
数値データの処理方法
本発明は、d次元空間において、少なくともベクトル(複数)の一部分1に対し、少なくとも一つのベクトルインデックスI1(英語でリーダーという)を計算するための量子化ステップを有するデジタルデータ処理方法に関する。前記ベクトル(複数)1は、入力データの記述子を構成し、前記方法は、前記リーダーベクトルインデックスI1が、リーダーベクトル全体の決定ステップをもつことなく、逆辞書順序で、前記リーダーベクトル1に先行するベクトルの数に対応することを特徴とする。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、デジタルデータの圧縮、検索、比較又は解凍などのアプリケーションのためのデジタルデータ処理の技術分野に関する。本発明は、オーディオビジュアルデータの処理、より一般的には、全てのタイプのデジタルデータの処理に関する。本発明の目的は、処理時間を削減し、コンピューティングパワー、メモリの容量に関する情報処理リソースの必要性を削減することである。
【背景技術】
【0002】
アプリケーションは、全てではないが、表示に大量のデータを必要とする画像処理に関係する。記憶に必要なサイズと伝送時間を削減するためには、ビデオ情報を抽出処理し、コード化して、情報圧縮を行う。このコード化された情報は、コード化のパフォーマンスに有害なリダンダンシーを避け、周波数と空間に関して、最適な再構成可能な状態にする必要がある。そのために、ウェーブレット変換技術が知られている。その座標は、ベクトルラティスを構成するもので、ベクトル量子化が行われる。
【0003】
ベクトル量子化(VQ)の原理は、各サンプルを個別にコード化する代わりに、ベクトルを形成するサンプルのシーケンスをコード化することである。コード化は、ベクトルによりシーケンスを近似することによって行われる。通常"コードブック"と呼ばれるカタログに属するベクトルを使ってコード化する。コードブックの各ベクトルには、インデックスが付けられる。コード化する時に、それを表わすために使用するのは、コード化するサンプルシーケンスに最も近いベクトルのインデックスである。
【0004】
公知の解決法では、各ベクトルを決定すること、それをメモリに記憶させること、更に、ベクトル全体に対し処理することが、必要である。ベクトルの基底(base)は、数ギガバイトを必要とする可能性がある。同様に大きい基底の計算には長時間が必要である。本発明の目的は、これらの欠点を回避する、カウント方法とインデキシング方法を提供することである。
【0005】
技術水準
量子化方法は、論文[1]により公知である。
【0006】
ラティス(reseau:lattice)は、数学的に、加法群(additif)を形成するn次元空間のベクトルの集合である。論文[2]は該ラティスについて説明している。
【0007】
従来技術として、国際特許出願WO9933185が公知である。このコード化方法は、予め決められた順序で、量子化ベクトルと同一の成分を有するベクトル(リーダー(代表)ベクトル:vecteur leader)を決定するステップと、前記リーダーベクトルと同一成分を持ち、前記グループにおいて予め決められた順序で並べられているベクトルにより形成された前記グループにおける量子化されたベクトルのオーダー(ordre)又はランク(rang)のレベルを決定するステップからなる。前記方法は、一方では前記決められたリーダーベクトルを表わすインデックスから、他方、前記ランクを表わすインデックスから一つのコードを形成する。
【0008】
圧縮のためのベクトル量子化の設計における重大な問題は、規則的点ラティス(le reseau regulier de points)(量子化辞書を形成する)におけるベクトルのカウントとインデキシングの問題である。本発明は、このために、一般ガウス分布のソース(source:例えば、ウェーブレット係数など)のケースで、これら問題を解決するための解決法を提供する。
【0009】
代数的ベクトル量子化(La quantification vectorielle algebrique):
量子化については、数十年に亘って研究されてきた。これら研究は、今日、レート歪理論に関して、多くの成果をもたらしている。特に、ベクトル量子化(QV)は、固定長のコード化が要求される場合には、スカラ量子化(QS)に比べて多くの利点を持っていることが証明された。また、シャノンは、n次元ベクトル量子化が十分に大きい場合は、QVのパフォーマンスは最適な理論的パフォーマンスに近いことを証明した。
【0010】
しかし、高度に複雑な計算を犠牲にして、QVを、最適なパフォーマンスに近づけようとすることに注意しなければならない;この複雑さは、ベクトルの次元と共に、指数関数的に増加する。通常、QVは、ソース(学習シーケンス)を表わす統計データから構成される非構造化辞書(dictionnaire non structure)を使って実行される。この場合において、複雑さと辞書のサイズによる記憶容量は、圧縮アプリケーションに対して阻害的要因となる。
【0011】
また、辞書のロバスト性(robustesse)の問題がある。辞書は、与えられたトレーニングシーケンス用に最適化されているので、トレーニングシーケンス以外の画像に対し、パフォーマンスが低い。これら問題を克服するための解決法は、代数的ベクトル量子化(QVA)、又は、点の規則的ラティス(reseaux reguliers)に対しベクトル量子化等の構造化されたn次元のQVを使用することである。
【0012】
辞書のベクトルは構造化された規則的ラティスに属するようになっているので、QVAのパフォーマンスは一般的に非構造化QAのパフォーマンスより低い。
【0013】
しかし、ほとんどのアプリケーションでは、この小さな欠点は、QVAに対しては、辞書を作成される、又は、記憶される必要はないということ、及び、コード化の複雑さが軽減されるということによって埋め合わされる。
【0014】
規則的点ラティスによる量子化は、一様なスカラ量子化の一般化と見なすことができる。非構造化QVの場合のように、本書では、用語QVAは、ベクトル量子化を意味するように、又は、ベクトル量子化器(quantificateur vectoriel)を意味するように、使用される。 QVAは、分割ゲイン及び形状と、ベクトルの係数の間で、空間依存性を考慮に入れる。ソース分布がどのようなものであろうと、QVAはQSより常に効率が良い。
【0015】
空間Rnの内の規則的ラティスは、基本的なラティスである線形独立ベクトルの集合の全ての組み合わせによって構成されている。これは、ラティスの基底(base)を形成する。{y│y = u1a1 + u2a2 + … unan}。但し、係数uiは整数である。空間の分割は、規則的であって、選択された基底ベクトルのみに依存する。各基底は、異なる点の規則的なラティスを定義する。
【0016】
QVAを使うと、一般化Lloydアルゴリズムに基づくアルゴリズムを使って設計された、1つのQVに関する計算コストと記憶に関するコストを大幅に削減できる可能性がある。確かに、量子化ベクトルのような規則的ラティスベクトルを使用すると、辞書の構築操作を削減できる:辞書は、選択したラティス構造により暗黙的に構築される。
【0017】
論文[1]には、n次元ベクトルのみに依存する丸め込み操作(operations d'arrondis)を単純に使う高速なアルゴリズムについて説明されている。 1979年、Gershoは、(高フローに対し)1つのレート歪み性能(performances debit-distorsion)は、ほぼ最適である、と予想した。
【0018】
しかしながら、QVAは数学的に低フローに対し最適化されていない。しかし、このような量子化要素(quantificateurs)によりもたらされる複雑さを低減させることにより、大きい次元のベクトルを使用することができ、与えられたフローの実験のパフォーマンスを向上させる。エントロピーコーダ(un codeur entropique)とQVAとを組み合わせて、レート歪みについての良好な性能を得ることができる。これにより、ウェーブレット分野における、QVAの研究に対するモーティベーションが高まった。QAに対する多くの研究がガウシアン、ラプラシアンソース(sources Gaussienne et Laplacienne)に対して行われた。更に、1より小さい減衰パラメータをもつ一般ガウシアンタイプのソースの場合は、レート歪に関して、キュービック ラティスZnは、ラティスE8、Leechラティスと比べると性能が良いことが証明された。この結果は、ウェーブレット変換とQVAとを組合せる我々の研究に刺激を与えた。
【先行技術文献】
【特許文献】
【0019】
【特許文献1】国際特許出願WO9933185
【発明の概要】
【発明が解決しようとする課題】
【0020】
QVAによる量子化が複雑である場合には、辞書の規則的幾何学的構造のために、その実装はすぐには行われない。漸近モデルの場合、過負荷ノイズは無視される。可変長符号化と無限大の辞書の使用を想定しているからである。これは、計算と記憶の観点から、具体的な複数の問題を提起する。特に、計算と記憶に関してである。これら二つの基本的な問題は、QVAの設計において、重要である。
【0021】
a)インデキシング
インデキシングは、各量子化ベクトルに対して、インデックスを、割り当てることであり、量子化とは別の操作である。一旦コード化されると、インデックスは、デコーダーまでチャネルを介して送信される。この操作は圧縮チェーンにおいて基本的である。それは、ビットレートを決定し、曖昧さのないベクトル復号化を可能にする。公知の方法によると、一般的にメモリについては極めて安価になるが、計算については、かなり複雑になる(再帰的アルゴリズム)。又は、特別な場合(ラティスタイプ又は特別のトランケーション)にだけ動作するものである。本発明は、一般化ガウス形分布に対しインデキシングすることを可能にし、一般的なアプローチに関するもので、メモリコスト/計算コストの妥協を実現する。
【0022】
b)カウント
インデックス法は、通常、ラティス数の増大に基づいている。したがって、ソースの分布に依存する、n次元面(又はボリューム内)のラティスベクトルをカウントできなければならない。カウントについての従来のアプローチは、生成された級数の使用に基づいている。この手順で、関数Nuが導入された。それらを使うと、ピラミッド上で(即ち、ラプラス分布の場合)カウントすることが可能になる。
本発明は、一般化ガウス分布上のカウントを可能にする一般的なアプローチを提案し、メモリコスト/演算コストの両立性を実現した。第2の特許では、この問題を解決する。
【0023】
本発明の目的
本発明の目的は、メモリ容量と時間が削減された情報処理リソースを使って実行可能なベクトル量子化ステップを含む処理方法を提案することである。
【課題を解決するための手段】
【0024】
この目的で、本発明は、少なくともベクトル(複数)の一部分1に対し、d次元空間において、少なくとも一つのリーダーベクトルインデックスI1を計算するための量子化ステップを有するデジタルデータ処理方法に関する。
前記ベクトル(複数)1は、入力データの記述子(descripteurs)を構成する。また、前記方法は、リーダーベクトル全体の決定するステップをもつことなく、前記リーダーベクトルのインデックスI1が、逆辞書順序で、前記リーダーベクトル1に先行するベクトルの数に対応することを特徴とする。
【0025】
前記処理方法は、計算において、リーダーベクトル以外の、どのようなリーダーベクトルを決定するステップを含まないことが好ましい。
【0026】
【化1】

【0027】
【化2】
【0028】
【化3】
【0029】
別の変形例では、リーダーベクトルインデックスI1を算出するステップは、“前記リーダーベクトル1(x1, x2, ...xd)のノルムrの算出ステップ(但し、x1 乃至 xdは、増加する順序に並べられている)”及び“dと1の間の変数iを持つ座標xi上で再帰的カウントステップ”を含んでいる。前記カウントステップは、座標xiがi+1とMIN(xi+1,r-xi+1)との間に含まれているベクトルをカウントするもので、インデックスIlは、カウントステップの結果の和に等しく、インデックスI1は、カウントステップの結果の和に等しい。
【0030】
別の変形例では、リーダーベクトルインデックスI1を算出するステップは、“前記リーダーベクトル1(x1, x2, ...xd)のノルムrの算出ステップ(但し、x1 乃至 xdは、減少する順序に並べられている)”及び“1とdの間の変数iを持つ座標xi上で再帰的カウントステップ”を含んでいる。前記カウントステップは、ベクトルをカウントするもので、その座標xiはxi+1とMIN(xi-1, r-xi-1)との間に含まれている。インデックスIlは、カウントステップの結果の和に等しい。
【0031】
本発明は、インデックスI1のバイナリコード化の結果、少なくとも一つの符合インデックスIs、ノルムインデックスIn及び置換(permutation)インデックスIpを記憶する、ベクトルデータの圧縮のための、前記方法のアプリケーションに関する。前記ベクトルデータは次のようなものである。
【0032】
−デジタル画像、
−デジタルビデオシーケンス、
−デジタルオーディオデータ、
−デジタル3次元オブジェクト、
−デジタルアニメ3次元オブジェクト、
−データベースにおいて登録された情報、
−前記ベクトルデータの変換に由来する複数係数(例:DCT係数、ウェーブレット係数)。
【0033】
また、本発明は、参照情報として、インデックスIl,ref 、少なくとも一つの符号インデックスIs,ref、ノルムインデックスIn,ref及び巡回インデックスIp,refを算出し、同一インデックスをもつデータをサーチするためのベクトルデータベースにおいて、サーチするための、前記方法のアプリケーションに関する。
【0034】
前記ベクトルデータは次のようなものである:
−デジタル画像、
−デジタルビデオシーケンス、
−デジタルオーディオデータ、
−デジタル3次元オブジェクト、
−デジタルアニメ3次元オブジェクト、
−テキストデータベースのオブジェクト、
−データベースにおいて登録された情報、
−前記ベクトルデータの変換に由来する複数係数(例:DCT係数、ウェーブレット係数)。
【0035】
本発明は、また、前記方法に基づいて算出されたリーダーベクトルインデックスI1から、デジタルデータを再構成する方法に関する。この方法は、1つのリーダーベクトルの座標(xl, x2, ..., xd)を算出することを特徴としている。また、全リーダーベクトルを決定するステップなしに、逆辞書順序で、前記リーダーベクトル1に先行するベクトルの数に対応するインデックスI1を持つリーダーベクトル1をサーチする処理に、一つのインデックスI1を付加することを特徴としている。
【0036】
【化4】
この加算は、和が前記インデックスI1より大きくなるまで行われる。前記サーチされた座標xiは、前記インデックスI1を超過するものであり、前記方法では、座標Xi-1に対して、値I1から加算が継続される。但し、I1は、前記インデックスを超過する前の、値I1に先行する値である。
【0037】
【化5】
また、前記関数F(A)を適用して、カウントステップの結果の加算が行われる。この加算は、和が前記インデックスI1より大きくなるまで行われる。前記サーチされた座標xiは、前記インデックスI1を超過するものであり、前記方法では、座標Xi+1に対して、値I1から加算が継続される。但し、I1は、前記インデックスを超過する前の、値I1に先行する値である。
【0038】
【化6】
再構成するためには、昇順にソートする場合、座標xdに対して、及び、降順にソートする場合、座標xlに対して、I1' = 0とする。
【図面の簡単な説明】
【0039】
本発明は、図面を参照し、非制限的な実施例を読むことにより、よりよく理解されるであろう。
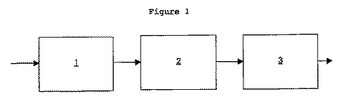
【図1】本発明に基づくデータ処理システムの基本を示す図である。
【図2】
【化7】
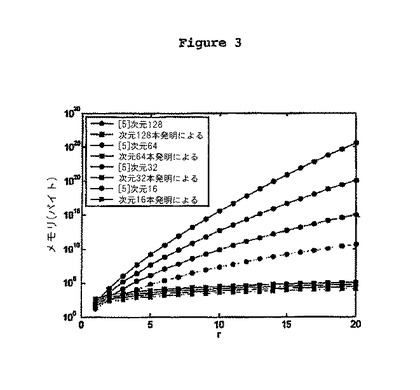
【図3】p = 1, δ = 1, B = 4の場合における、通常の方法と提案する方法の間のメモリ容量を比較する図である。−アネックス1は本発明を実施するためのコーディング、デコーディング アルゴリズムの1例である。
【発明を実施するための形態】
【0040】
データ処理システムは、通常、3つのメインモジュールを備えている。最初のモジュール(1)は、画像に対応するデジタル信号等の入力データを受信し、このサンプリングされた信号に基づいて、公知の方法で、ウェーブレット変換を行う。
【0041】
本発明の方法により、量子化モジュール(2)は、ウェーブレット係数のベクトル量子化/インデックス化方法を使って、ウェーブレット係数をコード化する。
【0042】
3番目のモジュールは、公知のロスなしの圧縮方法で、記憶又は送信する情報のサイズを削減するためにコード化を行う。
【0043】
量子化ステップとインデキシング ステップは、第2番目のモジュール(2)によって実行される。このステップが、本発明の対象である。このステップは、以前の技術において、多くのリソースを必要とした。それは、全リーダーべクトルを決定すること、メモリにそれらを一時的に記憶することを含んでいる。
【0044】
ラティス上でベクトル量子化する方法は公知である。また、それは、一般的にオーディオ、ビデオ、マルチメディアの圧縮システムで使用されている。ラティス上のベクトル量子化は、一様(uniforme)スカラ量子化を多次元拡張したものである。後者は、例えば、一つの画像の各ピクセルを表す、1つの信号を、個別に、2Nレベルに量子化するものである。但し、Nは、量子化器に割り当てられているビット数である。ラティス上のベクトル量子化については、規則的ラティスに関連しており、それにより、問題となるラティスの属する量子化ベクトルが1つ決まる。そのコンポーネントは、コード化信号が取る値を表す。
【0045】
具体的にいえば、量子化操作は、“各コンポーネントが1つのコード化信号により取られる値を表し、非可算の集合(実数の集合Rのような)に属する、1つのオリジナルベクトルの基づいて”、各コンポーネントが相対的数(nombres relatives:整数)の集合Zのような可算集合に属する、1つの量子化ベクトルxを決定することである。
【0046】
ラティスベクトルのインデキシングは、ラティスの量子化アプリケーションにおける重要な問題である。本発明は、ラティス リーダーベクトルとパーティション理論を使って、この問題に対するソリューションを与えるものである。一般化ガウス分布のソースに対して、それを使うことができ、それを使うと、プロダクトコードを使うことができる。また、それを使うと、高次元のベクトルのインデキシングが可能になる。
【0047】
ベクトルの次元がかなり高い場合は、ベクトル量子化(QV)を使うと、最適理論のパフォーマスを得ることができる。しかし、残念なことではあるが、LBG等の、最適に構造化(non structuree optimale)されていないQV計算の複雑さは、次元が高くなるにつれ、指数関数的に高まる。加えて、記憶容量が極めて重要になる。次元に関する問題を解決するためには、ラティスベクトル量子化(LVQ)のような拘束型QV(QV contrainte)を使用すればよい。
【0048】
LVQアプローチによると、コードベクトルが空間に規則的に分布している一つの構造化辞書を設計することになる。その結果、空間におけるベクトルの位置を最適化する代わりに、ラティスベクトルをインデキシングして、分布の形状に応じてソースを適合させることができる。大半の実データのソースに対して、プロダクトコードを使って、これを効率的に実行することができ、対称的ユニモーダルソース分布(des distributions de sources unimodales symetriques)に対して、レート-歪を最適な値に導くことができる。
【0049】
ソースの分布に応じて、これらの分布を、同一形状を持つ同心超曲面(hypersurface concentrique)の集合として解釈することができる。それぞれの面のノルム(半径)に対応する第1インデックス(prefixe)を割り当て、同一面に属するベクトルのカウントに対応する第2単一インデックス(suffixe)を割り当て、ラティスコードワードにインデックスを付与することができる。
【0050】
大量のデータソース(例えば、特に、ウェーブレット変換によって得られた、画像の係数と音声サブバンド等)は、一般化ガウス分布によってモデル化することができる。この分布のファミリーは、一変数(univariee)確率変数に対して、1つのシェープファクタp(GG(p))によってパラメータ化される。分布(GG(p))を持つソースの興味深い性質は、ノルム1pのエンベロープが一定確率面に対応していることである。
これは、効率的なプロダクトコードの開発につながる。
【0051】
prefixeの計算が簡単である場合でも、suffixeは、超曲面(hypersurface)上のラティスベクトルのカウント及びインデキシングが必要である。また、空間の次元が増大すると、インデキシング操作が非常に複雑になる。その理由は、次の表に示されるように、1つのエンベロープ上に存在するベクトルの数が、ノルムと共に大きく増加するからである。表は、一つのラティスZnと複数の次元とノルム値に関して、“1つのノルム11の場合における、1つの与えられた超曲面のベクトルの数”と、“このハイパーピラミッド(基数:cardinality)の上にあるラティスベクトルの全数”との比較を表している。
【0052】
【表1】
【0053】
この文献によると、suffixeのインデキシングは、通常、2つの異なるやり方で行われている。
【0054】
最初のアプローチは、超曲面上にあるベクトルの全数(cardinalite:基数)を考慮して、1つのインデックスを割り当てることである。第2のアプローチは、リーダーベクトルの概念を使って、ラティスの対称性を利用することである。ノルムlpのエンベロープの(複数)リーダーは、ラティスの(複数)ベクトルに対応している。そのベクトルを基にして、前記の対応するエンベロープに存在する他の全てのラティスベクトルは、それら座標の置換(permutation)、符号変化により、得ることができる。これら2つのアプローチは、isotropicソースに対し、同様のレート−歪パフォーマスを示す。
【0055】
しかしながら、ラティスのインデキシングについての多くの研究は、ラプラス分布又はガウス分布に対する解法を提案している。これら分布は、それぞれ、形状パラメータp=1、p=2を持つGG(p)の特別なケースである。p=0.5という特別なケースに対する解法を提案する研究者もいる。しかし、このカウント方法では、プロダクトコードを構成することはできず、実際には、インデキシングの方法も極めて複雑である。特に、高次元、大きいノルムをもつp≠0.5、1又は2の場合は複雑である。
【0056】
本発明は、0<p≦2を持つエンベロープGG(p)の上にあるラティスベクトルZnに対する新規な代替案を提案する。提案する解決法は、ベクトルに基礎を置いて、分割理論を使う。
【0057】
分割理論(la theorie des partitions)を使うと、前記複雑性、必要な記憶容量の問題を解決でき、リーダーベクトルを生成し、ベクトルにインデックスを付与することができる。本発明は、変換テーブルを使うことなく、suffixeインデックスを、素早く割り当てることができる、経済的なインデキシングアルゴリズムを提案する。
【0058】
以下の説明において、最初の章では、LVQの原則を説明してから、インデキシング問題について説明する。次の章では、形状パラメータpがどのようなものであろうとも、インデキシングの例を以って、極めて大きいコードブックLVQにインデックスを付与するための効率的なやり方を提案する。続いて、提案されたアプローチの、メモリ、演算のコストについて説明する。更に、実効的な実データ インデキシングに対するパフォーマンス値について説明する。
【0059】
ラティスベクトルのインデキシング
ラティスの定義
RnにおけるラティスΛは、線形独立ベクトルai(ラティスの基底)の集合の全部の組合せで、次のように構成される。
Λ = {x│x = u1a1 + u2a2 + … unan} (1)
【0060】
【化8】
【0061】
1つのラティスの各ベクトルvは、一定ノルムlpを持つベクトルを含む表面又は超平面に属していると見なすことができ、次式で与えられる。:
【0062】
【数1】
【0063】
プロダクトコード(code produit)を使って、指定したラティスのベクトルをコード化することができる。ソースベクトルの分布がラプラシアン分布であるならば、適切なプロダクトコードは、“1つのベクトルのノルム11に対応するprefixe”及び“問題とするノルム11に等しい1つの半径を持つハイパーピラミッド上の位置に対応するsuffixe”から構成されていることは、明らかである。 一定のノルムl1の超曲面は、ハイパーピラミッドと呼ばれる。
1つの超曲面の上のベクトルの位置は、カウントアルゴリズム(algorithme de denombrement)を使って取得することができる。このようなプロダクトコードは、デコーディングの一意性(unicite)を保証する。
【0064】
形状パラメータが1に等しい又は1より小さい、一般化ガウス分布を持つソースの場合、D4、E8上の立方体的ラティスZn又はLeechラティスの優位性が証明されている[12]。従って、本書の残りの部分では、立方体的ラティスZnに基づく1つのLVQの設計を中心に説明する。
【0065】
全カウント数に基づくインデキシング
ガウス分布又はラプラシアン分布について、及び、全カウントの原理に基づく種々のラティスについて、複数のカウント方法が、これまで提案されてきた。特に、ソースがラプラシアン分布の場合、ラティスZnに関して、ノルム11のハイパーピラミッド上にあるラティスのベクトルの全数を計算するための再帰的公式(formule recursive)が知られている。
カウントのこの公式は、0と2の間の形状ファクタpを使って、ソースの一般化ガウス分布に拡張されている。これら解法を使うと、tranctureノルム1pの内部に存在するベクトルの数を計算することができる。
しかしながら、これら解法は、インデックスをラティスZnに割り当てるアルゴリズムを提示するものではない。
また、この解法は、超曲面上にあるベクトルの数を決定するものではない。このため、プロダクトコードを使用することは困難である。
【0066】
従来の研究の中で提案されているアルゴリズムは、0<p≦2に対するプロダクト コードスキームに基づいて、ベクトル(複数)にインデックスを付与するものである。それは、一般化シータ級数(series theta)に基づいて[4]、ラティス幾何学を使うものである。p=1または2については、この級数の展開は比較的に単純である。これに対し、pがそれ以外の値である場合、この級数は極めて複雑になる。クローズドフォーム(forme fermee)が生成されず、公式(mathematiques formelles)を使用することができないからである。提案された解法によれば、種々の次元及び高次元について、可能なノルム値を決定する必要があるが、一般的には、これを所定時間内に実行することはできない。
【0067】
また、実施する際に、特に、高次元に対して(前記表を参照)、超曲面の基数(cardinalite)は、急速にnon-tractableな値(扱いにくい値)に達するので、エンベロープの基数に基づくインデキシング技術は、急速にコンピュータの計算精度(precision informatique)を越えてしまう。
【0068】
ベクトル(リーダー)に基づくインデキシング
リーダーに基づく方法は、ラティスの対称性を利用する。その方法は、一定ノルムのエンベロープに対する効率的なインデキシング アルゴリズムを使う。ラティスベクトルの全数に基づいてインデックスを割り当てるのではなく、リーダーと呼ばれる、少ない数のベクトルに基づいて割り当てるものである。
【0069】
ラティスの対称性は、様々であるので、個別に処理される。対称性がない場合には、これは、全カウント法と比べると、より効率的なソースのインデキシング方法である。
また、コード化アルゴリズムにより管理されるインデックスは、エンベロープの基数よりもっと小さい。これを使うと、全カウントに基づく方法ではインデックスを付与できないベクトルに対して、バイナリ精度(precision binaire)で、インデックスを付与することができる。
【0070】
プロダクトコードのアーキテクチャでは、ラティスの対称性を別にして、suffixeインデックスは、リーダーの数が少ないインデックスを含んでいる。前記suffixeインデックスに基づいて、超曲面の全ての他のベクトルを割り当てることができる。ラティスZnに関して、対称性は、2つの基本的な操作に対応している:即ち、ベクトル座標の“符号変化(changements de signe)”と“置換(permutation)”である。
第1の操作は、ベクトルが存在する一つの象限の変化に対応している。例えば、2次元のベクトル(7,−3)が第4象限にあるとする。これに対し、ベクトル(−7、−3)は第3象限にある。これらベクトルはy軸に対して対称である。
第2の操作は、象限内の対称性に対応する。例えば、ベクトル(−7、3)と(−3,7)は、2つ共に第2象限にあり、同象限の2等分線に対して、対称である。
この場合、“これらベクトルは、これらベクトルのリーダーであるベクトル(3,7)の置換及び符号変化から生成されること”が分かる。ベクトル(3,7)は、これらベクトルのリーダーベクトルである。全ての置換と符号変化を使って、リーダー(3,7)は8つのベクトルを代表することができる。
この比は、超曲面の次元と共に急速に大きくなる(表1参照)。
【0071】
従って、このインデキシング方法は、超曲面上の全ベクトルに直接インデックスを付与する代わりに、各ベクトルに対し、3つのインデックスのセットを割り当てる:即ち、1つは、リーダーに対応するものであり、他の2つは、リーダーの置換および符号変化に対応するものである。置換と符号のインデックスの計算方法の詳細については、[5]を参照のこと。
【0072】
提案するインデキシング方法
ノルム11の場合に提案するリーダーのインデックス付与方法。
原理
本発明は、逆辞書順序で、全てのベクトルを分類する分類に基づく解決方法を提案する。また、インデックスを付与しなければならないリーダーに先行するベクトルの数に応じて、インデックスを割り当てる。この場合、インデキシングは、もはやリソースを大量消費する1つのサーチアルゴリズム、又は、直接アドレッシングによるものではなく、むしろ、低コストのカウントアルゴリズムによるものである。これは、それらに関する明らかな知識に依存するものではなく、むしろ、リーダーの量に依存するもので、このようにすれば、変換表を作成しなくてもよくなる。
【0073】
半径rのハイパーピラミッドは、全てのベクトルv = (v1, v2, …, vd)から構成されている。但し、||v||1=rである。上述したように、リーダーは、超曲面の基本ベクトルである。置換と符号変化操作によって、そこから、同超曲面上にある他のベクトルを導き出す。確かに、リーダーは、(または降順)昇順でソートされる正の座標を持つベクトルである。したがって、ノルムr、次元dのベクトルは、次の条件を満足するベクトルである。:
【数2】
【0074】
分割理論との関係
ノルムl1の場合、セクション3.1.1で説明した条件は数論の分割理論(theorie des partitions)に関連していることに注意しなければならない。確かに、数論では、正の整数rの分割は、正の整数の和(partとも呼ばれる)としてrを記述する方法である。rの別の分割数は、次の分割関数P(r)で与えられる:
【数3】
【0075】
これは、級数q[10、16、17]と呼ばれるオイラー関数の逆数(reciproque)に相当する。数学の進歩は、関数P(r)の表現法を導き、計算の迅速化を可能にしている。
【0076】
たとえば、r=5に関して、上記式(2)によって,P(5)=7となる。確かに、数5の可能な全分割は、(5)、(1,4)、(2、3)、(1、1、3)、(1、2、2)、(1、1、1、1、1)である。5次元ベクトルとして、これらの分割を書き換えると、(0、0、0、0、5)、(0、0、0、1、4)、(0、0、0、2、3)、( 0、0、1、1、3)、(0、0、1、2、2)、(0、1、1、1、2)と(1、1、1、1、1)となる。これらが、まさに、ノルムr=5とd=5のハイパーピラミッドのリーダーと対応していることが分かる。つまり、セクション3.1.1の2つの要件を満たすノルムr=5とd=5のハイパーピラミッドにおける唯一のベクトル(複数)である。
【0077】
しかし、d次元のラティスにおいて、rに等しいノルム11のエンベロープは重要である。但し、r≠dとする。この場合、関数q(r、d)[10、18]を使うことができる。この関数は、d以下の部分(parts)を持つrの分割数を計算するものである(分割理論において、これは、部分の数は問わないが、dより大きい要素を持たない、rの分割数を計算することと同じことである)。
したがって、ノルムr=5と次元d=3のハイパーピラミッドに対して、q(5,3)=5である。即ち、5つのリーダーは次のとおりである。:(0、0、5) (0、1、4)、(0、2、3)、(1、1、3)、(1、2、2)。
【0078】
関数q(r、d)は、次の漸化式から計算することができる。
q(r,d) = q(r, d−1) + q(r−d, d) (3)
但し、q(r、d)=P(r)で、d≧r、q(1、d)=1、及び、q(r、0)=0。
【0079】
3.1.3 関数q(r、d)を使用して、リーダーにインデックスを付与する
以下に説明するように、式(3)が与えられたハイパーピラミッドの上のリーダーの全数を与えるのみならず、同式は、変換テーブルを使うことなく、リーダーに対し唯一の一群のインデックスを割り当てるのに使うことができる。
インデックス アルゴリズムの原理を説明するために、次のようにハイパーピラミッドのリーダーが、次のように逆辞書式順序で分類されていると仮定する。
【0080】
【表2】
【0081】
したがって、リーダー1のインデックスは、これに先行するリーダーの数に対応している。上記例では、リーダー(0、...、1、1、rn−2)にはインデックス3が割り当てられる。
【0082】
第1命題(proposition)では、リーダーのインデキシング アルゴリズムが記述されている。
【0083】
第1命題
v=(v1、v2、…、vn)は、一定ノルムl1の1つのエンベロープ上の1つのリーダーベクトルl=(x1、x2、…、xn)を持つラティスベクトルZnであるとする。リーダーのインデックスI1は次式で与えられる。:
【0084】
【数4】
【0085】
【化9】
【0086】
証明。
【化10】
逆辞書式順序でリーダーをソートしているから、1より前の第1リーダー群は、n番目の成分が、xnより大きい全リーダー(即ち、xn+1≦gn≦rnを満たす最大座標gnを持つ全リーダー)から構成されている。
【0087】
それら全てをリスト化せずに、第1グループのリーダーの数をカウントするために、分割関数q(r、d)が使われる。なぜなら、n番目の座標がgnに等しいリーダーの数は、次の注(remarque)を使って簡単に計算することができるからである。
【0088】
注(Remarque):
ノルムrn、次元nのリーダー(その最大座標がgnに等しい)の数の計算は、数rn-gn(但し、gnより大きい部分がなく、n−1部分より小さい)の分割数を、計算することに等しい。
【0089】
ほとんどの場合、q(rn-gn,n-1)を適用して、分割数をカウントすることができる。しかし、このアプローチは、rn-gn<gnの場合しか正しくない。この場合、rn-gnの全ての分割はgnより大きい部分を持っていないと暗黙に仮定されている。しかしながら、一般的な場合、rn-gn<gnは保証されない場合(例えば、ノルムrn=20、次元n=5、最大部分が7のベクトルの数は、q(20-7、5-1)=q(13、4)を導く場合(但し20−7≪7ではない))、q(rn-gn, n-1)の計算は、真(valide)のベクトルの数について誤った値を算出する。rn-gn の複数の分割がgnより大きい部分を持つこともあるからである(この場合セクション3.1.1の条件2が満たされていない)。
【0090】
【化11】
【0091】
【化12】
よって、n+1からrnに至るgnの変化を使うと、最大座標がxnより大きいリーダー数を、次式から決定することができる。
【0092】
【数5】
【0093】
【化13】
【0094】
先行するリーダーベクトルlの第2グループは、第n番の座標がxnに等しい全ベクトルからなる。但し、第n−1番の座標はxn−1より大きいとする。リーダーベクトルのこの数をカウントするために、上記の注(remarque)を使うが、今回は、次元n−1に応用する。
【化14】
関数minは、ノルムrnとオーダーgn−1≦gn=xnが満足されることを保証する。
【0095】
結果を追加次元(dimensions additionnelles)に拡張することにより、最大座標がxnに等しいベクトルであって、1に先行するベクトルの数は、次式で与えられる。
【0096】
【数6】
【0097】
式(5)、(6)を組合せて、一般式を導き、1より前に位置するリーダーベクトルの全数を計算し、従って、1のインデックスIIを計算することができる(式(4))。
【0098】
【数7】
【0099】
但し、j=0に対し、xn+1=+∞
【0100】
【化15】
【0101】
【化16】
【0102】
【化17】
【0103】
一つのベクトルのノルムlpは、精度δを持つことが知られており、次式で得られる。
【0104】
【数8】
【0105】
【化18】
【0106】
【化19】
【0107】
【化20】
【0108】
第2命題:
ベクトルν = (v1, v2, …, vn)を、一定ノルムlpの一つのエンベロープの上にある1つのリーダーベクトル1 = (x1, x2, …, xn)を持つ1つのラティスベクトルZnであるとする。リーダーベクトルI1のインデックスは次式により与えられる。
【0109】
【数9】
【0110】
【化21】
【0111】
証明:
【化22】
【0112】
【化23】
【0113】
【化24】
【0114】
【化25】
【0115】
【化26】
【0116】
【数10】
【0117】
【化27】
【0118】
式(9)において、jを0からn−2に亘って変化させると、xnからx2までの座標に対する先行するリーダーベクトル1の数を正確にカウントすることができる。
【化28】
【0119】
【数11】
【0120】
【化29】
【0121】
【化30】
【0122】
【化31】
【0123】
【化32】
【0124】
【化33】
セクション3.1で導入した原則を使うと、これは、次のように分割Npの数を計算することと同じである:
【0125】
【数12】
【0126】
そして、i(Np > I1)の最初の値をxnに割り当てる。次のステップで、xn-1をデコードする。
【0127】
【化34】
次に、Xn-1をデコードするために、式(11)のメカニズムに類似したメカニズムを使ってNpをカウントする。しかし、今回は、(n−1)番目の座標に関係して行う。
【0128】
この場合、Np > I1であるから、最初に、分割カウンタNpの値を最初のリーダーベクトル(xnに等しい第n成分を持つ)に戻して、パラメータNpを先行する値にしなければならない。以後、これをNpbckpと呼ぶことにする(“先行する値”とは、Np < I1で、Npの中で一番大きい値に対応する。即ち、iの最後の値が和に含まれる前のNpの値である)。
【化35】
【0129】
このプロセスは、次元について、次式で一般化される。
【0130】
【数13】
【0131】
【化36】
【0132】
【化37】
ただし、前記2つともに、厳密に同一の計算結果であることが前提である。
【0133】
【化38】
次のセクションでは、リーダーベクトルのコーディング、デコーディングの例を説明する。
【0134】
コーディングとデコーディングの例
v = (-20, 16, 15, -40) を、インデキシングしなければならない形状ファクターp=0.3の、一般化ガウス分布を持つ一つのソースの量子化された1つのラティスベクトルとする。置換と符号のインデックスの計算は、この研究の範囲内ではないので、また、[5,13]を使いながら簡単に実行することができるので、ここでは、リーダーベクトルのインデキシングを中心に説明する。ベクトルvに対応するリーダーベクトルは、l = (15, 16, 20, 40)である。
コーディングとデコーディングのアルゴリズムは、以下の原則に基づく。
【0135】
コーディング ステップ:
1)初期設定
p=0.3、精度δ=0.1とする。リーダーベクトルのインデックスをI1=0とする。
2)次式のように、精度δを持つベクトルlのノルムlpを計算する。
【0136】
【数14】
3)これら演算を実行する。
最初にf(101)を決める。この場合、f(101)=2264である。次に、j=0に対して式(8)を使う。但し、iは41(即ち、40+1)から2264(即ち、min(+∞、2264)。次式が得られる。
【0137】
【数15】
【0138】
4) 先行するリーダーベクトルlの先行する数を計算する。但し、最大成分g4が40であるとする。このことは、3部分の総和を、次のように計算することを意味する。
【0139】
【数16】
【0140】
f(71) = 704, j = 1、 iは21から40 (即ち、 min(40, 704))まで変化する)として、式(8)を使うと、次式を得る。
【0141】
【数17】
【0142】
5)先行するベクトルlの数を計算する。但し、最大成分g4が40、g3が20であるとする。この場合、2部分において、和を次式で計算しなければならない。
【0143】
【数18】
【0144】
f(46) = 167, j = 2 、 iは、17 乃至 20 (即ち min(20, 167))まで変化するとして、式(8)を使うと、次式を得る。
【0145】
【数19】
【0146】
6)最後のステップにおいて、次の式を計算してI1をアップデートする。
I1 = 100774 + (min(f(x)), x2)− xl)
= 100774 + (min(f(23), 16)−15)
= 100774 + (min(17, 16) −15)
= 100775.
【0147】
従って、p = 0.3 、δ = 0.1のときのリーダーベクトルl = (15, 16, 20, 40)のインデックスは、 I1 = 100775である。付属資料におけるアルゴリズムlは、全てのコーディングプロセスをコンパイルしたものである。
【0148】
【化39】
2)f(101) = 2264を計算する。
3)x4をデコードする。この場合、j=0として式(12)を使って、次式を得る。
【0149】
【数20】
【0150】
【化40】
【0151】
【化41】
【0152】
【数21】
【0153】
【化42】
【0154】
【化43】
【0155】
【数22】
【0156】
【化44】
【0157】
【化45】
= min(f(23), 16) −(100775 −100774)
= min(17, 16) − (100775 − 100774)
= 15.
【0158】
従って、1 = (15, 16, 20, 40)が得られる。付属資料のアルゴリズム2はデコーディングプロセス全体をコンパイルしたものである。
【0159】
メモリコスト及び演算コスト
必要なメモリ容量
【化46】
【0160】
【化47】
【0161】
【化48】
【0162】
【化49】
したがって、コーディング/デコーディングのステップのためのメモリコストの上限は次式で与えられる:
【0163】
【数23】
【0164】
メモリ容量は、主として、エンベロープのノルムと次元に依存していることに留意すべきである。ベクトルの数がBの選択を決定する。
【0165】
【化50】
必要なメモリ容量は、p=1、δ=1,B=4(整数タイプのデータ)として、半径rに応じて、式(13)に基づいて表わされ、[5]で説明したように、ベクトルに基づく従来の方法のメモリの上限と比較される。1つの次元と1つの半径がそれぞれ16,20程度に小さい場合、従来の方法では、10ギガバイト以上のメモリは必要としていなかった。これに対し、本発明で提案する方法では、必要な容量は100キロバイト以下である。
【0166】
必要とするメモリ容量が非常に低いこと及び全てのベクトルを知る必要がないという事実があるので、64, 128, 256, 512のように大きい次元のラティスベクトルに対しても、インデキシングすることができる。従前の研究においては、実際のアプリケーションでは、次元が16に制限されていた。
【0167】
【化51】
【0168】
【化52】
式(8)とアルゴリズム(1)及び(2)(付属資料、参照)に基づくと、必要な操作は、加算/減算(A)及び比較論理演算(LC)であることが推測される。メモリアクセスは無視する。前記2タイプの演算よりも、かなりコストが低いからである。
【0169】
次に、本発明のインデキシング アルゴリズムのコーディング/デコーディング コストについて評価する。デコーディング アルゴリズム2は、コーディングアルゴリズムの逆であって、ほぼ同一の演算数となる。コーディング/デコーディングアルゴリズムの複雑性は、アルゴリズム1の演算回数を次のようにカウントすることにより評価される。
【0170】
1)(n−1)Aを実行した総和
2)“if/break”テストのために、最初の《for》(《j》 の上の)が、約nnz(1)回実行される。但し、nnz(1)は、1の非0の値の数を意味する。
3)最初の《for》の各ループに対して、次のものを有している。
i. 最初の《if》のために、IAおよび7LC 。
ii.関数《min》のために、1LC。
【化53】
4)最後の"if"と続く行を使って,2Aと2LCを計算する。
【0171】
したがって、加算、論理演算、比較に関する、コーディング/デコーディングのアルゴリズムの総コストは、次の式により与えられる。
【0172】
【数24】
【0173】
【化54】
【0174】
本発明によれば、ラティスベクトルのインデキシングは、対応するレーダーベクトルのインデキシング、置換及び符号変化になる。本発明は、如何なる変換テーブルを必要とすることなくベクトルをインデキシングし、メモリの使用及び全ベクトルの生成の複雑さを低減する方法を提案する。
また、この解決法は、形状パラメータ0< p≦ 2を持つ一般化ガウス分布ソースに対して役立つ。本発明の方法は、分析的で、本方法を使うと、高次ベクトル次元の使用を可能にする。
【0175】
【表3】
【0176】
【表4】
【技術分野】
【0001】
本発明は、デジタルデータの圧縮、検索、比較又は解凍などのアプリケーションのためのデジタルデータ処理の技術分野に関する。本発明は、オーディオビジュアルデータの処理、より一般的には、全てのタイプのデジタルデータの処理に関する。本発明の目的は、処理時間を削減し、コンピューティングパワー、メモリの容量に関する情報処理リソースの必要性を削減することである。
【背景技術】
【0002】
アプリケーションは、全てではないが、表示に大量のデータを必要とする画像処理に関係する。記憶に必要なサイズと伝送時間を削減するためには、ビデオ情報を抽出処理し、コード化して、情報圧縮を行う。このコード化された情報は、コード化のパフォーマンスに有害なリダンダンシーを避け、周波数と空間に関して、最適な再構成可能な状態にする必要がある。そのために、ウェーブレット変換技術が知られている。その座標は、ベクトルラティスを構成するもので、ベクトル量子化が行われる。
【0003】
ベクトル量子化(VQ)の原理は、各サンプルを個別にコード化する代わりに、ベクトルを形成するサンプルのシーケンスをコード化することである。コード化は、ベクトルによりシーケンスを近似することによって行われる。通常"コードブック"と呼ばれるカタログに属するベクトルを使ってコード化する。コードブックの各ベクトルには、インデックスが付けられる。コード化する時に、それを表わすために使用するのは、コード化するサンプルシーケンスに最も近いベクトルのインデックスである。
【0004】
公知の解決法では、各ベクトルを決定すること、それをメモリに記憶させること、更に、ベクトル全体に対し処理することが、必要である。ベクトルの基底(base)は、数ギガバイトを必要とする可能性がある。同様に大きい基底の計算には長時間が必要である。本発明の目的は、これらの欠点を回避する、カウント方法とインデキシング方法を提供することである。
【0005】
技術水準
量子化方法は、論文[1]により公知である。
【0006】
ラティス(reseau:lattice)は、数学的に、加法群(additif)を形成するn次元空間のベクトルの集合である。論文[2]は該ラティスについて説明している。
【0007】
従来技術として、国際特許出願WO9933185が公知である。このコード化方法は、予め決められた順序で、量子化ベクトルと同一の成分を有するベクトル(リーダー(代表)ベクトル:vecteur leader)を決定するステップと、前記リーダーベクトルと同一成分を持ち、前記グループにおいて予め決められた順序で並べられているベクトルにより形成された前記グループにおける量子化されたベクトルのオーダー(ordre)又はランク(rang)のレベルを決定するステップからなる。前記方法は、一方では前記決められたリーダーベクトルを表わすインデックスから、他方、前記ランクを表わすインデックスから一つのコードを形成する。
【0008】
圧縮のためのベクトル量子化の設計における重大な問題は、規則的点ラティス(le reseau regulier de points)(量子化辞書を形成する)におけるベクトルのカウントとインデキシングの問題である。本発明は、このために、一般ガウス分布のソース(source:例えば、ウェーブレット係数など)のケースで、これら問題を解決するための解決法を提供する。
【0009】
代数的ベクトル量子化(La quantification vectorielle algebrique):
量子化については、数十年に亘って研究されてきた。これら研究は、今日、レート歪理論に関して、多くの成果をもたらしている。特に、ベクトル量子化(QV)は、固定長のコード化が要求される場合には、スカラ量子化(QS)に比べて多くの利点を持っていることが証明された。また、シャノンは、n次元ベクトル量子化が十分に大きい場合は、QVのパフォーマンスは最適な理論的パフォーマンスに近いことを証明した。
【0010】
しかし、高度に複雑な計算を犠牲にして、QVを、最適なパフォーマンスに近づけようとすることに注意しなければならない;この複雑さは、ベクトルの次元と共に、指数関数的に増加する。通常、QVは、ソース(学習シーケンス)を表わす統計データから構成される非構造化辞書(dictionnaire non structure)を使って実行される。この場合において、複雑さと辞書のサイズによる記憶容量は、圧縮アプリケーションに対して阻害的要因となる。
【0011】
また、辞書のロバスト性(robustesse)の問題がある。辞書は、与えられたトレーニングシーケンス用に最適化されているので、トレーニングシーケンス以外の画像に対し、パフォーマンスが低い。これら問題を克服するための解決法は、代数的ベクトル量子化(QVA)、又は、点の規則的ラティス(reseaux reguliers)に対しベクトル量子化等の構造化されたn次元のQVを使用することである。
【0012】
辞書のベクトルは構造化された規則的ラティスに属するようになっているので、QVAのパフォーマンスは一般的に非構造化QAのパフォーマンスより低い。
【0013】
しかし、ほとんどのアプリケーションでは、この小さな欠点は、QVAに対しては、辞書を作成される、又は、記憶される必要はないということ、及び、コード化の複雑さが軽減されるということによって埋め合わされる。
【0014】
規則的点ラティスによる量子化は、一様なスカラ量子化の一般化と見なすことができる。非構造化QVの場合のように、本書では、用語QVAは、ベクトル量子化を意味するように、又は、ベクトル量子化器(quantificateur vectoriel)を意味するように、使用される。 QVAは、分割ゲイン及び形状と、ベクトルの係数の間で、空間依存性を考慮に入れる。ソース分布がどのようなものであろうと、QVAはQSより常に効率が良い。
【0015】
空間Rnの内の規則的ラティスは、基本的なラティスである線形独立ベクトルの集合の全ての組み合わせによって構成されている。これは、ラティスの基底(base)を形成する。{y│y = u1a1 + u2a2 + … unan}。但し、係数uiは整数である。空間の分割は、規則的であって、選択された基底ベクトルのみに依存する。各基底は、異なる点の規則的なラティスを定義する。
【0016】
QVAを使うと、一般化Lloydアルゴリズムに基づくアルゴリズムを使って設計された、1つのQVに関する計算コストと記憶に関するコストを大幅に削減できる可能性がある。確かに、量子化ベクトルのような規則的ラティスベクトルを使用すると、辞書の構築操作を削減できる:辞書は、選択したラティス構造により暗黙的に構築される。
【0017】
論文[1]には、n次元ベクトルのみに依存する丸め込み操作(operations d'arrondis)を単純に使う高速なアルゴリズムについて説明されている。 1979年、Gershoは、(高フローに対し)1つのレート歪み性能(performances debit-distorsion)は、ほぼ最適である、と予想した。
【0018】
しかしながら、QVAは数学的に低フローに対し最適化されていない。しかし、このような量子化要素(quantificateurs)によりもたらされる複雑さを低減させることにより、大きい次元のベクトルを使用することができ、与えられたフローの実験のパフォーマンスを向上させる。エントロピーコーダ(un codeur entropique)とQVAとを組み合わせて、レート歪みについての良好な性能を得ることができる。これにより、ウェーブレット分野における、QVAの研究に対するモーティベーションが高まった。QAに対する多くの研究がガウシアン、ラプラシアンソース(sources Gaussienne et Laplacienne)に対して行われた。更に、1より小さい減衰パラメータをもつ一般ガウシアンタイプのソースの場合は、レート歪に関して、キュービック ラティスZnは、ラティスE8、Leechラティスと比べると性能が良いことが証明された。この結果は、ウェーブレット変換とQVAとを組合せる我々の研究に刺激を与えた。
【先行技術文献】
【特許文献】
【0019】
【特許文献1】国際特許出願WO9933185
【発明の概要】
【発明が解決しようとする課題】
【0020】
QVAによる量子化が複雑である場合には、辞書の規則的幾何学的構造のために、その実装はすぐには行われない。漸近モデルの場合、過負荷ノイズは無視される。可変長符号化と無限大の辞書の使用を想定しているからである。これは、計算と記憶の観点から、具体的な複数の問題を提起する。特に、計算と記憶に関してである。これら二つの基本的な問題は、QVAの設計において、重要である。
【0021】
a)インデキシング
インデキシングは、各量子化ベクトルに対して、インデックスを、割り当てることであり、量子化とは別の操作である。一旦コード化されると、インデックスは、デコーダーまでチャネルを介して送信される。この操作は圧縮チェーンにおいて基本的である。それは、ビットレートを決定し、曖昧さのないベクトル復号化を可能にする。公知の方法によると、一般的にメモリについては極めて安価になるが、計算については、かなり複雑になる(再帰的アルゴリズム)。又は、特別な場合(ラティスタイプ又は特別のトランケーション)にだけ動作するものである。本発明は、一般化ガウス形分布に対しインデキシングすることを可能にし、一般的なアプローチに関するもので、メモリコスト/計算コストの妥協を実現する。
【0022】
b)カウント
インデックス法は、通常、ラティス数の増大に基づいている。したがって、ソースの分布に依存する、n次元面(又はボリューム内)のラティスベクトルをカウントできなければならない。カウントについての従来のアプローチは、生成された級数の使用に基づいている。この手順で、関数Nuが導入された。それらを使うと、ピラミッド上で(即ち、ラプラス分布の場合)カウントすることが可能になる。
本発明は、一般化ガウス分布上のカウントを可能にする一般的なアプローチを提案し、メモリコスト/演算コストの両立性を実現した。第2の特許では、この問題を解決する。
【0023】
本発明の目的
本発明の目的は、メモリ容量と時間が削減された情報処理リソースを使って実行可能なベクトル量子化ステップを含む処理方法を提案することである。
【課題を解決するための手段】
【0024】
この目的で、本発明は、少なくともベクトル(複数)の一部分1に対し、d次元空間において、少なくとも一つのリーダーベクトルインデックスI1を計算するための量子化ステップを有するデジタルデータ処理方法に関する。
前記ベクトル(複数)1は、入力データの記述子(descripteurs)を構成する。また、前記方法は、リーダーベクトル全体の決定するステップをもつことなく、前記リーダーベクトルのインデックスI1が、逆辞書順序で、前記リーダーベクトル1に先行するベクトルの数に対応することを特徴とする。
【0025】
前記処理方法は、計算において、リーダーベクトル以外の、どのようなリーダーベクトルを決定するステップを含まないことが好ましい。
【0026】
【化1】
【0027】
【化2】
【0028】
【化3】
【0029】
別の変形例では、リーダーベクトルインデックスI1を算出するステップは、“前記リーダーベクトル1(x1, x2, ...xd)のノルムrの算出ステップ(但し、x1 乃至 xdは、増加する順序に並べられている)”及び“dと1の間の変数iを持つ座標xi上で再帰的カウントステップ”を含んでいる。前記カウントステップは、座標xiがi+1とMIN(xi+1,r-xi+1)との間に含まれているベクトルをカウントするもので、インデックスIlは、カウントステップの結果の和に等しく、インデックスI1は、カウントステップの結果の和に等しい。
【0030】
別の変形例では、リーダーベクトルインデックスI1を算出するステップは、“前記リーダーベクトル1(x1, x2, ...xd)のノルムrの算出ステップ(但し、x1 乃至 xdは、減少する順序に並べられている)”及び“1とdの間の変数iを持つ座標xi上で再帰的カウントステップ”を含んでいる。前記カウントステップは、ベクトルをカウントするもので、その座標xiはxi+1とMIN(xi-1, r-xi-1)との間に含まれている。インデックスIlは、カウントステップの結果の和に等しい。
【0031】
本発明は、インデックスI1のバイナリコード化の結果、少なくとも一つの符合インデックスIs、ノルムインデックスIn及び置換(permutation)インデックスIpを記憶する、ベクトルデータの圧縮のための、前記方法のアプリケーションに関する。前記ベクトルデータは次のようなものである。
【0032】
−デジタル画像、
−デジタルビデオシーケンス、
−デジタルオーディオデータ、
−デジタル3次元オブジェクト、
−デジタルアニメ3次元オブジェクト、
−データベースにおいて登録された情報、
−前記ベクトルデータの変換に由来する複数係数(例:DCT係数、ウェーブレット係数)。
【0033】
また、本発明は、参照情報として、インデックスIl,ref 、少なくとも一つの符号インデックスIs,ref、ノルムインデックスIn,ref及び巡回インデックスIp,refを算出し、同一インデックスをもつデータをサーチするためのベクトルデータベースにおいて、サーチするための、前記方法のアプリケーションに関する。
【0034】
前記ベクトルデータは次のようなものである:
−デジタル画像、
−デジタルビデオシーケンス、
−デジタルオーディオデータ、
−デジタル3次元オブジェクト、
−デジタルアニメ3次元オブジェクト、
−テキストデータベースのオブジェクト、
−データベースにおいて登録された情報、
−前記ベクトルデータの変換に由来する複数係数(例:DCT係数、ウェーブレット係数)。
【0035】
本発明は、また、前記方法に基づいて算出されたリーダーベクトルインデックスI1から、デジタルデータを再構成する方法に関する。この方法は、1つのリーダーベクトルの座標(xl, x2, ..., xd)を算出することを特徴としている。また、全リーダーベクトルを決定するステップなしに、逆辞書順序で、前記リーダーベクトル1に先行するベクトルの数に対応するインデックスI1を持つリーダーベクトル1をサーチする処理に、一つのインデックスI1を付加することを特徴としている。
【0036】
【化4】
この加算は、和が前記インデックスI1より大きくなるまで行われる。前記サーチされた座標xiは、前記インデックスI1を超過するものであり、前記方法では、座標Xi-1に対して、値I1から加算が継続される。但し、I1は、前記インデックスを超過する前の、値I1に先行する値である。
【0037】
【化5】
また、前記関数F(A)を適用して、カウントステップの結果の加算が行われる。この加算は、和が前記インデックスI1より大きくなるまで行われる。前記サーチされた座標xiは、前記インデックスI1を超過するものであり、前記方法では、座標Xi+1に対して、値I1から加算が継続される。但し、I1は、前記インデックスを超過する前の、値I1に先行する値である。
【0038】
【化6】
再構成するためには、昇順にソートする場合、座標xdに対して、及び、降順にソートする場合、座標xlに対して、I1' = 0とする。
【図面の簡単な説明】
【0039】
本発明は、図面を参照し、非制限的な実施例を読むことにより、よりよく理解されるであろう。
【図1】本発明に基づくデータ処理システムの基本を示す図である。
【図2】
【化7】
【図3】p = 1, δ = 1, B = 4の場合における、通常の方法と提案する方法の間のメモリ容量を比較する図である。−アネックス1は本発明を実施するためのコーディング、デコーディング アルゴリズムの1例である。
【発明を実施するための形態】
【0040】
データ処理システムは、通常、3つのメインモジュールを備えている。最初のモジュール(1)は、画像に対応するデジタル信号等の入力データを受信し、このサンプリングされた信号に基づいて、公知の方法で、ウェーブレット変換を行う。
【0041】
本発明の方法により、量子化モジュール(2)は、ウェーブレット係数のベクトル量子化/インデックス化方法を使って、ウェーブレット係数をコード化する。
【0042】
3番目のモジュールは、公知のロスなしの圧縮方法で、記憶又は送信する情報のサイズを削減するためにコード化を行う。
【0043】
量子化ステップとインデキシング ステップは、第2番目のモジュール(2)によって実行される。このステップが、本発明の対象である。このステップは、以前の技術において、多くのリソースを必要とした。それは、全リーダーべクトルを決定すること、メモリにそれらを一時的に記憶することを含んでいる。
【0044】
ラティス上でベクトル量子化する方法は公知である。また、それは、一般的にオーディオ、ビデオ、マルチメディアの圧縮システムで使用されている。ラティス上のベクトル量子化は、一様(uniforme)スカラ量子化を多次元拡張したものである。後者は、例えば、一つの画像の各ピクセルを表す、1つの信号を、個別に、2Nレベルに量子化するものである。但し、Nは、量子化器に割り当てられているビット数である。ラティス上のベクトル量子化については、規則的ラティスに関連しており、それにより、問題となるラティスの属する量子化ベクトルが1つ決まる。そのコンポーネントは、コード化信号が取る値を表す。
【0045】
具体的にいえば、量子化操作は、“各コンポーネントが1つのコード化信号により取られる値を表し、非可算の集合(実数の集合Rのような)に属する、1つのオリジナルベクトルの基づいて”、各コンポーネントが相対的数(nombres relatives:整数)の集合Zのような可算集合に属する、1つの量子化ベクトルxを決定することである。
【0046】
ラティスベクトルのインデキシングは、ラティスの量子化アプリケーションにおける重要な問題である。本発明は、ラティス リーダーベクトルとパーティション理論を使って、この問題に対するソリューションを与えるものである。一般化ガウス分布のソースに対して、それを使うことができ、それを使うと、プロダクトコードを使うことができる。また、それを使うと、高次元のベクトルのインデキシングが可能になる。
【0047】
ベクトルの次元がかなり高い場合は、ベクトル量子化(QV)を使うと、最適理論のパフォーマスを得ることができる。しかし、残念なことではあるが、LBG等の、最適に構造化(non structuree optimale)されていないQV計算の複雑さは、次元が高くなるにつれ、指数関数的に高まる。加えて、記憶容量が極めて重要になる。次元に関する問題を解決するためには、ラティスベクトル量子化(LVQ)のような拘束型QV(QV contrainte)を使用すればよい。
【0048】
LVQアプローチによると、コードベクトルが空間に規則的に分布している一つの構造化辞書を設計することになる。その結果、空間におけるベクトルの位置を最適化する代わりに、ラティスベクトルをインデキシングして、分布の形状に応じてソースを適合させることができる。大半の実データのソースに対して、プロダクトコードを使って、これを効率的に実行することができ、対称的ユニモーダルソース分布(des distributions de sources unimodales symetriques)に対して、レート-歪を最適な値に導くことができる。
【0049】
ソースの分布に応じて、これらの分布を、同一形状を持つ同心超曲面(hypersurface concentrique)の集合として解釈することができる。それぞれの面のノルム(半径)に対応する第1インデックス(prefixe)を割り当て、同一面に属するベクトルのカウントに対応する第2単一インデックス(suffixe)を割り当て、ラティスコードワードにインデックスを付与することができる。
【0050】
大量のデータソース(例えば、特に、ウェーブレット変換によって得られた、画像の係数と音声サブバンド等)は、一般化ガウス分布によってモデル化することができる。この分布のファミリーは、一変数(univariee)確率変数に対して、1つのシェープファクタp(GG(p))によってパラメータ化される。分布(GG(p))を持つソースの興味深い性質は、ノルム1pのエンベロープが一定確率面に対応していることである。
これは、効率的なプロダクトコードの開発につながる。
【0051】
prefixeの計算が簡単である場合でも、suffixeは、超曲面(hypersurface)上のラティスベクトルのカウント及びインデキシングが必要である。また、空間の次元が増大すると、インデキシング操作が非常に複雑になる。その理由は、次の表に示されるように、1つのエンベロープ上に存在するベクトルの数が、ノルムと共に大きく増加するからである。表は、一つのラティスZnと複数の次元とノルム値に関して、“1つのノルム11の場合における、1つの与えられた超曲面のベクトルの数”と、“このハイパーピラミッド(基数:cardinality)の上にあるラティスベクトルの全数”との比較を表している。
【0052】
【表1】
【0053】
この文献によると、suffixeのインデキシングは、通常、2つの異なるやり方で行われている。
【0054】
最初のアプローチは、超曲面上にあるベクトルの全数(cardinalite:基数)を考慮して、1つのインデックスを割り当てることである。第2のアプローチは、リーダーベクトルの概念を使って、ラティスの対称性を利用することである。ノルムlpのエンベロープの(複数)リーダーは、ラティスの(複数)ベクトルに対応している。そのベクトルを基にして、前記の対応するエンベロープに存在する他の全てのラティスベクトルは、それら座標の置換(permutation)、符号変化により、得ることができる。これら2つのアプローチは、isotropicソースに対し、同様のレート−歪パフォーマスを示す。
【0055】
しかしながら、ラティスのインデキシングについての多くの研究は、ラプラス分布又はガウス分布に対する解法を提案している。これら分布は、それぞれ、形状パラメータp=1、p=2を持つGG(p)の特別なケースである。p=0.5という特別なケースに対する解法を提案する研究者もいる。しかし、このカウント方法では、プロダクトコードを構成することはできず、実際には、インデキシングの方法も極めて複雑である。特に、高次元、大きいノルムをもつp≠0.5、1又は2の場合は複雑である。
【0056】
本発明は、0<p≦2を持つエンベロープGG(p)の上にあるラティスベクトルZnに対する新規な代替案を提案する。提案する解決法は、ベクトルに基礎を置いて、分割理論を使う。
【0057】
分割理論(la theorie des partitions)を使うと、前記複雑性、必要な記憶容量の問題を解決でき、リーダーベクトルを生成し、ベクトルにインデックスを付与することができる。本発明は、変換テーブルを使うことなく、suffixeインデックスを、素早く割り当てることができる、経済的なインデキシングアルゴリズムを提案する。
【0058】
以下の説明において、最初の章では、LVQの原則を説明してから、インデキシング問題について説明する。次の章では、形状パラメータpがどのようなものであろうとも、インデキシングの例を以って、極めて大きいコードブックLVQにインデックスを付与するための効率的なやり方を提案する。続いて、提案されたアプローチの、メモリ、演算のコストについて説明する。更に、実効的な実データ インデキシングに対するパフォーマンス値について説明する。
【0059】
ラティスベクトルのインデキシング
ラティスの定義
RnにおけるラティスΛは、線形独立ベクトルai(ラティスの基底)の集合の全部の組合せで、次のように構成される。
Λ = {x│x = u1a1 + u2a2 + … unan} (1)
【0060】
【化8】
【0061】
1つのラティスの各ベクトルvは、一定ノルムlpを持つベクトルを含む表面又は超平面に属していると見なすことができ、次式で与えられる。:
【0062】
【数1】
【0063】
プロダクトコード(code produit)を使って、指定したラティスのベクトルをコード化することができる。ソースベクトルの分布がラプラシアン分布であるならば、適切なプロダクトコードは、“1つのベクトルのノルム11に対応するprefixe”及び“問題とするノルム11に等しい1つの半径を持つハイパーピラミッド上の位置に対応するsuffixe”から構成されていることは、明らかである。 一定のノルムl1の超曲面は、ハイパーピラミッドと呼ばれる。
1つの超曲面の上のベクトルの位置は、カウントアルゴリズム(algorithme de denombrement)を使って取得することができる。このようなプロダクトコードは、デコーディングの一意性(unicite)を保証する。
【0064】
形状パラメータが1に等しい又は1より小さい、一般化ガウス分布を持つソースの場合、D4、E8上の立方体的ラティスZn又はLeechラティスの優位性が証明されている[12]。従って、本書の残りの部分では、立方体的ラティスZnに基づく1つのLVQの設計を中心に説明する。
【0065】
全カウント数に基づくインデキシング
ガウス分布又はラプラシアン分布について、及び、全カウントの原理に基づく種々のラティスについて、複数のカウント方法が、これまで提案されてきた。特に、ソースがラプラシアン分布の場合、ラティスZnに関して、ノルム11のハイパーピラミッド上にあるラティスのベクトルの全数を計算するための再帰的公式(formule recursive)が知られている。
カウントのこの公式は、0と2の間の形状ファクタpを使って、ソースの一般化ガウス分布に拡張されている。これら解法を使うと、tranctureノルム1pの内部に存在するベクトルの数を計算することができる。
しかしながら、これら解法は、インデックスをラティスZnに割り当てるアルゴリズムを提示するものではない。
また、この解法は、超曲面上にあるベクトルの数を決定するものではない。このため、プロダクトコードを使用することは困難である。
【0066】
従来の研究の中で提案されているアルゴリズムは、0<p≦2に対するプロダクト コードスキームに基づいて、ベクトル(複数)にインデックスを付与するものである。それは、一般化シータ級数(series theta)に基づいて[4]、ラティス幾何学を使うものである。p=1または2については、この級数の展開は比較的に単純である。これに対し、pがそれ以外の値である場合、この級数は極めて複雑になる。クローズドフォーム(forme fermee)が生成されず、公式(mathematiques formelles)を使用することができないからである。提案された解法によれば、種々の次元及び高次元について、可能なノルム値を決定する必要があるが、一般的には、これを所定時間内に実行することはできない。
【0067】
また、実施する際に、特に、高次元に対して(前記表を参照)、超曲面の基数(cardinalite)は、急速にnon-tractableな値(扱いにくい値)に達するので、エンベロープの基数に基づくインデキシング技術は、急速にコンピュータの計算精度(precision informatique)を越えてしまう。
【0068】
ベクトル(リーダー)に基づくインデキシング
リーダーに基づく方法は、ラティスの対称性を利用する。その方法は、一定ノルムのエンベロープに対する効率的なインデキシング アルゴリズムを使う。ラティスベクトルの全数に基づいてインデックスを割り当てるのではなく、リーダーと呼ばれる、少ない数のベクトルに基づいて割り当てるものである。
【0069】
ラティスの対称性は、様々であるので、個別に処理される。対称性がない場合には、これは、全カウント法と比べると、より効率的なソースのインデキシング方法である。
また、コード化アルゴリズムにより管理されるインデックスは、エンベロープの基数よりもっと小さい。これを使うと、全カウントに基づく方法ではインデックスを付与できないベクトルに対して、バイナリ精度(precision binaire)で、インデックスを付与することができる。
【0070】
プロダクトコードのアーキテクチャでは、ラティスの対称性を別にして、suffixeインデックスは、リーダーの数が少ないインデックスを含んでいる。前記suffixeインデックスに基づいて、超曲面の全ての他のベクトルを割り当てることができる。ラティスZnに関して、対称性は、2つの基本的な操作に対応している:即ち、ベクトル座標の“符号変化(changements de signe)”と“置換(permutation)”である。
第1の操作は、ベクトルが存在する一つの象限の変化に対応している。例えば、2次元のベクトル(7,−3)が第4象限にあるとする。これに対し、ベクトル(−7、−3)は第3象限にある。これらベクトルはy軸に対して対称である。
第2の操作は、象限内の対称性に対応する。例えば、ベクトル(−7、3)と(−3,7)は、2つ共に第2象限にあり、同象限の2等分線に対して、対称である。
この場合、“これらベクトルは、これらベクトルのリーダーであるベクトル(3,7)の置換及び符号変化から生成されること”が分かる。ベクトル(3,7)は、これらベクトルのリーダーベクトルである。全ての置換と符号変化を使って、リーダー(3,7)は8つのベクトルを代表することができる。
この比は、超曲面の次元と共に急速に大きくなる(表1参照)。
【0071】
従って、このインデキシング方法は、超曲面上の全ベクトルに直接インデックスを付与する代わりに、各ベクトルに対し、3つのインデックスのセットを割り当てる:即ち、1つは、リーダーに対応するものであり、他の2つは、リーダーの置換および符号変化に対応するものである。置換と符号のインデックスの計算方法の詳細については、[5]を参照のこと。
【0072】
提案するインデキシング方法
ノルム11の場合に提案するリーダーのインデックス付与方法。
原理
本発明は、逆辞書順序で、全てのベクトルを分類する分類に基づく解決方法を提案する。また、インデックスを付与しなければならないリーダーに先行するベクトルの数に応じて、インデックスを割り当てる。この場合、インデキシングは、もはやリソースを大量消費する1つのサーチアルゴリズム、又は、直接アドレッシングによるものではなく、むしろ、低コストのカウントアルゴリズムによるものである。これは、それらに関する明らかな知識に依存するものではなく、むしろ、リーダーの量に依存するもので、このようにすれば、変換表を作成しなくてもよくなる。
【0073】
半径rのハイパーピラミッドは、全てのベクトルv = (v1, v2, …, vd)から構成されている。但し、||v||1=rである。上述したように、リーダーは、超曲面の基本ベクトルである。置換と符号変化操作によって、そこから、同超曲面上にある他のベクトルを導き出す。確かに、リーダーは、(または降順)昇順でソートされる正の座標を持つベクトルである。したがって、ノルムr、次元dのベクトルは、次の条件を満足するベクトルである。:
【数2】
【0074】
分割理論との関係
ノルムl1の場合、セクション3.1.1で説明した条件は数論の分割理論(theorie des partitions)に関連していることに注意しなければならない。確かに、数論では、正の整数rの分割は、正の整数の和(partとも呼ばれる)としてrを記述する方法である。rの別の分割数は、次の分割関数P(r)で与えられる:
【数3】
【0075】
これは、級数q[10、16、17]と呼ばれるオイラー関数の逆数(reciproque)に相当する。数学の進歩は、関数P(r)の表現法を導き、計算の迅速化を可能にしている。
【0076】
たとえば、r=5に関して、上記式(2)によって,P(5)=7となる。確かに、数5の可能な全分割は、(5)、(1,4)、(2、3)、(1、1、3)、(1、2、2)、(1、1、1、1、1)である。5次元ベクトルとして、これらの分割を書き換えると、(0、0、0、0、5)、(0、0、0、1、4)、(0、0、0、2、3)、( 0、0、1、1、3)、(0、0、1、2、2)、(0、1、1、1、2)と(1、1、1、1、1)となる。これらが、まさに、ノルムr=5とd=5のハイパーピラミッドのリーダーと対応していることが分かる。つまり、セクション3.1.1の2つの要件を満たすノルムr=5とd=5のハイパーピラミッドにおける唯一のベクトル(複数)である。
【0077】
しかし、d次元のラティスにおいて、rに等しいノルム11のエンベロープは重要である。但し、r≠dとする。この場合、関数q(r、d)[10、18]を使うことができる。この関数は、d以下の部分(parts)を持つrの分割数を計算するものである(分割理論において、これは、部分の数は問わないが、dより大きい要素を持たない、rの分割数を計算することと同じことである)。
したがって、ノルムr=5と次元d=3のハイパーピラミッドに対して、q(5,3)=5である。即ち、5つのリーダーは次のとおりである。:(0、0、5) (0、1、4)、(0、2、3)、(1、1、3)、(1、2、2)。
【0078】
関数q(r、d)は、次の漸化式から計算することができる。
q(r,d) = q(r, d−1) + q(r−d, d) (3)
但し、q(r、d)=P(r)で、d≧r、q(1、d)=1、及び、q(r、0)=0。
【0079】
3.1.3 関数q(r、d)を使用して、リーダーにインデックスを付与する
以下に説明するように、式(3)が与えられたハイパーピラミッドの上のリーダーの全数を与えるのみならず、同式は、変換テーブルを使うことなく、リーダーに対し唯一の一群のインデックスを割り当てるのに使うことができる。
インデックス アルゴリズムの原理を説明するために、次のようにハイパーピラミッドのリーダーが、次のように逆辞書式順序で分類されていると仮定する。
【0080】
【表2】
【0081】
したがって、リーダー1のインデックスは、これに先行するリーダーの数に対応している。上記例では、リーダー(0、...、1、1、rn−2)にはインデックス3が割り当てられる。
【0082】
第1命題(proposition)では、リーダーのインデキシング アルゴリズムが記述されている。
【0083】
第1命題
v=(v1、v2、…、vn)は、一定ノルムl1の1つのエンベロープ上の1つのリーダーベクトルl=(x1、x2、…、xn)を持つラティスベクトルZnであるとする。リーダーのインデックスI1は次式で与えられる。:
【0084】
【数4】
【0085】
【化9】
【0086】
証明。
【化10】
逆辞書式順序でリーダーをソートしているから、1より前の第1リーダー群は、n番目の成分が、xnより大きい全リーダー(即ち、xn+1≦gn≦rnを満たす最大座標gnを持つ全リーダー)から構成されている。
【0087】
それら全てをリスト化せずに、第1グループのリーダーの数をカウントするために、分割関数q(r、d)が使われる。なぜなら、n番目の座標がgnに等しいリーダーの数は、次の注(remarque)を使って簡単に計算することができるからである。
【0088】
注(Remarque):
ノルムrn、次元nのリーダー(その最大座標がgnに等しい)の数の計算は、数rn-gn(但し、gnより大きい部分がなく、n−1部分より小さい)の分割数を、計算することに等しい。
【0089】
ほとんどの場合、q(rn-gn,n-1)を適用して、分割数をカウントすることができる。しかし、このアプローチは、rn-gn<gnの場合しか正しくない。この場合、rn-gnの全ての分割はgnより大きい部分を持っていないと暗黙に仮定されている。しかしながら、一般的な場合、rn-gn<gnは保証されない場合(例えば、ノルムrn=20、次元n=5、最大部分が7のベクトルの数は、q(20-7、5-1)=q(13、4)を導く場合(但し20−7≪7ではない))、q(rn-gn, n-1)の計算は、真(valide)のベクトルの数について誤った値を算出する。rn-gn の複数の分割がgnより大きい部分を持つこともあるからである(この場合セクション3.1.1の条件2が満たされていない)。
【0090】
【化11】
【0091】
【化12】
よって、n+1からrnに至るgnの変化を使うと、最大座標がxnより大きいリーダー数を、次式から決定することができる。
【0092】
【数5】
【0093】
【化13】
【0094】
先行するリーダーベクトルlの第2グループは、第n番の座標がxnに等しい全ベクトルからなる。但し、第n−1番の座標はxn−1より大きいとする。リーダーベクトルのこの数をカウントするために、上記の注(remarque)を使うが、今回は、次元n−1に応用する。
【化14】
関数minは、ノルムrnとオーダーgn−1≦gn=xnが満足されることを保証する。
【0095】
結果を追加次元(dimensions additionnelles)に拡張することにより、最大座標がxnに等しいベクトルであって、1に先行するベクトルの数は、次式で与えられる。
【0096】
【数6】
【0097】
式(5)、(6)を組合せて、一般式を導き、1より前に位置するリーダーベクトルの全数を計算し、従って、1のインデックスIIを計算することができる(式(4))。
【0098】
【数7】
【0099】
但し、j=0に対し、xn+1=+∞
【0100】
【化15】
【0101】
【化16】
【0102】
【化17】
【0103】
一つのベクトルのノルムlpは、精度δを持つことが知られており、次式で得られる。
【0104】
【数8】
【0105】
【化18】
【0106】
【化19】
【0107】
【化20】
【0108】
第2命題:
ベクトルν = (v1, v2, …, vn)を、一定ノルムlpの一つのエンベロープの上にある1つのリーダーベクトル1 = (x1, x2, …, xn)を持つ1つのラティスベクトルZnであるとする。リーダーベクトルI1のインデックスは次式により与えられる。
【0109】
【数9】
【0110】
【化21】
【0111】
証明:
【化22】
【0112】
【化23】
【0113】
【化24】
【0114】
【化25】
【0115】
【化26】
【0116】
【数10】
【0117】
【化27】
【0118】
式(9)において、jを0からn−2に亘って変化させると、xnからx2までの座標に対する先行するリーダーベクトル1の数を正確にカウントすることができる。
【化28】
【0119】
【数11】
【0120】
【化29】
【0121】
【化30】
【0122】
【化31】
【0123】
【化32】
【0124】
【化33】
セクション3.1で導入した原則を使うと、これは、次のように分割Npの数を計算することと同じである:
【0125】
【数12】
【0126】
そして、i(Np > I1)の最初の値をxnに割り当てる。次のステップで、xn-1をデコードする。
【0127】
【化34】
次に、Xn-1をデコードするために、式(11)のメカニズムに類似したメカニズムを使ってNpをカウントする。しかし、今回は、(n−1)番目の座標に関係して行う。
【0128】
この場合、Np > I1であるから、最初に、分割カウンタNpの値を最初のリーダーベクトル(xnに等しい第n成分を持つ)に戻して、パラメータNpを先行する値にしなければならない。以後、これをNpbckpと呼ぶことにする(“先行する値”とは、Np < I1で、Npの中で一番大きい値に対応する。即ち、iの最後の値が和に含まれる前のNpの値である)。
【化35】
【0129】
このプロセスは、次元について、次式で一般化される。
【0130】
【数13】
【0131】
【化36】
【0132】
【化37】
ただし、前記2つともに、厳密に同一の計算結果であることが前提である。
【0133】
【化38】
次のセクションでは、リーダーベクトルのコーディング、デコーディングの例を説明する。
【0134】
コーディングとデコーディングの例
v = (-20, 16, 15, -40) を、インデキシングしなければならない形状ファクターp=0.3の、一般化ガウス分布を持つ一つのソースの量子化された1つのラティスベクトルとする。置換と符号のインデックスの計算は、この研究の範囲内ではないので、また、[5,13]を使いながら簡単に実行することができるので、ここでは、リーダーベクトルのインデキシングを中心に説明する。ベクトルvに対応するリーダーベクトルは、l = (15, 16, 20, 40)である。
コーディングとデコーディングのアルゴリズムは、以下の原則に基づく。
【0135】
コーディング ステップ:
1)初期設定
p=0.3、精度δ=0.1とする。リーダーベクトルのインデックスをI1=0とする。
2)次式のように、精度δを持つベクトルlのノルムlpを計算する。
【0136】
【数14】
3)これら演算を実行する。
最初にf(101)を決める。この場合、f(101)=2264である。次に、j=0に対して式(8)を使う。但し、iは41(即ち、40+1)から2264(即ち、min(+∞、2264)。次式が得られる。
【0137】
【数15】
【0138】
4) 先行するリーダーベクトルlの先行する数を計算する。但し、最大成分g4が40であるとする。このことは、3部分の総和を、次のように計算することを意味する。
【0139】
【数16】
【0140】
f(71) = 704, j = 1、 iは21から40 (即ち、 min(40, 704))まで変化する)として、式(8)を使うと、次式を得る。
【0141】
【数17】
【0142】
5)先行するベクトルlの数を計算する。但し、最大成分g4が40、g3が20であるとする。この場合、2部分において、和を次式で計算しなければならない。
【0143】
【数18】
【0144】
f(46) = 167, j = 2 、 iは、17 乃至 20 (即ち min(20, 167))まで変化するとして、式(8)を使うと、次式を得る。
【0145】
【数19】
【0146】
6)最後のステップにおいて、次の式を計算してI1をアップデートする。
I1 = 100774 + (min(f(x)), x2)− xl)
= 100774 + (min(f(23), 16)−15)
= 100774 + (min(17, 16) −15)
= 100775.
【0147】
従って、p = 0.3 、δ = 0.1のときのリーダーベクトルl = (15, 16, 20, 40)のインデックスは、 I1 = 100775である。付属資料におけるアルゴリズムlは、全てのコーディングプロセスをコンパイルしたものである。
【0148】
【化39】
2)f(101) = 2264を計算する。
3)x4をデコードする。この場合、j=0として式(12)を使って、次式を得る。
【0149】
【数20】
【0150】
【化40】
【0151】
【化41】
【0152】
【数21】
【0153】
【化42】
【0154】
【化43】
【0155】
【数22】
【0156】
【化44】
【0157】
【化45】
= min(f(23), 16) −(100775 −100774)
= min(17, 16) − (100775 − 100774)
= 15.
【0158】
従って、1 = (15, 16, 20, 40)が得られる。付属資料のアルゴリズム2はデコーディングプロセス全体をコンパイルしたものである。
【0159】
メモリコスト及び演算コスト
必要なメモリ容量
【化46】
【0160】
【化47】
【0161】
【化48】
【0162】
【化49】
したがって、コーディング/デコーディングのステップのためのメモリコストの上限は次式で与えられる:
【0163】
【数23】
【0164】
メモリ容量は、主として、エンベロープのノルムと次元に依存していることに留意すべきである。ベクトルの数がBの選択を決定する。
【0165】
【化50】
必要なメモリ容量は、p=1、δ=1,B=4(整数タイプのデータ)として、半径rに応じて、式(13)に基づいて表わされ、[5]で説明したように、ベクトルに基づく従来の方法のメモリの上限と比較される。1つの次元と1つの半径がそれぞれ16,20程度に小さい場合、従来の方法では、10ギガバイト以上のメモリは必要としていなかった。これに対し、本発明で提案する方法では、必要な容量は100キロバイト以下である。
【0166】
必要とするメモリ容量が非常に低いこと及び全てのベクトルを知る必要がないという事実があるので、64, 128, 256, 512のように大きい次元のラティスベクトルに対しても、インデキシングすることができる。従前の研究においては、実際のアプリケーションでは、次元が16に制限されていた。
【0167】
【化51】
【0168】
【化52】
式(8)とアルゴリズム(1)及び(2)(付属資料、参照)に基づくと、必要な操作は、加算/減算(A)及び比較論理演算(LC)であることが推測される。メモリアクセスは無視する。前記2タイプの演算よりも、かなりコストが低いからである。
【0169】
次に、本発明のインデキシング アルゴリズムのコーディング/デコーディング コストについて評価する。デコーディング アルゴリズム2は、コーディングアルゴリズムの逆であって、ほぼ同一の演算数となる。コーディング/デコーディングアルゴリズムの複雑性は、アルゴリズム1の演算回数を次のようにカウントすることにより評価される。
【0170】
1)(n−1)Aを実行した総和
2)“if/break”テストのために、最初の《for》(《j》 の上の)が、約nnz(1)回実行される。但し、nnz(1)は、1の非0の値の数を意味する。
3)最初の《for》の各ループに対して、次のものを有している。
i. 最初の《if》のために、IAおよび7LC 。
ii.関数《min》のために、1LC。
【化53】
4)最後の"if"と続く行を使って,2Aと2LCを計算する。
【0171】
したがって、加算、論理演算、比較に関する、コーディング/デコーディングのアルゴリズムの総コストは、次の式により与えられる。
【0172】
【数24】
【0173】
【化54】
【0174】
本発明によれば、ラティスベクトルのインデキシングは、対応するレーダーベクトルのインデキシング、置換及び符号変化になる。本発明は、如何なる変換テーブルを必要とすることなくベクトルをインデキシングし、メモリの使用及び全ベクトルの生成の複雑さを低減する方法を提案する。
また、この解決法は、形状パラメータ0< p≦ 2を持つ一般化ガウス分布ソースに対して役立つ。本発明の方法は、分析的で、本方法を使うと、高次ベクトル次元の使用を可能にする。
【0175】
【表3】
【0176】
【表4】
【特許請求の範囲】
【請求項1】
d次元空間において、少なくともベクトル(複数)の一部分1に対し、少なくとも一つのリーダーベクトルインデックスI1を計算するための量子化ステップを有するデジタルデータ処理方法であって、
前記ベクトル(複数)1は、入力データの記述子を構成し、
前記方法は、前記リーダーベクトルインデックスI1が、リーダーベクトル全体の決定ステップをもつことなく、逆辞書順序で、前記リーダーベクトル1に先行するベクトルの数に対応することを特徴とする処理方法。
【請求項2】
前記処理方法は、計算において、リーダーベクトル1以外のベクトルを決定するステップを含まないことを特徴とする請求項1に記載の処理方法。
【請求項3】
rδpdに等しい前記リーダーベクトル1のノルムlpを算出するステップが、リーダーベクトルlの各座標(x1, x2, ..., xd)に関数Tを適用することを特徴とする請求項1乃至2のいずれか1項に記載の処理方法。
但し、rδpdは、1とdとの間を変化するiに対し前記関数T(xi)の結果の総和に等しく、前記関数T(xi)は、精度ファクタ デルタにより冪乗pに高められた座標xiの商(division)を出力し、前記商は、一番近い整数に丸められる。
【請求項4】
リーダーベクトル インデックスI1を算出する前記ステップが、前記リーダーベクトルl(x1, x2, ...xd)の前記ノルムrδpdを計算するステップ(但し、x1 乃至 xdは、増加する順序に並べられている)、及び、dと1の間の変数iを持つ座標xi上で再帰的カウントステップを有すること特徴とする請求項1乃至3のいずれか1項に記載の処理方法。
但し、前記カウントステップは、座標xiがxi+1とMIN(xi+1,F(rδpd))との間に含まれているベクトルをカウントするもので、インデックスIlは、カウントステップの結果の和に等しく、F(A)は、整数値wを出力する1つの関数であり、その値T(w)は前記関数Fの引数(argument)Aに等しい又はより小さい。
【請求項5】
リーダーベクトル インデックスI1を算出する前記ステップが、前記リーダーベクトル1(x1, x2, ...xd)のノルムrδpdの算出ステップ(但し、x1 乃至 xdは、減少する順序に並べられている)、及び、1とdの間の変数iを持つ座標xi上で再帰的カウントステップを有すること特徴とする請求項1乃至3のいずれか1項に記載の処理方法。
但し、前記カウントステップは、座標xiがxi+1とMIN(xi-1,F(rδpd))との間に含まれているベクトルをカウントするもので、インデックスIlは、カウントステップの結果の和に等しく、F(A)は、整数値wを出力する1つの関数であり、その値T(w)は前記関数Fの引数(argument)Aに等しい又はより小さい。
【請求項6】
リーダーベクトル インデックスI1を算出する前記ステップが、前記リーダーベクトル 1(x1, x2, ...xd)のノルムrの算出ステップ(但し、x1 乃至 xdは、増加する順序に並べられている)、及び、dと1の間の変数iを持つ座標xi上で再帰的カウントステップを有すること特徴とする請求項1乃至3のいずれか1項に記載の処理方法。
但し、前記カウントステップは、座標xiがixi+1とMIN(xi+1,r-xi+1)との間に含まれているベクトルをカウントするもので、インデックスIlは、カウントステップの結果の和に等しく、インデックスI1は、カウントステップの結果の和に等しい。
【請求項7】
リーダーベクトル インデックスI1を算出する前記ステップが、前記リーダーベクトル1(x1, x2, ...xd)のノルムrの算出ステップ(但し、x1 乃至 xdは、増加する順序に並べられている)、及び、dと1の間の変数iを持つ座標xi上で再帰的カウントステップを有すること特徴とする請求項1乃至3のいずれか1項に記載の処理方法。
但し、前記カウントステップは、座標xiがixi+1とMIN(xi-1, r-xi-1)との間に含まれているベクトルをカウントするもので、インデックスIlは、カウントステップの結果の和に等しく、インデックスI1は、カウントステップの結果の和に等しい。
【請求項8】
インデックスI1のバイナリコード化の結果並びに少なくとも一つの符合インデックスIs、ノルムインデックスIn及び置換インデックスIpを登録する、ベクトルデータの圧縮のための、請求項1ないし7のいずれか1項に記載の方法のアプリケーション。
【請求項9】
前記ベクトルデータは、デジタル画像であることを特徴とする請求項8に記載の圧縮アプリケーション。
【請求項10】
前記ベクトルデータは、デジタルビデオシーケンスであることを特徴とする請求項8に記載の圧縮アプリケーション。
【請求項11】
前記ベクトルデータは、デジタルオーディオデータであることを特徴とする請求項8に記載の圧縮アプリケーション。
【請求項12】
前記ベクトルデータは、デジタル3次元オブジェクトであることを特徴とする請求項8に記載の圧縮アプリケーション。
【請求項13】
前記ベクトルデータは、デジタルアニメ3次元オブジェクトであることを特徴とする請求項8に記載の圧縮アプリケーション。
【請求項14】
前記ベクトルデータは、前記ベクトルデータは変換に由来する複数係数(例:DCT係数、ウェーブレット係数)であることを特徴とする請求項8に記載の圧縮アプリケーション。
【請求項15】
前記ベクトルデータは、データベースにおいて登録された情報であることを特徴とする請求項8に記載の圧縮アプリケーション。
【請求項16】
ベクトルデータベースにおいてサーチすることは、1つのインデックスIl,ref 、及び、少なくとも一つの符号インデックスIs,ref、ノルムインデックスIn,ref及び置換インデックスIp,refを、参照情報として、算出すること、及び、同一インデックスを付加されたデータをサーチすること、からなる請求項1ないし7のいずれか1項に記載の方法のアプリケーション。
【請求項17】
前記ベクトルデータが、デジタル画像であることを特徴とする請求項16に記載のサーチアプリケーション。
【請求項18】
前記ベクトルデータが、デジタルビデオシーケンスであることを特徴とする請求項16に記載のサーチアプリケーション。
【請求項19】
前記ベクトルデータが、デジタルオーディオデータであることを特徴とする請求項16に記載のサーチアプリケーション。
【請求項20】
前記ベクトルデータが、デジタル3次元オブジェクトであることを特徴とする請求項16に記載のサーチアプリケーション。
【請求項21】
前記ベクトルデータが、デジタルアニメ3次元オブジェクトであることを特徴とする請求項16に記載のサーチアプリケーション。
【請求項22】
前記ベクトルデータが、テキストデータベースにおいて登録された情報であることを特徴とする請求項16に記載のサーチアプリケーション。
【請求項23】
前記ベクトルデータが、前記ベクトルデータの変換に由来する複数係数(例:DCT係数、ウェーブレット係数)であることを特徴とする請求項16に記載のサーチアプリケーション。
【請求項24】
少なくとも請求項1乃至7のいずれか1項に適合する方法に基づいて算出されたリーダーベクトル インデックスI1から、デジタルデータを再構成する方法であって、
1つのリーダーベクトルの座標(xl, x2, ..., xd)を算出すること、及び、全リーダーベクトルを決定するステップを経ることなしに、逆辞書順序で、前記リーダーベクトル1に先行するベクトルの数に対応するインデックスI1を持つリーダーベクトル1をサーチする処理に、一つのインデックスI1を付加することを特徴とする再構成する方法。
【請求項25】
請求項24に基づいてデジタルデータを再構成する方法であって、
dと1との間で変化する変数iの再帰的な処理を行い、前記処理は、MIN (xi+1, F (rPδ,i))から0のへ変化するxiを持つ座標xiに対して行われ、また、前記関数F(A)を適用して、カウントステップの結果の加算を、和が前記インデックスI1より大きくなるまで行うこと、及び、前記サーチされた座標xiは、前記インデックスI1を超過することを特徴とする方法。
なお、前記方法は、座標Xi-1に対して、値I1に基づく加算を継続する(但し、I1は、前記インデックスを超過する前の、値I1に先行する値である)。
【請求項26】
請求項24に基づいてデジタルデータを再構成する方法であって、
dと1との間で変化する変数iの再帰的な処理を行い、前記処理は、MIN (xi-1, F (rPδ,i))と0との間に含まれるxiを持つ座標xiに対して行われ、また、前記関数F(A)を適用して、カウントステップの結果を加算し、その和が前記インデックスI1より大きくなるまで加算すること、前記サーチされた座標xiは、前記インデックスI1を超過することを特徴とする方法。
なお、前記方法は、座標Xi+1に対して、値I1に基づく加算を継続する(但し、I1は、前記インデックスを超過する前の、値I1に先行する値である)。
【請求項1】
d次元空間において、少なくともベクトル(複数)の一部分1に対し、少なくとも一つのリーダーベクトルインデックスI1を計算するための量子化ステップを有するデジタルデータ処理方法であって、
前記ベクトル(複数)1は、入力データの記述子を構成し、
前記方法は、前記リーダーベクトルインデックスI1が、リーダーベクトル全体の決定ステップをもつことなく、逆辞書順序で、前記リーダーベクトル1に先行するベクトルの数に対応することを特徴とする処理方法。
【請求項2】
前記処理方法は、計算において、リーダーベクトル1以外のベクトルを決定するステップを含まないことを特徴とする請求項1に記載の処理方法。
【請求項3】
rδpdに等しい前記リーダーベクトル1のノルムlpを算出するステップが、リーダーベクトルlの各座標(x1, x2, ..., xd)に関数Tを適用することを特徴とする請求項1乃至2のいずれか1項に記載の処理方法。
但し、rδpdは、1とdとの間を変化するiに対し前記関数T(xi)の結果の総和に等しく、前記関数T(xi)は、精度ファクタ デルタにより冪乗pに高められた座標xiの商(division)を出力し、前記商は、一番近い整数に丸められる。
【請求項4】
リーダーベクトル インデックスI1を算出する前記ステップが、前記リーダーベクトルl(x1, x2, ...xd)の前記ノルムrδpdを計算するステップ(但し、x1 乃至 xdは、増加する順序に並べられている)、及び、dと1の間の変数iを持つ座標xi上で再帰的カウントステップを有すること特徴とする請求項1乃至3のいずれか1項に記載の処理方法。
但し、前記カウントステップは、座標xiがxi+1とMIN(xi+1,F(rδpd))との間に含まれているベクトルをカウントするもので、インデックスIlは、カウントステップの結果の和に等しく、F(A)は、整数値wを出力する1つの関数であり、その値T(w)は前記関数Fの引数(argument)Aに等しい又はより小さい。
【請求項5】
リーダーベクトル インデックスI1を算出する前記ステップが、前記リーダーベクトル1(x1, x2, ...xd)のノルムrδpdの算出ステップ(但し、x1 乃至 xdは、減少する順序に並べられている)、及び、1とdの間の変数iを持つ座標xi上で再帰的カウントステップを有すること特徴とする請求項1乃至3のいずれか1項に記載の処理方法。
但し、前記カウントステップは、座標xiがxi+1とMIN(xi-1,F(rδpd))との間に含まれているベクトルをカウントするもので、インデックスIlは、カウントステップの結果の和に等しく、F(A)は、整数値wを出力する1つの関数であり、その値T(w)は前記関数Fの引数(argument)Aに等しい又はより小さい。
【請求項6】
リーダーベクトル インデックスI1を算出する前記ステップが、前記リーダーベクトル 1(x1, x2, ...xd)のノルムrの算出ステップ(但し、x1 乃至 xdは、増加する順序に並べられている)、及び、dと1の間の変数iを持つ座標xi上で再帰的カウントステップを有すること特徴とする請求項1乃至3のいずれか1項に記載の処理方法。
但し、前記カウントステップは、座標xiがixi+1とMIN(xi+1,r-xi+1)との間に含まれているベクトルをカウントするもので、インデックスIlは、カウントステップの結果の和に等しく、インデックスI1は、カウントステップの結果の和に等しい。
【請求項7】
リーダーベクトル インデックスI1を算出する前記ステップが、前記リーダーベクトル1(x1, x2, ...xd)のノルムrの算出ステップ(但し、x1 乃至 xdは、増加する順序に並べられている)、及び、dと1の間の変数iを持つ座標xi上で再帰的カウントステップを有すること特徴とする請求項1乃至3のいずれか1項に記載の処理方法。
但し、前記カウントステップは、座標xiがixi+1とMIN(xi-1, r-xi-1)との間に含まれているベクトルをカウントするもので、インデックスIlは、カウントステップの結果の和に等しく、インデックスI1は、カウントステップの結果の和に等しい。
【請求項8】
インデックスI1のバイナリコード化の結果並びに少なくとも一つの符合インデックスIs、ノルムインデックスIn及び置換インデックスIpを登録する、ベクトルデータの圧縮のための、請求項1ないし7のいずれか1項に記載の方法のアプリケーション。
【請求項9】
前記ベクトルデータは、デジタル画像であることを特徴とする請求項8に記載の圧縮アプリケーション。
【請求項10】
前記ベクトルデータは、デジタルビデオシーケンスであることを特徴とする請求項8に記載の圧縮アプリケーション。
【請求項11】
前記ベクトルデータは、デジタルオーディオデータであることを特徴とする請求項8に記載の圧縮アプリケーション。
【請求項12】
前記ベクトルデータは、デジタル3次元オブジェクトであることを特徴とする請求項8に記載の圧縮アプリケーション。
【請求項13】
前記ベクトルデータは、デジタルアニメ3次元オブジェクトであることを特徴とする請求項8に記載の圧縮アプリケーション。
【請求項14】
前記ベクトルデータは、前記ベクトルデータは変換に由来する複数係数(例:DCT係数、ウェーブレット係数)であることを特徴とする請求項8に記載の圧縮アプリケーション。
【請求項15】
前記ベクトルデータは、データベースにおいて登録された情報であることを特徴とする請求項8に記載の圧縮アプリケーション。
【請求項16】
ベクトルデータベースにおいてサーチすることは、1つのインデックスIl,ref 、及び、少なくとも一つの符号インデックスIs,ref、ノルムインデックスIn,ref及び置換インデックスIp,refを、参照情報として、算出すること、及び、同一インデックスを付加されたデータをサーチすること、からなる請求項1ないし7のいずれか1項に記載の方法のアプリケーション。
【請求項17】
前記ベクトルデータが、デジタル画像であることを特徴とする請求項16に記載のサーチアプリケーション。
【請求項18】
前記ベクトルデータが、デジタルビデオシーケンスであることを特徴とする請求項16に記載のサーチアプリケーション。
【請求項19】
前記ベクトルデータが、デジタルオーディオデータであることを特徴とする請求項16に記載のサーチアプリケーション。
【請求項20】
前記ベクトルデータが、デジタル3次元オブジェクトであることを特徴とする請求項16に記載のサーチアプリケーション。
【請求項21】
前記ベクトルデータが、デジタルアニメ3次元オブジェクトであることを特徴とする請求項16に記載のサーチアプリケーション。
【請求項22】
前記ベクトルデータが、テキストデータベースにおいて登録された情報であることを特徴とする請求項16に記載のサーチアプリケーション。
【請求項23】
前記ベクトルデータが、前記ベクトルデータの変換に由来する複数係数(例:DCT係数、ウェーブレット係数)であることを特徴とする請求項16に記載のサーチアプリケーション。
【請求項24】
少なくとも請求項1乃至7のいずれか1項に適合する方法に基づいて算出されたリーダーベクトル インデックスI1から、デジタルデータを再構成する方法であって、
1つのリーダーベクトルの座標(xl, x2, ..., xd)を算出すること、及び、全リーダーベクトルを決定するステップを経ることなしに、逆辞書順序で、前記リーダーベクトル1に先行するベクトルの数に対応するインデックスI1を持つリーダーベクトル1をサーチする処理に、一つのインデックスI1を付加することを特徴とする再構成する方法。
【請求項25】
請求項24に基づいてデジタルデータを再構成する方法であって、
dと1との間で変化する変数iの再帰的な処理を行い、前記処理は、MIN (xi+1, F (rPδ,i))から0のへ変化するxiを持つ座標xiに対して行われ、また、前記関数F(A)を適用して、カウントステップの結果の加算を、和が前記インデックスI1より大きくなるまで行うこと、及び、前記サーチされた座標xiは、前記インデックスI1を超過することを特徴とする方法。
なお、前記方法は、座標Xi-1に対して、値I1に基づく加算を継続する(但し、I1は、前記インデックスを超過する前の、値I1に先行する値である)。
【請求項26】
請求項24に基づいてデジタルデータを再構成する方法であって、
dと1との間で変化する変数iの再帰的な処理を行い、前記処理は、MIN (xi-1, F (rPδ,i))と0との間に含まれるxiを持つ座標xiに対して行われ、また、前記関数F(A)を適用して、カウントステップの結果を加算し、その和が前記インデックスI1より大きくなるまで加算すること、前記サーチされた座標xiは、前記インデックスI1を超過することを特徴とする方法。
なお、前記方法は、座標Xi+1に対して、値I1に基づく加算を継続する(但し、I1は、前記インデックスを超過する前の、値I1に先行する値である)。
【図1】

【図2】
【図3】
【図2】
【図3】
【公表番号】特表2011−525728(P2011−525728A)
【公表日】平成23年9月22日(2011.9.22)
【国際特許分類】
【出願番号】特願2011−512164(P2011−512164)
【出願日】平成21年5月27日(2009.5.27)
【国際出願番号】PCT/FR2009/000616
【国際公開番号】WO2009/156605
【国際公開日】平成21年12月30日(2009.12.30)
【出願人】(501089863)サントル ナシオナル ドゥ ラ ルシェルシェサイアンティフィク(セエヌエールエス) (173)
【出願人】(510319672)ユニベルシテ ドゥ ニース ソフィア アンティポリ (3)
【Fターム(参考)】
【公表日】平成23年9月22日(2011.9.22)
【国際特許分類】
【出願日】平成21年5月27日(2009.5.27)
【国際出願番号】PCT/FR2009/000616
【国際公開番号】WO2009/156605
【国際公開日】平成21年12月30日(2009.12.30)
【出願人】(501089863)サントル ナシオナル ドゥ ラ ルシェルシェサイアンティフィク(セエヌエールエス) (173)
【出願人】(510319672)ユニベルシテ ドゥ ニース ソフィア アンティポリ (3)
【Fターム(参考)】
[ Back to top ]