
推薦手法の評価方法
【課題】利用者の過去の行動記録から、コミュニティや商品などのアイテムを推薦する手法について、その結果や手法それ自体を対比可能に評価する。
【解決手段】過去の属性データに対して関連性の低いデータは、一定期間経過後に、実際に当該利用者がその属性データに対して行動を起こしたもののみ、意外性がある対象として扱うようにする。その上で、全ての推薦する属性データのうち、新規性のある対象の占める割合と、意外性のある対象の占める割合とを求める。
【解決手段】過去の属性データに対して関連性の低いデータは、一定期間経過後に、実際に当該利用者がその属性データに対して行動を起こしたもののみ、意外性がある対象として扱うようにする。その上で、全ての推薦する属性データのうち、新規性のある対象の占める割合と、意外性のある対象の占める割合とを求める。
【発明の詳細な説明】
【技術分野】
【0001】
この発明は、ユーザに対して、趣味嗜好に沿った属性データを選び出して推薦する様々な手法について、その手法自体を評価する方法に関する。
【背景技術】
【0002】
ソーシャルネットワークサービスの運営や、マーケティングにあたり、ユーザの過去の行動を解析して、その行動に関連があるコミュニティを勧めたり、過去に購入した商品と関連ある商品を勧めたりといったことが行われている。ソーシャルネットワークサービスであれば、一のユーザがアクセスしたり登録したりしたコミュニティやパーソナルデータについて、同じコミュニティやパーソナルデータにアクセスしたり登録したりした別のユーザが別途アクセスしたり登録したりしたコミュニティやパーソナルデータを、当該一のユーザに勧めるべく、当該一のユーザの利用する画面に表示するといったことが行われている。また、マーケティングにあたっては、ある商品を購入した一のユーザに対し、同じ商品を購入した別のユーザが購入した別の商品を、当該一のユーザに勧めるべく、マーケティングサイトのお勧め欄に表示したり、メールマガジンのお勧め欄に記載したりするといったことが行われている。
【0003】
このような推奨方法は、ソーシャルネットワークサービスにおけるコミュニティの拡張や、マーケティングにおいて大きな効果を発揮するが、単純に趣味嗜好が類似しているユーザの中で特に多いものを選んで提示し続けていくと、提示するコミュニティや商品の傾向が偏ってしまい、コミュニティの拡大や商品の販売の拡大に限界があり、一定の範囲に留まりやすい。そうなると、提示できるコミュニティや商品が利用者にとって新鮮味のあるものでなくなり、驚きを覚えるような体験を提供できず、引いては当該サービスに対する興味を減退させてしまう。このため、趣味嗜好が類似しているユーザが行動の対象とする件数が最も多いものといった類似性の高いものを優先して推奨するだけではなく、比較的件数が少ないものの、一部のユーザ層が重なっている意外な対象を勧められる推薦手法が求められる場合がある。
【0004】
例えば特許文献1に記載の方法は、利用者の行動記録に基づいて、その利用者の嗜好モデルを学習して記憶し、複数の推薦候補についてその嗜好モデルに基づいて選択確率を計算して、各推薦候補について利用者が選択する確率を表す評価リストを作成し、利用者の行動記録に関する情報から当該利用者の習慣性を特定して、前記複数の推薦候補についてのデフォルト予測値を求め、前記選択確率からデフォルト予測値を引いた差を、意外性評価値として求めることで、コンテンツの意外性を評価し、意外性の高いコンテンツを提示するものである。すなわち、閾値から離れたデータも、意外性のあるものとして廃棄せずに提示する。
【0005】
一方で、意外性の高いものばかり推奨しては困るケースもある。例えば、急激なコミュニティの拡大を求めない場合や、安定した顧客に対して安定した販売を継続したい場合などである。
【0006】
従って、推薦手法は最良解があるわけではなく、様々な推薦手法を検討する必要がある。また、一つの推薦手法でも、パラメータを変更することで推薦結果が大きく変わることもある。
【先行技術文献】
【特許文献】
【0007】
【特許文献1】特開2008−262398号公報
【発明の概要】
【発明が解決しようとする課題】
【0008】
しかしながら、それらの推薦手法がどのような性質を持っているかということは容易に把握することは難しく、結果として、どのような推薦手法を用いればよいかという指標を設けることも難しかった。
【0009】
また、特許文献1の手法により、意外性があるとして提示するものは、あくまで、関連性が薄いものを意外なものとして提示するだけである。その結果、意外であって驚きを持って迎えられるコンテンツもある一方で、実際にはほとんど無関係で興味を持ちうるはずもないコンテンツまで、意外性があるものとして分類してしまい、実体とかけ離れた結果を出してしまうという問題があった。
【0010】
そこでこの発明は、推薦手法によって提示される候補や、推薦手法そのものの性質を、実体に則した意外性を踏まえて評価することにより、種種の推薦手法の性質を比較検討したり、推薦手法に代入するパラメータの効果などを検討できるようにすることを目的とする。
【課題を解決するための手段】
【0011】
この発明は、実態に則した意外性の評価として、利用者にとって新規な属性データを推薦するにあたり、過去の属性データに対して関連性の低いデータは、一定期間経過するまでに実際に当該利用者がその属性データに対して行動を起こしたもののみ、意外性がある対象として扱うようにし、その上で、一の利用者に、一のグループに、又は全ての利用者に対して、全ての推薦する属性データのうち、新規性のある対象の占める割合と、意外性のある対象の占める割合とを求め、これらの割合の数値により、上記の課題を解決したのである。すなわち、過去の属性データを採取するだけでなく、一定期間経過後にさらにデータを収集して、意外性のある対象とすべきか否かの判断に用いたことを特徴とする。推薦しても、利用者がそれに対して行動結果を示さなければ、推薦する意味が無いからである。
【発明の効果】
【0012】
この数値を一の利用者に提示された推薦内容について算出すると、提示された内容の新規性と意外性の評価として用いることができる。また、複数の利用者について同様の数値を算出した上で、その値について、平均、中間値、分布などの統計値を求めたり、グラフにプロットしたりする数的処理を行うことにより、その推薦手法がそれら複数の利用者に対して提示した結果の評価と、当該推薦手法の傾向を掴むことができる。さらに、同一の利用者に対して、異なる推薦手法による前記の数値を算出し、個々の推薦手法ごとに平均値などを求める数的処理を行い、推薦手法ごとの値を比較することで、複数の推薦手法についてその性質、利点、適正などを把握することができる。
【図面の簡単な説明】
【0013】
【図1】推薦手法の利用形態例の概略図
【図2】行動記録のタイミングを示す概念図
【図3】推薦コミュニティの例図
【図4】ユーザ1に示された推薦コミュニティの類似度の概念図
【図5】類似度計算を行う第一の演算部の処理フロー図
【図6】類似度に基づく新規性と意外性の分類の概念図
【図7】評価方法全体の処理フロー図
【図8】類似度計算を行う第二の演算部の処理フロー図
【発明を実施するための形態】
【0014】
以下、この発明について詳細に説明する。この発明は、一つ又は複数の推薦手法により、利用者に対して、その利用者が過去に行った行動記録を基礎として、関連性が様々に異なる属性データを推薦する結果又はその推薦手法自体の性質を評価する方法である。この評価を実行する環境としては、主に一つ又は複数のWEBサイトにおけるユーザの行動への推薦と評価が挙げられるが、ネットワーク上の事象に限らず、実店舗における会員登録した利用者の購入履歴を用いたマーケティングなど、実空間上の事象に対しても適用可能である。
【0015】
ここで属性データとは、人の趣味、嗜好、性格などを反映させた物理的な、又は概念的な属性を有するデータであり、他のデータと何らかの関連性を有するものである。アイテム、又はコンテンツと呼ばれるものも含む場合がある。具体的には、商品、趣味、コミュニティ、検索単語、入力単語、位置情報サービスでの立ち寄り場所、旅行先、走行ルートの選択など、趣味嗜好等が反映され得るものであれば特に限定されない。
【0016】
具体例を挙げる。例えば、マーケティングサイトやスポーツ用品店における商品について、「バスケットボール」と「バスケットシューズ」と「マラソンシューズ」が属性データとしてあったとする。バスケットボールを購入した利用者はバスケットシューズにも興味がある可能性が高いが、マラソンシューズに興味がある可能性はそれよりも低くなる。「バスケットボール」と「バスケットシューズ」とは高い関連性を有するが、「バスケットボール」と「マラソンシューズ」との関連性はそれに比べれば低くなる。
【0017】
また例えば、ソーシャルネットワークサービスにおけるコミュニティで、「野球」と「サッカー」と「アイスホッケー」と「ガーデニング」と「リアル系巨大ロボットアニメ作品」といった趣味のコミュニティを属性データとして例にとる。「野球」と「サッカー」と両方のコミュニティに所属している利用者は、スポーツ全般に興味がある可能性が高く、「アイスホッケー」のコミュニティについても興味を持つ可能性がそれなりに高いが、「ガーデニング」や「リアル系巨大ロボットアニメ作品」といったコミュニティに興味を持つ可能性はそれに比べると低くなる。ただし、一戸建ての家庭を持つ社会人が興味を抱きやすい傾向にある「ガーデニング」に比べると、スポーツ全般を楽しむ10代から20代の男性が好みやすい「リアル系巨大ロボットアニメ作品」は、やや関連性が高くなる。このため、「野球」を基準にすると、関連性の高いものから「サッカー」「アイスホッケー」「リアル系巨大ロボットアニメ作品」「ガーデニング」のような順となる。なお、ソーシャルネットワークサービス(SNS)とは、対人関係を構築するための手段を用意したサービスである。コミュニティとはそのSNSの一機能で、ある事象について興味を有したり、ある事象について賛同したりする、同一の方向性を持った利用者について、タグ付けやテーブルへの登録などによりまとめることができ、利用者間での交流が可能な専用の場を有していたりするものが挙げられる。
【0018】
さらに例えば、ニュースサイトでは、「少女アイドルグループ(1)」と「少女アイドルグループ(2)」と「大学受験」と「30代男性アイドルグループ(3)」といった、ニュース文書に含まれるキーワードやタグを属性データとして例にとる。「少女アイドルグループ(1)」についてのニュースを見ている利用者は他の「少女アイドルグループ(2)」についてのニュースに興味を持つ可能性が高いが、「大学受験」についてのニュースに興味を持つ可能性はそれより低く、「30代男性アイドルグループ(3)」に興味を持つ可能性はほとんど無い。「少女アイドルグループ(1)」と「少女アイドルグループ(2)」との関連性は高く、「少女アイドルグループ(1)」と「大学受験」との関連性はそれより低くなり、「少女アイドルグループ(1)」と「30代男性アイドルグループ(3)」との関連性はさらに低くなる。ここでは、内容としてはアイドルグループに関するもので似通っている「少女アイドルグループ(1)」と「30代男性アイドルグループ(3)」であるが、属性データの関連性で見ると、前者は10代から30代の男性が興味を持ち、後者は40代以上の女性が興味を持つ傾向が強く、閲覧する層が全く異なる。このため、例えば10代男性層は「少女アイドルグループ(1)」と「大学受験」とのいずれにも興味を持ちやすいので、「少女アイドルグループ(1)」は「30代男性アイドルグループ(3)」よりも、「大学受験」との類似度の方が高いということになる。
【0019】
属性データの関連性のモデル化にはいくつかの方式があり、一般的にはコンテンツに基づくフィルタリングと協調フィルタリングとが挙げられる。前者は、それぞれの属性データの内容に基づき情報を取捨選択するものであり、後者は、webサイト、或いはネットワークにおいて同じ好みを有するものが共通して好むものを選択するものである。コンテンツによるフィルタリングの方式としては、ルールベース方式、メモリベース方式(概念ベース方式)、モデルベース方式の三種類が主に挙げられる。協調フィルタリングの方式としては、ユーザベース方式(メモリベース方式)、アイテムベース方式(メモリベース方式)、モデルベース方式の三種類が主に挙げられる。コンテンツに基づくフィルタリングは、属性データをキーワードやタグとして処理しているため、ニュースサイトや検索サイトにおける記事の推奨に向いており、協調フィルタリングは、属性データそのものがいわゆるアイテム単位であるため、コミュニティや商品の推奨に向いている。
【0020】
この発明で利用する利用者の過去の行動記録は、アンケートやページ評価などの利用者が自ら行う明示的(直接的)手法と、アクセス解析や閲覧時間評価などの暗黙的(間接的)手法とがある。明示的手法は正確性が高いが利用者にかかる負担が大きい。暗黙的手法は利用者に対して推薦手法の評価をしていることを気づかせない程度に負荷が小さい。
【0021】
この発明が対象とする推薦手法とは、利用者の過去の行動記録から、上記の属性データを抽出し、基礎とする過去属性データとして扱い、この過去属性データから、あるアルゴリズムによって、別の属性データ(推薦属性データ)を提示、推薦することができるものである。この行動記録とは、コミュニティページや商品ページ、ニュースページ等のアクセス履歴だけでなく、登録コミュニティの一覧、商品の購入履歴、検索履歴、入力単語の履歴、RSSの登録項目などが挙げられる。基本的には、過去属性データとそれから提示推薦できる推薦属性データとは共通である。例えば、登録コミュニティの一覧から提示推薦できるのは、次に登録してはどうかと提案される登録コミュニティであり、ニュースページのアクセス履歴から提示推薦できるのは、別のニュースページである。しかし、実体的な内容を紐付けることができれば、過去属性データと推薦属性データが異なっていてもよい。例えば、登録コミュニティとしてNBA(ナショナルバスケットアソシエーション)ファンクラブに登録されている利用者に対して、推薦属性データとして、NBAチームのユニフォームの宣伝を提示するといったことが可能である。
【0022】
この発明では、上記の類似度として、それぞれの上記属性データの間の、利用者にとっての関連性の高さを数値的に比較できる値が算出できるものであれば、その算定基準と計算方式を特に限定するものではない。類似度の数値が高いほど関連性が高いと一応の想定ができ、類似度の数値がある閾値以上であるか否かによって、興味の飛躍が生じる、すなわち、意外であり得るとされるか否かを分類できればよい。一般的には、当該属性データにアクセスしたり、登録したり、購入したりする利用者がどの程度一致しているかを、個々の属性データの全てについて算出することで、基本的な値の算出は可能であるが、特にそれに限定されるものではない。
【0023】
例えば上記属性データとして、上記のSNSにおけるコミュニティ同士の類似度の値を求める方法として、合計利用者数で共通利用者数を割るといった方法が挙げられる。あるコミュニティXとコミュニティYがあり、一定期間中に、XにはユーザA,B,C,D,Eの5人がアクセスしており、YにはユーザA,C,D,F,Gの5人がアクセスしていて、全部で7人いるうち、共通してアクセスしていたのがA,C,Dの3人である場合、3/7=43%という計算をして、類似度を43%、とすることができる。
【0024】
また、ニュースサイトにおけるニュース文書の類似度を求める方法として、ニュース文書から属性データであるキーワードを概念抽出し、単語ベクトル間の兄弟概念や上位概念との単語ベクトル間の距離値を求める方法がある。これは、大量のニュース文書を取り込み、似た概念を有する単語の出現パターンが似通ってくることを利用して、単語の概念ベクトルを収集してデータベース化した上で、算出可能となる個々のキーワード間の距離を類似度として用いるものである。
【0025】
上記過去属性データが複数ある場合、過去属性データを一つのまとまり(群)として見なし、それ以外の属性データとの類似度は一意に定まる。これについて、上記のコミュニティの例に沿って計算例を示す。コミュニティZには、ユーザA,B,C,G,H,Iの6人がアクセスしていたとする。ここでXとYのコミュニティ群(以下、XY群)とZの類似度を計算する。XとYに共通的にアクセスしているユーザはA,B,C,D,E,F,Gとなる。そのため、XY群とZとの類似度は、上記と同じ手法で計算すると、全部で9人(ABCDEFGHI)いるうち、共通してアクセスしていたのが4人(ABCG)なので、4/9≒44%となる。
【0026】
ただし、類似度が低いことがすなわち意外性があるわけではない。行動記録上ある過去属性データを有する利用者に対して、その過去属性データとの類似度が低い推薦属性データを提示し、その推薦属性データに対して利用者が所定の行動を起こせば、それは意外性があるということになり、行動を起こさなければ、意外ではなく、無縁であったということになる。一方、既に行動の対象となった属性データが、推薦属性データに仮に含まれたとしても、以下の新規性対象、意外性対象からは除外する。
【0027】
この提示された推薦属性データについて類似度を求める。すなわち、推薦属性データのうち、過去属性データに含まれないものについて、それぞれの属性データごとに、比較対象となる当該利用者の過去属性データ群との類似度を求める。この類似度が閾値以上であるものを、新規性対象、すなわち、意外ではないが、未踏、未訪問、未登録、未見である新規なものとする。一方、この類似度が閾値未満であるものは、提示開始から一定期間経過までの間に、利用者の登録、アクセス、購入などといった、それぞれに適した行動の対象となったら、意外性対象、すなわち、関連性は薄くとも利用者が興味を持った意外なものとする、一定期間経過までに利用者の行動の対象とならなかったら、その数緯線属性データは用を為さなかったものとする。なお、この閾値も本発明によって評価可能なパラメータであり、閾値が変わることで、当該推薦手法の評価内容は変化する。
【0028】
その上で、推薦属性データの全数のうち、新規性対象の占める割合である新規性対象率と、前記意外性対象の占める割合である意外性対象率とを求める。これにより、当該利用者に対して提示された推薦属性データの内訳を評価できる。
【0029】
このようにして得られた新規性対象率と意外性対象率とを、複数の利用者について求め、それらの値について数的評価を行う。複数の利用者とは、全利用者でもよいし、抽出した利用者でもよい。対象とする利用者数が多い方が評価の信憑性は向上するが、その分解析に時間がかかる。ここで数的評価とは、統計値の算出や、グラフ上へのプロット、又はその両方が挙げられる。統計値としては、一般的な平均値の他、中間値、最小値、最大値、最頻値、分散、標準偏差などが挙げられる。これにより、当該推薦手法により提示されたデータの全体的な傾向を掴むことができる。例えば、対象とする利用者中での新規性対象率の平均値が高く、意外性対象率の平均値が低ければ、提示された推薦属性データは、堅実で類似性の高いものを推奨するものであるとわかる。逆に意外性対象率の平均値の方が高ければ、利用者の利用を飛躍的に高める傾向にあることがわかる。また、新規性対象率と意外性対象率とのいずれの平均値も低い場合は、その推薦手法は有用性に問題があることがわかる。また、最小値と最大値の幅が大きかったり、分散が大きかったりすると、推薦する内容にムラがあり、逆であればムラが少なく、照準が定めやすいということがわかる。
【0030】
このような統計値の算出を、複数の推薦手法により得られた推薦属性データについて行い、推薦手法ごとの値を求めて互いに比較することで、他の推薦手法と比べて、その推薦手法がどのような傾向にあり、どういう場合にどの推薦手法を採用すればよいかを判断できる。なお、ここで複数の推薦手法とは、アルゴリズムが同一であってもパラメータの違いによって異なる結果が得られるものであれば、複数の推薦手法として考えることができる。堅実な拡大路線を勧めようとするならば、新規性対象率が高い推薦手法を選び、常に興味を引きつけて利用を拡大させていこうとするならば意外性対象率が高い推薦手法を選ぶ、といったような選択ができる。
【0031】
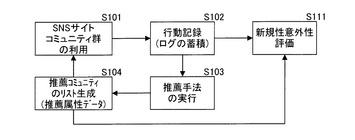
以上のような評価方法を、具体例を挙げて説明する。推薦手法を採用する対象は、SNSサイトにおけるコミュニティの推薦である。ここでコミュニティとは、サービス内である事柄について同項の士が集まる掲示板機能や新規通知機能などを有し、当該事柄についての話題をやりとりできる仮想的な場、ページのことである。推薦手法の利用形態の概略図を図1に示す。利用者が当該サイトを利用して、複数あるコミュニティにアクセスすることにより(S101)、行動記録であるアクセスログが蓄積されていく。このログは、それぞれの利用者がどのコミュニティにアクセスしたか、というデータを主に有する。このログを一定期間に亘って蓄積する(S102)。次に、蓄積した行動記録を過去属性データとして、評価しようとする複数の推薦手法を実施する(S103)。これにより、それぞれの利用者に対して推薦するコミュニティのリストである推薦属性データが得られる(S104)。
【0032】
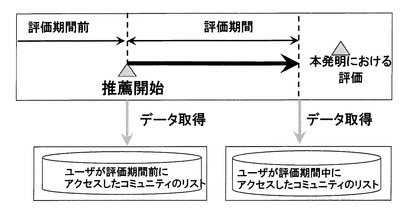
この推薦属性データを一定期間利用者に対して提示する。具体的には、当該利用者が当該SNSサイトを利用する(S101)際のスタートページなどに表示し続けることで、推薦するコミュニティへのアクセスを促す。これを一定期間に亘って続けて、アクセスログを収集する(S102)。この評価期間が終了した後、それらの推薦表示したコミュニティの内容、およびアクセスしたか否かを踏まえて、新規性、意外性の評価を行う(S111)。すなわち、この発明では利用者の行動を、図2に示すように、少なくとも二回の期間に亘って記録する。一つは、推薦属性データを導き出すための過去属性データの取得のためであり、もう一つは、推薦属性データに対する利用者の行動結果を記録し、意外性や新規性の評価に用いるためである。
【0033】
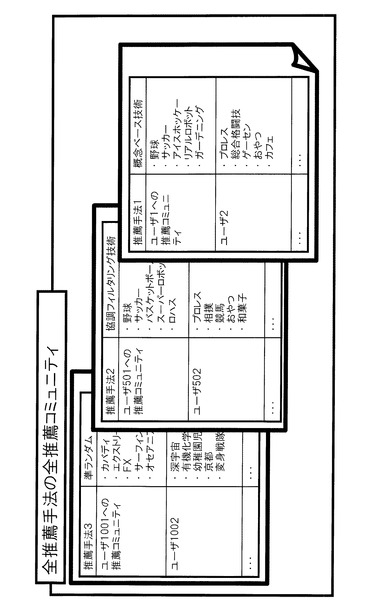
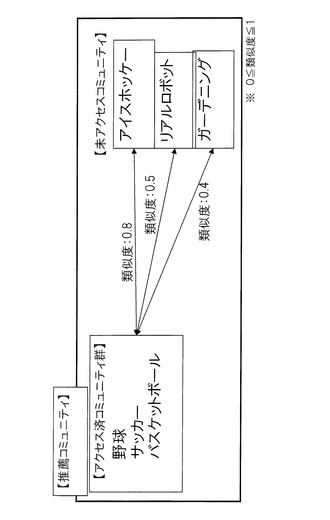
図3に、推薦コミュニティの例を示す。利用者を推薦手法の数だけグループ分けし、それぞれのグループについて、一の推薦手法を実行して、推薦コミュニティのリストを作成する。ここでは、概念ベース技術と、協調フィルタリング技術、ランダム選択の三種類を、五百人ごとに分けたグループのそれぞれに対して実行したとする。
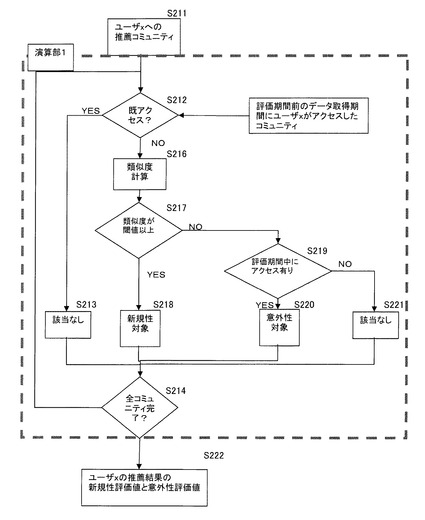
【0034】
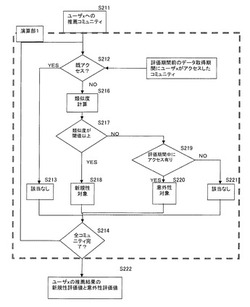
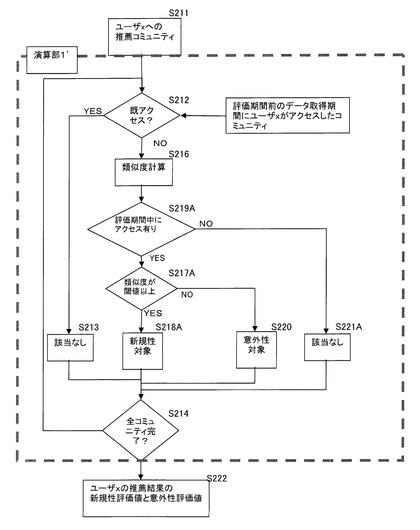
利用者の一人であるユーザ1を例に取り、類似度の計算を説明する。この概念図を図4に示し、処理のフローを図5に示す。まず、ユーザ1は最初のログを取得する期間(過去属性データ取得期間)に、「野球」「サッカー」「バスケットボール」のコミュニティにアクセスしていたとする。この事実は過去属性データ取得期間のアクセスログから把握できる。これを前提にすると、推薦されたリストに表示されたコミュニティのうち(S211)、「野球」「サッカー」は既にユーザ1がアクセスしていたことがわかる(S212)。この場合、「野球」「サッカー」は再訪問を促すものであり、新規なものでも意外なものでもない。よって、新規性対象、意外性対象のいずれにも属さない(S213)。一方、「アイスホッケー」「リアルロボット」「ガーデニング」はまだユーザ1がアクセスしていないコミュニティであるとする(S212)。
【0035】
次に、提示された推薦属性データである推薦コミュニティのうち、推薦前は未アクセスであった3つのコミュニティのそれぞれについて、全利用者、又は抽出したある程度の数の利用者のアクセスログを前提として、既訪問であるコミュニティ群との類似度を計算する(S216)。ここでは既訪問のコミュニティ群が「野球」及び「サッカー」と「バスケットボール」の3つあり、この3つのコミュニティを1つの過去属性データとみなし、この群からの類似度を求めて、未アクセスコミュニティを分類する。
【0036】
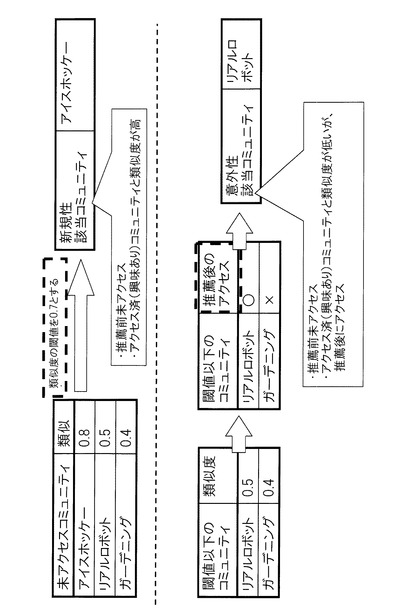
その分類の概念図を図6に示す。まず分類に当たり、類似度について閾値を決定する。ここで採用する類似度の範囲のうち、その閾値より高い値を示す関係にあるコミュニティは類似度が高いため、表示されても意外性は無いものとする。例えばここでは、閾値を0.7とするが、コミュニティの数により適切な閾値は変化する。ここでは、「アイスホッケー」は類似度が0.8と閾値以上であるので(S217)、新規性対象として分類する(S218)。一方、閾値が0.8より低い「リアルロボット」と「ガーデニング」とについては、上記評価期間(S102〜S104)の間に、ユーザ1がアクセスしたか否かによって分類する(S219)。上記評価期間の間にユーザ1がアクセスしている「リアルロボット」は、推薦前にアクセスしたコミュニティと類似度が低いにも拘わらず、ユーザ1が新たに興味を持った意外性対象となる(S220)。一方、上記評価期間の間にユーザ1がアクセスしなかった「ガーデニング」については、興味を惹くことができなかったものであり、新規性対象でも意外性対象でもないとして該当なしとなる(S221)。
【0037】
以上で、推薦属性データの全てについて評価が完了する(S214)。これにより、推薦属性データの傾向が評価できる。ここでは、推薦された属性データ数が5で、うち「野球」「サッカー」「ガーデニング」が「該当なし」となり、「アイスホッケー」が新規性対象、「リアルロボット」が意外性対象であった。従って、ユーザ1に提示された推薦属性データ中、新規性対象の占める割合である新規性対象率は1/5=20(%)であり、意外性対象の占める割合である意外性対象率は1/5=20(%)となる。このユーザ1に与えた結果としては、一応の興味の拡大に繋がったことがわかる。
【0038】
このような評価を、各々の推薦手法を用いたユーザ全体について行い、さらにそれを全ての推薦手法についても行うことで、結果や傾向の相互比較が可能となる。すなわち、推薦手法1,2、3……を用いて個々のユーザに推薦した全ての推薦属性データについて分類、統計処理を行う。
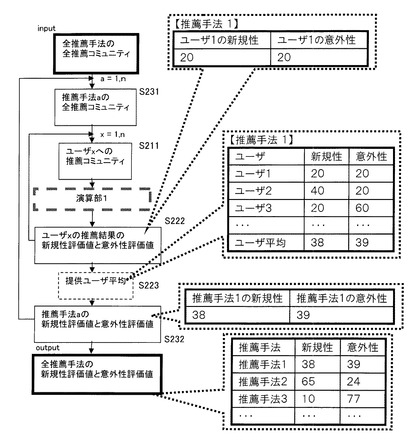
【0039】
そのためのフローの全体像を図7に示す。フロー中、中央にある演算部1が、上記の図5における新規性対象と意外性対象との分類に対応する。まず、推薦手法1により提示された全ての推薦コミュニティ(推薦属性データ)について、ユーザ1から順に上記の演算部1の処理を行う(S211〜S222)。その上で、推薦手法1により推薦したユーザ(ここではユーザ1〜500)の平均値を算出する(S223)。なお、図中、新規性対象率を「新規性」と、意外性対象率を「意外性」と略記する。これにより、推薦手法1により推薦したコミュニティについての数的処理と新規性及び意外性の分類がされた。この値は、推薦手法1で出力される推薦属性データの傾向を示すものである(S232)。
【0040】
この処理を、続けて推薦手法2,3……とについても行い(S231〜S232)、それぞれの推薦手法による、新規性対象率、意外性対象率を算出する。これにより、図7に記載のように、推薦手法ごとの新規性対象率及び意外性対象率が比較できるようになる。例えば図7のような結果となった場合、推薦手法1は新規性と意外性のバランスがよく、推薦手法2は新規性が多いために堅実な運用に向いており、推薦手法3は意外性に特化していて拡大傾向に拍車を掛けたいときに向いている、といった評価ができる。
【0041】
このように、利用者(ユーザ)ごとの新規性対象率、意外性対象率を求め、それを推薦手法ごとにまとめて数的処理し、推薦手法間で対比することで、推薦手法の評価ができる。この全体構造を保持すれば、それ以外の点は変更が可能である。
【0042】
例えば、上記の判断においては、アクセスしたコミュニティについて過去属性データを収集し、推薦属性データの意外性評価もアクセスの有無によって行っているが、これを、コミュニティへの登録について過去属性データを収集し、意外性評価も登録の有無について行っても同様のことができる。
【0043】
また例えば、上記のフローでは推薦属性データのうち類似度が閾値以上のものは無条件に新規性対象としているが、意外性対象の判断と同様に、実際にアクセスしなかったものは「該当なし」としてもよい。類似度が高いからといって、実際にアクセスに寄与しなければ、推薦する意義がないからである。この場合、上記の演算部1のフローは図8のようになる。それぞれの推薦属性データについて、最大類似度を抽出引用した後(S216)、まず評価期間中にアクセスがあったか否かを判断し(S219A)、アクセスがなかったものは、閾値とは関係なく「該当なし」となる(S221A)。一方で、評価期間中にアクセスがあった推薦属性データ(推薦コミュニティ)については、類似度が閾値以上か否かを判断し(S217A)、新規性対象であるか(S218A)、意外性対象であるか(S220)を判断する。
【0044】
さらに例えば、上記のフローでは推薦手法1〜3を異なるユーザグループに対して行っているが、推薦手法1〜3を全てのユーザに対して実施し、提供期間をずらして順に推薦属性データを示してもよい。ただしこの場合、推薦手法1による推薦属性データを見た利用者は、次の推薦手法2による推薦属性データに対して行動するときに、前に推薦された推薦属性データが記憶にあり、行動を左右されているため、提供順序によりある程度の誤差が生じる。
【技術分野】
【0001】
この発明は、ユーザに対して、趣味嗜好に沿った属性データを選び出して推薦する様々な手法について、その手法自体を評価する方法に関する。
【背景技術】
【0002】
ソーシャルネットワークサービスの運営や、マーケティングにあたり、ユーザの過去の行動を解析して、その行動に関連があるコミュニティを勧めたり、過去に購入した商品と関連ある商品を勧めたりといったことが行われている。ソーシャルネットワークサービスであれば、一のユーザがアクセスしたり登録したりしたコミュニティやパーソナルデータについて、同じコミュニティやパーソナルデータにアクセスしたり登録したりした別のユーザが別途アクセスしたり登録したりしたコミュニティやパーソナルデータを、当該一のユーザに勧めるべく、当該一のユーザの利用する画面に表示するといったことが行われている。また、マーケティングにあたっては、ある商品を購入した一のユーザに対し、同じ商品を購入した別のユーザが購入した別の商品を、当該一のユーザに勧めるべく、マーケティングサイトのお勧め欄に表示したり、メールマガジンのお勧め欄に記載したりするといったことが行われている。
【0003】
このような推奨方法は、ソーシャルネットワークサービスにおけるコミュニティの拡張や、マーケティングにおいて大きな効果を発揮するが、単純に趣味嗜好が類似しているユーザの中で特に多いものを選んで提示し続けていくと、提示するコミュニティや商品の傾向が偏ってしまい、コミュニティの拡大や商品の販売の拡大に限界があり、一定の範囲に留まりやすい。そうなると、提示できるコミュニティや商品が利用者にとって新鮮味のあるものでなくなり、驚きを覚えるような体験を提供できず、引いては当該サービスに対する興味を減退させてしまう。このため、趣味嗜好が類似しているユーザが行動の対象とする件数が最も多いものといった類似性の高いものを優先して推奨するだけではなく、比較的件数が少ないものの、一部のユーザ層が重なっている意外な対象を勧められる推薦手法が求められる場合がある。
【0004】
例えば特許文献1に記載の方法は、利用者の行動記録に基づいて、その利用者の嗜好モデルを学習して記憶し、複数の推薦候補についてその嗜好モデルに基づいて選択確率を計算して、各推薦候補について利用者が選択する確率を表す評価リストを作成し、利用者の行動記録に関する情報から当該利用者の習慣性を特定して、前記複数の推薦候補についてのデフォルト予測値を求め、前記選択確率からデフォルト予測値を引いた差を、意外性評価値として求めることで、コンテンツの意外性を評価し、意外性の高いコンテンツを提示するものである。すなわち、閾値から離れたデータも、意外性のあるものとして廃棄せずに提示する。
【0005】
一方で、意外性の高いものばかり推奨しては困るケースもある。例えば、急激なコミュニティの拡大を求めない場合や、安定した顧客に対して安定した販売を継続したい場合などである。
【0006】
従って、推薦手法は最良解があるわけではなく、様々な推薦手法を検討する必要がある。また、一つの推薦手法でも、パラメータを変更することで推薦結果が大きく変わることもある。
【先行技術文献】
【特許文献】
【0007】
【特許文献1】特開2008−262398号公報
【発明の概要】
【発明が解決しようとする課題】
【0008】
しかしながら、それらの推薦手法がどのような性質を持っているかということは容易に把握することは難しく、結果として、どのような推薦手法を用いればよいかという指標を設けることも難しかった。
【0009】
また、特許文献1の手法により、意外性があるとして提示するものは、あくまで、関連性が薄いものを意外なものとして提示するだけである。その結果、意外であって驚きを持って迎えられるコンテンツもある一方で、実際にはほとんど無関係で興味を持ちうるはずもないコンテンツまで、意外性があるものとして分類してしまい、実体とかけ離れた結果を出してしまうという問題があった。
【0010】
そこでこの発明は、推薦手法によって提示される候補や、推薦手法そのものの性質を、実体に則した意外性を踏まえて評価することにより、種種の推薦手法の性質を比較検討したり、推薦手法に代入するパラメータの効果などを検討できるようにすることを目的とする。
【課題を解決するための手段】
【0011】
この発明は、実態に則した意外性の評価として、利用者にとって新規な属性データを推薦するにあたり、過去の属性データに対して関連性の低いデータは、一定期間経過するまでに実際に当該利用者がその属性データに対して行動を起こしたもののみ、意外性がある対象として扱うようにし、その上で、一の利用者に、一のグループに、又は全ての利用者に対して、全ての推薦する属性データのうち、新規性のある対象の占める割合と、意外性のある対象の占める割合とを求め、これらの割合の数値により、上記の課題を解決したのである。すなわち、過去の属性データを採取するだけでなく、一定期間経過後にさらにデータを収集して、意外性のある対象とすべきか否かの判断に用いたことを特徴とする。推薦しても、利用者がそれに対して行動結果を示さなければ、推薦する意味が無いからである。
【発明の効果】
【0012】
この数値を一の利用者に提示された推薦内容について算出すると、提示された内容の新規性と意外性の評価として用いることができる。また、複数の利用者について同様の数値を算出した上で、その値について、平均、中間値、分布などの統計値を求めたり、グラフにプロットしたりする数的処理を行うことにより、その推薦手法がそれら複数の利用者に対して提示した結果の評価と、当該推薦手法の傾向を掴むことができる。さらに、同一の利用者に対して、異なる推薦手法による前記の数値を算出し、個々の推薦手法ごとに平均値などを求める数的処理を行い、推薦手法ごとの値を比較することで、複数の推薦手法についてその性質、利点、適正などを把握することができる。
【図面の簡単な説明】
【0013】
【図1】推薦手法の利用形態例の概略図
【図2】行動記録のタイミングを示す概念図
【図3】推薦コミュニティの例図
【図4】ユーザ1に示された推薦コミュニティの類似度の概念図
【図5】類似度計算を行う第一の演算部の処理フロー図
【図6】類似度に基づく新規性と意外性の分類の概念図
【図7】評価方法全体の処理フロー図
【図8】類似度計算を行う第二の演算部の処理フロー図
【発明を実施するための形態】
【0014】
以下、この発明について詳細に説明する。この発明は、一つ又は複数の推薦手法により、利用者に対して、その利用者が過去に行った行動記録を基礎として、関連性が様々に異なる属性データを推薦する結果又はその推薦手法自体の性質を評価する方法である。この評価を実行する環境としては、主に一つ又は複数のWEBサイトにおけるユーザの行動への推薦と評価が挙げられるが、ネットワーク上の事象に限らず、実店舗における会員登録した利用者の購入履歴を用いたマーケティングなど、実空間上の事象に対しても適用可能である。
【0015】
ここで属性データとは、人の趣味、嗜好、性格などを反映させた物理的な、又は概念的な属性を有するデータであり、他のデータと何らかの関連性を有するものである。アイテム、又はコンテンツと呼ばれるものも含む場合がある。具体的には、商品、趣味、コミュニティ、検索単語、入力単語、位置情報サービスでの立ち寄り場所、旅行先、走行ルートの選択など、趣味嗜好等が反映され得るものであれば特に限定されない。
【0016】
具体例を挙げる。例えば、マーケティングサイトやスポーツ用品店における商品について、「バスケットボール」と「バスケットシューズ」と「マラソンシューズ」が属性データとしてあったとする。バスケットボールを購入した利用者はバスケットシューズにも興味がある可能性が高いが、マラソンシューズに興味がある可能性はそれよりも低くなる。「バスケットボール」と「バスケットシューズ」とは高い関連性を有するが、「バスケットボール」と「マラソンシューズ」との関連性はそれに比べれば低くなる。
【0017】
また例えば、ソーシャルネットワークサービスにおけるコミュニティで、「野球」と「サッカー」と「アイスホッケー」と「ガーデニング」と「リアル系巨大ロボットアニメ作品」といった趣味のコミュニティを属性データとして例にとる。「野球」と「サッカー」と両方のコミュニティに所属している利用者は、スポーツ全般に興味がある可能性が高く、「アイスホッケー」のコミュニティについても興味を持つ可能性がそれなりに高いが、「ガーデニング」や「リアル系巨大ロボットアニメ作品」といったコミュニティに興味を持つ可能性はそれに比べると低くなる。ただし、一戸建ての家庭を持つ社会人が興味を抱きやすい傾向にある「ガーデニング」に比べると、スポーツ全般を楽しむ10代から20代の男性が好みやすい「リアル系巨大ロボットアニメ作品」は、やや関連性が高くなる。このため、「野球」を基準にすると、関連性の高いものから「サッカー」「アイスホッケー」「リアル系巨大ロボットアニメ作品」「ガーデニング」のような順となる。なお、ソーシャルネットワークサービス(SNS)とは、対人関係を構築するための手段を用意したサービスである。コミュニティとはそのSNSの一機能で、ある事象について興味を有したり、ある事象について賛同したりする、同一の方向性を持った利用者について、タグ付けやテーブルへの登録などによりまとめることができ、利用者間での交流が可能な専用の場を有していたりするものが挙げられる。
【0018】
さらに例えば、ニュースサイトでは、「少女アイドルグループ(1)」と「少女アイドルグループ(2)」と「大学受験」と「30代男性アイドルグループ(3)」といった、ニュース文書に含まれるキーワードやタグを属性データとして例にとる。「少女アイドルグループ(1)」についてのニュースを見ている利用者は他の「少女アイドルグループ(2)」についてのニュースに興味を持つ可能性が高いが、「大学受験」についてのニュースに興味を持つ可能性はそれより低く、「30代男性アイドルグループ(3)」に興味を持つ可能性はほとんど無い。「少女アイドルグループ(1)」と「少女アイドルグループ(2)」との関連性は高く、「少女アイドルグループ(1)」と「大学受験」との関連性はそれより低くなり、「少女アイドルグループ(1)」と「30代男性アイドルグループ(3)」との関連性はさらに低くなる。ここでは、内容としてはアイドルグループに関するもので似通っている「少女アイドルグループ(1)」と「30代男性アイドルグループ(3)」であるが、属性データの関連性で見ると、前者は10代から30代の男性が興味を持ち、後者は40代以上の女性が興味を持つ傾向が強く、閲覧する層が全く異なる。このため、例えば10代男性層は「少女アイドルグループ(1)」と「大学受験」とのいずれにも興味を持ちやすいので、「少女アイドルグループ(1)」は「30代男性アイドルグループ(3)」よりも、「大学受験」との類似度の方が高いということになる。
【0019】
属性データの関連性のモデル化にはいくつかの方式があり、一般的にはコンテンツに基づくフィルタリングと協調フィルタリングとが挙げられる。前者は、それぞれの属性データの内容に基づき情報を取捨選択するものであり、後者は、webサイト、或いはネットワークにおいて同じ好みを有するものが共通して好むものを選択するものである。コンテンツによるフィルタリングの方式としては、ルールベース方式、メモリベース方式(概念ベース方式)、モデルベース方式の三種類が主に挙げられる。協調フィルタリングの方式としては、ユーザベース方式(メモリベース方式)、アイテムベース方式(メモリベース方式)、モデルベース方式の三種類が主に挙げられる。コンテンツに基づくフィルタリングは、属性データをキーワードやタグとして処理しているため、ニュースサイトや検索サイトにおける記事の推奨に向いており、協調フィルタリングは、属性データそのものがいわゆるアイテム単位であるため、コミュニティや商品の推奨に向いている。
【0020】
この発明で利用する利用者の過去の行動記録は、アンケートやページ評価などの利用者が自ら行う明示的(直接的)手法と、アクセス解析や閲覧時間評価などの暗黙的(間接的)手法とがある。明示的手法は正確性が高いが利用者にかかる負担が大きい。暗黙的手法は利用者に対して推薦手法の評価をしていることを気づかせない程度に負荷が小さい。
【0021】
この発明が対象とする推薦手法とは、利用者の過去の行動記録から、上記の属性データを抽出し、基礎とする過去属性データとして扱い、この過去属性データから、あるアルゴリズムによって、別の属性データ(推薦属性データ)を提示、推薦することができるものである。この行動記録とは、コミュニティページや商品ページ、ニュースページ等のアクセス履歴だけでなく、登録コミュニティの一覧、商品の購入履歴、検索履歴、入力単語の履歴、RSSの登録項目などが挙げられる。基本的には、過去属性データとそれから提示推薦できる推薦属性データとは共通である。例えば、登録コミュニティの一覧から提示推薦できるのは、次に登録してはどうかと提案される登録コミュニティであり、ニュースページのアクセス履歴から提示推薦できるのは、別のニュースページである。しかし、実体的な内容を紐付けることができれば、過去属性データと推薦属性データが異なっていてもよい。例えば、登録コミュニティとしてNBA(ナショナルバスケットアソシエーション)ファンクラブに登録されている利用者に対して、推薦属性データとして、NBAチームのユニフォームの宣伝を提示するといったことが可能である。
【0022】
この発明では、上記の類似度として、それぞれの上記属性データの間の、利用者にとっての関連性の高さを数値的に比較できる値が算出できるものであれば、その算定基準と計算方式を特に限定するものではない。類似度の数値が高いほど関連性が高いと一応の想定ができ、類似度の数値がある閾値以上であるか否かによって、興味の飛躍が生じる、すなわち、意外であり得るとされるか否かを分類できればよい。一般的には、当該属性データにアクセスしたり、登録したり、購入したりする利用者がどの程度一致しているかを、個々の属性データの全てについて算出することで、基本的な値の算出は可能であるが、特にそれに限定されるものではない。
【0023】
例えば上記属性データとして、上記のSNSにおけるコミュニティ同士の類似度の値を求める方法として、合計利用者数で共通利用者数を割るといった方法が挙げられる。あるコミュニティXとコミュニティYがあり、一定期間中に、XにはユーザA,B,C,D,Eの5人がアクセスしており、YにはユーザA,C,D,F,Gの5人がアクセスしていて、全部で7人いるうち、共通してアクセスしていたのがA,C,Dの3人である場合、3/7=43%という計算をして、類似度を43%、とすることができる。
【0024】
また、ニュースサイトにおけるニュース文書の類似度を求める方法として、ニュース文書から属性データであるキーワードを概念抽出し、単語ベクトル間の兄弟概念や上位概念との単語ベクトル間の距離値を求める方法がある。これは、大量のニュース文書を取り込み、似た概念を有する単語の出現パターンが似通ってくることを利用して、単語の概念ベクトルを収集してデータベース化した上で、算出可能となる個々のキーワード間の距離を類似度として用いるものである。
【0025】
上記過去属性データが複数ある場合、過去属性データを一つのまとまり(群)として見なし、それ以外の属性データとの類似度は一意に定まる。これについて、上記のコミュニティの例に沿って計算例を示す。コミュニティZには、ユーザA,B,C,G,H,Iの6人がアクセスしていたとする。ここでXとYのコミュニティ群(以下、XY群)とZの類似度を計算する。XとYに共通的にアクセスしているユーザはA,B,C,D,E,F,Gとなる。そのため、XY群とZとの類似度は、上記と同じ手法で計算すると、全部で9人(ABCDEFGHI)いるうち、共通してアクセスしていたのが4人(ABCG)なので、4/9≒44%となる。
【0026】
ただし、類似度が低いことがすなわち意外性があるわけではない。行動記録上ある過去属性データを有する利用者に対して、その過去属性データとの類似度が低い推薦属性データを提示し、その推薦属性データに対して利用者が所定の行動を起こせば、それは意外性があるということになり、行動を起こさなければ、意外ではなく、無縁であったということになる。一方、既に行動の対象となった属性データが、推薦属性データに仮に含まれたとしても、以下の新規性対象、意外性対象からは除外する。
【0027】
この提示された推薦属性データについて類似度を求める。すなわち、推薦属性データのうち、過去属性データに含まれないものについて、それぞれの属性データごとに、比較対象となる当該利用者の過去属性データ群との類似度を求める。この類似度が閾値以上であるものを、新規性対象、すなわち、意外ではないが、未踏、未訪問、未登録、未見である新規なものとする。一方、この類似度が閾値未満であるものは、提示開始から一定期間経過までの間に、利用者の登録、アクセス、購入などといった、それぞれに適した行動の対象となったら、意外性対象、すなわち、関連性は薄くとも利用者が興味を持った意外なものとする、一定期間経過までに利用者の行動の対象とならなかったら、その数緯線属性データは用を為さなかったものとする。なお、この閾値も本発明によって評価可能なパラメータであり、閾値が変わることで、当該推薦手法の評価内容は変化する。
【0028】
その上で、推薦属性データの全数のうち、新規性対象の占める割合である新規性対象率と、前記意外性対象の占める割合である意外性対象率とを求める。これにより、当該利用者に対して提示された推薦属性データの内訳を評価できる。
【0029】
このようにして得られた新規性対象率と意外性対象率とを、複数の利用者について求め、それらの値について数的評価を行う。複数の利用者とは、全利用者でもよいし、抽出した利用者でもよい。対象とする利用者数が多い方が評価の信憑性は向上するが、その分解析に時間がかかる。ここで数的評価とは、統計値の算出や、グラフ上へのプロット、又はその両方が挙げられる。統計値としては、一般的な平均値の他、中間値、最小値、最大値、最頻値、分散、標準偏差などが挙げられる。これにより、当該推薦手法により提示されたデータの全体的な傾向を掴むことができる。例えば、対象とする利用者中での新規性対象率の平均値が高く、意外性対象率の平均値が低ければ、提示された推薦属性データは、堅実で類似性の高いものを推奨するものであるとわかる。逆に意外性対象率の平均値の方が高ければ、利用者の利用を飛躍的に高める傾向にあることがわかる。また、新規性対象率と意外性対象率とのいずれの平均値も低い場合は、その推薦手法は有用性に問題があることがわかる。また、最小値と最大値の幅が大きかったり、分散が大きかったりすると、推薦する内容にムラがあり、逆であればムラが少なく、照準が定めやすいということがわかる。
【0030】
このような統計値の算出を、複数の推薦手法により得られた推薦属性データについて行い、推薦手法ごとの値を求めて互いに比較することで、他の推薦手法と比べて、その推薦手法がどのような傾向にあり、どういう場合にどの推薦手法を採用すればよいかを判断できる。なお、ここで複数の推薦手法とは、アルゴリズムが同一であってもパラメータの違いによって異なる結果が得られるものであれば、複数の推薦手法として考えることができる。堅実な拡大路線を勧めようとするならば、新規性対象率が高い推薦手法を選び、常に興味を引きつけて利用を拡大させていこうとするならば意外性対象率が高い推薦手法を選ぶ、といったような選択ができる。
【0031】
以上のような評価方法を、具体例を挙げて説明する。推薦手法を採用する対象は、SNSサイトにおけるコミュニティの推薦である。ここでコミュニティとは、サービス内である事柄について同項の士が集まる掲示板機能や新規通知機能などを有し、当該事柄についての話題をやりとりできる仮想的な場、ページのことである。推薦手法の利用形態の概略図を図1に示す。利用者が当該サイトを利用して、複数あるコミュニティにアクセスすることにより(S101)、行動記録であるアクセスログが蓄積されていく。このログは、それぞれの利用者がどのコミュニティにアクセスしたか、というデータを主に有する。このログを一定期間に亘って蓄積する(S102)。次に、蓄積した行動記録を過去属性データとして、評価しようとする複数の推薦手法を実施する(S103)。これにより、それぞれの利用者に対して推薦するコミュニティのリストである推薦属性データが得られる(S104)。
【0032】
この推薦属性データを一定期間利用者に対して提示する。具体的には、当該利用者が当該SNSサイトを利用する(S101)際のスタートページなどに表示し続けることで、推薦するコミュニティへのアクセスを促す。これを一定期間に亘って続けて、アクセスログを収集する(S102)。この評価期間が終了した後、それらの推薦表示したコミュニティの内容、およびアクセスしたか否かを踏まえて、新規性、意外性の評価を行う(S111)。すなわち、この発明では利用者の行動を、図2に示すように、少なくとも二回の期間に亘って記録する。一つは、推薦属性データを導き出すための過去属性データの取得のためであり、もう一つは、推薦属性データに対する利用者の行動結果を記録し、意外性や新規性の評価に用いるためである。
【0033】
図3に、推薦コミュニティの例を示す。利用者を推薦手法の数だけグループ分けし、それぞれのグループについて、一の推薦手法を実行して、推薦コミュニティのリストを作成する。ここでは、概念ベース技術と、協調フィルタリング技術、ランダム選択の三種類を、五百人ごとに分けたグループのそれぞれに対して実行したとする。
【0034】
利用者の一人であるユーザ1を例に取り、類似度の計算を説明する。この概念図を図4に示し、処理のフローを図5に示す。まず、ユーザ1は最初のログを取得する期間(過去属性データ取得期間)に、「野球」「サッカー」「バスケットボール」のコミュニティにアクセスしていたとする。この事実は過去属性データ取得期間のアクセスログから把握できる。これを前提にすると、推薦されたリストに表示されたコミュニティのうち(S211)、「野球」「サッカー」は既にユーザ1がアクセスしていたことがわかる(S212)。この場合、「野球」「サッカー」は再訪問を促すものであり、新規なものでも意外なものでもない。よって、新規性対象、意外性対象のいずれにも属さない(S213)。一方、「アイスホッケー」「リアルロボット」「ガーデニング」はまだユーザ1がアクセスしていないコミュニティであるとする(S212)。
【0035】
次に、提示された推薦属性データである推薦コミュニティのうち、推薦前は未アクセスであった3つのコミュニティのそれぞれについて、全利用者、又は抽出したある程度の数の利用者のアクセスログを前提として、既訪問であるコミュニティ群との類似度を計算する(S216)。ここでは既訪問のコミュニティ群が「野球」及び「サッカー」と「バスケットボール」の3つあり、この3つのコミュニティを1つの過去属性データとみなし、この群からの類似度を求めて、未アクセスコミュニティを分類する。
【0036】
その分類の概念図を図6に示す。まず分類に当たり、類似度について閾値を決定する。ここで採用する類似度の範囲のうち、その閾値より高い値を示す関係にあるコミュニティは類似度が高いため、表示されても意外性は無いものとする。例えばここでは、閾値を0.7とするが、コミュニティの数により適切な閾値は変化する。ここでは、「アイスホッケー」は類似度が0.8と閾値以上であるので(S217)、新規性対象として分類する(S218)。一方、閾値が0.8より低い「リアルロボット」と「ガーデニング」とについては、上記評価期間(S102〜S104)の間に、ユーザ1がアクセスしたか否かによって分類する(S219)。上記評価期間の間にユーザ1がアクセスしている「リアルロボット」は、推薦前にアクセスしたコミュニティと類似度が低いにも拘わらず、ユーザ1が新たに興味を持った意外性対象となる(S220)。一方、上記評価期間の間にユーザ1がアクセスしなかった「ガーデニング」については、興味を惹くことができなかったものであり、新規性対象でも意外性対象でもないとして該当なしとなる(S221)。
【0037】
以上で、推薦属性データの全てについて評価が完了する(S214)。これにより、推薦属性データの傾向が評価できる。ここでは、推薦された属性データ数が5で、うち「野球」「サッカー」「ガーデニング」が「該当なし」となり、「アイスホッケー」が新規性対象、「リアルロボット」が意外性対象であった。従って、ユーザ1に提示された推薦属性データ中、新規性対象の占める割合である新規性対象率は1/5=20(%)であり、意外性対象の占める割合である意外性対象率は1/5=20(%)となる。このユーザ1に与えた結果としては、一応の興味の拡大に繋がったことがわかる。
【0038】
このような評価を、各々の推薦手法を用いたユーザ全体について行い、さらにそれを全ての推薦手法についても行うことで、結果や傾向の相互比較が可能となる。すなわち、推薦手法1,2、3……を用いて個々のユーザに推薦した全ての推薦属性データについて分類、統計処理を行う。
【0039】
そのためのフローの全体像を図7に示す。フロー中、中央にある演算部1が、上記の図5における新規性対象と意外性対象との分類に対応する。まず、推薦手法1により提示された全ての推薦コミュニティ(推薦属性データ)について、ユーザ1から順に上記の演算部1の処理を行う(S211〜S222)。その上で、推薦手法1により推薦したユーザ(ここではユーザ1〜500)の平均値を算出する(S223)。なお、図中、新規性対象率を「新規性」と、意外性対象率を「意外性」と略記する。これにより、推薦手法1により推薦したコミュニティについての数的処理と新規性及び意外性の分類がされた。この値は、推薦手法1で出力される推薦属性データの傾向を示すものである(S232)。
【0040】
この処理を、続けて推薦手法2,3……とについても行い(S231〜S232)、それぞれの推薦手法による、新規性対象率、意外性対象率を算出する。これにより、図7に記載のように、推薦手法ごとの新規性対象率及び意外性対象率が比較できるようになる。例えば図7のような結果となった場合、推薦手法1は新規性と意外性のバランスがよく、推薦手法2は新規性が多いために堅実な運用に向いており、推薦手法3は意外性に特化していて拡大傾向に拍車を掛けたいときに向いている、といった評価ができる。
【0041】
このように、利用者(ユーザ)ごとの新規性対象率、意外性対象率を求め、それを推薦手法ごとにまとめて数的処理し、推薦手法間で対比することで、推薦手法の評価ができる。この全体構造を保持すれば、それ以外の点は変更が可能である。
【0042】
例えば、上記の判断においては、アクセスしたコミュニティについて過去属性データを収集し、推薦属性データの意外性評価もアクセスの有無によって行っているが、これを、コミュニティへの登録について過去属性データを収集し、意外性評価も登録の有無について行っても同様のことができる。
【0043】
また例えば、上記のフローでは推薦属性データのうち類似度が閾値以上のものは無条件に新規性対象としているが、意外性対象の判断と同様に、実際にアクセスしなかったものは「該当なし」としてもよい。類似度が高いからといって、実際にアクセスに寄与しなければ、推薦する意義がないからである。この場合、上記の演算部1のフローは図8のようになる。それぞれの推薦属性データについて、最大類似度を抽出引用した後(S216)、まず評価期間中にアクセスがあったか否かを判断し(S219A)、アクセスがなかったものは、閾値とは関係なく「該当なし」となる(S221A)。一方で、評価期間中にアクセスがあった推薦属性データ(推薦コミュニティ)については、類似度が閾値以上か否かを判断し(S217A)、新規性対象であるか(S218A)、意外性対象であるか(S220)を判断する。
【0044】
さらに例えば、上記のフローでは推薦手法1〜3を異なるユーザグループに対して行っているが、推薦手法1〜3を全てのユーザに対して実施し、提供期間をずらして順に推薦属性データを示してもよい。ただしこの場合、推薦手法1による推薦属性データを見た利用者は、次の推薦手法2による推薦属性データに対して行動するときに、前に推薦された推薦属性データが記憶にあり、行動を左右されているため、提供順序によりある程度の誤差が生じる。
【特許請求の範囲】
【請求項1】
一の利用者の過去の行動記録を基礎として、一の推薦手法により、一の利用者に提示した複数の推薦属性データについて、
当該利用者が過去に行った行動記録に由来する過去属性データ群に対する関連性の高さである類似度を計算し、
所定の閾値未満である前記推薦属性データのうち提示開始から一定時間経過するまでに当該推薦属性データに対する行動が達成されたものを意外性対象と分類し、
前記類似度が所定の閾値以上である前記推薦属性データ、又はそのうち提示開始から一定時間経過するまでに当該推薦属性データに対する行動が達成されたものを新規性対象と分類し、
全推薦属性データ数に対する、前記新規性対象の割合である新規性対象率と、前記意外性対象の割合である意外性対象率とを求め、
提示された内容の新規性及び意外性の度合いを評価する、提示内容の評価方法。
【請求項2】
複数の前記過去属性データをひとつのまとまりとして見なし、個々の前記推薦属性データについて算出されたそのまとまりである群に対する類似度を、その推薦属性データについての前記新規性対象及び前記意外性対象の分類の基準である類似度として用いる、請求項1に記載の提示内容の評価方法。
【請求項3】
複数の利用者に対して、請求項1又は2に記載の提示内容の評価方法を実行し、その複数の利用者それぞれについて、前記新規性対象率と前記意外性対象率とを求め、
それらの値の数的評価により、当該一の推薦手法の新規性及び意外性の度合いを評価する、推薦手法の評価方法。
【請求項4】
複数の推薦手法について、請求項3に記載の推薦手法の評価方法を実行し、それぞれの数的評価を比較する、複数の推薦手法の評価方法。
【請求項1】
一の利用者の過去の行動記録を基礎として、一の推薦手法により、一の利用者に提示した複数の推薦属性データについて、
当該利用者が過去に行った行動記録に由来する過去属性データ群に対する関連性の高さである類似度を計算し、
所定の閾値未満である前記推薦属性データのうち提示開始から一定時間経過するまでに当該推薦属性データに対する行動が達成されたものを意外性対象と分類し、
前記類似度が所定の閾値以上である前記推薦属性データ、又はそのうち提示開始から一定時間経過するまでに当該推薦属性データに対する行動が達成されたものを新規性対象と分類し、
全推薦属性データ数に対する、前記新規性対象の割合である新規性対象率と、前記意外性対象の割合である意外性対象率とを求め、
提示された内容の新規性及び意外性の度合いを評価する、提示内容の評価方法。
【請求項2】
複数の前記過去属性データをひとつのまとまりとして見なし、個々の前記推薦属性データについて算出されたそのまとまりである群に対する類似度を、その推薦属性データについての前記新規性対象及び前記意外性対象の分類の基準である類似度として用いる、請求項1に記載の提示内容の評価方法。
【請求項3】
複数の利用者に対して、請求項1又は2に記載の提示内容の評価方法を実行し、その複数の利用者それぞれについて、前記新規性対象率と前記意外性対象率とを求め、
それらの値の数的評価により、当該一の推薦手法の新規性及び意外性の度合いを評価する、推薦手法の評価方法。
【請求項4】
複数の推薦手法について、請求項3に記載の推薦手法の評価方法を実行し、それぞれの数的評価を比較する、複数の推薦手法の評価方法。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【公開番号】特開2012−203663(P2012−203663A)
【公開日】平成24年10月22日(2012.10.22)
【国際特許分類】
【出願番号】特願2011−67930(P2011−67930)
【出願日】平成23年3月25日(2011.3.25)
【出願人】(399041158)西日本電信電話株式会社 (215)
【Fターム(参考)】
【公開日】平成24年10月22日(2012.10.22)
【国際特許分類】
【出願日】平成23年3月25日(2011.3.25)
【出願人】(399041158)西日本電信電話株式会社 (215)
【Fターム(参考)】
[ Back to top ]