
検索システム、索引作成装置、検索装置、索引作成方法、検索方法およびプログラム
【課題】 コンピュータに蓄積された文字列情報の高精度な検索を可能とすること。
【解決手段】 本検索システム200は、検索対象となる入力文字列を1以上のトークンに分割するトークン分割部222と、出現位置の算出に際し除外するものとして登録されたトークンを除外トークンとし、除外しないトークンを見出し語トークンとして、見出し語トークンに対し、出現位置を定義付ける位置定義部232と、除外トークンに対し、該除外トークンが後続する見出し語トークンを起点とした位置情報を付与する情報付与部234と、1以上のトークンについて除外トークンが後続するか否かを識別させて索引付けする索引付け処理部236とを含む。本検索システム200は、さらに、除外トークンを考慮した検索処理が求められる場合に、フレーズ検索クエリに含まれる検索トークン列に出現位置および位置情報を含め整合するトークン列を抽出する検索処理部250とを含む。
【解決手段】 本検索システム200は、検索対象となる入力文字列を1以上のトークンに分割するトークン分割部222と、出現位置の算出に際し除外するものとして登録されたトークンを除外トークンとし、除外しないトークンを見出し語トークンとして、見出し語トークンに対し、出現位置を定義付ける位置定義部232と、除外トークンに対し、該除外トークンが後続する見出し語トークンを起点とした位置情報を付与する情報付与部234と、1以上のトークンについて除外トークンが後続するか否かを識別させて索引付けする索引付け処理部236とを含む。本検索システム200は、さらに、除外トークンを考慮した検索処理が求められる場合に、フレーズ検索クエリに含まれる検索トークン列に出現位置および位置情報を含め整合するトークン列を抽出する検索処理部250とを含む。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、情報検索技術に関し、より詳細には、コンピュータに蓄積された文字列情報の高精度な検索を可能とする、検索システム、索引作成装置、検索装置、索引作成方法、検索方法およびプログラムに関する。
【背景技術】
【0002】
近年、コンピュータ、ブロードバンドなどの高速大容量通信基盤が普及し、官公庁、大学、企業など組織における業務のIT化が進み、日々膨大な非定型文書が発生している。このような背景から、検索者が意図する文書を高速かつ的確に検索可能な検索システムの必要性が、ますます高まっている。
【0003】
検索システムでは、適切な文字列分割方法を使用して、検索対象の文書の文字列を単語や文節などの単位(以下、トークンとして参照する。)に分割し、元文書内におけるトークンの出現順に位置番号を与え、逆引き索引(Inverted Index)に格納している。入力された検索語句も、単語や文節など所定の単位(以下、検索トークンとして参照する。)に分割され、検索対象の文書について登録されたトークンが検索トークンに一致するか否かの判断に応じて、該文書を検索結果として抽出するかどうかを決定している。
【0004】
検索精度を向上することを目的として、種々の従来技術が知られている。例えば、大量の文章から検索者が意図した文書を的確に検索するために、言語を特定し、形態素解析などの文字列解析を行うことによって、単純な文字列一致よりも高精度な検索を実現する技術が知られている。また、特開2010−250389号公報は、検索漏れをなくしつつ、適切な検索結果を得ることを目的として、1つの文書を形態素解析およびNグラムの2つの方式によってトークン分割して索引付けする技術を開示している。
【0005】
しかしながら、高度な文字列解析を導入すると、その反面、文字列が完全に一致していない文書でも、高度な解析結果の影響のために検索結果に含まれることになり、検索結果に含まれる文書が必ずしも検索者の意図したものではない場合が発生し得る。
【0006】
また、句読点や記号などは、文書作成者により恣意的に用いられるため、通常の検索システムでは、句読点や記号に関しては、これらの語の影響を受けないで検索できるよう、見出し語とせず、索引付けを行わないという手法がとられる。その反面、句読点や記号を考慮した検索ができない。
【0007】
フレーズ検索では、各トークンに与えられた位置番号を利用して、フレーズに含まれる検索トークンと一致したトークンに対し、連続する位置番号が与えられているか否かを判断する。このため、フレーズ検索をサポートするためには、文書内で隣り合うトークンは、位置番号の差分が固定(通常は1に固定)されるように索引付けしなければならない。この制限ため、フレーズ検索では、句読点や記号を見出し語に含めることは難くなる。
【0008】
しかしながら、企業においては、企業名、プロジェクト名、製品名などの固有名詞の中に記号がしばしば使用されており、記号を省略して検索処理がなされてしまうと、検索結果から検索者が意図した文書が漏れてしまうという不具合があった。また、固有名詞を単語として辞書登録することもできるが、辞書登録の作業が繁雑であり、さらに、辞書登録のたびに索引を再構築し直す必要があり、充分なものではなかった。
【先行技術文献】
【特許文献】
【0009】
【特許文献1】特開2010−250389号公報
【発明の概要】
【発明が解決しようとする課題】
【0010】
本発明は、上記従来技術における不具合に鑑みてなされたものであり、本発明は、句読点や記号など通常検索対象とならないトークンを考慮して情報検索が可能な検索システム、索引作成装置、検索装置、索引作成方法、検索方法およびプログラムを提供することを目的とする。
【課題を解決するための手段】
【0011】
本発明は、上記課題に鑑みてなされたものであり、本発明では、下記の特徴を有する、フレーズ検索を行うための検索システムを提供する。本検索システムは、索引付けのための機能部として、検索対象となる入力文字列から分割された1以上のトークンについて、出現位置の算出に際し除外するものとして登録されたトークンを除外トークンとし、除外しないトークンを見出し語トークンとして、見出し語トークンに対し出現位置を定義付ける位置定義部を含む。本検索システムは、さらに、除外トークンに対し、該除外トークンが後続する見出し語トークンを起点とした位置情報を付与する情報付与部と、上記1以上のトークンを除外トークンが後続するか否かを識別させて索引付けする索引付け処理部とを含む。
【0012】
さらに、本検索システムは、検索のための機能部として、フレーズ検索クエリに応答して、除外トークンを考慮した検索処理が求められる場合に、索引データを参照して、フレーズ検索クエリに含まれる検索トークン列に出現位置および位置情報を含め整合するトークン列を抽出する検索処理部を含むことができる。
【0013】
さらに本発明によれば、上記検索システムにおける索引付けのための機能部を備える索引作成装置、該索引作成装置が実行する索引作成方法、上記検索システムにおける検索のための機能部を備える検索装置、該検索装置が実行する検索方法、上記索引作成装置をコンピュータ上に実現するためのプログラム、上記検索装置をコンピュータ上に実現するためのプログラムを提供することができる。
【発明の効果】
【0014】
上記構成によれば、通常の検索では考慮されない除外トークンについても、該除外トークンが後続する見出し語トークンを起点とする位置情報が付与されて、索引付けされるため、検索時において、除外トークンを考慮してフレーズ検索することが可能となり、ひいては、検索者の意図をより正確に反映した検索結果を得ることができる。
【図面の簡単な説明】
【0015】
【図1】本実施形態による検索システムの概略図。
【図2】本実施形態によるサーバおよびクライアント上に実現される、検索システムの機能ブロック図。
【図3】入力文字列から索引付けまでの文字列解析部および索引構築部が実行する処理を、各処理により生成されるデータ構造とともに示す概略図。
【図4】(A)他の例文による入力文字列のトークン分割から索引付けまでの処理を説明する図、および(B)。他の実施形態による入力文字列のトークン分割から索引付けまでの処理を説明する図。
【図5】本実施形態による索引作成装置としてのサーバが実行する、索引作成方法を示すフローチャート。
【図6】本実施形態により作成される索引データのデータ構造を例示する図。
【図7】本実施形態による検索システムにおける、通常モードによるフレーズ検索処理について説明する図。
【図8】本実施形態による検索システムにおける、補正モードによるフレーズ検索処理について説明する図(1/3)。
【図9】本実施形態による検索システムにおける、補正モードによるフレーズ検索処理について説明する図(2/3)。
【図10】本実施形態による検索システムにおける、補正モードによるフレーズ検索処理について説明する図(3/3)。
【図11】本実施形態におけるランク付けのための重み付けを説明する図。
【図12】ブラウザ画面を例示する図。
【図13】固有フレーズが登録可能な実施形態によるサーバ上に実現される、検索部240の機能ブロック図。
【図14】本実施形態による検索装置としてのサーバが実行する、フレーズ検索方法を示すフローチャート(1/2)。
【図15】本実施形態による検索装置としてのサーバが実行する、フレーズ検索方法を示すフローチャート(2/2)。
【発明を実施するための形態】
【0016】
以下、本発明について実施形態をもって説明するが、本発明は、後述する実施形態に限定されるものではない。
【0017】
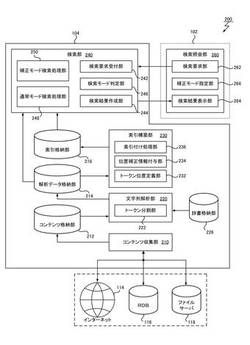
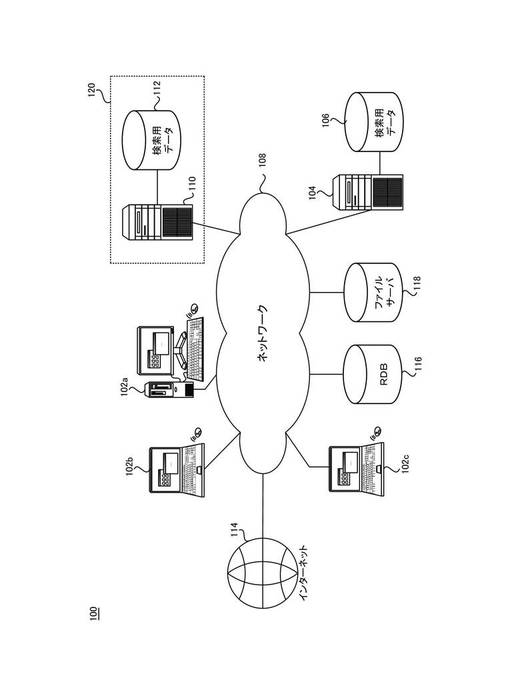
図1は、本実施形態による検索システム100の概略図である。検索システム100は、検索者が利用することができる複数のクライアント・コンピュータ(以下、クライアントとして参照する。)102a〜102cと、各クライアント102からの検索要求に応答して検索結果を返すサーバ・コンピュータ(以下、サーバとして参照する。)104とを含む。
【0018】
検索システム100には、さらに、検索対象となる情報(以下、単にコンテンツとして参照する。)を格納するコンピュータとして、リレーショナル・データベース(RDB)116と、ファイル・サーバ118とを含んでいてもよい。検索システム100は、さらに、図示しないルータなどを介して、インターネット114などの外部のネットワークに接続されてもよく、URL(Uniform Resource Locator)またはURN(Uniform Resource Name)などのリソース識別子が指し示す記憶位置にあるコンテンツも検索対象とすることができる。
【0019】
検索対象となるコンテンツとしては、ドキュメント・データ、イメージ・データ、マルチメディア・データなど、データ本体、タイトルや見出しなどのメタデータ内に文字列を含む各種データを検索対象とすることができる。以下、各コンテンツに含まれ、検索される入力文字列を文書データとして参照する。
【0020】
クライアント102と、サーバ104とは、ネットワーク108を介して相互接続されている。ネットワーク108は、特に限定されるものではないが、イーサネット(登録商標)やTCP/IPなどのトランザクション・プロトコルによるLAN(Local Area Network)、VPN(Virtual Private Network)や専用線を使用して接続されるWAN(Wide Area Network)などとして構成することができる。
【0021】
サーバ104は、CGI(Common Gateway Interface)、SSI(Server Side Include)、サーブレットなどのサーバ・プログラムを実装して構成することができる。例えば、サーバ104は、HTTPプロトコルを使用して、クライアント102からの検索要求を処理し、クライアント102に検索結果を返すことができる。サーバ104は、シングルコアまたはマルチコアのプロセッサ、RAM(Random Access Memory)、HDD(Hard Disk Drive)、NIC(Network Interface Card)を含み、WINDOWS(登録商標)200X、UNIX(登録商標)、LINUX(登録商標)などの適切なオペレーティング・システムにより制御される。
【0022】
クライアント102は、ウェブ・ブラウザなどを実装して構成され、検索用データ106を管理するサーバ104に検索要求を発行し、検索結果を取得してブラウザ上に表示する。クライアント102は、プロセッサ、RAM、HDD、NIC、ディスプレイ・デバイス、ポインティング・デバイスやキーボードなどの入力デバイスを含む、パーソナル・コンピュータまたはワークステーションなどの汎用コンピュータとして構成される。クライアント102も、適切オペレーティング・システムにより制御される。
【0023】
サーバ104は、コンテンツを検索するための索引データを含む検索用データ106を管理する。検索用データ106は、ハードディスク装置などの記憶装置上に構成されるファイルシステムやデータベース上に、コンピュータがアクセス可能なフォーマットで格納される。本実施形態のサーバ104は、ハードウェアおよびソフトウェアが協働して、索引作成装置としての機能と、検索エンジンとしての機能との両方の機能を提供する。ここで、索引作成装置としての機能とは、RDB116、ファイル・サーバ118、インターネット114などの情報ソース上のコンテンツを検索するための検索用データ106を作成する機能をいう。検索エンジンとしての機能とは、クライアント102からの検索要求に応答して検索結果を返す機能をいう。
【0024】
コンテンツを検索対象に加えるために検索用データ106に登録する場合、サーバ104は、コンテンツに含まれる文書データに対し、形態素解析法などのトークン分割処理法を適用してトークン列を生成し、トークンの文書データ内の出現位置を識別する情報と共に索引付けし、当該コンテンツの存在位置を示すURI(Uniform Resource Identifier)などのポインタに対応付けて検索用データ106に登録する。
【0025】
また、図1には、検索システム100の他の実施形態も示されている。図1に示す他の実施形態では、サーバ104は、ハードウェアおよびソフトウェアが協働して、検索エンジンとしての機能を専ら提供する。一方、破線枠120で示す別途配置されたサーバ110は、ハードウェアおよびソフトウェアが協働して、検索用データ112の管理、コンテンツの取得、索引付けなどの索引作成装置としての機能を専ら提供するものである。図1に示した他の実施形態では、検索用データ106は、サーバ110が管理する検索用データ112に同期される。
【0026】
さらに他の実施形態では、図示しないが、上記索引作成装置としての機能、上記検索エンジンとしての機能およびクライアントとしての機能を兼ね備えた、コンピュータ・システム内のデスクトップ検索システムとして構成してもよい。
【0027】
図2は、本実施形態によるサーバ104およびクライアント102上に実現される、検索システム100の機能ブロック200を示す。図2に示すクライアント102に含まれる各機能部は、クライアント102のメモリ上にプログラムを展開し、プログラムを実行することにより、各ハードウェア資源を動作制御することで、クライアント102上に実現される。クライアント102は、ディスプレイ・デバイス、入力装置などを含むユーザ・インタフェース部と、NICを含む通信処理部とを備える。クライアント102は、ユーザ・インタフェース部への入力に従って、通信処理部を用いてサーバ104へ検索要求を送信し、該要求に対してサーバ104から返信された検索結果を通信処理部で受信して、ユーザ・インタフェース部のディスプレイに提示させる。
【0028】
図2に示すサーバ104に含まれる各機能部は、サーバ104のメモリ上にプログラムを展開し、プログラムを実行することにより、各ハードウェア資源を動作制御することで、サーバ104上に実現される。サーバ104は、NICなどを含む通信処理部を備える。
【0029】
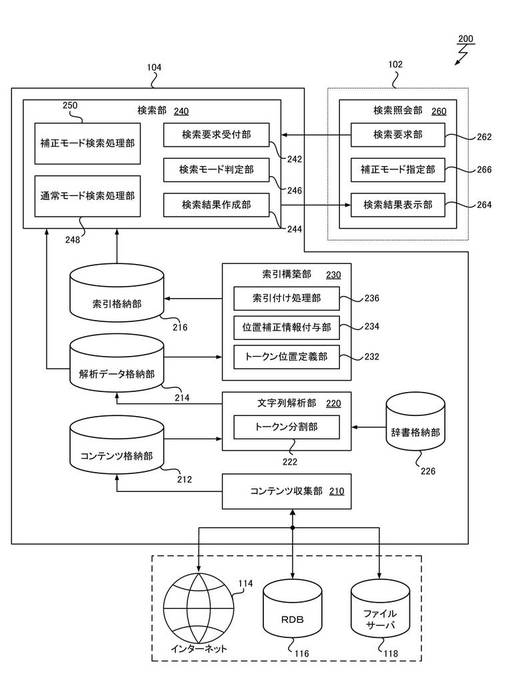
図2を参照すると、本実施形態のサーバ104は、コンテンツ収集部210と、文字列解析部220と、索引構築部230と、検索部240とを含んで構成される。
【0030】
コンテンツ収集部210は、検索対象として追加または更新する情報を収集する機能部である。コンテンツ収集部210は、予め収集範囲として設定された、例えばRDB116、ファイル・サーバ118、インターネット114上の所定URLなどの情報ソースから、コンテンツを収集し、収集したコンテンツと該コンテンツのポインタとを対応付けてコンテンツ格納部212に格納する。コンテンツ格納部212は、ハードディスク装置などの記憶装置上にデータベースまたはファイルシステムとして構成される。
【0031】
文字列解析部220は、コンテンツ格納部212に格納された種々のデータ形式のコンテンツから文書データを抽出し、文書データに対し言語の特定や形態素解析等の文字列解析処理を施す機能部である。文字列解析部220は、文字列解析処理を行った結果として、解析データを、元のコンテンツに対応付けて解析データ格納部214に格納する。解析データ格納部214は、ハードディスク装置などの記憶装置上にデータベースまたはファイルシステムとして構成される。
【0032】
索引構築部230は、解析データ格納部214に格納された解析データを読み出し、索引付け処理を行って、索引データを索引格納部216に格納する機能部である。索引格納部216は、ハードディスク装置などの記憶装置上にデータベースまたはファイルシステムとして構成され、検索要求に対し迅速に応答可能なデータ構造で上記索引データを格納する。索引格納部216が格納する索引データは、好適には、文書データ中のトークンの出現位置を示す情報を含んだ逆引き索引(Inverted Index)として構成することができる。
【0033】
検索部240は、クライアント102からの検索要求に応答して、索引格納部216の索引データを照合しながら検索処理を実行する機能部である。検索部240は、検索処理が完了すると、検索結果をクライアント102へ返す。
【0034】
以下、索引作成機能に関連する文字列解析部220および索引構築部230、並びに検索機能に関連する検索部240について、各処理の段階に分けて、より詳細に説明する。
【0035】
(1)サーバによる文字列解析
文字列解析部220は、コンテンツ格納部212に格納された種々のデータ形式のコンテンツから文書データを抽出し、文書データに対し文字列解析を行う。例えば、HTML(HyperText Markup Language)やXML(eXtensible Markup Language)などの構造化言語により記述されたコンテンツについては、文字列解析部220は、タグの除去処理などを施して、文書データを抽出する。PDF(Portable Document Format)、特定の文書作成アプリケーションによるファイルなどバイナリ形式のデータについては、文字列解析部220は、適切な文書フィルタを用いて文書データを抽出する。
【0036】
文字列解析部220は、より詳細には、トークン分割部222を含み構成される。トークン分割部222は、抽出された文書データに対し、特定した言語に対応した形態素解析法を実施し、辞書格納部226が格納する文法規則や辞書を参照しながら、文書データの入力文字列からトークンを切り出して、1以上のトークンの列に分割する。説明する実施形態では、形態素解析法を適用してトークン分割するものとして説明する。しかしながら、他の実施形態では、形態素解析法に代えて、または形態素解析法と共に、Nグラム法を適用してもよく、英語など分かち書きされる言語については、空白や記号等で区切る分割手法を適用してもよい。
【0037】
文書データから切り出されたトークン列は、元のコンテンツに対応付けて、解析データとして格納される。解析データは、例えば、対応するコンテンツに一意に割当てる文書識別値(DOC_ID)と、該コンテンツのURIなどのポインタとに関連付けられて格納される。
【0038】
本実施形態において、切り出されるトークンは、見出し語トークンおよび除外トークンに分類することができる。見出し語トークンは、詳細を後述する索引付け処理において、出現位置の算出の際に考慮される見出し語として登録されたトークンである。除外トークンは、上記出現位置の算出に際し除外されるが、検索時には考慮の対象となり得るものとして登録されたトークンである。
【0039】
除外トークンとしては、句読点や記号などの文書作成者が恣意的に付すものであるために、フレーズ検索における位置番号に関する制限に起因して、一般的なフレーズ検索において見出し語から除外されるトークンを含むことができる。本実施形態においては、上記除外トークンは、出現位置の算出に際しては除外されるが、検索時には考慮の対象となり得るものであるため、解析データおよび索引データに含ませられる。
【0040】
上記除外トークンとしては、より具体的には、句点、読点、カンマ、ピリオド、コロン、セミコロン、アポストロフィ、アスタリスク、アットマーク、括弧(丸括弧、二重丸括弧、かぎ括弧、二重かぎ括弧、角括弧、山括弧など)、リーダ(二点リーダ、三点リーダなど)、中点(中黒)、ハイフン、二重ハイフン、感嘆符、疑問符、米印、ダッシュ、波ダッシュ、踊り文字、繰り返し符号、反復符号など、一般に約物と呼ばれる記述記号類を挙げることができる。また、上記除外トークンには、携帯電話のメールサービスで使用される絵文字を含んでもよい。
【0041】
なお、いずれの記述記号類を除外トークンとして検索時に考慮するかは任意であり、検索システム100の管理者は、予め辞書等に登録することができる。上記出現位置の算出および検索の両方に際して考慮しないトークンがあれば、切り出したトークン列から予め削除しておいてもよい。
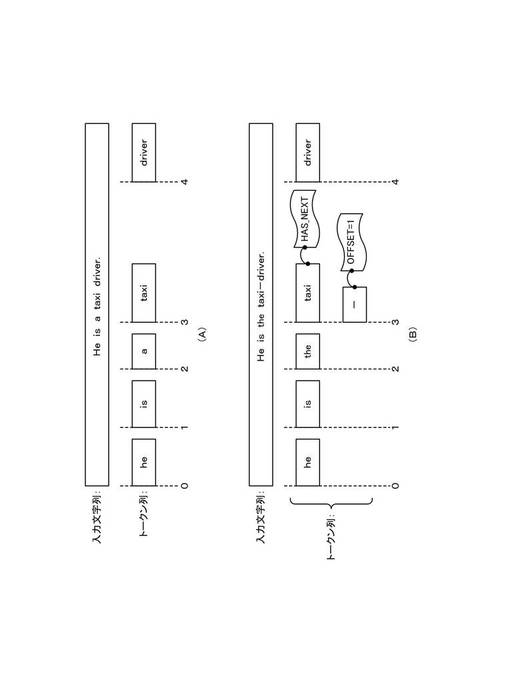
【0042】
図3は、入力文字列から索引付けまでの文字列解析部220および後述する索引構築部230が実行する処理を、各処理により生成されるデータ構造とともに示す概略図である。以下、例文1”He is a taxi driver”および例文2”He is the taxi−driver”を用いて説明する。図3(A)を参照すると、トークン分割部222は、例文1”He is a taxi driver”に対し形態素解析を適用すると、例文1の入力文字列を、「he」、「is」、「a」、「taxi」および「driver」の5つのトークンに分割して入力文字列に割当てる。これらのトークンは、説明においては、いずれも見出し語トークンとされる。
【0043】
一方、図3(B)を参照すると、例文2”He is the taxi−driver”に対し形態素解析を適用する場合、トークン分割部222は、例文2の入力文字列を「he」、「is」、「the」、「taxi」、「−」および「driver」の6つのトークンに分割する。上記例文2の場合、5つの見出し語トークンに加えて、記号「−」がトークンとして分割されており、説明においてこのトークン「−」は、上述した除外トークンとされる。
【0044】
トークン分割部222は、トークン分割処理中、入力文字列から分割されたトークンに対し、トークン間の位置関係を維持するデータ構造として解析データに書き込む。本実施形態では、辞書格納部226には、見出し語トークンおよび除外トークンが分けて予め登録されており、トークン分割部222は、各トークンが見出し語トークンであるか除外トークンであるかを識別可能な解析データを書き込む。
【0045】
なお、上記文字列解析部220は、特に限定されるものではないが、システム管理者からの外部指令に応答して、予めシステム管理者が設定したスケジュールに従って、または予めシステム管理者が設定した規定量の更新または追加すべきコンテンツがコンテンツ格納部212に新たに格納されたことに応答して、未処理のコンテンツについて文字列解析を開始することができる。
【0046】
(2)サーバによる索引作成
ここで再び図2を参照する。索引構築部230は、解析データ格納部214に格納された解析データを読み出して、トークン列の各トークンについて、フレーズ検索ができるよう位置番号および補足情報を付与して、索引データを作成する。索引構築部230は、より詳細には、トークン位置定義部232と、位置補正情報付与部234と、索引付け処理部236とを含み構成される。
【0047】
トークン位置定義部232は、各解析データに含まれるトークン間の位置関係から、各トークンに対して、文書内出現位置番号(TOKEN_POS:以下、単に位置番号として参照する。)を定義して割当てる。上記位置番号(TOKEN_POS)は、索引上、文書データ内でトークンが出現する位置を識別するものである。上述したように、解析データに含まれるトークンには、見出し語トークンと除外トークンとが存在するが、この位置番号(TOKEN_POS)は、見出し語トークンに対し、除外トークンを無視して該見出し語トークンが出現する順に定義付けられる。
【0048】
位置補正情報付与部234は、分割された1以上のトークンのうち除外トークンに対し、この除外トークンが後続する見出し語トークンを起点とした位置情報を付与する。ここで、上記位置情報には、この除外トークンが出現する位置を識別する位置番号と、この除外トークンが後続する起点となる見出し語トークンを基準として該除外トークンの位置関係を規定する位置補正情報とが含まれる。上記除外トークンの位置番号は、該除外トークンが後続する起点となる見出し語トークンと同一の位置番号となる。上記位置補正情報は、より具体的には、当該除外トークンの起点となる見出し語トークンからの該除外トークンの位置差分(以下、この位置差分を位置補正値と参照する。)となる。
【0049】
索引付け処理部236は、対応するコンテンツを識別する文書識別子(DOC_ID)と、トークンと、該トークンが出現する位置番号(TOKEN_POS)と、適宜補足情報とを関連付けて、索引データに対し索引エントリを追加する。その際に、索引付け処理部236は、上記見出し語トークンおよび除外トークンの両方について、該トークンに後続する除外トークンが存在するか否かを識別できるようにして、索引エントリの追加を行う。
【0050】
トークン位置定義部232、位置補正情報付与部234および索引付け処理部236による索引付けは、概略的には以下のように実行される。ここで、再び図3を参照する。図3(A)に示す例文1の場合は、5つのトークンに分割されるが、この場合、トークン位置定義部232は、5つの見出し語トークンに対し出現順に位置番号を定義する。
【0051】
一方、図3(B)に示す例文2の場合は、5つの見出し語トークンに加えて1つの除外トークン「−」が含まれるが、トークン位置定義部232は、除外トークン「−」を無視して5つの見出し語トークンに対し出現順に位置番号を定義する。したがって、図3に示す例では、「taxi」および「driver」には、その間に除外トークンが存在するか否かに関わらず、それぞれ、位置番号(TOKEN_POS=3)および位置番号(TOKEN_POS=4)が定義される。
【0052】
これに対し、除外トークン「−」については、位置補正情報付与部234は、該除外トークンが後続する起点となる見出し語トークン「taxi」と同一の位置番号(TOKEN_POS=3)を付与し、さらに、起点となる見出し語トークン「taxi」からの位置補正値(OFFSET=1)を付与する。
【0053】
図3(B)を参照すると、除外トークン「−」が後続する見出し語トークン「taxi」には、さらに、付加情報(HAS_NEXT=true)が付与されている。これは、当該トークンに、後続する除外トークンが存在することを識別できるよう付されるものである。付加情報(HAS_NEXT)の値がtrueである場合、後続する除外トークンが存在することを意味し、付加情報(HAS_NEXT)の値がfalseであるか、または省略されている場合、後続トークンが存在しないことを意味する。このように、索引付け処理部236は、除外トークンが後続する見出し語トークンに対し、付加情報(HAS_NEXT=true)を付加して、索引付けを行うことにより、逆引き索引付けした後も、当該見出し語トークンに除外トークンが後続していることを容易に識別可能としている。
【0054】
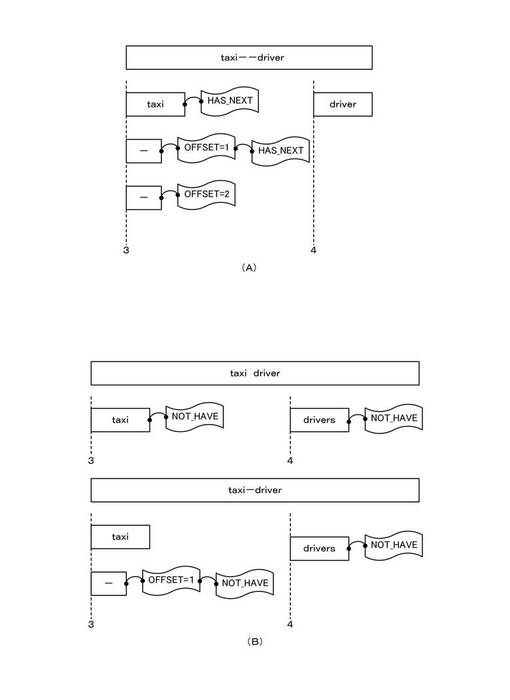
図4(A)は、他の例文による入力文字列のトークン分割から索引付けまでの処理を説明する図である。図4(A)を参照すると、2つの記号「−」が連続する場合、位置補正情報付与部234は、2つの除外トークン「−」各々に対し、これら起点となる見出し語トークン「taxi」と同一の位置番号(TOKEN_POS=3)を付与する。さらに、位置補正情報付与部234は、1番目の除外トークン「−」については、位置補正値(OFFSET=1)を付与し、2番目の除外トークン「−」については、起点となる見出し語トークンからの位置関係に対応して、位置補正値(OFFSET=2)を付与する。
【0055】
また、2番目の除外トークン「−」が後続する1番目の除外トークンには、さらに、付加情報(HAS_NEXT=true)が付与されているが、これは、上記と同様に、後続トークンが存在することを識別できるよう付されるものである。索引付け処理部236は、除外トークンが後続する除外トークンに対しても、付加情報(HAS_NEXT=true)を付加して、索引付けを行うことにより、逆引き索引付けした後も除外トークンが後続していることを容易に識別可能としている。
【0056】
なお、説明する実施形態では、付加情報が、除外トークンが後続するトークンを識別する情報であるとして説明したが、逆引き索引付けした後に除外トークンが後続するトークンを識別可能である限り、特に限定されるものではない。例えば、他の実施形態では、図4(B)に例示するように、除外トークンが後続しないトークンに対し、付加情報(NOT_HAVE=true)を付与し、付加情報(NOT_HAVE=true)が、除外トークンが後続しないトークンを示す情報であるとしてもよい。
【0057】
また、説明する実施形態では、位置番号は、見出し語トークン間の差分を固定値1として定義されるものとして説明したが、1以外の他の固定値を用いてもよく、またフレーズ検索をサポートできる限り、固定値に限定されず、本索引作成処理は、種々の変形例に対し適用することができる。
【0058】
索引構築部230は、各解析データ(コンテンツ)について得られた索引エントリを用いて、見出し語(除外トークンに対応する語も含まれる。)毎に全コンテンツにわたって整理し、最終的な逆引き索引付けを行い、索引データを索引格納部216に格納する。その際に、索引構築部230は、tf−idf(Term Frequency inverse Document Frequency)などで算出される統計値を、索引全体で各見出し語について整理して付加することもできる。
【0059】
なお、図1に示した検索用データ106,112は、図2に示す索引格納部216が格納する索引データと、解析データ格納部214が格納する解析データとを含んで構成することができる。解析データは、検索結果に含ませるコンテンツ・サマリなどを生成するためなどに使用することもできる。
【0060】
(3)サーバによる索引作成方法
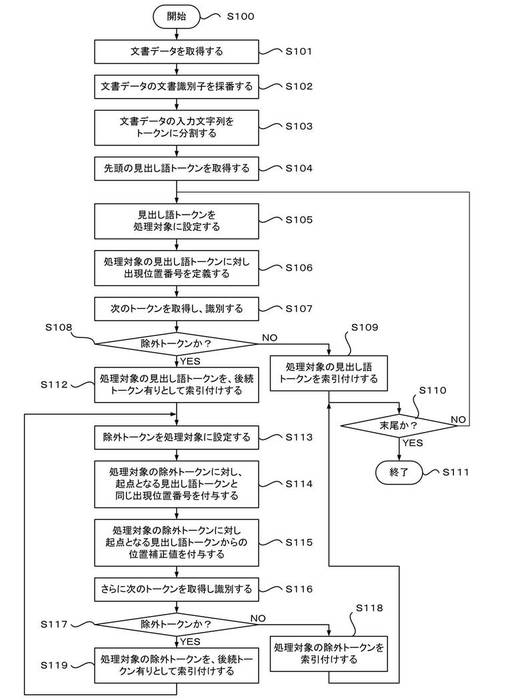
図5は、本実施形態による索引作成装置としてのサーバ104が実行する、索引作成方法を示すフローチャートである。図5に示す処理は、外部指令に応答して、スケジュールされたタイミングの到来に応答して、または新たな解析データが追加されたことに応答して、ステップS100から開始する。なお、図5では、新規追加されたコンテンツの文書データ毎に実行される処理として説明しているが、コンテンツの内容の更新に伴う再索引付けについても、図5に示すものと同様の処理によって行うことができる。
【0061】
ステップS101では、文字列解析部220は、コンテンツ格納部212に格納されたコンテンツから入力文字列を抽出して、文書データを取得する。ステップS102では、文字列解析部220は、索引データにおいてコンテンツ(文書データ)を一意に識別する文書識別子(DOC_ID)を採番する。ステップS103では、文字列解析部220は、トークン分割部222により、取得された文書データの入力文字列を1以上のトークンに分割する。得られた解析データは、解析データ格納部214に格納される。
【0062】
ステップS104では、索引構築部230は、解析データを読み出し、まず先頭に位置する見出し語トークンを取得する。ステップS105では、索引構築部230は、取得した見出し語トークンを現在の処理対象として設定する。ステップS106では、索引構築部230は、トークン位置定義部232により、処理対象の見出し語トークンに対し位置番号を定義する。位置番号は、例えば、先頭の見出し語トークンを始点の位置番号(TOKEN_POS=0)として、以降の見出し語トークンについて固定値を増分させながら定義される。
【0063】
ステップS107では、索引構築部230は、トークン列から当該処理対象の見出し語トークンの次に位置するトークンを取得し、その次トークンが除外トークンであるか否かを識別する。ステップS108では、索引構築部230は、次トークンが除外トークンであるか否かに対応して処理を分岐させる。
【0064】
ステップS108で、次トークンが除外トークンではないと判定された場合(NO)は、ステップS109へ処理を分岐させる。この場合、現在の処理対象の見出し語トークンを起点とする除外トークンが後続しないと判断できる。ステップS109では、索引構築部230は、索引付け処理部236により、処理対象の見出し語トークンについて、文書識別子(DOC_ID)および位置番号(TOKEN_POS)をセットにして索引エントリ("TOKEN" (DOC_ID, TOKEN_POS))を追加して、そのまま索引付けを行う。
【0065】
ステップS110では、索引構築部230は、次トークンが存在せず、トークン列の末尾に達したか否かを判定する。ステップS110で、トークン列の末尾にまだ達していないと判定された場合(NO)には、索引構築部230は、ステップS105へ処理をループさせて、現在処理対象の見出し語トークンの次の見出し語トークンを処理対象に設定し、トークン列の末尾に達するまで、ステップS105以降の処理を繰り返させる。
【0066】
一方、ステップS108で、次のトークンが除外トークンであると判定された場合(YES)は、ステップS112へ処理を分岐させる。この場合、現在の処理対象の見出し語トークンを起点として、後続する除外トークンが存在する。ステップS112では、索引構築部230は、索引付け処理部236により、処理対象の見出し語トークンについて、文書識別子(DOC_ID)、位置番号(TOKEN_POS)、さらに付加情報(HAS_NEXT=true)をセットにして、後続する除外トークン有りとして索引エントリ("TOKEN" (DOC_ID, TOKEN_POS, true))を追加し、索引付けする。
【0067】
ステップS113では、索引構築部230は、次トークンとして取得された除外トークンを現在の処理対象として設定する。ステップS114では、索引構築部230は、位置補正情報付与部234により、現在処理対象の除外トークンに対し、起点となる見出し語トークンと同一の位置番号を付与する。ステップS115では、索引構築部230は、位置補正情報付与部234により、現在処理対象の除外トークンに対し、さらに、起点となる見出し語トークンからの位置補正値(OFFSET)を算出し、付与する。
【0068】
ステップS116では、索引構築部230は、当該処理対象の除外トークンのさらに次に位置するトークンを取得し、次トークンが除外トークンであるか否かを識別する。ステップS117では、索引構築部230は、次トークンが除外トークンであるか否かに対応して処理を分岐させる。
【0069】
ステップS117で、次トークンが除外トークンではないと判定された場合(NO)は、ステップS118へ処理を分岐させる。この場合、現在処理対象の除外トークンに後続する除外トークンが存在しないと判断できる。ステップS118では、索引構築部230は、索引付け処理部236により、処理対象の除外トークンについて、文書識別子(DOC_ID)、位置番号(TOKEN_POS)および位置補正値(OFFSET)をセットにして、索引エントリ("TOKEN" (DOC_ID, TOKEN_POS, OFFSET))を追加し、索引付けし、ステップS110へ分岐させる。この場合、ステップS110でトークン列の末尾に達したか否かが判定されて、トークン列の末尾に未だ達していないと判定された場合(NO)には、ステップS105へループさせる。
【0070】
一方、ステップS117で、次トークンが除外トークンであると判定された場合(YES)は、ステップS119へ処理を分岐させる。この場合、現在処理対象の除外トークンにさらに後続する除外トークンが存在するため、ステップS119では、索引構築部230は、索引付け処理部236により、処理対象の除外トークンについて、文書識別子(DOC_ID)、位置番号(TOKEN_POS)、位置補正値(OFFSET)、さらに付加情報(HAS_NEXT=true)をセットにして、後続する除外トークン有りとして索引エントリ("TOKEN" (DOC_ID, TOKEN_POS, OFFSET, true))を追加し、索引付けする。この場合、索引構築部230は、ステップS113へ処理をループさせて、現在処理対象の次の除外トークンを処理対象に設定し、見出し語トークンを起点とした除外トークンの末端まで、ステップS113〜ステップS119の処理を繰り返させる。
【0071】
再びステップS110を参照すると、ステップS109で処理対象の見出し語トークンの索引付けが行われるか、またはステップS118で処理対象の除外トークンの索引付けが行われるかして、ステップS110で、トークン列の末尾に達したと判定される場合(YES)には、ステップS111へ処理を分岐させて、当該コンテンツについての処理を終了させる。
【0072】
上述した索引作成方法が行われ、索引構築部230により、トークン毎に全コンテンツにわたって整理されて、逆引き索引付けが完了すると、図6に例示されるような索引データが構築される。図6に示すように、索引データには、各見出し語トークンについて、該見出し語トークンが出現する文書データの文書識別子(DOC_ID)、その文書データ内の出現位置(TOKEN_POS)、および適宜その出現位置にかかるトークンに除外トークンが後続するか否かを示す付加情報(HAS_NEXT)が関連付けられたセットが登録される。
【0073】
除外トークンについても同様に、逆引き索引データには、その除外トークンが出現する文書データの文書識別子(DOC_ID)、該文書データ内における起点となる見出し語トークンの出現位置(TOKEN_POS)、該起点からの位置補正値(OFFSET)、および適宜その出現位置にかかる除外トークンにさらに除外トークンが後続するか否かを示す付加情報(HAS_NEXT)が関連付けられたセットが登録される。
【0074】
上述したように、本実施形態による索引作成処理では、コンテンツ内の入力文字列が除外トークンを含んで構成される場合でも、除外トークンに対し、該除外トークンが後続する起点となる見出し語トークンからの位置情報が付与される。これにより、詳細を後述するように、除外トークンを考慮したフレーズ検索が可能となる。
【0075】
(4)サーバによる検索処理
ここで再び図2を参照する。検索部240は、クライアント102からの検索要求に応答して、索引格納部216の索引データを照合して検索処理を実行し、クライアント102へ検索結果を返す処理を行う。検索部240は、より詳細には、検索要求受付部242と、検索結果作成部244と、検索モード判定部246と、通常モード検索処理部248と、補正モード検索処理部250とを含んで構成される。
【0076】
これに対し、クライアント102は、ウェブ・ブラウザ、プラグインなどのソフトウェアと、プロセッサ、該プロセッサの実行空間を提供するRAMなどのハードウェアとが協働して機能する検索照会部260を含んで構成される。検索照会部260は、より詳細には、検索要求部262と、検索結果表示部264と、補正モード指定部266とを含んで構成される。
【0077】
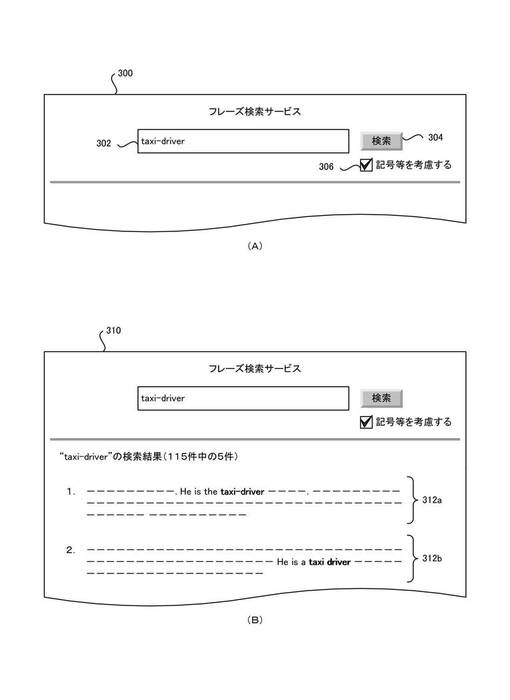
クライアント102の検索要求部262は、検索時において、例えば図12(A)に示すようなブラウザ画面300上の検索ボタン304がクリックされたことに応答して、検索テキスト・ボックス302に入力された検索クエリを含む検索要求をサーバ104に送信する。上記検索要求は、除外トークンの位置を補正して除外トークンを考慮した検索モード(以下、補正モードという。)による検索を行うか、除外トークンを考慮しない検索モード(以下、通常モードという。)による検索を行うかを指定するモード指定値を含むことができる。モード指定値は、例えばブラウザ画面300上の検索モードを指定するためのGUI部品(チェックボックス)306に対し、操作が行われたことに対応して、補正モード指定部266が設定する。
【0078】
サーバ104の検索要求受付部242は、クライアント102の検索要求部262からの検索要求を受け付けて、検索要求にかかる検索クエリを取得するとともに、モード指定値を取得する。検索モード判定部246は、取得したモード指定値を参照して、求められている検索モードを判定する。検索モード判定部246は、除外トークンを考慮した補正モードが指定される場合には、補正モード検索処理部250に対し検索処理依頼を発行する。一方、除外トークンを考慮しない通常モードが指定されている場合には、検索モード判定部246は、通常モード検索処理部248に対し検索処理依頼を発行する。
【0079】
クライアント102から送信される検索要求の検索クエリは、検索文字列を含み、検索要求受付部242は、形態素解析により検索文字列を検索トークンに分割して、検索トークン列を生成する。検索トークンが単一の場合は、単一語検索となり、検索トークンが複数ある場合は、フレーズ検索となる。単一の検索トークンによる単一語検索の場合は、トークンの位置関係が無関係であるため、モード指定値にかかわらず、通常モードの検索処理が行われる。
【0080】
通常モードが指定される場合、通常モード検索処理部248は、検索処理依頼を受領すると、索引格納部216の索引データを照会して、除外トークンを考慮しない検索処理を実行する。通常モード検索処理部248は、検索処理の実行結果として、除外トークンとの関係に関わらず、検索クエリに一致するトークン(列)を含むコンテンツの照会集合を取得する。
【0081】
単一語検索について説明すると、例えば、「taxi」、「driver」、「−」といった検索トークンによる単一語検索が要求される場合、通常モード検索処理部248は、そのまま、「taxi」、「driver」、「−」などの指定された検索トークンを含むコンテンツの照会集合を取得する。検索文字列から切り出される検索トークンについても、索引作成処理に関して上述したように、見出し語トークンと、除外トークンとが含まれる。検索トークン「−」が除外トークンであっても、除外トークン「−」を含めて索引データが索引付けされているため、単一語検索では、除外トークン「−」を見出し語として扱って、トークン「−」を含む照会集合を得ることができる。
【0082】
補正モードが指定される場合、補正モード検索処理部250は、検索処理依頼を受領すると、索引格納部216の索引データを照会し、詳細を後述する除外トークンを考慮した検索処理を実行する。補正モード検索処理部250は、検索処理の実行結果として、除外トークンとの関係を含めて検索クエリに一致するトークン列を含むコンテンツの照会集合を取得する。
【0083】
検索結果作成部244は、検索処理部248,250が作成したコンテンツ・リストを取得し、リストに含まれる識別値(DOC_ID)を解析データ格納部214に与えて、対応する解析データやコンテンツのポインタなどを取得し、検索結果を作成する。照会集合中のコンテンツがランク付けできる態様であれば、検索結果作成部244は、照会集合中の総合スコア上位所定数までスコア順にソートし、各コンテンツ毎に、URIやパス名を指定してリンク可能な態様としたコンテンツ・サマリを含むデータとして作成することができる。
【0084】
作成された検索結果のデータは、クライアント102に送信される。クライアント102の検索結果表示部264は、検索結果のデータを受信して、例えば、ブラウザ画面310上に、総合スコア上位所定数までのコンテンツ毎に、URIやパス名を指定してリンク可能な態様でコンテンツ・サマリ312a,312bを表示させる。
【0085】
(4−1)通常モードのフレーズ検索
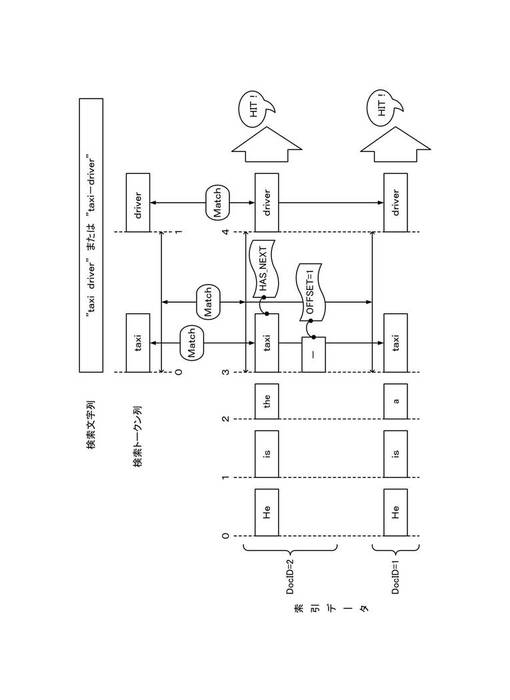
以下、通常モードにおけるフレーズ検索処理について説明する。図7は、通常モードによるフレーズ検索処理について説明する図である。図7は、検索文字列が「taxi driver」または「taxi−driver」である場合であって、例文1(DOC_ID=1)および例文2(DOC_ID=2)について索引データが索引付けされている場合における処理を例示する。検索文字列「taxi−driver」の場合、除外トークン「−」が無視されるため、両検索文字列は、共に、「taxi」および「driver」の検索トークンに分割され、先頭から順に、それぞれのトークンに位置番号0(TOKEN_POS=0)および位置番号1(TOKEN_POS=1)が付される。ここで、「taxi」および「driver」の検索トークン間の位置番号の差分は1となる。
【0086】
一方、索引データを参照すると、例文1(DOC_ID=1)および例文2(DOC_ID=2)の文書データは、共に、差分が1、すなわち連接するトークン「taxi」およびトークン「driver」を含む。したがって、例文1(DOC_ID=1)および例文2(DOC_ID=2)は、共に、検索クエリの検索トークン列に位置番号を含めて整合するトークン列を含むため、共にヒットとなる。この際、索引データにおいて、例文2(DOC_ID=2)のトークン「taxi」に対し、付加情報(HAS_NEXT=true)が付され、またトークン「taxi」と同じ位置番号を有する除外トークン「−」が存在することは、通常モードの検索結果に影響しない。
【0087】
(4−2)補正モードのフレーズ検索
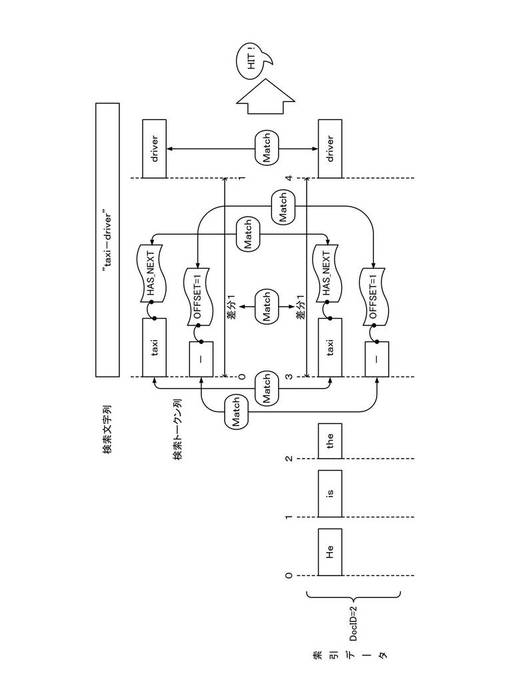
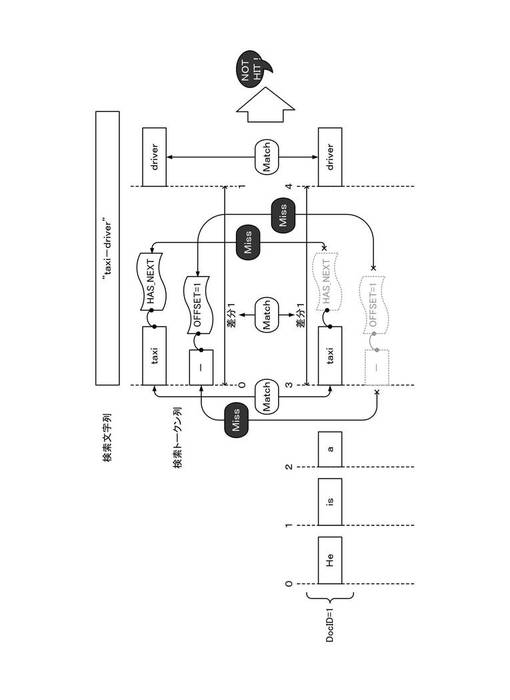
以下、補正モードにおけるフレーズ検索処理について説明する。図8〜図10は、補正モードによるフレーズ検索処理について説明する図である。図8は、検索文字列が「taxi−driver」である場合であって、例文2(DOC_ID=2)について索引データが索引付けされている場合における処理を例示する。
【0088】
検索文字列「taxi−driver」の場合、補正モードでは、除外トークン「−」も考慮されるため、「taxi」、「−」および「driver」の3つの検索トークンに分割される。また、補正モードであっても、位置番号の算出の際には除外トークン「−」は除外されるため、トークン「taxi」およびトークン「driver」には、それぞれ、先頭から順に位置番号0(TOKEN_POS=0)および位置番号1(TOKEN_POS=1)が付される。
【0089】
補正モードでは、除外トークンを考慮した検索を行うため、検索トークン列についても、索引作成処理と同様に補足情報が付される。除外トークン「−」が後続する見出し語トークン「taxi」には、後続トークンが存在することを示す付加情報(HAS_NEXT=true)が付される。除外トークン「−」については、その前方の見出し語トークン「taxi」と同一の位置番号0(TOKEN_POS=0)が付され、さらに、位置補正値(OFFSET=1)が付される。
【0090】
一方、索引データを参照すると、例文2(DOC_ID=2)の文書データは、位置番号の差分が1であるトークン「taxi」および「driver」を含む。さらに、例文2(DOC_ID=2)の文書データでは、トークン「taxi」には、付加情報(HAS_NEXT=true)が付され、さらにトークン「taxi」と同一の位置番号には、除外トークン「−」が存在し、その除外トークン「−」には、位置補正値(OFFSET=1)が付されている。
【0091】
したがって、図8に示す例では、例文2(DOC_ID=2)は、検索クエリを構成する検索トークン列に、見出し語トークンの連接関係(位置番号)が整合し、かつ、除外トークンとの連接関係(付加情報並びに除外トークンの位置番号および位置補正値を含む。)を含めて整合するトークン列を含むため、ヒットとなる。
【0092】
図9は、検索文字列が「taxi−driver」である場合であって、例文1(DOC_ID=1)について索引データが索引付けされている場合における処理を例示する。この場合、検索トークン列は、上述した図8の場合と同様となる。
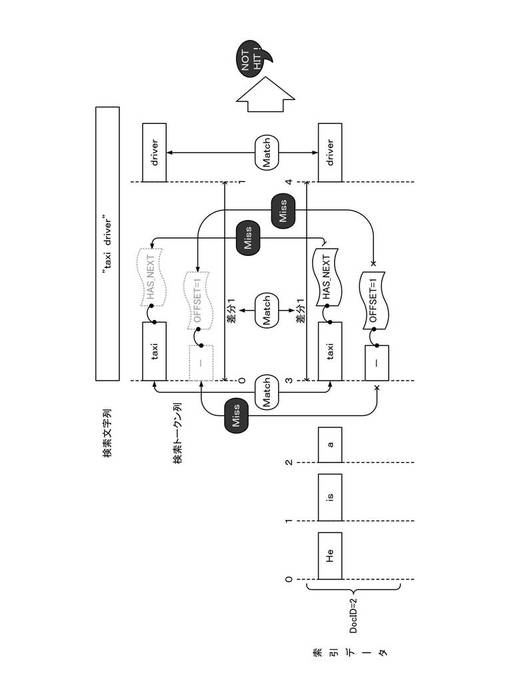
【0093】
索引データを参照すると、例文1(DOC_ID=1)の文書データは、位置番号の差分が1であるトークン「taxi」およびトークン「driver」を含む。しかしながら、例文1(DOC_ID=1)の文書データでは、トークン「taxi」には、付加情報が存在せず(HAS_NEXT=false)、トークン「taxi」と同一の位置番号に、除外トークン「−」は存在しない。したがって、例文1(DOC_ID=1)は、検索クエリを構成する検索トークン列に、見出し語トークンの連接関係(位置番号)が整合するトークン列を含むものの、除外トークンとの連接関係(付加情報並びに除外トークンの位置番号および位置補正値を含む。)を含めて整合するトークン列が存在しないため、ヒットとはならない。
【0094】
図10は、検索文字列が「taxi driver」である場合であって、例文2(DOC_ID=2)について索引データが索引付けされている場合における処理を例示する。この場合、位置番号(TOKEN_POS=0)を有する「taxi」と、位置番号(TOKEN_POS=1)を有する「driver」の2つの検索トークンに分割される。
【0095】
補正モードでは、除外トークンを考慮するため、検索トークン列についても、適宜補足情報が付される。除外トークンが後続しない見出し語トークン「taxi」および「driver」には、後続する除外トークンが存在しないことを示す付加情報(HAS_NEXT=false)が付されるか、またはそのまま省略される。
【0096】
索引データを参照すると、例文2(DOC_ID=2)の文書データは、位置番号の差分が1であるトークン「taxi」および「driver」を含む。しかしながら、例文2(DOC_ID=2)では、トークン「taxi」には、付加情報(HAS_NEXT=true)が存在し、さらに、トークン「taxi」と同一の位置番号に、位置補正値(OFFSET=1)を有する除外トークン「−」が存在する。
【0097】
したがって、例文2(DOC_ID=2)は、検索クエリを構成する検索トークン列に、見出し語トークンの連接関係が整合するトークン列を含むものの、検索トークン列に存在しない除外トークンを含むという意味で、除外トークンとの連接関係を含めて整合するトークン列が存在しないため、ヒットとはならない。
【0098】
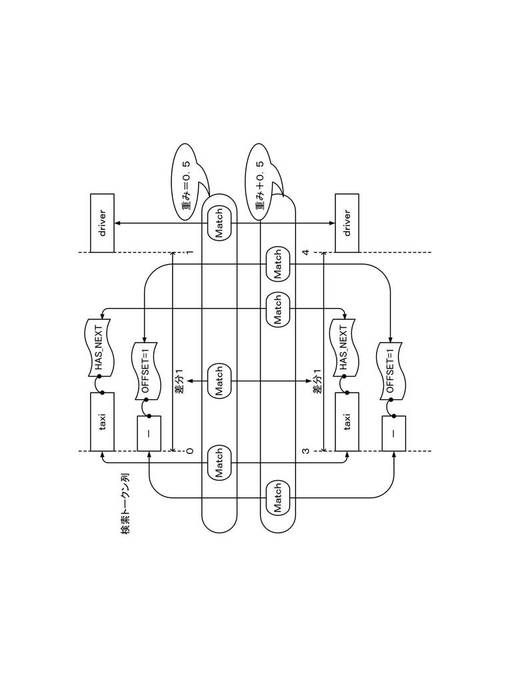
(4−3)ランク付け
以下、検索結果を作成するためのランク付け処理について説明する。図11は、本実施形態におけるランク付けのための重み付けを説明する図である。本実施形態による索引データを用いると、見出し語トークンの連接関係が整合し、かつ、除外トークンとの連接関係を含めて整合する完全一致のトークン列と、見出し語トークンの連接関係が整合するものの、除外トークンとの連接関係を含めると整合しない限定付き一致のトークン列とを識別することができる。そこで、本実施形態の検索システム100では、上記完全一致および限定付き一致に対し、ランク付け結果に差が生じるように、異なる重み値を与えることができる。
【0099】
例えば、特定の実施形態では、図11に示すように、見出し語トークンの連接関係が整合する場合に0.5の重み値を与え、さらに除外トークンとの連接関係を含めて整合する場合に0.5を加算した重み値とし、完全一致に対し、限定付き一致に比較して大きな重みを与えることができる。
【0100】
コンテンツに対して算出される総合スコアは、例えば、文書データ内で完全一致のトークン列が出現する回数に完全一致の重み付けを乗じたスコア(完全一致数×1)と、文書データ内で限定付き一致のトークン列が出現する回数に限定付き一致の重み付けを乗じたスコア(限定付き一致数×0.5)との総和とすることができる。
【0101】
上記構成により、除外トークンの整合を加味した検索結果を提供し、検索者が入力した検索文字列により近いコンテンツを上位に配置することができる。また、完全一致しない限定付き一致のコンテンツについても、検索結果に含ませてランク付けを行うことにより、検索漏れも少なくなり、高品質な検索が可能となる。
【0102】
(4−4)固有フレーズ検索
また、上述した説明においては、検索モードは、クライアント102側の補正モード指定部266によって通常モードまたは補正モードが指定されるものとして説明した。しかしながら、予め補正モードで検索する固有のフレーズを登録しておくことにより、クライアント102側に煩雑な操作を要求せずに、補正モードの検索処理を呼び出すことができる。
【0103】
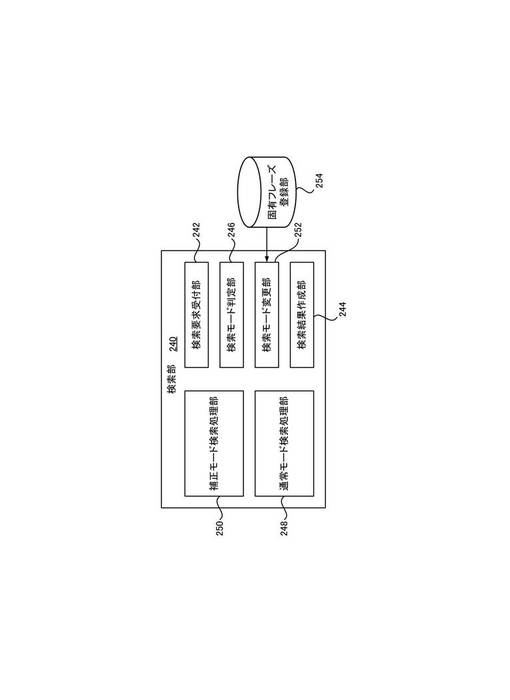
図13は、固有フレーズが登録可能な実施形態によるサーバ104上に実現される、検索部240の機能ブロック図である。図13を参照すると、図2にも示した検索要求受付部242、検索結果作成部244、検索モード判定部246、通常モード検索処理部248および補正モード検索処理部250に加えて、検索モード変更部252および固有フレーズ登録部254を含んで構成される。
【0104】
固有フレーズ登録部254は、予め登録処理された固有フレーズ(固有のトークン列)を登録している。この固有フレーズは、検索文字列を構成するトークン列中に該固有トークン列が含まれる場合に、指定されたモードが通常モードである場合でも、少なくとも当該固有トークン列かかる部分について、除外トークンを考慮した検索を行うものとして、予め登録されるフレーズである。なお、説明する実施形態では、検索文字列を構成するトークン列中に該固有トークン列が含まれる場合に、すべての検索トークン列について、補正モードによる検索を行うものとする。しかしながら、他の実施形態では、固有トークン列の部分だけ除外トークンを考慮した検索とするよう構成することもできる。
【0105】
固有フレーズが登録可能な実施形態においても、モード指定値は、ブラウザ画面300上のGUI部品306に対し操作が行われたことに対応して、クライアント102側の補正モード指定部266が設定することができる。検索モード変更部252は、検索クエリ内の検索文字列から分割された検索トークン列と、固有フレーズ登録部254に登録された固有フレーズ(固有トークン列)とを比較し、検索クエリ中に固有フレーズが含まれるか否かを判定する。そして、検索クエリ中に固有フレーズが含まれる場合は、検索モード変更部252は、指定された検索モードに関わらず、補正モードに変更する。検索モード判定部246は、検索モードが補正モードに変更されたことに伴い、補正モード検索処理部250に対し、検索処理依頼を発行する。
【0106】
社名、プロジェクト名、製品名などの固有フレーズを固有フレーズ登録部254に登録することで、検索時に、登録された固有フレーズが検索クエリに含まれる場合でも、検索者に追加の操作を要求せずに、暗黙的に除外トークンを考慮した検索結果を返すことが可能となる。
【0107】
例えば、検索者にとって「A−B」という語が製品名であり重要である場合、通常モードの検索では、「−」は無視され、「A/B」、「A B」のような必ずしも正確に一致しない語にもヒットしてしまい、検索者が必ずしも望まない結果となってしまう可能性がある。これに対して、「A−B」という語を固有フレーズとして登録しておくことにより、検索文字列に固有フレーズ「A−B」が含まれる場合、正確に一致する語にだけヒットとし、「A/B」、「A B」のような正確に一致しない語については、低い重みでランク付けするか、ヒットから除外することができる。
【0108】
また、社名、プロジェクト名、製品名などについては、固有名詞として索引付けの際の辞書に登録することも可能であるが、その場合、固有名詞を追加する度に索引データを一から再構築する必要がある。これに対し、説明する実施形態では、索引データを一から再構築する必要はなく、固有フレーズを固有フレーズ登録部254に登録するだけで、これまで構築された索引データをそのまま使用して、特定の固有フレーズについて暗黙的に除外トークンを考慮した検索結果を返すことが可能となる。
【0109】
(5)サーバによる検索方法
図14および図15は、本実施形態による検索装置としてのサーバ104が実行する、フレーズ検索方法を示すフローチャートである。図14および図15に示す処理は、連結点Aおよび連結点Bで接続されている点に留意されたい。
【0110】
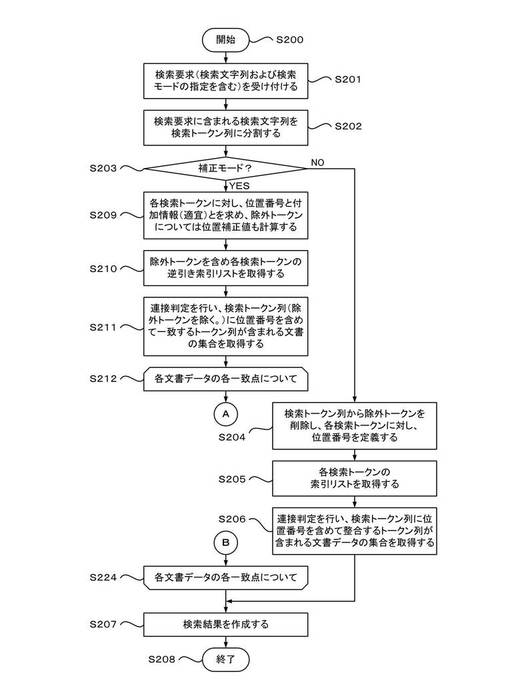
図14および図15に示す処理は、クライアント102から検索要求を受信したことに応答して、ステップS200から開始する。ステップS201では、検索部240は、検索要求受付部242により、クライアント102からの、検索文字列および検索モード指定を含む検索要求を受け付ける。ステップS202では、検索部240は、検索要求に含まれる検索文字列を1以上の検索トークンに分割し、検索トークン列を生成する。
【0111】
ステップS203では、検索部240は、検索モード判定部246により、検索モードを判定する。ステップS203で、検索モードが補正モードではないと判定された場合(NO)は、ステップS204へ処理を分岐し、通常モードによる検索を行う。
【0112】
ステップS204では、検索部240は、通常モード検索処理部248により、検索トークン列から除外トークンを削除し、各検索トークンに対し位置番号を計算する。ステップS205では、検索部240は、索引格納部216内から、各検索トークンに対応する各逆引き索引リストを取得する。ここで、逆引き索引リストとは、索引格納部216内のトークン毎に整理された逆引き索引データのうち、所定のトークンに関連して、出現文書、出現位置および適宜補足情報の配列を含むリストをいう。
【0113】
ステップS206では、検索部240は、通常モード検索処理部248により、連接判定を行いながら、検索トークン列(除外トークンは除外済みである。)に、位置番号を含めて一致するトークン列が含まれる文書データの集合(コンテンツ・リスト)を取得し、ステップS207へ処理を進める。ステップS207では、検索部240は、検索結果作成部244により、通常モード検索処理部248により作成されたコンテンツ・リストを用いて、対応する解析データやコンテンツのポインタなどを取得し、検索結果を作成し、検索要求に対する応答として要求元に返却する。ステップS208では、検索部240は、検索処理を終了する。
【0114】
一方、ステップS203で、検索モードが補正モードであると判定された場合(YES)は、ステップS209へ処理を分岐し、補正モードによる検索を行う。ステップS209では、検索部240は、補正モード検索処理部250により、検索トークン列の各検索トークンに対し、位置番号を計算し、適宜付加情報を求め、さらに、除外トークンについては、位置補正値(OFFSET)を計算する。ステップS210では、検索部240は、索引格納部216内から、各検索トークンに対応する各逆引き索引リストを取得する。
【0115】
ステップS211では、検索部240は、補正モード検索処理部250により、連接判定を行いながら、まず、検索トークン列(ここでは、除外トークンを除く。)に位置番号を含めて整合するトークン列が含まれる文書データの照会集合を取得し、ステップS212へ処理を進める。ステップS212〜ステップS224では、検索部240は、補正モード検索処理部250により、各文書データの各一致点について、ステップS213〜ステップS223の処理を行う。
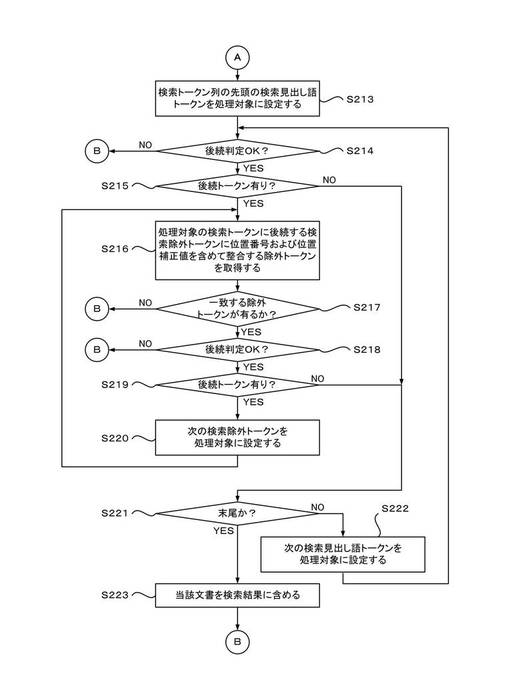
【0116】
ステップS213では、補正モード検索処理部250は、検索トークン列の先頭に位置する見出し語トークン(以下、検索見出し語トークンという。)を処理対象に設定する。ステップS214では、補正モード検索処理部250は、処理対象の検索見出し語トークンに関して、索引中の一致点にかかる見出し語トークンとを比較し、付加情報が整合するか否かを判定する。ステップS214で、検索トークンに付加情報が付され(HAS_NEXT=true)、索引中の見出し語トークンに付加情報が付されていない(HAS_NEXT=false)場合や、逆の場合など、整合しないと判定された場合(NO)には、連結点Bを介してステップS224へ分岐させ、次の一致点へと処理を進める。
【0117】
一方、ステップS214で、検索トークンおよび索引中の見出し語トークンが共に付加情報が付されている(HAS_NEXT=true)場合、または、共に付加情報が付されていない(HAS_NEXT=false)場合(YES)には、ステップS215へ処理を進める。
【0118】
ステップS215では、付加情報(HAS_NEXT=true)で整合しているか(つまり後続する除外トークンがあるか)否かを判定する。ステップS215で、付加情報なし(HAS_NEXT=false)として整合し、後続トークンが無いと判定された場合(NO)は、ステップS221へ処理を分岐させて、検索トークン列の末尾に達したか否かを判定する。ステップS221で、末尾に達していないと判定された場合(NO)には、ステップS222へ処理を分岐させ、次の検索見出し語トークンを処理対象に設定し、ステップS214へ処理をループさせる。
【0119】
一方、ステップS215で、付加情報あり(HAS_NEXT=true)として整合し、後続トークンが有ると判定された場合(YES)は、ステップS216へ処理を進める。ステップS216では、補正モード検索処理部250は、逆引き索引リストを参照し、現在処理対象の検索トークンに後続する除外トークン(以下、検索除外トークンという。)と、位置番号および位置補正値を含めて整合する除外トークンの取得を試みる。
【0120】
ステップS217では、ステップS216において整合する除外トークンが有るか否かを判定する。ここでは、上記検索除外トークンに対応する逆引き索引リスト中に、位置番号および位置補正値が整合するエントリが有れば、整合する除外トークンが有ると判定される。
【0121】
ステップS217で、整合する除外トークンが無いと判定された場合(NO)は、連結点Bを介してステップS224へ分岐させて、次の一致点へと処理を進める。一方、ステップS217で、整合する除外トークンが有ると判定された場合(YES)には、ステップS218へ処理を進める。
【0122】
ステップS218では、補正モード検索処理部250は、現在処理対象の検索トークンに後続する検索除外トークンに関して、索引中の一致点にかかる除外トークンとを比較し、付加情報(HAS_NEXT)が整合するか否かを判定する。ステップS218で、検索除外トークンに付加情報が付され(HAS_NEXT=true)、索引中の除外トークンに付加情報が付されていない(HAS_NEXT=false)場合や、逆の場合など、後続判定が整合しないと判定された場合(NO)には、連結点Bを介してステップS224へ分岐させて、次の一致点へと処理を進める。一方、ステップS218で、整合すると判定された場合(YES)には、ステップS219へ処理を進める。
【0123】
ステップS219では、補正モード検索処理部250は、さらに後続する除外トークンがあるか否かを判定する。ステップS219で、付加情報なし(HAS_NEXT=false)として整合し、後続するトークンが無いと判定された場合(NO)は、ステップS221へ処理を分岐させて、末尾であるか否かを判定する。一方、ステップS219で、付加情報あり(HAS_NEXT=true)として整合し、後続するトークンが有ると判定された場合(YES)は、ステップS220へ処理を分岐させる。
【0124】
ステップS220では、次の検索除外トークンを処理対象に設定し、ステップS216へ処理をループさせる。この場合、処理対象の検索見出し語トークンを起点とした除外トークンの末端に達するまで、ヒット判定を継続する。
【0125】
ステップS221で、末尾であると判定された場合(YES)には、ステップS223へ処理を分岐させる。この場合、検索トークン列の先頭から末尾まで、すべてにおいて整合しているため、当該一致点は、完全一致であると判断できる。ステップS223では、当該文書データを完全一致するトークン列を含むものとして検索結果に含めて、連結点Bを介してステップS224へ分岐させて、次の一致点へと処理を進める。
【0126】
ステップS212〜ステップS224のループを抜けると、検索結果には、完全一致するトークン列を含む文書データの集合(コンテンツ・リスト)が得られるので、ステップS207では、検索部240は、検索結果作成部244により、補正モード検索処理部250により作成されたコンテンツ・リストを用いて、対応する解析データやコンテンツのポインタなどを取得し、検索結果を作成し、検索要求に対する応答として要求元に返却する。ステップS208では、検索部240は、検索処理を終了する。
【0127】
以上説明したように、本実施形態の文字列解析部220および索引構築部230により作成された索引データは、除外トークンについても索引付けされており、該除外トークンについては、それが後続する見出し語トークンを起点とする位置情報(位置番号および位置補正値)が付与されて、索引データが構築されている。このため、除外トークンを考慮して検索することが可能となる。
【0128】
また、同一の索引データを用いて、除外トークンを考慮しない通常モードの検索と、上記補正モードの検索との両方を共存させることもできる。さらに、除外トークンが後続するトークンに対し、後続の有無を識別する付加情報が付与されているため、逆引き索引においても、効率的にヒット判定を行うことが可能となる。ひいては、検索者の意図をより正確に反映した検索結果を得ることができ、高い適合率かつ効率的な情報検索を実現することができる。
【0129】
以上説明したように、本発明の実施形態によれば、句読点や記号など通常検索対象とならないトークンを考慮して情報検索が可能な検索システム、索引作成装置、検索装置、索引作成方法、検索方法およびプログラムを提供することができる。さらに、本発明の実施形態によれば、検索者の意図を的確に反映した検索結果を効率的に提供することを可能とする、検索システム、索引作成装置、検索エンジン、索引作成方法、検索方法およびプログラムを提供することができる。
【0130】
なお、本発明の実施形態において、好適に適用できる言語としては、説明に用いた英語の他、例えば、日本語、ドイツ語、フランス語、ロシア語、韓国語、中国語、アラビア語など、上述した以外の言語についても適用可能であることはいうまでもない。
【0131】
また、本発明につき、発明の理解を容易にするために各機能部および各機能部の処理を記述したが、本発明は、上述した特定の機能部が特定の処理を実行するほか、処理効率や実装上のプログラミングなどの効率を考慮して、いかなる機能部に、上述した処理を実行するための機能を割当てることができる。
【0132】
本発明の上記機能は、C++、Java(登録商標)、Java(登録商標)Beans、Java(登録商標)Applet、JavaScript(登録商標)、Perl、Rubyなどのオブジェクト指向プログラミング言語、SQLなどの検索言語などで記述された装置実行可能なプログラムにより実現でき、装置可読な記録媒体に格納して頒布または伝送して頒布することができる。
【0133】
これまで本発明を、特定の実施形態をもって説明してきたが、本発明は、実施形態に限定されるものではなく、他の実施形態、追加、変更、削除など、当業者が想到することができる範囲内で変更することができ、いずれの態様においても本発明の作用・効果を奏する限り、本発明の範囲に含まれるものである。
【符号の説明】
【0134】
100…検索システム、102…クライアント、104…サーバ、106…検索用データ、108…ネットワーク、110…サーバ、112…検索用データ、114…インターネット、116…RDB、118…ファイル・サーバ、120…破線枠、200…機能ブロック、210…コンテンツ収集部、212…コンテンツ格納部、214…解析データ格納部、216…索引格納部、220…文字列解析部、222…トークン分割部、226…辞書格納部、230…索引構築部、232…トークン位置定義部、234…位置補正情報付与部、236…索引付け処理部、240…検索部、242…検索要求受付部、244…検索結果作成部、246…検索モード判定部、248…通常モード検索処理部、250…補正モード検索処理部、252…検索モード変更部、254…固有フレーズ登録部、260…検索照会部、262…検索要求部、264…検索結果表示部、266…補正モード指定部、300,310…ブラウザ画面
【技術分野】
【0001】
本発明は、情報検索技術に関し、より詳細には、コンピュータに蓄積された文字列情報の高精度な検索を可能とする、検索システム、索引作成装置、検索装置、索引作成方法、検索方法およびプログラムに関する。
【背景技術】
【0002】
近年、コンピュータ、ブロードバンドなどの高速大容量通信基盤が普及し、官公庁、大学、企業など組織における業務のIT化が進み、日々膨大な非定型文書が発生している。このような背景から、検索者が意図する文書を高速かつ的確に検索可能な検索システムの必要性が、ますます高まっている。
【0003】
検索システムでは、適切な文字列分割方法を使用して、検索対象の文書の文字列を単語や文節などの単位(以下、トークンとして参照する。)に分割し、元文書内におけるトークンの出現順に位置番号を与え、逆引き索引(Inverted Index)に格納している。入力された検索語句も、単語や文節など所定の単位(以下、検索トークンとして参照する。)に分割され、検索対象の文書について登録されたトークンが検索トークンに一致するか否かの判断に応じて、該文書を検索結果として抽出するかどうかを決定している。
【0004】
検索精度を向上することを目的として、種々の従来技術が知られている。例えば、大量の文章から検索者が意図した文書を的確に検索するために、言語を特定し、形態素解析などの文字列解析を行うことによって、単純な文字列一致よりも高精度な検索を実現する技術が知られている。また、特開2010−250389号公報は、検索漏れをなくしつつ、適切な検索結果を得ることを目的として、1つの文書を形態素解析およびNグラムの2つの方式によってトークン分割して索引付けする技術を開示している。
【0005】
しかしながら、高度な文字列解析を導入すると、その反面、文字列が完全に一致していない文書でも、高度な解析結果の影響のために検索結果に含まれることになり、検索結果に含まれる文書が必ずしも検索者の意図したものではない場合が発生し得る。
【0006】
また、句読点や記号などは、文書作成者により恣意的に用いられるため、通常の検索システムでは、句読点や記号に関しては、これらの語の影響を受けないで検索できるよう、見出し語とせず、索引付けを行わないという手法がとられる。その反面、句読点や記号を考慮した検索ができない。
【0007】
フレーズ検索では、各トークンに与えられた位置番号を利用して、フレーズに含まれる検索トークンと一致したトークンに対し、連続する位置番号が与えられているか否かを判断する。このため、フレーズ検索をサポートするためには、文書内で隣り合うトークンは、位置番号の差分が固定(通常は1に固定)されるように索引付けしなければならない。この制限ため、フレーズ検索では、句読点や記号を見出し語に含めることは難くなる。
【0008】
しかしながら、企業においては、企業名、プロジェクト名、製品名などの固有名詞の中に記号がしばしば使用されており、記号を省略して検索処理がなされてしまうと、検索結果から検索者が意図した文書が漏れてしまうという不具合があった。また、固有名詞を単語として辞書登録することもできるが、辞書登録の作業が繁雑であり、さらに、辞書登録のたびに索引を再構築し直す必要があり、充分なものではなかった。
【先行技術文献】
【特許文献】
【0009】
【特許文献1】特開2010−250389号公報
【発明の概要】
【発明が解決しようとする課題】
【0010】
本発明は、上記従来技術における不具合に鑑みてなされたものであり、本発明は、句読点や記号など通常検索対象とならないトークンを考慮して情報検索が可能な検索システム、索引作成装置、検索装置、索引作成方法、検索方法およびプログラムを提供することを目的とする。
【課題を解決するための手段】
【0011】
本発明は、上記課題に鑑みてなされたものであり、本発明では、下記の特徴を有する、フレーズ検索を行うための検索システムを提供する。本検索システムは、索引付けのための機能部として、検索対象となる入力文字列から分割された1以上のトークンについて、出現位置の算出に際し除外するものとして登録されたトークンを除外トークンとし、除外しないトークンを見出し語トークンとして、見出し語トークンに対し出現位置を定義付ける位置定義部を含む。本検索システムは、さらに、除外トークンに対し、該除外トークンが後続する見出し語トークンを起点とした位置情報を付与する情報付与部と、上記1以上のトークンを除外トークンが後続するか否かを識別させて索引付けする索引付け処理部とを含む。
【0012】
さらに、本検索システムは、検索のための機能部として、フレーズ検索クエリに応答して、除外トークンを考慮した検索処理が求められる場合に、索引データを参照して、フレーズ検索クエリに含まれる検索トークン列に出現位置および位置情報を含め整合するトークン列を抽出する検索処理部を含むことができる。
【0013】
さらに本発明によれば、上記検索システムにおける索引付けのための機能部を備える索引作成装置、該索引作成装置が実行する索引作成方法、上記検索システムにおける検索のための機能部を備える検索装置、該検索装置が実行する検索方法、上記索引作成装置をコンピュータ上に実現するためのプログラム、上記検索装置をコンピュータ上に実現するためのプログラムを提供することができる。
【発明の効果】
【0014】
上記構成によれば、通常の検索では考慮されない除外トークンについても、該除外トークンが後続する見出し語トークンを起点とする位置情報が付与されて、索引付けされるため、検索時において、除外トークンを考慮してフレーズ検索することが可能となり、ひいては、検索者の意図をより正確に反映した検索結果を得ることができる。
【図面の簡単な説明】
【0015】
【図1】本実施形態による検索システムの概略図。
【図2】本実施形態によるサーバおよびクライアント上に実現される、検索システムの機能ブロック図。
【図3】入力文字列から索引付けまでの文字列解析部および索引構築部が実行する処理を、各処理により生成されるデータ構造とともに示す概略図。
【図4】(A)他の例文による入力文字列のトークン分割から索引付けまでの処理を説明する図、および(B)。他の実施形態による入力文字列のトークン分割から索引付けまでの処理を説明する図。
【図5】本実施形態による索引作成装置としてのサーバが実行する、索引作成方法を示すフローチャート。
【図6】本実施形態により作成される索引データのデータ構造を例示する図。
【図7】本実施形態による検索システムにおける、通常モードによるフレーズ検索処理について説明する図。
【図8】本実施形態による検索システムにおける、補正モードによるフレーズ検索処理について説明する図(1/3)。
【図9】本実施形態による検索システムにおける、補正モードによるフレーズ検索処理について説明する図(2/3)。
【図10】本実施形態による検索システムにおける、補正モードによるフレーズ検索処理について説明する図(3/3)。
【図11】本実施形態におけるランク付けのための重み付けを説明する図。
【図12】ブラウザ画面を例示する図。
【図13】固有フレーズが登録可能な実施形態によるサーバ上に実現される、検索部240の機能ブロック図。
【図14】本実施形態による検索装置としてのサーバが実行する、フレーズ検索方法を示すフローチャート(1/2)。
【図15】本実施形態による検索装置としてのサーバが実行する、フレーズ検索方法を示すフローチャート(2/2)。
【発明を実施するための形態】
【0016】
以下、本発明について実施形態をもって説明するが、本発明は、後述する実施形態に限定されるものではない。
【0017】
図1は、本実施形態による検索システム100の概略図である。検索システム100は、検索者が利用することができる複数のクライアント・コンピュータ(以下、クライアントとして参照する。)102a〜102cと、各クライアント102からの検索要求に応答して検索結果を返すサーバ・コンピュータ(以下、サーバとして参照する。)104とを含む。
【0018】
検索システム100には、さらに、検索対象となる情報(以下、単にコンテンツとして参照する。)を格納するコンピュータとして、リレーショナル・データベース(RDB)116と、ファイル・サーバ118とを含んでいてもよい。検索システム100は、さらに、図示しないルータなどを介して、インターネット114などの外部のネットワークに接続されてもよく、URL(Uniform Resource Locator)またはURN(Uniform Resource Name)などのリソース識別子が指し示す記憶位置にあるコンテンツも検索対象とすることができる。
【0019】
検索対象となるコンテンツとしては、ドキュメント・データ、イメージ・データ、マルチメディア・データなど、データ本体、タイトルや見出しなどのメタデータ内に文字列を含む各種データを検索対象とすることができる。以下、各コンテンツに含まれ、検索される入力文字列を文書データとして参照する。
【0020】
クライアント102と、サーバ104とは、ネットワーク108を介して相互接続されている。ネットワーク108は、特に限定されるものではないが、イーサネット(登録商標)やTCP/IPなどのトランザクション・プロトコルによるLAN(Local Area Network)、VPN(Virtual Private Network)や専用線を使用して接続されるWAN(Wide Area Network)などとして構成することができる。
【0021】
サーバ104は、CGI(Common Gateway Interface)、SSI(Server Side Include)、サーブレットなどのサーバ・プログラムを実装して構成することができる。例えば、サーバ104は、HTTPプロトコルを使用して、クライアント102からの検索要求を処理し、クライアント102に検索結果を返すことができる。サーバ104は、シングルコアまたはマルチコアのプロセッサ、RAM(Random Access Memory)、HDD(Hard Disk Drive)、NIC(Network Interface Card)を含み、WINDOWS(登録商標)200X、UNIX(登録商標)、LINUX(登録商標)などの適切なオペレーティング・システムにより制御される。
【0022】
クライアント102は、ウェブ・ブラウザなどを実装して構成され、検索用データ106を管理するサーバ104に検索要求を発行し、検索結果を取得してブラウザ上に表示する。クライアント102は、プロセッサ、RAM、HDD、NIC、ディスプレイ・デバイス、ポインティング・デバイスやキーボードなどの入力デバイスを含む、パーソナル・コンピュータまたはワークステーションなどの汎用コンピュータとして構成される。クライアント102も、適切オペレーティング・システムにより制御される。
【0023】
サーバ104は、コンテンツを検索するための索引データを含む検索用データ106を管理する。検索用データ106は、ハードディスク装置などの記憶装置上に構成されるファイルシステムやデータベース上に、コンピュータがアクセス可能なフォーマットで格納される。本実施形態のサーバ104は、ハードウェアおよびソフトウェアが協働して、索引作成装置としての機能と、検索エンジンとしての機能との両方の機能を提供する。ここで、索引作成装置としての機能とは、RDB116、ファイル・サーバ118、インターネット114などの情報ソース上のコンテンツを検索するための検索用データ106を作成する機能をいう。検索エンジンとしての機能とは、クライアント102からの検索要求に応答して検索結果を返す機能をいう。
【0024】
コンテンツを検索対象に加えるために検索用データ106に登録する場合、サーバ104は、コンテンツに含まれる文書データに対し、形態素解析法などのトークン分割処理法を適用してトークン列を生成し、トークンの文書データ内の出現位置を識別する情報と共に索引付けし、当該コンテンツの存在位置を示すURI(Uniform Resource Identifier)などのポインタに対応付けて検索用データ106に登録する。
【0025】
また、図1には、検索システム100の他の実施形態も示されている。図1に示す他の実施形態では、サーバ104は、ハードウェアおよびソフトウェアが協働して、検索エンジンとしての機能を専ら提供する。一方、破線枠120で示す別途配置されたサーバ110は、ハードウェアおよびソフトウェアが協働して、検索用データ112の管理、コンテンツの取得、索引付けなどの索引作成装置としての機能を専ら提供するものである。図1に示した他の実施形態では、検索用データ106は、サーバ110が管理する検索用データ112に同期される。
【0026】
さらに他の実施形態では、図示しないが、上記索引作成装置としての機能、上記検索エンジンとしての機能およびクライアントとしての機能を兼ね備えた、コンピュータ・システム内のデスクトップ検索システムとして構成してもよい。
【0027】
図2は、本実施形態によるサーバ104およびクライアント102上に実現される、検索システム100の機能ブロック200を示す。図2に示すクライアント102に含まれる各機能部は、クライアント102のメモリ上にプログラムを展開し、プログラムを実行することにより、各ハードウェア資源を動作制御することで、クライアント102上に実現される。クライアント102は、ディスプレイ・デバイス、入力装置などを含むユーザ・インタフェース部と、NICを含む通信処理部とを備える。クライアント102は、ユーザ・インタフェース部への入力に従って、通信処理部を用いてサーバ104へ検索要求を送信し、該要求に対してサーバ104から返信された検索結果を通信処理部で受信して、ユーザ・インタフェース部のディスプレイに提示させる。
【0028】
図2に示すサーバ104に含まれる各機能部は、サーバ104のメモリ上にプログラムを展開し、プログラムを実行することにより、各ハードウェア資源を動作制御することで、サーバ104上に実現される。サーバ104は、NICなどを含む通信処理部を備える。
【0029】
図2を参照すると、本実施形態のサーバ104は、コンテンツ収集部210と、文字列解析部220と、索引構築部230と、検索部240とを含んで構成される。
【0030】
コンテンツ収集部210は、検索対象として追加または更新する情報を収集する機能部である。コンテンツ収集部210は、予め収集範囲として設定された、例えばRDB116、ファイル・サーバ118、インターネット114上の所定URLなどの情報ソースから、コンテンツを収集し、収集したコンテンツと該コンテンツのポインタとを対応付けてコンテンツ格納部212に格納する。コンテンツ格納部212は、ハードディスク装置などの記憶装置上にデータベースまたはファイルシステムとして構成される。
【0031】
文字列解析部220は、コンテンツ格納部212に格納された種々のデータ形式のコンテンツから文書データを抽出し、文書データに対し言語の特定や形態素解析等の文字列解析処理を施す機能部である。文字列解析部220は、文字列解析処理を行った結果として、解析データを、元のコンテンツに対応付けて解析データ格納部214に格納する。解析データ格納部214は、ハードディスク装置などの記憶装置上にデータベースまたはファイルシステムとして構成される。
【0032】
索引構築部230は、解析データ格納部214に格納された解析データを読み出し、索引付け処理を行って、索引データを索引格納部216に格納する機能部である。索引格納部216は、ハードディスク装置などの記憶装置上にデータベースまたはファイルシステムとして構成され、検索要求に対し迅速に応答可能なデータ構造で上記索引データを格納する。索引格納部216が格納する索引データは、好適には、文書データ中のトークンの出現位置を示す情報を含んだ逆引き索引(Inverted Index)として構成することができる。
【0033】
検索部240は、クライアント102からの検索要求に応答して、索引格納部216の索引データを照合しながら検索処理を実行する機能部である。検索部240は、検索処理が完了すると、検索結果をクライアント102へ返す。
【0034】
以下、索引作成機能に関連する文字列解析部220および索引構築部230、並びに検索機能に関連する検索部240について、各処理の段階に分けて、より詳細に説明する。
【0035】
(1)サーバによる文字列解析
文字列解析部220は、コンテンツ格納部212に格納された種々のデータ形式のコンテンツから文書データを抽出し、文書データに対し文字列解析を行う。例えば、HTML(HyperText Markup Language)やXML(eXtensible Markup Language)などの構造化言語により記述されたコンテンツについては、文字列解析部220は、タグの除去処理などを施して、文書データを抽出する。PDF(Portable Document Format)、特定の文書作成アプリケーションによるファイルなどバイナリ形式のデータについては、文字列解析部220は、適切な文書フィルタを用いて文書データを抽出する。
【0036】
文字列解析部220は、より詳細には、トークン分割部222を含み構成される。トークン分割部222は、抽出された文書データに対し、特定した言語に対応した形態素解析法を実施し、辞書格納部226が格納する文法規則や辞書を参照しながら、文書データの入力文字列からトークンを切り出して、1以上のトークンの列に分割する。説明する実施形態では、形態素解析法を適用してトークン分割するものとして説明する。しかしながら、他の実施形態では、形態素解析法に代えて、または形態素解析法と共に、Nグラム法を適用してもよく、英語など分かち書きされる言語については、空白や記号等で区切る分割手法を適用してもよい。
【0037】
文書データから切り出されたトークン列は、元のコンテンツに対応付けて、解析データとして格納される。解析データは、例えば、対応するコンテンツに一意に割当てる文書識別値(DOC_ID)と、該コンテンツのURIなどのポインタとに関連付けられて格納される。
【0038】
本実施形態において、切り出されるトークンは、見出し語トークンおよび除外トークンに分類することができる。見出し語トークンは、詳細を後述する索引付け処理において、出現位置の算出の際に考慮される見出し語として登録されたトークンである。除外トークンは、上記出現位置の算出に際し除外されるが、検索時には考慮の対象となり得るものとして登録されたトークンである。
【0039】
除外トークンとしては、句読点や記号などの文書作成者が恣意的に付すものであるために、フレーズ検索における位置番号に関する制限に起因して、一般的なフレーズ検索において見出し語から除外されるトークンを含むことができる。本実施形態においては、上記除外トークンは、出現位置の算出に際しては除外されるが、検索時には考慮の対象となり得るものであるため、解析データおよび索引データに含ませられる。
【0040】
上記除外トークンとしては、より具体的には、句点、読点、カンマ、ピリオド、コロン、セミコロン、アポストロフィ、アスタリスク、アットマーク、括弧(丸括弧、二重丸括弧、かぎ括弧、二重かぎ括弧、角括弧、山括弧など)、リーダ(二点リーダ、三点リーダなど)、中点(中黒)、ハイフン、二重ハイフン、感嘆符、疑問符、米印、ダッシュ、波ダッシュ、踊り文字、繰り返し符号、反復符号など、一般に約物と呼ばれる記述記号類を挙げることができる。また、上記除外トークンには、携帯電話のメールサービスで使用される絵文字を含んでもよい。
【0041】
なお、いずれの記述記号類を除外トークンとして検索時に考慮するかは任意であり、検索システム100の管理者は、予め辞書等に登録することができる。上記出現位置の算出および検索の両方に際して考慮しないトークンがあれば、切り出したトークン列から予め削除しておいてもよい。
【0042】
図3は、入力文字列から索引付けまでの文字列解析部220および後述する索引構築部230が実行する処理を、各処理により生成されるデータ構造とともに示す概略図である。以下、例文1”He is a taxi driver”および例文2”He is the taxi−driver”を用いて説明する。図3(A)を参照すると、トークン分割部222は、例文1”He is a taxi driver”に対し形態素解析を適用すると、例文1の入力文字列を、「he」、「is」、「a」、「taxi」および「driver」の5つのトークンに分割して入力文字列に割当てる。これらのトークンは、説明においては、いずれも見出し語トークンとされる。
【0043】
一方、図3(B)を参照すると、例文2”He is the taxi−driver”に対し形態素解析を適用する場合、トークン分割部222は、例文2の入力文字列を「he」、「is」、「the」、「taxi」、「−」および「driver」の6つのトークンに分割する。上記例文2の場合、5つの見出し語トークンに加えて、記号「−」がトークンとして分割されており、説明においてこのトークン「−」は、上述した除外トークンとされる。
【0044】
トークン分割部222は、トークン分割処理中、入力文字列から分割されたトークンに対し、トークン間の位置関係を維持するデータ構造として解析データに書き込む。本実施形態では、辞書格納部226には、見出し語トークンおよび除外トークンが分けて予め登録されており、トークン分割部222は、各トークンが見出し語トークンであるか除外トークンであるかを識別可能な解析データを書き込む。
【0045】
なお、上記文字列解析部220は、特に限定されるものではないが、システム管理者からの外部指令に応答して、予めシステム管理者が設定したスケジュールに従って、または予めシステム管理者が設定した規定量の更新または追加すべきコンテンツがコンテンツ格納部212に新たに格納されたことに応答して、未処理のコンテンツについて文字列解析を開始することができる。
【0046】
(2)サーバによる索引作成
ここで再び図2を参照する。索引構築部230は、解析データ格納部214に格納された解析データを読み出して、トークン列の各トークンについて、フレーズ検索ができるよう位置番号および補足情報を付与して、索引データを作成する。索引構築部230は、より詳細には、トークン位置定義部232と、位置補正情報付与部234と、索引付け処理部236とを含み構成される。
【0047】
トークン位置定義部232は、各解析データに含まれるトークン間の位置関係から、各トークンに対して、文書内出現位置番号(TOKEN_POS:以下、単に位置番号として参照する。)を定義して割当てる。上記位置番号(TOKEN_POS)は、索引上、文書データ内でトークンが出現する位置を識別するものである。上述したように、解析データに含まれるトークンには、見出し語トークンと除外トークンとが存在するが、この位置番号(TOKEN_POS)は、見出し語トークンに対し、除外トークンを無視して該見出し語トークンが出現する順に定義付けられる。
【0048】
位置補正情報付与部234は、分割された1以上のトークンのうち除外トークンに対し、この除外トークンが後続する見出し語トークンを起点とした位置情報を付与する。ここで、上記位置情報には、この除外トークンが出現する位置を識別する位置番号と、この除外トークンが後続する起点となる見出し語トークンを基準として該除外トークンの位置関係を規定する位置補正情報とが含まれる。上記除外トークンの位置番号は、該除外トークンが後続する起点となる見出し語トークンと同一の位置番号となる。上記位置補正情報は、より具体的には、当該除外トークンの起点となる見出し語トークンからの該除外トークンの位置差分(以下、この位置差分を位置補正値と参照する。)となる。
【0049】
索引付け処理部236は、対応するコンテンツを識別する文書識別子(DOC_ID)と、トークンと、該トークンが出現する位置番号(TOKEN_POS)と、適宜補足情報とを関連付けて、索引データに対し索引エントリを追加する。その際に、索引付け処理部236は、上記見出し語トークンおよび除外トークンの両方について、該トークンに後続する除外トークンが存在するか否かを識別できるようにして、索引エントリの追加を行う。
【0050】
トークン位置定義部232、位置補正情報付与部234および索引付け処理部236による索引付けは、概略的には以下のように実行される。ここで、再び図3を参照する。図3(A)に示す例文1の場合は、5つのトークンに分割されるが、この場合、トークン位置定義部232は、5つの見出し語トークンに対し出現順に位置番号を定義する。
【0051】
一方、図3(B)に示す例文2の場合は、5つの見出し語トークンに加えて1つの除外トークン「−」が含まれるが、トークン位置定義部232は、除外トークン「−」を無視して5つの見出し語トークンに対し出現順に位置番号を定義する。したがって、図3に示す例では、「taxi」および「driver」には、その間に除外トークンが存在するか否かに関わらず、それぞれ、位置番号(TOKEN_POS=3)および位置番号(TOKEN_POS=4)が定義される。
【0052】
これに対し、除外トークン「−」については、位置補正情報付与部234は、該除外トークンが後続する起点となる見出し語トークン「taxi」と同一の位置番号(TOKEN_POS=3)を付与し、さらに、起点となる見出し語トークン「taxi」からの位置補正値(OFFSET=1)を付与する。
【0053】
図3(B)を参照すると、除外トークン「−」が後続する見出し語トークン「taxi」には、さらに、付加情報(HAS_NEXT=true)が付与されている。これは、当該トークンに、後続する除外トークンが存在することを識別できるよう付されるものである。付加情報(HAS_NEXT)の値がtrueである場合、後続する除外トークンが存在することを意味し、付加情報(HAS_NEXT)の値がfalseであるか、または省略されている場合、後続トークンが存在しないことを意味する。このように、索引付け処理部236は、除外トークンが後続する見出し語トークンに対し、付加情報(HAS_NEXT=true)を付加して、索引付けを行うことにより、逆引き索引付けした後も、当該見出し語トークンに除外トークンが後続していることを容易に識別可能としている。
【0054】
図4(A)は、他の例文による入力文字列のトークン分割から索引付けまでの処理を説明する図である。図4(A)を参照すると、2つの記号「−」が連続する場合、位置補正情報付与部234は、2つの除外トークン「−」各々に対し、これら起点となる見出し語トークン「taxi」と同一の位置番号(TOKEN_POS=3)を付与する。さらに、位置補正情報付与部234は、1番目の除外トークン「−」については、位置補正値(OFFSET=1)を付与し、2番目の除外トークン「−」については、起点となる見出し語トークンからの位置関係に対応して、位置補正値(OFFSET=2)を付与する。
【0055】
また、2番目の除外トークン「−」が後続する1番目の除外トークンには、さらに、付加情報(HAS_NEXT=true)が付与されているが、これは、上記と同様に、後続トークンが存在することを識別できるよう付されるものである。索引付け処理部236は、除外トークンが後続する除外トークンに対しても、付加情報(HAS_NEXT=true)を付加して、索引付けを行うことにより、逆引き索引付けした後も除外トークンが後続していることを容易に識別可能としている。
【0056】
なお、説明する実施形態では、付加情報が、除外トークンが後続するトークンを識別する情報であるとして説明したが、逆引き索引付けした後に除外トークンが後続するトークンを識別可能である限り、特に限定されるものではない。例えば、他の実施形態では、図4(B)に例示するように、除外トークンが後続しないトークンに対し、付加情報(NOT_HAVE=true)を付与し、付加情報(NOT_HAVE=true)が、除外トークンが後続しないトークンを示す情報であるとしてもよい。
【0057】
また、説明する実施形態では、位置番号は、見出し語トークン間の差分を固定値1として定義されるものとして説明したが、1以外の他の固定値を用いてもよく、またフレーズ検索をサポートできる限り、固定値に限定されず、本索引作成処理は、種々の変形例に対し適用することができる。
【0058】
索引構築部230は、各解析データ(コンテンツ)について得られた索引エントリを用いて、見出し語(除外トークンに対応する語も含まれる。)毎に全コンテンツにわたって整理し、最終的な逆引き索引付けを行い、索引データを索引格納部216に格納する。その際に、索引構築部230は、tf−idf(Term Frequency inverse Document Frequency)などで算出される統計値を、索引全体で各見出し語について整理して付加することもできる。
【0059】
なお、図1に示した検索用データ106,112は、図2に示す索引格納部216が格納する索引データと、解析データ格納部214が格納する解析データとを含んで構成することができる。解析データは、検索結果に含ませるコンテンツ・サマリなどを生成するためなどに使用することもできる。
【0060】
(3)サーバによる索引作成方法
図5は、本実施形態による索引作成装置としてのサーバ104が実行する、索引作成方法を示すフローチャートである。図5に示す処理は、外部指令に応答して、スケジュールされたタイミングの到来に応答して、または新たな解析データが追加されたことに応答して、ステップS100から開始する。なお、図5では、新規追加されたコンテンツの文書データ毎に実行される処理として説明しているが、コンテンツの内容の更新に伴う再索引付けについても、図5に示すものと同様の処理によって行うことができる。
【0061】
ステップS101では、文字列解析部220は、コンテンツ格納部212に格納されたコンテンツから入力文字列を抽出して、文書データを取得する。ステップS102では、文字列解析部220は、索引データにおいてコンテンツ(文書データ)を一意に識別する文書識別子(DOC_ID)を採番する。ステップS103では、文字列解析部220は、トークン分割部222により、取得された文書データの入力文字列を1以上のトークンに分割する。得られた解析データは、解析データ格納部214に格納される。
【0062】
ステップS104では、索引構築部230は、解析データを読み出し、まず先頭に位置する見出し語トークンを取得する。ステップS105では、索引構築部230は、取得した見出し語トークンを現在の処理対象として設定する。ステップS106では、索引構築部230は、トークン位置定義部232により、処理対象の見出し語トークンに対し位置番号を定義する。位置番号は、例えば、先頭の見出し語トークンを始点の位置番号(TOKEN_POS=0)として、以降の見出し語トークンについて固定値を増分させながら定義される。
【0063】
ステップS107では、索引構築部230は、トークン列から当該処理対象の見出し語トークンの次に位置するトークンを取得し、その次トークンが除外トークンであるか否かを識別する。ステップS108では、索引構築部230は、次トークンが除外トークンであるか否かに対応して処理を分岐させる。
【0064】
ステップS108で、次トークンが除外トークンではないと判定された場合(NO)は、ステップS109へ処理を分岐させる。この場合、現在の処理対象の見出し語トークンを起点とする除外トークンが後続しないと判断できる。ステップS109では、索引構築部230は、索引付け処理部236により、処理対象の見出し語トークンについて、文書識別子(DOC_ID)および位置番号(TOKEN_POS)をセットにして索引エントリ("TOKEN" (DOC_ID, TOKEN_POS))を追加して、そのまま索引付けを行う。
【0065】
ステップS110では、索引構築部230は、次トークンが存在せず、トークン列の末尾に達したか否かを判定する。ステップS110で、トークン列の末尾にまだ達していないと判定された場合(NO)には、索引構築部230は、ステップS105へ処理をループさせて、現在処理対象の見出し語トークンの次の見出し語トークンを処理対象に設定し、トークン列の末尾に達するまで、ステップS105以降の処理を繰り返させる。
【0066】
一方、ステップS108で、次のトークンが除外トークンであると判定された場合(YES)は、ステップS112へ処理を分岐させる。この場合、現在の処理対象の見出し語トークンを起点として、後続する除外トークンが存在する。ステップS112では、索引構築部230は、索引付け処理部236により、処理対象の見出し語トークンについて、文書識別子(DOC_ID)、位置番号(TOKEN_POS)、さらに付加情報(HAS_NEXT=true)をセットにして、後続する除外トークン有りとして索引エントリ("TOKEN" (DOC_ID, TOKEN_POS, true))を追加し、索引付けする。
【0067】
ステップS113では、索引構築部230は、次トークンとして取得された除外トークンを現在の処理対象として設定する。ステップS114では、索引構築部230は、位置補正情報付与部234により、現在処理対象の除外トークンに対し、起点となる見出し語トークンと同一の位置番号を付与する。ステップS115では、索引構築部230は、位置補正情報付与部234により、現在処理対象の除外トークンに対し、さらに、起点となる見出し語トークンからの位置補正値(OFFSET)を算出し、付与する。
【0068】
ステップS116では、索引構築部230は、当該処理対象の除外トークンのさらに次に位置するトークンを取得し、次トークンが除外トークンであるか否かを識別する。ステップS117では、索引構築部230は、次トークンが除外トークンであるか否かに対応して処理を分岐させる。
【0069】
ステップS117で、次トークンが除外トークンではないと判定された場合(NO)は、ステップS118へ処理を分岐させる。この場合、現在処理対象の除外トークンに後続する除外トークンが存在しないと判断できる。ステップS118では、索引構築部230は、索引付け処理部236により、処理対象の除外トークンについて、文書識別子(DOC_ID)、位置番号(TOKEN_POS)および位置補正値(OFFSET)をセットにして、索引エントリ("TOKEN" (DOC_ID, TOKEN_POS, OFFSET))を追加し、索引付けし、ステップS110へ分岐させる。この場合、ステップS110でトークン列の末尾に達したか否かが判定されて、トークン列の末尾に未だ達していないと判定された場合(NO)には、ステップS105へループさせる。
【0070】
一方、ステップS117で、次トークンが除外トークンであると判定された場合(YES)は、ステップS119へ処理を分岐させる。この場合、現在処理対象の除外トークンにさらに後続する除外トークンが存在するため、ステップS119では、索引構築部230は、索引付け処理部236により、処理対象の除外トークンについて、文書識別子(DOC_ID)、位置番号(TOKEN_POS)、位置補正値(OFFSET)、さらに付加情報(HAS_NEXT=true)をセットにして、後続する除外トークン有りとして索引エントリ("TOKEN" (DOC_ID, TOKEN_POS, OFFSET, true))を追加し、索引付けする。この場合、索引構築部230は、ステップS113へ処理をループさせて、現在処理対象の次の除外トークンを処理対象に設定し、見出し語トークンを起点とした除外トークンの末端まで、ステップS113〜ステップS119の処理を繰り返させる。
【0071】
再びステップS110を参照すると、ステップS109で処理対象の見出し語トークンの索引付けが行われるか、またはステップS118で処理対象の除外トークンの索引付けが行われるかして、ステップS110で、トークン列の末尾に達したと判定される場合(YES)には、ステップS111へ処理を分岐させて、当該コンテンツについての処理を終了させる。
【0072】
上述した索引作成方法が行われ、索引構築部230により、トークン毎に全コンテンツにわたって整理されて、逆引き索引付けが完了すると、図6に例示されるような索引データが構築される。図6に示すように、索引データには、各見出し語トークンについて、該見出し語トークンが出現する文書データの文書識別子(DOC_ID)、その文書データ内の出現位置(TOKEN_POS)、および適宜その出現位置にかかるトークンに除外トークンが後続するか否かを示す付加情報(HAS_NEXT)が関連付けられたセットが登録される。
【0073】
除外トークンについても同様に、逆引き索引データには、その除外トークンが出現する文書データの文書識別子(DOC_ID)、該文書データ内における起点となる見出し語トークンの出現位置(TOKEN_POS)、該起点からの位置補正値(OFFSET)、および適宜その出現位置にかかる除外トークンにさらに除外トークンが後続するか否かを示す付加情報(HAS_NEXT)が関連付けられたセットが登録される。
【0074】
上述したように、本実施形態による索引作成処理では、コンテンツ内の入力文字列が除外トークンを含んで構成される場合でも、除外トークンに対し、該除外トークンが後続する起点となる見出し語トークンからの位置情報が付与される。これにより、詳細を後述するように、除外トークンを考慮したフレーズ検索が可能となる。
【0075】
(4)サーバによる検索処理
ここで再び図2を参照する。検索部240は、クライアント102からの検索要求に応答して、索引格納部216の索引データを照合して検索処理を実行し、クライアント102へ検索結果を返す処理を行う。検索部240は、より詳細には、検索要求受付部242と、検索結果作成部244と、検索モード判定部246と、通常モード検索処理部248と、補正モード検索処理部250とを含んで構成される。
【0076】
これに対し、クライアント102は、ウェブ・ブラウザ、プラグインなどのソフトウェアと、プロセッサ、該プロセッサの実行空間を提供するRAMなどのハードウェアとが協働して機能する検索照会部260を含んで構成される。検索照会部260は、より詳細には、検索要求部262と、検索結果表示部264と、補正モード指定部266とを含んで構成される。
【0077】
クライアント102の検索要求部262は、検索時において、例えば図12(A)に示すようなブラウザ画面300上の検索ボタン304がクリックされたことに応答して、検索テキスト・ボックス302に入力された検索クエリを含む検索要求をサーバ104に送信する。上記検索要求は、除外トークンの位置を補正して除外トークンを考慮した検索モード(以下、補正モードという。)による検索を行うか、除外トークンを考慮しない検索モード(以下、通常モードという。)による検索を行うかを指定するモード指定値を含むことができる。モード指定値は、例えばブラウザ画面300上の検索モードを指定するためのGUI部品(チェックボックス)306に対し、操作が行われたことに対応して、補正モード指定部266が設定する。
【0078】
サーバ104の検索要求受付部242は、クライアント102の検索要求部262からの検索要求を受け付けて、検索要求にかかる検索クエリを取得するとともに、モード指定値を取得する。検索モード判定部246は、取得したモード指定値を参照して、求められている検索モードを判定する。検索モード判定部246は、除外トークンを考慮した補正モードが指定される場合には、補正モード検索処理部250に対し検索処理依頼を発行する。一方、除外トークンを考慮しない通常モードが指定されている場合には、検索モード判定部246は、通常モード検索処理部248に対し検索処理依頼を発行する。
【0079】
クライアント102から送信される検索要求の検索クエリは、検索文字列を含み、検索要求受付部242は、形態素解析により検索文字列を検索トークンに分割して、検索トークン列を生成する。検索トークンが単一の場合は、単一語検索となり、検索トークンが複数ある場合は、フレーズ検索となる。単一の検索トークンによる単一語検索の場合は、トークンの位置関係が無関係であるため、モード指定値にかかわらず、通常モードの検索処理が行われる。
【0080】
通常モードが指定される場合、通常モード検索処理部248は、検索処理依頼を受領すると、索引格納部216の索引データを照会して、除外トークンを考慮しない検索処理を実行する。通常モード検索処理部248は、検索処理の実行結果として、除外トークンとの関係に関わらず、検索クエリに一致するトークン(列)を含むコンテンツの照会集合を取得する。
【0081】
単一語検索について説明すると、例えば、「taxi」、「driver」、「−」といった検索トークンによる単一語検索が要求される場合、通常モード検索処理部248は、そのまま、「taxi」、「driver」、「−」などの指定された検索トークンを含むコンテンツの照会集合を取得する。検索文字列から切り出される検索トークンについても、索引作成処理に関して上述したように、見出し語トークンと、除外トークンとが含まれる。検索トークン「−」が除外トークンであっても、除外トークン「−」を含めて索引データが索引付けされているため、単一語検索では、除外トークン「−」を見出し語として扱って、トークン「−」を含む照会集合を得ることができる。
【0082】
補正モードが指定される場合、補正モード検索処理部250は、検索処理依頼を受領すると、索引格納部216の索引データを照会し、詳細を後述する除外トークンを考慮した検索処理を実行する。補正モード検索処理部250は、検索処理の実行結果として、除外トークンとの関係を含めて検索クエリに一致するトークン列を含むコンテンツの照会集合を取得する。
【0083】
検索結果作成部244は、検索処理部248,250が作成したコンテンツ・リストを取得し、リストに含まれる識別値(DOC_ID)を解析データ格納部214に与えて、対応する解析データやコンテンツのポインタなどを取得し、検索結果を作成する。照会集合中のコンテンツがランク付けできる態様であれば、検索結果作成部244は、照会集合中の総合スコア上位所定数までスコア順にソートし、各コンテンツ毎に、URIやパス名を指定してリンク可能な態様としたコンテンツ・サマリを含むデータとして作成することができる。
【0084】
作成された検索結果のデータは、クライアント102に送信される。クライアント102の検索結果表示部264は、検索結果のデータを受信して、例えば、ブラウザ画面310上に、総合スコア上位所定数までのコンテンツ毎に、URIやパス名を指定してリンク可能な態様でコンテンツ・サマリ312a,312bを表示させる。
【0085】
(4−1)通常モードのフレーズ検索
以下、通常モードにおけるフレーズ検索処理について説明する。図7は、通常モードによるフレーズ検索処理について説明する図である。図7は、検索文字列が「taxi driver」または「taxi−driver」である場合であって、例文1(DOC_ID=1)および例文2(DOC_ID=2)について索引データが索引付けされている場合における処理を例示する。検索文字列「taxi−driver」の場合、除外トークン「−」が無視されるため、両検索文字列は、共に、「taxi」および「driver」の検索トークンに分割され、先頭から順に、それぞれのトークンに位置番号0(TOKEN_POS=0)および位置番号1(TOKEN_POS=1)が付される。ここで、「taxi」および「driver」の検索トークン間の位置番号の差分は1となる。
【0086】
一方、索引データを参照すると、例文1(DOC_ID=1)および例文2(DOC_ID=2)の文書データは、共に、差分が1、すなわち連接するトークン「taxi」およびトークン「driver」を含む。したがって、例文1(DOC_ID=1)および例文2(DOC_ID=2)は、共に、検索クエリの検索トークン列に位置番号を含めて整合するトークン列を含むため、共にヒットとなる。この際、索引データにおいて、例文2(DOC_ID=2)のトークン「taxi」に対し、付加情報(HAS_NEXT=true)が付され、またトークン「taxi」と同じ位置番号を有する除外トークン「−」が存在することは、通常モードの検索結果に影響しない。
【0087】
(4−2)補正モードのフレーズ検索
以下、補正モードにおけるフレーズ検索処理について説明する。図8〜図10は、補正モードによるフレーズ検索処理について説明する図である。図8は、検索文字列が「taxi−driver」である場合であって、例文2(DOC_ID=2)について索引データが索引付けされている場合における処理を例示する。
【0088】
検索文字列「taxi−driver」の場合、補正モードでは、除外トークン「−」も考慮されるため、「taxi」、「−」および「driver」の3つの検索トークンに分割される。また、補正モードであっても、位置番号の算出の際には除外トークン「−」は除外されるため、トークン「taxi」およびトークン「driver」には、それぞれ、先頭から順に位置番号0(TOKEN_POS=0)および位置番号1(TOKEN_POS=1)が付される。
【0089】
補正モードでは、除外トークンを考慮した検索を行うため、検索トークン列についても、索引作成処理と同様に補足情報が付される。除外トークン「−」が後続する見出し語トークン「taxi」には、後続トークンが存在することを示す付加情報(HAS_NEXT=true)が付される。除外トークン「−」については、その前方の見出し語トークン「taxi」と同一の位置番号0(TOKEN_POS=0)が付され、さらに、位置補正値(OFFSET=1)が付される。
【0090】
一方、索引データを参照すると、例文2(DOC_ID=2)の文書データは、位置番号の差分が1であるトークン「taxi」および「driver」を含む。さらに、例文2(DOC_ID=2)の文書データでは、トークン「taxi」には、付加情報(HAS_NEXT=true)が付され、さらにトークン「taxi」と同一の位置番号には、除外トークン「−」が存在し、その除外トークン「−」には、位置補正値(OFFSET=1)が付されている。
【0091】
したがって、図8に示す例では、例文2(DOC_ID=2)は、検索クエリを構成する検索トークン列に、見出し語トークンの連接関係(位置番号)が整合し、かつ、除外トークンとの連接関係(付加情報並びに除外トークンの位置番号および位置補正値を含む。)を含めて整合するトークン列を含むため、ヒットとなる。
【0092】
図9は、検索文字列が「taxi−driver」である場合であって、例文1(DOC_ID=1)について索引データが索引付けされている場合における処理を例示する。この場合、検索トークン列は、上述した図8の場合と同様となる。
【0093】
索引データを参照すると、例文1(DOC_ID=1)の文書データは、位置番号の差分が1であるトークン「taxi」およびトークン「driver」を含む。しかしながら、例文1(DOC_ID=1)の文書データでは、トークン「taxi」には、付加情報が存在せず(HAS_NEXT=false)、トークン「taxi」と同一の位置番号に、除外トークン「−」は存在しない。したがって、例文1(DOC_ID=1)は、検索クエリを構成する検索トークン列に、見出し語トークンの連接関係(位置番号)が整合するトークン列を含むものの、除外トークンとの連接関係(付加情報並びに除外トークンの位置番号および位置補正値を含む。)を含めて整合するトークン列が存在しないため、ヒットとはならない。
【0094】
図10は、検索文字列が「taxi driver」である場合であって、例文2(DOC_ID=2)について索引データが索引付けされている場合における処理を例示する。この場合、位置番号(TOKEN_POS=0)を有する「taxi」と、位置番号(TOKEN_POS=1)を有する「driver」の2つの検索トークンに分割される。
【0095】
補正モードでは、除外トークンを考慮するため、検索トークン列についても、適宜補足情報が付される。除外トークンが後続しない見出し語トークン「taxi」および「driver」には、後続する除外トークンが存在しないことを示す付加情報(HAS_NEXT=false)が付されるか、またはそのまま省略される。
【0096】
索引データを参照すると、例文2(DOC_ID=2)の文書データは、位置番号の差分が1であるトークン「taxi」および「driver」を含む。しかしながら、例文2(DOC_ID=2)では、トークン「taxi」には、付加情報(HAS_NEXT=true)が存在し、さらに、トークン「taxi」と同一の位置番号に、位置補正値(OFFSET=1)を有する除外トークン「−」が存在する。
【0097】
したがって、例文2(DOC_ID=2)は、検索クエリを構成する検索トークン列に、見出し語トークンの連接関係が整合するトークン列を含むものの、検索トークン列に存在しない除外トークンを含むという意味で、除外トークンとの連接関係を含めて整合するトークン列が存在しないため、ヒットとはならない。
【0098】
(4−3)ランク付け
以下、検索結果を作成するためのランク付け処理について説明する。図11は、本実施形態におけるランク付けのための重み付けを説明する図である。本実施形態による索引データを用いると、見出し語トークンの連接関係が整合し、かつ、除外トークンとの連接関係を含めて整合する完全一致のトークン列と、見出し語トークンの連接関係が整合するものの、除外トークンとの連接関係を含めると整合しない限定付き一致のトークン列とを識別することができる。そこで、本実施形態の検索システム100では、上記完全一致および限定付き一致に対し、ランク付け結果に差が生じるように、異なる重み値を与えることができる。
【0099】
例えば、特定の実施形態では、図11に示すように、見出し語トークンの連接関係が整合する場合に0.5の重み値を与え、さらに除外トークンとの連接関係を含めて整合する場合に0.5を加算した重み値とし、完全一致に対し、限定付き一致に比較して大きな重みを与えることができる。
【0100】
コンテンツに対して算出される総合スコアは、例えば、文書データ内で完全一致のトークン列が出現する回数に完全一致の重み付けを乗じたスコア(完全一致数×1)と、文書データ内で限定付き一致のトークン列が出現する回数に限定付き一致の重み付けを乗じたスコア(限定付き一致数×0.5)との総和とすることができる。
【0101】
上記構成により、除外トークンの整合を加味した検索結果を提供し、検索者が入力した検索文字列により近いコンテンツを上位に配置することができる。また、完全一致しない限定付き一致のコンテンツについても、検索結果に含ませてランク付けを行うことにより、検索漏れも少なくなり、高品質な検索が可能となる。
【0102】
(4−4)固有フレーズ検索
また、上述した説明においては、検索モードは、クライアント102側の補正モード指定部266によって通常モードまたは補正モードが指定されるものとして説明した。しかしながら、予め補正モードで検索する固有のフレーズを登録しておくことにより、クライアント102側に煩雑な操作を要求せずに、補正モードの検索処理を呼び出すことができる。
【0103】
図13は、固有フレーズが登録可能な実施形態によるサーバ104上に実現される、検索部240の機能ブロック図である。図13を参照すると、図2にも示した検索要求受付部242、検索結果作成部244、検索モード判定部246、通常モード検索処理部248および補正モード検索処理部250に加えて、検索モード変更部252および固有フレーズ登録部254を含んで構成される。
【0104】
固有フレーズ登録部254は、予め登録処理された固有フレーズ(固有のトークン列)を登録している。この固有フレーズは、検索文字列を構成するトークン列中に該固有トークン列が含まれる場合に、指定されたモードが通常モードである場合でも、少なくとも当該固有トークン列かかる部分について、除外トークンを考慮した検索を行うものとして、予め登録されるフレーズである。なお、説明する実施形態では、検索文字列を構成するトークン列中に該固有トークン列が含まれる場合に、すべての検索トークン列について、補正モードによる検索を行うものとする。しかしながら、他の実施形態では、固有トークン列の部分だけ除外トークンを考慮した検索とするよう構成することもできる。
【0105】
固有フレーズが登録可能な実施形態においても、モード指定値は、ブラウザ画面300上のGUI部品306に対し操作が行われたことに対応して、クライアント102側の補正モード指定部266が設定することができる。検索モード変更部252は、検索クエリ内の検索文字列から分割された検索トークン列と、固有フレーズ登録部254に登録された固有フレーズ(固有トークン列)とを比較し、検索クエリ中に固有フレーズが含まれるか否かを判定する。そして、検索クエリ中に固有フレーズが含まれる場合は、検索モード変更部252は、指定された検索モードに関わらず、補正モードに変更する。検索モード判定部246は、検索モードが補正モードに変更されたことに伴い、補正モード検索処理部250に対し、検索処理依頼を発行する。
【0106】
社名、プロジェクト名、製品名などの固有フレーズを固有フレーズ登録部254に登録することで、検索時に、登録された固有フレーズが検索クエリに含まれる場合でも、検索者に追加の操作を要求せずに、暗黙的に除外トークンを考慮した検索結果を返すことが可能となる。
【0107】
例えば、検索者にとって「A−B」という語が製品名であり重要である場合、通常モードの検索では、「−」は無視され、「A/B」、「A B」のような必ずしも正確に一致しない語にもヒットしてしまい、検索者が必ずしも望まない結果となってしまう可能性がある。これに対して、「A−B」という語を固有フレーズとして登録しておくことにより、検索文字列に固有フレーズ「A−B」が含まれる場合、正確に一致する語にだけヒットとし、「A/B」、「A B」のような正確に一致しない語については、低い重みでランク付けするか、ヒットから除外することができる。
【0108】
また、社名、プロジェクト名、製品名などについては、固有名詞として索引付けの際の辞書に登録することも可能であるが、その場合、固有名詞を追加する度に索引データを一から再構築する必要がある。これに対し、説明する実施形態では、索引データを一から再構築する必要はなく、固有フレーズを固有フレーズ登録部254に登録するだけで、これまで構築された索引データをそのまま使用して、特定の固有フレーズについて暗黙的に除外トークンを考慮した検索結果を返すことが可能となる。
【0109】
(5)サーバによる検索方法
図14および図15は、本実施形態による検索装置としてのサーバ104が実行する、フレーズ検索方法を示すフローチャートである。図14および図15に示す処理は、連結点Aおよび連結点Bで接続されている点に留意されたい。
【0110】
図14および図15に示す処理は、クライアント102から検索要求を受信したことに応答して、ステップS200から開始する。ステップS201では、検索部240は、検索要求受付部242により、クライアント102からの、検索文字列および検索モード指定を含む検索要求を受け付ける。ステップS202では、検索部240は、検索要求に含まれる検索文字列を1以上の検索トークンに分割し、検索トークン列を生成する。
【0111】
ステップS203では、検索部240は、検索モード判定部246により、検索モードを判定する。ステップS203で、検索モードが補正モードではないと判定された場合(NO)は、ステップS204へ処理を分岐し、通常モードによる検索を行う。
【0112】
ステップS204では、検索部240は、通常モード検索処理部248により、検索トークン列から除外トークンを削除し、各検索トークンに対し位置番号を計算する。ステップS205では、検索部240は、索引格納部216内から、各検索トークンに対応する各逆引き索引リストを取得する。ここで、逆引き索引リストとは、索引格納部216内のトークン毎に整理された逆引き索引データのうち、所定のトークンに関連して、出現文書、出現位置および適宜補足情報の配列を含むリストをいう。
【0113】
ステップS206では、検索部240は、通常モード検索処理部248により、連接判定を行いながら、検索トークン列(除外トークンは除外済みである。)に、位置番号を含めて一致するトークン列が含まれる文書データの集合(コンテンツ・リスト)を取得し、ステップS207へ処理を進める。ステップS207では、検索部240は、検索結果作成部244により、通常モード検索処理部248により作成されたコンテンツ・リストを用いて、対応する解析データやコンテンツのポインタなどを取得し、検索結果を作成し、検索要求に対する応答として要求元に返却する。ステップS208では、検索部240は、検索処理を終了する。
【0114】
一方、ステップS203で、検索モードが補正モードであると判定された場合(YES)は、ステップS209へ処理を分岐し、補正モードによる検索を行う。ステップS209では、検索部240は、補正モード検索処理部250により、検索トークン列の各検索トークンに対し、位置番号を計算し、適宜付加情報を求め、さらに、除外トークンについては、位置補正値(OFFSET)を計算する。ステップS210では、検索部240は、索引格納部216内から、各検索トークンに対応する各逆引き索引リストを取得する。
【0115】
ステップS211では、検索部240は、補正モード検索処理部250により、連接判定を行いながら、まず、検索トークン列(ここでは、除外トークンを除く。)に位置番号を含めて整合するトークン列が含まれる文書データの照会集合を取得し、ステップS212へ処理を進める。ステップS212〜ステップS224では、検索部240は、補正モード検索処理部250により、各文書データの各一致点について、ステップS213〜ステップS223の処理を行う。
【0116】
ステップS213では、補正モード検索処理部250は、検索トークン列の先頭に位置する見出し語トークン(以下、検索見出し語トークンという。)を処理対象に設定する。ステップS214では、補正モード検索処理部250は、処理対象の検索見出し語トークンに関して、索引中の一致点にかかる見出し語トークンとを比較し、付加情報が整合するか否かを判定する。ステップS214で、検索トークンに付加情報が付され(HAS_NEXT=true)、索引中の見出し語トークンに付加情報が付されていない(HAS_NEXT=false)場合や、逆の場合など、整合しないと判定された場合(NO)には、連結点Bを介してステップS224へ分岐させ、次の一致点へと処理を進める。
【0117】
一方、ステップS214で、検索トークンおよび索引中の見出し語トークンが共に付加情報が付されている(HAS_NEXT=true)場合、または、共に付加情報が付されていない(HAS_NEXT=false)場合(YES)には、ステップS215へ処理を進める。
【0118】
ステップS215では、付加情報(HAS_NEXT=true)で整合しているか(つまり後続する除外トークンがあるか)否かを判定する。ステップS215で、付加情報なし(HAS_NEXT=false)として整合し、後続トークンが無いと判定された場合(NO)は、ステップS221へ処理を分岐させて、検索トークン列の末尾に達したか否かを判定する。ステップS221で、末尾に達していないと判定された場合(NO)には、ステップS222へ処理を分岐させ、次の検索見出し語トークンを処理対象に設定し、ステップS214へ処理をループさせる。
【0119】
一方、ステップS215で、付加情報あり(HAS_NEXT=true)として整合し、後続トークンが有ると判定された場合(YES)は、ステップS216へ処理を進める。ステップS216では、補正モード検索処理部250は、逆引き索引リストを参照し、現在処理対象の検索トークンに後続する除外トークン(以下、検索除外トークンという。)と、位置番号および位置補正値を含めて整合する除外トークンの取得を試みる。
【0120】
ステップS217では、ステップS216において整合する除外トークンが有るか否かを判定する。ここでは、上記検索除外トークンに対応する逆引き索引リスト中に、位置番号および位置補正値が整合するエントリが有れば、整合する除外トークンが有ると判定される。
【0121】
ステップS217で、整合する除外トークンが無いと判定された場合(NO)は、連結点Bを介してステップS224へ分岐させて、次の一致点へと処理を進める。一方、ステップS217で、整合する除外トークンが有ると判定された場合(YES)には、ステップS218へ処理を進める。
【0122】
ステップS218では、補正モード検索処理部250は、現在処理対象の検索トークンに後続する検索除外トークンに関して、索引中の一致点にかかる除外トークンとを比較し、付加情報(HAS_NEXT)が整合するか否かを判定する。ステップS218で、検索除外トークンに付加情報が付され(HAS_NEXT=true)、索引中の除外トークンに付加情報が付されていない(HAS_NEXT=false)場合や、逆の場合など、後続判定が整合しないと判定された場合(NO)には、連結点Bを介してステップS224へ分岐させて、次の一致点へと処理を進める。一方、ステップS218で、整合すると判定された場合(YES)には、ステップS219へ処理を進める。
【0123】
ステップS219では、補正モード検索処理部250は、さらに後続する除外トークンがあるか否かを判定する。ステップS219で、付加情報なし(HAS_NEXT=false)として整合し、後続するトークンが無いと判定された場合(NO)は、ステップS221へ処理を分岐させて、末尾であるか否かを判定する。一方、ステップS219で、付加情報あり(HAS_NEXT=true)として整合し、後続するトークンが有ると判定された場合(YES)は、ステップS220へ処理を分岐させる。
【0124】
ステップS220では、次の検索除外トークンを処理対象に設定し、ステップS216へ処理をループさせる。この場合、処理対象の検索見出し語トークンを起点とした除外トークンの末端に達するまで、ヒット判定を継続する。
【0125】
ステップS221で、末尾であると判定された場合(YES)には、ステップS223へ処理を分岐させる。この場合、検索トークン列の先頭から末尾まで、すべてにおいて整合しているため、当該一致点は、完全一致であると判断できる。ステップS223では、当該文書データを完全一致するトークン列を含むものとして検索結果に含めて、連結点Bを介してステップS224へ分岐させて、次の一致点へと処理を進める。
【0126】
ステップS212〜ステップS224のループを抜けると、検索結果には、完全一致するトークン列を含む文書データの集合(コンテンツ・リスト)が得られるので、ステップS207では、検索部240は、検索結果作成部244により、補正モード検索処理部250により作成されたコンテンツ・リストを用いて、対応する解析データやコンテンツのポインタなどを取得し、検索結果を作成し、検索要求に対する応答として要求元に返却する。ステップS208では、検索部240は、検索処理を終了する。
【0127】
以上説明したように、本実施形態の文字列解析部220および索引構築部230により作成された索引データは、除外トークンについても索引付けされており、該除外トークンについては、それが後続する見出し語トークンを起点とする位置情報(位置番号および位置補正値)が付与されて、索引データが構築されている。このため、除外トークンを考慮して検索することが可能となる。
【0128】
また、同一の索引データを用いて、除外トークンを考慮しない通常モードの検索と、上記補正モードの検索との両方を共存させることもできる。さらに、除外トークンが後続するトークンに対し、後続の有無を識別する付加情報が付与されているため、逆引き索引においても、効率的にヒット判定を行うことが可能となる。ひいては、検索者の意図をより正確に反映した検索結果を得ることができ、高い適合率かつ効率的な情報検索を実現することができる。
【0129】
以上説明したように、本発明の実施形態によれば、句読点や記号など通常検索対象とならないトークンを考慮して情報検索が可能な検索システム、索引作成装置、検索装置、索引作成方法、検索方法およびプログラムを提供することができる。さらに、本発明の実施形態によれば、検索者の意図を的確に反映した検索結果を効率的に提供することを可能とする、検索システム、索引作成装置、検索エンジン、索引作成方法、検索方法およびプログラムを提供することができる。
【0130】
なお、本発明の実施形態において、好適に適用できる言語としては、説明に用いた英語の他、例えば、日本語、ドイツ語、フランス語、ロシア語、韓国語、中国語、アラビア語など、上述した以外の言語についても適用可能であることはいうまでもない。
【0131】
また、本発明につき、発明の理解を容易にするために各機能部および各機能部の処理を記述したが、本発明は、上述した特定の機能部が特定の処理を実行するほか、処理効率や実装上のプログラミングなどの効率を考慮して、いかなる機能部に、上述した処理を実行するための機能を割当てることができる。
【0132】
本発明の上記機能は、C++、Java(登録商標)、Java(登録商標)Beans、Java(登録商標)Applet、JavaScript(登録商標)、Perl、Rubyなどのオブジェクト指向プログラミング言語、SQLなどの検索言語などで記述された装置実行可能なプログラムにより実現でき、装置可読な記録媒体に格納して頒布または伝送して頒布することができる。
【0133】
これまで本発明を、特定の実施形態をもって説明してきたが、本発明は、実施形態に限定されるものではなく、他の実施形態、追加、変更、削除など、当業者が想到することができる範囲内で変更することができ、いずれの態様においても本発明の作用・効果を奏する限り、本発明の範囲に含まれるものである。
【符号の説明】
【0134】
100…検索システム、102…クライアント、104…サーバ、106…検索用データ、108…ネットワーク、110…サーバ、112…検索用データ、114…インターネット、116…RDB、118…ファイル・サーバ、120…破線枠、200…機能ブロック、210…コンテンツ収集部、212…コンテンツ格納部、214…解析データ格納部、216…索引格納部、220…文字列解析部、222…トークン分割部、226…辞書格納部、230…索引構築部、232…トークン位置定義部、234…位置補正情報付与部、236…索引付け処理部、240…検索部、242…検索要求受付部、244…検索結果作成部、246…検索モード判定部、248…通常モード検索処理部、250…補正モード検索処理部、252…検索モード変更部、254…固有フレーズ登録部、260…検索照会部、262…検索要求部、264…検索結果表示部、266…補正モード指定部、300,310…ブラウザ画面
【特許請求の範囲】
【請求項1】
フレーズ検索を行うための検索システムであって、
検索対象となる入力文字列を1以上のトークンに分割するトークン分割部と、
出現位置の算出に際し除外するものとして登録されたトークンを除外トークンとし、除外しないトークンを見出し語トークンとして、見出し語トークンに対し、出現位置を定義付ける位置定義部と、
除外トークンに対し、該除外トークンが後続する見出し語トークンを起点とした位置情報を付与する情報付与部と、
前記1以上のトークンを除外トークンが後続するか否かを識別させて索引付けする索引付け処理部と
を含む、検索システム。
【請求項2】
索引データであって、前記見出し語トークンに対し付与される前記出現位置と、前記除外トークンに対し付与される前記位置情報と、前記除外トークンが後続するか否かを識別する付加情報とを含み構成される当該索引データと、
フレーズ検索クエリに応答して、除外トークンを考慮した検索処理が求められる場合に、前記索引データを参照して、前記フレーズ検索クエリに含まれる検索トークン列に前記出現位置および前記位置情報を含め整合するトークン列を抽出する検索処理部と
をさらに含む、請求項1に記載の検索システム。
【請求項3】
前記フレーズ検索クエリの設定から、除外トークンを考慮した検索処理が求められているか否かを判定する判定部と、
フレーズ検索で除外トークンを考慮して検索するものとして登録されたトークン列が前記フレーズ検索クエリの検索トークン列に含まれる場合に、前記登録されたトークン列に関し前記除外トークンを考慮した検索処理に変更する変更部と
をさらに含む、請求項2に記載の検索システム。
【請求項4】
前記検索処理部は、抽出された前記出現位置および前記位置情報を含めて整合するトークン列に関し第1の重みを与え、前記フレーズ検索クエリに含まれる見出し語トークン列に前記出現位置を含め整合するものの、除外トークンとの連接関係が整合しないトークン列に関し第2の重みを与ることを特徴とする、請求項3に記載の検索システム。
【請求項5】
前記除外トークンに対し付与される前記見出し語トークンを起点とした位置情報は、該除外トークンの起点となる該見出し語トークンの出現位置と、該見出し語トークンおよび該除外トークン間の位置差分を含む、請求項1に記載の検索システム。
【請求項6】
前記索引付け処理部は、除外トークンが後続するトークンに対し除外トークンが後続する旨を示す付加情報を付すか、または、除外トークンが後続しないトークンに対して除外トークンが後続しない旨を示す付加情報を付して、索引付けを行う、請求項1に記載の検索システム。
【請求項7】
索引データを作成する索引作成装置であって、
検索対象となる入力文字列を構成する1以上のトークンを記憶する記憶部と、
除外するものとして登録されたトークンを除外トークンとし、除外しないトークンを見出し語トークンとして、見出し語トークンに対し、出現位置を定義付ける位置定義部と、
除外トークンに対し、該除外トークンが後続する見出し語トークンを起点とした位置情報を付与する情報付与部と、
前記1以上のトークンを除外トークンが後続するか否かを識別させて索引付けする索引付け処理部と
を含む、索引作成装置。
【請求項8】
前記除外トークンに対し付与される前記見出し語トークンを起点とした位置情報は、該除外トークンの起点となる該見出し語トークンの出現位置と、該見出し語トークンおよび該除外トークン間の位置差分を含む、請求項7に記載の索引作成装置。
【請求項9】
前記索引付け処理部は、除外トークンが後続するトークンに対し除外トークンが後続する旨を示す付加情報を付すか、または、除外トークンが後続しないトークンに対して除外トークンが後続しない旨を示す付加情報を付して、索引付けを行う、請求項7に記載の索引作成装置。
【請求項10】
フレーズ検索を実行する検索装置であって、
出現位置の算出に際し除外するものとして登録されたトークンを除外トークンとし、除外しないトークンを見出し語トークンとして、検索トークン列を含むフレーズ検索クエリを受け付ける受付部と、
索引データであって、検索対象となる入力文字列を構成する見出し語トークンに対し除外トークンを除外して定義される出現位置と、除外トークンに対し付与される該除外トークンが後続する見出し語トークンを起点とした位置情報とを含む当該索引データを参照し、除外トークンを考慮した検索処理が求められる場合に、前記フレーズ検索クエリに含まれる前記検索トークン列に前記出現位置および前記位置情報を含め整合するトークン列を抽出する検索処理部と
を含む、検索装置。
【請求項11】
前記フレーズ検索クエリの設定から、除外トークンを考慮した検索処理が求められているか否かを判定する判定部と、
フレーズ検索で除外トークンを考慮して検索するものとして登録されたトークン列が前記フレーズ検索クエリの検索トークン列に含まれる場合に、前記登録されたトークン列に関し前記除外トークンを考慮した検索処理に変更する変更部と
をさらに含む、請求項10に記載の検索装置。
【請求項12】
前記検索処理部は、抽出された前記出現位置および位置情報を含めて整合するトークン列に関し第1の重みを与え、前記フレーズ検索クエリに含まれる見出し語トークン列に前記出現位置を含め整合するものの、除外トークンとの連接関係が整合しないトークン列に関し第2の重みを与ることを特徴とし、
前記検索装置は、さらに、前記第1および第2の重みを考慮してランク付けされた検索結果を、前記フレーズ検索クエリに対する応答として作成する結果作成部を含む、請求項11に記載の検索装置。
【請求項13】
索引データを作成する索引作成方法であって、コンピュータ・システムに対し、
検索対象となる入力文字列を1以上のトークンに分割するステップと、
出現位置の算出に際し除外するものとして登録されたトークンを除外トークンとし、除外しないトークンを見出し語トークンとして、見出し語トークンに対し、出現位置を定義付けるステップと、
除外トークンが後続する見出し語トークンに関し、該除外トークンに対し、該除外トークンが後続する該見出し語トークンを起点とした位置情報を付与する情報付与部と、
見出し語トークンまたは除外トークンに関し、該トークンに除外トークンが後続するか否かを識別させて索引付けするステップと
を実行させる、索引作成方法。
【請求項14】
フレーズ検索を実行する検索方法であって、コンピュータ・システムに対し、
出現位置の算出に際し除外するものとして登録されたトークンを除外トークンとし、除外しないトークンを見出し語トークンとして、検索トークン列を含むフレーズ検索クエリを受け付けるステップと、
索引データであって、検索対象となる入力文字列を構成する見出し語トークンに対し除外トークンを除外して定義される出現位置と、除外トークンに対し付与される該除外トークンが後続する見出し語トークンを起点とした位置情報とを含む当該索引データを参照するステップと、
除外トークンを考慮した検索処理が求められる場合に、前記フレーズ検索クエリに含まれる検索トークン列に前記出現位置および前記位置情報を含め整合するトークン列を抽出するステップと
を実行させる、検索方法。
【請求項15】
索引データを作成する索引作成装置をコンピュータ上に実現するためのコンピュータ実行可能なプログラムであって、コンピュータ・システムを、
検索対象となる入力文字列を構成する1以上のトークンを記憶する記憶部、
除外するものとして登録されたトークンを除外トークンとし、除外しないトークンを見出し語トークンとして、見出し語トークンに対し、出現位置を定義付ける位置定義部、
除外トークンに対し、該除外トークンが後続する見出し語トークンを起点とした位置情報を付与する情報付与部、および
前記1以上のトークンを除外トークンが後続するか否かを識別させて索引付けする索引付け処理部
として機能させるためのプログラム。
【請求項16】
フレーズ検索を実行する検索装置をコンピュータ上に実現するためのコンピュータ実行可能なプログラムであって、コンピュータ・システムを、
出現位置の算出に際し除外するものとして登録されたトークンを除外トークンとし、除外しないトークンを見出し語トークンとして、検索トークン列を含むフレーズ検索クエリを受け付ける受付部、
索引データであって、検索対象となる入力文字列を構成する見出し語トークンに対し除外トークンを除外して定義される出現位置と、除外トークンに対し付与される該除外トークンが後続する見出し語トークンを起点とした位置情報とを含む当該索引データをし、除外トークンを考慮した検索処理が求められる場合に、前記フレーズ検索クエリに含まれる前記検索トークン列に前記出現位置および前記位置情報を含め整合するトークン列を抽出する検索処理部
として機能させるためのプログラム。
【請求項1】
フレーズ検索を行うための検索システムであって、
検索対象となる入力文字列を1以上のトークンに分割するトークン分割部と、
出現位置の算出に際し除外するものとして登録されたトークンを除外トークンとし、除外しないトークンを見出し語トークンとして、見出し語トークンに対し、出現位置を定義付ける位置定義部と、
除外トークンに対し、該除外トークンが後続する見出し語トークンを起点とした位置情報を付与する情報付与部と、
前記1以上のトークンを除外トークンが後続するか否かを識別させて索引付けする索引付け処理部と
を含む、検索システム。
【請求項2】
索引データであって、前記見出し語トークンに対し付与される前記出現位置と、前記除外トークンに対し付与される前記位置情報と、前記除外トークンが後続するか否かを識別する付加情報とを含み構成される当該索引データと、
フレーズ検索クエリに応答して、除外トークンを考慮した検索処理が求められる場合に、前記索引データを参照して、前記フレーズ検索クエリに含まれる検索トークン列に前記出現位置および前記位置情報を含め整合するトークン列を抽出する検索処理部と
をさらに含む、請求項1に記載の検索システム。
【請求項3】
前記フレーズ検索クエリの設定から、除外トークンを考慮した検索処理が求められているか否かを判定する判定部と、
フレーズ検索で除外トークンを考慮して検索するものとして登録されたトークン列が前記フレーズ検索クエリの検索トークン列に含まれる場合に、前記登録されたトークン列に関し前記除外トークンを考慮した検索処理に変更する変更部と
をさらに含む、請求項2に記載の検索システム。
【請求項4】
前記検索処理部は、抽出された前記出現位置および前記位置情報を含めて整合するトークン列に関し第1の重みを与え、前記フレーズ検索クエリに含まれる見出し語トークン列に前記出現位置を含め整合するものの、除外トークンとの連接関係が整合しないトークン列に関し第2の重みを与ることを特徴とする、請求項3に記載の検索システム。
【請求項5】
前記除外トークンに対し付与される前記見出し語トークンを起点とした位置情報は、該除外トークンの起点となる該見出し語トークンの出現位置と、該見出し語トークンおよび該除外トークン間の位置差分を含む、請求項1に記載の検索システム。
【請求項6】
前記索引付け処理部は、除外トークンが後続するトークンに対し除外トークンが後続する旨を示す付加情報を付すか、または、除外トークンが後続しないトークンに対して除外トークンが後続しない旨を示す付加情報を付して、索引付けを行う、請求項1に記載の検索システム。
【請求項7】
索引データを作成する索引作成装置であって、
検索対象となる入力文字列を構成する1以上のトークンを記憶する記憶部と、
除外するものとして登録されたトークンを除外トークンとし、除外しないトークンを見出し語トークンとして、見出し語トークンに対し、出現位置を定義付ける位置定義部と、
除外トークンに対し、該除外トークンが後続する見出し語トークンを起点とした位置情報を付与する情報付与部と、
前記1以上のトークンを除外トークンが後続するか否かを識別させて索引付けする索引付け処理部と
を含む、索引作成装置。
【請求項8】
前記除外トークンに対し付与される前記見出し語トークンを起点とした位置情報は、該除外トークンの起点となる該見出し語トークンの出現位置と、該見出し語トークンおよび該除外トークン間の位置差分を含む、請求項7に記載の索引作成装置。
【請求項9】
前記索引付け処理部は、除外トークンが後続するトークンに対し除外トークンが後続する旨を示す付加情報を付すか、または、除外トークンが後続しないトークンに対して除外トークンが後続しない旨を示す付加情報を付して、索引付けを行う、請求項7に記載の索引作成装置。
【請求項10】
フレーズ検索を実行する検索装置であって、
出現位置の算出に際し除外するものとして登録されたトークンを除外トークンとし、除外しないトークンを見出し語トークンとして、検索トークン列を含むフレーズ検索クエリを受け付ける受付部と、
索引データであって、検索対象となる入力文字列を構成する見出し語トークンに対し除外トークンを除外して定義される出現位置と、除外トークンに対し付与される該除外トークンが後続する見出し語トークンを起点とした位置情報とを含む当該索引データを参照し、除外トークンを考慮した検索処理が求められる場合に、前記フレーズ検索クエリに含まれる前記検索トークン列に前記出現位置および前記位置情報を含め整合するトークン列を抽出する検索処理部と
を含む、検索装置。
【請求項11】
前記フレーズ検索クエリの設定から、除外トークンを考慮した検索処理が求められているか否かを判定する判定部と、
フレーズ検索で除外トークンを考慮して検索するものとして登録されたトークン列が前記フレーズ検索クエリの検索トークン列に含まれる場合に、前記登録されたトークン列に関し前記除外トークンを考慮した検索処理に変更する変更部と
をさらに含む、請求項10に記載の検索装置。
【請求項12】
前記検索処理部は、抽出された前記出現位置および位置情報を含めて整合するトークン列に関し第1の重みを与え、前記フレーズ検索クエリに含まれる見出し語トークン列に前記出現位置を含め整合するものの、除外トークンとの連接関係が整合しないトークン列に関し第2の重みを与ることを特徴とし、
前記検索装置は、さらに、前記第1および第2の重みを考慮してランク付けされた検索結果を、前記フレーズ検索クエリに対する応答として作成する結果作成部を含む、請求項11に記載の検索装置。
【請求項13】
索引データを作成する索引作成方法であって、コンピュータ・システムに対し、
検索対象となる入力文字列を1以上のトークンに分割するステップと、
出現位置の算出に際し除外するものとして登録されたトークンを除外トークンとし、除外しないトークンを見出し語トークンとして、見出し語トークンに対し、出現位置を定義付けるステップと、
除外トークンが後続する見出し語トークンに関し、該除外トークンに対し、該除外トークンが後続する該見出し語トークンを起点とした位置情報を付与する情報付与部と、
見出し語トークンまたは除外トークンに関し、該トークンに除外トークンが後続するか否かを識別させて索引付けするステップと
を実行させる、索引作成方法。
【請求項14】
フレーズ検索を実行する検索方法であって、コンピュータ・システムに対し、
出現位置の算出に際し除外するものとして登録されたトークンを除外トークンとし、除外しないトークンを見出し語トークンとして、検索トークン列を含むフレーズ検索クエリを受け付けるステップと、
索引データであって、検索対象となる入力文字列を構成する見出し語トークンに対し除外トークンを除外して定義される出現位置と、除外トークンに対し付与される該除外トークンが後続する見出し語トークンを起点とした位置情報とを含む当該索引データを参照するステップと、
除外トークンを考慮した検索処理が求められる場合に、前記フレーズ検索クエリに含まれる検索トークン列に前記出現位置および前記位置情報を含め整合するトークン列を抽出するステップと
を実行させる、検索方法。
【請求項15】
索引データを作成する索引作成装置をコンピュータ上に実現するためのコンピュータ実行可能なプログラムであって、コンピュータ・システムを、
検索対象となる入力文字列を構成する1以上のトークンを記憶する記憶部、
除外するものとして登録されたトークンを除外トークンとし、除外しないトークンを見出し語トークンとして、見出し語トークンに対し、出現位置を定義付ける位置定義部、
除外トークンに対し、該除外トークンが後続する見出し語トークンを起点とした位置情報を付与する情報付与部、および
前記1以上のトークンを除外トークンが後続するか否かを識別させて索引付けする索引付け処理部
として機能させるためのプログラム。
【請求項16】
フレーズ検索を実行する検索装置をコンピュータ上に実現するためのコンピュータ実行可能なプログラムであって、コンピュータ・システムを、
出現位置の算出に際し除外するものとして登録されたトークンを除外トークンとし、除外しないトークンを見出し語トークンとして、検索トークン列を含むフレーズ検索クエリを受け付ける受付部、
索引データであって、検索対象となる入力文字列を構成する見出し語トークンに対し除外トークンを除外して定義される出現位置と、除外トークンに対し付与される該除外トークンが後続する見出し語トークンを起点とした位置情報とを含む当該索引データをし、除外トークンを考慮した検索処理が求められる場合に、前記フレーズ検索クエリに含まれる前記検索トークン列に前記出現位置および前記位置情報を含め整合するトークン列を抽出する検索処理部
として機能させるためのプログラム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】

【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【公開番号】特開2013−15967(P2013−15967A)
【公開日】平成25年1月24日(2013.1.24)
【国際特許分類】
【出願番号】特願2011−147417(P2011−147417)
【出願日】平成23年7月1日(2011.7.1)
【出願人】(390009531)インターナショナル・ビジネス・マシーンズ・コーポレーション (4,084)
【氏名又は名称原語表記】INTERNATIONAL BUSINESS MASCHINES CORPORATION
【復代理人】
【識別番号】100110607
【弁理士】
【氏名又は名称】間山 進也
【公開日】平成25年1月24日(2013.1.24)
【国際特許分類】
【出願日】平成23年7月1日(2011.7.1)
【出願人】(390009531)インターナショナル・ビジネス・マシーンズ・コーポレーション (4,084)
【氏名又は名称原語表記】INTERNATIONAL BUSINESS MASCHINES CORPORATION
【復代理人】
【識別番号】100110607
【弁理士】
【氏名又は名称】間山 進也
[ Back to top ]