
暗号処理装置、および暗号処理方法、並びにプログラム
【課題】暗号処理構成の小型化を実現する。
【解決手段】データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してデータ変換処理を繰り返して実行する暗号処理部を有し、暗号処理部は、複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行部と、F関数の出力に対する他ラインのデータとの排他的論理和演算を実行する排他的論理和演算実行部と、F関数実行部における変換データの生成過程の中間データを格納する中間データ格納レジスタと、中間データ格納レジスタの格納データに基づいて、F関数実行部に対する入力データを算出する逆演算実行部を有する。逆演算実行部における逆演算により、F関数実行部に対する入力値を算出可能となり、このデータを保持するレジスタを削減することが可能となる。
【解決手段】データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してデータ変換処理を繰り返して実行する暗号処理部を有し、暗号処理部は、複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行部と、F関数の出力に対する他ラインのデータとの排他的論理和演算を実行する排他的論理和演算実行部と、F関数実行部における変換データの生成過程の中間データを格納する中間データ格納レジスタと、中間データ格納レジスタの格納データに基づいて、F関数実行部に対する入力データを算出する逆演算実行部を有する。逆演算実行部における逆演算により、F関数実行部に対する入力値を算出可能となり、このデータを保持するレジスタを削減することが可能となる。
【発明の詳細な説明】
【技術分野】
【0001】
本開示は、暗号処理装置、および暗号処理方法、並びにプログラムに関する。さらに詳細には、共通鍵系暗号を実行する暗号処理装置、および暗号処理方法、並びにプログラムに関する。
【背景技術】
【0002】
情報化社会が発展すると共に、扱う情報を安全に守るための情報セキュリティ技術の重要性が増してきている。情報セキュリティ技術の構成要素の一つとして暗号技術があり、現在では様々な製品やシステムで暗号技術が利用されている。
【0003】
暗号処理アルゴリズムには様々なものがあるが、基本的な技術の一つとして、共通鍵ブロック暗号と呼ばれるものがある。共通鍵ブロック暗号では、暗号化用の鍵と復号用の鍵が共通のものとなっている。暗号化処理、復号処理共に、その共通鍵から複数の鍵を生成し、あるブロック単位、例えば64ビット、128ビット、256ビット等のブロックデータ単位でデータ変換処理を繰り返し実行する。
【0004】
代表的な共通鍵ブロック暗号のアルゴリズムとしては、過去の米国標準であるDES(Data Encryption Standard)や現在の米国標準であるAES(Advanced Encryption Standard)が知られている。他にも様々な共通鍵ブロック暗号が現在も提案され続けており、2007年にソニー株式会社が提案したCLEFIAも共通鍵ブロック暗号の一つである。
【0005】
このような、共通鍵ブロック暗号のアルゴリズムは、主として、入力データの変換を繰り返し実行するラウンド関数実行部を有する暗号処理部と、ラウンド関数部の各ラウンドで適用するラウンド鍵を生成する鍵スケジュール部とによって構成される。鍵スケジュール部は、秘密鍵であるマスター鍵(主鍵)に基づいて、まずビット数を増加させた拡大鍵を生成し、生成した拡大鍵に基づいて、暗号処理部の各ラウンド関数部で適用するラウンド鍵(副鍵)を生成する。
【0006】
このようなアルゴリズムを実行する具体的な構造として、線形変換部および非線形変換部を有するラウンド関数を繰り返し実行する構造が知られている。例えば代表的な構造にFeistel構造や拡張Feistel構造がある。Feistel構造や拡張Feistel構造は、データ変換関数としてのF関数を含むラウンド関数の単純な繰り返しにより、平文を暗号文に変換する構造を持つ。F関数においては、線形変換処理および非線形変換処理が実行される。なお、Feistel構造および拡張Feistel構造を適用した暗号処理について記載した文献としては、例えば非特許文献1、非特許文献2がある。
【0007】
暗号アルゴリズムの実装形態には、ソフトウェア実装とハードウェア実装の二種類が存在する。ハードウェア実装では、回路規模が小さくなるように実装することで、ハードウェア化の際のコストダウンや低消費電力化が期待できる。そのため、新アルゴリズム、既存アルゴリズムを問わず、小型化するための実装法が様々、提案されている。
【0008】
例えばHamalainen,Alho、Hannikainen、Hamalainenらは、Substitution Permutation Network(SPN)構造を持つAES暗号アルゴリズムに対する小型実装法を提案している。この小型実装法については、非特許文献3[Panu Hamalainen,Timo Alho,Marko Hannikainen,and Timo D.Hamalainen. Design and implementation of low-area and low-power AES encryption hardware core. In DSD,pages 577-583.IEEE Computer Society,2006.9]に開示されている。
【0009】
この開示された実装法では、128−bitブロック暗号のAESを8−bitごとの演算単位で処理することで、回路規模の小型化を達成している。Hamalainenらの実装法はSPN構造とは異なる拡張Feistel構造を持つCLEFIA等のアルゴリズムにも応用できる。
【0010】
ただし、既存の手法を単純に適用するとブロック長分のレジスタに加え、非線形処理部F関数の演算時の中間値を保持するために必要なレジスタが増加してしまう。例えば、CLEFIAへの適用を考えたときには、block長の128−bit分のレジスタに加え、32−bit分のレジスタが増加する。
【先行技術文献】
【非特許文献】
【0011】
【非特許文献1】K. Nyberg, "Generalized Feistel networks", ASIACRYPT'96, SpringerVerlag, 1996, pp.91--104.
【非特許文献2】Yuliang Zheng, Tsutomu Matsumoto, Hideki Imai: On the Construction of Block Ciphers Provably Secure and Not Relying on Any Unproved Hypotheses. CRYPTO 1989: 461-480
【非特許文献3】Panu Hamalainen,Timo Alho,Marko Hannikainen,and Timo D.Hamalainen. Design and implementation of low-area and low-power aes encryption hardware core. In DSD,pages 577-583.IEEE Computer Society,2006.9
【発明の概要】
【発明が解決しようとする課題】
【0012】
本開示は、例えば上述の状況に鑑みてなされたものであり、例えばCLEFIA等の拡張Feistel構造を持つ暗号アルゴリズムに対して、既存の手法よりも小型化が期待できるハードウェア構成を実現する暗号処理装置、および暗号処理方法、並びにプログラムを提供することを目的とする。
【0013】
具体的には、例えばF関数演算時の中間値からF関数への入力を復元する回路を導入することにより、block長以上のレジスタを必要としない実装法を実現する。その結果、構造によってはレジスタ削減効果により回路規模の小型化が期待できる。
【課題を解決するための手段】
【0014】
本開示の第1の側面は、
データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してデータ変換処理を繰り返して実行する暗号処理部を有し、
前記暗号処理部は、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行部と、
前記F関数の出力に対する他ラインのデータとの排他的論理和演算を実行する排他的論理和演算実行部と、
前記F関数実行部における変換データの生成過程の中間データを格納する中間データ格納レジスタと、
前記中間データ格納レジスタの格納データに基づいて、前記F関数実行部に対する入力データを算出する逆演算実行部と、
を有する暗号処理装置にある。
【0015】
さらに、本開示の暗号処理装置の一実施態様において、前記F関数実行部は、F関数実行部への入力データに対する非線形変換処理を実行するS−boxを有し、前記中間データ格納レジスタは、前記S−boxの出力値を中間データとして保持し、前記逆演算実行部は、前記S−boxによる非線形変換処理の逆演算を含む演算処理により、前記F関数実行部に対する入力データを算出する。
【0016】
さらに、本開示の暗号処理装置の一実施態様において、前記F関数実行部は、非線形変換部、および線形変換部を有し、前記非線形変換部の出力を前記中間データとして格納するレジスタを有し、前記線形変換部は、前記レジスタの格納値に対する線型変換処理を実行し、前記逆演算実行部は、前記レジスタの格納値に対する演算処理により、前記F関数実行部に対する入力データを算出する。
【0017】
さらに、本開示の暗号処理装置の一実施態様において、前記F関数実行部は、F関数実行部に対する入力に対して非線形変換部において非線形変換処理を実行し、さらに線形変換部において線形変換処理を実行するSP型F関数である。
【0018】
さらに、本開示の暗号処理装置の一実施態様において、前記F関数実行部は、F関数実行部に対する入力に対して非線形変換部において非線形変換処理を実行し、さらに線形変換部において線形変換処理を実行し、さらに非線形変換部において再度、非線形変換処理をするSPS型F関数である。
【0019】
さらに、本開示の暗号処理装置の一実施態様において、前記F関数実行部は、外部から入力するラウンド鍵との排他的論理和演算部を有する。
【0020】
さらに、本開示の暗号処理装置の一実施態様において、前記F関数実行部は、複数の非線形演算部の繰り返し構造を有する。
【0021】
さらに、本開示の暗号処理装置の一実施態様において、前記暗号処理部は、入力データとしての平文を暗号文に変換する暗号化処理、または、入力データとしての暗号文を平文に変換する復号処理を実行する。
【0022】
さらに、本開示の第2の側面は、
暗号処理装置において実行する暗号処理方法であり、
暗号処理部が、データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してデータ変換処理を繰り返して実行する暗号処理ステップを実行し、
前記暗号処理ステップは、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行ステップと、
前記F関数の出力に対する他ラインのデータとの排他的論理和演算を実行する排他的論理和演算実行ステップと、
前記F関数実行ステップにおける変換データの生成過程の中間データを中間データ格納レジスタに格納するステップと、
前記中間データ格納レジスタの格納データに基づいて、前記F関数実行部に対する入力データを算出する逆演算実行ステップと、
を実行する暗号処理方法にある。
【0023】
さらに、本開示の第3の側面は、
暗号処理装置において暗号処理を実行させるプログラムであり、
暗号処理部が、データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してデータ変換処理を繰り返して実行する暗号処理ステップを実行させ、
前記暗号処理ステップにおいて、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行ステップと、
前記F関数の出力に対する他ラインのデータとの排他的論理和演算を実行する排他的論理和演算実行ステップと、
前記F関数実行ステップにおける変換データの生成過程の中間データを中間データ格納レジスタに格納するステップと、
前記中間データ格納レジスタの格納データに基づいて、前記F関数実行部に対する入力データを算出する逆演算実行ステップと、
を実行させるプログラムにある。
【0024】
なお、本開示のプログラムは、例えば、様々なプログラム・コードを実行可能な情報処理装置やコンピュータ・システムに対して例えば記憶媒体によって提供されるプログラムである。このようなプログラムを情報処理装置やコンピュータ・システム上のプログラム実行部で実行することでプログラムに応じた処理が実現される。
【0025】
本開示のさらに他の目的、特徴や利点は、後述する本発明の実施例や添付する図面に基づくより詳細な説明によって明らかになるであろう。なお、本明細書においてシステムとは、複数の装置の論理的集合構成であり、各構成の装置が同一筐体内にあるものには限らない。
【発明の効果】
【0026】
本開示の一実施例によれば、暗号処理構成の小型化が実現される。
具体的には、データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してデータ変換処理を繰り返して実行する暗号処理部を有し、暗号処理部は、複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行部と、F関数の出力に対する他ラインのデータとの排他的論理和演算を実行する排他的論理和演算実行部と、F関数実行部における変換データの生成過程の中間データを格納する中間データ格納レジスタと、中間データ格納レジスタの格納データに基づいて、F関数実行部に対する入力データを算出する逆演算実行部を有する。逆演算実行部における逆演算により、F関数実行部に対する入力値を算出可能となり、このデータを保持するレジスタを削減することが可能となり、暗号処理構成の小型化が実現される。
【図面の簡単な説明】
【0027】
【図1】kビットの鍵長に対応したnビット共通鍵ブロック暗号アルゴリズムを説明する図である。
【図2】図1に示すkビットの鍵長に対応したnビット共通鍵ブロック暗号アルゴリズムに対応する復号アルゴリズムを説明する図である。
【図3】鍵スケジュール部とデータ暗号化部の関係について説明する図である。
【図4】データ暗号化部の構成例について説明する図である。
【図5】SPN構造のラウンド関数の例について説明する図である。
【図6】Feistel構造のラウンド関数の一例について説明する図である。
【図7】拡張Feistel構造の一例について説明する図である。
【図8】拡張Feistel構造の一例について説明する図である。
【図9】非線形変換部の構成例について説明する図である。
【図10】線形変換処理部の構成例について説明する図である。
【図11】共通鍵ブロック暗号について説明する図である。
【図12】Feistel構造について説明する図である。
【図13】拡張Feistel構造について説明する図である。
【図14】SPN構造を適用したAES暗号アルゴリズムのラウンド関数の構造について説明する図である。
【図15】Hamalainenらの提案したAES暗号を実行するデータ暗号化部のデータパスを示す図である。
【図16】データ暗号化部の構成例を説明する図である。
【図17】Hamalainenらの実装法を4−line拡張Feistel構造に適用した場合のデータ演算部回路の概要図を示す図である。
【図18】ラウンド関数内のF関数の具体例を説明する図である。
【図19】本開示の一実施例に係る暗号処理構成を、図18で表されるF関数を持つ4−line拡張Fesitel構造に適用した場合のデータ演算部回路の概要図である。
【図20】ラウンド関数を説明する図である。
【図21】SPS型F関数について説明する図である。
【図22】図21に記載のSPS型F関数に、本開示の方式を適用した場合に考えられるデータパスの例について説明する図である。
【図23】鍵挿入が複数入ったSPS型F関数について説明する図である。
【図24】図23に記載のSPS型F関数に、本開示の方式を適用した場合に考えられるデータパスの例について説明する図である。
【図25】鍵挿入がF関数入力直後にあるSP型F関数について説明する図である。
【図26】図25に記載のSP型F関数に、本開示の方式を適用した場合に考えられるデータパスの例について説明する図である。
【図27】F関数の構成例について説明する図である。
【図28】図27に記載のF関数に、本開示の方式を適用した場合に考えられるデータパスの例について説明する図である。
【図29】F関数の構成例について説明する図である。
【図30】ラウンド置換(round permutaion)の1つの構成例について説明する図である。
【図31】図30に記載のラウンド置換を持つ構成に対して、本開示の方式を適用した場合に考えられるデータパスの例について説明する図である。
【図32】暗号処理装置としてのICモジュール700の構成例を示す図である。
【発明を実施するための形態】
【0028】
以下、図面を参照しながら本開示に係る暗号処理装置、および暗号処理方法、並びにプログラムの詳細について説明する。説明は、以下の項目に従って行う。
1.共通鍵ブロック暗号の概要
2.共通鍵ブロック暗号の構造と従来型の小型化実装手法の概要について
3.レジスタ削減を実現する暗号処理構成例について
4.本開示の手法の効果のまとめ
5.その他の実施例について
6.暗号処理装置の構成例について
7.本開示の構成のまとめ
【0029】
[1.共通鍵ブロック暗号の概要]
まず、共通鍵ブロック暗号の概要について説明する。
(1−1.共通鍵ブロック暗号)
ここでは共通鍵ブロック暗号(以下ではブロック暗号)としては以下に定義するものを指すものとする。
ブロック暗号は入力として平文Pと鍵Kを取り、暗号文Cを出力する。平文と暗号文のビット長をブロックサイズと呼びここではnで著す。nは任意の整数値を取りうるが、通常、ブロック暗号アルゴリズムごとに、あらかじめひとつに決められている値である。ブロック長がnのブロック暗号のことをnビットブロック暗号と呼ぶこともある。
【0030】
鍵のビット長をkで表す。鍵は任意の整数値を取りうる。共通鍵ブロック暗号アルゴリズムは1つまたは複数の鍵サイズに対応することになる。例えば、あるブロック暗号アルゴリズムAはブロックサイズn=128であり、k=128またはk=192またはk=256の鍵サイズに対応するという構成もありうるものとする。
平文P:nビット
暗号文C:nビット
鍵K:kビット
【0031】
図1にkビットの鍵長に対応したnビット共通鍵ブロック暗号アルゴリズムEの図を示す。
暗号化アルゴリズムEに対応する復号アルゴリズムDは暗号化アルゴリズムEの逆関数E−1と定義でき、入力として暗号文Cと鍵Kを受け取り,平文Pを出力する。図2に図1に示した暗号アルゴリズムEに対応する復号アルゴリズムDの図を示す。
【0032】
(1−2.内部構成)
ブロック暗号は2つの部分に分けて考えることができる。ひとつは鍵Kを入力とし、
ある定められたステップによりビット長を拡大してできた拡大鍵K'(ビット長k')を出力する「鍵スケジュール部」と、もうひとつは平文Pと鍵スケジュール部から拡大された鍵K'を受け取ってデータの変換を行い暗号文Cを出力する「データ暗号化部」である。
2つの部分の関係は図3に示される。
【0033】
(1−3.データ暗号化部)
以下の実施例において用いるデータ暗号化部はラウンド関数という処理単位に分割できるものとする。ラウンド関数は入力としての2つのデータを受け取り、内部で処理を施したのち、1つのデータを出力する。入力データの一方は暗号化途中のnビットデータであり、あるラウンドにおけるラウンド関数の出力が次のラウンドの入力として供給される構成となる。もう1つの入力データは鍵スケジュールから出力された拡大鍵の一部のデータが用いられ、この鍵データのことをラウンド鍵と呼ぶものとする。またラウンド関数の総数は総ラウンド数と呼ばれ、暗号アルゴリズムごとにあらかじめ定められている値である。ここでは総ラウンド数をRで表す。
【0034】
データ暗号化部の入力側から見て1ラウンド目の入力データをX1とし、i番目のラウンド関数に入力されるデータをXi、ラウンド鍵をRKiとすると、データ暗号化部全体は図4のように示される。
【0035】
(1−4.ラウンド関数)
ブロック暗号アルゴリズムによってラウンド関数はさまざまな形態をとりうる。ラウンド関数はその暗号アルゴリズムが採用する構造(structure)によって分類できる。代表的な構造としてここではSPN構造、Feistel構造、拡張Feistel構造を例示する。
【0036】
(ア)SPN構造ラウンド関数
nビットの入力データすべてに対して、ラウンド鍵との排他的論理和演算、非線形変換、線形変換処理などが適用される構成。各演算の順番は特に決まっていない。図5にSPN構造のラウンド関数の例を示す。
【0037】
(イ)Feistel構造
nビットの入力データはn/2ビットの2つのデータに分割される。うち片方のデータとラウンド鍵を入力として持つ関数(F関数)が適用され、出力がもう片方のデータに排他的論理和される。そののちデータの左右を入れ替えたものを出力データとする。F関数の内部構成にもさまざまなタイプのものがあるが、基本的にはSPN構造同様にラウンド鍵データとの排他的論理和演算、非線形演算、線形変換の組み合わせで実現される。図6にFeistel構造のラウンド関数の一例を示す。
【0038】
(ウ)拡張Feistel構造
拡張Feistel構造はFeistel構造ではデータ分割数が2であったものを,3以上に分割する形に拡張したものである。分割数をdとすると、dによってさまざまな拡張Feistel構造を定義することができる。F関数の入出力のサイズが相対的に小さくなるため、小型実装に向いているとされる。図7にd=4でかつ、ひとつのラウンド内に2つのF関数が並列に適用される場合の拡張Feistel構造の一例を示す。また,図8にd=8でかつ,ひとつのラウンド内に1つのF関数が適用される場合の拡張Feistel構造の一例を示す。
【0039】
(1−5.非線形変換処理部)
非線形変換処理部は、入力されるデータのサイズが大きくなると実装上のコストが高くなる傾向がある。それを回避するために対象データを複数の単位に分割し、それぞれに対して非線形変換を施す構成がとられることが多い。例えば入力サイズをmsビットとして、それらをsビットずつのm個のデータに分割して、それぞれに対してsビット入出力を持つ非線形変換を行う構成である。それらのsビット単位の非線形変換をS−boxと呼ぶものとする。図9に例を示す。
【0040】
(1−6.線形変換処理部)
線形変換処理部はその性質上、行列として定義することが可能である。行列の要素はGF(28)の体の要素やGF(2)の要素など、一般的にはさまざまな表現ができる。図10にmsビット入出力をもち、GF(2s)の上で定義されるm×mの行列により定義される線形変換処理部の例を示す。
【0041】
[2.共通鍵ブロック暗号の構造と従来型の小型化実装手法の概要について]
次に、共通鍵ブロック暗号の構造と従来型の小型化実装手法の概要について説明する。
本開示に係る暗号処理構成の説明上、必要な用語について説明する。
【0042】
(2−1.共通鍵ブロック暗号について)
図11を参照して、再度、共通鍵ブロック暗号について説明する。共通鍵ブロック暗号のアルゴリズムは、入力データの変換を繰り返し実行するラウンド関数を有するデータ暗号化部と、ラウンド関数部の各ラウンドで適用するラウンド鍵を生成する鍵スケジュール部とによって構成される。鍵スケジュール部は秘密鍵を入力し、各ラウンド関数に入力するラウンド鍵を生成する。
例えば、r段のラウンド関数を行なう構成としたブロック暗号においては、1からr段までのラウンド関数にそれぞれRK1,RK2,...,Rrのラウンド鍵が入力される。また、初期鍵としてIKが,最終鍵としてFKが排他的論理和される。
【0043】
(2−2.Feistel構造)
図12を参照してFeistel構造について説明する。共通鍵ブロック暗号におけるデータ暗号化部の代表的な構造としてFeistel構造がある。ブロック長をn−bitとした際の具体的なFeistel構造の構成例を図12に示す。
【0044】
図12を見ると,n−bitのデータをn/2−bitずつの2−lineに分割し、そのn/2−bitの片方をラウンド内のF関数に入力し、その出力をもう片方のn/2−bitと排他的論理和していく構成となっている。F関数の構成には様々なタイプのものが考えられる。一例を挙げると、図12に示すF関数のように、ラウンド鍵との排他的論理和演算、S−boxと呼ばれる非線形演算、その後、行列演算により線形変換の処理を行なう構成が知られている。
また、図12に示した構造は,Feistel構造の構成例の1つであり,IK,FKを排他的論理和する位置を変更することで、別の構成例が可能である。
【0045】
(2−3.拡張Feistel構造)
図13を参照して拡張Feistel構造について説明する。前節のFeistel構造の説明では,n/2−bitずつの2−lineに分割し、処理を行なう構成であったが、3−line以上に分割する形にも拡張が可能である。例えば、n/4−bitずつの4−lineに分割し、処理を行なう4−line拡張Feistel構造と呼ばれるものもある。
【0046】
具体的な4−line拡張Feistel構造の構成例を図13に示す。図13を見ると,n−bitのデータをn/4−bitずつの4−lineに分割し、そのうちの2−lineをそれぞれF関数に入力し、その出力をその他の2−lineと排他的論理和していく構成となっている。2−lineから4−lineと変更することにより、ラウンド鍵RKi,初期鍵IK,最終鍵FKも、n/2−bitから、n/4−bitのRKi[0],RKi[1],IK[0],IK[1],FK[0],FK[1]に分割される。上記は、4−line拡張Feistel構造についての説明だが、2−line以上のFeistel構造については全て拡張Feistel構造と呼ぶ。本開示の実施例の説明においては簡単のため、4−line拡張Feistel構造についてのみ言及する.
【0047】
(2−4.従来型の小型化実装手法の概要と課題)
(2−4−1.SPN構造を適用したAES暗号アルゴリズムにおける小型実装手法について)
先に説明したように、SPN構造を適用したAES暗号アルゴリズムにおける小型実装手法についてHamalainen,Alho,Hannikainen,HamalainenらはAESの小型実装法を提案している。非特許文献3[Panu Hamalainen,Timo Alho,Marko Hannikainen,and Timo D.Hamalainen. Design and implementation of low-area and low-power AES encryption hardware core. In DSD,pages 577-583.IEEE Computer Society,2006.9]
【0048】
まず、図14を参照してSPN構造を適用したAES暗号アルゴリズムのラウンド関数の構造について説明する。なお、SPN構造を適用したAES暗号アルゴリズムにおいてもFeistel構造と同様、ラウンド関数を複数回繰り返し実行する構成を持つ。図14は,SPN構造を適用したAES暗号アルゴリズムにおいて利用されるラウンド関数実行部の構成例を示す図である。AESでは,図14に示すラウンド関数を、複数回繰り返して平文から暗号文、または、暗号文から平文の生成を行なう。
【0049】
図14に示すラウンド関数実行部は以下の構成要素によって構成される。非線形変換処理を実行する8−bit入出力の16個のS−boxからなる非線形変換部401,非線形変換部を構成するS−boxからの8−bit出力の入れ替え処理としてのShiftRow実行部402、ShiftRow実行部の出力を32−bit単位で入力して行列を適用した線形変換処理を実行する4つの行列演算部からなる線形変換部403、線形変換部403を構成する4つの行列演算部各々からの32−bit出力に対して32−bitのラウンド鍵との排他的論理和演算を実行する4つの演算部からなる排他的論理和演算部404を有する。
【0050】
図14に示す例は、入出力128−bitのラウンド関数実行部であり、16個のS−box各々に8−bit、計8×16=128−bitを入力し、4つの排他的論理和部の各々32−bit、計32×4=128−bit出力を行なう構成である。
【0051】
前述の非線形変換部401、ShiftRow実行部402、線形変換部403、排他的論理和演算部404、これらを適用した一連の処理を1回のラウンド関数の実行処理として実行し、このラウンド関数を複数回、繰り返して128−bitの入力データ(例えば平文)から、128−bitの出力(例えば暗号文)を生成して出力する。
【0052】
AESの実装において、1つのラウンド関数の処理(1round)、すなわち、非線形変換部401、ShiftRow実行部402、線形変換部403、排他的論理和演算部404、これらを適用した一連の処理を、1cycleで実行しようとすると、少なくとも、図14に示すように、16個のS−boxの回路と、4個の行列演算回路がデータ暗号化部の構成として必要となる。
【0053】
Hamalainenらは,1roundに16cycleかけることで、データ暗号化部の小型化を実現した。この小型化構成では、S−boxの回路は1個しか用いず、さらに、4cycleかけて1つの行列演算を実行するように実装することで、行列演算回路の小型化も実現している。
【0054】
図15にHamalainenらの提案したAES暗号を実行するデータ暗号化部のデータパスを示す。図15に示す構成は、図14に示すAES暗号のラウンド関数を実行するハードウェア構成に相当する。
【0055】
図15に示す構成において、演算中のデータは8−bit単位に分割され、各8−bitデータをレジスタR0〜R18に格納している。図15には、19個のレジスタが示されている。19個のレジスタ(R0〜R18)の各々は8−bitデータを保持する8−bitレジスタである。図14を参照して説明した通り、図14に示す構成は、入出力128−bitのラウンド関数実行部であり、図15は,入出力128−bitのラウンド関数を8−bit単位データのシリアル処理として実行するハードウェア構成に対応する。
【0056】
図15の構成において、入出力データを全て格納するために必要となる8−bitレジスタの数は、128/8=16であり、16個のレジスタがあればよい。図15には、19個のレジスタがあり、3つのレジスタが余分であるが、これら24−bit分の3つのレジスタは、行列を適用した線形変換処理を実行するための行列演算処理のために利用される。
【0057】
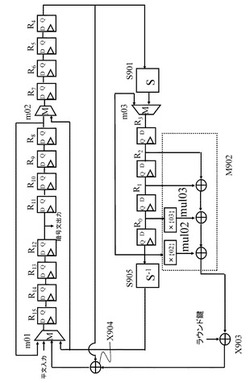
また、図14を参照して説明したように、AESでは、非線形変換を実行するS−boxと線形変換を実行する行列演算の間にShiftRow実行部によるデータ置換が実行される。Hamalainenらの実装手法では、図15中のいくつかのレジスタの前にマルチプレクサ(Multiplexer)m01〜m08を導入することにより、ShiftRow実行部で行なわれる置換を実現している。
【0058】
図15に示すように、非線形変換部としてのS−box,S501は1個しかない。このS−box,S501に対して8−bitデータを順次入力し、16cycleで図14に示す16個のS−boxによる非線形変換処理を実行する。S−box,S501の出力は、行列演算回路M502に入力され、行列演算回路M502において、行列を適用した線形変換処理が実行される。
【0059】
なお,図14の構成では、S−boxによる処理データをShiftRow実行部で置換した後、行列演算を行なう構成となっているが、図15に示す例では、S−box,S501の出力を行列演算回路M502に直接入力する構成としている。図15の構成では、ShiftRow実行部での置換処理に相当する処理は図15に示すレジスタR0〜R18とマルチプレクサm01〜m08の動作によって実行する。
【0060】
図15に示す行列演算回路M502では,図14に示す線形変換部403の4つの行列演算回路の処理が順次実行される。図14に示す線形変換部403の4つの行列演算回路の1つの行列演算回路で実行する行列を適用した線形変換処理を4cycleで実行する。図14に示す排他的論理和演算部404の排他的論理和演算処理は,図15の排他的論理和演算部X503,X504において実行される。これら排他的論理和演算部X503,X504において,処理データと鍵生成部K505の出力するラウンド鍵との排他的論理和処理を実行する。
【0061】
なお,本開示の構成に本質的に関連のある箇所のみを説明するため,ShiftRow等の置換を行なう回路や、鍵スケジュール部については図16のように省略したデータパスで説明する。図16中のレジスタ群と記述されている部分は、96−bit分のデータを保持し、ShiftRowも考慮されたレジスタの集合を表す。AESの実装において,1roundを1cycleで演算する場合、利用するデータ暗号化部用のレジスタはblock長である128−bit分のみで済む。
【0062】
それに対し、Hamalainenらの実装法では、152−bitと24−bit分増えている。これは、行列への入力を8−bitずつに分割した場合、行列を計算し終わるまでの途中演算結果の32−bit分を保持する必要性が出てくるためである。そのため、単純に考えると32−bit分のレジスタが追加されることになる。一方、行列へ入力する値は次のラウンドでは不要となる。このことを考慮すると、行列へ入力する32−bitのうち、はじめに入力する8−bit分のレジスタは行列演算部のレジスタと共有できるので、レジスタの増加分は、
32−8=24−bit
分に抑えられる。
【0063】
(2−4−2.SPN構造の小型実装構成の拡張Feistel 構造への適用と問題点について)
上述したように,Hamalainenらは,SPN構造の小型化を実現している。しかし、この小型化構成はSPN構造に対応した特有の構成であり、この小型実装構成を拡張Feistel構造へ適用しても十分な小型化の効果は得られない。
【0064】
以下、この問題点について説明する。なお、以下の説明では、拡張Feistel構造は、Feistel構造を含む概念であるものとして説明する。Hamalainenらの実装法を拡張Feistel構造を持つCLEFIA等のアルゴリズムを実行する構成に適用すると、行列演算のために、行列の出力ビット長分のデータを格納するレジスタが必要になる。
【0065】
これは、拡張Feistel構造がSPN構造とは異なり、例えばラウンド関数内のF関数に入力した値を、次のラウンドでも利用する必要があるという処理シーケンスの根本的な違いに起因するものである。
【0066】
図17は、Hamalainenらの実装法を4−line拡張Feistel構造に適用した場合のデータ演算部回路の概要図を示す図である。図17では、先に図16を参照して説明したAESのデータパスと同様、拡張Feistel構造のラウンド関数終了時の置換動作や鍵スケジュール部は省略してある。なお、ラウンド演算における処理データサイズとしてのブロックサイズはn−bitとする。
【0067】
先に図13を参照して説明したように,4−line拡張Feistel構造では、4つのライン各々にn/4−bitずつ入力され、順次転送される。図17中のレジスタ群R703は、図16に示すレジスタ群R601に対応する。ただし、4−line拡張Feistel構造に対応する図17中のレジスタ群R703は,(3/4)n−bit分のデータを保持するレジスタとラウンド終了時の置換動作と同様の処理を実現するマルチプレクサ等の組み合わせとして構成される。
【0068】
なお、図17に示す4−line拡張Feistel構造を適用した暗号アルゴリズムのデータパス(演算実行回路)を適用して実行する演算は、図13に示す4−line拡張Feistel構造を適用した演算処理に対応する。この図17に示すデータパスを利用して図13に示す4−line拡張Feistel構造内のF関数を含むラウンド関数を実行することになる。
【0069】
ラウンド関数内のF関数の具体例を図18に示す。図18に示すF関数は、以下の構成要素を持つ。
*非線形処理を実行するS−boxからなる非線形変換部S801、
*非線形変換部S801からの出力に対して、行列演算により線形変換の処理を行なうM802、
*線形変換部M802からの出力に対して、ラウンド鍵との排他的論理和演算を実行する排他的論理和演算部X803、
上記の構成要素を持つ。図18に示すF関数はSP型F関数と呼ばれる。
【0070】
ただし,4−line拡張Feistel構造におけるF関数に対する入出力は,n/4−bitになる。なお、図18に示されている線形変換部M801は、AES暗号アルゴリズムで採用されている行列と同様に下記の(式1)に示される巡回行列を想定している。
【0071】
【数1】

【0072】
なお、式1に示す(x0、x1、x2、x3)は、行列演算回路である線形変換部M801に対する入力(S−boxからの出力)、
(y0、y1、y2、y3)は、行列演算回路である線形変換部M801の出力(線形変換結果)、
4×4の行列は、行列演算回路である線形変換部M801において適用する行列(線形変換行列)に対応する。
なお、4×4の線形変換行列の要素は16進数値として示している。
本例では、(x0、x1、x2、x3)の各々は、S−boxからの1サイクルあたりの出力であり8ビットデータである。出力(y0、y1、y2、y3)の各々も8ビットデータである。
【0073】
先に図14〜図16を参照して説明したAES暗号アルゴリズムの構成と比較するため、処理単位としてのブロック構成ビットnは、n=128−bitとする。
図17に示す回路も、図16に示す回路と同様、S−boxは1つのみである。図17に示すS−box,S701である。このS−box,S701は、図18に示すF関数内に設定される1つのS−boxの処理を1cycleで実行する。
cycleごとに、順次、図18に示す各S−boxの処理を行なうことになる。
【0074】
図18に示すように、F関数の1つのS−boxには、4−line拡張Feistel構造の1つのラインを伝送するn/4−bitの1/4、すなわち、n/16−bitが入力され非線形変換処理が実行される。
【0075】
図17に示すS−boxS701には、n/16−bitずつがcycleごとに入力され、非線形変換処理が実行される。S−box,S701において非線形変換のなされたデータは、n/16−bitごとに1cycle単位で次の線形変換回路M702に入力される。線形変換回路M702では、所定の行列を適用した線形変換処理が実行されることになる。
【0076】
図17に示す4−line拡張Feistel構造を適用した暗号アルゴリズムのデータパス構成中、レジスタ群R703を除く演算実行回路と、先に図16を参照して説明したレジスタ群R601を除く、SPN構造を利用したAES暗号処理を実行する演算回路構成とを比較する。
【0077】
図16に示す演算回路では、8−bitレジスタがR0〜R3,R16〜R18の7個であるのに対して、図17に示す演算回路では、8−bitレジスタがR0〜R3,R16〜R19の8個である。すなわち、8−bitレジスタの数が1つ増加している。
【0078】
このように、Hamalainenらの提案構成を拡張Feistel構造に適用した場合、図17に示す演算回路のように、ブロック長分のレジスタに加え、1−line分のレジスタが必要となってくる。レジスタの増加は回路規模に大きく影響するため、ブロック長分のみのレジスタで構成できるならば、そのほうが望ましい。
【0079】
従来手法の課題点として以下の課題があげられる。
レジスタの回路規模は他のセルに比べて比較的大きなものとなり、レジスタ数の増加は回路規模に大きく影響する。そのため、小型化を実現するための一つの方向性として、レジスタの増加を抑えた実装法が考えられる。従来手法の実装法では、block長分よりも大きなレジスタが必要になってしまうことが課題と考えられる。
【0080】
[3.レジスタ削減を実現する暗号処理構成例について]
Hamalainenらの実装法を、拡張Feistel構造を持つアルゴリズムに適用した場合には、前節で述べたように必要なレジスタが増加してしまう。これは、F関数への入力は次のラウンドでも利用するため、F関数への入力を保持したまま、F関数の出力を演算しているためである。この考えのもとで実装すると、F関数への入力を保持するレジスタと、F関数演算時の中間値を保持するためのレジスタの両方が必要となる。
【0081】
先の図17、図18を用いて説明した4−line拡張Feistel構造を適用した暗号アルゴリズムでは、F関数内の線形変換部M802で表される行列演算時の中間値を保持する必要があったため、ブロック長分のレジスタに加え、1−line分の32−bit分のレジスタが必要となった。
【0082】
以下に説明する実施例では、F関数への入力は一度破棄し、その入力が格納されていたレジスタをF関数演算時の中間値を保持するためのレジスタとして利用する。
F関数の出力値と、F関数へ入力したラインとは別のラインとの排他的論理和を実行後、F関数演算時の中間値からF関数への入力を復元するように考える。
【0083】
このようにすることで、F関数への入力値とF関数演算時の中間値を同時に保持する必要がなくなり、レジスタ数を削減することができる。
【0084】
以下、具体例について説明する。前述した構成との対比を容易とするため、図18で表されるF関数を持つ4−line拡張Fesitel構造を例に説明する。なお,図18に示されている線形変換部M801は,AES暗号アルゴリズムで採用されている行列と同様に下記の(式2)で記される巡回行列を想定している。
【0085】
【数2】
【0086】
図19は、本開示の一実施例に係る暗号処理構成を、図18で表されるF関数を持つ4−line拡張Fesitel構造に適用した場合のデータ演算部回路の概要図である。
【0087】
先に説明した項目(2−4−2.SPN構造の小型実装構成の拡張Feistel 構造への適用と問題点について)で紹介したように、Hamalainenらの実装法を図18で表されるF関数を持つ4−line拡張Feistel構造に適用した場合、図18のF関数内の線形変換部M802で表される行列演算時の中間値を保持するレジスタが必要となった。
【0088】
それに対して、本開示の一実施例に係る暗号処理構成を用いて実現された図19では、中間値として、非線形演算部S801後の線形演算部M802に入力される値を保持するようにしている。この手法で保持すべき中間値を図18に保持する中間値I804として表す。図19では、上記の中間値を図19に示すR0〜R3で表されるレジスタ内に保持している。
【0089】
また、Hamalainenらの実装法を図18で表されるF関数を持つ4−line拡張Feistel構造に適用した場合、図18のF関数内の線形変換部M802で表される行列演算時の中間値を保持するレジスタとは別に、次のラウンドを演算するために必要となるF関数への入力値を保持するレジスタを必要としていた。それに対して、図19では、次のラウンドを演算するために必要となるF関数への入力値は保持せずに、代わりに上記で述べた図18のF関数内の非線形演算部S801後の線形演算部M802に入力される値である保持する中間値I804を保持している。
【0090】
先に説明した項目(2−4−2.SPN構造の小型実装構成の拡張Feistel 構造への適用と問題点について)で紹介したHamalainenらの実装法では,160−bit分のレジスタを利用していたのに対し,図19に示す構成においては、8−bitレジスタを、R0〜R15の16個、利用しており、合計で128−bit分のレジスタのみで回路を実現できる。
【0091】
この図19に示すデータパスを利用して図13,図18で表されるラウンド関数を実行することになる。
図13を参照すると、1ラウンドに演算する必要のあるF関数は2つあることが分かる。図19では,1つのF関数の出力を4cycleかけて実行し、その後の4cycleをかけて図18の保持する中間値I,804からF関数の入力を復元する。
【0092】
前述したように、1roundにF関数は2つ実行する必要があるため、合計16cycleを要することで1round分の演算を実行する。また、平文入力時には、16cycleかけて上位8−bitから8−bitずつ入力し、暗号文出力時にも16cycleかけて出力ポートから上位8−bitから8−bitずつ順次出力するように考える。
【0093】
以下、以下に示す表1を参照しながら平文入力時の16cycle分と,1roundの演算に必要な16cycle分と,暗号文出力時の16cycle分のデータの流れを説明する。
【0094】
【表1】
【0095】
まず、平文入力時の16cycle分の動きを説明する。
i∈{0,1,...,15}
に対して、
piを8−bitの要素とする。
このとき,(p0,p1,...,p15)で表される128−bitを平文として考える。
【0096】
平文入力時の1cycle目では,p0を図19に示す平文入力ポートからマルチプレクサm01を利用しR15に格納する.その後11cycleかけて,p0をマルチプレクサm02を利用し,R14,R13,...,R4の順に格納していく。
【0097】
上述したように、平文入力時の12cycle後にはp0はR4に格納されているとする。13cycle目には、R4に格納されていたp0を非線形演算部S901に入力し、その出力をマルチプレクサm03を利用しR3に格納する。
【0098】
p0を非線形演算部S901に入力したときの出力をS(p0)とする。その後、3cycleかけて,S(p0)をR2,R1,R0の順に格納していく。
【0099】
p0以外の値であるpi,i∈{1,2,...,15}に関しては、p0が格納されていたレジスタにicycleだけ遅れて格納されるようにする。ただし、R4に格納されていた値は次のサイクルで非線形演算部S901に入力され、その出力であるS(pi)がR3に入力されるとする。
【0100】
最終的に、平文入力時の16cycle後には,R0〜R3には,(S(p0),S(p1),S(p2),S(p3))が格納され、R4〜R15には、(p4,p5,...,p15)が格納されるようにマルチプレクサm01,m02,m03を利用する。
【0101】
なお、R0〜R3に入力された(S(p0),S(p1),S(p2),S(p3))は、1round目の図18に記載のF関数の保持する中間値I804の値と一致する。
【0102】
次に,1roundの演算に必要な16cycle分のデータの流れを説明する。
図20は,図13における、
i∈{1,...,r}ラウンド目のラウンド関数を表したものである。
【0103】
今、図20においてi∈{1,...,r}ラウンド目のラウンド関数への入力値を(x0,x1,...,x15)とし,iラウンド目のラウンド関数の出力値を(y0,y1,...,y15)とする。ただし、i=1のときは,(x0,x1,...,x15)は平文を表し、i=rのときは、(y0,y1,...,y15)は暗号文を表すこととする。
【0104】
図19では、ラウンド開始時の初期状態として、R0〜R3には、(S(x0),S(x1),S(x2),S(x3))が格納され、R4〜R15には、(x4,x5,...,x15)がそれぞれ格納されていると考える。
【0105】
なお、i=1の場合は、ラウンド開始時の初期状態として、前述の通り、
R0〜R3には、(S(p0),S(p1),S(p2),S(p3))が格納され、
R4〜R15には,(p4,p5,...,p15)がそれぞれ格納されている状態を表す。
【0106】
表1では、図19に記した発明手法におけるラウンド関数実行時のレジスタの保持内容を表している。1roundを16cycleで実行するため、各cycle後のR0,R1,...,R15のそれぞれのレジスタの保持内容を表している。また、図19記載のように(x0,x1,x2,x3),(x8,x9,x10,x11)をF関数の入力とした場合の出力を(f0,f1,f2,f3),(f8,f9,f10,f11)と表すことにする。
【0107】
ラウンド関数実行時の1〜4cycle目では、図18記載の線形演算部M801を図19記載の行列演算部M902を用いて実行する。行列演算部M902では,R0,R1に格納されている値に対して、有限体GF(28)上での0x02,0x03との乗算を図19記載のmul02,mul03で実行する。その乗算後の値を排他的論理和し、さらに、R2,R3に格納されている値とも排他的論理和したものを出力している。
【0108】
このようにすることで、1cycle目には,図18記載の線形演算部M801の出力値の上位8−bitが計算できる。
また、マルチプレクサm03を利用することにより、R0に格納されている値を次のcycleでR3に格納することで、2,3,4cycle目には同様に図18記載の線形演算部M801の出力値の9〜16,17〜24,25〜32−bit目がそれぞれ計算できる。
【0109】
これは、想定している行列が、行ごとの要素を1行ごとに右ローテーションしている巡回行列であることを利用している。(R0,R1,R2,R3)の保持内容をcycleごとに8−bit左ローテーションを施すことで、行列1行分の演算を実施する図19記載の行列演算部M902を用いて、cycleごとに各行の演算を実施するようにしている。
【0110】
さらに、ラウンド関数実行時の1〜4cycle目では、上述した線形演算部からの出力に対し、ラウンド鍵との排他的論理和演算が排他的論理和演算部X903で上位8−bitから8−bitずつ順次実行される。
【0111】
また、図20記載のF関数F192の出力との排他的論理和演算X191は、図19においてラウンド鍵との排他的論理和演算実行部X903の出力値とレジスタR4に格納されている値との排他的論理和演算部X904を利用することで実現される。
【0112】
R4には、1〜4cycle目において、x4,x5,x6,x7が順次格納されるため、排他的論理和演算部X904の出力をマルチプレクサm01を利用しレジスタR15に格納することで、4cycle後に(x0,x1,x2,x3)をF関数に入力したときの出力32−bitと32−bitの(x4,x5,x6,x7)を排他的論理和した値がR12,R13,R14,R15に8−bitずつ格納された状態となる。
【0113】
表1に記載の通り、ラウンド関数開始後の4cycle後には,R12,R13,R14,R15に(x0,x1,x2,x3)をF関数に入力したときの出力32−bitと32−bitの(x4,x5,x6,x7)を排他的論理和した値が格納されている。
【0114】
これらの値は、ラウンド関数の出力値の上位32−bitであるy0,y1,y2,y3となる。
また、図19記載のマルチプレクサm03を利用し、R0が保持している値を次のcycleではR3に格納するようにしていたので、表1を参照すると、ラウンド開始後の4cycle後には、R0,R1,R2,R3の保持内容は、ラウンド開始時の値と変化していないことが分かる。
【0115】
また、その他のx8,x9,...,x15は、図19記載のマルチプレクサm02を利用し、ラウンド開始後の4cycle後には、それぞれR4,R5,...,R11に格納される。
【0116】
次にラウンド関数実行時の5〜8cycle目についてデータの流れを説明する。上述したように、(x0,x1,x2,x3)をF関数に入力したときの出力を用いた演算は実行可能ということが分かった。
しかし、ラウンド関数開始後の4cycle後には、ラウンド関数出力の値として必要な(x0,x1,x2,x3)の値は保持しておらず、代わりにF関数演算時の中間値である(S(x0),S(x1),S(x2),S(x3))のみをR0,R1,R2,R3に保持している。
【0117】
5〜8cycle目では,本発明の1つのポイントとなるF関数演算時の中間値からF関数への入力を復元する回路を用いて(x0,x1,x2,x3)を復元する。ラウンド関数開始後の4cycle後には、F関数演算時の中間値として、R0,R1,R2,R3に(S(x0),S(x1),S(x2),S(x3))の値を保持している。
【0118】
図19記載の非線形演算部S−1関数S905は、非線形演算部S−boxS901の逆関数を表している。ラウンド関数開始後の5〜8cycle目には、R0の保持値を非線形演算部S−1関数に入力し、その出力をマルチプレクサm01を利用し、R15に格納する。
【0119】
このようにすることで、ラウンド関数開始後の8cycle後には、R12,R13,R14,R15にx0,x1,x2,x3がそれぞれ格納された状態になる。非線形演算S−boxの逆関数S−1関数は、拡張Feistel構造とは異なるSPN構造を利用した暗号アルゴリズムでは、復号関数を構成する際に導入されているが、通常、拡張Feistel構造では暗号化においても復号においても用いる必要がなく、F関数演算時の中間値からF関数への入力を復元するという目的のために導入された回路となる。
【0120】
さらに、ラウンド関数実行時の5〜8cycle目では,図20記載のF関数演算部F193の出力を計算するために、R4,R5,R6,R7に格納されている(x8,x9,x10,x11)をそれぞれ図19記載の非線形演算部S901に入力し、その出力をマルチプレクサm03を利用し,R0,R1,R2,R3に格納する。
【0121】
表1に記載の通り、ラウンド関数開始後の8cycle後には、R12,R13,R14,R15に(x0,x1,x2,x3)の値が格納されている。これらの値は、ラウンド関数の出力値の下位32−bitであるy12,y13,y14,y15となる。
【0122】
また、ラウンド関数開始後の4cycle後にR4,R5,R6,R7に格納されていたx8,x9,x10,x11は、ラウンド関数開始後の8cycle後には、非線形演算部S901への入力後、マルチプレクサm03を利用し、R0,R1,R2,R3に格納される。
【0123】
また、その他のx12,x13,x14,x15,y0,y1,y2,y3は、図19記載のマルチプレクサm02を利用し、ラウンド開始後の8cycle後には、それぞれR4,R5,...,R11に格納される。
【0124】
次にラウンド関数実行時の9〜12cycle目のデータの流れを説明する。まず、図20記載のF関数演算部F193中の図18記載の線形演算部M801を図19記載の行列演算部M902を用いて実行する。
【0125】
行列演算部M902では、R0,R1に格納されている値に対して,有限体GF(28)上での0x02,0x03との乗算を図19記載のmul02,mul03で実行する。その乗算後の値を排他的論理和し、さらに,R2,R3に格納されている値とも排他的論理和したものを出力している。
【0126】
このようにすることで、ラウンド関数開始後の9cycle目には、図18記載の線形演算部M801の出力値の上位8−bitが計算できる。また、マルチプレクサm03を利用することにより、R0に格納されている値を次のcycleでR3に格納することで、2,3,4cycle目には同様に図18記載の線形演算部M801の出力値の9〜16,17〜24,25〜32−bit目が計算できる。
【0127】
さらに、ラウンド関数実行時の9〜12cycle目では、上述した線形演算部からの出力に対し、ラウンド鍵との排他的論理和演算が排他的論理和演算部X903で上位8−bitから8−bitずつ順次実行される。また、図20記載のF関数F193の出力との排他的論理和演算X191は、図19においてラウンド鍵との排他的論理和演算実行部X903の出力値とレジスタR4に格納されている値との排他的論理和演算部X904を利用することで実現される。
【0128】
R4には、9〜12cycle目において、x12,x13,x14,x15が順次格納されるため、排他的論理和演算部X904の出力をマルチプレクサm01を利用しレジスタR15に格納することで、4cycle後に(x8,x9,x10,x11)をF関数に入力したときの出力32−bitと32−bitの(x12,x13,x14,x15)を排他的論理和した値がR12,R13,R14,R15に8−bitずつ格納された状態となる。
【0129】
表1に記載の通り、ラウンド関数開始後の4cycle後には,R12,R13,R14,R15に(x8,x9,x10,x11)をF関数に入力したときの出力32−bitと32−bitの(x12,x13,x14,x15)を排他的論理和した値が格納されている。
【0130】
これらの値は、ラウンド関数の出力値の65−bit目から96−bit目であるy8,y9,y10,y11となる。また、図19記載のマルチプレクサm03を利用し、R0が保持している値を次のcycleではR3に格納するようにしていたので、表1を参照すると、ラウンド開始後の8cycle後と12cycle後のR0,R1,R2,R3の保持内容は、変化しないことが分かる。
【0131】
また、その他のy0,y1,y2,y3,y12,y13,y14,y15は、図19記載のマルチプレクサm02を利用し、ラウンド開始後の12cycle後には、それぞれR4,R5,...,R11に格納される。
【0132】
次にラウンド関数実行時の13〜16cycle目についてデータの流れを説明する。上述したように,(x8,x9,x10,x11)をF関数に入力したときの出力を用いた演算は実行可能ということが分かった。
しかし、ラウンド関数開始後の4cycle後には、ラウンド関数出力の値として必要な(x8,x9,x10,x11)の値は保持しておらず、代わりにF関数演算時の中間値である(S(x8),S(x9),S(x10),S(x11))のみをR0,R1,R2,R3に保持している。
【0133】
13〜16cycle目では、本発明のポイントとなるF関数演算時の中間値からF関数への入力を復元する回路を用いて(x8,x9,x10,x11)を復元する。ラウンド関数開始後の12cycle後には、F関数演算時の中間値として,R0,R1,R2,R3に(S(x8),S(x9),S(x10),S(x11))の値を保持している。
【0134】
図19記載の非線形演算部S−1関数S905は,非線形演算部S−boxS901の逆関数を表している。ラウンド関数開始後の13〜16cycle目には、R0の保持値を非線形演算部S−1関数に入力し、その出力をマルチプレクサm02を利用し、R7に格納する。
【0135】
このようにすることで、ラウンド関数開始後の16cycle後には、R4,R5,R6,R7にx8,x9,x10,x11がそれぞれ格納された状態になる。さらに、ラウンド関数実行時の13〜16cycle目では、次のラウンド関数演算のため、R4,R5,R6,R7に格納されている(y0,y1,y2,y3)をそれぞれ図19記載の非線形演算部S901に入力し、その出力をマルチプレクサm03を利用し、R0,R1,R2,R3に格納する。
【0136】
表1に記載の通り、ラウンド関数開始後の16cycle後には、R4,R5,R6,R7に(x8,x9,x10,x11)の値が格納されている。これらの値は、ラウンド関数の出力値の33−bit目から64−bit目であるy4,y5,y6,y7となる。
【0137】
また、ラウンド関数開始後の12cycle後にR4,R5,R6,R7に格納されていたy0,y1,y2,y3は、ラウンド関数開始後の16cycle後には、非線形演算部S901への入力後、マルチプレクサm03を利用し、R0,R1,R2,R3に格納される。
【0138】
また、y8,y9,y10,y11は、ラウンド関数開始後の16cycle後には、R8,R9,R10,R11にそれぞれ格納される。
また、y12,y13,y14,y15は、図19記載のマルチプレクサm01を利用し、ラウンド関数開始後の16cycle後には、それぞれR12,R13,R14,R15に格納される。
【0139】
最後に、暗号文出力時の16cycle分のデータの流れを説明する。
i∈{0,1,...,15}
に対して、ciを8−bitの要素とする。
このとき、(c0,c1,...,c15)で表される128−bitを暗号文として考える。
【0140】
図13記載のrラウンド分のラウンド関数終了時には,図19記載のR0,R1,...,R15には、それぞれ、
S(c4),S(c5),S(c6),S(c7),c8,c9,c10,c11,c12,c13,c14,c15,c0,c1,c2,c3、
が格納されている。
【0141】
暗号文出力時の16cycleでは、R0に格納されている値は、毎サイクルごとに非線形演算部S−1関数S905に入力し、その出力をマルチプレクサm01を利用し、R15に格納するようにする。
【0142】
また、R8に格納されている値は、毎サイクルごとにマルチプレクサm02を利用し、R7に格納するようにする。また、R4に格納されている値は、毎サイクルごとに非線形演算部S−boxS901に入力し、その出力をマルチプレクサm03を利用し、R3に格納するようにする。また、暗号文出力時のは毎サイクルごとに、R12の値を図19での暗号文出力ポートから出力する。
上記のようにすることで,暗号文出力ポートから,毎サイクルごとにc0,c1,...,c15の順で順次出力される。
【0143】
上述したように、図19に示す構成において、非線形演算部S−1関数S905は、非線形演算部S−boxS901の逆関数を表している。非線形演算部S−1関数S905は、レジスタR0〜R3に格納されるF関数演算時の中間値(図18に示す中間値I804)からF関数への入力を復元する演算を実行する。この逆演算構成によって次段のラウンド関数に対する入力値が算出可能となり、上述したと同様のレジスタ削減効果が期待できる。
【0144】
[4.本開示の手法の効果のまとめ]
従来手法では、F関数への入力を保持したまま、F関数の出力を演算していた。この考えのもとでは、block長分のレジスタに加え,F関数演算時の中間値を保持するレジスタが必要となる。
【0145】
一方、上述した発開示に係る手法では、F関数への入力は一度破棄し、F関数の出力を計算後にF関数演算時の中間値から元の入力を復元するための回路を導入する構成としている。
【0146】
このようにすることで、必要なレジスタはblock長分のみとなり、従来手法において必要であったF関数演算時の中間値を保持するレジスタ分の回路を削減することが可能となる。前章の発明手法の適用例では、F関数演算時に必要な中間値として図18に記載の非線形演算部S801後の線形演算部M802に入力される値である保持する中間値I804とし、F関数の出力を計算可能としている。
【0147】
また,従来手法では用いないS−boxの逆演算処理回路を導入することにより、上記のF関数演算時の中間値からF関数への入力を復元するようにしている。このようにすることで,結果的にレジスタの削減を達成している。レジスタの回路規模は、他のセルに比べて比較的大きなものとなるため、レジスタの削減が小型化に寄与することは多い。
【0148】
[5.その他の実施例について]
前節では,4−line拡張Feistel構造においてラウンド関数内部の構成要素もある程度仮定し、適用法と効果について説明した。本開示の手法は、前節までに説明した具体的なラウンド関数の構造のみではなく、変形、拡張された構造についても適用可能である。
【0149】
また、本開示の手法は、4−line拡張Feistel構造のみでなく、2−lineのFeistel構造や,任意のx(xは2以上の自然数)に対して、x−line拡張Feistel構造に対しても同様な考え方が適用できる。
【0150】
(5−1.拡張例1)
本開示の方式は、図18に記載のSP型F関数だけではなく、図21に記載のSPS型F関数にも適用可能である。この場合に考えられるデータパスの例を図22に示す。
【0151】
図22では、行列の一例として,1行目の要素が(2,3,1,1)となる巡回行列を想定している。また、図21に記載のF関数を持つ拡張Feistel構造に対して本開示の手法を適用する場合のポイントである保持すべき中間値の例としては、第一非線形演算部S101の出力であり、線形演算部M102への入力となる。
図21に示す保持する中間値I104となる。
【0152】
この場合も、図18に記載のF関数を持つ拡張Feistel構造に対するHW実装構成例である図19でのデータの流れと同様に考えられるため、詳細な説明は省略する。
【0153】
図19に記載のデータパスと異なる点を簡単に説明すると、図22記載のデータパスでは、非線形演算部S−boxS111の入力前にマルチプレクサm01が導入され、行列演算部M112の出力がマルチプレクサm01を利用し、非線形演算部S−boxS111に入力され、S−boxS111の出力がラウンド鍵との排他的論理和部X114に直接入力されている点である。
【0154】
これは、図18記載のSP型F関数ではなく、図21記載のSPS型F関数を想定している点に起因する。図21記載のSPS型F関数では、線形変換部M102の出力を第二非線形変換部S103に入力し、その第二非線形変換部S103の出力をラウンド鍵との排他的論理和部X105に入力するからである。
【0155】
図22に示す構成において、非線形演算部S−1関数S113は、非線形演算部S−boxS111の逆関数を表している。非線形演算部S−1関数S113は、レジスタR0〜R3に格納されるF関数演算時の中間値(図21に示す中間値I104)からF関数への入力を復元する演算を実行する。この逆演算構成によって次段のラウンド関数に対する入力値が算出可能となり、上述したと同様のレジスタ削減効果が期待できる。
【0156】
(5−2.拡張例2)
本開示の方式は、図18に記載のSP型F関数だけではなく、図23に記載の鍵挿入が複数入ったSPS型F関数にも適用可能である。この場合に考えられるデータパスの例を図24に示す。
【0157】
図24では、行列の一例として、1行目の要素が(2,3,1,1)となる巡回行列を想定している。また、図23記載のF関数を持つ拡張Feistel構造に対して本開示の手法を適用する場合のポイントである保持すべき中間値の例としては、第一非線形演算部S121の出力であり、線形演算部M122への入力となる。
保持する中間値は、図23に示す保持する中間値I124となる。
【0158】
この場合も、図18に記載のF関数を持つ拡張Feistel構造に対するHW実装構成例である図19でのデータの流れを考察することで推測可能と考えられるため、詳細な説明は省略する。
【0159】
図19に記載のデータパスと異なる点を簡単に説明すると、図24記載のデータパスでは、非線形演算部S−boxS131の入力前にマルチプレクサm01が導入され、行列演算部M132の出力がラウンド鍵との排他的論理和演算部X134へ入力され、その出力がマルチプレクサm01を利用し、非線形演算部S−boxS131に入力され、S−boxS131の出力がラウンド鍵との排他的論理和部X135に直接入力されている点である。
【0160】
これは、図18記載のSP型F関数ではなく、図23記載の鍵挿入を複数行なうSPS型F関数を想定している点に起因する。図23記載の鍵挿入を複数行なうSPS型F関数では、線形変換部M122の出力を第一のラウンド鍵との排他的論理和演算部X125に入力し、その第一のラウンド鍵との排他的論理和演算部X125の出力を、第二非線形変換部S123に入力し、その第二非線形変換部S123の出力を第二のラウンド鍵との排他的論理和部X126に入力するからである。
【0161】
図24に示す構成において、非線形演算部S−1関数S133は、非線形演算部S−boxS131の逆関数を表している。非線形演算部S−1関数S133は、レジスタR0〜R3に格納されるF関数演算時の中間値(図23に示す中間値I124)からF関数への入力を復元する演算を実行する。この逆演算構成によって次段のラウンド関数に対する入力値が算出可能となり、上述したと同様のレジスタ削減効果が期待できる。
【0162】
(5−3.拡張例3)
本開示の方式は、図18に記載のSP型F関数だけではなく、図25に記載の鍵挿入がF関数入力直後にあるSP型F関数にも適用可能である。この場合に考えられるデータパスの例を図26に示す。
【0163】
図25に記載のF関数を持つ拡張Feistel構造に対して発明手法を適用する場合のポイントである保持すべき中間値の例としては、非線形演算部S141の出力であり、線形演算部M142への入力となる。
保持する中間値は、図25に示す保持する中間値I144となる。
【0164】
図18に表されるF関数と異なり、F関数演算時の中間値である図25記載の保持する中間値I144からF関数への入力を復元するためには、S−1だけでなく、F関数への入力直後に排他的論理和したときと同じラウンド鍵を排他的論理和する回路が必要となる。これは、図18に表されるF関数と異なり、図25に記載の保持する中間値からF関数の入力を復元するためには、非線形演算部S141の逆演算のみでなく、その逆演算した値に対して、ラウンド鍵との排他的論理和演算部X143の逆演算も必要となるためである。
【0165】
この場合も、図18記載のF関数を持つ拡張Feistel構造に対するHW実装構成例である図19でのデータの流れを考察することで推測可能と考えられるため、詳細な説明は省略する。図26記載のデータパスでは、非線形演算部S−boxS151の入力前にラウンド鍵との排他的論理和演算部X154が導入される。
【0166】
一方、行列演算部M152からの出力は、ラウンド鍵との排他的論理和演算を実行せずに、R4に格納されている値との排他的論理和演算部X156に直接入力される。また、R0に格納されている値は、非線形演算S−1関数に入力後、ラウンド鍵との排他的論理和演算部X155に入力されている点も図19と異なる点である。これは、前述の通り、図25記載の保持する中間値I144からF関数の入力を復元するためには、非線形演算部S141の逆演算のみでなく、その逆演算した値に対して、ラウンド鍵との排他的論理和演算部X143の逆演算も必要となるためである。
【0167】
図26に示す構成において、非線形演算部S−1関数S153は、非線形演算部S−boxS151の逆関数を表している。非線形演算部S−1関数S153は、レジスタR0〜R3に格納されるF関数演算時の中間値(図25に示す中間値I144)からF関数への入力を復元する演算を実行する。この逆演算構成によって次段のラウンド関数に対する入力値が算出可能となり、上述したと同様のレジスタ削減効果が期待できる。
【0168】
(5−4.拡張例4)
本開示の方式は、図18に記載のSP型F関数だけではなく、図27に記載のF関数にも適用可能である。図27に記載のF関数は、これまでに説明したF関数と大きく構造が異なるため、詳細に説明する。
【0169】
図27に記載のF関数は、F関数への入力を第一の非線形演算部S161で演算し、その第一の非線形演算部S161の出力を第二の非線形演算部S162へ入力する。その後、繰り返し構造となり、第一,第二の非線形演算部と同じ演算をs−1回施し、最終的に第一,第二の非線形演算部と同じ演算である、第sの非線形演算部S16sの出力をラウンド鍵との排他的論理和演算部X105に入力し、その出力をF関数の出力とするような構造である。
【0170】
このようなF関数においても、シリアル処理を実行するハードウェア回路を考えたときには、各サイクルごとにF関数演算時の中間値である図27に記載の保持する中間値I164の値を保持するレジスタが必要となる。
【0171】
図27に記載のF関数を保持する拡張Feistel構造を持つ暗号アルゴリズムに対しても発明手法の効果は得られる。図18,図19で紹介したことと同様に,図27に記載の保持する中間値I164からF関数の入力を復元することが可能であるため、そのための回路を導入することで、ブロック長分のみのレジスタで回路を実現できる。
【0172】
F関数内部が繰り返し構造となっているが、s=4としたときに考えられるデータパスの例を図28に示す。図27に記載のF関数は内部の繰り返し構造が4−line拡張Feistel構造と似ており、Feistel構造の性質から非線形回路S−1関数を用いずとも、S−box回路である非線形演算部S172,S173のみを用いることにより、図27に記載の保持する中間値I164からF関数の入力を復元することが可能である。
【0173】
図28に示す構成において、非線形演算部S172,S173は、レジスタR0〜R3に格納されるF関数演算時の中間値(図27に示す中間値I164)からF関数への入力を復元する演算を実行する。この演算構成によって次段のラウンド関数に対する入力値が算出可能となり、上述したと同様のレジスタ削減効果が期待できる。
【0174】
また、図28に記載のデータパスでは、S−box回路を二つ利用しているが、一つだけを利用することでもデータパスを記述することが可能であることは容易に推測できる。また、データパスは多少変更する必要があるが任意の繰り返し段数sに対してデータパスは構成可能である。また、図28に現れる"en"という記号で表される制御信号E174は、必要なタイミングでhighとなるように制御されるイネーブル信号を表し、図28には示されていないが制御部によって制御がされる。
【0175】
(5−5.拡張例5)
本開示の方式は、図18に記載のSP型F関数だけではなく、図29に記載のF関数にも適用可能である。図29は、図27に記載の繰り返し型のF関数の非線形演算部S161,S162,S16sが,図29記載の非線形演算部S181,S182,S18sに変更されたものと考えることができる。
【0176】
このようなF関数においても、シリアル処理を実行するハードウェア回路考えたときには、各サイクルごとにF関数演算時の中間値である図29記載の保持する中間値I184の値を保持するレジスタが必要となる。
【0177】
図29に記載のF関数を保持する拡張Feistel構造を持つ暗号アルゴリズムに対しても発明手法の効果は得られる。図18,図19を参照して説明したことと同様に、図29に記載の保持する中間値I184からF関数の入力を復元することが可能であるため、そのための回路を導入することで、ブロック長分のみのレジスタで回路を実現できる。
【0178】
F関数の構造上、S−boxの逆演算処理回路であるS−1を導入することで、図29に記載の保持する中間値I184からF関数の入力を復元することが可能である。また、F関数内部が繰り返し構造となっているが、任意の繰り返し段数に対して発明手法は適用可能である。
【0179】
(5−6.拡張例6)
ここで記載した具体的なF関数の構成は限られたものであるが、本開示の手法は、適した回路を導入することで中間値からF関数の入力を復元することが可能となる任意のF関数に適用可能である。
【0180】
(5−7.拡張例7)
F関数に行列演算を含む場合、本開示の手法は、巡回行列のみでなくアダマール行列に対しても適用可能であり、同様の効果が期待できる。また、上記以外の行列に対しても発明手法のアイデアは適用できる。
【0181】
(5−8.拡張例8)
F関数に行列演算を含む場合、本開示の方式は、4×4行列のみでなく任意のx(xは2以上の自然数)に対して,x×x行列でも同様の考えが適用可能であり、同様の効果が期待できる。
【0182】
(5−9.拡張例9)
4−linetype−2拡張Feistel構造を例に本開示の手法の適用例について説明したが、type−1,type−3の拡張Feistel構造に対しても適用可能であり、同様の効果が期待できる。
【0183】
(5−10.拡張例10)
4−linetype−2拡張Feistel構造を例に本開示の手法の適用例について説明したが、2−lineのFeistel構造に対しても適用可能であり、同様の効果が期待できる。
【0184】
(5−11.拡張例11)
4−line拡張Feistel構造への適用と同様の考えで、任意のx(xは3以上の自然数)に対して、x−line拡張Feistel構造に対しても適用可能であり、同様の効果が期待できる。
【0185】
(5−12.拡張例12)
図20に点線枠で示すように、1つのラウンド関数の出力は、次の段のラウンド関数へ出力する際に、各ラインのデータ単位でシフト処理等の入れ替え処理が行われる。
このラウンド関数間のデータ入れ替え、すなわち、前段のラウンドの出力を後段のラウンドへ出力する際に、各ライン単位でデータを入れ替える処理をラウンド置換(round permutaion)と呼ぶ。
【0186】
例えば、図20に示す4−line拡張Feistel構造における、ラウンド置換(round permutaion)は以下の設定となっている。
左から1番目のラインの出力を、次のラウンド関数の左から4番目のラインへの入力に設定、
左から2番目のラインの出力を、次のラウンド関数の左から1番目のラインへの入力に設定、
左から3番目のラインの出力を、次のラウンド関数の左から2番目のラインへの入力に設定、
左から4番目のラインの出力を、次のラウンド関数の左から3番目のラインへの入力に設定、
上記のラウンド置換(round permutaion)の設定例である。
【0187】
例えば図19を参照して説明したデータパスは、上記のラウンド置換(round permutaion)設定に対応したデータパス構成例である。
【0188】
本開示の方式は、図20に示すウンド置換(round permutaion)の設定に限らず、任意のラウンド置換(round permutaion)に対して適用可能である。
【0189】
すなわち、任意のラウンド置換(round permutaion)を持つ構成においても、F関数実行部における中間データからの逆演算構成を設定することで、上述したと同様のレジスタ削減効果が期待できる。
ただし、データパスの設定は、各ラウンド置換(round permutaion)の設定に応じた構成とすることが必要である。
【0190】
図20に示すラウンド置換(round permutaion)構成と異なるラウンド置換(round permutaion)の1つの構成例を図30に示す。
図30に示すラウンド置換(round permutaion)は、前段のラウンド関数の各ライン出力である(n/4)bitのそれぞれを2分割し、(n/8)bitの2つのライン出力に分割する。
各々が(n/8)bitのデータを持つ計8ラインのデータを次のラウンド関数に入力する際に、各ライン単位でデータ入れ替え(置換)を行う構成としている。
【0191】
図30に示す4−line拡張Feistel構造における、ラウンド置換(round permutaion)は以下の設定となっている。
左から1番目のラインの出力を2分割した前半データ(n/8)bitを、次のラウンド関数の左から4番目のラインの前半データ(n/8)bitの入力に設定、
左から1番目のラインの出力を2分割した後半データ(n/8)bitを、次のラウンド関数の左から2番目のラインの後半データ(n/8)bitの入力に設定、
左から2番目のラインの出力を2分割した前半データ(n/8)bitを、次のラウンド関数の左から1番目のラインの前半データ(n/8)bitの入力に設定、
左から2番目のラインの出力を2分割した後半データ(n/8)bitを、次のラウンド関数の左から3番目のラインの後半データ(n/8)bitの入力に設定、
【0192】
左から3番目のラインの出力を2分割した前半データ(n/8)bitを、次のラウンド関数の左から2番目のラインの前半データ(n/8)bitの入力に設定、
左から3番目のラインの出力を2分割した後半データ(n/8)bitを、次のラウンド関数の左から4番目のラインの後半データ(n/8)bitの入力に設定、
左から4番目のラインの出力を2分割した前半データ(n/8)bitを、次のラウンド関数の左から3番目のラインの前半データ(n/8)bitの入力に設定、
左から4番目のラインの出力を2分割した後半データ(n/8)bitを、次のラウンド関数の左から1番目のラインの後半データ(n/8)bitの入力に設定、
上記のラウンド置換(round permutaion)の設定例である。
なお、図30に示すラウンド関数におけるF関数は、図21に記載したSPS型F関数であると想定している。
【0193】
図30に示す、ラウンド置換(round permutaion)を実行する構成におけるラウンド関数部のデータパスの例を図31に示す。
図31に示すデータパスは、F関数として、図21に記載のSPS型F関数を適用した場合の構成例である。また、F関数における線形変換実行部である行列演算部M204で適用する行列の一例として,1行目の要素が(2,3,1,1)となる巡回行列を想定している。
【0194】
本構成例においてレジスタに保持する中間値は,図21に示す第一非線形演算部S101の出力であり、線形演算部M102への入力であり、図21に示す中間値I104となる。
図31において、これらの中間値は、レジスタR0〜R3に保持される。
基本的なデータの流れは、先に拡張例1として説明した図22に示すデータパスと同様のものであり、非線形演算部S−boxS203の入力前にマルチプレクサm202が設定されている。行列演算部M204の出力がマルチプレクサm202を利用し、非線形演算部S−boxS203に入力され、S−boxS203の出力が排他的論理和部X206に入力される。
【0195】
図31に記載のデータパスでは、図22に示す構成と異なり、S−boxS203の出力に対してラウンド鍵との排他的論理和演算を実行する前に、排他的論理和演算部X206に入力され、レジスタR4に格納されている値との排他的論理和演算を実行する構成としている。この排他的論理和結果とラウンド鍵が、排他的論理和演算部X201において排他的論理和演算される。
【0196】
また、レジスタR8とレジスタR15を結ぶパスp211と、ラウンド鍵との排他的論理和演算を実行する排他的論理和演算部X201の出力とレジスタR7を結ぶパスp212を加えている。これは、図22とは異なるラウンド置換(round permutation)、すなわち図30に示す設定のラウンド置換(round permutation)を実現するためのパス設定である。
【0197】
この図31に示すデータパスにおいても、前述した図19、図22他の実施例と同様、F関数実行部における中間データからの逆演算構成、すなわち非線形演算部S−1関数S205を設定することで、次段のラウンド関数に対する入力値を算出可能とすることで、上述したと同様のレジスタ削減効果が期待できる。
【0198】
[6.暗号処理装置の構成例について]
最後に、上述した実施例に従った暗号処理を実行する暗号処理装置の実装例について説明する。
上述した実施例に従った暗号処理を実行する暗号処理装置は、暗号処理を実行する様々な情報処理装置に搭載可能である。具体的には、PC、TV、レコーダ、プレーヤ、通信機器、さらに、RFID、スマートカード、センサネットワーク機器、デンチ/バッテリー認証モジュール、健康、医療機器、自立型ネットワーク機器等、例えばデータ処理や通信処理に伴う暗号処理を実行する様々な危機において利用可能である。
【0199】
本開示の暗号処理を実行する装置の一例としてのICモジュール700の構成例を図32に示す。上述の処理は、例えばPC、ICカード、リーダライタ、その他、様々な情報処理装置において実行可能であり、図32に示すICモジュール700は、これら様々な機器に構成することが可能である。
【0200】
図32に示すCPU(Central processing Unit)701は、暗号処理の開始や、終了、データの送受信の制御、各構成部間のデータ転送制御、その他の各種プログラムを実行するプロセッサである。メモリ702は、CPU701が実行するプログラム、あるいは演算パラメータなどの固定データを格納するROM(Read-Only-Memory)、CPU701の処理において実行されるプログラム、およびプログラム処理において適宜変化するパラメータの格納エリア、ワーク領域として使用されるRAM(Random Access Memory)等からなる。また、メモリ702は暗号処理に必要な鍵データや、暗号処理において適用する変換テーブル(置換表)や変換行列に適用するデータ等の格納領域として使用可能である。なおデータ格納領域は、耐タンパ構造を持つメモリとして構成されることが好ましい。
【0201】
暗号処理部703は、上記において説明した暗号処理構成、すなわち、例えば拡張Feistel構造や、Feistel構造を適用した共通鍵ブロック暗号処理アルゴリズムに従った暗号処理、復号処理を実行する。
【0202】
なお、ここでは、暗号処理手段を個別モジュールとした例を示したが、このような独立した暗号処理モジュールを設けず、例えば暗号処理プログラムをROMに格納し、CPU701がROM格納プログラムを読み出して実行するように構成してもよい。
【0203】
乱数発生器704は、暗号処理に必要となる鍵の生成などにおいて必要となる乱数の発生処理を実行する。
【0204】
送受信部705は、外部とのデータ通信を実行するデータ通信処理部であり、例えばリーダライタ等、ICモジュールとのデータ通信を実行し、ICモジュール内で生成した暗号文の出力、あるいは外部のリーダライタ等の機器からのデータ入力などを実行する。
【0205】
なお、上述した実施例において説明した暗号処理装置は、入力データとしての平文を暗号化する暗号化処理に適用可能であるのみならず、入力データとしての暗号文を平文に復元する復号処理にも適用可能である。
暗号化処理、復号処理、双方の処理において、上述した実施例において説明したレジスタ削減構成を持つF関数実行部の構成をそのまま適用することが可能である。
【0206】
[7.本開示の構成のまとめ]
以上、特定の実施例を参照しながら、本開示の実施例について詳解してきた。しかしながら、本開示の要旨を逸脱しない範囲で当業者が実施例の修正や代用を成し得ることは自明である。すなわち、例示という形態で本発明を開示してきたのであり、限定的に解釈されるべきではない。本開示の要旨を判断するためには、特許請求の範囲の欄を参酌すべきである。
【0207】
なお、本明細書において開示した技術は、以下のような構成をとることができる。
(1)データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してデータ変換処理を繰り返して実行する暗号処理部を有し、
前記暗号処理部は、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行部と、
前記F関数の出力に対する他ラインのデータとの排他的論理和演算を実行する排他的論理和演算実行部と、
前記F関数実行部における変換データの生成過程の中間データを格納する中間データ格納レジスタと、
前記中間データ格納レジスタの格納データに基づいて、前記F関数実行部に対する入力データを算出する逆演算実行部と、
を有する暗号処理装置。
【0208】
(2)前記F関数実行部は、F関数実行部への入力データに対する非線形変換処理を実行するS−boxを有し、前記中間データ格納レジスタは、前記S−boxの出力値を中間データとして保持し、前記逆演算実行部は、前記S−boxによる非線形変換処理の逆演算を含む演算処理により、前記F関数実行部に対する入力データを算出する前記(1)に記載の暗号処理装置。
【0209】
(3)前記F関数実行部は、非線形変換部、および線形変換部を有し、前記非線形変換部の出力を前記中間データとして格納するレジスタを有し、前記線形変換部は、前記レジスタの格納値に対する線型変換処理を実行し、前記逆演算実行部は、前記レジスタの格納値に対する演算処理により、前記F関数実行部に対する入力データを算出する前記(1)または(2)に記載の暗号処理装置。
【0210】
(4)前記F関数実行部は、F関数実行部に対する入力に対して非線形変換部において非線形変換処理を実行し、さらに線形変換部において線形変換処理を実行するSP型F関数である前記(1)〜(3)いずれかに記載の暗号処理装置。
【0211】
(5)前記F関数実行部は、F関数実行部に対する入力に対して非線形変換部において非線形変換処理を実行し、さらに線形変換部において線形変換処理を実行し、さらに非線形変換部において再度、非線形変換処理をするSPS型F関数である前記(1)〜(4)いずれかに記載の暗号処理装置。
【0212】
(6)前記F関数実行部は、外部から入力するラウンド鍵との排他的論理和演算部を有する前記(1)〜(5)いずれかに記載の暗号処理装置。
(7)前記F関数実行部は、複数の非線形演算部の繰り返し構造を有する前記(1)〜(6)いずれか1に記載の暗号処理装置。
(8)前記暗号処理部は、入力データとしての平文を暗号文に変換する暗号化処理、または、入力データとしての暗号文を平文に変換する復号処理を実行する前記(1)〜(7)いずれか1に記載の暗号処理装置。
【0213】
さらに、上記した装置およびシステムにおいて実行する処理の方法や、処理を実行させるプログラムも本開示の構成に含まれる。
【0214】
また、明細書中において説明した一連の処理はハードウェア、またはソフトウェア、あるいは両者の複合構成によって実行することが可能である。ソフトウェアによる処理を実行する場合は、処理シーケンスを記録したプログラムを、専用のハードウェアに組み込まれたコンピュータ内のメモリにインストールして実行させるか、あるいは、各種処理が実行可能な汎用コンピュータにプログラムをインストールして実行させることが可能である。例えば、プログラムは記録媒体に予め記録しておくことができる。記録媒体からコンピュータにインストールする他、LAN(Local Area Network)、インターネットといったネットワークを介してプログラムを受信し、内蔵するハードディスク等の記録媒体にインストールすることができる。
【0215】
なお、明細書に記載された各種の処理は、記載に従って時系列に実行されるのみならず、処理を実行する装置の処理能力あるいは必要に応じて並列的にあるいは個別に実行されてもよい。また、本明細書においてシステムとは、複数の装置の論理的集合構成であり、各構成の装置が同一筐体内にあるものには限らない。
【産業上の利用可能性】
【0216】
上述したように、本開示の一実施例の構成によれば、暗号処理構成の小型化が実現される。
具体的には、データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してデータ変換処理を繰り返して実行する暗号処理部を有し、暗号処理部は、複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行部と、F関数の出力に対する他ラインのデータとの排他的論理和演算を実行する排他的論理和演算実行部と、F関数実行部における変換データの生成過程の中間データを格納する中間データ格納レジスタと、中間データ格納レジスタの格納データに基づいて、F関数実行部に対する入力データを算出する逆演算実行部を有する。逆演算実行部における逆演算により、F関数実行部に対する入力値を算出可能となり、このデータを保持するレジスタを削減することが可能となり、暗号処理構成の小型化が実現される。
【符号の説明】
【0217】
700 ICモジュール
701 CPU(Central processing Unit)
702 メモリ
703 暗号処理部
704 乱数生成部
705 送受信部
【技術分野】
【0001】
本開示は、暗号処理装置、および暗号処理方法、並びにプログラムに関する。さらに詳細には、共通鍵系暗号を実行する暗号処理装置、および暗号処理方法、並びにプログラムに関する。
【背景技術】
【0002】
情報化社会が発展すると共に、扱う情報を安全に守るための情報セキュリティ技術の重要性が増してきている。情報セキュリティ技術の構成要素の一つとして暗号技術があり、現在では様々な製品やシステムで暗号技術が利用されている。
【0003】
暗号処理アルゴリズムには様々なものがあるが、基本的な技術の一つとして、共通鍵ブロック暗号と呼ばれるものがある。共通鍵ブロック暗号では、暗号化用の鍵と復号用の鍵が共通のものとなっている。暗号化処理、復号処理共に、その共通鍵から複数の鍵を生成し、あるブロック単位、例えば64ビット、128ビット、256ビット等のブロックデータ単位でデータ変換処理を繰り返し実行する。
【0004】
代表的な共通鍵ブロック暗号のアルゴリズムとしては、過去の米国標準であるDES(Data Encryption Standard)や現在の米国標準であるAES(Advanced Encryption Standard)が知られている。他にも様々な共通鍵ブロック暗号が現在も提案され続けており、2007年にソニー株式会社が提案したCLEFIAも共通鍵ブロック暗号の一つである。
【0005】
このような、共通鍵ブロック暗号のアルゴリズムは、主として、入力データの変換を繰り返し実行するラウンド関数実行部を有する暗号処理部と、ラウンド関数部の各ラウンドで適用するラウンド鍵を生成する鍵スケジュール部とによって構成される。鍵スケジュール部は、秘密鍵であるマスター鍵(主鍵)に基づいて、まずビット数を増加させた拡大鍵を生成し、生成した拡大鍵に基づいて、暗号処理部の各ラウンド関数部で適用するラウンド鍵(副鍵)を生成する。
【0006】
このようなアルゴリズムを実行する具体的な構造として、線形変換部および非線形変換部を有するラウンド関数を繰り返し実行する構造が知られている。例えば代表的な構造にFeistel構造や拡張Feistel構造がある。Feistel構造や拡張Feistel構造は、データ変換関数としてのF関数を含むラウンド関数の単純な繰り返しにより、平文を暗号文に変換する構造を持つ。F関数においては、線形変換処理および非線形変換処理が実行される。なお、Feistel構造および拡張Feistel構造を適用した暗号処理について記載した文献としては、例えば非特許文献1、非特許文献2がある。
【0007】
暗号アルゴリズムの実装形態には、ソフトウェア実装とハードウェア実装の二種類が存在する。ハードウェア実装では、回路規模が小さくなるように実装することで、ハードウェア化の際のコストダウンや低消費電力化が期待できる。そのため、新アルゴリズム、既存アルゴリズムを問わず、小型化するための実装法が様々、提案されている。
【0008】
例えばHamalainen,Alho、Hannikainen、Hamalainenらは、Substitution Permutation Network(SPN)構造を持つAES暗号アルゴリズムに対する小型実装法を提案している。この小型実装法については、非特許文献3[Panu Hamalainen,Timo Alho,Marko Hannikainen,and Timo D.Hamalainen. Design and implementation of low-area and low-power AES encryption hardware core. In DSD,pages 577-583.IEEE Computer Society,2006.9]に開示されている。
【0009】
この開示された実装法では、128−bitブロック暗号のAESを8−bitごとの演算単位で処理することで、回路規模の小型化を達成している。Hamalainenらの実装法はSPN構造とは異なる拡張Feistel構造を持つCLEFIA等のアルゴリズムにも応用できる。
【0010】
ただし、既存の手法を単純に適用するとブロック長分のレジスタに加え、非線形処理部F関数の演算時の中間値を保持するために必要なレジスタが増加してしまう。例えば、CLEFIAへの適用を考えたときには、block長の128−bit分のレジスタに加え、32−bit分のレジスタが増加する。
【先行技術文献】
【非特許文献】
【0011】
【非特許文献1】K. Nyberg, "Generalized Feistel networks", ASIACRYPT'96, SpringerVerlag, 1996, pp.91--104.
【非特許文献2】Yuliang Zheng, Tsutomu Matsumoto, Hideki Imai: On the Construction of Block Ciphers Provably Secure and Not Relying on Any Unproved Hypotheses. CRYPTO 1989: 461-480
【非特許文献3】Panu Hamalainen,Timo Alho,Marko Hannikainen,and Timo D.Hamalainen. Design and implementation of low-area and low-power aes encryption hardware core. In DSD,pages 577-583.IEEE Computer Society,2006.9
【発明の概要】
【発明が解決しようとする課題】
【0012】
本開示は、例えば上述の状況に鑑みてなされたものであり、例えばCLEFIA等の拡張Feistel構造を持つ暗号アルゴリズムに対して、既存の手法よりも小型化が期待できるハードウェア構成を実現する暗号処理装置、および暗号処理方法、並びにプログラムを提供することを目的とする。
【0013】
具体的には、例えばF関数演算時の中間値からF関数への入力を復元する回路を導入することにより、block長以上のレジスタを必要としない実装法を実現する。その結果、構造によってはレジスタ削減効果により回路規模の小型化が期待できる。
【課題を解決するための手段】
【0014】
本開示の第1の側面は、
データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してデータ変換処理を繰り返して実行する暗号処理部を有し、
前記暗号処理部は、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行部と、
前記F関数の出力に対する他ラインのデータとの排他的論理和演算を実行する排他的論理和演算実行部と、
前記F関数実行部における変換データの生成過程の中間データを格納する中間データ格納レジスタと、
前記中間データ格納レジスタの格納データに基づいて、前記F関数実行部に対する入力データを算出する逆演算実行部と、
を有する暗号処理装置にある。
【0015】
さらに、本開示の暗号処理装置の一実施態様において、前記F関数実行部は、F関数実行部への入力データに対する非線形変換処理を実行するS−boxを有し、前記中間データ格納レジスタは、前記S−boxの出力値を中間データとして保持し、前記逆演算実行部は、前記S−boxによる非線形変換処理の逆演算を含む演算処理により、前記F関数実行部に対する入力データを算出する。
【0016】
さらに、本開示の暗号処理装置の一実施態様において、前記F関数実行部は、非線形変換部、および線形変換部を有し、前記非線形変換部の出力を前記中間データとして格納するレジスタを有し、前記線形変換部は、前記レジスタの格納値に対する線型変換処理を実行し、前記逆演算実行部は、前記レジスタの格納値に対する演算処理により、前記F関数実行部に対する入力データを算出する。
【0017】
さらに、本開示の暗号処理装置の一実施態様において、前記F関数実行部は、F関数実行部に対する入力に対して非線形変換部において非線形変換処理を実行し、さらに線形変換部において線形変換処理を実行するSP型F関数である。
【0018】
さらに、本開示の暗号処理装置の一実施態様において、前記F関数実行部は、F関数実行部に対する入力に対して非線形変換部において非線形変換処理を実行し、さらに線形変換部において線形変換処理を実行し、さらに非線形変換部において再度、非線形変換処理をするSPS型F関数である。
【0019】
さらに、本開示の暗号処理装置の一実施態様において、前記F関数実行部は、外部から入力するラウンド鍵との排他的論理和演算部を有する。
【0020】
さらに、本開示の暗号処理装置の一実施態様において、前記F関数実行部は、複数の非線形演算部の繰り返し構造を有する。
【0021】
さらに、本開示の暗号処理装置の一実施態様において、前記暗号処理部は、入力データとしての平文を暗号文に変換する暗号化処理、または、入力データとしての暗号文を平文に変換する復号処理を実行する。
【0022】
さらに、本開示の第2の側面は、
暗号処理装置において実行する暗号処理方法であり、
暗号処理部が、データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してデータ変換処理を繰り返して実行する暗号処理ステップを実行し、
前記暗号処理ステップは、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行ステップと、
前記F関数の出力に対する他ラインのデータとの排他的論理和演算を実行する排他的論理和演算実行ステップと、
前記F関数実行ステップにおける変換データの生成過程の中間データを中間データ格納レジスタに格納するステップと、
前記中間データ格納レジスタの格納データに基づいて、前記F関数実行部に対する入力データを算出する逆演算実行ステップと、
を実行する暗号処理方法にある。
【0023】
さらに、本開示の第3の側面は、
暗号処理装置において暗号処理を実行させるプログラムであり、
暗号処理部が、データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してデータ変換処理を繰り返して実行する暗号処理ステップを実行させ、
前記暗号処理ステップにおいて、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行ステップと、
前記F関数の出力に対する他ラインのデータとの排他的論理和演算を実行する排他的論理和演算実行ステップと、
前記F関数実行ステップにおける変換データの生成過程の中間データを中間データ格納レジスタに格納するステップと、
前記中間データ格納レジスタの格納データに基づいて、前記F関数実行部に対する入力データを算出する逆演算実行ステップと、
を実行させるプログラムにある。
【0024】
なお、本開示のプログラムは、例えば、様々なプログラム・コードを実行可能な情報処理装置やコンピュータ・システムに対して例えば記憶媒体によって提供されるプログラムである。このようなプログラムを情報処理装置やコンピュータ・システム上のプログラム実行部で実行することでプログラムに応じた処理が実現される。
【0025】
本開示のさらに他の目的、特徴や利点は、後述する本発明の実施例や添付する図面に基づくより詳細な説明によって明らかになるであろう。なお、本明細書においてシステムとは、複数の装置の論理的集合構成であり、各構成の装置が同一筐体内にあるものには限らない。
【発明の効果】
【0026】
本開示の一実施例によれば、暗号処理構成の小型化が実現される。
具体的には、データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してデータ変換処理を繰り返して実行する暗号処理部を有し、暗号処理部は、複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行部と、F関数の出力に対する他ラインのデータとの排他的論理和演算を実行する排他的論理和演算実行部と、F関数実行部における変換データの生成過程の中間データを格納する中間データ格納レジスタと、中間データ格納レジスタの格納データに基づいて、F関数実行部に対する入力データを算出する逆演算実行部を有する。逆演算実行部における逆演算により、F関数実行部に対する入力値を算出可能となり、このデータを保持するレジスタを削減することが可能となり、暗号処理構成の小型化が実現される。
【図面の簡単な説明】
【0027】
【図1】kビットの鍵長に対応したnビット共通鍵ブロック暗号アルゴリズムを説明する図である。
【図2】図1に示すkビットの鍵長に対応したnビット共通鍵ブロック暗号アルゴリズムに対応する復号アルゴリズムを説明する図である。
【図3】鍵スケジュール部とデータ暗号化部の関係について説明する図である。
【図4】データ暗号化部の構成例について説明する図である。
【図5】SPN構造のラウンド関数の例について説明する図である。
【図6】Feistel構造のラウンド関数の一例について説明する図である。
【図7】拡張Feistel構造の一例について説明する図である。
【図8】拡張Feistel構造の一例について説明する図である。
【図9】非線形変換部の構成例について説明する図である。
【図10】線形変換処理部の構成例について説明する図である。
【図11】共通鍵ブロック暗号について説明する図である。
【図12】Feistel構造について説明する図である。
【図13】拡張Feistel構造について説明する図である。
【図14】SPN構造を適用したAES暗号アルゴリズムのラウンド関数の構造について説明する図である。
【図15】Hamalainenらの提案したAES暗号を実行するデータ暗号化部のデータパスを示す図である。
【図16】データ暗号化部の構成例を説明する図である。
【図17】Hamalainenらの実装法を4−line拡張Feistel構造に適用した場合のデータ演算部回路の概要図を示す図である。
【図18】ラウンド関数内のF関数の具体例を説明する図である。
【図19】本開示の一実施例に係る暗号処理構成を、図18で表されるF関数を持つ4−line拡張Fesitel構造に適用した場合のデータ演算部回路の概要図である。
【図20】ラウンド関数を説明する図である。
【図21】SPS型F関数について説明する図である。
【図22】図21に記載のSPS型F関数に、本開示の方式を適用した場合に考えられるデータパスの例について説明する図である。
【図23】鍵挿入が複数入ったSPS型F関数について説明する図である。
【図24】図23に記載のSPS型F関数に、本開示の方式を適用した場合に考えられるデータパスの例について説明する図である。
【図25】鍵挿入がF関数入力直後にあるSP型F関数について説明する図である。
【図26】図25に記載のSP型F関数に、本開示の方式を適用した場合に考えられるデータパスの例について説明する図である。
【図27】F関数の構成例について説明する図である。
【図28】図27に記載のF関数に、本開示の方式を適用した場合に考えられるデータパスの例について説明する図である。
【図29】F関数の構成例について説明する図である。
【図30】ラウンド置換(round permutaion)の1つの構成例について説明する図である。
【図31】図30に記載のラウンド置換を持つ構成に対して、本開示の方式を適用した場合に考えられるデータパスの例について説明する図である。
【図32】暗号処理装置としてのICモジュール700の構成例を示す図である。
【発明を実施するための形態】
【0028】
以下、図面を参照しながら本開示に係る暗号処理装置、および暗号処理方法、並びにプログラムの詳細について説明する。説明は、以下の項目に従って行う。
1.共通鍵ブロック暗号の概要
2.共通鍵ブロック暗号の構造と従来型の小型化実装手法の概要について
3.レジスタ削減を実現する暗号処理構成例について
4.本開示の手法の効果のまとめ
5.その他の実施例について
6.暗号処理装置の構成例について
7.本開示の構成のまとめ
【0029】
[1.共通鍵ブロック暗号の概要]
まず、共通鍵ブロック暗号の概要について説明する。
(1−1.共通鍵ブロック暗号)
ここでは共通鍵ブロック暗号(以下ではブロック暗号)としては以下に定義するものを指すものとする。
ブロック暗号は入力として平文Pと鍵Kを取り、暗号文Cを出力する。平文と暗号文のビット長をブロックサイズと呼びここではnで著す。nは任意の整数値を取りうるが、通常、ブロック暗号アルゴリズムごとに、あらかじめひとつに決められている値である。ブロック長がnのブロック暗号のことをnビットブロック暗号と呼ぶこともある。
【0030】
鍵のビット長をkで表す。鍵は任意の整数値を取りうる。共通鍵ブロック暗号アルゴリズムは1つまたは複数の鍵サイズに対応することになる。例えば、あるブロック暗号アルゴリズムAはブロックサイズn=128であり、k=128またはk=192またはk=256の鍵サイズに対応するという構成もありうるものとする。
平文P:nビット
暗号文C:nビット
鍵K:kビット
【0031】
図1にkビットの鍵長に対応したnビット共通鍵ブロック暗号アルゴリズムEの図を示す。
暗号化アルゴリズムEに対応する復号アルゴリズムDは暗号化アルゴリズムEの逆関数E−1と定義でき、入力として暗号文Cと鍵Kを受け取り,平文Pを出力する。図2に図1に示した暗号アルゴリズムEに対応する復号アルゴリズムDの図を示す。
【0032】
(1−2.内部構成)
ブロック暗号は2つの部分に分けて考えることができる。ひとつは鍵Kを入力とし、
ある定められたステップによりビット長を拡大してできた拡大鍵K'(ビット長k')を出力する「鍵スケジュール部」と、もうひとつは平文Pと鍵スケジュール部から拡大された鍵K'を受け取ってデータの変換を行い暗号文Cを出力する「データ暗号化部」である。
2つの部分の関係は図3に示される。
【0033】
(1−3.データ暗号化部)
以下の実施例において用いるデータ暗号化部はラウンド関数という処理単位に分割できるものとする。ラウンド関数は入力としての2つのデータを受け取り、内部で処理を施したのち、1つのデータを出力する。入力データの一方は暗号化途中のnビットデータであり、あるラウンドにおけるラウンド関数の出力が次のラウンドの入力として供給される構成となる。もう1つの入力データは鍵スケジュールから出力された拡大鍵の一部のデータが用いられ、この鍵データのことをラウンド鍵と呼ぶものとする。またラウンド関数の総数は総ラウンド数と呼ばれ、暗号アルゴリズムごとにあらかじめ定められている値である。ここでは総ラウンド数をRで表す。
【0034】
データ暗号化部の入力側から見て1ラウンド目の入力データをX1とし、i番目のラウンド関数に入力されるデータをXi、ラウンド鍵をRKiとすると、データ暗号化部全体は図4のように示される。
【0035】
(1−4.ラウンド関数)
ブロック暗号アルゴリズムによってラウンド関数はさまざまな形態をとりうる。ラウンド関数はその暗号アルゴリズムが採用する構造(structure)によって分類できる。代表的な構造としてここではSPN構造、Feistel構造、拡張Feistel構造を例示する。
【0036】
(ア)SPN構造ラウンド関数
nビットの入力データすべてに対して、ラウンド鍵との排他的論理和演算、非線形変換、線形変換処理などが適用される構成。各演算の順番は特に決まっていない。図5にSPN構造のラウンド関数の例を示す。
【0037】
(イ)Feistel構造
nビットの入力データはn/2ビットの2つのデータに分割される。うち片方のデータとラウンド鍵を入力として持つ関数(F関数)が適用され、出力がもう片方のデータに排他的論理和される。そののちデータの左右を入れ替えたものを出力データとする。F関数の内部構成にもさまざまなタイプのものがあるが、基本的にはSPN構造同様にラウンド鍵データとの排他的論理和演算、非線形演算、線形変換の組み合わせで実現される。図6にFeistel構造のラウンド関数の一例を示す。
【0038】
(ウ)拡張Feistel構造
拡張Feistel構造はFeistel構造ではデータ分割数が2であったものを,3以上に分割する形に拡張したものである。分割数をdとすると、dによってさまざまな拡張Feistel構造を定義することができる。F関数の入出力のサイズが相対的に小さくなるため、小型実装に向いているとされる。図7にd=4でかつ、ひとつのラウンド内に2つのF関数が並列に適用される場合の拡張Feistel構造の一例を示す。また,図8にd=8でかつ,ひとつのラウンド内に1つのF関数が適用される場合の拡張Feistel構造の一例を示す。
【0039】
(1−5.非線形変換処理部)
非線形変換処理部は、入力されるデータのサイズが大きくなると実装上のコストが高くなる傾向がある。それを回避するために対象データを複数の単位に分割し、それぞれに対して非線形変換を施す構成がとられることが多い。例えば入力サイズをmsビットとして、それらをsビットずつのm個のデータに分割して、それぞれに対してsビット入出力を持つ非線形変換を行う構成である。それらのsビット単位の非線形変換をS−boxと呼ぶものとする。図9に例を示す。
【0040】
(1−6.線形変換処理部)
線形変換処理部はその性質上、行列として定義することが可能である。行列の要素はGF(28)の体の要素やGF(2)の要素など、一般的にはさまざまな表現ができる。図10にmsビット入出力をもち、GF(2s)の上で定義されるm×mの行列により定義される線形変換処理部の例を示す。
【0041】
[2.共通鍵ブロック暗号の構造と従来型の小型化実装手法の概要について]
次に、共通鍵ブロック暗号の構造と従来型の小型化実装手法の概要について説明する。
本開示に係る暗号処理構成の説明上、必要な用語について説明する。
【0042】
(2−1.共通鍵ブロック暗号について)
図11を参照して、再度、共通鍵ブロック暗号について説明する。共通鍵ブロック暗号のアルゴリズムは、入力データの変換を繰り返し実行するラウンド関数を有するデータ暗号化部と、ラウンド関数部の各ラウンドで適用するラウンド鍵を生成する鍵スケジュール部とによって構成される。鍵スケジュール部は秘密鍵を入力し、各ラウンド関数に入力するラウンド鍵を生成する。
例えば、r段のラウンド関数を行なう構成としたブロック暗号においては、1からr段までのラウンド関数にそれぞれRK1,RK2,...,Rrのラウンド鍵が入力される。また、初期鍵としてIKが,最終鍵としてFKが排他的論理和される。
【0043】
(2−2.Feistel構造)
図12を参照してFeistel構造について説明する。共通鍵ブロック暗号におけるデータ暗号化部の代表的な構造としてFeistel構造がある。ブロック長をn−bitとした際の具体的なFeistel構造の構成例を図12に示す。
【0044】
図12を見ると,n−bitのデータをn/2−bitずつの2−lineに分割し、そのn/2−bitの片方をラウンド内のF関数に入力し、その出力をもう片方のn/2−bitと排他的論理和していく構成となっている。F関数の構成には様々なタイプのものが考えられる。一例を挙げると、図12に示すF関数のように、ラウンド鍵との排他的論理和演算、S−boxと呼ばれる非線形演算、その後、行列演算により線形変換の処理を行なう構成が知られている。
また、図12に示した構造は,Feistel構造の構成例の1つであり,IK,FKを排他的論理和する位置を変更することで、別の構成例が可能である。
【0045】
(2−3.拡張Feistel構造)
図13を参照して拡張Feistel構造について説明する。前節のFeistel構造の説明では,n/2−bitずつの2−lineに分割し、処理を行なう構成であったが、3−line以上に分割する形にも拡張が可能である。例えば、n/4−bitずつの4−lineに分割し、処理を行なう4−line拡張Feistel構造と呼ばれるものもある。
【0046】
具体的な4−line拡張Feistel構造の構成例を図13に示す。図13を見ると,n−bitのデータをn/4−bitずつの4−lineに分割し、そのうちの2−lineをそれぞれF関数に入力し、その出力をその他の2−lineと排他的論理和していく構成となっている。2−lineから4−lineと変更することにより、ラウンド鍵RKi,初期鍵IK,最終鍵FKも、n/2−bitから、n/4−bitのRKi[0],RKi[1],IK[0],IK[1],FK[0],FK[1]に分割される。上記は、4−line拡張Feistel構造についての説明だが、2−line以上のFeistel構造については全て拡張Feistel構造と呼ぶ。本開示の実施例の説明においては簡単のため、4−line拡張Feistel構造についてのみ言及する.
【0047】
(2−4.従来型の小型化実装手法の概要と課題)
(2−4−1.SPN構造を適用したAES暗号アルゴリズムにおける小型実装手法について)
先に説明したように、SPN構造を適用したAES暗号アルゴリズムにおける小型実装手法についてHamalainen,Alho,Hannikainen,HamalainenらはAESの小型実装法を提案している。非特許文献3[Panu Hamalainen,Timo Alho,Marko Hannikainen,and Timo D.Hamalainen. Design and implementation of low-area and low-power AES encryption hardware core. In DSD,pages 577-583.IEEE Computer Society,2006.9]
【0048】
まず、図14を参照してSPN構造を適用したAES暗号アルゴリズムのラウンド関数の構造について説明する。なお、SPN構造を適用したAES暗号アルゴリズムにおいてもFeistel構造と同様、ラウンド関数を複数回繰り返し実行する構成を持つ。図14は,SPN構造を適用したAES暗号アルゴリズムにおいて利用されるラウンド関数実行部の構成例を示す図である。AESでは,図14に示すラウンド関数を、複数回繰り返して平文から暗号文、または、暗号文から平文の生成を行なう。
【0049】
図14に示すラウンド関数実行部は以下の構成要素によって構成される。非線形変換処理を実行する8−bit入出力の16個のS−boxからなる非線形変換部401,非線形変換部を構成するS−boxからの8−bit出力の入れ替え処理としてのShiftRow実行部402、ShiftRow実行部の出力を32−bit単位で入力して行列を適用した線形変換処理を実行する4つの行列演算部からなる線形変換部403、線形変換部403を構成する4つの行列演算部各々からの32−bit出力に対して32−bitのラウンド鍵との排他的論理和演算を実行する4つの演算部からなる排他的論理和演算部404を有する。
【0050】
図14に示す例は、入出力128−bitのラウンド関数実行部であり、16個のS−box各々に8−bit、計8×16=128−bitを入力し、4つの排他的論理和部の各々32−bit、計32×4=128−bit出力を行なう構成である。
【0051】
前述の非線形変換部401、ShiftRow実行部402、線形変換部403、排他的論理和演算部404、これらを適用した一連の処理を1回のラウンド関数の実行処理として実行し、このラウンド関数を複数回、繰り返して128−bitの入力データ(例えば平文)から、128−bitの出力(例えば暗号文)を生成して出力する。
【0052】
AESの実装において、1つのラウンド関数の処理(1round)、すなわち、非線形変換部401、ShiftRow実行部402、線形変換部403、排他的論理和演算部404、これらを適用した一連の処理を、1cycleで実行しようとすると、少なくとも、図14に示すように、16個のS−boxの回路と、4個の行列演算回路がデータ暗号化部の構成として必要となる。
【0053】
Hamalainenらは,1roundに16cycleかけることで、データ暗号化部の小型化を実現した。この小型化構成では、S−boxの回路は1個しか用いず、さらに、4cycleかけて1つの行列演算を実行するように実装することで、行列演算回路の小型化も実現している。
【0054】
図15にHamalainenらの提案したAES暗号を実行するデータ暗号化部のデータパスを示す。図15に示す構成は、図14に示すAES暗号のラウンド関数を実行するハードウェア構成に相当する。
【0055】
図15に示す構成において、演算中のデータは8−bit単位に分割され、各8−bitデータをレジスタR0〜R18に格納している。図15には、19個のレジスタが示されている。19個のレジスタ(R0〜R18)の各々は8−bitデータを保持する8−bitレジスタである。図14を参照して説明した通り、図14に示す構成は、入出力128−bitのラウンド関数実行部であり、図15は,入出力128−bitのラウンド関数を8−bit単位データのシリアル処理として実行するハードウェア構成に対応する。
【0056】
図15の構成において、入出力データを全て格納するために必要となる8−bitレジスタの数は、128/8=16であり、16個のレジスタがあればよい。図15には、19個のレジスタがあり、3つのレジスタが余分であるが、これら24−bit分の3つのレジスタは、行列を適用した線形変換処理を実行するための行列演算処理のために利用される。
【0057】
また、図14を参照して説明したように、AESでは、非線形変換を実行するS−boxと線形変換を実行する行列演算の間にShiftRow実行部によるデータ置換が実行される。Hamalainenらの実装手法では、図15中のいくつかのレジスタの前にマルチプレクサ(Multiplexer)m01〜m08を導入することにより、ShiftRow実行部で行なわれる置換を実現している。
【0058】
図15に示すように、非線形変換部としてのS−box,S501は1個しかない。このS−box,S501に対して8−bitデータを順次入力し、16cycleで図14に示す16個のS−boxによる非線形変換処理を実行する。S−box,S501の出力は、行列演算回路M502に入力され、行列演算回路M502において、行列を適用した線形変換処理が実行される。
【0059】
なお,図14の構成では、S−boxによる処理データをShiftRow実行部で置換した後、行列演算を行なう構成となっているが、図15に示す例では、S−box,S501の出力を行列演算回路M502に直接入力する構成としている。図15の構成では、ShiftRow実行部での置換処理に相当する処理は図15に示すレジスタR0〜R18とマルチプレクサm01〜m08の動作によって実行する。
【0060】
図15に示す行列演算回路M502では,図14に示す線形変換部403の4つの行列演算回路の処理が順次実行される。図14に示す線形変換部403の4つの行列演算回路の1つの行列演算回路で実行する行列を適用した線形変換処理を4cycleで実行する。図14に示す排他的論理和演算部404の排他的論理和演算処理は,図15の排他的論理和演算部X503,X504において実行される。これら排他的論理和演算部X503,X504において,処理データと鍵生成部K505の出力するラウンド鍵との排他的論理和処理を実行する。
【0061】
なお,本開示の構成に本質的に関連のある箇所のみを説明するため,ShiftRow等の置換を行なう回路や、鍵スケジュール部については図16のように省略したデータパスで説明する。図16中のレジスタ群と記述されている部分は、96−bit分のデータを保持し、ShiftRowも考慮されたレジスタの集合を表す。AESの実装において,1roundを1cycleで演算する場合、利用するデータ暗号化部用のレジスタはblock長である128−bit分のみで済む。
【0062】
それに対し、Hamalainenらの実装法では、152−bitと24−bit分増えている。これは、行列への入力を8−bitずつに分割した場合、行列を計算し終わるまでの途中演算結果の32−bit分を保持する必要性が出てくるためである。そのため、単純に考えると32−bit分のレジスタが追加されることになる。一方、行列へ入力する値は次のラウンドでは不要となる。このことを考慮すると、行列へ入力する32−bitのうち、はじめに入力する8−bit分のレジスタは行列演算部のレジスタと共有できるので、レジスタの増加分は、
32−8=24−bit
分に抑えられる。
【0063】
(2−4−2.SPN構造の小型実装構成の拡張Feistel 構造への適用と問題点について)
上述したように,Hamalainenらは,SPN構造の小型化を実現している。しかし、この小型化構成はSPN構造に対応した特有の構成であり、この小型実装構成を拡張Feistel構造へ適用しても十分な小型化の効果は得られない。
【0064】
以下、この問題点について説明する。なお、以下の説明では、拡張Feistel構造は、Feistel構造を含む概念であるものとして説明する。Hamalainenらの実装法を拡張Feistel構造を持つCLEFIA等のアルゴリズムを実行する構成に適用すると、行列演算のために、行列の出力ビット長分のデータを格納するレジスタが必要になる。
【0065】
これは、拡張Feistel構造がSPN構造とは異なり、例えばラウンド関数内のF関数に入力した値を、次のラウンドでも利用する必要があるという処理シーケンスの根本的な違いに起因するものである。
【0066】
図17は、Hamalainenらの実装法を4−line拡張Feistel構造に適用した場合のデータ演算部回路の概要図を示す図である。図17では、先に図16を参照して説明したAESのデータパスと同様、拡張Feistel構造のラウンド関数終了時の置換動作や鍵スケジュール部は省略してある。なお、ラウンド演算における処理データサイズとしてのブロックサイズはn−bitとする。
【0067】
先に図13を参照して説明したように,4−line拡張Feistel構造では、4つのライン各々にn/4−bitずつ入力され、順次転送される。図17中のレジスタ群R703は、図16に示すレジスタ群R601に対応する。ただし、4−line拡張Feistel構造に対応する図17中のレジスタ群R703は,(3/4)n−bit分のデータを保持するレジスタとラウンド終了時の置換動作と同様の処理を実現するマルチプレクサ等の組み合わせとして構成される。
【0068】
なお、図17に示す4−line拡張Feistel構造を適用した暗号アルゴリズムのデータパス(演算実行回路)を適用して実行する演算は、図13に示す4−line拡張Feistel構造を適用した演算処理に対応する。この図17に示すデータパスを利用して図13に示す4−line拡張Feistel構造内のF関数を含むラウンド関数を実行することになる。
【0069】
ラウンド関数内のF関数の具体例を図18に示す。図18に示すF関数は、以下の構成要素を持つ。
*非線形処理を実行するS−boxからなる非線形変換部S801、
*非線形変換部S801からの出力に対して、行列演算により線形変換の処理を行なうM802、
*線形変換部M802からの出力に対して、ラウンド鍵との排他的論理和演算を実行する排他的論理和演算部X803、
上記の構成要素を持つ。図18に示すF関数はSP型F関数と呼ばれる。
【0070】
ただし,4−line拡張Feistel構造におけるF関数に対する入出力は,n/4−bitになる。なお、図18に示されている線形変換部M801は、AES暗号アルゴリズムで採用されている行列と同様に下記の(式1)に示される巡回行列を想定している。
【0071】
【数1】
【0072】
なお、式1に示す(x0、x1、x2、x3)は、行列演算回路である線形変換部M801に対する入力(S−boxからの出力)、
(y0、y1、y2、y3)は、行列演算回路である線形変換部M801の出力(線形変換結果)、
4×4の行列は、行列演算回路である線形変換部M801において適用する行列(線形変換行列)に対応する。
なお、4×4の線形変換行列の要素は16進数値として示している。
本例では、(x0、x1、x2、x3)の各々は、S−boxからの1サイクルあたりの出力であり8ビットデータである。出力(y0、y1、y2、y3)の各々も8ビットデータである。
【0073】
先に図14〜図16を参照して説明したAES暗号アルゴリズムの構成と比較するため、処理単位としてのブロック構成ビットnは、n=128−bitとする。
図17に示す回路も、図16に示す回路と同様、S−boxは1つのみである。図17に示すS−box,S701である。このS−box,S701は、図18に示すF関数内に設定される1つのS−boxの処理を1cycleで実行する。
cycleごとに、順次、図18に示す各S−boxの処理を行なうことになる。
【0074】
図18に示すように、F関数の1つのS−boxには、4−line拡張Feistel構造の1つのラインを伝送するn/4−bitの1/4、すなわち、n/16−bitが入力され非線形変換処理が実行される。
【0075】
図17に示すS−boxS701には、n/16−bitずつがcycleごとに入力され、非線形変換処理が実行される。S−box,S701において非線形変換のなされたデータは、n/16−bitごとに1cycle単位で次の線形変換回路M702に入力される。線形変換回路M702では、所定の行列を適用した線形変換処理が実行されることになる。
【0076】
図17に示す4−line拡張Feistel構造を適用した暗号アルゴリズムのデータパス構成中、レジスタ群R703を除く演算実行回路と、先に図16を参照して説明したレジスタ群R601を除く、SPN構造を利用したAES暗号処理を実行する演算回路構成とを比較する。
【0077】
図16に示す演算回路では、8−bitレジスタがR0〜R3,R16〜R18の7個であるのに対して、図17に示す演算回路では、8−bitレジスタがR0〜R3,R16〜R19の8個である。すなわち、8−bitレジスタの数が1つ増加している。
【0078】
このように、Hamalainenらの提案構成を拡張Feistel構造に適用した場合、図17に示す演算回路のように、ブロック長分のレジスタに加え、1−line分のレジスタが必要となってくる。レジスタの増加は回路規模に大きく影響するため、ブロック長分のみのレジスタで構成できるならば、そのほうが望ましい。
【0079】
従来手法の課題点として以下の課題があげられる。
レジスタの回路規模は他のセルに比べて比較的大きなものとなり、レジスタ数の増加は回路規模に大きく影響する。そのため、小型化を実現するための一つの方向性として、レジスタの増加を抑えた実装法が考えられる。従来手法の実装法では、block長分よりも大きなレジスタが必要になってしまうことが課題と考えられる。
【0080】
[3.レジスタ削減を実現する暗号処理構成例について]
Hamalainenらの実装法を、拡張Feistel構造を持つアルゴリズムに適用した場合には、前節で述べたように必要なレジスタが増加してしまう。これは、F関数への入力は次のラウンドでも利用するため、F関数への入力を保持したまま、F関数の出力を演算しているためである。この考えのもとで実装すると、F関数への入力を保持するレジスタと、F関数演算時の中間値を保持するためのレジスタの両方が必要となる。
【0081】
先の図17、図18を用いて説明した4−line拡張Feistel構造を適用した暗号アルゴリズムでは、F関数内の線形変換部M802で表される行列演算時の中間値を保持する必要があったため、ブロック長分のレジスタに加え、1−line分の32−bit分のレジスタが必要となった。
【0082】
以下に説明する実施例では、F関数への入力は一度破棄し、その入力が格納されていたレジスタをF関数演算時の中間値を保持するためのレジスタとして利用する。
F関数の出力値と、F関数へ入力したラインとは別のラインとの排他的論理和を実行後、F関数演算時の中間値からF関数への入力を復元するように考える。
【0083】
このようにすることで、F関数への入力値とF関数演算時の中間値を同時に保持する必要がなくなり、レジスタ数を削減することができる。
【0084】
以下、具体例について説明する。前述した構成との対比を容易とするため、図18で表されるF関数を持つ4−line拡張Fesitel構造を例に説明する。なお,図18に示されている線形変換部M801は,AES暗号アルゴリズムで採用されている行列と同様に下記の(式2)で記される巡回行列を想定している。
【0085】
【数2】
【0086】
図19は、本開示の一実施例に係る暗号処理構成を、図18で表されるF関数を持つ4−line拡張Fesitel構造に適用した場合のデータ演算部回路の概要図である。
【0087】
先に説明した項目(2−4−2.SPN構造の小型実装構成の拡張Feistel 構造への適用と問題点について)で紹介したように、Hamalainenらの実装法を図18で表されるF関数を持つ4−line拡張Feistel構造に適用した場合、図18のF関数内の線形変換部M802で表される行列演算時の中間値を保持するレジスタが必要となった。
【0088】
それに対して、本開示の一実施例に係る暗号処理構成を用いて実現された図19では、中間値として、非線形演算部S801後の線形演算部M802に入力される値を保持するようにしている。この手法で保持すべき中間値を図18に保持する中間値I804として表す。図19では、上記の中間値を図19に示すR0〜R3で表されるレジスタ内に保持している。
【0089】
また、Hamalainenらの実装法を図18で表されるF関数を持つ4−line拡張Feistel構造に適用した場合、図18のF関数内の線形変換部M802で表される行列演算時の中間値を保持するレジスタとは別に、次のラウンドを演算するために必要となるF関数への入力値を保持するレジスタを必要としていた。それに対して、図19では、次のラウンドを演算するために必要となるF関数への入力値は保持せずに、代わりに上記で述べた図18のF関数内の非線形演算部S801後の線形演算部M802に入力される値である保持する中間値I804を保持している。
【0090】
先に説明した項目(2−4−2.SPN構造の小型実装構成の拡張Feistel 構造への適用と問題点について)で紹介したHamalainenらの実装法では,160−bit分のレジスタを利用していたのに対し,図19に示す構成においては、8−bitレジスタを、R0〜R15の16個、利用しており、合計で128−bit分のレジスタのみで回路を実現できる。
【0091】
この図19に示すデータパスを利用して図13,図18で表されるラウンド関数を実行することになる。
図13を参照すると、1ラウンドに演算する必要のあるF関数は2つあることが分かる。図19では,1つのF関数の出力を4cycleかけて実行し、その後の4cycleをかけて図18の保持する中間値I,804からF関数の入力を復元する。
【0092】
前述したように、1roundにF関数は2つ実行する必要があるため、合計16cycleを要することで1round分の演算を実行する。また、平文入力時には、16cycleかけて上位8−bitから8−bitずつ入力し、暗号文出力時にも16cycleかけて出力ポートから上位8−bitから8−bitずつ順次出力するように考える。
【0093】
以下、以下に示す表1を参照しながら平文入力時の16cycle分と,1roundの演算に必要な16cycle分と,暗号文出力時の16cycle分のデータの流れを説明する。
【0094】
【表1】
【0095】
まず、平文入力時の16cycle分の動きを説明する。
i∈{0,1,...,15}
に対して、
piを8−bitの要素とする。
このとき,(p0,p1,...,p15)で表される128−bitを平文として考える。
【0096】
平文入力時の1cycle目では,p0を図19に示す平文入力ポートからマルチプレクサm01を利用しR15に格納する.その後11cycleかけて,p0をマルチプレクサm02を利用し,R14,R13,...,R4の順に格納していく。
【0097】
上述したように、平文入力時の12cycle後にはp0はR4に格納されているとする。13cycle目には、R4に格納されていたp0を非線形演算部S901に入力し、その出力をマルチプレクサm03を利用しR3に格納する。
【0098】
p0を非線形演算部S901に入力したときの出力をS(p0)とする。その後、3cycleかけて,S(p0)をR2,R1,R0の順に格納していく。
【0099】
p0以外の値であるpi,i∈{1,2,...,15}に関しては、p0が格納されていたレジスタにicycleだけ遅れて格納されるようにする。ただし、R4に格納されていた値は次のサイクルで非線形演算部S901に入力され、その出力であるS(pi)がR3に入力されるとする。
【0100】
最終的に、平文入力時の16cycle後には,R0〜R3には,(S(p0),S(p1),S(p2),S(p3))が格納され、R4〜R15には、(p4,p5,...,p15)が格納されるようにマルチプレクサm01,m02,m03を利用する。
【0101】
なお、R0〜R3に入力された(S(p0),S(p1),S(p2),S(p3))は、1round目の図18に記載のF関数の保持する中間値I804の値と一致する。
【0102】
次に,1roundの演算に必要な16cycle分のデータの流れを説明する。
図20は,図13における、
i∈{1,...,r}ラウンド目のラウンド関数を表したものである。
【0103】
今、図20においてi∈{1,...,r}ラウンド目のラウンド関数への入力値を(x0,x1,...,x15)とし,iラウンド目のラウンド関数の出力値を(y0,y1,...,y15)とする。ただし、i=1のときは,(x0,x1,...,x15)は平文を表し、i=rのときは、(y0,y1,...,y15)は暗号文を表すこととする。
【0104】
図19では、ラウンド開始時の初期状態として、R0〜R3には、(S(x0),S(x1),S(x2),S(x3))が格納され、R4〜R15には、(x4,x5,...,x15)がそれぞれ格納されていると考える。
【0105】
なお、i=1の場合は、ラウンド開始時の初期状態として、前述の通り、
R0〜R3には、(S(p0),S(p1),S(p2),S(p3))が格納され、
R4〜R15には,(p4,p5,...,p15)がそれぞれ格納されている状態を表す。
【0106】
表1では、図19に記した発明手法におけるラウンド関数実行時のレジスタの保持内容を表している。1roundを16cycleで実行するため、各cycle後のR0,R1,...,R15のそれぞれのレジスタの保持内容を表している。また、図19記載のように(x0,x1,x2,x3),(x8,x9,x10,x11)をF関数の入力とした場合の出力を(f0,f1,f2,f3),(f8,f9,f10,f11)と表すことにする。
【0107】
ラウンド関数実行時の1〜4cycle目では、図18記載の線形演算部M801を図19記載の行列演算部M902を用いて実行する。行列演算部M902では,R0,R1に格納されている値に対して、有限体GF(28)上での0x02,0x03との乗算を図19記載のmul02,mul03で実行する。その乗算後の値を排他的論理和し、さらに、R2,R3に格納されている値とも排他的論理和したものを出力している。
【0108】
このようにすることで、1cycle目には,図18記載の線形演算部M801の出力値の上位8−bitが計算できる。
また、マルチプレクサm03を利用することにより、R0に格納されている値を次のcycleでR3に格納することで、2,3,4cycle目には同様に図18記載の線形演算部M801の出力値の9〜16,17〜24,25〜32−bit目がそれぞれ計算できる。
【0109】
これは、想定している行列が、行ごとの要素を1行ごとに右ローテーションしている巡回行列であることを利用している。(R0,R1,R2,R3)の保持内容をcycleごとに8−bit左ローテーションを施すことで、行列1行分の演算を実施する図19記載の行列演算部M902を用いて、cycleごとに各行の演算を実施するようにしている。
【0110】
さらに、ラウンド関数実行時の1〜4cycle目では、上述した線形演算部からの出力に対し、ラウンド鍵との排他的論理和演算が排他的論理和演算部X903で上位8−bitから8−bitずつ順次実行される。
【0111】
また、図20記載のF関数F192の出力との排他的論理和演算X191は、図19においてラウンド鍵との排他的論理和演算実行部X903の出力値とレジスタR4に格納されている値との排他的論理和演算部X904を利用することで実現される。
【0112】
R4には、1〜4cycle目において、x4,x5,x6,x7が順次格納されるため、排他的論理和演算部X904の出力をマルチプレクサm01を利用しレジスタR15に格納することで、4cycle後に(x0,x1,x2,x3)をF関数に入力したときの出力32−bitと32−bitの(x4,x5,x6,x7)を排他的論理和した値がR12,R13,R14,R15に8−bitずつ格納された状態となる。
【0113】
表1に記載の通り、ラウンド関数開始後の4cycle後には,R12,R13,R14,R15に(x0,x1,x2,x3)をF関数に入力したときの出力32−bitと32−bitの(x4,x5,x6,x7)を排他的論理和した値が格納されている。
【0114】
これらの値は、ラウンド関数の出力値の上位32−bitであるy0,y1,y2,y3となる。
また、図19記載のマルチプレクサm03を利用し、R0が保持している値を次のcycleではR3に格納するようにしていたので、表1を参照すると、ラウンド開始後の4cycle後には、R0,R1,R2,R3の保持内容は、ラウンド開始時の値と変化していないことが分かる。
【0115】
また、その他のx8,x9,...,x15は、図19記載のマルチプレクサm02を利用し、ラウンド開始後の4cycle後には、それぞれR4,R5,...,R11に格納される。
【0116】
次にラウンド関数実行時の5〜8cycle目についてデータの流れを説明する。上述したように、(x0,x1,x2,x3)をF関数に入力したときの出力を用いた演算は実行可能ということが分かった。
しかし、ラウンド関数開始後の4cycle後には、ラウンド関数出力の値として必要な(x0,x1,x2,x3)の値は保持しておらず、代わりにF関数演算時の中間値である(S(x0),S(x1),S(x2),S(x3))のみをR0,R1,R2,R3に保持している。
【0117】
5〜8cycle目では,本発明の1つのポイントとなるF関数演算時の中間値からF関数への入力を復元する回路を用いて(x0,x1,x2,x3)を復元する。ラウンド関数開始後の4cycle後には、F関数演算時の中間値として、R0,R1,R2,R3に(S(x0),S(x1),S(x2),S(x3))の値を保持している。
【0118】
図19記載の非線形演算部S−1関数S905は、非線形演算部S−boxS901の逆関数を表している。ラウンド関数開始後の5〜8cycle目には、R0の保持値を非線形演算部S−1関数に入力し、その出力をマルチプレクサm01を利用し、R15に格納する。
【0119】
このようにすることで、ラウンド関数開始後の8cycle後には、R12,R13,R14,R15にx0,x1,x2,x3がそれぞれ格納された状態になる。非線形演算S−boxの逆関数S−1関数は、拡張Feistel構造とは異なるSPN構造を利用した暗号アルゴリズムでは、復号関数を構成する際に導入されているが、通常、拡張Feistel構造では暗号化においても復号においても用いる必要がなく、F関数演算時の中間値からF関数への入力を復元するという目的のために導入された回路となる。
【0120】
さらに、ラウンド関数実行時の5〜8cycle目では,図20記載のF関数演算部F193の出力を計算するために、R4,R5,R6,R7に格納されている(x8,x9,x10,x11)をそれぞれ図19記載の非線形演算部S901に入力し、その出力をマルチプレクサm03を利用し,R0,R1,R2,R3に格納する。
【0121】
表1に記載の通り、ラウンド関数開始後の8cycle後には、R12,R13,R14,R15に(x0,x1,x2,x3)の値が格納されている。これらの値は、ラウンド関数の出力値の下位32−bitであるy12,y13,y14,y15となる。
【0122】
また、ラウンド関数開始後の4cycle後にR4,R5,R6,R7に格納されていたx8,x9,x10,x11は、ラウンド関数開始後の8cycle後には、非線形演算部S901への入力後、マルチプレクサm03を利用し、R0,R1,R2,R3に格納される。
【0123】
また、その他のx12,x13,x14,x15,y0,y1,y2,y3は、図19記載のマルチプレクサm02を利用し、ラウンド開始後の8cycle後には、それぞれR4,R5,...,R11に格納される。
【0124】
次にラウンド関数実行時の9〜12cycle目のデータの流れを説明する。まず、図20記載のF関数演算部F193中の図18記載の線形演算部M801を図19記載の行列演算部M902を用いて実行する。
【0125】
行列演算部M902では、R0,R1に格納されている値に対して,有限体GF(28)上での0x02,0x03との乗算を図19記載のmul02,mul03で実行する。その乗算後の値を排他的論理和し、さらに,R2,R3に格納されている値とも排他的論理和したものを出力している。
【0126】
このようにすることで、ラウンド関数開始後の9cycle目には、図18記載の線形演算部M801の出力値の上位8−bitが計算できる。また、マルチプレクサm03を利用することにより、R0に格納されている値を次のcycleでR3に格納することで、2,3,4cycle目には同様に図18記載の線形演算部M801の出力値の9〜16,17〜24,25〜32−bit目が計算できる。
【0127】
さらに、ラウンド関数実行時の9〜12cycle目では、上述した線形演算部からの出力に対し、ラウンド鍵との排他的論理和演算が排他的論理和演算部X903で上位8−bitから8−bitずつ順次実行される。また、図20記載のF関数F193の出力との排他的論理和演算X191は、図19においてラウンド鍵との排他的論理和演算実行部X903の出力値とレジスタR4に格納されている値との排他的論理和演算部X904を利用することで実現される。
【0128】
R4には、9〜12cycle目において、x12,x13,x14,x15が順次格納されるため、排他的論理和演算部X904の出力をマルチプレクサm01を利用しレジスタR15に格納することで、4cycle後に(x8,x9,x10,x11)をF関数に入力したときの出力32−bitと32−bitの(x12,x13,x14,x15)を排他的論理和した値がR12,R13,R14,R15に8−bitずつ格納された状態となる。
【0129】
表1に記載の通り、ラウンド関数開始後の4cycle後には,R12,R13,R14,R15に(x8,x9,x10,x11)をF関数に入力したときの出力32−bitと32−bitの(x12,x13,x14,x15)を排他的論理和した値が格納されている。
【0130】
これらの値は、ラウンド関数の出力値の65−bit目から96−bit目であるy8,y9,y10,y11となる。また、図19記載のマルチプレクサm03を利用し、R0が保持している値を次のcycleではR3に格納するようにしていたので、表1を参照すると、ラウンド開始後の8cycle後と12cycle後のR0,R1,R2,R3の保持内容は、変化しないことが分かる。
【0131】
また、その他のy0,y1,y2,y3,y12,y13,y14,y15は、図19記載のマルチプレクサm02を利用し、ラウンド開始後の12cycle後には、それぞれR4,R5,...,R11に格納される。
【0132】
次にラウンド関数実行時の13〜16cycle目についてデータの流れを説明する。上述したように,(x8,x9,x10,x11)をF関数に入力したときの出力を用いた演算は実行可能ということが分かった。
しかし、ラウンド関数開始後の4cycle後には、ラウンド関数出力の値として必要な(x8,x9,x10,x11)の値は保持しておらず、代わりにF関数演算時の中間値である(S(x8),S(x9),S(x10),S(x11))のみをR0,R1,R2,R3に保持している。
【0133】
13〜16cycle目では、本発明のポイントとなるF関数演算時の中間値からF関数への入力を復元する回路を用いて(x8,x9,x10,x11)を復元する。ラウンド関数開始後の12cycle後には、F関数演算時の中間値として,R0,R1,R2,R3に(S(x8),S(x9),S(x10),S(x11))の値を保持している。
【0134】
図19記載の非線形演算部S−1関数S905は,非線形演算部S−boxS901の逆関数を表している。ラウンド関数開始後の13〜16cycle目には、R0の保持値を非線形演算部S−1関数に入力し、その出力をマルチプレクサm02を利用し、R7に格納する。
【0135】
このようにすることで、ラウンド関数開始後の16cycle後には、R4,R5,R6,R7にx8,x9,x10,x11がそれぞれ格納された状態になる。さらに、ラウンド関数実行時の13〜16cycle目では、次のラウンド関数演算のため、R4,R5,R6,R7に格納されている(y0,y1,y2,y3)をそれぞれ図19記載の非線形演算部S901に入力し、その出力をマルチプレクサm03を利用し、R0,R1,R2,R3に格納する。
【0136】
表1に記載の通り、ラウンド関数開始後の16cycle後には、R4,R5,R6,R7に(x8,x9,x10,x11)の値が格納されている。これらの値は、ラウンド関数の出力値の33−bit目から64−bit目であるy4,y5,y6,y7となる。
【0137】
また、ラウンド関数開始後の12cycle後にR4,R5,R6,R7に格納されていたy0,y1,y2,y3は、ラウンド関数開始後の16cycle後には、非線形演算部S901への入力後、マルチプレクサm03を利用し、R0,R1,R2,R3に格納される。
【0138】
また、y8,y9,y10,y11は、ラウンド関数開始後の16cycle後には、R8,R9,R10,R11にそれぞれ格納される。
また、y12,y13,y14,y15は、図19記載のマルチプレクサm01を利用し、ラウンド関数開始後の16cycle後には、それぞれR12,R13,R14,R15に格納される。
【0139】
最後に、暗号文出力時の16cycle分のデータの流れを説明する。
i∈{0,1,...,15}
に対して、ciを8−bitの要素とする。
このとき、(c0,c1,...,c15)で表される128−bitを暗号文として考える。
【0140】
図13記載のrラウンド分のラウンド関数終了時には,図19記載のR0,R1,...,R15には、それぞれ、
S(c4),S(c5),S(c6),S(c7),c8,c9,c10,c11,c12,c13,c14,c15,c0,c1,c2,c3、
が格納されている。
【0141】
暗号文出力時の16cycleでは、R0に格納されている値は、毎サイクルごとに非線形演算部S−1関数S905に入力し、その出力をマルチプレクサm01を利用し、R15に格納するようにする。
【0142】
また、R8に格納されている値は、毎サイクルごとにマルチプレクサm02を利用し、R7に格納するようにする。また、R4に格納されている値は、毎サイクルごとに非線形演算部S−boxS901に入力し、その出力をマルチプレクサm03を利用し、R3に格納するようにする。また、暗号文出力時のは毎サイクルごとに、R12の値を図19での暗号文出力ポートから出力する。
上記のようにすることで,暗号文出力ポートから,毎サイクルごとにc0,c1,...,c15の順で順次出力される。
【0143】
上述したように、図19に示す構成において、非線形演算部S−1関数S905は、非線形演算部S−boxS901の逆関数を表している。非線形演算部S−1関数S905は、レジスタR0〜R3に格納されるF関数演算時の中間値(図18に示す中間値I804)からF関数への入力を復元する演算を実行する。この逆演算構成によって次段のラウンド関数に対する入力値が算出可能となり、上述したと同様のレジスタ削減効果が期待できる。
【0144】
[4.本開示の手法の効果のまとめ]
従来手法では、F関数への入力を保持したまま、F関数の出力を演算していた。この考えのもとでは、block長分のレジスタに加え,F関数演算時の中間値を保持するレジスタが必要となる。
【0145】
一方、上述した発開示に係る手法では、F関数への入力は一度破棄し、F関数の出力を計算後にF関数演算時の中間値から元の入力を復元するための回路を導入する構成としている。
【0146】
このようにすることで、必要なレジスタはblock長分のみとなり、従来手法において必要であったF関数演算時の中間値を保持するレジスタ分の回路を削減することが可能となる。前章の発明手法の適用例では、F関数演算時に必要な中間値として図18に記載の非線形演算部S801後の線形演算部M802に入力される値である保持する中間値I804とし、F関数の出力を計算可能としている。
【0147】
また,従来手法では用いないS−boxの逆演算処理回路を導入することにより、上記のF関数演算時の中間値からF関数への入力を復元するようにしている。このようにすることで,結果的にレジスタの削減を達成している。レジスタの回路規模は、他のセルに比べて比較的大きなものとなるため、レジスタの削減が小型化に寄与することは多い。
【0148】
[5.その他の実施例について]
前節では,4−line拡張Feistel構造においてラウンド関数内部の構成要素もある程度仮定し、適用法と効果について説明した。本開示の手法は、前節までに説明した具体的なラウンド関数の構造のみではなく、変形、拡張された構造についても適用可能である。
【0149】
また、本開示の手法は、4−line拡張Feistel構造のみでなく、2−lineのFeistel構造や,任意のx(xは2以上の自然数)に対して、x−line拡張Feistel構造に対しても同様な考え方が適用できる。
【0150】
(5−1.拡張例1)
本開示の方式は、図18に記載のSP型F関数だけではなく、図21に記載のSPS型F関数にも適用可能である。この場合に考えられるデータパスの例を図22に示す。
【0151】
図22では、行列の一例として,1行目の要素が(2,3,1,1)となる巡回行列を想定している。また、図21に記載のF関数を持つ拡張Feistel構造に対して本開示の手法を適用する場合のポイントである保持すべき中間値の例としては、第一非線形演算部S101の出力であり、線形演算部M102への入力となる。
図21に示す保持する中間値I104となる。
【0152】
この場合も、図18に記載のF関数を持つ拡張Feistel構造に対するHW実装構成例である図19でのデータの流れと同様に考えられるため、詳細な説明は省略する。
【0153】
図19に記載のデータパスと異なる点を簡単に説明すると、図22記載のデータパスでは、非線形演算部S−boxS111の入力前にマルチプレクサm01が導入され、行列演算部M112の出力がマルチプレクサm01を利用し、非線形演算部S−boxS111に入力され、S−boxS111の出力がラウンド鍵との排他的論理和部X114に直接入力されている点である。
【0154】
これは、図18記載のSP型F関数ではなく、図21記載のSPS型F関数を想定している点に起因する。図21記載のSPS型F関数では、線形変換部M102の出力を第二非線形変換部S103に入力し、その第二非線形変換部S103の出力をラウンド鍵との排他的論理和部X105に入力するからである。
【0155】
図22に示す構成において、非線形演算部S−1関数S113は、非線形演算部S−boxS111の逆関数を表している。非線形演算部S−1関数S113は、レジスタR0〜R3に格納されるF関数演算時の中間値(図21に示す中間値I104)からF関数への入力を復元する演算を実行する。この逆演算構成によって次段のラウンド関数に対する入力値が算出可能となり、上述したと同様のレジスタ削減効果が期待できる。
【0156】
(5−2.拡張例2)
本開示の方式は、図18に記載のSP型F関数だけではなく、図23に記載の鍵挿入が複数入ったSPS型F関数にも適用可能である。この場合に考えられるデータパスの例を図24に示す。
【0157】
図24では、行列の一例として、1行目の要素が(2,3,1,1)となる巡回行列を想定している。また、図23記載のF関数を持つ拡張Feistel構造に対して本開示の手法を適用する場合のポイントである保持すべき中間値の例としては、第一非線形演算部S121の出力であり、線形演算部M122への入力となる。
保持する中間値は、図23に示す保持する中間値I124となる。
【0158】
この場合も、図18に記載のF関数を持つ拡張Feistel構造に対するHW実装構成例である図19でのデータの流れを考察することで推測可能と考えられるため、詳細な説明は省略する。
【0159】
図19に記載のデータパスと異なる点を簡単に説明すると、図24記載のデータパスでは、非線形演算部S−boxS131の入力前にマルチプレクサm01が導入され、行列演算部M132の出力がラウンド鍵との排他的論理和演算部X134へ入力され、その出力がマルチプレクサm01を利用し、非線形演算部S−boxS131に入力され、S−boxS131の出力がラウンド鍵との排他的論理和部X135に直接入力されている点である。
【0160】
これは、図18記載のSP型F関数ではなく、図23記載の鍵挿入を複数行なうSPS型F関数を想定している点に起因する。図23記載の鍵挿入を複数行なうSPS型F関数では、線形変換部M122の出力を第一のラウンド鍵との排他的論理和演算部X125に入力し、その第一のラウンド鍵との排他的論理和演算部X125の出力を、第二非線形変換部S123に入力し、その第二非線形変換部S123の出力を第二のラウンド鍵との排他的論理和部X126に入力するからである。
【0161】
図24に示す構成において、非線形演算部S−1関数S133は、非線形演算部S−boxS131の逆関数を表している。非線形演算部S−1関数S133は、レジスタR0〜R3に格納されるF関数演算時の中間値(図23に示す中間値I124)からF関数への入力を復元する演算を実行する。この逆演算構成によって次段のラウンド関数に対する入力値が算出可能となり、上述したと同様のレジスタ削減効果が期待できる。
【0162】
(5−3.拡張例3)
本開示の方式は、図18に記載のSP型F関数だけではなく、図25に記載の鍵挿入がF関数入力直後にあるSP型F関数にも適用可能である。この場合に考えられるデータパスの例を図26に示す。
【0163】
図25に記載のF関数を持つ拡張Feistel構造に対して発明手法を適用する場合のポイントである保持すべき中間値の例としては、非線形演算部S141の出力であり、線形演算部M142への入力となる。
保持する中間値は、図25に示す保持する中間値I144となる。
【0164】
図18に表されるF関数と異なり、F関数演算時の中間値である図25記載の保持する中間値I144からF関数への入力を復元するためには、S−1だけでなく、F関数への入力直後に排他的論理和したときと同じラウンド鍵を排他的論理和する回路が必要となる。これは、図18に表されるF関数と異なり、図25に記載の保持する中間値からF関数の入力を復元するためには、非線形演算部S141の逆演算のみでなく、その逆演算した値に対して、ラウンド鍵との排他的論理和演算部X143の逆演算も必要となるためである。
【0165】
この場合も、図18記載のF関数を持つ拡張Feistel構造に対するHW実装構成例である図19でのデータの流れを考察することで推測可能と考えられるため、詳細な説明は省略する。図26記載のデータパスでは、非線形演算部S−boxS151の入力前にラウンド鍵との排他的論理和演算部X154が導入される。
【0166】
一方、行列演算部M152からの出力は、ラウンド鍵との排他的論理和演算を実行せずに、R4に格納されている値との排他的論理和演算部X156に直接入力される。また、R0に格納されている値は、非線形演算S−1関数に入力後、ラウンド鍵との排他的論理和演算部X155に入力されている点も図19と異なる点である。これは、前述の通り、図25記載の保持する中間値I144からF関数の入力を復元するためには、非線形演算部S141の逆演算のみでなく、その逆演算した値に対して、ラウンド鍵との排他的論理和演算部X143の逆演算も必要となるためである。
【0167】
図26に示す構成において、非線形演算部S−1関数S153は、非線形演算部S−boxS151の逆関数を表している。非線形演算部S−1関数S153は、レジスタR0〜R3に格納されるF関数演算時の中間値(図25に示す中間値I144)からF関数への入力を復元する演算を実行する。この逆演算構成によって次段のラウンド関数に対する入力値が算出可能となり、上述したと同様のレジスタ削減効果が期待できる。
【0168】
(5−4.拡張例4)
本開示の方式は、図18に記載のSP型F関数だけではなく、図27に記載のF関数にも適用可能である。図27に記載のF関数は、これまでに説明したF関数と大きく構造が異なるため、詳細に説明する。
【0169】
図27に記載のF関数は、F関数への入力を第一の非線形演算部S161で演算し、その第一の非線形演算部S161の出力を第二の非線形演算部S162へ入力する。その後、繰り返し構造となり、第一,第二の非線形演算部と同じ演算をs−1回施し、最終的に第一,第二の非線形演算部と同じ演算である、第sの非線形演算部S16sの出力をラウンド鍵との排他的論理和演算部X105に入力し、その出力をF関数の出力とするような構造である。
【0170】
このようなF関数においても、シリアル処理を実行するハードウェア回路を考えたときには、各サイクルごとにF関数演算時の中間値である図27に記載の保持する中間値I164の値を保持するレジスタが必要となる。
【0171】
図27に記載のF関数を保持する拡張Feistel構造を持つ暗号アルゴリズムに対しても発明手法の効果は得られる。図18,図19で紹介したことと同様に,図27に記載の保持する中間値I164からF関数の入力を復元することが可能であるため、そのための回路を導入することで、ブロック長分のみのレジスタで回路を実現できる。
【0172】
F関数内部が繰り返し構造となっているが、s=4としたときに考えられるデータパスの例を図28に示す。図27に記載のF関数は内部の繰り返し構造が4−line拡張Feistel構造と似ており、Feistel構造の性質から非線形回路S−1関数を用いずとも、S−box回路である非線形演算部S172,S173のみを用いることにより、図27に記載の保持する中間値I164からF関数の入力を復元することが可能である。
【0173】
図28に示す構成において、非線形演算部S172,S173は、レジスタR0〜R3に格納されるF関数演算時の中間値(図27に示す中間値I164)からF関数への入力を復元する演算を実行する。この演算構成によって次段のラウンド関数に対する入力値が算出可能となり、上述したと同様のレジスタ削減効果が期待できる。
【0174】
また、図28に記載のデータパスでは、S−box回路を二つ利用しているが、一つだけを利用することでもデータパスを記述することが可能であることは容易に推測できる。また、データパスは多少変更する必要があるが任意の繰り返し段数sに対してデータパスは構成可能である。また、図28に現れる"en"という記号で表される制御信号E174は、必要なタイミングでhighとなるように制御されるイネーブル信号を表し、図28には示されていないが制御部によって制御がされる。
【0175】
(5−5.拡張例5)
本開示の方式は、図18に記載のSP型F関数だけではなく、図29に記載のF関数にも適用可能である。図29は、図27に記載の繰り返し型のF関数の非線形演算部S161,S162,S16sが,図29記載の非線形演算部S181,S182,S18sに変更されたものと考えることができる。
【0176】
このようなF関数においても、シリアル処理を実行するハードウェア回路考えたときには、各サイクルごとにF関数演算時の中間値である図29記載の保持する中間値I184の値を保持するレジスタが必要となる。
【0177】
図29に記載のF関数を保持する拡張Feistel構造を持つ暗号アルゴリズムに対しても発明手法の効果は得られる。図18,図19を参照して説明したことと同様に、図29に記載の保持する中間値I184からF関数の入力を復元することが可能であるため、そのための回路を導入することで、ブロック長分のみのレジスタで回路を実現できる。
【0178】
F関数の構造上、S−boxの逆演算処理回路であるS−1を導入することで、図29に記載の保持する中間値I184からF関数の入力を復元することが可能である。また、F関数内部が繰り返し構造となっているが、任意の繰り返し段数に対して発明手法は適用可能である。
【0179】
(5−6.拡張例6)
ここで記載した具体的なF関数の構成は限られたものであるが、本開示の手法は、適した回路を導入することで中間値からF関数の入力を復元することが可能となる任意のF関数に適用可能である。
【0180】
(5−7.拡張例7)
F関数に行列演算を含む場合、本開示の手法は、巡回行列のみでなくアダマール行列に対しても適用可能であり、同様の効果が期待できる。また、上記以外の行列に対しても発明手法のアイデアは適用できる。
【0181】
(5−8.拡張例8)
F関数に行列演算を含む場合、本開示の方式は、4×4行列のみでなく任意のx(xは2以上の自然数)に対して,x×x行列でも同様の考えが適用可能であり、同様の効果が期待できる。
【0182】
(5−9.拡張例9)
4−linetype−2拡張Feistel構造を例に本開示の手法の適用例について説明したが、type−1,type−3の拡張Feistel構造に対しても適用可能であり、同様の効果が期待できる。
【0183】
(5−10.拡張例10)
4−linetype−2拡張Feistel構造を例に本開示の手法の適用例について説明したが、2−lineのFeistel構造に対しても適用可能であり、同様の効果が期待できる。
【0184】
(5−11.拡張例11)
4−line拡張Feistel構造への適用と同様の考えで、任意のx(xは3以上の自然数)に対して、x−line拡張Feistel構造に対しても適用可能であり、同様の効果が期待できる。
【0185】
(5−12.拡張例12)
図20に点線枠で示すように、1つのラウンド関数の出力は、次の段のラウンド関数へ出力する際に、各ラインのデータ単位でシフト処理等の入れ替え処理が行われる。
このラウンド関数間のデータ入れ替え、すなわち、前段のラウンドの出力を後段のラウンドへ出力する際に、各ライン単位でデータを入れ替える処理をラウンド置換(round permutaion)と呼ぶ。
【0186】
例えば、図20に示す4−line拡張Feistel構造における、ラウンド置換(round permutaion)は以下の設定となっている。
左から1番目のラインの出力を、次のラウンド関数の左から4番目のラインへの入力に設定、
左から2番目のラインの出力を、次のラウンド関数の左から1番目のラインへの入力に設定、
左から3番目のラインの出力を、次のラウンド関数の左から2番目のラインへの入力に設定、
左から4番目のラインの出力を、次のラウンド関数の左から3番目のラインへの入力に設定、
上記のラウンド置換(round permutaion)の設定例である。
【0187】
例えば図19を参照して説明したデータパスは、上記のラウンド置換(round permutaion)設定に対応したデータパス構成例である。
【0188】
本開示の方式は、図20に示すウンド置換(round permutaion)の設定に限らず、任意のラウンド置換(round permutaion)に対して適用可能である。
【0189】
すなわち、任意のラウンド置換(round permutaion)を持つ構成においても、F関数実行部における中間データからの逆演算構成を設定することで、上述したと同様のレジスタ削減効果が期待できる。
ただし、データパスの設定は、各ラウンド置換(round permutaion)の設定に応じた構成とすることが必要である。
【0190】
図20に示すラウンド置換(round permutaion)構成と異なるラウンド置換(round permutaion)の1つの構成例を図30に示す。
図30に示すラウンド置換(round permutaion)は、前段のラウンド関数の各ライン出力である(n/4)bitのそれぞれを2分割し、(n/8)bitの2つのライン出力に分割する。
各々が(n/8)bitのデータを持つ計8ラインのデータを次のラウンド関数に入力する際に、各ライン単位でデータ入れ替え(置換)を行う構成としている。
【0191】
図30に示す4−line拡張Feistel構造における、ラウンド置換(round permutaion)は以下の設定となっている。
左から1番目のラインの出力を2分割した前半データ(n/8)bitを、次のラウンド関数の左から4番目のラインの前半データ(n/8)bitの入力に設定、
左から1番目のラインの出力を2分割した後半データ(n/8)bitを、次のラウンド関数の左から2番目のラインの後半データ(n/8)bitの入力に設定、
左から2番目のラインの出力を2分割した前半データ(n/8)bitを、次のラウンド関数の左から1番目のラインの前半データ(n/8)bitの入力に設定、
左から2番目のラインの出力を2分割した後半データ(n/8)bitを、次のラウンド関数の左から3番目のラインの後半データ(n/8)bitの入力に設定、
【0192】
左から3番目のラインの出力を2分割した前半データ(n/8)bitを、次のラウンド関数の左から2番目のラインの前半データ(n/8)bitの入力に設定、
左から3番目のラインの出力を2分割した後半データ(n/8)bitを、次のラウンド関数の左から4番目のラインの後半データ(n/8)bitの入力に設定、
左から4番目のラインの出力を2分割した前半データ(n/8)bitを、次のラウンド関数の左から3番目のラインの前半データ(n/8)bitの入力に設定、
左から4番目のラインの出力を2分割した後半データ(n/8)bitを、次のラウンド関数の左から1番目のラインの後半データ(n/8)bitの入力に設定、
上記のラウンド置換(round permutaion)の設定例である。
なお、図30に示すラウンド関数におけるF関数は、図21に記載したSPS型F関数であると想定している。
【0193】
図30に示す、ラウンド置換(round permutaion)を実行する構成におけるラウンド関数部のデータパスの例を図31に示す。
図31に示すデータパスは、F関数として、図21に記載のSPS型F関数を適用した場合の構成例である。また、F関数における線形変換実行部である行列演算部M204で適用する行列の一例として,1行目の要素が(2,3,1,1)となる巡回行列を想定している。
【0194】
本構成例においてレジスタに保持する中間値は,図21に示す第一非線形演算部S101の出力であり、線形演算部M102への入力であり、図21に示す中間値I104となる。
図31において、これらの中間値は、レジスタR0〜R3に保持される。
基本的なデータの流れは、先に拡張例1として説明した図22に示すデータパスと同様のものであり、非線形演算部S−boxS203の入力前にマルチプレクサm202が設定されている。行列演算部M204の出力がマルチプレクサm202を利用し、非線形演算部S−boxS203に入力され、S−boxS203の出力が排他的論理和部X206に入力される。
【0195】
図31に記載のデータパスでは、図22に示す構成と異なり、S−boxS203の出力に対してラウンド鍵との排他的論理和演算を実行する前に、排他的論理和演算部X206に入力され、レジスタR4に格納されている値との排他的論理和演算を実行する構成としている。この排他的論理和結果とラウンド鍵が、排他的論理和演算部X201において排他的論理和演算される。
【0196】
また、レジスタR8とレジスタR15を結ぶパスp211と、ラウンド鍵との排他的論理和演算を実行する排他的論理和演算部X201の出力とレジスタR7を結ぶパスp212を加えている。これは、図22とは異なるラウンド置換(round permutation)、すなわち図30に示す設定のラウンド置換(round permutation)を実現するためのパス設定である。
【0197】
この図31に示すデータパスにおいても、前述した図19、図22他の実施例と同様、F関数実行部における中間データからの逆演算構成、すなわち非線形演算部S−1関数S205を設定することで、次段のラウンド関数に対する入力値を算出可能とすることで、上述したと同様のレジスタ削減効果が期待できる。
【0198】
[6.暗号処理装置の構成例について]
最後に、上述した実施例に従った暗号処理を実行する暗号処理装置の実装例について説明する。
上述した実施例に従った暗号処理を実行する暗号処理装置は、暗号処理を実行する様々な情報処理装置に搭載可能である。具体的には、PC、TV、レコーダ、プレーヤ、通信機器、さらに、RFID、スマートカード、センサネットワーク機器、デンチ/バッテリー認証モジュール、健康、医療機器、自立型ネットワーク機器等、例えばデータ処理や通信処理に伴う暗号処理を実行する様々な危機において利用可能である。
【0199】
本開示の暗号処理を実行する装置の一例としてのICモジュール700の構成例を図32に示す。上述の処理は、例えばPC、ICカード、リーダライタ、その他、様々な情報処理装置において実行可能であり、図32に示すICモジュール700は、これら様々な機器に構成することが可能である。
【0200】
図32に示すCPU(Central processing Unit)701は、暗号処理の開始や、終了、データの送受信の制御、各構成部間のデータ転送制御、その他の各種プログラムを実行するプロセッサである。メモリ702は、CPU701が実行するプログラム、あるいは演算パラメータなどの固定データを格納するROM(Read-Only-Memory)、CPU701の処理において実行されるプログラム、およびプログラム処理において適宜変化するパラメータの格納エリア、ワーク領域として使用されるRAM(Random Access Memory)等からなる。また、メモリ702は暗号処理に必要な鍵データや、暗号処理において適用する変換テーブル(置換表)や変換行列に適用するデータ等の格納領域として使用可能である。なおデータ格納領域は、耐タンパ構造を持つメモリとして構成されることが好ましい。
【0201】
暗号処理部703は、上記において説明した暗号処理構成、すなわち、例えば拡張Feistel構造や、Feistel構造を適用した共通鍵ブロック暗号処理アルゴリズムに従った暗号処理、復号処理を実行する。
【0202】
なお、ここでは、暗号処理手段を個別モジュールとした例を示したが、このような独立した暗号処理モジュールを設けず、例えば暗号処理プログラムをROMに格納し、CPU701がROM格納プログラムを読み出して実行するように構成してもよい。
【0203】
乱数発生器704は、暗号処理に必要となる鍵の生成などにおいて必要となる乱数の発生処理を実行する。
【0204】
送受信部705は、外部とのデータ通信を実行するデータ通信処理部であり、例えばリーダライタ等、ICモジュールとのデータ通信を実行し、ICモジュール内で生成した暗号文の出力、あるいは外部のリーダライタ等の機器からのデータ入力などを実行する。
【0205】
なお、上述した実施例において説明した暗号処理装置は、入力データとしての平文を暗号化する暗号化処理に適用可能であるのみならず、入力データとしての暗号文を平文に復元する復号処理にも適用可能である。
暗号化処理、復号処理、双方の処理において、上述した実施例において説明したレジスタ削減構成を持つF関数実行部の構成をそのまま適用することが可能である。
【0206】
[7.本開示の構成のまとめ]
以上、特定の実施例を参照しながら、本開示の実施例について詳解してきた。しかしながら、本開示の要旨を逸脱しない範囲で当業者が実施例の修正や代用を成し得ることは自明である。すなわち、例示という形態で本発明を開示してきたのであり、限定的に解釈されるべきではない。本開示の要旨を判断するためには、特許請求の範囲の欄を参酌すべきである。
【0207】
なお、本明細書において開示した技術は、以下のような構成をとることができる。
(1)データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してデータ変換処理を繰り返して実行する暗号処理部を有し、
前記暗号処理部は、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行部と、
前記F関数の出力に対する他ラインのデータとの排他的論理和演算を実行する排他的論理和演算実行部と、
前記F関数実行部における変換データの生成過程の中間データを格納する中間データ格納レジスタと、
前記中間データ格納レジスタの格納データに基づいて、前記F関数実行部に対する入力データを算出する逆演算実行部と、
を有する暗号処理装置。
【0208】
(2)前記F関数実行部は、F関数実行部への入力データに対する非線形変換処理を実行するS−boxを有し、前記中間データ格納レジスタは、前記S−boxの出力値を中間データとして保持し、前記逆演算実行部は、前記S−boxによる非線形変換処理の逆演算を含む演算処理により、前記F関数実行部に対する入力データを算出する前記(1)に記載の暗号処理装置。
【0209】
(3)前記F関数実行部は、非線形変換部、および線形変換部を有し、前記非線形変換部の出力を前記中間データとして格納するレジスタを有し、前記線形変換部は、前記レジスタの格納値に対する線型変換処理を実行し、前記逆演算実行部は、前記レジスタの格納値に対する演算処理により、前記F関数実行部に対する入力データを算出する前記(1)または(2)に記載の暗号処理装置。
【0210】
(4)前記F関数実行部は、F関数実行部に対する入力に対して非線形変換部において非線形変換処理を実行し、さらに線形変換部において線形変換処理を実行するSP型F関数である前記(1)〜(3)いずれかに記載の暗号処理装置。
【0211】
(5)前記F関数実行部は、F関数実行部に対する入力に対して非線形変換部において非線形変換処理を実行し、さらに線形変換部において線形変換処理を実行し、さらに非線形変換部において再度、非線形変換処理をするSPS型F関数である前記(1)〜(4)いずれかに記載の暗号処理装置。
【0212】
(6)前記F関数実行部は、外部から入力するラウンド鍵との排他的論理和演算部を有する前記(1)〜(5)いずれかに記載の暗号処理装置。
(7)前記F関数実行部は、複数の非線形演算部の繰り返し構造を有する前記(1)〜(6)いずれか1に記載の暗号処理装置。
(8)前記暗号処理部は、入力データとしての平文を暗号文に変換する暗号化処理、または、入力データとしての暗号文を平文に変換する復号処理を実行する前記(1)〜(7)いずれか1に記載の暗号処理装置。
【0213】
さらに、上記した装置およびシステムにおいて実行する処理の方法や、処理を実行させるプログラムも本開示の構成に含まれる。
【0214】
また、明細書中において説明した一連の処理はハードウェア、またはソフトウェア、あるいは両者の複合構成によって実行することが可能である。ソフトウェアによる処理を実行する場合は、処理シーケンスを記録したプログラムを、専用のハードウェアに組み込まれたコンピュータ内のメモリにインストールして実行させるか、あるいは、各種処理が実行可能な汎用コンピュータにプログラムをインストールして実行させることが可能である。例えば、プログラムは記録媒体に予め記録しておくことができる。記録媒体からコンピュータにインストールする他、LAN(Local Area Network)、インターネットといったネットワークを介してプログラムを受信し、内蔵するハードディスク等の記録媒体にインストールすることができる。
【0215】
なお、明細書に記載された各種の処理は、記載に従って時系列に実行されるのみならず、処理を実行する装置の処理能力あるいは必要に応じて並列的にあるいは個別に実行されてもよい。また、本明細書においてシステムとは、複数の装置の論理的集合構成であり、各構成の装置が同一筐体内にあるものには限らない。
【産業上の利用可能性】
【0216】
上述したように、本開示の一実施例の構成によれば、暗号処理構成の小型化が実現される。
具体的には、データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してデータ変換処理を繰り返して実行する暗号処理部を有し、暗号処理部は、複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行部と、F関数の出力に対する他ラインのデータとの排他的論理和演算を実行する排他的論理和演算実行部と、F関数実行部における変換データの生成過程の中間データを格納する中間データ格納レジスタと、中間データ格納レジスタの格納データに基づいて、F関数実行部に対する入力データを算出する逆演算実行部を有する。逆演算実行部における逆演算により、F関数実行部に対する入力値を算出可能となり、このデータを保持するレジスタを削減することが可能となり、暗号処理構成の小型化が実現される。
【符号の説明】
【0217】
700 ICモジュール
701 CPU(Central processing Unit)
702 メモリ
703 暗号処理部
704 乱数生成部
705 送受信部
【特許請求の範囲】
【請求項1】
データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してデータ変換処理を繰り返して実行する暗号処理部を有し、
前記暗号処理部は、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行部と、
前記F関数の出力に対する他ラインのデータとの排他的論理和演算を実行する排他的論理和演算実行部と、
前記F関数実行部における変換データの生成過程の中間データを格納する中間データ格納レジスタと、
前記中間データ格納レジスタの格納データに基づいて、前記F関数実行部に対する入力データを算出する逆演算実行部と、
を有する暗号処理装置。
【請求項2】
前記F関数実行部は、
F関数実行部への入力データに対する非線形変換処理を実行するS−boxを有し、
前記中間データ格納レジスタは、前記S−boxの出力値を中間データとして保持し、
前記逆演算実行部は、
前記S−boxによる非線形変換処理の逆演算を含む演算処理により、前記F関数実行部に対する入力データを算出する請求項1に記載の暗号処理装置。
【請求項3】
前記F関数実行部は、
非線形変換部、および線形変換部を有し、前記非線形変換部の出力を前記中間データとして格納するレジスタを有し、
前記線形変換部は、前記レジスタの格納値に対する線型変換処理を実行し、
前記逆演算実行部は、前記レジスタの格納値に対する演算処理により、前記F関数実行部に対する入力データを算出する請求項1に記載の暗号処理装置。
【請求項4】
前記F関数実行部は、F関数実行部に対する入力に対して非線形変換部において非線形変換処理を実行し、さらに線形変換部において線形変換処理を実行するSP型F関数である請求項1に記載の暗号処理装置。
【請求項5】
前記F関数実行部は、F関数実行部に対する入力に対して非線形変換部において非線形変換処理を実行し、さらに線形変換部において線形変換処理を実行し、さらに非線形変換部において再度、非線形変換処理をするSPS型F関数である請求項1に記載の暗号処理装置。
【請求項6】
前記F関数実行部は、外部から入力するラウンド鍵との排他的論理和演算部を有する請求項1に記載の暗号処理装置。
【請求項7】
前記F関数実行部は、複数の非線形演算部の繰り返し構造を有する請求項1に記載の暗号処理装置。
【請求項8】
前記暗号処理部は、
入力データとしての平文を暗号文に変換する暗号化処理、または、
入力データとしての暗号文を平文に変換する復号処理を実行する請求項1に記載の暗号処理装置。
【請求項9】
暗号処理装置において実行する暗号処理方法であり、
暗号処理部が、データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してデータ変換処理を繰り返して実行する暗号処理ステップを実行し、
前記暗号処理ステップは、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行ステップと、
前記F関数の出力に対する他ラインのデータとの排他的論理和演算を実行する排他的論理和演算実行ステップと、
前記F関数実行ステップにおける変換データの生成過程の中間データを中間データ格納レジスタに格納するステップと、
前記中間データ格納レジスタの格納データに基づいて、前記F関数実行部に対する入力データを算出する逆演算実行ステップと、
を実行する暗号処理方法。
【請求項10】
暗号処理装置において暗号処理を実行させるプログラムであり、
暗号処理部が、データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してデータ変換処理を繰り返して実行する暗号処理ステップを実行させ、
前記暗号処理ステップにおいて、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行ステップと、
前記F関数の出力に対する他ラインのデータとの排他的論理和演算を実行する排他的論理和演算実行ステップと、
前記F関数実行ステップにおける変換データの生成過程の中間データを中間データ格納レジスタに格納するステップと、
前記中間データ格納レジスタの格納データに基づいて、前記F関数実行部に対する入力データを算出する逆演算実行ステップと、
を実行させるプログラム。
【請求項1】
データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してデータ変換処理を繰り返して実行する暗号処理部を有し、
前記暗号処理部は、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行部と、
前記F関数の出力に対する他ラインのデータとの排他的論理和演算を実行する排他的論理和演算実行部と、
前記F関数実行部における変換データの生成過程の中間データを格納する中間データ格納レジスタと、
前記中間データ格納レジスタの格納データに基づいて、前記F関数実行部に対する入力データを算出する逆演算実行部と、
を有する暗号処理装置。
【請求項2】
前記F関数実行部は、
F関数実行部への入力データに対する非線形変換処理を実行するS−boxを有し、
前記中間データ格納レジスタは、前記S−boxの出力値を中間データとして保持し、
前記逆演算実行部は、
前記S−boxによる非線形変換処理の逆演算を含む演算処理により、前記F関数実行部に対する入力データを算出する請求項1に記載の暗号処理装置。
【請求項3】
前記F関数実行部は、
非線形変換部、および線形変換部を有し、前記非線形変換部の出力を前記中間データとして格納するレジスタを有し、
前記線形変換部は、前記レジスタの格納値に対する線型変換処理を実行し、
前記逆演算実行部は、前記レジスタの格納値に対する演算処理により、前記F関数実行部に対する入力データを算出する請求項1に記載の暗号処理装置。
【請求項4】
前記F関数実行部は、F関数実行部に対する入力に対して非線形変換部において非線形変換処理を実行し、さらに線形変換部において線形変換処理を実行するSP型F関数である請求項1に記載の暗号処理装置。
【請求項5】
前記F関数実行部は、F関数実行部に対する入力に対して非線形変換部において非線形変換処理を実行し、さらに線形変換部において線形変換処理を実行し、さらに非線形変換部において再度、非線形変換処理をするSPS型F関数である請求項1に記載の暗号処理装置。
【請求項6】
前記F関数実行部は、外部から入力するラウンド鍵との排他的論理和演算部を有する請求項1に記載の暗号処理装置。
【請求項7】
前記F関数実行部は、複数の非線形演算部の繰り返し構造を有する請求項1に記載の暗号処理装置。
【請求項8】
前記暗号処理部は、
入力データとしての平文を暗号文に変換する暗号化処理、または、
入力データとしての暗号文を平文に変換する復号処理を実行する請求項1に記載の暗号処理装置。
【請求項9】
暗号処理装置において実行する暗号処理方法であり、
暗号処理部が、データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してデータ変換処理を繰り返して実行する暗号処理ステップを実行し、
前記暗号処理ステップは、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行ステップと、
前記F関数の出力に対する他ラインのデータとの排他的論理和演算を実行する排他的論理和演算実行ステップと、
前記F関数実行ステップにおける変換データの生成過程の中間データを中間データ格納レジスタに格納するステップと、
前記中間データ格納レジスタの格納データに基づいて、前記F関数実行部に対する入力データを算出する逆演算実行ステップと、
を実行する暗号処理方法。
【請求項10】
暗号処理装置において暗号処理を実行させるプログラムであり、
暗号処理部が、データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してデータ変換処理を繰り返して実行する暗号処理ステップを実行させ、
前記暗号処理ステップにおいて、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行ステップと、
前記F関数の出力に対する他ラインのデータとの排他的論理和演算を実行する排他的論理和演算実行ステップと、
前記F関数実行ステップにおける変換データの生成過程の中間データを中間データ格納レジスタに格納するステップと、
前記中間データ格納レジスタの格納データに基づいて、前記F関数実行部に対する入力データを算出する逆演算実行ステップと、
を実行させるプログラム。
【図1】

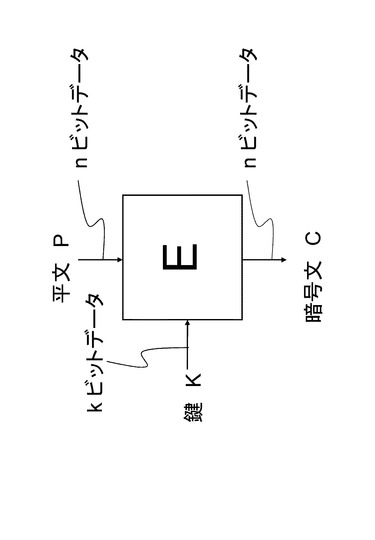
【図2】
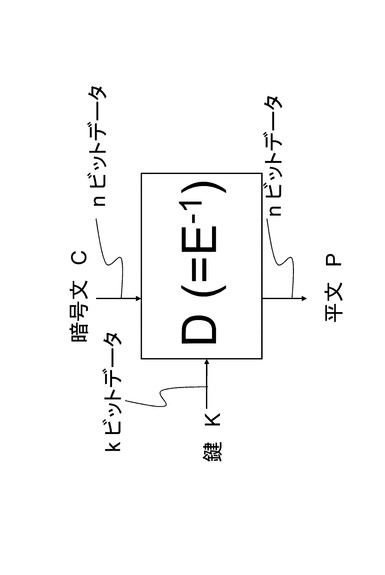
【図3】
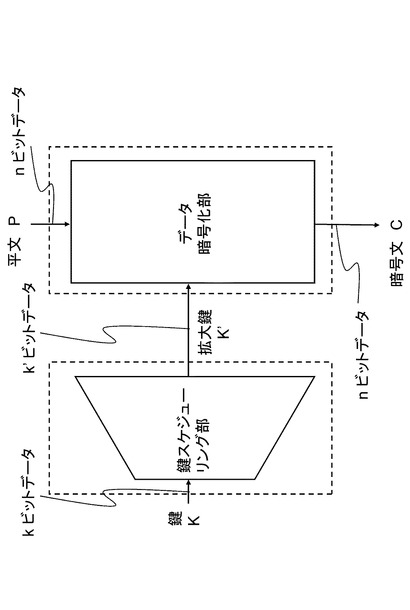
【図4】
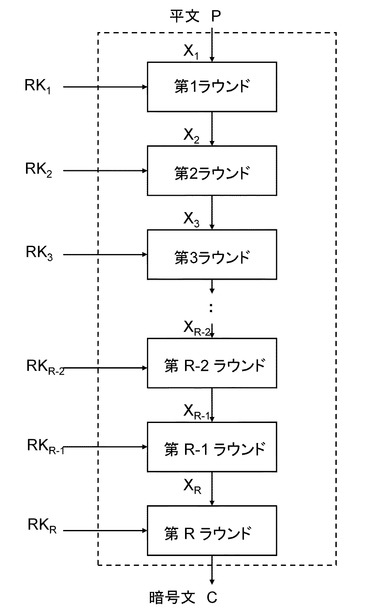
【図5】
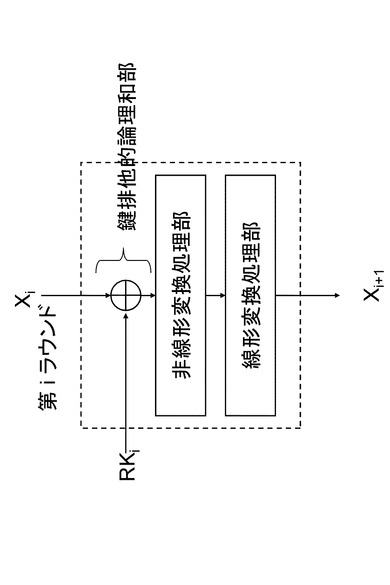
【図6】
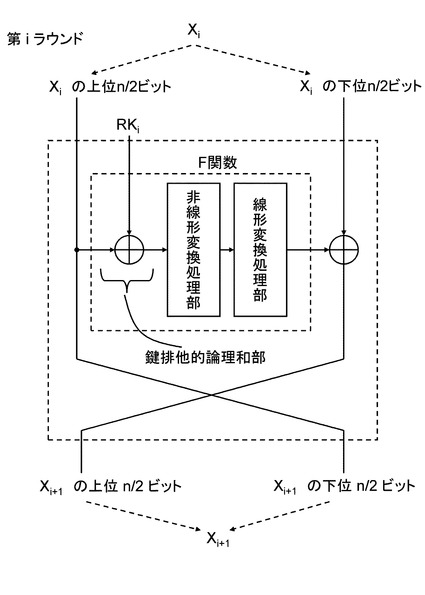
【図7】
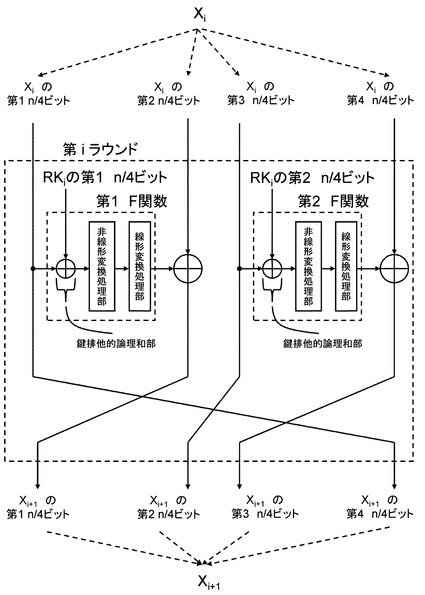
【図8】
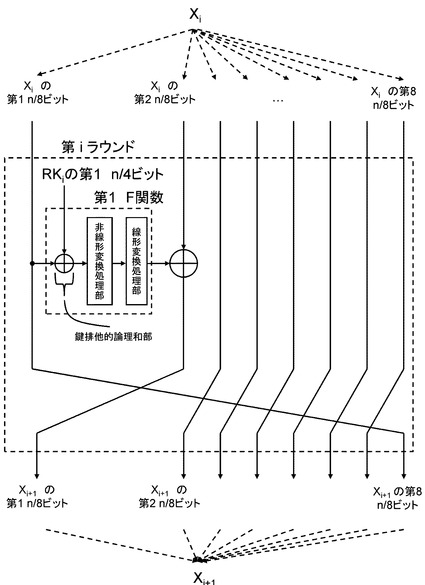
【図9】
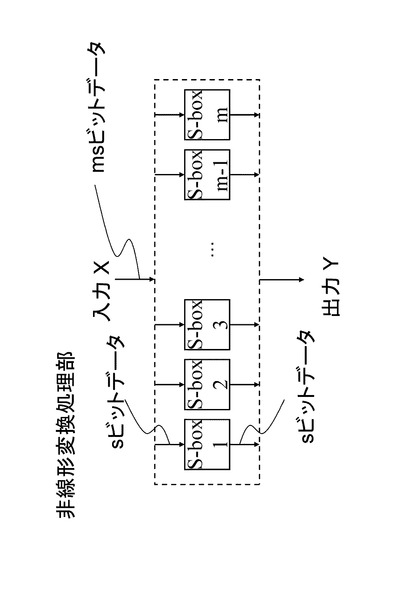
【図10】
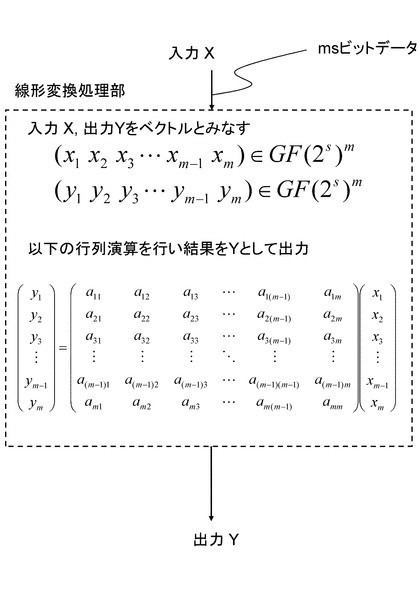
【図11】
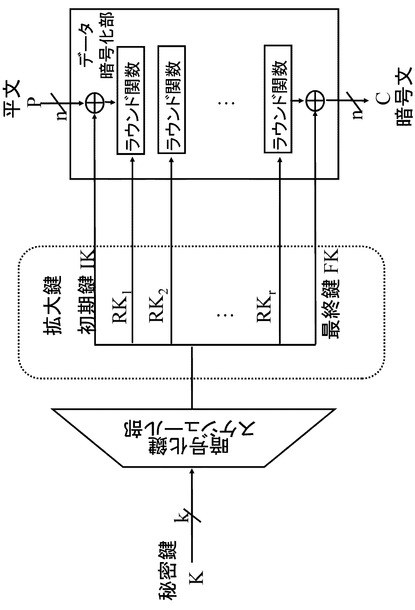
【図12】
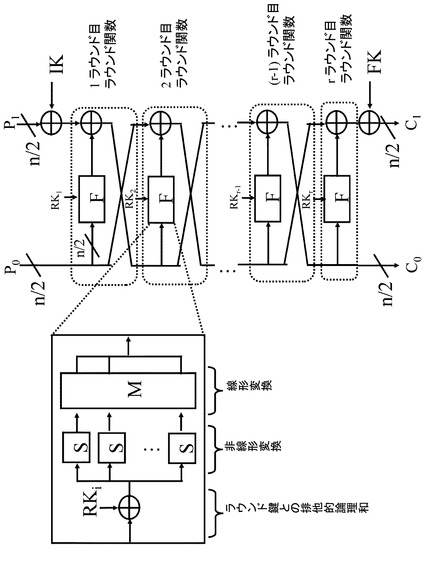
【図13】
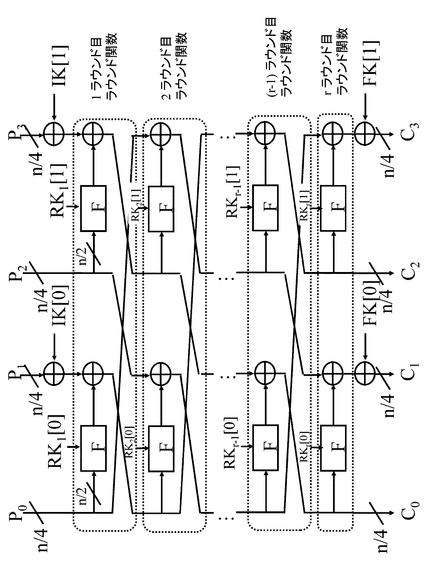
【図14】
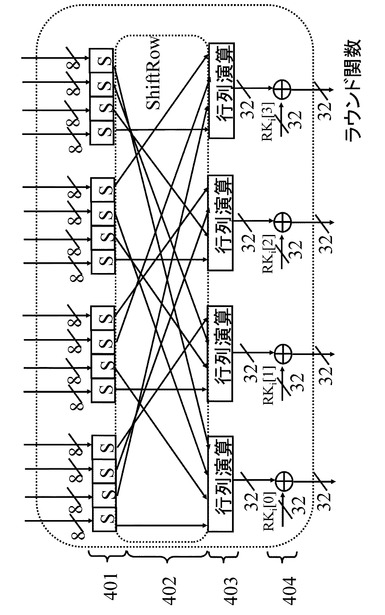
【図15】
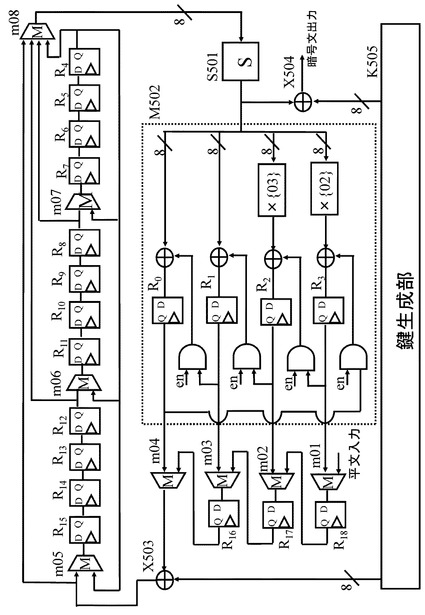
【図16】
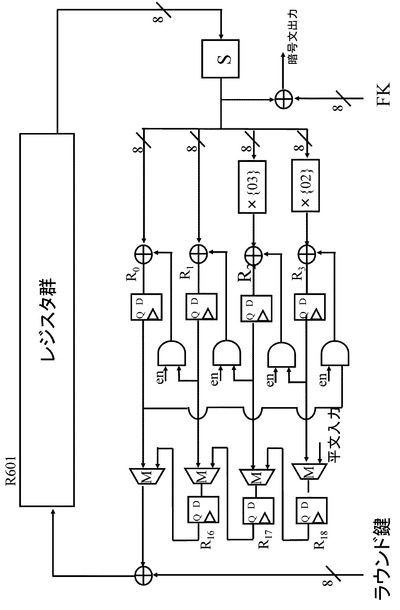
【図17】
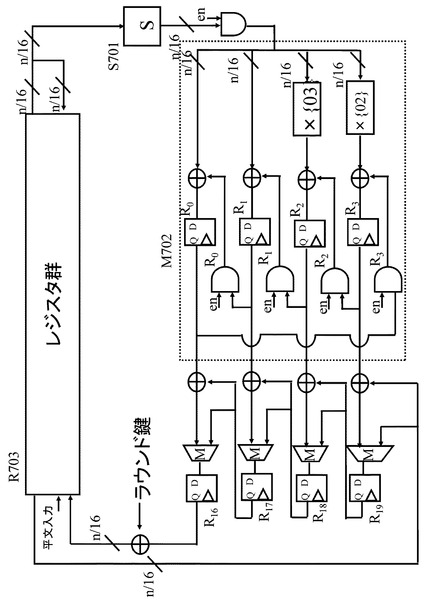
【図18】
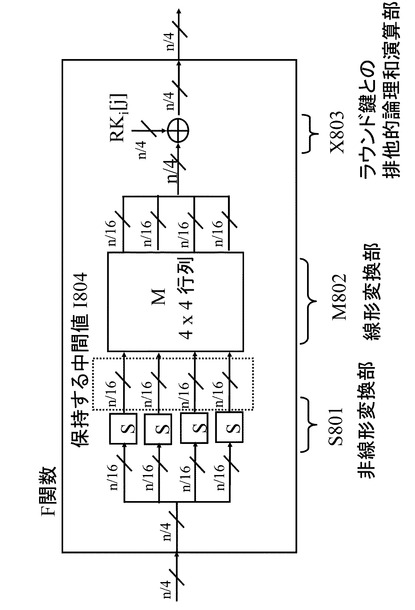
【図19】
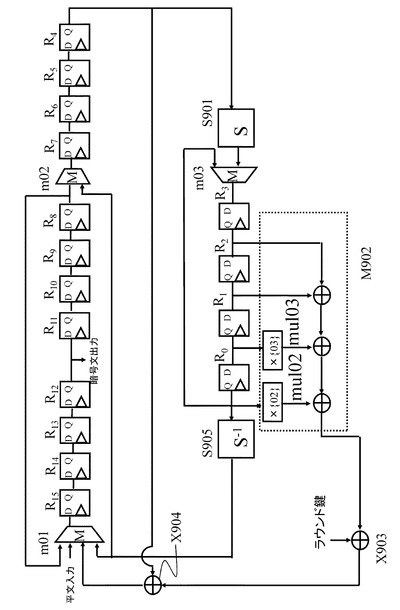
【図20】
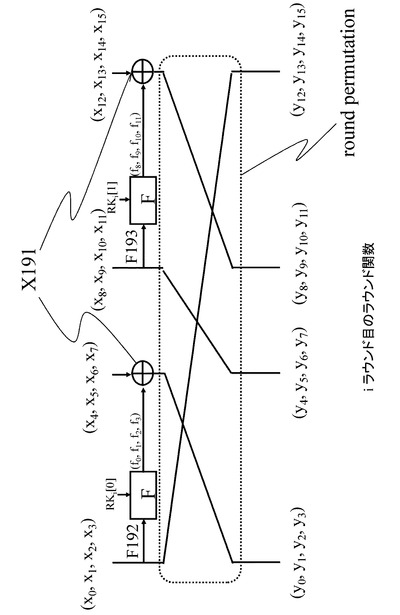
【図21】
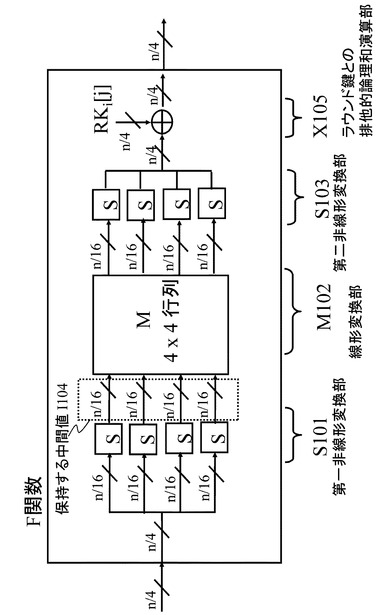
【図22】
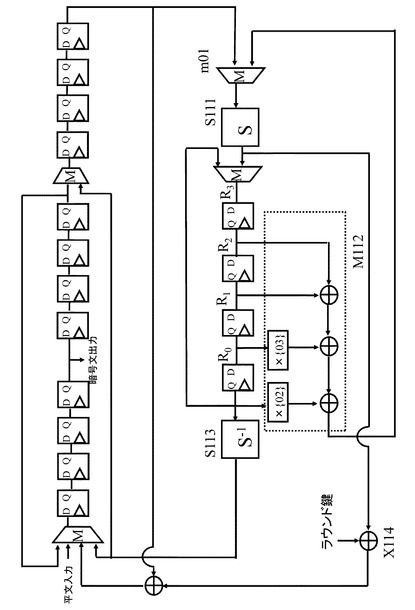
【図23】
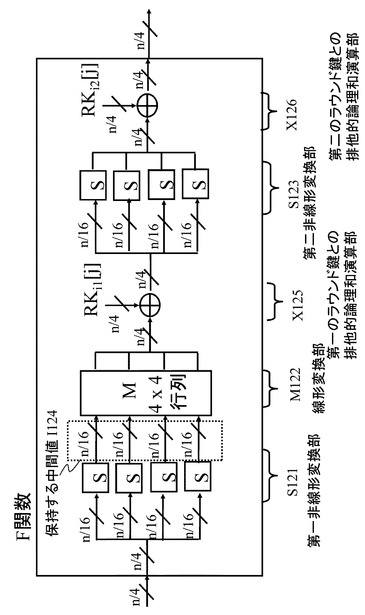
【図24】
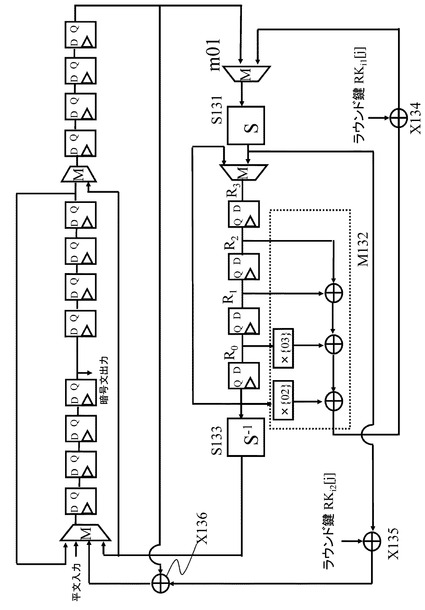
【図25】
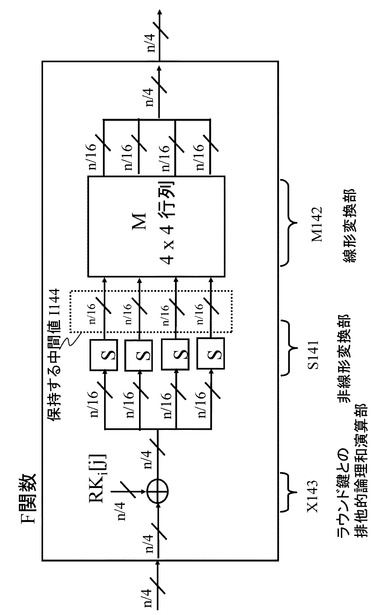
【図26】
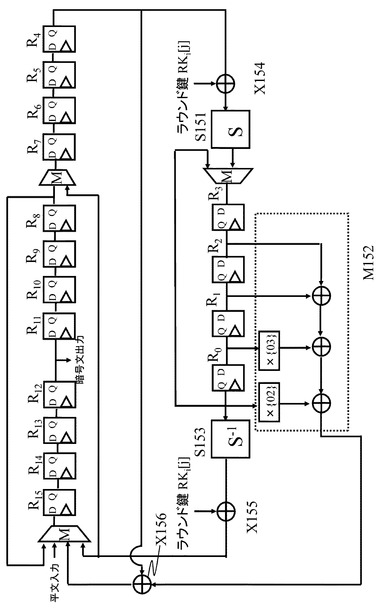
【図27】
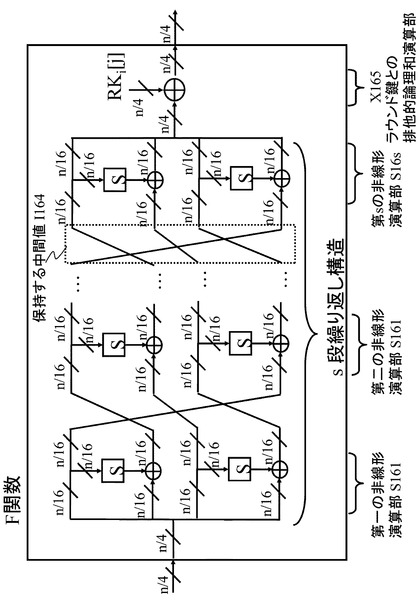
【図28】
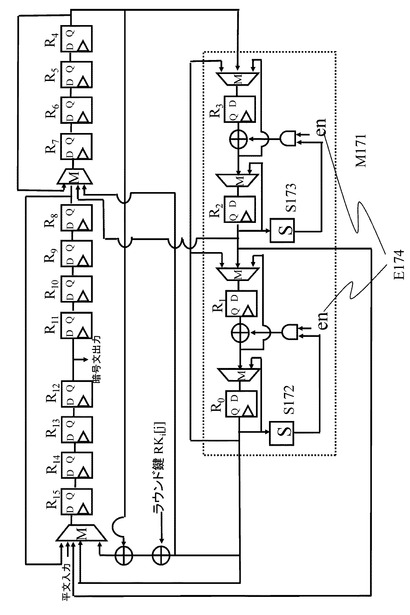
【図29】
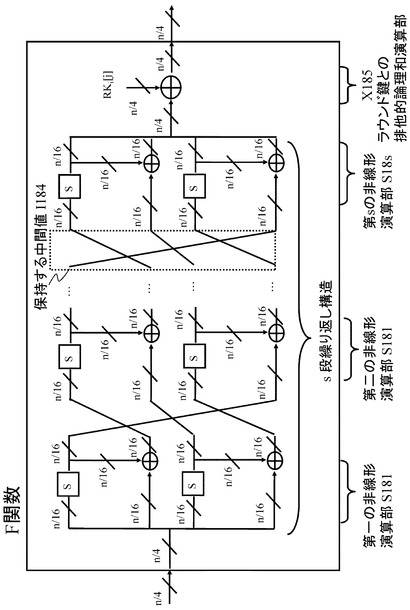
【図30】
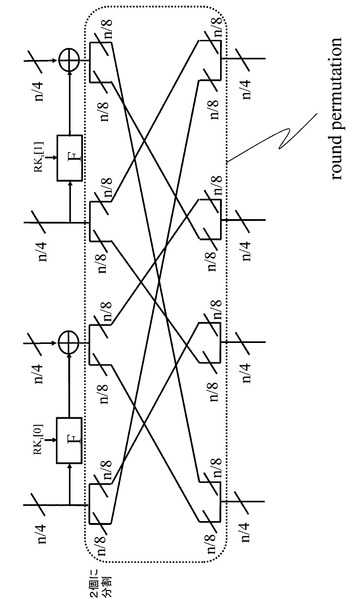
【図31】
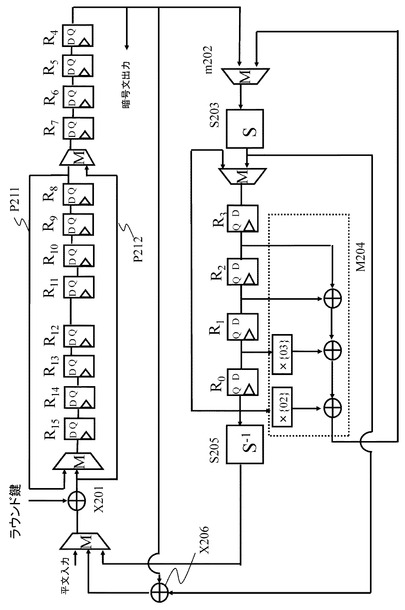
【図32】
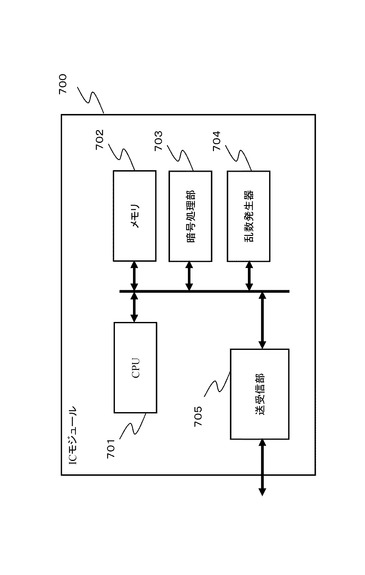
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【図23】
【図24】
【図25】
【図26】
【図27】
【図28】
【図29】
【図30】
【図31】
【図32】
【公開番号】特開2012−215814(P2012−215814A)
【公開日】平成24年11月8日(2012.11.8)
【国際特許分類】
【出願番号】特願2011−207703(P2011−207703)
【出願日】平成23年9月22日(2011.9.22)
【出願人】(000002185)ソニー株式会社 (34,172)
【Fターム(参考)】
【公開日】平成24年11月8日(2012.11.8)
【国際特許分類】
【出願日】平成23年9月22日(2011.9.22)
【出願人】(000002185)ソニー株式会社 (34,172)
【Fターム(参考)】
[ Back to top ]