
検索処理装置及びプログラム
【課題】構造化文書の索引のうち、少なくとも最下位階層のノードの情報に基づいて生成される索引に重みを付け、重みの高い索引を利用した検索により検索処理を高速化する。
【解決手段】重み付き語彙索引生成部52は、文書データベース42に登録されるべき構造化文書の各ノードの情報から語彙索引データベース43に登録されるべき索引を生成する。語彙索引生成部52は、少なくとも最下位階層のノードの情報に基づいて索引を生成する際に、当該索引に重みを付ける。検索部55は、ユーザによって指定された検索式の示す検索条件に合致する構造化文書をデータベース43に登録されている索引のうち一定レベルより高い重みの索引を用いて検索する。結果出力インタフェース514は、検索部55によって取得された検索結果をユーザに提示する。
【解決手段】重み付き語彙索引生成部52は、文書データベース42に登録されるべき構造化文書の各ノードの情報から語彙索引データベース43に登録されるべき索引を生成する。語彙索引生成部52は、少なくとも最下位階層のノードの情報に基づいて索引を生成する際に、当該索引に重みを付ける。検索部55は、ユーザによって指定された検索式の示す検索条件に合致する構造化文書をデータベース43に登録されている索引のうち一定レベルより高い重みの索引を用いて検索する。結果出力インタフェース514は、検索部55によって取得された検索結果をユーザに提示する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、複数の構造化文書が登録された文書データベースから索引を利用して検索条件に合致するデータを検索するのに好適な検索処理装置及びプログラムに関する。
【背景技術】
【0002】
従来から、複数の構造化文書が登録された文書データベースから検索条件に合致するデータを検索するのに索引を利用する検索処理装置が開発されている。このような検索処理装置のデータベースにテキストデータを含む文書を登録する場合、登録対象となるデータに索引付けをするのが一般的である。このような索引付けの手法としてN−グラム(N-gram)手法が知られている。N−グラム手法とは、例えば特許文献1に背景技術として記載されているように、文書に含まれる全ての文字をある固定の長さNの連続する文字列(N−グラム)として扱い、索引登録と検索を行う手法である。
【0003】
N−グラム手法における索引登録(N−グラム索引登録)は、次のように行われる。まず、データベースに登録される文書の文頭から機械的に1文字ずつずらしながら、長さNの文字列(N−グラム)が順に切り出される。この長さNの文字列(N−グラム)を便宜的に「語彙」と呼ぶ。但し、一般に良く知られている語彙と異なり、N−グラム手法で切り出される「語彙」には、意味を持たない「語彙」も存在する。1文字ずつずらして長さNの文字列を切り出すことにより、文書に含まれる全ての部分文字列を網羅して取り出すことができる。このようにして切り出される語彙の全てが索引登録の対象となる。次に、データベース内での文書の位置及び当該文書中での各語彙の出現位置を含む位置情報が、その語彙に対応付けて登録される。長さNには、言語や文字の種類によって適切な値が選ばれる。検索の際は、例えば検索条件として与えられた検索語句(文字列)が語彙に分割される。この語彙毎に索引(N−グラム索引)が検索される。これにより、語彙に一致する索引に対応付けて登録されている位置情報(文書位置−語彙出現位置)を得ることができる。
【特許文献1】特開2005−234930(段落0002)
【発明の開示】
【発明が解決しようとする課題】
【0004】
上述したようにN−グラム手法を適用する検索処理装置においては、索引登録及び検索のアルゴリズムが単純であるため、データベースに登録される文書に含まれている語句を抜けがなく完全に検索できるという利点がある。その一方、N−グラム手法を適用する検索処理装置は、辞書を利用した単語索引(語句索引)を持つ検索処理装置に比べて、語彙単位の索引の取り出し負荷が増えるために、検索処理に時間かかかる。特に、出現頻度が高い語彙(以下、頻出語彙と称する)を含む語句の検索処理では、語彙の出現位置を含む位置情報の取り出しや、切り出された各語彙の指す位置情報の評価などに時間を要する。このため、N−グラム手法を適用する従来の検索処理装置では、頻出語彙を含む語句の検索に時間がかかるという問題がある。このような問題は、XML(Extensible Markup Language)形式の文書(XML文書)のような階層構造を持つ構造化文書(つまり階層型データ)が登録されたデータベースを持つ検索処理装置においても同様である。
【0005】
本発明は上記事情を考慮してなされたものでその目的は、構造化文書の索引のうち、少なくとも最下位階層のノードの情報に基づいて生成される索引に重みを付加し、一定レベルより高い重みの索引を利用した検索を行うことで、検索処理を高速化できる検索処理装置及び及びプログラムを提供することにある。
【課題を解決するための手段】
【0006】
本発明の1つの観点によれば、複数の構造化文書が登録された文書データベースから、検索条件に合致する構造化文書を索引データベースに登録されている索引を用いて検索する検索処理装置が提供される。この検索処理装置は、前記文書データベースに登録されるべき構造化文書の各ノードの情報から前記索引データベースに登録されるべき索引を生成する索引生成手段であって、少なくとも最下位階層のノードの情報に基づいて索引を生成する際に、当該索引に重みを付ける索引生成手段と、ユーザによって指定された検索式の示す検索条件に合致する構造化文書を、前記索引データベースに登録されている索引のうち前記最下位階層のノードの情報に基づいて生成された索引を含む一定レベルより高い重みの索引を用いて前記文書データベースから検索して検索結果を取得する検索手段と、前記検索手段によって取得された検索結果を前記ユーザに提示する結果出力インタフェースとを具備する。
【発明の効果】
【0007】
本発明によれば、構造化文書の索引のうち、少なくとも最下位階層のノードの情報に基づいて生成される索引に重みを付加し、一定レベルより高い重みの索引を利用した検索を行うことで、ユーザが意図した重要度の高いデータを含んでいる可能性が極めて高い検索結果を短時間で取得できる。
【発明を実施するための最良の形態】
【0008】
以下、本発明の実施の形態につき図面を参照して説明する。
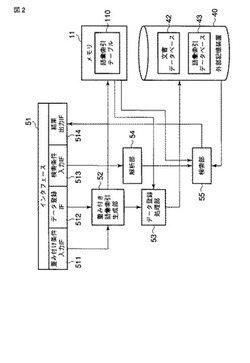
図1は本発明の一実施形態に係る検索処理装置を含むクライアント−サーバシステムのハードウェア構成を示すブロック図である。クライアント−サーバシステムは、主として、データベースサーバ(データベースサーバコンピュータ)10と、複数のクライアント端末とから構成される。複数のクライアント端末はクライアント端末20を含む。クライアント端末20上では、データベースサーバ10を利用するクライアントソフトウェアが動作する。クライアントソフトウェアは例えばブラウザである。クライアント端末20を含む複数のクライアント端末は、ローカルエリアネットワーク(LAN)のようなネットワーク30を介してデータベースサーバ10と接続されている。なお、図1にはクライアント端末20以外のクライアント端末は省略されている。
【0009】
データベースサーバ10は、主メモリのようなメモリ11を含む。データベースサーバ10は、ハードディスクドライブ(HDD)のような外部記憶装置40と接続されている。この外部記憶装置40は、データベースサーバ10による検索処理に用いられる検索処理プログラム41を格納する。データベースサーバ10及び外部記憶装置40は検索処理装置50を構成する。
【0010】
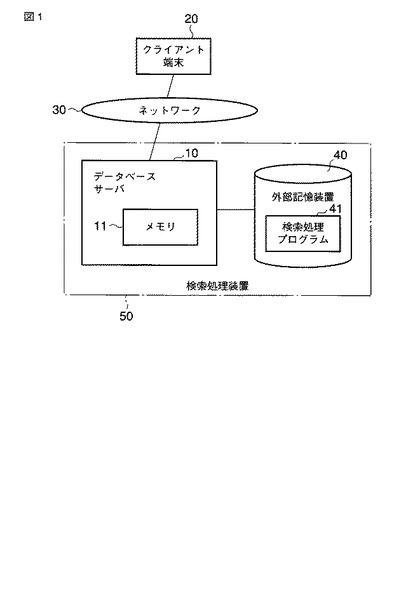
図2は図1に示される検索処理装置50の主として機能構成を示すブロック図である。検索処理装置50は、インタフェース51、重み付き語彙索引生成部52、データ登録処理部53、解析部54及び検索部55を含む。本実施形態において、これらの各部51乃至55は、図1のデータベースサーバ10が外部記憶装置40に格納されている検索処理プログラム41をメモリ11に読み込んで実行することにより実現されるものとする。このプログラム41は、コンピュータ読み取り可能な記憶媒体に予め格納して頒布可能である。また、このプログラム41が、ネットワーク30を介してデータベースサーバ10にダウンロードされても構わない。
【0011】
検索処理装置50はまた、メモリ11及び外部記憶装置40を含む。外部記憶装置40は、図1に示される検索処理プログラム41に加えて、文書データベース42及び語彙索引データベース43を格納する。文書データベース42は、複数の構造化文書(階層型データ)、例えばXML文書(XML文書データ)を格納する。語彙索引データベース43は、文書データベース42に登録されている全てのXML文書に含まれる語彙(N−グラム)毎に、その語彙の索引(N−グラム索引)を格納する。
【0012】
各語彙索引は、対応する語彙の位置(語彙位置)に関する情報(語彙位置情報)を持つ。この語彙位置情報は、当該位置情報に対応する語彙を含む全てのXML文書の文書データベース42内での位置(文書位置)と、当該XML文書において当該語彙が出現する全ての位置(語彙出現位置)とを表す。各語彙索引はまた、語彙位置情報に加えて、対応する語彙の重みの情報を持つ。各語彙索引で示される語彙の重みは、当該語彙のXML文書における階層位置に依存する。
【0013】
インタフェース51は、クライアント端末20を含むクライアント端末との間のデータの入出力を行うユーザインタフェースとして用いられる。インタフェース51は、重み付け条件入力インタフェース(重み付け条件入力IF)511、データ登録インタフェース(データ登録IF)512、検索条件入力インタフェース(検索条件入力IF)513及び結果出力インタフェース(結果出力IF)514を含む。
【0014】
重み付け条件入力IF511は、ユーザ、例えば管理者の操作に応じてクライアント端末(管理端末)から与えられる重み付け条件(つまりユーザ指定の重み付け条件)を入力する。この重み付け条件については後述する。データ登録IF512は、ユーザが例えばクライアント端末を操作して作成したXML文書を文書データベース42に登録する際の入出力インタフェースをなす。検索条件入力IF513は、ユーザの操作に応じてクライアント端末から与えられるXML文書検索の検索条件(つまりユーザ指定の検索条件)を入力する。結果出力IF514は、検索部55によるXML文書検索の結果を、当該検索を要求したクライアント端末に出力することにより、ユーザに提示する。
【0015】
重み付き語彙索引生成部52は、データ登録IF512によって入力されるXML文書(つまり、文書データベース42に登録されるべきXML文書)に含まれる語彙毎に、語彙索引を生成する。この語彙索引の生成は、メモリ11に格納される語彙索引テーブル110上で行われる。重み付き語彙索引生成部52は、語彙索引を生成する際に、当該語彙索引の重み付け、更に詳細に述べるならば当該語彙索により示される語彙の重み付けを行う。つまり重み付き語彙索引生成部52は、重み付き語彙索引を生成する。
【0016】
語彙の重みは、当該語彙のXML文書における階層位置に依存する。本実施形態では、語彙の重みは、最下位階層を基準に設定され、上位の階層ほど低くなるように設定される。この重み付けの条件、即ち最下位階層を基準とする階層位置と重みとの対応関係を表す条件(重み付け条件)は、例えば管理者がクライアント端末を操作することによって指定され、重み付け条件入力IF511によって入力される。
【0017】
データ登録処理部53は、重み付き語彙索引生成部52による語彙索引の生成の対象となるXML文書を文書データベース42に登録する。データ登録処理部53はまた、重み付き語彙索引生成部52によって生成された重み付き語彙索引を語彙索引データベース43に登録する。
【0018】
解析部54は、検索条件入力IF513によって入力される検索条件を解析する。この検索条件は、例えば構造化文書問い合わせで使用される検索式(XQueryの式)によって表されるものとする。ここでは、検索条件は文字列を含む。
【0019】
検索部55は、解析部54によって解析された検索条件に合致するXML文書データを文書データベース42から検索する。この検索には、語彙索引データベース43に登録されている重み付き語彙索引が用いられる。ここでは検索部55は、まず重みの高い語彙索引のみを参照して検索を実行し、検索結果を結果出力IF514に返す。
【0020】
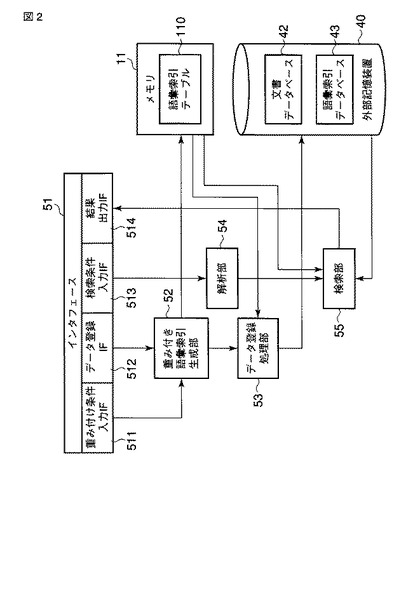
図3は、図2に示される重み付き語彙索引生成部52の構成を示すブロック図である。この重み付き語彙索引生成部52は、DOM展開部521、ノード取り出し部522、分解部523、語彙位置/階層位置取得部524及び重み付け部525から構成される。
【0021】
DOM展開部521は、データ登録IF512によって入力されるXML文書を構文解析してドキュメントオブジェクトモデル(Document Object Model:DOM)ツリーに展開する。DOMツリーは、XML文書の木構造を表す。
【0022】
ノード取り出し部522は、DOMツリーから逐次ノードを取り出す。分解部523は、取り出されたノードにテキストノードまたは属性ノードが存在する場合に、当該テキストノードまたは属性ノードの文字列を語彙(N−グラム)に分解する。
【0023】
語彙位置/階層位置取得部524は、分解された各語彙の文書位置及び語彙出現位置に関する情報(語彙位置情報)と階層位置に関する情報(階層位置情報)とを取得する。語彙位置/階層位置取得部524は、取得された各語彙の語彙位置情報及び階層位置情報を、当該語彙に対応付けて、語彙索引として語彙索引テーブル110に格納する。
【0024】
重み付け部525は、語彙索引テーブル110に登録されている語彙索引(により示される語彙)を重み付けする。ここでは、語彙索引に含まれる階層位置情報の示す階層位置に対応付けられた重みが当該語彙索引に付けられる。階層位置と重みとの対応関係は、重み付け条件入力IF511によって入力される重み付け条件によって指定される。
【0025】
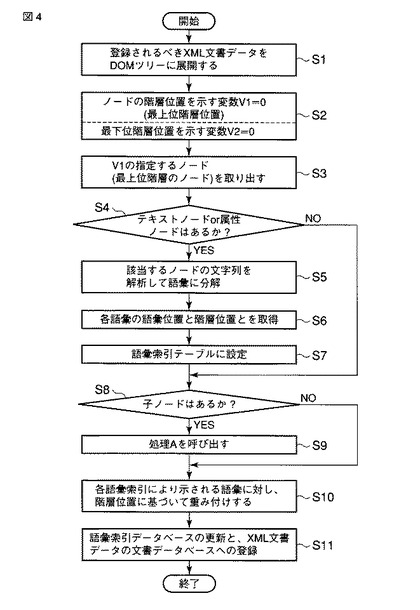
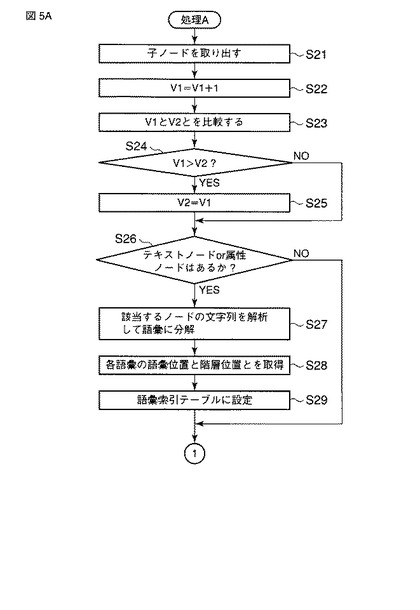
次に、本実施形態で適用される語彙索引生成を含むXML文書登録処理について、図4、図5A及び図5Bのフローチャートを参照して説明する。図4は語彙索引生成を含むXML文書登録処理の手順を示すフローチャート、図5A及び図5Bは図4のステップS9の詳細な処理手順を示すフローチャートである。
【0026】
今、ユーザがクライアント端末20を操作することにより、例えば当該クライアント端末20上で作成されたXML文書を文書データベース42に登録することが当該クライアント端末20から検索処理装置50に要求されたものとする。この場合、データ登録IF512によって、文書データベース42に登録されるべきXML文書が入力される。なお、このXML文書が、例えばネットワーク30に接続されたWebサーバ、或いはファイルサーバから検索処理装置50によって収集されたものであっても構わない。
【0027】
XML文書、つまり階層構造を持ったXML文書データは、リレーショナルデータベースの2次元表にマッピングしにくい非定型なデータを持つ場合がある。規定や規約のようなコンテンツをXML文書データとして扱う場合、スキーマが決定できず、文書毎に異なるデータ構造を持つ場合もある。このようなコンテンツを管理するのに、ネイティブなXMLデータベースが活用されている。本実施形態で適用される文書データベース42は、このネイティブなXMLデータベースに相当する。
【0028】
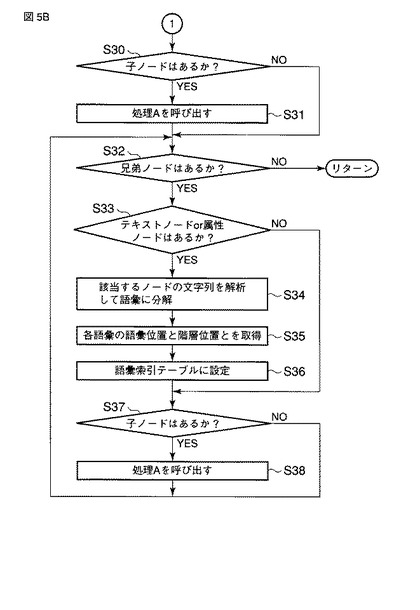
規定や規約のようなコンテンツは、階層が深く、構造が複雑な場合が多い。図6は、階層が深いコンテンツ(XML文書60)の一例を示す。規約や規定などのコンテンツ(XML文書)の場合、末端のノード(最下位階層のノード)の内容が、文書を検索する際のキーとなる語彙を含む重要な内容であることが多い。第6の例では、<PARAGRAF>タグの内容が、これに相当する。つまり、階層が深いXML文書では、上位のノードにXML文書自身の階層の説明を含み、下位のノード(特に末端ノード)に検索のキーとなる語彙を含む場合が多い。そこで本実施形態では、複雑な構造を持つXML文書の少なくとも末端ノードの語彙が優先的に検索されるように考慮されている。具体的には、XML文書の登録に伴う語彙登録(語彙索引生成)時に、図4のフローチャートに従って、次のような手順で末端(最下位階層)のノードの語彙に重みが付与される。
【0029】
まず、重み付き語彙索引生成部52のDOM展開部521は、データ登録IF512によって入力される登録されるべきXML文書(XML文書データ)をDOMツリーに展開する(ステップS1)。重み付き語彙索引生成部52のノード取り出し部522は、ノードの階層位置(現在の階層位置)を指し示す変数(階層位置変数)V1を、最上位階層位置を表す初期値0に設定する(ステップS2)。ノード取り出し部522はまた、登録されるべきXML文書において現在判明されている最下位階層位置を表す変数V2を初期値0に設定する。ノード取り出し部522は、変数V1(=0)の指定するノード、つまり最上位階層位置のノード(最上位ノード)をDOMツリーに展開されたXML文書(以下、DOMツリーと称する)から取り出す(ステップS3)。
【0030】
ノード取り出し部522は、取り出されたノードにテキストノードまたは属性ノードが存在するか否かを判定する(ステップS4)。もし、テキストノードまたは属性ノードが存在する場合、重み付き語彙索引生成部52の分解部523は当該テキストノードまたは属性ノードの文字列を解析(N−グラム解析)することにより、当該文字列を語彙(N−グラム)に分解する(ステップS5)。
【0031】
重み付き語彙索引生成部52の語彙位置/階層位置取得部524は、分解部523によって分解された各語彙の文書位置及び語彙出現位置を示す語彙位置情報と階層位置を示す階層位置情報とを取得する(ステップS6)。語彙位置/階層位置取得部524は、取得された語彙の語彙位置情報及び階層位置情報を、当該語彙に対応付けて語彙索引として語彙索引テーブル110に設定する(ステップS7)。
【0032】
ステップS7が実行されると、ノード取り出し部522は、変数V1で指定されるノードの子ノードが存在するか否かを判定する(ステップS8)。ノード取り出し部522は、ステップS3で取り出されたノードにテキストノードまたは属性ノードが存在しない場合にも(ステップS4)、ステップS8を実行する。
【0033】
もし、子ノードが存在するならば、以下に述べる処理Aが呼び出される(ステップS9)。処理Aにおいて、ノード取り出し部522は子ノードを取り出す(ステップS21)。ノード取り出し部522は、変数V1を1だけインクリメントする(ステップS22)。このインクリメント後の変数V1は、インクリメント前の階層位置より1つ下位の階層位置を示す。ノード取り出し部522は、変数V1と変数V2とを比較する(ステップS23)。即ちノード取り出し部522は、インクリメント後の変数V1によって示される現在の階層位置と変数V2によって示される最下位階層位置とを比較する。もし、現在の階層位置が現在の最下位階層位置よりも低いならば、即ちV1>V2であるならば(ステップS24)、ノード取り出し部522は変数V2を現在の階層位置を示すように更新する(ステップS25)。即ちノード取り出し部522は、現在の階層位置を現在判明されている最下位階層位置として設定する。
【0034】
ノード取り出し部522は、ステップS21で取り出された子ノードにテキストノードまたは属性ノードが存在するか否かを判定する(ステップS26)。もし、テキストノードまたは属性ノードが存在する場合、分解部523は当該テキストノードまたは属性ノードの文字列を解析することにより、当該文字列を語彙(N−グラム)に分解する(ステップS27)。
【0035】
語彙位置/階層位置取得部524は、分解された各語彙の語彙位置情報及び階層位置情報を取得する(ステップS28)。語彙位置/階層位置取得部524は、取得された語彙の語彙位置情報及び階層位置情報を、当該語彙に対応付けて語彙索引として語彙索引テーブル110に設定する(ステップS29)。
【0036】
さて、ステップS29が実行されると、ノード取り出し部522は、変数V1で指定されるノードの子ノードが存在するか否かを判定する(ステップS30)。ノード取り出し部522は、ステップS26でテキストノードまたは属性ノードが存在しないと判定された場合にも、ステップS30を実行する。
【0037】
もし、子ノードが存在するならば、処理Aが再び呼び出される(ステップS31)。次にノード取り出し部522は、変数V1で指定されるノードの兄弟ノードが存在するか否かを判定する(ステップS32)。このステップS32は、ステップS30で子ノードが存在しないと判定された場合にも実行される。
【0038】
もし、変数V1で指定されるノードの兄弟ノードが存在するならば、ノード取り出し部522は、当該兄弟ノードにテキストノードまたは属性ノードが存在するか否かを判定する(ステップS33)。もし、テキストノードまたは属性ノードが存在する場合、分解部523は当該テキストノードまたは属性ノードの文字列を語彙(N−グラム)に分解する(ステップS34)。
【0039】
語彙位置/階層位置取得部524は、分解された各語彙の語彙位置情報及び階層位置情報を取得する(ステップS35)。語彙位置/階層位置取得部524は、取得された語彙の語彙位置情報及び階層位置情報を、当該語彙に対応付けて語彙索引として語彙索引テーブル110に設定する(ステップS36)。
【0040】
ステップS36が実行されると、ノード取り出し部522は、変数V1で指定されるノードの子ノードが存在するか否かを判定する(ステップS37)。ノード取り出し部522は、ステップS33でテキストノードまたは属性ノードが存在しないと判定された場合にも、ステップS37を実行する。
【0041】
もし、子ノードが存在するならば、処理Aが再び呼び出され(ステップS38)、しかる後にステップS32が実行される。これに対し、子ノードが存在しないならば、ステップS38をスキップしてステップS32が実行される。このステップS32において、変数V1で指定されるノードの兄弟ノードが存在すると判定されると、上記ステップS33乃至S38が再び実行される。
【0042】
このように重み付き語彙索引生成部52は、DOMツリー(で示される登録されるべきXML文書)の階層を、再帰的な処理Aの呼び出しによって最上位階層から順に解析することにより、階層位置情報を含む語彙索引を生成する。
【0043】
やがて、DOMツリーの全ての階層の全ノードについて処理が行われると、重み付き語彙索引生成部52は処理Aの再帰的呼び出しから解放される。つまり、重み付き語彙索引生成部52の処理は、ステップS9で処理Aが呼び出された状態に戻る。このとき、登録されるべきXML文書の全ノードについての語彙索引が、語彙索引テーブル110に生成(設定)されたことになる。また、この時点の変数V2は、上記XML文書の末端ノード(最下位階層のノード)の位置を示す。
【0044】
すると、重み付き語彙索引生成部52の重み付け部525は、重み付け条件入力IF511によって入力される重み付け条件(以下、重み付け条件C1と称する)に従い、各語彙索引により示される語彙に対する重み付けを行う(ステップS10)。ここでは重み付け部525は、各語彙索引の語彙に、当該語彙索引中の階層位置情報の示す階層位置と最下位階層位置との位置関係に対応付けられた重みを付ける。この重み付けは、変数V2の示す最下位階層位置から階層位置を示す値の降順に行われる。ここでは、最下位階層位置の語彙(に対応する語彙索引)の重みが最も高く、上位の階層ほど低くなるように設定される。なお、語彙索引中の階層位置情報が当該階層位置情報の示す階層位置に対応する重みに置き換えられても構わない。
【0045】
データ登録処理部53は、語彙索引テーブル110に基づき語彙索引データベース43を更新すると共に、重み付き語彙索引生成部52による語彙索引生成に用いられたXML文書を文書データベース42に登録する(ステップS11)。
【0046】
図7は、図6に示すXML文書60に含まれる語彙に対する重み付けの結果の一部を当該XML文書60と対応付けて示す。
【0047】
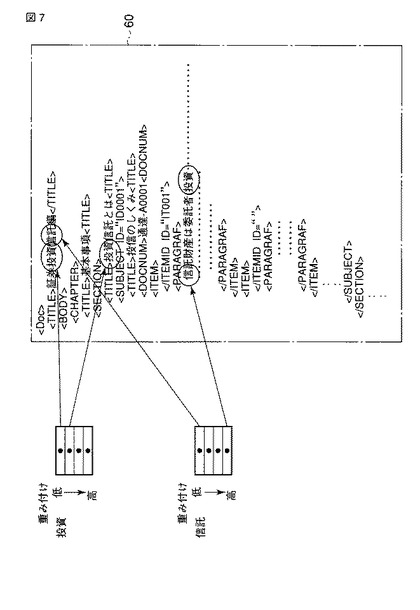
なお、重み付け条件C1に代えて、例えば最下位階層位置の語彙(に対応する語彙索引)のみに対する重み付けを指定する重み付け条件C2を用いることも可能である。図8は、重み付け条件C2を用いた場合における、図6に示すXML文書60に含まれる語彙に対する重み付けの結果の一部を当該XML文書60と対応付けて示す。
【0048】
また、例えば最下位階層を含む一定の階層範囲の階層位置の語彙のみに対する重み付けを指定する重み付け条件を用いることも可能である。この重み付け条件が、階層位置に対応付けられる重みの情報を必ずしも含む必要はない。例えば、最下位階層を含む一定の階層範囲の場合に、当該一定の階層範囲内の各階層位置の語彙(に対応する語彙索引)に対する重みを、上位の階層位置の語彙ほど低くなるように、最下位階層位置を基準に所定の重み付けアルゴリズムに従って付与しても良い。また、重み付け条件は、必ずしもユーザ(管理者)によって指定される必要はなく、検索処理プログラム41によって予め定められていても構わない。
【0049】
次に、本実施形態で適用される検索処理について、図9のフローチャートを参照して説明する。
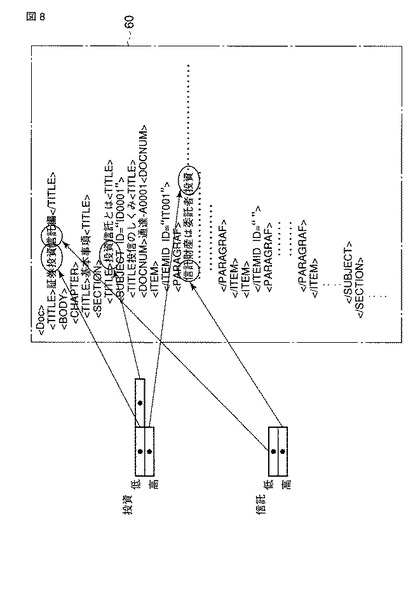
今、ユーザの操作により、クライアント端末20から検索処理装置50に対し、構造化文書問い合わせがネットワーク30を介して与えられたものとする。検索処理装置50の検索条件入力IF513は、このクライアント端末20からの構造化文書問い合わせを受け付けると、当該問い合わせを解析部54に渡す。解析部54は、この問い合わせで使用される検索式(ユーザ指定の検索式)を解析する。ここでは、文字列による検索が指定されているものとする。この場合、解析部54は検索式で指定されている文字列(指定文字列)を語彙(N−グラム)に分解する。つまり解析部54は、検索式から指定文字列を構成する全ての語彙を抽出する。解析部54は抽出された語彙を検索部55に渡して、当該検索部55を起動する。
【0050】
すると検索部55は、指定文字列を構成する各語彙に対応して語彙索引データベース43に登録されている語彙索引のうち、例えば一定レベル以上の重みが付されている語彙索引(つまり重みの高い語彙索引)を使用して、指定文字列の位置情報を取得する(ステップS41)。検索部55は、取得された位置情報に基づき文書データベース42から検索式(検索条件)に合致するXML文書を第1の検索結果として取得する(ステップS42)。この第1の検索結果は、重みの高い語彙索引のみを使用した検索処理により、短時間で取得される。しかも第1の検索結果は、ユーザが意図した重要度の高いデータを含んでいる可能性が極めて高い。検索部55は、この第1の検索結果を結果出力IF514によりクライアント端末20に返させる(ステップS43)。
【0051】
次に検索部55は、指定文字列を構成する各語彙に対応して語彙索引データベース43に登録されている語彙索引のうち、例えば一定レベル未満の重みが付されている語彙索引(つまり重みの低い語彙索引)を使用して、指定文字列の位置情報を取得する(ステップS44)。検索部55は、取得された位置情報に基づき文書データベース42から検索式(検索条件)に合致するXML文書を第2の検索結果として取得する(ステップS45)。検索部55は、この第2の検索結果を結果出力IF514によりクライアント端末20に返させる(ステップS46)。
【0052】
このように本実施形態によれば、最初に重みの高い語彙索引を使用した検索処理(第1の検索処理)を行うことで、重要度の高いデータを含む検索結果を高速で取得しながら、第1の検索処理の後に重みの低い語彙索引を使用した検索処理(第2の検索処理)を行うことで、漏れのない検索を実現している。
【0053】
なお、第1の検索処理だけが実行される構成とすることも可能である。また、第1の検索処理だけを実行する手法(手法1)を適用するか、或いは第1の検索処理と第2の検索処理とを連続して実行する手法(手法2)を適用するかを、クライアント端末20上でユーザに選択させることも可能である。この場合、ユーザは、例えば重要度の高いデータを含む検索結果を短時間で取得したいならば、手法1を選択すれば良い。また、重要度の高いデータを含む検索結果を確認している間に完全な検索結果とヒット件数を得たい場合は、手法2を選択すれば良い。
【0054】
また、適用される重みが(重み無しを含めて)3レベル以上の場合に、語彙索引を重みのレベルに応じて3つ以上の語彙索引グループに分類し、重みが最も高い語彙索引グループから順に使用して、逐次検索処理を行うようにしても良い。ここで、重み付けの階層範囲(つまり最下位階層を含む重み付けの階層範囲)が重み付け条件を用いてユーザによって指定される場合、検索の重み付け幅が適正となり、高速に結果を返す範囲を細かく設定できる。
【0055】
[変形例]
次に、上記実施形態の変形例について説明する。この変形例の特徴は、重み付き語彙索引生成部52に代えて、スキーマを利用して重み付けを行う重み付き語彙索引生成部520(図11参照)を用いることにある。したがって、必要ならば、図2において、重み付き語彙索引生成部52を重み付き語彙索引生成部520に置き換えられたい。
【0056】
この変形例では、文書データベース42に登録されるべきXML文書の階層が深くなく(例えば、ほぼフラットで)、且つスキーマ(によって定義される構造)が固定で、検索で利用する箇所がほぼ決定されている場合、ユーザがクライアント端末を操作してスキーマ上で重み付けされるべきタグを指定することで、該当するタグの語彙に対する正確な重み付けが実現される。そのため本変形例では、文書データベース42にスキーマ別のフォルダが確保される。文書データベース42内の各フォルダには、そのフォルダに対応付けられたスキーマ(スキーマ情報)が設定される。重み付き語彙索引生成部520は、このスキーマ上で、ユーザ指定のタグを重み付け箇所として設定する。文書データベース42内の各フォルダには、そのフォルダに設定されているスキーマによって定義される構造のXML文書のみが登録される。
【0057】
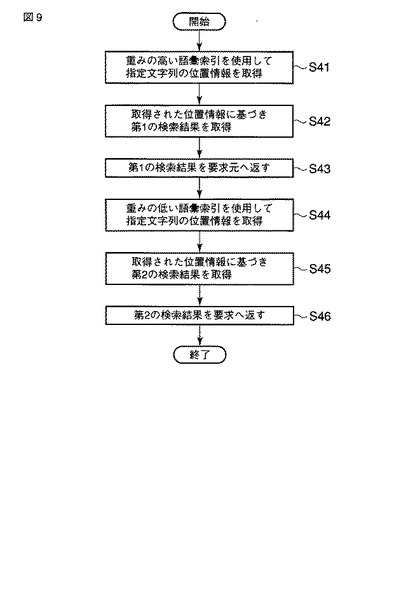
図10は、スキーマによる重み付け箇所の指定を説明するための図である。図10には、スキーマ(スキーマ情報)101及び当該スキーマ101で定義される構造のXML文書102の一例が対比して示されている。図10において、矢印103及び104は、スキーマ101上で設定された重み付け箇所を指し示す。また、矢印105は、矢印103で指し示される重み付け箇所に対応するXML文書102内の構造を指し示す。一方、矢印106a,106b及び106cは、矢印104で指し示される重み付け箇所に対応するXML文書102内の構造を指し示す。
【0058】
図10の例では、矢印103で指し示されるスキーマ101上の<Name>タグ、即ち<Category>タグと兄弟のタグである<Name>タグが、重み付け箇所として指定される。この場合、XML文書102内のノードのうち、矢印105で指し示される<Name>ノード(タグ)に存在するテキストノードが重み付け箇所として識別される。また、矢印103で指し示されるスキーマ101上の<Detail>タグの繰り返しに含まれる<Value>タグが、重み付け箇所として指定される。この場合、XML文書102内のノードのうち、矢印106a,106b及び106cでそれぞれ指し示される<Value>ノード(タグ)に存在するテキストノードが重み付け箇所として識別される。
【0059】
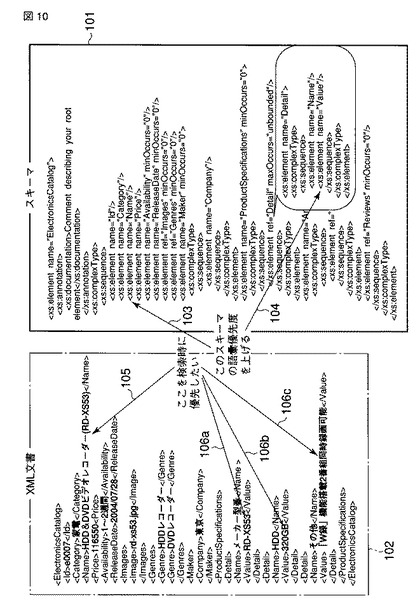
図11は重み付き語彙索引生成部520の構成を示すブロック図である。図11において、図3と同様の要素には同一参照符号を付してある。重み付き語彙索引生成部520は、DOM展開部521、ノード取り出し部522、分解部523、重み付け部525、スキーマ読み込み部526、語彙位置取得部527及び重み付け箇所抽出部528から構成される。
【0060】
スキーマ読み込み部526は、データ登録IF512によって入力されたXML文書が登録されるべき文書データベース42内のフォルダからスキーマ情報をメモリ11に読み込む。語彙位置取得部527は、分解された各語彙の語彙位置情報を取得する。重み付け箇所抽出部528は、語彙位置情報の示す語彙位置とスキーマ情報とに基づいて、重み付けが指定されている箇所の語彙を抽出(識別)する。重み付け部525は、取得された各語彙の語彙位置情報を、当該語彙に対応付けて、語彙索引として語彙索引テーブル110に格納する。その際に重み付け部525は、重み付けが指定されている箇所の語彙の語彙索引に重みを付ける。
【0061】
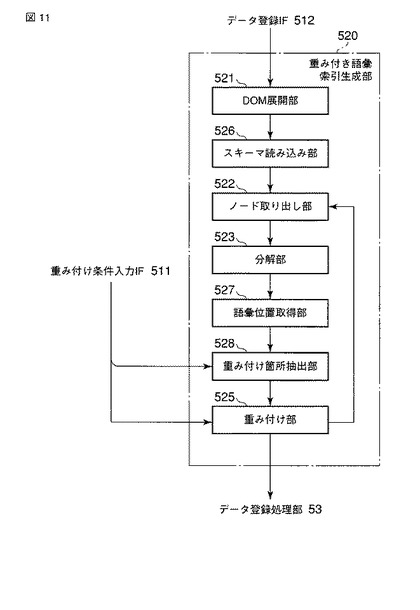
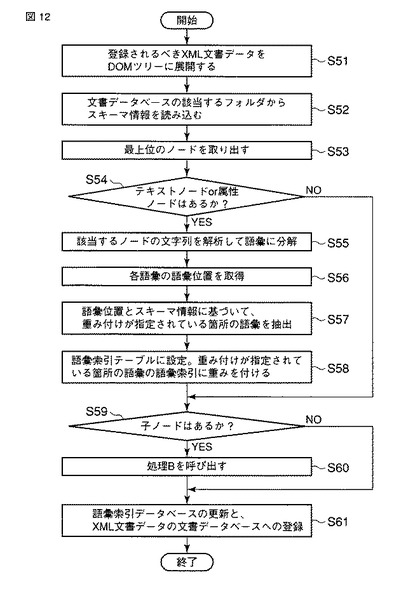
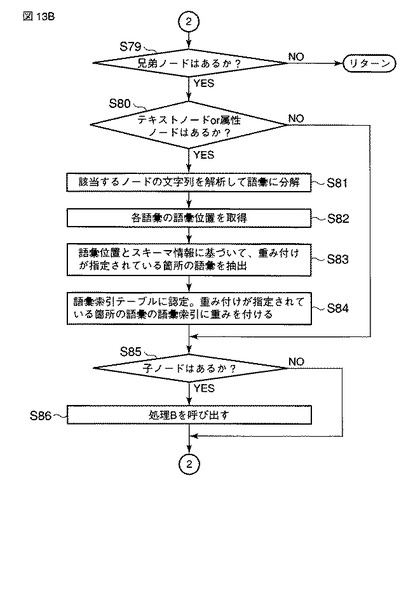
次に、上記実施形態の変形例で適用される語彙索引生成を含むXML文書登録処理について、図12、図13A及び図13Bのフローチャートを参照して説明する。図12は語彙索引生成を含むXML文書登録処理の手順を示すフローチャート、図13A及び図13Bは図12のステップS60の詳細な処理手順を示すフローチャートである。
【0062】
今、データ登録IF512によって、文書データベース42に登録されるべきXML文書が入力されたものとする。DOM展開部521は、入力されたXML文書(XML文書データ)をDOMツリーに展開する(ステップS51)。スキーマ読み込み部526は、入力されたXML文書が登録されるべき文書データベース42のフォルダからメモリ11に、当該XML文書の構造を示すスキーマ情報を読み込む(ステップS52)。
【0063】
ノード取り出し部522は、最上位階層位置のノード(最上位ノード)をDOMツリーから取り出す(ステップS53)。ノード取り出し部522は、取り出されたノードにテキストノードまたは属性ノードが存在するか否かを判定する(ステップS54)。もし、テキストノードまたは属性ノードが存在する場合、分解部523は当該テキストノードまたは属性ノードの文字列を解析(N−グラム解析)することにより、当該文字列を語彙(N−グラム)に分解する(ステップS55)。
【0064】
語彙位置取得部527は、分解部523によって分解された各語彙の文書位置及び語彙出現位置を示す語彙位置情報を取得する(ステップS56)。重み付け箇所抽出部528は、取得された語彙位置情報の示す語彙位置とステップS52でメモリ11に読み込まれたスキーマ情報とに基づいて、重み付けが指定されている箇所(タグ)の語彙を抽出(識別)する(ステップS57)。
【0065】
重み付け部525は、取得された各語彙の語彙位置情報を、当該語彙に対応付けて、語彙索引として語彙索引テーブル110に設定する(ステップS58)。このステップS58において、重み付け部525は、重み付けが指定されている箇所の語彙の語彙索引に重みを付ける。
【0066】
ノード取り出し部522は、取り出されたノードの子ノードが存在するか否かを判定する(ステップS59)。ノード取り出し部522は、取り出されたノードにテキストノードまたは属性ノードが存在しない場合にも(ステップS54)、ステップS59を実行する。
【0067】
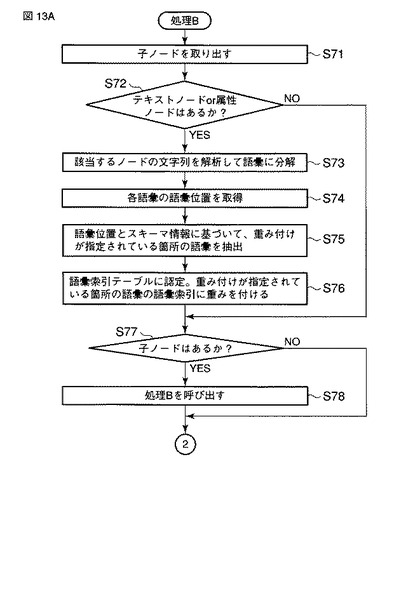
もし、子ノードが存在するならば、以下に述べる処理Bが呼び出される(ステップS60)。処理Bにおいて、ノード取り出し部522は子ノードを取り出す(ステップS71)。ノード取り出し部522は、ステップS71で取り出された子ノードにテキストノードまたは属性ノードが存在するか否かを判定する(ステップS72)。もし、テキストノードまたは属性ノードが存在する場合、上記ステップS55乃至S58と同様の処理(ステップS73乃至S76)が実行される。
【0068】
次にノード取り出し部522は、ステップS71で取り出されたノードの子ノードが存在するかを判定する(ステップS77)。ノード取り出し部522は、ステップS71で取り出されたノードにテキストノードまたは属性ノードが存在しない場合にも(ステップS72)、ステップS77を実行する。
【0069】
もし、子ノードが存在するならば、処理Bが再び呼び出される(ステップS78)。次にノード取り出し部522は、最も最近に取り出されたノードの兄弟ノードが存在するかを判定する(ステップS79)。このステップS79は、ステップS77で子ノードが存在しないと判定された場合にも実行される。
【0070】
もし、兄弟ノードが存在するならば、ノード取り出し部522は、当該兄弟ノードにテキストノードまたは属性ノードが存在するかを判定する(ステップS80)。もし、テキストノードまたは属性ノードが存在する場合、上記ステップS55乃至S58と同様の処理(ステップS81乃至S84)が実行される。
【0071】
次にノード取り出し部522は、兄弟ノードの子ノードが存在するかを判定する(ステップS85)。ノード取り出し部522は、兄弟ノードにテキストノードまたは属性ノードが存在しない場合にも(ステップS80)、ステップS85を実行する。
【0072】
もし、子ノードが存在するならば、処理Bが再び呼び出され(ステップS86)、しかる後にステップS79が実行される。これに対し、子ノードが存在しないならば、ステップS86をスキップしてステップS79が実行される。このステップS79において、兄弟ノードが存在すると判定されると、上記ステップS80乃至S86が再び実行される。
【0073】
やがて、DOMツリーの全ての階層の全ノードについて処理が行われると、重み付き語彙索引生成部520は処理Bの再帰的呼び出しから解放される。つまり、重み付き語彙索引生成部520の処理は、ステップS60で処理Bが呼び出された状態に戻る。このとき、登録されるべきXML文書の全ノードについての重み付き/重み無し語彙索引が、語彙索引テーブル110に生成(設定)されたことになる。
【0074】
するとデータ登録処理部53は、語彙索引テーブル110に基づき語彙索引データベース43を更新すると共に、重み付き語彙索引生成部52による語彙索引生成に用いられたXML文書を文書データベース42の該当するフォルダに登録する(ステップS61)。
【0075】
なお、本発明は、上記実施形態またはその変形例そのままに限定されるものではなく、実施段階ではその要旨を逸脱しない範囲で構成要素を変形して具体化できる。例えば、上記実施形態またはその変形例では、重み付き語彙索引生成部52または重み付き語彙索引生成部520によって語彙索引(に登録される語彙)に重みが付けられる。しかし、語彙索引以外の索引、例えばXML文書に含まれる数値または構造(文書構造)を含むノードを特定する索引(数値索引または構造索引)を用いて検索を行う検索処理装置では、当該数値索引または構造索引(に登録される数値または構造)に重みが付けられる構成とすることも可能である。ここでは、数値索引または構造索引を生成する索引生成部に、当該数値索引または構造索引に重みを付ける機能を持たせれば良い。また、上記実施形態またはその変形例に開示されている複数の構成要素の適宜な組み合せにより種々の発明を形成できる。例えば、実施形態またはその変形例に示される全構成要素から幾つかの構成要素を削除してもよい。
【図面の簡単な説明】
【0076】
【図1】本発明の一実施形態に係る検索処理装置を含むクライアント−サーバシステムのハードウェア構成を示すブロック図。
【図2】図1に示される検索処理装置の主として機能構成を示すブロック図。
【図3】図2に示される重み付き語彙索引生成部の構成を示すブロック図。
【図4】同実施形態で適用される語彙索引生成を含むXML文書登録処理の手順を示すフローチャート。
【図5A】図4のステップS9の詳細な処理手順を示すフローチャート。
【図5B】図4のステップS9の詳細な処理手順を示すフローチャート。
【図6】階層が深いXML文書の一例を示す図。
【図7】図6に示すXML文書に含まれる語彙に対する重み付けの結果の一部を当該XML文書と対応付けて示す図。
【図8】図7と異なる重み付け条件が指定された場合における、図6に示すXML文書に含まれる語彙に対する重み付けの結果の一部を当該XML文書と対応付けて示す図。
【図9】同実施形態で適用される検索処理の手順を示すフローチャート。
【図10】同実施形態の変形例で利用されるスキーマによる重み付け箇所の指定を説明するための図。
【図11】同変形例で適用される重み付き語彙索引生成部の構成を示すブロック図。
【図12】同変形例で適用される語彙索引生成を含むXML文書登録処理の手順を示すフローチャート。
【図13A】図12のステップS60の詳細な処理手順を示すフローチャート。
【図13B】図12のステップS60の詳細な処理手順を示すフローチャート。
【符号の説明】
【0077】
10…データベースサーバ(データベースサーバコンピュータ)、20…クライアント端末、40…外部記憶装置、41…検索処理プログラム、42…文書データベース、43…語彙索引データベース、50…検索処理装置、52,520…重み付き語彙索引生成部、53…データ登録処理部、55…検索部、60,102…XML文書、101…スキーマ、110…語彙索引テーブル、521…DOM展開部、522…ノード取り出し部、523…分解部、524…語彙位置/階層位置取得部、525…重み付け部、526…スキーマ読み込み部、527…語彙位置取得部、528…重み付け箇所抽出部。
【技術分野】
【0001】
本発明は、複数の構造化文書が登録された文書データベースから索引を利用して検索条件に合致するデータを検索するのに好適な検索処理装置及びプログラムに関する。
【背景技術】
【0002】
従来から、複数の構造化文書が登録された文書データベースから検索条件に合致するデータを検索するのに索引を利用する検索処理装置が開発されている。このような検索処理装置のデータベースにテキストデータを含む文書を登録する場合、登録対象となるデータに索引付けをするのが一般的である。このような索引付けの手法としてN−グラム(N-gram)手法が知られている。N−グラム手法とは、例えば特許文献1に背景技術として記載されているように、文書に含まれる全ての文字をある固定の長さNの連続する文字列(N−グラム)として扱い、索引登録と検索を行う手法である。
【0003】
N−グラム手法における索引登録(N−グラム索引登録)は、次のように行われる。まず、データベースに登録される文書の文頭から機械的に1文字ずつずらしながら、長さNの文字列(N−グラム)が順に切り出される。この長さNの文字列(N−グラム)を便宜的に「語彙」と呼ぶ。但し、一般に良く知られている語彙と異なり、N−グラム手法で切り出される「語彙」には、意味を持たない「語彙」も存在する。1文字ずつずらして長さNの文字列を切り出すことにより、文書に含まれる全ての部分文字列を網羅して取り出すことができる。このようにして切り出される語彙の全てが索引登録の対象となる。次に、データベース内での文書の位置及び当該文書中での各語彙の出現位置を含む位置情報が、その語彙に対応付けて登録される。長さNには、言語や文字の種類によって適切な値が選ばれる。検索の際は、例えば検索条件として与えられた検索語句(文字列)が語彙に分割される。この語彙毎に索引(N−グラム索引)が検索される。これにより、語彙に一致する索引に対応付けて登録されている位置情報(文書位置−語彙出現位置)を得ることができる。
【特許文献1】特開2005−234930(段落0002)
【発明の開示】
【発明が解決しようとする課題】
【0004】
上述したようにN−グラム手法を適用する検索処理装置においては、索引登録及び検索のアルゴリズムが単純であるため、データベースに登録される文書に含まれている語句を抜けがなく完全に検索できるという利点がある。その一方、N−グラム手法を適用する検索処理装置は、辞書を利用した単語索引(語句索引)を持つ検索処理装置に比べて、語彙単位の索引の取り出し負荷が増えるために、検索処理に時間かかかる。特に、出現頻度が高い語彙(以下、頻出語彙と称する)を含む語句の検索処理では、語彙の出現位置を含む位置情報の取り出しや、切り出された各語彙の指す位置情報の評価などに時間を要する。このため、N−グラム手法を適用する従来の検索処理装置では、頻出語彙を含む語句の検索に時間がかかるという問題がある。このような問題は、XML(Extensible Markup Language)形式の文書(XML文書)のような階層構造を持つ構造化文書(つまり階層型データ)が登録されたデータベースを持つ検索処理装置においても同様である。
【0005】
本発明は上記事情を考慮してなされたものでその目的は、構造化文書の索引のうち、少なくとも最下位階層のノードの情報に基づいて生成される索引に重みを付加し、一定レベルより高い重みの索引を利用した検索を行うことで、検索処理を高速化できる検索処理装置及び及びプログラムを提供することにある。
【課題を解決するための手段】
【0006】
本発明の1つの観点によれば、複数の構造化文書が登録された文書データベースから、検索条件に合致する構造化文書を索引データベースに登録されている索引を用いて検索する検索処理装置が提供される。この検索処理装置は、前記文書データベースに登録されるべき構造化文書の各ノードの情報から前記索引データベースに登録されるべき索引を生成する索引生成手段であって、少なくとも最下位階層のノードの情報に基づいて索引を生成する際に、当該索引に重みを付ける索引生成手段と、ユーザによって指定された検索式の示す検索条件に合致する構造化文書を、前記索引データベースに登録されている索引のうち前記最下位階層のノードの情報に基づいて生成された索引を含む一定レベルより高い重みの索引を用いて前記文書データベースから検索して検索結果を取得する検索手段と、前記検索手段によって取得された検索結果を前記ユーザに提示する結果出力インタフェースとを具備する。
【発明の効果】
【0007】
本発明によれば、構造化文書の索引のうち、少なくとも最下位階層のノードの情報に基づいて生成される索引に重みを付加し、一定レベルより高い重みの索引を利用した検索を行うことで、ユーザが意図した重要度の高いデータを含んでいる可能性が極めて高い検索結果を短時間で取得できる。
【発明を実施するための最良の形態】
【0008】
以下、本発明の実施の形態につき図面を参照して説明する。
図1は本発明の一実施形態に係る検索処理装置を含むクライアント−サーバシステムのハードウェア構成を示すブロック図である。クライアント−サーバシステムは、主として、データベースサーバ(データベースサーバコンピュータ)10と、複数のクライアント端末とから構成される。複数のクライアント端末はクライアント端末20を含む。クライアント端末20上では、データベースサーバ10を利用するクライアントソフトウェアが動作する。クライアントソフトウェアは例えばブラウザである。クライアント端末20を含む複数のクライアント端末は、ローカルエリアネットワーク(LAN)のようなネットワーク30を介してデータベースサーバ10と接続されている。なお、図1にはクライアント端末20以外のクライアント端末は省略されている。
【0009】
データベースサーバ10は、主メモリのようなメモリ11を含む。データベースサーバ10は、ハードディスクドライブ(HDD)のような外部記憶装置40と接続されている。この外部記憶装置40は、データベースサーバ10による検索処理に用いられる検索処理プログラム41を格納する。データベースサーバ10及び外部記憶装置40は検索処理装置50を構成する。
【0010】
図2は図1に示される検索処理装置50の主として機能構成を示すブロック図である。検索処理装置50は、インタフェース51、重み付き語彙索引生成部52、データ登録処理部53、解析部54及び検索部55を含む。本実施形態において、これらの各部51乃至55は、図1のデータベースサーバ10が外部記憶装置40に格納されている検索処理プログラム41をメモリ11に読み込んで実行することにより実現されるものとする。このプログラム41は、コンピュータ読み取り可能な記憶媒体に予め格納して頒布可能である。また、このプログラム41が、ネットワーク30を介してデータベースサーバ10にダウンロードされても構わない。
【0011】
検索処理装置50はまた、メモリ11及び外部記憶装置40を含む。外部記憶装置40は、図1に示される検索処理プログラム41に加えて、文書データベース42及び語彙索引データベース43を格納する。文書データベース42は、複数の構造化文書(階層型データ)、例えばXML文書(XML文書データ)を格納する。語彙索引データベース43は、文書データベース42に登録されている全てのXML文書に含まれる語彙(N−グラム)毎に、その語彙の索引(N−グラム索引)を格納する。
【0012】
各語彙索引は、対応する語彙の位置(語彙位置)に関する情報(語彙位置情報)を持つ。この語彙位置情報は、当該位置情報に対応する語彙を含む全てのXML文書の文書データベース42内での位置(文書位置)と、当該XML文書において当該語彙が出現する全ての位置(語彙出現位置)とを表す。各語彙索引はまた、語彙位置情報に加えて、対応する語彙の重みの情報を持つ。各語彙索引で示される語彙の重みは、当該語彙のXML文書における階層位置に依存する。
【0013】
インタフェース51は、クライアント端末20を含むクライアント端末との間のデータの入出力を行うユーザインタフェースとして用いられる。インタフェース51は、重み付け条件入力インタフェース(重み付け条件入力IF)511、データ登録インタフェース(データ登録IF)512、検索条件入力インタフェース(検索条件入力IF)513及び結果出力インタフェース(結果出力IF)514を含む。
【0014】
重み付け条件入力IF511は、ユーザ、例えば管理者の操作に応じてクライアント端末(管理端末)から与えられる重み付け条件(つまりユーザ指定の重み付け条件)を入力する。この重み付け条件については後述する。データ登録IF512は、ユーザが例えばクライアント端末を操作して作成したXML文書を文書データベース42に登録する際の入出力インタフェースをなす。検索条件入力IF513は、ユーザの操作に応じてクライアント端末から与えられるXML文書検索の検索条件(つまりユーザ指定の検索条件)を入力する。結果出力IF514は、検索部55によるXML文書検索の結果を、当該検索を要求したクライアント端末に出力することにより、ユーザに提示する。
【0015】
重み付き語彙索引生成部52は、データ登録IF512によって入力されるXML文書(つまり、文書データベース42に登録されるべきXML文書)に含まれる語彙毎に、語彙索引を生成する。この語彙索引の生成は、メモリ11に格納される語彙索引テーブル110上で行われる。重み付き語彙索引生成部52は、語彙索引を生成する際に、当該語彙索引の重み付け、更に詳細に述べるならば当該語彙索により示される語彙の重み付けを行う。つまり重み付き語彙索引生成部52は、重み付き語彙索引を生成する。
【0016】
語彙の重みは、当該語彙のXML文書における階層位置に依存する。本実施形態では、語彙の重みは、最下位階層を基準に設定され、上位の階層ほど低くなるように設定される。この重み付けの条件、即ち最下位階層を基準とする階層位置と重みとの対応関係を表す条件(重み付け条件)は、例えば管理者がクライアント端末を操作することによって指定され、重み付け条件入力IF511によって入力される。
【0017】
データ登録処理部53は、重み付き語彙索引生成部52による語彙索引の生成の対象となるXML文書を文書データベース42に登録する。データ登録処理部53はまた、重み付き語彙索引生成部52によって生成された重み付き語彙索引を語彙索引データベース43に登録する。
【0018】
解析部54は、検索条件入力IF513によって入力される検索条件を解析する。この検索条件は、例えば構造化文書問い合わせで使用される検索式(XQueryの式)によって表されるものとする。ここでは、検索条件は文字列を含む。
【0019】
検索部55は、解析部54によって解析された検索条件に合致するXML文書データを文書データベース42から検索する。この検索には、語彙索引データベース43に登録されている重み付き語彙索引が用いられる。ここでは検索部55は、まず重みの高い語彙索引のみを参照して検索を実行し、検索結果を結果出力IF514に返す。
【0020】
図3は、図2に示される重み付き語彙索引生成部52の構成を示すブロック図である。この重み付き語彙索引生成部52は、DOM展開部521、ノード取り出し部522、分解部523、語彙位置/階層位置取得部524及び重み付け部525から構成される。
【0021】
DOM展開部521は、データ登録IF512によって入力されるXML文書を構文解析してドキュメントオブジェクトモデル(Document Object Model:DOM)ツリーに展開する。DOMツリーは、XML文書の木構造を表す。
【0022】
ノード取り出し部522は、DOMツリーから逐次ノードを取り出す。分解部523は、取り出されたノードにテキストノードまたは属性ノードが存在する場合に、当該テキストノードまたは属性ノードの文字列を語彙(N−グラム)に分解する。
【0023】
語彙位置/階層位置取得部524は、分解された各語彙の文書位置及び語彙出現位置に関する情報(語彙位置情報)と階層位置に関する情報(階層位置情報)とを取得する。語彙位置/階層位置取得部524は、取得された各語彙の語彙位置情報及び階層位置情報を、当該語彙に対応付けて、語彙索引として語彙索引テーブル110に格納する。
【0024】
重み付け部525は、語彙索引テーブル110に登録されている語彙索引(により示される語彙)を重み付けする。ここでは、語彙索引に含まれる階層位置情報の示す階層位置に対応付けられた重みが当該語彙索引に付けられる。階層位置と重みとの対応関係は、重み付け条件入力IF511によって入力される重み付け条件によって指定される。
【0025】
次に、本実施形態で適用される語彙索引生成を含むXML文書登録処理について、図4、図5A及び図5Bのフローチャートを参照して説明する。図4は語彙索引生成を含むXML文書登録処理の手順を示すフローチャート、図5A及び図5Bは図4のステップS9の詳細な処理手順を示すフローチャートである。
【0026】
今、ユーザがクライアント端末20を操作することにより、例えば当該クライアント端末20上で作成されたXML文書を文書データベース42に登録することが当該クライアント端末20から検索処理装置50に要求されたものとする。この場合、データ登録IF512によって、文書データベース42に登録されるべきXML文書が入力される。なお、このXML文書が、例えばネットワーク30に接続されたWebサーバ、或いはファイルサーバから検索処理装置50によって収集されたものであっても構わない。
【0027】
XML文書、つまり階層構造を持ったXML文書データは、リレーショナルデータベースの2次元表にマッピングしにくい非定型なデータを持つ場合がある。規定や規約のようなコンテンツをXML文書データとして扱う場合、スキーマが決定できず、文書毎に異なるデータ構造を持つ場合もある。このようなコンテンツを管理するのに、ネイティブなXMLデータベースが活用されている。本実施形態で適用される文書データベース42は、このネイティブなXMLデータベースに相当する。
【0028】
規定や規約のようなコンテンツは、階層が深く、構造が複雑な場合が多い。図6は、階層が深いコンテンツ(XML文書60)の一例を示す。規約や規定などのコンテンツ(XML文書)の場合、末端のノード(最下位階層のノード)の内容が、文書を検索する際のキーとなる語彙を含む重要な内容であることが多い。第6の例では、<PARAGRAF>タグの内容が、これに相当する。つまり、階層が深いXML文書では、上位のノードにXML文書自身の階層の説明を含み、下位のノード(特に末端ノード)に検索のキーとなる語彙を含む場合が多い。そこで本実施形態では、複雑な構造を持つXML文書の少なくとも末端ノードの語彙が優先的に検索されるように考慮されている。具体的には、XML文書の登録に伴う語彙登録(語彙索引生成)時に、図4のフローチャートに従って、次のような手順で末端(最下位階層)のノードの語彙に重みが付与される。
【0029】
まず、重み付き語彙索引生成部52のDOM展開部521は、データ登録IF512によって入力される登録されるべきXML文書(XML文書データ)をDOMツリーに展開する(ステップS1)。重み付き語彙索引生成部52のノード取り出し部522は、ノードの階層位置(現在の階層位置)を指し示す変数(階層位置変数)V1を、最上位階層位置を表す初期値0に設定する(ステップS2)。ノード取り出し部522はまた、登録されるべきXML文書において現在判明されている最下位階層位置を表す変数V2を初期値0に設定する。ノード取り出し部522は、変数V1(=0)の指定するノード、つまり最上位階層位置のノード(最上位ノード)をDOMツリーに展開されたXML文書(以下、DOMツリーと称する)から取り出す(ステップS3)。
【0030】
ノード取り出し部522は、取り出されたノードにテキストノードまたは属性ノードが存在するか否かを判定する(ステップS4)。もし、テキストノードまたは属性ノードが存在する場合、重み付き語彙索引生成部52の分解部523は当該テキストノードまたは属性ノードの文字列を解析(N−グラム解析)することにより、当該文字列を語彙(N−グラム)に分解する(ステップS5)。
【0031】
重み付き語彙索引生成部52の語彙位置/階層位置取得部524は、分解部523によって分解された各語彙の文書位置及び語彙出現位置を示す語彙位置情報と階層位置を示す階層位置情報とを取得する(ステップS6)。語彙位置/階層位置取得部524は、取得された語彙の語彙位置情報及び階層位置情報を、当該語彙に対応付けて語彙索引として語彙索引テーブル110に設定する(ステップS7)。
【0032】
ステップS7が実行されると、ノード取り出し部522は、変数V1で指定されるノードの子ノードが存在するか否かを判定する(ステップS8)。ノード取り出し部522は、ステップS3で取り出されたノードにテキストノードまたは属性ノードが存在しない場合にも(ステップS4)、ステップS8を実行する。
【0033】
もし、子ノードが存在するならば、以下に述べる処理Aが呼び出される(ステップS9)。処理Aにおいて、ノード取り出し部522は子ノードを取り出す(ステップS21)。ノード取り出し部522は、変数V1を1だけインクリメントする(ステップS22)。このインクリメント後の変数V1は、インクリメント前の階層位置より1つ下位の階層位置を示す。ノード取り出し部522は、変数V1と変数V2とを比較する(ステップS23)。即ちノード取り出し部522は、インクリメント後の変数V1によって示される現在の階層位置と変数V2によって示される最下位階層位置とを比較する。もし、現在の階層位置が現在の最下位階層位置よりも低いならば、即ちV1>V2であるならば(ステップS24)、ノード取り出し部522は変数V2を現在の階層位置を示すように更新する(ステップS25)。即ちノード取り出し部522は、現在の階層位置を現在判明されている最下位階層位置として設定する。
【0034】
ノード取り出し部522は、ステップS21で取り出された子ノードにテキストノードまたは属性ノードが存在するか否かを判定する(ステップS26)。もし、テキストノードまたは属性ノードが存在する場合、分解部523は当該テキストノードまたは属性ノードの文字列を解析することにより、当該文字列を語彙(N−グラム)に分解する(ステップS27)。
【0035】
語彙位置/階層位置取得部524は、分解された各語彙の語彙位置情報及び階層位置情報を取得する(ステップS28)。語彙位置/階層位置取得部524は、取得された語彙の語彙位置情報及び階層位置情報を、当該語彙に対応付けて語彙索引として語彙索引テーブル110に設定する(ステップS29)。
【0036】
さて、ステップS29が実行されると、ノード取り出し部522は、変数V1で指定されるノードの子ノードが存在するか否かを判定する(ステップS30)。ノード取り出し部522は、ステップS26でテキストノードまたは属性ノードが存在しないと判定された場合にも、ステップS30を実行する。
【0037】
もし、子ノードが存在するならば、処理Aが再び呼び出される(ステップS31)。次にノード取り出し部522は、変数V1で指定されるノードの兄弟ノードが存在するか否かを判定する(ステップS32)。このステップS32は、ステップS30で子ノードが存在しないと判定された場合にも実行される。
【0038】
もし、変数V1で指定されるノードの兄弟ノードが存在するならば、ノード取り出し部522は、当該兄弟ノードにテキストノードまたは属性ノードが存在するか否かを判定する(ステップS33)。もし、テキストノードまたは属性ノードが存在する場合、分解部523は当該テキストノードまたは属性ノードの文字列を語彙(N−グラム)に分解する(ステップS34)。
【0039】
語彙位置/階層位置取得部524は、分解された各語彙の語彙位置情報及び階層位置情報を取得する(ステップS35)。語彙位置/階層位置取得部524は、取得された語彙の語彙位置情報及び階層位置情報を、当該語彙に対応付けて語彙索引として語彙索引テーブル110に設定する(ステップS36)。
【0040】
ステップS36が実行されると、ノード取り出し部522は、変数V1で指定されるノードの子ノードが存在するか否かを判定する(ステップS37)。ノード取り出し部522は、ステップS33でテキストノードまたは属性ノードが存在しないと判定された場合にも、ステップS37を実行する。
【0041】
もし、子ノードが存在するならば、処理Aが再び呼び出され(ステップS38)、しかる後にステップS32が実行される。これに対し、子ノードが存在しないならば、ステップS38をスキップしてステップS32が実行される。このステップS32において、変数V1で指定されるノードの兄弟ノードが存在すると判定されると、上記ステップS33乃至S38が再び実行される。
【0042】
このように重み付き語彙索引生成部52は、DOMツリー(で示される登録されるべきXML文書)の階層を、再帰的な処理Aの呼び出しによって最上位階層から順に解析することにより、階層位置情報を含む語彙索引を生成する。
【0043】
やがて、DOMツリーの全ての階層の全ノードについて処理が行われると、重み付き語彙索引生成部52は処理Aの再帰的呼び出しから解放される。つまり、重み付き語彙索引生成部52の処理は、ステップS9で処理Aが呼び出された状態に戻る。このとき、登録されるべきXML文書の全ノードについての語彙索引が、語彙索引テーブル110に生成(設定)されたことになる。また、この時点の変数V2は、上記XML文書の末端ノード(最下位階層のノード)の位置を示す。
【0044】
すると、重み付き語彙索引生成部52の重み付け部525は、重み付け条件入力IF511によって入力される重み付け条件(以下、重み付け条件C1と称する)に従い、各語彙索引により示される語彙に対する重み付けを行う(ステップS10)。ここでは重み付け部525は、各語彙索引の語彙に、当該語彙索引中の階層位置情報の示す階層位置と最下位階層位置との位置関係に対応付けられた重みを付ける。この重み付けは、変数V2の示す最下位階層位置から階層位置を示す値の降順に行われる。ここでは、最下位階層位置の語彙(に対応する語彙索引)の重みが最も高く、上位の階層ほど低くなるように設定される。なお、語彙索引中の階層位置情報が当該階層位置情報の示す階層位置に対応する重みに置き換えられても構わない。
【0045】
データ登録処理部53は、語彙索引テーブル110に基づき語彙索引データベース43を更新すると共に、重み付き語彙索引生成部52による語彙索引生成に用いられたXML文書を文書データベース42に登録する(ステップS11)。
【0046】
図7は、図6に示すXML文書60に含まれる語彙に対する重み付けの結果の一部を当該XML文書60と対応付けて示す。
【0047】
なお、重み付け条件C1に代えて、例えば最下位階層位置の語彙(に対応する語彙索引)のみに対する重み付けを指定する重み付け条件C2を用いることも可能である。図8は、重み付け条件C2を用いた場合における、図6に示すXML文書60に含まれる語彙に対する重み付けの結果の一部を当該XML文書60と対応付けて示す。
【0048】
また、例えば最下位階層を含む一定の階層範囲の階層位置の語彙のみに対する重み付けを指定する重み付け条件を用いることも可能である。この重み付け条件が、階層位置に対応付けられる重みの情報を必ずしも含む必要はない。例えば、最下位階層を含む一定の階層範囲の場合に、当該一定の階層範囲内の各階層位置の語彙(に対応する語彙索引)に対する重みを、上位の階層位置の語彙ほど低くなるように、最下位階層位置を基準に所定の重み付けアルゴリズムに従って付与しても良い。また、重み付け条件は、必ずしもユーザ(管理者)によって指定される必要はなく、検索処理プログラム41によって予め定められていても構わない。
【0049】
次に、本実施形態で適用される検索処理について、図9のフローチャートを参照して説明する。
今、ユーザの操作により、クライアント端末20から検索処理装置50に対し、構造化文書問い合わせがネットワーク30を介して与えられたものとする。検索処理装置50の検索条件入力IF513は、このクライアント端末20からの構造化文書問い合わせを受け付けると、当該問い合わせを解析部54に渡す。解析部54は、この問い合わせで使用される検索式(ユーザ指定の検索式)を解析する。ここでは、文字列による検索が指定されているものとする。この場合、解析部54は検索式で指定されている文字列(指定文字列)を語彙(N−グラム)に分解する。つまり解析部54は、検索式から指定文字列を構成する全ての語彙を抽出する。解析部54は抽出された語彙を検索部55に渡して、当該検索部55を起動する。
【0050】
すると検索部55は、指定文字列を構成する各語彙に対応して語彙索引データベース43に登録されている語彙索引のうち、例えば一定レベル以上の重みが付されている語彙索引(つまり重みの高い語彙索引)を使用して、指定文字列の位置情報を取得する(ステップS41)。検索部55は、取得された位置情報に基づき文書データベース42から検索式(検索条件)に合致するXML文書を第1の検索結果として取得する(ステップS42)。この第1の検索結果は、重みの高い語彙索引のみを使用した検索処理により、短時間で取得される。しかも第1の検索結果は、ユーザが意図した重要度の高いデータを含んでいる可能性が極めて高い。検索部55は、この第1の検索結果を結果出力IF514によりクライアント端末20に返させる(ステップS43)。
【0051】
次に検索部55は、指定文字列を構成する各語彙に対応して語彙索引データベース43に登録されている語彙索引のうち、例えば一定レベル未満の重みが付されている語彙索引(つまり重みの低い語彙索引)を使用して、指定文字列の位置情報を取得する(ステップS44)。検索部55は、取得された位置情報に基づき文書データベース42から検索式(検索条件)に合致するXML文書を第2の検索結果として取得する(ステップS45)。検索部55は、この第2の検索結果を結果出力IF514によりクライアント端末20に返させる(ステップS46)。
【0052】
このように本実施形態によれば、最初に重みの高い語彙索引を使用した検索処理(第1の検索処理)を行うことで、重要度の高いデータを含む検索結果を高速で取得しながら、第1の検索処理の後に重みの低い語彙索引を使用した検索処理(第2の検索処理)を行うことで、漏れのない検索を実現している。
【0053】
なお、第1の検索処理だけが実行される構成とすることも可能である。また、第1の検索処理だけを実行する手法(手法1)を適用するか、或いは第1の検索処理と第2の検索処理とを連続して実行する手法(手法2)を適用するかを、クライアント端末20上でユーザに選択させることも可能である。この場合、ユーザは、例えば重要度の高いデータを含む検索結果を短時間で取得したいならば、手法1を選択すれば良い。また、重要度の高いデータを含む検索結果を確認している間に完全な検索結果とヒット件数を得たい場合は、手法2を選択すれば良い。
【0054】
また、適用される重みが(重み無しを含めて)3レベル以上の場合に、語彙索引を重みのレベルに応じて3つ以上の語彙索引グループに分類し、重みが最も高い語彙索引グループから順に使用して、逐次検索処理を行うようにしても良い。ここで、重み付けの階層範囲(つまり最下位階層を含む重み付けの階層範囲)が重み付け条件を用いてユーザによって指定される場合、検索の重み付け幅が適正となり、高速に結果を返す範囲を細かく設定できる。
【0055】
[変形例]
次に、上記実施形態の変形例について説明する。この変形例の特徴は、重み付き語彙索引生成部52に代えて、スキーマを利用して重み付けを行う重み付き語彙索引生成部520(図11参照)を用いることにある。したがって、必要ならば、図2において、重み付き語彙索引生成部52を重み付き語彙索引生成部520に置き換えられたい。
【0056】
この変形例では、文書データベース42に登録されるべきXML文書の階層が深くなく(例えば、ほぼフラットで)、且つスキーマ(によって定義される構造)が固定で、検索で利用する箇所がほぼ決定されている場合、ユーザがクライアント端末を操作してスキーマ上で重み付けされるべきタグを指定することで、該当するタグの語彙に対する正確な重み付けが実現される。そのため本変形例では、文書データベース42にスキーマ別のフォルダが確保される。文書データベース42内の各フォルダには、そのフォルダに対応付けられたスキーマ(スキーマ情報)が設定される。重み付き語彙索引生成部520は、このスキーマ上で、ユーザ指定のタグを重み付け箇所として設定する。文書データベース42内の各フォルダには、そのフォルダに設定されているスキーマによって定義される構造のXML文書のみが登録される。
【0057】
図10は、スキーマによる重み付け箇所の指定を説明するための図である。図10には、スキーマ(スキーマ情報)101及び当該スキーマ101で定義される構造のXML文書102の一例が対比して示されている。図10において、矢印103及び104は、スキーマ101上で設定された重み付け箇所を指し示す。また、矢印105は、矢印103で指し示される重み付け箇所に対応するXML文書102内の構造を指し示す。一方、矢印106a,106b及び106cは、矢印104で指し示される重み付け箇所に対応するXML文書102内の構造を指し示す。
【0058】
図10の例では、矢印103で指し示されるスキーマ101上の<Name>タグ、即ち<Category>タグと兄弟のタグである<Name>タグが、重み付け箇所として指定される。この場合、XML文書102内のノードのうち、矢印105で指し示される<Name>ノード(タグ)に存在するテキストノードが重み付け箇所として識別される。また、矢印103で指し示されるスキーマ101上の<Detail>タグの繰り返しに含まれる<Value>タグが、重み付け箇所として指定される。この場合、XML文書102内のノードのうち、矢印106a,106b及び106cでそれぞれ指し示される<Value>ノード(タグ)に存在するテキストノードが重み付け箇所として識別される。
【0059】
図11は重み付き語彙索引生成部520の構成を示すブロック図である。図11において、図3と同様の要素には同一参照符号を付してある。重み付き語彙索引生成部520は、DOM展開部521、ノード取り出し部522、分解部523、重み付け部525、スキーマ読み込み部526、語彙位置取得部527及び重み付け箇所抽出部528から構成される。
【0060】
スキーマ読み込み部526は、データ登録IF512によって入力されたXML文書が登録されるべき文書データベース42内のフォルダからスキーマ情報をメモリ11に読み込む。語彙位置取得部527は、分解された各語彙の語彙位置情報を取得する。重み付け箇所抽出部528は、語彙位置情報の示す語彙位置とスキーマ情報とに基づいて、重み付けが指定されている箇所の語彙を抽出(識別)する。重み付け部525は、取得された各語彙の語彙位置情報を、当該語彙に対応付けて、語彙索引として語彙索引テーブル110に格納する。その際に重み付け部525は、重み付けが指定されている箇所の語彙の語彙索引に重みを付ける。
【0061】
次に、上記実施形態の変形例で適用される語彙索引生成を含むXML文書登録処理について、図12、図13A及び図13Bのフローチャートを参照して説明する。図12は語彙索引生成を含むXML文書登録処理の手順を示すフローチャート、図13A及び図13Bは図12のステップS60の詳細な処理手順を示すフローチャートである。
【0062】
今、データ登録IF512によって、文書データベース42に登録されるべきXML文書が入力されたものとする。DOM展開部521は、入力されたXML文書(XML文書データ)をDOMツリーに展開する(ステップS51)。スキーマ読み込み部526は、入力されたXML文書が登録されるべき文書データベース42のフォルダからメモリ11に、当該XML文書の構造を示すスキーマ情報を読み込む(ステップS52)。
【0063】
ノード取り出し部522は、最上位階層位置のノード(最上位ノード)をDOMツリーから取り出す(ステップS53)。ノード取り出し部522は、取り出されたノードにテキストノードまたは属性ノードが存在するか否かを判定する(ステップS54)。もし、テキストノードまたは属性ノードが存在する場合、分解部523は当該テキストノードまたは属性ノードの文字列を解析(N−グラム解析)することにより、当該文字列を語彙(N−グラム)に分解する(ステップS55)。
【0064】
語彙位置取得部527は、分解部523によって分解された各語彙の文書位置及び語彙出現位置を示す語彙位置情報を取得する(ステップS56)。重み付け箇所抽出部528は、取得された語彙位置情報の示す語彙位置とステップS52でメモリ11に読み込まれたスキーマ情報とに基づいて、重み付けが指定されている箇所(タグ)の語彙を抽出(識別)する(ステップS57)。
【0065】
重み付け部525は、取得された各語彙の語彙位置情報を、当該語彙に対応付けて、語彙索引として語彙索引テーブル110に設定する(ステップS58)。このステップS58において、重み付け部525は、重み付けが指定されている箇所の語彙の語彙索引に重みを付ける。
【0066】
ノード取り出し部522は、取り出されたノードの子ノードが存在するか否かを判定する(ステップS59)。ノード取り出し部522は、取り出されたノードにテキストノードまたは属性ノードが存在しない場合にも(ステップS54)、ステップS59を実行する。
【0067】
もし、子ノードが存在するならば、以下に述べる処理Bが呼び出される(ステップS60)。処理Bにおいて、ノード取り出し部522は子ノードを取り出す(ステップS71)。ノード取り出し部522は、ステップS71で取り出された子ノードにテキストノードまたは属性ノードが存在するか否かを判定する(ステップS72)。もし、テキストノードまたは属性ノードが存在する場合、上記ステップS55乃至S58と同様の処理(ステップS73乃至S76)が実行される。
【0068】
次にノード取り出し部522は、ステップS71で取り出されたノードの子ノードが存在するかを判定する(ステップS77)。ノード取り出し部522は、ステップS71で取り出されたノードにテキストノードまたは属性ノードが存在しない場合にも(ステップS72)、ステップS77を実行する。
【0069】
もし、子ノードが存在するならば、処理Bが再び呼び出される(ステップS78)。次にノード取り出し部522は、最も最近に取り出されたノードの兄弟ノードが存在するかを判定する(ステップS79)。このステップS79は、ステップS77で子ノードが存在しないと判定された場合にも実行される。
【0070】
もし、兄弟ノードが存在するならば、ノード取り出し部522は、当該兄弟ノードにテキストノードまたは属性ノードが存在するかを判定する(ステップS80)。もし、テキストノードまたは属性ノードが存在する場合、上記ステップS55乃至S58と同様の処理(ステップS81乃至S84)が実行される。
【0071】
次にノード取り出し部522は、兄弟ノードの子ノードが存在するかを判定する(ステップS85)。ノード取り出し部522は、兄弟ノードにテキストノードまたは属性ノードが存在しない場合にも(ステップS80)、ステップS85を実行する。
【0072】
もし、子ノードが存在するならば、処理Bが再び呼び出され(ステップS86)、しかる後にステップS79が実行される。これに対し、子ノードが存在しないならば、ステップS86をスキップしてステップS79が実行される。このステップS79において、兄弟ノードが存在すると判定されると、上記ステップS80乃至S86が再び実行される。
【0073】
やがて、DOMツリーの全ての階層の全ノードについて処理が行われると、重み付き語彙索引生成部520は処理Bの再帰的呼び出しから解放される。つまり、重み付き語彙索引生成部520の処理は、ステップS60で処理Bが呼び出された状態に戻る。このとき、登録されるべきXML文書の全ノードについての重み付き/重み無し語彙索引が、語彙索引テーブル110に生成(設定)されたことになる。
【0074】
するとデータ登録処理部53は、語彙索引テーブル110に基づき語彙索引データベース43を更新すると共に、重み付き語彙索引生成部52による語彙索引生成に用いられたXML文書を文書データベース42の該当するフォルダに登録する(ステップS61)。
【0075】
なお、本発明は、上記実施形態またはその変形例そのままに限定されるものではなく、実施段階ではその要旨を逸脱しない範囲で構成要素を変形して具体化できる。例えば、上記実施形態またはその変形例では、重み付き語彙索引生成部52または重み付き語彙索引生成部520によって語彙索引(に登録される語彙)に重みが付けられる。しかし、語彙索引以外の索引、例えばXML文書に含まれる数値または構造(文書構造)を含むノードを特定する索引(数値索引または構造索引)を用いて検索を行う検索処理装置では、当該数値索引または構造索引(に登録される数値または構造)に重みが付けられる構成とすることも可能である。ここでは、数値索引または構造索引を生成する索引生成部に、当該数値索引または構造索引に重みを付ける機能を持たせれば良い。また、上記実施形態またはその変形例に開示されている複数の構成要素の適宜な組み合せにより種々の発明を形成できる。例えば、実施形態またはその変形例に示される全構成要素から幾つかの構成要素を削除してもよい。
【図面の簡単な説明】
【0076】
【図1】本発明の一実施形態に係る検索処理装置を含むクライアント−サーバシステムのハードウェア構成を示すブロック図。
【図2】図1に示される検索処理装置の主として機能構成を示すブロック図。
【図3】図2に示される重み付き語彙索引生成部の構成を示すブロック図。
【図4】同実施形態で適用される語彙索引生成を含むXML文書登録処理の手順を示すフローチャート。
【図5A】図4のステップS9の詳細な処理手順を示すフローチャート。
【図5B】図4のステップS9の詳細な処理手順を示すフローチャート。
【図6】階層が深いXML文書の一例を示す図。
【図7】図6に示すXML文書に含まれる語彙に対する重み付けの結果の一部を当該XML文書と対応付けて示す図。
【図8】図7と異なる重み付け条件が指定された場合における、図6に示すXML文書に含まれる語彙に対する重み付けの結果の一部を当該XML文書と対応付けて示す図。
【図9】同実施形態で適用される検索処理の手順を示すフローチャート。
【図10】同実施形態の変形例で利用されるスキーマによる重み付け箇所の指定を説明するための図。
【図11】同変形例で適用される重み付き語彙索引生成部の構成を示すブロック図。
【図12】同変形例で適用される語彙索引生成を含むXML文書登録処理の手順を示すフローチャート。
【図13A】図12のステップS60の詳細な処理手順を示すフローチャート。
【図13B】図12のステップS60の詳細な処理手順を示すフローチャート。
【符号の説明】
【0077】
10…データベースサーバ(データベースサーバコンピュータ)、20…クライアント端末、40…外部記憶装置、41…検索処理プログラム、42…文書データベース、43…語彙索引データベース、50…検索処理装置、52,520…重み付き語彙索引生成部、53…データ登録処理部、55…検索部、60,102…XML文書、101…スキーマ、110…語彙索引テーブル、521…DOM展開部、522…ノード取り出し部、523…分解部、524…語彙位置/階層位置取得部、525…重み付け部、526…スキーマ読み込み部、527…語彙位置取得部、528…重み付け箇所抽出部。
【特許請求の範囲】
【請求項1】
複数の構造化文書が登録された文書データベースから、検索条件に合致する構造化文書を索引データベースに登録されている索引を用いて検索する検索処理装置において、
前記文書データベースに登録されるべき構造化文書の各ノードの情報から前記索引データベースに登録されるべき索引を生成する索引生成手段であって、少なくとも最下位階層のノードの情報に基づいて索引を生成する際に、当該索引に重みを付ける索引生成手段と、
ユーザによって指定された検索式の示す検索条件に合致する構造化文書を、前記索引データベースに登録されている索引のうち前記最下位階層のノードの情報に基づいて生成された索引を含む一定レベルより高い重みの索引を用いて前記文書データベースから検索して検索結果を取得する検索手段と、
前記検索手段によって取得された検索結果を前記ユーザに提示する結果出力インタフェースと
を具備することを特徴とする検索処理装置。
【請求項2】
前記索引生成手段は、生成される索引に対応するノードの階層位置に基づいて当該索引に重みを付けるように構成されており、最下位階層位置を基準に、上位の階層に対応する索引ほど低い重みを付けることを特徴とする請求項1記載の検索処理装置。
【請求項3】
前記検索手段は、前記索引データベースに登録されている索引を、前記一定レベルより高い重みの索引が属する最も重みの高い索引グループを含む複数の索引グループに重みに応じて分類し、前記最も重みの高い索引グループから順に、グループ単位で索引を利用して検索を行うことにより、グループ単位で検索結果を取得し、
前記結果出力インタフェースは、前記検索手段によってグループ単位で検索結果が取得される毎に、当該検索結果を前記ユーザに提示する
ことを特徴とする請求項2記載の検索処理装置。
【請求項4】
ユーザによって指定された重み付け条件を入力する重み付け条件入力インタフェースを更に具備し、
前記索引生成手段は、前記生成された索引に対する重み付けを前記重み付け条件入力インタフェースによって入力される重み付け条件に従って行う
ことを特徴とする請求項1記載の検索処理装置。
【請求項5】
前記重み付け条件は、最下位階層位置を含む一定の階層範囲のノードに対応する索引に対する重み付けを指定しており、
前記索引生成手段は、前記重み付け条件によって指定される階層範囲内の階層位置のノードに対応する索引に、最下位階層位置を基準に、上位の階層に対応する索引ほど低い重みを付けることを特徴とする請求項4記載の検索処理装置。
【請求項6】
複数の構造化文書が登録された文書データベースから、検索条件に合致する構造化文書を索引データベースに登録されている索引を用いて検索する検索処理装置において、
前記文書データベースに登録されるべき構造化文書の構造を定義するスキーマ情報であって、検索時に優先的に使用されるべき索引に対応する構造を重み付け箇所として指定するスキーマ情報を記憶する記憶手段から当該スキーマ情報を読み込む手段と、
前記文書データベースに登録されるべき構造化文書の各ノードの情報から前記索引データベースに登録されるべき索引を生成する索引生成手段であって、前記読み込まれたスキーマ情報によって指定される重み付け箇所のノードの情報に基づいて索引を生成する際に、当該索引に重みを付ける索引生成手段と、
ユーザによって指定された検索式の示す検索条件に合致する構造化文書を、前記索引データベースに登録されている索引のうち一定レベルより高い重みの索引を用いて前記文書データベースから検索して検索結果を取得する検索手段と、
前記検索手段によって取得された検索結果を前記ユーザに提示する結果出力インタフェースと
を具備することを特徴とする検索処理装置。
【請求項7】
前記記憶手段は、前記文書データベース内に確保されるフォルダであり、当該フォルダには、当該フォルダに記憶されるスキーマ情報によって定義される構造の構造化文書のみが登録され、
前記読み込む手段は、前記文書データベースに登録されるべき構造化文書の構造を定義するスキーマ情報を、当該構造化文書が登録されるフォルダから読み込む
ことを特徴とする請求項6記載の検索処理装置。
【請求項8】
前記検索手段は、前記索引データベースに登録されている索引を、前記一定レベルより高い重みの索引が属する最も重みの高い索引グループを含む複数の索引グループに重みに応じて分類し、前記最も重みの高い索引グループから順に、グループ単位で索引を利用して検索を行うことにより、グループ単位で検索結果を取得し、
前記結果出力インタフェースは、前記検索手段によってグループ単位で検索結果が取得される毎に、当該検索結果を前記ユーザに提示する
ことを特徴とする請求項6記載の検索処理装置。
【請求項9】
複数の構造化文書が登録された文書データベースから、検索条件に合致する構造化文書を索引データベースに登録されている索引を用いてコンピュータが検索するのに用いられるプログラムであって、
前記コンピュータに、
前記文書データベースに登録されるべき構造化文書の各ノードの情報から前記索引データベースに登録されるべき索引を生成するステップであって、少なくとも最下位階層のノードの情報に基づいて索引を生成する際に、当該索引に重みを付けるステップと、
前記生成された索引を前記索引データベースに登録するステップと、
ユーザによって指定された検索式の示す検索条件に合致する構造化文書を、前記索引データベースに登録されている索引のうち前記最下位階層のノードの情報に基づいて生成された索引を含む一定レベルより高い重みの索引を用いて前記文書データベースから検索して検索結果を取得するステップと、
前記取得された検索結果を前記ユーザに提示するステップと
を実行させるためのプログラム。
【請求項10】
複数の構造化文書が登録された文書データベースから、検索条件に合致する構造化文書を索引データベースに登録されている索引を用いてコンピュータが検索するのに用いられるプログラムであって、
前記コンピュータに、
前記文書データベースに登録されるべき構造化文書の構造を定義するスキーマ情報であって、検索時に優先的に使用されるべき索引に対応する構造を重み付け箇所として指定するスキーマ情報を読み込むステップと、
前記文書データベースに登録されるべき構造化文書の各ノードの情報から前記索引データベースに登録されるべき索引を生成するステップであって、前記読み込まれたスキーマ情報によって指定される重み付け箇所のノードの情報に基づいて索引を生成する際に、当該索引に重みを付けるステップと、
ユーザによって指定された検索式の示す検索条件に合致する構造化文書を、前記索引データベースに登録されている索引のうち一定レベルより高い重みの索引を用いて前記文書データベースから検索して検索結果を取得するステップと、
前記取得された検索結果を前記ユーザに提示するステップと
を実行させるためのプログラム。
【請求項1】
複数の構造化文書が登録された文書データベースから、検索条件に合致する構造化文書を索引データベースに登録されている索引を用いて検索する検索処理装置において、
前記文書データベースに登録されるべき構造化文書の各ノードの情報から前記索引データベースに登録されるべき索引を生成する索引生成手段であって、少なくとも最下位階層のノードの情報に基づいて索引を生成する際に、当該索引に重みを付ける索引生成手段と、
ユーザによって指定された検索式の示す検索条件に合致する構造化文書を、前記索引データベースに登録されている索引のうち前記最下位階層のノードの情報に基づいて生成された索引を含む一定レベルより高い重みの索引を用いて前記文書データベースから検索して検索結果を取得する検索手段と、
前記検索手段によって取得された検索結果を前記ユーザに提示する結果出力インタフェースと
を具備することを特徴とする検索処理装置。
【請求項2】
前記索引生成手段は、生成される索引に対応するノードの階層位置に基づいて当該索引に重みを付けるように構成されており、最下位階層位置を基準に、上位の階層に対応する索引ほど低い重みを付けることを特徴とする請求項1記載の検索処理装置。
【請求項3】
前記検索手段は、前記索引データベースに登録されている索引を、前記一定レベルより高い重みの索引が属する最も重みの高い索引グループを含む複数の索引グループに重みに応じて分類し、前記最も重みの高い索引グループから順に、グループ単位で索引を利用して検索を行うことにより、グループ単位で検索結果を取得し、
前記結果出力インタフェースは、前記検索手段によってグループ単位で検索結果が取得される毎に、当該検索結果を前記ユーザに提示する
ことを特徴とする請求項2記載の検索処理装置。
【請求項4】
ユーザによって指定された重み付け条件を入力する重み付け条件入力インタフェースを更に具備し、
前記索引生成手段は、前記生成された索引に対する重み付けを前記重み付け条件入力インタフェースによって入力される重み付け条件に従って行う
ことを特徴とする請求項1記載の検索処理装置。
【請求項5】
前記重み付け条件は、最下位階層位置を含む一定の階層範囲のノードに対応する索引に対する重み付けを指定しており、
前記索引生成手段は、前記重み付け条件によって指定される階層範囲内の階層位置のノードに対応する索引に、最下位階層位置を基準に、上位の階層に対応する索引ほど低い重みを付けることを特徴とする請求項4記載の検索処理装置。
【請求項6】
複数の構造化文書が登録された文書データベースから、検索条件に合致する構造化文書を索引データベースに登録されている索引を用いて検索する検索処理装置において、
前記文書データベースに登録されるべき構造化文書の構造を定義するスキーマ情報であって、検索時に優先的に使用されるべき索引に対応する構造を重み付け箇所として指定するスキーマ情報を記憶する記憶手段から当該スキーマ情報を読み込む手段と、
前記文書データベースに登録されるべき構造化文書の各ノードの情報から前記索引データベースに登録されるべき索引を生成する索引生成手段であって、前記読み込まれたスキーマ情報によって指定される重み付け箇所のノードの情報に基づいて索引を生成する際に、当該索引に重みを付ける索引生成手段と、
ユーザによって指定された検索式の示す検索条件に合致する構造化文書を、前記索引データベースに登録されている索引のうち一定レベルより高い重みの索引を用いて前記文書データベースから検索して検索結果を取得する検索手段と、
前記検索手段によって取得された検索結果を前記ユーザに提示する結果出力インタフェースと
を具備することを特徴とする検索処理装置。
【請求項7】
前記記憶手段は、前記文書データベース内に確保されるフォルダであり、当該フォルダには、当該フォルダに記憶されるスキーマ情報によって定義される構造の構造化文書のみが登録され、
前記読み込む手段は、前記文書データベースに登録されるべき構造化文書の構造を定義するスキーマ情報を、当該構造化文書が登録されるフォルダから読み込む
ことを特徴とする請求項6記載の検索処理装置。
【請求項8】
前記検索手段は、前記索引データベースに登録されている索引を、前記一定レベルより高い重みの索引が属する最も重みの高い索引グループを含む複数の索引グループに重みに応じて分類し、前記最も重みの高い索引グループから順に、グループ単位で索引を利用して検索を行うことにより、グループ単位で検索結果を取得し、
前記結果出力インタフェースは、前記検索手段によってグループ単位で検索結果が取得される毎に、当該検索結果を前記ユーザに提示する
ことを特徴とする請求項6記載の検索処理装置。
【請求項9】
複数の構造化文書が登録された文書データベースから、検索条件に合致する構造化文書を索引データベースに登録されている索引を用いてコンピュータが検索するのに用いられるプログラムであって、
前記コンピュータに、
前記文書データベースに登録されるべき構造化文書の各ノードの情報から前記索引データベースに登録されるべき索引を生成するステップであって、少なくとも最下位階層のノードの情報に基づいて索引を生成する際に、当該索引に重みを付けるステップと、
前記生成された索引を前記索引データベースに登録するステップと、
ユーザによって指定された検索式の示す検索条件に合致する構造化文書を、前記索引データベースに登録されている索引のうち前記最下位階層のノードの情報に基づいて生成された索引を含む一定レベルより高い重みの索引を用いて前記文書データベースから検索して検索結果を取得するステップと、
前記取得された検索結果を前記ユーザに提示するステップと
を実行させるためのプログラム。
【請求項10】
複数の構造化文書が登録された文書データベースから、検索条件に合致する構造化文書を索引データベースに登録されている索引を用いてコンピュータが検索するのに用いられるプログラムであって、
前記コンピュータに、
前記文書データベースに登録されるべき構造化文書の構造を定義するスキーマ情報であって、検索時に優先的に使用されるべき索引に対応する構造を重み付け箇所として指定するスキーマ情報を読み込むステップと、
前記文書データベースに登録されるべき構造化文書の各ノードの情報から前記索引データベースに登録されるべき索引を生成するステップであって、前記読み込まれたスキーマ情報によって指定される重み付け箇所のノードの情報に基づいて索引を生成する際に、当該索引に重みを付けるステップと、
ユーザによって指定された検索式の示す検索条件に合致する構造化文書を、前記索引データベースに登録されている索引のうち一定レベルより高い重みの索引を用いて前記文書データベースから検索して検索結果を取得するステップと、
前記取得された検索結果を前記ユーザに提示するステップと
を実行させるためのプログラム。
【図1】


【図2】
【図3】
【図4】
【図5A】
【図5B】
【図6】

【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13A】
【図13B】
【図2】
【図3】
【図4】
【図5A】
【図5B】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13A】
【図13B】
【公開番号】特開2008−26964(P2008−26964A)
【公開日】平成20年2月7日(2008.2.7)
【国際特許分類】
【出願番号】特願2006−195774(P2006−195774)
【出願日】平成18年7月18日(2006.7.18)
【出願人】(000003078)株式会社東芝 (54,554)
【出願人】(301063496)東芝ソリューション株式会社 (1,478)
【Fターム(参考)】
【公開日】平成20年2月7日(2008.2.7)
【国際特許分類】
【出願日】平成18年7月18日(2006.7.18)
【出願人】(000003078)株式会社東芝 (54,554)
【出願人】(301063496)東芝ソリューション株式会社 (1,478)
【Fターム(参考)】
[ Back to top ]