
文書翻訳システム
【課題】携帯情報端末で取得した文書の一部を含む画像から文書全体の翻訳を得る。
【解決手段】単語からなる原文と原文に対応する翻訳文を対応付けて保持すると共に、原文に含まれる各単語の配置情報を関連付けて保持する翻訳辞書を格納する記憶装置と、画像撮影部で撮影された画像から利用者により指定された着目単語パターンとその着目単語パターンの周辺の単語パターンを対象として文字認識処理を行い、単語パターンの文字コードを出力する文字認識部と、利用者により指定された着目単語パターンと着目単語パターンの周辺の単語パターンに関して相対的な配置情報を抽出する抽出部と、着目単語パターンとその着目単語パターンの周辺の単語パターンに関して、文字認識部より得られた文字コードと、抽出部より得られた相対的な配置情報を用いて翻訳辞書を検索する検索部とを有し、検索部より得られた翻訳文を表示部に表示する。
【解決手段】単語からなる原文と原文に対応する翻訳文を対応付けて保持すると共に、原文に含まれる各単語の配置情報を関連付けて保持する翻訳辞書を格納する記憶装置と、画像撮影部で撮影された画像から利用者により指定された着目単語パターンとその着目単語パターンの周辺の単語パターンを対象として文字認識処理を行い、単語パターンの文字コードを出力する文字認識部と、利用者により指定された着目単語パターンと着目単語パターンの周辺の単語パターンに関して相対的な配置情報を抽出する抽出部と、着目単語パターンとその着目単語パターンの周辺の単語パターンに関して、文字認識部より得られた文字コードと、抽出部より得られた相対的な配置情報を用いて翻訳辞書を検索する検索部とを有し、検索部より得られた翻訳文を表示部に表示する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は文書翻訳システムに係り、特に携帯情報端末で撮影した画像に含まれる文字を認識してその翻訳を得る文書翻訳システム及び翻訳処理方法に関するものである。
【背景技術】
【0002】
カメラを搭載した携帯電話等の携帯端末で撮影した画像に含まれる文字列の文字を認識して、その認識結果である文字テキストを翻訳する技術が種々提案されている。例えば、特許文献1(特開平09−138802公報)には、携帯端末内部に文字認識機能と翻訳機能を持ち、これらの機能を利用して、カメラで撮影した画像内の文字列を認識、翻訳処理する翻訳システムが開示されている。
【0003】
【特許文献1】特開平09−138802公報
【発明の開示】
【発明が解決しようとする課題】
【0004】
携帯端末のカメラで撮影した画像は解像度が低いので、その画像をそのまま文字認識処理した場合、正確に認識されないことがある。従って文字認識の結果得られた文字コードをそのまま翻訳しても翻訳ミスの可能性が高くなる。このような画像の解像度に起因する解決策も色々と提案されている。
【0005】
また、最近では、撮影した文字列の単語レベルではなく、文章レベル更には複数の文章から成る文書全体も翻訳したいというニーズがある。しかし、これは以下のような理由から実現されていない。
即ち、文字認識に適した解像度を得るためには、通常、接写モードで画像を撮影する必要がある。このため、翻訳したい文書全体を画像として取り込むことができないという課題がある。これに対して、対象とする文書全体を撮影しようとすると解像度が下がるので、文字の誤認識が多くなるという問題が生じる。
【0006】
仮に、撮像素子の高解像度化することで解像度の問題を解決できるとしても、翻訳対象の文書全体を撮影しようとすると紙文書の曲がりやレンズなどの光学的歪の影響が無視できなくなり、これも誤認識の原因となる。結果として翻訳ソフトに入力される文章が正しく認識されず、意図した翻訳が行われないという問題が生じる。
【0007】
本発明の目的は、携帯情報端末で取得した文書の一部を含む画像から文書全体の翻訳を得ることができる文書翻訳システムおよび方法を提供することにある。
【課題を解決するための手段】
【0008】
本発明は、画像撮影部と、利用者に操作されて情報を入力する入力部と、表示部を有する携帯情報端末を用いて、画像撮影部で撮影された画像に含まれる文字に関する翻訳を得て、その翻訳を表示部に表示する文書翻訳システムにおいて、単語からなる原文と原文に対応する翻訳文を対応付けて保持すると共に、原文に含まれる各単語の配置情報を関連付けて保持する翻訳辞書を格納する記憶装置と、画像撮影部で撮影された画像から利用者により指定された着目単語パターンとその着目単語パターンの周辺の単語パターンを対象として文字認識処理を行い、単語パターンの文字コードを出力する文字認識部と、利用者により指定された着目単語パターンと着目単語パターンの周辺の単語パターンに関して相対的な配置情報を抽出する抽出部と、着目単語パターンと着目単語パターンの周辺の単語パターンに関して、文字認識部より得られた文字コードと抽出部より得られた相対的な配置情報を用いて翻訳辞書を検索する検索部と、を有し、検索部より得られた翻訳文を表示部に表示する文書翻訳システムである。
好ましくは、前記翻訳辞書部は、原文としての英文とその和訳文を対応付けて格納する。
また、他の好ましい例では、前記翻訳辞書部は、スペースで区切られた単語からなる原文と該原文に対応する翻訳文を対応付けて格納する。
上記相対的な配置情報は、一例によれば、利用者により指定された着目単語パターンの矩形重心から着目単語パターンの各周辺単語パターンの矩形重心に線分を引きその線分間の角度である。
また、他の例では、上記相対的な配置情報は、利用者により指定された着目単語パターンが含まれる行、および、着目単語パターンの各周辺単語パターンが含まれる行の相対的な配置情報である。
【0009】
また、他の好ましい例における、本発明に係る文書翻訳システムは、画像撮影部と、利用者に操作されて情報を入力する入力部と、画像撮影部で撮影された画像に含まれる文字に関する翻訳を得るための処理を行う翻訳処理部と、翻訳処理部により得られた翻訳を表示する表示部を有する携帯情報端末を用いた文書翻訳システムにおいて、原文の文書と該原文に対応する翻訳文の文書を対応付けて格納すると共に、原文に含まれる各形態素の配置情報を関連付けて保持する翻訳辞書を格納する記憶装置と、画像撮影部で撮影された画像から利用者により指定された着目形態素パターンとその着目形態素パターンの周辺の形態素パターンに関して文字認識処理を行い、各形態素の文字コードを出力する文字認識部と、利用者により指定された着目形態素パターンと着目形態素パターンの周辺に存在する形態素パターンに関して相対的な配置情報を抽出する抽出部と、着目形態素パターンと着目形態素パターンの周辺に存在する形態素パターンに関して、文字認識部より得られた文字コードと抽出部より得られた相対的な配置情報を用いて翻訳辞書を検索する検索部と、を有し、検索部より得られた翻訳文を表示部に表示する文書翻訳システムである。
【0010】
また、更に他の好ましい例における、本発明に係る文書翻訳システムは、画像撮影部と、利用者に操作されて情報を入力する入力部と、表示部を有する携帯情報端末を用いて、画像撮影部で撮影された画像に含まれる文字に関する翻訳を得て、その翻訳を表示部に表示する文書翻訳システムにおいて、単語からなる原文と原文に対応する翻訳文を対応付けて保持すると共に、原文に含まれる各文字の配置情報を関連付けて保持する翻訳辞書を格納する記憶装置と、画像撮影部で撮影された画像から利用者により指定された着目文字パターンとその着目文字パターンの周辺の文字パターンを対象として文字認識処理を行い、文字パターンの文字コードを出力する文字認識部と、利用者により指定された着目文字パターンと着目文字パターンの周辺の文字パターンに関して相対的な配置情報を抽出する抽出部と、着目文字パターンと着目文字パターンの周辺の文字パターンに関して、文字認識部より得られた文字コードと抽出部より得られた該相対的な配置情報を用いて、翻訳辞書を検索する検索部と、を有し、検索部より得られた翻訳文を表示部に表示する文書翻訳システムである。
【0011】
本発明はまた、上記文書翻訳システムに関する他の例として、前記翻訳辞書を格納する記憶装置、及び前記検索部を備えるサーバを有する文書翻訳システムであって、携帯情報端末の文字認識部より得られた文字コードと、抽出部より得られた相対的な配置情報を、ネットワークを介してサーバに送信し、サーバにおいて検索部により翻訳辞書を検索した結果得られた翻訳文を、ネットワークを介して携帯情報端末に送信する。
更に、他の例として、前記文字認識部、前記抽出部、前記翻訳辞書を格納する記憶装置、及び前記検索部を備えるサーバを有する文書翻訳システムであって、携帯情報端末の画像撮影部より得られた画像をネットワークを介してサーバに送信し、サーバにおいて検索部により翻訳辞書を検索した結果得られた翻訳文を、ネットワークを介して携帯情報端末に送信する。
好ましい例では、この文書翻訳システムにおける前記翻訳辞書は、単語が含まれる原文を検索するための原単語インデックス部と、原文に含まれる原単語の幾何学情報と原単語の文字コードを格納した原文データ格納部と、各原文に対応する訳文を格納した訳文格納部を有する。
本発明は、また上記文書翻訳システムにおいて使用される特徴的な携帯情報端末、又はサーバとして把握される。
更に本発明は、上記文書翻訳システムにおいて、前記抽出部の機能を実現するためのコンピュータ上で実行可能なプログラムとして把握される。
【0012】
更に本発明は、翻訳処理方法として把握される。例えば、画像撮影部と、利用者に操作されて情報を入力する入力部と、表示部を有する携帯情報端末を用いて、画像撮影部で撮影された画像に含まれる文字に関する翻訳を得るための処理を行う翻訳処理方法において、単語からなる原文と原文に対応する翻訳文を対応付けて保持すると共に、原文に含まれる各文字の配置情報を関連付けて保持する翻訳辞書を記憶装置内に予め用意するステップと、画像撮影部で撮影された画像から利用者により指定された着目文字パターンとその着目文字パターンの周辺の文字パターンを対象として文字認識処理を行い、文字パターンの文字コードを出力するステップと、利用者により指定された着目文字パターンと着目文字パターンの周辺の文字パターンに関して相対的な配置情報を抽出するステップと、着目文字パターンと着目文字パターンの周辺の文字パターンに関して、文字認識部より得られた文字コードと抽出部より得られた相対的な配置情報を用いて、翻訳辞書を検索するステップと、検索の結果得られた翻訳文を表示部に表示するステップと、を有する文書翻訳処理方法である。
好ましい例では、上記翻訳辞書の検索の結果、着目文字パターンを含む1又は複数の翻訳の候補となる原文を表示部に表示するステップと、複数の候補の場合、複数の候補の中から利用者により入力部を介して指定された候補に対応する翻訳文を翻訳辞書から得るステップと、を更に有し、翻訳辞書から得られた翻訳文と原文とを対応させて表示部に表示する。
【発明の効果】
【0013】
本発明によれば、翻訳対象とする文章全体をカメラで撮影する必要がなく、原文の一部を撮影した部分画像に含まれる単語と単語の配置情報を利用して、原文の翻訳を得ることができる。
これにより、従来のように翻訳対象の文全体を撮影する場合に比べて、撮影された画像は翻訳対象文の任意の一部を含んでいれば良いので、撮影の自由度が大きくなり、利用者の使い勝手が大幅に向上する。
【発明を実施するための最良の形態】
【0014】
以下、図面を参照して本発明の実施形態について、説明する。
第1の実施形態では、英文和訳システムについて示す。翻訳対象の文章全体をカメラで一度に撮影して、文字認識処理により正しくテキストデータに変換して翻訳ソフトに入力することは困難である。そこで、本実施形態では、翻訳対象の文章全体をシステムに入力して翻訳アルゴリズムにより入力文を逐一翻訳するのではなく、予め被翻訳文(原文)である英文とその翻訳結果である和文を対応付けて電子辞書に格納されている。例えば、英語の教科書や英文のマニュアルの文書全体とその翻訳である和文の文書全体が予め対応付けられて電子辞書に格納されている。
【0015】
そこで、利用者が、翻訳対象とする英文全体或いは任意の複数の文章全体ではなく、翻訳対象に含まれる一部の単語を含む画像(部分画像)をカメラで撮影すると、その部分画像に含まれる単語は文字認識された後、その単語をキーにして電子辞書に格納されている翻訳対象の英文を検索する。さらに、検索結果の英文と対応付けられている和文を検索して画面に表示することで、英文から和文への文単位の翻訳を実現するものである。
【0016】
また、本実施形態においては、その部分画像をキーにして電子辞書に格納されている翻訳対象の英文を検索するために、英文に含まれる各単語の配置情報も併せて電子辞書に予め格納される。その後、撮影された部分画像に含まれる単語の文字コードと配置情報を文字認識処理によって抽出する。その抽出された単語の文字コードと配置情報に関して、電子辞書に格納されている和文の単語の文字コードと配置情報を検索する。その検索の結果、抽出された和文の単語の配置情報に最も類似した配置の単語を含む英文テキストを電子辞書から検索して取得する。そしてその後、検索された英文に対応付けて格納されている和文を取得する。
【0017】
使用される配置情報は、撮影の角度やスケールになるべく依存しない情報が望ましい。例えば、各単語が含まれる行の相対的な配置情報や角度情報である。
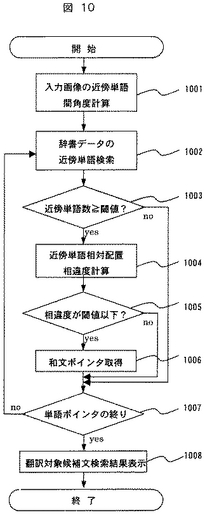
単語の配置情報の例として、部分画像に含まれる単語の相対的な位置関係を表す角度情報を抽出する手順に関しては、例えば、利用者が指定する着目単語“as”と着目単語の上下左右など周りに存在する複数の単語(以下では周辺単語と呼ぶ)に関して文字認識処理により単語の文字コードと各単語の矩形重心座標をそれぞれ抽出する。その後、着目単語の矩形重心から各周辺単語の矩形重心に線分1101〜1105を引きその線分間の角度1106〜1110を計算する。この角度計算は任意の周辺単語重心間について計算してよい。この重心間角度は画像のスケールに依存しないので安定した配置情報となりうる。(これらについては、図11を参照して詳しく後述される。)
以下、図1、図3〜14を参照して第1の実施形態について詳細に説明する。
第1の実施形態は、上記の機能乃至構成を携帯情報端末において実現するシステムの例である。
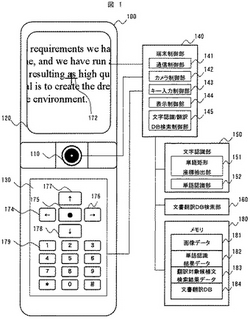
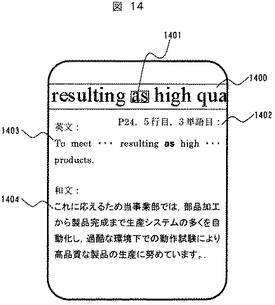
図1は、携帯情報端末の構成例を示すブロック図である。
携帯情報端末100は例えば携帯電話であり、その本体は、認識対象となる英語の教科書等を光学的に入力するカメラやスキャナなどの画像撮影部110と、認識対象の画像や文字認識結果、カーソル172等を表示する液晶などの表示部120と、利用者がキー操作して情報を入力するキー174〜179を配置した入力部130を備えている。更にその内部の構成として、携帯情報端末の全体の制御を行なう端末制御部140、画像撮影部110から得られた画像に含まれる単語等の認識を行なう文字認識部150、文字認識結果を用いて英文に対応する和訳文を検索するための文書翻訳DB検索部160、様々な処理結果データや電子辞書等のデータベースを格納するためのメモリ180を有する。
【0018】
端末制御部140は、通信制御部141、画像撮影部110を制御するためのカメラ制御部142、入力部130を制御するためのキー入力制御部143、表示部120を制御するための表示制御部144、文字認識部150や文書翻訳DB検索部160を制御するための文字認識/翻訳DB検索制御部145から構成される。文字認識部150は入力された画像から各単語の矩形座標を抽出するための単語矩形座標抽出部151、単語矩形座標抽出部151の出力に基づいて入力画像の矩形座標内の単語認識を行う単語認識部152を有して構成される。
【0019】
メモリ180は、入力部130の操作により取り込まれた画像データ181、文字認識部150による認識結果を格納する単語認識結果データ182、文書翻訳DB検索部160の出力を格納する翻訳対象候補文検索結果データ183、及び翻訳対象とする英文の文書とそれに対応した和文の文書を格納する電子辞書としての文書翻訳DB(データベース)184を格納する。文書翻訳DB184には英文に含まれる各単語の配置情報も併せて格納される。
【0020】
尚、ここで、文字認識部150、文書翻訳DB検索部160はソフトウェアの実行により実現される機能であってもよい。
【0021】
文書翻訳DB184は、文書翻訳DBがプレインストールされたROMが携帯情報端末100に実装されたことを前提にしてもよい。またはこの文書翻訳DBを格納したSD(Secure Digital)カードなどのメモリ媒体を購入して、そのSDカードから文書翻訳DBをメモリ180の文章翻訳DB184にインストールすることを想定してもよい。また、文書辞書DB184は半導体メモリのような静的記憶装置に限らず、ハードディスク装置のような記憶装置に格納されてもよい。
【0022】
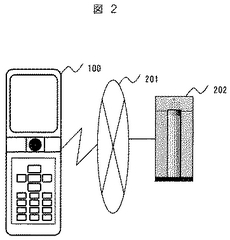
次に、図3に示す一連の翻訳処理フローを参照して、翻訳処理動作について説明する。
なお、図3による全体的な処理動作の説明において、各動作の詳細な説明については更に図4以降の図を参照することがある。
まず、利用者は携帯情報端末100の画像撮影部110を用いて文字認識対象となる雑誌や本等の画像を撮影する。撮影された画像はメモリ180中の画像データ181の領域にデジタル画像として格納される(301)。
【0023】
図4に翻訳対象の英文文書の例を示す。右上に「P24」とページ番号が付されている。401で囲まれた部分は、画像撮影部110で撮影された画像の範囲を示し、画像データ181に格納される。この画像データ181が文字認識部150に入力される画像の範囲である。なお、この例では3行目の”To meet”で始まり5行目の”quality products.”で終わる2番目の文を翻訳するために画像を取り込むことを仮定する。この文書の翻訳のために、本実施形態では2番目の英文を構成する任意の単語が着目対象となり得る。ここでは図1の表示部120に示すように、着目対象を示す「+」のマーク172は、“as”に重なっていると想定する。
【0024】
次に、単語矩形座標抽出部151にて、入力された画像から英単語の場所を示す矩形座標が抽出される(302)。ここでは、図5に示すように、着目している“as”501だけでなく、縦方向に見たときに“as”501の矩形とオーバーラップがある上下の行の単語パターン502、503、506、及び横方向に見たときに“as”の矩形とオーバーラップがあり、“as”に隣接している単語パターン504、505についても近傍の単語パターンとして一緒に矩形座標が抽出される。
【0025】
この矩形座標抽出処理302の動作の詳細について、図6を用いて説明する。
画像データ181に格納されている画像401が単語矩形座標抽出部151に入力されると、最初に2値画像が生成される(601)。次に、文字行の大雑把な位置を検出するために、画像の横方向に黒画素を加算して投影分布を求める(602)。
【0026】
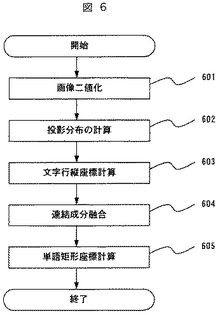
図7は画像情報として含まれる文字行の黒画素投影の算出の原理を示す図である。画像の原点は左上であり、702は画像縦方向の座標軸に相当し、703は横方向の投影分布を表す。この投影分布の算出後、文字行の存在する縦方向座標の範囲を求めるため、非零値の範囲704〜708を計算する(603)。求められた文字行の存在する縦方向座標の範囲で、黒画素が連結した塊である連結成分を求めると共にその外接矩形座標もあわせて計算する。そして、連結成分の外接矩形同士の隙間等を参照しながら距離が近い矩形を横方向に統合し(604)、統合された矩形の座標は単語の矩形座標として単語認識結果データ182に格納される(605)。
【0027】
図8は単語認識結果データ182の構成例を示す。
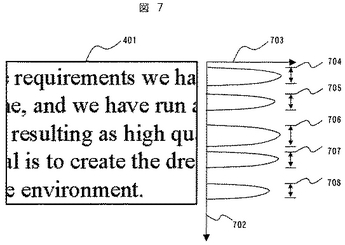
817から822は各単語のデータレコードを示しており、810は単語の文字コード格納領域、811は矩形左上X座標、812は矩形左上Y座標、813は矩形右下X座標、814は矩形右下Y座標、815は単語が含まれる行の行番号を表す。816は周辺単語と着目単語を区別するための着目単語フラグであり、着目単語に対しては“1”、それ以外の周辺単語は“0”を格納する。ステップ605の処理では、811から816のデータが格納される。
【0028】
次に、単語認識部152は、抽出された英単語矩形座標501から506に対して抽出された矩形座標内に存在する英単語パターンに関して文字認識処理を行う。具体的には、単語認識結果データ182の811から814の矩形座標データと画像データ181を入力し、認識結果である単語の文字コードを同じ単語認識結果データ182の単語の文字コード格納領域810に出力する(303)。
【0029】
文書翻訳DB検索部160は、単語認識結果データ182の内容を読み出し、文書翻訳DB184に対して、”as”が含まれる英文と対応する和訳文候補の検索を行う(304)。”as”など特定の単語が含まれる英文は、一般的に共通の文書翻訳DB184に複数箇所存在する。そのため、複数の英文候補から和訳対象英文を絞り込むために、ここでは図5における”as”501の周りに存在する502から506の英単語と”as”501との幾何学的な相対関係を用いる。
【0030】
図9は文書翻訳DB184に格納される辞書データの構造を示す。
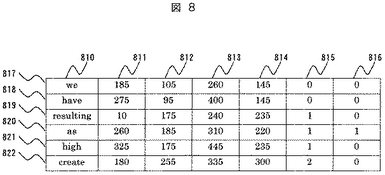
900は当該単語が含まれる英文を検索するための英単語インデックス部、901は英文に含まれる英単語の幾何学情報と英単語の文字コードを格納した英文データ格納部、902は各英文に対応する和訳文を格納した和訳文格納部である。英単語インデックス部900は高速に翻訳対象の英文データ901を検索するためのインデックステーブルであり、903は単語の文字コードデータ、904は当該単語が文書中に現れる数、905、906は当該単語が含まれる英文データ格納部901へのポインタである。
【0031】
英文データ格納部901において、一つの英文を構成する単語データのレコード916から922の各カラムの内容について説明する。910は英文を構成する英単語データである。911、912は英文が含まれる当該ページの左上を原点とした場合の当該英単語の矩形重心座標であり、911はX座標の値、912はY座標の値を示す。これら座標値は任意の解像度、あるいは、適当なスケールを仮定して決定してよい。913、914はそれぞれ当該単語が含まれるページ数、行番号である。915は単語が含まれる行中において左から数えて何番目の単語であるかを示す。922のレコードは英文の終りを示す”.”(ピリオド)と和訳文格納部902へのポインタからなっている。和訳文格納部902において、923から925は各英文に対応する和訳文データを示す。和文格納部902へのポインタは文単位に存在し、一つの英文が一つの和訳文に対応するようにリンクが張られている。
【0032】
次に、図10を参照して翻訳対象候補文の選択処理動作304の詳細について説明する。
まず、ステップ303にて抽出された着目単語”as”501の矩形重心から、近傍単語”we”502、”have”503、”resulting”504、”high”505、”create”506の各矩形重心座標に線を引き、その線分間の角度、あるいは、余弦を測定する(1001)。
【0033】
図11を用いてこの処理の詳細を説明する。着目単語”as”の矩形重心から、各近傍単語の矩形重心に引いた線分は1101、1102、1103、1104、1105で示される。例えば、近傍単語”we”、”have”に引かれた線分間の角度は1106で示される。以下、同様に各近傍単語の重心に引かれた線分間の角度を計算する。ここで角度を計算するのは、カメラで撮影した画像のスケールや撮影角度と辞書登録時に単語の位置を表すために使用したスケールや撮影角度が一般には異なるため、これらが変わっても変化しにくい幾何学的相対関係を記述する量を抽出するためである。不変量に相当すれば任意の量を用いることができ、例えば、各単語が属する相対的な行番号でもよい。”we”、”have”は1行目、”resulting”、”as”、”high”は2行目、”create”3行目等である。
【0034】
次に、文書翻訳DB184の英文インデックス部900の”as”レコード908を参照して、英文データ格納部901の”as”が含まれる英文データを検索し、さらにその近傍単語が存在するかを検索する(1002)。具体的には、最初に”as”が含まれるレコード919のデータを参照した後、カラム914の行番号の情報を参照しながら”as”が含まれる行の前後の行に存在する単語の中に入力画像から得られた近傍単語を検索する。検索の結果、近傍単語の数が閾値以上か否かを判定する(1003)。判定の結果、近傍単語の数が閾値以上存在すれば、近傍単語が存在したと見なしてステップ1004に進む。一方、閾値以上でなければ、ステップ1007に進む。ここで、近傍単語を全数見つけるのではなく閾値以上としたのは、誤認識により正しい単語が得られない場合を考慮している。
【0035】
次に、得られた近傍単語について、ステップ1001と同様な処理により着目単語”as”の矩形重心から近傍単語の矩形重心に引いた線分間の角度を計算する(1004)。具体的には、近傍単語の矩形重心X座標の値911、および、Y座標の値912を参照して、得られた各近傍単語の矩形重心間の角度とステップ1001で得られた角度との差分を取る。ここでは、計算コストを減らすため角度差分の代わりに角度の余弦差分のことを相違度と定義する。
例えば、辞書データに格納された単語矩形座標を用いて、”as”の矩形重心を基点とした単語”we”、”have”の矩形重心座標間の角度余弦計算は以下の通りである。
“as”から“we”への矩形重心ベクトル :a=(x、y)=(330-400、225-300)=(-70、-75)
“as”から“have”への矩形重心ベクトル:b=(x、y)=(470-400、225-300)=(+70、-75)
ベクトルa、b間の余弦=a・b/(‖a‖‖b‖)=0.07
次に、相違度が閾値以下かどうかを判断し(1005)、閾値以下であればステップ1006に進み、閾値を超えていればステップ1007に進む。ステップ1006では、英文データ格納部901において”as”レコード919以降の単語データを検索し、文末の記号である”.”(ピリオド)を含むレコード922を検索する。そして、ピリオドの後ろに格納されている和訳文データへのポインタを取得して、翻訳対象候補文検索結果データ183に格納する。
【0036】
この検索結果データ183には和訳文データへのポインタのみならず、翻訳対象の英文に含まれる全単語とその単語に付随するレイアウト情報や着目単語を表すフラグ値が格納されている。
【0037】
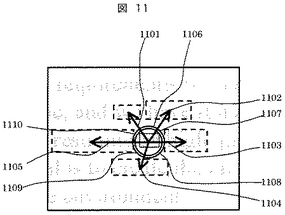
図12に翻訳対象候補文検索結果データ183の構成例を示す。
1200は翻訳対象候補の英文を構成する単語数であり、1201から1205は当該英文に含まれる各単語の属性データである。1201は単語の文字コード格納領域であり、1202から1204はそれぞれ図9のカラム913から915のデータをコピーして格納しており、各データは単語が存在するページ番号、行番号、行内の左から数えた単語番号である。1205は着目単語を表すフラグであり、着目単語であれば、“1”、それ以外は“0”が格納されており、本フラグは表示部の画面表示制御に用いる。1206から1213は翻訳対象候補の英文を構成する単語レコードであり、1200で示された数だけレコードが存在する。1214は当該英文に対応する和訳文データへのポインタであり、図9のレコード922のポインタデータをコピーして格納している。
【0038】
上記ステップ1002から1006までの処理をレコード908に格納されている905以降のポインタがなくなるまで、すなわち、”as”という単語へのポインタが無くなるまで繰り返す(1007)。このようにして得られた和訳文の候補ポインタと英文データを翻訳対象候補文検索結果データ183から読み出し、さらに、”as”近傍画像と矩形座標をそれぞれ画像データ181、単語認識結果データ182から読み出し、それらを表示部120上に表示する(1008)。
【0039】
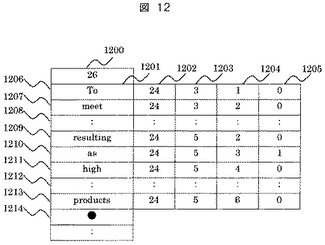
図13に翻訳対象英文候補の表示の例を示す。
1300は入力画像の着目単語である”as”を含む行画像を示し、1301は着目単語であることを示す矩形である。1302は文書翻訳DB184を検索した結果、着目単語”as”が存在する位置を示しており、この例では24ページ、5行目の左から3単語目に着目単語”as”が存在することを示している。また、ここでアンダーラインが表示されているが、このアンダーラインが引かれた文字を選択すると対応する和訳文を表示することができるというハイパーリンクを表しており、このリンクを選択すると図12の1214に格納されているポインタを参照して和訳文が表示できるようになっている。
【0040】
1303は1302の単語を含む英文の表示例であり、表示スペースを節約するために、ここでは英文の先頭・末尾単語、および、着目単語の前後の近傍単語のみを表示している。また、着目単語を明示するために”as”はボールド体で表示されている。1302と1303は対になっており、以下、1304から1307は同様に着目単語の存在位置と着目単語が含まれる英文が対になって表示されている。
以上のように図10のステップ1001から1008の処理により、着目単語”as”が含まれる英文と対応する和訳文候補を検索し、結果が表示部に表示される。
【0041】
利用者は、図13に表示された翻訳対象英文候補の内から、該当する対象のもの(この例では1302)を入力部130の操作により選択する。その時、検索部160は対応する和訳文ポインタを参照して図9に示す和訳文データ924を検索し(305)、検索結果を表示部120に表示する(306)。
【0042】
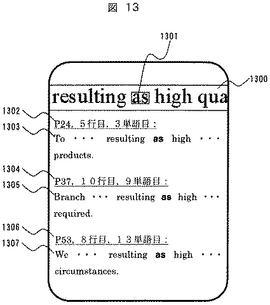
図14に和訳文の検索結果の表示例を示す。
表示画面には、検索のポインタとなった画像中の文字1400、1401、選択された翻訳対象英文候補1402〜1403、及び検索の結果得られた翻訳文である和文1404が表示される。
1400、1401は図13における1300、1301と同様であり、1402、1403はそれぞれ1302、1303に対応する。1404は1403の英文に対応する和訳文であり、図12における1214のポインタを参照した上で、文書翻訳DB184における924(図9)の和訳文データを取得して表示されている。
【0043】
以上説明したように、図3に示す処理により利用者は翻訳対象とする英文全体を撮影する必要がなく、該当する英文の和訳文を得ることができる。
【0044】
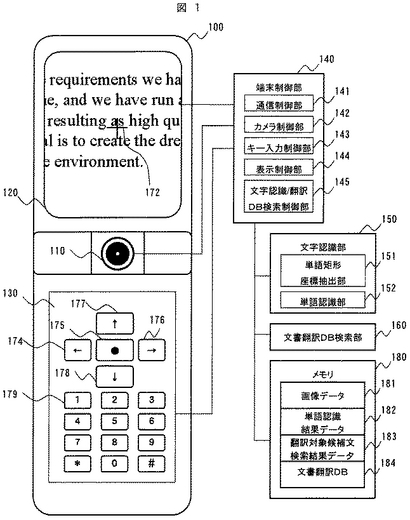
次に、図2、図15〜17を参照して第2の実施形態について説明する。
第2の実施形態は、図2に示すように、上述した文書翻訳DB及びその検索手段をサーバ202に保持させ、必要に応じて通信ネットワーク201を介してサーバ202からデータを携帯情報端末100にダウンロードする例である。即ち、携帯情報端末100では取得された画像から単語認識を行い、その認識結果をサーバ202に送信して、サーバ202において認識結果である文字コードを用いて文書翻訳DBを検索し、検索結果を携帯情報端末100に返送して表示するシステム構成とその処理手順について、以下説明する。
【0045】
図15は、第2の実施形態における携帯情報端末のブロック図である。
この例も第1の実施形態と同様に英文を和文に翻訳する例である。図1の構成との主な相違点は、文書翻訳DB184の代わって、和訳文のみを格納する和訳文データ185の格納部が設けられること、文字認識/翻訳DB検索制御部145による処理手順が変わること等である。
【0046】
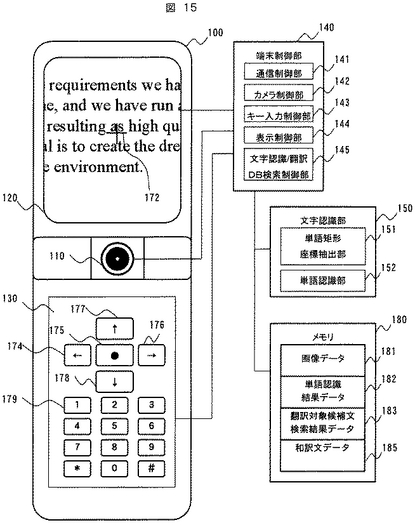
図16はサーバ202の概略的な構成を示す。
サーバ202では、通信制御部1601、中央演算装置1602、メモリ1603がバス1600を介して接続されている。メモリ1603には文書翻訳DB検索プログラム1604が格納されている。このプログラムは図1における文書翻訳DB検索部160と同様に文書翻訳DBの検索処理を行うためのプログラムである。単語認識結果データ1605、翻訳対象候補文検索結果データ1606、文書翻訳DB1607は、それぞれ図1における単語認識結果データ182、翻訳対象候補文検索結果データ183、文書翻訳DB184と同等のデータを格納する領域である。
【0047】
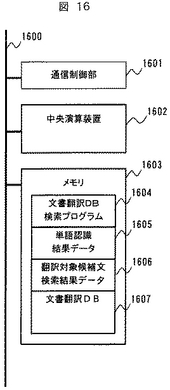
図17は、第2の実施例における携帯情報端末100とサーバ202のそれぞれの処理を示すフローチャートである。
図において、実線の矢印は処理のフローを示し、点線の矢印はデータの流れを示す。
画像入力処理(1701)から英単語認識処理(1703)は、図3におけるステップ301から303と同様であり、画像撮影部110により撮影された翻訳対象の文章を部分的に含む画像から英単語を認識し、認識結果を単語認識結果データ182に格納する。次に文字認識/翻訳DB検索制御部145は単語認識結果データ182に格納された英単語認識結果データを、通信制御部141を介してサーバ202に送信する(1704)。
【0048】
サーバ202では、携帯情報端末100から送信された単語認識結果データを受信して、そのデータを単語認識結果データ1605に格納する(1710)。その後、文書翻訳DB検索プログラム1604を実行して文書翻訳DB1607を検索して翻訳対象候補文の検索を行なう(1711)。この処理は、単語認識結果データ1605を用いて図10のステップ1001から1007と同様な処理手順で文書翻訳DB1607を検索し、検索結果をメモリ1603の翻訳対象候補文検索結果データ1606に格納する処理である。
次に、サーバ202は、メモリ1603に格納された翻訳対象候補文検索結果データ1606を携帯情報端末100に送信し(1712)、携帯情報端末100ではそのデータを受信して、翻訳対象候補文検索結果データ183に格納する(1705)。
【0049】
そして携帯情報端末100では、翻訳対象候補文検索結果データ183を参照して、図13に示すような翻訳対象候補検索結果を表示部120に表示する。利用者は、表示部に表示された翻訳候補から1つを選択する(1706)。選択結果として図12における英文に対応する和訳文データへのポインタ1114のデータのみをサーバ202に対して送信する(1707)。
【0050】
サーバ202では、携帯情報端末100から送信された和訳文データへのポインタを受信し(1713)、受信したポインタを参照して対応する和訳文データを検索する(1714)。そして、その検索の結果得られた和訳文データを携帯情報端末100に送信する(1715)。携帯情報端末100では、検索された和訳文データを受信して、メモリ180の和訳文データ185に格納し(1708)、そのデータを表示部120に表示する(1709)。表示部120の表示画面の内容は、図12と同様である。
【0051】
以上のように図17に示す処理動作により、利用者は翻訳対象とする英文全体を撮影する必要がなく、サーバ202に備えられた文書翻訳DB1607、及びそのDBを検索する検索手段を利用してネットワークを介して目的の和訳文を得ることができる。
【0052】
次に、図18〜図25を参照して第3の実施形態について説明する。
この例は和文を英文に翻訳する例である。英文の場合には単語と単語の間に空白が在る(第1、2の実施形態の場合)。しかし本実施形態における和文の場合には、文字認識対象となる和文は空白による単語の区切れ目のない文である。和文の場合、英単語に相当するのは和文の構成要素である「形態素」に着目するものであり、「形態素」に対する文字認識と、それを用いた翻訳候補文検索に特徴がある。以下、図面を参照して説明する。
【0053】
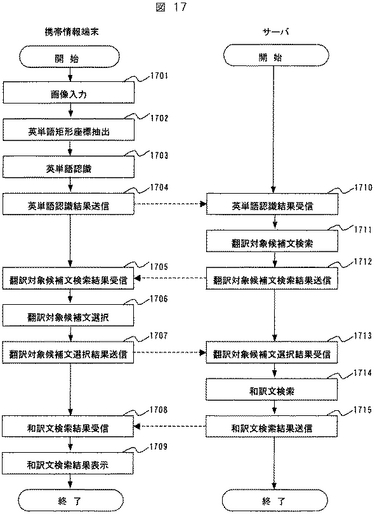
図18は、携帯情報端末の構成を示すブロック図である。
図1に示した携帯情報端末100の構成との主な相違点は、文字認識部150の構成及び処理動作にある。即ち、図18に示す形態情報端末100の文字認識部150の文字行座標抽出部1501、形態素認識部1502は、それぞれ図1の単語矩形座標抽出部151、単語認識部152に対応する。メモリ180では文字行座標データ1804が新たに追加された。形態素認識結果データ1805、翻訳対象候補文検索結果データ1806、文書翻訳DB1807は、それぞれ図1の182、183、184に対応する。
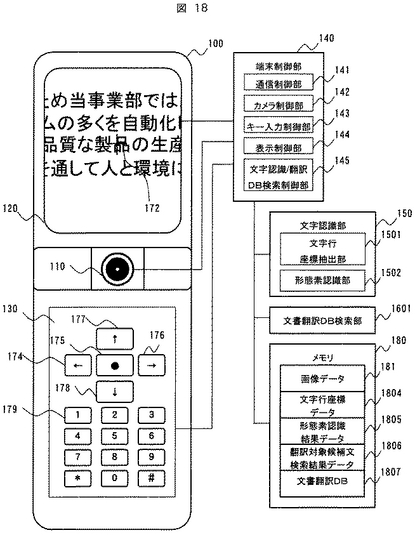
図19は第3の実施形態の翻訳処理フローを示す。以下、図19を用いて図18の携帯情報端末の処理動作について説明する。
【0054】
まず、画像撮影部110で撮影された文字認識対象画像が入力される(1901)。
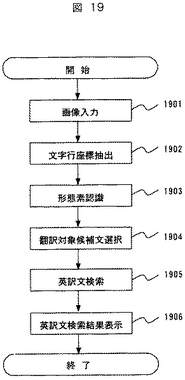
図20に、認識対象となる和文の文書の例を示す。右上に「P24」とページ番号の表示がある。2001は、画像撮影部110で撮影されて取り込まれた画像の範囲を示し、この範囲の画像が文字認識部150に入力される。この例では、3行目の「これに応える・・・」で始まり、5行目の「・・・努めています。」で終わる2番目の文を翻訳するために画像を取り込むことを仮定する。この文書の翻訳のために、この実施形態では2番目の和文を構成する任意の形態素が着目対象となり得る。ここでは着目対象を示す「+」のマークは5行目の「製品」に重なっていると想定する。
【0055】
文字認識部150の文字行抽出部1501にて、入力された画像から文字行の場所を示す矩形座標を抽出する(1902)。この処理は、図3のステップ302と同様な処理である。ここで、着目している「製品」を含む文字行座標だけでなく、上下の文字行座標も合わせて出力される。ステップ302では単語単位の矩形座標を抽出したが、日本語の場合は単語の区切れ目に相当する空白は存在しない。そこで、図7に示すような行方向の黒画素射影を取って行の位置を計算した後は、その中に含まれる近接した連結成分を統合して文字行の矩形座標を計算し、文字行座標データ1804に格納する。
【0056】
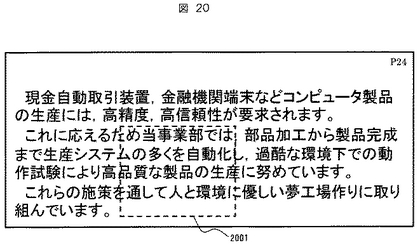
抽出された文字行の矩形座標に対して形態素認識部1502は抽出された矩形座標内に存在する文字パターンに対して文字認識処理を行うと共に形態素解析を行い、文字認識結果として各形態素の文字コードと形態素に対応する矩形の重心座標を形態素認識結果データ1805に出力する(1903)。ここで、図21に示すように「製品」2101の矩形座標と横方向にオーバーラップがある上下の文字行の形態素パターン、および、「製品」の隣接形態素パターン2102〜2109に対する文字コードと矩形重心座標が抽出される。
【0057】
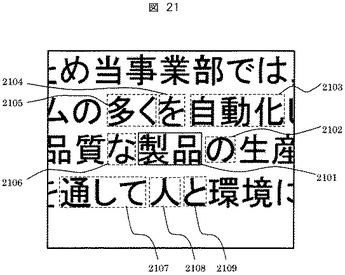
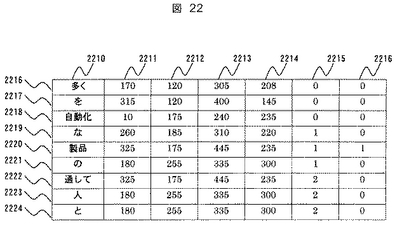
図22に形態素認識結果データ1805の構成を示す。
2216から2224は各形態素のデータレコードを示す。また2210は形態素の文字コード格納領域を示し、2211から2214はそれぞれ形態素矩形の左上X座標、左上Y座標、右下X座標、右下Y座標を示す。2215は形態素が含まれる行の行番号を示す。2216は周辺形態素と着目形態素を区別するための着目形態素フラグであり、着目形態素に対しては“1”、それ以外の周辺形態素は“0”を格納する。
【0058】
文字認識結果は文書翻訳DB1807に渡され、実施例1で説明した処理と同様な方法により、文字認識結果をキーとして「製品」が含まれる和文と対応する英訳文候補の検索を行う(1904)。
【0059】
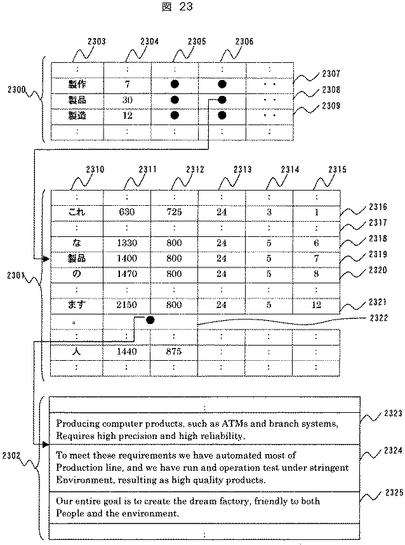
図23に文書翻訳DB1807に格納されるデータの構造を示す。2300は当該形態素が含まれる和文を検索するための形態素インデックス部、2301は和文データ格納部、2302は英訳文格納部である。形態素インデックス部2300において、2303は形態素データ、2304は当該形態素が文書中に現れる数、2305、2306は当該形態素が含まれる和文データ格納部2301へのポインタである。
【0060】
和文データ格納部2301において、一つの和文を構成する形態素データのレコード2316から2322の各カラムの内容について説明する。2310は和文を構成する形態素データである。2311、2312は和文が含まれる当該ページの左上を原点とした場合の当該形態素の矩形重心座標であり、2311はX座標の値、2312はY座標の値を示す。2313、2314はそれぞれ当該形態素が含まれるページ数、行番号である。2315は形態素が含まれる行中において左から数えて何番目の形態素であるかを示す。2322のレコードは和文の終りを示す”。”(読点)と英訳文格納部2302へのポインタからなっている。英訳文格納部2302において、2323から2325は各和文に対応する英訳文データを示す。
ステップ1904では、第1の実施例と同様に形態素間の相対的な配置情報を用いて英訳文候補ポインタとそれに対応する和文データを電子辞書部から検索し表示部上に表示し、利用者は該当すると思われる英訳文候補ポインタを選択する。
【0061】
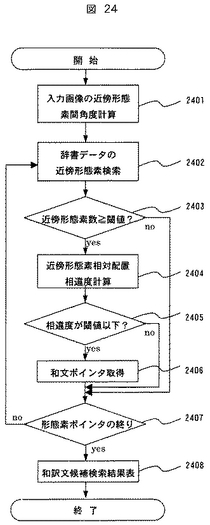
図24を参照してステップ1904の詳細を説明する。
まず、ステップ1903で抽出された着目形態素「製品」の矩形重心から図21に示す近傍形態素2102から2109への各矩形銃身座標に線を引き、図10のステップ1001と同様にその線分間の角度、あるいは、余弦を測定する(2401)。
【0062】
次に、文書翻訳DB1807の形態素インデックス部2300の「製品」レコード2308を参照して和文データ格納部2301の「製品」が含まれる和文データを検索し、さらに、その近傍形態素が存在するかをステップ1002と同様な処理手順により検索する(2402)。検索の結果、近傍形態素の数が閾値以上であるか否かを判定する。閾値以上であれば、近傍形態素が存在したと見なしてステップ2404に進む。これに対して、閾値以上でなければステップ2407に進む(2403)。
【0063】
近傍形態素の数が閾値以上である場合、得られた近傍形態素について、ステップ2401と同様な処理により着目形態素「製品」の矩形重心から近傍形態素の矩形重心に引いた線分間の角度を計算し、相違度を計算する(2404)。この計算はステップ1004と同様な計算処理である。その後、相違度が閾値以下かどうかを判断し(2405)、閾値以下であればステップ2406に進み、閾値を超えていればステップ2407に進む。
【0064】
相違度が閾値以下の場合、和文データ格納部2301において「製品」レコード2319以降の単語データを検索し、文末の記号である「。」(読点)を含むレコード2322を検索する。そして、読点の後ろに格納されている英訳文データへのポインタを取得して、翻訳対象候補文検索結果データ1806に格納する(2406)。
【0065】
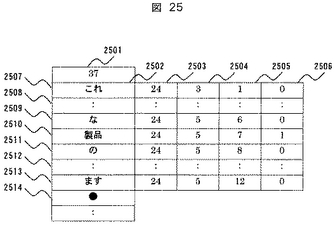
図25に翻訳対象候補文検索結果データ183の構成例を示す。
2501は翻訳対象候補の和文を構成する形態素数であり、2502から2506はこの和文に含まれる各形態素の属性データである。2502は形態素の文字コード格納領域であり、2503から2505はそれぞれ図23のカラム2313から2315のデータをコピーして格納しており、各データは形態素が存在するページ番号、行番号、行内の左から数えた形態素番号である。2306は着目形態素を表すフラグであり、着目形態素であれば、“1”、それ以外は“0”が格納されており、本フラグは表示部の画面表示制御に用いる。
2507から2513は翻訳対象候補の和文を構成する形態素レコードであり、2501で示された数だけレコードが存在する。2514は当該和文に対応する英訳文データへのポインタであり、図23のレコード2322のポインタデータをコピーして格納している。
【0066】
上記ステップ2402から2406までの処理をレコード2308に格納されている2305以降のポインタがなくなるまで、すなわち、「製品」という形態素へのポインタが無くなるまで繰り返す(2407)。このようにして得られた和訳文の候補ポインタと英文データを翻訳対象候補文検索結果データ1805から読み出し、さらに、「製品」近傍画像と矩形座標をそれぞれ画像データ181、形態素認識結果データ1804から読み出し、それらを表示部120に表示する(2408)。
【0067】
以上のように、図24に示す処理により、着目形態素「製品」が含まれる和文と対応する英訳文候補を検索し、結果が表示部に表示される。英訳文候補の内、該当する英訳文に関係するリンクを利用者が選択すると、対応する英訳文を文書翻訳DB1807から検索して(1905)、それを表示部120に表示する(1906)。
以上のように図19に示す処理により、利用者は和文全体を撮影することなく、該当する和文の英訳文を得ることができる。
【0068】
上記実施例では形態素を単位として説明したが、ここでは表示部上の「+」印がどの翻訳対象の和文を指しているかが分ればよい。従って、代替例においては、形態素を単位にして文字認識や検索処理を行なわないで、任意の文字長、例えば1文字や2文字と設定した文字列を形態素の代わりに処理を行ってもよい。
【0069】
更に、他の変形例について説明する。図15〜16を参照した第2の実施形態によれば、サーバ202に、文書翻訳DB1607及びその検索手段104等を具備する構成としたが、他の変形例によれば、第2の実施形態の構成に加え、更に図1の文字認識部150の機能をサーバ202に持たせてもよい。この構成によれば、携帯情報端末100では、翻訳対象の文を部分的に含む画像を取得してそれをサーバ202へ送信するだけでよく、以後の全ての処理はサーバ202で行なわれる。そしてサーバ202から送信される処理結果としての翻訳候補文を受信すればよい。
【0070】
更に、他の変形例について説明する。上記実施例では複数の単語等の配置情報から、文書中で着目している場所、すなわち、ページ番号、行番号、行中の単語番号を特定し、その場所と関連付けられている原文や訳文情報をDBから検索して画面に出力した。しかし、このような関連情報は必ずしも原文や訳文に限る必要は無く、その他の任意の情報をその場所と関連付けることが可能である。例えば、予めDBに登録しておくことにより、例えば図21の「製品」2101は「金融機関向けのATM」といった意味情報や、その製品の詳細情報が得られるURL等を関連付けることが可能である。
【図面の簡単な説明】
【0071】
【図1】第1実施形態による携帯情報端末を用いた文書翻訳システムの構成を示す図。
【図2】第2実施形態による携帯情報端末及びサーバを含む文書翻訳システムを示す図。
【図3】第1実施形態における翻訳処理フローを示す図。
【図4】第1実施形態における翻訳対象の英文の例を示す図。
【図5】第1実施形態における単語矩形座標の抽出例を示す図。
【図6】第1実施形態における英単語矩形座標抽出302の処理フローを示す図。
【図7】第1実施形態における英単語矩形座標抽出302のための黒画素投影処理の原理を説明するための図。
【図8】第1実施形態における単語認識結果データ182の構成例を示す図。
【図9】第1実施形態における英文を和文に翻訳するための文書翻訳DB184の構成を示す図。
【図10】第1実施形態における英文を和文に翻訳するための文書翻訳DB検索処理フローを示す図。
【図11】第1実施形態における着目単語を基準として周辺単語間の角度測定の説明図。
【図12】第1実施形態における英文の翻訳対象候補文検索結果データの構成例を示す図。
【図13】第1実施形態における翻訳対象英文候補の表示例を示す図。
【図14】第1実施形態における翻訳結果の表示例を示す図。
【図15】第2実施形態による携帯情報端末の構成を示す図。
【図16】第2実施形態によるサーバの構成を示す図。
【図17】第2実施形態における翻訳処理フローを示す図。
【図18】第3実施形態による携帯情報端末の構成を示す図。
【図19】第3実施形態における翻訳処理フローを示す図。
【図20】第3実施形態における文字認識・翻訳対象の和文の例を示す図。
【図21】第3実施形態における形態素矩形座標の抽出例を示す図。
【図22】第3実施形態における形態素認識結果データの構成例を示す図。
【図23】第3実施形態における和文を英文に翻訳するための文書翻訳DBの構成を示す図。
【図24】第3実施形態における和文を英文に翻訳するための文書翻訳DBの検索処理フローを示す図。
【図25】第3実施形態における和文の翻訳対象候補文検索結果データの構成例を示す図。
【符号の説明】
【0072】
100 携帯情報端末、 110 画像撮影部、
120 表示部、 130 キー入力部、
140 端末制御部、 150 文字認識部、
160 文書翻訳DB検索部、 180 メモリ、
184 文章翻訳DB、
202 サーバ。
【技術分野】
【0001】
本発明は文書翻訳システムに係り、特に携帯情報端末で撮影した画像に含まれる文字を認識してその翻訳を得る文書翻訳システム及び翻訳処理方法に関するものである。
【背景技術】
【0002】
カメラを搭載した携帯電話等の携帯端末で撮影した画像に含まれる文字列の文字を認識して、その認識結果である文字テキストを翻訳する技術が種々提案されている。例えば、特許文献1(特開平09−138802公報)には、携帯端末内部に文字認識機能と翻訳機能を持ち、これらの機能を利用して、カメラで撮影した画像内の文字列を認識、翻訳処理する翻訳システムが開示されている。
【0003】
【特許文献1】特開平09−138802公報
【発明の開示】
【発明が解決しようとする課題】
【0004】
携帯端末のカメラで撮影した画像は解像度が低いので、その画像をそのまま文字認識処理した場合、正確に認識されないことがある。従って文字認識の結果得られた文字コードをそのまま翻訳しても翻訳ミスの可能性が高くなる。このような画像の解像度に起因する解決策も色々と提案されている。
【0005】
また、最近では、撮影した文字列の単語レベルではなく、文章レベル更には複数の文章から成る文書全体も翻訳したいというニーズがある。しかし、これは以下のような理由から実現されていない。
即ち、文字認識に適した解像度を得るためには、通常、接写モードで画像を撮影する必要がある。このため、翻訳したい文書全体を画像として取り込むことができないという課題がある。これに対して、対象とする文書全体を撮影しようとすると解像度が下がるので、文字の誤認識が多くなるという問題が生じる。
【0006】
仮に、撮像素子の高解像度化することで解像度の問題を解決できるとしても、翻訳対象の文書全体を撮影しようとすると紙文書の曲がりやレンズなどの光学的歪の影響が無視できなくなり、これも誤認識の原因となる。結果として翻訳ソフトに入力される文章が正しく認識されず、意図した翻訳が行われないという問題が生じる。
【0007】
本発明の目的は、携帯情報端末で取得した文書の一部を含む画像から文書全体の翻訳を得ることができる文書翻訳システムおよび方法を提供することにある。
【課題を解決するための手段】
【0008】
本発明は、画像撮影部と、利用者に操作されて情報を入力する入力部と、表示部を有する携帯情報端末を用いて、画像撮影部で撮影された画像に含まれる文字に関する翻訳を得て、その翻訳を表示部に表示する文書翻訳システムにおいて、単語からなる原文と原文に対応する翻訳文を対応付けて保持すると共に、原文に含まれる各単語の配置情報を関連付けて保持する翻訳辞書を格納する記憶装置と、画像撮影部で撮影された画像から利用者により指定された着目単語パターンとその着目単語パターンの周辺の単語パターンを対象として文字認識処理を行い、単語パターンの文字コードを出力する文字認識部と、利用者により指定された着目単語パターンと着目単語パターンの周辺の単語パターンに関して相対的な配置情報を抽出する抽出部と、着目単語パターンと着目単語パターンの周辺の単語パターンに関して、文字認識部より得られた文字コードと抽出部より得られた相対的な配置情報を用いて翻訳辞書を検索する検索部と、を有し、検索部より得られた翻訳文を表示部に表示する文書翻訳システムである。
好ましくは、前記翻訳辞書部は、原文としての英文とその和訳文を対応付けて格納する。
また、他の好ましい例では、前記翻訳辞書部は、スペースで区切られた単語からなる原文と該原文に対応する翻訳文を対応付けて格納する。
上記相対的な配置情報は、一例によれば、利用者により指定された着目単語パターンの矩形重心から着目単語パターンの各周辺単語パターンの矩形重心に線分を引きその線分間の角度である。
また、他の例では、上記相対的な配置情報は、利用者により指定された着目単語パターンが含まれる行、および、着目単語パターンの各周辺単語パターンが含まれる行の相対的な配置情報である。
【0009】
また、他の好ましい例における、本発明に係る文書翻訳システムは、画像撮影部と、利用者に操作されて情報を入力する入力部と、画像撮影部で撮影された画像に含まれる文字に関する翻訳を得るための処理を行う翻訳処理部と、翻訳処理部により得られた翻訳を表示する表示部を有する携帯情報端末を用いた文書翻訳システムにおいて、原文の文書と該原文に対応する翻訳文の文書を対応付けて格納すると共に、原文に含まれる各形態素の配置情報を関連付けて保持する翻訳辞書を格納する記憶装置と、画像撮影部で撮影された画像から利用者により指定された着目形態素パターンとその着目形態素パターンの周辺の形態素パターンに関して文字認識処理を行い、各形態素の文字コードを出力する文字認識部と、利用者により指定された着目形態素パターンと着目形態素パターンの周辺に存在する形態素パターンに関して相対的な配置情報を抽出する抽出部と、着目形態素パターンと着目形態素パターンの周辺に存在する形態素パターンに関して、文字認識部より得られた文字コードと抽出部より得られた相対的な配置情報を用いて翻訳辞書を検索する検索部と、を有し、検索部より得られた翻訳文を表示部に表示する文書翻訳システムである。
【0010】
また、更に他の好ましい例における、本発明に係る文書翻訳システムは、画像撮影部と、利用者に操作されて情報を入力する入力部と、表示部を有する携帯情報端末を用いて、画像撮影部で撮影された画像に含まれる文字に関する翻訳を得て、その翻訳を表示部に表示する文書翻訳システムにおいて、単語からなる原文と原文に対応する翻訳文を対応付けて保持すると共に、原文に含まれる各文字の配置情報を関連付けて保持する翻訳辞書を格納する記憶装置と、画像撮影部で撮影された画像から利用者により指定された着目文字パターンとその着目文字パターンの周辺の文字パターンを対象として文字認識処理を行い、文字パターンの文字コードを出力する文字認識部と、利用者により指定された着目文字パターンと着目文字パターンの周辺の文字パターンに関して相対的な配置情報を抽出する抽出部と、着目文字パターンと着目文字パターンの周辺の文字パターンに関して、文字認識部より得られた文字コードと抽出部より得られた該相対的な配置情報を用いて、翻訳辞書を検索する検索部と、を有し、検索部より得られた翻訳文を表示部に表示する文書翻訳システムである。
【0011】
本発明はまた、上記文書翻訳システムに関する他の例として、前記翻訳辞書を格納する記憶装置、及び前記検索部を備えるサーバを有する文書翻訳システムであって、携帯情報端末の文字認識部より得られた文字コードと、抽出部より得られた相対的な配置情報を、ネットワークを介してサーバに送信し、サーバにおいて検索部により翻訳辞書を検索した結果得られた翻訳文を、ネットワークを介して携帯情報端末に送信する。
更に、他の例として、前記文字認識部、前記抽出部、前記翻訳辞書を格納する記憶装置、及び前記検索部を備えるサーバを有する文書翻訳システムであって、携帯情報端末の画像撮影部より得られた画像をネットワークを介してサーバに送信し、サーバにおいて検索部により翻訳辞書を検索した結果得られた翻訳文を、ネットワークを介して携帯情報端末に送信する。
好ましい例では、この文書翻訳システムにおける前記翻訳辞書は、単語が含まれる原文を検索するための原単語インデックス部と、原文に含まれる原単語の幾何学情報と原単語の文字コードを格納した原文データ格納部と、各原文に対応する訳文を格納した訳文格納部を有する。
本発明は、また上記文書翻訳システムにおいて使用される特徴的な携帯情報端末、又はサーバとして把握される。
更に本発明は、上記文書翻訳システムにおいて、前記抽出部の機能を実現するためのコンピュータ上で実行可能なプログラムとして把握される。
【0012】
更に本発明は、翻訳処理方法として把握される。例えば、画像撮影部と、利用者に操作されて情報を入力する入力部と、表示部を有する携帯情報端末を用いて、画像撮影部で撮影された画像に含まれる文字に関する翻訳を得るための処理を行う翻訳処理方法において、単語からなる原文と原文に対応する翻訳文を対応付けて保持すると共に、原文に含まれる各文字の配置情報を関連付けて保持する翻訳辞書を記憶装置内に予め用意するステップと、画像撮影部で撮影された画像から利用者により指定された着目文字パターンとその着目文字パターンの周辺の文字パターンを対象として文字認識処理を行い、文字パターンの文字コードを出力するステップと、利用者により指定された着目文字パターンと着目文字パターンの周辺の文字パターンに関して相対的な配置情報を抽出するステップと、着目文字パターンと着目文字パターンの周辺の文字パターンに関して、文字認識部より得られた文字コードと抽出部より得られた相対的な配置情報を用いて、翻訳辞書を検索するステップと、検索の結果得られた翻訳文を表示部に表示するステップと、を有する文書翻訳処理方法である。
好ましい例では、上記翻訳辞書の検索の結果、着目文字パターンを含む1又は複数の翻訳の候補となる原文を表示部に表示するステップと、複数の候補の場合、複数の候補の中から利用者により入力部を介して指定された候補に対応する翻訳文を翻訳辞書から得るステップと、を更に有し、翻訳辞書から得られた翻訳文と原文とを対応させて表示部に表示する。
【発明の効果】
【0013】
本発明によれば、翻訳対象とする文章全体をカメラで撮影する必要がなく、原文の一部を撮影した部分画像に含まれる単語と単語の配置情報を利用して、原文の翻訳を得ることができる。
これにより、従来のように翻訳対象の文全体を撮影する場合に比べて、撮影された画像は翻訳対象文の任意の一部を含んでいれば良いので、撮影の自由度が大きくなり、利用者の使い勝手が大幅に向上する。
【発明を実施するための最良の形態】
【0014】
以下、図面を参照して本発明の実施形態について、説明する。
第1の実施形態では、英文和訳システムについて示す。翻訳対象の文章全体をカメラで一度に撮影して、文字認識処理により正しくテキストデータに変換して翻訳ソフトに入力することは困難である。そこで、本実施形態では、翻訳対象の文章全体をシステムに入力して翻訳アルゴリズムにより入力文を逐一翻訳するのではなく、予め被翻訳文(原文)である英文とその翻訳結果である和文を対応付けて電子辞書に格納されている。例えば、英語の教科書や英文のマニュアルの文書全体とその翻訳である和文の文書全体が予め対応付けられて電子辞書に格納されている。
【0015】
そこで、利用者が、翻訳対象とする英文全体或いは任意の複数の文章全体ではなく、翻訳対象に含まれる一部の単語を含む画像(部分画像)をカメラで撮影すると、その部分画像に含まれる単語は文字認識された後、その単語をキーにして電子辞書に格納されている翻訳対象の英文を検索する。さらに、検索結果の英文と対応付けられている和文を検索して画面に表示することで、英文から和文への文単位の翻訳を実現するものである。
【0016】
また、本実施形態においては、その部分画像をキーにして電子辞書に格納されている翻訳対象の英文を検索するために、英文に含まれる各単語の配置情報も併せて電子辞書に予め格納される。その後、撮影された部分画像に含まれる単語の文字コードと配置情報を文字認識処理によって抽出する。その抽出された単語の文字コードと配置情報に関して、電子辞書に格納されている和文の単語の文字コードと配置情報を検索する。その検索の結果、抽出された和文の単語の配置情報に最も類似した配置の単語を含む英文テキストを電子辞書から検索して取得する。そしてその後、検索された英文に対応付けて格納されている和文を取得する。
【0017】
使用される配置情報は、撮影の角度やスケールになるべく依存しない情報が望ましい。例えば、各単語が含まれる行の相対的な配置情報や角度情報である。
単語の配置情報の例として、部分画像に含まれる単語の相対的な位置関係を表す角度情報を抽出する手順に関しては、例えば、利用者が指定する着目単語“as”と着目単語の上下左右など周りに存在する複数の単語(以下では周辺単語と呼ぶ)に関して文字認識処理により単語の文字コードと各単語の矩形重心座標をそれぞれ抽出する。その後、着目単語の矩形重心から各周辺単語の矩形重心に線分1101〜1105を引きその線分間の角度1106〜1110を計算する。この角度計算は任意の周辺単語重心間について計算してよい。この重心間角度は画像のスケールに依存しないので安定した配置情報となりうる。(これらについては、図11を参照して詳しく後述される。)
以下、図1、図3〜14を参照して第1の実施形態について詳細に説明する。
第1の実施形態は、上記の機能乃至構成を携帯情報端末において実現するシステムの例である。
図1は、携帯情報端末の構成例を示すブロック図である。
携帯情報端末100は例えば携帯電話であり、その本体は、認識対象となる英語の教科書等を光学的に入力するカメラやスキャナなどの画像撮影部110と、認識対象の画像や文字認識結果、カーソル172等を表示する液晶などの表示部120と、利用者がキー操作して情報を入力するキー174〜179を配置した入力部130を備えている。更にその内部の構成として、携帯情報端末の全体の制御を行なう端末制御部140、画像撮影部110から得られた画像に含まれる単語等の認識を行なう文字認識部150、文字認識結果を用いて英文に対応する和訳文を検索するための文書翻訳DB検索部160、様々な処理結果データや電子辞書等のデータベースを格納するためのメモリ180を有する。
【0018】
端末制御部140は、通信制御部141、画像撮影部110を制御するためのカメラ制御部142、入力部130を制御するためのキー入力制御部143、表示部120を制御するための表示制御部144、文字認識部150や文書翻訳DB検索部160を制御するための文字認識/翻訳DB検索制御部145から構成される。文字認識部150は入力された画像から各単語の矩形座標を抽出するための単語矩形座標抽出部151、単語矩形座標抽出部151の出力に基づいて入力画像の矩形座標内の単語認識を行う単語認識部152を有して構成される。
【0019】
メモリ180は、入力部130の操作により取り込まれた画像データ181、文字認識部150による認識結果を格納する単語認識結果データ182、文書翻訳DB検索部160の出力を格納する翻訳対象候補文検索結果データ183、及び翻訳対象とする英文の文書とそれに対応した和文の文書を格納する電子辞書としての文書翻訳DB(データベース)184を格納する。文書翻訳DB184には英文に含まれる各単語の配置情報も併せて格納される。
【0020】
尚、ここで、文字認識部150、文書翻訳DB検索部160はソフトウェアの実行により実現される機能であってもよい。
【0021】
文書翻訳DB184は、文書翻訳DBがプレインストールされたROMが携帯情報端末100に実装されたことを前提にしてもよい。またはこの文書翻訳DBを格納したSD(Secure Digital)カードなどのメモリ媒体を購入して、そのSDカードから文書翻訳DBをメモリ180の文章翻訳DB184にインストールすることを想定してもよい。また、文書辞書DB184は半導体メモリのような静的記憶装置に限らず、ハードディスク装置のような記憶装置に格納されてもよい。
【0022】
次に、図3に示す一連の翻訳処理フローを参照して、翻訳処理動作について説明する。
なお、図3による全体的な処理動作の説明において、各動作の詳細な説明については更に図4以降の図を参照することがある。
まず、利用者は携帯情報端末100の画像撮影部110を用いて文字認識対象となる雑誌や本等の画像を撮影する。撮影された画像はメモリ180中の画像データ181の領域にデジタル画像として格納される(301)。
【0023】
図4に翻訳対象の英文文書の例を示す。右上に「P24」とページ番号が付されている。401で囲まれた部分は、画像撮影部110で撮影された画像の範囲を示し、画像データ181に格納される。この画像データ181が文字認識部150に入力される画像の範囲である。なお、この例では3行目の”To meet”で始まり5行目の”quality products.”で終わる2番目の文を翻訳するために画像を取り込むことを仮定する。この文書の翻訳のために、本実施形態では2番目の英文を構成する任意の単語が着目対象となり得る。ここでは図1の表示部120に示すように、着目対象を示す「+」のマーク172は、“as”に重なっていると想定する。
【0024】
次に、単語矩形座標抽出部151にて、入力された画像から英単語の場所を示す矩形座標が抽出される(302)。ここでは、図5に示すように、着目している“as”501だけでなく、縦方向に見たときに“as”501の矩形とオーバーラップがある上下の行の単語パターン502、503、506、及び横方向に見たときに“as”の矩形とオーバーラップがあり、“as”に隣接している単語パターン504、505についても近傍の単語パターンとして一緒に矩形座標が抽出される。
【0025】
この矩形座標抽出処理302の動作の詳細について、図6を用いて説明する。
画像データ181に格納されている画像401が単語矩形座標抽出部151に入力されると、最初に2値画像が生成される(601)。次に、文字行の大雑把な位置を検出するために、画像の横方向に黒画素を加算して投影分布を求める(602)。
【0026】
図7は画像情報として含まれる文字行の黒画素投影の算出の原理を示す図である。画像の原点は左上であり、702は画像縦方向の座標軸に相当し、703は横方向の投影分布を表す。この投影分布の算出後、文字行の存在する縦方向座標の範囲を求めるため、非零値の範囲704〜708を計算する(603)。求められた文字行の存在する縦方向座標の範囲で、黒画素が連結した塊である連結成分を求めると共にその外接矩形座標もあわせて計算する。そして、連結成分の外接矩形同士の隙間等を参照しながら距離が近い矩形を横方向に統合し(604)、統合された矩形の座標は単語の矩形座標として単語認識結果データ182に格納される(605)。
【0027】
図8は単語認識結果データ182の構成例を示す。
817から822は各単語のデータレコードを示しており、810は単語の文字コード格納領域、811は矩形左上X座標、812は矩形左上Y座標、813は矩形右下X座標、814は矩形右下Y座標、815は単語が含まれる行の行番号を表す。816は周辺単語と着目単語を区別するための着目単語フラグであり、着目単語に対しては“1”、それ以外の周辺単語は“0”を格納する。ステップ605の処理では、811から816のデータが格納される。
【0028】
次に、単語認識部152は、抽出された英単語矩形座標501から506に対して抽出された矩形座標内に存在する英単語パターンに関して文字認識処理を行う。具体的には、単語認識結果データ182の811から814の矩形座標データと画像データ181を入力し、認識結果である単語の文字コードを同じ単語認識結果データ182の単語の文字コード格納領域810に出力する(303)。
【0029】
文書翻訳DB検索部160は、単語認識結果データ182の内容を読み出し、文書翻訳DB184に対して、”as”が含まれる英文と対応する和訳文候補の検索を行う(304)。”as”など特定の単語が含まれる英文は、一般的に共通の文書翻訳DB184に複数箇所存在する。そのため、複数の英文候補から和訳対象英文を絞り込むために、ここでは図5における”as”501の周りに存在する502から506の英単語と”as”501との幾何学的な相対関係を用いる。
【0030】
図9は文書翻訳DB184に格納される辞書データの構造を示す。
900は当該単語が含まれる英文を検索するための英単語インデックス部、901は英文に含まれる英単語の幾何学情報と英単語の文字コードを格納した英文データ格納部、902は各英文に対応する和訳文を格納した和訳文格納部である。英単語インデックス部900は高速に翻訳対象の英文データ901を検索するためのインデックステーブルであり、903は単語の文字コードデータ、904は当該単語が文書中に現れる数、905、906は当該単語が含まれる英文データ格納部901へのポインタである。
【0031】
英文データ格納部901において、一つの英文を構成する単語データのレコード916から922の各カラムの内容について説明する。910は英文を構成する英単語データである。911、912は英文が含まれる当該ページの左上を原点とした場合の当該英単語の矩形重心座標であり、911はX座標の値、912はY座標の値を示す。これら座標値は任意の解像度、あるいは、適当なスケールを仮定して決定してよい。913、914はそれぞれ当該単語が含まれるページ数、行番号である。915は単語が含まれる行中において左から数えて何番目の単語であるかを示す。922のレコードは英文の終りを示す”.”(ピリオド)と和訳文格納部902へのポインタからなっている。和訳文格納部902において、923から925は各英文に対応する和訳文データを示す。和文格納部902へのポインタは文単位に存在し、一つの英文が一つの和訳文に対応するようにリンクが張られている。
【0032】
次に、図10を参照して翻訳対象候補文の選択処理動作304の詳細について説明する。
まず、ステップ303にて抽出された着目単語”as”501の矩形重心から、近傍単語”we”502、”have”503、”resulting”504、”high”505、”create”506の各矩形重心座標に線を引き、その線分間の角度、あるいは、余弦を測定する(1001)。
【0033】
図11を用いてこの処理の詳細を説明する。着目単語”as”の矩形重心から、各近傍単語の矩形重心に引いた線分は1101、1102、1103、1104、1105で示される。例えば、近傍単語”we”、”have”に引かれた線分間の角度は1106で示される。以下、同様に各近傍単語の重心に引かれた線分間の角度を計算する。ここで角度を計算するのは、カメラで撮影した画像のスケールや撮影角度と辞書登録時に単語の位置を表すために使用したスケールや撮影角度が一般には異なるため、これらが変わっても変化しにくい幾何学的相対関係を記述する量を抽出するためである。不変量に相当すれば任意の量を用いることができ、例えば、各単語が属する相対的な行番号でもよい。”we”、”have”は1行目、”resulting”、”as”、”high”は2行目、”create”3行目等である。
【0034】
次に、文書翻訳DB184の英文インデックス部900の”as”レコード908を参照して、英文データ格納部901の”as”が含まれる英文データを検索し、さらにその近傍単語が存在するかを検索する(1002)。具体的には、最初に”as”が含まれるレコード919のデータを参照した後、カラム914の行番号の情報を参照しながら”as”が含まれる行の前後の行に存在する単語の中に入力画像から得られた近傍単語を検索する。検索の結果、近傍単語の数が閾値以上か否かを判定する(1003)。判定の結果、近傍単語の数が閾値以上存在すれば、近傍単語が存在したと見なしてステップ1004に進む。一方、閾値以上でなければ、ステップ1007に進む。ここで、近傍単語を全数見つけるのではなく閾値以上としたのは、誤認識により正しい単語が得られない場合を考慮している。
【0035】
次に、得られた近傍単語について、ステップ1001と同様な処理により着目単語”as”の矩形重心から近傍単語の矩形重心に引いた線分間の角度を計算する(1004)。具体的には、近傍単語の矩形重心X座標の値911、および、Y座標の値912を参照して、得られた各近傍単語の矩形重心間の角度とステップ1001で得られた角度との差分を取る。ここでは、計算コストを減らすため角度差分の代わりに角度の余弦差分のことを相違度と定義する。
例えば、辞書データに格納された単語矩形座標を用いて、”as”の矩形重心を基点とした単語”we”、”have”の矩形重心座標間の角度余弦計算は以下の通りである。
“as”から“we”への矩形重心ベクトル :a=(x、y)=(330-400、225-300)=(-70、-75)
“as”から“have”への矩形重心ベクトル:b=(x、y)=(470-400、225-300)=(+70、-75)
ベクトルa、b間の余弦=a・b/(‖a‖‖b‖)=0.07
次に、相違度が閾値以下かどうかを判断し(1005)、閾値以下であればステップ1006に進み、閾値を超えていればステップ1007に進む。ステップ1006では、英文データ格納部901において”as”レコード919以降の単語データを検索し、文末の記号である”.”(ピリオド)を含むレコード922を検索する。そして、ピリオドの後ろに格納されている和訳文データへのポインタを取得して、翻訳対象候補文検索結果データ183に格納する。
【0036】
この検索結果データ183には和訳文データへのポインタのみならず、翻訳対象の英文に含まれる全単語とその単語に付随するレイアウト情報や着目単語を表すフラグ値が格納されている。
【0037】
図12に翻訳対象候補文検索結果データ183の構成例を示す。
1200は翻訳対象候補の英文を構成する単語数であり、1201から1205は当該英文に含まれる各単語の属性データである。1201は単語の文字コード格納領域であり、1202から1204はそれぞれ図9のカラム913から915のデータをコピーして格納しており、各データは単語が存在するページ番号、行番号、行内の左から数えた単語番号である。1205は着目単語を表すフラグであり、着目単語であれば、“1”、それ以外は“0”が格納されており、本フラグは表示部の画面表示制御に用いる。1206から1213は翻訳対象候補の英文を構成する単語レコードであり、1200で示された数だけレコードが存在する。1214は当該英文に対応する和訳文データへのポインタであり、図9のレコード922のポインタデータをコピーして格納している。
【0038】
上記ステップ1002から1006までの処理をレコード908に格納されている905以降のポインタがなくなるまで、すなわち、”as”という単語へのポインタが無くなるまで繰り返す(1007)。このようにして得られた和訳文の候補ポインタと英文データを翻訳対象候補文検索結果データ183から読み出し、さらに、”as”近傍画像と矩形座標をそれぞれ画像データ181、単語認識結果データ182から読み出し、それらを表示部120上に表示する(1008)。
【0039】
図13に翻訳対象英文候補の表示の例を示す。
1300は入力画像の着目単語である”as”を含む行画像を示し、1301は着目単語であることを示す矩形である。1302は文書翻訳DB184を検索した結果、着目単語”as”が存在する位置を示しており、この例では24ページ、5行目の左から3単語目に着目単語”as”が存在することを示している。また、ここでアンダーラインが表示されているが、このアンダーラインが引かれた文字を選択すると対応する和訳文を表示することができるというハイパーリンクを表しており、このリンクを選択すると図12の1214に格納されているポインタを参照して和訳文が表示できるようになっている。
【0040】
1303は1302の単語を含む英文の表示例であり、表示スペースを節約するために、ここでは英文の先頭・末尾単語、および、着目単語の前後の近傍単語のみを表示している。また、着目単語を明示するために”as”はボールド体で表示されている。1302と1303は対になっており、以下、1304から1307は同様に着目単語の存在位置と着目単語が含まれる英文が対になって表示されている。
以上のように図10のステップ1001から1008の処理により、着目単語”as”が含まれる英文と対応する和訳文候補を検索し、結果が表示部に表示される。
【0041】
利用者は、図13に表示された翻訳対象英文候補の内から、該当する対象のもの(この例では1302)を入力部130の操作により選択する。その時、検索部160は対応する和訳文ポインタを参照して図9に示す和訳文データ924を検索し(305)、検索結果を表示部120に表示する(306)。
【0042】
図14に和訳文の検索結果の表示例を示す。
表示画面には、検索のポインタとなった画像中の文字1400、1401、選択された翻訳対象英文候補1402〜1403、及び検索の結果得られた翻訳文である和文1404が表示される。
1400、1401は図13における1300、1301と同様であり、1402、1403はそれぞれ1302、1303に対応する。1404は1403の英文に対応する和訳文であり、図12における1214のポインタを参照した上で、文書翻訳DB184における924(図9)の和訳文データを取得して表示されている。
【0043】
以上説明したように、図3に示す処理により利用者は翻訳対象とする英文全体を撮影する必要がなく、該当する英文の和訳文を得ることができる。
【0044】
次に、図2、図15〜17を参照して第2の実施形態について説明する。
第2の実施形態は、図2に示すように、上述した文書翻訳DB及びその検索手段をサーバ202に保持させ、必要に応じて通信ネットワーク201を介してサーバ202からデータを携帯情報端末100にダウンロードする例である。即ち、携帯情報端末100では取得された画像から単語認識を行い、その認識結果をサーバ202に送信して、サーバ202において認識結果である文字コードを用いて文書翻訳DBを検索し、検索結果を携帯情報端末100に返送して表示するシステム構成とその処理手順について、以下説明する。
【0045】
図15は、第2の実施形態における携帯情報端末のブロック図である。
この例も第1の実施形態と同様に英文を和文に翻訳する例である。図1の構成との主な相違点は、文書翻訳DB184の代わって、和訳文のみを格納する和訳文データ185の格納部が設けられること、文字認識/翻訳DB検索制御部145による処理手順が変わること等である。
【0046】
図16はサーバ202の概略的な構成を示す。
サーバ202では、通信制御部1601、中央演算装置1602、メモリ1603がバス1600を介して接続されている。メモリ1603には文書翻訳DB検索プログラム1604が格納されている。このプログラムは図1における文書翻訳DB検索部160と同様に文書翻訳DBの検索処理を行うためのプログラムである。単語認識結果データ1605、翻訳対象候補文検索結果データ1606、文書翻訳DB1607は、それぞれ図1における単語認識結果データ182、翻訳対象候補文検索結果データ183、文書翻訳DB184と同等のデータを格納する領域である。
【0047】
図17は、第2の実施例における携帯情報端末100とサーバ202のそれぞれの処理を示すフローチャートである。
図において、実線の矢印は処理のフローを示し、点線の矢印はデータの流れを示す。
画像入力処理(1701)から英単語認識処理(1703)は、図3におけるステップ301から303と同様であり、画像撮影部110により撮影された翻訳対象の文章を部分的に含む画像から英単語を認識し、認識結果を単語認識結果データ182に格納する。次に文字認識/翻訳DB検索制御部145は単語認識結果データ182に格納された英単語認識結果データを、通信制御部141を介してサーバ202に送信する(1704)。
【0048】
サーバ202では、携帯情報端末100から送信された単語認識結果データを受信して、そのデータを単語認識結果データ1605に格納する(1710)。その後、文書翻訳DB検索プログラム1604を実行して文書翻訳DB1607を検索して翻訳対象候補文の検索を行なう(1711)。この処理は、単語認識結果データ1605を用いて図10のステップ1001から1007と同様な処理手順で文書翻訳DB1607を検索し、検索結果をメモリ1603の翻訳対象候補文検索結果データ1606に格納する処理である。
次に、サーバ202は、メモリ1603に格納された翻訳対象候補文検索結果データ1606を携帯情報端末100に送信し(1712)、携帯情報端末100ではそのデータを受信して、翻訳対象候補文検索結果データ183に格納する(1705)。
【0049】
そして携帯情報端末100では、翻訳対象候補文検索結果データ183を参照して、図13に示すような翻訳対象候補検索結果を表示部120に表示する。利用者は、表示部に表示された翻訳候補から1つを選択する(1706)。選択結果として図12における英文に対応する和訳文データへのポインタ1114のデータのみをサーバ202に対して送信する(1707)。
【0050】
サーバ202では、携帯情報端末100から送信された和訳文データへのポインタを受信し(1713)、受信したポインタを参照して対応する和訳文データを検索する(1714)。そして、その検索の結果得られた和訳文データを携帯情報端末100に送信する(1715)。携帯情報端末100では、検索された和訳文データを受信して、メモリ180の和訳文データ185に格納し(1708)、そのデータを表示部120に表示する(1709)。表示部120の表示画面の内容は、図12と同様である。
【0051】
以上のように図17に示す処理動作により、利用者は翻訳対象とする英文全体を撮影する必要がなく、サーバ202に備えられた文書翻訳DB1607、及びそのDBを検索する検索手段を利用してネットワークを介して目的の和訳文を得ることができる。
【0052】
次に、図18〜図25を参照して第3の実施形態について説明する。
この例は和文を英文に翻訳する例である。英文の場合には単語と単語の間に空白が在る(第1、2の実施形態の場合)。しかし本実施形態における和文の場合には、文字認識対象となる和文は空白による単語の区切れ目のない文である。和文の場合、英単語に相当するのは和文の構成要素である「形態素」に着目するものであり、「形態素」に対する文字認識と、それを用いた翻訳候補文検索に特徴がある。以下、図面を参照して説明する。
【0053】
図18は、携帯情報端末の構成を示すブロック図である。
図1に示した携帯情報端末100の構成との主な相違点は、文字認識部150の構成及び処理動作にある。即ち、図18に示す形態情報端末100の文字認識部150の文字行座標抽出部1501、形態素認識部1502は、それぞれ図1の単語矩形座標抽出部151、単語認識部152に対応する。メモリ180では文字行座標データ1804が新たに追加された。形態素認識結果データ1805、翻訳対象候補文検索結果データ1806、文書翻訳DB1807は、それぞれ図1の182、183、184に対応する。
図19は第3の実施形態の翻訳処理フローを示す。以下、図19を用いて図18の携帯情報端末の処理動作について説明する。
【0054】
まず、画像撮影部110で撮影された文字認識対象画像が入力される(1901)。
図20に、認識対象となる和文の文書の例を示す。右上に「P24」とページ番号の表示がある。2001は、画像撮影部110で撮影されて取り込まれた画像の範囲を示し、この範囲の画像が文字認識部150に入力される。この例では、3行目の「これに応える・・・」で始まり、5行目の「・・・努めています。」で終わる2番目の文を翻訳するために画像を取り込むことを仮定する。この文書の翻訳のために、この実施形態では2番目の和文を構成する任意の形態素が着目対象となり得る。ここでは着目対象を示す「+」のマークは5行目の「製品」に重なっていると想定する。
【0055】
文字認識部150の文字行抽出部1501にて、入力された画像から文字行の場所を示す矩形座標を抽出する(1902)。この処理は、図3のステップ302と同様な処理である。ここで、着目している「製品」を含む文字行座標だけでなく、上下の文字行座標も合わせて出力される。ステップ302では単語単位の矩形座標を抽出したが、日本語の場合は単語の区切れ目に相当する空白は存在しない。そこで、図7に示すような行方向の黒画素射影を取って行の位置を計算した後は、その中に含まれる近接した連結成分を統合して文字行の矩形座標を計算し、文字行座標データ1804に格納する。
【0056】
抽出された文字行の矩形座標に対して形態素認識部1502は抽出された矩形座標内に存在する文字パターンに対して文字認識処理を行うと共に形態素解析を行い、文字認識結果として各形態素の文字コードと形態素に対応する矩形の重心座標を形態素認識結果データ1805に出力する(1903)。ここで、図21に示すように「製品」2101の矩形座標と横方向にオーバーラップがある上下の文字行の形態素パターン、および、「製品」の隣接形態素パターン2102〜2109に対する文字コードと矩形重心座標が抽出される。
【0057】
図22に形態素認識結果データ1805の構成を示す。
2216から2224は各形態素のデータレコードを示す。また2210は形態素の文字コード格納領域を示し、2211から2214はそれぞれ形態素矩形の左上X座標、左上Y座標、右下X座標、右下Y座標を示す。2215は形態素が含まれる行の行番号を示す。2216は周辺形態素と着目形態素を区別するための着目形態素フラグであり、着目形態素に対しては“1”、それ以外の周辺形態素は“0”を格納する。
【0058】
文字認識結果は文書翻訳DB1807に渡され、実施例1で説明した処理と同様な方法により、文字認識結果をキーとして「製品」が含まれる和文と対応する英訳文候補の検索を行う(1904)。
【0059】
図23に文書翻訳DB1807に格納されるデータの構造を示す。2300は当該形態素が含まれる和文を検索するための形態素インデックス部、2301は和文データ格納部、2302は英訳文格納部である。形態素インデックス部2300において、2303は形態素データ、2304は当該形態素が文書中に現れる数、2305、2306は当該形態素が含まれる和文データ格納部2301へのポインタである。
【0060】
和文データ格納部2301において、一つの和文を構成する形態素データのレコード2316から2322の各カラムの内容について説明する。2310は和文を構成する形態素データである。2311、2312は和文が含まれる当該ページの左上を原点とした場合の当該形態素の矩形重心座標であり、2311はX座標の値、2312はY座標の値を示す。2313、2314はそれぞれ当該形態素が含まれるページ数、行番号である。2315は形態素が含まれる行中において左から数えて何番目の形態素であるかを示す。2322のレコードは和文の終りを示す”。”(読点)と英訳文格納部2302へのポインタからなっている。英訳文格納部2302において、2323から2325は各和文に対応する英訳文データを示す。
ステップ1904では、第1の実施例と同様に形態素間の相対的な配置情報を用いて英訳文候補ポインタとそれに対応する和文データを電子辞書部から検索し表示部上に表示し、利用者は該当すると思われる英訳文候補ポインタを選択する。
【0061】
図24を参照してステップ1904の詳細を説明する。
まず、ステップ1903で抽出された着目形態素「製品」の矩形重心から図21に示す近傍形態素2102から2109への各矩形銃身座標に線を引き、図10のステップ1001と同様にその線分間の角度、あるいは、余弦を測定する(2401)。
【0062】
次に、文書翻訳DB1807の形態素インデックス部2300の「製品」レコード2308を参照して和文データ格納部2301の「製品」が含まれる和文データを検索し、さらに、その近傍形態素が存在するかをステップ1002と同様な処理手順により検索する(2402)。検索の結果、近傍形態素の数が閾値以上であるか否かを判定する。閾値以上であれば、近傍形態素が存在したと見なしてステップ2404に進む。これに対して、閾値以上でなければステップ2407に進む(2403)。
【0063】
近傍形態素の数が閾値以上である場合、得られた近傍形態素について、ステップ2401と同様な処理により着目形態素「製品」の矩形重心から近傍形態素の矩形重心に引いた線分間の角度を計算し、相違度を計算する(2404)。この計算はステップ1004と同様な計算処理である。その後、相違度が閾値以下かどうかを判断し(2405)、閾値以下であればステップ2406に進み、閾値を超えていればステップ2407に進む。
【0064】
相違度が閾値以下の場合、和文データ格納部2301において「製品」レコード2319以降の単語データを検索し、文末の記号である「。」(読点)を含むレコード2322を検索する。そして、読点の後ろに格納されている英訳文データへのポインタを取得して、翻訳対象候補文検索結果データ1806に格納する(2406)。
【0065】
図25に翻訳対象候補文検索結果データ183の構成例を示す。
2501は翻訳対象候補の和文を構成する形態素数であり、2502から2506はこの和文に含まれる各形態素の属性データである。2502は形態素の文字コード格納領域であり、2503から2505はそれぞれ図23のカラム2313から2315のデータをコピーして格納しており、各データは形態素が存在するページ番号、行番号、行内の左から数えた形態素番号である。2306は着目形態素を表すフラグであり、着目形態素であれば、“1”、それ以外は“0”が格納されており、本フラグは表示部の画面表示制御に用いる。
2507から2513は翻訳対象候補の和文を構成する形態素レコードであり、2501で示された数だけレコードが存在する。2514は当該和文に対応する英訳文データへのポインタであり、図23のレコード2322のポインタデータをコピーして格納している。
【0066】
上記ステップ2402から2406までの処理をレコード2308に格納されている2305以降のポインタがなくなるまで、すなわち、「製品」という形態素へのポインタが無くなるまで繰り返す(2407)。このようにして得られた和訳文の候補ポインタと英文データを翻訳対象候補文検索結果データ1805から読み出し、さらに、「製品」近傍画像と矩形座標をそれぞれ画像データ181、形態素認識結果データ1804から読み出し、それらを表示部120に表示する(2408)。
【0067】
以上のように、図24に示す処理により、着目形態素「製品」が含まれる和文と対応する英訳文候補を検索し、結果が表示部に表示される。英訳文候補の内、該当する英訳文に関係するリンクを利用者が選択すると、対応する英訳文を文書翻訳DB1807から検索して(1905)、それを表示部120に表示する(1906)。
以上のように図19に示す処理により、利用者は和文全体を撮影することなく、該当する和文の英訳文を得ることができる。
【0068】
上記実施例では形態素を単位として説明したが、ここでは表示部上の「+」印がどの翻訳対象の和文を指しているかが分ればよい。従って、代替例においては、形態素を単位にして文字認識や検索処理を行なわないで、任意の文字長、例えば1文字や2文字と設定した文字列を形態素の代わりに処理を行ってもよい。
【0069】
更に、他の変形例について説明する。図15〜16を参照した第2の実施形態によれば、サーバ202に、文書翻訳DB1607及びその検索手段104等を具備する構成としたが、他の変形例によれば、第2の実施形態の構成に加え、更に図1の文字認識部150の機能をサーバ202に持たせてもよい。この構成によれば、携帯情報端末100では、翻訳対象の文を部分的に含む画像を取得してそれをサーバ202へ送信するだけでよく、以後の全ての処理はサーバ202で行なわれる。そしてサーバ202から送信される処理結果としての翻訳候補文を受信すればよい。
【0070】
更に、他の変形例について説明する。上記実施例では複数の単語等の配置情報から、文書中で着目している場所、すなわち、ページ番号、行番号、行中の単語番号を特定し、その場所と関連付けられている原文や訳文情報をDBから検索して画面に出力した。しかし、このような関連情報は必ずしも原文や訳文に限る必要は無く、その他の任意の情報をその場所と関連付けることが可能である。例えば、予めDBに登録しておくことにより、例えば図21の「製品」2101は「金融機関向けのATM」といった意味情報や、その製品の詳細情報が得られるURL等を関連付けることが可能である。
【図面の簡単な説明】
【0071】
【図1】第1実施形態による携帯情報端末を用いた文書翻訳システムの構成を示す図。
【図2】第2実施形態による携帯情報端末及びサーバを含む文書翻訳システムを示す図。
【図3】第1実施形態における翻訳処理フローを示す図。
【図4】第1実施形態における翻訳対象の英文の例を示す図。
【図5】第1実施形態における単語矩形座標の抽出例を示す図。
【図6】第1実施形態における英単語矩形座標抽出302の処理フローを示す図。
【図7】第1実施形態における英単語矩形座標抽出302のための黒画素投影処理の原理を説明するための図。
【図8】第1実施形態における単語認識結果データ182の構成例を示す図。
【図9】第1実施形態における英文を和文に翻訳するための文書翻訳DB184の構成を示す図。
【図10】第1実施形態における英文を和文に翻訳するための文書翻訳DB検索処理フローを示す図。
【図11】第1実施形態における着目単語を基準として周辺単語間の角度測定の説明図。
【図12】第1実施形態における英文の翻訳対象候補文検索結果データの構成例を示す図。
【図13】第1実施形態における翻訳対象英文候補の表示例を示す図。
【図14】第1実施形態における翻訳結果の表示例を示す図。
【図15】第2実施形態による携帯情報端末の構成を示す図。
【図16】第2実施形態によるサーバの構成を示す図。
【図17】第2実施形態における翻訳処理フローを示す図。
【図18】第3実施形態による携帯情報端末の構成を示す図。
【図19】第3実施形態における翻訳処理フローを示す図。
【図20】第3実施形態における文字認識・翻訳対象の和文の例を示す図。
【図21】第3実施形態における形態素矩形座標の抽出例を示す図。
【図22】第3実施形態における形態素認識結果データの構成例を示す図。
【図23】第3実施形態における和文を英文に翻訳するための文書翻訳DBの構成を示す図。
【図24】第3実施形態における和文を英文に翻訳するための文書翻訳DBの検索処理フローを示す図。
【図25】第3実施形態における和文の翻訳対象候補文検索結果データの構成例を示す図。
【符号の説明】
【0072】
100 携帯情報端末、 110 画像撮影部、
120 表示部、 130 キー入力部、
140 端末制御部、 150 文字認識部、
160 文書翻訳DB検索部、 180 メモリ、
184 文章翻訳DB、
202 サーバ。
【特許請求の範囲】
【請求項1】
画像撮影部と、利用者に操作されて情報を入力する入力部と、表示部を有する携帯情報端末を用いて、該画像撮影部で撮影された画像に含まれる文字に関する翻訳を得て、その翻訳を該表示部に表示する文書翻訳システムにおいて、
単語からなる原文と該原文に対応する翻訳文を対応付けて保持すると共に、該原文に含まれる各単語の配置情報を関連付けて保持する翻訳辞書を格納する記憶装置と、
該画像撮影部で撮影された画像から利用者により指定された着目単語パターンとその着目単語パターンの周辺の単語パターンを対象として文字認識処理を行い、該単語パターンの文字コードを出力する文字認識部と、
利用者により指定された着目単語パターンと該着目単語パターンの周辺の単語パターンに関して相対的な配置情報を抽出する抽出部と、
該着目単語パターンと該着目単語パターンの周辺の単語パターンに関して、該文字認識部より得られた該文字コードと、該抽出部より得られた該相対的な配置情報を用いて該翻訳辞書を検索する検索部と、
を有し、該検索部より得られた翻訳文を該表示部に表示することを特徴とする文書翻訳システム。
【請求項2】
前記翻訳辞書部は、原文としての英文とその和訳文を対応付けて格納することを特徴とする請求項1の文書翻訳システム。
【請求項3】
前記翻訳辞書部は、スペースで区切られた単語からなる原文と該原文に対応する翻訳文を対応付けて格納することを特徴とする請求項1の文書翻訳システム。
【請求項4】
該相対的な配置情報は、利用者により指定された着目単語パターンの矩形重心から着目単語パターンの各周辺単語パターンの矩形重心に線分を引きその線分間の角度であることを特徴とする請求項1の文書翻訳システム。
【請求項5】
該相対的な配置情報は、利用者により指定された着目単語パターンが含まれる行、および、着目単語パターンの各周辺単語パターンが含まれる行の相対的な配置情報であることを特徴とする請求項1の文書翻訳システム。
【請求項6】
画像撮影部と、利用者に操作されて情報を入力する入力部と、該画像撮影部で撮影された画像に含まれる文字に関する翻訳を得るための処理を行う翻訳処理部と、該翻訳処理部により得られた翻訳を表示する表示部を有する携帯情報端末を用いた文書翻訳システムにおいて、
原文の文書と該原文に対応する翻訳文の文書を対応付けて格納すると共に、
原文に含まれる各形態素の配置情報を関連付けて保持する翻訳辞書を格納する記憶装置と、
該画像撮影部で撮影された画像から利用者により指定された着目形態素パターンとその着目形態素パターンの周辺の形態素パターンに関して文字認識処理を行い、各形態素の文字コードを出力する文字認識部と、
利用者により指定された着目形態素パターンと該着目形態素パターンの周辺に存在する形態素パターンに関して相対的な配置情報を抽出する抽出部と、
該着目形態素パターンと該着目形態素パターンの周辺に存在する形態素パターンに関して、該文字認識部より得られた文字コードと、該抽出部より得られた該相対的な配置情報を用いて該翻訳辞書を検索する検索部と、
を有し、該検索部より得られた翻訳文を該表示部に表示することを特徴とする文書翻訳システム。
【請求項7】
画像撮影部と、利用者に操作されて情報を入力する入力部と、表示部を有する携帯情報端末を用いて、該画像撮影部で撮影された画像に含まれる文字に関する翻訳を得て、その翻訳を該表示部に表示する文書翻訳システムにおいて、
単語からなる原文と該原文に対応する翻訳文を対応付けて保持すると共に、該原文に含まれる各文字の配置情報を関連付けて保持する翻訳辞書を格納する記憶装置と、
該画像撮影部で撮影された画像から利用者により指定された着目文字パターンとその着目文字パターンの周辺の文字パターンを対象として文字認識処理を行い、該文字パターンの文字コードを出力する文字認識部と、
利用者により指定された着目文字パターンと該着目文字パターンの周辺の文字パターンに関して相対的な配置情報を抽出する抽出部と、
該着目文字パターンと該着目文字パターンの周辺の文字パターンに関して、該文字認識部より得られた該文字コードと該抽出部より得られた該相対的な配置情報を用いて、該翻訳辞書を検索する検索部と、
を有し、該検索部より得られた翻訳文を該表示部に表示することを特徴とする文書翻訳システム。
【請求項8】
前記翻訳辞書を格納する記憶装置、及び前記検索部を備えるサーバを有する文書翻訳システムであって、
該携帯情報端末の該文字認識部より得られた該文字コードと、該抽出部より得られた該相対的な配置情報を、ネットワークを介して該サーバに送信し、該サーバにおいて該検索部により該翻訳辞書を検索した結果得られた翻訳文を、該ネットワークを介して該携帯情報端末に送信することを特徴とする請求項1乃至7のいずれかの文書翻訳システム。
【請求項9】
前記文字認識部、前記抽出部、前記翻訳辞書を格納する記憶装置、及び前記検索部を備えるサーバを有する文書翻訳システムであって、
該携帯情報端末の該画像撮影部より得られた画像をネットワークを介して該サーバに送信し、該サーバにおいて該検索部により該翻訳辞書を検索した結果得られた翻訳文を、該ネットワークを介して該携帯情報端末に送信することを特徴とする請求項1乃至7のいずれかの文書翻訳システム。
【請求項10】
前記翻訳辞書は、単語が含まれる原文を検索するための原単語インデックス部と、原文に含まれる原単語の幾何学情報と原単語の文字コードを格納した原文データ格納部と、各原文に対応する訳文を格納した訳文格納部を有することを特徴とする請求項1乃至9のいずれかの文書翻訳システム。
【請求項11】
請求項1乃至10のいずれかのシステムにおいて使用される携帯情報端末。
【請求項12】
請求項8又は9のシステムにおいて使用されるサーバ。
【請求項13】
請求項1乃至10のいずれかのシステムにおいて、前記抽出部の機能を実現するためのコンピュータ上で実行可能なプログラム。
【請求項14】
画像撮影部と、利用者に操作されて情報を入力する入力部と、表示部を有する携帯情報端末を用いて、該画像撮影部で撮影された画像に含まれる文字に関する翻訳を得るための処理を行う翻訳処理方法において、
単語からなる原文と該原文に対応する翻訳文を対応付けて保持すると共に、該原文に含まれる各文字の配置情報を関連付けて保持する翻訳辞書を記憶装置内に予め用意するステップと、
該画像撮影部で撮影された画像から利用者により指定された着目文字パターンとその着目文字パターンの周辺の文字パターンを対象として文字認識処理を行い、該文字パターンの文字コードを出力するステップと、
利用者により指定された着目文字パターンと該着目文字パターンの周辺の文字パターンに関して相対的な配置情報を抽出するステップと、
該着目文字パターンと該着目文字パターンの周辺の文字パターンに関して、該文字認識部より得られた該文字コードと該抽出部より得られた該相対的な配置情報を用いて、該翻訳辞書を検索するステップと、
該検索の結果得られた翻訳文を該表示部に表示するステップと、
を有する文書翻訳処理方法。
【請求項15】
該翻訳辞書の検索の結果、該着目文字パターンを含む1又は複数の翻訳の候補となる原文を該表示部に表示するステップと、
複数の候補の場合、該複数の候補の中から利用者により該入力部を介して指定された候補に対応する翻訳文を該翻訳辞書から得るステップと、を更に有し、
該翻訳辞書から得られた翻訳文と該原文とを対応させて該表示部に表示することを特徴とする請求項14の文書翻訳処理方法。
【請求項1】
画像撮影部と、利用者に操作されて情報を入力する入力部と、表示部を有する携帯情報端末を用いて、該画像撮影部で撮影された画像に含まれる文字に関する翻訳を得て、その翻訳を該表示部に表示する文書翻訳システムにおいて、
単語からなる原文と該原文に対応する翻訳文を対応付けて保持すると共に、該原文に含まれる各単語の配置情報を関連付けて保持する翻訳辞書を格納する記憶装置と、
該画像撮影部で撮影された画像から利用者により指定された着目単語パターンとその着目単語パターンの周辺の単語パターンを対象として文字認識処理を行い、該単語パターンの文字コードを出力する文字認識部と、
利用者により指定された着目単語パターンと該着目単語パターンの周辺の単語パターンに関して相対的な配置情報を抽出する抽出部と、
該着目単語パターンと該着目単語パターンの周辺の単語パターンに関して、該文字認識部より得られた該文字コードと、該抽出部より得られた該相対的な配置情報を用いて該翻訳辞書を検索する検索部と、
を有し、該検索部より得られた翻訳文を該表示部に表示することを特徴とする文書翻訳システム。
【請求項2】
前記翻訳辞書部は、原文としての英文とその和訳文を対応付けて格納することを特徴とする請求項1の文書翻訳システム。
【請求項3】
前記翻訳辞書部は、スペースで区切られた単語からなる原文と該原文に対応する翻訳文を対応付けて格納することを特徴とする請求項1の文書翻訳システム。
【請求項4】
該相対的な配置情報は、利用者により指定された着目単語パターンの矩形重心から着目単語パターンの各周辺単語パターンの矩形重心に線分を引きその線分間の角度であることを特徴とする請求項1の文書翻訳システム。
【請求項5】
該相対的な配置情報は、利用者により指定された着目単語パターンが含まれる行、および、着目単語パターンの各周辺単語パターンが含まれる行の相対的な配置情報であることを特徴とする請求項1の文書翻訳システム。
【請求項6】
画像撮影部と、利用者に操作されて情報を入力する入力部と、該画像撮影部で撮影された画像に含まれる文字に関する翻訳を得るための処理を行う翻訳処理部と、該翻訳処理部により得られた翻訳を表示する表示部を有する携帯情報端末を用いた文書翻訳システムにおいて、
原文の文書と該原文に対応する翻訳文の文書を対応付けて格納すると共に、
原文に含まれる各形態素の配置情報を関連付けて保持する翻訳辞書を格納する記憶装置と、
該画像撮影部で撮影された画像から利用者により指定された着目形態素パターンとその着目形態素パターンの周辺の形態素パターンに関して文字認識処理を行い、各形態素の文字コードを出力する文字認識部と、
利用者により指定された着目形態素パターンと該着目形態素パターンの周辺に存在する形態素パターンに関して相対的な配置情報を抽出する抽出部と、
該着目形態素パターンと該着目形態素パターンの周辺に存在する形態素パターンに関して、該文字認識部より得られた文字コードと、該抽出部より得られた該相対的な配置情報を用いて該翻訳辞書を検索する検索部と、
を有し、該検索部より得られた翻訳文を該表示部に表示することを特徴とする文書翻訳システム。
【請求項7】
画像撮影部と、利用者に操作されて情報を入力する入力部と、表示部を有する携帯情報端末を用いて、該画像撮影部で撮影された画像に含まれる文字に関する翻訳を得て、その翻訳を該表示部に表示する文書翻訳システムにおいて、
単語からなる原文と該原文に対応する翻訳文を対応付けて保持すると共に、該原文に含まれる各文字の配置情報を関連付けて保持する翻訳辞書を格納する記憶装置と、
該画像撮影部で撮影された画像から利用者により指定された着目文字パターンとその着目文字パターンの周辺の文字パターンを対象として文字認識処理を行い、該文字パターンの文字コードを出力する文字認識部と、
利用者により指定された着目文字パターンと該着目文字パターンの周辺の文字パターンに関して相対的な配置情報を抽出する抽出部と、
該着目文字パターンと該着目文字パターンの周辺の文字パターンに関して、該文字認識部より得られた該文字コードと該抽出部より得られた該相対的な配置情報を用いて、該翻訳辞書を検索する検索部と、
を有し、該検索部より得られた翻訳文を該表示部に表示することを特徴とする文書翻訳システム。
【請求項8】
前記翻訳辞書を格納する記憶装置、及び前記検索部を備えるサーバを有する文書翻訳システムであって、
該携帯情報端末の該文字認識部より得られた該文字コードと、該抽出部より得られた該相対的な配置情報を、ネットワークを介して該サーバに送信し、該サーバにおいて該検索部により該翻訳辞書を検索した結果得られた翻訳文を、該ネットワークを介して該携帯情報端末に送信することを特徴とする請求項1乃至7のいずれかの文書翻訳システム。
【請求項9】
前記文字認識部、前記抽出部、前記翻訳辞書を格納する記憶装置、及び前記検索部を備えるサーバを有する文書翻訳システムであって、
該携帯情報端末の該画像撮影部より得られた画像をネットワークを介して該サーバに送信し、該サーバにおいて該検索部により該翻訳辞書を検索した結果得られた翻訳文を、該ネットワークを介して該携帯情報端末に送信することを特徴とする請求項1乃至7のいずれかの文書翻訳システム。
【請求項10】
前記翻訳辞書は、単語が含まれる原文を検索するための原単語インデックス部と、原文に含まれる原単語の幾何学情報と原単語の文字コードを格納した原文データ格納部と、各原文に対応する訳文を格納した訳文格納部を有することを特徴とする請求項1乃至9のいずれかの文書翻訳システム。
【請求項11】
請求項1乃至10のいずれかのシステムにおいて使用される携帯情報端末。
【請求項12】
請求項8又は9のシステムにおいて使用されるサーバ。
【請求項13】
請求項1乃至10のいずれかのシステムにおいて、前記抽出部の機能を実現するためのコンピュータ上で実行可能なプログラム。
【請求項14】
画像撮影部と、利用者に操作されて情報を入力する入力部と、表示部を有する携帯情報端末を用いて、該画像撮影部で撮影された画像に含まれる文字に関する翻訳を得るための処理を行う翻訳処理方法において、
単語からなる原文と該原文に対応する翻訳文を対応付けて保持すると共に、該原文に含まれる各文字の配置情報を関連付けて保持する翻訳辞書を記憶装置内に予め用意するステップと、
該画像撮影部で撮影された画像から利用者により指定された着目文字パターンとその着目文字パターンの周辺の文字パターンを対象として文字認識処理を行い、該文字パターンの文字コードを出力するステップと、
利用者により指定された着目文字パターンと該着目文字パターンの周辺の文字パターンに関して相対的な配置情報を抽出するステップと、
該着目文字パターンと該着目文字パターンの周辺の文字パターンに関して、該文字認識部より得られた該文字コードと該抽出部より得られた該相対的な配置情報を用いて、該翻訳辞書を検索するステップと、
該検索の結果得られた翻訳文を該表示部に表示するステップと、
を有する文書翻訳処理方法。
【請求項15】
該翻訳辞書の検索の結果、該着目文字パターンを含む1又は複数の翻訳の候補となる原文を該表示部に表示するステップと、
複数の候補の場合、該複数の候補の中から利用者により該入力部を介して指定された候補に対応する翻訳文を該翻訳辞書から得るステップと、を更に有し、
該翻訳辞書から得られた翻訳文と該原文とを対応させて該表示部に表示することを特徴とする請求項14の文書翻訳処理方法。
【図1】


【図2】
【図3】
【図4】

【図5】

【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【図23】
【図24】
【図25】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【図23】
【図24】
【図25】
【公開番号】特開2006−48324(P2006−48324A)
【公開日】平成18年2月16日(2006.2.16)
【国際特許分類】
【出願番号】特願2004−227610(P2004−227610)
【出願日】平成16年8月4日(2004.8.4)
【出願人】(504373093)日立オムロンターミナルソリューションズ株式会社 (1,225)
【Fターム(参考)】
【公開日】平成18年2月16日(2006.2.16)
【国際特許分類】
【出願日】平成16年8月4日(2004.8.4)
【出願人】(504373093)日立オムロンターミナルソリューションズ株式会社 (1,225)
【Fターム(参考)】
[ Back to top ]