
暗号化システム及び復号化システム
【課題】処理が高速で安全性の高い暗号化システム及び復号化システムを提供する。
【解決手段】関数選択手段は、文書記憶手段からの文書の前記ブロック単位ごとに、擬似乱数により関数を順次選択し、関数実行手段は、選択された関数で、擬似乱数列のブロックをパラメータとして用いて、文書を変換して暗号化し、復号化システムでは、逆関数選択手段は、暗号化文書記憶手段からの暗号化文書のブロック単位ごとに、擬似乱数により逆関数を選択し、逆関数実行手段は、選択された逆関数で、擬似乱数列のブロックをパラメータとして用いて、暗号化文書を変換して復号する。各関数が基本的で高速なので、組み合わせた全体の変換も高速である。また、関数の組み合わせも反復数も変えられるので、将来の仕様強化が容易である。また、どの関数がどのような順番で施されたか分からないため、安全性が高い。
【解決手段】関数選択手段は、文書記憶手段からの文書の前記ブロック単位ごとに、擬似乱数により関数を順次選択し、関数実行手段は、選択された関数で、擬似乱数列のブロックをパラメータとして用いて、文書を変換して暗号化し、復号化システムでは、逆関数選択手段は、暗号化文書記憶手段からの暗号化文書のブロック単位ごとに、擬似乱数により逆関数を選択し、逆関数実行手段は、選択された逆関数で、擬似乱数列のブロックをパラメータとして用いて、暗号化文書を変換して復号する。各関数が基本的で高速なので、組み合わせた全体の変換も高速である。また、関数の組み合わせも反復数も変えられるので、将来の仕様強化が容易である。また、どの関数がどのような順番で施されたか分からないため、安全性が高い。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、共有鍵を用いたブロックサイファ及びストリームサイファにおける擬似乱数発生システムを利用した暗号化システム及び復号化システムである。
【背景技術】
【0002】
第三者に見られては困る文書を電子データとして保存する時には、データは暗号化され、パスワードを知らなければ解読できないように変換される。ここで利用される暗号技術として、現在広く使用されているのは、データを固定サイズのブロックに区切り、それぞれのブロックを秘密鍵に依存した特定の関数で暗号化する、ブロックサイファと呼ばれる暗号化方式と、データの位置によって異なる関数で暗号化されるストリームサイファと呼ばれる暗号化方式である。ストリームサイファではデータと暗号乱数列の排他的論理和を求めることが多い。
また、インターネットを用いて電子商取引を行なう際にも、第三者に知られることなく、安全に2点A,B間で通信を行なうために、データは暗号化して伝送されている。その時に利用される暗号技術として、現在広く利用されているのは、DESやTriple DES,AESに代表される共有鍵暗号方式である。これは、通信を行なうA,B間でのみ共有している共有暗号鍵をもとに、送信するデータを第三者に分からないデータに変換する方法である。
【0003】
DES(Data Encryption Standard)は、これまでアメリカ合衆国政府の国立標準研究所(NIST)が、データ暗号の標準として推奨してきた共有鍵暗号方式である。Triple DESはDESを3回繰り返すことで、その安全性を高めた暗号方式である。AES(Advanced Encryption Standard)は、DESに代わるデータ暗号の標準としてNISTが公募し、数学者J.Daemen,V.Rijmenによって開発されたRijindaelと呼ばれる暗号化方式である。これらはすべて、共有鍵を利用して、固定サイズのブロックに区切られたデータを高速に暗号化する共有鍵暗号方式であり、ブロックサイファである。この変換に必要な計算量は大変小さく、実用性が高い。
ストリームサイファでは、平方剰余により擬似乱数を生成するBlum−Blum−Shub(BBS)法により暗号乱数列を生成し、文書との排他的論理和を暗号文とする方法が知られている。BBS法は、暗号鍵kを次々に二乗して、秘密の2つの素数の積Nでの剰余を作り、その最下位ビットを並べて作った列を暗号乱数列とする方針である。このNが十分大きければ、この列が暗号的に大変優れたもの、すなわち連続するいくつものデータを集めても、次のビットをランダムより良い確率で予測することが難しい、という性質をもつ擬似乱数列になっていることは、文献「L. Blum, M. Blum, M. Shub: “A Simple Unpredictable Psudo-Random Number Generator”, SIAM J. Comput. Vol15, No.2, May 1986」で示されている。よって、これを用いれば、たくさんの文字を推定しても、法則を見つけることは大変に難しく、他の部分列を推定するには、全数チェック相当の計算が必要となると考えられている。
【0004】
しかしながら、従来の共有鍵暗号方式のブロックサイファでは、鍵情報から一つの複雑な暗号化関数を作り、これを用いて平文を変換するため、高速な暗号システムは作られる関数に偏りがあり、暗号解読のための情報を得られやすいという問題がある。たとえば暗号を解読しようとする際には、差分解読法や、線形解読法などの、既知の平文を暗号化させることによる攻撃がよく用いられている。すなわち攻撃する人物が、任意の文書を暗号化させられる状況では、解読に用いるデータを採取され、鍵の全数検索よりも簡単に暗号が破られるという問題があった。また、共有鍵暗号方式のストリームサイファでも、例えば上記のBBS法では大きな数の自乗と、その値の大きな数Nでの剰余を計算するため低速であるように、十分な安全性を持つ暗号乱数列を生成するための計算量は大きく低速になり、高速に生成できる擬似乱数は暗号的に安全でないという問題がある。
また、これまでに知られているストリームサイファ用暗号乱数列は周期が短く長く使い続けることができないという問題があった。
【0005】
これらの問題に対処する方法として、例えば特許文献1〜特許文献5がある。特許文献1および特許文献2では、複数の暗号化関数を用意し、鍵情報や外部からのデータにより、どの暗号化関数で暗号化するかを選択することで、平文によって異なる暗号化関数で暗号化し、これにより情報の漏洩を防いだり、認証効果を得たりしている。また、特許文献3〜特許文献5では、性質の良い暗号乱数列の作り方を与えている。特に特許文献3では、平文列を有限状態オートマトンで書き換えて暗号乱数列を生成していて、本発明と関係が深い。線形フィードバックシフトレジスタ(linear feedback shift register (LFSR))にもとづいた擬似乱数生成装置であるが、ソフトウェア実装した場合の処理速度が充分ではないという問題がある。また、LFSRにもとづいた擬似乱数生成装置についての従来技術としては、たとえば、文献「B. Schneier, "Applied Cryptography," John Wiley & Sons, Inc., 1996.pp. 369〜428」に開示されている。
【先行技術文献】
【特許文献】
【0006】
【特許文献1】特許公開平11−15940号公報
【特許文献2】特許公開平11−265146号公報
【特許文献3】特許公開平11−500849号公報
【特許文献4】特許公開2003−37482号公報
【特許文献5】特許公開2004−38020号公報
【発明の概要】
【発明が解決しようとする課題】
【0007】
しかしながら、上記の特許文献1および特許文献2の方法を用いて十分な効果を得るには、なるべく多くの暗号化関数を用意しなくてはならないが、複数の暗号化関数を保存するには、その個数倍のメモリや関数作成のための計算量が必要となるという問題がある。
また、特許文献3〜特許文献5の方法を用いて暗号乱数列を作っても、十分に長い周期を得ることはできず、速さまたは安全性に問題が生じる。
本発明の課題は、計算量を増やさずに安全性を高め、これらの問題を解決することである。
【課題を解決するための手段】
【0008】
本発明は、あらかじめ与えられた共有鍵で文書を暗号化する暗号化システムであって、前記文書を記憶している文書記憶手段と、あらかじめ定めたビット数をワードとして、あらかじめ定めたワード数のブロック単位に、複数種類の関数を実行する関数実行手段と、前記共有鍵から擬似乱数列を生成する擬似乱数生成手段と、前記関数実行手段の関数の種類を重複を許して選択する関数選択手段とを備えており、前記関数選択手段は、前記文書記憶手段からの文書の前記ブロック単位ごとに、前記擬似乱数により関数を順次選択し、前記関数実行手段は、前記選択された関数で、前記擬似乱数列のブロックをパラメータとして用いて、前記文書を変換して暗号化することを特徴とする暗号化システムである。
また、本発明は、あらかじめ与えられた共有鍵で暗号化文書を復号する復号化システムであって、前記暗号化文書を記憶する暗号化文書記憶手段と、あらかじめ定めたビット数をワードとして、あらかじめ定めたワード数のブロック単位に、暗号化に用いる複数種類の関数に対応する複数種類の逆関数を実行する逆関数実行手段と、前記共有鍵から擬似乱数列を生成する擬似乱数生成手段と、前記逆関数実行手段の逆関数の種類を重複を許して選択する逆関数選択手段とを備えており、前記逆関数選択手段は、前記暗号化文書記憶手段からの暗号化文書の前記ブロック単位ごとに、前記擬似乱数により逆関数を選択し、前記逆関数実行手段は、前記選択された逆関数で、前記擬似乱数列のブロックをパラメータとして用いて、前記暗号化文書を変換して復号することを特徴とする復号化システムである。
【0009】
前記暗号化システムにおいて、前記拡張鍵生成手段又は前記擬似乱数生成手段は、線形次状態関数を用いて擬似乱数を生成してもよい。
また、前記関数選択手段及び前記関数実行手段は、前記ブロックごとに、あらかじめ定めた回数選択・変換を繰り返して、前記文書を暗号化してもよい。
さらに、あらかじめ初期値を設定した、あらかじめ定めたビット数(ワード)の記憶手段を備えており、前記擬似乱数生成手段は、前記数列から擬似乱数列を生成した後に、該生成した擬似乱数列をワードに切り出して最下位ビットを1にし、前記記憶手段に前記切り出したワードを2のワード長乗を法として繰り返し乗算した結果のビット列の一部または全体を前記擬似乱数列としてもよい。
また、前記関数実行手段は、複数ワードに対するワード間関数を含み、該ワード間関数は、文書を暗号化するごとに、該複数ワードの間隔を変化してもよい。
【0010】
前記復号化システムにおいて、前記拡張鍵生成手段又は前記擬似乱数生成手段は、線形次状態関数を用いて擬似乱数を生成してもよい。
また、前記逆関数選択手段及び前記逆関数実行手段は、前記ブロックごとに、あらかじめ定めた回数選択・変換を繰り返して、前記暗号化文書を復号してもよい。
さらに、あらかじめ初期値を設定した、あらかじめ定めたビット数(ワード)の記憶手段を備えており、前記擬似乱数生成手段は、前記数列から擬似乱数列を生成した後に、該生成した擬似乱数列をワードに切り出して最下位ビットを1にし、前記記憶手段に前記切り出したワードを2のワード長乗を法として繰り返し乗算した結果のビット列の一部または全体を前記擬似乱数列としてもよい。
また、前記逆関数実行手段は、複数ワードに対するワード間逆関数を含み、該ワード間逆関数は、暗号化文書を復号するごとに、該複数ワードの間隔を変化してもよい。
【0011】
上記のいずれかに記載の暗号化システム及び復号化システムの機能をコンピュータ・システムに構築させるプログラムも、本発明である。
【発明の効果】
【0012】
本発明の実施形態2〜5の擬似乱数発生システム、暗号化システム及び復号化システムでは、鍵情報から一つの解読されにくい大きな暗号化関数を生成するのではなく、高速な異なるタイプの変換を複数個用意し、それらを鍵情報によって決まる組合せで複数回変換に用いることで暗号化する。それぞれの変換が基本的で高速なので、組み合わせた全体の変換も大変に高速である。また、関数の組み合わせ方も反復数も変えられるので、将来の仕様強化が容易である。関数属のうち、どれがどのような順番で施されたかわからないため安全性が高い。このため、従来の特許文献1および特許文献2のように複数の大掛かりな暗号化関数を用意するほどの負担をかけずに、鍵により使われる関数の種類が異なり解読の困難なシステムを実現できるようになった。
また、実施形態6に示すように、実施形態2〜5に実施形態1の方法を加えることで、より解読が難しいシステムを実現することができる。
このように、本発明によれば従来の方式に比べて暗号の安全性を高めることができる。
【図面の簡単な説明】
【0013】
【図1】本実施形態の実施形態1の擬似乱数発生システムを用いて文書の暗号化及び復号化を行なう場合のシステム構成例を示す図である。
【図2】本実施形態の実施形態2,3,5の暗号化システム及び復号化システムのシステム構成例を示す図である。
【図3】本実施形態の実施形態4の擬似乱数発生システムを用いて文書の暗号化及び復号化を行なう場合のシステム構成例を示す図である。
【図4】(a)従来のストリームサイファの処理の流れを示す図である。(b)従来のブロックサイファの処理の流れを示す図である。
【図5】実施形態1の擬似乱数発生システムの処理の流れを示す図である。
【図6】実施形態2,3の暗号化システム及び実施形態4の擬似乱数発生システムの処理の流れを示す図である。
【図7】実施形態5の暗号化システムの処理の流れを示す図である。
【発明を実施するための形態】
【0014】
以降、本発明の擬似乱数発生システム、暗号化システム及び復号化システムの実施形態を、具体的な例を挙げて詳細に説明する。実施形態1及び4は擬似乱数発生システムを文書の暗号化・復号化に用いる場合を例とした実施形態である。また、実施形態2,3,5は暗号化システム及び復号化システムの実施形態である。
なお、以降で用いる用語を以下のように定義する。
ワード: 本実施形態では、1ワード=32ビットとする。
ブロック: 何ワードごとに暗号化を行なうかの単位ブロック。(例えば1ブロック=4ワード)
【0015】
(実施形態1) あらかじめ用意した数列から生成した暗号的に安全でない擬似乱数列のワードと、1ワードのメモリに書かれたワードとの積を次々にとり、結果を該1ワードのメモリに格納し、その上位ビットから安全な暗号乱数列を生成することを特徴とする擬似乱数発生システム。数列に共有鍵を用いることにより、生成した暗号乱数列をストリームサイファによる文書の暗号化・復号化に用いることができる。
(実施形態2) ブロックに分割した文書を、ブロックごとに共有鍵から生成した擬似乱数列(拡張鍵)により選択される関数で変換して暗号化文書を生成することを特徴とする暗号化システム及び復号化システムの基本的な例(ブロックサイファ)である。
(実施形態3) ブロックに分割した文書を、ブロックごとに共有鍵から生成した擬似乱数列により選択される関数で変換して暗号化文書を生成することを特徴とする暗号化システム及び復号化システム(ストリームサイファ)である。
(実施形態4) あらかじめ用意した数列から生成した擬似乱数列のブロックを、当該擬似乱数列により選択される関数で変換して、安全な暗号乱数列を生成することを特徴とする擬似乱数列発生システム。数列に共有鍵を用いることにより、生成した暗号乱数列をストリームサイファによる文書の暗号化・復号化に用いることができる。
(実施形態5) 実施形態3と同様の暗号化システム及び復号化システムに、後述する「JUMP処理」を加えることにより、より効率的な暗号化を行なう手法を提案する。なお、このJUMP処理は実施形態2の暗号化システム及び復号化システム及び実施形態4の擬似乱数列発生システムにおいても使用することができる。
(実施形態6) 実施形態2〜5の各実施形態で用いる擬似乱数列を、実施形態1の方法で生成することにより、より複雑な暗号化を行なう手法を提案する。
以降、各実施形態を順に詳しく説明する。
【0016】
<1.実施形態1>
実施形態1は、あらかじめ用意した数列(共有鍵)から生成した暗号的に安全でない擬似乱数列のワードと、1ワードのメモリに書かれたワードとの積を次々にとり、結果を該1ワードのメモリに格納し、その上位ビットから安全な暗号乱数列を生成することを特徴とする擬似乱数発生システムである。暗号化通信における共有鍵を数列として用いることにより、生成した暗号乱数列をストリームサイファによる文書の暗号化・復号化に用いることができる。
【0017】
(1−1.従来のストリームサイファの概要と問題点)
文書のブロックbの集合をBLとすると、ストリームサイファとは、暗号化側でE1,E2,…なる暗号化関数
Ei: BL→BL’
の列を用意し、復号化側でD1,D2,…なる復号化関数
Di: BL’ →BL
の列を用意し、BLの全てのブロックbでDi(Ei(b))=bとなるようにしておいて、メッセージ=ブロックの列b1,b2,…を暗号化してE1(b1),E2(b2),…として送信し、復号化側はそれぞれにD1,D2,…を施して復号化するものである。
典型的には、BLの元からなる擬似乱数列r1,r2,…を生成して
Ei(b) := b EXOR ri
Di(b) := b EXOR ri
とするものである。すなわち、送信側、受信側は擬似乱数列riの生成手段を持っていればよい。
【0018】
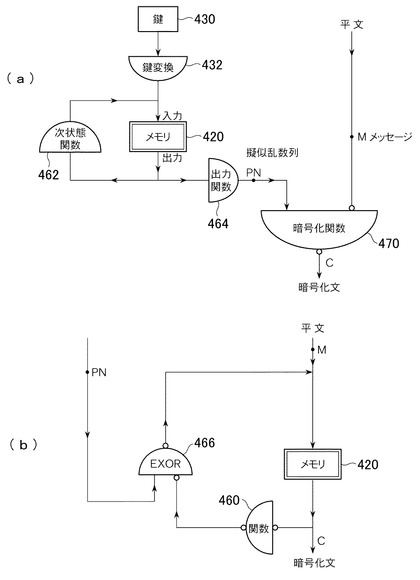
上述の従来のストリームサイファの処理の流れを示したのが、図4(a)である。擬似乱数列PN(pseudorandom numbers)を生成するのに、メモリ420(状態メモリ)を用い、それに次状態関数462を作用させ、メモリ420に書き込む。これを繰り返すことにより、メモリ420の内容は次々に変換される。このメモリ420の内容を、出力関数464を用いて変換し、擬似乱数列PNとして用いる。
生成されたPN(上述の例では列(ri)に該当)と、平文メッセージM(ブロックの列)に対し、暗号化関数470(上記の例ではE(ri,bi)に該当)を計算して、暗号化文C(cryptography)を計算する。
図4(a)の暗号化関数470に示すように、関数に小さな丸がついているのは、逆関数がつくれる、すなわち計算機で容易に計算できることを示している。この小さな丸の意味は、以降の図においても同じである。ここでは、復号化関数D(ri,ci)があって、D(ri,E(ri,b))=bとなるということである。上述したストリームサイファの典型的な例では、EもDもEXORである。
ストリームサイファであって、E1=E2=…,従ってD1=D2=…となっているものをブロックサイファという。
【0019】
図4(a)に示す従来のストリームサイファ(例えば、B. Schneier, "Applied Cryptography," John Wiley & Sons, Inc., 1996.pp. 369〜428)では、次状態関数462が複雑である(例えば、上述の従来技術BBS(Blum−Blum−Shub)では、メモリは大きな桁数の整数を保持し、その自乗をmodulo Mで計算するのが次状態関数)か、出力関数464が複雑(例えば、ハッシュ関数)であるか、暗号化関数470が複雑である(例えば、ブロック暗号)か、のいずれかによって暗号強度を保持している。
しかしながら、次状態関数を複雑にすると、擬似乱数列PNの生成速度が落ちる。また、PN周期や分布が計算できない。
次状態関数を線形にすればPNを高速生成でき、周期・分布も計算できる。例として、メルセンヌツイスター(MT)がある。(メルセンヌツイスターについては、http://www.math.keio.ac.jp/〜matsumoto/mt.html, M. Matsumoto and T. Nishimura, "Mersenne Twister: A 623-dimensionally equidistributed uniform pseudorandom number generator", ACM Trans. on Modeling and Computer Simulation Vol.8, No.1, January pp.3-30 (1998) を参照のこと。)この擬似乱数は高速に発生でき、周期が長い。しかし、出力関数が単純であれば、出力列から内部状態が推測されるので、暗号学的に安全であるとはいえない。
【0020】
(1−2.本実施形態の擬似乱数発生システム)
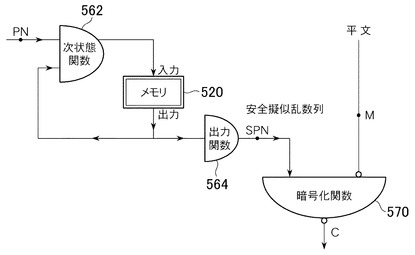
これに対し、本実施形態の擬似乱数発生システム(cryptMTと呼ぶ)は、暗号学的には安全ではないかも知れない擬似乱数列PNを、安全擬似乱数列SPN(secure pseudorandom numbers)に変換する。
図5は、本実施形態の擬似乱数発生システムの処理の流れを示す図である。なお、図5に示されたPN(安全ではないかも知れない擬似乱数列)の前には、図4(a)のPNの左側部分の処理を行なっている。なお、本実施形態において、この構成を何度も繰り返すようにしてもよい。つまり、図5のSPN生成までの処理を、図5の入力となるPNの位置にさらにつなげてもよい。
図5に示す本実施形態の構成において、次のような場合がスピード対安全性で最も効果がある。
・PN生成部分(図5につながる図4(a)のPNの左側部)には、高速高次元分布な線形生成法(図4(a)の次状態関数462が線形、例:上述のMT)を用いる。
・PN→SPN変換部分の次状態関数562は、線形ではないが高速に計算できるもの(例:32ビット整数とみての乗算)を用いる。
・SPN変換部分の出力関数564は、単純で高速なもの(例:32ビットから、上位8ビットのみをとり、残りは捨てる)を用いる。
これらの効果のある方法を用いたのが、本実施形態のcryptMTである。ただし、乗算を用いており、偶数の積はmodulo 2{32}で可逆でないため、MTの出力の最下位ビットを強制的に1にする必要がある。
【0021】
以降、図4(a)及び図5を参照しながら、本実施形態の擬似乱数発生システムを用いて、ストリームサイファにより文書(平文)の暗号化及び復号化を行なう場合の処理を説明する。なお、ここでは上述したように図4(a)の次状態関数462にメルセンヌツイスターを使用する例で説明する。
(1)共有鍵(図4(a)の鍵430)を初期シード配列として、非線形初期化法(init_by_array)により624ワードのデータを生成し、メルセンヌツイスター(以後MT)mt19937ar.cを初期化する。これは、図4(a)の鍵変換432の処理に該当し、これによりMT(次状態関数462)の状態メモリ(メモリ420)を初期化する。出力関数464は、単にメモリ420の最初のワードを出力する。
(2)初期化後のMTの出力ワード列をM(0),M(1),M(2),…とする。これが図4(a)に示す擬似乱数列PN(安全ではないかも知れない擬似乱数列)であり、図5に送られる(図5の左上のPNに該当)。なお、上述したようにM(n)はMTの出力の最下位ビットを強制的に1にしたものである。
(3)1ワード=32ビットのメモリ(変数)accumを用意する。これが図5のメモリ520に該当する。
(4)accumに初期値(例えば1)を代入する。なお、初期値は他の値(ただし、ゼロ以外)でもよい。
(5)以後、代入
accum←accum×M(n) (mod2{32})
を繰り返す(次状態関数562)。ここで、最初の64回は空回しし、65回目からあらかじめ定めた回数までaccumの上位8ビットを次々に出力する(出力関数564)。これにより、暗号学的に安全な8ビット整数擬似乱数列(SPN)を出力することができる。
なお、上述の演算の繰返し回数は例であり、システムに応じて必要な回数とすればよい。また、上述のaccumの上位8ビットの代わりに、accumのビット列の全部又は一部(例えば1ビットおきに出力するなど)を、安全擬似乱数列として次々に出力するようにしてもよい。
(6)出力された安全なSPNと、文書(平文M)とのEXORをとることにより(暗号化関数570に該当)、暗号文Cを出力する。
【0022】
また、上記(2)〜(5)の処理を、次のようにしてもよい。メルセンヌツイスターにより生成した擬似乱数のnワード目のデータの最下位ビットを1にしたデータをM(n)とし、32ビットのメモリaccumに、共有鍵データからハッシュ関数を用いた数列をつくってaccumの初期値とする。ここで、この数列の最下位ビットを強制的に1にしてもよい。次に、n=1,2,3,…について、
accum←accum×M(n) (mod2{32})
を計算し、accumの上位8ビットを出力して、暗号学的に安全な8ビット整数擬似乱数として出力する。
【0023】
(1−3.効果)
本実施形態では擬似乱数として、メルセンヌツイスター(mt19937ar.c)を用いたことで、出力される暗号乱数列は周期が219937−1であることが数学的に証明できる。この周期は従来知られているどの暗号乱数列よりも長く、安心して長期間利用することができる。
また、accumに非線形な演算(乗算)を行うことと、線形性の残る最下位ビットを使わないことで、暗号乱数列として十分な安全性を持つ。
また、メルセンヌツイスターのように、暗号的に安全でないが高速な擬似乱数を、32ビットの積という比較的速い関数で変換したことにより、このアルゴリズムを用いて生成する暗号乱数生成法は、現在アメリカのスタンダード暗号乱数生成法であるAESの最速オプティマイズ版の1.5倍以上と、非常に高速である。
また、MTの内部空間の大きさにより、time−memory−trade−off攻撃に対しても耐性が強い。
【0024】
(1−4.本実施例を用いた暗号化システム及び復号化システムの構成例)
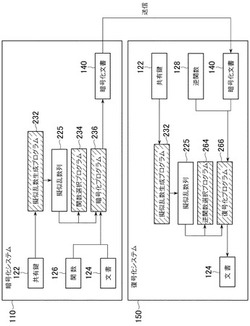
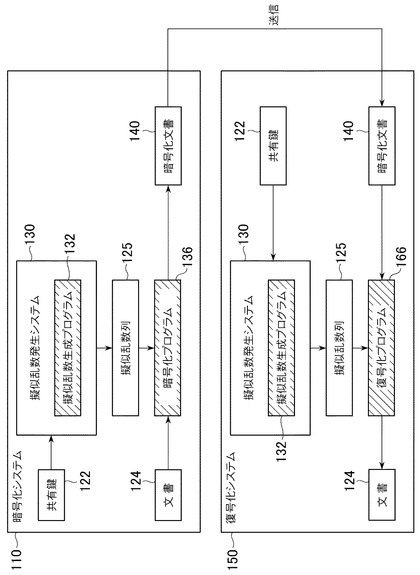
最後に、本実施形態の擬似乱数発生システムを用いて、ストリームサイファにより文書(平文)の暗号化及び復号化を行なう場合のシステム構成を、図1のシステム構成図を参照しながら説明する。
本実施形態のシステムは、例えば通常のパソコン等の端末に実装するものする。図1に示すように、文書を暗号化して送信する側の端末には暗号化システム110を、文書を受信して復号化する側の端末には復号化システム150を実装する。また、暗号化システム110及び復号化システム150の双方に、数列(共有鍵122)及び本実施形態の擬似乱数発生システム130を用意する。
暗号化システム110において、擬似乱数発生システム130の擬似乱数生成プログラム132により、共有鍵122から上述で説明した本実施形態の手法を用いて安全な擬似乱数列(安全擬似乱数列)125を生成する。次に、ストリームサイファの典型的な例として、暗号化プログラム136は、安全な擬似乱数列125と文書124のEXORをとることにより文書124を暗号化して、暗号化文書140を生成する。
【0025】
一方、復号化システム150においては、擬似乱数発生システム130の擬似乱数生成プログラム132により、共有鍵122から上述で説明した本実施形態の手法を用いて安全な擬似乱数列125を生成する。次に、復号化プログラム166は、安全な擬似乱数列125と復号化文書124のEXORをとることにより暗号化文書140を復号し、元の文書124を得る。暗号化システム110と復号化システム150とでは、同じ共有鍵122から同じ擬似乱数生成プログラム132を用いて、同じ安全な擬似乱数列125を生成するため、対応する暗号化・復号化の処理を行なうことができる。
【0026】
<2.実施形態2>
実施形態2は、ブロックに分割した文書を、ブロックごとに共有鍵から生成した擬似乱数列により選択される関数で変換して暗号化文書を生成することを特徴とする暗号化システム及び復号化システムの基本的な例であり、ブロックサイファである。関数の選択及び関数のパラメータには、共有鍵から生成した擬似乱数列が用いられる。ここで、後述の実施形態3では、文書が長いほど擬似乱数列を消費するが、本実施形態2は、一定の長さしか消費しない。このため、本実施例では、共有鍵から生成した一定の長さの擬似乱数列を「拡張鍵」とよぶ。
【0027】
(2−1.従来のブロックサイファの概要と問題点)
AESなどの従来のブロックサイファは、図4(b)に示す構成である。すなわち、平文Mのブロックをメモリ420に取り込み、擬似乱数列PNを使って変換(466に示すEXOR)を行ない、メモリ420に書き込む。これを数回繰り返して暗号文Cを得る。ここで、右下の関数460は複雑な全単射である。なお、上述の図4(a)で説明したとおり、関数に小さな丸がついているのは、逆関数がつくれる、すなわち計算機で容易に計算できることを示している。
しかしながら、上述したように、従来のブロックサイファは、鍵情報から一つの複雑な暗号化関数を作り、これを用いて平文を変換するため、高速な暗号システムでは作られる関数に偏りがあり、暗号解読のための情報を得られやすいという問題がある。たとえば暗号を解読しようとする際には、差分解読法や、線形解読法などの、既知の平文を暗号化させることによる攻撃がよく用いられている。すなわち攻撃する人物が、任意の文書を暗号化させられる状況では、解読に用いるデータを採取され、鍵の全数検索よりも簡単に暗号が破られてしまう。
【0028】
(2−2.処理の流れ)
これに対し、本実施形態では、次のような構成をとることにより、従来の問題点を解決する。
図6は、本実施形態の暗号化システムの処理の流れを示す図である。なお、後述の実施形態3の暗号化システムの処理も同図に示す通りである。
本実施形態(及び実施形態3)では、ブロックbの集合BLについて、
F: PARAM×BL→BL
の形をした単純な関数と、逆操作に当たる
F’: PARAM×BL→BL
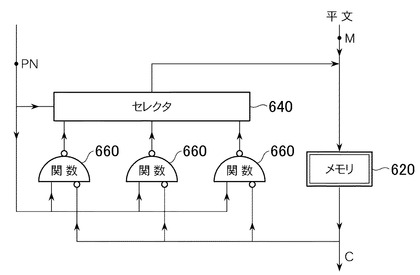
の関数を複数個用意し(F’(P,F(P,b))=bとなるものである)、図6に示すように、擬似乱数列PN(図6の左上に示すPN)をパラメータPとして消費しながら、平文Mのブロックが取り込まれたメモリ620の内容を繰り返し変換して、暗号文Cを得る。変換の際、どの関数660(上記のFに該当)を使うかは、PNをセレクタ640に送って選択する。
【0029】
上記の構成をとることにより、本実施形態(及び実施形態3)では関数の組み合わせの自由度が指数的に増大し、強固な暗号が実現できる。
また、擬似乱数列PNからパラメータ(図6における関数660で、白丸のついていないところ)を取り込むため柔軟性があり、より強固な暗号が実現できる。
さらに、共有鍵を図4(a)に示す鍵430として、上述のメルセンヌツイスターなどを用いて擬似乱数列PNを生成すれば、PNはいくらでも生成することができる。そのため、関数660による平文の変換の繰り返し回数を増やすことができ、暗号化の強度を上げることができる。
また、図6において、平文が複数のブロックからなる場合には、各ブロックに対して異なる組み合わせの関数による暗号化を行なうことができる(つまり、ストリームサイファとして使える)。
【0030】
(2−3.前提条件)
本実施形態では、1ブロック=4ワード(8ワードまたは16ワードでもよい)、128ビット以上の共有秘密鍵情報での暗号化方式を例に挙げて説明する。
前処理として、共有鍵を必要なサイズにハッシュ関数で拡張して擬似乱数列PN、すなわち拡張鍵(図6の左上のPNに該当)を生成する。本実施例では、文書はブロックサイズ(4ワード)に分割し、ブロックごとに変換するものとする。
【0031】
(2−4.用意する関数)
ブロックの変換には以下の7種類の、ブロックサイズのデータを高速で変換することができる、性質の全く異なる関数(図6の関数660に該当)を用いる。以降、これらの関数族をPEF(primitive encryption family)とよぶ。本実施形態では、ワード内の計算を行なう関数(ワード内関数)4種類と、ブロック内の複数のワードを跨ぐ計算を行なう関数(ワード間関数)3種類を用意する。なお、復号化において、ワード内関数に対応する逆関数をワード内逆関数、ワード間関数に対応する逆関数をワード間逆関数という。
t回目の演算(変換)には拡張鍵(擬似乱数列PN)のtブロック目のデータを用いる。また、拡張鍵の最後の1ブロックは関数の選択に用いる。
【0032】
(a)ワード内の計算(4種類)
(1)EXOR: ブロックの各ワードに、拡張鍵のtブロック目のデータをワードごとに排他的論理和で加える。
(2)+: ブロックの各ワードに、拡張鍵のtブロック目のデータをワードごとにmod232で加える。
(3)×: ブロックの各ワードに、拡張鍵のtブロック目の、対応するそれぞれのワードの最下位ビットを1に変えたものをmod232で掛け算する。なお、この変換については、最下位ビットを1に変えた拡張鍵のワードの掛け算の逆関数をすべて計算して辞書引きできるよう保存しておく。
(4)横シフト: ブロックの各ワードについて、拡張鍵のtブロック目の対応するそれぞれのワードの下5ビットずつを数字として用いて、その大きさの分だけのビットを右にシフトする。ワードの右にはみ出た部分をビット反転させて、左に書く。
【0033】
(b)ワードを跨ぐ計算(3種類)
(5)縦回転: 1ブロックをワードの4個(1ブロック=4ワードの場合。なお、1ブロック=8ワードとする場合は8個、1ブロック=16ワードとする場合は16個)の配列とみなし、4行32列(1ブロック=8ワードとする場合は8行32列、1ブロック=16ワードとする場合は16行32列)の0,1からなる行列とみなす。拡張鍵のtブロック目から1ワード取り出す。この1ワードでビットが1のところに対応する列をビット反転させて、さらに下方向に1行分シフトする。一番下の行のデータは一番上に書く(ローテート)。
(6)置換: 拡張鍵のtブロック目から2ビット(1ブロック=4ワードの場合。なお、1ブロック=8ワードとする場合は3ビット、1ブロック=16ワードとする場合は4ビット)を4回取り出し、それぞれを数として見た値kについて配列されたブロックのk行目と((k+5)mod4)行目(1ブロック=4ワードの場合。なお、1ブロック=8ワードとする場合は((k+5)mod8)行目,1ブロック=16ワードとする場合は((k+5)mod16)行目)を入れ換えることを、4回行う。
(7)和置換: 拡張鍵のtブロック目から2ビット(1ブロック=4ワードの場合。なお、1ブロック=8ワードとする場合は3ビット、1ブロック=16ワードとする場合は4ビット)を4回取り出し、それぞれを数として見た値kについて配列されたブロックのk行目に((k+7)mod4)行目(1ブロック=4ワードの場合。なお、1ブロック=8ワードとする場合は((k+7)mod8)行目,1ブロック=16ワードとする場合は((k+7)mod16)行目)を排他的論理和で加えることを4回行う。
【0034】
(2−5.文書の暗号化)
文書の暗号化は、文書をブロックサイズに区切り、それぞれのブロックに上述の関数を以下のように拡張鍵(擬似乱数列PN)に依存して選択して変換する。上述したように、t回目の演算(変換)には拡張鍵のtブロック目のデータを関数(図6の関数660)のパラメータとして用いる。また、拡張鍵の最後の1ブロックは関数の選択に用いる。図6で説明すると、PNの最後の1ブロックをセレクタ640に送り、セレクタ640により関数660を選択する。
本実施形態では、文書の各ブロック(図6ではメモリ620に取り込まれた平文Mのブロック)に対し、上述した7種類の関数を、例えば「横シフト・×・縦回転・(置換または和置換)・(+またはEXOR)」の順に施すことを1セットとし、これを8セット行なうことによりブロックを変換する。ただし、後ろ2つのそれぞれ2種類の関数を()内に示している箇所においては、拡張鍵の最終ブロックから1ビットずつを2×8回次々に用いて、0なら前者を、1なら後者を選択するものとする。この場合、t=40回の演算(変換)を行なうことになるため、拡張鍵は41ブロックのサイズに生成し、最後の41ブロック目を関数の選択に用いる。
なお、上記(1)〜(7)の関数は一例であり、高速に処理できる他の演算を用意してもよい。また、上記の関数の組み合わせや順序は一例であり、他の組み合わせや順序でもよい。また、繰り返し回数も上記の8セット以外の回数でもよい。また、最初の1セットと最後の1セットで全種類の変換を行ない、間のセットで全種類の関数の中から拡張鍵を用いてどれかを選択することを例えば5回以上繰り返すなどの方法を用いてもよい。1セットを複数回行なう理由は、本実施形態では全てのブロックに対して同じ変換を施すため、安全性を高める必要があるからである。
【0035】
(2−6.文書の復号化)
復号化は、暗号化の逆の順番で、それぞれの変換の逆写像を施せばよく、本実施形態では暗号化と同じくらいの時間で計算できる。
【0036】
(2−7.効果)
本実施形態の暗号化システム及び復号化システムによれば、それぞれの変換が高速であることから大量の文書を高速に暗号化でき、施された関数のタイプとその順番がわからないことから、従来のブロックサイファよりも解読が困難となる。
【0037】
(2−8.本実施例を用いた暗号化システム及び復号化システムの構成例)
最後に、本実施形態の暗号化システム及び復号化システムを用いて、文書の暗号通信を行なう場合のシステム構成例を、図2を参照しながら説明する。なお、後述の実施形態3,実施形態5も同様のシステム構成とすることができる。
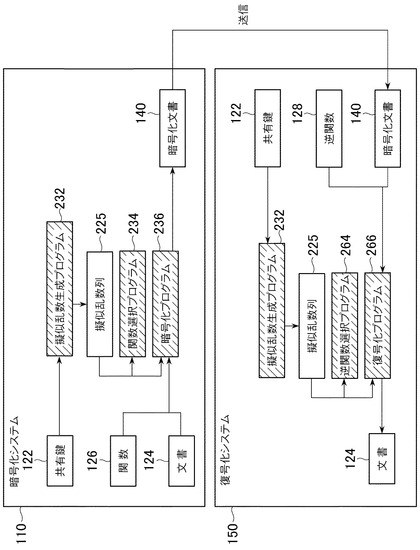
本実施形態の暗号化システム及び復号化システムは例えば通常のパソコン等の端末に実装するものとする。図2に示すように、文書を暗号化して送信する側の端末には暗号化システム110を、文書を受信して復号化する側の端末には復号化システム150を実装する。また、暗号化システム110には共有鍵122及び暗号化に用いる複数の関数126を用意し、復号化システム150には共有鍵122及び復号化に用いる複数の逆関数128(関数126の各関数に対応し、それぞれ逆の操作をする関数)を用意する。
【0038】
上述したように、本実施形態の暗号化システム及び復号化システムは、共有鍵の情報(共有鍵から生成した擬似乱数列)を暗号化関数の選択及び選択された関数のパラメータとして用いていることが主要な特徴であり、これにより高速で安全性の高いシステムを実現している。暗号化システム110では、まず、擬似乱数生成プログラム232により、共有鍵122から擬似乱数列225(本実施形態においては拡張鍵)を生成する。次に、生成された擬似乱数列(拡張鍵)225を用いて、関数選択プログラム234は関数126から文書124の暗号化に用いる関数を選択する。また、暗号化プログラム236は、擬似乱数列(拡張鍵)225を関数選択プログラム234で選択された関数のパラメータとして用いて関数を実行して文書124を暗号化する。これにより暗号化文書140を生成する。
一方、復号化システム150では、まず、擬似乱数生成プログラム232により、共有鍵122から送信端末110と同じ擬似乱数列(拡張鍵)225を生成する。次に、生成された擬似乱数列(拡張鍵)225を用いて、逆関数選択プログラム264は逆関数128から受信した暗号化文書140の復号に用いる逆関数を選択する。ここでは、送信端末110で選択された関数に対応する逆関数が選択されることになる。復号化プログラム266は、擬似乱数列(拡張鍵)225を逆関数選択プログラム264で選択された逆関数のパラメータとして用いて逆関数を実行し、暗号化文書140を復号する。これにより元の文書124を得る。
【0039】
<3.実施形態3>
実施形態3は、ブロックに分割した文書を、ブロックごとに共有鍵から生成した擬似乱数列により選択される関数で変換して暗号化文書を生成することを特徴とする暗号化システム及び復号化システムの例であり、ストリームサイファである。共有鍵の情報(共有鍵から生成した擬似乱数列)は、関数の選択及び関数のパラメータに用いられる。
本実施形態のシステム構成例は上述の実施形態2で図2を用いて説明した通りである。また、その処理の流れは実施形態2で図6を用いて説明した通りである。本実施形態と、上述の実施形態2との違いは、実施形態2(ブロックサイファ)では、一度複数の関数を選択してパラメータを決定したら、同じ関数及びパラメータですべてのブロックを変換するが、本実施形態(ストリームサイファ)では、文書のブロックごとに、関数とパラメータを決めて変換する。すなわち、全く同じブロックが2つあったときに、実施形態2ではこの2つのブロックは同じ暗号文に変換されるが、実施形態3では選択される関数もパラメータも違うため違う暗号文になる。また、上述したように、実施形態2は、一定の長さの擬似乱数列(拡張鍵)しか使わないが、実施形態3の方は、文書の長さに応じて擬似乱数を消費することになる。
【0040】
(3−1.前処理)
共有鍵に基づき擬似乱数を発生させて、32種類の乗算値(32ビット符号なしの整定数で、どれも奇数なもの)を準備する。そして、それらのmod232での乗法逆数値を計算して表にしておく。
【0041】
(3−2.ユーザが決めるマクロ定数)
(1)1ブロックのワード数(Tuple)を定義する。
#define Log_Tuple 2
#define Tuple (1UL<<Log_Tuple)
本実施形態においては、1ブロックはTuple個のワードとする。
Tupleの値は2巾であり、4以上16以下である必要がある。
Tupleの2を底としたログを、Log_Tupleとして指定する。
上記は、1ブロック=4ワードとする場合の記述である。
(2)文書のブロックの暗号化関数による変換回数(Iteration)を定義する。
#define Iteration 10
上記は、変換回数を10回とする場合の記述である。
【0042】
(3−3.グローバル変数)
暗号化したい文書(平文)を入れておく配列は二重配列
msg[Msg_Length][Tuple]
である。本実施形態で用いるグローバル変数は次の通りである。
(1)暗号化したい文書(平文)を格納する。
unsigned long msg[Msg_Length][Tuple];
(2)配列msgを直接書き換えて暗号化する。
hmnencode(key[],init_value[])
(3)配列msgを直接書き換えて復号化する。
hmndecode(key[],init_value[])
【0043】
(3−4.用意する関数)
Tuple個のワードからなるブロックの変換に用いる関数(PEF)(図6の関数660に該当)として、本実施形態では、あらかじめ、ワード内の計算を行なう関数5種類と、ブロック内の複数のワードを跨ぐ計算を行なう関数3種類の計8種類の関数を用意する。
これらの関数は全て、
PEF: BL×PARAM→BL
なる写像である。ここで、BLは文書のブロックの集合であり、PARAMは関数に与えるパラメータであり、PARAMはBLと同じくTuple個のワードからなるデータの集合であり、擬似乱数列PNから得る。
ここでは、Tuple=4の場合を例として
(w1, w2, w3, w4)←PEF(w1,w2,w3,w4; p1, p2, p3, p4)
の形で記述することにする。
以降、PEFの8種類の関数とその逆関数(_inv)をそれぞれ説明する。なお、これらの(1)〜(8)の関数は一例であり、高速に処理できる他の演算を用意してもよい。
【0044】
(a)ワード内の計算(ワード内関数及びそれに対応するワード内逆関数)5種類
(1)crypt_plus
crypt_plus
wi←wi+pi (i=1,2,3,4).
crypt_plus_inv
wi←wi−pi (i=1,2,3,4).
【0045】
(2)crypt_exor
crypt_exor
wi←wi EOR pi (i=1,2,3,4).
crypt_exor_inv
wi←wi EOR pi (i=1,2,3,4).
【0046】
(3)crypt_multi
最近のCPUは掛け算命令を持っているが、割り算は遅い。そのため、本実施形態では上述の(3−1.前処理)で述べたようにMulti_Size個(=32個)の掛け算用乱数定数を用意し、global変数の配列multi_tableに格納する。
実際の処理としては、
1)prepare_multi()を呼び出すと、multi_tableに乱数が格納される。
2)下位ビットを強制的に変換し、mod7で3のものと、mod16で7のものをmulti_table内に交互におく。これらは、mod232での乗法群を生成する。
3)prepare_multi_inv()を呼び出すと、inv_tableにmulti_tableの乗法逆数が格納される。
crypt_multi
wi←wi×mutli_table[piの上位5ビット]
wi←wi−pi
をi=1,2,3,4について行う。すなわち、パラメータpiの上位5ビットに対応する乗算用定数をmutli_table[]から読み出し、それをwiに掛ける。piの下位27ビットが捨てられるのはもったいないので、wiからpiを引いておく。
crypt_multi_inv
wi←wi+pi
wi←wi×inv_table[piの上位5ビット]
をi=1,2,3,4について行う。
【0047】
(4)crypt_hori_rotate
crypt_hori_rotate
ワードごとに、ビットを反転しながら横ローテートを行う。すなわち
si←piの上位5ビット、ただし下から4ビット目は常に1にセット
wi←(wiのビット反転の右32−siシフト)と(wiの左siシフト)のOR
wi←wi−pi
をi=1,2,3,4で行う。4ビット目を1にするのは、パラメータが0でもローテートをするため。
crypt_hori_rotate_inv
上述の逆変換
【0048】
(5)crypt_hori_rightshift
crypt_hori_rightshift
ワードごとに、ビットを反転しながら横ローテートを行う。すなわち
si←piの上位5ビット、ただし下から5ビット目は常に1にセット
wi←wi EOR (wiのビット反転の右siシフト)
wi←wi+pi
をi=1,2,3,4で行う。5ビット目を1にするのは、パラメータが0でもローテートをするためと、逆変換を易しくするため。
crypt_hori_rightshift_inv
上記の逆変換
【0049】
(b)ワードを跨ぐ計算(ワード間関数及びそれに対応するワード間逆関数)3種類
(6)crypt_vert_rotate
crypt_vert_rotate
key←p1+p4
keyを32ビットランダムパターンと思う。
w1,w2,w3,w4に関して、keyにおいて1になっているビットについては縦方向にビット反転しながらローテートする。乱数がもったいないので
wi←wi+pi
をi=1,2,3,4について行う。
crypt_vert_rotate_inv
上記の逆変換
【0050】
(7)crypt_add_permute
crypt_add_permute
i=1,2,3,4について、
wi←wi+wj
という和を行う。ここでjはpiの最下位Low_Mask=2ビットを用いて決められるが、たまたまそれがiと同じであるときにはjをmod Low_Maskでincrementしておく。
p1−p4の有効活用のために
wi←wi EOR pi
をi=1,2,3,4でやっておく。
crypt_add_permute_inv
上記の逆変換
【0051】
(8)crypt_exor_permute
crypt_exor_permute
i=1,2,3,4について、
wi←wi EXOR wj
という和を行う。ここでjはpiの最下位Low_Mask=2ビットを用いて決められるが、たまたまそれがiと同じであるときにはjをmod Low_Maskでincrementしておく。
p1−p4の有効活用のために
wi←wi−pi
をi=1,2,3,4でやっておく。
crypt_exor_permute_inv
上記の逆変換
【0052】
(3−5.擬似乱数列)
ここでは擬似乱数列PN(図6の左上のPNに該当)の生成方法として、上述のメルセンヌツイスター(mt19937ar.c)を用いる。mt19937ar.cは、任意長の配列を初期値として受け取る機能を持つ。
擬似乱数列は4ワードずつ読み込むようにした。内部配列長の624が4でわりきれるため、624/4回読み込むごとに配列全体に擬似乱数列を生成しなおす。
genrand_fourint32(param)
により、param[0]〜param[3]に32ビット長符号なし整数乱数が読み込まれる。
暗号化する際の
crypt_...(unsigned long block[Tuple])
では、どれも内部でgenrand_fourint32(param)を呼び出してp1,p2,p3,p4を生成している。それに対し、復号化する際の
crypt_..._inv(block[],param[])
では、paramのところにp1〜p4を指定する。この違いは、復号化する場合には擬似乱数列を逆向きに生成しなくてはならないことに起因する。復号化する場合には、擬似乱数列を配列temp_randにいったん記録しておき、逆向きに使う。
【0053】
(3−6.文書の暗号化)
hmnencode(key[],init_value[])
を呼び出すと、文書(図6においては、メモリ620に取り込んだ平文Mのブロック)の暗号化を行なう。key,init_valueは配列で、あわせてメルセンヌツイスターの初期化に使われる。
(1)multi_tableに乗算定数をしまう。
(2)擬似乱数列PNを4ワードfunc_choice[0]−[3]の4つに格納し、積とEORを用いて新たな4ワードに書き換える。(あとでこの4ワードを3ビットずつに切り出し、上述の5+3種のPEFの選択を行う。)
(3)まずは平文に対して次の3つを施す。
crypt_multi(msg[i]);
crypt_vert_rotate(msg[i]);
crypt_hori_rightshift(msg[i]);
(4)その後はIterate回、func_choiceを用いてPEF関数を選択し(図6のセレクタ640の処理に該当)、MTで生成した擬似乱数列PNをパラメータとして与えながら変換を繰り返す。
(5)最後に再び
crypt_multi(msg[i]);
crypt_vert_rotate(msg[i]);
crypt_hori_rightshift(msg[i]);
を作用させる。
【0054】
(3−7.文書の復号化)
hmndecode(key[], init_value[])
を呼び出すと、復号化を行なう。key,init_valueは配列で、あわせてメルセンヌツイスターの初期化に使われる。
(1)multi_tableに乗算定数をしまう。
(2)inv_tableにその乗算に関する逆元をしまう。
(3)擬似乱数を4ワードfunc_choice[0]〜[3]の4つに格納し、積とEORを用いて新たな4ワードに書き換える。(あとでこの4ワードを3ビットずつに切り出し、上述の5+3種のPEFの選択を行う。)
(4)後で使われるべき乱数ブロックを、3+Iteration+3個作って配列temp_randにしまっておく。
(5)暗号文に対して、3つの逆変換を施す。
crypt_hori_rightshift_inv(msg[i],temp_rand[−−k]);
crypt_vert_rotate_inv(msg[i],temp_rand[−−k]);
crypt_multi_inv(msg[i],temp_rand[−−k]);
(6)その後はIterate回、func_choiceを用いてPEF関数を選択し、格納しておいたMTの出力を与えながら逆変換を繰り返す。
(7)最後に再び
crypt_hori_rightshift_inv(msg[i],temp_rand[−−k]);
crypt_vert_rotate_inv(msg[i],temp_rand[−−k]);
crypt_multi_inv(msg[i],temp_rand[−−k]);
を作用させる。
【0055】
<4.実施形態4>
実施形態4は、あらかじめ用意した数列(共有鍵)から生成した擬似乱数列のブロックを、当該擬似乱数列により選択される関数で変換して、安全な暗号乱数列を生成することを特徴とする擬似乱数列発生システムである。ここで、数列は、関数の選択及び関数のパラメータとして用いられる。暗号化通信における共有鍵を数列として用いることにより、生成した暗号乱数列をストリームサイファによる文書の暗号化・復号化に用いることができる。
【0056】
(4−1.擬似乱数列の生成)
一般に実験などに利用されている擬似乱数列は、高速に生成されるが、いくつかのワードを見ると他のワードがわかってしまうため、暗号学的には安全でない。このため、従来、暗号乱数列の生成には、BBS法に代表される計算量の大きな暗号化方式が用いられている。本実施形態は、本発明のポイントである、鍵情報を関数選択に用いることで、高速な擬似乱数列を少ない計算量で暗号乱数列に書き換えることを特徴とした擬似乱数発生システムであり、高速で安全なストリームサイファを構成することができる。
ここでは擬似乱数PNの生成方法として実施形態1で説明したメルセンヌツイスター(mt19937ar.c)を用いる。高速で周期が長い擬似乱数列を生成できるためである。なお、他の擬似乱数生成方法を用いてもよい。
前処理として、あらかじめ暗号化・復号化を行う双方で、共有鍵を用いて624ワードの秘密の擬似乱数列の初期値を求めておく。使い続ける共有秘密鍵の他に、一回の通信ごとにセッション鍵を受け取る場合には、ここで作成した初期値の一部をセッション鍵に変えたものを、その通信で用いる擬似乱数列の初期値とし、乱数は初期値の次の値から使うものとする。
【0057】
擬似乱数列PNは、必要になった分だけ次々に作ることとして、以下のように安全な擬似乱数列を出力する。擬似乱数列PNの12nワード目のデータを、12n+1ワード目から12n+11ワード目のデータを用いて次のように書き換える。以下、擬似乱数のmワード目のデータをR(m)であらわす。
x=R(12n)とし、R(12n+1)のデータを上から2ビットずつ10回見て、この値により次の操作でxを書き換えていく。
t回目の2ビットが
(1)00ならば、xを、x+R(12n+t+1)mod232に書き換える。
(2)01ならば、xを、x EXOR R(12n+t+1)に書き換える。
(3)10ならば、xを、x×R(12n+t+1)*に書き換える。ただし、p*は、pの最下位ビットを1にした数とする。
(4)11ならば、xを、x shift R(12n+t+1)に書き換える。ただし、s shift tは、tの上5ビットの大きさの分だけのsのビットを右にシフトし、ワードの右にはみ出た部分をビット反転させて、左に書いたものとする。
10回書き換えたら、xを暗号乱数列のnワード目として出力する。
【0058】
なお、上記(1)〜(4)の関数は一例であり、高速に処理できる他の演算を用意してもよい。また、必要な強度に応じて変換の回数を増やし、また強制的に掛け算とシフトがあらわれるようにするなどの方法で、安全性を高めることができる。1つのワードを求めるのにm+2ワード(mは6〜16くらい)用いて変換の回数をm回とし、1回目とm−1回目の変換をシフト、2回目とm回目の変換を掛け算と決めるなど必要に応じて調整すると良い。
メルセンヌツイスターには、周期の完全な保障と、分布のある程度の保障がある。周期がとても長いことから、生成した安全擬似乱数列の周期も使い切ることができないくらい長くなり、共有鍵を取り替えずに長く使い続けることができる。
【0059】
(4−2.本実施例を用いた暗号化システム及び復号化システムの構成例)
最後に、本実施形態の擬似乱数発生システムを用いて、ストリームサイファにより文書(平文)の暗号化及び復号化を行なう場合のシステム構成例を、図3のシステム構成図を参照しながら説明する。
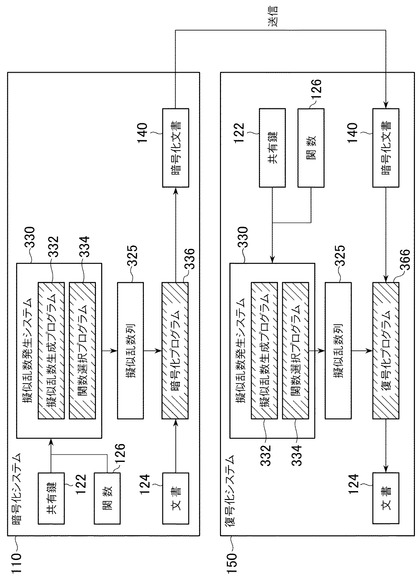
本実施形態のシステムは、例えば通常のパソコン等の端末に実装するものする。図1に示すように、文書を暗号化して送信する側の端末には暗号化システム110を、文書を受信して復号化する側の端末には復号化システム150を実装する。また、暗号化システム110及び復号化システム150の双方に、数列(共有鍵122)、関数126、及び本実施形態の擬似乱数発生システム330を用意する。
暗号化システム110では、まず、共有鍵122から従来技術の手法により安全ではないかもしれない擬似乱数列PNを生成する。次に、生成されたPNを用いて、関数選択プログラム334は関数126からPNの暗号化に用いる関数を選択する。また、擬似乱数生成プログラム332は、PNを関数選択プログラム334で選択された関数のパラメータとして用いて関数を実行し、PNを暗号化する。これにより、安全な擬似乱数列325を生成して、記憶領域に一時的に格納する。次に、ストリームサイファの典型的な例として、暗号化プログラム336は、擬似乱数列325と文書124のEXORをとることにより文書124を暗号化して、暗号化文書140を生成する。
【0060】
一方、復号化システム150でも、共有鍵122から従来技術の手法により安全ではないかもしれない擬似乱数列PNを生成する。次に、生成されたPNを用いて、関数選択プログラム334は関数126からPNの暗号化に用いる関数を選択する。また、擬似乱数生成プログラム332は、PNを関数選択プログラム334で選択された関数のパラメータとして用いて関数を実行し、PNを暗号化する。これにより、安全な擬似乱数列325を生成して、記憶領域に一時的に格納する。次に、復号化プログラム366は、擬似乱数列325と暗号化文書140のEXORをとることにより暗号化文書140を復号し、元の文書124を得る。
暗号化システム110と復号化システム150とでは、同じ共有鍵122及び関数126を用いて、同じ安全な擬似乱数列325を生成するため、暗号化に対応する復号化の処理を行なうことができる。
【0061】
<5.実施形態5>
実施形態5は、上述の実施形態2〜4のシステムに、後述する「JUMP処理」を加えることにより、より効率の良い暗号化を行なう手法を提案する。なお、ここでは実施形態3と同様の暗号化システム及び復号化システムにJUMP処理を追加する例で説明するが、使用する関数(PEF)等については、実施形態3とは異なるものを用意して説明する。
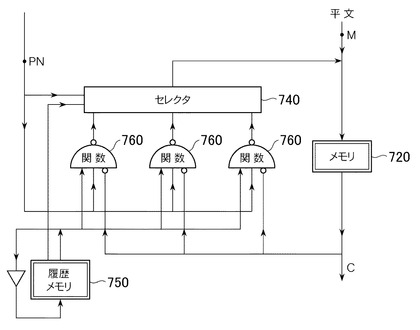
本実施形態の暗号化システムの処理の流れを、図7に示す。
まず、共有鍵(数列)から上述の実施形態2〜4と同様の方法(例えばメルセンヌツイスター)により擬似乱数列を生成して、これを本実施形態で使用する擬似乱数列PNとする(図7の左上部)。
次に、擬似乱数列PNをセレクタ740に送り、どの関数760を選ぶかを決定する。図6で示した実施形態2〜4との違いは、ブロックの変換が何ステップ目であるかを記録する履歴メモリ750が追加されている点であり。これによりjumpという値が計算される。
jumpは、「各ワードの情報を、どれだけ離れたワードに渡すか」を各関数に指定するものである。1つのブロックを変換するとき、jumpは1ステップ目の変換では1,2ステップ目は2,3ステップ目は4,…と二倍二倍に増えて行き、t(1ブロック内のワード数)以上になったら1に戻す。このjumpの処理は、履歴メモリ750がセレクタ740に指示を出すことにより行なう。
【0062】
また、本実施形態では、関数の選択においても、第1ステップでは本実施形態で用いる9種類の関数(PF1〜PF9)のうちからワード内関数PF1〜PF4(ワード内の計算を行なう関数)の1つを選び、第2ステップではワード間関数PF5〜PF8(ブロック内の複数のワード間に跨る計算を行なう関数)の1つを選び、第3ステップではPF9を選び、第4ステップではPF1〜PF4の1つを選び、…という具合に、ステップごとに関数選択の範囲が変わる。この処理も履歴メモリ750がセレクタ740に指示を出すことにより行なう。なお、本実施形態で用いる9種類の関数(PF1〜PF9)については後で詳しく説明する。
また、選択された関数760は、ブロックサイズと同程度の大きさのパラメータを受け取る。関数のパラメータには、実施形態2〜4と同様、共有鍵(数列)から生成した擬似乱数列PNを用いる。
【0063】
上述のjumpの効用は、次の通りである。1ブロック=tワードとして、ワード間関数を用いてワード間に跨る変換を行なう場合、あるワードの情報を他の全てのワードに早く渡すためには、隣接する次のワードのみに情報を渡すのは、あるワードの情報が他の全てのワードに達するのにt回の繰り返しが必要なため、最も効率的な方法ではない。高速に変換するには2ワードなど少ないワード間の計算の方がよく、変換を行なうごとに、最初は1ワード隣り(間隔1)、次は2ワード隣り(間隔2)、次は4ワード隣り(間隔4)、…という具合にワードの間隔を倍倍にしていくのが最も効率的である。
ここで対象となる2ワードを●で表すと、上記のワードの間隔とは、
●● 間隔1の関係
●○● 間隔2の関係
●○○○● 間隔4の関係
である。
このように、全ての自然数tがlog2(t)桁の2進数によって表されることにより、log2(t)回の繰り返しによって、0,1,…,t−1の全ての距離のワードに対して情報を渡すことができる。すなわち、JUMP処理はワード間関数が少ないワード間(本実施形態においては2ワード間)の計算であっても、少ない繰り返し回数で十分な撹拌がされるようにするための処理である。
【0064】
(5−1.前提条件及び前処理)
(1)Wを32bit=1ワード符号なし整数の集合とする。
ここには、二項演算としてビットごとのEXOR,AND,OR,足し算,掛け算(modulo 2{32})、単項演算として右シフト,左シフト,ビット反転が行える。これらは最近のCPUの命令セットに通常入っている演算である。
(2)ブロックbの集合BLを、
BL=Wt
で定義する。ただし、tは4,8,または16とする。
(3)パラメータpの集合PARAMを、
PARAM=Wt×{0,1,2,…,t/2}
で定義し、飛ばし値jの集合JUMPを
JUMP={1,2,4,8,…,t/2}
で定義する。
(4)次の形の関数(PEF)を9種類(PF1,...,PF9)用意する。これが図7でいうところの関数760に該当する。なお、9種類のPEFの詳細は後で詳しく説明する。
PF: JUMP×PARAM×BL→BL.
これらのJUMP,PARAM,BLが図7の関数760への入力線3本にそれぞれ対応している。
ここで、PFの逆関数
PF’: JUMP×PARAM×BL→BL.
も復号化のために構成しておく。ここで、
PF’(j, P, PF(j, P, b))=b
である必要があり、また高速に計算できるものが望ましい。
(5)本実施形態では、鍵情報(共有鍵)は上述の他の実施形態と同様にメルセンヌツイスター(MT)の処理に送られる。MTを用いて乗法定数テーブル、加法定数テーブルを作成する。乗法定数テーブル、加法定数テーブルについては後で詳しく説明する。
なお、上記以外の前提条件及び前処理は、上述の実施形態3の(3−1.前処理)〜(3−3.グローバル変数)で説明した通りであり、あらかじめIteration(変換回数)とLog_Tuple(ブロック内のワード数の対数)を決めておく。
【0065】
(5−2.文書の暗号化)
次に、平文ブロックを暗号化する。ここでは、1ブロック=4ワード、変換回数を4回として説明する。なお、本実施形態において、文書の暗号化は、JUMP処理以外の部分は実施形態3と同様である。
今、与えられた平文ブロックはワード長変数t個の配列
B:=(b0,b1,...,b{t−1})
に格納されているものとする。
本実施形態の一ラウンドは次のようになっている。
1)ラウンドの開始
2)PF1〜PF4から1つランダムに選んで、それを用いてBを書き換える
3)PF5〜PF8から1つランダムに選んで、それを用いてBを書き換える
4)PF9を用いてBを書き換える
5)ラウンドの終了
上記を4ラウンド行い、1ブロック分の暗号化ブロックを得る。
【0066】
具体的には、1ブロックの暗号化は、次のようにして行われる。
(0)jump←1
(1)MTから4ワードの擬似乱数を取得
(2)この4ワードから2ビットの擬似乱数を8組生成し、c1,c2,c3,...,c8とする(生成方法については後で説明する)
(3)c1=0,1,2,3に従って、PF1,PF2,PF3,PF4のうちの1つPF*を選択する
(4)MTから4ワードの擬似乱数を取得し、これをPとする
(5)PF*(jump,P,B)を用いてBを書き換える。jumpを2倍し、t以上になったら1にする
(6)c2=0,1,2,3に従って、PF5,PF6,PF7,PF8のうちの一つPF*を選択する
(7)MTから4ワードの擬似乱数を取得、Pとする
(8)PF*(jump,P,B)を用いてBを書き換える。jumpを2倍し、t以上になったら1にする
(9)MTから4ワードの擬似乱数を取得、Pとする
(10)PF9(jump,P,B)を用いてBを書き換える。jumpを2倍し、t以上になったら1にする
(3)〜(10)を4回繰り返す。2回目ではc1,c2の代わりにc3,c4を使う。
3回目ではc5,c6,4回目ではc7,c8をそれぞれ使う。なお、図7でいうと、jumpが履歴メモリ750に格納されている。
【0067】
次に、上述の(2)のc1〜c8の生成方法を説明する。
上記(1)で取得した4ワードをfunc_choice[0],...,func_choice[3]として、次の変換を行う。
func_choice[2]*=(func_choice[0]|1);
func_choice[3]*=(func_choice[1]|1);
func_choice[0]^=(func_choice[3]>>5);
func_choice[1]^=(func_choice[2]>>5);
ここで、*=は左辺に右辺を掛けて左辺に代入する命令,^=は左辺に右辺とEXORをとって、左辺に代入する命令,|はビットごとのOR,>>5は5ビット右シフトを表す。こうして、func_choice[0]の上位2ビットがc0,次の2ビットがc1,と順番にとっていく。ラウンドの回数が16より多いときには、例えばfunc_choice[1]の上位ビットから用いるようにする。
【0068】
(5−3.文書の復号化)
本実施形態における文書の復号化は、JUMP処理以外の部分は実施形態3と同様である。
(1)復号に用いるJUMPの初期値を求める。
これは暗号化に用いる上述の2つの定数、Iteration(変換回数)とLog_Tuple(ブロック内のワード数の対数)から、次の式で求める事が出来る。
JUMP=1<<((3*Iteration−1)%Log_Tuple)
ここで、%は剰余を求める演算であり、1 << は、1を<<の右の回数だけ2倍するという意味である。
(2)JUMPの変化は、暗号化の逆にする。
すなわち、1ブロック=4ワードの場合は、繰り返し毎に4,2,1と半分にしていき、1の次は4に戻る。
(3)このようにJUMPが決定されれば、暗号化の時に使用した関数に対応する逆関数を選択し、このJUMP値および暗号化時と同じパラメータを与えることができる。
【0069】
(5−4.用意する関数)
本実施形態で用いる関数として、ブロック内のそれぞれのワードを主にワード内で変換する関数としてPF1,PF2,PF3,PF4の4種類、ワード間の情報を混ぜるための変換を行なう関数としてPF5,PF6,PF7,PF8の4種類、関数として1種類、計9種類の関数を用意する。以降、これら9種類の関数について順に説明する。なお、これらのPF1〜PF9の関数は一例であり、高速に処理できる他の演算を用意してもよい。
【0070】
(1)PF1〜PF4(ワード内関数)
PF1〜PF4は、ブロック内のそれぞれのワードを主にワード内で変換するワード内関数である。復号化にはそれぞれ関数の逆の処理を行なう逆関数(ワード内逆関数)を用いる。
ブロックをb0,b1,…,b{t−1}なるtワードとし、パラメータをp0,p1,...,p{t−1}なるtワードとする。まず、
bj←bj EXOR pj
なる代入を行う。(j=0,1,…,t−1)。つぎに、奇数定数をかける:
bj←bj×cj(mod 2{32},以下modはいつもついているが省略)(j=0,1,…,t−1)。
cjは、あらかじめMTにより生成された奇数乱数のテーブルm0,m1,…,m{31}より次の方法で選ばれる。m0,…,m{31}はすべて奇数であるよう、最下位ビットを1にしてある。また、cj:=m{kj}であり、kjはp{j+ell}の最上位5ビットを0〜31の整数と見たものである。ここで、ellの値はPF1,PF2,PF3,PF4のときそれぞれ1,2,2,3である。なお、テーブルを用意したのは復号化の際にcjの逆数(modulo 2{32})を用いるからである。
本実施形態では、暗号化を行う前処理としてこの乗法定数テーブルm0,…,m{31}をMTにより作成し、そのmodulo 2{32}での乗法逆数のテーブルを作成して保存する。さらに、ある加法定数テーブルadd0,…,add{31}もMTにより作成して保存する。
【0071】
次に、
b{(j+jump)mod t}←b{(j+jump)mod t}□add{[bj>>(32−5)]}
なる代入を行なう。j=0,1,2,…,t−1を、この順序で計算する。これは、まずbjの上位5ビットを見て、それに対応するaddのテーブル(加法定数テーブル)の値と、b{j+jump}(添え字はmodulo tで見る)の値とを二項演算□を取って、その結果をb{j+jump}に格納するということである。二項演算□は、PF1,PF2,PF3,PF4のときにそれぞれ+,EOR,+,EORである。
次に、以下のようにして16〜23に値をとる擬似乱数sjを生成する。
sj←((pj>>(32−4))|0x10)&0x17
ここで、&はビットごとのAND演算である。
sjを用いて、bjに対して次の二つの変換のいずれかを行う。
bj←((〜bj)<<(32−sj))|(bj>>sj).
bj←bj EXOR ((〜sim bj)>>sj).
上はローテート(ただし、左からあふれた分はビット反転〜をとる)である。下は、ビット反転したものを右にsjシフトしたものをbjに足すものである(シフトと呼ぶ)。PF1,PF2,PF3,PF4で、それぞれローテート、ローテート、シフト、シフトを選ぶ。
【0072】
(2)PF5〜PF8(ワード間関数)
PF5〜PF8は、は、主にワード間(本実施形態においては2ワード間)の情報を混ぜるための変換を行なうワード間関数である。復号化にはそれぞれの関数の処理の逆の操作を行なう逆関数(ワード間逆関数)を用いる。
1)PF5
まずj=0とし、
bj←bj+(b{j−jump}×pj)
を行なう。
sj←((pj>>(32−4))|0x10)&0x17
により16〜23に値をとる擬似乱数を生成し、
bj←bj EXOR ((〜sim bj)>>sj).
を行う。これをj=0,1,2,…,t−1とこの順に繰り返す。
【0073】
2)PF6〜PF8
j=0とする。
s←(pj>>(32−log2(t)))
により、sにpjの上位log2(t)ビットを格納する。s=jとなったときは、sから1を引く(modulo tで計算する)。これにより、sとjは異なる。ここで、
PF6では、
bj←(bj EXOR (b{j−jump}×bs))−pj
bj←bj EXOR (bj>>16)
なる代入を行う。添え字はmodulo tで考える。
PF7,PF8では、
bj←(bj EXOR (b{j−jump}×(bs□−pj));
bj←bj EXOR (bj>>c);
なる代入を行う。ここで、□は、PF7の時にはビットごとのOR,PF8ではEXORである。また、cは、PF7のときには16、PF8のときには17である。
【0074】
(3)PF9
k=2(p0+p{t−1})+1 mod 2{32}
としておいて、jump_oddをjump以下の最大の奇数とする。ブロックb0,b1,…,b{t−1}において、kのビットパターンで1になっているところを、jump_oddとばしに巡回置換する。すなわち、以下の置換を行う。
1)kのビットパターンで1になっている部分に対応するb0のビットを抽出し、保存しておく。これは、b0とkのビットごとAND演算の結果を保存することと等しい。
2)次に、b0における上記のビットを、b{−jump_odd}における対応するビットによって置換する。ここで、bの添え字はmodulo tで計算するものとする。
3)次に、b{−jump_odd}における対応するビットを、b{−2jump_odd}に対応するビットによって置換する。このように、玉突き的にb{−j×jump_odd}における対応するビットを、
b{−(j+1)×jump_odd}における対応するビットに置換する、という操作をj=0,1,…t−1について行う。
4)最後に、b{−(t+1)×jump_odd}における対応するビットを、保存しておいたb0の対応するビットに置換する。
復号化には、上述の処理の逆の操作を行なう逆関数を用いる。
【0075】
<6.実施形態6>
実施形態6は、実施形態2〜5の各実施形態において、あらかじめ用意した数列(共有鍵)から上述のcryptMT(実施形態1)の方法で生成した暗号学的に安全な擬似乱数列SPNを、これらの実施形態で用いる擬似乱数列PNとする手法である。この手法では、暗号化に用いる関数の選択及び関数のパラメータに暗号学的に安全な擬似乱数列を用いるため、より解読が困難な暗号化を行なうことができる。
【技術分野】
【0001】
本発明は、共有鍵を用いたブロックサイファ及びストリームサイファにおける擬似乱数発生システムを利用した暗号化システム及び復号化システムである。
【背景技術】
【0002】
第三者に見られては困る文書を電子データとして保存する時には、データは暗号化され、パスワードを知らなければ解読できないように変換される。ここで利用される暗号技術として、現在広く使用されているのは、データを固定サイズのブロックに区切り、それぞれのブロックを秘密鍵に依存した特定の関数で暗号化する、ブロックサイファと呼ばれる暗号化方式と、データの位置によって異なる関数で暗号化されるストリームサイファと呼ばれる暗号化方式である。ストリームサイファではデータと暗号乱数列の排他的論理和を求めることが多い。
また、インターネットを用いて電子商取引を行なう際にも、第三者に知られることなく、安全に2点A,B間で通信を行なうために、データは暗号化して伝送されている。その時に利用される暗号技術として、現在広く利用されているのは、DESやTriple DES,AESに代表される共有鍵暗号方式である。これは、通信を行なうA,B間でのみ共有している共有暗号鍵をもとに、送信するデータを第三者に分からないデータに変換する方法である。
【0003】
DES(Data Encryption Standard)は、これまでアメリカ合衆国政府の国立標準研究所(NIST)が、データ暗号の標準として推奨してきた共有鍵暗号方式である。Triple DESはDESを3回繰り返すことで、その安全性を高めた暗号方式である。AES(Advanced Encryption Standard)は、DESに代わるデータ暗号の標準としてNISTが公募し、数学者J.Daemen,V.Rijmenによって開発されたRijindaelと呼ばれる暗号化方式である。これらはすべて、共有鍵を利用して、固定サイズのブロックに区切られたデータを高速に暗号化する共有鍵暗号方式であり、ブロックサイファである。この変換に必要な計算量は大変小さく、実用性が高い。
ストリームサイファでは、平方剰余により擬似乱数を生成するBlum−Blum−Shub(BBS)法により暗号乱数列を生成し、文書との排他的論理和を暗号文とする方法が知られている。BBS法は、暗号鍵kを次々に二乗して、秘密の2つの素数の積Nでの剰余を作り、その最下位ビットを並べて作った列を暗号乱数列とする方針である。このNが十分大きければ、この列が暗号的に大変優れたもの、すなわち連続するいくつものデータを集めても、次のビットをランダムより良い確率で予測することが難しい、という性質をもつ擬似乱数列になっていることは、文献「L. Blum, M. Blum, M. Shub: “A Simple Unpredictable Psudo-Random Number Generator”, SIAM J. Comput. Vol15, No.2, May 1986」で示されている。よって、これを用いれば、たくさんの文字を推定しても、法則を見つけることは大変に難しく、他の部分列を推定するには、全数チェック相当の計算が必要となると考えられている。
【0004】
しかしながら、従来の共有鍵暗号方式のブロックサイファでは、鍵情報から一つの複雑な暗号化関数を作り、これを用いて平文を変換するため、高速な暗号システムは作られる関数に偏りがあり、暗号解読のための情報を得られやすいという問題がある。たとえば暗号を解読しようとする際には、差分解読法や、線形解読法などの、既知の平文を暗号化させることによる攻撃がよく用いられている。すなわち攻撃する人物が、任意の文書を暗号化させられる状況では、解読に用いるデータを採取され、鍵の全数検索よりも簡単に暗号が破られるという問題があった。また、共有鍵暗号方式のストリームサイファでも、例えば上記のBBS法では大きな数の自乗と、その値の大きな数Nでの剰余を計算するため低速であるように、十分な安全性を持つ暗号乱数列を生成するための計算量は大きく低速になり、高速に生成できる擬似乱数は暗号的に安全でないという問題がある。
また、これまでに知られているストリームサイファ用暗号乱数列は周期が短く長く使い続けることができないという問題があった。
【0005】
これらの問題に対処する方法として、例えば特許文献1〜特許文献5がある。特許文献1および特許文献2では、複数の暗号化関数を用意し、鍵情報や外部からのデータにより、どの暗号化関数で暗号化するかを選択することで、平文によって異なる暗号化関数で暗号化し、これにより情報の漏洩を防いだり、認証効果を得たりしている。また、特許文献3〜特許文献5では、性質の良い暗号乱数列の作り方を与えている。特に特許文献3では、平文列を有限状態オートマトンで書き換えて暗号乱数列を生成していて、本発明と関係が深い。線形フィードバックシフトレジスタ(linear feedback shift register (LFSR))にもとづいた擬似乱数生成装置であるが、ソフトウェア実装した場合の処理速度が充分ではないという問題がある。また、LFSRにもとづいた擬似乱数生成装置についての従来技術としては、たとえば、文献「B. Schneier, "Applied Cryptography," John Wiley & Sons, Inc., 1996.pp. 369〜428」に開示されている。
【先行技術文献】
【特許文献】
【0006】
【特許文献1】特許公開平11−15940号公報
【特許文献2】特許公開平11−265146号公報
【特許文献3】特許公開平11−500849号公報
【特許文献4】特許公開2003−37482号公報
【特許文献5】特許公開2004−38020号公報
【発明の概要】
【発明が解決しようとする課題】
【0007】
しかしながら、上記の特許文献1および特許文献2の方法を用いて十分な効果を得るには、なるべく多くの暗号化関数を用意しなくてはならないが、複数の暗号化関数を保存するには、その個数倍のメモリや関数作成のための計算量が必要となるという問題がある。
また、特許文献3〜特許文献5の方法を用いて暗号乱数列を作っても、十分に長い周期を得ることはできず、速さまたは安全性に問題が生じる。
本発明の課題は、計算量を増やさずに安全性を高め、これらの問題を解決することである。
【課題を解決するための手段】
【0008】
本発明は、あらかじめ与えられた共有鍵で文書を暗号化する暗号化システムであって、前記文書を記憶している文書記憶手段と、あらかじめ定めたビット数をワードとして、あらかじめ定めたワード数のブロック単位に、複数種類の関数を実行する関数実行手段と、前記共有鍵から擬似乱数列を生成する擬似乱数生成手段と、前記関数実行手段の関数の種類を重複を許して選択する関数選択手段とを備えており、前記関数選択手段は、前記文書記憶手段からの文書の前記ブロック単位ごとに、前記擬似乱数により関数を順次選択し、前記関数実行手段は、前記選択された関数で、前記擬似乱数列のブロックをパラメータとして用いて、前記文書を変換して暗号化することを特徴とする暗号化システムである。
また、本発明は、あらかじめ与えられた共有鍵で暗号化文書を復号する復号化システムであって、前記暗号化文書を記憶する暗号化文書記憶手段と、あらかじめ定めたビット数をワードとして、あらかじめ定めたワード数のブロック単位に、暗号化に用いる複数種類の関数に対応する複数種類の逆関数を実行する逆関数実行手段と、前記共有鍵から擬似乱数列を生成する擬似乱数生成手段と、前記逆関数実行手段の逆関数の種類を重複を許して選択する逆関数選択手段とを備えており、前記逆関数選択手段は、前記暗号化文書記憶手段からの暗号化文書の前記ブロック単位ごとに、前記擬似乱数により逆関数を選択し、前記逆関数実行手段は、前記選択された逆関数で、前記擬似乱数列のブロックをパラメータとして用いて、前記暗号化文書を変換して復号することを特徴とする復号化システムである。
【0009】
前記暗号化システムにおいて、前記拡張鍵生成手段又は前記擬似乱数生成手段は、線形次状態関数を用いて擬似乱数を生成してもよい。
また、前記関数選択手段及び前記関数実行手段は、前記ブロックごとに、あらかじめ定めた回数選択・変換を繰り返して、前記文書を暗号化してもよい。
さらに、あらかじめ初期値を設定した、あらかじめ定めたビット数(ワード)の記憶手段を備えており、前記擬似乱数生成手段は、前記数列から擬似乱数列を生成した後に、該生成した擬似乱数列をワードに切り出して最下位ビットを1にし、前記記憶手段に前記切り出したワードを2のワード長乗を法として繰り返し乗算した結果のビット列の一部または全体を前記擬似乱数列としてもよい。
また、前記関数実行手段は、複数ワードに対するワード間関数を含み、該ワード間関数は、文書を暗号化するごとに、該複数ワードの間隔を変化してもよい。
【0010】
前記復号化システムにおいて、前記拡張鍵生成手段又は前記擬似乱数生成手段は、線形次状態関数を用いて擬似乱数を生成してもよい。
また、前記逆関数選択手段及び前記逆関数実行手段は、前記ブロックごとに、あらかじめ定めた回数選択・変換を繰り返して、前記暗号化文書を復号してもよい。
さらに、あらかじめ初期値を設定した、あらかじめ定めたビット数(ワード)の記憶手段を備えており、前記擬似乱数生成手段は、前記数列から擬似乱数列を生成した後に、該生成した擬似乱数列をワードに切り出して最下位ビットを1にし、前記記憶手段に前記切り出したワードを2のワード長乗を法として繰り返し乗算した結果のビット列の一部または全体を前記擬似乱数列としてもよい。
また、前記逆関数実行手段は、複数ワードに対するワード間逆関数を含み、該ワード間逆関数は、暗号化文書を復号するごとに、該複数ワードの間隔を変化してもよい。
【0011】
上記のいずれかに記載の暗号化システム及び復号化システムの機能をコンピュータ・システムに構築させるプログラムも、本発明である。
【発明の効果】
【0012】
本発明の実施形態2〜5の擬似乱数発生システム、暗号化システム及び復号化システムでは、鍵情報から一つの解読されにくい大きな暗号化関数を生成するのではなく、高速な異なるタイプの変換を複数個用意し、それらを鍵情報によって決まる組合せで複数回変換に用いることで暗号化する。それぞれの変換が基本的で高速なので、組み合わせた全体の変換も大変に高速である。また、関数の組み合わせ方も反復数も変えられるので、将来の仕様強化が容易である。関数属のうち、どれがどのような順番で施されたかわからないため安全性が高い。このため、従来の特許文献1および特許文献2のように複数の大掛かりな暗号化関数を用意するほどの負担をかけずに、鍵により使われる関数の種類が異なり解読の困難なシステムを実現できるようになった。
また、実施形態6に示すように、実施形態2〜5に実施形態1の方法を加えることで、より解読が難しいシステムを実現することができる。
このように、本発明によれば従来の方式に比べて暗号の安全性を高めることができる。
【図面の簡単な説明】
【0013】
【図1】本実施形態の実施形態1の擬似乱数発生システムを用いて文書の暗号化及び復号化を行なう場合のシステム構成例を示す図である。
【図2】本実施形態の実施形態2,3,5の暗号化システム及び復号化システムのシステム構成例を示す図である。
【図3】本実施形態の実施形態4の擬似乱数発生システムを用いて文書の暗号化及び復号化を行なう場合のシステム構成例を示す図である。
【図4】(a)従来のストリームサイファの処理の流れを示す図である。(b)従来のブロックサイファの処理の流れを示す図である。
【図5】実施形態1の擬似乱数発生システムの処理の流れを示す図である。
【図6】実施形態2,3の暗号化システム及び実施形態4の擬似乱数発生システムの処理の流れを示す図である。
【図7】実施形態5の暗号化システムの処理の流れを示す図である。
【発明を実施するための形態】
【0014】
以降、本発明の擬似乱数発生システム、暗号化システム及び復号化システムの実施形態を、具体的な例を挙げて詳細に説明する。実施形態1及び4は擬似乱数発生システムを文書の暗号化・復号化に用いる場合を例とした実施形態である。また、実施形態2,3,5は暗号化システム及び復号化システムの実施形態である。
なお、以降で用いる用語を以下のように定義する。
ワード: 本実施形態では、1ワード=32ビットとする。
ブロック: 何ワードごとに暗号化を行なうかの単位ブロック。(例えば1ブロック=4ワード)
【0015】
(実施形態1) あらかじめ用意した数列から生成した暗号的に安全でない擬似乱数列のワードと、1ワードのメモリに書かれたワードとの積を次々にとり、結果を該1ワードのメモリに格納し、その上位ビットから安全な暗号乱数列を生成することを特徴とする擬似乱数発生システム。数列に共有鍵を用いることにより、生成した暗号乱数列をストリームサイファによる文書の暗号化・復号化に用いることができる。
(実施形態2) ブロックに分割した文書を、ブロックごとに共有鍵から生成した擬似乱数列(拡張鍵)により選択される関数で変換して暗号化文書を生成することを特徴とする暗号化システム及び復号化システムの基本的な例(ブロックサイファ)である。
(実施形態3) ブロックに分割した文書を、ブロックごとに共有鍵から生成した擬似乱数列により選択される関数で変換して暗号化文書を生成することを特徴とする暗号化システム及び復号化システム(ストリームサイファ)である。
(実施形態4) あらかじめ用意した数列から生成した擬似乱数列のブロックを、当該擬似乱数列により選択される関数で変換して、安全な暗号乱数列を生成することを特徴とする擬似乱数列発生システム。数列に共有鍵を用いることにより、生成した暗号乱数列をストリームサイファによる文書の暗号化・復号化に用いることができる。
(実施形態5) 実施形態3と同様の暗号化システム及び復号化システムに、後述する「JUMP処理」を加えることにより、より効率的な暗号化を行なう手法を提案する。なお、このJUMP処理は実施形態2の暗号化システム及び復号化システム及び実施形態4の擬似乱数列発生システムにおいても使用することができる。
(実施形態6) 実施形態2〜5の各実施形態で用いる擬似乱数列を、実施形態1の方法で生成することにより、より複雑な暗号化を行なう手法を提案する。
以降、各実施形態を順に詳しく説明する。
【0016】
<1.実施形態1>
実施形態1は、あらかじめ用意した数列(共有鍵)から生成した暗号的に安全でない擬似乱数列のワードと、1ワードのメモリに書かれたワードとの積を次々にとり、結果を該1ワードのメモリに格納し、その上位ビットから安全な暗号乱数列を生成することを特徴とする擬似乱数発生システムである。暗号化通信における共有鍵を数列として用いることにより、生成した暗号乱数列をストリームサイファによる文書の暗号化・復号化に用いることができる。
【0017】
(1−1.従来のストリームサイファの概要と問題点)
文書のブロックbの集合をBLとすると、ストリームサイファとは、暗号化側でE1,E2,…なる暗号化関数
Ei: BL→BL’
の列を用意し、復号化側でD1,D2,…なる復号化関数
Di: BL’ →BL
の列を用意し、BLの全てのブロックbでDi(Ei(b))=bとなるようにしておいて、メッセージ=ブロックの列b1,b2,…を暗号化してE1(b1),E2(b2),…として送信し、復号化側はそれぞれにD1,D2,…を施して復号化するものである。
典型的には、BLの元からなる擬似乱数列r1,r2,…を生成して
Ei(b) := b EXOR ri
Di(b) := b EXOR ri
とするものである。すなわち、送信側、受信側は擬似乱数列riの生成手段を持っていればよい。
【0018】
上述の従来のストリームサイファの処理の流れを示したのが、図4(a)である。擬似乱数列PN(pseudorandom numbers)を生成するのに、メモリ420(状態メモリ)を用い、それに次状態関数462を作用させ、メモリ420に書き込む。これを繰り返すことにより、メモリ420の内容は次々に変換される。このメモリ420の内容を、出力関数464を用いて変換し、擬似乱数列PNとして用いる。
生成されたPN(上述の例では列(ri)に該当)と、平文メッセージM(ブロックの列)に対し、暗号化関数470(上記の例ではE(ri,bi)に該当)を計算して、暗号化文C(cryptography)を計算する。
図4(a)の暗号化関数470に示すように、関数に小さな丸がついているのは、逆関数がつくれる、すなわち計算機で容易に計算できることを示している。この小さな丸の意味は、以降の図においても同じである。ここでは、復号化関数D(ri,ci)があって、D(ri,E(ri,b))=bとなるということである。上述したストリームサイファの典型的な例では、EもDもEXORである。
ストリームサイファであって、E1=E2=…,従ってD1=D2=…となっているものをブロックサイファという。
【0019】
図4(a)に示す従来のストリームサイファ(例えば、B. Schneier, "Applied Cryptography," John Wiley & Sons, Inc., 1996.pp. 369〜428)では、次状態関数462が複雑である(例えば、上述の従来技術BBS(Blum−Blum−Shub)では、メモリは大きな桁数の整数を保持し、その自乗をmodulo Mで計算するのが次状態関数)か、出力関数464が複雑(例えば、ハッシュ関数)であるか、暗号化関数470が複雑である(例えば、ブロック暗号)か、のいずれかによって暗号強度を保持している。
しかしながら、次状態関数を複雑にすると、擬似乱数列PNの生成速度が落ちる。また、PN周期や分布が計算できない。
次状態関数を線形にすればPNを高速生成でき、周期・分布も計算できる。例として、メルセンヌツイスター(MT)がある。(メルセンヌツイスターについては、http://www.math.keio.ac.jp/〜matsumoto/mt.html, M. Matsumoto and T. Nishimura, "Mersenne Twister: A 623-dimensionally equidistributed uniform pseudorandom number generator", ACM Trans. on Modeling and Computer Simulation Vol.8, No.1, January pp.3-30 (1998) を参照のこと。)この擬似乱数は高速に発生でき、周期が長い。しかし、出力関数が単純であれば、出力列から内部状態が推測されるので、暗号学的に安全であるとはいえない。
【0020】
(1−2.本実施形態の擬似乱数発生システム)
これに対し、本実施形態の擬似乱数発生システム(cryptMTと呼ぶ)は、暗号学的には安全ではないかも知れない擬似乱数列PNを、安全擬似乱数列SPN(secure pseudorandom numbers)に変換する。
図5は、本実施形態の擬似乱数発生システムの処理の流れを示す図である。なお、図5に示されたPN(安全ではないかも知れない擬似乱数列)の前には、図4(a)のPNの左側部分の処理を行なっている。なお、本実施形態において、この構成を何度も繰り返すようにしてもよい。つまり、図5のSPN生成までの処理を、図5の入力となるPNの位置にさらにつなげてもよい。
図5に示す本実施形態の構成において、次のような場合がスピード対安全性で最も効果がある。
・PN生成部分(図5につながる図4(a)のPNの左側部)には、高速高次元分布な線形生成法(図4(a)の次状態関数462が線形、例:上述のMT)を用いる。
・PN→SPN変換部分の次状態関数562は、線形ではないが高速に計算できるもの(例:32ビット整数とみての乗算)を用いる。
・SPN変換部分の出力関数564は、単純で高速なもの(例:32ビットから、上位8ビットのみをとり、残りは捨てる)を用いる。
これらの効果のある方法を用いたのが、本実施形態のcryptMTである。ただし、乗算を用いており、偶数の積はmodulo 2{32}で可逆でないため、MTの出力の最下位ビットを強制的に1にする必要がある。
【0021】
以降、図4(a)及び図5を参照しながら、本実施形態の擬似乱数発生システムを用いて、ストリームサイファにより文書(平文)の暗号化及び復号化を行なう場合の処理を説明する。なお、ここでは上述したように図4(a)の次状態関数462にメルセンヌツイスターを使用する例で説明する。
(1)共有鍵(図4(a)の鍵430)を初期シード配列として、非線形初期化法(init_by_array)により624ワードのデータを生成し、メルセンヌツイスター(以後MT)mt19937ar.cを初期化する。これは、図4(a)の鍵変換432の処理に該当し、これによりMT(次状態関数462)の状態メモリ(メモリ420)を初期化する。出力関数464は、単にメモリ420の最初のワードを出力する。
(2)初期化後のMTの出力ワード列をM(0),M(1),M(2),…とする。これが図4(a)に示す擬似乱数列PN(安全ではないかも知れない擬似乱数列)であり、図5に送られる(図5の左上のPNに該当)。なお、上述したようにM(n)はMTの出力の最下位ビットを強制的に1にしたものである。
(3)1ワード=32ビットのメモリ(変数)accumを用意する。これが図5のメモリ520に該当する。
(4)accumに初期値(例えば1)を代入する。なお、初期値は他の値(ただし、ゼロ以外)でもよい。
(5)以後、代入
accum←accum×M(n) (mod2{32})
を繰り返す(次状態関数562)。ここで、最初の64回は空回しし、65回目からあらかじめ定めた回数までaccumの上位8ビットを次々に出力する(出力関数564)。これにより、暗号学的に安全な8ビット整数擬似乱数列(SPN)を出力することができる。
なお、上述の演算の繰返し回数は例であり、システムに応じて必要な回数とすればよい。また、上述のaccumの上位8ビットの代わりに、accumのビット列の全部又は一部(例えば1ビットおきに出力するなど)を、安全擬似乱数列として次々に出力するようにしてもよい。
(6)出力された安全なSPNと、文書(平文M)とのEXORをとることにより(暗号化関数570に該当)、暗号文Cを出力する。
【0022】
また、上記(2)〜(5)の処理を、次のようにしてもよい。メルセンヌツイスターにより生成した擬似乱数のnワード目のデータの最下位ビットを1にしたデータをM(n)とし、32ビットのメモリaccumに、共有鍵データからハッシュ関数を用いた数列をつくってaccumの初期値とする。ここで、この数列の最下位ビットを強制的に1にしてもよい。次に、n=1,2,3,…について、
accum←accum×M(n) (mod2{32})
を計算し、accumの上位8ビットを出力して、暗号学的に安全な8ビット整数擬似乱数として出力する。
【0023】
(1−3.効果)
本実施形態では擬似乱数として、メルセンヌツイスター(mt19937ar.c)を用いたことで、出力される暗号乱数列は周期が219937−1であることが数学的に証明できる。この周期は従来知られているどの暗号乱数列よりも長く、安心して長期間利用することができる。
また、accumに非線形な演算(乗算)を行うことと、線形性の残る最下位ビットを使わないことで、暗号乱数列として十分な安全性を持つ。
また、メルセンヌツイスターのように、暗号的に安全でないが高速な擬似乱数を、32ビットの積という比較的速い関数で変換したことにより、このアルゴリズムを用いて生成する暗号乱数生成法は、現在アメリカのスタンダード暗号乱数生成法であるAESの最速オプティマイズ版の1.5倍以上と、非常に高速である。
また、MTの内部空間の大きさにより、time−memory−trade−off攻撃に対しても耐性が強い。
【0024】
(1−4.本実施例を用いた暗号化システム及び復号化システムの構成例)
最後に、本実施形態の擬似乱数発生システムを用いて、ストリームサイファにより文書(平文)の暗号化及び復号化を行なう場合のシステム構成を、図1のシステム構成図を参照しながら説明する。
本実施形態のシステムは、例えば通常のパソコン等の端末に実装するものする。図1に示すように、文書を暗号化して送信する側の端末には暗号化システム110を、文書を受信して復号化する側の端末には復号化システム150を実装する。また、暗号化システム110及び復号化システム150の双方に、数列(共有鍵122)及び本実施形態の擬似乱数発生システム130を用意する。
暗号化システム110において、擬似乱数発生システム130の擬似乱数生成プログラム132により、共有鍵122から上述で説明した本実施形態の手法を用いて安全な擬似乱数列(安全擬似乱数列)125を生成する。次に、ストリームサイファの典型的な例として、暗号化プログラム136は、安全な擬似乱数列125と文書124のEXORをとることにより文書124を暗号化して、暗号化文書140を生成する。
【0025】
一方、復号化システム150においては、擬似乱数発生システム130の擬似乱数生成プログラム132により、共有鍵122から上述で説明した本実施形態の手法を用いて安全な擬似乱数列125を生成する。次に、復号化プログラム166は、安全な擬似乱数列125と復号化文書124のEXORをとることにより暗号化文書140を復号し、元の文書124を得る。暗号化システム110と復号化システム150とでは、同じ共有鍵122から同じ擬似乱数生成プログラム132を用いて、同じ安全な擬似乱数列125を生成するため、対応する暗号化・復号化の処理を行なうことができる。
【0026】
<2.実施形態2>
実施形態2は、ブロックに分割した文書を、ブロックごとに共有鍵から生成した擬似乱数列により選択される関数で変換して暗号化文書を生成することを特徴とする暗号化システム及び復号化システムの基本的な例であり、ブロックサイファである。関数の選択及び関数のパラメータには、共有鍵から生成した擬似乱数列が用いられる。ここで、後述の実施形態3では、文書が長いほど擬似乱数列を消費するが、本実施形態2は、一定の長さしか消費しない。このため、本実施例では、共有鍵から生成した一定の長さの擬似乱数列を「拡張鍵」とよぶ。
【0027】
(2−1.従来のブロックサイファの概要と問題点)
AESなどの従来のブロックサイファは、図4(b)に示す構成である。すなわち、平文Mのブロックをメモリ420に取り込み、擬似乱数列PNを使って変換(466に示すEXOR)を行ない、メモリ420に書き込む。これを数回繰り返して暗号文Cを得る。ここで、右下の関数460は複雑な全単射である。なお、上述の図4(a)で説明したとおり、関数に小さな丸がついているのは、逆関数がつくれる、すなわち計算機で容易に計算できることを示している。
しかしながら、上述したように、従来のブロックサイファは、鍵情報から一つの複雑な暗号化関数を作り、これを用いて平文を変換するため、高速な暗号システムでは作られる関数に偏りがあり、暗号解読のための情報を得られやすいという問題がある。たとえば暗号を解読しようとする際には、差分解読法や、線形解読法などの、既知の平文を暗号化させることによる攻撃がよく用いられている。すなわち攻撃する人物が、任意の文書を暗号化させられる状況では、解読に用いるデータを採取され、鍵の全数検索よりも簡単に暗号が破られてしまう。
【0028】
(2−2.処理の流れ)
これに対し、本実施形態では、次のような構成をとることにより、従来の問題点を解決する。
図6は、本実施形態の暗号化システムの処理の流れを示す図である。なお、後述の実施形態3の暗号化システムの処理も同図に示す通りである。
本実施形態(及び実施形態3)では、ブロックbの集合BLについて、
F: PARAM×BL→BL
の形をした単純な関数と、逆操作に当たる
F’: PARAM×BL→BL
の関数を複数個用意し(F’(P,F(P,b))=bとなるものである)、図6に示すように、擬似乱数列PN(図6の左上に示すPN)をパラメータPとして消費しながら、平文Mのブロックが取り込まれたメモリ620の内容を繰り返し変換して、暗号文Cを得る。変換の際、どの関数660(上記のFに該当)を使うかは、PNをセレクタ640に送って選択する。
【0029】
上記の構成をとることにより、本実施形態(及び実施形態3)では関数の組み合わせの自由度が指数的に増大し、強固な暗号が実現できる。
また、擬似乱数列PNからパラメータ(図6における関数660で、白丸のついていないところ)を取り込むため柔軟性があり、より強固な暗号が実現できる。
さらに、共有鍵を図4(a)に示す鍵430として、上述のメルセンヌツイスターなどを用いて擬似乱数列PNを生成すれば、PNはいくらでも生成することができる。そのため、関数660による平文の変換の繰り返し回数を増やすことができ、暗号化の強度を上げることができる。
また、図6において、平文が複数のブロックからなる場合には、各ブロックに対して異なる組み合わせの関数による暗号化を行なうことができる(つまり、ストリームサイファとして使える)。
【0030】
(2−3.前提条件)
本実施形態では、1ブロック=4ワード(8ワードまたは16ワードでもよい)、128ビット以上の共有秘密鍵情報での暗号化方式を例に挙げて説明する。
前処理として、共有鍵を必要なサイズにハッシュ関数で拡張して擬似乱数列PN、すなわち拡張鍵(図6の左上のPNに該当)を生成する。本実施例では、文書はブロックサイズ(4ワード)に分割し、ブロックごとに変換するものとする。
【0031】
(2−4.用意する関数)
ブロックの変換には以下の7種類の、ブロックサイズのデータを高速で変換することができる、性質の全く異なる関数(図6の関数660に該当)を用いる。以降、これらの関数族をPEF(primitive encryption family)とよぶ。本実施形態では、ワード内の計算を行なう関数(ワード内関数)4種類と、ブロック内の複数のワードを跨ぐ計算を行なう関数(ワード間関数)3種類を用意する。なお、復号化において、ワード内関数に対応する逆関数をワード内逆関数、ワード間関数に対応する逆関数をワード間逆関数という。
t回目の演算(変換)には拡張鍵(擬似乱数列PN)のtブロック目のデータを用いる。また、拡張鍵の最後の1ブロックは関数の選択に用いる。
【0032】
(a)ワード内の計算(4種類)
(1)EXOR: ブロックの各ワードに、拡張鍵のtブロック目のデータをワードごとに排他的論理和で加える。
(2)+: ブロックの各ワードに、拡張鍵のtブロック目のデータをワードごとにmod232で加える。
(3)×: ブロックの各ワードに、拡張鍵のtブロック目の、対応するそれぞれのワードの最下位ビットを1に変えたものをmod232で掛け算する。なお、この変換については、最下位ビットを1に変えた拡張鍵のワードの掛け算の逆関数をすべて計算して辞書引きできるよう保存しておく。
(4)横シフト: ブロックの各ワードについて、拡張鍵のtブロック目の対応するそれぞれのワードの下5ビットずつを数字として用いて、その大きさの分だけのビットを右にシフトする。ワードの右にはみ出た部分をビット反転させて、左に書く。
【0033】
(b)ワードを跨ぐ計算(3種類)
(5)縦回転: 1ブロックをワードの4個(1ブロック=4ワードの場合。なお、1ブロック=8ワードとする場合は8個、1ブロック=16ワードとする場合は16個)の配列とみなし、4行32列(1ブロック=8ワードとする場合は8行32列、1ブロック=16ワードとする場合は16行32列)の0,1からなる行列とみなす。拡張鍵のtブロック目から1ワード取り出す。この1ワードでビットが1のところに対応する列をビット反転させて、さらに下方向に1行分シフトする。一番下の行のデータは一番上に書く(ローテート)。
(6)置換: 拡張鍵のtブロック目から2ビット(1ブロック=4ワードの場合。なお、1ブロック=8ワードとする場合は3ビット、1ブロック=16ワードとする場合は4ビット)を4回取り出し、それぞれを数として見た値kについて配列されたブロックのk行目と((k+5)mod4)行目(1ブロック=4ワードの場合。なお、1ブロック=8ワードとする場合は((k+5)mod8)行目,1ブロック=16ワードとする場合は((k+5)mod16)行目)を入れ換えることを、4回行う。
(7)和置換: 拡張鍵のtブロック目から2ビット(1ブロック=4ワードの場合。なお、1ブロック=8ワードとする場合は3ビット、1ブロック=16ワードとする場合は4ビット)を4回取り出し、それぞれを数として見た値kについて配列されたブロックのk行目に((k+7)mod4)行目(1ブロック=4ワードの場合。なお、1ブロック=8ワードとする場合は((k+7)mod8)行目,1ブロック=16ワードとする場合は((k+7)mod16)行目)を排他的論理和で加えることを4回行う。
【0034】
(2−5.文書の暗号化)
文書の暗号化は、文書をブロックサイズに区切り、それぞれのブロックに上述の関数を以下のように拡張鍵(擬似乱数列PN)に依存して選択して変換する。上述したように、t回目の演算(変換)には拡張鍵のtブロック目のデータを関数(図6の関数660)のパラメータとして用いる。また、拡張鍵の最後の1ブロックは関数の選択に用いる。図6で説明すると、PNの最後の1ブロックをセレクタ640に送り、セレクタ640により関数660を選択する。
本実施形態では、文書の各ブロック(図6ではメモリ620に取り込まれた平文Mのブロック)に対し、上述した7種類の関数を、例えば「横シフト・×・縦回転・(置換または和置換)・(+またはEXOR)」の順に施すことを1セットとし、これを8セット行なうことによりブロックを変換する。ただし、後ろ2つのそれぞれ2種類の関数を()内に示している箇所においては、拡張鍵の最終ブロックから1ビットずつを2×8回次々に用いて、0なら前者を、1なら後者を選択するものとする。この場合、t=40回の演算(変換)を行なうことになるため、拡張鍵は41ブロックのサイズに生成し、最後の41ブロック目を関数の選択に用いる。
なお、上記(1)〜(7)の関数は一例であり、高速に処理できる他の演算を用意してもよい。また、上記の関数の組み合わせや順序は一例であり、他の組み合わせや順序でもよい。また、繰り返し回数も上記の8セット以外の回数でもよい。また、最初の1セットと最後の1セットで全種類の変換を行ない、間のセットで全種類の関数の中から拡張鍵を用いてどれかを選択することを例えば5回以上繰り返すなどの方法を用いてもよい。1セットを複数回行なう理由は、本実施形態では全てのブロックに対して同じ変換を施すため、安全性を高める必要があるからである。
【0035】
(2−6.文書の復号化)
復号化は、暗号化の逆の順番で、それぞれの変換の逆写像を施せばよく、本実施形態では暗号化と同じくらいの時間で計算できる。
【0036】
(2−7.効果)
本実施形態の暗号化システム及び復号化システムによれば、それぞれの変換が高速であることから大量の文書を高速に暗号化でき、施された関数のタイプとその順番がわからないことから、従来のブロックサイファよりも解読が困難となる。
【0037】
(2−8.本実施例を用いた暗号化システム及び復号化システムの構成例)
最後に、本実施形態の暗号化システム及び復号化システムを用いて、文書の暗号通信を行なう場合のシステム構成例を、図2を参照しながら説明する。なお、後述の実施形態3,実施形態5も同様のシステム構成とすることができる。
本実施形態の暗号化システム及び復号化システムは例えば通常のパソコン等の端末に実装するものとする。図2に示すように、文書を暗号化して送信する側の端末には暗号化システム110を、文書を受信して復号化する側の端末には復号化システム150を実装する。また、暗号化システム110には共有鍵122及び暗号化に用いる複数の関数126を用意し、復号化システム150には共有鍵122及び復号化に用いる複数の逆関数128(関数126の各関数に対応し、それぞれ逆の操作をする関数)を用意する。
【0038】
上述したように、本実施形態の暗号化システム及び復号化システムは、共有鍵の情報(共有鍵から生成した擬似乱数列)を暗号化関数の選択及び選択された関数のパラメータとして用いていることが主要な特徴であり、これにより高速で安全性の高いシステムを実現している。暗号化システム110では、まず、擬似乱数生成プログラム232により、共有鍵122から擬似乱数列225(本実施形態においては拡張鍵)を生成する。次に、生成された擬似乱数列(拡張鍵)225を用いて、関数選択プログラム234は関数126から文書124の暗号化に用いる関数を選択する。また、暗号化プログラム236は、擬似乱数列(拡張鍵)225を関数選択プログラム234で選択された関数のパラメータとして用いて関数を実行して文書124を暗号化する。これにより暗号化文書140を生成する。
一方、復号化システム150では、まず、擬似乱数生成プログラム232により、共有鍵122から送信端末110と同じ擬似乱数列(拡張鍵)225を生成する。次に、生成された擬似乱数列(拡張鍵)225を用いて、逆関数選択プログラム264は逆関数128から受信した暗号化文書140の復号に用いる逆関数を選択する。ここでは、送信端末110で選択された関数に対応する逆関数が選択されることになる。復号化プログラム266は、擬似乱数列(拡張鍵)225を逆関数選択プログラム264で選択された逆関数のパラメータとして用いて逆関数を実行し、暗号化文書140を復号する。これにより元の文書124を得る。
【0039】
<3.実施形態3>
実施形態3は、ブロックに分割した文書を、ブロックごとに共有鍵から生成した擬似乱数列により選択される関数で変換して暗号化文書を生成することを特徴とする暗号化システム及び復号化システムの例であり、ストリームサイファである。共有鍵の情報(共有鍵から生成した擬似乱数列)は、関数の選択及び関数のパラメータに用いられる。
本実施形態のシステム構成例は上述の実施形態2で図2を用いて説明した通りである。また、その処理の流れは実施形態2で図6を用いて説明した通りである。本実施形態と、上述の実施形態2との違いは、実施形態2(ブロックサイファ)では、一度複数の関数を選択してパラメータを決定したら、同じ関数及びパラメータですべてのブロックを変換するが、本実施形態(ストリームサイファ)では、文書のブロックごとに、関数とパラメータを決めて変換する。すなわち、全く同じブロックが2つあったときに、実施形態2ではこの2つのブロックは同じ暗号文に変換されるが、実施形態3では選択される関数もパラメータも違うため違う暗号文になる。また、上述したように、実施形態2は、一定の長さの擬似乱数列(拡張鍵)しか使わないが、実施形態3の方は、文書の長さに応じて擬似乱数を消費することになる。
【0040】
(3−1.前処理)
共有鍵に基づき擬似乱数を発生させて、32種類の乗算値(32ビット符号なしの整定数で、どれも奇数なもの)を準備する。そして、それらのmod232での乗法逆数値を計算して表にしておく。
【0041】
(3−2.ユーザが決めるマクロ定数)
(1)1ブロックのワード数(Tuple)を定義する。
#define Log_Tuple 2
#define Tuple (1UL<<Log_Tuple)
本実施形態においては、1ブロックはTuple個のワードとする。
Tupleの値は2巾であり、4以上16以下である必要がある。
Tupleの2を底としたログを、Log_Tupleとして指定する。
上記は、1ブロック=4ワードとする場合の記述である。
(2)文書のブロックの暗号化関数による変換回数(Iteration)を定義する。
#define Iteration 10
上記は、変換回数を10回とする場合の記述である。
【0042】
(3−3.グローバル変数)
暗号化したい文書(平文)を入れておく配列は二重配列
msg[Msg_Length][Tuple]
である。本実施形態で用いるグローバル変数は次の通りである。
(1)暗号化したい文書(平文)を格納する。
unsigned long msg[Msg_Length][Tuple];
(2)配列msgを直接書き換えて暗号化する。
hmnencode(key[],init_value[])
(3)配列msgを直接書き換えて復号化する。
hmndecode(key[],init_value[])
【0043】
(3−4.用意する関数)
Tuple個のワードからなるブロックの変換に用いる関数(PEF)(図6の関数660に該当)として、本実施形態では、あらかじめ、ワード内の計算を行なう関数5種類と、ブロック内の複数のワードを跨ぐ計算を行なう関数3種類の計8種類の関数を用意する。
これらの関数は全て、
PEF: BL×PARAM→BL
なる写像である。ここで、BLは文書のブロックの集合であり、PARAMは関数に与えるパラメータであり、PARAMはBLと同じくTuple個のワードからなるデータの集合であり、擬似乱数列PNから得る。
ここでは、Tuple=4の場合を例として
(w1, w2, w3, w4)←PEF(w1,w2,w3,w4; p1, p2, p3, p4)
の形で記述することにする。
以降、PEFの8種類の関数とその逆関数(_inv)をそれぞれ説明する。なお、これらの(1)〜(8)の関数は一例であり、高速に処理できる他の演算を用意してもよい。
【0044】
(a)ワード内の計算(ワード内関数及びそれに対応するワード内逆関数)5種類
(1)crypt_plus
crypt_plus
wi←wi+pi (i=1,2,3,4).
crypt_plus_inv
wi←wi−pi (i=1,2,3,4).
【0045】
(2)crypt_exor
crypt_exor
wi←wi EOR pi (i=1,2,3,4).
crypt_exor_inv
wi←wi EOR pi (i=1,2,3,4).
【0046】
(3)crypt_multi
最近のCPUは掛け算命令を持っているが、割り算は遅い。そのため、本実施形態では上述の(3−1.前処理)で述べたようにMulti_Size個(=32個)の掛け算用乱数定数を用意し、global変数の配列multi_tableに格納する。
実際の処理としては、
1)prepare_multi()を呼び出すと、multi_tableに乱数が格納される。
2)下位ビットを強制的に変換し、mod7で3のものと、mod16で7のものをmulti_table内に交互におく。これらは、mod232での乗法群を生成する。
3)prepare_multi_inv()を呼び出すと、inv_tableにmulti_tableの乗法逆数が格納される。
crypt_multi
wi←wi×mutli_table[piの上位5ビット]
wi←wi−pi
をi=1,2,3,4について行う。すなわち、パラメータpiの上位5ビットに対応する乗算用定数をmutli_table[]から読み出し、それをwiに掛ける。piの下位27ビットが捨てられるのはもったいないので、wiからpiを引いておく。
crypt_multi_inv
wi←wi+pi
wi←wi×inv_table[piの上位5ビット]
をi=1,2,3,4について行う。
【0047】
(4)crypt_hori_rotate
crypt_hori_rotate
ワードごとに、ビットを反転しながら横ローテートを行う。すなわち
si←piの上位5ビット、ただし下から4ビット目は常に1にセット
wi←(wiのビット反転の右32−siシフト)と(wiの左siシフト)のOR
wi←wi−pi
をi=1,2,3,4で行う。4ビット目を1にするのは、パラメータが0でもローテートをするため。
crypt_hori_rotate_inv
上述の逆変換
【0048】
(5)crypt_hori_rightshift
crypt_hori_rightshift
ワードごとに、ビットを反転しながら横ローテートを行う。すなわち
si←piの上位5ビット、ただし下から5ビット目は常に1にセット
wi←wi EOR (wiのビット反転の右siシフト)
wi←wi+pi
をi=1,2,3,4で行う。5ビット目を1にするのは、パラメータが0でもローテートをするためと、逆変換を易しくするため。
crypt_hori_rightshift_inv
上記の逆変換
【0049】
(b)ワードを跨ぐ計算(ワード間関数及びそれに対応するワード間逆関数)3種類
(6)crypt_vert_rotate
crypt_vert_rotate
key←p1+p4
keyを32ビットランダムパターンと思う。
w1,w2,w3,w4に関して、keyにおいて1になっているビットについては縦方向にビット反転しながらローテートする。乱数がもったいないので
wi←wi+pi
をi=1,2,3,4について行う。
crypt_vert_rotate_inv
上記の逆変換
【0050】
(7)crypt_add_permute
crypt_add_permute
i=1,2,3,4について、
wi←wi+wj
という和を行う。ここでjはpiの最下位Low_Mask=2ビットを用いて決められるが、たまたまそれがiと同じであるときにはjをmod Low_Maskでincrementしておく。
p1−p4の有効活用のために
wi←wi EOR pi
をi=1,2,3,4でやっておく。
crypt_add_permute_inv
上記の逆変換
【0051】
(8)crypt_exor_permute
crypt_exor_permute
i=1,2,3,4について、
wi←wi EXOR wj
という和を行う。ここでjはpiの最下位Low_Mask=2ビットを用いて決められるが、たまたまそれがiと同じであるときにはjをmod Low_Maskでincrementしておく。
p1−p4の有効活用のために
wi←wi−pi
をi=1,2,3,4でやっておく。
crypt_exor_permute_inv
上記の逆変換
【0052】
(3−5.擬似乱数列)
ここでは擬似乱数列PN(図6の左上のPNに該当)の生成方法として、上述のメルセンヌツイスター(mt19937ar.c)を用いる。mt19937ar.cは、任意長の配列を初期値として受け取る機能を持つ。
擬似乱数列は4ワードずつ読み込むようにした。内部配列長の624が4でわりきれるため、624/4回読み込むごとに配列全体に擬似乱数列を生成しなおす。
genrand_fourint32(param)
により、param[0]〜param[3]に32ビット長符号なし整数乱数が読み込まれる。
暗号化する際の
crypt_...(unsigned long block[Tuple])
では、どれも内部でgenrand_fourint32(param)を呼び出してp1,p2,p3,p4を生成している。それに対し、復号化する際の
crypt_..._inv(block[],param[])
では、paramのところにp1〜p4を指定する。この違いは、復号化する場合には擬似乱数列を逆向きに生成しなくてはならないことに起因する。復号化する場合には、擬似乱数列を配列temp_randにいったん記録しておき、逆向きに使う。
【0053】
(3−6.文書の暗号化)
hmnencode(key[],init_value[])
を呼び出すと、文書(図6においては、メモリ620に取り込んだ平文Mのブロック)の暗号化を行なう。key,init_valueは配列で、あわせてメルセンヌツイスターの初期化に使われる。
(1)multi_tableに乗算定数をしまう。
(2)擬似乱数列PNを4ワードfunc_choice[0]−[3]の4つに格納し、積とEORを用いて新たな4ワードに書き換える。(あとでこの4ワードを3ビットずつに切り出し、上述の5+3種のPEFの選択を行う。)
(3)まずは平文に対して次の3つを施す。
crypt_multi(msg[i]);
crypt_vert_rotate(msg[i]);
crypt_hori_rightshift(msg[i]);
(4)その後はIterate回、func_choiceを用いてPEF関数を選択し(図6のセレクタ640の処理に該当)、MTで生成した擬似乱数列PNをパラメータとして与えながら変換を繰り返す。
(5)最後に再び
crypt_multi(msg[i]);
crypt_vert_rotate(msg[i]);
crypt_hori_rightshift(msg[i]);
を作用させる。
【0054】
(3−7.文書の復号化)
hmndecode(key[], init_value[])
を呼び出すと、復号化を行なう。key,init_valueは配列で、あわせてメルセンヌツイスターの初期化に使われる。
(1)multi_tableに乗算定数をしまう。
(2)inv_tableにその乗算に関する逆元をしまう。
(3)擬似乱数を4ワードfunc_choice[0]〜[3]の4つに格納し、積とEORを用いて新たな4ワードに書き換える。(あとでこの4ワードを3ビットずつに切り出し、上述の5+3種のPEFの選択を行う。)
(4)後で使われるべき乱数ブロックを、3+Iteration+3個作って配列temp_randにしまっておく。
(5)暗号文に対して、3つの逆変換を施す。
crypt_hori_rightshift_inv(msg[i],temp_rand[−−k]);
crypt_vert_rotate_inv(msg[i],temp_rand[−−k]);
crypt_multi_inv(msg[i],temp_rand[−−k]);
(6)その後はIterate回、func_choiceを用いてPEF関数を選択し、格納しておいたMTの出力を与えながら逆変換を繰り返す。
(7)最後に再び
crypt_hori_rightshift_inv(msg[i],temp_rand[−−k]);
crypt_vert_rotate_inv(msg[i],temp_rand[−−k]);
crypt_multi_inv(msg[i],temp_rand[−−k]);
を作用させる。
【0055】
<4.実施形態4>
実施形態4は、あらかじめ用意した数列(共有鍵)から生成した擬似乱数列のブロックを、当該擬似乱数列により選択される関数で変換して、安全な暗号乱数列を生成することを特徴とする擬似乱数列発生システムである。ここで、数列は、関数の選択及び関数のパラメータとして用いられる。暗号化通信における共有鍵を数列として用いることにより、生成した暗号乱数列をストリームサイファによる文書の暗号化・復号化に用いることができる。
【0056】
(4−1.擬似乱数列の生成)
一般に実験などに利用されている擬似乱数列は、高速に生成されるが、いくつかのワードを見ると他のワードがわかってしまうため、暗号学的には安全でない。このため、従来、暗号乱数列の生成には、BBS法に代表される計算量の大きな暗号化方式が用いられている。本実施形態は、本発明のポイントである、鍵情報を関数選択に用いることで、高速な擬似乱数列を少ない計算量で暗号乱数列に書き換えることを特徴とした擬似乱数発生システムであり、高速で安全なストリームサイファを構成することができる。
ここでは擬似乱数PNの生成方法として実施形態1で説明したメルセンヌツイスター(mt19937ar.c)を用いる。高速で周期が長い擬似乱数列を生成できるためである。なお、他の擬似乱数生成方法を用いてもよい。
前処理として、あらかじめ暗号化・復号化を行う双方で、共有鍵を用いて624ワードの秘密の擬似乱数列の初期値を求めておく。使い続ける共有秘密鍵の他に、一回の通信ごとにセッション鍵を受け取る場合には、ここで作成した初期値の一部をセッション鍵に変えたものを、その通信で用いる擬似乱数列の初期値とし、乱数は初期値の次の値から使うものとする。
【0057】
擬似乱数列PNは、必要になった分だけ次々に作ることとして、以下のように安全な擬似乱数列を出力する。擬似乱数列PNの12nワード目のデータを、12n+1ワード目から12n+11ワード目のデータを用いて次のように書き換える。以下、擬似乱数のmワード目のデータをR(m)であらわす。
x=R(12n)とし、R(12n+1)のデータを上から2ビットずつ10回見て、この値により次の操作でxを書き換えていく。
t回目の2ビットが
(1)00ならば、xを、x+R(12n+t+1)mod232に書き換える。
(2)01ならば、xを、x EXOR R(12n+t+1)に書き換える。
(3)10ならば、xを、x×R(12n+t+1)*に書き換える。ただし、p*は、pの最下位ビットを1にした数とする。
(4)11ならば、xを、x shift R(12n+t+1)に書き換える。ただし、s shift tは、tの上5ビットの大きさの分だけのsのビットを右にシフトし、ワードの右にはみ出た部分をビット反転させて、左に書いたものとする。
10回書き換えたら、xを暗号乱数列のnワード目として出力する。
【0058】
なお、上記(1)〜(4)の関数は一例であり、高速に処理できる他の演算を用意してもよい。また、必要な強度に応じて変換の回数を増やし、また強制的に掛け算とシフトがあらわれるようにするなどの方法で、安全性を高めることができる。1つのワードを求めるのにm+2ワード(mは6〜16くらい)用いて変換の回数をm回とし、1回目とm−1回目の変換をシフト、2回目とm回目の変換を掛け算と決めるなど必要に応じて調整すると良い。
メルセンヌツイスターには、周期の完全な保障と、分布のある程度の保障がある。周期がとても長いことから、生成した安全擬似乱数列の周期も使い切ることができないくらい長くなり、共有鍵を取り替えずに長く使い続けることができる。
【0059】
(4−2.本実施例を用いた暗号化システム及び復号化システムの構成例)
最後に、本実施形態の擬似乱数発生システムを用いて、ストリームサイファにより文書(平文)の暗号化及び復号化を行なう場合のシステム構成例を、図3のシステム構成図を参照しながら説明する。
本実施形態のシステムは、例えば通常のパソコン等の端末に実装するものする。図1に示すように、文書を暗号化して送信する側の端末には暗号化システム110を、文書を受信して復号化する側の端末には復号化システム150を実装する。また、暗号化システム110及び復号化システム150の双方に、数列(共有鍵122)、関数126、及び本実施形態の擬似乱数発生システム330を用意する。
暗号化システム110では、まず、共有鍵122から従来技術の手法により安全ではないかもしれない擬似乱数列PNを生成する。次に、生成されたPNを用いて、関数選択プログラム334は関数126からPNの暗号化に用いる関数を選択する。また、擬似乱数生成プログラム332は、PNを関数選択プログラム334で選択された関数のパラメータとして用いて関数を実行し、PNを暗号化する。これにより、安全な擬似乱数列325を生成して、記憶領域に一時的に格納する。次に、ストリームサイファの典型的な例として、暗号化プログラム336は、擬似乱数列325と文書124のEXORをとることにより文書124を暗号化して、暗号化文書140を生成する。
【0060】
一方、復号化システム150でも、共有鍵122から従来技術の手法により安全ではないかもしれない擬似乱数列PNを生成する。次に、生成されたPNを用いて、関数選択プログラム334は関数126からPNの暗号化に用いる関数を選択する。また、擬似乱数生成プログラム332は、PNを関数選択プログラム334で選択された関数のパラメータとして用いて関数を実行し、PNを暗号化する。これにより、安全な擬似乱数列325を生成して、記憶領域に一時的に格納する。次に、復号化プログラム366は、擬似乱数列325と暗号化文書140のEXORをとることにより暗号化文書140を復号し、元の文書124を得る。
暗号化システム110と復号化システム150とでは、同じ共有鍵122及び関数126を用いて、同じ安全な擬似乱数列325を生成するため、暗号化に対応する復号化の処理を行なうことができる。
【0061】
<5.実施形態5>
実施形態5は、上述の実施形態2〜4のシステムに、後述する「JUMP処理」を加えることにより、より効率の良い暗号化を行なう手法を提案する。なお、ここでは実施形態3と同様の暗号化システム及び復号化システムにJUMP処理を追加する例で説明するが、使用する関数(PEF)等については、実施形態3とは異なるものを用意して説明する。
本実施形態の暗号化システムの処理の流れを、図7に示す。
まず、共有鍵(数列)から上述の実施形態2〜4と同様の方法(例えばメルセンヌツイスター)により擬似乱数列を生成して、これを本実施形態で使用する擬似乱数列PNとする(図7の左上部)。
次に、擬似乱数列PNをセレクタ740に送り、どの関数760を選ぶかを決定する。図6で示した実施形態2〜4との違いは、ブロックの変換が何ステップ目であるかを記録する履歴メモリ750が追加されている点であり。これによりjumpという値が計算される。
jumpは、「各ワードの情報を、どれだけ離れたワードに渡すか」を各関数に指定するものである。1つのブロックを変換するとき、jumpは1ステップ目の変換では1,2ステップ目は2,3ステップ目は4,…と二倍二倍に増えて行き、t(1ブロック内のワード数)以上になったら1に戻す。このjumpの処理は、履歴メモリ750がセレクタ740に指示を出すことにより行なう。
【0062】
また、本実施形態では、関数の選択においても、第1ステップでは本実施形態で用いる9種類の関数(PF1〜PF9)のうちからワード内関数PF1〜PF4(ワード内の計算を行なう関数)の1つを選び、第2ステップではワード間関数PF5〜PF8(ブロック内の複数のワード間に跨る計算を行なう関数)の1つを選び、第3ステップではPF9を選び、第4ステップではPF1〜PF4の1つを選び、…という具合に、ステップごとに関数選択の範囲が変わる。この処理も履歴メモリ750がセレクタ740に指示を出すことにより行なう。なお、本実施形態で用いる9種類の関数(PF1〜PF9)については後で詳しく説明する。
また、選択された関数760は、ブロックサイズと同程度の大きさのパラメータを受け取る。関数のパラメータには、実施形態2〜4と同様、共有鍵(数列)から生成した擬似乱数列PNを用いる。
【0063】
上述のjumpの効用は、次の通りである。1ブロック=tワードとして、ワード間関数を用いてワード間に跨る変換を行なう場合、あるワードの情報を他の全てのワードに早く渡すためには、隣接する次のワードのみに情報を渡すのは、あるワードの情報が他の全てのワードに達するのにt回の繰り返しが必要なため、最も効率的な方法ではない。高速に変換するには2ワードなど少ないワード間の計算の方がよく、変換を行なうごとに、最初は1ワード隣り(間隔1)、次は2ワード隣り(間隔2)、次は4ワード隣り(間隔4)、…という具合にワードの間隔を倍倍にしていくのが最も効率的である。
ここで対象となる2ワードを●で表すと、上記のワードの間隔とは、
●● 間隔1の関係
●○● 間隔2の関係
●○○○● 間隔4の関係
である。
このように、全ての自然数tがlog2(t)桁の2進数によって表されることにより、log2(t)回の繰り返しによって、0,1,…,t−1の全ての距離のワードに対して情報を渡すことができる。すなわち、JUMP処理はワード間関数が少ないワード間(本実施形態においては2ワード間)の計算であっても、少ない繰り返し回数で十分な撹拌がされるようにするための処理である。
【0064】
(5−1.前提条件及び前処理)
(1)Wを32bit=1ワード符号なし整数の集合とする。
ここには、二項演算としてビットごとのEXOR,AND,OR,足し算,掛け算(modulo 2{32})、単項演算として右シフト,左シフト,ビット反転が行える。これらは最近のCPUの命令セットに通常入っている演算である。
(2)ブロックbの集合BLを、
BL=Wt
で定義する。ただし、tは4,8,または16とする。
(3)パラメータpの集合PARAMを、
PARAM=Wt×{0,1,2,…,t/2}
で定義し、飛ばし値jの集合JUMPを
JUMP={1,2,4,8,…,t/2}
で定義する。
(4)次の形の関数(PEF)を9種類(PF1,...,PF9)用意する。これが図7でいうところの関数760に該当する。なお、9種類のPEFの詳細は後で詳しく説明する。
PF: JUMP×PARAM×BL→BL.
これらのJUMP,PARAM,BLが図7の関数760への入力線3本にそれぞれ対応している。
ここで、PFの逆関数
PF’: JUMP×PARAM×BL→BL.
も復号化のために構成しておく。ここで、
PF’(j, P, PF(j, P, b))=b
である必要があり、また高速に計算できるものが望ましい。
(5)本実施形態では、鍵情報(共有鍵)は上述の他の実施形態と同様にメルセンヌツイスター(MT)の処理に送られる。MTを用いて乗法定数テーブル、加法定数テーブルを作成する。乗法定数テーブル、加法定数テーブルについては後で詳しく説明する。
なお、上記以外の前提条件及び前処理は、上述の実施形態3の(3−1.前処理)〜(3−3.グローバル変数)で説明した通りであり、あらかじめIteration(変換回数)とLog_Tuple(ブロック内のワード数の対数)を決めておく。
【0065】
(5−2.文書の暗号化)
次に、平文ブロックを暗号化する。ここでは、1ブロック=4ワード、変換回数を4回として説明する。なお、本実施形態において、文書の暗号化は、JUMP処理以外の部分は実施形態3と同様である。
今、与えられた平文ブロックはワード長変数t個の配列
B:=(b0,b1,...,b{t−1})
に格納されているものとする。
本実施形態の一ラウンドは次のようになっている。
1)ラウンドの開始
2)PF1〜PF4から1つランダムに選んで、それを用いてBを書き換える
3)PF5〜PF8から1つランダムに選んで、それを用いてBを書き換える
4)PF9を用いてBを書き換える
5)ラウンドの終了
上記を4ラウンド行い、1ブロック分の暗号化ブロックを得る。
【0066】
具体的には、1ブロックの暗号化は、次のようにして行われる。
(0)jump←1
(1)MTから4ワードの擬似乱数を取得
(2)この4ワードから2ビットの擬似乱数を8組生成し、c1,c2,c3,...,c8とする(生成方法については後で説明する)
(3)c1=0,1,2,3に従って、PF1,PF2,PF3,PF4のうちの1つPF*を選択する
(4)MTから4ワードの擬似乱数を取得し、これをPとする
(5)PF*(jump,P,B)を用いてBを書き換える。jumpを2倍し、t以上になったら1にする
(6)c2=0,1,2,3に従って、PF5,PF6,PF7,PF8のうちの一つPF*を選択する
(7)MTから4ワードの擬似乱数を取得、Pとする
(8)PF*(jump,P,B)を用いてBを書き換える。jumpを2倍し、t以上になったら1にする
(9)MTから4ワードの擬似乱数を取得、Pとする
(10)PF9(jump,P,B)を用いてBを書き換える。jumpを2倍し、t以上になったら1にする
(3)〜(10)を4回繰り返す。2回目ではc1,c2の代わりにc3,c4を使う。
3回目ではc5,c6,4回目ではc7,c8をそれぞれ使う。なお、図7でいうと、jumpが履歴メモリ750に格納されている。
【0067】
次に、上述の(2)のc1〜c8の生成方法を説明する。
上記(1)で取得した4ワードをfunc_choice[0],...,func_choice[3]として、次の変換を行う。
func_choice[2]*=(func_choice[0]|1);
func_choice[3]*=(func_choice[1]|1);
func_choice[0]^=(func_choice[3]>>5);
func_choice[1]^=(func_choice[2]>>5);
ここで、*=は左辺に右辺を掛けて左辺に代入する命令,^=は左辺に右辺とEXORをとって、左辺に代入する命令,|はビットごとのOR,>>5は5ビット右シフトを表す。こうして、func_choice[0]の上位2ビットがc0,次の2ビットがc1,と順番にとっていく。ラウンドの回数が16より多いときには、例えばfunc_choice[1]の上位ビットから用いるようにする。
【0068】
(5−3.文書の復号化)
本実施形態における文書の復号化は、JUMP処理以外の部分は実施形態3と同様である。
(1)復号に用いるJUMPの初期値を求める。
これは暗号化に用いる上述の2つの定数、Iteration(変換回数)とLog_Tuple(ブロック内のワード数の対数)から、次の式で求める事が出来る。
JUMP=1<<((3*Iteration−1)%Log_Tuple)
ここで、%は剰余を求める演算であり、1 << は、1を<<の右の回数だけ2倍するという意味である。
(2)JUMPの変化は、暗号化の逆にする。
すなわち、1ブロック=4ワードの場合は、繰り返し毎に4,2,1と半分にしていき、1の次は4に戻る。
(3)このようにJUMPが決定されれば、暗号化の時に使用した関数に対応する逆関数を選択し、このJUMP値および暗号化時と同じパラメータを与えることができる。
【0069】
(5−4.用意する関数)
本実施形態で用いる関数として、ブロック内のそれぞれのワードを主にワード内で変換する関数としてPF1,PF2,PF3,PF4の4種類、ワード間の情報を混ぜるための変換を行なう関数としてPF5,PF6,PF7,PF8の4種類、関数として1種類、計9種類の関数を用意する。以降、これら9種類の関数について順に説明する。なお、これらのPF1〜PF9の関数は一例であり、高速に処理できる他の演算を用意してもよい。
【0070】
(1)PF1〜PF4(ワード内関数)
PF1〜PF4は、ブロック内のそれぞれのワードを主にワード内で変換するワード内関数である。復号化にはそれぞれ関数の逆の処理を行なう逆関数(ワード内逆関数)を用いる。
ブロックをb0,b1,…,b{t−1}なるtワードとし、パラメータをp0,p1,...,p{t−1}なるtワードとする。まず、
bj←bj EXOR pj
なる代入を行う。(j=0,1,…,t−1)。つぎに、奇数定数をかける:
bj←bj×cj(mod 2{32},以下modはいつもついているが省略)(j=0,1,…,t−1)。
cjは、あらかじめMTにより生成された奇数乱数のテーブルm0,m1,…,m{31}より次の方法で選ばれる。m0,…,m{31}はすべて奇数であるよう、最下位ビットを1にしてある。また、cj:=m{kj}であり、kjはp{j+ell}の最上位5ビットを0〜31の整数と見たものである。ここで、ellの値はPF1,PF2,PF3,PF4のときそれぞれ1,2,2,3である。なお、テーブルを用意したのは復号化の際にcjの逆数(modulo 2{32})を用いるからである。
本実施形態では、暗号化を行う前処理としてこの乗法定数テーブルm0,…,m{31}をMTにより作成し、そのmodulo 2{32}での乗法逆数のテーブルを作成して保存する。さらに、ある加法定数テーブルadd0,…,add{31}もMTにより作成して保存する。
【0071】
次に、
b{(j+jump)mod t}←b{(j+jump)mod t}□add{[bj>>(32−5)]}
なる代入を行なう。j=0,1,2,…,t−1を、この順序で計算する。これは、まずbjの上位5ビットを見て、それに対応するaddのテーブル(加法定数テーブル)の値と、b{j+jump}(添え字はmodulo tで見る)の値とを二項演算□を取って、その結果をb{j+jump}に格納するということである。二項演算□は、PF1,PF2,PF3,PF4のときにそれぞれ+,EOR,+,EORである。
次に、以下のようにして16〜23に値をとる擬似乱数sjを生成する。
sj←((pj>>(32−4))|0x10)&0x17
ここで、&はビットごとのAND演算である。
sjを用いて、bjに対して次の二つの変換のいずれかを行う。
bj←((〜bj)<<(32−sj))|(bj>>sj).
bj←bj EXOR ((〜sim bj)>>sj).
上はローテート(ただし、左からあふれた分はビット反転〜をとる)である。下は、ビット反転したものを右にsjシフトしたものをbjに足すものである(シフトと呼ぶ)。PF1,PF2,PF3,PF4で、それぞれローテート、ローテート、シフト、シフトを選ぶ。
【0072】
(2)PF5〜PF8(ワード間関数)
PF5〜PF8は、は、主にワード間(本実施形態においては2ワード間)の情報を混ぜるための変換を行なうワード間関数である。復号化にはそれぞれの関数の処理の逆の操作を行なう逆関数(ワード間逆関数)を用いる。
1)PF5
まずj=0とし、
bj←bj+(b{j−jump}×pj)
を行なう。
sj←((pj>>(32−4))|0x10)&0x17
により16〜23に値をとる擬似乱数を生成し、
bj←bj EXOR ((〜sim bj)>>sj).
を行う。これをj=0,1,2,…,t−1とこの順に繰り返す。
【0073】
2)PF6〜PF8
j=0とする。
s←(pj>>(32−log2(t)))
により、sにpjの上位log2(t)ビットを格納する。s=jとなったときは、sから1を引く(modulo tで計算する)。これにより、sとjは異なる。ここで、
PF6では、
bj←(bj EXOR (b{j−jump}×bs))−pj
bj←bj EXOR (bj>>16)
なる代入を行う。添え字はmodulo tで考える。
PF7,PF8では、
bj←(bj EXOR (b{j−jump}×(bs□−pj));
bj←bj EXOR (bj>>c);
なる代入を行う。ここで、□は、PF7の時にはビットごとのOR,PF8ではEXORである。また、cは、PF7のときには16、PF8のときには17である。
【0074】
(3)PF9
k=2(p0+p{t−1})+1 mod 2{32}
としておいて、jump_oddをjump以下の最大の奇数とする。ブロックb0,b1,…,b{t−1}において、kのビットパターンで1になっているところを、jump_oddとばしに巡回置換する。すなわち、以下の置換を行う。
1)kのビットパターンで1になっている部分に対応するb0のビットを抽出し、保存しておく。これは、b0とkのビットごとAND演算の結果を保存することと等しい。
2)次に、b0における上記のビットを、b{−jump_odd}における対応するビットによって置換する。ここで、bの添え字はmodulo tで計算するものとする。
3)次に、b{−jump_odd}における対応するビットを、b{−2jump_odd}に対応するビットによって置換する。このように、玉突き的にb{−j×jump_odd}における対応するビットを、
b{−(j+1)×jump_odd}における対応するビットに置換する、という操作をj=0,1,…t−1について行う。
4)最後に、b{−(t+1)×jump_odd}における対応するビットを、保存しておいたb0の対応するビットに置換する。
復号化には、上述の処理の逆の操作を行なう逆関数を用いる。
【0075】
<6.実施形態6>
実施形態6は、実施形態2〜5の各実施形態において、あらかじめ用意した数列(共有鍵)から上述のcryptMT(実施形態1)の方法で生成した暗号学的に安全な擬似乱数列SPNを、これらの実施形態で用いる擬似乱数列PNとする手法である。この手法では、暗号化に用いる関数の選択及び関数のパラメータに暗号学的に安全な擬似乱数列を用いるため、より解読が困難な暗号化を行なうことができる。
【特許請求の範囲】
【請求項1】
あらかじめ与えられた共有鍵で文書を暗号化する暗号化システムであって、
前記文書を記憶している文書記憶手段と、
あらかじめ定めたビット数をワードとして、あらかじめ定めたワード数のブロック単位に、複数種類の関数を実行する関数実行手段と、
前記共有鍵から擬似乱数列を生成する擬似乱数生成手段と、
前記関数実行手段の関数の種類を重複を許して選択する関数選択手段と
を備えており、
前記関数選択手段は、前記文書記憶手段からの文書の前記ブロック単位ごとに、前記擬似乱数により関数を順次選択し、
前記関数実行手段は、前記選択された関数で、前記擬似乱数列のブロックをパラメータとして用いて、前記文書を変換して暗号化すること
を特徴とする暗号化システム。
【請求項2】
あらかじめ与えられた共有鍵で暗号化文書を復号する復号化システムであって、
前記暗号化文書を記憶する暗号化文書記憶手段と、
あらかじめ定めたビット数をワードとして、あらかじめ定めたワード数のブロック単位に、暗号化に用いる複数種類の関数に対応する複数種類の逆関数を実行する逆関数実行手段と、
前記共有鍵から擬似乱数列を生成する擬似乱数生成手段と、
前記逆関数実行手段の逆関数の種類を重複を許して選択する逆関数選択手段と
を備えており、
前記逆関数選択手段は、前記暗号化文書記憶手段からの暗号化文書の前記ブロック単位ごとに、前記擬似乱数により逆関数を選択し、
前記逆関数実行手段は、前記選択された逆関数で、前記擬似乱数列のブロックをパラメータとして用いて、前記暗号化文書を変換して復号すること
を特徴とする復号化システム。
【請求項3】
請求項1に記載の暗号化システムであって、
前記擬似乱数生成手段は、線形次状態関数を用いて擬似乱数を生成すること
を特徴とする暗号化システム。
【請求項4】
請求項1又は3に記載の暗号化システムであって、
前記関数選択手段及び前記関数実行手段は、前記ブロックごとに、あらかじめ定めた回数選択・変換を繰り返して、前記文書を暗号化すること
を特徴とする暗号化システム。
【請求項5】
請求項1,3,4 のいずれかに記載の暗号化システムであって、
さらに、あらかじめ初期値を設定した、あらかじめ定めたビット数( ワード) の記憶手段を備えており、
前記擬似乱数生成手段は、前記数列から擬似乱数列を生成した後に、該生成した擬似乱数列をワードに切り出して最下位ビットを1
にし、前記記憶手段に前記切り出したワードを2 のワード長乗を法として繰り返し乗算した結果のビット列の一部または全体を前記擬似乱数列とすること
を特徴とする暗号化システム。
【請求項6】
請求項1,3〜5のいずれかに記載の暗号化システムであって、
前記関数実行手段は、複数ワードに対するワード間関数を含み、該ワード間関数は、文書を暗号化するごとに、該複数ワードの間隔を変化すること
を特徴とする暗号化システム。
【請求項7】
請求項2に記載の復号化システムであって、
前記擬似乱数生成手段は、線形次状態関数を用いて擬似乱数を生成すること
を特徴とする復号化システム。
【請求項8】
請求項2又は7に記載の復号化システムであって、
前記逆関数選択手段及び前記逆関数実行手段は、前記ブロックごとに、あらかじめ定めた回数選択・変換を繰り返して、前記暗号化文書を復号すること
を特徴とする復号化システム。
【請求項9】
請求項2,7,8のいずれかに記載の復号化システムであって、
さらに、あらかじめ初期値を設定した、あらかじめ定めたビット数( ワード) の記憶手段を備えており、
前記擬似乱数生成手段は、前記数列から擬似乱数列を生成した後に、該生成した擬似乱数列をワードに切り出して最下位ビットを1
にし、前記記憶手段に前記切り出したワードを2 のワード長乗を法として繰り返し乗算した結果のビット列の一部または全体を前記擬似乱数列とすること
を特徴とする復号化システム。
【請求項10】
請求項2,7〜9のいずれかに記載の復号化システムであって、
前記逆関数実行手段は、複数ワードに対するワード間逆関数を含み、該ワード間逆関数は、暗号化文書を復号するごとに、該複数ワードの間隔を変化すること
を特徴とする復号化システム。
【請求項11】
請求項1,3〜6のいずれかに記載の暗号化システムの機能をコンピュータ・システムに構築させるプログラム。
【請求項12】
請求項2,7〜10のいずれかに記載の復号化システムの機能をコンピュータ・システムに構築させるプログラム。
【請求項1】
あらかじめ与えられた共有鍵で文書を暗号化する暗号化システムであって、
前記文書を記憶している文書記憶手段と、
あらかじめ定めたビット数をワードとして、あらかじめ定めたワード数のブロック単位に、複数種類の関数を実行する関数実行手段と、
前記共有鍵から擬似乱数列を生成する擬似乱数生成手段と、
前記関数実行手段の関数の種類を重複を許して選択する関数選択手段と
を備えており、
前記関数選択手段は、前記文書記憶手段からの文書の前記ブロック単位ごとに、前記擬似乱数により関数を順次選択し、
前記関数実行手段は、前記選択された関数で、前記擬似乱数列のブロックをパラメータとして用いて、前記文書を変換して暗号化すること
を特徴とする暗号化システム。
【請求項2】
あらかじめ与えられた共有鍵で暗号化文書を復号する復号化システムであって、
前記暗号化文書を記憶する暗号化文書記憶手段と、
あらかじめ定めたビット数をワードとして、あらかじめ定めたワード数のブロック単位に、暗号化に用いる複数種類の関数に対応する複数種類の逆関数を実行する逆関数実行手段と、
前記共有鍵から擬似乱数列を生成する擬似乱数生成手段と、
前記逆関数実行手段の逆関数の種類を重複を許して選択する逆関数選択手段と
を備えており、
前記逆関数選択手段は、前記暗号化文書記憶手段からの暗号化文書の前記ブロック単位ごとに、前記擬似乱数により逆関数を選択し、
前記逆関数実行手段は、前記選択された逆関数で、前記擬似乱数列のブロックをパラメータとして用いて、前記暗号化文書を変換して復号すること
を特徴とする復号化システム。
【請求項3】
請求項1に記載の暗号化システムであって、
前記擬似乱数生成手段は、線形次状態関数を用いて擬似乱数を生成すること
を特徴とする暗号化システム。
【請求項4】
請求項1又は3に記載の暗号化システムであって、
前記関数選択手段及び前記関数実行手段は、前記ブロックごとに、あらかじめ定めた回数選択・変換を繰り返して、前記文書を暗号化すること
を特徴とする暗号化システム。
【請求項5】
請求項1,3,4 のいずれかに記載の暗号化システムであって、
さらに、あらかじめ初期値を設定した、あらかじめ定めたビット数( ワード) の記憶手段を備えており、
前記擬似乱数生成手段は、前記数列から擬似乱数列を生成した後に、該生成した擬似乱数列をワードに切り出して最下位ビットを1
にし、前記記憶手段に前記切り出したワードを2 のワード長乗を法として繰り返し乗算した結果のビット列の一部または全体を前記擬似乱数列とすること
を特徴とする暗号化システム。
【請求項6】
請求項1,3〜5のいずれかに記載の暗号化システムであって、
前記関数実行手段は、複数ワードに対するワード間関数を含み、該ワード間関数は、文書を暗号化するごとに、該複数ワードの間隔を変化すること
を特徴とする暗号化システム。
【請求項7】
請求項2に記載の復号化システムであって、
前記擬似乱数生成手段は、線形次状態関数を用いて擬似乱数を生成すること
を特徴とする復号化システム。
【請求項8】
請求項2又は7に記載の復号化システムであって、
前記逆関数選択手段及び前記逆関数実行手段は、前記ブロックごとに、あらかじめ定めた回数選択・変換を繰り返して、前記暗号化文書を復号すること
を特徴とする復号化システム。
【請求項9】
請求項2,7,8のいずれかに記載の復号化システムであって、
さらに、あらかじめ初期値を設定した、あらかじめ定めたビット数( ワード) の記憶手段を備えており、
前記擬似乱数生成手段は、前記数列から擬似乱数列を生成した後に、該生成した擬似乱数列をワードに切り出して最下位ビットを1
にし、前記記憶手段に前記切り出したワードを2 のワード長乗を法として繰り返し乗算した結果のビット列の一部または全体を前記擬似乱数列とすること
を特徴とする復号化システム。
【請求項10】
請求項2,7〜9のいずれかに記載の復号化システムであって、
前記逆関数実行手段は、複数ワードに対するワード間逆関数を含み、該ワード間逆関数は、暗号化文書を復号するごとに、該複数ワードの間隔を変化すること
を特徴とする復号化システム。
【請求項11】
請求項1,3〜6のいずれかに記載の暗号化システムの機能をコンピュータ・システムに構築させるプログラム。
【請求項12】
請求項2,7〜10のいずれかに記載の復号化システムの機能をコンピュータ・システムに構築させるプログラム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【公開番号】特開2011−145698(P2011−145698A)
【公開日】平成23年7月28日(2011.7.28)
【国際特許分類】
【出願番号】特願2011−61812(P2011−61812)
【出願日】平成23年3月19日(2011.3.19)
【分割の表示】特願2005−141725(P2005−141725)の分割
【原出願日】平成17年5月13日(2005.5.13)
【出願人】(305013910)国立大学法人お茶の水女子大学 (32)
【出願人】(504136568)国立大学法人広島大学 (924)
【Fターム(参考)】
【公開日】平成23年7月28日(2011.7.28)
【国際特許分類】
【出願日】平成23年3月19日(2011.3.19)
【分割の表示】特願2005−141725(P2005−141725)の分割
【原出願日】平成17年5月13日(2005.5.13)
【出願人】(305013910)国立大学法人お茶の水女子大学 (32)
【出願人】(504136568)国立大学法人広島大学 (924)
【Fターム(参考)】
[ Back to top ]