
文書処理装置および文書処理方法
【課題】表認識を行う装置は処理対象の表構造が限定されることが多い。
【解決手段】文書処理装置において、文書の画像データから抽出された処理対象表を取得し(S10)、罫線、文字列、数列などの前景を除去し、タイトル領域のみの情報を持つような前景除去画像を生成する(S12)。次に基本的な表構造を有するテンプレートデータとパターンマッチングしていくことにより、前景除去画像を部分表に分割していく(S14、S16)。次に罫線や文字列、数列の間隔に基づき部分表ごとにセルに分割し(S18)、各セルに記載された文字列、数列を認識していくことにより、タイトルセル中の文字列などとデータセル中の数列などとを対応付けたデータを抽出していく(S20)。
【解決手段】文書処理装置において、文書の画像データから抽出された処理対象表を取得し(S10)、罫線、文字列、数列などの前景を除去し、タイトル領域のみの情報を持つような前景除去画像を生成する(S12)。次に基本的な表構造を有するテンプレートデータとパターンマッチングしていくことにより、前景除去画像を部分表に分割していく(S14、S16)。次に罫線や文字列、数列の間隔に基づき部分表ごとにセルに分割し(S18)、各セルに記載された文字列、数列を認識していくことにより、タイトルセル中の文字列などとデータセル中の数列などとを対応付けたデータを抽出していく(S20)。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は文書解析技術に関し、特に文書内に表された表を読み取りデータを取得するための文書処理装置およびそれに適用される文書処理方法に関する。
【背景技術】
【0002】
近年、手書きの書類や印刷された文書を機械的に読み取り、文字を認識するOCR(Optical Character Reader)の技術が一般化してきた。これによりユーザは、紙面に書かれた内容を電子データとして保存したり、出力結果を表計算のソフトウェアに読み込ませて計算を行ったりすることができるようになった。
【0003】
また、紙面上の表を認識する技術は帳簿の自動管理や現金自動振込みなど身近な環境で利便性を発揮している。一般的に用いられる表は、罫線で囲まれた矩形の領域をさらに罫線で細分化して得られる複数の矩形領域を、項目名欄(以後、タイトルセルと呼ぶ)およびデータ欄(以後、データセルと呼ぶ)として使用することにより、項目とデータの対応付けを表している。したがって表を認識するためにはタイトルセルとデータセルとの区別、およびその対応関係を把握する必要がある。表認識の最も簡単な形態としては、あらかじめタイトルセルにのみ記入のある帳票等を読み込み、タイトルセルおよび対応するデータセルの位置と、項目名とを記憶しておく場合がある。この場合は、実際に入力された帳票のデータセルの位置にある文字列や数列などを読み取ることにより容易に項目とデータとの対応を取得することができる。
【0004】
この形態は、あらかじめ読み込んだ帳票と同一様式の帳票のみ認識が可能である。一方、表構造のバリエーションを許容できる技術も開発されている。例えば、各矩形領域の枠の辺の長さなどを比較することによりタイトルセルとデータセルとを区別する手法や、あらかじめタイトルセルに記載されるであろう「氏名」や「住所」などの文字列を辞書に登録しておくことにより、登録された文字列が記載されたセルをタイトルセルと判定する手法などがある(例えば特許文献1、特許文献2、非特許文献1参照)。
【特許文献1】特開平10−116314号公報
【特許文献2】特開2005−275830号公報
【非特許文献1】駱琴、渡邉豊英、杉江昇、帳票文書の構造認識のための書式構造知識の自動獲得,電子情報通信学会論文誌 D-II Vol. J76-D-II No. 3 pp.534-546, 1993年3月
【発明の開示】
【発明が解決しようとする課題】
【0005】
ところが上述のような技術では、多少のバリエーションは許されるものの、構造の種類や項目名が限定的であり、あくまで最初に想定した範囲内の表を処理することが前提であるため、汎用性に乏しい。汎用性を向上させるためには様々な表の種類に応じた多数の情報をあらかじめ準備しておかなければならず、開発コストが増大する。またこれらの技術は、罫線に囲まれた矩形によって各セルの存在を認識するため、横方向の罫線のみ引かれた表や、罫線が引かれず文字の間隔のみで各セルを表した表などは認識できない。
【0006】
本発明はこうした状況に鑑みてなされたものであり、その目的は、汎用性が高く導入コストの低い表認識技術を提供することにある。
【課題を解決するための手段】
【0007】
本発明のある態様は、文書処理装置に関する。この文書処理装置は、文書の画像データに含まれる表を認識し、当該表の記載内容の読み出しを行う文書処理装置であり、文書の画像データから処理対象の表の画像データを抽出する表抽出部と、処理対象の表の画像データから項目名欄の領域を所定の判定手法により特定し、当該項目名欄の領域の全体形状について画像解析を行うことにより、処理対象の表に含まれ独立した表の形式を有する部分表に分割する領域分割部と、部分表ごとに項目名欄およびデータ欄から記載内容を読み出し、項目名欄およびデータ欄との対応関係に基づき当該記載内容を対応付けたデータを作成するデータ抽出部と、を備えたことを特徴とする。
【0008】
ここで「全体形状」は罫線による区分けの情報を持たない項目名欄の「かたまり」の形状でよいが、孤立した1つの項目名欄であっても「全体形状」を構成しうる。また「全体形状」は1つの連続した領域の形状であってもよいし、2つ以上の領域の形状を含んでもよい。
【0009】
本発明の別の態様は、文書処理方法に関する。この文書処理方法は、文書の画像データに含まれる表を認識し、当該表の記載内容の読み出しを行う文書処理方法であり、文書の画像データから処理対象の表の画像データを抽出するステップと、処理対象の表の画像データから項目名欄の領域を所定の判定手法により特定し、当該項目名欄の領域の全体形状について画像解析を行うことにより、処理対象の表に含まれ独立した表の形式を有する部分表に分割するステップと、部分表ごとに項目名欄およびデータ欄から記載内容を読み出し、項目名欄およびデータ欄との対応関係に基づき当該記載内容を対応付けたデータを作成するステップと、を含むことを特徴とする。
【0010】
なお、以上の構成要素の任意の組合せ、本発明の表現を方法、装置、システムなどの間で変換したものもまた、本発明の態様として有効である。
【発明の効果】
【0011】
本発明によれば、汎用性の高い表認識技術を低コストで実現できる。
【発明を実施するための最良の形態】
【0012】
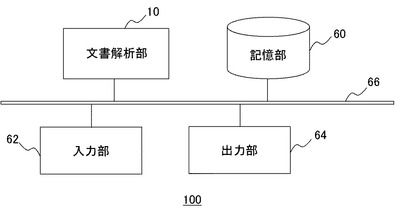
図1は本実施の形態における文書処理装置の全体的な構成を示している。文書処理装置100は、文書画像のデータなどを入力する入力部62、文書画像中に含まれる表を認識し、示されたデータを読み取る文書解析部10、表の認識に必要な情報などを記憶した記憶部60、表から読み取ったデータを適切な形式で出力する出力部64を含む。これらの機能ブロックはバス66を介して相互にデータの授受を行う。
【0013】
入力部62はユーザが処理に係る入力を行うユーザインターフェースであり、キーボード、ポインティングデバイスなど一般的な入力装置のいずれかまたは組み合わせを含む。また、文書を読み込み2次元の画像データとして取得するスキャナーを含んでいてもよい。さらに、画像化した文書の処理を行う図示しない画像文書処理機能の出力ブロックを入力部62に含んでもよい。スキャナや画像文書処理機能の出力ブロックより取得した文書画像のデータ、または、ユーザが記憶部60などにあらかじめ記憶させ、キーボードなどにより指定した文書画像のデータのファイル名が、処理対象文書画像の情報として文書解析部10に提供される。
【0014】
文書解析部10は文書処理装置100の主たる動作を掌るブロックであり、文書画像のデータから表データを抽出し、所定の処理を施すことにより解析を行って、タイトルセルとデータセルに記載された内容およびその対応関係を取得する。このとき文書解析部10はまず表を大域的に解析することで当該表を部分表に分割する。部分表とは文書画像から抽出した表に含まれ、タイトルセルおよびデータセルを有するそれ自体で独立して1つの表とすることのできる部分である。表がそれ以上分割できない場合は分割せずに当該表を部分表とする。そして部分表ごとに局所的な解析を行うことによりデータとその対応関係を取得する。
【0015】
記憶部60はハードディスクなどの記憶装置、CD−ROMやMDなどの記録媒体およびそれらの読取装置などのいずれかまたは組み合わせを含む。記憶部60には、文書解析部10が表を部分表に分割するために行う照合処理に用いる表構造のテンプレートを記憶させる。さらに文書解析部10などを動作させるためのコンピュータプログラムや、処理対象たる文書画像のデータを記憶させてもよい。
【0016】
出力部64はディスプレイおよびそれを制御するディスプレイコントローラを含む。処理を開始したり文書画像のファイル名を指定したりするための受け付け画面を表示させるなど、入力部62の補助たる機能も有する。さらに文書解析部10が取得したタイトルセルとデータセルに記載された内容およびその対応関係を適切な形式でデータ化したものを、図示しない別の機能ブロックなどに出力するインターフェースであってもよい。別の機能ブロックとは表計算や文書作成など当該データを利用してさらに別の処理を行うシステムの入力ブロックなどである。したがって適切な形式とはそのような機能ブロックが処理可能な形式である。出力部64の制御のもと、得られたデータを記憶部60やその他の記憶装置に出力し、データベースとして記憶させるようにしてもよい。
【0017】
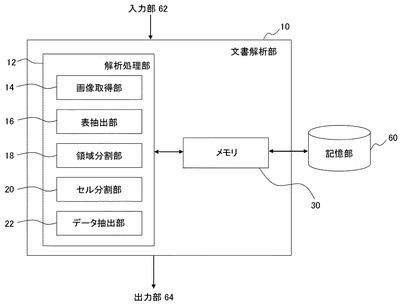
図2は文書解析部10の構造をより詳細に示している。ここに示す各ブロックは、ハードウェア的には、コンピュータのCPUをはじめとする素子や機械装置で実現でき、ソフトウェア的にはコンピュータプログラム等によって実現されるが、ここでは、それらの連携によって実現される機能ブロックを描いている。したがって、これらの機能ブロックはハードウェア、ソフトウェアの組合せによっていろいろなかたちで実現できることは、当業者には理解されるところである。
【0018】
文書解析部10は解析処理部12とメモリ30を含む。解析処理部12は画像取得部14、表抽出部16、領域分割部18、セル分割部20、およびデータ抽出部22を含む。画像取得部14は入力部62から入力された文書画像のデータ、あるいは入力部62により指定され記憶部60に記憶された文書画像のデータを読み出し、メモリ30に保存する。
【0019】
表抽出部16は文書画像のデータから表の領域のデータを抽出する。例えば文書画像を走査して連結した罫線集合を求め、その外接矩形を表の領域として認識し抽出を行う。なお、以後説明する機能ブロックでは、基本的にはメモリ30に保存されたデータを取得し、処理を施してメモリ30に保存し直す、という手順を踏むが、メモリ30に対する入出力についてはその説明を省略する場合がある。
【0020】
領域分割部18は表の全領域のうちタイトルセルが存在する領域(以後、タイトル領域と呼ぶ)を特定し、その領域の全体形状を2次元図形として画像解析することにより、部分表の境界を決定し分割する。例えば背景色が施されている領域、色など背景の属性が他と異なる領域、文字列と数列が認識された場合に文字列のみが存在する領域、文字列が太字であるなど所定の字体である領域、隣接する罫線が他よりも太い領域などのいずれか、またはそれらの組み合わせを、タイトル領域の判定手法に用いることにより特定する。
【0021】
タイトル領域の判定基準としてはこのほかに、日本語仮名漢字、アルファベットといった文字列の文字種、文字サイズ、文字色、アンダーラインなどの文字飾りといった文字列の属性、右寄せ、左寄せ、中央寄せといった文字列の配置、字面、文字数、日付など特定の文字列パターンといった文字列そのもの、罫線の線種や色といった属性、罫線の有無などに基づいてもよい。
【0022】
さらに表全体のうち左側、上側にあるなど、領域の位置情報を考慮してもよい。また、タイトル領域の特定は、上記のような判定手法を全て試行することにより総合的に判断してもよいし、ユーザに判定手法の選択を行わせたり、様々な判定手法によって導出されたタイトル領域の候補から選択させたりすることによって最終的な判断を行ってもよい。
【0023】
また部分表は、記憶部60からメモリ30に読み出した表構造のテンプレートを参照して認識する。テンプレートは部分表の構造の候補であり、基本となる表を画像データとして用意する。ここでは、前段で特定したタイトル領域と、テンプレートにおけるタイトル領域の形状とを比較することにより、テンプレートのいずれかに合致した領域を各部分表の領域として特定する。この処理で着目する箇所はタイトル領域の大域的な形状、すなわち配置であるため、表に含まれる罫線の情報や各セルの内容は使用しなくてもよい。具体例については後に詳述する。
【0024】
セル分割部20は、各部分表の領域に罫線の情報を付加することにより部分表を各セルに分割する。罫線が引かれていない場合は各文字列や数列の間隔によってセルの境界を決定して分割する。本実施の形態において、罫線はタイトル領域の特定には用いず、縦および横のセルの境界を決定するのに用いられるため、データの間隔など他の情報で容易に代替することが可能である。
【0025】
データ抽出部22は分割したセルのそれぞれから文字列、数列などを読み取り、認識する。ここでは一般的に用いられる文字認識の手法のいずれかを採用すればよい。領域分割部18において表を部分表に分割する際、タイトルセルの位置は把握済みであるため、タイトルセルに記載の文字列などと、データセルに記載の数列などとを対応づけて出力データとし、出力部64に提供する。
【0026】
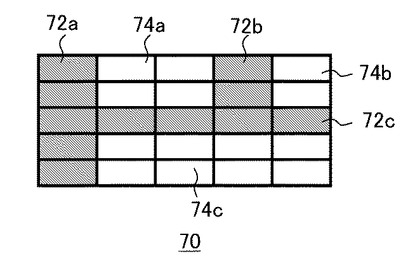
次に領域分割部18、セル分割部20、データ抽出部22が行う処理について具体的に説明する。なおここで示す表および処理手順は例示であり、本実施の形態を限定するものではない。図3は表抽出部16が文書画像のデータから抽出した処理対象の表の構造例を示している。処理対象表70は、タイトルセル72a、72b、72c、およびデータセル74a、74b、74cを含む。同図では斜線パターンを施したセルをタイトルセル、白抜きのセルをデータセルとして示しているが、図を煩雑にしないため代表するそれぞれ3つのセルのみに符号を付している。また各セルには文字列や数列などが記載されているがここでは図示を省略している。この例では処理対象表70は5行5列のセルによって構成されている。
【0027】
タイトルセルは、タイトルセル72aを含む最も左の1列を構成する5つのセル、タイトルセル72bを含む左から4列目の上から3つのセル、およびタイトルセル72cを含む上から3行目の1行を構成するセルである。それ以外のセル、すなわちデータセル74aを含む2行2列の4つのセル、データセル74bを含む2行1列の2つのセル、データセル74cを含む2行4列の8つのセルがデータセルである。
【0028】
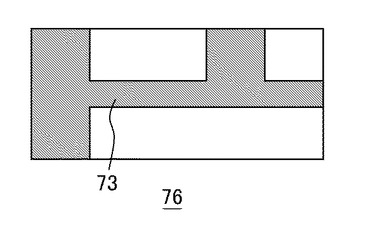
このような処理対象表70に対し、領域分割部18、セル分割部20、データ抽出部22は次に述べる処理を行う。図4〜図7は領域分割部18およびセル分割部20が処理対象表70の分割を行う様子を模式的に示している。まず図4に示すように、領域分割部18は、図3に示した処理対象表70のうちタイトル領域73を特定する。特定は上述したように背景色の有無、セル内の記載が文字列か数列か等、あるいはそれらの組み合わせに基づき行うが、ここでは一例としてタイトルセルにのみ背景色が施されていた場合について主に説明する。
【0029】
このとき領域分割部18は、処理対象表70の画像データのうち、罫線および各セル内に記載された文字列、数列などの前景を除去した、図4に示す前景除去画像76の画像データを生成しメモリ30に保存する。この際、各画素値の濃度に対するヒストグラムを生成することにより、前景および背景の濃度のしきい値を求め、それを超えた濃度の画素値を近隣の画素値と置き換えるなど一般的な除去手法を用いてよい。前景除去画像76はおよそ背景色の画素値と白抜きの画素値とのいずれかを有する画素で構成されるため、結果としてタイトル領域73の全体形状を得ることができる。このときノイズ除去処理を施して得られた2値画像を前景除去画像76としてもよい。
【0030】
文字の種類や形状をタイトル領域の判定手法とする場合は、罫線やセルの間隔に基づく境界線によってタイトル領域73を特定し、当該領域に所定の画素値、例えば「1」を代入し、その他の領域に別の画素値、例えば「0」を代入した2値画像を前景除去画像76としてもよい。
【0031】
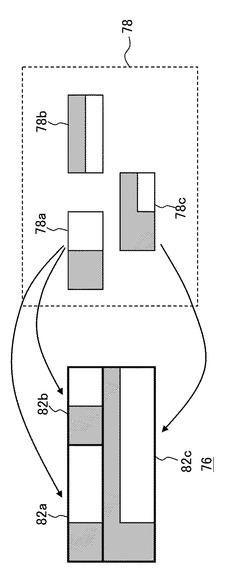
次に領域分割部18は図5に示すように、記憶部60が記憶した表構造のテンプレートデータ78と前景除去画像76とを照合していくことにより部分表を特定する。テンプレートデータとしては例えば、タイトル列のみを含む表78a、タイトル行のみを含む表78b、およびタイトル行およびタイトル列の双方を含む表78cの画像データを用意する。そして前景除去画像76の左上から一般的なテンプレートマッチングを行っていくことにより、部分表への分割を実施する。なおテンプレートデータは上記構造に限らず、例えば様々な構造の処理対象表で試行を行うことにより必要なものを様々に決定してよい。タイトル領域だけからなるテンプレートやデータ領域だけからなるテンプレートを含めてもよい。またパターンマッチングにおいて縦横に伸縮処理を施すことが可能なため、テンプレートデータは例えば正方形の表の画像データなどでよい。
【0032】
図5では、前景除去画像76のうち左上の領域82aおよび右上の領域82bがタイトル列のみを含む表78aと合致し、下の領域82cがタイトル行およびタイトル列の双方を含む表78cと合致している。例えば表の最も右側にタイトル領域が存在するなど、テンプレートデータのいずれとも合致しない領域が存在する場合は、その部分をデータセルと考えて隣接する部分表に含めることもできる。このようにテンプレートデータを用いることにより、タイトル領域の誤認識をスクリーニングすることもできる。
【0033】
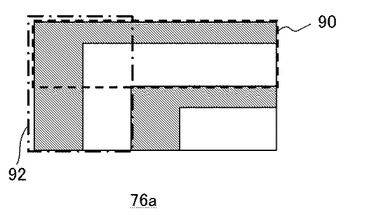
前景除去画像76をテンプレートデータ78と照合する際、前景除去画像76のうち同一の左上角を有する領域でも複数のテンプレートと合致したり、合致する領域が複数通り存在する場合が考えられる。このような場合に備え、どのテンプレート、どの領域を優先するかについてあらかじめ規則を設定しておく。例えば、合致する領域が縦長より横長となる方を優先させる。すなわち、図6のような前景除去画像76aに対しては、図5の78cのようなテンプレートが合致する領域として、点線で囲んだ領域90と一点鎖線で囲んだ領域92とが存在するが、横長である点線で囲んだ領域90を優先させて部分表とする。この規則は正確な部分表分割における経験則に基づいている。
【0034】
さらに、合致する領域の面積が大きい方を優先させてもよい。また、タイトル領域とデータ領域の双方を含むテンプレートを優先させたり、各テンプレートに優先順位を付与してもよい。以上のような規則のいずれか、またはその組み合わせを、想定される処理対象表70などを考慮した実験などによって最適なものをあらかじめ設定しておく。
【0035】
また、照合は前景除去画像76の左上から行わなくてもよい。例えば前景除去画像76の左上、左下、右上、右下の4箇所でそれぞれ照合を行い、合致した領域の面積がより大きい部分を部分表として分割し、さらに同様の照合を繰り返すようにしてもよい。
【0036】
領域分割部18は上述のようにテンプレートデータと照合することによって特定した部分表をなす領域82a、82b、82cの画像データを、それぞれ独立した表のデータとしてメモリ30に保存する。この際、処理対象表70と部分表をなす各領域との相対位置情報も保存しておく。
【0037】
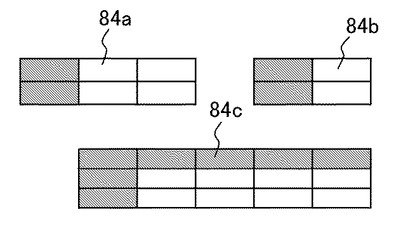
次にセル分割部20は、メモリ30に保存された部分表の領域ごとに、処理対象表70に付加されていた罫線および文字列、数列を当てはめ、図7に示すようなセルが区分けされた複数の部分表84a、84b、84cのデータを生成する。なおここでも各セルに記載された文字列および数列の図示を省略している。部分表84a、84b、84cは、部分表をなす各領域82a、82b、82cの処理対象表70に対する相対位置情報を基に、各画素値を処理対象表70の対応する画素の画素値に戻すことによって得られる。さらに罫線がある場合はそれをセルの境界線とし、罫線がない場合は文字列および数列のみを当てはめ、その間隔の中心線などを境界線とすることによってセル単位に分割する。
【0038】
データ抽出部22は、部分表84a、84b、84cの各セルに対し、一般的な文字認識処理を施すことより文字列および数列を読み出す。このとき、タイトルセルおよびデータセルとの境界はすでに判明しているため、タイトルセルに記載された文字列などと、その他のセルに記載された数列などとの対応づけは容易に行うことができる。またタイトルセルの配置も判明しているため、行または列内での対応か、行および列の交差による対応かを容易に区別することができる。
【0039】
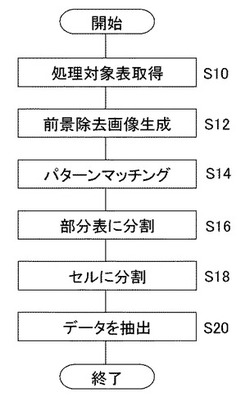
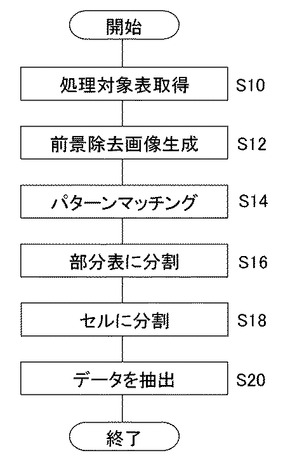
図8は以上述べた領域分割部18、セル分割部20、データ抽出部22が行う処理の手順を示している。まず領域分割部18は表抽出部16が抽出した処理対象表70を取得する(S10)。次に、背景色や文字列の種類などに基づきタイトルセルの領域を特定したうえで、処理対象表70から所定の手法で罫線、文字列、数列などの前景を除去した、前景除去画像76を生成する(S12)。次に記憶部60が記憶したテンプレートデータとのパターンマッチングを行うことにより、前景除去画像76から部分表の領域を特定し分割する(S14、S16)。
【0040】
次にセル分割部20は、各部分表に罫線、文字列、数列などもとの処理対象表70に記載されていた情報を当てはめることにより、セルに分割する(S18)。そしてデータ抽出部22は各セルに記載されてる文字列または数列を、所定の文字認識手法により読み取り、タイトルセルの記載内容とデータセルの記載内容とを、合致したテンプレートに基づく対応関係を参照して対応付けしながら抽出する(S20)。以上のようにして生成したcsvファイルなどのデータを別のソフトウェアへ入力したり、データベース化したりすることにより、表の内容を適宜電子処理することができる。
【0041】
以上述べた本実施の形態によれば、処理対象たる表の画像データからタイトルセルの配置を示す形状のみに着目してパターンマッチングを施し、画像処理的アプローチから部分表を特定する。これにより罫線が引かれていない表でも構造が単純な部分表に分割することができ、後の解析、すなわちデータの読み取りと対応付けを容易にすることができる。また処理対象表を大局的に解析することから元の画像に歪みや回転がある場合でも、特段の対策処理を行わずにデータ抽出処理までを進捗することができる。
【0042】
さらにタイトル領域を図形的に導き出すことから、あらかじめタイトルセルに記載される文字列について辞書登録を行う必要がない。さらに基本となる表構造をテンプレートデータとして用意することにより処理対象表を部分領域に分割していくため、いかに複雑な構造を有する表やサイズの大きな表でも同様に処理することが可能となり、あらかじめ全体的な表構造を登録しておく必要がない。さらに種々の手法によりタイトル領域を特定するため、記載された文字列に頼らずタイトル領域を特定でき、あらかじめ項目のみ記入された表を読み込ませるなどの手間を省略できる。結果として低い導入コストで汎用性の高い表認識技術を実現することができる。
【0043】
以上、本発明を実施の形態をもとに説明した。この実施の形態は例示であり、それらの各構成要素や各処理プロセスの組合せにいろいろな変形例が可能なこと、またそうした変形例も本発明の範囲にあることは当業者に理解されるところである。
【0044】
例えば、本実施の形態で述べた処理対象表は画素値の情報のみを有するラスタ画像であることを前提として説明したが、より高次の情報を有する画像データであっても本発明を適用できる。より高次の情報とは例えば、位置情報を有する矩形の塗りつぶし情報と位置情報を有する矩形の文字列情報などである。例えば、背景色を施された矩形領域、罫線の幅を有する罫線をなす矩形領域、文字列を囲む最小外接矩形領域のそれぞれを左上角、右下角のxy座標値で表した情報、および文字属性情報を含む文字列の情報からなってもよい。このような情報を有する画像においても、まず背景色を施された矩形領域の情報からなる前景除去画像とテンプレートデータとを照合して部分表に分割する。そして罫線をなす矩形領域や文字列を囲む矩形領域の情報を用いてセルに分割し、セルごとに文字列などを読み出す。これにより、本実施の形態と同様に、容易に汎用性の高い表認識技術を実現できる。
【0045】
同様にテンプレートデータもラスタ画像に限らず、タイトル領域の形状を現す情報であればよい。例えば、ベクトル画像でもよいし、矩形を表す文字コードと改行情報を含むテキストデータでもよい。後者の場合、例えば黒塗り矩形をタイトル領域、白塗り矩形をデータ領域として表すことができる。異なるデータ形式を有する前景除去画像とテンプレートデータとの照合のためには、例えば低次の情報を有する側に合わせるように高次の情報のデータ変換を行ってもよいし、それ以外の一般的な解析手法を用いてもよい。テンプレートデータのデータ形式は照合に用いる解析手法やデータを記憶する記憶部の容量などに鑑み決定する。これによりより様々なデータ形式や記憶容量に応じた表認識技術を実現できる。
【図面の簡単な説明】
【0046】
【図1】本実施の形態における文書処理装置の全体的な構成を示す図である。
【図2】本実施の形態の文書解析部の構造をより詳細に示す図である。
【図3】本実施の形態において表抽出部が文書画像のデータから抽出した処理対象の表の構造例を示す図である。
【図4】本実施の形態の領域分割部が処理対象表を分割する際、生成する前景除去画像を模式的に示す図である。
【図5】本実施の形態の領域分割部が処理対象表の分割を行う様子を模式的に示す図である。
【図6】テンプレートとの照合における優先順位の例を説明する図である。
【図7】本実施の形態のセル分割部が処理対象表の分割を行う様子を模式的に示す図である。
【図8】本実施の形態において領域分割部、セル分割部、データ抽出部が行う処理の手順を示すフローチャートである。
【符号の説明】
【0047】
10 文書解析部、 12 解析処理部、 14 画像取得部、 16 表抽出部、 18 領域分割部、 20 セル分割部、 22 データ抽出部、 60 記憶部、 62 入力部、 64 出力部、 70 処理対象表、 73 タイトル領域、 76 前景除去画像、 78 テンプレートデータ、 84 部分表、 100 文書処理装置。
【技術分野】
【0001】
本発明は文書解析技術に関し、特に文書内に表された表を読み取りデータを取得するための文書処理装置およびそれに適用される文書処理方法に関する。
【背景技術】
【0002】
近年、手書きの書類や印刷された文書を機械的に読み取り、文字を認識するOCR(Optical Character Reader)の技術が一般化してきた。これによりユーザは、紙面に書かれた内容を電子データとして保存したり、出力結果を表計算のソフトウェアに読み込ませて計算を行ったりすることができるようになった。
【0003】
また、紙面上の表を認識する技術は帳簿の自動管理や現金自動振込みなど身近な環境で利便性を発揮している。一般的に用いられる表は、罫線で囲まれた矩形の領域をさらに罫線で細分化して得られる複数の矩形領域を、項目名欄(以後、タイトルセルと呼ぶ)およびデータ欄(以後、データセルと呼ぶ)として使用することにより、項目とデータの対応付けを表している。したがって表を認識するためにはタイトルセルとデータセルとの区別、およびその対応関係を把握する必要がある。表認識の最も簡単な形態としては、あらかじめタイトルセルにのみ記入のある帳票等を読み込み、タイトルセルおよび対応するデータセルの位置と、項目名とを記憶しておく場合がある。この場合は、実際に入力された帳票のデータセルの位置にある文字列や数列などを読み取ることにより容易に項目とデータとの対応を取得することができる。
【0004】
この形態は、あらかじめ読み込んだ帳票と同一様式の帳票のみ認識が可能である。一方、表構造のバリエーションを許容できる技術も開発されている。例えば、各矩形領域の枠の辺の長さなどを比較することによりタイトルセルとデータセルとを区別する手法や、あらかじめタイトルセルに記載されるであろう「氏名」や「住所」などの文字列を辞書に登録しておくことにより、登録された文字列が記載されたセルをタイトルセルと判定する手法などがある(例えば特許文献1、特許文献2、非特許文献1参照)。
【特許文献1】特開平10−116314号公報
【特許文献2】特開2005−275830号公報
【非特許文献1】駱琴、渡邉豊英、杉江昇、帳票文書の構造認識のための書式構造知識の自動獲得,電子情報通信学会論文誌 D-II Vol. J76-D-II No. 3 pp.534-546, 1993年3月
【発明の開示】
【発明が解決しようとする課題】
【0005】
ところが上述のような技術では、多少のバリエーションは許されるものの、構造の種類や項目名が限定的であり、あくまで最初に想定した範囲内の表を処理することが前提であるため、汎用性に乏しい。汎用性を向上させるためには様々な表の種類に応じた多数の情報をあらかじめ準備しておかなければならず、開発コストが増大する。またこれらの技術は、罫線に囲まれた矩形によって各セルの存在を認識するため、横方向の罫線のみ引かれた表や、罫線が引かれず文字の間隔のみで各セルを表した表などは認識できない。
【0006】
本発明はこうした状況に鑑みてなされたものであり、その目的は、汎用性が高く導入コストの低い表認識技術を提供することにある。
【課題を解決するための手段】
【0007】
本発明のある態様は、文書処理装置に関する。この文書処理装置は、文書の画像データに含まれる表を認識し、当該表の記載内容の読み出しを行う文書処理装置であり、文書の画像データから処理対象の表の画像データを抽出する表抽出部と、処理対象の表の画像データから項目名欄の領域を所定の判定手法により特定し、当該項目名欄の領域の全体形状について画像解析を行うことにより、処理対象の表に含まれ独立した表の形式を有する部分表に分割する領域分割部と、部分表ごとに項目名欄およびデータ欄から記載内容を読み出し、項目名欄およびデータ欄との対応関係に基づき当該記載内容を対応付けたデータを作成するデータ抽出部と、を備えたことを特徴とする。
【0008】
ここで「全体形状」は罫線による区分けの情報を持たない項目名欄の「かたまり」の形状でよいが、孤立した1つの項目名欄であっても「全体形状」を構成しうる。また「全体形状」は1つの連続した領域の形状であってもよいし、2つ以上の領域の形状を含んでもよい。
【0009】
本発明の別の態様は、文書処理方法に関する。この文書処理方法は、文書の画像データに含まれる表を認識し、当該表の記載内容の読み出しを行う文書処理方法であり、文書の画像データから処理対象の表の画像データを抽出するステップと、処理対象の表の画像データから項目名欄の領域を所定の判定手法により特定し、当該項目名欄の領域の全体形状について画像解析を行うことにより、処理対象の表に含まれ独立した表の形式を有する部分表に分割するステップと、部分表ごとに項目名欄およびデータ欄から記載内容を読み出し、項目名欄およびデータ欄との対応関係に基づき当該記載内容を対応付けたデータを作成するステップと、を含むことを特徴とする。
【0010】
なお、以上の構成要素の任意の組合せ、本発明の表現を方法、装置、システムなどの間で変換したものもまた、本発明の態様として有効である。
【発明の効果】
【0011】
本発明によれば、汎用性の高い表認識技術を低コストで実現できる。
【発明を実施するための最良の形態】
【0012】
図1は本実施の形態における文書処理装置の全体的な構成を示している。文書処理装置100は、文書画像のデータなどを入力する入力部62、文書画像中に含まれる表を認識し、示されたデータを読み取る文書解析部10、表の認識に必要な情報などを記憶した記憶部60、表から読み取ったデータを適切な形式で出力する出力部64を含む。これらの機能ブロックはバス66を介して相互にデータの授受を行う。
【0013】
入力部62はユーザが処理に係る入力を行うユーザインターフェースであり、キーボード、ポインティングデバイスなど一般的な入力装置のいずれかまたは組み合わせを含む。また、文書を読み込み2次元の画像データとして取得するスキャナーを含んでいてもよい。さらに、画像化した文書の処理を行う図示しない画像文書処理機能の出力ブロックを入力部62に含んでもよい。スキャナや画像文書処理機能の出力ブロックより取得した文書画像のデータ、または、ユーザが記憶部60などにあらかじめ記憶させ、キーボードなどにより指定した文書画像のデータのファイル名が、処理対象文書画像の情報として文書解析部10に提供される。
【0014】
文書解析部10は文書処理装置100の主たる動作を掌るブロックであり、文書画像のデータから表データを抽出し、所定の処理を施すことにより解析を行って、タイトルセルとデータセルに記載された内容およびその対応関係を取得する。このとき文書解析部10はまず表を大域的に解析することで当該表を部分表に分割する。部分表とは文書画像から抽出した表に含まれ、タイトルセルおよびデータセルを有するそれ自体で独立して1つの表とすることのできる部分である。表がそれ以上分割できない場合は分割せずに当該表を部分表とする。そして部分表ごとに局所的な解析を行うことによりデータとその対応関係を取得する。
【0015】
記憶部60はハードディスクなどの記憶装置、CD−ROMやMDなどの記録媒体およびそれらの読取装置などのいずれかまたは組み合わせを含む。記憶部60には、文書解析部10が表を部分表に分割するために行う照合処理に用いる表構造のテンプレートを記憶させる。さらに文書解析部10などを動作させるためのコンピュータプログラムや、処理対象たる文書画像のデータを記憶させてもよい。
【0016】
出力部64はディスプレイおよびそれを制御するディスプレイコントローラを含む。処理を開始したり文書画像のファイル名を指定したりするための受け付け画面を表示させるなど、入力部62の補助たる機能も有する。さらに文書解析部10が取得したタイトルセルとデータセルに記載された内容およびその対応関係を適切な形式でデータ化したものを、図示しない別の機能ブロックなどに出力するインターフェースであってもよい。別の機能ブロックとは表計算や文書作成など当該データを利用してさらに別の処理を行うシステムの入力ブロックなどである。したがって適切な形式とはそのような機能ブロックが処理可能な形式である。出力部64の制御のもと、得られたデータを記憶部60やその他の記憶装置に出力し、データベースとして記憶させるようにしてもよい。
【0017】
図2は文書解析部10の構造をより詳細に示している。ここに示す各ブロックは、ハードウェア的には、コンピュータのCPUをはじめとする素子や機械装置で実現でき、ソフトウェア的にはコンピュータプログラム等によって実現されるが、ここでは、それらの連携によって実現される機能ブロックを描いている。したがって、これらの機能ブロックはハードウェア、ソフトウェアの組合せによっていろいろなかたちで実現できることは、当業者には理解されるところである。
【0018】
文書解析部10は解析処理部12とメモリ30を含む。解析処理部12は画像取得部14、表抽出部16、領域分割部18、セル分割部20、およびデータ抽出部22を含む。画像取得部14は入力部62から入力された文書画像のデータ、あるいは入力部62により指定され記憶部60に記憶された文書画像のデータを読み出し、メモリ30に保存する。
【0019】
表抽出部16は文書画像のデータから表の領域のデータを抽出する。例えば文書画像を走査して連結した罫線集合を求め、その外接矩形を表の領域として認識し抽出を行う。なお、以後説明する機能ブロックでは、基本的にはメモリ30に保存されたデータを取得し、処理を施してメモリ30に保存し直す、という手順を踏むが、メモリ30に対する入出力についてはその説明を省略する場合がある。
【0020】
領域分割部18は表の全領域のうちタイトルセルが存在する領域(以後、タイトル領域と呼ぶ)を特定し、その領域の全体形状を2次元図形として画像解析することにより、部分表の境界を決定し分割する。例えば背景色が施されている領域、色など背景の属性が他と異なる領域、文字列と数列が認識された場合に文字列のみが存在する領域、文字列が太字であるなど所定の字体である領域、隣接する罫線が他よりも太い領域などのいずれか、またはそれらの組み合わせを、タイトル領域の判定手法に用いることにより特定する。
【0021】
タイトル領域の判定基準としてはこのほかに、日本語仮名漢字、アルファベットといった文字列の文字種、文字サイズ、文字色、アンダーラインなどの文字飾りといった文字列の属性、右寄せ、左寄せ、中央寄せといった文字列の配置、字面、文字数、日付など特定の文字列パターンといった文字列そのもの、罫線の線種や色といった属性、罫線の有無などに基づいてもよい。
【0022】
さらに表全体のうち左側、上側にあるなど、領域の位置情報を考慮してもよい。また、タイトル領域の特定は、上記のような判定手法を全て試行することにより総合的に判断してもよいし、ユーザに判定手法の選択を行わせたり、様々な判定手法によって導出されたタイトル領域の候補から選択させたりすることによって最終的な判断を行ってもよい。
【0023】
また部分表は、記憶部60からメモリ30に読み出した表構造のテンプレートを参照して認識する。テンプレートは部分表の構造の候補であり、基本となる表を画像データとして用意する。ここでは、前段で特定したタイトル領域と、テンプレートにおけるタイトル領域の形状とを比較することにより、テンプレートのいずれかに合致した領域を各部分表の領域として特定する。この処理で着目する箇所はタイトル領域の大域的な形状、すなわち配置であるため、表に含まれる罫線の情報や各セルの内容は使用しなくてもよい。具体例については後に詳述する。
【0024】
セル分割部20は、各部分表の領域に罫線の情報を付加することにより部分表を各セルに分割する。罫線が引かれていない場合は各文字列や数列の間隔によってセルの境界を決定して分割する。本実施の形態において、罫線はタイトル領域の特定には用いず、縦および横のセルの境界を決定するのに用いられるため、データの間隔など他の情報で容易に代替することが可能である。
【0025】
データ抽出部22は分割したセルのそれぞれから文字列、数列などを読み取り、認識する。ここでは一般的に用いられる文字認識の手法のいずれかを採用すればよい。領域分割部18において表を部分表に分割する際、タイトルセルの位置は把握済みであるため、タイトルセルに記載の文字列などと、データセルに記載の数列などとを対応づけて出力データとし、出力部64に提供する。
【0026】
次に領域分割部18、セル分割部20、データ抽出部22が行う処理について具体的に説明する。なおここで示す表および処理手順は例示であり、本実施の形態を限定するものではない。図3は表抽出部16が文書画像のデータから抽出した処理対象の表の構造例を示している。処理対象表70は、タイトルセル72a、72b、72c、およびデータセル74a、74b、74cを含む。同図では斜線パターンを施したセルをタイトルセル、白抜きのセルをデータセルとして示しているが、図を煩雑にしないため代表するそれぞれ3つのセルのみに符号を付している。また各セルには文字列や数列などが記載されているがここでは図示を省略している。この例では処理対象表70は5行5列のセルによって構成されている。
【0027】
タイトルセルは、タイトルセル72aを含む最も左の1列を構成する5つのセル、タイトルセル72bを含む左から4列目の上から3つのセル、およびタイトルセル72cを含む上から3行目の1行を構成するセルである。それ以外のセル、すなわちデータセル74aを含む2行2列の4つのセル、データセル74bを含む2行1列の2つのセル、データセル74cを含む2行4列の8つのセルがデータセルである。
【0028】
このような処理対象表70に対し、領域分割部18、セル分割部20、データ抽出部22は次に述べる処理を行う。図4〜図7は領域分割部18およびセル分割部20が処理対象表70の分割を行う様子を模式的に示している。まず図4に示すように、領域分割部18は、図3に示した処理対象表70のうちタイトル領域73を特定する。特定は上述したように背景色の有無、セル内の記載が文字列か数列か等、あるいはそれらの組み合わせに基づき行うが、ここでは一例としてタイトルセルにのみ背景色が施されていた場合について主に説明する。
【0029】
このとき領域分割部18は、処理対象表70の画像データのうち、罫線および各セル内に記載された文字列、数列などの前景を除去した、図4に示す前景除去画像76の画像データを生成しメモリ30に保存する。この際、各画素値の濃度に対するヒストグラムを生成することにより、前景および背景の濃度のしきい値を求め、それを超えた濃度の画素値を近隣の画素値と置き換えるなど一般的な除去手法を用いてよい。前景除去画像76はおよそ背景色の画素値と白抜きの画素値とのいずれかを有する画素で構成されるため、結果としてタイトル領域73の全体形状を得ることができる。このときノイズ除去処理を施して得られた2値画像を前景除去画像76としてもよい。
【0030】
文字の種類や形状をタイトル領域の判定手法とする場合は、罫線やセルの間隔に基づく境界線によってタイトル領域73を特定し、当該領域に所定の画素値、例えば「1」を代入し、その他の領域に別の画素値、例えば「0」を代入した2値画像を前景除去画像76としてもよい。
【0031】
次に領域分割部18は図5に示すように、記憶部60が記憶した表構造のテンプレートデータ78と前景除去画像76とを照合していくことにより部分表を特定する。テンプレートデータとしては例えば、タイトル列のみを含む表78a、タイトル行のみを含む表78b、およびタイトル行およびタイトル列の双方を含む表78cの画像データを用意する。そして前景除去画像76の左上から一般的なテンプレートマッチングを行っていくことにより、部分表への分割を実施する。なおテンプレートデータは上記構造に限らず、例えば様々な構造の処理対象表で試行を行うことにより必要なものを様々に決定してよい。タイトル領域だけからなるテンプレートやデータ領域だけからなるテンプレートを含めてもよい。またパターンマッチングにおいて縦横に伸縮処理を施すことが可能なため、テンプレートデータは例えば正方形の表の画像データなどでよい。
【0032】
図5では、前景除去画像76のうち左上の領域82aおよび右上の領域82bがタイトル列のみを含む表78aと合致し、下の領域82cがタイトル行およびタイトル列の双方を含む表78cと合致している。例えば表の最も右側にタイトル領域が存在するなど、テンプレートデータのいずれとも合致しない領域が存在する場合は、その部分をデータセルと考えて隣接する部分表に含めることもできる。このようにテンプレートデータを用いることにより、タイトル領域の誤認識をスクリーニングすることもできる。
【0033】
前景除去画像76をテンプレートデータ78と照合する際、前景除去画像76のうち同一の左上角を有する領域でも複数のテンプレートと合致したり、合致する領域が複数通り存在する場合が考えられる。このような場合に備え、どのテンプレート、どの領域を優先するかについてあらかじめ規則を設定しておく。例えば、合致する領域が縦長より横長となる方を優先させる。すなわち、図6のような前景除去画像76aに対しては、図5の78cのようなテンプレートが合致する領域として、点線で囲んだ領域90と一点鎖線で囲んだ領域92とが存在するが、横長である点線で囲んだ領域90を優先させて部分表とする。この規則は正確な部分表分割における経験則に基づいている。
【0034】
さらに、合致する領域の面積が大きい方を優先させてもよい。また、タイトル領域とデータ領域の双方を含むテンプレートを優先させたり、各テンプレートに優先順位を付与してもよい。以上のような規則のいずれか、またはその組み合わせを、想定される処理対象表70などを考慮した実験などによって最適なものをあらかじめ設定しておく。
【0035】
また、照合は前景除去画像76の左上から行わなくてもよい。例えば前景除去画像76の左上、左下、右上、右下の4箇所でそれぞれ照合を行い、合致した領域の面積がより大きい部分を部分表として分割し、さらに同様の照合を繰り返すようにしてもよい。
【0036】
領域分割部18は上述のようにテンプレートデータと照合することによって特定した部分表をなす領域82a、82b、82cの画像データを、それぞれ独立した表のデータとしてメモリ30に保存する。この際、処理対象表70と部分表をなす各領域との相対位置情報も保存しておく。
【0037】
次にセル分割部20は、メモリ30に保存された部分表の領域ごとに、処理対象表70に付加されていた罫線および文字列、数列を当てはめ、図7に示すようなセルが区分けされた複数の部分表84a、84b、84cのデータを生成する。なおここでも各セルに記載された文字列および数列の図示を省略している。部分表84a、84b、84cは、部分表をなす各領域82a、82b、82cの処理対象表70に対する相対位置情報を基に、各画素値を処理対象表70の対応する画素の画素値に戻すことによって得られる。さらに罫線がある場合はそれをセルの境界線とし、罫線がない場合は文字列および数列のみを当てはめ、その間隔の中心線などを境界線とすることによってセル単位に分割する。
【0038】
データ抽出部22は、部分表84a、84b、84cの各セルに対し、一般的な文字認識処理を施すことより文字列および数列を読み出す。このとき、タイトルセルおよびデータセルとの境界はすでに判明しているため、タイトルセルに記載された文字列などと、その他のセルに記載された数列などとの対応づけは容易に行うことができる。またタイトルセルの配置も判明しているため、行または列内での対応か、行および列の交差による対応かを容易に区別することができる。
【0039】
図8は以上述べた領域分割部18、セル分割部20、データ抽出部22が行う処理の手順を示している。まず領域分割部18は表抽出部16が抽出した処理対象表70を取得する(S10)。次に、背景色や文字列の種類などに基づきタイトルセルの領域を特定したうえで、処理対象表70から所定の手法で罫線、文字列、数列などの前景を除去した、前景除去画像76を生成する(S12)。次に記憶部60が記憶したテンプレートデータとのパターンマッチングを行うことにより、前景除去画像76から部分表の領域を特定し分割する(S14、S16)。
【0040】
次にセル分割部20は、各部分表に罫線、文字列、数列などもとの処理対象表70に記載されていた情報を当てはめることにより、セルに分割する(S18)。そしてデータ抽出部22は各セルに記載されてる文字列または数列を、所定の文字認識手法により読み取り、タイトルセルの記載内容とデータセルの記載内容とを、合致したテンプレートに基づく対応関係を参照して対応付けしながら抽出する(S20)。以上のようにして生成したcsvファイルなどのデータを別のソフトウェアへ入力したり、データベース化したりすることにより、表の内容を適宜電子処理することができる。
【0041】
以上述べた本実施の形態によれば、処理対象たる表の画像データからタイトルセルの配置を示す形状のみに着目してパターンマッチングを施し、画像処理的アプローチから部分表を特定する。これにより罫線が引かれていない表でも構造が単純な部分表に分割することができ、後の解析、すなわちデータの読み取りと対応付けを容易にすることができる。また処理対象表を大局的に解析することから元の画像に歪みや回転がある場合でも、特段の対策処理を行わずにデータ抽出処理までを進捗することができる。
【0042】
さらにタイトル領域を図形的に導き出すことから、あらかじめタイトルセルに記載される文字列について辞書登録を行う必要がない。さらに基本となる表構造をテンプレートデータとして用意することにより処理対象表を部分領域に分割していくため、いかに複雑な構造を有する表やサイズの大きな表でも同様に処理することが可能となり、あらかじめ全体的な表構造を登録しておく必要がない。さらに種々の手法によりタイトル領域を特定するため、記載された文字列に頼らずタイトル領域を特定でき、あらかじめ項目のみ記入された表を読み込ませるなどの手間を省略できる。結果として低い導入コストで汎用性の高い表認識技術を実現することができる。
【0043】
以上、本発明を実施の形態をもとに説明した。この実施の形態は例示であり、それらの各構成要素や各処理プロセスの組合せにいろいろな変形例が可能なこと、またそうした変形例も本発明の範囲にあることは当業者に理解されるところである。
【0044】
例えば、本実施の形態で述べた処理対象表は画素値の情報のみを有するラスタ画像であることを前提として説明したが、より高次の情報を有する画像データであっても本発明を適用できる。より高次の情報とは例えば、位置情報を有する矩形の塗りつぶし情報と位置情報を有する矩形の文字列情報などである。例えば、背景色を施された矩形領域、罫線の幅を有する罫線をなす矩形領域、文字列を囲む最小外接矩形領域のそれぞれを左上角、右下角のxy座標値で表した情報、および文字属性情報を含む文字列の情報からなってもよい。このような情報を有する画像においても、まず背景色を施された矩形領域の情報からなる前景除去画像とテンプレートデータとを照合して部分表に分割する。そして罫線をなす矩形領域や文字列を囲む矩形領域の情報を用いてセルに分割し、セルごとに文字列などを読み出す。これにより、本実施の形態と同様に、容易に汎用性の高い表認識技術を実現できる。
【0045】
同様にテンプレートデータもラスタ画像に限らず、タイトル領域の形状を現す情報であればよい。例えば、ベクトル画像でもよいし、矩形を表す文字コードと改行情報を含むテキストデータでもよい。後者の場合、例えば黒塗り矩形をタイトル領域、白塗り矩形をデータ領域として表すことができる。異なるデータ形式を有する前景除去画像とテンプレートデータとの照合のためには、例えば低次の情報を有する側に合わせるように高次の情報のデータ変換を行ってもよいし、それ以外の一般的な解析手法を用いてもよい。テンプレートデータのデータ形式は照合に用いる解析手法やデータを記憶する記憶部の容量などに鑑み決定する。これによりより様々なデータ形式や記憶容量に応じた表認識技術を実現できる。
【図面の簡単な説明】
【0046】
【図1】本実施の形態における文書処理装置の全体的な構成を示す図である。
【図2】本実施の形態の文書解析部の構造をより詳細に示す図である。
【図3】本実施の形態において表抽出部が文書画像のデータから抽出した処理対象の表の構造例を示す図である。
【図4】本実施の形態の領域分割部が処理対象表を分割する際、生成する前景除去画像を模式的に示す図である。
【図5】本実施の形態の領域分割部が処理対象表の分割を行う様子を模式的に示す図である。
【図6】テンプレートとの照合における優先順位の例を説明する図である。
【図7】本実施の形態のセル分割部が処理対象表の分割を行う様子を模式的に示す図である。
【図8】本実施の形態において領域分割部、セル分割部、データ抽出部が行う処理の手順を示すフローチャートである。
【符号の説明】
【0047】
10 文書解析部、 12 解析処理部、 14 画像取得部、 16 表抽出部、 18 領域分割部、 20 セル分割部、 22 データ抽出部、 60 記憶部、 62 入力部、 64 出力部、 70 処理対象表、 73 タイトル領域、 76 前景除去画像、 78 テンプレートデータ、 84 部分表、 100 文書処理装置。
【特許請求の範囲】
【請求項1】
文書の画像データに含まれる表を認識し、当該表の記載内容の読み出しを行う文書処理装置であって、
前記文書の画像データから処理対象の表の画像データを抽出する表抽出部と、
前記処理対象の表の画像データから項目名欄の領域を所定の判定手法により特定し、当該項目名欄の領域の全体形状について画像解析を行うことにより、前記処理対象の表に含まれ独立した表の形式を有する部分表に分割する領域分割部と、
前記部分表ごとに項目名欄およびデータ欄から記載内容を読み出し、項目名欄およびデータ欄との対応関係に基づき当該記載内容を対応付けたデータを作成するデータ抽出部と、
を備えたことを特徴とする文書処理装置。
【請求項2】
一種類以上の前記部分表の構造候補を記憶した記憶部をさらに備え、
前記領域分割部は前記記憶部を参照して、前記処理対象の表における項目名欄の領域の全体形状を、前記構造候補における項目名欄の領域の形状とマッチングさせることにより、前記処理対象の表における前記部分表の境界を特定し、分割を行うことを特徴とする請求項1に記載の文書処理装置。
【請求項3】
前記領域分割部は、前記処理対象の表において背景色が設定された領域、背景色の属性が他と異なる領域のいずれか、またはその組み合わせを満たす領域を、前記項目名欄の領域として特定することを特徴とする請求項1または2に記載の文書処理装置。
【請求項4】
前記領域分割部は、前記処理対象の表において文字列のみが記載された領域、文字列が所定の字体を有する領域、文字列が所定の文字種を有する領域、文字列の属性が他と異なる領域、文字列の配置が他と異なる領域、文字列の字面が他と異なる領域、文字列が所定の文字数または文字数範囲を有する領域、文字列が所定の文字パターンを有する領域のいずれか、またはその組み合わせを満たす領域を、前記項目名欄の領域として特定することを特徴とする請求項1から3のいずれかに記載の文書処理装置。
【請求項5】
前記領域分割部は、前記処理対象の表において隣接する罫線が存在する領域、隣接する罫線の属性が他と異なる領域、のいずれか、またはその組み合わせを満たす領域を、前記項目名欄の領域として特定することを特徴とする請求項1から4のいずれかに記載の文書処理装置。
【請求項6】
文書の画像データに含まれる表を認識し、当該表の記載内容の読み出しを行う文書処理方法であって、
前記文書の画像データから処理対象の表の画像データを抽出するステップと、
前記処理対象の表の画像データから項目名欄の領域を所定の判定手法により特定し、当該項目名欄の領域の全体形状について画像解析を行うことにより、前記処理対象の表に含まれ独立した表の形式を有する部分表に分割するステップと、
前記部分表ごとに項目名欄およびデータ欄から記載内容を読み出し、項目名欄およびデータ欄との対応関係に基づき当該記載内容を対応付けたデータを作成するステップと、
を含むことを特徴とする文書処理方法。
【請求項7】
前記分割するステップは、
前記処理対象の表において特定した前記項目名欄の領域とそれ以外の領域とで異なる画素値を有する2値画像のデータを生成するステップと、
あらかじめ記憶装置に記憶させた、一種類以上の前記部分表の構造候補を、項目名欄の領域とそれ以外の領域とを前記2値画像と同様に区別して表したテンプレートデータと、前記2値画像のデータをマッチングさせることにより、前記処理対象の表における前記部分表の境界を特定するステップを含むことを特徴とする請求項6に記載の文書処理方法。
【請求項8】
文書の画像データに含まれる表を認識し、当該表の記載内容の読み出しを行う機能をコンピュータに実現させるコンピュータプログラムであって、
メモリに保存した前記文書の画像データから処理対象の表の画像データを抽出する機能と、
前記処理対象の表の画像データから項目名欄の領域を所定の判定手法により特定し、当該項目名欄の領域の全体形状について画像解析を行うことにより、前記処理対象の表に含まれ独立した表の形式を有する部分表に分割する機能と、
前記部分表ごとに項目名欄およびデータ欄から記載内容を読み出し、項目名欄およびデータ欄との対応関係に基づき当該記載内容を対応付けたデータを作成する機能と、
をコンピュータに実現させるコンピュータプログラム。
【請求項1】
文書の画像データに含まれる表を認識し、当該表の記載内容の読み出しを行う文書処理装置であって、
前記文書の画像データから処理対象の表の画像データを抽出する表抽出部と、
前記処理対象の表の画像データから項目名欄の領域を所定の判定手法により特定し、当該項目名欄の領域の全体形状について画像解析を行うことにより、前記処理対象の表に含まれ独立した表の形式を有する部分表に分割する領域分割部と、
前記部分表ごとに項目名欄およびデータ欄から記載内容を読み出し、項目名欄およびデータ欄との対応関係に基づき当該記載内容を対応付けたデータを作成するデータ抽出部と、
を備えたことを特徴とする文書処理装置。
【請求項2】
一種類以上の前記部分表の構造候補を記憶した記憶部をさらに備え、
前記領域分割部は前記記憶部を参照して、前記処理対象の表における項目名欄の領域の全体形状を、前記構造候補における項目名欄の領域の形状とマッチングさせることにより、前記処理対象の表における前記部分表の境界を特定し、分割を行うことを特徴とする請求項1に記載の文書処理装置。
【請求項3】
前記領域分割部は、前記処理対象の表において背景色が設定された領域、背景色の属性が他と異なる領域のいずれか、またはその組み合わせを満たす領域を、前記項目名欄の領域として特定することを特徴とする請求項1または2に記載の文書処理装置。
【請求項4】
前記領域分割部は、前記処理対象の表において文字列のみが記載された領域、文字列が所定の字体を有する領域、文字列が所定の文字種を有する領域、文字列の属性が他と異なる領域、文字列の配置が他と異なる領域、文字列の字面が他と異なる領域、文字列が所定の文字数または文字数範囲を有する領域、文字列が所定の文字パターンを有する領域のいずれか、またはその組み合わせを満たす領域を、前記項目名欄の領域として特定することを特徴とする請求項1から3のいずれかに記載の文書処理装置。
【請求項5】
前記領域分割部は、前記処理対象の表において隣接する罫線が存在する領域、隣接する罫線の属性が他と異なる領域、のいずれか、またはその組み合わせを満たす領域を、前記項目名欄の領域として特定することを特徴とする請求項1から4のいずれかに記載の文書処理装置。
【請求項6】
文書の画像データに含まれる表を認識し、当該表の記載内容の読み出しを行う文書処理方法であって、
前記文書の画像データから処理対象の表の画像データを抽出するステップと、
前記処理対象の表の画像データから項目名欄の領域を所定の判定手法により特定し、当該項目名欄の領域の全体形状について画像解析を行うことにより、前記処理対象の表に含まれ独立した表の形式を有する部分表に分割するステップと、
前記部分表ごとに項目名欄およびデータ欄から記載内容を読み出し、項目名欄およびデータ欄との対応関係に基づき当該記載内容を対応付けたデータを作成するステップと、
を含むことを特徴とする文書処理方法。
【請求項7】
前記分割するステップは、
前記処理対象の表において特定した前記項目名欄の領域とそれ以外の領域とで異なる画素値を有する2値画像のデータを生成するステップと、
あらかじめ記憶装置に記憶させた、一種類以上の前記部分表の構造候補を、項目名欄の領域とそれ以外の領域とを前記2値画像と同様に区別して表したテンプレートデータと、前記2値画像のデータをマッチングさせることにより、前記処理対象の表における前記部分表の境界を特定するステップを含むことを特徴とする請求項6に記載の文書処理方法。
【請求項8】
文書の画像データに含まれる表を認識し、当該表の記載内容の読み出しを行う機能をコンピュータに実現させるコンピュータプログラムであって、
メモリに保存した前記文書の画像データから処理対象の表の画像データを抽出する機能と、
前記処理対象の表の画像データから項目名欄の領域を所定の判定手法により特定し、当該項目名欄の領域の全体形状について画像解析を行うことにより、前記処理対象の表に含まれ独立した表の形式を有する部分表に分割する機能と、
前記部分表ごとに項目名欄およびデータ欄から記載内容を読み出し、項目名欄およびデータ欄との対応関係に基づき当該記載内容を対応付けたデータを作成する機能と、
をコンピュータに実現させるコンピュータプログラム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【公開番号】特開2008−108114(P2008−108114A)
【公開日】平成20年5月8日(2008.5.8)
【国際特許分類】
【出願番号】特願2006−291180(P2006−291180)
【出願日】平成18年10月26日(2006.10.26)
【出願人】(390024350)株式会社ジャストシステム (123)
【Fターム(参考)】
【公開日】平成20年5月8日(2008.5.8)
【国際特許分類】
【出願日】平成18年10月26日(2006.10.26)
【出願人】(390024350)株式会社ジャストシステム (123)
【Fターム(参考)】
[ Back to top ]