
核酸高次構造予測方法、核酸高次構造予測装置及び核酸高次構造予測プログラム
【課題】Gカルテット構造に代表される核酸の高次構造を予測し得る方法、並びにこの方法を実行する装置及びプログラムを提供する。
【解決手段】核酸配列の高次構造を予測する核酸高次構造予測方法であって、前記核酸配列において、高次構造を形成し得る塩基を高次構造候補として抽出する工程と、前記核酸配列において、ステム構造を形成し得る塩基をステム構造候補として抽出する工程と、前記高次構造候補と前記ステム構造候補とに基づいて、最適な組合せ構造を探索する工程と、を有することを特徴とする。
【解決手段】核酸配列の高次構造を予測する核酸高次構造予測方法であって、前記核酸配列において、高次構造を形成し得る塩基を高次構造候補として抽出する工程と、前記核酸配列において、ステム構造を形成し得る塩基をステム構造候補として抽出する工程と、前記高次構造候補と前記ステム構造候補とに基づいて、最適な組合せ構造を探索する工程と、を有することを特徴とする。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、核酸高次構造予測方法、並びにこの核酸高次構造予測方法を実行する核酸高次構造予測装置及び核酸高次構造予測プログラムに関する。
【背景技術】
【0002】
DNA、RNAなど核酸配列は、アデニン(A)、シトシン(C)、グアニン(G)又はチミン(T)若しくはウラシル(U)の4種類の塩基からなり、AとT若しくはU、又はGとCなどの組合せで水素結合を形成して塩基対となることが知られている。この一般的な塩基対のことを、ワトソン・クリック型塩基対と呼ぶ。核酸配列は、このような塩基対の組合せによって多様な構造を取ることが知られており、とりわけエクソンなどのいわゆる構造遺伝子に代表される機能性核酸において、配列の構造はその機能と密接に関わる。核酸配列の構造において、ワトソン・クリック型塩基対が構成される塩基対の大半を占める一方、配列によってはワトソン・クリック型に寄らない塩基対も形成され得ることが知られている。ワトソン・クリック型に寄らない塩基対とは、例えばA−T(U)、G−C以外のG−A型の塩基対などを指すが、一対一の塩基対ではないという意味で、ここでは三本鎖構造(ベーストリプル構造)や、四本鎖構造(ベースクアドルプル構造)など、一般的な二重螺旋構造ではない高次構造も含める。
【0003】
このような高次構造の有名な例として、4つのGが四本鎖を形成するGカルテット構造が挙げられる。Gカルテット構造は、例えば生体内では真核生物の染色体DNAの末端のテロメア配列で形成され、テロメアーゼによる伸張反応を阻害する機能を持つことが知られている。また、Gカルテット構造は、ある標的物質に対して特異的な親和性を持つ人工の核酸配列であるアプタマー分子においても、標的物質との結合においてGカルテット構造が重要である例が多数報告されている(例えば、非特許文献1)。つまり、Gカルテット構造、或いはそれに類する高次構造の存在を認識することは、核酸配列の機能上の重要な領域を特定する上で、極めて大きな手がかりとなる。
【0004】
しかし、従来の核酸の構造予測の手法は、基本的にはワトソン・クリック型の塩基対の予測を組合せたものであり、このような高次構造を予測するための手法ではない。したがって、Gカルテット構造に代表される核酸の高次構造を予測する方法の開発が求められていた。
【非特許文献1】STEFAN WEISSら著、”RNA Aptamers Specifically Interact with the Prion Protein PrP”、JOURNAL OF VIROLOGY、1997年、11月号、p.8790〜8797
【非特許文献2】J.Kondoら著、”Crystal structures of a DNA octaplex with I−motif of G−quartets and its splitting into two quadruplexes suggest a folding mechanism of eight tandem repeats”、Nucleic Acids Research、2004年、32巻、8号、p.2541〜2549
【発明の開示】
【発明が解決しようとする課題】
【0005】
本発明は、上述の要求に鑑みてなされたものであり、Gカルテット構造に代表される核酸の高次構造を予測し得る方法、並びにこの方法を実行する装置及びプログラムを提供することを目的とする。
【課題を解決するための手段】
【0006】
本発明による核酸高次構造予測方法は、核酸配列の高次構造を予測する核酸高次構造予測方法であって、前記核酸配列において、高次構造を形成し得る塩基を高次構造候補として抽出する工程と、前記核酸配列において、ステム構造を形成し得る塩基をステム構造候補として抽出する工程と、前記高次構造候補と前記ステム構造候補とに基づいて、最適な組合せ構造を探索する工程と、を有することを特徴とする。
【0007】
また、本発明による核酸高次構造予測装置は、核酸配列の高次構造を予測する核酸高次構造予測装置であって、前記核酸配列において、高次構造を形成し得る塩基を高次構造候補として抽出する高次構造候補抽出手段と、前記核酸配列において、ステム構造を形成し得る塩基をステム構造候補として抽出するステム構造候補抽出手段と、前記高次構造候補と前記ステム構造候補とに基づいて、最適な組合せ構造を探索する最適構造探索手段とを有することを特徴とする。
【0008】
また、本発明による核酸高次構造予測プログラムは、核酸配列の高次構造を予測する核酸高次構造予測プログラムであって、前記核酸配列において、高次構造を形成し得る塩基を高次構造候補として抽出する工程と、前記核酸配列において、ステム構造を形成し得る塩基をステム構造候補として抽出する工程と、前記高次構造候補と前記ステム構造候補とに基づいて、最適な組合せ構造を探索する工程と、を実行することを特徴とする。
【0009】
なお、本発明において、核酸高次構造予測装置及び核酸高次構造予測プログラムは、それぞれ核酸高次構造予測方法を実行する装置及びプログラムをいう。また、本発明において、「核酸配列」とは、DNA、RNAなど、種々の遺伝子の配列をいう。
【発明の効果】
【0010】
本発明によれば、ワトソン・クリック型の塩基対予測の組合せでは予測することが不可能である種類の核酸配列の高次構造を予測することが可能となる。
【0011】
その理由は、ワトソン・クリック型の塩基対によって形成されるステム構造の候補と、それには寄らない核酸の高次構造を、共通の構成要素(構成塩基、それに付随するパラメータなど)にまとめることによって、核酸の高次構造の予測を二次構造予測の範疇に落とし込むことができるためである。
【0012】
また、本発明によれば、機能未知の核酸配列から、遺伝子発現の制御等、生物学的に有意な遺伝子配列をスクリーニングする際の指標として用いることが可能となる。
【0013】
その理由は、通常の二次構造予測で予測される構造からその元配列に何らかの機能があるかどうかを判定することは困難であるが、本発明において予測が可能となるような核酸の高次構造は、生体内で何らかの特徴的な機能を持つことが多いためである。
【0014】
さらに、本発明によれば、高次構造を取り得る核酸配列の二次構造を精度良く予測できることにある。
【0015】
その理由は、このような高次構造を持つ配列に対して通常の二次構造予測を行った場合、高次構造を予測できないことは当然として、本来高次構造を形成するべき領域が何らかの他の構造を形成すると判定される影響でその他の領域に対する予測の精度も低下する可能性が高いが、本発明を用いればそのような事態は発生し得ないためである。
【発明を実施するための最良の形態】
【0016】
(本発明による核酸高次構造予測装置の構成および各構成の機能等)
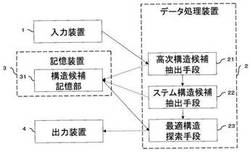
図1は、本発明による核酸高次構造予測装置の構成を示す概念図である。本発明による核酸高次構造予測装置は、キーボードなどの入力装置1と、プログラム制御により動作するデータ処理装置2と、情報を記憶する記憶装置3と、ディスプレイ装置や印刷装置などの出力装置4とを有する。
【0017】
データ処理装置2は、高次構造候補抽出手段21と、ステム構造候補抽出手段22と、最適構造探索手段23とを備える。
【0018】
高次構造候補抽出手段21は、入力装置1から入力された、構造予測の対象とする配列を取得し、その配列の中で任意の高次構造を形成し得る塩基の組合せを抽出する。
【0019】
任意の高次構造としては、ワトソン・クリック型を取る二重螺旋構造以外の、構成塩基を配列の特徴として配列上に示し得る構造であれば、特に制約はない。特にその構造を形成するためにある程度限定された塩基の組み合わせが必要であることが分かっており、その構造を形成し得る領域の候補を配列上に示すことができる構造が挙げられる。例示すれば、ワトソン・クリック型ではない塩基対からなる二重螺旋構造、ワトソン・クリック型を取る三本鎖以上の構造(三本鎖構造、四本鎖構造等)などが挙げられる。なかでも、グアニン残基が連続した4つの領域からなるGカルテット、8本のDNA鎖が寄り集まって形成される八重螺旋構造(Gカルテット I−モチーフ。非特許文献2参照。)が例示される。
【0020】
高次構造候補抽出手段21は、この任意の高次構造を形成するのに必要な塩基の要件に基づいて、構造予測の対象配列から高次構造の候補を抽出する。例えば、高次構造候補抽出手段21は、構造予測の対象とする高次構造がGカルテット構造である場合、数塩基のGが連続する配列中の領域を4領域抽出する。抽出された塩基は、構造の候補として構造候補記憶部31に記憶される。この際、記憶された各高次構造候補は、後に行う最適構造探索手段23で用いる構造候補の組合せ構造探索の指標となる、何らかのパラメータを任意に保持することが可能である。ここで言う何らかのパラメータとは、例えば構造候補が保持する自由エネルギーの値など、核酸配列の高次構造の取り易さを示す指標が挙げられる。
【0021】
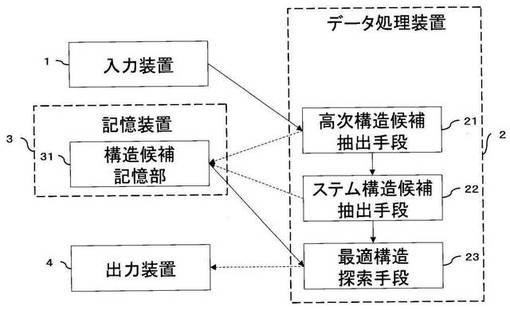
ステム構造候補抽出手段22は、高次構造候補抽出手段21で抽出の対象とされた配列から、ステム構造を形成し得る塩基の組合せを抽出する。ここで言うステム構造とは、ワトソン・クリック型塩基対の連続する領域のことであり、例えば、図2の黒丸で示した箇所の構造を言う。このステム構造は、上述の高次構造候補と同じく最適構造探索手段23で用いる構造候補の組合せ構造探索の指標となる、何らかのパラメータを任意に保持することが可能である。抽出された塩基は、構造の候補として、高次構造候補抽出手段21で記憶された構造候補と共に、構造候補記憶部31に記憶される。なお、組合せ構造探索の指標となる、何らかのパラメータとは、上記の高次構造候補抽出手段21で言及したパラメータと同様のものをいう。
【0022】
最適構造探索手段23は、構造候補記憶部31に記憶されている高次構造候補とステム構造候補とに基づいて、最適な組合せ構造の探索(本発明において、組合せ構造探索ともいう。)を行う。ここで行う組合せ構造探索のアルゴリズムは、高次構造候補及びステム構造候補の構造候補のそれぞれで使用される塩基が重複するなどの、矛盾がないことが最低条件となる。その具体的なアルゴリズムは、構造全体の自由エネルギーを最小にする構造候補の組合せを抜き出す方法の他に、ニューラルネットワークを用いて構造候補を抜き出す方法、遺伝的アルゴリズムを用いて構造候補を抜き出す方法など幾通りも考えられるため、ユーザーの要求に応じて任意のアルゴリズムを選択することが可能である。
【0023】
記憶装置3は、構造候補記憶部31を備える。
【0024】
構造候補記憶部31は、高次構造候補抽出手段21とステム構造候補抽出手段22とで抽出された各構造候補の形成に必要な塩基の位置などの情報を記憶する。ここで記憶される情報には、最適構造探索手段23で使用される各構造候補が形成されたときの自由エネルギーの値などの何らかのパラメータを含む。
【0025】
(本発明による核酸高次構造予測方法の各工程、並びに本発明による核酸高次構造予測装置及び核酸高次構造予測プログラムの動作等)
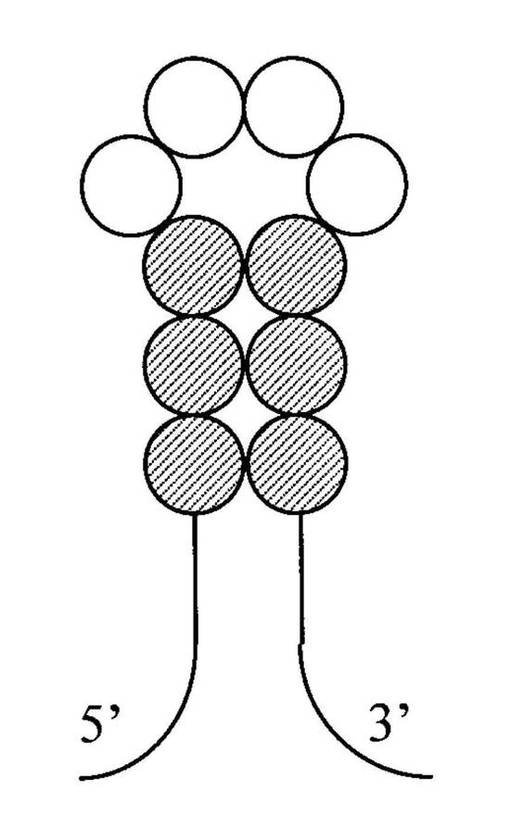
次に、図1、及び図3及び図4のフローチャートを参照して、本発明による核酸高次構造予測方法の各工程、並びに本発明による核酸高次構造予測装置及び核酸高次構造予測プログラムの動作等について詳細に説明する。
【0026】
入力装置1から与えられた核酸配列は、まずは高次構造候補抽出手段21に供給される(A1)。
【0027】
高次構造候補抽出手段21は、供給された配列の中から、任意の高次構造を形成するのに必要な要件を満たす、特徴的な塩基の組合せを抽出する。例えばGカルテット構造を任意の高次構造の予測対象とする場合、高次構造候補抽出手段21は、数塩基のGが連続する領域を4領域抽出する。このようにして抽出された高次構造候補には、その構成塩基に応じて適当なパラメータが与えられる。適当なパラメータとは、上記の高次構造候補抽出手段21で言及した何らかのパラメータに相当するものであって、例えばその高次構造候補が保持する自由エネルギーの値など、供給された配列において予測の対象とする高次構造の取り易さを示す指標が挙げられる。パラメータを与えられた高次構造候補の情報は、構造候補記憶部31に記憶される。この手順は、入力配列に高次構造を形成し得る塩基の組合せが存在する限り、繰り返される(A2)。
【0028】
次に、高次構造候補抽出手段21で抽出の対象とされた核酸配列は、ステム構造候補抽出手段22に供給される。ステム構造候補抽出手段22は、この配列中のステム構造を形成し得る塩基の組合せを抽出し、その構成塩基に応じて適当なパラメータを与える。このようにして抽出されたステム構造候補の情報も、高次構造候補と同様にして構造候補記憶部31に記憶される。この手順も、入力配列にステム構造を形成し得る塩基の組合せが存在する限り、繰り返される(A3)。
【0029】
次に、最適構造探索手段23は、構造候補記憶部31に記憶された高次構造候補及びステム構造候補に基づいて、これらを構成する塩基が重複するなどの、矛盾がないように、これらを単独、又は任意に組み合わせて得た組合せ構造候補のうち、核酸配列の二次構造として最適な組合せ構造を探索する。この最適な組合せ構造を探索する工程の一例として、図4を参照して、説明する。
【0030】
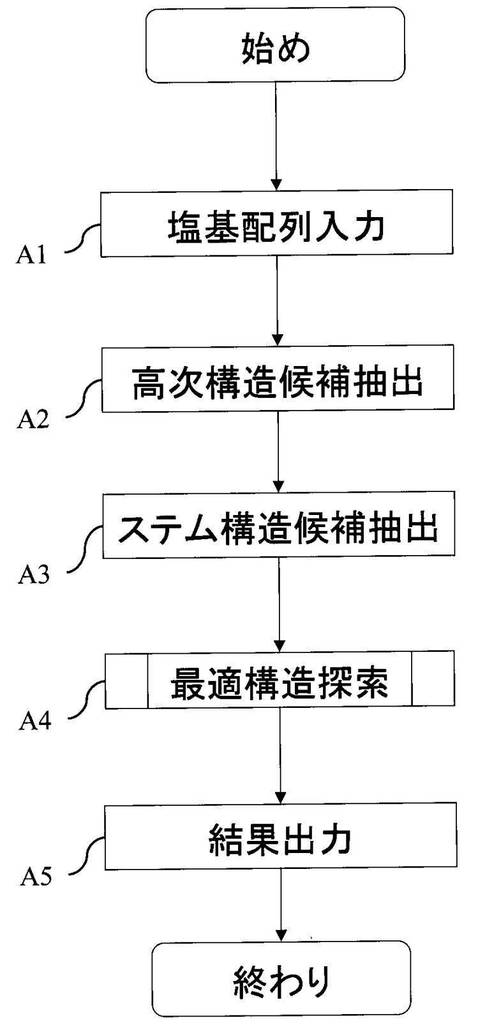
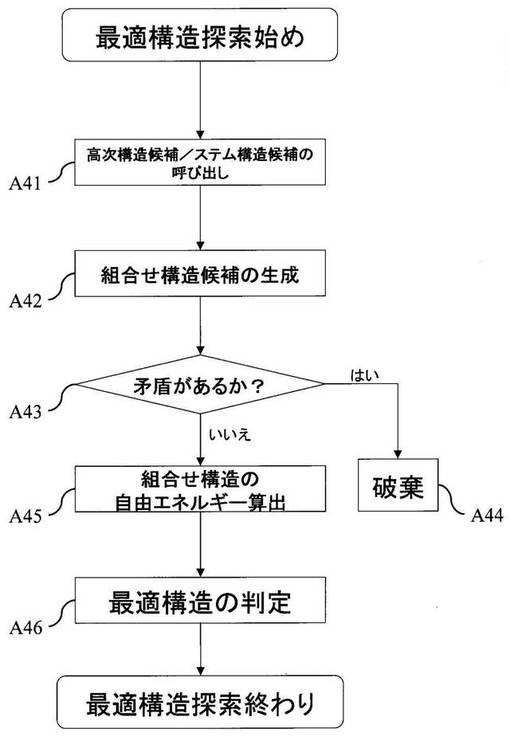
図4は、ステップA4の動作の一例を示すフローチャートである。ステップA4において、最適構造探索手段23は、構造候補記憶部31に記憶された高次構造候補とステム構造候補とを呼び出す(A41)。次に、最適構造探索手段23は、高次構造候補若しくはステム構造候補単独、又はこれらを組み合わせて、組合せ構造候補を生成する(A42)。次に、最適構造探索手段23は、この組合せ構造候補のそれぞれについて、この候補を構成する塩基が重複するなどの、矛盾があるかどうかを判定する(A43)。ステップA43において矛盾があると判定した場合、最適構造探索手段23は、この組合せ構造候補を破棄する(A44)。ステップA43において矛盾がないと判定した場合、最適構造探索手段23は、この組合せ構造候補を組合せ構造として保持し、それぞれの組合せ構造を構成する高次構造候補及び/又はステム構造候補に保持されている自由エネルギーを足し合わせることで、その組合せ構造についての自由エネルギーを算出する(A45)。次に、最適構造探索手段23は、このように算出した自由エネルギーを元に、いずれの組合せ構造が核酸配列の取り得る構造として最適か否かを判定する(A46)。この判定は、最も低い自由エネルギーを与える組合せ構造を最適構造とするものであってもよい。このようにして、最適な組合せ構造を探索する工程が終了する。
【0031】
この最適な組合せ構造を探索する工程としては、その他、ニューラルネットワーク、遺伝的アルゴリズムなどを用いる方法で任意に変更され得る(A4)。
【0032】
次に、ステップA5において、データ処理装置2は、最適構造探索手段23において最適構造と判定された組合せ構造についての情報を、出力装置4に出力する。この出力の際、データ処理装置2は、最適構造探索手段23において判定された最適構造に、高次構造候補抽出手段21で抽出された高次構造候補が含まれているか否かの情報を出力装置4に出力してもよい。また、データ処理装置2は、最適構造探索手段23において最適構造と判定された組合せ構造以外の組合せ構造についての情報も、上述の適当なパラメータの情報とともに、出力してもよい。
【0033】
なお、図1及び図7において、他の装置からデータ処理装置2に入る矢印を実線で示し、データ処理装置2から他の装置へ出る矢印を点線で示す。
【0034】
(その他の構成)
本発明において、複数の核酸配列を構造予測の対象としてもよい。この際、この複数の核酸配列間の一定の関係を、上述の自由エネルギーなどのパラメータとともに、組合せ構造探索の指標として用いてもよい。この複数の核酸配列としては、例えば、進化的に保存された複数の配列や、種間で保存された複数の配列や、類似の機能を持つ複数の配列などが挙げられる。また、複数の核酸配列を用いる際の指標としては、各配列間の保存度や、相同性、カウントベクトルなどにより抽出される塩基の出現傾向の類似度などが挙げられる。
【0035】
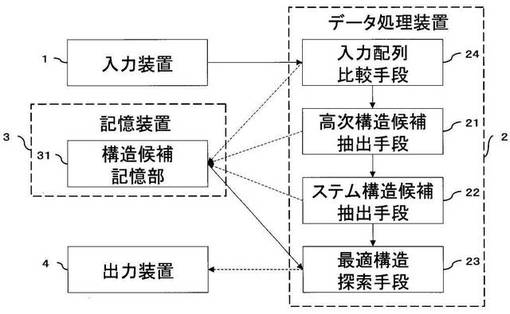
複数の核酸配列を構造予想の対象とする場合の一例について、図7を参照して説明する。図7は、本発明による核酸高次構造予測装置の他の構成を示す概念図である。図7によると、本発明による核酸高次構造予測装置は、入力装置1と、データ処理装置2と、記憶装置3と、出力装置4とを有する。データ処理装置2は、高次構造候補抽出手段21と、ステム構造候補抽出手段22と、最適構造探索手段23と、入力配列比較手段24とを有する。なお、入力装置1、データ処理装置2及び出力装置4、並びに高次構造候補抽出手段21、ステム構造候補抽出手段22及び最適構造探索手段23の構成及び動作については、上述と同様であるので、説明を割愛する。
【0036】
入力配列比較手段24の機能について説明する。入力配列比較手段24は、入力装置1から入力された複数の核酸配列について、これらの複数の核酸配列の間の一定の関係を数値化する。この一定の関係の数値化としては、アライメントなどの相同性検索の方法、カウントベクトルによって抽出された塩基の出現傾向の比較を行う方法などを採用してもよい。一定の関係で得られる数値としては、上述の指標で示した各配列間の保存度や相同性などであってもよい。このようにして得た指標は、構造候補記憶部31に記憶され、最適構造探索手段23による組合せ構造探索に用いられる(A45)。
【0037】
次に、入力配列比較手段24を有する場合の、本発明による核酸高次構造予測方法の各工程、並びに本発明による核酸高次構造予測装置及び核酸高次構造予測プログラムの動作等について、説明する。
【0038】
複数の核酸配列を入力装置1から入力され、上述のステップA2乃至A3の各ステップが行われ、ステップA41乃至A43が行われる。ステップA45において、最適構造探索手段23は、ステップA43において矛盾がないと判定して保持された組合せ構造を構成する高次構造候補及び/又はステム構造候補に保持されている自由エネルギーを足し合わせることで、その組合せ構造についての自由エネルギーを算出するとともに、この算出された自由エネルギーに、入力配列比較手段24で算出された指標で重み付けする。最適構造探索手段23は、このように重み付けされた自由エネルギーを元に、いずれの組合せ構造が核酸配列の取り得る構造として最適か否かを判定する(A46)。その後、ステップA5において、組合せ構造についての情報等の出力が行われる。
【0039】
このように、入力配列比較手段を用いることによって、入力に用いた複数の配列の類似度合いに応じて、個々の配列について良い予測精度を達成することが可能となる。
【実施例】
【0040】
次に、具体例を用いて本実施例の動作を説明する。
【0041】
(実施例1)
入力核酸配列として、入力配列1(GGGCCCGGGAAAGGGAAAGGG;配列番号1)を入力装置1より与え、この配列がGカルテット構造を含む配列であるかどうかを予測するとする(A1)。
【0042】
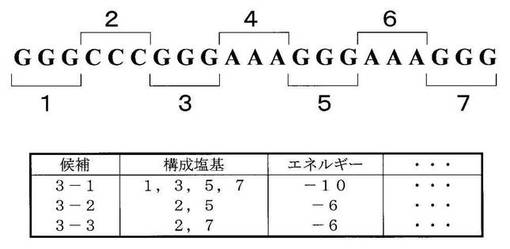
高次構造候補抽出手段21は、入力配列1から、任意の高次構造を形成するために必要な特徴的な塩基の組合せを抽出する。本実施例において、任意の高次構造とは、Gカルテット構造を指すため、入力配列1からGが連続する領域を4つの領域を抽出する。連続領域の長さを3以上と設定し、三つのGカルテット平面によって形成されるGカルテット構造のスタッキングによる自由エネルギーを−10と設定した場合、高次構造候補抽出手段21は、高次構造の候補として図5の候補3−1を構造候補記憶部31に記憶する。入力配列1からは、上述の設定条件において、候補3−1以外の高次構造候補は抽出できない(A2)。
【0043】
次に、ステム構造候補抽出手段22は、入力配列1からステム構造を形成するために必要な塩基の組合せを抽出する。高次構造候補抽出手段21と同じく塩基の連続領域を3以上と設定し、G−C、G−C塩基対間のスタッキングによる自由エネルギーを−3と仮定した場合、ステム構造候補抽出手段22は、ステム構造の候補として図5の候補3−2、候補3−3を構造候補記憶部31に候補3−1と同様にして記憶する。入力配列1からは候補3−2、候補3−3以外のステム構造の候補は抽出できない(A3)。
【0044】
次に、最適構造探索手段23は、最適な組合せ構造を探索する工程を行う。まず、最適構造探索手段23は、構造候補記憶部31に記憶されている高次構造候補である候補3−1と、ステム構造候補である候補3−2及び3−3を呼び出す(A41)。次に、最適構造探索手段23は、候補3−1乃至3−3をそれぞれ任意に組み合わせて、組合せ構造候補を生成し(A42)、矛盾があるかどうかを判定する(A43)。この場合、図5の候補3−1、候補3−2及び候補3−3は、それぞれ他の候補と構成塩基の矛盾が生じるため、最適構造探索手段23は、入力配列1の候補3−1乃至3−3のそれぞれを組合せ構造として保持する。これらの候補が形成されたときに同時に形成されるループ構造のエネルギーを無視した場合、入力配列1が形成する構造のエネルギーは、各構造候補の保持する自由エネルギーの総和と等しくなるため、最適構造探索手段23は、上記の自由エネルギーの設定値に基づいて、候補3−1乃至3−3についての自由エネルギーの総和を算出する(A45)。次に、最適構造探索手段23は、このように算出した自由エネルギーを元に、いずれの組合せ構造が核酸配列の取り得る構造として最適か否かを判定する(A46)。この場合は候補3−1によって形成される構造が最も自由エネルギーの値の低い、安定な構造であるということになる。即ち、自由エネルギー最小化による最適な組合せ構造を探索する工程の結果は、候補3−1の単独ということになる(A46)。この結果は、出力装置4によって出力され(A5)、候補3−1は、Gカルテット構造の候補であるため、入力配列1は、Gカルテット構造という高次構造を取り得るという予測結果が得られる。
【0045】
(実施例2)
同様にして、今度は入力核酸配列として、入力配列1の一部を変更した入力配列2(GGGCCCGGGAAAGGGCCCGGG;配列番号2)を入力装置1より与え、この配列がGカルテット構造を含む配列であるかどうかを予測するとする(A1)。
【0046】
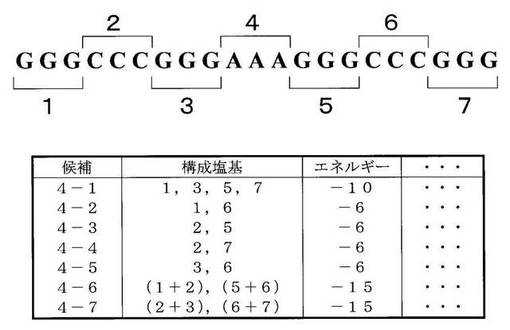
実施例1と同様に、入力配列2について、高次構造候補抽出手段21を用いた、高次構造候補の抽出と、ステム構造候補抽出手段22を用いた、ステム構造候補の抽出とを実行する。実施例1と同様に、連続領域の長さを3以上と設定し、三つのGカルテット平面によって形成されるGカルテット構造のスタッキングによる自由エネルギーを−10と設定し、G−C、C−G塩基対間のスタッキングによる自由エネルギーを−3と同様の値と仮定した場合、構造候補記憶部31には、図6のような構造の候補の情報が記憶される(A2、A3)。
【0047】
次に、最適構造探索手段23は、最適な組合せ構造を探索する工程を行う。まず、最適構造探索手段23は、構造候補記憶部31に記憶されている高次構造候補である候補4−1と、ステム構造候補である候補4−2乃至4−5を呼び出す(A41)。次に、最適構造探索手段23は、候補4−1乃至4−5をそれぞれ任意に組み合わせて組合せ構造候補を生成し(A42)、矛盾があるかどうかを判定する(A43)。この場合、候補4−2と候補4−3との組合せは、矛盾しないが、候補4−6と等しい。また、候補4−4と候補4−5との組合せは、候補4−2及び4−3並びに候補4−6と同様に、矛盾しないが、候補4−7と等しい。したがって、最適構造探索手段23は、入力配列2の候補4−1か候補4−6か候補4−7かのそれぞれを組合せ構造として保持する。実施例1で示した入力配列1と同様に考えると、最適構造探索手段23は、上記の自由エネルギーの設定値に基づいて、候補4−1、候補4−6及び候補4−7についての自由エネルギーの総和を算出する(A45)。次に、最適構造探索手段23は、このように算出した自由エネルギーを元に、いずれの組合せ構造が核酸配列の取り得る構造として最適か否かを判定する(A46)。この場合、候補4−6又は候補4−7のいずかによって形成される構造が最も自由エネルギーの値が低い、安定な構造であるということになる。即ち、自由エネルギー最小化による最適な組合せ構造を探索する工程の結果は、候補4−6又は候補4−7のいずか単独ということになる(A46)。この結果は、出力装置4によって出力される(A5)。ここで、候補4−6も候補4−7も、Gカルテット構造を有するものではないので、入力配列2はGカルテット構造という高次構造を取り得ないという予測結果が得られる。
【産業上の利用可能性】
【0048】
近年のポストゲノム研究において、機能性核酸、特にncRNAが生体内において遺伝子発現制御など様々な重要な機能を担っているということが分かり、ncRNAの同定作業が進んでいるものの、それらが実際に生体内においてどのような機能を担っているかを理解するためには更に詳細な実験を行う必要があるが、実験に用いるべきncRNAを情報学的にスクリーニングするための手段は未だ少ない。そのような問題において、本発明で予測が可能となる高次構造が存在するような配列は何らかの機能を持つことが推定されるため、本発明はこのようなncRNAのスクリーニングに用いることが可能である。
【0049】
また、このような高次構造は人工の核酸配列であるアプタマー分子においても重要な機能を持つと推定されるため、あるアプタマー分子を構成する核酸配列が与えられたときに、その配列の中からアプタマー分子と標的物質との結合において重要な領域を特定するという問題においても、本発明を用いることが可能である。
【0050】
以上、本発明の好適な実施の形態により本発明を説明した。ここでは特定の具体例を示して本発明を説明したが、特許請求の範囲に定義された本発明の広範な趣旨および範囲から逸脱することなく、これら具体例に様々な修正および変更を加えることができることは明らかである。すなわち、具体例の詳細および添付の図面により本発明が限定されるものと解釈してはならない。
【図面の簡単な説明】
【0051】
【図1】本発明による核酸高次構造予測装置の構成を示す概念図である。
【図2】ステム構造の概略図である。
【図3】本発明による核酸高次構造予測装置の動作を示すフローチャートである。
【図4】ステップA4の動作の一例を示すフローチャートである。
【図5】実施例1を説明する図である。
【図6】実施例2を説明する図である。
【図7】本発明による核酸高次構造予測装置の他の構成を示す概念図である。
【符号の説明】
【0052】
1 入力装置
2 データ処理装置
3 記憶装置
4 出力装置
21 高次構造候補抽出手段
22 ステム構造候補抽出手段
23 最適構造探索手段
24 入力配列比較手段
31 構造候補記憶部
【技術分野】
【0001】
本発明は、核酸高次構造予測方法、並びにこの核酸高次構造予測方法を実行する核酸高次構造予測装置及び核酸高次構造予測プログラムに関する。
【背景技術】
【0002】
DNA、RNAなど核酸配列は、アデニン(A)、シトシン(C)、グアニン(G)又はチミン(T)若しくはウラシル(U)の4種類の塩基からなり、AとT若しくはU、又はGとCなどの組合せで水素結合を形成して塩基対となることが知られている。この一般的な塩基対のことを、ワトソン・クリック型塩基対と呼ぶ。核酸配列は、このような塩基対の組合せによって多様な構造を取ることが知られており、とりわけエクソンなどのいわゆる構造遺伝子に代表される機能性核酸において、配列の構造はその機能と密接に関わる。核酸配列の構造において、ワトソン・クリック型塩基対が構成される塩基対の大半を占める一方、配列によってはワトソン・クリック型に寄らない塩基対も形成され得ることが知られている。ワトソン・クリック型に寄らない塩基対とは、例えばA−T(U)、G−C以外のG−A型の塩基対などを指すが、一対一の塩基対ではないという意味で、ここでは三本鎖構造(ベーストリプル構造)や、四本鎖構造(ベースクアドルプル構造)など、一般的な二重螺旋構造ではない高次構造も含める。
【0003】
このような高次構造の有名な例として、4つのGが四本鎖を形成するGカルテット構造が挙げられる。Gカルテット構造は、例えば生体内では真核生物の染色体DNAの末端のテロメア配列で形成され、テロメアーゼによる伸張反応を阻害する機能を持つことが知られている。また、Gカルテット構造は、ある標的物質に対して特異的な親和性を持つ人工の核酸配列であるアプタマー分子においても、標的物質との結合においてGカルテット構造が重要である例が多数報告されている(例えば、非特許文献1)。つまり、Gカルテット構造、或いはそれに類する高次構造の存在を認識することは、核酸配列の機能上の重要な領域を特定する上で、極めて大きな手がかりとなる。
【0004】
しかし、従来の核酸の構造予測の手法は、基本的にはワトソン・クリック型の塩基対の予測を組合せたものであり、このような高次構造を予測するための手法ではない。したがって、Gカルテット構造に代表される核酸の高次構造を予測する方法の開発が求められていた。
【非特許文献1】STEFAN WEISSら著、”RNA Aptamers Specifically Interact with the Prion Protein PrP”、JOURNAL OF VIROLOGY、1997年、11月号、p.8790〜8797
【非特許文献2】J.Kondoら著、”Crystal structures of a DNA octaplex with I−motif of G−quartets and its splitting into two quadruplexes suggest a folding mechanism of eight tandem repeats”、Nucleic Acids Research、2004年、32巻、8号、p.2541〜2549
【発明の開示】
【発明が解決しようとする課題】
【0005】
本発明は、上述の要求に鑑みてなされたものであり、Gカルテット構造に代表される核酸の高次構造を予測し得る方法、並びにこの方法を実行する装置及びプログラムを提供することを目的とする。
【課題を解決するための手段】
【0006】
本発明による核酸高次構造予測方法は、核酸配列の高次構造を予測する核酸高次構造予測方法であって、前記核酸配列において、高次構造を形成し得る塩基を高次構造候補として抽出する工程と、前記核酸配列において、ステム構造を形成し得る塩基をステム構造候補として抽出する工程と、前記高次構造候補と前記ステム構造候補とに基づいて、最適な組合せ構造を探索する工程と、を有することを特徴とする。
【0007】
また、本発明による核酸高次構造予測装置は、核酸配列の高次構造を予測する核酸高次構造予測装置であって、前記核酸配列において、高次構造を形成し得る塩基を高次構造候補として抽出する高次構造候補抽出手段と、前記核酸配列において、ステム構造を形成し得る塩基をステム構造候補として抽出するステム構造候補抽出手段と、前記高次構造候補と前記ステム構造候補とに基づいて、最適な組合せ構造を探索する最適構造探索手段とを有することを特徴とする。
【0008】
また、本発明による核酸高次構造予測プログラムは、核酸配列の高次構造を予測する核酸高次構造予測プログラムであって、前記核酸配列において、高次構造を形成し得る塩基を高次構造候補として抽出する工程と、前記核酸配列において、ステム構造を形成し得る塩基をステム構造候補として抽出する工程と、前記高次構造候補と前記ステム構造候補とに基づいて、最適な組合せ構造を探索する工程と、を実行することを特徴とする。
【0009】
なお、本発明において、核酸高次構造予測装置及び核酸高次構造予測プログラムは、それぞれ核酸高次構造予測方法を実行する装置及びプログラムをいう。また、本発明において、「核酸配列」とは、DNA、RNAなど、種々の遺伝子の配列をいう。
【発明の効果】
【0010】
本発明によれば、ワトソン・クリック型の塩基対予測の組合せでは予測することが不可能である種類の核酸配列の高次構造を予測することが可能となる。
【0011】
その理由は、ワトソン・クリック型の塩基対によって形成されるステム構造の候補と、それには寄らない核酸の高次構造を、共通の構成要素(構成塩基、それに付随するパラメータなど)にまとめることによって、核酸の高次構造の予測を二次構造予測の範疇に落とし込むことができるためである。
【0012】
また、本発明によれば、機能未知の核酸配列から、遺伝子発現の制御等、生物学的に有意な遺伝子配列をスクリーニングする際の指標として用いることが可能となる。
【0013】
その理由は、通常の二次構造予測で予測される構造からその元配列に何らかの機能があるかどうかを判定することは困難であるが、本発明において予測が可能となるような核酸の高次構造は、生体内で何らかの特徴的な機能を持つことが多いためである。
【0014】
さらに、本発明によれば、高次構造を取り得る核酸配列の二次構造を精度良く予測できることにある。
【0015】
その理由は、このような高次構造を持つ配列に対して通常の二次構造予測を行った場合、高次構造を予測できないことは当然として、本来高次構造を形成するべき領域が何らかの他の構造を形成すると判定される影響でその他の領域に対する予測の精度も低下する可能性が高いが、本発明を用いればそのような事態は発生し得ないためである。
【発明を実施するための最良の形態】
【0016】
(本発明による核酸高次構造予測装置の構成および各構成の機能等)
図1は、本発明による核酸高次構造予測装置の構成を示す概念図である。本発明による核酸高次構造予測装置は、キーボードなどの入力装置1と、プログラム制御により動作するデータ処理装置2と、情報を記憶する記憶装置3と、ディスプレイ装置や印刷装置などの出力装置4とを有する。
【0017】
データ処理装置2は、高次構造候補抽出手段21と、ステム構造候補抽出手段22と、最適構造探索手段23とを備える。
【0018】
高次構造候補抽出手段21は、入力装置1から入力された、構造予測の対象とする配列を取得し、その配列の中で任意の高次構造を形成し得る塩基の組合せを抽出する。
【0019】
任意の高次構造としては、ワトソン・クリック型を取る二重螺旋構造以外の、構成塩基を配列の特徴として配列上に示し得る構造であれば、特に制約はない。特にその構造を形成するためにある程度限定された塩基の組み合わせが必要であることが分かっており、その構造を形成し得る領域の候補を配列上に示すことができる構造が挙げられる。例示すれば、ワトソン・クリック型ではない塩基対からなる二重螺旋構造、ワトソン・クリック型を取る三本鎖以上の構造(三本鎖構造、四本鎖構造等)などが挙げられる。なかでも、グアニン残基が連続した4つの領域からなるGカルテット、8本のDNA鎖が寄り集まって形成される八重螺旋構造(Gカルテット I−モチーフ。非特許文献2参照。)が例示される。
【0020】
高次構造候補抽出手段21は、この任意の高次構造を形成するのに必要な塩基の要件に基づいて、構造予測の対象配列から高次構造の候補を抽出する。例えば、高次構造候補抽出手段21は、構造予測の対象とする高次構造がGカルテット構造である場合、数塩基のGが連続する配列中の領域を4領域抽出する。抽出された塩基は、構造の候補として構造候補記憶部31に記憶される。この際、記憶された各高次構造候補は、後に行う最適構造探索手段23で用いる構造候補の組合せ構造探索の指標となる、何らかのパラメータを任意に保持することが可能である。ここで言う何らかのパラメータとは、例えば構造候補が保持する自由エネルギーの値など、核酸配列の高次構造の取り易さを示す指標が挙げられる。
【0021】
ステム構造候補抽出手段22は、高次構造候補抽出手段21で抽出の対象とされた配列から、ステム構造を形成し得る塩基の組合せを抽出する。ここで言うステム構造とは、ワトソン・クリック型塩基対の連続する領域のことであり、例えば、図2の黒丸で示した箇所の構造を言う。このステム構造は、上述の高次構造候補と同じく最適構造探索手段23で用いる構造候補の組合せ構造探索の指標となる、何らかのパラメータを任意に保持することが可能である。抽出された塩基は、構造の候補として、高次構造候補抽出手段21で記憶された構造候補と共に、構造候補記憶部31に記憶される。なお、組合せ構造探索の指標となる、何らかのパラメータとは、上記の高次構造候補抽出手段21で言及したパラメータと同様のものをいう。
【0022】
最適構造探索手段23は、構造候補記憶部31に記憶されている高次構造候補とステム構造候補とに基づいて、最適な組合せ構造の探索(本発明において、組合せ構造探索ともいう。)を行う。ここで行う組合せ構造探索のアルゴリズムは、高次構造候補及びステム構造候補の構造候補のそれぞれで使用される塩基が重複するなどの、矛盾がないことが最低条件となる。その具体的なアルゴリズムは、構造全体の自由エネルギーを最小にする構造候補の組合せを抜き出す方法の他に、ニューラルネットワークを用いて構造候補を抜き出す方法、遺伝的アルゴリズムを用いて構造候補を抜き出す方法など幾通りも考えられるため、ユーザーの要求に応じて任意のアルゴリズムを選択することが可能である。
【0023】
記憶装置3は、構造候補記憶部31を備える。
【0024】
構造候補記憶部31は、高次構造候補抽出手段21とステム構造候補抽出手段22とで抽出された各構造候補の形成に必要な塩基の位置などの情報を記憶する。ここで記憶される情報には、最適構造探索手段23で使用される各構造候補が形成されたときの自由エネルギーの値などの何らかのパラメータを含む。
【0025】
(本発明による核酸高次構造予測方法の各工程、並びに本発明による核酸高次構造予測装置及び核酸高次構造予測プログラムの動作等)
次に、図1、及び図3及び図4のフローチャートを参照して、本発明による核酸高次構造予測方法の各工程、並びに本発明による核酸高次構造予測装置及び核酸高次構造予測プログラムの動作等について詳細に説明する。
【0026】
入力装置1から与えられた核酸配列は、まずは高次構造候補抽出手段21に供給される(A1)。
【0027】
高次構造候補抽出手段21は、供給された配列の中から、任意の高次構造を形成するのに必要な要件を満たす、特徴的な塩基の組合せを抽出する。例えばGカルテット構造を任意の高次構造の予測対象とする場合、高次構造候補抽出手段21は、数塩基のGが連続する領域を4領域抽出する。このようにして抽出された高次構造候補には、その構成塩基に応じて適当なパラメータが与えられる。適当なパラメータとは、上記の高次構造候補抽出手段21で言及した何らかのパラメータに相当するものであって、例えばその高次構造候補が保持する自由エネルギーの値など、供給された配列において予測の対象とする高次構造の取り易さを示す指標が挙げられる。パラメータを与えられた高次構造候補の情報は、構造候補記憶部31に記憶される。この手順は、入力配列に高次構造を形成し得る塩基の組合せが存在する限り、繰り返される(A2)。
【0028】
次に、高次構造候補抽出手段21で抽出の対象とされた核酸配列は、ステム構造候補抽出手段22に供給される。ステム構造候補抽出手段22は、この配列中のステム構造を形成し得る塩基の組合せを抽出し、その構成塩基に応じて適当なパラメータを与える。このようにして抽出されたステム構造候補の情報も、高次構造候補と同様にして構造候補記憶部31に記憶される。この手順も、入力配列にステム構造を形成し得る塩基の組合せが存在する限り、繰り返される(A3)。
【0029】
次に、最適構造探索手段23は、構造候補記憶部31に記憶された高次構造候補及びステム構造候補に基づいて、これらを構成する塩基が重複するなどの、矛盾がないように、これらを単独、又は任意に組み合わせて得た組合せ構造候補のうち、核酸配列の二次構造として最適な組合せ構造を探索する。この最適な組合せ構造を探索する工程の一例として、図4を参照して、説明する。
【0030】
図4は、ステップA4の動作の一例を示すフローチャートである。ステップA4において、最適構造探索手段23は、構造候補記憶部31に記憶された高次構造候補とステム構造候補とを呼び出す(A41)。次に、最適構造探索手段23は、高次構造候補若しくはステム構造候補単独、又はこれらを組み合わせて、組合せ構造候補を生成する(A42)。次に、最適構造探索手段23は、この組合せ構造候補のそれぞれについて、この候補を構成する塩基が重複するなどの、矛盾があるかどうかを判定する(A43)。ステップA43において矛盾があると判定した場合、最適構造探索手段23は、この組合せ構造候補を破棄する(A44)。ステップA43において矛盾がないと判定した場合、最適構造探索手段23は、この組合せ構造候補を組合せ構造として保持し、それぞれの組合せ構造を構成する高次構造候補及び/又はステム構造候補に保持されている自由エネルギーを足し合わせることで、その組合せ構造についての自由エネルギーを算出する(A45)。次に、最適構造探索手段23は、このように算出した自由エネルギーを元に、いずれの組合せ構造が核酸配列の取り得る構造として最適か否かを判定する(A46)。この判定は、最も低い自由エネルギーを与える組合せ構造を最適構造とするものであってもよい。このようにして、最適な組合せ構造を探索する工程が終了する。
【0031】
この最適な組合せ構造を探索する工程としては、その他、ニューラルネットワーク、遺伝的アルゴリズムなどを用いる方法で任意に変更され得る(A4)。
【0032】
次に、ステップA5において、データ処理装置2は、最適構造探索手段23において最適構造と判定された組合せ構造についての情報を、出力装置4に出力する。この出力の際、データ処理装置2は、最適構造探索手段23において判定された最適構造に、高次構造候補抽出手段21で抽出された高次構造候補が含まれているか否かの情報を出力装置4に出力してもよい。また、データ処理装置2は、最適構造探索手段23において最適構造と判定された組合せ構造以外の組合せ構造についての情報も、上述の適当なパラメータの情報とともに、出力してもよい。
【0033】
なお、図1及び図7において、他の装置からデータ処理装置2に入る矢印を実線で示し、データ処理装置2から他の装置へ出る矢印を点線で示す。
【0034】
(その他の構成)
本発明において、複数の核酸配列を構造予測の対象としてもよい。この際、この複数の核酸配列間の一定の関係を、上述の自由エネルギーなどのパラメータとともに、組合せ構造探索の指標として用いてもよい。この複数の核酸配列としては、例えば、進化的に保存された複数の配列や、種間で保存された複数の配列や、類似の機能を持つ複数の配列などが挙げられる。また、複数の核酸配列を用いる際の指標としては、各配列間の保存度や、相同性、カウントベクトルなどにより抽出される塩基の出現傾向の類似度などが挙げられる。
【0035】
複数の核酸配列を構造予想の対象とする場合の一例について、図7を参照して説明する。図7は、本発明による核酸高次構造予測装置の他の構成を示す概念図である。図7によると、本発明による核酸高次構造予測装置は、入力装置1と、データ処理装置2と、記憶装置3と、出力装置4とを有する。データ処理装置2は、高次構造候補抽出手段21と、ステム構造候補抽出手段22と、最適構造探索手段23と、入力配列比較手段24とを有する。なお、入力装置1、データ処理装置2及び出力装置4、並びに高次構造候補抽出手段21、ステム構造候補抽出手段22及び最適構造探索手段23の構成及び動作については、上述と同様であるので、説明を割愛する。
【0036】
入力配列比較手段24の機能について説明する。入力配列比較手段24は、入力装置1から入力された複数の核酸配列について、これらの複数の核酸配列の間の一定の関係を数値化する。この一定の関係の数値化としては、アライメントなどの相同性検索の方法、カウントベクトルによって抽出された塩基の出現傾向の比較を行う方法などを採用してもよい。一定の関係で得られる数値としては、上述の指標で示した各配列間の保存度や相同性などであってもよい。このようにして得た指標は、構造候補記憶部31に記憶され、最適構造探索手段23による組合せ構造探索に用いられる(A45)。
【0037】
次に、入力配列比較手段24を有する場合の、本発明による核酸高次構造予測方法の各工程、並びに本発明による核酸高次構造予測装置及び核酸高次構造予測プログラムの動作等について、説明する。
【0038】
複数の核酸配列を入力装置1から入力され、上述のステップA2乃至A3の各ステップが行われ、ステップA41乃至A43が行われる。ステップA45において、最適構造探索手段23は、ステップA43において矛盾がないと判定して保持された組合せ構造を構成する高次構造候補及び/又はステム構造候補に保持されている自由エネルギーを足し合わせることで、その組合せ構造についての自由エネルギーを算出するとともに、この算出された自由エネルギーに、入力配列比較手段24で算出された指標で重み付けする。最適構造探索手段23は、このように重み付けされた自由エネルギーを元に、いずれの組合せ構造が核酸配列の取り得る構造として最適か否かを判定する(A46)。その後、ステップA5において、組合せ構造についての情報等の出力が行われる。
【0039】
このように、入力配列比較手段を用いることによって、入力に用いた複数の配列の類似度合いに応じて、個々の配列について良い予測精度を達成することが可能となる。
【実施例】
【0040】
次に、具体例を用いて本実施例の動作を説明する。
【0041】
(実施例1)
入力核酸配列として、入力配列1(GGGCCCGGGAAAGGGAAAGGG;配列番号1)を入力装置1より与え、この配列がGカルテット構造を含む配列であるかどうかを予測するとする(A1)。
【0042】
高次構造候補抽出手段21は、入力配列1から、任意の高次構造を形成するために必要な特徴的な塩基の組合せを抽出する。本実施例において、任意の高次構造とは、Gカルテット構造を指すため、入力配列1からGが連続する領域を4つの領域を抽出する。連続領域の長さを3以上と設定し、三つのGカルテット平面によって形成されるGカルテット構造のスタッキングによる自由エネルギーを−10と設定した場合、高次構造候補抽出手段21は、高次構造の候補として図5の候補3−1を構造候補記憶部31に記憶する。入力配列1からは、上述の設定条件において、候補3−1以外の高次構造候補は抽出できない(A2)。
【0043】
次に、ステム構造候補抽出手段22は、入力配列1からステム構造を形成するために必要な塩基の組合せを抽出する。高次構造候補抽出手段21と同じく塩基の連続領域を3以上と設定し、G−C、G−C塩基対間のスタッキングによる自由エネルギーを−3と仮定した場合、ステム構造候補抽出手段22は、ステム構造の候補として図5の候補3−2、候補3−3を構造候補記憶部31に候補3−1と同様にして記憶する。入力配列1からは候補3−2、候補3−3以外のステム構造の候補は抽出できない(A3)。
【0044】
次に、最適構造探索手段23は、最適な組合せ構造を探索する工程を行う。まず、最適構造探索手段23は、構造候補記憶部31に記憶されている高次構造候補である候補3−1と、ステム構造候補である候補3−2及び3−3を呼び出す(A41)。次に、最適構造探索手段23は、候補3−1乃至3−3をそれぞれ任意に組み合わせて、組合せ構造候補を生成し(A42)、矛盾があるかどうかを判定する(A43)。この場合、図5の候補3−1、候補3−2及び候補3−3は、それぞれ他の候補と構成塩基の矛盾が生じるため、最適構造探索手段23は、入力配列1の候補3−1乃至3−3のそれぞれを組合せ構造として保持する。これらの候補が形成されたときに同時に形成されるループ構造のエネルギーを無視した場合、入力配列1が形成する構造のエネルギーは、各構造候補の保持する自由エネルギーの総和と等しくなるため、最適構造探索手段23は、上記の自由エネルギーの設定値に基づいて、候補3−1乃至3−3についての自由エネルギーの総和を算出する(A45)。次に、最適構造探索手段23は、このように算出した自由エネルギーを元に、いずれの組合せ構造が核酸配列の取り得る構造として最適か否かを判定する(A46)。この場合は候補3−1によって形成される構造が最も自由エネルギーの値の低い、安定な構造であるということになる。即ち、自由エネルギー最小化による最適な組合せ構造を探索する工程の結果は、候補3−1の単独ということになる(A46)。この結果は、出力装置4によって出力され(A5)、候補3−1は、Gカルテット構造の候補であるため、入力配列1は、Gカルテット構造という高次構造を取り得るという予測結果が得られる。
【0045】
(実施例2)
同様にして、今度は入力核酸配列として、入力配列1の一部を変更した入力配列2(GGGCCCGGGAAAGGGCCCGGG;配列番号2)を入力装置1より与え、この配列がGカルテット構造を含む配列であるかどうかを予測するとする(A1)。
【0046】
実施例1と同様に、入力配列2について、高次構造候補抽出手段21を用いた、高次構造候補の抽出と、ステム構造候補抽出手段22を用いた、ステム構造候補の抽出とを実行する。実施例1と同様に、連続領域の長さを3以上と設定し、三つのGカルテット平面によって形成されるGカルテット構造のスタッキングによる自由エネルギーを−10と設定し、G−C、C−G塩基対間のスタッキングによる自由エネルギーを−3と同様の値と仮定した場合、構造候補記憶部31には、図6のような構造の候補の情報が記憶される(A2、A3)。
【0047】
次に、最適構造探索手段23は、最適な組合せ構造を探索する工程を行う。まず、最適構造探索手段23は、構造候補記憶部31に記憶されている高次構造候補である候補4−1と、ステム構造候補である候補4−2乃至4−5を呼び出す(A41)。次に、最適構造探索手段23は、候補4−1乃至4−5をそれぞれ任意に組み合わせて組合せ構造候補を生成し(A42)、矛盾があるかどうかを判定する(A43)。この場合、候補4−2と候補4−3との組合せは、矛盾しないが、候補4−6と等しい。また、候補4−4と候補4−5との組合せは、候補4−2及び4−3並びに候補4−6と同様に、矛盾しないが、候補4−7と等しい。したがって、最適構造探索手段23は、入力配列2の候補4−1か候補4−6か候補4−7かのそれぞれを組合せ構造として保持する。実施例1で示した入力配列1と同様に考えると、最適構造探索手段23は、上記の自由エネルギーの設定値に基づいて、候補4−1、候補4−6及び候補4−7についての自由エネルギーの総和を算出する(A45)。次に、最適構造探索手段23は、このように算出した自由エネルギーを元に、いずれの組合せ構造が核酸配列の取り得る構造として最適か否かを判定する(A46)。この場合、候補4−6又は候補4−7のいずかによって形成される構造が最も自由エネルギーの値が低い、安定な構造であるということになる。即ち、自由エネルギー最小化による最適な組合せ構造を探索する工程の結果は、候補4−6又は候補4−7のいずか単独ということになる(A46)。この結果は、出力装置4によって出力される(A5)。ここで、候補4−6も候補4−7も、Gカルテット構造を有するものではないので、入力配列2はGカルテット構造という高次構造を取り得ないという予測結果が得られる。
【産業上の利用可能性】
【0048】
近年のポストゲノム研究において、機能性核酸、特にncRNAが生体内において遺伝子発現制御など様々な重要な機能を担っているということが分かり、ncRNAの同定作業が進んでいるものの、それらが実際に生体内においてどのような機能を担っているかを理解するためには更に詳細な実験を行う必要があるが、実験に用いるべきncRNAを情報学的にスクリーニングするための手段は未だ少ない。そのような問題において、本発明で予測が可能となる高次構造が存在するような配列は何らかの機能を持つことが推定されるため、本発明はこのようなncRNAのスクリーニングに用いることが可能である。
【0049】
また、このような高次構造は人工の核酸配列であるアプタマー分子においても重要な機能を持つと推定されるため、あるアプタマー分子を構成する核酸配列が与えられたときに、その配列の中からアプタマー分子と標的物質との結合において重要な領域を特定するという問題においても、本発明を用いることが可能である。
【0050】
以上、本発明の好適な実施の形態により本発明を説明した。ここでは特定の具体例を示して本発明を説明したが、特許請求の範囲に定義された本発明の広範な趣旨および範囲から逸脱することなく、これら具体例に様々な修正および変更を加えることができることは明らかである。すなわち、具体例の詳細および添付の図面により本発明が限定されるものと解釈してはならない。
【図面の簡単な説明】
【0051】
【図1】本発明による核酸高次構造予測装置の構成を示す概念図である。
【図2】ステム構造の概略図である。
【図3】本発明による核酸高次構造予測装置の動作を示すフローチャートである。
【図4】ステップA4の動作の一例を示すフローチャートである。
【図5】実施例1を説明する図である。
【図6】実施例2を説明する図である。
【図7】本発明による核酸高次構造予測装置の他の構成を示す概念図である。
【符号の説明】
【0052】
1 入力装置
2 データ処理装置
3 記憶装置
4 出力装置
21 高次構造候補抽出手段
22 ステム構造候補抽出手段
23 最適構造探索手段
24 入力配列比較手段
31 構造候補記憶部
【特許請求の範囲】
【請求項1】
核酸配列の高次構造を予測する核酸高次構造予測方法であって、
前記核酸配列において、高次構造を形成し得る塩基を高次構造候補として抽出する工程と、
前記核酸配列において、ステム構造を形成し得る塩基をステム構造候補として抽出する工程と、
前記高次構造候補と前記ステム構造候補とに基づいて、最適な組合せ構造を探索する工程と、
を有することを特徴とする核酸高次構造予測方法。
【請求項2】
前記の最適な組合せ構造を探索する工程は、前記高次構造候補及び前記ステム構造候補を構成する塩基に矛盾がないように、該高次構造候補又は該ステム構造候補を単独、又は任意に組み合わせて得た組合せ構造のうち、最も小さい自由エネルギーを与える組合せ構造を最適構造と判定する工程であることを特徴とする請求項1に記載の核酸高次構造予測方法。
【請求項3】
複数の前記核酸配列において、該複数の核酸配列の間の関係を数値化する工程をさらに有することを特徴とする請求項1又は2に記載の核酸高次構造予測方法。
【請求項4】
前記の複数の核酸配列の間の関係を数値化する工程は、該複数の核酸配列の間の保存度を算出する工程であることを特徴とする請求項3に記載の核酸高次構造予測方法。
【請求項5】
前記の複数の核酸配列は、進化的に保存されていることを特徴とする請求項3又は4に記載の核酸高次構造予測方法。
【請求項6】
前記高次構造は、Gカルテットであることを特徴とする請求項1乃至5のいずれか一項に記載の核酸高次構造予測方法。
【請求項7】
核酸配列の高次構造を予測する核酸高次構造予測装置であって、
前記核酸配列において、高次構造を形成し得る塩基を高次構造候補として抽出する高次構造候補抽出手段と、
前記核酸配列において、ステム構造を形成し得る塩基をステム構造候補として抽出するステム構造候補抽出手段と、
前記高次構造候補と前記ステム構造候補とに基づいて、最適な組合せ構造を探索する最適構造探索手段と
を有することを特徴とする核酸高次構造予測装置。
【請求項8】
前記最適構造探索手段は、前記高次構造候補及び前記ステム構造候補を構成する塩基に矛盾がないように、該高次構造候補又は該ステム構造候補を単独、又は任意に組み合わせて得た組合せ構造のうち、最も小さい自由エネルギーを与える組合せ構造を最適構造と判定することを特徴とする請求項7に記載の核酸高次構造予測装置。
【請求項9】
複数の前記核酸配列において、該複数の核酸配列の間の関係を数値化する入力配列比較手段をさらに有することを特徴とする請求項7又は8に記載の核酸高次構造予測装置。
【請求項10】
前記入力配列比較手段は、前記の複数の核酸配列の間の保存度を算出することを特徴とする請求項9に記載の核酸高次構造予測装置。
【請求項11】
前記の複数の核酸配列は、進化的に保存されていることを特徴とする請求項9又は10に記載の核酸高次構造予測装置。
【請求項12】
前記高次構造は、Gカルテットであることを特徴とする請求項7乃至11のいずれか一項に記載の核酸高次構造予測装置。
【請求項13】
核酸配列の高次構造を予測する核酸高次構造予測プログラムであって、
前記核酸配列において、高次構造を形成し得る塩基を高次構造候補として抽出する工程と、
前記核酸配列において、ステム構造を形成し得る塩基をステム構造候補として抽出する工程と、
前記高次構造候補と前記ステム構造候補とに基づいて、最適な組合せ構造を探索する工程と、
を実行することを特徴とする核酸高次構造予測プログラム。
【請求項14】
前記の最適な組合せ構造を探索する工程は、前記高次構造候補及び前記ステム構造候補を構成する塩基に矛盾がないように、該高次構造候補又は該ステム構造候補を単独、又は任意に組み合わせて得た組合せ構造のうち、最も小さい自由エネルギーを与える組合せ構造を最適構造と判定する工程であることを特徴とする請求項13に記載の核酸高次構造予測プログラム。
【請求項15】
複数の前記核酸配列において、該複数の核酸配列の間の関係を数値化する工程をさらに実行することを特徴とする請求項13又は14に記載の核酸高次構造予測プログラム。
【請求項16】
前記の複数の核酸配列の間の関係を数値化する工程は、該複数の核酸配列の間の保存度を算出する工程であることを特徴とする請求項15に記載の核酸高次構造予測プログラム。
【請求項17】
前記の複数の核酸配列は、進化的に保存されていることを特徴とする請求項15又は16に記載の核酸高次構造予測プログラム。
【請求項18】
前記高次構造は、Gカルテットであることを特徴とする請求項13乃至17のいずれか一項に記載の核酸高次構造予測プログラム。
【請求項1】
核酸配列の高次構造を予測する核酸高次構造予測方法であって、
前記核酸配列において、高次構造を形成し得る塩基を高次構造候補として抽出する工程と、
前記核酸配列において、ステム構造を形成し得る塩基をステム構造候補として抽出する工程と、
前記高次構造候補と前記ステム構造候補とに基づいて、最適な組合せ構造を探索する工程と、
を有することを特徴とする核酸高次構造予測方法。
【請求項2】
前記の最適な組合せ構造を探索する工程は、前記高次構造候補及び前記ステム構造候補を構成する塩基に矛盾がないように、該高次構造候補又は該ステム構造候補を単独、又は任意に組み合わせて得た組合せ構造のうち、最も小さい自由エネルギーを与える組合せ構造を最適構造と判定する工程であることを特徴とする請求項1に記載の核酸高次構造予測方法。
【請求項3】
複数の前記核酸配列において、該複数の核酸配列の間の関係を数値化する工程をさらに有することを特徴とする請求項1又は2に記載の核酸高次構造予測方法。
【請求項4】
前記の複数の核酸配列の間の関係を数値化する工程は、該複数の核酸配列の間の保存度を算出する工程であることを特徴とする請求項3に記載の核酸高次構造予測方法。
【請求項5】
前記の複数の核酸配列は、進化的に保存されていることを特徴とする請求項3又は4に記載の核酸高次構造予測方法。
【請求項6】
前記高次構造は、Gカルテットであることを特徴とする請求項1乃至5のいずれか一項に記載の核酸高次構造予測方法。
【請求項7】
核酸配列の高次構造を予測する核酸高次構造予測装置であって、
前記核酸配列において、高次構造を形成し得る塩基を高次構造候補として抽出する高次構造候補抽出手段と、
前記核酸配列において、ステム構造を形成し得る塩基をステム構造候補として抽出するステム構造候補抽出手段と、
前記高次構造候補と前記ステム構造候補とに基づいて、最適な組合せ構造を探索する最適構造探索手段と
を有することを特徴とする核酸高次構造予測装置。
【請求項8】
前記最適構造探索手段は、前記高次構造候補及び前記ステム構造候補を構成する塩基に矛盾がないように、該高次構造候補又は該ステム構造候補を単独、又は任意に組み合わせて得た組合せ構造のうち、最も小さい自由エネルギーを与える組合せ構造を最適構造と判定することを特徴とする請求項7に記載の核酸高次構造予測装置。
【請求項9】
複数の前記核酸配列において、該複数の核酸配列の間の関係を数値化する入力配列比較手段をさらに有することを特徴とする請求項7又は8に記載の核酸高次構造予測装置。
【請求項10】
前記入力配列比較手段は、前記の複数の核酸配列の間の保存度を算出することを特徴とする請求項9に記載の核酸高次構造予測装置。
【請求項11】
前記の複数の核酸配列は、進化的に保存されていることを特徴とする請求項9又は10に記載の核酸高次構造予測装置。
【請求項12】
前記高次構造は、Gカルテットであることを特徴とする請求項7乃至11のいずれか一項に記載の核酸高次構造予測装置。
【請求項13】
核酸配列の高次構造を予測する核酸高次構造予測プログラムであって、
前記核酸配列において、高次構造を形成し得る塩基を高次構造候補として抽出する工程と、
前記核酸配列において、ステム構造を形成し得る塩基をステム構造候補として抽出する工程と、
前記高次構造候補と前記ステム構造候補とに基づいて、最適な組合せ構造を探索する工程と、
を実行することを特徴とする核酸高次構造予測プログラム。
【請求項14】
前記の最適な組合せ構造を探索する工程は、前記高次構造候補及び前記ステム構造候補を構成する塩基に矛盾がないように、該高次構造候補又は該ステム構造候補を単独、又は任意に組み合わせて得た組合せ構造のうち、最も小さい自由エネルギーを与える組合せ構造を最適構造と判定する工程であることを特徴とする請求項13に記載の核酸高次構造予測プログラム。
【請求項15】
複数の前記核酸配列において、該複数の核酸配列の間の関係を数値化する工程をさらに実行することを特徴とする請求項13又は14に記載の核酸高次構造予測プログラム。
【請求項16】
前記の複数の核酸配列の間の関係を数値化する工程は、該複数の核酸配列の間の保存度を算出する工程であることを特徴とする請求項15に記載の核酸高次構造予測プログラム。
【請求項17】
前記の複数の核酸配列は、進化的に保存されていることを特徴とする請求項15又は16に記載の核酸高次構造予測プログラム。
【請求項18】
前記高次構造は、Gカルテットであることを特徴とする請求項13乃至17のいずれか一項に記載の核酸高次構造予測プログラム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【公開番号】特開2008−118923(P2008−118923A)
【公開日】平成20年5月29日(2008.5.29)
【国際特許分類】
【出願番号】特願2006−306621(P2006−306621)
【出願日】平成18年11月13日(2006.11.13)
【新規性喪失の例外の表示】特許法第30条第1項適用申請有り 平成18年7月18日、第8回日本RNA学会年会事務局発行の「第8回日本RNA学会年会(第8回RNAミーティング)要旨集」に発表 〔刊行物等〕平成18年7月18日、日本RNA学会主催の「第8回日本RNA学会年会(第8回RNAミーティング)」で「RNAアプタマーの二次構造予測アルゴリズム」のポスターをもって発表
【国等の委託研究の成果に係る記載事項】(出願人による申告)平成16年度、独立行政法人新エネルギー・産業技術総合開発機構、「ハイスループットアプタマー作成システムの開発事業(平成16年度新エネ研第1227003号)」に関する研究開発、産業再生法第30条の適用を受ける特許出願
【出願人】(000232092)NECソフト株式会社 (173)
【Fターム(参考)】
【公開日】平成20年5月29日(2008.5.29)
【国際特許分類】
【出願日】平成18年11月13日(2006.11.13)
【新規性喪失の例外の表示】特許法第30条第1項適用申請有り 平成18年7月18日、第8回日本RNA学会年会事務局発行の「第8回日本RNA学会年会(第8回RNAミーティング)要旨集」に発表 〔刊行物等〕平成18年7月18日、日本RNA学会主催の「第8回日本RNA学会年会(第8回RNAミーティング)」で「RNAアプタマーの二次構造予測アルゴリズム」のポスターをもって発表
【国等の委託研究の成果に係る記載事項】(出願人による申告)平成16年度、独立行政法人新エネルギー・産業技術総合開発機構、「ハイスループットアプタマー作成システムの開発事業(平成16年度新エネ研第1227003号)」に関する研究開発、産業再生法第30条の適用を受ける特許出願
【出願人】(000232092)NECソフト株式会社 (173)
【Fターム(参考)】
[ Back to top ]