
文書処理装置および文書処理方法
【課題】文書ファイルからの情報抽出精度を向上させる。
【解決手段】学習コーパス200の単語は、複数のクラスのいずれかに分類されている。文書処理装置100は、学習コーパス200における単語の素性をクラスごとのクラス素性情報としてクラス素性保持部170に保持する。文書処理装置100は、加工前検査対象文書210から単語を抽出し、加工前検査対象文書210におけるその単語の素性とクラス素性情報の適合度を複数のクラスのそれぞれについて算出し、所定のクラスに対して算出された適合度を調整した上で、各クラスに対する適合度に基づいて抽出した単語に対応するクラスを特定する。そして、特定されたクラス名をタグとして追記することにより加工済検査対象文書212を生成する。
【解決手段】学習コーパス200の単語は、複数のクラスのいずれかに分類されている。文書処理装置100は、学習コーパス200における単語の素性をクラスごとのクラス素性情報としてクラス素性保持部170に保持する。文書処理装置100は、加工前検査対象文書210から単語を抽出し、加工前検査対象文書210におけるその単語の素性とクラス素性情報の適合度を複数のクラスのそれぞれについて算出し、所定のクラスに対して算出された適合度を調整した上で、各クラスに対する適合度に基づいて抽出した単語に対応するクラスを特定する。そして、特定されたクラス名をタグとして追記することにより加工済検査対象文書212を生成する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、文書ファイルからの情報抽出技術に関し、特に、固有表現抽出技術に関する。
【0002】
コンピュータの普及とネットワーク技術の進展にともない、ネットワークを介した電子情報の交換が盛んになっている。これにより、従来においては紙ベースで行われていた事務処理の多くが、ネットワークベースの処理に置き換えられつつある。デジタル化とネットワーク技術の進展は、情報取得コストを急激に低下させている。このような状況において、個々の文書の中から中心的な情報を抜き出す情報抽出(Information Extraction)技術、中でも、文書中から人名、会社名、年月日、役職名といった固有表現(Named Entity)を抜き出す固有表現抽出技術が注目されている。
【特許文献1】特開2006−048536号公報
【発明の開示】
【発明が解決しようとする課題】
【0003】
文書ファイルに含まれるさまざまな用語のうち、いわゆる固有表現に該当する用語は、文書の内容を特徴づける重要な情報であることが多い。しかし、絶えず新たな固有表現が生み出されるという現状において、どの単語が固有表現に該当し、どの単語が固有表現に該当しないのかという判別は容易ではない。
【0004】
本発明の目的は、文書からの情報抽出精度、特には、固有表現抽出の精度を向上させるための技術、を提供することである。
【課題を解決するための手段】
【0005】
本発明のある態様は、文書処理装置である。
この装置は、複数のクラスに単語を分類した上で、所定のコーパス(corpus)における単語の素性(そせい)をクラスごとのクラス素性情報として保持する。この装置は、検査対象文書から単語を抽出し、検査対象文書におけるその単語の素性とクラス素性情報の適合度を複数のクラスのそれぞれについて算出し、所定のクラスに対して算出された適合度を調整した上で、各クラスに対する適合度に基づいて抽出した単語に対応するクラスを特定する。
【0006】
ここでいう素性とは、文書中における単語の出現態様を示す情報である。たとえば、後ろに「さん」が付いていたり、前に「ミスター」、「親愛なる」といった用語が付いている単語は、人名を示す単語である可能性が高いといえる。検査対象文書から抽出した単語の素性と、あるクラス(カテゴリ)に属する単語の素性の傾向を比較することにより、抽出した単語がどのクラスに対応した単語であるか特定される。このとき、所定のクラス、たとえば、コーパスにおいて最も多くの単語が属するクラスについての適合度を調整することにより、情報抽出精度を向上させている。
【0007】
なお、以上の構成要素の任意の組み合わせ、本発明の表現を方法、システム、記録媒体、コンピュータプログラムなどの間で変換したものもまた、本発明の態様として有効である。
【発明の効果】
【0008】
本発明によれば、文書からの情報抽出精度を向上させることができる。
【発明を実施するための最良の形態】
【0009】
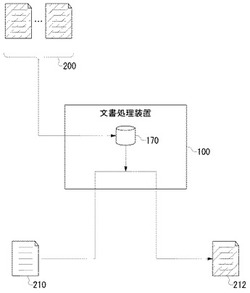
図1は、文書処理装置100による処理の概要を説明するための模式図である。
文書処理装置100の処理は、「学習処理」と「検査処理」の2段階に分けることができる。各段階について、それぞれの処理プロセスを概説すると以下の通りである。なお、本実施例における「文書ファイル」は、XML(eXtensible Markup Language)などの所定のタグセットによって構造化される構造化文書ファイルであるとして説明する。
【0010】
1.学習処理
学習処理は、学習コーパス(corpus)200からクラス素性情報を生成して、クラス素性保持部170に登録するまでの処理である。本実施例における学習コーパス200とは、大量の文書ファイルの集合である。
学習コーパス200に含まれている膨大な単語には、「クラス」が設定されている。クラスとは、単語のカテゴリを示す概念である。たとえば、学習コーパス200中のある文書ファイルにおいて「渋谷」という単語には「地名」というクラスが設定される。このような設定は、通常、人手で行われる。より具体的には、学習コーパス200内の所定の文書ファイル中の「渋谷」という単語に対して「クラス」という名前空間(namespace)にて<地名>というタグが設定されている。クラスは、タグではなく属性(attribute)として設定されてもよい。地名のほかにも人名や、年月日、組織名、役職、数値表現など、固有表現に該当する単語を分類するために数種類のクラスが用意されている。文書処理装置100は、このような学習コーパス200から単語を抽出する。
【0011】
学習コーパス200には明示的になんらかのクラスが指定される単語もあれば、固有表現に該当しないとして明示的にクラス指定されていない単語もある。通常は、前者に比べて後者の方が圧倒的に多くなる。このような固有表現に該当しない単語は、「Nクラス」として分類される。これに対して、固有表現に該当する単語に対して明示的に指定されているクラスのことを「固有クラス」とよぶことにする。本実施例においては、説明を簡単にするために、固有クラスとしては「人名」、「地名」、「日時」の3つのクラスだけを想定し、それ以外の単語は全てNクラスに分類される。すなわち、学習コーパス200に含まれる全ての単語は、「人名」、「地名」、「日時」の3つの固有クラスと1つのNクラスの計4つのクラスのうちのいずれかに分類されることになる。
【0012】
次に、文書処理装置100は学習コーパス200から収集された各単語について「素性(そせい)」を抽出する。素性とは、文書ファイル中における単語の出現態様を示す。たとえば、さきほどの「渋谷」という単語は、学習コーパス200では「渋谷駅で待ち合わせを・・・」という文脈で使用されていたとする。また、別の「代官山」という「地名」クラスに分類された単語は、学習コーパス200では「代官山駅で事故が・・」という文脈で使用されているとする。共に「地名」クラスに属する2つの単語に共通する点は、後ろに「駅」という単語が出現していることである。いいかえれば、文書ファイル中に「駅」という単語が出現するときには、直前に位置する単語は「地名」クラスである可能性が高いという推測が成り立つ。他の例として、「渋谷さんが・・・」というように後ろに「さん」という単語が付く場合には、「人名」クラスである可能性が高い。このように、学習コーパス200の単語、クラス、素性から、クラスごとの素性をクラス素性情報としてクラス素性保持部170に登録する。たとえば、「地名」クラスでは該当単語のうち、後ろに「駅」が付く確率は30%、「人名」クラスでは該当単語のうち、後ろに「駅」が付く確率は1%、といった具合にクラスごとに、その属する単語の素性がクラス素性情報として登録される。
【0013】
2.検査処理
検査処理は、「クラス」が明示的に指定されていない検査対象文書中の単語に対して、クラスを特定する処理である。「検査対象文書」とは、文書処理装置100の検査処理により、文書中の単語のクラスを新たに特定すべき文書ファイルである。
【0014】
まず、文書処理装置100は、「クラス」が指定されていない検査対象文書である加工前検査対象文書210を取得する。文書処理装置100は、加工前検査対象文書210から順次単語を抽出する。また、加工前検査対象文書210における各単語の素性も検出する。
【0015】
次に、文書処理装置100は、加工前検査対象文書210の単語の素性とクラス素性保持部170におけるクラス素性情報を比較する。たとえば、加工前検査対象文書210の単語Aに対して、単語Aの素性と「人名」クラスのクラス素性情報を比較し、その類似度を「適合度」として算出する。単語Aについては、そのほか、「地名」クラスに対する適合度、「日時」クラスに対する適合度、「N」クラスに対する適合度の計4種類の適合度が算出される。適合度の具体的な計算方法については後述する。
【0016】
文書処理装置100は、4種類の適合度のうち、最も大きい適合度となったクラスを、単語Aのクラスとして分類する。ここでは、単語Aが「地名」クラスに分類されたとする。その場合、文書処理装置100は加工前検査対象文書210の単語Aに対して<地名>タグを付与する。一方、単語Aが「N」クラスであれば、タグを付与しない。こうして、文書処理装置100は加工前検査対象文書210に含まれる全ての単語について、その素性とクラス素性情報からクラスを特定する。文書処理装置100は、加工済検査対象文書212を出力する。加工済検査対象文書212は、加工前検査対象文書210に対して固有クラスを示すタグ(以下、「固有タグ」とよぶ)が付与された文書ファイルである。なお、同図において、斜線が示されている文書ファイルは、固有タグが付与されている文書ファイルである。
加工済検査対象文書212の利用例として、加工済検査対象文書212の固有タグを検索キーとして、加工前検査対象文書210から求める情報を検索してもよい。たとえば、「渋谷で16時に加藤さんと待ち合わせ」という文章のように、「地名」クラスと「日時」クラス、「人名」クラスを含む文章構造を検索パターンとすることにより、加工前検査対象文書210に含まれる情報のうち、「いつ、どこで、誰と」というパターンの情報を効率的に捜すことができる。
【0017】
以上の処理プロセスは、ベイズ(bays)アルゴリズムを用いた典型的な固有表現抽出プロセスにおいても共通するプロセスである。しかし、上記したような処理プロセスの場合、加工前検査対象文書210中における単語群のうち、実際には固有表現にあたらない単語(以下、「非固有単語」とよぶ)であっても文書処理装置100によって固有表現にあたる単語(以下、「固有単語」とよぶ)にあたるとして固有クラスを特定されることが多い。本実施例では、上記プロセスに新たなプロセスを追加することにより、このような固有表現抽出アルゴリズムにおける課題を解決している。具体的な方法については、図5以降に関連して詳述するとして、まず、文書処理装置100の構成を先に説明する。
【0018】
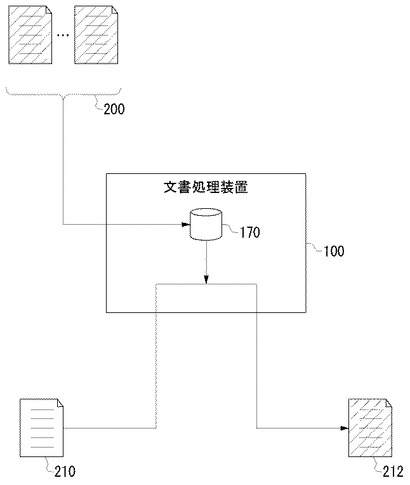
図2は、文書処理装置100の機能ブロック図である。
ここに示す各ブロックは、ハードウェア的には、コンピュータのCPUをはじめとする素子や機械装置で実現でき、ソフトウェア的にはコンピュータプログラム等によって実現されるが、ここでは、それらの連携によって実現される機能ブロックを描いている。したがって、これらの機能ブロックはハードウェア、ソフトウェアの組み合わせによっていろいろなかたちで実現できることは、当業者には理解されるところである。
【0019】
文書処理装置100は、ユーザインタフェース処理部110、データ処理部120およびデータ保持部130を含む。
ユーザインタフェース処理部110は、ユーザからの入力処理やユーザに対する情報表示のようなユーザインタフェース全般に関する処理を担当する。本実施例においては、ユーザインタフェース処理部110により文書処理装置100のユーザインタフェースサービスが提供されるものとして説明する。別例として、ユーザはインターネットを介して文書処理装置100を操作してもよい。この場合、図示しない通信部が、ユーザ端末からの操作指示情報を受信し、またその操作指示に基づいて実行された処理結果情報をユーザ端末に送信することになる。
【0020】
データ処理部120は、ユーザインタフェース処理部110から取得されたデータを元にして各種のデータ処理を実行する。データ処理部120は、ユーザインタフェース処理部110とデータ保持部130の間のインタフェースの役割も果たす。データ保持部130は、あらかじめ用意された設定データや、データ処理部120から受け取ったデータなど、さまざまなデータを格納する。データ保持部130は、クラス素性情報を保持するためのクラス素性保持部170を含む。
【0021】
ユーザインタフェース処理部110は、入力部112と表示部114を含む。入力部112は、ユーザからの入力操作を受け付ける。表示部114は、ユーザに対して各種情報を表示する。入力部112は、検査対象文書等の文書ファイルを取得するための文書取得部116を含む。
【0022】
データ処理部120は、検査部122と調整係数特定部134を含む。検査部122は、文書ファイルを検査して、文書ファイル中の単語についてのクラスを特定する。検査部122は、単語抽出部124、適合度計算部126、適合度調整部128およびクラス分類部132を含む。単語抽出部124は、文書ファイルから単語を抽出し、その素性を検出する。適合度計算部126は、クラス素性保持部170のクラス素性情報と、抽出された単語の素性の類似度を適合度という指標により算出する。適合度の計算方法については任意に設定すればよいが、一例として、次のような計算方法により算出してもよい。
【0023】
仮に、検査対象文書中の単語Aの直後の単語が「駅」であったとする(以下、単語Aのように、クラス分類のための検査対象となっている単語のことを「検査対象単語」とよぶことにする)。学習コーパス200から求められたクラス素性情報によると、地名クラスに属する1000単語のうち、直後に「駅」という単語が現れる単語は200単語(20%)であったとする。また、人名クラスに属する2000単語のうちでは20単語(1%)、日時クラスに属する500単語のうちでは10単語(2%)、Nクラスに属する10000単語のうちでは1500単語(15%)であったとする。このとき、単語Aの地名クラス、人名クラス、日時クラスおよびNクラスのそれぞれに対する適合度は、20点、1点、2点、15点となる。この場合、検査対象単語Aは、その素性から「地名」クラスに属する単語である可能性が高いという推測が成り立つ。なお、素性は、検査対象単語の直後の単語に限らず、文書ファイル中において検査対象単語の周辺に現れる各種単語を対象としてもよい。素性の定義としては、機械学習分野における既知のパラメータを用いればよい。ただし、本実施例では説明を簡単にするため、検査対象単語の直後の単語を、検査対象単語の素性として扱うものとする。
【0024】
クラス分類部132は、適合度に基づいて文書ファイル中の単語のクラスを特定する。上記設例の場合であれば、単語Aのクラスは適合度が最高の20点となっている地名クラスとなる。適合度調整部128は、適合度計算部126が算出した適合度を調整する。適合度調整部128による調整処理により、「実際には非固有単語であっても文書処理装置100によって固有単語として特定されることが多い」という先述した課題を解決している。適合度調整部128は調整係数特定部134によって特定された調整係数Tを用いて、検査対象単語のNクラスに対する適合度に(2−T)を乗じることによりその適合度を調整する。更に詳しくは図5以降に関連して後述する。
【0025】
調整係数特定部134は調整係数Tを特定する。調整係数特定部134は、暫定最適係数特定部136を含む。暫定最適係数特定部136は調整係数Tを求める上で必要となる暫定最適係数Sを特定する。暫定最適係数については、図7に関連して詳述する。
【0026】
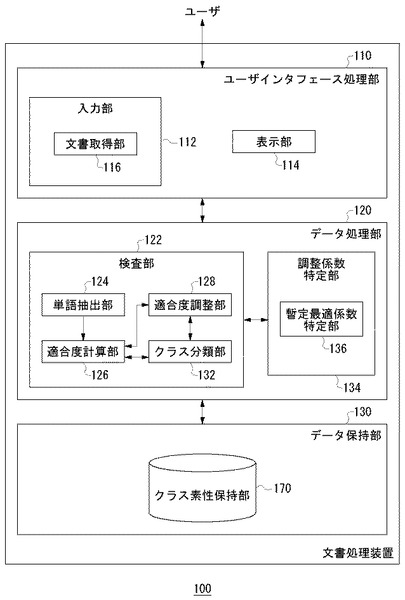
図3は、調整処理を実行しない場合における検査処理過程を示すフローチャートである。ここではある特定の検査対象文書中に含まれるある特定の単語を検査対象単語とした場合における処理過程を示している。したがって、同図に示すフローチャートは、検査対象文書中の各単語に対して順次実行される。
まず、単語抽出部124は、文書取得部116が取得した検査対象文書から検査対象単語を順次抽出する(S10)。単語抽出部124は検査対象単語の素性を検出する(S12)。ここでは、検査対象単語の直後に現れている単語を素性として検出する。
【0027】
適合度計算部126は、4種類のクラスのうち、まず、人名クラスを選択する(S14)。適合度計算部126は、クラス素性保持部170の人名クラスについてのクラス素性情報と検査対象単語の素性に基づいて、検査対象単語の人名クラスに対する適合度を計算する(S16)。S14およびS16の処理は、人名クラスのほかの各クラスについて実行される。全てのクラスについて適合度の計算が完了していないときには(S18のN)、処理はS14に戻って次のクラスが選択される。完了すると(S18のY)、クラス分類部132は4種類の適合度に基づいて、検査対象単語のクラスを特定する(S20)。特定されたクラスがNクラスでなければ(S22のN)、いいかえれば、いずれかの固有クラスであれば、クラス分類部132は検査対象単語に対して該当する固有タグを挿入する(S24)。Nクラスであれば(S22のY)、そのまま処理は終了する。このような処理を検査対象文書中の全ての単語について実行することにより、検査対象文書中の各単語のクラスを特定する。
【0028】
このような検査処理の精度を指標化するために、適合率(precision)、再現率(recall)およびF値(F measure)とよばれる3つの指標を用いている。本実施例では、これらの指標を、「実際の固有単語」と「固有単語として特定された単語」との一致の度合いを測るために用いている。仮に、検査対象文書中にN1個の単語が含まれており、そのうち、N2個が固有表現単語であるとする。そして、文書処理装置100は、この検査対象文書中のN1個の単語の中からN3個の単語を固有単語であるとして検出したとする。このとき、N4=N2∩N3、すなわち、N4を、実際の固有単語のうち文書処理装置100によって正しく検出された固有単語の数とすると、各指標は、
適合率V=N4/N3
再現率W=N4/N2
F値=2・V・W/(V+W)
として求められる。このようなF値の算出式は、適合率Vと再現率Wの調和平均である。
【0029】
適合率Vは、クラス分類部132によって固有単語と特定された単語のうち、実際に固有単語である単語の比率であり、いわば、誤検出がいかに発生していないかを示す指標である。再現率Wは、実際の固有単語のうちクラス分類部132によってに固有単語として検出された単語の比率であり、いわば、いかに固有単語がもれなく検出されているかを示す指標である。適合率Vと再現率Wは両方とも1.0に近いことが望ましいが、通常、両者はトレードオフの関係にある。F値は、これらの両方の指標に基づいて、システム全体を評価するために用いられる指標値である。F値が大きいほど、システムとしての固有表現検出性能がよいことになる。
【0030】
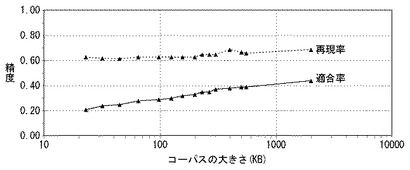
図4は、調整処理を実行しない場合における適合率と再現率を示すグラフ図である。
横軸は学習コーパス200のデータサイズを示す。縦軸は、適合率および再現率の値を示す。同図に示すグラフは、本発明者が所定の学習コーパス200を対象として実験を行った結果を示している。このグラフからわかるように、学習コーパス200のサイズが大きいほど、いいかえれば、クラス素性情報が充実するほど、再現率や適合率は共に漸増している。しかし、学習コーパス200のサイズが大きくなるということは、学習コーパス200中の単語にクラスを指定する作業が増加することになる。また、クラス素性保持部170のデータ量の増加は、文書処理装置100のメモリを圧迫することはいうまでもない。このグラフによれば、学習コーパス200のサイズが10倍、100倍となっても、再現率や適合率はそれほど大きく改善されないことがわかる。特に、適合率が低いという問題がある。適合率の低さは誤検出の多さを意味する。すなわち、固有単語と特定されている非固有単語が多く発生している。本発明者は、固有単語と特定されにくくするために、いいかえれば、非固有単語と特定されやすくするために調整係数Tを小さくして、検査対象単語のNクラスに対する適合度が大きくなるように調整することにより、F値を改善できると考えた。
【0031】
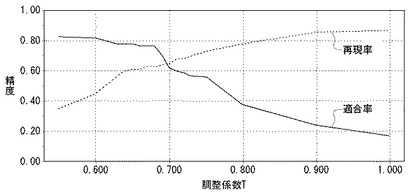
図5は、調整係数Tを変化させたときの適合率および再現率を示すグラフ図である。
横軸は、調整係数Tを示し、縦軸は、適合率および再現率の値を示す。以下、「Nクラスに対する適合度」として、調整前の適合度を調整前適合度X、調整後の適合度を調整後適合度Yとよぶ。
調整後適合度Y=調整前適合度X×(2−調整係数T)
である。したがって、調整係数T=1.0のときが、調整無しの場合に相当する。また、調整係数が小さいほど、調整後適合度Yが大きくなる。すなわち、検査対象単語がNクラスに分類されやすくなる。
【0032】
調整係数Tを小さくする場合、再現率は低下するが適合率は上昇する。調整係数Tが小さくなると、Nクラスに対する調整後適合度Yが増加する。固有単語に分類される単語の数N3が絞り込まれるため、適合率(V=N4/N3)が増加する。一方、固有単語として分類される単語の数N3の減少にともなって、実際の固有単語のうち文書処理装置100によって正しく検出された固有単語の数N4も減少するため、再現率(W=N4/N2)が減少することになる。調整係数Tを大きくする場合には逆となる。したがって、F値が最大になるように調整係数Tの値を設定することにより、文書処理装置100による検出対象単語の分類精度を向上させることができる。
次に、このような最適な調整係数Tを学習コーパス200に基づいて自動的に求めるためのアルゴリズムについて説明する。本実施例における文書処理装置100は、学習処理の段階で調整係数Tを特定する。
【0033】
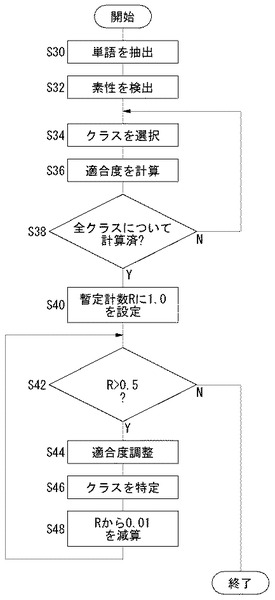
図6は、学習処理において、複数種類の調整係数に基づいて適合度を計算する処理過程を示すフローチャートである。
最適な調整係数Tの特定のために、学習コーパス200をK個(Kは2以上の整数)のグループに分割する。たとえば、学習コーパス200に1000個の文書ファイルが含まれ、これを10個のグループに分割する場合であれば、100文書ずつグループ化してもよい。K個のグループのうち、第iグループ(1≦i≦K)を検査グループ、それ以外のグループをコーパスグループとよぶことにする。たとえば、第1グループを検査グループとするときには、第2〜第Kグループまでをまとめたグループがコーパスグループとなる。同図は、K個のグループのうちの第iグループを検査グループとしたとき、第iグループのある特定の検査対象単語Aについて実行される処理を示している。したがって、同図に示す処理は、第iグループに含まれる他の検査対象単語についても実行される。また、第iグループ以外のグループについても同様である。
【0034】
まず、単語抽出部124は、検査グループである第iグループから検査対象単語Aを抽出する(S30)。単語抽出部124は、検査対象単語Aの素性を検出する(S32)。適合度計算部126は、4種類のクラスからクラスを選択する(S34)。適合度計算部126は、第iグループ以外のグループから成るコーパスグループ、すなわち、学習コーパス200から第iグループを除いた残りのコーパスに限定して得られるクラス素性情報と検査対象単語Aの素性に基づいて、検査対象単語AのS34にて選択されたクラスに対する適合度を計算する(S36)。全てのクラスについて適合度の計算が完了していないときには(S38のN)、処理はS34に戻って次のクラスが選択される。完了しているときには(S38のY)、適合度調整部128は暫定係数Rに1.0を設定する(S40)。暫定係数は、調整係数の値を確定する前に、所定範囲、たとえば0.5〜1.0の範囲で可変となる暫定的な係数である。
【0035】
暫定係数Rが0.5より大きければ(S42のY)、適合度調整部128は検査対象単語AのNクラスに対する適合度を暫定係数Rにより調整する(S44)。調整方法は、上述した通りである。クラス分類部132は4種類の適合度に基づいて、検査対象単語Aのクラスを特定する(S46)。適合度調整部128は、暫定係数から所定値、たとえば、0.01を減算する(S48)。暫定係数Rが0.5より大きければ、新たな暫定係数Rにより、S44〜S48までの処理が再実行される。暫定係数Rが0.5以下となると(S42のN)、検査対象単語Aに対する処理は終了する。このような処理により、第iグループの一つの検査対象単語Aのクラスが、さまざまな暫定係数に基づいて特定される。たとえば、この検査対象単語Aは暫定係数が0.8のときには人名クラスとして特定され、暫定係数が0.6のときにはNクラスとして特定されるかもしれない。全てのグループを順次検査グループとして選択し、各グループに含まれる全ての単語を検査対象単語として順次選択する。結果として、学習コーパス200の全ての単語について、暫定係数0.5から1.0までのそれぞれの場合におけるクラスが特定される。
【0036】
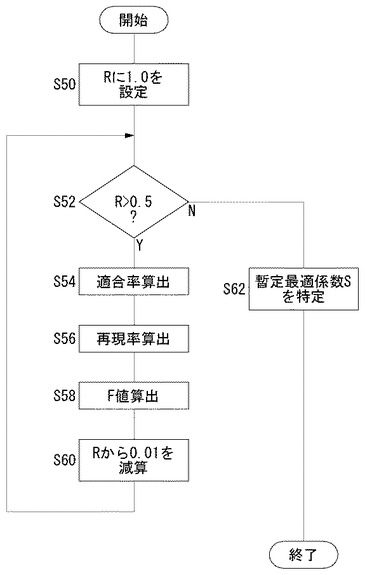
図7は、図6に示した処理が完了した後に、暫定最適係数Sを求める処理過程を示すフローチャートである。
ここでは、K個のグループのうちの第iグループについて最適な、いいかえれば、F値が最高となるときの暫定係数を暫定最適係数Sとして特定するための処理を示している。同図に示す処理は、第iグループ以外の各グループについても実行される。結果として、K個のグループに対して、K個の暫定最適係数Sが求められることになる。
【0037】
まず、調整係数特定部134は、暫定係数Rに1.0を設定する(S50)。暫定係数Rが0.5より大きければ(S52のY)、暫定最適係数特定部136は、第iグループに含まれる単語についての適合率を算出する(S54)。すなわち、第iグループに含まれる単語群のうち、固有単語として特定された単語のうち、実際に固有単語である単語の比率を適合率として算出する。次に、暫定最適係数特定部136は、第iグループに含まれる単語についての再現率を算出し(S56)、適合率と再現率に基づいてF値を算出する(S58)。暫定最適係数特定部136は、暫定係数Rから0.01を減算する(S60)。暫定係数Rが0.5以下となると(S52のN)、暫定最適係数特定部136は、各暫定係数に対するF値のうち、F値が最大となったときの暫定係数Rを暫定最適係数Sとして特定する(S62)。こうして、学習コーパス200における第iグループにとって、F値が最大となるときの調整係数である暫定最適係数Sが特定される。
【0038】
同様にして、K個のグループのそれぞれに対して、K個の暫定最適係数を求める。調整係数計算部138は、K個の暫定最適係数の平均値を調整係数Tとする。このような処理方法によれば、既に、単語に対する正しいクラスが設定済の学習コーパス200を利用して、好適なF値を求めることにより、学習コーパス200に応じた妥当な調整係数を探ることができる。なお、平均値に限らず、調整係数Tは、K個の暫定最適係数を変数とする所定の演算式にて求めればよい。たとえば、K個の暫定最適係数Sのうち、F値が最高となるときの暫定最適係数をそのまま調整係数Tとしてもよい。仮に、K=2として、第1グループにおける暫定最適係数Sが0.6でそのときのF値が0.8、第2グループにおける暫定最適係数Sが0.65でそのときのF値が0.75であったときには、調整係数Tは0.6となる。なぜならば、F値0.8の方が、他方のF値0.75よりも大きいためである。
【0039】
また、本実施例では、F値が最大になるときの暫定係数を暫定最適係数としたが、F値に限らず、検査グループに含まれる単語の本来のクラスと特定されたクラスとの一致度を示す任意の指標に基づいて、その一致度が最大になるときの暫定係数を暫定最適係数Sとしてもよい。たとえば、検査グループの単語のうち、本来のクラスと特定されたクラスが一致する単語の数が最大になるときの暫定係数を暫定最適係数Sとしてもよい。一例として、検査グループに人名クラスを指定されている単語のうち、実際に人名クラスとして指定された単語の数が最大となるときの暫定係数を暫定最適係数としてもよい。
【0040】
本実施例においては、学習コーパス200をK個のグループに分類し、それぞれのグループを順次検査グループとして、K個の暫定最適係数Sを求めるとして説明したが、学習コーパス200を2つに分割して、一方検査グループ、他方をコーパスグループとして1個の暫定最適係数Sを求めるとしてもよい。この場合、求められた暫定最適係数Sをそのまま調整係数としてもよい。学習コーパス200を分割した各グループの全ての組み合わせにて検査してもよいが、全ての組み合わせによる検査は本発明の必須条件ではない。たとえば、学習コーパス200をグループA、グループBおよびグループCの3つに分割した場合、(検査グループ、コーパスグループ)は(A、B+C)、(B、A+C)、(C、A+B)の3通りの組み合わせが考えられる。しかし、これら3つの組み合わせのうち、2つの組み合わせについてだけ検査を行うとしてもよい。
【0041】
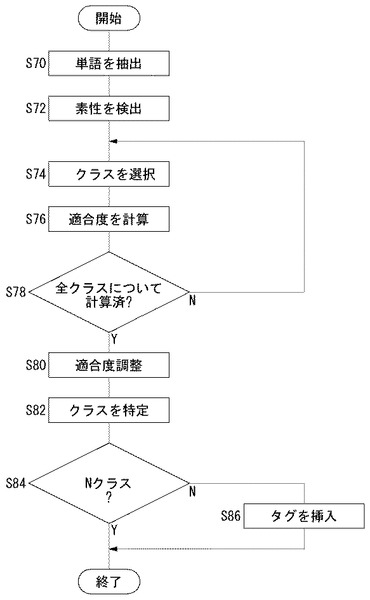
図8は、調整処理を実行する場合における検査処理過程を示すフローチャートである。ここでも、ある検査対象文書中に含まれる単語を検査対象単語とする処理内容を示している。したがって、同図に示すフローチャートは、検査対象文書中の各単語に対して実行される。
S70からS78までの処理は、図3のS10からS18の処理と同じであるため、説明を割愛する。適合度調整部128は、調整係数特定部134によって決定された調整係数により、Nクラスに対する適合度を調整する(S80)。クラス分類部132は、調整後の適合度を参照して、検査対象単語のクラスを特定する(S82)。S84以降の処理内容は、図3のS22以降の処理内容と同様である。すなわち、検査処理においては、事実上、Nクラスに対する適合度に(2−調整係数T)を乗算する処理が追加されるだけである。
【0042】
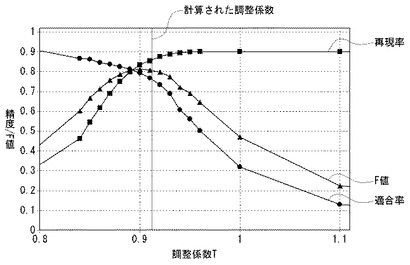
図9は、本実施例に示した調整係数特定アルゴリズムの検証結果を示すグラフ図である。
本発明者が所定の学習コーパス200に対する学習処理を実行すると、調整係数特定部134は調整係数T=0.912として算出された。このあと、あらかじめ特定されるべきクラスがわかっている検査対象文書について、調整係数Tをさまざまな値に変化させながら、適合率、再現率およびF値を実際に計算してみると、同図に示すようなグラフが形成された。実際には、調整係数T=0.900の近辺で、F値が極大値となっている。調整係数特定部134が特定した調整係数T=0.912とは若干のずれがあるものの、かなり高い精度で、最適な調整係数Tを学習コーパス200のデータから求めることに成功している。特に、調整処理を行わない場合、すなわち、調整係数T=1.0の場合に比べれば、F値を格段に改善できることが確認された。
【0043】
以上、本実施例に基づいて本発明を説明した。
文書処理装置100による調整処理によれば、ベイズアルゴリズムに基づく文書ファイルからの情報抽出において、その抽出精度を向上させることができる。具体的には、検査対象文書からの固有単語の抽出精度を高めることができる。本実施例においては、固有クラスとNクラスに大別することにより固有単語の抽出精度の向上を主たる目的として説明したが、所定のクラスAとそれ以外のクラスを任意に設定してF値を求めることで、クラスAに該当する単語の抽出精度を高めることもできる。Nクラスに限らず、複数のクラスのうち、学習コーパス200において、最も多くの単語が分類されるクラスを調整の対象としてもよい。ただし、通常の学習コーパス200の場合、最も多くの単語が分類されるクラスはNクラスとなることが多いと考えられる。
【0044】
更に、調整係数Tを学習コーパス200をベースとして自動的に特定するアルゴリズムについて説明した。このため、文書処理装置100は、学習処理の段階で、抽出精度が最大となる調整係数を自動的に求めることができる。
【0045】
加工前検査対象文書210から加工済検査対象文書212を生成することにより、任意の検査対象文書において、どのようなクラスに属する単語が使われているかを検出しやすくなる。たとえば、「私は京都から奈良に旅行しました」という文章のように、人名クラス、地名クラス、地名クラスという順序で単語を含む文章は、人の移動を示す文章である可能性が比較的高い。このように、クラスやその並び方から所定のイベントに関連する情報を抽出しやすくなる。
【0046】
なお、適合度=log(適合率)と定義すると(底は10とする)、適合率は0以上1以下の値であるため、適合度は必ず負の値となる。この場合、調整後適合度Y=調整前適合度X×調整係数Tとして計算してもよい。すなわち、1.0以下の調整係数Tを調整前適合度Xに乗じることにより、負の数である調整前適合度Xの絶対値が小さくなるため、結果として調整後適合度Yは調整前適合度Xよりも大きくなる。
【0047】
以上、本発明を実施の形態をもとに説明した。この実施の形態は例示であり、それらの各構成要素や各処理プロセスの組み合わせにいろいろな変形例が可能なこと、またそうした変形例も本発明の範囲にあることは当業者に理解されるところである。
【0048】
また、各請求項に記載の各構成要件が果たすべき機能は、本実施例において示された各機能ブロックの単体もしくはそれらの連係によって実現されることも当業者には理解されるところである。
【図面の簡単な説明】
【0049】
【図1】文書処理装置による処理の概要を説明するための模式図である。
【図2】文書処理装置の機能ブロック図である。
【図3】調整処理を実行しない場合における検査処理過程を示すフローチャートである。
【図4】調整処理を実行しない場合における適合率と再現率を示すグラフ図である。
【図5】調整係数Tを変化させたときの適合率および再現率を示すグラフ図である。
【図6】学習処理において、複数種類の調整係数に基づいて適合度を計算する処理過程を示すフローチャートである。
【図7】図6に示した処理が完了した後に、暫定最適係数Sを求める処理過程を示すフローチャートである。
【図8】調整処理を実行する場合における検査処理過程を示すフローチャートである。
【図9】本実施例に示した調整係数特定アルゴリズムの検証結果を示すグラフ図である。
【符号の説明】
【0050】
100 文書処理装置、 110 ユーザインタフェース処理部、 112 入力部、 114 表示部、 116 文書取得部、 120 データ処理部、 122 検査部、 124 単語抽出部、 126 適合度計算部、 128 適合度調整部、 130 データ保持部、 132 クラス分類部、 134 調整係数特定部、 136 暫定最適係数特定部、 170 クラス素性保持部、 200 学習コーパス、 210 加工前検査対象文書、 212 加工済検査対象文書。
【技術分野】
【0001】
本発明は、文書ファイルからの情報抽出技術に関し、特に、固有表現抽出技術に関する。
【0002】
コンピュータの普及とネットワーク技術の進展にともない、ネットワークを介した電子情報の交換が盛んになっている。これにより、従来においては紙ベースで行われていた事務処理の多くが、ネットワークベースの処理に置き換えられつつある。デジタル化とネットワーク技術の進展は、情報取得コストを急激に低下させている。このような状況において、個々の文書の中から中心的な情報を抜き出す情報抽出(Information Extraction)技術、中でも、文書中から人名、会社名、年月日、役職名といった固有表現(Named Entity)を抜き出す固有表現抽出技術が注目されている。
【特許文献1】特開2006−048536号公報
【発明の開示】
【発明が解決しようとする課題】
【0003】
文書ファイルに含まれるさまざまな用語のうち、いわゆる固有表現に該当する用語は、文書の内容を特徴づける重要な情報であることが多い。しかし、絶えず新たな固有表現が生み出されるという現状において、どの単語が固有表現に該当し、どの単語が固有表現に該当しないのかという判別は容易ではない。
【0004】
本発明の目的は、文書からの情報抽出精度、特には、固有表現抽出の精度を向上させるための技術、を提供することである。
【課題を解決するための手段】
【0005】
本発明のある態様は、文書処理装置である。
この装置は、複数のクラスに単語を分類した上で、所定のコーパス(corpus)における単語の素性(そせい)をクラスごとのクラス素性情報として保持する。この装置は、検査対象文書から単語を抽出し、検査対象文書におけるその単語の素性とクラス素性情報の適合度を複数のクラスのそれぞれについて算出し、所定のクラスに対して算出された適合度を調整した上で、各クラスに対する適合度に基づいて抽出した単語に対応するクラスを特定する。
【0006】
ここでいう素性とは、文書中における単語の出現態様を示す情報である。たとえば、後ろに「さん」が付いていたり、前に「ミスター」、「親愛なる」といった用語が付いている単語は、人名を示す単語である可能性が高いといえる。検査対象文書から抽出した単語の素性と、あるクラス(カテゴリ)に属する単語の素性の傾向を比較することにより、抽出した単語がどのクラスに対応した単語であるか特定される。このとき、所定のクラス、たとえば、コーパスにおいて最も多くの単語が属するクラスについての適合度を調整することにより、情報抽出精度を向上させている。
【0007】
なお、以上の構成要素の任意の組み合わせ、本発明の表現を方法、システム、記録媒体、コンピュータプログラムなどの間で変換したものもまた、本発明の態様として有効である。
【発明の効果】
【0008】
本発明によれば、文書からの情報抽出精度を向上させることができる。
【発明を実施するための最良の形態】
【0009】
図1は、文書処理装置100による処理の概要を説明するための模式図である。
文書処理装置100の処理は、「学習処理」と「検査処理」の2段階に分けることができる。各段階について、それぞれの処理プロセスを概説すると以下の通りである。なお、本実施例における「文書ファイル」は、XML(eXtensible Markup Language)などの所定のタグセットによって構造化される構造化文書ファイルであるとして説明する。
【0010】
1.学習処理
学習処理は、学習コーパス(corpus)200からクラス素性情報を生成して、クラス素性保持部170に登録するまでの処理である。本実施例における学習コーパス200とは、大量の文書ファイルの集合である。
学習コーパス200に含まれている膨大な単語には、「クラス」が設定されている。クラスとは、単語のカテゴリを示す概念である。たとえば、学習コーパス200中のある文書ファイルにおいて「渋谷」という単語には「地名」というクラスが設定される。このような設定は、通常、人手で行われる。より具体的には、学習コーパス200内の所定の文書ファイル中の「渋谷」という単語に対して「クラス」という名前空間(namespace)にて<地名>というタグが設定されている。クラスは、タグではなく属性(attribute)として設定されてもよい。地名のほかにも人名や、年月日、組織名、役職、数値表現など、固有表現に該当する単語を分類するために数種類のクラスが用意されている。文書処理装置100は、このような学習コーパス200から単語を抽出する。
【0011】
学習コーパス200には明示的になんらかのクラスが指定される単語もあれば、固有表現に該当しないとして明示的にクラス指定されていない単語もある。通常は、前者に比べて後者の方が圧倒的に多くなる。このような固有表現に該当しない単語は、「Nクラス」として分類される。これに対して、固有表現に該当する単語に対して明示的に指定されているクラスのことを「固有クラス」とよぶことにする。本実施例においては、説明を簡単にするために、固有クラスとしては「人名」、「地名」、「日時」の3つのクラスだけを想定し、それ以外の単語は全てNクラスに分類される。すなわち、学習コーパス200に含まれる全ての単語は、「人名」、「地名」、「日時」の3つの固有クラスと1つのNクラスの計4つのクラスのうちのいずれかに分類されることになる。
【0012】
次に、文書処理装置100は学習コーパス200から収集された各単語について「素性(そせい)」を抽出する。素性とは、文書ファイル中における単語の出現態様を示す。たとえば、さきほどの「渋谷」という単語は、学習コーパス200では「渋谷駅で待ち合わせを・・・」という文脈で使用されていたとする。また、別の「代官山」という「地名」クラスに分類された単語は、学習コーパス200では「代官山駅で事故が・・」という文脈で使用されているとする。共に「地名」クラスに属する2つの単語に共通する点は、後ろに「駅」という単語が出現していることである。いいかえれば、文書ファイル中に「駅」という単語が出現するときには、直前に位置する単語は「地名」クラスである可能性が高いという推測が成り立つ。他の例として、「渋谷さんが・・・」というように後ろに「さん」という単語が付く場合には、「人名」クラスである可能性が高い。このように、学習コーパス200の単語、クラス、素性から、クラスごとの素性をクラス素性情報としてクラス素性保持部170に登録する。たとえば、「地名」クラスでは該当単語のうち、後ろに「駅」が付く確率は30%、「人名」クラスでは該当単語のうち、後ろに「駅」が付く確率は1%、といった具合にクラスごとに、その属する単語の素性がクラス素性情報として登録される。
【0013】
2.検査処理
検査処理は、「クラス」が明示的に指定されていない検査対象文書中の単語に対して、クラスを特定する処理である。「検査対象文書」とは、文書処理装置100の検査処理により、文書中の単語のクラスを新たに特定すべき文書ファイルである。
【0014】
まず、文書処理装置100は、「クラス」が指定されていない検査対象文書である加工前検査対象文書210を取得する。文書処理装置100は、加工前検査対象文書210から順次単語を抽出する。また、加工前検査対象文書210における各単語の素性も検出する。
【0015】
次に、文書処理装置100は、加工前検査対象文書210の単語の素性とクラス素性保持部170におけるクラス素性情報を比較する。たとえば、加工前検査対象文書210の単語Aに対して、単語Aの素性と「人名」クラスのクラス素性情報を比較し、その類似度を「適合度」として算出する。単語Aについては、そのほか、「地名」クラスに対する適合度、「日時」クラスに対する適合度、「N」クラスに対する適合度の計4種類の適合度が算出される。適合度の具体的な計算方法については後述する。
【0016】
文書処理装置100は、4種類の適合度のうち、最も大きい適合度となったクラスを、単語Aのクラスとして分類する。ここでは、単語Aが「地名」クラスに分類されたとする。その場合、文書処理装置100は加工前検査対象文書210の単語Aに対して<地名>タグを付与する。一方、単語Aが「N」クラスであれば、タグを付与しない。こうして、文書処理装置100は加工前検査対象文書210に含まれる全ての単語について、その素性とクラス素性情報からクラスを特定する。文書処理装置100は、加工済検査対象文書212を出力する。加工済検査対象文書212は、加工前検査対象文書210に対して固有クラスを示すタグ(以下、「固有タグ」とよぶ)が付与された文書ファイルである。なお、同図において、斜線が示されている文書ファイルは、固有タグが付与されている文書ファイルである。
加工済検査対象文書212の利用例として、加工済検査対象文書212の固有タグを検索キーとして、加工前検査対象文書210から求める情報を検索してもよい。たとえば、「渋谷で16時に加藤さんと待ち合わせ」という文章のように、「地名」クラスと「日時」クラス、「人名」クラスを含む文章構造を検索パターンとすることにより、加工前検査対象文書210に含まれる情報のうち、「いつ、どこで、誰と」というパターンの情報を効率的に捜すことができる。
【0017】
以上の処理プロセスは、ベイズ(bays)アルゴリズムを用いた典型的な固有表現抽出プロセスにおいても共通するプロセスである。しかし、上記したような処理プロセスの場合、加工前検査対象文書210中における単語群のうち、実際には固有表現にあたらない単語(以下、「非固有単語」とよぶ)であっても文書処理装置100によって固有表現にあたる単語(以下、「固有単語」とよぶ)にあたるとして固有クラスを特定されることが多い。本実施例では、上記プロセスに新たなプロセスを追加することにより、このような固有表現抽出アルゴリズムにおける課題を解決している。具体的な方法については、図5以降に関連して詳述するとして、まず、文書処理装置100の構成を先に説明する。
【0018】
図2は、文書処理装置100の機能ブロック図である。
ここに示す各ブロックは、ハードウェア的には、コンピュータのCPUをはじめとする素子や機械装置で実現でき、ソフトウェア的にはコンピュータプログラム等によって実現されるが、ここでは、それらの連携によって実現される機能ブロックを描いている。したがって、これらの機能ブロックはハードウェア、ソフトウェアの組み合わせによっていろいろなかたちで実現できることは、当業者には理解されるところである。
【0019】
文書処理装置100は、ユーザインタフェース処理部110、データ処理部120およびデータ保持部130を含む。
ユーザインタフェース処理部110は、ユーザからの入力処理やユーザに対する情報表示のようなユーザインタフェース全般に関する処理を担当する。本実施例においては、ユーザインタフェース処理部110により文書処理装置100のユーザインタフェースサービスが提供されるものとして説明する。別例として、ユーザはインターネットを介して文書処理装置100を操作してもよい。この場合、図示しない通信部が、ユーザ端末からの操作指示情報を受信し、またその操作指示に基づいて実行された処理結果情報をユーザ端末に送信することになる。
【0020】
データ処理部120は、ユーザインタフェース処理部110から取得されたデータを元にして各種のデータ処理を実行する。データ処理部120は、ユーザインタフェース処理部110とデータ保持部130の間のインタフェースの役割も果たす。データ保持部130は、あらかじめ用意された設定データや、データ処理部120から受け取ったデータなど、さまざまなデータを格納する。データ保持部130は、クラス素性情報を保持するためのクラス素性保持部170を含む。
【0021】
ユーザインタフェース処理部110は、入力部112と表示部114を含む。入力部112は、ユーザからの入力操作を受け付ける。表示部114は、ユーザに対して各種情報を表示する。入力部112は、検査対象文書等の文書ファイルを取得するための文書取得部116を含む。
【0022】
データ処理部120は、検査部122と調整係数特定部134を含む。検査部122は、文書ファイルを検査して、文書ファイル中の単語についてのクラスを特定する。検査部122は、単語抽出部124、適合度計算部126、適合度調整部128およびクラス分類部132を含む。単語抽出部124は、文書ファイルから単語を抽出し、その素性を検出する。適合度計算部126は、クラス素性保持部170のクラス素性情報と、抽出された単語の素性の類似度を適合度という指標により算出する。適合度の計算方法については任意に設定すればよいが、一例として、次のような計算方法により算出してもよい。
【0023】
仮に、検査対象文書中の単語Aの直後の単語が「駅」であったとする(以下、単語Aのように、クラス分類のための検査対象となっている単語のことを「検査対象単語」とよぶことにする)。学習コーパス200から求められたクラス素性情報によると、地名クラスに属する1000単語のうち、直後に「駅」という単語が現れる単語は200単語(20%)であったとする。また、人名クラスに属する2000単語のうちでは20単語(1%)、日時クラスに属する500単語のうちでは10単語(2%)、Nクラスに属する10000単語のうちでは1500単語(15%)であったとする。このとき、単語Aの地名クラス、人名クラス、日時クラスおよびNクラスのそれぞれに対する適合度は、20点、1点、2点、15点となる。この場合、検査対象単語Aは、その素性から「地名」クラスに属する単語である可能性が高いという推測が成り立つ。なお、素性は、検査対象単語の直後の単語に限らず、文書ファイル中において検査対象単語の周辺に現れる各種単語を対象としてもよい。素性の定義としては、機械学習分野における既知のパラメータを用いればよい。ただし、本実施例では説明を簡単にするため、検査対象単語の直後の単語を、検査対象単語の素性として扱うものとする。
【0024】
クラス分類部132は、適合度に基づいて文書ファイル中の単語のクラスを特定する。上記設例の場合であれば、単語Aのクラスは適合度が最高の20点となっている地名クラスとなる。適合度調整部128は、適合度計算部126が算出した適合度を調整する。適合度調整部128による調整処理により、「実際には非固有単語であっても文書処理装置100によって固有単語として特定されることが多い」という先述した課題を解決している。適合度調整部128は調整係数特定部134によって特定された調整係数Tを用いて、検査対象単語のNクラスに対する適合度に(2−T)を乗じることによりその適合度を調整する。更に詳しくは図5以降に関連して後述する。
【0025】
調整係数特定部134は調整係数Tを特定する。調整係数特定部134は、暫定最適係数特定部136を含む。暫定最適係数特定部136は調整係数Tを求める上で必要となる暫定最適係数Sを特定する。暫定最適係数については、図7に関連して詳述する。
【0026】
図3は、調整処理を実行しない場合における検査処理過程を示すフローチャートである。ここではある特定の検査対象文書中に含まれるある特定の単語を検査対象単語とした場合における処理過程を示している。したがって、同図に示すフローチャートは、検査対象文書中の各単語に対して順次実行される。
まず、単語抽出部124は、文書取得部116が取得した検査対象文書から検査対象単語を順次抽出する(S10)。単語抽出部124は検査対象単語の素性を検出する(S12)。ここでは、検査対象単語の直後に現れている単語を素性として検出する。
【0027】
適合度計算部126は、4種類のクラスのうち、まず、人名クラスを選択する(S14)。適合度計算部126は、クラス素性保持部170の人名クラスについてのクラス素性情報と検査対象単語の素性に基づいて、検査対象単語の人名クラスに対する適合度を計算する(S16)。S14およびS16の処理は、人名クラスのほかの各クラスについて実行される。全てのクラスについて適合度の計算が完了していないときには(S18のN)、処理はS14に戻って次のクラスが選択される。完了すると(S18のY)、クラス分類部132は4種類の適合度に基づいて、検査対象単語のクラスを特定する(S20)。特定されたクラスがNクラスでなければ(S22のN)、いいかえれば、いずれかの固有クラスであれば、クラス分類部132は検査対象単語に対して該当する固有タグを挿入する(S24)。Nクラスであれば(S22のY)、そのまま処理は終了する。このような処理を検査対象文書中の全ての単語について実行することにより、検査対象文書中の各単語のクラスを特定する。
【0028】
このような検査処理の精度を指標化するために、適合率(precision)、再現率(recall)およびF値(F measure)とよばれる3つの指標を用いている。本実施例では、これらの指標を、「実際の固有単語」と「固有単語として特定された単語」との一致の度合いを測るために用いている。仮に、検査対象文書中にN1個の単語が含まれており、そのうち、N2個が固有表現単語であるとする。そして、文書処理装置100は、この検査対象文書中のN1個の単語の中からN3個の単語を固有単語であるとして検出したとする。このとき、N4=N2∩N3、すなわち、N4を、実際の固有単語のうち文書処理装置100によって正しく検出された固有単語の数とすると、各指標は、
適合率V=N4/N3
再現率W=N4/N2
F値=2・V・W/(V+W)
として求められる。このようなF値の算出式は、適合率Vと再現率Wの調和平均である。
【0029】
適合率Vは、クラス分類部132によって固有単語と特定された単語のうち、実際に固有単語である単語の比率であり、いわば、誤検出がいかに発生していないかを示す指標である。再現率Wは、実際の固有単語のうちクラス分類部132によってに固有単語として検出された単語の比率であり、いわば、いかに固有単語がもれなく検出されているかを示す指標である。適合率Vと再現率Wは両方とも1.0に近いことが望ましいが、通常、両者はトレードオフの関係にある。F値は、これらの両方の指標に基づいて、システム全体を評価するために用いられる指標値である。F値が大きいほど、システムとしての固有表現検出性能がよいことになる。
【0030】
図4は、調整処理を実行しない場合における適合率と再現率を示すグラフ図である。
横軸は学習コーパス200のデータサイズを示す。縦軸は、適合率および再現率の値を示す。同図に示すグラフは、本発明者が所定の学習コーパス200を対象として実験を行った結果を示している。このグラフからわかるように、学習コーパス200のサイズが大きいほど、いいかえれば、クラス素性情報が充実するほど、再現率や適合率は共に漸増している。しかし、学習コーパス200のサイズが大きくなるということは、学習コーパス200中の単語にクラスを指定する作業が増加することになる。また、クラス素性保持部170のデータ量の増加は、文書処理装置100のメモリを圧迫することはいうまでもない。このグラフによれば、学習コーパス200のサイズが10倍、100倍となっても、再現率や適合率はそれほど大きく改善されないことがわかる。特に、適合率が低いという問題がある。適合率の低さは誤検出の多さを意味する。すなわち、固有単語と特定されている非固有単語が多く発生している。本発明者は、固有単語と特定されにくくするために、いいかえれば、非固有単語と特定されやすくするために調整係数Tを小さくして、検査対象単語のNクラスに対する適合度が大きくなるように調整することにより、F値を改善できると考えた。
【0031】
図5は、調整係数Tを変化させたときの適合率および再現率を示すグラフ図である。
横軸は、調整係数Tを示し、縦軸は、適合率および再現率の値を示す。以下、「Nクラスに対する適合度」として、調整前の適合度を調整前適合度X、調整後の適合度を調整後適合度Yとよぶ。
調整後適合度Y=調整前適合度X×(2−調整係数T)
である。したがって、調整係数T=1.0のときが、調整無しの場合に相当する。また、調整係数が小さいほど、調整後適合度Yが大きくなる。すなわち、検査対象単語がNクラスに分類されやすくなる。
【0032】
調整係数Tを小さくする場合、再現率は低下するが適合率は上昇する。調整係数Tが小さくなると、Nクラスに対する調整後適合度Yが増加する。固有単語に分類される単語の数N3が絞り込まれるため、適合率(V=N4/N3)が増加する。一方、固有単語として分類される単語の数N3の減少にともなって、実際の固有単語のうち文書処理装置100によって正しく検出された固有単語の数N4も減少するため、再現率(W=N4/N2)が減少することになる。調整係数Tを大きくする場合には逆となる。したがって、F値が最大になるように調整係数Tの値を設定することにより、文書処理装置100による検出対象単語の分類精度を向上させることができる。
次に、このような最適な調整係数Tを学習コーパス200に基づいて自動的に求めるためのアルゴリズムについて説明する。本実施例における文書処理装置100は、学習処理の段階で調整係数Tを特定する。
【0033】
図6は、学習処理において、複数種類の調整係数に基づいて適合度を計算する処理過程を示すフローチャートである。
最適な調整係数Tの特定のために、学習コーパス200をK個(Kは2以上の整数)のグループに分割する。たとえば、学習コーパス200に1000個の文書ファイルが含まれ、これを10個のグループに分割する場合であれば、100文書ずつグループ化してもよい。K個のグループのうち、第iグループ(1≦i≦K)を検査グループ、それ以外のグループをコーパスグループとよぶことにする。たとえば、第1グループを検査グループとするときには、第2〜第Kグループまでをまとめたグループがコーパスグループとなる。同図は、K個のグループのうちの第iグループを検査グループとしたとき、第iグループのある特定の検査対象単語Aについて実行される処理を示している。したがって、同図に示す処理は、第iグループに含まれる他の検査対象単語についても実行される。また、第iグループ以外のグループについても同様である。
【0034】
まず、単語抽出部124は、検査グループである第iグループから検査対象単語Aを抽出する(S30)。単語抽出部124は、検査対象単語Aの素性を検出する(S32)。適合度計算部126は、4種類のクラスからクラスを選択する(S34)。適合度計算部126は、第iグループ以外のグループから成るコーパスグループ、すなわち、学習コーパス200から第iグループを除いた残りのコーパスに限定して得られるクラス素性情報と検査対象単語Aの素性に基づいて、検査対象単語AのS34にて選択されたクラスに対する適合度を計算する(S36)。全てのクラスについて適合度の計算が完了していないときには(S38のN)、処理はS34に戻って次のクラスが選択される。完了しているときには(S38のY)、適合度調整部128は暫定係数Rに1.0を設定する(S40)。暫定係数は、調整係数の値を確定する前に、所定範囲、たとえば0.5〜1.0の範囲で可変となる暫定的な係数である。
【0035】
暫定係数Rが0.5より大きければ(S42のY)、適合度調整部128は検査対象単語AのNクラスに対する適合度を暫定係数Rにより調整する(S44)。調整方法は、上述した通りである。クラス分類部132は4種類の適合度に基づいて、検査対象単語Aのクラスを特定する(S46)。適合度調整部128は、暫定係数から所定値、たとえば、0.01を減算する(S48)。暫定係数Rが0.5より大きければ、新たな暫定係数Rにより、S44〜S48までの処理が再実行される。暫定係数Rが0.5以下となると(S42のN)、検査対象単語Aに対する処理は終了する。このような処理により、第iグループの一つの検査対象単語Aのクラスが、さまざまな暫定係数に基づいて特定される。たとえば、この検査対象単語Aは暫定係数が0.8のときには人名クラスとして特定され、暫定係数が0.6のときにはNクラスとして特定されるかもしれない。全てのグループを順次検査グループとして選択し、各グループに含まれる全ての単語を検査対象単語として順次選択する。結果として、学習コーパス200の全ての単語について、暫定係数0.5から1.0までのそれぞれの場合におけるクラスが特定される。
【0036】
図7は、図6に示した処理が完了した後に、暫定最適係数Sを求める処理過程を示すフローチャートである。
ここでは、K個のグループのうちの第iグループについて最適な、いいかえれば、F値が最高となるときの暫定係数を暫定最適係数Sとして特定するための処理を示している。同図に示す処理は、第iグループ以外の各グループについても実行される。結果として、K個のグループに対して、K個の暫定最適係数Sが求められることになる。
【0037】
まず、調整係数特定部134は、暫定係数Rに1.0を設定する(S50)。暫定係数Rが0.5より大きければ(S52のY)、暫定最適係数特定部136は、第iグループに含まれる単語についての適合率を算出する(S54)。すなわち、第iグループに含まれる単語群のうち、固有単語として特定された単語のうち、実際に固有単語である単語の比率を適合率として算出する。次に、暫定最適係数特定部136は、第iグループに含まれる単語についての再現率を算出し(S56)、適合率と再現率に基づいてF値を算出する(S58)。暫定最適係数特定部136は、暫定係数Rから0.01を減算する(S60)。暫定係数Rが0.5以下となると(S52のN)、暫定最適係数特定部136は、各暫定係数に対するF値のうち、F値が最大となったときの暫定係数Rを暫定最適係数Sとして特定する(S62)。こうして、学習コーパス200における第iグループにとって、F値が最大となるときの調整係数である暫定最適係数Sが特定される。
【0038】
同様にして、K個のグループのそれぞれに対して、K個の暫定最適係数を求める。調整係数計算部138は、K個の暫定最適係数の平均値を調整係数Tとする。このような処理方法によれば、既に、単語に対する正しいクラスが設定済の学習コーパス200を利用して、好適なF値を求めることにより、学習コーパス200に応じた妥当な調整係数を探ることができる。なお、平均値に限らず、調整係数Tは、K個の暫定最適係数を変数とする所定の演算式にて求めればよい。たとえば、K個の暫定最適係数Sのうち、F値が最高となるときの暫定最適係数をそのまま調整係数Tとしてもよい。仮に、K=2として、第1グループにおける暫定最適係数Sが0.6でそのときのF値が0.8、第2グループにおける暫定最適係数Sが0.65でそのときのF値が0.75であったときには、調整係数Tは0.6となる。なぜならば、F値0.8の方が、他方のF値0.75よりも大きいためである。
【0039】
また、本実施例では、F値が最大になるときの暫定係数を暫定最適係数としたが、F値に限らず、検査グループに含まれる単語の本来のクラスと特定されたクラスとの一致度を示す任意の指標に基づいて、その一致度が最大になるときの暫定係数を暫定最適係数Sとしてもよい。たとえば、検査グループの単語のうち、本来のクラスと特定されたクラスが一致する単語の数が最大になるときの暫定係数を暫定最適係数Sとしてもよい。一例として、検査グループに人名クラスを指定されている単語のうち、実際に人名クラスとして指定された単語の数が最大となるときの暫定係数を暫定最適係数としてもよい。
【0040】
本実施例においては、学習コーパス200をK個のグループに分類し、それぞれのグループを順次検査グループとして、K個の暫定最適係数Sを求めるとして説明したが、学習コーパス200を2つに分割して、一方検査グループ、他方をコーパスグループとして1個の暫定最適係数Sを求めるとしてもよい。この場合、求められた暫定最適係数Sをそのまま調整係数としてもよい。学習コーパス200を分割した各グループの全ての組み合わせにて検査してもよいが、全ての組み合わせによる検査は本発明の必須条件ではない。たとえば、学習コーパス200をグループA、グループBおよびグループCの3つに分割した場合、(検査グループ、コーパスグループ)は(A、B+C)、(B、A+C)、(C、A+B)の3通りの組み合わせが考えられる。しかし、これら3つの組み合わせのうち、2つの組み合わせについてだけ検査を行うとしてもよい。
【0041】
図8は、調整処理を実行する場合における検査処理過程を示すフローチャートである。ここでも、ある検査対象文書中に含まれる単語を検査対象単語とする処理内容を示している。したがって、同図に示すフローチャートは、検査対象文書中の各単語に対して実行される。
S70からS78までの処理は、図3のS10からS18の処理と同じであるため、説明を割愛する。適合度調整部128は、調整係数特定部134によって決定された調整係数により、Nクラスに対する適合度を調整する(S80)。クラス分類部132は、調整後の適合度を参照して、検査対象単語のクラスを特定する(S82)。S84以降の処理内容は、図3のS22以降の処理内容と同様である。すなわち、検査処理においては、事実上、Nクラスに対する適合度に(2−調整係数T)を乗算する処理が追加されるだけである。
【0042】
図9は、本実施例に示した調整係数特定アルゴリズムの検証結果を示すグラフ図である。
本発明者が所定の学習コーパス200に対する学習処理を実行すると、調整係数特定部134は調整係数T=0.912として算出された。このあと、あらかじめ特定されるべきクラスがわかっている検査対象文書について、調整係数Tをさまざまな値に変化させながら、適合率、再現率およびF値を実際に計算してみると、同図に示すようなグラフが形成された。実際には、調整係数T=0.900の近辺で、F値が極大値となっている。調整係数特定部134が特定した調整係数T=0.912とは若干のずれがあるものの、かなり高い精度で、最適な調整係数Tを学習コーパス200のデータから求めることに成功している。特に、調整処理を行わない場合、すなわち、調整係数T=1.0の場合に比べれば、F値を格段に改善できることが確認された。
【0043】
以上、本実施例に基づいて本発明を説明した。
文書処理装置100による調整処理によれば、ベイズアルゴリズムに基づく文書ファイルからの情報抽出において、その抽出精度を向上させることができる。具体的には、検査対象文書からの固有単語の抽出精度を高めることができる。本実施例においては、固有クラスとNクラスに大別することにより固有単語の抽出精度の向上を主たる目的として説明したが、所定のクラスAとそれ以外のクラスを任意に設定してF値を求めることで、クラスAに該当する単語の抽出精度を高めることもできる。Nクラスに限らず、複数のクラスのうち、学習コーパス200において、最も多くの単語が分類されるクラスを調整の対象としてもよい。ただし、通常の学習コーパス200の場合、最も多くの単語が分類されるクラスはNクラスとなることが多いと考えられる。
【0044】
更に、調整係数Tを学習コーパス200をベースとして自動的に特定するアルゴリズムについて説明した。このため、文書処理装置100は、学習処理の段階で、抽出精度が最大となる調整係数を自動的に求めることができる。
【0045】
加工前検査対象文書210から加工済検査対象文書212を生成することにより、任意の検査対象文書において、どのようなクラスに属する単語が使われているかを検出しやすくなる。たとえば、「私は京都から奈良に旅行しました」という文章のように、人名クラス、地名クラス、地名クラスという順序で単語を含む文章は、人の移動を示す文章である可能性が比較的高い。このように、クラスやその並び方から所定のイベントに関連する情報を抽出しやすくなる。
【0046】
なお、適合度=log(適合率)と定義すると(底は10とする)、適合率は0以上1以下の値であるため、適合度は必ず負の値となる。この場合、調整後適合度Y=調整前適合度X×調整係数Tとして計算してもよい。すなわち、1.0以下の調整係数Tを調整前適合度Xに乗じることにより、負の数である調整前適合度Xの絶対値が小さくなるため、結果として調整後適合度Yは調整前適合度Xよりも大きくなる。
【0047】
以上、本発明を実施の形態をもとに説明した。この実施の形態は例示であり、それらの各構成要素や各処理プロセスの組み合わせにいろいろな変形例が可能なこと、またそうした変形例も本発明の範囲にあることは当業者に理解されるところである。
【0048】
また、各請求項に記載の各構成要件が果たすべき機能は、本実施例において示された各機能ブロックの単体もしくはそれらの連係によって実現されることも当業者には理解されるところである。
【図面の簡単な説明】
【0049】
【図1】文書処理装置による処理の概要を説明するための模式図である。
【図2】文書処理装置の機能ブロック図である。
【図3】調整処理を実行しない場合における検査処理過程を示すフローチャートである。
【図4】調整処理を実行しない場合における適合率と再現率を示すグラフ図である。
【図5】調整係数Tを変化させたときの適合率および再現率を示すグラフ図である。
【図6】学習処理において、複数種類の調整係数に基づいて適合度を計算する処理過程を示すフローチャートである。
【図7】図6に示した処理が完了した後に、暫定最適係数Sを求める処理過程を示すフローチャートである。
【図8】調整処理を実行する場合における検査処理過程を示すフローチャートである。
【図9】本実施例に示した調整係数特定アルゴリズムの検証結果を示すグラフ図である。
【符号の説明】
【0050】
100 文書処理装置、 110 ユーザインタフェース処理部、 112 入力部、 114 表示部、 116 文書取得部、 120 データ処理部、 122 検査部、 124 単語抽出部、 126 適合度計算部、 128 適合度調整部、 130 データ保持部、 132 クラス分類部、 134 調整係数特定部、 136 暫定最適係数特定部、 170 クラス素性保持部、 200 学習コーパス、 210 加工前検査対象文書、 212 加工済検査対象文書。
【特許請求の範囲】
【請求項1】
複数のクラスに単語を分類した上で、所定のコーパス(corpus)における単語の素性をクラスごとのクラス素性情報として保持するクラス素性保持部と、
検査対象文書を取得する文書取得部と、
前記検査対象文書から単語を抽出する単語抽出部と、
前記検査対象文書における前記抽出された単語の素性とクラス素性情報の適合度を前記複数のクラスのそれぞれについて算出する適合度計算部と、
前記複数のクラスのうち所定のクラスに対して算出された適合度を調整する適合度調整部と、
前記抽出された単語の各クラスに対する適合度に基づいて、前記抽出された単語に対応するクラスを特定するクラス分類部と、
を備えることを特徴とする文書処理装置。
【請求項2】
前記所定のコーパスは、文書中の単語に対してあらかじめクラスが指定されている文書群であることを特徴とする請求項1に記載の文書処理装置。
【請求項3】
前記所定のクラスは、前記所定のコーパスにおいて明示的にクラスが指定されていない単語が分類されるクラスであることを特徴とする請求項2に記載の文書処理装置。
【請求項4】
前記所定のクラスは、前記所定のコーパスにおいて最も多くの単語が分類されるクラスであることを特徴とする請求項1または2に記載の文書処理装置。
【請求項5】
前記適合度調整部は、前記所定のクラスに対する適合度に対して、調整係数を変数とする所定演算を実行することにより、前記抽出された単語の前記所定のクラスに対する適合度を調整することを特徴とする請求項1から4のいずれか記載の文書処理装置。
【請求項6】
調整係数の値を特定する調整係数特定部、を更に備え、
調整係数の特定に際しては、
前記適合度計算部は、前記所定のコーパスをコーパスグループと検査グループに分割し、検査グループにおける単語の素性とコーパスグループを対象として求められるクラス素性情報の適合度を前記複数のクラスのそれぞれに対して算出し、
前記適合度調整部は、暫定的な調整係数である暫定係数により、検査グループに含まれる単語の前記所定のクラスに対する適合度を調整し、
前記クラス分類部は、前記所定のクラスに対する適合度が暫定係数により調整された後に、検査グループに含まれる単語のクラスを特定し、
前記調整係数特定部は、検査グループに含まれる単語群における特定されたクラスと本来のクラスとの一致度に応じて複数種類の暫定係数の中から調整係数を特定することを特徴とする請求項5に記載の文書処理装置。
【請求項7】
前記調整係数特定部は、検査グループに含まれる単語のうち前記所定のクラス以外のクラスに属する単語と前記所定のクラス以外のクラスに属すると特定された単語を比較することによりクラス分類の精度を計算し、前記複数種類の暫定係数のうちクラス分類の精度が最大となるときの暫定係数を調整係数として特定することを特徴とする請求項6に記載の文書処理装置。
【請求項8】
前記調整係数特定部は、適合率(precision)と再現率(recall)から求められるF値(F measure)をクラス分類の精度として計算することを特徴とする請求項7に記載の文書処理装置。
【請求項9】
前記調整係数特定部は、前記複数種類の暫定係数のうち、検査グループに含まれる単語群において特定されたクラスと本来のクラスが一致する単語の数が最大となるときの暫定係数を調整係数として特定することを特徴とする請求項6に記載の文書処理装置。
【請求項10】
前記調整係数特定部は、前記所定のコーパスを2以上の所定数のグループに分割し、そのうちの一つを検査グループ、残りをコーパスグループとすることにより、検査グループに含まれる単語群における特定されたクラスと本来のクラスとの一致度に応じて複数種類の暫定係数の中から暫定最適係数を特定し、前記所定数のグループのそれぞれを検査グループとすることにより求められた前記所定数の暫定最適係数に基づいて調整係数を決定することを特徴とする請求項6から9のいずれかに記載の文書処理装置。
【請求項11】
前記調整係数特定部は、前記所定数の暫定最適係数の平均値を調整係数とすることを特徴とする請求項10に記載の文書処理装置。
【請求項12】
前記調整係数特定部は、前記所定数の暫定最適係数のうち、検査グループに含まれる単語群において本来のクラスと特定されたクラスの一致度が最大となるときの暫定最適係数を調整係数として決定することを特徴とする請求項10に記載の文書処理装置。
【請求項13】
検査対象文書を取得するステップと、
前記検査対象文書から単語を抽出するステップと、
複数のクラスに単語を分類した上で所定のコーパス(corpus)における単語の素性をクラスごとに分類したクラス素性情報を参照して、前記検査対象文書における前記抽出された単語の素性とクラス素性情報の適合度を前記複数のクラスのそれぞれについて算出するステップと、
前記複数のクラスのうち所定のクラスに対して算出された適合度を調整するステップと、
前記抽出された単語の各クラスに対する適合度に基づいて、前記抽出された単語に対応するクラスを特定するステップと、
を備えることを特徴とする文書処理方法。
【請求項14】
複数のクラスに単語を分類した上で、所定のコーパス(corpus)における単語の素性をクラスごとのクラス素性情報として保持する機能と、
検査対象文書を取得する機能と、
前記検査対象文書から単語を抽出する機能と、
前記検査対象文書における前記抽出された単語の素性とクラス素性情報の適合度を前記複数のクラスのそれぞれについて算出する機能と、
前記複数のクラスのうち所定のクラスに対して算出された適合度を調整する機能と、
前記抽出された単語の各クラスに対する適合度に基づいて、前記抽出された単語に対応するクラスを特定する機能と、
をコンピュータにて発揮させることを特徴とする文書処理プログラム。
【請求項1】
複数のクラスに単語を分類した上で、所定のコーパス(corpus)における単語の素性をクラスごとのクラス素性情報として保持するクラス素性保持部と、
検査対象文書を取得する文書取得部と、
前記検査対象文書から単語を抽出する単語抽出部と、
前記検査対象文書における前記抽出された単語の素性とクラス素性情報の適合度を前記複数のクラスのそれぞれについて算出する適合度計算部と、
前記複数のクラスのうち所定のクラスに対して算出された適合度を調整する適合度調整部と、
前記抽出された単語の各クラスに対する適合度に基づいて、前記抽出された単語に対応するクラスを特定するクラス分類部と、
を備えることを特徴とする文書処理装置。
【請求項2】
前記所定のコーパスは、文書中の単語に対してあらかじめクラスが指定されている文書群であることを特徴とする請求項1に記載の文書処理装置。
【請求項3】
前記所定のクラスは、前記所定のコーパスにおいて明示的にクラスが指定されていない単語が分類されるクラスであることを特徴とする請求項2に記載の文書処理装置。
【請求項4】
前記所定のクラスは、前記所定のコーパスにおいて最も多くの単語が分類されるクラスであることを特徴とする請求項1または2に記載の文書処理装置。
【請求項5】
前記適合度調整部は、前記所定のクラスに対する適合度に対して、調整係数を変数とする所定演算を実行することにより、前記抽出された単語の前記所定のクラスに対する適合度を調整することを特徴とする請求項1から4のいずれか記載の文書処理装置。
【請求項6】
調整係数の値を特定する調整係数特定部、を更に備え、
調整係数の特定に際しては、
前記適合度計算部は、前記所定のコーパスをコーパスグループと検査グループに分割し、検査グループにおける単語の素性とコーパスグループを対象として求められるクラス素性情報の適合度を前記複数のクラスのそれぞれに対して算出し、
前記適合度調整部は、暫定的な調整係数である暫定係数により、検査グループに含まれる単語の前記所定のクラスに対する適合度を調整し、
前記クラス分類部は、前記所定のクラスに対する適合度が暫定係数により調整された後に、検査グループに含まれる単語のクラスを特定し、
前記調整係数特定部は、検査グループに含まれる単語群における特定されたクラスと本来のクラスとの一致度に応じて複数種類の暫定係数の中から調整係数を特定することを特徴とする請求項5に記載の文書処理装置。
【請求項7】
前記調整係数特定部は、検査グループに含まれる単語のうち前記所定のクラス以外のクラスに属する単語と前記所定のクラス以外のクラスに属すると特定された単語を比較することによりクラス分類の精度を計算し、前記複数種類の暫定係数のうちクラス分類の精度が最大となるときの暫定係数を調整係数として特定することを特徴とする請求項6に記載の文書処理装置。
【請求項8】
前記調整係数特定部は、適合率(precision)と再現率(recall)から求められるF値(F measure)をクラス分類の精度として計算することを特徴とする請求項7に記載の文書処理装置。
【請求項9】
前記調整係数特定部は、前記複数種類の暫定係数のうち、検査グループに含まれる単語群において特定されたクラスと本来のクラスが一致する単語の数が最大となるときの暫定係数を調整係数として特定することを特徴とする請求項6に記載の文書処理装置。
【請求項10】
前記調整係数特定部は、前記所定のコーパスを2以上の所定数のグループに分割し、そのうちの一つを検査グループ、残りをコーパスグループとすることにより、検査グループに含まれる単語群における特定されたクラスと本来のクラスとの一致度に応じて複数種類の暫定係数の中から暫定最適係数を特定し、前記所定数のグループのそれぞれを検査グループとすることにより求められた前記所定数の暫定最適係数に基づいて調整係数を決定することを特徴とする請求項6から9のいずれかに記載の文書処理装置。
【請求項11】
前記調整係数特定部は、前記所定数の暫定最適係数の平均値を調整係数とすることを特徴とする請求項10に記載の文書処理装置。
【請求項12】
前記調整係数特定部は、前記所定数の暫定最適係数のうち、検査グループに含まれる単語群において本来のクラスと特定されたクラスの一致度が最大となるときの暫定最適係数を調整係数として決定することを特徴とする請求項10に記載の文書処理装置。
【請求項13】
検査対象文書を取得するステップと、
前記検査対象文書から単語を抽出するステップと、
複数のクラスに単語を分類した上で所定のコーパス(corpus)における単語の素性をクラスごとに分類したクラス素性情報を参照して、前記検査対象文書における前記抽出された単語の素性とクラス素性情報の適合度を前記複数のクラスのそれぞれについて算出するステップと、
前記複数のクラスのうち所定のクラスに対して算出された適合度を調整するステップと、
前記抽出された単語の各クラスに対する適合度に基づいて、前記抽出された単語に対応するクラスを特定するステップと、
を備えることを特徴とする文書処理方法。
【請求項14】
複数のクラスに単語を分類した上で、所定のコーパス(corpus)における単語の素性をクラスごとのクラス素性情報として保持する機能と、
検査対象文書を取得する機能と、
前記検査対象文書から単語を抽出する機能と、
前記検査対象文書における前記抽出された単語の素性とクラス素性情報の適合度を前記複数のクラスのそれぞれについて算出する機能と、
前記複数のクラスのうち所定のクラスに対して算出された適合度を調整する機能と、
前記抽出された単語の各クラスに対する適合度に基づいて、前記抽出された単語に対応するクラスを特定する機能と、
をコンピュータにて発揮させることを特徴とする文書処理プログラム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【公開番号】特開2007−304950(P2007−304950A)
【公開日】平成19年11月22日(2007.11.22)
【国際特許分類】
【出願番号】特願2006−133828(P2006−133828)
【出願日】平成18年5月12日(2006.5.12)
【出願人】(390024350)株式会社ジャストシステム (123)
【Fターム(参考)】
【公開日】平成19年11月22日(2007.11.22)
【国際特許分類】
【出願日】平成18年5月12日(2006.5.12)
【出願人】(390024350)株式会社ジャストシステム (123)
【Fターム(参考)】
[ Back to top ]