
文書分類装置及び文書分類方法
【課題】キーワード分類における文書の表記の差による影響を低減しつつ、異なる分野の文書を適切に分類することができる文書分類装置及び文書分類方法を提供する。
【解決手段】分類対象文書のうちの2文書間の共通キーワードに基づく類似度及び共通
組付与情報に基づく類似度を算出するキーワード類似度計算部92および組付与情報類似度計算部94と、これらの平均値を当該2文書間の文書類似度とする文書間類似度計算部95と、各2文書について文書類似度に基づいて安定文書間距離を算出する文書間距離計算部96と、分類対象文書を座標系に配置し、各2文書が安定文書間距離に近づくように各分類対象文書を移動させる処理を行う位置座標初期値設定部24および位置座標更新部28とを備えることにより、関連性の強い文書同士が集まるような配置を実現する。
【解決手段】分類対象文書のうちの2文書間の共通キーワードに基づく類似度及び共通
組付与情報に基づく類似度を算出するキーワード類似度計算部92および組付与情報類似度計算部94と、これらの平均値を当該2文書間の文書類似度とする文書間類似度計算部95と、各2文書について文書類似度に基づいて安定文書間距離を算出する文書間距離計算部96と、分類対象文書を座標系に配置し、各2文書が安定文書間距離に近づくように各分類対象文書を移動させる処理を行う位置座標初期値設定部24および位置座標更新部28とを備えることにより、関連性の強い文書同士が集まるような配置を実現する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、複数の分類対象文書をそれぞれの内容に応じて分類する文書分類方法に関するものである。
【背景技術】
【0002】
従来、文書分類方法として、キーワードが文書に固有に含まれる程度(非一般性)を示す評価値に基づいて算出された文書間の類似度によって文書を分類する文書分類方法があった(特許文献1および特許文献2を参照)。
【特許文献1】特開2005−327213号公報
【特許文献2】特開2006−190235号公報
【発明の開示】
【発明が解決しようとする課題】
【0003】
しかし、従来の文書分類方法によると、文書の内容が類似する場合(例えば国際特許分類のサブグループが同一である特許文献の場合)、表記の差による影響が大きくなり、適切な文書分類ができないという問題点があった。このような問題点に対して、引用文献情報を加味した分類方法も提唱されているが、引用文献情報が付与されていない文献に対しては適用することが不可能となる。また、引用文献情報の代わりに、発明者や著者といった創作者の氏名情報を使用する方法も考えられるが、例えば、分類対象文書中に同姓同名の創作者が存在する場合や、同一の創作者が複数の分野において発明や著作を行っている場合には、異なる分野の文書を類似な文書として分類してしまうおそれがある。
【0004】
本発明は、上記課題に鑑みてなされたものであり、キーワード分類における文書の表記の差による影響を低減しつつ、異なる分野の文書を適切に分類することが可能な文書分類装置および文書分類方法を提供することを課題とする。
【課題を解決するための手段】
【0005】
本発明に係る文書分類装置は、文書内容の分野を体系づける分類情報と文書内容の創作者の氏名と文書の識別番号とを付与された分類対象文書をそれぞれの内容に応じて分類する文書分類装置であって、分類対象文書のうちの2文書において共通して現れる共通キーワードを抽出する共通キーワード抽出手段と、分類対象文書のうちの2文書において共通して現れる分類情報および創作者の氏名とによって構成された共通組付与情報を抽出する共通組付与情報抽出手段と、分類対象文書の全て又は一部の文書で構成されたキーワード参照文書の識別番号と当該キーワード参照文書に含まれるキーワードとを関連付けて格納したキーワードテーブルを参照して、当該キーワードテーブルにおいて共通キーワードが出現する共通キーワード出現数を数え、当該共通キーワード出現数に基づき共通キーワードの非一般性を示す共通キーワード評価値を算出する共通キーワード評価値算出手段と、分類対象文書の全て又は一部の文書で構成された共通組付与情報参照文書の識別番号と当該共通組付与情報参照文書に含まれる共通組付与情報とを関連付けて格納した共通組付与情報テーブルを参照して、当該共通組付与情報テーブルにおいて共通組付与情報が出現する共通組付与情報出現数を数え、当該共通組付与情報出現数に基づき共通組付与情報の非一般性を示す共通組付与情報評価値を算出する共通組付与情報評価値算出手段と、各共通キーワード評価値を合算して、2文書の共通キーワードに基づく類似性を示すキーワード類似度を算出するキーワード類似度算出手段と、各共通組付与情報評価値を合算して、2文書の共通組付与情報に基づく類似性を示す組付与情報類似度を算出する組付与情報類似度算出手段と、キーワード類似度と組付与情報類似度とを総合した2文書の文書類似度を算出する文書類似度算出手段と、分類対象文書を座標系に配置し、文書類似度が増大するほど2文書間の文書間距離を減少させ、文書類似度が減少するほど2文書間の文書間距離を増大させるように各分類対象文書を移動させる文書移動手段と、を備えることを特徴とする。
【0006】
また、本発明に係る文書分類方法は、文書内容の分野を体系づける分類情報と文書内容の創作者の氏名と文書の識別番号とを付与された分類対象文書をそれぞれの内容に応じて分類する文書分類方法であって、共通キーワード抽出手段が、分類対象文書のうちの2文書において共通して現れる共通キーワードを抽出する共通キーワード抽出ステップと、
共通組付与情報抽出手段が、分類対象文書のうちの2文書において共通して現れる分類情報および創作者の氏名とによって構成された共通組付与情報を抽出する共通組付与情報抽出ステップと、共通キーワード評価値算出手段が、分類対象文書の全て又は一部の文書で構成されたキーワード参照文書の識別番号と当該キーワード参照文書に含まれるキーワードとを関連付けて格納したキーワードテーブルを参照して、当該キーワードテーブルにおいて共通キーワードが出現する共通キーワード出現数を数え、当該共通キーワード出現数に基づき共通キーワードの非一般性を示す共通キーワード評価値を算出する共通キーワード評価値算出ステップと、共通組付与情報評価値算出手段が、分類対象文書の全て又は一部の文書で構成された共通組付与情報参照文書の識別番号と当該共通組付与情報参照文書に含まれる共通組付与情報とを関連付けて格納した共通組付与情報テーブルを参照して、当該共通組付与情報テーブルにおいて共通組付与情報が出現する共通組付与情報出現数を数え、当該共通組付与情報出現数に基づき共通組付与情報の非一般性を示す共通組付与情報評価値を算出する共通組付与情報評価値算出ステップと、キーワード類似度算出手段が各共通キーワード評価値を合算して、2文書の共通キーワードに基づく類似性を示すキーワード類似度を算出するキーワード類似度算出ステップと、組付与情報類似度算出手段が各共通組付与情報評価値を合算して、2文書の共通組付与情報に基づく類似性を示す組付与情報類似度を算出する組付与情報類似度算出ステップと、文書類似度算出手段がキーワード類似度と組付与情報類似度とを総合した2文書の文書類似度を算出する文書類似度算出ステップと、分類対象文書を座標系の初期文書位置に配置し、文書類似度が増大するほど2文書間の文書間距離を減少させ、文書類似度が減少するほど2文書間の文書間距離を増大させるように各分類対象文書を移動させる文書移動ステップと、を備えることを特徴とする。
【0007】
これによれば、文書の分類は、文書類似度の増減に応じた文書間距離に分類対象文書を配置することによって行われる。文書間の文書類似度は、キーワード類似度と組付与情報類似度とを総合して算出される。そのため、文書類似度おけるキーワード類似度の影響が組付与情報類似度によって低減されるので、キーワード分類における文書の表記の差による影響を低減することができる。また、共通組付与情報は、文書内容の分野を体系づける分類情報と文書内容の創作者の氏名とによって構成されているので、分類対象文書の分野によって分類対象文書間の組付与情報類似度および文書類似度が増減する。文書類似度が増減するとそれに応じて分類対象文書間の文書間距離が変化するので、異なる分野の文書を適切に分類することが出来る。
【0008】
ここで、上記作用を好適に奏する上記文書分類方法は、キーワード類似度を初期文書類似度とする初期文書類似度算出ステップと、分類対象文書を座標系の任意文書位置に配置し、2文書間の初期文書類似度が大きいほど文書間距離を減少させ、初期文書類似度が減少するほど2文書間の文書間距離を増大させるように分類対象文書を初期文書位置に移動させる初期文書移動ステップと、をさらに備えることが好ましい。
【0009】
また、上記の組付与情報類似度算出ステップは、分類情報の階層ごとに組付与情報類似度を算出してもよい。
【0010】
この場合には、国際特許分類(以下、IPC)などの階層構造を有する分類情報を使用する場合が想定される。例えば、サブグループまでのIPCを含む共通組付与情報の類似度が0すなわち文書間に類似性が検出されなかった場合においても、より階層の浅いメイングループやサブクラスまでのIPCを含む共通組付与情報の類似度を算出することによって、文書間に類似性を見出される場合がある。また、多くの文書が近い文書間距離で近接している場合には、上記とは逆にIPCの階層を深くすることによって、より類似性の高い文書を検出することができる。したがって、分類対象文書の類似度合いに応じて、分類の分解能を調整することができるので、さまざまな類似状況にある分類対象文書を適切に分類することが出来る。
【発明の効果】
【0011】
本発明の文書分類装置および文書分類方法によれば、キーワード分類における文書の表記の差による影響を低減しつつ、異なる分野の文書を適切に分類することができる。
【発明を実施するための最良の形態】
【0012】
以下、添付図面を参照して、本発明の好適な実施形態を詳細に説明する。なお、図面の説明において同一の要素には同一の符号を付し、重複する説明を省略する。
【0013】
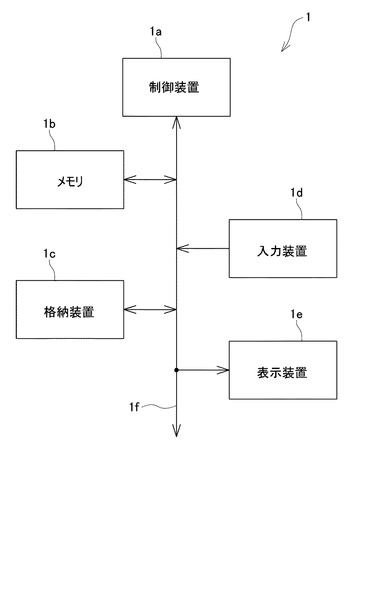
本実施形態では、本発明に係る文書分類装置を、特許文献分類に適用した場合について説明する。まず、図1乃至図6を参照して、第一実施形態にかかる文書分類装置の構成について説明する。ここで、図1は、本発明による文書分類装置の一実施形態を示すブロック図、図2は、文書間距離DB14のデータベースの一例を示す構成図、図3は、位置座標DB16のデータベースの一例を示す構成図、図4は、文書間力ベクトルDB18のデータベースの一例を示す構成図、図5は、表示部32による結果表示画面の一例を示す図、図6は、図1の文書分類装置1のハードウェア構成を示すブロック図である。
【0014】
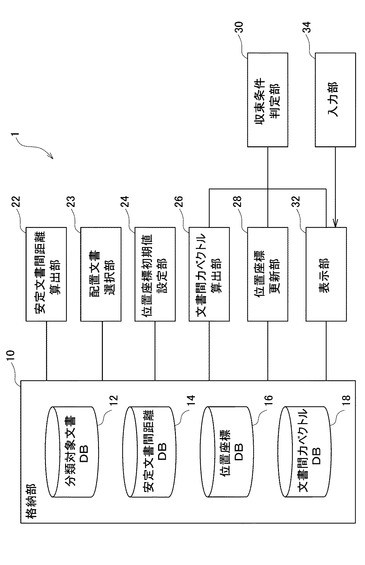
図1を参照すると、文書分類装置1は、複数の分類対象文書を、各分類対象文書の内容に応じて分類するものである。文書分類装置1は、データベース10、安定文書間距離算出部22、配置文書選択部23、位置座標初期値設定部24、文書間力ベクトル算出部26、及び位置座標更新部28を備えている。データベース10は、分類対象文書DB12、安定文書間距離DB14、位置座標DB16及び文書間力ベクトルDB18を有している。
【0015】
分類対象文書DB12は、複数の分類対象文書を、それを識別する文書コード(識別番号)に関連付けて格納している。分類対象文書は、分類対象文書DB12に予め格納されているが、適宜の入力手段により必要に応じて入力することもできる。
【0016】
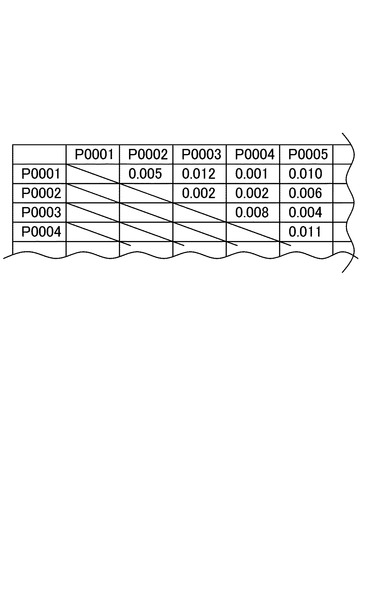
安定文書間距離DB14は、安定文書間距離算出部22により算出される安定文書間距離を文書コードに関連付けて格納する。例えば、図2に示すように、各2文書間の安定文書間距離が、それらの文書コード(P0001,P0002,・・・)に関連付けられて格納されている。この場合、文書(P0001)と文書(P0002)との間の安定文書間距離は、0.005である。
【0017】
位置座標DB16は、位置座標初期値設定部24により設定される各文書の位置座標の初期値、及び位置座標更新部28により更新された位置座標を文書コードに関連付けて格納する。例えば、図3に示すように、各文書の位置座標(X座標,Y座標)が文書コードに関連付けられて格納されている。この場合、文書(P0003)の位置座標は、(0.5155,0.3417)である。
【0018】
文書間力ベクトルDB18は、文書間力ベクトル算出部26により算出される総和文書間力ベクトルを文書コードに関連付けて格納する。例えば、図4に示すように、各文書に働く総和文書間力ベクトル(FX,FY)が文書コードに関連付けられて格納されている。この場合、文書(P0002)の総和文書間力ベクトルは(0.007,‐0.003)である。
【0019】
安定文書間距離算出部22は、分類対象文書DB12に格納されている複数の分類対象文書について、各2文書間の安定文書間距離を、両文書の類似する程度に応じて算出する。この安定文書間距離は、両文書の内容が類似する程度が高いほど小さく、類似する程度が低いほど大きくなる。
【0020】
位置座標初期値設定部24は、2次元座標平面上における各文書の位置座標の初期値を設定する。この初期値には、乱数を用いた任意の文書位置座標(任意文書位置座標)または後述するS117で算出される初期文書位置座標が用いられる。ここでは、任意文書位置座標を用いた初期値の設定方法の一例を説明する。説明の便宜のため、分類対象文書数をN(Nは2以上の整数)とし、各文書をTi(i=1,2,・・・,N)と表すことにする。
【0021】
まず、文書Tiと文書Tj(j=1,2,・・・,N、j≠i)との間の安定文書間距離L0(i,j)をテーブルLaに読み込む。全ての(i,j)の組について安定文書間距離L0(i,j)を読み込んだ後、L0(i,j)の平均値Lavgを求める。そして、各文書Tiの位置座標(Xi,Yi)を下記式、
【数1】

から求める。ここで、rndは乱数を表している。これにより、各文書の任意文書位置座標が設定される。なお、安定文書間距離L0(i,j)は平均値Lavgで除されることにより、正規化される。
【0022】
文書間力ベクトル算出部26は、各文書に働く総和文書間力ベクトルを算出する。総和文書間力ベクトルとは、各文書が他の文書から受ける文書間力のベクトル和である。また、文書間力とは、各2文書の位置座標から求められる座標平面上における距離が上記の安定文書間距離よりも大きい場合には両文書間に引力が働き、逆に座標平面上における距離が安定文書間距離よりも小さい場合には両文書間に斥力が働くと仮定して導入した概念である。これらの力の大きさは、座標平面上における距離と安定文書間距離との差の絶対値が増加するにつれて大きくなり、上記絶対値が減少するにつれて小さくなる。また、座標平面上における距離が安定文書間距離と一致する場合には、両文書間に働く文書間力は0である。
【0023】
文書間力ベクトル算出部26における文書間力ベクトルの算出方法の一例を説明する。まず、文書Tiと文書Tjの距離L(i,j)をその処理時点(現処理時点)(特に本実施形態では、位置座標の更新について「現処理時点」、「次回処理時点」というとき、「現処理時点」とは、移動処理(全部又は一部の配置文書の各々について、総和文書間力ベクトルを算出してこれに基づき位置座標を更新する処理を位置座標の収束が判断されるまで繰り返す処理)の繰返処理において、ある回が開始する時点を指し、「次回処理時点」とは、当該ある回の次の回が開始する時点を指すものとする。)における両者の位置座標に基づいて、下記式、
【数2】
から求める。なお、「その処理時点における両者の位置座標に基づいて」とあるのは、後述するように、各文書Tiの位置座標は必要に応じて更新されるため、常に同じ値をとるとは限らないからである。
【0024】
次に、文書Tiと文書Tjの文書間力f(i,j)を下記式、
【数3】
から求める。ここで、ε1は、L0(i,j)が0のときに対応するための定数であり、例えば1×10−12とされる。αは、安定文書間距離L0(i,j)が小さくなるに連れて文書間力f(i,j)が指数関数的に大きくように設定される。こうすることにより、文書間の類似度が高いときにより大きな文書間力が働くようになる。その結果、類似する文書の集団を形成するのが容易になると共に集団が配置される位置が人間の感覚に近いものになり、また分類対象文書数Nが多くなっても容易に収束させることができる。
【0025】
分類対象文書数が比較的少数である場合(Nが50未満の場合)にはα=0.8〜2.3の何れかの値に設定される。Nが100を超える場合にはα=1.8〜2.2の何れかの値に設定することにより容易に収束させることができる。特に、N=101〜3000の場合にはα=2とするのが好適である。特に、分類対象文書を2次元空間にマッピングする場合、αが上記範囲より小さい場合は、移動処理の繰返処理の過程で一部文書の座標が収束せず発散するケースが多くなり、上記範囲より大きい場合は、個々の文書の内容を反映しない均一な文書の集団を形成しやすくなる。
【0026】
次に、文書Tiが文書Tjから受ける文書間力のX成分fX(i,j)及びY成分fY(i,j)を下記式、
【数4】
から求める。ここで、ε2は、L(i,j)が0のときに対応するための定数であり、例えば1×10−12とされる。また、βは、例えば0.5に設定される。
【0027】
最後に、各文書Tiに働く文書間力の総和のX成分FXi及びY成分FYiを下記式、
【数5】
から求める。ここで、Σjは、全ての配置済み文書についての和をとることを意味する。このようにして算出されたFXi及びFYiを成分とするベクトルが上述の総和文書間力ベクトルである。
【0028】
位置座標更新部28は、文書間力ベクトル算出部26により算出された総和文書間力ベクトルの絶対値が小さくなるように、各文書の位置座標を更新する。位置座標更新部28における位置座標の更新方法の一例を説明する。すなわち、各文書Tiの位置座標(Xi,Yi)は、文書間力ベクトル算出部26により算出された文書間力ベクトル(FXi,FYi)に基づいて、下記式、
【数6】
により更新される。ここで、(Xi’,Yi’)は、更新後の位置座標を表す。また、kは移動係数であり、例えば1×10−23以上1×10−22以下の定数とされる。上記式は、各文書Tiを、文書間力ベクトルの向きに、そのベクトルの絶対値の大きさに比例した距離だけ移動させることを意味している。
【0029】
更新された位置座標は、位置座標DB16に格納され、それまで格納されていた位置座標に対して上書きされる。本実施形態において位置座標更新部28は、位置座標の更新と併せて、各文書Tiの移動距離の平均値MLを下記式、
【数7】
から求める。この平均値MLは、後述する収束条件判定部30による収束条件の判定の際に用いられる。
【0030】
なお、位置座標更新部28は、各文書に働く文書間力ベクトルの絶対値を全ての分類対象文書について和をとった値が極小となるまで、位置座標の更新を実行することが好適である。この場合、全ての分類対象文書間で特に高い整合性を保ちつつ、各文書の位置座標を決定することができる。
【0031】
図1を参照すると、文書分類装置1は、収束条件判定部30、表示部32(出力手段)、及び入力部34をさらに備えている。収束条件判定部30は、位置座標更新部28により位置座標が更新された後に、収束条件の判定を行う。例えば、上述の位置座標更新部28において求められた平均値MLが規定値以下になることを収束条件として設定することができる。この収束条件が満たされないときは、収束条件判定部30は、文書間力ベクトル算出部26に更新後の位置座標を用いて再度総和文書間力ベクトルを算出させるとともに、位置座標更新部28にその総和文書間力ベクトルを用いて再度位置座標を更新させる。したがって、位置座標更新部28による位置座標の更新は、上述の収束条件が満たされるまで実行される。
【0032】
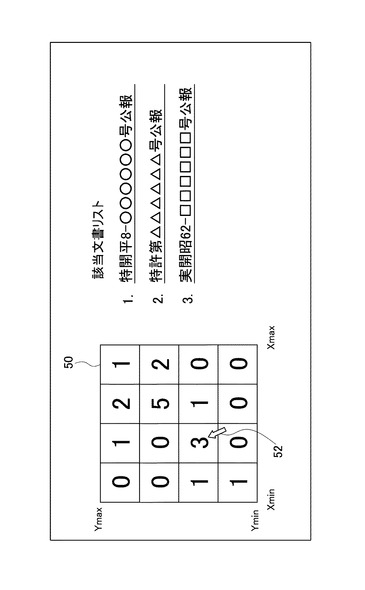
表示部32は、上述の収束条件が満たされ、位置座標更新部28による位置座標の更新が終了した後、決定した位置座標に基づいて、各文書Ti間の座標平面上における相対的な位置関係を可視化して表示する。これにより、ユーザは、表示部32による表示を見ることにより、容易に文書間の相対的な位置関係を知ることができる。ここで、図5を参照して、表示部32における表示方法の一例を説明する。
【0033】
まず、表示エリア50をm×n個(ここではm=n=4)のセルに区切る。また、後述する入力部34により表示エリアを規定するX座標、Y座標それぞれの最大値(Xmax、Ymax)及び最小値(Xmin、Ymin)を入力する。なお、これらの値を入力せずに、既に決定されている全文書の位置座標から、X座標及びY座標それぞれについて、最大のもの及び最小のものをデフォルト値として用いることもできる。
【0034】
次に、表示部32は、入力されたこれらの値から、各セルに相当する座標範囲を求める。そして、各セルに含まれる文書の数を、図5に示すように表示する。例えば、この場合、一番右上のセルに含まれる文書数は1である。さらに本例では、各セルに含まれる文書のイメージを作成するとともに、各セルにそのイメージをハイパーリンクさせる。図5に示すように、注目するセルにマウスポインタ52を合わせると、そのセルに含まれる文書を、該当文書リストとして表示させることができる。
【0035】
図5では、分類対象文書として公開特許公報等の特許文献(外国語又は外国で発行された特許文献も含む。)を想定しており、該当文書リストには特許文献の種別と公報番号とを表示させている。また、これらの表示にはハイパーリンクが貼られているので、例えば「特開平8−○○○○○○号公報」と表示されている部分を画面上でクリックすれば、その公開特許公報のイメージにアクセスして、その内容を見ることができる。
【0036】
図1を参照すると、入力部34は、表示部32により表示される対象となる座標平面上における表示エリア等を入力するためのものであり、例えばキーボードやマウス等が用いられる。例えば、図5の例では、表示エリア50を規定するXmax、Ymax、Xmin、Yminの値を入力部34から入力することができる。入力された情報は、表示部32へと渡される。これにより、ユーザは、座標平面上の所望の範囲を表示させ、その範囲における文書間の位置関係を詳細に知ることができる。
【0037】
次に、図6を参照して、文書分類装置1のハードウェア構成について説明する。図6に示すように、文書分類装置1は、物理的には、制御装置1a、メモリ1b、格納装置1c、入力装置1d、及び表示装置1eを備えて構成される。これら各装置は、バス1fを介して相互に各種信号の入出力が可能な様に電気的に接続されている。
【0038】
具体的には、制御装置1aは例えばCPU(Central Processing Unit)であり、メモリ1bはRAM(Random Access Memory)といった揮発性の半導体メモリである。格納装置1cはHDD(HardDisc Drive)を始めとする不揮発性の磁気ディスクである。入力装置1dは例えばキーボードやマウスであり、表示装置1eはLCD(LiquidCrystal Display)やCRT(Cathode Ray Tube)ディスプレイである。
【0039】
上記ハードウェア構成と機能的構成との対応関係を以下に示す。文書分類装置1に関して、データベース10の有する機能は、物理的な構成要素としての格納装置1cにより実現される。安定文書間距離算出部22、位置座標初期値設定部24、文書間力ベクトル算出部26、位置座標更新部28、収束条件判定部30の有する各機能は、制御装置1aが所定のプログラムを実行することにより実現される。入力部34の有する各機能は入力装置1dにより実現される。なお、表示部32の有する各機能は、制御装置1a及び表示装置1eにより実現される。すなわち、制御装置1aが所定の演算を施すことにより分類結果の表示内容を確定し、表示装置1eがその内容に従って分類結果を表示する。
【0040】
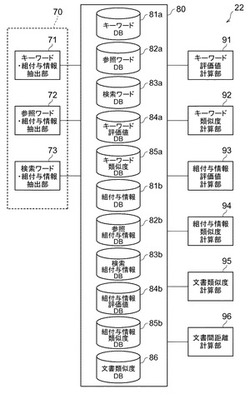
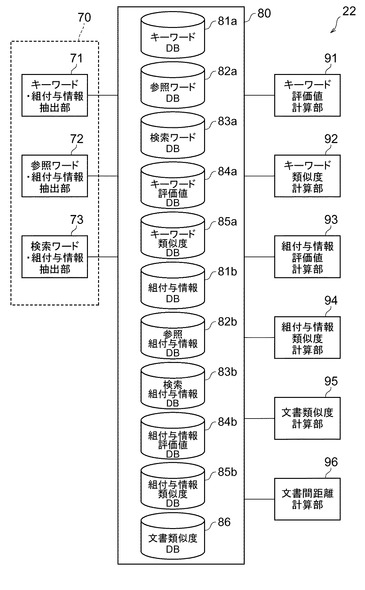
次に、図7乃至図16を参照して、安定文書間距離算出部22の詳細な構成について説明する。ここで、図7は、図1の安定文書間距離算出部22の構成の一例を示すブロック図、図8は、参照ワードDB82aのデータベースの一例を示す構成図、図9は、共通ワードカウントテーブルによるカウントを説明する図、図10は、キーワード評価値DB84aのデータベースの一例を示す構成図、図11は、キーワード類似度DB85aのデータベースの一例を示す構成図、図12は、参照組付与情報DB82bのデータベースの一例を示す構成図、図13は、共通参照組付与情報カウントテーブルによるカウントを説明する図、図14は、組付与情報評価値DB84bのデータベースの一例を示す構成図、図15は、組付与情報類似度DB85bのデータベースの一例を示す構成図、図16は、文書類似度DB86のデータベースの一例を示す構成図である。
【0041】
図7を参照すると、安定文書間距離算出部22は、各種文書からワード及び組付与情報を抽出するワード・組付与情報抽出部70と、ワード・組付与情報抽出部70によって抽出されたワード及び組付与情報を格納する各種データベース80とを備えている。
【0042】
ワード・組付与情報抽出部70は、キー文書からワード及び組付与情報をキーワード・組付与情報として抽出するキーワード・組付与情報抽出部71と、参照文書からワード及び組付与情報を参照ワード・組付与情報として抽出する参照ワード・組付与情報抽出部72と、検索文書からワード及び組付与情報を検索ワード・組付与情報として抽出する検索ワード・組付与情報抽出部73とを有している。
【0043】
ここで、「キー文書」及び「検索文書」の区分は便宜的なものであり、安定文書間距離算出部22においては、文書間距離を求めたい2文書のうちの一方がキー文書、他方が検索文書とされる。また、参照文書とは、キーワード評価値(各キーワードがキー文書に固有に含まれる程度(非一般性)を表す値)及び組付与情報評価値(各組付与情報がキー文書に固有に含まれる程度(非一般性)を表す値)を設定する際に参照される文書である。参照文書としては、例えば分類対象文書DB12(図1参照)内の全文書、或いは予めランダムに抽出した分類対象文書DB12内の一部の文書を用いることができる。参照文書は、適宜の入力手段により、必要に応じて安定文書間距離算出部22に入力することができる。また、安定文書間距離算出部22は、参照文書を格納する格納手段を備えている。
【0044】
抽出部71〜73は、日本語にあっては、ひらがな、句読点、特殊記号及びスペースを区切記号として或いは形態素解析ツール等を利用して文書内のワードを抽出する機能を有する。また、抽出部71〜73は、英語等のアルファベット表記がなされる言語にあっては、特殊記号及び/又はスペースを区切記号として或いは形態素解析ツール等を利用して文書内のワードを抽出する機能を有する。抽出部71〜73は、一つの文書から重複してワードを抽出しないように、ある文書から切り出されたワードは、同じ文書から既に切り出されたワードと照合され、一致しないワードのみを抽出する機能を有する。
【0045】
図7を参照すると、データベース(DB)80は、キーワードDB81a、参照ワードDB82a、検索ワードDB83a、キーワード評価値DB84a、キーワード類似度DB85a、組付与情報DB81b、参照組付与情報DB82b、検索組付与情報DB83b、組付与情報評価値DB84b、組付与情報類似度DB85b及び文書類似度DB86を有している。
【0046】
キーワードDB81aは、キー文書から抽出したキーワードを格納する。キーワードは、抽出元であるキー文書を特定するキー文書コードに関連付けて格納されている。
【0047】
参照ワードDB82a(各文書に含まれるワードを当該文書の文書番号と関連付けて格納したテーブル)は、参照文書から抽出された参照ワードを、それぞれの抽出元である参照文書を特定する参照文書コードと関連付けて格納する。参照ワードDB82aは、例えば図8に示すような、参照文書コードおよび参照ワードを項目とするリレーショナルデータベース(以下、RDB)である。図8では、5つの参照文書から抽出された参照ワードが、それらの文書コード(P1,P2,・・P5)に関連付けられて格納されている例が示されている。
【0048】
検索ワードDB83aは、検索文書から抽出される検索ワードを格納する。検索ワードは、抽出元である検索文書を特定する検索文書コードに関連付けて格納されている。
【0049】
キーワード評価値DB84aは、後述するキーワード評価値計算部91により算出される評価値を格納する。キーワード評価値DB84aは、例えば図10に示すような、参照ワードおよびキーワード評価値を項目とするRDBである。ここで、キーワード評価値DB84aに格納される参照ワードは、図8で得られた異なる参照ワードの集合である。
【0050】
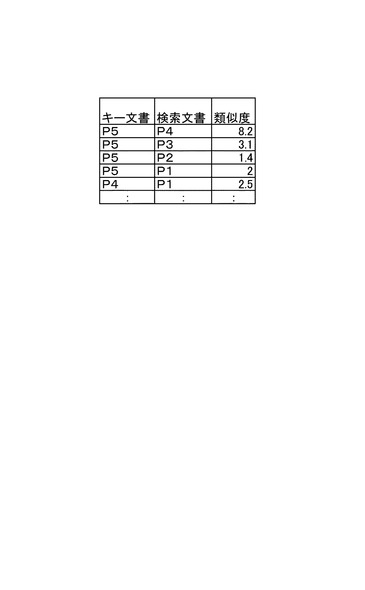
キーワード類似度DB85aは、後述するキーワード類似度計算部92により算出されるキーワード類似度を格納する。キーワード類似度DB85aは、例えば図11に示すような、キー文書、検索文書およびキーワード類似度を項目とするRDBである。
【0051】
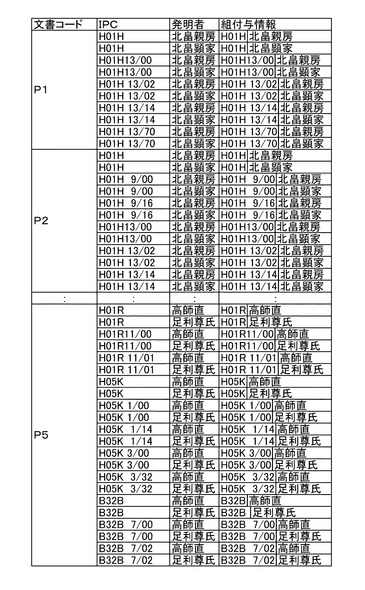
組付与情報DB81aは、キー文書から抽出した組付与情報を格納する。組付与情報は、抽出元であるキー文書を特定するキー文書コードに関連付けて格納されている。組付与情報としては、文書に付与されたIPCと発明者氏名を組合わせたものが好適である。
【0052】
参照組付与情報DB82bは、参照文書から抽出した組付与情報を格納する。組付与情報は、抽出元である参照文書を特定する参照文書コードに関連付けて格納されている。参照組付与情報DB82bは、例えば図12に示すような、参照文書コードおよび参照組付与情報を項目とするRDBであり、組付与情報は、IPC項目と発明者項目の要素を連結することによって得られる。
【0053】
IPCと発明者とがそれぞれ複数存在する場合には、それらのすべての組合せに対する組付与情報が格納される。また、IPCのように文書の分類情報が階層構造を有する場合には、それぞれの階層の分類情報と発明者氏名とのすべての組合せに対する組付与情報が格納される。図12には、サブクラス以降のIPCに対する組付与情報が示されている。また、組付与情報DB82bに格納される組付与情報は、ワード・組付与情報抽出部70により抽出されたものであってもよいし、入力されたデータに基づくものであってもよい。
【0054】
検索組付与情報DB83bは、検索文書から抽出される検索組付与情報を格納する。検索組付与情報は、抽出元である検索文書を特定する検索文書コードに関連付けて格納されている。
【0055】
組付与情報評価値DB84bは、後述する組付与情報評価値計算部93により算出される評価値を格納する。組付与情報評価値DB84bは、例えば図14に示すような、参照組付与情報および組付与情報評価値を項目とするRDBである。ここで、組付与情報評価値DB84bに格納される組付与情報は、図12で得られた異なる組付与情報の集合である。
【0056】
組付与情報類似度DB85bは、後述する組付与情報類似度計算部94により算出される組付与情報類似度を格納する。組付与情報類似度DB85bは、例えば図15に示すような、キー文書、検索文書、組付与情報、組付与情報類似度を項目とするRDBである。
【0057】
文書類似度DB86は、キーワード類似度と組付与情報類似度とを総合した類似度である文書類似度を格納する。文書類似度DB86は、例えば図16に示すような、キー文書、検索文書、文書類似度を項目とするRDBである。
【0058】
なお、上記のキーワード、参照ワード、及び検索ワードは、それぞれ抽出対象となる文書の全体から抽出してもよいし、一部から抽出してもよい。例えば、抽出対象となる文書が特許文献であれば、書誌的事項、要約、請求項、又は実施例等に抽出範囲を限定してもよい。特に、データ量に制限がある場合には、抽出範囲を文書の一部に絞ることが有効となる。また、参照ワードは参照文書の一部から抽出し、キーワード及び検索ワードはそれぞれキー文書及び検索文書の全体から抽出するというように、各ワード毎に適宜抽出範囲を変えることより、いわゆるノイズと漏れの関係を調整することができる。
【0059】
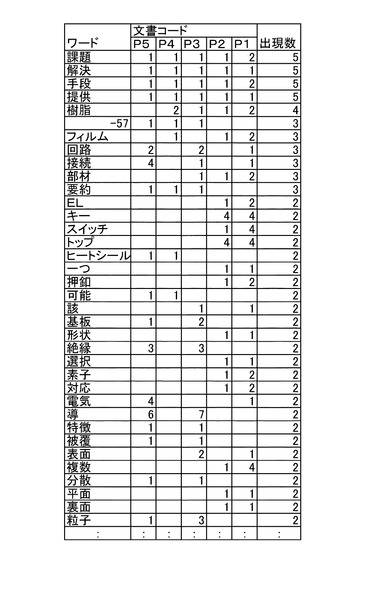
図7を参照すると、安定文書間距離算出部22は、キーワード評価値計算部91及びキーワード類似度計算部92を備えている。キーワード評価値計算部91は、全参照文書中でキー文書と共通のワードが出現する出現率を算出する機能を有する。参照文書がN個で、そのうちのB個に共通のワードが存在する場合には、全文書内キーワード出現率は、B/Nで算出される。
【0060】
キーワード評価値計算部91は、参照ワードDB82aに格納された参照ワードを検索して、キーワードと同一のものが何個存在するか算出する。キーワードの出現数の算出には、例えば、図9に示すような、カウントテーブルを用いてもよい。図9を参照すると、例えば「課題」が共通ワードであった場合、「課題」は参照文書P1〜P5すべてに出現しているため、出現数は5となっている。カウントされた出現数を全参照文書の数で除することによって、全文書内キーワード出現率が算出される。
【0061】
さらに、キーワード評価値計算部91は、全文書内キーワード出現率の逆数をとって、キーワード評価値を算出する機能を有する。すなわち、キーワード評価値は、N/Bで算出され、各キーワードがキー文書に固有に含まれる程度(非一般性)を示すものである。キーワード出現数Bを0.1〜0.8乗する調整を施すことが考えられる。この場合、たとえば0.5乗する調整を施すとき、キーワード評価値は、N/(B0.5)となる。
【0062】
キーワード類似度計算部92は、検索文書に含まれる全てのキーワードの評価値を加算することにより、キー文書と検索文書とが類似する程度を表すキーワード類似度を算出する機能を有する。更に加算値を2〜100で除した値をキーワード類似度として、後述する組付与情報類似度とのバランスをとることが考えられる。キーワード類似度計算部92は、このようにして算出したキーワード類似度をキーワード類似度DB85aに格納させる。
【0063】
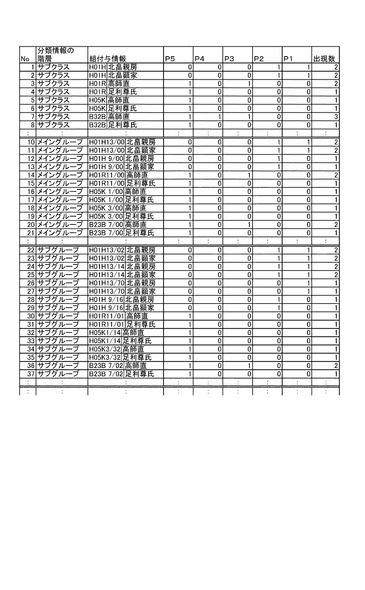
図7を参照すると、安定文書間距離算出部22は、組付与情報評価値計算部93及び組付与情報類似度計算部94を備えている。組付与情報評価値計算部93は、組付与情報DB81bを参照して、キー文書に付与された各組付与情報の全参照文書中における出現率を算出する機能を有する。具体的には、図13に示すような、カウントテーブルを用いてキー文書に付与された各組付与情報の出現数をカウントし、その出現数を全参照文書の数で除することによって、全文書内組付与情報出現率を算出する。参照文書がN個で、全文書中のC個において当該組付与情報が付与されている場合には、全文書内組付与情報出現率は、C/Nで算出される。
【0064】
さらに、組付与情報評価値計算部93は、全文書内組付与情報出現率の逆数をとって、組付与情報評価値を算出する機能を有する。すなわち、組付与情報評価値は、N/Cで算出され、各組付与情報がキー文書に固有に含まれる程度(非一般性)を示すものである。組付与情報出現数Cを0.1〜0.8乗する調整を施すことが考えられる。この場合、たとえば0.5乗する調整を施すとき、組付与情報評価値は、N/(C0.5)となる。
【0065】
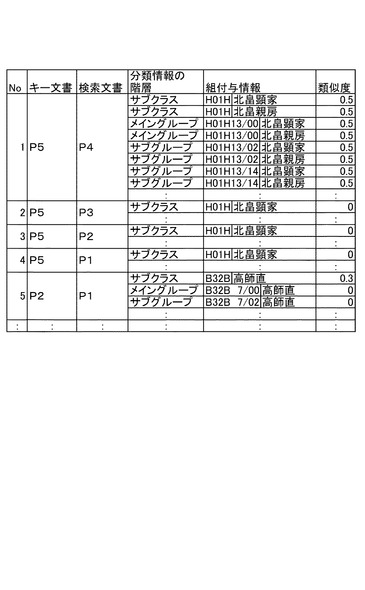
組付与情報類似度計算部94は、キー文書と検索文書が共通して引用する全ての文献についての評価値を加算することにより、キー文書と検索文書とが類似する程度を表す組付与情報類似度を算出する機能を有する。組付与情報類似度計算部94は、このようにして算出した組付与情報類似度を組付与情報類似度DB85bに格納させる。また、組付与情報類似度計算部94は、IPCのように文書の分類情報が階層構造を有する場合には、それぞれの階層の分類情報すなわち組付与情報に対する類似度を算出する。
【0066】
図7を参照すると、安定文書間距離算出部22は、文書類似度計算部95及び文書間距離計算部96を備えている。文書類似度計算部95は、キーワード類似度のみをキー文書と検索文書との類似度(初期文書類似度)とする機能と、キーワード類似度と組付与情報類似度とを総合してキー文書と検索文書との類似度(文書類似度)を算出する機能を有する。具体例として、文書類似度計算部95は、キーワード類似度と組付与情報類似度との平均値を文書類似度として文書類似度DB86に格納する。この際、前述したとおりキーワード類似度を適当な数で除することにより、キーワード類似度が安定文書間距離に与える影響の強さと組付与情報類似度が安定文書間距離に与える影響の強さとのバランスを調整することが考えられる。
【0067】
文書間距離計算部96は、文書類似度DB86に格納されている類似度を用いて文書Tiと文書Tjとの間の初期文書類似度に基づく初期安定文書間距離L0(1)(i,j)または文書類似度に基づく安定文書間距離L0(2)(i,j)を算出する機能を有する。ここで、初期安定文書間距離L0(1)(i,j)および安定文書間距離L0(2)(i,j)は、下記式、
【数8】
【数9】
から求められる。ここで、Sij(1)は、文書Tiをキー文書とし、文書Tjを検索文書としたときの初期文書類似度を表し、Sji(1)は、文書Tjをキー文書とし、文書Tiを検索文書としたときの初期文書類似度を表し、Sij(2)は、文書Tiをキー文書とし、文書Tjを検索文書としたときの文書類似度を表し、Sji(2)は、文書Tjをキー文書とし、文書Tiを検索文書としたときの文書類似度を表す。つまり、上記式は、文書Tiと文書Tjとの間で、キー文書と検索文書の関係を入れ替えて算出された類似度の平均値をとり、さらにその平均値の逆数をとることを意味している。キー文書と検索文書の関係を入れ替えて算出された類似度の平均値を用いるのは、上記のSij(1)とSji(1)(Sij(2)とSji(2))とは必ずしも一致しないからである。このようにして算出される初期安定文書間距離L0(1)(i,j)および安定文書間距離L0(2)(i,j)は、両文書間の類似度が高いほど小さくなり、類似度が低いほど大きくなる。
【0068】
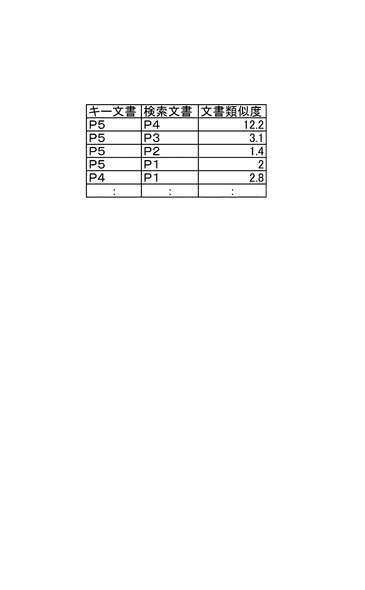
次に、図17乃至図22を参照して、文書分類装置1の動作を説明し、併せて本発明による文書分類方法の一実施形態を説明する。
【0069】
図17を参照すると、先ず、安定文書間距離算出部22が、分類対象文書DB12に格納されている分類対象文書を読み込んで、各2文書間における初期文書類似度に基づく安定文書間距離(初期安定文書間距離)を算出し、算出した初期安定文書間距離L0(1)(i,j)を安定文書間距離DB14に格納させる(S61)。続いて、安定文書間距離算出部22が、文書間距離DB14に格納されている初期安定文書間距離L0(1)(i,j)を読み込んで平均値Lavg(1)を算出し(S62)、各初期安定文書間距離L0(1)(i,j)をこの平均値Lavg(1)で除することにより正規化して安定文書間距離DB14のデータを更新する(S63)。
【0070】
次に、配置文書選択部23が、最初に表示座標系に配置する分類対象文書である初期配置文書Tkをint√N(分類対象文書の総数Nの平方根の小数点以下を切り捨てた値)個選択する(S64)。続いて、位置座標初期値設定部24は、任意文書位置座標を用いて各文書の位置座標の初期値を設定し、設定した位置座標の初期値を位置座標DB16に格納させる(S65)。
【0071】
そして、文書間力ベクトル算出部26が、文書間距離DB14に格納されている初期安定文書間距離L0(1)(i,j)及び位置座標DB16に格納されている位置座標を読み込み、それらの値を用いて、各文書に働く総和文書間力ベクトルを算出し、算出した総和文書間力ベクトルを文書間力ベクトルDB18に格納する(S66)。
【0072】
その後、位置座標更新部28が、文書間力ベクトルDB18に格納されている総和文書間力ベクトルを読み込み、そのベクトルに基づいて各文書の位置座標を更新し、更新した位置座標を位置座標DB16に格納させる(S67)。位置座標が更新されると、収束条件判定部30が収束条件の判定を行い、収束条件が満たされていない場合には上記ステップ(S66〜S67)を繰返し実行させる。収束条件が満たされている場合には、図21に示す表示座標系に追加の配置文書を加えていく処理(文書追加処理)に処理が移行する。
【0073】
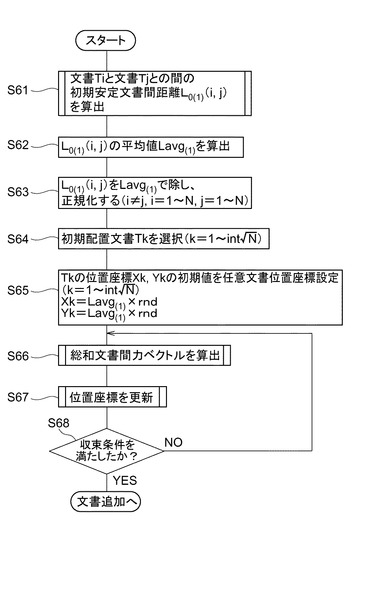
次に、図18を参照して、安定文書間距離を算出する処理(図17の安定文書間距離算出ステップ(S61)のサブルーチン)について説明する。まず、キーワード抽出部71がキー文書からキーワードを抽出し、抽出したキーワードをキーワードDB81aに格納させる(S801)。また、参照ワード抽出部72が参照文書から参照ワードを抽出し、抽出した参照ワードを参照ワードDB82aに格納させる(S802)。
【0074】
次に、キーワード評価値計算部91が、参照ワードDB82aに格納されている参照ワードを読み込み、各キーワードの評価値を計算し、その評価値をキーワード評価値DB84aに格納させる(S803)。また、検索ワード抽出部73が検索文書から検索ワードを抽出し、抽出した検索ワードを検索ワードDB83aに格納させる(S804)。次に、キーワード類似度計算部92が、キーワード評価値DB84aに格納されている評価値及び検索ワードDB83aに格納されている検索ワードを読み込み、キー文書と検索文書との間のキーワード類似度を計算し、その類似度をキーワード類似度DB85aに格納させる(S805)。
【0075】
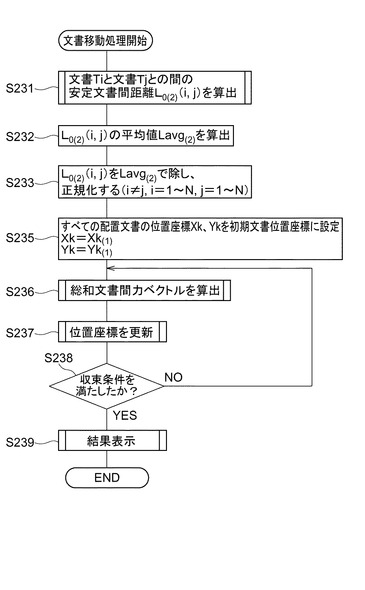
組付与情報評価値計算部93が、キー文書と検索文書に共通して付与される共通組付与情報を抽出し(S806)、これらの文献各々の組付与情報評価値を計算する(S807)。組付与情報類似度計算部94が、キー文書と検索文書との組付与情報類似度を計算し、組付与情報類似度DB85bに対してIPCの階層ごとに格納する(S808)。文書類似度計算部95が、キー文書と検索文書とに関して、初期文書類似度と、キーワード類似度及び組付与情報類似度とを平均した文書類似度とをそれぞれ計算する(S809)。最後に、文書間距離計算部93が、キー文書と検索文書における、初期文書類似度に基づく初期安定文書間距離L0(1)(i,j)と、文書類似度に基づく安定文書間距離L0(2)(i,j)とを計算する(S810)。
【0076】
なお、キーワード類似度及び組付与情報類似度の平均を求める際、例えば、組付与情報類似度に2〜40、好ましくは8〜11の係数を乗じて組付与情報類似度に重みをつけることで、表記のゆれが問題となる内容類似の文書間では組付与情報類似度による評価を、共通する組付与情報がない分野の異なる文書間では、キーワード類似度による評価を主体とすることが可能になり、この安定文書間距離に基づき位置座標を算出することで、広い技術分野にわたる特許文献をより詳細に分類配置することが可能になる。
【0077】
次に、図19を参照して、図17の総和文書間力ベクトル算出ステップ(S66)のサブルーチンについて説明する。まず、文書間力ベクトル算出部26が、位置座標DB16に格納されている各文書の位置座標を読み込み、その位置座標から各2文書間の座標平面上における距離(離間ベクトルの長さ)を算出する(S91)。また、文書間力ベクトル算出部26は、文書間距離DB14に格納されている初期安定文書間距離L0(1)(i,j)または安定文書間距離L0(2)(i,j)を読み込み、それらの安定文書間距離と前ステップS91で計算した距離とを用いて、文書間力を算出する(S92)。さらに、文書間力ベクトル算出部26は、離間ベクトルに基づいて文書間力のX成分及びY成分を算出し(S93)、ある文書に対して他の配置済み文書から働く文書間力の総和をベクトル和として求めることにより、総和文書間力ベクトルを算出する(S94)。そして、全ての配置済み文書について総和文書間力ベクトルが算出された場合にはフローが終了し、総和文書間力ベクトルが算出されていない文書がある場合には、上記ステップ(S91〜S94)が繰り返される(S95)。
【0078】
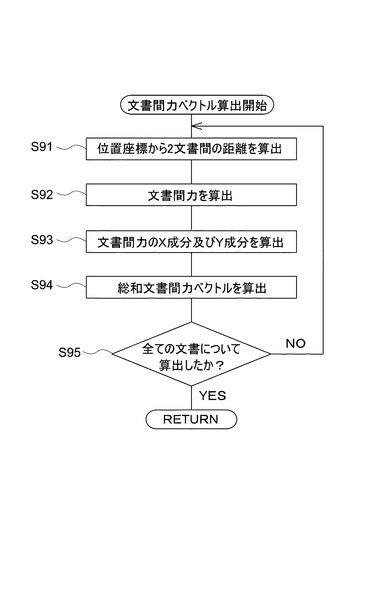
次に、図20を参照して、図17の位置座標の更新ステップ(S67)のサブルーチンについて説明する。まず、位置座標更新部28が、文書間力ベクトルDB18に格納されている文書間力ベクトルを読み込み、そのベクトルに応じて各文書の移動、すなわち位置座標の変更を行う(S101)。その後、位置座標更新部28は、収束条件の判定に用いられる、各文書の移動距離の平均値を算出する(S102)。これは、S68において、移動距離の平均値が閾値を下回ることを収束条件とすることができる。また、これに代えてint√N回位置座標の更新ステップを繰り返したことを収束条件とすることもできる。
【0079】
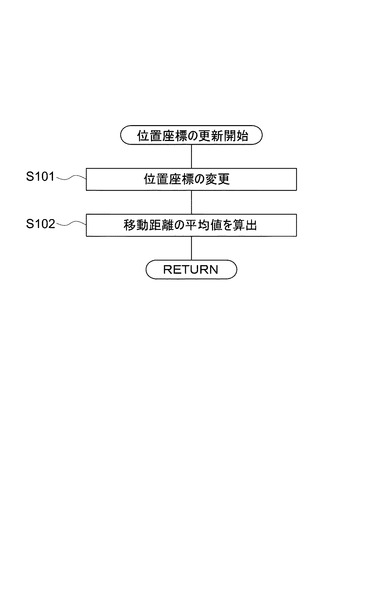
次に、図21を参照して、文書追加処理について説明する。図17に示した初期配置文書の配置・移動処理が終了してから、順次追加の配置文書を加えていって、全ての分類対象文書の配置・移動を完了させる場合を考える。
【0080】
配置文書選択部23が、次に表示座標系に加える時期配置文書を、int(mm/10)(ただし、mmは既に表示座標系に配置済みの分類対象文書の数)個無作為に選択する(S111)。ただし、分類対象文書の残りの個数がint(mm/10)に満たない場合には、残存している分類対象文書全てが時期配置文書になる。初期配置文書の配置・移動処理の直後に追加される時期配置文書の数は、int{(int√N)/10}個となる。
【0081】
位置座標初期値設定部24が、時期配置文書が最初に設置される表示座標系上の位置座標を算出する(S112)。本実施形態では、時期配置文書は、最も安定文書間距離が短い配置済み分類対象文書の近傍に位置するように初期設定される。具体的には、位置座標初期値設定部24は、安定文書間距離DB14を参照して、L0(1)(c,mm+k)が最小値となるcを求め(ただし、c=1〜mm)、時期配置文書Tkの位置座標の初期値を(Xk,Yk)=(Xc+ε,Yc+ε)(ε:定数)とする。また、以上に代えて初期配置文書の場合と同様に時期配置文書の初期値を乱数により決定してもよい。
【0082】
ある時期配置文書の位置座標が初期値に設定された後、文書間力ベクトル算出部26が、当該時期配置文書が他の配置済み分類対象文書から受ける現在の総和文書間力ベクトルを算出する(S113)。位置座標更新部28が、この総和文書間力ベクトルに基づき当該時期配置文書の位置座標を更新する(S114)。収束条件判定部30が、当該時期配置文書の今回の移動量が閾値以下であること又はS113〜S115の処理が所定の回数実行されたことをもって当該時期配置文書の位置座標の収束を判断する(S115)。収束が判断されなかった場合には、当該時期配置文書について再びS113〜S115の処理が繰り返される。
【0083】
時期配置文書のうちの他の文書についても、順次S112〜S115の処理が行われる。時期配置文書中の全ての文書について配置・移動処理が完了した場合には、今回表示座標系に加えられた時期配置文書を含む全ての配置済み文書について位置計算(S66〜S68の処理)が√N回行われる(S117)。この計算結果として得られる位置座標が、後述する文書移動処理(図23参照)で使用される初期文書位置座標(Xk(1),Yk(1))となる。このように、時期配置文書の全てを一度に配置して移動処理(全部又は一部の配置文書の各々について、総和文書間力ベクトルを算出してこれに基づき位置座標を更新する処理を位置座標の収束が判断されるまで繰り返す処理)を行う代わりに、他の配置済み文書の位置座標を固定しつつ一つずつ順次時期配置文書の配置・移動処理を行って全ての時期配置文書の位置座標を仮決めし、さらに今回の時期配置文書を含む全ての配置済み文書についての配置・移動処理を行うことにより、移動処理の繰返回数を減少させることができる。未配置の分類対象文書についてS111〜S117の処理が行われる。ただし、未配置の分類対象文書がなくなった場合には、上記で得られた初期文書位置座標に基づいて表示部32が結果表示を行い(S119)、図23に示される文書移動処理に移行する。
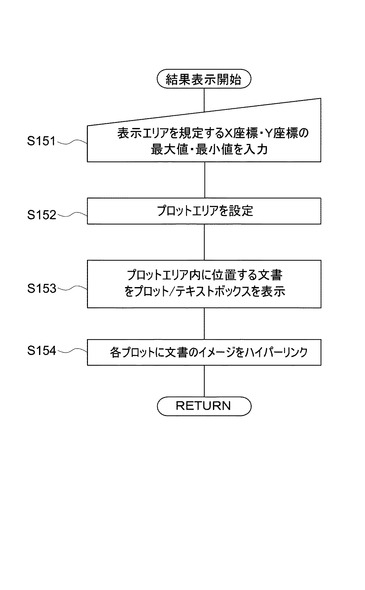
【0084】
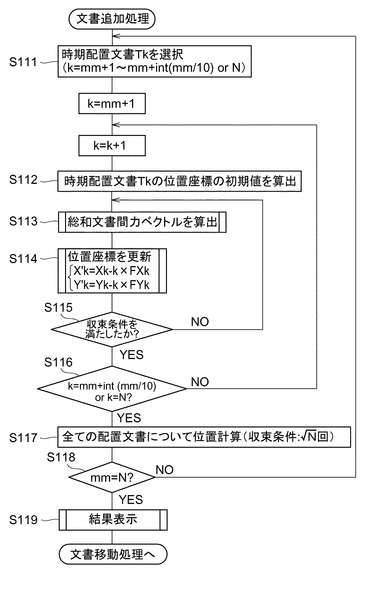
次に、図22を参照して、図21の結果表示ステップ(出力ステップ)のサブルーチンについて説明する。まず、表示部32が、表示エリアをm×n個のセルに区切る(S121)。ここで、入力部34により表示エリアを規定するX座標及びY座標それぞれの最大値及び最小値を入力する(S122)。この入力は、ユーザが行うものである。次に、表示部32は、入力部34より入力された上記の値に基づいて、各セルに相当する座標範囲を算出する(S123)。そして、表示部32は、各セルの座標範囲内に位置座標を有する文書数を表示エリアに表示する(S124)。また、表示部32は、各セルに含まれる文書のイメージを作成するとともに(S125)、各セルに文書のイメージをハイパーリンクさせる(S126)。
【0085】
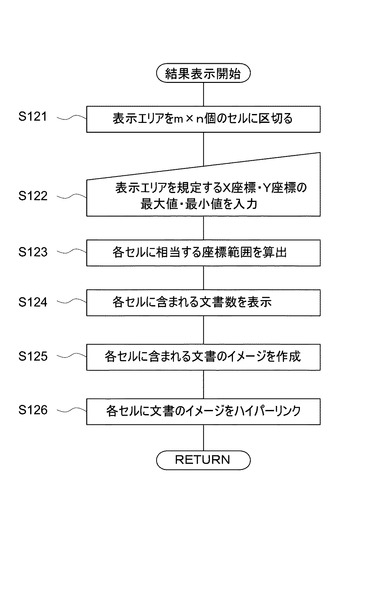
次に、図23を参照して、文書移動処理について説明する。先ず、安定文書間距離算出部22が、分類対象文書DB12に格納されている分類対象文書を読み込んで各2文書間の文書類似度に基づく安定文書間距離L0(2)(i,j)を算出し、算出した安定文書間距離L0(2)(i,j)を安定文書間距離DB14に格納させる(S231)。続いて、安定文書間距離算出部22が、文書間距離DB14に格納されている安定文書間距離L0(2)(i,j)を読み込んで平均値Lavg(2)を算出し(S232)、各安定文書間距離L0(2)(i,j)をこの平均値Lavg(2)で除することにより正規化して安定文書間距離DB14のデータを更新する(S233)。
【0086】
続いて、位置座標初期値設定部24は、ステップS117の計算の結果得られた初期文書位置座標(Xk(1),Yk(1))を用いて各文書の位置座標の初期値を設定し、設定した位置座標の初期値を位置座標DB16に格納させる(S235)。
【0087】
そして、文書間力ベクトル算出部26が、文書間距離DB14に格納されている安定文書間距離L0(2)及び位置座標DB16に格納されている位置座標を読み込み、それらの値を用いて、各文書に働く総和文書間力ベクトルを算出し、算出した総和文書間力ベクトルを文書間力ベクトルDB18に格納する(S236)。
【0088】
その後、位置座標更新部28が、文書間力ベクトルDB18に格納されている総和文書間力ベクトルを読み込み、そのベクトルに基づいて各文書の位置座標を更新し、更新した位置座標を位置座標DB16に格納させる(S237)。位置座標が更新されると、収束条件判定部30が収束条件の判定を行い、収束条件が満たされていない場合には上記ステップ(S236〜S237)を繰返し実行させる。収束条件が満たされている場合には、上記で更新された位置座標に基づいて表示部32が結果表示を行い(S239)、配置・移動処理が終了する。
【0089】
次に、第一実施形態にかかる文書分類装置1の作用及び効果について説明する。
【0090】
文書分類装置1の文書類似度計算部95は、ステップS809において、キーワード類似度と組付与情報類似度とを平均して文書類似度を算出する。そのため、文書類似度おけるキーワード類似度の影響が組付与情報類似度によって低減されるので、キーワード分類における文書の表記の差による影響を低減することができる。また、組付与情報は、IPCと発明者氏名とによって構成されているので、分類対象文書の分野によって分類対象文書間の組付与情報類似度および文書類似度が増減する。安定文書間距離算出部22は、文書類似度が増大すると安定文書間距離L0(2)(i,j)を減少させ、文書類似度が減少すると安定文書間距離L0(2)(i,j)を増大させるので、表示部32が異なる分野の文書を適切な文書間距離で表示することが出来る。
【0091】
また、文書分類装置1の組付与情報類似度計算部94は、ステップS808において、IPCの階層ごとに組付与情報類似度を算出する。そのため、図15のレコードNo5に示すように、サブグループまでのIPCを含む組付与情報類似度が0である場合においても、より階層の浅いサブクラスまでのIPCを含む組付与情報類似度を算出することによって、文書間に類似性を見出される場合がある。また、多くの文書が近い文書間距離で近接している場合には、上記とは逆にIPCの階層を深くすることによって、より類似性の高い文書を検出することができる。したがって、分類対象文書の類似度合いに応じて、分類の分解能を調整することができるので、さまざまな類似状況にある分類対象文書を適切に分類することが出来る。
【0092】
なお、本発明による文書分類装置は、上記実施形態に限られるものではなく、他に様々な変形が可能である。
【0093】
安定文書間距離の計算処理の別の例を示す。本例では、安定文書間距離算出部22において共通キーワードに基づく類似度を計算する処理機能(キーワード評価値計算部91及びキーワード類似度計算部92)と共通組付与情報に基づく類似度を計算する処理機能(組付与情報評価値計算部93及び組付与情報類似度計算部94)とが統合されている。また、本例の参照文書テーブルは参照ワードDB82aのデータと組付与情報DB81bのデータとを結合させたものである。
【0094】
図24は、安定文書間距離の計算処理の第2例におけるフローチャートを示す。図24を参照して、本例の計算処理について説明する。安定文書間距離算出部22(キーワード・組付与情報抽出部70)は、キー文書及び検索文書からワード・組付与情報を抽出して(S211)、共通キーワード及び共通組付与情報を抽出・格納する(S212)。安定文書間距離算出部22は、参照文書テーブルを参照して、参照文書テーブルにおける各共通キーワード及び共通組付与情報の出現率を計算し、これに基づき評価値を計算・格納する(S213)。安定文書間距離算出部22は、各共通組付与情報の評価値に2〜40、好ましくは8〜11の係数を乗じてこの値に置き換える(S214)。安定文書間距離算出部22は、S213で得られたキーワード評価値とS214で得られた組付与情報評価値とを合算することにより文書類似度を計算する(S215)。さらに、合算値をS211で抽出されたワード・組付与情報の総数で除した値を文書類似度とするのが好適である。この文書類似度に基づいて安定文書間距離が計算される(S216)。
【0095】
上記の例では共通キーワード及び共通組付与情報の評価値を合算することによりそれぞれに基づく類似度を算出するが、これに代えてベクトル空間法を適用してキーワード類似度と組付与情報類似度のそれぞれを求めてこれらに重みを乗じた上で文書類似度を算出する方法、共通キーワード及び共通組付与情報の評価値に予め重みを付けた上で一括してベクトル空間法で文書類似度を求めることも可能である。
【0096】
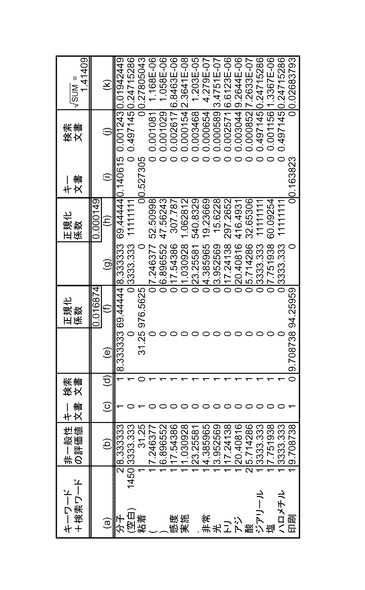
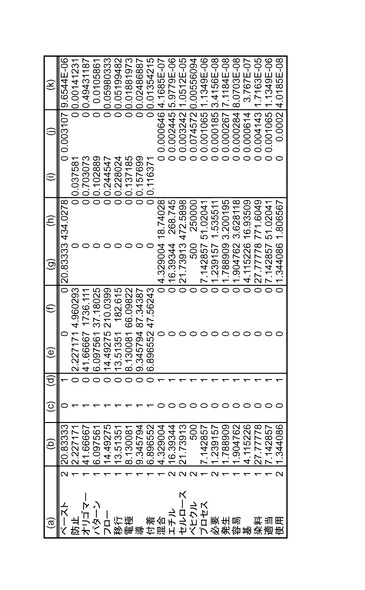
ベクトル空間法を適用してキーワード類似度を算出する場合、一例として、図25ないし図27に示される処理がなされる。具体的には、(c)及び(d)欄に示される該当文書中にワードが現れる場合に1、そうでない場合に0とするベクトルそれぞれと、(b)欄の評価値ベクトルの各要素を乗じる演算を行うことにより、(e)及び(g)欄のベクトルを算出する。(f)及び(h)欄に示されるように(e)及び(g)欄のベクトルの各要素を二乗する演算を行い、さらに正規化係数を乗じて(f)欄のベクトルの単位ベクトル(i)及び(h)欄のベクトルの単位ベクトル(j)を算出する。単位ベクトル(i)と単位ベクトル(j)との距離又は内積に基づいてキーワード類似度を算出することができる。組付与情報類似度も、上記と同様の処理により算出することができる。また、キーワード及び検索ワードに加えてキー文書及び検索文書で付与されている組付与情報を同時にベクトル空間法演算の対象にし(この場合(a)欄には図15の組付与情報と同様の入力がなされる。)、(b)欄における評価値を、キーワード類似度と組付与情報類似度とのバランスをとるための重みを乗じた数値とすれば、その後に上記の演算を行うことにより直接文書類似度を取得することができる。
【0097】
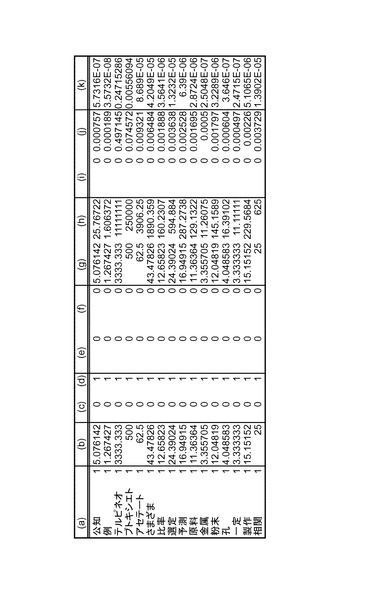
図28(a)及び図28(b)は、図1の表示部32による結果表示の第1の変形例を説明するための図である。図に示される表示エリア50は、図5に対応するものである。本例では、表示エリア50内の一部を新たな表示エリアとして指定することにより、その部分を表示エリア50全体に再表示させることができる。例えば、図28(a)において中央の4つのセル(外枠を太線で示している)を指定した場合、この指定した部分が、図28(b)に示すように、表示エリア50全体に再表示される。このとき、表示エリア50内のセル数は不変であるので、指定した部分はより細かいセルに分割されている。例えば、図28(a)において文書数が「5」と表示されているセルは、図28(b)において右上の4つのセルに対応している。したがって、この4つのセルの文書数の和は5となっている。表示エリアの指定は、例えば図1の入力部34に座標値を入力することにより、或いは画面上においてマウスで選択することにより行うことができる。
【0098】
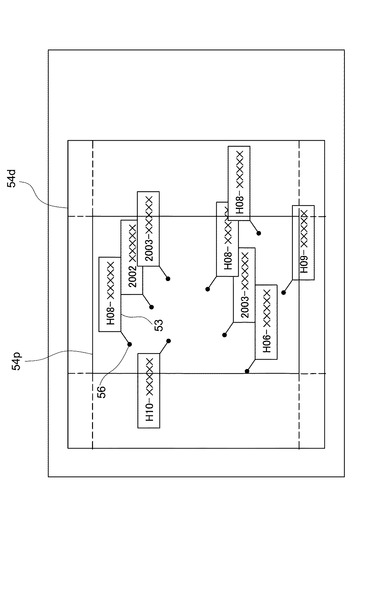
図29は、図1の表示部32による結果表示の第2の変形例を説明するための図である。本例において表示部32は、表示エリア54d内のプロットエリア54pに、各文書の表示座標系(二次元表示座標系)における位置座標をプロットして表示する。各プロット56には、対応する文書を特定できるように、各文書のタイトル等がテキストボックス53(「テキストボックス」とは、プロットされた文書の属性を表示するための一定の形状及び大きさの小エリアをいう。ただし、属性情報の表示量に応じて何段階かの異なる形状又は大きさのテキストボックスを設定することも考えられる。)内に表示される。テキストボックス53が表示エリア54dからはみ出すことがないように、プロットエリア54pは表示エリア54aからテキストボックス53のサイズ分(複数段階の形状又は大きさのテキストボックスが設定されている場合には、最も長い縦径又は横径の分)だけ内側に縮小されている。すなわち、表示エリア54aの各角に位置する点線と表示エリア54aの枠で囲われる領域はテキストボックス53と同じ大きさ及び形状になっている。
【0099】
ここでは、分類対象文書として公開特許公報を想定しており、その文献番号として出願番号が表示されている。また、表示されているテキストボックス53あるいは文献番号には、ハイパーリンクが貼られており、画面上で文献番号をクリックすることによりその文書のイメージにアクセスすることができる。また、テクストボックス53には文献番号の他に発明の名称や出願人、要約から切り出したキーワードを表示させることができ、これを行えば分類内容の把握が一層容易となる。
【0100】
図30は、図29の変形例に係るフローチャートを示している。まず、ユーザが表示エリア54aを規定するX座標及びY座標それぞれの最大値及び最小値を入力する(S151)。この入力は、図1の入力部34より行うことができる。表示部32はプロットエリア54pを設定する(S152)。表示部32は、プロットエリア54p内にある各文書の位置座標をプロットし、プロット56と関連付けてテキストボックス53を表示する(S153)。さらに、表示部32は、各プロットに文書イメージをハイパーリンクさせる(S154)。なお、図29の表示例では、表示の一部領域を指定し、これを新たな表示エリアとして拡大表示する、或いは、表示エリアの一点、例えばエリア中心部のテキストボックスをマウスポインタで指定し、これを中心に拡大/縮小表示することができる。また、指定した1又は2以上のテキストボックスの内容を表計算ソフト等のワークシート上にコピーすることで、分類に続く作業をより一層容易にすることができる。
【0101】
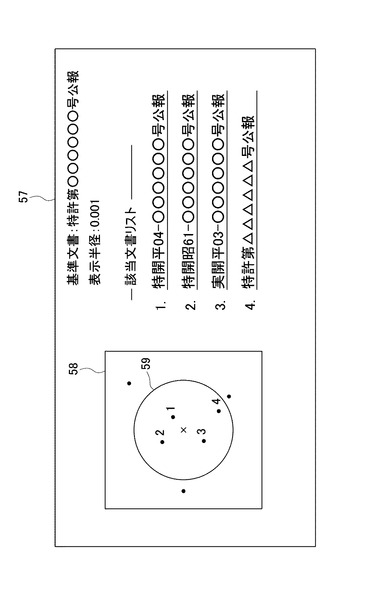
図31は、図1の表示部32による結果表示の第3の変形例を説明するための図である。本例において、表示部32は、ユーザが指定した基準文書の位置座標を基点として、座標平面上において表示半径内に位置座標をもつ文書を該当文書として表示する。基準文書及び表示半径の指定は、図1の入力部34より行うことができる。また、基準文書は、分類対象文書DB12に格納されている分類対象文書の中から選ばれる。図31において表示画面57内の右側に、該当文書リストが表示されている。これらの表示には、ハイパーリンクが貼られている。ここでは、基準文書から表示半径内に4つの文書が存在する。また、このリストは、基準文書からの距離が近い順にソートされて表示されている。さらに、本例では、表示画面57内の左側に、表示エリア58が設けられている。この表示エリア58には、基準文書を中心として各文書の位置座標がプロットされ、併せて基準文書を中心として表示半径を半径とする円59が表示される。この円59は、表示半径を再指定する際の目安とすることができる。各プロットに付されている数字は、該当文書リストにおける番号に対応している。本例によれば、基準文書に類似する文書を検索することができる。また、この場合、基準文書を色又は字体等を変える所謂ハイライト表示で表示することにより、目標とする基準文書とそれに類似する文書の位置関係の把握が容易になる。
【0102】
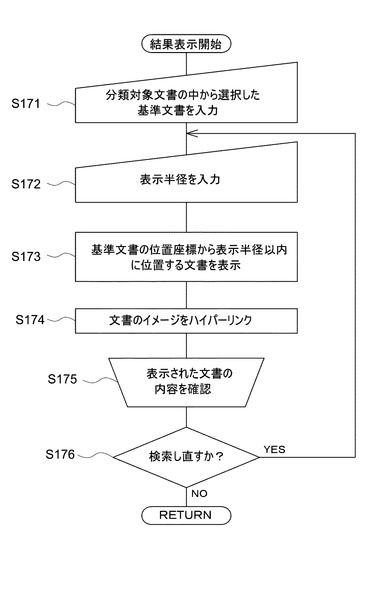
図32は、図31の変形例に係るフローチャートを示している。まず、ユーザが図1の入力部34より基準文書、及び表示変形を入力する(S171,S172)。すると、表示部32は、位置座標DB16に格納されている各文書の位置座標を読み込み、基準文書から表示半径内の距離にある文書を該当文書リストとして表示する(S173)。さらに、表示部32は、該当文書リストに表示される文書のイメージをハイパーリンクさせる(S174)。ここで、ユーザは、必要に応じて、ハイパーリンクを辿ることにより表示された文書のイメージにアクセスし、その内容を確認する(S175)。そして、表示半径を再指定して検索し直すときは、上記ステップ(S172〜S175)を繰り返し実行し、検索し直さないときはフローを終了する(S176)。
【0103】
また、上記実施形態では、2次元の座標平面上において各文書の位置座標を決定する構成を示したが、その座標平面は1次元であってもよい。このとき、各文書は1本の直線上に位置座標を有することになるが、この場合も便宜的に1次元の「座標平面」と呼ぶことにする。また、3次元以上に拡張して、各文書の位置座標を決定する構成としてもよい。
【0104】
また、各文書の移動距離の平均値が規定値以下となることを収束条件としたが、収束条件はこれに限られない。例えば、各文書の移動距離の最大値が規定値以下となることを収束条件としてもよい。
【0105】
また、位置座標の更新の際に用いられる移動係数kは、常に一定の値である必要はない。ある程度収束が進んだ後、収束速度を上げるために、各文書の移動距離の平均値の増減如何によって移動係数kを加減する構成としてもよい。例えば、移動距離の平均値が前回の更新後よりも大きければk’=k×0.01(k’:加減後の移動係数)とし、小さければk’=k×1.03とする。
【産業上の利用可能性】
【0106】
複数の特許文献の間の類似度の関係を視覚で認識できるように示すことができる。
【図面の簡単な説明】
【0107】
【図1】本発明による文書分類装置の一実施形態を示すブロック図である。
【図2】文書間距離DB14のデータベースの一例を示す構成図である。
【図3】位置座標DB16のデータベースの一例を示す構成図である。
【図4】文書間力ベクトルDB18のデータベースの一例を示す構成図である。
【図5】表示部32による結果表示画面の一例を示す図である。
【図6】図1の文書分類装置1のハードウェア構成を示すブロック図である。
【図7】図1の安定文書間距離算出部22の構成の一例を示すブロック図である。
【図8】参照ワードDB82aのデータベースの一例を示す構成図である。
【図9】共通ワードカウントテーブルによるカウントを説明する図である。
【図10】キーワード評価値DB84aのデータベースの一例を示す構成図である。
【図11】キーワード類似度DB85aのデータベースの一例を示す構成図である。
【図12】参照組付与情報DB82bのデータベースの一例を示す構成図である。
【図13】共通参照組付与情報カウントテーブルによるカウントを説明する図である。
【図14】組付与情報評価値DB84bのデータベースの一例を示す構成図である。
【図15】組付与情報類似度DB85bのデータベースの一例を示す構成図である。
【図16】文書類似度DB86のデータベースの一例を示す構成図である。
【図17】初期処理及び二次元表示座標系において初期配置文書を配置・移動する処理を示すフローチャートである。
【図18】図7の安定文書間距離算出部22の動作を示すフローチャートである。
【図19】図17の総和文書間力ベクトル算出ステップ(S66)のサブルーチンを示すフローチャートである。
【図20】図17の位置座標の更新ステップ(S67)のサブルーチンを示すフローチャートである。
【図21】表示座標系に追加の配置文書を加えていく処理を示すフローチャートである。
【図22】図21の結果表示ステップのサブルーチンを示すフローチャートである。
【図23】文書移動処理を示すフローチャートである。
【図24】安定文書間距離の計算処理の第2例におけるフローチャートを示す。
【図25】ベクトル空間法を適用した実施形態を説明する第1の図である。
【図26】ベクトル空間法を適用した実施形態を説明する第2の図である。
【図27】ベクトル空間法を適用した実施形態を説明する第3の図である。
【図28】(a)及び(b)は、図1の表示部32による結果表示の第1の変形例を説明するための図である。
【図29】図1の表示部32による結果表示の第2の変形例を説明するための図である。
【図30】図29の変形例に係るフローチャートを示している。
【図31】図1の表示部32による結果表示の第3の変形例を説明するための図である。
【図32】図31の変形例に係るフローチャートを示している。
【符号の説明】
【0108】
1…文書分類装置、10…データベース、12…分類対象文書DB、14…文書間距離DB、16…位置座標DB、18…文書間力ベクトルDB、22…安定文書間距離算出部、23…配置文書選択部、24…位置座標初期値設定部(文書移動手段)、26…文書間力ベクトル算出部(文書移動手段)、28…位置座標更新部(文書移動手段)、30…収束条件判定部(文書移動手段)、32…表示部、34…入力部、53…テキストボックス、54a…表示エリア、54p…プロットエリア、56…プロット、71…キーワード・組付与情報抽出部(共通キーワード抽出手段、共通組付与情報抽出手段)、72…参照ワード・組付与情報抽出部、73…検索ワード・組付与情報抽出部(共通キーワード抽出手段、共通組付与情報抽出手段)、91…キーワード評価値計算部(共通キーワード評価値算出手段)、92…キーワード類似度計算部(キーワード類似度算出手段)、93…組付与情報評価値計算部(共通組付与情報評価値算出手段)、94…組付与情報類似度計算部(組付与情報類似度算出手段)、95…文書類似度計算部(文書類似度算出手段)、96…文書間距離計算部、S803…(共通キーワード評価値算出手段)、S805…(キーワード類似度算出ステップ)、S806…(共通組付与情報抽出ステップ)、S807…(共通組付与情報評価値算出ステップ)、S808…(組付与情報類似度算出ステップ)、S809…(初期文書類似度算出ステップおよび文書類似度算出ステップ)、S61〜S68,S111〜S119…(初期文書移動ステップ)、S231〜S238…(文書移動ステップ)。
【技術分野】
【0001】
本発明は、複数の分類対象文書をそれぞれの内容に応じて分類する文書分類方法に関するものである。
【背景技術】
【0002】
従来、文書分類方法として、キーワードが文書に固有に含まれる程度(非一般性)を示す評価値に基づいて算出された文書間の類似度によって文書を分類する文書分類方法があった(特許文献1および特許文献2を参照)。
【特許文献1】特開2005−327213号公報
【特許文献2】特開2006−190235号公報
【発明の開示】
【発明が解決しようとする課題】
【0003】
しかし、従来の文書分類方法によると、文書の内容が類似する場合(例えば国際特許分類のサブグループが同一である特許文献の場合)、表記の差による影響が大きくなり、適切な文書分類ができないという問題点があった。このような問題点に対して、引用文献情報を加味した分類方法も提唱されているが、引用文献情報が付与されていない文献に対しては適用することが不可能となる。また、引用文献情報の代わりに、発明者や著者といった創作者の氏名情報を使用する方法も考えられるが、例えば、分類対象文書中に同姓同名の創作者が存在する場合や、同一の創作者が複数の分野において発明や著作を行っている場合には、異なる分野の文書を類似な文書として分類してしまうおそれがある。
【0004】
本発明は、上記課題に鑑みてなされたものであり、キーワード分類における文書の表記の差による影響を低減しつつ、異なる分野の文書を適切に分類することが可能な文書分類装置および文書分類方法を提供することを課題とする。
【課題を解決するための手段】
【0005】
本発明に係る文書分類装置は、文書内容の分野を体系づける分類情報と文書内容の創作者の氏名と文書の識別番号とを付与された分類対象文書をそれぞれの内容に応じて分類する文書分類装置であって、分類対象文書のうちの2文書において共通して現れる共通キーワードを抽出する共通キーワード抽出手段と、分類対象文書のうちの2文書において共通して現れる分類情報および創作者の氏名とによって構成された共通組付与情報を抽出する共通組付与情報抽出手段と、分類対象文書の全て又は一部の文書で構成されたキーワード参照文書の識別番号と当該キーワード参照文書に含まれるキーワードとを関連付けて格納したキーワードテーブルを参照して、当該キーワードテーブルにおいて共通キーワードが出現する共通キーワード出現数を数え、当該共通キーワード出現数に基づき共通キーワードの非一般性を示す共通キーワード評価値を算出する共通キーワード評価値算出手段と、分類対象文書の全て又は一部の文書で構成された共通組付与情報参照文書の識別番号と当該共通組付与情報参照文書に含まれる共通組付与情報とを関連付けて格納した共通組付与情報テーブルを参照して、当該共通組付与情報テーブルにおいて共通組付与情報が出現する共通組付与情報出現数を数え、当該共通組付与情報出現数に基づき共通組付与情報の非一般性を示す共通組付与情報評価値を算出する共通組付与情報評価値算出手段と、各共通キーワード評価値を合算して、2文書の共通キーワードに基づく類似性を示すキーワード類似度を算出するキーワード類似度算出手段と、各共通組付与情報評価値を合算して、2文書の共通組付与情報に基づく類似性を示す組付与情報類似度を算出する組付与情報類似度算出手段と、キーワード類似度と組付与情報類似度とを総合した2文書の文書類似度を算出する文書類似度算出手段と、分類対象文書を座標系に配置し、文書類似度が増大するほど2文書間の文書間距離を減少させ、文書類似度が減少するほど2文書間の文書間距離を増大させるように各分類対象文書を移動させる文書移動手段と、を備えることを特徴とする。
【0006】
また、本発明に係る文書分類方法は、文書内容の分野を体系づける分類情報と文書内容の創作者の氏名と文書の識別番号とを付与された分類対象文書をそれぞれの内容に応じて分類する文書分類方法であって、共通キーワード抽出手段が、分類対象文書のうちの2文書において共通して現れる共通キーワードを抽出する共通キーワード抽出ステップと、
共通組付与情報抽出手段が、分類対象文書のうちの2文書において共通して現れる分類情報および創作者の氏名とによって構成された共通組付与情報を抽出する共通組付与情報抽出ステップと、共通キーワード評価値算出手段が、分類対象文書の全て又は一部の文書で構成されたキーワード参照文書の識別番号と当該キーワード参照文書に含まれるキーワードとを関連付けて格納したキーワードテーブルを参照して、当該キーワードテーブルにおいて共通キーワードが出現する共通キーワード出現数を数え、当該共通キーワード出現数に基づき共通キーワードの非一般性を示す共通キーワード評価値を算出する共通キーワード評価値算出ステップと、共通組付与情報評価値算出手段が、分類対象文書の全て又は一部の文書で構成された共通組付与情報参照文書の識別番号と当該共通組付与情報参照文書に含まれる共通組付与情報とを関連付けて格納した共通組付与情報テーブルを参照して、当該共通組付与情報テーブルにおいて共通組付与情報が出現する共通組付与情報出現数を数え、当該共通組付与情報出現数に基づき共通組付与情報の非一般性を示す共通組付与情報評価値を算出する共通組付与情報評価値算出ステップと、キーワード類似度算出手段が各共通キーワード評価値を合算して、2文書の共通キーワードに基づく類似性を示すキーワード類似度を算出するキーワード類似度算出ステップと、組付与情報類似度算出手段が各共通組付与情報評価値を合算して、2文書の共通組付与情報に基づく類似性を示す組付与情報類似度を算出する組付与情報類似度算出ステップと、文書類似度算出手段がキーワード類似度と組付与情報類似度とを総合した2文書の文書類似度を算出する文書類似度算出ステップと、分類対象文書を座標系の初期文書位置に配置し、文書類似度が増大するほど2文書間の文書間距離を減少させ、文書類似度が減少するほど2文書間の文書間距離を増大させるように各分類対象文書を移動させる文書移動ステップと、を備えることを特徴とする。
【0007】
これによれば、文書の分類は、文書類似度の増減に応じた文書間距離に分類対象文書を配置することによって行われる。文書間の文書類似度は、キーワード類似度と組付与情報類似度とを総合して算出される。そのため、文書類似度おけるキーワード類似度の影響が組付与情報類似度によって低減されるので、キーワード分類における文書の表記の差による影響を低減することができる。また、共通組付与情報は、文書内容の分野を体系づける分類情報と文書内容の創作者の氏名とによって構成されているので、分類対象文書の分野によって分類対象文書間の組付与情報類似度および文書類似度が増減する。文書類似度が増減するとそれに応じて分類対象文書間の文書間距離が変化するので、異なる分野の文書を適切に分類することが出来る。
【0008】
ここで、上記作用を好適に奏する上記文書分類方法は、キーワード類似度を初期文書類似度とする初期文書類似度算出ステップと、分類対象文書を座標系の任意文書位置に配置し、2文書間の初期文書類似度が大きいほど文書間距離を減少させ、初期文書類似度が減少するほど2文書間の文書間距離を増大させるように分類対象文書を初期文書位置に移動させる初期文書移動ステップと、をさらに備えることが好ましい。
【0009】
また、上記の組付与情報類似度算出ステップは、分類情報の階層ごとに組付与情報類似度を算出してもよい。
【0010】
この場合には、国際特許分類(以下、IPC)などの階層構造を有する分類情報を使用する場合が想定される。例えば、サブグループまでのIPCを含む共通組付与情報の類似度が0すなわち文書間に類似性が検出されなかった場合においても、より階層の浅いメイングループやサブクラスまでのIPCを含む共通組付与情報の類似度を算出することによって、文書間に類似性を見出される場合がある。また、多くの文書が近い文書間距離で近接している場合には、上記とは逆にIPCの階層を深くすることによって、より類似性の高い文書を検出することができる。したがって、分類対象文書の類似度合いに応じて、分類の分解能を調整することができるので、さまざまな類似状況にある分類対象文書を適切に分類することが出来る。
【発明の効果】
【0011】
本発明の文書分類装置および文書分類方法によれば、キーワード分類における文書の表記の差による影響を低減しつつ、異なる分野の文書を適切に分類することができる。
【発明を実施するための最良の形態】
【0012】
以下、添付図面を参照して、本発明の好適な実施形態を詳細に説明する。なお、図面の説明において同一の要素には同一の符号を付し、重複する説明を省略する。
【0013】
本実施形態では、本発明に係る文書分類装置を、特許文献分類に適用した場合について説明する。まず、図1乃至図6を参照して、第一実施形態にかかる文書分類装置の構成について説明する。ここで、図1は、本発明による文書分類装置の一実施形態を示すブロック図、図2は、文書間距離DB14のデータベースの一例を示す構成図、図3は、位置座標DB16のデータベースの一例を示す構成図、図4は、文書間力ベクトルDB18のデータベースの一例を示す構成図、図5は、表示部32による結果表示画面の一例を示す図、図6は、図1の文書分類装置1のハードウェア構成を示すブロック図である。
【0014】
図1を参照すると、文書分類装置1は、複数の分類対象文書を、各分類対象文書の内容に応じて分類するものである。文書分類装置1は、データベース10、安定文書間距離算出部22、配置文書選択部23、位置座標初期値設定部24、文書間力ベクトル算出部26、及び位置座標更新部28を備えている。データベース10は、分類対象文書DB12、安定文書間距離DB14、位置座標DB16及び文書間力ベクトルDB18を有している。
【0015】
分類対象文書DB12は、複数の分類対象文書を、それを識別する文書コード(識別番号)に関連付けて格納している。分類対象文書は、分類対象文書DB12に予め格納されているが、適宜の入力手段により必要に応じて入力することもできる。
【0016】
安定文書間距離DB14は、安定文書間距離算出部22により算出される安定文書間距離を文書コードに関連付けて格納する。例えば、図2に示すように、各2文書間の安定文書間距離が、それらの文書コード(P0001,P0002,・・・)に関連付けられて格納されている。この場合、文書(P0001)と文書(P0002)との間の安定文書間距離は、0.005である。
【0017】
位置座標DB16は、位置座標初期値設定部24により設定される各文書の位置座標の初期値、及び位置座標更新部28により更新された位置座標を文書コードに関連付けて格納する。例えば、図3に示すように、各文書の位置座標(X座標,Y座標)が文書コードに関連付けられて格納されている。この場合、文書(P0003)の位置座標は、(0.5155,0.3417)である。
【0018】
文書間力ベクトルDB18は、文書間力ベクトル算出部26により算出される総和文書間力ベクトルを文書コードに関連付けて格納する。例えば、図4に示すように、各文書に働く総和文書間力ベクトル(FX,FY)が文書コードに関連付けられて格納されている。この場合、文書(P0002)の総和文書間力ベクトルは(0.007,‐0.003)である。
【0019】
安定文書間距離算出部22は、分類対象文書DB12に格納されている複数の分類対象文書について、各2文書間の安定文書間距離を、両文書の類似する程度に応じて算出する。この安定文書間距離は、両文書の内容が類似する程度が高いほど小さく、類似する程度が低いほど大きくなる。
【0020】
位置座標初期値設定部24は、2次元座標平面上における各文書の位置座標の初期値を設定する。この初期値には、乱数を用いた任意の文書位置座標(任意文書位置座標)または後述するS117で算出される初期文書位置座標が用いられる。ここでは、任意文書位置座標を用いた初期値の設定方法の一例を説明する。説明の便宜のため、分類対象文書数をN(Nは2以上の整数)とし、各文書をTi(i=1,2,・・・,N)と表すことにする。
【0021】
まず、文書Tiと文書Tj(j=1,2,・・・,N、j≠i)との間の安定文書間距離L0(i,j)をテーブルLaに読み込む。全ての(i,j)の組について安定文書間距離L0(i,j)を読み込んだ後、L0(i,j)の平均値Lavgを求める。そして、各文書Tiの位置座標(Xi,Yi)を下記式、
【数1】
から求める。ここで、rndは乱数を表している。これにより、各文書の任意文書位置座標が設定される。なお、安定文書間距離L0(i,j)は平均値Lavgで除されることにより、正規化される。
【0022】
文書間力ベクトル算出部26は、各文書に働く総和文書間力ベクトルを算出する。総和文書間力ベクトルとは、各文書が他の文書から受ける文書間力のベクトル和である。また、文書間力とは、各2文書の位置座標から求められる座標平面上における距離が上記の安定文書間距離よりも大きい場合には両文書間に引力が働き、逆に座標平面上における距離が安定文書間距離よりも小さい場合には両文書間に斥力が働くと仮定して導入した概念である。これらの力の大きさは、座標平面上における距離と安定文書間距離との差の絶対値が増加するにつれて大きくなり、上記絶対値が減少するにつれて小さくなる。また、座標平面上における距離が安定文書間距離と一致する場合には、両文書間に働く文書間力は0である。
【0023】
文書間力ベクトル算出部26における文書間力ベクトルの算出方法の一例を説明する。まず、文書Tiと文書Tjの距離L(i,j)をその処理時点(現処理時点)(特に本実施形態では、位置座標の更新について「現処理時点」、「次回処理時点」というとき、「現処理時点」とは、移動処理(全部又は一部の配置文書の各々について、総和文書間力ベクトルを算出してこれに基づき位置座標を更新する処理を位置座標の収束が判断されるまで繰り返す処理)の繰返処理において、ある回が開始する時点を指し、「次回処理時点」とは、当該ある回の次の回が開始する時点を指すものとする。)における両者の位置座標に基づいて、下記式、
【数2】
から求める。なお、「その処理時点における両者の位置座標に基づいて」とあるのは、後述するように、各文書Tiの位置座標は必要に応じて更新されるため、常に同じ値をとるとは限らないからである。
【0024】
次に、文書Tiと文書Tjの文書間力f(i,j)を下記式、
【数3】
から求める。ここで、ε1は、L0(i,j)が0のときに対応するための定数であり、例えば1×10−12とされる。αは、安定文書間距離L0(i,j)が小さくなるに連れて文書間力f(i,j)が指数関数的に大きくように設定される。こうすることにより、文書間の類似度が高いときにより大きな文書間力が働くようになる。その結果、類似する文書の集団を形成するのが容易になると共に集団が配置される位置が人間の感覚に近いものになり、また分類対象文書数Nが多くなっても容易に収束させることができる。
【0025】
分類対象文書数が比較的少数である場合(Nが50未満の場合)にはα=0.8〜2.3の何れかの値に設定される。Nが100を超える場合にはα=1.8〜2.2の何れかの値に設定することにより容易に収束させることができる。特に、N=101〜3000の場合にはα=2とするのが好適である。特に、分類対象文書を2次元空間にマッピングする場合、αが上記範囲より小さい場合は、移動処理の繰返処理の過程で一部文書の座標が収束せず発散するケースが多くなり、上記範囲より大きい場合は、個々の文書の内容を反映しない均一な文書の集団を形成しやすくなる。
【0026】
次に、文書Tiが文書Tjから受ける文書間力のX成分fX(i,j)及びY成分fY(i,j)を下記式、
【数4】
から求める。ここで、ε2は、L(i,j)が0のときに対応するための定数であり、例えば1×10−12とされる。また、βは、例えば0.5に設定される。
【0027】
最後に、各文書Tiに働く文書間力の総和のX成分FXi及びY成分FYiを下記式、
【数5】
から求める。ここで、Σjは、全ての配置済み文書についての和をとることを意味する。このようにして算出されたFXi及びFYiを成分とするベクトルが上述の総和文書間力ベクトルである。
【0028】
位置座標更新部28は、文書間力ベクトル算出部26により算出された総和文書間力ベクトルの絶対値が小さくなるように、各文書の位置座標を更新する。位置座標更新部28における位置座標の更新方法の一例を説明する。すなわち、各文書Tiの位置座標(Xi,Yi)は、文書間力ベクトル算出部26により算出された文書間力ベクトル(FXi,FYi)に基づいて、下記式、
【数6】
により更新される。ここで、(Xi’,Yi’)は、更新後の位置座標を表す。また、kは移動係数であり、例えば1×10−23以上1×10−22以下の定数とされる。上記式は、各文書Tiを、文書間力ベクトルの向きに、そのベクトルの絶対値の大きさに比例した距離だけ移動させることを意味している。
【0029】
更新された位置座標は、位置座標DB16に格納され、それまで格納されていた位置座標に対して上書きされる。本実施形態において位置座標更新部28は、位置座標の更新と併せて、各文書Tiの移動距離の平均値MLを下記式、
【数7】
から求める。この平均値MLは、後述する収束条件判定部30による収束条件の判定の際に用いられる。
【0030】
なお、位置座標更新部28は、各文書に働く文書間力ベクトルの絶対値を全ての分類対象文書について和をとった値が極小となるまで、位置座標の更新を実行することが好適である。この場合、全ての分類対象文書間で特に高い整合性を保ちつつ、各文書の位置座標を決定することができる。
【0031】
図1を参照すると、文書分類装置1は、収束条件判定部30、表示部32(出力手段)、及び入力部34をさらに備えている。収束条件判定部30は、位置座標更新部28により位置座標が更新された後に、収束条件の判定を行う。例えば、上述の位置座標更新部28において求められた平均値MLが規定値以下になることを収束条件として設定することができる。この収束条件が満たされないときは、収束条件判定部30は、文書間力ベクトル算出部26に更新後の位置座標を用いて再度総和文書間力ベクトルを算出させるとともに、位置座標更新部28にその総和文書間力ベクトルを用いて再度位置座標を更新させる。したがって、位置座標更新部28による位置座標の更新は、上述の収束条件が満たされるまで実行される。
【0032】
表示部32は、上述の収束条件が満たされ、位置座標更新部28による位置座標の更新が終了した後、決定した位置座標に基づいて、各文書Ti間の座標平面上における相対的な位置関係を可視化して表示する。これにより、ユーザは、表示部32による表示を見ることにより、容易に文書間の相対的な位置関係を知ることができる。ここで、図5を参照して、表示部32における表示方法の一例を説明する。
【0033】
まず、表示エリア50をm×n個(ここではm=n=4)のセルに区切る。また、後述する入力部34により表示エリアを規定するX座標、Y座標それぞれの最大値(Xmax、Ymax)及び最小値(Xmin、Ymin)を入力する。なお、これらの値を入力せずに、既に決定されている全文書の位置座標から、X座標及びY座標それぞれについて、最大のもの及び最小のものをデフォルト値として用いることもできる。
【0034】
次に、表示部32は、入力されたこれらの値から、各セルに相当する座標範囲を求める。そして、各セルに含まれる文書の数を、図5に示すように表示する。例えば、この場合、一番右上のセルに含まれる文書数は1である。さらに本例では、各セルに含まれる文書のイメージを作成するとともに、各セルにそのイメージをハイパーリンクさせる。図5に示すように、注目するセルにマウスポインタ52を合わせると、そのセルに含まれる文書を、該当文書リストとして表示させることができる。
【0035】
図5では、分類対象文書として公開特許公報等の特許文献(外国語又は外国で発行された特許文献も含む。)を想定しており、該当文書リストには特許文献の種別と公報番号とを表示させている。また、これらの表示にはハイパーリンクが貼られているので、例えば「特開平8−○○○○○○号公報」と表示されている部分を画面上でクリックすれば、その公開特許公報のイメージにアクセスして、その内容を見ることができる。
【0036】
図1を参照すると、入力部34は、表示部32により表示される対象となる座標平面上における表示エリア等を入力するためのものであり、例えばキーボードやマウス等が用いられる。例えば、図5の例では、表示エリア50を規定するXmax、Ymax、Xmin、Yminの値を入力部34から入力することができる。入力された情報は、表示部32へと渡される。これにより、ユーザは、座標平面上の所望の範囲を表示させ、その範囲における文書間の位置関係を詳細に知ることができる。
【0037】
次に、図6を参照して、文書分類装置1のハードウェア構成について説明する。図6に示すように、文書分類装置1は、物理的には、制御装置1a、メモリ1b、格納装置1c、入力装置1d、及び表示装置1eを備えて構成される。これら各装置は、バス1fを介して相互に各種信号の入出力が可能な様に電気的に接続されている。
【0038】
具体的には、制御装置1aは例えばCPU(Central Processing Unit)であり、メモリ1bはRAM(Random Access Memory)といった揮発性の半導体メモリである。格納装置1cはHDD(HardDisc Drive)を始めとする不揮発性の磁気ディスクである。入力装置1dは例えばキーボードやマウスであり、表示装置1eはLCD(LiquidCrystal Display)やCRT(Cathode Ray Tube)ディスプレイである。
【0039】
上記ハードウェア構成と機能的構成との対応関係を以下に示す。文書分類装置1に関して、データベース10の有する機能は、物理的な構成要素としての格納装置1cにより実現される。安定文書間距離算出部22、位置座標初期値設定部24、文書間力ベクトル算出部26、位置座標更新部28、収束条件判定部30の有する各機能は、制御装置1aが所定のプログラムを実行することにより実現される。入力部34の有する各機能は入力装置1dにより実現される。なお、表示部32の有する各機能は、制御装置1a及び表示装置1eにより実現される。すなわち、制御装置1aが所定の演算を施すことにより分類結果の表示内容を確定し、表示装置1eがその内容に従って分類結果を表示する。
【0040】
次に、図7乃至図16を参照して、安定文書間距離算出部22の詳細な構成について説明する。ここで、図7は、図1の安定文書間距離算出部22の構成の一例を示すブロック図、図8は、参照ワードDB82aのデータベースの一例を示す構成図、図9は、共通ワードカウントテーブルによるカウントを説明する図、図10は、キーワード評価値DB84aのデータベースの一例を示す構成図、図11は、キーワード類似度DB85aのデータベースの一例を示す構成図、図12は、参照組付与情報DB82bのデータベースの一例を示す構成図、図13は、共通参照組付与情報カウントテーブルによるカウントを説明する図、図14は、組付与情報評価値DB84bのデータベースの一例を示す構成図、図15は、組付与情報類似度DB85bのデータベースの一例を示す構成図、図16は、文書類似度DB86のデータベースの一例を示す構成図である。
【0041】
図7を参照すると、安定文書間距離算出部22は、各種文書からワード及び組付与情報を抽出するワード・組付与情報抽出部70と、ワード・組付与情報抽出部70によって抽出されたワード及び組付与情報を格納する各種データベース80とを備えている。
【0042】
ワード・組付与情報抽出部70は、キー文書からワード及び組付与情報をキーワード・組付与情報として抽出するキーワード・組付与情報抽出部71と、参照文書からワード及び組付与情報を参照ワード・組付与情報として抽出する参照ワード・組付与情報抽出部72と、検索文書からワード及び組付与情報を検索ワード・組付与情報として抽出する検索ワード・組付与情報抽出部73とを有している。
【0043】
ここで、「キー文書」及び「検索文書」の区分は便宜的なものであり、安定文書間距離算出部22においては、文書間距離を求めたい2文書のうちの一方がキー文書、他方が検索文書とされる。また、参照文書とは、キーワード評価値(各キーワードがキー文書に固有に含まれる程度(非一般性)を表す値)及び組付与情報評価値(各組付与情報がキー文書に固有に含まれる程度(非一般性)を表す値)を設定する際に参照される文書である。参照文書としては、例えば分類対象文書DB12(図1参照)内の全文書、或いは予めランダムに抽出した分類対象文書DB12内の一部の文書を用いることができる。参照文書は、適宜の入力手段により、必要に応じて安定文書間距離算出部22に入力することができる。また、安定文書間距離算出部22は、参照文書を格納する格納手段を備えている。
【0044】
抽出部71〜73は、日本語にあっては、ひらがな、句読点、特殊記号及びスペースを区切記号として或いは形態素解析ツール等を利用して文書内のワードを抽出する機能を有する。また、抽出部71〜73は、英語等のアルファベット表記がなされる言語にあっては、特殊記号及び/又はスペースを区切記号として或いは形態素解析ツール等を利用して文書内のワードを抽出する機能を有する。抽出部71〜73は、一つの文書から重複してワードを抽出しないように、ある文書から切り出されたワードは、同じ文書から既に切り出されたワードと照合され、一致しないワードのみを抽出する機能を有する。
【0045】
図7を参照すると、データベース(DB)80は、キーワードDB81a、参照ワードDB82a、検索ワードDB83a、キーワード評価値DB84a、キーワード類似度DB85a、組付与情報DB81b、参照組付与情報DB82b、検索組付与情報DB83b、組付与情報評価値DB84b、組付与情報類似度DB85b及び文書類似度DB86を有している。
【0046】
キーワードDB81aは、キー文書から抽出したキーワードを格納する。キーワードは、抽出元であるキー文書を特定するキー文書コードに関連付けて格納されている。
【0047】
参照ワードDB82a(各文書に含まれるワードを当該文書の文書番号と関連付けて格納したテーブル)は、参照文書から抽出された参照ワードを、それぞれの抽出元である参照文書を特定する参照文書コードと関連付けて格納する。参照ワードDB82aは、例えば図8に示すような、参照文書コードおよび参照ワードを項目とするリレーショナルデータベース(以下、RDB)である。図8では、5つの参照文書から抽出された参照ワードが、それらの文書コード(P1,P2,・・P5)に関連付けられて格納されている例が示されている。
【0048】
検索ワードDB83aは、検索文書から抽出される検索ワードを格納する。検索ワードは、抽出元である検索文書を特定する検索文書コードに関連付けて格納されている。
【0049】
キーワード評価値DB84aは、後述するキーワード評価値計算部91により算出される評価値を格納する。キーワード評価値DB84aは、例えば図10に示すような、参照ワードおよびキーワード評価値を項目とするRDBである。ここで、キーワード評価値DB84aに格納される参照ワードは、図8で得られた異なる参照ワードの集合である。
【0050】
キーワード類似度DB85aは、後述するキーワード類似度計算部92により算出されるキーワード類似度を格納する。キーワード類似度DB85aは、例えば図11に示すような、キー文書、検索文書およびキーワード類似度を項目とするRDBである。
【0051】
組付与情報DB81aは、キー文書から抽出した組付与情報を格納する。組付与情報は、抽出元であるキー文書を特定するキー文書コードに関連付けて格納されている。組付与情報としては、文書に付与されたIPCと発明者氏名を組合わせたものが好適である。
【0052】
参照組付与情報DB82bは、参照文書から抽出した組付与情報を格納する。組付与情報は、抽出元である参照文書を特定する参照文書コードに関連付けて格納されている。参照組付与情報DB82bは、例えば図12に示すような、参照文書コードおよび参照組付与情報を項目とするRDBであり、組付与情報は、IPC項目と発明者項目の要素を連結することによって得られる。
【0053】
IPCと発明者とがそれぞれ複数存在する場合には、それらのすべての組合せに対する組付与情報が格納される。また、IPCのように文書の分類情報が階層構造を有する場合には、それぞれの階層の分類情報と発明者氏名とのすべての組合せに対する組付与情報が格納される。図12には、サブクラス以降のIPCに対する組付与情報が示されている。また、組付与情報DB82bに格納される組付与情報は、ワード・組付与情報抽出部70により抽出されたものであってもよいし、入力されたデータに基づくものであってもよい。
【0054】
検索組付与情報DB83bは、検索文書から抽出される検索組付与情報を格納する。検索組付与情報は、抽出元である検索文書を特定する検索文書コードに関連付けて格納されている。
【0055】
組付与情報評価値DB84bは、後述する組付与情報評価値計算部93により算出される評価値を格納する。組付与情報評価値DB84bは、例えば図14に示すような、参照組付与情報および組付与情報評価値を項目とするRDBである。ここで、組付与情報評価値DB84bに格納される組付与情報は、図12で得られた異なる組付与情報の集合である。
【0056】
組付与情報類似度DB85bは、後述する組付与情報類似度計算部94により算出される組付与情報類似度を格納する。組付与情報類似度DB85bは、例えば図15に示すような、キー文書、検索文書、組付与情報、組付与情報類似度を項目とするRDBである。
【0057】
文書類似度DB86は、キーワード類似度と組付与情報類似度とを総合した類似度である文書類似度を格納する。文書類似度DB86は、例えば図16に示すような、キー文書、検索文書、文書類似度を項目とするRDBである。
【0058】
なお、上記のキーワード、参照ワード、及び検索ワードは、それぞれ抽出対象となる文書の全体から抽出してもよいし、一部から抽出してもよい。例えば、抽出対象となる文書が特許文献であれば、書誌的事項、要約、請求項、又は実施例等に抽出範囲を限定してもよい。特に、データ量に制限がある場合には、抽出範囲を文書の一部に絞ることが有効となる。また、参照ワードは参照文書の一部から抽出し、キーワード及び検索ワードはそれぞれキー文書及び検索文書の全体から抽出するというように、各ワード毎に適宜抽出範囲を変えることより、いわゆるノイズと漏れの関係を調整することができる。
【0059】
図7を参照すると、安定文書間距離算出部22は、キーワード評価値計算部91及びキーワード類似度計算部92を備えている。キーワード評価値計算部91は、全参照文書中でキー文書と共通のワードが出現する出現率を算出する機能を有する。参照文書がN個で、そのうちのB個に共通のワードが存在する場合には、全文書内キーワード出現率は、B/Nで算出される。
【0060】
キーワード評価値計算部91は、参照ワードDB82aに格納された参照ワードを検索して、キーワードと同一のものが何個存在するか算出する。キーワードの出現数の算出には、例えば、図9に示すような、カウントテーブルを用いてもよい。図9を参照すると、例えば「課題」が共通ワードであった場合、「課題」は参照文書P1〜P5すべてに出現しているため、出現数は5となっている。カウントされた出現数を全参照文書の数で除することによって、全文書内キーワード出現率が算出される。
【0061】
さらに、キーワード評価値計算部91は、全文書内キーワード出現率の逆数をとって、キーワード評価値を算出する機能を有する。すなわち、キーワード評価値は、N/Bで算出され、各キーワードがキー文書に固有に含まれる程度(非一般性)を示すものである。キーワード出現数Bを0.1〜0.8乗する調整を施すことが考えられる。この場合、たとえば0.5乗する調整を施すとき、キーワード評価値は、N/(B0.5)となる。
【0062】
キーワード類似度計算部92は、検索文書に含まれる全てのキーワードの評価値を加算することにより、キー文書と検索文書とが類似する程度を表すキーワード類似度を算出する機能を有する。更に加算値を2〜100で除した値をキーワード類似度として、後述する組付与情報類似度とのバランスをとることが考えられる。キーワード類似度計算部92は、このようにして算出したキーワード類似度をキーワード類似度DB85aに格納させる。
【0063】
図7を参照すると、安定文書間距離算出部22は、組付与情報評価値計算部93及び組付与情報類似度計算部94を備えている。組付与情報評価値計算部93は、組付与情報DB81bを参照して、キー文書に付与された各組付与情報の全参照文書中における出現率を算出する機能を有する。具体的には、図13に示すような、カウントテーブルを用いてキー文書に付与された各組付与情報の出現数をカウントし、その出現数を全参照文書の数で除することによって、全文書内組付与情報出現率を算出する。参照文書がN個で、全文書中のC個において当該組付与情報が付与されている場合には、全文書内組付与情報出現率は、C/Nで算出される。
【0064】
さらに、組付与情報評価値計算部93は、全文書内組付与情報出現率の逆数をとって、組付与情報評価値を算出する機能を有する。すなわち、組付与情報評価値は、N/Cで算出され、各組付与情報がキー文書に固有に含まれる程度(非一般性)を示すものである。組付与情報出現数Cを0.1〜0.8乗する調整を施すことが考えられる。この場合、たとえば0.5乗する調整を施すとき、組付与情報評価値は、N/(C0.5)となる。
【0065】
組付与情報類似度計算部94は、キー文書と検索文書が共通して引用する全ての文献についての評価値を加算することにより、キー文書と検索文書とが類似する程度を表す組付与情報類似度を算出する機能を有する。組付与情報類似度計算部94は、このようにして算出した組付与情報類似度を組付与情報類似度DB85bに格納させる。また、組付与情報類似度計算部94は、IPCのように文書の分類情報が階層構造を有する場合には、それぞれの階層の分類情報すなわち組付与情報に対する類似度を算出する。
【0066】
図7を参照すると、安定文書間距離算出部22は、文書類似度計算部95及び文書間距離計算部96を備えている。文書類似度計算部95は、キーワード類似度のみをキー文書と検索文書との類似度(初期文書類似度)とする機能と、キーワード類似度と組付与情報類似度とを総合してキー文書と検索文書との類似度(文書類似度)を算出する機能を有する。具体例として、文書類似度計算部95は、キーワード類似度と組付与情報類似度との平均値を文書類似度として文書類似度DB86に格納する。この際、前述したとおりキーワード類似度を適当な数で除することにより、キーワード類似度が安定文書間距離に与える影響の強さと組付与情報類似度が安定文書間距離に与える影響の強さとのバランスを調整することが考えられる。
【0067】
文書間距離計算部96は、文書類似度DB86に格納されている類似度を用いて文書Tiと文書Tjとの間の初期文書類似度に基づく初期安定文書間距離L0(1)(i,j)または文書類似度に基づく安定文書間距離L0(2)(i,j)を算出する機能を有する。ここで、初期安定文書間距離L0(1)(i,j)および安定文書間距離L0(2)(i,j)は、下記式、
【数8】
【数9】
から求められる。ここで、Sij(1)は、文書Tiをキー文書とし、文書Tjを検索文書としたときの初期文書類似度を表し、Sji(1)は、文書Tjをキー文書とし、文書Tiを検索文書としたときの初期文書類似度を表し、Sij(2)は、文書Tiをキー文書とし、文書Tjを検索文書としたときの文書類似度を表し、Sji(2)は、文書Tjをキー文書とし、文書Tiを検索文書としたときの文書類似度を表す。つまり、上記式は、文書Tiと文書Tjとの間で、キー文書と検索文書の関係を入れ替えて算出された類似度の平均値をとり、さらにその平均値の逆数をとることを意味している。キー文書と検索文書の関係を入れ替えて算出された類似度の平均値を用いるのは、上記のSij(1)とSji(1)(Sij(2)とSji(2))とは必ずしも一致しないからである。このようにして算出される初期安定文書間距離L0(1)(i,j)および安定文書間距離L0(2)(i,j)は、両文書間の類似度が高いほど小さくなり、類似度が低いほど大きくなる。
【0068】
次に、図17乃至図22を参照して、文書分類装置1の動作を説明し、併せて本発明による文書分類方法の一実施形態を説明する。
【0069】
図17を参照すると、先ず、安定文書間距離算出部22が、分類対象文書DB12に格納されている分類対象文書を読み込んで、各2文書間における初期文書類似度に基づく安定文書間距離(初期安定文書間距離)を算出し、算出した初期安定文書間距離L0(1)(i,j)を安定文書間距離DB14に格納させる(S61)。続いて、安定文書間距離算出部22が、文書間距離DB14に格納されている初期安定文書間距離L0(1)(i,j)を読み込んで平均値Lavg(1)を算出し(S62)、各初期安定文書間距離L0(1)(i,j)をこの平均値Lavg(1)で除することにより正規化して安定文書間距離DB14のデータを更新する(S63)。
【0070】
次に、配置文書選択部23が、最初に表示座標系に配置する分類対象文書である初期配置文書Tkをint√N(分類対象文書の総数Nの平方根の小数点以下を切り捨てた値)個選択する(S64)。続いて、位置座標初期値設定部24は、任意文書位置座標を用いて各文書の位置座標の初期値を設定し、設定した位置座標の初期値を位置座標DB16に格納させる(S65)。
【0071】
そして、文書間力ベクトル算出部26が、文書間距離DB14に格納されている初期安定文書間距離L0(1)(i,j)及び位置座標DB16に格納されている位置座標を読み込み、それらの値を用いて、各文書に働く総和文書間力ベクトルを算出し、算出した総和文書間力ベクトルを文書間力ベクトルDB18に格納する(S66)。
【0072】
その後、位置座標更新部28が、文書間力ベクトルDB18に格納されている総和文書間力ベクトルを読み込み、そのベクトルに基づいて各文書の位置座標を更新し、更新した位置座標を位置座標DB16に格納させる(S67)。位置座標が更新されると、収束条件判定部30が収束条件の判定を行い、収束条件が満たされていない場合には上記ステップ(S66〜S67)を繰返し実行させる。収束条件が満たされている場合には、図21に示す表示座標系に追加の配置文書を加えていく処理(文書追加処理)に処理が移行する。
【0073】
次に、図18を参照して、安定文書間距離を算出する処理(図17の安定文書間距離算出ステップ(S61)のサブルーチン)について説明する。まず、キーワード抽出部71がキー文書からキーワードを抽出し、抽出したキーワードをキーワードDB81aに格納させる(S801)。また、参照ワード抽出部72が参照文書から参照ワードを抽出し、抽出した参照ワードを参照ワードDB82aに格納させる(S802)。
【0074】
次に、キーワード評価値計算部91が、参照ワードDB82aに格納されている参照ワードを読み込み、各キーワードの評価値を計算し、その評価値をキーワード評価値DB84aに格納させる(S803)。また、検索ワード抽出部73が検索文書から検索ワードを抽出し、抽出した検索ワードを検索ワードDB83aに格納させる(S804)。次に、キーワード類似度計算部92が、キーワード評価値DB84aに格納されている評価値及び検索ワードDB83aに格納されている検索ワードを読み込み、キー文書と検索文書との間のキーワード類似度を計算し、その類似度をキーワード類似度DB85aに格納させる(S805)。
【0075】
組付与情報評価値計算部93が、キー文書と検索文書に共通して付与される共通組付与情報を抽出し(S806)、これらの文献各々の組付与情報評価値を計算する(S807)。組付与情報類似度計算部94が、キー文書と検索文書との組付与情報類似度を計算し、組付与情報類似度DB85bに対してIPCの階層ごとに格納する(S808)。文書類似度計算部95が、キー文書と検索文書とに関して、初期文書類似度と、キーワード類似度及び組付与情報類似度とを平均した文書類似度とをそれぞれ計算する(S809)。最後に、文書間距離計算部93が、キー文書と検索文書における、初期文書類似度に基づく初期安定文書間距離L0(1)(i,j)と、文書類似度に基づく安定文書間距離L0(2)(i,j)とを計算する(S810)。
【0076】
なお、キーワード類似度及び組付与情報類似度の平均を求める際、例えば、組付与情報類似度に2〜40、好ましくは8〜11の係数を乗じて組付与情報類似度に重みをつけることで、表記のゆれが問題となる内容類似の文書間では組付与情報類似度による評価を、共通する組付与情報がない分野の異なる文書間では、キーワード類似度による評価を主体とすることが可能になり、この安定文書間距離に基づき位置座標を算出することで、広い技術分野にわたる特許文献をより詳細に分類配置することが可能になる。
【0077】
次に、図19を参照して、図17の総和文書間力ベクトル算出ステップ(S66)のサブルーチンについて説明する。まず、文書間力ベクトル算出部26が、位置座標DB16に格納されている各文書の位置座標を読み込み、その位置座標から各2文書間の座標平面上における距離(離間ベクトルの長さ)を算出する(S91)。また、文書間力ベクトル算出部26は、文書間距離DB14に格納されている初期安定文書間距離L0(1)(i,j)または安定文書間距離L0(2)(i,j)を読み込み、それらの安定文書間距離と前ステップS91で計算した距離とを用いて、文書間力を算出する(S92)。さらに、文書間力ベクトル算出部26は、離間ベクトルに基づいて文書間力のX成分及びY成分を算出し(S93)、ある文書に対して他の配置済み文書から働く文書間力の総和をベクトル和として求めることにより、総和文書間力ベクトルを算出する(S94)。そして、全ての配置済み文書について総和文書間力ベクトルが算出された場合にはフローが終了し、総和文書間力ベクトルが算出されていない文書がある場合には、上記ステップ(S91〜S94)が繰り返される(S95)。
【0078】
次に、図20を参照して、図17の位置座標の更新ステップ(S67)のサブルーチンについて説明する。まず、位置座標更新部28が、文書間力ベクトルDB18に格納されている文書間力ベクトルを読み込み、そのベクトルに応じて各文書の移動、すなわち位置座標の変更を行う(S101)。その後、位置座標更新部28は、収束条件の判定に用いられる、各文書の移動距離の平均値を算出する(S102)。これは、S68において、移動距離の平均値が閾値を下回ることを収束条件とすることができる。また、これに代えてint√N回位置座標の更新ステップを繰り返したことを収束条件とすることもできる。
【0079】
次に、図21を参照して、文書追加処理について説明する。図17に示した初期配置文書の配置・移動処理が終了してから、順次追加の配置文書を加えていって、全ての分類対象文書の配置・移動を完了させる場合を考える。
【0080】
配置文書選択部23が、次に表示座標系に加える時期配置文書を、int(mm/10)(ただし、mmは既に表示座標系に配置済みの分類対象文書の数)個無作為に選択する(S111)。ただし、分類対象文書の残りの個数がint(mm/10)に満たない場合には、残存している分類対象文書全てが時期配置文書になる。初期配置文書の配置・移動処理の直後に追加される時期配置文書の数は、int{(int√N)/10}個となる。
【0081】
位置座標初期値設定部24が、時期配置文書が最初に設置される表示座標系上の位置座標を算出する(S112)。本実施形態では、時期配置文書は、最も安定文書間距離が短い配置済み分類対象文書の近傍に位置するように初期設定される。具体的には、位置座標初期値設定部24は、安定文書間距離DB14を参照して、L0(1)(c,mm+k)が最小値となるcを求め(ただし、c=1〜mm)、時期配置文書Tkの位置座標の初期値を(Xk,Yk)=(Xc+ε,Yc+ε)(ε:定数)とする。また、以上に代えて初期配置文書の場合と同様に時期配置文書の初期値を乱数により決定してもよい。
【0082】
ある時期配置文書の位置座標が初期値に設定された後、文書間力ベクトル算出部26が、当該時期配置文書が他の配置済み分類対象文書から受ける現在の総和文書間力ベクトルを算出する(S113)。位置座標更新部28が、この総和文書間力ベクトルに基づき当該時期配置文書の位置座標を更新する(S114)。収束条件判定部30が、当該時期配置文書の今回の移動量が閾値以下であること又はS113〜S115の処理が所定の回数実行されたことをもって当該時期配置文書の位置座標の収束を判断する(S115)。収束が判断されなかった場合には、当該時期配置文書について再びS113〜S115の処理が繰り返される。
【0083】
時期配置文書のうちの他の文書についても、順次S112〜S115の処理が行われる。時期配置文書中の全ての文書について配置・移動処理が完了した場合には、今回表示座標系に加えられた時期配置文書を含む全ての配置済み文書について位置計算(S66〜S68の処理)が√N回行われる(S117)。この計算結果として得られる位置座標が、後述する文書移動処理(図23参照)で使用される初期文書位置座標(Xk(1),Yk(1))となる。このように、時期配置文書の全てを一度に配置して移動処理(全部又は一部の配置文書の各々について、総和文書間力ベクトルを算出してこれに基づき位置座標を更新する処理を位置座標の収束が判断されるまで繰り返す処理)を行う代わりに、他の配置済み文書の位置座標を固定しつつ一つずつ順次時期配置文書の配置・移動処理を行って全ての時期配置文書の位置座標を仮決めし、さらに今回の時期配置文書を含む全ての配置済み文書についての配置・移動処理を行うことにより、移動処理の繰返回数を減少させることができる。未配置の分類対象文書についてS111〜S117の処理が行われる。ただし、未配置の分類対象文書がなくなった場合には、上記で得られた初期文書位置座標に基づいて表示部32が結果表示を行い(S119)、図23に示される文書移動処理に移行する。
【0084】
次に、図22を参照して、図21の結果表示ステップ(出力ステップ)のサブルーチンについて説明する。まず、表示部32が、表示エリアをm×n個のセルに区切る(S121)。ここで、入力部34により表示エリアを規定するX座標及びY座標それぞれの最大値及び最小値を入力する(S122)。この入力は、ユーザが行うものである。次に、表示部32は、入力部34より入力された上記の値に基づいて、各セルに相当する座標範囲を算出する(S123)。そして、表示部32は、各セルの座標範囲内に位置座標を有する文書数を表示エリアに表示する(S124)。また、表示部32は、各セルに含まれる文書のイメージを作成するとともに(S125)、各セルに文書のイメージをハイパーリンクさせる(S126)。
【0085】
次に、図23を参照して、文書移動処理について説明する。先ず、安定文書間距離算出部22が、分類対象文書DB12に格納されている分類対象文書を読み込んで各2文書間の文書類似度に基づく安定文書間距離L0(2)(i,j)を算出し、算出した安定文書間距離L0(2)(i,j)を安定文書間距離DB14に格納させる(S231)。続いて、安定文書間距離算出部22が、文書間距離DB14に格納されている安定文書間距離L0(2)(i,j)を読み込んで平均値Lavg(2)を算出し(S232)、各安定文書間距離L0(2)(i,j)をこの平均値Lavg(2)で除することにより正規化して安定文書間距離DB14のデータを更新する(S233)。
【0086】
続いて、位置座標初期値設定部24は、ステップS117の計算の結果得られた初期文書位置座標(Xk(1),Yk(1))を用いて各文書の位置座標の初期値を設定し、設定した位置座標の初期値を位置座標DB16に格納させる(S235)。
【0087】
そして、文書間力ベクトル算出部26が、文書間距離DB14に格納されている安定文書間距離L0(2)及び位置座標DB16に格納されている位置座標を読み込み、それらの値を用いて、各文書に働く総和文書間力ベクトルを算出し、算出した総和文書間力ベクトルを文書間力ベクトルDB18に格納する(S236)。
【0088】
その後、位置座標更新部28が、文書間力ベクトルDB18に格納されている総和文書間力ベクトルを読み込み、そのベクトルに基づいて各文書の位置座標を更新し、更新した位置座標を位置座標DB16に格納させる(S237)。位置座標が更新されると、収束条件判定部30が収束条件の判定を行い、収束条件が満たされていない場合には上記ステップ(S236〜S237)を繰返し実行させる。収束条件が満たされている場合には、上記で更新された位置座標に基づいて表示部32が結果表示を行い(S239)、配置・移動処理が終了する。
【0089】
次に、第一実施形態にかかる文書分類装置1の作用及び効果について説明する。
【0090】
文書分類装置1の文書類似度計算部95は、ステップS809において、キーワード類似度と組付与情報類似度とを平均して文書類似度を算出する。そのため、文書類似度おけるキーワード類似度の影響が組付与情報類似度によって低減されるので、キーワード分類における文書の表記の差による影響を低減することができる。また、組付与情報は、IPCと発明者氏名とによって構成されているので、分類対象文書の分野によって分類対象文書間の組付与情報類似度および文書類似度が増減する。安定文書間距離算出部22は、文書類似度が増大すると安定文書間距離L0(2)(i,j)を減少させ、文書類似度が減少すると安定文書間距離L0(2)(i,j)を増大させるので、表示部32が異なる分野の文書を適切な文書間距離で表示することが出来る。
【0091】
また、文書分類装置1の組付与情報類似度計算部94は、ステップS808において、IPCの階層ごとに組付与情報類似度を算出する。そのため、図15のレコードNo5に示すように、サブグループまでのIPCを含む組付与情報類似度が0である場合においても、より階層の浅いサブクラスまでのIPCを含む組付与情報類似度を算出することによって、文書間に類似性を見出される場合がある。また、多くの文書が近い文書間距離で近接している場合には、上記とは逆にIPCの階層を深くすることによって、より類似性の高い文書を検出することができる。したがって、分類対象文書の類似度合いに応じて、分類の分解能を調整することができるので、さまざまな類似状況にある分類対象文書を適切に分類することが出来る。
【0092】
なお、本発明による文書分類装置は、上記実施形態に限られるものではなく、他に様々な変形が可能である。
【0093】
安定文書間距離の計算処理の別の例を示す。本例では、安定文書間距離算出部22において共通キーワードに基づく類似度を計算する処理機能(キーワード評価値計算部91及びキーワード類似度計算部92)と共通組付与情報に基づく類似度を計算する処理機能(組付与情報評価値計算部93及び組付与情報類似度計算部94)とが統合されている。また、本例の参照文書テーブルは参照ワードDB82aのデータと組付与情報DB81bのデータとを結合させたものである。
【0094】
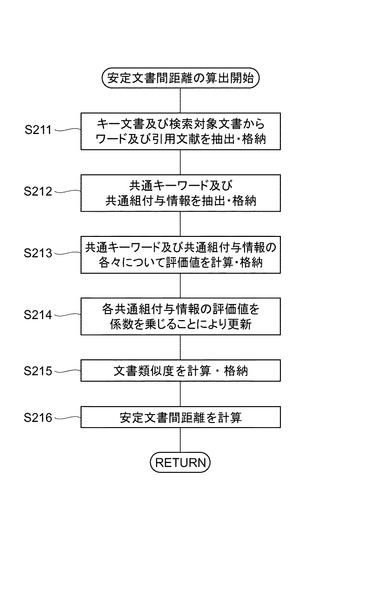
図24は、安定文書間距離の計算処理の第2例におけるフローチャートを示す。図24を参照して、本例の計算処理について説明する。安定文書間距離算出部22(キーワード・組付与情報抽出部70)は、キー文書及び検索文書からワード・組付与情報を抽出して(S211)、共通キーワード及び共通組付与情報を抽出・格納する(S212)。安定文書間距離算出部22は、参照文書テーブルを参照して、参照文書テーブルにおける各共通キーワード及び共通組付与情報の出現率を計算し、これに基づき評価値を計算・格納する(S213)。安定文書間距離算出部22は、各共通組付与情報の評価値に2〜40、好ましくは8〜11の係数を乗じてこの値に置き換える(S214)。安定文書間距離算出部22は、S213で得られたキーワード評価値とS214で得られた組付与情報評価値とを合算することにより文書類似度を計算する(S215)。さらに、合算値をS211で抽出されたワード・組付与情報の総数で除した値を文書類似度とするのが好適である。この文書類似度に基づいて安定文書間距離が計算される(S216)。
【0095】
上記の例では共通キーワード及び共通組付与情報の評価値を合算することによりそれぞれに基づく類似度を算出するが、これに代えてベクトル空間法を適用してキーワード類似度と組付与情報類似度のそれぞれを求めてこれらに重みを乗じた上で文書類似度を算出する方法、共通キーワード及び共通組付与情報の評価値に予め重みを付けた上で一括してベクトル空間法で文書類似度を求めることも可能である。
【0096】
ベクトル空間法を適用してキーワード類似度を算出する場合、一例として、図25ないし図27に示される処理がなされる。具体的には、(c)及び(d)欄に示される該当文書中にワードが現れる場合に1、そうでない場合に0とするベクトルそれぞれと、(b)欄の評価値ベクトルの各要素を乗じる演算を行うことにより、(e)及び(g)欄のベクトルを算出する。(f)及び(h)欄に示されるように(e)及び(g)欄のベクトルの各要素を二乗する演算を行い、さらに正規化係数を乗じて(f)欄のベクトルの単位ベクトル(i)及び(h)欄のベクトルの単位ベクトル(j)を算出する。単位ベクトル(i)と単位ベクトル(j)との距離又は内積に基づいてキーワード類似度を算出することができる。組付与情報類似度も、上記と同様の処理により算出することができる。また、キーワード及び検索ワードに加えてキー文書及び検索文書で付与されている組付与情報を同時にベクトル空間法演算の対象にし(この場合(a)欄には図15の組付与情報と同様の入力がなされる。)、(b)欄における評価値を、キーワード類似度と組付与情報類似度とのバランスをとるための重みを乗じた数値とすれば、その後に上記の演算を行うことにより直接文書類似度を取得することができる。
【0097】
図28(a)及び図28(b)は、図1の表示部32による結果表示の第1の変形例を説明するための図である。図に示される表示エリア50は、図5に対応するものである。本例では、表示エリア50内の一部を新たな表示エリアとして指定することにより、その部分を表示エリア50全体に再表示させることができる。例えば、図28(a)において中央の4つのセル(外枠を太線で示している)を指定した場合、この指定した部分が、図28(b)に示すように、表示エリア50全体に再表示される。このとき、表示エリア50内のセル数は不変であるので、指定した部分はより細かいセルに分割されている。例えば、図28(a)において文書数が「5」と表示されているセルは、図28(b)において右上の4つのセルに対応している。したがって、この4つのセルの文書数の和は5となっている。表示エリアの指定は、例えば図1の入力部34に座標値を入力することにより、或いは画面上においてマウスで選択することにより行うことができる。
【0098】
図29は、図1の表示部32による結果表示の第2の変形例を説明するための図である。本例において表示部32は、表示エリア54d内のプロットエリア54pに、各文書の表示座標系(二次元表示座標系)における位置座標をプロットして表示する。各プロット56には、対応する文書を特定できるように、各文書のタイトル等がテキストボックス53(「テキストボックス」とは、プロットされた文書の属性を表示するための一定の形状及び大きさの小エリアをいう。ただし、属性情報の表示量に応じて何段階かの異なる形状又は大きさのテキストボックスを設定することも考えられる。)内に表示される。テキストボックス53が表示エリア54dからはみ出すことがないように、プロットエリア54pは表示エリア54aからテキストボックス53のサイズ分(複数段階の形状又は大きさのテキストボックスが設定されている場合には、最も長い縦径又は横径の分)だけ内側に縮小されている。すなわち、表示エリア54aの各角に位置する点線と表示エリア54aの枠で囲われる領域はテキストボックス53と同じ大きさ及び形状になっている。
【0099】
ここでは、分類対象文書として公開特許公報を想定しており、その文献番号として出願番号が表示されている。また、表示されているテキストボックス53あるいは文献番号には、ハイパーリンクが貼られており、画面上で文献番号をクリックすることによりその文書のイメージにアクセスすることができる。また、テクストボックス53には文献番号の他に発明の名称や出願人、要約から切り出したキーワードを表示させることができ、これを行えば分類内容の把握が一層容易となる。
【0100】
図30は、図29の変形例に係るフローチャートを示している。まず、ユーザが表示エリア54aを規定するX座標及びY座標それぞれの最大値及び最小値を入力する(S151)。この入力は、図1の入力部34より行うことができる。表示部32はプロットエリア54pを設定する(S152)。表示部32は、プロットエリア54p内にある各文書の位置座標をプロットし、プロット56と関連付けてテキストボックス53を表示する(S153)。さらに、表示部32は、各プロットに文書イメージをハイパーリンクさせる(S154)。なお、図29の表示例では、表示の一部領域を指定し、これを新たな表示エリアとして拡大表示する、或いは、表示エリアの一点、例えばエリア中心部のテキストボックスをマウスポインタで指定し、これを中心に拡大/縮小表示することができる。また、指定した1又は2以上のテキストボックスの内容を表計算ソフト等のワークシート上にコピーすることで、分類に続く作業をより一層容易にすることができる。
【0101】
図31は、図1の表示部32による結果表示の第3の変形例を説明するための図である。本例において、表示部32は、ユーザが指定した基準文書の位置座標を基点として、座標平面上において表示半径内に位置座標をもつ文書を該当文書として表示する。基準文書及び表示半径の指定は、図1の入力部34より行うことができる。また、基準文書は、分類対象文書DB12に格納されている分類対象文書の中から選ばれる。図31において表示画面57内の右側に、該当文書リストが表示されている。これらの表示には、ハイパーリンクが貼られている。ここでは、基準文書から表示半径内に4つの文書が存在する。また、このリストは、基準文書からの距離が近い順にソートされて表示されている。さらに、本例では、表示画面57内の左側に、表示エリア58が設けられている。この表示エリア58には、基準文書を中心として各文書の位置座標がプロットされ、併せて基準文書を中心として表示半径を半径とする円59が表示される。この円59は、表示半径を再指定する際の目安とすることができる。各プロットに付されている数字は、該当文書リストにおける番号に対応している。本例によれば、基準文書に類似する文書を検索することができる。また、この場合、基準文書を色又は字体等を変える所謂ハイライト表示で表示することにより、目標とする基準文書とそれに類似する文書の位置関係の把握が容易になる。
【0102】
図32は、図31の変形例に係るフローチャートを示している。まず、ユーザが図1の入力部34より基準文書、及び表示変形を入力する(S171,S172)。すると、表示部32は、位置座標DB16に格納されている各文書の位置座標を読み込み、基準文書から表示半径内の距離にある文書を該当文書リストとして表示する(S173)。さらに、表示部32は、該当文書リストに表示される文書のイメージをハイパーリンクさせる(S174)。ここで、ユーザは、必要に応じて、ハイパーリンクを辿ることにより表示された文書のイメージにアクセスし、その内容を確認する(S175)。そして、表示半径を再指定して検索し直すときは、上記ステップ(S172〜S175)を繰り返し実行し、検索し直さないときはフローを終了する(S176)。
【0103】
また、上記実施形態では、2次元の座標平面上において各文書の位置座標を決定する構成を示したが、その座標平面は1次元であってもよい。このとき、各文書は1本の直線上に位置座標を有することになるが、この場合も便宜的に1次元の「座標平面」と呼ぶことにする。また、3次元以上に拡張して、各文書の位置座標を決定する構成としてもよい。
【0104】
また、各文書の移動距離の平均値が規定値以下となることを収束条件としたが、収束条件はこれに限られない。例えば、各文書の移動距離の最大値が規定値以下となることを収束条件としてもよい。
【0105】
また、位置座標の更新の際に用いられる移動係数kは、常に一定の値である必要はない。ある程度収束が進んだ後、収束速度を上げるために、各文書の移動距離の平均値の増減如何によって移動係数kを加減する構成としてもよい。例えば、移動距離の平均値が前回の更新後よりも大きければk’=k×0.01(k’:加減後の移動係数)とし、小さければk’=k×1.03とする。
【産業上の利用可能性】
【0106】
複数の特許文献の間の類似度の関係を視覚で認識できるように示すことができる。
【図面の簡単な説明】
【0107】
【図1】本発明による文書分類装置の一実施形態を示すブロック図である。
【図2】文書間距離DB14のデータベースの一例を示す構成図である。
【図3】位置座標DB16のデータベースの一例を示す構成図である。
【図4】文書間力ベクトルDB18のデータベースの一例を示す構成図である。
【図5】表示部32による結果表示画面の一例を示す図である。
【図6】図1の文書分類装置1のハードウェア構成を示すブロック図である。
【図7】図1の安定文書間距離算出部22の構成の一例を示すブロック図である。
【図8】参照ワードDB82aのデータベースの一例を示す構成図である。
【図9】共通ワードカウントテーブルによるカウントを説明する図である。
【図10】キーワード評価値DB84aのデータベースの一例を示す構成図である。
【図11】キーワード類似度DB85aのデータベースの一例を示す構成図である。
【図12】参照組付与情報DB82bのデータベースの一例を示す構成図である。
【図13】共通参照組付与情報カウントテーブルによるカウントを説明する図である。
【図14】組付与情報評価値DB84bのデータベースの一例を示す構成図である。
【図15】組付与情報類似度DB85bのデータベースの一例を示す構成図である。
【図16】文書類似度DB86のデータベースの一例を示す構成図である。
【図17】初期処理及び二次元表示座標系において初期配置文書を配置・移動する処理を示すフローチャートである。
【図18】図7の安定文書間距離算出部22の動作を示すフローチャートである。
【図19】図17の総和文書間力ベクトル算出ステップ(S66)のサブルーチンを示すフローチャートである。
【図20】図17の位置座標の更新ステップ(S67)のサブルーチンを示すフローチャートである。
【図21】表示座標系に追加の配置文書を加えていく処理を示すフローチャートである。
【図22】図21の結果表示ステップのサブルーチンを示すフローチャートである。
【図23】文書移動処理を示すフローチャートである。
【図24】安定文書間距離の計算処理の第2例におけるフローチャートを示す。
【図25】ベクトル空間法を適用した実施形態を説明する第1の図である。
【図26】ベクトル空間法を適用した実施形態を説明する第2の図である。
【図27】ベクトル空間法を適用した実施形態を説明する第3の図である。
【図28】(a)及び(b)は、図1の表示部32による結果表示の第1の変形例を説明するための図である。
【図29】図1の表示部32による結果表示の第2の変形例を説明するための図である。
【図30】図29の変形例に係るフローチャートを示している。
【図31】図1の表示部32による結果表示の第3の変形例を説明するための図である。
【図32】図31の変形例に係るフローチャートを示している。
【符号の説明】
【0108】
1…文書分類装置、10…データベース、12…分類対象文書DB、14…文書間距離DB、16…位置座標DB、18…文書間力ベクトルDB、22…安定文書間距離算出部、23…配置文書選択部、24…位置座標初期値設定部(文書移動手段)、26…文書間力ベクトル算出部(文書移動手段)、28…位置座標更新部(文書移動手段)、30…収束条件判定部(文書移動手段)、32…表示部、34…入力部、53…テキストボックス、54a…表示エリア、54p…プロットエリア、56…プロット、71…キーワード・組付与情報抽出部(共通キーワード抽出手段、共通組付与情報抽出手段)、72…参照ワード・組付与情報抽出部、73…検索ワード・組付与情報抽出部(共通キーワード抽出手段、共通組付与情報抽出手段)、91…キーワード評価値計算部(共通キーワード評価値算出手段)、92…キーワード類似度計算部(キーワード類似度算出手段)、93…組付与情報評価値計算部(共通組付与情報評価値算出手段)、94…組付与情報類似度計算部(組付与情報類似度算出手段)、95…文書類似度計算部(文書類似度算出手段)、96…文書間距離計算部、S803…(共通キーワード評価値算出手段)、S805…(キーワード類似度算出ステップ)、S806…(共通組付与情報抽出ステップ)、S807…(共通組付与情報評価値算出ステップ)、S808…(組付与情報類似度算出ステップ)、S809…(初期文書類似度算出ステップおよび文書類似度算出ステップ)、S61〜S68,S111〜S119…(初期文書移動ステップ)、S231〜S238…(文書移動ステップ)。
【特許請求の範囲】
【請求項1】
文書内容の分野を体系づける分類情報と文書内容の創作者の氏名と文書の識別番号とを付与された分類対象文書をそれぞれの内容に応じて分類する文書分類装置であって、
前記分類対象文書のうちの2文書において共通して現れる共通キーワードを抽出する共通キーワード抽出手段と、
前記分類対象文書のうちの前記2文書において共通して現れる分類情報および創作者の氏名とによって構成された共通組付与情報を抽出する共通組付与情報抽出手段と、
前記分類対象文書の全て又は一部の文書で構成されたキーワード参照文書の識別番号と当該キーワード参照文書に含まれるキーワードとを関連付けて格納したキーワードテーブルを参照して、当該キーワードテーブルにおいて前記共通キーワードが出現する共通キーワード出現数を数え、当該共通キーワード出現数に基づき前記共通キーワードの非一般性を示す共通キーワード評価値を算出する共通キーワード評価値算出手段と、
前記分類対象文書の全て又は一部の文書で構成された共通組付与情報参照文書の識別番号と当該共通組付与情報参照文書に含まれる共通組付与情報とを関連付けて格納した共通組付与情報テーブルを参照して、当該共通組付与情報テーブルにおいて前記共通組付与情報が出現する共通組付与情報出現数を数え、当該共通組付与情報出現数に基づき前記共通組付与情報の非一般性を示す共通組付与情報評価値を算出する共通組付与情報評価値算出手段と、
各前記共通キーワード評価値を合算して、前記2文書の前記共通キーワードに基づく類似性を示すキーワード類似度を算出するキーワード類似度算出手段と、
各前記共通組付与情報評価値を合算して、前記2文書の前記共通組付与情報に基づく類似性を示す組付与情報類似度を算出する組付与情報類似度算出手段と、
前記キーワード類似度と前記組付与情報類似度とを総合した前記2文書の文書類似度を算出する文書類似度算出手段と、
前記分類対象文書を座標系に配置し、前記文書類似度が増大するほど前記2文書間の文書間距離を減少させ、前記文書類似度が減少するほど前記2文書間の文書間距離を増大させるように各前記分類対象文書を移動させる文書移動手段と、
を備えることを特徴とする文書分類装置。
【請求項2】
文書内容の分野を体系づける分類情報と文書内容の創作者の氏名と文書の識別番号とを付与された分類対象文書をそれぞれの内容に応じて分類する文書分類方法であって、
前記共通キーワード抽出手段が、前記分類対象文書のうちの2文書において共通して現れる共通キーワードを抽出する共通キーワード抽出ステップと、
前記共通組付与情報抽出手段が、前記分類対象文書のうちの前記2文書において共通して現れる分類情報および創作者の氏名とによって構成された共通組付与情報を抽出する共通組付与情報抽出ステップと、
前記共通キーワード評価値算出手段が、前記分類対象文書の全て又は一部の文書で構成されたキーワード参照文書の識別番号と当該キーワード参照文書に含まれるキーワードとを関連付けて格納したキーワードテーブルを参照して、当該キーワードテーブルにおいて前記共通キーワードが出現する共通キーワード出現数を数え、当該共通キーワード出現数に基づき前記共通キーワードの非一般性を示す共通キーワード評価値を算出する共通キーワード評価値算出ステップと、
前記共通組付与情報評価値算出手段が、前記分類対象文書の全て又は一部の文書で構成された共通組付与情報参照文書の識別番号と当該共通組付与情報参照文書に含まれる共通組付与情報とを関連付けて格納した共通組付与情報テーブルを参照して、当該共通組付与情報テーブルにおいて前記共通組付与情報が出現する共通組付与情報出現数を数え、当該共通組付与情報出現数に基づき前記共通組付与情報の非一般性を示す共通組付与情報評価値を算出する共通組付与情報評価値算出ステップと、
前記キーワード類似度算出手段が各前記共通キーワード評価値を合算して、前記2文書の前記共通キーワードに基づく類似性を示すキーワード類似度を算出するキーワード類似度算出ステップと、
前記組付与情報類似度算出手段が各前記共通組付与情報評価値を合算して、前記2文書の前記共通組付与情報に基づく類似性を示す組付与情報類似度を算出する組付与情報類似度算出ステップと、
前記文書類似度算出手段が前記キーワード類似度と前記組付与情報類似度とを総合した前記2文書の文書類似度を算出する文書類似度算出ステップと、
前記分類対象文書を座標系の初期文書位置に配置し、前記文書類似度が増大するほど前記2文書間の文書間距離を減少させ、前記文書類似度が減少するほど前記2文書間の文書間距離を増大させるように各前記分類対象文書を移動させる文書移動ステップと、
を備えることを特徴とする文書分類方法。
【請求項3】
前記キーワード類似度を初期文書類似度とする初期文書類似度算出ステップと、
前記分類対象文書を座標系の任意文書位置に配置し、2文書間の前記初期文書類似度が大きいほど文書間距離を減少させ、前記初期文書類似度が減少するほど前記2文書間の文書間距離を増大させるように前記分類対象文書を前記初期文書位置に移動させる初期文書移動ステップと、
をさらに備えることを特徴とする請求項2に記載の文書分類方法。
【請求項4】
前記組付与情報類似度算出ステップは、前記分類情報の階層ごとに前記組付与情報類似度を算出することを特徴とする請求項2または3に記載の文書分類方法。
【請求項1】
文書内容の分野を体系づける分類情報と文書内容の創作者の氏名と文書の識別番号とを付与された分類対象文書をそれぞれの内容に応じて分類する文書分類装置であって、
前記分類対象文書のうちの2文書において共通して現れる共通キーワードを抽出する共通キーワード抽出手段と、
前記分類対象文書のうちの前記2文書において共通して現れる分類情報および創作者の氏名とによって構成された共通組付与情報を抽出する共通組付与情報抽出手段と、
前記分類対象文書の全て又は一部の文書で構成されたキーワード参照文書の識別番号と当該キーワード参照文書に含まれるキーワードとを関連付けて格納したキーワードテーブルを参照して、当該キーワードテーブルにおいて前記共通キーワードが出現する共通キーワード出現数を数え、当該共通キーワード出現数に基づき前記共通キーワードの非一般性を示す共通キーワード評価値を算出する共通キーワード評価値算出手段と、
前記分類対象文書の全て又は一部の文書で構成された共通組付与情報参照文書の識別番号と当該共通組付与情報参照文書に含まれる共通組付与情報とを関連付けて格納した共通組付与情報テーブルを参照して、当該共通組付与情報テーブルにおいて前記共通組付与情報が出現する共通組付与情報出現数を数え、当該共通組付与情報出現数に基づき前記共通組付与情報の非一般性を示す共通組付与情報評価値を算出する共通組付与情報評価値算出手段と、
各前記共通キーワード評価値を合算して、前記2文書の前記共通キーワードに基づく類似性を示すキーワード類似度を算出するキーワード類似度算出手段と、
各前記共通組付与情報評価値を合算して、前記2文書の前記共通組付与情報に基づく類似性を示す組付与情報類似度を算出する組付与情報類似度算出手段と、
前記キーワード類似度と前記組付与情報類似度とを総合した前記2文書の文書類似度を算出する文書類似度算出手段と、
前記分類対象文書を座標系に配置し、前記文書類似度が増大するほど前記2文書間の文書間距離を減少させ、前記文書類似度が減少するほど前記2文書間の文書間距離を増大させるように各前記分類対象文書を移動させる文書移動手段と、
を備えることを特徴とする文書分類装置。
【請求項2】
文書内容の分野を体系づける分類情報と文書内容の創作者の氏名と文書の識別番号とを付与された分類対象文書をそれぞれの内容に応じて分類する文書分類方法であって、
前記共通キーワード抽出手段が、前記分類対象文書のうちの2文書において共通して現れる共通キーワードを抽出する共通キーワード抽出ステップと、
前記共通組付与情報抽出手段が、前記分類対象文書のうちの前記2文書において共通して現れる分類情報および創作者の氏名とによって構成された共通組付与情報を抽出する共通組付与情報抽出ステップと、
前記共通キーワード評価値算出手段が、前記分類対象文書の全て又は一部の文書で構成されたキーワード参照文書の識別番号と当該キーワード参照文書に含まれるキーワードとを関連付けて格納したキーワードテーブルを参照して、当該キーワードテーブルにおいて前記共通キーワードが出現する共通キーワード出現数を数え、当該共通キーワード出現数に基づき前記共通キーワードの非一般性を示す共通キーワード評価値を算出する共通キーワード評価値算出ステップと、
前記共通組付与情報評価値算出手段が、前記分類対象文書の全て又は一部の文書で構成された共通組付与情報参照文書の識別番号と当該共通組付与情報参照文書に含まれる共通組付与情報とを関連付けて格納した共通組付与情報テーブルを参照して、当該共通組付与情報テーブルにおいて前記共通組付与情報が出現する共通組付与情報出現数を数え、当該共通組付与情報出現数に基づき前記共通組付与情報の非一般性を示す共通組付与情報評価値を算出する共通組付与情報評価値算出ステップと、
前記キーワード類似度算出手段が各前記共通キーワード評価値を合算して、前記2文書の前記共通キーワードに基づく類似性を示すキーワード類似度を算出するキーワード類似度算出ステップと、
前記組付与情報類似度算出手段が各前記共通組付与情報評価値を合算して、前記2文書の前記共通組付与情報に基づく類似性を示す組付与情報類似度を算出する組付与情報類似度算出ステップと、
前記文書類似度算出手段が前記キーワード類似度と前記組付与情報類似度とを総合した前記2文書の文書類似度を算出する文書類似度算出ステップと、
前記分類対象文書を座標系の初期文書位置に配置し、前記文書類似度が増大するほど前記2文書間の文書間距離を減少させ、前記文書類似度が減少するほど前記2文書間の文書間距離を増大させるように各前記分類対象文書を移動させる文書移動ステップと、
を備えることを特徴とする文書分類方法。
【請求項3】
前記キーワード類似度を初期文書類似度とする初期文書類似度算出ステップと、
前記分類対象文書を座標系の任意文書位置に配置し、2文書間の前記初期文書類似度が大きいほど文書間距離を減少させ、前記初期文書類似度が減少するほど前記2文書間の文書間距離を増大させるように前記分類対象文書を前記初期文書位置に移動させる初期文書移動ステップと、
をさらに備えることを特徴とする請求項2に記載の文書分類方法。
【請求項4】
前記組付与情報類似度算出ステップは、前記分類情報の階層ごとに前記組付与情報類似度を算出することを特徴とする請求項2または3に記載の文書分類方法。
【図1】

【図2】
【図3】

【図4】

【図5】
【図6】
【図7】
【図8】
【図9】
【図10】

【図11】
【図12】
【図13】
【図14】

【図15】
【図16】
【図17】
【図18】

【図19】
【図20】
【図21】
【図22】
【図23】
【図24】
【図25】
【図26】
【図27】
【図28】
【図29】
【図30】
【図31】
【図32】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【図23】
【図24】
【図25】
【図26】
【図27】
【図28】
【図29】
【図30】
【図31】
【図32】
【公開番号】特開2008−90510(P2008−90510A)
【公開日】平成20年4月17日(2008.4.17)
【国際特許分類】
【出願番号】特願2006−269115(P2006−269115)
【出願日】平成18年9月29日(2006.9.29)
【出願人】(000190116)信越ポリマー株式会社 (1,394)
【Fターム(参考)】
【公開日】平成20年4月17日(2008.4.17)
【国際特許分類】
【出願日】平成18年9月29日(2006.9.29)
【出願人】(000190116)信越ポリマー株式会社 (1,394)
【Fターム(参考)】
[ Back to top ]