
文字列予測プログラムおよび情報処理装置
【課題】限られた記憶領域や既存の辞書を有効に利用しつつ、検索処理の負荷の増大を抑え、入力される文字列が漢字等を含むか否かにかかわらずユーザが望む後続の文字列を素早く予測できるようにすること。
【解決手段】検索部は、文字認識部により認識される文字列にかな以外の文字列が含まれている場合に、漢字インデックスの中から当該かな以外の文字列に対応するかなの文字列を検索し、さらにヨミインデックスの中から当該検索したかなの文字列に対応するブロック識別情報を検索し、さらに当該検索したブロック識別情報に指定される前記辞書データ部のブロックの中から前記検索したかなの文字列に対応する文字列の表記を検索する。
【解決手段】検索部は、文字認識部により認識される文字列にかな以外の文字列が含まれている場合に、漢字インデックスの中から当該かな以外の文字列に対応するかなの文字列を検索し、さらにヨミインデックスの中から当該検索したかなの文字列に対応するブロック識別情報を検索し、さらに当該検索したブロック識別情報に指定される前記辞書データ部のブロックの中から前記検索したかなの文字列に対応する文字列の表記を検索する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、ユーザが望む文字や文字列を予測する機能を有する文字列予測プログラムおよび情報処理装置に関する。
【背景技術】
【0002】
従来、携帯情報端末(PDA: Personal Digital Assistant)においては、文字入力方式として、タッチパネルに対してスタイラスペン等を用いて手書きにより文字列を入力する方式(以下、「手書き入力方式」と称す。)を採用するものが一般的であった。その後、携帯電話機に見られるように、個々の文字が割り付けられているダイヤルキー(テンキー)やQWERTY配列のキーボードのキーを押し下げる方式(以下、「キー押下入力方式」と称す。)が一般的になるにつれ、「手書き入力方式」による文字列の入力はあまり利用されなくなっていった。その理由としては、以下のことが挙げられる。
【0003】
「キー押下入力方式」を採用する機器では、入力されるかなの文字や文字列を単漢字や単文節に変換する変換処理のほか、例えば変換後の文字や文字列をもとにユーザが望むであろう文章の一部を予測する「予測変換」や、予測された文章の一部を確定した後、これに続くものとしてユーザが望むであろう文章の一部をさらに予測する「連携予測変換」が実現され、少ないキー操作で所望の文章を早く簡単に作成することができた。
【0004】
これに対し、「手書き入力方式」を採用する機器は、一般に、例えば漢字混じりの文字列(漢字とひらがなとを含む文字列)が入力された場合、上述したような「予測変換」や「連携予測変換」は容易には行えなかった。このため、ユーザは漢字を手書きで入力する毎に、認識される文字を決定する処理又は選択してから決定する処理を行わなければならず、送りがななどについても一字ずつ手書きで入力しなければならなかった。
【0005】
なお、特許文献1には、「手書き入力方式」の機器において、入力される漢字からユーザが望む漢字の文字列を予測する文字列予測方法が開示されている。また、特許文献2には、入力される漢字などから後続の文字列を予測する「文字列予測部」と、予測された文字列がひらがなである場合に漢字を含む文字列に変換する「かな漢字変換部」とを備えた文字列予測装置が開示されている。
【先行技術文献】
【特許文献】
【0006】
【特許文献1】特開平9−16586号公報(図1〜図7等)
【特許文献2】特開平8−255158号公報(図3、図4等)
【発明の概要】
【発明が解決しようとする課題】
【0007】
上述の特許文献1,2の技術は、「手書き入力方式」の機器への適用を示すものであるが、以下のような問題がある。
【0008】
特許文献1の技術では、入力される文字列から予測される文字列を得るためには辞書の全体を検索する必要があるため、CPUの処理を占有し、携帯情報端末などのCPUクロック周波数の低い組込み機器の場合には、「キー押下入力方式」の機器に比べ、検索結果を得るまでに長時間を要し、その結果、入力操作が遅くなってしまう。
【0009】
一方、特許文献2の技術では、「手書き入力方式」で入力される文字列が例えばひらがなである場合、「かな漢字変換部」と「文字列予測部」の両方の機能を用いて検索が行われるため、特許文献1の場合と同様、CPUの処理を占有し、携帯情報端末などのCPUクロック周波数の低い組込み機器の場合には、「キー押下入力方式」の機器に比べ、検索結果を得るまでに長時間を要し、その結果、入力操作が遅くなってしまう。さらに、特許文献2の技術では、「かな漢字変換部」および「文字列予測部」のそれぞれが辞書を有しているため、携帯電話機などのROM領域に容量制限のある組込み機器の場合には、このROM領域を辞書により圧迫する可能性がある。
【0010】
本発明は上記実情に鑑みてなされたものであり、限られた記憶領域や同じ構造の辞書を有効に利用しつつ、検索処理の負荷の増大を抑え、入力される文字列が漢字等を含むか否かにかかわらずユーザが望む後続の文字列を素早く予測することが可能な文字列予測プログラムおよび情報処理装置を提供することを目的とする。
【課題を解決するための手段】
【0011】
本発明の一態様による文字列予測プログラムは、手書きによる文字列の入力が可能な入力装置と、情報を記憶する記憶媒体と、情報を画面に表示する表示装置とを備えたコンピュータに、1)かな文字以外を含む文字列の表記と当該文字列の読みの前方の一部を示すかな文字列とを対応付けた情報がコード順に配列され、かつコード順の配列方向に複数のブロックに区分され、各ブロックには前記情報とブロック識別情報とが付与されている辞書データ部と、2)前記辞書データ部に含まれる前記かな文字列の少なくとも前方の一部のかな文字列とかな文字以外の文字列とを対応付けた情報を含み、前記かな文字以外の文字列がコード順に配列される第1のインデックスと、3)前記ブロック識別情報と当該識別情報により指定されるブロックの先頭に位置するかな文字列とを対応付けた情報を含み、前記かな文字列がコード順に配列される第2のインデックスとを、前記記憶媒体の所定の記憶領域に記憶させる記憶処理機能と、前記入力装置により入力される手書きの文字列を認識する認識機能と、前記識別機能により識別される文字列にかな文字以外の文字列が含まれているか否かを判定し、かな文字以外の文字列が含まれている場合に、当該かな文字以外の文字列が含まれる文字列に続く文字列を予測する形態である第1の予測処理として、前記認識したかな文字以外の文字列を前記第1のインデックスの中から検索し、当該かな文字以外の文字列の読みの前方の一部を示すかな文字の少なくとも一つを選択し、該選択したかな文字が含まれるブロック識別情報を前記第2のインデックスから検索し、さらに当該検索したブロック識別情報に指定される前記辞書データ部のブロックの中から前記認識したかな文字以外の文字列が含まれる文字列の表記を予測文字列候補として検索し、一方、前記認識機能により認識される文字列にかな文字以外の文字列が含まれていない場合に、当該かな文字列に続く文字列を予測する形態である第2の予測処理として、前記認識したかな文字列を前記第2のインデックスの中から検索し、当該かな文字列が含まれるブロック識別情報を前記第2インデックスから検索し、さらに当該検索したブロック識別情報に指定される前記辞書データ部のブロックの中から前記認識したかな文字列に対応する文字列の表記を予測文字列候補として検索する検索機能と、前記検索機能により検索される文字列の表記を前記認識機能により認識される文字列に対する予測文字列候補として前記表示装置の画面に表示させる表示処理機能とを実現させるための文字列予測プログラムである。
【発明の効果】
【0012】
本発明によれば、限られた記憶領域や同じ構造の辞書を有効に利用しつつ、検索処理の負荷の増大を抑え、入力される文字列が漢字等を含むか否かにかかわらずユーザが望む後続の文字列を素早く予測することが可能となる。
【図面の簡単な説明】
【0013】
【図1】本発明の一実施形態に係る情報処理装置の構成の一例を示す図。
【図2】「漢字」を手書きで入力した場合の表示装置の画面上での予測変換等の動作の例を示す図。
【図3】「ひらがな」を手書きで入力した場合の表示装置の画面上での予測変換等の動作の例を示す図。
【図4】「漢字とひらがな」を手書きで入力した場合の表示装置の画面上での予測変換等の動作の例を示す図。
【図5】検索部による検索の動作の一例を示す概念図。
【図6】各種辞書の辞書データ部のデータ構造の例を表形式で示す図。
【図7】漢字インデックスの構成例を表形式で示す図。
【図8】予測変換候補出力画面の一例を示す図。
【図9】予測辞書の詳細例を表形式で示す図。
【図10】基本辞書の詳細例を表形式で示す図。
【図11】予測変換候補表示に係る動作の一例を示すフローチャート。
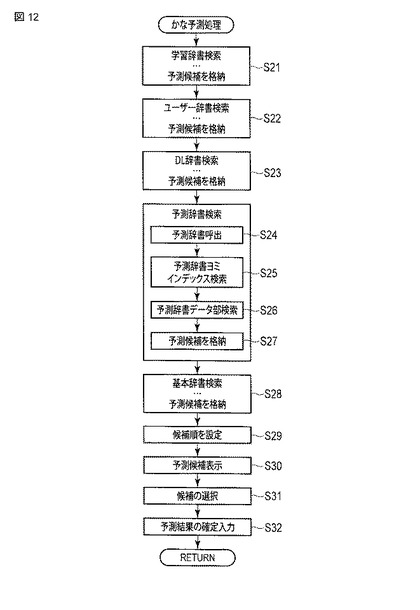
【図12】かな予測処理による予測変換候補の表示に係る動作の一例を示すフローチャート。
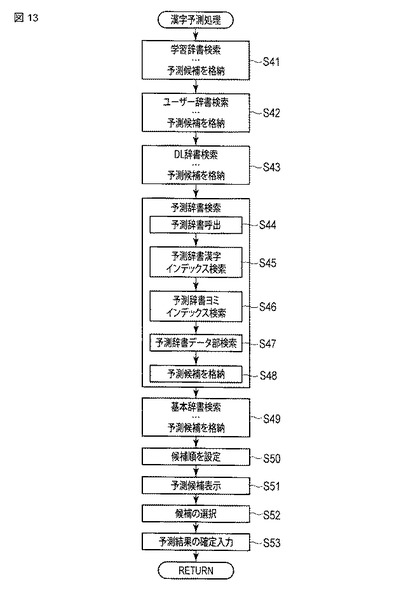
【図13】漢字予測処理による予測変換候補の表示に係る動作の一例を示すフローチャート。
【発明を実施するための形態】
【0014】
以下、図面を参照して、本発明の一実施形態について説明する。
なお、本願明細書でいう「文字列」とは、文字が1つのみの場合もあり得るものとする。「かな」とは、ひらがな又はカタカナを指す。「かな以外」とは、漢字、数字、英字だけではなく、記号、特殊文字なども含んでいることを示す。
【0015】
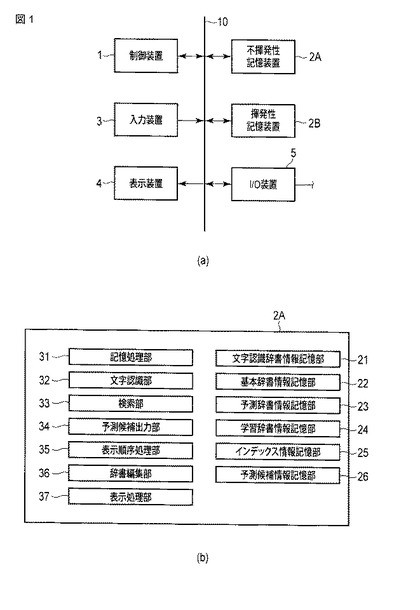
図1は、本発明の一実施形態に係る情報処理装置の構成の一例を示す図である。図1(a)は情報処理装置のハードウェア構成の一例を示し、図1(b)は情報処理装置に搭載されるコンピュータプログラムとしてのソフトウェアの構成の一例を示している。
【0016】
図1(a)に示す情報処理装置は、例えば、携帯電話機や携帯情報端末など、組込みシステムとして実現するのに適した機器に相当するものであり、実質的にはプログラムを実行するコンピュータとして動作する。この情報処理装置は、制御装置1、不揮発性記憶装置2A、揮発性記憶装置2B、入力装置3、表示装置4、およびI/O装置5を備えている。これらの要素は、バス10により相互に接続される。
【0017】
制御装置1は、例えばCPU等のプロセッサに相当するものであり、本装置全体の制御を司る。この制御装置1は、例えば、不揮発性記憶装置2Aに記憶されるプログラムやデータを読み出したり、読み出したプログラムやデータを揮発性記憶装置2Bへロードして各種の処理を実行したりする。さらに、制御装置1は、例えば、入力装置3を通じて入力されるデータや表示装置4へ出力するデータを不揮発性記憶装置2A、揮発性記憶装置2B、もしくは外部I/O装置5との間で送受する制御を行ったり、外部I/O装置5を通じて外部のネットワークから取得されるデータを不揮発性記憶装置2A等に記憶させる処理を行ったりする。
【0018】
不揮発性記憶装置2Aは、例えばフラッシュメモリなどの書換え可能な半導体メモリ、もしくはハードディスクドライブに相当するものである。この不揮発性記憶装置2Aは、本実施形態に係る文字列予測プログラムや、当該プログラムが使用する各種の辞書やインデックス(後述)などを含むデータを記憶している。
【0019】
揮発性記憶装置2Bは、例えばRAMなどの半導体メモリに相当するものである。この揮発性記憶装置2Bは、制御装置1の作業領域として使用され、不揮発性記憶装置2Aからロードされるプログラムやデータを記憶する。
【0020】
入力装置3は、表示装置4上に配置され、ペンタブレットもしくはタッチパネルを形成している。このペンタブレットもしくはタッチパネル上の所定の領域内において、スタイラスペンもしくは指先を押し当てながら文字を描く操作を行うことにより、手書きによる文字や文字列の入力が達成される。本実施形態では、ペンタブレットに対しスタイラスペンを用いて入力を行う場合を例にとって説明する。
【0021】
表示装置4は、例えば液晶ディスプレイ装置であり、入力装置3を通じて手書きにより入力される文字の筆跡を第1の表示領域に表示したり、入力後に認識された文字列の候補を第2の表示領域に表示したり、候補の中から自動もしくは手動により選択された文字列を第3の表示領域に表示したり、表示されている文字列をもとにユーザが望むものとして予測された文字列を第4の表示領域に表示したりする。
【0022】
I/O装置5は、外部のネットワークを通じて辞書などをダウンロードして不揮発性記憶装置2Aへ送ったりする。
【0023】
図1(b)には、上記不揮発性記憶装置2Aに格納された文字列予測プログラムおよびデータの記憶部が示されている。文字列予測プログラムには、記憶処理部31、文字認識部32、検索部33、予測候補出力部34、表示順序処理部35、辞書編集部36、および表示処理部37が備えられる。文字列予測プログラムが使用するデータの各記憶部としては、文字認識辞書情報記憶部21、基本辞書情報記憶部22、予測辞書情報記憶部23、学習辞書情報記憶部24、インデックス情報記憶部25、および予測候補情報記憶部26が設けられる。そのほか、図示しないが、ユーザ辞書情報記憶部、ダウンロード辞書情報記憶部(以下、「DL辞書記憶部」と称す。)、および連携予測辞書記憶部が設けられる。なお、これらの記憶部内のデータは、揮発性記憶装置2Bにロードされた際にもそれぞれ同じ記憶部(記憶領域)が確保される。
【0024】
記憶処理部31は、不揮発性記憶装置2Aから、1)「かな以外」を含む文字列(例えば、「かな以外」とかなとを含むかな混じりの文字列や、「かな以外」のみの文字列)の表記と当該文字列の少なくとも一部の読み又は見出しを示すかなの文字列とを対応付けた情報を含み、前記かなの文字列がコード順に配列され、当該情報がコード順の配列方向に複数のブロックに区分される辞書データ部と、2)前記辞書データ部に含まれる前記かなの文字列の少なくとも先頭から一部の文字列と「かな以外」の文字列とを対応付けた情報を含み、前記かな以外の文字列がコード順に配列される第1のインデックス(以下、「漢字インデックス」と称す。)と、3)前記辞書データ部のブロックを指定するブロック識別情報(ブロック番号)と当該識別情報により指定されるブロックの先頭に位置するかなの文字列とを対応付けた情報を含み、前記かなの文字列がコード順に配列される第2のインデックス(以下、「ヨミインデックス」と称す。)とを読み出し、揮発性記憶装置2B内の所定の記憶領域にロードして記憶させる機能である。なお、漢字インデックス、ヨミインデックス、および辞書データ部は、辞書を構成し、種類が異なる辞書毎に存在するものである。また、前記ブロックは、辞書データ部の記憶領域において、最も効率よく辞書内の文字列が検索できる容量ごとに分けた領域の一つを指す。
【0025】
ここで、ブロックについてより詳細に説明する。
ブロックとは、記憶デバイスおよびそのドライバによって、物理的あるいは論理的に定まる、統計的にもっともアクセス時間が少なくなるよう推奨される記憶容量の管理単位である。本実施形態では、1ブロックに辞書内の各レコードが収まるように記録される。レコードは、順次コード順に記録されもし、1レコードがブロックの境界にまたがる場合は、その部分は未使用として、次のブロックの先頭より記録される。これらのブロックは、連続した整数で表されるブロック番号を有する。また、本実施形態では、ヨミインデックスによって、その語の含まれる記憶部のブロックが限定されることによって検索時間を短く終わらせることができる。これを他の方法で実施しようとすると、もし検索対象の語が辞書に含まれていない場合、全部の辞書を検索することになり、非常に時間がかかることになる。
【0026】
文字認識部32は、入力装置3により入力される文字列を認識する機能である。具体的には、文字認識部32は、手書きにより入力された文字を文字認識辞書情報記憶部21に記憶される文字認識辞書をもとに手書き文字の認識を行い、この認識した単一又は複数の認識結果を、表示処理部37を通じて表示装置4における画面上の認識文字結果表示用ウインドウ42の領域に表示させる。
【0027】
検索部33は、文字認識部32により認識される文字列に「かな以外」の文字列が含まれている場合に、前記漢字インデックスの中から当該「かな以外」の文字列に対応するかなの文字列を検索し、さらに前記ヨミインデックスの中から当該検索したかなの文字列に対応するブロック識別情報を検索し、さらに当該検索したブロック識別情報に指定される前記辞書データ部のブロックの中から前記検索したかなの文字列に対応する文字列の表記を検索し、一方、文字認識部32により認識される文字列に「かな以外」の文字列が含まれておらず、かなの文字列が含まれている場合に、前記漢字インデックスを用いずに前記ヨミインデックスの中から当該かなの文字列に対応するブロック識別情報を検索し、さらに当該検索したブロック識別情報に指定される前記辞書データ部のブロックの中から前記検索したかなの文字列に対応する文字列の表記を検索する機能である。
【0028】
具体的には、検索部33は、文字認識部32による手書き入力文字の認識結果から入力文字としての確定前の文字列に「かな以外」が含まれるか否かを判定し、その判定結果によって、この文字列に続く文字の予測形態を、かな文字列に続く文字列を予測する形態である「かな予測処理」と、「かな以外」が含まれる文字列に続く文字列を予測する形態である「漢字予測処理」との間で切り替える機能を有する。また、検索部33は、候補文字表示用ウインドウ44に表示可能な数の予測変換候補を得るために各種辞書の検索を行う機能を有する。検索部33は、「漢字予測処理」により予測変換候補を得るためには、各種辞書について漢字インデックスを検索した上で、ヨミインデックスを検索し、さらに辞書データ部を検索する。一方、「かな予測処理」により予測変換候補を得るためには、ヨミインデックスを検索した上で、辞書データ部を検索する。すなわち、本実施形態では、「かな予測処理」に使用されるヨミインデックスおよび辞書データ部が「漢字予測処理」においても有効に利用される。このため、「漢字予測処理」のために専用のヨミインデックスおよび辞書データ部を個々に設ける必要がなく、辞書データ部に比べてデータ量が極端に少ない漢字インデックスを加えるだけで、限られた記憶領域を有効に利用し、入力される文字列が「かな以外」を含むか否かにかかわらず予測変換候補を素早く出力させることを実現している。
【0029】
また、検索部33は、漢字インデックス、ヨミインデックス、および辞書データ部のブロックのそれぞれの中においてコード順に配列された個々の文字列に対しバイナリサーチを実施することにより所望のデータが存在する位置を求める機能を有する。これにより、検索速度を一層高めることが可能となる。
【0030】
予測候補出力部34は、かな予測処理や漢字予測処理により得た予測変換候補を、表示処理部37を通じて表示装置4における画面上の候補文字表示用ウインドウ44に表示させる機能である。
【0031】
表示順序処理部35は、予測候補情報記憶部26に格納された予測変換候補の表示順を設定する機能である。
【0032】
辞書編集部36は、学習辞書情報記憶部24に記憶される学習辞書の編集を行う機能である。
【0033】
表示処理部37は、例えば、検索部33により検索される文字列の表記を候補として表示装置4の画面上に表示させるなど、各種の情報を表示させる機能である。
【0034】
文字認識辞書情報記憶部21は、手書きによる文字を認識するための文字認識辞書を記憶する。この文字認識辞書は、二次元パターンと文字との対応付けを示す情報を有する。
【0035】
基本辞書情報記憶部22は、基本辞書の本体となる辞書データ部を記憶する。この基本辞書の辞書データ部は、1列目のデータとしてかなの文字列を備え、2列目のデータとして、前記1列目のデータのかな文字列に対応する、「かな以外」を含む文字列(例えば、「かな以外」とかなとを含むかな混じりの文字列や、「かな以外」のみの文字列)を備えており、コード順の配列方向へ複数のブロックに区分された形態で記憶されている。この構造により、かなの文字列を「かな以外」を含む文字列に変換することができる。特に、この基本辞書の辞書データ部においては、1列目のデータであるかな文字列は、2列目のデータである「かな以外」を含む文字列の読みの全てをかな文字列にしたものとなっている。
【0036】
予測辞書情報記憶部23は、予測辞書の本体となる辞書データ部を記憶する。この予測辞書の辞書データ部は、前述の基本辞書の辞書データ部と同様の構造を有する。但し、この予測辞書の辞書データ部においては、1列目のデータであるかな文字列は、2列目のデータである「かな以外」を含む文字列の読みの前方の一部(例えば、当該文字列の後方を省略して読んだときの読みである省略読み)をかな文字列にしたものとなっている。この場合のかな文字列は、例えば1〜3文字からなる。
【0037】
学習辞書情報記憶部24は、学習辞書の本体となる辞書データ部を記憶する。この学習辞書の辞書データ部は、前述の各辞書の辞書データ部と同様の構造を有する。但し、この学習辞書の辞書データ部は、かなの文字列を「かな以外」を含む文字列に変換するための第1の学習辞書データ部と、「かな以外」を含む文字列をかなの文字列に変換するための第2の学習辞書データ部とから構成されている。また、この学習辞書の辞書データ部は、文字列毎にユーザが入力した頻度を示す情報も備えている。
【0038】
また、図示しないユーザ辞書情報記憶部は、ユーザ辞書の本体となる辞書データ部を記憶する。このユーザ辞書の辞書データ部は、前述の基本辞書や予測辞書や学習辞書の辞書データ部と同様の構造を有する。但し、このユーザ辞書の辞書データ部は、1列目のデータと2列目のデータ(例えば、ヨミと表記)をユーザが任意に登録できるようになっている。
【0039】
また、図示しないDL辞書情報記憶部は、ダウンロード辞書(以下、「DL辞書」と称す。)の本体となる辞書データ部を記憶する。このDL辞書の辞書データ部は、前述の各辞書の辞書データ部と同様の構造を有する。特に、DL辞書は、I/O装置5からネットワークを通じて外部からダウンロードすることができる。DL辞書は、当該辞書もしくは本文字列予測プログラムのプロバイダ、あるいは本情報処理装置のメーカなどがネットワークを通じてユーザに提供する。
【0040】
インデックス情報記憶部25は、漢字インデックスおよびヨミインデックスを記憶する。漢字インデックスは、2列目のデータとして、辞書データ部の1列目のデータ(かなの文字列)の前方2文字までの文字列(但し、3文字以上も可能)を備え、1列目のデータとして、前記辞書データ部の1列目のデータに対応する2列目のデータ(かな以外を含む文字列)の前方1文字を備えている。すなわち、漢字インデックスは、辞書データ部から収集したデータで構成されている。ヨミインデックスは、2列目のデータとして、辞書データ部のブロックを指定するブロック識別情報を備え、1列目のデータとして、そのブロックの第1列目のデータであってコード順における先頭レコードに位置するデータ(かなの文字列)を備えている。
【0041】
予測候補情報記憶部26は、予測変換候補として表示させる情報を記憶する。
【0042】
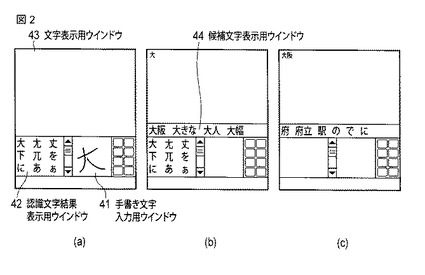
ここで、図2〜図4を参照して、「漢字」、「ひらがな」、「漢字とひらがな」を、それぞれ手書きで入力した場合の表示装置4の画面上での予測変換等の動作の例について説明する。
【0043】
なお、表示装置4の画面上に表示される文字の認識結果である認識文字候補の選択方法として、自動選択モードと手動選択モードが用意されている。モードは、画面上に表示される設定メニューからユーザが自由に選択できるようになっている。自動選択モードでは、ペンがパネルから離れたときに、認識文字候補の最上位が自動的に選択され、対応する予測候補が表示される。一方、手動選択モードでは、ペンがパネルから離れたときに、認識文字候補が表示され、ユーザは候補を選択し、対応する予測候補が表示される。
【0044】
図2は、「漢字」を手書きで入力した場合の表示装置4の画面上での予測変換等の動作の例を示す図である。
【0045】
まず、図2(a)に示すように、表示装置4に画面が表示され、この画面の右下にある手書き文字入力用ウインドウ41内に、ペンタッチにより手書きによる入力が開始されると、文字認識エンジンに従い、入力の軌跡をチェックし表示装置4の手書き文字入力用ウインドウ41からタッチペンが離れるまで、入力文字が文字認識エンジンに記憶されている文字パターンと比較し文字認識辞書情報記憶部21に記憶される辞書とを照合して、手書き入力された文字の認識結果を当該辞書から単一又は複数検索する。上記文字認識エンジンは当該技術で一般的に用いられるものであればよい。
【0046】
本実施形態の自動選択モードにおいては、図2(a)に示すように、手書き文字入力用ウインドウ41内に、ペンタッチにより漢字の「大」が入力されると、表示装置4の画面の左下にある認識文字結果表示用ウインドウ42内に、手書き入力された文字の認識結果が表示され、表示装置4の画面の上部にある文字表示用ウインドウ43内に、文字認識エンジンにより最も入力文字に近いであろう文字が、図2(b)に示すように表示され、さらに仮確定認識文字「大」に対する漢字予測処理により、表示装置4の画面の中央部の候補文字表示用ウインドウ44内に、予測変換候補の文字列「大阪」、「大きな」、「大人」、「大幅」が表示される。次に、予測変換候補の文字列のうち「大阪」がユーザにより選択されると、図2(c)に示すように、連携予測変換候補の文字列「府」、「府立」、「駅」等が表示される。
【0047】
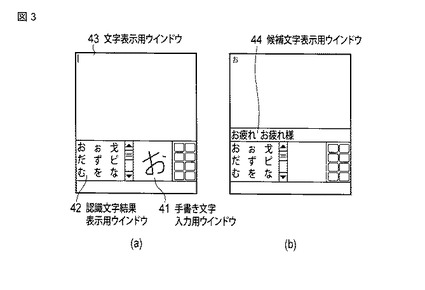
図3は、「ひらがな」を手書きで入力した場合の表示装置の画面上での予測変換等の動作の例を示す図である。
【0048】
まず、図3(a)に示すように、手書き文字入力用ウインドウ41内に、ペンタッチにより手書きによる一文字の文字である「お」が入力されると、次に、図3(b)に示すように、認識結果である文字の候補の中から文字が自動選択または手動選択され、選択された文字が仮確定認識文字「お」にされると、かな予測処理により、表示装置4の画面の中央部の候補文字表示用ウインドウ44内に、予測変換候補の文字列「お疲れ」、「お疲れ様」が表示される。
【0049】
図4は、「漢字とひらがな」を手書きで入力した場合の表示装置4の画面上での予測変換等の動作の例を示す図である。
【0050】
図4(a)では、図2(a),(b)と同様に、手書き文字入力用ウインドウ41内に漢字の「大」が入力された後に仮確定文字「大」に対する予測変換候補が候補文字表示用ウインドウ44に表示され、次に、図4(b)に示すように、手書き文字入力用ウインドウ41内に、ひらがなで「き」が手書きで入力されると、図4(c)に示すように、文字表示用ウインドウ43内に、仮確定文字の「大き」に対する予測変換候補が表示され、候補の中から「い」がユーザにより選択されると、図4(d)に示すように、候補文字表示用ウインドウ44内に、仮確定文字「大きい」に対する連携予測変換候補の文字列「。」、「?」、「!」、「のに」、「ので」が表示される。
【0051】
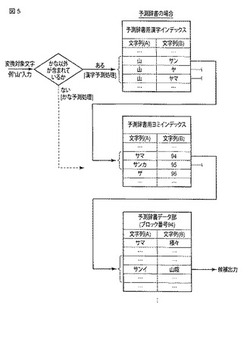
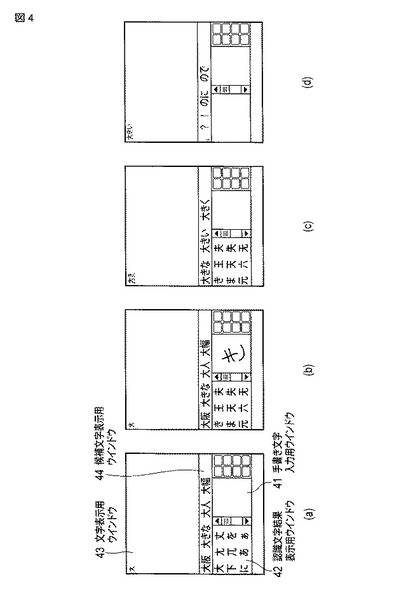
ここで、図5を参照して、検索部33による検索の動作の一例について説明する。
【0052】
検索部33は、検索処理において各種の辞書を用いるが、ここでは予測辞書を用いる処理のみに焦点を絞って説明する。なお、予測辞書は、予測辞書用漢字インデックスと、予測辞書用ヨミインデックスと、予測辞書データ部とからなる。これら3つの情報は、共通して、1列目のデータとして文字列(A)を備えるとともに、2列目のデータとして文字列(B)を備えている。文字列(A)は、検索キーとなる文字列との照合に供されるデータであり、文字列(B)は、検索結果として出力するためのデータである。
【0053】
最初に、検索部33は、変換対象文字にかな以外が含まれているか否かの漢字予測判定を行う。
【0054】
判定の結果、かな以外が含まれている場合には、漢字予測処理を行う。
【0055】
漢字予測処理において、例えば、漢字“山”が含まれている場合、検索部33は、予測辞書用漢字インデックスの1列目のデータである文字列(A)の中からバイナリサーチにより漢字の“山”が存在する位置を求め、この“山”に対応するかなの文字列“サン”,“ヤ”,“ヤマ”を2列目のデータである文字列(B)の中から抽出する。
【0056】
次に、検索部33は、予測辞書用ヨミインデックスの1列目のデータである文字列(A)の中からバイナリサーチによりかなの文字列“サン”,“ヤ”,“ヤマ”が存在する位置をそれぞれ求め、これらにそれぞれ対応するブロック番号を2列目のデータである文字列(B)の中から抽出する。例えば、“サン”は、文字列(A)の中の個々のかな文字列のうち、文字コード順で“サマ”と“サンカ”との間にあるため、“サマ”に対応するブロック番号94を2列目のデータである文字列(B)の中から抽出する。また、かな文字列“サンカ”は、“サン”を含むため、“サンカ”に対応するブロック番号95についても2列目のデータである文字列(B)の中から抽出する。なお、“ザ”は、“サン”よりも下位の文字コードであり、“ザ”は、“サン”を含まないため、抽出しない。
【0057】
続いて、検索部33は、辞書データ部のブロック番号94のブロックにおける1列目のデータである文字列(A)の中からバイナリサーチによりかなの文字列“サン”が含まれる文字列の位置を求めるとともに、辞書データ部のブロック番号95のブロックにおける1列目のデータである文字列(A)の中からバイナリサーチにより、かなの文字列“サン”を含む文字列の位置を求め、これらにそれぞれ対応する表記を2列目のデータである文字列(B)の中から“山”を含む文字列を抽出する。例えば、予測データ部の文字列(A)の中の個々のかな文字列のうち、“サンイ”は、“サン”を含む文字列であり、“サンイ”に対応する文字列(B)は、“山“を含むため“山陰”を抽出、この“山陰”を、“山”の予測変換候補の一つとして出力する。
【0058】
また、図示しない辞書データ部の他のブロックや、予測辞書以外の各種の辞書における辞書データ部のブロックからも、同様な手法により“山”の予測変換候補が出力される。
【0059】
一方、上記判定の結果、かな以外が含まれていない場合には、かな予測処理を行う。
【0060】
検索部33は、例えば、“サン”が含まれている場合、予測辞書用ヨミインデックスの1列目のデータである文字列(A)の中からバイナリサーチによりかなの文字列“サン”が存在する位置をそれぞれ求め、2列目のデータである文字列(B)の中から該当するブロック番号を抽出し、続いて、辞書データ部の該当するブロックにおける1列目のデータである文字列(A)の中からバイナリサーチによりかなの文字列“サン”が存在する位置を求め、対応する表記を2列目のデータである文字列(B)の中から抽出し、“サン”の予測変換候補の一つとして出力する。
【0061】
このような仕組みにより、辞書全体を検索するよりも、より素早く検索することができる。
【0062】
次に、図6〜図10を参照して、各種辞書の漢字インデックス、ヨミインデックス、および辞書データ部のデータ構造の詳細について説明する。
【0063】
各種辞書の漢字インデックス、ヨミインデックス、および辞書データ部は、共通して、1列目のデータとして文字列(A)、2列目のデータとして文字列(B)、3列目以降のデータとして属性を、それぞれ備えている。属性には、属性(1),属性(2),属性(3)の3種類がある。また、各辞書、各辞書毎の漢字インデックスは、1列目、2列目の文字列が同一の重複する情報は含まない。
【0064】
このようにデータ構造を共通化することにより、限られた記憶領域を無駄なく有効に使用でき、検索速度を向上させることができる。
【0065】
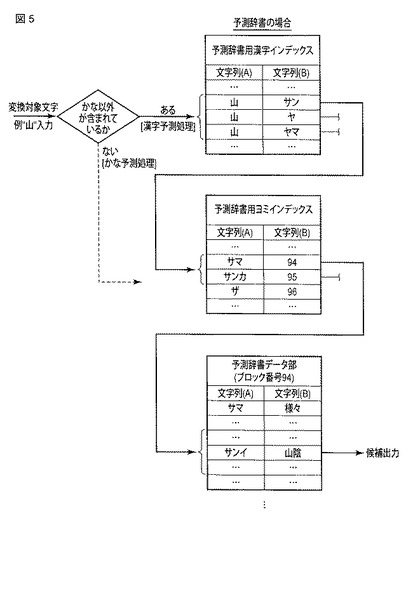
図6は、同実施形態における情報処理装置に記憶される各種辞書の辞書データ部のデータ構造の例を表形式で示す図である。
図6(a)の例に示される基本辞書の辞書データ部は、前述した通り基本辞書情報記憶部22に記憶されるもので、文字列(A)としてかなの文字列(…、サザンカ、…、サンカ、…、サンカク、…)を備え、文字列(B)として表記を示す「かな以外」を含む文字列(…、山茶花、…、参加、…、△、…)を備えており、複数のブロックに区分された形態で記憶されている。また、属性(1)として品詞を示す情報(…、普通名詞、…、普通名詞、…、普通名詞、…)と、属性(2)として優先度(予測変換候補の表示順の優先度)を示す情報(…、低優先、…、通常、…、通常、…)とを備えている。
【0066】
図6(b)の例に示される予測辞書の辞書データ部は、前述した通り予測辞書情報記憶部23に記憶されるもので、文字列(A)としてかなの文字列(…、サン、サン、…、サンイ、…)を備え、文字列(B)として表記を示す「かな以外」を含む文字列(…、三角、III等、…、山陰、…)を備えており、複数のブロックに区分された形態で記憶されている。また、属性(1)として品詞を示す情報(…、普通名詞、普通名詞、…、固有名詞、…)と、属性(2)として優先度(予測変換候補の表示順の優先度)を示す情報(…、通常、低優先、…、通常、…)とを備えている。
【0067】
図6(b)に示した例では、表記「三角」に対応する文字列「サン」は省略読みであり、表記「山陽新幹線」に対応する文字列「サンヨ」は省略読みである。つまり、手書き入力により「サン」を入力した場合には、これに続く文字を入力しなくとも、予測変換候補として「三角」が表示され、手書き入力により「サンヨ」を入力した場合には、これに続く文字を入力しなくとも、予測変換候補として「山陽新幹線」が表示されることになる。
【0068】
図6(c)の例に示される学習辞書の辞書データ部は、前述した通り学習辞書情報記憶部24に記憶されるもので、文字列(A)としてかなの文字列(…、サ、…、ヤ、…)を備え、文字列(B)としてとして表記を示す「かな以外」を含む文字列(…、山さん、…、山手線沿い、…)を備えており、複数のブロックに区分された形態で記憶されている。但し、図示されていないが、学習辞書の辞書データ部には、文字列(A)として「かな以外」を含む文字列を備え、文字列(B)としてかなの文字列を含む文字列を備えた情報も存在する。また、属性(3)として頻度を示す情報(…、5、…、2、…)を備えている。
【0069】
図6(c)の例に示されるように、文字列(A)と文字列(B)との組合せは、かな漢字変換による入力文字の確定にかかる頻度の高い順に配列されている。なお、頻度を採用する代わりに優先度を採用するようにしてもよい。また、前述した組み合わせの配列は、前回利用、つまり前回の入力文字として確定した文字を最上部に表示する配列としてもよい。
【0070】
図6(d)の例に示されるユーザ辞書の辞書データ部は、前述した通り図示しないユーザ辞書情報記憶部に記憶されるもので、文字列(A)としてかなの文字列(…、ア、…)を備え、文字列(B)として表記を示す「かな以外」を含む文字列(…、山陽新幹線、…)を備えており、複数のブロックに区分された形態で記憶されている。また、属性(1)として品詞を示す情報(…、普通名詞、…)と、属性(2)として優先度(予測変換候補の表示順の優先度)を示す情報(…、通常、…)とを備えている。文字列(A)の「ア」と文字列(B)の「山陽新幹線」は、ユーザが任意に登録したものである。
【0071】
図6(e)の例に示されるDL辞書の辞書データ部は、前述した通り図示しないDL辞書情報記憶部に記憶されるもので、例えば「関西弁辞書」等の方言辞書や、「医学用語辞書」等の専門辞書がある。
【0072】
DL辞書は、文字列(A)としてかなの文字列(…、サンカクコ、…)を備え、文字列(B)として表記を示す「かな以外」を含む文字列(…、△湖、…)を備えており、複数のブロックに区分された形態で記憶されている。また、属性(1)として品詞を示す情報(…、固有名詞、…)と、属性(2)として優先度(予測変換候補の表示順の優先度)を示す情報(…、通常、…)とを備えている。このDL辞書は、ユーザがダウンロードしたものである。
【0073】
そのほか、記憶装置2Aには、図示しない連携予測辞書が備えられる。この連携予測辞書は、例えば、予測変換候補として選択された表記である確定表記と、当該確定表記に連なる表記である連語・連想表記と、読みを示す文字列(ヨミ文字列)と、品詞と、優先度とが対応付けられる情報である。この連携予測辞書における確定表記および連語・連想表記は「かな以外の文字」を含む。一方、連携予測辞書におけるヨミ文字列は、かな文字である。
【0074】
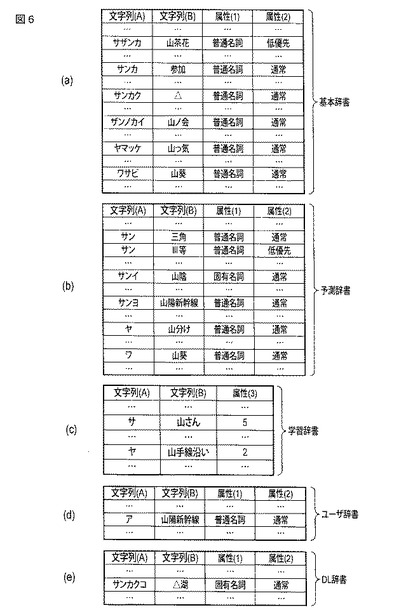
図7は、同実施形態における情報処理装置に記憶される漢字インデックスの構成例を表形式で示す図である。
図7(a)の例に示される基本辞書用漢字インデックスは、前述した通りインデックス情報記憶部25に記憶されるもので、文字列(A)として「かな以外」を含む文字列(…、山、山、山、山、…)を備え、文字列(B)としてかなの文字列(…、サザ、ザン、ヤマ、ワサ、…)を備えている。
【0075】
図7(b)の例に示される予測辞書用漢字インデックスは、前述した通りインデックス情報記憶部25に記憶されるもので、文字列(A)として「かな以外」を含む文字列(…、山、山、山、…)を備え、文字列(B)としてかなの文字列(…、サン、ヤ、ワ、…)を備えている。
【0076】
図7(a)および図7(b)の例では、文字列(B)は、辞書データ部のブロックにおける文字列(A)の文字列の前方2文字までの文字列である。但し、前方2文字までに限ることなく3文字以上とすることも可能である。また、これらの漢字インデックスは、前述した基本辞書や予測辞書の辞書データ部のヨミ文字列および表記の対応関係をもとに予め構築され、文字列(A)の配列は文字コード順とする。但し、文字コード順に限らずにその他のコード順とすることも可能である。
【0077】
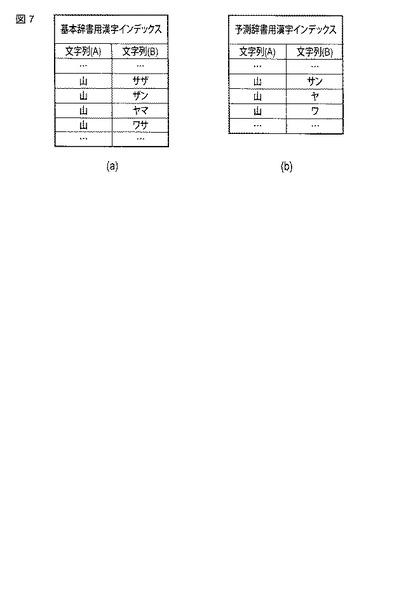
図8は、同実施形態における情報処理装置による候補文字表示ウインドウ44の一例を示す図である。図8の上位の文字列から順に、候補文字表示ウインドウ44の左に順番に表示される。
【0078】
この表示例では、「山さん」の表示順位が上であって、「山茶花」の表示順位が下である。この「山茶花」は基本辞書用予測辞書から「山ノ会」や「山っ気」より先に検索されたが、検索元の基本辞書用予測辞書にて対応付けられる優先度が「低優先」であることなどから、表示順序処理部35の処理により「山ノ会」や「山っ気」より表示順位が下となったことを示している。
【0079】
次に、本実施形態の詳細例について説明する。この詳細例では、予測辞書と基本辞書を、漢字インデックス、ヨミインデックスおよびデータ部で構成するものである。
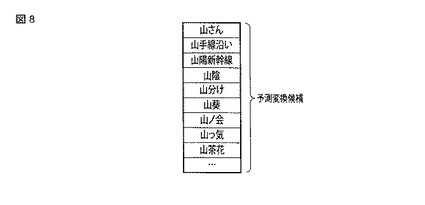
図9は、本発明の実施形態における情報処理装置に記憶される予測辞書の詳細を表形式で示す図である。
この詳細例における予測辞書は、図5においても説明した通り、予測辞書用漢字インデックス、予測辞書ヨミインデックス、および予測辞書データ部により構成される。
図9(a)の例に示される予測辞書用漢字インデックスは、インデックス情報記憶部25に記憶されるもので、文字列(A)として「かな以外」を含む文字列(…、山、山、山、…)を備え、文字列(B)としてかなの文字列(…、サン、ヤ、ヤマ、…)を備えている。
【0080】
図9(b)の例に示される予測辞書用ヨミインデックスは、インデックス情報記憶部25に記憶されるもので、文字列(A)としてかなの文字列(…、サマ、サンカ、ザ、…)を備え、文字列(B)として予測辞書の辞書データ部のブロックを指定するブロック番号(…、94、95、96、…)を備えている。文字列(A)には、文字列(B)のブロック番号により指定されるブロックの先頭に位置するかなの文字列がコード順に配列される。
【0081】
図9(c)の例に示されるブロック番号94の予測辞書データ部のブロックは、予測辞書情報記憶部23に記憶されるもので、文字列(A)としてかなの文字列(サマ、…、…、サンイ,…)を備え、文字列(B)として「かな以外」を含む文字列(様々、…、…、山陰、…)を備えている。
【0082】
図9(d)の例に示されるブロック番号95の予測辞書データ部のブロックは、予測辞書情報記憶部23に記憶されるもので、文字列(A)としてかなの文字列(サンカ、…、…)を備え、文字列(B)として「かな以外」を含む文字列(参画、…、…)を備えている。
【0083】
なお、図9に示される予測辞書の使い方については、図5の例で説明した通りである。
【0084】
図9の構成によれば、予測辞書による検索処理機能が向上し、予測変換候補の検索範囲を狭くすることができるので、予測変換処理にかかる処理負荷を軽減することができる。
【0085】
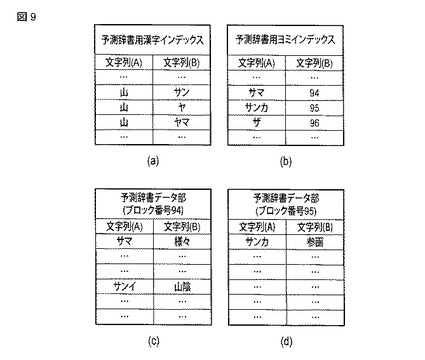
図10は、本発明の実施形態における情報処理装置に記憶される基本辞書の詳細例を表形式で示す図である。
この詳細例における基本辞書は、図5においても説明した通り、基本辞書用漢字インデックス、基本辞書ヨミインデックス、および基本辞書データ部により構成される。
図10(a)の例に示される基本辞書用漢字インデックスは、インデックス情報記憶部25に記憶されるもので、文字列(A)として「かな以外」を含む文字列(…、山、山、山、山、山、山、…)を備え、文字列(B)としてかなの文字列(…、サザ、サン、ザン、ヤキ、ヤマ、ワサ、…)を備えている。
【0086】
図10(b)の例に示される基本辞書用ヨミインデックスは、インデックス情報記憶部25に記憶されるもので、文字列(A)としてかなの文字列(…、サゲ、ササミ、サシタル、…)を備え、文字列(B)として基本辞書の辞書データ部のブロックを指定するブロック番号(…、401、402、403、…)を備えている。文字列(A)には、文字列(B)のブロック番号により指定されるブロックの先頭に位置するかなの文字列がコード順に配列される。
【0087】
図10(c)の例に示されるブロック番号401の基本辞書データ部のブロックは、基本辞書情報記憶部22に記憶されるもので、文字列(A)としてかなの文字列(サゲ、…、…)を備え、文字列(B)として「かな以外」を含む文字列(下げ、…、…)を備えている。
【0088】
図10(d)の例に示されるブロック番号402の基本辞書データ部のブロックは、基本辞書情報記憶部23に記憶されるもので、文字列(A)としてかなの文字列(…、サザンカ、…)を備え、文字列(B)として「かな以外」を含む文字列(…、山茶花、…)を備えている。
【0089】
なお、図10に示される基本辞書の使い方については、図5の例と同様となるため、その説明を省略する。
【0090】
また、図10の構成によれば、基本辞書による検索処理機能も向上し、予測変換候補の検索範囲を狭くすることができるので、予測変換処理にかかる処理負荷を軽減することができる。
【0091】
また、図9、図10と同様に、学習辞書、ユーザ辞書、DL辞書にも漢字インデッスク、ヨミインデックスを備える。
【0092】
なお、これまでの説明からわかるように、文字列(A)は例えばコード順に配列されているが、文字列(B)はコード順に配列されているわけではない。
【0093】
また、表示すべき複数の候補が、例えば図7中の文字列(A)に示されるような同じ文字列にそれぞれ対応するものである場合、表示順はどのような並び順でも良い。例えば、語の登録順でもよいし、文字列(B)の順でもよい。あるいは候補として出力される順を考慮して任意に調整されてもよい。
【0094】
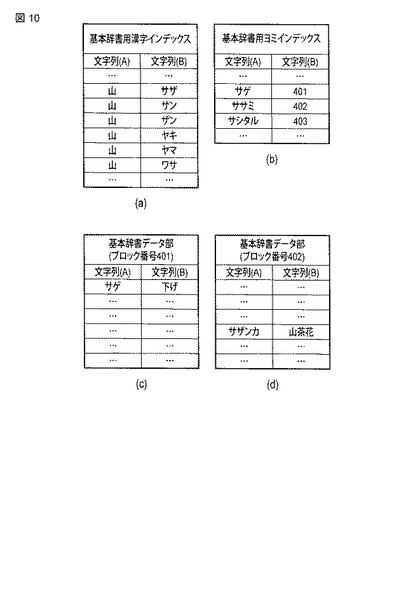
次に、本実施形態に係る情報処理装置による予測変換処理の動作について説明する。
図11は、同実施形態に係る情報処理装置による予測変換候補表示に係る動作の一例を示すフローチャートである。
まず、入力装置3への所定の操作により、図2(a),図3(a)と同様に文字が入力されると(ステップS1)、文字認識部32は、この入力された文字と文字認識辞書情報記憶部21に記憶される辞書とを照合することで、手書き入力された文字の認識結果の文字を当該辞書から単一又は複数検索し、この検索結果を、表示処理部37を通じて表示装置4の画面の左下にある認識文字結果表示用ウインドウ42内に表示させる(ステップS2)。
【0095】
文字認識部32は、手書き入力された文字の認識結果の文字の検索結果のうち、手書き入力された文字に最も近い検索結果を仮確定認識文字として、表示処理部37を通じて認識文字結果表示用ウインドウ42内の左上に表示させる。ユーザは、この表示された仮確定認識文字が、例えば自身が意図した文字に一致しない場合には(ステップS3のNO)、認識文字結果表示用ウインドウ42内の認識結果の文字のうち仮確定認識文字以外から、例えば自身が意図した文字を当該文字の表示部分へのペンタッチにより選択すると、この選択した文字が新たな仮確定認識文字として画面上の文字表示用ウインドウ43内に表示される(ステップS4)。この段階では、この表示された文字は入力文字として確定しておらず、この状態で、画面内に表示される「決定キー」が表示されている部分をペンタッチすることで、未確定だった文字列が入力済みの文字列として確定する。
【0096】
前述した未確定の状態において、仮確定認識文字に続く文字を入力したい場合には、再度入力画面の手書き文字入力用ウインドウ41内へのペンタッチにより手書きによる一文字の文字入力を行なえばよい。
【0097】
ステップS4の処理がなされた場合、もしくは認識文字結果表示用ウインドウ42内に表示された仮確定認識文字が、ユーザ自身が意図した文字に一致しているために(ステップS3のYES)、ステップS4の処理がなされない場合、検索部33は、仮確定の文字列に「かな以外」の文字が含まれているか否かを判別する(ステップS5)。
【0098】
この判別の結果、文字列に「かな以外」の文字が含まれている場合には(ステップS5のYES)、漢字予測処理がなされ(ステップS6)、文字列に「かな以外」の文字が含まれていない場合には(ステップS5のNO)、かな予測処理がなされる(ステップS7)。
【0099】
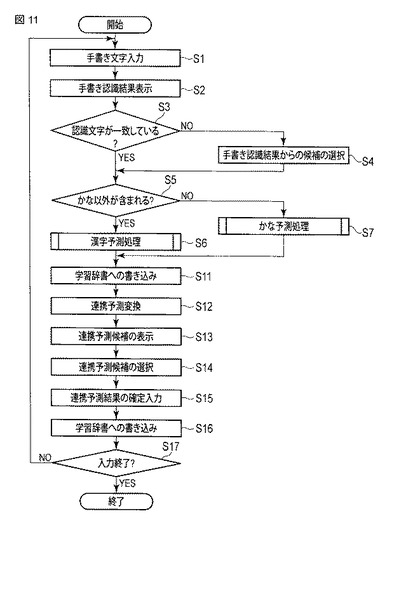
ここで、ステップS7のかな予測処理について説明する。
図12は、同実施形態における情報処理装置のかな予測処理による予測変換候補の表示に係る動作の一例を示すフローチャートである。
このかな予測処理では、検索部33は、学習辞書の検索(ステップS21)、ユーザ辞書の検索(ステップS22)、DL辞書の検索(ステップS23)、予測辞書の検索(ステップS24〜S27)、および基本辞書の検索(ステップS28)をこの順序で実行する。各辞書の検索のステップを構成する複数のステップは同様である。ここでは、予測辞書の検索に焦点を絞って複数のステップS24〜S27の処理の詳細について説明する。
【0100】
検索部33は、予測辞書を呼び出すと(ステップS24)、この予測辞書に含まれている予測辞書用ヨミインデックスを検索し(ステップS25)、予測辞書用ヨミインデックスの1列目のデータである文字列(A)の中からバイナリサーチにより対象のかな文字列が存在する位置をそれぞれ求め、それぞれ対応するブロック番号を2列目のデータである文字列(B)の中から抽出する。
【0101】
続いて、検索部33は、抽出したブロック番号によりそれぞれ指定される辞書データ部のブロックを検索し(ステップS26)、当該ブロックにおける1列目のデータである文字列(A)の中からバイナリサーチにより対象のかな文字列が含まれる文字列の位置を求め、それぞれ対応する表記を2列目のデータである文字列(B)の中から抽出し、それらを予測変換候補として所定の記憶領域に格納する(ステップS27)。これらのステップをヨミインデックスの文字列(A)と対象のカナ文字列が一致する間繰り返す。
【0102】
このようなステップS24〜S27の処理は、学習辞書の検索(ステップS21)、ユーザ辞書の検索(ステップS22)、DL辞書の検索(ステップS23)、および基本辞書の検索(ステップS28)においても同様となる。
【0103】
次に、表示順序処理部35は、予測候補情報記憶部26に格納された予測変換候補の情報の検索元の辞書における優先度情報および品詞情報を参照し、この優先度情報の区分および品詞情報で示される品詞の種別に対応する所定の優先度を認識して、予測変換候補の表示順を設定し(ステップS29)、設定した順番に予測変換候補を表示装置4の画面上に表示させる(ステップS30)。表示装置4の画面上に表示された予測変換候補の中から1つのユーザにより候補が選択され(ステップS31)、選択された候補への予測結果の確定入力がなされると(ステップS32)、この選択された候補が画面上の文字表示用ウインドウ44内に表示される。
【0104】
本実施形態では、学習辞書から検索された予測変換候補の表示順位は、表示順序処理部35による処理を経ても他の辞書から検索された予測変換候補の表示順位より高く、予測辞書から検索された予測変換候補の表示順位は、表示順序処理部35による処理を経ても基本辞書から検索された予測変換候補の表示順位より高いとする(ステップS7)。
【0105】
品詞ごとの優先順位の設定方法としては、各種品詞についての優先順位を選択メニューを設けユーザにより設定する手法、文字入力画面における各種入力フィールドの種別に応じて優先する品詞を設定する手法、および、入力された文字の品詞を解析してこの解析結果を記憶し、次に入力されるであろう品詞を選択して当該選択した品詞を予測変換候補として優先表示する文法解析処理により設定する手法が挙げられる。
【0106】
ここで、ステップS6の漢字予測処理について説明する。
図13は、同実施形態における情報処理装置の漢字予測処理による予測変換候補の表示に係る動作の一例を示すフローチャートである。
この漢字予測処理では、検索部33は、学習辞書の検索(ステップS41)、ユーザ辞書の検索(ステップS42)、DL辞書の検索(ステップS43)、予測辞書の検索(ステップS44〜S48)、および基本辞書の検索(ステップS49)をこの順序で実行する。各辞書の検索のステップを構成する複数のステップは同様である。ここでは、予測辞書の検索に焦点を絞って複数のステップS44〜S48の処理の詳細について説明する。
【0107】
検索部33は、予測辞書を呼び出すと(ステップS44)、この予測辞書に含まれている予測辞書用漢字インデックスを検索し(ステップS45)、予測辞書用漢字インデックスの1列目のデータである文字列(A)の中からバイナリサーチにより対象のかな以外の文字が存在する位置をそれぞれ求め、それぞれ対応するかな文字を2列目のデータである文字列(B)の中から抽出する。
【0108】
続いて、検索部33は、この予測辞書に含まれている予測辞書用ヨミインデックスを検索し(ステップS46)、予測辞書用ヨミインデックスの1列目のデータである文字列(A)の中からバイナリサーチにより抽出したかな文字列が存在する位置をそれぞれ求め、それぞれ対応するブロック番号を2列目のデータである文字列(B)の中から抽出する。
【0109】
続いて、検索部33は、抽出したブロック番号によりそれぞれ指定される辞書データ部のブロックを検索し(ステップS47)、当該ブロックにおける1列目のデータである文字列(A)の中からバイナリサーチにより対象のかな文字列が含まれる文字列の位置を求め、それぞれ対応する表記を2列目のデータである文字列(B)の中から抽出し、それらを予測変換候補として所定の記憶領域に格納する(ステップS48)。
【0110】
これらのステップを漢字インデックスの文字列(A)と対象のかな以外の文字列が一致するまで繰り返す。
【0111】
このようなステップS44〜S48の処理は、学習辞書の検索(ステップS41)、ユーザ辞書の検索(ステップS42)、DL辞書の検索(ステップS43)、および基本辞書の検索(ステップS49)においても同様となる。
【0112】
次に、表示順序処理部35は、予測候補情報記憶部26に格納された予測変換候補の情報の検索元の辞書における優先度情報および品詞情報を参照し、この優先度情報の区分および品詞情報で示される品詞の種別に対応する所定の優先度を認識して、予測変換候補の表示順を設定し(ステップS50)、設定した順番に予測変換候補を表示装置4の画面上に表示させる(ステップS51)。表示装置4の画面上に表示された予測変換候補の中から1つの候補が選択され(ステップS52)、選択された候補への予測結果の確定入力がなされると(ステップS53)、この選択された候補が画面上の文字表示用ウインドウ44内に表示される。
【0113】
そして、図11に戻り、辞書編集部36は、選択された結果を学習辞書に登録する。既に登録済の場合は、学習辞書上の頻度を更新する(ステップS11)。そして、辞書編集部36は、学習辞書上の当該選択した文字の情報を前回利用の履歴情報として所定の記憶領域に記憶させる。
【0114】
検索部33は、連携予測辞書の確定表記と確定済みの文字列とを照合することで、連携予測変換候補である連語・連想表記を検索し(ステップS12)、予測候補出力部34は、この検索した候補を、表示処理部37を通じて表示装置4に表示させる(ステップS13)。
【0115】
ユーザが、この表示された連携予測候補のうち、所望の候補の表示部分へのペンタッチにより選択すると(ステップS14)、この選択した候補への連携予測結果の確定入力がなされたことになり(ステップS15)、この選択した候補が画面上の文字表示用ウインドウ43内に表示されることになり、この選択した候補が画面上の文字表示用ウインドウ43内に表示される。辞書編集部36は、選択済みの候補の検索元の辞書および学習辞書上の頻度を更新する(ステップS16)。辞書編集部36は、学習辞書上の当該選択した文字の情報を前回利用の履歴情報として所定の記憶領域に記憶させる。
【0116】
手書きによる入力が終了していない場合には(ステップS17のNO)、ステップS1の処理に戻り、手書きによる入力が終了した場合には(ステップS17のYES)、一連の処理が終了する。
【0117】
以上のように、本発明の実施形態における情報処理装置では、「かな以外」を含む文字列が手書き入力された場合、この入力された文字の読みを示す表記を各種漢字インデックスから検索し、この検索結果に対応して、かつ、手書き入力された「かな以外」の字を含む表記を各種辞書から検索するので、従来の予測変換候補の表示のための構成と比較して、専用の辞書を新たに設ける必要なしに従来より用いられる基本辞書や予測辞書を有効に活用して、手書き入力された「かな以外」を含む文字列にもとづく予測変換処理や連携予測変換処理を行うことができる。よって、機器の記憶容量や処理負荷を著しく増大させること無しに、「かな以外」を含む文字列を手書き入力する際のユーザ入力操作にかかる負担を大幅に軽減することができる。
【0118】
よって、従来のように、かな文字のみを手書き入力した際の予測変換のための操作と同一の操作が「かな以外」を含む文字列を手書き入力した場合でも実現でき、操作性が大幅に向上する。よって、手書きにより入力された漢字をもとにした予測変換の機能実装の効率および入力作業の効率を大幅に向上させることができる。
【0119】
また、キー押下入力方式で行っていた文字列予測を手書き入力方式で実現し、かつ、専用の漢字予測変換辞書を設ける必要なしに、キー押下入力方式による文字入力予測処理と同等の処理速度を保つことができる。
【0120】
また、漢字インデックスを予測辞書用と基本辞書用とにそれぞれ設けることで、漢字インデックスをそれぞれの辞書に適した構成とすることができるので、漢字インデックスを予測辞書及び基本辞書に共通した単一のインデックス情報とした場合と比較して、不必要な検索を抑制できるので、検索のパフォーマンスが向上する。
【0121】
なお、この発明は前記実施形態そのままに限定されるものではなく実施段階ではその要旨を逸脱しない範囲で構成要素を変形して具体化できる。また、前記実施形態に開示されている複数の構成要素の適宜な組み合わせにより種々の発明を形成できる。例えば、実施形態に示される全構成要素から幾つかの構成要素を省略してもよい。更に、異なる実施形態に亘る構成要素を適宜組み合せてもよい。
【0122】
また、上記実施形態に記載した手法は、コンピュータに実行させることのできるプログラムとして、半導体メモリ(フラッシュメモリなど)、磁気ディスク(ハードディスク、フロッピー(登録商標)ディスクなど)、光ディスク(CD−ROM、DVDなど)、光磁気ディスク(MO)などの記憶媒体に格納して頒布することもできる。
【0123】
また、この記憶媒体としては、プログラムを記憶でき、かつコンピュータが読み取り可能な記憶媒体であれば、その記憶形式は何れの形態であっても良い。
【0124】
また、記憶媒体からコンピュータにインストールされたプログラムの指示に基づきコンピュータ上で稼働しているOS(オペレーティングシステム)や、データベース管理ソフト、ネットワークソフト等のMW(ミドルウェア)等が上記実施形態を実現するための各処理の一部を実行しても良い。
【0125】
さらに、本発明における記憶媒体は、コンピュータと独立した媒体に限らず、LANやインターネット等により伝送されたプログラムをダウンロードして記憶又は一時記憶した記憶媒体も含まれる。
【0126】
また、記憶媒体は1つに限らず、複数の媒体から上記実施形態における処理が実行される場合も本発明における記憶媒体に含まれ、媒体構成は何れの構成であっても良い。
【0127】
尚、本発明におけるコンピュータは、記憶媒体に記憶されたプログラムに基づき、上記実施形態における各処理を実行するものであって、パソコン等の1つからなる装置、複数の装置がネットワーク接続されたシステム等の何れの構成であっても良い。
【0128】
また、本発明におけるコンピュータとは、携帯情報端末、携帯電話機、パーソナルコンピュータなどに限らず、家庭電化製品等に含まれる演算処理装置、マイコン等も含み、プログラムによって本発明の機能を実現することが可能な機器、装置を総称している。
【符号の説明】
【0129】
1…制御装置、2A…不揮発性記憶装置、2B…揮発性記憶装置、3…入力装置、4…表示装置、5…I/O装置、10…バス、21…文字認識辞書情報記憶部、22…基本辞書情報記憶部、23…予測辞書情報記憶部、24…学習辞書情報記憶部、25…インデックス情報記憶部、26…予測候補情報記憶部、31…記憶処理部、32…文字認識部、33…検索部、34…予測候補出力部、35…表示順序処理部、36…辞書編集部、37…表示処理部。
【技術分野】
【0001】
本発明は、ユーザが望む文字や文字列を予測する機能を有する文字列予測プログラムおよび情報処理装置に関する。
【背景技術】
【0002】
従来、携帯情報端末(PDA: Personal Digital Assistant)においては、文字入力方式として、タッチパネルに対してスタイラスペン等を用いて手書きにより文字列を入力する方式(以下、「手書き入力方式」と称す。)を採用するものが一般的であった。その後、携帯電話機に見られるように、個々の文字が割り付けられているダイヤルキー(テンキー)やQWERTY配列のキーボードのキーを押し下げる方式(以下、「キー押下入力方式」と称す。)が一般的になるにつれ、「手書き入力方式」による文字列の入力はあまり利用されなくなっていった。その理由としては、以下のことが挙げられる。
【0003】
「キー押下入力方式」を採用する機器では、入力されるかなの文字や文字列を単漢字や単文節に変換する変換処理のほか、例えば変換後の文字や文字列をもとにユーザが望むであろう文章の一部を予測する「予測変換」や、予測された文章の一部を確定した後、これに続くものとしてユーザが望むであろう文章の一部をさらに予測する「連携予測変換」が実現され、少ないキー操作で所望の文章を早く簡単に作成することができた。
【0004】
これに対し、「手書き入力方式」を採用する機器は、一般に、例えば漢字混じりの文字列(漢字とひらがなとを含む文字列)が入力された場合、上述したような「予測変換」や「連携予測変換」は容易には行えなかった。このため、ユーザは漢字を手書きで入力する毎に、認識される文字を決定する処理又は選択してから決定する処理を行わなければならず、送りがななどについても一字ずつ手書きで入力しなければならなかった。
【0005】
なお、特許文献1には、「手書き入力方式」の機器において、入力される漢字からユーザが望む漢字の文字列を予測する文字列予測方法が開示されている。また、特許文献2には、入力される漢字などから後続の文字列を予測する「文字列予測部」と、予測された文字列がひらがなである場合に漢字を含む文字列に変換する「かな漢字変換部」とを備えた文字列予測装置が開示されている。
【先行技術文献】
【特許文献】
【0006】
【特許文献1】特開平9−16586号公報(図1〜図7等)
【特許文献2】特開平8−255158号公報(図3、図4等)
【発明の概要】
【発明が解決しようとする課題】
【0007】
上述の特許文献1,2の技術は、「手書き入力方式」の機器への適用を示すものであるが、以下のような問題がある。
【0008】
特許文献1の技術では、入力される文字列から予測される文字列を得るためには辞書の全体を検索する必要があるため、CPUの処理を占有し、携帯情報端末などのCPUクロック周波数の低い組込み機器の場合には、「キー押下入力方式」の機器に比べ、検索結果を得るまでに長時間を要し、その結果、入力操作が遅くなってしまう。
【0009】
一方、特許文献2の技術では、「手書き入力方式」で入力される文字列が例えばひらがなである場合、「かな漢字変換部」と「文字列予測部」の両方の機能を用いて検索が行われるため、特許文献1の場合と同様、CPUの処理を占有し、携帯情報端末などのCPUクロック周波数の低い組込み機器の場合には、「キー押下入力方式」の機器に比べ、検索結果を得るまでに長時間を要し、その結果、入力操作が遅くなってしまう。さらに、特許文献2の技術では、「かな漢字変換部」および「文字列予測部」のそれぞれが辞書を有しているため、携帯電話機などのROM領域に容量制限のある組込み機器の場合には、このROM領域を辞書により圧迫する可能性がある。
【0010】
本発明は上記実情に鑑みてなされたものであり、限られた記憶領域や同じ構造の辞書を有効に利用しつつ、検索処理の負荷の増大を抑え、入力される文字列が漢字等を含むか否かにかかわらずユーザが望む後続の文字列を素早く予測することが可能な文字列予測プログラムおよび情報処理装置を提供することを目的とする。
【課題を解決するための手段】
【0011】
本発明の一態様による文字列予測プログラムは、手書きによる文字列の入力が可能な入力装置と、情報を記憶する記憶媒体と、情報を画面に表示する表示装置とを備えたコンピュータに、1)かな文字以外を含む文字列の表記と当該文字列の読みの前方の一部を示すかな文字列とを対応付けた情報がコード順に配列され、かつコード順の配列方向に複数のブロックに区分され、各ブロックには前記情報とブロック識別情報とが付与されている辞書データ部と、2)前記辞書データ部に含まれる前記かな文字列の少なくとも前方の一部のかな文字列とかな文字以外の文字列とを対応付けた情報を含み、前記かな文字以外の文字列がコード順に配列される第1のインデックスと、3)前記ブロック識別情報と当該識別情報により指定されるブロックの先頭に位置するかな文字列とを対応付けた情報を含み、前記かな文字列がコード順に配列される第2のインデックスとを、前記記憶媒体の所定の記憶領域に記憶させる記憶処理機能と、前記入力装置により入力される手書きの文字列を認識する認識機能と、前記識別機能により識別される文字列にかな文字以外の文字列が含まれているか否かを判定し、かな文字以外の文字列が含まれている場合に、当該かな文字以外の文字列が含まれる文字列に続く文字列を予測する形態である第1の予測処理として、前記認識したかな文字以外の文字列を前記第1のインデックスの中から検索し、当該かな文字以外の文字列の読みの前方の一部を示すかな文字の少なくとも一つを選択し、該選択したかな文字が含まれるブロック識別情報を前記第2のインデックスから検索し、さらに当該検索したブロック識別情報に指定される前記辞書データ部のブロックの中から前記認識したかな文字以外の文字列が含まれる文字列の表記を予測文字列候補として検索し、一方、前記認識機能により認識される文字列にかな文字以外の文字列が含まれていない場合に、当該かな文字列に続く文字列を予測する形態である第2の予測処理として、前記認識したかな文字列を前記第2のインデックスの中から検索し、当該かな文字列が含まれるブロック識別情報を前記第2インデックスから検索し、さらに当該検索したブロック識別情報に指定される前記辞書データ部のブロックの中から前記認識したかな文字列に対応する文字列の表記を予測文字列候補として検索する検索機能と、前記検索機能により検索される文字列の表記を前記認識機能により認識される文字列に対する予測文字列候補として前記表示装置の画面に表示させる表示処理機能とを実現させるための文字列予測プログラムである。
【発明の効果】
【0012】
本発明によれば、限られた記憶領域や同じ構造の辞書を有効に利用しつつ、検索処理の負荷の増大を抑え、入力される文字列が漢字等を含むか否かにかかわらずユーザが望む後続の文字列を素早く予測することが可能となる。
【図面の簡単な説明】
【0013】
【図1】本発明の一実施形態に係る情報処理装置の構成の一例を示す図。
【図2】「漢字」を手書きで入力した場合の表示装置の画面上での予測変換等の動作の例を示す図。
【図3】「ひらがな」を手書きで入力した場合の表示装置の画面上での予測変換等の動作の例を示す図。
【図4】「漢字とひらがな」を手書きで入力した場合の表示装置の画面上での予測変換等の動作の例を示す図。
【図5】検索部による検索の動作の一例を示す概念図。
【図6】各種辞書の辞書データ部のデータ構造の例を表形式で示す図。
【図7】漢字インデックスの構成例を表形式で示す図。
【図8】予測変換候補出力画面の一例を示す図。
【図9】予測辞書の詳細例を表形式で示す図。
【図10】基本辞書の詳細例を表形式で示す図。
【図11】予測変換候補表示に係る動作の一例を示すフローチャート。
【図12】かな予測処理による予測変換候補の表示に係る動作の一例を示すフローチャート。
【図13】漢字予測処理による予測変換候補の表示に係る動作の一例を示すフローチャート。
【発明を実施するための形態】
【0014】
以下、図面を参照して、本発明の一実施形態について説明する。
なお、本願明細書でいう「文字列」とは、文字が1つのみの場合もあり得るものとする。「かな」とは、ひらがな又はカタカナを指す。「かな以外」とは、漢字、数字、英字だけではなく、記号、特殊文字なども含んでいることを示す。
【0015】
図1は、本発明の一実施形態に係る情報処理装置の構成の一例を示す図である。図1(a)は情報処理装置のハードウェア構成の一例を示し、図1(b)は情報処理装置に搭載されるコンピュータプログラムとしてのソフトウェアの構成の一例を示している。
【0016】
図1(a)に示す情報処理装置は、例えば、携帯電話機や携帯情報端末など、組込みシステムとして実現するのに適した機器に相当するものであり、実質的にはプログラムを実行するコンピュータとして動作する。この情報処理装置は、制御装置1、不揮発性記憶装置2A、揮発性記憶装置2B、入力装置3、表示装置4、およびI/O装置5を備えている。これらの要素は、バス10により相互に接続される。
【0017】
制御装置1は、例えばCPU等のプロセッサに相当するものであり、本装置全体の制御を司る。この制御装置1は、例えば、不揮発性記憶装置2Aに記憶されるプログラムやデータを読み出したり、読み出したプログラムやデータを揮発性記憶装置2Bへロードして各種の処理を実行したりする。さらに、制御装置1は、例えば、入力装置3を通じて入力されるデータや表示装置4へ出力するデータを不揮発性記憶装置2A、揮発性記憶装置2B、もしくは外部I/O装置5との間で送受する制御を行ったり、外部I/O装置5を通じて外部のネットワークから取得されるデータを不揮発性記憶装置2A等に記憶させる処理を行ったりする。
【0018】
不揮発性記憶装置2Aは、例えばフラッシュメモリなどの書換え可能な半導体メモリ、もしくはハードディスクドライブに相当するものである。この不揮発性記憶装置2Aは、本実施形態に係る文字列予測プログラムや、当該プログラムが使用する各種の辞書やインデックス(後述)などを含むデータを記憶している。
【0019】
揮発性記憶装置2Bは、例えばRAMなどの半導体メモリに相当するものである。この揮発性記憶装置2Bは、制御装置1の作業領域として使用され、不揮発性記憶装置2Aからロードされるプログラムやデータを記憶する。
【0020】
入力装置3は、表示装置4上に配置され、ペンタブレットもしくはタッチパネルを形成している。このペンタブレットもしくはタッチパネル上の所定の領域内において、スタイラスペンもしくは指先を押し当てながら文字を描く操作を行うことにより、手書きによる文字や文字列の入力が達成される。本実施形態では、ペンタブレットに対しスタイラスペンを用いて入力を行う場合を例にとって説明する。
【0021】
表示装置4は、例えば液晶ディスプレイ装置であり、入力装置3を通じて手書きにより入力される文字の筆跡を第1の表示領域に表示したり、入力後に認識された文字列の候補を第2の表示領域に表示したり、候補の中から自動もしくは手動により選択された文字列を第3の表示領域に表示したり、表示されている文字列をもとにユーザが望むものとして予測された文字列を第4の表示領域に表示したりする。
【0022】
I/O装置5は、外部のネットワークを通じて辞書などをダウンロードして不揮発性記憶装置2Aへ送ったりする。
【0023】
図1(b)には、上記不揮発性記憶装置2Aに格納された文字列予測プログラムおよびデータの記憶部が示されている。文字列予測プログラムには、記憶処理部31、文字認識部32、検索部33、予測候補出力部34、表示順序処理部35、辞書編集部36、および表示処理部37が備えられる。文字列予測プログラムが使用するデータの各記憶部としては、文字認識辞書情報記憶部21、基本辞書情報記憶部22、予測辞書情報記憶部23、学習辞書情報記憶部24、インデックス情報記憶部25、および予測候補情報記憶部26が設けられる。そのほか、図示しないが、ユーザ辞書情報記憶部、ダウンロード辞書情報記憶部(以下、「DL辞書記憶部」と称す。)、および連携予測辞書記憶部が設けられる。なお、これらの記憶部内のデータは、揮発性記憶装置2Bにロードされた際にもそれぞれ同じ記憶部(記憶領域)が確保される。
【0024】
記憶処理部31は、不揮発性記憶装置2Aから、1)「かな以外」を含む文字列(例えば、「かな以外」とかなとを含むかな混じりの文字列や、「かな以外」のみの文字列)の表記と当該文字列の少なくとも一部の読み又は見出しを示すかなの文字列とを対応付けた情報を含み、前記かなの文字列がコード順に配列され、当該情報がコード順の配列方向に複数のブロックに区分される辞書データ部と、2)前記辞書データ部に含まれる前記かなの文字列の少なくとも先頭から一部の文字列と「かな以外」の文字列とを対応付けた情報を含み、前記かな以外の文字列がコード順に配列される第1のインデックス(以下、「漢字インデックス」と称す。)と、3)前記辞書データ部のブロックを指定するブロック識別情報(ブロック番号)と当該識別情報により指定されるブロックの先頭に位置するかなの文字列とを対応付けた情報を含み、前記かなの文字列がコード順に配列される第2のインデックス(以下、「ヨミインデックス」と称す。)とを読み出し、揮発性記憶装置2B内の所定の記憶領域にロードして記憶させる機能である。なお、漢字インデックス、ヨミインデックス、および辞書データ部は、辞書を構成し、種類が異なる辞書毎に存在するものである。また、前記ブロックは、辞書データ部の記憶領域において、最も効率よく辞書内の文字列が検索できる容量ごとに分けた領域の一つを指す。
【0025】
ここで、ブロックについてより詳細に説明する。
ブロックとは、記憶デバイスおよびそのドライバによって、物理的あるいは論理的に定まる、統計的にもっともアクセス時間が少なくなるよう推奨される記憶容量の管理単位である。本実施形態では、1ブロックに辞書内の各レコードが収まるように記録される。レコードは、順次コード順に記録されもし、1レコードがブロックの境界にまたがる場合は、その部分は未使用として、次のブロックの先頭より記録される。これらのブロックは、連続した整数で表されるブロック番号を有する。また、本実施形態では、ヨミインデックスによって、その語の含まれる記憶部のブロックが限定されることによって検索時間を短く終わらせることができる。これを他の方法で実施しようとすると、もし検索対象の語が辞書に含まれていない場合、全部の辞書を検索することになり、非常に時間がかかることになる。
【0026】
文字認識部32は、入力装置3により入力される文字列を認識する機能である。具体的には、文字認識部32は、手書きにより入力された文字を文字認識辞書情報記憶部21に記憶される文字認識辞書をもとに手書き文字の認識を行い、この認識した単一又は複数の認識結果を、表示処理部37を通じて表示装置4における画面上の認識文字結果表示用ウインドウ42の領域に表示させる。
【0027】
検索部33は、文字認識部32により認識される文字列に「かな以外」の文字列が含まれている場合に、前記漢字インデックスの中から当該「かな以外」の文字列に対応するかなの文字列を検索し、さらに前記ヨミインデックスの中から当該検索したかなの文字列に対応するブロック識別情報を検索し、さらに当該検索したブロック識別情報に指定される前記辞書データ部のブロックの中から前記検索したかなの文字列に対応する文字列の表記を検索し、一方、文字認識部32により認識される文字列に「かな以外」の文字列が含まれておらず、かなの文字列が含まれている場合に、前記漢字インデックスを用いずに前記ヨミインデックスの中から当該かなの文字列に対応するブロック識別情報を検索し、さらに当該検索したブロック識別情報に指定される前記辞書データ部のブロックの中から前記検索したかなの文字列に対応する文字列の表記を検索する機能である。
【0028】
具体的には、検索部33は、文字認識部32による手書き入力文字の認識結果から入力文字としての確定前の文字列に「かな以外」が含まれるか否かを判定し、その判定結果によって、この文字列に続く文字の予測形態を、かな文字列に続く文字列を予測する形態である「かな予測処理」と、「かな以外」が含まれる文字列に続く文字列を予測する形態である「漢字予測処理」との間で切り替える機能を有する。また、検索部33は、候補文字表示用ウインドウ44に表示可能な数の予測変換候補を得るために各種辞書の検索を行う機能を有する。検索部33は、「漢字予測処理」により予測変換候補を得るためには、各種辞書について漢字インデックスを検索した上で、ヨミインデックスを検索し、さらに辞書データ部を検索する。一方、「かな予測処理」により予測変換候補を得るためには、ヨミインデックスを検索した上で、辞書データ部を検索する。すなわち、本実施形態では、「かな予測処理」に使用されるヨミインデックスおよび辞書データ部が「漢字予測処理」においても有効に利用される。このため、「漢字予測処理」のために専用のヨミインデックスおよび辞書データ部を個々に設ける必要がなく、辞書データ部に比べてデータ量が極端に少ない漢字インデックスを加えるだけで、限られた記憶領域を有効に利用し、入力される文字列が「かな以外」を含むか否かにかかわらず予測変換候補を素早く出力させることを実現している。
【0029】
また、検索部33は、漢字インデックス、ヨミインデックス、および辞書データ部のブロックのそれぞれの中においてコード順に配列された個々の文字列に対しバイナリサーチを実施することにより所望のデータが存在する位置を求める機能を有する。これにより、検索速度を一層高めることが可能となる。
【0030】
予測候補出力部34は、かな予測処理や漢字予測処理により得た予測変換候補を、表示処理部37を通じて表示装置4における画面上の候補文字表示用ウインドウ44に表示させる機能である。
【0031】
表示順序処理部35は、予測候補情報記憶部26に格納された予測変換候補の表示順を設定する機能である。
【0032】
辞書編集部36は、学習辞書情報記憶部24に記憶される学習辞書の編集を行う機能である。
【0033】
表示処理部37は、例えば、検索部33により検索される文字列の表記を候補として表示装置4の画面上に表示させるなど、各種の情報を表示させる機能である。
【0034】
文字認識辞書情報記憶部21は、手書きによる文字を認識するための文字認識辞書を記憶する。この文字認識辞書は、二次元パターンと文字との対応付けを示す情報を有する。
【0035】
基本辞書情報記憶部22は、基本辞書の本体となる辞書データ部を記憶する。この基本辞書の辞書データ部は、1列目のデータとしてかなの文字列を備え、2列目のデータとして、前記1列目のデータのかな文字列に対応する、「かな以外」を含む文字列(例えば、「かな以外」とかなとを含むかな混じりの文字列や、「かな以外」のみの文字列)を備えており、コード順の配列方向へ複数のブロックに区分された形態で記憶されている。この構造により、かなの文字列を「かな以外」を含む文字列に変換することができる。特に、この基本辞書の辞書データ部においては、1列目のデータであるかな文字列は、2列目のデータである「かな以外」を含む文字列の読みの全てをかな文字列にしたものとなっている。
【0036】
予測辞書情報記憶部23は、予測辞書の本体となる辞書データ部を記憶する。この予測辞書の辞書データ部は、前述の基本辞書の辞書データ部と同様の構造を有する。但し、この予測辞書の辞書データ部においては、1列目のデータであるかな文字列は、2列目のデータである「かな以外」を含む文字列の読みの前方の一部(例えば、当該文字列の後方を省略して読んだときの読みである省略読み)をかな文字列にしたものとなっている。この場合のかな文字列は、例えば1〜3文字からなる。
【0037】
学習辞書情報記憶部24は、学習辞書の本体となる辞書データ部を記憶する。この学習辞書の辞書データ部は、前述の各辞書の辞書データ部と同様の構造を有する。但し、この学習辞書の辞書データ部は、かなの文字列を「かな以外」を含む文字列に変換するための第1の学習辞書データ部と、「かな以外」を含む文字列をかなの文字列に変換するための第2の学習辞書データ部とから構成されている。また、この学習辞書の辞書データ部は、文字列毎にユーザが入力した頻度を示す情報も備えている。
【0038】
また、図示しないユーザ辞書情報記憶部は、ユーザ辞書の本体となる辞書データ部を記憶する。このユーザ辞書の辞書データ部は、前述の基本辞書や予測辞書や学習辞書の辞書データ部と同様の構造を有する。但し、このユーザ辞書の辞書データ部は、1列目のデータと2列目のデータ(例えば、ヨミと表記)をユーザが任意に登録できるようになっている。
【0039】
また、図示しないDL辞書情報記憶部は、ダウンロード辞書(以下、「DL辞書」と称す。)の本体となる辞書データ部を記憶する。このDL辞書の辞書データ部は、前述の各辞書の辞書データ部と同様の構造を有する。特に、DL辞書は、I/O装置5からネットワークを通じて外部からダウンロードすることができる。DL辞書は、当該辞書もしくは本文字列予測プログラムのプロバイダ、あるいは本情報処理装置のメーカなどがネットワークを通じてユーザに提供する。
【0040】
インデックス情報記憶部25は、漢字インデックスおよびヨミインデックスを記憶する。漢字インデックスは、2列目のデータとして、辞書データ部の1列目のデータ(かなの文字列)の前方2文字までの文字列(但し、3文字以上も可能)を備え、1列目のデータとして、前記辞書データ部の1列目のデータに対応する2列目のデータ(かな以外を含む文字列)の前方1文字を備えている。すなわち、漢字インデックスは、辞書データ部から収集したデータで構成されている。ヨミインデックスは、2列目のデータとして、辞書データ部のブロックを指定するブロック識別情報を備え、1列目のデータとして、そのブロックの第1列目のデータであってコード順における先頭レコードに位置するデータ(かなの文字列)を備えている。
【0041】
予測候補情報記憶部26は、予測変換候補として表示させる情報を記憶する。
【0042】
ここで、図2〜図4を参照して、「漢字」、「ひらがな」、「漢字とひらがな」を、それぞれ手書きで入力した場合の表示装置4の画面上での予測変換等の動作の例について説明する。
【0043】
なお、表示装置4の画面上に表示される文字の認識結果である認識文字候補の選択方法として、自動選択モードと手動選択モードが用意されている。モードは、画面上に表示される設定メニューからユーザが自由に選択できるようになっている。自動選択モードでは、ペンがパネルから離れたときに、認識文字候補の最上位が自動的に選択され、対応する予測候補が表示される。一方、手動選択モードでは、ペンがパネルから離れたときに、認識文字候補が表示され、ユーザは候補を選択し、対応する予測候補が表示される。
【0044】
図2は、「漢字」を手書きで入力した場合の表示装置4の画面上での予測変換等の動作の例を示す図である。
【0045】
まず、図2(a)に示すように、表示装置4に画面が表示され、この画面の右下にある手書き文字入力用ウインドウ41内に、ペンタッチにより手書きによる入力が開始されると、文字認識エンジンに従い、入力の軌跡をチェックし表示装置4の手書き文字入力用ウインドウ41からタッチペンが離れるまで、入力文字が文字認識エンジンに記憶されている文字パターンと比較し文字認識辞書情報記憶部21に記憶される辞書とを照合して、手書き入力された文字の認識結果を当該辞書から単一又は複数検索する。上記文字認識エンジンは当該技術で一般的に用いられるものであればよい。
【0046】
本実施形態の自動選択モードにおいては、図2(a)に示すように、手書き文字入力用ウインドウ41内に、ペンタッチにより漢字の「大」が入力されると、表示装置4の画面の左下にある認識文字結果表示用ウインドウ42内に、手書き入力された文字の認識結果が表示され、表示装置4の画面の上部にある文字表示用ウインドウ43内に、文字認識エンジンにより最も入力文字に近いであろう文字が、図2(b)に示すように表示され、さらに仮確定認識文字「大」に対する漢字予測処理により、表示装置4の画面の中央部の候補文字表示用ウインドウ44内に、予測変換候補の文字列「大阪」、「大きな」、「大人」、「大幅」が表示される。次に、予測変換候補の文字列のうち「大阪」がユーザにより選択されると、図2(c)に示すように、連携予測変換候補の文字列「府」、「府立」、「駅」等が表示される。
【0047】
図3は、「ひらがな」を手書きで入力した場合の表示装置の画面上での予測変換等の動作の例を示す図である。
【0048】
まず、図3(a)に示すように、手書き文字入力用ウインドウ41内に、ペンタッチにより手書きによる一文字の文字である「お」が入力されると、次に、図3(b)に示すように、認識結果である文字の候補の中から文字が自動選択または手動選択され、選択された文字が仮確定認識文字「お」にされると、かな予測処理により、表示装置4の画面の中央部の候補文字表示用ウインドウ44内に、予測変換候補の文字列「お疲れ」、「お疲れ様」が表示される。
【0049】
図4は、「漢字とひらがな」を手書きで入力した場合の表示装置4の画面上での予測変換等の動作の例を示す図である。
【0050】
図4(a)では、図2(a),(b)と同様に、手書き文字入力用ウインドウ41内に漢字の「大」が入力された後に仮確定文字「大」に対する予測変換候補が候補文字表示用ウインドウ44に表示され、次に、図4(b)に示すように、手書き文字入力用ウインドウ41内に、ひらがなで「き」が手書きで入力されると、図4(c)に示すように、文字表示用ウインドウ43内に、仮確定文字の「大き」に対する予測変換候補が表示され、候補の中から「い」がユーザにより選択されると、図4(d)に示すように、候補文字表示用ウインドウ44内に、仮確定文字「大きい」に対する連携予測変換候補の文字列「。」、「?」、「!」、「のに」、「ので」が表示される。
【0051】
ここで、図5を参照して、検索部33による検索の動作の一例について説明する。
【0052】
検索部33は、検索処理において各種の辞書を用いるが、ここでは予測辞書を用いる処理のみに焦点を絞って説明する。なお、予測辞書は、予測辞書用漢字インデックスと、予測辞書用ヨミインデックスと、予測辞書データ部とからなる。これら3つの情報は、共通して、1列目のデータとして文字列(A)を備えるとともに、2列目のデータとして文字列(B)を備えている。文字列(A)は、検索キーとなる文字列との照合に供されるデータであり、文字列(B)は、検索結果として出力するためのデータである。
【0053】
最初に、検索部33は、変換対象文字にかな以外が含まれているか否かの漢字予測判定を行う。
【0054】
判定の結果、かな以外が含まれている場合には、漢字予測処理を行う。
【0055】
漢字予測処理において、例えば、漢字“山”が含まれている場合、検索部33は、予測辞書用漢字インデックスの1列目のデータである文字列(A)の中からバイナリサーチにより漢字の“山”が存在する位置を求め、この“山”に対応するかなの文字列“サン”,“ヤ”,“ヤマ”を2列目のデータである文字列(B)の中から抽出する。
【0056】
次に、検索部33は、予測辞書用ヨミインデックスの1列目のデータである文字列(A)の中からバイナリサーチによりかなの文字列“サン”,“ヤ”,“ヤマ”が存在する位置をそれぞれ求め、これらにそれぞれ対応するブロック番号を2列目のデータである文字列(B)の中から抽出する。例えば、“サン”は、文字列(A)の中の個々のかな文字列のうち、文字コード順で“サマ”と“サンカ”との間にあるため、“サマ”に対応するブロック番号94を2列目のデータである文字列(B)の中から抽出する。また、かな文字列“サンカ”は、“サン”を含むため、“サンカ”に対応するブロック番号95についても2列目のデータである文字列(B)の中から抽出する。なお、“ザ”は、“サン”よりも下位の文字コードであり、“ザ”は、“サン”を含まないため、抽出しない。
【0057】
続いて、検索部33は、辞書データ部のブロック番号94のブロックにおける1列目のデータである文字列(A)の中からバイナリサーチによりかなの文字列“サン”が含まれる文字列の位置を求めるとともに、辞書データ部のブロック番号95のブロックにおける1列目のデータである文字列(A)の中からバイナリサーチにより、かなの文字列“サン”を含む文字列の位置を求め、これらにそれぞれ対応する表記を2列目のデータである文字列(B)の中から“山”を含む文字列を抽出する。例えば、予測データ部の文字列(A)の中の個々のかな文字列のうち、“サンイ”は、“サン”を含む文字列であり、“サンイ”に対応する文字列(B)は、“山“を含むため“山陰”を抽出、この“山陰”を、“山”の予測変換候補の一つとして出力する。
【0058】
また、図示しない辞書データ部の他のブロックや、予測辞書以外の各種の辞書における辞書データ部のブロックからも、同様な手法により“山”の予測変換候補が出力される。
【0059】
一方、上記判定の結果、かな以外が含まれていない場合には、かな予測処理を行う。
【0060】
検索部33は、例えば、“サン”が含まれている場合、予測辞書用ヨミインデックスの1列目のデータである文字列(A)の中からバイナリサーチによりかなの文字列“サン”が存在する位置をそれぞれ求め、2列目のデータである文字列(B)の中から該当するブロック番号を抽出し、続いて、辞書データ部の該当するブロックにおける1列目のデータである文字列(A)の中からバイナリサーチによりかなの文字列“サン”が存在する位置を求め、対応する表記を2列目のデータである文字列(B)の中から抽出し、“サン”の予測変換候補の一つとして出力する。
【0061】
このような仕組みにより、辞書全体を検索するよりも、より素早く検索することができる。
【0062】
次に、図6〜図10を参照して、各種辞書の漢字インデックス、ヨミインデックス、および辞書データ部のデータ構造の詳細について説明する。
【0063】
各種辞書の漢字インデックス、ヨミインデックス、および辞書データ部は、共通して、1列目のデータとして文字列(A)、2列目のデータとして文字列(B)、3列目以降のデータとして属性を、それぞれ備えている。属性には、属性(1),属性(2),属性(3)の3種類がある。また、各辞書、各辞書毎の漢字インデックスは、1列目、2列目の文字列が同一の重複する情報は含まない。
【0064】
このようにデータ構造を共通化することにより、限られた記憶領域を無駄なく有効に使用でき、検索速度を向上させることができる。
【0065】
図6は、同実施形態における情報処理装置に記憶される各種辞書の辞書データ部のデータ構造の例を表形式で示す図である。
図6(a)の例に示される基本辞書の辞書データ部は、前述した通り基本辞書情報記憶部22に記憶されるもので、文字列(A)としてかなの文字列(…、サザンカ、…、サンカ、…、サンカク、…)を備え、文字列(B)として表記を示す「かな以外」を含む文字列(…、山茶花、…、参加、…、△、…)を備えており、複数のブロックに区分された形態で記憶されている。また、属性(1)として品詞を示す情報(…、普通名詞、…、普通名詞、…、普通名詞、…)と、属性(2)として優先度(予測変換候補の表示順の優先度)を示す情報(…、低優先、…、通常、…、通常、…)とを備えている。
【0066】
図6(b)の例に示される予測辞書の辞書データ部は、前述した通り予測辞書情報記憶部23に記憶されるもので、文字列(A)としてかなの文字列(…、サン、サン、…、サンイ、…)を備え、文字列(B)として表記を示す「かな以外」を含む文字列(…、三角、III等、…、山陰、…)を備えており、複数のブロックに区分された形態で記憶されている。また、属性(1)として品詞を示す情報(…、普通名詞、普通名詞、…、固有名詞、…)と、属性(2)として優先度(予測変換候補の表示順の優先度)を示す情報(…、通常、低優先、…、通常、…)とを備えている。
【0067】
図6(b)に示した例では、表記「三角」に対応する文字列「サン」は省略読みであり、表記「山陽新幹線」に対応する文字列「サンヨ」は省略読みである。つまり、手書き入力により「サン」を入力した場合には、これに続く文字を入力しなくとも、予測変換候補として「三角」が表示され、手書き入力により「サンヨ」を入力した場合には、これに続く文字を入力しなくとも、予測変換候補として「山陽新幹線」が表示されることになる。
【0068】
図6(c)の例に示される学習辞書の辞書データ部は、前述した通り学習辞書情報記憶部24に記憶されるもので、文字列(A)としてかなの文字列(…、サ、…、ヤ、…)を備え、文字列(B)としてとして表記を示す「かな以外」を含む文字列(…、山さん、…、山手線沿い、…)を備えており、複数のブロックに区分された形態で記憶されている。但し、図示されていないが、学習辞書の辞書データ部には、文字列(A)として「かな以外」を含む文字列を備え、文字列(B)としてかなの文字列を含む文字列を備えた情報も存在する。また、属性(3)として頻度を示す情報(…、5、…、2、…)を備えている。
【0069】
図6(c)の例に示されるように、文字列(A)と文字列(B)との組合せは、かな漢字変換による入力文字の確定にかかる頻度の高い順に配列されている。なお、頻度を採用する代わりに優先度を採用するようにしてもよい。また、前述した組み合わせの配列は、前回利用、つまり前回の入力文字として確定した文字を最上部に表示する配列としてもよい。
【0070】
図6(d)の例に示されるユーザ辞書の辞書データ部は、前述した通り図示しないユーザ辞書情報記憶部に記憶されるもので、文字列(A)としてかなの文字列(…、ア、…)を備え、文字列(B)として表記を示す「かな以外」を含む文字列(…、山陽新幹線、…)を備えており、複数のブロックに区分された形態で記憶されている。また、属性(1)として品詞を示す情報(…、普通名詞、…)と、属性(2)として優先度(予測変換候補の表示順の優先度)を示す情報(…、通常、…)とを備えている。文字列(A)の「ア」と文字列(B)の「山陽新幹線」は、ユーザが任意に登録したものである。
【0071】
図6(e)の例に示されるDL辞書の辞書データ部は、前述した通り図示しないDL辞書情報記憶部に記憶されるもので、例えば「関西弁辞書」等の方言辞書や、「医学用語辞書」等の専門辞書がある。
【0072】
DL辞書は、文字列(A)としてかなの文字列(…、サンカクコ、…)を備え、文字列(B)として表記を示す「かな以外」を含む文字列(…、△湖、…)を備えており、複数のブロックに区分された形態で記憶されている。また、属性(1)として品詞を示す情報(…、固有名詞、…)と、属性(2)として優先度(予測変換候補の表示順の優先度)を示す情報(…、通常、…)とを備えている。このDL辞書は、ユーザがダウンロードしたものである。
【0073】
そのほか、記憶装置2Aには、図示しない連携予測辞書が備えられる。この連携予測辞書は、例えば、予測変換候補として選択された表記である確定表記と、当該確定表記に連なる表記である連語・連想表記と、読みを示す文字列(ヨミ文字列)と、品詞と、優先度とが対応付けられる情報である。この連携予測辞書における確定表記および連語・連想表記は「かな以外の文字」を含む。一方、連携予測辞書におけるヨミ文字列は、かな文字である。
【0074】
図7は、同実施形態における情報処理装置に記憶される漢字インデックスの構成例を表形式で示す図である。
図7(a)の例に示される基本辞書用漢字インデックスは、前述した通りインデックス情報記憶部25に記憶されるもので、文字列(A)として「かな以外」を含む文字列(…、山、山、山、山、…)を備え、文字列(B)としてかなの文字列(…、サザ、ザン、ヤマ、ワサ、…)を備えている。
【0075】
図7(b)の例に示される予測辞書用漢字インデックスは、前述した通りインデックス情報記憶部25に記憶されるもので、文字列(A)として「かな以外」を含む文字列(…、山、山、山、…)を備え、文字列(B)としてかなの文字列(…、サン、ヤ、ワ、…)を備えている。
【0076】
図7(a)および図7(b)の例では、文字列(B)は、辞書データ部のブロックにおける文字列(A)の文字列の前方2文字までの文字列である。但し、前方2文字までに限ることなく3文字以上とすることも可能である。また、これらの漢字インデックスは、前述した基本辞書や予測辞書の辞書データ部のヨミ文字列および表記の対応関係をもとに予め構築され、文字列(A)の配列は文字コード順とする。但し、文字コード順に限らずにその他のコード順とすることも可能である。
【0077】
図8は、同実施形態における情報処理装置による候補文字表示ウインドウ44の一例を示す図である。図8の上位の文字列から順に、候補文字表示ウインドウ44の左に順番に表示される。
【0078】
この表示例では、「山さん」の表示順位が上であって、「山茶花」の表示順位が下である。この「山茶花」は基本辞書用予測辞書から「山ノ会」や「山っ気」より先に検索されたが、検索元の基本辞書用予測辞書にて対応付けられる優先度が「低優先」であることなどから、表示順序処理部35の処理により「山ノ会」や「山っ気」より表示順位が下となったことを示している。
【0079】
次に、本実施形態の詳細例について説明する。この詳細例では、予測辞書と基本辞書を、漢字インデックス、ヨミインデックスおよびデータ部で構成するものである。
図9は、本発明の実施形態における情報処理装置に記憶される予測辞書の詳細を表形式で示す図である。
この詳細例における予測辞書は、図5においても説明した通り、予測辞書用漢字インデックス、予測辞書ヨミインデックス、および予測辞書データ部により構成される。
図9(a)の例に示される予測辞書用漢字インデックスは、インデックス情報記憶部25に記憶されるもので、文字列(A)として「かな以外」を含む文字列(…、山、山、山、…)を備え、文字列(B)としてかなの文字列(…、サン、ヤ、ヤマ、…)を備えている。
【0080】
図9(b)の例に示される予測辞書用ヨミインデックスは、インデックス情報記憶部25に記憶されるもので、文字列(A)としてかなの文字列(…、サマ、サンカ、ザ、…)を備え、文字列(B)として予測辞書の辞書データ部のブロックを指定するブロック番号(…、94、95、96、…)を備えている。文字列(A)には、文字列(B)のブロック番号により指定されるブロックの先頭に位置するかなの文字列がコード順に配列される。
【0081】
図9(c)の例に示されるブロック番号94の予測辞書データ部のブロックは、予測辞書情報記憶部23に記憶されるもので、文字列(A)としてかなの文字列(サマ、…、…、サンイ,…)を備え、文字列(B)として「かな以外」を含む文字列(様々、…、…、山陰、…)を備えている。
【0082】
図9(d)の例に示されるブロック番号95の予測辞書データ部のブロックは、予測辞書情報記憶部23に記憶されるもので、文字列(A)としてかなの文字列(サンカ、…、…)を備え、文字列(B)として「かな以外」を含む文字列(参画、…、…)を備えている。
【0083】
なお、図9に示される予測辞書の使い方については、図5の例で説明した通りである。
【0084】
図9の構成によれば、予測辞書による検索処理機能が向上し、予測変換候補の検索範囲を狭くすることができるので、予測変換処理にかかる処理負荷を軽減することができる。
【0085】
図10は、本発明の実施形態における情報処理装置に記憶される基本辞書の詳細例を表形式で示す図である。
この詳細例における基本辞書は、図5においても説明した通り、基本辞書用漢字インデックス、基本辞書ヨミインデックス、および基本辞書データ部により構成される。
図10(a)の例に示される基本辞書用漢字インデックスは、インデックス情報記憶部25に記憶されるもので、文字列(A)として「かな以外」を含む文字列(…、山、山、山、山、山、山、…)を備え、文字列(B)としてかなの文字列(…、サザ、サン、ザン、ヤキ、ヤマ、ワサ、…)を備えている。
【0086】
図10(b)の例に示される基本辞書用ヨミインデックスは、インデックス情報記憶部25に記憶されるもので、文字列(A)としてかなの文字列(…、サゲ、ササミ、サシタル、…)を備え、文字列(B)として基本辞書の辞書データ部のブロックを指定するブロック番号(…、401、402、403、…)を備えている。文字列(A)には、文字列(B)のブロック番号により指定されるブロックの先頭に位置するかなの文字列がコード順に配列される。
【0087】
図10(c)の例に示されるブロック番号401の基本辞書データ部のブロックは、基本辞書情報記憶部22に記憶されるもので、文字列(A)としてかなの文字列(サゲ、…、…)を備え、文字列(B)として「かな以外」を含む文字列(下げ、…、…)を備えている。
【0088】
図10(d)の例に示されるブロック番号402の基本辞書データ部のブロックは、基本辞書情報記憶部23に記憶されるもので、文字列(A)としてかなの文字列(…、サザンカ、…)を備え、文字列(B)として「かな以外」を含む文字列(…、山茶花、…)を備えている。
【0089】
なお、図10に示される基本辞書の使い方については、図5の例と同様となるため、その説明を省略する。
【0090】
また、図10の構成によれば、基本辞書による検索処理機能も向上し、予測変換候補の検索範囲を狭くすることができるので、予測変換処理にかかる処理負荷を軽減することができる。
【0091】
また、図9、図10と同様に、学習辞書、ユーザ辞書、DL辞書にも漢字インデッスク、ヨミインデックスを備える。
【0092】
なお、これまでの説明からわかるように、文字列(A)は例えばコード順に配列されているが、文字列(B)はコード順に配列されているわけではない。
【0093】
また、表示すべき複数の候補が、例えば図7中の文字列(A)に示されるような同じ文字列にそれぞれ対応するものである場合、表示順はどのような並び順でも良い。例えば、語の登録順でもよいし、文字列(B)の順でもよい。あるいは候補として出力される順を考慮して任意に調整されてもよい。
【0094】
次に、本実施形態に係る情報処理装置による予測変換処理の動作について説明する。
図11は、同実施形態に係る情報処理装置による予測変換候補表示に係る動作の一例を示すフローチャートである。
まず、入力装置3への所定の操作により、図2(a),図3(a)と同様に文字が入力されると(ステップS1)、文字認識部32は、この入力された文字と文字認識辞書情報記憶部21に記憶される辞書とを照合することで、手書き入力された文字の認識結果の文字を当該辞書から単一又は複数検索し、この検索結果を、表示処理部37を通じて表示装置4の画面の左下にある認識文字結果表示用ウインドウ42内に表示させる(ステップS2)。
【0095】
文字認識部32は、手書き入力された文字の認識結果の文字の検索結果のうち、手書き入力された文字に最も近い検索結果を仮確定認識文字として、表示処理部37を通じて認識文字結果表示用ウインドウ42内の左上に表示させる。ユーザは、この表示された仮確定認識文字が、例えば自身が意図した文字に一致しない場合には(ステップS3のNO)、認識文字結果表示用ウインドウ42内の認識結果の文字のうち仮確定認識文字以外から、例えば自身が意図した文字を当該文字の表示部分へのペンタッチにより選択すると、この選択した文字が新たな仮確定認識文字として画面上の文字表示用ウインドウ43内に表示される(ステップS4)。この段階では、この表示された文字は入力文字として確定しておらず、この状態で、画面内に表示される「決定キー」が表示されている部分をペンタッチすることで、未確定だった文字列が入力済みの文字列として確定する。
【0096】
前述した未確定の状態において、仮確定認識文字に続く文字を入力したい場合には、再度入力画面の手書き文字入力用ウインドウ41内へのペンタッチにより手書きによる一文字の文字入力を行なえばよい。
【0097】
ステップS4の処理がなされた場合、もしくは認識文字結果表示用ウインドウ42内に表示された仮確定認識文字が、ユーザ自身が意図した文字に一致しているために(ステップS3のYES)、ステップS4の処理がなされない場合、検索部33は、仮確定の文字列に「かな以外」の文字が含まれているか否かを判別する(ステップS5)。
【0098】
この判別の結果、文字列に「かな以外」の文字が含まれている場合には(ステップS5のYES)、漢字予測処理がなされ(ステップS6)、文字列に「かな以外」の文字が含まれていない場合には(ステップS5のNO)、かな予測処理がなされる(ステップS7)。
【0099】
ここで、ステップS7のかな予測処理について説明する。
図12は、同実施形態における情報処理装置のかな予測処理による予測変換候補の表示に係る動作の一例を示すフローチャートである。
このかな予測処理では、検索部33は、学習辞書の検索(ステップS21)、ユーザ辞書の検索(ステップS22)、DL辞書の検索(ステップS23)、予測辞書の検索(ステップS24〜S27)、および基本辞書の検索(ステップS28)をこの順序で実行する。各辞書の検索のステップを構成する複数のステップは同様である。ここでは、予測辞書の検索に焦点を絞って複数のステップS24〜S27の処理の詳細について説明する。
【0100】
検索部33は、予測辞書を呼び出すと(ステップS24)、この予測辞書に含まれている予測辞書用ヨミインデックスを検索し(ステップS25)、予測辞書用ヨミインデックスの1列目のデータである文字列(A)の中からバイナリサーチにより対象のかな文字列が存在する位置をそれぞれ求め、それぞれ対応するブロック番号を2列目のデータである文字列(B)の中から抽出する。
【0101】
続いて、検索部33は、抽出したブロック番号によりそれぞれ指定される辞書データ部のブロックを検索し(ステップS26)、当該ブロックにおける1列目のデータである文字列(A)の中からバイナリサーチにより対象のかな文字列が含まれる文字列の位置を求め、それぞれ対応する表記を2列目のデータである文字列(B)の中から抽出し、それらを予測変換候補として所定の記憶領域に格納する(ステップS27)。これらのステップをヨミインデックスの文字列(A)と対象のカナ文字列が一致する間繰り返す。
【0102】
このようなステップS24〜S27の処理は、学習辞書の検索(ステップS21)、ユーザ辞書の検索(ステップS22)、DL辞書の検索(ステップS23)、および基本辞書の検索(ステップS28)においても同様となる。
【0103】
次に、表示順序処理部35は、予測候補情報記憶部26に格納された予測変換候補の情報の検索元の辞書における優先度情報および品詞情報を参照し、この優先度情報の区分および品詞情報で示される品詞の種別に対応する所定の優先度を認識して、予測変換候補の表示順を設定し(ステップS29)、設定した順番に予測変換候補を表示装置4の画面上に表示させる(ステップS30)。表示装置4の画面上に表示された予測変換候補の中から1つのユーザにより候補が選択され(ステップS31)、選択された候補への予測結果の確定入力がなされると(ステップS32)、この選択された候補が画面上の文字表示用ウインドウ44内に表示される。
【0104】
本実施形態では、学習辞書から検索された予測変換候補の表示順位は、表示順序処理部35による処理を経ても他の辞書から検索された予測変換候補の表示順位より高く、予測辞書から検索された予測変換候補の表示順位は、表示順序処理部35による処理を経ても基本辞書から検索された予測変換候補の表示順位より高いとする(ステップS7)。
【0105】
品詞ごとの優先順位の設定方法としては、各種品詞についての優先順位を選択メニューを設けユーザにより設定する手法、文字入力画面における各種入力フィールドの種別に応じて優先する品詞を設定する手法、および、入力された文字の品詞を解析してこの解析結果を記憶し、次に入力されるであろう品詞を選択して当該選択した品詞を予測変換候補として優先表示する文法解析処理により設定する手法が挙げられる。
【0106】
ここで、ステップS6の漢字予測処理について説明する。
図13は、同実施形態における情報処理装置の漢字予測処理による予測変換候補の表示に係る動作の一例を示すフローチャートである。
この漢字予測処理では、検索部33は、学習辞書の検索(ステップS41)、ユーザ辞書の検索(ステップS42)、DL辞書の検索(ステップS43)、予測辞書の検索(ステップS44〜S48)、および基本辞書の検索(ステップS49)をこの順序で実行する。各辞書の検索のステップを構成する複数のステップは同様である。ここでは、予測辞書の検索に焦点を絞って複数のステップS44〜S48の処理の詳細について説明する。
【0107】
検索部33は、予測辞書を呼び出すと(ステップS44)、この予測辞書に含まれている予測辞書用漢字インデックスを検索し(ステップS45)、予測辞書用漢字インデックスの1列目のデータである文字列(A)の中からバイナリサーチにより対象のかな以外の文字が存在する位置をそれぞれ求め、それぞれ対応するかな文字を2列目のデータである文字列(B)の中から抽出する。
【0108】
続いて、検索部33は、この予測辞書に含まれている予測辞書用ヨミインデックスを検索し(ステップS46)、予測辞書用ヨミインデックスの1列目のデータである文字列(A)の中からバイナリサーチにより抽出したかな文字列が存在する位置をそれぞれ求め、それぞれ対応するブロック番号を2列目のデータである文字列(B)の中から抽出する。
【0109】
続いて、検索部33は、抽出したブロック番号によりそれぞれ指定される辞書データ部のブロックを検索し(ステップS47)、当該ブロックにおける1列目のデータである文字列(A)の中からバイナリサーチにより対象のかな文字列が含まれる文字列の位置を求め、それぞれ対応する表記を2列目のデータである文字列(B)の中から抽出し、それらを予測変換候補として所定の記憶領域に格納する(ステップS48)。
【0110】
これらのステップを漢字インデックスの文字列(A)と対象のかな以外の文字列が一致するまで繰り返す。
【0111】
このようなステップS44〜S48の処理は、学習辞書の検索(ステップS41)、ユーザ辞書の検索(ステップS42)、DL辞書の検索(ステップS43)、および基本辞書の検索(ステップS49)においても同様となる。
【0112】
次に、表示順序処理部35は、予測候補情報記憶部26に格納された予測変換候補の情報の検索元の辞書における優先度情報および品詞情報を参照し、この優先度情報の区分および品詞情報で示される品詞の種別に対応する所定の優先度を認識して、予測変換候補の表示順を設定し(ステップS50)、設定した順番に予測変換候補を表示装置4の画面上に表示させる(ステップS51)。表示装置4の画面上に表示された予測変換候補の中から1つの候補が選択され(ステップS52)、選択された候補への予測結果の確定入力がなされると(ステップS53)、この選択された候補が画面上の文字表示用ウインドウ44内に表示される。
【0113】
そして、図11に戻り、辞書編集部36は、選択された結果を学習辞書に登録する。既に登録済の場合は、学習辞書上の頻度を更新する(ステップS11)。そして、辞書編集部36は、学習辞書上の当該選択した文字の情報を前回利用の履歴情報として所定の記憶領域に記憶させる。
【0114】
検索部33は、連携予測辞書の確定表記と確定済みの文字列とを照合することで、連携予測変換候補である連語・連想表記を検索し(ステップS12)、予測候補出力部34は、この検索した候補を、表示処理部37を通じて表示装置4に表示させる(ステップS13)。
【0115】
ユーザが、この表示された連携予測候補のうち、所望の候補の表示部分へのペンタッチにより選択すると(ステップS14)、この選択した候補への連携予測結果の確定入力がなされたことになり(ステップS15)、この選択した候補が画面上の文字表示用ウインドウ43内に表示されることになり、この選択した候補が画面上の文字表示用ウインドウ43内に表示される。辞書編集部36は、選択済みの候補の検索元の辞書および学習辞書上の頻度を更新する(ステップS16)。辞書編集部36は、学習辞書上の当該選択した文字の情報を前回利用の履歴情報として所定の記憶領域に記憶させる。
【0116】
手書きによる入力が終了していない場合には(ステップS17のNO)、ステップS1の処理に戻り、手書きによる入力が終了した場合には(ステップS17のYES)、一連の処理が終了する。
【0117】
以上のように、本発明の実施形態における情報処理装置では、「かな以外」を含む文字列が手書き入力された場合、この入力された文字の読みを示す表記を各種漢字インデックスから検索し、この検索結果に対応して、かつ、手書き入力された「かな以外」の字を含む表記を各種辞書から検索するので、従来の予測変換候補の表示のための構成と比較して、専用の辞書を新たに設ける必要なしに従来より用いられる基本辞書や予測辞書を有効に活用して、手書き入力された「かな以外」を含む文字列にもとづく予測変換処理や連携予測変換処理を行うことができる。よって、機器の記憶容量や処理負荷を著しく増大させること無しに、「かな以外」を含む文字列を手書き入力する際のユーザ入力操作にかかる負担を大幅に軽減することができる。
【0118】
よって、従来のように、かな文字のみを手書き入力した際の予測変換のための操作と同一の操作が「かな以外」を含む文字列を手書き入力した場合でも実現でき、操作性が大幅に向上する。よって、手書きにより入力された漢字をもとにした予測変換の機能実装の効率および入力作業の効率を大幅に向上させることができる。
【0119】
また、キー押下入力方式で行っていた文字列予測を手書き入力方式で実現し、かつ、専用の漢字予測変換辞書を設ける必要なしに、キー押下入力方式による文字入力予測処理と同等の処理速度を保つことができる。
【0120】
また、漢字インデックスを予測辞書用と基本辞書用とにそれぞれ設けることで、漢字インデックスをそれぞれの辞書に適した構成とすることができるので、漢字インデックスを予測辞書及び基本辞書に共通した単一のインデックス情報とした場合と比較して、不必要な検索を抑制できるので、検索のパフォーマンスが向上する。
【0121】
なお、この発明は前記実施形態そのままに限定されるものではなく実施段階ではその要旨を逸脱しない範囲で構成要素を変形して具体化できる。また、前記実施形態に開示されている複数の構成要素の適宜な組み合わせにより種々の発明を形成できる。例えば、実施形態に示される全構成要素から幾つかの構成要素を省略してもよい。更に、異なる実施形態に亘る構成要素を適宜組み合せてもよい。
【0122】
また、上記実施形態に記載した手法は、コンピュータに実行させることのできるプログラムとして、半導体メモリ(フラッシュメモリなど)、磁気ディスク(ハードディスク、フロッピー(登録商標)ディスクなど)、光ディスク(CD−ROM、DVDなど)、光磁気ディスク(MO)などの記憶媒体に格納して頒布することもできる。
【0123】
また、この記憶媒体としては、プログラムを記憶でき、かつコンピュータが読み取り可能な記憶媒体であれば、その記憶形式は何れの形態であっても良い。
【0124】
また、記憶媒体からコンピュータにインストールされたプログラムの指示に基づきコンピュータ上で稼働しているOS(オペレーティングシステム)や、データベース管理ソフト、ネットワークソフト等のMW(ミドルウェア)等が上記実施形態を実現するための各処理の一部を実行しても良い。
【0125】
さらに、本発明における記憶媒体は、コンピュータと独立した媒体に限らず、LANやインターネット等により伝送されたプログラムをダウンロードして記憶又は一時記憶した記憶媒体も含まれる。
【0126】
また、記憶媒体は1つに限らず、複数の媒体から上記実施形態における処理が実行される場合も本発明における記憶媒体に含まれ、媒体構成は何れの構成であっても良い。
【0127】
尚、本発明におけるコンピュータは、記憶媒体に記憶されたプログラムに基づき、上記実施形態における各処理を実行するものであって、パソコン等の1つからなる装置、複数の装置がネットワーク接続されたシステム等の何れの構成であっても良い。
【0128】
また、本発明におけるコンピュータとは、携帯情報端末、携帯電話機、パーソナルコンピュータなどに限らず、家庭電化製品等に含まれる演算処理装置、マイコン等も含み、プログラムによって本発明の機能を実現することが可能な機器、装置を総称している。
【符号の説明】
【0129】
1…制御装置、2A…不揮発性記憶装置、2B…揮発性記憶装置、3…入力装置、4…表示装置、5…I/O装置、10…バス、21…文字認識辞書情報記憶部、22…基本辞書情報記憶部、23…予測辞書情報記憶部、24…学習辞書情報記憶部、25…インデックス情報記憶部、26…予測候補情報記憶部、31…記憶処理部、32…文字認識部、33…検索部、34…予測候補出力部、35…表示順序処理部、36…辞書編集部、37…表示処理部。
【特許請求の範囲】
【請求項1】
手書きによる文字列の入力が可能な入力装置と、情報を記憶する記憶媒体と、情報を画面に表示する表示装置とを備えたコンピュータに、
1)かな文字以外を含む文字列の表記と当該文字列の読みの前方の一部を示すかな文字列とを対応付けた情報がコード順に配列され、かつコード順の配列方向に複数のブロックに区分され、各ブロックには前記情報とブロック識別情報とが付与されている辞書データ部と、2)前記辞書データ部に含まれる前記かな文字列の少なくとも前方の一部のかな文字列とかな文字以外の文字列とを対応付けた情報を含み、前記かな文字以外の文字列がコード順に配列される第1のインデックスと、3)前記ブロック識別情報と当該識別情報により指定されるブロックの先頭に位置するかな文字列とを対応付けた情報を含み、前記かな文字列がコード順に配列される第2のインデックスとを、前記記憶媒体の所定の記憶領域に記憶させる記憶処理機能と、
前記入力装置により入力される手書きの文字列を認識する認識機能と、
前記識別機能により識別される文字列にかな文字以外の文字列が含まれているか否かを判定し、かな文字以外の文字列が含まれている場合に、当該かな文字以外の文字列が含まれる文字列に続く文字列を予測する形態である第1の予測処理として、前記認識したかな文字以外の文字列を前記第1のインデックスの中から検索し、当該かな文字以外の文字列の読みの前方の一部を示すかな文字の少なくとも一つを選択し、該選択したかな文字が含まれるブロック識別情報を前記第2のインデックスから検索し、さらに当該検索したブロック識別情報に指定される前記辞書データ部のブロックの中から前記認識したかな文字以外の文字列が含まれる文字列の表記を予測文字列候補として検索し、一方、前記認識機能により認識される文字列にかな文字以外の文字列が含まれていない場合に、当該かな文字列に続く文字列を予測する形態である第2の予測処理として、前記認識したかな文字列を前記第2のインデックスの中から検索し、当該かな文字列が含まれるブロック識別情報を前記第2インデックスから検索し、さらに当該検索したブロック識別情報に指定される前記辞書データ部のブロックの中から前記認識したかな文字列に対応する文字列の表記を予測文字列候補として検索する検索機能と、
前記検索機能により検索される文字列の表記を前記認識機能により認識される文字列に対する予測文字列候補として前記表示装置の画面に表示させる表示処理機能と
を実現させるための文字列予測プログラム。
【請求項2】
前記第1のインデックス、前記第2のインデックス、および辞書データ部は、種類が異なる辞書毎に存在しており、前記検索機能は、辞書毎に存在する前記第1のインデックス、前記第2のインデックス、および辞書データ部を用いて検索を行うことを特徴とする請求項1に記載の文字列予測プログラム。
【請求項3】
手書きによる文字列の入力が可能な入力装置と、
情報を記憶する記憶媒体と、
情報を画面に表示する表示装置と、
1)かな文字以外を含む文字列の表記と当該文字列の読みの前方の一部を示すかな文字列とを対応付けた情報がコード順に配列され、かつコード順の配列方向に複数のブロックに区分され、各ブロックには前記情報とブロック識別情報とが付与されている辞書データ部と、2)前記辞書データ部に含まれる前記かな文字列の少なくとも前方の一部のかな文字列とかな文字以外の文字列とを対応付けた情報を含み、前記かな文字以外の文字列がコード順に配列される第1のインデックスと、3)前記ブロック識別情報と当該識別情報により指定されるブロックの先頭に位置するかな文字列とを対応付けた情報を含み、前記かな文字列がコード順に配列される第2のインデックスとを、前記記憶媒体の所定の記憶領域に記憶させる記憶処理手段と、
前記入力装置により入力される手書きの文字列を認識する認識手段と、
前記識別手段により認識される文字列にかな文字以外の文字列が含まれているか否かを判定し、かな文字以外の文字列が含まれている場合に、当該かな文字以外の文字列が含まれる文字列に続く文字列を予測する形態である第1の予測処理として、前記認識したかな文字以外の文字列を前記第1のインデックスの中から検索し、当該かな文字以外の文字列の読みの前方の一部を示すかな文字の少なくとも一つを選択し、該選択したかな文字が含まれるブロック識別情報を前記第2のインデックスから検索し、さらに当該検索したブロック識別情報に指定される前記辞書データ部のブロックの中から前記認識したかな文字以外の文字列が含まれる文字列の表記を予測文字列候補として検索し、一方、前記認識手段により認識される文字列にかな文字以外の文字列が含まれていない場合に、当該かな文字列に続く文字列を予測する形態である第2の予測処理として、前記認識したかな文字列を前記第2のインデックスの中から検索し、当該かな文字列が含まれるブロック識別情報を前記第2インデックスから検索し、さらに当該検索したブロック識別情報に指定される前記辞書データ部のブロックの中から前記認識したかな文字列に対応する文字列の表記を予測文字列候補として検索する検索手段と、
前記検索手段により検索される文字列の表記を前記認識手段により認識される文字列に対する予測文字列候補として前記表示装置の画面に表示させる表示処理手段と
を具備することを特徴とする情報処理装置。
【請求項1】
手書きによる文字列の入力が可能な入力装置と、情報を記憶する記憶媒体と、情報を画面に表示する表示装置とを備えたコンピュータに、
1)かな文字以外を含む文字列の表記と当該文字列の読みの前方の一部を示すかな文字列とを対応付けた情報がコード順に配列され、かつコード順の配列方向に複数のブロックに区分され、各ブロックには前記情報とブロック識別情報とが付与されている辞書データ部と、2)前記辞書データ部に含まれる前記かな文字列の少なくとも前方の一部のかな文字列とかな文字以外の文字列とを対応付けた情報を含み、前記かな文字以外の文字列がコード順に配列される第1のインデックスと、3)前記ブロック識別情報と当該識別情報により指定されるブロックの先頭に位置するかな文字列とを対応付けた情報を含み、前記かな文字列がコード順に配列される第2のインデックスとを、前記記憶媒体の所定の記憶領域に記憶させる記憶処理機能と、
前記入力装置により入力される手書きの文字列を認識する認識機能と、
前記識別機能により識別される文字列にかな文字以外の文字列が含まれているか否かを判定し、かな文字以外の文字列が含まれている場合に、当該かな文字以外の文字列が含まれる文字列に続く文字列を予測する形態である第1の予測処理として、前記認識したかな文字以外の文字列を前記第1のインデックスの中から検索し、当該かな文字以外の文字列の読みの前方の一部を示すかな文字の少なくとも一つを選択し、該選択したかな文字が含まれるブロック識別情報を前記第2のインデックスから検索し、さらに当該検索したブロック識別情報に指定される前記辞書データ部のブロックの中から前記認識したかな文字以外の文字列が含まれる文字列の表記を予測文字列候補として検索し、一方、前記認識機能により認識される文字列にかな文字以外の文字列が含まれていない場合に、当該かな文字列に続く文字列を予測する形態である第2の予測処理として、前記認識したかな文字列を前記第2のインデックスの中から検索し、当該かな文字列が含まれるブロック識別情報を前記第2インデックスから検索し、さらに当該検索したブロック識別情報に指定される前記辞書データ部のブロックの中から前記認識したかな文字列に対応する文字列の表記を予測文字列候補として検索する検索機能と、
前記検索機能により検索される文字列の表記を前記認識機能により認識される文字列に対する予測文字列候補として前記表示装置の画面に表示させる表示処理機能と
を実現させるための文字列予測プログラム。
【請求項2】
前記第1のインデックス、前記第2のインデックス、および辞書データ部は、種類が異なる辞書毎に存在しており、前記検索機能は、辞書毎に存在する前記第1のインデックス、前記第2のインデックス、および辞書データ部を用いて検索を行うことを特徴とする請求項1に記載の文字列予測プログラム。
【請求項3】
手書きによる文字列の入力が可能な入力装置と、
情報を記憶する記憶媒体と、
情報を画面に表示する表示装置と、
1)かな文字以外を含む文字列の表記と当該文字列の読みの前方の一部を示すかな文字列とを対応付けた情報がコード順に配列され、かつコード順の配列方向に複数のブロックに区分され、各ブロックには前記情報とブロック識別情報とが付与されている辞書データ部と、2)前記辞書データ部に含まれる前記かな文字列の少なくとも前方の一部のかな文字列とかな文字以外の文字列とを対応付けた情報を含み、前記かな文字以外の文字列がコード順に配列される第1のインデックスと、3)前記ブロック識別情報と当該識別情報により指定されるブロックの先頭に位置するかな文字列とを対応付けた情報を含み、前記かな文字列がコード順に配列される第2のインデックスとを、前記記憶媒体の所定の記憶領域に記憶させる記憶処理手段と、
前記入力装置により入力される手書きの文字列を認識する認識手段と、
前記識別手段により認識される文字列にかな文字以外の文字列が含まれているか否かを判定し、かな文字以外の文字列が含まれている場合に、当該かな文字以外の文字列が含まれる文字列に続く文字列を予測する形態である第1の予測処理として、前記認識したかな文字以外の文字列を前記第1のインデックスの中から検索し、当該かな文字以外の文字列の読みの前方の一部を示すかな文字の少なくとも一つを選択し、該選択したかな文字が含まれるブロック識別情報を前記第2のインデックスから検索し、さらに当該検索したブロック識別情報に指定される前記辞書データ部のブロックの中から前記認識したかな文字以外の文字列が含まれる文字列の表記を予測文字列候補として検索し、一方、前記認識手段により認識される文字列にかな文字以外の文字列が含まれていない場合に、当該かな文字列に続く文字列を予測する形態である第2の予測処理として、前記認識したかな文字列を前記第2のインデックスの中から検索し、当該かな文字列が含まれるブロック識別情報を前記第2インデックスから検索し、さらに当該検索したブロック識別情報に指定される前記辞書データ部のブロックの中から前記認識したかな文字列に対応する文字列の表記を予測文字列候補として検索する検索手段と、
前記検索手段により検索される文字列の表記を前記認識手段により認識される文字列に対する予測文字列候補として前記表示装置の画面に表示させる表示処理手段と
を具備することを特徴とする情報処理装置。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【公開番号】特開2013−77310(P2013−77310A)
【公開日】平成25年4月25日(2013.4.25)
【国際特許分類】
【出願番号】特願2012−264346(P2012−264346)
【出願日】平成24年12月3日(2012.12.3)
【分割の表示】特願2009−291430(P2009−291430)の分割
【原出願日】平成21年12月22日(2009.12.22)
【出願人】(593059773)富士ソフト株式会社 (28)
【Fターム(参考)】
【公開日】平成25年4月25日(2013.4.25)
【国際特許分類】
【出願日】平成24年12月3日(2012.12.3)
【分割の表示】特願2009−291430(P2009−291430)の分割
【原出願日】平成21年12月22日(2009.12.22)
【出願人】(593059773)富士ソフト株式会社 (28)
【Fターム(参考)】
[ Back to top ]