
改善された類似文書検出方法、装置、及びコンピュータ読み取り可能な記録媒体
【課題】本発明は、改善された類似文書検出方法に関するものである。
【解決手段】類似文書検出装置で行われる方法であって、複数のウェブ文書それぞれからエンティティ(entity)及び重要度寄与要素を算出するエンティティを抽出し、算出された重要度寄与要素に基づいて各エンティティに対する加重値を計算し、算出された加重値に基づいて複数のウェブ文書が類似文書であるか否かを検出すること、を含むことを特徴とする。本発明によると、類似文書である可能性のある文書において、文書中の核心となる部分と核心ではない部分とを区別し、これにより互いに異なる加重値を与えることにより、より改善された方式で類似文書を判別して検索エンジンの精度を向上させることができる。
【解決手段】類似文書検出装置で行われる方法であって、複数のウェブ文書それぞれからエンティティ(entity)及び重要度寄与要素を算出するエンティティを抽出し、算出された重要度寄与要素に基づいて各エンティティに対する加重値を計算し、算出された加重値に基づいて複数のウェブ文書が類似文書であるか否かを検出すること、を含むことを特徴とする。本発明によると、類似文書である可能性のある文書において、文書中の核心となる部分と核心ではない部分とを区別し、これにより互いに異なる加重値を与えることにより、より改善された方式で類似文書を判別して検索エンジンの精度を向上させることができる。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、改善された類似文書検出方法、装置、及びコンピュータ読み取り可能な記録媒体に関し、より具体的には、収集されたウェブ文書のうち類似文書を検出する際に文書内で核心となる部分及び核心ではない部分を区別し、これにより互いに異なる加重値を与えて、類似文書を検出するためのより正確で改善された方法、装置及びコンピュータ読み取り可能な媒体に関する。
【背景技術】
【0002】
最近、インターネットの使用が普及するにつれて、ユーザはインターネット検索を介して多様な情報を取得できるようになった。すなわち、ユーザはインターネットへのアクセスが可能なパソコンなどの端末装置を介してウェブブラウザのアドレスバーにURLのような識別子を入力することにより、インターネット検索サイトにアクセスして、自分が確認しようとする検索キーワードを入力して、ニュース、知識、ゲーム、コミュニティ、ウェブ文書などの多様な分野に係わる検索結果を見ることができるようになった。
【0003】
上述のように、ユーザが検索しようとする内容を適切に示すために、インターネット検索サイト提供者はウェブ文書などを収集し、収集されたウェブ文書などに索引(index)を構成して、これに基づいて検索結果をユーザに提供する機能を有する検索エンジンを設計して構成することが一般的であり、その中でもインターネット上に存在するウェブ文書を組織的かつ自動化した方法で探索及び収集する機能を有するウェブクローラ(Web Crawler)は大きな役割を果たしている。
【0004】
このようなウェブクローラの動作方式の一つとして、シード(seed)と呼ばれるURLリストから始めて、シードに含まれる全てのハイパーリンク(Hyperlink)を認識してURLリストを更新(update)し、更新されたURLリストに該当するウェブ文書を再帰的に再び訪問する方式が用いられている。
【0005】
しかし、一般的に収集対象となるウェブ文書の中には、その内容が大同小異であり、強いて別個に収集する必要性のないものが多いにもかかわらず、基本的なウェブクローラの動作方式に従ってウェブ文書の検索及び収集を行う場合には、URLリストに含まれる全てのウェブ文書を訪問及び収集することになり、収集されたウェブ文書を保存する保存領域の問題、及び、これによる検索エンジンの性能及び効率性の低下などの様々な問題が現れた。
【0006】
そこで、このような問題を解決するために、従来は、類似文書の検出技術を導入し、類似したウェブ文書が検出された場合、収集された重複する類似文書を保存領域から削除したり、当該文書が発見された経路(path)の収集速度を減少させたりするなどの作業を行っていた。
【0007】
しかし、従来の類似文書検出技術の場合、同一または類似する領域の大きさに応じて類似文書であるか否かを検出するため、ウェブ文書におけるほとんどの領域が同一であっても核心となる部分が相違すれば、実際には類似文書ではないにもかかわらず、同一の部分が多いということにより一律に類似文書であると判断されるため、正常な文書の収集作業が妨害されることになり、その結果、検索精度が低下するという問題が存在する。
【0008】
図1a及び図1bは、従来技術における類似文書検出技術によって類似文書と認められる場合の例を例示的に示した図である。図1を参照して、従来技術における類似文書検出技術の問題点について説明する。
【0009】
図1a及び図1bに示された一例は、ウェブクローラによって収集される互いに異なるURLを有するそれぞれのウェブ文書を示す。ウェブ文書において核心となる部分である商品名、商品コードなど(図1aのA領域及び図1bのA´領域)は相違しているが、相違する領域がウェブ文書全体のうちの小さな領域のみを占めており、メニュー、オプション、商品の詳細情報など多くの領域(図1a及び図1bにおけるB領域、C領域など)において同一の部分が存在するため、従来の類似文書の検出技術では、同一の領域がどれほど多いかに応じて類似文書であるか否かを判断する。しかし、当該ページにおいて最も核心的な部分である商品名や商品コードが相違する、すなわち、相違する商品に対する相違するウェブ文書であるため、類似文書であるとは認められないにもかかわらず、従来技術によると類似文書であると判断され、このうち一方が保存領域から削除されるため、検索エンジンのユーザに提供されなくなり、検索精度低下の問題が生じる。
【先行技術文献】
【特許文献】
【0010】
【特許文献1】韓国公開特許第1999―0088678号公報
【特許文献2】韓国公開特許第1999―0048714号公報
【発明の概要】
【発明が解決しようとする課題】
【0011】
本発明は、前記の従来技術の問題点を解決することを目的とする。
【0012】
また、本発明は、類似文書である可能性のあるウェブ文書において、ウェブ文書中の核心となる部分と核心ではない部分とを区別し、これにより互いに異なる加重値を与えることにより、より改善された方式で類似文書を判別して検索エンジンの精度を向上させることを他の目的とする。
【0013】
また、本発明は、類似文書検出結果に応じて、重複する類似文書をウェブ文書保存領域から削除して保存領域の無駄使いを防ぎ、これにより検索エンジンの性能を向上させることをさらに他の目的とする。
【課題を解決するための手段】
【0014】
前記のような本発明の目的を達成して、後述する本発明に特有の効果を奏するための本発明の特徴的な構成は以下のとおりである。
【0015】
本発明の一実施形態によると、改善された類似文書検出方法において、類似文書検出装置で行われる各ステップは、複数のウェブ文書それぞれからエンティティ(entity)及び重要度寄与要素を算出するエンティティを抽出し、算出された重要度寄与要素に基づいて各エンティティに対する加重値を計算し、算出された加重値に基づいて複数のウェブ文書が類似文書であるか否かを検出すること、を含む。
【0016】
本発明の他の実施形態によると、改善された類似文書検出装置は、複数のウェブ文書それぞれからエンティティ(entity)及び重要度寄与要素を算出するエンティティ抽出手段と、算出された重要度寄与要素に基づいて各エンティティに対する加重値を計算する加重値計算手段と、算出された加重値に基づいて複数のウェブ文書が類似文書であるか否かを検出する類似文書検出手段と、を含む。
【発明の効果】
【0017】
前記のように本発明によると、類似文書である可能性のある文書において、文書中の核心となる部分と核心ではない部分とを区別し、これにより互いに異なる加重値を与えることにより、より改善された方式で類似文書を判別して検索エンジンの精度を向上させることができる。
【0018】
また、本発明によると、類似文書検出結果に応じて、重複する類似文書をウェブ文書保存領域から削除して保存領域の無駄使いを防ぎ、これによる検索エンジンの性能を向上させることができる。
【図面の簡単な説明】
【0019】
【図1a】従来技術における類似文書検出技術により類似文書であると判断される場合の例を例示的に示した図である。
【図1b】従来技術における類似文書検出技術により類似文書であると判断される場合の例を例示的に示した図である。
【図2】本発明の一実施形態における検索結果提供装置を含む全体システムを概略的に示した図である。
【図3】本発明の一実施形態における検索結果提供装置の詳細な構成を示した図である。
【図4】本発明の一実施形態における類似文書検出部の詳細な構成を示した図である。
【図5】本発明の一実施形態における類似文書検出方法を説明するためのフローチャートである。
【図6】本発明の一実施形態において、ウェブ文書のシムハッシュを計算する方式を説明するための図である。
【図7a】本発明の一実施形態におけるウェブ文書のDOM構造を抽出する方式を説明するための図である。
【図7b】本発明の一実施形態におけるウェブ文書のDOM構造を抽出する方式を説明するための図である。
【図8a】本発明の一実施形態におけるウェブ文書のエンティティ及びその関連値の抽出を説明するための図である。
【図8b】本発明の一実施形態におけるウェブ文書のエンティティ及びその関連値の抽出を説明するための図である。
【図8c】本発明の一実施形態におけるウェブ文書のエンティティ及びその関連値の抽出を説明するための図である。
【図9a】本発明の一実施形態におけるエンティティごとの加重値計算を説明するための図である。
【図9b】本発明の一実施形態におけるエンティティごとの加重値計算を説明するための図である。
【図10】本発明の一実施形態において加重値が適用されたシムハッシュを計算する方式を説明するための図である。
【発明を実施するための形態】
【0020】
後述する本発明の詳細な説明において、本発明を実施することができる特定の実施形態を例として示す添付の図面を参照する。これらの実施例は、当業者が本発明を十分に実施することができるように詳細に説明される。本発明の多様な実施例は互いに異なるが相互に排他的である必要はないということが理解されるべきである。例えば、本明細書に記載されている特定の形状、構造及び特性は、一実施例にすぎず、本発明の思想及び範囲を外れない限り他の実施例において実現されてもよい。また、開示された各実施例中の個別の構成要素の位置または配置は、本発明の思想及び範囲を外れない限り変更されてもよいということが理解されるべきである。従って、後述する詳細な説明は、限定的な意味に制限するものではない。本発明の範囲は、適切に説明されれば、その特許請求の範囲に記載されたものと均等な全ての範囲とともに添付の特許請求の範囲の記載によってのみ限定される。図面において類似する参照符号は様々な側面に亘って同一または類似する機能を指称する。
【0021】
以下、本発明が属する技術分野における通常の知識を有する者が本発明を容易に実施することができるように、本発明の好ましい実施例について添付の図面を参照して詳細に説明する。
【0022】
本発明の実施形態における「ウェブ文書」という用語は、インターネットエクスプローラなどのウェブブラウザプログラムを用いて読み込み可能な受動的または能動的な文書形式を全て含む広い意味で解釈されなければならず、ウェブ文書の文書形式として、主にHTML(HyperText Markup Language)が用いられるが、必ずしもこれに限定されず、XML(Extensible Markup Language)、SGML(Standard Generalized Markup Language)を含み、ウェブブラウザプログラムを用いて読み込み可能な文書形式であれば全てウェブ文書に該当する。ウェブブラウザプログラムを用いてウェブ文書を読み込むためには、一般的にウェブ文書が位置するアドレスをURLとして入力し、そのアドレス形式としてHTTP(HyperText Transfer Protocol)が多く用いられるが、必ずしもこれに限定されるものではない。
【0023】
一方、本発明の実施形態における「URL(Uniform Resource Locator)」という用語は、ウェブ上でサービスを提供する各サーバに存在するファイルの位置を明示するためのものであって、アクセスすべきサービスの種類、サーバの位置(ドメインネーム)、ファイルの位置を含む。URLの一般的な体系(syntax)は、「プロトコル://ホスト名/経路(path)/ファイル名?パラメータ」のような形式で構成されてもよい。ここで経路は、複数の経路を含んでもよく、パラメータも複数のパラメータを含んでもよい。例えば、http://www.xxx.com/a/b/c.html?x=1&y=2のようなURLにおいて、プロトコルはhttpであり、ホスト名はwww.xxx.comであり、経路は/a/b/であり、ファイル名はc.htmlであり、パラメータはx及びyの2つであって、その値はそれぞれ1及び2である。
【0024】
一方、本発明の実施形態における「類似文書」という用語は、その内容が同一であるかその内容の核心を含むほとんどが同一である複数のウェブ文書を示す広い意味で用いられる。検索エンジンの効率性を考慮して、類似文書を検出する際に基本となるウェブ文書以外のこれと重複する類似文書は、収集された保存領域から削除されて検索エンジンにより検索されないようにする。
【0025】
[装置の全体構成]
図2は、本発明の一実施形態において検出された重複する類似文書を削除した検索データベースを用いた検索結果提供装置を含む全体装置を概略的に示した図である。
【0026】
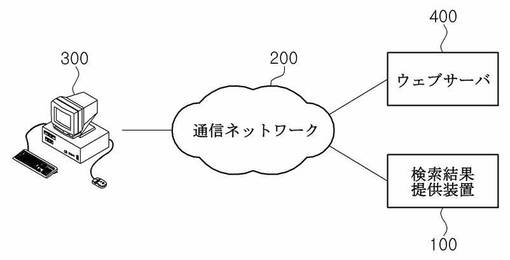
図2に示されているように、本発明の一実施形態における全体装置は、検索データベースを有する検索結果提供装置100が通信網200を介して複数のユーザ端末装置300及び複数のウェブ文書サーバ400に接続されてもよい。
【0027】
まず、本発明の一実施形態によると、検索結果提供装置100は、ユーザ端末装置300から探索キーワード、すなわち、問い合わせ言語を受信し、これに基づいて検索を行った後、その結果として出力される検索結果をユーザ端末装置300に伝送する機能を行う。また、検索結果提供装置100は、収集部120(図3参照)を用いて一つ以上のウェブ文書サーバ400から収集したウェブ文書において類似文書が存在する可能性のあるクラスタを生成し、生成されたクラスタから類似文書であるか否かを検出して、検出結果検索データベースに類似文書が保存された場合には、重複する類似文書を削除する機能を行ってもよい。
【0028】
また、本発明の一実施形態によると、通信網200は、有線・無線などのような通信状態を問わずに構成されてもよく、パーソナルエリアネットワーク(PAN;Personal Area Network)、ローカルエリアネットワーク(LAN;Local Area Network)、メトロポリタンエリアネットワーク(MAN;Metropolitan Area Network)、広域ネットワーク(WAN;Wide Area Network)など、多様な通信網で構成されてもよい。
【0029】
一方、本発明の一実施形態におけるユーザ端末装置300は、ユーザが所定の問い合わせ言語に対する検索結果を提供されるように、通信網200を介して検索結果提供装置100に接続するための機能を含む入出力装置を意味し、デスクトップパソコンだけでなく、ノートパソコン、ワークステーション、パームトップ(palmtop)パソコン、個人携帯情報端末(personal digital assistant;PDA)、ウェブパッド、スマートフォンを含む移動通信端末などのようにメモリ手段を備え、マイクロプロセッサを搭載して演算能力を備えたデジタル機器であればいずれも本発明におけるユーザ端末装置300として採用され得る。好ましくは、ユーザ端末装置300は、検索結果提供装置100に接続し、問い合わせ言語を入力して検索結果を提供されるために、ユーザ端末装置300内のウェブブラウザを実行して用いられてもよいが、必ずしもこれに限定されるものではない。
【0030】
一方、本発明の一実施形態におけるウェブ文書サーバ400は、検索結果提供装置100内の収集部が収集するウェブ文書を含むウェブサーバの通称であり、物理的に特定のサーバや特定の内容/形式のウェブ文書に限定されるものではない。収集部が通信網200を介してアクセスしてウェブ文書を収集することができるウェブサーバは全てウェブ文書サーバ400に含まれると認められる。
【0031】
[検索結果提供装置]
図3は、本発明の一実施形態における検索結果提供装置100の詳細な構成図である。
【0032】
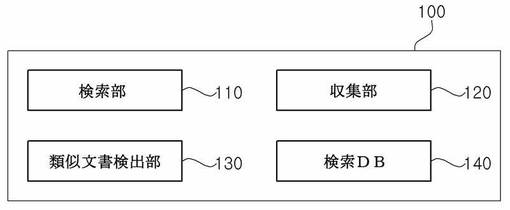
図2を参照すると、本発明の一実施形態における検索結果提供装置100は、検索部110、収集部120、類似文書検出部130、及び検索データベース140を含んでもよい。
【0033】
検索部110は、ユーザ端末装置300から受信した問い合わせ言語に対応する情報を検索データベース140から検索する。検索により抽出される検索結果はユーザ端末装置300に伝送される。
【0034】
収集部120は、ウェブ文書サーバ400に保存されたウェブ文書をウェブクローラなどの公知の組織的な自動化された方法により検索及び収集して検索データベース140に保存する機能を行う。
【0035】
類似文書検出部130は、収集部120を介して収集されるウェブ文書を多様な方法を用いて生成され得るクラスタに統合した後、ウェブ文書中のそれぞれのエンティティ(entity)がウェブ文書中の核心となる部分であるか否かに応じてその加重値を計算し、加重値を適用した類似文書を検出して類似文書が検出された場合、この結果を検索データベース140に保存されたウェブ文書に適用して重複して保存された類似したウェブ文書の削除を行うようにしてもよい。類似文書検出部130の各構成要素の詳細な機能については後述する。
【0036】
検索データベース140は、検索結果を提供するために収集されたり保存されたりする各種情報を含んでもよく、その他にも収集部120が収集したウェブ文書を保存してもよい。また、類似文書検出部130の動作によって検索データベース140内に既に収集されたウェブ文書が重複して保存されている場合、その一部または全部が削除されてもよい。
【0037】
図3には、検索データベース140のみを図示したが、本発明の一実施形態においいて収集部120が収集、検出したウェブ文書を保存するデータベースを別に構築し、そのうち類似文書検出部130によって検出された類似文書結果に基づいて重複するウェブ文書が削除された残りのみを検索データベース140に保存してもよい。また、図面において検索部110、収集部120、及び類似文書検出部130は、それぞれ別のブロックで示したが、これらは物理的に一つの装置において実現されてもよく、これらの一部またはそれぞれが物理的に異なる装置において実現されてもよく、同一の機能を行う複数の装置に物理的に並列的に実現されてもよい。このように、本発明は、各構成部分が設けられた機械またはデータベースの物理的な個数及び配置に限定されず、様々な方式によって設計、変更されてもよいことは、本発明の属する技術分野における通常の知識を有する者にとって自明である。
【0038】
[類似文書検出部]
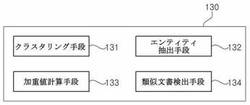
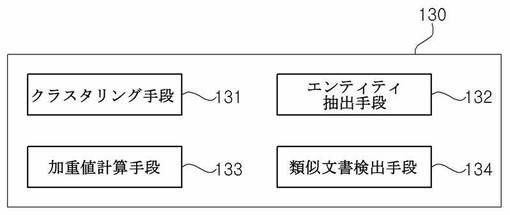
図4を参照して、本発明の一実施形態における検索結果提供装置100の類似文書検出部130についてより詳細に説明すると、類似文書検出部130は、クラスタリング(clustering)手段131、エンティティ(entity)抽出手段132、加重値計算手段133、及び類似文書検出手段134を含んでもよい。
【0039】
ここで、本発明の一実施形態におけるクラスタリング手段131は、検索データベース140または別のデータベースに保存されている収集部120によって収集されたウェブ文書の中に類似文書が存在する可能性のあるクラスタを所定の方法によって生成する機能を行ってもよい。
【0040】
本発明の一実施形態におけるクラスタリング手段131がクラスタを生成するために適用できる所定の方法は、例えば、ホスト(Host)クラスタリング、パス(Path)クラスタリング、クエリ(Query)クラスタリング、サイズ(Size)クラスタリング、シムハッシュ(SimHash)クラスタリング、DOM(Document Object Model)クラスタリングなどを含んでもよく、クラスタリング手段131は、例示されていない他の方法を用いてクラスタを生成してもよく、または例示されたクラスタリング方法及び例示されていない他の方法のうちのいずれか一つ以上を様々な順序で組み合わせて適用してもよく、類似文書が存在する可能性のあるクラスタを生成するために様々な方法を取捨選択してもよいということは当業者にとって自明であろう。
【0041】
前記例示されたそれぞれのクラスタリング方法について詳述すると、まず、ホストクラスタリングは、ウェブ文書の出処であるURLのうちホスト名が一致するURLを有するウェブ文書を一つのクラスタとして生成する方式を意味する。例えば、一つのウェブ文書がhttp://www.xxx.com/a/b/c.html?x=1&y=2というURLを有する場合、当該ウェブ文書をホストクラスタリングにより一つのクラスタを生成すると、当該ウェブ文書のホスト名であるwww.xxx.comと一致するウェブ文書を一つのクラスタとして生成する。
【0042】
次に、パスクラスタリングは、ウェブ文書の出処であるURLのうちホスト名とその経路まで一致するURLを有するウェブ文書を一つのクラスタとして生成する方式を意味する。前記例において、ホスト名とその経路であるwww.xxx.com/a/b/まで一致するウェブ文書を一つのクラスタとして生成する場合、これをパスクラスタリングという。
【0043】
また、クエリクラスタリングは、ウェブ文書の出処であるURLのうちホスト名、経路、及びファイル名まで一致するか、またはファイル名に加えてパラメータまで一致するURLを有するウェブ文書を一つのクラスタとして生成する方式を意味する。前記例に続いて、ホスト名と経路、及びファイル名まで含むwww.xxx.com/a/b/c.htmlが一致するURLを有するウェブ文書を一つのクラスタとして生成するか、またはこれに加えてパラメータまで一致する、すなわちパラメータとしてx及びyを含むURLを有するウェブ文書を一つのクラスタとして生成する場合、これをクエリクラスタリングと呼ぶ。
【0044】
前記ホストクラスタリング、パスクラスタリング及びクエリクラスタリングは、全てウェブ文書の出処であるURLに基づくクラスタ生成方法であって、一つのクラスタに含まれるウェブ文書の個数に基づき、一つ以上の最も適したクラスタリング方式が選択されてもよい。
【0045】
次に、サイズクラスタリングは、ウェブ文書の大きさ(size)に基づいて類似の大きさを有するウェブ文書を一つのクラスタとして生成する方式を意味する。例えば、ウェブ文書の大きさが1600byteから1615byteに該当する場合に、一つのクラスタとして生成すると定義されている場合、その大きさが1600byte、1608byte、1612byteであるウェブ文書は、サイズクラスタリングによって全て一つのクラスタとして生成される。
【0046】
一方、シムハッシュ(SimHash)クラスタリングは、各ウェブ文書別に抽出され得るシムハッシュ値が類似するウェブ文書を一つのクラスタとして生成する方式を意味する。シムハッシュとは、Similarity Hash基盤の技術であって、互いに異なるキーの値が入力された場合、互いに異なるハッシュ値を与える一般的なハッシング機能を維持すると共に、類似するキーの値が入力された場合、類似したハッシュ値を有するハッシュ関数を意味し、このようなシムハッシュ抽出方式を例にとって以下で説明する。
【0047】
一つのウェブ文書は、ワード単位でパーシングされて分離されてもよく、分離されたそれぞれのワードは、所定のハッシングアルゴリズムを適用したハッシュ関数を用いて特定のハッシュ値に計算されてもよく、計算された特定のハッシュ値は二進数で表現されてもよい。ハッシュ関数に用いることができるハッシングアルゴリズムは、標準アルゴリズムであるSHA−1、HAS−160などの既に公知されたアルゴリズムを含み、特定のキーに対する唯一の値を提供するハッシュ関数の機能を有するアルゴリズムであれば、本発明の一実施形態におけるシムハッシュクラスタリングに用いることができるということは当業者にとって自明である。シムハッシュ抽出方式により抽出されるシムハッシュは、このように一つのウェブ文書から分離された各ワード別に抽出されたハッシュ値をビット単位で計算した最終のハッシュ値を意味する。ビット単位で計算する際に特定の位置のビット値が1である場合は1に、0である場合は−1に変換した後、ハッシュ値別にビット単位の演算を行ってビット単位の最終値が正数である場合は1に、負数である場合は0に、再度変換する方式によりウェブ文書のシムハッシュを抽出してもよい。例えば、一つのウェブ文書をワード単位でパーシングした結果、合計3個のワードに分離され、各ワードに対するハッシュ値を二進数で表現した内容がそれぞれ11000101,01101110、及び10010010である場合、当該ウェブ文書のシムハッシュは、図6に示されるように、各ワードのハッシュ値でビット単位別に計算するために、11000101は、1,1,−1,−1,−1,1,−1,1に、01101110は、−1,1、1,−1,1、1,1,−1に、また10010010は、1,−1,−1,1,−1,−1,1,−1に変換された後、ハッシュ値別にビット単位の計算結果である1,1,−1,−1,−1,1、1,−1からハッシュ値をさらに変換すると、シムハッシュ11000110を抽出することができる。このように抽出されたシムハッシュは、複数のウェブ文書においてほとんどの内容が同一であれば、一部の内容が異なっていてもウェブ文書別に類似したシムハッシュを有する。
【0048】
シムハッシュクラスタリングは、このように各ウェブ文書に対して抽出されたシムハッシュが類似するウェブ文書を一つのクラスタとして生成してもよいが、ここでシムハッシュが類似するか否かを判断するためには、シムハッシュ間のハミング距離(hamming distance)が所定数値以下、例えば、シムハッシュが8ビットであると仮定した場合には1である場合を類似したウェブ文書として判断してもよい。ハミング距離は、同一のビット数を有する二進数の間に対応するビット値が一致しない個数を意味し、例えば、シムハッシュが11000101であるウェブ文書とシムハッシュが10010101であるウェブ文書との間のハミング距離は、合計8個のビットのうち、2番目のビット及び4番目の対応ビットが一致しないため、2であり、上述したように、例示的な類似基準である1よりハミング距離が小さいため、二つのウェブ文書は類似しないと判断されてもよい。また他の例として、シムハッシュが11000101であるウェブ文書と11010101であるウェブ文書との間のハミング距離は、合計8個のビットのうち4番目の対応ビットのみが一致しないため、1に該当し、従って、前記例示的な類似基準である1以下に対応するため、二つのウェブ文書は類似していると判断されてもよい。
【0049】
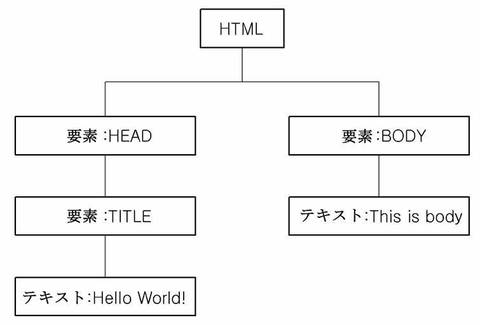
また、DOM(Document Object Model)クラスタリングは、各ウェブ文書別に抽出され得るDOM構造が類似したウェブ文書を一つのクラスタとして生成する方式を意味する。DOM構造とは、所定のウェブ文書の内容を抽出して、ツリー型に概念化した文書構造ツリーの一例であって、ウェブ文書のソースコードが図7aであると仮定した場合、当該ウェブ文書から図7bのような形式のDOM構造を抽出してもよいが、必ずしも図7bに例示されたような形式に限らず、ウェブ文書の内容を概念化できる所定の形式の文書構造であればいずれも本発明におけるDOM構造に含まれてもよい。
【0050】
DOMクラスタリングは、このように各ウェブ文書に対して抽出したDOM構造が類似するウェブ文書を一つのクラスタとして生成してもよいが、ここでDOM構造が類似するか否かを判断するためには、DOM構造間に共通するノードが特定の数値、例えば、80%以上である場合を類似したDOM構造を有するウェブ文書として判断してもよい。
【0051】
本発明の一実施形態におけるクラスタリング手段131は、前記例示した様々なクラスタリング方法、またこれと異なる公知のクラスタリング方法のうちの一つ以上を任意の順序で組み合わせることにより類似文書が存在する可能性のあるクラスタを生成してもよく、例えば、ホストクラスタリングを行った後、シムハッシュクラスタリングによりクラスタを生成したり、ホストクラスタリング、DOMクラスタリング、及びサイズクラスタリングによりクラスタを生成してもよく、様々な応用が可能である。
【0052】
本発明の一実施形態におけるクラスタリング手段131は、クラスタを生成した後、クラスタ内に属するウェブ文書の個数が特定の数値より小さい場合、その正確性のために当該クラスタを廃棄する機能をさらに行ってもよい。
【0053】
次に、本発明の一実施形態におけるエンティティ抽出手段132は、クラスタリング手段131によって生成されたクラスタに含まれるウェブ文書からエンティティを抽出し、加重値計算手段133で各エンティティがウェブ文書中で核心となる部分であるか否かに基づいて計算された加重値を用いるように各エンティティのハッシュ値、クラスタ内の全体ウェブ文書のうち当該エンティティが登場した回数あるいは頻度などの数値を含む各エンティティに対する重要度寄与要素を計算する機能を行う。
【0054】
本発明におけるエンティティとは、類似文書の検出のために比較され得る、ウェブ文書を構成している特徴的な構成要素を含む広義の概念であって、基本的にウェブ文書からパーシングされて分離され得るテキストを含んでもよく、その他にもウェブ文書中のタグ(tag)のうち類似文書の検出のために用いられるアンカー(anchor)、エンベッド(embed)、イメージ(img)タグなどに含まれる値をさらに含んでもよいが、必ずしもこれに限定されるものではない。抽出された各エンティティは、類似文書であるか否かを判断する際に寄与してもよく、すなわち核心となる部分であるか否かに基づく加重値がともに計算されてもよく、加重値は、上述したように、各エンティティに対する重要度寄与要素に基づいて計算される。ウェブ文書中のエンティティを抽出するためにエンティティ抽出手段132は、ウェブ文書から抽出されたDOM構造に基づき、このうちテキスト、アンカー、エンベッド、及びイメージタグが含まれたノード(node)を抽出してウェブ文書のエンティティとして用いてもよい。特に、テキストの場合には、ウェブ文書のどの位置で登場するかによって、同一の文書でも類似文書であるか否かに大きな影響を及ぼす可能性のある、すなわち核心となる部分に該当し得るため、テキストが登場した位置または属性を示す値をさらに含んでもよく、例えば、テキストノードの上位ノード(例えば、DIVノードなど)に存在するID値を当該テキストのID値として当該テキストと結合してエンティティとして使用してもよく、また、テキストの場合、これを空白スペース単位で分けて、そのそれぞれをエンティティとして処理してもよい。その他にアンカーの場合、エンベッドノードとイメージノードは、タグ内に含まれるsrc属性値をそのエンティティとして用いてもよい。
【0055】
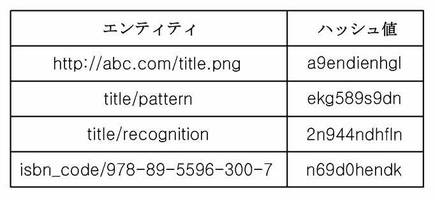
例えば、一つのウェブ文書のソースコードが図8aとおりであると仮定した場合、本発明の一実施形態におけるエンティティ抽出手段132によって抽出され得るエンティティは、図8bの左側のようにイメージノードに含まれるsrc属性から1個、またテキストノードに含まれるテキストを空白スペース単位で分けて、それぞれに属性を示すID値を結合した3個を含む合計4個に該当する。エンティティ抽出手段132は、抽出された各エンティティに対してハッシュ値をさらに求めてもよく、図8bの左側に抽出された4個のエンティティに対するハッシュ値は、図8bの右側に示されてもよい。
【0056】
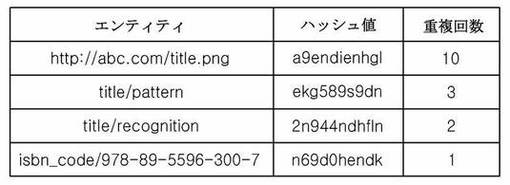
また、本発明の一実施形態におけるエンティティ抽出手段132は、前記例のように、一つのウェブ文書で同一のエンティティが複数個存在する場合、重複するエンティティを除去して一つのウェブ文書で重複するエンティティが存在しないようにする方式により同一のクラスタに含まれた各ウェブ文書から全体エンティティを抽出し、これに基づいて各エンティティがクラスタ内の全体ウェブ文書のうち何個のウェブ文書に重複して登場したのかその重複回数もさらに計算する。前記図8の例に続いて、クラスタ内にウェブ文書が合計10個存在し、このうち図8bの左側に該当する各エンティティが重複するウェブ文書の回数を計算した結果を図8cのように示してもよい。
【0057】
次に、本発明の一実施形態における加重値計算手段133は、前記エンティティ抽出手段132から抽出された各エンティティ、及び重要度寄与要素に基づいて各エンティティごとの加重値を計算する機能を行う。通常、所定ウェブ文書で重要度の高い、すなわち核心となる部分であるほどクラスタ内の複数のウェブ文書で重複する回数が少なく、ウェブ文書でよく用いられる基本形式であるテンプレート(template)として用いられるワードやリンクなどの場合、すなわちその重要度が低く核心とならない部分であるほどクラスタ内の複数のウェブ文書で重複する回数が多いという点に注目した文献出現頻度の逆数(IDF;Inverted Document Frequency)を用いることにより、クラスタ内のウェブ文書に多数重複して登場するエンティティの場合、その重要度が低く核心となる部分ではないと判断して加重値を低く与え、クラスタ内のウェブ文書に重複する回数が少ないほどその重要度が高く核心となる部分であると判断し、エンティティの加重値を高く与えるという概念を適用して抽出された各エンティティごとの加重値を計算する。
【0058】
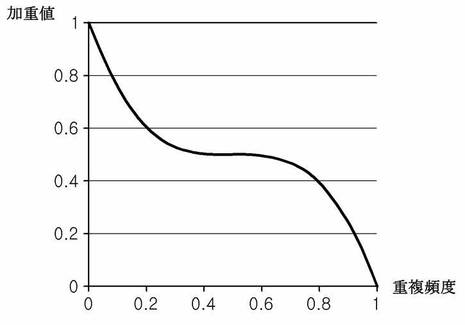
各エンティティごとの加重値を計算する際に用いられる計算式は、前記概念に基づく様々な式を適用してもよく、例えば、図9aに示されたグラフが挙げられる。図9aのグラフにおいて、横軸は重要度寄与要素のうちエンティティの重複頻度(クラスタ内の全体ウェブ文書のうち当該エンティティが登場したウェブ文書の割合)を示し、縦軸はエンティティの加重値を示し、エンティティの重複頻度が1に近いほど、すなわちエンティティがクラスタ内のウェブ文書で重複する回数が多いほど、エンティティの加重値は0に近くなって類似文書を検出する際に当該エンティティの影響が少なくなるため、当該エンティティは核心となる部分に該当しないと認められ、エンティティの重複頻度が0に近いほど、すなわちエンティティがクラスタ内のウェブ文書で重複する回数が少ないほど、エンティティの加重値は1に近くなって類似文書を検出する際に当該エンティティの影響が大きくなるため、当該エンティティは核心となる部分に該当すると認められることが分かる。前記図8cで抽出された4個のエンティティに対して図9aのグラフを用いてその加重値を求めた結果は図9bの表のように示すことができる。
【0059】
最後に、本発明の一実施形態における類似文書検出手段134は、加重値計算手段133によって計算された各エンティティごとの加重値を適用して、クラスタ内の各ウェブ文書に対して加重値が与えられた特性指数を計算し、これに基づいて類似文書を検出する機能を行う。ここで特性指数とは、一つのウェブ文書を他のウェブ文書と区分するために用いることができる所定の数値または文字列などを含む広い意味で解釈されなければならないが、以下では説明の便宜上、特性指数をその一例であるシムハッシュであると仮定して説明する。但し、特性指数をシムハッシュに限定して解釈してはならず、一つのウェブ文書を他のウェブ文書と区分するために用いられるものであればいずれも本発明における特性指数に該当し得る。
【0060】
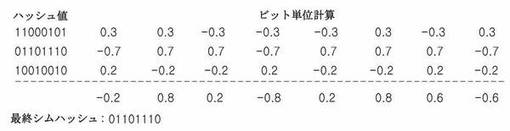
特性指数の一例であるシムハッシュを計算するために、類似文書検出手段134は、クラスタ内の各ウェブ文書からエンティティを抽出し、抽出されたエンティティに対するハッシュ値を計算する。シムハッシュ計算に用いることができる各ウェブ文書ごとのエンティティ及びこれに対するハッシュ値は、エンティティ抽出手段132から抽出された値をそのまま用いてもよい。次に、類似文書検出手段134は、各エンティティに対するハッシュ値を二進数で表現した後、ビット単位で加重値計算手段133によって計算された加重値を適用し、ビット単位で計算した最終のハッシュ値を計算してこれを当該ウェブ文書のシムハッシュとして用いてもよい。ビット単位を計算する際に特定の位置のビット値が1である場合には1に、0である場合には−1に変換した後、ビット別に各エンティティの加重値を乗じた値で再度演算し、全体エンティティに対してビット単位の演算を行いビット単位の最終値が正数である場合には1に、負数である場合には0に再変換する方式によりシムハッシュを抽出してもよい。例えば、上述した図6の例と類似して、一つのウェブ文書が合計3個のエンティティに分離され、各エンティティに対するハッシュ値を二進数で表現した内容がそれぞれ11000101、01101110、10010010であり、各エンティティに対する加重値が順に0.3、0.7、0.2である場合、当該ウェブ文書のエンティティは、図10に示されたように、各エンティティのハッシュ値でビット単位別に計算するために各ビット別に並べて各エンティティの加重値である0.3、0.7、0.2を適用すると、11000101は、0.3、0.3、−0.3、−0.3、−0.3、0.3、−0.3、0.3に、01101110は、−0.7、0.7、0.7、−0.7、0.7、0.7、0.7、−0.7に、また、10010010は、0.2、−0.2、−0.2、0.2、−0.2、−0.2、0.2、−0.2に並べられ、全体エンティティをビット単位別に計算すると、その結果は、−0.2、0.8、0.2、−0.8、0.2、0.8、0.6、−0.6に該当するため、これからシムハッシュ01101110を抽出してもよい。このように各エンティティのハッシュ値に加重値を適用する場合、各エンティティのウェブ文書中の重要度に応じて同一のエンティティのハッシュ値を有するウェブ文書でも互いに異なるシムハッシュが計算されてもよい。
【0061】
このようにクラスタリング内の各ウェブ文書に対して加重値が適用された特性指数が計算された後、本発明の一実施形態における類似文書検出手段134は、特性指数に基づいて類似文書であるか否かを検出してもよいが、ここで類似文書であるか否かの検出に用いることができる方法の一例として、特性指数がシムハッシュである場合、計算されたシムハッシュ間のハミング距離が所定数値以下、例えばシムハッシュが8ビットであると仮定した場合には1である場合を類似文書と判断してもよい。
【0062】
また、本発明の一実施形態における類似文書検出手段134は、類似文書として判断された重複するウェブ文書を検索データベース140から削除する機能をさらに含んでもよい。一方、類似文書検出手段134による検出結果、一つのクラスタ内における類似文書の割合が所定の数値、例えば50%以上に該当したり、類似文書が所定の個数、例えば100個以上存在したりする場合、類似文書検出手段134は、当該クラスタの生成方式及び各エンティティに対する加重値、また類似文書と判定されたウェブ文書の全ての加重値が適用された特性指数などを保存した後、その後クラスタリング手段131によって当該クラスタに属するウェブ文書が存在する場合、保存された各エンティティ及びその加重値を当該ウェブ文書に適用して特性指数を計算し、ハミング距離などの類似文書の判断に必要な別の数値を計算することなく当該クラスタに一致する特性指数がある場合すぐに当該ウェブ文書もまた類似文書であると判断して、類似文書検出速度を向上させてもよい。この場合、当該ウェブ文書のエンティティのうち予め保存されなかったエンティティが存在する場合には予め決定された所定の加重値、例えば0.5を適用して特性指数を計算してもよい。
【0063】
次に、図5を参照して、本発明の一実施形態における改善された類似文書検出方法について説明する。
【0064】
本発明の一実施形態によると、ユーザは、自分のユーザ端末装置300を用いて問い合わせ言語を検索結果提供装置100に伝送してもよく、検索結果提供装置100は、受信した問い合わせ言語に基づいて検索データベース140を参照して検索を行った後、その結果として出力される検索結果をユーザ端末装置300に伝送してもよい。但し、検索結果提供装置100は、前記した通常の動作の他にも、収集部120を介して収集したウェブ文書のうち類似文書を検出するために類似文書が存在する可能性のあるクラスタを生成し、生成されたクラスタに属するそれぞれのウェブ文書に対してエンティティ、及びエンティティに対する重要度寄与要素を抽出して、各エンティティに対する加重値を計算し、計算された加重値を用いてクラスタ内の各ウェブ文書に対して加重値が適用された特性指数を計算した後、計算された各ウェブ文書の特性指数を比較して類似文書であるか否かを検出する。また、検出された類似文書結果に基づいて検索データベース140または別のデータベースに保存された、収集されたウェブ文書から重複するウェブ文書を削除する機能を行ってもよく、図5は、このような作業の各ステップをフローチャートとして表現した図である。
【0065】
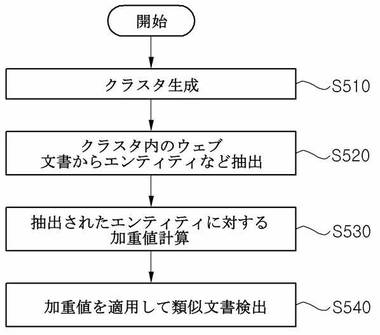
図5を参照すると、検索結果提供装置100(または、その内部の類似文書検出部130のうちクラスタリング手段131)は、検索データベースに保存されたウェブ文書から類似文書が存在する可能性のあるクラスタを生成する(ステップS510)。上述した具体的な実施形態のように、クラスタ生成に適用され得る方法は、ホストクラスタリング、パスクラスタリング、クエリクラスタリング、サイズクラスタリング、シムハッシュクラスタリング、DOMクラスタリングまたは他の公知のクラスタリング方式のうちいずれか一つ以上を任意の順序で組み合わせることにより適用してもよい。
【0066】
その後、類似文書検出部130のエンティティ抽出手段132は、クラスタリング手段131で生成されたクラスタ内のウェブ文書からエンティティ、及びエンティティの重要度寄与要素を抽出する機能を行ってもよい(ステップS520)。上述したように、エンティティは、ウェブ文書からパーシングされて分離され得るテキストを含んでもよく、その他にもアンカーに含まれるhref属性やエンベッド、イメージタグなどに含まれるsrc属性値などをさらに含んでもよい。また、重要度寄与要素には各エンティティのハッシュ値の他にも各エンティティがクラスタ内の全体ウェブ文書のうち何個のウェブ文書に重複するかに対する回数あるいは頻度などの数値が含まれてもよい。
【0067】
その後、類似文書検出部130の加重値計算手段133は、エンティティ抽出手段132から抽出された内容に基づいてクラスタ内の各エンティティに対する加重値を計算する機能を行ってもよい(ステップS530)。各エンティティに対する加重値は、当該エンティティがウェブ文書中で核心となる部分に該当するか否かに基づいて計算されてもよく、その具体的な一例として、文献出現頻度の逆数(IDF)を用いてクラスタ内のウェブ文書に重複する回数が多いほどその加重値が増加し、クラスタ内のウェブ文書に重複する回数が少ないほどその加重値が減少する概念に基づく様々な式を適用して計算されてもよい。
【0068】
その後、類似文書検出部130の類似文書検出手段134は、加重値計算手段133で計算された、クラスタ内のウェブ文書から抽出された各エンティティに対して加重値を適用したウェブ文書の特性指数を計算し、計算された各ウェブ文書の特性指数同士を比較して(例えば、特性指数がシムハッシュである場合、シムハッシュ間のハミング距離が特定数値以下であるか否かなどを計算して)類似文書であるか否かを検出する機能を行ってもよい(ステップS540)。また、類似文書検出手段134は、類似文書として検出された重複するウェブ文書を検索データベース140から削除する機能をさらに含んでもよい。
【0069】
本発明による実施形態は、多様なコンピュータ手段によって行われるプログラム命令語の形態で実現され、コンピュータ読み取り可能な媒体に記録されてもよい。コンピュータ読み取り可能な媒体は、プログラム命令語、データファイル、データ構造などを単独で、または組み合わせて含んでもよい。前記媒体に記録されるプログラム命令語は、本発明のために特に設計及び構成されたものであってもよく、コンピュータソフトウェア分野の当業者に公知であって使用可能なものであってもよい。コンピュータ読み取り可能な記録媒体の例としては、ハードディスク、フロッピー(登録商標)ディスク及び磁気テープのような磁気媒体(magnetic media)、CD−ROM、DVDなどのような光記録媒体(optical media)、フロプティカルディスク(floptical disk)のような磁気−光媒体(magneto−optical media)及びROM、RAM、フラッシュメモリなどのような、プログラム命令語を保存及び実行するように特に構成されたハードウェア装置が含まれる。プログラム命令語の例としては、コンパイラによって作成されるような機械語コードだけでなく、インタプリタなどを用いてコンピュータによって実行することができる高級言語コードも含まれる。ハードウェア装置は、本発明における動作を行うために一つ以上のソフトウェアモジュールとして動作するように構成されてもよく、その逆も同様である。
【0070】
以上、本発明を具体的な構成要素などのような特定の事項と限定された実施例及び図面を参照して説明したが、これは本発明のより全体的な理解を容易にするために提供されたものにすぎず、本発明は前記実施例によって限定されず、本発明が属する分野における通常の知識を有する者であれば、このような記載から多様な修正及び変形が可能である。
【0071】
従って、本発明の思想は前記実施例に限定されて決まってはならず、添付する特許請求の範囲の記載だけでなく、特許請求の範囲の記載と均等または等価的に変形された全てのものは、本発明の思想の範疇に属すると理解するべきであろう。
【符号の説明】
【0072】
100 検索結果提供装置
130 類似文書検出部
131 クラスタリング手段
132 エンティティ抽出手段
133 加重値計算手段
134 類似文書検出手段
【技術分野】
【0001】
本発明は、改善された類似文書検出方法、装置、及びコンピュータ読み取り可能な記録媒体に関し、より具体的には、収集されたウェブ文書のうち類似文書を検出する際に文書内で核心となる部分及び核心ではない部分を区別し、これにより互いに異なる加重値を与えて、類似文書を検出するためのより正確で改善された方法、装置及びコンピュータ読み取り可能な媒体に関する。
【背景技術】
【0002】
最近、インターネットの使用が普及するにつれて、ユーザはインターネット検索を介して多様な情報を取得できるようになった。すなわち、ユーザはインターネットへのアクセスが可能なパソコンなどの端末装置を介してウェブブラウザのアドレスバーにURLのような識別子を入力することにより、インターネット検索サイトにアクセスして、自分が確認しようとする検索キーワードを入力して、ニュース、知識、ゲーム、コミュニティ、ウェブ文書などの多様な分野に係わる検索結果を見ることができるようになった。
【0003】
上述のように、ユーザが検索しようとする内容を適切に示すために、インターネット検索サイト提供者はウェブ文書などを収集し、収集されたウェブ文書などに索引(index)を構成して、これに基づいて検索結果をユーザに提供する機能を有する検索エンジンを設計して構成することが一般的であり、その中でもインターネット上に存在するウェブ文書を組織的かつ自動化した方法で探索及び収集する機能を有するウェブクローラ(Web Crawler)は大きな役割を果たしている。
【0004】
このようなウェブクローラの動作方式の一つとして、シード(seed)と呼ばれるURLリストから始めて、シードに含まれる全てのハイパーリンク(Hyperlink)を認識してURLリストを更新(update)し、更新されたURLリストに該当するウェブ文書を再帰的に再び訪問する方式が用いられている。
【0005】
しかし、一般的に収集対象となるウェブ文書の中には、その内容が大同小異であり、強いて別個に収集する必要性のないものが多いにもかかわらず、基本的なウェブクローラの動作方式に従ってウェブ文書の検索及び収集を行う場合には、URLリストに含まれる全てのウェブ文書を訪問及び収集することになり、収集されたウェブ文書を保存する保存領域の問題、及び、これによる検索エンジンの性能及び効率性の低下などの様々な問題が現れた。
【0006】
そこで、このような問題を解決するために、従来は、類似文書の検出技術を導入し、類似したウェブ文書が検出された場合、収集された重複する類似文書を保存領域から削除したり、当該文書が発見された経路(path)の収集速度を減少させたりするなどの作業を行っていた。
【0007】
しかし、従来の類似文書検出技術の場合、同一または類似する領域の大きさに応じて類似文書であるか否かを検出するため、ウェブ文書におけるほとんどの領域が同一であっても核心となる部分が相違すれば、実際には類似文書ではないにもかかわらず、同一の部分が多いということにより一律に類似文書であると判断されるため、正常な文書の収集作業が妨害されることになり、その結果、検索精度が低下するという問題が存在する。
【0008】
図1a及び図1bは、従来技術における類似文書検出技術によって類似文書と認められる場合の例を例示的に示した図である。図1を参照して、従来技術における類似文書検出技術の問題点について説明する。
【0009】
図1a及び図1bに示された一例は、ウェブクローラによって収集される互いに異なるURLを有するそれぞれのウェブ文書を示す。ウェブ文書において核心となる部分である商品名、商品コードなど(図1aのA領域及び図1bのA´領域)は相違しているが、相違する領域がウェブ文書全体のうちの小さな領域のみを占めており、メニュー、オプション、商品の詳細情報など多くの領域(図1a及び図1bにおけるB領域、C領域など)において同一の部分が存在するため、従来の類似文書の検出技術では、同一の領域がどれほど多いかに応じて類似文書であるか否かを判断する。しかし、当該ページにおいて最も核心的な部分である商品名や商品コードが相違する、すなわち、相違する商品に対する相違するウェブ文書であるため、類似文書であるとは認められないにもかかわらず、従来技術によると類似文書であると判断され、このうち一方が保存領域から削除されるため、検索エンジンのユーザに提供されなくなり、検索精度低下の問題が生じる。
【先行技術文献】
【特許文献】
【0010】
【特許文献1】韓国公開特許第1999―0088678号公報
【特許文献2】韓国公開特許第1999―0048714号公報
【発明の概要】
【発明が解決しようとする課題】
【0011】
本発明は、前記の従来技術の問題点を解決することを目的とする。
【0012】
また、本発明は、類似文書である可能性のあるウェブ文書において、ウェブ文書中の核心となる部分と核心ではない部分とを区別し、これにより互いに異なる加重値を与えることにより、より改善された方式で類似文書を判別して検索エンジンの精度を向上させることを他の目的とする。
【0013】
また、本発明は、類似文書検出結果に応じて、重複する類似文書をウェブ文書保存領域から削除して保存領域の無駄使いを防ぎ、これにより検索エンジンの性能を向上させることをさらに他の目的とする。
【課題を解決するための手段】
【0014】
前記のような本発明の目的を達成して、後述する本発明に特有の効果を奏するための本発明の特徴的な構成は以下のとおりである。
【0015】
本発明の一実施形態によると、改善された類似文書検出方法において、類似文書検出装置で行われる各ステップは、複数のウェブ文書それぞれからエンティティ(entity)及び重要度寄与要素を算出するエンティティを抽出し、算出された重要度寄与要素に基づいて各エンティティに対する加重値を計算し、算出された加重値に基づいて複数のウェブ文書が類似文書であるか否かを検出すること、を含む。
【0016】
本発明の他の実施形態によると、改善された類似文書検出装置は、複数のウェブ文書それぞれからエンティティ(entity)及び重要度寄与要素を算出するエンティティ抽出手段と、算出された重要度寄与要素に基づいて各エンティティに対する加重値を計算する加重値計算手段と、算出された加重値に基づいて複数のウェブ文書が類似文書であるか否かを検出する類似文書検出手段と、を含む。
【発明の効果】
【0017】
前記のように本発明によると、類似文書である可能性のある文書において、文書中の核心となる部分と核心ではない部分とを区別し、これにより互いに異なる加重値を与えることにより、より改善された方式で類似文書を判別して検索エンジンの精度を向上させることができる。
【0018】
また、本発明によると、類似文書検出結果に応じて、重複する類似文書をウェブ文書保存領域から削除して保存領域の無駄使いを防ぎ、これによる検索エンジンの性能を向上させることができる。
【図面の簡単な説明】
【0019】
【図1a】従来技術における類似文書検出技術により類似文書であると判断される場合の例を例示的に示した図である。
【図1b】従来技術における類似文書検出技術により類似文書であると判断される場合の例を例示的に示した図である。
【図2】本発明の一実施形態における検索結果提供装置を含む全体システムを概略的に示した図である。
【図3】本発明の一実施形態における検索結果提供装置の詳細な構成を示した図である。
【図4】本発明の一実施形態における類似文書検出部の詳細な構成を示した図である。
【図5】本発明の一実施形態における類似文書検出方法を説明するためのフローチャートである。
【図6】本発明の一実施形態において、ウェブ文書のシムハッシュを計算する方式を説明するための図である。
【図7a】本発明の一実施形態におけるウェブ文書のDOM構造を抽出する方式を説明するための図である。
【図7b】本発明の一実施形態におけるウェブ文書のDOM構造を抽出する方式を説明するための図である。
【図8a】本発明の一実施形態におけるウェブ文書のエンティティ及びその関連値の抽出を説明するための図である。
【図8b】本発明の一実施形態におけるウェブ文書のエンティティ及びその関連値の抽出を説明するための図である。
【図8c】本発明の一実施形態におけるウェブ文書のエンティティ及びその関連値の抽出を説明するための図である。
【図9a】本発明の一実施形態におけるエンティティごとの加重値計算を説明するための図である。
【図9b】本発明の一実施形態におけるエンティティごとの加重値計算を説明するための図である。
【図10】本発明の一実施形態において加重値が適用されたシムハッシュを計算する方式を説明するための図である。
【発明を実施するための形態】
【0020】
後述する本発明の詳細な説明において、本発明を実施することができる特定の実施形態を例として示す添付の図面を参照する。これらの実施例は、当業者が本発明を十分に実施することができるように詳細に説明される。本発明の多様な実施例は互いに異なるが相互に排他的である必要はないということが理解されるべきである。例えば、本明細書に記載されている特定の形状、構造及び特性は、一実施例にすぎず、本発明の思想及び範囲を外れない限り他の実施例において実現されてもよい。また、開示された各実施例中の個別の構成要素の位置または配置は、本発明の思想及び範囲を外れない限り変更されてもよいということが理解されるべきである。従って、後述する詳細な説明は、限定的な意味に制限するものではない。本発明の範囲は、適切に説明されれば、その特許請求の範囲に記載されたものと均等な全ての範囲とともに添付の特許請求の範囲の記載によってのみ限定される。図面において類似する参照符号は様々な側面に亘って同一または類似する機能を指称する。
【0021】
以下、本発明が属する技術分野における通常の知識を有する者が本発明を容易に実施することができるように、本発明の好ましい実施例について添付の図面を参照して詳細に説明する。
【0022】
本発明の実施形態における「ウェブ文書」という用語は、インターネットエクスプローラなどのウェブブラウザプログラムを用いて読み込み可能な受動的または能動的な文書形式を全て含む広い意味で解釈されなければならず、ウェブ文書の文書形式として、主にHTML(HyperText Markup Language)が用いられるが、必ずしもこれに限定されず、XML(Extensible Markup Language)、SGML(Standard Generalized Markup Language)を含み、ウェブブラウザプログラムを用いて読み込み可能な文書形式であれば全てウェブ文書に該当する。ウェブブラウザプログラムを用いてウェブ文書を読み込むためには、一般的にウェブ文書が位置するアドレスをURLとして入力し、そのアドレス形式としてHTTP(HyperText Transfer Protocol)が多く用いられるが、必ずしもこれに限定されるものではない。
【0023】
一方、本発明の実施形態における「URL(Uniform Resource Locator)」という用語は、ウェブ上でサービスを提供する各サーバに存在するファイルの位置を明示するためのものであって、アクセスすべきサービスの種類、サーバの位置(ドメインネーム)、ファイルの位置を含む。URLの一般的な体系(syntax)は、「プロトコル://ホスト名/経路(path)/ファイル名?パラメータ」のような形式で構成されてもよい。ここで経路は、複数の経路を含んでもよく、パラメータも複数のパラメータを含んでもよい。例えば、http://www.xxx.com/a/b/c.html?x=1&y=2のようなURLにおいて、プロトコルはhttpであり、ホスト名はwww.xxx.comであり、経路は/a/b/であり、ファイル名はc.htmlであり、パラメータはx及びyの2つであって、その値はそれぞれ1及び2である。
【0024】
一方、本発明の実施形態における「類似文書」という用語は、その内容が同一であるかその内容の核心を含むほとんどが同一である複数のウェブ文書を示す広い意味で用いられる。検索エンジンの効率性を考慮して、類似文書を検出する際に基本となるウェブ文書以外のこれと重複する類似文書は、収集された保存領域から削除されて検索エンジンにより検索されないようにする。
【0025】
[装置の全体構成]
図2は、本発明の一実施形態において検出された重複する類似文書を削除した検索データベースを用いた検索結果提供装置を含む全体装置を概略的に示した図である。
【0026】
図2に示されているように、本発明の一実施形態における全体装置は、検索データベースを有する検索結果提供装置100が通信網200を介して複数のユーザ端末装置300及び複数のウェブ文書サーバ400に接続されてもよい。
【0027】
まず、本発明の一実施形態によると、検索結果提供装置100は、ユーザ端末装置300から探索キーワード、すなわち、問い合わせ言語を受信し、これに基づいて検索を行った後、その結果として出力される検索結果をユーザ端末装置300に伝送する機能を行う。また、検索結果提供装置100は、収集部120(図3参照)を用いて一つ以上のウェブ文書サーバ400から収集したウェブ文書において類似文書が存在する可能性のあるクラスタを生成し、生成されたクラスタから類似文書であるか否かを検出して、検出結果検索データベースに類似文書が保存された場合には、重複する類似文書を削除する機能を行ってもよい。
【0028】
また、本発明の一実施形態によると、通信網200は、有線・無線などのような通信状態を問わずに構成されてもよく、パーソナルエリアネットワーク(PAN;Personal Area Network)、ローカルエリアネットワーク(LAN;Local Area Network)、メトロポリタンエリアネットワーク(MAN;Metropolitan Area Network)、広域ネットワーク(WAN;Wide Area Network)など、多様な通信網で構成されてもよい。
【0029】
一方、本発明の一実施形態におけるユーザ端末装置300は、ユーザが所定の問い合わせ言語に対する検索結果を提供されるように、通信網200を介して検索結果提供装置100に接続するための機能を含む入出力装置を意味し、デスクトップパソコンだけでなく、ノートパソコン、ワークステーション、パームトップ(palmtop)パソコン、個人携帯情報端末(personal digital assistant;PDA)、ウェブパッド、スマートフォンを含む移動通信端末などのようにメモリ手段を備え、マイクロプロセッサを搭載して演算能力を備えたデジタル機器であればいずれも本発明におけるユーザ端末装置300として採用され得る。好ましくは、ユーザ端末装置300は、検索結果提供装置100に接続し、問い合わせ言語を入力して検索結果を提供されるために、ユーザ端末装置300内のウェブブラウザを実行して用いられてもよいが、必ずしもこれに限定されるものではない。
【0030】
一方、本発明の一実施形態におけるウェブ文書サーバ400は、検索結果提供装置100内の収集部が収集するウェブ文書を含むウェブサーバの通称であり、物理的に特定のサーバや特定の内容/形式のウェブ文書に限定されるものではない。収集部が通信網200を介してアクセスしてウェブ文書を収集することができるウェブサーバは全てウェブ文書サーバ400に含まれると認められる。
【0031】
[検索結果提供装置]
図3は、本発明の一実施形態における検索結果提供装置100の詳細な構成図である。
【0032】
図2を参照すると、本発明の一実施形態における検索結果提供装置100は、検索部110、収集部120、類似文書検出部130、及び検索データベース140を含んでもよい。
【0033】
検索部110は、ユーザ端末装置300から受信した問い合わせ言語に対応する情報を検索データベース140から検索する。検索により抽出される検索結果はユーザ端末装置300に伝送される。
【0034】
収集部120は、ウェブ文書サーバ400に保存されたウェブ文書をウェブクローラなどの公知の組織的な自動化された方法により検索及び収集して検索データベース140に保存する機能を行う。
【0035】
類似文書検出部130は、収集部120を介して収集されるウェブ文書を多様な方法を用いて生成され得るクラスタに統合した後、ウェブ文書中のそれぞれのエンティティ(entity)がウェブ文書中の核心となる部分であるか否かに応じてその加重値を計算し、加重値を適用した類似文書を検出して類似文書が検出された場合、この結果を検索データベース140に保存されたウェブ文書に適用して重複して保存された類似したウェブ文書の削除を行うようにしてもよい。類似文書検出部130の各構成要素の詳細な機能については後述する。
【0036】
検索データベース140は、検索結果を提供するために収集されたり保存されたりする各種情報を含んでもよく、その他にも収集部120が収集したウェブ文書を保存してもよい。また、類似文書検出部130の動作によって検索データベース140内に既に収集されたウェブ文書が重複して保存されている場合、その一部または全部が削除されてもよい。
【0037】
図3には、検索データベース140のみを図示したが、本発明の一実施形態においいて収集部120が収集、検出したウェブ文書を保存するデータベースを別に構築し、そのうち類似文書検出部130によって検出された類似文書結果に基づいて重複するウェブ文書が削除された残りのみを検索データベース140に保存してもよい。また、図面において検索部110、収集部120、及び類似文書検出部130は、それぞれ別のブロックで示したが、これらは物理的に一つの装置において実現されてもよく、これらの一部またはそれぞれが物理的に異なる装置において実現されてもよく、同一の機能を行う複数の装置に物理的に並列的に実現されてもよい。このように、本発明は、各構成部分が設けられた機械またはデータベースの物理的な個数及び配置に限定されず、様々な方式によって設計、変更されてもよいことは、本発明の属する技術分野における通常の知識を有する者にとって自明である。
【0038】
[類似文書検出部]
図4を参照して、本発明の一実施形態における検索結果提供装置100の類似文書検出部130についてより詳細に説明すると、類似文書検出部130は、クラスタリング(clustering)手段131、エンティティ(entity)抽出手段132、加重値計算手段133、及び類似文書検出手段134を含んでもよい。
【0039】
ここで、本発明の一実施形態におけるクラスタリング手段131は、検索データベース140または別のデータベースに保存されている収集部120によって収集されたウェブ文書の中に類似文書が存在する可能性のあるクラスタを所定の方法によって生成する機能を行ってもよい。
【0040】
本発明の一実施形態におけるクラスタリング手段131がクラスタを生成するために適用できる所定の方法は、例えば、ホスト(Host)クラスタリング、パス(Path)クラスタリング、クエリ(Query)クラスタリング、サイズ(Size)クラスタリング、シムハッシュ(SimHash)クラスタリング、DOM(Document Object Model)クラスタリングなどを含んでもよく、クラスタリング手段131は、例示されていない他の方法を用いてクラスタを生成してもよく、または例示されたクラスタリング方法及び例示されていない他の方法のうちのいずれか一つ以上を様々な順序で組み合わせて適用してもよく、類似文書が存在する可能性のあるクラスタを生成するために様々な方法を取捨選択してもよいということは当業者にとって自明であろう。
【0041】
前記例示されたそれぞれのクラスタリング方法について詳述すると、まず、ホストクラスタリングは、ウェブ文書の出処であるURLのうちホスト名が一致するURLを有するウェブ文書を一つのクラスタとして生成する方式を意味する。例えば、一つのウェブ文書がhttp://www.xxx.com/a/b/c.html?x=1&y=2というURLを有する場合、当該ウェブ文書をホストクラスタリングにより一つのクラスタを生成すると、当該ウェブ文書のホスト名であるwww.xxx.comと一致するウェブ文書を一つのクラスタとして生成する。
【0042】
次に、パスクラスタリングは、ウェブ文書の出処であるURLのうちホスト名とその経路まで一致するURLを有するウェブ文書を一つのクラスタとして生成する方式を意味する。前記例において、ホスト名とその経路であるwww.xxx.com/a/b/まで一致するウェブ文書を一つのクラスタとして生成する場合、これをパスクラスタリングという。
【0043】
また、クエリクラスタリングは、ウェブ文書の出処であるURLのうちホスト名、経路、及びファイル名まで一致するか、またはファイル名に加えてパラメータまで一致するURLを有するウェブ文書を一つのクラスタとして生成する方式を意味する。前記例に続いて、ホスト名と経路、及びファイル名まで含むwww.xxx.com/a/b/c.htmlが一致するURLを有するウェブ文書を一つのクラスタとして生成するか、またはこれに加えてパラメータまで一致する、すなわちパラメータとしてx及びyを含むURLを有するウェブ文書を一つのクラスタとして生成する場合、これをクエリクラスタリングと呼ぶ。
【0044】
前記ホストクラスタリング、パスクラスタリング及びクエリクラスタリングは、全てウェブ文書の出処であるURLに基づくクラスタ生成方法であって、一つのクラスタに含まれるウェブ文書の個数に基づき、一つ以上の最も適したクラスタリング方式が選択されてもよい。
【0045】
次に、サイズクラスタリングは、ウェブ文書の大きさ(size)に基づいて類似の大きさを有するウェブ文書を一つのクラスタとして生成する方式を意味する。例えば、ウェブ文書の大きさが1600byteから1615byteに該当する場合に、一つのクラスタとして生成すると定義されている場合、その大きさが1600byte、1608byte、1612byteであるウェブ文書は、サイズクラスタリングによって全て一つのクラスタとして生成される。
【0046】
一方、シムハッシュ(SimHash)クラスタリングは、各ウェブ文書別に抽出され得るシムハッシュ値が類似するウェブ文書を一つのクラスタとして生成する方式を意味する。シムハッシュとは、Similarity Hash基盤の技術であって、互いに異なるキーの値が入力された場合、互いに異なるハッシュ値を与える一般的なハッシング機能を維持すると共に、類似するキーの値が入力された場合、類似したハッシュ値を有するハッシュ関数を意味し、このようなシムハッシュ抽出方式を例にとって以下で説明する。
【0047】
一つのウェブ文書は、ワード単位でパーシングされて分離されてもよく、分離されたそれぞれのワードは、所定のハッシングアルゴリズムを適用したハッシュ関数を用いて特定のハッシュ値に計算されてもよく、計算された特定のハッシュ値は二進数で表現されてもよい。ハッシュ関数に用いることができるハッシングアルゴリズムは、標準アルゴリズムであるSHA−1、HAS−160などの既に公知されたアルゴリズムを含み、特定のキーに対する唯一の値を提供するハッシュ関数の機能を有するアルゴリズムであれば、本発明の一実施形態におけるシムハッシュクラスタリングに用いることができるということは当業者にとって自明である。シムハッシュ抽出方式により抽出されるシムハッシュは、このように一つのウェブ文書から分離された各ワード別に抽出されたハッシュ値をビット単位で計算した最終のハッシュ値を意味する。ビット単位で計算する際に特定の位置のビット値が1である場合は1に、0である場合は−1に変換した後、ハッシュ値別にビット単位の演算を行ってビット単位の最終値が正数である場合は1に、負数である場合は0に、再度変換する方式によりウェブ文書のシムハッシュを抽出してもよい。例えば、一つのウェブ文書をワード単位でパーシングした結果、合計3個のワードに分離され、各ワードに対するハッシュ値を二進数で表現した内容がそれぞれ11000101,01101110、及び10010010である場合、当該ウェブ文書のシムハッシュは、図6に示されるように、各ワードのハッシュ値でビット単位別に計算するために、11000101は、1,1,−1,−1,−1,1,−1,1に、01101110は、−1,1、1,−1,1、1,1,−1に、また10010010は、1,−1,−1,1,−1,−1,1,−1に変換された後、ハッシュ値別にビット単位の計算結果である1,1,−1,−1,−1,1、1,−1からハッシュ値をさらに変換すると、シムハッシュ11000110を抽出することができる。このように抽出されたシムハッシュは、複数のウェブ文書においてほとんどの内容が同一であれば、一部の内容が異なっていてもウェブ文書別に類似したシムハッシュを有する。
【0048】
シムハッシュクラスタリングは、このように各ウェブ文書に対して抽出されたシムハッシュが類似するウェブ文書を一つのクラスタとして生成してもよいが、ここでシムハッシュが類似するか否かを判断するためには、シムハッシュ間のハミング距離(hamming distance)が所定数値以下、例えば、シムハッシュが8ビットであると仮定した場合には1である場合を類似したウェブ文書として判断してもよい。ハミング距離は、同一のビット数を有する二進数の間に対応するビット値が一致しない個数を意味し、例えば、シムハッシュが11000101であるウェブ文書とシムハッシュが10010101であるウェブ文書との間のハミング距離は、合計8個のビットのうち、2番目のビット及び4番目の対応ビットが一致しないため、2であり、上述したように、例示的な類似基準である1よりハミング距離が小さいため、二つのウェブ文書は類似しないと判断されてもよい。また他の例として、シムハッシュが11000101であるウェブ文書と11010101であるウェブ文書との間のハミング距離は、合計8個のビットのうち4番目の対応ビットのみが一致しないため、1に該当し、従って、前記例示的な類似基準である1以下に対応するため、二つのウェブ文書は類似していると判断されてもよい。
【0049】
また、DOM(Document Object Model)クラスタリングは、各ウェブ文書別に抽出され得るDOM構造が類似したウェブ文書を一つのクラスタとして生成する方式を意味する。DOM構造とは、所定のウェブ文書の内容を抽出して、ツリー型に概念化した文書構造ツリーの一例であって、ウェブ文書のソースコードが図7aであると仮定した場合、当該ウェブ文書から図7bのような形式のDOM構造を抽出してもよいが、必ずしも図7bに例示されたような形式に限らず、ウェブ文書の内容を概念化できる所定の形式の文書構造であればいずれも本発明におけるDOM構造に含まれてもよい。
【0050】
DOMクラスタリングは、このように各ウェブ文書に対して抽出したDOM構造が類似するウェブ文書を一つのクラスタとして生成してもよいが、ここでDOM構造が類似するか否かを判断するためには、DOM構造間に共通するノードが特定の数値、例えば、80%以上である場合を類似したDOM構造を有するウェブ文書として判断してもよい。
【0051】
本発明の一実施形態におけるクラスタリング手段131は、前記例示した様々なクラスタリング方法、またこれと異なる公知のクラスタリング方法のうちの一つ以上を任意の順序で組み合わせることにより類似文書が存在する可能性のあるクラスタを生成してもよく、例えば、ホストクラスタリングを行った後、シムハッシュクラスタリングによりクラスタを生成したり、ホストクラスタリング、DOMクラスタリング、及びサイズクラスタリングによりクラスタを生成してもよく、様々な応用が可能である。
【0052】
本発明の一実施形態におけるクラスタリング手段131は、クラスタを生成した後、クラスタ内に属するウェブ文書の個数が特定の数値より小さい場合、その正確性のために当該クラスタを廃棄する機能をさらに行ってもよい。
【0053】
次に、本発明の一実施形態におけるエンティティ抽出手段132は、クラスタリング手段131によって生成されたクラスタに含まれるウェブ文書からエンティティを抽出し、加重値計算手段133で各エンティティがウェブ文書中で核心となる部分であるか否かに基づいて計算された加重値を用いるように各エンティティのハッシュ値、クラスタ内の全体ウェブ文書のうち当該エンティティが登場した回数あるいは頻度などの数値を含む各エンティティに対する重要度寄与要素を計算する機能を行う。
【0054】
本発明におけるエンティティとは、類似文書の検出のために比較され得る、ウェブ文書を構成している特徴的な構成要素を含む広義の概念であって、基本的にウェブ文書からパーシングされて分離され得るテキストを含んでもよく、その他にもウェブ文書中のタグ(tag)のうち類似文書の検出のために用いられるアンカー(anchor)、エンベッド(embed)、イメージ(img)タグなどに含まれる値をさらに含んでもよいが、必ずしもこれに限定されるものではない。抽出された各エンティティは、類似文書であるか否かを判断する際に寄与してもよく、すなわち核心となる部分であるか否かに基づく加重値がともに計算されてもよく、加重値は、上述したように、各エンティティに対する重要度寄与要素に基づいて計算される。ウェブ文書中のエンティティを抽出するためにエンティティ抽出手段132は、ウェブ文書から抽出されたDOM構造に基づき、このうちテキスト、アンカー、エンベッド、及びイメージタグが含まれたノード(node)を抽出してウェブ文書のエンティティとして用いてもよい。特に、テキストの場合には、ウェブ文書のどの位置で登場するかによって、同一の文書でも類似文書であるか否かに大きな影響を及ぼす可能性のある、すなわち核心となる部分に該当し得るため、テキストが登場した位置または属性を示す値をさらに含んでもよく、例えば、テキストノードの上位ノード(例えば、DIVノードなど)に存在するID値を当該テキストのID値として当該テキストと結合してエンティティとして使用してもよく、また、テキストの場合、これを空白スペース単位で分けて、そのそれぞれをエンティティとして処理してもよい。その他にアンカーの場合、エンベッドノードとイメージノードは、タグ内に含まれるsrc属性値をそのエンティティとして用いてもよい。
【0055】
例えば、一つのウェブ文書のソースコードが図8aとおりであると仮定した場合、本発明の一実施形態におけるエンティティ抽出手段132によって抽出され得るエンティティは、図8bの左側のようにイメージノードに含まれるsrc属性から1個、またテキストノードに含まれるテキストを空白スペース単位で分けて、それぞれに属性を示すID値を結合した3個を含む合計4個に該当する。エンティティ抽出手段132は、抽出された各エンティティに対してハッシュ値をさらに求めてもよく、図8bの左側に抽出された4個のエンティティに対するハッシュ値は、図8bの右側に示されてもよい。
【0056】
また、本発明の一実施形態におけるエンティティ抽出手段132は、前記例のように、一つのウェブ文書で同一のエンティティが複数個存在する場合、重複するエンティティを除去して一つのウェブ文書で重複するエンティティが存在しないようにする方式により同一のクラスタに含まれた各ウェブ文書から全体エンティティを抽出し、これに基づいて各エンティティがクラスタ内の全体ウェブ文書のうち何個のウェブ文書に重複して登場したのかその重複回数もさらに計算する。前記図8の例に続いて、クラスタ内にウェブ文書が合計10個存在し、このうち図8bの左側に該当する各エンティティが重複するウェブ文書の回数を計算した結果を図8cのように示してもよい。
【0057】
次に、本発明の一実施形態における加重値計算手段133は、前記エンティティ抽出手段132から抽出された各エンティティ、及び重要度寄与要素に基づいて各エンティティごとの加重値を計算する機能を行う。通常、所定ウェブ文書で重要度の高い、すなわち核心となる部分であるほどクラスタ内の複数のウェブ文書で重複する回数が少なく、ウェブ文書でよく用いられる基本形式であるテンプレート(template)として用いられるワードやリンクなどの場合、すなわちその重要度が低く核心とならない部分であるほどクラスタ内の複数のウェブ文書で重複する回数が多いという点に注目した文献出現頻度の逆数(IDF;Inverted Document Frequency)を用いることにより、クラスタ内のウェブ文書に多数重複して登場するエンティティの場合、その重要度が低く核心となる部分ではないと判断して加重値を低く与え、クラスタ内のウェブ文書に重複する回数が少ないほどその重要度が高く核心となる部分であると判断し、エンティティの加重値を高く与えるという概念を適用して抽出された各エンティティごとの加重値を計算する。
【0058】
各エンティティごとの加重値を計算する際に用いられる計算式は、前記概念に基づく様々な式を適用してもよく、例えば、図9aに示されたグラフが挙げられる。図9aのグラフにおいて、横軸は重要度寄与要素のうちエンティティの重複頻度(クラスタ内の全体ウェブ文書のうち当該エンティティが登場したウェブ文書の割合)を示し、縦軸はエンティティの加重値を示し、エンティティの重複頻度が1に近いほど、すなわちエンティティがクラスタ内のウェブ文書で重複する回数が多いほど、エンティティの加重値は0に近くなって類似文書を検出する際に当該エンティティの影響が少なくなるため、当該エンティティは核心となる部分に該当しないと認められ、エンティティの重複頻度が0に近いほど、すなわちエンティティがクラスタ内のウェブ文書で重複する回数が少ないほど、エンティティの加重値は1に近くなって類似文書を検出する際に当該エンティティの影響が大きくなるため、当該エンティティは核心となる部分に該当すると認められることが分かる。前記図8cで抽出された4個のエンティティに対して図9aのグラフを用いてその加重値を求めた結果は図9bの表のように示すことができる。
【0059】
最後に、本発明の一実施形態における類似文書検出手段134は、加重値計算手段133によって計算された各エンティティごとの加重値を適用して、クラスタ内の各ウェブ文書に対して加重値が与えられた特性指数を計算し、これに基づいて類似文書を検出する機能を行う。ここで特性指数とは、一つのウェブ文書を他のウェブ文書と区分するために用いることができる所定の数値または文字列などを含む広い意味で解釈されなければならないが、以下では説明の便宜上、特性指数をその一例であるシムハッシュであると仮定して説明する。但し、特性指数をシムハッシュに限定して解釈してはならず、一つのウェブ文書を他のウェブ文書と区分するために用いられるものであればいずれも本発明における特性指数に該当し得る。
【0060】
特性指数の一例であるシムハッシュを計算するために、類似文書検出手段134は、クラスタ内の各ウェブ文書からエンティティを抽出し、抽出されたエンティティに対するハッシュ値を計算する。シムハッシュ計算に用いることができる各ウェブ文書ごとのエンティティ及びこれに対するハッシュ値は、エンティティ抽出手段132から抽出された値をそのまま用いてもよい。次に、類似文書検出手段134は、各エンティティに対するハッシュ値を二進数で表現した後、ビット単位で加重値計算手段133によって計算された加重値を適用し、ビット単位で計算した最終のハッシュ値を計算してこれを当該ウェブ文書のシムハッシュとして用いてもよい。ビット単位を計算する際に特定の位置のビット値が1である場合には1に、0である場合には−1に変換した後、ビット別に各エンティティの加重値を乗じた値で再度演算し、全体エンティティに対してビット単位の演算を行いビット単位の最終値が正数である場合には1に、負数である場合には0に再変換する方式によりシムハッシュを抽出してもよい。例えば、上述した図6の例と類似して、一つのウェブ文書が合計3個のエンティティに分離され、各エンティティに対するハッシュ値を二進数で表現した内容がそれぞれ11000101、01101110、10010010であり、各エンティティに対する加重値が順に0.3、0.7、0.2である場合、当該ウェブ文書のエンティティは、図10に示されたように、各エンティティのハッシュ値でビット単位別に計算するために各ビット別に並べて各エンティティの加重値である0.3、0.7、0.2を適用すると、11000101は、0.3、0.3、−0.3、−0.3、−0.3、0.3、−0.3、0.3に、01101110は、−0.7、0.7、0.7、−0.7、0.7、0.7、0.7、−0.7に、また、10010010は、0.2、−0.2、−0.2、0.2、−0.2、−0.2、0.2、−0.2に並べられ、全体エンティティをビット単位別に計算すると、その結果は、−0.2、0.8、0.2、−0.8、0.2、0.8、0.6、−0.6に該当するため、これからシムハッシュ01101110を抽出してもよい。このように各エンティティのハッシュ値に加重値を適用する場合、各エンティティのウェブ文書中の重要度に応じて同一のエンティティのハッシュ値を有するウェブ文書でも互いに異なるシムハッシュが計算されてもよい。
【0061】
このようにクラスタリング内の各ウェブ文書に対して加重値が適用された特性指数が計算された後、本発明の一実施形態における類似文書検出手段134は、特性指数に基づいて類似文書であるか否かを検出してもよいが、ここで類似文書であるか否かの検出に用いることができる方法の一例として、特性指数がシムハッシュである場合、計算されたシムハッシュ間のハミング距離が所定数値以下、例えばシムハッシュが8ビットであると仮定した場合には1である場合を類似文書と判断してもよい。
【0062】
また、本発明の一実施形態における類似文書検出手段134は、類似文書として判断された重複するウェブ文書を検索データベース140から削除する機能をさらに含んでもよい。一方、類似文書検出手段134による検出結果、一つのクラスタ内における類似文書の割合が所定の数値、例えば50%以上に該当したり、類似文書が所定の個数、例えば100個以上存在したりする場合、類似文書検出手段134は、当該クラスタの生成方式及び各エンティティに対する加重値、また類似文書と判定されたウェブ文書の全ての加重値が適用された特性指数などを保存した後、その後クラスタリング手段131によって当該クラスタに属するウェブ文書が存在する場合、保存された各エンティティ及びその加重値を当該ウェブ文書に適用して特性指数を計算し、ハミング距離などの類似文書の判断に必要な別の数値を計算することなく当該クラスタに一致する特性指数がある場合すぐに当該ウェブ文書もまた類似文書であると判断して、類似文書検出速度を向上させてもよい。この場合、当該ウェブ文書のエンティティのうち予め保存されなかったエンティティが存在する場合には予め決定された所定の加重値、例えば0.5を適用して特性指数を計算してもよい。
【0063】
次に、図5を参照して、本発明の一実施形態における改善された類似文書検出方法について説明する。
【0064】
本発明の一実施形態によると、ユーザは、自分のユーザ端末装置300を用いて問い合わせ言語を検索結果提供装置100に伝送してもよく、検索結果提供装置100は、受信した問い合わせ言語に基づいて検索データベース140を参照して検索を行った後、その結果として出力される検索結果をユーザ端末装置300に伝送してもよい。但し、検索結果提供装置100は、前記した通常の動作の他にも、収集部120を介して収集したウェブ文書のうち類似文書を検出するために類似文書が存在する可能性のあるクラスタを生成し、生成されたクラスタに属するそれぞれのウェブ文書に対してエンティティ、及びエンティティに対する重要度寄与要素を抽出して、各エンティティに対する加重値を計算し、計算された加重値を用いてクラスタ内の各ウェブ文書に対して加重値が適用された特性指数を計算した後、計算された各ウェブ文書の特性指数を比較して類似文書であるか否かを検出する。また、検出された類似文書結果に基づいて検索データベース140または別のデータベースに保存された、収集されたウェブ文書から重複するウェブ文書を削除する機能を行ってもよく、図5は、このような作業の各ステップをフローチャートとして表現した図である。
【0065】
図5を参照すると、検索結果提供装置100(または、その内部の類似文書検出部130のうちクラスタリング手段131)は、検索データベースに保存されたウェブ文書から類似文書が存在する可能性のあるクラスタを生成する(ステップS510)。上述した具体的な実施形態のように、クラスタ生成に適用され得る方法は、ホストクラスタリング、パスクラスタリング、クエリクラスタリング、サイズクラスタリング、シムハッシュクラスタリング、DOMクラスタリングまたは他の公知のクラスタリング方式のうちいずれか一つ以上を任意の順序で組み合わせることにより適用してもよい。
【0066】
その後、類似文書検出部130のエンティティ抽出手段132は、クラスタリング手段131で生成されたクラスタ内のウェブ文書からエンティティ、及びエンティティの重要度寄与要素を抽出する機能を行ってもよい(ステップS520)。上述したように、エンティティは、ウェブ文書からパーシングされて分離され得るテキストを含んでもよく、その他にもアンカーに含まれるhref属性やエンベッド、イメージタグなどに含まれるsrc属性値などをさらに含んでもよい。また、重要度寄与要素には各エンティティのハッシュ値の他にも各エンティティがクラスタ内の全体ウェブ文書のうち何個のウェブ文書に重複するかに対する回数あるいは頻度などの数値が含まれてもよい。
【0067】
その後、類似文書検出部130の加重値計算手段133は、エンティティ抽出手段132から抽出された内容に基づいてクラスタ内の各エンティティに対する加重値を計算する機能を行ってもよい(ステップS530)。各エンティティに対する加重値は、当該エンティティがウェブ文書中で核心となる部分に該当するか否かに基づいて計算されてもよく、その具体的な一例として、文献出現頻度の逆数(IDF)を用いてクラスタ内のウェブ文書に重複する回数が多いほどその加重値が増加し、クラスタ内のウェブ文書に重複する回数が少ないほどその加重値が減少する概念に基づく様々な式を適用して計算されてもよい。
【0068】
その後、類似文書検出部130の類似文書検出手段134は、加重値計算手段133で計算された、クラスタ内のウェブ文書から抽出された各エンティティに対して加重値を適用したウェブ文書の特性指数を計算し、計算された各ウェブ文書の特性指数同士を比較して(例えば、特性指数がシムハッシュである場合、シムハッシュ間のハミング距離が特定数値以下であるか否かなどを計算して)類似文書であるか否かを検出する機能を行ってもよい(ステップS540)。また、類似文書検出手段134は、類似文書として検出された重複するウェブ文書を検索データベース140から削除する機能をさらに含んでもよい。
【0069】
本発明による実施形態は、多様なコンピュータ手段によって行われるプログラム命令語の形態で実現され、コンピュータ読み取り可能な媒体に記録されてもよい。コンピュータ読み取り可能な媒体は、プログラム命令語、データファイル、データ構造などを単独で、または組み合わせて含んでもよい。前記媒体に記録されるプログラム命令語は、本発明のために特に設計及び構成されたものであってもよく、コンピュータソフトウェア分野の当業者に公知であって使用可能なものであってもよい。コンピュータ読み取り可能な記録媒体の例としては、ハードディスク、フロッピー(登録商標)ディスク及び磁気テープのような磁気媒体(magnetic media)、CD−ROM、DVDなどのような光記録媒体(optical media)、フロプティカルディスク(floptical disk)のような磁気−光媒体(magneto−optical media)及びROM、RAM、フラッシュメモリなどのような、プログラム命令語を保存及び実行するように特に構成されたハードウェア装置が含まれる。プログラム命令語の例としては、コンパイラによって作成されるような機械語コードだけでなく、インタプリタなどを用いてコンピュータによって実行することができる高級言語コードも含まれる。ハードウェア装置は、本発明における動作を行うために一つ以上のソフトウェアモジュールとして動作するように構成されてもよく、その逆も同様である。
【0070】
以上、本発明を具体的な構成要素などのような特定の事項と限定された実施例及び図面を参照して説明したが、これは本発明のより全体的な理解を容易にするために提供されたものにすぎず、本発明は前記実施例によって限定されず、本発明が属する分野における通常の知識を有する者であれば、このような記載から多様な修正及び変形が可能である。
【0071】
従って、本発明の思想は前記実施例に限定されて決まってはならず、添付する特許請求の範囲の記載だけでなく、特許請求の範囲の記載と均等または等価的に変形された全てのものは、本発明の思想の範疇に属すると理解するべきであろう。
【符号の説明】
【0072】
100 検索結果提供装置
130 類似文書検出部
131 クラスタリング手段
132 エンティティ抽出手段
133 加重値計算手段
134 類似文書検出手段
【特許請求の範囲】
【請求項1】
類似文書検出装置で行われる方法であって、
複数のウェブ文書それぞれからエンティティ(entity)及び重要度寄与要素を算出するエンティティを抽出し、
前記算出された重要度寄与要素に基づいて各エンティティに対する加重値を計算し、
前記算出された加重値に基づいて前記複数のウェブ文書が類似文書であるか否かを検出すること、を含むことを特徴とする改善された類似文書検出方法。
【請求項2】
前記複数のウェブ文書を所定の方式により一つのクラスタに統合するクラスタリングすることをさらに含むことを特徴とする請求項1に記載の改善された類似文書検出方法。
【請求項3】
前記所定の方式は、ホスト(Host)クラスタリング、パス(Path)クラスタリング、クエリ(Query)クラスタリング、サイズ(Size)クラスタリング、シムハッシュ(Simhash)クラスタリングまたはDOM(Document Object Model)クラスタリングのうち少なくとも一つ以上を任意の順序で組み合わせたものであることを特徴とする請求項2に記載の改善された類似文書検出方法。
【請求項4】
前記エンティティを抽出することは、
前記複数のウェブ文書のうちいずれか一つから文書構造を抽出し、
前記抽出された文書構造に基づいてエンティティを抽出すること、を前記複数のウェブ文書全てに対して繰り返すことにより行われ、
前記エンティティは、前記文書構造のテキストノード、アンカー(anchor)ノード、エンベッド(embed)ノードまたはイメージ(img)ノードのうちいずれか一つ以上のノードから抽出されることを特徴とする請求項1から3のいずれか一項に記載の改善された類似文書検出方法。
【請求項5】
前記エンティティがテキストノードから抽出される場合、
前記テキストノードの上位ノードの中に存在するID値を前記エンティティに結合して使用することを特徴とする請求項4に記載の改善された類似文書検出方法。
【請求項6】
前記重要度寄与要素は、
前記エンティティが前記複数のウェブ文書中で核心となる程度の重要度を反映するものであることを特徴とする請求項1から5のいずれか一項に記載の改善された類似文書検出方法。
【請求項7】
前記重要度寄与要素は、前記エンティティのハッシュ値、または前記エンティティが前記複数のウェブ文書中で重複する回数や頻度のうちいずれか一つ以上を含む値であることを特徴とする請求項6に記載の改善された類似文書検出方法。
【請求項8】
前記加重値は、前記算出されたエンティティの重複する回数や頻度に反比例する文献出現頻度の逆数(Inverted Document Frequency)を用いて計算されることを特徴とする請求項7に記載の改善された類似文書検出方法。
【請求項9】
前記類似文書を検出することは、
前記複数のウェブ文書それぞれに含まれるエンティティ及び前記エンティティの加重値に基づいて前記複数のウェブ文書それぞれの特性指数を計算し、
前記計算されたそれぞれの特性指数に基づいて前記複数のウェブ文書が類似文書であるか否かを検出すること、を含むことを特徴とする請求項1から8のいずれか一項に記載の改善された類似文書検出方法。
【請求項10】
前記特性指数はシムハッシュ(Simhash)であることを特徴とする請求項9に記載の改善された類似文書検出方法。
【請求項11】
前記特性指数に基づいて類似文書であるか否かを検出することは、
前記複数のウェブ文書それぞれが有する特性指数であるシムハッシュ間のハミング距離(hamming distance)が所定数値以下である場合、類似文書として検出されることを特徴とする請求項9又は10に記載の改善された類似文書検出方法。
【請求項12】
前記類似文書検出結果に基づいて前記複数のウェブ文書のうち重複する類似文書を削除する類似文書を削除することをさらに含むことを特徴とする請求項1から11のいずれか一項に記載の類似文書検出方法。
【請求項13】
請求項1から12のいずれか一項に記載の方法の各ステップをコンピュータ上で行うためのプログラムを記録したことを特徴とするコンピュータ読み取り可能な記録媒体。
【請求項14】
複数のウェブ文書それぞれからエンティティ(entity)及び重要度寄与要素を算出するエンティティ抽出手段と、
前記算出された重要度寄与要素に基づいて各エンティティに対する加重値を計算する加重値計算手段と、
前記算出された加重値に基づいて前記複数のウェブ文書が類似文書であるか否かを検出する類似文書検出手段と、を含むことを特徴とする改善された類似文書検出装置。
【請求項15】
前記複数のウェブ文書を所定の方式により一つのクラスタに統合し、統合した前記クラスタを前記複数のウェブ文書として前記エンティティ抽出手段に提供するクラスタリング手段をさらに含むことを特徴とする請求項14に記載の改善された類似文書検出装置。
【請求項16】
前記所定の方式は、ホスト(Host)クラスタリング、パス(Path)クラスタリング、クエリ(Query)クラスタリング、サイズ(Size)クラスタリング、シムハッシュ(Simhash)クラスタリングまたはDOM(Document Object ModeL)クラスタリングのうち少なくとも一つ以上を任意の順序で組み合わせたものであることを特徴とする請求項15に記載の改善された類似文書検出装置。
【請求項17】
前記エンティティ抽出手段は、
前記複数のウェブ文書のうちいずれか一つから文書構造を抽出し、前記抽出された文書構造に基づいてエンティティを抽出することを前記複数のウェブ文書全てに対して繰り返して行い、
前記エンティティは、前記文書構造のテキストノード、アンカー(anchor)ノード、エンベッド(embed)ノードまたはイメージ(img)ノードのうちいずれか一つ以上のノードから抽出されることを特徴とする請求項14から16のいずれか一項に記載の改善された類似文書検出装置。
【請求項18】
前記エンティティがテキストノードから抽出される場合、
前記テキストノードの上位ノードの中に存在するID値を前記エンティティに結合して使用することを特徴とする請求項17に記載の改善された類似文書検出装置。
【請求項19】
前記重要度寄与要素は、
前記エンティティが前記複数のウェブ文書中で核心となる程度の重要度を反映するものであることを特徴とする請求項14から18のいずれか一項に記載の改善された類似文書検出装置。
【請求項20】
前記重要度寄与要素は、前記エンティティのハッシュ値、または前記エンティティが前記複数のウェブ文書中で重複する回数や頻度のうちいずれか一つ以上を含む値であることを特徴とする請求項19に記載の改善された類似文書検出装置。
【請求項21】
前記加重値は、前記算出されたエンティティの重複する回数や頻度に反比例する文献出現頻度の逆数(Inverted Document Frequency)を用いて計算されることを特徴とする請求項20に記載の改善された類似文書検出装置。
【請求項22】
前記類似文書検出手段は、
前記複数のウェブ文書それぞれに含まれるエンティティ及び前記エンティティの加重値に基づいて前記複数のウェブ文書それぞれの特性指数を計算し、前記計算されたそれぞれの特性指数に基づいて前記複数のウェブ文書が類似文書であるか否かを検出するものであることを特徴とする請求項14から21のいずれか一項に記載の改善された類似文書検出装置。
【請求項23】
前記特性指数はシムハッシュ(Simhash)であることを特徴とする請求項22に記載の改善された類似文書検出装置。
【請求項24】
前記特性指数に基づいて類似文書であるか否かを検出することは、
前記複数のウェブ文書それぞれが有する特性指数であるシムハッシュ間のハミング距離(hamming distance)が所定数値以下である場合、類似文書として検出されることを特徴とする請求項23に記載の改善された類似文書検出装置。
【請求項25】
前記類似文書検出手段は、前記類似文書検出結果に基づいて前記複数のウェブ文書のうち重複する類似文書を削除することをさらに含むことを特徴とする請求項14から24のいずれか一項に記載の改善された類似文書検出装置。
【請求項1】
類似文書検出装置で行われる方法であって、
複数のウェブ文書それぞれからエンティティ(entity)及び重要度寄与要素を算出するエンティティを抽出し、
前記算出された重要度寄与要素に基づいて各エンティティに対する加重値を計算し、
前記算出された加重値に基づいて前記複数のウェブ文書が類似文書であるか否かを検出すること、を含むことを特徴とする改善された類似文書検出方法。
【請求項2】
前記複数のウェブ文書を所定の方式により一つのクラスタに統合するクラスタリングすることをさらに含むことを特徴とする請求項1に記載の改善された類似文書検出方法。
【請求項3】
前記所定の方式は、ホスト(Host)クラスタリング、パス(Path)クラスタリング、クエリ(Query)クラスタリング、サイズ(Size)クラスタリング、シムハッシュ(Simhash)クラスタリングまたはDOM(Document Object Model)クラスタリングのうち少なくとも一つ以上を任意の順序で組み合わせたものであることを特徴とする請求項2に記載の改善された類似文書検出方法。
【請求項4】
前記エンティティを抽出することは、
前記複数のウェブ文書のうちいずれか一つから文書構造を抽出し、
前記抽出された文書構造に基づいてエンティティを抽出すること、を前記複数のウェブ文書全てに対して繰り返すことにより行われ、
前記エンティティは、前記文書構造のテキストノード、アンカー(anchor)ノード、エンベッド(embed)ノードまたはイメージ(img)ノードのうちいずれか一つ以上のノードから抽出されることを特徴とする請求項1から3のいずれか一項に記載の改善された類似文書検出方法。
【請求項5】
前記エンティティがテキストノードから抽出される場合、
前記テキストノードの上位ノードの中に存在するID値を前記エンティティに結合して使用することを特徴とする請求項4に記載の改善された類似文書検出方法。
【請求項6】
前記重要度寄与要素は、
前記エンティティが前記複数のウェブ文書中で核心となる程度の重要度を反映するものであることを特徴とする請求項1から5のいずれか一項に記載の改善された類似文書検出方法。
【請求項7】
前記重要度寄与要素は、前記エンティティのハッシュ値、または前記エンティティが前記複数のウェブ文書中で重複する回数や頻度のうちいずれか一つ以上を含む値であることを特徴とする請求項6に記載の改善された類似文書検出方法。
【請求項8】
前記加重値は、前記算出されたエンティティの重複する回数や頻度に反比例する文献出現頻度の逆数(Inverted Document Frequency)を用いて計算されることを特徴とする請求項7に記載の改善された類似文書検出方法。
【請求項9】
前記類似文書を検出することは、
前記複数のウェブ文書それぞれに含まれるエンティティ及び前記エンティティの加重値に基づいて前記複数のウェブ文書それぞれの特性指数を計算し、
前記計算されたそれぞれの特性指数に基づいて前記複数のウェブ文書が類似文書であるか否かを検出すること、を含むことを特徴とする請求項1から8のいずれか一項に記載の改善された類似文書検出方法。
【請求項10】
前記特性指数はシムハッシュ(Simhash)であることを特徴とする請求項9に記載の改善された類似文書検出方法。
【請求項11】
前記特性指数に基づいて類似文書であるか否かを検出することは、
前記複数のウェブ文書それぞれが有する特性指数であるシムハッシュ間のハミング距離(hamming distance)が所定数値以下である場合、類似文書として検出されることを特徴とする請求項9又は10に記載の改善された類似文書検出方法。
【請求項12】
前記類似文書検出結果に基づいて前記複数のウェブ文書のうち重複する類似文書を削除する類似文書を削除することをさらに含むことを特徴とする請求項1から11のいずれか一項に記載の類似文書検出方法。
【請求項13】
請求項1から12のいずれか一項に記載の方法の各ステップをコンピュータ上で行うためのプログラムを記録したことを特徴とするコンピュータ読み取り可能な記録媒体。
【請求項14】
複数のウェブ文書それぞれからエンティティ(entity)及び重要度寄与要素を算出するエンティティ抽出手段と、
前記算出された重要度寄与要素に基づいて各エンティティに対する加重値を計算する加重値計算手段と、
前記算出された加重値に基づいて前記複数のウェブ文書が類似文書であるか否かを検出する類似文書検出手段と、を含むことを特徴とする改善された類似文書検出装置。
【請求項15】
前記複数のウェブ文書を所定の方式により一つのクラスタに統合し、統合した前記クラスタを前記複数のウェブ文書として前記エンティティ抽出手段に提供するクラスタリング手段をさらに含むことを特徴とする請求項14に記載の改善された類似文書検出装置。
【請求項16】
前記所定の方式は、ホスト(Host)クラスタリング、パス(Path)クラスタリング、クエリ(Query)クラスタリング、サイズ(Size)クラスタリング、シムハッシュ(Simhash)クラスタリングまたはDOM(Document Object ModeL)クラスタリングのうち少なくとも一つ以上を任意の順序で組み合わせたものであることを特徴とする請求項15に記載の改善された類似文書検出装置。
【請求項17】
前記エンティティ抽出手段は、
前記複数のウェブ文書のうちいずれか一つから文書構造を抽出し、前記抽出された文書構造に基づいてエンティティを抽出することを前記複数のウェブ文書全てに対して繰り返して行い、
前記エンティティは、前記文書構造のテキストノード、アンカー(anchor)ノード、エンベッド(embed)ノードまたはイメージ(img)ノードのうちいずれか一つ以上のノードから抽出されることを特徴とする請求項14から16のいずれか一項に記載の改善された類似文書検出装置。
【請求項18】
前記エンティティがテキストノードから抽出される場合、
前記テキストノードの上位ノードの中に存在するID値を前記エンティティに結合して使用することを特徴とする請求項17に記載の改善された類似文書検出装置。
【請求項19】
前記重要度寄与要素は、
前記エンティティが前記複数のウェブ文書中で核心となる程度の重要度を反映するものであることを特徴とする請求項14から18のいずれか一項に記載の改善された類似文書検出装置。
【請求項20】
前記重要度寄与要素は、前記エンティティのハッシュ値、または前記エンティティが前記複数のウェブ文書中で重複する回数や頻度のうちいずれか一つ以上を含む値であることを特徴とする請求項19に記載の改善された類似文書検出装置。
【請求項21】
前記加重値は、前記算出されたエンティティの重複する回数や頻度に反比例する文献出現頻度の逆数(Inverted Document Frequency)を用いて計算されることを特徴とする請求項20に記載の改善された類似文書検出装置。
【請求項22】
前記類似文書検出手段は、
前記複数のウェブ文書それぞれに含まれるエンティティ及び前記エンティティの加重値に基づいて前記複数のウェブ文書それぞれの特性指数を計算し、前記計算されたそれぞれの特性指数に基づいて前記複数のウェブ文書が類似文書であるか否かを検出するものであることを特徴とする請求項14から21のいずれか一項に記載の改善された類似文書検出装置。
【請求項23】
前記特性指数はシムハッシュ(Simhash)であることを特徴とする請求項22に記載の改善された類似文書検出装置。
【請求項24】
前記特性指数に基づいて類似文書であるか否かを検出することは、
前記複数のウェブ文書それぞれが有する特性指数であるシムハッシュ間のハミング距離(hamming distance)が所定数値以下である場合、類似文書として検出されることを特徴とする請求項23に記載の改善された類似文書検出装置。
【請求項25】
前記類似文書検出手段は、前記類似文書検出結果に基づいて前記複数のウェブ文書のうち重複する類似文書を削除することをさらに含むことを特徴とする請求項14から24のいずれか一項に記載の改善された類似文書検出装置。
【図1a】



【図1b】

【図2】
【図3】
【図4】
【図5】
【図6】

【図7a】

【図7b】
【図8a】

【図8b】
【図8c】
【図9a】
【図9b】

【図10】
【図1b】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7a】
【図7b】
【図8a】
【図8b】
【図8c】
【図9a】
【図9b】
【図10】
【公開番号】特開2012−234522(P2012−234522A)
【公開日】平成24年11月29日(2012.11.29)
【国際特許分類】
【出願番号】特願2012−63358(P2012−63358)
【出願日】平成24年3月21日(2012.3.21)
【出願人】(505205812)エヌエイチエヌ コーポレーション (408)
【公開日】平成24年11月29日(2012.11.29)
【国際特許分類】
【出願日】平成24年3月21日(2012.3.21)
【出願人】(505205812)エヌエイチエヌ コーポレーション (408)
[ Back to top ]