
映像アノテーション付与・表示方法及び装置及びプログラム及びコンピュータ読取可能な記録媒体
【課題】映像を対象に映像と資料に対してネットワーク上で映像区間単位にアノテーション付与・表示を行う。
【解決手段】本発明は、アノテーション付与単位となる映像区間が複数の階層を有しており、映像区間に階層毎に設定された検出のためのイベント情報に基づいて、映像及び映像撮影と同期して計測された複数の情報のうちの少なくとも1つを用いて検出されるイベントに従って、該映像を映像区間に分割して映像区間情報記憶手段に格納し、映像区間情報記憶手段から映像区間を読み出して、それぞれの映像区間に対して、イベントに従ったアノテーションを付与する。
【解決手段】本発明は、アノテーション付与単位となる映像区間が複数の階層を有しており、映像区間に階層毎に設定された検出のためのイベント情報に基づいて、映像及び映像撮影と同期して計測された複数の情報のうちの少なくとも1つを用いて検出されるイベントに従って、該映像を映像区間に分割して映像区間情報記憶手段に格納し、映像区間情報記憶手段から映像区間を読み出して、それぞれの映像区間に対して、イベントに従ったアノテーションを付与する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、映像アノテーション付与・表示方法及び装置及びプログラム及びコンピュータ読取可能な記録媒体に係り、特に、同期撮影した複数の映像、撮影映像と同期して計測された記録情報とを利用して、準備された複数映像及び、映像時間と関連付いた資料に対してネットワーク上で映像区間単位にアノテーション付与・表示を行う映像アノテーション付与・表示方法及び装置及びプログラム及びコンピュータ読取可能な記録媒体に関する。
【背景技術】
【0002】
映像に対して対象映像を解析して、映像区間を定義し、映像区間に対してアノテーションを行い、個人的あるいは複数人で共有して映像とアノテーションを表示し、映像を活用する技術として以下のようなものが提案されている。
【0003】
従来の技術は、1つの映像に対して、映像区間を予め設定し、設定された映像区間単位に映像のある対象範囲に対してアノテーションを付与したり、映像区間単位に映像と同期してアノテーションを閲覧したりするものである(例えば、特許文献1参照)。
【0004】
映像区間を設定するための技術としては、イベントを検出する方法(例えば、非特許文献1参照)や、スライド映像のシーン切り替え検出により、スライドの切り替え点を検出し、同一のスライド表示区間を検出する方法(例えば、特許文献2参照)、音声の発話区間及びスライドに含まれるキーワードを発話した場合をトピックとして検出する方法(例えば、非特許文献2参照)等が提案されている。
【0005】
スライドの切り替え点を検出し、同一のスライド表示区間を検出する手法は、具体的には、図30に示すように、映像を読み込み(ステップ601)、ステップ幅Sの間隔内の複数フレーム画像を読み込み(ステップ602)、その複数フレーム画像の画素値をフレーム順に並べて、その変化量よりラベリング処理を行う(ステップ603)。ラベリングとしてはconstant(変化量小)、linear(持続的な上昇)に、step(急激な変化)、no-label(ラベルなし)を画素毎に判定して、このステップ幅の全constant、linear、step、 no-labelの数(Nc,Nl,Ns,Nu)をカウントする。そして、Ns/N−Nuの値が、Tdisを超えるかどうかでシーン切り替えを判定する(ステップ604)。その結果、シーン切り替え点の検出を行うことができる。
【0006】
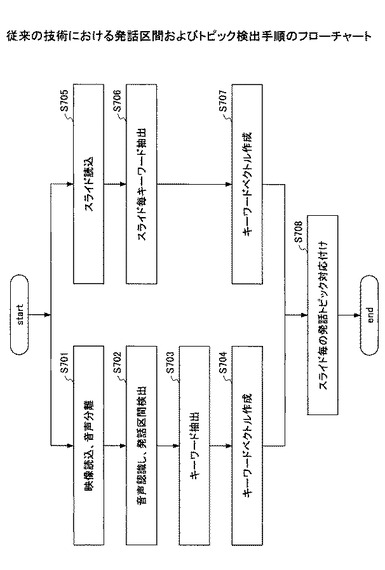
また、音声の発話区間及びスライドに含まれるキーワードを発話した場合をトピックとして検出する手法は、具体的には、図31に示す手順により発話区間及びスライドに対応したトピック検出を行う。まず、映像を読み込み、音声分離を行う(ステップ701)。次に、その分離した音声に対して音声認識を行うが、入力として連続して音素として認識できる区間を発話区間として検出する(ステップ702)。音素列から名詞、数詞、記号などの単語として判別できる場合、発話区間毎にキーワード(U:発話系列)として抽出する(ステップ703)。次に、発話区間毎のキーワードをもとにキーワード数の次元とキーワードの出現頻度により発話キーワードベクトル(W(U))が作成される(ステップ704)。一方、スライド側の処理として、スライドを読み込み(ステップ705)、スライド内の文について形態素解析処理を行い、名詞、数詞、記号等の品詞の単語を判別し、キーワード(S:スライド系列)として抽出する(ステップ706)。上記と同様の方法で、スライドキーワードベクトル(W(S))が作成される(ステップ707)。各スライドを状態とするマルコフモデルを構築し、スライド間の遷移により最尤の出力系列を算出し、その最尤出力を発話とスライドの対応付け結果とする(ステップ708)。スライド系列の状態出力尤度をU及びSのコサイン距離等とする。これらの処理により、発話区間及びスライドに対応した発話のトピック検出を行う。
【0007】
上記従来の仕組みでは、アノテーションを付与する際に、映像区間の映像内容がアノテーションの背景知識となるため、アノテーションは意図のみ記述すれば理解可能となる。しかし、映像区間に関する映像内容とアノテーションとの関連の整合が取れないと、アノテーションの意図が把握できないことを意味する。
【0008】
映像に対して、アノテーションを付与する場合、各アノテーション付与者の立場によりアノテーションを付与する注目対象・注目範囲が異なるため、アノテーションを付与したい映像区間及びアノテーションの対象が様々となる。映像にはストーリーがあり、ストーリーの流れとなるシナリオ・複数の人物や複数の注目すべき対象物の状態の変化の連鎖がストーリーを構成するが、アノテーション付与者の注目範囲は、シナリオ状態、人物及び対象物の状態など様々存在する。そのため、多様なアノテーション付与者の注目範囲とシステムで定義した映像区間が一致しないと、アノテーション付与者がアノテーション付与する作業負荷が高くなり、アノテーションの意図と映像区間が一致しないと、充分な質のアノテーションを行うことが難しくなる。また、同様に、アノテーションを閲覧する場合も、アノテーション閲覧者の立場により、閲覧したいアノテーションの注目対象及び注目範囲が異なるため、閲覧者の立場に合った重要なアノテーションを見つける時間がかかり、またアノテーション閲覧の効率も低くなる。
【0009】
映像区間定義の観点では、上記からアノテーション付与者・閲覧者といった利用者の様々な注目対象のシナリオ状態、人物・対象物の同一状態といった意味的な映像区間は、様々あるため、1映像の映像解析だけでは区間を定義することは難しい。
【0010】
また、映像区間定義を利用したアノテーション付与閲覧の観点では、アノテーション付与者が自分の立場で映像区間を制御する方が効果的であるが、上記の従来の技術では、映像区間の設定がシステムに固定であるため、アノテーション付与者が制御できない。また、映像とアノテーションを表示閲覧する場合、注目する映像対象が異なるため、アノテーション閲覧者が制御する方が効果的であるが、従来の技術では、同様にアノテーション閲覧者が制御できない。
【0011】
上記のように映像区間の定義において、ユーザ映像区間を制御するには意味的な映像区間を多視点で定義することが重要である。従来の技術での映像区間の定義方法は人手で意味的な区間を定義する方法、または、1映像を映像解析することで物理的な映像区間を定義する方法が挙げられている。人手による映像区間定義の場合は、映像区間を定義するために映像を見て判断して区間を定義するといった時間及び作業手間が大きい。また、物理的な映像区間の場合、定義された映像区間が意味的にはどのような映像区間を表すかを示さないとユーザがアノテーション付与する際に、アノテーションの意図と映像区間を一致させることが難しい。また、アノテーション閲覧する場合も、アノテーションの意図を把握することが困難である。
【特許文献1】特開2003−283981号公報
【特許文献2】特許第3378773号公報
【非特許文献1】杉本吉隆、丸谷宜史、角所考、美濃導彦、「講師行動の統計的性質に基づいた講義撮影のための講義状況の認識手法」情報処理学会、研究報告CVIM Vol.2006 No.25 pp.179-186
【非特許文献2】北出祐、河原達也、「講義の自動アーカイブ化のためのスライドと発話の対応付け」情報処理学会、研究報告 CVIM Vol.2005 No.12 pp.59-64
【発明の開示】
【発明が解決しようとする課題】
【0012】
上記の従来の技術には以下のような問題がある。
【0013】
1.意味的な映像区間を定義するには、これまで主に人手で定義していたが、作業時間・作業手間が大きい。
【0014】
2.1映像からの映像解析による物理的な映像区間による映像区間定義では、アノテーション付与者・閲覧者の立場に合った多様な映像区間定義は難しく、物理的な映像区間のまま、映像区間定義に利用すると映像区間の意味が曖昧となる。
【0015】
3.アノテーション付与者・閲覧者毎にアノテーション付与・閲覧したい映像区間が異なるが、アノテーション付与者・閲覧者といったユーザ自身が意図に合った映像区間を設定することができないため、アノテーションの意図と映像区間内容との不一致が起こる。
【0016】
本発明は、上記の点に鑑みなされたもので、上記従来の問題点を解決し、映像を対象に映像と資料に対してネットワーク上で映像区間単位にアノテーション付与・表示を行うことが可能な映像アノテーション付与・表示方法及び装置及びプログラム及びコンピュータ読取可能な記録媒体を提供することを目的とする。
【課題を解決するための手段】
【0017】
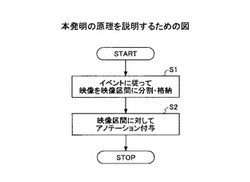
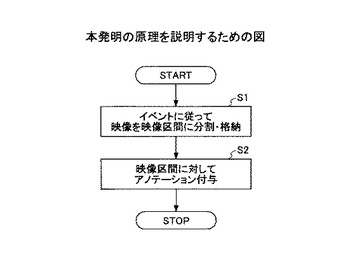
図1は、本発明の原理を説明するための図である。
【0018】
本発明(請求項1)は、映像に対して映像を構成する映像区間毎にアノテーションを付与する装置における映像アノテーション付与方法であって、
アノテーション付与単位となる映像区間が複数の階層を有しており、
映像区間に階層毎に設定された検出のためのイベント情報に基づいて、映像及び映像撮影と同期して計測された複数の情報のうちの少なくとも1つを用いて検出されるイベントに従って、該映像を映像区間に分割して映像区間情報記憶手段に格納し(ステップ1)、
映像区間情報記憶手段から映像区間を読み出して、それぞれの映像区間に対して、ユーザが付与するアノテーションを取得してアノテーション情報記憶手段に格納する(ステップ2)。
【0019】
また、本発明(請求項2)は、請求項1の映像区間が三階層以上から構成され、
第1の階層が映像全体のシナリオを表す映像区間であり、
第2の階層がシナリオ内のトピックを表す映像区間であり、
第3以下の下位階層が映像内の個別の事象を表す映像区間である。
【0020】
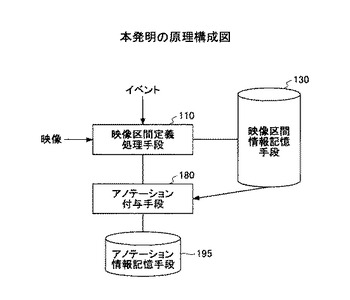
図2は、本発明の原理構成図である。
【0021】
本発明(請求項3)は、映像に対して映像を構成する映像区間毎にアノテーションを付与する映像アノテーション付与装置であって、
アノテーション付与単位となる映像区間が複数の階層を有しており、
映像区間に階層毎に設定された検出のためのイベント情報に基づいて、映像及び映像撮影と同期して計測された複数の情報のうちの少なくとも1つを用いて検出されるイベントに従って、該映像を映像区間に分割して映像区間情報記憶手段130に格納する映像区間定義処理手段110と、
映像区間情報記憶手段130から映像区間を読み出して、それぞれの映像区間に対して、ユーザが付与するアノテーションを取得して、アノテーション情報記憶手段に格納するアノテーション付与手段180と、を有する。
【0022】
また、本発明(請求項4)は、請求項3の映像区間情報記憶手段に格納される映像区間が、三階層以上から構成され、
第1の階層が映像全体のシナリオを表す映像区間であり、
第2の階層がシナリオ内のトピックを表す映像区間であり、
第3以下の下位階層が映像内の個別の事象を表す映像区間である。
【0023】
本発明(請求項5)は、請求項3または4に記載の映像アノテーション付与装置を構成する各手段としてコンピュータを機能させる映像アノテーション付与プログラムである。
【0024】
本発明(請求項6)は、請求項5記載の映像アノテーション付与プログラムを格納したコンピュータ読取可能な記録媒体である。
【発明の効果】
【0025】
上記のように本発明によれば、複数映像とそれら映像と同期して計測された情報を基に、意味的な映像区間を撮影前でも決定可能な階層とイベント検出結果の対応設定、つまり、第1階層であるシナリオ状態と対応するイベント検出、第2階層であるトピック状態と対応するイベント検出、第3階層以下の状態と対応するイベント検出、を予め設定することで、自動的に階層的な映像区間を定義することができる。
【0026】
また、映像撮影シナリオに沿った、シナリオ状態、トピック状態、対象状態といった階層化により、意味的な映像区間を定義することができ、アノテーション付与者及びアノテーション閲覧者が自分の意図にあった映像区間を設定することができ、自分の意図に合った映像区間に対してアノテーション付与を行うことができる。これは、アノテーション付与者が意図通りアノテーションを行えるため、映像区間に対するアノテーションの整合性がとれ、また、アノテーション閲覧者は、アノテーションの意図を理解しやすい形で自由な視点で映像区間内容とアノテーション情報を閲覧することが可能となり、双方意図に合致した形態でアノテーションを楽しむことができる。
【発明を実施するための最良の形態】
【0027】
以下、図面と共に本発明の実施の形態を説明する。
【0028】
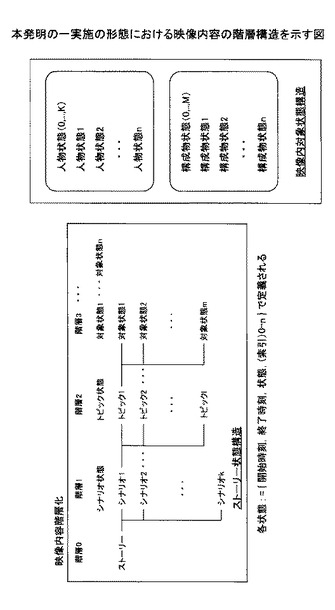
講義やプレゼンテーション、スポーツ、ドラマ等、基本的に映像はストーリーを構成するシナリオが予め設定されている中で撮影されている。そのように撮影された映像には、ストーリーを構成するシナリオがあり、そのシナリオに従って、撮影対象の人物、構成物が状態を変化させながら進行していくものと考えられる。つまり映像を中心としたストーリーとして、図3に示すように、ストーリーを構成するシナリオがあり、シナリオを構成する1以上のトピックがあり、そのトピックを具体的に構成する1以上の対象の状態があると階層的に捉える。具体的には、野球などであれば、シナリオとして試合前解説(メンバー紹介等)、試合開始、1回表、1回裏、・・・9回表(、9回裏)、試合終了、試合後解説(結果等)といった形でシナリオがあり、各打席というトピックがあり、人物としてプレーヤ(攻撃・守備)、審判、解説者、ゲスト等が存在し、主要対象物として各ベース、スコアボードなどが存在し、シナリオの各場面内で、主要人物、主要対象物の振る舞い(状態変化)によって、トピックの内容が形作られる。上記を構造化として考えると、最上位にシナリオという階層があり、シナリオを特徴付けるトピックという階層が第2階層として存在し、各トピックを具体化する人物、主要対象物といった対象の状態が第3階層以下に存在する。
【0029】
ユーザは、シナリオ、トピック、または、各対象のいずれかに興味を持ち、興味対象に対してアノテーションを付与する行動を起こす。つまり視聴者が、映像の中のストーリーの中のあるトピックに興味がある場合、映像中のある人物に興味がある場合、映像中のある対象物に興味がある場合など、様々な観点で映像を閲覧する。そしてストーリーの中のシナリオやトピック、映像中の人物のある状態、映像中の対象物のある状態等がユーザのアノテーションを付与する対象となる。アノテーション付与者は、各シナリオの内容、対象人物のある状態の中の興味ある対象に関してアノテーションを付与する。
【0030】
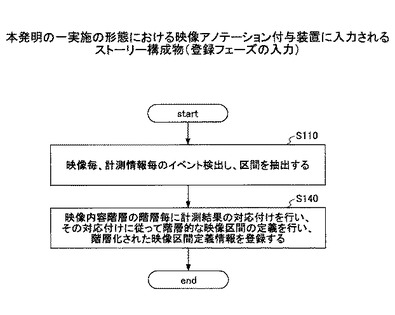
そのような対象物及び対象人物の状態変化を抽出するため、映像の解析や映像と同期して計測したセンサ、マイク等の計測情報が入力としての前提となる。本発明の映像アノテーション付与装置に、図4に示すように1つ以上の映像(音声及び動画からなる)及び0以上の各計測情報から構成されるストリー構成物が入力される。
【0031】
以下に、講義やプレゼンテーションの場合を例に、映像アノテーション付与及び表示処理の概要を説明する。
【0032】
講義やプレゼンテーション等では、映像内の主要人物として、説明者と受講者といった人物が存在し、説明者が説明するためにスライド、ホワイトボード、PC等を主要対象物として利用しながら説明する映像が典型である。そのような講義やプレゼンテーションでは、スライド、ホワイトボード、PC、受講者等を対象に映像撮影し、それと同期して説明者に複数センサ、マイクを設置することで、説明者の位置、振る舞いなどを計測した結果を入力の情報としての例と考える。
【0033】
以下では、登録フェーズと利用フェーズに分けて説明する。
【0034】
登録フェーズでは、まず、映像アノテーション付与装置において、入力である計測情報や映像からイベントを検出して、各イベント検出結果から変化点を考慮する等を行うことで、各イベント結果から区間を検出することで、イベント検出毎の映像区間が抽出できる。次に、図3のようなシナリオ状態、トピック状態、さらに各対象状態階層といったどの階層にどのイベント結果をマッピングするかのマッピングを行い、階層化された映像区間を定義する。
【0035】
次に、利用フェーズでは、映像アノテーション付与装置において、その階層化された映像区間において、ユーザがどの階層をアノテーション付与、閲覧のために利用するかを設定し、その設定によって、アノテーションを付与する単位となる映像区間(アノテーション付与区間と呼ぶ)を決定する。その映像区間を使って、前述の特許文献1のような方法を用いることで、効果的に映像区間単位に映像アノテーション付与・表示を行えるようになる。
【0036】
以下に、具体的に説明する。以下では、主に講義に関して計測した情報、講義の説明者映像、聴講者映像、ホワイトボード映像、スライド撮影映像等を例にして説明するが、本発明は、こういった講義映像に限らず、スポーツ撮影映像(複数カメラ、観客、スポーツ実施者の位置など計測情報)等でも複数カメラ、計測情報などを使って、後に映像アノテーションを付与するケース、他のケース等、様々に適用可能であり、以下で説明する形態に限定されるものではない。
【0037】
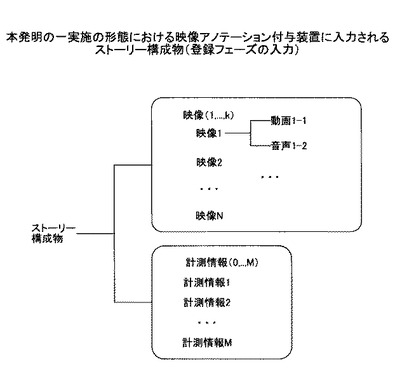
図5は、本発明の一実施の形態におけるシステム構成を示す。
【0038】
同図に示すシステムは、映像アノテーション付与装置100とユーザ端末200から構成される。
【0039】
映像アノテーション付与装置100は、映像区間定義処理部110、イベント結果記憶部120、階層的な映像区間情報記憶部(以下、映像区間情報記憶部と記す)130、階層的映像区間一覧表示部140、アノテーション付与区間決定処理部150、アノテーション付与区間情報記憶部160、階層的映像区間一覧表示部170、アノテーション登録部180、アノテーション表示部190、アノテーション情報記憶部195から構成される。
【0040】
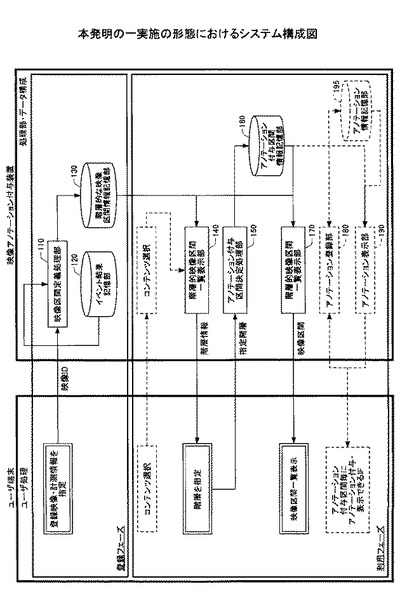
図6は、本発明の一実施の形態における動作の概要を示すフローチャートである。
【0041】
以下、上記の図5の各構成の動作を説明する。
【0042】
以下の動作の前提として、ユーザが映像と同期して計測した情報を映像アノテーション付与装置100内のデータベースで映像と共に管理しているものとする。
【0043】
ステップ100) まず、登録フェーズとして、ユーザ端末200から、対象となる映像とその映像撮影時の計測情報を取得するための映像IDをユーザが指定すると、映像アノテーション付与装置100の映像区間定義処理部110は、後述する映像区間定義処理手順により、ユーザから指定された映像IDに基づいて、階層的な映像区間情報を作成し、映像区間情報記憶部130に格納する。
【0044】
ステップ200) 登録フェーズにより階層的に映像区間が映像区間情報記憶部130で管理された状態で、階層的映像区間一覧表示部140により、映像区間情報記憶部130に格納されている階層情報をユーザ端末200に送信する。これにより、ユーザ端末200では、表示手段(図示せず)に表示する。これによりユーザは、スライド映像のスライドのサムネイル、トピック、講義映像のサムネイルと講義状態、聴講状態、発話区間と発話概要等でアノテーションを付与しやすい単位を確認し、階層1以下でどの階層をアノテーション付与区間として利用するかを指定することができる。
【0045】
ステップ300) 映像アノテーション付与装置100のアノテーション付与区間決定処理部150は、ユーザ端末200から階層が指定されると、映像区間情報記憶部130から指定された階層の映像区間データを読み込み、各映像区間の開始時刻、終了時刻をマージして、アノテーション付与区間を決定し、アノテーション付与区間情報記憶部160に格納する。さらに、階層的映像区間一覧表示部170が、アノテーション付与区間情報記憶部160から、決定したアノテーション付与区間を読み出して、その映像区間をユーザ端末200に送信する。これにより、ユーザ端末200では、決定したアノテーション付与区間がどのような区間なのか表示する。
【0046】
ステップ400) 次に、映像区間の定義が完了したら、ユーザは、アノテーション付与区間に対してアノテーション付与を行う。これにより、映像アノテーション付与装置100は、アノテーション登録部180において、アノテーションを付与しアノテーション情報記憶部195に格納する。また、アノテーション情報は、アノテーション表示部190からユーザ端末200に送信する。
【0047】
以下に、上記のステップ100〜400の処理を詳細に説明する。
【0048】
<登録フェーズ:ステップ100>
ステップ100の映像区間定義処理手順について説明する。
【0049】
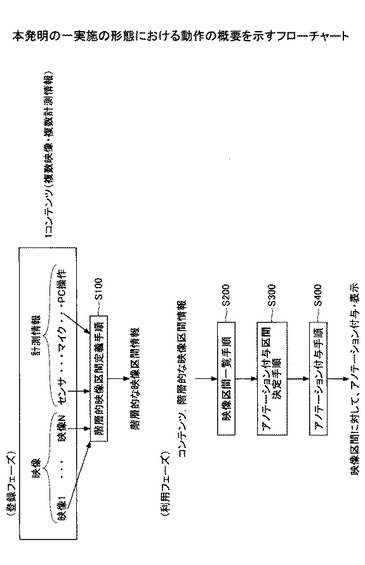
図7は、本発明の一実施の形態における登録フェーズの処理概念を示す図である。同図に示すように、登録フェーズでは、映像アノテーション付与装置100において、カメラ、センサ、PC、マイク等からの出力についてイベント検出を行い、イベント結果記憶部120に格納する。映像アノテーション付与装置100の映像区間定義処理部110において検出されたイベントに基づいて、映像を階層化して、映像区間定義情報を記憶部130に格納するものである。このとき、階層となるイベント指定として、シナリオはイベントA,トピックはイベントB,対象物はイベントC等が入力されると、映像区間定義処理部110は検出されたイベントの中からこれらの指定に基づいて映像から映像区間を抽出し、格納する。
【0050】
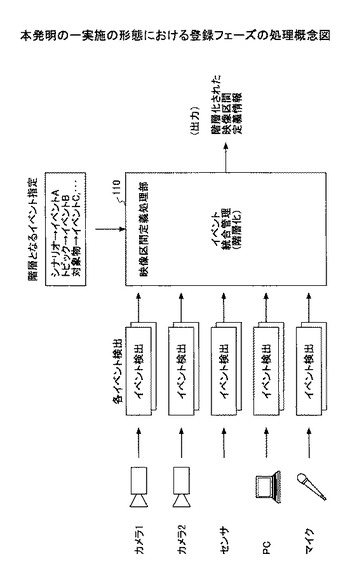
図8は、本発明の一実施の形態における映像区間定義処理のフローチャートである。
【0051】
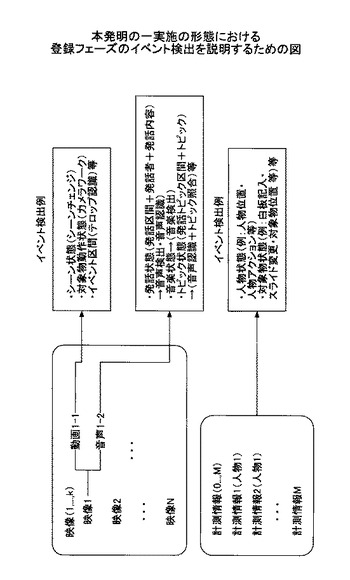
ステップ110) 各映像からのイベント検出結果、各計測情報からのイベント検出結果を用いて、情報毎に区間を抽出する。このステップでは、図9に示すように、映像中の動画、音声を解析することや、センサ・マイク等の計測情報を解析することでイベントを検出し、その結果、映像のシナリオ状態、対象物動作状態、イベント状態、発話状態、音楽状態、人物状態、対象物状態などをイベント検出結果としてイベント結果記憶部120に格納する。そして、イベント検出結果を参照して映像区間を求め、映像区間情報記憶部130に格納する。
【0052】
区間データを抽出する具体的な方法としては、以下のようなものがある。
【0053】
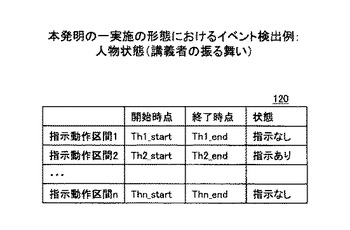
センサ等の計測情報から前述の非特許文献1に示す方法等により、映像内の主要人物である講義者の説明状態が検出できる。以下に具体的なイベント検出例とイベント検出結果である区間抽出結果について示す。語りかけ、スライド説明、板書説明、その他といった4つの講義状態の識別情報を区間として検出できる。手・肩のセンサにより手に関する身振りである指示の有無等が検出可能である。
【0054】
また、前述の特許文献2の方法により、スライド映像のシーン切り替え検出により、スライドの切り替え点を検出し、同一のスライド表示区間を検出する手法がある。
【0055】
更に、前述の非特許文献2の方法により、音声の発話区間及びスライドに含まれるキーワードを発話した場合をトピックとして検出する方法がある。
【0056】
また、被写体が聴講者の映像の場合、聴講者の映像から顔認識により聴講者が顔を上げている割合の変化点から顔を上げている割合からノート記述、聴講、ノート記述・聴講混在などの聴講者状態の区間を検出する手法がある。
【0057】
上記の映像処理手法により、「発話区間」、「トピック」、「スライド状態」、「聴講状態」が検出可能である。これら検出した結果は、例えば、発話区間の場合は元々区間を持つデータのため、そのままイベント結果記憶部120の映像時間にマッピングされる。
【0058】
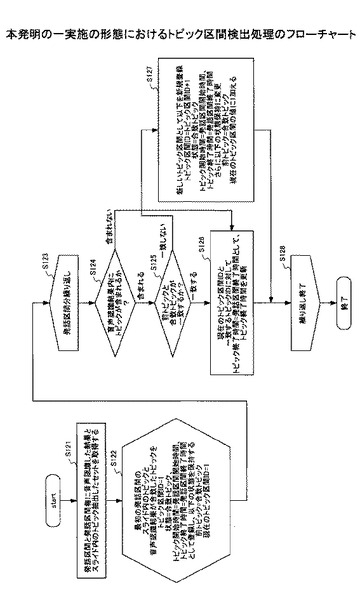
一方、トピック等は瞬間的イベントのため、図10に示すトピック区間検出処理によりイベント結果記憶部120の映像時間にマッピングされる。図10は、本発明の一実施の形態におけるトピック区間検出のフローチャートである。
【0059】
ステップ121) 発話区間と発話区間毎に音声認識され、イベント結果記憶部120に格納されている結果とスライド内のトピック抽出したセットを取得することを行う。
【0060】
ステップ122) 初期処理として、最初の発話区間のスライド内のトピックと音声認識結果が合致したトピックを、
トピック区間ID=1;
状態=合致トピック;
トピック開始時刻=発話区間開始時刻;
トピック終了時刻=発話区間終了時刻;
としてイベント結果記憶部120に登録する。さらに以下の状態をイベント結果記憶部120に保持する。
【0061】
前トピック=合致トピック;
現在のトピック区間ID=1;
ステップ123) 発話区間が存在するかチェックする(当該ステップ123からステップ127まで発話区間が存在する限り繰り返す)。
【0062】
ステップ124) メモリ(図示せず)の音声認識結果内にスライド内のトピックが存在するかチェックする。含まれない場合は、新トピックが顕在化していないため、まだ前のトピックが続いていると捉え、ステップ126に移行する。含まれる場合は、ステップ125に移行する。
【0063】
ステップ125) 更に保持している前トピックと合致トピックが同一かを判定し、一致した場合は同じトピックが続いているため、ステップ126に移行し、一致しない場合は、ステップ127に移行する。
【0064】
ステップ126) ステップ125で一致した場合は、同じトピックが続いているため、まだ前区間のトピックが続いていると判断し、現在のトピック区間IDと一致するトピックIDに対して、トピック終了時刻=発話区間終了時刻、としてトピック終了時刻を更新する処理で次の発話区間の処理に移行する。
【0065】
ステップ127) ステップ125においてトピックが一致しなった場合は、新しいトピックが顕在化したので、新しいトピック区間の開始として解釈する。このステップ127の処理は、新しいトピック区間として、
トピック区間ID=トピック区間ID+1;
状態=合致トピック;
トピック開始時刻=発話区間開始時刻;
トピック終了時刻=発話区間終了時刻;
を新規に登録する。
【0066】
更に、前トピック=合致トピックとし、現在のトピック区間の値に1を加える。
【0067】
ステップ128) 発話区間が存在しなくなった場合は、図11に示すようなデータ構造でトピック区間をイベント結果記憶部120に蓄積する。
【0068】
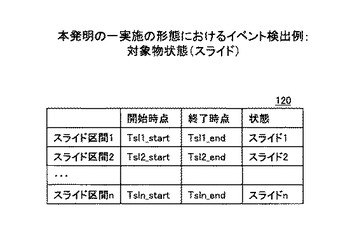
「スライド状態」については、スライドの次のスライドの切り替え点までをスライド区間と捉えることができる。
【0069】
「聴講状態」は、以下のようにして取得する。
【0070】
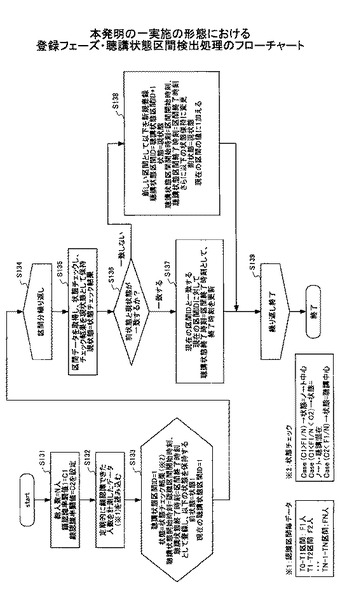
図12は、本発明の一実施の形態における登録フェーズの聴講状態区間検出フローチャートである。同図において、聴講状態もある顔認識率の閾値を決めて、閾値を超えた点で聴講状態の変化点と考えれば、映像時間に区間として対応できる。
【0071】
ステップ131) 閾値や人数について以下のように設定する。
【0072】
総人数=N人;
顔認識率閾値1=C1;
顔認識率閾値2=C2;
ステップ132) 提起的に顔認識できた人数を計測したデータを読み込む。
【0073】
ステップ133) 初期処理として、
聴講状態区間ID=1;
状態=状態チェック結果;
聴講状態開始時刻=認識区間開始時刻;
聴講状態終了時刻=区間終了時刻;
としてイベント結果記憶部120に登録する。また、更に以下の状態を保持する。
【0074】
前状態=状態1;
現在の聴講状態区間ID=1;
ステップ134) 区間が存在するかチェックする。
【0075】
ステップ135) 当該ステップからステップ138いついて区間が存在する限り繰り返し処理される。
【0076】
区間データを取得し、状態チェックし、チェック結果を現状態として以下のように保持する。
【0077】
現状態=状態チェック結果;
また、状態チェックでは、以下のようにノート中心か、ノート・聴講混在、聴講中心か当、定性的な量として判断される。
【0078】
Case(C1>F1/N)⇒状態=ノート中心;
Case(C1<F1/N<C2)⇒ノート・聴講混在;
Case(C2<F1/N)⇒状態=聴講中心
ステップ136) 前状態と現状態が一致するかをチェックする。一致する場合は、状態の変化がないため、前の状態が引き続いていると判断され、ステップ137に移行する。一致しない場合は、ステップ138に移行する。
【0079】
ステップ137) 前の状態の引き続きであるので、終了時刻を更新する。現在の区間IDと一致する現在の区間IDに対して
聴講状態終了時刻=区間終了時刻
として、終了時刻を更新する処理を行う。
【0080】
ステップ138) ステップ136で一致しなかった場合は、状態変化が起こったと判断し、新しい区間として以下をイベント結果記憶部120に新規登録する。
【0081】
聴講状態区間ID=聴講状態区間ID+1;
状態=現状態;
聴講状態区間開始時刻=区間開始時刻;
聴講状態区間終了時刻=区間終了時刻;
更に、前状態を現状態とし、現在の区間の値に1を加える。
【0082】
ステップ139) 区間が存在しなくなった場合は、処理が終了となり、図13に示すようなデータ構造で聴講状態をイベント結果記憶部120に蓄積する。
【0083】
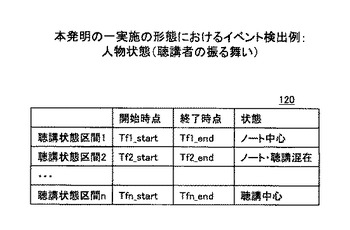
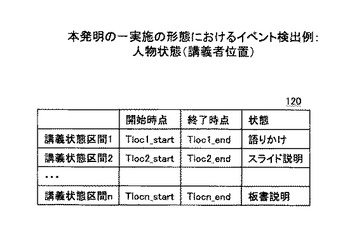
このようにして、計測情報や映像の特徴から各特長を映像区間に対応付けし、例えば、図11、図13や、図14〜図17のような形でイベント結果記憶部120にイベント検出のデータを保持することができる。なお、図14は人物状態(講義者の位置)のイベント検出例であり、図15は、人物状態(講義者の振る舞い)のイベント検出例である。映像位置計測情報記憶部120には予め講義者の立っている位置が壇上の説明位置(センサ等で取得)に近い、スライド提示画面に近い、ホワイトボードに近いというデータと、講義者の指示棒の高さ(センサ等で取得)のデータが格納されており、このようなデータを撮影時間と併せて時間順に並べることで、講義者の講義状態を特定したものである。例えば、スライド映像の近くで指示棒の高さが上がれば、スライド説明していることがわかり、また、その前後でスライド画面の近くにいる場合はスライド説明をしている確率が高くなる。
【0084】
これで、図8のステップ110の処理が完了する。
【0085】
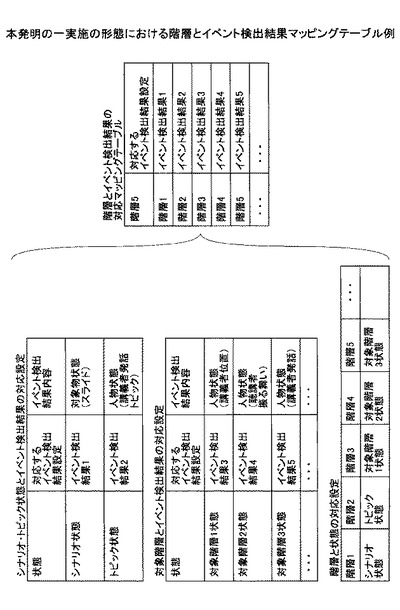
ステップ140) 次に、上記のステップで得られた各イベント検出結果から階層的な映像区間の定義を行う。
【0086】
図18のような階層とイベント検出結果からなるメモリ(図示せず)上のマッピングテーブルを利用して、階層上位がより広い映像区間となるようにセットする。一般的な講義では、予めスライド順に順序立てて講義を行うことが計画されているケースが多いため、そのようなケースでは、スライドが前提にあり、1枚のスライド内にもトピックが存在する。そのトピックを補足説明するために講義者がスライド説明、板書説明、語りかけ説明といった形態が行われる。また、各説明状態内部で、講義者が発話している区間が存在すると考えられるため、そのような想定から予めメモリ(図示せず)にマッピングテーブルを用意することができる。
【0087】
この階層順序の決定データとイベント検出結果記憶部120の図11、図13、図14〜図17のようなイベント検出結果とを用いて、映像から階層毎に映像区間を決定しておく方法を以下に示す。
【0088】
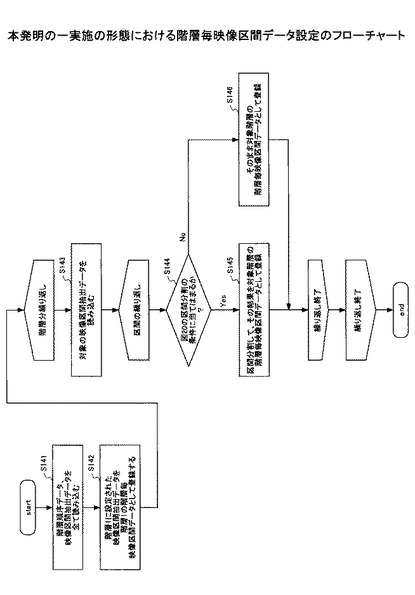
図19は、本発明の一実施の形態における階層毎映像区間データ設定のフローチャートである。
【0089】
ステップ141) 図18のような予めメモリ(図示せず)に格納されたマッピングデータとイベント検出結果記憶部120に格納されている図11、図13、図14〜図17のようなイベント検出結果を読み込む。
【0090】
ステップ142) 階層1に割り当てられた映像区間抽出データをそのまま階層1の階層毎映像区間データとしてメモリ(図示せず)に登録する。
【0091】
ステップ143) 以下、ステップ146までを階層が存在する間繰り返し処理する。
【0092】
対象のデータの映像区間抽出結果をメモリ(図示せず)から読み込む。
【0093】
ステップ144) 以下ステップ146までを読み込んだデータで区間が存在する間繰り返し処理する。
【0094】
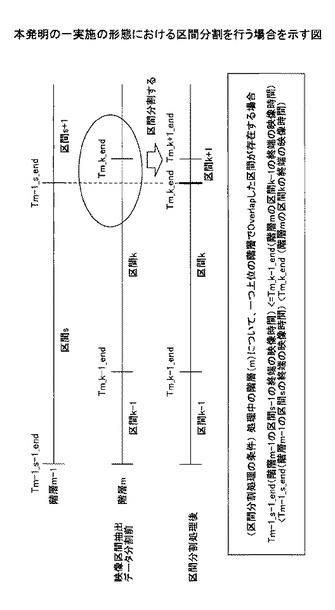
図20の区間分割処理の条件に基づいて、一つ上位の階層の区間データと比較しながら、上位階層の区間の終端を跨ぐ形での区間データが読み込まれた場合かのチェックを行い、そうであればステップ145に移行し、そうでなければステップ146に移行する。
【0095】
ステップ145) メモリ(図示せず)から読み込まれた区間データを分割した上で処理している階層の階層毎映像区間データとして映像区間情報記憶部130に登録する。このとき現在処理している階層mの現在の区間(区間k−1の終端の映像時間及び区間kの終端の映像時間)内の階層mにおける終端で全て区間分割を行う。
【0096】
ステップ146) 上記以外のケース(ステップ144でNoの場合)は、メモリ(図示せず)から読み込んだ区間データをそのまま次の区間として映像区間情報記憶部130に登録していく。上位階層の区間の終端を跨ぐ形での区間データが読み込まれた場合とは、図20に示すように、以下の状態になった場合である。
【0097】
Tm-1_s-1_end(階層m−1の区間s−1の終端の映像時間)
<=Tm_k1_end(階層mの区間k−1の終端の映像時間)
<Tm-1_s_end(階層m−1の区間sの終端の映像時間)
<Tm_k_end(階層mの区間kの終端の映像時間)
基本的に上位の階層の区間の切れ目は必ずそれより下の階層の区間の切れ目となるようにする。
【0098】
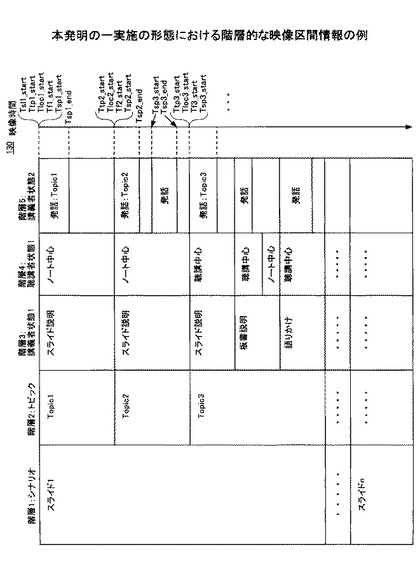
上記の処理により、図21に示すような階層的な映像区間情報が得られ、映像区間情報記憶部130に格納される。
【0099】
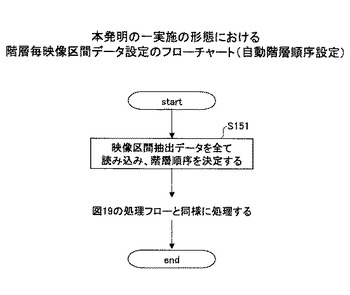
一方、シナリオを設定する部分まで自動化することで、登録を自動化し作業負担を下げることも考えられる。その場合は、階層順序を上記のデータごとの映像区間の制約から自動的に階層構造化する場合は、図22に示すように、まず、ステップ151として、各データの階層順序を決定する処理を行う。この処理は、色々なパターンが考えられる。各データのうち区間数の少ないものから順に階層1,階層2,…,階層Nという形式でデータ毎に階層順序を決める方法や、別のデータの区間を内包する割合が高いものから順に階層順序を決める方法などがある。階層順序を決定後は、上記の手動で階層順序を設定した場合と同様の処理を行う。その結果として、講義の全てを網羅するスライドがなく、口頭で説明が中心となるような場合、映像区間情報記憶部130に格納される情報は、図21のようなケースとは異なる講義状態が階層のトップになる等のパターンも考えられる。
【0100】
以上で、映像区間定義処理の内部のステップ140の処理が終了するため、登録フェーズの処理である階層化された映像区間の登録が完了する。
【0101】
<利用フェーズ>
[ステップ200:映像区間一覧手順]
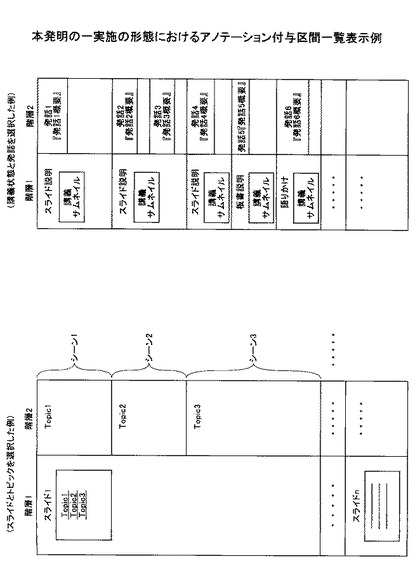
上記のステップ100で階層的に映像区間が映像区間情報記憶部130に管理された状態で、次に、階層的映像区間一覧表示部140により、図23に示すように、階層的に管理された映像区間を映像区間情報記憶部130から読み出して、ユーザ端末200に対して送信することにより図24に示すような情報を表示する。スライド映像のスライドのサムネイル、トピック、講義映像のサムネイルと講義状態、聴講状態、発話区間と発話概要等でアノテーションを付与しやすい単位を確認し、階層1以下でどの階層をアノテーション付与区間として利用するかを講義映像配信の受け手側が指定することができる。
【0102】
[ステップ300:アノテーション付与区間決定手順]
アノテーション付与区間決定処理部150は、ユーザ端末200から送信された、ユーザが指定した階層を基にアノテーション付与区間を決定する。
【0103】
アノテーション付与区間決定処理部150は、以下に示す処理によりアノテーション付与区間を決定する。アノテーション付与区間決定処理部150は、ユーザより指定された階層の映像区間データを映像区間情報記憶部130から読み込み、各映像区間の開始時刻、終了時刻をマージして、アノテーション付与区間を決定する。このアノテーション付与区間決定処理部150により、アノテーション付与区間単位が決定する。
【0104】
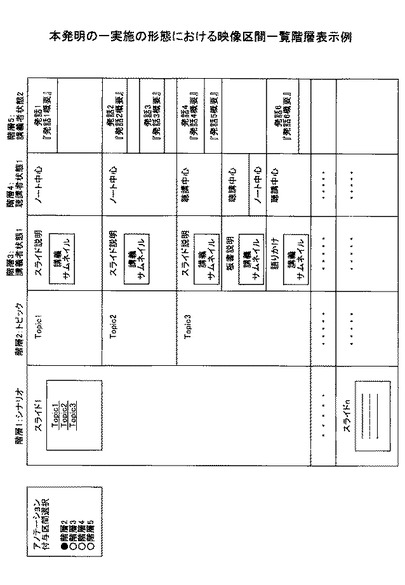
図25は、本発明の一実施の形態におけるアノテーション付与区間決定処理のフローチャートである。
【0105】
ステップ301) 映像区間情報記憶部130からユーザにより指定された階層の映像区間開始時刻、終了時刻を読み込む。
【0106】
ステップ302) 全ての開始時刻、終了時刻をソートし、また、重複する時刻は1つ以外全て削除する。
【0107】
ステップ303) 最後に、アノテーション付与区間として、ソートされた結果の時間要素間を区間とし、ソート順でアノテーション区間IDとその開始時刻、終了時刻を決定し、アノテーション付与区間情報記憶部160に格納する。
【0108】
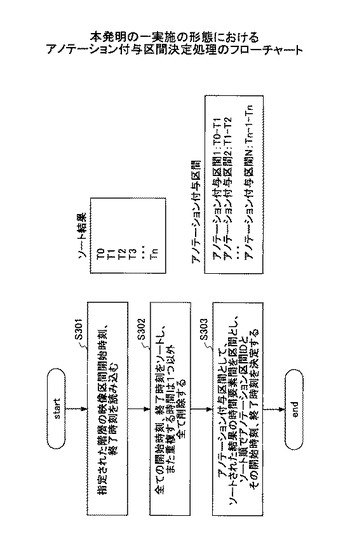
最後に、階層的映像区間一覧表示部170において、決定したアノテーション付与区間がどのような区間なのかをユーザ端末200に表示させるために、アノテーション付与区間情報記憶部160から読み出してユーザ端末200に送信する。ユーザ端末200では、選択した階層を図26に示すように階層的に表示する。これによりユーザは、決定したアノテーション付与区間がどの範囲であるかを見ることができる。図26では、スライドが講義の中心となる場合等のパターンを考慮して階層表示した例であるが、図26は一例であり、階層的な映像区間、アノテーション付与区間がわかる表示であれば、これに限定されるものではない。
【0109】
これらの手順により、映像区間の定義が完了する。
【0110】
[ステップ400:アノテーション付与手順]
以下、アノテーション付与区間毎にアノテーション付与・表示できるインタフェースを用いてユーザが映像区間に対してアノテーション付与を行い、映像アノテーション付与装置100側でアノテーション付与を映像時間と関連付けて管理することで、ユーザに対してユーザの設定したアノテーション付与区間単位に複数の始点で映像視聴しながら、アノテーションも同期して見ることが可能となる。
【0111】
図27は、本発明の一実施の形態におけるアノテーション表示画面例である。当該表示は、ユーザ端末200上の表示装置に表示されるものである。表示画面には、アノテーションン付与用映像区間表示領域a、講義/スライド/板書表示領域b、アノテーション表示領域cが表示される。
【0112】
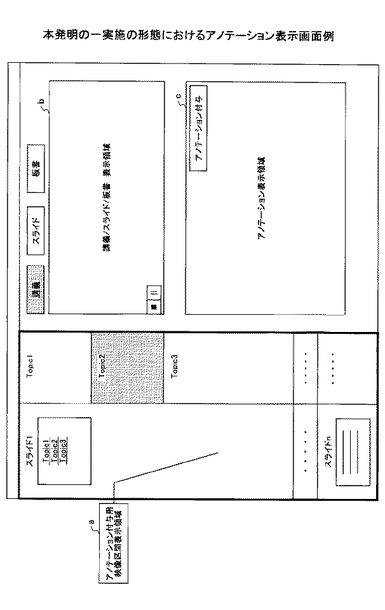
図28は、本発明の一実施の形態におけるアノテーション付与手順のフローチャートである。
【0113】
ステップ401) ユーザがユーザ端末200において、映像の再生や一時停止などの映像の再生制御を行う。
【0114】
ステップ402) 再生制御された映像の中でアノテーションを入力したい場所の対象となる階層、映像時間情報及び空間情報を図27に示す画面上で指定する。
【0115】
ステップ403) ユーザからアノテーションが入力される。
【0116】
ステップ404) 上記のステップ403で入力されたアノテーションと、ステップ402で指定されたアノテーションを入力したい場所の対象となる階層、時間情報及び空間情報を位置情報として映像アノテーション付与装置100に送信する。これにより映像アノテーション付与装置100のアノテーション登録部180においてアノテーション情報記憶部195に蓄積する。
【0117】
ステップ405) 映像アノテーション付与装置100のアノテーション表示部190は、ユーザ端末200から再生制御されている映像の時間を取得する。
【0118】
ステップ406) 映像アノテーション付与装置100のアノテーション表示部190は、アノテーション情報記憶部195に蓄積されたアノテーションの中から、取得した時間を含む対応映像区間のアノテーションを取得する。
【0119】
ステップ407) アノテーション表示部190は、ユーザ端末200から表示したいアノテーション、アノテーションの対象となる階層、アノテーションを表示したい場所、及び、アノテーションの量、あるいは表示したいアノテーションの階層が指定されると、それらの指定情報に基づいてアノテーション表示制御する。
【0120】
ステップ408) ユーザ端末200は、アノテーションを入力した位置情報に合わせてアノテーション表示領域cを用意し、アノテーションを入力したい場所として指定された場所を指し示すようにアノテーション表示領域を画面上に表示する。
【0121】
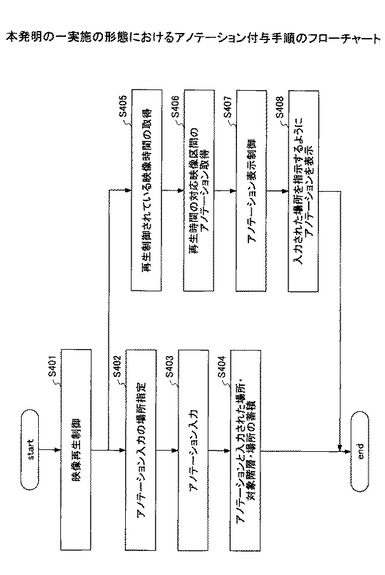
上記の手順により映像再生しながらアノテーションの付与を、階層、映像時間、位置と関連付けて行うことができる。なお、ステップ402のアノテーションを入力したい場所として、映像時間情報以外は指定しなくてもよい。また、ステップ402において、映像時間についてはステップ405の処理結果から取得可能であり、階層については、アノテーション付与区間決定時に選択された階層をデフォルト設定し、さらに一つ限定するのであれば、図26の画面上で階層を選択することで設定することができる。また、位置情報はマウスなどで再生中の映像画面上をクリックすること等で設定することができる。このように設定することで、図29に示すように、上記のステップ402,403で指定・入力されたアノテーション情報をステップ404でアノテーション情報記憶部195に登録することができる。
【0122】
また、ステップ406におけるアノテーションの取得時には、アノテーションの映像時間により、対象となる映像区間が決定されるため、対象となるアノテーションを取得することが可能となる。更に具体的な詳細については、前述の特許文献1を参照されたい。
【0123】
また、上記の実施の形態における映像アノテーション付与装置の構成要素の動作をプログラムをとして構築し、映像アノテーション付与装置として利用されるコンピュータにインストールして実行させる、または、ネットワークを介して流通させることが可能である。
【0124】
また、構築されたプログラムをハードディスクや、フレキシブルディスク・CD−ROM等の可搬記憶媒体に格納しておき、コンピュータにインストールする、または、配布することが可能である。
【0125】
なお、本発明は、上記の実施の形態に限定されることなく、特許請求の範囲内において種々変更・応用が可能である。
【産業上の利用可能性】
【0126】
本実施の形態では、センサ等の撮影時の計測情報、複数のカメラ映像を基に映像区間を定義する上でわかりやすい講義映像を例として説明した。本発明は、メイン映像に含まれる情報だけでなく、メイン映像外の情報に価値がある、例えば、フィールドスポーツや音楽ライブなど人を中心とする実際のライブに関する映像であれば適用可能であり、効果的にアノテーションの付与閲覧できる映像区間を定義できる。
【図面の簡単な説明】
【0127】
【図1】本発明の原理を説明するための図である。
【図2】本発明の原理構成図である。
【図3】本発明の一実施の形態における映像内容の階層構造を示す図である。
【図4】本発明の一実施の形態における映像アノテーション付与装置に入力されるストーリー構成物(登録フェーズの入力)である。
【図5】本発明の一実施の形態におけるシステム構成図である。
【図6】本発明の一実施の形態における動作の概要を示すフローチャートである。
【図7】本発明の一実施の形態における登録フェーズの処理概念図である。
【図8】本発明の一実施の形態における映像区間定義処理のフローチャートである。
【図9】本発明の一実施の形態における登録フェーズのイベント検出を説明するための図である。
【図10】本発明の一実施の形態におけるトピック区間検出処理のフローチャートである。
【図11】本発明の一実施の形態における登録フェーズのイベント検出例:人物状態(講義者発話トピック)である。
【図12】本発明の一実施の形態における登録フェーズの聴講状態区間検出処理のフローチャートである。
【図13】本発明の一実施の形態におけるイベント検出例:人物状態(聴講者の振る舞い)である。
【図14】本発明の一実施の形態におけるイベント検出例:人物状態(講義者の位置)である。
【図15】本発明の一実施の形態におけるイベント検出例:人物状態(講義者の振る舞い)である。
【図16】本発明の一実施の形態におけるイベント検出例:対象物状態(スライド)である。
【図17】本発明の一実施の形態におけるイベント検出例:人物状態(講義者発話)である。
【図18】本発明の一実施の形態における階層とイベント検出結果マッピングデータテーブル例である。
【図19】本発明の一実施の形態における階層毎映像区間データ設定のフローチャートである。
【図20】本発明の一実施の形態における区間分割を行う場合を示す図である。
【図21】本発明の一実施の形態における階層的な映像区間情報の例である。
【図22】本発明の一実施の形態における階層毎映像区間データ設定のフローチャート(自動階層順序設定)である。
【図23】本発明の一実施の形態における階層毎映像区間データである。
【図24】本発明の一実施の形態における映像区間一覧階層表示例である。
【図25】本発明の一実施の形態におけるアノテーション付与区間決定処理のフローチャートである。
【図26】本発明の一実施の形態におけるアノテーション付与区間一覧表示例である。
【図27】本発明の一実施の形態におけるアノテーション表示画面例である。
【図28】本発明の一実施の形態におけるアノテーション付与手順のフローチャートである。
【図29】本発明の一実施の形態におけるアノテーション付与に関する登録情報である。
【図30】従来の技術におけるシーン切り替え検出手順のフローチャートである。
【図31】従来の技術における発話区間及びトピック検出手順のフローチャートである。
【符号の説明】
【0128】
100 映像アノテーション付与装置
110 映像区間定義処理手段、映像区間定義処理部
120 イベント結果記憶部
130 映像区間情報記憶手段、階層的な映像区間情報記憶部
140 階層的映像区間一覧表示部
150 アノテーション付与区間決定処理部
160 アノテーション付与区間情報記憶部
170 階層的映像区間一覧表示部
180 アノテーション付与手段、アノテーション登録部
190 アノテーション表示部
195 アノテーション情報記憶手段、アノテーション情報記憶部
200 ユーザ端末
【技術分野】
【0001】
本発明は、映像アノテーション付与・表示方法及び装置及びプログラム及びコンピュータ読取可能な記録媒体に係り、特に、同期撮影した複数の映像、撮影映像と同期して計測された記録情報とを利用して、準備された複数映像及び、映像時間と関連付いた資料に対してネットワーク上で映像区間単位にアノテーション付与・表示を行う映像アノテーション付与・表示方法及び装置及びプログラム及びコンピュータ読取可能な記録媒体に関する。
【背景技術】
【0002】
映像に対して対象映像を解析して、映像区間を定義し、映像区間に対してアノテーションを行い、個人的あるいは複数人で共有して映像とアノテーションを表示し、映像を活用する技術として以下のようなものが提案されている。
【0003】
従来の技術は、1つの映像に対して、映像区間を予め設定し、設定された映像区間単位に映像のある対象範囲に対してアノテーションを付与したり、映像区間単位に映像と同期してアノテーションを閲覧したりするものである(例えば、特許文献1参照)。
【0004】
映像区間を設定するための技術としては、イベントを検出する方法(例えば、非特許文献1参照)や、スライド映像のシーン切り替え検出により、スライドの切り替え点を検出し、同一のスライド表示区間を検出する方法(例えば、特許文献2参照)、音声の発話区間及びスライドに含まれるキーワードを発話した場合をトピックとして検出する方法(例えば、非特許文献2参照)等が提案されている。
【0005】
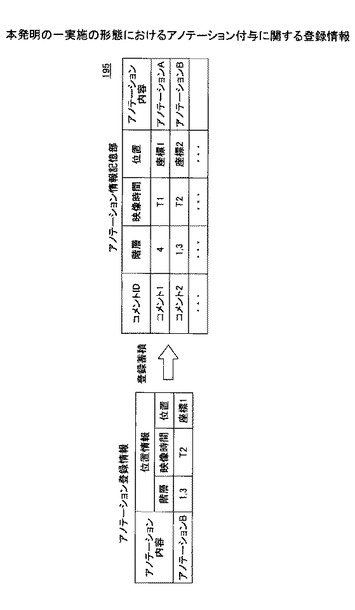
スライドの切り替え点を検出し、同一のスライド表示区間を検出する手法は、具体的には、図30に示すように、映像を読み込み(ステップ601)、ステップ幅Sの間隔内の複数フレーム画像を読み込み(ステップ602)、その複数フレーム画像の画素値をフレーム順に並べて、その変化量よりラベリング処理を行う(ステップ603)。ラベリングとしてはconstant(変化量小)、linear(持続的な上昇)に、step(急激な変化)、no-label(ラベルなし)を画素毎に判定して、このステップ幅の全constant、linear、step、 no-labelの数(Nc,Nl,Ns,Nu)をカウントする。そして、Ns/N−Nuの値が、Tdisを超えるかどうかでシーン切り替えを判定する(ステップ604)。その結果、シーン切り替え点の検出を行うことができる。
【0006】
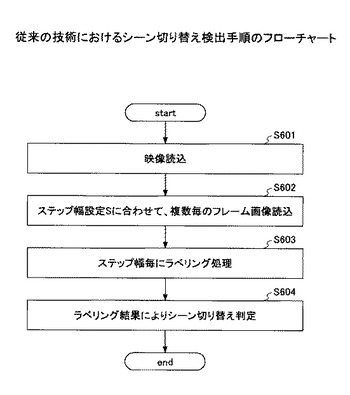
また、音声の発話区間及びスライドに含まれるキーワードを発話した場合をトピックとして検出する手法は、具体的には、図31に示す手順により発話区間及びスライドに対応したトピック検出を行う。まず、映像を読み込み、音声分離を行う(ステップ701)。次に、その分離した音声に対して音声認識を行うが、入力として連続して音素として認識できる区間を発話区間として検出する(ステップ702)。音素列から名詞、数詞、記号などの単語として判別できる場合、発話区間毎にキーワード(U:発話系列)として抽出する(ステップ703)。次に、発話区間毎のキーワードをもとにキーワード数の次元とキーワードの出現頻度により発話キーワードベクトル(W(U))が作成される(ステップ704)。一方、スライド側の処理として、スライドを読み込み(ステップ705)、スライド内の文について形態素解析処理を行い、名詞、数詞、記号等の品詞の単語を判別し、キーワード(S:スライド系列)として抽出する(ステップ706)。上記と同様の方法で、スライドキーワードベクトル(W(S))が作成される(ステップ707)。各スライドを状態とするマルコフモデルを構築し、スライド間の遷移により最尤の出力系列を算出し、その最尤出力を発話とスライドの対応付け結果とする(ステップ708)。スライド系列の状態出力尤度をU及びSのコサイン距離等とする。これらの処理により、発話区間及びスライドに対応した発話のトピック検出を行う。
【0007】
上記従来の仕組みでは、アノテーションを付与する際に、映像区間の映像内容がアノテーションの背景知識となるため、アノテーションは意図のみ記述すれば理解可能となる。しかし、映像区間に関する映像内容とアノテーションとの関連の整合が取れないと、アノテーションの意図が把握できないことを意味する。
【0008】
映像に対して、アノテーションを付与する場合、各アノテーション付与者の立場によりアノテーションを付与する注目対象・注目範囲が異なるため、アノテーションを付与したい映像区間及びアノテーションの対象が様々となる。映像にはストーリーがあり、ストーリーの流れとなるシナリオ・複数の人物や複数の注目すべき対象物の状態の変化の連鎖がストーリーを構成するが、アノテーション付与者の注目範囲は、シナリオ状態、人物及び対象物の状態など様々存在する。そのため、多様なアノテーション付与者の注目範囲とシステムで定義した映像区間が一致しないと、アノテーション付与者がアノテーション付与する作業負荷が高くなり、アノテーションの意図と映像区間が一致しないと、充分な質のアノテーションを行うことが難しくなる。また、同様に、アノテーションを閲覧する場合も、アノテーション閲覧者の立場により、閲覧したいアノテーションの注目対象及び注目範囲が異なるため、閲覧者の立場に合った重要なアノテーションを見つける時間がかかり、またアノテーション閲覧の効率も低くなる。
【0009】
映像区間定義の観点では、上記からアノテーション付与者・閲覧者といった利用者の様々な注目対象のシナリオ状態、人物・対象物の同一状態といった意味的な映像区間は、様々あるため、1映像の映像解析だけでは区間を定義することは難しい。
【0010】
また、映像区間定義を利用したアノテーション付与閲覧の観点では、アノテーション付与者が自分の立場で映像区間を制御する方が効果的であるが、上記の従来の技術では、映像区間の設定がシステムに固定であるため、アノテーション付与者が制御できない。また、映像とアノテーションを表示閲覧する場合、注目する映像対象が異なるため、アノテーション閲覧者が制御する方が効果的であるが、従来の技術では、同様にアノテーション閲覧者が制御できない。
【0011】
上記のように映像区間の定義において、ユーザ映像区間を制御するには意味的な映像区間を多視点で定義することが重要である。従来の技術での映像区間の定義方法は人手で意味的な区間を定義する方法、または、1映像を映像解析することで物理的な映像区間を定義する方法が挙げられている。人手による映像区間定義の場合は、映像区間を定義するために映像を見て判断して区間を定義するといった時間及び作業手間が大きい。また、物理的な映像区間の場合、定義された映像区間が意味的にはどのような映像区間を表すかを示さないとユーザがアノテーション付与する際に、アノテーションの意図と映像区間を一致させることが難しい。また、アノテーション閲覧する場合も、アノテーションの意図を把握することが困難である。
【特許文献1】特開2003−283981号公報
【特許文献2】特許第3378773号公報
【非特許文献1】杉本吉隆、丸谷宜史、角所考、美濃導彦、「講師行動の統計的性質に基づいた講義撮影のための講義状況の認識手法」情報処理学会、研究報告CVIM Vol.2006 No.25 pp.179-186
【非特許文献2】北出祐、河原達也、「講義の自動アーカイブ化のためのスライドと発話の対応付け」情報処理学会、研究報告 CVIM Vol.2005 No.12 pp.59-64
【発明の開示】
【発明が解決しようとする課題】
【0012】
上記の従来の技術には以下のような問題がある。
【0013】
1.意味的な映像区間を定義するには、これまで主に人手で定義していたが、作業時間・作業手間が大きい。
【0014】
2.1映像からの映像解析による物理的な映像区間による映像区間定義では、アノテーション付与者・閲覧者の立場に合った多様な映像区間定義は難しく、物理的な映像区間のまま、映像区間定義に利用すると映像区間の意味が曖昧となる。
【0015】
3.アノテーション付与者・閲覧者毎にアノテーション付与・閲覧したい映像区間が異なるが、アノテーション付与者・閲覧者といったユーザ自身が意図に合った映像区間を設定することができないため、アノテーションの意図と映像区間内容との不一致が起こる。
【0016】
本発明は、上記の点に鑑みなされたもので、上記従来の問題点を解決し、映像を対象に映像と資料に対してネットワーク上で映像区間単位にアノテーション付与・表示を行うことが可能な映像アノテーション付与・表示方法及び装置及びプログラム及びコンピュータ読取可能な記録媒体を提供することを目的とする。
【課題を解決するための手段】
【0017】
図1は、本発明の原理を説明するための図である。
【0018】
本発明(請求項1)は、映像に対して映像を構成する映像区間毎にアノテーションを付与する装置における映像アノテーション付与方法であって、
アノテーション付与単位となる映像区間が複数の階層を有しており、
映像区間に階層毎に設定された検出のためのイベント情報に基づいて、映像及び映像撮影と同期して計測された複数の情報のうちの少なくとも1つを用いて検出されるイベントに従って、該映像を映像区間に分割して映像区間情報記憶手段に格納し(ステップ1)、
映像区間情報記憶手段から映像区間を読み出して、それぞれの映像区間に対して、ユーザが付与するアノテーションを取得してアノテーション情報記憶手段に格納する(ステップ2)。
【0019】
また、本発明(請求項2)は、請求項1の映像区間が三階層以上から構成され、
第1の階層が映像全体のシナリオを表す映像区間であり、
第2の階層がシナリオ内のトピックを表す映像区間であり、
第3以下の下位階層が映像内の個別の事象を表す映像区間である。
【0020】
図2は、本発明の原理構成図である。
【0021】
本発明(請求項3)は、映像に対して映像を構成する映像区間毎にアノテーションを付与する映像アノテーション付与装置であって、
アノテーション付与単位となる映像区間が複数の階層を有しており、
映像区間に階層毎に設定された検出のためのイベント情報に基づいて、映像及び映像撮影と同期して計測された複数の情報のうちの少なくとも1つを用いて検出されるイベントに従って、該映像を映像区間に分割して映像区間情報記憶手段130に格納する映像区間定義処理手段110と、
映像区間情報記憶手段130から映像区間を読み出して、それぞれの映像区間に対して、ユーザが付与するアノテーションを取得して、アノテーション情報記憶手段に格納するアノテーション付与手段180と、を有する。
【0022】
また、本発明(請求項4)は、請求項3の映像区間情報記憶手段に格納される映像区間が、三階層以上から構成され、
第1の階層が映像全体のシナリオを表す映像区間であり、
第2の階層がシナリオ内のトピックを表す映像区間であり、
第3以下の下位階層が映像内の個別の事象を表す映像区間である。
【0023】
本発明(請求項5)は、請求項3または4に記載の映像アノテーション付与装置を構成する各手段としてコンピュータを機能させる映像アノテーション付与プログラムである。
【0024】
本発明(請求項6)は、請求項5記載の映像アノテーション付与プログラムを格納したコンピュータ読取可能な記録媒体である。
【発明の効果】
【0025】
上記のように本発明によれば、複数映像とそれら映像と同期して計測された情報を基に、意味的な映像区間を撮影前でも決定可能な階層とイベント検出結果の対応設定、つまり、第1階層であるシナリオ状態と対応するイベント検出、第2階層であるトピック状態と対応するイベント検出、第3階層以下の状態と対応するイベント検出、を予め設定することで、自動的に階層的な映像区間を定義することができる。
【0026】
また、映像撮影シナリオに沿った、シナリオ状態、トピック状態、対象状態といった階層化により、意味的な映像区間を定義することができ、アノテーション付与者及びアノテーション閲覧者が自分の意図にあった映像区間を設定することができ、自分の意図に合った映像区間に対してアノテーション付与を行うことができる。これは、アノテーション付与者が意図通りアノテーションを行えるため、映像区間に対するアノテーションの整合性がとれ、また、アノテーション閲覧者は、アノテーションの意図を理解しやすい形で自由な視点で映像区間内容とアノテーション情報を閲覧することが可能となり、双方意図に合致した形態でアノテーションを楽しむことができる。
【発明を実施するための最良の形態】
【0027】
以下、図面と共に本発明の実施の形態を説明する。
【0028】
講義やプレゼンテーション、スポーツ、ドラマ等、基本的に映像はストーリーを構成するシナリオが予め設定されている中で撮影されている。そのように撮影された映像には、ストーリーを構成するシナリオがあり、そのシナリオに従って、撮影対象の人物、構成物が状態を変化させながら進行していくものと考えられる。つまり映像を中心としたストーリーとして、図3に示すように、ストーリーを構成するシナリオがあり、シナリオを構成する1以上のトピックがあり、そのトピックを具体的に構成する1以上の対象の状態があると階層的に捉える。具体的には、野球などであれば、シナリオとして試合前解説(メンバー紹介等)、試合開始、1回表、1回裏、・・・9回表(、9回裏)、試合終了、試合後解説(結果等)といった形でシナリオがあり、各打席というトピックがあり、人物としてプレーヤ(攻撃・守備)、審判、解説者、ゲスト等が存在し、主要対象物として各ベース、スコアボードなどが存在し、シナリオの各場面内で、主要人物、主要対象物の振る舞い(状態変化)によって、トピックの内容が形作られる。上記を構造化として考えると、最上位にシナリオという階層があり、シナリオを特徴付けるトピックという階層が第2階層として存在し、各トピックを具体化する人物、主要対象物といった対象の状態が第3階層以下に存在する。
【0029】
ユーザは、シナリオ、トピック、または、各対象のいずれかに興味を持ち、興味対象に対してアノテーションを付与する行動を起こす。つまり視聴者が、映像の中のストーリーの中のあるトピックに興味がある場合、映像中のある人物に興味がある場合、映像中のある対象物に興味がある場合など、様々な観点で映像を閲覧する。そしてストーリーの中のシナリオやトピック、映像中の人物のある状態、映像中の対象物のある状態等がユーザのアノテーションを付与する対象となる。アノテーション付与者は、各シナリオの内容、対象人物のある状態の中の興味ある対象に関してアノテーションを付与する。
【0030】
そのような対象物及び対象人物の状態変化を抽出するため、映像の解析や映像と同期して計測したセンサ、マイク等の計測情報が入力としての前提となる。本発明の映像アノテーション付与装置に、図4に示すように1つ以上の映像(音声及び動画からなる)及び0以上の各計測情報から構成されるストリー構成物が入力される。
【0031】
以下に、講義やプレゼンテーションの場合を例に、映像アノテーション付与及び表示処理の概要を説明する。
【0032】
講義やプレゼンテーション等では、映像内の主要人物として、説明者と受講者といった人物が存在し、説明者が説明するためにスライド、ホワイトボード、PC等を主要対象物として利用しながら説明する映像が典型である。そのような講義やプレゼンテーションでは、スライド、ホワイトボード、PC、受講者等を対象に映像撮影し、それと同期して説明者に複数センサ、マイクを設置することで、説明者の位置、振る舞いなどを計測した結果を入力の情報としての例と考える。
【0033】
以下では、登録フェーズと利用フェーズに分けて説明する。
【0034】
登録フェーズでは、まず、映像アノテーション付与装置において、入力である計測情報や映像からイベントを検出して、各イベント検出結果から変化点を考慮する等を行うことで、各イベント結果から区間を検出することで、イベント検出毎の映像区間が抽出できる。次に、図3のようなシナリオ状態、トピック状態、さらに各対象状態階層といったどの階層にどのイベント結果をマッピングするかのマッピングを行い、階層化された映像区間を定義する。
【0035】
次に、利用フェーズでは、映像アノテーション付与装置において、その階層化された映像区間において、ユーザがどの階層をアノテーション付与、閲覧のために利用するかを設定し、その設定によって、アノテーションを付与する単位となる映像区間(アノテーション付与区間と呼ぶ)を決定する。その映像区間を使って、前述の特許文献1のような方法を用いることで、効果的に映像区間単位に映像アノテーション付与・表示を行えるようになる。
【0036】
以下に、具体的に説明する。以下では、主に講義に関して計測した情報、講義の説明者映像、聴講者映像、ホワイトボード映像、スライド撮影映像等を例にして説明するが、本発明は、こういった講義映像に限らず、スポーツ撮影映像(複数カメラ、観客、スポーツ実施者の位置など計測情報)等でも複数カメラ、計測情報などを使って、後に映像アノテーションを付与するケース、他のケース等、様々に適用可能であり、以下で説明する形態に限定されるものではない。
【0037】
図5は、本発明の一実施の形態におけるシステム構成を示す。
【0038】
同図に示すシステムは、映像アノテーション付与装置100とユーザ端末200から構成される。
【0039】
映像アノテーション付与装置100は、映像区間定義処理部110、イベント結果記憶部120、階層的な映像区間情報記憶部(以下、映像区間情報記憶部と記す)130、階層的映像区間一覧表示部140、アノテーション付与区間決定処理部150、アノテーション付与区間情報記憶部160、階層的映像区間一覧表示部170、アノテーション登録部180、アノテーション表示部190、アノテーション情報記憶部195から構成される。
【0040】
図6は、本発明の一実施の形態における動作の概要を示すフローチャートである。
【0041】
以下、上記の図5の各構成の動作を説明する。
【0042】
以下の動作の前提として、ユーザが映像と同期して計測した情報を映像アノテーション付与装置100内のデータベースで映像と共に管理しているものとする。
【0043】
ステップ100) まず、登録フェーズとして、ユーザ端末200から、対象となる映像とその映像撮影時の計測情報を取得するための映像IDをユーザが指定すると、映像アノテーション付与装置100の映像区間定義処理部110は、後述する映像区間定義処理手順により、ユーザから指定された映像IDに基づいて、階層的な映像区間情報を作成し、映像区間情報記憶部130に格納する。
【0044】
ステップ200) 登録フェーズにより階層的に映像区間が映像区間情報記憶部130で管理された状態で、階層的映像区間一覧表示部140により、映像区間情報記憶部130に格納されている階層情報をユーザ端末200に送信する。これにより、ユーザ端末200では、表示手段(図示せず)に表示する。これによりユーザは、スライド映像のスライドのサムネイル、トピック、講義映像のサムネイルと講義状態、聴講状態、発話区間と発話概要等でアノテーションを付与しやすい単位を確認し、階層1以下でどの階層をアノテーション付与区間として利用するかを指定することができる。
【0045】
ステップ300) 映像アノテーション付与装置100のアノテーション付与区間決定処理部150は、ユーザ端末200から階層が指定されると、映像区間情報記憶部130から指定された階層の映像区間データを読み込み、各映像区間の開始時刻、終了時刻をマージして、アノテーション付与区間を決定し、アノテーション付与区間情報記憶部160に格納する。さらに、階層的映像区間一覧表示部170が、アノテーション付与区間情報記憶部160から、決定したアノテーション付与区間を読み出して、その映像区間をユーザ端末200に送信する。これにより、ユーザ端末200では、決定したアノテーション付与区間がどのような区間なのか表示する。
【0046】
ステップ400) 次に、映像区間の定義が完了したら、ユーザは、アノテーション付与区間に対してアノテーション付与を行う。これにより、映像アノテーション付与装置100は、アノテーション登録部180において、アノテーションを付与しアノテーション情報記憶部195に格納する。また、アノテーション情報は、アノテーション表示部190からユーザ端末200に送信する。
【0047】
以下に、上記のステップ100〜400の処理を詳細に説明する。
【0048】
<登録フェーズ:ステップ100>
ステップ100の映像区間定義処理手順について説明する。
【0049】
図7は、本発明の一実施の形態における登録フェーズの処理概念を示す図である。同図に示すように、登録フェーズでは、映像アノテーション付与装置100において、カメラ、センサ、PC、マイク等からの出力についてイベント検出を行い、イベント結果記憶部120に格納する。映像アノテーション付与装置100の映像区間定義処理部110において検出されたイベントに基づいて、映像を階層化して、映像区間定義情報を記憶部130に格納するものである。このとき、階層となるイベント指定として、シナリオはイベントA,トピックはイベントB,対象物はイベントC等が入力されると、映像区間定義処理部110は検出されたイベントの中からこれらの指定に基づいて映像から映像区間を抽出し、格納する。
【0050】
図8は、本発明の一実施の形態における映像区間定義処理のフローチャートである。
【0051】
ステップ110) 各映像からのイベント検出結果、各計測情報からのイベント検出結果を用いて、情報毎に区間を抽出する。このステップでは、図9に示すように、映像中の動画、音声を解析することや、センサ・マイク等の計測情報を解析することでイベントを検出し、その結果、映像のシナリオ状態、対象物動作状態、イベント状態、発話状態、音楽状態、人物状態、対象物状態などをイベント検出結果としてイベント結果記憶部120に格納する。そして、イベント検出結果を参照して映像区間を求め、映像区間情報記憶部130に格納する。
【0052】
区間データを抽出する具体的な方法としては、以下のようなものがある。
【0053】
センサ等の計測情報から前述の非特許文献1に示す方法等により、映像内の主要人物である講義者の説明状態が検出できる。以下に具体的なイベント検出例とイベント検出結果である区間抽出結果について示す。語りかけ、スライド説明、板書説明、その他といった4つの講義状態の識別情報を区間として検出できる。手・肩のセンサにより手に関する身振りである指示の有無等が検出可能である。
【0054】
また、前述の特許文献2の方法により、スライド映像のシーン切り替え検出により、スライドの切り替え点を検出し、同一のスライド表示区間を検出する手法がある。
【0055】
更に、前述の非特許文献2の方法により、音声の発話区間及びスライドに含まれるキーワードを発話した場合をトピックとして検出する方法がある。
【0056】
また、被写体が聴講者の映像の場合、聴講者の映像から顔認識により聴講者が顔を上げている割合の変化点から顔を上げている割合からノート記述、聴講、ノート記述・聴講混在などの聴講者状態の区間を検出する手法がある。
【0057】
上記の映像処理手法により、「発話区間」、「トピック」、「スライド状態」、「聴講状態」が検出可能である。これら検出した結果は、例えば、発話区間の場合は元々区間を持つデータのため、そのままイベント結果記憶部120の映像時間にマッピングされる。
【0058】
一方、トピック等は瞬間的イベントのため、図10に示すトピック区間検出処理によりイベント結果記憶部120の映像時間にマッピングされる。図10は、本発明の一実施の形態におけるトピック区間検出のフローチャートである。
【0059】
ステップ121) 発話区間と発話区間毎に音声認識され、イベント結果記憶部120に格納されている結果とスライド内のトピック抽出したセットを取得することを行う。
【0060】
ステップ122) 初期処理として、最初の発話区間のスライド内のトピックと音声認識結果が合致したトピックを、
トピック区間ID=1;
状態=合致トピック;
トピック開始時刻=発話区間開始時刻;
トピック終了時刻=発話区間終了時刻;
としてイベント結果記憶部120に登録する。さらに以下の状態をイベント結果記憶部120に保持する。
【0061】
前トピック=合致トピック;
現在のトピック区間ID=1;
ステップ123) 発話区間が存在するかチェックする(当該ステップ123からステップ127まで発話区間が存在する限り繰り返す)。
【0062】
ステップ124) メモリ(図示せず)の音声認識結果内にスライド内のトピックが存在するかチェックする。含まれない場合は、新トピックが顕在化していないため、まだ前のトピックが続いていると捉え、ステップ126に移行する。含まれる場合は、ステップ125に移行する。
【0063】
ステップ125) 更に保持している前トピックと合致トピックが同一かを判定し、一致した場合は同じトピックが続いているため、ステップ126に移行し、一致しない場合は、ステップ127に移行する。
【0064】
ステップ126) ステップ125で一致した場合は、同じトピックが続いているため、まだ前区間のトピックが続いていると判断し、現在のトピック区間IDと一致するトピックIDに対して、トピック終了時刻=発話区間終了時刻、としてトピック終了時刻を更新する処理で次の発話区間の処理に移行する。
【0065】
ステップ127) ステップ125においてトピックが一致しなった場合は、新しいトピックが顕在化したので、新しいトピック区間の開始として解釈する。このステップ127の処理は、新しいトピック区間として、
トピック区間ID=トピック区間ID+1;
状態=合致トピック;
トピック開始時刻=発話区間開始時刻;
トピック終了時刻=発話区間終了時刻;
を新規に登録する。
【0066】
更に、前トピック=合致トピックとし、現在のトピック区間の値に1を加える。
【0067】
ステップ128) 発話区間が存在しなくなった場合は、図11に示すようなデータ構造でトピック区間をイベント結果記憶部120に蓄積する。
【0068】
「スライド状態」については、スライドの次のスライドの切り替え点までをスライド区間と捉えることができる。
【0069】
「聴講状態」は、以下のようにして取得する。
【0070】
図12は、本発明の一実施の形態における登録フェーズの聴講状態区間検出フローチャートである。同図において、聴講状態もある顔認識率の閾値を決めて、閾値を超えた点で聴講状態の変化点と考えれば、映像時間に区間として対応できる。
【0071】
ステップ131) 閾値や人数について以下のように設定する。
【0072】
総人数=N人;
顔認識率閾値1=C1;
顔認識率閾値2=C2;
ステップ132) 提起的に顔認識できた人数を計測したデータを読み込む。
【0073】
ステップ133) 初期処理として、
聴講状態区間ID=1;
状態=状態チェック結果;
聴講状態開始時刻=認識区間開始時刻;
聴講状態終了時刻=区間終了時刻;
としてイベント結果記憶部120に登録する。また、更に以下の状態を保持する。
【0074】
前状態=状態1;
現在の聴講状態区間ID=1;
ステップ134) 区間が存在するかチェックする。
【0075】
ステップ135) 当該ステップからステップ138いついて区間が存在する限り繰り返し処理される。
【0076】
区間データを取得し、状態チェックし、チェック結果を現状態として以下のように保持する。
【0077】
現状態=状態チェック結果;
また、状態チェックでは、以下のようにノート中心か、ノート・聴講混在、聴講中心か当、定性的な量として判断される。
【0078】
Case(C1>F1/N)⇒状態=ノート中心;
Case(C1<F1/N<C2)⇒ノート・聴講混在;
Case(C2<F1/N)⇒状態=聴講中心
ステップ136) 前状態と現状態が一致するかをチェックする。一致する場合は、状態の変化がないため、前の状態が引き続いていると判断され、ステップ137に移行する。一致しない場合は、ステップ138に移行する。
【0079】
ステップ137) 前の状態の引き続きであるので、終了時刻を更新する。現在の区間IDと一致する現在の区間IDに対して
聴講状態終了時刻=区間終了時刻
として、終了時刻を更新する処理を行う。
【0080】
ステップ138) ステップ136で一致しなかった場合は、状態変化が起こったと判断し、新しい区間として以下をイベント結果記憶部120に新規登録する。
【0081】
聴講状態区間ID=聴講状態区間ID+1;
状態=現状態;
聴講状態区間開始時刻=区間開始時刻;
聴講状態区間終了時刻=区間終了時刻;
更に、前状態を現状態とし、現在の区間の値に1を加える。
【0082】
ステップ139) 区間が存在しなくなった場合は、処理が終了となり、図13に示すようなデータ構造で聴講状態をイベント結果記憶部120に蓄積する。
【0083】
このようにして、計測情報や映像の特徴から各特長を映像区間に対応付けし、例えば、図11、図13や、図14〜図17のような形でイベント結果記憶部120にイベント検出のデータを保持することができる。なお、図14は人物状態(講義者の位置)のイベント検出例であり、図15は、人物状態(講義者の振る舞い)のイベント検出例である。映像位置計測情報記憶部120には予め講義者の立っている位置が壇上の説明位置(センサ等で取得)に近い、スライド提示画面に近い、ホワイトボードに近いというデータと、講義者の指示棒の高さ(センサ等で取得)のデータが格納されており、このようなデータを撮影時間と併せて時間順に並べることで、講義者の講義状態を特定したものである。例えば、スライド映像の近くで指示棒の高さが上がれば、スライド説明していることがわかり、また、その前後でスライド画面の近くにいる場合はスライド説明をしている確率が高くなる。
【0084】
これで、図8のステップ110の処理が完了する。
【0085】
ステップ140) 次に、上記のステップで得られた各イベント検出結果から階層的な映像区間の定義を行う。
【0086】
図18のような階層とイベント検出結果からなるメモリ(図示せず)上のマッピングテーブルを利用して、階層上位がより広い映像区間となるようにセットする。一般的な講義では、予めスライド順に順序立てて講義を行うことが計画されているケースが多いため、そのようなケースでは、スライドが前提にあり、1枚のスライド内にもトピックが存在する。そのトピックを補足説明するために講義者がスライド説明、板書説明、語りかけ説明といった形態が行われる。また、各説明状態内部で、講義者が発話している区間が存在すると考えられるため、そのような想定から予めメモリ(図示せず)にマッピングテーブルを用意することができる。
【0087】
この階層順序の決定データとイベント検出結果記憶部120の図11、図13、図14〜図17のようなイベント検出結果とを用いて、映像から階層毎に映像区間を決定しておく方法を以下に示す。
【0088】
図19は、本発明の一実施の形態における階層毎映像区間データ設定のフローチャートである。
【0089】
ステップ141) 図18のような予めメモリ(図示せず)に格納されたマッピングデータとイベント検出結果記憶部120に格納されている図11、図13、図14〜図17のようなイベント検出結果を読み込む。
【0090】
ステップ142) 階層1に割り当てられた映像区間抽出データをそのまま階層1の階層毎映像区間データとしてメモリ(図示せず)に登録する。
【0091】
ステップ143) 以下、ステップ146までを階層が存在する間繰り返し処理する。
【0092】
対象のデータの映像区間抽出結果をメモリ(図示せず)から読み込む。
【0093】
ステップ144) 以下ステップ146までを読み込んだデータで区間が存在する間繰り返し処理する。
【0094】
図20の区間分割処理の条件に基づいて、一つ上位の階層の区間データと比較しながら、上位階層の区間の終端を跨ぐ形での区間データが読み込まれた場合かのチェックを行い、そうであればステップ145に移行し、そうでなければステップ146に移行する。
【0095】
ステップ145) メモリ(図示せず)から読み込まれた区間データを分割した上で処理している階層の階層毎映像区間データとして映像区間情報記憶部130に登録する。このとき現在処理している階層mの現在の区間(区間k−1の終端の映像時間及び区間kの終端の映像時間)内の階層mにおける終端で全て区間分割を行う。
【0096】
ステップ146) 上記以外のケース(ステップ144でNoの場合)は、メモリ(図示せず)から読み込んだ区間データをそのまま次の区間として映像区間情報記憶部130に登録していく。上位階層の区間の終端を跨ぐ形での区間データが読み込まれた場合とは、図20に示すように、以下の状態になった場合である。
【0097】
Tm-1_s-1_end(階層m−1の区間s−1の終端の映像時間)
<=Tm_k1_end(階層mの区間k−1の終端の映像時間)
<Tm-1_s_end(階層m−1の区間sの終端の映像時間)
<Tm_k_end(階層mの区間kの終端の映像時間)
基本的に上位の階層の区間の切れ目は必ずそれより下の階層の区間の切れ目となるようにする。
【0098】
上記の処理により、図21に示すような階層的な映像区間情報が得られ、映像区間情報記憶部130に格納される。
【0099】
一方、シナリオを設定する部分まで自動化することで、登録を自動化し作業負担を下げることも考えられる。その場合は、階層順序を上記のデータごとの映像区間の制約から自動的に階層構造化する場合は、図22に示すように、まず、ステップ151として、各データの階層順序を決定する処理を行う。この処理は、色々なパターンが考えられる。各データのうち区間数の少ないものから順に階層1,階層2,…,階層Nという形式でデータ毎に階層順序を決める方法や、別のデータの区間を内包する割合が高いものから順に階層順序を決める方法などがある。階層順序を決定後は、上記の手動で階層順序を設定した場合と同様の処理を行う。その結果として、講義の全てを網羅するスライドがなく、口頭で説明が中心となるような場合、映像区間情報記憶部130に格納される情報は、図21のようなケースとは異なる講義状態が階層のトップになる等のパターンも考えられる。
【0100】
以上で、映像区間定義処理の内部のステップ140の処理が終了するため、登録フェーズの処理である階層化された映像区間の登録が完了する。
【0101】
<利用フェーズ>
[ステップ200:映像区間一覧手順]
上記のステップ100で階層的に映像区間が映像区間情報記憶部130に管理された状態で、次に、階層的映像区間一覧表示部140により、図23に示すように、階層的に管理された映像区間を映像区間情報記憶部130から読み出して、ユーザ端末200に対して送信することにより図24に示すような情報を表示する。スライド映像のスライドのサムネイル、トピック、講義映像のサムネイルと講義状態、聴講状態、発話区間と発話概要等でアノテーションを付与しやすい単位を確認し、階層1以下でどの階層をアノテーション付与区間として利用するかを講義映像配信の受け手側が指定することができる。
【0102】
[ステップ300:アノテーション付与区間決定手順]
アノテーション付与区間決定処理部150は、ユーザ端末200から送信された、ユーザが指定した階層を基にアノテーション付与区間を決定する。
【0103】
アノテーション付与区間決定処理部150は、以下に示す処理によりアノテーション付与区間を決定する。アノテーション付与区間決定処理部150は、ユーザより指定された階層の映像区間データを映像区間情報記憶部130から読み込み、各映像区間の開始時刻、終了時刻をマージして、アノテーション付与区間を決定する。このアノテーション付与区間決定処理部150により、アノテーション付与区間単位が決定する。
【0104】
図25は、本発明の一実施の形態におけるアノテーション付与区間決定処理のフローチャートである。
【0105】
ステップ301) 映像区間情報記憶部130からユーザにより指定された階層の映像区間開始時刻、終了時刻を読み込む。
【0106】
ステップ302) 全ての開始時刻、終了時刻をソートし、また、重複する時刻は1つ以外全て削除する。
【0107】
ステップ303) 最後に、アノテーション付与区間として、ソートされた結果の時間要素間を区間とし、ソート順でアノテーション区間IDとその開始時刻、終了時刻を決定し、アノテーション付与区間情報記憶部160に格納する。
【0108】
最後に、階層的映像区間一覧表示部170において、決定したアノテーション付与区間がどのような区間なのかをユーザ端末200に表示させるために、アノテーション付与区間情報記憶部160から読み出してユーザ端末200に送信する。ユーザ端末200では、選択した階層を図26に示すように階層的に表示する。これによりユーザは、決定したアノテーション付与区間がどの範囲であるかを見ることができる。図26では、スライドが講義の中心となる場合等のパターンを考慮して階層表示した例であるが、図26は一例であり、階層的な映像区間、アノテーション付与区間がわかる表示であれば、これに限定されるものではない。
【0109】
これらの手順により、映像区間の定義が完了する。
【0110】
[ステップ400:アノテーション付与手順]
以下、アノテーション付与区間毎にアノテーション付与・表示できるインタフェースを用いてユーザが映像区間に対してアノテーション付与を行い、映像アノテーション付与装置100側でアノテーション付与を映像時間と関連付けて管理することで、ユーザに対してユーザの設定したアノテーション付与区間単位に複数の始点で映像視聴しながら、アノテーションも同期して見ることが可能となる。
【0111】
図27は、本発明の一実施の形態におけるアノテーション表示画面例である。当該表示は、ユーザ端末200上の表示装置に表示されるものである。表示画面には、アノテーションン付与用映像区間表示領域a、講義/スライド/板書表示領域b、アノテーション表示領域cが表示される。
【0112】
図28は、本発明の一実施の形態におけるアノテーション付与手順のフローチャートである。
【0113】
ステップ401) ユーザがユーザ端末200において、映像の再生や一時停止などの映像の再生制御を行う。
【0114】
ステップ402) 再生制御された映像の中でアノテーションを入力したい場所の対象となる階層、映像時間情報及び空間情報を図27に示す画面上で指定する。
【0115】
ステップ403) ユーザからアノテーションが入力される。
【0116】
ステップ404) 上記のステップ403で入力されたアノテーションと、ステップ402で指定されたアノテーションを入力したい場所の対象となる階層、時間情報及び空間情報を位置情報として映像アノテーション付与装置100に送信する。これにより映像アノテーション付与装置100のアノテーション登録部180においてアノテーション情報記憶部195に蓄積する。
【0117】
ステップ405) 映像アノテーション付与装置100のアノテーション表示部190は、ユーザ端末200から再生制御されている映像の時間を取得する。
【0118】
ステップ406) 映像アノテーション付与装置100のアノテーション表示部190は、アノテーション情報記憶部195に蓄積されたアノテーションの中から、取得した時間を含む対応映像区間のアノテーションを取得する。
【0119】
ステップ407) アノテーション表示部190は、ユーザ端末200から表示したいアノテーション、アノテーションの対象となる階層、アノテーションを表示したい場所、及び、アノテーションの量、あるいは表示したいアノテーションの階層が指定されると、それらの指定情報に基づいてアノテーション表示制御する。
【0120】
ステップ408) ユーザ端末200は、アノテーションを入力した位置情報に合わせてアノテーション表示領域cを用意し、アノテーションを入力したい場所として指定された場所を指し示すようにアノテーション表示領域を画面上に表示する。
【0121】
上記の手順により映像再生しながらアノテーションの付与を、階層、映像時間、位置と関連付けて行うことができる。なお、ステップ402のアノテーションを入力したい場所として、映像時間情報以外は指定しなくてもよい。また、ステップ402において、映像時間についてはステップ405の処理結果から取得可能であり、階層については、アノテーション付与区間決定時に選択された階層をデフォルト設定し、さらに一つ限定するのであれば、図26の画面上で階層を選択することで設定することができる。また、位置情報はマウスなどで再生中の映像画面上をクリックすること等で設定することができる。このように設定することで、図29に示すように、上記のステップ402,403で指定・入力されたアノテーション情報をステップ404でアノテーション情報記憶部195に登録することができる。
【0122】
また、ステップ406におけるアノテーションの取得時には、アノテーションの映像時間により、対象となる映像区間が決定されるため、対象となるアノテーションを取得することが可能となる。更に具体的な詳細については、前述の特許文献1を参照されたい。
【0123】
また、上記の実施の形態における映像アノテーション付与装置の構成要素の動作をプログラムをとして構築し、映像アノテーション付与装置として利用されるコンピュータにインストールして実行させる、または、ネットワークを介して流通させることが可能である。
【0124】
また、構築されたプログラムをハードディスクや、フレキシブルディスク・CD−ROM等の可搬記憶媒体に格納しておき、コンピュータにインストールする、または、配布することが可能である。
【0125】
なお、本発明は、上記の実施の形態に限定されることなく、特許請求の範囲内において種々変更・応用が可能である。
【産業上の利用可能性】
【0126】
本実施の形態では、センサ等の撮影時の計測情報、複数のカメラ映像を基に映像区間を定義する上でわかりやすい講義映像を例として説明した。本発明は、メイン映像に含まれる情報だけでなく、メイン映像外の情報に価値がある、例えば、フィールドスポーツや音楽ライブなど人を中心とする実際のライブに関する映像であれば適用可能であり、効果的にアノテーションの付与閲覧できる映像区間を定義できる。
【図面の簡単な説明】
【0127】
【図1】本発明の原理を説明するための図である。
【図2】本発明の原理構成図である。
【図3】本発明の一実施の形態における映像内容の階層構造を示す図である。
【図4】本発明の一実施の形態における映像アノテーション付与装置に入力されるストーリー構成物(登録フェーズの入力)である。
【図5】本発明の一実施の形態におけるシステム構成図である。
【図6】本発明の一実施の形態における動作の概要を示すフローチャートである。
【図7】本発明の一実施の形態における登録フェーズの処理概念図である。
【図8】本発明の一実施の形態における映像区間定義処理のフローチャートである。
【図9】本発明の一実施の形態における登録フェーズのイベント検出を説明するための図である。
【図10】本発明の一実施の形態におけるトピック区間検出処理のフローチャートである。
【図11】本発明の一実施の形態における登録フェーズのイベント検出例:人物状態(講義者発話トピック)である。
【図12】本発明の一実施の形態における登録フェーズの聴講状態区間検出処理のフローチャートである。
【図13】本発明の一実施の形態におけるイベント検出例:人物状態(聴講者の振る舞い)である。
【図14】本発明の一実施の形態におけるイベント検出例:人物状態(講義者の位置)である。
【図15】本発明の一実施の形態におけるイベント検出例:人物状態(講義者の振る舞い)である。
【図16】本発明の一実施の形態におけるイベント検出例:対象物状態(スライド)である。
【図17】本発明の一実施の形態におけるイベント検出例:人物状態(講義者発話)である。
【図18】本発明の一実施の形態における階層とイベント検出結果マッピングデータテーブル例である。
【図19】本発明の一実施の形態における階層毎映像区間データ設定のフローチャートである。
【図20】本発明の一実施の形態における区間分割を行う場合を示す図である。
【図21】本発明の一実施の形態における階層的な映像区間情報の例である。
【図22】本発明の一実施の形態における階層毎映像区間データ設定のフローチャート(自動階層順序設定)である。
【図23】本発明の一実施の形態における階層毎映像区間データである。
【図24】本発明の一実施の形態における映像区間一覧階層表示例である。
【図25】本発明の一実施の形態におけるアノテーション付与区間決定処理のフローチャートである。
【図26】本発明の一実施の形態におけるアノテーション付与区間一覧表示例である。
【図27】本発明の一実施の形態におけるアノテーション表示画面例である。
【図28】本発明の一実施の形態におけるアノテーション付与手順のフローチャートである。
【図29】本発明の一実施の形態におけるアノテーション付与に関する登録情報である。
【図30】従来の技術におけるシーン切り替え検出手順のフローチャートである。
【図31】従来の技術における発話区間及びトピック検出手順のフローチャートである。
【符号の説明】
【0128】
100 映像アノテーション付与装置
110 映像区間定義処理手段、映像区間定義処理部
120 イベント結果記憶部
130 映像区間情報記憶手段、階層的な映像区間情報記憶部
140 階層的映像区間一覧表示部
150 アノテーション付与区間決定処理部
160 アノテーション付与区間情報記憶部
170 階層的映像区間一覧表示部
180 アノテーション付与手段、アノテーション登録部
190 アノテーション表示部
195 アノテーション情報記憶手段、アノテーション情報記憶部
200 ユーザ端末
【特許請求の範囲】
【請求項1】
映像に対して映像を構成する映像区間毎にアノテーションを付与する装置における映像アノテーション付与方法であって、
アノテーション付与単位となる映像区間が複数の階層を有しており、
映像区間に階層毎に設定された検出のためのイベント情報に基づいて、映像及び映像撮影と同期して計測された複数の情報のうちの少なくとも1つを用いて検出されるイベントに従って、該映像を映像区間に分割して映像区間情報記憶手段に格納し、
前記映像区間情報記憶手段から前記映像区間を読み出して、それぞれの映像区間に対して、ユーザが付与するアノテーションを取得して、アノテーション情報記憶手段に格納する
ことを特徴とする映像アノテーション付与方法。
【請求項2】
前記映像区間が三階層以上から構成され、
第1の階層が映像全体のシナリオを表す映像区間であり、
第2の階層がシナリオ内のトピックを表す映像区間であり、
第3以下の下位階層が映像内の個別の事象を表す映像区間である
請求項1記載の映像アノテーション付与方法。
【請求項3】
映像に対して映像を構成する映像区間毎にアノテーションを付与する映像アノテーション付与装置であって、
アノテーション付与単位となる映像区間が複数の階層を有しており、
映像区間に階層毎に設定された検出のためのイベント情報に基づいて、映像及び映像撮影と同期して計測された複数の情報のうちの少なくとも1つを用いて検出されるイベントに従って、該映像を映像区間に分割して映像区間情報記憶手段に格納する映像区間定義処理手段と、
前記映像区間情報記憶手段から前記映像区間を読み出して、それぞれの映像区間に対して、ユーザが付与するアノテーションを取得してアノテーション情報記憶手段に格納するアノテーション付与手段と、
を有することを特徴とする映像アノテーション付与装置。
【請求項4】
前記映像区間情報記憶手段に格納される前記映像区間は三階層以上から構成され、
第1の階層が映像全体のシナリオを表す映像区間であり、
第2の階層がシナリオ内のトピックを表す映像区間であり、
第3以下の下位階層が映像内の個別の事象を表す映像区間である
請求項3記載の映像アノテーション付与装置。
【請求項5】
請求項3または4に記載の映像アノテーション付与装置を構成する各手段としてコンピュータを機能させる映像アノテーション付与プログラム。
【請求項6】
請求項5記載の映像アノテーション付与プログラムを格納したコンピュータ読取可能な記録媒体。
【請求項1】
映像に対して映像を構成する映像区間毎にアノテーションを付与する装置における映像アノテーション付与方法であって、
アノテーション付与単位となる映像区間が複数の階層を有しており、
映像区間に階層毎に設定された検出のためのイベント情報に基づいて、映像及び映像撮影と同期して計測された複数の情報のうちの少なくとも1つを用いて検出されるイベントに従って、該映像を映像区間に分割して映像区間情報記憶手段に格納し、
前記映像区間情報記憶手段から前記映像区間を読み出して、それぞれの映像区間に対して、ユーザが付与するアノテーションを取得して、アノテーション情報記憶手段に格納する
ことを特徴とする映像アノテーション付与方法。
【請求項2】
前記映像区間が三階層以上から構成され、
第1の階層が映像全体のシナリオを表す映像区間であり、
第2の階層がシナリオ内のトピックを表す映像区間であり、
第3以下の下位階層が映像内の個別の事象を表す映像区間である
請求項1記載の映像アノテーション付与方法。
【請求項3】
映像に対して映像を構成する映像区間毎にアノテーションを付与する映像アノテーション付与装置であって、
アノテーション付与単位となる映像区間が複数の階層を有しており、
映像区間に階層毎に設定された検出のためのイベント情報に基づいて、映像及び映像撮影と同期して計測された複数の情報のうちの少なくとも1つを用いて検出されるイベントに従って、該映像を映像区間に分割して映像区間情報記憶手段に格納する映像区間定義処理手段と、
前記映像区間情報記憶手段から前記映像区間を読み出して、それぞれの映像区間に対して、ユーザが付与するアノテーションを取得してアノテーション情報記憶手段に格納するアノテーション付与手段と、
を有することを特徴とする映像アノテーション付与装置。
【請求項4】
前記映像区間情報記憶手段に格納される前記映像区間は三階層以上から構成され、
第1の階層が映像全体のシナリオを表す映像区間であり、
第2の階層がシナリオ内のトピックを表す映像区間であり、
第3以下の下位階層が映像内の個別の事象を表す映像区間である
請求項3記載の映像アノテーション付与装置。
【請求項5】
請求項3または4に記載の映像アノテーション付与装置を構成する各手段としてコンピュータを機能させる映像アノテーション付与プログラム。
【請求項6】
請求項5記載の映像アノテーション付与プログラムを格納したコンピュータ読取可能な記録媒体。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】

【図12】
【図13】
【図14】
【図15】
【図16】
【図17】

【図18】
【図19】
【図20】
【図21】
【図22】
【図23】

【図24】
【図25】
【図26】
【図27】
【図28】
【図29】
【図30】
【図31】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【図23】
【図24】
【図25】
【図26】
【図27】
【図28】
【図29】
【図30】
【図31】
【公開番号】特開2009−147538(P2009−147538A)
【公開日】平成21年7月2日(2009.7.2)
【国際特許分類】
【出願番号】特願2007−320983(P2007−320983)
【出願日】平成19年12月12日(2007.12.12)
【出願人】(000004226)日本電信電話株式会社 (13,992)
【出願人】(504132272)国立大学法人京都大学 (1,269)
【Fターム(参考)】
【公開日】平成21年7月2日(2009.7.2)
【国際特許分類】
【出願日】平成19年12月12日(2007.12.12)
【出願人】(000004226)日本電信電話株式会社 (13,992)
【出願人】(504132272)国立大学法人京都大学 (1,269)
【Fターム(参考)】
[ Back to top ]