
検索方法、検索装置及びプログラム
【課題】 意味ドリフトの回避に適した、新たな検索方法等を提案する。
【解決手段】 検索装置1において、一つ又は複数の検索単語を用いて、検索対象データ記憶手段に記憶された検索対象データ群を検索する。検索部15は、検索単語を用いて検索対象データ群を検索する。抽出部23は、検索結果から複数の関連語を抽出する。選択部27は、複数の関連語のうち、個数を限定して、検索重要単語として選択する。検索部15は、検索重要単語を用いて検索対象データ群をさらに検索する。選択部27が、個数を限定して選択することによって、意味ドリフトを回避することが可能になる。
【解決手段】 検索装置1において、一つ又は複数の検索単語を用いて、検索対象データ記憶手段に記憶された検索対象データ群を検索する。検索部15は、検索単語を用いて検索対象データ群を検索する。抽出部23は、検索結果から複数の関連語を抽出する。選択部27は、複数の関連語のうち、個数を限定して、検索重要単語として選択する。検索部15は、検索重要単語を用いて検索対象データ群をさらに検索する。選択部27が、個数を限定して選択することによって、意味ドリフトを回避することが可能になる。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、検索方法、検索装置及びプログラムに関し、特に、意味ドリフトの回避に適した検索方法等に関する。
【背景技術】
【0002】
検索結果の文書集合の重要語を抽出する手法として、文書に対するブートストラッピング法が知られている(特許文献1及び2並びに非特許文献1参照)。ブートストラッピング法は、単語集合を検索条件として与え、その条件を満たす文書集合を求める工程と、文書集合からその文書集合に含まれる重要語集合を求める工程という、二つの工程を交互に繰り返す。十分な回数の反復後には、単語の重みと文書の重みは一定の値に収束する。そのため、単語の重要度を自動的に求めることができる。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開2008−191877号公報
【特許文献2】特開2007−41700号公報
【非特許文献】
【0004】
【非特許文献1】小町守、外3名著,“Espresso型ブートストラッピング法における意味ドリフトのグラフ理論に基づく分析−語義曖昧性解消における評価−”,人工知能学会論文誌,vol.25,No.2,pp.233-242,2010.
【発明の概要】
【発明が解決しようとする課題】
【0005】
ブートストラッピング法は、反復を繰り返す過程で、最初の目的から外れた単語を抽出するようになるという問題がある。その結果、単語集合は、最初に与えた単語とは関係のない、より一般的な単語ばかりになってしまう。これは、意味ドリフトと呼ばれており、抜本的な解決方法は知られていない。
【0006】
従来、意味ドリフトを避けるため、文書や単語の重要度の計算法の改良や、単語の出現パターンを制限するなど人手による工夫(ヒューリスティック)が使われている(特許文献1及び2並びに非特許文献1参照)。しかし、これらの手法には、一般性がない。
【0007】
そこで、本願発明は、意味ドリフトの回避に適した、新たな検索方法等を提案することを目的とする。
【課題を解決するための手段】
【0008】
本願発明の第1の観点は、検索装置において、一つ又は複数の検索単語を用いて、検索対象データ記憶手段に記憶された検索対象データ群を検索する検索方法であって、検索手段が、前記検索単語を用いて前記検索対象データ群を検索する検索ステップと、抽出手段が、検索結果から複数の関連語を抽出する抽出ステップと、選択手段が、前記複数の関連語の一部を検索重要単語として選択する選択ステップと、前記検索手段が、前記検索重要単語を用いて前記検索対象データ群をさらに検索する再検索ステップを含むものである。
【0009】
本願発明の第2の観点は、第1の観点において、前記抽出手段が、前記再検索ステップにおける検索結果から新たに複数の関連語を抽出する再抽出ステップと、個数決定手段が、前記再抽出ステップにおいて抽出された関連語群において、前記検索単語又はその同義語の重要度が高い場合には、前記選択手段が選択する検索重要単語の個数を維持又は増加する個数決定ステップを含むものである。
【0010】
本願発明の第3の観点は、第2の観点において、前記個数決定ステップにおいて、前記個数決定手段は、前記再抽出ステップにおいて抽出された関連語群において、前記検索単語又はその同義語の重要度が低い場合には、前記選択手段が選択する検索重要単語の個数を減少し、前記選択手段が、前記再抽出ステップにおいて抽出された関連語群において、前記検索単語又はその同義語の重要度が高い場合に、前記新たに抽出された複数の関連語から新たな検索重要単語を選択し、前記再抽出ステップにおいて抽出された関連語群において、前記検索単語又はその同義語の重要度が低い場合に、以前に抽出された関連語から個数を減少して新たな検索重要単語を再度選択する再選択ステップを含むものである。
【0011】
本願発明の第4の観点は、第2又は第3の観点において、前記個数決定手段は、前記検索単語又はその同義語の重要度の高低を、前記検索対象データ群全体における前記検索単語又はその同義語の重要度と、前記検索手段による検索結果における前記検索単語又はその同義語の重要度とを比較して決定するものである。
【0012】
本願発明の第5の観点は、第2又は第3の観点において、前記個数決定手段は、前記検索単語又はその同義語の重要度の高低を、前記検索単語と、前記複数の関連語との類似性により決定するものである。
【0013】
本願発明の第6の観点は、第1から第5のいずれかにおいて、前記検索手段は、前記検索対象データ群を検索して、一つ又は複数の検索対象データを抽出し、又は/及び、前記検索対象データ群の全部又は一部に重み付けを行うことにより、前記検索結果を得るものである。
【0014】
本願発明の第7の観点は、一つ又は複数の検索単語を用いて検索対象データ群を検索する検索装置であって、前記検索対象データ群を記憶する検索対象データ記憶手段と、前記検索単語を用いて前記検索対象データ群を検索する検索手段と、前記抽出された検索対象データから複数の関連語を抽出する抽出手段と、選択手段が、前記複数の関連語の一部を検索重要単語として選択する選択手段と、を備え、前記検索手段は、前記検索重要単語を用いて前記検索対象データ群をさらに検索するものである。
【0015】
本願発明の第8の観点は、コンピュータにおいて、第1から第6のいずれかの観点の検索方法を実現するためのプログラムである。
【0016】
なお、選択手段が選択する検索重要単語の個数は、例えば、検索単語の個数よりも大きい値である。これにより、検索単語以外の単語のうち、検索単語に近い意味合いの単語を少なくとも一つ、検索重要単語として選択することができる。また、第2の観点において、個数決定手段は、再検索ステップと再抽出ステップを、個数を維持したまま所定の回数繰り返し、その後に、前記検索単語又はその同義語の重要度が高い場合には、前記選択手段が選択する検索重要単語の個数を増加するものであってもよい。また、第8の観点のプログラムを定常的に記録するコンピュータ読み取り可能な記録媒体として捉えてもよい。
【発明の効果】
【0017】
本願発明の各観点は、単語集合から文書集合を求める工程と、文書集合から単語集合を求める工程とを、交互に繰り返すものである。このとき、選択手段は、関連語のうち、重要度が上位のt個に限定して、検索重要単語を選択する。選択手段が、個数を限定して選択することによって、意味ドリフトを回避することが可能になる。
【0018】
また、本願発明の第2の観点によれば、意味ドリフトの発生を制御しつつ、tの値を増加することが可能になる。
【0019】
さらに、本願発明の第3の観点によれば、意味ドリフトが発生していない状態であれば最新の関連語群から検索重要単語を選択し、意味ドリフトが発生すると以前に抽出された関連語群から個数を減らして検索重要単語を選択することにより、自動的にtの値を調整して、意味ドリフトを回避しつつ、検索処理を実現することが可能になる。
【0020】
なお、本願発明を、第2の観点において、前記検索手段、前記抽出手段及び前記選択手段は、前記再抽出ステップにおいて抽出された複数の関連語において、前記検索単語よりも前記検索結果における重要度が高い単語がk個(kは、予め定められた自然数である。)以上存在するまでtの値を増加して検索して、表示手段に前記検索単語よりも重要度が高い単語の全部又は一部を表示するものとして捉えてもよい。検索装置の利用者は、表示された単語群を参照して、例えば求めたい単語群の一般性をその文書頻度としたとき、目標とする文書頻度Fの単語を求めるためのパラメータtを事前に定めることができる。これにより、tの値によって、意味ドリフトのレベルを調整することができる。
【図面の簡単な説明】
【0021】
【図1】本願発明の実施例に係る検索装置1の概要を示すブロック図である。
【図2】図1の検索装置1の動作の一例を示すフロー図である。
【図3】検索対象データ群が倒産情報に関する文献群であり、検索単語が「建築」である場合に、抽出する単語数tを変更した検索結果を示す図である。
【図4】検索対象データ群が図3と同じ文献群であり、検索単語が「建築」である場合に、「建築」の順位と関連語の上位10個を示す図である。
【図5】図2の検索装置1の動作の具体的な一例を示すフロー図である。
【図6】図3の抽出する個数の決定処理の一例を示すフロー図である。
【図7】図2の検索装置1の動作の具体的な他の一例を示す図である。
【図8】図2の検索装置1の具体的な動作のさらに他の一例を示す図である。
【発明を実施するための形態】
【0022】
以下では、図面を参照して、本願発明の実施例について説明する。なお、本願発明は、この実施例に限定されるものではない。
【実施例】
【0023】
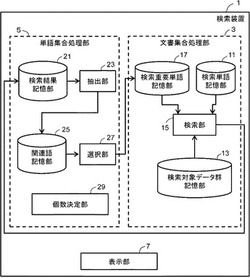
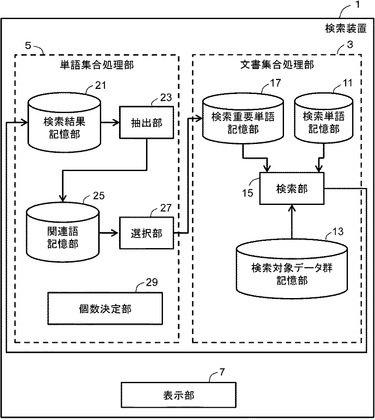
図1は、本願発明の実施例に係る検索装置の概要を示すブロック図である。検索装置1は、文書集合処理部3と、単語集合処理部5と、表示部7を備える。文書集合処理部3は、検索単語記憶部11と、検索対象データ群記憶部13(本願請求項の「検索対象データ群記憶部」の一例)と、検索部15(本願請求項の「検索手段」の一例)と、検索重要単語記憶部17を備える。単語集合処理部5は、検索結果記憶部21と、抽出部23(本願請求項の「抽出手段」の一例)と、関連語記憶部25と、選択部27(本願請求項の「選択手段」の一例)と、個数決定部29(本願請求項の「個数決定手段」の一例)を備える。表示部7は、検索結果等を表示するものである。
【0024】
図2は、図1の検索装置1の動作の一例を示すフロー図である。以下、図1の検索装置1の動作を、図2を参照して説明する。
【0025】
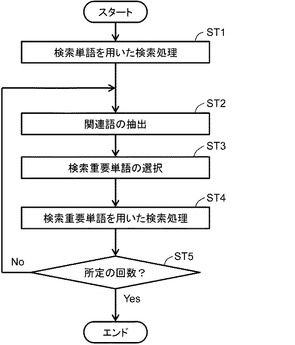
検索単語記憶部11は、一つ又は複数の検索単語を記憶するものである。検索単語は、例えば、検索装置1の利用者が入力したクエリである。検索対象データ群記憶部13は、検索対象データ群を記憶するものである。検索対象データ群は、文書、文と単語を節点とする二分グラフ等の複数の検索対象データである。検索部15は、検索単語を用いて、検索対象データ群を検索する(図2のステップST1)(本願請求項の「検索ステップ」の一例)。以下では、検索部15が、検索結果として、検索対象データ群のうち、一つ又は複数の検索対象データを抽出する場合について説明する。検索部15は、検索結果記憶部21に、検索結果を記憶する。
【0026】
個数決定部29は、選択部27が選択する単語の個数tを決定する。抽出部23は、検索結果記憶部21に記憶された検索対象データから、複数の関連語を抽出する(ステップST2)(本願請求項の「抽出ステップ」の一例)。抽出部23は、関連語記憶部25に対して、抽出部23が抽出した関連語を記憶させる。選択部27は、抽出部23により抽出された関連語のうち、重要度が高い方からt個を検索重要単語として選択する(ステップST3)(本願請求項の「選択ステップ」の一例)。重要度は、例えば、検索結果記憶部21に記憶された検索対象データにおける出現頻度である。選択部27は、検索重要単語記憶部17に、選択した検索重要単語を記憶する。検索部15は、検索重要単語記憶部17に記憶された検索重要単語を用いて、検索対象データ群をさらに検索する(ステップST4)(本願請求項の「再検索ステップ」の一例)。そして、検索装置1は、図2のステップST2〜4の処理を、所定の回数に至るまで、反復して行う(ステップST5)。
【0027】
文書集合処理部3は、文書集合を抽出する。単語集合処理部5は、単語集合を作成する。このとき、選択部27は、関連語のうち、重要度が上位のt個に限定して、検索重要単語を選択する。例えば、十分大きなtに対しては、一般的な重要語が選択される。反復して検索するうちに、一般的な重要語の影響が大きくなる。そのため、単語集合は、一般的な重要語が中心のものとなる。他方、例えば、検索単語が一つの場合に、t=1とすれば、単語集合は基本的に検索単語となる。このように、tの値を小さく設定すれば、特殊な分野や対象についての重要語となる。よって、選択部27が、個数を制限して、関連語の一部を検索重要単語として選択することによって、検索装置1全体として、意味ドリフトを回避しつつ、一つ又は複数の検索単語を用いて、記憶された検索対象データ群を検索することが可能になる。
【0028】
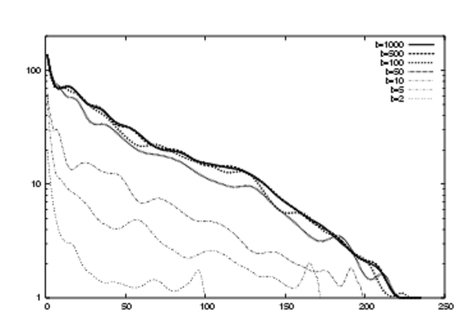
図3は、抽出する単語数tを変更した検索結果を示す図である。横軸は、検索単語の重要度の順位を示す。縦軸は、単語の出現頻度(frequency)を示す。実験では、検索対象データ群を企業の倒産情報に関する文献群とした。検索単語を「建築」とした。実験で使用したtは、2、5、10、50、100、500、1000の7通りである。t=2では、上位の単語でも頻度が低い特殊な単語である。しかし、t=100、1000では、重要度上位の単語は、出現頻度が高い単語(つまり、本来の検索語とか関係なく一般的な単語)である。そのため、tを大きくした場合に、意味ドリフトが生じていることがわかる。よって、例えば、企業の倒産情報を対象として、倒産原因を抽出する検索システムを構築することにより、tを大きくして検索処理を行うことにより、一般的な倒産理由を抽出することもできる。さらに、tを小さくして、例えば「建築」業界に限定した倒産理由を抽出することもできる。
【0029】
図4は、図3と同じ文献群に対して、「建築」をキーワードとして検索して得られる検索結果を示す図である。実験では、図3と同様に、検索対象データ群を企業の倒産情報に関する文献群とした。検索単語を「建築」とした。1列目はtの値である。2列目は上位t個で検索した検索結果における検索単語(つまり、「建築」)の順位である。3列目以降は、関連語の上位10個である。t=1の場合は、建築のみが抽出されている。t=4までは、「建築」は、高い重要度で評価されている。t=5で、「サブプライムローン」という用語があらわれ、やや一般的な傾向を示すようになった。そして、t=30以上で、「減少」という用語が最も高く評価されるようになった。この「減少」等は、検索対象データ群全体で、一般的な単語であると考えられる。その結果、これらの単語の影響が大きくなり、意味ドリフトが発生したものと考えられる。
【0030】
図4より、tが小さい場合には、意味ドリフトを回避することができることがわかる。また、tが大きい場合には、意味ドリフトが発生している。よって、tを変更することにより、意味ドリフトの発生をコントロールすることが可能である。図5及び図6を参照して、予めtを決定して、意味ドリフトの発生をコントロールしつつ、検索処理を行う場合について具体的に説明する。
【0031】
さらに、意味ドリフトが生じた場合、単語集合の上位は、一般的な単語が占める。その結果、図4では、t=50以上で、「建築」の順位は、200位前後となっている。これは、検索対象データ群全体として、「建築」という単語の重要度の評価と考えられる。よって、意味ドリフトが生じたか否かの指標の一つとして、検索単語の重要度の順位を用いることができる。図5〜図8を参照して、この指標を用いて、反復処理において、意味ドリフトが発生したか否かを判断し、適切なtの値を調整するものについて説明する。
【0032】
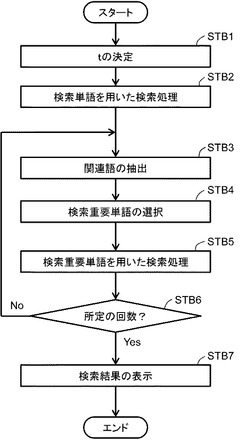
図5は、図2の検索装置1の動作の具体的な一例を示すフロー図である。まず、個数決定部29は、抽出する単語数tを決定する(ステップSTB1)。続いて、検索部15は、検索単語を用いて、検索対象データ群を検索する(ステップSTB2)。検索部15は、検索結果記憶部21に、検索結果を記憶する。抽出部23は、検索結果記憶部21に記憶された検索対象データから、複数の関連語を抽出する(ステップSTB3)。選択部27は、抽出部23により抽出された関連語のうち、重要度が高い方からt個を検索重要単語として選択する(ステップSTB4)。選択部27は、検索重要単語記憶部17に、選択した検索重要単語を記憶する。検索部15は、検索重要単語記憶部17に記憶された検索重要単語を用いて、検索対象データ群をさらに検索する(ステップSTB5)。そして、検索装置1は、図5のステップSTB3〜5の処理を、所定の回数に至るまで、反復して行う(ステップSTB6)。検索装置1は、表示装置に、検索結果を表示する(ステップSTB7)。
【0033】
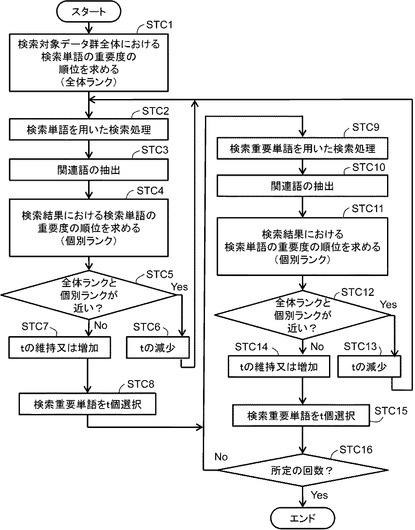
図6は、図5のステップSTB1におけるtの決定処理の一例を示すフロー図である。検索装置1の利用者は、検索単語wと、関連語数kを入力する(ステップSTK1)。個数決定部29は、閾値初期値設定処理として、tを、検索単語の個数とする(ステップSTK2)。図6では、検索単語はwの1つのみを仮定している。そのため、tを1とする。続いて、検索部15は、検索単語を用いて、検索対象データ群を検索する(ステップSTK3)(本願請求項の「検索ステップ」の一例)。検索部15は、検索結果記憶部21に、検索結果を記憶する。抽出部23は、検索結果記憶部21に記憶された検索対象データから、複数の関連語を抽出する(ステップSTK4)(本願請求項の「抽出ステップ」の一例)。選択部27は、抽出部23により抽出された関連語のうち、重要度が高い方からt個を検索重要単語として選択する(ステップSTK5)(本願請求項の「選択ステップ」の一例)。図6の説明において、この検索重要単語群を重要度の順位に並べたリストを「関連語リストL」という。選択部27は、検索重要単語記憶部17に、検索語リストLを記憶する。個数決定部29は、L中での検索単語wの重要度順位r=rank(L,w)を計算する(ステップSTK6)。これは、例えば、検索単語wそのものがあらわれる順位でもよく、実質的に同じと評価できる単語(例えば同義語など)があらわれる順位などであってもよい。個数決定部29は、rとkとを比較する(ステップSTK7)。rがk以上であれば、ステップSTK14に進む。rがkよりも小さいならば、ステップSTK8に進む。
【0034】
個数決定部29は、tの値を1増加する(ステップSTK8)。検索部15は、検索重要単語を用いて、検索対象データ群を検索する(ステップSTK9)(本願請求項の「再検索ステップ」の一例)。検索部15は、検索結果記憶部21に、検索結果を記憶する。抽出部23は、検索結果記憶部21に記憶された検索対象データから、複数の関連語を抽出する(ステップSTK10)。選択部27は、抽出部23により抽出された関連語から、新たな関連語リストLを生成する(ステップSTK11)。選択部27は、検索重要単語記憶部17に、検索語リストLを記憶する。個数決定部29は、L中での検索単語wの重要度順位r=rank(L,w)を計算する(ステップSTK12)。個数決定部29は、rとkとを比較する(ステップSTK13)。rがk以上であれば、ステップSTK14に進む。rがkよりも小さいならば、ステップSTK8に進む。なお、ステップSTK13の処理において、所定の回数を経るまでは、個数を維持したままステップSTK8〜STK12の処理を行い、その後に比較処理を行ってもよい。
【0035】
ステップSTK14において、個数決定部29は、表示部7に、Lにおいてwより上位のk個の単語と、wより下位のk個の単語を表示する。
【0036】
図6の処理により、検索装置1は、利用者に対して、tの値を変更して得られる関連語を重要度の降順に並べたとき、表示部7に、入力した検索単語wを中心に、それより上位k個と下位k個を提示する。すなわち、tの値を増加すると、関連語の数も増え、wの順位は下がる(図3、図4参照)。そのため、図6にあるように、t=1から始めて、wより上位の単語がk個以上となるまでtを増加させることで、このようなtを求めることができる。利用者は、表示された単語群により、検索対象データ群の検索処理において、検索単語wを解釈することができる。
【0037】
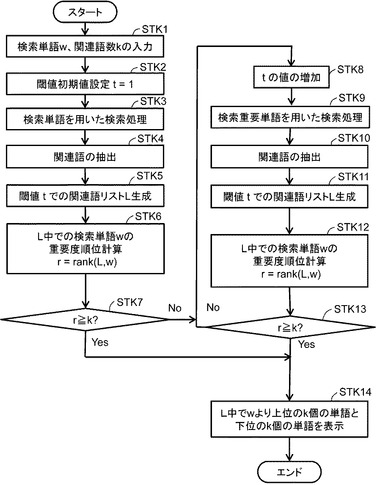
図7は、図2の検索装置1の動作の具体的な他の一例を示す図である。
【0038】
まず、個数決定部29は、検索対象データ群記憶部13に記憶された検索対象データ群において、検索単語の重要度の順位(以下、この順位を「全体ランク」という。)を求める(ステップSTC1)。なお、全体ランクは、例えば、検索単語が複数の場合には、その最高順位により決定してもよい。また、検索単語及びその同義語のうち、最高順位とするなど、同義語を参酌して決定してもよい。ここで、個数決定部29は、tに初期値を設定する。
【0039】
続いて、検索部15は、検索単語を用いて、検索対象データ群を検索する(ステップSTC2)(本願請求項の「検索ステップ」の一例)。検索部15は、検索結果記憶部21に、検索結果を記憶する。抽出部23は、検索結果記憶部21に記憶された検索対象データから、複数の関連語を抽出する(ステップSTC3)(本願請求項の「抽出ステップ」の一例)。
【0040】
続いて、個数決定部29は、検索結果記憶部21に記憶された検索結果において、検索単語の重要度の順位を求める(ステップSTC4)。以下、この順位を「個別ランク」という。そして、検索装置1は、全体ランクと個別ランクを比較する(ステップSTC5)。全体ランクと個別ランクが近い場合には、意味ドリフトが発生したと判断して、tの値を少なくし(ステップSTC6)、ステップSTC2の処理に戻る。全体ランクと個別ランクが近くない場合には、ステップSTC7の処理を行う。ここで、全体ランクと個別ランクの近さは、例えば、一定数以下か否かという絶対数で判断してもよく、全体ランクを個別ランクで割った値を用いるように、割合的に判断してもよい。
【0041】
個数決定部29は、tの値を維持又は増加する(ステップSTC7)。個数決定部29は、例えば、全体ランクと個別ランクの違いが十分に大きいときにはtの値を増加し、そうでないときには、tの値を維持する。選択部27は、抽出部23により抽出された関連語のうち、重要度が高い方からt個を検索重要単語として選択する(ステップSTC8)(本願請求項の「選択ステップ」の一例)。選択部27は、検索重要単語記憶部17に、選択した検索重要単語を記憶する。
【0042】
検索部15は、検索重要単語記憶部17に記憶された検索重要単語を用いて、検索対象データ群をさらに検索する(ステップSTC9)(本願請求項の「再検索ステップ」の一例)。検索部15は、検索結果記憶部21に、検索結果を記憶する。抽出部23は、検索結果記憶部21に記憶された検索対象データから、複数の関連語を抽出する(ステップSTC10)続いて、個数決定部29は、個別ランクを新たに求める(ステップSTC11)。そして、検索装置1は、全体ランクと個別ランクを比較する(ステップSTC12)。全体ランクと個別ランクが近い場合には、意味ドリフトが発生したと判断して、tの値を少なくし(ステップSTC13)、ステップSTC2の処理に戻る。全体ランクと個別ランクが近くない場合には、個数決定部29は、tの値を維持又は増加する(ステップSTC14)。選択部27は、抽出部23により抽出された関連語のうち、重要度が高い方からt個を検索重要単語として選択する(ステップSTC15)。そして、検索装置1は、ステップSTC9〜15の処理を、所定の回数に至るまで、反復して行う(ステップSTC16)。なお、ステップSTC12の処理において、所定の回数を経るまでは、tを維持したままステップSTC9〜STC16の処理を行い、その後に比較処理を行ってもよい。
【0043】
図7の処理により、関連語の重要度の順位によって意味ドリフトが発生したか否かを判断し、tの値を増減することにより、自動的に、tの値を調整して、意味ドリフトを回避しつつ、検索処理を実現することが可能になる。
【0044】
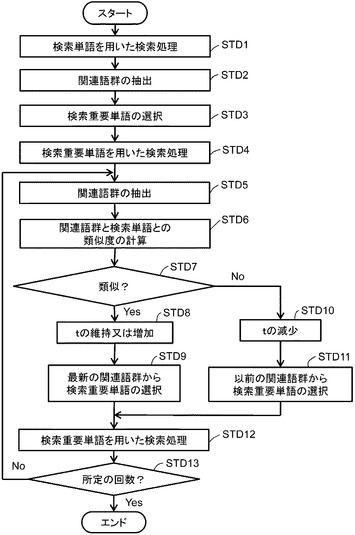
図8は、図2の検索装置1の具体的な動作のさらに他の一例を示す図である。
【0045】
まず、個数決定部27は、tに初期値を設定する。検索部15は、検索単語を用いて、検索対象データ群を検索する(ステップSTD1)(本願請求項の「検索ステップ」の一例)。検索部15は、検索結果記憶部21に、検索結果を記憶する。抽出部23は、検索結果記憶部21に記憶された検索対象データから、複数の関連語を抽出する(ステップSTD2)(本願請求項の「抽出ステップ」の一例)。抽出部23は、関連語記憶部25に、抽出された関連語を記憶する。選択部27は、関連語記憶部25に記憶された関連語のうち、重要度が高い方からt個を検索重要単語として選択する(ステップSTD3)(本願請求項の「選択ステップ」の一例)。選択部27は、検索重要単語記憶部17に、選択した検索重要単語を記憶する。
【0046】
検索部15は、検索重要単語記憶部17に記憶された検索重要単語を用いて、検索対象データ群をさらに検索する(ステップSTD4)(本願請求項の「再検索ステップ」の一例)。検索部15は、検索結果記憶部21に、検索結果を記憶する。抽出部23は、検索結果記憶部21に記憶された検索対象データから、複数の関連語を抽出する(ステップSTD5)。抽出部23は、関連語記憶部25に、以前に抽出された関連語とは区別して、新たに抽出された関連語を記憶する。続いて、個数決定部29は、新たに抽出された関連語と検索単語との類似度を計算する。類似度が高い場合には、意味ドリフトが発生していないと判断し、ステップSTD8の処理を行う。類似度が低い場合には、意味ドリフトが発生したと判断し、ステップSTD10の処理を行う。類似度は、例えば、新たに抽出された関連語について、重要度に応じた重み付けを行い、検索単語(同義語を含んでもよい。)と比較して計算してもよい。また、t以上の個数を抽出して、検索単語(同義語を含んでもよい。)と比較して計算してもよい。
【0047】
ステップSTD8において、個数決定部29は、tの値を維持又は増加する。例えば、類似度が十分に大きい場合には、tの値を増加する。続いて、選択部27は、新たに抽出された関連語群から、重要度が高い方からt個を検索重要単語として選択する(ステップSTD9)。そして、ステップSTD12に進む。
【0048】
ステップSTD10において、個数決定部29は、tの値を減らす。そして、選択部27は、以前に抽出された関連語群から、重要度が高い方からt個を選択する(ステップSTD11)。なお、検索重要単語記憶部17には、直前に選択した検索重要単語が記憶されている。そのため、この検索重要単語記憶部17に記憶された検索重要単語の一部を、新たな検索重要単語として選択してもよい。選択部27は、ステップSTD9又はステップSTD11の処理に続き、検索重要単語記憶部17に選択した検索重要単語を記憶し、ステップSTD12の処理を行う。
【0049】
ステップSTD12では、検索部15は、検索重要単語記憶部17に記憶された検索重要単語を用いて、検索対象データ群をさらに検索する(本願請求項の「再検索ステップ」の一例)。そして、検索装置1は、図8のステップSTD5〜12の処理を、所定の回数に至るまで、反復して行う(ステップSTD13)。なお、ステップSTD7の処理において、所定の回数を経るまでは、tを維持させたままステップSTD5〜STD13の処理を行い、その後に判断処理を行ってもよい。
【0050】
図8の処理によれば、意味ドリフトが発生していない状態であれば最新の関連語群から検索重要単語を選択し、意味ドリフトが発生すると以前の関連語群からtを減らして検索重要単語を選択することにより、自動的にtの値を調整して、意味ドリフトを回避しつつ、検索処理を実現することが可能になる。
【0051】
なお、検索部15は、例えば、複数の検索対象データを抽出して、抽出された検索対象データに重み付けを行うものであってもよい。また、検索部15は、検索対象データ群の全部に対して重み付けを行うものであってもよい。(検索対象データ群の一部を選択することは、例えば、各検索対象データに対して0又は1の重み付けを行っていると捉えることができる。)この場合、抽出部23及び選択部27は、低く重み付けされた検索対象データにのみ表われる単語よりも、高く重み付けされた検索対象データに表われる単語を重視して、関連語を抽出し、検索重要単語を選択する。
【0052】
また、図7では、重要度の順位により、tの値を調整した。図8では、関連語と検索単語の類似度により、tの値を調整した。図7において、図8と同様に、関連語と検索単語の類似度により調整するようにしてもよい。図8において、図7と同様に、検索単語の重要度の順位により、tの値を調整するようにしてもよい。また、両方を加味して、調整するようにしてもよい。
【符号の説明】
【0053】
1 検索装置、3 文書集合処理部、5 単語集合処理部、7 表示部、11 検索単語記憶部、13 検索対象データ群記憶部、15 検索部、17 検索重要単語記憶部、21 検索結果記憶部、23 抽出部、25 関連語記憶部、27 選択部、29 個数決定部
【技術分野】
【0001】
本発明は、検索方法、検索装置及びプログラムに関し、特に、意味ドリフトの回避に適した検索方法等に関する。
【背景技術】
【0002】
検索結果の文書集合の重要語を抽出する手法として、文書に対するブートストラッピング法が知られている(特許文献1及び2並びに非特許文献1参照)。ブートストラッピング法は、単語集合を検索条件として与え、その条件を満たす文書集合を求める工程と、文書集合からその文書集合に含まれる重要語集合を求める工程という、二つの工程を交互に繰り返す。十分な回数の反復後には、単語の重みと文書の重みは一定の値に収束する。そのため、単語の重要度を自動的に求めることができる。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開2008−191877号公報
【特許文献2】特開2007−41700号公報
【非特許文献】
【0004】
【非特許文献1】小町守、外3名著,“Espresso型ブートストラッピング法における意味ドリフトのグラフ理論に基づく分析−語義曖昧性解消における評価−”,人工知能学会論文誌,vol.25,No.2,pp.233-242,2010.
【発明の概要】
【発明が解決しようとする課題】
【0005】
ブートストラッピング法は、反復を繰り返す過程で、最初の目的から外れた単語を抽出するようになるという問題がある。その結果、単語集合は、最初に与えた単語とは関係のない、より一般的な単語ばかりになってしまう。これは、意味ドリフトと呼ばれており、抜本的な解決方法は知られていない。
【0006】
従来、意味ドリフトを避けるため、文書や単語の重要度の計算法の改良や、単語の出現パターンを制限するなど人手による工夫(ヒューリスティック)が使われている(特許文献1及び2並びに非特許文献1参照)。しかし、これらの手法には、一般性がない。
【0007】
そこで、本願発明は、意味ドリフトの回避に適した、新たな検索方法等を提案することを目的とする。
【課題を解決するための手段】
【0008】
本願発明の第1の観点は、検索装置において、一つ又は複数の検索単語を用いて、検索対象データ記憶手段に記憶された検索対象データ群を検索する検索方法であって、検索手段が、前記検索単語を用いて前記検索対象データ群を検索する検索ステップと、抽出手段が、検索結果から複数の関連語を抽出する抽出ステップと、選択手段が、前記複数の関連語の一部を検索重要単語として選択する選択ステップと、前記検索手段が、前記検索重要単語を用いて前記検索対象データ群をさらに検索する再検索ステップを含むものである。
【0009】
本願発明の第2の観点は、第1の観点において、前記抽出手段が、前記再検索ステップにおける検索結果から新たに複数の関連語を抽出する再抽出ステップと、個数決定手段が、前記再抽出ステップにおいて抽出された関連語群において、前記検索単語又はその同義語の重要度が高い場合には、前記選択手段が選択する検索重要単語の個数を維持又は増加する個数決定ステップを含むものである。
【0010】
本願発明の第3の観点は、第2の観点において、前記個数決定ステップにおいて、前記個数決定手段は、前記再抽出ステップにおいて抽出された関連語群において、前記検索単語又はその同義語の重要度が低い場合には、前記選択手段が選択する検索重要単語の個数を減少し、前記選択手段が、前記再抽出ステップにおいて抽出された関連語群において、前記検索単語又はその同義語の重要度が高い場合に、前記新たに抽出された複数の関連語から新たな検索重要単語を選択し、前記再抽出ステップにおいて抽出された関連語群において、前記検索単語又はその同義語の重要度が低い場合に、以前に抽出された関連語から個数を減少して新たな検索重要単語を再度選択する再選択ステップを含むものである。
【0011】
本願発明の第4の観点は、第2又は第3の観点において、前記個数決定手段は、前記検索単語又はその同義語の重要度の高低を、前記検索対象データ群全体における前記検索単語又はその同義語の重要度と、前記検索手段による検索結果における前記検索単語又はその同義語の重要度とを比較して決定するものである。
【0012】
本願発明の第5の観点は、第2又は第3の観点において、前記個数決定手段は、前記検索単語又はその同義語の重要度の高低を、前記検索単語と、前記複数の関連語との類似性により決定するものである。
【0013】
本願発明の第6の観点は、第1から第5のいずれかにおいて、前記検索手段は、前記検索対象データ群を検索して、一つ又は複数の検索対象データを抽出し、又は/及び、前記検索対象データ群の全部又は一部に重み付けを行うことにより、前記検索結果を得るものである。
【0014】
本願発明の第7の観点は、一つ又は複数の検索単語を用いて検索対象データ群を検索する検索装置であって、前記検索対象データ群を記憶する検索対象データ記憶手段と、前記検索単語を用いて前記検索対象データ群を検索する検索手段と、前記抽出された検索対象データから複数の関連語を抽出する抽出手段と、選択手段が、前記複数の関連語の一部を検索重要単語として選択する選択手段と、を備え、前記検索手段は、前記検索重要単語を用いて前記検索対象データ群をさらに検索するものである。
【0015】
本願発明の第8の観点は、コンピュータにおいて、第1から第6のいずれかの観点の検索方法を実現するためのプログラムである。
【0016】
なお、選択手段が選択する検索重要単語の個数は、例えば、検索単語の個数よりも大きい値である。これにより、検索単語以外の単語のうち、検索単語に近い意味合いの単語を少なくとも一つ、検索重要単語として選択することができる。また、第2の観点において、個数決定手段は、再検索ステップと再抽出ステップを、個数を維持したまま所定の回数繰り返し、その後に、前記検索単語又はその同義語の重要度が高い場合には、前記選択手段が選択する検索重要単語の個数を増加するものであってもよい。また、第8の観点のプログラムを定常的に記録するコンピュータ読み取り可能な記録媒体として捉えてもよい。
【発明の効果】
【0017】
本願発明の各観点は、単語集合から文書集合を求める工程と、文書集合から単語集合を求める工程とを、交互に繰り返すものである。このとき、選択手段は、関連語のうち、重要度が上位のt個に限定して、検索重要単語を選択する。選択手段が、個数を限定して選択することによって、意味ドリフトを回避することが可能になる。
【0018】
また、本願発明の第2の観点によれば、意味ドリフトの発生を制御しつつ、tの値を増加することが可能になる。
【0019】
さらに、本願発明の第3の観点によれば、意味ドリフトが発生していない状態であれば最新の関連語群から検索重要単語を選択し、意味ドリフトが発生すると以前に抽出された関連語群から個数を減らして検索重要単語を選択することにより、自動的にtの値を調整して、意味ドリフトを回避しつつ、検索処理を実現することが可能になる。
【0020】
なお、本願発明を、第2の観点において、前記検索手段、前記抽出手段及び前記選択手段は、前記再抽出ステップにおいて抽出された複数の関連語において、前記検索単語よりも前記検索結果における重要度が高い単語がk個(kは、予め定められた自然数である。)以上存在するまでtの値を増加して検索して、表示手段に前記検索単語よりも重要度が高い単語の全部又は一部を表示するものとして捉えてもよい。検索装置の利用者は、表示された単語群を参照して、例えば求めたい単語群の一般性をその文書頻度としたとき、目標とする文書頻度Fの単語を求めるためのパラメータtを事前に定めることができる。これにより、tの値によって、意味ドリフトのレベルを調整することができる。
【図面の簡単な説明】
【0021】
【図1】本願発明の実施例に係る検索装置1の概要を示すブロック図である。
【図2】図1の検索装置1の動作の一例を示すフロー図である。
【図3】検索対象データ群が倒産情報に関する文献群であり、検索単語が「建築」である場合に、抽出する単語数tを変更した検索結果を示す図である。
【図4】検索対象データ群が図3と同じ文献群であり、検索単語が「建築」である場合に、「建築」の順位と関連語の上位10個を示す図である。
【図5】図2の検索装置1の動作の具体的な一例を示すフロー図である。
【図6】図3の抽出する個数の決定処理の一例を示すフロー図である。
【図7】図2の検索装置1の動作の具体的な他の一例を示す図である。
【図8】図2の検索装置1の具体的な動作のさらに他の一例を示す図である。
【発明を実施するための形態】
【0022】
以下では、図面を参照して、本願発明の実施例について説明する。なお、本願発明は、この実施例に限定されるものではない。
【実施例】
【0023】
図1は、本願発明の実施例に係る検索装置の概要を示すブロック図である。検索装置1は、文書集合処理部3と、単語集合処理部5と、表示部7を備える。文書集合処理部3は、検索単語記憶部11と、検索対象データ群記憶部13(本願請求項の「検索対象データ群記憶部」の一例)と、検索部15(本願請求項の「検索手段」の一例)と、検索重要単語記憶部17を備える。単語集合処理部5は、検索結果記憶部21と、抽出部23(本願請求項の「抽出手段」の一例)と、関連語記憶部25と、選択部27(本願請求項の「選択手段」の一例)と、個数決定部29(本願請求項の「個数決定手段」の一例)を備える。表示部7は、検索結果等を表示するものである。
【0024】
図2は、図1の検索装置1の動作の一例を示すフロー図である。以下、図1の検索装置1の動作を、図2を参照して説明する。
【0025】
検索単語記憶部11は、一つ又は複数の検索単語を記憶するものである。検索単語は、例えば、検索装置1の利用者が入力したクエリである。検索対象データ群記憶部13は、検索対象データ群を記憶するものである。検索対象データ群は、文書、文と単語を節点とする二分グラフ等の複数の検索対象データである。検索部15は、検索単語を用いて、検索対象データ群を検索する(図2のステップST1)(本願請求項の「検索ステップ」の一例)。以下では、検索部15が、検索結果として、検索対象データ群のうち、一つ又は複数の検索対象データを抽出する場合について説明する。検索部15は、検索結果記憶部21に、検索結果を記憶する。
【0026】
個数決定部29は、選択部27が選択する単語の個数tを決定する。抽出部23は、検索結果記憶部21に記憶された検索対象データから、複数の関連語を抽出する(ステップST2)(本願請求項の「抽出ステップ」の一例)。抽出部23は、関連語記憶部25に対して、抽出部23が抽出した関連語を記憶させる。選択部27は、抽出部23により抽出された関連語のうち、重要度が高い方からt個を検索重要単語として選択する(ステップST3)(本願請求項の「選択ステップ」の一例)。重要度は、例えば、検索結果記憶部21に記憶された検索対象データにおける出現頻度である。選択部27は、検索重要単語記憶部17に、選択した検索重要単語を記憶する。検索部15は、検索重要単語記憶部17に記憶された検索重要単語を用いて、検索対象データ群をさらに検索する(ステップST4)(本願請求項の「再検索ステップ」の一例)。そして、検索装置1は、図2のステップST2〜4の処理を、所定の回数に至るまで、反復して行う(ステップST5)。
【0027】
文書集合処理部3は、文書集合を抽出する。単語集合処理部5は、単語集合を作成する。このとき、選択部27は、関連語のうち、重要度が上位のt個に限定して、検索重要単語を選択する。例えば、十分大きなtに対しては、一般的な重要語が選択される。反復して検索するうちに、一般的な重要語の影響が大きくなる。そのため、単語集合は、一般的な重要語が中心のものとなる。他方、例えば、検索単語が一つの場合に、t=1とすれば、単語集合は基本的に検索単語となる。このように、tの値を小さく設定すれば、特殊な分野や対象についての重要語となる。よって、選択部27が、個数を制限して、関連語の一部を検索重要単語として選択することによって、検索装置1全体として、意味ドリフトを回避しつつ、一つ又は複数の検索単語を用いて、記憶された検索対象データ群を検索することが可能になる。
【0028】
図3は、抽出する単語数tを変更した検索結果を示す図である。横軸は、検索単語の重要度の順位を示す。縦軸は、単語の出現頻度(frequency)を示す。実験では、検索対象データ群を企業の倒産情報に関する文献群とした。検索単語を「建築」とした。実験で使用したtは、2、5、10、50、100、500、1000の7通りである。t=2では、上位の単語でも頻度が低い特殊な単語である。しかし、t=100、1000では、重要度上位の単語は、出現頻度が高い単語(つまり、本来の検索語とか関係なく一般的な単語)である。そのため、tを大きくした場合に、意味ドリフトが生じていることがわかる。よって、例えば、企業の倒産情報を対象として、倒産原因を抽出する検索システムを構築することにより、tを大きくして検索処理を行うことにより、一般的な倒産理由を抽出することもできる。さらに、tを小さくして、例えば「建築」業界に限定した倒産理由を抽出することもできる。
【0029】
図4は、図3と同じ文献群に対して、「建築」をキーワードとして検索して得られる検索結果を示す図である。実験では、図3と同様に、検索対象データ群を企業の倒産情報に関する文献群とした。検索単語を「建築」とした。1列目はtの値である。2列目は上位t個で検索した検索結果における検索単語(つまり、「建築」)の順位である。3列目以降は、関連語の上位10個である。t=1の場合は、建築のみが抽出されている。t=4までは、「建築」は、高い重要度で評価されている。t=5で、「サブプライムローン」という用語があらわれ、やや一般的な傾向を示すようになった。そして、t=30以上で、「減少」という用語が最も高く評価されるようになった。この「減少」等は、検索対象データ群全体で、一般的な単語であると考えられる。その結果、これらの単語の影響が大きくなり、意味ドリフトが発生したものと考えられる。
【0030】
図4より、tが小さい場合には、意味ドリフトを回避することができることがわかる。また、tが大きい場合には、意味ドリフトが発生している。よって、tを変更することにより、意味ドリフトの発生をコントロールすることが可能である。図5及び図6を参照して、予めtを決定して、意味ドリフトの発生をコントロールしつつ、検索処理を行う場合について具体的に説明する。
【0031】
さらに、意味ドリフトが生じた場合、単語集合の上位は、一般的な単語が占める。その結果、図4では、t=50以上で、「建築」の順位は、200位前後となっている。これは、検索対象データ群全体として、「建築」という単語の重要度の評価と考えられる。よって、意味ドリフトが生じたか否かの指標の一つとして、検索単語の重要度の順位を用いることができる。図5〜図8を参照して、この指標を用いて、反復処理において、意味ドリフトが発生したか否かを判断し、適切なtの値を調整するものについて説明する。
【0032】
図5は、図2の検索装置1の動作の具体的な一例を示すフロー図である。まず、個数決定部29は、抽出する単語数tを決定する(ステップSTB1)。続いて、検索部15は、検索単語を用いて、検索対象データ群を検索する(ステップSTB2)。検索部15は、検索結果記憶部21に、検索結果を記憶する。抽出部23は、検索結果記憶部21に記憶された検索対象データから、複数の関連語を抽出する(ステップSTB3)。選択部27は、抽出部23により抽出された関連語のうち、重要度が高い方からt個を検索重要単語として選択する(ステップSTB4)。選択部27は、検索重要単語記憶部17に、選択した検索重要単語を記憶する。検索部15は、検索重要単語記憶部17に記憶された検索重要単語を用いて、検索対象データ群をさらに検索する(ステップSTB5)。そして、検索装置1は、図5のステップSTB3〜5の処理を、所定の回数に至るまで、反復して行う(ステップSTB6)。検索装置1は、表示装置に、検索結果を表示する(ステップSTB7)。
【0033】
図6は、図5のステップSTB1におけるtの決定処理の一例を示すフロー図である。検索装置1の利用者は、検索単語wと、関連語数kを入力する(ステップSTK1)。個数決定部29は、閾値初期値設定処理として、tを、検索単語の個数とする(ステップSTK2)。図6では、検索単語はwの1つのみを仮定している。そのため、tを1とする。続いて、検索部15は、検索単語を用いて、検索対象データ群を検索する(ステップSTK3)(本願請求項の「検索ステップ」の一例)。検索部15は、検索結果記憶部21に、検索結果を記憶する。抽出部23は、検索結果記憶部21に記憶された検索対象データから、複数の関連語を抽出する(ステップSTK4)(本願請求項の「抽出ステップ」の一例)。選択部27は、抽出部23により抽出された関連語のうち、重要度が高い方からt個を検索重要単語として選択する(ステップSTK5)(本願請求項の「選択ステップ」の一例)。図6の説明において、この検索重要単語群を重要度の順位に並べたリストを「関連語リストL」という。選択部27は、検索重要単語記憶部17に、検索語リストLを記憶する。個数決定部29は、L中での検索単語wの重要度順位r=rank(L,w)を計算する(ステップSTK6)。これは、例えば、検索単語wそのものがあらわれる順位でもよく、実質的に同じと評価できる単語(例えば同義語など)があらわれる順位などであってもよい。個数決定部29は、rとkとを比較する(ステップSTK7)。rがk以上であれば、ステップSTK14に進む。rがkよりも小さいならば、ステップSTK8に進む。
【0034】
個数決定部29は、tの値を1増加する(ステップSTK8)。検索部15は、検索重要単語を用いて、検索対象データ群を検索する(ステップSTK9)(本願請求項の「再検索ステップ」の一例)。検索部15は、検索結果記憶部21に、検索結果を記憶する。抽出部23は、検索結果記憶部21に記憶された検索対象データから、複数の関連語を抽出する(ステップSTK10)。選択部27は、抽出部23により抽出された関連語から、新たな関連語リストLを生成する(ステップSTK11)。選択部27は、検索重要単語記憶部17に、検索語リストLを記憶する。個数決定部29は、L中での検索単語wの重要度順位r=rank(L,w)を計算する(ステップSTK12)。個数決定部29は、rとkとを比較する(ステップSTK13)。rがk以上であれば、ステップSTK14に進む。rがkよりも小さいならば、ステップSTK8に進む。なお、ステップSTK13の処理において、所定の回数を経るまでは、個数を維持したままステップSTK8〜STK12の処理を行い、その後に比較処理を行ってもよい。
【0035】
ステップSTK14において、個数決定部29は、表示部7に、Lにおいてwより上位のk個の単語と、wより下位のk個の単語を表示する。
【0036】
図6の処理により、検索装置1は、利用者に対して、tの値を変更して得られる関連語を重要度の降順に並べたとき、表示部7に、入力した検索単語wを中心に、それより上位k個と下位k個を提示する。すなわち、tの値を増加すると、関連語の数も増え、wの順位は下がる(図3、図4参照)。そのため、図6にあるように、t=1から始めて、wより上位の単語がk個以上となるまでtを増加させることで、このようなtを求めることができる。利用者は、表示された単語群により、検索対象データ群の検索処理において、検索単語wを解釈することができる。
【0037】
図7は、図2の検索装置1の動作の具体的な他の一例を示す図である。
【0038】
まず、個数決定部29は、検索対象データ群記憶部13に記憶された検索対象データ群において、検索単語の重要度の順位(以下、この順位を「全体ランク」という。)を求める(ステップSTC1)。なお、全体ランクは、例えば、検索単語が複数の場合には、その最高順位により決定してもよい。また、検索単語及びその同義語のうち、最高順位とするなど、同義語を参酌して決定してもよい。ここで、個数決定部29は、tに初期値を設定する。
【0039】
続いて、検索部15は、検索単語を用いて、検索対象データ群を検索する(ステップSTC2)(本願請求項の「検索ステップ」の一例)。検索部15は、検索結果記憶部21に、検索結果を記憶する。抽出部23は、検索結果記憶部21に記憶された検索対象データから、複数の関連語を抽出する(ステップSTC3)(本願請求項の「抽出ステップ」の一例)。
【0040】
続いて、個数決定部29は、検索結果記憶部21に記憶された検索結果において、検索単語の重要度の順位を求める(ステップSTC4)。以下、この順位を「個別ランク」という。そして、検索装置1は、全体ランクと個別ランクを比較する(ステップSTC5)。全体ランクと個別ランクが近い場合には、意味ドリフトが発生したと判断して、tの値を少なくし(ステップSTC6)、ステップSTC2の処理に戻る。全体ランクと個別ランクが近くない場合には、ステップSTC7の処理を行う。ここで、全体ランクと個別ランクの近さは、例えば、一定数以下か否かという絶対数で判断してもよく、全体ランクを個別ランクで割った値を用いるように、割合的に判断してもよい。
【0041】
個数決定部29は、tの値を維持又は増加する(ステップSTC7)。個数決定部29は、例えば、全体ランクと個別ランクの違いが十分に大きいときにはtの値を増加し、そうでないときには、tの値を維持する。選択部27は、抽出部23により抽出された関連語のうち、重要度が高い方からt個を検索重要単語として選択する(ステップSTC8)(本願請求項の「選択ステップ」の一例)。選択部27は、検索重要単語記憶部17に、選択した検索重要単語を記憶する。
【0042】
検索部15は、検索重要単語記憶部17に記憶された検索重要単語を用いて、検索対象データ群をさらに検索する(ステップSTC9)(本願請求項の「再検索ステップ」の一例)。検索部15は、検索結果記憶部21に、検索結果を記憶する。抽出部23は、検索結果記憶部21に記憶された検索対象データから、複数の関連語を抽出する(ステップSTC10)続いて、個数決定部29は、個別ランクを新たに求める(ステップSTC11)。そして、検索装置1は、全体ランクと個別ランクを比較する(ステップSTC12)。全体ランクと個別ランクが近い場合には、意味ドリフトが発生したと判断して、tの値を少なくし(ステップSTC13)、ステップSTC2の処理に戻る。全体ランクと個別ランクが近くない場合には、個数決定部29は、tの値を維持又は増加する(ステップSTC14)。選択部27は、抽出部23により抽出された関連語のうち、重要度が高い方からt個を検索重要単語として選択する(ステップSTC15)。そして、検索装置1は、ステップSTC9〜15の処理を、所定の回数に至るまで、反復して行う(ステップSTC16)。なお、ステップSTC12の処理において、所定の回数を経るまでは、tを維持したままステップSTC9〜STC16の処理を行い、その後に比較処理を行ってもよい。
【0043】
図7の処理により、関連語の重要度の順位によって意味ドリフトが発生したか否かを判断し、tの値を増減することにより、自動的に、tの値を調整して、意味ドリフトを回避しつつ、検索処理を実現することが可能になる。
【0044】
図8は、図2の検索装置1の具体的な動作のさらに他の一例を示す図である。
【0045】
まず、個数決定部27は、tに初期値を設定する。検索部15は、検索単語を用いて、検索対象データ群を検索する(ステップSTD1)(本願請求項の「検索ステップ」の一例)。検索部15は、検索結果記憶部21に、検索結果を記憶する。抽出部23は、検索結果記憶部21に記憶された検索対象データから、複数の関連語を抽出する(ステップSTD2)(本願請求項の「抽出ステップ」の一例)。抽出部23は、関連語記憶部25に、抽出された関連語を記憶する。選択部27は、関連語記憶部25に記憶された関連語のうち、重要度が高い方からt個を検索重要単語として選択する(ステップSTD3)(本願請求項の「選択ステップ」の一例)。選択部27は、検索重要単語記憶部17に、選択した検索重要単語を記憶する。
【0046】
検索部15は、検索重要単語記憶部17に記憶された検索重要単語を用いて、検索対象データ群をさらに検索する(ステップSTD4)(本願請求項の「再検索ステップ」の一例)。検索部15は、検索結果記憶部21に、検索結果を記憶する。抽出部23は、検索結果記憶部21に記憶された検索対象データから、複数の関連語を抽出する(ステップSTD5)。抽出部23は、関連語記憶部25に、以前に抽出された関連語とは区別して、新たに抽出された関連語を記憶する。続いて、個数決定部29は、新たに抽出された関連語と検索単語との類似度を計算する。類似度が高い場合には、意味ドリフトが発生していないと判断し、ステップSTD8の処理を行う。類似度が低い場合には、意味ドリフトが発生したと判断し、ステップSTD10の処理を行う。類似度は、例えば、新たに抽出された関連語について、重要度に応じた重み付けを行い、検索単語(同義語を含んでもよい。)と比較して計算してもよい。また、t以上の個数を抽出して、検索単語(同義語を含んでもよい。)と比較して計算してもよい。
【0047】
ステップSTD8において、個数決定部29は、tの値を維持又は増加する。例えば、類似度が十分に大きい場合には、tの値を増加する。続いて、選択部27は、新たに抽出された関連語群から、重要度が高い方からt個を検索重要単語として選択する(ステップSTD9)。そして、ステップSTD12に進む。
【0048】
ステップSTD10において、個数決定部29は、tの値を減らす。そして、選択部27は、以前に抽出された関連語群から、重要度が高い方からt個を選択する(ステップSTD11)。なお、検索重要単語記憶部17には、直前に選択した検索重要単語が記憶されている。そのため、この検索重要単語記憶部17に記憶された検索重要単語の一部を、新たな検索重要単語として選択してもよい。選択部27は、ステップSTD9又はステップSTD11の処理に続き、検索重要単語記憶部17に選択した検索重要単語を記憶し、ステップSTD12の処理を行う。
【0049】
ステップSTD12では、検索部15は、検索重要単語記憶部17に記憶された検索重要単語を用いて、検索対象データ群をさらに検索する(本願請求項の「再検索ステップ」の一例)。そして、検索装置1は、図8のステップSTD5〜12の処理を、所定の回数に至るまで、反復して行う(ステップSTD13)。なお、ステップSTD7の処理において、所定の回数を経るまでは、tを維持させたままステップSTD5〜STD13の処理を行い、その後に判断処理を行ってもよい。
【0050】
図8の処理によれば、意味ドリフトが発生していない状態であれば最新の関連語群から検索重要単語を選択し、意味ドリフトが発生すると以前の関連語群からtを減らして検索重要単語を選択することにより、自動的にtの値を調整して、意味ドリフトを回避しつつ、検索処理を実現することが可能になる。
【0051】
なお、検索部15は、例えば、複数の検索対象データを抽出して、抽出された検索対象データに重み付けを行うものであってもよい。また、検索部15は、検索対象データ群の全部に対して重み付けを行うものであってもよい。(検索対象データ群の一部を選択することは、例えば、各検索対象データに対して0又は1の重み付けを行っていると捉えることができる。)この場合、抽出部23及び選択部27は、低く重み付けされた検索対象データにのみ表われる単語よりも、高く重み付けされた検索対象データに表われる単語を重視して、関連語を抽出し、検索重要単語を選択する。
【0052】
また、図7では、重要度の順位により、tの値を調整した。図8では、関連語と検索単語の類似度により、tの値を調整した。図7において、図8と同様に、関連語と検索単語の類似度により調整するようにしてもよい。図8において、図7と同様に、検索単語の重要度の順位により、tの値を調整するようにしてもよい。また、両方を加味して、調整するようにしてもよい。
【符号の説明】
【0053】
1 検索装置、3 文書集合処理部、5 単語集合処理部、7 表示部、11 検索単語記憶部、13 検索対象データ群記憶部、15 検索部、17 検索重要単語記憶部、21 検索結果記憶部、23 抽出部、25 関連語記憶部、27 選択部、29 個数決定部
【特許請求の範囲】
【請求項1】
検索装置において、一つ又は複数の検索単語を用いて、検索対象データ記憶手段に記憶された検索対象データ群を検索する検索方法であって、
検索手段が、前記検索単語を用いて前記検索対象データ群を検索する検索ステップと、
抽出手段が、検索結果から複数の関連語を抽出する抽出ステップと、
選択手段が、前記複数の関連語の一部を検索重要単語として選択する選択ステップと、
前記検索手段が、前記検索重要単語を用いて前記検索対象データ群をさらに検索する再検索ステップを含む検索方法。
【請求項2】
前記抽出手段が、前記再検索ステップにおける検索結果から新たに複数の関連語を抽出する再抽出ステップと、
個数決定手段が、前記再抽出ステップにおいて抽出された関連語群において、前記検索単語又はその同義語の重要度が高い場合には、前記選択手段が選択する検索重要単語の個数を維持又は増加する個数決定ステップを含む請求項1記載の検索方法。
【請求項3】
前記個数決定ステップにおいて、前記個数決定手段は、前記再抽出ステップにおいて抽出された関連語群において、前記検索単語又はその同義語の重要度が低い場合には、前記選択手段が選択する検索重要単語の個数を減少し、
前記選択手段が、
前記再抽出ステップにおいて抽出された関連語群において、前記検索単語又はその同義語の重要度が高い場合に、前記新たに抽出された複数の関連語から新たな検索重要単語を選択し、
前記再抽出ステップにおいて抽出された関連語群において、前記検索単語又はその同義語の重要度が低い場合に、以前に抽出された関連語から個数を減少して新たな検索重要単語を再度選択する再選択ステップを含む請求項2記載の検索方法。
【請求項4】
前記個数決定手段は、前記検索単語又はその同義語の重要度の高低を、前記検索対象データ群全体における前記検索単語又はその同義語の重要度と、前記検索手段による検索結果における前記検索単語又はその同義語の重要度とを比較して決定する、請求項2又は3に記載の検索方法。
【請求項5】
前記個数決定手段は、前記検索単語又はその同義語の重要度の高低を、前記検索単語と、前記複数の関連語との類似性により決定する、請求項2又は3に記載の検索方法。
【請求項6】
前記検索手段は、前記検索対象データ群を検索して、一つ又は複数の検索対象データを抽出し、又は/及び、前記検索対象データ群の全部又は一部に重み付けを行うことにより、前記検索結果を得るものである、請求項1から5のいずれかに記載の検索方法。
【請求項7】
一つ又は複数の検索単語を用いて検索対象データ群を検索する検索装置であって、
前記検索対象データ群を記憶する検索対象データ記憶手段と、
前記検索単語を用いて前記検索対象データ群を検索する検索手段と、
前記抽出された検索対象データから複数の関連語を抽出する抽出手段と、
選択手段が、前記複数の関連語の一部を検索重要単語として選択する選択手段と、を備え、
前記検索手段は、前記検索重要単語を用いて前記検索対象データ群をさらに検索する、検索装置。
【請求項8】
コンピュータにおいて、請求項1から6のいずれかに記載の検索方法を実現するためのプログラム。
【請求項1】
検索装置において、一つ又は複数の検索単語を用いて、検索対象データ記憶手段に記憶された検索対象データ群を検索する検索方法であって、
検索手段が、前記検索単語を用いて前記検索対象データ群を検索する検索ステップと、
抽出手段が、検索結果から複数の関連語を抽出する抽出ステップと、
選択手段が、前記複数の関連語の一部を検索重要単語として選択する選択ステップと、
前記検索手段が、前記検索重要単語を用いて前記検索対象データ群をさらに検索する再検索ステップを含む検索方法。
【請求項2】
前記抽出手段が、前記再検索ステップにおける検索結果から新たに複数の関連語を抽出する再抽出ステップと、
個数決定手段が、前記再抽出ステップにおいて抽出された関連語群において、前記検索単語又はその同義語の重要度が高い場合には、前記選択手段が選択する検索重要単語の個数を維持又は増加する個数決定ステップを含む請求項1記載の検索方法。
【請求項3】
前記個数決定ステップにおいて、前記個数決定手段は、前記再抽出ステップにおいて抽出された関連語群において、前記検索単語又はその同義語の重要度が低い場合には、前記選択手段が選択する検索重要単語の個数を減少し、
前記選択手段が、
前記再抽出ステップにおいて抽出された関連語群において、前記検索単語又はその同義語の重要度が高い場合に、前記新たに抽出された複数の関連語から新たな検索重要単語を選択し、
前記再抽出ステップにおいて抽出された関連語群において、前記検索単語又はその同義語の重要度が低い場合に、以前に抽出された関連語から個数を減少して新たな検索重要単語を再度選択する再選択ステップを含む請求項2記載の検索方法。
【請求項4】
前記個数決定手段は、前記検索単語又はその同義語の重要度の高低を、前記検索対象データ群全体における前記検索単語又はその同義語の重要度と、前記検索手段による検索結果における前記検索単語又はその同義語の重要度とを比較して決定する、請求項2又は3に記載の検索方法。
【請求項5】
前記個数決定手段は、前記検索単語又はその同義語の重要度の高低を、前記検索単語と、前記複数の関連語との類似性により決定する、請求項2又は3に記載の検索方法。
【請求項6】
前記検索手段は、前記検索対象データ群を検索して、一つ又は複数の検索対象データを抽出し、又は/及び、前記検索対象データ群の全部又は一部に重み付けを行うことにより、前記検索結果を得るものである、請求項1から5のいずれかに記載の検索方法。
【請求項7】
一つ又は複数の検索単語を用いて検索対象データ群を検索する検索装置であって、
前記検索対象データ群を記憶する検索対象データ記憶手段と、
前記検索単語を用いて前記検索対象データ群を検索する検索手段と、
前記抽出された検索対象データから複数の関連語を抽出する抽出手段と、
選択手段が、前記複数の関連語の一部を検索重要単語として選択する選択手段と、を備え、
前記検索手段は、前記検索重要単語を用いて前記検索対象データ群をさらに検索する、検索装置。
【請求項8】
コンピュータにおいて、請求項1から6のいずれかに記載の検索方法を実現するためのプログラム。
【図1】


【図2】
【図4】

【図5】
【図6】
【図7】
【図8】
【図3】
【図2】
【図4】
【図5】
【図6】
【図7】
【図8】
【図3】
【公開番号】特開2012−234485(P2012−234485A)
【公開日】平成24年11月29日(2012.11.29)
【国際特許分類】
【出願番号】特願2011−104414(P2011−104414)
【出願日】平成23年5月9日(2011.5.9)
【出願人】(504145342)国立大学法人九州大学 (960)
【公開日】平成24年11月29日(2012.11.29)
【国際特許分類】
【出願日】平成23年5月9日(2011.5.9)
【出願人】(504145342)国立大学法人九州大学 (960)
[ Back to top ]