
検索方法、検索装置、ならびに、コンピュータプログラム
【課題】複数の文書グループからの検索結果を効果的に提示するのに好適な検索方法、検索装置、ならびに、コンピュータプログラムを提供する。
【解決手段】検索装置1において、抽出部101は、複数の文書グループ300a〜300nのそれぞれが備える複数の文書データのうちから、所望の検索文字列を含む文書データを抽出する。設定部102は、抽出された文書データのそれぞれに、所定の設定規則に基づいて、出力優先度を設定する。判定部103は、複数の文書グループ300a〜300nのそれぞれが、出力優先度が設定された文書データのうち所定の出力条件を満たす文書データを備えるか否かを、順に判定する。出力部104は、判定した文書グループ300a〜300nが所定の出力条件を満たす文書データを備える場合、当該文書データのうち所定の個数を出力する。
【解決手段】検索装置1において、抽出部101は、複数の文書グループ300a〜300nのそれぞれが備える複数の文書データのうちから、所望の検索文字列を含む文書データを抽出する。設定部102は、抽出された文書データのそれぞれに、所定の設定規則に基づいて、出力優先度を設定する。判定部103は、複数の文書グループ300a〜300nのそれぞれが、出力優先度が設定された文書データのうち所定の出力条件を満たす文書データを備えるか否かを、順に判定する。出力部104は、判定した文書グループ300a〜300nが所定の出力条件を満たす文書データを備える場合、当該文書データのうち所定の個数を出力する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、複数の文書グループからの検索結果を効果的に提示するのに好適な検索方法、検索装置、ならびに、コンピュータプログラムに関する。
【背景技術】
【0002】
従来から、国語辞書や英和辞書、和英辞書、英英辞書等の各種辞書のデータベース(辞書DB)を内蔵した電子辞書装置(以下、単に「電子辞書」という)が知られている。辞書DBとは、見出し語と当該見出し語を説明解説する説明情報(文字データや画像データ、動画データ、音声データ等)が対応付けられた情報を集合させ、コンピュータを用いて検索処理することができるように体系的に構成させたものである。
【0003】
また、電子辞書には、検索の利便性を高めるために様々な機能が備えられている。とくに、複数の辞書についてのDBを内蔵した電子辞書では、複数の辞書を同時に検索することでユーザに辞書を選択する手間を省くようにするなど、使い勝手をよくするための工夫がされているものが多い。
【0004】
例えば特許文献1には、複数の辞書情報が内蔵された電子辞書において、ユーザのレベルに応じて辞書に優先度をつけ、当該優先度の順序で検索結果の一覧を表示する技術が開示されている。これによれば、ユーザは、例えば中学/高校/大学などといった自身のレベルに応じた辞書についての検索結果を優先的に得ることができ、電子辞書の使い勝手を向上させることができる。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開2006−106889号公報
【発明の概要】
【発明が解決しようとする課題】
【0006】
辞書DBを複数内蔵した装置のように、複数の文書グループを備える検索装置は、複数の文書グループを同時に検索するように利便性を高めているものが多い。しかし、複数の文書グループを検索したにもかかわらず、検索結果が全ての文書グループから満遍なく出力されずに一部の文書グループに偏って出力される等、複数の文書グループからの検索結果が効果的にユーザに提示されない場合があった。
【0007】
具体的に複数の辞書DBを内蔵した電子辞書装置を例として説明すると、日本語の検索語で検索した場合、当該日本語の検索語は英英辞書よりも国語辞書の説明情報中に含まれることが多いため、実際には英英辞書の検索を行なっていても、ユーザに提示される検索結果は国語辞書からのものがほとんどを占めることになりやすく、逆に英語の検索語で検索すると、ユーザに提示される検索結果は英英辞書からのものがほとんどを占めることが起こりやすかった。
【0008】
本発明は、以上のような課題を解決するためのものであり、複数の文書グループからの検索結果を効果的に提示するのに好適な検索方法、検索装置、ならびに、コンピュータプログラムを提供することを目的とする。
【課題を解決するための手段】
【0009】
上記目的を達成するため、本発明にかかる検索方法は、
複数の文書グループのそれぞれが備える複数の文書データのうちから、所望の検索文字列を含む文書データを抽出する抽出ステップと、
前記抽出された文書データのそれぞれに、所定の設定規則に基づいて、出力優先度を設定する設定ステップと、
前記複数の文書グループのそれぞれが、前記出力優先度が設定された文書データのうち所定の出力条件を満たす文書データを備えるか否かを、順に判定する判定ステップと、
前記判定した文書グループが前記所定の出力条件を満たす文書データを備える場合、当該文書データのうち所定の個数を出力する出力ステップと、
を備えることを特徴とする。
【発明の効果】
【0010】
本発明によれば、複数の文書グループからの検索結果を効果的に提示するのに好適な検索方法、検索装置、ならびに、コンピュータプログラムを提供することができる。
【図面の簡単な説明】
【0011】
【図1】本発明の実施形態に係る検索装置の概要構成を示す図である。
【図2】本発明の実施形態に係る検索装置の物理構成を示す図である。
【図3】(a)、(b)ともに、本発明の実施形態に係る複数の文書グループおよび文書データの構成を示す図である。
【図4】本発明の実施形態に係る検索装置の処理の流れを示すフローチャートである。
【図5】本発明の実施形態において、文書データにスコアが設定され、並べ替えられる様子を示す図である。
【図6】本発明の実施形態に係る検索装置において、出力処理の流れを示すフローチャートである。
【図7】本発明の実施形態において、複数の文書グループから巡回的に出力される様子を示す図である。
【図8】本発明に係る検索装置の構成概要について、別の例を示す図である。
【発明を実施するための形態】
【0012】
以下、本発明の実施形態について、図面を参照して説明する。なお、以下に説明する実施形態は説明のためのものであり、本発明の範囲を制限するものではない。したがって、当業者であれば下記の各構成要素を均等なものに置換した実施形態を採用することが可能であるが、これらの実施形態も本発明の範囲に含まれる。また、以下の説明では、本発明の理解を容易にするため、重要でない公知の技術的事項の説明を適宜省略する。
【0013】
本実施形態では、検索装置が実現される情報処理装置として、電子辞書等の機能を備える小型の情報処理装置を想定して説明する。すなわち、本実施形態に係る検索装置は、電子辞書を構成する複数の文書データのうちから、所望の検索語を含む文書データを検索する装置である。
【0014】
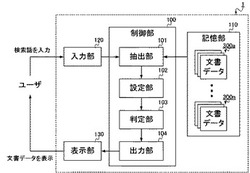
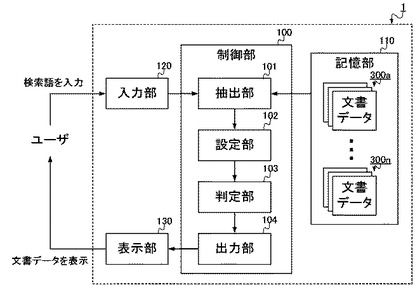
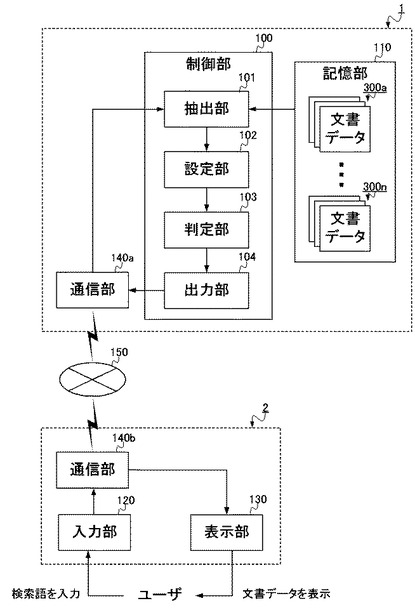
このような検索装置1は、図1に示されるような構成をとり、制御部100と、記憶部110と、入力部120と、表示部130と、を備える。一方、当該検索装置1は、物理的には図2に示されるように構成され、CPU(Central Processing Unit)151と、ROM(Read Only Memory)152と、RAM(Random Access Memory)153と、キーボード154と、モニタ155と、を備える。以下、図1および図2を参照して、検索装置1の構成要素の説明をする。
【0015】
制御部100は、検索装置1全体の動作を制御し、各構成要素と接続され、制御信号やデータをやりとりする。すなわち、制御部100は、記憶部110、入力部120、表示部130と接続され、これら各部の機能を活用しながら、検索処理を実行する。
【0016】
ここで制御部100は、抽出部101と、設定部102と、判定部103と、出力部104と、を備える。これらの各部は、詳細には後述するように、記憶部110に記憶されている複数の文書グループ300a〜300nのうちから、所望の検索語を含む文書データを特定し、所定の出力優先度を対応付けて出力する処理を実行する。
【0017】
このような制御部100(抽出部101、設定部102、判定部103、出力部104)は、例えばCPU151によって構成される。ここでCPU151は、命令やデータを転送するための伝送経路であるシステムバスにより各構成要素と相互に接続され、ROM152に記録されている検索装置1全体の動作制御に必要なコンピュータプログラムや各種データに従って動作する。そしてCPU151は、ROM152から読み出したコンピュータプログラムやデータ、その他処理の進行に必要なデータを、RAM153に一時的に記憶しながら、各種動作を制御する。このようにCPU151がROM152やRAM153と協働することで、制御部100は、検索装置1全体の動作を制御する。
【0018】
記憶部110は、例えば検索装置1内に備えられたROM152のような読出し専用の記憶媒体によって構成され、制御部100が検索処理に必要な各種データを記憶する。具体的にここでは、検索対象とされる複数の文書グループ300a〜300nがあらかじめ記憶される。
【0019】
ここで、記憶部110にあらかじめ記憶される文書グループ300a〜300nは、それぞれ異なる種類の辞書に相当する。具体的には図3(a)に示されるように、文書グループ300aは国語辞典、文書グループ300bは英和辞典、そして文書グループ300nは百科事典といったように、それぞれ互いに独立した辞書である。すなわち、検索装置1は、このような複数種類の辞書を備えており、当該複数種類の辞書を検索対象として検索を行う。
【0020】
また、これら文書グループ300a〜300nは、それぞれ辞書の構成単位として、文書データ301を複数備える。具体的には図3(b)に示されるように、例えば国語辞典に相当する文書グループ300aは、複数の文書データ301a〜301c等によって構成され、さらに、当該文書データ301a〜301c等はそれぞれ、「見出し語」と「説明文」とから構成される。ここで「見出し語」とは、当該辞書の見出しとなる1つの語句であり、1つの文書データ301に対して1つの見出し語が対応付けられる。そして、「見出し語」には当該見出し語を説明する「説明文」が対応付けられ、これらを合わせて1つの文書データ301を構成する。文書グループ300a〜300nはそれぞれ、このような文書データ301が「見出し語」の数だけ存在し、全体で1つの文書グループ300を構成する。
【0021】
図1および図2に戻って、入力部120は、例えばキーボード154のような入力装置によって構成され、ユーザからの入力を受け付ける。具体的にここでは、ユーザからの検索語を受け付ける。受け付けられた検索語は、制御部100の抽出部101へと供給され、当該検索語を含む文書データ301を抽出する処理に用いられる。
【0022】
表示部130は、例えばモニタ155のような表示装置によって構成され、制御部100が処理を行った結果をユーザへ提示する。具体的にここでは、ユーザが入力した検索語を含む文書データ301を、後述する所定の出力優先度に基づいてモニタ155に表示することで、当該ユーザへと提示する。これにより、ユーザは、自身が入力した検索語を含む文書データ301を出力結果として取得し、種々に利用することができるようになる。
【0023】
なお、入力部120と表示部130は、タッチパネル等のような入力装置と表示装置が組み合わされた装置によって構成されてもよい。この場合には、タッチパネルに内蔵されたタッチセンサ等からなる位置入力装置が入力部120を、液晶ディスプレイ等からなる表示装置が表示部130を、それぞれ構成する。
【0024】
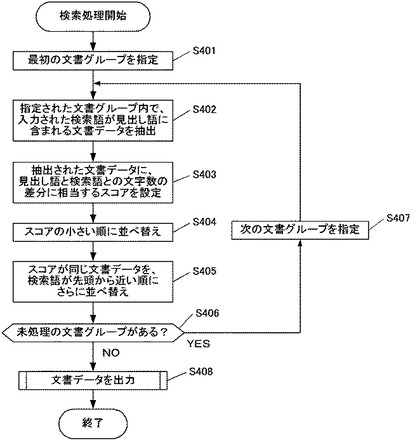
以上のように構成される検索装置1は、制御部100の制御のもと、検索処理を行う。具体的には、図4のフローチャートに示される手順で処理を実行する。
【0025】
本処理は、ユーザから入力された検索語を、検索装置1の入力部120が受け付けることを契機として、開始される。すなわち、キーボード154を用いて、ユーザが所望の検索語を入力し、検索する旨を指示することで、本処理が開始する。
【0026】
処理が開始されると、まず検索装置1の抽出部101が、最初の文書グループ300を指定する(ステップS401)。ここで、最初の文書グループ300とは、検索装置1が記憶部110に備える複数の文書グループ300a〜300nのうち、あらかじめ定められた順序で並べられた最初の文書グループ300をいう。すなわち、複数の文書グループ300a〜300nは、あらかじめ所定の順序が定められて記憶部110に記憶されており、当該所定の順序に基づいて、ここから述べる抽出処理や出力処理等が行われる。以下では便宜上、文書グループ300a、文書グループ300b、・・・文書グループ300nという順序があらかじめ定められているとして、説明する。
【0027】
最初の文書グループ300aが指定されると、抽出部101が、当該指定された文書グループ300a内で、入力された検索語が見出し語に含まれる文書データ301を抽出する(ステップS402)。すなわち、抽出部101は、入力された検索語の文字列(検索文字列)と、文書グループ300aが備える複数の文書データ301a〜301c等の見出し語の文字列とを比較し、検索文字列に一致する文字列が見出し語に含まれる文書データ301を抽出する。
【0028】
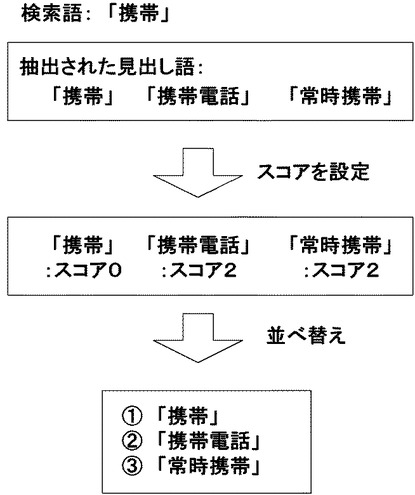
例えば、ユーザが「携帯」という検索語を入力した場合、見出し語が「携帯」という語句そのものである文書データ301や、あるいは「携帯電話」や「常時携帯」というように検索文字列を含む文書データ301が抽出される。このように見出し語に入力された検索語が含まれる文書データ301が、例えば1000個の文書データ301を備える文書グループ300a内に10個あった場合、当該10個の文書データ301が抽出される。
【0029】
なお、このとき行われる検索の詳細な方法は、公知の検索技術のいずれに基づくものであってもよい。すなわち、抽出部101は、例えば複数の文書データ301a〜301c等の見出し語の文字列を順次走査して検索文字列を探し出す逐次型の検索(grep型の検索)を行ってもよいし、あるいは検索処理の高速化のためあらかじめ索引ファイルを用意しておく索引型(インデックス型)の検索を行ってもよい。
【0030】
このようにして検索語が見出し語に含まれる文書データ301を抽出すると、次に設定部102が、抽出された文書データ301に、見出し語と検索語との文字数の差分に相当するスコアを設定する(ステップS403)。ここで「スコア」とは、後述する出力処理における出力優先度を示す指標であり、1つの文書データ301に対して1つの値が設定される。すなわち、ここで設定されるスコアに基づいた優先度で、後に文書データ301が出力される処理が行われる。
【0031】
このとき設定部102は、見出し語と検索語との文字数の差分を取得し、スコアの値として設定する。すなわち、見出し語と検索語との文字数の差分が大きいと、スコアは大きな値となり、差分が小さいと、スコアは小さな値となる。見出し語と検索語との文字数の差分が小さいということは、見出し語と検索語との一致の度合いが大きいということであり、ユーザの意図する文書データ301である可能性が高いことが想定される。そのため、差分(スコア)が小さい文書データ301ほど優先して出力されるよう、出力優先度は高いものとなる。
【0032】
具体的に図5に示される例を参照して説明すると、ユーザが「携帯」という検索語を入力した場合に抽出された「携帯」「携帯電話」「常時携帯」という見出し語の文書データ301のそれぞれに対して、見出し語が「携帯」という語句そのものである文書データ301には、文字数の差分がない(0文字)ため、スコアが「0」と設定される。一方、見出し語が「携帯電話」や「常時携帯」というような文書データ301には、文字数の差分が2文字であるため、スコアが「2」と設定される。
【0033】
図4のフローチャートに戻って、このようにスコアが設定されると、さらに検索装置1の制御部100が、抽出された文書データ301を、スコアの小さい順に並べ替える(ステップS404)。すなわち、出力優先度が高い順に、文書データ301を並べ替える。例えば、スコアが「0」である「携帯」という見出し語の文書データ301は、スコアが「2」である「携帯電話」や「常時携帯」という見出し語の文書データ301よりも先の位置に並べられる。
【0034】
このとき制御部100は、スコアが同じ文書データ301を、検索語が先頭から近い順にさらに並べ替える(ステップS405)。すなわち、スコア順に並べ替えられた文書データ301に対して、さらに等しいスコアを有する文書データ301の間でも並べ替えを行う。このときの並べ替えの基準として、制御部100は、見出し語内の検索語の位置に着目し、先頭により近いものを優先する。検索語が先頭により近いものの方が、ユーザが意図する文書データ301である可能性が高いと想定されるからである。
【0035】
具体的に図5に示される例を参照して説明すると、スコアが同じ「2」である「携帯電話」と「常時携帯」という見出し語を有する2つの文書データ301については、「携帯電話」という見出し語の方が、「常時携帯」という見出し語よりも、検索語「携帯」の文字列が先の位置に含まれているため、先の位置に並べられる。その結果、ユーザが「携帯」という検索語を入力した場合に抽出された「携帯」「携帯電話」「常時携帯」という見出し語を有する3つの文書データ301については、スコアが「0」で最も小さい「携帯」という見出し語の文書データ301が1番目に、スコアが「2」の「携帯電話」という見出し語の文書データ301が2番目に、スコアが同じく「2」であるが検索語が先頭にない「常時携帯」という見出し語の文書データ301が3番目に並べられることになる。
【0036】
なお、スコアも検索語の位置も同じ場合は、文書グループ300内での見出し語の50音順やアルファベット順等、その他の要素に基づいて、並べ替えられる。
【0037】
図4のフローチャートに戻って、このように指定された文書グループ300aから抽出された文書データ301のそれぞれが、スコアが設定されて並べ替えられると、当該文書データ301をRAM153に一時的に保持しつつ、次に検索装置1の制御部100は、未処理の文書グループ300があるか否かを判定する(ステップS406)。
【0038】
未処理の文書グループ300がある場合(ステップS406;YES)、次の文書グループ300が指定され(ステップS407)、処理はステップS402へと戻る。すなわち、文書グループ300aの処理の後であれば、次の文書グループ300bが指定され、当該指定された文書グループ300bに対して、上記ステップS402〜S405での文書データ301の抽出、スコアの設定、並べ替えの各処理が行われる。これらの処理がすべての文書グループ300a〜300nのそれぞれについて行われ、入力された検索語を含む文書データ301が、スコアの小さい順に並べられることになる。
【0039】
その後、未処理の文書グループ300がなくなると(ステップS406;NO)、設定されたスコア、すなわち出力優先度に基づいて、文書データ301を出力する処理(ステップS408)へ移行する。この出力処理については、フローチャートを図6に改めて、詳細に説明する。
【0040】
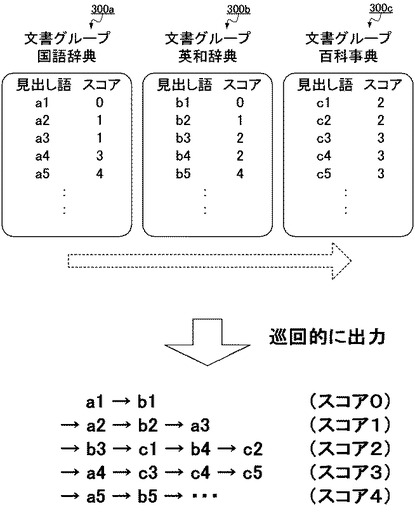
出力処理が開始されると、検索装置1の判定部103が、文書データ301を出力する判定基準となる出力スコアSを「0」に初期化し、そして、最初の文書グループ300を指定する(ステップS601)。ここで、最初の文書グループ300とは、上述した所定の順序で記憶された最初の文書グループ300をいう。具体的には図7の例のように、国語辞典の文書グループ300a、英和辞典の文書グループ300b、百科事典の文書グループ300c、という3つの文書グループ300a〜300cがこの順序で記憶されている場合には、当該ステップS601では、国語辞典の文書グループ300aが指定されることになる。
【0041】
なお、図7の例では、各文書グループ300a〜300cは、上述したステップS402〜S405までの処理を経た状態にあるものとする。すなわち、各文書グループ300a〜300cが備える文書データ301のうち、入力された検索語を含む文書データ301が抽出され、それらにスコアが設定され、さらにスコアが小さい順に並べ替えられている状態にある。ここからの出力処理の説明では、図6のフローチャートと図7の具体例との双方を参照しながら説明する。
【0042】
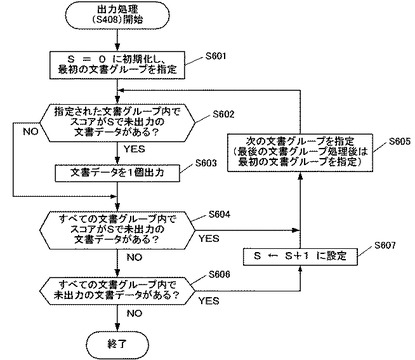
最初の文書グループ300aが指定されると、判定部103は、指定された文書グループ300a内でスコアがSで未出力の文書データ301があるか否かを判定し(ステップS602)、ある場合に(ステップS602;YES)、出力部104が、該当する文書データ301を1個出力する(ステップS603)。ここでは出力スコアSの値は「0」に初期化されているので、文書グループ300a内にスコアが「0」の文書データ301があるか否かが判定され、ある場合にそのうちの1個が出力される。ここで、スコアが「0」(出力優先度が最大)の文書データ301を全て出力せず、1個のみ出力するとした理由は、1度に多くの文書データ301を出力すると、複数の文書グループ300a〜300cからなるべく偏りのない順序で文書データ301を出力することができなくなるからである。そのため検索装置1は、1度に出力する個数としてあらかじめ所定の個数(ここでは1個)を定めて記憶部110等に記憶しておき、出力部104が、指定された文書グループ300ごとに所定の個数ずつ文書データ301を出力するようにする。
【0043】
具体的に図7では、文書グループ300a内には、スコアが「0」に設定された文書データ301として、「a1」という見出し語の文書データ301が1個存在する。そのため、ここで出力部104は、当該「a1」の文書データ301を、検索装置1の表示部130によりモニタ155に表示する等により、ユーザへと出力する。
【0044】
図6のフローチャートに戻って、次に判定部103が、すべての文書グループ300a〜300c内でスコアがSで未出力の文書データ301があるか否かを判定する(ステップS604)。すなわち、出力された「a1」と同じスコアが「0」の文書データ301が、他の文書グループ300内も含めてまだあるか否かが判定される。
【0045】
ある場合には(ステップS604;YES)、次の文書グループ300bが指定され(ステップS605)、処理はステップS602へと戻る。そして、判定部103が、当該指定された文書グループ300b内に、該当する文書データ301があるか否かを判定し、あった場合には、ステップS603にて出力部104が、該当する文書データ301を1個出力する。
【0046】
具体的に図7では、出力された「a1」の文書データ301とスコアが同じく「0」である「b1」という文書データ301が、指定された英和辞典の文書グループ300b内に存在するため、出力部104は、「a1」に引き続いて「b1」の文書データ301を出力することになる。
【0047】
「b1」の文書データ301を出力すると、もはやすべての文書グループ300a〜300c内に、スコアが「0」で未出力の文書データ301はなくなる。そのため、図6のフローチャートでは、スコアが「0」で未出力の文書データ301はないと判定され(ステップS604;NO)、次に、出力スコアの値を「1」に増やして、すなわち未出力の文書データ301のうちで出力優先度が最大の文書データ301に着目して、処理を行う。
【0048】
そのためにまず、判定部103が、すべての文書グループ300a〜300c内で未出力の文書データ301があるか否かを判定する(ステップS606)。ここでは、まだスコアが「0」の文書データ301しか出力されておらず、スコアが「1」以上の文書データ301が未出力であるため、あると判定される(ステップS606;YES)。このとき、出力スコアSの値をS+1にインクリメント、すなわち「0」であったものを「1」に設定し(ステップS607)、さらに次の文書グループ300cを指定した上で(ステップS605)、再びステップS602の処理を行う。
【0049】
ここで、図7に示されるように、指定された百科事典の文書グループ300cが有する文書データ301は、スコアが「2」以上のものばかりである。そのため、図6のステップS602にて判定部103は、指定された文書グループ300c内にスコアが「1」に設定された文書データ301がないと判定し(ステップS602;NO)、ここではステップS603を通らず、いずれの文書データ301も出力されない。そして、そのまま処理は再びステップS604、S605へと移行して、次の文書グループ300aが指定されて、ステップS602へと戻ることになる。
【0050】
ここで、それまで指定されていた文書グループ300cは、所定の順序で記憶された最後であるため、ステップS605では、次に指定されるものとして、所定の順序の最初にまで巡回的に戻り、国語辞典の文書グループ300aが指定されることになる。そして、当該最初の文書グループ300aである国語辞典内において、再びスコアが「1」に設定された未出力の文書データ301があるか否かが判定される(ステップS602)。具体的に、当該最初の文書グループ300aには、スコアが「1」に設定された未出力の文書データ301が「a2」と「a3」の2つ存在する。そのため、ここではあると判定され、ステップS603の文書データ301の出力処理が実行される。
【0051】
このとき出力部104は、当該2つの文書データ301(「a2」と「a3」)のうち、所定の個数、すなわちここでは1個の文書データ301を出力する。すなわち、出力部104は当該2個の文書データ301を同時には出力せず、より先頭に並べられた「a2」の文書データ301を1個出力するのみ行い、次の英和辞典の文書グループ300bの処理へと移行する。これにより、複数の文書グループ300a〜300cのそれぞれから1個ずつの文書データ301を出力していくことで、複数の文書グループ300a〜300cのうちからなるべく満遍のない出力を実現する。
【0052】
以上のような処理を繰り返し、検索装置1の出力部104は、文書グループ300a〜300cを巡回的に指定しながら、スコアの小さい文書データ301から順に、1個ずつ出力していく。その結果、図7のような3個の文書グループ300a〜300cからは、「a1」、「b1」、「a2」、「b2」、「a3」、「b3」、「c1」、「b4」、「c2」、「a4」、「c3」、「c4」、「c5」、「a5」、「b5」・・・という順に、文書データ301が出力されることになる。
【0053】
以上のような構成により、本実施形態の検索装置1は、複数の文書グループ300a〜300nのうちから所望の検索語を含む文書データ301の検索において、文書データ301に検索語と見出し語との文字数の差分に基づく出力優先度を設定し、当該出力優先度の高い順に、複数の文書グループ300a〜300nを巡回させながら文書データ301を1個ずつ出力する。
【0054】
その結果、検索語を含む文書データ301が、複数の文書グループ300a〜300nから満遍なく出力されることになり、ユーザは、明示的にいずれかの文書グループ300を指定して検索せずとも、意図に沿う可能性の高い文書データ301を、複数の文書グループ300a〜300nのそれぞれから確認し、また複数の文書グループ300a〜300n間で比較等しながら、見つけ出すことができる。
【0055】
なお、上記実施形態は一例であり、本発明の適用範囲はこれに限られない。すなわち、種々の応用が可能であり、あらゆる実施の形態が本発明の範囲に含まれる。
【0056】
例えば、上記実施形態では、検索装置1は、ROM152のような記憶部110内に文書グループ300a〜300nを記憶した。しかしこれに限られず、検索装置1は、ハードディスク等の大容量記憶装置やDVD−ROMドライブを備え、文書グループ300a〜300nがハードディスクやDVD−ROM等に記憶されるようにしてもよい。あるいは、検索装置1は、ネットワークに接続され、文書グループ300a〜300nがネットワーク上に存在するようにしてもよい。
【0057】
また、上記実施形態では、検索装置1は、ユーザが検索語を入力する入力部120や検索結果を表示する表示部130は、制御部100や記憶部110と同一の装置内に存在した。しかしこれに限られず、入力部120と表示部130は、検索装置1の外部にあってもよい。すなわち、例えば図8に示すように、検索装置1は入力部120と表示部130を備えず、これらを備える端末装置2とネットワーク150を介して接続されるようにし、オンライン型の電子辞書のような情報機器として構成するようにしてもよい。
【0058】
このとき、検索装置1と端末装置2は、それぞれが備える通信部140a,140bにより、ネットワーク150を介して互いにデータを通信しあう。すなわち、端末装置2のユーザが入力した検索語は、検索装置1へと送信され、制御部100により検索処理が実行される。その後、検索結果としての文書データの情報が、それぞれに設定された出力の順序を対応付けられた上で、再び端末装置2へと送信され、表示部130を介してユーザへと表示される。このような構成をとることで、検索装置1内の文書グループ300a〜300n等を一括して管理して複数のユーザに利用できるようになり、またユーザ側の端末装置2は、文書グループ300a〜300n等を保持する必要がないため、データサイズを抑えることができるといった利点がある。
【0059】
また、上記実施形態では、検索装置1として電子辞書のような小型の情報処理装置を想定して説明した。しかしこれに限られず、検索装置1は、ビジネス用・家庭用の一般的なコンピュータ装置や、携帯電話等の他の情報機器であってもよい。すなわち、検索装置1は、例えば一般的なコンピュータ装置において、ハードディスク等の大容量記憶装置やDVD−ROM等に用意された文書グループ300a〜300nのうちから所望の検索語を含む文書データ301を検索するものであってもよいし、携帯電話において、ネットワーク150上に用意された文書グループ300a〜300nのうちから所望の検索語を含む文書データ301を検索するものであってもよい。
【0060】
また、上記実施形態では、検索装置1は、検索語を「見出し語」の中に含む文書データ301を抽出(いわゆる「見出し語検索」)し、設定された出力優先度に基づく所定の規則に従って、当該抽出された文書データ301を出力した。しかしこれに限られず、文書データ301中の「説明文」に、検索語を含むものも抽出(いわゆる「全文検索」)するようにしてもよい。すなわち、検索対象を「見出し語」と「説明文」との両方に広げ、いずれか一方にでも検索語が含まれる文書データ301を、ユーザへ出力するようにしてもよい。
【0061】
この場合、「全文検索」により抽出された文書データ301については、「見出し語検索」により抽出された文書データ301に比べて、出力優先度を低く(スコアを大きく)設定するようにしてもよい。これによって、ユーザが「見出し語検索」と「全文検索」とを明示的に指定して検索せずとも、ユーザの検索意図に沿う文書データ301である可能性が高い「見出し語検索」により抽出された文書データ301が優先して出力され、その後で、「説明文」に検索語を含む文書データ301が出力されることになり、ユーザは、意図にあった検索結果をより簡便に得ることができるようになる。
【0062】
この場合さらに、あらかじめ出力される文書データ301の個数に最大値を決めておき、「見出し語」に検索語を含む文書データ301が当該最大値に満たない場合に、残りの数だけ「説明文」に検索語を含む文書データ301を抽出するようにしてもよい。一般的に、「説明文」も検索対象に含めると検索対象が大きく広がることになるため、ここでは出力個数に満たない場合にだけ検索対象を「説明文」にも広げるようにすることで、処理全体の負荷の抑制へとつなげることができる。
【0063】
また、上記実施形態では、単一の検索語がユーザから受け付けられた場合を想定して、説明した。しかしこれに限られず、検索装置1は、複数の検索語を受け付け、それらの論理積や論理和等の各種演算処理を施したものについての検索を行い、所定の規則で設定された出力優先度に基づいて、ユーザへと出力するものであってもよい。この場合、検索結果として抽出された文書データ301に設定される出力優先度は、そこに含まれる複数の検索語の出現位置や出現頻度、あるいは複数の検索語間の出現位置の間隔といった、種々の出現態様によって設定されうる。
【0064】
また、上記実施形態では、文書グループ300a〜300nが備える複数の文書データ301a〜301c等は、「見出し語」と「説明文」とから構成された。しかしこれらに限られず、様々な要素から構成されてもよい。例えば、「見出し語」を説明するための図や表を有するものであってもよい。あるいは、このような「見出し語」と「説明文」とから構成される辞書の構成単位に限られず、検索装置1は、種々の電子データを検索するものであってもよい。例えば、一般的なコンピュータ装置において、ハードディスク等の大容量記憶装置に記憶された電子ファイルのうちから、所望の検索文字列を含む電子ファイルを検索するものであってもよい。あるいは、ネットワークと接続され、ネットワーク上に存在するウェブページを検索するものであってもよい。
【0065】
また、上記実施形態では、文書グループ300a〜300nは、あらかじめ所定の順序が定められ、当該所定の順序に基づいて、検索装置1の処理が行われた。ここで、所定の順序は、あらかじめ定められた1つの順序から設定変更が不可能なものとは限らず、種々に設定されるものであってもよい。例えば、文書グループ300ごとに使用頻度を記憶しておき、当該使用頻度の高い順に所定の順序を定めるものであってもよい。あるいは、ユーザが自身で順序を決められるようにしてもよい。これによって、ユーザの意図にあう可能性の高い文書グループ300の検索結果から順に出力されるようになり、検索装置1の使い勝手の向上につながる。
【0066】
あるいは、記憶部110に記憶されたすべての文書グループ300a〜300nを検索対象とすることに限られず、ユーザが自身で検索対象の文書グループ300を選択できるようにし、当該選択された文書グループ300のうちから、所定の順序に基づいて、検索処理が行われるようにしてもよい。これにより、よりユーザの意図にあう検索結果の出力が行われやすくなる。
【0067】
また、上記実施形態では、複数の文書グループ300a〜300nが備える文書データ301のうち出力優先度の高いものを1個ずつ、巡回的に出力した。しかし1個ずつ出力することに限られず、2個ずつでも3個ずつでも、あるいはその他の個数ずつ巡回的に出力するようにしてもよい。すなわち、出力部104が1度当たりに出力する文書データ301の個数として定められた所定の個数は、1個に限られず、いくつの個数であってもよい。一般的に、所定の個数を1個や2個のように比較的少ない個数とすると、全ての文書グループ300から満遍のない文書データ301の出力が可能となる。逆に、所定の個数を増大させると、各文書グループ300からの文書データ301の出力はある程度まとまった個数ずつになる。あるいは、このような1度当たりに出力する文書データ301の個数を、ユーザが自身で指定できるようにしてもよい。これにより、複数の文書グループ300a〜300nから満遍なく出力する度合いを、柔軟に設計することができる。
【0068】
なお、本発明に係る機能を実現するための構成を予め備えた検索装置として提供できることはもとより、プログラムの適用により、既存のパーソナルコンピュータや情報端末機器等を、本発明に係る検索装置として機能させることもできる。すなわち、上記実施形態で例示した検索装置1による各機能構成を実現させるための検索プログラムを、既存のパーソナルコンピュータや情報端末機器等を制御するCPU等が実行できるように適用することで、本発明に係る検索装置1として機能させることができる。また、本発明に係る検索方法は、検索装置1を用いて実施できる。
【0069】
また、このようなプログラムの適用方法は任意であり、例えば、CD−ROMやDVD−ROM、メモリカードなどのコンピュータ読み取り可能な記憶媒体に格納して適用できる他、例えば、インターネットなどの通信媒体を介して適用することもできる。
【0070】
以上、本発明の好ましい実施形態について説明したが、本発明は係る特定の実施形態に限定されるものではなく、本発明には、特許請求の範囲に記載された発明とその均等の範囲が含まれる。以下に、本願出願の当初の特許請求の範囲に記載された発明を付記する。
【0071】
(付記1)
複数の文書グループのそれぞれが備える複数の文書データのうちから、所望の検索文字列を含む文書データを抽出する抽出ステップと、
前記抽出された文書データのそれぞれに、所定の設定規則に基づいて、出力優先度を設定する設定ステップと、
前記複数の文書グループのそれぞれが、前記出力優先度が設定された文書データのうち所定の出力条件を満たす文書データを備えるか否かを、順に判定する判定ステップと、
前記判定した文書グループが前記所定の出力条件を満たす文書データを備える場合、当該文書データのうち所定の個数を出力する出力ステップと、
を備えることを特徴とする検索方法。
【0072】
(付記2)
前記所定の出力条件を満たす文書データとは、前記出力ステップにおいて未だ出力されていない文書データのうち、前記設定された出力優先度が最大である文書データである、
ことを特徴とする付記1に記載の検索方法。
【0073】
(付記3)
前記複数の文書グループは所定の順序で並べられ、
前記判定ステップでは、前記複数の文書グループのそれぞれが、前記出力優先度が設定された文書データのうち所定の出力条件を満たす文書データを備えるか否かを、前記所定の順序で巡回的に判定する、
ことを特徴とする付記1または2に記載の検索方法。
【0074】
(付記4)
前記複数の文書グループのそれぞれが備える複数の文書データのぞれぞれは、見出し語と対応する説明文とから構成され、
前記設定ステップでは、前記抽出された文書データのうち、見出し語に前記検索文字列を含む文書データの出力優先度を、当該見出し語と当該検索文字列との文字数の差分に基づいて設定する、
ことを特徴とする付記1から3のいずれか1つに記載の検索方法。
【0075】
(付記5)
前記設定ステップでは、見出し語と前記検索文字列との文字数の差分が等しい文書データを、当該見出し語の先頭文字と前記検索文字列との間の文字数が小さい順に、さらに出力優先度を設定する、
ことを特徴とする付記4に記載の検索方法。
【0076】
(付記6)
前記設定ステップでは、前記抽出された文書データのうち、見出し語に前記検索文字列を含まない文書データの出力優先度を、見出し語に前記検索文字列を含む文書データの出力優先度よりも、低く設定する、
ことを特徴とする付記4または5に記載の検索方法。
【0077】
(付記7)
前記抽出ステップでは、前記複数の文書グループのそれぞれが備える複数の文書データのうちから、前記検索文字列を見出し語に含む文書データを抽出し、当該抽出された文書データの個数が所定の最大数に満たない場合に、前記検索文字列を説明文に含む文書データをさらに抽出する、
ことを特徴とする付記4から6のいずれか1つに記載の検索方法。
【0078】
(付記8)
複数の文書グループのそれぞれが備える複数の文書データのうちから、所望の検索文字列を含む文書データを抽出する抽出手段と、
前記抽出された文書データのそれぞれに、所定の設定規則に基づいて、出力優先度を設定する設定手段と、
前記複数の文書グループのそれぞれが、前記出力優先度が設定された文書データのうち所定の出力条件を満たす文書データを備えるか否かを、順に判定する判定手段と、
前記判定した文書グループが前記所定の出力条件を満たす文書データを備える場合、当該文書データのうち所定の個数を出力する出力手段と、
を備えることを特徴とする検索装置。
【0079】
(付記9)
コンピュータを、
複数の文書グループのそれぞれが備える複数の文書データのうちから、所望の検索文字列を含む文書データを抽出する抽出手段、
前記抽出された文書データのそれぞれに、所定の設定規則に基づいて、出力優先度を設定する設定手段、
前記複数の文書グループのそれぞれが、前記出力優先度が設定された文書データのうち所定の出力条件を満たす文書データを備えるか否かを、順に判定する判定手段、
前記判定した文書グループが前記所定の出力条件を満たす文書データを備える場合、当該文書データのうち所定の個数を出力する出力手段、
として機能させることを特徴とするコンピュータプログラム。
【符号の説明】
【0080】
1…検索装置、2…端末装置、100…制御部、101…抽出部、102…設定部、103…判定部、104…出力部、110…記憶部、120…入力部、130…表示部、140a,140b…通信部、150…ネットワーク、151…CPU、152…ROM、153…RAM、154…キーボード、155…モニタ、300a,300b,300c,300n…文書グループ、301a,301b,301c…文書データ
【技術分野】
【0001】
本発明は、複数の文書グループからの検索結果を効果的に提示するのに好適な検索方法、検索装置、ならびに、コンピュータプログラムに関する。
【背景技術】
【0002】
従来から、国語辞書や英和辞書、和英辞書、英英辞書等の各種辞書のデータベース(辞書DB)を内蔵した電子辞書装置(以下、単に「電子辞書」という)が知られている。辞書DBとは、見出し語と当該見出し語を説明解説する説明情報(文字データや画像データ、動画データ、音声データ等)が対応付けられた情報を集合させ、コンピュータを用いて検索処理することができるように体系的に構成させたものである。
【0003】
また、電子辞書には、検索の利便性を高めるために様々な機能が備えられている。とくに、複数の辞書についてのDBを内蔵した電子辞書では、複数の辞書を同時に検索することでユーザに辞書を選択する手間を省くようにするなど、使い勝手をよくするための工夫がされているものが多い。
【0004】
例えば特許文献1には、複数の辞書情報が内蔵された電子辞書において、ユーザのレベルに応じて辞書に優先度をつけ、当該優先度の順序で検索結果の一覧を表示する技術が開示されている。これによれば、ユーザは、例えば中学/高校/大学などといった自身のレベルに応じた辞書についての検索結果を優先的に得ることができ、電子辞書の使い勝手を向上させることができる。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開2006−106889号公報
【発明の概要】
【発明が解決しようとする課題】
【0006】
辞書DBを複数内蔵した装置のように、複数の文書グループを備える検索装置は、複数の文書グループを同時に検索するように利便性を高めているものが多い。しかし、複数の文書グループを検索したにもかかわらず、検索結果が全ての文書グループから満遍なく出力されずに一部の文書グループに偏って出力される等、複数の文書グループからの検索結果が効果的にユーザに提示されない場合があった。
【0007】
具体的に複数の辞書DBを内蔵した電子辞書装置を例として説明すると、日本語の検索語で検索した場合、当該日本語の検索語は英英辞書よりも国語辞書の説明情報中に含まれることが多いため、実際には英英辞書の検索を行なっていても、ユーザに提示される検索結果は国語辞書からのものがほとんどを占めることになりやすく、逆に英語の検索語で検索すると、ユーザに提示される検索結果は英英辞書からのものがほとんどを占めることが起こりやすかった。
【0008】
本発明は、以上のような課題を解決するためのものであり、複数の文書グループからの検索結果を効果的に提示するのに好適な検索方法、検索装置、ならびに、コンピュータプログラムを提供することを目的とする。
【課題を解決するための手段】
【0009】
上記目的を達成するため、本発明にかかる検索方法は、
複数の文書グループのそれぞれが備える複数の文書データのうちから、所望の検索文字列を含む文書データを抽出する抽出ステップと、
前記抽出された文書データのそれぞれに、所定の設定規則に基づいて、出力優先度を設定する設定ステップと、
前記複数の文書グループのそれぞれが、前記出力優先度が設定された文書データのうち所定の出力条件を満たす文書データを備えるか否かを、順に判定する判定ステップと、
前記判定した文書グループが前記所定の出力条件を満たす文書データを備える場合、当該文書データのうち所定の個数を出力する出力ステップと、
を備えることを特徴とする。
【発明の効果】
【0010】
本発明によれば、複数の文書グループからの検索結果を効果的に提示するのに好適な検索方法、検索装置、ならびに、コンピュータプログラムを提供することができる。
【図面の簡単な説明】
【0011】
【図1】本発明の実施形態に係る検索装置の概要構成を示す図である。
【図2】本発明の実施形態に係る検索装置の物理構成を示す図である。
【図3】(a)、(b)ともに、本発明の実施形態に係る複数の文書グループおよび文書データの構成を示す図である。
【図4】本発明の実施形態に係る検索装置の処理の流れを示すフローチャートである。
【図5】本発明の実施形態において、文書データにスコアが設定され、並べ替えられる様子を示す図である。
【図6】本発明の実施形態に係る検索装置において、出力処理の流れを示すフローチャートである。
【図7】本発明の実施形態において、複数の文書グループから巡回的に出力される様子を示す図である。
【図8】本発明に係る検索装置の構成概要について、別の例を示す図である。
【発明を実施するための形態】
【0012】
以下、本発明の実施形態について、図面を参照して説明する。なお、以下に説明する実施形態は説明のためのものであり、本発明の範囲を制限するものではない。したがって、当業者であれば下記の各構成要素を均等なものに置換した実施形態を採用することが可能であるが、これらの実施形態も本発明の範囲に含まれる。また、以下の説明では、本発明の理解を容易にするため、重要でない公知の技術的事項の説明を適宜省略する。
【0013】
本実施形態では、検索装置が実現される情報処理装置として、電子辞書等の機能を備える小型の情報処理装置を想定して説明する。すなわち、本実施形態に係る検索装置は、電子辞書を構成する複数の文書データのうちから、所望の検索語を含む文書データを検索する装置である。
【0014】
このような検索装置1は、図1に示されるような構成をとり、制御部100と、記憶部110と、入力部120と、表示部130と、を備える。一方、当該検索装置1は、物理的には図2に示されるように構成され、CPU(Central Processing Unit)151と、ROM(Read Only Memory)152と、RAM(Random Access Memory)153と、キーボード154と、モニタ155と、を備える。以下、図1および図2を参照して、検索装置1の構成要素の説明をする。
【0015】
制御部100は、検索装置1全体の動作を制御し、各構成要素と接続され、制御信号やデータをやりとりする。すなわち、制御部100は、記憶部110、入力部120、表示部130と接続され、これら各部の機能を活用しながら、検索処理を実行する。
【0016】
ここで制御部100は、抽出部101と、設定部102と、判定部103と、出力部104と、を備える。これらの各部は、詳細には後述するように、記憶部110に記憶されている複数の文書グループ300a〜300nのうちから、所望の検索語を含む文書データを特定し、所定の出力優先度を対応付けて出力する処理を実行する。
【0017】
このような制御部100(抽出部101、設定部102、判定部103、出力部104)は、例えばCPU151によって構成される。ここでCPU151は、命令やデータを転送するための伝送経路であるシステムバスにより各構成要素と相互に接続され、ROM152に記録されている検索装置1全体の動作制御に必要なコンピュータプログラムや各種データに従って動作する。そしてCPU151は、ROM152から読み出したコンピュータプログラムやデータ、その他処理の進行に必要なデータを、RAM153に一時的に記憶しながら、各種動作を制御する。このようにCPU151がROM152やRAM153と協働することで、制御部100は、検索装置1全体の動作を制御する。
【0018】
記憶部110は、例えば検索装置1内に備えられたROM152のような読出し専用の記憶媒体によって構成され、制御部100が検索処理に必要な各種データを記憶する。具体的にここでは、検索対象とされる複数の文書グループ300a〜300nがあらかじめ記憶される。
【0019】
ここで、記憶部110にあらかじめ記憶される文書グループ300a〜300nは、それぞれ異なる種類の辞書に相当する。具体的には図3(a)に示されるように、文書グループ300aは国語辞典、文書グループ300bは英和辞典、そして文書グループ300nは百科事典といったように、それぞれ互いに独立した辞書である。すなわち、検索装置1は、このような複数種類の辞書を備えており、当該複数種類の辞書を検索対象として検索を行う。
【0020】
また、これら文書グループ300a〜300nは、それぞれ辞書の構成単位として、文書データ301を複数備える。具体的には図3(b)に示されるように、例えば国語辞典に相当する文書グループ300aは、複数の文書データ301a〜301c等によって構成され、さらに、当該文書データ301a〜301c等はそれぞれ、「見出し語」と「説明文」とから構成される。ここで「見出し語」とは、当該辞書の見出しとなる1つの語句であり、1つの文書データ301に対して1つの見出し語が対応付けられる。そして、「見出し語」には当該見出し語を説明する「説明文」が対応付けられ、これらを合わせて1つの文書データ301を構成する。文書グループ300a〜300nはそれぞれ、このような文書データ301が「見出し語」の数だけ存在し、全体で1つの文書グループ300を構成する。
【0021】
図1および図2に戻って、入力部120は、例えばキーボード154のような入力装置によって構成され、ユーザからの入力を受け付ける。具体的にここでは、ユーザからの検索語を受け付ける。受け付けられた検索語は、制御部100の抽出部101へと供給され、当該検索語を含む文書データ301を抽出する処理に用いられる。
【0022】
表示部130は、例えばモニタ155のような表示装置によって構成され、制御部100が処理を行った結果をユーザへ提示する。具体的にここでは、ユーザが入力した検索語を含む文書データ301を、後述する所定の出力優先度に基づいてモニタ155に表示することで、当該ユーザへと提示する。これにより、ユーザは、自身が入力した検索語を含む文書データ301を出力結果として取得し、種々に利用することができるようになる。
【0023】
なお、入力部120と表示部130は、タッチパネル等のような入力装置と表示装置が組み合わされた装置によって構成されてもよい。この場合には、タッチパネルに内蔵されたタッチセンサ等からなる位置入力装置が入力部120を、液晶ディスプレイ等からなる表示装置が表示部130を、それぞれ構成する。
【0024】
以上のように構成される検索装置1は、制御部100の制御のもと、検索処理を行う。具体的には、図4のフローチャートに示される手順で処理を実行する。
【0025】
本処理は、ユーザから入力された検索語を、検索装置1の入力部120が受け付けることを契機として、開始される。すなわち、キーボード154を用いて、ユーザが所望の検索語を入力し、検索する旨を指示することで、本処理が開始する。
【0026】
処理が開始されると、まず検索装置1の抽出部101が、最初の文書グループ300を指定する(ステップS401)。ここで、最初の文書グループ300とは、検索装置1が記憶部110に備える複数の文書グループ300a〜300nのうち、あらかじめ定められた順序で並べられた最初の文書グループ300をいう。すなわち、複数の文書グループ300a〜300nは、あらかじめ所定の順序が定められて記憶部110に記憶されており、当該所定の順序に基づいて、ここから述べる抽出処理や出力処理等が行われる。以下では便宜上、文書グループ300a、文書グループ300b、・・・文書グループ300nという順序があらかじめ定められているとして、説明する。
【0027】
最初の文書グループ300aが指定されると、抽出部101が、当該指定された文書グループ300a内で、入力された検索語が見出し語に含まれる文書データ301を抽出する(ステップS402)。すなわち、抽出部101は、入力された検索語の文字列(検索文字列)と、文書グループ300aが備える複数の文書データ301a〜301c等の見出し語の文字列とを比較し、検索文字列に一致する文字列が見出し語に含まれる文書データ301を抽出する。
【0028】
例えば、ユーザが「携帯」という検索語を入力した場合、見出し語が「携帯」という語句そのものである文書データ301や、あるいは「携帯電話」や「常時携帯」というように検索文字列を含む文書データ301が抽出される。このように見出し語に入力された検索語が含まれる文書データ301が、例えば1000個の文書データ301を備える文書グループ300a内に10個あった場合、当該10個の文書データ301が抽出される。
【0029】
なお、このとき行われる検索の詳細な方法は、公知の検索技術のいずれに基づくものであってもよい。すなわち、抽出部101は、例えば複数の文書データ301a〜301c等の見出し語の文字列を順次走査して検索文字列を探し出す逐次型の検索(grep型の検索)を行ってもよいし、あるいは検索処理の高速化のためあらかじめ索引ファイルを用意しておく索引型(インデックス型)の検索を行ってもよい。
【0030】
このようにして検索語が見出し語に含まれる文書データ301を抽出すると、次に設定部102が、抽出された文書データ301に、見出し語と検索語との文字数の差分に相当するスコアを設定する(ステップS403)。ここで「スコア」とは、後述する出力処理における出力優先度を示す指標であり、1つの文書データ301に対して1つの値が設定される。すなわち、ここで設定されるスコアに基づいた優先度で、後に文書データ301が出力される処理が行われる。
【0031】
このとき設定部102は、見出し語と検索語との文字数の差分を取得し、スコアの値として設定する。すなわち、見出し語と検索語との文字数の差分が大きいと、スコアは大きな値となり、差分が小さいと、スコアは小さな値となる。見出し語と検索語との文字数の差分が小さいということは、見出し語と検索語との一致の度合いが大きいということであり、ユーザの意図する文書データ301である可能性が高いことが想定される。そのため、差分(スコア)が小さい文書データ301ほど優先して出力されるよう、出力優先度は高いものとなる。
【0032】
具体的に図5に示される例を参照して説明すると、ユーザが「携帯」という検索語を入力した場合に抽出された「携帯」「携帯電話」「常時携帯」という見出し語の文書データ301のそれぞれに対して、見出し語が「携帯」という語句そのものである文書データ301には、文字数の差分がない(0文字)ため、スコアが「0」と設定される。一方、見出し語が「携帯電話」や「常時携帯」というような文書データ301には、文字数の差分が2文字であるため、スコアが「2」と設定される。
【0033】
図4のフローチャートに戻って、このようにスコアが設定されると、さらに検索装置1の制御部100が、抽出された文書データ301を、スコアの小さい順に並べ替える(ステップS404)。すなわち、出力優先度が高い順に、文書データ301を並べ替える。例えば、スコアが「0」である「携帯」という見出し語の文書データ301は、スコアが「2」である「携帯電話」や「常時携帯」という見出し語の文書データ301よりも先の位置に並べられる。
【0034】
このとき制御部100は、スコアが同じ文書データ301を、検索語が先頭から近い順にさらに並べ替える(ステップS405)。すなわち、スコア順に並べ替えられた文書データ301に対して、さらに等しいスコアを有する文書データ301の間でも並べ替えを行う。このときの並べ替えの基準として、制御部100は、見出し語内の検索語の位置に着目し、先頭により近いものを優先する。検索語が先頭により近いものの方が、ユーザが意図する文書データ301である可能性が高いと想定されるからである。
【0035】
具体的に図5に示される例を参照して説明すると、スコアが同じ「2」である「携帯電話」と「常時携帯」という見出し語を有する2つの文書データ301については、「携帯電話」という見出し語の方が、「常時携帯」という見出し語よりも、検索語「携帯」の文字列が先の位置に含まれているため、先の位置に並べられる。その結果、ユーザが「携帯」という検索語を入力した場合に抽出された「携帯」「携帯電話」「常時携帯」という見出し語を有する3つの文書データ301については、スコアが「0」で最も小さい「携帯」という見出し語の文書データ301が1番目に、スコアが「2」の「携帯電話」という見出し語の文書データ301が2番目に、スコアが同じく「2」であるが検索語が先頭にない「常時携帯」という見出し語の文書データ301が3番目に並べられることになる。
【0036】
なお、スコアも検索語の位置も同じ場合は、文書グループ300内での見出し語の50音順やアルファベット順等、その他の要素に基づいて、並べ替えられる。
【0037】
図4のフローチャートに戻って、このように指定された文書グループ300aから抽出された文書データ301のそれぞれが、スコアが設定されて並べ替えられると、当該文書データ301をRAM153に一時的に保持しつつ、次に検索装置1の制御部100は、未処理の文書グループ300があるか否かを判定する(ステップS406)。
【0038】
未処理の文書グループ300がある場合(ステップS406;YES)、次の文書グループ300が指定され(ステップS407)、処理はステップS402へと戻る。すなわち、文書グループ300aの処理の後であれば、次の文書グループ300bが指定され、当該指定された文書グループ300bに対して、上記ステップS402〜S405での文書データ301の抽出、スコアの設定、並べ替えの各処理が行われる。これらの処理がすべての文書グループ300a〜300nのそれぞれについて行われ、入力された検索語を含む文書データ301が、スコアの小さい順に並べられることになる。
【0039】
その後、未処理の文書グループ300がなくなると(ステップS406;NO)、設定されたスコア、すなわち出力優先度に基づいて、文書データ301を出力する処理(ステップS408)へ移行する。この出力処理については、フローチャートを図6に改めて、詳細に説明する。
【0040】
出力処理が開始されると、検索装置1の判定部103が、文書データ301を出力する判定基準となる出力スコアSを「0」に初期化し、そして、最初の文書グループ300を指定する(ステップS601)。ここで、最初の文書グループ300とは、上述した所定の順序で記憶された最初の文書グループ300をいう。具体的には図7の例のように、国語辞典の文書グループ300a、英和辞典の文書グループ300b、百科事典の文書グループ300c、という3つの文書グループ300a〜300cがこの順序で記憶されている場合には、当該ステップS601では、国語辞典の文書グループ300aが指定されることになる。
【0041】
なお、図7の例では、各文書グループ300a〜300cは、上述したステップS402〜S405までの処理を経た状態にあるものとする。すなわち、各文書グループ300a〜300cが備える文書データ301のうち、入力された検索語を含む文書データ301が抽出され、それらにスコアが設定され、さらにスコアが小さい順に並べ替えられている状態にある。ここからの出力処理の説明では、図6のフローチャートと図7の具体例との双方を参照しながら説明する。
【0042】
最初の文書グループ300aが指定されると、判定部103は、指定された文書グループ300a内でスコアがSで未出力の文書データ301があるか否かを判定し(ステップS602)、ある場合に(ステップS602;YES)、出力部104が、該当する文書データ301を1個出力する(ステップS603)。ここでは出力スコアSの値は「0」に初期化されているので、文書グループ300a内にスコアが「0」の文書データ301があるか否かが判定され、ある場合にそのうちの1個が出力される。ここで、スコアが「0」(出力優先度が最大)の文書データ301を全て出力せず、1個のみ出力するとした理由は、1度に多くの文書データ301を出力すると、複数の文書グループ300a〜300cからなるべく偏りのない順序で文書データ301を出力することができなくなるからである。そのため検索装置1は、1度に出力する個数としてあらかじめ所定の個数(ここでは1個)を定めて記憶部110等に記憶しておき、出力部104が、指定された文書グループ300ごとに所定の個数ずつ文書データ301を出力するようにする。
【0043】
具体的に図7では、文書グループ300a内には、スコアが「0」に設定された文書データ301として、「a1」という見出し語の文書データ301が1個存在する。そのため、ここで出力部104は、当該「a1」の文書データ301を、検索装置1の表示部130によりモニタ155に表示する等により、ユーザへと出力する。
【0044】
図6のフローチャートに戻って、次に判定部103が、すべての文書グループ300a〜300c内でスコアがSで未出力の文書データ301があるか否かを判定する(ステップS604)。すなわち、出力された「a1」と同じスコアが「0」の文書データ301が、他の文書グループ300内も含めてまだあるか否かが判定される。
【0045】
ある場合には(ステップS604;YES)、次の文書グループ300bが指定され(ステップS605)、処理はステップS602へと戻る。そして、判定部103が、当該指定された文書グループ300b内に、該当する文書データ301があるか否かを判定し、あった場合には、ステップS603にて出力部104が、該当する文書データ301を1個出力する。
【0046】
具体的に図7では、出力された「a1」の文書データ301とスコアが同じく「0」である「b1」という文書データ301が、指定された英和辞典の文書グループ300b内に存在するため、出力部104は、「a1」に引き続いて「b1」の文書データ301を出力することになる。
【0047】
「b1」の文書データ301を出力すると、もはやすべての文書グループ300a〜300c内に、スコアが「0」で未出力の文書データ301はなくなる。そのため、図6のフローチャートでは、スコアが「0」で未出力の文書データ301はないと判定され(ステップS604;NO)、次に、出力スコアの値を「1」に増やして、すなわち未出力の文書データ301のうちで出力優先度が最大の文書データ301に着目して、処理を行う。
【0048】
そのためにまず、判定部103が、すべての文書グループ300a〜300c内で未出力の文書データ301があるか否かを判定する(ステップS606)。ここでは、まだスコアが「0」の文書データ301しか出力されておらず、スコアが「1」以上の文書データ301が未出力であるため、あると判定される(ステップS606;YES)。このとき、出力スコアSの値をS+1にインクリメント、すなわち「0」であったものを「1」に設定し(ステップS607)、さらに次の文書グループ300cを指定した上で(ステップS605)、再びステップS602の処理を行う。
【0049】
ここで、図7に示されるように、指定された百科事典の文書グループ300cが有する文書データ301は、スコアが「2」以上のものばかりである。そのため、図6のステップS602にて判定部103は、指定された文書グループ300c内にスコアが「1」に設定された文書データ301がないと判定し(ステップS602;NO)、ここではステップS603を通らず、いずれの文書データ301も出力されない。そして、そのまま処理は再びステップS604、S605へと移行して、次の文書グループ300aが指定されて、ステップS602へと戻ることになる。
【0050】
ここで、それまで指定されていた文書グループ300cは、所定の順序で記憶された最後であるため、ステップS605では、次に指定されるものとして、所定の順序の最初にまで巡回的に戻り、国語辞典の文書グループ300aが指定されることになる。そして、当該最初の文書グループ300aである国語辞典内において、再びスコアが「1」に設定された未出力の文書データ301があるか否かが判定される(ステップS602)。具体的に、当該最初の文書グループ300aには、スコアが「1」に設定された未出力の文書データ301が「a2」と「a3」の2つ存在する。そのため、ここではあると判定され、ステップS603の文書データ301の出力処理が実行される。
【0051】
このとき出力部104は、当該2つの文書データ301(「a2」と「a3」)のうち、所定の個数、すなわちここでは1個の文書データ301を出力する。すなわち、出力部104は当該2個の文書データ301を同時には出力せず、より先頭に並べられた「a2」の文書データ301を1個出力するのみ行い、次の英和辞典の文書グループ300bの処理へと移行する。これにより、複数の文書グループ300a〜300cのそれぞれから1個ずつの文書データ301を出力していくことで、複数の文書グループ300a〜300cのうちからなるべく満遍のない出力を実現する。
【0052】
以上のような処理を繰り返し、検索装置1の出力部104は、文書グループ300a〜300cを巡回的に指定しながら、スコアの小さい文書データ301から順に、1個ずつ出力していく。その結果、図7のような3個の文書グループ300a〜300cからは、「a1」、「b1」、「a2」、「b2」、「a3」、「b3」、「c1」、「b4」、「c2」、「a4」、「c3」、「c4」、「c5」、「a5」、「b5」・・・という順に、文書データ301が出力されることになる。
【0053】
以上のような構成により、本実施形態の検索装置1は、複数の文書グループ300a〜300nのうちから所望の検索語を含む文書データ301の検索において、文書データ301に検索語と見出し語との文字数の差分に基づく出力優先度を設定し、当該出力優先度の高い順に、複数の文書グループ300a〜300nを巡回させながら文書データ301を1個ずつ出力する。
【0054】
その結果、検索語を含む文書データ301が、複数の文書グループ300a〜300nから満遍なく出力されることになり、ユーザは、明示的にいずれかの文書グループ300を指定して検索せずとも、意図に沿う可能性の高い文書データ301を、複数の文書グループ300a〜300nのそれぞれから確認し、また複数の文書グループ300a〜300n間で比較等しながら、見つけ出すことができる。
【0055】
なお、上記実施形態は一例であり、本発明の適用範囲はこれに限られない。すなわち、種々の応用が可能であり、あらゆる実施の形態が本発明の範囲に含まれる。
【0056】
例えば、上記実施形態では、検索装置1は、ROM152のような記憶部110内に文書グループ300a〜300nを記憶した。しかしこれに限られず、検索装置1は、ハードディスク等の大容量記憶装置やDVD−ROMドライブを備え、文書グループ300a〜300nがハードディスクやDVD−ROM等に記憶されるようにしてもよい。あるいは、検索装置1は、ネットワークに接続され、文書グループ300a〜300nがネットワーク上に存在するようにしてもよい。
【0057】
また、上記実施形態では、検索装置1は、ユーザが検索語を入力する入力部120や検索結果を表示する表示部130は、制御部100や記憶部110と同一の装置内に存在した。しかしこれに限られず、入力部120と表示部130は、検索装置1の外部にあってもよい。すなわち、例えば図8に示すように、検索装置1は入力部120と表示部130を備えず、これらを備える端末装置2とネットワーク150を介して接続されるようにし、オンライン型の電子辞書のような情報機器として構成するようにしてもよい。
【0058】
このとき、検索装置1と端末装置2は、それぞれが備える通信部140a,140bにより、ネットワーク150を介して互いにデータを通信しあう。すなわち、端末装置2のユーザが入力した検索語は、検索装置1へと送信され、制御部100により検索処理が実行される。その後、検索結果としての文書データの情報が、それぞれに設定された出力の順序を対応付けられた上で、再び端末装置2へと送信され、表示部130を介してユーザへと表示される。このような構成をとることで、検索装置1内の文書グループ300a〜300n等を一括して管理して複数のユーザに利用できるようになり、またユーザ側の端末装置2は、文書グループ300a〜300n等を保持する必要がないため、データサイズを抑えることができるといった利点がある。
【0059】
また、上記実施形態では、検索装置1として電子辞書のような小型の情報処理装置を想定して説明した。しかしこれに限られず、検索装置1は、ビジネス用・家庭用の一般的なコンピュータ装置や、携帯電話等の他の情報機器であってもよい。すなわち、検索装置1は、例えば一般的なコンピュータ装置において、ハードディスク等の大容量記憶装置やDVD−ROM等に用意された文書グループ300a〜300nのうちから所望の検索語を含む文書データ301を検索するものであってもよいし、携帯電話において、ネットワーク150上に用意された文書グループ300a〜300nのうちから所望の検索語を含む文書データ301を検索するものであってもよい。
【0060】
また、上記実施形態では、検索装置1は、検索語を「見出し語」の中に含む文書データ301を抽出(いわゆる「見出し語検索」)し、設定された出力優先度に基づく所定の規則に従って、当該抽出された文書データ301を出力した。しかしこれに限られず、文書データ301中の「説明文」に、検索語を含むものも抽出(いわゆる「全文検索」)するようにしてもよい。すなわち、検索対象を「見出し語」と「説明文」との両方に広げ、いずれか一方にでも検索語が含まれる文書データ301を、ユーザへ出力するようにしてもよい。
【0061】
この場合、「全文検索」により抽出された文書データ301については、「見出し語検索」により抽出された文書データ301に比べて、出力優先度を低く(スコアを大きく)設定するようにしてもよい。これによって、ユーザが「見出し語検索」と「全文検索」とを明示的に指定して検索せずとも、ユーザの検索意図に沿う文書データ301である可能性が高い「見出し語検索」により抽出された文書データ301が優先して出力され、その後で、「説明文」に検索語を含む文書データ301が出力されることになり、ユーザは、意図にあった検索結果をより簡便に得ることができるようになる。
【0062】
この場合さらに、あらかじめ出力される文書データ301の個数に最大値を決めておき、「見出し語」に検索語を含む文書データ301が当該最大値に満たない場合に、残りの数だけ「説明文」に検索語を含む文書データ301を抽出するようにしてもよい。一般的に、「説明文」も検索対象に含めると検索対象が大きく広がることになるため、ここでは出力個数に満たない場合にだけ検索対象を「説明文」にも広げるようにすることで、処理全体の負荷の抑制へとつなげることができる。
【0063】
また、上記実施形態では、単一の検索語がユーザから受け付けられた場合を想定して、説明した。しかしこれに限られず、検索装置1は、複数の検索語を受け付け、それらの論理積や論理和等の各種演算処理を施したものについての検索を行い、所定の規則で設定された出力優先度に基づいて、ユーザへと出力するものであってもよい。この場合、検索結果として抽出された文書データ301に設定される出力優先度は、そこに含まれる複数の検索語の出現位置や出現頻度、あるいは複数の検索語間の出現位置の間隔といった、種々の出現態様によって設定されうる。
【0064】
また、上記実施形態では、文書グループ300a〜300nが備える複数の文書データ301a〜301c等は、「見出し語」と「説明文」とから構成された。しかしこれらに限られず、様々な要素から構成されてもよい。例えば、「見出し語」を説明するための図や表を有するものであってもよい。あるいは、このような「見出し語」と「説明文」とから構成される辞書の構成単位に限られず、検索装置1は、種々の電子データを検索するものであってもよい。例えば、一般的なコンピュータ装置において、ハードディスク等の大容量記憶装置に記憶された電子ファイルのうちから、所望の検索文字列を含む電子ファイルを検索するものであってもよい。あるいは、ネットワークと接続され、ネットワーク上に存在するウェブページを検索するものであってもよい。
【0065】
また、上記実施形態では、文書グループ300a〜300nは、あらかじめ所定の順序が定められ、当該所定の順序に基づいて、検索装置1の処理が行われた。ここで、所定の順序は、あらかじめ定められた1つの順序から設定変更が不可能なものとは限らず、種々に設定されるものであってもよい。例えば、文書グループ300ごとに使用頻度を記憶しておき、当該使用頻度の高い順に所定の順序を定めるものであってもよい。あるいは、ユーザが自身で順序を決められるようにしてもよい。これによって、ユーザの意図にあう可能性の高い文書グループ300の検索結果から順に出力されるようになり、検索装置1の使い勝手の向上につながる。
【0066】
あるいは、記憶部110に記憶されたすべての文書グループ300a〜300nを検索対象とすることに限られず、ユーザが自身で検索対象の文書グループ300を選択できるようにし、当該選択された文書グループ300のうちから、所定の順序に基づいて、検索処理が行われるようにしてもよい。これにより、よりユーザの意図にあう検索結果の出力が行われやすくなる。
【0067】
また、上記実施形態では、複数の文書グループ300a〜300nが備える文書データ301のうち出力優先度の高いものを1個ずつ、巡回的に出力した。しかし1個ずつ出力することに限られず、2個ずつでも3個ずつでも、あるいはその他の個数ずつ巡回的に出力するようにしてもよい。すなわち、出力部104が1度当たりに出力する文書データ301の個数として定められた所定の個数は、1個に限られず、いくつの個数であってもよい。一般的に、所定の個数を1個や2個のように比較的少ない個数とすると、全ての文書グループ300から満遍のない文書データ301の出力が可能となる。逆に、所定の個数を増大させると、各文書グループ300からの文書データ301の出力はある程度まとまった個数ずつになる。あるいは、このような1度当たりに出力する文書データ301の個数を、ユーザが自身で指定できるようにしてもよい。これにより、複数の文書グループ300a〜300nから満遍なく出力する度合いを、柔軟に設計することができる。
【0068】
なお、本発明に係る機能を実現するための構成を予め備えた検索装置として提供できることはもとより、プログラムの適用により、既存のパーソナルコンピュータや情報端末機器等を、本発明に係る検索装置として機能させることもできる。すなわち、上記実施形態で例示した検索装置1による各機能構成を実現させるための検索プログラムを、既存のパーソナルコンピュータや情報端末機器等を制御するCPU等が実行できるように適用することで、本発明に係る検索装置1として機能させることができる。また、本発明に係る検索方法は、検索装置1を用いて実施できる。
【0069】
また、このようなプログラムの適用方法は任意であり、例えば、CD−ROMやDVD−ROM、メモリカードなどのコンピュータ読み取り可能な記憶媒体に格納して適用できる他、例えば、インターネットなどの通信媒体を介して適用することもできる。
【0070】
以上、本発明の好ましい実施形態について説明したが、本発明は係る特定の実施形態に限定されるものではなく、本発明には、特許請求の範囲に記載された発明とその均等の範囲が含まれる。以下に、本願出願の当初の特許請求の範囲に記載された発明を付記する。
【0071】
(付記1)
複数の文書グループのそれぞれが備える複数の文書データのうちから、所望の検索文字列を含む文書データを抽出する抽出ステップと、
前記抽出された文書データのそれぞれに、所定の設定規則に基づいて、出力優先度を設定する設定ステップと、
前記複数の文書グループのそれぞれが、前記出力優先度が設定された文書データのうち所定の出力条件を満たす文書データを備えるか否かを、順に判定する判定ステップと、
前記判定した文書グループが前記所定の出力条件を満たす文書データを備える場合、当該文書データのうち所定の個数を出力する出力ステップと、
を備えることを特徴とする検索方法。
【0072】
(付記2)
前記所定の出力条件を満たす文書データとは、前記出力ステップにおいて未だ出力されていない文書データのうち、前記設定された出力優先度が最大である文書データである、
ことを特徴とする付記1に記載の検索方法。
【0073】
(付記3)
前記複数の文書グループは所定の順序で並べられ、
前記判定ステップでは、前記複数の文書グループのそれぞれが、前記出力優先度が設定された文書データのうち所定の出力条件を満たす文書データを備えるか否かを、前記所定の順序で巡回的に判定する、
ことを特徴とする付記1または2に記載の検索方法。
【0074】
(付記4)
前記複数の文書グループのそれぞれが備える複数の文書データのぞれぞれは、見出し語と対応する説明文とから構成され、
前記設定ステップでは、前記抽出された文書データのうち、見出し語に前記検索文字列を含む文書データの出力優先度を、当該見出し語と当該検索文字列との文字数の差分に基づいて設定する、
ことを特徴とする付記1から3のいずれか1つに記載の検索方法。
【0075】
(付記5)
前記設定ステップでは、見出し語と前記検索文字列との文字数の差分が等しい文書データを、当該見出し語の先頭文字と前記検索文字列との間の文字数が小さい順に、さらに出力優先度を設定する、
ことを特徴とする付記4に記載の検索方法。
【0076】
(付記6)
前記設定ステップでは、前記抽出された文書データのうち、見出し語に前記検索文字列を含まない文書データの出力優先度を、見出し語に前記検索文字列を含む文書データの出力優先度よりも、低く設定する、
ことを特徴とする付記4または5に記載の検索方法。
【0077】
(付記7)
前記抽出ステップでは、前記複数の文書グループのそれぞれが備える複数の文書データのうちから、前記検索文字列を見出し語に含む文書データを抽出し、当該抽出された文書データの個数が所定の最大数に満たない場合に、前記検索文字列を説明文に含む文書データをさらに抽出する、
ことを特徴とする付記4から6のいずれか1つに記載の検索方法。
【0078】
(付記8)
複数の文書グループのそれぞれが備える複数の文書データのうちから、所望の検索文字列を含む文書データを抽出する抽出手段と、
前記抽出された文書データのそれぞれに、所定の設定規則に基づいて、出力優先度を設定する設定手段と、
前記複数の文書グループのそれぞれが、前記出力優先度が設定された文書データのうち所定の出力条件を満たす文書データを備えるか否かを、順に判定する判定手段と、
前記判定した文書グループが前記所定の出力条件を満たす文書データを備える場合、当該文書データのうち所定の個数を出力する出力手段と、
を備えることを特徴とする検索装置。
【0079】
(付記9)
コンピュータを、
複数の文書グループのそれぞれが備える複数の文書データのうちから、所望の検索文字列を含む文書データを抽出する抽出手段、
前記抽出された文書データのそれぞれに、所定の設定規則に基づいて、出力優先度を設定する設定手段、
前記複数の文書グループのそれぞれが、前記出力優先度が設定された文書データのうち所定の出力条件を満たす文書データを備えるか否かを、順に判定する判定手段、
前記判定した文書グループが前記所定の出力条件を満たす文書データを備える場合、当該文書データのうち所定の個数を出力する出力手段、
として機能させることを特徴とするコンピュータプログラム。
【符号の説明】
【0080】
1…検索装置、2…端末装置、100…制御部、101…抽出部、102…設定部、103…判定部、104…出力部、110…記憶部、120…入力部、130…表示部、140a,140b…通信部、150…ネットワーク、151…CPU、152…ROM、153…RAM、154…キーボード、155…モニタ、300a,300b,300c,300n…文書グループ、301a,301b,301c…文書データ
【特許請求の範囲】
【請求項1】
複数の文書グループのそれぞれが備える複数の文書データのうちから、所望の検索文字列を含む文書データを抽出する抽出ステップと、
前記抽出された文書データのそれぞれに、所定の設定規則に基づいて、出力優先度を設定する設定ステップと、
前記複数の文書グループのそれぞれが、前記出力優先度が設定された文書データのうち所定の出力条件を満たす文書データを備えるか否かを、順に判定する判定ステップと、
前記判定した文書グループが前記所定の出力条件を満たす文書データを備える場合、当該文書データのうち所定の個数を出力する出力ステップと、
を備えることを特徴とする検索方法。
【請求項2】
前記所定の出力条件を満たす文書データとは、前記出力ステップにおいて未だ出力されていない文書データのうち、前記設定された出力優先度が最大である文書データである、
ことを特徴とする請求項1に記載の検索方法。
【請求項3】
前記複数の文書グループは所定の順序で並べられ、
前記判定ステップでは、前記複数の文書グループのそれぞれが、前記出力優先度が設定された文書データのうち所定の出力条件を満たす文書データを備えるか否かを、前記所定の順序で巡回的に判定する、
ことを特徴とする請求項1または2に記載の検索方法。
【請求項4】
前記複数の文書グループのそれぞれが備える複数の文書データのぞれぞれは、見出し語と対応する説明文とから構成され、
前記設定ステップでは、前記抽出された文書データのうち、見出し語に前記検索文字列を含む文書データの出力優先度を、当該見出し語と当該検索文字列との文字数の差分に基づいて設定する、
ことを特徴とする請求項1から3のいずれか1項に記載の検索方法。
【請求項5】
前記設定ステップでは、見出し語と前記検索文字列との文字数の差分が等しい文書データを、当該見出し語の先頭文字と前記検索文字列との間の文字数が小さい順に、さらに出力優先度を設定する、
ことを特徴とする請求項4に記載の検索方法。
【請求項6】
前記設定ステップでは、前記抽出された文書データのうち、見出し語に前記検索文字列を含まない文書データの出力優先度を、見出し語に前記検索文字列を含む文書データの出力優先度よりも、低く設定する、
ことを特徴とする請求項4または5に記載の検索方法。
【請求項7】
前記抽出ステップでは、前記複数の文書グループのそれぞれが備える複数の文書データのうちから、前記検索文字列を見出し語に含む文書データを抽出し、当該抽出された文書データの個数が所定の最大数に満たない場合に、前記検索文字列を説明文に含む文書データをさらに抽出する、
ことを特徴とする請求項4から6のいずれか1項に記載の検索方法。
【請求項8】
複数の文書グループのそれぞれが備える複数の文書データのうちから、所望の検索文字列を含む文書データを抽出する抽出手段と、
前記抽出された文書データのそれぞれに、所定の設定規則に基づいて、出力優先度を設定する設定手段と、
前記複数の文書グループのそれぞれが、前記出力優先度が設定された文書データのうち所定の出力条件を満たす文書データを備えるか否かを、順に判定する判定手段と、
前記判定した文書グループが前記所定の出力条件を満たす文書データを備える場合、当該文書データのうち所定の個数を出力する出力手段と、
を備えることを特徴とする検索装置。
【請求項9】
コンピュータを、
複数の文書グループのそれぞれが備える複数の文書データのうちから、所望の検索文字列を含む文書データを抽出する抽出手段、
前記抽出された文書データのそれぞれに、所定の設定規則に基づいて、出力優先度を設定する設定手段、
前記複数の文書グループのそれぞれが、前記出力優先度が設定された文書データのうち所定の出力条件を満たす文書データを備えるか否かを、順に判定する判定手段、
前記判定した文書グループが前記所定の出力条件を満たす文書データを備える場合、当該文書データのうち所定の個数を出力する出力手段、
として機能させることを特徴とするコンピュータプログラム。
【請求項1】
複数の文書グループのそれぞれが備える複数の文書データのうちから、所望の検索文字列を含む文書データを抽出する抽出ステップと、
前記抽出された文書データのそれぞれに、所定の設定規則に基づいて、出力優先度を設定する設定ステップと、
前記複数の文書グループのそれぞれが、前記出力優先度が設定された文書データのうち所定の出力条件を満たす文書データを備えるか否かを、順に判定する判定ステップと、
前記判定した文書グループが前記所定の出力条件を満たす文書データを備える場合、当該文書データのうち所定の個数を出力する出力ステップと、
を備えることを特徴とする検索方法。
【請求項2】
前記所定の出力条件を満たす文書データとは、前記出力ステップにおいて未だ出力されていない文書データのうち、前記設定された出力優先度が最大である文書データである、
ことを特徴とする請求項1に記載の検索方法。
【請求項3】
前記複数の文書グループは所定の順序で並べられ、
前記判定ステップでは、前記複数の文書グループのそれぞれが、前記出力優先度が設定された文書データのうち所定の出力条件を満たす文書データを備えるか否かを、前記所定の順序で巡回的に判定する、
ことを特徴とする請求項1または2に記載の検索方法。
【請求項4】
前記複数の文書グループのそれぞれが備える複数の文書データのぞれぞれは、見出し語と対応する説明文とから構成され、
前記設定ステップでは、前記抽出された文書データのうち、見出し語に前記検索文字列を含む文書データの出力優先度を、当該見出し語と当該検索文字列との文字数の差分に基づいて設定する、
ことを特徴とする請求項1から3のいずれか1項に記載の検索方法。
【請求項5】
前記設定ステップでは、見出し語と前記検索文字列との文字数の差分が等しい文書データを、当該見出し語の先頭文字と前記検索文字列との間の文字数が小さい順に、さらに出力優先度を設定する、
ことを特徴とする請求項4に記載の検索方法。
【請求項6】
前記設定ステップでは、前記抽出された文書データのうち、見出し語に前記検索文字列を含まない文書データの出力優先度を、見出し語に前記検索文字列を含む文書データの出力優先度よりも、低く設定する、
ことを特徴とする請求項4または5に記載の検索方法。
【請求項7】
前記抽出ステップでは、前記複数の文書グループのそれぞれが備える複数の文書データのうちから、前記検索文字列を見出し語に含む文書データを抽出し、当該抽出された文書データの個数が所定の最大数に満たない場合に、前記検索文字列を説明文に含む文書データをさらに抽出する、
ことを特徴とする請求項4から6のいずれか1項に記載の検索方法。
【請求項8】
複数の文書グループのそれぞれが備える複数の文書データのうちから、所望の検索文字列を含む文書データを抽出する抽出手段と、
前記抽出された文書データのそれぞれに、所定の設定規則に基づいて、出力優先度を設定する設定手段と、
前記複数の文書グループのそれぞれが、前記出力優先度が設定された文書データのうち所定の出力条件を満たす文書データを備えるか否かを、順に判定する判定手段と、
前記判定した文書グループが前記所定の出力条件を満たす文書データを備える場合、当該文書データのうち所定の個数を出力する出力手段と、
を備えることを特徴とする検索装置。
【請求項9】
コンピュータを、
複数の文書グループのそれぞれが備える複数の文書データのうちから、所望の検索文字列を含む文書データを抽出する抽出手段、
前記抽出された文書データのそれぞれに、所定の設定規則に基づいて、出力優先度を設定する設定手段、
前記複数の文書グループのそれぞれが、前記出力優先度が設定された文書データのうち所定の出力条件を満たす文書データを備えるか否かを、順に判定する判定手段、
前記判定した文書グループが前記所定の出力条件を満たす文書データを備える場合、当該文書データのうち所定の個数を出力する出力手段、
として機能させることを特徴とするコンピュータプログラム。
【図1】


【図2】
【図3】

【図4】
【図5】
【図6】
【図7】
【図8】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【公開番号】特開2012−208775(P2012−208775A)
【公開日】平成24年10月25日(2012.10.25)
【国際特許分類】
【出願番号】特願2011−74477(P2011−74477)
【出願日】平成23年3月30日(2011.3.30)
【出願人】(000001443)カシオ計算機株式会社 (8,748)
【Fターム(参考)】
【公開日】平成24年10月25日(2012.10.25)
【国際特許分類】
【出願日】平成23年3月30日(2011.3.30)
【出願人】(000001443)カシオ計算機株式会社 (8,748)
【Fターム(参考)】
[ Back to top ]