
施設検索装置及びプログラム
【課題】名称リストを展開するメモリ容量の増大を抑止することができると共に、文字数の少ない複数の検索語に対して検索を高速で行い、応答性の低下を防止することが可能となる施設検索装置及びプログラムを提供する。
【解決手段】キーワード先頭文字情報記憶手段において、入力手段を介して入力された一の検索語と前方一致する分割文字列に関連付けて記憶されている区分毎のカウント情報から、該入力手段を介して入力された各検索語の先頭文字の属する区分に対応するカウント情報に基づいて該各検索語に対応する分割文字列を取得する。そして、施設名記憶手段において、この取得した分割文字列に関連付けて記憶されている施設名から、入力手段によって入力された検索語と前方一致するキーワードを有する施設名を候補施設名として取得する。
【解決手段】キーワード先頭文字情報記憶手段において、入力手段を介して入力された一の検索語と前方一致する分割文字列に関連付けて記憶されている区分毎のカウント情報から、該入力手段を介して入力された各検索語の先頭文字の属する区分に対応するカウント情報に基づいて該各検索語に対応する分割文字列を取得する。そして、施設名記憶手段において、この取得した分割文字列に関連付けて記憶されている施設名から、入力手段によって入力された検索語と前方一致するキーワードを有する施設名を候補施設名として取得する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、入力された検索語に基づいて施設情報を検索する施設検索装置及びプログラムに関するものである。
【背景技術】
【0002】
従来より、入力された検索語に基づいて施設情報を検索する技術に関し種々提案されている。
例えば、目的地を表す施設名を単語分割し、分割した単語の順番を入れ替えた全名称を読み順にソートして当該施設名として登録した名称リストを作成しておき、入力された検索語と前方一致する名称を検索して、当該名称に該当する施設名を抽出して、表示手段に候補地点名として表示する車両用ナビゲーション装置がある(例えば、特許文献1参照。)。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開平9−97266号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
前記した特許文献1に記載された車両用ナビゲーション装置によれば、入力された検索語と前方一致する名称を検索することによって該当する施設名を高速で検索することが可能となる。
しかしながら、各施設毎に複数の名称を作成して記憶しておく必要があるため、名称リストのデータ容量が増大するが、メモリ上に施設検索用のアプリケーションプログラムを展開した場合には、名称リストを展開するメモリ容量に限界が生じ、大量のデータから抽出することが難しいという問題がある。
【0005】
また、文字数の少ない(例えば、1文字又は2文字である。)複数の検索語が入力された場合には、入力された1番目の検索語と前方一致する施設名の数が多くなり、2番目以降の検索語と前方一致する読みが名称中に含まれるか否かを全ての施設名について行う必要が生じるため、検索時間が増大し、応答性能が低下するという問題がある。
【0006】
そこで、本発明は、上述した問題点を解決するためになされたものであり、名称リストを展開するメモリ容量の増大を抑止することができると共に、文字数の少ない複数の検索語に対して検索を高速で行い、応答性の低下を防止することが可能となる施設検索装置及びプログラムを提供することを目的とする。
【課題を解決するための手段】
【0007】
前記目的を達成するため請求項1に係る施設検索装置は、検索対象となる複数の施設名をそれぞれ複数のキーワードに区切って、各施設名を各キーワードと前方一致する所定文字数の分割文字列に関連付けて記憶する施設名記憶手段と、前記所定文字数の分割文字列に関連付けられた各施設名について、互いに異なる1文字から構成されて所定順序を付与された複数の区分文字が所定個数ずつ属する複数の区分別に、各区分に属する区分文字と一致する各キーワードの先頭文字をカウントした区分毎のカウント情報を、該所定文字数の分割文字列に関連付けて記憶するキーワード先頭文字情報記憶手段と、検索語を入力する入力手段と、前記キーワード先頭文字情報記憶手段において、前記入力手段を介して入力された各検索語の先頭文字の属する区分に対応するカウント情報に基づいて該各検索語に対応する前記分割文字列を取得する分割文字列取得手段と、前記施設名記憶手段において、前記分割文字列取得手段を介して取得した前記分割文字列に関連付けて記憶されている施設名から前記入力手段によって入力された検索語と前方一致するキーワードを有する施設名を候補施設名として取得する検索手段と、を備えたことを特徴とする。
【0008】
また、請求項2に係る施設検索装置は、請求項1に記載の施設検索装置において、前記区分毎のカウント情報は、前記所定文字数の分割文字列に関連付けられた各施設名について、前記複数の区分別に、各区分に属する前記区分文字と一致する各キーワードの先頭文字をカウントした最大カウント値であり、前記分割文字列取得手段は、前記入力手段を介して入力された各検索語の先頭文字の属する区分の前記最大カウント値の全てが、当該各検索語の先頭文字の属する区分毎の該先頭文字のカウント値以上であるカウント情報に関連付けられた前記分割文字列を取得することを特徴とする。
【0009】
また、請求項3に係る施設検索装置は、請求項1に記載の施設検索装置において、前記区分毎のカウント情報は、前記所定文字数の分割文字列に関連付けられた各施設名について、前記複数の区分別に、各区分に属する前記区分文字と一致する各キーワードの先頭文字をカウントしたカウント値があるか否かを表す有無情報であり、前記分割文字列取得手段は、前記入力手段を介して入力された各検索語の先頭文字の属する区分毎の前記有無情報が全てカウント値がある旨を表すカウント情報に関連付けられた前記分割文字列を取得することを特徴とする。
【0010】
また、請求項4に係る施設検索装置は、請求項1乃至請求項3のいずれかに記載の施設検索装置において、前記区分文字は、50音仮名であって、前記区分は、50音の行別に区分されていることを特徴とする。ここで、50音仮名は、平仮名や片仮名を含む。
【0011】
また、請求項1乃至請求項3のいずれかに記載の施設検索装置において、前記区分文字は、アルファベット、数字、所定の記号(例えば、算術記号や矢印等である。)等でもよい。また、前記区分文字がアルファベットの場合には、前記複数の区分は、アルファベットがアルファベット順に所定個数ずつ属するように区分してもよい。また、前記分割文字列は、所定文字数のアルファベットとするようにしてもよい。
【0012】
更に、請求項5に係るプログラムは、検索対象となる複数の施設名をそれぞれ複数のキーワードに区切って、各施設名を各キーワードと前方一致する所定文字数の分割文字列に関連付けて記憶する施設名記憶手段と、前記所定文字数の分割文字列に関連付けられた各施設名について、互いに異なる1文字から構成されて所定順序を付与された複数の区分文字が所定個数ずつ属する複数の区分別に、各区分に属する区分文字と一致する各キーワードの先頭文字をカウントした区分毎のカウント情報を、該所定文字数の分割文字列に関連付けて記憶するキーワード先頭文字情報記憶手段と、を備えたコンピュータに、検索語を入力する入力工程と、前記キーワード先頭文字情報記憶手段において、前記入力工程で入力された各検索語の先頭文字の属する区分に対応するカウント情報に基づいて該各検索語に対応する前記分割文字列を取得する分割文字列取得工程と、前記施設名記憶手段において、前記分割文字列取得工程で取得した前記分割文字列に関連付けて記憶されている施設名から前記入力工程で入力された検索語と前方一致するキーワードを有する施設名を候補施設名として取得する検索工程と、を実行させるためのプログラムである。
【発明の効果】
【0013】
前記構成を有する請求項1に係る施設検索装置では、複数の施設名をそれぞれ複数のキーワードに区切って、各施設名を各キーワードと前方一致する所定文字数の分割文字列に関連付けて施設名記憶手段に記憶している。これにより、各分割文字列に関連付けられた目的地を表す施設名は、1個だけ記憶されるため、重複記憶される施設名を減少させて、名称リストのデータ容量の削減化を図り、名称リストを展開するメモリ容量の増大を抑止することが可能となる。
【0014】
また、キーワード先頭文字情報記憶手段において、入力された一の検索語と前方一致する分割文字列に関連付けて記憶されている区分毎のカウント情報から、各検索語の先頭文字の属する区分に対応するカウント情報に基づいて該各検索語に対応する分割文字列を取得する。そして、この取得された分割文字列を施設名記憶手段の分割文字列として、該分割文字列に関連付けられた施設名から検索語と前方一致するキーワードを有する施設名を候補施設名として取得する。
【0015】
これにより、文字数の少ない(例えば、1文字又は2文字である。)複数の検索語が入力されても、各検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された分割文字列だけをキーワード先頭文字情報記憶手段から抽出することが可能となる。従って、この抽出された分割文字列に関連付けられて施設名記憶手段に格納された施設名から候補施設名を検索するため、検索対象となる施設名を少なくすることができ、検索を高速で行い、応答性の低下を防止することが可能となる。
【0016】
また、請求項2に係る施設検索装置では、キーワード先頭文字情報記憶手段において、入力された一の検索語と前方一致する分割文字列から、各検索語の先頭文字の属する区分毎の各最大カウント値の全てが、当該各検索語の先頭文字の属する区分毎の該先頭文字のカウント値以上であるカウント情報に関連付けられた分割文字列を取得する。そして、この取得された分割文字列を施設名記憶手段の分割文字列として、該分割文字列に関連付けられた施設名から検索語と前方一致するキーワードを有する施設名を候補施設名として取得する。
【0017】
これにより、文字数の少ない(例えば、1文字又は2文字である。)複数の検索語が入力されても、各検索語の先頭文字を各キーワードの先頭文字に有する施設名が関連付けられた分割文字列だけをキーワード先頭文字情報記憶手段から確実に抽出することが可能となる。従って、この抽出された分割文字列に関連付けられて施設名記憶手段に格納された施設名から候補施設名を検索するため、検索対象となる施設名を少なくすることができ、検索を高速で行い、応答性の低下を防止することが可能となる。
【0018】
また、先頭文字が同じ複数の検索語が入力された場合には、この複数の検索語の先頭文字の属する区分の各最大カウント値が、当該検索語の個数以上のカウント情報に関連付けられた分割文字列だけを取得することが可能となる。これにより、抽出される分割文字列を少なくすることが可能となるため、検索対象となる施設名を更に少なくすることができ、検索を高速で行い、応答性の低下を防止することが可能となる。
【0019】
また、請求項3に係る施設検索装置では、キーワード先頭文字情報記憶手段において、入力された一の検索語と前方一致する分割文字列から、各検索語の先頭文字の属する区分毎の有無情報が全てカウント値がある旨を表すカウント情報に関連付けられた分割文字列を取得する。そして、この取得された分割文字列を施設名記憶手段の分割文字列として、該分割文字列に関連付けられた施設名から検索語と前方一致するキーワードを有する施設名を候補施設名として取得する。
【0020】
これにより、文字数の少ない(例えば、1文字又は2文字である。)複数の検索語が入力されても、各検索語の先頭文字を各キーワードの先頭文字に有する施設名が関連付けられた分割文字列だけをキーワード先頭文字情報記憶手段から確実に抽出することが可能となる。従って、この抽出された分割文字列に関連付けられて施設名記憶手段に格納された施設名から候補施設名を検索するため、検索対象となる施設名を少なくすることができ、検索を高速で行い、応答性の低下を防止することが可能となる。
【0021】
また、請求項4に係る施設検索装置では、キーワード先頭文字情報記憶手段において、50音の行別に、各行に属する50音仮名(平仮名又は片仮名である。)と一致する各キーワードの先頭文字をカウントした行毎のカウント情報を、所定文字数の分割文字列に関連付けて記憶する。これにより、所定文字数の分割文字列に関連付けて記憶するカウント情報の区分を10個に限定して、少なくすることができ、検索語に対応する分割文字列を更に迅速に抽出することが可能となる。
【0022】
また、請求項5に係るプログラムでは、コンピュータは当該プログラムを読み込むことによって、キーワード先頭文字情報記憶手段において、入力された一の検索語と前方一致する分割文字列に関連付けて記憶されている区分毎のカウント情報から、各検索語の先頭文字の属する区分に対応するカウント情報に基づいて該各検索語に対応する分割文字列を取得する。そして、コンピュータは、この取得した分割文字列を施設名記憶手段の分割文字列として、該分割文字列に関連付けられた施設名から検索語と前方一致するキーワードを有する施設名を候補施設名として取得する。
【0023】
これにより、コンピュータは文字数の少ない(例えば、1文字又は2文字である。)複数の検索語が入力されても、各検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された分割文字列だけをキーワード先頭文字情報記憶手段から抽出することが可能となる。従って、コンピュータは、この抽出した分割文字列に関連付けられて施設名記憶手段に格納された施設名から候補施設名を検索するため、検索対象となる施設名を少なくすることができ、検索を高速で行い、応答性の低下を防止することが可能となる。
【図面の簡単な説明】
【0024】
【図1】実施例1に係るナビゲーション装置を示したブロック図である。
【図2】施設名DBに格納された施設名データテーブルの一例を示す図である。
【図3】施設名DBに格納された先頭文字情報データテーブルの一例を示す図である。
【図4】入力された検索語に基づいて施設情報を検索してリスト表示する「施設情報表示処理」を示すフローチャートである。
【図5】図3の「候補施設名抽出処理」のサブ処理を示すサブフローチャートである。
【図6】検索語を入力する検索語入力画面の一例を示す図である。
【図7】抽出した施設名をリスト表示した検索結果表示画面の一例を示す図である。
【図8】実施例2に係る施設名DBに格納された先頭文字情報データテーブルの一例を示す図である。
【図9】実施例3に係る施設名DBに格納された先頭文字情報データテーブルの一例を示す図である。
【図10】実施例4に係る施設名DBに格納された施設名データテーブルの一例を示す図である。
【図11】実施例4に係る施設名DBに格納された先頭文字情報データテーブルの一例を示す図である。
【図12】実施例5に係る施設名DBに格納された先頭文字情報データテーブルの一例を示す図である。
【図13】実施例6に係る施設名DBに格納された先頭文字情報データテーブルの一例を示す図である。
【発明を実施するための形態】
【0025】
以下、本発明に係る施設検索装置及びプログラムをナビゲーション装置について具体化した実施例1乃至実施例6に基づき図面を参照しつつ詳細に説明する。
【実施例1】
【0026】
[ナビゲーション装置の概略構成]
先ず、実施例1に係るナビゲーション装置の概略構成について図1に基づいて説明する。図1は実施例1に係るナビゲーション装置1を示したブロック図である。
図1に示すように、実施例1に係るナビゲーション装置1は、自車の現在位置(以下、「自車位置」という。)等を検出する現在地検出処理部11と、各種のデータが記録されたデータ記録部12と、入力された情報に基づいて、各種の演算処理を行うナビゲーション制御部13と、操作者からの操作を受け付ける操作部14と、操作者に対して地図等の情報を表示する液晶ディスプレイ15と、経路案内等に関する音声ガイダンスを出力するスピーカ16と、不図示の道路交通情報センタや地図情報配信センタ等との間で携帯電話網等を介して通信を行う通信装置17と、液晶ディスプレイ15の表面に装着されたタッチパネル18とから構成されている。また、ナビゲーション制御部13には自車の走行速度を検出する車速センサ21が接続されている。
【0027】
以下に、ナビゲーション装置1を構成する各構成要素について説明すると、現在地検出処理部11は、GPS31、方位センサ32、距離センサ33等からなり、自車位置、自車の向きを表す自車方位、走行距離等を検出することが可能となっている。
【0028】
また、データ記録部12は、外部記憶装置及び記録媒体としてのハードディスク(図示せず)と、ハードディスクに記憶された地図情報データベース(地図情報DB)25、施設名データベース(施設名DB)27及び所定のプログラム等を読み出すとともにハードディスクに所定のデータを書き込む為のドライバを備えている。
【0029】
また、地図情報DB25には、ナビゲーション装置1の走行案内や経路探索に使用されるナビ地図情報26が格納されている。ここで、ナビ地図情報26には、経路案内及び地図表示に必要な各種情報から構成されており、例えば、各新設道路を特定するための新設道路情報、地図を表示するための地図表示データ、各交差点に関する交差点データ、ノード点に関するノードデータ、施設の一種である道路(リンク)に関するリンクデータ、経路を探索するための探索データ、施設の一種である店舗等のPOI(Point of Interest)に関する店舗データ、地点を検索するための検索データ等から構成されている。
【0030】
尚、店舗データには、各地域のホテル、病院、ガソリンスタンド、駐車場、駅、空港、フェリー乗り場等のPOIに関する名称や住所、電話番号等に加えて、後述の検索結果表示画面71(図7参照)にリスト表示する表示優先度のデータをPOIを特定するIDとともに記憶するようにしてもよい。例えば、表示優先度は、「88」や「256」等の数値で表され、数値の大きいものほど優先度が高くなる。また、地図情報DB25の内容は、不図示の地図情報配信センタから通信装置17を介して配信された更新情報をダウンロードすることによって更新される。
【0031】
また、施設名DB27には、後述の施設名及び該施設名の読みを所定文字数(実施例1では、1文字又は2文字である。)の分割文字列に関連付けて分割単位毎に記憶する施設名データテーブル51(図2参照)が格納されている。また、施設名DB27には、後述の施設名の読みを構成する各キーワードの先頭文字が属する50音の行を表す「キーワードの先頭文字情報」を所定文字数(実施例1では、1文字又は2文字である。)の分割文字列に関連付けて分割単位毎に記憶する先頭文字情報データテーブル52(図3参照)が格納されている。
【0032】
また、図1に示すように、ナビゲーション装置1を構成するナビゲーション制御部13は、ナビゲーション装置1の全体の制御を行う演算装置及び制御装置としてのCPU41、並びにCPU41が各種の演算処理を行うに当たってワーキングメモリとして使用されるとともに、経路が探索されたときの経路データ等が記憶されるRAM42、制御用のプログラム等が記憶されたROM43、ROM43から読み出したプログラムを記憶するフラッシュメモリ44等の内部記憶装置や、時間を計測するタイマ45等を備えている。
【0033】
また、ROM43には、後述の50音キー62から入力された検索語に基づいて地点情報を検索してリスト表示する施設情報表示処理のプログラム(図3参照)等が記憶されている。
更に、前記ナビゲーション制御部13には、操作部14、液晶ディスプレイ15、スピーカ16、通信装置17、タッチパネル18の各周辺装置(アクチュエータ)が電気的に接続されている。
【0034】
この操作部14は、走行開始時の現在地を修正し、案内開始地点としての出発地及び案内終了地点としての目的地を入力する際や施設に関する情報の検索を行う場合等に操作され、各種のキーや複数の操作スイッチから構成される。そして、ナビゲーション制御部13は、各スイッチの押下等により出力されるスイッチ信号に基づき、対応する各種の動作を実行すべく制御を行う。
【0035】
また、液晶ディスプレイ15には、現在走行中の地図情報、後述の検索語入力画面61(図6参照)、検索した施設の名称をリスト表示する検索結果表示画面71、操作案内、操作メニュー、キーの案内、現在地から目的地までの推奨経路、推奨経路に沿った案内情報、交通情報、ニュース、天気予報、時刻、メール、テレビ番組等が表示される。
【0036】
また、スピーカ16は、ナビゲーション制御部13からの指示に基づいて、推奨経路に沿った走行を案内する音声ガイダンス等を出力する。ここで、案内される音声ガイダンスとしては、例えば、「200m先、○○交差点を右方向です。」等がある。
【0037】
また、通信装置17は、地図情報配信センタと通信を行う携帯電話網等による通信手段であり、地図情報配信センタとの間で最もバージョンの新しい更新地図情報等の送受信を行う。また、通信装置17は地図情報配信センタに加えて、道路交通情報センタ等から送信された渋滞情報やサービスエリアの混雑状況等の各情報から成る交通情報を受信する。
【0038】
また、タッチパネル18は、液晶ディスプレイ15の表面部に装着された透明なパネル状のタッチスイッチであり、液晶ディスプレイ15の画面に表示されたボタンや地図上を押下することによって各種指示コマンドを入力することが可能に構成されている。尚、タッチパネル18は、液晶ディスプレイ15の画面を直接押下する光センサ液晶方式等で構成してもよい。
【0039】
ここで、施設名DB27に格納される施設名データテーブル51について図2に基づいて説明する。
図2に示すように、施設名データテーブル51は、「分割単位」と、施設名の読みを記憶する「読み」と、「施設名」とから構成されている。この「分割単位」には、施設名の読みを構成するキーワードと前方一致する平仮名が、50音順に1文字又は2文字ずつ記憶されている。ここで、キーワードは、意味を成す単位で構成された読みの文字列である。
【0040】
尚、「分割単位」には、例えば、「あああ」、「ああい」、「ああう」・・・等、50音順に3文字以上ずつ記憶するようにしてもよい。また、「分割単位」の一部区間だけ、例えば、・・・「お」、「かあ」、「かい」、・・・「かん」、「き」、「く」・・等、50音順に2文字以上ずつ記憶するようにしてもよい。
【0041】
また、「読み」には、各「分割単位」に記憶される平仮名と前方一致するキーワードを含む施設名の読みが記憶されている。また、施設名の読みは、キーワード毎に区切り文字(例えば「/」である。)で区切られて記憶されている。また、施設名の読みは、分割単位に記憶されている平仮名と前方一致するキーワードが先頭になるように、各キーワードの順序が当該施設名の読みの順番に従って循環するように並べ替えられて記憶されている。
【0042】
例えば、施設名の読みが「せいと/どーむ」では、「せいと」、「どーむ」が、施設名の読みのキーワードとして「読み」に記憶されている。また、施設名の読みの「せいと/どーむ」は、施設名データテーブル51の「分割単位」の各平仮名「せい」、「とお」に対応する「読み」にそれぞれ記憶される。
【0043】
尚、施設名の読みに含まれる「が」、「ぱ」等の濁音・半濁音は「か」、「は」等の清音に、「ゃ」、「っ」等の小文字仮名(拗音・促音)は「や」、「つ」等の大文字仮名に、長音は対応する母音等のように、仮名の基本文字に変換して記憶される。例えば、「せいと/どーむ」は、実際には「せいと/とおむ」と記憶されるが、本実施形態においては説明を簡単にするために施設名と読みとを一致させ「せいと/どーむ」として説明する。
【0044】
そして、平仮名「せい」が記憶されている「分割単位」に対応する施設名の「読み」には、キーワード「せいと」が先頭になるように「せいと/どーむ」が記憶されている。また、平仮名「とお」が記憶されている「分割単位」に対応する施設名の「読み」には、キーワード「どーむ」が先頭になるように「どーむ/せいと」が記憶されている。
【0045】
また、「施設名」には、検索対象となる目的地を表す施設名が、「読み」に記憶された施設名の読みに対応して記憶されている。例えば、施設名「西都ドーム」が、施設名の読みの「せいと/どーむ」に対応して記憶されている。従って、施設名「西都ドーム」は、施設名データテーブル51の「分割単位」の各平仮名「せい」、「とお」内の「読み」の「せいと/どーむ」、「どーむ/せいと」のそれぞれに対応する「施設名」に記憶されている。
【0046】
これにより、施設名データテーブル51の「分割単位」間では「施設名」に記憶された施設名の重複はあるが、各「分割単位」内においては、「施設名」に記憶された施設名の重複は無く、1つの施設名だけが記憶されている。従って、施設名データテーブル51の「分割単位」間では「読み」に記憶された施設名の読みの重複はあるが、各「分割単位」内においては、「読み」に記憶された施設名の読みの重複は無く、1つの施設名の読みだけが記憶されている。また、各「分割単位」毎の「読み」と「施設名」との合計データ容量を所定データ容量以下(例えば、1メガバイト〜10メガバイト以下である。)に設定することが可能となる。
【0047】
次に、施設名DB27に格納される先頭文字情報データテーブル52について図3に基づいて説明する。
図3に示すように、先頭文字情報データテーブル52は、「分割単位」と、「キーワードの先頭文字情報」と、「読み」とから構成されている。また、「キーワードの先頭文字情報」は、「あ行」〜「わ行」の50音の行別に区分されている。
【0048】
この「分割単位」は、施設名データテーブル51の「分割単位」に対応するものであり、施設名の読みを構成するキーワードと前方一致する平仮名が、50音順に1文字又は2文字ずつ記憶されている。従って、上記施設名データテーブル51の「分割単位」に、例えば、「あ」、「ああ」、「あい」、・・・等と1文字又は2文字の平仮名を記憶した場合には、先頭文字情報データテーブル52も同様に、「分割単位」に「あ」、「ああ」、「あい」、・・・等と1文字又は2文字の平仮名を記憶する。
【0049】
また、各「分割単位」に対応する「読み」には、施設名データテーブル51の各「分割単位」内の「読み」に記憶された施設名の読みがそれぞれ格納されている。例えば、平仮名「せい」が記憶された「分割単位」に対応する「読み」には、施設名データテーブル51の平仮名「せい」が記憶された「分割単位」内の「読み」に記憶されている施設名の読み「せいと/どーむ」、「せいと/ひゃっかてん」、「せいげん/そめや」、「せいとか/としょかん」が、区切り文字「;」で区切られて記憶されている。
【0050】
また、各「分割単位」に対応する「キーワードの先頭文字情報」には、同じ「分割単位」に対応する「読み」に記憶された各施設名の読み毎に、各キーワードの先頭文字が属する50音の行を行別にカウントし、各50音の行別のカウント値のうちの各施設名の読みの間の最大カウント値をそれぞれ抽出して、「キーワードの先頭文字情報」の「あ行」〜「わ行」の50音の行別に区分して記憶されている。
【0051】
例えば、図3に示すように、平仮名「せい」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」には、施設名の読み「せいげん/そめや」の各キーワード「せいげん」、「そめや」の先頭文字が属する「さ行」のカウント値「2」が、各キーワードの先頭文字が属する50音の行を行別にカウントした最大カウント値として記憶されている。
【0052】
また同様に、平仮名「せい」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」には、各施設名の読み「せいと/どーむ」、「せいとか/としょかん」の各キーワード「どーむ」、「としょかん」の先頭文字が属する「た行」の各カウント値「1」が、各キーワードの先頭文字が属する50音の行を行別にカウントした最大カウント値として記憶されている。
【0053】
また同様に、平仮名「せい」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」には、施設名の読み「せいと/ひゃっかてん」のキーワード「ひゃっかてん」の先頭文字が属する「は行」のカウント値「1」が、各キーワードの先頭文字が属する50音の行を行別にカウントした最大カウント値として記憶されている。また、平仮名「せい」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」の「あ行」、「か行」、「な行」、「ま行」〜「わ行」には、施設名の読みの各キーワードの先頭文字が属していない旨を表す「0」が記憶されている。
【0054】
従って、先頭文字情報データテーブル52の各「分割単位」に対応する「キーワードの先頭文字情報」の「あ行」〜「わ行」の50音の行別に区分して記憶されたカウント値によって、各「分割単位」内に記憶されている施設名の読みの各キーワードの先頭文字が属する50音の行の有・無を判別することが可能となる。
【0055】
[施設情報表示処理]
次に、上記のように構成されたナビゲーション装置1のCPU41が実行する処理であって、50音キー62から入力された検索語に基づいて施設情報を検索してリスト表示する「施設情報表示処理」について図4乃至図7に基づいて説明する。
【0056】
図4はCPU41が実行する処理であって、入力された検索語に基づいて施設情報を検索してリスト表示する「施設情報表示処理」を示すフローチャートである。尚、図4にフローチャートで示されるプログラムは、操作部14の不図示の目的地設定ボタンが押下された場合に、CPU41により実行される。
【0057】
図4に示すように、先ず、ステップ(以下、Sと略記する)11において、CPU41は、液晶ディスプレイ15の画面に、施設情報として目的地の住所や施設に関する名称等を検索するための検索語を入力する検索語入力画面61を表示する。
ここで、検索語入力画面61の一例について図6に基づいて説明する。図6に示すように、検索語入力画面61には、50音キー62、入力文字表示部63、検索語表示部64、修正ボタン65、戻るボタン66、次ワードボタン67、完了ボタン68、件数表示部69が表示される。
【0058】
この入力文字表示部63には、50音キー62によって入力された入力文字が表示される。そして、次ワードボタン67が押下された場合には、入力文字表示部63に表示されている文字列が検索語として検索語表示部64に確定表示されるとともに、次の文字列を入力することが可能となる。また、修正ボタン65を押下する毎に、入力文字表示部63に表示されている文字列の最終入力文字を1文字ずつ削除することができる。
【0059】
また、戻るボタン66を押下することによって、検索語入力画面61の前の画面に戻ることができる。更に、完了ボタン68を押下することによって、検索語表示部64に表示されている各文字列と入力文字表示部63に表示されている文字列を検索語として、施設情報としての施設に関する名称等を検索してリスト表示するように指示することができる。また、件数表示部69には、入力文字表示部63に表示されている文字列と検索語表示部64に表示されている各文字列によって検索された施設名の件数が表示される。
【0060】
続いて、図4に示すように、S12において、CPU41は、50音キー62が押下されたか否か、つまり、50音キー62から検索語が入力されたか否かを判定する判定処理を実行する。そして、50音キー62が押下されたと判定した場合には(S12:YES)、CPU41は、50音キー62から入力された入力文字を入力文字表示部63に表示すると共に、入力文字表示部63に表示している文字列を検索語としてRAM42に記憶後、S13の処理に移行する。
【0061】
S13において、CPU41は、検索語表示部64に表示されている各文字列と入力文字表示部63に表示されている文字列を検索語として、施設名データテーブル51に記憶された施設名から目的地候補である候補施設名を抽出する後述の「候補施設名抽出処理」のサブ処理(図5参照)を実行後、再度、S12以降の処理を実行する。
【0062】
一方、50音キー62が押下されていないと判定した場合には(S12:NO)、CPU41は、S14の処理に移行する。S14において、CPU41は、次ワードボタン67が押下されたか否かを判定する判定処理を実行する。そして、次ワードボタン67が押下されたと判定した場合には(S14:YES)、CPU41は、S15の処理に移行する。
【0063】
S15において、CPU41は、入力文字表示部63に表示されている文字列を検索語として検索語表示部64に確定表示すると共に、この文字列を確定検索語としてRAM42に時系列的に記憶する。また、CPU41は、入力文字表示部63に表示されている文字列をクリアして、50音キー62から新たな文字列を入力できるように設定した後、再度、S12以降の処理を実行する。
【0064】
一方、次ワードボタン67が押下されていないと判定した場合には(S14:NO)、CPU41は、S16の処理に移行する。S16において、CPU41は、完了ボタン68が押下されたか否かを判定する判定処理を実行する。そして、完了ボタン68が押下されていないと判定した場合には(S16:NO)、CPU41は、S17の処理に移行する。
【0065】
S17において、CPU41は、修正ボタン65又は戻るボタン66が押下されたか否かを判定する判定処理を実行する。そして、修正ボタン65が押下されたと判定した場合には、CPU41は、入力文字表示部63に表示されている文字列の最終入力文字を1文字削除した後、再度、S12以降の処理を実行する。
【0066】
また、戻るボタン66が押下されたと判定した場合には、CPU41は、図3に示す当該処理を終了し、検索語入力画面61の前の画面に戻る。更に、修正ボタン65及び戻るボタン66が押下されなかった場合には、CPU41は、再度、S12以降の処理を実行する。
【0067】
一方、完了ボタン68が押下されたと判定した場合には(S16:YES)、CPU41は、S18の処理に移行する。S18において、CPU41は、上記S13で抽出された全候補施設名をリスト表示後(図7参照)、当該処理を終了する。
【0068】
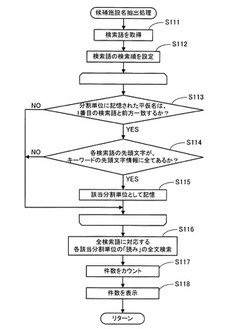
[候補施設名抽出処理]
次に、上記S13で実行する「候補施設名抽出処理」のサブ処理について図5に基づいて説明する。
図5に示すように、S111において、CPU41は、入力文字表示部63に表示されている検索語と各検索語表示部64に表示されている確定検索語とをRAM42から読み出す。
【0069】
そして、S112において、CPU41は、このRAM42から読み出した各検索語の包含関係に従って検索語の検索順を設定し、この検索順に検索語をRAM42に記憶する。
【0070】
具体的には、CPU41は、RAM42から読み出した各検索語の文字数の多い順に検索語の検索順を設定し、この検索順に検索語をRAM42に記憶する。また、CPU41は、RAM42から読み出した各検索語の文字数が同じ場合には、時系列的に早くRAM42に記憶した順に検索語の検索順を設定し、この検索順に検索語をRAM42に記憶する。
【0071】
例えば、CPU41は、RAM42から読み出した各検索語が、図6に示すように、「せ」、「と」の場合には、検索語「せ」の検索順を1番目に設定し、検索語「と」の検索順を2番目に設定する。そして、CPU41は、この検索順に各検索語「せ」、「と」をRAM42に記憶する。
【0072】
続いて、S113において、CPU41は、先頭文字情報データテーブル52の1番目の「分割単位」に記憶されている平仮名を読み出す。そして、CPU41は、当該「分割単位」に記憶されている平仮名が、検索順が1番目の検索語と前方一致するか否かを判定する判定処理を実行する。
【0073】
そして、当該「分割単位」に記憶されている平仮名が、検索順が1番目の検索語と前方一致しないと判定した場合には(S113:NO)、CPU41は、先頭文字情報データテーブル52に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。そして、先頭文字情報データテーブル52に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル52の次の「分割単位」に記憶されている平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル52に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了してS116の処理に移行する。
【0074】
一方、S113で当該「分割単位」に記憶されている平仮名が、検索順が1番目の検索語と前方一致すると判定した場合には(S113:YES)、CPU41は、S114の処理に移行する。S114において、CPU41は、全検索語をRAM42から読み出し、全検索語の各先頭文字の属する50音の行を行別にカウントする。
【0075】
そして、CPU41は、当該「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されている各カウント値が、全検索語の各先頭文字の属する50音の行の行別のカウント値以上か否かを判定する判定処理を実行する。つまり、全検索語の各先頭文字の属する50音の行に、各キーワードの先頭文字が属する施設名の読みが、当該「分割単位」に対応する施設名データテーブル51の「分割単位」内の「読み」に記憶されているか否かを判定する判定処理を実行する。
【0076】
そして、当該「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されているカウント値が、全検索語の各先頭文字の属する50音の行の行別のカウント値より少ない50音の行の区分やカウント値が「0」の50音の行の区分が1つでもあると判定した場合には(S114:NO)、CPU41は、先頭文字情報データテーブル52に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。
【0077】
そして、先頭文字情報データテーブル52に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル52の次の「分割単位」に記憶されている平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル52に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了してS116の処理に移行する。
【0078】
一方、S114で当該「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されているカウント値が、全検索語の各先頭文字の属する50音の行の行別のカウント値以上であると判定した場合には(S114:YES)、CPU41は、S115の処理に移行する。S115において、CPU41は、当該「分割単位」を施設名データテーブル51の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0079】
続いて、CPU41は、先頭文字情報データテーブル52に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。そして、先頭文字情報データテーブル52に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル52の次の「分割単位」に記憶されている平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル52に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了してS116の処理に移行する。
【0080】
例えば、図3に示すように、上記S112で1番目の検索順に設定された検索語が「せ」で、2番目の検索順に設定された検索語が「と」の場合には、CPU41は、当該検索語の先頭文字「せ」と前方一致する各平仮名「せ」、「せあ」、「せい」、「せう」、・・・「せん」が記憶された各「分割単位」について、S114の処理を実行する。
【0081】
そして、CPU41は、「キーワードの先頭文字情報」の全検索語「せ」、「と」の各先頭文字「せ」、「と」の属する50音の「さ行」、「た行」の区分に記憶されている各カウント値が、「1」以上である各平仮名「せい」、「せん」が記憶された「分割単位」を施設名データテーブル51の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0082】
そして、図5に示すように、S116において、CPU41は、RAM42から上記S115で記憶した施設名データテーブル51の候補施設名を検索する該当「分割単位」を順番に読み出し、施設名データテーブル51の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出す。そして、CPU41は、この読み出した各施設名の読みを構成するキーワードの中に、上記S112で検索順を設定した各検索語と前方一致するキーワードがあるか否かを判定する判定処理を実行する、つまり、読み出した全施設名の「読み」について各検索語の全文検索を行う。
【0083】
そして、CPU41は、読み出した施設名の読みを構成するキーワードの中に各検索語と前方一致するキーワードがある場合には、この施設名の読みに対応する「施設名」を施設名データテーブル51から読み出し、目的地候補である候補施設名としてRAM42に順番に記憶後、S117の処理に移行する。
【0084】
尚、CPU41は、検索語と前方一致する施設名の読みのキーワードが、この検索語よりも短い文字列の場合には、更に、検索語のキーワードと一致していない残りの文字列と前方一致するキーワードが、当該施設名の読みを構成するキーワードの中にあるか否かを判定する判定処理を実行する。
【0085】
そして、CPU41は、検索語のキーワードと一致していない残りの文字列と前方一致するキーワードが、当該施設名の読みを構成するキーワードの中にある場合には、この施設名の読みに対応する「施設名」を施設名データテーブル51から読み出し、目的地候補である候補施設名としてRAM42に記憶する。
【0086】
例えば、各平仮名「せい」、「せん」が記憶された「分割単位」を施設名データテーブル51の候補施設名を検索する該当「分割単位」としてRAM42に記憶した場合には、CPU41は、施設名データテーブル51の各平仮名「せい」、「せん」が記憶された「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出す。
【0087】
そして、図2に示すように、CPU41は、この読み出した各施設名の読みを構成するキーワードの中に、各検索語「せ」、「と」と前方一致するキーワードがある各施設名の読み「せいと/どーむ」、「せいとか/としょかん」、「せんけ/とけい」に対応する各施設名「西都ドーム」、「西都科図書館」、「千家時計」を施設名データテーブル51から読み出し、目的地候補である候補施設名としてRAM42に順番に記憶する。
【0088】
続いて、図5に示すように、S117において、CPU41は、候補施設名をRAM42から順番に読み出してカウントし、入力された検索語によって検索可能な候補施設名の件数としてRAM42に記憶する。例えば、候補施設名が各施設名「西都ドーム」、「西都科図書館」、「千家時計」の場合には、件数として「3件」をRAM42に記憶する。
【0089】
尚、検索語に含まれる濁音、半濁音、拗音、促音、長音等の特殊文字はそれぞれ基本文字に変換して処理される。例えば、「とうきょう」は「とうきよう」、「らんど」は「らんと」として検索される。前述したように、施設名データテーブル51に記憶されている施設名の読みに含まれる特殊文字も基本文字に変換して記憶されているため、結果的には特殊文字を無視した検索を行うことになる。
【0090】
そして、S118において、CPU41は、RAM42から件数を読み出し、検索語入力画面61の件数表示部69に表示後、当該サブ処理を終了してメインフローチャートに戻り、S12以降の処理を実行する。例えば、RAM42から読み出した件数が「3件」の場合には、図6に示すように、件数表示部69に「3件」と表示後、当該サブ処理を終了してメインフローチャートに戻り、S12以降の処理を実行する。
【0091】
ここで、図6に示すように、50音キー62から各検索語「せ」、「と」を入力して、完了ボタン68を押下した場合の、抽出した施設名をリスト表示した検索結果表示画面71の一例を図7に基づいて説明する。尚、各検索語「せ」、「と」によって、候補施設名として各施設名「西都ドーム」、「西都科図書館」、「千家時計」が抽出されているとする。
【0092】
図7に示すように、PU41は、液晶ディスプレイ15に検索結果表示画面71を表示し、候補施設名として各施設名「西都ドーム」、「西都科図書館」、「千家時計」をRAM42から読み出し、一番上の検索結果表示欄72から順番に表示する。また、CPU41は、件数「3件」をRAM42から読み出し、検索結果表示画面71の上部に設けられた件数表示部73に表示する。
【0093】
ここで、ユーザが、各検索結果表示欄72の施設情報を押下して選択すると、CPU41は、当該施設を目的地に設定して経路探索を行い、推奨経路を地図上に表示する。また、当該施設に関する施設情報(例えば、営業時間、料金等である。)を表示する。
また、各検索結果表示欄72の左側には、検索結果表示欄72の施設の名称を1件ずつスクロールダウン、スクロールアップするための前ボタン74、次ボタン75と、検索結果表示欄72の施設の名称を5件ずつスクロールダウン、スクロールアップするための各頁ボタン76、77とが表示されている。
【0094】
以上詳細に説明した通り、実施例1に係るナビゲーション装置1では、CPU41は、先頭文字情報データテーブル52の各「分割単位」のうち、検索順が1番目の検索語と前方一致する平仮名が記憶された「分割単位」を抽出する。そして、CPU41は、この抽出した各「分割単位」のうち、各「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されているカウント値が、全検索語の各先頭文字の属する50音の行の行別のカウント値以上のものだけを、施設名データテーブル51の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0095】
続いて、CPU41は、施設名データテーブル51の候補施設名を検索する該当「分割単位」を順番に読み出し、施設名データテーブル51の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出す。そして、CPU41は、読み出した全施設名の「読み」について各検索語の全文検索を行い、読み出した施設名の読みを構成するキーワードの中に各検索語と前方一致するキーワードがある場合には、この施設名の読みに対応する「施設名」を施設名データテーブル51から読み出し、目的地候補である候補施設名としてRAM42に記憶する。
【0096】
これにより、文字数の少ない(例えば、1文字又は2文字である。)複数の検索語が入力されても、CPU41は、検索順が1番目の検索語と前方一致する平仮名が記憶された「分割単位」のうち、全検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された「分割単位」だけを先頭文字情報データテーブル52から抽出することが可能となる。従って、CPU41は、全検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された「分割単位」だけを先頭文字情報データテーブル52から抽出して、施設名データテーブル51の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出して全検索語について全文検索を行うため、検索対象となる施設名の読みを少なくすることができ、検索を高速で行い、応答性の低下を防止することが可能となる。
【0097】
また、施設名データテーブル51の「分割単位」間では「施設名」に記憶された施設名の重複はあるが、各「分割単位」内においては、「施設名」に記憶された施設名の重複は無く、1つの施設名だけが記憶されている。従って、施設名データテーブル51の「分割単位」間では「読み」に記憶された施設名の読みの重複はあるが、各「分割単位」内においては、「読み」に記憶された施設名の読みの重複は無く、1つの施設名の読みだけが記憶されている。これにより、各「分割単位」の「施設名」に記憶された施設名は、1個だけ記憶されるため、重複記憶される施設名を減少させて、名称リストのデータ容量の削減化を図り、名称リストを展開するメモリ容量の増大を抑止することが可能となる。
【実施例2】
【0098】
次に、実施例2に係るナビゲーション装置81について図8に基づいて説明する。尚、以下の説明において上記図1乃至図7の実施例1に係るナビゲーション装置1の構成と同一符号は、前記実施例1に係るナビゲーション装置1の構成と同一あるいは相当部分を示すものである。
【0099】
この実施例2に係るナビゲーション装置81の概略構成は、実施例1に係るナビゲーション装置1とほぼ同じ構成である。また、各種制御処理も実施例1に係るナビゲーション装置1とほぼ同じ制御処理である。
但し、ナビゲーション装置81は、先頭文字情報データテーブル52に替えて、図8に示す先頭文字情報データテーブル82を施設名DB27に格納している点で異なっている。このため、後述のように、上記S114における処理も異なっている。
【0100】
ここで、先頭文字情報データテーブル82について図8に基づいて説明する。
図8に示すように、実施例2に係る先頭文字情報データテーブル82は、上記先頭文字情報データテーブル52と同様に、「分割単位」と、「キーワードの先頭文字情報」と、「読み」とから構成されている。また、「キーワードの先頭文字情報」は、「あ行」〜「わ行」の50音の行別に区分されている。
【0101】
但し、図8に示すように、各「分割単位」に対応する「キーワードの先頭文字情報」には、同じ「分割単位」に対応する「読み」に記憶された各施設名の読み毎に、各キーワードの先頭文字が属する50音の行を行別にカウントし、カウント値が「1」以上の50音の行別の区分には、「1」を代入して記憶し、カウント値が「0」の50音の行別の区分には、「0」を代入して記憶する。つまり、各キーワードの先頭文字が属する50音の行の区分には「1」が記憶され、それ以外の50音の行の区分には「0」が記憶されている。
【0102】
例えば、図8に示すように、平仮名「せい」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」には、施設名の読み「せいげん/そめや」の各キーワード「せいげん」、「そめや」の先頭文字が属する「さ行」のカウント値は「2」であるため(図3参照)、当該「キーワードの先頭文字情報」の「さ行」には、「1」が記憶されている。
【0103】
また同様に、平仮名「せい」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」には、各施設名の読み「せいと/どーむ」、「せいとか/としょかん」の各キーワード「どーむ」、「としょかん」の先頭文字が属する「た行」の各カウント値は「1」であるため(図3参照)、当該「キーワードの先頭文字情報」の「た行」には、「1」が記憶されている。
【0104】
また同様に、平仮名「せい」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」には、施設名の読み「せいと/ひゃっかてん」のキーワード「ひゃっかてん」の先頭文字が属する「は行」のカウント値は「1」であるため(図3参照)、当該「キーワードの先頭文字情報」の「は行」には、「1」が記憶されている。また、平仮名「せい」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」の「あ行」、「か行」、「な行」、「ま行」〜「わ行」には、施設名の読みの各キーワードの先頭文字が属していない旨を表す「0」が記憶されている。
【0105】
従って、先頭文字情報データテーブル82の各「分割単位」に対応する「キーワードの先頭文字情報」の「あ行」〜「わ行」の50音の各行に記憶された値が「1」か否かによって、各「分割単位」内に記憶されている施設名の読みの各キーワードの先頭文字が属する50音の行の有・無を判別することが可能となる。
【0106】
次に、実施例2に係るナビゲーション装置81のCPU41が実行するS114の処理について説明する。
S114において、CPU41は、全検索語をRAM42から読み出し、上記S113で特定した「分割単位」に対応する「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されている値が、全て「1」か否かを判定する判定処理を実行する。つまり、全検索語の各先頭文字の属する50音の行に、各キーワードの先頭文字が属する施設名の読みが、当該「分割単位」に対応する施設名データテーブル51の「分割単位」内の「読み」に記憶されているか否かを判定する判定処理を実行する。
【0107】
そして、当該「分割単位」の「キーワードの先頭文字情報」の50音の行の区分に記憶されている値が、全て「1」でない、つまり、値の「0」のものがあると判定した場合には(S114:NO)、CPU41は、先頭文字情報データテーブル82に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。
【0108】
そして、先頭文字情報データテーブル82に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル82の次の「分割単位」に記憶されている平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル82に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了して上記S116の処理に移行する。
【0109】
一方、S114で当該「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されているカウント値が、全て「1」であると判定した場合には(S114:YES)、CPU41は、S115の処理に移行する。S115において、CPU41は、当該「分割単位」を施設名データテーブル51の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0110】
続いて、CPU41は、先頭文字情報データテーブル82に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。そして、先頭文字情報データテーブル82に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル82の次の「分割単位」に記憶されている平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル82に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了して上記S116の処理に移行する。
【0111】
例えば、図8に示すように、上記S112で1番目の検索順に設定された検索語が「せ」で、2番目の検索順に設定された検索語が「と」の場合には、CPU41は、当該検索語の先頭文字「せ」と前方一致する各平仮名「せ」、「せあ」、「せい」、「せう」、・・・「せん」が記憶された各「分割単位」について、S114の処理を実行する。
【0112】
そして、CPU41は、「キーワードの先頭文字情報」の全検索語「せ」、「と」の各先頭文字「せ」、「と」の属する50音の「さ行」、「た行」に記憶されている値が、全て「1」である各平仮名「せい」、「せん」が記憶された「分割単位」を施設名データテーブル51の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0113】
以上詳細に説明した通り、実施例2に係るナビゲーション装置81では、CPU41は、先頭文字情報データテーブル82の各「分割単位」のうち、検索順が1番目の検索語と前方一致する平仮名が記憶された「分割単位」を抽出する。そして、CPU41は、この抽出した各「分割単位」のうち、各「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されている値が、全て「1」のものだけを、施設名データテーブル51の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0114】
続いて、CPU41は、施設名データテーブル51の候補施設名を検索する該当「分割単位」を順番に読み出し、施設名データテーブル51の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出す。そして、CPU41は、読み出した全施設名の「読み」について各検索語の全文検索を行い、読み出した施設名の読みを構成するキーワードの中に各検索語と前方一致するキーワードがある場合には、この施設名の読みに対応する「施設名」を施設名データテーブル51から読み出し、目的地候補である候補施設名としてRAM42に記憶する。
【0115】
これにより、文字数の少ない(例えば、1文字又は2文字である。)複数の検索語が入力されても、CPU41は、検索順が1番目の検索語と前方一致する平仮名が記憶された「分割単位」のうち、全検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された「分割単位」だけを先頭文字情報データテーブル82から抽出することが可能となる。
【0116】
従って、CPU41は、全検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された「分割単位」だけを先頭文字情報データテーブル82から抽出して、施設名データテーブル51の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出して全検索語について全文検索を行うため、検索対象となる施設名の読みを少なくすることができ、検索を高速で行い、応答性の低下を防止することが可能となる。
【実施例3】
【0117】
次に、実施例3に係るナビゲーション装置85について図9に基づいて説明する。尚、以下の説明において上記図1乃至図7の実施例1に係るナビゲーション装置1の構成と同一符号は、前記実施例1に係るナビゲーション装置1の構成と同一あるいは相当部分を示すものである。
【0118】
この実施例3に係るナビゲーション装置85の概略構成は、実施例1に係るナビゲーション装置1とほぼ同じ構成である。また、各種制御処理も実施例1に係るナビゲーション装置1とほぼ同じ制御処理である。
但し、ナビゲーション装置85は、先頭文字情報データテーブル52に替えて、図9に示す先頭文字情報データテーブル86を施設名DB27に格納している点で異なっている。このため、後述のように、上記S114における処理も異なっている。
【0119】
ここで、先頭文字情報データテーブル86について図9に基づいて説明する。
図9に示すように、実施例3に係る先頭文字情報データテーブル86は、上記先頭文字情報データテーブル52と同様に、「分割単位」と、「キーワードの先頭文字情報」と、「読み」とから構成されている。但し、「キーワードの先頭文字情報」は、平仮名が50音順に1文字ずつ属するように区分されている。
【0120】
また、各「分割単位」に対応する「キーワードの先頭文字情報」には、同じ「分割単位」に対応する「読み」に記憶された各施設名の読み毎に、各キーワードの先頭文字を50音別にそれぞれカウントし、各50音別のカウント値のうちの各施設名の読みの間の最大カウント値をそれぞれ抽出して、「キーワードの先頭文字情報」の各キーワードの先頭文字が属する「あ」〜「ん」の区分に記憶されている。
【0121】
例えば、図9に示すように、平仮名「せい」が記憶された「分割単位」に対応する各施設名の読みには、「せいと/どーむ」、「せいと/ひゃっかてん」、「せいげん/そめや」、「せいとか/としょかん」が記憶されている。このため、施設名の読み「せいと/どーむ」の各キーワード「せいと」、「どーむ」の先頭文字のカウント値は、「せ」が「1」、「と」が「1」である。また、施設名の読み「せいと/ひゃっかてん」の各キーワード「せいと」、「ひゃっかてん」の先頭文字のカウント値は、「せ」が「1」、「ひ」が「1」である。
【0122】
また、施設名の読み「せいげん/そめや」の各キーワード「せいげん」、「そめや」の先頭文字のカウント値は、「せ」が「1」、「そ」が「1」である。また、施設名の読み「せいとか/としょかん」の各キーワード「せいとか」、「としょかん」の先頭文字のカウント値は、「せ」が「1」、「と」が「1」である。
【0123】
従って、平仮名「せい」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」の各平仮名「せ」、「そ」、「と」、「ひ」が属する区分には、それぞれ最大カウント値として「1」が記憶されている。また、平仮名「せい」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」の各平仮名「あ」〜「す」、「た」〜「て」、「な」〜「は」、「ふ」〜「ん」が属する区分には、「0」が記憶されている。
【0124】
これにより、先頭文字情報データテーブル86の各「分割単位」に対応する「キーワードの先頭文字情報」の「あ」〜「ん」が属する各区分に記憶されたカウント値によって、各「分割単位」内に記憶されている施設名の読みの各キーワードの先頭文字を構成する平仮名を判別することが可能となる。
【0125】
次に、実施例3に係るナビゲーション装置85のCPU41が実行するS114の処理について説明する。
S114において、CPU41は、全検索語をRAM42から読み出し、全検索語の各先頭文字を50音別にカウントする。そして、CPU41は、上記S113で特定した「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する区分に記憶されている各カウント値が、全検索語の各先頭文字の50音別のカウント値以上か否かを判定する判定処理を実行する。つまり、全検索語の各先頭文字の属する50音の区分に、各キーワードの先頭文字が属する施設名の読みが、当該「分割単位」に対応する施設名データテーブル51の「分割単位」内の「読み」に記憶されているか否かを判定する判定処理を実行する。
【0126】
そして、当該「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する区分に、全検索語の各先頭文字の50音別のカウント値より少ない区分やカウント値が「0」の区分が1つでもあると判定した場合には(S114:NO)、CPU41は、先頭文字情報データテーブル86に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。
【0127】
そして、先頭文字情報データテーブル86に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル86の次の「分割単位」に記憶されている平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル86に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了してS116の処理に移行する。
【0128】
一方、S114で当該「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する区分に記憶されているカウント値が、全検索語の各先頭文字の50音別のカウント値以上であると判定した場合には(S114:YES)、CPU41は、S115の処理に移行する。S115において、CPU41は、当該「分割単位」を施設名データテーブル51の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0129】
続いて、CPU41は、先頭文字情報データテーブル86に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。そして、先頭文字情報データテーブル86に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル86の次の「分割単位」に記憶されている平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル86に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了してS116の処理に移行する。
【0130】
例えば、図9に示すように、上記S112で1番目の検索順に設定された検索語が「せ」で、2番目の検索順に設定された検索語が「と」の場合には、CPU41は、当該検索語の先頭文字「せ」と前方一致する各平仮名「せ」、「せあ」、「せい」、「せう」、・・・「せん」が記憶された各「分割単位」について、S114の処理を実行する。
【0131】
そして、CPU41は、「キーワードの先頭文字情報」の全検索語「せ」、「と」の各先頭文字「せ」、「と」の属する区分に記憶されている各カウント値が、「1」以上である各平仮名「せい」、「せん」が記憶された「分割単位」を施設名データテーブル51の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0132】
以上詳細に説明した通り、実施例3に係るナビゲーション装置85では、CPU41は、先頭文字情報データテーブル86の各「分割単位」のうち、検索順が1番目の検索語と前方一致する平仮名が記憶された「分割単位」を抽出する。そして、CPU41は、この抽出した各「分割単位」のうち、各「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する区分に記憶されているカウント値が、全検索語の各先頭文字の50音別のカウント値以上のものだけを、施設名データテーブル51の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0133】
続いて、CPU41は、施設名データテーブル51の候補施設名を検索する該当「分割単位」を順番に読み出し、施設名データテーブル51の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出す。そして、CPU41は、読み出した全施設名の「読み」について各検索語の全文検索を行い、読み出した施設名の読みを構成するキーワードの中に各検索語と前方一致するキーワードがある場合には、この施設名の読みに対応する「施設名」を施設名データテーブル51から読み出し、目的地候補である候補施設名としてRAM42に記憶する。
【0134】
これにより、文字数の少ない(例えば、1文字又は2文字である。)複数の検索語が入力されても、CPU41は、検索順が1番目の検索語と前方一致する平仮名が記憶された「分割単位」のうち、全検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された「分割単位」だけを先頭文字情報データテーブル86から抽出することが可能となる。
【0135】
従って、CPU41は、全検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された「分割単位」だけを先頭文字情報データテーブル86から抽出して、施設名データテーブル51の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出して全検索語について全文検索を行うため、検索対象となる施設名の読みを少なくすることができ、検索を高速で行い、応答性の低下を防止することが可能となる。
【実施例4】
【0136】
次に、実施例4に係るナビゲーション装置91について図10及び図11に基づいて説明する。尚、以下の説明において上記図1乃至図7の実施例1に係るナビゲーション装置1の構成と同一符号は、前記実施例1に係るナビゲーション装置1の構成と同一あるいは相当部分を示すものである。
【0137】
この実施例4に係るナビゲーション装置91の概略構成は、実施例1に係るナビゲーション装置1とほぼ同じ構成である。また、各種制御処理も実施例1に係るナビゲーション装置1とほぼ同じ制御処理である。
但し、ナビゲーション装置91は、施設名データテーブル51に替えて、図10に示す施設名データテーブル92を施設名DB27に格納し、また、先頭文字情報データテーブル52に替えて、図11に示す先頭文字情報データテーブル93を施設名DB27に格納している点で異なっている。
【0138】
ここで、施設名データテーブル92について図10に基づいて説明する。
図10に示すように、施設名データテーブル92は、施設名データテーブル51と同様に、「分割単位」と、施設名の読みを記憶する「読み」と、「施設名」とから構成されている。
但し、この「分割単位」には、施設名の読みを構成するキーワードと前方一致する1文字乃至3文字の平仮名が、その属する50音の1行乃至3行の組み合わせに対応されて記憶されている。例えば、「分割単位」が「た行あ行」には、施設名の読みのキーワードと前方一致する2文字の各平仮名「たあ」、「たい」、「たう」、・・・・「とえ」、「とお」が属している。
【0139】
尚、「分割単位」には、例えば「あ行あ行あ行あ行」、「あ行あ行あ行か行」、「あ行あ行あ行さ行」・・・等、50音の4行以上の組み合わせを記憶するようにしてもよい。また、「分割単位」の一部区間だけ、例えば、・・・「あ行わ行」、「か行あ行あ行あ行」、「か行あ行あ行か行」、・・・「か行あ行あ行わ行」、「か行か行」、「か行さ行」・・等、50音の4行以上の組み合わせを記憶するようにしてもよい。
【0140】
また、「読み」には、「分割単位」に属する1文字乃至3文字の各平仮名と前方一致するキーワードを含む施設名の読みが記憶されている。例えば、施設名の読みが「あいし/えいあーる/おかざき/こうじょう/せっけいか」は、各キーワードの前方3文字の「あいし」、「えいあ」、「おかざ」、「こうじ」、「せっけ」に対応する施設名データテーブル92の「分割単位」の50音の3行の各組み合わせ「あ行あ行さ行」、「あ行あ行あ行」、「あ行か行さ行」、「か行あ行さ行」、「さ行た行か行」に対応する「読み」にそれぞれ記憶される。
【0141】
また、「施設名」には、検索対象となる目的地を表す施設名が、「読み」に記憶された施設名の読みに対応して記憶されている。例えば、施設名「あいしAR岡崎工場設計課」は、施設名データテーブル92の「分割単位」の「あ行あ行さ行」、「あ行あ行あ行」、「あ行か行さ行」、「か行あ行さ行」、「さ行た行か行」内の「読み」の「あいし/えいあーる/おかざき/こうじょう/せっけいか」に対応する「施設名」にそれぞれ記憶される。
【0142】
次に、先頭文字情報データテーブル93について図11に基づいて説明する。
図11に示すように、先頭文字情報データテーブル93は、先頭文字情報データテーブル52と同様に、「分割単位」と、「キーワードの先頭文字情報」と、「読み」とから構成されている。また、「キーワードの先頭文字情報」は、「あ行」〜「わ行」の50音の行別に区分されている。
【0143】
但し、この「分割単位」は、施設名データテーブル92の「分割単位」に対応するものであり、施設名の読みを構成するキーワードと前方一致する1文字乃至3文字の平仮名が、その属する50音の1行乃至3行の組み合わせに対応されて記憶されている。例えば、「分割単位」が「あ行あ行」には、施設名の読みのキーワードと前方一致する2文字の各平仮名「ああ」、「あい」、「あう」、・・・・「おえ」、「おお」が属している。
【0144】
また、各「分割単位」に対応する「読み」には、施設名データテーブル92の各「分割単位」内の「読み」に記憶された施設名の読みがそれぞれ格納されている。例えば、50音の2行の組み合わせ「あ行あ行」が記憶された「分割単位」に対応する「読み」には、施設名データテーブル92の50音の2行の組み合わせ「あ行あ行」が記憶された「分割単位」内の「読み」に記憶されている施設名の読み「ああ」、「えい」、・・・が、区切り文字「;」で区切られて記憶されている。
【0145】
また、各「分割単位」に対応する「キーワードの先頭文字情報」には、同じ「分割単位」に対応する「読み」に記憶された各施設名の読み毎に、各キーワードの先頭文字が属する50音の行を行別にカウントし、各50音の行別のカウント値のうちの各施設名の読みの間の最大カウント値をそれぞれ抽出して、「キーワードの先頭文字情報」の「あ行」〜「わ行」の50音の行別に区分して記憶されている。
【0146】
例えば、図11に示すように、50音の3行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」には、施設名の読み「おおさか/おおい/おおさまじょう/おおて/おみやげ」の各キーワード「おおさか」、「おおい」、「おおさまじょう」、「おおて」、「おみやげ」の先頭文字が属する「あ行」のカウント値「5」が、各キーワードの先頭文字が属する50音の行を行別にカウントした最大カウント値として記憶されている。
【0147】
また同様に、50音の3行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」には、施設名の読み「あいし/えいあーる/おかざき/こうじょう/せっけいか」のキーワード「こうじょう」の先頭文字が属する「か行」のカウント値「1」が、各キーワードの先頭文字が属する50音の行を行別にカウントした最大カウント値として記憶されている。
【0148】
また同様に、50音の3行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」には、施設名の読み「うえしの/しあたー」のキーワード「しあたー」の先頭文字が属する「さ行」のカウント値「1」が、各キーワードの先頭文字が属する50音の行を行別にカウントした最大カウント値として記憶されている。また、50音の3行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」の「た行」〜「わ行」には、施設名の読みの各キーワードの先頭文字が属していない旨を表す「0」が記憶されている。
【0149】
従って、先頭文字情報データテーブル93の各「分割単位」に対応する「キーワードの先頭文字情報」の「あ行」〜「わ行」の50音の行別に区分して記憶されたカウント値によって、各「分割単位」内に記憶されている施設名の読みの各キーワードの先頭文字が属する50音の行の有・無を判別することが可能となる。
【0150】
そして、実施例4に係るナビゲーション装置91のCPU41は、上記図5に示す「候補施設名抽出処理」のサブ処理のS113〜S116において、施設名データテーブル51及び先頭文字情報データテーブル52に替えて、施設名データテーブル92及び先頭文字情報データテーブル93を使用する。
【0151】
具体的には、上記S113において、CPU41は、先頭文字情報データテーブル93の1番目の「分割単位」に記憶されている50音の行の組み合わせに属する平仮名が、検索順が1番目の検索語と前方一致するか否かを判定する判定処理を実行する。そして、当該「分割単位」に記憶されている50音の行の組み合わせに属する平仮名が、検索順が1番目の検索語と前方一致しないと判定した場合には(S113:NO)、CPU41は、先頭文字情報データテーブル93に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。
【0152】
そして、先頭文字情報データテーブル93に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル93の次の「分割単位」に記憶されている50音の行の組み合わせに属する平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル93に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了してS116の処理に移行する。
【0153】
一方、S113で当該「分割単位」に記憶されている50音の行の組み合わせに属する平仮名が、検索順が1番目の検索語と前方一致すると判定した場合には(S113:YES)、CPU41は、S114の処理に移行する。S114において、CPU41は、全検索語をRAM42から読み出し、全検索語の各先頭文字の属する50音の行を行別にカウントする。
【0154】
そして、CPU41は、当該「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されている各カウント値が、全検索語の各先頭文字の属する50音の行の行別のカウント値以上か否かを判定する判定処理を実行する。つまり、全検索語の各先頭文字の属する50音の行に、各キーワードの先頭文字が属する施設名の読みが、当該「分割単位」に対応する施設名データテーブル92の「分割単位」内の「読み」に記憶されているか否かを判定する判定処理を実行する。
【0155】
そして、当該「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されているカウント値が、全検索語の各先頭文字の属する50音の行の行別のカウント値より少ない50音の行の区分やカウント値が「0」の50音の行の区分が1つでもあると判定した場合には(S114:NO)、CPU41は、先頭文字情報データテーブル93に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。
【0156】
そして、先頭文字情報データテーブル93に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル93の次の「分割単位」に記憶されている50音の行の組み合わせに属する平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル93に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了してS116の処理に移行する。
【0157】
一方、S114で当該「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されているカウント値が、全検索語の各先頭文字の属する50音の行の行別のカウント値以上であると判定した場合には(S114:YES)、CPU41は、S115の処理に移行する。S115において、CPU41は、当該「分割単位」を施設名データテーブル92の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0158】
続いて、CPU41は、先頭文字情報データテーブル93に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。そして、先頭文字情報データテーブル93に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル93の次の「分割単位」に記憶されている50音の行の組み合わせに属する平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル93に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了してS116の処理に移行する。
【0159】
例えば、図11に示すように、上記S112で1番目の検索順に設定された検索語が「あい」で、2番目の検索順に設定された検索語が「こ」の場合には、CPU41は、当該検索語の先頭文字「あ」と前方一致する各50音の行の組み合わせ「あ行」、「あ行あ行」、・・・「あ行あ行さ行」・・・「あ行わ行わ行」が記憶された各「分割単位」について、S114の処理を実行する。
【0160】
そして、CPU41は、「キーワードの先頭文字情報」の全検索語「あい」、「こ」の各先頭文字「あ」、「こ」の属する50音の「あ行」、「か行」の区分に記憶されている各カウント値が、「1」以上である50音の行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」を施設名データテーブル92の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0161】
そして、S116において、CPU41は、RAM42から上記S115で記憶した施設名データテーブル92の候補施設名を検索する該当「分割単位」を順番に読み出し、施設名データテーブル92の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出す。そして、CPU41は、この読み出した各施設名の読みを構成するキーワードの中に、上記S112で検索順を設定した各検索語と前方一致するキーワードがあるか否かを判定する判定処理を実行する、つまり、読み出した全施設名の「読み」について各検索語の全文検索を行う。
【0162】
そして、CPU41は、読み出した施設名の読みを構成するキーワードの中に各検索語と前方一致するキーワードがある場合には、この施設名の読みに対応する「施設名」を施設名データテーブル92から読み出し、目的地候補である候補施設名としてRAM42に順番に記憶後、S117の処理に移行する。
【0163】
以上詳細に説明した通り、実施例4に係るナビゲーション装置91では、CPU41は、先頭文字情報データテーブル93の各「分割単位」のうち、検索順が1番目の検索語と前方一致する平仮名が属する50音の行の組み合わせが記憶された「分割単位」を抽出する。そして、CPU41は、この抽出した各「分割単位」のうち、全検索語の各先頭文字の属する50音の行に対応する、各「分割単位」の「キーワードの先頭文字情報」の50音の行の区分に記憶されているカウント値が、全検索語の各先頭文字の属する50音の行の行別のカウント値以上のものだけを、施設名データテーブル92の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0164】
続いて、CPU41は、施設名データテーブル92の候補施設名を検索する該当「分割単位」を順番に読み出し、施設名データテーブル92の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出す。そして、CPU41は、読み出した全施設名の「読み」について各検索語の全文検索を行い、読み出した施設名の読みを構成するキーワードの中に各検索語と前方一致するキーワードがある場合には、この施設名の読みに対応する「施設名」を施設名データテーブル92から読み出し、目的地候補である候補施設名としてRAM42に記憶する。
【0165】
これにより、文字数の少ない(例えば、1文字又は2文字である。)複数の検索語が入力されても、CPU41は、検索順が1番目の検索語と前方一致する平仮名が属する50音の行の組み合わせが記憶された「分割単位」のうち、全検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された「分割単位」だけを先頭文字情報データテーブル93から抽出することが可能となる。
【0166】
従って、CPU41は、全検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された「分割単位」だけを先頭文字情報データテーブル93から抽出して、施設名データテーブル92の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出して全検索語について全文検索を行うため、検索対象となる施設名の読みを少なくすることができ、検索を高速で行い、応答性の低下を防止することが可能となる。
【0167】
また、施設名データテーブル92の「分割単位」間では「施設名」に記憶された施設名の重複はあるが、各「分割単位」内においては、「施設名」に記憶された施設名の重複は無く、1つの施設名だけが記憶されている。従って、施設名データテーブル92の「分割単位」間では「読み」に記憶された施設名の読みの重複はあるが、各「分割単位」内においては、「読み」に記憶された施設名の読みの重複は無く、1つの施設名の読みだけが記憶されている。これにより、各「分割単位」の「施設名」に記憶された施設名は、1個だけ記憶されるため、重複記憶される施設名を減少させて、名称リストのデータ容量の削減化を図り、名称リストを展開するメモリ容量の増大を抑止することが可能となる。
【実施例5】
【0168】
次に、実施例5に係るナビゲーション装置95について図12に基づいて説明する。尚、以下の説明において上記図1乃至図7の実施例1に係るナビゲーション装置1の構成と同一符号は、前記実施例1に係るナビゲーション装置1の構成と同一あるいは相当部分を示すものである。また、上記図10及び図11の実施例4に係るナビゲーション装置91の構成と同一符号は、前記実施例4に係るナビゲーション装置91の構成と同一あるいは相当部分を示すものである。
【0169】
この実施例5に係るナビゲーション装置95の概略構成は、実施例4に係るナビゲーション装置91とほぼ同じ構成である。また、各種制御処理も実施例4に係るナビゲーション装置91とほぼ同じ制御処理である。
但し、ナビゲーション装置95は、先頭文字情報データテーブル93に替えて、図12に示す先頭文字情報データテーブル96を施設名DB27に格納している点で異なっている。このため、後述のように、上記S114における処理も異なっている。
【0170】
ここで、先頭文字情報データテーブル96について図12に基づいて説明する。
図12に示すように、実施例5に係る先頭文字情報データテーブル96は、上記先頭文字情報データテーブル93と同様に、「分割単位」と、「キーワードの先頭文字情報」と、「読み」とから構成されている。また、「キーワードの先頭文字情報」は、「あ行」〜「わ行」の50音の行別に区分されている。
【0171】
但し、図12に示すように、各「分割単位」に対応する「キーワードの先頭文字情報」には、同じ「分割単位」に対応する「読み」に記憶された各施設名の読み毎に、各キーワードの先頭文字が属する50音の行を行別にカウントし、カウント値が「1」以上の50音の行別の区分には、「1」を代入して記憶し、カウント値が「0」の50音の行別の区分には、「0」を代入して記憶する。つまり、各キーワードの先頭文字が属する50音の行の区分には「1」が記憶され、それ以外の50音の行の区分には「0」が記憶されている。
【0172】
例えば、図12に示すように、50音の3行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」には、施設名の読み「おおさか/おおい/おおさまじょう/おおて/おみやげ」の各キーワード「おおさか」、「おおい」、「おおさまじょう」、「おおて」、「おみやげ」の先頭文字が属する「あ行」のカウント値は「5」であるため(図11参照)、当該「キーワードの先頭文字情報」の「あ行」には、「1」が記憶されている。
【0173】
また同様に、50音の3行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」には、施設名の読み「あいし/えいあーる/おかざき/こうじょう/せっけいか」のキーワード「こうじょう」の先頭文字が属する「か行」のカウント値が「1」であるため(図11参照)、当該「キーワードの先頭文字情報」の「か行」には、「1」が記憶されている。
【0174】
また同様に、50音の3行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」には、施設名の読み「うえしの/しあたー」のキーワード「しあたー」の先頭文字が属する「さ行」のカウント値が「1」であるため(図3参照)、当該「キーワードの先頭文字情報」の「さ行」には、「1」が記憶されている。また、50音の3行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」の「た行」〜「わ行」には、施設名の読みの各キーワードの先頭文字が属していない旨を表す「0」が記憶されている。
【0175】
従って、先頭文字情報データテーブル96の各「分割単位」に対応する「キーワードの先頭文字情報」の「あ行」〜「わ行」の50音の各行に記憶された値が「1」か否かによって、各「分割単位」内に記憶されている施設名の読みの各キーワードの先頭文字が属する50音の行の有・無を判別することが可能となる。
【0176】
次に、実施例5に係るナビゲーション装置95のCPU41が実行するS114の処理について説明する。
S114において、CPU41は、全検索語をRAM42から読み出し、S113で特定した「分割単位」(実施例4参照)に対応する「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されている値が、全て「1」か否かを判定する判定処理を実行する。つまり、全検索語の各先頭文字の属する50音の行に、各キーワードの先頭文字が属する施設名の読みが、当該「分割単位」に対応する施設名データテーブル92の「分割単位」内の「読み」に記憶されているか否かを判定する判定処理を実行する。
【0177】
そして、当該「分割単位」の「キーワードの先頭文字情報」の50音の行の区分に記憶されている値が、全て「1」でない、つまり、値の「0」のものがあると判定した場合には(S114:NO)、CPU41は、先頭文字情報データテーブル96に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。
【0178】
そして、先頭文字情報データテーブル96に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル96の次の「分割単位」に記憶されている50音の行の組み合わせに属する平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル96に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了して上記S116の処理に移行する。
【0179】
一方、S114で当該「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されているカウント値が、全て「1」であると判定した場合には(S114:YES)、CPU41は、S115の処理に移行する。S115において、CPU41は、当該「分割単位」を施設名データテーブル92の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0180】
続いて、CPU41は、先頭文字情報データテーブル96に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。そして、先頭文字情報データテーブル96に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル96の次の「分割単位」に記憶されている50音の行の組み合わせに属する平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル96に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了して上記S116の処理に移行する。
【0181】
例えば、図12に示すように、上記S112で1番目の検索順に設定された検索語が「あい」で、2番目の検索順に設定された検索語が「こ」の場合には、CPU41は、当該検索語の先頭文字「あ」と前方一致する各50音の行の組み合わせ「あ行」、「あ行あ行」、・・・「あ行あ行さ行」・・・「あ行わ行わ行」が記憶された各「分割単位」について、S114の処理を実行する。
【0182】
そして、CPU41は、「キーワードの先頭文字情報」の全検索語「あい」、「こ」の各先頭文字「あ」、「こ」の属する50音の「あ行」、「か行」の区分に記憶されている値が、全て「1」である50音の行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」を施設名データテーブル92の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0183】
以上詳細に説明した通り、実施例5に係るナビゲーション装置95では、CPU41は、先頭文字情報データテーブル96の各「分割単位」のうち、検索順が1番目の検索語と前方一致する平仮名が属する50音の行の組み合わせが記憶された「分割単位」を抽出する。そして、CPU41は、この抽出した各「分割単位」のうち、各「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されている値が、全て「1」のものだけを、施設名データテーブル92の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0184】
続いて、CPU41は、施設名データテーブル92の候補施設名を検索する該当「分割単位」を順番に読み出し、施設名データテーブル92の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出す。そして、CPU41は、読み出した全施設名の「読み」について各検索語の全文検索を行い、読み出した施設名の読みを構成するキーワードの中に各検索語と前方一致するキーワードがある場合には、この施設名の読みに対応する「施設名」を施設名データテーブル92から読み出し、目的地候補である候補施設名としてRAM42に記憶する。
【0185】
これにより、文字数の少ない(例えば、1文字又は2文字である。)複数の検索語が入力されても、CPU41は、検索順が1番目の検索語と前方一致する平仮名が属する50音の行の組み合わせが記憶された「分割単位」のうち、全検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された「分割単位」だけを先頭文字情報データテーブル96から抽出することが可能となる。
【0186】
従って、CPU41は、全検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された「分割単位」だけを先頭文字情報データテーブル96から抽出して、施設名データテーブル92の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出して全検索語について全文検索を行うため、検索対象となる施設名の読みを少なくすることができ、検索を高速で行い、応答性の低下を防止することが可能となる。
【実施例6】
【0187】
次に、実施例6に係るナビゲーション装置98について図13に基づいて説明する。尚、以下の説明において上記図1乃至図7の実施例1に係るナビゲーション装置1の構成と同一符号は、前記実施例1に係るナビゲーション装置1の構成と同一あるいは相当部分を示すものである。また、上記図10及び図11の実施例4に係るナビゲーション装置91の構成と同一符号は、前記実施例4に係るナビゲーション装置91の構成と同一あるいは相当部分を示すものである。
【0188】
この実施例6に係るナビゲーション装置98の概略構成は、実施例4に係るナビゲーション装置91とほぼ同じ構成である。また、各種制御処理も実施例4に係るナビゲーション装置91とほぼ同じ制御処理である。
但し、ナビゲーション装置98は、先頭文字情報データテーブル93に替えて、図13に示す先頭文字情報データテーブル99を施設名DB27に格納している点で異なっている。このため、後述のように、上記S114における処理も異なっている。
【0189】
ここで、先頭文字情報データテーブル99について図13に基づいて説明する。
図13に示すように、実施例6に係る先頭文字情報データテーブル99は、上記先頭文字情報データテーブル93と同様に、「分割単位」と、「キーワードの先頭文字情報」と、「読み」とから構成されている。但し、「キーワードの先頭文字情報」は、平仮名が50音順に1文字ずつ属するように区分されている。
【0190】
また、各「分割単位」に対応する「キーワードの先頭文字情報」には、同じ「分割単位」に対応する「読み」に記憶された各施設名の読み毎に、各キーワードの先頭文字を50音別にそれぞれカウントし、各50音別のカウント値のうちの各施設名の読みの間の最大カウント値をそれぞれ抽出して、「キーワードの先頭文字情報」の各キーワードの先頭文字が属する「あ」〜「ん」の区分に記憶されている。
【0191】
例えば、図13に示すように、50音の3行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」に対応する各施設名の読みには、「あいし/えいあーる/おかざき/こうじょう/せっけいか」、「おおさか/おおい/おおさまじょう/おおて/おみやげ」、「うえしの/しあたー」が記憶されている。このため、施設名の読み「あいし/えいあーる/おかざき/こうじょう/せっけいか」の各キーワード「あいし」、「えいあーる」、「おかざき」、「こうじょう」、「せっけいか」の先頭文字のカウント値は、「あ」が「1」、「え」が「1」、「お」が「1」、「こ」が「1」、「せ」が「1」である。
【0192】
また、施設名の読み「おおさか/おおい/おおさまじょう/おおて/おみやげ」の各キーワード「おおさか」、「おおい」、「おおさまじょう」、「おおて」、「おみやげ」の先頭文字のカウント値は、「お」が「5」である。また、施設名の読み「うえしの/しあたー」の各キーワード「うれしの」、「しあたー」の先頭文字のカウント値は、「う」が「1」、「し」が「1」である。
【0193】
従って、50音の3行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」の各平仮名「あ」、「う」、「え」、「こ」、「し」、「せ」が属する区分には、それぞれ最大カウント値として「1」が記憶され、平仮名「お」が属する区分には、最大カウント値として「5」が記憶されている。また、50音の3行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」の各平仮名「い」、「か」〜「け」、「さ」、「す」、「そ」〜「ん」が属する区分には、「0」が記憶されている。
【0194】
これにより、先頭文字情報データテーブル99の各「分割単位」に対応する「キーワードの先頭文字情報」の「あ」〜「ん」が属する各区分に記憶されたカウント値によって、各「分割単位」内に記憶されている施設名の読みの各キーワードの先頭文字を構成する平仮名を判別することが可能となる。
【0195】
次に、実施例6に係るナビゲーション装置98のCPU41が実行するS114の処理について説明する。
S114において、CPU41は、全検索語をRAM42から読み出し、全検索語の各先頭文字を50音別にカウントする。そして、CPU41は、S113で特定した「分割単位」(実施例4参照)の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する区分に記憶されている各カウント値が、全検索語の各先頭文字の50音別のカウント値以上か否かを判定する判定処理を実行する。つまり、全検索語の各先頭文字の属する50音の区分に、各キーワードの先頭文字が属する施設名の読みが、当該「分割単位」に対応する施設名データテーブル92の「分割単位」内の「読み」に記憶されているか否かを判定する判定処理を実行する。
【0196】
そして、当該「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する区分に、全検索語の各先頭文字の50音別のカウント値より少ない区分やカウント値が「0」の区分が1つでもあると判定した場合には(S114:NO)、CPU41は、先頭文字情報データテーブル99に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。
【0197】
そして、先頭文字情報データテーブル99に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル99の次の「分割単位」に記憶されている50音の行の組み合わせに属する平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル99に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了してS116の処理に移行する。
【0198】
一方、S114で当該「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する区分に記憶されているカウント値が、全検索語の各先頭文字の50音別のカウント値以上であると判定した場合には(S114:YES)、CPU41は、S115の処理に移行する。S115において、CPU41は、当該「分割単位」を施設名データテーブル92の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0199】
続いて、CPU41は、先頭文字情報データテーブル99に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。そして、先頭文字情報データテーブル99に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル99の次の「分割単位」に記憶されている50音の行の組み合わせに属する平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル99に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了してS116の処理に移行する。
【0200】
例えば、図13に示すように、上記S112で1番目の検索順に設定された検索語が「あい」で、2番目の検索順に設定された検索語が「こ」の場合には、CPU41は、当該検索語の先頭文字「あ」と前方一致する各50音の行の組み合わせ「あ行」、「あ行あ行」、・・・「あ行あ行さ行」・・・「あ行わ行わ行」が記憶された各「分割単位」について、S114の処理を実行する。
【0201】
そして、CPU41は、「キーワードの先頭文字情報」の全検索語「あい」、「こ」の各先頭文字「あ」、「こ」の属する50音の「あ」、「こ」の区分に記憶されている値が、全て「1」以上である50音の行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」を施設名データテーブル92の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0202】
以上詳細に説明した通り、実施例6に係るナビゲーション装置98では、CPU41は、先頭文字情報データテーブル99の各「分割単位」のうち、検索順が1番目の検索語と前方一致する平仮名が属する50音の行の組み合わせが記憶された「分割単位」を抽出する。そして、CPU41は、この抽出した各「分割単位」のうち、各「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する区分に記憶されているカウント値が、全検索語の各先頭文字の50音別のカウント値以上のものだけを、施設名データテーブル92の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0203】
続いて、CPU41は、施設名データテーブル92の候補施設名を検索する該当「分割単位」を順番に読み出し、施設名データテーブル92の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出す。そして、CPU41は、読み出した全施設名の「読み」について各検索語の全文検索を行い、読み出した施設名の読みを構成するキーワードの中に各検索語と前方一致するキーワードがある場合には、この施設名の読みに対応する「施設名」を施設名データテーブル51から読み出し、目的地候補である候補施設名としてRAM42に記憶する。
【0204】
これにより、文字数の少ない(例えば、1文字又は2文字である。)複数の検索語が入力されても、CPU41は、検索順が1番目の検索語と前方一致する平仮名が属する50音の行の組み合わせが記憶された「分割単位」のうち、全検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された「分割単位」だけを先頭文字情報データテーブル99から抽出することが可能となる。
【0205】
従って、CPU41は、全検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された「分割単位」だけを先頭文字情報データテーブル99から抽出して、施設名データテーブル92の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出して全検索語について全文検索を行うため、検索対象となる施設名の読みを少なくすることができ、検索を高速で行い、応答性の低下を防止することが可能となる。
【0206】
尚、本発明は前記実施例に限定されるものではなく、本発明の要旨を逸脱しない範囲内で種々の改良、変形が可能であることは勿論である。
【0207】
(A)例えば、実施例3に係る先頭文字情報データテーブル86又は実施例6に係る先頭文字情報データテーブル99において、各「分割単位」に対応する「キーワードの先頭文字情報」には、同じ「分割単位」に対応する「読み」に記憶された各施設名の読み毎に、各キーワードの先頭文字を50音別にそれぞれカウントし、カウント値が「1」以上の50音の区分には、「1」を代入して記憶し、カウント値が「0」の50音の区分には、「0」を代入して記憶するようにしてもよい。
【0208】
そして、上記S114において、CPU41は、全検索語をRAM42から読み出し、S113で特定した「分割単位」に対応する「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の区分に記憶されている値が、全て「1」か否かを判定する判定処理を実行するようにしてもよい。
【0209】
(B)また、例えば、各先頭文字情報データテーブル52、82、86、93、96、99の「読み」の欄のデータを記憶しなくてもよい。これにより、各先頭文字情報データテーブル52、82、86、93、96、99のデータ容量の削減化を図ることができる。
【0210】
(C)また、例えば、各施設名データテーブル51、92、及び、各先頭文字情報データテーブル52、82、86、93、96、99の「分割単位」に、平仮名だけでなく、片仮名、アルファベット、数字、所定の記号(例えば、算術記号や矢印等である。)を記憶するようにしてもよい。
【0211】
例えば、各施設名データテーブル51、92、及び、各先頭文字情報データテーブル52、82、86、93、96、99の「分割単位」にアルファベットをアルファベット順に1文字乃至5文字ずつ記憶するようにしてもよい。そして、各施設名データテーブル51、92の「施設名」には、アルファベットで施設名を記憶し、「読み」には、施設名をキーワードに区切って記憶するようにしてもよい。
【0212】
また、各先頭文字情報データテーブル52、82、86、93、96、99の「キーワードの先頭文字情報」には、アルファベットがアルファベット順に1文字又は複数文字ずつ属するように区分してもよい。また、各先頭文字情報データテーブル52、82、86、93、96、99の各「分割単位」に対応する「読み」には、各施設名データテーブル51、92の各「分割単位」内の「読み」に記憶されたキーワードに区切られた施設名を記憶するようにしてもよい。
【符号の説明】
【0213】
1、81、85、91、95、98 ナビゲーション装置
14 操作部
15 液晶ディスプレイ
18 タッチパネル
25 地図情報DB
27 施設名DB
41 CPU
42 RAM
43 ROM
51、92 施設名データテーブル
52、82、86、93、96、99 先頭文字情報データテーブル
61 検索語入力画面
62 50音キー
71 検索結果表示画面
72 検索結果表示欄
【技術分野】
【0001】
本発明は、入力された検索語に基づいて施設情報を検索する施設検索装置及びプログラムに関するものである。
【背景技術】
【0002】
従来より、入力された検索語に基づいて施設情報を検索する技術に関し種々提案されている。
例えば、目的地を表す施設名を単語分割し、分割した単語の順番を入れ替えた全名称を読み順にソートして当該施設名として登録した名称リストを作成しておき、入力された検索語と前方一致する名称を検索して、当該名称に該当する施設名を抽出して、表示手段に候補地点名として表示する車両用ナビゲーション装置がある(例えば、特許文献1参照。)。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開平9−97266号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
前記した特許文献1に記載された車両用ナビゲーション装置によれば、入力された検索語と前方一致する名称を検索することによって該当する施設名を高速で検索することが可能となる。
しかしながら、各施設毎に複数の名称を作成して記憶しておく必要があるため、名称リストのデータ容量が増大するが、メモリ上に施設検索用のアプリケーションプログラムを展開した場合には、名称リストを展開するメモリ容量に限界が生じ、大量のデータから抽出することが難しいという問題がある。
【0005】
また、文字数の少ない(例えば、1文字又は2文字である。)複数の検索語が入力された場合には、入力された1番目の検索語と前方一致する施設名の数が多くなり、2番目以降の検索語と前方一致する読みが名称中に含まれるか否かを全ての施設名について行う必要が生じるため、検索時間が増大し、応答性能が低下するという問題がある。
【0006】
そこで、本発明は、上述した問題点を解決するためになされたものであり、名称リストを展開するメモリ容量の増大を抑止することができると共に、文字数の少ない複数の検索語に対して検索を高速で行い、応答性の低下を防止することが可能となる施設検索装置及びプログラムを提供することを目的とする。
【課題を解決するための手段】
【0007】
前記目的を達成するため請求項1に係る施設検索装置は、検索対象となる複数の施設名をそれぞれ複数のキーワードに区切って、各施設名を各キーワードと前方一致する所定文字数の分割文字列に関連付けて記憶する施設名記憶手段と、前記所定文字数の分割文字列に関連付けられた各施設名について、互いに異なる1文字から構成されて所定順序を付与された複数の区分文字が所定個数ずつ属する複数の区分別に、各区分に属する区分文字と一致する各キーワードの先頭文字をカウントした区分毎のカウント情報を、該所定文字数の分割文字列に関連付けて記憶するキーワード先頭文字情報記憶手段と、検索語を入力する入力手段と、前記キーワード先頭文字情報記憶手段において、前記入力手段を介して入力された各検索語の先頭文字の属する区分に対応するカウント情報に基づいて該各検索語に対応する前記分割文字列を取得する分割文字列取得手段と、前記施設名記憶手段において、前記分割文字列取得手段を介して取得した前記分割文字列に関連付けて記憶されている施設名から前記入力手段によって入力された検索語と前方一致するキーワードを有する施設名を候補施設名として取得する検索手段と、を備えたことを特徴とする。
【0008】
また、請求項2に係る施設検索装置は、請求項1に記載の施設検索装置において、前記区分毎のカウント情報は、前記所定文字数の分割文字列に関連付けられた各施設名について、前記複数の区分別に、各区分に属する前記区分文字と一致する各キーワードの先頭文字をカウントした最大カウント値であり、前記分割文字列取得手段は、前記入力手段を介して入力された各検索語の先頭文字の属する区分の前記最大カウント値の全てが、当該各検索語の先頭文字の属する区分毎の該先頭文字のカウント値以上であるカウント情報に関連付けられた前記分割文字列を取得することを特徴とする。
【0009】
また、請求項3に係る施設検索装置は、請求項1に記載の施設検索装置において、前記区分毎のカウント情報は、前記所定文字数の分割文字列に関連付けられた各施設名について、前記複数の区分別に、各区分に属する前記区分文字と一致する各キーワードの先頭文字をカウントしたカウント値があるか否かを表す有無情報であり、前記分割文字列取得手段は、前記入力手段を介して入力された各検索語の先頭文字の属する区分毎の前記有無情報が全てカウント値がある旨を表すカウント情報に関連付けられた前記分割文字列を取得することを特徴とする。
【0010】
また、請求項4に係る施設検索装置は、請求項1乃至請求項3のいずれかに記載の施設検索装置において、前記区分文字は、50音仮名であって、前記区分は、50音の行別に区分されていることを特徴とする。ここで、50音仮名は、平仮名や片仮名を含む。
【0011】
また、請求項1乃至請求項3のいずれかに記載の施設検索装置において、前記区分文字は、アルファベット、数字、所定の記号(例えば、算術記号や矢印等である。)等でもよい。また、前記区分文字がアルファベットの場合には、前記複数の区分は、アルファベットがアルファベット順に所定個数ずつ属するように区分してもよい。また、前記分割文字列は、所定文字数のアルファベットとするようにしてもよい。
【0012】
更に、請求項5に係るプログラムは、検索対象となる複数の施設名をそれぞれ複数のキーワードに区切って、各施設名を各キーワードと前方一致する所定文字数の分割文字列に関連付けて記憶する施設名記憶手段と、前記所定文字数の分割文字列に関連付けられた各施設名について、互いに異なる1文字から構成されて所定順序を付与された複数の区分文字が所定個数ずつ属する複数の区分別に、各区分に属する区分文字と一致する各キーワードの先頭文字をカウントした区分毎のカウント情報を、該所定文字数の分割文字列に関連付けて記憶するキーワード先頭文字情報記憶手段と、を備えたコンピュータに、検索語を入力する入力工程と、前記キーワード先頭文字情報記憶手段において、前記入力工程で入力された各検索語の先頭文字の属する区分に対応するカウント情報に基づいて該各検索語に対応する前記分割文字列を取得する分割文字列取得工程と、前記施設名記憶手段において、前記分割文字列取得工程で取得した前記分割文字列に関連付けて記憶されている施設名から前記入力工程で入力された検索語と前方一致するキーワードを有する施設名を候補施設名として取得する検索工程と、を実行させるためのプログラムである。
【発明の効果】
【0013】
前記構成を有する請求項1に係る施設検索装置では、複数の施設名をそれぞれ複数のキーワードに区切って、各施設名を各キーワードと前方一致する所定文字数の分割文字列に関連付けて施設名記憶手段に記憶している。これにより、各分割文字列に関連付けられた目的地を表す施設名は、1個だけ記憶されるため、重複記憶される施設名を減少させて、名称リストのデータ容量の削減化を図り、名称リストを展開するメモリ容量の増大を抑止することが可能となる。
【0014】
また、キーワード先頭文字情報記憶手段において、入力された一の検索語と前方一致する分割文字列に関連付けて記憶されている区分毎のカウント情報から、各検索語の先頭文字の属する区分に対応するカウント情報に基づいて該各検索語に対応する分割文字列を取得する。そして、この取得された分割文字列を施設名記憶手段の分割文字列として、該分割文字列に関連付けられた施設名から検索語と前方一致するキーワードを有する施設名を候補施設名として取得する。
【0015】
これにより、文字数の少ない(例えば、1文字又は2文字である。)複数の検索語が入力されても、各検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された分割文字列だけをキーワード先頭文字情報記憶手段から抽出することが可能となる。従って、この抽出された分割文字列に関連付けられて施設名記憶手段に格納された施設名から候補施設名を検索するため、検索対象となる施設名を少なくすることができ、検索を高速で行い、応答性の低下を防止することが可能となる。
【0016】
また、請求項2に係る施設検索装置では、キーワード先頭文字情報記憶手段において、入力された一の検索語と前方一致する分割文字列から、各検索語の先頭文字の属する区分毎の各最大カウント値の全てが、当該各検索語の先頭文字の属する区分毎の該先頭文字のカウント値以上であるカウント情報に関連付けられた分割文字列を取得する。そして、この取得された分割文字列を施設名記憶手段の分割文字列として、該分割文字列に関連付けられた施設名から検索語と前方一致するキーワードを有する施設名を候補施設名として取得する。
【0017】
これにより、文字数の少ない(例えば、1文字又は2文字である。)複数の検索語が入力されても、各検索語の先頭文字を各キーワードの先頭文字に有する施設名が関連付けられた分割文字列だけをキーワード先頭文字情報記憶手段から確実に抽出することが可能となる。従って、この抽出された分割文字列に関連付けられて施設名記憶手段に格納された施設名から候補施設名を検索するため、検索対象となる施設名を少なくすることができ、検索を高速で行い、応答性の低下を防止することが可能となる。
【0018】
また、先頭文字が同じ複数の検索語が入力された場合には、この複数の検索語の先頭文字の属する区分の各最大カウント値が、当該検索語の個数以上のカウント情報に関連付けられた分割文字列だけを取得することが可能となる。これにより、抽出される分割文字列を少なくすることが可能となるため、検索対象となる施設名を更に少なくすることができ、検索を高速で行い、応答性の低下を防止することが可能となる。
【0019】
また、請求項3に係る施設検索装置では、キーワード先頭文字情報記憶手段において、入力された一の検索語と前方一致する分割文字列から、各検索語の先頭文字の属する区分毎の有無情報が全てカウント値がある旨を表すカウント情報に関連付けられた分割文字列を取得する。そして、この取得された分割文字列を施設名記憶手段の分割文字列として、該分割文字列に関連付けられた施設名から検索語と前方一致するキーワードを有する施設名を候補施設名として取得する。
【0020】
これにより、文字数の少ない(例えば、1文字又は2文字である。)複数の検索語が入力されても、各検索語の先頭文字を各キーワードの先頭文字に有する施設名が関連付けられた分割文字列だけをキーワード先頭文字情報記憶手段から確実に抽出することが可能となる。従って、この抽出された分割文字列に関連付けられて施設名記憶手段に格納された施設名から候補施設名を検索するため、検索対象となる施設名を少なくすることができ、検索を高速で行い、応答性の低下を防止することが可能となる。
【0021】
また、請求項4に係る施設検索装置では、キーワード先頭文字情報記憶手段において、50音の行別に、各行に属する50音仮名(平仮名又は片仮名である。)と一致する各キーワードの先頭文字をカウントした行毎のカウント情報を、所定文字数の分割文字列に関連付けて記憶する。これにより、所定文字数の分割文字列に関連付けて記憶するカウント情報の区分を10個に限定して、少なくすることができ、検索語に対応する分割文字列を更に迅速に抽出することが可能となる。
【0022】
また、請求項5に係るプログラムでは、コンピュータは当該プログラムを読み込むことによって、キーワード先頭文字情報記憶手段において、入力された一の検索語と前方一致する分割文字列に関連付けて記憶されている区分毎のカウント情報から、各検索語の先頭文字の属する区分に対応するカウント情報に基づいて該各検索語に対応する分割文字列を取得する。そして、コンピュータは、この取得した分割文字列を施設名記憶手段の分割文字列として、該分割文字列に関連付けられた施設名から検索語と前方一致するキーワードを有する施設名を候補施設名として取得する。
【0023】
これにより、コンピュータは文字数の少ない(例えば、1文字又は2文字である。)複数の検索語が入力されても、各検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された分割文字列だけをキーワード先頭文字情報記憶手段から抽出することが可能となる。従って、コンピュータは、この抽出した分割文字列に関連付けられて施設名記憶手段に格納された施設名から候補施設名を検索するため、検索対象となる施設名を少なくすることができ、検索を高速で行い、応答性の低下を防止することが可能となる。
【図面の簡単な説明】
【0024】
【図1】実施例1に係るナビゲーション装置を示したブロック図である。
【図2】施設名DBに格納された施設名データテーブルの一例を示す図である。
【図3】施設名DBに格納された先頭文字情報データテーブルの一例を示す図である。
【図4】入力された検索語に基づいて施設情報を検索してリスト表示する「施設情報表示処理」を示すフローチャートである。
【図5】図3の「候補施設名抽出処理」のサブ処理を示すサブフローチャートである。
【図6】検索語を入力する検索語入力画面の一例を示す図である。
【図7】抽出した施設名をリスト表示した検索結果表示画面の一例を示す図である。
【図8】実施例2に係る施設名DBに格納された先頭文字情報データテーブルの一例を示す図である。
【図9】実施例3に係る施設名DBに格納された先頭文字情報データテーブルの一例を示す図である。
【図10】実施例4に係る施設名DBに格納された施設名データテーブルの一例を示す図である。
【図11】実施例4に係る施設名DBに格納された先頭文字情報データテーブルの一例を示す図である。
【図12】実施例5に係る施設名DBに格納された先頭文字情報データテーブルの一例を示す図である。
【図13】実施例6に係る施設名DBに格納された先頭文字情報データテーブルの一例を示す図である。
【発明を実施するための形態】
【0025】
以下、本発明に係る施設検索装置及びプログラムをナビゲーション装置について具体化した実施例1乃至実施例6に基づき図面を参照しつつ詳細に説明する。
【実施例1】
【0026】
[ナビゲーション装置の概略構成]
先ず、実施例1に係るナビゲーション装置の概略構成について図1に基づいて説明する。図1は実施例1に係るナビゲーション装置1を示したブロック図である。
図1に示すように、実施例1に係るナビゲーション装置1は、自車の現在位置(以下、「自車位置」という。)等を検出する現在地検出処理部11と、各種のデータが記録されたデータ記録部12と、入力された情報に基づいて、各種の演算処理を行うナビゲーション制御部13と、操作者からの操作を受け付ける操作部14と、操作者に対して地図等の情報を表示する液晶ディスプレイ15と、経路案内等に関する音声ガイダンスを出力するスピーカ16と、不図示の道路交通情報センタや地図情報配信センタ等との間で携帯電話網等を介して通信を行う通信装置17と、液晶ディスプレイ15の表面に装着されたタッチパネル18とから構成されている。また、ナビゲーション制御部13には自車の走行速度を検出する車速センサ21が接続されている。
【0027】
以下に、ナビゲーション装置1を構成する各構成要素について説明すると、現在地検出処理部11は、GPS31、方位センサ32、距離センサ33等からなり、自車位置、自車の向きを表す自車方位、走行距離等を検出することが可能となっている。
【0028】
また、データ記録部12は、外部記憶装置及び記録媒体としてのハードディスク(図示せず)と、ハードディスクに記憶された地図情報データベース(地図情報DB)25、施設名データベース(施設名DB)27及び所定のプログラム等を読み出すとともにハードディスクに所定のデータを書き込む為のドライバを備えている。
【0029】
また、地図情報DB25には、ナビゲーション装置1の走行案内や経路探索に使用されるナビ地図情報26が格納されている。ここで、ナビ地図情報26には、経路案内及び地図表示に必要な各種情報から構成されており、例えば、各新設道路を特定するための新設道路情報、地図を表示するための地図表示データ、各交差点に関する交差点データ、ノード点に関するノードデータ、施設の一種である道路(リンク)に関するリンクデータ、経路を探索するための探索データ、施設の一種である店舗等のPOI(Point of Interest)に関する店舗データ、地点を検索するための検索データ等から構成されている。
【0030】
尚、店舗データには、各地域のホテル、病院、ガソリンスタンド、駐車場、駅、空港、フェリー乗り場等のPOIに関する名称や住所、電話番号等に加えて、後述の検索結果表示画面71(図7参照)にリスト表示する表示優先度のデータをPOIを特定するIDとともに記憶するようにしてもよい。例えば、表示優先度は、「88」や「256」等の数値で表され、数値の大きいものほど優先度が高くなる。また、地図情報DB25の内容は、不図示の地図情報配信センタから通信装置17を介して配信された更新情報をダウンロードすることによって更新される。
【0031】
また、施設名DB27には、後述の施設名及び該施設名の読みを所定文字数(実施例1では、1文字又は2文字である。)の分割文字列に関連付けて分割単位毎に記憶する施設名データテーブル51(図2参照)が格納されている。また、施設名DB27には、後述の施設名の読みを構成する各キーワードの先頭文字が属する50音の行を表す「キーワードの先頭文字情報」を所定文字数(実施例1では、1文字又は2文字である。)の分割文字列に関連付けて分割単位毎に記憶する先頭文字情報データテーブル52(図3参照)が格納されている。
【0032】
また、図1に示すように、ナビゲーション装置1を構成するナビゲーション制御部13は、ナビゲーション装置1の全体の制御を行う演算装置及び制御装置としてのCPU41、並びにCPU41が各種の演算処理を行うに当たってワーキングメモリとして使用されるとともに、経路が探索されたときの経路データ等が記憶されるRAM42、制御用のプログラム等が記憶されたROM43、ROM43から読み出したプログラムを記憶するフラッシュメモリ44等の内部記憶装置や、時間を計測するタイマ45等を備えている。
【0033】
また、ROM43には、後述の50音キー62から入力された検索語に基づいて地点情報を検索してリスト表示する施設情報表示処理のプログラム(図3参照)等が記憶されている。
更に、前記ナビゲーション制御部13には、操作部14、液晶ディスプレイ15、スピーカ16、通信装置17、タッチパネル18の各周辺装置(アクチュエータ)が電気的に接続されている。
【0034】
この操作部14は、走行開始時の現在地を修正し、案内開始地点としての出発地及び案内終了地点としての目的地を入力する際や施設に関する情報の検索を行う場合等に操作され、各種のキーや複数の操作スイッチから構成される。そして、ナビゲーション制御部13は、各スイッチの押下等により出力されるスイッチ信号に基づき、対応する各種の動作を実行すべく制御を行う。
【0035】
また、液晶ディスプレイ15には、現在走行中の地図情報、後述の検索語入力画面61(図6参照)、検索した施設の名称をリスト表示する検索結果表示画面71、操作案内、操作メニュー、キーの案内、現在地から目的地までの推奨経路、推奨経路に沿った案内情報、交通情報、ニュース、天気予報、時刻、メール、テレビ番組等が表示される。
【0036】
また、スピーカ16は、ナビゲーション制御部13からの指示に基づいて、推奨経路に沿った走行を案内する音声ガイダンス等を出力する。ここで、案内される音声ガイダンスとしては、例えば、「200m先、○○交差点を右方向です。」等がある。
【0037】
また、通信装置17は、地図情報配信センタと通信を行う携帯電話網等による通信手段であり、地図情報配信センタとの間で最もバージョンの新しい更新地図情報等の送受信を行う。また、通信装置17は地図情報配信センタに加えて、道路交通情報センタ等から送信された渋滞情報やサービスエリアの混雑状況等の各情報から成る交通情報を受信する。
【0038】
また、タッチパネル18は、液晶ディスプレイ15の表面部に装着された透明なパネル状のタッチスイッチであり、液晶ディスプレイ15の画面に表示されたボタンや地図上を押下することによって各種指示コマンドを入力することが可能に構成されている。尚、タッチパネル18は、液晶ディスプレイ15の画面を直接押下する光センサ液晶方式等で構成してもよい。
【0039】
ここで、施設名DB27に格納される施設名データテーブル51について図2に基づいて説明する。
図2に示すように、施設名データテーブル51は、「分割単位」と、施設名の読みを記憶する「読み」と、「施設名」とから構成されている。この「分割単位」には、施設名の読みを構成するキーワードと前方一致する平仮名が、50音順に1文字又は2文字ずつ記憶されている。ここで、キーワードは、意味を成す単位で構成された読みの文字列である。
【0040】
尚、「分割単位」には、例えば、「あああ」、「ああい」、「ああう」・・・等、50音順に3文字以上ずつ記憶するようにしてもよい。また、「分割単位」の一部区間だけ、例えば、・・・「お」、「かあ」、「かい」、・・・「かん」、「き」、「く」・・等、50音順に2文字以上ずつ記憶するようにしてもよい。
【0041】
また、「読み」には、各「分割単位」に記憶される平仮名と前方一致するキーワードを含む施設名の読みが記憶されている。また、施設名の読みは、キーワード毎に区切り文字(例えば「/」である。)で区切られて記憶されている。また、施設名の読みは、分割単位に記憶されている平仮名と前方一致するキーワードが先頭になるように、各キーワードの順序が当該施設名の読みの順番に従って循環するように並べ替えられて記憶されている。
【0042】
例えば、施設名の読みが「せいと/どーむ」では、「せいと」、「どーむ」が、施設名の読みのキーワードとして「読み」に記憶されている。また、施設名の読みの「せいと/どーむ」は、施設名データテーブル51の「分割単位」の各平仮名「せい」、「とお」に対応する「読み」にそれぞれ記憶される。
【0043】
尚、施設名の読みに含まれる「が」、「ぱ」等の濁音・半濁音は「か」、「は」等の清音に、「ゃ」、「っ」等の小文字仮名(拗音・促音)は「や」、「つ」等の大文字仮名に、長音は対応する母音等のように、仮名の基本文字に変換して記憶される。例えば、「せいと/どーむ」は、実際には「せいと/とおむ」と記憶されるが、本実施形態においては説明を簡単にするために施設名と読みとを一致させ「せいと/どーむ」として説明する。
【0044】
そして、平仮名「せい」が記憶されている「分割単位」に対応する施設名の「読み」には、キーワード「せいと」が先頭になるように「せいと/どーむ」が記憶されている。また、平仮名「とお」が記憶されている「分割単位」に対応する施設名の「読み」には、キーワード「どーむ」が先頭になるように「どーむ/せいと」が記憶されている。
【0045】
また、「施設名」には、検索対象となる目的地を表す施設名が、「読み」に記憶された施設名の読みに対応して記憶されている。例えば、施設名「西都ドーム」が、施設名の読みの「せいと/どーむ」に対応して記憶されている。従って、施設名「西都ドーム」は、施設名データテーブル51の「分割単位」の各平仮名「せい」、「とお」内の「読み」の「せいと/どーむ」、「どーむ/せいと」のそれぞれに対応する「施設名」に記憶されている。
【0046】
これにより、施設名データテーブル51の「分割単位」間では「施設名」に記憶された施設名の重複はあるが、各「分割単位」内においては、「施設名」に記憶された施設名の重複は無く、1つの施設名だけが記憶されている。従って、施設名データテーブル51の「分割単位」間では「読み」に記憶された施設名の読みの重複はあるが、各「分割単位」内においては、「読み」に記憶された施設名の読みの重複は無く、1つの施設名の読みだけが記憶されている。また、各「分割単位」毎の「読み」と「施設名」との合計データ容量を所定データ容量以下(例えば、1メガバイト〜10メガバイト以下である。)に設定することが可能となる。
【0047】
次に、施設名DB27に格納される先頭文字情報データテーブル52について図3に基づいて説明する。
図3に示すように、先頭文字情報データテーブル52は、「分割単位」と、「キーワードの先頭文字情報」と、「読み」とから構成されている。また、「キーワードの先頭文字情報」は、「あ行」〜「わ行」の50音の行別に区分されている。
【0048】
この「分割単位」は、施設名データテーブル51の「分割単位」に対応するものであり、施設名の読みを構成するキーワードと前方一致する平仮名が、50音順に1文字又は2文字ずつ記憶されている。従って、上記施設名データテーブル51の「分割単位」に、例えば、「あ」、「ああ」、「あい」、・・・等と1文字又は2文字の平仮名を記憶した場合には、先頭文字情報データテーブル52も同様に、「分割単位」に「あ」、「ああ」、「あい」、・・・等と1文字又は2文字の平仮名を記憶する。
【0049】
また、各「分割単位」に対応する「読み」には、施設名データテーブル51の各「分割単位」内の「読み」に記憶された施設名の読みがそれぞれ格納されている。例えば、平仮名「せい」が記憶された「分割単位」に対応する「読み」には、施設名データテーブル51の平仮名「せい」が記憶された「分割単位」内の「読み」に記憶されている施設名の読み「せいと/どーむ」、「せいと/ひゃっかてん」、「せいげん/そめや」、「せいとか/としょかん」が、区切り文字「;」で区切られて記憶されている。
【0050】
また、各「分割単位」に対応する「キーワードの先頭文字情報」には、同じ「分割単位」に対応する「読み」に記憶された各施設名の読み毎に、各キーワードの先頭文字が属する50音の行を行別にカウントし、各50音の行別のカウント値のうちの各施設名の読みの間の最大カウント値をそれぞれ抽出して、「キーワードの先頭文字情報」の「あ行」〜「わ行」の50音の行別に区分して記憶されている。
【0051】
例えば、図3に示すように、平仮名「せい」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」には、施設名の読み「せいげん/そめや」の各キーワード「せいげん」、「そめや」の先頭文字が属する「さ行」のカウント値「2」が、各キーワードの先頭文字が属する50音の行を行別にカウントした最大カウント値として記憶されている。
【0052】
また同様に、平仮名「せい」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」には、各施設名の読み「せいと/どーむ」、「せいとか/としょかん」の各キーワード「どーむ」、「としょかん」の先頭文字が属する「た行」の各カウント値「1」が、各キーワードの先頭文字が属する50音の行を行別にカウントした最大カウント値として記憶されている。
【0053】
また同様に、平仮名「せい」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」には、施設名の読み「せいと/ひゃっかてん」のキーワード「ひゃっかてん」の先頭文字が属する「は行」のカウント値「1」が、各キーワードの先頭文字が属する50音の行を行別にカウントした最大カウント値として記憶されている。また、平仮名「せい」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」の「あ行」、「か行」、「な行」、「ま行」〜「わ行」には、施設名の読みの各キーワードの先頭文字が属していない旨を表す「0」が記憶されている。
【0054】
従って、先頭文字情報データテーブル52の各「分割単位」に対応する「キーワードの先頭文字情報」の「あ行」〜「わ行」の50音の行別に区分して記憶されたカウント値によって、各「分割単位」内に記憶されている施設名の読みの各キーワードの先頭文字が属する50音の行の有・無を判別することが可能となる。
【0055】
[施設情報表示処理]
次に、上記のように構成されたナビゲーション装置1のCPU41が実行する処理であって、50音キー62から入力された検索語に基づいて施設情報を検索してリスト表示する「施設情報表示処理」について図4乃至図7に基づいて説明する。
【0056】
図4はCPU41が実行する処理であって、入力された検索語に基づいて施設情報を検索してリスト表示する「施設情報表示処理」を示すフローチャートである。尚、図4にフローチャートで示されるプログラムは、操作部14の不図示の目的地設定ボタンが押下された場合に、CPU41により実行される。
【0057】
図4に示すように、先ず、ステップ(以下、Sと略記する)11において、CPU41は、液晶ディスプレイ15の画面に、施設情報として目的地の住所や施設に関する名称等を検索するための検索語を入力する検索語入力画面61を表示する。
ここで、検索語入力画面61の一例について図6に基づいて説明する。図6に示すように、検索語入力画面61には、50音キー62、入力文字表示部63、検索語表示部64、修正ボタン65、戻るボタン66、次ワードボタン67、完了ボタン68、件数表示部69が表示される。
【0058】
この入力文字表示部63には、50音キー62によって入力された入力文字が表示される。そして、次ワードボタン67が押下された場合には、入力文字表示部63に表示されている文字列が検索語として検索語表示部64に確定表示されるとともに、次の文字列を入力することが可能となる。また、修正ボタン65を押下する毎に、入力文字表示部63に表示されている文字列の最終入力文字を1文字ずつ削除することができる。
【0059】
また、戻るボタン66を押下することによって、検索語入力画面61の前の画面に戻ることができる。更に、完了ボタン68を押下することによって、検索語表示部64に表示されている各文字列と入力文字表示部63に表示されている文字列を検索語として、施設情報としての施設に関する名称等を検索してリスト表示するように指示することができる。また、件数表示部69には、入力文字表示部63に表示されている文字列と検索語表示部64に表示されている各文字列によって検索された施設名の件数が表示される。
【0060】
続いて、図4に示すように、S12において、CPU41は、50音キー62が押下されたか否か、つまり、50音キー62から検索語が入力されたか否かを判定する判定処理を実行する。そして、50音キー62が押下されたと判定した場合には(S12:YES)、CPU41は、50音キー62から入力された入力文字を入力文字表示部63に表示すると共に、入力文字表示部63に表示している文字列を検索語としてRAM42に記憶後、S13の処理に移行する。
【0061】
S13において、CPU41は、検索語表示部64に表示されている各文字列と入力文字表示部63に表示されている文字列を検索語として、施設名データテーブル51に記憶された施設名から目的地候補である候補施設名を抽出する後述の「候補施設名抽出処理」のサブ処理(図5参照)を実行後、再度、S12以降の処理を実行する。
【0062】
一方、50音キー62が押下されていないと判定した場合には(S12:NO)、CPU41は、S14の処理に移行する。S14において、CPU41は、次ワードボタン67が押下されたか否かを判定する判定処理を実行する。そして、次ワードボタン67が押下されたと判定した場合には(S14:YES)、CPU41は、S15の処理に移行する。
【0063】
S15において、CPU41は、入力文字表示部63に表示されている文字列を検索語として検索語表示部64に確定表示すると共に、この文字列を確定検索語としてRAM42に時系列的に記憶する。また、CPU41は、入力文字表示部63に表示されている文字列をクリアして、50音キー62から新たな文字列を入力できるように設定した後、再度、S12以降の処理を実行する。
【0064】
一方、次ワードボタン67が押下されていないと判定した場合には(S14:NO)、CPU41は、S16の処理に移行する。S16において、CPU41は、完了ボタン68が押下されたか否かを判定する判定処理を実行する。そして、完了ボタン68が押下されていないと判定した場合には(S16:NO)、CPU41は、S17の処理に移行する。
【0065】
S17において、CPU41は、修正ボタン65又は戻るボタン66が押下されたか否かを判定する判定処理を実行する。そして、修正ボタン65が押下されたと判定した場合には、CPU41は、入力文字表示部63に表示されている文字列の最終入力文字を1文字削除した後、再度、S12以降の処理を実行する。
【0066】
また、戻るボタン66が押下されたと判定した場合には、CPU41は、図3に示す当該処理を終了し、検索語入力画面61の前の画面に戻る。更に、修正ボタン65及び戻るボタン66が押下されなかった場合には、CPU41は、再度、S12以降の処理を実行する。
【0067】
一方、完了ボタン68が押下されたと判定した場合には(S16:YES)、CPU41は、S18の処理に移行する。S18において、CPU41は、上記S13で抽出された全候補施設名をリスト表示後(図7参照)、当該処理を終了する。
【0068】
[候補施設名抽出処理]
次に、上記S13で実行する「候補施設名抽出処理」のサブ処理について図5に基づいて説明する。
図5に示すように、S111において、CPU41は、入力文字表示部63に表示されている検索語と各検索語表示部64に表示されている確定検索語とをRAM42から読み出す。
【0069】
そして、S112において、CPU41は、このRAM42から読み出した各検索語の包含関係に従って検索語の検索順を設定し、この検索順に検索語をRAM42に記憶する。
【0070】
具体的には、CPU41は、RAM42から読み出した各検索語の文字数の多い順に検索語の検索順を設定し、この検索順に検索語をRAM42に記憶する。また、CPU41は、RAM42から読み出した各検索語の文字数が同じ場合には、時系列的に早くRAM42に記憶した順に検索語の検索順を設定し、この検索順に検索語をRAM42に記憶する。
【0071】
例えば、CPU41は、RAM42から読み出した各検索語が、図6に示すように、「せ」、「と」の場合には、検索語「せ」の検索順を1番目に設定し、検索語「と」の検索順を2番目に設定する。そして、CPU41は、この検索順に各検索語「せ」、「と」をRAM42に記憶する。
【0072】
続いて、S113において、CPU41は、先頭文字情報データテーブル52の1番目の「分割単位」に記憶されている平仮名を読み出す。そして、CPU41は、当該「分割単位」に記憶されている平仮名が、検索順が1番目の検索語と前方一致するか否かを判定する判定処理を実行する。
【0073】
そして、当該「分割単位」に記憶されている平仮名が、検索順が1番目の検索語と前方一致しないと判定した場合には(S113:NO)、CPU41は、先頭文字情報データテーブル52に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。そして、先頭文字情報データテーブル52に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル52の次の「分割単位」に記憶されている平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル52に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了してS116の処理に移行する。
【0074】
一方、S113で当該「分割単位」に記憶されている平仮名が、検索順が1番目の検索語と前方一致すると判定した場合には(S113:YES)、CPU41は、S114の処理に移行する。S114において、CPU41は、全検索語をRAM42から読み出し、全検索語の各先頭文字の属する50音の行を行別にカウントする。
【0075】
そして、CPU41は、当該「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されている各カウント値が、全検索語の各先頭文字の属する50音の行の行別のカウント値以上か否かを判定する判定処理を実行する。つまり、全検索語の各先頭文字の属する50音の行に、各キーワードの先頭文字が属する施設名の読みが、当該「分割単位」に対応する施設名データテーブル51の「分割単位」内の「読み」に記憶されているか否かを判定する判定処理を実行する。
【0076】
そして、当該「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されているカウント値が、全検索語の各先頭文字の属する50音の行の行別のカウント値より少ない50音の行の区分やカウント値が「0」の50音の行の区分が1つでもあると判定した場合には(S114:NO)、CPU41は、先頭文字情報データテーブル52に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。
【0077】
そして、先頭文字情報データテーブル52に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル52の次の「分割単位」に記憶されている平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル52に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了してS116の処理に移行する。
【0078】
一方、S114で当該「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されているカウント値が、全検索語の各先頭文字の属する50音の行の行別のカウント値以上であると判定した場合には(S114:YES)、CPU41は、S115の処理に移行する。S115において、CPU41は、当該「分割単位」を施設名データテーブル51の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0079】
続いて、CPU41は、先頭文字情報データテーブル52に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。そして、先頭文字情報データテーブル52に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル52の次の「分割単位」に記憶されている平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル52に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了してS116の処理に移行する。
【0080】
例えば、図3に示すように、上記S112で1番目の検索順に設定された検索語が「せ」で、2番目の検索順に設定された検索語が「と」の場合には、CPU41は、当該検索語の先頭文字「せ」と前方一致する各平仮名「せ」、「せあ」、「せい」、「せう」、・・・「せん」が記憶された各「分割単位」について、S114の処理を実行する。
【0081】
そして、CPU41は、「キーワードの先頭文字情報」の全検索語「せ」、「と」の各先頭文字「せ」、「と」の属する50音の「さ行」、「た行」の区分に記憶されている各カウント値が、「1」以上である各平仮名「せい」、「せん」が記憶された「分割単位」を施設名データテーブル51の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0082】
そして、図5に示すように、S116において、CPU41は、RAM42から上記S115で記憶した施設名データテーブル51の候補施設名を検索する該当「分割単位」を順番に読み出し、施設名データテーブル51の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出す。そして、CPU41は、この読み出した各施設名の読みを構成するキーワードの中に、上記S112で検索順を設定した各検索語と前方一致するキーワードがあるか否かを判定する判定処理を実行する、つまり、読み出した全施設名の「読み」について各検索語の全文検索を行う。
【0083】
そして、CPU41は、読み出した施設名の読みを構成するキーワードの中に各検索語と前方一致するキーワードがある場合には、この施設名の読みに対応する「施設名」を施設名データテーブル51から読み出し、目的地候補である候補施設名としてRAM42に順番に記憶後、S117の処理に移行する。
【0084】
尚、CPU41は、検索語と前方一致する施設名の読みのキーワードが、この検索語よりも短い文字列の場合には、更に、検索語のキーワードと一致していない残りの文字列と前方一致するキーワードが、当該施設名の読みを構成するキーワードの中にあるか否かを判定する判定処理を実行する。
【0085】
そして、CPU41は、検索語のキーワードと一致していない残りの文字列と前方一致するキーワードが、当該施設名の読みを構成するキーワードの中にある場合には、この施設名の読みに対応する「施設名」を施設名データテーブル51から読み出し、目的地候補である候補施設名としてRAM42に記憶する。
【0086】
例えば、各平仮名「せい」、「せん」が記憶された「分割単位」を施設名データテーブル51の候補施設名を検索する該当「分割単位」としてRAM42に記憶した場合には、CPU41は、施設名データテーブル51の各平仮名「せい」、「せん」が記憶された「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出す。
【0087】
そして、図2に示すように、CPU41は、この読み出した各施設名の読みを構成するキーワードの中に、各検索語「せ」、「と」と前方一致するキーワードがある各施設名の読み「せいと/どーむ」、「せいとか/としょかん」、「せんけ/とけい」に対応する各施設名「西都ドーム」、「西都科図書館」、「千家時計」を施設名データテーブル51から読み出し、目的地候補である候補施設名としてRAM42に順番に記憶する。
【0088】
続いて、図5に示すように、S117において、CPU41は、候補施設名をRAM42から順番に読み出してカウントし、入力された検索語によって検索可能な候補施設名の件数としてRAM42に記憶する。例えば、候補施設名が各施設名「西都ドーム」、「西都科図書館」、「千家時計」の場合には、件数として「3件」をRAM42に記憶する。
【0089】
尚、検索語に含まれる濁音、半濁音、拗音、促音、長音等の特殊文字はそれぞれ基本文字に変換して処理される。例えば、「とうきょう」は「とうきよう」、「らんど」は「らんと」として検索される。前述したように、施設名データテーブル51に記憶されている施設名の読みに含まれる特殊文字も基本文字に変換して記憶されているため、結果的には特殊文字を無視した検索を行うことになる。
【0090】
そして、S118において、CPU41は、RAM42から件数を読み出し、検索語入力画面61の件数表示部69に表示後、当該サブ処理を終了してメインフローチャートに戻り、S12以降の処理を実行する。例えば、RAM42から読み出した件数が「3件」の場合には、図6に示すように、件数表示部69に「3件」と表示後、当該サブ処理を終了してメインフローチャートに戻り、S12以降の処理を実行する。
【0091】
ここで、図6に示すように、50音キー62から各検索語「せ」、「と」を入力して、完了ボタン68を押下した場合の、抽出した施設名をリスト表示した検索結果表示画面71の一例を図7に基づいて説明する。尚、各検索語「せ」、「と」によって、候補施設名として各施設名「西都ドーム」、「西都科図書館」、「千家時計」が抽出されているとする。
【0092】
図7に示すように、PU41は、液晶ディスプレイ15に検索結果表示画面71を表示し、候補施設名として各施設名「西都ドーム」、「西都科図書館」、「千家時計」をRAM42から読み出し、一番上の検索結果表示欄72から順番に表示する。また、CPU41は、件数「3件」をRAM42から読み出し、検索結果表示画面71の上部に設けられた件数表示部73に表示する。
【0093】
ここで、ユーザが、各検索結果表示欄72の施設情報を押下して選択すると、CPU41は、当該施設を目的地に設定して経路探索を行い、推奨経路を地図上に表示する。また、当該施設に関する施設情報(例えば、営業時間、料金等である。)を表示する。
また、各検索結果表示欄72の左側には、検索結果表示欄72の施設の名称を1件ずつスクロールダウン、スクロールアップするための前ボタン74、次ボタン75と、検索結果表示欄72の施設の名称を5件ずつスクロールダウン、スクロールアップするための各頁ボタン76、77とが表示されている。
【0094】
以上詳細に説明した通り、実施例1に係るナビゲーション装置1では、CPU41は、先頭文字情報データテーブル52の各「分割単位」のうち、検索順が1番目の検索語と前方一致する平仮名が記憶された「分割単位」を抽出する。そして、CPU41は、この抽出した各「分割単位」のうち、各「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されているカウント値が、全検索語の各先頭文字の属する50音の行の行別のカウント値以上のものだけを、施設名データテーブル51の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0095】
続いて、CPU41は、施設名データテーブル51の候補施設名を検索する該当「分割単位」を順番に読み出し、施設名データテーブル51の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出す。そして、CPU41は、読み出した全施設名の「読み」について各検索語の全文検索を行い、読み出した施設名の読みを構成するキーワードの中に各検索語と前方一致するキーワードがある場合には、この施設名の読みに対応する「施設名」を施設名データテーブル51から読み出し、目的地候補である候補施設名としてRAM42に記憶する。
【0096】
これにより、文字数の少ない(例えば、1文字又は2文字である。)複数の検索語が入力されても、CPU41は、検索順が1番目の検索語と前方一致する平仮名が記憶された「分割単位」のうち、全検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された「分割単位」だけを先頭文字情報データテーブル52から抽出することが可能となる。従って、CPU41は、全検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された「分割単位」だけを先頭文字情報データテーブル52から抽出して、施設名データテーブル51の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出して全検索語について全文検索を行うため、検索対象となる施設名の読みを少なくすることができ、検索を高速で行い、応答性の低下を防止することが可能となる。
【0097】
また、施設名データテーブル51の「分割単位」間では「施設名」に記憶された施設名の重複はあるが、各「分割単位」内においては、「施設名」に記憶された施設名の重複は無く、1つの施設名だけが記憶されている。従って、施設名データテーブル51の「分割単位」間では「読み」に記憶された施設名の読みの重複はあるが、各「分割単位」内においては、「読み」に記憶された施設名の読みの重複は無く、1つの施設名の読みだけが記憶されている。これにより、各「分割単位」の「施設名」に記憶された施設名は、1個だけ記憶されるため、重複記憶される施設名を減少させて、名称リストのデータ容量の削減化を図り、名称リストを展開するメモリ容量の増大を抑止することが可能となる。
【実施例2】
【0098】
次に、実施例2に係るナビゲーション装置81について図8に基づいて説明する。尚、以下の説明において上記図1乃至図7の実施例1に係るナビゲーション装置1の構成と同一符号は、前記実施例1に係るナビゲーション装置1の構成と同一あるいは相当部分を示すものである。
【0099】
この実施例2に係るナビゲーション装置81の概略構成は、実施例1に係るナビゲーション装置1とほぼ同じ構成である。また、各種制御処理も実施例1に係るナビゲーション装置1とほぼ同じ制御処理である。
但し、ナビゲーション装置81は、先頭文字情報データテーブル52に替えて、図8に示す先頭文字情報データテーブル82を施設名DB27に格納している点で異なっている。このため、後述のように、上記S114における処理も異なっている。
【0100】
ここで、先頭文字情報データテーブル82について図8に基づいて説明する。
図8に示すように、実施例2に係る先頭文字情報データテーブル82は、上記先頭文字情報データテーブル52と同様に、「分割単位」と、「キーワードの先頭文字情報」と、「読み」とから構成されている。また、「キーワードの先頭文字情報」は、「あ行」〜「わ行」の50音の行別に区分されている。
【0101】
但し、図8に示すように、各「分割単位」に対応する「キーワードの先頭文字情報」には、同じ「分割単位」に対応する「読み」に記憶された各施設名の読み毎に、各キーワードの先頭文字が属する50音の行を行別にカウントし、カウント値が「1」以上の50音の行別の区分には、「1」を代入して記憶し、カウント値が「0」の50音の行別の区分には、「0」を代入して記憶する。つまり、各キーワードの先頭文字が属する50音の行の区分には「1」が記憶され、それ以外の50音の行の区分には「0」が記憶されている。
【0102】
例えば、図8に示すように、平仮名「せい」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」には、施設名の読み「せいげん/そめや」の各キーワード「せいげん」、「そめや」の先頭文字が属する「さ行」のカウント値は「2」であるため(図3参照)、当該「キーワードの先頭文字情報」の「さ行」には、「1」が記憶されている。
【0103】
また同様に、平仮名「せい」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」には、各施設名の読み「せいと/どーむ」、「せいとか/としょかん」の各キーワード「どーむ」、「としょかん」の先頭文字が属する「た行」の各カウント値は「1」であるため(図3参照)、当該「キーワードの先頭文字情報」の「た行」には、「1」が記憶されている。
【0104】
また同様に、平仮名「せい」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」には、施設名の読み「せいと/ひゃっかてん」のキーワード「ひゃっかてん」の先頭文字が属する「は行」のカウント値は「1」であるため(図3参照)、当該「キーワードの先頭文字情報」の「は行」には、「1」が記憶されている。また、平仮名「せい」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」の「あ行」、「か行」、「な行」、「ま行」〜「わ行」には、施設名の読みの各キーワードの先頭文字が属していない旨を表す「0」が記憶されている。
【0105】
従って、先頭文字情報データテーブル82の各「分割単位」に対応する「キーワードの先頭文字情報」の「あ行」〜「わ行」の50音の各行に記憶された値が「1」か否かによって、各「分割単位」内に記憶されている施設名の読みの各キーワードの先頭文字が属する50音の行の有・無を判別することが可能となる。
【0106】
次に、実施例2に係るナビゲーション装置81のCPU41が実行するS114の処理について説明する。
S114において、CPU41は、全検索語をRAM42から読み出し、上記S113で特定した「分割単位」に対応する「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されている値が、全て「1」か否かを判定する判定処理を実行する。つまり、全検索語の各先頭文字の属する50音の行に、各キーワードの先頭文字が属する施設名の読みが、当該「分割単位」に対応する施設名データテーブル51の「分割単位」内の「読み」に記憶されているか否かを判定する判定処理を実行する。
【0107】
そして、当該「分割単位」の「キーワードの先頭文字情報」の50音の行の区分に記憶されている値が、全て「1」でない、つまり、値の「0」のものがあると判定した場合には(S114:NO)、CPU41は、先頭文字情報データテーブル82に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。
【0108】
そして、先頭文字情報データテーブル82に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル82の次の「分割単位」に記憶されている平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル82に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了して上記S116の処理に移行する。
【0109】
一方、S114で当該「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されているカウント値が、全て「1」であると判定した場合には(S114:YES)、CPU41は、S115の処理に移行する。S115において、CPU41は、当該「分割単位」を施設名データテーブル51の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0110】
続いて、CPU41は、先頭文字情報データテーブル82に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。そして、先頭文字情報データテーブル82に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル82の次の「分割単位」に記憶されている平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル82に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了して上記S116の処理に移行する。
【0111】
例えば、図8に示すように、上記S112で1番目の検索順に設定された検索語が「せ」で、2番目の検索順に設定された検索語が「と」の場合には、CPU41は、当該検索語の先頭文字「せ」と前方一致する各平仮名「せ」、「せあ」、「せい」、「せう」、・・・「せん」が記憶された各「分割単位」について、S114の処理を実行する。
【0112】
そして、CPU41は、「キーワードの先頭文字情報」の全検索語「せ」、「と」の各先頭文字「せ」、「と」の属する50音の「さ行」、「た行」に記憶されている値が、全て「1」である各平仮名「せい」、「せん」が記憶された「分割単位」を施設名データテーブル51の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0113】
以上詳細に説明した通り、実施例2に係るナビゲーション装置81では、CPU41は、先頭文字情報データテーブル82の各「分割単位」のうち、検索順が1番目の検索語と前方一致する平仮名が記憶された「分割単位」を抽出する。そして、CPU41は、この抽出した各「分割単位」のうち、各「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されている値が、全て「1」のものだけを、施設名データテーブル51の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0114】
続いて、CPU41は、施設名データテーブル51の候補施設名を検索する該当「分割単位」を順番に読み出し、施設名データテーブル51の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出す。そして、CPU41は、読み出した全施設名の「読み」について各検索語の全文検索を行い、読み出した施設名の読みを構成するキーワードの中に各検索語と前方一致するキーワードがある場合には、この施設名の読みに対応する「施設名」を施設名データテーブル51から読み出し、目的地候補である候補施設名としてRAM42に記憶する。
【0115】
これにより、文字数の少ない(例えば、1文字又は2文字である。)複数の検索語が入力されても、CPU41は、検索順が1番目の検索語と前方一致する平仮名が記憶された「分割単位」のうち、全検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された「分割単位」だけを先頭文字情報データテーブル82から抽出することが可能となる。
【0116】
従って、CPU41は、全検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された「分割単位」だけを先頭文字情報データテーブル82から抽出して、施設名データテーブル51の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出して全検索語について全文検索を行うため、検索対象となる施設名の読みを少なくすることができ、検索を高速で行い、応答性の低下を防止することが可能となる。
【実施例3】
【0117】
次に、実施例3に係るナビゲーション装置85について図9に基づいて説明する。尚、以下の説明において上記図1乃至図7の実施例1に係るナビゲーション装置1の構成と同一符号は、前記実施例1に係るナビゲーション装置1の構成と同一あるいは相当部分を示すものである。
【0118】
この実施例3に係るナビゲーション装置85の概略構成は、実施例1に係るナビゲーション装置1とほぼ同じ構成である。また、各種制御処理も実施例1に係るナビゲーション装置1とほぼ同じ制御処理である。
但し、ナビゲーション装置85は、先頭文字情報データテーブル52に替えて、図9に示す先頭文字情報データテーブル86を施設名DB27に格納している点で異なっている。このため、後述のように、上記S114における処理も異なっている。
【0119】
ここで、先頭文字情報データテーブル86について図9に基づいて説明する。
図9に示すように、実施例3に係る先頭文字情報データテーブル86は、上記先頭文字情報データテーブル52と同様に、「分割単位」と、「キーワードの先頭文字情報」と、「読み」とから構成されている。但し、「キーワードの先頭文字情報」は、平仮名が50音順に1文字ずつ属するように区分されている。
【0120】
また、各「分割単位」に対応する「キーワードの先頭文字情報」には、同じ「分割単位」に対応する「読み」に記憶された各施設名の読み毎に、各キーワードの先頭文字を50音別にそれぞれカウントし、各50音別のカウント値のうちの各施設名の読みの間の最大カウント値をそれぞれ抽出して、「キーワードの先頭文字情報」の各キーワードの先頭文字が属する「あ」〜「ん」の区分に記憶されている。
【0121】
例えば、図9に示すように、平仮名「せい」が記憶された「分割単位」に対応する各施設名の読みには、「せいと/どーむ」、「せいと/ひゃっかてん」、「せいげん/そめや」、「せいとか/としょかん」が記憶されている。このため、施設名の読み「せいと/どーむ」の各キーワード「せいと」、「どーむ」の先頭文字のカウント値は、「せ」が「1」、「と」が「1」である。また、施設名の読み「せいと/ひゃっかてん」の各キーワード「せいと」、「ひゃっかてん」の先頭文字のカウント値は、「せ」が「1」、「ひ」が「1」である。
【0122】
また、施設名の読み「せいげん/そめや」の各キーワード「せいげん」、「そめや」の先頭文字のカウント値は、「せ」が「1」、「そ」が「1」である。また、施設名の読み「せいとか/としょかん」の各キーワード「せいとか」、「としょかん」の先頭文字のカウント値は、「せ」が「1」、「と」が「1」である。
【0123】
従って、平仮名「せい」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」の各平仮名「せ」、「そ」、「と」、「ひ」が属する区分には、それぞれ最大カウント値として「1」が記憶されている。また、平仮名「せい」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」の各平仮名「あ」〜「す」、「た」〜「て」、「な」〜「は」、「ふ」〜「ん」が属する区分には、「0」が記憶されている。
【0124】
これにより、先頭文字情報データテーブル86の各「分割単位」に対応する「キーワードの先頭文字情報」の「あ」〜「ん」が属する各区分に記憶されたカウント値によって、各「分割単位」内に記憶されている施設名の読みの各キーワードの先頭文字を構成する平仮名を判別することが可能となる。
【0125】
次に、実施例3に係るナビゲーション装置85のCPU41が実行するS114の処理について説明する。
S114において、CPU41は、全検索語をRAM42から読み出し、全検索語の各先頭文字を50音別にカウントする。そして、CPU41は、上記S113で特定した「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する区分に記憶されている各カウント値が、全検索語の各先頭文字の50音別のカウント値以上か否かを判定する判定処理を実行する。つまり、全検索語の各先頭文字の属する50音の区分に、各キーワードの先頭文字が属する施設名の読みが、当該「分割単位」に対応する施設名データテーブル51の「分割単位」内の「読み」に記憶されているか否かを判定する判定処理を実行する。
【0126】
そして、当該「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する区分に、全検索語の各先頭文字の50音別のカウント値より少ない区分やカウント値が「0」の区分が1つでもあると判定した場合には(S114:NO)、CPU41は、先頭文字情報データテーブル86に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。
【0127】
そして、先頭文字情報データテーブル86に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル86の次の「分割単位」に記憶されている平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル86に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了してS116の処理に移行する。
【0128】
一方、S114で当該「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する区分に記憶されているカウント値が、全検索語の各先頭文字の50音別のカウント値以上であると判定した場合には(S114:YES)、CPU41は、S115の処理に移行する。S115において、CPU41は、当該「分割単位」を施設名データテーブル51の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0129】
続いて、CPU41は、先頭文字情報データテーブル86に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。そして、先頭文字情報データテーブル86に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル86の次の「分割単位」に記憶されている平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル86に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了してS116の処理に移行する。
【0130】
例えば、図9に示すように、上記S112で1番目の検索順に設定された検索語が「せ」で、2番目の検索順に設定された検索語が「と」の場合には、CPU41は、当該検索語の先頭文字「せ」と前方一致する各平仮名「せ」、「せあ」、「せい」、「せう」、・・・「せん」が記憶された各「分割単位」について、S114の処理を実行する。
【0131】
そして、CPU41は、「キーワードの先頭文字情報」の全検索語「せ」、「と」の各先頭文字「せ」、「と」の属する区分に記憶されている各カウント値が、「1」以上である各平仮名「せい」、「せん」が記憶された「分割単位」を施設名データテーブル51の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0132】
以上詳細に説明した通り、実施例3に係るナビゲーション装置85では、CPU41は、先頭文字情報データテーブル86の各「分割単位」のうち、検索順が1番目の検索語と前方一致する平仮名が記憶された「分割単位」を抽出する。そして、CPU41は、この抽出した各「分割単位」のうち、各「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する区分に記憶されているカウント値が、全検索語の各先頭文字の50音別のカウント値以上のものだけを、施設名データテーブル51の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0133】
続いて、CPU41は、施設名データテーブル51の候補施設名を検索する該当「分割単位」を順番に読み出し、施設名データテーブル51の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出す。そして、CPU41は、読み出した全施設名の「読み」について各検索語の全文検索を行い、読み出した施設名の読みを構成するキーワードの中に各検索語と前方一致するキーワードがある場合には、この施設名の読みに対応する「施設名」を施設名データテーブル51から読み出し、目的地候補である候補施設名としてRAM42に記憶する。
【0134】
これにより、文字数の少ない(例えば、1文字又は2文字である。)複数の検索語が入力されても、CPU41は、検索順が1番目の検索語と前方一致する平仮名が記憶された「分割単位」のうち、全検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された「分割単位」だけを先頭文字情報データテーブル86から抽出することが可能となる。
【0135】
従って、CPU41は、全検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された「分割単位」だけを先頭文字情報データテーブル86から抽出して、施設名データテーブル51の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出して全検索語について全文検索を行うため、検索対象となる施設名の読みを少なくすることができ、検索を高速で行い、応答性の低下を防止することが可能となる。
【実施例4】
【0136】
次に、実施例4に係るナビゲーション装置91について図10及び図11に基づいて説明する。尚、以下の説明において上記図1乃至図7の実施例1に係るナビゲーション装置1の構成と同一符号は、前記実施例1に係るナビゲーション装置1の構成と同一あるいは相当部分を示すものである。
【0137】
この実施例4に係るナビゲーション装置91の概略構成は、実施例1に係るナビゲーション装置1とほぼ同じ構成である。また、各種制御処理も実施例1に係るナビゲーション装置1とほぼ同じ制御処理である。
但し、ナビゲーション装置91は、施設名データテーブル51に替えて、図10に示す施設名データテーブル92を施設名DB27に格納し、また、先頭文字情報データテーブル52に替えて、図11に示す先頭文字情報データテーブル93を施設名DB27に格納している点で異なっている。
【0138】
ここで、施設名データテーブル92について図10に基づいて説明する。
図10に示すように、施設名データテーブル92は、施設名データテーブル51と同様に、「分割単位」と、施設名の読みを記憶する「読み」と、「施設名」とから構成されている。
但し、この「分割単位」には、施設名の読みを構成するキーワードと前方一致する1文字乃至3文字の平仮名が、その属する50音の1行乃至3行の組み合わせに対応されて記憶されている。例えば、「分割単位」が「た行あ行」には、施設名の読みのキーワードと前方一致する2文字の各平仮名「たあ」、「たい」、「たう」、・・・・「とえ」、「とお」が属している。
【0139】
尚、「分割単位」には、例えば「あ行あ行あ行あ行」、「あ行あ行あ行か行」、「あ行あ行あ行さ行」・・・等、50音の4行以上の組み合わせを記憶するようにしてもよい。また、「分割単位」の一部区間だけ、例えば、・・・「あ行わ行」、「か行あ行あ行あ行」、「か行あ行あ行か行」、・・・「か行あ行あ行わ行」、「か行か行」、「か行さ行」・・等、50音の4行以上の組み合わせを記憶するようにしてもよい。
【0140】
また、「読み」には、「分割単位」に属する1文字乃至3文字の各平仮名と前方一致するキーワードを含む施設名の読みが記憶されている。例えば、施設名の読みが「あいし/えいあーる/おかざき/こうじょう/せっけいか」は、各キーワードの前方3文字の「あいし」、「えいあ」、「おかざ」、「こうじ」、「せっけ」に対応する施設名データテーブル92の「分割単位」の50音の3行の各組み合わせ「あ行あ行さ行」、「あ行あ行あ行」、「あ行か行さ行」、「か行あ行さ行」、「さ行た行か行」に対応する「読み」にそれぞれ記憶される。
【0141】
また、「施設名」には、検索対象となる目的地を表す施設名が、「読み」に記憶された施設名の読みに対応して記憶されている。例えば、施設名「あいしAR岡崎工場設計課」は、施設名データテーブル92の「分割単位」の「あ行あ行さ行」、「あ行あ行あ行」、「あ行か行さ行」、「か行あ行さ行」、「さ行た行か行」内の「読み」の「あいし/えいあーる/おかざき/こうじょう/せっけいか」に対応する「施設名」にそれぞれ記憶される。
【0142】
次に、先頭文字情報データテーブル93について図11に基づいて説明する。
図11に示すように、先頭文字情報データテーブル93は、先頭文字情報データテーブル52と同様に、「分割単位」と、「キーワードの先頭文字情報」と、「読み」とから構成されている。また、「キーワードの先頭文字情報」は、「あ行」〜「わ行」の50音の行別に区分されている。
【0143】
但し、この「分割単位」は、施設名データテーブル92の「分割単位」に対応するものであり、施設名の読みを構成するキーワードと前方一致する1文字乃至3文字の平仮名が、その属する50音の1行乃至3行の組み合わせに対応されて記憶されている。例えば、「分割単位」が「あ行あ行」には、施設名の読みのキーワードと前方一致する2文字の各平仮名「ああ」、「あい」、「あう」、・・・・「おえ」、「おお」が属している。
【0144】
また、各「分割単位」に対応する「読み」には、施設名データテーブル92の各「分割単位」内の「読み」に記憶された施設名の読みがそれぞれ格納されている。例えば、50音の2行の組み合わせ「あ行あ行」が記憶された「分割単位」に対応する「読み」には、施設名データテーブル92の50音の2行の組み合わせ「あ行あ行」が記憶された「分割単位」内の「読み」に記憶されている施設名の読み「ああ」、「えい」、・・・が、区切り文字「;」で区切られて記憶されている。
【0145】
また、各「分割単位」に対応する「キーワードの先頭文字情報」には、同じ「分割単位」に対応する「読み」に記憶された各施設名の読み毎に、各キーワードの先頭文字が属する50音の行を行別にカウントし、各50音の行別のカウント値のうちの各施設名の読みの間の最大カウント値をそれぞれ抽出して、「キーワードの先頭文字情報」の「あ行」〜「わ行」の50音の行別に区分して記憶されている。
【0146】
例えば、図11に示すように、50音の3行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」には、施設名の読み「おおさか/おおい/おおさまじょう/おおて/おみやげ」の各キーワード「おおさか」、「おおい」、「おおさまじょう」、「おおて」、「おみやげ」の先頭文字が属する「あ行」のカウント値「5」が、各キーワードの先頭文字が属する50音の行を行別にカウントした最大カウント値として記憶されている。
【0147】
また同様に、50音の3行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」には、施設名の読み「あいし/えいあーる/おかざき/こうじょう/せっけいか」のキーワード「こうじょう」の先頭文字が属する「か行」のカウント値「1」が、各キーワードの先頭文字が属する50音の行を行別にカウントした最大カウント値として記憶されている。
【0148】
また同様に、50音の3行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」には、施設名の読み「うえしの/しあたー」のキーワード「しあたー」の先頭文字が属する「さ行」のカウント値「1」が、各キーワードの先頭文字が属する50音の行を行別にカウントした最大カウント値として記憶されている。また、50音の3行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」の「た行」〜「わ行」には、施設名の読みの各キーワードの先頭文字が属していない旨を表す「0」が記憶されている。
【0149】
従って、先頭文字情報データテーブル93の各「分割単位」に対応する「キーワードの先頭文字情報」の「あ行」〜「わ行」の50音の行別に区分して記憶されたカウント値によって、各「分割単位」内に記憶されている施設名の読みの各キーワードの先頭文字が属する50音の行の有・無を判別することが可能となる。
【0150】
そして、実施例4に係るナビゲーション装置91のCPU41は、上記図5に示す「候補施設名抽出処理」のサブ処理のS113〜S116において、施設名データテーブル51及び先頭文字情報データテーブル52に替えて、施設名データテーブル92及び先頭文字情報データテーブル93を使用する。
【0151】
具体的には、上記S113において、CPU41は、先頭文字情報データテーブル93の1番目の「分割単位」に記憶されている50音の行の組み合わせに属する平仮名が、検索順が1番目の検索語と前方一致するか否かを判定する判定処理を実行する。そして、当該「分割単位」に記憶されている50音の行の組み合わせに属する平仮名が、検索順が1番目の検索語と前方一致しないと判定した場合には(S113:NO)、CPU41は、先頭文字情報データテーブル93に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。
【0152】
そして、先頭文字情報データテーブル93に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル93の次の「分割単位」に記憶されている50音の行の組み合わせに属する平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル93に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了してS116の処理に移行する。
【0153】
一方、S113で当該「分割単位」に記憶されている50音の行の組み合わせに属する平仮名が、検索順が1番目の検索語と前方一致すると判定した場合には(S113:YES)、CPU41は、S114の処理に移行する。S114において、CPU41は、全検索語をRAM42から読み出し、全検索語の各先頭文字の属する50音の行を行別にカウントする。
【0154】
そして、CPU41は、当該「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されている各カウント値が、全検索語の各先頭文字の属する50音の行の行別のカウント値以上か否かを判定する判定処理を実行する。つまり、全検索語の各先頭文字の属する50音の行に、各キーワードの先頭文字が属する施設名の読みが、当該「分割単位」に対応する施設名データテーブル92の「分割単位」内の「読み」に記憶されているか否かを判定する判定処理を実行する。
【0155】
そして、当該「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されているカウント値が、全検索語の各先頭文字の属する50音の行の行別のカウント値より少ない50音の行の区分やカウント値が「0」の50音の行の区分が1つでもあると判定した場合には(S114:NO)、CPU41は、先頭文字情報データテーブル93に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。
【0156】
そして、先頭文字情報データテーブル93に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル93の次の「分割単位」に記憶されている50音の行の組み合わせに属する平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル93に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了してS116の処理に移行する。
【0157】
一方、S114で当該「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されているカウント値が、全検索語の各先頭文字の属する50音の行の行別のカウント値以上であると判定した場合には(S114:YES)、CPU41は、S115の処理に移行する。S115において、CPU41は、当該「分割単位」を施設名データテーブル92の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0158】
続いて、CPU41は、先頭文字情報データテーブル93に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。そして、先頭文字情報データテーブル93に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル93の次の「分割単位」に記憶されている50音の行の組み合わせに属する平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル93に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了してS116の処理に移行する。
【0159】
例えば、図11に示すように、上記S112で1番目の検索順に設定された検索語が「あい」で、2番目の検索順に設定された検索語が「こ」の場合には、CPU41は、当該検索語の先頭文字「あ」と前方一致する各50音の行の組み合わせ「あ行」、「あ行あ行」、・・・「あ行あ行さ行」・・・「あ行わ行わ行」が記憶された各「分割単位」について、S114の処理を実行する。
【0160】
そして、CPU41は、「キーワードの先頭文字情報」の全検索語「あい」、「こ」の各先頭文字「あ」、「こ」の属する50音の「あ行」、「か行」の区分に記憶されている各カウント値が、「1」以上である50音の行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」を施設名データテーブル92の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0161】
そして、S116において、CPU41は、RAM42から上記S115で記憶した施設名データテーブル92の候補施設名を検索する該当「分割単位」を順番に読み出し、施設名データテーブル92の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出す。そして、CPU41は、この読み出した各施設名の読みを構成するキーワードの中に、上記S112で検索順を設定した各検索語と前方一致するキーワードがあるか否かを判定する判定処理を実行する、つまり、読み出した全施設名の「読み」について各検索語の全文検索を行う。
【0162】
そして、CPU41は、読み出した施設名の読みを構成するキーワードの中に各検索語と前方一致するキーワードがある場合には、この施設名の読みに対応する「施設名」を施設名データテーブル92から読み出し、目的地候補である候補施設名としてRAM42に順番に記憶後、S117の処理に移行する。
【0163】
以上詳細に説明した通り、実施例4に係るナビゲーション装置91では、CPU41は、先頭文字情報データテーブル93の各「分割単位」のうち、検索順が1番目の検索語と前方一致する平仮名が属する50音の行の組み合わせが記憶された「分割単位」を抽出する。そして、CPU41は、この抽出した各「分割単位」のうち、全検索語の各先頭文字の属する50音の行に対応する、各「分割単位」の「キーワードの先頭文字情報」の50音の行の区分に記憶されているカウント値が、全検索語の各先頭文字の属する50音の行の行別のカウント値以上のものだけを、施設名データテーブル92の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0164】
続いて、CPU41は、施設名データテーブル92の候補施設名を検索する該当「分割単位」を順番に読み出し、施設名データテーブル92の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出す。そして、CPU41は、読み出した全施設名の「読み」について各検索語の全文検索を行い、読み出した施設名の読みを構成するキーワードの中に各検索語と前方一致するキーワードがある場合には、この施設名の読みに対応する「施設名」を施設名データテーブル92から読み出し、目的地候補である候補施設名としてRAM42に記憶する。
【0165】
これにより、文字数の少ない(例えば、1文字又は2文字である。)複数の検索語が入力されても、CPU41は、検索順が1番目の検索語と前方一致する平仮名が属する50音の行の組み合わせが記憶された「分割単位」のうち、全検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された「分割単位」だけを先頭文字情報データテーブル93から抽出することが可能となる。
【0166】
従って、CPU41は、全検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された「分割単位」だけを先頭文字情報データテーブル93から抽出して、施設名データテーブル92の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出して全検索語について全文検索を行うため、検索対象となる施設名の読みを少なくすることができ、検索を高速で行い、応答性の低下を防止することが可能となる。
【0167】
また、施設名データテーブル92の「分割単位」間では「施設名」に記憶された施設名の重複はあるが、各「分割単位」内においては、「施設名」に記憶された施設名の重複は無く、1つの施設名だけが記憶されている。従って、施設名データテーブル92の「分割単位」間では「読み」に記憶された施設名の読みの重複はあるが、各「分割単位」内においては、「読み」に記憶された施設名の読みの重複は無く、1つの施設名の読みだけが記憶されている。これにより、各「分割単位」の「施設名」に記憶された施設名は、1個だけ記憶されるため、重複記憶される施設名を減少させて、名称リストのデータ容量の削減化を図り、名称リストを展開するメモリ容量の増大を抑止することが可能となる。
【実施例5】
【0168】
次に、実施例5に係るナビゲーション装置95について図12に基づいて説明する。尚、以下の説明において上記図1乃至図7の実施例1に係るナビゲーション装置1の構成と同一符号は、前記実施例1に係るナビゲーション装置1の構成と同一あるいは相当部分を示すものである。また、上記図10及び図11の実施例4に係るナビゲーション装置91の構成と同一符号は、前記実施例4に係るナビゲーション装置91の構成と同一あるいは相当部分を示すものである。
【0169】
この実施例5に係るナビゲーション装置95の概略構成は、実施例4に係るナビゲーション装置91とほぼ同じ構成である。また、各種制御処理も実施例4に係るナビゲーション装置91とほぼ同じ制御処理である。
但し、ナビゲーション装置95は、先頭文字情報データテーブル93に替えて、図12に示す先頭文字情報データテーブル96を施設名DB27に格納している点で異なっている。このため、後述のように、上記S114における処理も異なっている。
【0170】
ここで、先頭文字情報データテーブル96について図12に基づいて説明する。
図12に示すように、実施例5に係る先頭文字情報データテーブル96は、上記先頭文字情報データテーブル93と同様に、「分割単位」と、「キーワードの先頭文字情報」と、「読み」とから構成されている。また、「キーワードの先頭文字情報」は、「あ行」〜「わ行」の50音の行別に区分されている。
【0171】
但し、図12に示すように、各「分割単位」に対応する「キーワードの先頭文字情報」には、同じ「分割単位」に対応する「読み」に記憶された各施設名の読み毎に、各キーワードの先頭文字が属する50音の行を行別にカウントし、カウント値が「1」以上の50音の行別の区分には、「1」を代入して記憶し、カウント値が「0」の50音の行別の区分には、「0」を代入して記憶する。つまり、各キーワードの先頭文字が属する50音の行の区分には「1」が記憶され、それ以外の50音の行の区分には「0」が記憶されている。
【0172】
例えば、図12に示すように、50音の3行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」には、施設名の読み「おおさか/おおい/おおさまじょう/おおて/おみやげ」の各キーワード「おおさか」、「おおい」、「おおさまじょう」、「おおて」、「おみやげ」の先頭文字が属する「あ行」のカウント値は「5」であるため(図11参照)、当該「キーワードの先頭文字情報」の「あ行」には、「1」が記憶されている。
【0173】
また同様に、50音の3行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」には、施設名の読み「あいし/えいあーる/おかざき/こうじょう/せっけいか」のキーワード「こうじょう」の先頭文字が属する「か行」のカウント値が「1」であるため(図11参照)、当該「キーワードの先頭文字情報」の「か行」には、「1」が記憶されている。
【0174】
また同様に、50音の3行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」には、施設名の読み「うえしの/しあたー」のキーワード「しあたー」の先頭文字が属する「さ行」のカウント値が「1」であるため(図3参照)、当該「キーワードの先頭文字情報」の「さ行」には、「1」が記憶されている。また、50音の3行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」の「た行」〜「わ行」には、施設名の読みの各キーワードの先頭文字が属していない旨を表す「0」が記憶されている。
【0175】
従って、先頭文字情報データテーブル96の各「分割単位」に対応する「キーワードの先頭文字情報」の「あ行」〜「わ行」の50音の各行に記憶された値が「1」か否かによって、各「分割単位」内に記憶されている施設名の読みの各キーワードの先頭文字が属する50音の行の有・無を判別することが可能となる。
【0176】
次に、実施例5に係るナビゲーション装置95のCPU41が実行するS114の処理について説明する。
S114において、CPU41は、全検索語をRAM42から読み出し、S113で特定した「分割単位」(実施例4参照)に対応する「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されている値が、全て「1」か否かを判定する判定処理を実行する。つまり、全検索語の各先頭文字の属する50音の行に、各キーワードの先頭文字が属する施設名の読みが、当該「分割単位」に対応する施設名データテーブル92の「分割単位」内の「読み」に記憶されているか否かを判定する判定処理を実行する。
【0177】
そして、当該「分割単位」の「キーワードの先頭文字情報」の50音の行の区分に記憶されている値が、全て「1」でない、つまり、値の「0」のものがあると判定した場合には(S114:NO)、CPU41は、先頭文字情報データテーブル96に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。
【0178】
そして、先頭文字情報データテーブル96に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル96の次の「分割単位」に記憶されている50音の行の組み合わせに属する平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル96に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了して上記S116の処理に移行する。
【0179】
一方、S114で当該「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されているカウント値が、全て「1」であると判定した場合には(S114:YES)、CPU41は、S115の処理に移行する。S115において、CPU41は、当該「分割単位」を施設名データテーブル92の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0180】
続いて、CPU41は、先頭文字情報データテーブル96に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。そして、先頭文字情報データテーブル96に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル96の次の「分割単位」に記憶されている50音の行の組み合わせに属する平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル96に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了して上記S116の処理に移行する。
【0181】
例えば、図12に示すように、上記S112で1番目の検索順に設定された検索語が「あい」で、2番目の検索順に設定された検索語が「こ」の場合には、CPU41は、当該検索語の先頭文字「あ」と前方一致する各50音の行の組み合わせ「あ行」、「あ行あ行」、・・・「あ行あ行さ行」・・・「あ行わ行わ行」が記憶された各「分割単位」について、S114の処理を実行する。
【0182】
そして、CPU41は、「キーワードの先頭文字情報」の全検索語「あい」、「こ」の各先頭文字「あ」、「こ」の属する50音の「あ行」、「か行」の区分に記憶されている値が、全て「1」である50音の行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」を施設名データテーブル92の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0183】
以上詳細に説明した通り、実施例5に係るナビゲーション装置95では、CPU41は、先頭文字情報データテーブル96の各「分割単位」のうち、検索順が1番目の検索語と前方一致する平仮名が属する50音の行の組み合わせが記憶された「分割単位」を抽出する。そして、CPU41は、この抽出した各「分割単位」のうち、各「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の行の区分に記憶されている値が、全て「1」のものだけを、施設名データテーブル92の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0184】
続いて、CPU41は、施設名データテーブル92の候補施設名を検索する該当「分割単位」を順番に読み出し、施設名データテーブル92の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出す。そして、CPU41は、読み出した全施設名の「読み」について各検索語の全文検索を行い、読み出した施設名の読みを構成するキーワードの中に各検索語と前方一致するキーワードがある場合には、この施設名の読みに対応する「施設名」を施設名データテーブル92から読み出し、目的地候補である候補施設名としてRAM42に記憶する。
【0185】
これにより、文字数の少ない(例えば、1文字又は2文字である。)複数の検索語が入力されても、CPU41は、検索順が1番目の検索語と前方一致する平仮名が属する50音の行の組み合わせが記憶された「分割単位」のうち、全検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された「分割単位」だけを先頭文字情報データテーブル96から抽出することが可能となる。
【0186】
従って、CPU41は、全検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された「分割単位」だけを先頭文字情報データテーブル96から抽出して、施設名データテーブル92の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出して全検索語について全文検索を行うため、検索対象となる施設名の読みを少なくすることができ、検索を高速で行い、応答性の低下を防止することが可能となる。
【実施例6】
【0187】
次に、実施例6に係るナビゲーション装置98について図13に基づいて説明する。尚、以下の説明において上記図1乃至図7の実施例1に係るナビゲーション装置1の構成と同一符号は、前記実施例1に係るナビゲーション装置1の構成と同一あるいは相当部分を示すものである。また、上記図10及び図11の実施例4に係るナビゲーション装置91の構成と同一符号は、前記実施例4に係るナビゲーション装置91の構成と同一あるいは相当部分を示すものである。
【0188】
この実施例6に係るナビゲーション装置98の概略構成は、実施例4に係るナビゲーション装置91とほぼ同じ構成である。また、各種制御処理も実施例4に係るナビゲーション装置91とほぼ同じ制御処理である。
但し、ナビゲーション装置98は、先頭文字情報データテーブル93に替えて、図13に示す先頭文字情報データテーブル99を施設名DB27に格納している点で異なっている。このため、後述のように、上記S114における処理も異なっている。
【0189】
ここで、先頭文字情報データテーブル99について図13に基づいて説明する。
図13に示すように、実施例6に係る先頭文字情報データテーブル99は、上記先頭文字情報データテーブル93と同様に、「分割単位」と、「キーワードの先頭文字情報」と、「読み」とから構成されている。但し、「キーワードの先頭文字情報」は、平仮名が50音順に1文字ずつ属するように区分されている。
【0190】
また、各「分割単位」に対応する「キーワードの先頭文字情報」には、同じ「分割単位」に対応する「読み」に記憶された各施設名の読み毎に、各キーワードの先頭文字を50音別にそれぞれカウントし、各50音別のカウント値のうちの各施設名の読みの間の最大カウント値をそれぞれ抽出して、「キーワードの先頭文字情報」の各キーワードの先頭文字が属する「あ」〜「ん」の区分に記憶されている。
【0191】
例えば、図13に示すように、50音の3行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」に対応する各施設名の読みには、「あいし/えいあーる/おかざき/こうじょう/せっけいか」、「おおさか/おおい/おおさまじょう/おおて/おみやげ」、「うえしの/しあたー」が記憶されている。このため、施設名の読み「あいし/えいあーる/おかざき/こうじょう/せっけいか」の各キーワード「あいし」、「えいあーる」、「おかざき」、「こうじょう」、「せっけいか」の先頭文字のカウント値は、「あ」が「1」、「え」が「1」、「お」が「1」、「こ」が「1」、「せ」が「1」である。
【0192】
また、施設名の読み「おおさか/おおい/おおさまじょう/おおて/おみやげ」の各キーワード「おおさか」、「おおい」、「おおさまじょう」、「おおて」、「おみやげ」の先頭文字のカウント値は、「お」が「5」である。また、施設名の読み「うえしの/しあたー」の各キーワード「うれしの」、「しあたー」の先頭文字のカウント値は、「う」が「1」、「し」が「1」である。
【0193】
従って、50音の3行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」の各平仮名「あ」、「う」、「え」、「こ」、「し」、「せ」が属する区分には、それぞれ最大カウント値として「1」が記憶され、平仮名「お」が属する区分には、最大カウント値として「5」が記憶されている。また、50音の3行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」に対応する「キーワードの先頭文字情報」の各平仮名「い」、「か」〜「け」、「さ」、「す」、「そ」〜「ん」が属する区分には、「0」が記憶されている。
【0194】
これにより、先頭文字情報データテーブル99の各「分割単位」に対応する「キーワードの先頭文字情報」の「あ」〜「ん」が属する各区分に記憶されたカウント値によって、各「分割単位」内に記憶されている施設名の読みの各キーワードの先頭文字を構成する平仮名を判別することが可能となる。
【0195】
次に、実施例6に係るナビゲーション装置98のCPU41が実行するS114の処理について説明する。
S114において、CPU41は、全検索語をRAM42から読み出し、全検索語の各先頭文字を50音別にカウントする。そして、CPU41は、S113で特定した「分割単位」(実施例4参照)の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する区分に記憶されている各カウント値が、全検索語の各先頭文字の50音別のカウント値以上か否かを判定する判定処理を実行する。つまり、全検索語の各先頭文字の属する50音の区分に、各キーワードの先頭文字が属する施設名の読みが、当該「分割単位」に対応する施設名データテーブル92の「分割単位」内の「読み」に記憶されているか否かを判定する判定処理を実行する。
【0196】
そして、当該「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する区分に、全検索語の各先頭文字の50音別のカウント値より少ない区分やカウント値が「0」の区分が1つでもあると判定した場合には(S114:NO)、CPU41は、先頭文字情報データテーブル99に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。
【0197】
そして、先頭文字情報データテーブル99に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル99の次の「分割単位」に記憶されている50音の行の組み合わせに属する平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル99に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了してS116の処理に移行する。
【0198】
一方、S114で当該「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する区分に記憶されているカウント値が、全検索語の各先頭文字の50音別のカウント値以上であると判定した場合には(S114:YES)、CPU41は、S115の処理に移行する。S115において、CPU41は、当該「分割単位」を施設名データテーブル92の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0199】
続いて、CPU41は、先頭文字情報データテーブル99に次の「分割単位」が記憶されているか否かを判定する判定処理を実行する。そして、先頭文字情報データテーブル99に次の「分割単位」が記憶されていると判定した場合には、CPU41は、先頭文字情報データテーブル99の次の「分割単位」に記憶されている50音の行の組み合わせに属する平仮名を読み出し、再度、S113以降のループを実行する。一方、先頭文字情報データテーブル99に次の「分割単位」が記憶されていないと判定した場合には、CPU41は、ループを終了してS116の処理に移行する。
【0200】
例えば、図13に示すように、上記S112で1番目の検索順に設定された検索語が「あい」で、2番目の検索順に設定された検索語が「こ」の場合には、CPU41は、当該検索語の先頭文字「あ」と前方一致する各50音の行の組み合わせ「あ行」、「あ行あ行」、・・・「あ行あ行さ行」・・・「あ行わ行わ行」が記憶された各「分割単位」について、S114の処理を実行する。
【0201】
そして、CPU41は、「キーワードの先頭文字情報」の全検索語「あい」、「こ」の各先頭文字「あ」、「こ」の属する50音の「あ」、「こ」の区分に記憶されている値が、全て「1」以上である50音の行の組み合わせ「あ行あ行さ行」が記憶された「分割単位」を施設名データテーブル92の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0202】
以上詳細に説明した通り、実施例6に係るナビゲーション装置98では、CPU41は、先頭文字情報データテーブル99の各「分割単位」のうち、検索順が1番目の検索語と前方一致する平仮名が属する50音の行の組み合わせが記憶された「分割単位」を抽出する。そして、CPU41は、この抽出した各「分割単位」のうち、各「分割単位」の「キーワードの先頭文字情報」の全検索語の各先頭文字の属する区分に記憶されているカウント値が、全検索語の各先頭文字の50音別のカウント値以上のものだけを、施設名データテーブル92の候補施設名を検索する該当「分割単位」としてRAM42に記憶する。
【0203】
続いて、CPU41は、施設名データテーブル92の候補施設名を検索する該当「分割単位」を順番に読み出し、施設名データテーブル92の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出す。そして、CPU41は、読み出した全施設名の「読み」について各検索語の全文検索を行い、読み出した施設名の読みを構成するキーワードの中に各検索語と前方一致するキーワードがある場合には、この施設名の読みに対応する「施設名」を施設名データテーブル51から読み出し、目的地候補である候補施設名としてRAM42に記憶する。
【0204】
これにより、文字数の少ない(例えば、1文字又は2文字である。)複数の検索語が入力されても、CPU41は、検索順が1番目の検索語と前方一致する平仮名が属する50音の行の組み合わせが記憶された「分割単位」のうち、全検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された「分割単位」だけを先頭文字情報データテーブル99から抽出することが可能となる。
【0205】
従って、CPU41は、全検索語の先頭文字を各キーワードの先頭文字に有する施設名が記憶された「分割単位」だけを先頭文字情報データテーブル99から抽出して、施設名データテーブル92の該当「分割単位」内の全施設名の「読み」を順番にそれぞれ読み出して全検索語について全文検索を行うため、検索対象となる施設名の読みを少なくすることができ、検索を高速で行い、応答性の低下を防止することが可能となる。
【0206】
尚、本発明は前記実施例に限定されるものではなく、本発明の要旨を逸脱しない範囲内で種々の改良、変形が可能であることは勿論である。
【0207】
(A)例えば、実施例3に係る先頭文字情報データテーブル86又は実施例6に係る先頭文字情報データテーブル99において、各「分割単位」に対応する「キーワードの先頭文字情報」には、同じ「分割単位」に対応する「読み」に記憶された各施設名の読み毎に、各キーワードの先頭文字を50音別にそれぞれカウントし、カウント値が「1」以上の50音の区分には、「1」を代入して記憶し、カウント値が「0」の50音の区分には、「0」を代入して記憶するようにしてもよい。
【0208】
そして、上記S114において、CPU41は、全検索語をRAM42から読み出し、S113で特定した「分割単位」に対応する「キーワードの先頭文字情報」の全検索語の各先頭文字の属する50音の区分に記憶されている値が、全て「1」か否かを判定する判定処理を実行するようにしてもよい。
【0209】
(B)また、例えば、各先頭文字情報データテーブル52、82、86、93、96、99の「読み」の欄のデータを記憶しなくてもよい。これにより、各先頭文字情報データテーブル52、82、86、93、96、99のデータ容量の削減化を図ることができる。
【0210】
(C)また、例えば、各施設名データテーブル51、92、及び、各先頭文字情報データテーブル52、82、86、93、96、99の「分割単位」に、平仮名だけでなく、片仮名、アルファベット、数字、所定の記号(例えば、算術記号や矢印等である。)を記憶するようにしてもよい。
【0211】
例えば、各施設名データテーブル51、92、及び、各先頭文字情報データテーブル52、82、86、93、96、99の「分割単位」にアルファベットをアルファベット順に1文字乃至5文字ずつ記憶するようにしてもよい。そして、各施設名データテーブル51、92の「施設名」には、アルファベットで施設名を記憶し、「読み」には、施設名をキーワードに区切って記憶するようにしてもよい。
【0212】
また、各先頭文字情報データテーブル52、82、86、93、96、99の「キーワードの先頭文字情報」には、アルファベットがアルファベット順に1文字又は複数文字ずつ属するように区分してもよい。また、各先頭文字情報データテーブル52、82、86、93、96、99の各「分割単位」に対応する「読み」には、各施設名データテーブル51、92の各「分割単位」内の「読み」に記憶されたキーワードに区切られた施設名を記憶するようにしてもよい。
【符号の説明】
【0213】
1、81、85、91、95、98 ナビゲーション装置
14 操作部
15 液晶ディスプレイ
18 タッチパネル
25 地図情報DB
27 施設名DB
41 CPU
42 RAM
43 ROM
51、92 施設名データテーブル
52、82、86、93、96、99 先頭文字情報データテーブル
61 検索語入力画面
62 50音キー
71 検索結果表示画面
72 検索結果表示欄
【特許請求の範囲】
【請求項1】
検索対象となる複数の施設名をそれぞれ複数のキーワードに区切って、各施設名を各キーワードと前方一致する所定文字数の分割文字列に関連付けて記憶する施設名記憶手段と、
前記所定文字数の分割文字列に関連付けられた各施設名について、互いに異なる1文字から構成されて所定順序を付与された複数の区分文字が所定個数ずつ属する複数の区分別に、各区分に属する区分文字と一致する各キーワードの先頭文字をカウントした区分毎のカウント情報を、該所定文字数の分割文字列に関連付けて記憶するキーワード先頭文字情報記憶手段と、
検索語を入力する入力手段と、
前記キーワード先頭文字情報記憶手段において、前記入力手段を介して入力された各検索語の先頭文字の属する区分に対応するカウント情報に基づいて該各検索語に対応する前記分割文字列を取得する分割文字列取得手段と、
前記施設名記憶手段において、前記分割文字列取得手段を介して取得した前記分割文字列に関連付けて記憶されている施設名から前記入力手段によって入力された検索語と前方一致するキーワードを有する施設名を候補施設名として取得する検索手段と、
を備えたことを特徴とする施設検索装置。
【請求項2】
前記区分毎のカウント情報は、前記所定文字数の分割文字列に関連付けられた各施設名について、前記複数の区分別に、各区分に属する前記区分文字と一致する各キーワードの先頭文字をカウントした最大カウント値であり、
前記分割文字列取得手段は、前記入力手段を介して入力された各検索語の先頭文字の属する区分の前記最大カウント値の全てが、当該各検索語の先頭文字の属する区分毎の該先頭文字のカウント値以上であるカウント情報に関連付けられた前記分割文字列を取得することを特徴とする請求項1に記載の施設検索装置。
【請求項3】
前記区分毎のカウント情報は、前記所定文字数の分割文字列に関連付けられた各施設名について、前記複数の区分別に、各区分に属する前記区分文字と一致する各キーワードの先頭文字をカウントしたカウント値があるか否かを表す有無情報であり、
前記分割文字列取得手段は、前記入力手段を介して入力された各検索語の先頭文字の属する区分毎の前記有無情報が全てカウント値がある旨を表すカウント情報に関連付けられた前記分割文字列を取得することを特徴とする請求項1に記載の施設検索装置。
【請求項4】
前記区分文字は、50音仮名であって、前記区分は、50音の行別に区分されていることを特徴とする請求項1乃至請求項3のいずれかに記載の施設検索装置。
【請求項5】
検索対象となる複数の施設名をそれぞれ複数のキーワードに区切って、各施設名を各キーワードと前方一致する所定文字数の分割文字列に関連付けて記憶する施設名記憶手段と、
前記所定文字数の分割文字列に関連付けられた各施設名について、互いに異なる1文字から構成されて所定順序を付与された複数の区分文字が所定個数ずつ属する複数の区分別に、各区分に属する区分文字と一致する各キーワードの先頭文字をカウントした区分毎のカウント情報を、該所定文字数の分割文字列に関連付けて記憶するキーワード先頭文字情報記憶手段と、
を備えたコンピュータに、
検索語を入力する入力工程と、
前記キーワード先頭文字情報記憶手段において、前記入力工程で入力された各検索語の先頭文字の属する区分に対応するカウント情報に基づいて該各検索語に対応する前記分割文字列を取得する分割文字列取得工程と、
前記施設名記憶手段において、前記分割文字列取得工程で取得した前記分割文字列に関連付けて記憶されている施設名から前記入力工程で入力された検索語と前方一致するキーワードを有する施設名を候補施設名として取得する検索工程と、
を実行させるためのプログラム。
【請求項1】
検索対象となる複数の施設名をそれぞれ複数のキーワードに区切って、各施設名を各キーワードと前方一致する所定文字数の分割文字列に関連付けて記憶する施設名記憶手段と、
前記所定文字数の分割文字列に関連付けられた各施設名について、互いに異なる1文字から構成されて所定順序を付与された複数の区分文字が所定個数ずつ属する複数の区分別に、各区分に属する区分文字と一致する各キーワードの先頭文字をカウントした区分毎のカウント情報を、該所定文字数の分割文字列に関連付けて記憶するキーワード先頭文字情報記憶手段と、
検索語を入力する入力手段と、
前記キーワード先頭文字情報記憶手段において、前記入力手段を介して入力された各検索語の先頭文字の属する区分に対応するカウント情報に基づいて該各検索語に対応する前記分割文字列を取得する分割文字列取得手段と、
前記施設名記憶手段において、前記分割文字列取得手段を介して取得した前記分割文字列に関連付けて記憶されている施設名から前記入力手段によって入力された検索語と前方一致するキーワードを有する施設名を候補施設名として取得する検索手段と、
を備えたことを特徴とする施設検索装置。
【請求項2】
前記区分毎のカウント情報は、前記所定文字数の分割文字列に関連付けられた各施設名について、前記複数の区分別に、各区分に属する前記区分文字と一致する各キーワードの先頭文字をカウントした最大カウント値であり、
前記分割文字列取得手段は、前記入力手段を介して入力された各検索語の先頭文字の属する区分の前記最大カウント値の全てが、当該各検索語の先頭文字の属する区分毎の該先頭文字のカウント値以上であるカウント情報に関連付けられた前記分割文字列を取得することを特徴とする請求項1に記載の施設検索装置。
【請求項3】
前記区分毎のカウント情報は、前記所定文字数の分割文字列に関連付けられた各施設名について、前記複数の区分別に、各区分に属する前記区分文字と一致する各キーワードの先頭文字をカウントしたカウント値があるか否かを表す有無情報であり、
前記分割文字列取得手段は、前記入力手段を介して入力された各検索語の先頭文字の属する区分毎の前記有無情報が全てカウント値がある旨を表すカウント情報に関連付けられた前記分割文字列を取得することを特徴とする請求項1に記載の施設検索装置。
【請求項4】
前記区分文字は、50音仮名であって、前記区分は、50音の行別に区分されていることを特徴とする請求項1乃至請求項3のいずれかに記載の施設検索装置。
【請求項5】
検索対象となる複数の施設名をそれぞれ複数のキーワードに区切って、各施設名を各キーワードと前方一致する所定文字数の分割文字列に関連付けて記憶する施設名記憶手段と、
前記所定文字数の分割文字列に関連付けられた各施設名について、互いに異なる1文字から構成されて所定順序を付与された複数の区分文字が所定個数ずつ属する複数の区分別に、各区分に属する区分文字と一致する各キーワードの先頭文字をカウントした区分毎のカウント情報を、該所定文字数の分割文字列に関連付けて記憶するキーワード先頭文字情報記憶手段と、
を備えたコンピュータに、
検索語を入力する入力工程と、
前記キーワード先頭文字情報記憶手段において、前記入力工程で入力された各検索語の先頭文字の属する区分に対応するカウント情報に基づいて該各検索語に対応する前記分割文字列を取得する分割文字列取得工程と、
前記施設名記憶手段において、前記分割文字列取得工程で取得した前記分割文字列に関連付けて記憶されている施設名から前記入力工程で入力された検索語と前方一致するキーワードを有する施設名を候補施設名として取得する検索工程と、
を実行させるためのプログラム。
【図1】


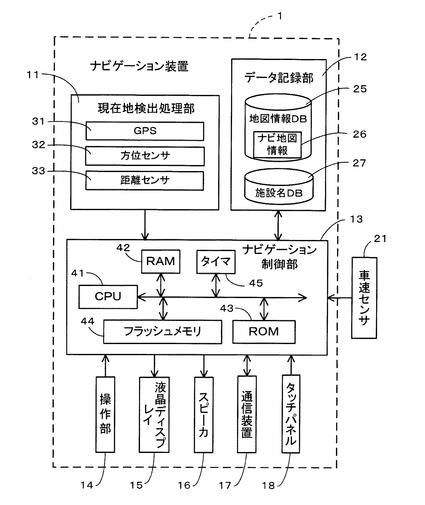
【図2】

【図3】
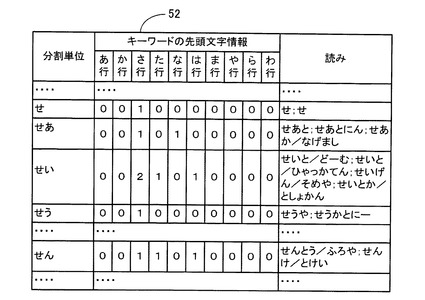
【図4】
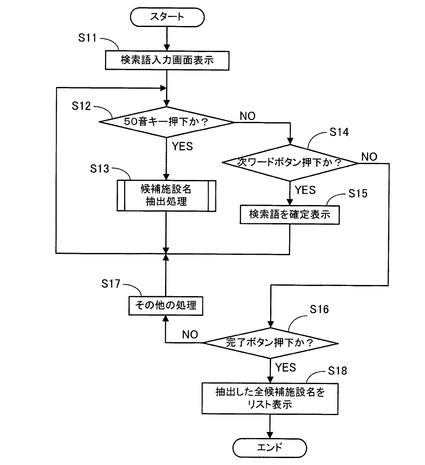
【図5】
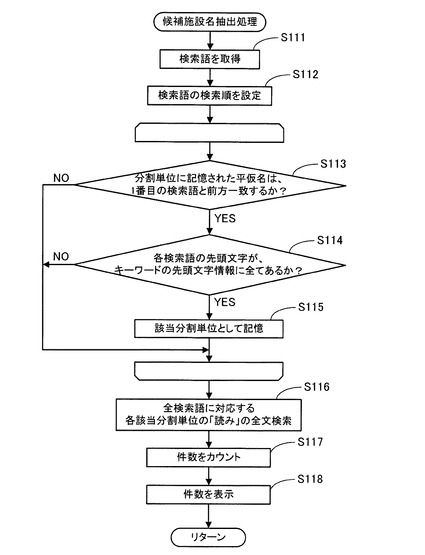
【図6】
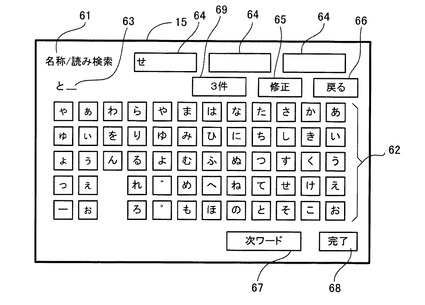
【図7】
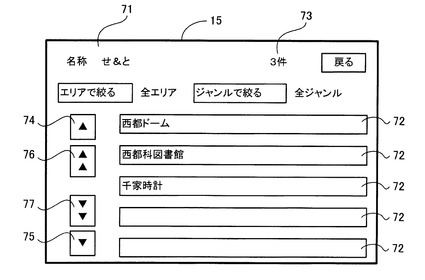
【図8】
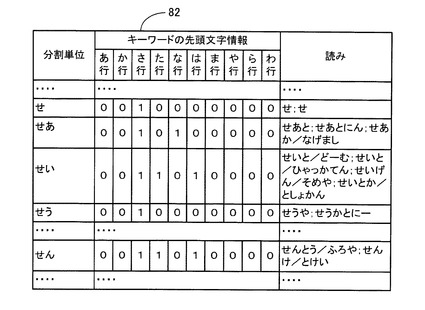
【図9】
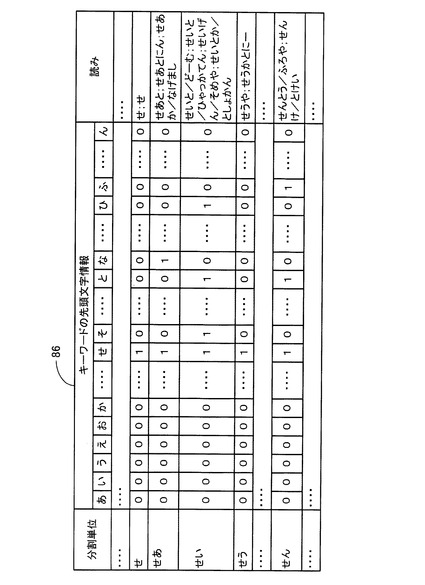
【図10】
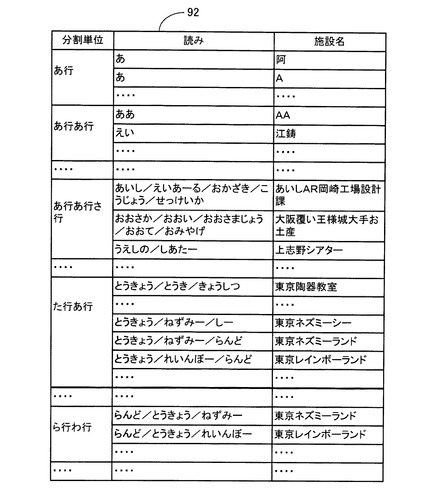
【図11】
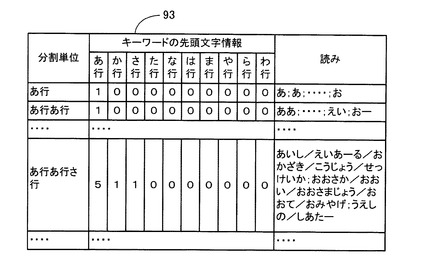
【図12】
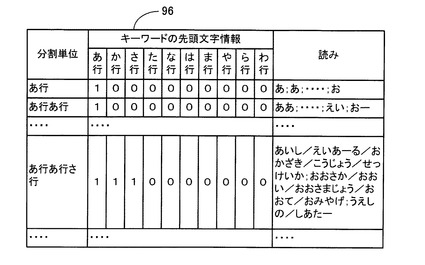
【図13】
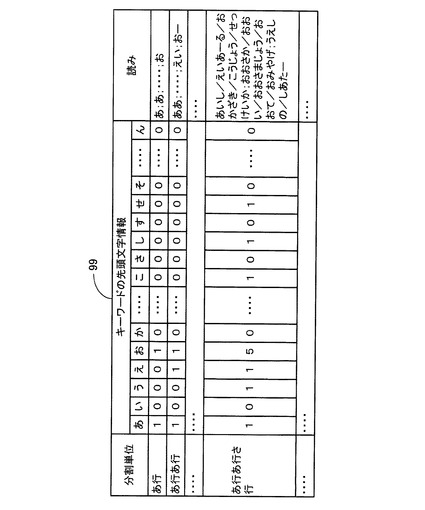
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【公開番号】特開2011−221951(P2011−221951A)
【公開日】平成23年11月4日(2011.11.4)
【国際特許分類】
【出願番号】特願2010−93127(P2010−93127)
【出願日】平成22年4月14日(2010.4.14)
【出願人】(000100768)アイシン・エィ・ダブリュ株式会社 (3,717)
【Fターム(参考)】
【公開日】平成23年11月4日(2011.11.4)
【国際特許分類】
【出願日】平成22年4月14日(2010.4.14)
【出願人】(000100768)アイシン・エィ・ダブリュ株式会社 (3,717)
【Fターム(参考)】
[ Back to top ]