
新規セルラーゼ遺伝子
【課題】アクレモニウム・セルロリティカスよりエンドグルカナーゼやβ−グルコシターゼに分類されるセルラーゼ遺伝子を含むゲノムDNAを単離し、その塩基配列を解析することによってエンドグルカナーゼ及びβ−グルコシターゼ遺伝子を特定することを課題とした。
【解決手段】既知のエンドグルカナーゼ及びβ−グルコシターゼのアミノ酸配列を鋭意比較し、アクレモニウム・セルロリティカスにおいても保存されうるアミノ酸配列を見出し、本情報をもとに様々なプライマーを設計した。この様にして設計された様々なプライマーを用いて、ゲノムDNAもしくはcDNAを鋳型にしたPCRを実施した。その結果、エンドグルカナーゼ及びβ−グルコシターゼの遺伝子断片が得られたので、本遺伝子断片を基に、プライマーを設計し、PCRを継続することにより、エンドグルカナーゼ及びβ−グルコシターゼの遺伝子9種を増幅し、塩基配列を解析し本発明を完成するに至った。
【解決手段】既知のエンドグルカナーゼ及びβ−グルコシターゼのアミノ酸配列を鋭意比較し、アクレモニウム・セルロリティカスにおいても保存されうるアミノ酸配列を見出し、本情報をもとに様々なプライマーを設計した。この様にして設計された様々なプライマーを用いて、ゲノムDNAもしくはcDNAを鋳型にしたPCRを実施した。その結果、エンドグルカナーゼ及びβ−グルコシターゼの遺伝子断片が得られたので、本遺伝子断片を基に、プライマーを設計し、PCRを継続することにより、エンドグルカナーゼ及びβ−グルコシターゼの遺伝子9種を増幅し、塩基配列を解析し本発明を完成するに至った。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、セルラーゼに関するものであり、詳細には、アクレモニウム・セルロリティカス(Acremonium cellulolyticus)由来のセルラーゼ、該セルラーゼをコードするポリヌクレオチド、該ポリヌクレオチドを利用したセルラーゼの製造方法及びその用途に関するものである。なお、本明細書において「ポリヌクレオチド」には、例えば、DNA若しくはRNA、又はそれらの修飾体若しくはキメラ体が含まれ、好ましくはDNAである。
【背景技術】
【0002】
セルラーゼはセルロースを分解する酵素の総称であり、一般に微生物の生産するセルラーゼには多種類のセルラーゼ成分からなる。セルラーゼ成分は、その基質特異性から、セロビオハイドロラーゼ、エンドグルカナーゼ、β−グルコシターゼの3種類に分類され、セルラーゼを産生する糸状菌であるアスペルギルス・ニガー(Aspergillus niger)の場合には、最大4種類セロビオハイドロラーゼ、15種類のエンドグルカナーゼ、15種類のβ−グルコシターゼが産生されると考えられている。よって、微生物の産生するセルラーゼを産業上利用する場合は、その微生物が生産する様々なセルラーゼ成分の混合物として利用されることになる。
【0003】
糸状菌アクレモニウム・セルロリティカスは糖化力の強いセルラーゼを生産することが特徴であり(非特許文献1)、飼料用途やサイレージ用途で、高い有用性を持つことが報告されている(特許文献1−3)。また、含有されているセルラーゼ成分(特許文献4−10)に関しても詳細な検討がなされており、その他の糸状菌と同様に多種類のセルラーゼ成分が分泌されていることが明らかにされている。
【0004】
ある用途に限った場合は、多種類のセルラーゼ成分の内、特定の酵素の数種の成分がその用途に重要であると考えられている。従って、微生物が生産するセルラーゼを、利用させる用途に応じてセルラーゼ成分組成を最適化できれば、より活性の高いセルラーゼが得られることが期待される。そのための最良の方法は、遺伝子組換えの手法により特定の酵素遺伝子を導入して過剰発現させる、もしくは特定の酵素の遺伝子を欠損させることである。
【0005】
しかしながら、アクレモニウム・セルロリティカスの場合には、多種類のセルラーゼ成分の内、2種類のセロビオハイドロラーゼ遺伝子(特許文献4、5)及び1種類のβ−グルコシターゼ遺伝子(特許文献10)が単離されているのみであり、その他のセルラーゼについては、その遺伝子導入による発現増強や、欠損による発現抑制をすることができない状況にあった。
【0006】
この様な背景の中、アクレモニウム・セルロリティカスの産生するセルラーゼの組成を遺伝子組換え技術により最適化するために、エンドグルカナーゼやβ−グルコシターゼなどの多糖分解酵素遺伝子の単離が所望されていた。
【0007】
【非特許文献1】「アグリカルチュラル・アンド・バイオロジカル・ケミストリー(Agricultural and Biological Chemistry)」,(日本),1987年,第51巻,p. 65
【特許文献1】特開平7−264994号公報
【特許文献2】特許第2531595号明細書
【特許文献3】特開平7−236431号公報
【特許文献4】特開2001−17180号公報
【特許文献5】国際公開WO97/33982号パンフレット
【特許文献6】国際公開WO99/011767号パンフレット
【特許文献7】特開2000−69978号公報
【特許文献8】特開平10−066569号公報
【特許文献9】特開2002−101876号公報
【特許文献10】特開2000−298262号公報
【発明の開示】
【発明が解決しようとする課題】
【0008】
本発明は、アクレモニウム・セルロリティカスよりエンドグルカナーゼやβ−グルコシターゼに分類されるセルラーゼ遺伝子を含むゲノムDNAを単離し、その塩基配列を解析することによってエンドグルカナーゼ及びβ−グルコシターゼ遺伝子を特定することを課題とする。
【課題を解決するための手段】
【0009】
本発明者らは、上記課題を解決するため、既知のエンドグルカナーゼ及びβ−グルコシターゼをアミノ酸配列を鋭意比較し、アクレモニウム・セルロリティカスにおいても保存されうるアミノ酸配列を見出し、本情報をもとに様々なプライマーを設計した。この様にして設計された様々なプライマーを用いて、ゲノムDNAもしくはcDNAを鋳型にしたPCRを実施した。その結果、エンドグルカナーゼ及びβ−グルコシターゼの遺伝子断片が得られたので、本遺伝子断片を基に、プライマーを設計し、PCRを継続することにより、エンドグルカナーゼ及びβ−グルコシターゼの遺伝子9種を増幅し、塩基配列を解析し本発明を完成するに至った。
【0010】
即ち、本発明は、
[1]以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号2に記載のアミノ酸配列の1〜306番の配列を含むタンパク質;
(ii)配列番号2に記載のアミノ酸配列の1〜306番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号2に記載のアミノ酸配列の1〜306番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ、
[2]以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号4に記載のアミノ酸配列の1〜475番の配列を含むタンパク質;
(ii)配列番号4に記載のアミノ酸配列の1〜475番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号4に記載のアミノ酸配列の1〜475番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ、
[3]以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号6に記載のアミノ酸配列の1〜391番の配列を含むタンパク質;
(ii)配列番号6に記載のアミノ酸配列の1〜391番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号6に記載のアミノ酸配列の1〜391番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ、
[4]以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号8に記載のアミノ酸配列の1〜376番の配列を含むタンパク質;
(ii)配列番号8に記載のアミノ酸配列の1〜376番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号8に記載のアミノ酸配列の1〜376番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ、
[5]以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号10に記載のアミノ酸配列の1〜221番の配列を含むタンパク質;
(ii)配列番号10に記載のアミノ酸配列の1〜221番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号10に記載のアミノ酸配列の1〜221番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ、
[6]以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号12に記載のアミノ酸配列の1〜319番の配列を含むタンパク質;
(ii)配列番号12に記載のアミノ酸配列の1〜319番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号12に記載のアミノ酸配列の1〜319番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ、
[7]以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号14に記載のアミノ酸配列の1〜301番の配列を含むタンパク質;
(ii)配列番号14に記載のアミノ酸配列の1〜301番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号14に記載のアミノ酸配列の1〜301番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ、
[8]以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号16に記載のアミノ酸配列の1〜458番の配列を含むタンパク質;
(ii)配列番号16に記載のアミノ酸配列の1〜458番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むβ−グルコシダーゼ;
(iii)配列番号16に記載のアミノ酸配列の1〜458番の配列と70%以上の同一性を有するアミノ酸配列を含むβ−グルコシダーゼ、
[9]以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号18に記載のアミノ酸配列の1〜457番の配列を含むタンパク質;
(ii)配列番号18に記載のアミノ酸配列の1〜457番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むβ−グルコシダーゼ;
(iii)配列番号18に記載のアミノ酸配列の1〜457番の配列と70%以上の同一性を有するアミノ酸配列を含むβ−グルコシダーゼ、
[10]糸状菌由来である、[1]〜[9]に記載のタンパク質、
[11]糸状菌がアクレモニウム・セルロリティカス(Acremonium cellulolyticus)に属する糸状菌である、[10]に記載のタンパク質、
[12][1]〜[9]に記載のタンパク質をコードする塩基配列を含む、ポリヌクレオチド、
[13]配列番号1に記載の塩基配列、又はその改変配列を含む、DNA、
[14]以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)[1]に記載のタンパク質をコードするDNA;
(ii)配列番号1に記載の塩基配列の136〜1437番の配列を含むDNA;
(iii)配列番号1に記載の塩基配列の136〜1437番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA、
[15][14]に記載のDNAから、イントロン配列を除去したDNA、
[16]イントロン配列が、配列番号1に記載の塩基配列の233〜291番、351〜425番、579〜631番、697〜754番、又は、853〜907番の配列から選択される1以上の配列を含む配列である、[15]に記載のDNA、
[17][13]〜[16]に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA、
[18]シグナル配列をコードする塩基配列が、配列番号1に記載の塩基配列の136〜216番の配列である、[17]に記載のDNA、
[19]配列番号3に記載の塩基配列、又はその改変配列を含む、DNA、
[20]以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)[2]に記載のタンパク質をコードするDNA;
(ii)配列番号3に記載の塩基配列の128〜1615番の配列を含むDNA;
(iii)配列番号3に記載の塩基配列の128〜1615番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA、
[21][19]〜[20]に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA、
[22]シグナル配列をコードする塩基配列が、配列番号3に記載の塩基配列の128〜187番の配列である、[21]に記載のDNA、
[23]配列番号5に記載の塩基配列、又はその改変配列を含む、DNA、
[24]以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)[3]に記載のタンパク質をコードするDNA;
(ii)配列番号5に記載の塩基配列の169〜1598番の配列を含むDNA;
(iii)配列番号5に記載の塩基配列の169〜1598番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA、
[25][24]に記載のDNAから、イントロン配列を除去したDNA、
[26]イントロン配列が、配列番号5に記載の塩基配列の254〜309番、406〜461番、又は、1372〜1450番の配列から選択される1以上の配列を含む配列である、[25]に記載のDNA、
[27][23]〜[26]に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA、
[28]シグナル配列をコードする塩基配列が、配列番号5に記載の塩基配列の169〜231番の配列である、[27]に記載のDNA、
[29]配列番号7に記載の塩基配列、又はその改変配列を含む、DNA、
[30]以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)[4]に記載のタンパク質をコードするDNA;
(ii)配列番号7に記載の塩基配列の70〜1376番の配列を含むDNA;
(iii)配列番号7に記載の塩基配列の70〜1376番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA、
[31][30]に記載のDNAから、イントロン配列を除去したDNA、
[32]イントロン配列が、配列番号7に記載の塩基配列の451〜500番、又は、765〜830番の配列から選択される1以上の配列を含む配列である、[31]に記載のDNA、
[33][29]〜[32]に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA、
[34]シグナル配列をコードする塩基配列が、配列番号7に記載の塩基配列の70〜129番の配列である、[33]に記載のDNA、
[35]配列番号9に記載の塩基配列、又はその改変配列を含む、DNA、
[36]以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)[5]に記載のタンパク質をコードするDNA;
(ii)配列番号9に記載の塩基配列の141〜974番の配列を含むDNA;
(iii)配列番号9に記載の塩基配列の141〜974番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA、
[37][36]に記載のDNAから、イントロン配列を除去したDNA、
[38]イントロン配列が、配列番号9に記載の塩基配列の551〜609番、又は、831〜894番の配列から選択される1以上の配列を含む配列である、[37]に記載のDNA、
[39][35]〜[38]に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA、
[40]シグナル配列をコードする塩基配列が、配列番号9に記載の塩基配列の141〜185番の配列である[39]に記載のDNA、
[41]配列番号11に記載の塩基配列、又はその改変配列を含む、DNA、
[42]以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)[6]に記載のタンパク質をコードするDNA;
(ii)配列番号11に記載の塩基配列の114〜1230番の配列を含むDNA;
(iii)配列番号11に記載の塩基配列の114〜1230番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA、
[43][42]に記載のDNAから、イントロン配列を除去したDNA、
[44]イントロン配列が、配列番号11に記載の塩基配列の183〜232番、又は、299〜357番の配列から選択される1以上の配列を含む配列である、[43]に記載のDNA、
[45][41]〜[44]に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA、
[46]シグナル配列をコードする塩基配列が、配列番号11に記載の塩基配列の114〜161番の配列である、[45]に記載のDNA、
[47]配列番号13に記載の塩基配列、又はその改変配列を含む、DNA、
[48]以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)[7]に記載のタンパク質をコードするDNA;
(ii)配列番号13に記載の塩基配列の124〜1143番の配列を含むDNA;
(iii)配列番号13に記載の塩基配列の124〜1143番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA、
[49][48]に記載のDNAから、イントロン配列を除去したDNA、
[50]イントロン配列が、配列番号13に記載の塩基配列の225〜275番の配列である、[49]に記載のDNA、
[51][47]〜[50]に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA、
[52]シグナル配列をコードする塩基配列が、配列番号13に記載の塩基配列の124〜186番の配列である、[51]に記載のDNA、
[53]配列番号15に記載の塩基配列、又はその改変配列を含む、DNA、
[54]以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)[8]に記載のタンパク質をコードするDNA;
(ii)配列番号15に記載の塩基配列の238〜1887番の配列を含むDNA;
(iii)配列番号15に記載の塩基配列の238〜1887番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつβ−グルコシダーゼ活性を有するタンパク質をコードするDNA、
[55][54]に記載のDNAから、イントロン配列を除去したDNA、
[56]イントロン配列が、配列番号15に記載の塩基配列の784〜850番、1138〜1205番、又は、1703〜1756番の配列から選択される1以上の配列を含む配列である、[55]に記載のDNA、
[57][53]〜[56]に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA、
[58]シグナル配列をコードする塩基配列が、配列番号15に記載の塩基配列の238〜321番の配列である、[57]に記載のDNA、
[59]配列番号17に記載の塩基配列、又はその改変配列を含む、DNA、
[60]以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)[9]に記載のタンパク質をコードするDNA;
(ii)配列番号17に記載の塩基配列の66〜1765番の配列を含むDNA;
(iii)配列番号17に記載の塩基配列の66〜1765番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつβ−グルコシダーゼ活性を有するタンパク質をコードするDNA、
[61][60]に記載のDNAから、イントロン配列を除去したDNA、
[62]イントロン配列が、配列番号17に記載の塩基配列の149〜211番、404〜460番、934〜988番、又は、1575〜1626番の配列から選択される1以上の配列を含む配列である、[61]に記載のDNA、
[63][59]〜[62]に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA、
[64]シグナル配列をコードする塩基配列が、配列番号17に記載の塩基配列の66〜227番の配列である、[63]に記載のDNA、
[65][12]〜[64]に記載のDNAを含む、発現ベクター、
[66][65]に記載の発現ベクターで形質転換された、宿主細胞、
[67]宿主細胞が酵母又は糸状菌である、[66]に記載の宿主細胞、
[68]酵母が、サッカロミセス(Saccharomyces)属、ハンゼヌラ(Hansenula)属又はピキア(Pichia)属に属するものである、[67]に記載の宿主細胞、
[69]酵母が、サッカロミセス・セレビシエ(Saccharomyces cerevisiae)である、[68]に記載の宿主細胞、
[70]糸状菌が、フミコーラ(Humicola)属、アスペルギルス(Aspergillus)属、トリコデルマ(Trichoderma)属、フザリウム(Fusarium)又はアクレモニウム(Acremonium)属に属するものである、[67]に記載の宿主細胞、
[71]糸状菌が、アクレモニウム・セルロリティカス(Acremonium cellulolyticus)、フミコーラ・インソレンス(Humicola insolens)、アスペルギルス・ニガー(Aspergillus niger)もしくはアスペルギルス・オリゼー(Aspergillus oryzae)、トリコデルマ・ビリデ(Trichoderma viride)、又はフザリウム・オキシスポーラム(Fusarium oxysporum)である、[70]に記載の宿主細胞、
[72][12]〜[64]に記載のDNAに対応する遺伝子を、相同組み換えにより欠損させたアクレモニウム(Acremonium)属の糸状菌、
[73]糸状菌がアクレモニウム・セルロリティカス(Acremonium cellulolyticus)である、[72]に記載の糸状菌、
[74][66]〜[73]に記載の宿主細胞を培養し、その宿主及び/又はその培養物から[1]〜[9]に記載のタンパク質を採取する工程を含む、前記タンパク質の製造法、
[75][74]に記載の方法で生産された、タンパク質、
[76][1]〜[9]若しくは[75]に記載のタンパク質を含む、セルラーゼ調製物、
[77]バイオマスを糖化する処理方法であって、セルロース含有バイオマスを、[1]〜[9]若しくは[75]に記載のタンパク質、又は[76]に記載のセルラーゼ調製物と接触させる工程を含む、方法、
[78]セルロース含有繊維の処理方法であって、セルロース含有繊維を、[1]〜[9]若しくは[75]に記載のタンパク質、又は[76]に記載のセルラーゼ調製物と接触させる工程を含む、方法、
[79]古紙を脱インキ薬品により処理して脱インキを行う工程において、[1]〜[9]若しくは[75]に記載のタンパク質、又は[76]に記載のセルラーゼ調製物を用いることを特徴とする古紙の脱インキ方法、
[80]紙パルプのろ水性の改善方法であって、紙パルプを、[1]〜[9]若しくは[75]に記載のタンパク質、又は[76]に記載のセルラーゼ調製物で処理する工程を含む、方法、
[81]動物飼料の消化能を改善する方法であって、動物飼料を、[1]〜[9]若しくは[75]に記載のタンパク質、又は[76]に記載のセルラーゼ調製物で処理する工程を含む、方法
に関する。
【発明の効果】
【0011】
本発明により、アクレモニウム・セルロリティカスに由来する特定のエンドグルカナーゼ及びβ−グルコシターゼを組換えタンパク質として効率良く生産するために必要なDNAを得ることができ、また、これらセルラーゼ成分を効率良く発現する組換え微生物を得ることができる。更に、得られた組換え微生物を培養することにより、効率よく安価に特定のエンドグルカナーゼ及びβ−グルコシターゼを生産することができる。
【0012】
また本発明により、アクレモニウム・セルロリティカスのゲノムより特定のエンドグルカナーゼ及びβ−グルコシターゼ遺伝子を欠損させることができ、その結果、これらのエンドグルカナーゼ及びβ−グルコシターゼが含まれていないセルラーゼを生産する組換えアクレモニウム・セルロリティカスを得て、特定のエンドグルカナーゼ及びβ−グルコシターゼセルラーゼが含まれていないセルラーゼを生産することができる。
【0013】
本発明で得られる様々なセルラーゼの中から、最適なセルラーゼ群を選択し、セルロース系基質を処理することにより、これらセルロース系基質を効率的かつ安価に分解することができる。
【発明を実施するための最良の形態】
【0014】
エンドグルカナーゼ及びβ−グルコシターゼ
本発明のタンパク質であるエンドグルカナーゼ及びβ−グルコシターゼは、配列番号2、4、6、8、10、12、14、16、18から選択されるアミノ酸配列における成熟タンパク質部分に対応する配列を含むか、あるいは、該アミノ酸配列と実質的に同等なアミノ酸配列を含むことができる。
【0015】
本発明において「実質的に同等なアミノ酸配列」とは、例えば、1つ若しくは複数個(好ましくは数個)のアミノ酸の置換、欠失、及び/又は付加による改変を有するが、ポリペプチドの活性に影響を受けないアミノ酸配列や、70%以上の同一性を有するが、ポリペプチドの活性に影響を受けないアミノ酸配列を意味する。
【0016】
改変されるアミノ酸残基の数は、好ましくは1〜40個、より好ましくは1〜数個、更に好ましくは1〜8個、最も好ましくは1〜4個である。本発明でいう「活性に影響を与えない改変」の例としては、保存的置換が挙げられる。「保存的置換」とは、ポリペプチドの活性を実質的に変化しないように1若しくは複数個のアミノ酸残基を、別の化学的に類似したアミノ酸残基で置き換えることを意味する。例えば、ある疎水性アミノ酸残基を別の疎水性アミノ酸残基によって置換する場合、ある極性アミノ酸残基を同じ電荷を有する別の極性アミノ酸残基によって置換する場合などが挙げられる。このような置換を行うことができる機能的に類似したアミノ酸は、アミノ酸毎に当該技術分野において公知である。具体例を挙げると、非極性(疎水性)アミノ酸としては、アラニン、バリン、イソロイシン、ロイシン、プロリン、トリプトファン、フェニルアラニン、メチオニン等が挙げられる。極性(中性)アミノ酸としては、グリシン、セリン、スレオニン、チロシン、グルタミン、アスパラギン、システイン等が挙げられる。陽電荷をもつ(塩基性)アミノ酸としては、アルギニン、ヒスチジン、リジン等が挙げられる。また、負電荷をもつ(酸性)アミノ酸としては、アスパラギン酸、グルタミン酸等が挙げられる。
【0017】
本明細書における「同一性(identity)」とは、当業者に公知の相同性検索プログラムであるFASTA3[Science,227,1435−1441(1985);Proc.Natl.Acad.Sci.USA,85,2444−2448(1988);http://www.ddbj.nig.ac.jp/E−mail/homology−j.html]においてデフォルト(初期設定)のパラメータを用いて算出される数値である。前記同一性としては、好ましくは80%以上の同一性、より好ましくは90%以上の同一性、更に好ましくは95%以上の同一性、更に好ましくは98%以上の同一性、特に好ましくは99%以上の同一性であることができる。
【0018】
本発明のタンパク質は、成熟タンパク質部分に対応する各アミノ酸配列、又はそれらと実質的に同等なアミノ酸配列のN末端及び/又はC末端に、酵素活性に影響を与えない範囲で、任意のポリペプチド配列を付与することができる。このようなポリペプチド配列としては、例えば、シグナル配列、検出用マーカー(例えば、FLAGタグ)、精製用ポリペプチド[例えば、グルタチオンS−トランスフェラーゼ(GST)]を挙げることができる。
【0019】
エンドグルカナーゼ及びβ−グルコシターゼ遺伝子
本発明のポリヌクレオチドであるエンドグルカナーゼ及びβ−グルコシターゼ遺伝子は、前記の本発明のタンパク質をコードする塩基配列を含むことができ、また、配列番号1に記載の塩基配列の136〜1437番の配列、配列番号3に記載の塩基配列の128〜1615番の配列、配列番号5に記載の塩基配列の169〜1598番の配列、配列番号7に記載の塩基配列の70〜1376番の配列、配列番号9に記載の塩基配列の141〜974番の配列、配列番号11に記載の塩基配列の114〜1230番の配列、配列番号13に記載の塩基配列の124〜1143番の配列、配列番号15に記載の塩基配列の238〜1887番の配列、配列番号17に記載の塩基配列の66〜1765番の配列から選択される塩基配列、あるいは、該塩基配列とストリンジェントな条件下でハイブリダイズ可能な塩基配列を含むことができる。
本発明において「ストリンジェントな条件」とは、ハイブリダイゼーション後のメンブレンの洗浄操作を、高温度低塩濃度溶液中で行うことを意味し、例えば、2×SSC濃度(1×SSC:15mmol/Lクエン酸3ナトリウム、150mmol/L塩化ナトリウム)、0.5%SDS溶液中で、60℃、20分間の洗浄条件を意味する。
【0020】
エンドグルカナーゼ及びβ−グルコシターゼ遺伝子の取得
本発明のエンドグルカナーゼ及びβ−グルコシターゼ遺伝子は、例えば、以下の方法によりアクレモニウム・セルロリティカス又はその変異株から単離することができる。また、本発明に開示するように塩基配列が明らかとなっているため、人工的に化学合成することも可能である。
【0021】
アクレモニウム・セルロリティカスの菌体から、慣行法によりゲノムDNAを抽出する。このゲノムDNAを適当な制限酵素にて消化後、適当なベクターと連結することにより、アクレモニウム・セルロリティカスのゲノムDNAライブラリーを作製する。ベクターとしては、例えば、プラスミドベクター、ファージベクター、コスミドベクター、BACベクター等、多様なものが使用できる。
【0022】
次に、本明細書において開示したエンドグルカナーゼ及びβ−グルコシターゼ遺伝子の塩基配列に基づいて適当なプローブを作成し、ゲノムDNAライブラリーからハイブリダイゼーションによって所望のエンドグルカナーゼ及びβ−グルコシターゼ遺伝子を含むDNA断片を単離することができる。また、本明細書において開示したエンドグルカナーゼ及びβ−グルコシターゼ遺伝子の塩基配列に基づいて所望の遺伝子を増幅させるためのプライマーを作成し、アクレモニウム・セルロリティカスのゲノムDNAを鋳型としてPCRを実施し、増幅したDNA断片を適当なベクターと連結することにより所望の遺伝子を単離することができる。更に、本発明によるエンドグルカナーゼ及びβ−グルコシターゼ遺伝子は、プラスミドpACC3、pACC5、pACC6、pACC7、pACC8、pACC9、pACC10、pBGLC、及びプラスミドpBGLDに含まれていることから、これらをPCRの鋳型DNAとして利用することが可能である。また、これらプラスミドから適当な制限酵素にて所望のDNA断片を調製することができる。
【0023】
微生物の寄託
pACC3で形質転換された大腸菌(Escherichia coli TOP10/pACC3)は、平成20(2008)年10月9日付で独立行政法人産業技術総合研究所特許生物寄託センター(〒305−8566日本国茨城県つくば市東1丁目1番地1中央第6)に国際寄託された。受託番号は、FERM BP−11029である。
pACC5で形質転換された大腸菌(Escherichia coli TOP10/pACC5)は、平成20(2008)年10月9日付で独立行政法人産業技術総合研究所特許生物寄託センター(〒305−8566日本国茨城県つくば市東1丁目1番地1中央第6)に国際寄託された。受託番号は、FERM BP−11030である。
pACC6で形質転換された大腸菌(Escherichia coli TOP10/pACC6)は、平成20(2008)年10月9日付で独立行政法人産業技術総合研究所特許生物寄託センター(〒305−8566日本国茨城県つくば市東1丁目1番地1中央第6)に国際寄託された。受託番号は、FERM BP−11031である。
pACC7で形質転換された大腸菌(Escherichia coli TOP10/pACC7)は、平成20(2008)年10月9日付で独立行政法人産業技術総合研究所特許生物寄託センター(〒305−8566日本国茨城県つくば市東1丁目1番地1中央第6)に国際寄託された。受託番号は、FERM BP−11032である。
pACC8で形質転換された大腸菌(Escherichia coli TOP10/pACC8)は、平成20(2008)年10月9日付で独立行政法人産業技術総合研究所特許生物寄託センター(〒305−8566日本国茨城県つくば市東1丁目1番地1中央第6)に国際寄託された。受託番号は、FERM BP−11033である。
pACC9で形質転換された大腸菌(Escherichia coli TOP10/pACC9)は、平成20(2008)年10月9日付で独立行政法人産業技術総合研究所特許生物寄託センター(〒305−8566日本国茨城県つくば市東1丁目1番地1中央第6)に国際寄託された。受託番号は、FERM BP−11034である。
pACC10で形質転換された大腸菌(Escherichia coli TOP10/pACC10)は、平成20(2008)年10月9日付で独立行政法人産業技術総合研究所特許生物寄託センター(〒305−8566日本国茨城県つくば市東1丁目1番地1中央第6)に国際寄託された。受託番号は、FERM BP−11035である。
pBGLCで形質転換された大腸菌(Escherichia coli TOP10/pBGLC)は、平成20(2008)年10月9日付で独立行政法人産業技術総合研究所特許生物寄託センター(〒305−8566日本国茨城県つくば市東1丁目1番地1中央第6)に国際寄託された。受託番号は、FERM BP−11036である。
pBGLDで形質転換された大腸菌(Escherichia coli TOP10/pBGLD)は、平成20(2008)年10月9日付で独立行政法人産業技術総合研究所特許生物寄託センター(〒305−8566日本国茨城県つくば市東1丁目1番地1中央第6)に国際寄託された。受託番号は、FERM BP−11037である。
【0024】
発現ベクター及び形質転換された微生物
本発明においては、前記の配列番号2、4、6、8、10、12、14、16、18に記載されるアミノ酸配列、又はその改変アミノ酸配列をコードする塩基配列を含むDNA(以下、単に「本発明によるDNA配列」という)を、宿主微生物内で複製可能で、かつ、そのDNA配列がコードするタンパク質を発現可能な状態で含む発現ベクターが提供される。本発現ベクターは、自己複製ベクター、すなわち、染色体外の独立体として存在し、その複製が染色体の複製に依存しない、例えば、プラスミドを基本に構築することができる。また、本発現ベクターは、宿主微生物に導入されたとき、その宿主微生物のゲノム中に組み込まれ、それが組み込まれた染色体と一緒に複製されるものであってもよい。本発明によるベクター構築の手順及び方法は、遺伝子工学の分野で慣用されているものを用いることができる。
【0025】
本発明による発現ベクターは、これを実際に宿主微生物に導入して所望の活性を有するタンパク質を発現させるために、前記の本発明によるDNA配列の他に、その発現を制御するDNA配列や微生物を選択するための遺伝子マーカー等を含んでいるのが望ましい。発現を制御するDNA配列としては、プロモーター及びターミネーター及びシグナルペプチドをコードするDNA配列等がこれに含まれる。プロモーターは宿主微生物において転写活性を示すものであれば特に限定されず、宿主微生物と同種若しくは異種のいずれかのタンパク質をコードする遺伝子の発現を制御するDNA配列として得ることができる。また、シグナルペプチドは、宿主微生物において、タンパク質の分泌に寄与するものであれば特に限定されず、宿主微生物と同種若しくは異種のいずれかのタンパク質をコードする遺伝子から誘導されるDNA配列より得ることができる。また、本発明における遺伝子マーカーは、形質転換体の選択の方法に応じて適宜選択されてよいが、例えば薬剤耐性をコードする遺伝子、栄養要求性を相補する遺伝子を利用することができる。
【0026】
更に、本発明によれば、この発現ベクターによって形質転換された微生物が提供される。この宿主−ベクター系は特に限定されず、例えば、大腸菌、放線菌、酵母、糸状菌などを用いた系、及び、それらを用いた他のタンパク質との融合タンパク質発現系などを用いることができる。
また、この発現ベクターによる微生物の形質転換も、この分野で慣用されている方法に従い実施することができる。
更に、この形質転換体を適当な培地で培養し、その培養物から上記の本発明によるタンパク質を単離して得ることができる。従って、本発明の別の態様によれば、前記の本発明による新規タンパク質の製造方法が提供される。形質転換体の培養及びその条件は、使用する微生物についてのそれと本質的に同等であってよい。また、形質転換体を培養した後、目的のタンパク質を回収する方法は、この分野で慣用されているものを用いることができる。
【0027】
また、本発明における好ましい態様によれば、本発明によるDNA配列によってコードされるエンドグルカナーゼ及びβ−グルコシターゼ酵素を発現させ得る酵母細胞が提供される。本発明における酵母細胞としては、例えばサッカロミセス(Saccharomyces)属、ハンゼヌラ(Hansenula)属、又はピキア(Pichia)属に属する微生物、例えばサッカロミセス・セレビシエ(Saccharomyces cerevisiae)が挙げられる。
本発明における宿主糸状菌は、フミコーラ(Humicola)属、アスペルギルス(Aspergillus)属又はトリコデルマ(Trichoderma)属、フザリウム(Fusarium)属、又はアクレモニウム(Acremonium)属に属するものであることができる。更にそれらの好ましい例としては、フミコーラ・インソレンス(Humicola insolens)、アスペルギルス・ニガー(Aspergillus niger)若しくはアスペルギルス・オリゼー(Aspergillus oryzae)、又はトリコデルマ・ビリデ(Trichoderma viride)、フザリウム・オキシスポーラム(Fusarium oxysporum)、又はアクレモニウム・セルロリティカス(Acremonium cellulolyticus)が挙げられる。
【0028】
本発明によるエンドグルカナーゼ及びβ−グルコシターゼ遺伝子を適当なベクターに連結してアクレモニウム・セルロリティカスに導入し、その発現を抑制すること、又はこれら遺伝子について相同組換えを利用して遺伝子破壊を行いその機能を欠損させることにより、特定のエンドグルカナーゼ及びβ−グルコシターゼの発現を抑制することができる。相同組換えを利用した遺伝子破壊は慣用の方法に従って実施することができ、遺伝子破壊に用いられるベクターの作成やベクターの宿主への導入は当業者に自明であろう。
【0029】
セルラーゼの調製
こうして得られた形質転換体を適当な培地で培養し、その培養物から上記した本発明のタンパク質を単離して得ることができる。形質転換体の培養及びその条件は、使用する微生物に応じて適宜に設定すればよい。また、培養液からの目的とするタンパク質の回収、精製も常法に従って行うことができる。
【0030】
セルラーゼ調製物
本発明の別の態様によれば、上記の本発明によるタンパク質(セルラーゼ)を含むセルラーゼ調製物が提供される。本発明によるセルラーゼ調製物は、本発明によるセルラーゼに、一般的に含まれる成分、例えば賦形剤(例えば、乳糖、塩化ナトリウム、ソルビトール等)、界面活性剤、防腐剤等とともに混合され製造されてもよい。また、本発明におけるセルラーゼ調製物はいずれか適当な形状、例えば粉末又は液体状に調製することができる。
【0031】
セルラーゼの用途
本発明によれば、バイオマス糖化について本発明のセルラーゼ酵素(群)又はセルラーゼ調製物による処理で有意に糖化を改善できるものと考えられる。従って、本発明によれば、バイオマス糖化の改善方法であって、本発明のセルラーゼ酵素(群)又はセルラーゼ調製物でバイオマスを処理する工程を含む方法が提供される。本発明で処理できるバイオマスの例としては、稲わら、バガス、コーンストーバー、椰子の実などの果実の絞りかす、廃木材、並びにこれらに適切な前処理を施した材料が挙げられる。
【0032】
更に本発明によれば、着色セルロース含有繊維の澄明化をもたらす方法であって、セルラーゼ酵素(群)又はセルラーゼ調製物で着色セルロース含有繊維を処理する工程を含む方法、並びに、着色セルロース含有繊維の色の局所的な変化をもたらす方法、すなわち、着色セルロース含有繊維にストーンウオッシュの外観を与える方法が提供される。そして、この方法は、本発明のエンドグルカナーゼ酵素又はセルラーゼ調製物により着色セルロース含有繊維を処理する工程を含む。
【0033】
また、本発明によれば、紙パルプのろ水性が、強度の著しい低下を伴うことなく、本発明によるエンドグルカナーゼ酵素による処理で有意に改善できるものと考えられる。従って、本発明によれば、パルプのろ水性の改善方法であって、本発明のエンドグルカナーゼ酵素又はセルラーゼ調製物で紙パルプを処理する工程を含む方法が提供される。本発明で処理できるパルプの例としては、古紙パルプ、再循環板紙パルプ、クラフトパルプ、亜硫酸パルプ又は加工熱処理及び他の高収率パルプが挙げられる。
【0034】
更に、本発明によるエンドグルカナーゼを動物飼料中で用いることにより、飼料中のグルカンの消化能を改善することができる。従って、本発明によれば、動物飼料の消化能を改善する方法であって、本発明のエンドグルカナーゼ酵素又はセルラーゼ調製物で動物飼料を処理する工程を含む方法が提供される。
【実施例】
【0035】
本発明を実施例により更に具体的に説明するが、本発明はその要旨を越えない限り以下の実施例に限定されるものではない。
【0036】
《実施例1:ACC3遺伝子のクローニング》
(1-1)ゲノムDNAの単離
アクレモニウム・セルロリティカス(Acremonium cellulolyticus)ACCP-5-1株を(s)培地(2%ブイヨン、0.5%イーストエキス及び2%グルコース)で32℃にて2日間培養し、遠心分離により菌体を回収した。得られた菌体より、堀内らの方法(H.Horiuchi et. al., J.Bacteriol., 170, 272-278, (1988))に従いゲノムDNAを単離した。
【0037】
(1-2)ACC3遺伝子断片の取得
Glycoside Hydrolase family 5に分類される既知のエンドグルカナーゼの配列を基に以下のプライマーを作製した。
ACC3-F:GGGCGTCTGTRTTYGARTGT(配列番号:19)
ACC3-R:AAAATGTAGTCTCCCCACCA(配列番号:20)
【0038】
ACC3-F及びACC3-Rをプライマーとして使用し、ゲノムDNAを鋳型としてPCRを行った。PCRはLA taqポリメラーゼ(タカラバイオ社製)を用いて実施した。PCRは94℃で30秒、アニールを30秒、72℃で1分間を40サイクル実施するプログラムで実施したが、アニール温度は最初の20サイクルで63℃から53℃へ段階的に低下させ、その後の20サイクルにおいては53℃に固定した。増幅された1kbpのDNA断片を、TOPO TAクローニングキット(インビトロジェン社製)により、添付のプロトコールに従ってpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドTOPO-pACC3-partialを得た。
【0039】
プラスミドTOPO-pACC3-partialにクローニングされた挿入DNA断片のシークエンスはBigDye Terminator v3.1 Cycle Sequebcing Kit(アプライドバイオシステムズ社製)とABI PRISMジェネティックアナライザー(アプライドバイオシステムズ社製)を用いて、添付のプロトコールに従って行った。その結果得られた塩基配列をアミノ酸配列に翻訳し、そのアミノ酸配列をホモロジー検索した結果、タラロマイセス・エメルソニ(Talaromyces emersonii)由来のエンドグルカナーゼEG1(Q8WZD7)と74%の同一性を示したため、本DNA断片をエンドグルカナーゼ(Glycoside Hydrolase family 5)遺伝子の一部であると判断した。
【0040】
(1-3)インバースPCR法によるACC3遺伝子全長の取得
インバースPCR法はTrigliaらの方法(T Triglia et. al., Nucleic Acids Research, 16, 8186, (1988))に従い実施した。アクレモニウム・セルロリティカスのゲノムDNAをSalIで一晩消化し、Mighty Mix(タカラバイオ社製)を用いて環状DNAを作製した。本環状DNAをテンプレートに、ACC3遺伝子断片に含まれる下記の配列によりPCRを実施し、ACC3遺伝子の5’上流領域並びに3’下流領域を取得した。
ACC3-inv-F:ACTTCCAGACTTTCTGGTCC(配列番号:21)
ACC3-inv-R:AGGCCGAGAGTAAGTATCTC(配列番号:22)
上記5’上流領域並びに3’下流領域を実施例1-2に記載の方法により解析し、ACC3遺伝子の全長塩基配列を決定した。
インバースPCR法により得た塩基配列を基に以下のプライマーを作製し、ゲノムDNAをテンプレートにPCRを実施し、ACC3遺伝子を増幅した。
pACC3-F:GAAGGATGGTAGATTGTCCG(配列番号:23)
pACC3-R:ACCGAGAAGGATTTCTCGCA(配列番号:24)
増幅されたDNAをTOPO TAクローニングキット(インビトロジェン社製)によりpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドpACC3を得た。得られたプラスミドpACC3により大腸菌(Escherichia coli)TOP10株(インビトロジェン社製)を形質転換することによりEscherichia coli TOP10株/pACC3を得た。
【0041】
(1-4)cDNAの作製並びにACC3遺伝子のイントロン解析
アクレモニウム・セルロリティカスACCP-5-1株をセルラーゼ誘導培地で32℃にて2日間培養し、遠心分離により菌体を回収した。得られた菌体を液体窒素で凍結後、乳鉢と乳棒を用いて磨砕した。この磨砕した菌体からISOGEN(ニッポンジーン社)により、添付のプロトコールに従い全RNAを単離した。更に全RNAから、mRNA Purification Kit(ファルマシア社)により、添付のプロトコールに従い、mRNAを精製した。
【0042】
こうして得られたmRNAから、TimeSaver cDNA Synthesis Kit(ファルマシア社)により、添付のプロトコールに従い、cDNAを合成した。ACC3遺伝子配列から開始コドン並びに終始コドンを含む下記のプライマーを作製し、cDNAをテンプレートにPCRを実施し、ACC3 cDNA遺伝子を増幅した。
ACC3-N:ATGAAGACCAGCATCATTTCTATC(配列番号:25)
ACC3-C:TCATGGGAAATAACTCTCCAGAAT(配列番号:26)
上記ACC3 cDNA遺伝子を実施例1-2に記載の方法により解析し、pACC3遺伝子と比較することでイントロンの位置を決定した。
【0043】
(1-5)ACC3のアミノ酸配列の推定
上記の方法によりアクレモニウム・セルロリティカスより単離されたエンドグルカナーゼACC3遺伝子は配列番号1に記載の塩基配列の136〜1437番に示された1302bpの塩基からなっていた。また、本ACC3遺伝子は配列番号1に記載の塩基配列の233〜291番、351〜425番、579〜631番、697〜754番、及び853〜907番に示される5つのイントロンが含まれていることが示された。オープンリーディングフレーム(ORF)から予測されるACC3のアミノ酸配列は配列番号2に示される通りであった。なお、シグナル配列予測ソフトSignalP 3.0により本ACC3の-27〜-1アミノ酸残基までがシグナル配列と推定した。
【0044】
《実施例2:ACC5遺伝子のクローニング》
(2-1)ゲノムDNA並びにmRNAの単離とcDNAの作製
実施例1-1に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のゲノムDNAを単離した。また、実施例1-4に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のcDNAを作製した。
【0045】
(2-2)ACC5遺伝子断片の取得
Glycoside Hydrolase family 7に分類される既知のエンドグルカナーゼのN末端アミノ酸配列並びにポリA塩基配列を基に以下のプライマーを作製した。
ACC5-F:CAGCAGGCCCCCACCCCNGAYAAYYTNGC(配列番号:27)
ACC5-R:AATTCGCGGCCGCTAAAAAAAAA(配列番号:28)
【0046】
ACC5-F及びACC5-Rをプライマーとして使用し、cDNAを鋳型としてPCRを行った。PCRはLA taqポリメラーゼ(タカラバイオ社製)を用いて実施した。PCRは94℃で30秒、アニールを30秒、72℃で1分間を40サイクル実施するプログラムで実施したが、アニール温度は最初の20サイクルで63℃から53℃へ段階的に低下させ、その後の20サイクルにおいては53℃に固定した。増幅された1.5kbpのDNA断片を、TOPO TAクローニングキット(インビトロジェン社製)により、添付のプロトコールに従ってpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドTOPO-pACC5-partialを得た。
【0047】
プラスミドTOPO-pACC5-partialにクローニングされた挿入DNA断片の塩基配列を解析し、得られた塩基配列をアミノ酸配列に翻訳し、そのアミノ酸配列をホモロジー検索した結果、アスペルギルス・フミガタス(Aspergillus fumigatus)由来のエンドグルカナーゼ(Q4WCM9)と60%の同一性を示したため、本DNA断片をエンドグルカナーゼ(Glycoside Hydrolase family 7)遺伝子の一部であると判断した。
【0048】
(2-3)インバースPCR法によるACC5遺伝子全長の取得
実施例1-3に記載の方法で、HindIIIで消化した環状DNAをテンプレートに、ACC5遺伝子断片に含まれる下記の配列によりPCRを実施し、ACC5遺伝子の5’上流領域並びに3’下流領域を取得した。
ACC5-inv-F:ATCTCACCTGCAACCTACGA(配列番号:29)
ACC5-inv-R:CCTCTTCCGTTCCACATAAA(配列番号:30)
上記5’上流領域並びに3’下流領域の塩基配列を解析し、ACC5遺伝子の全長塩基配列を決定した。
インバースPCR法により得た塩基配列を基に以下のプライマーを作製し、ゲノムDNAをテンプレートにPCRを実施し、ACC5遺伝子を増幅した。
pACC5-F:ATTGCTCCGCATAGGTTCAA(配列番号:31)
pACC5-R:TTCAGAGTTAGTGCCTCCAG(配列番号:32)
増幅されたDNAをTOPO TAクローニングキット(インビトロジェン社製)によりpCR2.1-TOPO プラスミドベクターに挿入し、プラスミドpACC5を得た。得られたプラスミドpACC5により大腸菌(Escherichia coli)TOP10株(インビトロジェン社製)を形質転換することによりEscherichia coli TOP10株/pACC5を得た。
【0049】
(2-4)ACC5遺伝子のイントロン解析
ACC5遺伝子配列から開始コドン並びに終始コドンを含む下記のプライマーを作製し、cDNAをテンプレートにPCRを実施し、ACC5 cDNA遺伝子を増幅した。
ACC5-N:ATGGCGACTAGACCATTGGCTTTTG(配列番号:33)
ACC5-C:CTAAAGGCACTGTGAATAGTACGGA(配列番号:34)
上記ACC5 cDNA遺伝子の塩基配列を解析し、pACC5遺伝子と比較することでイントロンの位置を決定した。
【0050】
(2-5)ACC5のアミノ酸配列の推定
上記の方法によりアクレモニウム・セルロリティカスより単離されたエンドグルカナーゼACC5遺伝子は配列番号3に記載の塩基配列の128〜1615番に示された1488bpの塩基からなっていた。オープンリーディングフレーム(ORF)から予測されるACC5のアミノ酸配列は配列番号4に示される通りであった。なお、シグナル配列予測ソフトSignalP 3.0により本ACC5の-20〜-1アミノ酸残基までがシグナル配列と推定した。
【0051】
《実施例3:ACC6遺伝子のクローニング》
(3-1)ゲノムDNAの単離とゲノムライブラリーの作製
実施例1-1に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のゲノムDNAを単離した。単離したゲノムDNAをSau3AIにより部分消化した。これをファージベクター・dMBL3クローニングキット(ストラタジーン社製)のBamHIアームに、ライゲーションキットVer.2(宝酒造社製)を用いて連結させた。これをエタノール沈殿後、TE緩衝液に溶解した。連結混合物をMaxPlaxλpackerging kit(エピセンターテクノロジー社製)を用い、ファージ粒子を形成させ、大腸菌XL1-blue MRA(P2)株に感染させた。この方法により1.1 X 104個のファージから成るゲノムDNAライブラリーが得られた。
【0052】
(3-2)ACC6遺伝子断片の取得
Glycoside Hydrolase family 5に分類される既知のエンドグルカナーゼの配列を基に以下のプライマーを作製した。
ACC6-F:GTGAACATCGCCGGCTTYGAYTTYGG(配列番号:35)
ACC6-R:CCGTTCCACCGGGCRTARTTRTG(配列番号:36)
【0053】
ACC6-F及びACC6-Rをプライマーとして使用し、ゲノムDNAを鋳型としてPCRを行った。PCRはLA taqポリメラーゼ(タカラバイオ社製)を用いて実施した。PCRは94℃で30秒、アニールを30秒、72℃で1分間を40サイクル実施するプログラムで実施したが、アニール温度は最初の20サイクルで63℃から53℃へ段階的に低下させ、その後の20サイクルにおいては53℃に固定した。増幅された300bpのDNA断片を、TOPO TAクローニングキット(インビトロジェン社製)により、添付のプロトコールに従ってpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドTOPO-pACC6-partialを得た。
【0054】
プラスミドTOPO-pACC6-partialにクローニングされた挿入DNA断片の塩基配列を解析し、得られた塩基配列をアミノ酸配列に翻訳し、そのアミノ酸配列をホモロジー検索した結果、トリコデルマ・ビリデ(Trichoderma viride)由来のエンドグルカナーゼEG3(Q7Z7X2)と61%の同一性を示したため、本DNA断片をエンドグルカナーゼ(Glycoside Hydrolase family 5)遺伝子の一部であると判断した。本DNA断片をプラスミドTOPO-pACC6-partialを鋳型として上記と同様の方法でPCRに増幅し、得られたPCR産物はECLダイレクトシステム(アマシャムファルマシアバイオテク社製)を用いて標識しプローブとした。
【0055】
(3-3)プラークハイブリダイゼーションによるスクリーニング
実施例3-1において作成したファージプラークを、ハイボンドN+ナイロントランスファーメンブラン(アマシャム社製)に転写し、アルカリ変性後、5倍濃度SSC(SSC:15mmol/Lクエン酸3ナトリウム、150mmol/L塩化ナトリウム)で洗浄し、乾燥させてDNAを固定した。ハイブリダイゼーションは、1時間のプレハイブリダイゼーション(42℃)の後、HRP標識プローブを添加し、4時間(42℃)ハイブリダイゼーションを行った。プローブの洗浄は6M尿素、0.4%SDS添加0.5倍濃度SSCで2回、2倍濃度SSCで2回行った。
プローブの洗浄を行ったナイロン膜は、検出溶液に1分間浸したあと、同社製ハイパーフィルムECLに感光させ、1個の陽性クローンを得た。陽性クローンからのDNA調製は、Maniatisらの方法(J.Sambrook,E.F.Fritsch and T.Maniat1s,"Molecular Cloning",Cold Spring Harbor Laboratory Press.1989)に従い、宿主大腸菌としてLE392を用いて行った。まず、LE392をLB-MM培地(1%ペプトン、0.5%イーストエキス、0.5%塩化ナトリウム、10mmol/L硫酸マグネシウム、0.2%マルトース)で一晩培養した。これにシングルプラーク由来のファージ溶液を感染させ、LB-MM培地で一晩培養した。これに、塩化ナトリウムを1Mに、そしてクロロホルムを0.8%になるよう加え、大腸菌の溶菌を促進させた。遠心分離により、菌体残渣をのぞき、10%PEG6000による沈澱からファージ粒子を回収した。ファージ粒子はSDS存在下、プロティナーゼKで消化し、これをフェノール処理、エタノール沈澱化によりファージDNAを回収した。
以上のように調製したDNAはECLダイレクトシステムを用い、サザンブロット解析を行った。実施例3-2のPCR増幅断片をプローブにハイブリダイゼーションを行った結果、2.9kbpのXbaI断片が染色体DNAと共通のハイブリダイゼーションパターンを示した。このXbaI断片をpUC118にクローン化し、プラスミドpUC-ACC6を得た後、プラスミドの塩基配列を解析した。
【0056】
(3-4)ACC6遺伝子全長の取得
pUC-ACC6より得た塩基配列を基に以下のプライマーを作製し、ゲノムDNAをテンプレートにPCRを実施し、ACC6遺伝子を増幅した。
pACC6-F:CTCTGCATTGAATCCCGAGA(配列番号:37)
pACC6-R:GCAACGCTAAAGTGCTCATC(配列番号:38)
増幅されたDNAをTOPO TAクローニングキット(インビトロジェン社製)によりpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドpACC6を得た。得られたプラスミドpACC6により大腸菌(Escherichia coli)TOP10株(インビトロジェン社製)を形質転換することによりEscherichia coli TOP10株/pACC6を得た。
【0057】
(3-5)cDNAの作製並びにACC6遺伝子のイントロン解析
実施例1-4に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のcDNAを作製した。ACC6遺伝子配列から開始コドン並びに終始コドンを含む下記のプライマーを作製し、cDNAをテンプレートにPCRを実施し、ACC6 cDNA遺伝子を増幅した。
ACC6-N:ATGACAATCATCTCAAAATTCGGT(配列番号:39)
ACC6-C:TCAGGATTTCCACTTTGGAACGAA(配列番号:40)
上記ACC6 cDNA遺伝子の塩基配列を解析し、pACC6遺伝子と比較することでイントロンの位置を決定した。
【0058】
(3-6)ACC6のアミノ酸配列の推定
上記の方法によりアクレモニウム・セルロリティカスより単離されたエンドグルカナーゼACC6遺伝子は配列番号5に記載の塩基配列の169〜1598番に示された1430bpの塩基からなっていた。また、本ACC6遺伝子は配列番号5に記載の塩基配列の254〜309番、406〜461番、及び1372〜1450番に示される3つのイントロンが含まれていることが示された。オープンリーディングフレーム(ORF)から予測されるACC6のアミノ酸配列は配列番号6に示される通りであった。なお、シグナル配列予測ソフトSignalP 3.0により本ACC6の-21〜-1アミノ酸残基までがシグナル配列と推定した。
【0059】
《実施例4:ACC7遺伝子のクローニング》
(4-1)ゲノムDNAの単離とゲノムライブラリーの作製
実施例3-1に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のゲノムDNAライブラリーを調製した。
【0060】
(4-2)ACC7遺伝子断片の取得
Glycoside Hydrolase family 5に分類される既知のエンドグルカナーゼの配列を基に以下のプライマーを作製した。
ACC7-F:CACGCCATGATCGACCCNCAYAAYTAYG(配列番号:41)
ACC7-R:ACCAGGGGCCGGCNGYCCACCA(配列番号:42)
【0061】
ACC7-F及びACC7-Rをプライマーとして使用し、ゲノムDNAを鋳型としてPCRを行った。PCRはLA taqポリメラーゼ(タカラバイオ社製)を用いて実施した。PCRは94℃で30秒、アニールを30秒、72℃で1分間を40サイクル実施するプログラムで実施したが、アニール温度は最初の20サイクルで63℃から53℃へ段階的に低下させ、その後の20サイクルにおいては53℃に固定した。増幅された670bpのDNA断片を、TOPO TAクローニングキット(インビトロジェン社製)により、添付のプロトコールに従ってpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドTOPO-pACC7-partialを得た。
【0062】
プラスミドTOPO-pACC7-partialにクローニングされた挿入DNA断片の塩基配列を解析し、得られた塩基配列をアミノ酸配列に翻訳し、そのアミノ酸配列をホモロジー検索した結果、アスペルギルス・フミガタス(Aspergillus fumigatus)由来のエンドグルカナーゼ(Q4WM09)と63%の同一性を示したため、本DNA断片をエンドグルカナーゼ(Glycoside Hydrolase family 5)遺伝子の一部であると判断した。本DNA断片をプラスミドTOPO-pACC7-partialを鋳型として上記と同様の方法でPCRに増幅し、得られたPCR産物はECLダイレクトシステム(アマシャムファルマシアバイオテク社製)を用いて標識しプローブとした。
【0063】
(4-3)プラークハイブリダイゼーションによるスクリーニング
実施例3-3の記載の方法で、ゲノムDNAライブラリーをスクリーニングした結果、1個の陽性クローンを得た。得られた陽性クローンについてサザンブロット解析を行った結果、3.7kbpのXbaI断片が染色体DNAと共通のハイブリダイゼーションパターンを示した。このXbaI断片をpUC118にクローン化し、プラスミドpUC-ACC7を得た後、プラスミドの塩基配列を解析した。
【0064】
(4-4)ACC7遺伝子全長の取得
pUC-ACC7より得た塩基配列を基に以下のプライマーを作製し、ゲノムDNAをテンプレートにPCRを実施し、ACC7遺伝子を増幅した。
pACC7-F:CAGTCAGTTGTGTAGACACG(配列番号:43)
pACC7-R:ACTCAGCTGGGTCTTCATAG(配列番号:44)
増幅されたDNAをTOPO TAクローニングキット(インビトロジェン社製)によりpCR2.1-TOPO プラスミドベクターに挿入し、プラスミドpACC7を得た。得られたプラスミドpACC7により大腸菌(Escherichia coli)TOP10株(インビトロジェン社製)を形質転換することによりEscherichia coli TOP10株/pACC7を得た。
【0065】
(4-5)cDNAの作製並びにACC7遺伝子のイントロン解析
実施例1-4に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のcDNAを作製した。ACC7遺伝子配列から開始コドン並びに終始コドンを含む下記のプライマーを作製し、cDNAをテンプレートにPCRを実施し、ACC7 cDNA遺伝子を増幅した。
ACC7-N:ATGAGGTCTACATCAACATTTGTA(配列番号:45)
ACC7-C:CTAAGGGGTGTAGGCCTGCAGGAT(配列番号:46)
上記ACC7 cDNA遺伝子の塩基配列を解析し、pACC7遺伝子と比較することでイントロンの位置を決定した。
【0066】
(4-6)ACC7のアミノ酸配列の推定
上記の方法によりアクレモニウム・セルロリティカスより単離されたエンドグルカナーゼACC7遺伝子は配列番号7に記載の塩基配列の70〜1376番に示された1307bpの塩基からなっていた。また、本ACC7遺伝子は配列番号7に記載の塩基配列の451〜500番、及び765〜830番に示される2つのイントロンが含まれていることが示された。オープンリーディングフレーム(ORF)から予測されるACC7のアミノ酸配列は配列番号8に示される通りであった。なお、シグナル配列予測ソフトSignalP 3.0により本ACC7の-20〜-1アミノ酸残基までがシグナル配列であると推定した。
【0067】
《実施例5:ACC8遺伝子のクローニング》
(5-1)ゲノムDNAの単離とゲノムライブラリーの作製
実施例3-1に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のゲノムDNAライブラリーを調製した。
【0068】
(5-2)ACC8遺伝子断片の取得
ペニシリウム・ベルクロッサム(Penicillium verruculosum)由来のエンドグルカナーゼIIIのN末端、C末端のアミノ酸配列に対応するDNA配列に基づき、以下のプライマーを作製した。
MSW-N:CAACAGAGTCTATGCGCTCAATACTCGAGCTACACCAGT(配列番号:47)
MSW-C:CTAATTGACAGCTGCAGACCAA(配列番号:48)
【0069】
MSW-N及びMSW-Cをプライマーとして使用し、ゲノムDNAを鋳型としてPCRを行った。PCRはLA taqポリメラーゼ(タカラバイオ社製)を用いて実施した。PCRは94℃で30秒、アニールを30秒、72℃で1分間を40サイクル実施するプログラムで実施したが、アニール温度は最初の20サイクルで63℃から53℃へ段階的に低下させ、その後の20サイクルにおいては53℃に固定した。増幅された800bpのDNA断片を、TOPO TAクローニングキット(インビトロジェン社製)により、添付のプロトコールに従ってpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドTOPO-pACC8-partialを得た。
【0070】
プラスミドTOPO-pACC8-partialにクローニングされた挿入DNA断片の塩基配列を解析し、得られた塩基配列をアミノ酸配列に翻訳し、そのアミノ酸配列をホモロジー検索した結果、トリコデルマ・ビリデ(Trichoderma viride)由来のエンドグルカナーゼCel12A(Q8NJY4)と60%の同一性を示したため、本DNA断片をエンドグルカナーゼ(Glycoside Hydrolase family 12)遺伝子の一部であると判断した。本DNA断片をプラスミドTOPO-pACC8-partialを鋳型として上記と同様の方法でPCRに増幅し、得られたPCR産物はECLダイレクトシステム(アマシャムファルマシアバイオテク社製)を用いて標識しプローブとした。
【0071】
(5-3)プラークハイブリダイゼーションによるスクリーニング
実施例3-3の記載の方法で、ゲノムDNAライブラリーをスクリーニングした結果、1個の陽性クローンを得た。得られた陽性クローンについてサザンブロット解析を行った結果、約5kbpのSalI断片が染色体DNAと共通のハイブリダイゼーションパターンを示した。このSalI断片をpUC118にクローン化し、プラスミドpUC-ACC8を得た後、プラスミドの塩基配列を解析した。
【0072】
(5-4)ACC8遺伝子全長の取得
pUC-ACC8より得た塩基配列を基に以下のプライマーを作製し、ゲノムDNAをテンプレートにPCRを実施し、ACC8遺伝子を増幅した。
pACC8-F:AAAGACCGCGTGTTAGGATC(配列番号:49)
pACC8-R:CGCGTAGGAAATAAGACACC(配列番号:50)
増幅されたDNAをTOPO TAクローニングキット(インビトロジェン社製)によりpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドpACC8を得た。得られたプラスミドpACC8により大腸菌(Escherichia coli)TOP10株(インビトロジェン社製)を形質転換することによりEscherichia coli TOP10株/pACC8を得た。
【0073】
(5-5)cDNAの作製並びにACC8遺伝子のイントロン解析
実施例1-4に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のcDNAを作製した。ACC8遺伝子配列から開始コドン並びに終始コドンを含む下記のプライマーを作製し、cDNAをテンプレートにPCRを実施し、ACC8 cDNA遺伝子を増幅した。
ACC8-N:ATGAAGCTAACTTTTCTCCTGAAC(配列番号:51)
ACC8-C:CTAATTGACAGATGCAGACCAATG(配列番号:52)
上記ACC8 cDNA遺伝子の塩基配列を解析し、pACC8遺伝子と比較することでイントロンの位置を決定した。
【0074】
(5-6)ACC8のアミノ酸配列の推定
上記の方法によりアクレモニウム・セルロリティカスより単離されたエンドグルカナーゼACC8遺伝子は配列番号9に記載の塩基配列の141〜974番に示された834bpの塩基からなっていた。また、本ACC8遺伝子は配列番号9に記載の塩基配列の551〜609番、及び831〜894番に示される2つのイントロンが含まれていることが示された。オープンリーディングフレーム(ORF)から予測されるACC8のアミノ酸配列は配列番号10に示される通りであった。なお、シグナル配列予測ソフトSignalP 3.0により本ACC8の-15〜-1アミノ酸残基までがシグナル配列であると推定した。
【0075】
《実施例6:ACC9遺伝子のクローニング》
(6-1)ゲノムDNA並びにmRNAの単離とcDNAの作製
実施例1-1に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のゲノムDNAを単離した。また、実施例1-4に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のcDNAを作製した。
【0076】
(6-2)ACC9遺伝子断片の取得
Glycoside Hydrolase family 45に分類される既知のエンドグルカナーゼの配列を基に以下のプライマーを作製した。
ACC9-F:CCGGCTGCGGCAARTGYTAYMA(配列番号:53)
ACC9-R:AGTACCACTGGTTCTGCACCTTRCANGTNSC(配列番号:54)
【0077】
ACC9-F及びACC9-Rをプライマーとして使用し、ゲノムDNAを鋳型としてPCRを行った。PCRはLA taqポリメラーゼ(タカラバイオ社製)を用いて実施した。PCRは94℃で30秒、アニールを30秒、72℃で1分間を40サイクル実施するプログラムで実施したが、アニール温度は最初の20サイクルで63℃から53℃へ段階的に低下させ、その後の20サイクルにおいては53℃に固定した。増幅された800bpのDNA断片を、TOPO TAクローニングキット(インビトロジェン社製)により、添付のプロトコールに従ってpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドTOPO-pACC9-partialを得た。
【0078】
プラスミドTOPO-pACC9-partialにクローニングされた挿入DNA断片の塩基配列を解析し、得られた塩基配列をアミノ酸配列に翻訳し、そのアミノ酸配列をホモロジー検索した結果、トリコデルマ・ビリデ(Trichoderma viride)由来のエンドグルカナーゼEGV(Q7Z7X0)と79%の同一性を示したため、本DNA断片をエンドグルカナーゼ(Glycoside Hydrolase family 45)遺伝子の一部であると判断した。
【0079】
(6-3)インバースPCR法によるACC9遺伝子全長の取得
実施例1-3に記載の方法で、SalI又はXbaIで消化した環状DNAをテンプレートに、ACC9遺伝子断片に含まれる下記の配列によりPCRを実施し、ACC9遺伝子の5’上流領域並びに3’下流領域を取得した。
ACC9-inv-F:CGAAGTGTTTGGTGACAACG(配列番号:55)
ACC9-inv-R:GTGGTAGCTGTATCCGTAGT(配列番号:56)
上記5’上流領域並びに3’下流領域の塩基配列を解析し、ACC9遺伝子の全長塩基配列を決定した。
インバースPCR法により得た塩基配列を基に以下のプライマーを作製し、ゲノムDNAをテンプレートにPCRを実施し、ACC9遺伝子を増幅した。
pACC9-F:TACATTCCGAAGGCACAGTT(配列番号:57)
pACC9-R:CTGAGCTGATTATCCTGACC(配列番号:58)
増幅されたDNAをTOPO TAクローニングキット(インビトロジェン社製)によりpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドpACC9を得た。得られたプラスミドpACC9により大腸菌(Escherichia coli)TOP10株(インビトロジェン社製)を形質転換することによりEscherichia coli TOP10株/pACC9を得た。
【0080】
(6-4)ACC9遺伝子のイントロン解析
ACC9遺伝子配列から開始コドン並びに終始コドンを含む下記のプライマーを作製し、cDNAをテンプレートにPCRを実施し、ACC9 cDNA遺伝子を増幅した。
ACC9-N:ATGAAGGCTTTCTATCTTTCTCTC(配列番号:59)
ACC9-C:TTAGGACGAGCTGACGCACTGGTA(配列番号:60)
上記ACC9 cDNA遺伝子の塩基配列を解析し、pACC9遺伝子と比較することでイントロンの位置を決定した。
【0081】
(6-5)ACC9のアミノ酸配列の推定
上記の方法によりアクレモニウム・セルロリティカスより単離されたエンドグルカナーゼACC9遺伝子は配列番号11に記載の塩基配列の114〜1230番に示された1117bpの塩基からなっていた。また、本ACC9遺伝子は配列番号11に記載の塩基配列の183〜232番、及び299〜357番に示される2つのイントロンが含まれていることが示された。オープンリーディングフレーム(ORF)から予測されるACC9のアミノ酸配列は配列番号12に示される通りであった。なお、シグナル配列予測ソフトSignalP 3.0により本ACC9の-16〜-1アミノ酸残基までがシグナル配列であると推定した。
【0082】
《実施例7:ACC10遺伝子のクローニング》
(7-1)ゲノムDNA並びにmRNAの単離とcDNAの作製
実施例1-1に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のゲノムDNAを単離した。また、実施例1-4に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のcDNAを作製した。
【0083】
(7-2)ACC10遺伝子断片の取得
Glycoside Hydrolase family 61に分類される既知のエンドグルカナーゼの配列並びにポリA塩基配列を基に以下のプライマーを作製した。
ACC10-F:GGTGTACGTGGGCACCAAYGGNMGNGG(配列番号:61)
ACC10-R:AATTCGCGGCCGCTAAAAAAAAA(配列番号:62)
【0084】
ACC10-F及びACC10-Rをプライマーとして使用し、cDNAを鋳型としてPCRを行った。PCRはLA taqポリメラーゼ(タカラバイオ社製)を用いて実施した。PCRは94℃で30秒、アニールを30秒、72℃で1分間を40サイクル実施するプログラムで実施したが、アニール温度は最初の20サイクルで63℃から53℃へ段階的に低下させ、その後の20サイクルにおいては53℃に固定した。増幅された300bpのDNA断片を、TOPO TAクローニングキット(インビトロジェン社製)により、添付のプロトコールに従ってpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドTOPO-pACC10-partialを得た。
【0085】
プラスミドTOPO-pACC10-partialにクローニングされた挿入DNA断片の塩基配列を解析し、得られた塩基配列をアミノ酸配列に翻訳し、そのアミノ酸配列をホモロジー検索した結果、アスペルギルス・テレウス(Aspergillus terreus)由来のエンドグルカナーゼEGIV(Q0D0T6)と65%の同一性を示したため、本DNA断片をエンドグルカナーゼ(Glycoside Hydrolase family 61)遺伝子の一部であると判断した。
【0086】
(7-3)インバースPCR法によるACC10遺伝子全長の取得
実施例1-3に記載の方法で、HindIIIで消化した環状DNAをテンプレートに、ACC10遺伝子断片に含まれる下記の配列によりPCRを実施し、ACC5遺伝子の5’上流領域並びに3’下流領域を取得した。
ACC10-inv-F:TTCTGCTACTGCGGTTGCTA(配列番号:63)
ACC10-inv-R:GAATAACGTAGGTCGACAAG(配列番号:64)
上記5’上流領域並びに3’下流領域の塩基配列を解析し、ACC10遺伝子の全長塩基配列を決定した。
インバースPCR法により得た塩基配列を基に以下のプライマーを作製し、ゲノムDNAをテンプレートにPCRを実施し、ACC10遺伝子を増幅した。
pACC10-F:CGTTGACCGAAAGCCACTT(配列番号:65)
pACC10-R:TGGCCTAAAGCTAAATGATG(配列番号:66)
増幅されたDNAをTOPO TAクローニングキット(インビトロジェン社製)によりpCR2.1-TOPO プラスミドベクターに挿入し、プラスミドpACC10を得た。得られたプラスミドpACC10により大腸菌(Escherichia coli)TOP10株(インビトロジェン社製)を形質転換することによりEscherichia coli TOP10株/pACC10を得た。
【0087】
(7-4)ACC10遺伝子のイントロン解析
ACC10遺伝子配列から開始コドン並びに終始コドンを含む下記のプライマーを作製し、cDNAをテンプレートにPCRを実施し、ACC10 cDNA遺伝子を増幅した。
ACC10-N:ATGCCTTCTACTAAAGTCGCTGCCC(配列番号:67)
ACC10-C:TTAAAGGACAGTAGTGGTGATGACG(配列番号:68)
上記ACC10 cDNA遺伝子の塩基配列を解析し、pACC10遺伝子と比較することでイントロンの位置を決定した。
【0088】
(7-5)ACC10のアミノ酸配列の推定
上記の方法によりアクレモニウム・セルロリティカスより単離されたエンドグルカナーゼACC10遺伝子は配列番号13に記載の塩基配列の124〜1143番に示された1020bpの塩基からなっていた。また、本ACC10遺伝子は配列番号13に記載の塩基配列の225〜275番に示される1つのイントロンが含まれていることが示された。オープンリーディングフレーム(ORF)から予測されるACC10のアミノ酸配列は配列番号14に示される通りであった。なお、シグナル配列予測ソフトSignalP 3.0により本ACC10の-21〜-1アミノ酸残基までがシグナル配列であると推定した。
【0089】
《実施例8:BGLC遺伝子のクローニング》
(8-1)ゲノムDNA並びにcDNAの作製
実施例1-1に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のゲノムDNAを単離した。また、実施例1-4に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のcDNAを作製した。
【0090】
(8-2)BGLC遺伝子断片の取得
Glycoside Hydrolase family 1に分類される既知のβ−グルコシダーゼの配列を基に以下のプライマーを作製した。
BGLC-F:CCTGGGTGACCCTGTACCAYTGGGAYYT(配列番号:69)
BGLC-R:TGGGCAGGAGCAGCCRWWYTCNGT(配列番号:70)
【0091】
BGLC-F及びBGLC -Rをプライマーとして使用し、ゲノムDNAを鋳型としてPCRを行った。PCRはLA taqポリメラーゼ(タカラバイオ社製)を用いて実施した。PCRは94℃で30秒、アニールを30秒、72℃で1分間を40サイクル実施するプログラムで実施したが、アニール温度は最初の20サイクルで63℃から53℃へ段階的に低下させ、その後の20サイクルにおいては53℃に固定した。増幅された1.2kbpのDNA断片を、TOPO TAクローニングキット(インビトロジェン社製)により、添付のプロトコールに従ってpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドTOPO-pBGLC-partialを得た。
【0092】
プラスミドTOPO-pBGLC-partialにクローニングされた挿入DNA断片の塩基配列を解析し、得られた塩基配列をアミノ酸配列に翻訳し、そのアミノ酸配列をホモロジー検索した結果、アスペルギルス・フミガタス(Aspergillus fumigatus)由来のβ−グルコシダーゼ1(Q4WRG4)と69%の同一性を示したため、本DNA断片をβ−グルコシダーゼ(Glycoside Hydrolase family 1)遺伝子の一部であると判断した。
【0093】
(8-3)インバースPCR法によるBGLC遺伝子全長の取得
実施例1-3に記載の方法で、XbaIで消化した環状DNAをテンプレートに、BGLC遺伝子断片に含まれる下記の配列によりPCRを実施し、BGLC遺伝子の5’上流領域並びに3’下流領域を取得した。
BGLC-inv-F:GGAGTTCTTCTACATTTCCC(配列番号:71)
BGLC-inv-R:AACAAGGACGGCGTGTCAGT(配列番号:72)
上記5’上流領域並びに3’下流領域の塩基配列を解析し、BGLC遺伝子の全長塩基配列を決定した。
インバースPCR法により得た塩基配列を基に以下のプライマーを作製し、ゲノムDNAをテンプレートにPCRを実施し、BGLC遺伝子を増幅した。
pBGLC-F:CTCCGTCAAGTGCGAAGTAT(配列番号:73)
pBGLC-R:GGCTCGCTAATACTAACTGC(配列番号:74)
増幅されたDNAをTOPO TAクローニングキット(インビトロジェン社製)によりpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドpBGLCを得た。得られたプラスミドpBGLCにより大腸菌(Escherichia coli)TOP10株(インビトロジェン社製)を形質転換することによりEscherichia coli TOP10株/pBGLCを得た。
【0094】
(8-4)BGLC遺伝子のイントロン解析
BGLC遺伝子配列から開始コドン並びに終始コドンを含む下記のプライマーを作製し、cDNAをテンプレートにPCRを実施し、BGLC cDNA遺伝子を増幅した。
BGLC-N:ATGGGCTCTACATCTCCTGCCCAA(配列番号:75)
BGLC-C:CTAGTTCCTCGGCTCTATGTATTT(配列番号:76)
上記BGLC cDNA遺伝子の塩基配列を解析し、pBGLC遺伝子と比較することでイントロンの位置を決定した。
【0095】
(8-5)BGLCのアミノ酸配列の推定
上記の方法によりアクレモニウム・セルロリティカスより単離されたβ−グルコシダーゼBGLC遺伝子は配列番号15に記載の塩基配列の238〜1887番に示された1650bpの塩基からなっていた。また、本BGLC遺伝子は配列番号15に記載の塩基配列の784〜850番、1138〜1205番、及び1703〜1756番に示される3つのイントロンが含まれていることが示された。オープンリーディングフレーム(ORF)から予測されるBGLCのアミノ酸配列は配列番号16に示される通りであった。なお、シグナル配列予測ソフトSignalP 3.0により本BGLCの-28〜-1アミノ酸残基までがシグナル配列であると推定した。
【0096】
《実施例9:BGLD遺伝子のクローニング》
(9-1)ゲノムDNA並びにcDNAの作製
実施例1-1に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のゲノムDNAを単離した。また、実施例1-4に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のcDNAを作製した。
【0097】
(9-2)BGLD遺伝子断片の取得
Glycoside Hydrolase family 1に分類される既知のβ−グルコシダーゼの配列を基に以下のプライマーを作製した。
BGLD-F:CACCGCCGCCTACCARRTNGARGG(配列番号:77)
BGLD-R:TGGCGGTGTAGTGGTTCATGSCRWARWARTC(配列番号:78)
【0098】
BGLD-F及びBGLD -Rをプライマーとして使用し、ゲノムDNAを鋳型としてPCRを行った。PCRはLA taqポリメラーゼ(タカラバイオ社製)を用いて実施した。PCRは94℃で30秒、アニールを30秒、72℃で1分間を40サイクル実施するプログラムで実施したが、アニール温度は最初の20サイクルで63℃から53℃へ段階的に低下させ、その後の20サイクルにおいては53℃に固定した。増幅された1kbpのDNA断片を、TOPO TAクローニングキット(インビトロジェン社製)により、添付のプロトコールに従ってpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドTOPO-pBGLD-partialを得た。
【0099】
プラスミドTOPO-pBGLD-partialにクローニングされた挿入DNA断片の塩基配列を解析し、得られた塩基配列をアミノ酸配列に翻訳し、そのアミノ酸配列をホモロジー検索した結果、タラロマイセス・エメルソニ(Talaromyces emersonii)由来のβ−グルコシダーゼ1(Q8X214)と76%の同一性を示したため、本DNA断片をβ−グルコシダーゼ(Glycoside Hydrolase family 1)遺伝子の一部であると判断した。
【0100】
(9-3)インバースPCR法によるBGLD遺伝子全長の取得
実施例1-3に記載の方法で、XhoIで消化した環状DNAをテンプレートに、BGLD遺伝子断片に含まれる下記の配列によりPCRを実施し、BGLD遺伝子の5’上流領域並びに3’下流領域を取得した。
BGLD-inv-F:CGGTTTCAATATCGGTAAGC(配列番号:79)
BGLD-inv-R:GTGTCCAAAGCTCTGGAATG(配列番号:80)
上記5’上流領域並びに3’下流領域の塩基配列を解析し、BGLD遺伝子の全長塩基配列を決定した。
インバースPCR法により得た塩基配列を基に以下のプライマーを作製し、ゲノムDNAをテンプレートにPCRを実施し、BGLD遺伝子を増幅した。
pBGLD-F:TTCTCTCACTTTCCCTTTCC(配列番号:81)
pBGLD-R:AATTGATGCTCCTGATGCGG(配列番号:82)
増幅されたDNAをTOPO TAクローニングキット(インビトロジェン社製)によりpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドpBGLDを得た。得られたプラスミドpBGLDにより大腸菌(Escherichia coli)TOP10株(インビトロジェン社製)を形質転換することによりEscherichia coli TOP10株/pBGLDを得た。
【0101】
(9-4)BGLD遺伝子のイントロン解析
BGLD遺伝子配列から開始コドン並びに終始コドンを含む下記のプライマーを作製し、cDNAをテンプレートにPCRを実施し、BGLD cDNA遺伝子を増幅した。
BGLD-N:ATGGGTAGCGTAACTAGTACCAAC(配列番号:83)
BGLD-C:CTACTCTTTCGAGATGTATTTGTT(配列番号:84)
上記BGLD cDNA遺伝子の塩基配列を解析し、pBGLD遺伝子と比較することでイントロンの位置を決定した。
【0102】
(9-5)BGLDのアミノ酸配列の推定
上記の方法によりアクレモニウム・セルロリティカスより単離されたβ−グルコシダーゼBGLD遺伝子は配列番号17に記載の塩基配列の66〜1765番に示された1700bpの塩基からなっていた。また、本BGLD遺伝子は配列番号17に記載の塩基配列の149〜211番、404〜460番、934〜988番、及び1575〜1626番に示される4つのイントロンが含まれていることが示された。オープンリーディングフレーム(ORF)から予測されるBGLDのアミノ酸配列は配列番号18に示される通りであった。なお、シグナル配列予測ソフトSignalP 3.0により本BGLDの-33〜-1アミノ酸残基までがシグナル配列であると推定した。
【産業上の利用可能性】
【0103】
本発明のタンパク質は、セルラーゼ調製物として使用することができ、セルロース系基質分解の用途に適用することができる。
【配列表フリーテキスト】
【0104】
配列表の配列番号19〜84の配列で表される各塩基配列は、人工的に合成したプライマー配列である。配列番号27(18位及び27位)、配列番号41(18位)、配列番号42(14位)、配列番号54(26位及び29位)、配列番号61(22位及び25位)、配列番号70(22位)、配列番号77(19位)における記号”n”は任意塩基を意味する。
【図面の簡単な説明】
【0105】
【図1】プラスミドpACC3の制限酵素地図である。
【図2】プラスミドpACC5の制限酵素地図である。
【図3】プラスミドpACC6の制限酵素地図である。
【図4】プラスミドpACC7の制限酵素地図である。
【図5】プラスミドpACC8の制限酵素地図である。
【図6】プラスミドpACC9の制限酵素地図である。
【図7】プラスミドpACC10の制限酵素地図である。
【図8】プラスミドpBGLCの制限酵素地図である。
【図9】プラスミドpBGLDの制限酵素地図である。
【技術分野】
【0001】
本発明は、セルラーゼに関するものであり、詳細には、アクレモニウム・セルロリティカス(Acremonium cellulolyticus)由来のセルラーゼ、該セルラーゼをコードするポリヌクレオチド、該ポリヌクレオチドを利用したセルラーゼの製造方法及びその用途に関するものである。なお、本明細書において「ポリヌクレオチド」には、例えば、DNA若しくはRNA、又はそれらの修飾体若しくはキメラ体が含まれ、好ましくはDNAである。
【背景技術】
【0002】
セルラーゼはセルロースを分解する酵素の総称であり、一般に微生物の生産するセルラーゼには多種類のセルラーゼ成分からなる。セルラーゼ成分は、その基質特異性から、セロビオハイドロラーゼ、エンドグルカナーゼ、β−グルコシターゼの3種類に分類され、セルラーゼを産生する糸状菌であるアスペルギルス・ニガー(Aspergillus niger)の場合には、最大4種類セロビオハイドロラーゼ、15種類のエンドグルカナーゼ、15種類のβ−グルコシターゼが産生されると考えられている。よって、微生物の産生するセルラーゼを産業上利用する場合は、その微生物が生産する様々なセルラーゼ成分の混合物として利用されることになる。
【0003】
糸状菌アクレモニウム・セルロリティカスは糖化力の強いセルラーゼを生産することが特徴であり(非特許文献1)、飼料用途やサイレージ用途で、高い有用性を持つことが報告されている(特許文献1−3)。また、含有されているセルラーゼ成分(特許文献4−10)に関しても詳細な検討がなされており、その他の糸状菌と同様に多種類のセルラーゼ成分が分泌されていることが明らかにされている。
【0004】
ある用途に限った場合は、多種類のセルラーゼ成分の内、特定の酵素の数種の成分がその用途に重要であると考えられている。従って、微生物が生産するセルラーゼを、利用させる用途に応じてセルラーゼ成分組成を最適化できれば、より活性の高いセルラーゼが得られることが期待される。そのための最良の方法は、遺伝子組換えの手法により特定の酵素遺伝子を導入して過剰発現させる、もしくは特定の酵素の遺伝子を欠損させることである。
【0005】
しかしながら、アクレモニウム・セルロリティカスの場合には、多種類のセルラーゼ成分の内、2種類のセロビオハイドロラーゼ遺伝子(特許文献4、5)及び1種類のβ−グルコシターゼ遺伝子(特許文献10)が単離されているのみであり、その他のセルラーゼについては、その遺伝子導入による発現増強や、欠損による発現抑制をすることができない状況にあった。
【0006】
この様な背景の中、アクレモニウム・セルロリティカスの産生するセルラーゼの組成を遺伝子組換え技術により最適化するために、エンドグルカナーゼやβ−グルコシターゼなどの多糖分解酵素遺伝子の単離が所望されていた。
【0007】
【非特許文献1】「アグリカルチュラル・アンド・バイオロジカル・ケミストリー(Agricultural and Biological Chemistry)」,(日本),1987年,第51巻,p. 65
【特許文献1】特開平7−264994号公報
【特許文献2】特許第2531595号明細書
【特許文献3】特開平7−236431号公報
【特許文献4】特開2001−17180号公報
【特許文献5】国際公開WO97/33982号パンフレット
【特許文献6】国際公開WO99/011767号パンフレット
【特許文献7】特開2000−69978号公報
【特許文献8】特開平10−066569号公報
【特許文献9】特開2002−101876号公報
【特許文献10】特開2000−298262号公報
【発明の開示】
【発明が解決しようとする課題】
【0008】
本発明は、アクレモニウム・セルロリティカスよりエンドグルカナーゼやβ−グルコシターゼに分類されるセルラーゼ遺伝子を含むゲノムDNAを単離し、その塩基配列を解析することによってエンドグルカナーゼ及びβ−グルコシターゼ遺伝子を特定することを課題とする。
【課題を解決するための手段】
【0009】
本発明者らは、上記課題を解決するため、既知のエンドグルカナーゼ及びβ−グルコシターゼをアミノ酸配列を鋭意比較し、アクレモニウム・セルロリティカスにおいても保存されうるアミノ酸配列を見出し、本情報をもとに様々なプライマーを設計した。この様にして設計された様々なプライマーを用いて、ゲノムDNAもしくはcDNAを鋳型にしたPCRを実施した。その結果、エンドグルカナーゼ及びβ−グルコシターゼの遺伝子断片が得られたので、本遺伝子断片を基に、プライマーを設計し、PCRを継続することにより、エンドグルカナーゼ及びβ−グルコシターゼの遺伝子9種を増幅し、塩基配列を解析し本発明を完成するに至った。
【0010】
即ち、本発明は、
[1]以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号2に記載のアミノ酸配列の1〜306番の配列を含むタンパク質;
(ii)配列番号2に記載のアミノ酸配列の1〜306番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号2に記載のアミノ酸配列の1〜306番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ、
[2]以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号4に記載のアミノ酸配列の1〜475番の配列を含むタンパク質;
(ii)配列番号4に記載のアミノ酸配列の1〜475番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号4に記載のアミノ酸配列の1〜475番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ、
[3]以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号6に記載のアミノ酸配列の1〜391番の配列を含むタンパク質;
(ii)配列番号6に記載のアミノ酸配列の1〜391番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号6に記載のアミノ酸配列の1〜391番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ、
[4]以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号8に記載のアミノ酸配列の1〜376番の配列を含むタンパク質;
(ii)配列番号8に記載のアミノ酸配列の1〜376番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号8に記載のアミノ酸配列の1〜376番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ、
[5]以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号10に記載のアミノ酸配列の1〜221番の配列を含むタンパク質;
(ii)配列番号10に記載のアミノ酸配列の1〜221番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号10に記載のアミノ酸配列の1〜221番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ、
[6]以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号12に記載のアミノ酸配列の1〜319番の配列を含むタンパク質;
(ii)配列番号12に記載のアミノ酸配列の1〜319番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号12に記載のアミノ酸配列の1〜319番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ、
[7]以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号14に記載のアミノ酸配列の1〜301番の配列を含むタンパク質;
(ii)配列番号14に記載のアミノ酸配列の1〜301番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号14に記載のアミノ酸配列の1〜301番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ、
[8]以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号16に記載のアミノ酸配列の1〜458番の配列を含むタンパク質;
(ii)配列番号16に記載のアミノ酸配列の1〜458番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むβ−グルコシダーゼ;
(iii)配列番号16に記載のアミノ酸配列の1〜458番の配列と70%以上の同一性を有するアミノ酸配列を含むβ−グルコシダーゼ、
[9]以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号18に記載のアミノ酸配列の1〜457番の配列を含むタンパク質;
(ii)配列番号18に記載のアミノ酸配列の1〜457番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むβ−グルコシダーゼ;
(iii)配列番号18に記載のアミノ酸配列の1〜457番の配列と70%以上の同一性を有するアミノ酸配列を含むβ−グルコシダーゼ、
[10]糸状菌由来である、[1]〜[9]に記載のタンパク質、
[11]糸状菌がアクレモニウム・セルロリティカス(Acremonium cellulolyticus)に属する糸状菌である、[10]に記載のタンパク質、
[12][1]〜[9]に記載のタンパク質をコードする塩基配列を含む、ポリヌクレオチド、
[13]配列番号1に記載の塩基配列、又はその改変配列を含む、DNA、
[14]以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)[1]に記載のタンパク質をコードするDNA;
(ii)配列番号1に記載の塩基配列の136〜1437番の配列を含むDNA;
(iii)配列番号1に記載の塩基配列の136〜1437番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA、
[15][14]に記載のDNAから、イントロン配列を除去したDNA、
[16]イントロン配列が、配列番号1に記載の塩基配列の233〜291番、351〜425番、579〜631番、697〜754番、又は、853〜907番の配列から選択される1以上の配列を含む配列である、[15]に記載のDNA、
[17][13]〜[16]に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA、
[18]シグナル配列をコードする塩基配列が、配列番号1に記載の塩基配列の136〜216番の配列である、[17]に記載のDNA、
[19]配列番号3に記載の塩基配列、又はその改変配列を含む、DNA、
[20]以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)[2]に記載のタンパク質をコードするDNA;
(ii)配列番号3に記載の塩基配列の128〜1615番の配列を含むDNA;
(iii)配列番号3に記載の塩基配列の128〜1615番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA、
[21][19]〜[20]に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA、
[22]シグナル配列をコードする塩基配列が、配列番号3に記載の塩基配列の128〜187番の配列である、[21]に記載のDNA、
[23]配列番号5に記載の塩基配列、又はその改変配列を含む、DNA、
[24]以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)[3]に記載のタンパク質をコードするDNA;
(ii)配列番号5に記載の塩基配列の169〜1598番の配列を含むDNA;
(iii)配列番号5に記載の塩基配列の169〜1598番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA、
[25][24]に記載のDNAから、イントロン配列を除去したDNA、
[26]イントロン配列が、配列番号5に記載の塩基配列の254〜309番、406〜461番、又は、1372〜1450番の配列から選択される1以上の配列を含む配列である、[25]に記載のDNA、
[27][23]〜[26]に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA、
[28]シグナル配列をコードする塩基配列が、配列番号5に記載の塩基配列の169〜231番の配列である、[27]に記載のDNA、
[29]配列番号7に記載の塩基配列、又はその改変配列を含む、DNA、
[30]以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)[4]に記載のタンパク質をコードするDNA;
(ii)配列番号7に記載の塩基配列の70〜1376番の配列を含むDNA;
(iii)配列番号7に記載の塩基配列の70〜1376番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA、
[31][30]に記載のDNAから、イントロン配列を除去したDNA、
[32]イントロン配列が、配列番号7に記載の塩基配列の451〜500番、又は、765〜830番の配列から選択される1以上の配列を含む配列である、[31]に記載のDNA、
[33][29]〜[32]に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA、
[34]シグナル配列をコードする塩基配列が、配列番号7に記載の塩基配列の70〜129番の配列である、[33]に記載のDNA、
[35]配列番号9に記載の塩基配列、又はその改変配列を含む、DNA、
[36]以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)[5]に記載のタンパク質をコードするDNA;
(ii)配列番号9に記載の塩基配列の141〜974番の配列を含むDNA;
(iii)配列番号9に記載の塩基配列の141〜974番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA、
[37][36]に記載のDNAから、イントロン配列を除去したDNA、
[38]イントロン配列が、配列番号9に記載の塩基配列の551〜609番、又は、831〜894番の配列から選択される1以上の配列を含む配列である、[37]に記載のDNA、
[39][35]〜[38]に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA、
[40]シグナル配列をコードする塩基配列が、配列番号9に記載の塩基配列の141〜185番の配列である[39]に記載のDNA、
[41]配列番号11に記載の塩基配列、又はその改変配列を含む、DNA、
[42]以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)[6]に記載のタンパク質をコードするDNA;
(ii)配列番号11に記載の塩基配列の114〜1230番の配列を含むDNA;
(iii)配列番号11に記載の塩基配列の114〜1230番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA、
[43][42]に記載のDNAから、イントロン配列を除去したDNA、
[44]イントロン配列が、配列番号11に記載の塩基配列の183〜232番、又は、299〜357番の配列から選択される1以上の配列を含む配列である、[43]に記載のDNA、
[45][41]〜[44]に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA、
[46]シグナル配列をコードする塩基配列が、配列番号11に記載の塩基配列の114〜161番の配列である、[45]に記載のDNA、
[47]配列番号13に記載の塩基配列、又はその改変配列を含む、DNA、
[48]以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)[7]に記載のタンパク質をコードするDNA;
(ii)配列番号13に記載の塩基配列の124〜1143番の配列を含むDNA;
(iii)配列番号13に記載の塩基配列の124〜1143番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA、
[49][48]に記載のDNAから、イントロン配列を除去したDNA、
[50]イントロン配列が、配列番号13に記載の塩基配列の225〜275番の配列である、[49]に記載のDNA、
[51][47]〜[50]に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA、
[52]シグナル配列をコードする塩基配列が、配列番号13に記載の塩基配列の124〜186番の配列である、[51]に記載のDNA、
[53]配列番号15に記載の塩基配列、又はその改変配列を含む、DNA、
[54]以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)[8]に記載のタンパク質をコードするDNA;
(ii)配列番号15に記載の塩基配列の238〜1887番の配列を含むDNA;
(iii)配列番号15に記載の塩基配列の238〜1887番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつβ−グルコシダーゼ活性を有するタンパク質をコードするDNA、
[55][54]に記載のDNAから、イントロン配列を除去したDNA、
[56]イントロン配列が、配列番号15に記載の塩基配列の784〜850番、1138〜1205番、又は、1703〜1756番の配列から選択される1以上の配列を含む配列である、[55]に記載のDNA、
[57][53]〜[56]に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA、
[58]シグナル配列をコードする塩基配列が、配列番号15に記載の塩基配列の238〜321番の配列である、[57]に記載のDNA、
[59]配列番号17に記載の塩基配列、又はその改変配列を含む、DNA、
[60]以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)[9]に記載のタンパク質をコードするDNA;
(ii)配列番号17に記載の塩基配列の66〜1765番の配列を含むDNA;
(iii)配列番号17に記載の塩基配列の66〜1765番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつβ−グルコシダーゼ活性を有するタンパク質をコードするDNA、
[61][60]に記載のDNAから、イントロン配列を除去したDNA、
[62]イントロン配列が、配列番号17に記載の塩基配列の149〜211番、404〜460番、934〜988番、又は、1575〜1626番の配列から選択される1以上の配列を含む配列である、[61]に記載のDNA、
[63][59]〜[62]に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA、
[64]シグナル配列をコードする塩基配列が、配列番号17に記載の塩基配列の66〜227番の配列である、[63]に記載のDNA、
[65][12]〜[64]に記載のDNAを含む、発現ベクター、
[66][65]に記載の発現ベクターで形質転換された、宿主細胞、
[67]宿主細胞が酵母又は糸状菌である、[66]に記載の宿主細胞、
[68]酵母が、サッカロミセス(Saccharomyces)属、ハンゼヌラ(Hansenula)属又はピキア(Pichia)属に属するものである、[67]に記載の宿主細胞、
[69]酵母が、サッカロミセス・セレビシエ(Saccharomyces cerevisiae)である、[68]に記載の宿主細胞、
[70]糸状菌が、フミコーラ(Humicola)属、アスペルギルス(Aspergillus)属、トリコデルマ(Trichoderma)属、フザリウム(Fusarium)又はアクレモニウム(Acremonium)属に属するものである、[67]に記載の宿主細胞、
[71]糸状菌が、アクレモニウム・セルロリティカス(Acremonium cellulolyticus)、フミコーラ・インソレンス(Humicola insolens)、アスペルギルス・ニガー(Aspergillus niger)もしくはアスペルギルス・オリゼー(Aspergillus oryzae)、トリコデルマ・ビリデ(Trichoderma viride)、又はフザリウム・オキシスポーラム(Fusarium oxysporum)である、[70]に記載の宿主細胞、
[72][12]〜[64]に記載のDNAに対応する遺伝子を、相同組み換えにより欠損させたアクレモニウム(Acremonium)属の糸状菌、
[73]糸状菌がアクレモニウム・セルロリティカス(Acremonium cellulolyticus)である、[72]に記載の糸状菌、
[74][66]〜[73]に記載の宿主細胞を培養し、その宿主及び/又はその培養物から[1]〜[9]に記載のタンパク質を採取する工程を含む、前記タンパク質の製造法、
[75][74]に記載の方法で生産された、タンパク質、
[76][1]〜[9]若しくは[75]に記載のタンパク質を含む、セルラーゼ調製物、
[77]バイオマスを糖化する処理方法であって、セルロース含有バイオマスを、[1]〜[9]若しくは[75]に記載のタンパク質、又は[76]に記載のセルラーゼ調製物と接触させる工程を含む、方法、
[78]セルロース含有繊維の処理方法であって、セルロース含有繊維を、[1]〜[9]若しくは[75]に記載のタンパク質、又は[76]に記載のセルラーゼ調製物と接触させる工程を含む、方法、
[79]古紙を脱インキ薬品により処理して脱インキを行う工程において、[1]〜[9]若しくは[75]に記載のタンパク質、又は[76]に記載のセルラーゼ調製物を用いることを特徴とする古紙の脱インキ方法、
[80]紙パルプのろ水性の改善方法であって、紙パルプを、[1]〜[9]若しくは[75]に記載のタンパク質、又は[76]に記載のセルラーゼ調製物で処理する工程を含む、方法、
[81]動物飼料の消化能を改善する方法であって、動物飼料を、[1]〜[9]若しくは[75]に記載のタンパク質、又は[76]に記載のセルラーゼ調製物で処理する工程を含む、方法
に関する。
【発明の効果】
【0011】
本発明により、アクレモニウム・セルロリティカスに由来する特定のエンドグルカナーゼ及びβ−グルコシターゼを組換えタンパク質として効率良く生産するために必要なDNAを得ることができ、また、これらセルラーゼ成分を効率良く発現する組換え微生物を得ることができる。更に、得られた組換え微生物を培養することにより、効率よく安価に特定のエンドグルカナーゼ及びβ−グルコシターゼを生産することができる。
【0012】
また本発明により、アクレモニウム・セルロリティカスのゲノムより特定のエンドグルカナーゼ及びβ−グルコシターゼ遺伝子を欠損させることができ、その結果、これらのエンドグルカナーゼ及びβ−グルコシターゼが含まれていないセルラーゼを生産する組換えアクレモニウム・セルロリティカスを得て、特定のエンドグルカナーゼ及びβ−グルコシターゼセルラーゼが含まれていないセルラーゼを生産することができる。
【0013】
本発明で得られる様々なセルラーゼの中から、最適なセルラーゼ群を選択し、セルロース系基質を処理することにより、これらセルロース系基質を効率的かつ安価に分解することができる。
【発明を実施するための最良の形態】
【0014】
エンドグルカナーゼ及びβ−グルコシターゼ
本発明のタンパク質であるエンドグルカナーゼ及びβ−グルコシターゼは、配列番号2、4、6、8、10、12、14、16、18から選択されるアミノ酸配列における成熟タンパク質部分に対応する配列を含むか、あるいは、該アミノ酸配列と実質的に同等なアミノ酸配列を含むことができる。
【0015】
本発明において「実質的に同等なアミノ酸配列」とは、例えば、1つ若しくは複数個(好ましくは数個)のアミノ酸の置換、欠失、及び/又は付加による改変を有するが、ポリペプチドの活性に影響を受けないアミノ酸配列や、70%以上の同一性を有するが、ポリペプチドの活性に影響を受けないアミノ酸配列を意味する。
【0016】
改変されるアミノ酸残基の数は、好ましくは1〜40個、より好ましくは1〜数個、更に好ましくは1〜8個、最も好ましくは1〜4個である。本発明でいう「活性に影響を与えない改変」の例としては、保存的置換が挙げられる。「保存的置換」とは、ポリペプチドの活性を実質的に変化しないように1若しくは複数個のアミノ酸残基を、別の化学的に類似したアミノ酸残基で置き換えることを意味する。例えば、ある疎水性アミノ酸残基を別の疎水性アミノ酸残基によって置換する場合、ある極性アミノ酸残基を同じ電荷を有する別の極性アミノ酸残基によって置換する場合などが挙げられる。このような置換を行うことができる機能的に類似したアミノ酸は、アミノ酸毎に当該技術分野において公知である。具体例を挙げると、非極性(疎水性)アミノ酸としては、アラニン、バリン、イソロイシン、ロイシン、プロリン、トリプトファン、フェニルアラニン、メチオニン等が挙げられる。極性(中性)アミノ酸としては、グリシン、セリン、スレオニン、チロシン、グルタミン、アスパラギン、システイン等が挙げられる。陽電荷をもつ(塩基性)アミノ酸としては、アルギニン、ヒスチジン、リジン等が挙げられる。また、負電荷をもつ(酸性)アミノ酸としては、アスパラギン酸、グルタミン酸等が挙げられる。
【0017】
本明細書における「同一性(identity)」とは、当業者に公知の相同性検索プログラムであるFASTA3[Science,227,1435−1441(1985);Proc.Natl.Acad.Sci.USA,85,2444−2448(1988);http://www.ddbj.nig.ac.jp/E−mail/homology−j.html]においてデフォルト(初期設定)のパラメータを用いて算出される数値である。前記同一性としては、好ましくは80%以上の同一性、より好ましくは90%以上の同一性、更に好ましくは95%以上の同一性、更に好ましくは98%以上の同一性、特に好ましくは99%以上の同一性であることができる。
【0018】
本発明のタンパク質は、成熟タンパク質部分に対応する各アミノ酸配列、又はそれらと実質的に同等なアミノ酸配列のN末端及び/又はC末端に、酵素活性に影響を与えない範囲で、任意のポリペプチド配列を付与することができる。このようなポリペプチド配列としては、例えば、シグナル配列、検出用マーカー(例えば、FLAGタグ)、精製用ポリペプチド[例えば、グルタチオンS−トランスフェラーゼ(GST)]を挙げることができる。
【0019】
エンドグルカナーゼ及びβ−グルコシターゼ遺伝子
本発明のポリヌクレオチドであるエンドグルカナーゼ及びβ−グルコシターゼ遺伝子は、前記の本発明のタンパク質をコードする塩基配列を含むことができ、また、配列番号1に記載の塩基配列の136〜1437番の配列、配列番号3に記載の塩基配列の128〜1615番の配列、配列番号5に記載の塩基配列の169〜1598番の配列、配列番号7に記載の塩基配列の70〜1376番の配列、配列番号9に記載の塩基配列の141〜974番の配列、配列番号11に記載の塩基配列の114〜1230番の配列、配列番号13に記載の塩基配列の124〜1143番の配列、配列番号15に記載の塩基配列の238〜1887番の配列、配列番号17に記載の塩基配列の66〜1765番の配列から選択される塩基配列、あるいは、該塩基配列とストリンジェントな条件下でハイブリダイズ可能な塩基配列を含むことができる。
本発明において「ストリンジェントな条件」とは、ハイブリダイゼーション後のメンブレンの洗浄操作を、高温度低塩濃度溶液中で行うことを意味し、例えば、2×SSC濃度(1×SSC:15mmol/Lクエン酸3ナトリウム、150mmol/L塩化ナトリウム)、0.5%SDS溶液中で、60℃、20分間の洗浄条件を意味する。
【0020】
エンドグルカナーゼ及びβ−グルコシターゼ遺伝子の取得
本発明のエンドグルカナーゼ及びβ−グルコシターゼ遺伝子は、例えば、以下の方法によりアクレモニウム・セルロリティカス又はその変異株から単離することができる。また、本発明に開示するように塩基配列が明らかとなっているため、人工的に化学合成することも可能である。
【0021】
アクレモニウム・セルロリティカスの菌体から、慣行法によりゲノムDNAを抽出する。このゲノムDNAを適当な制限酵素にて消化後、適当なベクターと連結することにより、アクレモニウム・セルロリティカスのゲノムDNAライブラリーを作製する。ベクターとしては、例えば、プラスミドベクター、ファージベクター、コスミドベクター、BACベクター等、多様なものが使用できる。
【0022】
次に、本明細書において開示したエンドグルカナーゼ及びβ−グルコシターゼ遺伝子の塩基配列に基づいて適当なプローブを作成し、ゲノムDNAライブラリーからハイブリダイゼーションによって所望のエンドグルカナーゼ及びβ−グルコシターゼ遺伝子を含むDNA断片を単離することができる。また、本明細書において開示したエンドグルカナーゼ及びβ−グルコシターゼ遺伝子の塩基配列に基づいて所望の遺伝子を増幅させるためのプライマーを作成し、アクレモニウム・セルロリティカスのゲノムDNAを鋳型としてPCRを実施し、増幅したDNA断片を適当なベクターと連結することにより所望の遺伝子を単離することができる。更に、本発明によるエンドグルカナーゼ及びβ−グルコシターゼ遺伝子は、プラスミドpACC3、pACC5、pACC6、pACC7、pACC8、pACC9、pACC10、pBGLC、及びプラスミドpBGLDに含まれていることから、これらをPCRの鋳型DNAとして利用することが可能である。また、これらプラスミドから適当な制限酵素にて所望のDNA断片を調製することができる。
【0023】
微生物の寄託
pACC3で形質転換された大腸菌(Escherichia coli TOP10/pACC3)は、平成20(2008)年10月9日付で独立行政法人産業技術総合研究所特許生物寄託センター(〒305−8566日本国茨城県つくば市東1丁目1番地1中央第6)に国際寄託された。受託番号は、FERM BP−11029である。
pACC5で形質転換された大腸菌(Escherichia coli TOP10/pACC5)は、平成20(2008)年10月9日付で独立行政法人産業技術総合研究所特許生物寄託センター(〒305−8566日本国茨城県つくば市東1丁目1番地1中央第6)に国際寄託された。受託番号は、FERM BP−11030である。
pACC6で形質転換された大腸菌(Escherichia coli TOP10/pACC6)は、平成20(2008)年10月9日付で独立行政法人産業技術総合研究所特許生物寄託センター(〒305−8566日本国茨城県つくば市東1丁目1番地1中央第6)に国際寄託された。受託番号は、FERM BP−11031である。
pACC7で形質転換された大腸菌(Escherichia coli TOP10/pACC7)は、平成20(2008)年10月9日付で独立行政法人産業技術総合研究所特許生物寄託センター(〒305−8566日本国茨城県つくば市東1丁目1番地1中央第6)に国際寄託された。受託番号は、FERM BP−11032である。
pACC8で形質転換された大腸菌(Escherichia coli TOP10/pACC8)は、平成20(2008)年10月9日付で独立行政法人産業技術総合研究所特許生物寄託センター(〒305−8566日本国茨城県つくば市東1丁目1番地1中央第6)に国際寄託された。受託番号は、FERM BP−11033である。
pACC9で形質転換された大腸菌(Escherichia coli TOP10/pACC9)は、平成20(2008)年10月9日付で独立行政法人産業技術総合研究所特許生物寄託センター(〒305−8566日本国茨城県つくば市東1丁目1番地1中央第6)に国際寄託された。受託番号は、FERM BP−11034である。
pACC10で形質転換された大腸菌(Escherichia coli TOP10/pACC10)は、平成20(2008)年10月9日付で独立行政法人産業技術総合研究所特許生物寄託センター(〒305−8566日本国茨城県つくば市東1丁目1番地1中央第6)に国際寄託された。受託番号は、FERM BP−11035である。
pBGLCで形質転換された大腸菌(Escherichia coli TOP10/pBGLC)は、平成20(2008)年10月9日付で独立行政法人産業技術総合研究所特許生物寄託センター(〒305−8566日本国茨城県つくば市東1丁目1番地1中央第6)に国際寄託された。受託番号は、FERM BP−11036である。
pBGLDで形質転換された大腸菌(Escherichia coli TOP10/pBGLD)は、平成20(2008)年10月9日付で独立行政法人産業技術総合研究所特許生物寄託センター(〒305−8566日本国茨城県つくば市東1丁目1番地1中央第6)に国際寄託された。受託番号は、FERM BP−11037である。
【0024】
発現ベクター及び形質転換された微生物
本発明においては、前記の配列番号2、4、6、8、10、12、14、16、18に記載されるアミノ酸配列、又はその改変アミノ酸配列をコードする塩基配列を含むDNA(以下、単に「本発明によるDNA配列」という)を、宿主微生物内で複製可能で、かつ、そのDNA配列がコードするタンパク質を発現可能な状態で含む発現ベクターが提供される。本発現ベクターは、自己複製ベクター、すなわち、染色体外の独立体として存在し、その複製が染色体の複製に依存しない、例えば、プラスミドを基本に構築することができる。また、本発現ベクターは、宿主微生物に導入されたとき、その宿主微生物のゲノム中に組み込まれ、それが組み込まれた染色体と一緒に複製されるものであってもよい。本発明によるベクター構築の手順及び方法は、遺伝子工学の分野で慣用されているものを用いることができる。
【0025】
本発明による発現ベクターは、これを実際に宿主微生物に導入して所望の活性を有するタンパク質を発現させるために、前記の本発明によるDNA配列の他に、その発現を制御するDNA配列や微生物を選択するための遺伝子マーカー等を含んでいるのが望ましい。発現を制御するDNA配列としては、プロモーター及びターミネーター及びシグナルペプチドをコードするDNA配列等がこれに含まれる。プロモーターは宿主微生物において転写活性を示すものであれば特に限定されず、宿主微生物と同種若しくは異種のいずれかのタンパク質をコードする遺伝子の発現を制御するDNA配列として得ることができる。また、シグナルペプチドは、宿主微生物において、タンパク質の分泌に寄与するものであれば特に限定されず、宿主微生物と同種若しくは異種のいずれかのタンパク質をコードする遺伝子から誘導されるDNA配列より得ることができる。また、本発明における遺伝子マーカーは、形質転換体の選択の方法に応じて適宜選択されてよいが、例えば薬剤耐性をコードする遺伝子、栄養要求性を相補する遺伝子を利用することができる。
【0026】
更に、本発明によれば、この発現ベクターによって形質転換された微生物が提供される。この宿主−ベクター系は特に限定されず、例えば、大腸菌、放線菌、酵母、糸状菌などを用いた系、及び、それらを用いた他のタンパク質との融合タンパク質発現系などを用いることができる。
また、この発現ベクターによる微生物の形質転換も、この分野で慣用されている方法に従い実施することができる。
更に、この形質転換体を適当な培地で培養し、その培養物から上記の本発明によるタンパク質を単離して得ることができる。従って、本発明の別の態様によれば、前記の本発明による新規タンパク質の製造方法が提供される。形質転換体の培養及びその条件は、使用する微生物についてのそれと本質的に同等であってよい。また、形質転換体を培養した後、目的のタンパク質を回収する方法は、この分野で慣用されているものを用いることができる。
【0027】
また、本発明における好ましい態様によれば、本発明によるDNA配列によってコードされるエンドグルカナーゼ及びβ−グルコシターゼ酵素を発現させ得る酵母細胞が提供される。本発明における酵母細胞としては、例えばサッカロミセス(Saccharomyces)属、ハンゼヌラ(Hansenula)属、又はピキア(Pichia)属に属する微生物、例えばサッカロミセス・セレビシエ(Saccharomyces cerevisiae)が挙げられる。
本発明における宿主糸状菌は、フミコーラ(Humicola)属、アスペルギルス(Aspergillus)属又はトリコデルマ(Trichoderma)属、フザリウム(Fusarium)属、又はアクレモニウム(Acremonium)属に属するものであることができる。更にそれらの好ましい例としては、フミコーラ・インソレンス(Humicola insolens)、アスペルギルス・ニガー(Aspergillus niger)若しくはアスペルギルス・オリゼー(Aspergillus oryzae)、又はトリコデルマ・ビリデ(Trichoderma viride)、フザリウム・オキシスポーラム(Fusarium oxysporum)、又はアクレモニウム・セルロリティカス(Acremonium cellulolyticus)が挙げられる。
【0028】
本発明によるエンドグルカナーゼ及びβ−グルコシターゼ遺伝子を適当なベクターに連結してアクレモニウム・セルロリティカスに導入し、その発現を抑制すること、又はこれら遺伝子について相同組換えを利用して遺伝子破壊を行いその機能を欠損させることにより、特定のエンドグルカナーゼ及びβ−グルコシターゼの発現を抑制することができる。相同組換えを利用した遺伝子破壊は慣用の方法に従って実施することができ、遺伝子破壊に用いられるベクターの作成やベクターの宿主への導入は当業者に自明であろう。
【0029】
セルラーゼの調製
こうして得られた形質転換体を適当な培地で培養し、その培養物から上記した本発明のタンパク質を単離して得ることができる。形質転換体の培養及びその条件は、使用する微生物に応じて適宜に設定すればよい。また、培養液からの目的とするタンパク質の回収、精製も常法に従って行うことができる。
【0030】
セルラーゼ調製物
本発明の別の態様によれば、上記の本発明によるタンパク質(セルラーゼ)を含むセルラーゼ調製物が提供される。本発明によるセルラーゼ調製物は、本発明によるセルラーゼに、一般的に含まれる成分、例えば賦形剤(例えば、乳糖、塩化ナトリウム、ソルビトール等)、界面活性剤、防腐剤等とともに混合され製造されてもよい。また、本発明におけるセルラーゼ調製物はいずれか適当な形状、例えば粉末又は液体状に調製することができる。
【0031】
セルラーゼの用途
本発明によれば、バイオマス糖化について本発明のセルラーゼ酵素(群)又はセルラーゼ調製物による処理で有意に糖化を改善できるものと考えられる。従って、本発明によれば、バイオマス糖化の改善方法であって、本発明のセルラーゼ酵素(群)又はセルラーゼ調製物でバイオマスを処理する工程を含む方法が提供される。本発明で処理できるバイオマスの例としては、稲わら、バガス、コーンストーバー、椰子の実などの果実の絞りかす、廃木材、並びにこれらに適切な前処理を施した材料が挙げられる。
【0032】
更に本発明によれば、着色セルロース含有繊維の澄明化をもたらす方法であって、セルラーゼ酵素(群)又はセルラーゼ調製物で着色セルロース含有繊維を処理する工程を含む方法、並びに、着色セルロース含有繊維の色の局所的な変化をもたらす方法、すなわち、着色セルロース含有繊維にストーンウオッシュの外観を与える方法が提供される。そして、この方法は、本発明のエンドグルカナーゼ酵素又はセルラーゼ調製物により着色セルロース含有繊維を処理する工程を含む。
【0033】
また、本発明によれば、紙パルプのろ水性が、強度の著しい低下を伴うことなく、本発明によるエンドグルカナーゼ酵素による処理で有意に改善できるものと考えられる。従って、本発明によれば、パルプのろ水性の改善方法であって、本発明のエンドグルカナーゼ酵素又はセルラーゼ調製物で紙パルプを処理する工程を含む方法が提供される。本発明で処理できるパルプの例としては、古紙パルプ、再循環板紙パルプ、クラフトパルプ、亜硫酸パルプ又は加工熱処理及び他の高収率パルプが挙げられる。
【0034】
更に、本発明によるエンドグルカナーゼを動物飼料中で用いることにより、飼料中のグルカンの消化能を改善することができる。従って、本発明によれば、動物飼料の消化能を改善する方法であって、本発明のエンドグルカナーゼ酵素又はセルラーゼ調製物で動物飼料を処理する工程を含む方法が提供される。
【実施例】
【0035】
本発明を実施例により更に具体的に説明するが、本発明はその要旨を越えない限り以下の実施例に限定されるものではない。
【0036】
《実施例1:ACC3遺伝子のクローニング》
(1-1)ゲノムDNAの単離
アクレモニウム・セルロリティカス(Acremonium cellulolyticus)ACCP-5-1株を(s)培地(2%ブイヨン、0.5%イーストエキス及び2%グルコース)で32℃にて2日間培養し、遠心分離により菌体を回収した。得られた菌体より、堀内らの方法(H.Horiuchi et. al., J.Bacteriol., 170, 272-278, (1988))に従いゲノムDNAを単離した。
【0037】
(1-2)ACC3遺伝子断片の取得
Glycoside Hydrolase family 5に分類される既知のエンドグルカナーゼの配列を基に以下のプライマーを作製した。
ACC3-F:GGGCGTCTGTRTTYGARTGT(配列番号:19)
ACC3-R:AAAATGTAGTCTCCCCACCA(配列番号:20)
【0038】
ACC3-F及びACC3-Rをプライマーとして使用し、ゲノムDNAを鋳型としてPCRを行った。PCRはLA taqポリメラーゼ(タカラバイオ社製)を用いて実施した。PCRは94℃で30秒、アニールを30秒、72℃で1分間を40サイクル実施するプログラムで実施したが、アニール温度は最初の20サイクルで63℃から53℃へ段階的に低下させ、その後の20サイクルにおいては53℃に固定した。増幅された1kbpのDNA断片を、TOPO TAクローニングキット(インビトロジェン社製)により、添付のプロトコールに従ってpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドTOPO-pACC3-partialを得た。
【0039】
プラスミドTOPO-pACC3-partialにクローニングされた挿入DNA断片のシークエンスはBigDye Terminator v3.1 Cycle Sequebcing Kit(アプライドバイオシステムズ社製)とABI PRISMジェネティックアナライザー(アプライドバイオシステムズ社製)を用いて、添付のプロトコールに従って行った。その結果得られた塩基配列をアミノ酸配列に翻訳し、そのアミノ酸配列をホモロジー検索した結果、タラロマイセス・エメルソニ(Talaromyces emersonii)由来のエンドグルカナーゼEG1(Q8WZD7)と74%の同一性を示したため、本DNA断片をエンドグルカナーゼ(Glycoside Hydrolase family 5)遺伝子の一部であると判断した。
【0040】
(1-3)インバースPCR法によるACC3遺伝子全長の取得
インバースPCR法はTrigliaらの方法(T Triglia et. al., Nucleic Acids Research, 16, 8186, (1988))に従い実施した。アクレモニウム・セルロリティカスのゲノムDNAをSalIで一晩消化し、Mighty Mix(タカラバイオ社製)を用いて環状DNAを作製した。本環状DNAをテンプレートに、ACC3遺伝子断片に含まれる下記の配列によりPCRを実施し、ACC3遺伝子の5’上流領域並びに3’下流領域を取得した。
ACC3-inv-F:ACTTCCAGACTTTCTGGTCC(配列番号:21)
ACC3-inv-R:AGGCCGAGAGTAAGTATCTC(配列番号:22)
上記5’上流領域並びに3’下流領域を実施例1-2に記載の方法により解析し、ACC3遺伝子の全長塩基配列を決定した。
インバースPCR法により得た塩基配列を基に以下のプライマーを作製し、ゲノムDNAをテンプレートにPCRを実施し、ACC3遺伝子を増幅した。
pACC3-F:GAAGGATGGTAGATTGTCCG(配列番号:23)
pACC3-R:ACCGAGAAGGATTTCTCGCA(配列番号:24)
増幅されたDNAをTOPO TAクローニングキット(インビトロジェン社製)によりpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドpACC3を得た。得られたプラスミドpACC3により大腸菌(Escherichia coli)TOP10株(インビトロジェン社製)を形質転換することによりEscherichia coli TOP10株/pACC3を得た。
【0041】
(1-4)cDNAの作製並びにACC3遺伝子のイントロン解析
アクレモニウム・セルロリティカスACCP-5-1株をセルラーゼ誘導培地で32℃にて2日間培養し、遠心分離により菌体を回収した。得られた菌体を液体窒素で凍結後、乳鉢と乳棒を用いて磨砕した。この磨砕した菌体からISOGEN(ニッポンジーン社)により、添付のプロトコールに従い全RNAを単離した。更に全RNAから、mRNA Purification Kit(ファルマシア社)により、添付のプロトコールに従い、mRNAを精製した。
【0042】
こうして得られたmRNAから、TimeSaver cDNA Synthesis Kit(ファルマシア社)により、添付のプロトコールに従い、cDNAを合成した。ACC3遺伝子配列から開始コドン並びに終始コドンを含む下記のプライマーを作製し、cDNAをテンプレートにPCRを実施し、ACC3 cDNA遺伝子を増幅した。
ACC3-N:ATGAAGACCAGCATCATTTCTATC(配列番号:25)
ACC3-C:TCATGGGAAATAACTCTCCAGAAT(配列番号:26)
上記ACC3 cDNA遺伝子を実施例1-2に記載の方法により解析し、pACC3遺伝子と比較することでイントロンの位置を決定した。
【0043】
(1-5)ACC3のアミノ酸配列の推定
上記の方法によりアクレモニウム・セルロリティカスより単離されたエンドグルカナーゼACC3遺伝子は配列番号1に記載の塩基配列の136〜1437番に示された1302bpの塩基からなっていた。また、本ACC3遺伝子は配列番号1に記載の塩基配列の233〜291番、351〜425番、579〜631番、697〜754番、及び853〜907番に示される5つのイントロンが含まれていることが示された。オープンリーディングフレーム(ORF)から予測されるACC3のアミノ酸配列は配列番号2に示される通りであった。なお、シグナル配列予測ソフトSignalP 3.0により本ACC3の-27〜-1アミノ酸残基までがシグナル配列と推定した。
【0044】
《実施例2:ACC5遺伝子のクローニング》
(2-1)ゲノムDNA並びにmRNAの単離とcDNAの作製
実施例1-1に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のゲノムDNAを単離した。また、実施例1-4に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のcDNAを作製した。
【0045】
(2-2)ACC5遺伝子断片の取得
Glycoside Hydrolase family 7に分類される既知のエンドグルカナーゼのN末端アミノ酸配列並びにポリA塩基配列を基に以下のプライマーを作製した。
ACC5-F:CAGCAGGCCCCCACCCCNGAYAAYYTNGC(配列番号:27)
ACC5-R:AATTCGCGGCCGCTAAAAAAAAA(配列番号:28)
【0046】
ACC5-F及びACC5-Rをプライマーとして使用し、cDNAを鋳型としてPCRを行った。PCRはLA taqポリメラーゼ(タカラバイオ社製)を用いて実施した。PCRは94℃で30秒、アニールを30秒、72℃で1分間を40サイクル実施するプログラムで実施したが、アニール温度は最初の20サイクルで63℃から53℃へ段階的に低下させ、その後の20サイクルにおいては53℃に固定した。増幅された1.5kbpのDNA断片を、TOPO TAクローニングキット(インビトロジェン社製)により、添付のプロトコールに従ってpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドTOPO-pACC5-partialを得た。
【0047】
プラスミドTOPO-pACC5-partialにクローニングされた挿入DNA断片の塩基配列を解析し、得られた塩基配列をアミノ酸配列に翻訳し、そのアミノ酸配列をホモロジー検索した結果、アスペルギルス・フミガタス(Aspergillus fumigatus)由来のエンドグルカナーゼ(Q4WCM9)と60%の同一性を示したため、本DNA断片をエンドグルカナーゼ(Glycoside Hydrolase family 7)遺伝子の一部であると判断した。
【0048】
(2-3)インバースPCR法によるACC5遺伝子全長の取得
実施例1-3に記載の方法で、HindIIIで消化した環状DNAをテンプレートに、ACC5遺伝子断片に含まれる下記の配列によりPCRを実施し、ACC5遺伝子の5’上流領域並びに3’下流領域を取得した。
ACC5-inv-F:ATCTCACCTGCAACCTACGA(配列番号:29)
ACC5-inv-R:CCTCTTCCGTTCCACATAAA(配列番号:30)
上記5’上流領域並びに3’下流領域の塩基配列を解析し、ACC5遺伝子の全長塩基配列を決定した。
インバースPCR法により得た塩基配列を基に以下のプライマーを作製し、ゲノムDNAをテンプレートにPCRを実施し、ACC5遺伝子を増幅した。
pACC5-F:ATTGCTCCGCATAGGTTCAA(配列番号:31)
pACC5-R:TTCAGAGTTAGTGCCTCCAG(配列番号:32)
増幅されたDNAをTOPO TAクローニングキット(インビトロジェン社製)によりpCR2.1-TOPO プラスミドベクターに挿入し、プラスミドpACC5を得た。得られたプラスミドpACC5により大腸菌(Escherichia coli)TOP10株(インビトロジェン社製)を形質転換することによりEscherichia coli TOP10株/pACC5を得た。
【0049】
(2-4)ACC5遺伝子のイントロン解析
ACC5遺伝子配列から開始コドン並びに終始コドンを含む下記のプライマーを作製し、cDNAをテンプレートにPCRを実施し、ACC5 cDNA遺伝子を増幅した。
ACC5-N:ATGGCGACTAGACCATTGGCTTTTG(配列番号:33)
ACC5-C:CTAAAGGCACTGTGAATAGTACGGA(配列番号:34)
上記ACC5 cDNA遺伝子の塩基配列を解析し、pACC5遺伝子と比較することでイントロンの位置を決定した。
【0050】
(2-5)ACC5のアミノ酸配列の推定
上記の方法によりアクレモニウム・セルロリティカスより単離されたエンドグルカナーゼACC5遺伝子は配列番号3に記載の塩基配列の128〜1615番に示された1488bpの塩基からなっていた。オープンリーディングフレーム(ORF)から予測されるACC5のアミノ酸配列は配列番号4に示される通りであった。なお、シグナル配列予測ソフトSignalP 3.0により本ACC5の-20〜-1アミノ酸残基までがシグナル配列と推定した。
【0051】
《実施例3:ACC6遺伝子のクローニング》
(3-1)ゲノムDNAの単離とゲノムライブラリーの作製
実施例1-1に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のゲノムDNAを単離した。単離したゲノムDNAをSau3AIにより部分消化した。これをファージベクター・dMBL3クローニングキット(ストラタジーン社製)のBamHIアームに、ライゲーションキットVer.2(宝酒造社製)を用いて連結させた。これをエタノール沈殿後、TE緩衝液に溶解した。連結混合物をMaxPlaxλpackerging kit(エピセンターテクノロジー社製)を用い、ファージ粒子を形成させ、大腸菌XL1-blue MRA(P2)株に感染させた。この方法により1.1 X 104個のファージから成るゲノムDNAライブラリーが得られた。
【0052】
(3-2)ACC6遺伝子断片の取得
Glycoside Hydrolase family 5に分類される既知のエンドグルカナーゼの配列を基に以下のプライマーを作製した。
ACC6-F:GTGAACATCGCCGGCTTYGAYTTYGG(配列番号:35)
ACC6-R:CCGTTCCACCGGGCRTARTTRTG(配列番号:36)
【0053】
ACC6-F及びACC6-Rをプライマーとして使用し、ゲノムDNAを鋳型としてPCRを行った。PCRはLA taqポリメラーゼ(タカラバイオ社製)を用いて実施した。PCRは94℃で30秒、アニールを30秒、72℃で1分間を40サイクル実施するプログラムで実施したが、アニール温度は最初の20サイクルで63℃から53℃へ段階的に低下させ、その後の20サイクルにおいては53℃に固定した。増幅された300bpのDNA断片を、TOPO TAクローニングキット(インビトロジェン社製)により、添付のプロトコールに従ってpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドTOPO-pACC6-partialを得た。
【0054】
プラスミドTOPO-pACC6-partialにクローニングされた挿入DNA断片の塩基配列を解析し、得られた塩基配列をアミノ酸配列に翻訳し、そのアミノ酸配列をホモロジー検索した結果、トリコデルマ・ビリデ(Trichoderma viride)由来のエンドグルカナーゼEG3(Q7Z7X2)と61%の同一性を示したため、本DNA断片をエンドグルカナーゼ(Glycoside Hydrolase family 5)遺伝子の一部であると判断した。本DNA断片をプラスミドTOPO-pACC6-partialを鋳型として上記と同様の方法でPCRに増幅し、得られたPCR産物はECLダイレクトシステム(アマシャムファルマシアバイオテク社製)を用いて標識しプローブとした。
【0055】
(3-3)プラークハイブリダイゼーションによるスクリーニング
実施例3-1において作成したファージプラークを、ハイボンドN+ナイロントランスファーメンブラン(アマシャム社製)に転写し、アルカリ変性後、5倍濃度SSC(SSC:15mmol/Lクエン酸3ナトリウム、150mmol/L塩化ナトリウム)で洗浄し、乾燥させてDNAを固定した。ハイブリダイゼーションは、1時間のプレハイブリダイゼーション(42℃)の後、HRP標識プローブを添加し、4時間(42℃)ハイブリダイゼーションを行った。プローブの洗浄は6M尿素、0.4%SDS添加0.5倍濃度SSCで2回、2倍濃度SSCで2回行った。
プローブの洗浄を行ったナイロン膜は、検出溶液に1分間浸したあと、同社製ハイパーフィルムECLに感光させ、1個の陽性クローンを得た。陽性クローンからのDNA調製は、Maniatisらの方法(J.Sambrook,E.F.Fritsch and T.Maniat1s,"Molecular Cloning",Cold Spring Harbor Laboratory Press.1989)に従い、宿主大腸菌としてLE392を用いて行った。まず、LE392をLB-MM培地(1%ペプトン、0.5%イーストエキス、0.5%塩化ナトリウム、10mmol/L硫酸マグネシウム、0.2%マルトース)で一晩培養した。これにシングルプラーク由来のファージ溶液を感染させ、LB-MM培地で一晩培養した。これに、塩化ナトリウムを1Mに、そしてクロロホルムを0.8%になるよう加え、大腸菌の溶菌を促進させた。遠心分離により、菌体残渣をのぞき、10%PEG6000による沈澱からファージ粒子を回収した。ファージ粒子はSDS存在下、プロティナーゼKで消化し、これをフェノール処理、エタノール沈澱化によりファージDNAを回収した。
以上のように調製したDNAはECLダイレクトシステムを用い、サザンブロット解析を行った。実施例3-2のPCR増幅断片をプローブにハイブリダイゼーションを行った結果、2.9kbpのXbaI断片が染色体DNAと共通のハイブリダイゼーションパターンを示した。このXbaI断片をpUC118にクローン化し、プラスミドpUC-ACC6を得た後、プラスミドの塩基配列を解析した。
【0056】
(3-4)ACC6遺伝子全長の取得
pUC-ACC6より得た塩基配列を基に以下のプライマーを作製し、ゲノムDNAをテンプレートにPCRを実施し、ACC6遺伝子を増幅した。
pACC6-F:CTCTGCATTGAATCCCGAGA(配列番号:37)
pACC6-R:GCAACGCTAAAGTGCTCATC(配列番号:38)
増幅されたDNAをTOPO TAクローニングキット(インビトロジェン社製)によりpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドpACC6を得た。得られたプラスミドpACC6により大腸菌(Escherichia coli)TOP10株(インビトロジェン社製)を形質転換することによりEscherichia coli TOP10株/pACC6を得た。
【0057】
(3-5)cDNAの作製並びにACC6遺伝子のイントロン解析
実施例1-4に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のcDNAを作製した。ACC6遺伝子配列から開始コドン並びに終始コドンを含む下記のプライマーを作製し、cDNAをテンプレートにPCRを実施し、ACC6 cDNA遺伝子を増幅した。
ACC6-N:ATGACAATCATCTCAAAATTCGGT(配列番号:39)
ACC6-C:TCAGGATTTCCACTTTGGAACGAA(配列番号:40)
上記ACC6 cDNA遺伝子の塩基配列を解析し、pACC6遺伝子と比較することでイントロンの位置を決定した。
【0058】
(3-6)ACC6のアミノ酸配列の推定
上記の方法によりアクレモニウム・セルロリティカスより単離されたエンドグルカナーゼACC6遺伝子は配列番号5に記載の塩基配列の169〜1598番に示された1430bpの塩基からなっていた。また、本ACC6遺伝子は配列番号5に記載の塩基配列の254〜309番、406〜461番、及び1372〜1450番に示される3つのイントロンが含まれていることが示された。オープンリーディングフレーム(ORF)から予測されるACC6のアミノ酸配列は配列番号6に示される通りであった。なお、シグナル配列予測ソフトSignalP 3.0により本ACC6の-21〜-1アミノ酸残基までがシグナル配列と推定した。
【0059】
《実施例4:ACC7遺伝子のクローニング》
(4-1)ゲノムDNAの単離とゲノムライブラリーの作製
実施例3-1に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のゲノムDNAライブラリーを調製した。
【0060】
(4-2)ACC7遺伝子断片の取得
Glycoside Hydrolase family 5に分類される既知のエンドグルカナーゼの配列を基に以下のプライマーを作製した。
ACC7-F:CACGCCATGATCGACCCNCAYAAYTAYG(配列番号:41)
ACC7-R:ACCAGGGGCCGGCNGYCCACCA(配列番号:42)
【0061】
ACC7-F及びACC7-Rをプライマーとして使用し、ゲノムDNAを鋳型としてPCRを行った。PCRはLA taqポリメラーゼ(タカラバイオ社製)を用いて実施した。PCRは94℃で30秒、アニールを30秒、72℃で1分間を40サイクル実施するプログラムで実施したが、アニール温度は最初の20サイクルで63℃から53℃へ段階的に低下させ、その後の20サイクルにおいては53℃に固定した。増幅された670bpのDNA断片を、TOPO TAクローニングキット(インビトロジェン社製)により、添付のプロトコールに従ってpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドTOPO-pACC7-partialを得た。
【0062】
プラスミドTOPO-pACC7-partialにクローニングされた挿入DNA断片の塩基配列を解析し、得られた塩基配列をアミノ酸配列に翻訳し、そのアミノ酸配列をホモロジー検索した結果、アスペルギルス・フミガタス(Aspergillus fumigatus)由来のエンドグルカナーゼ(Q4WM09)と63%の同一性を示したため、本DNA断片をエンドグルカナーゼ(Glycoside Hydrolase family 5)遺伝子の一部であると判断した。本DNA断片をプラスミドTOPO-pACC7-partialを鋳型として上記と同様の方法でPCRに増幅し、得られたPCR産物はECLダイレクトシステム(アマシャムファルマシアバイオテク社製)を用いて標識しプローブとした。
【0063】
(4-3)プラークハイブリダイゼーションによるスクリーニング
実施例3-3の記載の方法で、ゲノムDNAライブラリーをスクリーニングした結果、1個の陽性クローンを得た。得られた陽性クローンについてサザンブロット解析を行った結果、3.7kbpのXbaI断片が染色体DNAと共通のハイブリダイゼーションパターンを示した。このXbaI断片をpUC118にクローン化し、プラスミドpUC-ACC7を得た後、プラスミドの塩基配列を解析した。
【0064】
(4-4)ACC7遺伝子全長の取得
pUC-ACC7より得た塩基配列を基に以下のプライマーを作製し、ゲノムDNAをテンプレートにPCRを実施し、ACC7遺伝子を増幅した。
pACC7-F:CAGTCAGTTGTGTAGACACG(配列番号:43)
pACC7-R:ACTCAGCTGGGTCTTCATAG(配列番号:44)
増幅されたDNAをTOPO TAクローニングキット(インビトロジェン社製)によりpCR2.1-TOPO プラスミドベクターに挿入し、プラスミドpACC7を得た。得られたプラスミドpACC7により大腸菌(Escherichia coli)TOP10株(インビトロジェン社製)を形質転換することによりEscherichia coli TOP10株/pACC7を得た。
【0065】
(4-5)cDNAの作製並びにACC7遺伝子のイントロン解析
実施例1-4に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のcDNAを作製した。ACC7遺伝子配列から開始コドン並びに終始コドンを含む下記のプライマーを作製し、cDNAをテンプレートにPCRを実施し、ACC7 cDNA遺伝子を増幅した。
ACC7-N:ATGAGGTCTACATCAACATTTGTA(配列番号:45)
ACC7-C:CTAAGGGGTGTAGGCCTGCAGGAT(配列番号:46)
上記ACC7 cDNA遺伝子の塩基配列を解析し、pACC7遺伝子と比較することでイントロンの位置を決定した。
【0066】
(4-6)ACC7のアミノ酸配列の推定
上記の方法によりアクレモニウム・セルロリティカスより単離されたエンドグルカナーゼACC7遺伝子は配列番号7に記載の塩基配列の70〜1376番に示された1307bpの塩基からなっていた。また、本ACC7遺伝子は配列番号7に記載の塩基配列の451〜500番、及び765〜830番に示される2つのイントロンが含まれていることが示された。オープンリーディングフレーム(ORF)から予測されるACC7のアミノ酸配列は配列番号8に示される通りであった。なお、シグナル配列予測ソフトSignalP 3.0により本ACC7の-20〜-1アミノ酸残基までがシグナル配列であると推定した。
【0067】
《実施例5:ACC8遺伝子のクローニング》
(5-1)ゲノムDNAの単離とゲノムライブラリーの作製
実施例3-1に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のゲノムDNAライブラリーを調製した。
【0068】
(5-2)ACC8遺伝子断片の取得
ペニシリウム・ベルクロッサム(Penicillium verruculosum)由来のエンドグルカナーゼIIIのN末端、C末端のアミノ酸配列に対応するDNA配列に基づき、以下のプライマーを作製した。
MSW-N:CAACAGAGTCTATGCGCTCAATACTCGAGCTACACCAGT(配列番号:47)
MSW-C:CTAATTGACAGCTGCAGACCAA(配列番号:48)
【0069】
MSW-N及びMSW-Cをプライマーとして使用し、ゲノムDNAを鋳型としてPCRを行った。PCRはLA taqポリメラーゼ(タカラバイオ社製)を用いて実施した。PCRは94℃で30秒、アニールを30秒、72℃で1分間を40サイクル実施するプログラムで実施したが、アニール温度は最初の20サイクルで63℃から53℃へ段階的に低下させ、その後の20サイクルにおいては53℃に固定した。増幅された800bpのDNA断片を、TOPO TAクローニングキット(インビトロジェン社製)により、添付のプロトコールに従ってpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドTOPO-pACC8-partialを得た。
【0070】
プラスミドTOPO-pACC8-partialにクローニングされた挿入DNA断片の塩基配列を解析し、得られた塩基配列をアミノ酸配列に翻訳し、そのアミノ酸配列をホモロジー検索した結果、トリコデルマ・ビリデ(Trichoderma viride)由来のエンドグルカナーゼCel12A(Q8NJY4)と60%の同一性を示したため、本DNA断片をエンドグルカナーゼ(Glycoside Hydrolase family 12)遺伝子の一部であると判断した。本DNA断片をプラスミドTOPO-pACC8-partialを鋳型として上記と同様の方法でPCRに増幅し、得られたPCR産物はECLダイレクトシステム(アマシャムファルマシアバイオテク社製)を用いて標識しプローブとした。
【0071】
(5-3)プラークハイブリダイゼーションによるスクリーニング
実施例3-3の記載の方法で、ゲノムDNAライブラリーをスクリーニングした結果、1個の陽性クローンを得た。得られた陽性クローンについてサザンブロット解析を行った結果、約5kbpのSalI断片が染色体DNAと共通のハイブリダイゼーションパターンを示した。このSalI断片をpUC118にクローン化し、プラスミドpUC-ACC8を得た後、プラスミドの塩基配列を解析した。
【0072】
(5-4)ACC8遺伝子全長の取得
pUC-ACC8より得た塩基配列を基に以下のプライマーを作製し、ゲノムDNAをテンプレートにPCRを実施し、ACC8遺伝子を増幅した。
pACC8-F:AAAGACCGCGTGTTAGGATC(配列番号:49)
pACC8-R:CGCGTAGGAAATAAGACACC(配列番号:50)
増幅されたDNAをTOPO TAクローニングキット(インビトロジェン社製)によりpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドpACC8を得た。得られたプラスミドpACC8により大腸菌(Escherichia coli)TOP10株(インビトロジェン社製)を形質転換することによりEscherichia coli TOP10株/pACC8を得た。
【0073】
(5-5)cDNAの作製並びにACC8遺伝子のイントロン解析
実施例1-4に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のcDNAを作製した。ACC8遺伝子配列から開始コドン並びに終始コドンを含む下記のプライマーを作製し、cDNAをテンプレートにPCRを実施し、ACC8 cDNA遺伝子を増幅した。
ACC8-N:ATGAAGCTAACTTTTCTCCTGAAC(配列番号:51)
ACC8-C:CTAATTGACAGATGCAGACCAATG(配列番号:52)
上記ACC8 cDNA遺伝子の塩基配列を解析し、pACC8遺伝子と比較することでイントロンの位置を決定した。
【0074】
(5-6)ACC8のアミノ酸配列の推定
上記の方法によりアクレモニウム・セルロリティカスより単離されたエンドグルカナーゼACC8遺伝子は配列番号9に記載の塩基配列の141〜974番に示された834bpの塩基からなっていた。また、本ACC8遺伝子は配列番号9に記載の塩基配列の551〜609番、及び831〜894番に示される2つのイントロンが含まれていることが示された。オープンリーディングフレーム(ORF)から予測されるACC8のアミノ酸配列は配列番号10に示される通りであった。なお、シグナル配列予測ソフトSignalP 3.0により本ACC8の-15〜-1アミノ酸残基までがシグナル配列であると推定した。
【0075】
《実施例6:ACC9遺伝子のクローニング》
(6-1)ゲノムDNA並びにmRNAの単離とcDNAの作製
実施例1-1に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のゲノムDNAを単離した。また、実施例1-4に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のcDNAを作製した。
【0076】
(6-2)ACC9遺伝子断片の取得
Glycoside Hydrolase family 45に分類される既知のエンドグルカナーゼの配列を基に以下のプライマーを作製した。
ACC9-F:CCGGCTGCGGCAARTGYTAYMA(配列番号:53)
ACC9-R:AGTACCACTGGTTCTGCACCTTRCANGTNSC(配列番号:54)
【0077】
ACC9-F及びACC9-Rをプライマーとして使用し、ゲノムDNAを鋳型としてPCRを行った。PCRはLA taqポリメラーゼ(タカラバイオ社製)を用いて実施した。PCRは94℃で30秒、アニールを30秒、72℃で1分間を40サイクル実施するプログラムで実施したが、アニール温度は最初の20サイクルで63℃から53℃へ段階的に低下させ、その後の20サイクルにおいては53℃に固定した。増幅された800bpのDNA断片を、TOPO TAクローニングキット(インビトロジェン社製)により、添付のプロトコールに従ってpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドTOPO-pACC9-partialを得た。
【0078】
プラスミドTOPO-pACC9-partialにクローニングされた挿入DNA断片の塩基配列を解析し、得られた塩基配列をアミノ酸配列に翻訳し、そのアミノ酸配列をホモロジー検索した結果、トリコデルマ・ビリデ(Trichoderma viride)由来のエンドグルカナーゼEGV(Q7Z7X0)と79%の同一性を示したため、本DNA断片をエンドグルカナーゼ(Glycoside Hydrolase family 45)遺伝子の一部であると判断した。
【0079】
(6-3)インバースPCR法によるACC9遺伝子全長の取得
実施例1-3に記載の方法で、SalI又はXbaIで消化した環状DNAをテンプレートに、ACC9遺伝子断片に含まれる下記の配列によりPCRを実施し、ACC9遺伝子の5’上流領域並びに3’下流領域を取得した。
ACC9-inv-F:CGAAGTGTTTGGTGACAACG(配列番号:55)
ACC9-inv-R:GTGGTAGCTGTATCCGTAGT(配列番号:56)
上記5’上流領域並びに3’下流領域の塩基配列を解析し、ACC9遺伝子の全長塩基配列を決定した。
インバースPCR法により得た塩基配列を基に以下のプライマーを作製し、ゲノムDNAをテンプレートにPCRを実施し、ACC9遺伝子を増幅した。
pACC9-F:TACATTCCGAAGGCACAGTT(配列番号:57)
pACC9-R:CTGAGCTGATTATCCTGACC(配列番号:58)
増幅されたDNAをTOPO TAクローニングキット(インビトロジェン社製)によりpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドpACC9を得た。得られたプラスミドpACC9により大腸菌(Escherichia coli)TOP10株(インビトロジェン社製)を形質転換することによりEscherichia coli TOP10株/pACC9を得た。
【0080】
(6-4)ACC9遺伝子のイントロン解析
ACC9遺伝子配列から開始コドン並びに終始コドンを含む下記のプライマーを作製し、cDNAをテンプレートにPCRを実施し、ACC9 cDNA遺伝子を増幅した。
ACC9-N:ATGAAGGCTTTCTATCTTTCTCTC(配列番号:59)
ACC9-C:TTAGGACGAGCTGACGCACTGGTA(配列番号:60)
上記ACC9 cDNA遺伝子の塩基配列を解析し、pACC9遺伝子と比較することでイントロンの位置を決定した。
【0081】
(6-5)ACC9のアミノ酸配列の推定
上記の方法によりアクレモニウム・セルロリティカスより単離されたエンドグルカナーゼACC9遺伝子は配列番号11に記載の塩基配列の114〜1230番に示された1117bpの塩基からなっていた。また、本ACC9遺伝子は配列番号11に記載の塩基配列の183〜232番、及び299〜357番に示される2つのイントロンが含まれていることが示された。オープンリーディングフレーム(ORF)から予測されるACC9のアミノ酸配列は配列番号12に示される通りであった。なお、シグナル配列予測ソフトSignalP 3.0により本ACC9の-16〜-1アミノ酸残基までがシグナル配列であると推定した。
【0082】
《実施例7:ACC10遺伝子のクローニング》
(7-1)ゲノムDNA並びにmRNAの単離とcDNAの作製
実施例1-1に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のゲノムDNAを単離した。また、実施例1-4に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のcDNAを作製した。
【0083】
(7-2)ACC10遺伝子断片の取得
Glycoside Hydrolase family 61に分類される既知のエンドグルカナーゼの配列並びにポリA塩基配列を基に以下のプライマーを作製した。
ACC10-F:GGTGTACGTGGGCACCAAYGGNMGNGG(配列番号:61)
ACC10-R:AATTCGCGGCCGCTAAAAAAAAA(配列番号:62)
【0084】
ACC10-F及びACC10-Rをプライマーとして使用し、cDNAを鋳型としてPCRを行った。PCRはLA taqポリメラーゼ(タカラバイオ社製)を用いて実施した。PCRは94℃で30秒、アニールを30秒、72℃で1分間を40サイクル実施するプログラムで実施したが、アニール温度は最初の20サイクルで63℃から53℃へ段階的に低下させ、その後の20サイクルにおいては53℃に固定した。増幅された300bpのDNA断片を、TOPO TAクローニングキット(インビトロジェン社製)により、添付のプロトコールに従ってpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドTOPO-pACC10-partialを得た。
【0085】
プラスミドTOPO-pACC10-partialにクローニングされた挿入DNA断片の塩基配列を解析し、得られた塩基配列をアミノ酸配列に翻訳し、そのアミノ酸配列をホモロジー検索した結果、アスペルギルス・テレウス(Aspergillus terreus)由来のエンドグルカナーゼEGIV(Q0D0T6)と65%の同一性を示したため、本DNA断片をエンドグルカナーゼ(Glycoside Hydrolase family 61)遺伝子の一部であると判断した。
【0086】
(7-3)インバースPCR法によるACC10遺伝子全長の取得
実施例1-3に記載の方法で、HindIIIで消化した環状DNAをテンプレートに、ACC10遺伝子断片に含まれる下記の配列によりPCRを実施し、ACC5遺伝子の5’上流領域並びに3’下流領域を取得した。
ACC10-inv-F:TTCTGCTACTGCGGTTGCTA(配列番号:63)
ACC10-inv-R:GAATAACGTAGGTCGACAAG(配列番号:64)
上記5’上流領域並びに3’下流領域の塩基配列を解析し、ACC10遺伝子の全長塩基配列を決定した。
インバースPCR法により得た塩基配列を基に以下のプライマーを作製し、ゲノムDNAをテンプレートにPCRを実施し、ACC10遺伝子を増幅した。
pACC10-F:CGTTGACCGAAAGCCACTT(配列番号:65)
pACC10-R:TGGCCTAAAGCTAAATGATG(配列番号:66)
増幅されたDNAをTOPO TAクローニングキット(インビトロジェン社製)によりpCR2.1-TOPO プラスミドベクターに挿入し、プラスミドpACC10を得た。得られたプラスミドpACC10により大腸菌(Escherichia coli)TOP10株(インビトロジェン社製)を形質転換することによりEscherichia coli TOP10株/pACC10を得た。
【0087】
(7-4)ACC10遺伝子のイントロン解析
ACC10遺伝子配列から開始コドン並びに終始コドンを含む下記のプライマーを作製し、cDNAをテンプレートにPCRを実施し、ACC10 cDNA遺伝子を増幅した。
ACC10-N:ATGCCTTCTACTAAAGTCGCTGCCC(配列番号:67)
ACC10-C:TTAAAGGACAGTAGTGGTGATGACG(配列番号:68)
上記ACC10 cDNA遺伝子の塩基配列を解析し、pACC10遺伝子と比較することでイントロンの位置を決定した。
【0088】
(7-5)ACC10のアミノ酸配列の推定
上記の方法によりアクレモニウム・セルロリティカスより単離されたエンドグルカナーゼACC10遺伝子は配列番号13に記載の塩基配列の124〜1143番に示された1020bpの塩基からなっていた。また、本ACC10遺伝子は配列番号13に記載の塩基配列の225〜275番に示される1つのイントロンが含まれていることが示された。オープンリーディングフレーム(ORF)から予測されるACC10のアミノ酸配列は配列番号14に示される通りであった。なお、シグナル配列予測ソフトSignalP 3.0により本ACC10の-21〜-1アミノ酸残基までがシグナル配列であると推定した。
【0089】
《実施例8:BGLC遺伝子のクローニング》
(8-1)ゲノムDNA並びにcDNAの作製
実施例1-1に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のゲノムDNAを単離した。また、実施例1-4に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のcDNAを作製した。
【0090】
(8-2)BGLC遺伝子断片の取得
Glycoside Hydrolase family 1に分類される既知のβ−グルコシダーゼの配列を基に以下のプライマーを作製した。
BGLC-F:CCTGGGTGACCCTGTACCAYTGGGAYYT(配列番号:69)
BGLC-R:TGGGCAGGAGCAGCCRWWYTCNGT(配列番号:70)
【0091】
BGLC-F及びBGLC -Rをプライマーとして使用し、ゲノムDNAを鋳型としてPCRを行った。PCRはLA taqポリメラーゼ(タカラバイオ社製)を用いて実施した。PCRは94℃で30秒、アニールを30秒、72℃で1分間を40サイクル実施するプログラムで実施したが、アニール温度は最初の20サイクルで63℃から53℃へ段階的に低下させ、その後の20サイクルにおいては53℃に固定した。増幅された1.2kbpのDNA断片を、TOPO TAクローニングキット(インビトロジェン社製)により、添付のプロトコールに従ってpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドTOPO-pBGLC-partialを得た。
【0092】
プラスミドTOPO-pBGLC-partialにクローニングされた挿入DNA断片の塩基配列を解析し、得られた塩基配列をアミノ酸配列に翻訳し、そのアミノ酸配列をホモロジー検索した結果、アスペルギルス・フミガタス(Aspergillus fumigatus)由来のβ−グルコシダーゼ1(Q4WRG4)と69%の同一性を示したため、本DNA断片をβ−グルコシダーゼ(Glycoside Hydrolase family 1)遺伝子の一部であると判断した。
【0093】
(8-3)インバースPCR法によるBGLC遺伝子全長の取得
実施例1-3に記載の方法で、XbaIで消化した環状DNAをテンプレートに、BGLC遺伝子断片に含まれる下記の配列によりPCRを実施し、BGLC遺伝子の5’上流領域並びに3’下流領域を取得した。
BGLC-inv-F:GGAGTTCTTCTACATTTCCC(配列番号:71)
BGLC-inv-R:AACAAGGACGGCGTGTCAGT(配列番号:72)
上記5’上流領域並びに3’下流領域の塩基配列を解析し、BGLC遺伝子の全長塩基配列を決定した。
インバースPCR法により得た塩基配列を基に以下のプライマーを作製し、ゲノムDNAをテンプレートにPCRを実施し、BGLC遺伝子を増幅した。
pBGLC-F:CTCCGTCAAGTGCGAAGTAT(配列番号:73)
pBGLC-R:GGCTCGCTAATACTAACTGC(配列番号:74)
増幅されたDNAをTOPO TAクローニングキット(インビトロジェン社製)によりpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドpBGLCを得た。得られたプラスミドpBGLCにより大腸菌(Escherichia coli)TOP10株(インビトロジェン社製)を形質転換することによりEscherichia coli TOP10株/pBGLCを得た。
【0094】
(8-4)BGLC遺伝子のイントロン解析
BGLC遺伝子配列から開始コドン並びに終始コドンを含む下記のプライマーを作製し、cDNAをテンプレートにPCRを実施し、BGLC cDNA遺伝子を増幅した。
BGLC-N:ATGGGCTCTACATCTCCTGCCCAA(配列番号:75)
BGLC-C:CTAGTTCCTCGGCTCTATGTATTT(配列番号:76)
上記BGLC cDNA遺伝子の塩基配列を解析し、pBGLC遺伝子と比較することでイントロンの位置を決定した。
【0095】
(8-5)BGLCのアミノ酸配列の推定
上記の方法によりアクレモニウム・セルロリティカスより単離されたβ−グルコシダーゼBGLC遺伝子は配列番号15に記載の塩基配列の238〜1887番に示された1650bpの塩基からなっていた。また、本BGLC遺伝子は配列番号15に記載の塩基配列の784〜850番、1138〜1205番、及び1703〜1756番に示される3つのイントロンが含まれていることが示された。オープンリーディングフレーム(ORF)から予測されるBGLCのアミノ酸配列は配列番号16に示される通りであった。なお、シグナル配列予測ソフトSignalP 3.0により本BGLCの-28〜-1アミノ酸残基までがシグナル配列であると推定した。
【0096】
《実施例9:BGLD遺伝子のクローニング》
(9-1)ゲノムDNA並びにcDNAの作製
実施例1-1に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のゲノムDNAを単離した。また、実施例1-4に記載の方法で、アクレモニウム・セルロリティカスACCP-5-1株のcDNAを作製した。
【0097】
(9-2)BGLD遺伝子断片の取得
Glycoside Hydrolase family 1に分類される既知のβ−グルコシダーゼの配列を基に以下のプライマーを作製した。
BGLD-F:CACCGCCGCCTACCARRTNGARGG(配列番号:77)
BGLD-R:TGGCGGTGTAGTGGTTCATGSCRWARWARTC(配列番号:78)
【0098】
BGLD-F及びBGLD -Rをプライマーとして使用し、ゲノムDNAを鋳型としてPCRを行った。PCRはLA taqポリメラーゼ(タカラバイオ社製)を用いて実施した。PCRは94℃で30秒、アニールを30秒、72℃で1分間を40サイクル実施するプログラムで実施したが、アニール温度は最初の20サイクルで63℃から53℃へ段階的に低下させ、その後の20サイクルにおいては53℃に固定した。増幅された1kbpのDNA断片を、TOPO TAクローニングキット(インビトロジェン社製)により、添付のプロトコールに従ってpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドTOPO-pBGLD-partialを得た。
【0099】
プラスミドTOPO-pBGLD-partialにクローニングされた挿入DNA断片の塩基配列を解析し、得られた塩基配列をアミノ酸配列に翻訳し、そのアミノ酸配列をホモロジー検索した結果、タラロマイセス・エメルソニ(Talaromyces emersonii)由来のβ−グルコシダーゼ1(Q8X214)と76%の同一性を示したため、本DNA断片をβ−グルコシダーゼ(Glycoside Hydrolase family 1)遺伝子の一部であると判断した。
【0100】
(9-3)インバースPCR法によるBGLD遺伝子全長の取得
実施例1-3に記載の方法で、XhoIで消化した環状DNAをテンプレートに、BGLD遺伝子断片に含まれる下記の配列によりPCRを実施し、BGLD遺伝子の5’上流領域並びに3’下流領域を取得した。
BGLD-inv-F:CGGTTTCAATATCGGTAAGC(配列番号:79)
BGLD-inv-R:GTGTCCAAAGCTCTGGAATG(配列番号:80)
上記5’上流領域並びに3’下流領域の塩基配列を解析し、BGLD遺伝子の全長塩基配列を決定した。
インバースPCR法により得た塩基配列を基に以下のプライマーを作製し、ゲノムDNAをテンプレートにPCRを実施し、BGLD遺伝子を増幅した。
pBGLD-F:TTCTCTCACTTTCCCTTTCC(配列番号:81)
pBGLD-R:AATTGATGCTCCTGATGCGG(配列番号:82)
増幅されたDNAをTOPO TAクローニングキット(インビトロジェン社製)によりpCR2.1-TOPOプラスミドベクターに挿入し、プラスミドpBGLDを得た。得られたプラスミドpBGLDにより大腸菌(Escherichia coli)TOP10株(インビトロジェン社製)を形質転換することによりEscherichia coli TOP10株/pBGLDを得た。
【0101】
(9-4)BGLD遺伝子のイントロン解析
BGLD遺伝子配列から開始コドン並びに終始コドンを含む下記のプライマーを作製し、cDNAをテンプレートにPCRを実施し、BGLD cDNA遺伝子を増幅した。
BGLD-N:ATGGGTAGCGTAACTAGTACCAAC(配列番号:83)
BGLD-C:CTACTCTTTCGAGATGTATTTGTT(配列番号:84)
上記BGLD cDNA遺伝子の塩基配列を解析し、pBGLD遺伝子と比較することでイントロンの位置を決定した。
【0102】
(9-5)BGLDのアミノ酸配列の推定
上記の方法によりアクレモニウム・セルロリティカスより単離されたβ−グルコシダーゼBGLD遺伝子は配列番号17に記載の塩基配列の66〜1765番に示された1700bpの塩基からなっていた。また、本BGLD遺伝子は配列番号17に記載の塩基配列の149〜211番、404〜460番、934〜988番、及び1575〜1626番に示される4つのイントロンが含まれていることが示された。オープンリーディングフレーム(ORF)から予測されるBGLDのアミノ酸配列は配列番号18に示される通りであった。なお、シグナル配列予測ソフトSignalP 3.0により本BGLDの-33〜-1アミノ酸残基までがシグナル配列であると推定した。
【産業上の利用可能性】
【0103】
本発明のタンパク質は、セルラーゼ調製物として使用することができ、セルロース系基質分解の用途に適用することができる。
【配列表フリーテキスト】
【0104】
配列表の配列番号19〜84の配列で表される各塩基配列は、人工的に合成したプライマー配列である。配列番号27(18位及び27位)、配列番号41(18位)、配列番号42(14位)、配列番号54(26位及び29位)、配列番号61(22位及び25位)、配列番号70(22位)、配列番号77(19位)における記号”n”は任意塩基を意味する。
【図面の簡単な説明】
【0105】
【図1】プラスミドpACC3の制限酵素地図である。
【図2】プラスミドpACC5の制限酵素地図である。
【図3】プラスミドpACC6の制限酵素地図である。
【図4】プラスミドpACC7の制限酵素地図である。
【図5】プラスミドpACC8の制限酵素地図である。
【図6】プラスミドpACC9の制限酵素地図である。
【図7】プラスミドpACC10の制限酵素地図である。
【図8】プラスミドpBGLCの制限酵素地図である。
【図9】プラスミドpBGLDの制限酵素地図である。
【特許請求の範囲】
【請求項1】
以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号2に記載のアミノ酸配列の1〜306番の配列を含むタンパク質;
(ii)配列番号2に記載のアミノ酸配列の1〜306番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号2に記載のアミノ酸配列の1〜306番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ。
【請求項2】
以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号4に記載のアミノ酸配列の1〜475番の配列を含むタンパク質;
(ii)配列番号4に記載のアミノ酸配列の1〜475番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号4に記載のアミノ酸配列の1〜475番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ。
【請求項3】
以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号6に記載のアミノ酸配列の1〜391番の配列を含むタンパク質;
(ii)配列番号6に記載のアミノ酸配列の1〜391番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号6に記載のアミノ酸配列の1〜391番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ。
【請求項4】
以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号8に記載のアミノ酸配列の1〜376番の配列を含むタンパク質;
(ii)配列番号8に記載のアミノ酸配列の1〜376番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号8に記載のアミノ酸配列の1〜376番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ。
【請求項5】
以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号10に記載のアミノ酸配列の1〜221番の配列を含むタンパク質;
(ii)配列番号10に記載のアミノ酸配列の1〜221番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号10に記載のアミノ酸配列の1〜221番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ。
【請求項6】
以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号12に記載のアミノ酸配列の1〜319番の配列を含むタンパク質;
(ii)配列番号12に記載のアミノ酸配列の1〜319番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号12に記載のアミノ酸配列の1〜319番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ。
【請求項7】
以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号14に記載のアミノ酸配列の1〜301番の配列を含むタンパク質;
(ii)配列番号14に記載のアミノ酸配列の1〜301番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号14に記載のアミノ酸配列の1〜301番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ。
【請求項8】
以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号16に記載のアミノ酸配列の1〜458番の配列を含むタンパク質;
(ii)配列番号16に記載のアミノ酸配列の1〜458番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むβ−グルコシダーゼ;
(iii)配列番号16に記載のアミノ酸配列の1〜458番の配列と70%以上の同一性を有するアミノ酸配列を含むβ−グルコシダーゼ。
【請求項9】
以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号18に記載のアミノ酸配列の1〜457番の配列を含むタンパク質;
(ii)配列番号18に記載のアミノ酸配列の1〜457番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むβ−グルコシダーゼ;
(iii)配列番号18に記載のアミノ酸配列の1〜457番の配列と70%以上の同一性を有するアミノ酸配列を含むβ−グルコシダーゼ。
【請求項10】
糸状菌由来である、請求項1〜9のいずれか一項に記載のタンパク質。
【請求項11】
糸状菌がアクレモニウム・セルロリティカス(Acremonium cellulolyticus)に属する糸状菌である、請求項10に記載のタンパク質。
【請求項12】
請求項1〜9のいずれか一項に記載のタンパク質をコードする塩基配列を含む、ポリヌクレオチド。
【請求項13】
配列番号1に記載の塩基配列、又はその改変配列を含む、DNA。
【請求項14】
以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)請求項1に記載のタンパク質をコードするDNA;
(ii)配列番号1に記載の塩基配列の136〜1437番の配列を含むDNA;
(iii)配列番号1に記載の塩基配列の136〜1437番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA。
【請求項15】
請求項14に記載のDNAから、イントロン配列を除去したDNA。
【請求項16】
イントロン配列が、配列番号1に記載の塩基配列の233〜291番、351〜425番、579〜631番、697〜754番、又は、853〜907番の配列から選択される1以上の配列を含む配列である、請求項15に記載のDNA。
【請求項17】
請求項13〜16のいずれか一項に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA。
【請求項18】
シグナル配列をコードする塩基配列が、配列番号1に記載の塩基配列の136〜216番の配列である、請求項17に記載のDNA。
【請求項19】
配列番号3に記載の塩基配列、又はその改変配列を含む、DNA。
【請求項20】
以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)請求項2に記載のタンパク質をコードするDNA;
(ii)配列番号3に記載の塩基配列の128〜1615番の配列を含むDNA;
(iii)配列番号3に記載の塩基配列の128〜1615番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA。
【請求項21】
請求項19〜20のいずれか一項に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA。
【請求項22】
シグナル配列をコードする塩基配列が、配列番号3に記載の塩基配列の128〜187番の配列である、請求項21に記載のDNA。
【請求項23】
配列番号5に記載の塩基配列、又はその改変配列を含む、DNA。
【請求項24】
以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)請求項3に記載のタンパク質をコードするDNA;
(ii)配列番号5に記載の塩基配列の169〜1598番の配列を含むDNA;
(iii)配列番号5に記載の塩基配列の169〜1598番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA。
【請求項25】
請求項24に記載のDNAから、イントロン配列を除去したDNA。
【請求項26】
イントロン配列が、配列番号5に記載の塩基配列の254〜309番、406〜461番、又は、1372〜1450番の配列から選択される1以上の配列を含む配列である、請求項25に記載のDNA。
【請求項27】
請求項23〜26のいずれか一項に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA。
【請求項28】
シグナル配列をコードする塩基配列が、配列番号5に記載の塩基配列の169〜231番の配列である、請求項27に記載のDNA。
【請求項29】
配列番号7に記載の塩基配列、又はその改変配列を含む、DNA。
【請求項30】
以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)請求項4に記載のタンパク質をコードするDNA;
(ii)配列番号7に記載の塩基配列の70〜1376番の配列を含むDNA;
(iii)配列番号7に記載の塩基配列の70〜1376番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA。
【請求項31】
請求項30に記載のDNAから、イントロン配列を除去したDNA。
【請求項32】
イントロン配列が、配列番号7に記載の塩基配列の451〜500番、又は、765〜830番の配列から選択される1以上の配列を含む配列である、請求項31に記載のDNA。
【請求項33】
請求項29〜32のいずれか一項に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA。
【請求項34】
シグナル配列をコードする塩基配列が、配列番号7に記載の塩基配列の70〜129番の配列である、請求項33に記載のDNA。
【請求項35】
配列番号9に記載の塩基配列、又はその改変配列を含む、DNA。
【請求項36】
以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)請求項5に記載のタンパク質をコードするDNA;
(ii)配列番号9に記載の塩基配列の141〜974番の配列を含むDNA;
(iii)配列番号9に記載の塩基配列の141〜974番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA。
【請求項37】
請求項36に記載のDNAから、イントロン配列を除去したDNA。
【請求項38】
イントロン配列が、配列番号9に記載の塩基配列の551〜609番、又は、831〜894番の配列から選択される1以上の配列を含む配列である、請求項37に記載のDNA。
【請求項39】
請求項35〜38のいずれか一項に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA。
【請求項40】
シグナル配列をコードする塩基配列が、配列番号9に記載の塩基配列の141〜185番の配列である請求項39に記載のDNA。
【請求項41】
配列番号11に記載の塩基配列、又はその改変配列を含む、DNA。
【請求項42】
以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)請求項6に記載のタンパク質をコードするDNA;
(ii)配列番号11に記載の塩基配列の114〜1230番の配列を含むDNA;
(iii)配列番号11に記載の塩基配列の114〜1230番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA。
【請求項43】
請求項42に記載のDNAから、イントロン配列を除去したDNA。
【請求項44】
イントロン配列が、配列番号11に記載の塩基配列の183〜232番、又は、299〜357番の配列から選択される1以上の配列を含む配列である、請求項43に記載のDNA。
【請求項45】
請求項41〜44のいずれか一項に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA。
【請求項46】
シグナル配列をコードする塩基配列が、配列番号11に記載の塩基配列の114〜161番の配列である、請求項45に記載のDNA。
【請求項47】
配列番号13に記載の塩基配列、又はその改変配列を含む、DNA。
【請求項48】
以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)請求項7に記載のタンパク質をコードするDNA;
(ii)配列番号13に記載の塩基配列の124〜1143番の配列を含むDNA;
(iii)配列番号13に記載の塩基配列の124〜1143番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA。
【請求項49】
請求項48に記載のDNAから、イントロン配列を除去したDNA。
【請求項50】
イントロン配列が、配列番号13に記載の塩基配列の225〜275番の配列である、請求項49に記載のDNA。
【請求項51】
請求項47〜50のいずれか一項に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA。
【請求項52】
シグナル配列をコードする塩基配列が、配列番号13に記載の塩基配列の124〜186番の配列である、請求項51に記載のDNA。
【請求項53】
配列番号15に記載の塩基配列、又はその改変配列を含む、DNA。
【請求項54】
以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)請求項8に記載のタンパク質をコードするDNA;
(ii)配列番号15に記載の塩基配列の238〜1887番の配列を含むDNA;
(iii)配列番号15に記載の塩基配列の238〜1887番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつβ−グルコシダーゼ活性を有するタンパク質をコードするDNA。
【請求項55】
請求項54に記載のDNAから、イントロン配列を除去したDNA。
【請求項56】
イントロン配列が、配列番号15に記載の塩基配列の784〜850番、1138〜1205番、又は、1703〜1756番の配列から選択される1以上の配列を含む配列である、請求項55に記載のDNA。
【請求項57】
請求項53〜56のいずれか一項に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA。
【請求項58】
シグナル配列をコードする塩基配列が、配列番号15に記載の塩基配列の238〜321番の配列である、請求項57に記載のDNA。
【請求項59】
配列番号17に記載の塩基配列、又はその改変配列を含む、DNA。
【請求項60】
以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)請求項9に記載のタンパク質をコードするDNA;
(ii)配列番号17に記載の塩基配列の66〜1765番の配列を含むDNA;
(iii)配列番号17に記載の塩基配列の66〜1765番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつβ−グルコシダーゼ活性を有するタンパク質をコードするDNA。
【請求項61】
請求項60に記載のDNAから、イントロン配列を除去したDNA。
【請求項62】
イントロン配列が、配列番号17に記載の塩基配列の149〜211番、404〜460番、934〜988番、又は、1575〜1626番の配列から選択される1以上の配列を含む配列である、請求項61に記載のDNA。
【請求項63】
請求項59〜62のいずれか一項に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA。
【請求項64】
シグナル配列をコードする塩基配列が、配列番号17に記載の塩基配列の66〜227番の配列である、請求項63に記載のDNA。
【請求項65】
請求項12〜64のいずれか一項に記載のDNAを含む、発現ベクター。
【請求項66】
請求項65に記載の発現ベクターで形質転換された、宿主細胞。
【請求項67】
宿主細胞が酵母又は糸状菌である、請求項66に記載の宿主細胞。
【請求項68】
酵母が、サッカロミセス(Saccharomyces)属、ハンゼヌラ(Hansenula)属又はピキア(Pichia)属に属するものである、請求項67に記載の宿主細胞。
【請求項69】
酵母が、サッカロミセス・セレビシエ(Saccharomyces cerevisiae)である、請求項68に記載の宿主細胞。
【請求項70】
糸状菌が、フミコーラ(Humicola)属、アスペルギルス(Aspergillus)属、トリコデルマ(Trichoderma)属、フザリウム(Fusarium)又はアクレモニウム(Acremonium)属に属するものである、請求項67に記載の宿主細胞。
【請求項71】
糸状菌が、アクレモニウム・セルロリティカス(Acremonium cellulolyticus)、フミコーラ・インソレンス(Humicola insolens)、アスペルギルス・ニガー(Aspergillus niger)もしくはアスペルギルス・オリゼー(Aspergillus oryzae)、トリコデルマ・ビリデ(Trichoderma viride)、又はフザリウム・オキシスポーラム(Fusarium oxysporum)である、請求項70に記載の宿主細胞。
【請求項72】
請求項12〜64のいずれか一項に記載のDNAに対応する遺伝子を、相同組み換えにより欠損させたアクレモニウム(Acremonium)属の糸状菌。
【請求項73】
糸状菌がアクレモニウム・セルロリティカス(Acremonium cellulolyticus)である、請求項72に記載の糸状菌。
【請求項74】
請求項66〜73のいずれか一項に記載の宿主細胞を培養し、その宿主及び/又はその培養物から請求項1〜9のいずれか一項に記載のタンパク質を採取する工程を含む、前記タンパク質の製造法。
【請求項75】
請求項74に記載の方法で生産された、タンパク質。
【請求項76】
請求項1〜9及び75のいずれか一項に記載のタンパク質を含む、セルラーゼ調製物。
【請求項77】
バイオマスを糖化する処理方法であって、セルロース含有バイオマスを、請求項1〜9及び75のいずれか一項に記載のタンパク質、又は請求項76に記載のセルラーゼ調製物と接触させる工程を含む、方法。
【請求項78】
セルロース含有繊維の処理方法であって、セルロース含有繊維を、請求項1〜9及び75のいずれか一項に記載のタンパク質、又は請求項76に記載のセルラーゼ調製物と接触させる工程を含む、方法。
【請求項79】
古紙を脱インキ薬品により処理して脱インキを行う工程において、請求項1〜9及び75のいずれか一項に記載のタンパク質、又は請求項76に記載のセルラーゼ調製物を用いることを特徴とする古紙の脱インキ方法。
【請求項80】
紙パルプのろ水性の改善方法であって、紙パルプを、請求項1〜9及び75のいずれか一項に記載のタンパク質、又は請求項76に記載のセルラーゼ調製物で処理する工程を含む、方法。
【請求項81】
動物飼料の消化能を改善する方法であって、動物飼料を、請求項1〜9及び75のいずれか一項に記載のタンパク質、又は請求項76に記載のセルラーゼ調製物で処理する工程を含む、方法。
【請求項1】
以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号2に記載のアミノ酸配列の1〜306番の配列を含むタンパク質;
(ii)配列番号2に記載のアミノ酸配列の1〜306番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号2に記載のアミノ酸配列の1〜306番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ。
【請求項2】
以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号4に記載のアミノ酸配列の1〜475番の配列を含むタンパク質;
(ii)配列番号4に記載のアミノ酸配列の1〜475番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号4に記載のアミノ酸配列の1〜475番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ。
【請求項3】
以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号6に記載のアミノ酸配列の1〜391番の配列を含むタンパク質;
(ii)配列番号6に記載のアミノ酸配列の1〜391番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号6に記載のアミノ酸配列の1〜391番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ。
【請求項4】
以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号8に記載のアミノ酸配列の1〜376番の配列を含むタンパク質;
(ii)配列番号8に記載のアミノ酸配列の1〜376番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号8に記載のアミノ酸配列の1〜376番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ。
【請求項5】
以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号10に記載のアミノ酸配列の1〜221番の配列を含むタンパク質;
(ii)配列番号10に記載のアミノ酸配列の1〜221番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号10に記載のアミノ酸配列の1〜221番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ。
【請求項6】
以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号12に記載のアミノ酸配列の1〜319番の配列を含むタンパク質;
(ii)配列番号12に記載のアミノ酸配列の1〜319番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号12に記載のアミノ酸配列の1〜319番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ。
【請求項7】
以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号14に記載のアミノ酸配列の1〜301番の配列を含むタンパク質;
(ii)配列番号14に記載のアミノ酸配列の1〜301番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むエンドグルカナーゼ;
(iii)配列番号14に記載のアミノ酸配列の1〜301番の配列と70%以上の同一性を有するアミノ酸配列を含むエンドグルカナーゼ。
【請求項8】
以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号16に記載のアミノ酸配列の1〜458番の配列を含むタンパク質;
(ii)配列番号16に記載のアミノ酸配列の1〜458番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むβ−グルコシダーゼ;
(iii)配列番号16に記載のアミノ酸配列の1〜458番の配列と70%以上の同一性を有するアミノ酸配列を含むβ−グルコシダーゼ。
【請求項9】
以下の(i)、(ii)、及び(iii)から選択されるタンパク質:
(i)配列番号18に記載のアミノ酸配列の1〜457番の配列を含むタンパク質;
(ii)配列番号18に記載のアミノ酸配列の1〜457番の配列において、1もしくは複数個のアミノ酸が欠失、置換、及び/又は付加されたアミノ酸配列を含むβ−グルコシダーゼ;
(iii)配列番号18に記載のアミノ酸配列の1〜457番の配列と70%以上の同一性を有するアミノ酸配列を含むβ−グルコシダーゼ。
【請求項10】
糸状菌由来である、請求項1〜9のいずれか一項に記載のタンパク質。
【請求項11】
糸状菌がアクレモニウム・セルロリティカス(Acremonium cellulolyticus)に属する糸状菌である、請求項10に記載のタンパク質。
【請求項12】
請求項1〜9のいずれか一項に記載のタンパク質をコードする塩基配列を含む、ポリヌクレオチド。
【請求項13】
配列番号1に記載の塩基配列、又はその改変配列を含む、DNA。
【請求項14】
以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)請求項1に記載のタンパク質をコードするDNA;
(ii)配列番号1に記載の塩基配列の136〜1437番の配列を含むDNA;
(iii)配列番号1に記載の塩基配列の136〜1437番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA。
【請求項15】
請求項14に記載のDNAから、イントロン配列を除去したDNA。
【請求項16】
イントロン配列が、配列番号1に記載の塩基配列の233〜291番、351〜425番、579〜631番、697〜754番、又は、853〜907番の配列から選択される1以上の配列を含む配列である、請求項15に記載のDNA。
【請求項17】
請求項13〜16のいずれか一項に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA。
【請求項18】
シグナル配列をコードする塩基配列が、配列番号1に記載の塩基配列の136〜216番の配列である、請求項17に記載のDNA。
【請求項19】
配列番号3に記載の塩基配列、又はその改変配列を含む、DNA。
【請求項20】
以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)請求項2に記載のタンパク質をコードするDNA;
(ii)配列番号3に記載の塩基配列の128〜1615番の配列を含むDNA;
(iii)配列番号3に記載の塩基配列の128〜1615番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA。
【請求項21】
請求項19〜20のいずれか一項に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA。
【請求項22】
シグナル配列をコードする塩基配列が、配列番号3に記載の塩基配列の128〜187番の配列である、請求項21に記載のDNA。
【請求項23】
配列番号5に記載の塩基配列、又はその改変配列を含む、DNA。
【請求項24】
以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)請求項3に記載のタンパク質をコードするDNA;
(ii)配列番号5に記載の塩基配列の169〜1598番の配列を含むDNA;
(iii)配列番号5に記載の塩基配列の169〜1598番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA。
【請求項25】
請求項24に記載のDNAから、イントロン配列を除去したDNA。
【請求項26】
イントロン配列が、配列番号5に記載の塩基配列の254〜309番、406〜461番、又は、1372〜1450番の配列から選択される1以上の配列を含む配列である、請求項25に記載のDNA。
【請求項27】
請求項23〜26のいずれか一項に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA。
【請求項28】
シグナル配列をコードする塩基配列が、配列番号5に記載の塩基配列の169〜231番の配列である、請求項27に記載のDNA。
【請求項29】
配列番号7に記載の塩基配列、又はその改変配列を含む、DNA。
【請求項30】
以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)請求項4に記載のタンパク質をコードするDNA;
(ii)配列番号7に記載の塩基配列の70〜1376番の配列を含むDNA;
(iii)配列番号7に記載の塩基配列の70〜1376番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA。
【請求項31】
請求項30に記載のDNAから、イントロン配列を除去したDNA。
【請求項32】
イントロン配列が、配列番号7に記載の塩基配列の451〜500番、又は、765〜830番の配列から選択される1以上の配列を含む配列である、請求項31に記載のDNA。
【請求項33】
請求項29〜32のいずれか一項に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA。
【請求項34】
シグナル配列をコードする塩基配列が、配列番号7に記載の塩基配列の70〜129番の配列である、請求項33に記載のDNA。
【請求項35】
配列番号9に記載の塩基配列、又はその改変配列を含む、DNA。
【請求項36】
以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)請求項5に記載のタンパク質をコードするDNA;
(ii)配列番号9に記載の塩基配列の141〜974番の配列を含むDNA;
(iii)配列番号9に記載の塩基配列の141〜974番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA。
【請求項37】
請求項36に記載のDNAから、イントロン配列を除去したDNA。
【請求項38】
イントロン配列が、配列番号9に記載の塩基配列の551〜609番、又は、831〜894番の配列から選択される1以上の配列を含む配列である、請求項37に記載のDNA。
【請求項39】
請求項35〜38のいずれか一項に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA。
【請求項40】
シグナル配列をコードする塩基配列が、配列番号9に記載の塩基配列の141〜185番の配列である請求項39に記載のDNA。
【請求項41】
配列番号11に記載の塩基配列、又はその改変配列を含む、DNA。
【請求項42】
以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)請求項6に記載のタンパク質をコードするDNA;
(ii)配列番号11に記載の塩基配列の114〜1230番の配列を含むDNA;
(iii)配列番号11に記載の塩基配列の114〜1230番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA。
【請求項43】
請求項42に記載のDNAから、イントロン配列を除去したDNA。
【請求項44】
イントロン配列が、配列番号11に記載の塩基配列の183〜232番、又は、299〜357番の配列から選択される1以上の配列を含む配列である、請求項43に記載のDNA。
【請求項45】
請求項41〜44のいずれか一項に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA。
【請求項46】
シグナル配列をコードする塩基配列が、配列番号11に記載の塩基配列の114〜161番の配列である、請求項45に記載のDNA。
【請求項47】
配列番号13に記載の塩基配列、又はその改変配列を含む、DNA。
【請求項48】
以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)請求項7に記載のタンパク質をコードするDNA;
(ii)配列番号13に記載の塩基配列の124〜1143番の配列を含むDNA;
(iii)配列番号13に記載の塩基配列の124〜1143番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつエンドグルカナーゼ活性を有するタンパク質をコードするDNA。
【請求項49】
請求項48に記載のDNAから、イントロン配列を除去したDNA。
【請求項50】
イントロン配列が、配列番号13に記載の塩基配列の225〜275番の配列である、請求項49に記載のDNA。
【請求項51】
請求項47〜50のいずれか一項に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA。
【請求項52】
シグナル配列をコードする塩基配列が、配列番号13に記載の塩基配列の124〜186番の配列である、請求項51に記載のDNA。
【請求項53】
配列番号15に記載の塩基配列、又はその改変配列を含む、DNA。
【請求項54】
以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)請求項8に記載のタンパク質をコードするDNA;
(ii)配列番号15に記載の塩基配列の238〜1887番の配列を含むDNA;
(iii)配列番号15に記載の塩基配列の238〜1887番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつβ−グルコシダーゼ活性を有するタンパク質をコードするDNA。
【請求項55】
請求項54に記載のDNAから、イントロン配列を除去したDNA。
【請求項56】
イントロン配列が、配列番号15に記載の塩基配列の784〜850番、1138〜1205番、又は、1703〜1756番の配列から選択される1以上の配列を含む配列である、請求項55に記載のDNA。
【請求項57】
請求項53〜56のいずれか一項に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA。
【請求項58】
シグナル配列をコードする塩基配列が、配列番号15に記載の塩基配列の238〜321番の配列である、請求項57に記載のDNA。
【請求項59】
配列番号17に記載の塩基配列、又はその改変配列を含む、DNA。
【請求項60】
以下の(i)、(ii)、及び(iii)から選択されるDNA:
(i)請求項9に記載のタンパク質をコードするDNA;
(ii)配列番号17に記載の塩基配列の66〜1765番の配列を含むDNA;
(iii)配列番号17に記載の塩基配列の66〜1765番の配列からなるDNAとストリンジェントな条件でハイブリダイズし、かつβ−グルコシダーゼ活性を有するタンパク質をコードするDNA。
【請求項61】
請求項60に記載のDNAから、イントロン配列を除去したDNA。
【請求項62】
イントロン配列が、配列番号17に記載の塩基配列の149〜211番、404〜460番、934〜988番、又は、1575〜1626番の配列から選択される1以上の配列を含む配列である、請求項61に記載のDNA。
【請求項63】
請求項59〜62のいずれか一項に記載のDNAから、シグナル配列をコードする塩基配列を除去したDNA。
【請求項64】
シグナル配列をコードする塩基配列が、配列番号17に記載の塩基配列の66〜227番の配列である、請求項63に記載のDNA。
【請求項65】
請求項12〜64のいずれか一項に記載のDNAを含む、発現ベクター。
【請求項66】
請求項65に記載の発現ベクターで形質転換された、宿主細胞。
【請求項67】
宿主細胞が酵母又は糸状菌である、請求項66に記載の宿主細胞。
【請求項68】
酵母が、サッカロミセス(Saccharomyces)属、ハンゼヌラ(Hansenula)属又はピキア(Pichia)属に属するものである、請求項67に記載の宿主細胞。
【請求項69】
酵母が、サッカロミセス・セレビシエ(Saccharomyces cerevisiae)である、請求項68に記載の宿主細胞。
【請求項70】
糸状菌が、フミコーラ(Humicola)属、アスペルギルス(Aspergillus)属、トリコデルマ(Trichoderma)属、フザリウム(Fusarium)又はアクレモニウム(Acremonium)属に属するものである、請求項67に記載の宿主細胞。
【請求項71】
糸状菌が、アクレモニウム・セルロリティカス(Acremonium cellulolyticus)、フミコーラ・インソレンス(Humicola insolens)、アスペルギルス・ニガー(Aspergillus niger)もしくはアスペルギルス・オリゼー(Aspergillus oryzae)、トリコデルマ・ビリデ(Trichoderma viride)、又はフザリウム・オキシスポーラム(Fusarium oxysporum)である、請求項70に記載の宿主細胞。
【請求項72】
請求項12〜64のいずれか一項に記載のDNAに対応する遺伝子を、相同組み換えにより欠損させたアクレモニウム(Acremonium)属の糸状菌。
【請求項73】
糸状菌がアクレモニウム・セルロリティカス(Acremonium cellulolyticus)である、請求項72に記載の糸状菌。
【請求項74】
請求項66〜73のいずれか一項に記載の宿主細胞を培養し、その宿主及び/又はその培養物から請求項1〜9のいずれか一項に記載のタンパク質を採取する工程を含む、前記タンパク質の製造法。
【請求項75】
請求項74に記載の方法で生産された、タンパク質。
【請求項76】
請求項1〜9及び75のいずれか一項に記載のタンパク質を含む、セルラーゼ調製物。
【請求項77】
バイオマスを糖化する処理方法であって、セルロース含有バイオマスを、請求項1〜9及び75のいずれか一項に記載のタンパク質、又は請求項76に記載のセルラーゼ調製物と接触させる工程を含む、方法。
【請求項78】
セルロース含有繊維の処理方法であって、セルロース含有繊維を、請求項1〜9及び75のいずれか一項に記載のタンパク質、又は請求項76に記載のセルラーゼ調製物と接触させる工程を含む、方法。
【請求項79】
古紙を脱インキ薬品により処理して脱インキを行う工程において、請求項1〜9及び75のいずれか一項に記載のタンパク質、又は請求項76に記載のセルラーゼ調製物を用いることを特徴とする古紙の脱インキ方法。
【請求項80】
紙パルプのろ水性の改善方法であって、紙パルプを、請求項1〜9及び75のいずれか一項に記載のタンパク質、又は請求項76に記載のセルラーゼ調製物で処理する工程を含む、方法。
【請求項81】
動物飼料の消化能を改善する方法であって、動物飼料を、請求項1〜9及び75のいずれか一項に記載のタンパク質、又は請求項76に記載のセルラーゼ調製物で処理する工程を含む、方法。
【図1】


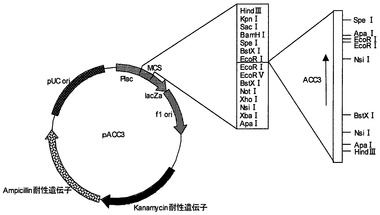
【図2】
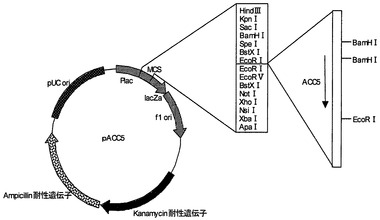
【図3】
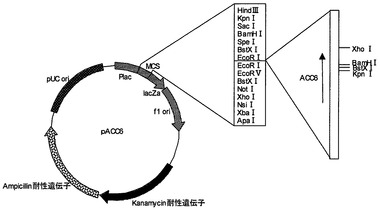
【図4】
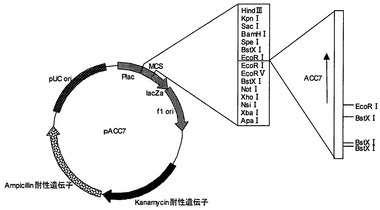
【図5】
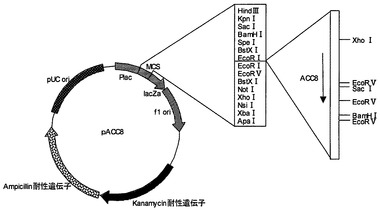
【図6】
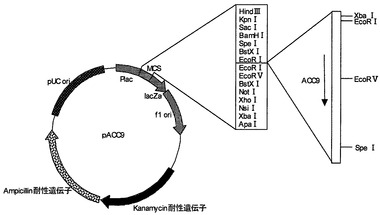
【図7】
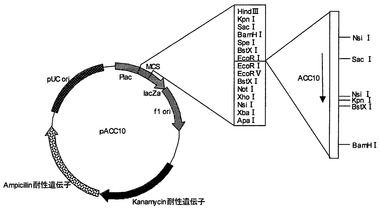
【図8】
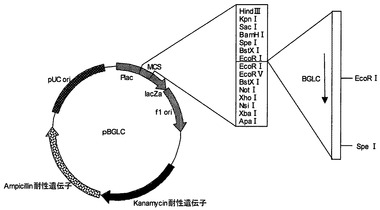
【図9】
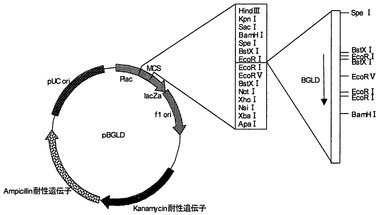
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【公開番号】特開2010−148427(P2010−148427A)
【公開日】平成22年7月8日(2010.7.8)
【国際特許分類】
【出願番号】特願2008−329902(P2008−329902)
【出願日】平成20年12月25日(2008.12.25)
【出願人】(000006091)明治製菓株式会社 (180)
【Fターム(参考)】
【公開日】平成22年7月8日(2010.7.8)
【国際特許分類】
【出願日】平成20年12月25日(2008.12.25)
【出願人】(000006091)明治製菓株式会社 (180)
【Fターム(参考)】
[ Back to top ]