントロイド間の最小距離が保証され、抑制されて記載されるように構成される。実施例において、量子化されるパラメータは、対数目盛上に取られる。この領域の一定の間隔は、エネルギー領域での対数間隔に等しく、人の耳の感度に相当する。したがって、認識しきい値に応じて間隔pを選択することによって、本発明の方法の結果、認識しきい値を考慮した統計的ベクトル量子化の辞書を生成することが可能となる。
さらに、辞書を丸め駆動ベクトルと合成することによって、符号ベクトルのより良い分布が得られる。
【0051】
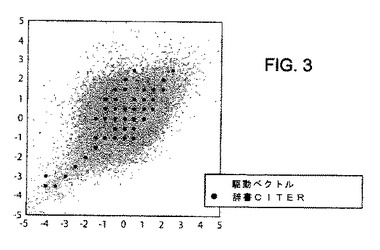
図3は、2次元上で点の集まりを形成する辞書C”を示す。上記の方法に従って取得された辞書C”が、駆動ベクトルの広い範囲をカバーするとともに、符号ベクトル2つずつの間の最小距離を有するということが、図3から読み取れる。
たとえ2つの辞書が実際には同じ数の符号ベクトルを有するとしても、図3の辞書の外見上の点の数は、図2のそれより少ない。実際には、図2及び図3は、より高次のベクトルの2次元への投射のみを示す。図3に示された辞書の符号ベクトルが正規格子上で丸められ、いくつかのベクトルは1点に省略され、それらは図2に示された場合とは異なる。
【0052】
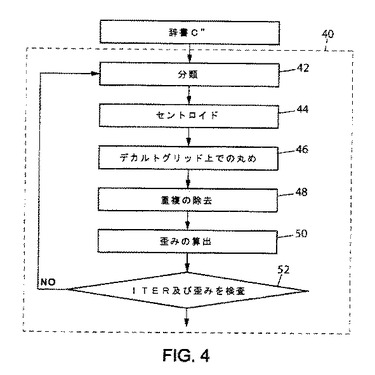
好ましくは、また、本方法は、辞書C”の最適化を行う段階40を有する。段階40を図4に示す。
最適化は、図1ないし図3に記載された方法の最後で得られた辞書C”の受け取りから開始される。
記載された実施形態において、最適化段階は、同一の処理ステップの反復を行う段階と、それらを辞書C”の符号ベクトルへ適用する段階とから成る。しかしながら、記載された最適化段階においては、各繰り返しで、分類、セントロイドの決定、符合ベクトルの修正、及び重複の除去が実行される。
よって、段階40は、辞書C”の符号ベクトルに適用される分類ステップ42から開始され、その後に、セントロイドを決定するステップ44が続く。これらのステップ42及び44は、先に記載したステップ16及び18と同一である。
次に、正規格子上での丸めによる修正ステップ46が実行される。このステップ46の後に、重複除去ステップ48が続く。最後に、最適化段階は、歪みを測定するステップ50と、歪みが許容しきい値より小さいかどうか、又は最大反復回数に到達したかどうかを判断する検査52を有する。
このような最適化段階によって、辞書の品質をさらに向上できるようになる。
【0053】
当然ながら、他の実施形態も実施可能である。
変形例において、初期辞書は、正規格子上で丸められた駆動ベクトルを取り除いて生成される。これは、初期辞書の生成が、正規格子上で選択された隣接ベクトルによる駆動ベクトルの置換と、その後の、それらの出現頻度に応じた丸め駆動ベクトルの選択的消去とを有することを意味する。
さらに別の変形例では、最適化段階は、初期辞書として以前得られた辞書を用いて、図1とまったく同じ方法の反復から成る。
別の変形例では、合成ステップが、修正された符号ベクトルと、丸められてない符号ベクトルとの間で実行される。しかしながら、このような実施形態では、使用される駆動ベクトルは、辞書の符号ベクトル間の最小距離の維持を保証するために選択される。
上記の辞書の生成方法は、任意のタイプの計算機及びコンピュータに対するプログラムを用いて実行可能である。
【0054】
図5及び図6には、本発明の方法に従って得られる辞書を使用するエンコーダ及びデコーダが記載されている。
これらのエンコーダ及びデコーダは、サブバンドで階層的オーディオエンコード及びデコードを行う総合システムの一部分であって、8、12、又は13.65kbit/sの3つの利用可能な速度で機能する。例えば、エンコーダは、常に、13.65kbit/sの最大速度で機能するのに対して、デコーダは、8kbit/sを中心として、かつ12又は13.65kbit/sでの1つ又は2つの強化層でもそれぞれ同様に、受信可能である。
【0055】
図5に示されたエンコーダ60は、入力信号を受け取る2つの経路を具備する。第1経路は、信号から0〜4000Hzの低帯域LFを抽出するために適するフィルタユニット62を具備する。第2経路は、4000〜8000Hzにかけて広がる高帯域HFを抽出するために適する同様のユニット64を具備する。これらのユニット62,64は、例えば、標準的な方法で実行されるフィルタ及びデシメーションモジュールから成る。
【0056】
ついで、エンコードユニット66において、8〜12kbit/sの組込みCELPエンコードのような標準的CELPエンコードに従って、低帯域信号が符号化される。
高帯域信号の符号化は、特にユニット70でベクトル量子化を用いて行われる。記載された実施形態において、ユニット70は、パラメトリックエンコードユニットである。パラメトリックエンコードユニットでは、符号化されたパラメータは、信号の時間及び周波数エンベロープであり、高帯域信号のサブフレーム又はサブバンドにつき2乗平均によって得られる有効値に個々に対応する。これらのエンベロープは、以下の対数領域に挿入される。
【0057】
【数3】
【0058】
ここで、σは、エンベロープの値である。
入力信号の各フレームに対し、時間及び周波数エンベロープパラメータは、パラメータ解析モジュール72,74で抽出される。ついで、対数領域のこれらのパラメータは、本発明に従って生成された辞書を用いて、ベクトル量子化モジュール76で連帯的に量子化される。
【0059】
より正確には、記載された実施形態において、パラメータは、抑制された平均を備えたデカルト積と称されるベクトル量子化によって符号化される。時間エンベロープベクトルの平均μが算出され、ついで、この平均が量子化される。量子化された平均は、記号μqで表される。ついで、時間及び周波数エンベロープベクトルは、個々に量子化及び多重化される前に、μq上で中心となる。
平均μは、均一スカラー量子化によって量子化される。その間隔p=0.99657が、認識しきい値であり、辞書を生成するために使用される正規格子の間隔となる。
デカルト積ベクトル量子化は、本発明に従って得られた辞書を用いて実行される。辞書に格納された符号ベクトルは、6dBの間隔に対応する最小距離p=0.99657を有する語である。
ついで、2つの経路HF及びLFが、マルチプレクサ80で多重化されて、エンコーダ60の出力信号が形成される。
【0060】
対応するエンコーダ100が、図6に記載される。
このデコーダは、まず、信号の低帯域及び高帯域に対応する経路へ分配を行うデマルチプレクサ102を具備する。
低帯域信号に対応する経路は、CELPデコーダ104に流れ込む。また、このCELPデコーダは、既知の方法で算出される励起パラメータを提供する。
高帯域信号に対応する経路は、デコードユニット110に流れ込み、具体的には、逆ベクトル量子化に用いられる。
【0061】
このモジュール112の出力は、一時整形モジュール116に印加される。また、このモジュール116は、CELPデコーダ104によって提供されたCELP励起パラメータに基づいてモジュール114によって生成される合成励起信号を受信する。
最後に、ユニット10は、周波数整形モジュール118を具備する。
【0062】
パラメータの符号化と同時に、逆量子化手段によって逆量子化された時間及び周波数エンベロープの逆正規化によって、復号が行われる。
最後に、2つの経路は、混合器124で互いに再合成される前に、演算モジュール120,122で処理される。
上記エンコーダ及び上記デコーダの構造及び動作は既知であり、明細書中に詳細には記載しない。詳細な説明は、非特許文献4で与えられる。
【図面の簡単な説明】
【0063】
【図1】本発明の方法のフローチャートである。
【図2】本発明の方法の一ステップでの辞書の表示である。
【図3】本発明の方法の他のステップでの辞書の表示である。
【図4】最適化された方法のフローチャートである。
【図5】本発明の方法によって得られた辞書を使用するエンコーダのブロック図である。
【図6】本発明の方法によって得られた辞書を使用するデコーダのブロック図である。
【符号の説明】
【0064】
60 エンコーダ
62,64 フィルタユニット
66 符号化ユニット
70 パラメトリック符号化ユニット
72,74 パラメータ解析モジュール
76 ベクトル量子化モジュール
80 マルチプレクサ
100 デコーダ
102 デマルチプレクサ
104 CELPデコーダ
110 復号ユニット
112 ベクトル逆量子化モジュール
114 合成励起信号生成モジュール
116 時間整形モジュール
118 周波数整形モジュール
120,122 演算モジュール
124 混合部
【技術分野】
【0001】
本発明は、音声及び映像信号、並びに、より一般的には、マルチメディア信号といった信号に対して、それらの格納又は転送を目的とした符号化及び復号を行うための量子化辞書に関する。
より正確には、本発明は、歪みしきい値の事前知識を含む非構造化統計的ベクトル量子化の問題への解決策を提案する。
【背景技術】
【0002】
信号処理、特に、デジタル信号の処理に対して広く用いられているソリューションが、ベクトル量子化(VQ)である。一般に、ベクトル量子化は、有限集合の中から選択された同一次元のベクトルによって入力ベクトルを表す。この有限集合は、再生アルファベット、辞書、又はインデックスと称され、かつその構成要素は、符号ベクトル、符号語、出力ポイント、又は代表と称される。
【0003】
ベクトル量子化において、信号のn個のサンプルのひとかたまりは、n次元のベクトルとして扱われる。ベクトルは、有限集合の中から、そのベクトルに最も「似ている(resemble)」符号ベクトルを選び出すことによって符号化される。例えば、この構成要素と入力ベクトルとの間の距離が最も小さい辞書構成要素を選択するために、辞書の構成要素のすべてにわたる全数検索が実行される。
【0004】
一般に、ベクトル量子化辞書は、符号化が行われる信号のサンプルの解析に基づいて設計されるとともに、GLA(generalized Lloyd-Max algorithm)又はLBG(for Linde, Buzo and Gray)アルゴリズムといった統計的手法を用いる駆動シーケンス又は学習シーケンスを形成する。このようなタイプのアルゴリズムが、例えば、非特許文献1に記載されている。
【0005】
駆動シーケンス及び初期辞書に基づき、辞書は繰り返し構築される。各繰り返しは、最近傍則に従って駆動シーケンスの量子化範囲を構成するための駆動ベクトルの分類ステップと、セントロイド法と称される規則に従って、以前の符号ベクトルを範囲内のセントロイドで置き換えることによる辞書の改良ステップとを有する。
【0006】
この決定的反復アルゴリズムの極小への収束を回避するために、セントロイド構成のステップ及び/又はクラス構成のステップへランダムなパートを挿入する確率緩和(SKA: Stochastic K-means algorithm)と称される変形手法が提案されている。このような修正が、例えば、非特許文献2に記載されている。
【0007】
この方法で得られる辞書又は統計的ベクトル量子化器は、特殊な構成を有しておらず、それらの調査を、計算及び記録の面で割高とする。その上、従来の統計的ベクトル量子化によって得られたこのような辞書の使用は、しばしば制限を受け、特にリアルタイムで、ベクトル毎に4ないし10ビット程度の低い次元及び/又は低いレートの符号化しか行えない。
【0008】
一般に、統計的ベクトル量子化は、処理される信号の確率分布の形状を利用する。それは、統計的ベクトル量子化の辞書の符号ベクトルの分布に再び見出せる。ベクトル量子化で使用される構造アルゴリズムは、平均歪みの最小化を目的とし、したがって、それらは、高密度の部位に多くの符号ベクトルを配置する傾向にある。符号化される信号の高密度部位でのセントロイドの集中は、必ずしも認識の観点に基づく関連性があるとは限らない。故に、高密度部位の2つの符号ベクトルは、他方に対する一方の代理によって生成された歪みがごくわずかとなる可能性が高い。
【0009】
さらに、低分解能の量子化、すなわち、わずかな符号ベクトルしか備えない場合には、この集中は、符号化される信号の確率分布の低密度部位の損失を引き起こす。このとき、上記部位は悪い状態で表される。すなわち、間違った符号化がなされる。
【0010】
大きさ及び次元の制限から解放するために、統計的ベクトル量子化のいくつかの変形手法が開発されている。特に、辞書の構造の不備を改善し、それによって、計算量を品質の損失に換えることが試みられている。しかしながら、妥協していた計算能力が改善されることによって、ベクトル量子化が効率的に適用可能な分解能の範囲及び/又は次元を増大できるようになった。抑制された(constrained)ベクトル量子化ための多くの手法が、文献に提案されており、具体的には、ツリーベクトル量子化、多段ベクトル量子化、“デカルト積”ベクトル量子化、又は特殊なデカルト積ベクトル量子化である“ゲイン/オリエンテーション”ベクトル量子化がある。
【0011】
非構造化ベクトル量子化として、抑制された方法によって得られる辞書は、互いに接近した非常に大量の符号ベクトル、具体的には、その違いが受信機には感知できない複数の符号ベクトルを常に有する。これは、最適ではない品質をもたらす。
【0012】
また、代数的ベクトル量子化と称される別の取り組みが提案されている。代数的ベクトル量子化は、正規格子(regular lattice)の点又は誤り訂正符号に比べて、高度に構造化された辞書を用いる。正規格子の一例が、立方格子であり、これは、例えば、整数座標の点集合で形成される。
【0013】
これらの辞書の代数的特性により、代数的ベクトル量子化は、容易に実行されるとともに、メモリに格納される必要が無い。これらの辞書の規則的構造の開発によって、対応する符号ベクトルにインデックスを関連付けるための、例えば、計算式による最適かつ高速な検索アルゴリズム及びメカニズムを開発できるようになった。
【0014】
代数的ベクトル量子化のために従来技術で開発された技術は、正規格子又は配列の部分集合である辞書をもたらす。
【0015】
正規格子の主要パラメータのうちの1つは、符号ベクトルが位置した2点間の最小二乗距離である。インデックス付与を容易にするために、一般に、辞書は、超立方体又は超球体のような正規多面体、又はその表面と、格子との交点として選択される。そして、この交点の外側の点が外れ値である。所与の割合、すなわち、決められた数の交点に対する外れ値の制限は、2つの符号ベクトル間の最短距離の増大をもたらす。
【0016】
代数的ベクトル量子化は、実行する計算量が少なく、かつ多くのメモリを必要としないが、一様な分布の信号を符号化するためのみにしか適さない。
【0017】
また、符号ベクトルにインデックスを付与するための演算又は番号を付与するための演算、及び復号のための逆演算は、統計的ベクトル量子化の場合よりも多くの計算を要することに留意しなければならない。統計的ベクトル量子化での演算は、テーブルから読み取るだけで実行される。
【0018】
最後に、代数的量子化と統計的量子化とを組み合わせた、さらに別のベクトル量子化がある。これは、非特許文献3に記載されたファイン−コース(fine-coarse)ベクトル量子化に該当する。この量子化は、2つの量子化を含む。第1の高分解能又は細分解能量子化は、一般に、充分に構造化され、かつ実行が複雑でない。一方、第2の粗分解能量子化は、非構造化統計的ベクトル量子化である。第1段は、事前計算のためのものであり、第2段での検索を高速化する。
【0019】
“ファイン−コース”量子化は、統計的ベクトル量子化に対して上記で示されたものと同様の欠点を有する。実際には、細分解能量子化と粗分解能量子化との間のリンクは、単なる対応テーブルである。それによって、たとえ高分解能ベクトル量子化が符号ベクトル間の最小距離を備えた正規格子の有限集合であっても、この条件は、統計的ベクトル量子化の基本的な技術によって構成される粗分解能ベクトル量子化に課せられない。
【0020】
故に、統計的ベクトル量子化は、点の分布が不適切な辞書をもたらすと考えられる。これらの点のいくつかは、受信機のレベルでは感知できないので、冗長となる。
【0021】
一方、代数的ベクトル量子化は、一様な確率分布を備えた信号に対してのみ適する分布の辞書をもたらすとともに、他の信号に対する符号化品質の低下をもたらす。
【非特許文献1】Gersho A., Gray R. M, "Vector Quantization and Signal Compression", Kluwer Academic Publishers, 1992
【非特許文献2】Kovesi, B.; Saoudi, S.; Boucher, J. M.; Reguly, Z., "A fast robust stochastic algorithm for vector quantizer design for nonstationary channels", IEEE International Conference on Acoustics, Speech, and Signal Processing, Vol. 1, pp. 269-272, 1995
【非特許文献3】Moayeri, N., Neuhoff D. L.; Stark, W. E., "Fine-coarse vector quantization", IEEE Trans. on Information Theory, Vol. 37, Issue 4, pp. 1503-1515, July 1991
【非特許文献4】UIT-T, COM 16, D214(WP 3/16), "High level description of the scalable 8-32 kbit/s algorithm submitted to the Qualification Test by Matsushita, Mindspeed and Siemens," Q.10/16, Study Period 2005-2008, Geneva, 26 July - 5 August 2005 (Source: Siemens)
【発明の開示】
【発明が解決しようとする課題】
【0022】
本発明は、符号化が行われる信号に適し、かつ認識しきい値を考慮に入れた統計的ベクトル量子化による辞書取得の適切な方法を定義する格別な利点を有する。
【課題を解決するための手段】
【0023】
この目的に対して、本発明の要旨は、信号に対するベクトル量子化辞書の生成方法を提供することにあり、本方法は、信号を表す複数の駆動ベクトルの統計解析を行って、上記複数の駆動ベクトルを代表する符号ベクトルの有限集合を決定する段階から成る方式の方法であって、修正された符号ベクトル2つずつの間の距離が最小となるように、上記符号ベクトル有限集合の修正を行う段階をさらに有する。上記複数の修正された符号ベクトルが上記辞書を形成する。
故に、本発明は、複数の駆動ベクトルの統計解析を行う段階により、符号ベクトル間の距離が最小となるため、信号に適した辞書をもたらし、それによって、非常に接近した符号ベクトル同士は認識のレベルでは区別が付かないということを考慮できるようになる。
【0024】
本発明の他の特徴により、統計解析を行う段階は、初期辞書を生成する副段階と、量子化範囲を形成するために、初期辞書に基づいて複数の駆動ベクトルを分類する副段階と、範囲毎のセントロイドを決定する副段階とを有する。上記セントロイドが、上記符号ベクトルとなる。このような実施態様は、統計解析の特殊な実行に対応する。
好ましくは、上記初期辞書を生成する副段階は、上記複数の駆動ベクトルに基づいて実行されるとともに、正規格子の点上で選択された丸めベクトルによる各駆動ベクトルの置換と、それらの出現頻度に応じた丸めベクトルの選択的除去とを含む。
【0025】
本発明の特殊な実施態様において、統計解析を行う段階は、初期辞書の歪みを算出する副段階と、この歪みを許容しきい値と比較する副段階とをさらに有する。上記比較の結果が不一致である場合、上記統計解析を行う段階が繰り返される。このような反復手法によって、より良い品質の初期辞書を得ることができるようになる。
【0026】
変形例において、修正を行う段階は、正規格子の点上で選択された隣接符号ベクトルによって、上記複数の符号ベクトルのそれぞれを置き換えること含む。このような一実施態様によって、符号ベクトル間の最小距離を確保できるようになる。
【0027】
好ましくは、本方法は、上記複数の修正された符号ベクトル中の重複の除去を行う段階をさらに有する。その結果、辞書のサイズが小さくなる。
特殊な実施態様において、重複の除去を行う段階は、複数の修正された符号ベクトルを互いに比較することによって、重複の検索を行う副段階と、重複の削除を行う副段階とを有する。
【0028】
好ましくは、本方法は、辞書の複数の駆動ベクトルの分布を改善するように、複数の修正された符号ベクトルを、少なくとも互いに上記最小距離を有する複数の駆動ベクトルと統合する段階を有する。
特殊な実施態様において、この統合を行う段階は、正規格子の点上で選択された丸めベクトルによって、各駆動ベクトルの置換を行う副段階と、複数の修正された符号ベクトルと複数の丸め駆動ベクトルとを合成する副段階とを有する。故にまた、複数の修正された符号ベクトルと合成された丸め駆動ベクトルの2つずつは、最小距離を有する。
【0029】
別の変形例において、上記統合を行う段階は、それらの出現頻度に従って複数の丸め駆動ベクトルの整列を行うことと、上記複数の丸め駆動ベクトルを複数の修正された符号ベクトルと合成するために、上記複数の丸めベクトルの有限数の選択を行なうこととをさらに含む。
一実施態様において、上記合成を行う副段階は、有限数の丸め駆動ベクトルを上記複数の修正された符号ベクトルに追加することを含む。上記有限数の丸め駆動ベクトルは、上記複数の修正された符号ベクトルとは異なるものである。
【0030】
変形例において、正規格子の点は、上記信号の送信先である受信機の感度レベルに対応した間隔を有する。それによって、実際の認識に対応して、2つの符号ベクトル間の距離を最小化できるようになる。
【0031】
別の実施態様において、本方法は、上記辞書の最適化を行う段階をさらに有する。
例えば、最適化を行う段階は、辞書の歪みを算出する段階と、この歪みを許容しきい値と比較する段階とを有する。上記比較の結果が不一致である場合、上記統計解析を行う段階及び修正を行う段階が繰り返される。
あるいは、最適化を行う段階は、上記複数の修正された符号ベクトルから形成された辞書に基づいて実行される方法の少なくとも1回の繰り返しを含む。
【0032】
本発明の別の目的は、上記の方法を実行する命令コードを具備するコンピュータプログラムと、このコンピュータプログラムを実行するための、例えば、ワークメモリ、プロセッサなどの手段からなるデバイスと、を提供することにある。それによって、本発明の手法に含まれるベクトル量子化辞書を生成する。
また、この発明は、符号化及び復号の方法、並びに本発明に従って得られた辞書を使用するデコーダを対象とする。
【発明を実施するための最良の形態】
【0033】
本発明は、限定を目的としない実施形態として与えられた以下の記載に照らし、かつ添付の図面の参照によって、一層の理解を得られる。
【0034】
これより、図1を参照して、本発明によるベクトル量子化辞書の取得方法を記載する。
記載された実施形態において、この方法は、音声信号などのデジタルオーディオ信号を表す複数の駆動ベクトルに対して実行される。
【0035】
この方法は、最初に、駆動ベクトルの統計解析を行うステップ10を有する。記載された実施形態において、ステップ10は、GLAの適用に相当する。
ステップ10は、C0で示される初期辞書を生成するサブステップ12から開始される。この辞書は、駆動ベクトルの解析に基づいて生成されるか、又は他の既知の手段、例えば、駆動ベクトルの有限数のランダム選択、又は「分割(splitting)」LBGアルゴリズムと称されるアルゴリズムなどによって生成される。この初期辞書C0は、決められたサイズの辞書である。
【0036】
記載された実施形態において、本方法は、次に、現在の変数を初期化するサブステップ14を有する。具体的には、サブステップ14は、反復回数に相当する変数ITERと、歪み値に相当する変数DITERとの初期化を行う。
【0037】
ついで、ステップ10は、分類範囲を形成するために、初期辞書C0に関連する駆動ベクトルの分類を行うサブステップ16と、範囲毎のセントロイドを決定するサブステップ18とを有する。
より正確には、分類を行うサブステップ16において、駆動ベクトル毎に現在の辞書全体が走査される。すなわち、辞書C0が連続的な反復によって修正されて、駆動ベクトルとの二乗誤差を最小化する符号ベクトルが辞書から選択される。
【0038】
サブステップ18は、以下のように表される。クラス又は範囲Vi毎に、新しいセントロイドが算出される。
Viは、Q(xj)=yiとなる駆動ベクトルxjの集合として定義される。ここで、Q()は、量子化関数であり、yiは、辞書の符号ベクトルである。
NiをViのベクトルの数とし、Vi(j,k)をViのj番目のベクトルのk番目の要素とする。
セントロイドyiのk番目の要素が、以下の式で示される。
【0039】
【数1】
【0040】
サブステップ20において、現在の辞書に対する歪み値が算出される。
このサブステップ20では、駆動ベクトルは、上記のステップによって与えられた現在の辞書を用いて量子化される。駆動ベクトルとそれらの量子化バージョンとの間の二乗誤差は、歪み寸法を形成する。
【0041】
そして、サブステップ16、18、及び20は、最大反復回数ITERMAXに達するまで、又は歪みが許容しきい値より小さくなるまで、繰り返し実行される。この検査は、サブステップ22で実行される。
【0042】
上記で示されたように、実施例において、このステップ10、具体的には、サブステップ16、18、20、及び22の繰り返しは、GLAの適用に相当する。
よって、ステップ10の終端で、本方法は、駆動ベクトルの反復統計解析によって形成された辞書CITERを生成する。
【0043】
辞書CITERの2つの次元での表示が図2に示されている。ここで、符号ベクトルは、点の集まりによって表される。この表示において、灰色の点は、駆動ベクトル又は信号ベクトルに対応し、黒い点は、辞書のベクトルに対応する。辞書CITERのベクトルの歪みが駆動ベクトルの密度に従い、かつ多数のベクトルが互いに近接していることが見て取れる。
【0044】
ついで、本方法は、符号ベクトル2つずつの間の距離を最小化するために、辞書CITERの修正を行うステップ30を有する。
この修正ステップ30は、符号ベクトルのそれぞれを、デカルトグリッドのような正規格子の点上で選択された隣接ベクトルで置き換えることを含む。これらの修正されたベクトルは、丸め(rounded)ベクトルとも称される。記載された実施形態において、選択された隣接ベクトルは、符号ベクトルに最も近い正規格子上に位置するベクトルである。実施の形態及びベクトルのタイプに応じて、ベクトル間の距離以外の基準が、符号ベクトルの隣接ベクトルを決定するために使用されてよい。
【0045】
よって、ステップ30は、ステップ10で得られた辞書CITERを正規格子上で丸めることによって得られる新しい辞書C’を提供する。
正規格子上の符号語の丸めは、pを格子の間隔と置き、以下のように実行される。
【0046】
【数2】
【0047】
ここで、i=1...Mであり、k=1...nであり、かつ[.]は最も近い値の整数に丸めることを示す。
【0048】
ついで、本方法は、辞書C’を形成する修正された符号ベクトルから重複の除去を行うステップ32を有する。
ステップ32は、重複の検索を行うサブステップと、続いて、重複の抑制を行うサブステップとを有する。重複の検索を行うサブステップは、符号ベクトルのそれぞれを辞書中の他のベクトルと比較することによって、辞書C’全体で実行される。
このステップ32の終端では、辞書C’は、辞書CITERよりも少ない符号ベクトルを含むこととなる。
【0049】
ついで、本方法は、辞書のサイズが縮小されたならば、辞書を完成させるために、修正された辞書を丸められた駆動ベクトルと統合するステップ34を有する。
このステップ34は、各駆動ベクトルを、正規格子の点上で選択された隣接ベクトルで置き換えるサブステップ36から開始される。上記隣接ベクトルは、丸め駆動ベクトルと称される。好ましくは、ステップ30と同一の格子が使用される。ついで、丸め駆動ベクトルは、出現頻度の高いものから順に整列される。好ましくは、上記整列は、重複の除去が行われた後に行われる。
【0050】
ついで、本方法は、修正された符号ベクトルの辞書C’を丸め駆動ベクトルと合成するサブステップ38を有する。このサブステップの過程では、辞書C’は、当該辞書には存在しない丸め駆動ベクトルを追加することによって完成する。好ましくは、上記追加は、丸めベクトルの出現頻度の高い順に行われる。
よって、辞書C”は、辞書の符号ベクトルを形成するセントロイド間の最小距離が保証され、抑制されて記載されるように構成される。実施例において、量子化されるパラメータは、対数目盛上に取られる。この領域の一定の間隔は、エネルギー領域での対数間隔に等しく、人の耳の感度に相当する。したがって、認識しきい値に応じて間隔pを選択することによって、本発明の方法の結果、認識しきい値を考慮した統計的ベクトル量子化の辞書を生成することが可能となる。
さらに、辞書を丸め駆動ベクトルと合成することによって、符号ベクトルのより良い分布が得られる。
【0051】
図3は、2次元上で点の集まりを形成する辞書C”を示す。上記の方法に従って取得された辞書C”が、駆動ベクトルの広い範囲をカバーするとともに、符号ベクトル2つずつの間の最小距離を有するということが、図3から読み取れる。
たとえ2つの辞書が実際には同じ数の符号ベクトルを有するとしても、図3の辞書の外見上の点の数は、図2のそれより少ない。実際には、図2及び図3は、より高次のベクトルの2次元への投射のみを示す。図3に示された辞書の符号ベクトルが正規格子上で丸められ、いくつかのベクトルは1点に省略され、それらは図2に示された場合とは異なる。
【0052】
好ましくは、また、本方法は、辞書C”の最適化を行う段階40を有する。段階40を図4に示す。
最適化は、図1ないし図3に記載された方法の最後で得られた辞書C”の受け取りから開始される。
記載された実施形態において、最適化段階は、同一の処理ステップの反復を行う段階と、それらを辞書C”の符号ベクトルへ適用する段階とから成る。しかしながら、記載された最適化段階においては、各繰り返しで、分類、セントロイドの決定、符合ベクトルの修正、及び重複の除去が実行される。
よって、段階40は、辞書C”の符号ベクトルに適用される分類ステップ42から開始され、その後に、セントロイドを決定するステップ44が続く。これらのステップ42及び44は、先に記載したステップ16及び18と同一である。
次に、正規格子上での丸めによる修正ステップ46が実行される。このステップ46の後に、重複除去ステップ48が続く。最後に、最適化段階は、歪みを測定するステップ50と、歪みが許容しきい値より小さいかどうか、又は最大反復回数に到達したかどうかを判断する検査52を有する。
このような最適化段階によって、辞書の品質をさらに向上できるようになる。
【0053】
当然ながら、他の実施形態も実施可能である。
変形例において、初期辞書は、正規格子上で丸められた駆動ベクトルを取り除いて生成される。これは、初期辞書の生成が、正規格子上で選択された隣接ベクトルによる駆動ベクトルの置換と、その後の、それらの出現頻度に応じた丸め駆動ベクトルの選択的消去とを有することを意味する。
さらに別の変形例では、最適化段階は、初期辞書として以前得られた辞書を用いて、図1とまったく同じ方法の反復から成る。
別の変形例では、合成ステップが、修正された符号ベクトルと、丸められてない符号ベクトルとの間で実行される。しかしながら、このような実施形態では、使用される駆動ベクトルは、辞書の符号ベクトル間の最小距離の維持を保証するために選択される。
上記の辞書の生成方法は、任意のタイプの計算機及びコンピュータに対するプログラムを用いて実行可能である。
【0054】
図5及び図6には、本発明の方法に従って得られる辞書を使用するエンコーダ及びデコーダが記載されている。
これらのエンコーダ及びデコーダは、サブバンドで階層的オーディオエンコード及びデコードを行う総合システムの一部分であって、8、12、又は13.65kbit/sの3つの利用可能な速度で機能する。例えば、エンコーダは、常に、13.65kbit/sの最大速度で機能するのに対して、デコーダは、8kbit/sを中心として、かつ12又は13.65kbit/sでの1つ又は2つの強化層でもそれぞれ同様に、受信可能である。
【0055】
図5に示されたエンコーダ60は、入力信号を受け取る2つの経路を具備する。第1経路は、信号から0〜4000Hzの低帯域LFを抽出するために適するフィルタユニット62を具備する。第2経路は、4000〜8000Hzにかけて広がる高帯域HFを抽出するために適する同様のユニット64を具備する。これらのユニット62,64は、例えば、標準的な方法で実行されるフィルタ及びデシメーションモジュールから成る。
【0056】
ついで、エンコードユニット66において、8〜12kbit/sの組込みCELPエンコードのような標準的CELPエンコードに従って、低帯域信号が符号化される。
高帯域信号の符号化は、特にユニット70でベクトル量子化を用いて行われる。記載された実施形態において、ユニット70は、パラメトリックエンコードユニットである。パラメトリックエンコードユニットでは、符号化されたパラメータは、信号の時間及び周波数エンベロープであり、高帯域信号のサブフレーム又はサブバンドにつき2乗平均によって得られる有効値に個々に対応する。これらのエンベロープは、以下の対数領域に挿入される。
【0057】
【数3】
【0058】
ここで、σは、エンベロープの値である。
入力信号の各フレームに対し、時間及び周波数エンベロープパラメータは、パラメータ解析モジュール72,74で抽出される。ついで、対数領域のこれらのパラメータは、本発明に従って生成された辞書を用いて、ベクトル量子化モジュール76で連帯的に量子化される。
【0059】
より正確には、記載された実施形態において、パラメータは、抑制された平均を備えたデカルト積と称されるベクトル量子化によって符号化される。時間エンベロープベクトルの平均μが算出され、ついで、この平均が量子化される。量子化された平均は、記号μqで表される。ついで、時間及び周波数エンベロープベクトルは、個々に量子化及び多重化される前に、μq上で中心となる。
平均μは、均一スカラー量子化によって量子化される。その間隔p=0.99657が、認識しきい値であり、辞書を生成するために使用される正規格子の間隔となる。
デカルト積ベクトル量子化は、本発明に従って得られた辞書を用いて実行される。辞書に格納された符号ベクトルは、6dBの間隔に対応する最小距離p=0.99657を有する語である。
ついで、2つの経路HF及びLFが、マルチプレクサ80で多重化されて、エンコーダ60の出力信号が形成される。
【0060】
対応するエンコーダ100が、図6に記載される。
このデコーダは、まず、信号の低帯域及び高帯域に対応する経路へ分配を行うデマルチプレクサ102を具備する。
低帯域信号に対応する経路は、CELPデコーダ104に流れ込む。また、このCELPデコーダは、既知の方法で算出される励起パラメータを提供する。
高帯域信号に対応する経路は、デコードユニット110に流れ込み、具体的には、逆ベクトル量子化に用いられる。
【0061】
このモジュール112の出力は、一時整形モジュール116に印加される。また、このモジュール116は、CELPデコーダ104によって提供されたCELP励起パラメータに基づいてモジュール114によって生成される合成励起信号を受信する。
最後に、ユニット10は、周波数整形モジュール118を具備する。
【0062】
パラメータの符号化と同時に、逆量子化手段によって逆量子化された時間及び周波数エンベロープの逆正規化によって、復号が行われる。
最後に、2つの経路は、混合器124で互いに再合成される前に、演算モジュール120,122で処理される。
上記エンコーダ及び上記デコーダの構造及び動作は既知であり、明細書中に詳細には記載しない。詳細な説明は、非特許文献4で与えられる。
【図面の簡単な説明】
【0063】
【図1】本発明の方法のフローチャートである。
【図2】本発明の方法の一ステップでの辞書の表示である。
【図3】本発明の方法の他のステップでの辞書の表示である。
【図4】最適化された方法のフローチャートである。
【図5】本発明の方法によって得られた辞書を使用するエンコーダのブロック図である。
【図6】本発明の方法によって得られた辞書を使用するデコーダのブロック図である。
【符号の説明】
【0064】
60 エンコーダ
62,64 フィルタユニット
66 符号化ユニット
70 パラメトリック符号化ユニット
72,74 パラメータ解析モジュール
76 ベクトル量子化モジュール
80 マルチプレクサ
100 デコーダ
102 デマルチプレクサ
104 CELPデコーダ
110 復号ユニット
112 ベクトル逆量子化モジュール
114 合成励起信号生成モジュール
116 時間整形モジュール
118 周波数整形モジュール
120,122 演算モジュール
124 混合部
【特許請求の範囲】
【請求項1】
信号を表す複数の駆動ベクトルの統計解析を行って、前記複数の駆動ベクトルを代表する符号ベクトルの有限集合を決定する段階から成る方式による、信号に対するベクトル量子化辞書の生成方法であって、
2つの修正された符号ベクトル間の距離が最小となるように、前記符号ベクトル有限集合の修正を行う段階をさらに有し、
前記複数の修正された符号ベクトルが前記辞書を形成することを特徴とする方法。
【請求項2】
前記統計解析を行う段階が、
初期辞書を生成する副段階と、
量子化範囲を形成するために、初期辞書に基づいて前記複数の駆動ベクトルを分類する副段階と、
範囲毎のセントロイドを決定する副段階と
を有し、
前記セントロイドが前記符号ベクトルとなることを特徴とする請求項1に記載の方法。
【請求項3】
前記初期辞書を生成する副段階が、前記複数の駆動ベクトルに基づいて実行されるとともに、正規格子の点上で選択された丸めベクトルによる各駆動ベクトルの置換と、出現頻度に応じた丸めベクトルの選択的除去とを含むことを特徴とする請求項2に記載の方法。
【請求項4】
前記統計解析を行う段階が、
初期辞書の歪みを算出する副段階と、
前記歪みを許容しきい値と比較する副段階と
をさらに有し、
前記比較の結果が不一致である場合、前記統計解析を行う段階が繰り返されることを特徴とする請求項1ないし3のいずれか1項に記載の方法。
【請求項5】
前記修正を行う段階が、正規格子の点上で選択された隣接符号ベクトルによって、有限集合の前記複数の符号ベクトルのそれぞれを置き換えること含むことを特徴とする請求項1ないし4のいずれか1項に記載の方法。
【請求項6】
前記複数の修正された符号ベクトル中の重複の除去を行う段階をさらに有することを特徴とする請求項1ないし5のいずれか1項に記載の方法。
【請求項7】
前記重複の除去を行う段階が、
前記複数の修正された符号ベクトルを互いに比較することによって、重複の検索を行う副段階と、
出現頻度に応じた重複の削除を行う副段階と
を有することを特徴とする請求項6に記載の方法。
【請求項8】
複数の修正された符号ベクトルを、少なくとも互いに前記最小距離を有する複数の駆動ベクトルと統合する段階をさらに有することを特徴とする請求項1ないし7のいずれか1項に記載の方法。
【請求項9】
前記統合を行う段階が、
正規格子の点上で選択された丸めベクトルによって、各駆動ベクトルの置換を行う副段階と、
複数の修正された符号ベクトルと複数の丸め駆動ベクトルとを合成する副段階と
を有することを特徴とする請求項8に記載の方法。
【請求項10】
前記統合を行う段階が、
出現頻度に従って複数の丸め駆動ベクトルの整列を行うことと、
前記複数の丸め駆動ベクトルを複数の修正された符号ベクトルと合成するために、前記複数の丸めベクトルの有限数の選択を行なうことと
をさらに含むことを特徴とする請求項9に記載の方法。
【請求項11】
前記合成を行う副段階が、有限数の丸め駆動ベクトルを前記複数の修正された符号ベクトルに追加することを含み、
前記有限数の丸め駆動ベクトルは前記複数の修正された符号ベクトルとは異なることを特徴とする請求項9又は10に記載の方法。
【請求項12】
前記正規格子の点が、前記信号の送信先である受信機の感度レベルに対応した間隔を有することを特徴とする請求項3、5、又は9のいずれか1項に記載の方法。
【請求項13】
前記複数の修正された符号ベクトルから形成された前記辞書の最適化を行う段階をさらに有することを特徴とする請求項1ないし12のいずれか1項に記載の方法。
【請求項14】
前記最適化を行う段階が、
辞書の歪みを算出する段階と、
前記歪みを許容しきい値と比較する段階と
を有し、
前記比較の結果が不一致である場合、前記統計解析を行う段階及び前記修正を行う段階が繰り返されることを特徴とする請求項13に記載の方法。
【請求項15】
前記最適化を行う段階が、前記複数の修正された符号ベクトルから形成された辞書に基づいて実行される方法の少なくとも1回の繰り返しを含むことを特徴とする請求項13に記載の方法。
【請求項16】
信号を表す複数の駆動ベクトルを代表する複数の符号ベクトルから成るベクトル量子化辞書であって、
請求項1ないし15のいずれか1項に記載の方法によって得られることを特徴とするベクトル量子化辞書。
【請求項17】
信号のベクトル量子化辞書を生成するためのコンピュータプログラムであって、
コンピュータ上で実行されたとき、請求項1ないし15のいずれか1項に記載の方法を実行するための命令コードを有することを特徴とするコンピュータプログラム。
【請求項18】
ベクトル量子化辞書を生成するためのデバイスであって、請求項17に記載のコンピュータプログラムを実行する手段を具備することを特徴とするデバイス。
【請求項19】
信号から複数の代表パラメータを得るために前記信号の解析を行う少なくとも1つの段階から成る、信号の符号化方法であって、
前記複数の代表パラメータのうちの少なくとも1つが、請求項1ないし15のいずれか1項に記載の方法によって生成された辞書を用いたベクトル量子化によって符号化されることを特徴とする方法。
【請求項20】
信号から複数の代表パラメータを得るために前記信号の解析を行う手段を少なくとも具備する信号エンコーダであって、
請求項1ないし15のいずれか1項に記載の方法によって生成された辞書を用いたベクトル量子化によって、前記複数の代表パラメータのうちの少なくとも1つの符号化を行う手段をさらに具備することを特徴とする信号エンコーダ。
【請求項21】
前記信号の複数の代表パラメータを処理する少なくとも1つの段階から成る、信号の復号方法であって、
前記複数の代表パラメータのうちの少なくとも1つが、請求項1ないし15のいずれか1項に記載の方法によって生成された辞書を用いたベクトル逆量子化によって復号されることを特徴とする方法。
【請求項22】
前記信号の複数の代表パラメータを処理する手段を少なくとも具備する信号デコーダであって、
請求項1ないし15のいずれか1項に記載の方法によって生成された辞書を用いたベクトル逆量子化によって、前記複数の代表パラメータのうちの少なくとも1つの復号を行う手段をさらに具備することを特徴とする信号デコーダ。
【請求項1】
信号を表す複数の駆動ベクトルの統計解析を行って、前記複数の駆動ベクトルを代表する符号ベクトルの有限集合を決定する段階から成る方式による、信号に対するベクトル量子化辞書の生成方法であって、
2つの修正された符号ベクトル間の距離が最小となるように、前記符号ベクトル有限集合の修正を行う段階をさらに有し、
前記複数の修正された符号ベクトルが前記辞書を形成することを特徴とする方法。
【請求項2】
前記統計解析を行う段階が、
初期辞書を生成する副段階と、
量子化範囲を形成するために、初期辞書に基づいて前記複数の駆動ベクトルを分類する副段階と、
範囲毎のセントロイドを決定する副段階と
を有し、
前記セントロイドが前記符号ベクトルとなることを特徴とする請求項1に記載の方法。
【請求項3】
前記初期辞書を生成する副段階が、前記複数の駆動ベクトルに基づいて実行されるとともに、正規格子の点上で選択された丸めベクトルによる各駆動ベクトルの置換と、出現頻度に応じた丸めベクトルの選択的除去とを含むことを特徴とする請求項2に記載の方法。
【請求項4】
前記統計解析を行う段階が、
初期辞書の歪みを算出する副段階と、
前記歪みを許容しきい値と比較する副段階と
をさらに有し、
前記比較の結果が不一致である場合、前記統計解析を行う段階が繰り返されることを特徴とする請求項1ないし3のいずれか1項に記載の方法。
【請求項5】
前記修正を行う段階が、正規格子の点上で選択された隣接符号ベクトルによって、有限集合の前記複数の符号ベクトルのそれぞれを置き換えること含むことを特徴とする請求項1ないし4のいずれか1項に記載の方法。
【請求項6】
前記複数の修正された符号ベクトル中の重複の除去を行う段階をさらに有することを特徴とする請求項1ないし5のいずれか1項に記載の方法。
【請求項7】
前記重複の除去を行う段階が、
前記複数の修正された符号ベクトルを互いに比較することによって、重複の検索を行う副段階と、
出現頻度に応じた重複の削除を行う副段階と
を有することを特徴とする請求項6に記載の方法。
【請求項8】
複数の修正された符号ベクトルを、少なくとも互いに前記最小距離を有する複数の駆動ベクトルと統合する段階をさらに有することを特徴とする請求項1ないし7のいずれか1項に記載の方法。
【請求項9】
前記統合を行う段階が、
正規格子の点上で選択された丸めベクトルによって、各駆動ベクトルの置換を行う副段階と、
複数の修正された符号ベクトルと複数の丸め駆動ベクトルとを合成する副段階と
を有することを特徴とする請求項8に記載の方法。
【請求項10】
前記統合を行う段階が、
出現頻度に従って複数の丸め駆動ベクトルの整列を行うことと、
前記複数の丸め駆動ベクトルを複数の修正された符号ベクトルと合成するために、前記複数の丸めベクトルの有限数の選択を行なうことと
をさらに含むことを特徴とする請求項9に記載の方法。
【請求項11】
前記合成を行う副段階が、有限数の丸め駆動ベクトルを前記複数の修正された符号ベクトルに追加することを含み、
前記有限数の丸め駆動ベクトルは前記複数の修正された符号ベクトルとは異なることを特徴とする請求項9又は10に記載の方法。
【請求項12】
前記正規格子の点が、前記信号の送信先である受信機の感度レベルに対応した間隔を有することを特徴とする請求項3、5、又は9のいずれか1項に記載の方法。
【請求項13】
前記複数の修正された符号ベクトルから形成された前記辞書の最適化を行う段階をさらに有することを特徴とする請求項1ないし12のいずれか1項に記載の方法。
【請求項14】
前記最適化を行う段階が、
辞書の歪みを算出する段階と、
前記歪みを許容しきい値と比較する段階と
を有し、
前記比較の結果が不一致である場合、前記統計解析を行う段階及び前記修正を行う段階が繰り返されることを特徴とする請求項13に記載の方法。
【請求項15】
前記最適化を行う段階が、前記複数の修正された符号ベクトルから形成された辞書に基づいて実行される方法の少なくとも1回の繰り返しを含むことを特徴とする請求項13に記載の方法。
【請求項16】
信号を表す複数の駆動ベクトルを代表する複数の符号ベクトルから成るベクトル量子化辞書であって、
請求項1ないし15のいずれか1項に記載の方法によって得られることを特徴とするベクトル量子化辞書。
【請求項17】
信号のベクトル量子化辞書を生成するためのコンピュータプログラムであって、
コンピュータ上で実行されたとき、請求項1ないし15のいずれか1項に記載の方法を実行するための命令コードを有することを特徴とするコンピュータプログラム。
【請求項18】
ベクトル量子化辞書を生成するためのデバイスであって、請求項17に記載のコンピュータプログラムを実行する手段を具備することを特徴とするデバイス。
【請求項19】
信号から複数の代表パラメータを得るために前記信号の解析を行う少なくとも1つの段階から成る、信号の符号化方法であって、
前記複数の代表パラメータのうちの少なくとも1つが、請求項1ないし15のいずれか1項に記載の方法によって生成された辞書を用いたベクトル量子化によって符号化されることを特徴とする方法。
【請求項20】
信号から複数の代表パラメータを得るために前記信号の解析を行う手段を少なくとも具備する信号エンコーダであって、
請求項1ないし15のいずれか1項に記載の方法によって生成された辞書を用いたベクトル量子化によって、前記複数の代表パラメータのうちの少なくとも1つの符号化を行う手段をさらに具備することを特徴とする信号エンコーダ。
【請求項21】
前記信号の複数の代表パラメータを処理する少なくとも1つの段階から成る、信号の復号方法であって、
前記複数の代表パラメータのうちの少なくとも1つが、請求項1ないし15のいずれか1項に記載の方法によって生成された辞書を用いたベクトル逆量子化によって復号されることを特徴とする方法。
【請求項22】
前記信号の複数の代表パラメータを処理する手段を少なくとも具備する信号デコーダであって、
請求項1ないし15のいずれか1項に記載の方法によって生成された辞書を用いたベクトル逆量子化によって、前記複数の代表パラメータのうちの少なくとも1つの復号を行う手段をさらに具備することを特徴とする信号デコーダ。
【図1】


【図2】
【図3】
【図4】
【図5】

【図6】

【図2】
【図3】
【図4】
【図5】
【図6】
【公表番号】特表2009−530940(P2009−530940A)
【公表日】平成21年8月27日(2009.8.27)
【国際特許分類】
【出願番号】特願2009−500891(P2009−500891)
【出願日】平成19年3月9日(2007.3.9)
【国際出願番号】PCT/FR2007/050908
【国際公開番号】WO2007/107659
【国際公開日】平成19年9月27日(2007.9.27)
【出願人】(591034154)フランス テレコム (290)
【Fターム(参考)】
【公表日】平成21年8月27日(2009.8.27)
【国際特許分類】
【出願日】平成19年3月9日(2007.3.9)
【国際出願番号】PCT/FR2007/050908
【国際公開番号】WO2007/107659
【国際公開日】平成19年9月27日(2007.9.27)
【出願人】(591034154)フランス テレコム (290)
【Fターム(参考)】
[ Back to top ]