
拾い読み支援システム、拾い読み支援方法及びプログラム
【課題】多数の文書の拾い読みを支援すること。
【解決手段】実施形態によれば、文書記憶部、表示部、入力部、分類情報記憶部、抽出部、特定部を含む。文書記憶部は、複数の文書を識別情報とともに記憶する。ユーザは、表示部の文書を閲覧し、文書と付与する分類タイプを入力部から指示する。分類情報記憶部は、ユーザ指示された文書の分類タイプを記憶する。抽出部は、同一の分類タイプが対応付けられている1又は複数の前記文書から、当該分類タイプについてハイライト表示すべき1又は複数の単語又はフレーズを抽出する。特定部は、ユーザから分類タイプが付与されていない文書の各々について、当該文書中で上記単語又はフレーズをハイライト表示すべき箇所を特定する。表示部は、文書を表示するにあたって、上記箇所で上記単語又はフレーズをハイライト表示する。
【解決手段】実施形態によれば、文書記憶部、表示部、入力部、分類情報記憶部、抽出部、特定部を含む。文書記憶部は、複数の文書を識別情報とともに記憶する。ユーザは、表示部の文書を閲覧し、文書と付与する分類タイプを入力部から指示する。分類情報記憶部は、ユーザ指示された文書の分類タイプを記憶する。抽出部は、同一の分類タイプが対応付けられている1又は複数の前記文書から、当該分類タイプについてハイライト表示すべき1又は複数の単語又はフレーズを抽出する。特定部は、ユーザから分類タイプが付与されていない文書の各々について、当該文書中で上記単語又はフレーズをハイライト表示すべき箇所を特定する。表示部は、文書を表示するにあたって、上記箇所で上記単語又はフレーズをハイライト表示する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明の実施形態は、多数の文書の拾い読みを支援するための拾い読み支援システム、方法及びプログラムに関する。
【背景技術】
【0002】
コンピュータが広く浸透し、通信速度・処理速度などの高速化、ハードディスク・メモリの大容量化などハードウェアの進化とともに、文書の電子化が進み、日常的に大量の情報を扱うことが多くなった。一般ユーザにとっては、情報検索など様々なソフトウェアの技術革新とともに、大量の情報から知りたい情報を利用するための支援を受けられるようになってきた。
【0003】
しかし、例えば特許調査・文献調査・市場調査のように漏れなく網羅的に内容を調査しなければならないビジネスシーンなどでは、大量文書にユーザ自身が目を通す必要があり、検索や分類などの機械的処理で高精度に読むべき文書を少量に減らすことは難しい。また、時間的な制約があることが一般的で、通常は人手で或いは無意識的に、精読すべき箇所を選別するなどの拾い読みを行っている。あるいは、多数の文書を複数人で分担できるように、精読する前処理として、各人の専門分野などを元に拾い読みによって割り振りを行うなどを行っている。
【先行技術文献】
【特許文献】
【0004】
【特許文献1】特開2008−171164号公報
【発明の概要】
【発明が解決しようとする課題】
【0005】
多数の文書の拾い読みを支援する技術は知られていなかった。
【0006】
本実施形態は、多数の文書の拾い読みを支援することの可能な拾い読み支援システム、拾い読み支援方法及びプログラムを提供することを目的とする。
【課題を解決するための手段】
【0007】
実施形態によれば、文書記憶部と、表示部と、入力部と、分類情報記憶部と、抽出部と、特定部とを備える。文書記憶部は、識別情報が対応付けられた複数の文書を記憶する。表示部は、前記複数の文書のうちの全部又は一部を、単語又はフレーズのハイライト表示を伴って又はハイライト表示を伴わずに表示する。入力部は、表示された前記文書のうちの特定の文書の指示及び予め定められた複数種類の分類タイプのうちから当該特定の文書に付与する特定の分類タイプの指示をユーザから入力する。分類情報記憶部は、前記識別情報と前記特定の分類タイプとを対応付けた分類情報を記憶する。抽出部は、同一の分類タイプが対応付けられている1又は複数の前記文書から、当該分類タイプについてハイライト表示すべき1又は複数の単語又はフレーズを抽出する。特定部は、前記文書の全部又は一部の各々について、前記抽出部により抽出された各々の単語又はフレーズが当該文書中に存在する場合に当該文書中でハイライト表示すべき箇所を特定する。
【図面の簡単な説明】
【0008】
【図1】第1の実施形態に係る拾い読み支援システムの機能構成例を示す図。
【図2】文書データ記憶部に記憶される文書データの一例を示す図。
【図3】分類情報記憶部に記憶される文書分類情報(初期状態)の一例を示す図。
【図4】拾い読み単語抽出部により作成されるスコア付けされた単語リスト(初期状態)の一例を示す図。
【図5】拾い読み支援システムのシステム画面例及び動作例について説明するための図。
【図6】第1の実施形態の拾い読み支援システムの処理手順の一例を示すフローチャート。
【図7】ハイライト表示を伴わない文書表示例を示す図。
【図8】更新された文書分類情報の一例を示す図。
【図9】更新されたスコア付けされた単語リストの一例を示す図。
【図10】拾い読み単語抽出部の処理手順の一例を示すフローチャート。
【図11】ハイライト箇所特定部の処理手順の一例を示すフローチャート。
【図12】テキスト表示部の処理手順の一例を示すフローチャート。
【図13】ハイライト表示を伴う文書表示例を示す図。
【図14】第2の実施形態に係る拾い読み支援システムの機能構成例を示す図。
【図15】拾い読み単語抽出部の処理手順の一例を示すフローチャート。
【図16】スコア付けされた単語リスト及び異言語間の単語置換の一例について説明するための図。
【図17】テキスト表示部の処理手順の他の例を示すフローチャート。
【図18】スコア付けされた単語リスト及び異言語間の単語置換の一例について説明するための図。
【図19】異言語によるハイライト表示を伴う文書表示例を示す図。
【図20】第3の実施形態に係る拾い読み支援システムの機能構成例を示す図。
【図21】第4の実施形態に係る拾い読み支援システムの機能構成例を示す図。
【発明を実施するための形態】
【0009】
以下、図面を参照しながら本発明の実施形態に係る拾い読み支援システムについて詳細に説明する。なお、以下の実施形態では、同一の番号を付した部分については同様の動作を行うものとして、重ねての説明を省略する。
【0010】
(第1の実施形態)
従来、例えば特許調査・文献調査・市場調査をはじめとする文書調査などのように多数の文書を閲覧する際に、検索や分類などの機械的処理だけで高精度に読むべき文書を少量に減らすことは難しく、ユーザ自身が目で単語を走査し、拾い読みを行っていた。
【0011】
第1の実施形態では、(例えば表示された文書をユーザが任意に閲覧してその分類タイプを判断した上で)ユーザが入力した幾つかの文書に対する分類を示す情報(分類タイプ)に基づいて、自動的に拾い読みのキーワード抽出を行い、ユーザが未分類の文書中のキーワードのハイライト表示を行うことによって、ユーザの拾い読みを支援する場合を例にとって説明する。
【0012】
以下では、ユーザが文書に付与する分類タイプとして、当該文書が必要な文書であるか否かによって、少なくとも以下の2種類の文書タイプが設けられる具体例を中心に説明する。
(a)ユーザが必要であるとした文書を示す分類タイプ(以下、必要文書タイプ)、
(b)ユーザが不要であるとした文書を示す分類タイプ(以下、不要文書タイプ)。
【0013】
この例の場合には、ユーザは、所望の文書に対して、分類タイプとして、「必要文書タイプ」又は「不要文書タイプ」のいずれかを入力できる。
【0014】
上記は一例であり、他にも様々な分類方法を使用することが可能である。
【0015】
例えば、当該文書がいずれの担当者に関連するかによって分類する方法が可能である。例えば、A〜Eの5人の担当者が設定される場合に、少なくとも以下の5種類の文書タイプが設けられる。
・担当者Aに関連する文書を示す分類タイプ(担当者A文書タイプ)、
・担当者Bに関連する文書を示す分類タイプ(担当者B文書タイプ)、
・担当者Cに関連する文書を示す分類タイプ(担当者C文書タイプ)、
・担当者Dに関連する文書を示す分類タイプ(担当者D文書タイプ)、
・担当者Eに関連する文書を示す分類タイプ(担当者E文書タイプ)。
【0016】
この例の場合には、ユーザは、所望の文書に対して、分類タイプとして、「担当者A文書タイプ」〜「担当者E文書タイプ」のいずれかを入力できる。
【0017】
また、上記二つの例を併せて、例えば少なくとも以下の6種類の文書タイプを設けることも可能である。
・担当者Aに関連する文書を示す分類タイプ(担当者A文書タイプ)、
・担当者Bに関連する文書を示す分類タイプ(担当者B文書タイプ)、
・担当者Cに関連する文書を示す分類タイプ(担当者C文書タイプ)、
・担当者Dに関連する文書を示す分類タイプ(担当者D文書タイプ)、
・担当者Eに関連する文書を示す分類タイプ(担当者E文書タイプ)、
・ユーザが不要であるとした文書を示す分類タイプ(不要文書タイプ)。
【0018】
なお、分類タイプの一つとして、更に、ユーザが未だ分類タイプを入力していない文書であることを示すタイプ(ここでは、未読文書タイプと呼ぶ)を設けることも可能である。例えば、上記具体例において、更に未読文書タイプを使用する場合には、ユーザが幾つかの文書に対して必要文書タイプを入力し、他の幾つかの文書に対して不要文書タイプを入力した場合に、残りの文書には、自動的に、「未読文書タイプ」が付与されることになる。
【0019】
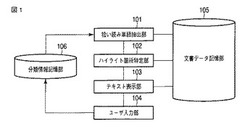
図1に、第1の実施形態の拾い読み支援システムの機能構成例を示す。
【0020】
図1に示されるように本実施形態の拾い読み支援システムは、拾い読み支援システムの構成は、拾い読み単語抽出部101、ハイライト箇所特定部102、テキスト表示部103、ユーザ入力部104、文書データ記憶部105、分類情報記憶部106を備えている。
【0021】
文書データ記憶部105は、複数の文書のデータを記憶する。
【0022】
文書は、どのようなものであっても良い。例えば、文書は、何らかのドキュメント本文であっても良いし、そのドキュメント本文に対する要約文であっても良い。例えば、ドキュメント本文が特許明細書であり、文書データ記憶部105に記憶される各文書が、各特許明細書に対応する要約文である場合に、ユーザは、各要約文に対応する各特許文書を実際に読むかどうかを判断するために、各要約文を拾い読みすることがある。本実施形態では、文書の例として、特許明細書の要約文を例にとりつつ説明する。
【0023】
図2に、文書データ記憶部105に記憶される文書データの一例を示す。図2の例では、各文書データに、文書識別子(以下、文書ID)(図中、0001〜0006)が付与されている。なお、文書データの記憶フォーマットは、図2に制限されない。
【0024】
なお、文書データ記憶部105に記憶される文書データは、記録媒体から入力されたものであっても良いし、インターネットなどのネットワークを介してダウンロードされたものであっても良いし、キー入力された文書を含んでも良いし、他のどのような方法で得られたものであっても良い。
【0025】
また、文書データ記憶部105に記憶される文書データは、例えば、文書ID又は他の何らかの基準によってソートされていても良いし、特にソートされていなくても良い。
【0026】
テキスト表示部103は、文書データ記憶部105に記憶されている複数の文書(その文書数をNとする)について、一度に所望の文書数dの文書を表示する。なお、ここでは、2≦d≦Nとして説明するが、d=1の表示状態があっても構わない。
【0027】
その際、表示の仕方に制限はなく、例えば、表示対象となった各々の文書について、その文書全体を表示する方法も可能であり、また、例えば、その文書の一部を表示する(例えば、その文書を、予め定められた上限となる文字数の部分まで表示し、残りの部分はユーザが所定の操作を行うことによって表示されるようになる)方法も可能である。また、一つの画面に同時に表示する文書数nをユーザが指示できるようにしても良いし、一つの文書について表示する上限文字数をユーザが指示できるようにしても良いし、その他にも様々な表示方法が可能である。
【0028】
また、複数の文書のうちの一部の文書を表示する場合に、表示する文書の選択方法に制限はない。例えば、表示する文書を、文書ID又は他の何らかの基準によって選択しても良いし、ユーザが表示する文書を指示しても良い。
【0029】
ユーザ入力部104は、ユーザが指定する文書の指示とその文書に対するユーザが指定する分類タイプの指示を入力する。例えば、ユーザは、テキスト表示部103に表示された文書のうちから、所定の方法で所望の文書を選択するとともに、その文書に対する所望の分類タイプを所定の方法で選択しても良い。なお、文書選択方法や分類タイプ選択方法に特に制限はない。
【0030】
分類タイプは、分類方法が予め1種類に定められていても良いし(例えば、「必要文書タイプ」「不要文書タイプ」のいずれか)、分類方法が予め複数種類に定められていて、それらのうちからユーザが選択するようにしても良いし(例えば、「必要文書タイプ」「不要文書タイプ」のいずれか、又は、「担当者A文書タイプ」)〜「担当者E文書タイプ」のいずれか)、いつでもユーザが自由な分類タイプを任意に設定可能であっても良いし、それらの組み合わせであっても良い。
【0031】
分類情報記憶部106は、各々の文書IDと、当該文書IDに対する分類タイプとの対応を示す文書分類情報を記憶する。
【0032】
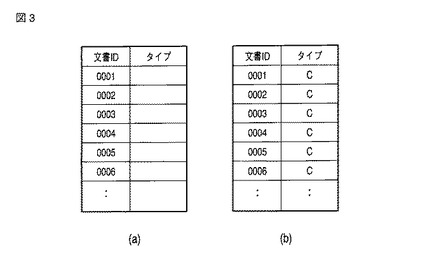
図3(a)に、分類情報記憶部106に記憶される文書分類情報の例を示す。図3(a)の例は、分類タイプが何も入力されていない初期的な状態を示す。以下、一例として、文書分類情報において、「不要文書タイプ」については値「A」が記憶され、「必要文書タイプ」については値「B」が記憶されるものとして説明する。
【0033】
なお、前述の「未読文書タイプ」を使用しない場合には、図3(a)の例を使用すれば良い。また、「未読文書タイプ」を使用する場合には、図3(b)のように文書分類情報の初期状態として全文書について、ユーザが入力する分類タイプ以外の値(例えば値「C」)を記憶しておき、値「C」が記憶されている文書は、「未読文書タイプ」として扱うようにしても良いし、または、図3(a)の例を使用して、値が何も記憶されていない(あるいは、値が「null」である)文書は、「未読文書タイプ」として扱うようにしても良い。
【0034】
いずれの場合においても、文書データ記憶部105に記憶されている文書の文書数がNである場合に、文書分類情報においてユーザにより入力された分類タイプに対応する値が記憶される数cは、0≦c≦Nである。
【0035】
以下では、c=0の場合には、ハイライト表示を行わないものとし、また、c=Nに達した場合には、すべての文書についてユーザによる分類がなされたことを意味するので、それ以上の拾い読み単語抽出部101及びハイライト箇所特定部102の処理は、行わないものとする。ただし、「未読文書タイプ」を使用する場合に、c=0のときに、ハイライト表示を行うことも可能である。
【0036】
また、以下では、まだユーザにより分類タイプが付与されていない(N−c)個の文書のみを、ハイライト表示の対象とするものとして説明する。ただし、N個のすべての文書を、ハイライト表示の対象とすることも可能である。
【0037】
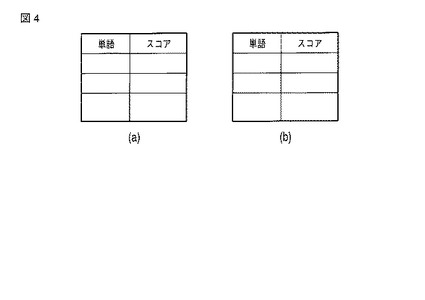
拾い読み単語抽出部101は、文書分類情報において、少なくとも一つの文書について、ユーザにより入力された分類タイプが記憶されている場合に(すなわち、c≧1である場合に)、文書分類情報中に対応する値が存在する分類タイプごとに、当該分類タイプに対応する文書から、当該分類タイプに特徴的な単語のリストを作成する。その際、各単語について、当該分類タイプに特徴的である程度を表すスコアを計算する。
【0038】
図4に、拾い読み単語抽出部101がその処理において作成するスコア付けされた単語リスト(スコア付単語リスト)の例を示す。本具体例のように「必要文書タイプ」及び「不要文書タイプ」を使用する場合には、文書タイプごとにスコア付単語リストが作成される。図4(a)及び(b)の例は、それぞれ、「不要文書タイプ」用のスコア付単語リスト及び「必要文書タイプ」用のスコア付単語リストの初期的な状態を示す。なお、「未読文書タイプ」を使用する場合には、更に、「未読文書タイプ」用のスコア付単語リストも設けられる。
【0039】
各々の分類タイプごとに、そのスコア付単語リスト中の単語が、ハイライト表示されるものとして選択される。なお、例えば、スコア付単語リスト中の単語が予め定められた個数kを超えた場合には、スコア付単語リスト中でスコアが上位のk個を選択する方法、スコアが予め定められた閾値以上の単語のみ使用する方法など、あるいは、それらを組み合わせた方法なども可能であり、また、他の様々な方法が可能である。
【0040】
なお、文書分類情報中に対応する値が存在しない分類タイプについては、その間、スコア付単語リストは作成されない。例えば、上記具体例において、文書分類情報中に、図3(a)については値「B」のみ存在する場合に、図3(b)については、「B」及び「C」のみ存在する場合に、値「A」に対応する「不要文書タイプ」については、スコア付単語リストは作成されない。
【0041】
以下、各々の分類タイプごとに、ハイライト表示されるものとして選択された単語(又は又は用語又はフレーズ)を、「拾い読み単語候補」と呼ぶものとする。
【0042】
ハイライト箇所特定部102は、ユーザが分類タイプを入力していない各々の文書について、当該文書中で各々の「拾い読み単語候補」が出現する箇所を探し(なお、「拾い読み単語候補」の全部又は一部が存在しないこともある)、当該文書中において出現する各々の「拾い読み単語候補」からハイライトすべき箇所を選択する。例えば、一つの文書において、同一の「拾い読み単語候補」について1箇所のみハイライト表示するものとした場合に、ある文書中にある「拾い読み単語候補」が複数存在するときに、いずれの箇所をハイライト表示するかを選択する。
【0043】
ユーザが少なくとも一つの文書に対して分類タイプを入力した後は、テキスト表示部103は、ユーザが分類タイプを入力していない文書について、その文書中の単語のうち、拾い読み単語抽出部101により分類タイプごとに抽出された単語であって且つハイライト箇所特定部102により特定された箇所の単語をハイライト表示する。
【0044】
その際、「拾い読み単語候補」をハイライト表示するにあたって、その分類タイプに対応するハイライト形態でハイライト表示するようにしても良い。例えば、フォントを変えることによって拾い読み単語候補を示す場合に、分類タイプごとに、文字の色等のフォントを変えても良いし、拾い読み単語候補を枠で囲んで示す場合に、分類タイプごとに、枠の形状、線種、色、枠内のハッチングの有無、ハッチングの種類等を変えても良いし、それらを組み合わせても良いし、また、他にも様々なハイライト形態が可能である。
【0045】
また、例えば、必要文書タイプを一番に目立つハイライト形態、不要文書タイプを次に目立つハイライト形態、未読文書タイプをその次に目立つハイライト形態にするような方法も可能である。
【0046】
ユーザ入力部104でユーザからの入力が起こると、分類情報記憶部106が更新され、拾い読み単語抽出部101、ハイライト箇所特定部102、テキスト表示部103の一連の処理が行われる。
【0047】
なお、上記一連の処理は、ユーザ入力部104から一つの文書に係る文書分類情報を入力するごとに、これを契機として実行することとしても良いし、あるいは、ユーザ入力部104から文書分類情報が入力されただけでは、上記一連の処理を実行せず、(例えばユーザ入力部104から)上記一連の処理を実行するための所定の指示が入力されたときに、これを契機として上記一連の処理を実行することとしても良い。
【0048】
ここで、図5のシステム画面例を参照しながら、本実施形態の全体的な動作例の概要について説明する。図5では、各文書が特許明細書に対応する要約文である場合を例にとって説明する。
【0049】
なお、以下では、必要文書タイプを「○」、不要文書タイプを「×」でも表すものとする。
【0050】
まず、テキスト表示部103が、図5のシステム画面(121)の内側に、各文書(図中、122参照)を表示する。なお、初期的な状態では、ユーザによる分類タイプの入力がなされておらず、実際には図5と異なり、「○」「×」は表示されておらず、ハイライト表示も行われていない。
【0051】
図5の具体例は、システム画面(121)の内側に、各文書を5行2列に表示するものである。
【0052】
次に、ユーザは、図5のシステム画面(121)中に表示された文書を任意に読む。
【0053】
なお、図5の5行2列に表示する例において、11以上の文書が存在する場合には、ユーザは、例えばスクロール又はページ更新をするなどして他の文書を表示させても良い。もちろん、文書の表示は、5行2列の表示に制限されない。
【0054】
そして、ユーザは、分類タイプを入力すると判断した文書を選択するとともに、その文書についてユーザが判断した分類タイプを選択することによって、文書分類情報{文書,分類タイプ}を入力する。すなわち、システム側は、ユーザ入力部104において、ユーザが選択する{文書,分類タイプ}の入力を受け付ける。
【0055】
例えば、ユーザが124で示される文書を読んで、この文書を不要と判断した場合(例えば、この要約文に対応する特許明細書の全文は読まなくて良いと判断した場合)、この文書データ(124)に対して不要文書タイプ記号「×」をユーザが選択する。
【0056】
同様の、ユーザが125で示される文書を読んで、この文書を必要と判断した場合(例えば、この要約文に対応する特許明細書の全文は読む必要があると判断した場合)、この文書データ(124)に対して必要文書タイプ記号「○」をユーザが選択する。
【0057】
なお、ユーザは、それら以外の文書には分類を付与していないとする。
【0058】
この場合に、図5に示されるように、分類が付与された文書124,125についてそれぞれ付与された分類タイプを示す「×」「○」が表示されても良い。もちろん、他の付与された分類タイプを識別可能にしても良い。
【0059】
さて、文書データ124,125に対して分類タイプが付与されたときに、システム内では、文書データ124の文書ID及び付与された分類タイプを示す文書分類情報と、文書データ125の文書ID及び付与された分類タイプを示す文書分類情報を受け取る。
【0060】
そして、上記二つの文書分類情報をもとに、拾い読み単語抽出部101の処理、ハイライト箇所特定部102の処理、テキスト表示部103の処理からなる一連の処理を行って、図5に例示されるように、文書データ124,125以外の文書に対して、拾い読み単語をハイライト表示する。
【0061】
なお、拾い読み単語抽出部101では、分類タイプごとにスコアを計算する。
【0062】
例えば、図5中のタイプ分け凡例(123)のように、必要文書タイプ・不要文書タイプ・未読文書タイプの3分類でそれぞれスコアの高い語を用意することで、タイプごとに単語のハイライト方法を変えることができる。
【0063】
異なるハイライト方法を適用する例として、例えば、前述のようにハイライト色を変更しても良い。例えば、必要文書タイプをピンク、不要文書タイプを黄色、未読文書タイプを緑で各タイプの拾い読み単語をハイライトしても良い。
【0064】
図5では、タイプごとに単語のハイライト方法を変える様子を例示するために、必要文書タイプでハイライトする単語の部分についてはクロスハッチング枠で、不要文書タイプについては斜線ハッチング枠で、未読文書タイプについてはハッチングなしの枠で、それぞれハイライトを行う例を示した。
【0065】
図5に例示するような表示状態において、ユーザは、単語にハイライトが付加された文書群を閲覧しながら、ハイライトされた単語を中心に拾い読みすることができ、更に、未分類の文書へ分類を付与していくことができる。その際、例えば、必要に応じてハイライトされた単語の周辺単語も合わせて読むこともできる。
【0066】
図6に、本実施形態の拾い読み支援システムの処理手順の一例を示す。
【0067】
ステップS1において、テキスト表示部103は、初期的に文書を表示する。
【0068】
図7に、図2に例示した文書を表示した例を示す。
【0069】
なお、この初期の段階では、分類情報記憶部106に記憶される文書分類情報は、図3(a)又は図3(b)に例示したようになる。また、スコア付単語リストは、図4に例示したようになる。
【0070】
ステップS2において、ユーザ入力部104は、ユーザから文書分類情報{文書ID,分類タイプ}の入力を受け付ける。
【0071】
ステップS3において、入力された上記の文書分類情報{文書ID,分類タイプ}を、分類情報記憶部106に記録する。
【0072】
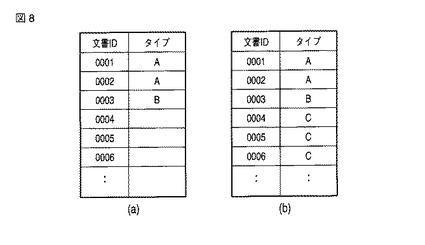
ここでは、図2の文書ID=0001〜0003の各文書に対して、それぞれ、「不要文書タイプ」「不要文書タイプ」「必要文書タイプ」がユーザにより入力されているものとすると、分類情報記憶部106に記憶された文書分類情報例は、図3(a)については図8(a)に例示するようになり、図3(b)については図8(b)に例示するようになる。
【0073】
なお、ステップS4において、終了条件が成立したならば、処理を終了し、終了条件が成立していないならば、次のステップS5に進む。
【0074】
終了条件には、種々のものが考えられる。例えば、文書データ記憶部105に記憶されている文書の文書数がNである場合に、N個の文書すべてについて上記の文書分類情報{文書ID,分類タイプ}がユーザにより入力されたことを終了条件としても良いし、あるいは、上記の文書分類情報{文書ID,分類タイプ}がユーザにより入力された文書の数をcとして、(N−c)の値(すなわち、まだユーザにより分類タイプが付与されていない文書の数)が、予め定められた閾値を下回ったことを終了条件としても良い。もちろん、これらに制限されない。
【0075】
さて、ステップS4において、終了条件が成立していないならば、以下の一連の処理が行われる。
【0076】
ステップS5において、拾い読み単語抽出部101の処理を行って、スコア付単語リストを作成する。
【0077】
例えば、「不要文書タイプ」用のスコア付単語リストが図9(a)に例示するようになり、「必要文書タイプ」用のスコア付単語リストが図9(b)に例示するようになる。なお、a1,a2,b1,b2はそれぞれのスコア値を示している。また、各スコア付単語リストは、スコア順にソートされても良い。
【0078】
ステップS6において、ハイライト箇所特定部102の処理を行って、各文書中のハイライト箇所を特定する。
【0079】
ステップS7において、テキスト表示部103の処理を行って、テキスト表示(のハイライト状態)を更新する(例えば後で説明する図13参照)。
【0080】
以下、拾い読み単語抽出部101、ハイライト箇所特定部102、テキスト表示部103の各処理について順番に詳しく説明する。
【0081】
まず、拾い読み単語抽出部101について説明する。
【0082】
拾い読み単語抽出部101は、文書データと既知の分類とから、拾い読みに適した単語を抽出するモジュールである。
【0083】
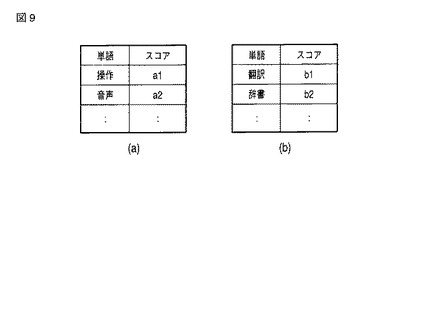
図10に、拾い読み単語抽出部101の処理手順の一例を示す。
【0084】
ステップS11において、拾い読み単語抽出部101は、文書データ記憶部105及び分類情報記憶部106から、文書データとそれに対してユーザにより付与された分類を読み込む。
【0085】
ステップS12において、各文書の分類及び各文書の単語から、拾い読み単語としてのスコアを計算する。
【0086】
ステップS13において、スコア順に単語をソートし、上位の単語を拾い読み単語候補とし、ステップS14において、拾い読み単語候補とそのスコアを出力する。
【0087】
拾い読み単語のスコア計算として、例えば、次のような式で計算を行っても良い。ここでは、『ある文書D内に出現する単語tを見た場合、この文書Dが文書タイプCであるとすぐに判断できるかどうか』、というスコアとして速判度(t,C)を導入する。
速判度(t,C)=読みコスト(t)×判別度(t,C) …(1)
ここで、読みコストとは、人が単語を認識するのにかかるコストを指し、文字長や文字の複雑さなどに依存する。例えば、文字数の逆数(例:1/(文字数))などとする。また、ひらがな・カタカナなどの文字種は、漢字に比べて画数が少なく目につきやすいことを考慮して、スコアを上げるなどの工夫が考えられる(例:k/(文字数))。
【0088】
判別度とは、ある文書タイプCの判別に使える単語であるかの度合いを指す。ある単語が、文書タイプCらしい単語あるいは文書タイプCらしくない単語であれば、判別度は高く、逆に、文書タイプCなのかがわかりにくい単語であれば、判別度は低い。例えば、tf(t)*log(df(t|C)/df(t))*score_pos(t)といった式で計算する。ここで、tf(t)は、単語tの文書D内での単語頻度、df(t|C)は、文書タイプCに分類された文書での、単語tの出る文書数、df(t)は、単語tの出る文書数、score_pos(t)は、単語tの品詞のスコアで例えば単語tが名詞のときの名詞スコアを指す。このとき、名詞のスコアを高く設定するなどして、特定の品詞の単語のスコアが高くなるようにもできる。
【0089】
次に、ハイライト箇所特定部102について説明する。
【0090】
ハイライト箇所特定部102は、各々の文書について、当該文書中で拾い読み単語抽出部101により選択された拾い読み単語候補が出現する箇所を探し、当該文書中でハイライトすべき箇所を選択するモジュールである。
【0091】
図11に、ハイライト箇所特定部104の処理手順の一例を示す。
【0092】
ここで、Lはハイライト語数の上限、Nは文書数、Mはハイライト単語候補の総数、Xは文書i中のハイライト単語として記憶している単語数である。
【0093】
まず、ハイライトする箇所が多いと拾い読みにならないため、ハイライト語数の上限Lを設定する。
【0094】
ステップS21において、ハイライト箇所特定部104は、文書データ記憶部105から文書データを読み込むとともに、拾い読み単語抽出部101の出力する単語リストとスコアを読み込む。
【0095】
ステップS22において、iに1を代入する。
【0096】
ステップS23〜S25では、各文書について、各拾い読み単語候補が出現しているかを確認する。
【0097】
ただし、文書データ記憶部105の総文書数をN、拾い読み単語候補の総数をMとする。
【0098】
文書iで、単語jがp回出現した場合、ステップS27において、ハイライトする単語位置を、p個の単語jの中から選択する。例えば、初出の箇所を選択する、近傍単語重要度で選択する、複合語に含まれない単語を選択するなどである。ここで、近傍単語重要度とは、単語tの近傍に出現する語の重要度を指す。ハイライト箇所には目が行くため、その近傍にも重要語がある方をよりスコアを高くするものである。なお、重要語の計算には、一般的にキーワード抽出として知られる計算式などを使って計算できる。例えば、近傍単語重要度(ti)を、その周辺の語tjの重要度とtiまでの距離を使いスコア付けし、Σj {tf(tj)*log(N/df(tj))*(1/|j−i|)}といった式で表す。ここで、Nは、全文書数を表し、j−iは単語tiとtjの距離を表す。また、複合語を構成する1単語となっている場合には、1単語だけでは意味をなさない可能性があるため、スコアを低くするなどでもよい。
【0099】
ステップS28では、文書iに対しハイライトする単語とその出現位置を記憶し、ハイライト単語数Xがハイライト語数の上限L以下である間同様の操作を繰り返す。
【0100】
ステップS25において条件一致がNoになった場合、ステップS23へ戻り、次の文書i+1に進み、ステップS24〜S28について同様の作業を繰り返す。
【0101】
ステップS21で読み込んだ文書すべてにハイライト箇所特定が終わったならば、ステップS29で各文書のハイライト単語とその位置を出力する。
【0102】
次に、テキスト表示部103について説明する。
【0103】
テキスト表示部103は、文書データ記憶部105の各文書データに対し、ハイライト箇所特定部102で特定したハイライト単語位置をハイライトして表示するモジュールである。
【0104】
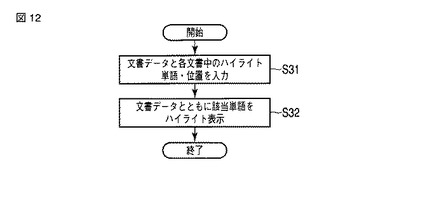
図12に、テキスト表示部103の処理手順の一例を示す。
【0105】
ステップS31において、テキスト表示部103は、文書データ記憶部105の文書データを読み込むとともに、ハイライト箇所特定部102で出力するハイライトの単語とその位置を読み込む。
【0106】
ステップS32において、文書データ中のハイライト箇所にハイライトを施して、各文書データを出力する。
【0107】
図5は、各文書データのハイライトの一例である。
【0108】
また、図13に、各文書データの他のハイライト例を示す。図13は、図7に例示された文書群のうち、最初の3文書に分類が付与された際の他の文書の表示例である。また、図5と同様、必要文書タイプはクロスハッチング枠で、不要文書タイプは斜線ハッチング枠で、未読文書タイプはハッチングなしの枠でそれぞれハイライトする例を示した。
【0109】
さて、上記のようなハイライト表示された後に、ユーザは更に未分類の文書に対して、分類を付与することができる。
【0110】
ユーザ入力部104は、テキスト表示部103で表示した各文書に対し、ユーザが付与する分類を受け付けるモジュールである。図5の各文書に対し、ユーザは分類を付与する(例:「○」「×」)。このとき、ユーザ入力部104がこの分類情報を受け取る。ユーザ入力部104がユーザの付与した分類を受け取ると、続けて101〜103の処理を行い、ハイライト単語の更新を行う。
【0111】
次に、処理の具体的な例を示す。
【0112】
図13のような6つの文書1201〜1206が存在した場合で、最初の3つの文書1201〜1203に分類が付与された場合で考える。分類情報記憶部106には、文書1201に「×」、文書1202に「×」、文書1203に「○」が与えられている。
【0113】
この3文書と分類を元に、拾い読み単語抽出部101で、単語抽出を行う。式(1)のscore_posにおいて、名詞について1、それ以外について0である場合に、格文書から名詞を抽出する。文書1201から、「文書」「音声」「指示」「入力」「頻度」「状況」「合成」「売上げ」「スタイル」「出力」「装置」といった名詞を抽出する。同様に、文書1202、文書1203からも名詞を抽出する。そして、抽出された各々の名詞について、式(1)の計算をする。この例では文書数が少なく単語間でスコアがほとんど変わらないため、各名詞が出現する文書の分類に対応する拾い読み単語候補となる。文書1204で上記3文書に出てきた名詞は、「操作」「音声」「出力」である。このうち、「出力」は文書1201中で複合語でしか出てこないため、スコアを下げ、「操作」と「音声」をハイライトするとする。
【0114】
続いて、ハイライト箇所特定部で、文書1204中でハイライトする単語を選ぶ。「操作」は一回しか出現しないため、そのまま選択する。また、「音声」は、「音声出力処理方式」と「音声出力」の2箇所に出現する。この際には、例えば、いずれも複合語なので、より短い「音声出力」の方の「音声」をハイライトすることにし、2回目の「音声」をハイライト箇所とする。
【0115】
なお、上記では、具体例として日本語を用いて説明したが、本実施形態は他の言語の場合にも同様に適用可能である。
【0116】
本実施形態によれば、例えば特許調査・文献調査・市場調査などのように多数の文書を漏れなく網羅的に内容を調査したいようなケースにおいて、ユーザが多数の文書(例えばドキュメント本文又はその要約文)のうちの幾つかの文書を読みながら、例えば読んで確認すべき或いは精読すべき文書とそうでない文書等の分類や、分担して読む担当を分けるための分類などを付与し、ユーザによる分類が付与された文書をもとに、例えば未分類の文書から分類判断のための拾い読みに適した単語や、未分類の文書を弁別する根拠となりそうなキーワードなどを抽出し、適切な箇所にハイライト表示やマーカ付与を行って提示することによって、ユーザ自身が行っている拾い読みを効率的に行えるように支援することができる。
【0117】
(第2の実施形態)
第2の実施形態では、第1の言語で既に分類が付与されているときに、その分類を利用して、第1の言語とは異なる第2の言語の文書で拾い読み用のキーワードをハイライトする例を示す。
【0118】
例えば、第1の言語をユーザの母国語とし、第2の言語を外国語としても良いし、逆に、第2の言語をユーザの母国語とし、第1の言語を外国語としても良い。
【0119】
ここでは、第1の言語を英語、第2の言語を日本語とする場合を例に取りつつ説明する。
【0120】
図14に、第2の実施形態に係る支援システムの機能構成例を示す。
【0121】
図14に示されるように、拾い読み支援システムの構成は、拾い読み単語抽出部101、置換部201、二言語間辞書202、ハイライト箇所特定部102、テキスト表示部103、ユーザ入力部104、第1言語文書データ記憶部203、第1言語分類情報記憶部204、第2言語文書データ記憶部205、第2言語分類情報記憶部206を備える。
【0122】
第1言語文書データ記憶部203には、第1言語での文書データが保存されている。また、各文書に対応した分類がすでに付与されており、その分類情報が第1言語分類情報記憶部204に保存されている。
【0123】
拾い読み単語抽出部101は、基本的には第1の実施形態と同様にして、第1言語文書データ記憶部203及び第1言語分類情報記憶部204の情報を読み込み、拾い読み単語抽出を行う。第1言語分類情報記憶部204の内容は変化しないので、ここでの抽出は、1回のみ行えば良い。
【0124】
一方、第2言語文書データ記憶部205は、第1の実施形態の文書データ記憶部105に対応し、第2言語分類情報記憶部206は、第1の実施形態の分類情報記憶部106に対応する。拾い読み単語抽出部101は、第2言語文書データ記憶部205及び第2言語分類情報記憶部206について、第1の実施形態と同様の処理を繰り返し行うことになる。
【0125】
拾い読み単語抽出部101で出力された拾い読み単語候補とスコアは、置換部201に入力される。
【0126】
置換部201は、第1言語文書データ記憶部203及び第1言語分類情報記憶部204を対象として拾い読み単語抽出部101により抽出された第1言語による単語を、(文書データ上の第2言語の単語との対応を付けるために)第2言語の単語に置き換えるためのモジュールである。
【0127】
置換部201では、第1言語で記載された拾い読み単語候補から、二言語間辞書202を用いて第2言語への翻訳単語を検索し、第2言語の翻訳語を作成する。このとき、第2言語の翻訳語が複数ある単語の場合や、第2言語の翻訳語になる第1言語の単語が他にもある場合には、第1言語から第2言語へ翻訳すると曖昧性が生じている可能性があるため、このような場合にはこの単語の拾い読み単語スコアを下げるなどして、あいまい性のない他の単語を優先する。
【0128】
ハイライト箇所特定部102、テキスト表示部103、ユーザ入力部104の一連の処理は、基本的には第1の実施形態と同様である。ただし、ハイライト箇所特定部102とテキスト表示部103が読み込む文書データは、第2言語文書データ記憶部205、ユーザ入力部104で付与された分類情報を記憶するのは第2言語分類情報記憶部206である。
【0129】
第2の実施形態では、ユーザが分類したい文書データである第2言語の文書データに分類がまだ付与されていない状況でも、ユーザが既に分類を付与した第1言語のデータ、すなわち第1言語文書データ記憶部203と第1言語分類情報記憶部204から、拾い読み単語抽出部101の処理を行うことができる。
【0130】
また、第2言語分類情報記憶部206にデータが追加された後は、第2言語文書データ記憶部205と第2言語分類情報記憶部206のデータから拾い読み単語抽出部101の処理を行うこともできる。
【0131】
後者の場合には、置換部201が不要となる(図1の構成に切り替わる)。
【0132】
図15に、拾い読み単語抽出部101の処理手順の一例を示す。
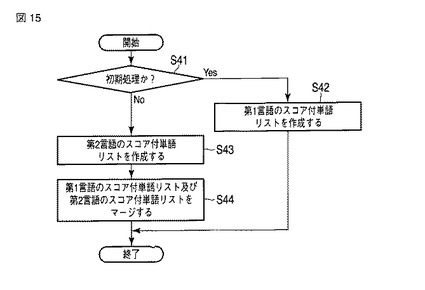
【0133】
まだ、ユーザにより文書に対して分類が付与されていない初期の状態において処理を行う場合には(ステップS41でYes)、拾い読み単語抽出部101は、第1言語文書データ記憶部203及び第1言語分類情報記憶部204の情報を用いて、第1言語のスコア付単語リストを作成する(ステップS42)。図16に、そのスコア付単語リストの一例を示す。なお、図16(a)のスコア付単語リストは、置換部201及び二言語間辞書202により、単語が第1言語から第2言語へ置換される。図16(b)に、その一例を示す。なお、s1はスコア値を示している。
【0134】
ユーザにより少なくとも一つの文書に対して分類が付与された後に処理を行う場合には(ステップS41でNo)、拾い読み単語抽出部101は、第2言語文書データ記憶部205及び第2言語分類情報記憶部206の情報を用いて、第2言語のスコア付単語リストを作成する(ステップS43)。本具体例では、例えば、図9のようになる。そして、ステップS42で既に作成されている第1言語のスコア付単語リスト(単語を置換したもの)と、このステップS43で作成された第2言語のスコア付単語リストとを、マージする。
【0135】
なお、予め定められた条件が成立した場合には、ステップS43を行わずに、第2言語のスコア付単語リストのみを使用するようにしても良い。
【0136】
予め定められた条件は、例えば、第2言語の全文書数をN、第2言語の文書に対してユーザにより分類タイプが付与された文書数をcとして、c/Nが予め定められた値を上回った場合、若しくは、cが予め定められた値を上回った場合、又は、最初に第2言語の文書に対してユーザにより分類タイプが付与されてから、所定の時間が経過した場合など、様々なものが可能である。
【0137】
(第2の実施形態の変形例1)
なお、上記において第1の言語を第2の言語と同じにすることも可能である。この場合には、置換部201及び二言語間辞書202が不要になる。
【0138】
(第2の実施形態の変形例2)
第2の実施形態の変形例2では、第2の実施形態で第2言語の文書中の単語をハイライト表示する代わりに、第1言語で単語を翻訳して表示する例を示す。
【0139】
第2の実施形態の変形例の機能構成例は、図14と同様で構わない。
【0140】
ただし、置換部201からの出力は、拾い読み単語抽出部101から出力された第1言語の単語の第2言語への翻訳だけでなく、第1言語と第2言語への翻訳のセットにし、ハイライト箇所特定部102へと渡される。
【0141】
ハイライト箇所特定部102の処理は、第2の実施例と同様の処理を行うが、その際の出力は、第1言語と第2言語への翻訳のセットにしてテキスト表示部103へ渡される。
【0142】
テキスト表示部103の処理は、第2の実施形態と異なる。
【0143】
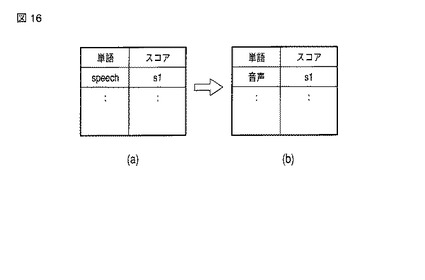
図17に、テキスト表示部103の処理手順の一例を示す。
【0144】
ステップS51において、テキスト表示部103は、第2言語文書データと、ハイライト箇所特定部102の出力であるハイライト単語・その単語の第1言語への翻訳語・ハイライト単語位置を入力する。
【0145】
ステップS52において、第2言語文書データを表示するとともに、ハイライト箇所の単語を第1言語への翻訳単語に変換して文中に表示する。
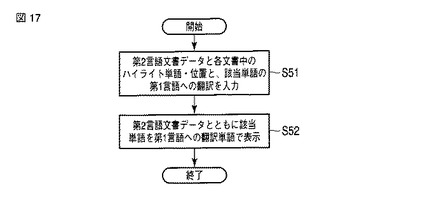
【0146】
図18に、第2の実施形態の変形例2のスコア付単語リストの例を示す。
【0147】
拾い読み単語抽出部101により生成される第1の言語のスコア付単語リストの例を、(a)に示す。第1の言語の単語を第2の言語に置換し、これを更にスコア付単語リストに追加した例を、(b)に示す。なお、e1はスコア値を示している。
【0148】
拾い読み単語抽出部101により生成される第2の言語のスコア付単語リストの例を、(c)に示す。第2の言語の単語を第1の言語に置換し、これを更にスコア付単語リストに追加した例を、(d)に示す。なお、j1はスコア値を示している。
【0149】
図19に、第2言語(日本語)の文書を表示する際に、各分類タイプについて抽出された単語について、第1言語(英語)でハイライトする例を示す。また、図19では、更に、必要文書タイプは枠で、不要文書タイプは斜線ハッチング枠で、更なるハイライトを行い、未読文書タイプは第1言語(英語)でのハイライトのみとした例を示している。
【0150】
(第3の実施形態)
第3の実施形態では、拾い読みに使う単語をユーザ自身が選択する例を示す。
【0151】
図20に、第3の実施形態に係る支援システムの機能構成例を示す。
【0152】
図20は、最初にユーザが拾い読みに使う単語を幾つか入力し、それを元に初期動作を始める場合の例である。
【0153】
単語入力部301は、ユーザが拾い読みに使う単語の入力を受け付ける。この場合、ユーザによって入力された単語をそのまま拾い読み単語候補とし、この候補語を元にハイライト箇所特定部102でハイライト箇所を特定する。その他の処理は、第1の実施形態と同様である。なお、ユーザ入力部104でユーザ入力後、分類情報記憶部106の更新にともない拾い読み単語抽出部101、ハイライト箇所特定部102、テキスト表示部103の一連の処理が行われる際にも、単語入力部301から新たに単語入力をしても良い。
【0154】
(第4の実施形態)
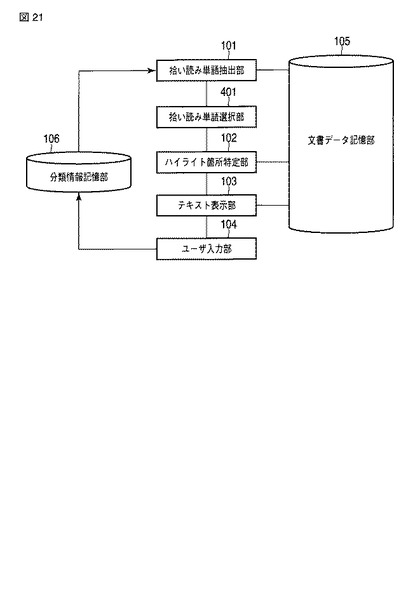
第4の実施形態では、拾い読みに使う単語をユーザ自身が選択する例を示す。
【0155】
図21に、第2の実施形態に係る支援システムの機能構成例を示す。
【0156】
図21は、拾い読み単語抽出部101で計算された拾い読み単語候補中から、ユーザが拾い読みに使いたい単語を選択する場合の例である。
【0157】
拾い読み単語抽出部101、ハイライト箇所特定部102、テキスト表示部103、ユーザ入力部104の処理は、第1の実施形態と同様である。
【0158】
拾い読み単語選択部401では、拾い読み単語抽出部101で抽出された拾い読み単語候補をユーザに提示する。ユーザは、使いたい拾い読み単語あるいは使いたくない拾い読み単語を選択し、その選択を拾い読み単語選択部401が受け付ける。選択の結果、ユーザに拾い読み単語として使いたい単語の優先度を高くし、ハイライト箇所特定部102へスコア付の単語リストとして入力する。
【0159】
なお、これまでに説明してきた各実施形態や変形例は、任意に組み合わせて実施することが可能である。
【0160】
また、本実施形態(これまで説明してきた各実施形態や変形例又はそれらを任意に組み合わせたもののいずれによっても)、多数の文書の拾い読みを支援することができる。
【0161】
また、上述の実施形態の中で示した処理手順に示された指示は、ソフトウェアであるプログラムに基づいて実行されることが可能である。汎用の計算機システムが、このプログラムを予め記憶しておき、このプログラムを読み込むことにより、上述した実施形態の拾い読み支援システムによる効果と同様な効果を得ることも可能である。上述の実施形態で記述された指示は、コンピュータに実行させることのできるプログラムとして、磁気ディスク(フレキシブルディスク、ハードディスクなど)、光ディスク(CD−ROM、CD−R、CD−RW、DVD−ROM、DVD±R、DVD±RWなど)、半導体メモリ、またはこれに類する記録媒体に記録される。コンピュータまたは組み込みシステムが読み取り可能な記録媒体であれば、その記憶形式は何れの形態であってもよい。コンピュータは、この記録媒体からプログラムを読み込み、このプログラムに基づいてプログラムに記述されている指示をCPUで実行させれば、上述した実施形態の拾い読み支援システムと同様な動作を実現することができる。もちろん、コンピュータがプログラムを取得する場合または読み込む場合はネットワークを通じて取得または読み込んでもよい。
また、記録媒体からコンピュータや組み込みシステムにインストールされたプログラムの指示に基づきコンピュータ上で稼働しているOS(オペレーティングシステム)や、データベース管理ソフト、ネットワーク等のMW(ミドルウェア)等が本実施形態を実現するための各処理の一部を実行してもよい。
さらに、本実施形態における記録媒体は、コンピュータあるいは組み込みシステムと独立した媒体に限らず、LANやインターネット等により伝達されたプログラムをダウンロードして記憶または一時記憶した記録媒体も含まれる。
また、記録媒体は1つに限られず、複数の媒体から本実施形態における処理が実行される場合も、本実施形態における記録媒体に含まれ、媒体の構成は何れの構成であってもよい。
【0162】
なお、本実施形態におけるコンピュータまたは組み込みシステムは、記録媒体に記憶されたプログラムに基づき、本実施形態における各処理を実行するためのものであって、パソコン、マイコン等の1つからなる装置、複数の装置がネットワーク接続されたシステム等の何れの構成であってもよい。
また、本実施形態におけるコンピュータとは、パソコンに限らず、情報処理機器に含まれる演算処理装置、マイコン等も含み、プログラムによって本実施形態における機能を実現することが可能な機器、装置を総称している。
【0163】
本発明のいくつかの実施形態を説明したが、これらの実施形態は、例として提示したものであり、発明の範囲を限定することは意図していない。これら新規な実施形態は、その他の様々な形態で実施されることが可能であり、発明の要旨を逸脱しない範囲で、種々の省略、置き換え、変更を行うことができる。これら実施形態やその変形は、発明の範囲や要旨に含まれるとともに、特許請求の範囲に記載された発明とその均等の範囲に含まれる。
【符号の説明】
【0164】
101…拾い読み単語抽出部、102…ハイライト箇所特定部、103…テキスト表示部、104…ユーザ入力部、105…文書データ記憶部、106…分類情報記憶部、201…置換部、202…二言語間辞書、203…第1言語文書データ記憶部、204…第1言語分類情報記憶部、205…第2言語文書データ記憶部、206…第2言語分類情報記憶部、301…単語入力部、401…拾い読み単語選択部。
【技術分野】
【0001】
本発明の実施形態は、多数の文書の拾い読みを支援するための拾い読み支援システム、方法及びプログラムに関する。
【背景技術】
【0002】
コンピュータが広く浸透し、通信速度・処理速度などの高速化、ハードディスク・メモリの大容量化などハードウェアの進化とともに、文書の電子化が進み、日常的に大量の情報を扱うことが多くなった。一般ユーザにとっては、情報検索など様々なソフトウェアの技術革新とともに、大量の情報から知りたい情報を利用するための支援を受けられるようになってきた。
【0003】
しかし、例えば特許調査・文献調査・市場調査のように漏れなく網羅的に内容を調査しなければならないビジネスシーンなどでは、大量文書にユーザ自身が目を通す必要があり、検索や分類などの機械的処理で高精度に読むべき文書を少量に減らすことは難しい。また、時間的な制約があることが一般的で、通常は人手で或いは無意識的に、精読すべき箇所を選別するなどの拾い読みを行っている。あるいは、多数の文書を複数人で分担できるように、精読する前処理として、各人の専門分野などを元に拾い読みによって割り振りを行うなどを行っている。
【先行技術文献】
【特許文献】
【0004】
【特許文献1】特開2008−171164号公報
【発明の概要】
【発明が解決しようとする課題】
【0005】
多数の文書の拾い読みを支援する技術は知られていなかった。
【0006】
本実施形態は、多数の文書の拾い読みを支援することの可能な拾い読み支援システム、拾い読み支援方法及びプログラムを提供することを目的とする。
【課題を解決するための手段】
【0007】
実施形態によれば、文書記憶部と、表示部と、入力部と、分類情報記憶部と、抽出部と、特定部とを備える。文書記憶部は、識別情報が対応付けられた複数の文書を記憶する。表示部は、前記複数の文書のうちの全部又は一部を、単語又はフレーズのハイライト表示を伴って又はハイライト表示を伴わずに表示する。入力部は、表示された前記文書のうちの特定の文書の指示及び予め定められた複数種類の分類タイプのうちから当該特定の文書に付与する特定の分類タイプの指示をユーザから入力する。分類情報記憶部は、前記識別情報と前記特定の分類タイプとを対応付けた分類情報を記憶する。抽出部は、同一の分類タイプが対応付けられている1又は複数の前記文書から、当該分類タイプについてハイライト表示すべき1又は複数の単語又はフレーズを抽出する。特定部は、前記文書の全部又は一部の各々について、前記抽出部により抽出された各々の単語又はフレーズが当該文書中に存在する場合に当該文書中でハイライト表示すべき箇所を特定する。
【図面の簡単な説明】
【0008】
【図1】第1の実施形態に係る拾い読み支援システムの機能構成例を示す図。
【図2】文書データ記憶部に記憶される文書データの一例を示す図。
【図3】分類情報記憶部に記憶される文書分類情報(初期状態)の一例を示す図。
【図4】拾い読み単語抽出部により作成されるスコア付けされた単語リスト(初期状態)の一例を示す図。
【図5】拾い読み支援システムのシステム画面例及び動作例について説明するための図。
【図6】第1の実施形態の拾い読み支援システムの処理手順の一例を示すフローチャート。
【図7】ハイライト表示を伴わない文書表示例を示す図。
【図8】更新された文書分類情報の一例を示す図。
【図9】更新されたスコア付けされた単語リストの一例を示す図。
【図10】拾い読み単語抽出部の処理手順の一例を示すフローチャート。
【図11】ハイライト箇所特定部の処理手順の一例を示すフローチャート。
【図12】テキスト表示部の処理手順の一例を示すフローチャート。
【図13】ハイライト表示を伴う文書表示例を示す図。
【図14】第2の実施形態に係る拾い読み支援システムの機能構成例を示す図。
【図15】拾い読み単語抽出部の処理手順の一例を示すフローチャート。
【図16】スコア付けされた単語リスト及び異言語間の単語置換の一例について説明するための図。
【図17】テキスト表示部の処理手順の他の例を示すフローチャート。
【図18】スコア付けされた単語リスト及び異言語間の単語置換の一例について説明するための図。
【図19】異言語によるハイライト表示を伴う文書表示例を示す図。
【図20】第3の実施形態に係る拾い読み支援システムの機能構成例を示す図。
【図21】第4の実施形態に係る拾い読み支援システムの機能構成例を示す図。
【発明を実施するための形態】
【0009】
以下、図面を参照しながら本発明の実施形態に係る拾い読み支援システムについて詳細に説明する。なお、以下の実施形態では、同一の番号を付した部分については同様の動作を行うものとして、重ねての説明を省略する。
【0010】
(第1の実施形態)
従来、例えば特許調査・文献調査・市場調査をはじめとする文書調査などのように多数の文書を閲覧する際に、検索や分類などの機械的処理だけで高精度に読むべき文書を少量に減らすことは難しく、ユーザ自身が目で単語を走査し、拾い読みを行っていた。
【0011】
第1の実施形態では、(例えば表示された文書をユーザが任意に閲覧してその分類タイプを判断した上で)ユーザが入力した幾つかの文書に対する分類を示す情報(分類タイプ)に基づいて、自動的に拾い読みのキーワード抽出を行い、ユーザが未分類の文書中のキーワードのハイライト表示を行うことによって、ユーザの拾い読みを支援する場合を例にとって説明する。
【0012】
以下では、ユーザが文書に付与する分類タイプとして、当該文書が必要な文書であるか否かによって、少なくとも以下の2種類の文書タイプが設けられる具体例を中心に説明する。
(a)ユーザが必要であるとした文書を示す分類タイプ(以下、必要文書タイプ)、
(b)ユーザが不要であるとした文書を示す分類タイプ(以下、不要文書タイプ)。
【0013】
この例の場合には、ユーザは、所望の文書に対して、分類タイプとして、「必要文書タイプ」又は「不要文書タイプ」のいずれかを入力できる。
【0014】
上記は一例であり、他にも様々な分類方法を使用することが可能である。
【0015】
例えば、当該文書がいずれの担当者に関連するかによって分類する方法が可能である。例えば、A〜Eの5人の担当者が設定される場合に、少なくとも以下の5種類の文書タイプが設けられる。
・担当者Aに関連する文書を示す分類タイプ(担当者A文書タイプ)、
・担当者Bに関連する文書を示す分類タイプ(担当者B文書タイプ)、
・担当者Cに関連する文書を示す分類タイプ(担当者C文書タイプ)、
・担当者Dに関連する文書を示す分類タイプ(担当者D文書タイプ)、
・担当者Eに関連する文書を示す分類タイプ(担当者E文書タイプ)。
【0016】
この例の場合には、ユーザは、所望の文書に対して、分類タイプとして、「担当者A文書タイプ」〜「担当者E文書タイプ」のいずれかを入力できる。
【0017】
また、上記二つの例を併せて、例えば少なくとも以下の6種類の文書タイプを設けることも可能である。
・担当者Aに関連する文書を示す分類タイプ(担当者A文書タイプ)、
・担当者Bに関連する文書を示す分類タイプ(担当者B文書タイプ)、
・担当者Cに関連する文書を示す分類タイプ(担当者C文書タイプ)、
・担当者Dに関連する文書を示す分類タイプ(担当者D文書タイプ)、
・担当者Eに関連する文書を示す分類タイプ(担当者E文書タイプ)、
・ユーザが不要であるとした文書を示す分類タイプ(不要文書タイプ)。
【0018】
なお、分類タイプの一つとして、更に、ユーザが未だ分類タイプを入力していない文書であることを示すタイプ(ここでは、未読文書タイプと呼ぶ)を設けることも可能である。例えば、上記具体例において、更に未読文書タイプを使用する場合には、ユーザが幾つかの文書に対して必要文書タイプを入力し、他の幾つかの文書に対して不要文書タイプを入力した場合に、残りの文書には、自動的に、「未読文書タイプ」が付与されることになる。
【0019】
図1に、第1の実施形態の拾い読み支援システムの機能構成例を示す。
【0020】
図1に示されるように本実施形態の拾い読み支援システムは、拾い読み支援システムの構成は、拾い読み単語抽出部101、ハイライト箇所特定部102、テキスト表示部103、ユーザ入力部104、文書データ記憶部105、分類情報記憶部106を備えている。
【0021】
文書データ記憶部105は、複数の文書のデータを記憶する。
【0022】
文書は、どのようなものであっても良い。例えば、文書は、何らかのドキュメント本文であっても良いし、そのドキュメント本文に対する要約文であっても良い。例えば、ドキュメント本文が特許明細書であり、文書データ記憶部105に記憶される各文書が、各特許明細書に対応する要約文である場合に、ユーザは、各要約文に対応する各特許文書を実際に読むかどうかを判断するために、各要約文を拾い読みすることがある。本実施形態では、文書の例として、特許明細書の要約文を例にとりつつ説明する。
【0023】
図2に、文書データ記憶部105に記憶される文書データの一例を示す。図2の例では、各文書データに、文書識別子(以下、文書ID)(図中、0001〜0006)が付与されている。なお、文書データの記憶フォーマットは、図2に制限されない。
【0024】
なお、文書データ記憶部105に記憶される文書データは、記録媒体から入力されたものであっても良いし、インターネットなどのネットワークを介してダウンロードされたものであっても良いし、キー入力された文書を含んでも良いし、他のどのような方法で得られたものであっても良い。
【0025】
また、文書データ記憶部105に記憶される文書データは、例えば、文書ID又は他の何らかの基準によってソートされていても良いし、特にソートされていなくても良い。
【0026】
テキスト表示部103は、文書データ記憶部105に記憶されている複数の文書(その文書数をNとする)について、一度に所望の文書数dの文書を表示する。なお、ここでは、2≦d≦Nとして説明するが、d=1の表示状態があっても構わない。
【0027】
その際、表示の仕方に制限はなく、例えば、表示対象となった各々の文書について、その文書全体を表示する方法も可能であり、また、例えば、その文書の一部を表示する(例えば、その文書を、予め定められた上限となる文字数の部分まで表示し、残りの部分はユーザが所定の操作を行うことによって表示されるようになる)方法も可能である。また、一つの画面に同時に表示する文書数nをユーザが指示できるようにしても良いし、一つの文書について表示する上限文字数をユーザが指示できるようにしても良いし、その他にも様々な表示方法が可能である。
【0028】
また、複数の文書のうちの一部の文書を表示する場合に、表示する文書の選択方法に制限はない。例えば、表示する文書を、文書ID又は他の何らかの基準によって選択しても良いし、ユーザが表示する文書を指示しても良い。
【0029】
ユーザ入力部104は、ユーザが指定する文書の指示とその文書に対するユーザが指定する分類タイプの指示を入力する。例えば、ユーザは、テキスト表示部103に表示された文書のうちから、所定の方法で所望の文書を選択するとともに、その文書に対する所望の分類タイプを所定の方法で選択しても良い。なお、文書選択方法や分類タイプ選択方法に特に制限はない。
【0030】
分類タイプは、分類方法が予め1種類に定められていても良いし(例えば、「必要文書タイプ」「不要文書タイプ」のいずれか)、分類方法が予め複数種類に定められていて、それらのうちからユーザが選択するようにしても良いし(例えば、「必要文書タイプ」「不要文書タイプ」のいずれか、又は、「担当者A文書タイプ」)〜「担当者E文書タイプ」のいずれか)、いつでもユーザが自由な分類タイプを任意に設定可能であっても良いし、それらの組み合わせであっても良い。
【0031】
分類情報記憶部106は、各々の文書IDと、当該文書IDに対する分類タイプとの対応を示す文書分類情報を記憶する。
【0032】
図3(a)に、分類情報記憶部106に記憶される文書分類情報の例を示す。図3(a)の例は、分類タイプが何も入力されていない初期的な状態を示す。以下、一例として、文書分類情報において、「不要文書タイプ」については値「A」が記憶され、「必要文書タイプ」については値「B」が記憶されるものとして説明する。
【0033】
なお、前述の「未読文書タイプ」を使用しない場合には、図3(a)の例を使用すれば良い。また、「未読文書タイプ」を使用する場合には、図3(b)のように文書分類情報の初期状態として全文書について、ユーザが入力する分類タイプ以外の値(例えば値「C」)を記憶しておき、値「C」が記憶されている文書は、「未読文書タイプ」として扱うようにしても良いし、または、図3(a)の例を使用して、値が何も記憶されていない(あるいは、値が「null」である)文書は、「未読文書タイプ」として扱うようにしても良い。
【0034】
いずれの場合においても、文書データ記憶部105に記憶されている文書の文書数がNである場合に、文書分類情報においてユーザにより入力された分類タイプに対応する値が記憶される数cは、0≦c≦Nである。
【0035】
以下では、c=0の場合には、ハイライト表示を行わないものとし、また、c=Nに達した場合には、すべての文書についてユーザによる分類がなされたことを意味するので、それ以上の拾い読み単語抽出部101及びハイライト箇所特定部102の処理は、行わないものとする。ただし、「未読文書タイプ」を使用する場合に、c=0のときに、ハイライト表示を行うことも可能である。
【0036】
また、以下では、まだユーザにより分類タイプが付与されていない(N−c)個の文書のみを、ハイライト表示の対象とするものとして説明する。ただし、N個のすべての文書を、ハイライト表示の対象とすることも可能である。
【0037】
拾い読み単語抽出部101は、文書分類情報において、少なくとも一つの文書について、ユーザにより入力された分類タイプが記憶されている場合に(すなわち、c≧1である場合に)、文書分類情報中に対応する値が存在する分類タイプごとに、当該分類タイプに対応する文書から、当該分類タイプに特徴的な単語のリストを作成する。その際、各単語について、当該分類タイプに特徴的である程度を表すスコアを計算する。
【0038】
図4に、拾い読み単語抽出部101がその処理において作成するスコア付けされた単語リスト(スコア付単語リスト)の例を示す。本具体例のように「必要文書タイプ」及び「不要文書タイプ」を使用する場合には、文書タイプごとにスコア付単語リストが作成される。図4(a)及び(b)の例は、それぞれ、「不要文書タイプ」用のスコア付単語リスト及び「必要文書タイプ」用のスコア付単語リストの初期的な状態を示す。なお、「未読文書タイプ」を使用する場合には、更に、「未読文書タイプ」用のスコア付単語リストも設けられる。
【0039】
各々の分類タイプごとに、そのスコア付単語リスト中の単語が、ハイライト表示されるものとして選択される。なお、例えば、スコア付単語リスト中の単語が予め定められた個数kを超えた場合には、スコア付単語リスト中でスコアが上位のk個を選択する方法、スコアが予め定められた閾値以上の単語のみ使用する方法など、あるいは、それらを組み合わせた方法なども可能であり、また、他の様々な方法が可能である。
【0040】
なお、文書分類情報中に対応する値が存在しない分類タイプについては、その間、スコア付単語リストは作成されない。例えば、上記具体例において、文書分類情報中に、図3(a)については値「B」のみ存在する場合に、図3(b)については、「B」及び「C」のみ存在する場合に、値「A」に対応する「不要文書タイプ」については、スコア付単語リストは作成されない。
【0041】
以下、各々の分類タイプごとに、ハイライト表示されるものとして選択された単語(又は又は用語又はフレーズ)を、「拾い読み単語候補」と呼ぶものとする。
【0042】
ハイライト箇所特定部102は、ユーザが分類タイプを入力していない各々の文書について、当該文書中で各々の「拾い読み単語候補」が出現する箇所を探し(なお、「拾い読み単語候補」の全部又は一部が存在しないこともある)、当該文書中において出現する各々の「拾い読み単語候補」からハイライトすべき箇所を選択する。例えば、一つの文書において、同一の「拾い読み単語候補」について1箇所のみハイライト表示するものとした場合に、ある文書中にある「拾い読み単語候補」が複数存在するときに、いずれの箇所をハイライト表示するかを選択する。
【0043】
ユーザが少なくとも一つの文書に対して分類タイプを入力した後は、テキスト表示部103は、ユーザが分類タイプを入力していない文書について、その文書中の単語のうち、拾い読み単語抽出部101により分類タイプごとに抽出された単語であって且つハイライト箇所特定部102により特定された箇所の単語をハイライト表示する。
【0044】
その際、「拾い読み単語候補」をハイライト表示するにあたって、その分類タイプに対応するハイライト形態でハイライト表示するようにしても良い。例えば、フォントを変えることによって拾い読み単語候補を示す場合に、分類タイプごとに、文字の色等のフォントを変えても良いし、拾い読み単語候補を枠で囲んで示す場合に、分類タイプごとに、枠の形状、線種、色、枠内のハッチングの有無、ハッチングの種類等を変えても良いし、それらを組み合わせても良いし、また、他にも様々なハイライト形態が可能である。
【0045】
また、例えば、必要文書タイプを一番に目立つハイライト形態、不要文書タイプを次に目立つハイライト形態、未読文書タイプをその次に目立つハイライト形態にするような方法も可能である。
【0046】
ユーザ入力部104でユーザからの入力が起こると、分類情報記憶部106が更新され、拾い読み単語抽出部101、ハイライト箇所特定部102、テキスト表示部103の一連の処理が行われる。
【0047】
なお、上記一連の処理は、ユーザ入力部104から一つの文書に係る文書分類情報を入力するごとに、これを契機として実行することとしても良いし、あるいは、ユーザ入力部104から文書分類情報が入力されただけでは、上記一連の処理を実行せず、(例えばユーザ入力部104から)上記一連の処理を実行するための所定の指示が入力されたときに、これを契機として上記一連の処理を実行することとしても良い。
【0048】
ここで、図5のシステム画面例を参照しながら、本実施形態の全体的な動作例の概要について説明する。図5では、各文書が特許明細書に対応する要約文である場合を例にとって説明する。
【0049】
なお、以下では、必要文書タイプを「○」、不要文書タイプを「×」でも表すものとする。
【0050】
まず、テキスト表示部103が、図5のシステム画面(121)の内側に、各文書(図中、122参照)を表示する。なお、初期的な状態では、ユーザによる分類タイプの入力がなされておらず、実際には図5と異なり、「○」「×」は表示されておらず、ハイライト表示も行われていない。
【0051】
図5の具体例は、システム画面(121)の内側に、各文書を5行2列に表示するものである。
【0052】
次に、ユーザは、図5のシステム画面(121)中に表示された文書を任意に読む。
【0053】
なお、図5の5行2列に表示する例において、11以上の文書が存在する場合には、ユーザは、例えばスクロール又はページ更新をするなどして他の文書を表示させても良い。もちろん、文書の表示は、5行2列の表示に制限されない。
【0054】
そして、ユーザは、分類タイプを入力すると判断した文書を選択するとともに、その文書についてユーザが判断した分類タイプを選択することによって、文書分類情報{文書,分類タイプ}を入力する。すなわち、システム側は、ユーザ入力部104において、ユーザが選択する{文書,分類タイプ}の入力を受け付ける。
【0055】
例えば、ユーザが124で示される文書を読んで、この文書を不要と判断した場合(例えば、この要約文に対応する特許明細書の全文は読まなくて良いと判断した場合)、この文書データ(124)に対して不要文書タイプ記号「×」をユーザが選択する。
【0056】
同様の、ユーザが125で示される文書を読んで、この文書を必要と判断した場合(例えば、この要約文に対応する特許明細書の全文は読む必要があると判断した場合)、この文書データ(124)に対して必要文書タイプ記号「○」をユーザが選択する。
【0057】
なお、ユーザは、それら以外の文書には分類を付与していないとする。
【0058】
この場合に、図5に示されるように、分類が付与された文書124,125についてそれぞれ付与された分類タイプを示す「×」「○」が表示されても良い。もちろん、他の付与された分類タイプを識別可能にしても良い。
【0059】
さて、文書データ124,125に対して分類タイプが付与されたときに、システム内では、文書データ124の文書ID及び付与された分類タイプを示す文書分類情報と、文書データ125の文書ID及び付与された分類タイプを示す文書分類情報を受け取る。
【0060】
そして、上記二つの文書分類情報をもとに、拾い読み単語抽出部101の処理、ハイライト箇所特定部102の処理、テキスト表示部103の処理からなる一連の処理を行って、図5に例示されるように、文書データ124,125以外の文書に対して、拾い読み単語をハイライト表示する。
【0061】
なお、拾い読み単語抽出部101では、分類タイプごとにスコアを計算する。
【0062】
例えば、図5中のタイプ分け凡例(123)のように、必要文書タイプ・不要文書タイプ・未読文書タイプの3分類でそれぞれスコアの高い語を用意することで、タイプごとに単語のハイライト方法を変えることができる。
【0063】
異なるハイライト方法を適用する例として、例えば、前述のようにハイライト色を変更しても良い。例えば、必要文書タイプをピンク、不要文書タイプを黄色、未読文書タイプを緑で各タイプの拾い読み単語をハイライトしても良い。
【0064】
図5では、タイプごとに単語のハイライト方法を変える様子を例示するために、必要文書タイプでハイライトする単語の部分についてはクロスハッチング枠で、不要文書タイプについては斜線ハッチング枠で、未読文書タイプについてはハッチングなしの枠で、それぞれハイライトを行う例を示した。
【0065】
図5に例示するような表示状態において、ユーザは、単語にハイライトが付加された文書群を閲覧しながら、ハイライトされた単語を中心に拾い読みすることができ、更に、未分類の文書へ分類を付与していくことができる。その際、例えば、必要に応じてハイライトされた単語の周辺単語も合わせて読むこともできる。
【0066】
図6に、本実施形態の拾い読み支援システムの処理手順の一例を示す。
【0067】
ステップS1において、テキスト表示部103は、初期的に文書を表示する。
【0068】
図7に、図2に例示した文書を表示した例を示す。
【0069】
なお、この初期の段階では、分類情報記憶部106に記憶される文書分類情報は、図3(a)又は図3(b)に例示したようになる。また、スコア付単語リストは、図4に例示したようになる。
【0070】
ステップS2において、ユーザ入力部104は、ユーザから文書分類情報{文書ID,分類タイプ}の入力を受け付ける。
【0071】
ステップS3において、入力された上記の文書分類情報{文書ID,分類タイプ}を、分類情報記憶部106に記録する。
【0072】
ここでは、図2の文書ID=0001〜0003の各文書に対して、それぞれ、「不要文書タイプ」「不要文書タイプ」「必要文書タイプ」がユーザにより入力されているものとすると、分類情報記憶部106に記憶された文書分類情報例は、図3(a)については図8(a)に例示するようになり、図3(b)については図8(b)に例示するようになる。
【0073】
なお、ステップS4において、終了条件が成立したならば、処理を終了し、終了条件が成立していないならば、次のステップS5に進む。
【0074】
終了条件には、種々のものが考えられる。例えば、文書データ記憶部105に記憶されている文書の文書数がNである場合に、N個の文書すべてについて上記の文書分類情報{文書ID,分類タイプ}がユーザにより入力されたことを終了条件としても良いし、あるいは、上記の文書分類情報{文書ID,分類タイプ}がユーザにより入力された文書の数をcとして、(N−c)の値(すなわち、まだユーザにより分類タイプが付与されていない文書の数)が、予め定められた閾値を下回ったことを終了条件としても良い。もちろん、これらに制限されない。
【0075】
さて、ステップS4において、終了条件が成立していないならば、以下の一連の処理が行われる。
【0076】
ステップS5において、拾い読み単語抽出部101の処理を行って、スコア付単語リストを作成する。
【0077】
例えば、「不要文書タイプ」用のスコア付単語リストが図9(a)に例示するようになり、「必要文書タイプ」用のスコア付単語リストが図9(b)に例示するようになる。なお、a1,a2,b1,b2はそれぞれのスコア値を示している。また、各スコア付単語リストは、スコア順にソートされても良い。
【0078】
ステップS6において、ハイライト箇所特定部102の処理を行って、各文書中のハイライト箇所を特定する。
【0079】
ステップS7において、テキスト表示部103の処理を行って、テキスト表示(のハイライト状態)を更新する(例えば後で説明する図13参照)。
【0080】
以下、拾い読み単語抽出部101、ハイライト箇所特定部102、テキスト表示部103の各処理について順番に詳しく説明する。
【0081】
まず、拾い読み単語抽出部101について説明する。
【0082】
拾い読み単語抽出部101は、文書データと既知の分類とから、拾い読みに適した単語を抽出するモジュールである。
【0083】
図10に、拾い読み単語抽出部101の処理手順の一例を示す。
【0084】
ステップS11において、拾い読み単語抽出部101は、文書データ記憶部105及び分類情報記憶部106から、文書データとそれに対してユーザにより付与された分類を読み込む。
【0085】
ステップS12において、各文書の分類及び各文書の単語から、拾い読み単語としてのスコアを計算する。
【0086】
ステップS13において、スコア順に単語をソートし、上位の単語を拾い読み単語候補とし、ステップS14において、拾い読み単語候補とそのスコアを出力する。
【0087】
拾い読み単語のスコア計算として、例えば、次のような式で計算を行っても良い。ここでは、『ある文書D内に出現する単語tを見た場合、この文書Dが文書タイプCであるとすぐに判断できるかどうか』、というスコアとして速判度(t,C)を導入する。
速判度(t,C)=読みコスト(t)×判別度(t,C) …(1)
ここで、読みコストとは、人が単語を認識するのにかかるコストを指し、文字長や文字の複雑さなどに依存する。例えば、文字数の逆数(例:1/(文字数))などとする。また、ひらがな・カタカナなどの文字種は、漢字に比べて画数が少なく目につきやすいことを考慮して、スコアを上げるなどの工夫が考えられる(例:k/(文字数))。
【0088】
判別度とは、ある文書タイプCの判別に使える単語であるかの度合いを指す。ある単語が、文書タイプCらしい単語あるいは文書タイプCらしくない単語であれば、判別度は高く、逆に、文書タイプCなのかがわかりにくい単語であれば、判別度は低い。例えば、tf(t)*log(df(t|C)/df(t))*score_pos(t)といった式で計算する。ここで、tf(t)は、単語tの文書D内での単語頻度、df(t|C)は、文書タイプCに分類された文書での、単語tの出る文書数、df(t)は、単語tの出る文書数、score_pos(t)は、単語tの品詞のスコアで例えば単語tが名詞のときの名詞スコアを指す。このとき、名詞のスコアを高く設定するなどして、特定の品詞の単語のスコアが高くなるようにもできる。
【0089】
次に、ハイライト箇所特定部102について説明する。
【0090】
ハイライト箇所特定部102は、各々の文書について、当該文書中で拾い読み単語抽出部101により選択された拾い読み単語候補が出現する箇所を探し、当該文書中でハイライトすべき箇所を選択するモジュールである。
【0091】
図11に、ハイライト箇所特定部104の処理手順の一例を示す。
【0092】
ここで、Lはハイライト語数の上限、Nは文書数、Mはハイライト単語候補の総数、Xは文書i中のハイライト単語として記憶している単語数である。
【0093】
まず、ハイライトする箇所が多いと拾い読みにならないため、ハイライト語数の上限Lを設定する。
【0094】
ステップS21において、ハイライト箇所特定部104は、文書データ記憶部105から文書データを読み込むとともに、拾い読み単語抽出部101の出力する単語リストとスコアを読み込む。
【0095】
ステップS22において、iに1を代入する。
【0096】
ステップS23〜S25では、各文書について、各拾い読み単語候補が出現しているかを確認する。
【0097】
ただし、文書データ記憶部105の総文書数をN、拾い読み単語候補の総数をMとする。
【0098】
文書iで、単語jがp回出現した場合、ステップS27において、ハイライトする単語位置を、p個の単語jの中から選択する。例えば、初出の箇所を選択する、近傍単語重要度で選択する、複合語に含まれない単語を選択するなどである。ここで、近傍単語重要度とは、単語tの近傍に出現する語の重要度を指す。ハイライト箇所には目が行くため、その近傍にも重要語がある方をよりスコアを高くするものである。なお、重要語の計算には、一般的にキーワード抽出として知られる計算式などを使って計算できる。例えば、近傍単語重要度(ti)を、その周辺の語tjの重要度とtiまでの距離を使いスコア付けし、Σj {tf(tj)*log(N/df(tj))*(1/|j−i|)}といった式で表す。ここで、Nは、全文書数を表し、j−iは単語tiとtjの距離を表す。また、複合語を構成する1単語となっている場合には、1単語だけでは意味をなさない可能性があるため、スコアを低くするなどでもよい。
【0099】
ステップS28では、文書iに対しハイライトする単語とその出現位置を記憶し、ハイライト単語数Xがハイライト語数の上限L以下である間同様の操作を繰り返す。
【0100】
ステップS25において条件一致がNoになった場合、ステップS23へ戻り、次の文書i+1に進み、ステップS24〜S28について同様の作業を繰り返す。
【0101】
ステップS21で読み込んだ文書すべてにハイライト箇所特定が終わったならば、ステップS29で各文書のハイライト単語とその位置を出力する。
【0102】
次に、テキスト表示部103について説明する。
【0103】
テキスト表示部103は、文書データ記憶部105の各文書データに対し、ハイライト箇所特定部102で特定したハイライト単語位置をハイライトして表示するモジュールである。
【0104】
図12に、テキスト表示部103の処理手順の一例を示す。
【0105】
ステップS31において、テキスト表示部103は、文書データ記憶部105の文書データを読み込むとともに、ハイライト箇所特定部102で出力するハイライトの単語とその位置を読み込む。
【0106】
ステップS32において、文書データ中のハイライト箇所にハイライトを施して、各文書データを出力する。
【0107】
図5は、各文書データのハイライトの一例である。
【0108】
また、図13に、各文書データの他のハイライト例を示す。図13は、図7に例示された文書群のうち、最初の3文書に分類が付与された際の他の文書の表示例である。また、図5と同様、必要文書タイプはクロスハッチング枠で、不要文書タイプは斜線ハッチング枠で、未読文書タイプはハッチングなしの枠でそれぞれハイライトする例を示した。
【0109】
さて、上記のようなハイライト表示された後に、ユーザは更に未分類の文書に対して、分類を付与することができる。
【0110】
ユーザ入力部104は、テキスト表示部103で表示した各文書に対し、ユーザが付与する分類を受け付けるモジュールである。図5の各文書に対し、ユーザは分類を付与する(例:「○」「×」)。このとき、ユーザ入力部104がこの分類情報を受け取る。ユーザ入力部104がユーザの付与した分類を受け取ると、続けて101〜103の処理を行い、ハイライト単語の更新を行う。
【0111】
次に、処理の具体的な例を示す。
【0112】
図13のような6つの文書1201〜1206が存在した場合で、最初の3つの文書1201〜1203に分類が付与された場合で考える。分類情報記憶部106には、文書1201に「×」、文書1202に「×」、文書1203に「○」が与えられている。
【0113】
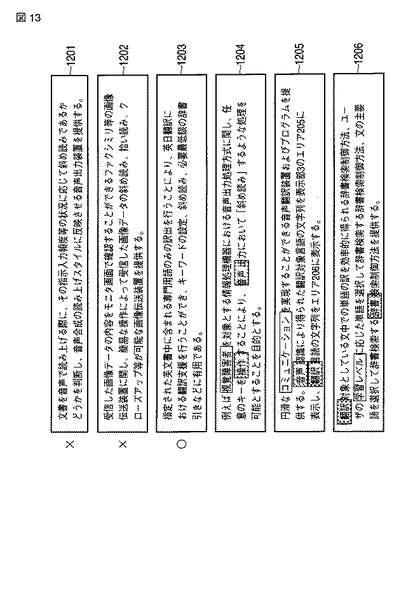
この3文書と分類を元に、拾い読み単語抽出部101で、単語抽出を行う。式(1)のscore_posにおいて、名詞について1、それ以外について0である場合に、格文書から名詞を抽出する。文書1201から、「文書」「音声」「指示」「入力」「頻度」「状況」「合成」「売上げ」「スタイル」「出力」「装置」といった名詞を抽出する。同様に、文書1202、文書1203からも名詞を抽出する。そして、抽出された各々の名詞について、式(1)の計算をする。この例では文書数が少なく単語間でスコアがほとんど変わらないため、各名詞が出現する文書の分類に対応する拾い読み単語候補となる。文書1204で上記3文書に出てきた名詞は、「操作」「音声」「出力」である。このうち、「出力」は文書1201中で複合語でしか出てこないため、スコアを下げ、「操作」と「音声」をハイライトするとする。
【0114】
続いて、ハイライト箇所特定部で、文書1204中でハイライトする単語を選ぶ。「操作」は一回しか出現しないため、そのまま選択する。また、「音声」は、「音声出力処理方式」と「音声出力」の2箇所に出現する。この際には、例えば、いずれも複合語なので、より短い「音声出力」の方の「音声」をハイライトすることにし、2回目の「音声」をハイライト箇所とする。
【0115】
なお、上記では、具体例として日本語を用いて説明したが、本実施形態は他の言語の場合にも同様に適用可能である。
【0116】
本実施形態によれば、例えば特許調査・文献調査・市場調査などのように多数の文書を漏れなく網羅的に内容を調査したいようなケースにおいて、ユーザが多数の文書(例えばドキュメント本文又はその要約文)のうちの幾つかの文書を読みながら、例えば読んで確認すべき或いは精読すべき文書とそうでない文書等の分類や、分担して読む担当を分けるための分類などを付与し、ユーザによる分類が付与された文書をもとに、例えば未分類の文書から分類判断のための拾い読みに適した単語や、未分類の文書を弁別する根拠となりそうなキーワードなどを抽出し、適切な箇所にハイライト表示やマーカ付与を行って提示することによって、ユーザ自身が行っている拾い読みを効率的に行えるように支援することができる。
【0117】
(第2の実施形態)
第2の実施形態では、第1の言語で既に分類が付与されているときに、その分類を利用して、第1の言語とは異なる第2の言語の文書で拾い読み用のキーワードをハイライトする例を示す。
【0118】
例えば、第1の言語をユーザの母国語とし、第2の言語を外国語としても良いし、逆に、第2の言語をユーザの母国語とし、第1の言語を外国語としても良い。
【0119】
ここでは、第1の言語を英語、第2の言語を日本語とする場合を例に取りつつ説明する。
【0120】
図14に、第2の実施形態に係る支援システムの機能構成例を示す。
【0121】
図14に示されるように、拾い読み支援システムの構成は、拾い読み単語抽出部101、置換部201、二言語間辞書202、ハイライト箇所特定部102、テキスト表示部103、ユーザ入力部104、第1言語文書データ記憶部203、第1言語分類情報記憶部204、第2言語文書データ記憶部205、第2言語分類情報記憶部206を備える。
【0122】
第1言語文書データ記憶部203には、第1言語での文書データが保存されている。また、各文書に対応した分類がすでに付与されており、その分類情報が第1言語分類情報記憶部204に保存されている。
【0123】
拾い読み単語抽出部101は、基本的には第1の実施形態と同様にして、第1言語文書データ記憶部203及び第1言語分類情報記憶部204の情報を読み込み、拾い読み単語抽出を行う。第1言語分類情報記憶部204の内容は変化しないので、ここでの抽出は、1回のみ行えば良い。
【0124】
一方、第2言語文書データ記憶部205は、第1の実施形態の文書データ記憶部105に対応し、第2言語分類情報記憶部206は、第1の実施形態の分類情報記憶部106に対応する。拾い読み単語抽出部101は、第2言語文書データ記憶部205及び第2言語分類情報記憶部206について、第1の実施形態と同様の処理を繰り返し行うことになる。
【0125】
拾い読み単語抽出部101で出力された拾い読み単語候補とスコアは、置換部201に入力される。
【0126】
置換部201は、第1言語文書データ記憶部203及び第1言語分類情報記憶部204を対象として拾い読み単語抽出部101により抽出された第1言語による単語を、(文書データ上の第2言語の単語との対応を付けるために)第2言語の単語に置き換えるためのモジュールである。
【0127】
置換部201では、第1言語で記載された拾い読み単語候補から、二言語間辞書202を用いて第2言語への翻訳単語を検索し、第2言語の翻訳語を作成する。このとき、第2言語の翻訳語が複数ある単語の場合や、第2言語の翻訳語になる第1言語の単語が他にもある場合には、第1言語から第2言語へ翻訳すると曖昧性が生じている可能性があるため、このような場合にはこの単語の拾い読み単語スコアを下げるなどして、あいまい性のない他の単語を優先する。
【0128】
ハイライト箇所特定部102、テキスト表示部103、ユーザ入力部104の一連の処理は、基本的には第1の実施形態と同様である。ただし、ハイライト箇所特定部102とテキスト表示部103が読み込む文書データは、第2言語文書データ記憶部205、ユーザ入力部104で付与された分類情報を記憶するのは第2言語分類情報記憶部206である。
【0129】
第2の実施形態では、ユーザが分類したい文書データである第2言語の文書データに分類がまだ付与されていない状況でも、ユーザが既に分類を付与した第1言語のデータ、すなわち第1言語文書データ記憶部203と第1言語分類情報記憶部204から、拾い読み単語抽出部101の処理を行うことができる。
【0130】
また、第2言語分類情報記憶部206にデータが追加された後は、第2言語文書データ記憶部205と第2言語分類情報記憶部206のデータから拾い読み単語抽出部101の処理を行うこともできる。
【0131】
後者の場合には、置換部201が不要となる(図1の構成に切り替わる)。
【0132】
図15に、拾い読み単語抽出部101の処理手順の一例を示す。
【0133】
まだ、ユーザにより文書に対して分類が付与されていない初期の状態において処理を行う場合には(ステップS41でYes)、拾い読み単語抽出部101は、第1言語文書データ記憶部203及び第1言語分類情報記憶部204の情報を用いて、第1言語のスコア付単語リストを作成する(ステップS42)。図16に、そのスコア付単語リストの一例を示す。なお、図16(a)のスコア付単語リストは、置換部201及び二言語間辞書202により、単語が第1言語から第2言語へ置換される。図16(b)に、その一例を示す。なお、s1はスコア値を示している。
【0134】
ユーザにより少なくとも一つの文書に対して分類が付与された後に処理を行う場合には(ステップS41でNo)、拾い読み単語抽出部101は、第2言語文書データ記憶部205及び第2言語分類情報記憶部206の情報を用いて、第2言語のスコア付単語リストを作成する(ステップS43)。本具体例では、例えば、図9のようになる。そして、ステップS42で既に作成されている第1言語のスコア付単語リスト(単語を置換したもの)と、このステップS43で作成された第2言語のスコア付単語リストとを、マージする。
【0135】
なお、予め定められた条件が成立した場合には、ステップS43を行わずに、第2言語のスコア付単語リストのみを使用するようにしても良い。
【0136】
予め定められた条件は、例えば、第2言語の全文書数をN、第2言語の文書に対してユーザにより分類タイプが付与された文書数をcとして、c/Nが予め定められた値を上回った場合、若しくは、cが予め定められた値を上回った場合、又は、最初に第2言語の文書に対してユーザにより分類タイプが付与されてから、所定の時間が経過した場合など、様々なものが可能である。
【0137】
(第2の実施形態の変形例1)
なお、上記において第1の言語を第2の言語と同じにすることも可能である。この場合には、置換部201及び二言語間辞書202が不要になる。
【0138】
(第2の実施形態の変形例2)
第2の実施形態の変形例2では、第2の実施形態で第2言語の文書中の単語をハイライト表示する代わりに、第1言語で単語を翻訳して表示する例を示す。
【0139】
第2の実施形態の変形例の機能構成例は、図14と同様で構わない。
【0140】
ただし、置換部201からの出力は、拾い読み単語抽出部101から出力された第1言語の単語の第2言語への翻訳だけでなく、第1言語と第2言語への翻訳のセットにし、ハイライト箇所特定部102へと渡される。
【0141】
ハイライト箇所特定部102の処理は、第2の実施例と同様の処理を行うが、その際の出力は、第1言語と第2言語への翻訳のセットにしてテキスト表示部103へ渡される。
【0142】
テキスト表示部103の処理は、第2の実施形態と異なる。
【0143】
図17に、テキスト表示部103の処理手順の一例を示す。
【0144】
ステップS51において、テキスト表示部103は、第2言語文書データと、ハイライト箇所特定部102の出力であるハイライト単語・その単語の第1言語への翻訳語・ハイライト単語位置を入力する。
【0145】
ステップS52において、第2言語文書データを表示するとともに、ハイライト箇所の単語を第1言語への翻訳単語に変換して文中に表示する。
【0146】
図18に、第2の実施形態の変形例2のスコア付単語リストの例を示す。
【0147】
拾い読み単語抽出部101により生成される第1の言語のスコア付単語リストの例を、(a)に示す。第1の言語の単語を第2の言語に置換し、これを更にスコア付単語リストに追加した例を、(b)に示す。なお、e1はスコア値を示している。
【0148】
拾い読み単語抽出部101により生成される第2の言語のスコア付単語リストの例を、(c)に示す。第2の言語の単語を第1の言語に置換し、これを更にスコア付単語リストに追加した例を、(d)に示す。なお、j1はスコア値を示している。
【0149】
図19に、第2言語(日本語)の文書を表示する際に、各分類タイプについて抽出された単語について、第1言語(英語)でハイライトする例を示す。また、図19では、更に、必要文書タイプは枠で、不要文書タイプは斜線ハッチング枠で、更なるハイライトを行い、未読文書タイプは第1言語(英語)でのハイライトのみとした例を示している。
【0150】
(第3の実施形態)
第3の実施形態では、拾い読みに使う単語をユーザ自身が選択する例を示す。
【0151】
図20に、第3の実施形態に係る支援システムの機能構成例を示す。
【0152】
図20は、最初にユーザが拾い読みに使う単語を幾つか入力し、それを元に初期動作を始める場合の例である。
【0153】
単語入力部301は、ユーザが拾い読みに使う単語の入力を受け付ける。この場合、ユーザによって入力された単語をそのまま拾い読み単語候補とし、この候補語を元にハイライト箇所特定部102でハイライト箇所を特定する。その他の処理は、第1の実施形態と同様である。なお、ユーザ入力部104でユーザ入力後、分類情報記憶部106の更新にともない拾い読み単語抽出部101、ハイライト箇所特定部102、テキスト表示部103の一連の処理が行われる際にも、単語入力部301から新たに単語入力をしても良い。
【0154】
(第4の実施形態)
第4の実施形態では、拾い読みに使う単語をユーザ自身が選択する例を示す。
【0155】
図21に、第2の実施形態に係る支援システムの機能構成例を示す。
【0156】
図21は、拾い読み単語抽出部101で計算された拾い読み単語候補中から、ユーザが拾い読みに使いたい単語を選択する場合の例である。
【0157】
拾い読み単語抽出部101、ハイライト箇所特定部102、テキスト表示部103、ユーザ入力部104の処理は、第1の実施形態と同様である。
【0158】
拾い読み単語選択部401では、拾い読み単語抽出部101で抽出された拾い読み単語候補をユーザに提示する。ユーザは、使いたい拾い読み単語あるいは使いたくない拾い読み単語を選択し、その選択を拾い読み単語選択部401が受け付ける。選択の結果、ユーザに拾い読み単語として使いたい単語の優先度を高くし、ハイライト箇所特定部102へスコア付の単語リストとして入力する。
【0159】
なお、これまでに説明してきた各実施形態や変形例は、任意に組み合わせて実施することが可能である。
【0160】
また、本実施形態(これまで説明してきた各実施形態や変形例又はそれらを任意に組み合わせたもののいずれによっても)、多数の文書の拾い読みを支援することができる。
【0161】
また、上述の実施形態の中で示した処理手順に示された指示は、ソフトウェアであるプログラムに基づいて実行されることが可能である。汎用の計算機システムが、このプログラムを予め記憶しておき、このプログラムを読み込むことにより、上述した実施形態の拾い読み支援システムによる効果と同様な効果を得ることも可能である。上述の実施形態で記述された指示は、コンピュータに実行させることのできるプログラムとして、磁気ディスク(フレキシブルディスク、ハードディスクなど)、光ディスク(CD−ROM、CD−R、CD−RW、DVD−ROM、DVD±R、DVD±RWなど)、半導体メモリ、またはこれに類する記録媒体に記録される。コンピュータまたは組み込みシステムが読み取り可能な記録媒体であれば、その記憶形式は何れの形態であってもよい。コンピュータは、この記録媒体からプログラムを読み込み、このプログラムに基づいてプログラムに記述されている指示をCPUで実行させれば、上述した実施形態の拾い読み支援システムと同様な動作を実現することができる。もちろん、コンピュータがプログラムを取得する場合または読み込む場合はネットワークを通じて取得または読み込んでもよい。
また、記録媒体からコンピュータや組み込みシステムにインストールされたプログラムの指示に基づきコンピュータ上で稼働しているOS(オペレーティングシステム)や、データベース管理ソフト、ネットワーク等のMW(ミドルウェア)等が本実施形態を実現するための各処理の一部を実行してもよい。
さらに、本実施形態における記録媒体は、コンピュータあるいは組み込みシステムと独立した媒体に限らず、LANやインターネット等により伝達されたプログラムをダウンロードして記憶または一時記憶した記録媒体も含まれる。
また、記録媒体は1つに限られず、複数の媒体から本実施形態における処理が実行される場合も、本実施形態における記録媒体に含まれ、媒体の構成は何れの構成であってもよい。
【0162】
なお、本実施形態におけるコンピュータまたは組み込みシステムは、記録媒体に記憶されたプログラムに基づき、本実施形態における各処理を実行するためのものであって、パソコン、マイコン等の1つからなる装置、複数の装置がネットワーク接続されたシステム等の何れの構成であってもよい。
また、本実施形態におけるコンピュータとは、パソコンに限らず、情報処理機器に含まれる演算処理装置、マイコン等も含み、プログラムによって本実施形態における機能を実現することが可能な機器、装置を総称している。
【0163】
本発明のいくつかの実施形態を説明したが、これらの実施形態は、例として提示したものであり、発明の範囲を限定することは意図していない。これら新規な実施形態は、その他の様々な形態で実施されることが可能であり、発明の要旨を逸脱しない範囲で、種々の省略、置き換え、変更を行うことができる。これら実施形態やその変形は、発明の範囲や要旨に含まれるとともに、特許請求の範囲に記載された発明とその均等の範囲に含まれる。
【符号の説明】
【0164】
101…拾い読み単語抽出部、102…ハイライト箇所特定部、103…テキスト表示部、104…ユーザ入力部、105…文書データ記憶部、106…分類情報記憶部、201…置換部、202…二言語間辞書、203…第1言語文書データ記憶部、204…第1言語分類情報記憶部、205…第2言語文書データ記憶部、206…第2言語分類情報記憶部、301…単語入力部、401…拾い読み単語選択部。
【特許請求の範囲】
【請求項1】
識別情報が対応付けられた複数の文書を記憶するための文書記憶部と、
前記複数の文書のうちの全部又は一部を、単語又はフレーズのハイライト表示を伴って又はハイライト表示を伴わずに表示するための表示部と、
表示された前記文書のうちの特定の文書の指示及び予め定められた複数種類の分類タイプのうちから当該特定の文書に付与する特定の分類タイプの指示をユーザから入力するための入力部と、
前記識別情報と前記特定の分類タイプとを対応付けた分類情報を記憶する分類情報記憶部と、
同一の分類タイプが対応付けられている1又は複数の前記文書から、当該分類タイプについてハイライト表示すべき1又は複数の単語又はフレーズを抽出する抽出部と、
前記文書の全部又は一部の各々について、前記抽出部により抽出された各々の単語又はフレーズが当該文書中に存在する場合に当該文書中でハイライト表示すべき箇所を特定する特定部とを備えたことを特徴とする拾い読み支援システム。
【請求項2】
前記特定部は、前記特定の文書以外の前記文書の各々について、前記特定を行うことを特徴とする請求項1に記載の拾い読み支援システム。
【請求項3】
前記表示部は、前記ハイライト表示すべき箇所が特定される前は、前記複数の文書のうちの全部又は一部を、前記ハイライト表示を伴わずに表示し、前記ハイライト表示すべき箇所が特定された後は、前記複数の文書のうちの全部又は一部を表示するにあたって、当該文書中でハイライト表示すべき箇所が特定された前記単語又はフレーズを、当該分類タイプに対応するハイライト形態でハイライト表示することを特徴とする請求項1に記載の拾い読み支援システム。
【請求項4】
前記抽出部は、前記分類情報の内容が更新されたことを契機として、前記抽出部による前記抽出、前記特定部による前記特定及び前記表示部による表示内容の更新を行うことを特徴とする請求項1に記載の拾い読み支援システム。
【請求項5】
前記抽出部は、ユーザからの更新指示が入力されたことを契機として、前記抽出部による前記抽出、前記特定部による前記特定及び前記表示部による表示内容の更新を行うことを特徴とする請求項1に記載の拾い読み支援システム。
【請求項6】
前記表示部は、前記複数の文書のうちの全部又は一部を表示するにあたって、前記特定の文書の各々について、当該文書に付与された前記分類タイプを示す情報を併せて表示することを特徴とする請求項1に記載の拾い読み支援システム。
【請求項7】
前記文書記憶部に記憶された文書は、特定の言語で記述されたものであり、
前記拾い読み支援システムは、
識別情報が対応付けられた前記特定の言語とは異なる言語で記述された複数の文書を記憶するための異言語文書記憶部と、
前記異言語文書記憶部に記憶された全文書について前記識別情報と予めユーザにより付与された前記分類タイプとを対応付けた分類情報を記憶する異言語分類情報記憶部とを更に備え、
前記抽出部は、前記異言語文書記憶部に記憶された前記文書及び前記異言語分類情報記憶部に記憶された前記分類情報に基づく、前記ハイライト表示すべき1又は複数の前記特定の言語とは異なる言語による単語又はフレーズの抽出をも行い、
前記拾い読み支援システムは、
前記特定の言語とは異なる言語による単語又はフレーズを、前記特定の言語に置き換える置換部を更に備えたことを特徴とする請求項1に記載の拾い読み支援システム。
【請求項8】
前記抽出部は、所定の条件が成立するまでは、前記異言語文書記憶部に記憶された前記文書及び前記異言語分類情報記憶部に記憶された前記分類情報に基づいて抽出され前記置換部により前記特定の言語に置き換えられた前記単語又はフレーズのみ、又は、前記異言語文書記憶部に記憶された前記文書及び前記異言語分類情報記憶部に記憶された前記分類情報のみに基づいて抽出され前記置換部により前記特定の言語に置き換えられた前記単語又はフレーズと、前記文書記憶部に記憶された前記文書及び前記分類情報記憶部に記憶された前記分類情報に基づいて抽出された前記特定の言語による前記単語又はフレーズとをマージしたものを、前記抽出の結果とし、所定の条件が成立した後は、前記文書記憶部に記憶された前記文書及び前記分類情報記憶部に記憶された前記分類情報に基づいて抽出された前記特定の言語による前記単語又はフレーズのみを、前記抽出の結果とすることを特徴とする請求項7に記載の拾い読み支援システム。
【請求項9】
前記置換部は、複数の単語又はフレーズについて、前記特定の言語と前記特定の言語とは異なる言語との対応を登録した二言語間辞書を参照して、前記置き換えを行うものであり、
前記抽出部は、前記二言語間辞書において前記特定の言語と前記特定の言語とは異なる言語との対応が1対1対応である単語又はフレーズを優先的に抽出することを特徴とする請求項8に記載の拾い読み支援システム。
【請求項10】
前記入力部を介して指示される前記分類タイプは、少なくとも適合文書に係る分類タイプ又は不適合文書に係る分類タイプを含むことを特徴とする請求項1に記載の拾い読み支援システム。
【請求項11】
前記入力部を介して指示される前記分類タイプは、少なくとも複数人の担当者のそれぞれへの割り当て文書に係るそれぞれの分類タイプを含むことを特徴とする請求項1に記載の拾い読み支援システム。
【請求項12】
単語又はフレーズをユーザから入力するための単語入力部を更に備え、
前記単語入力部を介して入力された前記単語又はフレーズを、前記抽出部により抽出された前記単語又はフレーズに加えて又はその代わりに利用することを特徴とする請求項1に記載の拾い読み支援システム。
【請求項13】
前記抽出部は、前記単語又はフレーズの候補を抽出し、
前記拾い読み支援システムは、前記単語又はフレーズの候補を表示するとともに、該表示した候補のうち、前記単語又はフレーズの選択をユーザから入力するための単語選択部を更に備え、
前記抽出部は、前記単語又はフレーズの候補の一部を選択するにあたって、前記単語選択部を介して選択された前記単語又はフレーズをより選択され易くすることを特徴とする請求項1に記載の拾い読み支援システム。
【請求項14】
前記文書は、目的とするドキュメント本文又はその要約文である請求項1に記載の拾い読み支援システム。
【請求項15】
識別情報が対応付けられた複数の文書を記憶するための文書記憶部を備えた拾い読み支援システムの拾い読み支援方法であって、
前記複数の文書のうちの全部又は一部を、単語又はフレーズのハイライト表示を伴って又はハイライト表示を伴わずに表示し、
表示された前記文書のうちの特定の文書の指示及び予め定められた複数種類の分類タイプのうちから当該特定の文書に付与する特定の分類タイプの指示をユーザから入力し、
前記識別情報と前記特定の分類タイプとを対応付けた分類情報を記憶し、
同一の分類タイプが対応付けられている1又は複数の前記文書から、当該分類タイプについてハイライト表示すべき1又は複数の単語又はフレーズを抽出し、
前記文書の全部又は一部の各々について、前記抽出部により抽出された各々の単語又はフレーズが当該文書中に存在する場合に当該文書中でハイライト表示すべき箇所を特定することを特徴とする拾い読み支援方法。
【請求項16】
識別情報が対応付けられた複数の文書を記憶するための文書記憶部を備えた拾い読み支援システムとしてコンピュータを機能させるためのプログラムであって、
識別情報が対応付けられた複数の文書を記憶するための文書記憶部と、
前記複数の文書のうちの全部又は一部を、単語又はフレーズのハイライト表示を伴って又はハイライト表示を伴わずに表示するための表示部と、
表示された前記文書のうちの特定の文書の指示及び予め定められた複数種類の分類タイプのうちから当該特定の文書に付与する特定の分類タイプの指示をユーザから入力するための入力部と、
前記識別情報と前記特定の分類タイプとを対応付けた分類情報を記憶する分類情報記憶部と、
同一の分類タイプが対応付けられている1又は複数の前記文書から、当該分類タイプについてハイライト表示すべき1又は複数の単語又はフレーズを抽出する抽出部と、
前記文書の全部又は一部の各々について、前記抽出部により抽出された各々の単語又はフレーズが当該文書中に存在する場合に当該文書中でハイライト表示すべき箇所を特定する特定部としてコンピュータを機能させるためのプログラム。
【請求項1】
識別情報が対応付けられた複数の文書を記憶するための文書記憶部と、
前記複数の文書のうちの全部又は一部を、単語又はフレーズのハイライト表示を伴って又はハイライト表示を伴わずに表示するための表示部と、
表示された前記文書のうちの特定の文書の指示及び予め定められた複数種類の分類タイプのうちから当該特定の文書に付与する特定の分類タイプの指示をユーザから入力するための入力部と、
前記識別情報と前記特定の分類タイプとを対応付けた分類情報を記憶する分類情報記憶部と、
同一の分類タイプが対応付けられている1又は複数の前記文書から、当該分類タイプについてハイライト表示すべき1又は複数の単語又はフレーズを抽出する抽出部と、
前記文書の全部又は一部の各々について、前記抽出部により抽出された各々の単語又はフレーズが当該文書中に存在する場合に当該文書中でハイライト表示すべき箇所を特定する特定部とを備えたことを特徴とする拾い読み支援システム。
【請求項2】
前記特定部は、前記特定の文書以外の前記文書の各々について、前記特定を行うことを特徴とする請求項1に記載の拾い読み支援システム。
【請求項3】
前記表示部は、前記ハイライト表示すべき箇所が特定される前は、前記複数の文書のうちの全部又は一部を、前記ハイライト表示を伴わずに表示し、前記ハイライト表示すべき箇所が特定された後は、前記複数の文書のうちの全部又は一部を表示するにあたって、当該文書中でハイライト表示すべき箇所が特定された前記単語又はフレーズを、当該分類タイプに対応するハイライト形態でハイライト表示することを特徴とする請求項1に記載の拾い読み支援システム。
【請求項4】
前記抽出部は、前記分類情報の内容が更新されたことを契機として、前記抽出部による前記抽出、前記特定部による前記特定及び前記表示部による表示内容の更新を行うことを特徴とする請求項1に記載の拾い読み支援システム。
【請求項5】
前記抽出部は、ユーザからの更新指示が入力されたことを契機として、前記抽出部による前記抽出、前記特定部による前記特定及び前記表示部による表示内容の更新を行うことを特徴とする請求項1に記載の拾い読み支援システム。
【請求項6】
前記表示部は、前記複数の文書のうちの全部又は一部を表示するにあたって、前記特定の文書の各々について、当該文書に付与された前記分類タイプを示す情報を併せて表示することを特徴とする請求項1に記載の拾い読み支援システム。
【請求項7】
前記文書記憶部に記憶された文書は、特定の言語で記述されたものであり、
前記拾い読み支援システムは、
識別情報が対応付けられた前記特定の言語とは異なる言語で記述された複数の文書を記憶するための異言語文書記憶部と、
前記異言語文書記憶部に記憶された全文書について前記識別情報と予めユーザにより付与された前記分類タイプとを対応付けた分類情報を記憶する異言語分類情報記憶部とを更に備え、
前記抽出部は、前記異言語文書記憶部に記憶された前記文書及び前記異言語分類情報記憶部に記憶された前記分類情報に基づく、前記ハイライト表示すべき1又は複数の前記特定の言語とは異なる言語による単語又はフレーズの抽出をも行い、
前記拾い読み支援システムは、
前記特定の言語とは異なる言語による単語又はフレーズを、前記特定の言語に置き換える置換部を更に備えたことを特徴とする請求項1に記載の拾い読み支援システム。
【請求項8】
前記抽出部は、所定の条件が成立するまでは、前記異言語文書記憶部に記憶された前記文書及び前記異言語分類情報記憶部に記憶された前記分類情報に基づいて抽出され前記置換部により前記特定の言語に置き換えられた前記単語又はフレーズのみ、又は、前記異言語文書記憶部に記憶された前記文書及び前記異言語分類情報記憶部に記憶された前記分類情報のみに基づいて抽出され前記置換部により前記特定の言語に置き換えられた前記単語又はフレーズと、前記文書記憶部に記憶された前記文書及び前記分類情報記憶部に記憶された前記分類情報に基づいて抽出された前記特定の言語による前記単語又はフレーズとをマージしたものを、前記抽出の結果とし、所定の条件が成立した後は、前記文書記憶部に記憶された前記文書及び前記分類情報記憶部に記憶された前記分類情報に基づいて抽出された前記特定の言語による前記単語又はフレーズのみを、前記抽出の結果とすることを特徴とする請求項7に記載の拾い読み支援システム。
【請求項9】
前記置換部は、複数の単語又はフレーズについて、前記特定の言語と前記特定の言語とは異なる言語との対応を登録した二言語間辞書を参照して、前記置き換えを行うものであり、
前記抽出部は、前記二言語間辞書において前記特定の言語と前記特定の言語とは異なる言語との対応が1対1対応である単語又はフレーズを優先的に抽出することを特徴とする請求項8に記載の拾い読み支援システム。
【請求項10】
前記入力部を介して指示される前記分類タイプは、少なくとも適合文書に係る分類タイプ又は不適合文書に係る分類タイプを含むことを特徴とする請求項1に記載の拾い読み支援システム。
【請求項11】
前記入力部を介して指示される前記分類タイプは、少なくとも複数人の担当者のそれぞれへの割り当て文書に係るそれぞれの分類タイプを含むことを特徴とする請求項1に記載の拾い読み支援システム。
【請求項12】
単語又はフレーズをユーザから入力するための単語入力部を更に備え、
前記単語入力部を介して入力された前記単語又はフレーズを、前記抽出部により抽出された前記単語又はフレーズに加えて又はその代わりに利用することを特徴とする請求項1に記載の拾い読み支援システム。
【請求項13】
前記抽出部は、前記単語又はフレーズの候補を抽出し、
前記拾い読み支援システムは、前記単語又はフレーズの候補を表示するとともに、該表示した候補のうち、前記単語又はフレーズの選択をユーザから入力するための単語選択部を更に備え、
前記抽出部は、前記単語又はフレーズの候補の一部を選択するにあたって、前記単語選択部を介して選択された前記単語又はフレーズをより選択され易くすることを特徴とする請求項1に記載の拾い読み支援システム。
【請求項14】
前記文書は、目的とするドキュメント本文又はその要約文である請求項1に記載の拾い読み支援システム。
【請求項15】
識別情報が対応付けられた複数の文書を記憶するための文書記憶部を備えた拾い読み支援システムの拾い読み支援方法であって、
前記複数の文書のうちの全部又は一部を、単語又はフレーズのハイライト表示を伴って又はハイライト表示を伴わずに表示し、
表示された前記文書のうちの特定の文書の指示及び予め定められた複数種類の分類タイプのうちから当該特定の文書に付与する特定の分類タイプの指示をユーザから入力し、
前記識別情報と前記特定の分類タイプとを対応付けた分類情報を記憶し、
同一の分類タイプが対応付けられている1又は複数の前記文書から、当該分類タイプについてハイライト表示すべき1又は複数の単語又はフレーズを抽出し、
前記文書の全部又は一部の各々について、前記抽出部により抽出された各々の単語又はフレーズが当該文書中に存在する場合に当該文書中でハイライト表示すべき箇所を特定することを特徴とする拾い読み支援方法。
【請求項16】
識別情報が対応付けられた複数の文書を記憶するための文書記憶部を備えた拾い読み支援システムとしてコンピュータを機能させるためのプログラムであって、
識別情報が対応付けられた複数の文書を記憶するための文書記憶部と、
前記複数の文書のうちの全部又は一部を、単語又はフレーズのハイライト表示を伴って又はハイライト表示を伴わずに表示するための表示部と、
表示された前記文書のうちの特定の文書の指示及び予め定められた複数種類の分類タイプのうちから当該特定の文書に付与する特定の分類タイプの指示をユーザから入力するための入力部と、
前記識別情報と前記特定の分類タイプとを対応付けた分類情報を記憶する分類情報記憶部と、
同一の分類タイプが対応付けられている1又は複数の前記文書から、当該分類タイプについてハイライト表示すべき1又は複数の単語又はフレーズを抽出する抽出部と、
前記文書の全部又は一部の各々について、前記抽出部により抽出された各々の単語又はフレーズが当該文書中に存在する場合に当該文書中でハイライト表示すべき箇所を特定する特定部としてコンピュータを機能させるためのプログラム。
【図1】



【図2】

【図3】
【図4】
【図5】

【図6】
【図7】

【図8】
【図9】
【図10】
【図11】

【図12】
【図13】
【図14】

【図15】
【図16】
【図17】
【図18】

【図19】

【図20】

【図21】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【公開番号】特開2012−203868(P2012−203868A)
【公開日】平成24年10月22日(2012.10.22)
【国際特許分類】
【出願番号】特願2011−70926(P2011−70926)
【出願日】平成23年3月28日(2011.3.28)
【出願人】(000003078)株式会社東芝 (54,554)
【Fターム(参考)】
【公開日】平成24年10月22日(2012.10.22)
【国際特許分類】
【出願日】平成23年3月28日(2011.3.28)
【出願人】(000003078)株式会社東芝 (54,554)
【Fターム(参考)】
[ Back to top ]