
核酸の塩基配列及び塩基修飾を解析する装置、方法及びプログラム
【課題】核酸の解析を迅速且つ正確に行うことのできる装置を提供する。
【解決手段】核酸の全体塩基組成に基づいて複数の塩基組成セットを作成するとともに、塩基組成セットが末端位置の部分塩基組成の塩基数の昇順に階層化された階層構造を作成し、塩基組成セットとその末端位置の部分塩基組成に塩基を1つ追加した部分塩基組成を末端位置に有する他の塩基組成セットとの間に接続関係を作成する処理部と、部分塩基組成について、対応したプロダクトイオンの予測される質量値を算出し、予測される質量値と核酸由来のプロダクトイオンの実際に得られた質量値との比較に基づいて塩基組成セットに重みを付与する処理部と、塩基組成セットに付与された重みに基づいて階層構造の最外階層から接続関係を辿りながら、各階層に属する塩基組成セットのうち1つを選択することによって、核酸の末端塩基から塩基配列を順次決定する処理部と、を含む核酸解析装置とする。
【解決手段】核酸の全体塩基組成に基づいて複数の塩基組成セットを作成するとともに、塩基組成セットが末端位置の部分塩基組成の塩基数の昇順に階層化された階層構造を作成し、塩基組成セットとその末端位置の部分塩基組成に塩基を1つ追加した部分塩基組成を末端位置に有する他の塩基組成セットとの間に接続関係を作成する処理部と、部分塩基組成について、対応したプロダクトイオンの予測される質量値を算出し、予測される質量値と核酸由来のプロダクトイオンの実際に得られた質量値との比較に基づいて塩基組成セットに重みを付与する処理部と、塩基組成セットに付与された重みに基づいて階層構造の最外階層から接続関係を辿りながら、各階層に属する塩基組成セットのうち1つを選択することによって、核酸の末端塩基から塩基配列を順次決定する処理部と、を含む核酸解析装置とする。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、核酸の塩基配列及び塩基修飾を解析する装置、方法及びプログラムに関し、特に、質量分析の結果を利用して核酸の塩基配列及び塩基修飾を解析する装置、方法及びプログラムに関する。
【背景技術】
【0002】
RNA干渉やマイクロRNAの発見によって、タンパク質をコードしないRNA(機能性RNA)が担う新しい機能が注目されている。機能性RNAは、それ自身が遺伝子の最終産物であり、機能性高分子として振る舞い、遺伝子発現の調節、発生、分化等の高次生命現象に関わる重要な働きを担っていることが次第に明らかになりつつある。また、機能性RNAの異常が疾患の原因になっているという報告例もあり、疾患の原因として、タンパク質の異常のみならずRNAの異常も視野に入れる必要性が指摘されている。
【0003】
従来、このようなRNAを解析する方法としては、例えば、逆転写PCRによりcDNAを増幅し、当該cDNAの配列を決定する方法があった。
【0004】
また、例えば、非特許文献1においては、解析の対象とする核酸の塩基配列として予想される全ての塩基配列候補を作成し、当該全ての塩基配列候補の各々から生じ得る複数組のプロダクトイオンについて、理論的に予測される質量/電荷比と、当該核酸から生じたプロダクトイオンについて実際の質量分析により得られた質量/電荷比と、を比較することにより、当該全ての塩基配列候補の各々をスコア付けし、当該スコアの高いものを当該核酸の塩基配列として決定する方法が提案されている。
【非特許文献1】Oberacher H., Mayr B.M., Huber C.G.; Journal of the American Societyfor Mass Spectrometry, 15 (1), pp. 32-42, 2004.
【発明の開示】
【発明が解決しようとする課題】
【0005】
しかしながら、上記cDNAを用いた方法は、熟練した技術が必要であり、時間と手間がかかる上に、PCRによるバイアスを考慮すると定量的とは言い難い。
【0006】
また、上記非特許文献1に記載の方法は、対象とする核酸の塩基数が増加するにつれて、予想される塩基配列候補の数が急激に増加するため、塩基配列を決定するための計算量が膨大になる。また、各塩基配列候補から生じ得る複数組のプロダクトイオンの全てについて理論値と実測値とを比較した結果に基づいて、当該各塩基配列候補をスコア付けするため、例えば、信頼性の高い末端由来の短いプロダクトイオンの実測結果を十分に活用できないことがある。また、核酸の塩基修飾を解析する上でも同様の問題があった。
【0007】
本発明は、上記課題に鑑みて為されたものであり、塩基配列や塩基修飾等に関する核酸の解析を迅速且つ正確に行うことのできる装置、方法及びプログラムを提供することをその目的の一つとする。
【課題を解決するための手段】
【0008】
上記課題を解決するための本発明の一実施形態に係る核酸解析装置は、核酸の全体塩基組成に基づいて、各々が一組の部分塩基組成から構成される、複数の塩基組成セットを作成するとともに、前記塩基組成セットが、その少なくとも一方の末端位置の部分塩基組成の塩基数の昇順に階層化された階層構造を作成し、さらに前記塩基組成セットの各々と、その前記末端位置の部分塩基組成に塩基を1つ追加した部分塩基組成を前記末端位置に有する他の塩基組成セットと、の間に接続関係を作成する第一処理部と、前記部分塩基組成の各々について、対応したプロダクトイオンの質量分析において得られることが予測される質量値を算出するとともに、前記予測される質量値と、前記核酸由来のプロダクトイオンの質量分析において実際に得られた質量値と、の比較に基づいて、前記塩基組成セットの各々に重みを付与する第二処理部と、前記塩基組成セットの各々に付与された重みに基づいて、前記階層構造の前記末端位置の部分塩基組成の塩基数が最も少ない前記塩基組成セットが属する最外階層から前記接続関係を辿りながら、各階層に属する塩基組成セットのうち1つを選択する選択処理を行うことによって、前記核酸の前記末端位置に対応する少なくとも一方の末端から塩基配列を順次決定する第三処理部と、を含むことを特徴とする。本発明によれば、塩基配列や塩基修飾等に関する核酸の解析を迅速且つ正確に行うことのできる装置を提供することができる。すなわち、計算量を効果的に低減しつつ、末端由来のプロダクトイオンの質量分析結果を効果的に利用して、塩基配列の決定、塩基修飾の有無、塩基修飾の内容(修飾の種類、位置、数等)等について、信頼性の高い解析を行うことができる。
【0009】
また、前記第一処理部は、前記階層構造の一方の最外階層からは、5’端位置又は3’端位置のうち一方の末端位置の部分塩基組成の塩基数の昇順となり、また、他方の最外階層からは、5’端位置又は3’端位置のうち他方の末端位置の部分塩基組成の塩基数の昇順となるよう、前記塩基組成セットを階層化し、前記第三処理部は、前記階層構造の前記一方の最外階層及び前記他方の最外階層の両方の最外階層から内部の階層に向けて前記接続関係を辿りながら、前記選択処理を行うことによって、前記核酸の5’端及び3’端の両末端から塩基配列を順次決定することもできる。また、前記第二処理部は、前記接続関係の各々により接続される一対の前記塩基組成セットに付与された重みに基づいて、前記接続関係の各々に重みを付与し、前記第三処理部は、前記塩基組成セットの各々に付与された重みと前記接続関係の各々に付与された重みとに基づいて、前記選択処理を行うこともできる。また、前記第一処理部は、前記塩基組成セットの各々に対応する階層化されたノードと、前記接続関係の各々に対応して前記ノードを接続するエッジと、を有する有向グラフを作成し、前記第三処理部は、前記塩基組成セットの各々に付与された重みに基づいて、前記有向グラフの前記末端位置の部分塩基組成の塩基数が最も少ない前記塩基組成セットが属する階層側の末端から最適経路を探索することにより、前記選択処理を行うこともできる。この場合、前記第三処理部は、動的計画法を適用して、前記選択処理を行うこともできる。さらに、この場合、前記第一処理部は、前記有向グラフの一方端からは、対応する前記塩基組成セットの5’端位置又は3’端位置のうち一方の末端位置の部分塩基組成の塩基数の昇順となり、また、前記有向グラフの他方端からは、対応する前記塩基組成セットの5’端位置又は3’端位置のうち他方の末端位置の部分塩基組成の塩基数の昇順となるよう、前記ノードを階層化し、前記第三処理部は、前記有向グラフの前記一方端及び前記他方端の両端から内部に向けて動的計画法を適用して前記エッジを辿りながら、前記選択処理を行うことによって、前記核酸の5’端及び3’端の両末端から塩基配列を順次決定することもできる。
【0010】
また、前記第二処理部は、前記部分塩基組成の各々について、前記対応したプロダクトイオンの質量分析において、前記対応したプロダクトイオンに修飾塩基が含まれないと仮定した場合に予測される第一の予測質量値と、前記対応したプロダクトイオンに修飾塩基が含まれると仮定した場合に予測される第二の予測質量値と、を作成し、前記第一の予測質量値及び前記第二の予測質量値の各々と、前記実際に得られた質量値と、の比較に基づいて、前記部分塩基組成の各々に重みを付与することもできる。この場合、前記第二処理部は、前記部分塩基組成の各々について、前記第一の予測質量値及び前記第二の予測質量値の各々と、前記実際に得られた質量値と、の比較に基づいて、前記対応したプロダクトイオンに前記修飾塩基が含まれるか否かを判断し、前記対応したプロダクトイオンに前記修飾塩基が含まれると判断した場合には、前記部分塩基組成の各々に、前記修飾塩基に関する修飾情報を関連付けて保持し、前記第三処理部は、前記階層構造の隣接する階層間で、前記選択された塩基組成セットにおいて前記修飾情報が関連付けられている部分塩基組成の位置が移動するか否かの判断結果に基づいて、前記核酸に含まれる修飾塩基の位置を決定することもできる。
【0011】
上記課題を解決するための本発明の一実施形態に係る核酸解析方法は、核酸の全体塩基組成に基づいて、各々が一組の部分塩基組成から構成される、複数の塩基組成セットを作成するとともに、前記塩基組成セットが、その少なくとも一方の末端位置の部分塩基組成の塩基数の昇順に階層化された階層構造を作成し、さらに前記塩基組成セットの各々と、その前記末端位置の部分塩基組成に塩基を1つ追加した部分塩基組成を前記末端位置に有する他の塩基組成セットと、の間に接続関係を作成する第一ステップと、前記部分塩基組成の各々について、対応したプロダクトイオンの質量分析において得られることが予測される質量値を算出するとともに、前記予測される質量値と、前記核酸由来のプロダクトイオンの質量分析において実際に得られた質量値と、の比較に基づいて、前記塩基組成セットの各々に重みを付与する第二ステップと、前記塩基組成セットの各々に付与された重みに基づいて、前記階層構造の前記末端位置の部分塩基組成の塩基数が最も少ない前記塩基組成セットが属する最外階層から前記接続関係を辿りながら、各階層に属する塩基組成セットのうち1つを選択する選択処理を行うことによって、前記核酸の前記末端位置に対応する少なくとも一方の末端から塩基配列を順次決定する第三ステップと、を含むことを特徴とする。本発明によれば、核酸の解析を迅速且つ正確に行うことのできる方法を提供することができる。
【0012】
上記課題を解決するための本発明の一実施形態に係る核酸解析プログラムは、コンピュータに、核酸の全体塩基組成に基づいて、各々が一組の部分塩基組成から構成される、複数の塩基組成セットを作成するとともに、前記塩基組成セットが、その少なくとも一方の末端位置の部分塩基組成の塩基数の昇順に階層化された階層構造を作成し、さらに前記塩基組成セットの各々と、その前記末端位置の部分塩基組成に塩基を1つ追加した部分塩基組成を前記末端位置に有する他の塩基組成セットと、の間に接続関係を作成する第一手順と、前記部分塩基組成の各々について、対応したプロダクトイオンの質量分析において得られることが予測される質量値を算出するとともに、前記予測される質量値と、前記核酸由来のプロダクトイオンの質量分析において実際に得られた質量値と、の比較に基づいて、前記塩基組成セットの各々に重みを付与する第二手順と、前記塩基組成セットの各々に付与された重みに基づいて、前記階層構造の前記末端位置の部分塩基組成の塩基数が最も少ない前記塩基組成セットが属する最外階層から前記接続関係を辿りながら、各階層に属する塩基組成セットのうち1つを選択する選択処理を行うことによって、前記核酸の前記末端位置に対応する少なくとも一方の末端から塩基配列を順次決定する第三手順と、を実行させることを特徴とする。本発明によれば、核酸の解析を迅速且つ正確に行うことのできるプログラムを提供することができる。
【発明を実施するための最良の形態】
【0013】
以下に、本発明の一実施形態に係る核酸の塩基配列及び塩基修飾を解析する装置(以下、「本装置」という)、方法(以下、「本方法」という)、及びプログラム(以下、「本プログラム」という)について、図面を参照しつつ説明する。本実施形態においては、本プログラムに従って動作する本装置を用いて、本方法を実施する場合を例として説明する。
【0014】
まず、本装置及び本プログラムの概要について説明する。本装置は、その少なくとも一部にコンピュータを含んで構成することができる。図1は、本装置1の主な構成を示すブロック図である。図1に示すように、本装置1は、制御部10と、記憶部20と、入力部30と、出力部40と、質量分析部50と、を含んでいる。
【0015】
制御部10は、CPU等の演算装置によって実現できる。制御部10は、記憶部20に格納されているプログラムに従って動作し、記憶部20、入力部30、出力部40、質量分析部50との間でデータの入出力を行うことができる。すなわち、制御部10は、質量分析部50から受け入れた質量分析に関するデータを記憶部20に格納するとともに、記憶部20から読み出したデータと入力部30から受け入れたデータとに基づいて所定の演算処理を実行することができる。また、制御部10は、演算処理の結果に関連するデータに基づいて、出力部40に当該結果を表す所定の画像を表示させることができる。また、制御部10は、質量分析部50に指示データを出力して所定の質量分析を実行させることもできる。
【0016】
図2は、この制御部10によって行われる主な処理を示す機能ブロック図である。図2に示すように、制御部10は、塩基組成処理部11と、重み付け処理部12と、解析処理部13と、を機能的に含んでいる。制御部10による処理の具体的内容については後に詳しく説明する。
【0017】
記憶部20は、ハードディスク等の外部記憶装置や、RAM、ROM等の主記憶装置によって実現できる。すなわち、例えば、記憶部20はハードディスクを備え、制御部10が実行するプログラム(本プログラムや、質量分析部50が質量分析を実行し又は質量分析結果を解析するためのプログラム等)、制御部10が演算処理で利用するデータベース、制御部10が質量分析部50から受け入れた質量分析に関するデータを当該ハードディスクに格納する。また、記憶部20は、制御部10により行われる処理で利用されるデータを保持するワークメモリとして動作することもできる。すなわち、例えば、記憶部20はRAMを備え、制御部10が入力部30や質量分析部50から受け入れたデータや、制御部10による演算処理の過程で生成されたデータを当該RAMに一時的に保持する。
【0018】
入力部30は、キーボード、マウス、タッチパッド等の入力装置によって実現できる。入力部30は、本装置のユーザからデータの入力を受け入れることができる。また、入力部30は、CDやDVD等の記録媒体のドライブ装置を含んで実現することもできる、この場合、入力部30は、ドライブ装置に挿入された記録媒体に記録されているデータを読み出して制御部10に出力する。
【0019】
出力部40は、液晶ディスプレイ等の表示装置によって実現できる。出力部40は、制御部10から受け入れたデータに基づいて、制御部10により行われた処理の結果を表す画面や、ユーザにデータの入力を促す画面をユーザに提示することができる。
【0020】
質量分析部50は、QqTOF型のLC/MS/MS等の核酸の質量分析に適した質量分析計によって実現できる。質量分析部50は、対象とする核酸の質量分析を実行し、その分析結果に関するデータを制御部10に出力する。
【0021】
本プログラムは、コンピュータに、本発明に関する処理を実行させることができる。例えば、本プログラムは、本装置に、本方法に関する処理を実行させることができる。また、本プログラムは、コンピュータ読み取り可能な記録媒体に記録することができる。
【0022】
次に、本装置、本方法及び本プログラムの詳細について説明する。ここでは、核酸として、所定長さのRNA分子をRNA分解酵素の一種であるRNaseAを使用して切断することにより得られたRNA断片(以下、「対象断片」という)を解析の対象とする場合を例として説明する。
【0023】
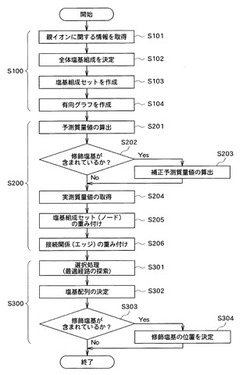
図3は、本方法に含まれる主なステップの一例を示すフロー図である。図3に示すように、本方法は、第一のステップS100と、第二のステップS200と、第三のステップS300と、を含んでいる。
【0024】
第一のステップS100において、本装置1の塩基組成処理部11は、対象断片の親イオンに関する情報を取得する(S101)。この親イオンは、質量分析部50が備える質量分析計において、エレクトロスプレーイオン化(ESI)法やマトリックス支援レーザー脱離イオン化(MALDI)法等の核酸の質量分析に適したイオン化法により、対象断片から生成することができる。
【0025】
親イオンに関する情報としては、例えば、親イオンの質量対電荷比(m/z値)、価数、対象断片の作製に使用されたRNA分解酵素の種類、対象断片に含まれる修飾塩基の種類等を用いることができる。親イオンのm/z値や価数は、例えば、質量分析部50が備えるLC−QqTOF型の質量分析計を用いて、当該質量分析計の誤差範囲内で親イオンの質量分析を行うことにより、高い精度で測定することができる。
【0026】
塩基組成処理部11は、これらの親イオンに関する情報を、質量分析部50から受け入れることができる。なお、塩基組成処理部11は、親イオンに関する情報を、入力部30を介して本装置1のユーザから受け入れ、又は記憶部20から読み出すことにより、取得することもできる。
【0027】
次に、塩基組成処理部11は、親イオンに関する情報に基づいて、対象断片の全体塩基組成を決定する(S102)。ここで、「塩基組成」とは、所定長さの核酸分子に含まれる塩基の種類及び各塩基の数から構成され、当該核酸分子における各塩基の配列順序とは無関係に決定される。対象断片の「全体塩基組成」とは、当該対象断片の全体としての塩基組成である。
【0028】
本実施形態においては、例えば、対象断片が、3残基のアデニン(A)、1残基のウラシル(U)、及び2残基のグアニン(G)から構成され、シトシン(C)を含まない場合、当該対象断片の全体塩基組成を「A3G2U」と記述する。この塩基組成の記述において、塩基の記載順序は、対象断片における塩基の配列順序とは無関係である。
【0029】
このステップS102において、塩基組成処理部11は、まず、親イオンのm/z値や価数等の情報に基づいて、親イオンの分子量(質量)を算出する。そして、塩基組成処理部11は、この親イオンの分子量に基づいて、対象断片の全体塩基組成を決定する。
【0030】
すなわち、例えば、記憶部20が、RNA断片の様々な塩基組成と、その分子量と、を関連付けたデータベースを格納している場合には、塩基組成処理部11は、親イオンの分子量と、当該データベースに格納されている各塩基組成の分子量と、を照合する。そして、塩基組成処理部11は、データベースに登録されている塩基組成のうちから、親イオンの分子量に一致し、又は分子量の差分が所定の誤差範囲内である塩基組成を抽出し、当該抽出された塩基組成を、対象断片の全体塩基組成として決定する。なお、所定の誤差範囲は、例えば、親イオンの質量分析に用いられた質量分析計の性能や分析条件等に応じた分析精度に基づいて決定することができる。
【0031】
具体的に、ここでは、塩基組成処理部11が、親イオンのm/z値「999.7」と価数「−2」とに基づいて、分子量「2001.4(Da)」を算出し、当該分子量に基づくデータベース検索により、対象断片の全体塩基組成を「A3G2U」と決定した場合を例として説明する。
【0032】
次に、塩基組成処理部11は、決定された全体塩基組成に基づいて、複数の塩基組成セットを作成する(S103)。この複数の塩基組成セットの各々は、一組の部分塩基組成から構成される。
【0033】
ここで、「一組の部分塩基組成」は、全体塩基組成の互いに異なる一部(部分塩基組成)の組合せとして構成される。すなわち、一組の部分塩基組成を構成する各部分塩基組成は、全体塩基組成を複数に分割して得られる互いに異なる複数の部分の各々である。
【0034】
また、各部分塩基組成は、塩基の種類、各塩基の数、及び対象断片における位置により特定される。したがって、例えば、2つの部分塩基組成について、各々を構成する塩基の種類及び各塩基の数が互いに同一であったとしても、各々の対象断片における位置が互いに異なる場合には、当該2つの部分塩基組成は互いに異なるものとなる。この部分塩基組成の位置は、例えば、対象断片の末端位置(5’端位置又は3’端位置)や、末端以外の内部位置等として決定することができる。
【0035】
そして、一組の部分塩基組成は、少なくとも5’端位置の部分塩基組成(5’端塩基を含む部分塩基組成)と3’端位置の部分塩基組成(3’端塩基を含む部分塩基組成)とを含む。具体的に、例えば、全体塩基組成「A3G2U」を2つに分割して一組の部分塩基組成を作成する場合の一例として、当該一組の部分塩基組成は、5’端位置の部分塩基組成「A」と3’端位置の部分塩基組成「A2G2U」とから構成される。また、全体塩基組成「A3G2U」を3つに分割して一組の部分塩基組成を作成する場合の一例として、当該一組の部分塩基組成は、5’端位置の部分塩基組成「A」と3’端位置の部分塩基組成「U」と内部(インターナル)位置の部分塩基組成「A2G2」とから構成される。
【0036】
このような一組の部分塩基組成は、対象断片由来の仮想的な一組のプロダクトイオンに対応すると考えることもできる。すなわち、各部分塩基組成は、対象断片をイオン化して親イオンを生成し、さらに当該親イオンを解離させてプロダクトイオンを生成した場合において、1分子の親イオンから生成された一組のプロダクトイオンを構成する各プロダクトイオンの塩基組成に対応していると考えることができる。したがって、例えば、一組の部分塩基組成は、5’端の塩基を含むプロダクトイオンに対応する5’端位置の部分塩基組成と、3’端の塩基を含むプロダクトイオンに対応する3’端位置の部分塩基組成と、を少なくとも含むこととなる。なお、もちろん、各部分塩基組成に対応するプロダクトイオンが、後述するような質量分析において実際に検出されるとは限らない。
【0037】
各塩基組成セットは、上述のようにして決定される一組の部分塩基組成から構成されるため、その全体としての塩基組成は全体塩基組成に一致する。すなわち、各塩基組成セットを構成する各部分塩基組成の合計は、全体塩基組成に一致する。また、本実施形態において、各塩基組成セットの構成は、コロン(:)を介して、5’端側の部分塩基組成を左側に、3’端側の部分塩基組成を右側に、それぞれ配置して記述される。具体的に、例えば、全体塩基組成「A3G2U」を2つに分割して塩基組成セットを作成する場合の一例として、5’端位置の部分塩基組成「A」と3’端位置の部分塩基組成「A2G2U」とから構成される塩基組成セットの構成は「A:A2G2U」と記述される。また、全体塩基組成「A3G2U」を3つに分割して塩基組成セットを作成する場合の一例として、5’端位置の部分塩基組成「A」と3’端位置の部分塩基組成「U」と内部(インターナル)位置の部分塩基組成「A2G2」とから構成される塩基組成セットの構成は「A:A2G2:U」と記述される。
【0038】
また、1つの全体塩基組成から作成される複数の塩基組成セットの各々は、互いに異なる一組の部分塩基組成から構成される。ここで、例えば、2つの塩基組成セットのうち一方を構成する一組の部分塩基組成と、他方を構成する一組の部分塩基組成と、を比較した場合に、少なくとも一部の対応する部分塩基組成が異なる場合には、当該2つの塩基組成セットは、互いに異なる一組の部分塩基組成から構成されていることとなる。
【0039】
なお、対応する部分塩基組成とは、対象断片における位置が同一の部分塩基組成である。例えば、2つの塩基組成セットのうち一方に含まれる5’端の部分塩基組成と、他方に含まれる5’端の部分塩基組成と、は対応する部分塩基組成である。対応する2つの部分塩基組成の塩基の種類又は各塩基の数の少なくとも一方が異なる場合、当該対応する2つの部分塩基組成は互いに異なることとなる。
【0040】
このステップS103において、塩基組成処理部11は、対象断片の全体塩基組成、当該全体塩基組成の分割条件、当該対象断片の作製に使用されたRNA分解酵素の種類等に関するデータに基づいて、当該全体塩基組成から予想される、可能な部分塩基組成の組合せの全部又は一部を作成することにより、互いに異なる複数の塩基組成セットを作成する。すなわち、例えば、塩基組成処理部11は、全体塩基組成を2つに分割して一組の部分塩基組成を作成する場合において可能な全ての部分塩基組成の組を算出し、その各々がこれら複数組の部分塩基組成のうち互いに異なる一組から構成される複数の塩基組成セットを表すデータを生成する。なお、塩基組成処理部11は、これら部分塩基組成セットの作成に利用するデータの全部又は一部を、入力部30を介してユーザから受け入れ、又は記憶部20から読み出すことにより取得することもできる。
【0041】
ここで、上述のように対象断片はRNAaseAによる切断処理によって作製されたRNA断片であるため、当該対象断片の3’端の塩基はウラシル(U)又はシトシン(C)であると予想することができる。一方、上記ステップS102で決定された対象断片の全体塩基組成は「A3G2U」であってシトシン(C)を含まない。このため、対象断片の3’端はウラシル(U)であると決定できる。また、ここでは親イオンは一箇所で切断される(すなわち、5’端の塩基を含むプロダクトイオンと3’端の塩基を含むプロダクトイオンとからなる一組のプロダクトイオンが生成される)と仮定する。
【0042】
したがって、このように対象断片の作製に使用されたRNA分解酵素の種類によって当該対象断片の末端(5’端又は3’端)の塩基の種類を特定することができる場合には、塩基組成処理部11は、全体塩基組成「A3G2U」と、当該全体塩基組成の分割数「2」と、当該RNA分解酵素の種類「RNAaseA」と、に基づいて、当該対象断片の末端位置の塩基の種類を「ウラシル(U)」と決定する。そして、塩基組成処理部11は、全体塩基組成と、末端塩基の決定結果と、に基づいて、複数の塩基組成セットを作成する。すなわち、塩基組成処理部11は、全体塩基組成に含まれるウラシル(U)の位置を3’端に固定した上で、当該全体塩基組成の残りの塩基組成に基づいて、部分塩基組成の組を複数作成する。
【0043】
具体的に、塩基組成処理部11は、3’端位置の部分塩基組成がウラシル(U)を含む場合に可能な全ての部分塩基組成の組合せを算出して、その構成がそれぞれ「A:A2UG2」、「G:A3UG」、「A2:AUG2」、「AG:A2UG」、「G2:A3U」、「A3:UG2」、「A2G:AUG」、「AG2:A2U」、「A3G:UG」、「A2G2:AU」、「A3G2:U」で表される、互いに異なる11個の塩基組成セットを作成する。
【0044】
また、このステップS103において、塩基組成処理部11は、塩基組成セットが、その少なくとも一方の末端位置の部分塩基組成の塩基数の昇順に階層化された階層構造を作成する。すなわち、塩基組成処理部11は、例えば、入力部30を介して受け入れたユーザからの指示に基づいて、5’端又は3’端のうち少なくとも一方を着目末端として決定し、当該着目末端位置の部分塩基組成に含まれる塩基の数に基づいて塩基組成セットを階層化する。具体的に、ここでは、塩基組成処理部11は、5’端を着目末端として決定し、5’端位置の部分塩基組成の塩基数が同一の塩基組成セットを同一の階層に分類する。すなわち、塩基組成処理部11は、各階層に、5’端位置の部分塩基組成の塩基数として互いに異なる所定数を関連付け、各階層には、5’端位置の部分塩基組成の塩基数が当該各階層に対応する所定数である、全体塩基組成から可能な全ての塩基組成セットを分類する。そして、塩基組成処理部11は、各階層に属する塩基組成セットを構成する5’端位置の部分塩基組成の塩基数の昇順に当該各階層を順位付けする。
【0045】
そして、塩基組成処理部11は、例えば、図4に示すように、11個の塩基組成セットの各々について、各塩基組成セットに割り当てられた識別情報S1〜S11と、当該各塩基組成セットの構成と、当該各塩基組成セットが属する階層の番号と、を関連付けたデータテーブルを階層データとして作成する。
【0046】
図4に示すように、この階層構造においては、一方の最外階層(階層番号が「1」の第一階層)から他方の最外階層(階層番号が「5」の第五階層)まで、各階層に属する塩基組成セットを構成する5’端位置の部分塩基組成に含まれる塩基の数が1つずつ増加している。
【0047】
すなわち、5’端の部分塩基組成の塩基数が最も小さい「1」である2つの塩基組成セットS1,S2は、階層構造における一方の最外階層である第一階層に分類され、当該塩基数が1つ大きい「2」である3つの塩基組成セットS3,S4,S5はその内側の第二階層に分類され、当該塩基数がさらに1つ大きい「3」である3つの塩基組成セットS6,S7,S8はさらに深い第三階層に分類され、当該塩基数がさらに1つ大きい「4」である2つの塩基組成セットS9,S10はさらに深い第四階層に分類され、当該塩基数が最も大きい「5」である1つの塩基組成セットS11は、当該階層構造における他方の最外階層である第五階層に分類されている。
【0048】
一方、この階層構造においては、3’端位置の部分塩基組成の塩基数に着目すると、逆に、第五階層から第一階層まで、当該3’端位置の部分塩基組成の塩基数の昇順に、塩基組成セットが階層化されている。すなわち、この階層構造においては、一方の最外階層(第一階層)からは5’端位置の部分塩基組成の塩基数の昇順となり、また、他方の最外階層(第五階層)からは3’端位置の部分塩基組成の昇順となるよう、塩基組成セットが階層化されている。
【0049】
さらに、このステップS103において、塩基組成処理部11は、塩基組成セットの各々と、その末端位置の部分塩基組成に塩基を1つ追加した部分塩基組成を当該末端位置に有する他の塩基組成セットと、の間に接続関係を作成する。
【0050】
すなわち、塩基組成処理部11は、隣接する階層のうち、5’端位置の部分塩基組成の塩基数が小さい塩基組成セットが属する一方の階層に属する塩基組成セットの各々と、5’端位置の部分塩基組成の塩基数が大きい塩基組成セットが属する他方の階層に属し、当該一方の階層の塩基組成セットにおける5’端位置の部分塩基組成に塩基を1つ追加した部分塩基組成を、当該5’端位置の部分塩基組成として有する塩基組成セットと、の間に1つの接続関係を作成する。
【0051】
具体的に、塩基組成処理部11は、図4に示す階層化された11個の塩基組成セットのうち、例えば、第一階層に属する、5’端位置の部分塩基組成が1つのアデニン(A)から構成される塩基組成セットS1と、隣接する第二階層に属する3つの塩基組成セットS3,S4,S5のうち、5’端位置の部分塩基組成が1つのアデニン(A)にもう1つのアデニン(A)を加えて構成される塩基組成セットS3との間に接続関係を作成すると共に、5’端位置の部分塩基組成が1つのアデニン(A)に1つのグアニン(G)を加えて構成される塩基組成セットS4との間にも接続関係を作成する。
【0052】
そして、塩基組成処理部11は、例えば、図5に示すように、作成した接続関係の各々について、各接続関係に割り当てられた識別情報C1〜C15と、当該各接続関係によって接続される一対の塩基組成セットを特定する情報と、当該各接続関係が属する階層の番号と、を関連付けたデータテーブルを接続データとして作成する。図5に示す例において、各接続関係によって接続される一対の塩基組成セットを特定する情報は、予め各塩基組成セットに割り当てられた識別情報(図4参照)の組合せとなっている。また、各接続関係が属する階層の番号は、当該各接続関係によって接続される各塩基組成セットが属する階層番号(図4参照)のうち、小さいほうの階層番号となっている。
【0053】
次に、塩基組成処理部11は、塩基組成セットの各々に対応する階層化されたノードと、上述の接続関係の各々に対応して当該ノードを接続するエッジと、を有する有向グラフを作成する(S104)。すなわち、塩基組成処理部11は、上述したような階層データと接続データとに基づいて、塩基組成セットの接続関係を視覚化した有向グラフを作成する。具体的に、例えば、塩基組成処理部11は、図6に示すような有向グラフを作成する。
【0054】
図6に示す有向グラフにおいては、図4に示した階層構造に従い、一方端(図中の左端)の最外階層(第一階層)から他方端(図中の右端)の最外階層(第五階層)に向けては、各ノードに対応する塩基組成セットを構成する5’端位置の部分塩基組成の塩基数の昇順となり、また、当該第五階層から当該第一階層に向けては、各ノードに対応する塩基組成セットを構成する3’端位置の部分塩基組成の塩基数の昇順となるよう、図4に示した11個の塩基組成セットS1〜S11に対応する11個のノードN1〜N11が階層化されて配置されている。なお、以下、有向グラフにおいて第一階層側の末端を5’端、第五階層側の末端を3’端と呼ぶ。
【0055】
すなわち、この有向グラフにおいては、5’端から内部に向けて、5’端位置の部分塩基組成の塩基数が1ずつ増加する一方で、3’端から内部に向けては、3’端位置の部分塩基組成の塩基数が1ずつ増加するように、ノードN1〜N11が階層化されて配置されている。
【0056】
また、この有向グラフにおいては、接続関係によって接続される一対の塩基組成セットに対応した一対のノードが、図5に示した接続関係C1〜C15に対応するエッジE1〜E15により接続されている。すなわち、隣接する階層のうち5’端位置の部分塩基組成の塩基数が小さい塩基組成セットが属する一方の階層に属する塩基組成セットに対応するノードの各々と、5’端位置の部分塩基組成の塩基数が大きい塩基組成セットが属する他方の階層に属し、当該一方の階層の塩基組成セットにおける5’端位置の部分塩基組成に塩基を1つ追加した部分塩基組成を、当該5’端位置の部分塩基組成として有する塩基組成セットに対応するノードと、が1つのエッジにより接続されている。
【0057】
また、この有向グラフにおいて、各エッジは、図6に示すように、5’端階層及び3’端階層から、予め中央の階層として決定された第三階層(図6において破線で囲まれた階層)に向かうよう方向付けされている。なお、塩基組成処理部11は、両端の最外階層を除く任意の階層を中央の階層として決定することができる。すなわち、例えば、塩基組成処理部11は、両端の最外階層から等しい階層数の階層、又は一方の最外階層からの階層数と他方の最外階層からの階層数との差が1だけ異なる階層を中央の階層と決定することができる。また、例えば、塩基組成処理部11は、入力部30を介してユーザから受け入れたデータによって指示される階層を中央の階層と決定することができる。
【0058】
また、塩基組成処理部11は、この有向グラフを画像としてユーザに提示するよう出力部40に指示することができる。この場合、出力部40は、図6に示すような有向グラフを液晶ディスプレイ等の画面上に表示する。さらに、この場合、塩基組成処理部11は、ユーザからの修正指示を入力部30から受け入れて、有向グラフを修正することもできる。例えば、塩基組成処理部11は、ユーザから中央の階層を変更するよう指示を受け入れた場合には、当該指示に従い、中央の階層を変更した有効グラフを作成する。
【0059】
そして、塩基組成処理部11は、上述の階層データや接続データ等、塩基組成セットや有向グラフに関する情報を含む塩基組成データを重み付け処理部12に出力する。
【0060】
第二のステップS200においては、まず、部分塩基組成の各々について、対応したプロダクトイオンの質量分析において得られることが予測される質量値を算出する(S201)。ここで、質量値は、例えば、m/z値とすることができ、又はm/z値をデコンボリューションした値(すなわち0(ゼロ)価に変換した値)とすることもできる。すなわち、重み付け処理部12は、塩基組成処理部11から受け入れた塩基組成データに基づいて、その塩基組成が各部分塩基組成に一致するプロダクトイオンを質量分析したと仮定した場合に、分析結果として得られることが予測される、当該プロダクトイオンの質量値(予測質量値)を算出する。
【0061】
ここで、一般に、核酸由来の親イオン(前駆イオン)は、図7Aに示すように、各ホスホジエステル結合の主に4ヶ所で切断されて様々なプロダクトイオンが生成される。なお、ここでは、RNAaseAを使用した切断処理によって作製された4merのRNA断片(「B」は塩基を示す)を核酸の一例として示している。
【0062】
すなわち、図7A,図7Bに示すように、McLuckeyらの命名法に基づけば、このRNA断片からは、5’端の塩基を含む5’端プロダクトイオンとして、a、b、c、d系列のプロダクトイオンが生じ、3’端の塩基を含む3’端プロダクトイオンとして、w、x、y、z系列のプロダクトイオンが生じる。また、例えば、a系列のプロダクトイオンであって、塩基が欠損したプロダクトイオン(a_B)が生じることもある。
【0063】
したがって、RNA断片の所定の塩基間位置で切断される場合、5’端位置又は3’端位置の部分組成の塩基数が、切断位置に基づいて決定される所定数である、可能な全ての塩基組成セットの各々について、各系列のプロダクトイオンが生成されると考えることができる。すなわち、このRNA断片の全体塩基組成が「AUCG」であって、その5’端から1つ目の塩基と2つ目の塩基との間で切断される場合には、図7Bに示すように、例えば、5’端位置の部分塩基組成の塩基数が「1」である可能な全ての塩基組成セット「A:UCG]、「U:ACG]、「C:AUG]、「G:AUC]の各々について、5種類の5’端プロダクトイオン「a1」、「b1」、「c1」、「d1」、「a1_B」と、4種類の3’端プロダクトイオン「w3」、「x3」、「y3」、「z3」と、が生成されると考えることができる。なお、図7Aに示すように、RNAaseAによって作製されたRNA断片は、5’端に水酸基(OH)を有し、3’端にリン酸基(PO4H)を有することが多い。これは、RNAaseTによって作製されたRNA断片についても同様である。したがって、核酸断片の作製に使用された核酸分解酵素の種類に基づいて、当該核酸断片の末端の官能基の種類を予測し、当該官能基のイオン化のしやすさ等、イオン化に関する情報に基づいて、生成されるプロダクトイオンの系列を予測することもできる。
【0064】
そこで、このステップS201において、重み付け処理部12は、各塩基組成セットを構成する各部分塩基組成と、図7Aに示すような様々な切断パターンと、に基づいて、当該各部分塩基組成に対応する少なくとも1つの系列のプロダクトイオンについて予測質量値を算出する。
【0065】
具体的に、重み付け処理部12は、各部分塩基組成に対応したプロダクトイオンの予測質量値として、当該プロダクトイオンに対応するピークが検出されることが理論的に予想されるm/z値を算出する。すなわち、重み付け処理部12は、まず、各部分塩基組成について、図7Aに示すような4つの切断箇所の各々で切断された場合に生じるプロダクトイオンの分子組成(当該プロダクトイオンに含まれる原子の種類及び各原子の数)を算出する。次いで、重み付け処理部12は、プロダクトイオンの分子組成に基づいて、当該プロダクトイオンの分子量を算出する。さらに重み付け処理部12は、プロダクトイオンの分子量と価数とに基づいて、当該プロダクトイオンのm/z値を予測質量値として算出する。なお、この予測質量値の算出においては、一部に経験的な知見を利用することもできる。
【0066】
そして、重み付け処理部12は、各塩基組成セットについて、当該各塩基組成セットを構成する複数の部分塩基組成の各々について算出された予測m/z値に基づいて、図7Cに示すような理論スペクトルを生成する。すなわち、各理論スペクトルにおいては、1つの塩基組成セットと、当該塩基組成セットを構成する各部分塩基組成に対応する各系列のプロダクトイオンについて算出された予測m/z値と、が関連付けられている。ここで、重み付け処理部12は、図4に示す各塩基組成セット又は図6に示す各ノードについて、一組の部分塩基組成の予測m/z値を算出する。すなわち、例えば、構成が「A2G:AGU」の塩基組成セットについて、当該塩基組成セットが有し得る全ての塩基配列の候補を算出する場合には、5’端位置の塩基配列として可能な3つの塩基配列「AAG」「AGA」、「GAA」と、3’端位置の塩基配列として可能な2つの塩基配列「AGU」、「GAU」と、の可能な全ての組合せを考慮した6回の演算処理を行う必要があるのに対し、重み付け処理部12は、当該塩基組成セットについては、部分塩基組成の1つの組合せについて演算処理を実行する。このため、本発明においては、上述のように全ての塩基配列候補について予測m/z値を算出するような場合に比べて、計算量を効果的に低減できる。
【0067】
次に、重み付け処理部12は、対象断片由来のプロダクトイオンの質量分析において実際に得られた質量値(実測質量値)を取得する(S204)。なお、ここでは、まず対象断片に修飾塩基が含まれていない場合又は対象断片における塩基修飾を考慮しない場合について説明するため、図3に示すステップS202、S203についての説明は省略する。
【0068】
重み付け処理部12が取得する実測質量値は、例えば、対象断片をイオン化して得られた親イオンを、質量分析部50が備える質量分析計の内部で所定の方法により解離させてプロダクトイオンを生成し、当該質量分析計による当該プロダクトイオンの質量分析(MS/MS分析)により得られた質量値とすることができる。なお、この親イオンの解離方法は、プロダクトイオンを生成できる方法であれば特に限られないが、例えば、衝突誘起解離(Collision−Induced dissociation:CID)法を好ましく用いることができる。また、親イオンの解離条件としては、解析に適したプロダクトイオンを生じさせる任意の条件を適宜設定することができ、例えば、CIDを用いる場合には、好ましい系列のプロダクトイオンを効率よく生じさせる上で適切な衝突電圧を解離条件の一つとして決定することができる。重み付け処理部12は、例えば、プロダクトイオンについて実際に得られたマススペクトル(実測スペクトル)データを質量分析部50から受け入れることにより、当該実測スペクトルデータに含まれる実測m/z値を実測質量値として取得することができる。また、重み付け処理部12は、この実測m/z値を、入力部30を介してユーザから受け入れ、又は記憶部20から読み出すことによって取得することもできる。
【0069】
次に、重み付け処理部12は、予測質量値と実測質量値との比較に基づいて、塩基組成セットの各々に重みを付与する(S205)。すなわち、重み付け処理部12は、例えば、予測m/z値との差分が予め定められた条件を満たす実測m/z値に対応するピーク強度に基づいて、当該予測m/z値に対応する部分塩基組成を含む塩基組成セットのノードに重みを付与する。
【0070】
具体的に、重み付け処理部12は、まず、実測スペクトルに含まれるピークに対応する実測m/z値のうち、理論スペクトルに含まれる各予測m/z値との差分が予め定められた閾値以下のものがあるかどうかを判断する。なお、この閾値は、例えば、実測m/z値を得るために使用した質量分析計の許容誤差に基づいて決定することができる。
【0071】
そして、重み付け処理部12は、ある予測m/z値と、ある実測m/z値と、の差分が閾値以下である場合には、当該予測m/z値と当該実測m/z値とが一致した、すなわち、実測スペクトルにおいて当該予測m/z値に対応するピークがヒットした、と判断する。この場合、重み付け処理部12は、実測スペクトルにおいて、予測m/z値と一致した実測m/z値の位置で検出されたピーク(ヒットしたピーク)の強度に基づいて、当該予測m/z値に対応する部分塩基組成の部分重みを決定する。そして、重み付け処理部12は、各ノードに対応する複数の部分塩基組成の各々について決定された部分重みの合計を、当該各ノードの重みとして付与する。
【0072】
図8は、この予測質量値と実測質量値との比較に基づく各ノードへの重み付け処理の一例を示す概念図である。図8に示すように、重み付け処理部12は、「A:A2G2U」の構成を有する塩基組成セットS1及び「G:A3GU」の構成を有する塩基組成セットS2の各々について理論スペクトルを作成する。この各理論スペクトルにおいては、各塩基組成セットを構成する各部分塩基組成について算出された予測m/z値が特定されている。そして、重み付け処理12は、これら各理論スペクトルと、プロダクトイオンについて実際に得られた実測スペクトルと、を照合するマッチング処理を行う。
【0073】
すなわち、重み付け処理部12は、まず、実測スペクトルに含まれるピークの実測m/z値のいずれかが、塩基組成セットS1の理論スペクトルに含まれる、5’端位置の部分塩基組成「A」について算出された第一の予測m/z値又は3’端位置の部分塩基組成「A2G2U」について算出された第二の予測m/z値のいずれかに一致するか否かを判断する。
【0074】
そして、重み付け処理部12は、このマッチング処理の結果に基づいて各ノードの重み付けを行う。すなわち、重み付け処理部12は、例えば、第一の予測m/z値に一致する第一の実測m/z値と、第二の予測m/z値と一致する第二の実測m/z値と、の両方を検出した場合には、当該第一の実測m/z値で検出されたピークの強度と、当該第二の実測m/z値で検出されたピークの強度と、の合計を塩基組成セットS1に対応するノードの重みとして決定する。
【0075】
一方、重み付け処理部12は、同様のマッチング処理において、実測スペクトルに含まれるピークの実測m/z値の一つが、塩基組成セットS2の理論スペクトルに含まれる、5’端位置の部分塩基組成「G」について算出された第一の予測m/z値と一致したが、3’端位置の部分塩基組成「A2G2U」について算出された第二の予測m/z値と一致する実測m/z値はなかったと判断した場合には、当該第一の予測m/z値と一致した実測m/z値で検出されたピークの強度のみを、当該塩基組成セットS2に対応するノードの重みとして決定する。重み付け処理部12は、このような重み付け処理を全てのノードについて実行する。
【0076】
そして、重み付け処理部12は、例えば、各ノードに割り当てられた識別情報N1〜N11(図6参照)と、当該各ノードに対応する塩基組成セットと、当該各ノードに付与された重みと、を関連付けたデータテーブルをノード重みデータとして生成する。
【0077】
さらに、重み付け処理部12は、各ノードが当該各ノードの重みに応じた態様で表示されるよう、有向グラフを更新する。すなわち、重み付け処理部12は、例えば、図9に示すように、各ノードを、その重みに応じたサイズで表示した有向グラフを作成する。図9に示す有向グラフにおいては、重みが大きいほど、ノードの径が大きくなっている。重み付け処理部12は、図9に示すような有向グラフを描画するための有向グラフデータを生成して出力部40に出力し、出力部40は、液晶ディスプレイ等の画面に当該有向グラフを表示する。このような有向グラフを提示されたユーザは、各ノードの重み付け処理の結果を視覚的に理解することができる。
【0078】
次に、重み付け処理部12は、接続関係の各々により接続される一対の塩基組成セットに付与された重みに基づいて、当該接続関係の各々に重みを付与する(S206)。すなわち、例えば、重み付け処理部12は、図9に示すような有向グラフにおいて、各エッジの両端に接続される2つのノードの各々に付与された重みの合計に基づいて、当該各エッジに重みを付与する。
【0079】
具体的に、例えば、重み付け処理部12は、上述のノード重みデータに基づいて、図9に示すエッジE2の一方に接続されたノードN1に付与されている重みと、他方に接続されたノードN4に付与されている重みと、の合計を当該各エッジE2の重みとして付与する。重み付け処理部12は、このような重み付け処理を全てのエッジについて実行する。
【0080】
そして、重み付け処理部12は、例えば、各エッジに割り当てられた識別情報E1〜E15と、当該各エッジにより接続された一対のノードを特定する情報と、当該各エッジに付与された重みと、を関連付けたデータテーブルをエッジ重みデータとして生成する。
【0081】
さらに、重み付け処理部12は、各エッジが当該各エッジの重みに応じた態様で表示されるよう、有向グラフを更新する。すなわち、重み付け処理部12は、例えば、図9に示すように、各エッジを、その重みに応じた太さで表示した有向グラフを作成する。図9に示す有向グラフにおいては、重みが大きいほど、エッジの太さが大きくなっている。
【0082】
なお、重み付け処理部12は、エッジの重みをノーマライズすることもできる。この場合、重み付け処理部12は、例えば、各階層に属する各エッジの重みを、当該各階層に属するエッジに付与された最大の重みで除することにより、当該各エッジの重みをノーマライズする。この結果、例えば、0〜1の範囲の値で表される重みを各エッジに付与することができる。重み付け処理部12は、ノード重みデータやエッジ重みデータ等、上述のような重み付け処理の結果を表すデータを解析処理部13に出力する。
【0083】
第三のステップS300において、解析処理部13は、塩基組成セットの各々に付与された重みに基づいて、階層構造の両方の最外階層から接続関係を辿りながら、各階層に属する塩基組成セットのうち1つを選択する選択処理を行う(S301)。すなわち、解析処理部13は、例えば、図9に示す有向グラフにおいて、各ノードに付与された重みに基づいて、当該有向グラフの5’端又は3’端の両端から内部に向けて、エッジを辿りながら、各階層に属するノードのうち1つを順次選択する。なお、ここでは、解析処理部13が、動的計画法を適用して、有向グラフの最適経路を探索することにより選択処理を行う場合を例として説明する。
【0084】
また、通常、親イオンが解離して生成されたプロダクトイオンの質量分析においては、5’端の塩基又は3’端の塩基を含む短い断片のプロダクトイオンが高い強度で検出される傾向がある。したがって、質量分析において、末端塩基を含む短いプロダクトイオンの実測結果は、それより長いプロダクトイオンの実測結果に比べて信頼性が高い場合が多い。
【0085】
そこで、解析処理部13は、有向グラフにおいて、5’端位置の部分塩基組成の塩基数が最も小さい塩基組成セットが属している5’端の第一階層と、3’端位置の部分塩基組成の塩基数が最も小さい塩基組成セットが属している3’端の第五階層と、の両最外階層から、予め中央の階層として定められた第三階層に向かって、動的計画法に基づいて各ノードの重みを更新しながら、エッジを辿っていくことによって、当該有向グラフの5’端又は3’端から各ノードに至る最大の重みをもった経路を最適経路として決定する。
【0086】
具体的に、解析処理部13は、まず、エッジの方向に従って、有向グラフの5’端又は3’端のノードから各ノードに至る経路のうち、最大の重みが付与された経路を当該各ノードに至る最適経路として決定する。そして、解析処理部13は、上述の重み付け処理部12により付与された各ノードの重み(初期重み)を、当該各ノードに至る最適経路の重み(更新重み)に変更する重み更新処理を行う。なお、有向グラフの末端のノードから各ノードまでの経路の重みは、例えば、当該末端のノードから各ノードに至るまでに通過した各エッジの重みの合計とすることができる。
【0087】
解析処理部13は、この重み更新処理を、5’端の第一階層及び3’端の第五階層から中央の第三階層に至るまで、各階層に属する各ノードについて順次実行する。この最適経路の探索処理は、例えば、動的計画法について良く知られているBelmanの公式を用いて表すことができる。すなわち、ここで、kを中央階層の階層番号とし、関数g(x)をノードxの階層番号を返す関数とする。また、5’端の最外階層から中央階層までの間において、エッジで接続されているノードm,nは、g(n)<g(m)≦kの条件を満たすものとする。そして、f(m)を5’端のノードからノードmまでの最大スコアとし、Wnmをノードn,mが接続されているエッジの重みとすると、式f(m)=max[Wnm+f(n)]が成り立つ。同様に、3’端の最外階層から中央階層までの間において、エッジで接続されているノードm、nは、g(n)>g(m)≧kの条件を満たすものとし、f(m)を3’端のノードからノードmまでの最大スコアとし、Wnmをノードn,mが接続されているエッジの重みとすると、式f(m)=max[Wnm+f(n)]が成り立つ。なお、解析処理部13は、有向グラフの5’端の最外階層のノードから中央階層のノードまでは前進型動的計画法を適用し、3’端の最外階層のノードから中央階層のノードまでは後進型動的計画法を適用する。
【0088】
具体的に、解析処理部13は、図9に示す有向グラフの5’端の第一階層に属する2つのノードN1,N2の重みを0(ゼロ)と決定する。次に、解析処理部13は、第二階層に属するノードN3,N4,N5のうち、例えば、ノードN4の重みを更新するにあたって、3’端側で当該ノードN4に接続されているエッジE2の重みと当該エッジE2の5’端側に接続されているノードN1の重みとを合計した第一候補重みと、3’端側で当該ノードN4に接続されている他のエッジE3の重みと当該エッジE3の5’端側に接続されているノードN2の重みとを合計した第二候補重みと、を比較する。そして、解析処理部13は、これらの候補重みのうち第一候補重みのほうが大きいと判断した場合には、当該第一候補重みをノードN4の更新重みとして決定する。そして、解析処理部13は、この決定された更新重みと、当該更新重みを付与したエッジE2を特定する情報(例えば、図5に示すようにエッジE2に対応する接続関係C2に付与された識別情報「C2」や、エッジE2に付与された識別情報「E2」)と、をノードN4に関連付けて保持しておく。
【0089】
解析処理部13は、このような重み更新処理を、第二階層の他のノードN3,N5についても行う。また、解析処理部13は、同様に、3’端の第五階層に属するノードN11の重み更新処理、次いで第四階層に属する2つのノードN9,N10の重み更新処理、を順次実行する。
【0090】
そして、解析処理部13は、中央階層として指定された第三階層に属するノードN6,N7,N8の重み更新処理を、有向グラフの5’端側から当該ノードN6,N7,N8の各々に至る最適経路の重みと、有向グラフの3’端側から当該ノードN6,N7,N8の各々に至る最適経路の重みと、に基づいて行う。すなわち、解析処理部13は、例えば、中央階層に属するノードN7の重みを、ノードN1、エッジE2、ノードN4、エッジE7を接続して構成される、5’端側から当該ノードN7までの最適経路の重みと、ノードN11、エッジE14、ノードN9、エッジE11を接続して構成される、3’端側から当該ノードN7までの最適経路の重みと、を合計した更新重みに変更する。具体的に、解析処理部13は、例えば、ノードN4の更新重みとエッジE7の重みとを合計した5’端側の部分更新重みと、ノードN9の更新重みとエッジE11の重みとを合計した3’端側の部分更新重みと、を合計して、ノードN7の更新重みを算出する。そして、解析処理部13は、この部分更新重みを合計した更新重みと、5’端側の部分更新重みを付与したエッジE7を特定する情報と、3’端側の部分更新重みを付与したエッジE11を特定する情報と、をノードN7に関連付けて保持しておく。解析処理部13は、同様にして、中央階層の属する他のノードN6,N8についても重み更新処理を実行する。このように、解析処理部13は、有向グラフの両端から中央に向けて、より末端側のノード及びエッジに付与された重みに応じて、各ノードの重み更新処理を行う。また、解析処理部12は、各ノードが当該各ノードの更新重みに応じた態様で表示されるよう、有向グラフを更新することができる。すなわち、この場合、解析処理部12は、例えば、図10に示すように、各ノードを、その更新重みに応じたサイズで表示した有向グラフを作成する。図10に示す有向グラフにおいては、更新重みが大きいほど、ノードの径が大きくなっている。解析処理部13は、図10に示すような有向グラフを描画するための有向グラフデータを生成して出力部40に出力し、出力部40は、液晶ディスプレイ等の画面に当該有向グラフを表示する。このような有向グラフを提示されたユーザは、各ノードの重み付け更新処理の結果を視覚的に理解することができる。なお、解析処理部13は、更新重みと、更新前の重みと、をそれぞれ記憶部20に格納することができる。
【0091】
そして、次に、解析処理部13は、図10に破線の矢印で示すように、有向グラフの中央階層(破線で囲まれた第三階層)から両端の最外階層まで、最適経路を辿るトレースバック処理を行うことにより、各階層に属するノードのうち1つを選択する。
【0092】
すなわち、解析処理部13は、まず、中央階層に属する3つのノードN6,N7,N8の更新重みを互いに比較し、最も大きい更新重みが付与されたノードN7を選択する。次いで、解析処理部13は、中央階層で選択されたノードN7に3’端側が接続された、5’端側の第二階層に属するエッジE6,E7のうち、上述のように予めノードN7に関連付けられている、5’端側の部分更新重みを付与したエッジE7を選択するとともに、当該第二階層に属するノードN3,N4,N5のうち、当該選択されたエッジE7の5’端側に接続されているノードN4を選択する。また、解析処理部13は、同様にして、3’端側の第四階層に属するエッジE11,E12のうち、上述のように予めノードN7に関連付けられている、3’端側の部分更新重みを付与したエッジE11を選択するとともに、当該第四階層に属するノードN9,N10のうち、当該選択されたエッジE11の3’端側に接続されているノードN9を選択する。さらに、解析処理部13は、同様にして、5’端の第一階層に属するエッジE2、E3のうち、上述のように予めノードN4に関連付けられている、更新重みを付与したエッジE2を選択するとともに、当該第一階層に属するノードN1,N2のうち、当該選択されたエッジE2の5’端側に接続されているノードN1を選択する。一方、解析処理部13は、3’端の第五階層にはノードN11のみが属しているので、当該ノードN11を選択する。
【0093】
このように、解析処理部13は、有向グラフの中央階層から両端の最外階層に向かって動的計画法に基づくトレースバック処理を行い、当該両端の最外階層から中央階層で選択されたノードN7に至るまでに通過してきた最適経路を確定させる。すなわち、解析処理部13は、このトレースバック処理によって、最適経路上で各階層に属するノードを1つずつ選択する。この結果、図10に示す有向グラフにおいて、解析処理部13は、5’端の第一階層ではノードN1、第二階層ではノードN4、中央階層ではノードN7、第四階層ではノードN9、そして3’端の第五階層ではノードN11を、それぞれ選択する。
【0094】
次に、解析処理部13は、上述の選択処理の結果に基づいて、対象断片の両方の末端から塩基配列を順次決定する(S302)。すなわち、解析処理部13は、隣接する階層の各々で選択された2つの塩基組成セット間で、対応する部分塩基組成を比較し、当該対応する部分塩基組成の差異を構成する塩基を特定するという塩基特定処理を、5’端位置の部分塩基組成については第一階層から第三階層に向けて、また、3’端位置の部分塩基組成については第五階層から第三階層に向けて、それぞれ実行することにより、対象断片の塩基配列を5’端側及び3’端側の両側から順次決定する。
【0095】
具体的に、解析処理部13は、図11に示すように、上述の選択処理によって確定された有向グラフの最適経路上で隣接して配置されるノード間で、対応する部分塩基組成の差異を構成する塩基を、当該有向グラフの5’端側及び3’端側の両端側から順次特定する。
【0096】
すなわち、解析処理部13は、まず、5’端の第一階層で選択されたノードN1の5’端位置の部分塩基組成が1つのアデニン(A)であることから、対象断片の5’端の塩基はアデニン(A)であると決定する。次に、解析処理部13は、第一階層で選択されたノードN1の5’端位置の部分塩基組成と、当該第一階層の内側(3’端側)に隣接する第二階層で選択されたノードN4の5’端位置の部分塩基組成と、を比較して、これらの部分塩基組成の差異を構成する塩基としてグアニン(G)を特定する。すなわち、解析処理部13は、対象断片の5’端から2番目の塩基(すなわち、アデニン(A)の3’端側に隣接する塩基)はグアニン(G)であると決定する。
【0097】
また、解析処理部13は、同様にして、3’端の第五階層で選択されたノードN11の3’端位置の部分塩基組成が1つのウラシル(U)であることから、対象断片の3’端の塩基はウラシル(U)であると決定する。次に、解析処理部13は、第五階層で選択されたノードN11の3’端位置の部分塩基組成と、当該第五階層の内側(5’端側)に隣接する第四階層で選択されたノードN9の3’端位置の部分塩基組成と、を比較して、これらの部分塩基組成の差異を構成する塩基としてグアニン(G)を特定する。すなわち、解析処理部13は、対象断片の3’端から2番目の塩基(すなわち、ウラシル(U)の5’端側に隣接する塩基)はグアニン(G)であると決定する。
【0098】
さらに、解析処理部13は、同様にして、第二階層で選択されたノードN4の5’端位置の部分塩基組成と、中央の第三階層で選択されたノードN7の5’端位置の部分塩基組成と、の差異を構成する塩基がアデニン(A)であると特定する一方で、第四階層で選択されたノードN9の3’端位置の部分塩基組成と、中央の第三階層で選択されたノードN7の3’端位置の部分塩基組成と、の差異を構成する塩基がアデニン(A)であると特定する。この結果、解析処理部13は、対象断片の全塩基配列を「AGAAGU」であると決定する。そして、解析処理部13は、この塩基配列の決定結果を表す画像を含むインタフェース画面をユーザに提示するよう、出力部40に指示する。すなわち、例えば、解析処理部13は、図11に示すように、各階層で選択されたノードと、他のノードと、を区別可能に表示し、当該各階層で選択されたノード間を接続するエッジと、その他のエッジとを区別可能に表示した有向グラフを描画するための有向グラフデータを生成し、当該有向グラフデータを出力部40に出力することができる。この有向グラフデータには、図11に示すように、各階層で選択されたノード間の部分塩基組成の差異を構成する塩基を、当該ノード間を接続するエッジに対応して表示させるためのデータを含むこともできる。また、解析処理部13は、例えば、各ノードの更新前の重みと、塩基配列の決定結果と、が関連付けられて表示された有向グラフをユーザに提示することもできる。すなわち、この場合、例えば、解析処理部13は、各ノードが、その更新前の重みに応じたサイズで表示され、各階層で選択されたノードと、他のノードと、が区別可能に表示され、当該各階層で選択されたノード間を接続するエッジと、その他のエッジとが区別可能に表示され、各階層で選択されたノード間の部分塩基組成の差異を構成する塩基が、当該ノード間を接続するエッジに対応して表示された有向グラフを描画するための有向グラフデータを生成して出力部40に出力し、出力部40は、液晶ディスプレイ等の画面に当該有向グラフを表示する。このような有向グラフを提示されたユーザは、塩基配列の解析結果を、各ノードの更新前の重みや更新後の重み、エッジの重み等と関連付けて視覚的に理解することができる。このため、例えば、ユーザは、解析条件を修正すべき指示を容易に決定することができ、修正指示の入力を受け入れた本装置1は、当該修正指示に従って更に解析を行った結果を当該ユーザに提示することができる。
【0099】
このように、本発明によれば、核酸の解析を迅速且つ正確に行うことができる。すなわち、例えば、全体塩基組成から予想される、可能な全ての塩基配列の候補を生成するような技術においては、塩基数の増加に伴って計算量が急激に増加することとなるのに対し、本発明においては、そのような可能な全ての塩基配列候補を生成することなく、各々が一組の部分塩基組成から構成される塩基組成セットを生成するため、塩基数の増加に伴う計算量の増加を効果的に抑制することができる。また、本発明によれば、必ずしも既知の核酸の塩基配列が登録されたデータベースの検索を行う必要はなく、質量分析の結果に基づいた演算処理によって、in silicoで核酸の全塩基配列を迅速に決定することができる(de novo sequencing)。
【0100】
また、本発明においては、塩基組成セットの重みに基づいて階層構造の最外階層から内部に向けて、塩基組成セットの選択処理を行うため、信頼性の高い末端由来のプロダクトイオンの質量分析結果を効果的に利用して、核酸の末端から塩基配列を決定していくことができ、信頼性の高い解析を行うことができる。
【0101】
本発明は、RNAを標的とした新しい診断技術の開発や、RNA−タンパク質ネットワークの解析技術の開発等、生命科学における基盤技術を提供するものであり、極めて広い応用が期待できる。
【0102】
また、本発明によれば、さらに、対象断片に含まれる塩基修飾を解析することもできる。この場合の処理について、図3を参照しつつ説明するが、上述の内容と重複する内容については詳細な説明を省略する。
【0103】
まず、第一のステップS100において、対象断片に含まれる塩基修飾の内容を推定する。すなわち、例えば、上述のステップS102において、塩基組成処理部11は、実測された対象断片の分子量に基づいて、当該対象断片の全体塩基組成を決定する際に、所定の修飾部分(メチル基等の官能基等)の存在を考慮する必要がある場合、当該対象断片は、当該所定の修飾部分を含むと推定する。なお、例えば、液体クロマトグラフィー分析における対象断片の溶出時間等の他の解析手法の結果から、対象断片に所定の修飾部分が含まれていることを推定することもできる。
【0104】
塩基組成処理部11は、対象断片に修飾部分が含まれていると判断した場合には、その修飾部分の内容(すなわち、修飾基の種類、分子量、数、価数等)を表す修飾データを生成し、重み付け処理部12に出力する。
【0105】
次に、第二のステップS200において、対象断片に修飾塩基が含まれると仮定した場合に予測される、各プロダクトイオンの質量分析結果を作成する。すなわち、重み付け処理部12は、上述のステップS201において、各部分塩基組成に対応するプロダクトイオンに修飾された塩基が含まれないと仮定した場合に予測される第一の予測質量値を算出する一方で、ステップS202においては、対象断片に修飾塩基が含まれているか否かを判断する。ここで、重み付け処理部12は、塩基組成処理部11から修飾データを受け入れた場合には、対象断片に修飾塩基が含まれていると判断し(S202においてYes)、ステップS203において、各部分塩基組成に対応するプロダクトイオンに当該修飾塩基が含まれると仮定した場合に予測される第二の予測質量値を算出する。
【0106】
具体的に、例えば、重み付け処理部12は、修飾データに含まれる修飾基の種類、分子量、数、価数等に基づいて、第一の予測質量値を補正することによって、第二の予測質量値を算出する。すなわち、重み付け処理部12は、例えば、ステップS201において、各部分塩基組成に対応するプロダクトイオンの分子量に基づいて第一の予測m/z値を算出した場合には、ステップS203において、当該プロダクトイオンの分子量に修飾基の分子量を加算した補正分子量に基づいて、当該プロダクトイオンに当該修飾基が含まれると仮定した場合に予測される第二の予測m/z値を算出する。
【0107】
そして、重み付け処理部12は、ステップS205において、これら第一の予測m/z値及び第二の予測m/z値の各々と、実測m/z値と、の比較に基づいて、各ノードの重み付けを行う。すなわち、重み付け処理部12は、実測スペクトルの中に、第一の予測m/z値又は第二の予測m/z値に近い実測m/z値があるかどうか検索を行う。
【0108】
そして、重み付け処理部12は、第一の予測m/z値と所定の誤差範囲とに基づいて、当該第一の予測m/z値より所定値だけ小さい下限値から当該第一の予測m/z値より所定値だけ大きい上限値までの第一のm/z範囲を算出し、当該第一のm/z範囲内の実測m/z値が実測スペクトルに含まれるか否かを判断する。ここで、重み付け処理部12は、第一のm/z範囲内の実測m/z値(第一の実測m/z値)を検出した場合には、例えば、実測スペクトルに含まれるピークのうち、当該第一の実測m/z値で検出されたピークの強度に基づいて、第一の仮重みを決定する。一方、重み付け処理部12は、同様に、第二の予測m/z値と所定の誤差範囲とに基づいて、当該第二の予測m/z値より所定値だけ小さい下限値から当該第二の予測m/z値より所定値だけ大きい上限値までの第二のm/z範囲を算出し、当該第二のm/z範囲内の実測m/z値が実測スペクトルに含まれるか否かを判断する。そして、重み付け処理部12は、第二のm/z範囲内の実測m/z値(第二の実測m/z値)を検出した場合には、例えば、実測スペクトルに含まれるピークのうち、当該第二の実測m/z値で検出されたピークの強度に基づいて、第二の仮重みを決定する。次に、重み付け処理部12は、これら第一の仮重みと第二の仮重みとを比較して、大きい方の仮重みに基づいて、対応するノードの重み付けを行う。すなわち、例えば、重み付け処理部12は、第二の仮重みが第一の仮重みよりも大きいと判断した場合には、対象とするプロダクトイオンに修飾塩基が含まれていると判断する。そして、この場合、重み付け処理部12は、例えば、実測スペクトルに含まれるピークのうち、第二の実測m/z値で検出されたピークの強度に基づいて、対応するノードの重み付けを行う。なお、重み付け処理部12は、第一のm/z範囲内又は第二のm/z範囲内の実測m/z値が実測スペクトルに含まれないと判断した場合には、第一のm/z値又は第二のm/z値についての重み付けを行わない。また、上述の所定の誤差範囲は、例えば、親イオンの質量分析に用いられた質量分析計の性能や分析条件等に応じた分析精度に基づいて決定することができる。
【0109】
また、重み付け処理部12は、プロダクトイオンに修飾塩基が含まれると判断した場合には、当該プロダクトイオンに対応した部分塩基組成に、修飾塩基が含まれる旨を表す修飾タグデータを関連付けて保持しておく。
【0110】
そして、第三のステップS300において、解析処理部13は、対象断片の塩基配列を決定した(S302)後、当該対象断片に修飾塩基が含まれているか否かを判断する(S303)。そして、解析処理部13は、対象断片に修飾塩基が含まれていると判断した場合(S303においてYes)には、各塩基組成セットを構成する部分塩基組成のうち、修飾タグデータが関連付けられている部分塩基組成の位置に基づいて、修飾塩基の位置を決定する(S304)。
【0111】
すなわち、解析処理部13は、例えば、階層構造の隣接する階層間で、上述の選択処理により選択された塩基組成セットにおいて、修飾タグデータが関連付けられている部分塩基組成の位置が移動した場合に、当該隣接する階層で選択された当該塩基組成セット間で当該部分塩基組成の差異を構成する塩基を、修飾された塩基として特定する。
【0112】
すなわち、例えば、図11に示す有向グラフにおいて、第二階層で選択されたノードN4に対応する塩基組成セット「AG:A2GU」の3’端位置の部分塩基組成「A2GU」に修飾タグデータが関連付けられているのに対して、第三階層で選択されたノードN7に対応する塩基組成セット「A2G:AGU」については、5’端位置の部分塩基組成「A2G」に修飾タグデータが関連付けられている場合、解析処理部13は、修飾タグデータが関連付けられている部分塩基組成の位置が、3’端位置から5’端位置に移動していると判断する。
【0113】
そして、この場合、解析処理部13は、塩基数の増加に伴って、内側の階層(第三階層)で新たに修飾タグデータが関連付けられたノードN7に係る5’端位置の部分塩基組成「A2G」と、末端側の階層のノードN4に係る5’端位置の部分塩基組成「AG」と、を比較して、これらの部分塩基組成の差異を構成する、5’端から3つ目のアデニン(A)が修飾塩基であると特定する。また、このような修飾塩基を特定する場合と同様に、例えば、対象断片の末端構造を特定することもできる。すなわち、例えば、重み付け処理部12が、5’端位置又は3’端位置の部分塩基組成について、末端塩基に付加された所定の官能基の存在を考慮しない第一の予測質量値と、当該官能基の存在を考慮した第二の予測質量値と、を算出して実測質量値とのマッチング処理を行い、当該実測質量値との一致度が、当該第二の予測質量値の方が高かった場合には、解析処理部13は、5’端又は3’端の塩基には、当該官能基が付加されていると決定することができる。そして、解析処理部13は、例えば、修飾されている塩基と、その他の塩基と、が区別可能に表された有向グラフを作成する。すなわち、各階層で選択されたノード間の部分塩基組成の差異を構成する塩基を、当該ノード間を接続するエッジに対応して表示させる場合には、当該差異を構成する塩基のうち、修飾されている塩基については、修飾されていることを表す文字や記号を関連付けて表示する。解析処理部13は、このような有向グラフを描画するための有向グラフデータを出力部40に出力し、出力部40は当該有向グラフが表示されたインタフェース画面をユーザに提示する。このような有向グラフを提示されたユーザは、塩基配列の解析結果のみならず、修飾構造の解析結果をも視覚的に理解することができる。
【0114】
このように、本発明によれば、迅速且つ正確に核酸に含まれる塩基修飾構造を解析することができる。すなわち、本発明によれば、例えば、RNA分子について、転写後プロセシングや修飾構造などの質的な情報を得ることもできる。
【0115】
また、本方法においては、塩基組成セットの各々に付与された重みに基づいて、階層構造の最外階層から接続関係を辿りながら、各階層に属する塩基組成セットのうち1つを選択する選択処理を、当該最外階層から、任意の内部階層までとすることもできる。すなわち、この場合、解析処理部13は、例えば、入力部30を介して、ユーザから選択処理を実行する階層深さを指定する指示データを受け入れる。そして、解析処理部13は、最外階層から、指示データにより指定された階層深さに対応する内部階層まで、選択処理を順次実行する。この結果、解析処理部13は、対象断片の末端側の一部(末端から指定された階層深さに対応する位置までの部分)について、塩基配列や塩基修飾を決定することができる。
【0116】
具体的に、例えば、塩基組成処理部11が9つの階層からなる階層構造を作成し、解析処理部13が、選択処理を終了する内部階層を最外階層から三番目の階層と指定する指示データを受け入れた場合には、解析処理部13は、5’端から三番目の第三階層を第一の中央階層として決定するとともに、3’端から三番目の第七階層を第二の中央階層として決定する。そして、解析処理部13は、5’端の最外階層(第一階層)から第一の中央階層(第三階層)まで、及び3’端の最外階層(第九階層)から第二の中央階層(第七階層)まで、それぞれ各階層に属する塩基組成セットの1つを選択したところで、選択処理を終了する。なお、この場合、重み付け処理部12は、5’端の第一階層から第三階層まで、及び3’端の第九階層から第七階層まで、それぞれ各ノードの重みを更新したところで、重み更新処理を終了することもできる。そして、解析処理部13は、上述のように、これら選択処理の対象となった階層の各々で選択された塩基組成セット間で、対応する部分塩基配列を比較し、対応する部分塩基組成の差異を構成する塩基を特定する。こうして、解析処理部13は、対象断片の5’端側の一部(5’端から第一中央階層に対応する位置までの部分)と、当該対象断片の3’端側の一部(3’端から第二中央階層に対応する位置までの部分)と、について、塩基配列や塩基修飾を決定することができる。
【0117】
また、この場合、まず出力部40がユーザに対して、選択処理を行う階層深さを決定する上で参考になる情報を提示することもできる。すなわち、例えば、出力部40は、対象断片の分子量や末端構造(末端塩基に付加されている官能基の種類等)等の親イオンの質量分析結果に関連する情報や、プロダクトイオンについて実測されたマススペクトル等のプロダクトイオンの質量分析結果に関連する情報、理論スペクトルと実測スペクトルとのマッチング処理の結果に関連する情報等の参考情報を表すインタフェース画像を、ディスプレイ装置に表示する。この結果、ユーザは、インタフェース画像に表された参考情報に基づいて、階層構造に含まれる全階層について選択処理を行うか又は末端側の一部の階層について選択処理を行うかを決定することができ、さらに、一部の階層についてのみ選択処理を行う場合には、選択処理の対象とする階層範囲を決定することができる。そして、入力部30は、ユーザから、選択処理を行うべき階層範囲を指定する指示データを受け入れることとなる。
【0118】
このように、階層構造のうち末端の任意の一部の階層についてのみ選択処理を行うことにより、例えば、対象とする核酸の分子鎖が長い場合や、プロダクトイオンの測定に用いる質量分析計の性能や測定条件(核酸試料の量や親イオンを解離させる条件等)が不十分な場合であって、階層構造の中央付近に分類された塩基組成セットについて信頼性のある重み付けがなされない場合であっても、計算量を低減しつつ、核酸の少なくとも末端側の一部分については迅速かつ正確に、塩基配列や塩基修飾の決定を行うことができる。
【0119】
また、このように、核酸の末端側の一部分についてのみ塩基配列を決定した場合には、解析処理部13は、例えば、当該一部の塩基配列と、当該核酸の全体塩基組成と、に基づいて、既知の核酸の塩基配列が登録されているデータベースに対する検索処理を行い、当該検索処理の結果に基づいて、当該核酸の全塩基配列を決定することもできる。すなわち、解析処理部13は、例えば、ヒトのRNA断片を解析の対象とする場合には、ヒトゲノムデータベースに基づいて、ヒトゲノムのうち、その塩基組成が当該RNA断片の全体塩基組成に対応し、且つその末端部分の塩基配列が当該RNA断片の決定された塩基配列に対応するという検索条件を満たすゲノム部分を探索する。そして、解析処理部13は、検索条件を満たすゲノム部分を検出した場合には、当該ゲノム部分の塩基配列に基づいて、RNA断片の全塩基配列を決定するとともに、そのヒトゲノム上の位置を特定する。
【0120】
なお、このように、既知の核酸の塩基配列が登録されたデータベースに対する検索処理を行う方法として、解析処理部13は、例えば、RNAマスフィンガープリンティング法(RMF)を利用することができる。すなわち、解析処理部13は、対象断片がRNA分解酵素(例えば、RNAaseT1)を用いてヒトのRNAを切断することにより作製されたヒトRNA断片である場合、まず、ヒトゲノムのデータベースに基づいて、ヒトゲノムを当該RNA分解酵素が特異的に切断する位置(例えば、RNAaseT1を用いた場合にはグアニン(G)の位置)で仮想的に切断することにより、仮想的なゲノム断片を作成する。すなわち、解析処理部13は、例えば、各仮想ゲノム断片と、ヒトゲノム上における当該各仮想ゲノム断片の位置と、を関連付けた仮想断片データベースを生成する。また、解析処理部13は、対象断片由来の親イオンの質量分析で得られた当該親イオンの分子量に基づいて、当該対象断片の全体塩基配列を決定する。さらに、解析処理部13は、上述のようにして、対象断片の末端付近の塩基配列を決定する。また、解析処理部13は、対象断片の作製に用いられたヒトRNA全体の長さに対応するフレーム長を、例えば、入力部30を介してユーザから受け入れた指示データに基づいて決定する。そして、解析処理部13は、ヒトゲノムデータベースと、仮想断片データベースと、対象断片の全体塩基組成と、対象断片の末端付近の塩基配列と、フレーム長と、に基づいて、次のようなヒトゲノムに対する検索処理を実行する。すなわち、解析処理部13は、ヒトゲノムのうち、長さが上述のフレーム長である部分領域を検索対象として決定し、当該部分領域において、その塩基組成が上述のように決定された対象断片の全体塩基組成に対応し、且つその末端部分の塩基配列が上述のように決定された対象断片の塩基配列に対応する、という条件を満たす仮想ゲノム断片が含まれるかどうかを検索する。解析処理部13は、ヒトゲノム上をフレーム長で走査しながら、ヒトゲノムの互いに異なる部分領域を検索対象として順次決定し、検索対象となった各部分領域について、上記の検索処理を実行する。そして、解析処理部13は、各部分領域に含まれる少なくとも一つの仮想ゲノム断片が上記条件を満たす場合には、ヒトゲノム上で当該仮想ゲノム断片がヒットしたと判断する。この場合、解析処理部13は、ヒットした仮想ゲノム断片のうち、ヒトゲノム中でヒットした回数(出現頻度)の少ない仮想ゲノム断片に高いスコアを付与するとともに、当該スコアを当該仮想ゲノム断片が含まれる部分領域にも付与する。なお、このスコアは、例えば、二項定理に基づいて算出した仮想ゲノム断片の出現確率から算出することができる。そして、解析処理部13は、部分領域をスコアに基づいて順位付けし、スコアの高い部分領域に基づいて、対象断片の作製に用いられたヒトRNAのヒトゲノム上における位置を決定するとともに、当該ヒトRNAの全塩基配列(対象断片の全塩基配列を一部に含む)を決定する。すなわち、解析処理部13は、例えば、スコアの最も高い部分領域がヒトRNAに対応するゲノム部分であると決定し、当該部分領域の塩基配列に基づいて、対象断片を含むヒトRNAの全塩基配列を決定する。
【0121】
次に、本プログラムに従って動作する本装置を用いて本方法を実施した具体的な例について説明する。
【0122】
[実施例1]
精製した大腸菌5SリボソームRNA分子にRNaseAを作用させることによりRNA断片群を作製した。このRNA断片群をLC/MS質量分析計(LC−QqTOF)(QStar、アプライドバイオシステムズジャパン株式会社)にて測定した。なお、以下の全ての実施例において、この質量分析計を使用した。イオン化はESI法により行った。この測定データから、m/z値が「999.7」、価数が「−2」のイオンを、解析の対象とするRNA断片の親イオンとして選択した。そして、この親イオンを質量分析計内でCIDにより解離させて、MS/MSのマススペクトルを得た。CIDにおける衝突電圧(Collision Energy)は45eVとした。この親イオンのm/z値と価数とに基づいて決定された全体塩基組成は「A3UG2」であった。さらに、この全体塩基組成に基づいて、図6に示すような有向グラフを作成した。
【0123】
また、有向グラフに含まれるそれぞれのノードに対して、各部分塩基組成に対応するa,b,c,d,w,x,y,zのそれぞれの系列のプロダクトイオンの理論的なm/z値を算出することで、理論スペクトルを得た。すなわち、a,b,c,dの5’端部分由来のプロダクトイオンについては5’端位置の部分塩基組成から、w,x,y,zの3’端部分由来のプロダクトイオンについては3’端位置の部分塩基組成から、それぞれ理論的に予測m/z値を計算した。
【0124】
図12及び図13は、理論的に算出された予測m/z値を示すデータテーブルである。これらのデータテーブルにおいては、各塩基組成セットと、その5’端位置又は3’端位置の部分塩基組成に対応して生じ得るプロダクトイオンの予測m/z値と、が関連付けられている。すなわち、各塩基組成セットの構成と、各プロダクトイオンの系列及び価数と、各プロダクトイオンの予測m/z値と、が関連付けられている。なお、プロダクトイオンの分子量からm/z値を算出する際に、価数は「−1」から親イオンの価数である「−2」までの値を用いて計算したが、塩基配列の長さが「1」のプロダクトイオン(1つの塩基から構成されるプロダクトイオン)については価数として「−1」のみを用いて計算した。
【0125】
そして、質量分析計のトレランスとして「0.2」を設定して、これらの理論スペクトルを実測されたマススペクトルとマッチングさせた。予測m/z値と実測m/z値との差異が「0.2」以内である場合には、当該予測m/z値と当該実測m/z値とは一致すると判断した。そして、理論スペクトルの予測m/z値と実測スペクトルの実測m/z値とがマッチした場合には、マッチした実測ピークの強度の合計をノードのスコア(重み)とした。例えば、構成が「AG:A2UG」の塩基組成セットに対応するノードではa,b,c,d系列とw,y,z系列のプロダクトイオンに対応する理論スペクトルが、実測スペクトルの一部にマッチした。したがって、これらマッチしたピークの強度の合計をこのノードのスコアとした。この結果に基づいて、図14に示すような、各ノードと、スコアと、を関連付けたデータテーブルを作成した。
【0126】
次に、ノードとノードとをつないでいるエッジのスコア付けを行った。エッジの両端に接続された一対のノードのスコアを合計することで当該エッジのスコアとした。この結果に基づいて、図15に示すような、各エッジと、スコアと、を関連付けたデータテーブルを作成した。
【0127】
さらに末端の塩基が欠損した「a_B」イオンについては、エッジの情報(すなわち、エッジにより接続される2つのノードに対応する塩基組成セットの構成)から当該「a_B」イオンの予測m/z値を算出し、当該予測m/z値のうち、実測スペクトルにマッチするものは、マッチしたピークの強度を当該エッジのスコアに加算した。例えば、構成「A:A2UG2」のノードと構成「AG:A2UG」のノードとをつなぐエッジから、「AG」の組成から「G」の塩基部分だけが欠落した「a_B」イオンの予測m/z値を「442.09」と算出した。図16は、各エッジと、当該各エッジに対応する塩基欠損イオンの予測m/z値と、を関連付けたデータテーブルである。本実施例では、この予測m/z値も実測スペクトルにヒットしたので、ヒットしたピークの強度もエッジのスコアに加算した。
【0128】
さらに、エッジのスコアをノーマライズした。すなわち、各階層のエッジに付与されたスコアのうち最大のスコアで、当該各階層の各エッジのスコアを除した。図17は、各エッジと、ノーマライズされたスコアと、を関連付けたデータテーブルである。
【0129】
そして、動的計画法を適用して、各ノードのスコアの更新処理を両端のノードから行った。図18は、このスコアの更新処理後の、各ノードと、更新後のスコアと、当該各ノードが属する階層の番号と、を関連付けたデータテーブルである。
【0130】
この結果、図19に示すような有向グラフを作成した。図19に示すように、中央階層においては、塩基組成セット「A2G:AGU」に対応するノードが最大のスコアをもつノードとして選択された。さらに本プログラムに従ってトレースバック処理を行い、最適経路上に配置されるノードとして、中央階層である第三階層で選択されたノード「A2G:AGU」から5’端側に向けては、第二階層のノード「AG:A2GU」、さらに5’端の第一階層のノード「A:A2G2U」の順で、また、当該中央階層のノード「A2G:AGU」から3’端側に向けては、第四階層のノード「A3G:GU」、さらに3’端の第五階層のノード「A3G2:U」の順で、それぞれ選択した。この結果、対象としたRNA断片の全塩基配列は「AGAAGU」と決定され、正解の全塩基配列と一致した。
【0131】
なお、図19に示す、最適経路を決定した後の有向グラフにおいて、円形又は楕円形の各ノードの径は、当該各ノードのが属する階層における他のノードとの相対的なスコアを反映して、スコアが大きいほど大きな径で表示されている。また、エッジの太さは、当該エッジに付与されたスコアの大きさを反映して、スコアが大きいほど大きな太さで表示されている。また、図19に示す有向グラフにおいては、各ノード及び各エッジを、付与されたスコアに応じた色で表示することもできる。図19の下端部分に示すバーは、この色のグラデーションを表すスケールバーである。また、図20は、実際に測定されたプロダクトイオンのピークのうち、最適経路を構成するノードに対応する理論スペクトルにヒットしたピークにラベルを付したMS/MSマススペクトルを示している。すなわち、ラベルが付されているピークは、その実測m/z値が予測m/z値にマッチしたピークである。
【0132】
[実施例2]
実施例1と同様の大腸菌5sRNAをRNaseT1により切断して得られたRNA断片の塩基配列を解析した。m/z値が「1044.5」、価数が「−3」の親イオンに対応するRNA断片を解析の対象とした。このRNA断片の全体塩基組成は「AU4C4G」と算出された。この親イオンからプロダクトイオンを生成する際のCIDに用いた衝突電圧は50eVであった。本実施例ではエッジのスコアのノーマライズは行わなかった。解析の結果、RNA断片の全塩基配列は「UCUCCUCAUG」と決定され、これは当該RNA断片の実際の全塩基配列に一致した。図21には、本実施例における最適経路決定後の有向グラフを示す。
【0133】
[実施例3]
全塩基配列が「AUCG」の合成RNAを用い、本発明のアルゴリズムにより塩基配列の解析を行った。親イオンのm/z値は「1222.2」、価数は「−1」であった。全体塩基組成は「AUCG」と決定された。CIDにおける衝突電圧は50eVであった。RNase切断断片ではないため、予め末端塩基を決定することはできなかったが、全塩基配列を決定することができた。図22には、最適経路決定後の有向グラフを示す。
【0134】
[実施例4]
塩基配列が「UGGAGUGUGACAAUGGUGUUUGU」である、合成されたマイクロRNA(mmu−miR−122a)を解析の対象とし、当該マイクロRNAの両端から予め決定した所望の長さの部分についてのみ塩基配列を解析した。すなわち、本実施例において、本装置1は、入力部30を介して、ユーザから、解析の対象とする階層深さを指定する指示データとして、解析の対象とする末端部分の塩基数を「6」と指定する指示データを受け入れた。そして、本装置1の制御部10は、当該指示データに基づいて、塩基数が1〜6の範囲である5’端位置の部分塩基組成を有するノードと、塩基数が1〜6の範囲である3’端位置の部分塩基組成を有するノードと、を対象として解析を行った。親イオンのm/z値は「832.2」、価数は「−9」であった。全体塩基組成は「A4U9CG9」と決定された。CIDにおける衝突電圧は25eVであった。本装置1は、動的計画法に基づく経路探索を有向グラフの5’端及び3’端からそれぞれ6番目の階層まで実行し、当該経路探索の結果に基づいて、マイクロRNAの5’端から6残基の部分の塩基配列を「5’UGGAGU」、3’端から6残基の部分の塩基配列を「GUUUGU3’」とそれぞれ正しく決定することができた。図23には、最適経路決定後の有向グラフを示す。
【0135】
[実施例5]
RNaseT1を用いて作製したRNA断片を解析の対象とした。親イオンのm/zは「986.2」、価数は「−2」であった。修飾基の存在を考慮しない場合と考慮した場合とで解析を行った。図24には、修飾塩基の存在を考慮しない場合に最終的に得られた有向グラフを示す。この場合もRNA断片の全塩基配列を「ACCUG」と正しく決定することができた。
【0136】
また、図25には、修飾塩基の存在を考慮した補正により算出した予測m/z値を用いて全塩基配列及び修飾塩基の位置を決定した場合の有向グラフを示す。この場合には、RNA断片の全塩基配列を「ACCUG」と正しく決定することができるとともに、さらに修飾基としてメチル基が付加された塩基の位置を同定することができた。すなわち、図25に示す有向グラフにおいて、ノード「AC:UCG」の3’端位置の部分塩基組成「UCG」の予測m/z値と、ノード「AC2:UG」の5’端位置の塩基組成「AC2」にメチル基分の分子量を補正した予測m/z値が、補正を行わない予測m/z値に比べて、実測m/z値に対して、よりマッチする(m/z値の差分が小さい)ことから、全塩基配列「ACCUG」のうち中央のシトシン(C)にメチル基による塩基修飾があると判断した。すなわち、塩基配列が「ACCUG」であるRNA断片のうち、5’端から3番目のシトシン(C)にメチル基の修飾があることを正しく検出できた。なお、図25において、シトシン(C)に付与された「*」印は、当該シトシン(C)塩基が修飾されていることを示す。また、図25では図24に比べて、上記修飾塩基を含んだ2つのノードについてより強いピーク強度が検出されたことが、当該2つのノードの径の違いによって容易に認識することができる。
【0137】
[実施例6]
大腸菌5sRNAをRNaseT1で消化したRNA断片群を作製し、当該RNA断片群のうちの7つのRNA断片をLC−QqTOF型の質量分析計により計測し、当該各RNA断片の全体塩基組成に基づくRMF(RNA MassFingerprinting)法により、大腸菌のゲノムのデータベースから、当該5sRNAに対応する遺伝子の位置を正しく検出した例である。すなわち、質量分析により、7つのRNA断片に対応して、分子量が「2829.43」、「2547.35」、「2266.32」、「1655.25」、「1632.23」、「1302.19」、「1279.16」である7つの親イオンが計測された。そして、7つの親イオンに対応するRNA断片の全体塩基組成はそれぞれ、「AU2C5G」、「A2UC4G」、「A3UC2G」、「A3CG」、「A2UCG」、「A1C2G」、「UC2G」と決定された。そして、大腸菌ゲノムデータベースに対して、5sRNAの長さに対応するフレーム長のゲノム部分領域であって、塩基組成が上記7つの全体塩基組成である部分を含むゲノム部分領域を検索する処理を実行し、図26に示す結果を得た。すなわち、図26に示すように、大腸菌ゲノムに含まれる、図中、破線で囲まれた最も高い同一のスコアが付与された上位8つの部分領域が、正解領域として検出された。なお、ゲノム上の複数の位置に、同一配列の複製の各々が存在する場合には、このように、同一スコアの部分領域が複数検出されることがある。
【0138】
一方、これらのRNA断片に対して、上述のような本発明に係る解析方法を適用することにより、7つのRNA断片の全塩基配列は、それぞれ「UCCCACCUG」、「ACCCCAUG」、「AACUCAG」、「AAACG」、「AACUG」、「CCAG」、「CCUG」、と決定することができた。そして、本発明に係る解析方法の一部としてRMF法を利用して、大腸菌ゲノムデータベースに対して、5sRNAの長さに対応するフレーム長のゲノム部分領域であって、上記7つの塩基配列を含むゲノム部分領域を検索する処理を実行することにより、図27に示す結果を得た。すなわち、図27に示すように、本発明により決定された塩基配列の情報を付加した検索を実行することで、RMF法の検出感度を高めることができた。図27においては、図26における上位8つの部分領域のうち、図中、破線で囲まれた上位7つの部分領域を最もスコアが高い正解領域として更に抽出できた。また、これら8つの部分領域と、他の部分領域と、のスコアの差分を図26に示した場合に比べて顕著に増加させることができ、正解候補と不正解候補とをより明確に分離することができた。
【0139】
[実施例7]
本発明のアルゴリズムをRMF法に組み込んでヒト7skRNAの検索を行った例である。ヒト7skRNAを含むRNP(ribonucleoprotein)を抗体を用いて免疫沈降させ、当該沈降物を精製することにより、得られた当該ヒト7skRNAを含むサンプルを得た。このサンプルに対してRNaseT1を用いたゲル内断片化処理を行い、断片化処理後のサンプルをLC/MS質量分析計で解析することにより、6つのRNA断片の各々について、それぞれ分子量「3464.5」、「2805.4」、「2572.4」、「2548.3」、「2526.3」、「2500.3」(Da)を得た。このうち、分子量「3464.5」と「2548.3」の2つのRNA断片を本発明のアルゴリズムにより解析した。その結果、2つのRNA断片の全塩基配列をそれぞれ「UCACCCCAUUG」、「CUUCCAAG」と決定することができた。そして、RMF法を利用して、このヒト7skRNAの長さに対応する300塩基の幅(フレーム長さ)で、当該ヒト7skRNAの全体塩基組成と、当該決定されたヒト7skRNAの部分的な塩基配列(上記2つのRNA断片の全塩基配列)と、を有するゲノム部分をヒトゲノム上から検索した。その結果、図28に示すように、高いスコアが付与された上位17つのゲノム部分はすべてヒト7sk遺伝子にヒットした。一方、部分的な塩基配列の情報を使用することなく、全体塩基組成のみを用いて同様のデータベース検索を行った結果、ゲノム部分をスコアによって十分に差別化することができず、正解の塩基配列を決定することは不可能であった。
【0140】
なお、本発明は上述の例に限られない。すなわち、解析の対象とする核酸は、RNAやRNA断片に限られず、例えば、DNA、DNA分解酵素を用いて作製されたDNA断片、さらに核酸医薬等のために合成された種々の修飾核酸等、任意の核酸を解析の対象とすることができる。また、解析の対象とする核酸の長さは特に限られないが、既知配列のデータベースの検索を利用することなく核酸の全体の塩基配列を決定する上では、例えば、塩基数が20以下の核酸(例えば、マイクロRNA(miRNA)等)を好ましい対象とすることができ、塩基数が15以下の核酸を特に好ましい対象とすることができる。ただし、この好ましい塩基数は、質量分析計の分析精度(核酸のイオン化効率も含む)が向上すれば増加させることができ、本発明による解析の対象を制限するものではない。また、2つの質量分離部を備えた質量分析計(MS/MS)のみならず、例えば、3つ以上の質量分析部を備えた質量分析計(MSn)による質量分析を利用することにより、より塩基数の大きい核酸についても全体の塩基配列を決定することができる。すなわち、この場合、例えば、3つの質量分析部を備えた質量分析計(MS/MS/MS)を用いて、1段階目の質量分析により親イオンの測定(MS)を行い、2段階目の質量分析によりそのプロダクトイオン(子イオン)の測定(MS/MS)を行い、3段階目の質量分析により当該子イオンのプロダクトイオン(孫イオン)の測定(MS/MS/MS)を行うことによって、当該孫イオンの質量分析結果を利用して子イオンの全塩基配列を決定し、当該子イオンの質量分析結果及び全塩基配列を利用して、対象とする核酸の全塩基配列を決定することができる。また、塩基組成セットの作成に用いる全体塩基組成は、親イオンの実際の質量分析結果に基づいて決定されるものに限られず、例えば、ユーザから入力された任意の全体塩基組成とすることもできる。
【0141】
また、本方法に含まれる処理の順番は、処理の効率等を考慮して適宜設定することができ、互いに区別して上述した処理のうち一部を並行して実行することもできる。すなわち、例えば、本装置1の制御部10は、本プログラムに基づいて、塩基組成セットを作成する処理、塩基組成セットの階層構造を作成する処理、塩基組成セット間の接続関係を作成する処理を順次実行することができ、また、並行して行うこともできる。具体的に、例えば、対象断片に含まれる塩基数が「n」であり、当該対象断片の末端の塩基はRNA分解酵素の種類等によって特定することができず、一対の部分塩基組成から構成される塩基組成セットを作成する場合、塩基組成処理部11は、まず、5’端位置の部分塩基組成に含まれる塩基数が「1」であり、3’端位置の部分塩基組成に含まれる塩基数が「n−1」である塩基組成セットを保持したオブジェクトを生成するセット生成関数を記憶部20から読み出す。また、塩基組成処理部11は、アデニン(A)、ウラシル(U)、シトシン(C)、グアニン(G)のうち全体塩基組成に含まれている塩基を末端塩基として決定する。そして、塩基組成処理部11は、セット生成関数に基づいて、5’端位置の部分塩基組成が当該末端塩基1つから構成され、且つ3’端位置の部分塩基組成が全体塩基組成から当該末端塩基を除いた塩基組成である塩基組成セットを、当該5’端位置の部分塩基組成の塩基数が最も少ない最外階層の階層番号「1」と関連付けたオブジェクトを生成し、記憶部20に格納する。同様に、塩基組成処理部11は、5’端位置の部分塩基組成の塩基数が「i」(「i」は2〜nの整数)であり、3’端位置の部分塩基組成に含まれる塩基数が「n−i」である塩基組成セットを作成するにあたって、まず、1つ小さい階層番号「i−1」に関連付けられている、当該5’端位置の部分塩基組成の塩基数が1つ少ない全ての塩基組成セットを呼び出すとともに、呼び出された各塩基組成セットを構成する5’端位置の部分塩基組成及び3’位置の部分塩基組成を取り出す。さらに、塩基組成処理部11は、階層番号「i−1」に関連付けられている各塩基組成セットについて、A、U、C、Gのうち3’端位置の部分塩基組成に含まれている塩基を移動塩基として決定する。そして、塩基組成処理部11は、セット生成関数に基づいて、階層番号「i−1」に関連付けられている各塩基組成セットの5’端位置の部分塩基組成に1つの移動塩基が追加された5’端位置の部分塩基組成と、当該各塩基組成セットの3’端位置の部分塩基組成から当該1つの移動塩基が除かれた3’端位置の部分塩基組成と、からなる塩基組成セットを、当該5’端位置の部分塩基組成の塩基数に対応する階層番号「i」と関連付けたオブジェクトを新たに生成し、記憶部20に格納する。また、塩基組成処理部11は、階層番号「i−1」に関連付けられた塩基組成セットのオブジェクトと、階層番号「i」に関連付けられた塩基組成セットのオブジェクトと、の間の接続関係を保持したオブジェクトを生成し、記憶部20に格納する。すなわち、階層番号「i−1」に関連付けられた各塩基組成セットと、階層番号「i」に関連付けられた塩基組成セットのうち、当該各塩基組成セットの5’端位置の部分塩基組成に1つの移動塩基が追加された5’端位置の部分塩基組成を有する塩基組成セットと、の間の接続関係を表す接続データを生成し、記憶部20に格納する。なお、この接続関係を生成する際に、塩基組成処理部11は、新たに作成した接続関係で接続される新たな塩基組成セットの5’端位置の部分塩基組成が、既に格納されているオブジェクトの塩基組成セットの5’端位置の部分塩基組成と一致する場合には、当該新たな塩基組成セットのオブジェクトは格納することなく、当該既に格納されていた塩基組成セットのオブジェクトとの新たな接続関係を保持するオブジェクトを生成し、記憶部20に格納する。すなわち、塩基組成処理部11は、1つの部分塩基組成の組に対して1つのオブジェクトを生成し、格納する。塩基組成処理部11は、このような処理を「1」から「n」までの「i」について実行する。
【0142】
また、塩基組成セット及びノードに付与する重みは、プロダクトイオンのピーク強度に限られず、例えば、当該ピーク強度に応じて所定の関数を用いて算出される重みとすることもできる。また、この重みは、例えば、各ピーク強度に加えて、部分塩基組成について予測された質量値と各プロダクトイオンについて実測された質量値との誤差や、各部分塩基組成について予測された理論スペクトルに対する実測ピークのヒット数をも用いて決定することができる。すなわち、例えば、質量値の予測値と実測値との差分が小さいほど重みを大きくすることができる。また、例えば、親イオンの解離条件(CIDにおける解離電圧等)等に基づいて、各部分塩基組成について予測される複数の質量値(c−y系列、a−w系列等の互いに異なる系列から算出される互いに異なる質量値)のうち、所定の閾値以上の強度で測定されることが期待される主要なピークに対応する質量値を注目質量値として決定し、実測スペクトルにおいて、当該注目質量値と一致する実測質量値の位置で検出されたピークの数(すなわち、ヒットした主要ピークの数)に基づいて、重みを決定することもできる。
【0143】
また、有向グラフにおける最適経路の探索は、動的計画法によるものに限られず、例えば、欲張りアルゴリズムや他の経路探索方法を用いることもできる。すなわち、例えば、欲張りアルゴリズムを適用する場合、解析処理部13は、各階層に属するノードのうち、最も大きな重みが付与されているノードを選択する選択処理を、少なくとも一方の最外階層から順次実行することにより、核酸の少なくとも一方の末端塩基から塩基配列を順次決定することができる。
【0144】
また、塩基組成セットは、全体塩基組成を2つに分割して得られる一組の部分塩基組成から構成されるものに限られず、全体塩基組成を3つ以上に分割して得られる一組の部分塩基組成から構成されるものとすることもできる。すなわち、全体塩基組成を3つに分割して得られる一組の部分塩基組成から構成される塩基組成セットを作成する場合には、例えば、図29、図30に示すような有向グラフを作成することができる。
【0145】
図29に示す例においては、塩基組成セットが、その両方の末端位置の部分塩基組成の塩基数の昇順に階層化されている。すなわち、この例では、各ノードに対応する塩基組成セットが有する5’端位置の部分塩基組成の塩基数と3’端位置の部分塩基組成の塩基数とは同一であり、且つ有向グラフの5’端から3’端に向けて、5’端位置の部分塩基組成及び3’端位置の部分塩基組成の両方の塩基数が1つずつ増加するよう、塩基組成セットが階層化されている。この場合、有向グラフの5’端から3’端に向けて、各階層に含まれるノードのうち1つを選択する選択処理により、解析の対象とする核酸の両末端塩基から順次塩基配列を決定することができる。
【0146】
また、図30に示す例においては、塩基組成セットが、その一方の末端位置である5’端位置の部分塩基組成の塩基数の昇順に階層化されている。すなわち、この例では、有向グラフの5’端から3’端に向けて、各階層に含まれるノードのうち1つを選択する選択処理により、解析の対象とする核酸の5’端塩基から順次塩基配列を決定することができる。
【0147】
また、本装置1は、その構成の一部として必ずしも質量分析部50を備える必要はない。すなわち、例えば、本装置1は、質量分析計が設置されている分析室とは物理的に離隔された他の解析室に設置することができる。この場合、本装置1は、入力部30を介して、ユーザから入力され又はCD等の記録媒体から読み出される、質量分析の結果に関するデータを受け入れることができる。
【0148】
また、本装置1は、LANやインターネット等のネットワークと接続することもできる。この場合、例えば、ユーザは、本装置1とネットワークを介して接続されたコンピュータを用いて、本装置1を動作させることもできる。また、本装置1の構成の一部をネットワークを介して接続することもできる。例えば、入力部30及び出力部40として機能するユーザのコンピュータと、制御部10及び記憶部20として機能するサーバコンピュータと、をネットワークを介して接続することによって本装置1を構成することもできる。また、本装置1の制御部10と質量分析部50とをネットワークを介して接続することもできる。
【図面の簡単な説明】
【0149】
【図1】本発明の一実施形態に係る核酸解析装置の主な構成を示すブロック図である。
【図2】本発明の一実施形態に係る核酸解析装置の制御部が行う主な処理を示す機能ブロック図である。
【図3】本発明の一実施形態に係る核酸解析方法に含まれる主な処理を示すフロー図である。
【図4】本発明の一実施形態において作成される階層データの一例を示す説明図である。
【図5】本発明の一実施形態において作成される接続データの一例を示す説明図である。
【図6】本発明の一実施形態において作成される有向グラフの一例を示す説明図である。
【図7】本発明の一実施形態における理論スペクトルの作成についての説明図である。
【図8】本発明の一実施形態におけるマッチング処理の一例についての説明図である。
【図9】本発明の一実施形態において作成される有向グラフの重み付け処理の一例についての説明図である。
【図10】本発明の一実施形態において作成される有向グラフのトレースバック処理の一例についての説明図である。
【図11】本発明の一実施形態において作成される有向グラフを用いた塩基配列決定の一例についての説明図である。
【図12】本発明の一実施形態において作成されたプロダクトイオンの一部と予測質量値とを関連付けたデータテーブルの一例を示す説明図である。
【図13】本発明の一実施形態において作成されたプロダクトイオンの他の一部と予測質量値とを関連付けたデータテーブルの一例を示す説明図である。
【図14】本発明の一実施形態において作成されたノードとスコアとを関連付けたデータテーブルの一例を示す説明図である。
【図15】本発明の一実施形態において作成されたエッジとスコアとを関連付けたデータテーブルの一例を示す説明図である。
【図16】本発明の一実施形態において作成された塩基欠損イオンと予測質量値とを関連付けたデータテーブルの一例を示す説明図である。
【図17】本発明の一実施形態において作成されたエッジとノーマライズされたスコアとを関連付けたデータテーブルの一例を示す説明図である。
【図18】本発明の一実施形態において作成されたノードと更新されたスコアとを関連付けたデータテーブルの一例を示す説明図である。
【図19】本発明の一実施形態で作成された有向グラフの一例を示す説明図である。
【図20】本発明の一実施形態で作成されたマッチング処理の結果を含むマススペクトルの一例を示す説明図である。
【図21】本発明の一実施形態で作成された有向グラフの他の一例を示す説明図である。
【図22】本発明の一実施形態で作成された有向グラフの更に他の一例を示す説明図である。
【図23】本発明の一実施形態で作成された有向グラフの更に他の一例を示す説明図である。
【図24】本発明の一実施形態で作成された有向グラフの更に他の一例を示す説明図である。
【図25】本発明の一実施形態で作成された有向グラフの更に他の一例を示す説明図である。
【図26】本発明の一実施形態における大腸菌ゲノムの候補領域をスコアに基づいて順位付けした結果の一例を示す説明図である。
【図27】本発明の一実施形態における大腸菌ゲノムの候補領域をスコアに基づいて順位付けした結果の他の例を示す説明図である。
【図28】本発明の一実施形態におけるヒトゲノムの候補領域をスコアに基づいて順位付けした結果の一例を示す説明図である。
【図29】本発明の一実施形態において全体塩基組成を3つに分割して塩基組成セットを作成した場合の有向グラフの一例を示す説明図である。
【図30】本発明の一実施形態において全体塩基組成を3つに分割して塩基組成セットを作成した場合の有向グラフの他の例を示す説明図である。
【符号の説明】
【0150】
1 核酸解析装置、10 制御部、11 塩基組成処理部、12 重み付け処理部、13 解析処理部、20 記憶部、30 入力部、40 出力部、50 質量分析部。
【技術分野】
【0001】
本発明は、核酸の塩基配列及び塩基修飾を解析する装置、方法及びプログラムに関し、特に、質量分析の結果を利用して核酸の塩基配列及び塩基修飾を解析する装置、方法及びプログラムに関する。
【背景技術】
【0002】
RNA干渉やマイクロRNAの発見によって、タンパク質をコードしないRNA(機能性RNA)が担う新しい機能が注目されている。機能性RNAは、それ自身が遺伝子の最終産物であり、機能性高分子として振る舞い、遺伝子発現の調節、発生、分化等の高次生命現象に関わる重要な働きを担っていることが次第に明らかになりつつある。また、機能性RNAの異常が疾患の原因になっているという報告例もあり、疾患の原因として、タンパク質の異常のみならずRNAの異常も視野に入れる必要性が指摘されている。
【0003】
従来、このようなRNAを解析する方法としては、例えば、逆転写PCRによりcDNAを増幅し、当該cDNAの配列を決定する方法があった。
【0004】
また、例えば、非特許文献1においては、解析の対象とする核酸の塩基配列として予想される全ての塩基配列候補を作成し、当該全ての塩基配列候補の各々から生じ得る複数組のプロダクトイオンについて、理論的に予測される質量/電荷比と、当該核酸から生じたプロダクトイオンについて実際の質量分析により得られた質量/電荷比と、を比較することにより、当該全ての塩基配列候補の各々をスコア付けし、当該スコアの高いものを当該核酸の塩基配列として決定する方法が提案されている。
【非特許文献1】Oberacher H., Mayr B.M., Huber C.G.; Journal of the American Societyfor Mass Spectrometry, 15 (1), pp. 32-42, 2004.
【発明の開示】
【発明が解決しようとする課題】
【0005】
しかしながら、上記cDNAを用いた方法は、熟練した技術が必要であり、時間と手間がかかる上に、PCRによるバイアスを考慮すると定量的とは言い難い。
【0006】
また、上記非特許文献1に記載の方法は、対象とする核酸の塩基数が増加するにつれて、予想される塩基配列候補の数が急激に増加するため、塩基配列を決定するための計算量が膨大になる。また、各塩基配列候補から生じ得る複数組のプロダクトイオンの全てについて理論値と実測値とを比較した結果に基づいて、当該各塩基配列候補をスコア付けするため、例えば、信頼性の高い末端由来の短いプロダクトイオンの実測結果を十分に活用できないことがある。また、核酸の塩基修飾を解析する上でも同様の問題があった。
【0007】
本発明は、上記課題に鑑みて為されたものであり、塩基配列や塩基修飾等に関する核酸の解析を迅速且つ正確に行うことのできる装置、方法及びプログラムを提供することをその目的の一つとする。
【課題を解決するための手段】
【0008】
上記課題を解決するための本発明の一実施形態に係る核酸解析装置は、核酸の全体塩基組成に基づいて、各々が一組の部分塩基組成から構成される、複数の塩基組成セットを作成するとともに、前記塩基組成セットが、その少なくとも一方の末端位置の部分塩基組成の塩基数の昇順に階層化された階層構造を作成し、さらに前記塩基組成セットの各々と、その前記末端位置の部分塩基組成に塩基を1つ追加した部分塩基組成を前記末端位置に有する他の塩基組成セットと、の間に接続関係を作成する第一処理部と、前記部分塩基組成の各々について、対応したプロダクトイオンの質量分析において得られることが予測される質量値を算出するとともに、前記予測される質量値と、前記核酸由来のプロダクトイオンの質量分析において実際に得られた質量値と、の比較に基づいて、前記塩基組成セットの各々に重みを付与する第二処理部と、前記塩基組成セットの各々に付与された重みに基づいて、前記階層構造の前記末端位置の部分塩基組成の塩基数が最も少ない前記塩基組成セットが属する最外階層から前記接続関係を辿りながら、各階層に属する塩基組成セットのうち1つを選択する選択処理を行うことによって、前記核酸の前記末端位置に対応する少なくとも一方の末端から塩基配列を順次決定する第三処理部と、を含むことを特徴とする。本発明によれば、塩基配列や塩基修飾等に関する核酸の解析を迅速且つ正確に行うことのできる装置を提供することができる。すなわち、計算量を効果的に低減しつつ、末端由来のプロダクトイオンの質量分析結果を効果的に利用して、塩基配列の決定、塩基修飾の有無、塩基修飾の内容(修飾の種類、位置、数等)等について、信頼性の高い解析を行うことができる。
【0009】
また、前記第一処理部は、前記階層構造の一方の最外階層からは、5’端位置又は3’端位置のうち一方の末端位置の部分塩基組成の塩基数の昇順となり、また、他方の最外階層からは、5’端位置又は3’端位置のうち他方の末端位置の部分塩基組成の塩基数の昇順となるよう、前記塩基組成セットを階層化し、前記第三処理部は、前記階層構造の前記一方の最外階層及び前記他方の最外階層の両方の最外階層から内部の階層に向けて前記接続関係を辿りながら、前記選択処理を行うことによって、前記核酸の5’端及び3’端の両末端から塩基配列を順次決定することもできる。また、前記第二処理部は、前記接続関係の各々により接続される一対の前記塩基組成セットに付与された重みに基づいて、前記接続関係の各々に重みを付与し、前記第三処理部は、前記塩基組成セットの各々に付与された重みと前記接続関係の各々に付与された重みとに基づいて、前記選択処理を行うこともできる。また、前記第一処理部は、前記塩基組成セットの各々に対応する階層化されたノードと、前記接続関係の各々に対応して前記ノードを接続するエッジと、を有する有向グラフを作成し、前記第三処理部は、前記塩基組成セットの各々に付与された重みに基づいて、前記有向グラフの前記末端位置の部分塩基組成の塩基数が最も少ない前記塩基組成セットが属する階層側の末端から最適経路を探索することにより、前記選択処理を行うこともできる。この場合、前記第三処理部は、動的計画法を適用して、前記選択処理を行うこともできる。さらに、この場合、前記第一処理部は、前記有向グラフの一方端からは、対応する前記塩基組成セットの5’端位置又は3’端位置のうち一方の末端位置の部分塩基組成の塩基数の昇順となり、また、前記有向グラフの他方端からは、対応する前記塩基組成セットの5’端位置又は3’端位置のうち他方の末端位置の部分塩基組成の塩基数の昇順となるよう、前記ノードを階層化し、前記第三処理部は、前記有向グラフの前記一方端及び前記他方端の両端から内部に向けて動的計画法を適用して前記エッジを辿りながら、前記選択処理を行うことによって、前記核酸の5’端及び3’端の両末端から塩基配列を順次決定することもできる。
【0010】
また、前記第二処理部は、前記部分塩基組成の各々について、前記対応したプロダクトイオンの質量分析において、前記対応したプロダクトイオンに修飾塩基が含まれないと仮定した場合に予測される第一の予測質量値と、前記対応したプロダクトイオンに修飾塩基が含まれると仮定した場合に予測される第二の予測質量値と、を作成し、前記第一の予測質量値及び前記第二の予測質量値の各々と、前記実際に得られた質量値と、の比較に基づいて、前記部分塩基組成の各々に重みを付与することもできる。この場合、前記第二処理部は、前記部分塩基組成の各々について、前記第一の予測質量値及び前記第二の予測質量値の各々と、前記実際に得られた質量値と、の比較に基づいて、前記対応したプロダクトイオンに前記修飾塩基が含まれるか否かを判断し、前記対応したプロダクトイオンに前記修飾塩基が含まれると判断した場合には、前記部分塩基組成の各々に、前記修飾塩基に関する修飾情報を関連付けて保持し、前記第三処理部は、前記階層構造の隣接する階層間で、前記選択された塩基組成セットにおいて前記修飾情報が関連付けられている部分塩基組成の位置が移動するか否かの判断結果に基づいて、前記核酸に含まれる修飾塩基の位置を決定することもできる。
【0011】
上記課題を解決するための本発明の一実施形態に係る核酸解析方法は、核酸の全体塩基組成に基づいて、各々が一組の部分塩基組成から構成される、複数の塩基組成セットを作成するとともに、前記塩基組成セットが、その少なくとも一方の末端位置の部分塩基組成の塩基数の昇順に階層化された階層構造を作成し、さらに前記塩基組成セットの各々と、その前記末端位置の部分塩基組成に塩基を1つ追加した部分塩基組成を前記末端位置に有する他の塩基組成セットと、の間に接続関係を作成する第一ステップと、前記部分塩基組成の各々について、対応したプロダクトイオンの質量分析において得られることが予測される質量値を算出するとともに、前記予測される質量値と、前記核酸由来のプロダクトイオンの質量分析において実際に得られた質量値と、の比較に基づいて、前記塩基組成セットの各々に重みを付与する第二ステップと、前記塩基組成セットの各々に付与された重みに基づいて、前記階層構造の前記末端位置の部分塩基組成の塩基数が最も少ない前記塩基組成セットが属する最外階層から前記接続関係を辿りながら、各階層に属する塩基組成セットのうち1つを選択する選択処理を行うことによって、前記核酸の前記末端位置に対応する少なくとも一方の末端から塩基配列を順次決定する第三ステップと、を含むことを特徴とする。本発明によれば、核酸の解析を迅速且つ正確に行うことのできる方法を提供することができる。
【0012】
上記課題を解決するための本発明の一実施形態に係る核酸解析プログラムは、コンピュータに、核酸の全体塩基組成に基づいて、各々が一組の部分塩基組成から構成される、複数の塩基組成セットを作成するとともに、前記塩基組成セットが、その少なくとも一方の末端位置の部分塩基組成の塩基数の昇順に階層化された階層構造を作成し、さらに前記塩基組成セットの各々と、その前記末端位置の部分塩基組成に塩基を1つ追加した部分塩基組成を前記末端位置に有する他の塩基組成セットと、の間に接続関係を作成する第一手順と、前記部分塩基組成の各々について、対応したプロダクトイオンの質量分析において得られることが予測される質量値を算出するとともに、前記予測される質量値と、前記核酸由来のプロダクトイオンの質量分析において実際に得られた質量値と、の比較に基づいて、前記塩基組成セットの各々に重みを付与する第二手順と、前記塩基組成セットの各々に付与された重みに基づいて、前記階層構造の前記末端位置の部分塩基組成の塩基数が最も少ない前記塩基組成セットが属する最外階層から前記接続関係を辿りながら、各階層に属する塩基組成セットのうち1つを選択する選択処理を行うことによって、前記核酸の前記末端位置に対応する少なくとも一方の末端から塩基配列を順次決定する第三手順と、を実行させることを特徴とする。本発明によれば、核酸の解析を迅速且つ正確に行うことのできるプログラムを提供することができる。
【発明を実施するための最良の形態】
【0013】
以下に、本発明の一実施形態に係る核酸の塩基配列及び塩基修飾を解析する装置(以下、「本装置」という)、方法(以下、「本方法」という)、及びプログラム(以下、「本プログラム」という)について、図面を参照しつつ説明する。本実施形態においては、本プログラムに従って動作する本装置を用いて、本方法を実施する場合を例として説明する。
【0014】
まず、本装置及び本プログラムの概要について説明する。本装置は、その少なくとも一部にコンピュータを含んで構成することができる。図1は、本装置1の主な構成を示すブロック図である。図1に示すように、本装置1は、制御部10と、記憶部20と、入力部30と、出力部40と、質量分析部50と、を含んでいる。
【0015】
制御部10は、CPU等の演算装置によって実現できる。制御部10は、記憶部20に格納されているプログラムに従って動作し、記憶部20、入力部30、出力部40、質量分析部50との間でデータの入出力を行うことができる。すなわち、制御部10は、質量分析部50から受け入れた質量分析に関するデータを記憶部20に格納するとともに、記憶部20から読み出したデータと入力部30から受け入れたデータとに基づいて所定の演算処理を実行することができる。また、制御部10は、演算処理の結果に関連するデータに基づいて、出力部40に当該結果を表す所定の画像を表示させることができる。また、制御部10は、質量分析部50に指示データを出力して所定の質量分析を実行させることもできる。
【0016】
図2は、この制御部10によって行われる主な処理を示す機能ブロック図である。図2に示すように、制御部10は、塩基組成処理部11と、重み付け処理部12と、解析処理部13と、を機能的に含んでいる。制御部10による処理の具体的内容については後に詳しく説明する。
【0017】
記憶部20は、ハードディスク等の外部記憶装置や、RAM、ROM等の主記憶装置によって実現できる。すなわち、例えば、記憶部20はハードディスクを備え、制御部10が実行するプログラム(本プログラムや、質量分析部50が質量分析を実行し又は質量分析結果を解析するためのプログラム等)、制御部10が演算処理で利用するデータベース、制御部10が質量分析部50から受け入れた質量分析に関するデータを当該ハードディスクに格納する。また、記憶部20は、制御部10により行われる処理で利用されるデータを保持するワークメモリとして動作することもできる。すなわち、例えば、記憶部20はRAMを備え、制御部10が入力部30や質量分析部50から受け入れたデータや、制御部10による演算処理の過程で生成されたデータを当該RAMに一時的に保持する。
【0018】
入力部30は、キーボード、マウス、タッチパッド等の入力装置によって実現できる。入力部30は、本装置のユーザからデータの入力を受け入れることができる。また、入力部30は、CDやDVD等の記録媒体のドライブ装置を含んで実現することもできる、この場合、入力部30は、ドライブ装置に挿入された記録媒体に記録されているデータを読み出して制御部10に出力する。
【0019】
出力部40は、液晶ディスプレイ等の表示装置によって実現できる。出力部40は、制御部10から受け入れたデータに基づいて、制御部10により行われた処理の結果を表す画面や、ユーザにデータの入力を促す画面をユーザに提示することができる。
【0020】
質量分析部50は、QqTOF型のLC/MS/MS等の核酸の質量分析に適した質量分析計によって実現できる。質量分析部50は、対象とする核酸の質量分析を実行し、その分析結果に関するデータを制御部10に出力する。
【0021】
本プログラムは、コンピュータに、本発明に関する処理を実行させることができる。例えば、本プログラムは、本装置に、本方法に関する処理を実行させることができる。また、本プログラムは、コンピュータ読み取り可能な記録媒体に記録することができる。
【0022】
次に、本装置、本方法及び本プログラムの詳細について説明する。ここでは、核酸として、所定長さのRNA分子をRNA分解酵素の一種であるRNaseAを使用して切断することにより得られたRNA断片(以下、「対象断片」という)を解析の対象とする場合を例として説明する。
【0023】
図3は、本方法に含まれる主なステップの一例を示すフロー図である。図3に示すように、本方法は、第一のステップS100と、第二のステップS200と、第三のステップS300と、を含んでいる。
【0024】
第一のステップS100において、本装置1の塩基組成処理部11は、対象断片の親イオンに関する情報を取得する(S101)。この親イオンは、質量分析部50が備える質量分析計において、エレクトロスプレーイオン化(ESI)法やマトリックス支援レーザー脱離イオン化(MALDI)法等の核酸の質量分析に適したイオン化法により、対象断片から生成することができる。
【0025】
親イオンに関する情報としては、例えば、親イオンの質量対電荷比(m/z値)、価数、対象断片の作製に使用されたRNA分解酵素の種類、対象断片に含まれる修飾塩基の種類等を用いることができる。親イオンのm/z値や価数は、例えば、質量分析部50が備えるLC−QqTOF型の質量分析計を用いて、当該質量分析計の誤差範囲内で親イオンの質量分析を行うことにより、高い精度で測定することができる。
【0026】
塩基組成処理部11は、これらの親イオンに関する情報を、質量分析部50から受け入れることができる。なお、塩基組成処理部11は、親イオンに関する情報を、入力部30を介して本装置1のユーザから受け入れ、又は記憶部20から読み出すことにより、取得することもできる。
【0027】
次に、塩基組成処理部11は、親イオンに関する情報に基づいて、対象断片の全体塩基組成を決定する(S102)。ここで、「塩基組成」とは、所定長さの核酸分子に含まれる塩基の種類及び各塩基の数から構成され、当該核酸分子における各塩基の配列順序とは無関係に決定される。対象断片の「全体塩基組成」とは、当該対象断片の全体としての塩基組成である。
【0028】
本実施形態においては、例えば、対象断片が、3残基のアデニン(A)、1残基のウラシル(U)、及び2残基のグアニン(G)から構成され、シトシン(C)を含まない場合、当該対象断片の全体塩基組成を「A3G2U」と記述する。この塩基組成の記述において、塩基の記載順序は、対象断片における塩基の配列順序とは無関係である。
【0029】
このステップS102において、塩基組成処理部11は、まず、親イオンのm/z値や価数等の情報に基づいて、親イオンの分子量(質量)を算出する。そして、塩基組成処理部11は、この親イオンの分子量に基づいて、対象断片の全体塩基組成を決定する。
【0030】
すなわち、例えば、記憶部20が、RNA断片の様々な塩基組成と、その分子量と、を関連付けたデータベースを格納している場合には、塩基組成処理部11は、親イオンの分子量と、当該データベースに格納されている各塩基組成の分子量と、を照合する。そして、塩基組成処理部11は、データベースに登録されている塩基組成のうちから、親イオンの分子量に一致し、又は分子量の差分が所定の誤差範囲内である塩基組成を抽出し、当該抽出された塩基組成を、対象断片の全体塩基組成として決定する。なお、所定の誤差範囲は、例えば、親イオンの質量分析に用いられた質量分析計の性能や分析条件等に応じた分析精度に基づいて決定することができる。
【0031】
具体的に、ここでは、塩基組成処理部11が、親イオンのm/z値「999.7」と価数「−2」とに基づいて、分子量「2001.4(Da)」を算出し、当該分子量に基づくデータベース検索により、対象断片の全体塩基組成を「A3G2U」と決定した場合を例として説明する。
【0032】
次に、塩基組成処理部11は、決定された全体塩基組成に基づいて、複数の塩基組成セットを作成する(S103)。この複数の塩基組成セットの各々は、一組の部分塩基組成から構成される。
【0033】
ここで、「一組の部分塩基組成」は、全体塩基組成の互いに異なる一部(部分塩基組成)の組合せとして構成される。すなわち、一組の部分塩基組成を構成する各部分塩基組成は、全体塩基組成を複数に分割して得られる互いに異なる複数の部分の各々である。
【0034】
また、各部分塩基組成は、塩基の種類、各塩基の数、及び対象断片における位置により特定される。したがって、例えば、2つの部分塩基組成について、各々を構成する塩基の種類及び各塩基の数が互いに同一であったとしても、各々の対象断片における位置が互いに異なる場合には、当該2つの部分塩基組成は互いに異なるものとなる。この部分塩基組成の位置は、例えば、対象断片の末端位置(5’端位置又は3’端位置)や、末端以外の内部位置等として決定することができる。
【0035】
そして、一組の部分塩基組成は、少なくとも5’端位置の部分塩基組成(5’端塩基を含む部分塩基組成)と3’端位置の部分塩基組成(3’端塩基を含む部分塩基組成)とを含む。具体的に、例えば、全体塩基組成「A3G2U」を2つに分割して一組の部分塩基組成を作成する場合の一例として、当該一組の部分塩基組成は、5’端位置の部分塩基組成「A」と3’端位置の部分塩基組成「A2G2U」とから構成される。また、全体塩基組成「A3G2U」を3つに分割して一組の部分塩基組成を作成する場合の一例として、当該一組の部分塩基組成は、5’端位置の部分塩基組成「A」と3’端位置の部分塩基組成「U」と内部(インターナル)位置の部分塩基組成「A2G2」とから構成される。
【0036】
このような一組の部分塩基組成は、対象断片由来の仮想的な一組のプロダクトイオンに対応すると考えることもできる。すなわち、各部分塩基組成は、対象断片をイオン化して親イオンを生成し、さらに当該親イオンを解離させてプロダクトイオンを生成した場合において、1分子の親イオンから生成された一組のプロダクトイオンを構成する各プロダクトイオンの塩基組成に対応していると考えることができる。したがって、例えば、一組の部分塩基組成は、5’端の塩基を含むプロダクトイオンに対応する5’端位置の部分塩基組成と、3’端の塩基を含むプロダクトイオンに対応する3’端位置の部分塩基組成と、を少なくとも含むこととなる。なお、もちろん、各部分塩基組成に対応するプロダクトイオンが、後述するような質量分析において実際に検出されるとは限らない。
【0037】
各塩基組成セットは、上述のようにして決定される一組の部分塩基組成から構成されるため、その全体としての塩基組成は全体塩基組成に一致する。すなわち、各塩基組成セットを構成する各部分塩基組成の合計は、全体塩基組成に一致する。また、本実施形態において、各塩基組成セットの構成は、コロン(:)を介して、5’端側の部分塩基組成を左側に、3’端側の部分塩基組成を右側に、それぞれ配置して記述される。具体的に、例えば、全体塩基組成「A3G2U」を2つに分割して塩基組成セットを作成する場合の一例として、5’端位置の部分塩基組成「A」と3’端位置の部分塩基組成「A2G2U」とから構成される塩基組成セットの構成は「A:A2G2U」と記述される。また、全体塩基組成「A3G2U」を3つに分割して塩基組成セットを作成する場合の一例として、5’端位置の部分塩基組成「A」と3’端位置の部分塩基組成「U」と内部(インターナル)位置の部分塩基組成「A2G2」とから構成される塩基組成セットの構成は「A:A2G2:U」と記述される。
【0038】
また、1つの全体塩基組成から作成される複数の塩基組成セットの各々は、互いに異なる一組の部分塩基組成から構成される。ここで、例えば、2つの塩基組成セットのうち一方を構成する一組の部分塩基組成と、他方を構成する一組の部分塩基組成と、を比較した場合に、少なくとも一部の対応する部分塩基組成が異なる場合には、当該2つの塩基組成セットは、互いに異なる一組の部分塩基組成から構成されていることとなる。
【0039】
なお、対応する部分塩基組成とは、対象断片における位置が同一の部分塩基組成である。例えば、2つの塩基組成セットのうち一方に含まれる5’端の部分塩基組成と、他方に含まれる5’端の部分塩基組成と、は対応する部分塩基組成である。対応する2つの部分塩基組成の塩基の種類又は各塩基の数の少なくとも一方が異なる場合、当該対応する2つの部分塩基組成は互いに異なることとなる。
【0040】
このステップS103において、塩基組成処理部11は、対象断片の全体塩基組成、当該全体塩基組成の分割条件、当該対象断片の作製に使用されたRNA分解酵素の種類等に関するデータに基づいて、当該全体塩基組成から予想される、可能な部分塩基組成の組合せの全部又は一部を作成することにより、互いに異なる複数の塩基組成セットを作成する。すなわち、例えば、塩基組成処理部11は、全体塩基組成を2つに分割して一組の部分塩基組成を作成する場合において可能な全ての部分塩基組成の組を算出し、その各々がこれら複数組の部分塩基組成のうち互いに異なる一組から構成される複数の塩基組成セットを表すデータを生成する。なお、塩基組成処理部11は、これら部分塩基組成セットの作成に利用するデータの全部又は一部を、入力部30を介してユーザから受け入れ、又は記憶部20から読み出すことにより取得することもできる。
【0041】
ここで、上述のように対象断片はRNAaseAによる切断処理によって作製されたRNA断片であるため、当該対象断片の3’端の塩基はウラシル(U)又はシトシン(C)であると予想することができる。一方、上記ステップS102で決定された対象断片の全体塩基組成は「A3G2U」であってシトシン(C)を含まない。このため、対象断片の3’端はウラシル(U)であると決定できる。また、ここでは親イオンは一箇所で切断される(すなわち、5’端の塩基を含むプロダクトイオンと3’端の塩基を含むプロダクトイオンとからなる一組のプロダクトイオンが生成される)と仮定する。
【0042】
したがって、このように対象断片の作製に使用されたRNA分解酵素の種類によって当該対象断片の末端(5’端又は3’端)の塩基の種類を特定することができる場合には、塩基組成処理部11は、全体塩基組成「A3G2U」と、当該全体塩基組成の分割数「2」と、当該RNA分解酵素の種類「RNAaseA」と、に基づいて、当該対象断片の末端位置の塩基の種類を「ウラシル(U)」と決定する。そして、塩基組成処理部11は、全体塩基組成と、末端塩基の決定結果と、に基づいて、複数の塩基組成セットを作成する。すなわち、塩基組成処理部11は、全体塩基組成に含まれるウラシル(U)の位置を3’端に固定した上で、当該全体塩基組成の残りの塩基組成に基づいて、部分塩基組成の組を複数作成する。
【0043】
具体的に、塩基組成処理部11は、3’端位置の部分塩基組成がウラシル(U)を含む場合に可能な全ての部分塩基組成の組合せを算出して、その構成がそれぞれ「A:A2UG2」、「G:A3UG」、「A2:AUG2」、「AG:A2UG」、「G2:A3U」、「A3:UG2」、「A2G:AUG」、「AG2:A2U」、「A3G:UG」、「A2G2:AU」、「A3G2:U」で表される、互いに異なる11個の塩基組成セットを作成する。
【0044】
また、このステップS103において、塩基組成処理部11は、塩基組成セットが、その少なくとも一方の末端位置の部分塩基組成の塩基数の昇順に階層化された階層構造を作成する。すなわち、塩基組成処理部11は、例えば、入力部30を介して受け入れたユーザからの指示に基づいて、5’端又は3’端のうち少なくとも一方を着目末端として決定し、当該着目末端位置の部分塩基組成に含まれる塩基の数に基づいて塩基組成セットを階層化する。具体的に、ここでは、塩基組成処理部11は、5’端を着目末端として決定し、5’端位置の部分塩基組成の塩基数が同一の塩基組成セットを同一の階層に分類する。すなわち、塩基組成処理部11は、各階層に、5’端位置の部分塩基組成の塩基数として互いに異なる所定数を関連付け、各階層には、5’端位置の部分塩基組成の塩基数が当該各階層に対応する所定数である、全体塩基組成から可能な全ての塩基組成セットを分類する。そして、塩基組成処理部11は、各階層に属する塩基組成セットを構成する5’端位置の部分塩基組成の塩基数の昇順に当該各階層を順位付けする。
【0045】
そして、塩基組成処理部11は、例えば、図4に示すように、11個の塩基組成セットの各々について、各塩基組成セットに割り当てられた識別情報S1〜S11と、当該各塩基組成セットの構成と、当該各塩基組成セットが属する階層の番号と、を関連付けたデータテーブルを階層データとして作成する。
【0046】
図4に示すように、この階層構造においては、一方の最外階層(階層番号が「1」の第一階層)から他方の最外階層(階層番号が「5」の第五階層)まで、各階層に属する塩基組成セットを構成する5’端位置の部分塩基組成に含まれる塩基の数が1つずつ増加している。
【0047】
すなわち、5’端の部分塩基組成の塩基数が最も小さい「1」である2つの塩基組成セットS1,S2は、階層構造における一方の最外階層である第一階層に分類され、当該塩基数が1つ大きい「2」である3つの塩基組成セットS3,S4,S5はその内側の第二階層に分類され、当該塩基数がさらに1つ大きい「3」である3つの塩基組成セットS6,S7,S8はさらに深い第三階層に分類され、当該塩基数がさらに1つ大きい「4」である2つの塩基組成セットS9,S10はさらに深い第四階層に分類され、当該塩基数が最も大きい「5」である1つの塩基組成セットS11は、当該階層構造における他方の最外階層である第五階層に分類されている。
【0048】
一方、この階層構造においては、3’端位置の部分塩基組成の塩基数に着目すると、逆に、第五階層から第一階層まで、当該3’端位置の部分塩基組成の塩基数の昇順に、塩基組成セットが階層化されている。すなわち、この階層構造においては、一方の最外階層(第一階層)からは5’端位置の部分塩基組成の塩基数の昇順となり、また、他方の最外階層(第五階層)からは3’端位置の部分塩基組成の昇順となるよう、塩基組成セットが階層化されている。
【0049】
さらに、このステップS103において、塩基組成処理部11は、塩基組成セットの各々と、その末端位置の部分塩基組成に塩基を1つ追加した部分塩基組成を当該末端位置に有する他の塩基組成セットと、の間に接続関係を作成する。
【0050】
すなわち、塩基組成処理部11は、隣接する階層のうち、5’端位置の部分塩基組成の塩基数が小さい塩基組成セットが属する一方の階層に属する塩基組成セットの各々と、5’端位置の部分塩基組成の塩基数が大きい塩基組成セットが属する他方の階層に属し、当該一方の階層の塩基組成セットにおける5’端位置の部分塩基組成に塩基を1つ追加した部分塩基組成を、当該5’端位置の部分塩基組成として有する塩基組成セットと、の間に1つの接続関係を作成する。
【0051】
具体的に、塩基組成処理部11は、図4に示す階層化された11個の塩基組成セットのうち、例えば、第一階層に属する、5’端位置の部分塩基組成が1つのアデニン(A)から構成される塩基組成セットS1と、隣接する第二階層に属する3つの塩基組成セットS3,S4,S5のうち、5’端位置の部分塩基組成が1つのアデニン(A)にもう1つのアデニン(A)を加えて構成される塩基組成セットS3との間に接続関係を作成すると共に、5’端位置の部分塩基組成が1つのアデニン(A)に1つのグアニン(G)を加えて構成される塩基組成セットS4との間にも接続関係を作成する。
【0052】
そして、塩基組成処理部11は、例えば、図5に示すように、作成した接続関係の各々について、各接続関係に割り当てられた識別情報C1〜C15と、当該各接続関係によって接続される一対の塩基組成セットを特定する情報と、当該各接続関係が属する階層の番号と、を関連付けたデータテーブルを接続データとして作成する。図5に示す例において、各接続関係によって接続される一対の塩基組成セットを特定する情報は、予め各塩基組成セットに割り当てられた識別情報(図4参照)の組合せとなっている。また、各接続関係が属する階層の番号は、当該各接続関係によって接続される各塩基組成セットが属する階層番号(図4参照)のうち、小さいほうの階層番号となっている。
【0053】
次に、塩基組成処理部11は、塩基組成セットの各々に対応する階層化されたノードと、上述の接続関係の各々に対応して当該ノードを接続するエッジと、を有する有向グラフを作成する(S104)。すなわち、塩基組成処理部11は、上述したような階層データと接続データとに基づいて、塩基組成セットの接続関係を視覚化した有向グラフを作成する。具体的に、例えば、塩基組成処理部11は、図6に示すような有向グラフを作成する。
【0054】
図6に示す有向グラフにおいては、図4に示した階層構造に従い、一方端(図中の左端)の最外階層(第一階層)から他方端(図中の右端)の最外階層(第五階層)に向けては、各ノードに対応する塩基組成セットを構成する5’端位置の部分塩基組成の塩基数の昇順となり、また、当該第五階層から当該第一階層に向けては、各ノードに対応する塩基組成セットを構成する3’端位置の部分塩基組成の塩基数の昇順となるよう、図4に示した11個の塩基組成セットS1〜S11に対応する11個のノードN1〜N11が階層化されて配置されている。なお、以下、有向グラフにおいて第一階層側の末端を5’端、第五階層側の末端を3’端と呼ぶ。
【0055】
すなわち、この有向グラフにおいては、5’端から内部に向けて、5’端位置の部分塩基組成の塩基数が1ずつ増加する一方で、3’端から内部に向けては、3’端位置の部分塩基組成の塩基数が1ずつ増加するように、ノードN1〜N11が階層化されて配置されている。
【0056】
また、この有向グラフにおいては、接続関係によって接続される一対の塩基組成セットに対応した一対のノードが、図5に示した接続関係C1〜C15に対応するエッジE1〜E15により接続されている。すなわち、隣接する階層のうち5’端位置の部分塩基組成の塩基数が小さい塩基組成セットが属する一方の階層に属する塩基組成セットに対応するノードの各々と、5’端位置の部分塩基組成の塩基数が大きい塩基組成セットが属する他方の階層に属し、当該一方の階層の塩基組成セットにおける5’端位置の部分塩基組成に塩基を1つ追加した部分塩基組成を、当該5’端位置の部分塩基組成として有する塩基組成セットに対応するノードと、が1つのエッジにより接続されている。
【0057】
また、この有向グラフにおいて、各エッジは、図6に示すように、5’端階層及び3’端階層から、予め中央の階層として決定された第三階層(図6において破線で囲まれた階層)に向かうよう方向付けされている。なお、塩基組成処理部11は、両端の最外階層を除く任意の階層を中央の階層として決定することができる。すなわち、例えば、塩基組成処理部11は、両端の最外階層から等しい階層数の階層、又は一方の最外階層からの階層数と他方の最外階層からの階層数との差が1だけ異なる階層を中央の階層と決定することができる。また、例えば、塩基組成処理部11は、入力部30を介してユーザから受け入れたデータによって指示される階層を中央の階層と決定することができる。
【0058】
また、塩基組成処理部11は、この有向グラフを画像としてユーザに提示するよう出力部40に指示することができる。この場合、出力部40は、図6に示すような有向グラフを液晶ディスプレイ等の画面上に表示する。さらに、この場合、塩基組成処理部11は、ユーザからの修正指示を入力部30から受け入れて、有向グラフを修正することもできる。例えば、塩基組成処理部11は、ユーザから中央の階層を変更するよう指示を受け入れた場合には、当該指示に従い、中央の階層を変更した有効グラフを作成する。
【0059】
そして、塩基組成処理部11は、上述の階層データや接続データ等、塩基組成セットや有向グラフに関する情報を含む塩基組成データを重み付け処理部12に出力する。
【0060】
第二のステップS200においては、まず、部分塩基組成の各々について、対応したプロダクトイオンの質量分析において得られることが予測される質量値を算出する(S201)。ここで、質量値は、例えば、m/z値とすることができ、又はm/z値をデコンボリューションした値(すなわち0(ゼロ)価に変換した値)とすることもできる。すなわち、重み付け処理部12は、塩基組成処理部11から受け入れた塩基組成データに基づいて、その塩基組成が各部分塩基組成に一致するプロダクトイオンを質量分析したと仮定した場合に、分析結果として得られることが予測される、当該プロダクトイオンの質量値(予測質量値)を算出する。
【0061】
ここで、一般に、核酸由来の親イオン(前駆イオン)は、図7Aに示すように、各ホスホジエステル結合の主に4ヶ所で切断されて様々なプロダクトイオンが生成される。なお、ここでは、RNAaseAを使用した切断処理によって作製された4merのRNA断片(「B」は塩基を示す)を核酸の一例として示している。
【0062】
すなわち、図7A,図7Bに示すように、McLuckeyらの命名法に基づけば、このRNA断片からは、5’端の塩基を含む5’端プロダクトイオンとして、a、b、c、d系列のプロダクトイオンが生じ、3’端の塩基を含む3’端プロダクトイオンとして、w、x、y、z系列のプロダクトイオンが生じる。また、例えば、a系列のプロダクトイオンであって、塩基が欠損したプロダクトイオン(a_B)が生じることもある。
【0063】
したがって、RNA断片の所定の塩基間位置で切断される場合、5’端位置又は3’端位置の部分組成の塩基数が、切断位置に基づいて決定される所定数である、可能な全ての塩基組成セットの各々について、各系列のプロダクトイオンが生成されると考えることができる。すなわち、このRNA断片の全体塩基組成が「AUCG」であって、その5’端から1つ目の塩基と2つ目の塩基との間で切断される場合には、図7Bに示すように、例えば、5’端位置の部分塩基組成の塩基数が「1」である可能な全ての塩基組成セット「A:UCG]、「U:ACG]、「C:AUG]、「G:AUC]の各々について、5種類の5’端プロダクトイオン「a1」、「b1」、「c1」、「d1」、「a1_B」と、4種類の3’端プロダクトイオン「w3」、「x3」、「y3」、「z3」と、が生成されると考えることができる。なお、図7Aに示すように、RNAaseAによって作製されたRNA断片は、5’端に水酸基(OH)を有し、3’端にリン酸基(PO4H)を有することが多い。これは、RNAaseTによって作製されたRNA断片についても同様である。したがって、核酸断片の作製に使用された核酸分解酵素の種類に基づいて、当該核酸断片の末端の官能基の種類を予測し、当該官能基のイオン化のしやすさ等、イオン化に関する情報に基づいて、生成されるプロダクトイオンの系列を予測することもできる。
【0064】
そこで、このステップS201において、重み付け処理部12は、各塩基組成セットを構成する各部分塩基組成と、図7Aに示すような様々な切断パターンと、に基づいて、当該各部分塩基組成に対応する少なくとも1つの系列のプロダクトイオンについて予測質量値を算出する。
【0065】
具体的に、重み付け処理部12は、各部分塩基組成に対応したプロダクトイオンの予測質量値として、当該プロダクトイオンに対応するピークが検出されることが理論的に予想されるm/z値を算出する。すなわち、重み付け処理部12は、まず、各部分塩基組成について、図7Aに示すような4つの切断箇所の各々で切断された場合に生じるプロダクトイオンの分子組成(当該プロダクトイオンに含まれる原子の種類及び各原子の数)を算出する。次いで、重み付け処理部12は、プロダクトイオンの分子組成に基づいて、当該プロダクトイオンの分子量を算出する。さらに重み付け処理部12は、プロダクトイオンの分子量と価数とに基づいて、当該プロダクトイオンのm/z値を予測質量値として算出する。なお、この予測質量値の算出においては、一部に経験的な知見を利用することもできる。
【0066】
そして、重み付け処理部12は、各塩基組成セットについて、当該各塩基組成セットを構成する複数の部分塩基組成の各々について算出された予測m/z値に基づいて、図7Cに示すような理論スペクトルを生成する。すなわち、各理論スペクトルにおいては、1つの塩基組成セットと、当該塩基組成セットを構成する各部分塩基組成に対応する各系列のプロダクトイオンについて算出された予測m/z値と、が関連付けられている。ここで、重み付け処理部12は、図4に示す各塩基組成セット又は図6に示す各ノードについて、一組の部分塩基組成の予測m/z値を算出する。すなわち、例えば、構成が「A2G:AGU」の塩基組成セットについて、当該塩基組成セットが有し得る全ての塩基配列の候補を算出する場合には、5’端位置の塩基配列として可能な3つの塩基配列「AAG」「AGA」、「GAA」と、3’端位置の塩基配列として可能な2つの塩基配列「AGU」、「GAU」と、の可能な全ての組合せを考慮した6回の演算処理を行う必要があるのに対し、重み付け処理部12は、当該塩基組成セットについては、部分塩基組成の1つの組合せについて演算処理を実行する。このため、本発明においては、上述のように全ての塩基配列候補について予測m/z値を算出するような場合に比べて、計算量を効果的に低減できる。
【0067】
次に、重み付け処理部12は、対象断片由来のプロダクトイオンの質量分析において実際に得られた質量値(実測質量値)を取得する(S204)。なお、ここでは、まず対象断片に修飾塩基が含まれていない場合又は対象断片における塩基修飾を考慮しない場合について説明するため、図3に示すステップS202、S203についての説明は省略する。
【0068】
重み付け処理部12が取得する実測質量値は、例えば、対象断片をイオン化して得られた親イオンを、質量分析部50が備える質量分析計の内部で所定の方法により解離させてプロダクトイオンを生成し、当該質量分析計による当該プロダクトイオンの質量分析(MS/MS分析)により得られた質量値とすることができる。なお、この親イオンの解離方法は、プロダクトイオンを生成できる方法であれば特に限られないが、例えば、衝突誘起解離(Collision−Induced dissociation:CID)法を好ましく用いることができる。また、親イオンの解離条件としては、解析に適したプロダクトイオンを生じさせる任意の条件を適宜設定することができ、例えば、CIDを用いる場合には、好ましい系列のプロダクトイオンを効率よく生じさせる上で適切な衝突電圧を解離条件の一つとして決定することができる。重み付け処理部12は、例えば、プロダクトイオンについて実際に得られたマススペクトル(実測スペクトル)データを質量分析部50から受け入れることにより、当該実測スペクトルデータに含まれる実測m/z値を実測質量値として取得することができる。また、重み付け処理部12は、この実測m/z値を、入力部30を介してユーザから受け入れ、又は記憶部20から読み出すことによって取得することもできる。
【0069】
次に、重み付け処理部12は、予測質量値と実測質量値との比較に基づいて、塩基組成セットの各々に重みを付与する(S205)。すなわち、重み付け処理部12は、例えば、予測m/z値との差分が予め定められた条件を満たす実測m/z値に対応するピーク強度に基づいて、当該予測m/z値に対応する部分塩基組成を含む塩基組成セットのノードに重みを付与する。
【0070】
具体的に、重み付け処理部12は、まず、実測スペクトルに含まれるピークに対応する実測m/z値のうち、理論スペクトルに含まれる各予測m/z値との差分が予め定められた閾値以下のものがあるかどうかを判断する。なお、この閾値は、例えば、実測m/z値を得るために使用した質量分析計の許容誤差に基づいて決定することができる。
【0071】
そして、重み付け処理部12は、ある予測m/z値と、ある実測m/z値と、の差分が閾値以下である場合には、当該予測m/z値と当該実測m/z値とが一致した、すなわち、実測スペクトルにおいて当該予測m/z値に対応するピークがヒットした、と判断する。この場合、重み付け処理部12は、実測スペクトルにおいて、予測m/z値と一致した実測m/z値の位置で検出されたピーク(ヒットしたピーク)の強度に基づいて、当該予測m/z値に対応する部分塩基組成の部分重みを決定する。そして、重み付け処理部12は、各ノードに対応する複数の部分塩基組成の各々について決定された部分重みの合計を、当該各ノードの重みとして付与する。
【0072】
図8は、この予測質量値と実測質量値との比較に基づく各ノードへの重み付け処理の一例を示す概念図である。図8に示すように、重み付け処理部12は、「A:A2G2U」の構成を有する塩基組成セットS1及び「G:A3GU」の構成を有する塩基組成セットS2の各々について理論スペクトルを作成する。この各理論スペクトルにおいては、各塩基組成セットを構成する各部分塩基組成について算出された予測m/z値が特定されている。そして、重み付け処理12は、これら各理論スペクトルと、プロダクトイオンについて実際に得られた実測スペクトルと、を照合するマッチング処理を行う。
【0073】
すなわち、重み付け処理部12は、まず、実測スペクトルに含まれるピークの実測m/z値のいずれかが、塩基組成セットS1の理論スペクトルに含まれる、5’端位置の部分塩基組成「A」について算出された第一の予測m/z値又は3’端位置の部分塩基組成「A2G2U」について算出された第二の予測m/z値のいずれかに一致するか否かを判断する。
【0074】
そして、重み付け処理部12は、このマッチング処理の結果に基づいて各ノードの重み付けを行う。すなわち、重み付け処理部12は、例えば、第一の予測m/z値に一致する第一の実測m/z値と、第二の予測m/z値と一致する第二の実測m/z値と、の両方を検出した場合には、当該第一の実測m/z値で検出されたピークの強度と、当該第二の実測m/z値で検出されたピークの強度と、の合計を塩基組成セットS1に対応するノードの重みとして決定する。
【0075】
一方、重み付け処理部12は、同様のマッチング処理において、実測スペクトルに含まれるピークの実測m/z値の一つが、塩基組成セットS2の理論スペクトルに含まれる、5’端位置の部分塩基組成「G」について算出された第一の予測m/z値と一致したが、3’端位置の部分塩基組成「A2G2U」について算出された第二の予測m/z値と一致する実測m/z値はなかったと判断した場合には、当該第一の予測m/z値と一致した実測m/z値で検出されたピークの強度のみを、当該塩基組成セットS2に対応するノードの重みとして決定する。重み付け処理部12は、このような重み付け処理を全てのノードについて実行する。
【0076】
そして、重み付け処理部12は、例えば、各ノードに割り当てられた識別情報N1〜N11(図6参照)と、当該各ノードに対応する塩基組成セットと、当該各ノードに付与された重みと、を関連付けたデータテーブルをノード重みデータとして生成する。
【0077】
さらに、重み付け処理部12は、各ノードが当該各ノードの重みに応じた態様で表示されるよう、有向グラフを更新する。すなわち、重み付け処理部12は、例えば、図9に示すように、各ノードを、その重みに応じたサイズで表示した有向グラフを作成する。図9に示す有向グラフにおいては、重みが大きいほど、ノードの径が大きくなっている。重み付け処理部12は、図9に示すような有向グラフを描画するための有向グラフデータを生成して出力部40に出力し、出力部40は、液晶ディスプレイ等の画面に当該有向グラフを表示する。このような有向グラフを提示されたユーザは、各ノードの重み付け処理の結果を視覚的に理解することができる。
【0078】
次に、重み付け処理部12は、接続関係の各々により接続される一対の塩基組成セットに付与された重みに基づいて、当該接続関係の各々に重みを付与する(S206)。すなわち、例えば、重み付け処理部12は、図9に示すような有向グラフにおいて、各エッジの両端に接続される2つのノードの各々に付与された重みの合計に基づいて、当該各エッジに重みを付与する。
【0079】
具体的に、例えば、重み付け処理部12は、上述のノード重みデータに基づいて、図9に示すエッジE2の一方に接続されたノードN1に付与されている重みと、他方に接続されたノードN4に付与されている重みと、の合計を当該各エッジE2の重みとして付与する。重み付け処理部12は、このような重み付け処理を全てのエッジについて実行する。
【0080】
そして、重み付け処理部12は、例えば、各エッジに割り当てられた識別情報E1〜E15と、当該各エッジにより接続された一対のノードを特定する情報と、当該各エッジに付与された重みと、を関連付けたデータテーブルをエッジ重みデータとして生成する。
【0081】
さらに、重み付け処理部12は、各エッジが当該各エッジの重みに応じた態様で表示されるよう、有向グラフを更新する。すなわち、重み付け処理部12は、例えば、図9に示すように、各エッジを、その重みに応じた太さで表示した有向グラフを作成する。図9に示す有向グラフにおいては、重みが大きいほど、エッジの太さが大きくなっている。
【0082】
なお、重み付け処理部12は、エッジの重みをノーマライズすることもできる。この場合、重み付け処理部12は、例えば、各階層に属する各エッジの重みを、当該各階層に属するエッジに付与された最大の重みで除することにより、当該各エッジの重みをノーマライズする。この結果、例えば、0〜1の範囲の値で表される重みを各エッジに付与することができる。重み付け処理部12は、ノード重みデータやエッジ重みデータ等、上述のような重み付け処理の結果を表すデータを解析処理部13に出力する。
【0083】
第三のステップS300において、解析処理部13は、塩基組成セットの各々に付与された重みに基づいて、階層構造の両方の最外階層から接続関係を辿りながら、各階層に属する塩基組成セットのうち1つを選択する選択処理を行う(S301)。すなわち、解析処理部13は、例えば、図9に示す有向グラフにおいて、各ノードに付与された重みに基づいて、当該有向グラフの5’端又は3’端の両端から内部に向けて、エッジを辿りながら、各階層に属するノードのうち1つを順次選択する。なお、ここでは、解析処理部13が、動的計画法を適用して、有向グラフの最適経路を探索することにより選択処理を行う場合を例として説明する。
【0084】
また、通常、親イオンが解離して生成されたプロダクトイオンの質量分析においては、5’端の塩基又は3’端の塩基を含む短い断片のプロダクトイオンが高い強度で検出される傾向がある。したがって、質量分析において、末端塩基を含む短いプロダクトイオンの実測結果は、それより長いプロダクトイオンの実測結果に比べて信頼性が高い場合が多い。
【0085】
そこで、解析処理部13は、有向グラフにおいて、5’端位置の部分塩基組成の塩基数が最も小さい塩基組成セットが属している5’端の第一階層と、3’端位置の部分塩基組成の塩基数が最も小さい塩基組成セットが属している3’端の第五階層と、の両最外階層から、予め中央の階層として定められた第三階層に向かって、動的計画法に基づいて各ノードの重みを更新しながら、エッジを辿っていくことによって、当該有向グラフの5’端又は3’端から各ノードに至る最大の重みをもった経路を最適経路として決定する。
【0086】
具体的に、解析処理部13は、まず、エッジの方向に従って、有向グラフの5’端又は3’端のノードから各ノードに至る経路のうち、最大の重みが付与された経路を当該各ノードに至る最適経路として決定する。そして、解析処理部13は、上述の重み付け処理部12により付与された各ノードの重み(初期重み)を、当該各ノードに至る最適経路の重み(更新重み)に変更する重み更新処理を行う。なお、有向グラフの末端のノードから各ノードまでの経路の重みは、例えば、当該末端のノードから各ノードに至るまでに通過した各エッジの重みの合計とすることができる。
【0087】
解析処理部13は、この重み更新処理を、5’端の第一階層及び3’端の第五階層から中央の第三階層に至るまで、各階層に属する各ノードについて順次実行する。この最適経路の探索処理は、例えば、動的計画法について良く知られているBelmanの公式を用いて表すことができる。すなわち、ここで、kを中央階層の階層番号とし、関数g(x)をノードxの階層番号を返す関数とする。また、5’端の最外階層から中央階層までの間において、エッジで接続されているノードm,nは、g(n)<g(m)≦kの条件を満たすものとする。そして、f(m)を5’端のノードからノードmまでの最大スコアとし、Wnmをノードn,mが接続されているエッジの重みとすると、式f(m)=max[Wnm+f(n)]が成り立つ。同様に、3’端の最外階層から中央階層までの間において、エッジで接続されているノードm、nは、g(n)>g(m)≧kの条件を満たすものとし、f(m)を3’端のノードからノードmまでの最大スコアとし、Wnmをノードn,mが接続されているエッジの重みとすると、式f(m)=max[Wnm+f(n)]が成り立つ。なお、解析処理部13は、有向グラフの5’端の最外階層のノードから中央階層のノードまでは前進型動的計画法を適用し、3’端の最外階層のノードから中央階層のノードまでは後進型動的計画法を適用する。
【0088】
具体的に、解析処理部13は、図9に示す有向グラフの5’端の第一階層に属する2つのノードN1,N2の重みを0(ゼロ)と決定する。次に、解析処理部13は、第二階層に属するノードN3,N4,N5のうち、例えば、ノードN4の重みを更新するにあたって、3’端側で当該ノードN4に接続されているエッジE2の重みと当該エッジE2の5’端側に接続されているノードN1の重みとを合計した第一候補重みと、3’端側で当該ノードN4に接続されている他のエッジE3の重みと当該エッジE3の5’端側に接続されているノードN2の重みとを合計した第二候補重みと、を比較する。そして、解析処理部13は、これらの候補重みのうち第一候補重みのほうが大きいと判断した場合には、当該第一候補重みをノードN4の更新重みとして決定する。そして、解析処理部13は、この決定された更新重みと、当該更新重みを付与したエッジE2を特定する情報(例えば、図5に示すようにエッジE2に対応する接続関係C2に付与された識別情報「C2」や、エッジE2に付与された識別情報「E2」)と、をノードN4に関連付けて保持しておく。
【0089】
解析処理部13は、このような重み更新処理を、第二階層の他のノードN3,N5についても行う。また、解析処理部13は、同様に、3’端の第五階層に属するノードN11の重み更新処理、次いで第四階層に属する2つのノードN9,N10の重み更新処理、を順次実行する。
【0090】
そして、解析処理部13は、中央階層として指定された第三階層に属するノードN6,N7,N8の重み更新処理を、有向グラフの5’端側から当該ノードN6,N7,N8の各々に至る最適経路の重みと、有向グラフの3’端側から当該ノードN6,N7,N8の各々に至る最適経路の重みと、に基づいて行う。すなわち、解析処理部13は、例えば、中央階層に属するノードN7の重みを、ノードN1、エッジE2、ノードN4、エッジE7を接続して構成される、5’端側から当該ノードN7までの最適経路の重みと、ノードN11、エッジE14、ノードN9、エッジE11を接続して構成される、3’端側から当該ノードN7までの最適経路の重みと、を合計した更新重みに変更する。具体的に、解析処理部13は、例えば、ノードN4の更新重みとエッジE7の重みとを合計した5’端側の部分更新重みと、ノードN9の更新重みとエッジE11の重みとを合計した3’端側の部分更新重みと、を合計して、ノードN7の更新重みを算出する。そして、解析処理部13は、この部分更新重みを合計した更新重みと、5’端側の部分更新重みを付与したエッジE7を特定する情報と、3’端側の部分更新重みを付与したエッジE11を特定する情報と、をノードN7に関連付けて保持しておく。解析処理部13は、同様にして、中央階層の属する他のノードN6,N8についても重み更新処理を実行する。このように、解析処理部13は、有向グラフの両端から中央に向けて、より末端側のノード及びエッジに付与された重みに応じて、各ノードの重み更新処理を行う。また、解析処理部12は、各ノードが当該各ノードの更新重みに応じた態様で表示されるよう、有向グラフを更新することができる。すなわち、この場合、解析処理部12は、例えば、図10に示すように、各ノードを、その更新重みに応じたサイズで表示した有向グラフを作成する。図10に示す有向グラフにおいては、更新重みが大きいほど、ノードの径が大きくなっている。解析処理部13は、図10に示すような有向グラフを描画するための有向グラフデータを生成して出力部40に出力し、出力部40は、液晶ディスプレイ等の画面に当該有向グラフを表示する。このような有向グラフを提示されたユーザは、各ノードの重み付け更新処理の結果を視覚的に理解することができる。なお、解析処理部13は、更新重みと、更新前の重みと、をそれぞれ記憶部20に格納することができる。
【0091】
そして、次に、解析処理部13は、図10に破線の矢印で示すように、有向グラフの中央階層(破線で囲まれた第三階層)から両端の最外階層まで、最適経路を辿るトレースバック処理を行うことにより、各階層に属するノードのうち1つを選択する。
【0092】
すなわち、解析処理部13は、まず、中央階層に属する3つのノードN6,N7,N8の更新重みを互いに比較し、最も大きい更新重みが付与されたノードN7を選択する。次いで、解析処理部13は、中央階層で選択されたノードN7に3’端側が接続された、5’端側の第二階層に属するエッジE6,E7のうち、上述のように予めノードN7に関連付けられている、5’端側の部分更新重みを付与したエッジE7を選択するとともに、当該第二階層に属するノードN3,N4,N5のうち、当該選択されたエッジE7の5’端側に接続されているノードN4を選択する。また、解析処理部13は、同様にして、3’端側の第四階層に属するエッジE11,E12のうち、上述のように予めノードN7に関連付けられている、3’端側の部分更新重みを付与したエッジE11を選択するとともに、当該第四階層に属するノードN9,N10のうち、当該選択されたエッジE11の3’端側に接続されているノードN9を選択する。さらに、解析処理部13は、同様にして、5’端の第一階層に属するエッジE2、E3のうち、上述のように予めノードN4に関連付けられている、更新重みを付与したエッジE2を選択するとともに、当該第一階層に属するノードN1,N2のうち、当該選択されたエッジE2の5’端側に接続されているノードN1を選択する。一方、解析処理部13は、3’端の第五階層にはノードN11のみが属しているので、当該ノードN11を選択する。
【0093】
このように、解析処理部13は、有向グラフの中央階層から両端の最外階層に向かって動的計画法に基づくトレースバック処理を行い、当該両端の最外階層から中央階層で選択されたノードN7に至るまでに通過してきた最適経路を確定させる。すなわち、解析処理部13は、このトレースバック処理によって、最適経路上で各階層に属するノードを1つずつ選択する。この結果、図10に示す有向グラフにおいて、解析処理部13は、5’端の第一階層ではノードN1、第二階層ではノードN4、中央階層ではノードN7、第四階層ではノードN9、そして3’端の第五階層ではノードN11を、それぞれ選択する。
【0094】
次に、解析処理部13は、上述の選択処理の結果に基づいて、対象断片の両方の末端から塩基配列を順次決定する(S302)。すなわち、解析処理部13は、隣接する階層の各々で選択された2つの塩基組成セット間で、対応する部分塩基組成を比較し、当該対応する部分塩基組成の差異を構成する塩基を特定するという塩基特定処理を、5’端位置の部分塩基組成については第一階層から第三階層に向けて、また、3’端位置の部分塩基組成については第五階層から第三階層に向けて、それぞれ実行することにより、対象断片の塩基配列を5’端側及び3’端側の両側から順次決定する。
【0095】
具体的に、解析処理部13は、図11に示すように、上述の選択処理によって確定された有向グラフの最適経路上で隣接して配置されるノード間で、対応する部分塩基組成の差異を構成する塩基を、当該有向グラフの5’端側及び3’端側の両端側から順次特定する。
【0096】
すなわち、解析処理部13は、まず、5’端の第一階層で選択されたノードN1の5’端位置の部分塩基組成が1つのアデニン(A)であることから、対象断片の5’端の塩基はアデニン(A)であると決定する。次に、解析処理部13は、第一階層で選択されたノードN1の5’端位置の部分塩基組成と、当該第一階層の内側(3’端側)に隣接する第二階層で選択されたノードN4の5’端位置の部分塩基組成と、を比較して、これらの部分塩基組成の差異を構成する塩基としてグアニン(G)を特定する。すなわち、解析処理部13は、対象断片の5’端から2番目の塩基(すなわち、アデニン(A)の3’端側に隣接する塩基)はグアニン(G)であると決定する。
【0097】
また、解析処理部13は、同様にして、3’端の第五階層で選択されたノードN11の3’端位置の部分塩基組成が1つのウラシル(U)であることから、対象断片の3’端の塩基はウラシル(U)であると決定する。次に、解析処理部13は、第五階層で選択されたノードN11の3’端位置の部分塩基組成と、当該第五階層の内側(5’端側)に隣接する第四階層で選択されたノードN9の3’端位置の部分塩基組成と、を比較して、これらの部分塩基組成の差異を構成する塩基としてグアニン(G)を特定する。すなわち、解析処理部13は、対象断片の3’端から2番目の塩基(すなわち、ウラシル(U)の5’端側に隣接する塩基)はグアニン(G)であると決定する。
【0098】
さらに、解析処理部13は、同様にして、第二階層で選択されたノードN4の5’端位置の部分塩基組成と、中央の第三階層で選択されたノードN7の5’端位置の部分塩基組成と、の差異を構成する塩基がアデニン(A)であると特定する一方で、第四階層で選択されたノードN9の3’端位置の部分塩基組成と、中央の第三階層で選択されたノードN7の3’端位置の部分塩基組成と、の差異を構成する塩基がアデニン(A)であると特定する。この結果、解析処理部13は、対象断片の全塩基配列を「AGAAGU」であると決定する。そして、解析処理部13は、この塩基配列の決定結果を表す画像を含むインタフェース画面をユーザに提示するよう、出力部40に指示する。すなわち、例えば、解析処理部13は、図11に示すように、各階層で選択されたノードと、他のノードと、を区別可能に表示し、当該各階層で選択されたノード間を接続するエッジと、その他のエッジとを区別可能に表示した有向グラフを描画するための有向グラフデータを生成し、当該有向グラフデータを出力部40に出力することができる。この有向グラフデータには、図11に示すように、各階層で選択されたノード間の部分塩基組成の差異を構成する塩基を、当該ノード間を接続するエッジに対応して表示させるためのデータを含むこともできる。また、解析処理部13は、例えば、各ノードの更新前の重みと、塩基配列の決定結果と、が関連付けられて表示された有向グラフをユーザに提示することもできる。すなわち、この場合、例えば、解析処理部13は、各ノードが、その更新前の重みに応じたサイズで表示され、各階層で選択されたノードと、他のノードと、が区別可能に表示され、当該各階層で選択されたノード間を接続するエッジと、その他のエッジとが区別可能に表示され、各階層で選択されたノード間の部分塩基組成の差異を構成する塩基が、当該ノード間を接続するエッジに対応して表示された有向グラフを描画するための有向グラフデータを生成して出力部40に出力し、出力部40は、液晶ディスプレイ等の画面に当該有向グラフを表示する。このような有向グラフを提示されたユーザは、塩基配列の解析結果を、各ノードの更新前の重みや更新後の重み、エッジの重み等と関連付けて視覚的に理解することができる。このため、例えば、ユーザは、解析条件を修正すべき指示を容易に決定することができ、修正指示の入力を受け入れた本装置1は、当該修正指示に従って更に解析を行った結果を当該ユーザに提示することができる。
【0099】
このように、本発明によれば、核酸の解析を迅速且つ正確に行うことができる。すなわち、例えば、全体塩基組成から予想される、可能な全ての塩基配列の候補を生成するような技術においては、塩基数の増加に伴って計算量が急激に増加することとなるのに対し、本発明においては、そのような可能な全ての塩基配列候補を生成することなく、各々が一組の部分塩基組成から構成される塩基組成セットを生成するため、塩基数の増加に伴う計算量の増加を効果的に抑制することができる。また、本発明によれば、必ずしも既知の核酸の塩基配列が登録されたデータベースの検索を行う必要はなく、質量分析の結果に基づいた演算処理によって、in silicoで核酸の全塩基配列を迅速に決定することができる(de novo sequencing)。
【0100】
また、本発明においては、塩基組成セットの重みに基づいて階層構造の最外階層から内部に向けて、塩基組成セットの選択処理を行うため、信頼性の高い末端由来のプロダクトイオンの質量分析結果を効果的に利用して、核酸の末端から塩基配列を決定していくことができ、信頼性の高い解析を行うことができる。
【0101】
本発明は、RNAを標的とした新しい診断技術の開発や、RNA−タンパク質ネットワークの解析技術の開発等、生命科学における基盤技術を提供するものであり、極めて広い応用が期待できる。
【0102】
また、本発明によれば、さらに、対象断片に含まれる塩基修飾を解析することもできる。この場合の処理について、図3を参照しつつ説明するが、上述の内容と重複する内容については詳細な説明を省略する。
【0103】
まず、第一のステップS100において、対象断片に含まれる塩基修飾の内容を推定する。すなわち、例えば、上述のステップS102において、塩基組成処理部11は、実測された対象断片の分子量に基づいて、当該対象断片の全体塩基組成を決定する際に、所定の修飾部分(メチル基等の官能基等)の存在を考慮する必要がある場合、当該対象断片は、当該所定の修飾部分を含むと推定する。なお、例えば、液体クロマトグラフィー分析における対象断片の溶出時間等の他の解析手法の結果から、対象断片に所定の修飾部分が含まれていることを推定することもできる。
【0104】
塩基組成処理部11は、対象断片に修飾部分が含まれていると判断した場合には、その修飾部分の内容(すなわち、修飾基の種類、分子量、数、価数等)を表す修飾データを生成し、重み付け処理部12に出力する。
【0105】
次に、第二のステップS200において、対象断片に修飾塩基が含まれると仮定した場合に予測される、各プロダクトイオンの質量分析結果を作成する。すなわち、重み付け処理部12は、上述のステップS201において、各部分塩基組成に対応するプロダクトイオンに修飾された塩基が含まれないと仮定した場合に予測される第一の予測質量値を算出する一方で、ステップS202においては、対象断片に修飾塩基が含まれているか否かを判断する。ここで、重み付け処理部12は、塩基組成処理部11から修飾データを受け入れた場合には、対象断片に修飾塩基が含まれていると判断し(S202においてYes)、ステップS203において、各部分塩基組成に対応するプロダクトイオンに当該修飾塩基が含まれると仮定した場合に予測される第二の予測質量値を算出する。
【0106】
具体的に、例えば、重み付け処理部12は、修飾データに含まれる修飾基の種類、分子量、数、価数等に基づいて、第一の予測質量値を補正することによって、第二の予測質量値を算出する。すなわち、重み付け処理部12は、例えば、ステップS201において、各部分塩基組成に対応するプロダクトイオンの分子量に基づいて第一の予測m/z値を算出した場合には、ステップS203において、当該プロダクトイオンの分子量に修飾基の分子量を加算した補正分子量に基づいて、当該プロダクトイオンに当該修飾基が含まれると仮定した場合に予測される第二の予測m/z値を算出する。
【0107】
そして、重み付け処理部12は、ステップS205において、これら第一の予測m/z値及び第二の予測m/z値の各々と、実測m/z値と、の比較に基づいて、各ノードの重み付けを行う。すなわち、重み付け処理部12は、実測スペクトルの中に、第一の予測m/z値又は第二の予測m/z値に近い実測m/z値があるかどうか検索を行う。
【0108】
そして、重み付け処理部12は、第一の予測m/z値と所定の誤差範囲とに基づいて、当該第一の予測m/z値より所定値だけ小さい下限値から当該第一の予測m/z値より所定値だけ大きい上限値までの第一のm/z範囲を算出し、当該第一のm/z範囲内の実測m/z値が実測スペクトルに含まれるか否かを判断する。ここで、重み付け処理部12は、第一のm/z範囲内の実測m/z値(第一の実測m/z値)を検出した場合には、例えば、実測スペクトルに含まれるピークのうち、当該第一の実測m/z値で検出されたピークの強度に基づいて、第一の仮重みを決定する。一方、重み付け処理部12は、同様に、第二の予測m/z値と所定の誤差範囲とに基づいて、当該第二の予測m/z値より所定値だけ小さい下限値から当該第二の予測m/z値より所定値だけ大きい上限値までの第二のm/z範囲を算出し、当該第二のm/z範囲内の実測m/z値が実測スペクトルに含まれるか否かを判断する。そして、重み付け処理部12は、第二のm/z範囲内の実測m/z値(第二の実測m/z値)を検出した場合には、例えば、実測スペクトルに含まれるピークのうち、当該第二の実測m/z値で検出されたピークの強度に基づいて、第二の仮重みを決定する。次に、重み付け処理部12は、これら第一の仮重みと第二の仮重みとを比較して、大きい方の仮重みに基づいて、対応するノードの重み付けを行う。すなわち、例えば、重み付け処理部12は、第二の仮重みが第一の仮重みよりも大きいと判断した場合には、対象とするプロダクトイオンに修飾塩基が含まれていると判断する。そして、この場合、重み付け処理部12は、例えば、実測スペクトルに含まれるピークのうち、第二の実測m/z値で検出されたピークの強度に基づいて、対応するノードの重み付けを行う。なお、重み付け処理部12は、第一のm/z範囲内又は第二のm/z範囲内の実測m/z値が実測スペクトルに含まれないと判断した場合には、第一のm/z値又は第二のm/z値についての重み付けを行わない。また、上述の所定の誤差範囲は、例えば、親イオンの質量分析に用いられた質量分析計の性能や分析条件等に応じた分析精度に基づいて決定することができる。
【0109】
また、重み付け処理部12は、プロダクトイオンに修飾塩基が含まれると判断した場合には、当該プロダクトイオンに対応した部分塩基組成に、修飾塩基が含まれる旨を表す修飾タグデータを関連付けて保持しておく。
【0110】
そして、第三のステップS300において、解析処理部13は、対象断片の塩基配列を決定した(S302)後、当該対象断片に修飾塩基が含まれているか否かを判断する(S303)。そして、解析処理部13は、対象断片に修飾塩基が含まれていると判断した場合(S303においてYes)には、各塩基組成セットを構成する部分塩基組成のうち、修飾タグデータが関連付けられている部分塩基組成の位置に基づいて、修飾塩基の位置を決定する(S304)。
【0111】
すなわち、解析処理部13は、例えば、階層構造の隣接する階層間で、上述の選択処理により選択された塩基組成セットにおいて、修飾タグデータが関連付けられている部分塩基組成の位置が移動した場合に、当該隣接する階層で選択された当該塩基組成セット間で当該部分塩基組成の差異を構成する塩基を、修飾された塩基として特定する。
【0112】
すなわち、例えば、図11に示す有向グラフにおいて、第二階層で選択されたノードN4に対応する塩基組成セット「AG:A2GU」の3’端位置の部分塩基組成「A2GU」に修飾タグデータが関連付けられているのに対して、第三階層で選択されたノードN7に対応する塩基組成セット「A2G:AGU」については、5’端位置の部分塩基組成「A2G」に修飾タグデータが関連付けられている場合、解析処理部13は、修飾タグデータが関連付けられている部分塩基組成の位置が、3’端位置から5’端位置に移動していると判断する。
【0113】
そして、この場合、解析処理部13は、塩基数の増加に伴って、内側の階層(第三階層)で新たに修飾タグデータが関連付けられたノードN7に係る5’端位置の部分塩基組成「A2G」と、末端側の階層のノードN4に係る5’端位置の部分塩基組成「AG」と、を比較して、これらの部分塩基組成の差異を構成する、5’端から3つ目のアデニン(A)が修飾塩基であると特定する。また、このような修飾塩基を特定する場合と同様に、例えば、対象断片の末端構造を特定することもできる。すなわち、例えば、重み付け処理部12が、5’端位置又は3’端位置の部分塩基組成について、末端塩基に付加された所定の官能基の存在を考慮しない第一の予測質量値と、当該官能基の存在を考慮した第二の予測質量値と、を算出して実測質量値とのマッチング処理を行い、当該実測質量値との一致度が、当該第二の予測質量値の方が高かった場合には、解析処理部13は、5’端又は3’端の塩基には、当該官能基が付加されていると決定することができる。そして、解析処理部13は、例えば、修飾されている塩基と、その他の塩基と、が区別可能に表された有向グラフを作成する。すなわち、各階層で選択されたノード間の部分塩基組成の差異を構成する塩基を、当該ノード間を接続するエッジに対応して表示させる場合には、当該差異を構成する塩基のうち、修飾されている塩基については、修飾されていることを表す文字や記号を関連付けて表示する。解析処理部13は、このような有向グラフを描画するための有向グラフデータを出力部40に出力し、出力部40は当該有向グラフが表示されたインタフェース画面をユーザに提示する。このような有向グラフを提示されたユーザは、塩基配列の解析結果のみならず、修飾構造の解析結果をも視覚的に理解することができる。
【0114】
このように、本発明によれば、迅速且つ正確に核酸に含まれる塩基修飾構造を解析することができる。すなわち、本発明によれば、例えば、RNA分子について、転写後プロセシングや修飾構造などの質的な情報を得ることもできる。
【0115】
また、本方法においては、塩基組成セットの各々に付与された重みに基づいて、階層構造の最外階層から接続関係を辿りながら、各階層に属する塩基組成セットのうち1つを選択する選択処理を、当該最外階層から、任意の内部階層までとすることもできる。すなわち、この場合、解析処理部13は、例えば、入力部30を介して、ユーザから選択処理を実行する階層深さを指定する指示データを受け入れる。そして、解析処理部13は、最外階層から、指示データにより指定された階層深さに対応する内部階層まで、選択処理を順次実行する。この結果、解析処理部13は、対象断片の末端側の一部(末端から指定された階層深さに対応する位置までの部分)について、塩基配列や塩基修飾を決定することができる。
【0116】
具体的に、例えば、塩基組成処理部11が9つの階層からなる階層構造を作成し、解析処理部13が、選択処理を終了する内部階層を最外階層から三番目の階層と指定する指示データを受け入れた場合には、解析処理部13は、5’端から三番目の第三階層を第一の中央階層として決定するとともに、3’端から三番目の第七階層を第二の中央階層として決定する。そして、解析処理部13は、5’端の最外階層(第一階層)から第一の中央階層(第三階層)まで、及び3’端の最外階層(第九階層)から第二の中央階層(第七階層)まで、それぞれ各階層に属する塩基組成セットの1つを選択したところで、選択処理を終了する。なお、この場合、重み付け処理部12は、5’端の第一階層から第三階層まで、及び3’端の第九階層から第七階層まで、それぞれ各ノードの重みを更新したところで、重み更新処理を終了することもできる。そして、解析処理部13は、上述のように、これら選択処理の対象となった階層の各々で選択された塩基組成セット間で、対応する部分塩基配列を比較し、対応する部分塩基組成の差異を構成する塩基を特定する。こうして、解析処理部13は、対象断片の5’端側の一部(5’端から第一中央階層に対応する位置までの部分)と、当該対象断片の3’端側の一部(3’端から第二中央階層に対応する位置までの部分)と、について、塩基配列や塩基修飾を決定することができる。
【0117】
また、この場合、まず出力部40がユーザに対して、選択処理を行う階層深さを決定する上で参考になる情報を提示することもできる。すなわち、例えば、出力部40は、対象断片の分子量や末端構造(末端塩基に付加されている官能基の種類等)等の親イオンの質量分析結果に関連する情報や、プロダクトイオンについて実測されたマススペクトル等のプロダクトイオンの質量分析結果に関連する情報、理論スペクトルと実測スペクトルとのマッチング処理の結果に関連する情報等の参考情報を表すインタフェース画像を、ディスプレイ装置に表示する。この結果、ユーザは、インタフェース画像に表された参考情報に基づいて、階層構造に含まれる全階層について選択処理を行うか又は末端側の一部の階層について選択処理を行うかを決定することができ、さらに、一部の階層についてのみ選択処理を行う場合には、選択処理の対象とする階層範囲を決定することができる。そして、入力部30は、ユーザから、選択処理を行うべき階層範囲を指定する指示データを受け入れることとなる。
【0118】
このように、階層構造のうち末端の任意の一部の階層についてのみ選択処理を行うことにより、例えば、対象とする核酸の分子鎖が長い場合や、プロダクトイオンの測定に用いる質量分析計の性能や測定条件(核酸試料の量や親イオンを解離させる条件等)が不十分な場合であって、階層構造の中央付近に分類された塩基組成セットについて信頼性のある重み付けがなされない場合であっても、計算量を低減しつつ、核酸の少なくとも末端側の一部分については迅速かつ正確に、塩基配列や塩基修飾の決定を行うことができる。
【0119】
また、このように、核酸の末端側の一部分についてのみ塩基配列を決定した場合には、解析処理部13は、例えば、当該一部の塩基配列と、当該核酸の全体塩基組成と、に基づいて、既知の核酸の塩基配列が登録されているデータベースに対する検索処理を行い、当該検索処理の結果に基づいて、当該核酸の全塩基配列を決定することもできる。すなわち、解析処理部13は、例えば、ヒトのRNA断片を解析の対象とする場合には、ヒトゲノムデータベースに基づいて、ヒトゲノムのうち、その塩基組成が当該RNA断片の全体塩基組成に対応し、且つその末端部分の塩基配列が当該RNA断片の決定された塩基配列に対応するという検索条件を満たすゲノム部分を探索する。そして、解析処理部13は、検索条件を満たすゲノム部分を検出した場合には、当該ゲノム部分の塩基配列に基づいて、RNA断片の全塩基配列を決定するとともに、そのヒトゲノム上の位置を特定する。
【0120】
なお、このように、既知の核酸の塩基配列が登録されたデータベースに対する検索処理を行う方法として、解析処理部13は、例えば、RNAマスフィンガープリンティング法(RMF)を利用することができる。すなわち、解析処理部13は、対象断片がRNA分解酵素(例えば、RNAaseT1)を用いてヒトのRNAを切断することにより作製されたヒトRNA断片である場合、まず、ヒトゲノムのデータベースに基づいて、ヒトゲノムを当該RNA分解酵素が特異的に切断する位置(例えば、RNAaseT1を用いた場合にはグアニン(G)の位置)で仮想的に切断することにより、仮想的なゲノム断片を作成する。すなわち、解析処理部13は、例えば、各仮想ゲノム断片と、ヒトゲノム上における当該各仮想ゲノム断片の位置と、を関連付けた仮想断片データベースを生成する。また、解析処理部13は、対象断片由来の親イオンの質量分析で得られた当該親イオンの分子量に基づいて、当該対象断片の全体塩基配列を決定する。さらに、解析処理部13は、上述のようにして、対象断片の末端付近の塩基配列を決定する。また、解析処理部13は、対象断片の作製に用いられたヒトRNA全体の長さに対応するフレーム長を、例えば、入力部30を介してユーザから受け入れた指示データに基づいて決定する。そして、解析処理部13は、ヒトゲノムデータベースと、仮想断片データベースと、対象断片の全体塩基組成と、対象断片の末端付近の塩基配列と、フレーム長と、に基づいて、次のようなヒトゲノムに対する検索処理を実行する。すなわち、解析処理部13は、ヒトゲノムのうち、長さが上述のフレーム長である部分領域を検索対象として決定し、当該部分領域において、その塩基組成が上述のように決定された対象断片の全体塩基組成に対応し、且つその末端部分の塩基配列が上述のように決定された対象断片の塩基配列に対応する、という条件を満たす仮想ゲノム断片が含まれるかどうかを検索する。解析処理部13は、ヒトゲノム上をフレーム長で走査しながら、ヒトゲノムの互いに異なる部分領域を検索対象として順次決定し、検索対象となった各部分領域について、上記の検索処理を実行する。そして、解析処理部13は、各部分領域に含まれる少なくとも一つの仮想ゲノム断片が上記条件を満たす場合には、ヒトゲノム上で当該仮想ゲノム断片がヒットしたと判断する。この場合、解析処理部13は、ヒットした仮想ゲノム断片のうち、ヒトゲノム中でヒットした回数(出現頻度)の少ない仮想ゲノム断片に高いスコアを付与するとともに、当該スコアを当該仮想ゲノム断片が含まれる部分領域にも付与する。なお、このスコアは、例えば、二項定理に基づいて算出した仮想ゲノム断片の出現確率から算出することができる。そして、解析処理部13は、部分領域をスコアに基づいて順位付けし、スコアの高い部分領域に基づいて、対象断片の作製に用いられたヒトRNAのヒトゲノム上における位置を決定するとともに、当該ヒトRNAの全塩基配列(対象断片の全塩基配列を一部に含む)を決定する。すなわち、解析処理部13は、例えば、スコアの最も高い部分領域がヒトRNAに対応するゲノム部分であると決定し、当該部分領域の塩基配列に基づいて、対象断片を含むヒトRNAの全塩基配列を決定する。
【0121】
次に、本プログラムに従って動作する本装置を用いて本方法を実施した具体的な例について説明する。
【0122】
[実施例1]
精製した大腸菌5SリボソームRNA分子にRNaseAを作用させることによりRNA断片群を作製した。このRNA断片群をLC/MS質量分析計(LC−QqTOF)(QStar、アプライドバイオシステムズジャパン株式会社)にて測定した。なお、以下の全ての実施例において、この質量分析計を使用した。イオン化はESI法により行った。この測定データから、m/z値が「999.7」、価数が「−2」のイオンを、解析の対象とするRNA断片の親イオンとして選択した。そして、この親イオンを質量分析計内でCIDにより解離させて、MS/MSのマススペクトルを得た。CIDにおける衝突電圧(Collision Energy)は45eVとした。この親イオンのm/z値と価数とに基づいて決定された全体塩基組成は「A3UG2」であった。さらに、この全体塩基組成に基づいて、図6に示すような有向グラフを作成した。
【0123】
また、有向グラフに含まれるそれぞれのノードに対して、各部分塩基組成に対応するa,b,c,d,w,x,y,zのそれぞれの系列のプロダクトイオンの理論的なm/z値を算出することで、理論スペクトルを得た。すなわち、a,b,c,dの5’端部分由来のプロダクトイオンについては5’端位置の部分塩基組成から、w,x,y,zの3’端部分由来のプロダクトイオンについては3’端位置の部分塩基組成から、それぞれ理論的に予測m/z値を計算した。
【0124】
図12及び図13は、理論的に算出された予測m/z値を示すデータテーブルである。これらのデータテーブルにおいては、各塩基組成セットと、その5’端位置又は3’端位置の部分塩基組成に対応して生じ得るプロダクトイオンの予測m/z値と、が関連付けられている。すなわち、各塩基組成セットの構成と、各プロダクトイオンの系列及び価数と、各プロダクトイオンの予測m/z値と、が関連付けられている。なお、プロダクトイオンの分子量からm/z値を算出する際に、価数は「−1」から親イオンの価数である「−2」までの値を用いて計算したが、塩基配列の長さが「1」のプロダクトイオン(1つの塩基から構成されるプロダクトイオン)については価数として「−1」のみを用いて計算した。
【0125】
そして、質量分析計のトレランスとして「0.2」を設定して、これらの理論スペクトルを実測されたマススペクトルとマッチングさせた。予測m/z値と実測m/z値との差異が「0.2」以内である場合には、当該予測m/z値と当該実測m/z値とは一致すると判断した。そして、理論スペクトルの予測m/z値と実測スペクトルの実測m/z値とがマッチした場合には、マッチした実測ピークの強度の合計をノードのスコア(重み)とした。例えば、構成が「AG:A2UG」の塩基組成セットに対応するノードではa,b,c,d系列とw,y,z系列のプロダクトイオンに対応する理論スペクトルが、実測スペクトルの一部にマッチした。したがって、これらマッチしたピークの強度の合計をこのノードのスコアとした。この結果に基づいて、図14に示すような、各ノードと、スコアと、を関連付けたデータテーブルを作成した。
【0126】
次に、ノードとノードとをつないでいるエッジのスコア付けを行った。エッジの両端に接続された一対のノードのスコアを合計することで当該エッジのスコアとした。この結果に基づいて、図15に示すような、各エッジと、スコアと、を関連付けたデータテーブルを作成した。
【0127】
さらに末端の塩基が欠損した「a_B」イオンについては、エッジの情報(すなわち、エッジにより接続される2つのノードに対応する塩基組成セットの構成)から当該「a_B」イオンの予測m/z値を算出し、当該予測m/z値のうち、実測スペクトルにマッチするものは、マッチしたピークの強度を当該エッジのスコアに加算した。例えば、構成「A:A2UG2」のノードと構成「AG:A2UG」のノードとをつなぐエッジから、「AG」の組成から「G」の塩基部分だけが欠落した「a_B」イオンの予測m/z値を「442.09」と算出した。図16は、各エッジと、当該各エッジに対応する塩基欠損イオンの予測m/z値と、を関連付けたデータテーブルである。本実施例では、この予測m/z値も実測スペクトルにヒットしたので、ヒットしたピークの強度もエッジのスコアに加算した。
【0128】
さらに、エッジのスコアをノーマライズした。すなわち、各階層のエッジに付与されたスコアのうち最大のスコアで、当該各階層の各エッジのスコアを除した。図17は、各エッジと、ノーマライズされたスコアと、を関連付けたデータテーブルである。
【0129】
そして、動的計画法を適用して、各ノードのスコアの更新処理を両端のノードから行った。図18は、このスコアの更新処理後の、各ノードと、更新後のスコアと、当該各ノードが属する階層の番号と、を関連付けたデータテーブルである。
【0130】
この結果、図19に示すような有向グラフを作成した。図19に示すように、中央階層においては、塩基組成セット「A2G:AGU」に対応するノードが最大のスコアをもつノードとして選択された。さらに本プログラムに従ってトレースバック処理を行い、最適経路上に配置されるノードとして、中央階層である第三階層で選択されたノード「A2G:AGU」から5’端側に向けては、第二階層のノード「AG:A2GU」、さらに5’端の第一階層のノード「A:A2G2U」の順で、また、当該中央階層のノード「A2G:AGU」から3’端側に向けては、第四階層のノード「A3G:GU」、さらに3’端の第五階層のノード「A3G2:U」の順で、それぞれ選択した。この結果、対象としたRNA断片の全塩基配列は「AGAAGU」と決定され、正解の全塩基配列と一致した。
【0131】
なお、図19に示す、最適経路を決定した後の有向グラフにおいて、円形又は楕円形の各ノードの径は、当該各ノードのが属する階層における他のノードとの相対的なスコアを反映して、スコアが大きいほど大きな径で表示されている。また、エッジの太さは、当該エッジに付与されたスコアの大きさを反映して、スコアが大きいほど大きな太さで表示されている。また、図19に示す有向グラフにおいては、各ノード及び各エッジを、付与されたスコアに応じた色で表示することもできる。図19の下端部分に示すバーは、この色のグラデーションを表すスケールバーである。また、図20は、実際に測定されたプロダクトイオンのピークのうち、最適経路を構成するノードに対応する理論スペクトルにヒットしたピークにラベルを付したMS/MSマススペクトルを示している。すなわち、ラベルが付されているピークは、その実測m/z値が予測m/z値にマッチしたピークである。
【0132】
[実施例2]
実施例1と同様の大腸菌5sRNAをRNaseT1により切断して得られたRNA断片の塩基配列を解析した。m/z値が「1044.5」、価数が「−3」の親イオンに対応するRNA断片を解析の対象とした。このRNA断片の全体塩基組成は「AU4C4G」と算出された。この親イオンからプロダクトイオンを生成する際のCIDに用いた衝突電圧は50eVであった。本実施例ではエッジのスコアのノーマライズは行わなかった。解析の結果、RNA断片の全塩基配列は「UCUCCUCAUG」と決定され、これは当該RNA断片の実際の全塩基配列に一致した。図21には、本実施例における最適経路決定後の有向グラフを示す。
【0133】
[実施例3]
全塩基配列が「AUCG」の合成RNAを用い、本発明のアルゴリズムにより塩基配列の解析を行った。親イオンのm/z値は「1222.2」、価数は「−1」であった。全体塩基組成は「AUCG」と決定された。CIDにおける衝突電圧は50eVであった。RNase切断断片ではないため、予め末端塩基を決定することはできなかったが、全塩基配列を決定することができた。図22には、最適経路決定後の有向グラフを示す。
【0134】
[実施例4]
塩基配列が「UGGAGUGUGACAAUGGUGUUUGU」である、合成されたマイクロRNA(mmu−miR−122a)を解析の対象とし、当該マイクロRNAの両端から予め決定した所望の長さの部分についてのみ塩基配列を解析した。すなわち、本実施例において、本装置1は、入力部30を介して、ユーザから、解析の対象とする階層深さを指定する指示データとして、解析の対象とする末端部分の塩基数を「6」と指定する指示データを受け入れた。そして、本装置1の制御部10は、当該指示データに基づいて、塩基数が1〜6の範囲である5’端位置の部分塩基組成を有するノードと、塩基数が1〜6の範囲である3’端位置の部分塩基組成を有するノードと、を対象として解析を行った。親イオンのm/z値は「832.2」、価数は「−9」であった。全体塩基組成は「A4U9CG9」と決定された。CIDにおける衝突電圧は25eVであった。本装置1は、動的計画法に基づく経路探索を有向グラフの5’端及び3’端からそれぞれ6番目の階層まで実行し、当該経路探索の結果に基づいて、マイクロRNAの5’端から6残基の部分の塩基配列を「5’UGGAGU」、3’端から6残基の部分の塩基配列を「GUUUGU3’」とそれぞれ正しく決定することができた。図23には、最適経路決定後の有向グラフを示す。
【0135】
[実施例5]
RNaseT1を用いて作製したRNA断片を解析の対象とした。親イオンのm/zは「986.2」、価数は「−2」であった。修飾基の存在を考慮しない場合と考慮した場合とで解析を行った。図24には、修飾塩基の存在を考慮しない場合に最終的に得られた有向グラフを示す。この場合もRNA断片の全塩基配列を「ACCUG」と正しく決定することができた。
【0136】
また、図25には、修飾塩基の存在を考慮した補正により算出した予測m/z値を用いて全塩基配列及び修飾塩基の位置を決定した場合の有向グラフを示す。この場合には、RNA断片の全塩基配列を「ACCUG」と正しく決定することができるとともに、さらに修飾基としてメチル基が付加された塩基の位置を同定することができた。すなわち、図25に示す有向グラフにおいて、ノード「AC:UCG」の3’端位置の部分塩基組成「UCG」の予測m/z値と、ノード「AC2:UG」の5’端位置の塩基組成「AC2」にメチル基分の分子量を補正した予測m/z値が、補正を行わない予測m/z値に比べて、実測m/z値に対して、よりマッチする(m/z値の差分が小さい)ことから、全塩基配列「ACCUG」のうち中央のシトシン(C)にメチル基による塩基修飾があると判断した。すなわち、塩基配列が「ACCUG」であるRNA断片のうち、5’端から3番目のシトシン(C)にメチル基の修飾があることを正しく検出できた。なお、図25において、シトシン(C)に付与された「*」印は、当該シトシン(C)塩基が修飾されていることを示す。また、図25では図24に比べて、上記修飾塩基を含んだ2つのノードについてより強いピーク強度が検出されたことが、当該2つのノードの径の違いによって容易に認識することができる。
【0137】
[実施例6]
大腸菌5sRNAをRNaseT1で消化したRNA断片群を作製し、当該RNA断片群のうちの7つのRNA断片をLC−QqTOF型の質量分析計により計測し、当該各RNA断片の全体塩基組成に基づくRMF(RNA MassFingerprinting)法により、大腸菌のゲノムのデータベースから、当該5sRNAに対応する遺伝子の位置を正しく検出した例である。すなわち、質量分析により、7つのRNA断片に対応して、分子量が「2829.43」、「2547.35」、「2266.32」、「1655.25」、「1632.23」、「1302.19」、「1279.16」である7つの親イオンが計測された。そして、7つの親イオンに対応するRNA断片の全体塩基組成はそれぞれ、「AU2C5G」、「A2UC4G」、「A3UC2G」、「A3CG」、「A2UCG」、「A1C2G」、「UC2G」と決定された。そして、大腸菌ゲノムデータベースに対して、5sRNAの長さに対応するフレーム長のゲノム部分領域であって、塩基組成が上記7つの全体塩基組成である部分を含むゲノム部分領域を検索する処理を実行し、図26に示す結果を得た。すなわち、図26に示すように、大腸菌ゲノムに含まれる、図中、破線で囲まれた最も高い同一のスコアが付与された上位8つの部分領域が、正解領域として検出された。なお、ゲノム上の複数の位置に、同一配列の複製の各々が存在する場合には、このように、同一スコアの部分領域が複数検出されることがある。
【0138】
一方、これらのRNA断片に対して、上述のような本発明に係る解析方法を適用することにより、7つのRNA断片の全塩基配列は、それぞれ「UCCCACCUG」、「ACCCCAUG」、「AACUCAG」、「AAACG」、「AACUG」、「CCAG」、「CCUG」、と決定することができた。そして、本発明に係る解析方法の一部としてRMF法を利用して、大腸菌ゲノムデータベースに対して、5sRNAの長さに対応するフレーム長のゲノム部分領域であって、上記7つの塩基配列を含むゲノム部分領域を検索する処理を実行することにより、図27に示す結果を得た。すなわち、図27に示すように、本発明により決定された塩基配列の情報を付加した検索を実行することで、RMF法の検出感度を高めることができた。図27においては、図26における上位8つの部分領域のうち、図中、破線で囲まれた上位7つの部分領域を最もスコアが高い正解領域として更に抽出できた。また、これら8つの部分領域と、他の部分領域と、のスコアの差分を図26に示した場合に比べて顕著に増加させることができ、正解候補と不正解候補とをより明確に分離することができた。
【0139】
[実施例7]
本発明のアルゴリズムをRMF法に組み込んでヒト7skRNAの検索を行った例である。ヒト7skRNAを含むRNP(ribonucleoprotein)を抗体を用いて免疫沈降させ、当該沈降物を精製することにより、得られた当該ヒト7skRNAを含むサンプルを得た。このサンプルに対してRNaseT1を用いたゲル内断片化処理を行い、断片化処理後のサンプルをLC/MS質量分析計で解析することにより、6つのRNA断片の各々について、それぞれ分子量「3464.5」、「2805.4」、「2572.4」、「2548.3」、「2526.3」、「2500.3」(Da)を得た。このうち、分子量「3464.5」と「2548.3」の2つのRNA断片を本発明のアルゴリズムにより解析した。その結果、2つのRNA断片の全塩基配列をそれぞれ「UCACCCCAUUG」、「CUUCCAAG」と決定することができた。そして、RMF法を利用して、このヒト7skRNAの長さに対応する300塩基の幅(フレーム長さ)で、当該ヒト7skRNAの全体塩基組成と、当該決定されたヒト7skRNAの部分的な塩基配列(上記2つのRNA断片の全塩基配列)と、を有するゲノム部分をヒトゲノム上から検索した。その結果、図28に示すように、高いスコアが付与された上位17つのゲノム部分はすべてヒト7sk遺伝子にヒットした。一方、部分的な塩基配列の情報を使用することなく、全体塩基組成のみを用いて同様のデータベース検索を行った結果、ゲノム部分をスコアによって十分に差別化することができず、正解の塩基配列を決定することは不可能であった。
【0140】
なお、本発明は上述の例に限られない。すなわち、解析の対象とする核酸は、RNAやRNA断片に限られず、例えば、DNA、DNA分解酵素を用いて作製されたDNA断片、さらに核酸医薬等のために合成された種々の修飾核酸等、任意の核酸を解析の対象とすることができる。また、解析の対象とする核酸の長さは特に限られないが、既知配列のデータベースの検索を利用することなく核酸の全体の塩基配列を決定する上では、例えば、塩基数が20以下の核酸(例えば、マイクロRNA(miRNA)等)を好ましい対象とすることができ、塩基数が15以下の核酸を特に好ましい対象とすることができる。ただし、この好ましい塩基数は、質量分析計の分析精度(核酸のイオン化効率も含む)が向上すれば増加させることができ、本発明による解析の対象を制限するものではない。また、2つの質量分離部を備えた質量分析計(MS/MS)のみならず、例えば、3つ以上の質量分析部を備えた質量分析計(MSn)による質量分析を利用することにより、より塩基数の大きい核酸についても全体の塩基配列を決定することができる。すなわち、この場合、例えば、3つの質量分析部を備えた質量分析計(MS/MS/MS)を用いて、1段階目の質量分析により親イオンの測定(MS)を行い、2段階目の質量分析によりそのプロダクトイオン(子イオン)の測定(MS/MS)を行い、3段階目の質量分析により当該子イオンのプロダクトイオン(孫イオン)の測定(MS/MS/MS)を行うことによって、当該孫イオンの質量分析結果を利用して子イオンの全塩基配列を決定し、当該子イオンの質量分析結果及び全塩基配列を利用して、対象とする核酸の全塩基配列を決定することができる。また、塩基組成セットの作成に用いる全体塩基組成は、親イオンの実際の質量分析結果に基づいて決定されるものに限られず、例えば、ユーザから入力された任意の全体塩基組成とすることもできる。
【0141】
また、本方法に含まれる処理の順番は、処理の効率等を考慮して適宜設定することができ、互いに区別して上述した処理のうち一部を並行して実行することもできる。すなわち、例えば、本装置1の制御部10は、本プログラムに基づいて、塩基組成セットを作成する処理、塩基組成セットの階層構造を作成する処理、塩基組成セット間の接続関係を作成する処理を順次実行することができ、また、並行して行うこともできる。具体的に、例えば、対象断片に含まれる塩基数が「n」であり、当該対象断片の末端の塩基はRNA分解酵素の種類等によって特定することができず、一対の部分塩基組成から構成される塩基組成セットを作成する場合、塩基組成処理部11は、まず、5’端位置の部分塩基組成に含まれる塩基数が「1」であり、3’端位置の部分塩基組成に含まれる塩基数が「n−1」である塩基組成セットを保持したオブジェクトを生成するセット生成関数を記憶部20から読み出す。また、塩基組成処理部11は、アデニン(A)、ウラシル(U)、シトシン(C)、グアニン(G)のうち全体塩基組成に含まれている塩基を末端塩基として決定する。そして、塩基組成処理部11は、セット生成関数に基づいて、5’端位置の部分塩基組成が当該末端塩基1つから構成され、且つ3’端位置の部分塩基組成が全体塩基組成から当該末端塩基を除いた塩基組成である塩基組成セットを、当該5’端位置の部分塩基組成の塩基数が最も少ない最外階層の階層番号「1」と関連付けたオブジェクトを生成し、記憶部20に格納する。同様に、塩基組成処理部11は、5’端位置の部分塩基組成の塩基数が「i」(「i」は2〜nの整数)であり、3’端位置の部分塩基組成に含まれる塩基数が「n−i」である塩基組成セットを作成するにあたって、まず、1つ小さい階層番号「i−1」に関連付けられている、当該5’端位置の部分塩基組成の塩基数が1つ少ない全ての塩基組成セットを呼び出すとともに、呼び出された各塩基組成セットを構成する5’端位置の部分塩基組成及び3’位置の部分塩基組成を取り出す。さらに、塩基組成処理部11は、階層番号「i−1」に関連付けられている各塩基組成セットについて、A、U、C、Gのうち3’端位置の部分塩基組成に含まれている塩基を移動塩基として決定する。そして、塩基組成処理部11は、セット生成関数に基づいて、階層番号「i−1」に関連付けられている各塩基組成セットの5’端位置の部分塩基組成に1つの移動塩基が追加された5’端位置の部分塩基組成と、当該各塩基組成セットの3’端位置の部分塩基組成から当該1つの移動塩基が除かれた3’端位置の部分塩基組成と、からなる塩基組成セットを、当該5’端位置の部分塩基組成の塩基数に対応する階層番号「i」と関連付けたオブジェクトを新たに生成し、記憶部20に格納する。また、塩基組成処理部11は、階層番号「i−1」に関連付けられた塩基組成セットのオブジェクトと、階層番号「i」に関連付けられた塩基組成セットのオブジェクトと、の間の接続関係を保持したオブジェクトを生成し、記憶部20に格納する。すなわち、階層番号「i−1」に関連付けられた各塩基組成セットと、階層番号「i」に関連付けられた塩基組成セットのうち、当該各塩基組成セットの5’端位置の部分塩基組成に1つの移動塩基が追加された5’端位置の部分塩基組成を有する塩基組成セットと、の間の接続関係を表す接続データを生成し、記憶部20に格納する。なお、この接続関係を生成する際に、塩基組成処理部11は、新たに作成した接続関係で接続される新たな塩基組成セットの5’端位置の部分塩基組成が、既に格納されているオブジェクトの塩基組成セットの5’端位置の部分塩基組成と一致する場合には、当該新たな塩基組成セットのオブジェクトは格納することなく、当該既に格納されていた塩基組成セットのオブジェクトとの新たな接続関係を保持するオブジェクトを生成し、記憶部20に格納する。すなわち、塩基組成処理部11は、1つの部分塩基組成の組に対して1つのオブジェクトを生成し、格納する。塩基組成処理部11は、このような処理を「1」から「n」までの「i」について実行する。
【0142】
また、塩基組成セット及びノードに付与する重みは、プロダクトイオンのピーク強度に限られず、例えば、当該ピーク強度に応じて所定の関数を用いて算出される重みとすることもできる。また、この重みは、例えば、各ピーク強度に加えて、部分塩基組成について予測された質量値と各プロダクトイオンについて実測された質量値との誤差や、各部分塩基組成について予測された理論スペクトルに対する実測ピークのヒット数をも用いて決定することができる。すなわち、例えば、質量値の予測値と実測値との差分が小さいほど重みを大きくすることができる。また、例えば、親イオンの解離条件(CIDにおける解離電圧等)等に基づいて、各部分塩基組成について予測される複数の質量値(c−y系列、a−w系列等の互いに異なる系列から算出される互いに異なる質量値)のうち、所定の閾値以上の強度で測定されることが期待される主要なピークに対応する質量値を注目質量値として決定し、実測スペクトルにおいて、当該注目質量値と一致する実測質量値の位置で検出されたピークの数(すなわち、ヒットした主要ピークの数)に基づいて、重みを決定することもできる。
【0143】
また、有向グラフにおける最適経路の探索は、動的計画法によるものに限られず、例えば、欲張りアルゴリズムや他の経路探索方法を用いることもできる。すなわち、例えば、欲張りアルゴリズムを適用する場合、解析処理部13は、各階層に属するノードのうち、最も大きな重みが付与されているノードを選択する選択処理を、少なくとも一方の最外階層から順次実行することにより、核酸の少なくとも一方の末端塩基から塩基配列を順次決定することができる。
【0144】
また、塩基組成セットは、全体塩基組成を2つに分割して得られる一組の部分塩基組成から構成されるものに限られず、全体塩基組成を3つ以上に分割して得られる一組の部分塩基組成から構成されるものとすることもできる。すなわち、全体塩基組成を3つに分割して得られる一組の部分塩基組成から構成される塩基組成セットを作成する場合には、例えば、図29、図30に示すような有向グラフを作成することができる。
【0145】
図29に示す例においては、塩基組成セットが、その両方の末端位置の部分塩基組成の塩基数の昇順に階層化されている。すなわち、この例では、各ノードに対応する塩基組成セットが有する5’端位置の部分塩基組成の塩基数と3’端位置の部分塩基組成の塩基数とは同一であり、且つ有向グラフの5’端から3’端に向けて、5’端位置の部分塩基組成及び3’端位置の部分塩基組成の両方の塩基数が1つずつ増加するよう、塩基組成セットが階層化されている。この場合、有向グラフの5’端から3’端に向けて、各階層に含まれるノードのうち1つを選択する選択処理により、解析の対象とする核酸の両末端塩基から順次塩基配列を決定することができる。
【0146】
また、図30に示す例においては、塩基組成セットが、その一方の末端位置である5’端位置の部分塩基組成の塩基数の昇順に階層化されている。すなわち、この例では、有向グラフの5’端から3’端に向けて、各階層に含まれるノードのうち1つを選択する選択処理により、解析の対象とする核酸の5’端塩基から順次塩基配列を決定することができる。
【0147】
また、本装置1は、その構成の一部として必ずしも質量分析部50を備える必要はない。すなわち、例えば、本装置1は、質量分析計が設置されている分析室とは物理的に離隔された他の解析室に設置することができる。この場合、本装置1は、入力部30を介して、ユーザから入力され又はCD等の記録媒体から読み出される、質量分析の結果に関するデータを受け入れることができる。
【0148】
また、本装置1は、LANやインターネット等のネットワークと接続することもできる。この場合、例えば、ユーザは、本装置1とネットワークを介して接続されたコンピュータを用いて、本装置1を動作させることもできる。また、本装置1の構成の一部をネットワークを介して接続することもできる。例えば、入力部30及び出力部40として機能するユーザのコンピュータと、制御部10及び記憶部20として機能するサーバコンピュータと、をネットワークを介して接続することによって本装置1を構成することもできる。また、本装置1の制御部10と質量分析部50とをネットワークを介して接続することもできる。
【図面の簡単な説明】
【0149】
【図1】本発明の一実施形態に係る核酸解析装置の主な構成を示すブロック図である。
【図2】本発明の一実施形態に係る核酸解析装置の制御部が行う主な処理を示す機能ブロック図である。
【図3】本発明の一実施形態に係る核酸解析方法に含まれる主な処理を示すフロー図である。
【図4】本発明の一実施形態において作成される階層データの一例を示す説明図である。
【図5】本発明の一実施形態において作成される接続データの一例を示す説明図である。
【図6】本発明の一実施形態において作成される有向グラフの一例を示す説明図である。
【図7】本発明の一実施形態における理論スペクトルの作成についての説明図である。
【図8】本発明の一実施形態におけるマッチング処理の一例についての説明図である。
【図9】本発明の一実施形態において作成される有向グラフの重み付け処理の一例についての説明図である。
【図10】本発明の一実施形態において作成される有向グラフのトレースバック処理の一例についての説明図である。
【図11】本発明の一実施形態において作成される有向グラフを用いた塩基配列決定の一例についての説明図である。
【図12】本発明の一実施形態において作成されたプロダクトイオンの一部と予測質量値とを関連付けたデータテーブルの一例を示す説明図である。
【図13】本発明の一実施形態において作成されたプロダクトイオンの他の一部と予測質量値とを関連付けたデータテーブルの一例を示す説明図である。
【図14】本発明の一実施形態において作成されたノードとスコアとを関連付けたデータテーブルの一例を示す説明図である。
【図15】本発明の一実施形態において作成されたエッジとスコアとを関連付けたデータテーブルの一例を示す説明図である。
【図16】本発明の一実施形態において作成された塩基欠損イオンと予測質量値とを関連付けたデータテーブルの一例を示す説明図である。
【図17】本発明の一実施形態において作成されたエッジとノーマライズされたスコアとを関連付けたデータテーブルの一例を示す説明図である。
【図18】本発明の一実施形態において作成されたノードと更新されたスコアとを関連付けたデータテーブルの一例を示す説明図である。
【図19】本発明の一実施形態で作成された有向グラフの一例を示す説明図である。
【図20】本発明の一実施形態で作成されたマッチング処理の結果を含むマススペクトルの一例を示す説明図である。
【図21】本発明の一実施形態で作成された有向グラフの他の一例を示す説明図である。
【図22】本発明の一実施形態で作成された有向グラフの更に他の一例を示す説明図である。
【図23】本発明の一実施形態で作成された有向グラフの更に他の一例を示す説明図である。
【図24】本発明の一実施形態で作成された有向グラフの更に他の一例を示す説明図である。
【図25】本発明の一実施形態で作成された有向グラフの更に他の一例を示す説明図である。
【図26】本発明の一実施形態における大腸菌ゲノムの候補領域をスコアに基づいて順位付けした結果の一例を示す説明図である。
【図27】本発明の一実施形態における大腸菌ゲノムの候補領域をスコアに基づいて順位付けした結果の他の例を示す説明図である。
【図28】本発明の一実施形態におけるヒトゲノムの候補領域をスコアに基づいて順位付けした結果の一例を示す説明図である。
【図29】本発明の一実施形態において全体塩基組成を3つに分割して塩基組成セットを作成した場合の有向グラフの一例を示す説明図である。
【図30】本発明の一実施形態において全体塩基組成を3つに分割して塩基組成セットを作成した場合の有向グラフの他の例を示す説明図である。
【符号の説明】
【0150】
1 核酸解析装置、10 制御部、11 塩基組成処理部、12 重み付け処理部、13 解析処理部、20 記憶部、30 入力部、40 出力部、50 質量分析部。
【特許請求の範囲】
【請求項1】
核酸の全体塩基組成に基づいて、各々が一組の部分塩基組成から構成される、複数の塩基組成セットを作成するとともに、前記塩基組成セットが、その少なくとも一方の末端位置の部分塩基組成の塩基数の昇順に階層化された階層構造を作成し、さらに前記塩基組成セットの各々と、その前記末端位置の部分塩基組成に塩基を1つ追加した部分塩基組成を前記末端位置に有する他の塩基組成セットと、の間に接続関係を作成する第一処理部と、
前記部分塩基組成の各々について、対応したプロダクトイオンの質量分析において得られることが予測される質量値を算出するとともに、前記予測される質量値と、前記核酸由来のプロダクトイオンの質量分析において実際に得られた質量値と、の比較に基づいて、前記塩基組成セットの各々に重みを付与する第二処理部と、
前記塩基組成セットの各々に付与された重みに基づいて、前記階層構造の前記末端位置の部分塩基組成の塩基数が最も少ない前記塩基組成セットが属する最外階層から前記接続関係を辿りながら、各階層に属する塩基組成セットのうち1つを選択する選択処理を行うことによって、前記核酸の前記末端位置に対応する少なくとも一方の末端から塩基配列を順次決定する第三処理部と、
を含む
ことを特徴とする核酸解析装置。
【請求項2】
前記第一処理部は、前記階層構造の一方の最外階層からは、5’端位置又は3’端位置のうち一方の末端位置の部分塩基組成の塩基数の昇順となり、また、他方の最外階層からは、5’端位置又は3’端位置のうち他方の末端位置の部分塩基組成の塩基数の昇順となるよう、前記塩基組成セットを階層化し、
前記第三処理部は、前記階層構造の前記一方の最外階層及び前記他方の最外階層の両方の最外階層から内部の階層に向けて前記接続関係を辿りながら、前記選択処理を行うことによって、前記核酸の5’端及び3’端の両末端から塩基配列を順次決定する
ことを特徴とする請求項1に記載の核酸解析装置。
【請求項3】
前記第二処理部は、前記接続関係の各々により接続される一対の前記塩基組成セットに付与された重みに基づいて、前記接続関係の各々に重みを付与し、
前記第三処理部は、前記塩基組成セットの各々に付与された重みと前記接続関係の各々に付与された重みとに基づいて、前記選択処理を行う
ことを特徴とする請求項1又は2に記載の核酸解析装置。
【請求項4】
前記第一処理部は、前記塩基組成セットの各々に対応する階層化されたノードと、前記接続関係の各々に対応して前記ノードを接続するエッジと、を有する有向グラフを作成し、
前記第三処理部は、前記塩基組成セットの各々に付与された重みに基づいて、前記有向グラフの前記末端位置の部分塩基組成の塩基数が最も少ない前記塩基組成セットが属する階層側の末端から最適経路を探索することにより、前記選択処理を行う
ことを特徴とする請求項1乃至3のいずれかに記載の核酸解析装置。
【請求項5】
前記第三処理部は、動的計画法を適用して、前記選択処理を行う
ことを特徴とする請求項4に記載の核酸解析装置。
【請求項6】
前記第一処理部は、前記有向グラフの一方端からは、対応する前記塩基組成セットの5’端位置又は3’端位置のうち一方の末端位置の部分塩基組成の塩基数の昇順となり、また、前記有向グラフの他方端からは、対応する前記塩基組成セットの5’端位置又は3’端位置のうち他方の末端位置の部分塩基組成の塩基数の昇順となるよう、前記ノードを階層化し、
前記第三処理部は、前記有向グラフの前記一方端及び前記他方端の両端から内部に向けて動的計画法を適用して前記エッジを辿りながら、前記選択処理を行うことによって、前記核酸の5’端及び3’端の両末端から塩基配列を順次決定する
ことを特徴とする請求項5に記載の核酸解析装置。
【請求項7】
前記第二処理部は、前記部分塩基組成の各々について、前記対応したプロダクトイオンの質量分析において、前記対応したプロダクトイオンに修飾塩基が含まれないと仮定した場合に予測される第一の予測質量値と、前記対応したプロダクトイオンに修飾塩基が含まれると仮定した場合に予測される第二の予測質量値と、を作成し、前記第一の予測質量値及び前記第二の予測質量値の各々と、前記実際に得られた質量値と、の比較に基づいて、前記部分塩基組成の各々に重みを付与する
ことを特徴とする請求項1乃至6のいずれかに記載の核酸解析装置。
【請求項8】
前記第二処理部は、前記部分塩基組成の各々について、前記第一の予測質量値及び前記第二の予測質量値の各々と、前記実際に得られた質量値と、の比較に基づいて、前記対応したプロダクトイオンに前記修飾塩基が含まれるか否かを判断し、前記対応したプロダクトイオンに前記修飾塩基が含まれると判断した場合には、前記部分塩基組成の各々に、前記修飾塩基に関する修飾情報を関連付けて保持し、
前記第三処理部は、前記階層構造の隣接する階層間で、前記選択された塩基組成セットにおいて前記修飾情報が関連付けられている部分塩基組成の位置が移動するか否かの判断結果に基づいて、前記核酸に含まれる修飾塩基の位置を決定する
ことを特徴とする請求項7に記載の核酸解析装置。
【請求項9】
核酸の全体塩基組成に基づいて、各々が一組の部分塩基組成から構成される、複数の塩基組成セットを作成するとともに、前記塩基組成セットが、その少なくとも一方の末端位置の部分塩基組成の塩基数の昇順に階層化された階層構造を作成し、さらに前記塩基組成セットの各々と、その前記末端位置の部分塩基組成に塩基を1つ追加した部分塩基組成を前記末端位置に有する他の塩基組成セットと、の間に接続関係を作成する第一ステップと、
前記部分塩基組成の各々について、対応したプロダクトイオンの質量分析において得られることが予測される質量値を算出するとともに、前記予測される質量値と、前記核酸由来のプロダクトイオンの質量分析において実際に得られた質量値と、の比較に基づいて、前記塩基組成セットの各々に重みを付与する第二ステップと、
前記塩基組成セットの各々に付与された重みに基づいて、前記階層構造の前記末端位置の部分塩基組成の塩基数が最も少ない前記塩基組成セットが属する最外階層から前記接続関係を辿りながら、各階層に属する塩基組成セットのうち1つを選択する選択処理を行うことによって、前記核酸の前記末端位置に対応する少なくとも一方の末端から塩基配列を順次決定する第三ステップと、
を含む
ことを特徴とする核酸解析方法。
【請求項10】
コンピュータに、
核酸の全体塩基組成に基づいて、各々が一組の部分塩基組成から構成される、複数の塩基組成セットを作成するとともに、前記塩基組成セットが、その少なくとも一方の末端位置の部分塩基組成の塩基数の昇順に階層化された階層構造を作成し、さらに前記塩基組成セットの各々と、その前記末端位置の部分塩基組成に塩基を1つ追加した部分塩基組成を前記末端位置に有する他の塩基組成セットと、の間に接続関係を作成する第一手順と、
前記部分塩基組成の各々について、対応したプロダクトイオンの質量分析において得られることが予測される質量値を算出するとともに、前記予測される質量値と、前記核酸由来のプロダクトイオンの質量分析において実際に得られた質量値と、の比較に基づいて、前記塩基組成セットの各々に重みを付与する第二手順と、
前記塩基組成セットの各々に付与された重みに基づいて、前記階層構造の前記末端位置の部分塩基組成の塩基数が最も少ない前記塩基組成セットが属する最外階層から前記接続関係を辿りながら、各階層に属する塩基組成セットのうち1つを選択する選択処理を行うことによって、前記核酸の前記末端位置に対応する少なくとも一方の末端から塩基配列を順次決定する第三手順と、
を実行させる
ことを特徴とする核酸解析プログラム。
【請求項1】
核酸の全体塩基組成に基づいて、各々が一組の部分塩基組成から構成される、複数の塩基組成セットを作成するとともに、前記塩基組成セットが、その少なくとも一方の末端位置の部分塩基組成の塩基数の昇順に階層化された階層構造を作成し、さらに前記塩基組成セットの各々と、その前記末端位置の部分塩基組成に塩基を1つ追加した部分塩基組成を前記末端位置に有する他の塩基組成セットと、の間に接続関係を作成する第一処理部と、
前記部分塩基組成の各々について、対応したプロダクトイオンの質量分析において得られることが予測される質量値を算出するとともに、前記予測される質量値と、前記核酸由来のプロダクトイオンの質量分析において実際に得られた質量値と、の比較に基づいて、前記塩基組成セットの各々に重みを付与する第二処理部と、
前記塩基組成セットの各々に付与された重みに基づいて、前記階層構造の前記末端位置の部分塩基組成の塩基数が最も少ない前記塩基組成セットが属する最外階層から前記接続関係を辿りながら、各階層に属する塩基組成セットのうち1つを選択する選択処理を行うことによって、前記核酸の前記末端位置に対応する少なくとも一方の末端から塩基配列を順次決定する第三処理部と、
を含む
ことを特徴とする核酸解析装置。
【請求項2】
前記第一処理部は、前記階層構造の一方の最外階層からは、5’端位置又は3’端位置のうち一方の末端位置の部分塩基組成の塩基数の昇順となり、また、他方の最外階層からは、5’端位置又は3’端位置のうち他方の末端位置の部分塩基組成の塩基数の昇順となるよう、前記塩基組成セットを階層化し、
前記第三処理部は、前記階層構造の前記一方の最外階層及び前記他方の最外階層の両方の最外階層から内部の階層に向けて前記接続関係を辿りながら、前記選択処理を行うことによって、前記核酸の5’端及び3’端の両末端から塩基配列を順次決定する
ことを特徴とする請求項1に記載の核酸解析装置。
【請求項3】
前記第二処理部は、前記接続関係の各々により接続される一対の前記塩基組成セットに付与された重みに基づいて、前記接続関係の各々に重みを付与し、
前記第三処理部は、前記塩基組成セットの各々に付与された重みと前記接続関係の各々に付与された重みとに基づいて、前記選択処理を行う
ことを特徴とする請求項1又は2に記載の核酸解析装置。
【請求項4】
前記第一処理部は、前記塩基組成セットの各々に対応する階層化されたノードと、前記接続関係の各々に対応して前記ノードを接続するエッジと、を有する有向グラフを作成し、
前記第三処理部は、前記塩基組成セットの各々に付与された重みに基づいて、前記有向グラフの前記末端位置の部分塩基組成の塩基数が最も少ない前記塩基組成セットが属する階層側の末端から最適経路を探索することにより、前記選択処理を行う
ことを特徴とする請求項1乃至3のいずれかに記載の核酸解析装置。
【請求項5】
前記第三処理部は、動的計画法を適用して、前記選択処理を行う
ことを特徴とする請求項4に記載の核酸解析装置。
【請求項6】
前記第一処理部は、前記有向グラフの一方端からは、対応する前記塩基組成セットの5’端位置又は3’端位置のうち一方の末端位置の部分塩基組成の塩基数の昇順となり、また、前記有向グラフの他方端からは、対応する前記塩基組成セットの5’端位置又は3’端位置のうち他方の末端位置の部分塩基組成の塩基数の昇順となるよう、前記ノードを階層化し、
前記第三処理部は、前記有向グラフの前記一方端及び前記他方端の両端から内部に向けて動的計画法を適用して前記エッジを辿りながら、前記選択処理を行うことによって、前記核酸の5’端及び3’端の両末端から塩基配列を順次決定する
ことを特徴とする請求項5に記載の核酸解析装置。
【請求項7】
前記第二処理部は、前記部分塩基組成の各々について、前記対応したプロダクトイオンの質量分析において、前記対応したプロダクトイオンに修飾塩基が含まれないと仮定した場合に予測される第一の予測質量値と、前記対応したプロダクトイオンに修飾塩基が含まれると仮定した場合に予測される第二の予測質量値と、を作成し、前記第一の予測質量値及び前記第二の予測質量値の各々と、前記実際に得られた質量値と、の比較に基づいて、前記部分塩基組成の各々に重みを付与する
ことを特徴とする請求項1乃至6のいずれかに記載の核酸解析装置。
【請求項8】
前記第二処理部は、前記部分塩基組成の各々について、前記第一の予測質量値及び前記第二の予測質量値の各々と、前記実際に得られた質量値と、の比較に基づいて、前記対応したプロダクトイオンに前記修飾塩基が含まれるか否かを判断し、前記対応したプロダクトイオンに前記修飾塩基が含まれると判断した場合には、前記部分塩基組成の各々に、前記修飾塩基に関する修飾情報を関連付けて保持し、
前記第三処理部は、前記階層構造の隣接する階層間で、前記選択された塩基組成セットにおいて前記修飾情報が関連付けられている部分塩基組成の位置が移動するか否かの判断結果に基づいて、前記核酸に含まれる修飾塩基の位置を決定する
ことを特徴とする請求項7に記載の核酸解析装置。
【請求項9】
核酸の全体塩基組成に基づいて、各々が一組の部分塩基組成から構成される、複数の塩基組成セットを作成するとともに、前記塩基組成セットが、その少なくとも一方の末端位置の部分塩基組成の塩基数の昇順に階層化された階層構造を作成し、さらに前記塩基組成セットの各々と、その前記末端位置の部分塩基組成に塩基を1つ追加した部分塩基組成を前記末端位置に有する他の塩基組成セットと、の間に接続関係を作成する第一ステップと、
前記部分塩基組成の各々について、対応したプロダクトイオンの質量分析において得られることが予測される質量値を算出するとともに、前記予測される質量値と、前記核酸由来のプロダクトイオンの質量分析において実際に得られた質量値と、の比較に基づいて、前記塩基組成セットの各々に重みを付与する第二ステップと、
前記塩基組成セットの各々に付与された重みに基づいて、前記階層構造の前記末端位置の部分塩基組成の塩基数が最も少ない前記塩基組成セットが属する最外階層から前記接続関係を辿りながら、各階層に属する塩基組成セットのうち1つを選択する選択処理を行うことによって、前記核酸の前記末端位置に対応する少なくとも一方の末端から塩基配列を順次決定する第三ステップと、
を含む
ことを特徴とする核酸解析方法。
【請求項10】
コンピュータに、
核酸の全体塩基組成に基づいて、各々が一組の部分塩基組成から構成される、複数の塩基組成セットを作成するとともに、前記塩基組成セットが、その少なくとも一方の末端位置の部分塩基組成の塩基数の昇順に階層化された階層構造を作成し、さらに前記塩基組成セットの各々と、その前記末端位置の部分塩基組成に塩基を1つ追加した部分塩基組成を前記末端位置に有する他の塩基組成セットと、の間に接続関係を作成する第一手順と、
前記部分塩基組成の各々について、対応したプロダクトイオンの質量分析において得られることが予測される質量値を算出するとともに、前記予測される質量値と、前記核酸由来のプロダクトイオンの質量分析において実際に得られた質量値と、の比較に基づいて、前記塩基組成セットの各々に重みを付与する第二手順と、
前記塩基組成セットの各々に付与された重みに基づいて、前記階層構造の前記末端位置の部分塩基組成の塩基数が最も少ない前記塩基組成セットが属する最外階層から前記接続関係を辿りながら、各階層に属する塩基組成セットのうち1つを選択する選択処理を行うことによって、前記核酸の前記末端位置に対応する少なくとも一方の末端から塩基配列を順次決定する第三手順と、
を実行させる
ことを特徴とする核酸解析プログラム。
【図1】


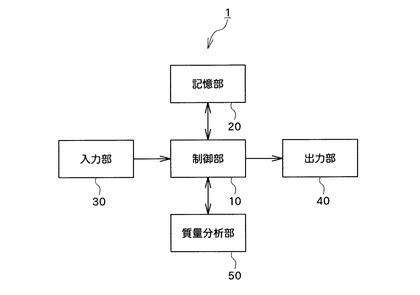
【図2】
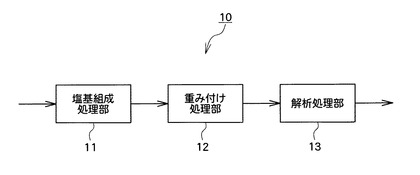
【図3】
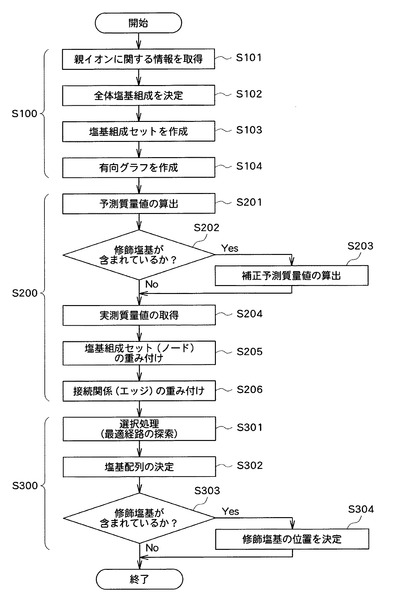
【図4】
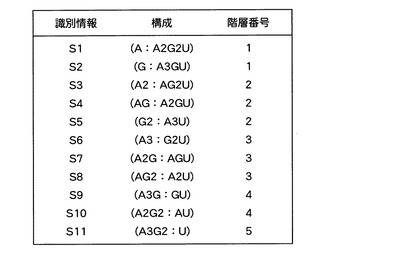
【図5】

【図6】
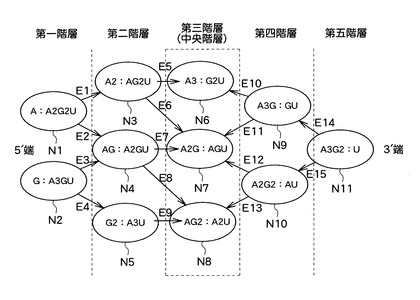
【図7】
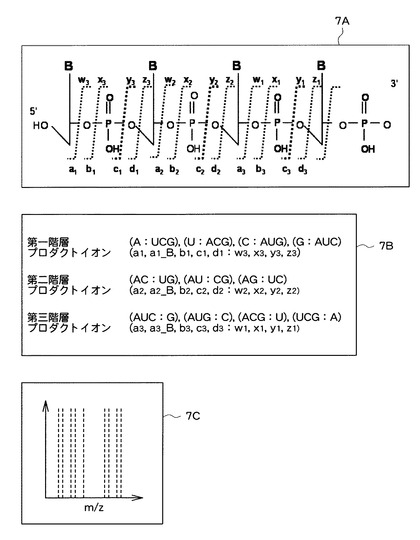
【図8】
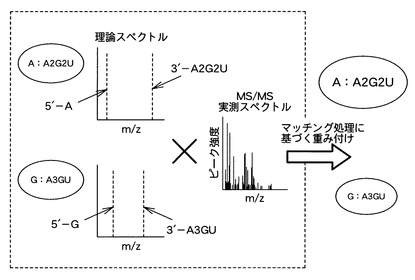
【図9】
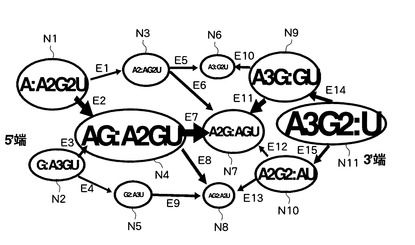
【図10】
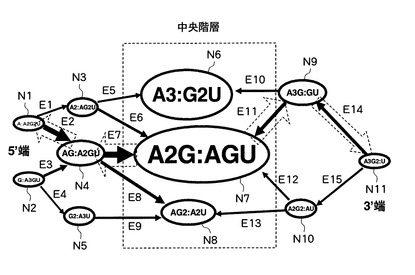
【図11】

【図12】
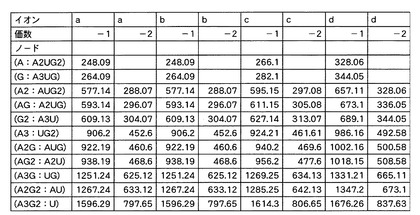
【図13】
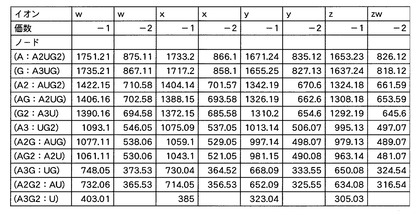
【図14】
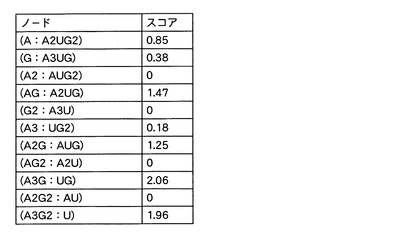
【図15】
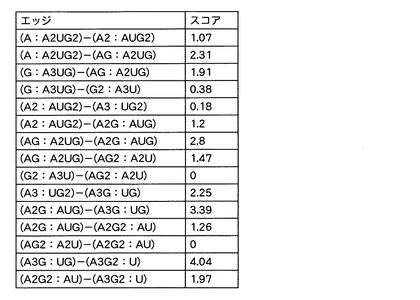
【図16】
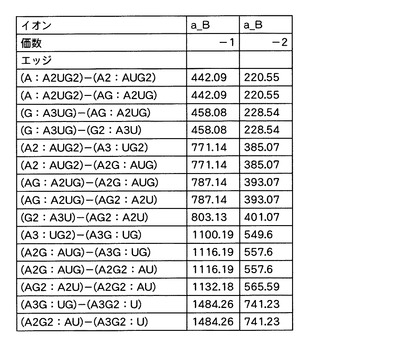
【図17】
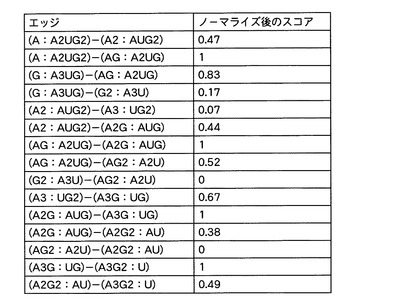
【図18】
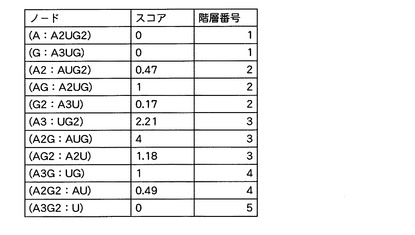
【図19】
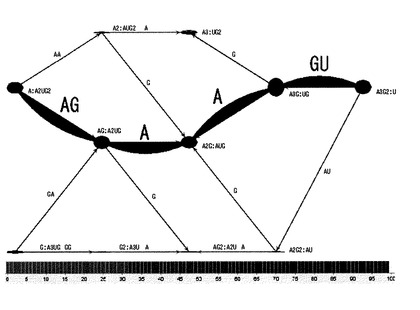
【図20】

【図21】
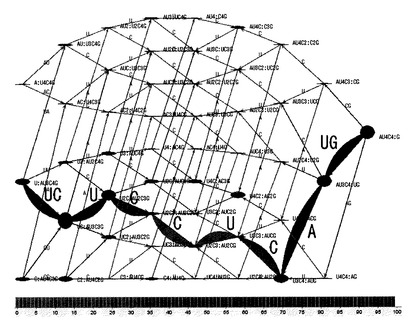
【図22】
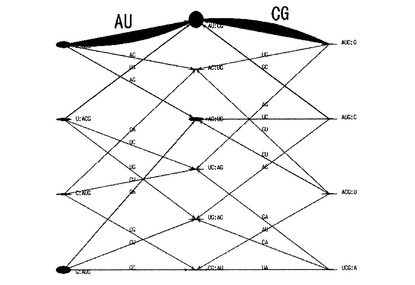
【図23】
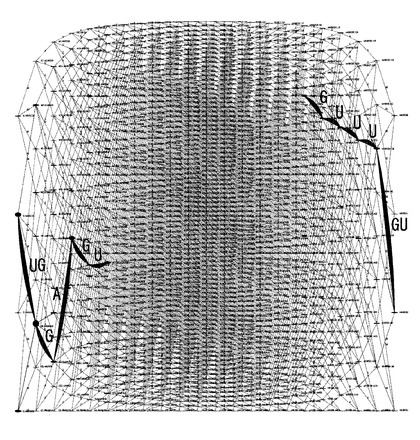
【図24】
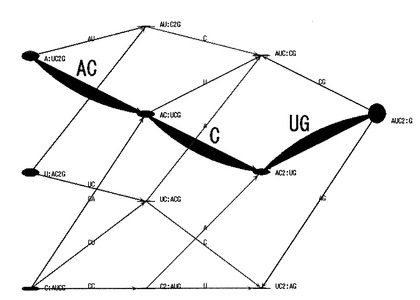
【図25】
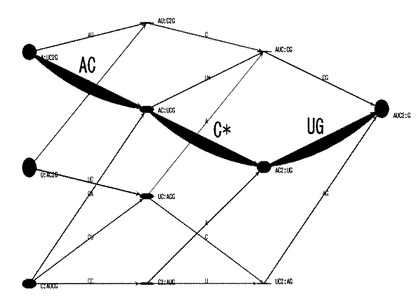
【図26】
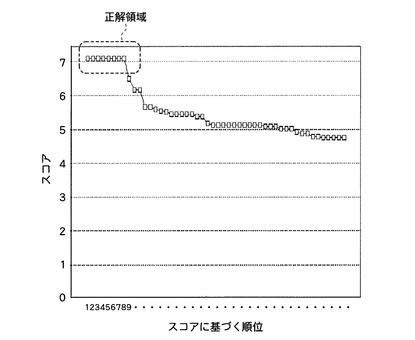
【図27】
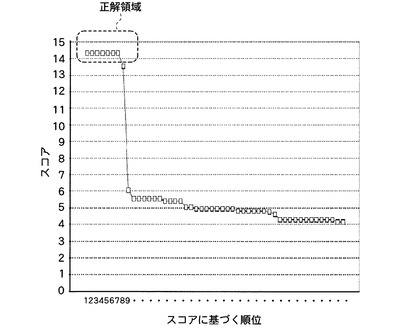
【図28】
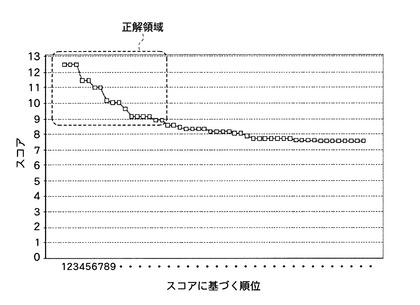
【図29】
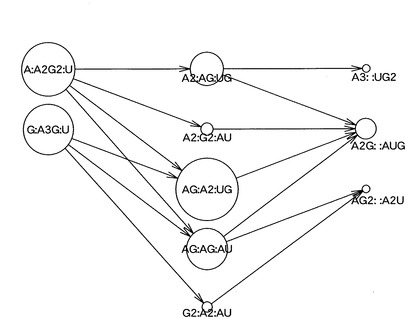
【図30】
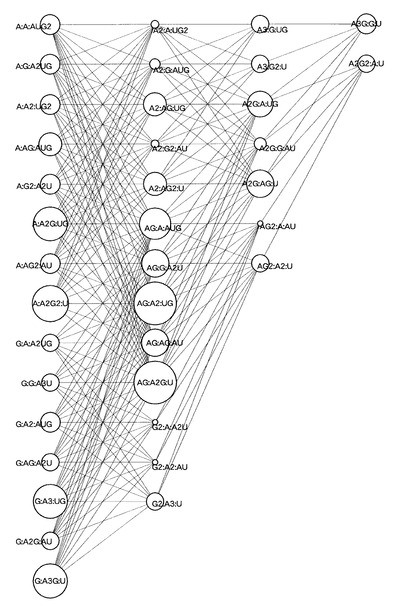
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【図23】
【図24】
【図25】
【図26】
【図27】
【図28】
【図29】
【図30】
【公開番号】特開2009−31128(P2009−31128A)
【公開日】平成21年2月12日(2009.2.12)
【国際特許分類】
【出願番号】特願2007−195555(P2007−195555)
【出願日】平成19年7月27日(2007.7.27)
【国等の委託研究の成果に係る記載事項】(出願人による申告)平成19年度、独立行政法人新エネルギー・産業技術総合開発機構、「機能性RNAプロジェクト」に係る委託研究、産業活力再生特別措置法第30条の適用を受ける特許出願
【出願人】(504137912)国立大学法人 東京大学 (1,942)
【出願人】(500535301)社団法人バイオ産業情報化コンソーシアム (22)
【Fターム(参考)】
【公開日】平成21年2月12日(2009.2.12)
【国際特許分類】
【出願日】平成19年7月27日(2007.7.27)
【国等の委託研究の成果に係る記載事項】(出願人による申告)平成19年度、独立行政法人新エネルギー・産業技術総合開発機構、「機能性RNAプロジェクト」に係る委託研究、産業活力再生特別措置法第30条の適用を受ける特許出願
【出願人】(504137912)国立大学法人 東京大学 (1,942)
【出願人】(500535301)社団法人バイオ産業情報化コンソーシアム (22)
【Fターム(参考)】
[ Back to top ]