
検索クエリ関連単語出力装置、検索クエリ関連単語出力方法および検索補助システム
【課題】入力されたキーワードに対して適切なキーワードを出力できる検索クエリ関連単語出力装置を提供すること。
【解決手段】検索クエリ関連単語出力装置10は、ウェブコーパスを記憶するウェブコーパスDB17と、因果関係モデルに基づいて定義される第1ノードおよび第2ノードと、各ノードに該当する単語を抽出する抽出条件とを設定し、この抽出条件で前記ウェブコーパスを解析して各ノードに該当する単語を抽出する属性解析部12と、第1ノードに含まれる単語と第2ノードに含まれる単語の共起頻度に基づく因果関係情報を記憶する因果関係DB18と、入力されたキーワードに対応する第1ノードを判定するノード判定部15と、ノード判定部15で判定された第1ノードに対応する第2ノードにおいて、前記キーワードに対する共起確率の高い単語を、前記因果関係記憶部に記憶された因果関係情報から求めて出力する出力部16とを備える。
【解決手段】検索クエリ関連単語出力装置10は、ウェブコーパスを記憶するウェブコーパスDB17と、因果関係モデルに基づいて定義される第1ノードおよび第2ノードと、各ノードに該当する単語を抽出する抽出条件とを設定し、この抽出条件で前記ウェブコーパスを解析して各ノードに該当する単語を抽出する属性解析部12と、第1ノードに含まれる単語と第2ノードに含まれる単語の共起頻度に基づく因果関係情報を記憶する因果関係DB18と、入力されたキーワードに対応する第1ノードを判定するノード判定部15と、ノード判定部15で判定された第1ノードに対応する第2ノードにおいて、前記キーワードに対する共起確率の高い単語を、前記因果関係記憶部に記憶された因果関係情報から求めて出力する出力部16とを備える。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、検索クエリに関連する単語を出力する検索クエリ関連単語出力装置、検索クエリ関連単語出力方法および検索補助システムに関する。
【背景技術】
【0002】
インターネット上の情報を検索するシステムとして、キーワード検索機能を備えたサーチエンジンが用いられている。
この際、検索を行うユーザが、適切なキーワードを入力できない可能性もある。このため、キーワードを入力したユーザの検索意図に適したキーワードを抽出する手段を備えた検索装置が提案されている(例えば、特許文献1参照)。
【0003】
特許文献1では、クエリログに基づき、入力されたキーワードに関連があるキーワードを出力することで、ユーザの検索意図を推測し、適切なキーワードを出力している。
【先行技術文献】
【特許文献】
【0004】
【特許文献1】特開2009−69874号公報
【発明の概要】
【発明が解決しようとする課題】
【0005】
しかしながら、前記特許文献1では、入力されたキーワードに対して、統計的に関連のあるキーワードを出力しているに過ぎないため、必ずしもユーザの意図を反映したキーワードを出力できないという問題があった。
【0006】
本発明の目的は、入力されたキーワードに対して適切なキーワードを出力できる検索クエリ関連単語出力装置、検索クエリ関連単語出力方法および検索補助システムを提供することにある。
【課題を解決するための手段】
【0007】
本発明の検索クエリ関連単語出力装置は、ウェブコーパスを記憶するコーパス記憶部と、あらかじめ設定された因果関係モデルに基づいて、単語の属性によって定義される第1ノードおよび第2ノードと、各ノードに該当する単語を抽出する抽出条件とを設定し、この抽出条件で前記コーパス記憶部に記憶されたウェブコーパスを解析して、各ノードに該当する単語を抽出する属性解析部と、前記第1ノードに含まれる単語と、第2ノードに含まれる単語の共起頻度に基づく因果関係情報を記憶する因果関係記憶部と、入力されたキーワードを解析し、そのキーワードに対応する第1ノードを判定するノード判定部と、前記ノード判定部で判定された前記第1ノードに対応する第2ノードにおいて、前記キーワードに対する共起確率の高い単語を、前記因果関係記憶部に記憶された因果関係情報から求めて出力する単語出力部と、を備えることを特徴とする。
【0008】
本発明において、ウェブコーパスとは、ウェブ(WEB)ページから収集されたテキスト情報を構造化したものである。
本発明によれば、属性解析部は、あらかじめ設定された因果関係モデルに基づいてコーパス記憶部に記憶されたウェブコーパスのデータを解析する。具体的には、属性解析部は、単語の属性によって定義される第1ノードおよび第2ノードを前記因果関係モデルによって設定し、さらに、各ノードに該当する単語を抽出する抽出条件を前記因果関係モデルによって設定する。そして、属性解析部は、前記抽出条件でウェブコーパスを解析して、各ノードに該当する単語を抽出する。たとえば、外出するための情報を検索する意図に対応した因果関係モデルとして、第1ノードに地名、第2ノードにオブジェクト・イベントを設定した場合、前記抽出条件には、たとえば、地名+格助詞「で」+オブジェクト・イベントに関する名詞といったものが設定される。この場合、「新宿で食事をする」という文であれば、「新宿(属性:地名)」が第1ノードの単語として抽出され、「食事(属性:イベント)」が第2ノードの単語として抽出される。
このように抽出された単語と、これらの単語の共起頻度とに基づく因果関係情報は因果関係記憶部に記憶される。従って、因果関係情報は、単語の属性(地名やイベントなど)に基づいて定義される第1ノードおよび第2ノードと、第1,2ノードの各単語の共起頻度(前記例では、新宿と食事の単語が共に含まれる文の抽出件数)や、その共起確率の情報である。この際、因果関係モデルとしては、各ノード間を特定の方向性を有するリンクで結合するベイジアンネットワークを採用してもよいし、方向性を有さない無向リンクで結合するマルコフネットワークを採用してもよい。
【0009】
このように、本発明によれば、属性解析部は、あらかじめ設定された因果関係モデルに基づいてウェブコーパスを分析して各ノードに該当する単語を抽出する。そして、因果関係記憶部は、この単語の抽出によって得られる因果関係情報を記憶する。
このため、ノード判定部によって、ユーザが入力したキーワードの第1ノードを判定し、単語出力部によって、前記第1ノードに対応する第2ノードを前記因果関係情報から求め、その中で共起確率の高い単語を判定して出力することができる。
この際、因果関係モデルをあらかじめ設定し、属性解析部は、この因果関係モデルに基づいてウェブコーパスを分析して各ノードに該当する単語を抽出しているので、第1ノードの各単語に関連性(因果関係)の高い単語を第2ノードから容易に求めることができる。
従って、入力されたキーワードに対して、単に共起確率の高い単語を出力するのではなく、そのキーワードに対して因果関係の高い単語を出力できる。よって、そのキーワードを入力してウェブ上の情報を検索しようとするユーザの意図にあった単語を出力できるので、ユーザが入力したキーワードと、出力された単語とを含むクエリでウェブ情報を検索すれば、ユーザが求める情報を検索できる確率も高くできる。
【0010】
本発明の検索クエリ関連単語出力装置において、前記第1ノードに対応する第2ノードが複数設定されている場合、前記単語出力部で判定している第2ノードの各単語の共起確率は、各第2ノードにおけるすべての単語の共起頻度の合計値に対する各単語の共起頻度の割合で求められ、前記単語出力部は、すべての第2ノードの単語の中で最も共起確率の高い単語を判定して出力することが好ましい。
【0011】
この発明では、第2ノードが複数設定されている場合に、第2ノードごとに単語の共起確率を求めているので、すべての第2ノードのなかで共起頻度が高い単語を選択する場合に比べて、ノードの属性の影響を受けずに適切な単語を選択できる。
たとえば、外出時の情報検索用に適した因果関係モデルとして、「外出理由」、「外出先の施設、地名」、「外出時の行為」、「外出目的やイベント」の4つのノードを設定した場合、「行為」ノードは、「食べる、飲む、買う、見る」など単語数が他のノードに比べて少ない場合がある。このようにノードの属性によって、そのノードに含まれる単語数に大きな差があると、単語数の少ないノードのほうが、共起頻度が高くなる可能性が高い。従って、複数の第2ノードが存在する場合に、共起頻度が高い単語を選択すると、単語数が少ない属性のノードの単語が選択されてしまう。これに対し、各ノードごとに共起確率を算出すれば、前記属性による単語数の偏りが影響せず、より適切な単語を選択することができる。
【0012】
本発明の検索クエリ関連単語出力装置において、前記因果関係モデルは、外出用の情報を得るためのクエリに対応するものであり、外出理由の属性を有する単語からなる「理由」ノードと、外出先の施設名または地名の属性を有する単語からなる「施設、地名」ノードと、外出時の行為の属性を有する単語からなる「行為」ノードと、外出目的やイベントの属性を有する単語からなる「オブジェクト・イベント」ノードと、の4つのノードを備えることが好ましい。
【0013】
この発明では、因果関係モデルとして、「理由」、「施設、地名」、「行為」、「オブジェクト・イベント」の4種類のノードを設定しているので、特に外出時に有用な情報を検索するクエリに適した単語を出力できる。
【0014】
本発明は、ウェブコーパスを記憶するコーパス記憶部と、因果関係情報を記憶する因果関係記憶部とを備えた検索クエリ関連単語出力装置における検索クエリ関連単語出力方法であって、あらかじめ設定された因果関係モデルに基づいて、単語の属性によって定義される第1ノードおよび第2ノードと、各ノードに該当する単語を抽出する抽出条件とを設定し、この抽出条件で前記コーパス記憶部に記憶されたウェブコーパスを解析して、各ノードに該当する単語を抽出する属性解析ステップと、前記第1ノードに含まれる単語と、第2ノードに含まれる単語の共起頻度に基づく因果関係情報を前記因果関係記憶部に記憶する因果関係記憶ステップと、入力されたキーワードを解析し、そのキーワードに対応する第1ノードを判定するノード判定ステップと、前記ノード判定ステップで判定された前記第1ノードに対応する第2ノードにおいて、前記キーワードに対する共起確率の高い単語を、前記因果関係記憶部に記憶された因果関係情報から求めて出力する単語出力ステップと、を備えることを特徴とする。
【0015】
本発明においても、前記検索クエリ関連単語出力装置と同じく、入力されたキーワードに対して、単に共起確率の高い単語を出力するのではなく、そのキーワードに対して因果関係の高い単語を出力できる。よって、そのキーワードを入力してウェブ上の情報を検索しようとするユーザの意図にあった単語を出力できるので、ユーザが入力したキーワードと、出力された単語とを含むクエリでウェブ情報を検索すれば、ユーザが求める情報を検索できる確率も高くできる。
【0016】
本発明は、前記検索クエリ関連単語出力装置と、前記検索クエリ関連単語出力装置にネットワークを介して接続されたユーザ端末とを備えた検索補助システムであって、前記ユーザ端末は、入力されたキーワードを前記検索クエリ関連単語出力装置に送信し、前記検索クエリ関連単語出力装置は、前記ユーザ端末から送信されたキーワードを取得するクエリ取得部を有し、前記単語出力部は、前記クエリ取得部で取得されたキーワードおよび前記単語出力部で求められた単語を組み合わせたクエリを、前記ユーザ端末に対して出力することを特徴とする。
【0017】
この本発明では、ユーザは、ユーザ端末に検索用のキーワードを入力すれば、そのキーワードに対して因果関係の高い単語が付加されたクエリが、検索クエリ関連単語出力装置から出力される。このため、ユーザ端末に前記検索クエリ関連単語出力装置から出力されたクエリを表示でき、ユーザが自分の検索意図に適した単語が含まれるクエリを選択して検索することができるので、ユーザが求める情報を適切に検索できる。
【図面の簡単な説明】
【0018】
【図1】本発明の実施形態にかかる検索システム1の構成を示すブロック図。
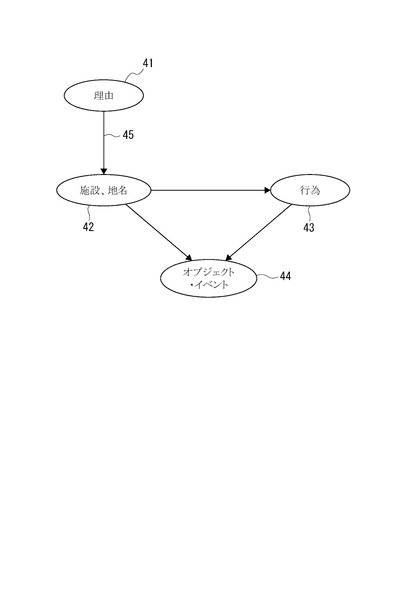
【図2】本実施形態の因果関係モデルを示す図。
【図3】本実施形態の「施設、地名」ノードの一例を示す図。
【図4】本実施形態の「理由」ノードの一例を示す図。
【図5】本実施形態の「施設、地名」ノードと「行為」ノードの関係を示す図。
【図6】本実施形態の各ノードに該当する単語の例を示す図。
【図7】本実施形態の第1ノードの単語が「六本木タワー」の場合の各単語の共起確率を示す図。
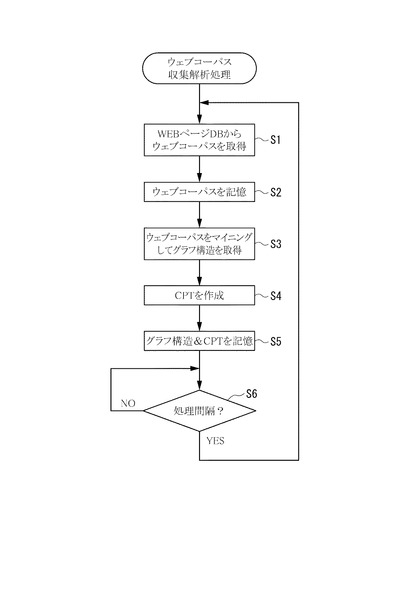
【図8】本実施形態のウェブコーパス収集解析処理を示すフローチャート。
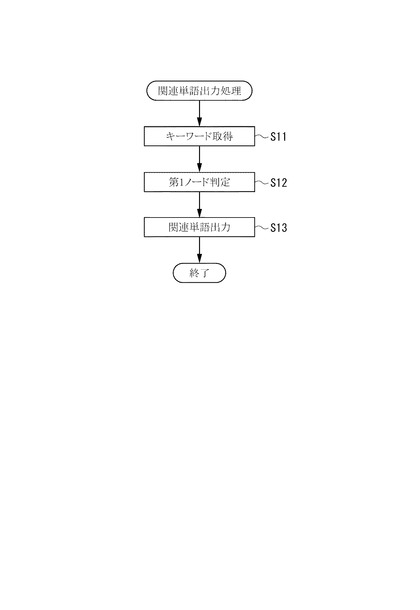
【図9】本実施形態の関連単語出力処理を示すフローチャート。
【図10】因果関係モデルの他の例を示す図。
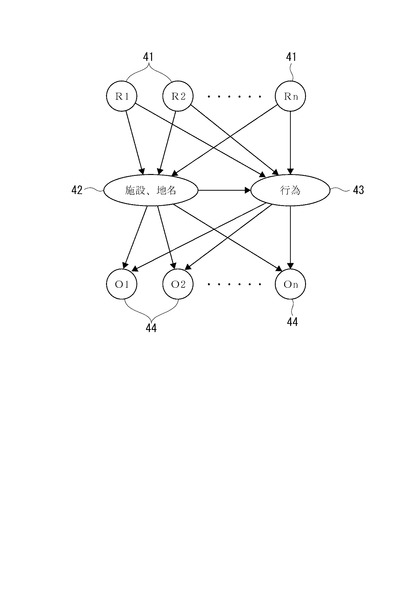
【図11】因果関係モデルの他の例を示す図。
【発明を実施するための形態】
【0019】
以下、本発明の実施形態を図面に基づいて説明する。
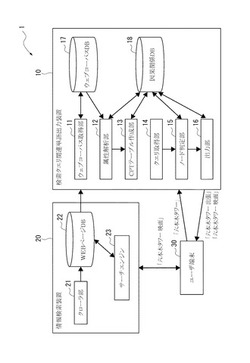
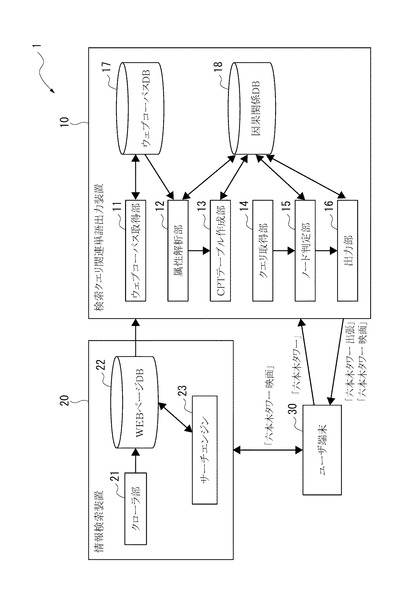
図1には、本発明の検索クエリ関連単語出力装置を用いた検索システム1を示す。
検索システム1は、検索クエリ関連単語出力装置10と、ウェブページの情報を収集・検索する情報検索装置20と、ユーザ端末30とを備えている。検索クエリ関連単語出力装置10および情報検索装置20と、ユーザ端末30とは、図示略のインターネットを介して通信可能に構成されている。また、後述するように、検索クエリ関連単語出力装置10およびユーザ端末30によって、本発明の検索補助システムが構成されている。
【0020】
インターネットは、TCP/IPなどの汎用のプロトコルに基づくインターネットである。各ユーザ端末30は、移動しながらインターネットに接続可能であることが好ましい。このため、ユーザ端末30は、携帯電話網を介してインターネットに接続したり、無線LAN(LOCAL AREA NETWORK)を介してインターネットに接続する。
なお、ユーザ端末30を検索クエリ関連単語出力装置10や情報検索装置20に接続させるための構成は、インターネットに限定されず、無線媒体により情報が送受信可能な複数の基地局がネットワークを構成する通信回線網や放送網などのネットワーク、さらには、データを直接受信するための媒体となる無線媒体自体など、データを送受信させるいずれの構成も利用できる。
【0021】
検索クエリ関連単語出力装置10や情報検索装置20は、ハードウェア構成として、RAM(RANDOM ACCESS MEMORY)やROM(READ ONLY MEMORY)等の図示しない記憶手段と、CPU(CENTRAL PROCESSING UNIT)等の制御手段と、を備えている。RAMはデータなどを一時的に記憶できる一時領域などを有しており、ROMはOS(OPERATING SYSTEM:基本ソフトウェア)や各種サーバを制御するプログラム、各種アプリケーション、各種データ等が格納されている。CPUは、これらの記憶手段に格納されているプログラムを読み出し、このプログラムに従って各種処理を行う。
【0022】
[情報検索装置]
情報検索装置20は、図1に示すように、クローラ部21と、ウェブページデータベース(WEBページDB)22と、サーチエンジン23を備えている。
クローラ部21は、インターネット上のウェブページを巡回し、その内容を収集し、前記WEBページDB22に登録する検索ロボットである。
サーチエンジン23は、全文検索などを行うものであり、ユーザ端末30から検索用のキーワードが入力されると、前記WEBページDB22を用いてキーワードを検索し、その検索結果をユーザ端末30に出力する。
このような情報検索装置20は、従来から知られているものであり、詳細な説明は省略する。
【0023】
[検索クエリ関連単語出力装置]
検索クエリ関連単語出力装置10は、図1に示すように、ウェブコーパス取得部11、属性解析部12、CPTテーブル作成部13、クエリ取得部14、ノード判定部15、単語出力部である出力部16、コーパス記憶部であるウェブコーパスデータベース(ウェブコーパスDB)17、因果関係記憶部である因果関係データベース(因果関係DB)18を備える。
【0024】
ウェブコーパス取得部11は、情報検索装置20のWEBページDB22を解析してウェブコーパスを取得し、ウェブコーパスDB17に登録する。
ウェブコーパス取得部11におけるウェブコーパスの取得(作成)方法は、周知技術であるため詳細な説明は省略する。
【0025】
属性解析部12は、前記ウェブコーパスDB17に記憶されたウェブコーパスを解析する。具体的には、属性解析部12は、あらかじめ設定された因果関係モデルに基づいて、単語の属性によって定義される第1ノードおよび第2ノードと、各ノードに該当する単語を抽出する抽出条件とを設定し、この抽出条件で前記コーパス記憶部に記憶されたウェブコーパスを解析して、各ノードに該当する単語を抽出する。
【0026】
この属性解析部12における処理を、具体例に基づいて説明する。
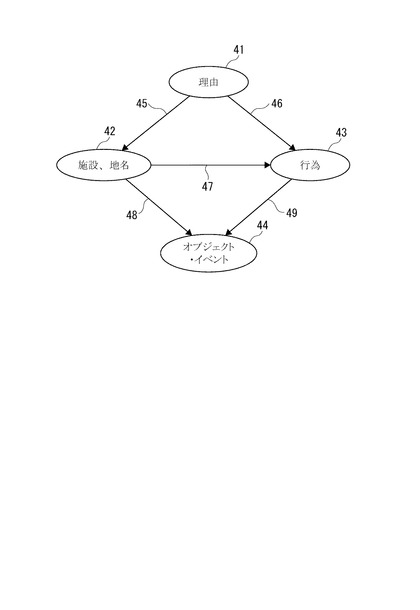
まず、属性解析部12において設定される因果関係モデルの一例について、図2に基づいて説明する。
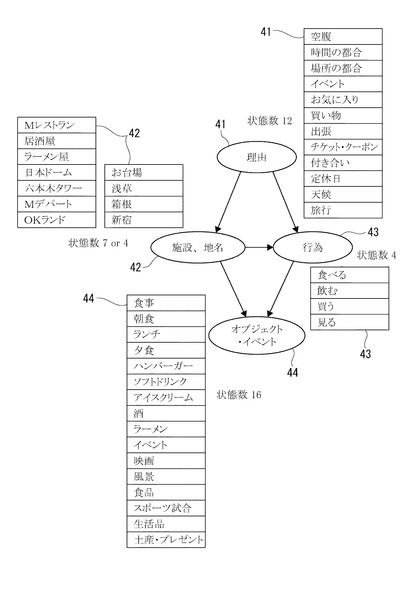
図2に示す因果関係モデルは、外出意図(お出かけ意図)を有するユーザがキーワード検索する場合のモデルであり、ノードおよび有向リンクを備えるベイジアンネットワークで表現されている。すなわち、ノードとして、「理由」、「施設、地名」、「行為」、「オブジェクト・イベント」の4つの属性のノード41〜44を設定している。
【0027】
また、各ノード41〜44間の有向リンク45〜49には、リンク元の第1ノードからリンク先の第2ノードに遷移する場合に、各ノードに該当する単語を抽出する抽出条件が設定されている。この抽出条件は、述語項構造や理由節に基づいて各ノードに該当する単語間の意味関係を解析するために設定された条件である。
たとえば、「理由」ノード41を第1ノードとし、「施設、地名」ノード42を第2ノードとした場合に各ノードに含まれる単語間の関係は、ウェブコーパスにおいて、外出理由を説明する「ノデ節」や「タメ節」の名詞が「理由」ノード41の単語となり、「デ格」、「へ格」、「ニ格」のように特定の動詞と共に用いられて外出先の施設や地名を表す名詞が「施設、地名」ノード42の単語となる。
同様に、「理由」ノード41を第1ノードとし、「行為」ノード43を第2ノードとした場合に各ノードに含まれる単語間の関係は、「ノデ節」、「タメ節」、「デ格」に用いられる名詞が「理由」ノード41の単語となり、「食べる、見る」などの行為を表す動詞が「行為」ノード43の単語となる。
また、「施設、地名」ノード42を第1ノードとし、「オブジェクト・イベント」ノード44を第2ノードとした場合に各ノードに含まれる単語間の関係は、場所を示す「デ格」や「へ格」で用いられる名詞が「施設、地名」ノード42の単語となり、対象を示す「ヲ格」で用いられる名詞が「オブジェクト・イベント」ノード44の単語となる。
さらに、「行為」ノード43を第1ノードとし、「オブジェクト・イベント」ノード44を第2ノードとした場合に各ノードに含まれる単語間の関係は、対象を示す「デ格」や「ヲ格」で用いられる名詞が「オブジェクト・イベント」ノード44の単語となり、動詞が「行為」ノード43の単語となる。
【0028】
このため、たとえば、「空腹なので、新宿で、ハンバーガーを食べる。」という文を、属性解析部12が解析すると、ノデ節である「空腹なので」の名詞「空腹」が「理由」ノード41の単語として抽出され、デ格でありかつ地名を示す名詞「新宿」が「施設、地名」ノード42の単語として抽出され、ヲ格で用いられる名詞「ハンバーガー」が「オブジェクト・イベント」ノード44の単語として抽出され、動詞「食べる」が「行為」ノード43の単語として抽出される。
なお、図2に示す因果関係モデルは一例であり、他の因果関係モデルを設定することも可能である。たとえば、「施設、地名」ノード42を第1ノードとし、「理由」ノード41を第2ノードとする因果関係モデルを設定することもできる。すなわち、各ノード、有向リンク、単語の抽出条件は、因果関係モデルに応じて設定すればよい。因果関係モデル自体は、検索クエリ関連単語出力装置10を運営する会社の担当者などが、データ分析などに基づいて設計すればよい。
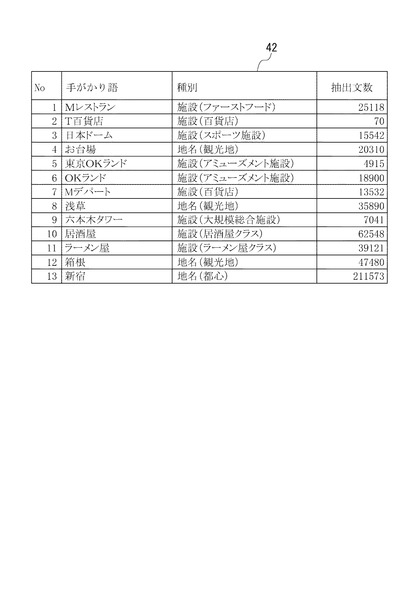
【0029】
図3には、9個の施設名と、4個の地名を手がかり語として設定し、ウェブコーパスDB17から、これらの語句が含まれる文を取得した結果(抽出文数)が記載されている。
そして、属性解析部12は、抽出された文に対し、さらに、以下の手がかり語が含まれているもの、つまり前記施設名や地名と、以下の手がかり語との共起を抽出条件として用いて、述語項構造+理由節を取得する。
手がかり語としては、動詞、動詞に係る格助詞、理由節の3種類を設定した。そして、動詞としては、「食べる、飲む、買う、見る、遊ぶ」の5個を設定した。また、動詞に係る格助詞としては、「で、へ、に、を」の4個を設定した。さらに、理由節としては、「ため、ので」の2個を設定した。
【0030】
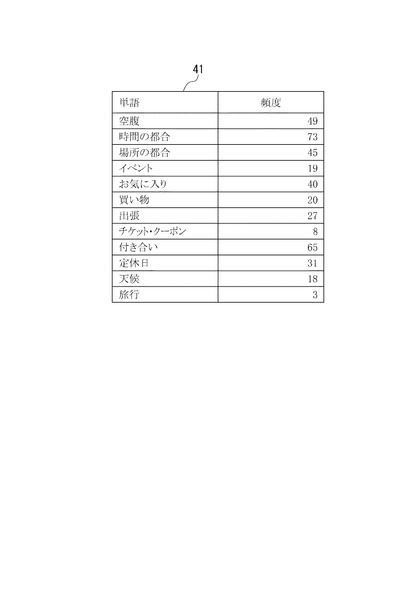
図4には、上記抽出条件で抽出した「理由」ノード41の値(単語)と、その頻度(抽出文数)の例が記載されている。
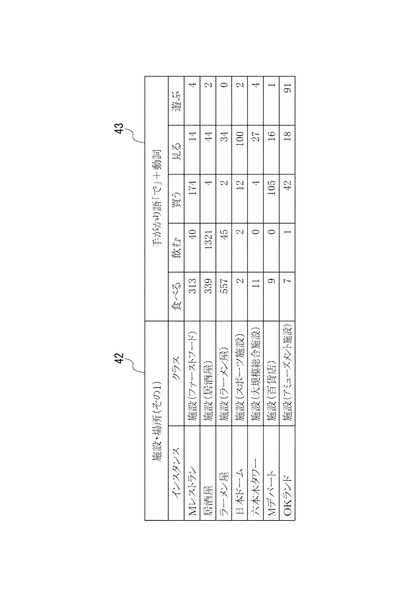
図5には、上記抽出条件で抽出した「施設名」ノード42の値(インスタンス)と、各施設がどのような種類の施設であるのかを示す属性(クラス)と、「施設名」ノード42に共起する「行為」ノード43の各動詞の頻度(抽出文数)の例が記載されている。この例は、手がかり語である施設名の単語+格助詞「デ」+動詞の文を抽出したものである。
【0031】
図6には、属性解析部12による解析結果(マイニング結果)に基づく、各ノード41〜44の値(単語)の例を示す。
すなわち、「理由」ノード41には、「空腹、時間の都合、場所の都合、イベント、天候、旅行」などの単語が抽出されている。また、「施設、地名」ノード42には、「居酒屋、ラーメン屋」などの施設名と、「新宿」などの地名の単語が抽出されている。
さらに、「オブジェクト・イベント」ノード44には、「食事、夕食、映画」などの単語が抽出され、「行為」ノード43には、「食べる、飲む、買う、見る」などの単語が抽出されている。
【0032】
属性解析部12は、以上のマイニング結果により得られたグラフ構造、具体的には図2に示すベイジアンネットワークを、因果関係DB18に記憶する。
【0033】
CPTテーブル作成部13は、CPT(CONDITIONAL PROBABILITY TABLE:条件付き確率表)を作成する。CPTは、各ノード41〜44の値(単語)の頻度を、ノード41〜44ごとの頻度合計に対する割合(確率)として正規化したものである。
【0034】
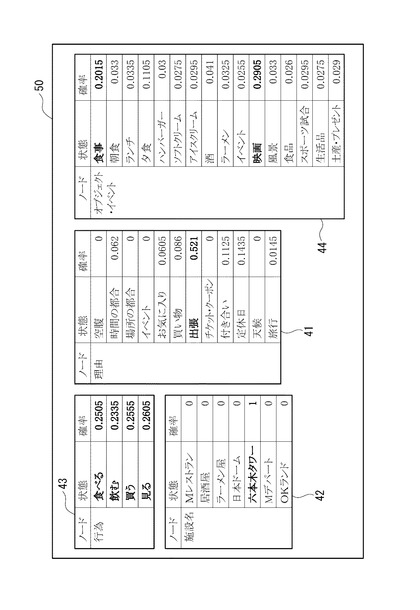
図7には、第1ノードの単語として施設名である「六本木タワー」を選択した場合のCPT50の例が示されている。各ノード41〜44における各単語の確率は、合計値が「1」となるように正規化されている。
すなわち、「施設、地名」ノード42では、「六本木タワー」の確率が「1」となり、他の単語の確率は「0」となる。
また、「行為」ノード43では、4つの単語「食べる、飲む、買う、見る」のいずれもが、施設名「六本木タワー」と共起する例があり、その頻度に基づく確率も図7に示すように各単語でほぼ同程度であった。具体的には、「見る」の単語の確率が「0.2605」で最も高かったが、他の単語の確率も0.25前後であり、それほど大きな違いはなかった。
【0035】
さらに、「理由」ノード41では、図7に示すように、「出張」や「定休日」のように施設名「六本木タワー」と共起する単語と、「空腹」や「天候」のように共起しない単語とがある。この中では、「出張」の単語の確率が「0.521」で最も高く、他の単語の確率は0.15以下と小さかった。
「オブジェクト・イベント」ノード44では、図7に示すように、「映画」の単語の確率が「0.2905」で一番高く、「食事」の単語の確率が「0.2015」で二番目に高く、他の単語の確率は0.12以下と小さかった。
【0036】
CPTテーブル作成部13は、図7に示すような、CPT50を作成し、因果関係DB18に記憶する。
従って、因果関係DB18には、属性解析部12のマイニング結果により得た図2に示すようなグラフ構造と、CPTテーブル作成部13により得た各ノードに割り当てた条件付き確率の集合(CPT50)によって構成されるベイジアンネットワークが記憶されていることになる。
【0037】
クエリ取得部14は、ユーザ端末30から入力されたキーワードを取得し、ノード判定部15に出力する。
ノード判定部15は、入力されたキーワードの属性を判定して第1ノードを特定する。
さらに、出力部16は、入力されたキーワードが第1ノードの単語となった場合の第2ノードにおける単語を、確率の高いものから抽出する。
たとえば、入力されたキーワードが「六本木タワー」の場合、その単語の属性は施設名であるため、ノード判定部15は、第1ノードは「施設、地名」ノード42であると判定する。
そして、出力部16は、第2ノードとなる他のノード「理由」、「行為」、「オブジェクト・イベント」のなかで、共起確率が高い単語を関連単語の候補とする。図7の例では、「出張」の確率が0.521で最も高く、「映画」が0.2905で2番目に高い。出力部16において、最も共起確率が高い単語のみを候補とする場合には、「出張」を候補とし、共起確率が高い順に2番目までを候補とする場合には、「出張」、「映画」が候補となる。
【0038】
出力部16は、この関連単語の候補を、入力されたクエリ(キーワード)とともにユーザ端末30に出力する。
上記第2ノードの各単語は、入力されたキーワードの属性が施設(第1ノード)の場合に、「行為」、「オブジェクト・イベント」、「理由」の各ノードにおいて頻度の高い単語、つまりウェブ上の文章において出願する頻度が高い単語であり、入力されたキーワードに関係性の高い単語と多くの人が認識しているものになる。このため、そのキーワードを入力したユーザの意図に沿った単語を出力することができる可能性が高い。従って、ユーザは、出力部16から出力されてユーザ端末30に表示されたクエリにおいて、自分の意図に合ったものを選択して入力することができ、この適切な単語でウェブ情報を検索することができるので、ユーザが求める情報を検索候補の上位に表示できる。
たとえば、図1に示すように、ユーザ端末30で「六本木タワー」と入力すると、検索クエリ関連単語出力装置10からは、「六本木タワー 出張」、「六本木タワー 映画」の2つのクエリ候補がユーザ端末30に出力される。
従って、検索クエリ関連単語出力装置10およびユーザ端末30により、本願発明の検索補助システムが構成されている。
【0039】
[検索クエリ関連単語出力装置の動作]
次に、検索クエリ関連単語出力装置10の処理に関し、図8,9のフローチャートに基づいて説明する。
【0040】
[ウェブコーパス収集解析処理]
本実施形態の検索クエリ関連単語出力装置10は、図8に示すように、定期的にウェブコーパスの収集および解析を実行する。なお、この処理間隔は、適宜設定できるが、少なくとも、情報検索装置20のクローラ部21による情報収集処理の実行間隔以上の間隔で実行すればよい。すなわち、クローラ部21による情報収集が行われないと、ウェブコーパスの情報更新も行われないためである。
【0041】
検索クエリ関連単語出力装置10がウェブコーパス収集解析処理を開始すると、まず、ウェブコーパス取得部11が情報検索装置20にアクセスし、WEBページDB22からウェブコーパスを取得する(ステップS1)。
そして、ウェブコーパス取得部11は、取得したウェブコーパスをウェブコーパスDB17に記憶する(ステップS2)。
【0042】
次に、属性解析部12は、ウェブコーパスDB17のデータをマイニングしてグラフ構造を取得する(ステップS3)。
また、CPTテーブル作成部13は、属性解析部12でマイニングされた結果に基づきCPTを作成する(ステップS4)。
そして、属性解析部12およびCPTテーブル作成部13は、前記グラフ構造およびCPT(つまりベイジアンネットワーク)を因果関係DB18に記憶する(ステップS5)。
【0043】
その後、検索クエリ関連単語出力装置10は、予め設定された処理間隔(たとえば12時間間隔など)が経過したかを判定する(ステップS6)。
検索クエリ関連単語出力装置10は、S6で処理間隔が経過して「YES」と判定した場合、ステップS1〜S5の処理を繰り返す。
一方、検索クエリ関連単語出力装置10は、S6で「NO」と判定した場合、S6の判定処理を繰り返す。
【0044】
[関連単語出力処理]
次に、ユーザ端末30において、検索用のキーワードが入力された場合の処理について、図9を参照して説明する。
検索クエリ関連単語出力装置10のクエリ取得部14は、ユーザ端末30から送信されるキーワードを取得する(ステップS11)。
次に、ノード判定部15は、クエリ取得部14で取得したキーワードを解析し、そのキーワードに対応する第1ノードを判定する(ステップS12)。
【0045】
次に、出力部16は、ノード判定部15で判定された第1ノードに対応する第2ノードにおいて、前記キーワードに対する共起確率が高い単語(関連単語)を、因果関係DB18から求めて出力する(ステップS13)。この際、単語の出力数としては、共起確率が高い順に所定数(たとえば2つ)としてもよいし、共起確率が所定値以上のものを出力してもよい。
また、本実施形態の出力部16は、前記関連単語と、ユーザ端末30で入力されたキーワードを組み合わせたクエリを、ユーザ端末30に出力する(ステップS13)。
以上により、関連単語出力処理が終了し、検索クエリ関連単語出力装置10は、ユーザ端末30からキーワードが入力されるたびに、前記ステップS11〜S13の処理を実行する。
【0046】
ユーザ端末30においては、ユーザが入力したキーワードに、検索クエリ関連単語出力装置10から出力された関連単語を組み合わせたクエリ候補が表示される。そして、ユーザが表示されたクエリ候補から検索意図に合ったものを選択すると、ユーザ端末30は、サーチエンジン23にクエリを出力し、その検索結果を取得して表示する。
従って、前記ステップS3,S4により本願発明の属性解析ステップが構成され、ステップS5により本願発明の因果関係記憶ステップが構成され、ステップS12により本願発明のノード判定ステップが構成され、ステップS13により本願発明の単語出力ステップが構成される。
【0047】
[実施形態の作用効果]
以上の実施形態によれば、以下の作用効果を奏することができる。
検索クエリ関連単語出力装置10は、ウェブコーパスを解析した因果関係DB18を作成し、入力したキーワードの属性を判定し、このキーワードに関係する単語を出力部16により出力しているので、ユーザ端末30に表示されたクエリにおいて、自分の意図に合ったものを選択して入力することができ、この適切な単語でウェブ情報を検索することができるので、ユーザが求める情報を検索できる。
【0048】
また、属性解析部12は、あらかじめ設定された因果関係モデルに基づいてウェブコーパスをマイニングしているので、単に共起確率が高い単語を選択して出力する場合に比べ、ユーザの検索意図に沿った単語を出力することができる。
すなわち、属性解析部12は、外出意図で検索する場合の因果関係モデルとして、4種類の属性(理由、施設or地名、行為、オブジェクト・イベント)を各ノード41〜44として設定し、ノード判定部15は、入力されたキーワードの属性から第1ノードを判定し、出力部16は、判定された第1ノードに対応する第2ノードに分類された単語から共起確率の高い単語を判定して出力している。このため、キーワード検索するユーザが求める情報に関連性の高い属性の単語を出力でき、ユーザの検索意図に沿ったクエリを出力できる。
【0049】
さらに、各単語の共起確率は、ノードごとに正規化しているので、適切な単語を選択して出力できる。すなわち、各単語の共起確率を、すべてのノードの単語全体の頻度に対する各単語の頻度で求めると、たとえば、「行為」ノード43のように、単語数(選択肢)が少ないノードに含まれる単語の共起確率が高くなり、選択肢が多い「理由」ノード41や「オブジェクト・イベント」ノード44の単語の共起確率は低くなる。一方、本実施形態では、ノードごとに正規化、つまりそのノードに属する単語の出願頻度の総数に対する各単語の頻度の割合を共起確率としているので、ノードごとの単語数(選択肢)の影響を受けずに単語の共起確率を求めることができる。このため、すべてのノードにおいて、入力されたキーワードに対する共起確率の高い単語を出力できる。この点でも、ユーザの検索意図に沿った単語を出力でき、入力されたキーワードと、検索クエリ関連単語出力装置10から出力された単語とを組み合わせてクエリとすることで、ユーザの検索意図を考慮したクエリを作成できる。
【0050】
属性解析部12は、ウェブコーパスDB17に記憶されたウェブコーパスを解析しているので、情報検索装置20のWEBページDB22を直接解析する場合に比べて、精度の高い分析を短時間で行うことができる。
【0051】
因果関係DB18として、グラフ構造とCPT50からなるベイジアンネットワークを用いているので、各ノード間の複雑な表現が可能となり、データの欠損や偏りがあっても適切に処理できるとともに、因果関係を全体で捉えることができる。
【0052】
[変形例]
なお、本発明は、上述した実施形態に限定されるものではなく、本発明の目的を達成できる範囲で、以下に示される変形をも含むものである。
たとえば、上記実施形態では、属性解析部12で用いた因果関係モデルとして、図3に示すものを用いていたが、「外出意図」を持ったクエリの因果関係モデルとしては、図10に示すように、「理由」ノード41からのリンク45が「施設、地名」ノード42のみに接続されたモデルを用いてもよい。この場合、第1ノードとして「理由」ノード41に該当する属性のキーワードが入力された場合、第2ノードとしては「施設、地名」ノード42の単語が出力されることになる。外出意図を持ったユーザが「理由」ノード41のキーワードを入力した場合、その外出先となる「施設、地名」の単語がクエリに含まれていないと、適切な情報を提供することが難しいためである。
【0053】
また、属性解析部12で用いる因果関係モデルとしては、図11に示すように、「理由」ノード41および「オブジェクト・イベント」ノード44が、単語ごとR1〜Rn(理由ノード)、O1〜On(オブジェクト・イベントノード)に分かれて設定されたものでもよい。
さらに、因果関係モデルとしては、ベイジアンネットワークの代わりにマルコフネットワークを用いてもよい。また、決定木や、各単語の組み合わせ頻度による絞り込みを用いてもよいし、ランダムに関係している名詞をつなげたモデルなどでもよい。要するに、因果関係モデルは、検索クエリの意図、具体的には入力されたキーワードの属性などに応じて適切なモデルを設定して利用すればよい。
【0054】
また、因果関係モデルなどによって、CPT50を作成する必要がない場合には、CPTテーブル作成部13を設けずに、属性解析部12の解析結果を因果関係DB18に記憶してもよい。
【0055】
さらに、上記実施形態では、検索クエリ関連単語出力装置10と情報検索装置20とを別々の装置として構成していたが、これらのまとめた1つの装置として構成してもよい。
この場合は、入力されたキーワードと、検索クエリ関連単語出力装置10で出力された単語とを組み合わせたクエリによってWEBページDB22を検索し、その検索結果をユーザ端末30に自動的に出力するようにしてもよい。
【産業上の利用可能性】
【0056】
本発明は、入力されたキーワードに対して適切なキーワードを出力できる検索クエリ関連単語出力装置、検索クエリ関連単語出力方法および検索補助システムとして利用できる。
【符号の説明】
【0057】
1…検索システム、10…検索クエリ関連単語出力装置、11…ウェブコーパス取得部、12…属性解析部、13…CPTテーブル作成部、14…クエリ取得部、15…ノード判定部、16…出力部、17…ウェブコーパスデータベース(ウェブコーパスDB)、18…因果関係データベース(因果関係DB)、20…情報検索装置、21…クローラ部、22…ウェブページデータベース(WEBページDB)、23…サーチエンジン、30…ユーザ端末。
【技術分野】
【0001】
本発明は、検索クエリに関連する単語を出力する検索クエリ関連単語出力装置、検索クエリ関連単語出力方法および検索補助システムに関する。
【背景技術】
【0002】
インターネット上の情報を検索するシステムとして、キーワード検索機能を備えたサーチエンジンが用いられている。
この際、検索を行うユーザが、適切なキーワードを入力できない可能性もある。このため、キーワードを入力したユーザの検索意図に適したキーワードを抽出する手段を備えた検索装置が提案されている(例えば、特許文献1参照)。
【0003】
特許文献1では、クエリログに基づき、入力されたキーワードに関連があるキーワードを出力することで、ユーザの検索意図を推測し、適切なキーワードを出力している。
【先行技術文献】
【特許文献】
【0004】
【特許文献1】特開2009−69874号公報
【発明の概要】
【発明が解決しようとする課題】
【0005】
しかしながら、前記特許文献1では、入力されたキーワードに対して、統計的に関連のあるキーワードを出力しているに過ぎないため、必ずしもユーザの意図を反映したキーワードを出力できないという問題があった。
【0006】
本発明の目的は、入力されたキーワードに対して適切なキーワードを出力できる検索クエリ関連単語出力装置、検索クエリ関連単語出力方法および検索補助システムを提供することにある。
【課題を解決するための手段】
【0007】
本発明の検索クエリ関連単語出力装置は、ウェブコーパスを記憶するコーパス記憶部と、あらかじめ設定された因果関係モデルに基づいて、単語の属性によって定義される第1ノードおよび第2ノードと、各ノードに該当する単語を抽出する抽出条件とを設定し、この抽出条件で前記コーパス記憶部に記憶されたウェブコーパスを解析して、各ノードに該当する単語を抽出する属性解析部と、前記第1ノードに含まれる単語と、第2ノードに含まれる単語の共起頻度に基づく因果関係情報を記憶する因果関係記憶部と、入力されたキーワードを解析し、そのキーワードに対応する第1ノードを判定するノード判定部と、前記ノード判定部で判定された前記第1ノードに対応する第2ノードにおいて、前記キーワードに対する共起確率の高い単語を、前記因果関係記憶部に記憶された因果関係情報から求めて出力する単語出力部と、を備えることを特徴とする。
【0008】
本発明において、ウェブコーパスとは、ウェブ(WEB)ページから収集されたテキスト情報を構造化したものである。
本発明によれば、属性解析部は、あらかじめ設定された因果関係モデルに基づいてコーパス記憶部に記憶されたウェブコーパスのデータを解析する。具体的には、属性解析部は、単語の属性によって定義される第1ノードおよび第2ノードを前記因果関係モデルによって設定し、さらに、各ノードに該当する単語を抽出する抽出条件を前記因果関係モデルによって設定する。そして、属性解析部は、前記抽出条件でウェブコーパスを解析して、各ノードに該当する単語を抽出する。たとえば、外出するための情報を検索する意図に対応した因果関係モデルとして、第1ノードに地名、第2ノードにオブジェクト・イベントを設定した場合、前記抽出条件には、たとえば、地名+格助詞「で」+オブジェクト・イベントに関する名詞といったものが設定される。この場合、「新宿で食事をする」という文であれば、「新宿(属性:地名)」が第1ノードの単語として抽出され、「食事(属性:イベント)」が第2ノードの単語として抽出される。
このように抽出された単語と、これらの単語の共起頻度とに基づく因果関係情報は因果関係記憶部に記憶される。従って、因果関係情報は、単語の属性(地名やイベントなど)に基づいて定義される第1ノードおよび第2ノードと、第1,2ノードの各単語の共起頻度(前記例では、新宿と食事の単語が共に含まれる文の抽出件数)や、その共起確率の情報である。この際、因果関係モデルとしては、各ノード間を特定の方向性を有するリンクで結合するベイジアンネットワークを採用してもよいし、方向性を有さない無向リンクで結合するマルコフネットワークを採用してもよい。
【0009】
このように、本発明によれば、属性解析部は、あらかじめ設定された因果関係モデルに基づいてウェブコーパスを分析して各ノードに該当する単語を抽出する。そして、因果関係記憶部は、この単語の抽出によって得られる因果関係情報を記憶する。
このため、ノード判定部によって、ユーザが入力したキーワードの第1ノードを判定し、単語出力部によって、前記第1ノードに対応する第2ノードを前記因果関係情報から求め、その中で共起確率の高い単語を判定して出力することができる。
この際、因果関係モデルをあらかじめ設定し、属性解析部は、この因果関係モデルに基づいてウェブコーパスを分析して各ノードに該当する単語を抽出しているので、第1ノードの各単語に関連性(因果関係)の高い単語を第2ノードから容易に求めることができる。
従って、入力されたキーワードに対して、単に共起確率の高い単語を出力するのではなく、そのキーワードに対して因果関係の高い単語を出力できる。よって、そのキーワードを入力してウェブ上の情報を検索しようとするユーザの意図にあった単語を出力できるので、ユーザが入力したキーワードと、出力された単語とを含むクエリでウェブ情報を検索すれば、ユーザが求める情報を検索できる確率も高くできる。
【0010】
本発明の検索クエリ関連単語出力装置において、前記第1ノードに対応する第2ノードが複数設定されている場合、前記単語出力部で判定している第2ノードの各単語の共起確率は、各第2ノードにおけるすべての単語の共起頻度の合計値に対する各単語の共起頻度の割合で求められ、前記単語出力部は、すべての第2ノードの単語の中で最も共起確率の高い単語を判定して出力することが好ましい。
【0011】
この発明では、第2ノードが複数設定されている場合に、第2ノードごとに単語の共起確率を求めているので、すべての第2ノードのなかで共起頻度が高い単語を選択する場合に比べて、ノードの属性の影響を受けずに適切な単語を選択できる。
たとえば、外出時の情報検索用に適した因果関係モデルとして、「外出理由」、「外出先の施設、地名」、「外出時の行為」、「外出目的やイベント」の4つのノードを設定した場合、「行為」ノードは、「食べる、飲む、買う、見る」など単語数が他のノードに比べて少ない場合がある。このようにノードの属性によって、そのノードに含まれる単語数に大きな差があると、単語数の少ないノードのほうが、共起頻度が高くなる可能性が高い。従って、複数の第2ノードが存在する場合に、共起頻度が高い単語を選択すると、単語数が少ない属性のノードの単語が選択されてしまう。これに対し、各ノードごとに共起確率を算出すれば、前記属性による単語数の偏りが影響せず、より適切な単語を選択することができる。
【0012】
本発明の検索クエリ関連単語出力装置において、前記因果関係モデルは、外出用の情報を得るためのクエリに対応するものであり、外出理由の属性を有する単語からなる「理由」ノードと、外出先の施設名または地名の属性を有する単語からなる「施設、地名」ノードと、外出時の行為の属性を有する単語からなる「行為」ノードと、外出目的やイベントの属性を有する単語からなる「オブジェクト・イベント」ノードと、の4つのノードを備えることが好ましい。
【0013】
この発明では、因果関係モデルとして、「理由」、「施設、地名」、「行為」、「オブジェクト・イベント」の4種類のノードを設定しているので、特に外出時に有用な情報を検索するクエリに適した単語を出力できる。
【0014】
本発明は、ウェブコーパスを記憶するコーパス記憶部と、因果関係情報を記憶する因果関係記憶部とを備えた検索クエリ関連単語出力装置における検索クエリ関連単語出力方法であって、あらかじめ設定された因果関係モデルに基づいて、単語の属性によって定義される第1ノードおよび第2ノードと、各ノードに該当する単語を抽出する抽出条件とを設定し、この抽出条件で前記コーパス記憶部に記憶されたウェブコーパスを解析して、各ノードに該当する単語を抽出する属性解析ステップと、前記第1ノードに含まれる単語と、第2ノードに含まれる単語の共起頻度に基づく因果関係情報を前記因果関係記憶部に記憶する因果関係記憶ステップと、入力されたキーワードを解析し、そのキーワードに対応する第1ノードを判定するノード判定ステップと、前記ノード判定ステップで判定された前記第1ノードに対応する第2ノードにおいて、前記キーワードに対する共起確率の高い単語を、前記因果関係記憶部に記憶された因果関係情報から求めて出力する単語出力ステップと、を備えることを特徴とする。
【0015】
本発明においても、前記検索クエリ関連単語出力装置と同じく、入力されたキーワードに対して、単に共起確率の高い単語を出力するのではなく、そのキーワードに対して因果関係の高い単語を出力できる。よって、そのキーワードを入力してウェブ上の情報を検索しようとするユーザの意図にあった単語を出力できるので、ユーザが入力したキーワードと、出力された単語とを含むクエリでウェブ情報を検索すれば、ユーザが求める情報を検索できる確率も高くできる。
【0016】
本発明は、前記検索クエリ関連単語出力装置と、前記検索クエリ関連単語出力装置にネットワークを介して接続されたユーザ端末とを備えた検索補助システムであって、前記ユーザ端末は、入力されたキーワードを前記検索クエリ関連単語出力装置に送信し、前記検索クエリ関連単語出力装置は、前記ユーザ端末から送信されたキーワードを取得するクエリ取得部を有し、前記単語出力部は、前記クエリ取得部で取得されたキーワードおよび前記単語出力部で求められた単語を組み合わせたクエリを、前記ユーザ端末に対して出力することを特徴とする。
【0017】
この本発明では、ユーザは、ユーザ端末に検索用のキーワードを入力すれば、そのキーワードに対して因果関係の高い単語が付加されたクエリが、検索クエリ関連単語出力装置から出力される。このため、ユーザ端末に前記検索クエリ関連単語出力装置から出力されたクエリを表示でき、ユーザが自分の検索意図に適した単語が含まれるクエリを選択して検索することができるので、ユーザが求める情報を適切に検索できる。
【図面の簡単な説明】
【0018】
【図1】本発明の実施形態にかかる検索システム1の構成を示すブロック図。
【図2】本実施形態の因果関係モデルを示す図。
【図3】本実施形態の「施設、地名」ノードの一例を示す図。
【図4】本実施形態の「理由」ノードの一例を示す図。
【図5】本実施形態の「施設、地名」ノードと「行為」ノードの関係を示す図。
【図6】本実施形態の各ノードに該当する単語の例を示す図。
【図7】本実施形態の第1ノードの単語が「六本木タワー」の場合の各単語の共起確率を示す図。
【図8】本実施形態のウェブコーパス収集解析処理を示すフローチャート。
【図9】本実施形態の関連単語出力処理を示すフローチャート。
【図10】因果関係モデルの他の例を示す図。
【図11】因果関係モデルの他の例を示す図。
【発明を実施するための形態】
【0019】
以下、本発明の実施形態を図面に基づいて説明する。
図1には、本発明の検索クエリ関連単語出力装置を用いた検索システム1を示す。
検索システム1は、検索クエリ関連単語出力装置10と、ウェブページの情報を収集・検索する情報検索装置20と、ユーザ端末30とを備えている。検索クエリ関連単語出力装置10および情報検索装置20と、ユーザ端末30とは、図示略のインターネットを介して通信可能に構成されている。また、後述するように、検索クエリ関連単語出力装置10およびユーザ端末30によって、本発明の検索補助システムが構成されている。
【0020】
インターネットは、TCP/IPなどの汎用のプロトコルに基づくインターネットである。各ユーザ端末30は、移動しながらインターネットに接続可能であることが好ましい。このため、ユーザ端末30は、携帯電話網を介してインターネットに接続したり、無線LAN(LOCAL AREA NETWORK)を介してインターネットに接続する。
なお、ユーザ端末30を検索クエリ関連単語出力装置10や情報検索装置20に接続させるための構成は、インターネットに限定されず、無線媒体により情報が送受信可能な複数の基地局がネットワークを構成する通信回線網や放送網などのネットワーク、さらには、データを直接受信するための媒体となる無線媒体自体など、データを送受信させるいずれの構成も利用できる。
【0021】
検索クエリ関連単語出力装置10や情報検索装置20は、ハードウェア構成として、RAM(RANDOM ACCESS MEMORY)やROM(READ ONLY MEMORY)等の図示しない記憶手段と、CPU(CENTRAL PROCESSING UNIT)等の制御手段と、を備えている。RAMはデータなどを一時的に記憶できる一時領域などを有しており、ROMはOS(OPERATING SYSTEM:基本ソフトウェア)や各種サーバを制御するプログラム、各種アプリケーション、各種データ等が格納されている。CPUは、これらの記憶手段に格納されているプログラムを読み出し、このプログラムに従って各種処理を行う。
【0022】
[情報検索装置]
情報検索装置20は、図1に示すように、クローラ部21と、ウェブページデータベース(WEBページDB)22と、サーチエンジン23を備えている。
クローラ部21は、インターネット上のウェブページを巡回し、その内容を収集し、前記WEBページDB22に登録する検索ロボットである。
サーチエンジン23は、全文検索などを行うものであり、ユーザ端末30から検索用のキーワードが入力されると、前記WEBページDB22を用いてキーワードを検索し、その検索結果をユーザ端末30に出力する。
このような情報検索装置20は、従来から知られているものであり、詳細な説明は省略する。
【0023】
[検索クエリ関連単語出力装置]
検索クエリ関連単語出力装置10は、図1に示すように、ウェブコーパス取得部11、属性解析部12、CPTテーブル作成部13、クエリ取得部14、ノード判定部15、単語出力部である出力部16、コーパス記憶部であるウェブコーパスデータベース(ウェブコーパスDB)17、因果関係記憶部である因果関係データベース(因果関係DB)18を備える。
【0024】
ウェブコーパス取得部11は、情報検索装置20のWEBページDB22を解析してウェブコーパスを取得し、ウェブコーパスDB17に登録する。
ウェブコーパス取得部11におけるウェブコーパスの取得(作成)方法は、周知技術であるため詳細な説明は省略する。
【0025】
属性解析部12は、前記ウェブコーパスDB17に記憶されたウェブコーパスを解析する。具体的には、属性解析部12は、あらかじめ設定された因果関係モデルに基づいて、単語の属性によって定義される第1ノードおよび第2ノードと、各ノードに該当する単語を抽出する抽出条件とを設定し、この抽出条件で前記コーパス記憶部に記憶されたウェブコーパスを解析して、各ノードに該当する単語を抽出する。
【0026】
この属性解析部12における処理を、具体例に基づいて説明する。
まず、属性解析部12において設定される因果関係モデルの一例について、図2に基づいて説明する。
図2に示す因果関係モデルは、外出意図(お出かけ意図)を有するユーザがキーワード検索する場合のモデルであり、ノードおよび有向リンクを備えるベイジアンネットワークで表現されている。すなわち、ノードとして、「理由」、「施設、地名」、「行為」、「オブジェクト・イベント」の4つの属性のノード41〜44を設定している。
【0027】
また、各ノード41〜44間の有向リンク45〜49には、リンク元の第1ノードからリンク先の第2ノードに遷移する場合に、各ノードに該当する単語を抽出する抽出条件が設定されている。この抽出条件は、述語項構造や理由節に基づいて各ノードに該当する単語間の意味関係を解析するために設定された条件である。
たとえば、「理由」ノード41を第1ノードとし、「施設、地名」ノード42を第2ノードとした場合に各ノードに含まれる単語間の関係は、ウェブコーパスにおいて、外出理由を説明する「ノデ節」や「タメ節」の名詞が「理由」ノード41の単語となり、「デ格」、「へ格」、「ニ格」のように特定の動詞と共に用いられて外出先の施設や地名を表す名詞が「施設、地名」ノード42の単語となる。
同様に、「理由」ノード41を第1ノードとし、「行為」ノード43を第2ノードとした場合に各ノードに含まれる単語間の関係は、「ノデ節」、「タメ節」、「デ格」に用いられる名詞が「理由」ノード41の単語となり、「食べる、見る」などの行為を表す動詞が「行為」ノード43の単語となる。
また、「施設、地名」ノード42を第1ノードとし、「オブジェクト・イベント」ノード44を第2ノードとした場合に各ノードに含まれる単語間の関係は、場所を示す「デ格」や「へ格」で用いられる名詞が「施設、地名」ノード42の単語となり、対象を示す「ヲ格」で用いられる名詞が「オブジェクト・イベント」ノード44の単語となる。
さらに、「行為」ノード43を第1ノードとし、「オブジェクト・イベント」ノード44を第2ノードとした場合に各ノードに含まれる単語間の関係は、対象を示す「デ格」や「ヲ格」で用いられる名詞が「オブジェクト・イベント」ノード44の単語となり、動詞が「行為」ノード43の単語となる。
【0028】
このため、たとえば、「空腹なので、新宿で、ハンバーガーを食べる。」という文を、属性解析部12が解析すると、ノデ節である「空腹なので」の名詞「空腹」が「理由」ノード41の単語として抽出され、デ格でありかつ地名を示す名詞「新宿」が「施設、地名」ノード42の単語として抽出され、ヲ格で用いられる名詞「ハンバーガー」が「オブジェクト・イベント」ノード44の単語として抽出され、動詞「食べる」が「行為」ノード43の単語として抽出される。
なお、図2に示す因果関係モデルは一例であり、他の因果関係モデルを設定することも可能である。たとえば、「施設、地名」ノード42を第1ノードとし、「理由」ノード41を第2ノードとする因果関係モデルを設定することもできる。すなわち、各ノード、有向リンク、単語の抽出条件は、因果関係モデルに応じて設定すればよい。因果関係モデル自体は、検索クエリ関連単語出力装置10を運営する会社の担当者などが、データ分析などに基づいて設計すればよい。
【0029】
図3には、9個の施設名と、4個の地名を手がかり語として設定し、ウェブコーパスDB17から、これらの語句が含まれる文を取得した結果(抽出文数)が記載されている。
そして、属性解析部12は、抽出された文に対し、さらに、以下の手がかり語が含まれているもの、つまり前記施設名や地名と、以下の手がかり語との共起を抽出条件として用いて、述語項構造+理由節を取得する。
手がかり語としては、動詞、動詞に係る格助詞、理由節の3種類を設定した。そして、動詞としては、「食べる、飲む、買う、見る、遊ぶ」の5個を設定した。また、動詞に係る格助詞としては、「で、へ、に、を」の4個を設定した。さらに、理由節としては、「ため、ので」の2個を設定した。
【0030】
図4には、上記抽出条件で抽出した「理由」ノード41の値(単語)と、その頻度(抽出文数)の例が記載されている。
図5には、上記抽出条件で抽出した「施設名」ノード42の値(インスタンス)と、各施設がどのような種類の施設であるのかを示す属性(クラス)と、「施設名」ノード42に共起する「行為」ノード43の各動詞の頻度(抽出文数)の例が記載されている。この例は、手がかり語である施設名の単語+格助詞「デ」+動詞の文を抽出したものである。
【0031】
図6には、属性解析部12による解析結果(マイニング結果)に基づく、各ノード41〜44の値(単語)の例を示す。
すなわち、「理由」ノード41には、「空腹、時間の都合、場所の都合、イベント、天候、旅行」などの単語が抽出されている。また、「施設、地名」ノード42には、「居酒屋、ラーメン屋」などの施設名と、「新宿」などの地名の単語が抽出されている。
さらに、「オブジェクト・イベント」ノード44には、「食事、夕食、映画」などの単語が抽出され、「行為」ノード43には、「食べる、飲む、買う、見る」などの単語が抽出されている。
【0032】
属性解析部12は、以上のマイニング結果により得られたグラフ構造、具体的には図2に示すベイジアンネットワークを、因果関係DB18に記憶する。
【0033】
CPTテーブル作成部13は、CPT(CONDITIONAL PROBABILITY TABLE:条件付き確率表)を作成する。CPTは、各ノード41〜44の値(単語)の頻度を、ノード41〜44ごとの頻度合計に対する割合(確率)として正規化したものである。
【0034】
図7には、第1ノードの単語として施設名である「六本木タワー」を選択した場合のCPT50の例が示されている。各ノード41〜44における各単語の確率は、合計値が「1」となるように正規化されている。
すなわち、「施設、地名」ノード42では、「六本木タワー」の確率が「1」となり、他の単語の確率は「0」となる。
また、「行為」ノード43では、4つの単語「食べる、飲む、買う、見る」のいずれもが、施設名「六本木タワー」と共起する例があり、その頻度に基づく確率も図7に示すように各単語でほぼ同程度であった。具体的には、「見る」の単語の確率が「0.2605」で最も高かったが、他の単語の確率も0.25前後であり、それほど大きな違いはなかった。
【0035】
さらに、「理由」ノード41では、図7に示すように、「出張」や「定休日」のように施設名「六本木タワー」と共起する単語と、「空腹」や「天候」のように共起しない単語とがある。この中では、「出張」の単語の確率が「0.521」で最も高く、他の単語の確率は0.15以下と小さかった。
「オブジェクト・イベント」ノード44では、図7に示すように、「映画」の単語の確率が「0.2905」で一番高く、「食事」の単語の確率が「0.2015」で二番目に高く、他の単語の確率は0.12以下と小さかった。
【0036】
CPTテーブル作成部13は、図7に示すような、CPT50を作成し、因果関係DB18に記憶する。
従って、因果関係DB18には、属性解析部12のマイニング結果により得た図2に示すようなグラフ構造と、CPTテーブル作成部13により得た各ノードに割り当てた条件付き確率の集合(CPT50)によって構成されるベイジアンネットワークが記憶されていることになる。
【0037】
クエリ取得部14は、ユーザ端末30から入力されたキーワードを取得し、ノード判定部15に出力する。
ノード判定部15は、入力されたキーワードの属性を判定して第1ノードを特定する。
さらに、出力部16は、入力されたキーワードが第1ノードの単語となった場合の第2ノードにおける単語を、確率の高いものから抽出する。
たとえば、入力されたキーワードが「六本木タワー」の場合、その単語の属性は施設名であるため、ノード判定部15は、第1ノードは「施設、地名」ノード42であると判定する。
そして、出力部16は、第2ノードとなる他のノード「理由」、「行為」、「オブジェクト・イベント」のなかで、共起確率が高い単語を関連単語の候補とする。図7の例では、「出張」の確率が0.521で最も高く、「映画」が0.2905で2番目に高い。出力部16において、最も共起確率が高い単語のみを候補とする場合には、「出張」を候補とし、共起確率が高い順に2番目までを候補とする場合には、「出張」、「映画」が候補となる。
【0038】
出力部16は、この関連単語の候補を、入力されたクエリ(キーワード)とともにユーザ端末30に出力する。
上記第2ノードの各単語は、入力されたキーワードの属性が施設(第1ノード)の場合に、「行為」、「オブジェクト・イベント」、「理由」の各ノードにおいて頻度の高い単語、つまりウェブ上の文章において出願する頻度が高い単語であり、入力されたキーワードに関係性の高い単語と多くの人が認識しているものになる。このため、そのキーワードを入力したユーザの意図に沿った単語を出力することができる可能性が高い。従って、ユーザは、出力部16から出力されてユーザ端末30に表示されたクエリにおいて、自分の意図に合ったものを選択して入力することができ、この適切な単語でウェブ情報を検索することができるので、ユーザが求める情報を検索候補の上位に表示できる。
たとえば、図1に示すように、ユーザ端末30で「六本木タワー」と入力すると、検索クエリ関連単語出力装置10からは、「六本木タワー 出張」、「六本木タワー 映画」の2つのクエリ候補がユーザ端末30に出力される。
従って、検索クエリ関連単語出力装置10およびユーザ端末30により、本願発明の検索補助システムが構成されている。
【0039】
[検索クエリ関連単語出力装置の動作]
次に、検索クエリ関連単語出力装置10の処理に関し、図8,9のフローチャートに基づいて説明する。
【0040】
[ウェブコーパス収集解析処理]
本実施形態の検索クエリ関連単語出力装置10は、図8に示すように、定期的にウェブコーパスの収集および解析を実行する。なお、この処理間隔は、適宜設定できるが、少なくとも、情報検索装置20のクローラ部21による情報収集処理の実行間隔以上の間隔で実行すればよい。すなわち、クローラ部21による情報収集が行われないと、ウェブコーパスの情報更新も行われないためである。
【0041】
検索クエリ関連単語出力装置10がウェブコーパス収集解析処理を開始すると、まず、ウェブコーパス取得部11が情報検索装置20にアクセスし、WEBページDB22からウェブコーパスを取得する(ステップS1)。
そして、ウェブコーパス取得部11は、取得したウェブコーパスをウェブコーパスDB17に記憶する(ステップS2)。
【0042】
次に、属性解析部12は、ウェブコーパスDB17のデータをマイニングしてグラフ構造を取得する(ステップS3)。
また、CPTテーブル作成部13は、属性解析部12でマイニングされた結果に基づきCPTを作成する(ステップS4)。
そして、属性解析部12およびCPTテーブル作成部13は、前記グラフ構造およびCPT(つまりベイジアンネットワーク)を因果関係DB18に記憶する(ステップS5)。
【0043】
その後、検索クエリ関連単語出力装置10は、予め設定された処理間隔(たとえば12時間間隔など)が経過したかを判定する(ステップS6)。
検索クエリ関連単語出力装置10は、S6で処理間隔が経過して「YES」と判定した場合、ステップS1〜S5の処理を繰り返す。
一方、検索クエリ関連単語出力装置10は、S6で「NO」と判定した場合、S6の判定処理を繰り返す。
【0044】
[関連単語出力処理]
次に、ユーザ端末30において、検索用のキーワードが入力された場合の処理について、図9を参照して説明する。
検索クエリ関連単語出力装置10のクエリ取得部14は、ユーザ端末30から送信されるキーワードを取得する(ステップS11)。
次に、ノード判定部15は、クエリ取得部14で取得したキーワードを解析し、そのキーワードに対応する第1ノードを判定する(ステップS12)。
【0045】
次に、出力部16は、ノード判定部15で判定された第1ノードに対応する第2ノードにおいて、前記キーワードに対する共起確率が高い単語(関連単語)を、因果関係DB18から求めて出力する(ステップS13)。この際、単語の出力数としては、共起確率が高い順に所定数(たとえば2つ)としてもよいし、共起確率が所定値以上のものを出力してもよい。
また、本実施形態の出力部16は、前記関連単語と、ユーザ端末30で入力されたキーワードを組み合わせたクエリを、ユーザ端末30に出力する(ステップS13)。
以上により、関連単語出力処理が終了し、検索クエリ関連単語出力装置10は、ユーザ端末30からキーワードが入力されるたびに、前記ステップS11〜S13の処理を実行する。
【0046】
ユーザ端末30においては、ユーザが入力したキーワードに、検索クエリ関連単語出力装置10から出力された関連単語を組み合わせたクエリ候補が表示される。そして、ユーザが表示されたクエリ候補から検索意図に合ったものを選択すると、ユーザ端末30は、サーチエンジン23にクエリを出力し、その検索結果を取得して表示する。
従って、前記ステップS3,S4により本願発明の属性解析ステップが構成され、ステップS5により本願発明の因果関係記憶ステップが構成され、ステップS12により本願発明のノード判定ステップが構成され、ステップS13により本願発明の単語出力ステップが構成される。
【0047】
[実施形態の作用効果]
以上の実施形態によれば、以下の作用効果を奏することができる。
検索クエリ関連単語出力装置10は、ウェブコーパスを解析した因果関係DB18を作成し、入力したキーワードの属性を判定し、このキーワードに関係する単語を出力部16により出力しているので、ユーザ端末30に表示されたクエリにおいて、自分の意図に合ったものを選択して入力することができ、この適切な単語でウェブ情報を検索することができるので、ユーザが求める情報を検索できる。
【0048】
また、属性解析部12は、あらかじめ設定された因果関係モデルに基づいてウェブコーパスをマイニングしているので、単に共起確率が高い単語を選択して出力する場合に比べ、ユーザの検索意図に沿った単語を出力することができる。
すなわち、属性解析部12は、外出意図で検索する場合の因果関係モデルとして、4種類の属性(理由、施設or地名、行為、オブジェクト・イベント)を各ノード41〜44として設定し、ノード判定部15は、入力されたキーワードの属性から第1ノードを判定し、出力部16は、判定された第1ノードに対応する第2ノードに分類された単語から共起確率の高い単語を判定して出力している。このため、キーワード検索するユーザが求める情報に関連性の高い属性の単語を出力でき、ユーザの検索意図に沿ったクエリを出力できる。
【0049】
さらに、各単語の共起確率は、ノードごとに正規化しているので、適切な単語を選択して出力できる。すなわち、各単語の共起確率を、すべてのノードの単語全体の頻度に対する各単語の頻度で求めると、たとえば、「行為」ノード43のように、単語数(選択肢)が少ないノードに含まれる単語の共起確率が高くなり、選択肢が多い「理由」ノード41や「オブジェクト・イベント」ノード44の単語の共起確率は低くなる。一方、本実施形態では、ノードごとに正規化、つまりそのノードに属する単語の出願頻度の総数に対する各単語の頻度の割合を共起確率としているので、ノードごとの単語数(選択肢)の影響を受けずに単語の共起確率を求めることができる。このため、すべてのノードにおいて、入力されたキーワードに対する共起確率の高い単語を出力できる。この点でも、ユーザの検索意図に沿った単語を出力でき、入力されたキーワードと、検索クエリ関連単語出力装置10から出力された単語とを組み合わせてクエリとすることで、ユーザの検索意図を考慮したクエリを作成できる。
【0050】
属性解析部12は、ウェブコーパスDB17に記憶されたウェブコーパスを解析しているので、情報検索装置20のWEBページDB22を直接解析する場合に比べて、精度の高い分析を短時間で行うことができる。
【0051】
因果関係DB18として、グラフ構造とCPT50からなるベイジアンネットワークを用いているので、各ノード間の複雑な表現が可能となり、データの欠損や偏りがあっても適切に処理できるとともに、因果関係を全体で捉えることができる。
【0052】
[変形例]
なお、本発明は、上述した実施形態に限定されるものではなく、本発明の目的を達成できる範囲で、以下に示される変形をも含むものである。
たとえば、上記実施形態では、属性解析部12で用いた因果関係モデルとして、図3に示すものを用いていたが、「外出意図」を持ったクエリの因果関係モデルとしては、図10に示すように、「理由」ノード41からのリンク45が「施設、地名」ノード42のみに接続されたモデルを用いてもよい。この場合、第1ノードとして「理由」ノード41に該当する属性のキーワードが入力された場合、第2ノードとしては「施設、地名」ノード42の単語が出力されることになる。外出意図を持ったユーザが「理由」ノード41のキーワードを入力した場合、その外出先となる「施設、地名」の単語がクエリに含まれていないと、適切な情報を提供することが難しいためである。
【0053】
また、属性解析部12で用いる因果関係モデルとしては、図11に示すように、「理由」ノード41および「オブジェクト・イベント」ノード44が、単語ごとR1〜Rn(理由ノード)、O1〜On(オブジェクト・イベントノード)に分かれて設定されたものでもよい。
さらに、因果関係モデルとしては、ベイジアンネットワークの代わりにマルコフネットワークを用いてもよい。また、決定木や、各単語の組み合わせ頻度による絞り込みを用いてもよいし、ランダムに関係している名詞をつなげたモデルなどでもよい。要するに、因果関係モデルは、検索クエリの意図、具体的には入力されたキーワードの属性などに応じて適切なモデルを設定して利用すればよい。
【0054】
また、因果関係モデルなどによって、CPT50を作成する必要がない場合には、CPTテーブル作成部13を設けずに、属性解析部12の解析結果を因果関係DB18に記憶してもよい。
【0055】
さらに、上記実施形態では、検索クエリ関連単語出力装置10と情報検索装置20とを別々の装置として構成していたが、これらのまとめた1つの装置として構成してもよい。
この場合は、入力されたキーワードと、検索クエリ関連単語出力装置10で出力された単語とを組み合わせたクエリによってWEBページDB22を検索し、その検索結果をユーザ端末30に自動的に出力するようにしてもよい。
【産業上の利用可能性】
【0056】
本発明は、入力されたキーワードに対して適切なキーワードを出力できる検索クエリ関連単語出力装置、検索クエリ関連単語出力方法および検索補助システムとして利用できる。
【符号の説明】
【0057】
1…検索システム、10…検索クエリ関連単語出力装置、11…ウェブコーパス取得部、12…属性解析部、13…CPTテーブル作成部、14…クエリ取得部、15…ノード判定部、16…出力部、17…ウェブコーパスデータベース(ウェブコーパスDB)、18…因果関係データベース(因果関係DB)、20…情報検索装置、21…クローラ部、22…ウェブページデータベース(WEBページDB)、23…サーチエンジン、30…ユーザ端末。
【特許請求の範囲】
【請求項1】
ウェブコーパスを記憶するコーパス記憶部と、
あらかじめ設定された因果関係モデルに基づいて、単語の属性によって定義される第1ノードおよび第2ノードと、各ノードに該当する単語を抽出する抽出条件とを設定し、この抽出条件で前記コーパス記憶部に記憶されたウェブコーパスを解析して、各ノードに該当する単語を抽出する属性解析部と、
前記第1ノードに含まれる単語と、第2ノードに含まれる単語の共起頻度に基づく因果関係情報を記憶する因果関係記憶部と、
入力されたキーワードを解析し、そのキーワードに対応する第1ノードを判定するノード判定部と、
前記ノード判定部で判定された前記第1ノードに対応する第2ノードにおいて、前記キーワードに対する共起確率の高い単語を、前記因果関係記憶部に記憶された因果関係情報から求めて出力する単語出力部と、
を備えることを特徴とする検索クエリ関連単語出力装置。
【請求項2】
請求項1に記載の検索クエリ関連単語出力装置において、
前記第1ノードに対応する第2ノードが複数設定されている場合、
前記単語出力部で判定している第2ノードの各単語の共起確率は、各第2ノードにおけるすべての単語の共起頻度の合計値に対する各単語の共起頻度の割合で求められ、
前記単語出力部は、すべての第2ノードの単語の中で最も共起確率の高い単語を判定して出力する
ことを特徴とする検索クエリ関連単語出力装置。
【請求項3】
請求項1または請求項2に記載の検索クエリ関連単語出力装置において、
前記因果関係モデルは、外出用の情報を得るためのクエリに対応するものであり、
外出理由の属性を有する単語からなる「理由」ノードと、外出先の施設名または地名の属性を有する単語からなる「施設、地名」ノードと、外出時の行為の属性を有する単語からなる「行為」ノードと、外出目的やイベントの属性を有する単語からなる「オブジェクト・イベント」ノードと、の4つのノードを備える
ことを特徴とする検索クエリ関連単語出力装置。
【請求項4】
ウェブコーパスを記憶するコーパス記憶部と、
因果関係情報を記憶する因果関係記憶部とを備えた検索クエリ関連単語出力装置における検索クエリ関連単語出力方法であって、
あらかじめ設定された因果関係モデルに基づいて、単語の属性によって定義される第1ノードおよび第2ノードと、各ノードに該当する単語を抽出する抽出条件とを設定し、この抽出条件で前記コーパス記憶部に記憶されたウェブコーパスを解析して、各ノードに該当する単語を抽出する属性解析ステップと、
前記第1ノードに含まれる単語と、第2ノードに含まれる単語の共起頻度に基づく因果関係情報を前記因果関係記憶部に記憶する因果関係記憶ステップと、
入力されたキーワードを解析し、そのキーワードに対応する第1ノードを判定するノード判定ステップと、
前記ノード判定ステップで判定された前記第1ノードに対応する第2ノードにおいて、前記キーワードに対する共起確率の高い単語を、前記因果関係記憶部に記憶された因果関係情報から求めて出力する単語出力ステップと、
を備えることを特徴とする検索クエリ関連単語出力方法。
【請求項5】
請求項1から請求項3のいずれかに記載の検索クエリ関連単語出力装置と、
前記検索クエリ関連単語出力装置にネットワークを介して接続されたユーザ端末とを備えた検索補助システムであって、
前記ユーザ端末は、入力されたキーワードを前記検索クエリ関連単語出力装置に送信し、
前記検索クエリ関連単語出力装置は、前記ユーザ端末から送信されたキーワードを取得するクエリ取得部を有し、
前記単語出力部は、前記クエリ取得部で取得されたキーワードおよび前記単語出力部で求められた単語を組み合わせたクエリを、前記ユーザ端末に対して出力する
ことを特徴とする検索補助システム。
【請求項1】
ウェブコーパスを記憶するコーパス記憶部と、
あらかじめ設定された因果関係モデルに基づいて、単語の属性によって定義される第1ノードおよび第2ノードと、各ノードに該当する単語を抽出する抽出条件とを設定し、この抽出条件で前記コーパス記憶部に記憶されたウェブコーパスを解析して、各ノードに該当する単語を抽出する属性解析部と、
前記第1ノードに含まれる単語と、第2ノードに含まれる単語の共起頻度に基づく因果関係情報を記憶する因果関係記憶部と、
入力されたキーワードを解析し、そのキーワードに対応する第1ノードを判定するノード判定部と、
前記ノード判定部で判定された前記第1ノードに対応する第2ノードにおいて、前記キーワードに対する共起確率の高い単語を、前記因果関係記憶部に記憶された因果関係情報から求めて出力する単語出力部と、
を備えることを特徴とする検索クエリ関連単語出力装置。
【請求項2】
請求項1に記載の検索クエリ関連単語出力装置において、
前記第1ノードに対応する第2ノードが複数設定されている場合、
前記単語出力部で判定している第2ノードの各単語の共起確率は、各第2ノードにおけるすべての単語の共起頻度の合計値に対する各単語の共起頻度の割合で求められ、
前記単語出力部は、すべての第2ノードの単語の中で最も共起確率の高い単語を判定して出力する
ことを特徴とする検索クエリ関連単語出力装置。
【請求項3】
請求項1または請求項2に記載の検索クエリ関連単語出力装置において、
前記因果関係モデルは、外出用の情報を得るためのクエリに対応するものであり、
外出理由の属性を有する単語からなる「理由」ノードと、外出先の施設名または地名の属性を有する単語からなる「施設、地名」ノードと、外出時の行為の属性を有する単語からなる「行為」ノードと、外出目的やイベントの属性を有する単語からなる「オブジェクト・イベント」ノードと、の4つのノードを備える
ことを特徴とする検索クエリ関連単語出力装置。
【請求項4】
ウェブコーパスを記憶するコーパス記憶部と、
因果関係情報を記憶する因果関係記憶部とを備えた検索クエリ関連単語出力装置における検索クエリ関連単語出力方法であって、
あらかじめ設定された因果関係モデルに基づいて、単語の属性によって定義される第1ノードおよび第2ノードと、各ノードに該当する単語を抽出する抽出条件とを設定し、この抽出条件で前記コーパス記憶部に記憶されたウェブコーパスを解析して、各ノードに該当する単語を抽出する属性解析ステップと、
前記第1ノードに含まれる単語と、第2ノードに含まれる単語の共起頻度に基づく因果関係情報を前記因果関係記憶部に記憶する因果関係記憶ステップと、
入力されたキーワードを解析し、そのキーワードに対応する第1ノードを判定するノード判定ステップと、
前記ノード判定ステップで判定された前記第1ノードに対応する第2ノードにおいて、前記キーワードに対する共起確率の高い単語を、前記因果関係記憶部に記憶された因果関係情報から求めて出力する単語出力ステップと、
を備えることを特徴とする検索クエリ関連単語出力方法。
【請求項5】
請求項1から請求項3のいずれかに記載の検索クエリ関連単語出力装置と、
前記検索クエリ関連単語出力装置にネットワークを介して接続されたユーザ端末とを備えた検索補助システムであって、
前記ユーザ端末は、入力されたキーワードを前記検索クエリ関連単語出力装置に送信し、
前記検索クエリ関連単語出力装置は、前記ユーザ端末から送信されたキーワードを取得するクエリ取得部を有し、
前記単語出力部は、前記クエリ取得部で取得されたキーワードおよび前記単語出力部で求められた単語を組み合わせたクエリを、前記ユーザ端末に対して出力する
ことを特徴とする検索補助システム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【公開番号】特開2013−92826(P2013−92826A)
【公開日】平成25年5月16日(2013.5.16)
【国際特許分類】
【出願番号】特願2011−232892(P2011−232892)
【出願日】平成23年10月24日(2011.10.24)
【出願人】(500257300)ヤフー株式会社 (1,128)
【公開日】平成25年5月16日(2013.5.16)
【国際特許分類】
【出願日】平成23年10月24日(2011.10.24)
【出願人】(500257300)ヤフー株式会社 (1,128)
[ Back to top ]