
文字認識装置、文字認識方法及びプログラム

【課題】類似字種への誤認識を防ぐとともに、認識速度を著しく向上する。
【解決手段】特定語句と、特定語句の文字数の長さとの関係を記憶する特定語句記憶部41と、手書き入力された文字列を取得する文字列取得部31と、取得した文字列を複数個のユニットに仮切出しする仮切出部32と、切り出された各ユニット毎に複数の文字パターン候補を構成する文字パターン候補構成部33と、各文字パターン候補を連結する文字パターン候補連結部34と、連結された各文字パターン候補における終端までの文字数の長さを算出する文字数算出部35と、構成された文字パターン候補を、特定語句記憶部41に記憶された特定語句と、文字パターン候補毎に算出された終端までの文字数の長さと、に基づき限定する文字パターン候補限定部36と、限定された文字パターン候補に基づいて文字の認識を行う文字認識部37と、を備える。
【解決手段】特定語句と、特定語句の文字数の長さとの関係を記憶する特定語句記憶部41と、手書き入力された文字列を取得する文字列取得部31と、取得した文字列を複数個のユニットに仮切出しする仮切出部32と、切り出された各ユニット毎に複数の文字パターン候補を構成する文字パターン候補構成部33と、各文字パターン候補を連結する文字パターン候補連結部34と、連結された各文字パターン候補における終端までの文字数の長さを算出する文字数算出部35と、構成された文字パターン候補を、特定語句記憶部41に記憶された特定語句と、文字パターン候補毎に算出された終端までの文字数の長さと、に基づき限定する文字パターン候補限定部36と、限定された文字パターン候補に基づいて文字の認識を行う文字認識部37と、を備える。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、文字認識装置、文字認識方法及びプログラムに関し、特に特定語句認識において類似字種への誤認識を防ぐとともに、認識速度を著しく向上する技術に関する。
【背景技術】
【0002】
近年、手書き入力が可能なタブレット型のコンピュータの普及に伴い、ペンやマーカ、指などによる入力できる手書き入力システムが拡大する兆しを見せている。このような手書き入力システムを用いることにより、ユーザは、キーボードを用いずに手書きで文字を入力することができる。このような手書き入力においては、特定語句の認識が頻出する。住所、人名、日付、部署名などはその例である。
【0003】
このような手書き入力された特定語句を電子データとして認識させるために、様々な手書き文字列認識方式が提供されている。
また、このような特定語句認識方式に関しては、予め作成したトライ(trie)辞書の中でビームサーチによりサーチスペースを展開する文字同期方式を適用することで各文字パターン候補の認識字種を限定し、認識精度と認識速度の向上を図る方法も提案されている(例えば、非特許文献1参照)。
【先行技術文献】
【非特許文献】
【0004】
【非特許文献1】C.-L. Liu, M. Koga, and H. Fujisawa, “Lexicon-Driven Segmentation and Recognition of Handwritten Character Strings for Japanese Address Reading,” IEEE Trans. Pattern Analysis and Machine Intelligence, 24(11), pp. 1425-1437, 2002.
【発明の概要】
【発明が解決しようとする課題】
【0005】
汎用の手書き文字列認識方式を特定語句の認識に適用すると、特定語句の語彙集合に含まれない語句と誤認識されることがよくあった。
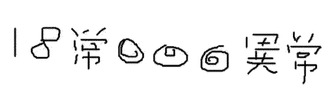
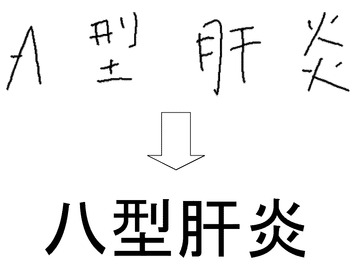
例えば、図19に示すように、「A型肝炎」の手書き文字列に対し汎用の手書き文字列認識方式により文字認識を行った場合、「A」の文字の類似字種である「八」と誤認識することがあった。これにより、「A型肝炎」の手書き文字列を特定語句の語彙集合に含まれない「八型肝炎」と誤認識する場合があるという問題点があった。
また、特定語句を1つの単語と見なし英語などの単語認識方式を適用することもできるが、文字認識の対象となる特定語句を全ての単語と比較する必要があるため、多くの処理時間を要するという問題点があった。
【0006】
本発明は、上述の課題に鑑みてなされたものであり、類似字種への誤認識を防ぐとともに、認識速度を著しく向上することができるようにすることにある。即ち、本発明は、以下の技術的事項から構成される。
【課題を解決するための手段】
【0007】
(1) 特定語句と、前記特定語句の文字数の長さとの関係を記憶する特定語句記憶手段と、
手書き入力された文字列を取得する文字列取得手段と、
前記文字列取得手段により取得した前記文字列を複数個のユニットに仮切出しする仮切出手段と、
前記仮切出手段により切り出された各ユニット毎に複数の文字パターン候補を構成する文字パターン候補構成手段と、
前記文字パターン候補構成手段により構成された各文字パターン候補を連結する文字パターン候補連結手段と、
前記文字パターン候補連結手段により連結された前記各文字パターン候補における終端までの文字数の長さを算出する文字数算出手段と、
前記文字パターン候補構成手段により構成された文字パターン候補を、前記特定語句記憶手段に記憶された前記特定語句と、前記文字数算出手段により文字パターン候補毎に算出された終端までの文字数の長さと、に基づき限定する文字パターン候補限定手段と、
前記文字パターン候補限定手段により限定された前記文字パターン候補に基づいて文字の認識を行う文字認識手段と、
を備える文字認識装置。
【0008】
(1)の文字認識装置によると、手書き入力された特定語句の文字列の認識を行う際に、文字パターン候補構成手段により構成された文字パターン候補を、文字数算出手段により文字パターン候補毎に算出された終端までの文字数の長さに基づいて、予め特定語句記憶手段に記憶された特定語句により限定する。
これにより、手書き入力した文字を認識する際において、類似する字種が手書き入力された場合であっても、予め記憶された特定語句のみに基づき限定されるため、他の字種と誤認識するという問題を解消することができる。また、文字の認識に際し、予め記憶された特定語句の中から、文字の認識が行われるため、認識速度を著しく向上させることができる。
【0009】
(2) 前記文字パターン候補限定手段は、
前記文字数算出手段により文字パターン候補毎に算出された終端までの文字数の長さと同一の終端までの文字数の長さを有する特定語句を、前記特定語句記憶手段に記憶された前記特定語句から選別し、
選別した前記特定語句を構成する各文字を、前記文字パターン候補構成手段により構成された文字パターン候補の認識字種として限定する(1)に記載の文字認識装置。
【0010】
(2)の文字認識装置によると、語句の限定に際し、終端までの文字数の長さが同一の語句に基づき特定語句を選別し、その選別された語句に基づき文字パターン候補の認識字種を限定することができる。これにより、終端までの長さに基づき語句の限定が行われるため、類似する字種が存在した場合であっても、他の字種と誤認識される可能性を大幅に低減することができる。また、終端までの文字数の長さに基づき認識字種の対象を限定することで、認識対象を減少させ、認識速度を著しく向上させることができる。
【0011】
(3) 前記文字パターン候補限定手段による文字パターン候補の限定は、前記仮切出手段により切出したユニットの順番で行う(1)に記載の文字認識装置。
【0012】
(3)の文字認識装置によると、語句の限定に際し、仮切出手段による切出しポイント毎に、文字パターン候補を限定することができる。これにより、探索を限定して認識率と処理速度の向上を図ることができる。
【0013】
(4) 文字の認識を行う制御を実行する文字認識装置の文字認識方法であって、
特定語句と、前記特定語句の文字数の長さとの関係を記憶する特定語句記憶ステップと、
手書き入力された文字列を取得する文字列取得ステップと、
前記文字列取得ステップにより取得した前記文字列を複数個のユニットに仮切出しする仮切出ステップと、
前記仮切出ステップにより切り出された各ユニット毎に複数の文字パターン候補を構成する文字パターン候補構成ステップと、
前記文字パターン候補構成ステップにより構成された各文字パターン候補を連結する文字パターン候補連結ステップと、
前記文字パターン候補連結ステップにより連結された前記各文字パターン候補における終端までの文字数の長さを算出する文字数算出ステップと、
前記文字パターン候補構成ステップにより構成された文字パターン候補を、前記特定語句記憶ステップに記憶された前記特定語句と、前記文字数算出ステップにより文字パターン候補毎に算出された終端までの文字数の長さと、に基づき限定する文字パターン候補限定ステップと、
前記文字パターン候補限定ステップにより限定された前記文字パターン候補に基づいて文字の認識を行う文字認識ステップと、
を含む文字認識方法。
【0014】
(4)の文字認識方法によると、手書き入力された文字列の認識を行う際に、文字パターン候補構成ステップにより構成された文字パターン候補を、文字数算出ステップにより文字パターン候補毎に算出された終端までの文字数の長さに基づいて、予め特定語句記憶ステップに記憶された特定語句により限定する。
これにより、手書き入力した文字を認識する際において、類似する字種が手書きされた場合であっても、予め記憶された特定語句のみに基づき限定されるため、他の字種と誤認識するという問題を解消することができる。また、文字の認識に際し、予め記憶された特定語句の中から、文字の認識が行われるため、認識速度を著しく向上させることができる。
【0015】
(5) 文字の認識を行う制御を実行する文字認識手段を備える文字認識装置を制御するコンピュータに、
特定語句と、前記特定語句の文字数の長さとの関係を記憶する特定語句記憶機能と、
手書き入力された文字列を取得する文字列取得機能と、
前記文字列取得機能により取得した前記文字列を複数個のユニットに仮切出しする仮切出機能と、
前記仮切出機能により切り出された各ユニット毎に複数の文字パターン候補を構成する文字パターン候補構成機能と、
前記文字パターン候補構成機能により構成された各文字パターン候補を連結する文字パターン候補連結機能と、
前記文字パターン候補連結機能により連結された前記各文字パターン候補における終端までの文字数の長さを算出する文字数算出機能と、
前記文字パターン候補構成機能により構成された文字パターン候補を、前記特定語句記憶機能に記憶された前記特定語句と、前記文字数算出機能により文字パターン候補毎に算出された終端までの文字数の長さと、に基づき限定する文字パターン候補限定機能と、
前記文字パターン候補限定機能により限定された前記文字パターン候補に基づいて文字の認識を行う文字認識機能と、
を実現させるプログラム。
【0016】
(5)のプログラムによると、手書き入力された文字列の認識を行う際に、文字パターン候補構成機能により構成された文字パターン候補を、文字数算出機能により文字パターン候補毎に算出された終端までの文字数の長さに基づいて、予め特定語句記憶機能に記憶された特定語句により限定する。
これにより、手書き入力した文字を認識する際において、類似する字種が手書きされた場合であっても、予め記憶された特定語句のみに基づき限定されるため、他の字種と誤認識するという問題を解消することができる。また、文字の認識に際し、予め記憶された特定語句の中から、文字の認識が行われるため、認識速度を著しく向上させることができる。
【発明の効果】
【0017】
本発明によれば、類似字種への誤認識を防ぐとともに、認識速度を著しく向上することができる。
【図面の簡単な説明】
【0018】
【図1】本発明の一実施形態に係る文字認識装置の機能的構成を示す機能ブロック図である。
【図2】本実施形態の文字認識装置で利用するトライ辞書を構築するための特定語句の語彙集合を含むリストを示す図である。
【図3】本実施形態の文字認識装置で利用するトライ辞書の構成を示す図である。
【図4】トライ辞書構築処理の流れを説明するフローチャートである。
【図5】文字認識処理の流れを説明するフローチャートである。
【図6】文字認識処理の具体的な処理結果を説明する図である。
【図7】文字認識処理の具体的な処理結果を説明する図である。
【図8】文字認識処理の具体的な処理結果を説明する図である。
【図9】文字認識処理の具体的な処理結果を説明する図である。
【図10】文字認識処理の具体的な処理結果を説明する図である。
【図11】文字認識処理の具体的な処理結果を説明する図である。
【図12】文字認識処理の具体的な処理結果を説明する図である。
【図13】文字認識処理の具体的な処理結果を説明する図である。
【図14】図2のリストに含まれる特定語句の語長とその比率との関係を示す図である。
【図15】図3のトライ辞書に含まれる特定語句の文字順位置とその文字順位置における平均分岐数との関係を示す図である。
【図16】本実施形態に係る文字認識装置を利用した文字認識方法と、汎用の手書き日本語文字列認識方法と、における認識率及び認識速度の比較結果を示す図である。
【図17】手書き入力された文字例である。
【図18】手書き入力された文字例である。
【図19】従来の文字認識結果を示す図である。
【発明を実施するための形態】
【0019】
以下、本発明の実施形態について図を用いながら説明する。なお、これはあくまでも一例であって、本発明の技術的範囲はこれに限定されるものではない。
【0020】
[文字認識方法の概要]
はじめに、本発明の実施の形態に係る文字認識装置を用いた文字認識方法の手法の概要について説明する。
はじめに、第1実施形態に係る文字認識装置を用いた文字認識方法の手法の概要について説明する。
【0021】
[文字認識装置の機能的構成]
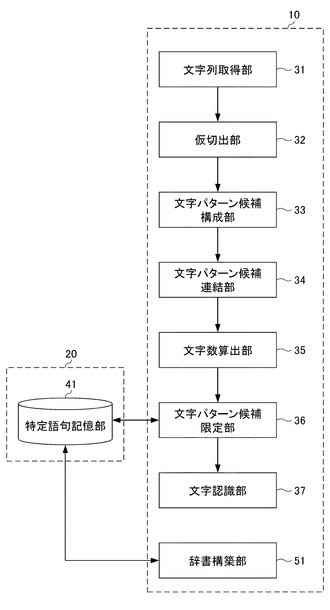
図1を参照して、本発明の一実施形態に係る文字認識装置1の機能的構成について説明する。
文字認識装置1は、取得した手書きの文字列に対し、文字認識処理を実行することができる。
文字認識処理とは、取得した文字列を複数個のユニットに切出して、各ユニット毎に文字パターン候補を構成し、各文字パターン候補における終端までの文字数の長さに基づき、文字パターン候補を限定して文字認識を行う処理をいう。
図1に示す文字認識装置1は、CPU(Central Processing Unit)10と、記憶部20と、を備えている。
文字認識装置1のCPU10は、このような文字認識処理を実行すべく、文字列取得部31と、仮切出部32と、文字パターン候補構成部33と、文字パターン候補連結部34と、文字数算出部35と、文字パターン候補限定部36と、文字認識部37と、を備えている。
また、文字認識装置1の記憶部20は、RAM(Random Access Memory)やハードディスクドライブ(Hard disk drive)により構成され、特定語句を構成する各文字と、各文字における終端までの文字数の長さとの関係を記憶する特定語句記憶部41を備えている。
更に、CPU10は、特定語句記憶部41に記憶されている後述のトライ辞書を構築するための辞書構築部51を備えている。
【0022】
文字列取得部31は、ユーザがペンで手書き入力した文字列を取得するためのものであり、その機能は、タブレット(図示せず)などにより入力された手書きの文字列のデータを取得する。文字列取得部31は、取得した文字列のデータを仮切出部32に供給する。
【0023】
仮切出部32は、複数の切出しポイントS0〜S5に基づいて文字列取得部31により取得した文字列を複数個のユニットに仮切出しする。ユニットの切出しは、隣接ストローク間の空間情報などの特徴値に基づいて複数個の原始切出しユニットに切出す。切出しポイントS0〜S5は、仮切出部32により切り出された1つの切出しポイントを示す。仮切出部32は、切出した各ユニットの情報を文字パターン候補構成部33に供給する。
【0024】
文字パターン候補構成部33は、仮切出部32により切り出された各ユニット毎に複数の文字パターン候補を構成する。仮切出部32による切出しは、確定的な切出しと非確定的な切出しとがあり、非確定的な切出しである場合には、各ユニットを分割した場合と結合した場合の両方を想定して各文字パターン候補を構成する。文字パターン候補構成部33は、構成した各文字パターン候補の情報を文字パターン候補連結部34に供給する。
【0025】
文字パターン候補連結部34は、文字パターン候補構成部33により構成された各文字パターン候補を連結し、後述する図6乃至図13に示すような切出し候補ラティスを構築する。
切出し候補ラティスにおいては、各ノードND(後述の図6乃至図13において丸数字1〜丸数字7と表記する(以下、それぞれ「ノードND(1)」〜「ノードND(7)」と呼ぶ))は、文字パターン候補構成部により構成された1つの文字パターン候補を示す。
【0026】
文字数算出部35は、文字パターン候補連結部34により連結して構築された切出し候補ラティスの各ノードND(文字パターン候補)から終端に至るまでに取り得ることが可能な文字数の長さ(以下、「可能長」と呼ぶ)を算出する。尚、可能長の算出は、切出し候補ラティスの終端から反対方向(始端)へ向かって行う。文字数算出部35は、算出した各ノードNDにおける可能長の情報を文字パターン候補限定部36に供給する。
【0027】
文字パターン候補限定部36は、文字パターン候補構成部33により構成された文字パターン候補の認識字種を、特定語句記憶部41に記憶された特定語句を構成する各文字と、文字数算出部35により文字パターン候補毎に算出された終端までの文字数の長さと、に基づき限定する。
具体的には、文字パターン候補限定部36は、文字数算出部35により文字パターン候補毎に算出された可能長と同一の可能長を有する特定語句を、特定語句記憶部41に記憶された特定語句から選別する。
そして、文字パターン候補限定部36は、特定語句記憶部41の中から選別した特定語句を構成する各文字を、文字パターン候補構成部33により構成された文字パターン候補の認識字種として限定する。前記文字パターン候補限定部36による文字パターン候補の限定は、前記仮切出部32により切出したユニットの順番で行う。文字パターン候補限定部36は、限定した文字パターン候補の認識字種を文字認識部37に供給する。
【0028】
文字認識部37は、文字パターン候補限定部36により限定された文字パターン候補に基づいて文字の認識を行う。
具体的には、文字認識部37は、次に述べる評価尺度により切出し候補とその対応の文字列候補の尤度とに基づき、文字パターン候補限定部36により限定された文字パターン候補に至る文字列候補の経路(文字列候補経路、以下簡略して経路と呼ぶ)の評価を行う。
経路の評価尺度は、重みパラメータを持つ文字認識と幾何的な特徴(文字パターンサイズ、文字パターン内分割、シングル文字パターン位置、ペア文字パターン位置、文字切出しポイント)の確からしさからなるスコアを結合する。遺伝的アルゴリズムにより学習パターンを利用し重みパラメータを学習する。
そして、文字認識部37は、評価した経路を評価順にソートして上位M個の経路だけを選択し、それ以外の経路を削除する。
即ち、文字認識部37は、経路評価尺度に基づいて文字列候補を削除することで、文字パターン候補連結部34により構築された切出し候補ラティスのサーチ経路を限定して文字の認識を行うことができる。即ち、本実施形態では、特定語句記憶部41に記憶されている特定語句の語彙集合、即ち後述の図3のトライ辞書に基づいて、最適な語句を選び文字の認識を行うことができる。
順番に切り出された切出しポイントS0〜SLがあり、最初から最後への順で各切出しポイントについてその後の文字パターン候補を文字パターン候補限定部36により処理し、そして、それに至る全ての文字列候補経路を文字認識部37により評価を行う。
【0029】
辞書構築部51は、特定語句記憶部41において、後述の図2の特定語句の語彙集合のリストから図3のトライ辞書を構築する。トライ辞書の構築については、図4のトライ辞書構築処理を参照して後述する。
【0030】
[トライ辞書の構築]
図2乃至図4を参照して、特定語句を構成する各文字と、各文字における終端までの文字数の長さとの関係を示すトライ辞書の構築について説明する。
【0031】
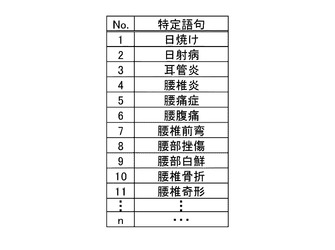
図2は、本実施形態の文字認識装置1で利用するトライ辞書を構築するための特定語句の語彙集合を含むリストを示す図である。本実施形態においては、トライ辞書を構築するための特定語句の語彙集合は病名を用いて行う。
【0032】
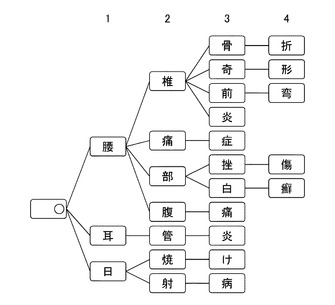
図3は、本実施形態の文字認識装置1で利用するトライ辞書の構成を示す図である。
トライ辞書は、特定語句と、特定語句の文字数の長さとの関係が記述され、特定語句を構成する各文字をキーとして下位の各文字を子ノードNDに分岐して構成されている。トライ辞書において、特定語句を構成する各文字は、子ノードNDの数に応じて段数毎に構成されている。
【0033】
[トライ辞書構築処理]
次に、図4を参照して、図2の特定語句の語彙集合を含むリストからトライ辞書を構築するトライ辞書構築処理の詳細な流れについて説明する。
【0034】
図4は、トライ辞書構築処理の流れを説明するフローチャートである。
【0035】
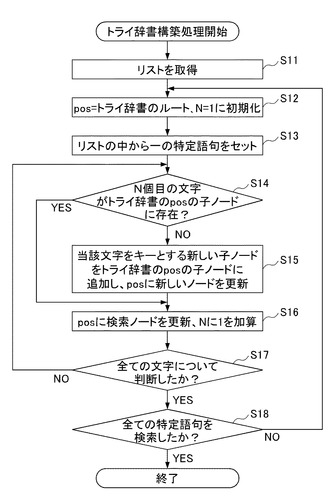
はじめに、ユーザがトライ辞書の構築開始の操作をすることによって、トライ辞書構築処理が開始され、図4のステップS11において、辞書構築部51は、図2の特定語句の語彙集合を含むリストを取得する。
【0036】
ステップS12において、辞書構築部51は、トライの現検索位置ノードpos=トライ辞書のルート、N=1に初期化する。Nは、構築対象の特定語句の文字の位置及び現在構築している子ノードNDの段数を示す値であり、後述のステップS14及びステップS16において参照される。
【0037】
ステップS13において、辞書構築部51は、図2の特定語句の語彙集合のリストの中から構築対象とする一の特定語句をセットする。
【0038】
ステップS14において、辞書構築部51は、ステップS13においてセットした特定語句のN個目の文字がトライ辞書のトライの現検索位置ノードposの子ノードに存在するか否かを判定する。N個目の文字がトライ辞書のposの子ノードに存在していると判定した場合には、処理はステップS16に進む。
これに対して、N個目の文字がトライ辞書のposの子ノードに存在していないと判定した場合には、処理はステップS15に進む。
【0039】
ステップS15において、辞書構築部51は、当該文字をキーとする新しい子ノードをトライ辞書のposの子ノードに追加する。posに新しい子ノードを更新する。即ち、この処理では、辞書構築部51は、ステップS13においてセットした特定語句の該当する段数の文字がトライ辞書に登録されていない場合には、新たなキーとして登録する。
【0040】
ステップS16において、辞書構築部51は、Nに1を加算し、pos=検索ノードをし、ステップS17の処理に進む。
【0041】
ステップS17において、辞書構築部51は、ステップS13においてセットした特定語句の全ての文字についてステップS14乃至ステップS15の判断をしたか否かを判定する。全ての文字について判断したと判定した場合には、処理はステップS18に進む。これに対して、全ての文字ついて判断していないと判定した場合には、処理はステップS14に戻る。ステップS13においてセットした特定語句の全ての文字についてステップS14乃至ステップS15の判断が終了していない場合、即ち、トライ辞書に記憶されているか否かの判断が終了していない場合には、次の文字に対してステップS14乃至ステップS16の判断が行われる。そして、ステップS13においてセットした特定語句の全ての文字についてステップS14乃至ステップS15の判断が行われるまで、ステップS14乃至ステップS17の処理が繰り返し行われる。
【0042】
ステップS18において、辞書構築部51は、全ての特定語句を検索したか否かを判定する。全ての特定語句を検索していないと判定した場合には、処理はステップS12に戻る。即ち、この処理では、ステップS11において取得したリストに含まれる全ての特定語句に対してステップS14乃至ステップS15の判断が終了していない場合、即ち、トライ辞書に記憶されているか否かの判断が終了していない場合には、全ての特定語句についてステップS14乃至ステップS15の判断が行われるまで、ステップS12乃至ステップS18の処理が繰り返し行われる。これに対して全ての特定語句についてステップS14乃至ステップS15の判断が終了したと判定した場合には、トライ辞書構築処理を終了する。
【0043】
[文字認識処理]
次に、図5を参照して、図4のトライ辞書構築処理において構築したトライ辞書を用いて、文字認識を行う文字認識処理の詳細な流れについて説明する。
【0044】
図5は、文字認識処理の流れを説明するフローチャートである。
【0045】
はじめに、ユーザが文字認識処理の開始の操作をすることによって、文字認識処理が開始され、図5のステップS31において、文字列取得部31は、タブレットにより手書き入力された文字列を取得する。文字列取得部31は、取得した文字列のデータを仮切出部32に供給する。
【0046】
ステップS32において、仮切出部32は、文字列取得部31により取得した文字列を複数個のユニットに仮切出しする。仮切出部32は、切出した各ユニットの情報を文字パターン候補構成部33に供給する。
【0047】
ステップS33において、文字パターン候補構成部33は、仮切出部32により切り出された各ユニット毎に複数の文字パターン候補、即ち、複数のノードNDを構成する。文字パターン候補構成部33は、構成した各ノードNDの情報を文字パターン候補連結部34に供給する。
【0048】
ステップS34において、文字パターン候補連結部34は、文字パターン候補構成部33により構成された各ノードNDを連結し、切出し候補ラティスを構築する。
【0049】
ステップS35において、文字数算出部35は、文字パターン候補連結部34により連結して構築された切出し候補ラティスの各ノードNDにおける可能長を算出する。文字数算出部35は、算出した各ノードNDにおける可能長の情報を文字パターン候補限定部36に供給する。
【0050】
ステップS36において、i=1に初期化する。iは、順番に切り出されたL個の切出しポイントS0〜SLのインデックスであり、後述のステップS37乃至ステップS39において参照される。
【0051】
ステップS37において、終端切出しポイントの前の全ての切出しポイントについてステップS38乃至ステップS39の処理をしたか否かを判定する。処理したと判定した場合には、処理はステップS41に進む。これに対して、処理していないと判定した場合には、処理はステップS38に進む。
【0052】
ステップS38において、文字列の先端からSiの前の全ての文字パターン候補に至る全ての経路を評価し上位M個の経路を選択し、それ以外の経路を削除する。
【0053】
ステップS39において、文字パターン候補限定部36は、文字パターン候補構成部33により構成されたSiの後の全てのノードNDの認識字種を、ステップS38で選択した上位M個の経路とトライ辞書の特定語句を構成する各文字と、文字数算出部35によりノードND毎に算出された可能長と、に基づき限定する。
具体的には、文字パターン候補限定部36は、ステップS38で選択した上位M個の経路へ続くトライ辞書の特定語句について、文字数算出部35によりノードND毎に算出された可能長と同一の可能長を有する特定語句を構成する各文字を、特定語句記憶部41に記憶されたトライ辞書の特定語句から選別する。
そして、文字パターン候補限定部36は、トライ辞書の中から選別した特定語句を構成する各文字を、文字パターン候補構成部33により構成されたノードNDの認識字種として限定する。文字パターン候補限定部36は、限定したノードNDの認識字種を文字認識部37に供給する。
【0054】
ステップS40において、iに1を加算し、ステップS37の処理に戻る。
【0055】
ステップS41において、文字認識部37は、先端から終端切出しポイントSLに至るすべての経路について経路評価尺度に従い評価を行う。そして、処理は終端に至るすべてのサーチ経路のうち認識スコアが最も高い最優の経路を文字認識の認識結果とする。
従って、ノードNDの可能長に基づきサーチ経路を限定することにより、認識精度と文字認識の速度を向上することができる。この限定は、病名に限らず特定語彙集合の特殊性に依存しない。つまり、どのような種類の語彙集合にも適応できる。
【0056】
[文字認識処理の具体例]
更に、図6乃至図13を参照して、文字認識処理について具体的に説明する。
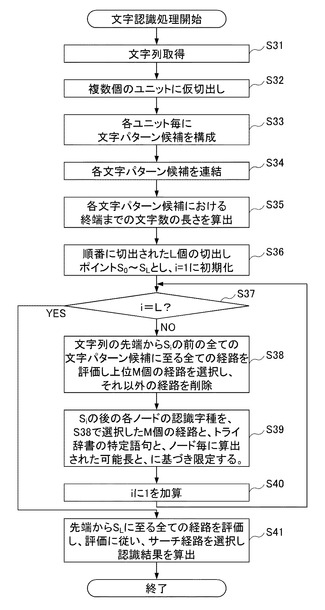
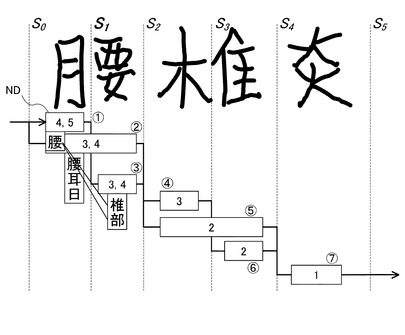
図6乃至図13は、文字認識処理の具体的な処理結果を説明する図である。
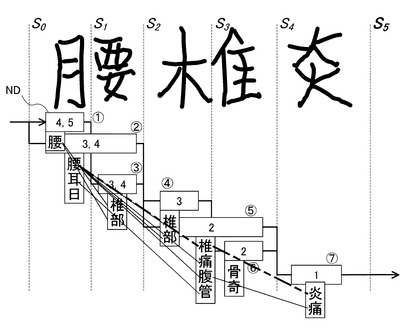
【0057】
図6、図7の上方には、文字列取得部31により取得された手書き入力された文字列が示されている。本実施形態においては、ユーザにより手書き入力された文字列として「腰椎炎」が示されている。
文字列の上方には、仮切出部32により切り出された各切出しポイントS0〜S5が示されている。
文字列の下方には、各切出しポイントS0〜S5において分割する場合と結合する場合の両方を想定した文字パターン候補が示されている。そして、考えられる全ての文字パターン候補を連結して切出し候補ラティスが構築される。切出し候補ラティスにおいては、各ノードNDは1つの文字パターン候補を示す。図6乃至図13の図においては、各ノードND(1)〜(7)が示されている。図8〜図13には、それぞれ切出しポイントS0〜S5おいて認識字種を設定する場合の例が示されている。
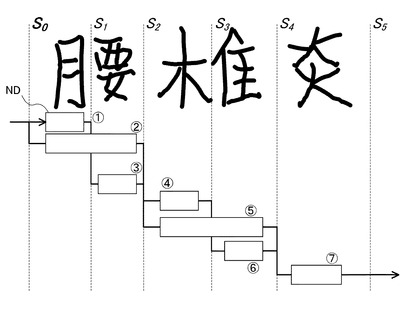
図7には、ノード(1)、(2)、(3)・・・(7)で示される7個のノードNDを持つ切出し候補ラティスが示されている。
切出し候補ラティスの各ノードNDについて終端までの文字数の可能な長さ(可能長)の算出の概略について図7を参照して説明する。
各ノードNDのボックスに示される数字はそのノードNDの終端までの可能長を示す。
ノード(7)は、文字数は「1」しかあり得ない。ノード(6)では、それ自身とノード(7)の分を含めて文字数は「2」である。ノード(5)も同様に「2」である。ノード(4)では、それ自身とノード(6),ノード(7)の分を含めて文字数は「3」である。ノード(3)では、その分とノード(5),ノード(7)の分を含めて文字数が「3」になる場合と、それ自身とノード(4),ノード(6),ノード(7)の分を含めて文字数が「4」になる場合がある。従って可能長は{3,4}である。一般に、あるノードに後続するノードの可能長の集合に「1」を加えればよい。同様にして、ノード(2)の可能性は{3,4}、ノード(1)の可能長は{4,5}になる。このように、可能長は切出し候補らティスの終端から反対方向に求められる。
【0058】
上述したように、ユーザが文字認識処理の開始の操作をすることによって、文字認識処理が開始され、図5のステップS31の処理で、ユーザが手書き入力した文字列「腰椎炎」の取得が行われる。
【0059】
次に、ステップS32の処理で、取得された文字列「腰椎炎」が複数の切出しポイントS0〜S5の順に基づき、複数個のユニットに仮切出しされる。
【0060】
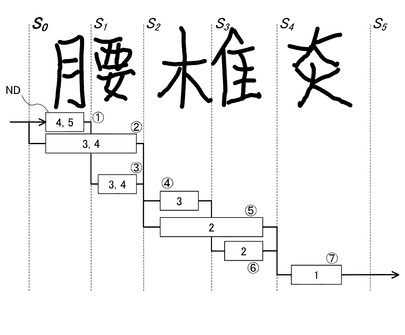
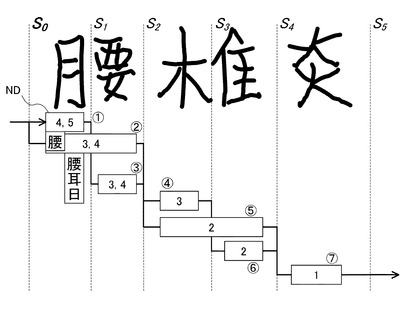
はじめに、図6を参照して、切出しポイントS0について考えると、切出しポイントS0は先頭であるから、その前にはノードNDが存在せず、その後には、2つのノードND(1)(2)が存在する。
図3のトライ辞書に基づき、トライ辞書の先頭位置でサーチを開始すると、図3のトライ辞書の先頭の子ノードは、「腰」、「耳」「日」であり、それらをノード(1)(2)の認識字種に設定する。
【0061】
ノードND(1)について考えると、ノードND(1)から終端までの可能長は、ノードND(1)、(3)、(5)、(7)を選択した場合の「4」又は、ノードND(1)、(3)、(4)、(6)、(7)を選択した場合の「5」である。(図7乃至13において、ノードND内の数字は、各ノードNDにおける可能長を示す)
これに対し、図3のトライ辞書を参照すると、認識字種「耳」と「日」に続く語句は、その終端までの文字の長さが「3」であるからノードND(1)おける可能長には合わないため削除し、終端までの文字の長さが「4」を取り得る認識字種「腰」のみを保留し、「腰」に対する認識スコアを文字認識エンジンから得る。
【0062】
同様に、ノードND(2)について考えると、ノードND(2)から終端までの可能長は、ノードND(2)、(5)、(7)を選択した場合の「3」又は、ノードND(2)、(4)、(6)、(7)を選択した場合の「4」である。
これに対し、図3のトライ辞書を参照すると、認識字種「腰」に続く語句は、その終端までの文字の長さは「3」又は「4」であり、認識字種「耳」と「日」に続く語句は、その終端までの文字の長さが「3」である。
従って、「腰」、「耳」「日」の全ての認識字種において可能長を満たすため、3つの認識字種「腰」「耳」「日」を保留し、各認識字種に対する認識スコアを文字認識エンジンより得る。
【0063】
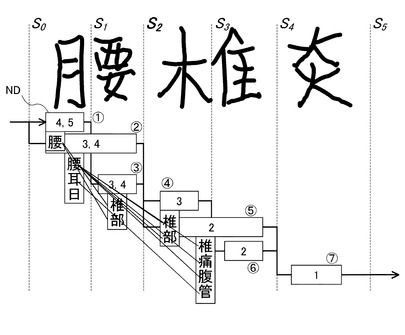
次に、図9を参照して、切出しポイントS1について考えると、その前には1つのノードND(1)が存在しており、その後には、1つのノードND(3)が存在する。
各切出しポイントに至るすべての経路について経路評価尺度に従って評価し、そしてそれらをソートし、上位M個の経路だけ選択し、その以外の経路を削除する。個数Mをビームバンドと呼ぶ。ここでの例においてはビームバンドが2であり、S1においては[腰]を保留している1つの経路しかない。
従って、保留している経路と同一の文字列に続く経路に続く字種は、図3のトライ辞書においては、「椎」「痛」「部」「腹」であり、それらをノード(3)の認識字種に設定する。
【0064】
ノードND(3)について考えると、ノードND(3)から終端までの可能長は、ノードND(3)、(5)、(7)を選択した場合の「3」又は、ノードND(3)、(4)、(6)、(7)を選択した場合の「4」である。
これに対し、図3のトライ辞書を参照すると、認識字種「痛」と「腹」に続く語句は、その終端までの文字の長さが「2」であるからノードND(3)おける可能長には合わないため削除し、終端までの文字長さが「3」を取り得る認識字種「椎」と「部」のみを保留し、「椎」と「部」に対する認識スコアを文字認識エンジンから得る。
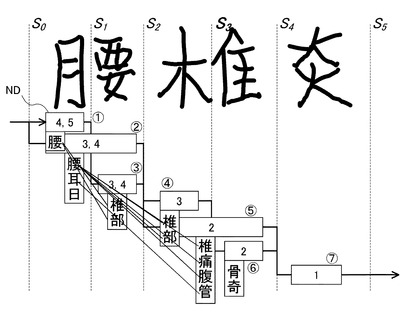
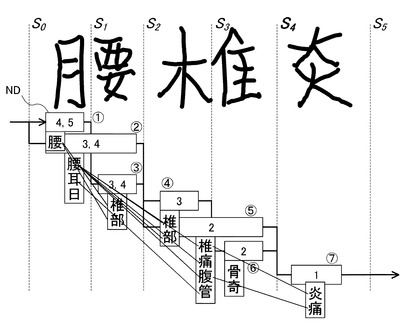
【0065】
同様の処理を図10乃至図12に示すように、切出しポイントS2、S3、S4の順に適用し、図13に示すように、最後の切出しポイントS5において文字認識処理を行う。そして、最初の切出しポイントS0から最終の切出しポイントS5に至る全てのノード(1)乃至(7)の経路について経路評価尺度に従って評価を行い、評価に基づき全ての経路をソートして最良の評価を有する経路を選択し、当該認識結果を算出する。本実施形態においては、最優の評価を有する経路として、ノード(1)において「腰」が選択され、ノード(5)において「椎」が選択され、ノード(7)において「炎」が選択され、それら最優の経路を選択した「腰椎炎」の文字列が文字認識処理の認識結果として算出されている。
【0066】
[特定語句の特徴]
図14及び図15を参照して、文字認識処理において取り扱う特定語句の特徴について説明する。
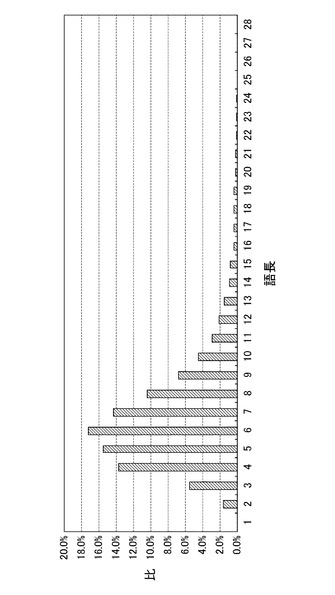
図14は、図2のリストに含まれる特定語句(病名)の語長(文字数の長さ)と、その比率と、の関係を示す図である。
図14の図において、横軸は特定語句の文字数の長さを示し、縦軸は、該当する文字数の長さを有する特定語句の比率を示す。
本実施形態において特定語句の平均長は「6.9」である。
【0067】
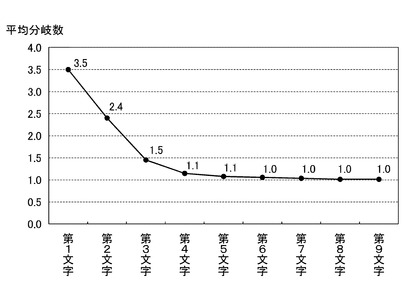
図15は、図3のトライ辞書に含まれる特定語句(病名)の文字順位置(n文字目に対する位置)と、その文字順位置における平均分岐数(n文字目位置での分岐数)と、の関係を示す図である。
図15に示すように、図3のトライ辞書を参照して可能長に基づきサーチ経路上の認識字種を限定することにより、本来数千個の認識字種から候補を大幅に削減することができ、類似字種への誤認識を防ぐとともに、認識速度の著しい向上を期待することができる。
【0068】
[実施例]
図16乃至図18を参照して、文字認識処理を適用した実施例について説明する。
【0069】
本実施形態においては、オンライン手書き日本語文字データベースNakayosi(M. Nakagawa, K. Matsumoto, “Collection of on-line handwritten Japanese character pattern databases and their analysis,” Int. J. Document Analysis and Recognition (IJDAR), 7(1), pp. 69-81, 2004 参照)により文字認識と幾何的な特徴の評価関数を学習した。文字列方向と文字方向自由のオンライン手書きパターンデータベースHANDS-Kondate_t_bf-2001-1を利用し、仮切出しポイントの確かさしさのためのSVMモデルと経路評価の重みパラメータを学習した。それらの詳細については、B. Zhu, X.-D. Zhou, C.-L. Liu and M. Nakagawa, “A Robust Model for On-line Handwritten the Japanese Text Recognition,” Int. J. Document Analysis and Recognition (IJDAR), Vol. 13, No. 2, pp.121-131, 2010.(以下、非特許文献2と呼ぶ)を参照されたい。
これらの学習後、総文字数3,803からなる1,112のオンライン手書き病名を用いて、本実施形態における文字認識装置1を利用した文字認識方法の評価を行った。実験環境はGenuine Intel(R) CPU U1400 1.20 GHz with 1.49 GBメモリである。
本実施形態に係る文字認識装置1を利用した文字認識方法と汎用の手書き日本語文字列認識方式(非特許文献2参照)を利用した文字認識方法との性能を比較した。公平に比較するために2つの方式とも同じ文字認識と幾何的な特徴の評価関数を使用した。本実施形態に係る文字認識方法では図2で示した病名リストにより図3のトライ辞書を構築した。非特許文献1に記載の汎用の手書き日本語文字列認識方式を利用した文字認識方法の経路評価では、図3のトライ辞書の代わりにtri-gramによる言語の文脈確からしさのスコアを使用した。このtri-gram表は,1993年の朝日新聞と2002年の日経新聞の記事から作成した。
【0070】
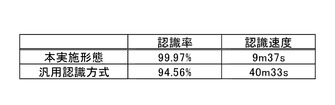
図16は、これら本実施形態に係る文字認識装置1を利用した文字認識方法と、汎用の手書き日本語文字列認識方法と、における認識率及び認識速度の比較結果を示す図である。図16において、認識時間は1,112全ての病名を認識するための時間である。
図17及び図18は手書き入力された文字例である。
【0071】
図16に示すように、本実施形態の文字認識方法は、汎用認識方式と比べて,認識率は94.56%から99.97%へ向上し,認識速度は9m37sから40m33sへ4.3倍高速化したことが分かる。
認識率について検討すると、図17に示すような手書き入力された文字列を本実施形態に係る文字認識方法により認識すると、「うっ血肝」と正しく認識できたのに対し、汎用認識方式により認識した場合には、「う。血肝」と誤認識された。従って、「うっ血肝」のような汎用認識方式で誤認識しやすい病名の文字列であっても、本実施形態の文字認識方法においては認識字種の限定を行うことで,類似字種間の誤認識を削減し認識率を向上することができる。
また、図18に示すような手書き入力された文字列を本実施形態に係る文字認識方法により認識すると、「18常染色体異常」と正しく認識されたのに対し、汎用認識方式により認識した場合には、認識ができなかった。従って、正しく語句を手書き入力できていない場合であっても、図3のトライ辞書に基づき可能長から認識字種を選択し、一番類似している認識字種を選択することで認識率を向上することができる。
【0072】
以上のことから、本実施形態に係る文字認識装置1を利用した文字認識方法では、特定語句のトライ辞書と語句の可能長とから認識字種を限定することにより本来数千個の認識字種から候補を大幅に削減できる。これにより、認識字種を大幅に限定することで、類似字種への誤認識を防ぐとともに認識速度を著しく向上させることができる。
また,正しく記入されていない特定語句に対しても,本方式はトライ辞書の中から一番類似しているものを選択するために正しく認識することができる。
【0073】
なお本発明は、上述の実施の形態に限定されるものでは無く、その趣旨を逸脱しない範囲で、上述の実施形態に種々の変形を加えた形態とすることができる。
【0074】
具体的に、上述の実施形態では、トライ辞書を構築するための特定語句の語彙集合は病名を用いて行うが、特定語句の種類は特にこれに限定されるものではなく、住所、氏名などの特定語句のリストを用いてトライ辞書を構築してもよい。
【0075】
また、上述の実施形態では、文字列取得部31により取得する文字列のデータは、タブレットにより入力された手書きの文字列のデータを用いて行うが、特にこれに限定されるものではなく、スキャナーや、手書き入力された筆跡をメモリ上に記憶するペンによって入力される文字列のデータであってもよい。
【0076】
また、上述の実施形態においては、CPU10と記憶部20とを備えた文字認識装置1について文字認識方法を行っているがこれに限られない。例えば、CPU10と記憶部20とを備えた文字認識システムに適用することもできる。
【0077】
また、上述した一連の処理は、ハードウェア及びソフトウェアの何れにより実行させることもできる。上述の一連の処理をソフトウェアにより実行させる場合には、そのソフトウェアを構成するプログラムが、コンピュータの記憶媒体からインストールされる。
【符号の説明】
【0078】
1 文字認識装置
10 CPU
20 記憶部
31 文字列取得部
32 仮切出部
33 文字パターン候補構成部
34 文字パターン候補連結部
35 文字数算出部
36 文字パターン候補限定部
37 文字認識部
41 特定語句記憶部
51 辞書構築部
【技術分野】
【0001】
本発明は、文字認識装置、文字認識方法及びプログラムに関し、特に特定語句認識において類似字種への誤認識を防ぐとともに、認識速度を著しく向上する技術に関する。
【背景技術】
【0002】
近年、手書き入力が可能なタブレット型のコンピュータの普及に伴い、ペンやマーカ、指などによる入力できる手書き入力システムが拡大する兆しを見せている。このような手書き入力システムを用いることにより、ユーザは、キーボードを用いずに手書きで文字を入力することができる。このような手書き入力においては、特定語句の認識が頻出する。住所、人名、日付、部署名などはその例である。
【0003】
このような手書き入力された特定語句を電子データとして認識させるために、様々な手書き文字列認識方式が提供されている。
また、このような特定語句認識方式に関しては、予め作成したトライ(trie)辞書の中でビームサーチによりサーチスペースを展開する文字同期方式を適用することで各文字パターン候補の認識字種を限定し、認識精度と認識速度の向上を図る方法も提案されている(例えば、非特許文献1参照)。
【先行技術文献】
【非特許文献】
【0004】
【非特許文献1】C.-L. Liu, M. Koga, and H. Fujisawa, “Lexicon-Driven Segmentation and Recognition of Handwritten Character Strings for Japanese Address Reading,” IEEE Trans. Pattern Analysis and Machine Intelligence, 24(11), pp. 1425-1437, 2002.
【発明の概要】
【発明が解決しようとする課題】
【0005】
汎用の手書き文字列認識方式を特定語句の認識に適用すると、特定語句の語彙集合に含まれない語句と誤認識されることがよくあった。
例えば、図19に示すように、「A型肝炎」の手書き文字列に対し汎用の手書き文字列認識方式により文字認識を行った場合、「A」の文字の類似字種である「八」と誤認識することがあった。これにより、「A型肝炎」の手書き文字列を特定語句の語彙集合に含まれない「八型肝炎」と誤認識する場合があるという問題点があった。
また、特定語句を1つの単語と見なし英語などの単語認識方式を適用することもできるが、文字認識の対象となる特定語句を全ての単語と比較する必要があるため、多くの処理時間を要するという問題点があった。
【0006】
本発明は、上述の課題に鑑みてなされたものであり、類似字種への誤認識を防ぐとともに、認識速度を著しく向上することができるようにすることにある。即ち、本発明は、以下の技術的事項から構成される。
【課題を解決するための手段】
【0007】
(1) 特定語句と、前記特定語句の文字数の長さとの関係を記憶する特定語句記憶手段と、
手書き入力された文字列を取得する文字列取得手段と、
前記文字列取得手段により取得した前記文字列を複数個のユニットに仮切出しする仮切出手段と、
前記仮切出手段により切り出された各ユニット毎に複数の文字パターン候補を構成する文字パターン候補構成手段と、
前記文字パターン候補構成手段により構成された各文字パターン候補を連結する文字パターン候補連結手段と、
前記文字パターン候補連結手段により連結された前記各文字パターン候補における終端までの文字数の長さを算出する文字数算出手段と、
前記文字パターン候補構成手段により構成された文字パターン候補を、前記特定語句記憶手段に記憶された前記特定語句と、前記文字数算出手段により文字パターン候補毎に算出された終端までの文字数の長さと、に基づき限定する文字パターン候補限定手段と、
前記文字パターン候補限定手段により限定された前記文字パターン候補に基づいて文字の認識を行う文字認識手段と、
を備える文字認識装置。
【0008】
(1)の文字認識装置によると、手書き入力された特定語句の文字列の認識を行う際に、文字パターン候補構成手段により構成された文字パターン候補を、文字数算出手段により文字パターン候補毎に算出された終端までの文字数の長さに基づいて、予め特定語句記憶手段に記憶された特定語句により限定する。
これにより、手書き入力した文字を認識する際において、類似する字種が手書き入力された場合であっても、予め記憶された特定語句のみに基づき限定されるため、他の字種と誤認識するという問題を解消することができる。また、文字の認識に際し、予め記憶された特定語句の中から、文字の認識が行われるため、認識速度を著しく向上させることができる。
【0009】
(2) 前記文字パターン候補限定手段は、
前記文字数算出手段により文字パターン候補毎に算出された終端までの文字数の長さと同一の終端までの文字数の長さを有する特定語句を、前記特定語句記憶手段に記憶された前記特定語句から選別し、
選別した前記特定語句を構成する各文字を、前記文字パターン候補構成手段により構成された文字パターン候補の認識字種として限定する(1)に記載の文字認識装置。
【0010】
(2)の文字認識装置によると、語句の限定に際し、終端までの文字数の長さが同一の語句に基づき特定語句を選別し、その選別された語句に基づき文字パターン候補の認識字種を限定することができる。これにより、終端までの長さに基づき語句の限定が行われるため、類似する字種が存在した場合であっても、他の字種と誤認識される可能性を大幅に低減することができる。また、終端までの文字数の長さに基づき認識字種の対象を限定することで、認識対象を減少させ、認識速度を著しく向上させることができる。
【0011】
(3) 前記文字パターン候補限定手段による文字パターン候補の限定は、前記仮切出手段により切出したユニットの順番で行う(1)に記載の文字認識装置。
【0012】
(3)の文字認識装置によると、語句の限定に際し、仮切出手段による切出しポイント毎に、文字パターン候補を限定することができる。これにより、探索を限定して認識率と処理速度の向上を図ることができる。
【0013】
(4) 文字の認識を行う制御を実行する文字認識装置の文字認識方法であって、
特定語句と、前記特定語句の文字数の長さとの関係を記憶する特定語句記憶ステップと、
手書き入力された文字列を取得する文字列取得ステップと、
前記文字列取得ステップにより取得した前記文字列を複数個のユニットに仮切出しする仮切出ステップと、
前記仮切出ステップにより切り出された各ユニット毎に複数の文字パターン候補を構成する文字パターン候補構成ステップと、
前記文字パターン候補構成ステップにより構成された各文字パターン候補を連結する文字パターン候補連結ステップと、
前記文字パターン候補連結ステップにより連結された前記各文字パターン候補における終端までの文字数の長さを算出する文字数算出ステップと、
前記文字パターン候補構成ステップにより構成された文字パターン候補を、前記特定語句記憶ステップに記憶された前記特定語句と、前記文字数算出ステップにより文字パターン候補毎に算出された終端までの文字数の長さと、に基づき限定する文字パターン候補限定ステップと、
前記文字パターン候補限定ステップにより限定された前記文字パターン候補に基づいて文字の認識を行う文字認識ステップと、
を含む文字認識方法。
【0014】
(4)の文字認識方法によると、手書き入力された文字列の認識を行う際に、文字パターン候補構成ステップにより構成された文字パターン候補を、文字数算出ステップにより文字パターン候補毎に算出された終端までの文字数の長さに基づいて、予め特定語句記憶ステップに記憶された特定語句により限定する。
これにより、手書き入力した文字を認識する際において、類似する字種が手書きされた場合であっても、予め記憶された特定語句のみに基づき限定されるため、他の字種と誤認識するという問題を解消することができる。また、文字の認識に際し、予め記憶された特定語句の中から、文字の認識が行われるため、認識速度を著しく向上させることができる。
【0015】
(5) 文字の認識を行う制御を実行する文字認識手段を備える文字認識装置を制御するコンピュータに、
特定語句と、前記特定語句の文字数の長さとの関係を記憶する特定語句記憶機能と、
手書き入力された文字列を取得する文字列取得機能と、
前記文字列取得機能により取得した前記文字列を複数個のユニットに仮切出しする仮切出機能と、
前記仮切出機能により切り出された各ユニット毎に複数の文字パターン候補を構成する文字パターン候補構成機能と、
前記文字パターン候補構成機能により構成された各文字パターン候補を連結する文字パターン候補連結機能と、
前記文字パターン候補連結機能により連結された前記各文字パターン候補における終端までの文字数の長さを算出する文字数算出機能と、
前記文字パターン候補構成機能により構成された文字パターン候補を、前記特定語句記憶機能に記憶された前記特定語句と、前記文字数算出機能により文字パターン候補毎に算出された終端までの文字数の長さと、に基づき限定する文字パターン候補限定機能と、
前記文字パターン候補限定機能により限定された前記文字パターン候補に基づいて文字の認識を行う文字認識機能と、
を実現させるプログラム。
【0016】
(5)のプログラムによると、手書き入力された文字列の認識を行う際に、文字パターン候補構成機能により構成された文字パターン候補を、文字数算出機能により文字パターン候補毎に算出された終端までの文字数の長さに基づいて、予め特定語句記憶機能に記憶された特定語句により限定する。
これにより、手書き入力した文字を認識する際において、類似する字種が手書きされた場合であっても、予め記憶された特定語句のみに基づき限定されるため、他の字種と誤認識するという問題を解消することができる。また、文字の認識に際し、予め記憶された特定語句の中から、文字の認識が行われるため、認識速度を著しく向上させることができる。
【発明の効果】
【0017】
本発明によれば、類似字種への誤認識を防ぐとともに、認識速度を著しく向上することができる。
【図面の簡単な説明】
【0018】
【図1】本発明の一実施形態に係る文字認識装置の機能的構成を示す機能ブロック図である。
【図2】本実施形態の文字認識装置で利用するトライ辞書を構築するための特定語句の語彙集合を含むリストを示す図である。
【図3】本実施形態の文字認識装置で利用するトライ辞書の構成を示す図である。
【図4】トライ辞書構築処理の流れを説明するフローチャートである。
【図5】文字認識処理の流れを説明するフローチャートである。
【図6】文字認識処理の具体的な処理結果を説明する図である。
【図7】文字認識処理の具体的な処理結果を説明する図である。
【図8】文字認識処理の具体的な処理結果を説明する図である。
【図9】文字認識処理の具体的な処理結果を説明する図である。
【図10】文字認識処理の具体的な処理結果を説明する図である。
【図11】文字認識処理の具体的な処理結果を説明する図である。
【図12】文字認識処理の具体的な処理結果を説明する図である。
【図13】文字認識処理の具体的な処理結果を説明する図である。
【図14】図2のリストに含まれる特定語句の語長とその比率との関係を示す図である。
【図15】図3のトライ辞書に含まれる特定語句の文字順位置とその文字順位置における平均分岐数との関係を示す図である。
【図16】本実施形態に係る文字認識装置を利用した文字認識方法と、汎用の手書き日本語文字列認識方法と、における認識率及び認識速度の比較結果を示す図である。
【図17】手書き入力された文字例である。
【図18】手書き入力された文字例である。
【図19】従来の文字認識結果を示す図である。
【発明を実施するための形態】
【0019】
以下、本発明の実施形態について図を用いながら説明する。なお、これはあくまでも一例であって、本発明の技術的範囲はこれに限定されるものではない。
【0020】
[文字認識方法の概要]
はじめに、本発明の実施の形態に係る文字認識装置を用いた文字認識方法の手法の概要について説明する。
はじめに、第1実施形態に係る文字認識装置を用いた文字認識方法の手法の概要について説明する。
【0021】
[文字認識装置の機能的構成]
図1を参照して、本発明の一実施形態に係る文字認識装置1の機能的構成について説明する。
文字認識装置1は、取得した手書きの文字列に対し、文字認識処理を実行することができる。
文字認識処理とは、取得した文字列を複数個のユニットに切出して、各ユニット毎に文字パターン候補を構成し、各文字パターン候補における終端までの文字数の長さに基づき、文字パターン候補を限定して文字認識を行う処理をいう。
図1に示す文字認識装置1は、CPU(Central Processing Unit)10と、記憶部20と、を備えている。
文字認識装置1のCPU10は、このような文字認識処理を実行すべく、文字列取得部31と、仮切出部32と、文字パターン候補構成部33と、文字パターン候補連結部34と、文字数算出部35と、文字パターン候補限定部36と、文字認識部37と、を備えている。
また、文字認識装置1の記憶部20は、RAM(Random Access Memory)やハードディスクドライブ(Hard disk drive)により構成され、特定語句を構成する各文字と、各文字における終端までの文字数の長さとの関係を記憶する特定語句記憶部41を備えている。
更に、CPU10は、特定語句記憶部41に記憶されている後述のトライ辞書を構築するための辞書構築部51を備えている。
【0022】
文字列取得部31は、ユーザがペンで手書き入力した文字列を取得するためのものであり、その機能は、タブレット(図示せず)などにより入力された手書きの文字列のデータを取得する。文字列取得部31は、取得した文字列のデータを仮切出部32に供給する。
【0023】
仮切出部32は、複数の切出しポイントS0〜S5に基づいて文字列取得部31により取得した文字列を複数個のユニットに仮切出しする。ユニットの切出しは、隣接ストローク間の空間情報などの特徴値に基づいて複数個の原始切出しユニットに切出す。切出しポイントS0〜S5は、仮切出部32により切り出された1つの切出しポイントを示す。仮切出部32は、切出した各ユニットの情報を文字パターン候補構成部33に供給する。
【0024】
文字パターン候補構成部33は、仮切出部32により切り出された各ユニット毎に複数の文字パターン候補を構成する。仮切出部32による切出しは、確定的な切出しと非確定的な切出しとがあり、非確定的な切出しである場合には、各ユニットを分割した場合と結合した場合の両方を想定して各文字パターン候補を構成する。文字パターン候補構成部33は、構成した各文字パターン候補の情報を文字パターン候補連結部34に供給する。
【0025】
文字パターン候補連結部34は、文字パターン候補構成部33により構成された各文字パターン候補を連結し、後述する図6乃至図13に示すような切出し候補ラティスを構築する。
切出し候補ラティスにおいては、各ノードND(後述の図6乃至図13において丸数字1〜丸数字7と表記する(以下、それぞれ「ノードND(1)」〜「ノードND(7)」と呼ぶ))は、文字パターン候補構成部により構成された1つの文字パターン候補を示す。
【0026】
文字数算出部35は、文字パターン候補連結部34により連結して構築された切出し候補ラティスの各ノードND(文字パターン候補)から終端に至るまでに取り得ることが可能な文字数の長さ(以下、「可能長」と呼ぶ)を算出する。尚、可能長の算出は、切出し候補ラティスの終端から反対方向(始端)へ向かって行う。文字数算出部35は、算出した各ノードNDにおける可能長の情報を文字パターン候補限定部36に供給する。
【0027】
文字パターン候補限定部36は、文字パターン候補構成部33により構成された文字パターン候補の認識字種を、特定語句記憶部41に記憶された特定語句を構成する各文字と、文字数算出部35により文字パターン候補毎に算出された終端までの文字数の長さと、に基づき限定する。
具体的には、文字パターン候補限定部36は、文字数算出部35により文字パターン候補毎に算出された可能長と同一の可能長を有する特定語句を、特定語句記憶部41に記憶された特定語句から選別する。
そして、文字パターン候補限定部36は、特定語句記憶部41の中から選別した特定語句を構成する各文字を、文字パターン候補構成部33により構成された文字パターン候補の認識字種として限定する。前記文字パターン候補限定部36による文字パターン候補の限定は、前記仮切出部32により切出したユニットの順番で行う。文字パターン候補限定部36は、限定した文字パターン候補の認識字種を文字認識部37に供給する。
【0028】
文字認識部37は、文字パターン候補限定部36により限定された文字パターン候補に基づいて文字の認識を行う。
具体的には、文字認識部37は、次に述べる評価尺度により切出し候補とその対応の文字列候補の尤度とに基づき、文字パターン候補限定部36により限定された文字パターン候補に至る文字列候補の経路(文字列候補経路、以下簡略して経路と呼ぶ)の評価を行う。
経路の評価尺度は、重みパラメータを持つ文字認識と幾何的な特徴(文字パターンサイズ、文字パターン内分割、シングル文字パターン位置、ペア文字パターン位置、文字切出しポイント)の確からしさからなるスコアを結合する。遺伝的アルゴリズムにより学習パターンを利用し重みパラメータを学習する。
そして、文字認識部37は、評価した経路を評価順にソートして上位M個の経路だけを選択し、それ以外の経路を削除する。
即ち、文字認識部37は、経路評価尺度に基づいて文字列候補を削除することで、文字パターン候補連結部34により構築された切出し候補ラティスのサーチ経路を限定して文字の認識を行うことができる。即ち、本実施形態では、特定語句記憶部41に記憶されている特定語句の語彙集合、即ち後述の図3のトライ辞書に基づいて、最適な語句を選び文字の認識を行うことができる。
順番に切り出された切出しポイントS0〜SLがあり、最初から最後への順で各切出しポイントについてその後の文字パターン候補を文字パターン候補限定部36により処理し、そして、それに至る全ての文字列候補経路を文字認識部37により評価を行う。
【0029】
辞書構築部51は、特定語句記憶部41において、後述の図2の特定語句の語彙集合のリストから図3のトライ辞書を構築する。トライ辞書の構築については、図4のトライ辞書構築処理を参照して後述する。
【0030】
[トライ辞書の構築]
図2乃至図4を参照して、特定語句を構成する各文字と、各文字における終端までの文字数の長さとの関係を示すトライ辞書の構築について説明する。
【0031】
図2は、本実施形態の文字認識装置1で利用するトライ辞書を構築するための特定語句の語彙集合を含むリストを示す図である。本実施形態においては、トライ辞書を構築するための特定語句の語彙集合は病名を用いて行う。
【0032】
図3は、本実施形態の文字認識装置1で利用するトライ辞書の構成を示す図である。
トライ辞書は、特定語句と、特定語句の文字数の長さとの関係が記述され、特定語句を構成する各文字をキーとして下位の各文字を子ノードNDに分岐して構成されている。トライ辞書において、特定語句を構成する各文字は、子ノードNDの数に応じて段数毎に構成されている。
【0033】
[トライ辞書構築処理]
次に、図4を参照して、図2の特定語句の語彙集合を含むリストからトライ辞書を構築するトライ辞書構築処理の詳細な流れについて説明する。
【0034】
図4は、トライ辞書構築処理の流れを説明するフローチャートである。
【0035】
はじめに、ユーザがトライ辞書の構築開始の操作をすることによって、トライ辞書構築処理が開始され、図4のステップS11において、辞書構築部51は、図2の特定語句の語彙集合を含むリストを取得する。
【0036】
ステップS12において、辞書構築部51は、トライの現検索位置ノードpos=トライ辞書のルート、N=1に初期化する。Nは、構築対象の特定語句の文字の位置及び現在構築している子ノードNDの段数を示す値であり、後述のステップS14及びステップS16において参照される。
【0037】
ステップS13において、辞書構築部51は、図2の特定語句の語彙集合のリストの中から構築対象とする一の特定語句をセットする。
【0038】
ステップS14において、辞書構築部51は、ステップS13においてセットした特定語句のN個目の文字がトライ辞書のトライの現検索位置ノードposの子ノードに存在するか否かを判定する。N個目の文字がトライ辞書のposの子ノードに存在していると判定した場合には、処理はステップS16に進む。
これに対して、N個目の文字がトライ辞書のposの子ノードに存在していないと判定した場合には、処理はステップS15に進む。
【0039】
ステップS15において、辞書構築部51は、当該文字をキーとする新しい子ノードをトライ辞書のposの子ノードに追加する。posに新しい子ノードを更新する。即ち、この処理では、辞書構築部51は、ステップS13においてセットした特定語句の該当する段数の文字がトライ辞書に登録されていない場合には、新たなキーとして登録する。
【0040】
ステップS16において、辞書構築部51は、Nに1を加算し、pos=検索ノードをし、ステップS17の処理に進む。
【0041】
ステップS17において、辞書構築部51は、ステップS13においてセットした特定語句の全ての文字についてステップS14乃至ステップS15の判断をしたか否かを判定する。全ての文字について判断したと判定した場合には、処理はステップS18に進む。これに対して、全ての文字ついて判断していないと判定した場合には、処理はステップS14に戻る。ステップS13においてセットした特定語句の全ての文字についてステップS14乃至ステップS15の判断が終了していない場合、即ち、トライ辞書に記憶されているか否かの判断が終了していない場合には、次の文字に対してステップS14乃至ステップS16の判断が行われる。そして、ステップS13においてセットした特定語句の全ての文字についてステップS14乃至ステップS15の判断が行われるまで、ステップS14乃至ステップS17の処理が繰り返し行われる。
【0042】
ステップS18において、辞書構築部51は、全ての特定語句を検索したか否かを判定する。全ての特定語句を検索していないと判定した場合には、処理はステップS12に戻る。即ち、この処理では、ステップS11において取得したリストに含まれる全ての特定語句に対してステップS14乃至ステップS15の判断が終了していない場合、即ち、トライ辞書に記憶されているか否かの判断が終了していない場合には、全ての特定語句についてステップS14乃至ステップS15の判断が行われるまで、ステップS12乃至ステップS18の処理が繰り返し行われる。これに対して全ての特定語句についてステップS14乃至ステップS15の判断が終了したと判定した場合には、トライ辞書構築処理を終了する。
【0043】
[文字認識処理]
次に、図5を参照して、図4のトライ辞書構築処理において構築したトライ辞書を用いて、文字認識を行う文字認識処理の詳細な流れについて説明する。
【0044】
図5は、文字認識処理の流れを説明するフローチャートである。
【0045】
はじめに、ユーザが文字認識処理の開始の操作をすることによって、文字認識処理が開始され、図5のステップS31において、文字列取得部31は、タブレットにより手書き入力された文字列を取得する。文字列取得部31は、取得した文字列のデータを仮切出部32に供給する。
【0046】
ステップS32において、仮切出部32は、文字列取得部31により取得した文字列を複数個のユニットに仮切出しする。仮切出部32は、切出した各ユニットの情報を文字パターン候補構成部33に供給する。
【0047】
ステップS33において、文字パターン候補構成部33は、仮切出部32により切り出された各ユニット毎に複数の文字パターン候補、即ち、複数のノードNDを構成する。文字パターン候補構成部33は、構成した各ノードNDの情報を文字パターン候補連結部34に供給する。
【0048】
ステップS34において、文字パターン候補連結部34は、文字パターン候補構成部33により構成された各ノードNDを連結し、切出し候補ラティスを構築する。
【0049】
ステップS35において、文字数算出部35は、文字パターン候補連結部34により連結して構築された切出し候補ラティスの各ノードNDにおける可能長を算出する。文字数算出部35は、算出した各ノードNDにおける可能長の情報を文字パターン候補限定部36に供給する。
【0050】
ステップS36において、i=1に初期化する。iは、順番に切り出されたL個の切出しポイントS0〜SLのインデックスであり、後述のステップS37乃至ステップS39において参照される。
【0051】
ステップS37において、終端切出しポイントの前の全ての切出しポイントについてステップS38乃至ステップS39の処理をしたか否かを判定する。処理したと判定した場合には、処理はステップS41に進む。これに対して、処理していないと判定した場合には、処理はステップS38に進む。
【0052】
ステップS38において、文字列の先端からSiの前の全ての文字パターン候補に至る全ての経路を評価し上位M個の経路を選択し、それ以外の経路を削除する。
【0053】
ステップS39において、文字パターン候補限定部36は、文字パターン候補構成部33により構成されたSiの後の全てのノードNDの認識字種を、ステップS38で選択した上位M個の経路とトライ辞書の特定語句を構成する各文字と、文字数算出部35によりノードND毎に算出された可能長と、に基づき限定する。
具体的には、文字パターン候補限定部36は、ステップS38で選択した上位M個の経路へ続くトライ辞書の特定語句について、文字数算出部35によりノードND毎に算出された可能長と同一の可能長を有する特定語句を構成する各文字を、特定語句記憶部41に記憶されたトライ辞書の特定語句から選別する。
そして、文字パターン候補限定部36は、トライ辞書の中から選別した特定語句を構成する各文字を、文字パターン候補構成部33により構成されたノードNDの認識字種として限定する。文字パターン候補限定部36は、限定したノードNDの認識字種を文字認識部37に供給する。
【0054】
ステップS40において、iに1を加算し、ステップS37の処理に戻る。
【0055】
ステップS41において、文字認識部37は、先端から終端切出しポイントSLに至るすべての経路について経路評価尺度に従い評価を行う。そして、処理は終端に至るすべてのサーチ経路のうち認識スコアが最も高い最優の経路を文字認識の認識結果とする。
従って、ノードNDの可能長に基づきサーチ経路を限定することにより、認識精度と文字認識の速度を向上することができる。この限定は、病名に限らず特定語彙集合の特殊性に依存しない。つまり、どのような種類の語彙集合にも適応できる。
【0056】
[文字認識処理の具体例]
更に、図6乃至図13を参照して、文字認識処理について具体的に説明する。
図6乃至図13は、文字認識処理の具体的な処理結果を説明する図である。
【0057】
図6、図7の上方には、文字列取得部31により取得された手書き入力された文字列が示されている。本実施形態においては、ユーザにより手書き入力された文字列として「腰椎炎」が示されている。
文字列の上方には、仮切出部32により切り出された各切出しポイントS0〜S5が示されている。
文字列の下方には、各切出しポイントS0〜S5において分割する場合と結合する場合の両方を想定した文字パターン候補が示されている。そして、考えられる全ての文字パターン候補を連結して切出し候補ラティスが構築される。切出し候補ラティスにおいては、各ノードNDは1つの文字パターン候補を示す。図6乃至図13の図においては、各ノードND(1)〜(7)が示されている。図8〜図13には、それぞれ切出しポイントS0〜S5おいて認識字種を設定する場合の例が示されている。
図7には、ノード(1)、(2)、(3)・・・(7)で示される7個のノードNDを持つ切出し候補ラティスが示されている。
切出し候補ラティスの各ノードNDについて終端までの文字数の可能な長さ(可能長)の算出の概略について図7を参照して説明する。
各ノードNDのボックスに示される数字はそのノードNDの終端までの可能長を示す。
ノード(7)は、文字数は「1」しかあり得ない。ノード(6)では、それ自身とノード(7)の分を含めて文字数は「2」である。ノード(5)も同様に「2」である。ノード(4)では、それ自身とノード(6),ノード(7)の分を含めて文字数は「3」である。ノード(3)では、その分とノード(5),ノード(7)の分を含めて文字数が「3」になる場合と、それ自身とノード(4),ノード(6),ノード(7)の分を含めて文字数が「4」になる場合がある。従って可能長は{3,4}である。一般に、あるノードに後続するノードの可能長の集合に「1」を加えればよい。同様にして、ノード(2)の可能性は{3,4}、ノード(1)の可能長は{4,5}になる。このように、可能長は切出し候補らティスの終端から反対方向に求められる。
【0058】
上述したように、ユーザが文字認識処理の開始の操作をすることによって、文字認識処理が開始され、図5のステップS31の処理で、ユーザが手書き入力した文字列「腰椎炎」の取得が行われる。
【0059】
次に、ステップS32の処理で、取得された文字列「腰椎炎」が複数の切出しポイントS0〜S5の順に基づき、複数個のユニットに仮切出しされる。
【0060】
はじめに、図6を参照して、切出しポイントS0について考えると、切出しポイントS0は先頭であるから、その前にはノードNDが存在せず、その後には、2つのノードND(1)(2)が存在する。
図3のトライ辞書に基づき、トライ辞書の先頭位置でサーチを開始すると、図3のトライ辞書の先頭の子ノードは、「腰」、「耳」「日」であり、それらをノード(1)(2)の認識字種に設定する。
【0061】
ノードND(1)について考えると、ノードND(1)から終端までの可能長は、ノードND(1)、(3)、(5)、(7)を選択した場合の「4」又は、ノードND(1)、(3)、(4)、(6)、(7)を選択した場合の「5」である。(図7乃至13において、ノードND内の数字は、各ノードNDにおける可能長を示す)
これに対し、図3のトライ辞書を参照すると、認識字種「耳」と「日」に続く語句は、その終端までの文字の長さが「3」であるからノードND(1)おける可能長には合わないため削除し、終端までの文字の長さが「4」を取り得る認識字種「腰」のみを保留し、「腰」に対する認識スコアを文字認識エンジンから得る。
【0062】
同様に、ノードND(2)について考えると、ノードND(2)から終端までの可能長は、ノードND(2)、(5)、(7)を選択した場合の「3」又は、ノードND(2)、(4)、(6)、(7)を選択した場合の「4」である。
これに対し、図3のトライ辞書を参照すると、認識字種「腰」に続く語句は、その終端までの文字の長さは「3」又は「4」であり、認識字種「耳」と「日」に続く語句は、その終端までの文字の長さが「3」である。
従って、「腰」、「耳」「日」の全ての認識字種において可能長を満たすため、3つの認識字種「腰」「耳」「日」を保留し、各認識字種に対する認識スコアを文字認識エンジンより得る。
【0063】
次に、図9を参照して、切出しポイントS1について考えると、その前には1つのノードND(1)が存在しており、その後には、1つのノードND(3)が存在する。
各切出しポイントに至るすべての経路について経路評価尺度に従って評価し、そしてそれらをソートし、上位M個の経路だけ選択し、その以外の経路を削除する。個数Mをビームバンドと呼ぶ。ここでの例においてはビームバンドが2であり、S1においては[腰]を保留している1つの経路しかない。
従って、保留している経路と同一の文字列に続く経路に続く字種は、図3のトライ辞書においては、「椎」「痛」「部」「腹」であり、それらをノード(3)の認識字種に設定する。
【0064】
ノードND(3)について考えると、ノードND(3)から終端までの可能長は、ノードND(3)、(5)、(7)を選択した場合の「3」又は、ノードND(3)、(4)、(6)、(7)を選択した場合の「4」である。
これに対し、図3のトライ辞書を参照すると、認識字種「痛」と「腹」に続く語句は、その終端までの文字の長さが「2」であるからノードND(3)おける可能長には合わないため削除し、終端までの文字長さが「3」を取り得る認識字種「椎」と「部」のみを保留し、「椎」と「部」に対する認識スコアを文字認識エンジンから得る。
【0065】
同様の処理を図10乃至図12に示すように、切出しポイントS2、S3、S4の順に適用し、図13に示すように、最後の切出しポイントS5において文字認識処理を行う。そして、最初の切出しポイントS0から最終の切出しポイントS5に至る全てのノード(1)乃至(7)の経路について経路評価尺度に従って評価を行い、評価に基づき全ての経路をソートして最良の評価を有する経路を選択し、当該認識結果を算出する。本実施形態においては、最優の評価を有する経路として、ノード(1)において「腰」が選択され、ノード(5)において「椎」が選択され、ノード(7)において「炎」が選択され、それら最優の経路を選択した「腰椎炎」の文字列が文字認識処理の認識結果として算出されている。
【0066】
[特定語句の特徴]
図14及び図15を参照して、文字認識処理において取り扱う特定語句の特徴について説明する。
図14は、図2のリストに含まれる特定語句(病名)の語長(文字数の長さ)と、その比率と、の関係を示す図である。
図14の図において、横軸は特定語句の文字数の長さを示し、縦軸は、該当する文字数の長さを有する特定語句の比率を示す。
本実施形態において特定語句の平均長は「6.9」である。
【0067】
図15は、図3のトライ辞書に含まれる特定語句(病名)の文字順位置(n文字目に対する位置)と、その文字順位置における平均分岐数(n文字目位置での分岐数)と、の関係を示す図である。
図15に示すように、図3のトライ辞書を参照して可能長に基づきサーチ経路上の認識字種を限定することにより、本来数千個の認識字種から候補を大幅に削減することができ、類似字種への誤認識を防ぐとともに、認識速度の著しい向上を期待することができる。
【0068】
[実施例]
図16乃至図18を参照して、文字認識処理を適用した実施例について説明する。
【0069】
本実施形態においては、オンライン手書き日本語文字データベースNakayosi(M. Nakagawa, K. Matsumoto, “Collection of on-line handwritten Japanese character pattern databases and their analysis,” Int. J. Document Analysis and Recognition (IJDAR), 7(1), pp. 69-81, 2004 参照)により文字認識と幾何的な特徴の評価関数を学習した。文字列方向と文字方向自由のオンライン手書きパターンデータベースHANDS-Kondate_t_bf-2001-1を利用し、仮切出しポイントの確かさしさのためのSVMモデルと経路評価の重みパラメータを学習した。それらの詳細については、B. Zhu, X.-D. Zhou, C.-L. Liu and M. Nakagawa, “A Robust Model for On-line Handwritten the Japanese Text Recognition,” Int. J. Document Analysis and Recognition (IJDAR), Vol. 13, No. 2, pp.121-131, 2010.(以下、非特許文献2と呼ぶ)を参照されたい。
これらの学習後、総文字数3,803からなる1,112のオンライン手書き病名を用いて、本実施形態における文字認識装置1を利用した文字認識方法の評価を行った。実験環境はGenuine Intel(R) CPU U1400 1.20 GHz with 1.49 GBメモリである。
本実施形態に係る文字認識装置1を利用した文字認識方法と汎用の手書き日本語文字列認識方式(非特許文献2参照)を利用した文字認識方法との性能を比較した。公平に比較するために2つの方式とも同じ文字認識と幾何的な特徴の評価関数を使用した。本実施形態に係る文字認識方法では図2で示した病名リストにより図3のトライ辞書を構築した。非特許文献1に記載の汎用の手書き日本語文字列認識方式を利用した文字認識方法の経路評価では、図3のトライ辞書の代わりにtri-gramによる言語の文脈確からしさのスコアを使用した。このtri-gram表は,1993年の朝日新聞と2002年の日経新聞の記事から作成した。
【0070】
図16は、これら本実施形態に係る文字認識装置1を利用した文字認識方法と、汎用の手書き日本語文字列認識方法と、における認識率及び認識速度の比較結果を示す図である。図16において、認識時間は1,112全ての病名を認識するための時間である。
図17及び図18は手書き入力された文字例である。
【0071】
図16に示すように、本実施形態の文字認識方法は、汎用認識方式と比べて,認識率は94.56%から99.97%へ向上し,認識速度は9m37sから40m33sへ4.3倍高速化したことが分かる。
認識率について検討すると、図17に示すような手書き入力された文字列を本実施形態に係る文字認識方法により認識すると、「うっ血肝」と正しく認識できたのに対し、汎用認識方式により認識した場合には、「う。血肝」と誤認識された。従って、「うっ血肝」のような汎用認識方式で誤認識しやすい病名の文字列であっても、本実施形態の文字認識方法においては認識字種の限定を行うことで,類似字種間の誤認識を削減し認識率を向上することができる。
また、図18に示すような手書き入力された文字列を本実施形態に係る文字認識方法により認識すると、「18常染色体異常」と正しく認識されたのに対し、汎用認識方式により認識した場合には、認識ができなかった。従って、正しく語句を手書き入力できていない場合であっても、図3のトライ辞書に基づき可能長から認識字種を選択し、一番類似している認識字種を選択することで認識率を向上することができる。
【0072】
以上のことから、本実施形態に係る文字認識装置1を利用した文字認識方法では、特定語句のトライ辞書と語句の可能長とから認識字種を限定することにより本来数千個の認識字種から候補を大幅に削減できる。これにより、認識字種を大幅に限定することで、類似字種への誤認識を防ぐとともに認識速度を著しく向上させることができる。
また,正しく記入されていない特定語句に対しても,本方式はトライ辞書の中から一番類似しているものを選択するために正しく認識することができる。
【0073】
なお本発明は、上述の実施の形態に限定されるものでは無く、その趣旨を逸脱しない範囲で、上述の実施形態に種々の変形を加えた形態とすることができる。
【0074】
具体的に、上述の実施形態では、トライ辞書を構築するための特定語句の語彙集合は病名を用いて行うが、特定語句の種類は特にこれに限定されるものではなく、住所、氏名などの特定語句のリストを用いてトライ辞書を構築してもよい。
【0075】
また、上述の実施形態では、文字列取得部31により取得する文字列のデータは、タブレットにより入力された手書きの文字列のデータを用いて行うが、特にこれに限定されるものではなく、スキャナーや、手書き入力された筆跡をメモリ上に記憶するペンによって入力される文字列のデータであってもよい。
【0076】
また、上述の実施形態においては、CPU10と記憶部20とを備えた文字認識装置1について文字認識方法を行っているがこれに限られない。例えば、CPU10と記憶部20とを備えた文字認識システムに適用することもできる。
【0077】
また、上述した一連の処理は、ハードウェア及びソフトウェアの何れにより実行させることもできる。上述の一連の処理をソフトウェアにより実行させる場合には、そのソフトウェアを構成するプログラムが、コンピュータの記憶媒体からインストールされる。
【符号の説明】
【0078】
1 文字認識装置
10 CPU
20 記憶部
31 文字列取得部
32 仮切出部
33 文字パターン候補構成部
34 文字パターン候補連結部
35 文字数算出部
36 文字パターン候補限定部
37 文字認識部
41 特定語句記憶部
51 辞書構築部
【特許請求の範囲】
【請求項1】
特定語句と、前記特定語句の文字数の長さとの関係を記憶する特定語句記憶手段と、
手書き入力された文字列を取得する文字列取得手段と、
前記文字列取得手段により取得した前記文字列を複数個のユニットに仮切出しする仮切出手段と、
前記仮切出手段により切り出された各ユニット毎に複数の文字パターン候補を構成する文字パターン候補構成手段と、
前記文字パターン候補構成手段により構成された各文字パターン候補を連結する文字パターン候補連結手段と、
前記文字パターン候補連結手段により連結された前記各文字パターン候補における終端までの文字数の長さを算出する文字数算出手段と、
前記文字パターン候補構成手段により構成された文字パターン候補を、前記特定語句記憶手段に記憶された前記特定語句と、前記文字数算出手段により文字パターン候補毎に算出された終端までの文字数の長さと、に基づき限定する文字パターン候補限定手段と、
前記文字パターン候補限定手段により限定された前記文字パターン候補に基づいて文字の認識を行う文字認識手段と、
を備える文字認識装置。
【請求項2】
前記文字パターン候補限定手段は、
前記文字数算出手段により文字パターン候補毎に算出された終端までの文字数の長さと同一の終端までの文字数の長さを有する特定語句を、前記特定語句記憶手段に記憶された前記特定語句から選別し、
選別した前記特定語句を構成する各文字を、前記文字パターン候補構成手段により構成された文字パターン候補の認識字種として限定する請求項1に記載の文字認識装置。
【請求項3】
前記文字パターン候補限定手段による文字パターン候補の限定は、前記仮切出手段により切出したユニットの順番で行う請求項1に記載の文字認識装置。
【請求項4】
文字の認識を行う制御を実行する文字認識装置の文字認識方法であって、
特定語句と、前記特定語句の文字数の長さとの関係を記憶する特定語句記憶ステップと、
手書き入力された文字列を取得する文字列取得ステップと、
前記文字列取得ステップにより取得した前記文字列を複数個のユニットに仮切出しする仮切出ステップと、
前記仮切出ステップにより切り出された各ユニット毎に複数の文字パターン候補を構成する文字パターン候補構成ステップと、
前記文字パターン候補構成ステップにより構成された各文字パターン候補を連結する文字パターン候補連結ステップと、
前記文字パターン候補連結ステップにより連結された前記各文字パターン候補における終端までの文字数の長さを算出する文字数算出ステップと、
前記文字パターン候補構成ステップにより構成された文字パターン候補を、前記特定語句記憶ステップに記憶された前記特定語句と、前記文字数算出ステップにより文字パターン候補毎に算出された終端までの文字数の長さと、に基づき限定する文字パターン候補限定ステップと、
前記文字パターン候補限定ステップにより限定された前記文字パターン候補に基づいて文字の認識を行う文字認識ステップと、
を含む文字認識方法。
【請求項5】
文字の認識を行う制御を実行する文字認識手段を備える文字認識装置を制御するコンピュータに、
特定語句と、前記特定語句の文字数の長さとの関係を記憶する特定語句記憶機能と、
手書き入力された文字列を取得する文字列取得機能と、
前記文字列取得機能により取得した前記文字列を複数個のユニットに仮切出しする仮切出機能と、
前記仮切出機能により切り出された各ユニット毎に複数の文字パターン候補を構成する文字パターン候補構成機能と、
前記文字パターン候補構成機能により構成された各文字パターン候補を連結する文字パターン候補連結機能と、
前記文字パターン候補連結機能により連結された前記各文字パターン候補における終端までの文字数の長さを算出する文字数算出機能と、
前記文字パターン候補構成機能により構成された文字パターン候補を、前記特定語句記憶機能に記憶された前記特定語句と、前記文字数算出機能により文字パターン候補毎に算出された終端までの文字数の長さと、に基づき限定する文字パターン候補限定機能と、
前記文字パターン候補限定機能により限定された前記文字パターン候補に基づいて文字の認識を行う文字認識機能と、
を実現させるプログラム。
【請求項1】
特定語句と、前記特定語句の文字数の長さとの関係を記憶する特定語句記憶手段と、
手書き入力された文字列を取得する文字列取得手段と、
前記文字列取得手段により取得した前記文字列を複数個のユニットに仮切出しする仮切出手段と、
前記仮切出手段により切り出された各ユニット毎に複数の文字パターン候補を構成する文字パターン候補構成手段と、
前記文字パターン候補構成手段により構成された各文字パターン候補を連結する文字パターン候補連結手段と、
前記文字パターン候補連結手段により連結された前記各文字パターン候補における終端までの文字数の長さを算出する文字数算出手段と、
前記文字パターン候補構成手段により構成された文字パターン候補を、前記特定語句記憶手段に記憶された前記特定語句と、前記文字数算出手段により文字パターン候補毎に算出された終端までの文字数の長さと、に基づき限定する文字パターン候補限定手段と、
前記文字パターン候補限定手段により限定された前記文字パターン候補に基づいて文字の認識を行う文字認識手段と、
を備える文字認識装置。
【請求項2】
前記文字パターン候補限定手段は、
前記文字数算出手段により文字パターン候補毎に算出された終端までの文字数の長さと同一の終端までの文字数の長さを有する特定語句を、前記特定語句記憶手段に記憶された前記特定語句から選別し、
選別した前記特定語句を構成する各文字を、前記文字パターン候補構成手段により構成された文字パターン候補の認識字種として限定する請求項1に記載の文字認識装置。
【請求項3】
前記文字パターン候補限定手段による文字パターン候補の限定は、前記仮切出手段により切出したユニットの順番で行う請求項1に記載の文字認識装置。
【請求項4】
文字の認識を行う制御を実行する文字認識装置の文字認識方法であって、
特定語句と、前記特定語句の文字数の長さとの関係を記憶する特定語句記憶ステップと、
手書き入力された文字列を取得する文字列取得ステップと、
前記文字列取得ステップにより取得した前記文字列を複数個のユニットに仮切出しする仮切出ステップと、
前記仮切出ステップにより切り出された各ユニット毎に複数の文字パターン候補を構成する文字パターン候補構成ステップと、
前記文字パターン候補構成ステップにより構成された各文字パターン候補を連結する文字パターン候補連結ステップと、
前記文字パターン候補連結ステップにより連結された前記各文字パターン候補における終端までの文字数の長さを算出する文字数算出ステップと、
前記文字パターン候補構成ステップにより構成された文字パターン候補を、前記特定語句記憶ステップに記憶された前記特定語句と、前記文字数算出ステップにより文字パターン候補毎に算出された終端までの文字数の長さと、に基づき限定する文字パターン候補限定ステップと、
前記文字パターン候補限定ステップにより限定された前記文字パターン候補に基づいて文字の認識を行う文字認識ステップと、
を含む文字認識方法。
【請求項5】
文字の認識を行う制御を実行する文字認識手段を備える文字認識装置を制御するコンピュータに、
特定語句と、前記特定語句の文字数の長さとの関係を記憶する特定語句記憶機能と、
手書き入力された文字列を取得する文字列取得機能と、
前記文字列取得機能により取得した前記文字列を複数個のユニットに仮切出しする仮切出機能と、
前記仮切出機能により切り出された各ユニット毎に複数の文字パターン候補を構成する文字パターン候補構成機能と、
前記文字パターン候補構成機能により構成された各文字パターン候補を連結する文字パターン候補連結機能と、
前記文字パターン候補連結機能により連結された前記各文字パターン候補における終端までの文字数の長さを算出する文字数算出機能と、
前記文字パターン候補構成機能により構成された文字パターン候補を、前記特定語句記憶機能に記憶された前記特定語句と、前記文字数算出機能により文字パターン候補毎に算出された終端までの文字数の長さと、に基づき限定する文字パターン候補限定機能と、
前記文字パターン候補限定機能により限定された前記文字パターン候補に基づいて文字の認識を行う文字認識機能と、
を実現させるプログラム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】

【図18】
【図19】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【公開番号】特開2012−98905(P2012−98905A)
【公開日】平成24年5月24日(2012.5.24)
【国際特許分類】
【出願番号】特願2010−245882(P2010−245882)
【出願日】平成22年11月2日(2010.11.2)
【出願人】(504132881)国立大学法人東京農工大学 (595)
【Fターム(参考)】
【公開日】平成24年5月24日(2012.5.24)
【国際特許分類】
【出願日】平成22年11月2日(2010.11.2)
【出願人】(504132881)国立大学法人東京農工大学 (595)
【Fターム(参考)】
[ Back to top ]