
文書検索装置、文書検索方法および文書検索プログラム

【課題】自然言語に基づく文書検索の精度を改善する。
【解決手段】所定のコーパスから、検索用テキストと関連する内容の文書ファイルを検索するための文書検索装置に関する。この装置は、グラムごとの文書内位置や形態素内位置を示すインデックス情報を保持する。文書検索装置は、ユーザから検索用テキストの入力を受け付け、形態素とグラムを抽出する。そして、形態素のコーパスにおける稀少性を推定数により指標化し、形態素を含む文書ファイルを検出した上で、そのような形態素が文書ファイルに出現する回数を出現頻度として計数する。形態素についての推定数と出現頻度から、検索用テキストと文書ファイルの内容の関連性を関連スコアとして指標化する。
【解決手段】所定のコーパスから、検索用テキストと関連する内容の文書ファイルを検索するための文書検索装置に関する。この装置は、グラムごとの文書内位置や形態素内位置を示すインデックス情報を保持する。文書検索装置は、ユーザから検索用テキストの入力を受け付け、形態素とグラムを抽出する。そして、形態素のコーパスにおける稀少性を推定数により指標化し、形態素を含む文書ファイルを検出した上で、そのような形態素が文書ファイルに出現する回数を出現頻度として計数する。形態素についての推定数と出現頻度から、検索用テキストと文書ファイルの内容の関連性を関連スコアとして指標化する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、文書処理技術に関し、特に、検索用に与えられたテキストと関連する内容の文書ファイルを検索するための技術、に関する。
【背景技術】
【0002】
コンピュータの普及とネットワーク技術の進展にともない、ネットワークを介した電子情報の交換が盛んになっている。これにより、従来においては紙ベースで行われていた事務処理の多くが、ネットワークベースの処理に置き換えられつつある。デジタル化とネットワーク技術の進展は、情報取得コストを急激に低下させている。このような状況において、ユーザから入力されたテキスト(以下、「検索用テキスト」とよぶ)と関連する内容の文書ファイル(以下、特に「関連文書」または「関連文書ファイル」とよぶ)を検索するための文書検索技術が注目されている。自然言語に基づく文書検索技術の代表例として、形態素解析やNgram解析がある。
【特許文献1】特開2005−99972号公報
【発明の開示】
【発明が解決しようとする課題】
【0003】
形態素解析では、所定規則にしたがってテキストを形態素とよばれる意味単位に分解する。たとえば、「アメリカ合衆国の大統領」というテキストであれば、「アメリカ合衆国:の:大統領」のように、名詞や助詞といった品詞に基づいて、3つの形態素に分解する。そして、検索用テキスト中の形態素と同じ形態素を文書ファイルがどの程度含んでいるかに応じて、検索用テキストと文書ファイルの内容の関連性を判定する。形態素という意味のある文字列をベースとした検索・判定のため、非関連文書を関連文書と判定するミスが発生しにくいという長所がある。反面、関連文書を非関連文書と判定しやすいという短所がある。たとえば、「アメリカ合衆国」という形態素について文書検索を行った場合、「アメリカでは、・・・」という文書ファイルは検出対象から漏れてしまう。検索用テキストも文書ファイルも「アメリカに関する内容」という点で共通しても、一方では「アメリカ合衆国」、他方では「アメリカ」のため、形態素が一致しないからである。
【0004】
Ngram解析は、テキストをグラム(gram)とよばれる所定長の文字列単位に分解する。「アメリカ合衆国の大統領」というテキストであれば、「アメリ:メリカ:・・・:大統領」のように複数のグラムが抽出される。グラムは、必ずしも意味を持つ単位とはならない。そのため、先ほどの「アメリカでは、・・・」という文書ファイルであっても、「アメリ」や「メリカ」というグラムが検索用テキストと一致することになる。形態素のような意味単位ではないため、Ngram解析には、関連文書を非関連文書と判定してしまうミス、いわば検索漏れが発生しにくいという長所がある。反面、非関連文書を関連文書と判定するミスが発生しやすいという短所がある。たとえば、「メリカエッセンスとは、・・・」のような、本来、検索用テキストとの関連性がほとんどない文書ファイルでも、「メリカ」というグラムが一致することにより検出されてしまう可能性がある。
【0005】
このように形態素解析とNgram解析は、互いの長所と短所が相反関係にある。そこで本発明者は、「意味単位」と「文字列単位」という2種類の解析方法を融合させることにより、従来よりも高精度な文書検索が可能となるのではないかと考えた。
【0006】
本発明はこうした状況に鑑みてなされたものであり、その目的は、自然言語に基づく文書検索の精度を改善する技術、を提供することにある。
【課題を解決するための手段】
【0007】
本発明のある態様は、所定の文書ファイル群から、検索用テキストと関連する内容の文書ファイルを検索するための文書検索装置に関する。この装置は、グラムと、そのグラムを含む文書ファイルと、文書ファイルの形態素中におけるグラムの位置が、グラムごとに対応づけられたインデックス情報を保持する。
この装置は、検索用テキストの入力を受け付け、1以上の検索用形態素を抽出し、更に1以上のグラムを抽出する。そして、ある検索用形態素中における特定グラムの位置と文書ファイルの形態素中における特定グラムの位置が整合する文書ファイルの数を、その検索用形態素の稀少性を示す推定数として特定し、検索用形態素を含む文書ファイルを検出した上で、検索用形態素が文書ファイルに出現する回数を出現頻度として計数する。検索用形態素についての推定数と出現頻度から、検索用テキストと文書ファイルの内容の関連性を関連スコアとして指標化する。
【0008】
本発明の別の態様も、所定の文書ファイル群から、検索用テキストと関連する内容の文書ファイルを検索するための文書検索装置に関する。この装置は、グラムと、そのグラムを含む文書ファイルと、文書ファイルの形態素中におけるグラムの位置が、グラムごとに対応づけられたインデックス情報を保持する。
この装置は、検索用テキストの入力を受け付け、1以上の検索用形態素を抽出し、1以上のグラムを抽出する。そして、ある検索用形態素に含まれる複数のグラムについての前方出現率と後方出現率から、その検索用形態素を複数の部分形態素に分離し、ある部分形態素を含む文書ファイルを検出した上で、そのような部分形態素が文書ファイルに出現する回数を出現頻度として計数する。部分形態素について計数された出現頻度と検索用形態素中における部分形態素の位置により、検索用テキストと検出された文書ファイルの内容の関連性を関連スコアとして指標化する。
【0009】
なお、以上の構成要素の任意の組合せ、本発明の表現を方法、システム、プログラム、記録媒体などの間で変換したものもまた、本発明の態様として有効である。
【発明の効果】
【0010】
本発明によれば、自然言語に基づく文書検索の精度を高めることができる。
【発明を実施するための最良の形態】
【0011】
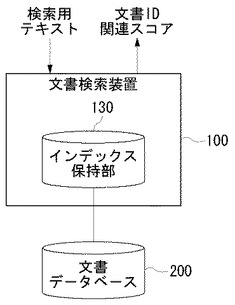
図1は、文書検索装置100による処理の概要を説明するための模式図である。
ユーザが文書検索装置100に対して検索用テキストを入力すると、文書検索装置100はその検索用テキストと関連する内容の文書ファイルを文書データベース200から検索する。検索用テキストは一定の意味をなす文字列であり、自然文であってもよいしキーワードであってもよい。文書データベース200の文書ファイルは、XML(eXtensible Markup Language)文書やXHTML(eXtensible HyperText Markup Language)文書のようにタグによって構造化されたファイルであってもよいし、単なるテキストファイルであってもよい。本実施例においては、検索対象となる文書ファイルはXMLファイルであるとする。なお、文書データベース200に格納され、検索対象となる文書ファイル群のことを、以下「コーパス(corpus)」とよぶことにする。
【0012】
文書検索装置100のインデックス保持部130は、各文書ファイルを検索するためのインデックス情報を保持する。インデックス情報については後に詳述する。文書検索装置100は、検索用テキストとインデックス情報に基づいて、コーパスから文書ファイルを検出し、検索用テキストとの内容の関連性を「関連スコア」として指標化する。文書検索装置100は、所定数、たとえば、関連スコアが上位20位以内の文書ファイルの文書IDと、その関連スコアを画面表示させる。こうして、文書検索装置100のユーザは、任意の検索用テキストに対して、内容の関連性が高い文書ファイルをコーパスから探し出すことができる。
【0013】
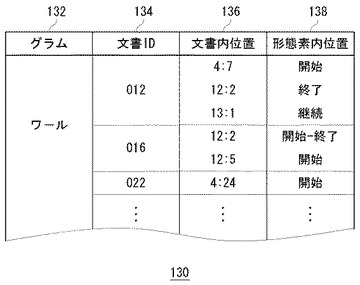
図2は、インデックス保持部130のデータ構造図である。
本実施例における文書検索処理を実行するためには、コーパスについてのインデックス情報が必要である。インデックス情報の生成方法については図3に関連して後述するとして、まず、インデックス情報のデータ構造について説明する。インデックス情報は、グラム名欄132、文書ID欄134、文書内位置欄136、形態素内位置欄138という5つの項目を持つ。
【0014】
グラム名欄132はグラム名を示す。グラムとは所定数の連続する文字列である。同図は、3文字のカタカナ文字列のグラム「ワール」についてのインデックス情報を示している。文書ID欄134は、該当グラムを含む文書ファイルの文書IDを示す。文書IDとは、コーパスにおいて文書ファイルを一意に識別するためのIDである。同図によると、グラム「ワール」は、文書ID「012」、「016」、「022」、・・・という複数の文書ファイル内に含まれている。ただし、グラム「ワール」が各文書ファイルにおいてどのような文脈で使用されているかについては、インデックス情報からは直接的にはわからない。
【0015】
文書内位置欄136は、各文書ファイル内における該当グラムの位置を「ノード番号:オフセット」のかたちで示す。このような文書内におけるグラムの位置を「文書内位置」とよぶ。たとえば、「・・・<node>2006年のワールドシリーズでは、・・・」という文書ファイルにおいて、<node>タグは、文書ファイル中において先頭から4番目のタグであるとする。この文書ファイルでは、<node>タグの要素のうち、7文字目から「ワール」というグラムが現れている。したがって、文書内位置は「4:7」となる。
【0016】
形態素内位置欄138は、形態素内における該当グラムの位置を「開始」、「終了」、「継続」、「開始−終了」の4種類の「形態素内位置」により示す。さきほどのテキストを、「2006:年:の:ワールドシリーズ:では:、:・・・」のように形態素に分解したとする。グラム「ワール」は形態素「ワールドシリーズ」の開始部分に位置している。したがって、形態素内位置は「開始」となる。形態素「ルノワール」や「コートジボワール」に含まれるグラム「ワール」であれば、形態素内位置は「終了」になる。形態素「コワールスキー」や「サッカーワールド」であれば、グラム「ワール」の形態素内位置は「継続」である。また、形態素自体が「ワール」であれば、グラム「ワール」の形態素内位置は「開始−終了」となる。
【0017】
インデックス保持部130は、コーパスから検出される各グラムについてのインデックス情報を保持する。本発明者らの調査によると、23万文書(約250MB)から約54万種類のグラムが検出された。この場合、54万種類の各グラムについて、同図に示すようなインデックス情報が用意されることになる。
【0018】
ところで、グラムを構成する文字の数(以下、「N数」とよぶ)は、「ワール」のように3文字に限る必要はない。N数が大きいほど、検索用テキストと文書ファイルの関連性判定の適合率が高くなる。適合率が高いほど、非関連文書を関連文書と判定するミスが発生しにくくなることを示す。たとえば、「アームストロング砲」の関連文書を検索する場合、「ア」という1文字のグラムを含む文書ファイルを検索するとすれば、非関連文書を大量に検出してしまうことになる。しかし、「アームストロング」のような8文字のグラムを含む文書ファイルを検索した場合、こういったノイズ(非関連文書)を低減できる。反面、N数が大きくなると、グラムの種類が増えるためインデックス情報が大きくなってしまう。また、再現率が悪くなる。再現率が高いほど、関連文書の検出漏れが発生しにくくなることを示す。
【0019】
そこで、最適なN数を求めるために、本発明者はコーパスにおいて連続する文字数を字種別に調査した。文字の連続数として多い数は以下の通りであった。
漢字:1〜2文字。
ひらがな:1〜3文字。ただし、1文字となるのは「の、は、を」などの助詞の場合が多い。
カタカナ:2〜4文字。
英数字:3〜6文字。
以上の知見に基づき、本実施例においては、字種に応じてグラムのN数を以下のように設定する。
漢字:2、ひらがな:3、カタカナ:4、英数字:4、字種連結:2
たとえば、「アメリカ合衆国」という形態素の場合、抽出されるグラムは「アメリ:メリカ:カ合:合衆:衆国」の5つである。グラム「カ合」は、カタカナと漢字の接続部分である。このようなグラムが字種連結のグラムである。
【0020】
図3は、インデックス情報の生成過程を示すフローチャートである。
文書データベース200に新しく文書ファイルが登録されるとき、その文書ファイルに含まれるグラムがインデックス情報に登録される。文書検索装置100は、まず、新しい文書ファイルを取得すると(S10)、その文書ファイル中からテキスト部分を抽出する(S12)。次に、テキストを形態素に分解し(S14)、形態素を更にグラムに分解する(S16)。最後に、抽出されたグラムの文書内位置や形態素内位置をインデックス情報に登録する。
【0021】
コーパスから文書ファイルを削除するときには、インデックス情報から削除される文書ファイル中のグラムがインデックス情報から削除される。このように、コーパスの変化に応じて、インデックス情報も変化する。なお、S14において抽出された形態素を、後述する形態素分離処理により、更に、小さな形態素に分解してもよい。形態素分離処理については、図7に関連して詳述する。
【0022】
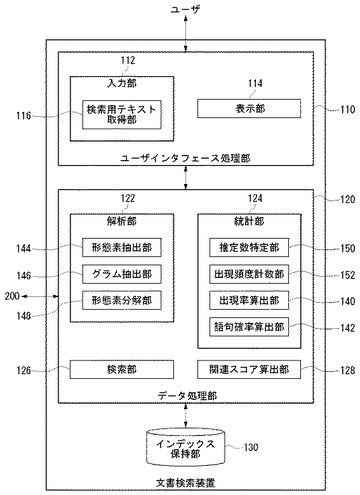
図4は、文書検索装置100の機能ブロック図である。
ここに示す各ブロックは、ハードウェア的には、コンピュータのCPUをはじめとする素子や機械装置で実現でき、ソフトウェア的にはコンピュータプログラム等によって実現されるが、ここでは、それらの連携によって実現される機能ブロックを描いている。したがって、これらの機能ブロックはハードウェア、ソフトウェアの組合せによっていろいろなかたちで実現できることは、当業者には理解されるところである。
【0023】
文書検索装置100は、ユーザインタフェース処理部110、データ処理部120およびインデックス保持部130を含む。
ユーザインタフェース処理部110は、ユーザからの入力処理やユーザに対する情報表示のようなユーザインタフェース全般に関する処理を担当する。本実施例においては、ユーザインタフェース処理部110により文書検索装置100のユーザインタフェースサービスが提供されるものとして説明する。別例として、ユーザはインターネットを介して文書検索装置100を操作してもよい。この場合、図示しない通信部が、ユーザ端末からの操作指示情報を受信し、またその操作指示に基づいて実行された処理結果情報をユーザ端末に送信することになる。
【0024】
データ処理部120は、ユーザインタフェース処理部110や文書データベース200から取得されたデータを元にして各種のデータ処理を実行する。データ処理部120は、ユーザインタフェース処理部110とインデックス保持部130の間のインタフェースの役割も果たす。
【0025】
ユーザインタフェース処理部110は、入力部112と表示部114を含む。入力部112は、ユーザからの入力操作を受け付ける。表示部114は、ユーザに対して各種情報を表示する。入力部112は、検索用テキストを取得するための検索用テキスト取得部116を含む。
【0026】
データ処理部120は、解析部122と統計部124、検索部126、関連スコア算出部128を含む。
解析部122は、検索用テキストや文書ファイルの文書構造を解析する。解析部122は、形態素抽出部144、グラム抽出部146、形態素分解部148を含む。形態素抽出部144は、テキストから1以上の形態素を抽出する。ここでいうテキストとは、文書ファイルから抽出されるテキストや検索用テキストである。形態素抽出部144は、あらかじめ用意された辞書データを参照して、その辞書データに登録されている単語を形態素として抽出してもよいし、品詞や字種によって形態素を抽出してもよい。形態素抽出部144による形態素の抽出方法は既知の技術の応用でよい。グラム抽出部146は、形態素抽出部144が抽出した形態素から1以上のグラムを抽出する。形態素分解部148は、形態素抽出部144が抽出した形態素をより小さい形態素に分解する。このような処理を「形態素分離処理」とよぶ。たとえば、形態素抽出部144が「サッカーワールドカップ」という形態素を抽出したとき、形態素分解部148はこの形態素から更に「サッカー」、「ワールド」、「カップ」という3つの形態素を抽出する。形態素分離処理の詳細については、図7に関連して後述する。以下、形態素抽出部144が抽出する形態素と形態素分解部148の形態素分離処理により抽出される形態素を区別するときには、前者を「原形態素」、後者を「部分形態素」とよぶ。
【0027】
統計部124は、形態素やグラムの稀少性、出現頻度などを統計解析する。統計部124は、推定数特定部150、出現頻度計数部152、出現率算出部140、語句確率算出部142を含む。
推定数特定部150は、形態素のコーパスにおける稀少性を推定数として指標化する。推定数が小さいほど稀少性が高い。推定数の考え方については、図6に関連して詳述する。出現頻度計数部152は、検索用テキストに含まれる形態素が、調査対象の文書ファイルに出現する回数を出現頻度として計数する。出現率算出部140は、コーパスを対象として、あるグラムがどのような形態素内位置に存在する可能性が高いかを定量化するために、前方出現率や後方出現率といった出現率を計算する。出現率の考え方については、図7に関連して詳述する。語句確率算出部142は、形態素分離処理を実行するための語句確率を算出する。語句確率とは、ある形態素がコーパスにおいて本来の意味で用いられている可能性の高さを指標化した数値である。語句確率の考え方についても図7の形態素分離処理の説明に関連して詳述する。
【0028】
検索部126は、検索用テキストの形態素を含む文書ファイルをコーパスから検索する。検索部126は、形態素におけるグラムの並び順と同じ並び順にてグラムを含む文書ファイルをインデックス情報を参照して検出する。たとえば、検索用テキストから「アメリカ合衆国」という形態素が抽出されたとする。抽出されるグラムは「アメリ:メリカ:カ合:合衆:衆国」の5つであるから、検出対象となるのは、これら5つのグラムを含む文書ファイルである。検索部126は、インデックス情報のグラム名欄132と文書ID欄134を参照して、5つのグラムの全てを含む文書ファイルを検出する。このような文書ファイルのことを「中間候補ファイル」とよぶことにする。次に、検索部126は、文書内位置欄136を参照して、これら5つのグラムが連続的に並んでいる中間候補ファイルを特定する。このような中間候補ファイルは、「アメリカ合衆国」という形態素を含む文書ファイルである。このような文書ファイルのことを「関連候補ファイル」ともよぶ。
【0029】
このように、検索部126は、あくまでもグラムをベースとしながら、検索用テキスト中の形態素についての関連候補ファイルを検出する。そのため、検索部126は文書ファイルの内容を精査することなく、インデックス情報だけで関連候補ファイルを特定できる。
【0030】
関連スコア算出部128は、各関連候補ファイルについて関連スコアを算出する。関連スコアとは、検索用テキストと文書ファイルの内容の関連性の大きさを示すスコアである。関連スコアの算出方法については、図8および図10に関連して2種類の計算方法について後に詳述する。
【0031】
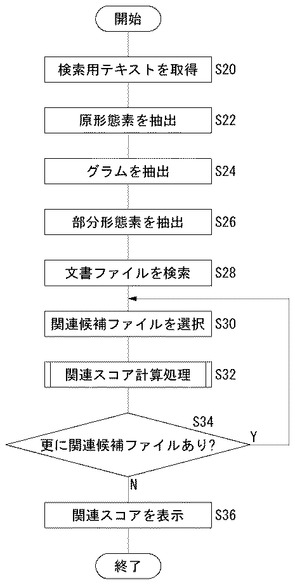
図5は、関連文書ファイルを特定するための処理過程を示すフローチャートである。
検索用テキスト取得部116は、まず、検索用テキストを取得する(S20)。例として、「2006年のサッカーワールドカップに優勝するチームとして・・・」という検索用テキストが入力されたとする。形態素抽出部144は、この検索用テキストから原形態素を抽出する(S22)。「2006:年:の:サッカーワールドカップ:に:優勝:する:チーム:として・・・」のように複数の原形態素が抽出されたとする。以下の処理は、原形態素のそれぞれについて実行されるが、説明を簡単にするため、ここでは「サッカーワールドカップ」という原形態素を対象として説明する。
【0032】
グラム抽出部146は、原形態素から1以上のグラムを抽出する(S24)。原形態素「サッカーワールドカップ」の場合、「サッカ:ッカー:カーワ:ーワー:ワール:ールド:ルドカ:ドカッ:カップ」の計9つのグラムが抽出される。次に、形態素分解部148は、原形態素「サッカーワールドカップ」から、「サッカー」、「ワールド」、「カップ」という部分形態素を抽出する(S26)。より具体的には、形態素分解部148は、形態素に含まれるグラムの前方出現率と後方出現率に基づいて、原形態素「サッカーワールドカップ」から3つの部分形態素を抽出するが、詳細については図7に関連して後述する。検索用テキストから抽出された原形態素、および、部分形態素に基づいて文書検索処理が実行される。「サッカーワールドカップ」であれば、「サッカーワールドカップ」、「サッカー」、「ワールド」、「カップ」の4つの形態素について文書検索処理が実行される。以下、このような文書検索のベースとなる形態素のことを「検索ターム」とよぶ。
【0033】
検索部126は、検索タームに含まれるグラムの並び順に基づいて、関連候補ファイルを検出する(S28)。すなわち、「サッカー」、「ワールド」、「カップ」、「サッカーワールドカップ」といった各検索タームのいずれかを含む文書ファイルが関連候補ファイルとして検出される。
【0034】
関連スコア算出部128は、これらの関連候補ファイル群から1つの文書ファイルを選択し(S30)、関連スコア計算処理を実行し(S32)、関連候補ファイル群から次の文書ファイルを選択する(S34のY、S30)。全ての関連候補ファイルについて関連スコア計算処理を完了すると(S34のN)、関連スコアが上位20位以内となる関連候補ファイルを「関連文書ファイル」として、表示部114は関連文書ファイルの文書IDと関連スコアを画面に一覧表示させる(S36)。
本実施例においては、S32における関連スコア計算処理として、第1計算方法と第2計算方法という2つの計算方法を提案する。それぞれ、図8と図10に関連して詳述する。その前に、第1計算方法の前提となる推定数や出現率について説明する。
【0035】
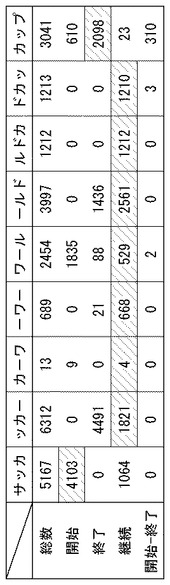
図6は、原形態素「サッカーワールドカップ」に含まれる各グラムのコーパスにおける出現態様を示す図である。
本実施例におけるコーパスは、23万文書ファイルの集合体である。インデックス情報によると、グラム「サッカ」はこのうちの5167文書から検出される。「ッカー」は6312文書、「カーワ」は、たった13文書にしか含まれない。グラム「ッカー」に比べてグラム「カーワ」は、稀少性が高いグラムであることがわかる。
【0036】
グラム「サッカ」を含む5167文書のうち、その形態素内位置が「開始」となるのは4103文書(約79%)であり、「継続」となるのは1064文書(約20%)である。インデックス保持部130には、各グラムごとの同図に示すような統計情報も格納されている。ある文書ファイルに同種のグラムが複数個含まれている場合には、そのうち最も多くのグラムの間で共通する形態素内位置が、その文書ファイルにおける当該グラムの形態素内位置として集計される。たとえば、ある文書ファイルにグラム「サッカ」が3つ含まれ、そのうち2つの「サッカ」の形態素内位置が「継続」であれば、残りの「サッカ」の形態素内位置の如何に関わらずその文書ファイルは「サッカ(継続)」としてカウントされる。
【0037】
原形態素「サッカーワールドカップ」において、グラム「サッカ」の形態素内位置は「開始」、グラム「カップ」は「終了」、それ以外のグラムの形態素内位置は「継続」である。9種類のグラムのうち、グラムと形態素内位置が一致する文書ファイルの数が最も少ないのは「カーワ(継続)」であり、文書ファイル数は4である。コーパスにおいて「カーワ(継続)」を含む文書ファイルだけが、形態素「サッカーワールドカップ」を含む可能性があるから、この「4」は形態素「サッカーワールドカップ」の稀少性を示唆する数字である。推定数特定部150は、検索用テキストから抽出された形態素「サッカーワールドカップ」に含まれるグラム「カーワ」の形態素内位置「継続」に基づき、グラム「カーワ(継続)」を含む文書ファイルの数「4」を推定数として特定する。推定数が小さいほど、「カーワ(継続)」を含む文書ファイルと検索用テキストとの関連スコアが大きくなるが、詳しいアルゴリズムについては図8に関連して詳述する。
【0038】
本実施例における推定数特定部150は、検索用テキストの形態素に含まれるグラムのうち、コーパスにおいてその形態素内位置が整合する文書ファイルが最も少なくなるグラムについて、その文書ファイル数を推定数として算出している。変形例として、推定数特定部150は、各グラムについて推定数を算出してもよい。たとえば、「サッカ(開始)」の4013や「ッカー(継続)」の1821といった文書数の平均値を推定数として算出してもよい。
【0039】
なお、原形態素「サッカーワールドカップ」からは「サッカー」、「ワールド」、「カップ」という3つの部分形態素が抽出される。部分形態素「サッカー」の推定数はmin(4103,1821)より1821となる。ここで、minとは変数群の中の最小値を返す関数である。「サッカ(開始)」を含む文書の数は4103、「ッカー(終了)」を含む文書の数は1821だからである。同様の理由から、「ワールド」の推定数はmin(1835,1436)より1436、「カップ」の推定数は310となる。すなわち、コーパスにおいて、「サッカーワールドカップ」>「カップ」>「ワールド」>「サッカー」の順に稀少性が高い。
【0040】
図7は、原形態素「サッカーワールドカップ」に含まれる各グラムのコーパスにおける出現率を示す図である。
グラム「サッカ」の形態素内位置は79%(4103÷5167)の確率で「開始」となる。出現率算出部140は、コーパスにおいてあるグラムの形態素内位置が「開始」または「開始−終了」となる確率を「前方出現率」として算出する。一方、グラム「ッカー」は6312文書に含まれ、そのうち、4491文書において形態素内位置は「終了」となる。出現率算出部140は、コーパスにおいてあるグラムの形態素内位置が「終了」または「開始−終了」となる確率を「後方出現率」として算出する。グラム「ッカー」の後方出現率は71%である。
【0041】
形態素抽出部144が対象テキストから原形態素を抽出し、グラム抽出部146がその形態素からグラムを抽出すると、出現率算出部140は各グラムについて前方出現率と後方出現率を計算する。同図によると、「サッカーワールドカップ」において「ッカー」というグラムは形態素の終了に使われることが多く、形態素「サッカーワールドカップ」においてグラム「ッカー」の後方に隣接するグラム「ワール」は、形態素の先頭に使われることが多い。すなわち、「サッカーワールドカップ」という一連の形態素においては、「サッカー」と「ワールドカップ」の間に意味上の境界が存在する可能性が高いという推定が成り立つ。同様にして、「ワールドカップ」は「ワールド」と「カップ」の間に意味上の境界が存在する可能性が高い。
【0042】
形態素分解部148は、各グラムの前方出現率と後方出現率を参照し、形態素中におけるグラムAの後方出現率が所定値、たとえば、30%以上、形態素中においてグラムAの後方に隣接するグラムBの前方出現率が所定値、たとえば、25%以上となるとき、形態素においてグラムAとグラムBの間に意味上の境界が存在すると判定する。先ほどの例に戻ると、形態素分解部148は、原形態素「サッカーワールドカップ」から「サッカー」、「ワールド」、「カップ」という3つの部分形態素を抽出する。このようなアルゴリズムにより形態素分離処理が実行される。
【0043】
図8は、図5のS32における関連スコア計算処理について、第1計算方法の処理過程を示すフローチャートである。
ここでは、検索部126により検索用テキストに含まれる全ての検索タームを対象として関連候補ファイルが検出されている。先述した検索用テキスト「2006年のサッカーワールドカップに優勝するチームとして・・・」からは、「2006」や「サッカーワールドカップ」、「サッカー」、・・・など、多くの検索タームが抽出されることになる。
【0044】
推定数特定部150は、図5のS28で特定された1以上の検索タームから、調査対象の検索タームを選択し(S40)、推定数を特定する(S42)。出現頻度計数部152は、その検索タームについての関連候補ファイルにおいて検索タームが出現する回数を出現頻度として計数する(S44)。関連スコア算出部128は、検索タームと関連候補ファイルの内容の関連性の高さをタームスコアとして算出する。関連スコア算出部128は、出現頻度が大きく推定数が小さいほどタームスコアが高くなる任意の関数によりタームスコアを算出する(S46)。これは、コーパスにおいて稀少な検索タームであるほど、また、その検索タームが文書中に多く出現するほど、その文書ファイルは検索タームとの関連性が高いという判断に基づく。検索タームの稀少性と出現頻度に基づく文書内容評価方法は、自然言語による検索アルゴリズムとして実績のあるTF/IDF(Term Frequency/Inverce Document Frequency)法の考え方を踏襲したものである。本実施例では、
タームスコア=出現頻度×(log(1/推定数)+1)
という計算式により、タームスコアを算出する。
【0045】
関連スコア算出部128は、更に検索タームがあれば(S48のY)、その検索タームについてのタームスコアを計算する。全ての検索タームについてタームスコアが算出されると(S48のN)、関連スコア算出部128はこれらのタームスコアの合計値や平均値を関連スコアとして算出する(S50)。
【0046】
第1計算方法による関連スコア計算処理によると、検索用テキストに含まれる検索タームと同じ形態素を含む文書ファイルを対象とし、その検索タームのコーパスにおける稀少性を考慮してタームスコアを算出できる。なお、必ずしも全ての検索タームについてタームスコアを算出しなくてもよい。たとえば、1文字の形態素については、タームスコアの算出対象から除外すれば、関連スコア計算をより高速に実行できる。あるいは、複数のタームスコアの最高値や最低値を関連スコアとしてもよい。
次に第2計算方法による関連スコア計算処理を説明するが、その前に、その前提となる第1出現数、第2出現数、語句確率、重み係数および中間値の考え方について説明する。
【0047】
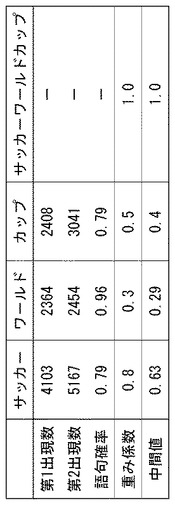
図9は、原形態素「サッカーワールドカップ」に含まれる各部分形態素の語句確率と中間値の関係を示す図である。
同図に示す第1出現数の考え方は、推定数の考え方と似ている。たとえば、部分形態素「ワールド」や原形態素「サッカーワールドカップ」において、グラム「ワール」の形態素内位置は「開始」または「継続」、グラム「ールド」の形態素内位置は「終了」または「継続」である。このとき、部分形態素「ワールド」の第1出現数を
第1出現数=min(「ワール(開始)」または「ワール(継続)」を含む文書数、「ールド(継続)」または「ールド(終了)」を含む文書数)
により算出する。図6に示したデータによると、「ワールド」についての第1出現数はmin(1835+529,1436+2561)より、2364となる。
【0048】
この第1出現数は、「文書ファイル中においてある形態素Aが、本来の意味において用いられていると推定される文書ファイルの数」を示す。たとえば、「プラス」という部分形態素は、ある文書ファイルにおいては「ラプラス」という形態素の一部として検出されるかもしれないし、「プラスチック」という形態素の一部として検出されるかもしれない。第1出現数は、その部分形態素を含む文書ファイル群から、その部分形態素を示す文字列が別の意味を示す形態素の一部となっている文書ファイルを除いたときの文書ファイル数を特定するための数値である。部分形態素「サッカー」の第1出現数は、min(4103,4491+1821)より4103、部分形態素「カップ」の第1出現数は、2098+310より2408となる。このように、第1出現数は、グラムの原形態素や部分形態素に対する形態素内位置と、文書ファイルにおけるそのグラムの形態素内位置が整合する文書ファイルの数に基づいて特定される。
【0049】
第2出現数は、意味としての整合性を考慮することなく特定される。たとえば、形態素「ワールド」の第2出現数は、min(「ワール」を含む文書数(2454)、「ールド」を含む文書数(3997))より2454となる。第2出現数は、部分形態素中のグラムを含む文書ファイルの数に基づいて特定される。
【0050】
図5のS32における関連スコア計算処理を、第2計算方法により実行する場合、語句確率算出部142は第1出現数÷第2出現数により語句確率を算出する。同図の場合、「ワールド」の語句確率は2364÷2454=0.96である。語句確率は、「その形態素を文字列として含む文書ファイル群のうち、その形態素が本来の意味において使われている確率」を示唆する数値である。本実施例の場合、「サッカー」、「ワールド」、「カップ」のそれぞれの語句確率は、0.79、0.96、0.79となる。部分形態素「ワールド」はコーパスにおいても96%という高い確率にて本来の意味にて使用されていることがわかる。いいかえれば、部分形態素「ワールド」は、先に示した部分形態素「プラス」のように、他の形態素の一部として一体化しにくい独立性の高い用語であることがわかる。「プラス」という文字列を含む文書ファイルでは、「プラス」が「ラプラス」や「プラスチック」のような違う意味で使われている可能性があるが、「ワールド」という文字列を含む文書ファイルでは、「ワールド」という本来の意味で使われている可能性が高い。第2計算方法においては、「ワールド」のような独立性の高い検索タームについてのタームスコアを高く評価する。
【0051】
部分形態素「サッカー」、「ワールド」、「カップ」のうち、「サッカーワールドカップ」という用語にとって最も重要な部分形態素は「サッカー」であると考えられる。これは、長い文字列であらわされる用語において、その用語の先頭部分にその用語の意味が現れることが多いという経験則に基づく。たとえば、「徳島県」という原形態素の場合、先頭の「徳島」という部分形態素は「県」という部分形態素よりも原形態素の特徴をより強く示している。そこで、第2計算方法においては、部分形態素「サッカー」のように原形態素の開始部分に位置する部分形態素はそれ以外に位置する部分形態素よりもタームスコアに重みをつける。本発明者らの調査によると、原形態素の開始部分の部分形態素、継続部分の部分形態素、終了部分の部分形態素に8:3:5の比率で重み付けをしたときに、再現率(検索漏れの少なさ)および適合率(ミスヒットの少なさ)が共に最適値となった。そこで、本実施例における第2計算方法では、重み係数を開始:0.8、継続:0.3、終了:0.5と設定し、関連スコア算出部128は、
中間値=語句確率×重み係数
として検索タームごとに中間値を算出する。中間値は1以下の数値であり、検索タームの用語としての独立性の高さと検索用テキストにおける重要度を示す数値である。「サッカーワールドカップ」のような原形態素の中間値は「1」に固定する。第2計算方法においては、この中間値に基づいて関連スコアが算出される。
【0052】
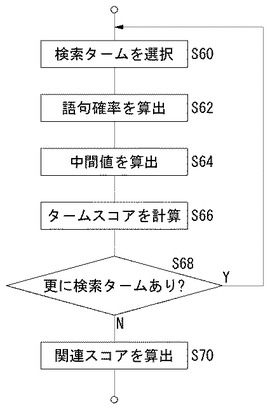
図10は、図5のS32における関連スコア計算処理について、第2計算方法の処理過程を示すフローチャートである。
語句確率算出部142は、検索タームを選択し(S60)、語句確率を算出する(S62)。関連スコア算出部128は、上記式により検索タームの中間値を算出する(S64)。関連スコア算出部128は、関連候補ファイルにおける検索タームの出現頻度を計数し、出現頻度と中間値が高いほどタームスコアが高くなる任意の関数によりタームスコアを算出する(S66)。形態素が本来の意味で用いられる可能性が高く、また、部分形態素であれば原形態素において重要な位置であるほど、また、その検索タームが文書中に多く出現するほど、その文書ファイルは検索用テキストとの関連性が高い内容であるという判断に基づく。本実施例では、
タームスコア=中間値×出現頻度
という計算式により、タームスコアを算出する。
【0053】
更に発展した例では、関連候補ファイルの形態素中における検索タームの位置により、タームスコアを調整してもよい。たとえば、検索タームが「京都」である場合、「京都」、「京都府」、「東京都」、「東京都営」という形態素を含む文書ファイルは、いずれも関連候補ファイルとして検出されることになる。しかし、完全一致の「京都」、前方一致の「京都府」であればまだしも、後方一致の「東京都」、部分一致の「東京都営」は、検索ターム「京都」とは文字列として一致しても内容としての関連性は低い。そこで、文書ファイルにおける形態素と検索タームとの一致の仕方に応じて調整係数を設定する。具体的には、完全一致:1.0、前方一致:0.6、部分一致:0.2、後方一致:0.4として設定する。この場合、
タームスコア=中間値×Σ(調整係数)
という計算式により、タームスコアを算出する。Σ(調整係数)は、関連候補ファイルに含まれる検索タームの数だけ、調整係数を合計することを意味する。
【0054】
たとえば、ある文書ファイルにおいて、「京都」という文字列が3つ検出され、それぞれの一致の仕方が完全一致、前方一致、部分一致であったとする。中間値が0.6とすると、
タームスコア=0.6×(1.0+0.6+0.2)=1.08
となる。このような計算方法によれば、関連候補ファイルにおける検索タームの一致の仕方とその出現頻度を加味したタームスコアを算出できる。
【0055】
関連スコア算出部128は、更に検索タームがあれば(S68のY)、その検索タームについてタームスコアを計算する。検索用テキストから検出された全ての検索タームについてタームスコアが算出されると(S68のN)、関連スコア算出部128はこれらのタームスコアの合計値を関連スコアとして算出する。
【0056】
第2計算方法による関連スコア計算処理によると、検索タームの重要性と文書ファイルにおける出現態様を考慮したタームスコアを算出できる。なお、必ずしも全ての検索タームについてタームスコアを算出しなくてもよいことは第1計算方法と同様である。
【0057】
第2計算方法における語句確率や重み係数、調整係数という考え方は、第1計算方法にも応用可能である。たとえば、第1の計算方法において、
A:タームスコア=Σ(調整係数)×(log(1/推定数)+1)
B:タームスコア=Σ(中間値)×(log(1/推定数)+1)
C:タームスコア=Σ(中間値×調整係数)×(log(1/推定数)+1)
としてタームスコアを算出してもよい。
【0058】
以上、本実施例に示す文書検索装置100によると、第1計算方法、第2計算方法のいずれについても、形態素解析のみに基づく文書検索処理に比べて再現率および適合率共に改善された。形態素解析の場合、どのような意味単位で形態素を抽出するかにより文書検索の精度が変化する。本実施例の文書検索装置100の場合、前方出現率や後方出現率によって、原形態素から合理的に部分形態素を抽出できる。原形態素のみならず部分形態素も検索タームとして関連スコアを算出するため、形態素解析における「どのような意味単位で形態素を抽出すべきか」という曖昧性・恣意性を、合理的に解決できる。
【0059】
たとえば、「一般教養課程」を「般教」と略して使用することが多いコーパスを想定する。従来の形態素解析の場合、形態素「一般教養課程」から俗語的な形態素「般教」を抽出することは困難である。しかし、本実施例の文書検索装置100によれば、前方出現率と後方出現率によって、「般教」という用語を意味を持つ形態素として抽出できる。したがって、「一般教養課程」という原形態素を含む検索用テキストが入力されたとき、形態素分解部148はこの原形態素から部分形態素「般教」を抽出しやすくなる。そのため、「一般教養課程」と「般教」という文字列としては別物であっても意味としては近い関係にある形態素を関連スコア計算の上で考慮できる。形態素分解処理が文書検索精度を向上させる一因となっている。
【0060】
第1計算方法においては、推定数によって、検索タームのコーパスにおける稀少性を指標化している。「サッカーワールドカップ」という文字列を含む文書の数を厳密に計数するとすれば、インデックス情報を参照して「サッカーワールドカップ」という11文字が並ぶ文書ファイルを検出するための処理が必要である。これに対し、インデックス情報から、あらかじめ図6に示すデータを集計しておけば、推定数特定部150は、任意の形態素の稀少性を推定数により簡単に指標化できる。推定数は、形態素の稀少性を厳密に示す数値ではないが、その稀少性を近似的に示す数値として有効に利用できる。
【0061】
第2計算方法においては、語句確率によって、検索タームの用語としての独立性を指標化している。語句確率により、検索用テキストの形態素と文書ファイルの形態素が文字列として一致しても、異なる意味で使われる可能性を考慮に入れることができる。更に、原形態素における部分形態素の位置や、文書ファイルにおける検索タームの出現態様を重み係数や調整係数により考慮に入れることができるため、文書検索の精度をいっそう高めることができる。
【0062】
以上、本発明を実施の形態をもとに説明した。この実施の形態は例示であり、それらの各構成要素や各処理プロセスの組合せにいろいろな変形例が可能なこと、またそうした変形例も本発明の範囲にあることは当業者に理解されるところである。
【0063】
請求項に記載の「検索用形態素」は、本実施例における原形態素または部分形態素の双方または一方により表現されている。請求項に記載の「特定グラム」は、本実施例におけるグラム「カーワ」により表現されている。
これら請求項に記載の各構成要件が果たすべき機能は、本実施例において示された各機能ブロックの単体もしくはそれらの連係によって実現されることも当業者には理解されるところである。
【図面の簡単な説明】
【0064】
【図1】文書検索装置による処理の概要を説明するための模式図である。
【図2】インデックス保持部のデータ構造図である。
【図3】インデックス情報の生成過程を示すフローチャートである。
【図4】文書検索装置の機能ブロック図である。
【図5】関連文書ファイルを特定するための処理過程を示すフローチャートである。
【図6】原形態素「サッカーワールドカップ」に含まれる各グラムのコーパスにおける出現態様を示す図である。
【図7】原形態素「サッカーワールドカップ」に含まれる各グラムのコーパスにおける出現率を示す図である。
【図8】図5のS32における関連スコア計算処理について、第1計算方法の処理過程を示すフローチャートである。
【図9】原形態素「サッカーワールドカップ」に含まれる各部分形態素の語句確率と中間値の関係を示す図である。
【図10】図5のS32における関連スコア計算処理について、第2の計算方法の処理過程を示すフローチャートである。
【符号の説明】
【0065】
100 文書検索装置、 110 ユーザインタフェース処理部、 112 入力部、 114 表示部、 116 検索用テキスト取得部、 120 データ処理部、 122 解析部、 124 統計部、 126 検索部、 128 関連スコア算出部、 130 インデックス保持部、 132 グラム名欄、 134 文書ID欄、 136 文書内位置欄、 138 形態素内位置欄、 140 出現率算出部、 142 語句確率算出部、 144 形態素抽出部、 146 グラム抽出部、 148 形態素分解部、 150 推定数特定部、 152 出現頻度計数部、 200 文書データベース。
【技術分野】
【0001】
本発明は、文書処理技術に関し、特に、検索用に与えられたテキストと関連する内容の文書ファイルを検索するための技術、に関する。
【背景技術】
【0002】
コンピュータの普及とネットワーク技術の進展にともない、ネットワークを介した電子情報の交換が盛んになっている。これにより、従来においては紙ベースで行われていた事務処理の多くが、ネットワークベースの処理に置き換えられつつある。デジタル化とネットワーク技術の進展は、情報取得コストを急激に低下させている。このような状況において、ユーザから入力されたテキスト(以下、「検索用テキスト」とよぶ)と関連する内容の文書ファイル(以下、特に「関連文書」または「関連文書ファイル」とよぶ)を検索するための文書検索技術が注目されている。自然言語に基づく文書検索技術の代表例として、形態素解析やNgram解析がある。
【特許文献1】特開2005−99972号公報
【発明の開示】
【発明が解決しようとする課題】
【0003】
形態素解析では、所定規則にしたがってテキストを形態素とよばれる意味単位に分解する。たとえば、「アメリカ合衆国の大統領」というテキストであれば、「アメリカ合衆国:の:大統領」のように、名詞や助詞といった品詞に基づいて、3つの形態素に分解する。そして、検索用テキスト中の形態素と同じ形態素を文書ファイルがどの程度含んでいるかに応じて、検索用テキストと文書ファイルの内容の関連性を判定する。形態素という意味のある文字列をベースとした検索・判定のため、非関連文書を関連文書と判定するミスが発生しにくいという長所がある。反面、関連文書を非関連文書と判定しやすいという短所がある。たとえば、「アメリカ合衆国」という形態素について文書検索を行った場合、「アメリカでは、・・・」という文書ファイルは検出対象から漏れてしまう。検索用テキストも文書ファイルも「アメリカに関する内容」という点で共通しても、一方では「アメリカ合衆国」、他方では「アメリカ」のため、形態素が一致しないからである。
【0004】
Ngram解析は、テキストをグラム(gram)とよばれる所定長の文字列単位に分解する。「アメリカ合衆国の大統領」というテキストであれば、「アメリ:メリカ:・・・:大統領」のように複数のグラムが抽出される。グラムは、必ずしも意味を持つ単位とはならない。そのため、先ほどの「アメリカでは、・・・」という文書ファイルであっても、「アメリ」や「メリカ」というグラムが検索用テキストと一致することになる。形態素のような意味単位ではないため、Ngram解析には、関連文書を非関連文書と判定してしまうミス、いわば検索漏れが発生しにくいという長所がある。反面、非関連文書を関連文書と判定するミスが発生しやすいという短所がある。たとえば、「メリカエッセンスとは、・・・」のような、本来、検索用テキストとの関連性がほとんどない文書ファイルでも、「メリカ」というグラムが一致することにより検出されてしまう可能性がある。
【0005】
このように形態素解析とNgram解析は、互いの長所と短所が相反関係にある。そこで本発明者は、「意味単位」と「文字列単位」という2種類の解析方法を融合させることにより、従来よりも高精度な文書検索が可能となるのではないかと考えた。
【0006】
本発明はこうした状況に鑑みてなされたものであり、その目的は、自然言語に基づく文書検索の精度を改善する技術、を提供することにある。
【課題を解決するための手段】
【0007】
本発明のある態様は、所定の文書ファイル群から、検索用テキストと関連する内容の文書ファイルを検索するための文書検索装置に関する。この装置は、グラムと、そのグラムを含む文書ファイルと、文書ファイルの形態素中におけるグラムの位置が、グラムごとに対応づけられたインデックス情報を保持する。
この装置は、検索用テキストの入力を受け付け、1以上の検索用形態素を抽出し、更に1以上のグラムを抽出する。そして、ある検索用形態素中における特定グラムの位置と文書ファイルの形態素中における特定グラムの位置が整合する文書ファイルの数を、その検索用形態素の稀少性を示す推定数として特定し、検索用形態素を含む文書ファイルを検出した上で、検索用形態素が文書ファイルに出現する回数を出現頻度として計数する。検索用形態素についての推定数と出現頻度から、検索用テキストと文書ファイルの内容の関連性を関連スコアとして指標化する。
【0008】
本発明の別の態様も、所定の文書ファイル群から、検索用テキストと関連する内容の文書ファイルを検索するための文書検索装置に関する。この装置は、グラムと、そのグラムを含む文書ファイルと、文書ファイルの形態素中におけるグラムの位置が、グラムごとに対応づけられたインデックス情報を保持する。
この装置は、検索用テキストの入力を受け付け、1以上の検索用形態素を抽出し、1以上のグラムを抽出する。そして、ある検索用形態素に含まれる複数のグラムについての前方出現率と後方出現率から、その検索用形態素を複数の部分形態素に分離し、ある部分形態素を含む文書ファイルを検出した上で、そのような部分形態素が文書ファイルに出現する回数を出現頻度として計数する。部分形態素について計数された出現頻度と検索用形態素中における部分形態素の位置により、検索用テキストと検出された文書ファイルの内容の関連性を関連スコアとして指標化する。
【0009】
なお、以上の構成要素の任意の組合せ、本発明の表現を方法、システム、プログラム、記録媒体などの間で変換したものもまた、本発明の態様として有効である。
【発明の効果】
【0010】
本発明によれば、自然言語に基づく文書検索の精度を高めることができる。
【発明を実施するための最良の形態】
【0011】
図1は、文書検索装置100による処理の概要を説明するための模式図である。
ユーザが文書検索装置100に対して検索用テキストを入力すると、文書検索装置100はその検索用テキストと関連する内容の文書ファイルを文書データベース200から検索する。検索用テキストは一定の意味をなす文字列であり、自然文であってもよいしキーワードであってもよい。文書データベース200の文書ファイルは、XML(eXtensible Markup Language)文書やXHTML(eXtensible HyperText Markup Language)文書のようにタグによって構造化されたファイルであってもよいし、単なるテキストファイルであってもよい。本実施例においては、検索対象となる文書ファイルはXMLファイルであるとする。なお、文書データベース200に格納され、検索対象となる文書ファイル群のことを、以下「コーパス(corpus)」とよぶことにする。
【0012】
文書検索装置100のインデックス保持部130は、各文書ファイルを検索するためのインデックス情報を保持する。インデックス情報については後に詳述する。文書検索装置100は、検索用テキストとインデックス情報に基づいて、コーパスから文書ファイルを検出し、検索用テキストとの内容の関連性を「関連スコア」として指標化する。文書検索装置100は、所定数、たとえば、関連スコアが上位20位以内の文書ファイルの文書IDと、その関連スコアを画面表示させる。こうして、文書検索装置100のユーザは、任意の検索用テキストに対して、内容の関連性が高い文書ファイルをコーパスから探し出すことができる。
【0013】
図2は、インデックス保持部130のデータ構造図である。
本実施例における文書検索処理を実行するためには、コーパスについてのインデックス情報が必要である。インデックス情報の生成方法については図3に関連して後述するとして、まず、インデックス情報のデータ構造について説明する。インデックス情報は、グラム名欄132、文書ID欄134、文書内位置欄136、形態素内位置欄138という5つの項目を持つ。
【0014】
グラム名欄132はグラム名を示す。グラムとは所定数の連続する文字列である。同図は、3文字のカタカナ文字列のグラム「ワール」についてのインデックス情報を示している。文書ID欄134は、該当グラムを含む文書ファイルの文書IDを示す。文書IDとは、コーパスにおいて文書ファイルを一意に識別するためのIDである。同図によると、グラム「ワール」は、文書ID「012」、「016」、「022」、・・・という複数の文書ファイル内に含まれている。ただし、グラム「ワール」が各文書ファイルにおいてどのような文脈で使用されているかについては、インデックス情報からは直接的にはわからない。
【0015】
文書内位置欄136は、各文書ファイル内における該当グラムの位置を「ノード番号:オフセット」のかたちで示す。このような文書内におけるグラムの位置を「文書内位置」とよぶ。たとえば、「・・・<node>2006年のワールドシリーズでは、・・・」という文書ファイルにおいて、<node>タグは、文書ファイル中において先頭から4番目のタグであるとする。この文書ファイルでは、<node>タグの要素のうち、7文字目から「ワール」というグラムが現れている。したがって、文書内位置は「4:7」となる。
【0016】
形態素内位置欄138は、形態素内における該当グラムの位置を「開始」、「終了」、「継続」、「開始−終了」の4種類の「形態素内位置」により示す。さきほどのテキストを、「2006:年:の:ワールドシリーズ:では:、:・・・」のように形態素に分解したとする。グラム「ワール」は形態素「ワールドシリーズ」の開始部分に位置している。したがって、形態素内位置は「開始」となる。形態素「ルノワール」や「コートジボワール」に含まれるグラム「ワール」であれば、形態素内位置は「終了」になる。形態素「コワールスキー」や「サッカーワールド」であれば、グラム「ワール」の形態素内位置は「継続」である。また、形態素自体が「ワール」であれば、グラム「ワール」の形態素内位置は「開始−終了」となる。
【0017】
インデックス保持部130は、コーパスから検出される各グラムについてのインデックス情報を保持する。本発明者らの調査によると、23万文書(約250MB)から約54万種類のグラムが検出された。この場合、54万種類の各グラムについて、同図に示すようなインデックス情報が用意されることになる。
【0018】
ところで、グラムを構成する文字の数(以下、「N数」とよぶ)は、「ワール」のように3文字に限る必要はない。N数が大きいほど、検索用テキストと文書ファイルの関連性判定の適合率が高くなる。適合率が高いほど、非関連文書を関連文書と判定するミスが発生しにくくなることを示す。たとえば、「アームストロング砲」の関連文書を検索する場合、「ア」という1文字のグラムを含む文書ファイルを検索するとすれば、非関連文書を大量に検出してしまうことになる。しかし、「アームストロング」のような8文字のグラムを含む文書ファイルを検索した場合、こういったノイズ(非関連文書)を低減できる。反面、N数が大きくなると、グラムの種類が増えるためインデックス情報が大きくなってしまう。また、再現率が悪くなる。再現率が高いほど、関連文書の検出漏れが発生しにくくなることを示す。
【0019】
そこで、最適なN数を求めるために、本発明者はコーパスにおいて連続する文字数を字種別に調査した。文字の連続数として多い数は以下の通りであった。
漢字:1〜2文字。
ひらがな:1〜3文字。ただし、1文字となるのは「の、は、を」などの助詞の場合が多い。
カタカナ:2〜4文字。
英数字:3〜6文字。
以上の知見に基づき、本実施例においては、字種に応じてグラムのN数を以下のように設定する。
漢字:2、ひらがな:3、カタカナ:4、英数字:4、字種連結:2
たとえば、「アメリカ合衆国」という形態素の場合、抽出されるグラムは「アメリ:メリカ:カ合:合衆:衆国」の5つである。グラム「カ合」は、カタカナと漢字の接続部分である。このようなグラムが字種連結のグラムである。
【0020】
図3は、インデックス情報の生成過程を示すフローチャートである。
文書データベース200に新しく文書ファイルが登録されるとき、その文書ファイルに含まれるグラムがインデックス情報に登録される。文書検索装置100は、まず、新しい文書ファイルを取得すると(S10)、その文書ファイル中からテキスト部分を抽出する(S12)。次に、テキストを形態素に分解し(S14)、形態素を更にグラムに分解する(S16)。最後に、抽出されたグラムの文書内位置や形態素内位置をインデックス情報に登録する。
【0021】
コーパスから文書ファイルを削除するときには、インデックス情報から削除される文書ファイル中のグラムがインデックス情報から削除される。このように、コーパスの変化に応じて、インデックス情報も変化する。なお、S14において抽出された形態素を、後述する形態素分離処理により、更に、小さな形態素に分解してもよい。形態素分離処理については、図7に関連して詳述する。
【0022】
図4は、文書検索装置100の機能ブロック図である。
ここに示す各ブロックは、ハードウェア的には、コンピュータのCPUをはじめとする素子や機械装置で実現でき、ソフトウェア的にはコンピュータプログラム等によって実現されるが、ここでは、それらの連携によって実現される機能ブロックを描いている。したがって、これらの機能ブロックはハードウェア、ソフトウェアの組合せによっていろいろなかたちで実現できることは、当業者には理解されるところである。
【0023】
文書検索装置100は、ユーザインタフェース処理部110、データ処理部120およびインデックス保持部130を含む。
ユーザインタフェース処理部110は、ユーザからの入力処理やユーザに対する情報表示のようなユーザインタフェース全般に関する処理を担当する。本実施例においては、ユーザインタフェース処理部110により文書検索装置100のユーザインタフェースサービスが提供されるものとして説明する。別例として、ユーザはインターネットを介して文書検索装置100を操作してもよい。この場合、図示しない通信部が、ユーザ端末からの操作指示情報を受信し、またその操作指示に基づいて実行された処理結果情報をユーザ端末に送信することになる。
【0024】
データ処理部120は、ユーザインタフェース処理部110や文書データベース200から取得されたデータを元にして各種のデータ処理を実行する。データ処理部120は、ユーザインタフェース処理部110とインデックス保持部130の間のインタフェースの役割も果たす。
【0025】
ユーザインタフェース処理部110は、入力部112と表示部114を含む。入力部112は、ユーザからの入力操作を受け付ける。表示部114は、ユーザに対して各種情報を表示する。入力部112は、検索用テキストを取得するための検索用テキスト取得部116を含む。
【0026】
データ処理部120は、解析部122と統計部124、検索部126、関連スコア算出部128を含む。
解析部122は、検索用テキストや文書ファイルの文書構造を解析する。解析部122は、形態素抽出部144、グラム抽出部146、形態素分解部148を含む。形態素抽出部144は、テキストから1以上の形態素を抽出する。ここでいうテキストとは、文書ファイルから抽出されるテキストや検索用テキストである。形態素抽出部144は、あらかじめ用意された辞書データを参照して、その辞書データに登録されている単語を形態素として抽出してもよいし、品詞や字種によって形態素を抽出してもよい。形態素抽出部144による形態素の抽出方法は既知の技術の応用でよい。グラム抽出部146は、形態素抽出部144が抽出した形態素から1以上のグラムを抽出する。形態素分解部148は、形態素抽出部144が抽出した形態素をより小さい形態素に分解する。このような処理を「形態素分離処理」とよぶ。たとえば、形態素抽出部144が「サッカーワールドカップ」という形態素を抽出したとき、形態素分解部148はこの形態素から更に「サッカー」、「ワールド」、「カップ」という3つの形態素を抽出する。形態素分離処理の詳細については、図7に関連して後述する。以下、形態素抽出部144が抽出する形態素と形態素分解部148の形態素分離処理により抽出される形態素を区別するときには、前者を「原形態素」、後者を「部分形態素」とよぶ。
【0027】
統計部124は、形態素やグラムの稀少性、出現頻度などを統計解析する。統計部124は、推定数特定部150、出現頻度計数部152、出現率算出部140、語句確率算出部142を含む。
推定数特定部150は、形態素のコーパスにおける稀少性を推定数として指標化する。推定数が小さいほど稀少性が高い。推定数の考え方については、図6に関連して詳述する。出現頻度計数部152は、検索用テキストに含まれる形態素が、調査対象の文書ファイルに出現する回数を出現頻度として計数する。出現率算出部140は、コーパスを対象として、あるグラムがどのような形態素内位置に存在する可能性が高いかを定量化するために、前方出現率や後方出現率といった出現率を計算する。出現率の考え方については、図7に関連して詳述する。語句確率算出部142は、形態素分離処理を実行するための語句確率を算出する。語句確率とは、ある形態素がコーパスにおいて本来の意味で用いられている可能性の高さを指標化した数値である。語句確率の考え方についても図7の形態素分離処理の説明に関連して詳述する。
【0028】
検索部126は、検索用テキストの形態素を含む文書ファイルをコーパスから検索する。検索部126は、形態素におけるグラムの並び順と同じ並び順にてグラムを含む文書ファイルをインデックス情報を参照して検出する。たとえば、検索用テキストから「アメリカ合衆国」という形態素が抽出されたとする。抽出されるグラムは「アメリ:メリカ:カ合:合衆:衆国」の5つであるから、検出対象となるのは、これら5つのグラムを含む文書ファイルである。検索部126は、インデックス情報のグラム名欄132と文書ID欄134を参照して、5つのグラムの全てを含む文書ファイルを検出する。このような文書ファイルのことを「中間候補ファイル」とよぶことにする。次に、検索部126は、文書内位置欄136を参照して、これら5つのグラムが連続的に並んでいる中間候補ファイルを特定する。このような中間候補ファイルは、「アメリカ合衆国」という形態素を含む文書ファイルである。このような文書ファイルのことを「関連候補ファイル」ともよぶ。
【0029】
このように、検索部126は、あくまでもグラムをベースとしながら、検索用テキスト中の形態素についての関連候補ファイルを検出する。そのため、検索部126は文書ファイルの内容を精査することなく、インデックス情報だけで関連候補ファイルを特定できる。
【0030】
関連スコア算出部128は、各関連候補ファイルについて関連スコアを算出する。関連スコアとは、検索用テキストと文書ファイルの内容の関連性の大きさを示すスコアである。関連スコアの算出方法については、図8および図10に関連して2種類の計算方法について後に詳述する。
【0031】
図5は、関連文書ファイルを特定するための処理過程を示すフローチャートである。
検索用テキスト取得部116は、まず、検索用テキストを取得する(S20)。例として、「2006年のサッカーワールドカップに優勝するチームとして・・・」という検索用テキストが入力されたとする。形態素抽出部144は、この検索用テキストから原形態素を抽出する(S22)。「2006:年:の:サッカーワールドカップ:に:優勝:する:チーム:として・・・」のように複数の原形態素が抽出されたとする。以下の処理は、原形態素のそれぞれについて実行されるが、説明を簡単にするため、ここでは「サッカーワールドカップ」という原形態素を対象として説明する。
【0032】
グラム抽出部146は、原形態素から1以上のグラムを抽出する(S24)。原形態素「サッカーワールドカップ」の場合、「サッカ:ッカー:カーワ:ーワー:ワール:ールド:ルドカ:ドカッ:カップ」の計9つのグラムが抽出される。次に、形態素分解部148は、原形態素「サッカーワールドカップ」から、「サッカー」、「ワールド」、「カップ」という部分形態素を抽出する(S26)。より具体的には、形態素分解部148は、形態素に含まれるグラムの前方出現率と後方出現率に基づいて、原形態素「サッカーワールドカップ」から3つの部分形態素を抽出するが、詳細については図7に関連して後述する。検索用テキストから抽出された原形態素、および、部分形態素に基づいて文書検索処理が実行される。「サッカーワールドカップ」であれば、「サッカーワールドカップ」、「サッカー」、「ワールド」、「カップ」の4つの形態素について文書検索処理が実行される。以下、このような文書検索のベースとなる形態素のことを「検索ターム」とよぶ。
【0033】
検索部126は、検索タームに含まれるグラムの並び順に基づいて、関連候補ファイルを検出する(S28)。すなわち、「サッカー」、「ワールド」、「カップ」、「サッカーワールドカップ」といった各検索タームのいずれかを含む文書ファイルが関連候補ファイルとして検出される。
【0034】
関連スコア算出部128は、これらの関連候補ファイル群から1つの文書ファイルを選択し(S30)、関連スコア計算処理を実行し(S32)、関連候補ファイル群から次の文書ファイルを選択する(S34のY、S30)。全ての関連候補ファイルについて関連スコア計算処理を完了すると(S34のN)、関連スコアが上位20位以内となる関連候補ファイルを「関連文書ファイル」として、表示部114は関連文書ファイルの文書IDと関連スコアを画面に一覧表示させる(S36)。
本実施例においては、S32における関連スコア計算処理として、第1計算方法と第2計算方法という2つの計算方法を提案する。それぞれ、図8と図10に関連して詳述する。その前に、第1計算方法の前提となる推定数や出現率について説明する。
【0035】
図6は、原形態素「サッカーワールドカップ」に含まれる各グラムのコーパスにおける出現態様を示す図である。
本実施例におけるコーパスは、23万文書ファイルの集合体である。インデックス情報によると、グラム「サッカ」はこのうちの5167文書から検出される。「ッカー」は6312文書、「カーワ」は、たった13文書にしか含まれない。グラム「ッカー」に比べてグラム「カーワ」は、稀少性が高いグラムであることがわかる。
【0036】
グラム「サッカ」を含む5167文書のうち、その形態素内位置が「開始」となるのは4103文書(約79%)であり、「継続」となるのは1064文書(約20%)である。インデックス保持部130には、各グラムごとの同図に示すような統計情報も格納されている。ある文書ファイルに同種のグラムが複数個含まれている場合には、そのうち最も多くのグラムの間で共通する形態素内位置が、その文書ファイルにおける当該グラムの形態素内位置として集計される。たとえば、ある文書ファイルにグラム「サッカ」が3つ含まれ、そのうち2つの「サッカ」の形態素内位置が「継続」であれば、残りの「サッカ」の形態素内位置の如何に関わらずその文書ファイルは「サッカ(継続)」としてカウントされる。
【0037】
原形態素「サッカーワールドカップ」において、グラム「サッカ」の形態素内位置は「開始」、グラム「カップ」は「終了」、それ以外のグラムの形態素内位置は「継続」である。9種類のグラムのうち、グラムと形態素内位置が一致する文書ファイルの数が最も少ないのは「カーワ(継続)」であり、文書ファイル数は4である。コーパスにおいて「カーワ(継続)」を含む文書ファイルだけが、形態素「サッカーワールドカップ」を含む可能性があるから、この「4」は形態素「サッカーワールドカップ」の稀少性を示唆する数字である。推定数特定部150は、検索用テキストから抽出された形態素「サッカーワールドカップ」に含まれるグラム「カーワ」の形態素内位置「継続」に基づき、グラム「カーワ(継続)」を含む文書ファイルの数「4」を推定数として特定する。推定数が小さいほど、「カーワ(継続)」を含む文書ファイルと検索用テキストとの関連スコアが大きくなるが、詳しいアルゴリズムについては図8に関連して詳述する。
【0038】
本実施例における推定数特定部150は、検索用テキストの形態素に含まれるグラムのうち、コーパスにおいてその形態素内位置が整合する文書ファイルが最も少なくなるグラムについて、その文書ファイル数を推定数として算出している。変形例として、推定数特定部150は、各グラムについて推定数を算出してもよい。たとえば、「サッカ(開始)」の4013や「ッカー(継続)」の1821といった文書数の平均値を推定数として算出してもよい。
【0039】
なお、原形態素「サッカーワールドカップ」からは「サッカー」、「ワールド」、「カップ」という3つの部分形態素が抽出される。部分形態素「サッカー」の推定数はmin(4103,1821)より1821となる。ここで、minとは変数群の中の最小値を返す関数である。「サッカ(開始)」を含む文書の数は4103、「ッカー(終了)」を含む文書の数は1821だからである。同様の理由から、「ワールド」の推定数はmin(1835,1436)より1436、「カップ」の推定数は310となる。すなわち、コーパスにおいて、「サッカーワールドカップ」>「カップ」>「ワールド」>「サッカー」の順に稀少性が高い。
【0040】
図7は、原形態素「サッカーワールドカップ」に含まれる各グラムのコーパスにおける出現率を示す図である。
グラム「サッカ」の形態素内位置は79%(4103÷5167)の確率で「開始」となる。出現率算出部140は、コーパスにおいてあるグラムの形態素内位置が「開始」または「開始−終了」となる確率を「前方出現率」として算出する。一方、グラム「ッカー」は6312文書に含まれ、そのうち、4491文書において形態素内位置は「終了」となる。出現率算出部140は、コーパスにおいてあるグラムの形態素内位置が「終了」または「開始−終了」となる確率を「後方出現率」として算出する。グラム「ッカー」の後方出現率は71%である。
【0041】
形態素抽出部144が対象テキストから原形態素を抽出し、グラム抽出部146がその形態素からグラムを抽出すると、出現率算出部140は各グラムについて前方出現率と後方出現率を計算する。同図によると、「サッカーワールドカップ」において「ッカー」というグラムは形態素の終了に使われることが多く、形態素「サッカーワールドカップ」においてグラム「ッカー」の後方に隣接するグラム「ワール」は、形態素の先頭に使われることが多い。すなわち、「サッカーワールドカップ」という一連の形態素においては、「サッカー」と「ワールドカップ」の間に意味上の境界が存在する可能性が高いという推定が成り立つ。同様にして、「ワールドカップ」は「ワールド」と「カップ」の間に意味上の境界が存在する可能性が高い。
【0042】
形態素分解部148は、各グラムの前方出現率と後方出現率を参照し、形態素中におけるグラムAの後方出現率が所定値、たとえば、30%以上、形態素中においてグラムAの後方に隣接するグラムBの前方出現率が所定値、たとえば、25%以上となるとき、形態素においてグラムAとグラムBの間に意味上の境界が存在すると判定する。先ほどの例に戻ると、形態素分解部148は、原形態素「サッカーワールドカップ」から「サッカー」、「ワールド」、「カップ」という3つの部分形態素を抽出する。このようなアルゴリズムにより形態素分離処理が実行される。
【0043】
図8は、図5のS32における関連スコア計算処理について、第1計算方法の処理過程を示すフローチャートである。
ここでは、検索部126により検索用テキストに含まれる全ての検索タームを対象として関連候補ファイルが検出されている。先述した検索用テキスト「2006年のサッカーワールドカップに優勝するチームとして・・・」からは、「2006」や「サッカーワールドカップ」、「サッカー」、・・・など、多くの検索タームが抽出されることになる。
【0044】
推定数特定部150は、図5のS28で特定された1以上の検索タームから、調査対象の検索タームを選択し(S40)、推定数を特定する(S42)。出現頻度計数部152は、その検索タームについての関連候補ファイルにおいて検索タームが出現する回数を出現頻度として計数する(S44)。関連スコア算出部128は、検索タームと関連候補ファイルの内容の関連性の高さをタームスコアとして算出する。関連スコア算出部128は、出現頻度が大きく推定数が小さいほどタームスコアが高くなる任意の関数によりタームスコアを算出する(S46)。これは、コーパスにおいて稀少な検索タームであるほど、また、その検索タームが文書中に多く出現するほど、その文書ファイルは検索タームとの関連性が高いという判断に基づく。検索タームの稀少性と出現頻度に基づく文書内容評価方法は、自然言語による検索アルゴリズムとして実績のあるTF/IDF(Term Frequency/Inverce Document Frequency)法の考え方を踏襲したものである。本実施例では、
タームスコア=出現頻度×(log(1/推定数)+1)
という計算式により、タームスコアを算出する。
【0045】
関連スコア算出部128は、更に検索タームがあれば(S48のY)、その検索タームについてのタームスコアを計算する。全ての検索タームについてタームスコアが算出されると(S48のN)、関連スコア算出部128はこれらのタームスコアの合計値や平均値を関連スコアとして算出する(S50)。
【0046】
第1計算方法による関連スコア計算処理によると、検索用テキストに含まれる検索タームと同じ形態素を含む文書ファイルを対象とし、その検索タームのコーパスにおける稀少性を考慮してタームスコアを算出できる。なお、必ずしも全ての検索タームについてタームスコアを算出しなくてもよい。たとえば、1文字の形態素については、タームスコアの算出対象から除外すれば、関連スコア計算をより高速に実行できる。あるいは、複数のタームスコアの最高値や最低値を関連スコアとしてもよい。
次に第2計算方法による関連スコア計算処理を説明するが、その前に、その前提となる第1出現数、第2出現数、語句確率、重み係数および中間値の考え方について説明する。
【0047】
図9は、原形態素「サッカーワールドカップ」に含まれる各部分形態素の語句確率と中間値の関係を示す図である。
同図に示す第1出現数の考え方は、推定数の考え方と似ている。たとえば、部分形態素「ワールド」や原形態素「サッカーワールドカップ」において、グラム「ワール」の形態素内位置は「開始」または「継続」、グラム「ールド」の形態素内位置は「終了」または「継続」である。このとき、部分形態素「ワールド」の第1出現数を
第1出現数=min(「ワール(開始)」または「ワール(継続)」を含む文書数、「ールド(継続)」または「ールド(終了)」を含む文書数)
により算出する。図6に示したデータによると、「ワールド」についての第1出現数はmin(1835+529,1436+2561)より、2364となる。
【0048】
この第1出現数は、「文書ファイル中においてある形態素Aが、本来の意味において用いられていると推定される文書ファイルの数」を示す。たとえば、「プラス」という部分形態素は、ある文書ファイルにおいては「ラプラス」という形態素の一部として検出されるかもしれないし、「プラスチック」という形態素の一部として検出されるかもしれない。第1出現数は、その部分形態素を含む文書ファイル群から、その部分形態素を示す文字列が別の意味を示す形態素の一部となっている文書ファイルを除いたときの文書ファイル数を特定するための数値である。部分形態素「サッカー」の第1出現数は、min(4103,4491+1821)より4103、部分形態素「カップ」の第1出現数は、2098+310より2408となる。このように、第1出現数は、グラムの原形態素や部分形態素に対する形態素内位置と、文書ファイルにおけるそのグラムの形態素内位置が整合する文書ファイルの数に基づいて特定される。
【0049】
第2出現数は、意味としての整合性を考慮することなく特定される。たとえば、形態素「ワールド」の第2出現数は、min(「ワール」を含む文書数(2454)、「ールド」を含む文書数(3997))より2454となる。第2出現数は、部分形態素中のグラムを含む文書ファイルの数に基づいて特定される。
【0050】
図5のS32における関連スコア計算処理を、第2計算方法により実行する場合、語句確率算出部142は第1出現数÷第2出現数により語句確率を算出する。同図の場合、「ワールド」の語句確率は2364÷2454=0.96である。語句確率は、「その形態素を文字列として含む文書ファイル群のうち、その形態素が本来の意味において使われている確率」を示唆する数値である。本実施例の場合、「サッカー」、「ワールド」、「カップ」のそれぞれの語句確率は、0.79、0.96、0.79となる。部分形態素「ワールド」はコーパスにおいても96%という高い確率にて本来の意味にて使用されていることがわかる。いいかえれば、部分形態素「ワールド」は、先に示した部分形態素「プラス」のように、他の形態素の一部として一体化しにくい独立性の高い用語であることがわかる。「プラス」という文字列を含む文書ファイルでは、「プラス」が「ラプラス」や「プラスチック」のような違う意味で使われている可能性があるが、「ワールド」という文字列を含む文書ファイルでは、「ワールド」という本来の意味で使われている可能性が高い。第2計算方法においては、「ワールド」のような独立性の高い検索タームについてのタームスコアを高く評価する。
【0051】
部分形態素「サッカー」、「ワールド」、「カップ」のうち、「サッカーワールドカップ」という用語にとって最も重要な部分形態素は「サッカー」であると考えられる。これは、長い文字列であらわされる用語において、その用語の先頭部分にその用語の意味が現れることが多いという経験則に基づく。たとえば、「徳島県」という原形態素の場合、先頭の「徳島」という部分形態素は「県」という部分形態素よりも原形態素の特徴をより強く示している。そこで、第2計算方法においては、部分形態素「サッカー」のように原形態素の開始部分に位置する部分形態素はそれ以外に位置する部分形態素よりもタームスコアに重みをつける。本発明者らの調査によると、原形態素の開始部分の部分形態素、継続部分の部分形態素、終了部分の部分形態素に8:3:5の比率で重み付けをしたときに、再現率(検索漏れの少なさ)および適合率(ミスヒットの少なさ)が共に最適値となった。そこで、本実施例における第2計算方法では、重み係数を開始:0.8、継続:0.3、終了:0.5と設定し、関連スコア算出部128は、
中間値=語句確率×重み係数
として検索タームごとに中間値を算出する。中間値は1以下の数値であり、検索タームの用語としての独立性の高さと検索用テキストにおける重要度を示す数値である。「サッカーワールドカップ」のような原形態素の中間値は「1」に固定する。第2計算方法においては、この中間値に基づいて関連スコアが算出される。
【0052】
図10は、図5のS32における関連スコア計算処理について、第2計算方法の処理過程を示すフローチャートである。
語句確率算出部142は、検索タームを選択し(S60)、語句確率を算出する(S62)。関連スコア算出部128は、上記式により検索タームの中間値を算出する(S64)。関連スコア算出部128は、関連候補ファイルにおける検索タームの出現頻度を計数し、出現頻度と中間値が高いほどタームスコアが高くなる任意の関数によりタームスコアを算出する(S66)。形態素が本来の意味で用いられる可能性が高く、また、部分形態素であれば原形態素において重要な位置であるほど、また、その検索タームが文書中に多く出現するほど、その文書ファイルは検索用テキストとの関連性が高い内容であるという判断に基づく。本実施例では、
タームスコア=中間値×出現頻度
という計算式により、タームスコアを算出する。
【0053】
更に発展した例では、関連候補ファイルの形態素中における検索タームの位置により、タームスコアを調整してもよい。たとえば、検索タームが「京都」である場合、「京都」、「京都府」、「東京都」、「東京都営」という形態素を含む文書ファイルは、いずれも関連候補ファイルとして検出されることになる。しかし、完全一致の「京都」、前方一致の「京都府」であればまだしも、後方一致の「東京都」、部分一致の「東京都営」は、検索ターム「京都」とは文字列として一致しても内容としての関連性は低い。そこで、文書ファイルにおける形態素と検索タームとの一致の仕方に応じて調整係数を設定する。具体的には、完全一致:1.0、前方一致:0.6、部分一致:0.2、後方一致:0.4として設定する。この場合、
タームスコア=中間値×Σ(調整係数)
という計算式により、タームスコアを算出する。Σ(調整係数)は、関連候補ファイルに含まれる検索タームの数だけ、調整係数を合計することを意味する。
【0054】
たとえば、ある文書ファイルにおいて、「京都」という文字列が3つ検出され、それぞれの一致の仕方が完全一致、前方一致、部分一致であったとする。中間値が0.6とすると、
タームスコア=0.6×(1.0+0.6+0.2)=1.08
となる。このような計算方法によれば、関連候補ファイルにおける検索タームの一致の仕方とその出現頻度を加味したタームスコアを算出できる。
【0055】
関連スコア算出部128は、更に検索タームがあれば(S68のY)、その検索タームについてタームスコアを計算する。検索用テキストから検出された全ての検索タームについてタームスコアが算出されると(S68のN)、関連スコア算出部128はこれらのタームスコアの合計値を関連スコアとして算出する。
【0056】
第2計算方法による関連スコア計算処理によると、検索タームの重要性と文書ファイルにおける出現態様を考慮したタームスコアを算出できる。なお、必ずしも全ての検索タームについてタームスコアを算出しなくてもよいことは第1計算方法と同様である。
【0057】
第2計算方法における語句確率や重み係数、調整係数という考え方は、第1計算方法にも応用可能である。たとえば、第1の計算方法において、
A:タームスコア=Σ(調整係数)×(log(1/推定数)+1)
B:タームスコア=Σ(中間値)×(log(1/推定数)+1)
C:タームスコア=Σ(中間値×調整係数)×(log(1/推定数)+1)
としてタームスコアを算出してもよい。
【0058】
以上、本実施例に示す文書検索装置100によると、第1計算方法、第2計算方法のいずれについても、形態素解析のみに基づく文書検索処理に比べて再現率および適合率共に改善された。形態素解析の場合、どのような意味単位で形態素を抽出するかにより文書検索の精度が変化する。本実施例の文書検索装置100の場合、前方出現率や後方出現率によって、原形態素から合理的に部分形態素を抽出できる。原形態素のみならず部分形態素も検索タームとして関連スコアを算出するため、形態素解析における「どのような意味単位で形態素を抽出すべきか」という曖昧性・恣意性を、合理的に解決できる。
【0059】
たとえば、「一般教養課程」を「般教」と略して使用することが多いコーパスを想定する。従来の形態素解析の場合、形態素「一般教養課程」から俗語的な形態素「般教」を抽出することは困難である。しかし、本実施例の文書検索装置100によれば、前方出現率と後方出現率によって、「般教」という用語を意味を持つ形態素として抽出できる。したがって、「一般教養課程」という原形態素を含む検索用テキストが入力されたとき、形態素分解部148はこの原形態素から部分形態素「般教」を抽出しやすくなる。そのため、「一般教養課程」と「般教」という文字列としては別物であっても意味としては近い関係にある形態素を関連スコア計算の上で考慮できる。形態素分解処理が文書検索精度を向上させる一因となっている。
【0060】
第1計算方法においては、推定数によって、検索タームのコーパスにおける稀少性を指標化している。「サッカーワールドカップ」という文字列を含む文書の数を厳密に計数するとすれば、インデックス情報を参照して「サッカーワールドカップ」という11文字が並ぶ文書ファイルを検出するための処理が必要である。これに対し、インデックス情報から、あらかじめ図6に示すデータを集計しておけば、推定数特定部150は、任意の形態素の稀少性を推定数により簡単に指標化できる。推定数は、形態素の稀少性を厳密に示す数値ではないが、その稀少性を近似的に示す数値として有効に利用できる。
【0061】
第2計算方法においては、語句確率によって、検索タームの用語としての独立性を指標化している。語句確率により、検索用テキストの形態素と文書ファイルの形態素が文字列として一致しても、異なる意味で使われる可能性を考慮に入れることができる。更に、原形態素における部分形態素の位置や、文書ファイルにおける検索タームの出現態様を重み係数や調整係数により考慮に入れることができるため、文書検索の精度をいっそう高めることができる。
【0062】
以上、本発明を実施の形態をもとに説明した。この実施の形態は例示であり、それらの各構成要素や各処理プロセスの組合せにいろいろな変形例が可能なこと、またそうした変形例も本発明の範囲にあることは当業者に理解されるところである。
【0063】
請求項に記載の「検索用形態素」は、本実施例における原形態素または部分形態素の双方または一方により表現されている。請求項に記載の「特定グラム」は、本実施例におけるグラム「カーワ」により表現されている。
これら請求項に記載の各構成要件が果たすべき機能は、本実施例において示された各機能ブロックの単体もしくはそれらの連係によって実現されることも当業者には理解されるところである。
【図面の簡単な説明】
【0064】
【図1】文書検索装置による処理の概要を説明するための模式図である。
【図2】インデックス保持部のデータ構造図である。
【図3】インデックス情報の生成過程を示すフローチャートである。
【図4】文書検索装置の機能ブロック図である。
【図5】関連文書ファイルを特定するための処理過程を示すフローチャートである。
【図6】原形態素「サッカーワールドカップ」に含まれる各グラムのコーパスにおける出現態様を示す図である。
【図7】原形態素「サッカーワールドカップ」に含まれる各グラムのコーパスにおける出現率を示す図である。
【図8】図5のS32における関連スコア計算処理について、第1計算方法の処理過程を示すフローチャートである。
【図9】原形態素「サッカーワールドカップ」に含まれる各部分形態素の語句確率と中間値の関係を示す図である。
【図10】図5のS32における関連スコア計算処理について、第2の計算方法の処理過程を示すフローチャートである。
【符号の説明】
【0065】
100 文書検索装置、 110 ユーザインタフェース処理部、 112 入力部、 114 表示部、 116 検索用テキスト取得部、 120 データ処理部、 122 解析部、 124 統計部、 126 検索部、 128 関連スコア算出部、 130 インデックス保持部、 132 グラム名欄、 134 文書ID欄、 136 文書内位置欄、 138 形態素内位置欄、 140 出現率算出部、 142 語句確率算出部、 144 形態素抽出部、 146 グラム抽出部、 148 形態素分解部、 150 推定数特定部、 152 出現頻度計数部、 200 文書データベース。
【特許請求の範囲】
【請求項1】
所定の文書ファイル群から、検索用テキストと関連性が高い内容の文書ファイルを検索するための装置であって、
所定文字数の文字列であるグラム(gram)と、前記グラムを含む文書ファイルの文書IDと、前記文書ファイルの形態素中における前記グラムの位置が、前記所定の文書ファイル群に含まれるグラムごとに対応づけられたインデックス情報を保持するインデックス保持部と、
検索用テキストの入力を受け付ける検索テキスト取得部と、
検索用テキストから1以上の検索用形態素を抽出する形態素抽出部と、
検索用形態素から1以上のグラムを抽出するグラム抽出部と、
インデックス情報を参照して、ある検索用形態素中における特定グラムの位置と文書ファイルの形態素中における前記特定グラムの位置が整合する文書ファイルの数を、その検索用形態素を含む文書ファイルの推定数として特定する推定数特定部と、
インデックス情報を参照して、前記検索用形態素に含まれる1以上のグラムの並び順と文書ファイルの形態素中における1以上のグラムの並び順が整合する文書ファイルを検出する文書検索部と、
前記並び順と整合する前記1以上のグラムが前記検出された文書ファイルに出現する回数を出現頻度として計数する出現頻度計数部と、
前記検索用形態素についての出現頻度と推定数から、前記検索用テキストと前記検出された文書ファイルの内容の関連性を関連スコアとして指標化する関連スコア算出部と、
を備えることを特徴とする文書検索装置。
【請求項2】
形態素中におけるグラムの位置とは、グラムが形態素の先頭部、末尾部、それ以外の一部である継続部のいずれに位置するかを示す情報であることを特徴とする請求項1に記載の文書検索装置。
【請求項3】
前記関連スコア算出部は、出現頻度が大きく推定数が小さいほど前記検出された文書ファイルと前記検索用テキストとの関連性が高くなるように関連スコアを算出することを特徴とする請求項1または2に記載の文書検索装置。
【請求項4】
検査対象グラムを形態素の先頭部に含む文書ファイルの数とその検査対象グラムを含む文書ファイルの総数との比率を前方出現率、検査対象グラムを形態素の末尾部に含む文書ファイルの数とその検査対象グラムを含む文書ファイルの総数との比率を後方出現率としてそれぞれ算出する出現率算出部と、
検索用形態素に含まれる複数のグラムの前方出現率と後方出現率から、前記検索用形態素を更に複数の検索用形態素に分離する形態素分解部と、
を更に備えることを特徴とする請求項1から3のいずれかに記載の文書検索装置。
【請求項5】
前記形態素分解部は、検索用形態素に含まれる第1のグラムの後方出現率が所定値以上であって、かつ、前記検索用形態素において前記第1のグラムの後方に隣接する第2のグラムの前方出現率が所定値以上のとき、前記第1のグラムと前記第2のグラムの境界により前記検索用形態素を分離することを特徴とする請求項4に記載の文書検索装置。
【請求項6】
前記関連スコア算出部は、検索用テキストに含まれる複数の検索用形態素のそれぞれについて特定された出現頻度と推定数から関連スコアを算出することを特徴とする請求項1から5のいずれかに記載の文書検索装置。
【請求項7】
前記推定数特定部は、前記検索用形態素に含まれるグラムのうち、前記整合する文書ファイルの数が最も少なくなるときのグラムを前記特定グラムとし、そのときの文書ファイル数を前記検索用形態素についての推定数として特定することを特徴とする請求項1から6のいずれかに記載の文書検索装置。
【請求項8】
前記インデックス保持部は、字種に応じて文字数が異なるグラムについてのインデックス情報を保持することを特徴とする請求項1から7のいずれかに記載の文書検索装置。
【請求項9】
所定の文書ファイル群から、検索用テキストと関連性が高い内容の文書ファイルを検索するための方法であって、
所定文字数の文字列であるグラム(gram)と、前記グラムを含む文書ファイルの文書IDと、前記文書ファイルの形態素中における前記グラムの位置が、前記所定の文書ファイル群に含まれるグラムごとに対応づけられたインデックス情報を取得するステップと、
検索用テキストの入力を受け付けるステップと、
検索用テキストから1以上の検索用形態素を抽出するステップと、
検索用形態素から1以上のグラムを抽出するステップと、
インデックス情報を参照して、ある検索用形態素中における特定グラムの位置と文書ファイルの形態素中における前記特定グラムの位置が整合する文書ファイルの数を、その検索用形態素を含む文書ファイルの推定数として特定するステップと、
インデックス情報を参照して、前記検索用形態素に含まれる1以上のグラムの並び順と文書ファイルの形態素中における1以上のグラムの並び順が整合する文書ファイルを検出するステップと、
前記並び順と整合する前記1以上のグラムが前記検出された文書ファイルに出現する回数を出現頻度として計数するステップと、
前記検索用形態素についての出現頻度と推定数から、前記検索用テキストと前記検出された文書ファイルの内容の関連性を関連スコアとして指標化するステップと、
を備えることを特徴とする文書検索方法。
【請求項10】
所定の文書ファイル群から、検索用テキストと関連性が高い内容の文書ファイルを検索するためのコンピュータプログラムであって、
所定文字数の文字列であるグラム(gram)と、前記グラムを含む文書ファイルの文書IDと、前記文書ファイルの形態素中における前記グラムの位置が、前記所定の文書ファイル群に含まれるグラムごとに対応づけられたインデックス情報を保持する機能と、
検索用テキストの入力を受け付ける機能と、
検索用テキストから1以上の検索用形態素を抽出する機能と、
検索用形態素から1以上のグラムを抽出する機能と、
インデックス情報を参照して、ある検索用形態素中における特定グラムの位置と文書ファイルの形態素中における前記特定グラムの位置が整合する文書ファイルの数を、その検索用形態素を含む文書ファイルの推定数として特定する機能と、
インデックス情報を参照して、前記検索用形態素に含まれる1以上のグラムの並び順と文書ファイルの形態素中における1以上のグラムの並び順が整合する文書ファイルを検出する機能と、
前記並び順と整合する前記1以上のグラムが前記検出された文書ファイルに出現する回数を出現頻度として計数する機能と、
前記検索用形態素についての出現頻度と推定数から、前記検索用テキストと前記検出された文書ファイルの内容の関連性を関連スコアとして指標化する機能と、
をコンピュータに発揮させることを特徴とする文書検索プログラム。
【請求項11】
所定の文書ファイル群から、検索用テキストと関連性が高い内容の文書ファイルを検索するための装置であって、
所定文字数の文字列であるグラム(gram)と、前記グラムを含む文書ファイルの文書IDと、前記文書ファイルの形態素中における前記グラムの位置が、前記所定の文書ファイル群に含まれるグラムごとに対応づけられたインデックス情報を保持するインデックス保持部と、
検索用テキストの入力を受け付ける検索テキスト取得部と、
検索用テキストから1以上の検索用形態素を抽出する形態素抽出部と、
検索用形態素から1以上のグラムを抽出するグラム抽出部と、
インデックス情報を参照して、検査対象グラムを形態素の先頭部に含む文書ファイル数とその検査対象グラムを含む文書ファイルの総数との比率を前方出現率、検査対象グラムを形態素の末尾部に含む文書ファイル数とその検査対象グラムを含む文書ファイルの総数との比率を後方出現率としてそれぞれ算出する出現率算出部と、
ある検索用形態素に含まれる複数のグラムについての前方出現率と後方出現率から、その検索用形態素を複数の部分形態素に分離する形態素分解部と、
インデックス情報を参照して、ある部分形態素に含まれる1以上のグラムの並び順と文書ファイル中の形態素における1以上のグラムの並び順が整合する文書ファイルを検出する文書検索部と、
前記並び順と整合する前記1以上のグラムが前記検出された文書ファイルに出現する回数を出現頻度として計数する出現頻度計数部と、
前記部分形態素について計数された出現頻度と前記検索用形態素中における前記部分形態素の位置に応じた重み付け係数により、前記検索用テキストと前記検出された文書ファイルの内容の関連性を関連スコアとして指標化する関連スコア算出部と、
を備えることを特徴とする文書検索装置。
【請求項12】
検索用形態素中における部分形態素の位置とは、部分形態素が検索用形態素の先頭部、末尾部、それ以外の一部である継続部のいずれに位置するかを示す情報であるであることを特徴とする請求項11に記載の文書検索装置。
【請求項13】
前記形態素分解部は、検索用形態素に含まれる第1のグラムの後方出現率が所定値以上であって、かつ、前記検索用形態素において前記第1のグラムの後方に隣接する第2のグラムの前方出現率が所定値以上のとき、前記第1のグラムと前記第2のグラムの境界により前記検索用形態素を分離することを特徴とする請求項11または12に記載の文書検索装置。
【請求項14】
前記関連スコア算出部は、検索用テキストに含まれる複数の部分形態素のそれぞれについて特定された出現頻度と重み付け係数から関連スコアを算出することを特徴とする請求項11から13のいずれかに記載の文書検索装置。
【請求項15】
前記関連スコア算出部は、検索用形態素の先頭部の部分形態素は前記検索用形態素の他の位置の部分形態素よりも関連スコアに対する影響が大きくなるように重み付け係数を設定することを特徴とする請求項11から14のいずれかに記載の文書検索装置。
【請求項16】
第1出現数=検索用テキストの部分形態素中におけるグラムの位置と文書ファイルの形態素中における前記グラムの位置が整合する文書ファイルの数
第2出現数=前記部分形態素に含まれるグラムを含む文書ファイルの数
としたとき、
前記第1出現数と前記第2出現数から、前記部分形態素が前記所定の文書ファイル群において本来の意味にて用いられている割合を語句確率として算出する語句確率算出部、を更に備え、
前記関連スコア算出部は、前記部分形態素の語句確率、前記重み付け係数、前記部分形態素の出現頻度により、関連スコアを計算することを特徴とする請求項11から15のいずれかに記載の文書検索装置。
【請求項17】
前記形態素抽出部は、前記検出された文書ファイルからも形態素を抽出し、
前記関連スコア算出部は、前記検出された文書ファイル中の形態素とその形態素に含まれる部分形態素の位置関係により関連スコアを調整することを特徴とする請求項11から16のいずれかに記載の文書検索装置。
【請求項18】
前記関連スコア算出部は、前記検出された文書ファイル中において、形態素の先頭部から前記部分形態素が検出されたときには前記形態素の他の位置から検出されるときよりも関連性が高くなるように関連スコアを調整することを特徴とする請求項17に記載の文書検索装置。
【請求項19】
所定の文書ファイル群から、検索用テキストと関連性が高い内容の文書ファイルを検索するための方法であって、
所定文字数の文字列であるグラム(gram)と、前記グラムを含む文書ファイルの文書IDと、前記文書ファイルの形態素中における前記グラムの位置が、前記所定の文書ファイル群に含まれるグラムごとに対応づけられたインデックス情報を取得するステップと、
検索用テキストの入力を受け付けるステップと、
検索用テキストから1以上の検索用形態素を抽出するステップと、
検索用形態素から1以上のグラムを抽出するステップと、
インデックス情報を参照して、検査対象グラムを形態素の先頭部に含む文書ファイル数とその検査対象グラムを含む文書ファイルの総数との比率を前方出現率、検査対象グラムを形態素の末尾部に含む文書ファイル数とその検査対象グラムを含む文書ファイルの総数との比率を後方出現率としてそれぞれ算出するステップと、
ある検索用形態素に含まれる複数のグラムについての前方出現率と後方出現率から、その検索用形態素を複数の部分形態素に分離するステップと、
インデックス情報を参照して、ある部分形態素に含まれる1以上のグラムの並び順と文書ファイル中の形態素における1以上のグラムの並び順が整合する文書ファイルを検出するステップと、
前記並び順と整合する前記1以上のグラムが前記検出された文書ファイルに出現する回数を出現頻度として計数するステップと、
前記部分形態素について計数された出現頻度と前記検索用形態素中における前記部分形態素の位置に応じた重み付け係数により、前記検索用テキストと前記検出された文書ファイルの内容の関連性を関連スコアとして指標化するステップと、
を備えることを特徴とする文書検索方法。
【請求項20】
所定の文書ファイル群から、検索用テキストと関連性が高い内容の文書ファイルを検索するためのコンピュータプログラムであって、
所定文字数の文字列であるグラム(gram)と、前記グラムを含む文書ファイルの文書IDと、前記文書ファイルの形態素中における前記グラムの位置が、前記所定の文書ファイル群に含まれるグラムごとに対応づけられたインデックス情報を保持する機能と、
検索用テキストの入力を受け付ける機能と、
検索用テキストから1以上の検索用形態素を抽出する機能と、
検索用形態素から1以上のグラムを抽出する機能と、
インデックス情報を参照して、検査対象グラムを形態素の先頭部に含む文書ファイル数とその検査対象グラムを含む文書ファイルの総数との比率を前方出現率、検査対象グラムを形態素の末尾部に含む文書ファイル数とその検査対象グラムを含む文書ファイルの総数との比率を後方出現率としてそれぞれ算出する機能と、
ある検索用形態素に含まれる複数のグラムについての前方出現率と後方出現率から、その検索用形態素を複数の部分形態素に分離する機能と、
インデックス情報を参照して、ある部分形態素に含まれる1以上のグラムの並び順と文書ファイル中の形態素における1以上のグラムの並び順が整合する文書ファイルを検出する機能と、
前記並び順と整合する前記1以上のグラムが前記検出された文書ファイルに出現する回数を出現頻度として計数する機能と、
前記部分形態素について計数された出現頻度と前記検索用形態素中における前記部分形態素の位置に応じた重み付け係数により、前記検索用テキストと前記検出された文書ファイルの内容の関連性を関連スコアとして指標化する機能と、
をコンピュータに発揮させることを特徴とする文書検索プログラム。
【請求項1】
所定の文書ファイル群から、検索用テキストと関連性が高い内容の文書ファイルを検索するための装置であって、
所定文字数の文字列であるグラム(gram)と、前記グラムを含む文書ファイルの文書IDと、前記文書ファイルの形態素中における前記グラムの位置が、前記所定の文書ファイル群に含まれるグラムごとに対応づけられたインデックス情報を保持するインデックス保持部と、
検索用テキストの入力を受け付ける検索テキスト取得部と、
検索用テキストから1以上の検索用形態素を抽出する形態素抽出部と、
検索用形態素から1以上のグラムを抽出するグラム抽出部と、
インデックス情報を参照して、ある検索用形態素中における特定グラムの位置と文書ファイルの形態素中における前記特定グラムの位置が整合する文書ファイルの数を、その検索用形態素を含む文書ファイルの推定数として特定する推定数特定部と、
インデックス情報を参照して、前記検索用形態素に含まれる1以上のグラムの並び順と文書ファイルの形態素中における1以上のグラムの並び順が整合する文書ファイルを検出する文書検索部と、
前記並び順と整合する前記1以上のグラムが前記検出された文書ファイルに出現する回数を出現頻度として計数する出現頻度計数部と、
前記検索用形態素についての出現頻度と推定数から、前記検索用テキストと前記検出された文書ファイルの内容の関連性を関連スコアとして指標化する関連スコア算出部と、
を備えることを特徴とする文書検索装置。
【請求項2】
形態素中におけるグラムの位置とは、グラムが形態素の先頭部、末尾部、それ以外の一部である継続部のいずれに位置するかを示す情報であることを特徴とする請求項1に記載の文書検索装置。
【請求項3】
前記関連スコア算出部は、出現頻度が大きく推定数が小さいほど前記検出された文書ファイルと前記検索用テキストとの関連性が高くなるように関連スコアを算出することを特徴とする請求項1または2に記載の文書検索装置。
【請求項4】
検査対象グラムを形態素の先頭部に含む文書ファイルの数とその検査対象グラムを含む文書ファイルの総数との比率を前方出現率、検査対象グラムを形態素の末尾部に含む文書ファイルの数とその検査対象グラムを含む文書ファイルの総数との比率を後方出現率としてそれぞれ算出する出現率算出部と、
検索用形態素に含まれる複数のグラムの前方出現率と後方出現率から、前記検索用形態素を更に複数の検索用形態素に分離する形態素分解部と、
を更に備えることを特徴とする請求項1から3のいずれかに記載の文書検索装置。
【請求項5】
前記形態素分解部は、検索用形態素に含まれる第1のグラムの後方出現率が所定値以上であって、かつ、前記検索用形態素において前記第1のグラムの後方に隣接する第2のグラムの前方出現率が所定値以上のとき、前記第1のグラムと前記第2のグラムの境界により前記検索用形態素を分離することを特徴とする請求項4に記載の文書検索装置。
【請求項6】
前記関連スコア算出部は、検索用テキストに含まれる複数の検索用形態素のそれぞれについて特定された出現頻度と推定数から関連スコアを算出することを特徴とする請求項1から5のいずれかに記載の文書検索装置。
【請求項7】
前記推定数特定部は、前記検索用形態素に含まれるグラムのうち、前記整合する文書ファイルの数が最も少なくなるときのグラムを前記特定グラムとし、そのときの文書ファイル数を前記検索用形態素についての推定数として特定することを特徴とする請求項1から6のいずれかに記載の文書検索装置。
【請求項8】
前記インデックス保持部は、字種に応じて文字数が異なるグラムについてのインデックス情報を保持することを特徴とする請求項1から7のいずれかに記載の文書検索装置。
【請求項9】
所定の文書ファイル群から、検索用テキストと関連性が高い内容の文書ファイルを検索するための方法であって、
所定文字数の文字列であるグラム(gram)と、前記グラムを含む文書ファイルの文書IDと、前記文書ファイルの形態素中における前記グラムの位置が、前記所定の文書ファイル群に含まれるグラムごとに対応づけられたインデックス情報を取得するステップと、
検索用テキストの入力を受け付けるステップと、
検索用テキストから1以上の検索用形態素を抽出するステップと、
検索用形態素から1以上のグラムを抽出するステップと、
インデックス情報を参照して、ある検索用形態素中における特定グラムの位置と文書ファイルの形態素中における前記特定グラムの位置が整合する文書ファイルの数を、その検索用形態素を含む文書ファイルの推定数として特定するステップと、
インデックス情報を参照して、前記検索用形態素に含まれる1以上のグラムの並び順と文書ファイルの形態素中における1以上のグラムの並び順が整合する文書ファイルを検出するステップと、
前記並び順と整合する前記1以上のグラムが前記検出された文書ファイルに出現する回数を出現頻度として計数するステップと、
前記検索用形態素についての出現頻度と推定数から、前記検索用テキストと前記検出された文書ファイルの内容の関連性を関連スコアとして指標化するステップと、
を備えることを特徴とする文書検索方法。
【請求項10】
所定の文書ファイル群から、検索用テキストと関連性が高い内容の文書ファイルを検索するためのコンピュータプログラムであって、
所定文字数の文字列であるグラム(gram)と、前記グラムを含む文書ファイルの文書IDと、前記文書ファイルの形態素中における前記グラムの位置が、前記所定の文書ファイル群に含まれるグラムごとに対応づけられたインデックス情報を保持する機能と、
検索用テキストの入力を受け付ける機能と、
検索用テキストから1以上の検索用形態素を抽出する機能と、
検索用形態素から1以上のグラムを抽出する機能と、
インデックス情報を参照して、ある検索用形態素中における特定グラムの位置と文書ファイルの形態素中における前記特定グラムの位置が整合する文書ファイルの数を、その検索用形態素を含む文書ファイルの推定数として特定する機能と、
インデックス情報を参照して、前記検索用形態素に含まれる1以上のグラムの並び順と文書ファイルの形態素中における1以上のグラムの並び順が整合する文書ファイルを検出する機能と、
前記並び順と整合する前記1以上のグラムが前記検出された文書ファイルに出現する回数を出現頻度として計数する機能と、
前記検索用形態素についての出現頻度と推定数から、前記検索用テキストと前記検出された文書ファイルの内容の関連性を関連スコアとして指標化する機能と、
をコンピュータに発揮させることを特徴とする文書検索プログラム。
【請求項11】
所定の文書ファイル群から、検索用テキストと関連性が高い内容の文書ファイルを検索するための装置であって、
所定文字数の文字列であるグラム(gram)と、前記グラムを含む文書ファイルの文書IDと、前記文書ファイルの形態素中における前記グラムの位置が、前記所定の文書ファイル群に含まれるグラムごとに対応づけられたインデックス情報を保持するインデックス保持部と、
検索用テキストの入力を受け付ける検索テキスト取得部と、
検索用テキストから1以上の検索用形態素を抽出する形態素抽出部と、
検索用形態素から1以上のグラムを抽出するグラム抽出部と、
インデックス情報を参照して、検査対象グラムを形態素の先頭部に含む文書ファイル数とその検査対象グラムを含む文書ファイルの総数との比率を前方出現率、検査対象グラムを形態素の末尾部に含む文書ファイル数とその検査対象グラムを含む文書ファイルの総数との比率を後方出現率としてそれぞれ算出する出現率算出部と、
ある検索用形態素に含まれる複数のグラムについての前方出現率と後方出現率から、その検索用形態素を複数の部分形態素に分離する形態素分解部と、
インデックス情報を参照して、ある部分形態素に含まれる1以上のグラムの並び順と文書ファイル中の形態素における1以上のグラムの並び順が整合する文書ファイルを検出する文書検索部と、
前記並び順と整合する前記1以上のグラムが前記検出された文書ファイルに出現する回数を出現頻度として計数する出現頻度計数部と、
前記部分形態素について計数された出現頻度と前記検索用形態素中における前記部分形態素の位置に応じた重み付け係数により、前記検索用テキストと前記検出された文書ファイルの内容の関連性を関連スコアとして指標化する関連スコア算出部と、
を備えることを特徴とする文書検索装置。
【請求項12】
検索用形態素中における部分形態素の位置とは、部分形態素が検索用形態素の先頭部、末尾部、それ以外の一部である継続部のいずれに位置するかを示す情報であるであることを特徴とする請求項11に記載の文書検索装置。
【請求項13】
前記形態素分解部は、検索用形態素に含まれる第1のグラムの後方出現率が所定値以上であって、かつ、前記検索用形態素において前記第1のグラムの後方に隣接する第2のグラムの前方出現率が所定値以上のとき、前記第1のグラムと前記第2のグラムの境界により前記検索用形態素を分離することを特徴とする請求項11または12に記載の文書検索装置。
【請求項14】
前記関連スコア算出部は、検索用テキストに含まれる複数の部分形態素のそれぞれについて特定された出現頻度と重み付け係数から関連スコアを算出することを特徴とする請求項11から13のいずれかに記載の文書検索装置。
【請求項15】
前記関連スコア算出部は、検索用形態素の先頭部の部分形態素は前記検索用形態素の他の位置の部分形態素よりも関連スコアに対する影響が大きくなるように重み付け係数を設定することを特徴とする請求項11から14のいずれかに記載の文書検索装置。
【請求項16】
第1出現数=検索用テキストの部分形態素中におけるグラムの位置と文書ファイルの形態素中における前記グラムの位置が整合する文書ファイルの数
第2出現数=前記部分形態素に含まれるグラムを含む文書ファイルの数
としたとき、
前記第1出現数と前記第2出現数から、前記部分形態素が前記所定の文書ファイル群において本来の意味にて用いられている割合を語句確率として算出する語句確率算出部、を更に備え、
前記関連スコア算出部は、前記部分形態素の語句確率、前記重み付け係数、前記部分形態素の出現頻度により、関連スコアを計算することを特徴とする請求項11から15のいずれかに記載の文書検索装置。
【請求項17】
前記形態素抽出部は、前記検出された文書ファイルからも形態素を抽出し、
前記関連スコア算出部は、前記検出された文書ファイル中の形態素とその形態素に含まれる部分形態素の位置関係により関連スコアを調整することを特徴とする請求項11から16のいずれかに記載の文書検索装置。
【請求項18】
前記関連スコア算出部は、前記検出された文書ファイル中において、形態素の先頭部から前記部分形態素が検出されたときには前記形態素の他の位置から検出されるときよりも関連性が高くなるように関連スコアを調整することを特徴とする請求項17に記載の文書検索装置。
【請求項19】
所定の文書ファイル群から、検索用テキストと関連性が高い内容の文書ファイルを検索するための方法であって、
所定文字数の文字列であるグラム(gram)と、前記グラムを含む文書ファイルの文書IDと、前記文書ファイルの形態素中における前記グラムの位置が、前記所定の文書ファイル群に含まれるグラムごとに対応づけられたインデックス情報を取得するステップと、
検索用テキストの入力を受け付けるステップと、
検索用テキストから1以上の検索用形態素を抽出するステップと、
検索用形態素から1以上のグラムを抽出するステップと、
インデックス情報を参照して、検査対象グラムを形態素の先頭部に含む文書ファイル数とその検査対象グラムを含む文書ファイルの総数との比率を前方出現率、検査対象グラムを形態素の末尾部に含む文書ファイル数とその検査対象グラムを含む文書ファイルの総数との比率を後方出現率としてそれぞれ算出するステップと、
ある検索用形態素に含まれる複数のグラムについての前方出現率と後方出現率から、その検索用形態素を複数の部分形態素に分離するステップと、
インデックス情報を参照して、ある部分形態素に含まれる1以上のグラムの並び順と文書ファイル中の形態素における1以上のグラムの並び順が整合する文書ファイルを検出するステップと、
前記並び順と整合する前記1以上のグラムが前記検出された文書ファイルに出現する回数を出現頻度として計数するステップと、
前記部分形態素について計数された出現頻度と前記検索用形態素中における前記部分形態素の位置に応じた重み付け係数により、前記検索用テキストと前記検出された文書ファイルの内容の関連性を関連スコアとして指標化するステップと、
を備えることを特徴とする文書検索方法。
【請求項20】
所定の文書ファイル群から、検索用テキストと関連性が高い内容の文書ファイルを検索するためのコンピュータプログラムであって、
所定文字数の文字列であるグラム(gram)と、前記グラムを含む文書ファイルの文書IDと、前記文書ファイルの形態素中における前記グラムの位置が、前記所定の文書ファイル群に含まれるグラムごとに対応づけられたインデックス情報を保持する機能と、
検索用テキストの入力を受け付ける機能と、
検索用テキストから1以上の検索用形態素を抽出する機能と、
検索用形態素から1以上のグラムを抽出する機能と、
インデックス情報を参照して、検査対象グラムを形態素の先頭部に含む文書ファイル数とその検査対象グラムを含む文書ファイルの総数との比率を前方出現率、検査対象グラムを形態素の末尾部に含む文書ファイル数とその検査対象グラムを含む文書ファイルの総数との比率を後方出現率としてそれぞれ算出する機能と、
ある検索用形態素に含まれる複数のグラムについての前方出現率と後方出現率から、その検索用形態素を複数の部分形態素に分離する機能と、
インデックス情報を参照して、ある部分形態素に含まれる1以上のグラムの並び順と文書ファイル中の形態素における1以上のグラムの並び順が整合する文書ファイルを検出する機能と、
前記並び順と整合する前記1以上のグラムが前記検出された文書ファイルに出現する回数を出現頻度として計数する機能と、
前記部分形態素について計数された出現頻度と前記検索用形態素中における前記部分形態素の位置に応じた重み付け係数により、前記検索用テキストと前記検出された文書ファイルの内容の関連性を関連スコアとして指標化する機能と、
をコンピュータに発揮させることを特徴とする文書検索プログラム。
【図1】


【図2】
【図3】

【図4】
【図5】
【図6】
【図7】

【図8】

【図9】
【図10】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【公開番号】特開2008−90401(P2008−90401A)
【公開日】平成20年4月17日(2008.4.17)
【国際特許分類】
【出願番号】特願2006−267886(P2006−267886)
【出願日】平成18年9月29日(2006.9.29)
【出願人】(390024350)株式会社ジャストシステム (123)
【Fターム(参考)】
【公開日】平成20年4月17日(2008.4.17)
【国際特許分類】
【出願日】平成18年9月29日(2006.9.29)
【出願人】(390024350)株式会社ジャストシステム (123)
【Fターム(参考)】
[ Back to top ]