
概周期性を持つデジタルデータに対する異常信号検出システムの初期設定の自動化方法および装置

【課題】 本発明は、従来の方法の初期設定の時間を短縮し、さらに確率モデルおよびしきい値の初期設定を自動化するための方法および装置を提供することを目的とする。
【解決手段】 本発明は、概周期性を持つデジタルデータに対する異常信号検出システムの初期設定の自動化のための方法であって、概周期性を持つデジタルデータの部分系列から学習系列を取得する、学習系列設定工程と、学習系列から確率モデルを構築する、確率モデル構築工程と、構築された確率モデルを用いて、確率モデルの構築に利用した学習系列を圧縮するデータ圧縮工程と、データ圧縮工程で圧縮されたデータを用いて、確率モデルに対する検出用のしきい値を設定する、しきい値設定工程とを含む、異常信号検出システムの初期設定の方法を提供する。
【解決手段】 本発明は、概周期性を持つデジタルデータに対する異常信号検出システムの初期設定の自動化のための方法であって、概周期性を持つデジタルデータの部分系列から学習系列を取得する、学習系列設定工程と、学習系列から確率モデルを構築する、確率モデル構築工程と、構築された確率モデルを用いて、確率モデルの構築に利用した学習系列を圧縮するデータ圧縮工程と、データ圧縮工程で圧縮されたデータを用いて、確率モデルに対する検出用のしきい値を設定する、しきい値設定工程とを含む、異常信号検出システムの初期設定の方法を提供する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、概周期性を持つデジタルデータに対する異常信号検出システムの初期設定の自動化のための方法および自動化のための装置に関する。具体的には、本発明は、不整脈波形の検出装置における初期設定の自動化のための方法および自動化のための装置に関する。
【背景技術】
【0002】
概周期性を持つデジタルデータである心電図データをデータ圧縮する手法がいくつか提案されている。たとえば、固定幅の時間窓内の平均圧縮率が与えられたしきい値を超えた場合に、超過部分を含む波形を異常波形(不整脈)として判断する手法が提案されている(たとえば、非特許文献1を参照)。また、圧縮率ではなく、同じ患者から得られた二つの心電図データの相互情報量を用いた不整脈検出方法が提案されている(たとえば、特許文献1を参照。)。
【0003】
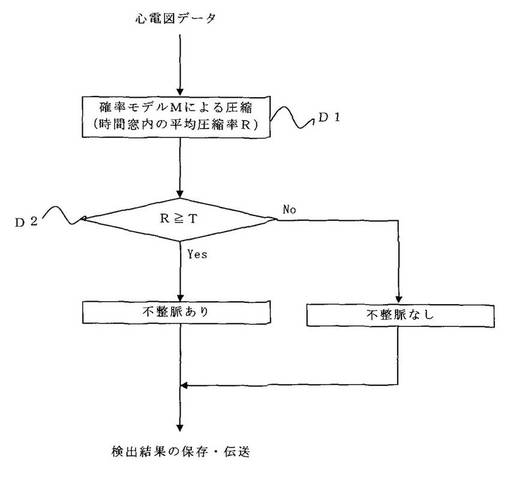
図4に、非特許文献1の方法のフロー図を示す。当該手法では、検出用の確率モデルとしきい値の初期設定のための工程(S1)、先の確率モデルを用いて心電図データを圧縮する工程(S2)、圧縮率が先のしきい値を超えた場合に不整脈であると判断する工程(S3)の流れで不整脈の検出を行う方法である。
【0004】
S1においては、まず、心電図データから所定拍数(X拍)連続する正常同調律をすべて(Yセット)取り出し、Yセットの集まりから、セットの合計時間が所定時間範囲内となるようにNセットを取り出す。与えられたデータに関する所定時間範囲の取得方法については、非特許文献2に示されている。
【0005】
次に、Nセットの正常同調律W1、W2、…、WNから、それぞれの反辞書A1、A2、…、ANを構築する。次いで、A1、A2、…、ANのすべてに共通な要素の集合(反辞書A)を得る。
【0006】
ここで、与えられたデータ系列に対して、自分自身のパターンは現れないが、先頭の1データを削ったパターンと末尾の1データを削ったパターンがいずれも与えられたデータ系列に現れるような系列を極小禁止語と呼び、与えられたデータ系列に対するすべての極小禁止語の集まりを反辞書と呼ぶ。
【0007】
次に、反辞書Aから圧縮に利用するための確率モデルを構築する。非特許文献1の方法では、W1、W2、…、WNを連結したものを学習系列と呼ぶ。
【0008】
続いて、検出精度がよい確率モデルMおよびしきい値Tを得るために、Yセットからセットの合計時間が所定時間範囲を満たすように任意に選んで得られる学習系列およびしきい値として設定可能な数値のすべての組み合わせに対して、心電図データ全体に対する不整脈検出の予備実験(初期設定)を行い、最もよい検出率が得られた確率モデルとしきい値の組み合わせを検出に用いる確率モデルMおよびしきい値Tとして設定する。
【0009】
S2においては、図1の圧縮処理(D1)に示すように、確率モデルMを用いて心電図データを圧縮し、固定時間幅の時間窓内の平均圧縮率Rを計算する。たとえば、図7に示したように、上段の心電図データを圧縮すると、下段の圧縮率データが得られる。
【0010】
S3においては、図1の検出処理(D2)に示すように、平均圧縮率Rがしきい値Tを超えた場合に時間窓内のデータの先頭位置を含む波形を不整脈と判断する。たとえば、図7に示したように、下段の圧縮率データにおいて、しきい値T=1.5と設定すると、しきい値T=1.5を越えているデータの先頭位置を含む波形は、不整脈と判断される。
【0011】
一方、特許文献1の方法では、二つ以上の心電図データの相互情報量を計算するために、患者に複数の電極を設置して、同じ患者から異なる電極から得られる二つ以上の心電図データを測定する必要がある。
【0012】
通常の心電図データの測定では、特許文献1の方法に必要とされる複数の心電図データは得られないため、一般的な心電図データにおける異常波形の検出に関しては、特許文献1の方法は適さない問題点がある。
【先行技術文献】
【特許文献】
【0013】
【特許文献1】特開2008-200120号公報
【非特許文献】
【0014】
【非特許文献1】太田隆博、森田啓義、外2名、“反辞書符号化法を用いた不整脈検出”、平成22年5月14日、電子情報通信学会技術研究報告、MBE、MEとバイオサイバネティックス、110巻、52号、35-40ページ、社団法人電子情報通信学会
【非特許文献2】太田隆博、森田啓義、“反辞書を用いた心電図の1パス無ひずみ圧縮 ”、電子情報通信学会論文誌A、J87-A巻、9号、1187-1195ページ、平成16年9月、社団法人電子情報通信学会
【発明の概要】
【発明が解決しようとする課題】
【0015】
非特許文献1の方法は、一般的な心電図データに対して、異常波形検出を行うことができる。しかしながら、非特許文献1の方法の一つ目の問題点として、確率モデルMおよびしきいT値の設定のために、心電図データ全体を必要とするため、測定と同時に不整脈検出を行うことができないという問題点がある。
【0016】
また、心電図データには、学習系列として利用可能な正常同調律の組み合わせが多く存在する。さらに、しきい値に関しても、その候補として、心電図データを圧縮したときの圧縮率の下限値と上限値の範囲内の値のすべてが該当する。したがって、二つ目の問題点として、非特許文献1の方法では、初期設定において、調べなければならない確率モデルおよびしきい値の組み合わせが非常に多くなり、この処理に時間がかかるという問題点がある。
【0017】
本発明は、上記の二つの問題点を解決して、非特許文献1の方法の初期設定の時間を短縮し、さらに、確率モデルおよびしきい値の初期設定を自動化するための方法および装置を提供することを目的とする。
【課題を解決するための手段】
【0018】
本発明は、概周期性を持つデジタルデータに対する異常信号検出システムの初期設定の自動化のための方法であって、前記概周期性を持つデジタルデータの部分系列から学習系列を取得する、学習系列設定工程と、前記学習系列から確率モデルを構築する、確率モデル構築工程と、前記構築された確率モデルを用いて、前記確率モデルの構築に利用した学習系列を圧縮するデータ圧縮工程と、前記データ圧縮工程で圧縮されたデータを用いて、前記確率モデルに対する検出用のしきい値を設定する、しきい値設定工程とを含む、異常信号検出システムの初期設定の方法を提供する。
【0019】
また、本発明は、前記しきい値は、式1:
TI=(INT(RI×C)+1)/C
(式中、Cは、100であり、INT(RI×C)は、RI×Cの整数部分を表し、RIは、圧縮率の中の最大値を表す。)
によって算出される、上記方法を提供する。
【0020】
さらに、本発明は、概周期性を持つデジタルデータに対する異常信号検出システムの初期設定の自動化のための装置であって、前記概周期性を持つデジタルデータの部分系列から学習系列を取得する、学習系列設定手段と、前記学習系列から確率モデルを構築する、確率モデル構築工程と、前記構築された確率モデルを用いて、前記確率モデルの構築に利用した学習系列を圧縮するデータ圧縮手段と、前記データ圧縮工程で圧縮されたデータを用いて、前記確率モデルに対する検出用のしきい値を設定する、しきい値設定手段とを備える装置を提供する。
【0021】
また、本発明は、前記しきい値は、式1:
TI=(INT(RI×C)+1)/C
(式中、Cは、100であり、INT(RI×C)は、RI×Cの整数部分を表し、RIは、圧縮率の中の最大値を表す。)
によって算出される、上記の異常信号検出システムの初期設定の方法を提供する。
【0022】
さらに、本発明は、不整脈波形の検出装置であって、心電図データの部分系列から学習系列を取得する、学習系列設定手段と、前記学習系列から確率モデルを構築する、確率モデル構築工程と、前記構築された確率モデルを用いて、前記確率モデルの構築に利用した学習系列を圧縮するデータ圧縮手段と、前記データ圧縮工程で圧縮されたデータを用いて、前記確率モデルに対する検出用のしきい値を設定する、しきい値設定手段とを備える、不整脈波形の検出装置を提供する。
【0023】
また、本発明は、前記構築された確率モデルおよび前記設定されたしきい値のペアを用いて、テストデータに対して異常信号検出を行う、テストデータに対する検出工程と、前記得られた検出結果から、実際の信号に対する異常信号検出に用いるための確率モデルとしきい値のペアを選出する、検出用ペアの設定工程とをさらに含む、上記方法を提供する。
【0024】
また、本発明は、前記構築された確率モデルおよび前記設定されたしきい値のペアを用いて、テストデータに対して異常信号検出を行う、テストデータに対する検出手段と、前記得られた検出結果から、実際の信号に対する異常信号検出に用いるための確率モデルとしきい値のペアを選出する、検出用ペアの設定手段と、
をさらに備える、上記装置を提供する。
【発明の効果】
【0025】
本発明の方法および装置によれば、心電図データにおける不整脈波形などの、概周期性を持つデジタルデータに対する異常信号検出システムにおいて、初期設定の時間を短縮することができる。また、本発明の方法および装置によれば、心電図データにおける不整脈波形などの、概周期性を持つデジタルデータに対する異常信号検出システムにおいて、確率モデルおよびしきい値の初期設定を自動化することができる。したがって、本発明の方法および装置によれば、テストデータを用意することにより、データの入力から不整脈検出までのすべてを自動化できる。
【図面の簡単な説明】
【0026】
【図1】非特許文献1に記載された、従来の方法の不整脈検出処理部分のフロー図。
【図2】本発明の方法において、心電図データから学習系列を取得する位置の関係を表した図。
【図3】本発明の方法において、心電図データからの学習系列の長さと所定時間範囲との関係を表した図。
【図4】非特許文献1に記載された、従来の方法のフロー図。
【図5】本発明の方法の一実施形態に係る確率モデルおよびしきい値の設定方法を示すフロー図。
【図6】本発明の装置の一実施形態に係る不整脈の異常信号検出装置における処理を示した図。
【図7】心電図データから得られる圧縮データとしきい値とを示す図。
【発明を実施するための形態】
【0027】
以下、本発明の概周期性を持つデジタルデータに対する異常信号検出システムの初期設定の自動化のための方法について、図面を参照して説明する。また、概周期性を持つデジタルデータの例として、特に心電図データを使用した場合について説明する。
【0028】
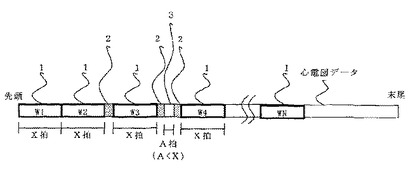
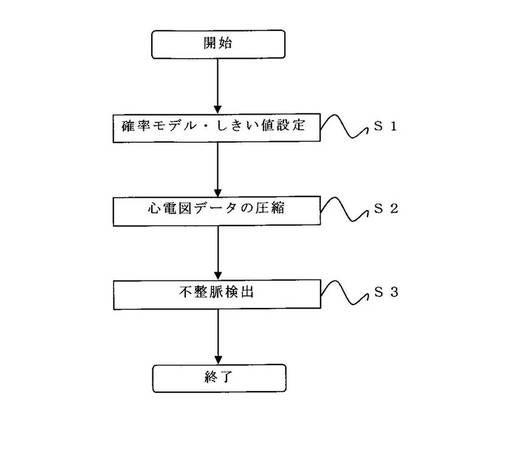
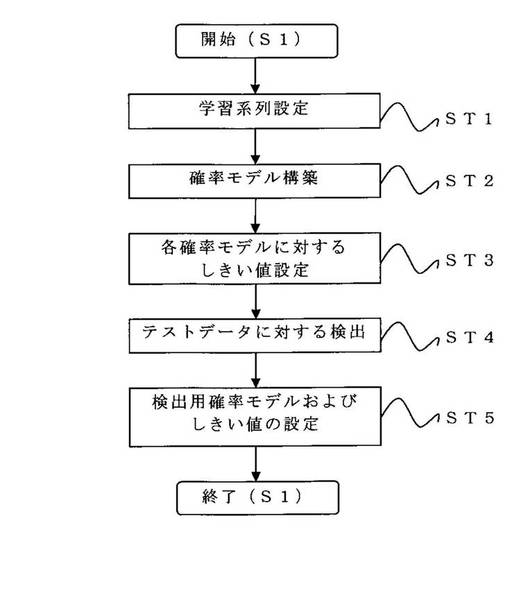
本発明の方法は、図5に示した工程にしたがって異常信号検出システムの初期設定を行う。本発明の方法は、まず、学習系列設定工程(ST1)において、概周期性を持つデジタルデータの部分系列から学習系列を取得する。本発明の方法において、学習系列は、データ全体ではなく、データの一部分のみを使用して構築される。たとえば、学習系列を設定するためには、図2に示すように、一連の心電図データの先頭から順番に正常同調律を所定拍数(X拍)単位毎に取得する。図2に示したように、心電図データにおいては、所定拍数(X拍)単位の正常同調律1をそれぞれ(W1、W2、…、WN)と表す。この所定拍数(X拍)単位の正常同調律1(W1、W2、…、WN)を連結したものを学習系列として設定する。一方、異常波形2は、学習系列から排除する。また、図2に示されるように、X拍に満たないA拍の正常同調律も、学習系列から排除する。
【0029】
したがって、本発明の方法において、学習系列は、一連の概周期性を持つデジタルデータのうち、所定の周期(X周期)単位で取得されるデータを連結したものをいう。また、学習系列には、所定の周期数単位に満たないデータを含まない。また、学習系列には、周期性を持たない部分のデータを含まない。
【0030】
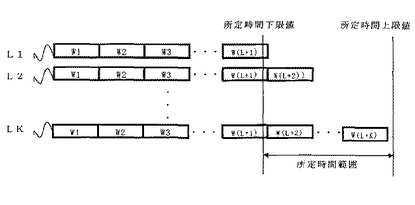
学習系列設定工程(ST1)では、図3に示されるように、学習系列をK個作成することもできる。作成された学習系列は、たとえば学習系列長について昇順にそれぞれL1、…、LKとする。以下、複数個の学習系列LJ(J=1、…、K)がある場合について説明する。
【0031】
次に、確率モデル構築工程(ST2)では、ST1で設定した学習系列に対して確率モデルを構築する。確率モデルを構築するためには、まず学習系列LJ(J=1、…、K)に対して、LJを構成するIセットの正常同調律W1、…、WIからそれぞれ反辞書A1、…、AIを生成する。
【0032】
本明細書において、与えられたデータ系列に対して、自分自身のパターンは現れないが、先頭の1データを削ったパターンと末尾の1データを削ったパターンがいずれも与えられたデータ系列に現れるような系列を極小禁止語と呼ぶ。そして、与えられたデータ系列に対するすべての極小禁止語の集まりを反辞書と呼ぶ。反辞書は、非特許文献1に記載されたとおりに生成することができる。簡潔には、以下のとおりに反辞書を生成することができる。
【0033】
まず、データ系列に出現するすべてのパターンを登録したデータ構造である辞書を生成する。次に、パターンの末尾に1データを付加して、そのパターンが極小禁止語の3つの条件を満たすかどうかをチェックし、条件を満たしていれば、そのパターンを反辞書に登録する。これを辞書に登録されたすべてのパターンに対して行う。このチェックを高速かつ省メモリで行う反辞書生成方法の一つとして、たとえばT. Ota and H. Morita, “On the Construction of an Antidictionary with Linear Complexity Using the Suffix Tree”, IEICE Transactions on Fundamentals of Electronics Communications and Computer Sciences、Vol. E90-A, No. 11, pp. 2533-2539, November 2007, The Institute of Electronics, Information and Communication Engineers(IEICE)に示される方法がある。
【0034】
続いて、A1、…、ANのすべてに共通な要素の集まりAJを取得する。次いで、反辞書AJから、確率モデルMJを構築する。簡潔には、以下のとおりに確率モデルを生成することができる。
【0035】
反辞書による確率モデルは、極小禁止語を部分列として受理しない決定性有限オートマトンである。生成方法としては、まず、反辞書に含まれるすべての極小禁止語をデータ検索によく用いられる木構造と呼ばれるデータ構造で表現する。生成された木の各接点は、ある極小禁止語の先頭データ列(極小禁止語自身を含む)のいずれかと対応している。次に、任意の節点Aに対応するデータ列の終端に任意の1データ(Z)を追加した新データ列を用意し、この新データ列に対応する節点Bを探索する。対応する節点がない場合には、新データ列の先頭1データを削りながら、節点Bが見つかるまで探索を行う。節点Bが見つかったなら、節点AからデータZでの遷移先として節点Bを設定する。この処理をすべての節点に対して、出現可能性のある1データを追加した場合で行うと確率モデルが生成される。これを高速に行う方法として、たとえばM. Crochemore, F. Mignosi, and A. Restivo, “Automata and Forbidden Words”, Information Processing Letters, Vol. 67, No. 3, pp. 111-117, October 1998.に示される方法がある。
【0036】
したがって、本発明の方法において、確率モデルは、学習系列から生成される反辞書A1、…、ANにおいて、A1、…、ANの要素を部分列として含むような系列を受理しない決定性有限オートマンである。
【0037】
次に、確率モデルに対するしきい値設定工程(ST3)では、構築された確率モデルを用いて、確率モデルの構築に利用した学習系列を圧縮する。複数個の学習系列LJ(J=1、…、K)がある場合、K個の確率モデルM1、…、MKを用いて、それぞれの確率モデル構築に利用した学習系列L1、…、LKを圧縮する。簡潔には、以下のとおりに学習系列圧縮することができる。
【0038】
圧縮を行うために、決定性有限オートマトン(確率モデル)の初期節点からデータ系列により、オートマトン上の節点の遷移を行う。圧縮は、遷移において、節点が遷移先として一つの節点しか持たない場合には、その遷移に用いた1データを削除、節点が二つ以上の遷移先を持つ場合には、節点においてデータ毎の遷移回数をカウントし、各データの出現確率をエントロピー符号と呼ばれる圧縮手法を用いて行われる。具体的には、T. OTA, “Antidictionary Data Compression Using Dynamic Suffix Trees”, Ph.D. Thesis, The University of Electro-Communications, 2007.に示される方法がある。
【0039】
次いで、得られた圧縮率の中でのそれぞれの最大値R1、…、RKに対して、数式1により、確率モデルM1、…、MKに対するそれぞれのしきい値T1、…、TKを定める。
【0040】
数式1 TI=(INT(RI×C)+1)/C
式中、Cは、100であり、INT(RI×C)は、RI×Cの整数部分を表し、RIは、圧縮率の中の最大値を表す。
【0041】
上記の工程により、概周期性を持つデジタルデータに対する異常信号検出システムの初期設定において、心電図などの概周期性を持つデジタルデータから、周期性を持つデジタルデータと異常信号とを区別するためのしきい値を自動的に設定することができる。具体的には、上記工程により、図7に示したように、上段の心電図データから、下段の圧縮率データおよびしきい値(図7の場合、T=1.5)を自動的に設定することができる。
【0042】
本発明の方法において、複数個の学習系列LJ(J=1、…、K)がある場合、図5に示したように、さらにテストデータに対する検出工程(ST4)を含むことができる。
【0043】
テストデータに対する検出工程(ST4)では、確率モデルとしきい値のペア(M1、T1)、…、(MK、TK)を用いて、所定時間範囲内の長さのテストデータに対して、異常信号検出(心電図の場合、不整脈検出)のための実験を行うことができる。ここで、テストデータは、医師等により波形ごとに正常同調律とそれ以外の判別が行われているものを利用することが好ましい。検出精度は、表1に示される頻度tp、fn、tn、fpを用いて、感度(sensitivity)=tp/(tp+fn)×100 (%)、特異度(specificity)=tn/(tn+fp)×100(%)により計算される。
【0044】
【表1】

【0045】
検出用確率モデルとしきい値の設定工程(ST5)では、テストデータに対する検出工程(ST4)で求められた感度と特異度の和が最も大きくなる確率モデルとしきい値のペア(MJ、TJ)を検出用の確率モデルおよびしきい値(M、T)として設定する。最大値を取るペアが複数存在する場合には、学習系列が最も長いものを選ぶ。
【0046】
上記方法において、所定拍数と所定時間範囲およびテストデータの長さを、患者の様態や心電図データの測定精度に合わせて変更可能であることとしてよい。
【0047】
また、上記方法において、Cは、10以上の10のべき乗の値に変更することができる。
【0048】
また、上記発明においては、平均圧縮率取得に係る時間窓の幅は、心電図データの測定精度に合わせて、変更することができる。
【0049】
また、上記方法の説明において、概周期性を持つデジタルデータとして、心電図データについて説明したが、代わりに任意の概周期性を持つデジタルデータを使用してもよい。この場合、正常同調律および不整脈を検出する代わりに、それぞれデジタルデータにおける正常信号および異常信号を検出することができる。
【0050】
図6は、本発明に方法を利用した確率モデルおよびしきい値の自動設定装置の回路構成図を示す。概周期性を持つデジタルデータとして心電図データを使用し、異常信号として心電図における不整脈を検出する場合を例示している。
【0051】
図6において、PC5は、入力として、入出力装置4から正常波形と異常波形が識別済みの心電図データを読み込む。一方、出力として、検出用の確率モデルおよびしきい値のペアを異常信号検出装置6に出力する。演算ブロック内の各手段13〜18の呼び出し順序などは、プログラム(ROM)12に格納されている。
【0052】
詳細な手順としては、PC5内部において、CPU11は、最初に、入力された識別済み心電図データから演算ブロック7の学習系列設定手段13を用いて、学習系列LJ(J=1、…、K)を生成する。生成された学習系列は、反辞書テーブル(RAM)8に格納される。
【0053】
続いて、CPU11は、学習系列・反辞書テーブル(RAM)8に格納された学習系列LJ(J=1、…、K)から、演算ブロック7の反辞書構築手段14を用いて、それぞれの反辞書AJ(J=1、…、K)を構築する。構築された反辞書AJは、学習系列・反辞書テーブル(RAM)8に格納される。
【0054】
続いて、CPU11は、学習系列・反辞書テーブル(RAM)8に格納された反辞書AJ(J=1、…、K)から、確率モデル構築手段15を用いて、それぞれに対応する確率モデルMJ(J=1、…、K)を構築する。構築された確率モデルMJは、確率モデル・しきい値テーブル(RAM)9に格納される。
【0055】
続いて、CPU11は、確率モデル・しきい値テーブル(RAM)9に格納された確率モデルMJ(J=1、…、K)およびデータ圧縮部10により、学習系列・反辞書テーブル(RAM)8に格納されたMJの構築に用いた学習系列LJを圧縮する。圧縮後、演算ブロック7の最大値検出手段16を用いて、圧縮率の最大値RJを得る。さらに、このRJおよび数式1から、しきい値設定手段17を用いて、しきい値TJを得る。得られたしきい値TJは、確率モデル・しきい値テーブル(RAM)9に格納される。
【0056】
上記のとおりの手順により、概周期性を持つデジタルデータに対する異常信号検出システムの初期設定において、心電図などの概周期性を持つデジタルデータから、周期性を持つデジタルデータと異常信号とを区別するためのしきい値を自動的に設定することができる。
【0057】
本発明の装置において、学習系列LJは、1つであることができるが、上記のように複数個の学習系列LJ(J=1、…、K)を生成する場合、図6に示したように、さらに以下の処理を行うことができる。
【0058】
CPU11は、確率モデル・しきい値テーブル(RAM)9に格納された確率モデルとしきい値のペア(MJ、TJ)(J=1、…、K)および正常波形と異常波形とが識別済みのテストデータにより、演算ブロック7のテストデータ検出手段18を用いて、不整脈検出を行い、感度SeJと特異度SpJを得る。ここで、テストデータとしては、学習系列生成用に利用した識別済み心電図データを使用することができる。
【0059】
続いて、SeJとSpJとの和が最大となる(MJ、TJ)のペアを検出用確率モデルおよびしきい値のペア(M、J)として、PC2から異常信号検出装置6に出力する。
【0060】
上記の(M、T)の選び方については、先に述べた和の最大値ではなく特異度または感度の最大値などの他の指標に変更してもよい。
【0061】
本発明の装置によれば、どのような入力データに対しても、テストデータを用意すれことにより、非特許文献1の方法を使用した装置において、初期設定の自動化およびその処理時間の削減が図れる。このため、非特許文献1の方法を使用した装の使用価値を高めることができる。
【実施例】
【0062】
本発明の方法を使用した不整脈検出方法の実施例について、表2から表8を参照して以下に説明する。本実施例では、不整脈として心室性期外収縮(PVC)の検出を行った。最初に、本実施例に関わる心電図データの仕様を表2に示す。また、表3には、検出を行った患者の心電図ファイル(ファイルA)の総拍数とPVC数を示す。
【0063】
【表2】
【0064】
【表3】
【0065】
本実施例では、所定時間範囲は、20,722サンプル(約58秒間)から72,762サンプル(約202秒間)である。また、平均圧縮率取得に係る時間窓の幅は、5サンプル(約0.01秒間)である。また、所定拍数Xは、11拍であり、テストデータの長さは、72,000サンプル(200秒間)である。
【0066】
表4に、図5に示すST1で得られた所定時間範囲の11×17拍、11×18拍、…、11×23拍からなる6個の学習系列の仕様を示す。
【0067】
【表4】
【0068】
次に、表5には、図5に示したST2で得られた6個の学習波形から得られた反辞書に含まれる極小禁止語数、反辞書サイズおよび確率モデルサイズを示す。表において、1バイトは、8ビットである。
【0069】
【表5】
【0070】
次に、表6は、所定時間範囲の11×17拍、11×18拍、…、11×23拍からなる6個の学習系列について、図5に示したST3により定められるしきい値を示す。
【0071】
【表6】
【0072】
表7は、11×17拍、11×18拍、…、11×23拍の学習系列について、図5のST4に示したテストデータに対する検出結果を表す。表7に示したとおり、テストデータに対して、11×19拍の感度および特異度の和は、他の5個の学習系列に対して大きい。感度および特異度の和が一番大きい11×19拍の学習波形から生成された確率モデルおよびそのしきい値1.40を、非特許文献1の不整脈検出システムのファイルAに対する確率モデルおよびしきい値とする。
【0073】
【表7】
【0074】
11×19拍の学習波形から生成された確率モデルMおよびしきい値T=1.40を用いて、非特許文献1の不整脈検出システムでファイルAに対するPVCの検出実験を行った結果を表8に示す。
【0075】
【表8】
【0076】
表8に示したとおり、本発明の方法によって生成されるしきい値を使用することにより、感度100%および特異度95.0%でPVCの検出を行うことができることが分かる。
【産業上の利用可能性】
【0077】
本発明の方法および装置は、省メモリでリアルタイム動作可能で携帯型測定器への組み込み用途として特に有効である。したがって、本発明の方法および装置は、製造用機械類などにおける異常信号検知や在宅医療などに用いられる携帯型医療機器の利便性を高めることができる。
【符号の説明】
【0078】
1 正常同調律(学習系列に含まれるもの)
2 異常波形
3 正常同調律(学習系列に含まれないもの)
4 入出力装置
5 PC(コンピュータ)
6 異常信号検出装置
7 演算ブロック
8 学習系列・反辞書テーブル(RAM)
9 確率モデル・しきい値テーブル(RAM)
10 データ圧縮部
11 CPU
12 プログラム(ROM)
13 学習系列設定手段
14 反辞書構築手段
15 確率モデル構築手段
16 最大値検出手段
17 しきい値設定手段
18 テストデータ検出手
【技術分野】
【0001】
本発明は、概周期性を持つデジタルデータに対する異常信号検出システムの初期設定の自動化のための方法および自動化のための装置に関する。具体的には、本発明は、不整脈波形の検出装置における初期設定の自動化のための方法および自動化のための装置に関する。
【背景技術】
【0002】
概周期性を持つデジタルデータである心電図データをデータ圧縮する手法がいくつか提案されている。たとえば、固定幅の時間窓内の平均圧縮率が与えられたしきい値を超えた場合に、超過部分を含む波形を異常波形(不整脈)として判断する手法が提案されている(たとえば、非特許文献1を参照)。また、圧縮率ではなく、同じ患者から得られた二つの心電図データの相互情報量を用いた不整脈検出方法が提案されている(たとえば、特許文献1を参照。)。
【0003】
図4に、非特許文献1の方法のフロー図を示す。当該手法では、検出用の確率モデルとしきい値の初期設定のための工程(S1)、先の確率モデルを用いて心電図データを圧縮する工程(S2)、圧縮率が先のしきい値を超えた場合に不整脈であると判断する工程(S3)の流れで不整脈の検出を行う方法である。
【0004】
S1においては、まず、心電図データから所定拍数(X拍)連続する正常同調律をすべて(Yセット)取り出し、Yセットの集まりから、セットの合計時間が所定時間範囲内となるようにNセットを取り出す。与えられたデータに関する所定時間範囲の取得方法については、非特許文献2に示されている。
【0005】
次に、Nセットの正常同調律W1、W2、…、WNから、それぞれの反辞書A1、A2、…、ANを構築する。次いで、A1、A2、…、ANのすべてに共通な要素の集合(反辞書A)を得る。
【0006】
ここで、与えられたデータ系列に対して、自分自身のパターンは現れないが、先頭の1データを削ったパターンと末尾の1データを削ったパターンがいずれも与えられたデータ系列に現れるような系列を極小禁止語と呼び、与えられたデータ系列に対するすべての極小禁止語の集まりを反辞書と呼ぶ。
【0007】
次に、反辞書Aから圧縮に利用するための確率モデルを構築する。非特許文献1の方法では、W1、W2、…、WNを連結したものを学習系列と呼ぶ。
【0008】
続いて、検出精度がよい確率モデルMおよびしきい値Tを得るために、Yセットからセットの合計時間が所定時間範囲を満たすように任意に選んで得られる学習系列およびしきい値として設定可能な数値のすべての組み合わせに対して、心電図データ全体に対する不整脈検出の予備実験(初期設定)を行い、最もよい検出率が得られた確率モデルとしきい値の組み合わせを検出に用いる確率モデルMおよびしきい値Tとして設定する。
【0009】
S2においては、図1の圧縮処理(D1)に示すように、確率モデルMを用いて心電図データを圧縮し、固定時間幅の時間窓内の平均圧縮率Rを計算する。たとえば、図7に示したように、上段の心電図データを圧縮すると、下段の圧縮率データが得られる。
【0010】
S3においては、図1の検出処理(D2)に示すように、平均圧縮率Rがしきい値Tを超えた場合に時間窓内のデータの先頭位置を含む波形を不整脈と判断する。たとえば、図7に示したように、下段の圧縮率データにおいて、しきい値T=1.5と設定すると、しきい値T=1.5を越えているデータの先頭位置を含む波形は、不整脈と判断される。
【0011】
一方、特許文献1の方法では、二つ以上の心電図データの相互情報量を計算するために、患者に複数の電極を設置して、同じ患者から異なる電極から得られる二つ以上の心電図データを測定する必要がある。
【0012】
通常の心電図データの測定では、特許文献1の方法に必要とされる複数の心電図データは得られないため、一般的な心電図データにおける異常波形の検出に関しては、特許文献1の方法は適さない問題点がある。
【先行技術文献】
【特許文献】
【0013】
【特許文献1】特開2008-200120号公報
【非特許文献】
【0014】
【非特許文献1】太田隆博、森田啓義、外2名、“反辞書符号化法を用いた不整脈検出”、平成22年5月14日、電子情報通信学会技術研究報告、MBE、MEとバイオサイバネティックス、110巻、52号、35-40ページ、社団法人電子情報通信学会
【非特許文献2】太田隆博、森田啓義、“反辞書を用いた心電図の1パス無ひずみ圧縮 ”、電子情報通信学会論文誌A、J87-A巻、9号、1187-1195ページ、平成16年9月、社団法人電子情報通信学会
【発明の概要】
【発明が解決しようとする課題】
【0015】
非特許文献1の方法は、一般的な心電図データに対して、異常波形検出を行うことができる。しかしながら、非特許文献1の方法の一つ目の問題点として、確率モデルMおよびしきいT値の設定のために、心電図データ全体を必要とするため、測定と同時に不整脈検出を行うことができないという問題点がある。
【0016】
また、心電図データには、学習系列として利用可能な正常同調律の組み合わせが多く存在する。さらに、しきい値に関しても、その候補として、心電図データを圧縮したときの圧縮率の下限値と上限値の範囲内の値のすべてが該当する。したがって、二つ目の問題点として、非特許文献1の方法では、初期設定において、調べなければならない確率モデルおよびしきい値の組み合わせが非常に多くなり、この処理に時間がかかるという問題点がある。
【0017】
本発明は、上記の二つの問題点を解決して、非特許文献1の方法の初期設定の時間を短縮し、さらに、確率モデルおよびしきい値の初期設定を自動化するための方法および装置を提供することを目的とする。
【課題を解決するための手段】
【0018】
本発明は、概周期性を持つデジタルデータに対する異常信号検出システムの初期設定の自動化のための方法であって、前記概周期性を持つデジタルデータの部分系列から学習系列を取得する、学習系列設定工程と、前記学習系列から確率モデルを構築する、確率モデル構築工程と、前記構築された確率モデルを用いて、前記確率モデルの構築に利用した学習系列を圧縮するデータ圧縮工程と、前記データ圧縮工程で圧縮されたデータを用いて、前記確率モデルに対する検出用のしきい値を設定する、しきい値設定工程とを含む、異常信号検出システムの初期設定の方法を提供する。
【0019】
また、本発明は、前記しきい値は、式1:
TI=(INT(RI×C)+1)/C
(式中、Cは、100であり、INT(RI×C)は、RI×Cの整数部分を表し、RIは、圧縮率の中の最大値を表す。)
によって算出される、上記方法を提供する。
【0020】
さらに、本発明は、概周期性を持つデジタルデータに対する異常信号検出システムの初期設定の自動化のための装置であって、前記概周期性を持つデジタルデータの部分系列から学習系列を取得する、学習系列設定手段と、前記学習系列から確率モデルを構築する、確率モデル構築工程と、前記構築された確率モデルを用いて、前記確率モデルの構築に利用した学習系列を圧縮するデータ圧縮手段と、前記データ圧縮工程で圧縮されたデータを用いて、前記確率モデルに対する検出用のしきい値を設定する、しきい値設定手段とを備える装置を提供する。
【0021】
また、本発明は、前記しきい値は、式1:
TI=(INT(RI×C)+1)/C
(式中、Cは、100であり、INT(RI×C)は、RI×Cの整数部分を表し、RIは、圧縮率の中の最大値を表す。)
によって算出される、上記の異常信号検出システムの初期設定の方法を提供する。
【0022】
さらに、本発明は、不整脈波形の検出装置であって、心電図データの部分系列から学習系列を取得する、学習系列設定手段と、前記学習系列から確率モデルを構築する、確率モデル構築工程と、前記構築された確率モデルを用いて、前記確率モデルの構築に利用した学習系列を圧縮するデータ圧縮手段と、前記データ圧縮工程で圧縮されたデータを用いて、前記確率モデルに対する検出用のしきい値を設定する、しきい値設定手段とを備える、不整脈波形の検出装置を提供する。
【0023】
また、本発明は、前記構築された確率モデルおよび前記設定されたしきい値のペアを用いて、テストデータに対して異常信号検出を行う、テストデータに対する検出工程と、前記得られた検出結果から、実際の信号に対する異常信号検出に用いるための確率モデルとしきい値のペアを選出する、検出用ペアの設定工程とをさらに含む、上記方法を提供する。
【0024】
また、本発明は、前記構築された確率モデルおよび前記設定されたしきい値のペアを用いて、テストデータに対して異常信号検出を行う、テストデータに対する検出手段と、前記得られた検出結果から、実際の信号に対する異常信号検出に用いるための確率モデルとしきい値のペアを選出する、検出用ペアの設定手段と、
をさらに備える、上記装置を提供する。
【発明の効果】
【0025】
本発明の方法および装置によれば、心電図データにおける不整脈波形などの、概周期性を持つデジタルデータに対する異常信号検出システムにおいて、初期設定の時間を短縮することができる。また、本発明の方法および装置によれば、心電図データにおける不整脈波形などの、概周期性を持つデジタルデータに対する異常信号検出システムにおいて、確率モデルおよびしきい値の初期設定を自動化することができる。したがって、本発明の方法および装置によれば、テストデータを用意することにより、データの入力から不整脈検出までのすべてを自動化できる。
【図面の簡単な説明】
【0026】
【図1】非特許文献1に記載された、従来の方法の不整脈検出処理部分のフロー図。
【図2】本発明の方法において、心電図データから学習系列を取得する位置の関係を表した図。
【図3】本発明の方法において、心電図データからの学習系列の長さと所定時間範囲との関係を表した図。
【図4】非特許文献1に記載された、従来の方法のフロー図。
【図5】本発明の方法の一実施形態に係る確率モデルおよびしきい値の設定方法を示すフロー図。
【図6】本発明の装置の一実施形態に係る不整脈の異常信号検出装置における処理を示した図。
【図7】心電図データから得られる圧縮データとしきい値とを示す図。
【発明を実施するための形態】
【0027】
以下、本発明の概周期性を持つデジタルデータに対する異常信号検出システムの初期設定の自動化のための方法について、図面を参照して説明する。また、概周期性を持つデジタルデータの例として、特に心電図データを使用した場合について説明する。
【0028】
本発明の方法は、図5に示した工程にしたがって異常信号検出システムの初期設定を行う。本発明の方法は、まず、学習系列設定工程(ST1)において、概周期性を持つデジタルデータの部分系列から学習系列を取得する。本発明の方法において、学習系列は、データ全体ではなく、データの一部分のみを使用して構築される。たとえば、学習系列を設定するためには、図2に示すように、一連の心電図データの先頭から順番に正常同調律を所定拍数(X拍)単位毎に取得する。図2に示したように、心電図データにおいては、所定拍数(X拍)単位の正常同調律1をそれぞれ(W1、W2、…、WN)と表す。この所定拍数(X拍)単位の正常同調律1(W1、W2、…、WN)を連結したものを学習系列として設定する。一方、異常波形2は、学習系列から排除する。また、図2に示されるように、X拍に満たないA拍の正常同調律も、学習系列から排除する。
【0029】
したがって、本発明の方法において、学習系列は、一連の概周期性を持つデジタルデータのうち、所定の周期(X周期)単位で取得されるデータを連結したものをいう。また、学習系列には、所定の周期数単位に満たないデータを含まない。また、学習系列には、周期性を持たない部分のデータを含まない。
【0030】
学習系列設定工程(ST1)では、図3に示されるように、学習系列をK個作成することもできる。作成された学習系列は、たとえば学習系列長について昇順にそれぞれL1、…、LKとする。以下、複数個の学習系列LJ(J=1、…、K)がある場合について説明する。
【0031】
次に、確率モデル構築工程(ST2)では、ST1で設定した学習系列に対して確率モデルを構築する。確率モデルを構築するためには、まず学習系列LJ(J=1、…、K)に対して、LJを構成するIセットの正常同調律W1、…、WIからそれぞれ反辞書A1、…、AIを生成する。
【0032】
本明細書において、与えられたデータ系列に対して、自分自身のパターンは現れないが、先頭の1データを削ったパターンと末尾の1データを削ったパターンがいずれも与えられたデータ系列に現れるような系列を極小禁止語と呼ぶ。そして、与えられたデータ系列に対するすべての極小禁止語の集まりを反辞書と呼ぶ。反辞書は、非特許文献1に記載されたとおりに生成することができる。簡潔には、以下のとおりに反辞書を生成することができる。
【0033】
まず、データ系列に出現するすべてのパターンを登録したデータ構造である辞書を生成する。次に、パターンの末尾に1データを付加して、そのパターンが極小禁止語の3つの条件を満たすかどうかをチェックし、条件を満たしていれば、そのパターンを反辞書に登録する。これを辞書に登録されたすべてのパターンに対して行う。このチェックを高速かつ省メモリで行う反辞書生成方法の一つとして、たとえばT. Ota and H. Morita, “On the Construction of an Antidictionary with Linear Complexity Using the Suffix Tree”, IEICE Transactions on Fundamentals of Electronics Communications and Computer Sciences、Vol. E90-A, No. 11, pp. 2533-2539, November 2007, The Institute of Electronics, Information and Communication Engineers(IEICE)に示される方法がある。
【0034】
続いて、A1、…、ANのすべてに共通な要素の集まりAJを取得する。次いで、反辞書AJから、確率モデルMJを構築する。簡潔には、以下のとおりに確率モデルを生成することができる。
【0035】
反辞書による確率モデルは、極小禁止語を部分列として受理しない決定性有限オートマトンである。生成方法としては、まず、反辞書に含まれるすべての極小禁止語をデータ検索によく用いられる木構造と呼ばれるデータ構造で表現する。生成された木の各接点は、ある極小禁止語の先頭データ列(極小禁止語自身を含む)のいずれかと対応している。次に、任意の節点Aに対応するデータ列の終端に任意の1データ(Z)を追加した新データ列を用意し、この新データ列に対応する節点Bを探索する。対応する節点がない場合には、新データ列の先頭1データを削りながら、節点Bが見つかるまで探索を行う。節点Bが見つかったなら、節点AからデータZでの遷移先として節点Bを設定する。この処理をすべての節点に対して、出現可能性のある1データを追加した場合で行うと確率モデルが生成される。これを高速に行う方法として、たとえばM. Crochemore, F. Mignosi, and A. Restivo, “Automata and Forbidden Words”, Information Processing Letters, Vol. 67, No. 3, pp. 111-117, October 1998.に示される方法がある。
【0036】
したがって、本発明の方法において、確率モデルは、学習系列から生成される反辞書A1、…、ANにおいて、A1、…、ANの要素を部分列として含むような系列を受理しない決定性有限オートマンである。
【0037】
次に、確率モデルに対するしきい値設定工程(ST3)では、構築された確率モデルを用いて、確率モデルの構築に利用した学習系列を圧縮する。複数個の学習系列LJ(J=1、…、K)がある場合、K個の確率モデルM1、…、MKを用いて、それぞれの確率モデル構築に利用した学習系列L1、…、LKを圧縮する。簡潔には、以下のとおりに学習系列圧縮することができる。
【0038】
圧縮を行うために、決定性有限オートマトン(確率モデル)の初期節点からデータ系列により、オートマトン上の節点の遷移を行う。圧縮は、遷移において、節点が遷移先として一つの節点しか持たない場合には、その遷移に用いた1データを削除、節点が二つ以上の遷移先を持つ場合には、節点においてデータ毎の遷移回数をカウントし、各データの出現確率をエントロピー符号と呼ばれる圧縮手法を用いて行われる。具体的には、T. OTA, “Antidictionary Data Compression Using Dynamic Suffix Trees”, Ph.D. Thesis, The University of Electro-Communications, 2007.に示される方法がある。
【0039】
次いで、得られた圧縮率の中でのそれぞれの最大値R1、…、RKに対して、数式1により、確率モデルM1、…、MKに対するそれぞれのしきい値T1、…、TKを定める。
【0040】
数式1 TI=(INT(RI×C)+1)/C
式中、Cは、100であり、INT(RI×C)は、RI×Cの整数部分を表し、RIは、圧縮率の中の最大値を表す。
【0041】
上記の工程により、概周期性を持つデジタルデータに対する異常信号検出システムの初期設定において、心電図などの概周期性を持つデジタルデータから、周期性を持つデジタルデータと異常信号とを区別するためのしきい値を自動的に設定することができる。具体的には、上記工程により、図7に示したように、上段の心電図データから、下段の圧縮率データおよびしきい値(図7の場合、T=1.5)を自動的に設定することができる。
【0042】
本発明の方法において、複数個の学習系列LJ(J=1、…、K)がある場合、図5に示したように、さらにテストデータに対する検出工程(ST4)を含むことができる。
【0043】
テストデータに対する検出工程(ST4)では、確率モデルとしきい値のペア(M1、T1)、…、(MK、TK)を用いて、所定時間範囲内の長さのテストデータに対して、異常信号検出(心電図の場合、不整脈検出)のための実験を行うことができる。ここで、テストデータは、医師等により波形ごとに正常同調律とそれ以外の判別が行われているものを利用することが好ましい。検出精度は、表1に示される頻度tp、fn、tn、fpを用いて、感度(sensitivity)=tp/(tp+fn)×100 (%)、特異度(specificity)=tn/(tn+fp)×100(%)により計算される。
【0044】
【表1】
【0045】
検出用確率モデルとしきい値の設定工程(ST5)では、テストデータに対する検出工程(ST4)で求められた感度と特異度の和が最も大きくなる確率モデルとしきい値のペア(MJ、TJ)を検出用の確率モデルおよびしきい値(M、T)として設定する。最大値を取るペアが複数存在する場合には、学習系列が最も長いものを選ぶ。
【0046】
上記方法において、所定拍数と所定時間範囲およびテストデータの長さを、患者の様態や心電図データの測定精度に合わせて変更可能であることとしてよい。
【0047】
また、上記方法において、Cは、10以上の10のべき乗の値に変更することができる。
【0048】
また、上記発明においては、平均圧縮率取得に係る時間窓の幅は、心電図データの測定精度に合わせて、変更することができる。
【0049】
また、上記方法の説明において、概周期性を持つデジタルデータとして、心電図データについて説明したが、代わりに任意の概周期性を持つデジタルデータを使用してもよい。この場合、正常同調律および不整脈を検出する代わりに、それぞれデジタルデータにおける正常信号および異常信号を検出することができる。
【0050】
図6は、本発明に方法を利用した確率モデルおよびしきい値の自動設定装置の回路構成図を示す。概周期性を持つデジタルデータとして心電図データを使用し、異常信号として心電図における不整脈を検出する場合を例示している。
【0051】
図6において、PC5は、入力として、入出力装置4から正常波形と異常波形が識別済みの心電図データを読み込む。一方、出力として、検出用の確率モデルおよびしきい値のペアを異常信号検出装置6に出力する。演算ブロック内の各手段13〜18の呼び出し順序などは、プログラム(ROM)12に格納されている。
【0052】
詳細な手順としては、PC5内部において、CPU11は、最初に、入力された識別済み心電図データから演算ブロック7の学習系列設定手段13を用いて、学習系列LJ(J=1、…、K)を生成する。生成された学習系列は、反辞書テーブル(RAM)8に格納される。
【0053】
続いて、CPU11は、学習系列・反辞書テーブル(RAM)8に格納された学習系列LJ(J=1、…、K)から、演算ブロック7の反辞書構築手段14を用いて、それぞれの反辞書AJ(J=1、…、K)を構築する。構築された反辞書AJは、学習系列・反辞書テーブル(RAM)8に格納される。
【0054】
続いて、CPU11は、学習系列・反辞書テーブル(RAM)8に格納された反辞書AJ(J=1、…、K)から、確率モデル構築手段15を用いて、それぞれに対応する確率モデルMJ(J=1、…、K)を構築する。構築された確率モデルMJは、確率モデル・しきい値テーブル(RAM)9に格納される。
【0055】
続いて、CPU11は、確率モデル・しきい値テーブル(RAM)9に格納された確率モデルMJ(J=1、…、K)およびデータ圧縮部10により、学習系列・反辞書テーブル(RAM)8に格納されたMJの構築に用いた学習系列LJを圧縮する。圧縮後、演算ブロック7の最大値検出手段16を用いて、圧縮率の最大値RJを得る。さらに、このRJおよび数式1から、しきい値設定手段17を用いて、しきい値TJを得る。得られたしきい値TJは、確率モデル・しきい値テーブル(RAM)9に格納される。
【0056】
上記のとおりの手順により、概周期性を持つデジタルデータに対する異常信号検出システムの初期設定において、心電図などの概周期性を持つデジタルデータから、周期性を持つデジタルデータと異常信号とを区別するためのしきい値を自動的に設定することができる。
【0057】
本発明の装置において、学習系列LJは、1つであることができるが、上記のように複数個の学習系列LJ(J=1、…、K)を生成する場合、図6に示したように、さらに以下の処理を行うことができる。
【0058】
CPU11は、確率モデル・しきい値テーブル(RAM)9に格納された確率モデルとしきい値のペア(MJ、TJ)(J=1、…、K)および正常波形と異常波形とが識別済みのテストデータにより、演算ブロック7のテストデータ検出手段18を用いて、不整脈検出を行い、感度SeJと特異度SpJを得る。ここで、テストデータとしては、学習系列生成用に利用した識別済み心電図データを使用することができる。
【0059】
続いて、SeJとSpJとの和が最大となる(MJ、TJ)のペアを検出用確率モデルおよびしきい値のペア(M、J)として、PC2から異常信号検出装置6に出力する。
【0060】
上記の(M、T)の選び方については、先に述べた和の最大値ではなく特異度または感度の最大値などの他の指標に変更してもよい。
【0061】
本発明の装置によれば、どのような入力データに対しても、テストデータを用意すれことにより、非特許文献1の方法を使用した装置において、初期設定の自動化およびその処理時間の削減が図れる。このため、非特許文献1の方法を使用した装の使用価値を高めることができる。
【実施例】
【0062】
本発明の方法を使用した不整脈検出方法の実施例について、表2から表8を参照して以下に説明する。本実施例では、不整脈として心室性期外収縮(PVC)の検出を行った。最初に、本実施例に関わる心電図データの仕様を表2に示す。また、表3には、検出を行った患者の心電図ファイル(ファイルA)の総拍数とPVC数を示す。
【0063】
【表2】
【0064】
【表3】
【0065】
本実施例では、所定時間範囲は、20,722サンプル(約58秒間)から72,762サンプル(約202秒間)である。また、平均圧縮率取得に係る時間窓の幅は、5サンプル(約0.01秒間)である。また、所定拍数Xは、11拍であり、テストデータの長さは、72,000サンプル(200秒間)である。
【0066】
表4に、図5に示すST1で得られた所定時間範囲の11×17拍、11×18拍、…、11×23拍からなる6個の学習系列の仕様を示す。
【0067】
【表4】
【0068】
次に、表5には、図5に示したST2で得られた6個の学習波形から得られた反辞書に含まれる極小禁止語数、反辞書サイズおよび確率モデルサイズを示す。表において、1バイトは、8ビットである。
【0069】
【表5】
【0070】
次に、表6は、所定時間範囲の11×17拍、11×18拍、…、11×23拍からなる6個の学習系列について、図5に示したST3により定められるしきい値を示す。
【0071】
【表6】
【0072】
表7は、11×17拍、11×18拍、…、11×23拍の学習系列について、図5のST4に示したテストデータに対する検出結果を表す。表7に示したとおり、テストデータに対して、11×19拍の感度および特異度の和は、他の5個の学習系列に対して大きい。感度および特異度の和が一番大きい11×19拍の学習波形から生成された確率モデルおよびそのしきい値1.40を、非特許文献1の不整脈検出システムのファイルAに対する確率モデルおよびしきい値とする。
【0073】
【表7】
【0074】
11×19拍の学習波形から生成された確率モデルMおよびしきい値T=1.40を用いて、非特許文献1の不整脈検出システムでファイルAに対するPVCの検出実験を行った結果を表8に示す。
【0075】
【表8】
【0076】
表8に示したとおり、本発明の方法によって生成されるしきい値を使用することにより、感度100%および特異度95.0%でPVCの検出を行うことができることが分かる。
【産業上の利用可能性】
【0077】
本発明の方法および装置は、省メモリでリアルタイム動作可能で携帯型測定器への組み込み用途として特に有効である。したがって、本発明の方法および装置は、製造用機械類などにおける異常信号検知や在宅医療などに用いられる携帯型医療機器の利便性を高めることができる。
【符号の説明】
【0078】
1 正常同調律(学習系列に含まれるもの)
2 異常波形
3 正常同調律(学習系列に含まれないもの)
4 入出力装置
5 PC(コンピュータ)
6 異常信号検出装置
7 演算ブロック
8 学習系列・反辞書テーブル(RAM)
9 確率モデル・しきい値テーブル(RAM)
10 データ圧縮部
11 CPU
12 プログラム(ROM)
13 学習系列設定手段
14 反辞書構築手段
15 確率モデル構築手段
16 最大値検出手段
17 しきい値設定手段
18 テストデータ検出手
【特許請求の範囲】
【請求項1】
概周期性を持つデジタルデータに対する異常信号検出システムの初期設定の自動化のための方法であって、
前記概周期性を持つデジタルデータの部分系列から学習系列を取得する、学習系列設定工程と、
前記学習系列から確率モデルを構築する、確率モデル構築工程と、
前記構築された確率モデルを用いて、前記確率モデルの構築に利用した学習系列を圧縮するデータ圧縮工程と、
前記データ圧縮工程で圧縮されたデータを用いて、前記確率モデルに対する検出用のしきい値を設定する、しきい値設定工程と、
を含む、異常信号検出システムの初期設定の方法。
【請求項2】
前記しきい値は、式1:
TI=(INT(RI×C)+1)/C
式中、Cは、100であり、INT(RI×C)は、RI×Cの整数部分を表し、RIは、圧縮率の中の最大値を表す。
によって算出される、請求項1に記載の異常信号検出システムの初期設定の方法。
【請求項3】
概周期性を持つデジタルデータに対する異常信号検出システムの初期設定の自動化のための装置であって、
前記概周期性を持つデジタルデータの部分系列から学習系列を取得する、学習系列設定手段と、
前記学習系列から確率モデルを構築する、確率モデル構築工程と、
前記構築された確率モデルを用いて、前記確率モデルの構築に利用した学習系列を圧縮するデータ圧縮手段と、
前記データ圧縮工程で圧縮されたデータを用いて、前記確率モデルに対する検出用のしきい値を設定する、しきい値設定手段と、
を備える装置。
【請求項4】
前記しきい値は、式1:
TI=(INT(RI×C)+1)/C
式中、Cは、100であり、INT(RI×C)は、RI×Cの整数部分を表し、RIは、圧縮率の中の最大値を表す。
によって算出される、請求項1に記載の異常信号検出システムの初期設定の方法。
【請求項5】
不整脈波形の検出装置であって、
心電図データの部分系列から学習系列を取得する、学習系列設定手段と、
前記学習系列から確率モデルを構築する、確率モデル構築工程と、
前記構築された確率モデルを用いて、前記確率モデルの構築に利用した学習系列を圧縮するデータ圧縮手段と、
前記データ圧縮工程で圧縮されたデータを用いて、前記確率モデルに対する検出用のしきい値を設定する、しきい値設定手段と、
を備える、不整脈波形の検出装置。
【請求項6】
前記構築された確率モデルおよび前記設定されたしきい値のペアを用いて、テストデータに対して異常信号検出を行う、テストデータに対する検出工程と、
前記得られた検出結果から、実際の信号に対する異常信号検出に用いるための確率モデルとしきい値のペアを選出する、検出用ペアの設定工程と、
をさらに含む、請求項1または2に記載の方法。
【請求項7】
前記構築された確率モデルおよび前記設定されたしきい値のペアを用いて、テストデータに対して異常信号検出を行う、テストデータに対する検出手段と、
前記得られた検出結果から、実際の信号に対する異常信号検出に用いるための確率モデルとしきい値のペアを選出する、検出用ペアの設定手段と、
をさらに備える、請求項3または4に記載の装置。
【請求項1】
概周期性を持つデジタルデータに対する異常信号検出システムの初期設定の自動化のための方法であって、
前記概周期性を持つデジタルデータの部分系列から学習系列を取得する、学習系列設定工程と、
前記学習系列から確率モデルを構築する、確率モデル構築工程と、
前記構築された確率モデルを用いて、前記確率モデルの構築に利用した学習系列を圧縮するデータ圧縮工程と、
前記データ圧縮工程で圧縮されたデータを用いて、前記確率モデルに対する検出用のしきい値を設定する、しきい値設定工程と、
を含む、異常信号検出システムの初期設定の方法。
【請求項2】
前記しきい値は、式1:
TI=(INT(RI×C)+1)/C
式中、Cは、100であり、INT(RI×C)は、RI×Cの整数部分を表し、RIは、圧縮率の中の最大値を表す。
によって算出される、請求項1に記載の異常信号検出システムの初期設定の方法。
【請求項3】
概周期性を持つデジタルデータに対する異常信号検出システムの初期設定の自動化のための装置であって、
前記概周期性を持つデジタルデータの部分系列から学習系列を取得する、学習系列設定手段と、
前記学習系列から確率モデルを構築する、確率モデル構築工程と、
前記構築された確率モデルを用いて、前記確率モデルの構築に利用した学習系列を圧縮するデータ圧縮手段と、
前記データ圧縮工程で圧縮されたデータを用いて、前記確率モデルに対する検出用のしきい値を設定する、しきい値設定手段と、
を備える装置。
【請求項4】
前記しきい値は、式1:
TI=(INT(RI×C)+1)/C
式中、Cは、100であり、INT(RI×C)は、RI×Cの整数部分を表し、RIは、圧縮率の中の最大値を表す。
によって算出される、請求項1に記載の異常信号検出システムの初期設定の方法。
【請求項5】
不整脈波形の検出装置であって、
心電図データの部分系列から学習系列を取得する、学習系列設定手段と、
前記学習系列から確率モデルを構築する、確率モデル構築工程と、
前記構築された確率モデルを用いて、前記確率モデルの構築に利用した学習系列を圧縮するデータ圧縮手段と、
前記データ圧縮工程で圧縮されたデータを用いて、前記確率モデルに対する検出用のしきい値を設定する、しきい値設定手段と、
を備える、不整脈波形の検出装置。
【請求項6】
前記構築された確率モデルおよび前記設定されたしきい値のペアを用いて、テストデータに対して異常信号検出を行う、テストデータに対する検出工程と、
前記得られた検出結果から、実際の信号に対する異常信号検出に用いるための確率モデルとしきい値のペアを選出する、検出用ペアの設定工程と、
をさらに含む、請求項1または2に記載の方法。
【請求項7】
前記構築された確率モデルおよび前記設定されたしきい値のペアを用いて、テストデータに対して異常信号検出を行う、テストデータに対する検出手段と、
前記得られた検出結果から、実際の信号に対する異常信号検出に用いるための確率モデルとしきい値のペアを選出する、検出用ペアの設定手段と、
をさらに備える、請求項3または4に記載の装置。
【図2】

【図3】
【図6】

【図7】

【図1】
【図4】
【図5】
【図3】
【図6】
【図7】
【図1】
【図4】
【図5】
【公開番号】特開2013−42904(P2013−42904A)
【公開日】平成25年3月4日(2013.3.4)
【国際特許分類】
【出願番号】特願2011−182227(P2011−182227)
【出願日】平成23年8月24日(2011.8.24)
【出願人】(391001619)長野県 (64)
【出願人】(504133110)国立大学法人電気通信大学 (383)
【Fターム(参考)】
【公開日】平成25年3月4日(2013.3.4)
【国際特許分類】
【出願日】平成23年8月24日(2011.8.24)
【出願人】(391001619)長野県 (64)
【出願人】(504133110)国立大学法人電気通信大学 (383)
【Fターム(参考)】
[ Back to top ]