
文書検索装置および文書検索方法

【課題】Ngram解析を用いた文書検索は検索処理に時間がかかる場合がある。
【解決手段】新たな文書ファイルをインデックスに登録する際、登録済みのデータを含め、ポスティングデータを1つ有する登録キーからの、登録キーの個数の累積割合を算出する(S30)。しきい値N以下の数のポスティングデータを有する登録キーのポスティングデータは、登録キーで構成されるB+ツリーのリーフページに格納し(S46)、しきい値Nより大きい数のポスティングデータを有する登録キーのポスティングデータは、ポスティング格納部のページへ格納する(S40、S48)。累積登録文書数iが所定の文書数目であった場合は(S32のY)、ポスティングデータ数のしきい値Nを、累積割合が60%を超えない登録キーが有する最大のポスティングデータ数に変更する(S34)。
【解決手段】新たな文書ファイルをインデックスに登録する際、登録済みのデータを含め、ポスティングデータを1つ有する登録キーからの、登録キーの個数の累積割合を算出する(S30)。しきい値N以下の数のポスティングデータを有する登録キーのポスティングデータは、登録キーで構成されるB+ツリーのリーフページに格納し(S46)、しきい値Nより大きい数のポスティングデータを有する登録キーのポスティングデータは、ポスティング格納部のページへ格納する(S40、S48)。累積登録文書数iが所定の文書数目であった場合は(S32のY)、ポスティングデータ数のしきい値Nを、累積割合が60%を超えない登録キーが有する最大のポスティングデータ数に変更する(S34)。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は文書処理技術に関し、特に入力されたテキストを含む文書ファイルを検索するための文書検索装置およびそれに適用される文書検索方法に関する。
【背景技術】
【0002】
情報処理技術やネットワークの充実に伴い、PC(Personal Computer)や携帯電話などの情報端末からウェブサイトやデータベースへアクセスして必要な情報を取得することが日常的に行われるようになった。一方でデータベース化される情報は膨大化の一途をたどり、それらの情報の中から必要な情報を取得する際の効率性が求められるようになってきた。ウェブサイトやネットワーク上に開示された情報を検索する検索エンジンから、各種のデータベースを検索する検索システムまで、文書検索の機能は適切かつ最新の情報取得には欠かせないものとなっている。
【0003】
自然言語に基づく文書検索技術のひとつにNgram解析がある。Ngram解析ではまず、検索対象の文書から所定数の文字列、すなわち「キー」を切り出し、文書における出現場所の情報をキーごとに記憶させておく。このようなデータを「インデックス」と呼ぶ。そして検索時は、検索クエリに含まれるキーに基づきインデックスを検索し、検索クエリ内のキーの順序などに基づき、検索クエリを含む文書を特定する(例えば特許文献1参照)。
【特許文献1】特開平5−274355号公報
【発明の開示】
【発明が解決しようとする課題】
【0004】
Ngram解析は、意味をなす、なさないに関わらず、文書に含まれるキーを全て切り出してインデックスを生成し、検索クエリに含まれるキーと照合する。そのため意味をなす語句を抽出する形態素解析と比較し検索結果に漏れが生じにくい、という特徴を有するが、一方で検索対象の文書数が増加するのに従い、インデックスのデータ量が急増する。そのため検索クエリを含む所望の文書情報を特定するまでには、膨大なデータ量のインデックスにアクセスする必要があり、処理に時間がかかる場合が多い。
【0005】
本発明はこうした状況に鑑みてなされたものであり、その目的は、Ngram解析を用いた検索を効率的に行う技術を提供することにある。
【課題を解決するための手段】
【0006】
本発明のある態様は、文書検索装置に関する。この文書検索装置は、文書から所定数の文字列を登録キーとして抽出するキー抽出部と、登録キーが抽出された文書の識別情報と当該文書における抽出箇所とを含むデータセットを1単位とするポスティングデータを登録キーごとに記憶したポスティング格納部と、ポスティング格納部におけるポスティングデータの格納領域と、対応する登録キーとを関連付けたツリー構造を構成する記憶領域を有するキー格納部と、を含むインデックス保持部と、検索クエリから所定数の文字列を検索キーとして抽出し、インデックス保持部を参照して検索キーに対するポスティングデータを取得することにより検索クエリを含む文書の検索を行う検索部と、を備え、キー格納部におけるツリー構造の最下層のノードを構成する記憶領域の少なくとも一部に、ポスティングデータの少なくとも一部が記憶され、検索部は少なくとも一部の検索キーについて、キー格納部のみを参照してポスティングデータを取得することを特徴とする。
【0007】
ここで「抽出箇所」は登録キーの開始位置、終了位置などであるが、文書検索装置において共有される所定の規則に従えばその形式は問わない。またポスティングデータは文書の識別情報と抽出箇所以外のパラメータを含んでいてよい。さらに「ツリー構造を構成する記憶領域」とはアルゴリズム上でツリー構造を構成する各ノードに対応した記憶領域のことであり、実際の記憶領域は連続していても分散していてもよい。「検索クエリ」は文書検索を行うためにユーザが入力した文字列であり、語句あるいは文章のいずれでもよく、1つでも複数でもよい。
【0008】
本発明の別の態様は、文書検索方法に関する。この文書検索方法は、文書から所定数の文字列を登録キーとして抽出するステップと、登録キーが抽出された文書の識別情報と当該文書における抽出箇所とを含むデータセットを1単位とするポスティングデータを登録キーごとに生成するステップと、ポスティングデータを登録キーごとに記憶装置に記憶させるステップと、検索クエリから所定数の文字列を検索キーとして抽出するステップと、記憶装置を参照して検索キーに対する前記ポスティングデータを取得することにより検索クエリを含む文書の検索を行うステップと、を含み、記憶装置におけるポスティングデータの記憶領域を、登録キーごとのポスティングデータ数に応じて異ならせることを特徴とする。
【0009】
なお、以上の構成要素の任意の組合せ、本発明の表現を方法、装置、システムなどの間で変換したものもまた、本発明の態様として有効である。
【発明の効果】
【0010】
本発明によれば、ユーザは漏れのない検索を効率的に行うことができる。
【発明を実施するための最良の形態】
【0011】
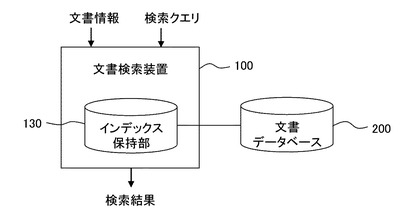
図1は、文書検索装置100による処理の概要を説明するための模式図である。ユーザが文書検索装置100に対して検索クエリを入力すると、文書検索装置100はその検索クエリを含む文書ファイルを文書データベース200から検索する。検索クエリは一定の意味をなす文字列であり、自然文であってもよいしキーワードであってもよい。文書データベース200の文書ファイルは、XML(eXtensible Markup Language)文書やXHTML(eXtensible HyperText Markup Language)文書のようにタグによって構造化されたファイルであってもよいし、単なるテキストファイルであってもよい。また文書データベース200は図示しないネットワークを介して文書検索装置100と接続されていてもよい。
【0012】
検索に先立ち、文書検索装置100は文書データベース200内の文書についてNgram解析を行いインデックスを作成してインデックス保持部130に格納する。インデックス保持部130はハードディスクなど大容量の記憶装置、またはその一部で実現できる。インデックスの構造については後に詳述する。文書検索装置100は検索クエリに基づきインデックスを参照して、文書データベース200内の適合する文書ファイルを特定し、検索結果として画面表示する。その際、一般的に用いられるスコアリングの手法によって得られたスコアに基づき結果の表示順を決定してもよい。こうして、文書検索装置100のユーザは、任意の検索クエリを含む文書ファイルを探し出すことができる。
【0013】
図2は文書検索装置100の詳細な構成を示している。ここに示す各ブロックは、ハードウェア的には、コンピュータのCPUをはじめとする素子や機械装置で実現でき、ソフトウェア的にはコンピュータプログラム等によって実現されるが、ここでは、それらの連携によって実現される機能ブロックを描いている。したがって、これらの機能ブロックはハードウェア、ソフトウェアの組合せによっていろいろなかたちで実現できることは、当業者には理解されるところである。
【0014】
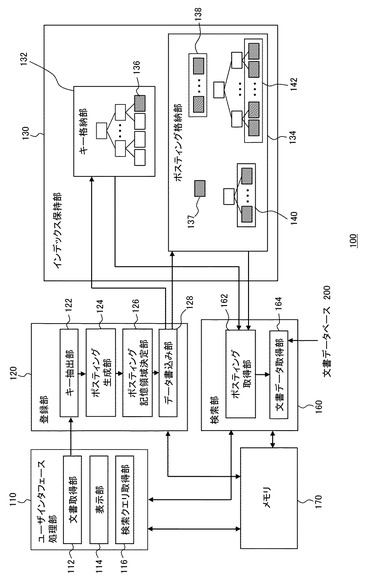
文書検索装置100はユーザによる入力の受け付けや結果の出力を担うユーザインタフェース処理部110、検索対象の文書についてのデータをインデックスに登録する登録部120、入力された検索クエリに基づき検索を行う検索部160、およびインデックス保持部130を含む。文書検索装置100はさらに、各機能ブロックが処理を行うために必要なデータやプログラムを一時的に格納するメモリ170を含む。
【0015】
ユーザインタフェース処理部110は、ユーザからの入力処理やユーザに対する情報表示のようなユーザインタフェース全般に関する処理を担当する。本実施の形態においては、ユーザインタフェース処理部110により文書検索装置100のユーザインタフェースサービスが提供されるものとして説明する。別例として、ユーザはインターネットを介して文書検索装置100を操作してもよい。この場合、図示しない通信部が、ユーザ端末からの操作指示情報を受信し、またその操作指示に基づいて実行された処理結果情報をユーザ端末に送信することになる。
【0016】
ユーザインタフェース処理部110は文書取得部112、表示部114、および検索クエリ取得部116を含む。新規の文書データベース200を構築した場合や、元からある文書データベース200に新規の文書ファイルを登録して検索対象とする場合に、文書取得部112は当該文書ファイル(以後、登録文書ファイルと呼ぶ)の情報をユーザからの入力によって取得し、登録部120へ供給する。この文書ファイルの情報は、文書データベース200に保存されている文書ファイルを指定する情報でもよいし、別の場所に保存されている文書ファイルを指定する情報でもよい。後者の場合、文書検索装置100は読み出した文書ファイルを文書データベース200へ保存するようにしてもよい。検索クエリ取得部116は、検索を行いたいユーザによって入力された検索クエリを受け付け、検索部160に供給する。
【0017】
登録部120はキー抽出部122、ポスティング生成部124、ポスティング記憶領域決定部126、およびデータ書込み部128を含む。キー抽出部122は、文書取得部112から供給された文書ファイルの情報に従い登録文書ファイルを読み出し、走査することにより、あらかじめ定められた文字数、すなわち所定のグラム数を有するキーを抽出する。例えば「アメリカ合衆国の大統領」というテキストであれば、「アメ:メリ:リカ:・・・:統領」のようにキーを抽出する。この例におけるキーは2グラムである。グラム数は最適な値をあらかじめ設定しておく。以後の説明では登録文書ファイルから抽出されたキーを「登録キー」と呼ぶ。
【0018】
ポスティング生成部124は、登録文書ファイルに対し一意に定めた識別情情報である文書IDを付与するとともに、各登録キーに対するポスティングデータを生成する。ポスティングデータは、各登録キーがどの文書のどの位置に出現したかを表す情報であり、例えば[文書ID,キー開始位置,キー終了位置]という構造を有するデータセットである。抽出した登録キーの中に同一のものがあれば、対応するポスティングデータをまとめる。例えば「アメ」なるキーが4つ抽出されていれば、キー「アメ」に対し4つのポスティングデータが生成される。
【0019】
ポスティング記憶領域決定部126は、生成されたポスティングデータをインデックス保持部130のどの領域に記憶させるかを決定し、データ書込み部128は当該決定に従いポスティングデータおよびそれに係る情報をインデックス保持部130に追加して書き込む。ポスティング記憶領域決定部126は、ポスティングデータを記憶させる記憶領域の決定以外に、記憶領域決定のための各種処理も行う。ポスティングデータの記憶領域については後に詳述する。
【0020】
検索部160はポスティング取得部162および文書データ取得部164を含む。ポスティング取得部162は検索クエリからキーを抽出し、インデックス保持部130を参照して当該キーに対応するポスティングデータを取得する。以後、検索クエリから抽出したキーを「検索キー」と呼ぶ。ポスティング取得部162は、検索キーが全て含まれる文書を各キーのポスティングデータに含まれる文書IDから特定し、さらにそれらの検索キーが検索クエリにおける順序で連続して出現する文書を、ポスティングデータに含まれるキー開始位置、キー終了位置に基づき絞り込む。これにより検索クエリを含む文書を特定できる。なおここでは基本的な処理内容のみを説明するが、検索処理に一般的に用いられるあらゆる技術を組み合わせてもよい。
【0021】
文書データ取得部164は、特定された文書の文書IDに基づき文書データベース200から該当文書の少なくとも一部や記憶先のアドレスなどを取得し、ユーザインタフェース処理部110の表示部114が検索結果として表示できるように表示データを整えメモリ170に保存する。
【0022】
ここでインデックス保持部130に保持されたインデックスの構造および記憶領域について説明する。インデックスは、登録文書ファイルから抽出された登録キーとポスティングデータとを関連付けたデータである。登録キーはグラム数に応じて機械的に切り出されるため、同一の登録キーをまとめてもその種類は膨大である。一方、検索時には検索キーに合致した、インデックス内の登録キーを探し出し、それと関連付けられたポスティングデータを特定する処理がなされる。膨大な種類の登録キーの中から検索キーを効率よく検出するために、一般に利用されるのがB+ツリー(Balanced plus tree)のアルゴリズムである。
【0023】
このとき用いられるB+ツリーは、所定の規則でソートされた登録キーの列の範囲によって下層のノードへの分岐を決定するルートノードおよびブランチノードと、末端のノードであり、ツリーによって最終的に絞り込まれた登録キーの候補と、各登録キーのポスティングデータの記憶領域を示すポインタとが記述されたリーフノードからなるツリー構造を有する。検索処理時には、検索キーに従いルートノードから下層へノードを辿っていけば、行き着いたリーフノードに記述された登録キーの候補の中に検索キーと同一のものが含まれており、最終的に所望のポスティングデータへのポインタが得られることになる。
【0024】
このような検索処理においてはまず、(1)B+ツリー構造が格納された記憶領域にアクセスしてポスティングデータへのポインタを取得し、(2)ポスティングデータが格納された記憶領域にアクセスしてポスティングデータを取得する、という最低2回のアクセスを必要とする。1つの検索クエリからは通常、複数の検索キーが抽出されるため、それらの検索キーに対し同様の処理を繰り返すと、記憶領域へのアクセス回数が増大する。キャッシュメモリなどを用いても、検索条件によっては看過できない程の時間を要する場合がある。
【0025】
本発明者は検索に要する時間を短縮するため鋭意研究を重ねた結果、インデックスに係る以下の知見を得るに至った。表1は、一般的な文書データベースのインデックスにおける、キーごとのポスティングデータ数の分布を表している。このデータは87万7713の文書ファイルから2グラムの登録キーを抽出した場合であり、このとき抽出された登録キーは1339103個であった。
【0026】
【表1】

【0027】
例えば「ポスティング数」が「3」の行を見ると、3個のポスティングデータを有する登録キーは、「合計」欄のとおり「94038」個あり、ポスティングデータ数が3個までの累積値、すなわち1〜3個のポスティングデータを有する登録キーの個数は「累積」欄のとおり「613369」個である。そして全登録キーのうち1〜3個のポスティングデータを有する登録キーの割合は、「累積割合」欄のとおり「45.8%」である。同表によれば、全登録キーのうち55%程度はポスティングデータ数が5個以下の登録キーであることがわかる。それに対し、1001個以上のポスティングデータを有する登録キーは全体のわずか0.6%である。
【0028】
したがって上述のようにB+ツリーからポインタを取得し、ポインタからポスティングデータを取得する構成においては、わずか数個のポスティングデータを取得するために別の記憶領域へアクセスし直している可能性が少なからずあるといえる。本発明者はこの点に改良の余地を見出し、ポスティングデータの取得を効率的に行うために次のような実施の形態に想到した。
【0029】
本実施の形態でも基本的には上述のアルゴリズムを採用する。そのため、インデックス保持部130には、B+ツリーを格納するキー格納部132および各ポスティングデータを格納するポスティング格納部134が含まれる。したがって一般的なB+ツリーのリーフノードにおいて記述されるポスティングデータへのポインタは、ポスティング格納部134内の記憶領域を示す。以後、リーフノードやポスティングデータの記憶領域はページを単位として説明し、ポインタはページ番号とする。またこれ以後、登録キーとポスティングデータとの関連付けはB+ツリーを用いて行うものとするが、本実施の形態はこれに限らず、例えばBツリーなどでもよい。
【0030】
一方、本実施の形態では、登録キーの絞込みを行うためのB+ツリー構造の中に、ポスティングデータの一部を組み入れる。すなわち、本実施の形態のリーフページ136には、登録キーとポスティングデータのページ番号との組み合わせのみならず、登録キーとポスティングデータそのものの組み合わせも記述される。したがってポスティング記憶領域決定部126は、ポスティングデータをキー格納部132、すなわちB+ツリーのリーフページ136に記憶させるか、ポスティング格納部134へ記憶させるか、を決定する。
【0031】
ポスティング記憶領域決定部126は、登録キーごとのポスティングデータの数、すなわち、登録文書ファイルから新たに生成された登録キーのポスティングデータと、同一の登録キーに対しインデックスに登録済みのポスティングデータとの合計によって、当該登録キーのポスティングデータの記憶領域を決定する。具体的にはポスティングデータの数にしきい値を設け、しきい値以下の数のポスティングデータしか持たない登録キーであればB+ツリーのリーフページ136に記述し、しきい値より大きい数のポスティングデータを有する登録キーについてはポスティング格納部134内の領域に記述する。
【0032】
例えばしきい値を「5」とした場合、表1に示したような文書データベースでは、約55%の登録キーのポスティングデータは、キー格納部132のみにアクセスすることによって取得することができる。また5個程度のポスティングのデータサイズであればリーフページ136の記憶容量を圧迫することがなく、B+ツリー構造はそのバランスを損なうことなくそのまま用いることができる。結果としてインデックス保持部130へのアクセス回数のみが削減され、短期間で効率のよい検索処理が可能となる。
【0033】
さらにポスティング記憶領域決定部126は、所定の文書数が登録されるごとに、全体に対する登録キーの割合に基づき上述のしきい値を変化させる。例えば文書が10万文書登録されるごとに、1個のポスティングデータを有する登録キーからの累積割合が60%を超えない登録キーが有する最大のポスティングデータ数へしきい値を変更する。これは、登録される文書数が増加するほど、当然登録キーごとのポスティング数が増加する傾向となるための措置である。そのような状況でしきい値をあるポスティングデータ数で固定してしまうと、登録文書の増加とともに、しきい値より多くのポスティングデータ数を有する登録キーの割合が増加していき、結局アクセス回数の削減効果が薄れてしまう。
【0034】
そこで累積割合に基づきしきい値を調整し、常にある割合の登録キーについてはリーフページ136からポスティングデータが得られるようにする。表1によれば、キーごとのポスティングデータ数が増加するほど累積割合の増加量は小さくなる。すなわち登録文書数が増加しても、累積割合が60%などとなる登録キーのポスティングデータ数が急激に増加する可能性は低いと考えられる。したがって、上述のようにしきい値を変化させても、リーフページ136の容量を圧迫したりB+ツリーのバランスを損なったりする程のポスティングデータが記述される可能性は低く、結果として上述したような効果を登録文書数の多少に関わらず定常的に得ることができる。
【0035】
ポスティングデータをリーフページ136に記述する場合、データ書込み部128は、対応する登録キーが記述されているリーフページ136にポスティングデータを追加して書き込む。ポスティングデータをポスティング格納部134に格納する場合、データ書込み部128は、対応する登録キーが記述されているリーフページ136を参照し、当該登録キーに対応づけて記述された、ポスティングデータのページ番号を取得して、ポスティング格納部134内の該当ページにポスティングデータを追加して書き込む。
【0036】
図2のキー格納部132やポスティング格納部134に示した最も小さい単位の矩形はページを表している。上述したとおり、キー格納部132およびポスティング格納部134はそれぞれB+ツリーおよびポスティングデータを格納するが、B+ツリーのリーフページ136に記述されたデータにはポスティングデータも含まれる。同図ではそのようなページを網掛けで表している。リーフページ136以外のリーフページにもポスティングデータを記述してよいが、ここではリーフページ136に代表させている。
【0037】
ポスティング格納部134には当然、ポスティングデータが格納されるため、それを記述したページとして網掛けされた矩形がいくつか示されているが、本実施の形態では登録キーごとのポスティングデータの数により、そのページ構成を異ならせる。具体的には、1ページに複数の登録キーのポスティングデータを記述する共有ページ137、1ページ以上に一の登録キーのポスティングデータを記述する専有ページ138、文書IDをキーとした2層のB+ツリー構造のリーフページに一の登録キーのポスティングデータを記述した2層ツリーページ140、同じく3層のB+ツリー構造により一の登録キーのポスティングデータを記述した3層ツリーページ142である。なお各ページの総数はポスティングデータの数によって増減する。それぞれのページ構成の詳細は後に述べる。
【0038】
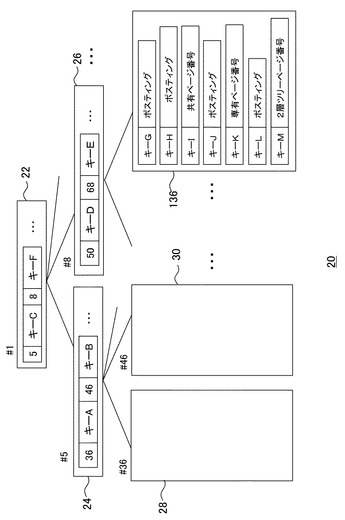
図3は、キー格納部132に格納されるB+ツリーの構造を模式的に示している。B+ツリー20は、ルートページ22、ブランチページ24および26、リーフページ28、30、および136を含む。ただしページ数や層の深さはこれに限らない。各ページの左上に示した「#番号」はそれぞれのページに一意に設定されたページ番号である。
【0039】
まずページ番号#1のルートページ22を見ると、「5」、「キーC」、「8」、「キーF」といったデータ列が記述されている。ここで「キーC」、「キーF」は「アメ」、「メリ」など具体的な登録キーの文字列である。同図の場合、ソートされた登録キーの列の先頭から「キーC」の前までの登録キーについては下層のページ番号#5のページに記述されており、「キーC」から「キーF」の前までの登録キーについては下層のページ番号#8のページに記述されていることを示している。
【0040】
ページ番号#5のブランチページ24も同様に、先頭から「キーA」の前までの登録キーについてはページ番号#36のページに、「キーA」から「キーB」の前までの登録キーについてはページ番号#46のページに記述されていることを示している。ページ番号#8のブランチページ26も同様である。これに従い、ページ番号#36のリーフページ28には先頭から「キーA」の前までの登録キーのポスティングデータについての情報が、ページ番号#46のリーフページ30には「キーA」から「キーB」の前までの登録キーのポスティングデータについての情報が記述される。
【0041】
同図では、リーフページ28、30などに記述されるデータを、リーフページ136を代表させて図示している。上述したとおりリーフページ136には、複数の登録キーのそれぞれに対し、ポスティングデータそのもの、またはポスティング格納部134におけるポスティングデータを記述したページ番号のいずれかが記述される。同図は、「キーG」、「キーH」、「キーJ」、「キーL」に対しポスティングデータそのものが記述され、「キーI」に対しては図2の共有ページ137のページ番号、「キーK」に対しては専有ページ138の先頭のページ番号、「キーM」に対しては2層ツリーページ140のルートページのページ番号が記述されていることを示している。
【0042】
次に、これまで述べた構成を有する文書検索装置100の動作について説明する。なお検索部160が行う検索クエリに基づく検索処理の手順は、上述したとおり一般的な手法を用いることができるため、ここではインデックスへの登録手法に主眼を置き説明する。図4は文書検索装置100によって登録文書ファイルを解析し、インデックスへ登録する処理手順を示すフローチャートである。ここではインデックス保持部130に、それまでに解析を済ませた文書ファイルのインデックスが既に格納されており、新たな登録文書の情報を登録する場合について述べるが、新規にインデックスを生成する場合でも、本実施の形態の特徴的な手順は同様であり、B+ツリーの構築などは一般的な手法を適用することができる。
【0043】
まずユーザが、ユーザインタフェース処理部110の文書取得部112に対し登録文書ファイルの情報を入力すると、登録部120のキー抽出部122は当該登録文書ファイルを読み出し、メモリ170に保存する(S10)。キー抽出部122は、登録文書ファイルからテキストデータを抽出し(S12)、それを走査することにより所定のグラム数の登録キーを抽出していく(S14)。次にポスティング生成部124は、登録文書ファイルに文書IDを付与するとともに、キー抽出部122が抽出した登録キーごとに、当該文書IDと、テキストデータにおける当該登録キーの開始位置および終了位置とからなるポスティングデータを生成する(S16)。
【0044】
次にポスティング記憶領域決定部126が、生成したポスティングデータの格納領域を決定し、データ書込み部128がそれに従い書き込みを行う(S18)。この際、前述したとおり、インデックスに登録済みのポスティングデータを含めた登録キーごとのポスティングデータ数としきい値との大小関係によって格納場所を決定する。また今回抽出した登録キーのポスティングデータをリーフページ136に書き込むことによりその登録キーのポスティングデータ数がしきい値を超えてしまう場合は、リーフページ136に記述済みのポスティングデータごとポスティング格納部134へ移動させる。具体的な処理手順は図5を参照して説明する。
【0045】
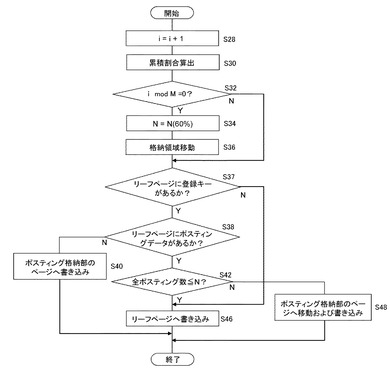
図5は、S18においてポスティング記憶領域決定部126がポスティングデータの記憶領域を決定し、データ書込み部128が書き込みを行う手順を示すフローチャートである。前提として、文書ファイルの累積数を示す変数iは“0”に初期化され、リーフページ136に記述できるポスティングデータ数のしきい値Nには初期値、たとえば“5”が代入されているとする。まず変数iをインクリメントした後(S28)、登録文書ファイルの情報を新たに登録した場合のインデックスについて表1に示した各数値を計算し、登録キーごとのポスティング数に対する登録キーの個数の累積割合を算出する(S30)。累積割合を含む表1のデータは、メモリ170などに一時保存し、文書検索装置100の処理を終了させる際にインデックス保持部130を構成するハードディスクなどに保存しておく。新たな文書登録を行う際は、そのように保存された以前のデータを参照して計算を行い、各値を更新してけばよい。
【0046】
次に変数iに対し所定の文書数M、例えば10万で剰余算を行い、解が0でなければ、すなわち今回の登録文書ファイルが10万の倍数文書目でなければ(S32のN)、抽出した各登録キーについてB+ツリーを辿り、まずリーフページ136に当該登録キーが記述されているかどうかを確認する(S37)。登録キーが以前に登録されていなければ、リーフページ136には当該登録キーが記述されていないため(S37のN)、リーフページ136に登録キーとそのポスティングデータを書き込む(S46)。
【0047】
登録キーが記述されていた場合は(S37のY)、さらにリーフページ136に当該登録キーのポスティングデータが記述されているかどうかを確認する(S38)。ポスティングデータが記述されておらず、ページ番号が記述されている場合は(S38のN)、ポスティング格納部134における当該ページ番号のページにポスティングデータを追加して書き込む(S40)。
【0048】
リーフページ136にポスティングデータが記述されている場合は(S38のY)、新たなポスティングデータの追加によりポスティングデータ数がしきい値Nを超えるかどうかを確認する(S42)。しきい値Nを超えない場合は(S42のY)、そのリーフページ136にポスティングデータを追加して書き込む(S46)。ポスティングデータ数がしきい値Nを超える場合は(S42のN)、それまで記述されていた当該登録キーのポスティングデータをポスティング格納部134に用意されている共有ページ137などに移動させたうえで、新たなポスティングデータを同ページに追加して書き込む(S48)。この際、移動元のリーフページ136には、当該キーに対応させて移動先のページのページ番号を書き込んでおく。
【0049】
S32において当該登録文書ファイルが所定の文書数Mの倍数であった場合は(S32のY)、S30において算出した累積割合に基づきしきい値Nを変更する(S34)。ここでN(60%)は累積割合が60%を超えない登録キーの最大のポスティングデータ数を表す。なお60%は例示であり、データベースの種類や文書検索装置100の処理性能などに鑑み実験などにより最適値を決定してよい。そしてしきい値Nの変更によってリーフページ136に記述されるべきとなったポスティングデータがあれば、ポスティング格納部134のページからリーフページ136に移動する(S36)。その後の処理は上述したのと同様である。
【0050】
以上の手順により、登録されている文書数の増加に伴いポスティングデータ数のしきい値を変化させながら、ポスティングデータをリーフページ136およびポスティング格納部134へ振り分ける態様を実現することができる。
【0051】
次にポスティング格納部134に格納された、ポスティングデータを記述するページの構成について説明する。上述したように本実施の形態では登録キーごとのポスティングデータ数により、共有ページ137、専有ページ138、2層ツリーページ140、3層ツリーページ142のいずれかにポスティングデータを記述し、記憶領域を効率的に使用するとともに検索の処理効率を向上させる。なおツリーページは必要に応じて4層以上でもよい。
【0052】
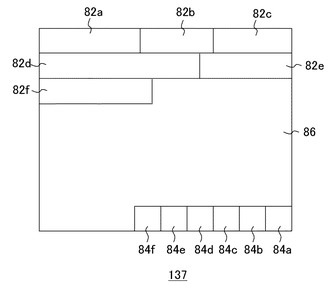
図6は共有ページ137の構成を模式的に示している。共有ページ137には複数のキーのポスティングデータを可能な限り詰めた状態で記述する。リーフページ136においてポスティングデータ数がしきい値を超えた登録キーのポスティングデータは、この共有ページ137に移動する。1ページのデータ容量、8KBを考慮すると、登録キーごとのポスティングデータ数が最大500個程度であれば、共有ページ137内に記述できる。
【0053】
共有ページ137は、ポスティングデータ領域82a〜82f、ポインタ領域84a〜84f、および空き領域86を含む。同図は、6つの登録キーのポスティングデータが、6つの連続したポスティングデータ領域82a〜82fのぞれぞれに記述されている状態を示している。登録キーごとのポスティングデータ数は一定でないため、ポスティングデータ長も変動する。そこで各ポスティングデータ領域82a〜82fの、ページ先頭からのオフセット値をポインタ領域84a〜84fにそれぞれ記述する。新たなポスティングデータをポスティングデータ領域82a〜82fのいずれかに追加した場合は、以後のポスティングデータ領域のオフセット値を更新する。
【0054】
リーフページ136からポスティングデータを移動する際は、充填率が高くなるような共有ページ137を探して格納する。そのために空き領域86の容量を管理する。例えば2ビットのレジスタ(図示せず)を用意し、空き領域86の容量について、25%未満、25%以上50%未満、50%以上75%未満、75%以上100%以下、の4段階を表すデータを保持する。レジスタの値は文書検索装置100の処理終了時にはハードディスクなどに保存し、次回の登録処理において参照する。
【0055】
表1によれば、500個以下のポスティングデータを有する登録キーは全体の90%程度にも上るため、ポスティングデータをリーフページ136に格納するほか、共有ページ137に詰めて格納することにより、キーごとに1ページを用意するといった従来の手法に比べて格段に所要容量を削減することができる。また、新たな空きページを確保するなどの領域管理の処理を省略でき、登録処理時の効率が向上する。
【0056】
共有ページ137に記述したある登録キーのポスティングデータが増加し、1ページ以内で収まらなくなった場合は、当該ポスティングデータを専有ページ138へ移動させる。専有ページは一の登録キーが専有して使う1以上のページで構成され、ポスティングデータ数によってページを単純連結していく。例えば最大8ページまで連結可能とする。これにより一の登録キーにつき500〜4000個程度のポスティングデータが格納できる。
【0057】
最大に連結した専有ページ138の容量をポスティングデータが超えた場合は、当該ポスティングデータをリーフページに格納した2層ツリーページ140を構築する。図7は2層ツリーページ140の構成を模式的に示している。2層ツリーページ140は基本的には図3で示したのと同様のB+ツリー構造を有する。ただしページの分岐は登録キーに代わり文書IDによって行う。
【0058】
前述したように、検索部160が検索処理を行う場合、入力された検索クエリから検索キーを抽出し、検索キーの全てを含み、かつ検索クエリにおける順番で連続して出現する文書を検出する。検索クエリから検索キーとして「キーa」、「キーb」が抽出されたとすると、まず「キーa」のポスティングデータを取得し、その文書IDをメモリ170に保存する。そして「キーb」のポスティングデータのうち、メモリ170に保存しておいた文書IDを有するポスティングデータを取得すれば、それはすなわち「キーa」および「キーb」を含む文書のポスティングデータである。
【0059】
ここで「キーb」が4000個を超える膨大なポスティングデータを有するとすると、それらのポスティングデータを単に羅列したデータ構造においては、先頭から全てのポスティングデータを確認し、「キーa」を含む文書の文書IDと照合していかなければならない。検索キーが多いほど、この処理を繰り返す必要が生じ、結果としてポスティング格納部134へのアクセス回数が増大する。
【0060】
そこで本実施の形態では、4000個を超えるようなポスティングデータを有する「キーb」のポスティングデータを取得する際、「キーa」を含む文書の文書IDを元に図7に示すようなB+ツリー構造を辿ることにより、「キーa」を含む文書のポスティングデータのみを確認する。図7において2層ツリーページ140は、ルートページ42、ブランチページ44および46、リーフページ48、50、52、54を含む。図3と同様、ルートページ42には、ある登録キーに対する全ポスティングデータに記載された文書IDをソートした文書ID列のうち、先頭から「ID_c」の前までの文書IDを有するポスティングデータの情報がページ番号#1のページに、「ID_c」から「ID_f」の前までの文書IDを有するポスティングデータの情報がページ番号#52のページに記述されていることが示されている。
【0061】
同様に、ページ番号#1のブランチページ44には、先頭から「ID_a」の前までの文書IDを有するポスティングデータがページ番号#2のページに、「ID_a」から「ID_b」の前までの文書IDを有するポスティングデータがページ番号#3のページに記述されていることが示されている。ページ番号#52のブランチページ46も同様である。ページ番号#2のリーフページ48、ページ番号#3のリーフページ50、ページ番号#17のリーフページ52、ページ番号#18のリーフページ54にはそれぞれ、該当する文書IDを有するポスティングデータが記述されている。
【0062】
このような構成とすることにより、上述の例では、「キーa」を含まない文書に対するポスティングデータを読み飛ばすことができ、ポスティング格納部134へのアクセス回数を削減することができる。ポスティングの確認に係る処理も省略できるため、結果として検索処理にかかる時間を顕著に削減することができる。
【0063】
2層ツリーページ140には、最大約8MB、すなわち50万個程度のポスティングデータを格納することができる。ある登録キーのポスティングデータが2層ツリーページ140に格納できる数を超えた場合は、当該ポスティングデータをリーフページに格納した3層ツリーページ142を構築する。3層ツリーページ142はブランチページが2層になっているほかは2層ツリーページ140と同様である。3層ツリーページ142には、最大8GB、すなわち5億個程度のポスティングデータを格納することができる。
【0064】
以上述べた本実施の形態によれば、登録キーごとのポスティングデータ数に応じて、ポスティングデータの格納領域を、キー格納部132におけるB+ツリー構造のリーフページ136、ポスティング格納部134における共有ページ137、専有ページ138、2層ツリーページ140、3層ツリーページ142と変化させる。また、文書の登録数によってポスティングデータ数が増加した場合は、上述の順番でデータを移動させていく。これにより、常にポスティングデータのデータサイズに適合し、かつ無駄のない記憶領域管理を行うことができる。
【0065】
さらにB+ツリー構造のバランスを損なわない程度のサイズのポスティングデータをキー格納部132のB+ツリーのリーフページ136に格納することにより、検索処理時にポスティング格納部134へアクセスし直す必要がなくなり、全体としてアクセス回数が減るため、検索処理を高速化できる。一般的な文書データベースでは、多くの登録キーのポスティングデータが数個程度であるため、その効果を顕著に得ることができる。
【0066】
また、ポスティングデータが1ページに満たないサイズの場合は、複数の登録キーのポスティングデータを共有ページ137内に詰めて格納する。これにより、余分な記憶領域を確保する必要がなくなり、記憶領域の節約になる。また、リーフページ136からポスティングデータを移動させた場合などに新たにページを確保する処理を省略できる可能性が高くなる。さらに、4000個を超えるような膨大なポスティングデータを有する登録キーについては、B+ツリーを構築してリーフページにポスティングデータを格納する。文書IDによってB+ツリーを辿ることにより、不必要なポスティングデータを読み飛ばすことができ、ポスティング格納部134へのアクセス回数を削減できるとともにポスティングデータの確認に要する時間を短縮することができる。
【0067】
さらに本実施の形態では、登録された文書数が増加するのに伴い、キー格納部132のB+ツリーのリーフページ136に格納するポスティングデータ数のしきい値を調整する。これにより、登録文書数の増加により全体的にポスティングデータ数が増加しても、常にある割合の登録キーのポスティングデータがリーフページ136に格納される。一般的な文書データベースでは、文書数が増加しても登録キーごとのポスティングデータ数はそれほど増加しないため、しきい値を多少変化させてもB+ツリーのバランスを損なうことがない。結果として他に影響を及ぼすことなく実施の形態の形骸化を防止することができる。
【0068】
以上、本発明を実施の形態をもとに説明した。この実施の形態は例示であり、それらの各構成要素や各処理プロセスの組合せにいろいろな変形例が可能なこと、またそうした変形例も本発明の範囲にあることは当業者に理解されるところである。
【0069】
例えば上述の実施の形態では、共有ページ、専有ページ、2層ツリーページ、3層ツリーページなる順序で、それまで格納されていたページの容量を超えた時点で、ポスティングデータを移動させた。一方、あらかじめポスティングデータのサイズを予想して、それに応じたページを用意するようにしてもよい。例えば、一般的な文書データベースで出現しやすい登録キーと、登録文書数の範囲ごとのポスティングデータのデータサイズとを対応づけた辞書をあらかじめ作成しておき、所定の文書数が登録されるたびに当該辞書を参照して、登録キーごとに必要と予測されるページを用意してもよい。
【0070】
また、登録文書の増加に対するポスティングデータの増加速度を学習することにより、定期的に格納するページの見直しを行ってもよい。これらの場合も、上述の実施の形態と同様の効果を得ることができる。またポスティングデータを移動させる処理の実行予定が把握できるため、並列して他の処理を行っている場合などにトータルな処理の効率化を図ることができる。
【0071】
また本実施の形態では、キー格納部132におけるB+ツリーのリーフページへ格納するポスティングデータは、あるしきい値以下のポスティングデータを有する登録キーのものとした。一方、しきい値を設定せずに、登録キーそのものによって決定してもよい。この場合も、登録キーと、登録文書数の範囲ごとの最適な格納先とを対応付けた辞書をあらかじめ作成しておき、それを参照することにより、リーフページまたはその他のページを格納先として決定してもよい。
【図面の簡単な説明】
【0072】
【図1】本実施の形態の文書検索装置による処理の概要を説明するための模式図である。
【図2】本実施の形態の文書検索装置の詳細な構成を示す図である。
【図3】本実施の形態においてキー格納部に格納されるB+ツリーの構造を模式的に示す図である。
【図4】本実施の形態の文書検索装置によって登録文書ファイルを解析し、インデックスへ登録する処理手順を示すフローチャートである。
【図5】本実施の形態においてポスティングデータを格納する記憶領域を決定し、書き込みを行う手順を示すフローチャートである。
【図6】本実施の形態における共有ページの構成を模式的に示す図である。
【図7】本実施の形態における2層ツリーページの構成を模式的に示す図である。
【符号の説明】
【0073】
100 文書検索装置、 110 ユーザインタフェース処理部、 112 文書取得部、 116 検索クエリ取得部、 120 登録部、 122 キー抽出部、 124 ポスティング生成部、 126 ポスティング記憶領域決定部、 128 データ書込み部、 130 インデックス保持部、 132 キー格納部、 134 ポスティング格納部、 137 共有ページ、 138 専有ページ、 140 2層ツリーページ、 142 3層ツリーページ、 160 検索部、 162 ポスティング取得部、 164 文書データ取得部、 200 文書データベース。
【技術分野】
【0001】
本発明は文書処理技術に関し、特に入力されたテキストを含む文書ファイルを検索するための文書検索装置およびそれに適用される文書検索方法に関する。
【背景技術】
【0002】
情報処理技術やネットワークの充実に伴い、PC(Personal Computer)や携帯電話などの情報端末からウェブサイトやデータベースへアクセスして必要な情報を取得することが日常的に行われるようになった。一方でデータベース化される情報は膨大化の一途をたどり、それらの情報の中から必要な情報を取得する際の効率性が求められるようになってきた。ウェブサイトやネットワーク上に開示された情報を検索する検索エンジンから、各種のデータベースを検索する検索システムまで、文書検索の機能は適切かつ最新の情報取得には欠かせないものとなっている。
【0003】
自然言語に基づく文書検索技術のひとつにNgram解析がある。Ngram解析ではまず、検索対象の文書から所定数の文字列、すなわち「キー」を切り出し、文書における出現場所の情報をキーごとに記憶させておく。このようなデータを「インデックス」と呼ぶ。そして検索時は、検索クエリに含まれるキーに基づきインデックスを検索し、検索クエリ内のキーの順序などに基づき、検索クエリを含む文書を特定する(例えば特許文献1参照)。
【特許文献1】特開平5−274355号公報
【発明の開示】
【発明が解決しようとする課題】
【0004】
Ngram解析は、意味をなす、なさないに関わらず、文書に含まれるキーを全て切り出してインデックスを生成し、検索クエリに含まれるキーと照合する。そのため意味をなす語句を抽出する形態素解析と比較し検索結果に漏れが生じにくい、という特徴を有するが、一方で検索対象の文書数が増加するのに従い、インデックスのデータ量が急増する。そのため検索クエリを含む所望の文書情報を特定するまでには、膨大なデータ量のインデックスにアクセスする必要があり、処理に時間がかかる場合が多い。
【0005】
本発明はこうした状況に鑑みてなされたものであり、その目的は、Ngram解析を用いた検索を効率的に行う技術を提供することにある。
【課題を解決するための手段】
【0006】
本発明のある態様は、文書検索装置に関する。この文書検索装置は、文書から所定数の文字列を登録キーとして抽出するキー抽出部と、登録キーが抽出された文書の識別情報と当該文書における抽出箇所とを含むデータセットを1単位とするポスティングデータを登録キーごとに記憶したポスティング格納部と、ポスティング格納部におけるポスティングデータの格納領域と、対応する登録キーとを関連付けたツリー構造を構成する記憶領域を有するキー格納部と、を含むインデックス保持部と、検索クエリから所定数の文字列を検索キーとして抽出し、インデックス保持部を参照して検索キーに対するポスティングデータを取得することにより検索クエリを含む文書の検索を行う検索部と、を備え、キー格納部におけるツリー構造の最下層のノードを構成する記憶領域の少なくとも一部に、ポスティングデータの少なくとも一部が記憶され、検索部は少なくとも一部の検索キーについて、キー格納部のみを参照してポスティングデータを取得することを特徴とする。
【0007】
ここで「抽出箇所」は登録キーの開始位置、終了位置などであるが、文書検索装置において共有される所定の規則に従えばその形式は問わない。またポスティングデータは文書の識別情報と抽出箇所以外のパラメータを含んでいてよい。さらに「ツリー構造を構成する記憶領域」とはアルゴリズム上でツリー構造を構成する各ノードに対応した記憶領域のことであり、実際の記憶領域は連続していても分散していてもよい。「検索クエリ」は文書検索を行うためにユーザが入力した文字列であり、語句あるいは文章のいずれでもよく、1つでも複数でもよい。
【0008】
本発明の別の態様は、文書検索方法に関する。この文書検索方法は、文書から所定数の文字列を登録キーとして抽出するステップと、登録キーが抽出された文書の識別情報と当該文書における抽出箇所とを含むデータセットを1単位とするポスティングデータを登録キーごとに生成するステップと、ポスティングデータを登録キーごとに記憶装置に記憶させるステップと、検索クエリから所定数の文字列を検索キーとして抽出するステップと、記憶装置を参照して検索キーに対する前記ポスティングデータを取得することにより検索クエリを含む文書の検索を行うステップと、を含み、記憶装置におけるポスティングデータの記憶領域を、登録キーごとのポスティングデータ数に応じて異ならせることを特徴とする。
【0009】
なお、以上の構成要素の任意の組合せ、本発明の表現を方法、装置、システムなどの間で変換したものもまた、本発明の態様として有効である。
【発明の効果】
【0010】
本発明によれば、ユーザは漏れのない検索を効率的に行うことができる。
【発明を実施するための最良の形態】
【0011】
図1は、文書検索装置100による処理の概要を説明するための模式図である。ユーザが文書検索装置100に対して検索クエリを入力すると、文書検索装置100はその検索クエリを含む文書ファイルを文書データベース200から検索する。検索クエリは一定の意味をなす文字列であり、自然文であってもよいしキーワードであってもよい。文書データベース200の文書ファイルは、XML(eXtensible Markup Language)文書やXHTML(eXtensible HyperText Markup Language)文書のようにタグによって構造化されたファイルであってもよいし、単なるテキストファイルであってもよい。また文書データベース200は図示しないネットワークを介して文書検索装置100と接続されていてもよい。
【0012】
検索に先立ち、文書検索装置100は文書データベース200内の文書についてNgram解析を行いインデックスを作成してインデックス保持部130に格納する。インデックス保持部130はハードディスクなど大容量の記憶装置、またはその一部で実現できる。インデックスの構造については後に詳述する。文書検索装置100は検索クエリに基づきインデックスを参照して、文書データベース200内の適合する文書ファイルを特定し、検索結果として画面表示する。その際、一般的に用いられるスコアリングの手法によって得られたスコアに基づき結果の表示順を決定してもよい。こうして、文書検索装置100のユーザは、任意の検索クエリを含む文書ファイルを探し出すことができる。
【0013】
図2は文書検索装置100の詳細な構成を示している。ここに示す各ブロックは、ハードウェア的には、コンピュータのCPUをはじめとする素子や機械装置で実現でき、ソフトウェア的にはコンピュータプログラム等によって実現されるが、ここでは、それらの連携によって実現される機能ブロックを描いている。したがって、これらの機能ブロックはハードウェア、ソフトウェアの組合せによっていろいろなかたちで実現できることは、当業者には理解されるところである。
【0014】
文書検索装置100はユーザによる入力の受け付けや結果の出力を担うユーザインタフェース処理部110、検索対象の文書についてのデータをインデックスに登録する登録部120、入力された検索クエリに基づき検索を行う検索部160、およびインデックス保持部130を含む。文書検索装置100はさらに、各機能ブロックが処理を行うために必要なデータやプログラムを一時的に格納するメモリ170を含む。
【0015】
ユーザインタフェース処理部110は、ユーザからの入力処理やユーザに対する情報表示のようなユーザインタフェース全般に関する処理を担当する。本実施の形態においては、ユーザインタフェース処理部110により文書検索装置100のユーザインタフェースサービスが提供されるものとして説明する。別例として、ユーザはインターネットを介して文書検索装置100を操作してもよい。この場合、図示しない通信部が、ユーザ端末からの操作指示情報を受信し、またその操作指示に基づいて実行された処理結果情報をユーザ端末に送信することになる。
【0016】
ユーザインタフェース処理部110は文書取得部112、表示部114、および検索クエリ取得部116を含む。新規の文書データベース200を構築した場合や、元からある文書データベース200に新規の文書ファイルを登録して検索対象とする場合に、文書取得部112は当該文書ファイル(以後、登録文書ファイルと呼ぶ)の情報をユーザからの入力によって取得し、登録部120へ供給する。この文書ファイルの情報は、文書データベース200に保存されている文書ファイルを指定する情報でもよいし、別の場所に保存されている文書ファイルを指定する情報でもよい。後者の場合、文書検索装置100は読み出した文書ファイルを文書データベース200へ保存するようにしてもよい。検索クエリ取得部116は、検索を行いたいユーザによって入力された検索クエリを受け付け、検索部160に供給する。
【0017】
登録部120はキー抽出部122、ポスティング生成部124、ポスティング記憶領域決定部126、およびデータ書込み部128を含む。キー抽出部122は、文書取得部112から供給された文書ファイルの情報に従い登録文書ファイルを読み出し、走査することにより、あらかじめ定められた文字数、すなわち所定のグラム数を有するキーを抽出する。例えば「アメリカ合衆国の大統領」というテキストであれば、「アメ:メリ:リカ:・・・:統領」のようにキーを抽出する。この例におけるキーは2グラムである。グラム数は最適な値をあらかじめ設定しておく。以後の説明では登録文書ファイルから抽出されたキーを「登録キー」と呼ぶ。
【0018】
ポスティング生成部124は、登録文書ファイルに対し一意に定めた識別情情報である文書IDを付与するとともに、各登録キーに対するポスティングデータを生成する。ポスティングデータは、各登録キーがどの文書のどの位置に出現したかを表す情報であり、例えば[文書ID,キー開始位置,キー終了位置]という構造を有するデータセットである。抽出した登録キーの中に同一のものがあれば、対応するポスティングデータをまとめる。例えば「アメ」なるキーが4つ抽出されていれば、キー「アメ」に対し4つのポスティングデータが生成される。
【0019】
ポスティング記憶領域決定部126は、生成されたポスティングデータをインデックス保持部130のどの領域に記憶させるかを決定し、データ書込み部128は当該決定に従いポスティングデータおよびそれに係る情報をインデックス保持部130に追加して書き込む。ポスティング記憶領域決定部126は、ポスティングデータを記憶させる記憶領域の決定以外に、記憶領域決定のための各種処理も行う。ポスティングデータの記憶領域については後に詳述する。
【0020】
検索部160はポスティング取得部162および文書データ取得部164を含む。ポスティング取得部162は検索クエリからキーを抽出し、インデックス保持部130を参照して当該キーに対応するポスティングデータを取得する。以後、検索クエリから抽出したキーを「検索キー」と呼ぶ。ポスティング取得部162は、検索キーが全て含まれる文書を各キーのポスティングデータに含まれる文書IDから特定し、さらにそれらの検索キーが検索クエリにおける順序で連続して出現する文書を、ポスティングデータに含まれるキー開始位置、キー終了位置に基づき絞り込む。これにより検索クエリを含む文書を特定できる。なおここでは基本的な処理内容のみを説明するが、検索処理に一般的に用いられるあらゆる技術を組み合わせてもよい。
【0021】
文書データ取得部164は、特定された文書の文書IDに基づき文書データベース200から該当文書の少なくとも一部や記憶先のアドレスなどを取得し、ユーザインタフェース処理部110の表示部114が検索結果として表示できるように表示データを整えメモリ170に保存する。
【0022】
ここでインデックス保持部130に保持されたインデックスの構造および記憶領域について説明する。インデックスは、登録文書ファイルから抽出された登録キーとポスティングデータとを関連付けたデータである。登録キーはグラム数に応じて機械的に切り出されるため、同一の登録キーをまとめてもその種類は膨大である。一方、検索時には検索キーに合致した、インデックス内の登録キーを探し出し、それと関連付けられたポスティングデータを特定する処理がなされる。膨大な種類の登録キーの中から検索キーを効率よく検出するために、一般に利用されるのがB+ツリー(Balanced plus tree)のアルゴリズムである。
【0023】
このとき用いられるB+ツリーは、所定の規則でソートされた登録キーの列の範囲によって下層のノードへの分岐を決定するルートノードおよびブランチノードと、末端のノードであり、ツリーによって最終的に絞り込まれた登録キーの候補と、各登録キーのポスティングデータの記憶領域を示すポインタとが記述されたリーフノードからなるツリー構造を有する。検索処理時には、検索キーに従いルートノードから下層へノードを辿っていけば、行き着いたリーフノードに記述された登録キーの候補の中に検索キーと同一のものが含まれており、最終的に所望のポスティングデータへのポインタが得られることになる。
【0024】
このような検索処理においてはまず、(1)B+ツリー構造が格納された記憶領域にアクセスしてポスティングデータへのポインタを取得し、(2)ポスティングデータが格納された記憶領域にアクセスしてポスティングデータを取得する、という最低2回のアクセスを必要とする。1つの検索クエリからは通常、複数の検索キーが抽出されるため、それらの検索キーに対し同様の処理を繰り返すと、記憶領域へのアクセス回数が増大する。キャッシュメモリなどを用いても、検索条件によっては看過できない程の時間を要する場合がある。
【0025】
本発明者は検索に要する時間を短縮するため鋭意研究を重ねた結果、インデックスに係る以下の知見を得るに至った。表1は、一般的な文書データベースのインデックスにおける、キーごとのポスティングデータ数の分布を表している。このデータは87万7713の文書ファイルから2グラムの登録キーを抽出した場合であり、このとき抽出された登録キーは1339103個であった。
【0026】
【表1】
【0027】
例えば「ポスティング数」が「3」の行を見ると、3個のポスティングデータを有する登録キーは、「合計」欄のとおり「94038」個あり、ポスティングデータ数が3個までの累積値、すなわち1〜3個のポスティングデータを有する登録キーの個数は「累積」欄のとおり「613369」個である。そして全登録キーのうち1〜3個のポスティングデータを有する登録キーの割合は、「累積割合」欄のとおり「45.8%」である。同表によれば、全登録キーのうち55%程度はポスティングデータ数が5個以下の登録キーであることがわかる。それに対し、1001個以上のポスティングデータを有する登録キーは全体のわずか0.6%である。
【0028】
したがって上述のようにB+ツリーからポインタを取得し、ポインタからポスティングデータを取得する構成においては、わずか数個のポスティングデータを取得するために別の記憶領域へアクセスし直している可能性が少なからずあるといえる。本発明者はこの点に改良の余地を見出し、ポスティングデータの取得を効率的に行うために次のような実施の形態に想到した。
【0029】
本実施の形態でも基本的には上述のアルゴリズムを採用する。そのため、インデックス保持部130には、B+ツリーを格納するキー格納部132および各ポスティングデータを格納するポスティング格納部134が含まれる。したがって一般的なB+ツリーのリーフノードにおいて記述されるポスティングデータへのポインタは、ポスティング格納部134内の記憶領域を示す。以後、リーフノードやポスティングデータの記憶領域はページを単位として説明し、ポインタはページ番号とする。またこれ以後、登録キーとポスティングデータとの関連付けはB+ツリーを用いて行うものとするが、本実施の形態はこれに限らず、例えばBツリーなどでもよい。
【0030】
一方、本実施の形態では、登録キーの絞込みを行うためのB+ツリー構造の中に、ポスティングデータの一部を組み入れる。すなわち、本実施の形態のリーフページ136には、登録キーとポスティングデータのページ番号との組み合わせのみならず、登録キーとポスティングデータそのものの組み合わせも記述される。したがってポスティング記憶領域決定部126は、ポスティングデータをキー格納部132、すなわちB+ツリーのリーフページ136に記憶させるか、ポスティング格納部134へ記憶させるか、を決定する。
【0031】
ポスティング記憶領域決定部126は、登録キーごとのポスティングデータの数、すなわち、登録文書ファイルから新たに生成された登録キーのポスティングデータと、同一の登録キーに対しインデックスに登録済みのポスティングデータとの合計によって、当該登録キーのポスティングデータの記憶領域を決定する。具体的にはポスティングデータの数にしきい値を設け、しきい値以下の数のポスティングデータしか持たない登録キーであればB+ツリーのリーフページ136に記述し、しきい値より大きい数のポスティングデータを有する登録キーについてはポスティング格納部134内の領域に記述する。
【0032】
例えばしきい値を「5」とした場合、表1に示したような文書データベースでは、約55%の登録キーのポスティングデータは、キー格納部132のみにアクセスすることによって取得することができる。また5個程度のポスティングのデータサイズであればリーフページ136の記憶容量を圧迫することがなく、B+ツリー構造はそのバランスを損なうことなくそのまま用いることができる。結果としてインデックス保持部130へのアクセス回数のみが削減され、短期間で効率のよい検索処理が可能となる。
【0033】
さらにポスティング記憶領域決定部126は、所定の文書数が登録されるごとに、全体に対する登録キーの割合に基づき上述のしきい値を変化させる。例えば文書が10万文書登録されるごとに、1個のポスティングデータを有する登録キーからの累積割合が60%を超えない登録キーが有する最大のポスティングデータ数へしきい値を変更する。これは、登録される文書数が増加するほど、当然登録キーごとのポスティング数が増加する傾向となるための措置である。そのような状況でしきい値をあるポスティングデータ数で固定してしまうと、登録文書の増加とともに、しきい値より多くのポスティングデータ数を有する登録キーの割合が増加していき、結局アクセス回数の削減効果が薄れてしまう。
【0034】
そこで累積割合に基づきしきい値を調整し、常にある割合の登録キーについてはリーフページ136からポスティングデータが得られるようにする。表1によれば、キーごとのポスティングデータ数が増加するほど累積割合の増加量は小さくなる。すなわち登録文書数が増加しても、累積割合が60%などとなる登録キーのポスティングデータ数が急激に増加する可能性は低いと考えられる。したがって、上述のようにしきい値を変化させても、リーフページ136の容量を圧迫したりB+ツリーのバランスを損なったりする程のポスティングデータが記述される可能性は低く、結果として上述したような効果を登録文書数の多少に関わらず定常的に得ることができる。
【0035】
ポスティングデータをリーフページ136に記述する場合、データ書込み部128は、対応する登録キーが記述されているリーフページ136にポスティングデータを追加して書き込む。ポスティングデータをポスティング格納部134に格納する場合、データ書込み部128は、対応する登録キーが記述されているリーフページ136を参照し、当該登録キーに対応づけて記述された、ポスティングデータのページ番号を取得して、ポスティング格納部134内の該当ページにポスティングデータを追加して書き込む。
【0036】
図2のキー格納部132やポスティング格納部134に示した最も小さい単位の矩形はページを表している。上述したとおり、キー格納部132およびポスティング格納部134はそれぞれB+ツリーおよびポスティングデータを格納するが、B+ツリーのリーフページ136に記述されたデータにはポスティングデータも含まれる。同図ではそのようなページを網掛けで表している。リーフページ136以外のリーフページにもポスティングデータを記述してよいが、ここではリーフページ136に代表させている。
【0037】
ポスティング格納部134には当然、ポスティングデータが格納されるため、それを記述したページとして網掛けされた矩形がいくつか示されているが、本実施の形態では登録キーごとのポスティングデータの数により、そのページ構成を異ならせる。具体的には、1ページに複数の登録キーのポスティングデータを記述する共有ページ137、1ページ以上に一の登録キーのポスティングデータを記述する専有ページ138、文書IDをキーとした2層のB+ツリー構造のリーフページに一の登録キーのポスティングデータを記述した2層ツリーページ140、同じく3層のB+ツリー構造により一の登録キーのポスティングデータを記述した3層ツリーページ142である。なお各ページの総数はポスティングデータの数によって増減する。それぞれのページ構成の詳細は後に述べる。
【0038】
図3は、キー格納部132に格納されるB+ツリーの構造を模式的に示している。B+ツリー20は、ルートページ22、ブランチページ24および26、リーフページ28、30、および136を含む。ただしページ数や層の深さはこれに限らない。各ページの左上に示した「#番号」はそれぞれのページに一意に設定されたページ番号である。
【0039】
まずページ番号#1のルートページ22を見ると、「5」、「キーC」、「8」、「キーF」といったデータ列が記述されている。ここで「キーC」、「キーF」は「アメ」、「メリ」など具体的な登録キーの文字列である。同図の場合、ソートされた登録キーの列の先頭から「キーC」の前までの登録キーについては下層のページ番号#5のページに記述されており、「キーC」から「キーF」の前までの登録キーについては下層のページ番号#8のページに記述されていることを示している。
【0040】
ページ番号#5のブランチページ24も同様に、先頭から「キーA」の前までの登録キーについてはページ番号#36のページに、「キーA」から「キーB」の前までの登録キーについてはページ番号#46のページに記述されていることを示している。ページ番号#8のブランチページ26も同様である。これに従い、ページ番号#36のリーフページ28には先頭から「キーA」の前までの登録キーのポスティングデータについての情報が、ページ番号#46のリーフページ30には「キーA」から「キーB」の前までの登録キーのポスティングデータについての情報が記述される。
【0041】
同図では、リーフページ28、30などに記述されるデータを、リーフページ136を代表させて図示している。上述したとおりリーフページ136には、複数の登録キーのそれぞれに対し、ポスティングデータそのもの、またはポスティング格納部134におけるポスティングデータを記述したページ番号のいずれかが記述される。同図は、「キーG」、「キーH」、「キーJ」、「キーL」に対しポスティングデータそのものが記述され、「キーI」に対しては図2の共有ページ137のページ番号、「キーK」に対しては専有ページ138の先頭のページ番号、「キーM」に対しては2層ツリーページ140のルートページのページ番号が記述されていることを示している。
【0042】
次に、これまで述べた構成を有する文書検索装置100の動作について説明する。なお検索部160が行う検索クエリに基づく検索処理の手順は、上述したとおり一般的な手法を用いることができるため、ここではインデックスへの登録手法に主眼を置き説明する。図4は文書検索装置100によって登録文書ファイルを解析し、インデックスへ登録する処理手順を示すフローチャートである。ここではインデックス保持部130に、それまでに解析を済ませた文書ファイルのインデックスが既に格納されており、新たな登録文書の情報を登録する場合について述べるが、新規にインデックスを生成する場合でも、本実施の形態の特徴的な手順は同様であり、B+ツリーの構築などは一般的な手法を適用することができる。
【0043】
まずユーザが、ユーザインタフェース処理部110の文書取得部112に対し登録文書ファイルの情報を入力すると、登録部120のキー抽出部122は当該登録文書ファイルを読み出し、メモリ170に保存する(S10)。キー抽出部122は、登録文書ファイルからテキストデータを抽出し(S12)、それを走査することにより所定のグラム数の登録キーを抽出していく(S14)。次にポスティング生成部124は、登録文書ファイルに文書IDを付与するとともに、キー抽出部122が抽出した登録キーごとに、当該文書IDと、テキストデータにおける当該登録キーの開始位置および終了位置とからなるポスティングデータを生成する(S16)。
【0044】
次にポスティング記憶領域決定部126が、生成したポスティングデータの格納領域を決定し、データ書込み部128がそれに従い書き込みを行う(S18)。この際、前述したとおり、インデックスに登録済みのポスティングデータを含めた登録キーごとのポスティングデータ数としきい値との大小関係によって格納場所を決定する。また今回抽出した登録キーのポスティングデータをリーフページ136に書き込むことによりその登録キーのポスティングデータ数がしきい値を超えてしまう場合は、リーフページ136に記述済みのポスティングデータごとポスティング格納部134へ移動させる。具体的な処理手順は図5を参照して説明する。
【0045】
図5は、S18においてポスティング記憶領域決定部126がポスティングデータの記憶領域を決定し、データ書込み部128が書き込みを行う手順を示すフローチャートである。前提として、文書ファイルの累積数を示す変数iは“0”に初期化され、リーフページ136に記述できるポスティングデータ数のしきい値Nには初期値、たとえば“5”が代入されているとする。まず変数iをインクリメントした後(S28)、登録文書ファイルの情報を新たに登録した場合のインデックスについて表1に示した各数値を計算し、登録キーごとのポスティング数に対する登録キーの個数の累積割合を算出する(S30)。累積割合を含む表1のデータは、メモリ170などに一時保存し、文書検索装置100の処理を終了させる際にインデックス保持部130を構成するハードディスクなどに保存しておく。新たな文書登録を行う際は、そのように保存された以前のデータを参照して計算を行い、各値を更新してけばよい。
【0046】
次に変数iに対し所定の文書数M、例えば10万で剰余算を行い、解が0でなければ、すなわち今回の登録文書ファイルが10万の倍数文書目でなければ(S32のN)、抽出した各登録キーについてB+ツリーを辿り、まずリーフページ136に当該登録キーが記述されているかどうかを確認する(S37)。登録キーが以前に登録されていなければ、リーフページ136には当該登録キーが記述されていないため(S37のN)、リーフページ136に登録キーとそのポスティングデータを書き込む(S46)。
【0047】
登録キーが記述されていた場合は(S37のY)、さらにリーフページ136に当該登録キーのポスティングデータが記述されているかどうかを確認する(S38)。ポスティングデータが記述されておらず、ページ番号が記述されている場合は(S38のN)、ポスティング格納部134における当該ページ番号のページにポスティングデータを追加して書き込む(S40)。
【0048】
リーフページ136にポスティングデータが記述されている場合は(S38のY)、新たなポスティングデータの追加によりポスティングデータ数がしきい値Nを超えるかどうかを確認する(S42)。しきい値Nを超えない場合は(S42のY)、そのリーフページ136にポスティングデータを追加して書き込む(S46)。ポスティングデータ数がしきい値Nを超える場合は(S42のN)、それまで記述されていた当該登録キーのポスティングデータをポスティング格納部134に用意されている共有ページ137などに移動させたうえで、新たなポスティングデータを同ページに追加して書き込む(S48)。この際、移動元のリーフページ136には、当該キーに対応させて移動先のページのページ番号を書き込んでおく。
【0049】
S32において当該登録文書ファイルが所定の文書数Mの倍数であった場合は(S32のY)、S30において算出した累積割合に基づきしきい値Nを変更する(S34)。ここでN(60%)は累積割合が60%を超えない登録キーの最大のポスティングデータ数を表す。なお60%は例示であり、データベースの種類や文書検索装置100の処理性能などに鑑み実験などにより最適値を決定してよい。そしてしきい値Nの変更によってリーフページ136に記述されるべきとなったポスティングデータがあれば、ポスティング格納部134のページからリーフページ136に移動する(S36)。その後の処理は上述したのと同様である。
【0050】
以上の手順により、登録されている文書数の増加に伴いポスティングデータ数のしきい値を変化させながら、ポスティングデータをリーフページ136およびポスティング格納部134へ振り分ける態様を実現することができる。
【0051】
次にポスティング格納部134に格納された、ポスティングデータを記述するページの構成について説明する。上述したように本実施の形態では登録キーごとのポスティングデータ数により、共有ページ137、専有ページ138、2層ツリーページ140、3層ツリーページ142のいずれかにポスティングデータを記述し、記憶領域を効率的に使用するとともに検索の処理効率を向上させる。なおツリーページは必要に応じて4層以上でもよい。
【0052】
図6は共有ページ137の構成を模式的に示している。共有ページ137には複数のキーのポスティングデータを可能な限り詰めた状態で記述する。リーフページ136においてポスティングデータ数がしきい値を超えた登録キーのポスティングデータは、この共有ページ137に移動する。1ページのデータ容量、8KBを考慮すると、登録キーごとのポスティングデータ数が最大500個程度であれば、共有ページ137内に記述できる。
【0053】
共有ページ137は、ポスティングデータ領域82a〜82f、ポインタ領域84a〜84f、および空き領域86を含む。同図は、6つの登録キーのポスティングデータが、6つの連続したポスティングデータ領域82a〜82fのぞれぞれに記述されている状態を示している。登録キーごとのポスティングデータ数は一定でないため、ポスティングデータ長も変動する。そこで各ポスティングデータ領域82a〜82fの、ページ先頭からのオフセット値をポインタ領域84a〜84fにそれぞれ記述する。新たなポスティングデータをポスティングデータ領域82a〜82fのいずれかに追加した場合は、以後のポスティングデータ領域のオフセット値を更新する。
【0054】
リーフページ136からポスティングデータを移動する際は、充填率が高くなるような共有ページ137を探して格納する。そのために空き領域86の容量を管理する。例えば2ビットのレジスタ(図示せず)を用意し、空き領域86の容量について、25%未満、25%以上50%未満、50%以上75%未満、75%以上100%以下、の4段階を表すデータを保持する。レジスタの値は文書検索装置100の処理終了時にはハードディスクなどに保存し、次回の登録処理において参照する。
【0055】
表1によれば、500個以下のポスティングデータを有する登録キーは全体の90%程度にも上るため、ポスティングデータをリーフページ136に格納するほか、共有ページ137に詰めて格納することにより、キーごとに1ページを用意するといった従来の手法に比べて格段に所要容量を削減することができる。また、新たな空きページを確保するなどの領域管理の処理を省略でき、登録処理時の効率が向上する。
【0056】
共有ページ137に記述したある登録キーのポスティングデータが増加し、1ページ以内で収まらなくなった場合は、当該ポスティングデータを専有ページ138へ移動させる。専有ページは一の登録キーが専有して使う1以上のページで構成され、ポスティングデータ数によってページを単純連結していく。例えば最大8ページまで連結可能とする。これにより一の登録キーにつき500〜4000個程度のポスティングデータが格納できる。
【0057】
最大に連結した専有ページ138の容量をポスティングデータが超えた場合は、当該ポスティングデータをリーフページに格納した2層ツリーページ140を構築する。図7は2層ツリーページ140の構成を模式的に示している。2層ツリーページ140は基本的には図3で示したのと同様のB+ツリー構造を有する。ただしページの分岐は登録キーに代わり文書IDによって行う。
【0058】
前述したように、検索部160が検索処理を行う場合、入力された検索クエリから検索キーを抽出し、検索キーの全てを含み、かつ検索クエリにおける順番で連続して出現する文書を検出する。検索クエリから検索キーとして「キーa」、「キーb」が抽出されたとすると、まず「キーa」のポスティングデータを取得し、その文書IDをメモリ170に保存する。そして「キーb」のポスティングデータのうち、メモリ170に保存しておいた文書IDを有するポスティングデータを取得すれば、それはすなわち「キーa」および「キーb」を含む文書のポスティングデータである。
【0059】
ここで「キーb」が4000個を超える膨大なポスティングデータを有するとすると、それらのポスティングデータを単に羅列したデータ構造においては、先頭から全てのポスティングデータを確認し、「キーa」を含む文書の文書IDと照合していかなければならない。検索キーが多いほど、この処理を繰り返す必要が生じ、結果としてポスティング格納部134へのアクセス回数が増大する。
【0060】
そこで本実施の形態では、4000個を超えるようなポスティングデータを有する「キーb」のポスティングデータを取得する際、「キーa」を含む文書の文書IDを元に図7に示すようなB+ツリー構造を辿ることにより、「キーa」を含む文書のポスティングデータのみを確認する。図7において2層ツリーページ140は、ルートページ42、ブランチページ44および46、リーフページ48、50、52、54を含む。図3と同様、ルートページ42には、ある登録キーに対する全ポスティングデータに記載された文書IDをソートした文書ID列のうち、先頭から「ID_c」の前までの文書IDを有するポスティングデータの情報がページ番号#1のページに、「ID_c」から「ID_f」の前までの文書IDを有するポスティングデータの情報がページ番号#52のページに記述されていることが示されている。
【0061】
同様に、ページ番号#1のブランチページ44には、先頭から「ID_a」の前までの文書IDを有するポスティングデータがページ番号#2のページに、「ID_a」から「ID_b」の前までの文書IDを有するポスティングデータがページ番号#3のページに記述されていることが示されている。ページ番号#52のブランチページ46も同様である。ページ番号#2のリーフページ48、ページ番号#3のリーフページ50、ページ番号#17のリーフページ52、ページ番号#18のリーフページ54にはそれぞれ、該当する文書IDを有するポスティングデータが記述されている。
【0062】
このような構成とすることにより、上述の例では、「キーa」を含まない文書に対するポスティングデータを読み飛ばすことができ、ポスティング格納部134へのアクセス回数を削減することができる。ポスティングの確認に係る処理も省略できるため、結果として検索処理にかかる時間を顕著に削減することができる。
【0063】
2層ツリーページ140には、最大約8MB、すなわち50万個程度のポスティングデータを格納することができる。ある登録キーのポスティングデータが2層ツリーページ140に格納できる数を超えた場合は、当該ポスティングデータをリーフページに格納した3層ツリーページ142を構築する。3層ツリーページ142はブランチページが2層になっているほかは2層ツリーページ140と同様である。3層ツリーページ142には、最大8GB、すなわち5億個程度のポスティングデータを格納することができる。
【0064】
以上述べた本実施の形態によれば、登録キーごとのポスティングデータ数に応じて、ポスティングデータの格納領域を、キー格納部132におけるB+ツリー構造のリーフページ136、ポスティング格納部134における共有ページ137、専有ページ138、2層ツリーページ140、3層ツリーページ142と変化させる。また、文書の登録数によってポスティングデータ数が増加した場合は、上述の順番でデータを移動させていく。これにより、常にポスティングデータのデータサイズに適合し、かつ無駄のない記憶領域管理を行うことができる。
【0065】
さらにB+ツリー構造のバランスを損なわない程度のサイズのポスティングデータをキー格納部132のB+ツリーのリーフページ136に格納することにより、検索処理時にポスティング格納部134へアクセスし直す必要がなくなり、全体としてアクセス回数が減るため、検索処理を高速化できる。一般的な文書データベースでは、多くの登録キーのポスティングデータが数個程度であるため、その効果を顕著に得ることができる。
【0066】
また、ポスティングデータが1ページに満たないサイズの場合は、複数の登録キーのポスティングデータを共有ページ137内に詰めて格納する。これにより、余分な記憶領域を確保する必要がなくなり、記憶領域の節約になる。また、リーフページ136からポスティングデータを移動させた場合などに新たにページを確保する処理を省略できる可能性が高くなる。さらに、4000個を超えるような膨大なポスティングデータを有する登録キーについては、B+ツリーを構築してリーフページにポスティングデータを格納する。文書IDによってB+ツリーを辿ることにより、不必要なポスティングデータを読み飛ばすことができ、ポスティング格納部134へのアクセス回数を削減できるとともにポスティングデータの確認に要する時間を短縮することができる。
【0067】
さらに本実施の形態では、登録された文書数が増加するのに伴い、キー格納部132のB+ツリーのリーフページ136に格納するポスティングデータ数のしきい値を調整する。これにより、登録文書数の増加により全体的にポスティングデータ数が増加しても、常にある割合の登録キーのポスティングデータがリーフページ136に格納される。一般的な文書データベースでは、文書数が増加しても登録キーごとのポスティングデータ数はそれほど増加しないため、しきい値を多少変化させてもB+ツリーのバランスを損なうことがない。結果として他に影響を及ぼすことなく実施の形態の形骸化を防止することができる。
【0068】
以上、本発明を実施の形態をもとに説明した。この実施の形態は例示であり、それらの各構成要素や各処理プロセスの組合せにいろいろな変形例が可能なこと、またそうした変形例も本発明の範囲にあることは当業者に理解されるところである。
【0069】
例えば上述の実施の形態では、共有ページ、専有ページ、2層ツリーページ、3層ツリーページなる順序で、それまで格納されていたページの容量を超えた時点で、ポスティングデータを移動させた。一方、あらかじめポスティングデータのサイズを予想して、それに応じたページを用意するようにしてもよい。例えば、一般的な文書データベースで出現しやすい登録キーと、登録文書数の範囲ごとのポスティングデータのデータサイズとを対応づけた辞書をあらかじめ作成しておき、所定の文書数が登録されるたびに当該辞書を参照して、登録キーごとに必要と予測されるページを用意してもよい。
【0070】
また、登録文書の増加に対するポスティングデータの増加速度を学習することにより、定期的に格納するページの見直しを行ってもよい。これらの場合も、上述の実施の形態と同様の効果を得ることができる。またポスティングデータを移動させる処理の実行予定が把握できるため、並列して他の処理を行っている場合などにトータルな処理の効率化を図ることができる。
【0071】
また本実施の形態では、キー格納部132におけるB+ツリーのリーフページへ格納するポスティングデータは、あるしきい値以下のポスティングデータを有する登録キーのものとした。一方、しきい値を設定せずに、登録キーそのものによって決定してもよい。この場合も、登録キーと、登録文書数の範囲ごとの最適な格納先とを対応付けた辞書をあらかじめ作成しておき、それを参照することにより、リーフページまたはその他のページを格納先として決定してもよい。
【図面の簡単な説明】
【0072】
【図1】本実施の形態の文書検索装置による処理の概要を説明するための模式図である。
【図2】本実施の形態の文書検索装置の詳細な構成を示す図である。
【図3】本実施の形態においてキー格納部に格納されるB+ツリーの構造を模式的に示す図である。
【図4】本実施の形態の文書検索装置によって登録文書ファイルを解析し、インデックスへ登録する処理手順を示すフローチャートである。
【図5】本実施の形態においてポスティングデータを格納する記憶領域を決定し、書き込みを行う手順を示すフローチャートである。
【図6】本実施の形態における共有ページの構成を模式的に示す図である。
【図7】本実施の形態における2層ツリーページの構成を模式的に示す図である。
【符号の説明】
【0073】
100 文書検索装置、 110 ユーザインタフェース処理部、 112 文書取得部、 116 検索クエリ取得部、 120 登録部、 122 キー抽出部、 124 ポスティング生成部、 126 ポスティング記憶領域決定部、 128 データ書込み部、 130 インデックス保持部、 132 キー格納部、 134 ポスティング格納部、 137 共有ページ、 138 専有ページ、 140 2層ツリーページ、 142 3層ツリーページ、 160 検索部、 162 ポスティング取得部、 164 文書データ取得部、 200 文書データベース。
【特許請求の範囲】
【請求項1】
文書から所定数の文字列を登録キーとして抽出するキー抽出部と、
前記登録キーが抽出された文書の識別情報と当該文書における抽出箇所とを含むデータセットを1単位とするポスティングデータを前記登録キーごとに記憶したポスティング格納部と、前記ポスティング格納部における前記ポスティングデータの格納領域と、対応する登録キーとを関連付けたツリー構造を構成する記憶領域を有するキー格納部と、を含むインデックス保持部と、
検索クエリから所定数の文字列を検索キーとして抽出し、前記インデックス保持部を参照して前記検索キーに対する前記ポスティングデータを取得することにより前記検索クエリを含む文書の検索を行う検索部と、
を備え、
前記キー格納部における前記ツリー構造の最下層のノードを構成する記憶領域の少なくとも一部に、前記ポスティングデータの少なくとも一部が記憶され、前記検索部は少なくとも一部の検索キーについて、前記キー格納部のみを参照して前記ポスティングデータを取得することを特徴とする文書検索装置。
【請求項2】
前記キー格納部における前記ツリー構造の最下層のノードを構成する記憶領域に記憶されるポスティングデータは、前記ポスティングデータの数が与えられたしきい値以下である前記登録キーのポスティングデータであることを特徴とする請求項1に記載の文書検索装置。
【請求項3】
前記キー抽出部が新たな文書から前記登録キーを抽出した際、当該登録キーごとに前記ポスティングデータを生成するポスティング生成部と、
前記ポスティング生成部が生成した前記ポスティングデータの記憶先を、前記登録キーごとに、前記ツリー構造の最下層のノードを構成する記憶領域および前記ポスティング格納部のいずれかに決定するポスティング記憶領域決定部と、
をさらに備え、
それまで前記ツリー構造の最下層のノードを構成する記憶領域に記憶されていたポスティングデータに新たなポスティングデータを追加することにより、当該登録キーのポスティングデータ数が前記しきい値を超える場合は、前記ポスティング記憶領域決定部は、当該登録キーのポスティングデータを全て、前記ポスティング格納部に移動して記憶させることを特徴とする請求項2に記載の文書検索装置。
【請求項4】
前記ポスティング記憶領域決定部は、前記インデックス保持部に記憶された全登録キーに対して所定の割合をなす前記登録キーのポスティングデータが、前記ツリー構造の最下層のノードを構成する記憶領域に記憶されるように、前記しきい値を調整することを特徴とする請求項3に記載の文書検索装置。
【請求項5】
前記ポスティング格納部は、複数の前記登録キーのそれぞれに与えた可変長の記憶領域が混在する共有記憶領域と、各登録キーが専有する所定単位の記憶領域を有する専有記憶領域と、各登録キーに対し構築され、前記文書の識別情報と前記ポスティングデータとを関連付けたツリー構造を構成する記憶領域を有するツリー記憶領域と、の少なくともいずれかを含み、
前記ポスティング記憶領域決定部は、前記ポスティング格納部に格納する前記ポスティングデータの記憶先を、前記登録キーごとのポスティングデータの数に応じて、前記共有記憶領域、前記専有記憶領域、前記ツリー記憶領域のいずれかに決定することを特徴とする請求項3に記載の文書検索装置。
【請求項6】
文書から所定数の文字列を登録キーとして抽出するステップと、
前記登録キーが抽出された文書の識別情報と当該文書における抽出箇所とを含むデータセットを1単位とするポスティングデータを前記登録キーごとに生成するステップと、
前記ポスティングデータを前記登録キーごとに記憶装置に記憶させるステップと、
検索クエリから所定数の文字列を検索キーとして抽出するステップと、
前記記憶装置を参照して前記検索キーに対する前記ポスティングデータを取得することにより前記検索クエリを含む文書の検索を行うステップと、を含み、
前記記憶装置における前記ポスティングデータの記憶領域を、前記登録キーごとのポスティングデータ数に応じて異ならせることを特徴とする文書検索方法。
【請求項7】
前記登録キーと前記ポスティングデータの前記記憶装置における格納領域とを関連付けたツリー構造を前記記憶装置に記憶させるステップをさらに含み、
前記ポスティングデータを前記記憶装置に記憶させるステップは、前記ポスティングデータの少なくとも一部を、前記ツリー構造の最下層のノードを構成する記憶領域の少なくとも一部に記憶させることを特徴とする請求項6に記載の文書検索方法。
【請求項8】
前記登録キーごとの前記ポスティングデータ数の最新値に応じて、少なくとも一部の前記登録キーの前記ポスティングデータを、別の記憶領域へ移動させるステップをさらに含むことを特徴とする請求項6に記載の文書検索方法。
【請求項9】
文書から所定数の文字列を登録キーとして全て抽出する機能と、
前記登録キーが抽出された文書の識別情報と当該文書における抽出箇所とを1単位とするポスティングデータを前記登録キーごとに生成する機能と、
前記ポスティングデータを前記登録キーごとに記憶装置に記憶させる機能と、
検索クエリから所定数の文字列を検索キーとして抽出する機能と、
前記記憶装置を参照して前記検索キーに対する前記ポスティングデータを取得することにより前記検索クエリを含む文書の検索を行う機能と、
をコンピュータに実現させるコンピュータプログラムであって、
前記記憶装置における前記ポスティングデータの記憶領域を、前記登録キーごとのポスティングデータ数に応じて異ならせることを特徴とするコンピュータプログラム。
【請求項1】
文書から所定数の文字列を登録キーとして抽出するキー抽出部と、
前記登録キーが抽出された文書の識別情報と当該文書における抽出箇所とを含むデータセットを1単位とするポスティングデータを前記登録キーごとに記憶したポスティング格納部と、前記ポスティング格納部における前記ポスティングデータの格納領域と、対応する登録キーとを関連付けたツリー構造を構成する記憶領域を有するキー格納部と、を含むインデックス保持部と、
検索クエリから所定数の文字列を検索キーとして抽出し、前記インデックス保持部を参照して前記検索キーに対する前記ポスティングデータを取得することにより前記検索クエリを含む文書の検索を行う検索部と、
を備え、
前記キー格納部における前記ツリー構造の最下層のノードを構成する記憶領域の少なくとも一部に、前記ポスティングデータの少なくとも一部が記憶され、前記検索部は少なくとも一部の検索キーについて、前記キー格納部のみを参照して前記ポスティングデータを取得することを特徴とする文書検索装置。
【請求項2】
前記キー格納部における前記ツリー構造の最下層のノードを構成する記憶領域に記憶されるポスティングデータは、前記ポスティングデータの数が与えられたしきい値以下である前記登録キーのポスティングデータであることを特徴とする請求項1に記載の文書検索装置。
【請求項3】
前記キー抽出部が新たな文書から前記登録キーを抽出した際、当該登録キーごとに前記ポスティングデータを生成するポスティング生成部と、
前記ポスティング生成部が生成した前記ポスティングデータの記憶先を、前記登録キーごとに、前記ツリー構造の最下層のノードを構成する記憶領域および前記ポスティング格納部のいずれかに決定するポスティング記憶領域決定部と、
をさらに備え、
それまで前記ツリー構造の最下層のノードを構成する記憶領域に記憶されていたポスティングデータに新たなポスティングデータを追加することにより、当該登録キーのポスティングデータ数が前記しきい値を超える場合は、前記ポスティング記憶領域決定部は、当該登録キーのポスティングデータを全て、前記ポスティング格納部に移動して記憶させることを特徴とする請求項2に記載の文書検索装置。
【請求項4】
前記ポスティング記憶領域決定部は、前記インデックス保持部に記憶された全登録キーに対して所定の割合をなす前記登録キーのポスティングデータが、前記ツリー構造の最下層のノードを構成する記憶領域に記憶されるように、前記しきい値を調整することを特徴とする請求項3に記載の文書検索装置。
【請求項5】
前記ポスティング格納部は、複数の前記登録キーのそれぞれに与えた可変長の記憶領域が混在する共有記憶領域と、各登録キーが専有する所定単位の記憶領域を有する専有記憶領域と、各登録キーに対し構築され、前記文書の識別情報と前記ポスティングデータとを関連付けたツリー構造を構成する記憶領域を有するツリー記憶領域と、の少なくともいずれかを含み、
前記ポスティング記憶領域決定部は、前記ポスティング格納部に格納する前記ポスティングデータの記憶先を、前記登録キーごとのポスティングデータの数に応じて、前記共有記憶領域、前記専有記憶領域、前記ツリー記憶領域のいずれかに決定することを特徴とする請求項3に記載の文書検索装置。
【請求項6】
文書から所定数の文字列を登録キーとして抽出するステップと、
前記登録キーが抽出された文書の識別情報と当該文書における抽出箇所とを含むデータセットを1単位とするポスティングデータを前記登録キーごとに生成するステップと、
前記ポスティングデータを前記登録キーごとに記憶装置に記憶させるステップと、
検索クエリから所定数の文字列を検索キーとして抽出するステップと、
前記記憶装置を参照して前記検索キーに対する前記ポスティングデータを取得することにより前記検索クエリを含む文書の検索を行うステップと、を含み、
前記記憶装置における前記ポスティングデータの記憶領域を、前記登録キーごとのポスティングデータ数に応じて異ならせることを特徴とする文書検索方法。
【請求項7】
前記登録キーと前記ポスティングデータの前記記憶装置における格納領域とを関連付けたツリー構造を前記記憶装置に記憶させるステップをさらに含み、
前記ポスティングデータを前記記憶装置に記憶させるステップは、前記ポスティングデータの少なくとも一部を、前記ツリー構造の最下層のノードを構成する記憶領域の少なくとも一部に記憶させることを特徴とする請求項6に記載の文書検索方法。
【請求項8】
前記登録キーごとの前記ポスティングデータ数の最新値に応じて、少なくとも一部の前記登録キーの前記ポスティングデータを、別の記憶領域へ移動させるステップをさらに含むことを特徴とする請求項6に記載の文書検索方法。
【請求項9】
文書から所定数の文字列を登録キーとして全て抽出する機能と、
前記登録キーが抽出された文書の識別情報と当該文書における抽出箇所とを1単位とするポスティングデータを前記登録キーごとに生成する機能と、
前記ポスティングデータを前記登録キーごとに記憶装置に記憶させる機能と、
検索クエリから所定数の文字列を検索キーとして抽出する機能と、
前記記憶装置を参照して前記検索キーに対する前記ポスティングデータを取得することにより前記検索クエリを含む文書の検索を行う機能と、
をコンピュータに実現させるコンピュータプログラムであって、
前記記憶装置における前記ポスティングデータの記憶領域を、前記登録キーごとのポスティングデータ数に応じて異ならせることを特徴とするコンピュータプログラム。
【図1】

【図2】
【図3】
【図4】

【図5】
【図6】
【図7】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【公開番号】特開2008−83769(P2008−83769A)
【公開日】平成20年4月10日(2008.4.10)
【国際特許分類】
【出願番号】特願2006−260107(P2006−260107)
【出願日】平成18年9月26日(2006.9.26)
【出願人】(390024350)株式会社ジャストシステム (123)
【Fターム(参考)】
【公開日】平成20年4月10日(2008.4.10)
【国際特許分類】
【出願日】平成18年9月26日(2006.9.26)
【出願人】(390024350)株式会社ジャストシステム (123)
【Fターム(参考)】
[ Back to top ]