
文書処理装置、およびプログラム
【課題】従来、既知の用語であるか未知の用語であるかを精度高く把握できなかった。
【解決手段】1以上の文書と、各文書に対応付けられている1以上の用語とを格納し得る文書情報格納部と、1以上の既読用語を格納し得る既読用語格納部と、1以上の未読用語を格納し得る未読用語格納部と、文書のオープン指示を含む読書行為指示を受け付ける受付部と、オープン指示を受け付けた場合に文書を出力する文書出力部と、受付部が受け付けた読書行為指示に対応した読書履歴情報を取得する読書履歴情報取得部と、1以上のいずれかの未読用語であり、読書履歴情報に対応する文書に対応する1以上の用語を既読用語として、既読用語格納部に蓄積する既読用語蓄積部とを具備する文書処理装置により、既知の用語であるか未知の用語であるかを精度高く把握できる。
【解決手段】1以上の文書と、各文書に対応付けられている1以上の用語とを格納し得る文書情報格納部と、1以上の既読用語を格納し得る既読用語格納部と、1以上の未読用語を格納し得る未読用語格納部と、文書のオープン指示を含む読書行為指示を受け付ける受付部と、オープン指示を受け付けた場合に文書を出力する文書出力部と、受付部が受け付けた読書行為指示に対応した読書履歴情報を取得する読書履歴情報取得部と、1以上のいずれかの未読用語であり、読書履歴情報に対応する文書に対応する1以上の用語を既読用語として、既読用語格納部に蓄積する既読用語蓄積部とを具備する文書処理装置により、既知の用語であるか未知の用語であるかを精度高く把握できる。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、電子書籍等の文書を処理する文書処理装置等に関するものである。
【背景技術】
【0002】
従来、未読文書の閲覧を促す文書管理システムがあった(特許文献1参照)。本システムは、参照依頼したユーザ側からその文書の重要度や緊急度を指定して未読一覧を表示させ、文書の閲覧を依頼してから時間が経過しても、未読の場合に、文書の重要度や緊急度を上げることにより、参照を促進させるシステムである。
【0003】
また、未読の記事をRSSリーダに登録済のサイトの記事と未登録のサイトの記事とに分類することにより、ユーザにとって未知の情報であり利用価値の高い記事を特定して検索効率の向上を図るシステムがあった(特許文献2参照)。
【0004】
一方、未読文書を読んだからといって、必ずしも未知で有用な情報が得られるわけではなく、例えば、未読文書には既知の事項しか記述されていないものが存在する。よって、例えば、次に読むべき文書を決定する場合は、ユーザにとって、文書が未読であるか既読であるかは重要ではなく、既知の用語、未知の用語を把握した上で、文書を選択することが重要である。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開2007−188239号公報
【特許文献2】特開2010−231740号公報
【発明の概要】
【発明が解決しようとする課題】
【0006】
しかしながら、上記の従来技術においては、文書の読書行為から、既知の用語であるか未知の用語であるかを精度高く把握できなかった。また、従来技術においては、文書の内容と、ユーザの過去の読書行為とを考慮して、例えば、次に読むべき文書を決定する際に有効な情報を提示したり、次に読むべき文書を推薦したりすることができなかった。
【課題を解決するための手段】
【0007】
本第一の発明の文書処理装置は、1以上の文書と、各文書に対応付けられている1以上の用語または各文書の特定の箇所に対応付けられている1以上の用語とを格納し得る文書情報格納部と、未読の文書に対応する用語である1以上の未読用語を格納し得る未読用語格納部と、文書を開く指示であるオープン指示を含む読書行為指示を受け付ける受付部と、受付部がオープン指示を受け付けた場合に、オープン指示に対応する文書を出力する文書出力部と、受付部が受け付けた読書行為指示に対応した読書履歴情報を取得する読書履歴情報取得部とを具備し、未読用語格納部に格納されている1以上のいずれかの未読用語であり、読書履歴情報に対応する文書に対応する1以上の用語、または読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、未読用語から除外する文書処理装置である。
かかる構成により、未知の用語を精度高く把握できる。
また、本第二の発明の文書処理装置は、第一の発明に対して、既読の文書に対応する用語である1以上の既読用語を格納し得る既読用語格納部と、未読用語格納部に格納されている1以上のいずれかの未読用語であり、読書履歴情報に対応する文書に対応する1以上の用語、または読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、既読用語として、既読用語格納部に蓄積する既読用語蓄積部とをさらに具備する文書処理装置である。
かかる構成により、既知の用語であるか未知の用語であるかを精度高く把握できる。
また、本第三の発明の文書処理装置は、第二の発明に対して、1以上の読書履歴情報を格納し得る読書履歴情報格納部と、読書履歴情報取得部が取得した1以上の読書履歴情報を、読書履歴情報格納部に蓄積する読書履歴情報蓄積部と、読書履歴情報格納部に格納されている1以上の読書履歴情報から決定され得る文書情報格納部に格納されている未読文書であり、既読用語格納部の1以上の既読用語、または未読用語格納部の1以上の未読用語、または既読用語格納部の1以上の既読用語と未読用語格納部の1以上の未読用語を用いて、未読文書に対応付けられている1以上の用語から、1以上の未読文書を選択する、または読書履歴情報格納部に格納されている1以上の読書履歴情報から決定され得る文書情報格納部に格納されている既読文書であり、既読用語格納部の1以上の既読用語を用いて、既読文書に対応付けられている1以上の用語から、1以上の既読文書を選択する文書選択部と、文書選択部が選択した未読文書または既読文書を特定する情報を出力する文書特定情報出力部とをさらに具備する文書処理装置である。
かかる構成により、既知の用語または未知の用語を把握できることにより、適切な未読文書を推薦できる。
また、本第四の発明の文書処理装置は、第三の発明に対して、文書選択部は、読書履歴情報格納部に格納されている1以上の読書履歴情報から決定され得る文書情報格納部に格納されている1以上の未読文書を決定する文書決定手段と、既読用語格納部の1以上の既読用語、または未読用語格納部の1以上の未読用語、または既読用語格納部の1以上の既読用語と未読用語格納部の1以上の未読用語を用いて、1以上の未読文書に対応付けられている1以上の用語を照合する照合手段と、照合手段が照合した結果、予め決められた条件に合致する1以上の用語に対応付けられた未読文書を決定する文書選択手段とを具備する文書処理装置である。
かかる構成により、既知の用語または未知の用語を把握できることにより、適切な未読文書を推薦できる。
また、本第五の発明の文書処理装置は、第二から第四いずれかの発明に対して、既読用語格納部は、既読用語と既読用語に対応するスコアとを有する1以上の既読用語情報を格納しており、既読用語蓄積部は、未読用語格納部に格納されている1以上のいずれかの未読用語であり、読書履歴情報に対応する文書に対応する1以上の用語、または読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、既読用語として、既読用語格納部に蓄積し、かつ、既読用語格納部に格納されている1以上のいずれかの既読用語であり、読書履歴情報に対応する文書に対応する1以上の用語、または読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語に対応するスコアを増加させる文書処理装置である。
かかる構成により、既知の用語であるか未知の用語であるかを極めて精度高く把握できる。
また、本第六の発明の文書処理装置は、第一の発明に対して、受付部は、1以上の未読用語を受け付け、受付部が1以上の未読用語を受け付けた場合に、1以上の未読用語のすべて、または1以上の未読用語のいずれかに対応する未読文書を選択する文書選択部と、未読文書を特定する情報を出力する文書特定情報出力部とをさらに具備する文書処理装置である。
かかる構成により、学習したい内容を指定すると、当該内容について説明されている文書を提示してくれる。
また、本第七の発明の文書処理装置は、第一から第六いずれかの発明に対して、受付部は、一の文書を特定する情報を受け付け、一の文書に対応する1以上の用語を文書情報格納部から取得する用語取得部と、用語取得部が取得した1以上の用語を出力する文書用語出力部とをさらに具備する文書処理装置である。
かかる構成により、文書を指定すると、当該文書で出現する用語を提示してくれる。
【0008】
かかる構成により、文書に対する用語を容易に取得できる。
【発明の効果】
【0009】
本発明による文書処理装置によれば、既知の用語であるか未知の用語であるかを精度高く把握できる。
【図面の簡単な説明】
【0010】
【図1】実施の形態1における文書処理装置のブロック図
【図2】同文書処理装置の動作について説明するフローチャート
【図3】同既読用語取得処理の動作について説明するフローチャート
【図4】同用語抽出処理の動作について説明するフローチャート
【図5】同文書選択処理の動作について説明するフローチャート
【図6】同文書管理表を示す図
【図7】同用語情報管理表を示す図
【図8】同読書履歴情報管理表を示す図
【図9】同レコメンド条件管理表を示す図
【図10】同レコメンドする文書に関する情報の出力例を示す図
【図11】実施の形態2における文書処理装置のブロック図
【図12】同文書処理装置の動作について説明するフローチャート
【図13】同既読用語と未読用語の出力例を示す図
【図14】同文書処理装置の具体的な動作を説明する図
【図15】同文書処理装置の具体的な動作を説明する図
【図16】同文書処理装置の具体的な動作を説明する図
【図17】実施の形態1における他の文書処理装置のブロック図
【図18】上記実施の形態コンピュータシステムの概観図
【図19】同コンピュータシステムのブロック図
【発明を実施するための形態】
【0011】
以下、文書処理装置等の実施形態について図面を参照して説明する。なお、実施の形態において同じ符号を付した構成要素は同様の動作を行うので、再度の説明を省略する場合がある。
【0012】
(実施の形態1)
【0013】
本実施の形態において、既読の文書に対応する既知の用語(以下、「既読用語」という。)と、未読の文書に対応する未知の用語(以下、「未読用語」という。)とを管理しており、文書を読んだ場合に、当該文書に出現する未知の用語を既知の用語として管理を更新する文書処理装置について説明する。
【0014】
また、本実施の形態において、既読用語または/および未読用語を用いて、未読の文書の中の文書をレコメンドする文書処理装置について説明する。
【0015】
また、本実施の形態において、既読用語はスコア(「ポイント」とも言える。)を保持しており、文書を読めば、当該文書に対応する用語のスコアが増加する文書処理装置について説明する。
【0016】
また、本実施の形態において、文書に対する各用語のポイントは、用語によって異なる文書処理装置について説明する。
【0017】
さらに、本実施の形態において、文書に対応する用語は、文書全体から用語抽出により取得されたり、目次や索引等の予め決められた箇所から取得されたり、サーバ装置から受信されたりする文書処理装置について説明する。
【0018】
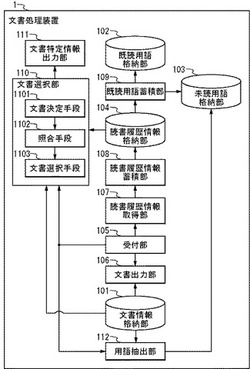
図1は、本実施の形態における文書処理装置1のブロック図である。文書処理装置1は、文書情報格納部101、既読用語格納部102、未読用語格納部103、読書履歴情報格納部104、受付部105、文書出力部106、読書履歴情報取得部107、読書履歴情報蓄積部108、既読用語蓄積部109、文書選択部110、文書特定情報出力部111、および用語抽出部112を備える。
【0019】
また、文書選択部110は、文書決定手段1101、照合手段1102、および文書選択手段1103を備える。
【0020】
文書情報格納部101は、文書と当該文書に対応付けられている1以上の用語との組を1組以上、格納し得る。また、各用語は、スコアと対応付けられていても良い。つまり、文書情報格納部101は、文書と1以上の用語と各用語に対するスコアの集合を1以上格納していても良い。なお、文書とは、電子書籍、Webページ、ファイルなどである。また、スコアとは、文書と用語との関連の度合いを示す情報である。スコアは、例えば、文書内での出現頻度や、出現確率である。また、スコアは、例えば、出現「1」、未出現「0」などのフラグでも良い。また、用語とスコアとを有する情報を用語情報とも言う。
【0021】
また、文書情報格納部101は、文書と、各文書の特定の箇所に対応付けられている1以上の用語との組を1組以上、格納していても良い。つまり、文書情報格納部101は、文書と、1以上の用語と、各用語が出現する文書の特定の箇所を識別する情報(例えば、ページ番号)との集合を1以上格納していても良い。また、各用語は、スコアと対応付けられていても良い。なお、特定の箇所とは、ページ、段落、章などである。また、用語が特定の箇所に対応付けられている場合、スコアは、当該特定の箇所と用語との関連の度合いを示す情報である。
【0022】
また、文書情報格納部101の文書は、ジャンルや種類やレベル(難易度)などの属性値を有していても良い。そして、文書の属性値は、文書を選択する場合に利用されることは好適である。
【0023】
なお、文書は、通常、文書の識別子(「文書識別子」と言い、例えば、「タイトル」である。)、著者、出版社等の書誌情報を含む。また、文書識別子は、文書を特定する情報であれば何でも良い、例えば、ファイル名、文書の最初のN文字等でも良い。また、文書に対応付けられている用語は、一時的に文書情報格納部101に格納されても良い。
【0024】
また、用語は、名詞や名詞句であることが好適であるが、形容詞などでも良い。また、用語は、品詞を問わなくても良い。
【0025】
既読用語格納部102は、1以上の既読用語を格納し得る。既読用語とは、既読の文書や、文書中の既読の箇所に対応する用語である。既読用語は、既知の用語であると考えても良い。また、用語とは、通常、単語であるが、1以上の単語を有する句などでも良い。
【0026】
また、既読用語格納部102は、既読用語と当該既読用語に対応するスコアとを有する1以上の既読用語情報を格納していても良い。ここでのスコアは、用語に対する既知の度合いを示す情報である。既読用語に対応するスコアは、例えば、既読の文書に対応する用語のスコアの総和である。既読用語に対応するスコアは、通常、既読の文書に対応する用語のスコアから算出される。
【0027】
未読用語格納部103は、1以上の未読用語を格納し得る。未読用語とは、未読の文書や、文書中の未読の箇所に対応する用語である。未読用語は、未知の用語であると考えても良い。後述する用語抽出部112により、抽出された用語のうち、既読用語格納部102に存在しない用語を、未読用語として未読用語格納部103に蓄積されていることは好適である。
【0028】
既読用語格納部102と未読用語格納部103とは、同一のデータベース、同一のテーブル等でも良い。かかる場合、例えば、各用語に既読用語であることを示すフラグ、または未読用語であることを示すフラグが付与されていても良い。また、例えば、各用語にスコアが付与されており、出現回数を示すスコアが「0」、または出現回数以外の情報であるスコアが所定の条件(例えば、「0」)を満たす場合に、未読用語と判断されても良い。つまり、既読用語格納部102と未読用語格納部103とは、物理的に分離されている必要はなく、既読用語と未読用語とが区別される態様で管理されていれば良い。
【0029】
読書履歴情報格納部104は、1以上の読書履歴情報を格納し得る。読書履歴情報とは、ユーザが行った文書に対する読書行為に関する履歴の情報である。読書履歴情報は、読書の経過、履歴を示す情報であるとも言える。また、文書が電子書籍である場合、読書履歴情報は、例えば、文書識別子(例えば、タイトル)、ページ番号、時刻を示す時刻情報を有する。ただし、読書履歴情報は、文書識別子(例えば、タイトル)、ページ番号だけでも良い。ここでのページ番号は、既に読んだページを特定する情報、または未読のページを特定する情報である。また、読書履歴情報は、既読の文書の文書識別子のみでも良い。なお、一定時間以上、ページの表示状態が継続した場合に、読書履歴情報が取得されることは好適である。つまり、ぱらぱらめくりの場合等、一時のみオープンした頁の情報について、読書履歴情報に含めないことは好適である。また、文書がファイルである場合、読書履歴情報は、例えば、文書のタイトル(例えば、タイトルタグに対応する文字列)、時刻を示す時刻情報を有する。また、文書がファイルである場合、読書履歴情報は、例えば、文書の最初のN文字(例えば、N=10)、画面上に表示された箇所までのオフセットを有する。
【0030】
受付部105は、指示やデータ等を受け付ける。指示は、例えば、文書を開く指示であるオープン指示を含む読書行為指示を受け付ける。また、指示は、例えば、用語抽出指示、文書レコメンド指示などでも良い。ここで、オープン指示とは、通常、文書情報格納部101の文書を読み出し、オープンすることの指示であるが、文書を外部(サーバ装置など)から受信する指示と考えても良い。また、読書行為指示とは、その他、ページめくり指示、ページジャンプ指示などを含むことは好適である。また、用語抽出指示とは、文書から用語を自動抽出して、当該用語を文書情報格納部101に蓄積する処理である。さらに、文書レコメンド指示とは、次に読むべき文書を推薦する指示である。
【0031】
また、受け付けとは、キーボードやマウス、タッチパネルなどの入力デバイスから入力された情報の受け付け、有線もしくは無線の通信回線を介して送信された情報の受信、光ディスクや磁気ディスク、半導体メモリなどの記録媒体から読み出された情報の受け付けなどを含む概念である。さらに、指示等の入力手段は、キーボードやマウスやメニュー画面によるもの等、何でも良い。受付部105は、キーボード等の入力手段のデバイスドライバーや、メニュー画面の制御ソフトウェア等で実現され得る。
【0032】
文書出力部106は、受付部105がオープン指示を受け付けた場合に、オープン指示に対応する文書を出力する。また、文書出力部106は、ページめくり指示、ページジャンプ指示などの読書行為指示に対応して、対応するページに表示を切り替える処理も行うことは好適である。また、文書がファイルである場合、文書出力部106は、ウィンドウに対するスクロール指示に対応して、表示中のファイルをスクロールする。
【0033】
ここで、出力とは、ディスプレイへの表示、プロジェクターを用いた投影、プリンタでの印字、音出力、外部の装置への送信、記録媒体への蓄積、他の処理装置や他のプログラムなどへの処理結果の引渡しなどを含む概念である。
【0034】
文書出力部106は、ディスプレイやスピーカー等の出力デバイスを含むと考えても含まないと考えても良い。文書出力部106は、出力デバイスのドライバーソフトまたは、出力デバイスのドライバーソフトと出力デバイス等で実現され得る。
【0035】
読書履歴情報取得部107は、受付部105が受け付けた読書行為指示に対応した読書履歴情報を取得する。読書履歴情報は、通常、表示中の文書のタイトル、ページ番号、時刻情報を有する。ただし、読書履歴情報は、タイトルや文書識別子のみでも良い。なお、読書履歴情報取得部107は、一定時間以上、ページの表示状態が継続した場合に、読書履歴情報を取得することは好適である。つまり、ぱらぱらめくりの場合等、一時のみオープンした頁について、読書履歴情報に含めないことは好適である。読書履歴情報取得部107は、ユーザからのページめくり指示等の指示があるごとに、読書履歴情報を取得することは好適であるが、読書履歴情報を取得するタイミングが問わない。また、読書履歴情報取得部107は、例えば、当該文書処理装置1の保有者のジャンルごとの読む速さに関する情報(読書速度情報)を保持しており、かかる情報に従って、当該ページを読んだのか、ぱらぱらめくっただけなのかを判断することは好適である。例えば、読書履歴情報取得部107は、「ジャンル「小説」、1分/ページ」「ジャンル「専門書」、2分/ページ」「ジャンル「雑誌」、30秒/ページ」などの読書速度情報を格納しており、かかる読書速度情報を用いて、読書速度情報が示す速度と同程度以上の速度でページがめくられれば、当該ページを既読とし、所定の条件(例えば、読書速度情報が示す1ページあたりの読書時間の70%以内)を満たすほど読書速度情報が示す速度より速い速度でページがめくられれば、ぱらぱらめくり(既読ではない)と判断することは好適である。
【0036】
読書履歴情報蓄積部108は、読書履歴情報取得部107が取得した1以上の読書履歴情報を、読書履歴情報格納部104に蓄積する。読書履歴情報蓄積部108は、読書履歴情報を追記しても良いし、上書きしても良い。上書きする場合、通常、読書履歴情報格納部104には、読んだ最終ページの識別子(ページ番号など)が蓄積されていることとなる。また、追記する場合、通常、読書履歴情報格納部104には、読んだすべてのページの識別子が蓄積されていることとなる。つまり、文書が小説などの連続性のある電子書籍の場合は、上書きすることが好適である。一方、文書がランダムに学習する対象である参考書や百科辞典などの連続性のない電子書籍の場合は、追記することが好適である。
【0037】
既読用語蓄積部109は、未読用語を既読用語の状態とする。既読用語蓄積部109は、未読用語格納部103に格納されている1以上のいずれかの未読用語であり、読書履歴情報に対応する文書に対応する1以上の用語、または読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、未読用語から除外する。ある用語を未読用語から除外する処理は、未読用語格納部103から削除する処理でも良いし、未読用語ではない旨を示すフラグを付与するなどしても良い。
具体的には、例えば、既読用語蓄積部109は、未読用語格納部103に格納されている1以上のいずれかの未読用語であり、読書履歴情報に対応する文書に対応する1以上の用語、または読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、既読用語として、既読用語格納部102に蓄積しても良い。なお、ここで、既読用語蓄積部109は、既読用語とした用語を、未読用語格納部103から削除することは好適である。
【0038】
また、既読用語蓄積部109は、未読用語格納部103に格納されている1以上のいずれかの未読用語であり、読書履歴情報に対応する文書に対応する1以上の用語、または読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、既読用語として、既読用語格納部102に蓄積し、かつ、既読用語格納部102に格納されている1以上のいずれかの既読用語であり、読書履歴情報に対応する文書に対応する1以上の用語、または読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語に対応するスコアを増加させても良い。
【0039】
また、既読用語蓄積部109は、未読用語格納部103に格納されている1以上のいずれかの未読用語であり、読書履歴情報に対応する文書に対応する1以上の用語および各用語に対応するスコア、または読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語および各用語に対応するスコアを、既読用語格納部102に蓄積し、かつ、既読用語格納部102に格納されている1以上のいずれかの既読用語であり、読書履歴情報に対応する文書に対応する1以上の用語、または読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語に対応するスコアを、文書情報格納部101のスコアだけ増加させても良い。
【0040】
文書選択部110は、ユーザに読むべき文書を推薦するために、未読文書を選択する。ここで、未読文書の選択とは、通常、未読文書を特定する情報(文書識別子など)の取得である。また、ここでの未読文書は、読書履歴情報格納部104に格納されている1以上の読書履歴情報から決定され得る文書情報格納部101に格納されている未読文書である。つまり、未読文書は、読書履歴情報格納部104に文書識別子が存在しない文書である、また、未読文書は、読書履歴情報格納部104に文書識別子が存在しない文書であり、かつ、文書情報格納部101に存在する文書である。
また、文書選択部110は、読書履歴情報格納部104から決定され得る文書情報格納部101に格納されている既読文書であり、既読用語格納部102の1以上の既読用語を用いて、既読文書に対応付けられている1以上の用語から、1以上の既読文書を選択しても良い。
文書選択部110は、通常、1以上の既読用語、または1以上の未読用語、または1以上の既読用語と1以上の未読用語を用いて、未読文書を選択する。また、文書選択部110は、1以上の既読用語を用いて、既読文書を選択しても良い。
【0041】
文書選択部110は、例えば、未読文書の中で、最も多くの未読用語に対応する文書を選択する。かかる場合、新しい多くの知識を増やすことができる文書を選択することとなる。また、例えば、文書選択部110は、未読文書の中で、最も多くの既読用語に対応する文書を選択する。かかる場合、過去に学習した事項について復習の意義を有する文書を選択することとなる。
【0042】
また、文書選択部110は、スコアが中程度であることを示す条件である中程度条件を満たす第一種類の用語と、スコアが低度であることを示す条件である低度条件を満たす第二種類の用語の、いずれの種類の用語とも対応付けられている1以上の未読文書を選択することは好適である。なお、中程度条件とは、例えば、スコアが「7>=スコア>=3」である。また、低度条件とは、例えば、スコアが「3>スコア」である。かかる場合、読みやすい文書であり、かつ、ある程度の学習になる文書を選択することとなる。
【0043】
文書選択部110を構成する文書決定手段1101は、読書履歴情報格納部104に格納されている1以上の読書履歴情報を用いて、文書情報格納部101に格納されている1以上の未読文書を決定する。また、文書決定手段1101は、読書履歴情報格納部104に格納されている1以上の読書履歴情報を用いて、文書情報格納部101に格納されている1以上の既読文書を決定しても良い。
【0044】
照合手段1102は、既読用語格納部102の1以上の既読用語、または未読用語格納部103の1以上の未読用語、または既読用語格納部102の1以上の既読用語と未読用語格納部103の1以上の未読用語を用いて、文書情報格納部101を検索し、1以上の未読文書に対応付けられている1以上の用語を照合する。また、照合手段1102は、既読用語格納部102の1以上の既読用語を用いて、文書情報格納部101を検索し、1以上の既読文書に対応付けられている1以上の用語を照合しても良い。
【0045】
文書選択手段1103は、照合手段1102が照合した結果、予め決められた条件に合致する1以上の用語に対応付けられた未読文書を決定する。文書選択手段1103は、例えば、次に読むべき文書を選択する。
また、文書選択手段1103は、照合手段1102が照合した結果、予め決められた条件に合致する1以上の用語に対応付けられた既読文書を決定する。つまり、文書選択手段1103は、再度、読むべき文書を選択しても良い。
【0046】
なお、文書選択部110は、1以上の未読文書を選択してから、当該1以上の各未読文書に対応する1以上の用語と、1以上の既読用語または/および1以上の未読用語とを照らし合わせて、レコメンドする文書を決定した。しかし、文書選択部110は、1以上の既読用語または/および1以上の未読用語とを照らし合わせて、レコメンドする文書の候補を選択し、当該文書の候補から未読文書を決定しても良い。つまり、文書選択部110は、1以上の既読用語または/および1以上の未読用語を用いて、レコメンドする文書を選択できれば良い。
【0047】
文書特定情報出力部111は、文書選択部110が選択した未読文書を特定する情報を出力する。ここで、未読文書を特定する情報とは、通常、タイトルを含む。ただし、未読文書を特定する情報は、未読文書の最初のN文字や目次などでも良い。また、文書特定情報出力部111が未読文書を特定する情報を出力する態様は問わない。
【0048】
用語抽出部112は、文書から、1以上の用語、または1以上の用語と各用語のスコア(例えば、出現頻度)を取得する。例えば、用語抽出部112は、文書を形態素解析し、名詞または名詞句を取得する。次に、用語抽出部112は、名詞または名詞句の出現頻度を、文書から取得する。次に、用語抽出部112は、閾値以上の出現頻度である名詞または名詞句を取得する。
【0049】
また、用語抽出部112は、文書の予め決められた箇所から1以上の用語を抽出しても良い。さらに、用語抽出部112は、1以上のサーバ装置(図示しない)から、各文書に対応付けられている1以上の用語、または各文書の特定の箇所に対応付けられている1以上の用語、または各文書に対応付けられている1以上の用語と各用語のスコア、または各文書の特定の箇所に対応付けられている1以上の用語と各用語のスコアを受信しても良い。
また、用語抽出部112は、抽出した1以上の用語を文書情報格納部101に蓄積する。また、用語抽出部112は、かかる用語のうち、既読用語格納部102に存在しない用語を、未読用語格納部103に蓄積することは好適である。
【0050】
文書情報格納部101、既読用語格納部102、未読用語格納部103、および読書履歴情報格納部104は、不揮発性の記録媒体が好適であるが、揮発性の記録媒体でも実現可能である。
【0051】
文書情報格納部101等に文書等が記憶される過程は問わない。例えば、記録媒体を介して文書等が文書情報格納部101で記憶されるようになってもよく、通信回線等を介して送信された文書等が文書情報格納部101で記憶されるようになってもよく、あるいは、入力デバイスを介して入力された文書等が文書情報格納部101で記憶されるようになってもよい。
【0052】
読書履歴情報取得部107、読書履歴情報蓄積部108、既読用語蓄積部109、文書選択部110、および用語抽出部112は、通常、MPUやメモリ等から実現され得る。読書履歴情報取得部107等の処理手順は、通常、ソフトウェアで実現され、当該ソフトウェアはROM等の記録媒体に記録されている。但し、ハードウェア(専用回路)で実現しても良い。
【0053】
次に、文書処理装置1の動作について、図2のフローチャートを用いて説明する。
【0054】
(ステップS201)受付部105は、指示を受け付けたか否かを判断する。指示を受け付ければステップS202に行き、指示を受け付けなければステップS201に戻る。
【0055】
(ステップS202)文書出力部106は、ステップS201で受け付けられた指示がオープン指示であるか否かを判断する。オープン指示であればステップS203に行き、オープン指示でなければステップS205に行く。なお、オープン指示は、文書識別子を含む、とする。
【0056】
(ステップS203)文書出力部106は、オープン指示に含まれる文書識別子に対応する既読箇所情報(既に読んだ箇所を特定する情報)を読書履歴情報格納部104から取得する。なお、ここで、既読箇所情報が取得されないこともある。
【0057】
(ステップS204)文書出力部106は、文書識別子に対応する文書のページであり、ステップS203で取得された既読箇所情報が示す既読のページの次のページを文書情報格納部101から読み出し、出力する。ステップS201に戻る。なお、文書出力部106は、常に、文書識別子に対応する文書の初めの箇所を出力しても良い。かかる場合、ステップS203は不要である。また、なお、ステップS203で、既読箇所情報が取得されなかった場合、通常、文書出力部106は、文書識別子に対応する文書の初めの箇所を出力する。
【0058】
(ステップS205)読書履歴情報取得部107は、ステップS201で受け付けられた指示がページめくり指示であるか否かを判断する。ページめくり指示であればステップS206に行き、ページめくり指示でなければステップS212に行く。
【0059】
(ステップS206)読書履歴情報取得部107は、読書履歴情報を取得する条件に合致するか否かを判断する。つまり、例えば、読書履歴情報取得部107は、例えば、一定時間以上、現在表示中のページの表示状態が継続した等、読んだと言える条件を満たすか否かを判断する。条件に合致する場合はステップS207に行き、条件に合致しない場合はステップS201に戻る。なお、読書履歴情報取得部107は、図示しない時計を用いて、表示中のページの表示時間をカウントする、とする。
【0060】
(ステップS207)読書履歴情報取得部107は、読書履歴情報を取得する。読書履歴情報取得部107は、例えば、表示中の文書の文書識別子(例えば、タイトル)、ページ番号、時刻情報を取得する。なお、読書履歴情報取得部107は、図示しない時計から時刻情報を取得する。
【0061】
(ステップS208)読書履歴情報蓄積部108は、読書履歴情報取得部107が取得した読書履歴情報を読書履歴情報格納部104に蓄積する。
【0062】
(ステップS209)文書出力部106は、ページめくり指示に対応するページを、文書情報格納部101から読み出す。
【0063】
(ステップS210)文書出力部106は、ステップS209で読み出したページを出力する。ステップS201に戻る。
【0064】
(ステップS211)既読用語蓄積部109は、既読用語の取得処理を行う。かかる既読用語の取得処理については、図3のフローチャートを用いて説明する。
【0065】
(ステップS212)用語抽出部112は、ステップS201で受け付けられた指示が用語抽出指示であるか否かを判断する。用語抽出指示であればステップS213に行き、用語抽出指示でなければステップS214に行く。
【0066】
(ステップS213)用語抽出部112は、用語抽出処理を行う。用語抽出処理については、図4のフローチャートを用いて説明する。ステップS201に戻る。
【0067】
(ステップS214)文書選択部110は、ステップS201で受け付けられた指示が文書レコメンド指示であるか否かを判断する。文書レコメンド指示であればステップS215に行き、文書レコメンド指示でなければステップS217に行く。
【0068】
(ステップS215)文書選択部110は、レコメンドすべき文書を選択する。かかる文書選択処理については、図5のフローチャートを用いて説明する。
【0069】
(ステップS216)文書特定情報出力部111は、ステップS215で選択された文書を特定する情報を出力する。ステップS201に戻る。
【0070】
(ステップS217)文書出力部106は、ステップS201で受け付けられた指示がクローズ指示であるか否かを判断する。クローズ指示であればステップS218に行き、クローズ指示でなければステップS201に戻る。
【0071】
(ステップS218)文書出力部106は、出力中の文書の出力を停止する。ステップS206に行く。
【0072】
なお、図2のフローチャートにおいて既読用語格納部102に蓄積された既読用語やスコアなどは、どのように利用しても良い。また、図2のフローチャートにおいて未読用語格納部103に蓄積された未読用語をどのように利用しても良い。例えば、未読用語を出力するだけで、学習していない事項が明らかになる。また、既読用語を出力するだけで、学習した事項が明らかになる。
【0073】
また、図2のフローチャートにおいて、既読用語取得処理を、ページをめくるごとに行ったが、文書をすべて読んだ際に行うようにしても良い。既読用語取得処理を行うタイミングは問わない。
また、図2のフローチャートにおいて、用語抽出指示が受け付けられた場合に、用語抽出処理を行った。しかし、用語抽出処理を行うタイミングは問わない。
また、図2のフローチャートにおいて、クローズ指示が受け付けられた場合に、既読用語取得処理を行った。しかし、ページがめくられる毎に既読用語取得処理を行うなど、既読用語取得処理を行うタイミングは問わない。
また、図2のフローチャートにおいて、文書選択(ステップS215)は、未読文書の選択であった。ただし、文書選択処理において、既読文書を選択するようにしても良い。
【0074】
さらに、図2のフローチャートにおいて、電源オフや処理終了の割り込みにより処理は終了する。
【0075】
次に、ステップS211の既読用語の取得処理について、図3のフローチャートを用いて説明する。
【0076】
(ステップS301)既読用語蓄積部109は、文書に対応する1以上の用語を文書情報格納部101から取得する。
【0077】
(ステップS302)既読用語蓄積部109は、カウンタiに1を代入する。
【0078】
(ステップS303)既読用語蓄積部109は、ステップS301で取得した用語の中に、i番目の用語が存在するか否かを判断する。i番目の用語が存在すればステップS304に行き、存在しなければ上位処理にリターンする。
【0079】
(ステップS304)既読用語蓄積部109は、i番目の用語が既読箇所(ここでは、出力中のページ)に存在するか否かを判断する。i番目の用語が既読箇所に存在すればステップS305に行き、存在しなければステップS309に行く。
【0080】
(ステップS305)既読用語蓄積部109は、i番目の用語に対応するスコアを取得する。ここで、既読用語蓄積部109は、i番目の用語の既読箇所における出現頻度を取得し、スコアとしても良い。また、既読用語蓄積部109は、i番目の用語に対応するスコアを文書情報格納部101から取得しても良い。また、既読用語蓄積部109は、i番目の用語に対する固定的なスコア「1」を取得しても良い。
【0081】
(ステップS306)既読用語蓄積部109は、i番目の用語をキーとして、未読用語格納部103を検索し、i番目の用語が未読用語であるか否かを判断する。i番目の用語が未読用語であればステップS307に行き、i番目の用語が未読用語でなければステップS308に行く。
【0082】
(ステップS307)既読用語蓄積部109は、i番目の用語を既読用語格納部102に登録する。なお、かかる登録は、通常、i番目の用語を既読用語格納部102に書き込むことであるが、i番目の用語に対するスコアを付与するだけでも良い。
【0083】
(ステップS308)既読用語蓄積部109は、ステップS305で取得したスコアをi番目の用語に対応付けて、既読用語格納部102に蓄積する。また、既読用語蓄積部109は、ステップS305で取得したスコア分を増加させるように、i番目の用語に対応するスコアを更新しても良い。
【0084】
(ステップS309)既読用語蓄積部109は、カウンタiを1、インクリメントする。ステップS303に戻る。
【0085】
なお、図3のフローチャートにおいて、既読用語蓄積部109は、通常、未読用語を既読用語として登録した後、未読用語格納部103から、当該未読用語を削除する。
【0086】
次に、ステップS213の用語抽出処理について、図4のフローチャートを用いて説明する。
【0087】
(ステップS401)用語抽出部112は、カウンタiに1を代入する。
【0088】
(ステップS402)用語抽出部112は、文書情報格納部101に、用語を有しないi番目の文書が存在するか否かを判断する。用語を有しないi番目の文書が存在すればステップS403に行き、存在しなければ上位処理にリターンする。
【0089】
(ステップS403)用語抽出部112は、i番目の文書を特定する文書識別子を文書情報格納部101から取得し、当該文書識別子を用いて、1以上の図示しないサーバ装置にアクセスし、1以上の用語を受信しようとする。なお、用語抽出部112は、1以上の図示しないサーバ装置にアクセスするための情報(IPアドレスやURLなど)を格納している、とする。
【0090】
(ステップS404)用語抽出部112は、ステップS403におけるアクセスの結果、1以上の用語である用語集を取得できたか否かを判断する。用語集を取得できればステップS405に行き、用語集を取得できなければステップS407に行く。用語集を取得できない場合、文書を自然言語処理し、1以上の用語を取得する。
【0091】
(ステップS405)用語抽出部112は、1以上の用語を文書情報格納部101に蓄積する。また、用語抽出部112は、かかる用語のうち、既読用語格納部102に存在しない用語を、未読用語格納部103に蓄積することは好適である。
【0092】
(ステップS406)用語抽出部112は、カウンタiを1、インクリメントする。ステップS402に戻る。
【0093】
(ステップS407)用語抽出部112は、用語を有しないi番目の文書に対して形態素解析を行う。
【0094】
(ステップS408)用語抽出部112は、ステップS407における形態素解析の出力から、名詞や名詞句等の予め決められた条件に合致する用語を取得する。
【0095】
(ステップS409)用語抽出部112は、カウンタjに1を代入する。
【0096】
(ステップS410)用語抽出部112は、j番目の名詞等が存在するか否かを判断する。j番目の名詞等が存在すればステップS411に行き、存在しなければステップS406に戻る。
【0097】
(ステップS411)用語抽出部112は、j番目の名詞等のスコアを算出する。例えば、用語抽出部112は、j番目の名詞等の出現頻度を取得し、スコアとしても良い。
【0098】
(ステップS412)用語抽出部112は、j番目の名詞等の出現箇所(例えば、ページ番号)を取得する。
【0099】
(ステップS413)用語抽出部112は、j番目の名詞等、スコア、出現箇所等を用いて、用語情報を構成する。
【0100】
(ステップS414)用語抽出部112は、ステップS413で構成した用語情報を、i番目の文書に対応付けて、文書情報格納部101に蓄積する。
【0101】
(ステップS415)用語抽出部112は、カウンタjを1、インクリメントする。ステップS410に戻る。
【0102】
なお、図4のフローチャートにおいて、名詞等の出現箇所や、スコアを取得しなくても良い。かかる場合、用語情報は、取得した情報から構成される。
【0103】
次に、ステップS215の文書選択処理について、図5のフローチャートを用いて説明する。
【0104】
(ステップS501)文書選択部110は、未読文書の識別子を、文書情報格納部101から取得する。文書選択部110は、例えば、読書履歴情報取得部107の読書履歴情報には存在しない文書識別子であり、文書情報格納部101に存在する文書識別子を取得しても良い。また、文書選択部110は、例えば、読書履歴情報取得部107の読書履歴情報から、完読していない文書に対する文書識別子であり、かつ、文書情報格納部101に存在する文書識別子を未読文書の文書識別子として取得しても良い。
【0105】
(ステップS502)文書選択部110は、ステップS501で取得した1以上の未読文書の各識別子に対応する1以上の用語を、文書情報格納部101から取得する。なお、文書情報格納部101に文書に対応する用語が存在しない場合、この時点で、ステップS501で取得した1以上の未読文書の各識別子に対応する文書から、用語抽出処理を行っても良い。
【0106】
(ステップS503)文書選択部110は、既読用語格納部102に格納されている1以上の既読用語、未読用語格納部103に格納されている1以上の未読用語を取得する。
【0107】
(ステップS504)文書選択部110は、カウンタiに1を代入する。
【0108】
(ステップS505)文書選択部110は、レコメンドする文書を選択するためのi番目の条件を保持しているか否かを判断する。i番目の条件を保持していればステップS504に行き、保持していなければ上位処理にリターンする。なお、レコメンドする文書を選択するための1以上の条件は、文書選択部110に格納されている、とする。
【0109】
(ステップS506)文書選択部110は、i番目の条件を取得する。
【0110】
(ステップS507)文書選択部110は、ステップS502で取得した1以上の未読文書の各識別子に対応する1以上の用語、およびステップS503で取得した1以上の既読用語または/および1以上の未読用語を用いて、i番目の条件に合致する1以上の未読文書の識別子を取得する。
【0111】
(ステップS508)文書選択部110は、1以上の未読文書の識別子を取得できたか否かを判断する。取得できればステップS509に行き、取得できなければステップS510に行く。
【0112】
(ステップS509)文書選択部110は、i番目の条件に対応付けて、ステップS507で取得した1以上の未読文書の識別子をバッファに一時蓄積する。
【0113】
(ステップS510)文書選択部110は、カウンタiを1、インクリメントする。ステップS505に戻る。
【0114】
なお、図5のフローチャートにおいて、レコメンドする文書を選択するための条件は、文書に対応する1以上の用語と、1以上の既読用語または/および1以上の未読用語とを用いた条件である。
【0115】
以下、本実施の形態における文書処理装置1の具体的な動作について説明する。今、文書情報格納部101には、購入した多数の電子書籍が格納されている。電子書籍は、文書の一種である。
【0116】
また、文書情報格納部101は、図6に示す構造を有する文書管理表を格納している。文書管理表は、「ID」「文書識別子」「用語情報」「既読フラグ」を有するレコードを1以上格納している。また、「用語情報」は、「用語」と「スコア」とを有する。「ID」は、レコードを識別する情報である。「文書識別子」は、ここでは電子書籍のタイトルである。「用語」は、文書に対応する用語である。「スコア」は、文書と用語との関連度を示す。また、「既読フラグ」は、文書を読んだか否かを示す情報である。「既読フラグ」において、未読の場合は「0」、読んでいる途中の場合(一部のみを読んだ場合)は「1」、完読した場合は「2」である。
【0117】
なお、図6の文書管理表の用語とスコアは、用語抽出部112が取得した情報である。つまり、用語抽出部112は、文書管理表が有する各文書識別子に対応する文書を読み出し、当該文書から、名詞および名詞句であり、閾値以上の出現頻度の名詞および名詞句を取得した。そして、用語抽出部112は、演算式「スコア=f(出現頻度)」(fは、出現頻度をパラメータとする増加関数)により、用語ごとにスコアを算出し、用語とスコアを有する1以上の用語情報を、文書に対応付けて蓄積した。なお、スコアは、ここでは、1から10までである、とする。図6の文書管理表の既読フラグの初期値は、すべて「0」である。
【0118】
また、既読用語格納部102、および未読用語格納部103は、図7に示す構造を有する用語情報管理表を保持している、とする。用語情報管理表は、既読用語、未読用語の2種類の用語を管理する。用語情報管理表は、「ID」「キーワード」「スコア」を有する1以上のレコードを格納している。未読の用語のスコアは「0」である。「0」以外のスコアに対応する用語は既読用語である。また、スコアが大きい用語であるほど、通常、ユーザが深く学習した用語である、と言える。図7の用語情報管理表のスコアの初期値は、すべて「0」である。
【0119】
また、読書履歴情報格納部104は、図8に示す構造を有する読書履歴情報管理表を格納している。読書履歴情報管理表には、「ID」「読書履歴情報」を有するレコードが1以上、格納されている。「読書履歴情報」は、「文書識別子」「ページ番号」「時刻」を有する。「ID」は読書履歴情報管理表のレコードを識別する情報である。また、「文書識別子」は、ここでは電子書籍のタイトルである。「ページ番号」は、既読のページを識別する情報である。「ページ番号」は、読んだページを示す情報であるが、既読の最後のページ番号のみでも良い。さらに、「時刻」は、最後に読んだ時刻を示す。なお、「時刻」は、各ページと当該ページを読んだ時刻を示す情報でも良い。
【0120】
また、文書選択部110は、図9に示すレコメンド条件管理表を保持している。レコメンド条件管理表は、「ID」「項目」「条件」を有するレコード(レコメンド条件)を1以上格納している。「項目」とは、レコメンド条件の意味を示す情報である。また、「条件」とは、文書を選択する際の条件を示す情報である。
【0121】
かかる状況において、ユーザは、文書識別子「株式会社の××」を有するオープン指示を入力した、とする。次に、受付部105は、オープン指示を受け付ける。次に、文書出力部106は、オープン指示に含まれる文書識別子「株式会社の××」に対応する既読箇所情報を読書履歴情報管理表から取得しようとするが、ここでは、取得できなかった、とする。次に、文書出力部106は、文書識別子「株式会社の××」の文書を、文書情報格納部101から読み出し、最初のページ(例えば、表紙)を出力する。
【0122】
そして、ユーザは、ページめくり指示を入力しながら、電子書籍「株式会社の××」を読み進めていく。ユーザがページめくり指示を入力した場合、受付部105は、ページめくり指示を受け付ける。そして、読書履歴情報取得部107は、読書履歴情報を取得する条件(例えば、ページの表示時間が1分以上)に合致するほど、長く(例えば、85秒)、現在のページを出力していた、と判断した、とする。
【0123】
次に、読書履歴情報取得部107は、文書識別子「株式会社の××」、およびページ番号「1」、および時刻「2011/1/26 12:58:51」を取得し、かかる情報を有する読書履歴情報を構成する。そして、読書履歴情報蓄積部108は、かかる読書履歴情報を読書履歴情報格納部104に蓄積する。そして、レコード「ID=1、文書識別子=株式会社の××、ページ番号=1、時刻=2011/1/26 12:58:51」が、図8の読書履歴情報管理表に追記される。そして、読書履歴情報蓄積部108は、図6の文書管理表の「ID=3」のレコードの「既読フラグ」を
「0」から「1」(読書の途中であることを示す)に更新する。
【0124】
そして、ユーザは、電子書籍「株式会社の××」を読み進めて、最終ページの210ページ目を読み終わり、2011/1/26 18:01:59に、クローズ指示を入力した、とする。
【0125】
次に、受付部105は、クローズ指示を受け付ける。そして、文書出力部106は、出力中の電子書籍「株式会社の××」の出力を停止する。
【0126】
次に、読書履歴情報取得部107は、読書履歴情報を取得する条件(例えば、ページの表示時間が1分以上)に合致するほど、長く(例えば、85秒)、210ページを出力していた、と判断した、とする。
【0127】
そして、読書履歴情報取得部107は、文書識別子「株式会社の××」、およびページ番号「210」、および時刻「2011/1/26 18:01:59」を取得し、かかる情報を有する読書履歴情報を構成する。そして、読書履歴情報蓄積部108は、かかる読書履歴情報を読書履歴情報格納部104に上書きする。そして、レコード「ID=1、文書識別子=株式会社の××、ページ番号=1−210、時刻=2011/1/26 18:01:59」が、図8の読書履歴情報管理表に上書きされる(ID=1を参照のこと)。そして、読書履歴情報蓄積部108は、図6の文書管理表の「ID=3」のレコードの「既読フラグ」を「2」(既読であることを示す)に更新する。なお、ページがめくられるごとに、上記で説明した読書履歴情報の更新処理は行われていた、とする。
【0128】
次に、既読用語蓄積部109は、文書識別子「株式会社の××」で識別される文書がすべて読み終えられたことを検出する。なお、既読の検出について、例えば、既読用語蓄積部109は、読み終えた最大のページ番号と、文書の最終のページ番号とを比較して、一致するか否かにより判断する。次に、既読用語蓄積部109は、文書識別子「株式会社の××」に対応する用語「マネジメントサイクル」「事業継続計画」などを、スコアとともに取得する。つまり、既読用語蓄積部109は、例えば、「マネジメントサイクル,5」「事業継続計画,6」などを取得する。
【0129】
次に、既読用語蓄積部109は、用語「マネジメントサイクル」「事業継続計画」等のスコアを、取得したスコア分、増加させるように、図7の用語情報管理表を更新する。ここでは、例えば、「マネジメントサイクル,0」「事業継続計画,0」が、「マネジメントサイクル,5」「事業継続計画,6」に更新される。
【0130】
また、ユーザは、文書識別子「日本企業××論」を有するオープン指示を入力した、とする。次に、受付部105は、オープン指示を受け付ける。次に、文書出力部106は、オープン指示に含まれる文書識別子「日本企業××論」に対応する既読箇所情報を読書履歴情報管理表から取得しようとするが、ここでは、取得できなかった、とする。次に、文書出力部106は、文書識別子「日本企業××論」の文書を、文書情報格納部101から読み出し、最初のページ(例えば、表紙)を出力する。
【0131】
そして、ユーザは、電子書籍「日本企業××論」を読み進めて、38ページを読み終わり、2011/3/1 20:58:05に、クローズ指示を入力した、とする。ここまでの処理において、読書履歴情報蓄積部108は、図6の文書管理表の「ID=5」のレコードの「既読フラグ」を「1」に更新している、とする。
【0132】
次に、受付部105は、クローズ指示を受け付ける。そして、文書出力部106は、出力中の電子書籍「日本企業××論」の出力を停止する。
【0133】
次に、読書履歴情報取得部107は、読書履歴情報を取得する条件(例えば、ページの表示時間が1分以上)に合致するほど、長く(例えば、85秒)、38ページを出力していた、と判断した、とする。
【0134】
そして、読書履歴情報取得部107は、文書識別子「日本企業××論」、およびページ番号「38」、および時刻「2011/3/1 20:58:05」を取得し、かかる情報を有する読書履歴情報を構成する。そして、読書履歴情報蓄積部108は、かかる読書履歴情報を読書履歴情報格納部104に上書きする。そして、レコード「ID=1、文書識別子=株式会社の××、ページ番号=1−38、時刻=2011/3/1 20:58:05」が、図8の読書履歴情報管理表に上書きされる(ID=2を参照のこと)。
【0135】
なお、ここの段階では、既読用語蓄積部109は、既読用語取得処理を行わないものとする。ただし、図2のフローチャートに示したように、ページをめくるごとに、既読用語取得処理を行っても良い。かかる場合、ページと用語とが対応づけて管理されているか、めくられるページ中に出現する用語を検出して、用語または用語とスコアを取得する必要がある。かかる処理は、既読用語蓄積部109が行う。
【0136】
以上の処理により、文書情報格納部101の文書情報管理表は図6の状態となり、既読用語格納部102および未読用語格納部103の用語管理表は図7の状態となり、読書履歴情報格納部104の読書履歴情報管理表は図8の状態となった、とする。
【0137】
かかる状況において、ユーザは、文書レコメンド指示を入力した、とする。そして、受付部105は、文書レコメンド指示を受け付ける。
【0138】
次に、文書選択部110の文書決定手段1101は、図8の読書履歴管理表から文書識別子を取得する。そして、文書決定手段1101は、文書情報管理表(図6参照)の文書識別子の中で、図8の読書履歴管理表に存在しない文書識別子「×××経営塾」「××でも分かる会社法」「××の中の企業」などを取得する。
【0139】
次に、文書選択部110の照合手段1102は、取得された未読文書の各識別子に対応する1以上の用語を、文書情報格納部101から取得する。また、照合手段1102は、既読用語格納部102に格納されている1以上の既読用語、未読用語格納部103に格納されている1以上の未読用語を取得する。
【0140】
次に、照合手段1102は、1番目の条件「未読用語の数>=10」を、図9のレコメンド条件管理表から取得する。そして、照合手段1102は、未読文書「×××経営塾」「××でも分かる会社法」「××の中の企業」等の各未読文書に対応する用語の中で、未読文書ごとに、未読用語を取得する。そして、照合手段1102は、未読文書ごとに、未読用語の数を取得する。そして、例えば、照合手段1102は、未読文書「×××経営塾」の「未読用語の数=13」、未読文書「××でも分かる会社法」の「未読用語の数=8」、未読文「××の中の企業」の「未読用語の数=5」等を取得した、とする。
【0141】
次に、文書選択手段1103は、1番目の条件「未読用語の数>=10」に合致する未読文書識別子「×××経営塾」を取得する。そして、文書選択手段1103は、1番目の条件と対応付けて、未読文書識別子「×××経営塾」をバッファに一時蓄積する。
【0142】
次に、照合手段1102は、2番目の条件「3<=既読用語の数<=5 and 未読用語の数>=3」を、図9のレコメンド条件管理表から取得する。そして、照合手段1102は、未読文書「×××経営塾」「××でも分かる会社法」「××の中の企業」等の各未読文書に対応する用語の中で、未読文書ごとに、既読用語を取得する。そして、照合手段1102は、未読文書ごとに、既読用語の数を取得する。そして、例えば、照合手段1102は、未読文書「×××経営塾」の「既読用語の数=0」、未読文書「××でも分かる会社法」の「既読用語の数=4」、未読文「××の中の企業」の「既読用語の数=6」等を取得した、とする。
【0143】
次に、文書選択手段1103は、2番目の条件「3<=既読用語の数<=5 and 未読用語の数>=3」に合致する未読文書識別子「××でも分かる会社法」を取得する。そして、文書選択手段1103は、2番目の条件と対応付けて、未読文書識別子「××でも分かる会社法」をバッファに一時蓄積する。
【0144】
次に、照合手段1102は、3番目の条件「「スコアが3以下の既読用語の数」>=6」を、図9のレコメンド条件管理表から取得する。そして、照合手段1102は、未読文書「×××経営塾」「××でも分かる会社法」「××の中の企業」等の各未読文書に対応する用語の中で、未読文書ごとに、既読用語およびスコアを取得する。そして、例えば、照合手段1102は、未読文書ごとに、スコアが3以下の既読用語を取得する。次に、照合手段1102は、未読文書ごとに、スコアが3以下の既読用語(「1<=スコア<=3」の用語)の数を算出する。そして、照合手段1102は、未読文書「××の中の企業」に対応する用語の中に、「1<=スコア<=3」の用語が8存在することを検知した、とする。なお、「×××経営塾」「××でも分かる会社法」等の未読文書に対応する用語の中に、「1<=スコア<=3」の用語は、5以下しか存在しなかった、とする。そして、文書選択手段1103は、3番目の条件と対応付けて、未読文書識別子「××の中の企業」をバッファに一時蓄積する。
【0145】
文書選択部110は、以上の処理を4番目以降のレコメンド条件に対しても実行する。そして、文書特定情報出力部111は、レコメンドする文書に関する情報を、図10に示すように出力した、とする。
【0146】
なお、ユーザは、レコメンド条件を指示し、当該指示されたレコメンド条件に対応する文書のみが推薦されても良い。
【0147】
以上、本実施の形態によれば、文書の読書行為から、既知の用語であるか未知の用語であるかを精度高く把握できる。
【0148】
また、本実施の形態によれば、文書の内容と、ユーザの過去の読書行為とを考慮して、次に読むべき文書を決定する際に有効な情報を提示したり、次に読むべき文書を推薦したりすることができる。
【0149】
また、本実施の形態によれば、用語に対する読書による習熟度が精度高く把握できる。
【0150】
なお、本実施の形態において、文書情報格納部101の文書は、通常、購入などによりユーザが取得した文書であるが、一時的にサーバ装置から受信した文書などでも良い。
また、本実施の形態において、文書処理装置1は、既読用語を取得する処理などを行わない構成でも良い。かかる場合、文書処理装置1のブロック図は、図17である。かかる場合、文書処理装置1は、文書情報格納部101、未読用語格納部103、受付部105、文書出力部106、読書履歴情報取得部107、読書履歴情報蓄積部108、および未読用語除外部171を備える。
また、文書処理装置1は、1以上の文書と、各文書に対応付けられている1以上の用語または各文書の特定の箇所に対応付けられている1以上の用語とを格納し得る文書情報格納部101と、未読の文書に対応する用語である1以上の未読用語を格納し得る未読用語格納部103と、文書を開く指示であるオープン指示を含む読書行為指示を受け付ける受付部105と、前記受付部105が前記オープン指示を受け付けた場合に、前記オープン指示に対応する文書を出力する文書出力部106と、前記受付部が受け付けた読書行為指示に対応した読書履歴情報を取得する読書履歴情報取得部107とを具備し、前記未読用語格納部103に格納されている1以上のいずれかの未読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、未読用語から除外する未読用語除外部171とを具備する文書処理装置である。なお、未読用語除外部171の処理は、既読用語蓄積部109が行っても良い。
【0151】
また、本実施の形態における処理は、ソフトウェアで実現しても良い。そして、このソフトウェアをソフトウェアダウンロード等により配布しても良い。また、このソフトウェアをCD−ROMなどの記録媒体に記録して流布しても良い。なお、このことは、本明細書における他の実施の形態においても該当する。なお、本実施の形態における文書処理装置を実現するソフトウェアは、以下のようなプログラムである。つまり、このプログラムは、記憶媒体に、1以上の文書と、各文書に対応付けられている1以上の用語または各文書の特定の箇所に対応付けられている1以上の用語と、未読の文書に対応する用語である1以上の未読用語とを格納しており、コンピュータを、文書を開く指示であるオープン指示を含む読書行為指示を受け付ける受付部と、前記受付部が前記オープン指示を受け付けた場合に、前記オープン指示に対応する文書を出力する文書出力部と、前記受付部が受け付けた読書行為指示に対応した読書履歴情報を取得する読書履歴情報取得部と、前記記憶媒体に格納されている1以上のいずれかの未読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、未読用語から除外する既読用語蓄積部として機能させるためのプログラム、である。
また、上記プログラムにおいて、記憶媒体に、既読の文書に対応する用語である1以上の既読用語をさらに格納しており、前記既読用語蓄積部は、前記記憶媒体に格納されている1以上のいずれかの未読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、既読用語として、前記記憶媒体に蓄積するものとして、コンピュータを機能させるためのプログラムであることは好適である。
【0152】
また、上記プログラムにおいて、記憶媒体に、1以上の読書履歴情報をさらに格納しており、コンピュータを、前記読書履歴情報取得部が取得した1以上の読書履歴情報を、前記読書履歴情報格納部に蓄積する読書履歴情報蓄積部と、前記記憶媒体に格納されている1以上の読書履歴情報から決定され得る前記記憶媒体に格納されている未読文書であり、前記記憶媒体の1以上の既読用語、または前記記憶媒体の1以上の未読用語、または前記記憶媒体の1以上の既読用語と前記記憶媒体の1以上の未読用語を用いて、前記未読文書に対応付けられている1以上の用語から、1以上の未読文書を選択する文書選択部と、前記文書選択部が選択した未読文書を特定する情報を出力する文書特定情報出力部としてさらに機能させるプログラムであることは好適である。
【0153】
また、上記プログラムにおいて、前記文書選択部は、前記記憶媒体に格納されている1以上の読書履歴情報から決定され得る前記記憶媒体に格納されている1以上の未読文書を決定する文書決定手段と、前記1以上の既読用語、または前記1以上の未読用語、または前記1以上の既読用語と前記1以上の未読用語を用いて、前記1以上の未読文書に対応付けられている1以上の用語を照合する照合手段と、前記照合手段が照合した結果、予め決められた条件に合致する1以上の用語に対応付けられた未読文書を決定する文書選択手段とを具備するプログラムであることは好適である。
【0154】
また、上記プログラムにおいて、前記記憶媒体には、既読用語と当該既読用語に対応するスコアとを有する1以上の既読用語情報を格納しており、前記既読用語蓄積部は、前記記憶媒体に格納されている1以上のいずれかの未読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、既読用語として、前記記憶媒体に蓄積し、かつ、前記記憶媒体に格納されている1以上のいずれかの既読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語に対応するスコアを増加させるプログラムであることは好適である。
【0155】
また、上記プログラムにおいて、前記文書選択部は、前記スコアが中程度であることを示す条件である中程度条件を満たす第一種類の用語と、前記スコアが低度であることを示す条件である低度条件を満たす第二種類の用語の、いずれの種類の用語とも対応付けられている1以上の未読文書を選択するプログラムであることは好適である。
【0156】
また、上記プログラムにおいて、前記記憶媒体には、1以上の文書と、各文書に対応付けられている1以上の用語または各文書の特定の箇所に対応付けられている1以上の用語と、各用語に対応するスコアとを格納しており、前記既読用語蓄積部は、前記記憶媒体に格納されている1以上のいずれかの未読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語および各用語に対応するスコア、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語および各用語に対応するスコアを、前記記憶媒体に蓄積し、かつ、前記記憶媒体に格納されている1以上のいずれかの既読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語に対応するスコアを、前記記憶媒体のスコアだけ増加させるプログラムであることは好適である。
【0157】
(実施の形態2)
【0158】
本実施の形態において、例えば、未読用語を指定すると、当該未読用語に対応する文書が選択され、文書を特定する情報が出力される文書処理装置について説明する。また、本実施の形態における文書処理装置は、例えば、既読用語を指定すると、当該既読用語に対応する文書が選択され、文書を特定する情報が出力される文書処理装置でも良い。
【0159】
また、本実施の形態において、文書を指定すると、当該文書に対応する用語が出力される文書処理装置について説明する。かかる場合、未読用語と既読用語とを、視覚的に区別する態様で出力されることは好適である。
【0160】
図11は、本実施の形態における文書処理装置2のブロック図である。文書処理装置2は、文書情報格納部101、既読用語格納部102、未読用語格納部103、読書履歴情報格納部104、受付部201、文書出力部106、読書履歴情報取得部107、読書履歴情報蓄積部108、文書選択部202、文書特定情報出力部203、用語取得部204、文書用語出力部205、用語抽出部112、および情報出力部206を備える。
【0161】
受付部201は、受付部105と同様、指示やデータ等を受け付ける。受付部201は、用語出力指示、用語指示、文書指示、文書出力指示などの指示も受け付ける。用語出力指示とは、既読用語、または未読用語、または既読用語と未読用語を出力する指示である。また、用語指示は、出力されている用語に対する指示である。なお、用語指示が入力された場合、当該用語に対応する文書の文書識別子が出力される。また、文書指示は、出力されている文書識別子に対する指示である。文書指示が入力された場合、当該文書に対応する用語(既読用語、または未読用語、または既読用語と未読用語)が出力される。さらに、文書出力指示は、文書識別子を出力する指示である。かかる文書出力指示が入力された場合、1以上の文書識別子が出力される。文書識別子は、既読文書と未読文書を視覚的に区別する態様で出力されても良い。
【0162】
また、受け付けとは、キーボードやマウス、タッチパネルなどの入力デバイスから入力された情報の受け付け、有線もしくは無線の通信回線を介して送信された情報の受信、光ディスクや磁気ディスク、半導体メモリなどの記録媒体から読み出された情報の受け付けなどを含む概念である。さらに、指示等の入力手段は、キーボードやマウスやメニュー画面によるもの等、何でも良い。受付部201は、キーボード等の入力手段のデバイスドライバーや、メニュー画面の制御ソフトウェア等で実現され得る。
【0163】
文書選択部202は、受付部201が1以上の未読用語を受け付けた場合に、1以上の未読用語のすべて、または1以上の未読用語のいずれかに対応する未読文書を選択する。文書選択部202は、受付部201が1以上の未読用語を受け付けた場合に、当該未読用語に対するスコアが予め決められた条件を満たすほど大きい未読文書を選択することは好適である。文書選択部202は、文書情報格納部101の情報から、未読文書を選択する。
また、文書選択部202は、受付部201が1以上の既読用語を受け付けた場合に、1以上の既読用語のすべて、または1以上の既読用語のいずれかに対応する既読文書を選択しても良い。
【0164】
文書特定情報出力部203は、文書選択部202が選択した1以上の各未読文書を特定する情報を出力する。文書特定情報出力部203は、文書選択部202が選択した1以上の各既読文書を特定する情報を出力しても良い。
【0165】
用語取得部204は、受付部201が文書指示を受け付けた場合に、当該文書に対応する1以上の用語を文書情報格納部101から取得する。用語取得部204は、既読用語と未読用語とに区別して、1以上の用語を取得することは好適である。
【0166】
文書用語出力部205は、用語取得部204が取得した1以上の用語を出力する。文書用語出力部205は、既読用語と未読用語とを視覚的に区別して、1以上の用語を出力することは好適である。
【0167】
情報出力部206は、受付部201が用語出力指示を受け付けた場合、既読用語格納部102の1以上の既読用語、または未読用語格納部103の1以上の未読用語、または1以上の既読用語と1以上の未読用語を出力する。なお、情報出力部206は、既読用語と未読用語を視覚的に区別して出力することは好適である。
【0168】
また、情報出力部206は、受付部201が文書出力指示を受け付けた場合、文書情報格納部101の1以上の文書識別子を出力する。なお、情報出力部206は、既読文書と未読文書を視覚的に区別して、文書識別子を出力することは好適である。
【0169】
文書選択部202、用語取得部204は、通常、MPUやメモリ等から実現され得る。文書選択部202の処理手順は、通常、ソフトウェアで実現され、当該ソフトウェアはROM等の記録媒体に記録されている。但し、ハードウェア(専用回路)で実現しても良い。
【0170】
文書特定情報出力部203、文書用語出力部205、および情報出力部206は、ディスプレイやスピーカー等の出力デバイスを含むと考えても含まないと考えても良い。文書特定情報出力部203等は、出力デバイスのドライバーソフトまたは、出力デバイスのドライバーソフトと出力デバイス等で実現され得る。
【0171】
次に、文書処理装置2の動作について、図12のフローチャートを用いて説明する。図12のフローチャートにおいて、図2のフローチャートと同一のステップについて、説明を省略する。
【0172】
(ステップS1201)情報出力部206は、受付部201が用語出力指示を受け付けか否かを判断する。用語出力指示を受け付ければステップS1202に行き、用語出力指示を受け付けなければステップS1205に行く。
【0173】
(ステップS1202)情報出力部206は、既読用語格納部102に格納されている1以上の既読用語を取得する。
【0174】
(ステップS1203)情報出力部206は、未読用語格納部103に格納されている1以上の未読用語を取得する。
【0175】
(ステップS1204)情報出力部206は、ステップS1202で取得した1以上の既読用語、ステップS1203で取得した1以上の未読用語を出力する。ステップS201に戻る。
【0176】
(ステップS1205)情報出力部206は、受付部201が文書出力指示を受け付けか否かを判断する。文書出力指示を受け付ければステップS1206に行き、文書出力指示を受け付けなければステップS1209に行く。
【0177】
(ステップS1206)情報出力部206は、文書情報格納部101から1以上の既読文書の識別子を取得する。
【0178】
(ステップS1207)情報出力部206は、文書情報格納部101から1以上の未読文書の識別子を取得する。
【0179】
(ステップS1208)情報出力部206は、ステップS1206で取得した1以上の既読文書の識別子、ステップS1207で取得した1以上の未読文書の識別子を出力する。ステップS201に戻る。
【0180】
(ステップS1209)文書選択部202は、受付部201が用語指示を受け付けたか否かを判断する。用語指示を受け付ければステップS1210に行き、用語指示を受け付けなければステップS1214に行く。
【0181】
(ステップS1210)文書選択部202は、受付部201が受け付けた1以上の用語を取得する。
【0182】
(ステップS1211)文書選択部202は、予め決められたテーマ、またはユーザ指定のテーマを取得する。テーマとは、選択する文書を決定するためのテーマである。テーマは、例えば、「未知との遭遇」「周辺の開拓」「既知の深耕」などである。また、文書選択部202は、テーマに対応付けて、異なるアルゴリズムを実現するプログラム、データ等を保持している、とする。
【0183】
(ステップS1212)文書選択部202は、ステップS1210で取得した1以上の用語に対応する文書であり、ステップS1211で取得したテーマに合致する1以上の文書の文書識別子を取得する。
【0184】
(ステップS1213)文書特定情報出力部203は、ステップS1212で取得した1以上の文書識別子を出力する。ステップS201に戻る。
【0185】
(ステップS1214)用語取得部204は、受付部201が文書指示を受け付けたか否かを判断する。文書指示を受け付ければステップS1215に行き、文書指示を受け付けなければステップS201に戻る。
【0186】
(ステップS1215)用語取得部204は、文書指示が有する文書識別子に対応する1以上の既読用語と当該用語のスコアとを、文書情報格納部101から取得する。なお、例えば、用語取得部204は、文書指示が有する文書識別子に対応する1以上の用語を文書情報格納部101から取得し、当該取得した用語の中から、既読用語格納部102の既読用語を選択する。
【0187】
(ステップS1216)用語取得部204は、文書指示が有する文書識別子に対応する1以上の未読用語を文書情報格納部101から取得する。なお、例えば、用語取得部204は、文書指示が有する文書識別子に対応する1以上の用語を文書情報格納部101から取得し、当該取得した用語の中から、未読用語格納部103の未読用語を選択する。
【0188】
(ステップS1217)文書用語出力部205は、ステップS1215で取得した1以上の既読用語、ステップS1216で取得した1以上の未読用語を出力する。ステップS201に戻る。
【0189】
なお、図12のフローチャートにおいて、電源オフや処理終了の割り込みにより処理は終了する。
【0190】
以下、本実施の形態における文書処理装置2の具体的な動作について説明する。今、文書情報格納部101は、図6に示す文書管理表を格納している。
【0191】
また、既読用語格納部102、および未読用語格納部103は、図7に示す用語情報管理表を保持している。
【0192】
また、読書履歴情報格納部104は、図8に示す読書履歴情報管理表を格納している。
【0193】
かかる状況において、ユーザは、文書処理装置2に、用語出力指示を入力した、とする。すると、受付部201は、用語出力指示を受け付ける。
【0194】
次に、情報出力部206は、既読用語格納部102に格納されている1以上の既読用語を取得する。また、情報出力部206は、未読用語格納部103に格納されている1以上の未読用語を取得する。
【0195】
次に、情報出力部206は、図13に示すように、1以上の既読用語と1以上の未読用語とを、視覚的に区別する態様で出力する。なお、図13は、文書処理装置2の画面例である。また、図13において、1以上の既読用語と1以上の未読用語とは異なるウィンドウ(枠)に表示されている。
【0196】
次に、ユーザは、図13に示す画面から、未読用語「内部統制」「SOX法」を含む用語指示を入力した、とする。すると、受付部201は、かかる用語指示を受け付ける。
【0197】
次に、文書選択部202は、テーマ「未読用語が学習することができる文書を選択する」を取得する。なお、かかるテーマは、未読用語が選択された場合に、自動的に決定されても良いし、ユーザが入力しても良い。
【0198】
次に、文書選択部202は、用語指示から、未読用語「内部統制」「SOX法」を取得する。
【0199】
次に、文書選択部202は、未読用語「内部統制」「SOX法」を含む、かつ各未読用語「内部統制」「SOX法」のスコアが閾値(例えば、「3」)以上の文書を、文書管理表から検索する。そして、文書選択部202は、文書管理表から、文書識別子「×××経営塾」、「SOX法のすべて」を取得した、とする。次に、文書特定情報出力部203は、文書識別子「×××経営塾」、「SOX法のすべて」を出力する。つまり、ユーザは、未読用語を入力すれば、当該未読用語を学習するための適切な文書を知ることができる。また、次に、ユーザが、出力された一の文書識別子を指示すれば、当該文書識別子で識別される文書が出力されても良い。
【0200】
次に、図13の状態で、ユーザが未読用語「コーポレート・ガバナンス」を指示した、とする。かかる場合、当該用語「コーポレート・ガバナンス」に対応する文書の識別子が出力される(図14(1)参照)。文書の識別子は、未読文書、既読文書、読書が途中の文書に区別されて、出力される。図14において、未読文書は下線かつBoldフォント、既読文書は下線なし、読書が途中の文書は下線かつ通常フォントである。また、図14(1)の文書識別子「情報戦略と統治」をユーザが指示した場合、当該「情報戦略と統治」が文書情報格納部101から読み出され、出力される(図14(2)参照)。なお、図14(2)は電子書籍がオープンされている概念を示した図である。
【0201】
次に、ユーザは、文書出力指示を入力した、とする。すると、受付部201は文書出力指示を受け付ける。
【0202】
次に、情報出力部206は、文書情報管理表から1以上の既読文書の識別子を取得する。また、情報出力部206は、文書情報管理表から1以上の未読文書の識別子を取得する。そして、情報出力部206は、1以上の既読文書の識別子、および1以上の未読文書の識別子を出力する。
【0203】
以下、文書処理装置2の他の具体的な動作を説明する。
(具体例1)
【0204】
具体例1において、文書処理装置2には、図15の(1)に示す電子書籍の活用メニューが表示されている、とする。ここで、ユーザは、「1.未知との遭遇」を選択した、とする。
【0205】
次に、情報出力部206は、未読用語格納部103から1以上の未読用語を取得する。そして、情報出力部206は、1以上の未読用語を出力する。かかる出力例が図15(2)である。そして、図15(2)の未読用語リストから、ユーザは、学習した事項「コーポレート・ガバナンス」を選択した、とする。
【0206】
次に、文書処理装置2の文書選択部202は、「コーポレート・ガバナンス」に対応する未読文書の識別子を取得し、出力する。かかる出力例が図15(3)である。そして、ユーザは、未読文書「×××経営塾」を指示する。そして、文書「×××経営塾」が出力される(図15(4))。
(具体例2)
【0207】
具体例2において、過去に読んだ書籍において、面白かった話題に対応する書籍を読みたい場合の書籍の選択である。
【0208】
まず、具体例2において、具体例1と同様、図16の(1)に示す電子書籍の活用メニューが表示されている、とする。ここで、ユーザは、「2.周辺の開拓」を選択し、キーワード「コーポレート・ガバナンス」を入力し、検索ボタンを押下した、とする。
【0209】
すると、文書処理装置2は、文書情報格納部101に存在する文書であり、かつ、「コーポレート・ガバナンス」に対応する文書の識別子を取得する。そして、文書処理装置2は、文書の識別子のリストを出力する。かかる出力例が図16(2)である。なお、かかる処理は、情報出力部206が行っても良い。
【0210】
次に、ユーザは、文書の識別子のリストから一の識別子「××の中の企業」を選択する。すると、文書処理装置2の用語取得部204は、「××の中の企業」に対応するすべての用語を、文書情報格納部101から取得する。ここで取得される用語には、既読用語が含まれても良い。次に、文書処理装置2の文書用語出力部205は、取得した1以上の用語を出力する(図16(3)参照)。なお、図16(3)において、既読用語と未読用語とが視覚的に区別されて出力されることは好適である。
【0211】
そして、ユーザは、1以上の用語をチェックした後、文書の識別子を指示すれば、当該文書が出力される(図16(4)参照)。
【0212】
以上、本実施の形態によれば、未読文書の中の情報を効率的に探し出すことができる。
【0213】
また、学本実施の形態によれば、学習したい内容を指定すると、当該内容について説明されている文書を提示できる。
【0214】
また、学本実施の形態によれば、文書を指定すると、当該文書で出現する用語を提示できる。
【0215】
なお、本実施の形態における文書処理装置を実現するソフトウェアは、以下のようなプログラムである。つまり、このプログラムは、記憶媒体に、1以上の文書と、各文書に対応付けられている1以上の用語または各文書の特定の箇所に対応付けられている1以上の用語と、既読の文書に対応する用語である1以上の既読用語と、未読の文書に対応する用語である1以上の未読用語とを格納しており、コンピュータを、文書を開く指示であるオープン指示を含む読書行為指示を受け付ける受付部と、前記受付部が前記オープン指示を受け付けた場合に、前記オープン指示に対応する文書を出力する文書出力部と、前記受付部が受け付けた読書行為指示に対応した読書履歴情報を取得する読書履歴情報取得部と、前記記憶媒体に格納されている1以上のいずれかの未読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、既読用語として、前記記憶媒体に蓄積する既読用語蓄積部として機能させるためのプログラム、である。
【0216】
また、上記プログラムにおいて、前記受付部は、1以上の未読用語を受け付け、前記受付部が1以上の未読用語を受け付けた場合に、当該1以上の未読用語のすべて、または当該1以上の未読用語のいずれかに対応する未読文書を選択する文書選択部と、前記未読文書を特定する情報を出力する文書特定情報出力部として、コンピュータをさらに機能させるプログラムであることは好適である。
【0217】
また、上記プログラムにおいて、前記受付部は、一の文書を特定する情報を受け付け、前記一の文書に対応する1以上の用語を前記文書情報格納部から取得する用語取得部と、前記用語取得部が取得した1以上の用語を出力する文書用語出力部とをさらに具備するものとして、コンピュータをさらに機能させるプログラムであることは好適である。
【0218】
また、図17は、本明細書で述べたプログラムを実行して、上述した実施の形態の文書処理装置等を実現するコンピュータの外観を示す。上述の実施の形態は、コンピュータハードウェア及びその上で実行されるコンピュータプログラムで実現され得る。図17は、このコンピュータシステム340の概観図であり、図18は、コンピュータシステム340のブロック図である。
【0219】
図17において、コンピュータシステム340は、FDドライブ、CD−ROMドライブを含むコンピュータ341と、キーボード342と、マウス343と、モニタ344とを含む。
【0220】
図18において、コンピュータ341は、FDドライブ3411、CD−ROMドライブ3412に加えて、MPU3413と、CD−ROMドライブ3412及びFDドライブ3411に接続されたバス3414と、ブートアッププログラム等のプログラムを記憶するためのROM3415とに接続され、アプリケーションプログラムの命令を一時的に記憶するとともに一時記憶空間を提供するためのRAM3416と、アプリケーションプログラム、システムプログラム、及びデータを記憶するためのハードディスク3417とを含む。ここでは、図示しないが、コンピュータ341は、さらに、LANへの接続を提供するネットワークカードを含んでも良い。
【0221】
コンピュータシステム340に、上述した実施の形態の文書処理装置等の機能を実行させるプログラムは、CD−ROM3501、またはFD3502に記憶されて、CD−ROMドライブ3412またはFDドライブ3411に挿入され、さらにハードディスク3417に転送されても良い。これに代えて、プログラムは、図示しないネットワークを介してコンピュータ341に送信され、ハードディスク3417に記憶されても良い。プログラムは実行の際にRAM3416にロードされる。プログラムは、CD−ROM3501、FD3502またはネットワークから直接、ロードされても良い。
【0222】
プログラムは、コンピュータ341に、上述した実施の形態の文書処理装置等の機能を実行させるオペレーティングシステム(OS)、またはサードパーティープログラム等は、必ずしも含まなくても良い。プログラムは、制御された態様で適切な機能(モジュール)を呼び出し、所望の結果が得られるようにする命令の部分のみを含んでいれば良い。コンピュータシステム340がどのように動作するかは周知であり、詳細な説明は省略する。
【0223】
また、上記プログラムを実行するコンピュータは、単数であってもよく、複数であってもよい。すなわち、集中処理を行ってもよく、あるいは分散処理を行ってもよい。
【0224】
また、上記各実施の形態において、各処理(各機能)は、単一の装置(システム)によって集中処理されることによって実現されてもよく、あるいは、複数の装置によって分散処理されることによって実現されてもよい。
【0225】
本発明は、以上の実施の形態に限定されることなく、種々の変更が可能であり、それらも本発明の範囲内に包含されるものであることは言うまでもない。
【産業上の利用可能性】
【0226】
以上のように、本発明にかかる文書処理装置は、既知の用語であるか未知の用語であるかを精度高く把握できる、という効果を有し、電子書籍装置等として有用である。
【符号の説明】
【0227】
1、2 文書処理装置
101 文書情報格納部
102 既読用語格納部
103 未読用語格納部
104 読書履歴情報格納部
105、201 受付部
106 文書出力部
107 読書履歴情報取得部
108 読書履歴情報蓄積部
109 既読用語蓄積部
110、202 文書選択部
111、203 文書特定情報出力部
112 用語抽出部
171 未読用語除外部
204 用語取得部
205 文書用語出力部
206 情報出力部
1101 文書決定手段
1102 照合手段
1103 文書選択手段
【技術分野】
【0001】
本発明は、電子書籍等の文書を処理する文書処理装置等に関するものである。
【背景技術】
【0002】
従来、未読文書の閲覧を促す文書管理システムがあった(特許文献1参照)。本システムは、参照依頼したユーザ側からその文書の重要度や緊急度を指定して未読一覧を表示させ、文書の閲覧を依頼してから時間が経過しても、未読の場合に、文書の重要度や緊急度を上げることにより、参照を促進させるシステムである。
【0003】
また、未読の記事をRSSリーダに登録済のサイトの記事と未登録のサイトの記事とに分類することにより、ユーザにとって未知の情報であり利用価値の高い記事を特定して検索効率の向上を図るシステムがあった(特許文献2参照)。
【0004】
一方、未読文書を読んだからといって、必ずしも未知で有用な情報が得られるわけではなく、例えば、未読文書には既知の事項しか記述されていないものが存在する。よって、例えば、次に読むべき文書を決定する場合は、ユーザにとって、文書が未読であるか既読であるかは重要ではなく、既知の用語、未知の用語を把握した上で、文書を選択することが重要である。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開2007−188239号公報
【特許文献2】特開2010−231740号公報
【発明の概要】
【発明が解決しようとする課題】
【0006】
しかしながら、上記の従来技術においては、文書の読書行為から、既知の用語であるか未知の用語であるかを精度高く把握できなかった。また、従来技術においては、文書の内容と、ユーザの過去の読書行為とを考慮して、例えば、次に読むべき文書を決定する際に有効な情報を提示したり、次に読むべき文書を推薦したりすることができなかった。
【課題を解決するための手段】
【0007】
本第一の発明の文書処理装置は、1以上の文書と、各文書に対応付けられている1以上の用語または各文書の特定の箇所に対応付けられている1以上の用語とを格納し得る文書情報格納部と、未読の文書に対応する用語である1以上の未読用語を格納し得る未読用語格納部と、文書を開く指示であるオープン指示を含む読書行為指示を受け付ける受付部と、受付部がオープン指示を受け付けた場合に、オープン指示に対応する文書を出力する文書出力部と、受付部が受け付けた読書行為指示に対応した読書履歴情報を取得する読書履歴情報取得部とを具備し、未読用語格納部に格納されている1以上のいずれかの未読用語であり、読書履歴情報に対応する文書に対応する1以上の用語、または読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、未読用語から除外する文書処理装置である。
かかる構成により、未知の用語を精度高く把握できる。
また、本第二の発明の文書処理装置は、第一の発明に対して、既読の文書に対応する用語である1以上の既読用語を格納し得る既読用語格納部と、未読用語格納部に格納されている1以上のいずれかの未読用語であり、読書履歴情報に対応する文書に対応する1以上の用語、または読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、既読用語として、既読用語格納部に蓄積する既読用語蓄積部とをさらに具備する文書処理装置である。
かかる構成により、既知の用語であるか未知の用語であるかを精度高く把握できる。
また、本第三の発明の文書処理装置は、第二の発明に対して、1以上の読書履歴情報を格納し得る読書履歴情報格納部と、読書履歴情報取得部が取得した1以上の読書履歴情報を、読書履歴情報格納部に蓄積する読書履歴情報蓄積部と、読書履歴情報格納部に格納されている1以上の読書履歴情報から決定され得る文書情報格納部に格納されている未読文書であり、既読用語格納部の1以上の既読用語、または未読用語格納部の1以上の未読用語、または既読用語格納部の1以上の既読用語と未読用語格納部の1以上の未読用語を用いて、未読文書に対応付けられている1以上の用語から、1以上の未読文書を選択する、または読書履歴情報格納部に格納されている1以上の読書履歴情報から決定され得る文書情報格納部に格納されている既読文書であり、既読用語格納部の1以上の既読用語を用いて、既読文書に対応付けられている1以上の用語から、1以上の既読文書を選択する文書選択部と、文書選択部が選択した未読文書または既読文書を特定する情報を出力する文書特定情報出力部とをさらに具備する文書処理装置である。
かかる構成により、既知の用語または未知の用語を把握できることにより、適切な未読文書を推薦できる。
また、本第四の発明の文書処理装置は、第三の発明に対して、文書選択部は、読書履歴情報格納部に格納されている1以上の読書履歴情報から決定され得る文書情報格納部に格納されている1以上の未読文書を決定する文書決定手段と、既読用語格納部の1以上の既読用語、または未読用語格納部の1以上の未読用語、または既読用語格納部の1以上の既読用語と未読用語格納部の1以上の未読用語を用いて、1以上の未読文書に対応付けられている1以上の用語を照合する照合手段と、照合手段が照合した結果、予め決められた条件に合致する1以上の用語に対応付けられた未読文書を決定する文書選択手段とを具備する文書処理装置である。
かかる構成により、既知の用語または未知の用語を把握できることにより、適切な未読文書を推薦できる。
また、本第五の発明の文書処理装置は、第二から第四いずれかの発明に対して、既読用語格納部は、既読用語と既読用語に対応するスコアとを有する1以上の既読用語情報を格納しており、既読用語蓄積部は、未読用語格納部に格納されている1以上のいずれかの未読用語であり、読書履歴情報に対応する文書に対応する1以上の用語、または読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、既読用語として、既読用語格納部に蓄積し、かつ、既読用語格納部に格納されている1以上のいずれかの既読用語であり、読書履歴情報に対応する文書に対応する1以上の用語、または読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語に対応するスコアを増加させる文書処理装置である。
かかる構成により、既知の用語であるか未知の用語であるかを極めて精度高く把握できる。
また、本第六の発明の文書処理装置は、第一の発明に対して、受付部は、1以上の未読用語を受け付け、受付部が1以上の未読用語を受け付けた場合に、1以上の未読用語のすべて、または1以上の未読用語のいずれかに対応する未読文書を選択する文書選択部と、未読文書を特定する情報を出力する文書特定情報出力部とをさらに具備する文書処理装置である。
かかる構成により、学習したい内容を指定すると、当該内容について説明されている文書を提示してくれる。
また、本第七の発明の文書処理装置は、第一から第六いずれかの発明に対して、受付部は、一の文書を特定する情報を受け付け、一の文書に対応する1以上の用語を文書情報格納部から取得する用語取得部と、用語取得部が取得した1以上の用語を出力する文書用語出力部とをさらに具備する文書処理装置である。
かかる構成により、文書を指定すると、当該文書で出現する用語を提示してくれる。
【0008】
かかる構成により、文書に対する用語を容易に取得できる。
【発明の効果】
【0009】
本発明による文書処理装置によれば、既知の用語であるか未知の用語であるかを精度高く把握できる。
【図面の簡単な説明】
【0010】
【図1】実施の形態1における文書処理装置のブロック図
【図2】同文書処理装置の動作について説明するフローチャート
【図3】同既読用語取得処理の動作について説明するフローチャート
【図4】同用語抽出処理の動作について説明するフローチャート
【図5】同文書選択処理の動作について説明するフローチャート
【図6】同文書管理表を示す図
【図7】同用語情報管理表を示す図
【図8】同読書履歴情報管理表を示す図
【図9】同レコメンド条件管理表を示す図
【図10】同レコメンドする文書に関する情報の出力例を示す図
【図11】実施の形態2における文書処理装置のブロック図
【図12】同文書処理装置の動作について説明するフローチャート
【図13】同既読用語と未読用語の出力例を示す図
【図14】同文書処理装置の具体的な動作を説明する図
【図15】同文書処理装置の具体的な動作を説明する図
【図16】同文書処理装置の具体的な動作を説明する図
【図17】実施の形態1における他の文書処理装置のブロック図
【図18】上記実施の形態コンピュータシステムの概観図
【図19】同コンピュータシステムのブロック図
【発明を実施するための形態】
【0011】
以下、文書処理装置等の実施形態について図面を参照して説明する。なお、実施の形態において同じ符号を付した構成要素は同様の動作を行うので、再度の説明を省略する場合がある。
【0012】
(実施の形態1)
【0013】
本実施の形態において、既読の文書に対応する既知の用語(以下、「既読用語」という。)と、未読の文書に対応する未知の用語(以下、「未読用語」という。)とを管理しており、文書を読んだ場合に、当該文書に出現する未知の用語を既知の用語として管理を更新する文書処理装置について説明する。
【0014】
また、本実施の形態において、既読用語または/および未読用語を用いて、未読の文書の中の文書をレコメンドする文書処理装置について説明する。
【0015】
また、本実施の形態において、既読用語はスコア(「ポイント」とも言える。)を保持しており、文書を読めば、当該文書に対応する用語のスコアが増加する文書処理装置について説明する。
【0016】
また、本実施の形態において、文書に対する各用語のポイントは、用語によって異なる文書処理装置について説明する。
【0017】
さらに、本実施の形態において、文書に対応する用語は、文書全体から用語抽出により取得されたり、目次や索引等の予め決められた箇所から取得されたり、サーバ装置から受信されたりする文書処理装置について説明する。
【0018】
図1は、本実施の形態における文書処理装置1のブロック図である。文書処理装置1は、文書情報格納部101、既読用語格納部102、未読用語格納部103、読書履歴情報格納部104、受付部105、文書出力部106、読書履歴情報取得部107、読書履歴情報蓄積部108、既読用語蓄積部109、文書選択部110、文書特定情報出力部111、および用語抽出部112を備える。
【0019】
また、文書選択部110は、文書決定手段1101、照合手段1102、および文書選択手段1103を備える。
【0020】
文書情報格納部101は、文書と当該文書に対応付けられている1以上の用語との組を1組以上、格納し得る。また、各用語は、スコアと対応付けられていても良い。つまり、文書情報格納部101は、文書と1以上の用語と各用語に対するスコアの集合を1以上格納していても良い。なお、文書とは、電子書籍、Webページ、ファイルなどである。また、スコアとは、文書と用語との関連の度合いを示す情報である。スコアは、例えば、文書内での出現頻度や、出現確率である。また、スコアは、例えば、出現「1」、未出現「0」などのフラグでも良い。また、用語とスコアとを有する情報を用語情報とも言う。
【0021】
また、文書情報格納部101は、文書と、各文書の特定の箇所に対応付けられている1以上の用語との組を1組以上、格納していても良い。つまり、文書情報格納部101は、文書と、1以上の用語と、各用語が出現する文書の特定の箇所を識別する情報(例えば、ページ番号)との集合を1以上格納していても良い。また、各用語は、スコアと対応付けられていても良い。なお、特定の箇所とは、ページ、段落、章などである。また、用語が特定の箇所に対応付けられている場合、スコアは、当該特定の箇所と用語との関連の度合いを示す情報である。
【0022】
また、文書情報格納部101の文書は、ジャンルや種類やレベル(難易度)などの属性値を有していても良い。そして、文書の属性値は、文書を選択する場合に利用されることは好適である。
【0023】
なお、文書は、通常、文書の識別子(「文書識別子」と言い、例えば、「タイトル」である。)、著者、出版社等の書誌情報を含む。また、文書識別子は、文書を特定する情報であれば何でも良い、例えば、ファイル名、文書の最初のN文字等でも良い。また、文書に対応付けられている用語は、一時的に文書情報格納部101に格納されても良い。
【0024】
また、用語は、名詞や名詞句であることが好適であるが、形容詞などでも良い。また、用語は、品詞を問わなくても良い。
【0025】
既読用語格納部102は、1以上の既読用語を格納し得る。既読用語とは、既読の文書や、文書中の既読の箇所に対応する用語である。既読用語は、既知の用語であると考えても良い。また、用語とは、通常、単語であるが、1以上の単語を有する句などでも良い。
【0026】
また、既読用語格納部102は、既読用語と当該既読用語に対応するスコアとを有する1以上の既読用語情報を格納していても良い。ここでのスコアは、用語に対する既知の度合いを示す情報である。既読用語に対応するスコアは、例えば、既読の文書に対応する用語のスコアの総和である。既読用語に対応するスコアは、通常、既読の文書に対応する用語のスコアから算出される。
【0027】
未読用語格納部103は、1以上の未読用語を格納し得る。未読用語とは、未読の文書や、文書中の未読の箇所に対応する用語である。未読用語は、未知の用語であると考えても良い。後述する用語抽出部112により、抽出された用語のうち、既読用語格納部102に存在しない用語を、未読用語として未読用語格納部103に蓄積されていることは好適である。
【0028】
既読用語格納部102と未読用語格納部103とは、同一のデータベース、同一のテーブル等でも良い。かかる場合、例えば、各用語に既読用語であることを示すフラグ、または未読用語であることを示すフラグが付与されていても良い。また、例えば、各用語にスコアが付与されており、出現回数を示すスコアが「0」、または出現回数以外の情報であるスコアが所定の条件(例えば、「0」)を満たす場合に、未読用語と判断されても良い。つまり、既読用語格納部102と未読用語格納部103とは、物理的に分離されている必要はなく、既読用語と未読用語とが区別される態様で管理されていれば良い。
【0029】
読書履歴情報格納部104は、1以上の読書履歴情報を格納し得る。読書履歴情報とは、ユーザが行った文書に対する読書行為に関する履歴の情報である。読書履歴情報は、読書の経過、履歴を示す情報であるとも言える。また、文書が電子書籍である場合、読書履歴情報は、例えば、文書識別子(例えば、タイトル)、ページ番号、時刻を示す時刻情報を有する。ただし、読書履歴情報は、文書識別子(例えば、タイトル)、ページ番号だけでも良い。ここでのページ番号は、既に読んだページを特定する情報、または未読のページを特定する情報である。また、読書履歴情報は、既読の文書の文書識別子のみでも良い。なお、一定時間以上、ページの表示状態が継続した場合に、読書履歴情報が取得されることは好適である。つまり、ぱらぱらめくりの場合等、一時のみオープンした頁の情報について、読書履歴情報に含めないことは好適である。また、文書がファイルである場合、読書履歴情報は、例えば、文書のタイトル(例えば、タイトルタグに対応する文字列)、時刻を示す時刻情報を有する。また、文書がファイルである場合、読書履歴情報は、例えば、文書の最初のN文字(例えば、N=10)、画面上に表示された箇所までのオフセットを有する。
【0030】
受付部105は、指示やデータ等を受け付ける。指示は、例えば、文書を開く指示であるオープン指示を含む読書行為指示を受け付ける。また、指示は、例えば、用語抽出指示、文書レコメンド指示などでも良い。ここで、オープン指示とは、通常、文書情報格納部101の文書を読み出し、オープンすることの指示であるが、文書を外部(サーバ装置など)から受信する指示と考えても良い。また、読書行為指示とは、その他、ページめくり指示、ページジャンプ指示などを含むことは好適である。また、用語抽出指示とは、文書から用語を自動抽出して、当該用語を文書情報格納部101に蓄積する処理である。さらに、文書レコメンド指示とは、次に読むべき文書を推薦する指示である。
【0031】
また、受け付けとは、キーボードやマウス、タッチパネルなどの入力デバイスから入力された情報の受け付け、有線もしくは無線の通信回線を介して送信された情報の受信、光ディスクや磁気ディスク、半導体メモリなどの記録媒体から読み出された情報の受け付けなどを含む概念である。さらに、指示等の入力手段は、キーボードやマウスやメニュー画面によるもの等、何でも良い。受付部105は、キーボード等の入力手段のデバイスドライバーや、メニュー画面の制御ソフトウェア等で実現され得る。
【0032】
文書出力部106は、受付部105がオープン指示を受け付けた場合に、オープン指示に対応する文書を出力する。また、文書出力部106は、ページめくり指示、ページジャンプ指示などの読書行為指示に対応して、対応するページに表示を切り替える処理も行うことは好適である。また、文書がファイルである場合、文書出力部106は、ウィンドウに対するスクロール指示に対応して、表示中のファイルをスクロールする。
【0033】
ここで、出力とは、ディスプレイへの表示、プロジェクターを用いた投影、プリンタでの印字、音出力、外部の装置への送信、記録媒体への蓄積、他の処理装置や他のプログラムなどへの処理結果の引渡しなどを含む概念である。
【0034】
文書出力部106は、ディスプレイやスピーカー等の出力デバイスを含むと考えても含まないと考えても良い。文書出力部106は、出力デバイスのドライバーソフトまたは、出力デバイスのドライバーソフトと出力デバイス等で実現され得る。
【0035】
読書履歴情報取得部107は、受付部105が受け付けた読書行為指示に対応した読書履歴情報を取得する。読書履歴情報は、通常、表示中の文書のタイトル、ページ番号、時刻情報を有する。ただし、読書履歴情報は、タイトルや文書識別子のみでも良い。なお、読書履歴情報取得部107は、一定時間以上、ページの表示状態が継続した場合に、読書履歴情報を取得することは好適である。つまり、ぱらぱらめくりの場合等、一時のみオープンした頁について、読書履歴情報に含めないことは好適である。読書履歴情報取得部107は、ユーザからのページめくり指示等の指示があるごとに、読書履歴情報を取得することは好適であるが、読書履歴情報を取得するタイミングが問わない。また、読書履歴情報取得部107は、例えば、当該文書処理装置1の保有者のジャンルごとの読む速さに関する情報(読書速度情報)を保持しており、かかる情報に従って、当該ページを読んだのか、ぱらぱらめくっただけなのかを判断することは好適である。例えば、読書履歴情報取得部107は、「ジャンル「小説」、1分/ページ」「ジャンル「専門書」、2分/ページ」「ジャンル「雑誌」、30秒/ページ」などの読書速度情報を格納しており、かかる読書速度情報を用いて、読書速度情報が示す速度と同程度以上の速度でページがめくられれば、当該ページを既読とし、所定の条件(例えば、読書速度情報が示す1ページあたりの読書時間の70%以内)を満たすほど読書速度情報が示す速度より速い速度でページがめくられれば、ぱらぱらめくり(既読ではない)と判断することは好適である。
【0036】
読書履歴情報蓄積部108は、読書履歴情報取得部107が取得した1以上の読書履歴情報を、読書履歴情報格納部104に蓄積する。読書履歴情報蓄積部108は、読書履歴情報を追記しても良いし、上書きしても良い。上書きする場合、通常、読書履歴情報格納部104には、読んだ最終ページの識別子(ページ番号など)が蓄積されていることとなる。また、追記する場合、通常、読書履歴情報格納部104には、読んだすべてのページの識別子が蓄積されていることとなる。つまり、文書が小説などの連続性のある電子書籍の場合は、上書きすることが好適である。一方、文書がランダムに学習する対象である参考書や百科辞典などの連続性のない電子書籍の場合は、追記することが好適である。
【0037】
既読用語蓄積部109は、未読用語を既読用語の状態とする。既読用語蓄積部109は、未読用語格納部103に格納されている1以上のいずれかの未読用語であり、読書履歴情報に対応する文書に対応する1以上の用語、または読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、未読用語から除外する。ある用語を未読用語から除外する処理は、未読用語格納部103から削除する処理でも良いし、未読用語ではない旨を示すフラグを付与するなどしても良い。
具体的には、例えば、既読用語蓄積部109は、未読用語格納部103に格納されている1以上のいずれかの未読用語であり、読書履歴情報に対応する文書に対応する1以上の用語、または読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、既読用語として、既読用語格納部102に蓄積しても良い。なお、ここで、既読用語蓄積部109は、既読用語とした用語を、未読用語格納部103から削除することは好適である。
【0038】
また、既読用語蓄積部109は、未読用語格納部103に格納されている1以上のいずれかの未読用語であり、読書履歴情報に対応する文書に対応する1以上の用語、または読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、既読用語として、既読用語格納部102に蓄積し、かつ、既読用語格納部102に格納されている1以上のいずれかの既読用語であり、読書履歴情報に対応する文書に対応する1以上の用語、または読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語に対応するスコアを増加させても良い。
【0039】
また、既読用語蓄積部109は、未読用語格納部103に格納されている1以上のいずれかの未読用語であり、読書履歴情報に対応する文書に対応する1以上の用語および各用語に対応するスコア、または読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語および各用語に対応するスコアを、既読用語格納部102に蓄積し、かつ、既読用語格納部102に格納されている1以上のいずれかの既読用語であり、読書履歴情報に対応する文書に対応する1以上の用語、または読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語に対応するスコアを、文書情報格納部101のスコアだけ増加させても良い。
【0040】
文書選択部110は、ユーザに読むべき文書を推薦するために、未読文書を選択する。ここで、未読文書の選択とは、通常、未読文書を特定する情報(文書識別子など)の取得である。また、ここでの未読文書は、読書履歴情報格納部104に格納されている1以上の読書履歴情報から決定され得る文書情報格納部101に格納されている未読文書である。つまり、未読文書は、読書履歴情報格納部104に文書識別子が存在しない文書である、また、未読文書は、読書履歴情報格納部104に文書識別子が存在しない文書であり、かつ、文書情報格納部101に存在する文書である。
また、文書選択部110は、読書履歴情報格納部104から決定され得る文書情報格納部101に格納されている既読文書であり、既読用語格納部102の1以上の既読用語を用いて、既読文書に対応付けられている1以上の用語から、1以上の既読文書を選択しても良い。
文書選択部110は、通常、1以上の既読用語、または1以上の未読用語、または1以上の既読用語と1以上の未読用語を用いて、未読文書を選択する。また、文書選択部110は、1以上の既読用語を用いて、既読文書を選択しても良い。
【0041】
文書選択部110は、例えば、未読文書の中で、最も多くの未読用語に対応する文書を選択する。かかる場合、新しい多くの知識を増やすことができる文書を選択することとなる。また、例えば、文書選択部110は、未読文書の中で、最も多くの既読用語に対応する文書を選択する。かかる場合、過去に学習した事項について復習の意義を有する文書を選択することとなる。
【0042】
また、文書選択部110は、スコアが中程度であることを示す条件である中程度条件を満たす第一種類の用語と、スコアが低度であることを示す条件である低度条件を満たす第二種類の用語の、いずれの種類の用語とも対応付けられている1以上の未読文書を選択することは好適である。なお、中程度条件とは、例えば、スコアが「7>=スコア>=3」である。また、低度条件とは、例えば、スコアが「3>スコア」である。かかる場合、読みやすい文書であり、かつ、ある程度の学習になる文書を選択することとなる。
【0043】
文書選択部110を構成する文書決定手段1101は、読書履歴情報格納部104に格納されている1以上の読書履歴情報を用いて、文書情報格納部101に格納されている1以上の未読文書を決定する。また、文書決定手段1101は、読書履歴情報格納部104に格納されている1以上の読書履歴情報を用いて、文書情報格納部101に格納されている1以上の既読文書を決定しても良い。
【0044】
照合手段1102は、既読用語格納部102の1以上の既読用語、または未読用語格納部103の1以上の未読用語、または既読用語格納部102の1以上の既読用語と未読用語格納部103の1以上の未読用語を用いて、文書情報格納部101を検索し、1以上の未読文書に対応付けられている1以上の用語を照合する。また、照合手段1102は、既読用語格納部102の1以上の既読用語を用いて、文書情報格納部101を検索し、1以上の既読文書に対応付けられている1以上の用語を照合しても良い。
【0045】
文書選択手段1103は、照合手段1102が照合した結果、予め決められた条件に合致する1以上の用語に対応付けられた未読文書を決定する。文書選択手段1103は、例えば、次に読むべき文書を選択する。
また、文書選択手段1103は、照合手段1102が照合した結果、予め決められた条件に合致する1以上の用語に対応付けられた既読文書を決定する。つまり、文書選択手段1103は、再度、読むべき文書を選択しても良い。
【0046】
なお、文書選択部110は、1以上の未読文書を選択してから、当該1以上の各未読文書に対応する1以上の用語と、1以上の既読用語または/および1以上の未読用語とを照らし合わせて、レコメンドする文書を決定した。しかし、文書選択部110は、1以上の既読用語または/および1以上の未読用語とを照らし合わせて、レコメンドする文書の候補を選択し、当該文書の候補から未読文書を決定しても良い。つまり、文書選択部110は、1以上の既読用語または/および1以上の未読用語を用いて、レコメンドする文書を選択できれば良い。
【0047】
文書特定情報出力部111は、文書選択部110が選択した未読文書を特定する情報を出力する。ここで、未読文書を特定する情報とは、通常、タイトルを含む。ただし、未読文書を特定する情報は、未読文書の最初のN文字や目次などでも良い。また、文書特定情報出力部111が未読文書を特定する情報を出力する態様は問わない。
【0048】
用語抽出部112は、文書から、1以上の用語、または1以上の用語と各用語のスコア(例えば、出現頻度)を取得する。例えば、用語抽出部112は、文書を形態素解析し、名詞または名詞句を取得する。次に、用語抽出部112は、名詞または名詞句の出現頻度を、文書から取得する。次に、用語抽出部112は、閾値以上の出現頻度である名詞または名詞句を取得する。
【0049】
また、用語抽出部112は、文書の予め決められた箇所から1以上の用語を抽出しても良い。さらに、用語抽出部112は、1以上のサーバ装置(図示しない)から、各文書に対応付けられている1以上の用語、または各文書の特定の箇所に対応付けられている1以上の用語、または各文書に対応付けられている1以上の用語と各用語のスコア、または各文書の特定の箇所に対応付けられている1以上の用語と各用語のスコアを受信しても良い。
また、用語抽出部112は、抽出した1以上の用語を文書情報格納部101に蓄積する。また、用語抽出部112は、かかる用語のうち、既読用語格納部102に存在しない用語を、未読用語格納部103に蓄積することは好適である。
【0050】
文書情報格納部101、既読用語格納部102、未読用語格納部103、および読書履歴情報格納部104は、不揮発性の記録媒体が好適であるが、揮発性の記録媒体でも実現可能である。
【0051】
文書情報格納部101等に文書等が記憶される過程は問わない。例えば、記録媒体を介して文書等が文書情報格納部101で記憶されるようになってもよく、通信回線等を介して送信された文書等が文書情報格納部101で記憶されるようになってもよく、あるいは、入力デバイスを介して入力された文書等が文書情報格納部101で記憶されるようになってもよい。
【0052】
読書履歴情報取得部107、読書履歴情報蓄積部108、既読用語蓄積部109、文書選択部110、および用語抽出部112は、通常、MPUやメモリ等から実現され得る。読書履歴情報取得部107等の処理手順は、通常、ソフトウェアで実現され、当該ソフトウェアはROM等の記録媒体に記録されている。但し、ハードウェア(専用回路)で実現しても良い。
【0053】
次に、文書処理装置1の動作について、図2のフローチャートを用いて説明する。
【0054】
(ステップS201)受付部105は、指示を受け付けたか否かを判断する。指示を受け付ければステップS202に行き、指示を受け付けなければステップS201に戻る。
【0055】
(ステップS202)文書出力部106は、ステップS201で受け付けられた指示がオープン指示であるか否かを判断する。オープン指示であればステップS203に行き、オープン指示でなければステップS205に行く。なお、オープン指示は、文書識別子を含む、とする。
【0056】
(ステップS203)文書出力部106は、オープン指示に含まれる文書識別子に対応する既読箇所情報(既に読んだ箇所を特定する情報)を読書履歴情報格納部104から取得する。なお、ここで、既読箇所情報が取得されないこともある。
【0057】
(ステップS204)文書出力部106は、文書識別子に対応する文書のページであり、ステップS203で取得された既読箇所情報が示す既読のページの次のページを文書情報格納部101から読み出し、出力する。ステップS201に戻る。なお、文書出力部106は、常に、文書識別子に対応する文書の初めの箇所を出力しても良い。かかる場合、ステップS203は不要である。また、なお、ステップS203で、既読箇所情報が取得されなかった場合、通常、文書出力部106は、文書識別子に対応する文書の初めの箇所を出力する。
【0058】
(ステップS205)読書履歴情報取得部107は、ステップS201で受け付けられた指示がページめくり指示であるか否かを判断する。ページめくり指示であればステップS206に行き、ページめくり指示でなければステップS212に行く。
【0059】
(ステップS206)読書履歴情報取得部107は、読書履歴情報を取得する条件に合致するか否かを判断する。つまり、例えば、読書履歴情報取得部107は、例えば、一定時間以上、現在表示中のページの表示状態が継続した等、読んだと言える条件を満たすか否かを判断する。条件に合致する場合はステップS207に行き、条件に合致しない場合はステップS201に戻る。なお、読書履歴情報取得部107は、図示しない時計を用いて、表示中のページの表示時間をカウントする、とする。
【0060】
(ステップS207)読書履歴情報取得部107は、読書履歴情報を取得する。読書履歴情報取得部107は、例えば、表示中の文書の文書識別子(例えば、タイトル)、ページ番号、時刻情報を取得する。なお、読書履歴情報取得部107は、図示しない時計から時刻情報を取得する。
【0061】
(ステップS208)読書履歴情報蓄積部108は、読書履歴情報取得部107が取得した読書履歴情報を読書履歴情報格納部104に蓄積する。
【0062】
(ステップS209)文書出力部106は、ページめくり指示に対応するページを、文書情報格納部101から読み出す。
【0063】
(ステップS210)文書出力部106は、ステップS209で読み出したページを出力する。ステップS201に戻る。
【0064】
(ステップS211)既読用語蓄積部109は、既読用語の取得処理を行う。かかる既読用語の取得処理については、図3のフローチャートを用いて説明する。
【0065】
(ステップS212)用語抽出部112は、ステップS201で受け付けられた指示が用語抽出指示であるか否かを判断する。用語抽出指示であればステップS213に行き、用語抽出指示でなければステップS214に行く。
【0066】
(ステップS213)用語抽出部112は、用語抽出処理を行う。用語抽出処理については、図4のフローチャートを用いて説明する。ステップS201に戻る。
【0067】
(ステップS214)文書選択部110は、ステップS201で受け付けられた指示が文書レコメンド指示であるか否かを判断する。文書レコメンド指示であればステップS215に行き、文書レコメンド指示でなければステップS217に行く。
【0068】
(ステップS215)文書選択部110は、レコメンドすべき文書を選択する。かかる文書選択処理については、図5のフローチャートを用いて説明する。
【0069】
(ステップS216)文書特定情報出力部111は、ステップS215で選択された文書を特定する情報を出力する。ステップS201に戻る。
【0070】
(ステップS217)文書出力部106は、ステップS201で受け付けられた指示がクローズ指示であるか否かを判断する。クローズ指示であればステップS218に行き、クローズ指示でなければステップS201に戻る。
【0071】
(ステップS218)文書出力部106は、出力中の文書の出力を停止する。ステップS206に行く。
【0072】
なお、図2のフローチャートにおいて既読用語格納部102に蓄積された既読用語やスコアなどは、どのように利用しても良い。また、図2のフローチャートにおいて未読用語格納部103に蓄積された未読用語をどのように利用しても良い。例えば、未読用語を出力するだけで、学習していない事項が明らかになる。また、既読用語を出力するだけで、学習した事項が明らかになる。
【0073】
また、図2のフローチャートにおいて、既読用語取得処理を、ページをめくるごとに行ったが、文書をすべて読んだ際に行うようにしても良い。既読用語取得処理を行うタイミングは問わない。
また、図2のフローチャートにおいて、用語抽出指示が受け付けられた場合に、用語抽出処理を行った。しかし、用語抽出処理を行うタイミングは問わない。
また、図2のフローチャートにおいて、クローズ指示が受け付けられた場合に、既読用語取得処理を行った。しかし、ページがめくられる毎に既読用語取得処理を行うなど、既読用語取得処理を行うタイミングは問わない。
また、図2のフローチャートにおいて、文書選択(ステップS215)は、未読文書の選択であった。ただし、文書選択処理において、既読文書を選択するようにしても良い。
【0074】
さらに、図2のフローチャートにおいて、電源オフや処理終了の割り込みにより処理は終了する。
【0075】
次に、ステップS211の既読用語の取得処理について、図3のフローチャートを用いて説明する。
【0076】
(ステップS301)既読用語蓄積部109は、文書に対応する1以上の用語を文書情報格納部101から取得する。
【0077】
(ステップS302)既読用語蓄積部109は、カウンタiに1を代入する。
【0078】
(ステップS303)既読用語蓄積部109は、ステップS301で取得した用語の中に、i番目の用語が存在するか否かを判断する。i番目の用語が存在すればステップS304に行き、存在しなければ上位処理にリターンする。
【0079】
(ステップS304)既読用語蓄積部109は、i番目の用語が既読箇所(ここでは、出力中のページ)に存在するか否かを判断する。i番目の用語が既読箇所に存在すればステップS305に行き、存在しなければステップS309に行く。
【0080】
(ステップS305)既読用語蓄積部109は、i番目の用語に対応するスコアを取得する。ここで、既読用語蓄積部109は、i番目の用語の既読箇所における出現頻度を取得し、スコアとしても良い。また、既読用語蓄積部109は、i番目の用語に対応するスコアを文書情報格納部101から取得しても良い。また、既読用語蓄積部109は、i番目の用語に対する固定的なスコア「1」を取得しても良い。
【0081】
(ステップS306)既読用語蓄積部109は、i番目の用語をキーとして、未読用語格納部103を検索し、i番目の用語が未読用語であるか否かを判断する。i番目の用語が未読用語であればステップS307に行き、i番目の用語が未読用語でなければステップS308に行く。
【0082】
(ステップS307)既読用語蓄積部109は、i番目の用語を既読用語格納部102に登録する。なお、かかる登録は、通常、i番目の用語を既読用語格納部102に書き込むことであるが、i番目の用語に対するスコアを付与するだけでも良い。
【0083】
(ステップS308)既読用語蓄積部109は、ステップS305で取得したスコアをi番目の用語に対応付けて、既読用語格納部102に蓄積する。また、既読用語蓄積部109は、ステップS305で取得したスコア分を増加させるように、i番目の用語に対応するスコアを更新しても良い。
【0084】
(ステップS309)既読用語蓄積部109は、カウンタiを1、インクリメントする。ステップS303に戻る。
【0085】
なお、図3のフローチャートにおいて、既読用語蓄積部109は、通常、未読用語を既読用語として登録した後、未読用語格納部103から、当該未読用語を削除する。
【0086】
次に、ステップS213の用語抽出処理について、図4のフローチャートを用いて説明する。
【0087】
(ステップS401)用語抽出部112は、カウンタiに1を代入する。
【0088】
(ステップS402)用語抽出部112は、文書情報格納部101に、用語を有しないi番目の文書が存在するか否かを判断する。用語を有しないi番目の文書が存在すればステップS403に行き、存在しなければ上位処理にリターンする。
【0089】
(ステップS403)用語抽出部112は、i番目の文書を特定する文書識別子を文書情報格納部101から取得し、当該文書識別子を用いて、1以上の図示しないサーバ装置にアクセスし、1以上の用語を受信しようとする。なお、用語抽出部112は、1以上の図示しないサーバ装置にアクセスするための情報(IPアドレスやURLなど)を格納している、とする。
【0090】
(ステップS404)用語抽出部112は、ステップS403におけるアクセスの結果、1以上の用語である用語集を取得できたか否かを判断する。用語集を取得できればステップS405に行き、用語集を取得できなければステップS407に行く。用語集を取得できない場合、文書を自然言語処理し、1以上の用語を取得する。
【0091】
(ステップS405)用語抽出部112は、1以上の用語を文書情報格納部101に蓄積する。また、用語抽出部112は、かかる用語のうち、既読用語格納部102に存在しない用語を、未読用語格納部103に蓄積することは好適である。
【0092】
(ステップS406)用語抽出部112は、カウンタiを1、インクリメントする。ステップS402に戻る。
【0093】
(ステップS407)用語抽出部112は、用語を有しないi番目の文書に対して形態素解析を行う。
【0094】
(ステップS408)用語抽出部112は、ステップS407における形態素解析の出力から、名詞や名詞句等の予め決められた条件に合致する用語を取得する。
【0095】
(ステップS409)用語抽出部112は、カウンタjに1を代入する。
【0096】
(ステップS410)用語抽出部112は、j番目の名詞等が存在するか否かを判断する。j番目の名詞等が存在すればステップS411に行き、存在しなければステップS406に戻る。
【0097】
(ステップS411)用語抽出部112は、j番目の名詞等のスコアを算出する。例えば、用語抽出部112は、j番目の名詞等の出現頻度を取得し、スコアとしても良い。
【0098】
(ステップS412)用語抽出部112は、j番目の名詞等の出現箇所(例えば、ページ番号)を取得する。
【0099】
(ステップS413)用語抽出部112は、j番目の名詞等、スコア、出現箇所等を用いて、用語情報を構成する。
【0100】
(ステップS414)用語抽出部112は、ステップS413で構成した用語情報を、i番目の文書に対応付けて、文書情報格納部101に蓄積する。
【0101】
(ステップS415)用語抽出部112は、カウンタjを1、インクリメントする。ステップS410に戻る。
【0102】
なお、図4のフローチャートにおいて、名詞等の出現箇所や、スコアを取得しなくても良い。かかる場合、用語情報は、取得した情報から構成される。
【0103】
次に、ステップS215の文書選択処理について、図5のフローチャートを用いて説明する。
【0104】
(ステップS501)文書選択部110は、未読文書の識別子を、文書情報格納部101から取得する。文書選択部110は、例えば、読書履歴情報取得部107の読書履歴情報には存在しない文書識別子であり、文書情報格納部101に存在する文書識別子を取得しても良い。また、文書選択部110は、例えば、読書履歴情報取得部107の読書履歴情報から、完読していない文書に対する文書識別子であり、かつ、文書情報格納部101に存在する文書識別子を未読文書の文書識別子として取得しても良い。
【0105】
(ステップS502)文書選択部110は、ステップS501で取得した1以上の未読文書の各識別子に対応する1以上の用語を、文書情報格納部101から取得する。なお、文書情報格納部101に文書に対応する用語が存在しない場合、この時点で、ステップS501で取得した1以上の未読文書の各識別子に対応する文書から、用語抽出処理を行っても良い。
【0106】
(ステップS503)文書選択部110は、既読用語格納部102に格納されている1以上の既読用語、未読用語格納部103に格納されている1以上の未読用語を取得する。
【0107】
(ステップS504)文書選択部110は、カウンタiに1を代入する。
【0108】
(ステップS505)文書選択部110は、レコメンドする文書を選択するためのi番目の条件を保持しているか否かを判断する。i番目の条件を保持していればステップS504に行き、保持していなければ上位処理にリターンする。なお、レコメンドする文書を選択するための1以上の条件は、文書選択部110に格納されている、とする。
【0109】
(ステップS506)文書選択部110は、i番目の条件を取得する。
【0110】
(ステップS507)文書選択部110は、ステップS502で取得した1以上の未読文書の各識別子に対応する1以上の用語、およびステップS503で取得した1以上の既読用語または/および1以上の未読用語を用いて、i番目の条件に合致する1以上の未読文書の識別子を取得する。
【0111】
(ステップS508)文書選択部110は、1以上の未読文書の識別子を取得できたか否かを判断する。取得できればステップS509に行き、取得できなければステップS510に行く。
【0112】
(ステップS509)文書選択部110は、i番目の条件に対応付けて、ステップS507で取得した1以上の未読文書の識別子をバッファに一時蓄積する。
【0113】
(ステップS510)文書選択部110は、カウンタiを1、インクリメントする。ステップS505に戻る。
【0114】
なお、図5のフローチャートにおいて、レコメンドする文書を選択するための条件は、文書に対応する1以上の用語と、1以上の既読用語または/および1以上の未読用語とを用いた条件である。
【0115】
以下、本実施の形態における文書処理装置1の具体的な動作について説明する。今、文書情報格納部101には、購入した多数の電子書籍が格納されている。電子書籍は、文書の一種である。
【0116】
また、文書情報格納部101は、図6に示す構造を有する文書管理表を格納している。文書管理表は、「ID」「文書識別子」「用語情報」「既読フラグ」を有するレコードを1以上格納している。また、「用語情報」は、「用語」と「スコア」とを有する。「ID」は、レコードを識別する情報である。「文書識別子」は、ここでは電子書籍のタイトルである。「用語」は、文書に対応する用語である。「スコア」は、文書と用語との関連度を示す。また、「既読フラグ」は、文書を読んだか否かを示す情報である。「既読フラグ」において、未読の場合は「0」、読んでいる途中の場合(一部のみを読んだ場合)は「1」、完読した場合は「2」である。
【0117】
なお、図6の文書管理表の用語とスコアは、用語抽出部112が取得した情報である。つまり、用語抽出部112は、文書管理表が有する各文書識別子に対応する文書を読み出し、当該文書から、名詞および名詞句であり、閾値以上の出現頻度の名詞および名詞句を取得した。そして、用語抽出部112は、演算式「スコア=f(出現頻度)」(fは、出現頻度をパラメータとする増加関数)により、用語ごとにスコアを算出し、用語とスコアを有する1以上の用語情報を、文書に対応付けて蓄積した。なお、スコアは、ここでは、1から10までである、とする。図6の文書管理表の既読フラグの初期値は、すべて「0」である。
【0118】
また、既読用語格納部102、および未読用語格納部103は、図7に示す構造を有する用語情報管理表を保持している、とする。用語情報管理表は、既読用語、未読用語の2種類の用語を管理する。用語情報管理表は、「ID」「キーワード」「スコア」を有する1以上のレコードを格納している。未読の用語のスコアは「0」である。「0」以外のスコアに対応する用語は既読用語である。また、スコアが大きい用語であるほど、通常、ユーザが深く学習した用語である、と言える。図7の用語情報管理表のスコアの初期値は、すべて「0」である。
【0119】
また、読書履歴情報格納部104は、図8に示す構造を有する読書履歴情報管理表を格納している。読書履歴情報管理表には、「ID」「読書履歴情報」を有するレコードが1以上、格納されている。「読書履歴情報」は、「文書識別子」「ページ番号」「時刻」を有する。「ID」は読書履歴情報管理表のレコードを識別する情報である。また、「文書識別子」は、ここでは電子書籍のタイトルである。「ページ番号」は、既読のページを識別する情報である。「ページ番号」は、読んだページを示す情報であるが、既読の最後のページ番号のみでも良い。さらに、「時刻」は、最後に読んだ時刻を示す。なお、「時刻」は、各ページと当該ページを読んだ時刻を示す情報でも良い。
【0120】
また、文書選択部110は、図9に示すレコメンド条件管理表を保持している。レコメンド条件管理表は、「ID」「項目」「条件」を有するレコード(レコメンド条件)を1以上格納している。「項目」とは、レコメンド条件の意味を示す情報である。また、「条件」とは、文書を選択する際の条件を示す情報である。
【0121】
かかる状況において、ユーザは、文書識別子「株式会社の××」を有するオープン指示を入力した、とする。次に、受付部105は、オープン指示を受け付ける。次に、文書出力部106は、オープン指示に含まれる文書識別子「株式会社の××」に対応する既読箇所情報を読書履歴情報管理表から取得しようとするが、ここでは、取得できなかった、とする。次に、文書出力部106は、文書識別子「株式会社の××」の文書を、文書情報格納部101から読み出し、最初のページ(例えば、表紙)を出力する。
【0122】
そして、ユーザは、ページめくり指示を入力しながら、電子書籍「株式会社の××」を読み進めていく。ユーザがページめくり指示を入力した場合、受付部105は、ページめくり指示を受け付ける。そして、読書履歴情報取得部107は、読書履歴情報を取得する条件(例えば、ページの表示時間が1分以上)に合致するほど、長く(例えば、85秒)、現在のページを出力していた、と判断した、とする。
【0123】
次に、読書履歴情報取得部107は、文書識別子「株式会社の××」、およびページ番号「1」、および時刻「2011/1/26 12:58:51」を取得し、かかる情報を有する読書履歴情報を構成する。そして、読書履歴情報蓄積部108は、かかる読書履歴情報を読書履歴情報格納部104に蓄積する。そして、レコード「ID=1、文書識別子=株式会社の××、ページ番号=1、時刻=2011/1/26 12:58:51」が、図8の読書履歴情報管理表に追記される。そして、読書履歴情報蓄積部108は、図6の文書管理表の「ID=3」のレコードの「既読フラグ」を
「0」から「1」(読書の途中であることを示す)に更新する。
【0124】
そして、ユーザは、電子書籍「株式会社の××」を読み進めて、最終ページの210ページ目を読み終わり、2011/1/26 18:01:59に、クローズ指示を入力した、とする。
【0125】
次に、受付部105は、クローズ指示を受け付ける。そして、文書出力部106は、出力中の電子書籍「株式会社の××」の出力を停止する。
【0126】
次に、読書履歴情報取得部107は、読書履歴情報を取得する条件(例えば、ページの表示時間が1分以上)に合致するほど、長く(例えば、85秒)、210ページを出力していた、と判断した、とする。
【0127】
そして、読書履歴情報取得部107は、文書識別子「株式会社の××」、およびページ番号「210」、および時刻「2011/1/26 18:01:59」を取得し、かかる情報を有する読書履歴情報を構成する。そして、読書履歴情報蓄積部108は、かかる読書履歴情報を読書履歴情報格納部104に上書きする。そして、レコード「ID=1、文書識別子=株式会社の××、ページ番号=1−210、時刻=2011/1/26 18:01:59」が、図8の読書履歴情報管理表に上書きされる(ID=1を参照のこと)。そして、読書履歴情報蓄積部108は、図6の文書管理表の「ID=3」のレコードの「既読フラグ」を「2」(既読であることを示す)に更新する。なお、ページがめくられるごとに、上記で説明した読書履歴情報の更新処理は行われていた、とする。
【0128】
次に、既読用語蓄積部109は、文書識別子「株式会社の××」で識別される文書がすべて読み終えられたことを検出する。なお、既読の検出について、例えば、既読用語蓄積部109は、読み終えた最大のページ番号と、文書の最終のページ番号とを比較して、一致するか否かにより判断する。次に、既読用語蓄積部109は、文書識別子「株式会社の××」に対応する用語「マネジメントサイクル」「事業継続計画」などを、スコアとともに取得する。つまり、既読用語蓄積部109は、例えば、「マネジメントサイクル,5」「事業継続計画,6」などを取得する。
【0129】
次に、既読用語蓄積部109は、用語「マネジメントサイクル」「事業継続計画」等のスコアを、取得したスコア分、増加させるように、図7の用語情報管理表を更新する。ここでは、例えば、「マネジメントサイクル,0」「事業継続計画,0」が、「マネジメントサイクル,5」「事業継続計画,6」に更新される。
【0130】
また、ユーザは、文書識別子「日本企業××論」を有するオープン指示を入力した、とする。次に、受付部105は、オープン指示を受け付ける。次に、文書出力部106は、オープン指示に含まれる文書識別子「日本企業××論」に対応する既読箇所情報を読書履歴情報管理表から取得しようとするが、ここでは、取得できなかった、とする。次に、文書出力部106は、文書識別子「日本企業××論」の文書を、文書情報格納部101から読み出し、最初のページ(例えば、表紙)を出力する。
【0131】
そして、ユーザは、電子書籍「日本企業××論」を読み進めて、38ページを読み終わり、2011/3/1 20:58:05に、クローズ指示を入力した、とする。ここまでの処理において、読書履歴情報蓄積部108は、図6の文書管理表の「ID=5」のレコードの「既読フラグ」を「1」に更新している、とする。
【0132】
次に、受付部105は、クローズ指示を受け付ける。そして、文書出力部106は、出力中の電子書籍「日本企業××論」の出力を停止する。
【0133】
次に、読書履歴情報取得部107は、読書履歴情報を取得する条件(例えば、ページの表示時間が1分以上)に合致するほど、長く(例えば、85秒)、38ページを出力していた、と判断した、とする。
【0134】
そして、読書履歴情報取得部107は、文書識別子「日本企業××論」、およびページ番号「38」、および時刻「2011/3/1 20:58:05」を取得し、かかる情報を有する読書履歴情報を構成する。そして、読書履歴情報蓄積部108は、かかる読書履歴情報を読書履歴情報格納部104に上書きする。そして、レコード「ID=1、文書識別子=株式会社の××、ページ番号=1−38、時刻=2011/3/1 20:58:05」が、図8の読書履歴情報管理表に上書きされる(ID=2を参照のこと)。
【0135】
なお、ここの段階では、既読用語蓄積部109は、既読用語取得処理を行わないものとする。ただし、図2のフローチャートに示したように、ページをめくるごとに、既読用語取得処理を行っても良い。かかる場合、ページと用語とが対応づけて管理されているか、めくられるページ中に出現する用語を検出して、用語または用語とスコアを取得する必要がある。かかる処理は、既読用語蓄積部109が行う。
【0136】
以上の処理により、文書情報格納部101の文書情報管理表は図6の状態となり、既読用語格納部102および未読用語格納部103の用語管理表は図7の状態となり、読書履歴情報格納部104の読書履歴情報管理表は図8の状態となった、とする。
【0137】
かかる状況において、ユーザは、文書レコメンド指示を入力した、とする。そして、受付部105は、文書レコメンド指示を受け付ける。
【0138】
次に、文書選択部110の文書決定手段1101は、図8の読書履歴管理表から文書識別子を取得する。そして、文書決定手段1101は、文書情報管理表(図6参照)の文書識別子の中で、図8の読書履歴管理表に存在しない文書識別子「×××経営塾」「××でも分かる会社法」「××の中の企業」などを取得する。
【0139】
次に、文書選択部110の照合手段1102は、取得された未読文書の各識別子に対応する1以上の用語を、文書情報格納部101から取得する。また、照合手段1102は、既読用語格納部102に格納されている1以上の既読用語、未読用語格納部103に格納されている1以上の未読用語を取得する。
【0140】
次に、照合手段1102は、1番目の条件「未読用語の数>=10」を、図9のレコメンド条件管理表から取得する。そして、照合手段1102は、未読文書「×××経営塾」「××でも分かる会社法」「××の中の企業」等の各未読文書に対応する用語の中で、未読文書ごとに、未読用語を取得する。そして、照合手段1102は、未読文書ごとに、未読用語の数を取得する。そして、例えば、照合手段1102は、未読文書「×××経営塾」の「未読用語の数=13」、未読文書「××でも分かる会社法」の「未読用語の数=8」、未読文「××の中の企業」の「未読用語の数=5」等を取得した、とする。
【0141】
次に、文書選択手段1103は、1番目の条件「未読用語の数>=10」に合致する未読文書識別子「×××経営塾」を取得する。そして、文書選択手段1103は、1番目の条件と対応付けて、未読文書識別子「×××経営塾」をバッファに一時蓄積する。
【0142】
次に、照合手段1102は、2番目の条件「3<=既読用語の数<=5 and 未読用語の数>=3」を、図9のレコメンド条件管理表から取得する。そして、照合手段1102は、未読文書「×××経営塾」「××でも分かる会社法」「××の中の企業」等の各未読文書に対応する用語の中で、未読文書ごとに、既読用語を取得する。そして、照合手段1102は、未読文書ごとに、既読用語の数を取得する。そして、例えば、照合手段1102は、未読文書「×××経営塾」の「既読用語の数=0」、未読文書「××でも分かる会社法」の「既読用語の数=4」、未読文「××の中の企業」の「既読用語の数=6」等を取得した、とする。
【0143】
次に、文書選択手段1103は、2番目の条件「3<=既読用語の数<=5 and 未読用語の数>=3」に合致する未読文書識別子「××でも分かる会社法」を取得する。そして、文書選択手段1103は、2番目の条件と対応付けて、未読文書識別子「××でも分かる会社法」をバッファに一時蓄積する。
【0144】
次に、照合手段1102は、3番目の条件「「スコアが3以下の既読用語の数」>=6」を、図9のレコメンド条件管理表から取得する。そして、照合手段1102は、未読文書「×××経営塾」「××でも分かる会社法」「××の中の企業」等の各未読文書に対応する用語の中で、未読文書ごとに、既読用語およびスコアを取得する。そして、例えば、照合手段1102は、未読文書ごとに、スコアが3以下の既読用語を取得する。次に、照合手段1102は、未読文書ごとに、スコアが3以下の既読用語(「1<=スコア<=3」の用語)の数を算出する。そして、照合手段1102は、未読文書「××の中の企業」に対応する用語の中に、「1<=スコア<=3」の用語が8存在することを検知した、とする。なお、「×××経営塾」「××でも分かる会社法」等の未読文書に対応する用語の中に、「1<=スコア<=3」の用語は、5以下しか存在しなかった、とする。そして、文書選択手段1103は、3番目の条件と対応付けて、未読文書識別子「××の中の企業」をバッファに一時蓄積する。
【0145】
文書選択部110は、以上の処理を4番目以降のレコメンド条件に対しても実行する。そして、文書特定情報出力部111は、レコメンドする文書に関する情報を、図10に示すように出力した、とする。
【0146】
なお、ユーザは、レコメンド条件を指示し、当該指示されたレコメンド条件に対応する文書のみが推薦されても良い。
【0147】
以上、本実施の形態によれば、文書の読書行為から、既知の用語であるか未知の用語であるかを精度高く把握できる。
【0148】
また、本実施の形態によれば、文書の内容と、ユーザの過去の読書行為とを考慮して、次に読むべき文書を決定する際に有効な情報を提示したり、次に読むべき文書を推薦したりすることができる。
【0149】
また、本実施の形態によれば、用語に対する読書による習熟度が精度高く把握できる。
【0150】
なお、本実施の形態において、文書情報格納部101の文書は、通常、購入などによりユーザが取得した文書であるが、一時的にサーバ装置から受信した文書などでも良い。
また、本実施の形態において、文書処理装置1は、既読用語を取得する処理などを行わない構成でも良い。かかる場合、文書処理装置1のブロック図は、図17である。かかる場合、文書処理装置1は、文書情報格納部101、未読用語格納部103、受付部105、文書出力部106、読書履歴情報取得部107、読書履歴情報蓄積部108、および未読用語除外部171を備える。
また、文書処理装置1は、1以上の文書と、各文書に対応付けられている1以上の用語または各文書の特定の箇所に対応付けられている1以上の用語とを格納し得る文書情報格納部101と、未読の文書に対応する用語である1以上の未読用語を格納し得る未読用語格納部103と、文書を開く指示であるオープン指示を含む読書行為指示を受け付ける受付部105と、前記受付部105が前記オープン指示を受け付けた場合に、前記オープン指示に対応する文書を出力する文書出力部106と、前記受付部が受け付けた読書行為指示に対応した読書履歴情報を取得する読書履歴情報取得部107とを具備し、前記未読用語格納部103に格納されている1以上のいずれかの未読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、未読用語から除外する未読用語除外部171とを具備する文書処理装置である。なお、未読用語除外部171の処理は、既読用語蓄積部109が行っても良い。
【0151】
また、本実施の形態における処理は、ソフトウェアで実現しても良い。そして、このソフトウェアをソフトウェアダウンロード等により配布しても良い。また、このソフトウェアをCD−ROMなどの記録媒体に記録して流布しても良い。なお、このことは、本明細書における他の実施の形態においても該当する。なお、本実施の形態における文書処理装置を実現するソフトウェアは、以下のようなプログラムである。つまり、このプログラムは、記憶媒体に、1以上の文書と、各文書に対応付けられている1以上の用語または各文書の特定の箇所に対応付けられている1以上の用語と、未読の文書に対応する用語である1以上の未読用語とを格納しており、コンピュータを、文書を開く指示であるオープン指示を含む読書行為指示を受け付ける受付部と、前記受付部が前記オープン指示を受け付けた場合に、前記オープン指示に対応する文書を出力する文書出力部と、前記受付部が受け付けた読書行為指示に対応した読書履歴情報を取得する読書履歴情報取得部と、前記記憶媒体に格納されている1以上のいずれかの未読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、未読用語から除外する既読用語蓄積部として機能させるためのプログラム、である。
また、上記プログラムにおいて、記憶媒体に、既読の文書に対応する用語である1以上の既読用語をさらに格納しており、前記既読用語蓄積部は、前記記憶媒体に格納されている1以上のいずれかの未読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、既読用語として、前記記憶媒体に蓄積するものとして、コンピュータを機能させるためのプログラムであることは好適である。
【0152】
また、上記プログラムにおいて、記憶媒体に、1以上の読書履歴情報をさらに格納しており、コンピュータを、前記読書履歴情報取得部が取得した1以上の読書履歴情報を、前記読書履歴情報格納部に蓄積する読書履歴情報蓄積部と、前記記憶媒体に格納されている1以上の読書履歴情報から決定され得る前記記憶媒体に格納されている未読文書であり、前記記憶媒体の1以上の既読用語、または前記記憶媒体の1以上の未読用語、または前記記憶媒体の1以上の既読用語と前記記憶媒体の1以上の未読用語を用いて、前記未読文書に対応付けられている1以上の用語から、1以上の未読文書を選択する文書選択部と、前記文書選択部が選択した未読文書を特定する情報を出力する文書特定情報出力部としてさらに機能させるプログラムであることは好適である。
【0153】
また、上記プログラムにおいて、前記文書選択部は、前記記憶媒体に格納されている1以上の読書履歴情報から決定され得る前記記憶媒体に格納されている1以上の未読文書を決定する文書決定手段と、前記1以上の既読用語、または前記1以上の未読用語、または前記1以上の既読用語と前記1以上の未読用語を用いて、前記1以上の未読文書に対応付けられている1以上の用語を照合する照合手段と、前記照合手段が照合した結果、予め決められた条件に合致する1以上の用語に対応付けられた未読文書を決定する文書選択手段とを具備するプログラムであることは好適である。
【0154】
また、上記プログラムにおいて、前記記憶媒体には、既読用語と当該既読用語に対応するスコアとを有する1以上の既読用語情報を格納しており、前記既読用語蓄積部は、前記記憶媒体に格納されている1以上のいずれかの未読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、既読用語として、前記記憶媒体に蓄積し、かつ、前記記憶媒体に格納されている1以上のいずれかの既読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語に対応するスコアを増加させるプログラムであることは好適である。
【0155】
また、上記プログラムにおいて、前記文書選択部は、前記スコアが中程度であることを示す条件である中程度条件を満たす第一種類の用語と、前記スコアが低度であることを示す条件である低度条件を満たす第二種類の用語の、いずれの種類の用語とも対応付けられている1以上の未読文書を選択するプログラムであることは好適である。
【0156】
また、上記プログラムにおいて、前記記憶媒体には、1以上の文書と、各文書に対応付けられている1以上の用語または各文書の特定の箇所に対応付けられている1以上の用語と、各用語に対応するスコアとを格納しており、前記既読用語蓄積部は、前記記憶媒体に格納されている1以上のいずれかの未読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語および各用語に対応するスコア、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語および各用語に対応するスコアを、前記記憶媒体に蓄積し、かつ、前記記憶媒体に格納されている1以上のいずれかの既読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語に対応するスコアを、前記記憶媒体のスコアだけ増加させるプログラムであることは好適である。
【0157】
(実施の形態2)
【0158】
本実施の形態において、例えば、未読用語を指定すると、当該未読用語に対応する文書が選択され、文書を特定する情報が出力される文書処理装置について説明する。また、本実施の形態における文書処理装置は、例えば、既読用語を指定すると、当該既読用語に対応する文書が選択され、文書を特定する情報が出力される文書処理装置でも良い。
【0159】
また、本実施の形態において、文書を指定すると、当該文書に対応する用語が出力される文書処理装置について説明する。かかる場合、未読用語と既読用語とを、視覚的に区別する態様で出力されることは好適である。
【0160】
図11は、本実施の形態における文書処理装置2のブロック図である。文書処理装置2は、文書情報格納部101、既読用語格納部102、未読用語格納部103、読書履歴情報格納部104、受付部201、文書出力部106、読書履歴情報取得部107、読書履歴情報蓄積部108、文書選択部202、文書特定情報出力部203、用語取得部204、文書用語出力部205、用語抽出部112、および情報出力部206を備える。
【0161】
受付部201は、受付部105と同様、指示やデータ等を受け付ける。受付部201は、用語出力指示、用語指示、文書指示、文書出力指示などの指示も受け付ける。用語出力指示とは、既読用語、または未読用語、または既読用語と未読用語を出力する指示である。また、用語指示は、出力されている用語に対する指示である。なお、用語指示が入力された場合、当該用語に対応する文書の文書識別子が出力される。また、文書指示は、出力されている文書識別子に対する指示である。文書指示が入力された場合、当該文書に対応する用語(既読用語、または未読用語、または既読用語と未読用語)が出力される。さらに、文書出力指示は、文書識別子を出力する指示である。かかる文書出力指示が入力された場合、1以上の文書識別子が出力される。文書識別子は、既読文書と未読文書を視覚的に区別する態様で出力されても良い。
【0162】
また、受け付けとは、キーボードやマウス、タッチパネルなどの入力デバイスから入力された情報の受け付け、有線もしくは無線の通信回線を介して送信された情報の受信、光ディスクや磁気ディスク、半導体メモリなどの記録媒体から読み出された情報の受け付けなどを含む概念である。さらに、指示等の入力手段は、キーボードやマウスやメニュー画面によるもの等、何でも良い。受付部201は、キーボード等の入力手段のデバイスドライバーや、メニュー画面の制御ソフトウェア等で実現され得る。
【0163】
文書選択部202は、受付部201が1以上の未読用語を受け付けた場合に、1以上の未読用語のすべて、または1以上の未読用語のいずれかに対応する未読文書を選択する。文書選択部202は、受付部201が1以上の未読用語を受け付けた場合に、当該未読用語に対するスコアが予め決められた条件を満たすほど大きい未読文書を選択することは好適である。文書選択部202は、文書情報格納部101の情報から、未読文書を選択する。
また、文書選択部202は、受付部201が1以上の既読用語を受け付けた場合に、1以上の既読用語のすべて、または1以上の既読用語のいずれかに対応する既読文書を選択しても良い。
【0164】
文書特定情報出力部203は、文書選択部202が選択した1以上の各未読文書を特定する情報を出力する。文書特定情報出力部203は、文書選択部202が選択した1以上の各既読文書を特定する情報を出力しても良い。
【0165】
用語取得部204は、受付部201が文書指示を受け付けた場合に、当該文書に対応する1以上の用語を文書情報格納部101から取得する。用語取得部204は、既読用語と未読用語とに区別して、1以上の用語を取得することは好適である。
【0166】
文書用語出力部205は、用語取得部204が取得した1以上の用語を出力する。文書用語出力部205は、既読用語と未読用語とを視覚的に区別して、1以上の用語を出力することは好適である。
【0167】
情報出力部206は、受付部201が用語出力指示を受け付けた場合、既読用語格納部102の1以上の既読用語、または未読用語格納部103の1以上の未読用語、または1以上の既読用語と1以上の未読用語を出力する。なお、情報出力部206は、既読用語と未読用語を視覚的に区別して出力することは好適である。
【0168】
また、情報出力部206は、受付部201が文書出力指示を受け付けた場合、文書情報格納部101の1以上の文書識別子を出力する。なお、情報出力部206は、既読文書と未読文書を視覚的に区別して、文書識別子を出力することは好適である。
【0169】
文書選択部202、用語取得部204は、通常、MPUやメモリ等から実現され得る。文書選択部202の処理手順は、通常、ソフトウェアで実現され、当該ソフトウェアはROM等の記録媒体に記録されている。但し、ハードウェア(専用回路)で実現しても良い。
【0170】
文書特定情報出力部203、文書用語出力部205、および情報出力部206は、ディスプレイやスピーカー等の出力デバイスを含むと考えても含まないと考えても良い。文書特定情報出力部203等は、出力デバイスのドライバーソフトまたは、出力デバイスのドライバーソフトと出力デバイス等で実現され得る。
【0171】
次に、文書処理装置2の動作について、図12のフローチャートを用いて説明する。図12のフローチャートにおいて、図2のフローチャートと同一のステップについて、説明を省略する。
【0172】
(ステップS1201)情報出力部206は、受付部201が用語出力指示を受け付けか否かを判断する。用語出力指示を受け付ければステップS1202に行き、用語出力指示を受け付けなければステップS1205に行く。
【0173】
(ステップS1202)情報出力部206は、既読用語格納部102に格納されている1以上の既読用語を取得する。
【0174】
(ステップS1203)情報出力部206は、未読用語格納部103に格納されている1以上の未読用語を取得する。
【0175】
(ステップS1204)情報出力部206は、ステップS1202で取得した1以上の既読用語、ステップS1203で取得した1以上の未読用語を出力する。ステップS201に戻る。
【0176】
(ステップS1205)情報出力部206は、受付部201が文書出力指示を受け付けか否かを判断する。文書出力指示を受け付ければステップS1206に行き、文書出力指示を受け付けなければステップS1209に行く。
【0177】
(ステップS1206)情報出力部206は、文書情報格納部101から1以上の既読文書の識別子を取得する。
【0178】
(ステップS1207)情報出力部206は、文書情報格納部101から1以上の未読文書の識別子を取得する。
【0179】
(ステップS1208)情報出力部206は、ステップS1206で取得した1以上の既読文書の識別子、ステップS1207で取得した1以上の未読文書の識別子を出力する。ステップS201に戻る。
【0180】
(ステップS1209)文書選択部202は、受付部201が用語指示を受け付けたか否かを判断する。用語指示を受け付ければステップS1210に行き、用語指示を受け付けなければステップS1214に行く。
【0181】
(ステップS1210)文書選択部202は、受付部201が受け付けた1以上の用語を取得する。
【0182】
(ステップS1211)文書選択部202は、予め決められたテーマ、またはユーザ指定のテーマを取得する。テーマとは、選択する文書を決定するためのテーマである。テーマは、例えば、「未知との遭遇」「周辺の開拓」「既知の深耕」などである。また、文書選択部202は、テーマに対応付けて、異なるアルゴリズムを実現するプログラム、データ等を保持している、とする。
【0183】
(ステップS1212)文書選択部202は、ステップS1210で取得した1以上の用語に対応する文書であり、ステップS1211で取得したテーマに合致する1以上の文書の文書識別子を取得する。
【0184】
(ステップS1213)文書特定情報出力部203は、ステップS1212で取得した1以上の文書識別子を出力する。ステップS201に戻る。
【0185】
(ステップS1214)用語取得部204は、受付部201が文書指示を受け付けたか否かを判断する。文書指示を受け付ければステップS1215に行き、文書指示を受け付けなければステップS201に戻る。
【0186】
(ステップS1215)用語取得部204は、文書指示が有する文書識別子に対応する1以上の既読用語と当該用語のスコアとを、文書情報格納部101から取得する。なお、例えば、用語取得部204は、文書指示が有する文書識別子に対応する1以上の用語を文書情報格納部101から取得し、当該取得した用語の中から、既読用語格納部102の既読用語を選択する。
【0187】
(ステップS1216)用語取得部204は、文書指示が有する文書識別子に対応する1以上の未読用語を文書情報格納部101から取得する。なお、例えば、用語取得部204は、文書指示が有する文書識別子に対応する1以上の用語を文書情報格納部101から取得し、当該取得した用語の中から、未読用語格納部103の未読用語を選択する。
【0188】
(ステップS1217)文書用語出力部205は、ステップS1215で取得した1以上の既読用語、ステップS1216で取得した1以上の未読用語を出力する。ステップS201に戻る。
【0189】
なお、図12のフローチャートにおいて、電源オフや処理終了の割り込みにより処理は終了する。
【0190】
以下、本実施の形態における文書処理装置2の具体的な動作について説明する。今、文書情報格納部101は、図6に示す文書管理表を格納している。
【0191】
また、既読用語格納部102、および未読用語格納部103は、図7に示す用語情報管理表を保持している。
【0192】
また、読書履歴情報格納部104は、図8に示す読書履歴情報管理表を格納している。
【0193】
かかる状況において、ユーザは、文書処理装置2に、用語出力指示を入力した、とする。すると、受付部201は、用語出力指示を受け付ける。
【0194】
次に、情報出力部206は、既読用語格納部102に格納されている1以上の既読用語を取得する。また、情報出力部206は、未読用語格納部103に格納されている1以上の未読用語を取得する。
【0195】
次に、情報出力部206は、図13に示すように、1以上の既読用語と1以上の未読用語とを、視覚的に区別する態様で出力する。なお、図13は、文書処理装置2の画面例である。また、図13において、1以上の既読用語と1以上の未読用語とは異なるウィンドウ(枠)に表示されている。
【0196】
次に、ユーザは、図13に示す画面から、未読用語「内部統制」「SOX法」を含む用語指示を入力した、とする。すると、受付部201は、かかる用語指示を受け付ける。
【0197】
次に、文書選択部202は、テーマ「未読用語が学習することができる文書を選択する」を取得する。なお、かかるテーマは、未読用語が選択された場合に、自動的に決定されても良いし、ユーザが入力しても良い。
【0198】
次に、文書選択部202は、用語指示から、未読用語「内部統制」「SOX法」を取得する。
【0199】
次に、文書選択部202は、未読用語「内部統制」「SOX法」を含む、かつ各未読用語「内部統制」「SOX法」のスコアが閾値(例えば、「3」)以上の文書を、文書管理表から検索する。そして、文書選択部202は、文書管理表から、文書識別子「×××経営塾」、「SOX法のすべて」を取得した、とする。次に、文書特定情報出力部203は、文書識別子「×××経営塾」、「SOX法のすべて」を出力する。つまり、ユーザは、未読用語を入力すれば、当該未読用語を学習するための適切な文書を知ることができる。また、次に、ユーザが、出力された一の文書識別子を指示すれば、当該文書識別子で識別される文書が出力されても良い。
【0200】
次に、図13の状態で、ユーザが未読用語「コーポレート・ガバナンス」を指示した、とする。かかる場合、当該用語「コーポレート・ガバナンス」に対応する文書の識別子が出力される(図14(1)参照)。文書の識別子は、未読文書、既読文書、読書が途中の文書に区別されて、出力される。図14において、未読文書は下線かつBoldフォント、既読文書は下線なし、読書が途中の文書は下線かつ通常フォントである。また、図14(1)の文書識別子「情報戦略と統治」をユーザが指示した場合、当該「情報戦略と統治」が文書情報格納部101から読み出され、出力される(図14(2)参照)。なお、図14(2)は電子書籍がオープンされている概念を示した図である。
【0201】
次に、ユーザは、文書出力指示を入力した、とする。すると、受付部201は文書出力指示を受け付ける。
【0202】
次に、情報出力部206は、文書情報管理表から1以上の既読文書の識別子を取得する。また、情報出力部206は、文書情報管理表から1以上の未読文書の識別子を取得する。そして、情報出力部206は、1以上の既読文書の識別子、および1以上の未読文書の識別子を出力する。
【0203】
以下、文書処理装置2の他の具体的な動作を説明する。
(具体例1)
【0204】
具体例1において、文書処理装置2には、図15の(1)に示す電子書籍の活用メニューが表示されている、とする。ここで、ユーザは、「1.未知との遭遇」を選択した、とする。
【0205】
次に、情報出力部206は、未読用語格納部103から1以上の未読用語を取得する。そして、情報出力部206は、1以上の未読用語を出力する。かかる出力例が図15(2)である。そして、図15(2)の未読用語リストから、ユーザは、学習した事項「コーポレート・ガバナンス」を選択した、とする。
【0206】
次に、文書処理装置2の文書選択部202は、「コーポレート・ガバナンス」に対応する未読文書の識別子を取得し、出力する。かかる出力例が図15(3)である。そして、ユーザは、未読文書「×××経営塾」を指示する。そして、文書「×××経営塾」が出力される(図15(4))。
(具体例2)
【0207】
具体例2において、過去に読んだ書籍において、面白かった話題に対応する書籍を読みたい場合の書籍の選択である。
【0208】
まず、具体例2において、具体例1と同様、図16の(1)に示す電子書籍の活用メニューが表示されている、とする。ここで、ユーザは、「2.周辺の開拓」を選択し、キーワード「コーポレート・ガバナンス」を入力し、検索ボタンを押下した、とする。
【0209】
すると、文書処理装置2は、文書情報格納部101に存在する文書であり、かつ、「コーポレート・ガバナンス」に対応する文書の識別子を取得する。そして、文書処理装置2は、文書の識別子のリストを出力する。かかる出力例が図16(2)である。なお、かかる処理は、情報出力部206が行っても良い。
【0210】
次に、ユーザは、文書の識別子のリストから一の識別子「××の中の企業」を選択する。すると、文書処理装置2の用語取得部204は、「××の中の企業」に対応するすべての用語を、文書情報格納部101から取得する。ここで取得される用語には、既読用語が含まれても良い。次に、文書処理装置2の文書用語出力部205は、取得した1以上の用語を出力する(図16(3)参照)。なお、図16(3)において、既読用語と未読用語とが視覚的に区別されて出力されることは好適である。
【0211】
そして、ユーザは、1以上の用語をチェックした後、文書の識別子を指示すれば、当該文書が出力される(図16(4)参照)。
【0212】
以上、本実施の形態によれば、未読文書の中の情報を効率的に探し出すことができる。
【0213】
また、学本実施の形態によれば、学習したい内容を指定すると、当該内容について説明されている文書を提示できる。
【0214】
また、学本実施の形態によれば、文書を指定すると、当該文書で出現する用語を提示できる。
【0215】
なお、本実施の形態における文書処理装置を実現するソフトウェアは、以下のようなプログラムである。つまり、このプログラムは、記憶媒体に、1以上の文書と、各文書に対応付けられている1以上の用語または各文書の特定の箇所に対応付けられている1以上の用語と、既読の文書に対応する用語である1以上の既読用語と、未読の文書に対応する用語である1以上の未読用語とを格納しており、コンピュータを、文書を開く指示であるオープン指示を含む読書行為指示を受け付ける受付部と、前記受付部が前記オープン指示を受け付けた場合に、前記オープン指示に対応する文書を出力する文書出力部と、前記受付部が受け付けた読書行為指示に対応した読書履歴情報を取得する読書履歴情報取得部と、前記記憶媒体に格納されている1以上のいずれかの未読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、既読用語として、前記記憶媒体に蓄積する既読用語蓄積部として機能させるためのプログラム、である。
【0216】
また、上記プログラムにおいて、前記受付部は、1以上の未読用語を受け付け、前記受付部が1以上の未読用語を受け付けた場合に、当該1以上の未読用語のすべて、または当該1以上の未読用語のいずれかに対応する未読文書を選択する文書選択部と、前記未読文書を特定する情報を出力する文書特定情報出力部として、コンピュータをさらに機能させるプログラムであることは好適である。
【0217】
また、上記プログラムにおいて、前記受付部は、一の文書を特定する情報を受け付け、前記一の文書に対応する1以上の用語を前記文書情報格納部から取得する用語取得部と、前記用語取得部が取得した1以上の用語を出力する文書用語出力部とをさらに具備するものとして、コンピュータをさらに機能させるプログラムであることは好適である。
【0218】
また、図17は、本明細書で述べたプログラムを実行して、上述した実施の形態の文書処理装置等を実現するコンピュータの外観を示す。上述の実施の形態は、コンピュータハードウェア及びその上で実行されるコンピュータプログラムで実現され得る。図17は、このコンピュータシステム340の概観図であり、図18は、コンピュータシステム340のブロック図である。
【0219】
図17において、コンピュータシステム340は、FDドライブ、CD−ROMドライブを含むコンピュータ341と、キーボード342と、マウス343と、モニタ344とを含む。
【0220】
図18において、コンピュータ341は、FDドライブ3411、CD−ROMドライブ3412に加えて、MPU3413と、CD−ROMドライブ3412及びFDドライブ3411に接続されたバス3414と、ブートアッププログラム等のプログラムを記憶するためのROM3415とに接続され、アプリケーションプログラムの命令を一時的に記憶するとともに一時記憶空間を提供するためのRAM3416と、アプリケーションプログラム、システムプログラム、及びデータを記憶するためのハードディスク3417とを含む。ここでは、図示しないが、コンピュータ341は、さらに、LANへの接続を提供するネットワークカードを含んでも良い。
【0221】
コンピュータシステム340に、上述した実施の形態の文書処理装置等の機能を実行させるプログラムは、CD−ROM3501、またはFD3502に記憶されて、CD−ROMドライブ3412またはFDドライブ3411に挿入され、さらにハードディスク3417に転送されても良い。これに代えて、プログラムは、図示しないネットワークを介してコンピュータ341に送信され、ハードディスク3417に記憶されても良い。プログラムは実行の際にRAM3416にロードされる。プログラムは、CD−ROM3501、FD3502またはネットワークから直接、ロードされても良い。
【0222】
プログラムは、コンピュータ341に、上述した実施の形態の文書処理装置等の機能を実行させるオペレーティングシステム(OS)、またはサードパーティープログラム等は、必ずしも含まなくても良い。プログラムは、制御された態様で適切な機能(モジュール)を呼び出し、所望の結果が得られるようにする命令の部分のみを含んでいれば良い。コンピュータシステム340がどのように動作するかは周知であり、詳細な説明は省略する。
【0223】
また、上記プログラムを実行するコンピュータは、単数であってもよく、複数であってもよい。すなわち、集中処理を行ってもよく、あるいは分散処理を行ってもよい。
【0224】
また、上記各実施の形態において、各処理(各機能)は、単一の装置(システム)によって集中処理されることによって実現されてもよく、あるいは、複数の装置によって分散処理されることによって実現されてもよい。
【0225】
本発明は、以上の実施の形態に限定されることなく、種々の変更が可能であり、それらも本発明の範囲内に包含されるものであることは言うまでもない。
【産業上の利用可能性】
【0226】
以上のように、本発明にかかる文書処理装置は、既知の用語であるか未知の用語であるかを精度高く把握できる、という効果を有し、電子書籍装置等として有用である。
【符号の説明】
【0227】
1、2 文書処理装置
101 文書情報格納部
102 既読用語格納部
103 未読用語格納部
104 読書履歴情報格納部
105、201 受付部
106 文書出力部
107 読書履歴情報取得部
108 読書履歴情報蓄積部
109 既読用語蓄積部
110、202 文書選択部
111、203 文書特定情報出力部
112 用語抽出部
171 未読用語除外部
204 用語取得部
205 文書用語出力部
206 情報出力部
1101 文書決定手段
1102 照合手段
1103 文書選択手段
【特許請求の範囲】
【請求項1】
1以上の文書と、各文書に対応付けられている1以上の用語または各文書の特定の箇所に対応付けられている1以上の用語とを格納し得る文書情報格納部と、
未読の文書に対応する用語である1以上の未読用語を格納し得る未読用語格納部と、
文書を開く指示であるオープン指示を含む読書行為指示を受け付ける受付部と、
前記受付部が前記オープン指示を受け付けた場合に、前記オープン指示に対応する文書を出力する文書出力部と、
前記受付部が受け付けた読書行為指示に対応した読書履歴情報を取得する読書履歴情報取得部とを具備し、
前記未読用語格納部に格納されている1以上のいずれかの未読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、未読用語から除外する文書処理装置。
【請求項2】
既読の文書に対応する用語である1以上の既読用語を格納し得る既読用語格納部と、
前記未読用語格納部に格納されている1以上のいずれかの未読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、既読用語として、前記既読用語格納部に蓄積する既読用語蓄積部とをさらに具備する請求項1記載の文書処理装置。
【請求項3】
1以上の読書履歴情報を格納し得る読書履歴情報格納部と、
前記読書履歴情報取得部が取得した1以上の読書履歴情報を、前記読書履歴情報格納部に蓄積する読書履歴情報蓄積部と、
前記読書履歴情報格納部に格納されている1以上の読書履歴情報から決定され得る前記文書情報格納部に格納されている未読文書であり、前記既読用語格納部の1以上の既読用語、または前記未読用語格納部の1以上の未読用語、または前記既読用語格納部の1以上の既読用語と前記未読用語格納部の1以上の未読用語を用いて、前記未読文書に対応付けられている1以上の用語から、1以上の未読文書を選択する、または
前記読書履歴情報格納部に格納されている1以上の読書履歴情報から決定され得る前記文書情報格納部に格納されている既読文書であり、前記既読用語格納部の1以上の既読用語を用いて、前記既読文書に対応付けられている1以上の用語から、1以上の既読文書を選択する文書選択部と、
前記文書選択部が選択した未読文書または既読文書を特定する情報を出力する文書特定情報出力部とをさらに具備する請求項2記載の文書処理装置。
【請求項4】
前記文書選択部は、
前記読書履歴情報格納部に格納されている1以上の読書履歴情報から決定され得る前記文書情報格納部に格納されている1以上の未読文書を決定する文書決定手段と、
前記既読用語格納部の1以上の既読用語、または前記未読用語格納部の1以上の未読用語、または前記既読用語格納部の1以上の既読用語と前記未読用語格納部の1以上の未読用語を用いて、前記1以上の未読文書に対応付けられている1以上の用語を照合する照合手段と、
前記照合手段が照合した結果、予め決められた条件に合致する1以上の用語に対応付けられた未読文書を決定する文書選択手段とを具備する請求項3記載の文書処理装置。
【請求項5】
前記既読用語格納部は、
既読用語と当該既読用語に対応するスコアとを有する1以上の既読用語情報を格納しており、
前記既読用語蓄積部は、
前記未読用語格納部に格納されている1以上のいずれかの未読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、既読用語として、前記既読用語格納部に蓄積し、かつ、
前記既読用語格納部に格納されている1以上のいずれかの既読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語に対応するスコアを増加させる請求項2から請求項4いずれか記載の文書処理装置。
【請求項6】
前記受付部は、
1以上の未読用語を受け付け、
前記受付部が1以上の未読用語を受け付けた場合に、当該1以上の未読用語のすべて、または当該1以上の未読用語のいずれかに対応する未読文書を選択する文書選択部と、
前記未読文書を特定する情報を出力する文書特定情報出力部とをさらに具備する請求項1記載の文書処理装置。
【請求項7】
前記受付部は、
一の文書を特定する情報を受け付け、
前記一の文書に対応する1以上の用語を前記文書情報格納部から取得する用語取得部と、
前記用語取得部が取得した1以上の用語を出力する文書用語出力部とをさらに具備する請求項1から請求項6いずれか記載の文書処理装置。
【請求項8】
記憶媒体に、
1以上の文書と、各文書に対応付けられている1以上の用語または各文書の特定の箇所に対応付けられている1以上の用語と、
未読の文書に対応する用語である1以上の未読用語とを格納しており、
コンピュータを、
文書を開く指示であるオープン指示を含む読書行為指示を受け付ける受付部と、
前記受付部が前記オープン指示を受け付けた場合に、前記オープン指示に対応する文書を出力する文書出力部と、
前記受付部が受け付けた読書行為指示に対応した読書履歴情報を取得する読書履歴情報取得部と、
前記記憶媒体に格納されている1以上のいずれかの未読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、未読用語から除外する既読用語蓄積部として機能させるためのプログラム。
【請求項9】
記憶媒体に、
既読の文書に対応する用語である1以上の既読用語をさらに格納しており、
前記既読用語蓄積部は、
前記記憶媒体に格納されている1以上のいずれかの未読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、既読用語として、前記記憶媒体に蓄積するものとして、コンピュータを機能させるための請求項8記載のプログラム。
【請求項10】
記憶媒体に、
1以上の読書履歴情報をさらに格納しており、
コンピュータを、
前記読書履歴情報取得部が取得した1以上の読書履歴情報を、前記記憶媒体に蓄積する読書履歴情報蓄積部と、
前記記憶媒体に格納されている1以上の読書履歴情報から決定され得る前記記憶媒体に格納されている未読文書であり、前記1以上の既読用語、または前記1以上の未読用語、または前記1以上の既読用語と前記1以上の未読用語を用いて、前記未読文書に対応付けられている1以上の用語から、1以上の未読文書を選択する未読文書選択部と、
前記未読文書選択部が選択した未読文書を特定する情報を出力する未読文書特定情報出力部としてさらに機能させるための請求項9記載のプログラム。
【請求項1】
1以上の文書と、各文書に対応付けられている1以上の用語または各文書の特定の箇所に対応付けられている1以上の用語とを格納し得る文書情報格納部と、
未読の文書に対応する用語である1以上の未読用語を格納し得る未読用語格納部と、
文書を開く指示であるオープン指示を含む読書行為指示を受け付ける受付部と、
前記受付部が前記オープン指示を受け付けた場合に、前記オープン指示に対応する文書を出力する文書出力部と、
前記受付部が受け付けた読書行為指示に対応した読書履歴情報を取得する読書履歴情報取得部とを具備し、
前記未読用語格納部に格納されている1以上のいずれかの未読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、未読用語から除外する文書処理装置。
【請求項2】
既読の文書に対応する用語である1以上の既読用語を格納し得る既読用語格納部と、
前記未読用語格納部に格納されている1以上のいずれかの未読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、既読用語として、前記既読用語格納部に蓄積する既読用語蓄積部とをさらに具備する請求項1記載の文書処理装置。
【請求項3】
1以上の読書履歴情報を格納し得る読書履歴情報格納部と、
前記読書履歴情報取得部が取得した1以上の読書履歴情報を、前記読書履歴情報格納部に蓄積する読書履歴情報蓄積部と、
前記読書履歴情報格納部に格納されている1以上の読書履歴情報から決定され得る前記文書情報格納部に格納されている未読文書であり、前記既読用語格納部の1以上の既読用語、または前記未読用語格納部の1以上の未読用語、または前記既読用語格納部の1以上の既読用語と前記未読用語格納部の1以上の未読用語を用いて、前記未読文書に対応付けられている1以上の用語から、1以上の未読文書を選択する、または
前記読書履歴情報格納部に格納されている1以上の読書履歴情報から決定され得る前記文書情報格納部に格納されている既読文書であり、前記既読用語格納部の1以上の既読用語を用いて、前記既読文書に対応付けられている1以上の用語から、1以上の既読文書を選択する文書選択部と、
前記文書選択部が選択した未読文書または既読文書を特定する情報を出力する文書特定情報出力部とをさらに具備する請求項2記載の文書処理装置。
【請求項4】
前記文書選択部は、
前記読書履歴情報格納部に格納されている1以上の読書履歴情報から決定され得る前記文書情報格納部に格納されている1以上の未読文書を決定する文書決定手段と、
前記既読用語格納部の1以上の既読用語、または前記未読用語格納部の1以上の未読用語、または前記既読用語格納部の1以上の既読用語と前記未読用語格納部の1以上の未読用語を用いて、前記1以上の未読文書に対応付けられている1以上の用語を照合する照合手段と、
前記照合手段が照合した結果、予め決められた条件に合致する1以上の用語に対応付けられた未読文書を決定する文書選択手段とを具備する請求項3記載の文書処理装置。
【請求項5】
前記既読用語格納部は、
既読用語と当該既読用語に対応するスコアとを有する1以上の既読用語情報を格納しており、
前記既読用語蓄積部は、
前記未読用語格納部に格納されている1以上のいずれかの未読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、既読用語として、前記既読用語格納部に蓄積し、かつ、
前記既読用語格納部に格納されている1以上のいずれかの既読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語に対応するスコアを増加させる請求項2から請求項4いずれか記載の文書処理装置。
【請求項6】
前記受付部は、
1以上の未読用語を受け付け、
前記受付部が1以上の未読用語を受け付けた場合に、当該1以上の未読用語のすべて、または当該1以上の未読用語のいずれかに対応する未読文書を選択する文書選択部と、
前記未読文書を特定する情報を出力する文書特定情報出力部とをさらに具備する請求項1記載の文書処理装置。
【請求項7】
前記受付部は、
一の文書を特定する情報を受け付け、
前記一の文書に対応する1以上の用語を前記文書情報格納部から取得する用語取得部と、
前記用語取得部が取得した1以上の用語を出力する文書用語出力部とをさらに具備する請求項1から請求項6いずれか記載の文書処理装置。
【請求項8】
記憶媒体に、
1以上の文書と、各文書に対応付けられている1以上の用語または各文書の特定の箇所に対応付けられている1以上の用語と、
未読の文書に対応する用語である1以上の未読用語とを格納しており、
コンピュータを、
文書を開く指示であるオープン指示を含む読書行為指示を受け付ける受付部と、
前記受付部が前記オープン指示を受け付けた場合に、前記オープン指示に対応する文書を出力する文書出力部と、
前記受付部が受け付けた読書行為指示に対応した読書履歴情報を取得する読書履歴情報取得部と、
前記記憶媒体に格納されている1以上のいずれかの未読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、未読用語から除外する既読用語蓄積部として機能させるためのプログラム。
【請求項9】
記憶媒体に、
既読の文書に対応する用語である1以上の既読用語をさらに格納しており、
前記既読用語蓄積部は、
前記記憶媒体に格納されている1以上のいずれかの未読用語であり、前記読書履歴情報に対応する文書に対応する1以上の用語、または前記読書履歴情報に対応する文書中の特定箇所に対応する用語である1以上の用語を、既読用語として、前記記憶媒体に蓄積するものとして、コンピュータを機能させるための請求項8記載のプログラム。
【請求項10】
記憶媒体に、
1以上の読書履歴情報をさらに格納しており、
コンピュータを、
前記読書履歴情報取得部が取得した1以上の読書履歴情報を、前記記憶媒体に蓄積する読書履歴情報蓄積部と、
前記記憶媒体に格納されている1以上の読書履歴情報から決定され得る前記記憶媒体に格納されている未読文書であり、前記1以上の既読用語、または前記1以上の未読用語、または前記1以上の既読用語と前記1以上の未読用語を用いて、前記未読文書に対応付けられている1以上の用語から、1以上の未読文書を選択する未読文書選択部と、
前記未読文書選択部が選択した未読文書を特定する情報を出力する未読文書特定情報出力部としてさらに機能させるための請求項9記載のプログラム。
【図1】


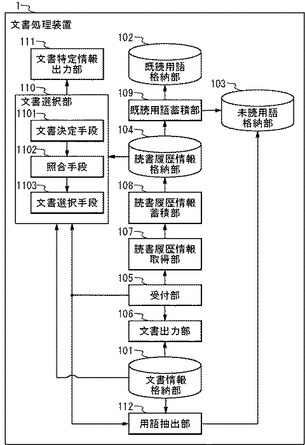
【図2】
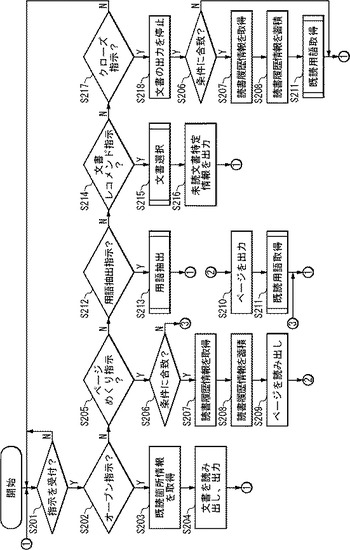
【図3】
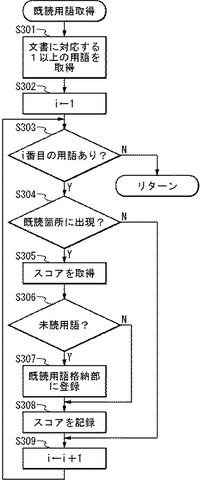
【図4】
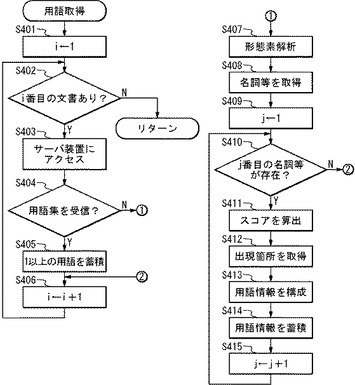
【図5】
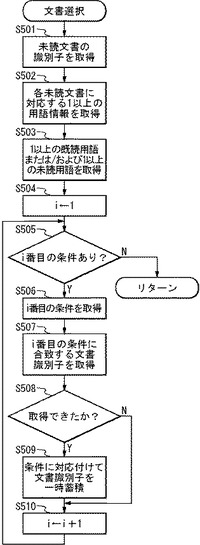
【図6】
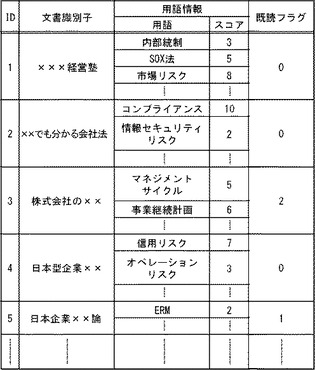
【図7】
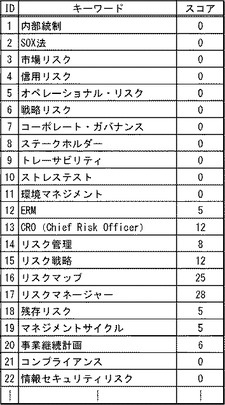
【図8】
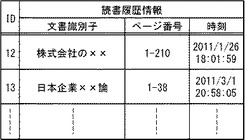
【図9】
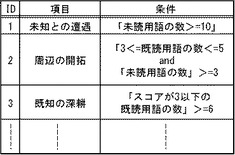
【図11】
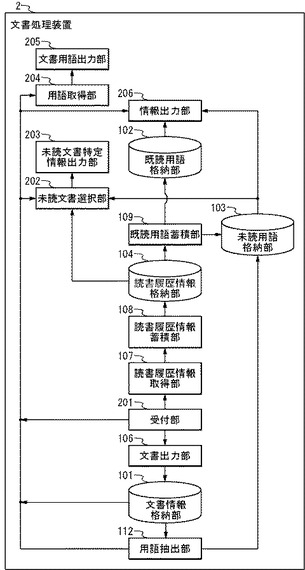
【図12】
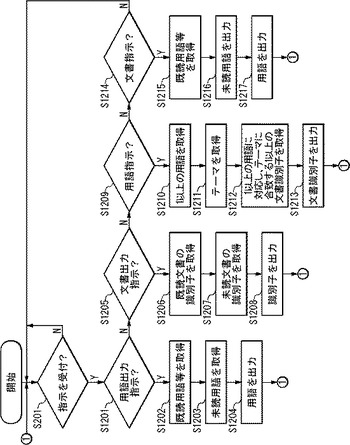
【図17】
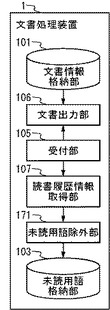
【図18】
【図19】
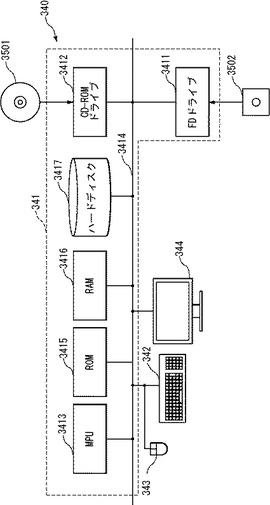
【図10】

【図13】

【図14】
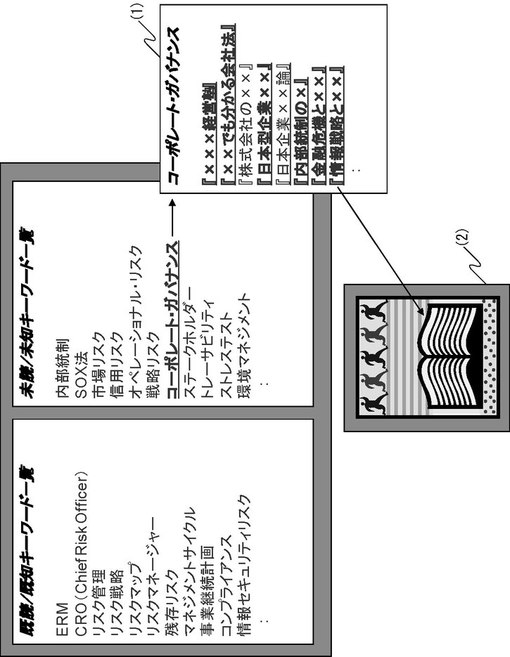
【図15】
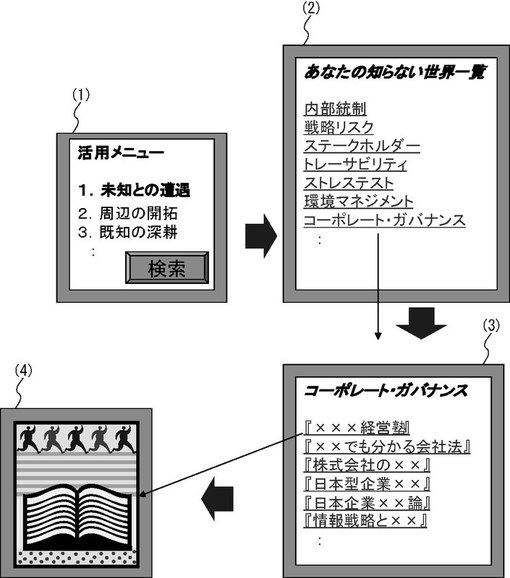
【図16】
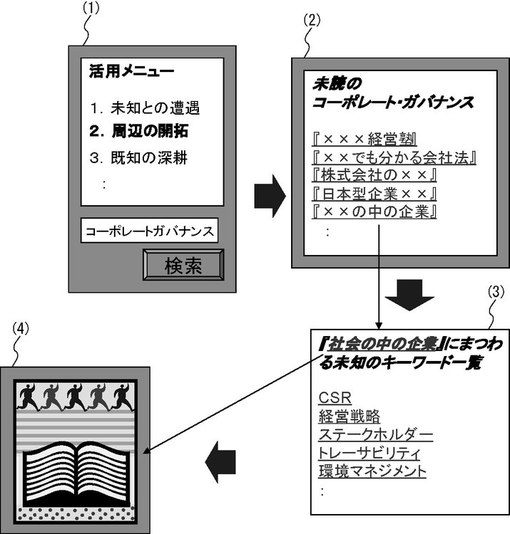
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図11】
【図12】
【図17】
【図18】
【図19】
【図10】
【図13】
【図14】
【図15】
【図16】
【公開番号】特開2012−203603(P2012−203603A)
【公開日】平成24年10月22日(2012.10.22)
【国際特許分類】
【出願番号】特願2011−66922(P2011−66922)
【出願日】平成23年3月25日(2011.3.25)
【出願人】(507228172)株式会社JSOL (23)
【Fターム(参考)】
【公開日】平成24年10月22日(2012.10.22)
【国際特許分類】
【出願日】平成23年3月25日(2011.3.25)
【出願人】(507228172)株式会社JSOL (23)
【Fターム(参考)】
[ Back to top ]