
文字列入力支援装置、文字列入力支援方法およびプログラム
【課題】文字列入力支援装置が、入力文字に含まれる文字の出現位置に応じて用語候補の選択や優先順位付けをより適切に行う。
【解決手段】文字位置情報生成部123が、ユーザにより入力済みの文字列に含まれる文字が、用語記憶部131の記憶する用語中に出現する位置を示す文字位置情報を生成する。そして、順位決定部124が、文字位置情報生成部123が生成した文字位置情報に基づいて、用語の順位を決定する。
【解決手段】文字位置情報生成部123が、ユーザにより入力済みの文字列に含まれる文字が、用語記憶部131の記憶する用語中に出現する位置を示す文字位置情報を生成する。そして、順位決定部124が、文字位置情報生成部123が生成した文字位置情報に基づいて、用語の順位を決定する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、文字列入力支援装置、文字列入力支援方法およびプログラムに関する。
【背景技術】
【0002】
コンピュータ等においてユーザが用語(文字列)を入力する負担を軽減する用語入力支援方法の1つに、当該コンピュータ等が、予め記憶する用語群の中から、入力済みの文字列に類似する用語を用語候補として選択して表示し、表示した用語候補のいずれかに対するユーザの選択操作を受け付ける方法がある。
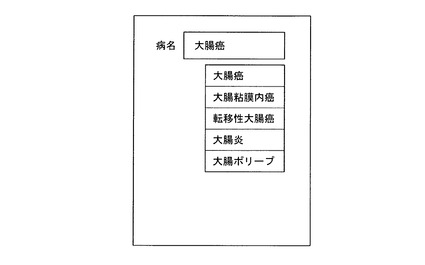
例えば、コンピュータの表示画面に表示される診断書に病名を入力する際、図10(a)に示すように、ユーザによる「大腸」の入力に対して、コンピュータは、この「大腸」に類似する用語として、「大腸炎」や「大腸癌」など、「大腸」を含む用語を選択し、入力欄の下方近傍に表示する。そして、カーソルキーあるいはマウスを用いてユーザが「大腸ポリープ」を選択すると、コンピュータは、選択された「大腸ポリープ」を入力欄に表示する。
【0003】
一方、ユーザが用語の選択を行わずに、更に「癌」を入力すると、コンピュータは、同図(b)に示すように、入力された文字列「大腸癌」のうち2文字以上を含む、「大腸炎」や「大腸粘膜内癌」などの用語を選択して表示する。
このように、入力された文字列の全部を含む用語に限らず、一部を含む用語も表示することにより、「大腸炎」を誤って「大腸癌」と入力する文字違いや、「転移性大腸癌」を誤って「転移大腸癌」と入力する入力不足など、入力された文字列に誤りがある場合にもユーザの意図する用語を表示し得る。
【0004】
このような、入力済みの文字列に類似する用語を用語候補として選択する方法として、例えば、特許文献1に示される方法を用いることが考えられる。同文献では、"leucocyte"と"leukocyte"など、同一の事物を示す用語の表記が異なる「表記揺れ」の用語を取得する方法が示されている。この方法では、注目する用語に対する表記揺れの用語を収集するために、まず、予め記憶する用語の各々について、注目する用語とのNグラム(文字数Nの部分文字列)の一致度および文字列長の類似度を比較することにより、類似する用語の絞込みを行う。そして、大文字と小文字との置換は10点、数字の置換は100点など、編集内容毎に設定されたコストで重み付けされた編集距離に基づいて、さらに用語の絞込みを行う。
この方法を、用語候補の選択に用いると、入力済みの文字列と共通の部分文字列を多く含み、入力済みの文字列に文字数が類似し、かつ、入力済みの文字列に対してコストの小さい変換操作を行って得られる文字列を抽出できる。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開2005−352888号公報
【発明の概要】
【発明が解決しようとする課題】
【0006】
しかしながら、特許文献1に示される方法を用語候補の選択に用いた場合、入力済みの文字列に含まれる各文字が予め記憶された用語の各々の中に出現する位置の情報が、用語候補の選択および表示に際して充分に反映されない。
例えば、「腸」が入力された場合、通常、ユーザは「腸」で始まる用語、あるいは、入力不足がある場合は「腸」が先頭付近にある用語を入力しようとしていると考えられる。したがって、「大腸ポリープ」と「転移性大腸癌」とでは、「腸」が先頭に近い「大腸ポリープ」を優先的に表示することが好ましい。すなわち、いずれか一方のみを表示する場合には「大腸ポリープ」のほうを表示し、両方を表示する場合には「大腸ポリープ」のほうを「転移性大腸癌」よりも入力欄に近い位置に表示することが好ましい。
【0007】
ところが、「大腸ポリープ」および「転移性大腸癌」について見ると、いずれも、「腸」と共通するNグラムは、N=1のときに「腸」の1つであり、N=2以上では共通するNグラムは存在しない。
また、「大腸ポリープ」と「転移性大腸癌」とは、共に6文字であるため「腸」との文字数差も、共に5である。
さらに、「腸」からの編集距離は、いずれも、5文字の挿入である。
このため、特許文献1に示される方法を用語候補の選択に用いた場合、「大腸ポリープ」と「転移性大腸癌」とは、同一の優先順位となってしまい、どちらを優先するかを特定することができない。
【0008】
本発明は、このような事情を考慮してなされたものであり、その目的は、入力文字に含まれる文字の出現位置に応じて用語候補の選択や優先順位付けをより適切に行える文字列入力支援装置、文字列入力支援方法およびプログラムを提供することにある。
【課題を解決するための手段】
【0009】
[1]この発明は上述した課題を解決するためになされたもので、本発明の一態様による文字列入力支援装置は、入力済みの文字列に基づいて、予め記憶された文字列候補に対して順位を決定する文字列入力支援装置であって、前記文字列候補を記憶する文字列候補記憶部と、前記文字列候補記憶部が記憶する前記文字列候補の各々について、当該文字列候補中に、前記入力済みの文字列に含まれる文字が出現する位置を示す情報であって、当該文字列候補の先頭を基準として数えられる文字の数で、当該文字列中における文字の位置を示す文字位置情報を生成する文字位置情報生成部と、前記文字位置情報に基づいて、前記文字列候補中に、前記入力済みの文字列に含まれる文字が出現する位置が、当該文字列候補の先頭に近いほど当該文字列候補を上位として順位を決定する順位決定部とを具備することを特徴とする。
【0010】
[2]また、本発明の一態様による文字列入力支援装置は、上述の文字列入力支援装置であって、前記文字列候補記憶部が記憶する前記文字列候補の各々と前記入力済みの文字列との、最長共通部分列の文字数を示す文字数情報を生成する文字数情報生成部をさらに具備し、前記文字位置情報生成部は、前記文字列候補記憶部が記憶する前記文字列候補の各々と前記入力済みの文字列との、最長共通部分列に含まれる各文字が、当該文字列候補中に出現する位置を示す情報であって、当該文字列候補の先頭を基準として数えられる文字の数で、当該文字列中における文字の位置を示す前記文字位置情報を生成し、前記順位決定部は、前記最長共通部分列の文字数が多い前記文字列候補を上位とし、前記最長共通部分列の文字数が同一の前記文字列候補に対しては、当該文字列候補中に、前記最長共通部分列に含まれる文字が出現する位置が先頭に近いほど当該文字列候補を上位として順位を決定することを特徴とする。
【0011】
[3]また、本発明の一態様による文字列入力支援装置は、上述の文字列入力支援装置であって、前記文字位置情報生成部は、前記文字列候補の先頭から前記最長共通部分列の末尾の文字が前記文字列候補中に出現する位置までの文字数に対応したビット数のビット列であり、前記文字位置情報で表された位置に対応するビットを用いて前記最長共通部分列に含まれる文字が出現することが表されたビット列を生成することを特徴とする。
【0012】
[4]また、本発明の一態様による文字列入力支援方法は、文字列候補を記憶する文字列候補記憶部を具備し、入力済みの文字列に基づいて、予め記憶された文字列候補に対して順位を決定する文字列入力支援装置の文字列入力支援方法であって、文字位置情報生成部が、前記文字列候補記憶部が記憶する前記文字列候補の各々について、当該文字列候補中に、前記入力済みの文字列に含まれる文字が出現する位置を示す情報であって、当該文字列候補の先頭を基準として数えられる文字の数で、当該文字列中における文字の位置を示す文字位置情報を生成する文字位置情報生成ステップと、順位決定部が、前記文字位置情報に基づいて、前記文字列候補中に、前記入力済みの文字列に含まれる文字が出現する位置が、当該文字列候補の先頭に近いほど当該文字列候補を上位として順位を決定する順位決定ステップとを具備することを特徴とする。
【0013】
[5]また、本発明の一態様によるプログラムは、文字列候補を記憶する文字列候補記憶部を具備し、入力済みの文字列に基づいて、予め記憶された文字列候補に対して順位を決定する文字列入力支援装置としてのコンピュータに、前記文字列候補記憶部が記憶する前記文字列候補の各々について、当該文字列候補中に、前記入力済みの文字列に含まれる文字が出現する位置を示す情報であって、当該文字列候補の先頭を基準として数えられる文字の数で、当該文字列中における文字の位置を示す文字位置情報を生成する文字位置情報生成ステップと、前記文字位置情報に基づいて、前記文字列候補中に、前記入力済みの文字列に含まれる文字が出現する位置が、当該文字列候補の先頭に近いほど当該文字列候補を上位として順位を決定する順位決定ステップとを実行させるためのプログラムである。
【発明の効果】
【0014】
この発明によれば、入力文字に含まれる文字の出現位置に応じて用語候補の選択や優先順位付けをより適切に行える。
【図面の簡単な説明】
【0015】
【図1】本発明の一実施形態における文字列入力支援システムの概略構成を示す構成図である。
【図2】同実施形態において、用語記憶部131が記憶する用語リストの例を示す図である。
【図3】同実施形態において、LCS長行列記憶部132が記憶するLCS長行列の例を示す図である。
【図4】同実施形態において、文字位置情報行列記憶部133が記憶する文字位置情報行列の例を示す図である。
【図5】同実施形態において、処理部120がLCS長を算出し、文字位置情報を生成する処理手順を示すフローチャートである。
【図6】同実施形態において、処理部120がLCS長を算出し、文字位置情報を生成する処理手順を示すフローチャートである。
【図7】同実施形態において、順位決定部124による用語の順位決定の例を示す図である。
【図8】同実施形態において、順位決定部124が生成する指標の例を示す図である。
【図9】同実施形態において、表示部230が用語のリストを表示した例を示す図である。
【図10】ユーザが文字列を入力する際の、ユーザが入力した文字列の候補の表示例を示す図である。
【発明を実施するための形態】
【0016】
以下、図面を参照して、本発明の一実施形態について説明する。
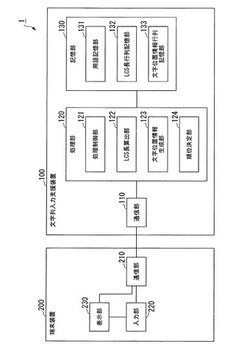
図1は、本発明の一実施形態における文字列入力支援システムの概略構成を示す構成図である。同図において、文字列入力支援システム1は、文字列入力支援装置100と、端末装置200とを具備する。文字列入力支援装置100は、通信部110と、処理部120と、記憶部130とを具備する。処理部120は、処理制御部121と、LCS長算出部(文字数情報生成部)122と、文字位置情報生成部123と、順位決定部124とを具備する。記憶部130は、用語記憶部(文字列候補記憶部)131と、LCS長行列記憶部 132と、文字位置情報行列記憶部133とを具備する。端末装置200は、通信部210と、入力部220と、表示部230とを具備する。
【0017】
文字列入力支援システム1は、ユーザが入力済みの文字列(以下では、「入力文字列」と称する)に基づいて、ユーザが入力したい文字列の候補(文字列候補)を表示する。
文字列入力支援装置100は、入力文字列を端末装置200から取得し、取得した文字列に基づいて、ユーザが入力したい文字列の候補の各々の順位を決定し、ユーザが入力したい文字列の候補を、決定した順位に従って並べたリストを生成して端末装置200に送信する。
通信部110は、端末装置200との間でデータの送受信を行う。
記憶部130は、ユーザが入力したい文字列の候補である用語を予め記憶する。また、記憶部130は、ユーザが入力したい文字列の候補である用語の順位を、文字列入力支援装置100が決定する際のワーキングメモリとして機能する。記憶部130は、文字列入力支援装置100が具備する記憶装置上に実現される。
【0018】
用語記憶部131は、ユーザが入力したい文字列の候補である用語をリスト形式にて予め記憶する。
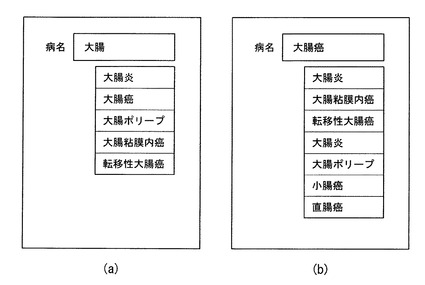
図2は、用語記憶部131が記憶する用語リストの例を示す図である。同図に示すように、用語リストの各行に、ユーザが入力したい文字列の候補である用語と、当該用語の識別番号である用語IDとが対応付けて記憶されている。用語リストは、例えば、ある分野の辞書に含まれる用語の各々に用語IDを付して生成される。同図の例では、用語リストは、病名に用語IDを付して生成されている。
用語IDは、各用語を識別する情報であると共に、用語リスト中における各用語の順序を示す情報でもある。
なお、用語リストに記憶される用語の数は、同図に示す7つに限らず、任意の個数であってよい。
【0019】
LCS長行列記憶部132は、文字列入力支援装置100が用語の順位を決定する際に生成するLCS長行列を記憶するワーキングメモリである。
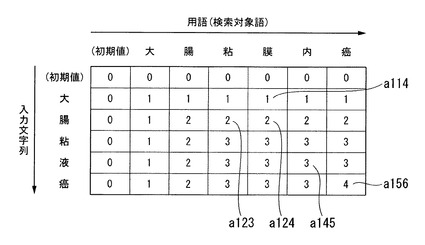
図3は、LCS長行列記憶部132が記憶するLCS長行列の例を示す図である。同図に示すように、LCS長行列は、入力文字列の文字数+1の行、および、用語記憶部131が記憶する用語の文字数+1の列を有する行列であり、各要素には非負整数が格納される。以下では、LCS長行列の最上行(初期値に対応する行)を第0行とし、最左列(初期値に対応する列)を第0列とする。
LCS長行列記憶部132は、用語記憶部131が記憶する用語毎に、LCS長行列を記憶する。
【0020】
ここで、LCS(Longest Common Subsequence、最長共通部分列)は、2つの文字列に共通する部分列(共通部分列、Common Subsequence)のうち、最も長い(文字数の多い)ものである。この共通部分列は、各文字列中に連続して出現する必要はないが、2つの文字列中に同じ順序で出現する必要がある。図3の「大腸粘膜内癌」と「大腸粘液癌」との場合、「大」「腸」「粘」「癌」の各文字が同順序で出現しているので、両者のLCSは「大腸粘癌」であり、LCSの文字数(以下では、「LCS長」と称する)は4である。
LCS長行列の各要素は、当該要素の位置に対応する、用語またはその部分文字列と、入力文字列またはその部分文字列とのLCS長を示す。例えば、LCS長行列の第5行第6列の要素a156は、入力文字列「大腸粘液癌」と、用語「大腸粘膜内癌」とのLCS長「4」を示している。また、LCS長行列の第2行第4列の要素a124は、入力文字列の先頭から2文字の部分文字列(すなわち、先頭から2文字を入力した時点での入力文字列)「大腸」と、用語の先頭から4文字の部分文字列「大腸粘膜」とのLCS「大腸」の文字数「2」を示している。
【0021】
この、2つの文字列のLCSは、部分文字列のLCSから再帰的に算出できる。
2つの文字列の末尾の文字が同じ場合は、各文字列から当該末尾の文字を除いた部分文字列のLCSに、当該末尾の文字を加えることによりLCSを得られる。例えば、入力文字列「大腸粘液癌」と用語「大腸粘膜内癌」との末尾の文字は共に「癌」である。そして、「大腸粘液癌」と「大腸粘膜内癌」とのLCS「大腸粘癌」は、入力文字列「大腸粘液癌」から「癌」を除いた「大腸粘液」と、用語「大腸粘膜内癌」から「癌」を除いた「大腸粘膜内」との「大腸粘」に「癌」を加えて得られる。したがって、第5行第6列の要素a156の値「4」(「大腸粘癌」の文字数)は、第4行第5列の要素a145の値「3」(「大腸粘」の文字数)に1(「癌」の文字数)を加えた値となっている。
【0022】
一方、2つの文字列の末尾が異なる場合は、一方の文字列から当該末尾の文字を除いた部分文字列のLCSのうち、文字数の多いほうのLCSと同一(両者の値が等しい場合は、両者の値と同一)である。例えば、「大腸」と「大腸粘膜」との末尾の文字は、それぞれ「腸」と「膜」とであり異なる。ここで、「大腸」と、「大腸粘膜」から末尾の文字「膜」を除いた「大腸粘」とのLCSは「大腸」である。また、「大腸」から末尾の文字「腸」を除いた「大」と、「大腸粘膜」とのLCSは「大」である。そして、「大腸」と「大腸粘膜」とのLCS「大腸」は、この2つのLCS「大腸」および「大」のうち文字数の多いほうである「大腸」と同一である。したがって、第2行第4列の要素a124の値「2」(「大腸」の文字数)は、第2行第3列の要素a123の値「2」(「大腸」の文字数)と、第1行第4列の要素a114の値「1」(「大」の文字数)とのうち、値の大きいほうである「2」と同一である。
【0023】
このように、LCS長行列の各要素の値は、入力文字列中の対応する文字と、用語中の対応する文字とが同じ場合は、左上の要素の値に1を加えた値と同一である。一方、入力文字列中の対応する文字と、用語中の対応する文字とが異なる場合は、左隣の要素の値と、上隣の要素の値とのうち大きいほうの値と同一(両者の値が等しい場合は、両者の値と同一)である。
【0024】
図1に戻って、文字位置情報行列記憶部133は、文字列入力支援装置100が用語の順位を決定する際に生成する文字位置情報行列を記憶するワーキングメモリである。
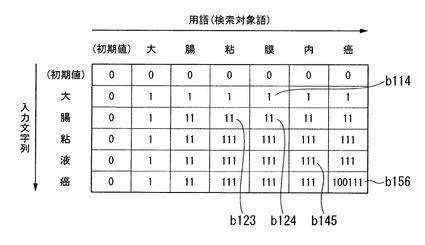
図4は、文字位置情報行列記憶部133が記憶する文字位置情報行列の例を示す図である。同図に示すように、文字位置情報行列は、入力文字列の文字数+1の行数、および、用語記憶部131が記憶する用語の文字数+1の列数を有する行列であり、各要素にはビット列(二進数)が格納される。以下では、文字位置情報行列の最上行(初期値に対応する行)を第0行とし、最左列(初期値に対応する列)を第0列とする。
文字位置情報行列記憶部133は、用語記憶部131が記憶する用語毎に、文字位置情報行列を記憶する。
【0025】
文字位置情報行列の各要素には、入力文字列と、用語記憶部131が記憶する用語とのLCSの各文字が、当該用語中に出現する位置を示す文字位置情報が格納されている。文字位置情報行列の各要素のビット列は、1の位(最右ビット)から順に、入力文字列中の1番目(先頭)から順の各文字の位置を示す。例えば、文字位置情報行列の第5行第6列の要素b156は、最右ビットが入力文字列の先頭の文字「大」の位置を示し、以下同様に、右から2番目のビットが「腸」の位置、3番目が「粘」の位置、・・・、6番目(最左ビット)が「癌」の位置を示す。ここで、入力文字列「大腸粘液癌」と用語「大腸粘膜内癌」とのLCS「大腸粘癌」の各文字は、それぞれ、用語「大腸粘膜内癌」の先頭から1文字目(「大」)と、2文字目(「腸」)と、3文字目(「粘」)と、6文字目(「癌」)とに出現する。したがって、文字位置情報行列の第5行第6列の要素b156は、右から1、2、3、6番目のビットが「1」、4、5番目のビットが「0」となっている。
【0026】
上述したように、2つの文字列のLCSは、部分文字列のLCSから再帰的に算出できる。このため、文字位置情報行列も、部分文字列の文字位置情報行列から再帰的に生成できる。
2つの文字列(入力文字列またはその部分文字列、および、用語またはその部分文字列)の末尾の文字が同じ場合、これらの文字列の文字位置情報は、各文字列から当該末尾の文字を除いた部分文字列の文字位置情報に、当該末尾の文字の位置に対応する桁を1とした数を加算した値となる。例えば、図4の文字位置情報行列の、第5行第6列の要素b156の値「100111」(二進数)は、第4行第5列の要素b145の値「111」(二進数。「00111」の先頭の0が省略されている。以下同様に、文字位置情報の先頭の0の表示を省略する)に、末尾の文字「癌」の位置に対応する右から6桁目が1の「100000」(二進数)を加算した値となっている。
【0027】
一方、2つの文字列の末尾が異なる場合、これらの文字列の文字位置情報は、一方の文字列から当該末尾の文字を除いた場合の文字位置情報のうち、LCS長が長いほうの文字列の文字位置情報と同一である。例えば、図4の文字位置情報行列の、第2行第4列の要素b124の値「11」(二進数)は、第2行第3列の要素b123の値「11」(二進数)と、第1行第4列の要素b114の値「1」(二進数)とのうち、LCS長が長い文字列に対応する、第2行第3列の要素b123の値「11」(二進数)と同一である。
いずれの文字列から末尾の文字を除いてもLCS長が同一の場合は、いずれの文字位置情報と同一としてもよい。本実施形態では、値が小さいほうの文字位置情報と同一とする。後述するように、LCSに含まれる文字が先頭に近い位置に出現する用語を上位とするためである。
【0028】
このように、文字位置情報行列の各要素の値は、入力文字列中の対応する文字と、用語中の対応する文字とが同じ場合は、左上の要素の値に、用語の末尾の位置に対応する桁を1とした数を加えた値と同一である。一方、入力文字列中の対応する文字と、用語中の対応する文字とが異なる場合は、左隣の要素の値と、上隣の要素の値とのうち、LCS長が長いほうの値と同一(両者のLCS長が同一の場合は、値が小さいほうの要素の値と同一。さらに両要素の値が同一の場合は、両要素の値と同一)である。
【0029】
図1に戻って、処理部120は、通信部110を介して、ユーザが入力済みの文字列を端末装置200から取得し、取得した文字列に基づいて、ユーザが入力したい文字列の候補の各々の順位を決定する。そして、処理部120は、ユーザが入力したい文字列の候補を、決定した順位に従って並べたリストを生成し、通信部110を介して端末装置200に送信する。処理部120は、例えば、文字列入力支援装置100の具備するCPUが、記憶部130からプログラムを読み出して実行することにより実現される。
処理制御部121は、各部を制御して処理を行わせる。LCS長算出部122は、入力文字列と、用語記憶部131が記憶する各用語とのLCS長を算出する。文字位置情報生成部123は、入力文字列と、用語記憶部131が記憶する各用語との文字位置情報を生成する。順位決定部124は、LCS長算出部122が算出するLCS長および文字位置情報生成部123が生成する文字位置情報に基づいて、用語記憶部131が記憶する各用語の順位を決定する。
【0030】
端末装置200は、ユーザによる文字列の入力を受け付けて文字列入力支援装置100に送信し、文字列入力支援装置100から送信される用語(ユーザが入力しようとしている文字列の候補)を、文字列入力支援装置100が決定した順位に従って表示する。
通信部210は、文字列入力支援装置100との間でデータの送受信を行う。
入力部220は、キーボードおよびマウスを備え、ユーザによる文字列の入力を受け付けて、入力された文字列を、通信部210を介して文字列入力支援装置100に送信する。表示部230は、液晶ディスプレイ等の表示画面を備え、文字列の入力欄を表示し、ユーザの入力した文字列を入力欄に表示する。また、表示部230は、順位付けされた用語を、通信部210を介して文字列入力支援装置100から受信し、受信した用語を、その順位に従って入力欄の下方近傍に表示する。
【0031】
次に、文字列入力支援システム1の動作について説明する。
文字列入力支援システム1では、まず、端末装置200の表示部230が入力欄を表示し、入力部220がユーザの入力操作を待ち受ける。入力部220は、ユーザの入力操作を受けると、当該操作に基づいて、入力文字列を生成する。すなわち、入力部220は、過去の入力操作に基づく入力文字列を記憶しており、文字の追加や削除等の新たな入力操作を受けると、記憶している入力文字列を当該操作に基づいて更新(編集)する。入力部220は、更新された入力文字列を、表示部230および通信部210に出力する。
表示部230は、入力部220から出力された入力文字列を入力欄に表示(既に入力文字列を表示しているときは更新)する。また、通信部210は、入力部220から出力された入力文字列を、文字列入力支援装置100の通信部110に送信する。
通信部110は、通信部210からの入力文字列を受信すると、受信した入力文字列を処理部120に出力する。
【0032】
処理部120は、通信部110から出力される入力文字列と、用語記憶部131の記憶する各用語とのLCS長の算出および文字位置情報の生成を行う。
図5および図6は、処理部120がLCS長を算出し、文字位置情報を生成する処理手順を示すフローチャートである。処理部120は、通信部110から入力文字列が出力されると同図の処理を開始する。
まず、処理部120の処理制御部121は、LCS長行列記憶部132のLCS長行列を初期化するようLCS長算出部122を制御し、文字位置情報行列記憶部133の文字位置情報行列を初期化するよう文字位置情報生成部123を制御する。
【0033】
LCS長算出部122は、用語記憶部131が記憶する用語の各々について、LCS長行列の行数を入力文字列の文字数+1とし、列数を当該用語の文字数+1とする。そして、最上行(図3の例で、「初期値」に対応する行)の各要素の値と、最左列(図3の例で、「初期値」に対応する列)の各要素の値とを、いずれも「0」とする。他の要素の値は、この時点では未定である。
また、文字位置情報生成部123は、用語記憶部131が記憶する用語の各々について、文字位置情報行列の行数を入力文字列の文字数+1とし、列数を当該用語の文字数+1とする。そして、最上行(図4の例で、「初期値」に対応する行)の各要素の値と、最左列(図4の例で、「初期値」に対応する列)の各要素の値とを、いずれも「0」とする。他の要素の値は、この時点では未定である(以上、ステップS101)。
【0034】
次に、処理制御部121は、入力文字列の各文字について先頭から順に処理を行うループL11の処理を開始する。以下では、ループL11にて処理対象となっている文字の位置を「j」(先頭から順に、1、2、・・・とする)にて表示する。(以上、ステップS102)。
そして、処理制御部121は、用語記憶部131の記憶する各用語について処理を行うループL12の処理を開始する(ステップS103)。
さらに、処理制御部121は、処理対象の用語(以下では、「W」にて表示する)の各文字について先頭から順に処理を行うループL13の処理を開始する。以下では、ループL11にて処理対象となっている文字の位置を「k」(先頭から順に、1、2、・・・とする)にて表示する。(以上、ステップS104)。
【0035】
そして、処理制御部121は、入力文字列のj番目の文字と、用語Wのk番目の文字とが同一か否かを判定する(ステップS105)。同一であると判定した場合(ステップS105:YES)、処理制御部121は、文字が同一であることを示す信号を、LCS長算出部122に出力する。
文字が同一であることを示す信号が処理制御部121から出力されると、LCS長算出部122は、LCS長行列の第j行第k列の要素の値として、第j−1行第k−1列の要素の値+1を書き込む。すなわち、図3で説明したように、左上の要素の値に1を加えた値とする(以上、ステップS111)。
【0036】
また、ステップS105において文字が同一であると判定した(ステップS105:YES)処理制御部121は、文字が同一であることを示す信号を、文字位置情報生成部123にも出力する。
文字が同一であることを示す信号が処理制御部121から出力されると、文字位置情報生成部123は、文字位置情報行列の第j行第k列の要素の値として、第j−1行第k−1列の要素の値+2k−1を書き込む。すなわち、図4で説明したように、左上の要素の値に、用語の末尾の位置に対応する桁を1とした数を加えた値とする(以上、ステップS112)。
【0037】
その後、処理制御部121は、用語Wの全ての文字に対してループL13の処理を行ったか否かを判定する。未処理の文字があると判定した場合は、ステップS104に戻って、未処理の文字に対して引き続きループL13の処理を行う。一方、全ての文字に対して処理を行ったと判定した場合は、次のステップS142に進む(以上、ステップS141)。
そして、処理制御部121は、用語記憶部131の記憶する全ての用語に対してループL12の処理を行ったか否かを判定する。未処理の用語があると判定した場合は、ステップS103に戻って、未処理の用語に対して引き続きループL12の処理を行う。一方、全ての用語に対して処理を行ったと判定した場合は、次のステップS143に進む(以上、ステップS142)。
そして、処理制御部121は、入力文字列の全ての文字に対してループL11の処理を行ったか否かを判定する。未処理の文字があると判定した場合は、ステップS102に戻って、未処理の文字に対して引き続きループL11の処理を行う。一方、全ての文字に対して処理を行ったと判定した場合は、同図の処理を終了する(以上、ステップS143)。
【0038】
一方、ステップS105において文字が異なると判定した場合(ステップS105:NO)、処理制御部121は、LCS長行列の第j−1行第k列の要素の値が、第j行第k−1列の要素の値以上か否かを判定する(ステップS121)。第j−1行第k列の要素の値が、第j行第k−1列の要素の値以上であると判定した場合(ステップS121:YES)、処理制御部121は、第j−1行第k列の要素の値が、第j行第k−1列の要素の値以上であることを示す信号を、LCS長算出部122に出力する。
当該信号が処理制御部121から出力されると、LCS長算出部122は、LCS長行列の第j行第k列の要素の値として、第j−1行第k列の要素の値を書き込む。すなわち、図3で説明したように、左隣の値と、上隣の値とのうち大きいほう(ここでは、上隣の要素)の値と同一(両者の値が等しい場合は、両者の値と同一)とする(以上、ステップS122)。
【0039】
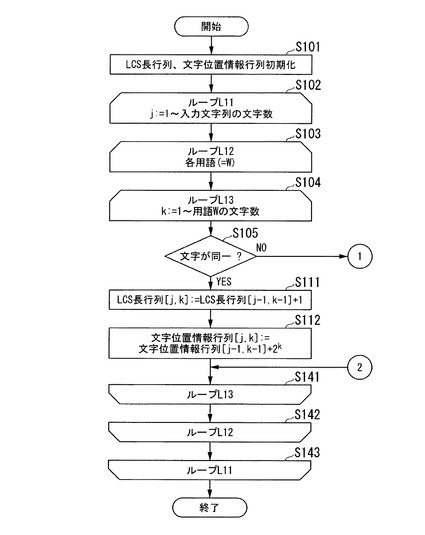
また、ステップS121において、第j−1行第k列の要素の値が、第j行第k−1列の要素の値以上であると判定した(ステップS121:YES)処理制御部121は、LCS長行列の第j−1行第k列の要素の値が、第j行第k−1列の要素の値と等しいか否かを判定する(ステップS123)。値が等しいと判定した場合(ステップS123:YES)、処理制御部121は、さらに、文字位置情報行列の第j−1行第k列の要素の値が、第j行第k−1列の要素の値以下か否かを判定する(ステップS124)。
ステップS123において両者の値が異なると判定した場合(ステップS123:NO)、および、ステップS124において、第j−1行第k列の要素の値が、第j行第k−1列の要素の値以下であると判定した場合(ステップS124:YES)、処理制御部121は、上隣の要素を書き込むよう指示する信号を、文字位置情報生成部123に出力する。
当該信号が処理制御部121から出力されると、文字位置情報生成部123は、文字位置情報行列の第j行第k列の要素の値として、第j−1行第k列の要素の値を書き込む。すなわち、図4で説明したように、左隣の要素の値と、上隣の要素の値とのうち、LCS長が長いほう(ここでは、上隣の要素)の値と同一(両者のLCS長が同一の場合は、値が小さいほうの要素の値と同一。さらに両要素の値が同一の場合は、両要素の値と同一)とする(以上、ステップS125)。
その後、処理制御部121は、ステップS141に進む。
【0040】
一方、ステップS121において、第j−1行第k列の要素の値が、第j行第k−1列の要素の値未満であると判定した場合(ステップS121:NO)、処理制御部121は、第j−1行第k列の要素の値が、第j行第k−1列の要素の値未満であることを示す信号を、LCS長算出部122に出力する。
当該信号が処理制御部121から出力されると、LCS長算出部122は、LCS長行列の第j行第k列の要素の値として、第j行第k−1列の要素の値を書き込む。すなわち、図3で説明したように、左隣の値と、上隣の値とのうち大きいほう(ここでは、左隣の要素)の値と同一とする(以上、ステップS131)。
【0041】
また、ステップS121において、第j−1行第k列の要素の値が、第j行第k−1列の要素の値未満であると判定した場合(ステップS121:NO)、および、ステップS124において、第j−1行第k列の要素の値が、第j行第k−1列の要素の値より大きいと判定した場合(ステップS124:NO)、処理制御部121は、左隣の要素を書き込むよう指示する信号を、文字位置情報生成部123に出力する。
当該信号が処理制御部121から出力されると、文字位置情報生成部123は、文字位置情報行列の第j行第k列の要素の値として、第j行第k−1列の要素の値を書き込む。すなわち、図4で説明したように、左隣の要素の値と、上隣の要素の値とのうち、LCS長が長いほう(ここでは、左隣の要素)の値と同一(両者のLCS長が同一の場合は、値が小さいほうの要素の値と同一)とする(以上、ステップS132)。
その後、処理制御部121は、ステップS141に進む。
【0042】
以上により、LCS長行列および文字位置情報行列が完成する。そして、LCS長行列の最上行最右列の要素の値が、対応する用語のLCS長を示し、文字位置情報行列の最上行最右列の要素の値が、対応する用語中における、LCSに含まれる文字の出現位置、すなわち文字位置情報を示している。
【0043】
なお、処理部120が、LCS長行列と文字位置情報行列とを常に新たに生成するのではなく、生成済みのLCS長行列および文字位置情報行列を更新するようにしてもよい。例えば、ユーザの操作入力により入力文字列の末尾に新たに1文字追加された場合、処理部120に入力される入力文字列のうち、末尾の文字を除いた部分文字列は、前回の入力文字列と同一である。そこで、LCS長算出部122が、各LCS長行列の末尾に行を追加し、文字位置情報生成部123が、各文字位置情報行列の末尾に行を追加するようにしてもよい。そして、処理部120は、新たに入力された入力文字列の末尾の文字に基づき、ループL12の処理手順に従って、LCS長行列および文字位置情報行列を完成させる。
【0044】
LCS長行列および文字位置情報行列が完成すると、処理制御部121は、用語記憶部131の記憶する各用語の順位を決定するように順位決定部124を制御する。
順位決定部124は、用語記憶部131の記憶する各用語の、LCS長と、文字位置情報と、用語の長さ(文字数)と、用語リストにおける順序(用語IDの値)とに基づいて、順位を決定し、決定した順位に基づいて並べられた用語のリストを生成する。
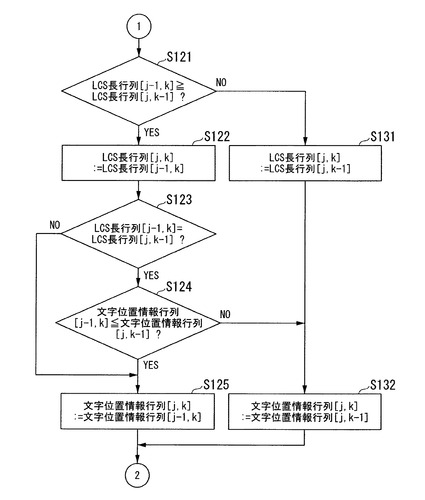
図7は、順位決定部124による用語の順位決定の例を示す図である。同図は、入力文字列が「大腸癌」である場合の例であり、図1に示す用語リストに含まれる用語と、各用語の順位と、順位を決定する基準となるLCS長と文字位置情報と用語の文字数と用語IDとを示している。
順位決定部124は、各用語に対して、LCS長が長いほど上位とし(上位の用語ほど高い優先順位、すなわち表示部230の入力欄に近い位置に表示されやすくなる)、LCS長が同じ用語に対しては、文字位置情報の値が小さい用語を上位とする。さらに、LCS長および文字位置情報の値が同じ用語に対しては、用語の文字数が少ない用語を上位とし、用語の文字数も同じである用語に対しては、用語IDの小さい用語を上位とする。
【0045】
順位決定部124は、例えば、順位を示す指標を用語毎に生成し、生成した指標に基づいて用語を並べ替える。
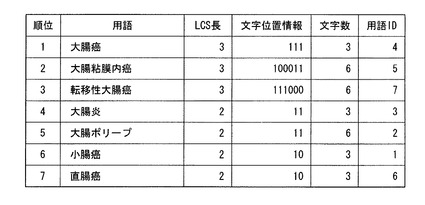
図8は、順位決定部124が生成する指標の例を示す図である。
同図に示す指標は、LCSの長さ(二進数表示)と、小数点と、文字位置情報(二進数表示)の2の補数と、用語の長さ(二進数表示)の2の補数と、用語ID(二進数表示)の2の補数とが、この順に結合されて生成される。その際、順位決定部124は、文字位置情報(二進数表示)の桁数を、当該用語文字数に揃える。また、用語の長さ(二進数表示)の桁数を、用語記憶部131が記憶する用語のうち最長のものを表現可能な桁数に揃える。また、用語ID(二進数表示)の桁数を、用語記憶部131が記憶する用語IDのうち最大のものを表現可能な桁数に揃える。
【0046】
また、同図の値は、入力文字列が「大腸癌」である場合に、用語「大腸粘膜内癌」に対して生成される指標の値を示している。
「大腸癌」の文字数は「3」であるため、同図に示す指標の整数部分は「11」となっており、また、小数部分は、文字位置情報「100011」の2の補数「011100」と、用語の長さ「6」の二進数表示「0・・・0110」の2の補数「1・・・1001」と、用語ID「5」の二進数表示「0・・・0101」の2の補数「1・・・1010」とを結合した値となっている。2の補数を取ることにより、元となる値が小さいほど大きい値の指標が生成される。
【0047】
順位決定部124が、この指標の大きい順に用語を並べ替えることにより、各用語は、LCSの長さが長い順に並べられ、LCSの長さが同一の場合は、文字位置情報の値が小さい順に並べられ、文字位置情報の値も同一の場合は、用語の長さが短い順に並べられ、用語の長さも同一の場合は、用語IDの値が小さい順に並べられる。
ここで、LCSに含まれる文字が用語に出現する位置のうち、最も後ろ(用語の末尾側)の位置が先頭に近い用語ほど、文字位置情報の値が小さくなる。また、LCSに含まれる文字が用語に出現する位置のうち、最も後ろの出現位置が同一の場合は、後ろから2番目の出現位置が先頭に近い用語ほど、文字位置情報の値が小さくなる。同様に、1〜i−1(iはLCS長以下の正整数)番目の各出現位置が同一の場合は、i番目の出現位置が先頭に近い用語ほど、文字位置情報の値が小さくなる。この点で、文字位置情報生成部123は、LCSに含まれる文字が用語中に出現する位置が先頭に近いほど小さい値を示す文字位置情報を生成する。
【0048】
順位決定部124は、並べ替えた用語のうち、例えば上位5つなど、予め定められた数の用語のリストを、通信部110を介して端末装置200に送信する。
端末装置200の通信部210は、順位決定部124からの用語のリストを受信すると、受信したリストを表示部230に出力する。表示部230は、通信部210から出力される用語のリストを、入力欄の下方近傍に表示する。
【0049】
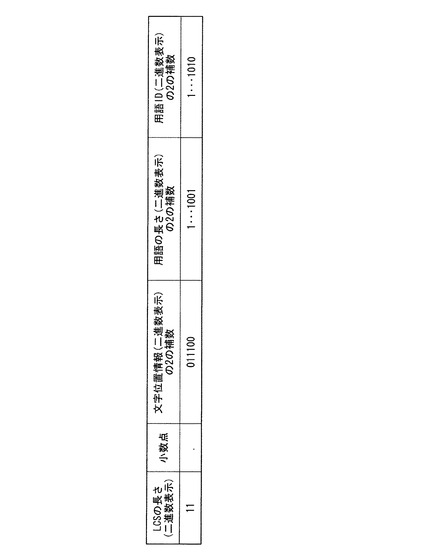
図9は、表示部230が用語のリストを表示した例を示す図である。同図では、入力文字列が「大腸癌」である場合に、図2に示した用語リストの用語のうち、上位5つの用語を表示した例が示されている。この場合、順位決定部124は、図7で示した順位に従って用語を並べ替え、そのうち上位5つ(順位1〜5)の用語を、上位から順に含むリストを生成し、表示部230がこのリストを表示する。
ユーザが、このリストに含まれる用語のいずれかを、マウスでクリックする等により選択すると、入力部220は、選択された用語を入力文字列として表示部230と通信部210に出力する。以下、各部は上述した処理を行う。
【0050】
以上のように、文字列入力支援装置100の文字位置情報生成部123が、入力文字列に含まれる文字、より具体的にはLCSに含まれる文字が用語中に出現する位置を示す文字位置情報を生成し、順位決定部124が、文字位置情報生成部123の生成した文字位置情報に基づいて用語の順位を決定するので、ユーザの入力したい文字列が上位となる、すなわち、文字位置情報に基づいて、文字列候補中に、入力済みの文字列に含まれる文字が出現する位置が、当該文字列候補の先頭に近いほど当該文字列候補を上位として順位を決定されるので、用語候補の選択や優先順位付けをより適切に行えることが期待できる。
例えば、ユーザが文字列を入力する場合、通常は、入力したい文字列の先頭の文字から順に入力する。したがって、入力文字列に含まれる文字が、用語の先頭近くに出現する場合に当該用語を上位とすることにより、ユーザが入力したい文字列(用語)が上位となることが期待できる。
また、ユーザが用語を記憶する場合、用語の先頭付近の文字は、最初に見るあるいは聞く文字である点で印象に残り易いと考えられる。そうすると、ユーザが曖昧な記憶に基づいて文字列を入力する場合、入力される文字列の先頭に近い位置の文字ほど信頼性が高いと考えられる。したがって、この場合も、入力文字列に含まれる文字が、用語の先頭近くに出現する場合に当該用語を上位とすることにより、ユーザが入力したい文字列(用語)が上位となることが期待できる。
【0051】
また、LCS長算出部122が、用語記憶部131の記憶する各用語と入力文字列とのLCS長を算出し、順位決定部124が、LCS長算出部122の算出したLCS長に基づいて用語の順位を決定するので、ユーザの入力したい文字列が、より上位となることが期待できる。すなわち、LCS長の長い用語ほど、入力文字列中の文字と共通の文字を、入力文字列と同じ順序で多数含んでいる点で、入力文字列に類似している。この入力文字列に類似する用語を上位とすることにより、ユーザの入力したい文字列(用語)が上位となる。すなわち、最長共通部分列の文字数が多い文字列候補を上位とし、最長共通部分列の文字数が同一の文字列候補に対しては、当該文字列候補中に、最長共通部分列に含まれる文字が出現する位置が先頭に近いほど当該文字列候補を上位として順位が決定される。これにより、用語候補の選択や優先順位付けをより適切に行えることが期待できる。
また、順位決定部124が、LCS長や、LCSに含まれる文字が用語中に出現する位置の情報を用いて用語の順位を決定することにより、入力文字列に文字違いや入力不足などの誤りがある場合にも、ユーザの入力したい文字列(用語)が上位となる、すなわち、用語候補の選択や優先順位付けをより適切に行えることが期待できる。
例えば、入力文字列の先頭からの部分文字列と用語の先頭からの部分文字列とを比較して、完全に一致する部分文字列の長い順に用語の順位を決定する方法では、入力文字列の先頭の文字が文字違いによって誤った文字となっている場合や、入力不足により入力文字列の先頭の文字が欠けている(2番目の文字となるべき文字が先頭に来ている)場合には、ユーザの入力したい文字列(用語)を上位とすることができない。これに対して、本実施形態の順位決定部124は、LCS長や、LCSに含まれる文字が用語中に出現する位置の情報を用いて用語の順位を決定するので、入力文字列の先頭の文字が文字違いまたは入力不足の場合でも、用語候補の選択や優先順位付けをより適切に行えることが期待できる。入力文字列中の先頭以外の位置に文字違いや入力不足がある場合も同様である。
【0052】
また、文字位置情報生成部123が、文字列候補の先頭から最長共通部分列の末尾の文字が文字列候補中に出現する位置までの文字数に対応したビット数のビット列であり、文字位置情報で表された位置に対応するビットを用いて最長共通部分列に含まれる文字が出現することが表されたビット列を生成する。これにより、文字位置情報行列記憶部133は、より少ない記憶領域で文字位置情報を記憶できる。
例えば、8バイト分の記憶領域があれば、64文字以下の用語の文字位置情報を記憶できる。また、順位決定部124が、文字位置情報の値の大小を判定する際に、ビット列に対する演算にて判定することができるので、高速に判定を行えることが期待できる。例えば、図8で説明した指標を生成する際に、2の補数を生成する操作、すなわち、各ビットの「1」と「0」とを反転させるという簡単な操作により、文字位置情報の値が小さいほど大きな値となる指標を生成できる。
【0053】
また、文字位置情報生成部123が、LCSに含まれる文字が用語中に出現する位置が先頭に近いほど小さい値を示す文字位置情報を生成し、順位決定部124が、より小さい値を示す文字位置情報に対応付けられた用語を、より上位とするので、LCSに含まれる文字が用語中に出現する位置が先頭に近い用語ほど上位とされる。これにより、上述したように、ユーザが入力したい文字列(用語)が上位となることが期待できる。
【0054】
なお、順位決定部124が文字位置情報に基づいて用語の順位を決定する方法は、上述した、文字位置情報の値が小さい用語ほど上位とする方法に限らない。例えば、順位決定部124が、文字位置情報を、二進数表示した場合の中央の桁から前後2つのグループに分割し、中央より前のグループに含まれる桁で「1」となっている桁の数から、中央より後ろのグループに含まれる桁で「1」となっている桁の数を引き、得られた数が大きい用語ほど上位とするなど、他の方法で順位を決定するようにしてもよい。
この、文字位置情報を中央から分割する方法でも、LCSに含まれる文字が用語中に出現する位置が先頭に近い用語ほど上位とすることができる。
【0055】
なお、上述したように、文字列入力支援装置100は、コンピュータによって実現するようにしてもよい。すなわち、文字列入力支援装置100の全部または一部の機能を実現するためのプログラムをコンピュータ読み取り可能な記録媒体に記録して、この記録媒体に記録されたプログラムをコンピュータシステムに読み込ませ、実行することにより各部の処理を行ってもよい。なお、ここでいう「コンピュータシステム」とは、OSや周辺機器等のハードウェアを含むものとする。
また、「コンピュータシステム」は、WWWシステムを利用している場合であれば、ホームページ提供環境(あるいは表示環境)も含むものとする。
また、「コンピュータ読み取り可能な記録媒体」とは、フレキシブルディスク、光磁気ディスク、ROM、CD−ROM等の可搬媒体、コンピュータシステムに内蔵されるハードディスク等の記憶装置のことをいう。さらに「コンピュータ読み取り可能な記録媒体」とは、インターネット等のネットワークや電話回線等の通信回線を介してプログラムを送信する場合の通信線のように、短時間の間、動的にプログラムを保持するもの、その場合のサーバやクライアントとなるコンピュータシステム内部の揮発性メモリのように、一定時間プログラムを保持しているものも含むものとする。また上記プログラムは、前述した機能の一部を実現するためのものであっても良く、さらに前述した機能をコンピュータシステムにすでに記録されているプログラムとの組み合わせで実現できるものであっても良い。
【0056】
以上、この発明の実施形態を図面を参照して詳述してきたが、具体的な構成はこの実施形態に限られるものではなく、この発明の要旨を逸脱しない範囲の設計変更等も含まれる。
【符号の説明】
【0057】
1 文字列入力支援システム
100 文字列入力支援装置
110 通信部
120 処理部
121 処理制御部
122 LCS長算出部
123 文字位置情報生成部
124 順位決定部
130 記憶部
131 用語記憶部
132 LCS長行列記憶部
133 文字位置情報行列記憶部
200 端末装置
210 通信部
220 入力部
230 表示部
【技術分野】
【0001】
本発明は、文字列入力支援装置、文字列入力支援方法およびプログラムに関する。
【背景技術】
【0002】
コンピュータ等においてユーザが用語(文字列)を入力する負担を軽減する用語入力支援方法の1つに、当該コンピュータ等が、予め記憶する用語群の中から、入力済みの文字列に類似する用語を用語候補として選択して表示し、表示した用語候補のいずれかに対するユーザの選択操作を受け付ける方法がある。
例えば、コンピュータの表示画面に表示される診断書に病名を入力する際、図10(a)に示すように、ユーザによる「大腸」の入力に対して、コンピュータは、この「大腸」に類似する用語として、「大腸炎」や「大腸癌」など、「大腸」を含む用語を選択し、入力欄の下方近傍に表示する。そして、カーソルキーあるいはマウスを用いてユーザが「大腸ポリープ」を選択すると、コンピュータは、選択された「大腸ポリープ」を入力欄に表示する。
【0003】
一方、ユーザが用語の選択を行わずに、更に「癌」を入力すると、コンピュータは、同図(b)に示すように、入力された文字列「大腸癌」のうち2文字以上を含む、「大腸炎」や「大腸粘膜内癌」などの用語を選択して表示する。
このように、入力された文字列の全部を含む用語に限らず、一部を含む用語も表示することにより、「大腸炎」を誤って「大腸癌」と入力する文字違いや、「転移性大腸癌」を誤って「転移大腸癌」と入力する入力不足など、入力された文字列に誤りがある場合にもユーザの意図する用語を表示し得る。
【0004】
このような、入力済みの文字列に類似する用語を用語候補として選択する方法として、例えば、特許文献1に示される方法を用いることが考えられる。同文献では、"leucocyte"と"leukocyte"など、同一の事物を示す用語の表記が異なる「表記揺れ」の用語を取得する方法が示されている。この方法では、注目する用語に対する表記揺れの用語を収集するために、まず、予め記憶する用語の各々について、注目する用語とのNグラム(文字数Nの部分文字列)の一致度および文字列長の類似度を比較することにより、類似する用語の絞込みを行う。そして、大文字と小文字との置換は10点、数字の置換は100点など、編集内容毎に設定されたコストで重み付けされた編集距離に基づいて、さらに用語の絞込みを行う。
この方法を、用語候補の選択に用いると、入力済みの文字列と共通の部分文字列を多く含み、入力済みの文字列に文字数が類似し、かつ、入力済みの文字列に対してコストの小さい変換操作を行って得られる文字列を抽出できる。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開2005−352888号公報
【発明の概要】
【発明が解決しようとする課題】
【0006】
しかしながら、特許文献1に示される方法を用語候補の選択に用いた場合、入力済みの文字列に含まれる各文字が予め記憶された用語の各々の中に出現する位置の情報が、用語候補の選択および表示に際して充分に反映されない。
例えば、「腸」が入力された場合、通常、ユーザは「腸」で始まる用語、あるいは、入力不足がある場合は「腸」が先頭付近にある用語を入力しようとしていると考えられる。したがって、「大腸ポリープ」と「転移性大腸癌」とでは、「腸」が先頭に近い「大腸ポリープ」を優先的に表示することが好ましい。すなわち、いずれか一方のみを表示する場合には「大腸ポリープ」のほうを表示し、両方を表示する場合には「大腸ポリープ」のほうを「転移性大腸癌」よりも入力欄に近い位置に表示することが好ましい。
【0007】
ところが、「大腸ポリープ」および「転移性大腸癌」について見ると、いずれも、「腸」と共通するNグラムは、N=1のときに「腸」の1つであり、N=2以上では共通するNグラムは存在しない。
また、「大腸ポリープ」と「転移性大腸癌」とは、共に6文字であるため「腸」との文字数差も、共に5である。
さらに、「腸」からの編集距離は、いずれも、5文字の挿入である。
このため、特許文献1に示される方法を用語候補の選択に用いた場合、「大腸ポリープ」と「転移性大腸癌」とは、同一の優先順位となってしまい、どちらを優先するかを特定することができない。
【0008】
本発明は、このような事情を考慮してなされたものであり、その目的は、入力文字に含まれる文字の出現位置に応じて用語候補の選択や優先順位付けをより適切に行える文字列入力支援装置、文字列入力支援方法およびプログラムを提供することにある。
【課題を解決するための手段】
【0009】
[1]この発明は上述した課題を解決するためになされたもので、本発明の一態様による文字列入力支援装置は、入力済みの文字列に基づいて、予め記憶された文字列候補に対して順位を決定する文字列入力支援装置であって、前記文字列候補を記憶する文字列候補記憶部と、前記文字列候補記憶部が記憶する前記文字列候補の各々について、当該文字列候補中に、前記入力済みの文字列に含まれる文字が出現する位置を示す情報であって、当該文字列候補の先頭を基準として数えられる文字の数で、当該文字列中における文字の位置を示す文字位置情報を生成する文字位置情報生成部と、前記文字位置情報に基づいて、前記文字列候補中に、前記入力済みの文字列に含まれる文字が出現する位置が、当該文字列候補の先頭に近いほど当該文字列候補を上位として順位を決定する順位決定部とを具備することを特徴とする。
【0010】
[2]また、本発明の一態様による文字列入力支援装置は、上述の文字列入力支援装置であって、前記文字列候補記憶部が記憶する前記文字列候補の各々と前記入力済みの文字列との、最長共通部分列の文字数を示す文字数情報を生成する文字数情報生成部をさらに具備し、前記文字位置情報生成部は、前記文字列候補記憶部が記憶する前記文字列候補の各々と前記入力済みの文字列との、最長共通部分列に含まれる各文字が、当該文字列候補中に出現する位置を示す情報であって、当該文字列候補の先頭を基準として数えられる文字の数で、当該文字列中における文字の位置を示す前記文字位置情報を生成し、前記順位決定部は、前記最長共通部分列の文字数が多い前記文字列候補を上位とし、前記最長共通部分列の文字数が同一の前記文字列候補に対しては、当該文字列候補中に、前記最長共通部分列に含まれる文字が出現する位置が先頭に近いほど当該文字列候補を上位として順位を決定することを特徴とする。
【0011】
[3]また、本発明の一態様による文字列入力支援装置は、上述の文字列入力支援装置であって、前記文字位置情報生成部は、前記文字列候補の先頭から前記最長共通部分列の末尾の文字が前記文字列候補中に出現する位置までの文字数に対応したビット数のビット列であり、前記文字位置情報で表された位置に対応するビットを用いて前記最長共通部分列に含まれる文字が出現することが表されたビット列を生成することを特徴とする。
【0012】
[4]また、本発明の一態様による文字列入力支援方法は、文字列候補を記憶する文字列候補記憶部を具備し、入力済みの文字列に基づいて、予め記憶された文字列候補に対して順位を決定する文字列入力支援装置の文字列入力支援方法であって、文字位置情報生成部が、前記文字列候補記憶部が記憶する前記文字列候補の各々について、当該文字列候補中に、前記入力済みの文字列に含まれる文字が出現する位置を示す情報であって、当該文字列候補の先頭を基準として数えられる文字の数で、当該文字列中における文字の位置を示す文字位置情報を生成する文字位置情報生成ステップと、順位決定部が、前記文字位置情報に基づいて、前記文字列候補中に、前記入力済みの文字列に含まれる文字が出現する位置が、当該文字列候補の先頭に近いほど当該文字列候補を上位として順位を決定する順位決定ステップとを具備することを特徴とする。
【0013】
[5]また、本発明の一態様によるプログラムは、文字列候補を記憶する文字列候補記憶部を具備し、入力済みの文字列に基づいて、予め記憶された文字列候補に対して順位を決定する文字列入力支援装置としてのコンピュータに、前記文字列候補記憶部が記憶する前記文字列候補の各々について、当該文字列候補中に、前記入力済みの文字列に含まれる文字が出現する位置を示す情報であって、当該文字列候補の先頭を基準として数えられる文字の数で、当該文字列中における文字の位置を示す文字位置情報を生成する文字位置情報生成ステップと、前記文字位置情報に基づいて、前記文字列候補中に、前記入力済みの文字列に含まれる文字が出現する位置が、当該文字列候補の先頭に近いほど当該文字列候補を上位として順位を決定する順位決定ステップとを実行させるためのプログラムである。
【発明の効果】
【0014】
この発明によれば、入力文字に含まれる文字の出現位置に応じて用語候補の選択や優先順位付けをより適切に行える。
【図面の簡単な説明】
【0015】
【図1】本発明の一実施形態における文字列入力支援システムの概略構成を示す構成図である。
【図2】同実施形態において、用語記憶部131が記憶する用語リストの例を示す図である。
【図3】同実施形態において、LCS長行列記憶部132が記憶するLCS長行列の例を示す図である。
【図4】同実施形態において、文字位置情報行列記憶部133が記憶する文字位置情報行列の例を示す図である。
【図5】同実施形態において、処理部120がLCS長を算出し、文字位置情報を生成する処理手順を示すフローチャートである。
【図6】同実施形態において、処理部120がLCS長を算出し、文字位置情報を生成する処理手順を示すフローチャートである。
【図7】同実施形態において、順位決定部124による用語の順位決定の例を示す図である。
【図8】同実施形態において、順位決定部124が生成する指標の例を示す図である。
【図9】同実施形態において、表示部230が用語のリストを表示した例を示す図である。
【図10】ユーザが文字列を入力する際の、ユーザが入力した文字列の候補の表示例を示す図である。
【発明を実施するための形態】
【0016】
以下、図面を参照して、本発明の一実施形態について説明する。
図1は、本発明の一実施形態における文字列入力支援システムの概略構成を示す構成図である。同図において、文字列入力支援システム1は、文字列入力支援装置100と、端末装置200とを具備する。文字列入力支援装置100は、通信部110と、処理部120と、記憶部130とを具備する。処理部120は、処理制御部121と、LCS長算出部(文字数情報生成部)122と、文字位置情報生成部123と、順位決定部124とを具備する。記憶部130は、用語記憶部(文字列候補記憶部)131と、LCS長行列記憶部 132と、文字位置情報行列記憶部133とを具備する。端末装置200は、通信部210と、入力部220と、表示部230とを具備する。
【0017】
文字列入力支援システム1は、ユーザが入力済みの文字列(以下では、「入力文字列」と称する)に基づいて、ユーザが入力したい文字列の候補(文字列候補)を表示する。
文字列入力支援装置100は、入力文字列を端末装置200から取得し、取得した文字列に基づいて、ユーザが入力したい文字列の候補の各々の順位を決定し、ユーザが入力したい文字列の候補を、決定した順位に従って並べたリストを生成して端末装置200に送信する。
通信部110は、端末装置200との間でデータの送受信を行う。
記憶部130は、ユーザが入力したい文字列の候補である用語を予め記憶する。また、記憶部130は、ユーザが入力したい文字列の候補である用語の順位を、文字列入力支援装置100が決定する際のワーキングメモリとして機能する。記憶部130は、文字列入力支援装置100が具備する記憶装置上に実現される。
【0018】
用語記憶部131は、ユーザが入力したい文字列の候補である用語をリスト形式にて予め記憶する。
図2は、用語記憶部131が記憶する用語リストの例を示す図である。同図に示すように、用語リストの各行に、ユーザが入力したい文字列の候補である用語と、当該用語の識別番号である用語IDとが対応付けて記憶されている。用語リストは、例えば、ある分野の辞書に含まれる用語の各々に用語IDを付して生成される。同図の例では、用語リストは、病名に用語IDを付して生成されている。
用語IDは、各用語を識別する情報であると共に、用語リスト中における各用語の順序を示す情報でもある。
なお、用語リストに記憶される用語の数は、同図に示す7つに限らず、任意の個数であってよい。
【0019】
LCS長行列記憶部132は、文字列入力支援装置100が用語の順位を決定する際に生成するLCS長行列を記憶するワーキングメモリである。
図3は、LCS長行列記憶部132が記憶するLCS長行列の例を示す図である。同図に示すように、LCS長行列は、入力文字列の文字数+1の行、および、用語記憶部131が記憶する用語の文字数+1の列を有する行列であり、各要素には非負整数が格納される。以下では、LCS長行列の最上行(初期値に対応する行)を第0行とし、最左列(初期値に対応する列)を第0列とする。
LCS長行列記憶部132は、用語記憶部131が記憶する用語毎に、LCS長行列を記憶する。
【0020】
ここで、LCS(Longest Common Subsequence、最長共通部分列)は、2つの文字列に共通する部分列(共通部分列、Common Subsequence)のうち、最も長い(文字数の多い)ものである。この共通部分列は、各文字列中に連続して出現する必要はないが、2つの文字列中に同じ順序で出現する必要がある。図3の「大腸粘膜内癌」と「大腸粘液癌」との場合、「大」「腸」「粘」「癌」の各文字が同順序で出現しているので、両者のLCSは「大腸粘癌」であり、LCSの文字数(以下では、「LCS長」と称する)は4である。
LCS長行列の各要素は、当該要素の位置に対応する、用語またはその部分文字列と、入力文字列またはその部分文字列とのLCS長を示す。例えば、LCS長行列の第5行第6列の要素a156は、入力文字列「大腸粘液癌」と、用語「大腸粘膜内癌」とのLCS長「4」を示している。また、LCS長行列の第2行第4列の要素a124は、入力文字列の先頭から2文字の部分文字列(すなわち、先頭から2文字を入力した時点での入力文字列)「大腸」と、用語の先頭から4文字の部分文字列「大腸粘膜」とのLCS「大腸」の文字数「2」を示している。
【0021】
この、2つの文字列のLCSは、部分文字列のLCSから再帰的に算出できる。
2つの文字列の末尾の文字が同じ場合は、各文字列から当該末尾の文字を除いた部分文字列のLCSに、当該末尾の文字を加えることによりLCSを得られる。例えば、入力文字列「大腸粘液癌」と用語「大腸粘膜内癌」との末尾の文字は共に「癌」である。そして、「大腸粘液癌」と「大腸粘膜内癌」とのLCS「大腸粘癌」は、入力文字列「大腸粘液癌」から「癌」を除いた「大腸粘液」と、用語「大腸粘膜内癌」から「癌」を除いた「大腸粘膜内」との「大腸粘」に「癌」を加えて得られる。したがって、第5行第6列の要素a156の値「4」(「大腸粘癌」の文字数)は、第4行第5列の要素a145の値「3」(「大腸粘」の文字数)に1(「癌」の文字数)を加えた値となっている。
【0022】
一方、2つの文字列の末尾が異なる場合は、一方の文字列から当該末尾の文字を除いた部分文字列のLCSのうち、文字数の多いほうのLCSと同一(両者の値が等しい場合は、両者の値と同一)である。例えば、「大腸」と「大腸粘膜」との末尾の文字は、それぞれ「腸」と「膜」とであり異なる。ここで、「大腸」と、「大腸粘膜」から末尾の文字「膜」を除いた「大腸粘」とのLCSは「大腸」である。また、「大腸」から末尾の文字「腸」を除いた「大」と、「大腸粘膜」とのLCSは「大」である。そして、「大腸」と「大腸粘膜」とのLCS「大腸」は、この2つのLCS「大腸」および「大」のうち文字数の多いほうである「大腸」と同一である。したがって、第2行第4列の要素a124の値「2」(「大腸」の文字数)は、第2行第3列の要素a123の値「2」(「大腸」の文字数)と、第1行第4列の要素a114の値「1」(「大」の文字数)とのうち、値の大きいほうである「2」と同一である。
【0023】
このように、LCS長行列の各要素の値は、入力文字列中の対応する文字と、用語中の対応する文字とが同じ場合は、左上の要素の値に1を加えた値と同一である。一方、入力文字列中の対応する文字と、用語中の対応する文字とが異なる場合は、左隣の要素の値と、上隣の要素の値とのうち大きいほうの値と同一(両者の値が等しい場合は、両者の値と同一)である。
【0024】
図1に戻って、文字位置情報行列記憶部133は、文字列入力支援装置100が用語の順位を決定する際に生成する文字位置情報行列を記憶するワーキングメモリである。
図4は、文字位置情報行列記憶部133が記憶する文字位置情報行列の例を示す図である。同図に示すように、文字位置情報行列は、入力文字列の文字数+1の行数、および、用語記憶部131が記憶する用語の文字数+1の列数を有する行列であり、各要素にはビット列(二進数)が格納される。以下では、文字位置情報行列の最上行(初期値に対応する行)を第0行とし、最左列(初期値に対応する列)を第0列とする。
文字位置情報行列記憶部133は、用語記憶部131が記憶する用語毎に、文字位置情報行列を記憶する。
【0025】
文字位置情報行列の各要素には、入力文字列と、用語記憶部131が記憶する用語とのLCSの各文字が、当該用語中に出現する位置を示す文字位置情報が格納されている。文字位置情報行列の各要素のビット列は、1の位(最右ビット)から順に、入力文字列中の1番目(先頭)から順の各文字の位置を示す。例えば、文字位置情報行列の第5行第6列の要素b156は、最右ビットが入力文字列の先頭の文字「大」の位置を示し、以下同様に、右から2番目のビットが「腸」の位置、3番目が「粘」の位置、・・・、6番目(最左ビット)が「癌」の位置を示す。ここで、入力文字列「大腸粘液癌」と用語「大腸粘膜内癌」とのLCS「大腸粘癌」の各文字は、それぞれ、用語「大腸粘膜内癌」の先頭から1文字目(「大」)と、2文字目(「腸」)と、3文字目(「粘」)と、6文字目(「癌」)とに出現する。したがって、文字位置情報行列の第5行第6列の要素b156は、右から1、2、3、6番目のビットが「1」、4、5番目のビットが「0」となっている。
【0026】
上述したように、2つの文字列のLCSは、部分文字列のLCSから再帰的に算出できる。このため、文字位置情報行列も、部分文字列の文字位置情報行列から再帰的に生成できる。
2つの文字列(入力文字列またはその部分文字列、および、用語またはその部分文字列)の末尾の文字が同じ場合、これらの文字列の文字位置情報は、各文字列から当該末尾の文字を除いた部分文字列の文字位置情報に、当該末尾の文字の位置に対応する桁を1とした数を加算した値となる。例えば、図4の文字位置情報行列の、第5行第6列の要素b156の値「100111」(二進数)は、第4行第5列の要素b145の値「111」(二進数。「00111」の先頭の0が省略されている。以下同様に、文字位置情報の先頭の0の表示を省略する)に、末尾の文字「癌」の位置に対応する右から6桁目が1の「100000」(二進数)を加算した値となっている。
【0027】
一方、2つの文字列の末尾が異なる場合、これらの文字列の文字位置情報は、一方の文字列から当該末尾の文字を除いた場合の文字位置情報のうち、LCS長が長いほうの文字列の文字位置情報と同一である。例えば、図4の文字位置情報行列の、第2行第4列の要素b124の値「11」(二進数)は、第2行第3列の要素b123の値「11」(二進数)と、第1行第4列の要素b114の値「1」(二進数)とのうち、LCS長が長い文字列に対応する、第2行第3列の要素b123の値「11」(二進数)と同一である。
いずれの文字列から末尾の文字を除いてもLCS長が同一の場合は、いずれの文字位置情報と同一としてもよい。本実施形態では、値が小さいほうの文字位置情報と同一とする。後述するように、LCSに含まれる文字が先頭に近い位置に出現する用語を上位とするためである。
【0028】
このように、文字位置情報行列の各要素の値は、入力文字列中の対応する文字と、用語中の対応する文字とが同じ場合は、左上の要素の値に、用語の末尾の位置に対応する桁を1とした数を加えた値と同一である。一方、入力文字列中の対応する文字と、用語中の対応する文字とが異なる場合は、左隣の要素の値と、上隣の要素の値とのうち、LCS長が長いほうの値と同一(両者のLCS長が同一の場合は、値が小さいほうの要素の値と同一。さらに両要素の値が同一の場合は、両要素の値と同一)である。
【0029】
図1に戻って、処理部120は、通信部110を介して、ユーザが入力済みの文字列を端末装置200から取得し、取得した文字列に基づいて、ユーザが入力したい文字列の候補の各々の順位を決定する。そして、処理部120は、ユーザが入力したい文字列の候補を、決定した順位に従って並べたリストを生成し、通信部110を介して端末装置200に送信する。処理部120は、例えば、文字列入力支援装置100の具備するCPUが、記憶部130からプログラムを読み出して実行することにより実現される。
処理制御部121は、各部を制御して処理を行わせる。LCS長算出部122は、入力文字列と、用語記憶部131が記憶する各用語とのLCS長を算出する。文字位置情報生成部123は、入力文字列と、用語記憶部131が記憶する各用語との文字位置情報を生成する。順位決定部124は、LCS長算出部122が算出するLCS長および文字位置情報生成部123が生成する文字位置情報に基づいて、用語記憶部131が記憶する各用語の順位を決定する。
【0030】
端末装置200は、ユーザによる文字列の入力を受け付けて文字列入力支援装置100に送信し、文字列入力支援装置100から送信される用語(ユーザが入力しようとしている文字列の候補)を、文字列入力支援装置100が決定した順位に従って表示する。
通信部210は、文字列入力支援装置100との間でデータの送受信を行う。
入力部220は、キーボードおよびマウスを備え、ユーザによる文字列の入力を受け付けて、入力された文字列を、通信部210を介して文字列入力支援装置100に送信する。表示部230は、液晶ディスプレイ等の表示画面を備え、文字列の入力欄を表示し、ユーザの入力した文字列を入力欄に表示する。また、表示部230は、順位付けされた用語を、通信部210を介して文字列入力支援装置100から受信し、受信した用語を、その順位に従って入力欄の下方近傍に表示する。
【0031】
次に、文字列入力支援システム1の動作について説明する。
文字列入力支援システム1では、まず、端末装置200の表示部230が入力欄を表示し、入力部220がユーザの入力操作を待ち受ける。入力部220は、ユーザの入力操作を受けると、当該操作に基づいて、入力文字列を生成する。すなわち、入力部220は、過去の入力操作に基づく入力文字列を記憶しており、文字の追加や削除等の新たな入力操作を受けると、記憶している入力文字列を当該操作に基づいて更新(編集)する。入力部220は、更新された入力文字列を、表示部230および通信部210に出力する。
表示部230は、入力部220から出力された入力文字列を入力欄に表示(既に入力文字列を表示しているときは更新)する。また、通信部210は、入力部220から出力された入力文字列を、文字列入力支援装置100の通信部110に送信する。
通信部110は、通信部210からの入力文字列を受信すると、受信した入力文字列を処理部120に出力する。
【0032】
処理部120は、通信部110から出力される入力文字列と、用語記憶部131の記憶する各用語とのLCS長の算出および文字位置情報の生成を行う。
図5および図6は、処理部120がLCS長を算出し、文字位置情報を生成する処理手順を示すフローチャートである。処理部120は、通信部110から入力文字列が出力されると同図の処理を開始する。
まず、処理部120の処理制御部121は、LCS長行列記憶部132のLCS長行列を初期化するようLCS長算出部122を制御し、文字位置情報行列記憶部133の文字位置情報行列を初期化するよう文字位置情報生成部123を制御する。
【0033】
LCS長算出部122は、用語記憶部131が記憶する用語の各々について、LCS長行列の行数を入力文字列の文字数+1とし、列数を当該用語の文字数+1とする。そして、最上行(図3の例で、「初期値」に対応する行)の各要素の値と、最左列(図3の例で、「初期値」に対応する列)の各要素の値とを、いずれも「0」とする。他の要素の値は、この時点では未定である。
また、文字位置情報生成部123は、用語記憶部131が記憶する用語の各々について、文字位置情報行列の行数を入力文字列の文字数+1とし、列数を当該用語の文字数+1とする。そして、最上行(図4の例で、「初期値」に対応する行)の各要素の値と、最左列(図4の例で、「初期値」に対応する列)の各要素の値とを、いずれも「0」とする。他の要素の値は、この時点では未定である(以上、ステップS101)。
【0034】
次に、処理制御部121は、入力文字列の各文字について先頭から順に処理を行うループL11の処理を開始する。以下では、ループL11にて処理対象となっている文字の位置を「j」(先頭から順に、1、2、・・・とする)にて表示する。(以上、ステップS102)。
そして、処理制御部121は、用語記憶部131の記憶する各用語について処理を行うループL12の処理を開始する(ステップS103)。
さらに、処理制御部121は、処理対象の用語(以下では、「W」にて表示する)の各文字について先頭から順に処理を行うループL13の処理を開始する。以下では、ループL11にて処理対象となっている文字の位置を「k」(先頭から順に、1、2、・・・とする)にて表示する。(以上、ステップS104)。
【0035】
そして、処理制御部121は、入力文字列のj番目の文字と、用語Wのk番目の文字とが同一か否かを判定する(ステップS105)。同一であると判定した場合(ステップS105:YES)、処理制御部121は、文字が同一であることを示す信号を、LCS長算出部122に出力する。
文字が同一であることを示す信号が処理制御部121から出力されると、LCS長算出部122は、LCS長行列の第j行第k列の要素の値として、第j−1行第k−1列の要素の値+1を書き込む。すなわち、図3で説明したように、左上の要素の値に1を加えた値とする(以上、ステップS111)。
【0036】
また、ステップS105において文字が同一であると判定した(ステップS105:YES)処理制御部121は、文字が同一であることを示す信号を、文字位置情報生成部123にも出力する。
文字が同一であることを示す信号が処理制御部121から出力されると、文字位置情報生成部123は、文字位置情報行列の第j行第k列の要素の値として、第j−1行第k−1列の要素の値+2k−1を書き込む。すなわち、図4で説明したように、左上の要素の値に、用語の末尾の位置に対応する桁を1とした数を加えた値とする(以上、ステップS112)。
【0037】
その後、処理制御部121は、用語Wの全ての文字に対してループL13の処理を行ったか否かを判定する。未処理の文字があると判定した場合は、ステップS104に戻って、未処理の文字に対して引き続きループL13の処理を行う。一方、全ての文字に対して処理を行ったと判定した場合は、次のステップS142に進む(以上、ステップS141)。
そして、処理制御部121は、用語記憶部131の記憶する全ての用語に対してループL12の処理を行ったか否かを判定する。未処理の用語があると判定した場合は、ステップS103に戻って、未処理の用語に対して引き続きループL12の処理を行う。一方、全ての用語に対して処理を行ったと判定した場合は、次のステップS143に進む(以上、ステップS142)。
そして、処理制御部121は、入力文字列の全ての文字に対してループL11の処理を行ったか否かを判定する。未処理の文字があると判定した場合は、ステップS102に戻って、未処理の文字に対して引き続きループL11の処理を行う。一方、全ての文字に対して処理を行ったと判定した場合は、同図の処理を終了する(以上、ステップS143)。
【0038】
一方、ステップS105において文字が異なると判定した場合(ステップS105:NO)、処理制御部121は、LCS長行列の第j−1行第k列の要素の値が、第j行第k−1列の要素の値以上か否かを判定する(ステップS121)。第j−1行第k列の要素の値が、第j行第k−1列の要素の値以上であると判定した場合(ステップS121:YES)、処理制御部121は、第j−1行第k列の要素の値が、第j行第k−1列の要素の値以上であることを示す信号を、LCS長算出部122に出力する。
当該信号が処理制御部121から出力されると、LCS長算出部122は、LCS長行列の第j行第k列の要素の値として、第j−1行第k列の要素の値を書き込む。すなわち、図3で説明したように、左隣の値と、上隣の値とのうち大きいほう(ここでは、上隣の要素)の値と同一(両者の値が等しい場合は、両者の値と同一)とする(以上、ステップS122)。
【0039】
また、ステップS121において、第j−1行第k列の要素の値が、第j行第k−1列の要素の値以上であると判定した(ステップS121:YES)処理制御部121は、LCS長行列の第j−1行第k列の要素の値が、第j行第k−1列の要素の値と等しいか否かを判定する(ステップS123)。値が等しいと判定した場合(ステップS123:YES)、処理制御部121は、さらに、文字位置情報行列の第j−1行第k列の要素の値が、第j行第k−1列の要素の値以下か否かを判定する(ステップS124)。
ステップS123において両者の値が異なると判定した場合(ステップS123:NO)、および、ステップS124において、第j−1行第k列の要素の値が、第j行第k−1列の要素の値以下であると判定した場合(ステップS124:YES)、処理制御部121は、上隣の要素を書き込むよう指示する信号を、文字位置情報生成部123に出力する。
当該信号が処理制御部121から出力されると、文字位置情報生成部123は、文字位置情報行列の第j行第k列の要素の値として、第j−1行第k列の要素の値を書き込む。すなわち、図4で説明したように、左隣の要素の値と、上隣の要素の値とのうち、LCS長が長いほう(ここでは、上隣の要素)の値と同一(両者のLCS長が同一の場合は、値が小さいほうの要素の値と同一。さらに両要素の値が同一の場合は、両要素の値と同一)とする(以上、ステップS125)。
その後、処理制御部121は、ステップS141に進む。
【0040】
一方、ステップS121において、第j−1行第k列の要素の値が、第j行第k−1列の要素の値未満であると判定した場合(ステップS121:NO)、処理制御部121は、第j−1行第k列の要素の値が、第j行第k−1列の要素の値未満であることを示す信号を、LCS長算出部122に出力する。
当該信号が処理制御部121から出力されると、LCS長算出部122は、LCS長行列の第j行第k列の要素の値として、第j行第k−1列の要素の値を書き込む。すなわち、図3で説明したように、左隣の値と、上隣の値とのうち大きいほう(ここでは、左隣の要素)の値と同一とする(以上、ステップS131)。
【0041】
また、ステップS121において、第j−1行第k列の要素の値が、第j行第k−1列の要素の値未満であると判定した場合(ステップS121:NO)、および、ステップS124において、第j−1行第k列の要素の値が、第j行第k−1列の要素の値より大きいと判定した場合(ステップS124:NO)、処理制御部121は、左隣の要素を書き込むよう指示する信号を、文字位置情報生成部123に出力する。
当該信号が処理制御部121から出力されると、文字位置情報生成部123は、文字位置情報行列の第j行第k列の要素の値として、第j行第k−1列の要素の値を書き込む。すなわち、図4で説明したように、左隣の要素の値と、上隣の要素の値とのうち、LCS長が長いほう(ここでは、左隣の要素)の値と同一(両者のLCS長が同一の場合は、値が小さいほうの要素の値と同一)とする(以上、ステップS132)。
その後、処理制御部121は、ステップS141に進む。
【0042】
以上により、LCS長行列および文字位置情報行列が完成する。そして、LCS長行列の最上行最右列の要素の値が、対応する用語のLCS長を示し、文字位置情報行列の最上行最右列の要素の値が、対応する用語中における、LCSに含まれる文字の出現位置、すなわち文字位置情報を示している。
【0043】
なお、処理部120が、LCS長行列と文字位置情報行列とを常に新たに生成するのではなく、生成済みのLCS長行列および文字位置情報行列を更新するようにしてもよい。例えば、ユーザの操作入力により入力文字列の末尾に新たに1文字追加された場合、処理部120に入力される入力文字列のうち、末尾の文字を除いた部分文字列は、前回の入力文字列と同一である。そこで、LCS長算出部122が、各LCS長行列の末尾に行を追加し、文字位置情報生成部123が、各文字位置情報行列の末尾に行を追加するようにしてもよい。そして、処理部120は、新たに入力された入力文字列の末尾の文字に基づき、ループL12の処理手順に従って、LCS長行列および文字位置情報行列を完成させる。
【0044】
LCS長行列および文字位置情報行列が完成すると、処理制御部121は、用語記憶部131の記憶する各用語の順位を決定するように順位決定部124を制御する。
順位決定部124は、用語記憶部131の記憶する各用語の、LCS長と、文字位置情報と、用語の長さ(文字数)と、用語リストにおける順序(用語IDの値)とに基づいて、順位を決定し、決定した順位に基づいて並べられた用語のリストを生成する。
図7は、順位決定部124による用語の順位決定の例を示す図である。同図は、入力文字列が「大腸癌」である場合の例であり、図1に示す用語リストに含まれる用語と、各用語の順位と、順位を決定する基準となるLCS長と文字位置情報と用語の文字数と用語IDとを示している。
順位決定部124は、各用語に対して、LCS長が長いほど上位とし(上位の用語ほど高い優先順位、すなわち表示部230の入力欄に近い位置に表示されやすくなる)、LCS長が同じ用語に対しては、文字位置情報の値が小さい用語を上位とする。さらに、LCS長および文字位置情報の値が同じ用語に対しては、用語の文字数が少ない用語を上位とし、用語の文字数も同じである用語に対しては、用語IDの小さい用語を上位とする。
【0045】
順位決定部124は、例えば、順位を示す指標を用語毎に生成し、生成した指標に基づいて用語を並べ替える。
図8は、順位決定部124が生成する指標の例を示す図である。
同図に示す指標は、LCSの長さ(二進数表示)と、小数点と、文字位置情報(二進数表示)の2の補数と、用語の長さ(二進数表示)の2の補数と、用語ID(二進数表示)の2の補数とが、この順に結合されて生成される。その際、順位決定部124は、文字位置情報(二進数表示)の桁数を、当該用語文字数に揃える。また、用語の長さ(二進数表示)の桁数を、用語記憶部131が記憶する用語のうち最長のものを表現可能な桁数に揃える。また、用語ID(二進数表示)の桁数を、用語記憶部131が記憶する用語IDのうち最大のものを表現可能な桁数に揃える。
【0046】
また、同図の値は、入力文字列が「大腸癌」である場合に、用語「大腸粘膜内癌」に対して生成される指標の値を示している。
「大腸癌」の文字数は「3」であるため、同図に示す指標の整数部分は「11」となっており、また、小数部分は、文字位置情報「100011」の2の補数「011100」と、用語の長さ「6」の二進数表示「0・・・0110」の2の補数「1・・・1001」と、用語ID「5」の二進数表示「0・・・0101」の2の補数「1・・・1010」とを結合した値となっている。2の補数を取ることにより、元となる値が小さいほど大きい値の指標が生成される。
【0047】
順位決定部124が、この指標の大きい順に用語を並べ替えることにより、各用語は、LCSの長さが長い順に並べられ、LCSの長さが同一の場合は、文字位置情報の値が小さい順に並べられ、文字位置情報の値も同一の場合は、用語の長さが短い順に並べられ、用語の長さも同一の場合は、用語IDの値が小さい順に並べられる。
ここで、LCSに含まれる文字が用語に出現する位置のうち、最も後ろ(用語の末尾側)の位置が先頭に近い用語ほど、文字位置情報の値が小さくなる。また、LCSに含まれる文字が用語に出現する位置のうち、最も後ろの出現位置が同一の場合は、後ろから2番目の出現位置が先頭に近い用語ほど、文字位置情報の値が小さくなる。同様に、1〜i−1(iはLCS長以下の正整数)番目の各出現位置が同一の場合は、i番目の出現位置が先頭に近い用語ほど、文字位置情報の値が小さくなる。この点で、文字位置情報生成部123は、LCSに含まれる文字が用語中に出現する位置が先頭に近いほど小さい値を示す文字位置情報を生成する。
【0048】
順位決定部124は、並べ替えた用語のうち、例えば上位5つなど、予め定められた数の用語のリストを、通信部110を介して端末装置200に送信する。
端末装置200の通信部210は、順位決定部124からの用語のリストを受信すると、受信したリストを表示部230に出力する。表示部230は、通信部210から出力される用語のリストを、入力欄の下方近傍に表示する。
【0049】
図9は、表示部230が用語のリストを表示した例を示す図である。同図では、入力文字列が「大腸癌」である場合に、図2に示した用語リストの用語のうち、上位5つの用語を表示した例が示されている。この場合、順位決定部124は、図7で示した順位に従って用語を並べ替え、そのうち上位5つ(順位1〜5)の用語を、上位から順に含むリストを生成し、表示部230がこのリストを表示する。
ユーザが、このリストに含まれる用語のいずれかを、マウスでクリックする等により選択すると、入力部220は、選択された用語を入力文字列として表示部230と通信部210に出力する。以下、各部は上述した処理を行う。
【0050】
以上のように、文字列入力支援装置100の文字位置情報生成部123が、入力文字列に含まれる文字、より具体的にはLCSに含まれる文字が用語中に出現する位置を示す文字位置情報を生成し、順位決定部124が、文字位置情報生成部123の生成した文字位置情報に基づいて用語の順位を決定するので、ユーザの入力したい文字列が上位となる、すなわち、文字位置情報に基づいて、文字列候補中に、入力済みの文字列に含まれる文字が出現する位置が、当該文字列候補の先頭に近いほど当該文字列候補を上位として順位を決定されるので、用語候補の選択や優先順位付けをより適切に行えることが期待できる。
例えば、ユーザが文字列を入力する場合、通常は、入力したい文字列の先頭の文字から順に入力する。したがって、入力文字列に含まれる文字が、用語の先頭近くに出現する場合に当該用語を上位とすることにより、ユーザが入力したい文字列(用語)が上位となることが期待できる。
また、ユーザが用語を記憶する場合、用語の先頭付近の文字は、最初に見るあるいは聞く文字である点で印象に残り易いと考えられる。そうすると、ユーザが曖昧な記憶に基づいて文字列を入力する場合、入力される文字列の先頭に近い位置の文字ほど信頼性が高いと考えられる。したがって、この場合も、入力文字列に含まれる文字が、用語の先頭近くに出現する場合に当該用語を上位とすることにより、ユーザが入力したい文字列(用語)が上位となることが期待できる。
【0051】
また、LCS長算出部122が、用語記憶部131の記憶する各用語と入力文字列とのLCS長を算出し、順位決定部124が、LCS長算出部122の算出したLCS長に基づいて用語の順位を決定するので、ユーザの入力したい文字列が、より上位となることが期待できる。すなわち、LCS長の長い用語ほど、入力文字列中の文字と共通の文字を、入力文字列と同じ順序で多数含んでいる点で、入力文字列に類似している。この入力文字列に類似する用語を上位とすることにより、ユーザの入力したい文字列(用語)が上位となる。すなわち、最長共通部分列の文字数が多い文字列候補を上位とし、最長共通部分列の文字数が同一の文字列候補に対しては、当該文字列候補中に、最長共通部分列に含まれる文字が出現する位置が先頭に近いほど当該文字列候補を上位として順位が決定される。これにより、用語候補の選択や優先順位付けをより適切に行えることが期待できる。
また、順位決定部124が、LCS長や、LCSに含まれる文字が用語中に出現する位置の情報を用いて用語の順位を決定することにより、入力文字列に文字違いや入力不足などの誤りがある場合にも、ユーザの入力したい文字列(用語)が上位となる、すなわち、用語候補の選択や優先順位付けをより適切に行えることが期待できる。
例えば、入力文字列の先頭からの部分文字列と用語の先頭からの部分文字列とを比較して、完全に一致する部分文字列の長い順に用語の順位を決定する方法では、入力文字列の先頭の文字が文字違いによって誤った文字となっている場合や、入力不足により入力文字列の先頭の文字が欠けている(2番目の文字となるべき文字が先頭に来ている)場合には、ユーザの入力したい文字列(用語)を上位とすることができない。これに対して、本実施形態の順位決定部124は、LCS長や、LCSに含まれる文字が用語中に出現する位置の情報を用いて用語の順位を決定するので、入力文字列の先頭の文字が文字違いまたは入力不足の場合でも、用語候補の選択や優先順位付けをより適切に行えることが期待できる。入力文字列中の先頭以外の位置に文字違いや入力不足がある場合も同様である。
【0052】
また、文字位置情報生成部123が、文字列候補の先頭から最長共通部分列の末尾の文字が文字列候補中に出現する位置までの文字数に対応したビット数のビット列であり、文字位置情報で表された位置に対応するビットを用いて最長共通部分列に含まれる文字が出現することが表されたビット列を生成する。これにより、文字位置情報行列記憶部133は、より少ない記憶領域で文字位置情報を記憶できる。
例えば、8バイト分の記憶領域があれば、64文字以下の用語の文字位置情報を記憶できる。また、順位決定部124が、文字位置情報の値の大小を判定する際に、ビット列に対する演算にて判定することができるので、高速に判定を行えることが期待できる。例えば、図8で説明した指標を生成する際に、2の補数を生成する操作、すなわち、各ビットの「1」と「0」とを反転させるという簡単な操作により、文字位置情報の値が小さいほど大きな値となる指標を生成できる。
【0053】
また、文字位置情報生成部123が、LCSに含まれる文字が用語中に出現する位置が先頭に近いほど小さい値を示す文字位置情報を生成し、順位決定部124が、より小さい値を示す文字位置情報に対応付けられた用語を、より上位とするので、LCSに含まれる文字が用語中に出現する位置が先頭に近い用語ほど上位とされる。これにより、上述したように、ユーザが入力したい文字列(用語)が上位となることが期待できる。
【0054】
なお、順位決定部124が文字位置情報に基づいて用語の順位を決定する方法は、上述した、文字位置情報の値が小さい用語ほど上位とする方法に限らない。例えば、順位決定部124が、文字位置情報を、二進数表示した場合の中央の桁から前後2つのグループに分割し、中央より前のグループに含まれる桁で「1」となっている桁の数から、中央より後ろのグループに含まれる桁で「1」となっている桁の数を引き、得られた数が大きい用語ほど上位とするなど、他の方法で順位を決定するようにしてもよい。
この、文字位置情報を中央から分割する方法でも、LCSに含まれる文字が用語中に出現する位置が先頭に近い用語ほど上位とすることができる。
【0055】
なお、上述したように、文字列入力支援装置100は、コンピュータによって実現するようにしてもよい。すなわち、文字列入力支援装置100の全部または一部の機能を実現するためのプログラムをコンピュータ読み取り可能な記録媒体に記録して、この記録媒体に記録されたプログラムをコンピュータシステムに読み込ませ、実行することにより各部の処理を行ってもよい。なお、ここでいう「コンピュータシステム」とは、OSや周辺機器等のハードウェアを含むものとする。
また、「コンピュータシステム」は、WWWシステムを利用している場合であれば、ホームページ提供環境(あるいは表示環境)も含むものとする。
また、「コンピュータ読み取り可能な記録媒体」とは、フレキシブルディスク、光磁気ディスク、ROM、CD−ROM等の可搬媒体、コンピュータシステムに内蔵されるハードディスク等の記憶装置のことをいう。さらに「コンピュータ読み取り可能な記録媒体」とは、インターネット等のネットワークや電話回線等の通信回線を介してプログラムを送信する場合の通信線のように、短時間の間、動的にプログラムを保持するもの、その場合のサーバやクライアントとなるコンピュータシステム内部の揮発性メモリのように、一定時間プログラムを保持しているものも含むものとする。また上記プログラムは、前述した機能の一部を実現するためのものであっても良く、さらに前述した機能をコンピュータシステムにすでに記録されているプログラムとの組み合わせで実現できるものであっても良い。
【0056】
以上、この発明の実施形態を図面を参照して詳述してきたが、具体的な構成はこの実施形態に限られるものではなく、この発明の要旨を逸脱しない範囲の設計変更等も含まれる。
【符号の説明】
【0057】
1 文字列入力支援システム
100 文字列入力支援装置
110 通信部
120 処理部
121 処理制御部
122 LCS長算出部
123 文字位置情報生成部
124 順位決定部
130 記憶部
131 用語記憶部
132 LCS長行列記憶部
133 文字位置情報行列記憶部
200 端末装置
210 通信部
220 入力部
230 表示部
【特許請求の範囲】
【請求項1】
入力済みの文字列に基づいて、予め記憶された文字列候補に対して順位を決定する文字列入力支援装置であって、
前記文字列候補を記憶する文字列候補記憶部と、
前記文字列候補記憶部が記憶する前記文字列候補の各々について、当該文字列候補中に、前記入力済みの文字列に含まれる文字が出現する位置を示す情報であって、当該文字列候補の先頭を基準として数えられる文字の数で、当該文字列中における文字の位置を示す文字位置情報を生成する文字位置情報生成部と、
前記文字位置情報に基づいて、前記文字列候補中に、前記入力済みの文字列に含まれる文字が出現する位置が、当該文字列候補の先頭に近いほど当該文字列候補を上位として順位を決定する順位決定部と
を具備することを特徴とする文字列入力支援装置。
【請求項2】
前記文字列候補記憶部が記憶する前記文字列候補の各々と前記入力済みの文字列との、最長共通部分列の文字数を示す文字数情報を生成する文字数情報生成部をさらに具備し、
前記文字位置情報生成部は、前記文字列候補記憶部が記憶する前記文字列候補の各々と前記入力済みの文字列との、最長共通部分列に含まれる各文字が、当該文字列候補中に出現する位置を示す情報であって、当該文字列候補の先頭を基準として数えられる文字の数で、当該文字列中における文字の位置を示す前記文字位置情報を生成し、
前記順位決定部は、前記最長共通部分列の文字数が多い前記文字列候補を上位とし、前記最長共通部分列の文字数が同一の前記文字列候補に対しては、当該文字列候補中に、前記最長共通部分列に含まれる文字が出現する位置が先頭に近いほど当該文字列候補を上位として順位を決定する
ことを特徴とする請求項1に記載の文字列入力支援装置。
【請求項3】
前記文字位置情報生成部は、前記文字列候補の先頭から前記最長共通部分列の末尾の文字が前記文字列候補中に出現する位置までの文字数に対応したビット数のビット列であり、前記文字位置情報で表された位置に対応するビットを用いて前記最長共通部分列に含まれる文字が出現することが表されたビット列を生成することを特徴とする請求項1または請求項2に記載の文字列入力支援装置。
【請求項4】
文字列候補を記憶する文字列候補記憶部を具備し、
入力済みの文字列に基づいて、予め記憶された文字列候補に対して順位を決定する文字列入力支援装置の文字列入力支援方法であって、
文字位置情報生成部が、前記文字列候補記憶部が記憶する前記文字列候補の各々について、当該文字列候補中に、前記入力済みの文字列に含まれる文字が出現する位置を示す情報であって、当該文字列候補の先頭を基準として数えられる文字の数で、当該文字列中における文字の位置を示す文字位置情報を生成する文字位置情報生成ステップと、
順位決定部が、前記文字位置情報に基づいて、前記文字列候補中に、前記入力済みの文字列に含まれる文字が出現する位置が、当該文字列候補の先頭に近いほど当該文字列候補を上位として順位を決定する順位決定ステップと
を具備することを特徴とする文字列入力支援方法。
【請求項5】
文字列候補を記憶する文字列候補記憶部を具備し、入力済みの文字列に基づいて、予め記憶された文字列候補に対して順位を決定する文字列入力支援装置としてのコンピュータに、
前記文字列候補記憶部が記憶する前記文字列候補の各々について、当該文字列候補中に、前記入力済みの文字列に含まれる文字が出現する位置を示す情報であって、当該文字列候補の先頭を基準として数えられる文字の数で、当該文字列中における文字の位置を示す文字位置情報を生成する文字位置情報生成ステップと、
前記文字位置情報に基づいて、前記文字列候補中に、前記入力済みの文字列に含まれる文字が出現する位置が、当該文字列候補の先頭に近いほど当該文字列候補を上位として順位を決定する順位決定ステップと
を実行させるためのプログラム。
【請求項1】
入力済みの文字列に基づいて、予め記憶された文字列候補に対して順位を決定する文字列入力支援装置であって、
前記文字列候補を記憶する文字列候補記憶部と、
前記文字列候補記憶部が記憶する前記文字列候補の各々について、当該文字列候補中に、前記入力済みの文字列に含まれる文字が出現する位置を示す情報であって、当該文字列候補の先頭を基準として数えられる文字の数で、当該文字列中における文字の位置を示す文字位置情報を生成する文字位置情報生成部と、
前記文字位置情報に基づいて、前記文字列候補中に、前記入力済みの文字列に含まれる文字が出現する位置が、当該文字列候補の先頭に近いほど当該文字列候補を上位として順位を決定する順位決定部と
を具備することを特徴とする文字列入力支援装置。
【請求項2】
前記文字列候補記憶部が記憶する前記文字列候補の各々と前記入力済みの文字列との、最長共通部分列の文字数を示す文字数情報を生成する文字数情報生成部をさらに具備し、
前記文字位置情報生成部は、前記文字列候補記憶部が記憶する前記文字列候補の各々と前記入力済みの文字列との、最長共通部分列に含まれる各文字が、当該文字列候補中に出現する位置を示す情報であって、当該文字列候補の先頭を基準として数えられる文字の数で、当該文字列中における文字の位置を示す前記文字位置情報を生成し、
前記順位決定部は、前記最長共通部分列の文字数が多い前記文字列候補を上位とし、前記最長共通部分列の文字数が同一の前記文字列候補に対しては、当該文字列候補中に、前記最長共通部分列に含まれる文字が出現する位置が先頭に近いほど当該文字列候補を上位として順位を決定する
ことを特徴とする請求項1に記載の文字列入力支援装置。
【請求項3】
前記文字位置情報生成部は、前記文字列候補の先頭から前記最長共通部分列の末尾の文字が前記文字列候補中に出現する位置までの文字数に対応したビット数のビット列であり、前記文字位置情報で表された位置に対応するビットを用いて前記最長共通部分列に含まれる文字が出現することが表されたビット列を生成することを特徴とする請求項1または請求項2に記載の文字列入力支援装置。
【請求項4】
文字列候補を記憶する文字列候補記憶部を具備し、
入力済みの文字列に基づいて、予め記憶された文字列候補に対して順位を決定する文字列入力支援装置の文字列入力支援方法であって、
文字位置情報生成部が、前記文字列候補記憶部が記憶する前記文字列候補の各々について、当該文字列候補中に、前記入力済みの文字列に含まれる文字が出現する位置を示す情報であって、当該文字列候補の先頭を基準として数えられる文字の数で、当該文字列中における文字の位置を示す文字位置情報を生成する文字位置情報生成ステップと、
順位決定部が、前記文字位置情報に基づいて、前記文字列候補中に、前記入力済みの文字列に含まれる文字が出現する位置が、当該文字列候補の先頭に近いほど当該文字列候補を上位として順位を決定する順位決定ステップと
を具備することを特徴とする文字列入力支援方法。
【請求項5】
文字列候補を記憶する文字列候補記憶部を具備し、入力済みの文字列に基づいて、予め記憶された文字列候補に対して順位を決定する文字列入力支援装置としてのコンピュータに、
前記文字列候補記憶部が記憶する前記文字列候補の各々について、当該文字列候補中に、前記入力済みの文字列に含まれる文字が出現する位置を示す情報であって、当該文字列候補の先頭を基準として数えられる文字の数で、当該文字列中における文字の位置を示す文字位置情報を生成する文字位置情報生成ステップと、
前記文字位置情報に基づいて、前記文字列候補中に、前記入力済みの文字列に含まれる文字が出現する位置が、当該文字列候補の先頭に近いほど当該文字列候補を上位として順位を決定する順位決定ステップと
を実行させるためのプログラム。
【図1】


【図2】

【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【公開番号】特開2011−257922(P2011−257922A)
【公開日】平成23年12月22日(2011.12.22)
【国際特許分類】
【出願番号】特願2010−131072(P2010−131072)
【出願日】平成22年6月8日(2010.6.8)
【出願人】(000102728)株式会社エヌ・ティ・ティ・データ (438)
【Fターム(参考)】
【公開日】平成23年12月22日(2011.12.22)
【国際特許分類】
【出願日】平成22年6月8日(2010.6.8)
【出願人】(000102728)株式会社エヌ・ティ・ティ・データ (438)
【Fターム(参考)】
[ Back to top ]